# A Survey on Uncertainty Quantification of Large Language Models: Taxonomy, Open Research Challenges, and Future Directions
**Authors**: Ola Shorinwa, Zhiting Mei, Justin Lidard, Allen Z. Ren, AnirudhaMajumdar
> shoa@princeton.edu
> maymei@princeton.edu
> jlidard@princeton.edu
> allen.ren@princeton.edu
> ani.majumdar@princeton.eduPrincetonUniversityPrincetonNJUSA
Abstract.
The remarkable performance of large language models (LLMs) in content generation, coding, and common-sense reasoning has spurred widespread integration into many facets of society. However, integration of LLMs raises valid questions on their reliability and trustworthiness, given their propensity to generate hallucinations: plausible, factually-incorrect responses, which are expressed with striking confidence. Previous work has shown that hallucinations and other non-factual responses generated by LLMs can be detected by examining the uncertainty of the LLM in its response to the pertinent prompt, driving significant research efforts devoted to quantifying the uncertainty of LLMs. This survey seeks to provide an extensive review of existing uncertainty quantification methods for LLMs, identifying their salient features, along with their strengths and weaknesses. We present existing methods within a relevant taxonomy, unifying ostensibly disparate methods to aid understanding of the state of the art. Furthermore, we highlight applications of uncertainty quantification methods for LLMs, spanning chatbot and textual applications to embodied artificial intelligence applications in robotics. We conclude with open research challenges in uncertainty quantification of LLMs, seeking to motivate future research.
Uncertainty Quantification; Large Language Models (LLMs); Confidence Estimation. doi: 1111111.1111111 ccs: Computing methodologies ccs: Computing methodologies Artificial intelligence ccs: Computing methodologies Natural language processing ccs: Computing methodologies Natural language generation
1. Introduction
Large language models have demonstrated remarkable language generation capabilities, surpassing average human performance on many benchmarks including math, reasoning, and coding (Achiam et al., 2023; Anthropic, 2024; Brown, 2020; Touvron et al., 2023; Dubey et al., 2024; Chiang et al., 2023). For example, recent (multi-modal) large language models were shown to achieve impressive scores, e.g., in the $90\%$ percentile, on simulated Law School Admission Test (LSAT) exams, the American Mathematics Competition (AMC) contests, the Multistate Bar Exam, and the Graduate Record Exam (GRE) General Test, outperforming a majority of test takers (Katz et al., 2024; Achiam et al., 2023; Anthropic, 2024). Likewise, LLMs have advanced the state of the art in machine translation, text summarization, and question-and-answer tasks. However, LLMs also tend to produce plausible, factually-incorrect responses to their input prompts, termed hallucinations (Lee et al., 2018). In some scenarios, the hallucinated response is overtly incorrect; however, in many cases, the factuality of the LLM response is harder to discern, posing significant risk as a user might falsely assume factuality of the response, which can result in devastating consequences, especially when safety is of paramount importance. As a result, hallucinations pose a notable danger to the safe, widespread adoption of LLMs.
<details>
<summary>extracted/6588127/images/teaser/uq_for_llms.png Details</summary>

### Visual Description
\n
## Screenshot: Chatbot Interaction - Fact Check Failure
### Overview
This image is a screenshot of a chatbot conversation. A user asks a question about the lowest temperature recorded in Antarctica. The chatbot provides an answer with high confidence, but a subsequent "Fact-Check" indicates the answer is false.
### Components/Axes
The screenshot displays a chat interface with message bubbles. The elements are:
* **User Message 1:** "What is the lowest-ever temperature recorded in Antarctica?" (Top-left, blue bubble)
* **Chatbot Response 1:** "The lowest-ever temperature recorded in Antarctica was a staggering -128.6°F (-89.2°C)." (Center-left, green bubble with a checkmark icon)
* **User Message 2:** "How confident are you?" (Bottom-left, blue bubble)
* **Chatbot Response 2:** "I am 100% confident." (Bottom-center-left, green bubble with a checkmark icon)
* **Fact-Check Indicator:** A large red "X" with the text "Fact-Check: False" (Bottom-center, red)
### Detailed Analysis or Content Details
The chatbot initially states the lowest temperature in Antarctica is -128.6°F, which is equivalent to -89.2°C. The chatbot expresses 100% confidence in this answer. However, the "Fact-Check: False" indicator reveals the provided information is inaccurate.
### Key Observations
The key observation is the discrepancy between the chatbot's confident assertion and the fact-check result. This highlights a potential issue with the chatbot's knowledge base or reasoning capabilities. The chatbot confidently provides incorrect information.
### Interpretation
This screenshot demonstrates a failure of a chatbot's fact-checking mechanism. The chatbot confidently delivers an incorrect answer, indicating a flaw in its data sources or its ability to verify information. The "Fact-Check: False" label suggests an external system or process identified the error. This example underscores the importance of verifying information provided by AI models, even when presented with high confidence. The actual lowest temperature recorded in Antarctica is -89.2°C (-128.6°F), which the chatbot stated, but the context implies it is incorrect. This is a paradox. The chatbot is correct in its numerical answer, but incorrect in its overall statement. This suggests the chatbot may be misinterpreting the question or providing a temperature from a different location.
</details>
Figure 1. A user asks an LLM the question: What is the lowest-ever temperature recorded in Antarctica?; in response, the LLM answers definitively. Afterwards, the user asks the LLM how confident the LLM is. Although the LLM states that it is “100% confident,” the LLM’s response fails to pass a fact-check test. Confidence scores provided by LLMs are generally miscalibrated. UQ methods seek to provide calibrated estimates of the confidence of LLMs in their interaction with users.
\Description
[A user asks an LLM the question: What is the lowest-ever temperature recorded in Antarctica?; in response, the LLM answers definitively. Afterwards, the user asks the LLM how confident the LLM is. Although the LLM states that it is “100% confident,” the LLM’s response fails to pass a fact-check test. Confidence scores provided by LLMs are generally miscalibrated. UQ methods seek to provide calibrated estimates of the confidence of LLMs in their interaction with users.]A user asks an LLM the question: What is the lowest-ever temperature recorded in Antarctica?; in response, the LLM answers definitively. Afterwards, the user asks the LLM how confident the LLM is. Although the LLM states that it is “100% confident,” the LLM’s response fails to pass a fact-check test. Confidence scores provided by LLMs are generally miscalibrated. UQ methods seek to provide calibrated estimates of the confidence of LLMs in their interaction with users.
To ensure the trustworthiness of LLMs, substantial research has been devoted to examining the mechanisms behind hallucinations in LLMs (Lee et al., 2018; Chen et al., 2023; Azamfirei et al., 2023; Xu et al., 2024a; Ji et al., 2023), detecting its occurrence, identifying potential causes, and proposing mitigating actions. However, even in the absence of hallucinations, LLMs are susceptible to doubt when given prompts at the boundary of their knowledge base. In these situations, prior work has shown that LLMs fail to accurately convey their uncertainty to a user, either implicitly or explicitly, unlike typical humans (Liu et al., 2023c; Alkaissi and McFarlane, 2023). In fact, LLMs tend to be overconfident even when they should be uncertain about the factuality of their response (Xiong et al., 2023; Groot and Valdenegro-Toro, 2024). We provide an example in Figure 1, where an LLM is asked: “What is the lowest-ever temperature recorded in Antarctica?”, to which the LLM responds definitively. Even when prompted for its confidence in its answer, the LLM claims that it is “100% confident.” However, the LLM’s answer fails to pass a fact-check test. Knowing how much to trust an LLM-generated response is critical for users (Kim et al., 2024a), helping inform the development of contingency strategies commensurate with the degree of uncertainty of the LLM in its response. For example, in applications such as robotics, an LLM-equipped robot could seek human guidance (Ren et al., 2023a) or necessitate further review in the judicial practice (Delacroix, 2024). Uncertainty quantification (UQ) methods for LLMs seek to address this challenge by providing users with an estimate of an LLM’s confidence in its response to a given prompt. Indeed, uncertainty quantification can be important in factuality analysis (Huang et al., 2023a).
The rapid adoption of LLMs in many applications has contributed to the fast-pace development of UQ methods for LLMs to promote their safe integration into a wide range of applications. However, the huge volume of UQ methods for LLMs has made it particularly challenging to ascertain the research scope and guarantees provided by existing UQ methods, complicating the identification of useful UQ methods for practitioners seeking to leverage them in their application areas, as well as the identification of impactful future directions for research. We claim that this challenge arises from the lack of a taxonomy that unifies related existing methods and presents an organized view of existing work in this research area.
Through this survey, we seek not only to enumerate existing work in UQ for LLMs, but also to provide a useful taxonomy of UQ methods for LLMs to aid understanding the state of the art in this research area. We reiterate that the introduction of an effective taxonomy for these methods can facilitate their adoption in wide-ranging applications, such as in factuality analysis, hallucination detection, and robotics. We categorize existing uncertainty quantification methods for LLMs into four main classes: (1) token-level uncertainty quantification methods; (2) self-verbalized uncertainty quantification methods; (3) semantic-similarity uncertainty quantification methods; and (4) mechanistic interpretability methods. These categories encompass uncertainty quantification of multi-claim, multi-sentence LLM responses. We elaborate on each category in this survey, identifying the key features shared by methods within each category. Moreover, we identify open research challenges and provide directions for future research, hoping to inspire future effort in advancing the state of the art.
Comparison to other Surveys
A number of surveys on hallucinations in LLMs exists, e.g., (Rawte et al., 2023; Huang et al., 2023b; Tonmoy et al., 2024; Liu et al., 2024e; Bai et al., 2024). These surveys discuss hallucinations in detail, introducing the notion of hallucinations (Rawte et al., 2023), identifying its types and potential causes (Huang et al., 2023b), and presenting mitigation techniques (Tonmoy et al., 2024). However, these papers provide little to no discussion on uncertainty quantification methods for LLMs, as this research area lies outside the scope of these surveys. In contrast, only two surveys on uncertainty quantification methods for LLMs exist, to the best of our knowledge. The first survey (Geng et al., 2024) categorizes confidence estimation and calibration methods into two broad classes: methods for generation tasks and methods for classification tasks, defined by the application domain. The survey in (Geng et al., 2024) focuses more heavily on calibration methods, with a less extensive discussion on confidence estimation methods. In contrast, our paper provides an extensive survey of uncertainty quantification methods with a brief discussion on calibration of uncertainty estimates. For example, whereas (Geng et al., 2024) lacks a detailed discussion on the emerging field of mechanistic interpretability, our survey presents this field in detail, along with potential applications to uncertainty quantification. Moreover, our survey discusses a broad range of applications of uncertainty quantification methods for LLMs, e.g., embodied applications such as in robotics, beyond those discussed in (Geng et al., 2024). A concurrent survey (Huang et al., 2024) on uncertainty quantification of LLMs categorizes existing uncertainty quantification methods within more traditional classes, which do not consider the unique architecture and characteristics of LLMs. In contrast, our survey categorizes existing work within the lens of LLMs, considering the underlying transformer architecture of LLMs and the autoregressive token-based procedure utilized in language generation.
Organization
In Section 2, we begin with a review of essential concepts that are necessary for understanding the salient components of uncertainty quantification of LLMs. We discuss the general notion of uncertainty and introduce the main categories of uncertainty quantification methods within the broader field of deep learning. Subsequently, we identify the relevant metrics utilized by a majority of uncertainty quantification methods for LLMs. In Sections 3, 4, 5, and 6, we discuss the four main categories of uncertainty quantification methods for LLMs, highlighting the key ideas leveraged by the methods in each category. In Section 7, we provide a brief discussion of calibration techniques for uncertainty quantification, with applications to uncertainty quantification of LLMs. In Section 8, we summarize the existing datasets and benchmarks for uncertainty quantification of LLMs and present applications of uncertainty quantification methods for LLMs in Section 9. We highlight open challenges in Section 10 and suggest directions for future research. Lastly, we provide concluding remarks in Section 11. Figure 2 summarizes the organization of this survey, highlighting the key details presented therein.
Uncertainty Quantification for LLMs
Taxonomy
Datasets and Benchmarks
Applications
Open Challenges and Future Directions
Token-Level UQ
Self-Verbalized UQ
Semantic-Similarity UQ
Mechanistic Interpretability
Reading Comprehension
Mathematics
Multi-Hop Reasoning
Factuality Analysis
Chatbot and Textual
Robotics
Consistency and Factuality
Entropy and Factuality
Multi-Episode UQ for Interactive Agents
Mechanistic Interpretability and UQ
Datasets and Benchmarks
(Xiao and Wang, 2021; Kadavath et al., 2022; Bakman et al., 2024; Ling et al., 2024; Vazhentsev et al., 2024; Fadeeva et al., 2024; Ren et al., 2023b)
(Mielke et al., 2022; Lin et al., 2022; Stengel-Eskin et al., 2024; Yang et al., 2024b; Xu et al., 2024b; Tao et al., 2024; Band et al., 2024)
(Kuhn et al., 2023; Chen and Mueller, 2023; Lin et al., 2023; Kossen et al., 2024; Wang et al., 2024a; Qiu and Miikkulainen, 2024; Ao et al., 2024)
(Ahdritz et al., 2024)
(Joshi et al., 2017; Reddy et al., 2019; Lebret et al., 2016)
(Lin et al., 2022)
(Yang et al., 2018; Geva et al., 2021)
(Lin et al., 2021; Li et al., 2023; Thorne et al., 2018)
(Tsai et al., 2024; Ren et al., 2023a; Wang et al., 2023b; Liang et al., 2024; Mullen Jr and Manocha, 2024; Wang et al., 2024c; Zheng et al., 2024)
(Zhang et al., 2023a; Yadkori et al., 2024; Mohri and Hashimoto, 2024; Pacchiardi et al., 2023; Tai et al., 2024; Kolagar and Zarcone, 2024; Steindl et al., 2024)
Figure 2. The overview of this survey, including a taxonomy of uncertainty quantification methods for LLMs, relevant datasets and benchmarks, applications, and open challenges and directions for future research.
2. Background
We review fundamental concepts that are crucial to understanding uncertainty quantification of LLMs. We assume basic familiarity with deep learning and build upon this foundation to introduce more specific concepts, describing the notion of uncertainty, the inner workings of LLMs, and the development of metrics and probes to illuminate the uncertainty of LLMs in their response to a user’s prompt.
2.1. Uncertainty
Uncertainty is a widely-known, yet vaguely-defined concept. For example, people generally associate uncertainty with doubt or a lack of understanding, knowledge, or control, but cannot generally provide a precise definition, especially a mathematical one. This general ambiguity applies to the field of LLMs (Keeling and Street, 2024). For example, a subset of the LLM research field considers the uncertainty of a model to be distinct from its level of confidence in a response generated by the model (Lin et al., 2023), stating that confidence scores are associated with a prompt (input) and a prediction by the model, whereas uncertainty is independent of the model’s prediction. However, a large subset of the field considers uncertainty and the lack of confidence to be mostly-related, generally-interchangeable concepts. In this section, for simplicity, we consider uncertainty and confidence to be mostly interchangeable.
When prompted, LLMs tend to hallucinate when uncertainty about the correct answer exists, e.g., when a lack of understanding or a lack of knowledge exists (see Figures 4 and 4). In Figures 4 and 4, we ask GPT-4o mini to name the best cooking book written by a (likely) fictional person Jamie Feldman. GPT-4o mini provides a confident response: “The Ultimate Guide to Cooking for One.” However, based on an internet search, this cookbook does not exist (although many similar ones do). Moreover, when prompted about its confidence, GPT-4o mini apologizes before providing yet another confident, but factually-incorrect response: “The Jewish Cookbook.” This book is authored by Leah Koenig, not Jamie Feldman. Uncertainty quantification (UQ) methods aim to provide a more rigorous estimate of the model’s confidence in its response, e.g., from the entropy of the distribution from which the tokens are sampled. Before discussing UQ techniques for LLMs, we identify the types of uncertainty and the methods suitable for characterizing uncertainty in deep-learned models, more broadly.
<details>
<summary>extracted/6588127/images/background/uncertainty/hallucination_chatgpt_4.png Details</summary>

### Visual Description
\n
## Screenshot: Chat Conversation
### Overview
The image is a screenshot of a chat conversation. It depicts a question and an answer related to cooking books by Jaime Feldman. The interface resembles a messaging application with speech bubbles.
### Components/Axes
The screenshot contains two speech bubbles:
* **Top Bubble:** Contains a question from a user with a profile icon.
* **Bottom Bubble:** Contains an answer from a bot or assistant, indicated by a circular icon with a stylized "X" inside.
### Detailed Analysis or Content Details
**Top Bubble (Question):**
The text reads: "What is the best cooking book written by Jaime Feldman?"
The bubble is light blue and positioned in the top-center of the image. A user profile icon is present in the top-right corner.
**Bottom Bubble (Answer):**
The text reads: "Jamie Feldman is known for her book "The Ultimate Guide to Cooking for One." This book features recipes designed for solo cooks, focusing on simple, delicious meals that minimize waste and maximize flavor. It’s a great resource for anyone cooking for themselves and looking for practical and tasty ideas!"
The bubble is a darker blue and positioned in the bottom-center of the image. A circular icon with a stylized "X" is present in the top-left corner.
### Key Observations
The conversation is focused on identifying a cooking book by Jaime Feldman. The answer specifically names "The Ultimate Guide to Cooking for One" and describes its focus on single-person cooking.
### Interpretation
The data suggests that "The Ultimate Guide to Cooking for One" is considered Jaime Feldman's most notable or best-known cooking book. The description highlights the book's practicality and suitability for individuals cooking for themselves, emphasizing waste reduction and flavor maximization. The exchange demonstrates a question-answer interaction within a conversational interface, likely a chatbot or virtual assistant. The bot provides a direct answer and elaborates on the book's features, indicating a helpful and informative response.
</details>
Figure 3. Hallucination in LLMs: When asked for information about a possibly fictional person, LLMs tend to fabricate a response that sounds coherent but is entirely false.
\Description
[Hallucination in LLMs: When asked for information about a possibly fictional person, LLMs tend to fabricate a response that sounds coherent but is entirely false.]Hallucination in LLMs: When asked for information about a possibly fictional person, LLMs tend to fabricate a response that sounds coherent but is entirely false.
<details>
<summary>extracted/6588127/images/background/uncertainty/hallucination_chatgpt_4_followup.png Details</summary>
### Visual Description
\n
## Screenshot: Chat Conversation
### Overview
The image is a screenshot of a chat conversation. It depicts a question and an answer related to Jamie Feldman. The conversation is presented in a messaging app interface with speech bubbles.
### Components/Axes
The screenshot contains the following elements:
* **User Profile Icon:** Top-right corner, representing the person asking the question.
* **Question Bubble (Blue):** Contains the question "Are you confident about your response on Jamie Feldman?".
* **Answer Bubble (Light Blue):** Contains the response from the AI assistant.
* **AI Assistant Icon:** Top-left corner of the answer bubble, a circular icon with a checkmark and an "X".
### Content Details
The text content of the screenshot is as follows:
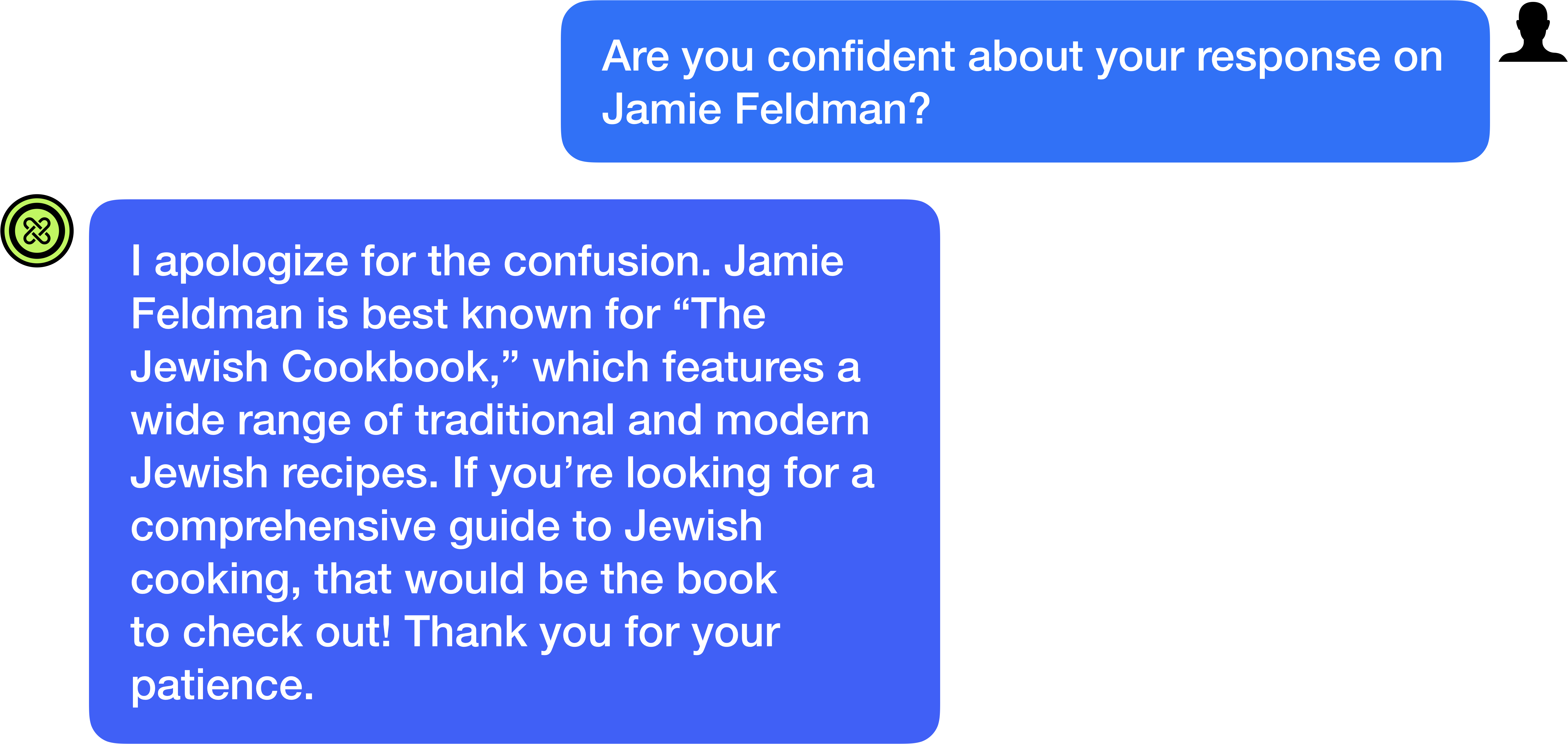
**Question:** "Are you confident about your response on Jamie Feldman?"
**Answer:** "I apologize for the confusion. Jamie Feldman is best known for “The Jewish Cookbook,” which features a wide range of traditional and modern Jewish recipes. If you’re looking for a comprehensive guide to Jewish cooking, that would be the book to check out! Thank you for your patience."
### Key Observations
The AI assistant acknowledges a previous error or uncertainty regarding Jamie Feldman and clarifies that Jamie Feldman is known for writing "The Jewish Cookbook". The response is polite and apologetic.
### Interpretation
The conversation suggests that the AI assistant initially provided an incorrect or incomplete response about Jamie Feldman. The user questioned the accuracy of the response, prompting the AI to correct itself and provide more accurate information. The AI's response demonstrates its ability to acknowledge errors and learn from user feedback. The focus of the conversation is on identifying Jamie Feldman's primary work as "The Jewish Cookbook," a resource for Jewish recipes. The AI's tone is conciliatory, expressing apology and gratitude for the user's patience.
</details>
Figure 4. Hallucination in LLMs: When asked about its confidence, the LLM apologizes before hallucinating another response. The Jewish Cookbook is authored by Leah Koenig, not Jaime Feldman.
\Description
[Hallucination in LLMs: When asked about its confidence, the LLM apologizes before hallucinating another response. The Jewish Cookbook is authored by Leah Koenig, not Jaime Feldman.]Hallucination in LLMs: When asked about its confidence, the LLM apologizes before hallucinating another response. The Jewish Cookbook is authored by Leah Koenig, not Jaime Feldman.
2.2. Types of Uncertainty
Uncertainty can be broadly categorized into two classes, namely: aleatoric uncertainty and epistemic uncertainty. When considered collectively, the resulting uncertainty is referred to as predictive uncertainty, without a distinction between the two components.
2.2.1. Aleatoric Uncertainty
Aleatoric uncertainty encompasses the lack of definiteness of the outcome of an event due to the inherent randomness in the process which determines the outcome of the event. For example, a model cannot predict with certainty the outcome of an unbiased coin toss due to the random effects in the coin toss, regardless of the complexity of the model or the size of the training dataset used in training the model. This irreducible uncertainty is referred to as aleatoric uncertainty. For example, in the case of LLMs, aleatoric uncertainty can arise when there is inherent randomness in the ground-truth response, e.g., when prompted with “What will the temperature be tomorrow?”, the uncertainty associated with the LLM’s output can be characterized as aleatoric uncertainty, which is entirely due to the random effects associated with daily weather conditions. In essence, daily weather conditions cannot be predicted with absolute certainty, irrespective of the amount of training data available.
2.2.2. Epistemic Uncertainty
In contrast to aleatoric uncertainty, epistemic uncertainty characterizes the doubt associated with a certain outcome (prediction) due to a lack of knowledge or “ignorance” by a model, often due to limited training data. For example, when prompted to provide the digit in the $7$ th decimal place in the square-root of $2$ , GPT-4o mini responds with the answer $6$ . However, this answer is wrong: the digit in the $7$ th decimal place is $5$ . The uncertainty in the LLM’s output can be characterized as epistemic uncertainty, which can be eliminated by training the LLM on more data specific to this prompt. In other words, epistemic uncertainty describes reducible uncertainty, i.e., epistemic uncertainty should reduce when there is more knowledge about the state on which the decision is being made, e.g., via choosing the right model to use for learning, using more training data, or by incorporating any prior knowledge. The uncertainty associated with the response in Figure 4 is entirely epistemic and stems from missing training data. If we train the LLM on more data, including the fact that Jamie Feldman did not write a cookbook, we can eliminate the uncertainty associated with the model’s response. Before concluding, we note that prior work has explored decomposing predictive uncertainty into epistemic and aleatoric components (Hou et al., 2023).
2.3. Uncertainty Quantification in Deep Learning
Broadly, uncertainty quantification for deep learning lies along a spectrum between two extremes: training-based and training-free methods, illustrated in Figure 5. Whereas training-based methods assume partial or complete visibility and access to the internal structure of the neural network, modifying it to probe its uncertainty, training-free methods use auxiliary models or additional data to quantify the uncertainty of the model post-hoc.
Training-based Training-free BNNs (Jospin et al., 2022) MCMC (Hastings, 1970) Variational Inference (Posch et al., 2019) MC-Dropout (Gal and Ghahramani, 2016; Gal et al., 2017)
| Deep Ensemble |
| --- |
| (Lakshminarayanan et al., 2017; Guo et al., 2018; Cavalcanti et al., 2016; Martinez-Munoz et al., 2008; Buciluǎ et al., 2006; Hinton, 2015) |
| ENNs |
| --- |
| (Osband et al., 2023; Wang and Ji, 2024) |
| Test-time Data Augmentation |
| --- |
| (Lee and AlRegib, 2020; Ayhan and Berens, 2018; Wu and Williamson, 2024; Bahat and Shakhnarovich, 2020) |
Dropout Injection (Loquercio et al., 2020; Ledda et al., 2023) Gradient-based (Lee and AlRegib, 2020; Huang et al., 2021; Igoe et al., 2022)
Figure 5. Uncertainty quantification methods in deep learning span the spectrum from training-based methods to training-free methods.
2.3.1. Training-Based Methods
Training-based uncertainty quantification methods span Bayesian Neural Networks, Monte Carlo Dropout methods, and Deep Ensembles, which we review in the subsequent discussion. Instead of training a set of parameters to predict a single outcome, a Bayesian neural network (BNN) (Jospin et al., 2022) learns a distribution over the model’s weights $\theta$ . Specifically, a BNN learns a distribution over the parameters, $p(\theta|D)$ , with dataset $D$ , with its prediction consisting of two parts: a maximum a posteriori estimation component $\hat{y}$ , and the uncertainty associated with it, defined by the covariance of the prediction $\Sigma_{\hat{y}|x,D}$ .
Despite being statistically principled, the prohibitive computational costs associated with BNNs prevent them from being directly employed. In order to train BNNs, a variety of methods have been proposed, among which the most popular ones are Markov Chain Monte-Carlo (MCMC) (Hastings, 1970) and variational inference (Posch et al., 2019). The former samples from the exact posterior distribution, while the latter learns to approximate the posterior with a variational distribution, $q_{\varphi}$ . Due to the relaxed requirement of access to large amounts of samples, the variational inference method has been more widely used, with Monte-Carlo dropout (Gal and Ghahramani, 2016; Gal et al., 2017) and Deep ensemble (Lakshminarayanan et al., 2017) being representative methods. More recently, epistemic neural networks (ENNs) (Osband et al., 2023; Wang and Ji, 2024) have been introduced to reduce the computational challenges associated with BNNs. To make ensemble methods more efficient, e.g., in out-of-distribution detection (Vyas et al., 2018), pruning methods (Guo et al., 2018; Cavalcanti et al., 2016; Martinez-Munoz et al., 2008), which reduce redundancy among ensemble members, and distillation methods (Buciluǎ et al., 2006; Hinton, 2015), which reduce the number of networks to one, teaching it to represent the knowledge of a group of networks, have been introduced. While these methods are easy to implement and require much less computation compared to regular BNNs or MCMC, they do suffer from being an approximation of the true posterior distribution. In fact, the model’s uncertainty predictions could be worse when data augmentation, ensembling, and post-processing calibration are used together (Rahaman et al., 2021).
2.3.2. Training-Free Methods
Training-free methods for estimating uncertainty have become popular due to their ease of implementation. Since neither the network architecture nor the training process need to be revised, training-free methods work well with large-scale foundation models that are costly to train or fine-tune. In (Ayhan and Berens, 2018; Lee and AlRegib, 2020; Wu and Williamson, 2024; Bahat and Shakhnarovich, 2020), the authors perform data augmentation at test time to generate a predictive distribution, quantifying the model’s uncertainty. Similarly, dropout injection (Loquercio et al., 2020; Ledda et al., 2023) extends MC-dropout to the training-free domain by only performing dropout at inference time to estimate epistemic uncertainty. In (Mi et al., 2022), the authors estimate uncertainty for regression using similar perturbation techniques. Lastly, gradient-based uncertainty quantification methods (Lee and AlRegib, 2020) generate gradients at test-time, which provide an signal for epistemic uncertainty and for OOD detection in (Huang et al., 2021; Igoe et al., 2022), by constructing confounding labels.
2.4. Uncertainty Quantification for LLMs
The introduction of the transformer (Vaswani, 2017) for sequence-to-sequence machine translation tasks spurred the development of large language models. However, as noted in the preceding discussion, LLMs have gained some notoriety for their tendency to hallucinate when uncertain about a response to a specified prompt. Here, we review the general architecture of LLMs and provide some motivation for the development of LLM-specific metrics for quantifying uncertainty.
2.4.1. LLM Architecture
LLMs use the transformer architecture to provide free-form responses to input prompts specified in natural language. The transformer architecture consists of an encoder, which processes the input to the model, and a decoder, which generates the model’s outputs auto-regressively, where the previous outputs of the model are passed into the model to generate the future outputs. Given an input prompt, the words (elements) of the prompt are tokenized (i.e., the sentences/phrases in natural-language are decomposed into simple units referred to as tokens) and transformed to input embeddings using a learned model. The encoder takes in the input embeddings augmented with positional encodings to incorporate positional context and generates a sequence of latent embeddings, which serves as an input to the decoder, using a stack of $N$ multi-head attention sub-blocks and fully-connected feedforward networks. The decoder takes in the embeddings associated with the previous outputs of the decoder, preceded by a start token, and computes an output embedding using a similar stack of multi-head attention heads and feedforward networks as the encoder. The resulting output embeddings are passed into a linear layer prior to a softmax output layer, which converts the decoder embeddings to a probability distribution over the tokens in the dictionary of the model. In subsequent discussion, we denote the probability of the $j$ ’th token in the $i$ ’th sentence of an LLM’s output as $p_{ij}$ . The output token is selected from this probability distribution: e.g., by greedily taking the token associated with the maximum probability mass. The resulting output is passed into the decoder for auto-regressive generation of text.
<details>
<summary>extracted/6588127/images/background/architecture/llm_architecture.png Details</summary>

### Visual Description
\n
## Diagram: Transformer Model Architecture
### Overview
This diagram illustrates the architecture of a Transformer model, specifically focusing on the encoder side. It depicts the flow of data through various sub-layers, including positional encoding, embedding, normalization, multi-head attention, feed-forward networks, and a final softmax layer. The diagram highlights the repeated application of "N multi-head attention sub-blocks".
### Components/Axes
The diagram consists of the following components, arranged in a sequential flow from left to right:
* **Positional Encoding:** (Green circle with a looping arrow) - Input to the model.
* **Embedding:** (Yellow rectangle) - Transforms input into a vector representation.
* **Addition/Residual Connection:** (White circle with a plus sign) - Adds the input to the output of a layer.
* **Norm:** (Blue rectangle) - Normalization layer.
* **Masked Multi-Head Attention:** (Blue rectangle) - Attention mechanism.
* **Feed-Forward:** (Blue rectangle) - Feed-forward neural network.
* **Linear:** (Blue rectangle) - Linear transformation.
* **Softmax:** (Orange rectangle) - Output layer, producing probabilities.
* **N multi-head attention sub-blocks:** (Text label indicating repetition of the central block)
* **Dotted Gray Lines:** Indicate the boundaries of the repeated sub-blocks and the overall model flow.
### Detailed Analysis or Content Details
The diagram shows a clear sequential flow of data:
1. **Positional Encoding** is fed into the **Embedding** layer.
2. The output of the Embedding layer is added to the Positional Encoding via a **Residual Connection**.
3. The result is passed through a **Norm** layer.
4. The output of the Norm layer is fed into a **Masked Multi-Head Attention** layer.
5. The output of the Attention layer is added to its input via another **Residual Connection**.
6. The result is passed through another **Norm** layer.
7. The output of the second Norm layer is fed into a **Feed-Forward** network.
8. The output of the Feed-Forward network is added to its input via a **Residual Connection**.
9. The result is passed through a final **Norm** layer.
10. The output of the final Norm layer is passed through a **Linear** layer.
11. Finally, the output of the Linear layer is passed through a **Softmax** layer to produce the final output.
The central block consisting of "Masked Multi-Head Attention", "Norm", "Feed-Forward", "Norm", and the residual connections is repeated "N" times, as indicated by the label above the block. The dotted gray lines visually delineate the boundaries of these repeated blocks.
### Key Observations
The diagram emphasizes the use of residual connections (addition operations) around each major sub-layer (Norm, Attention, Feed-Forward). This is a common practice in deep neural networks to help with gradient flow during training. The repeated application of the attention sub-blocks suggests that the model learns hierarchical representations of the input data. The use of "Masked" Multi-Head Attention suggests this is likely part of a decoder, or a model dealing with sequential data where future information should be masked.
### Interpretation
This diagram represents a core component of the Transformer architecture, a powerful neural network model that has achieved state-of-the-art results in various natural language processing tasks. The diagram illustrates the key building blocks of the Transformer, including the attention mechanism, normalization layers, and residual connections. The repeated application of the attention sub-blocks allows the model to capture complex relationships between different parts of the input sequence. The use of residual connections helps to mitigate the vanishing gradient problem, enabling the training of deeper models. The overall architecture is designed to process sequential data in parallel, making it more efficient than traditional recurrent neural networks. The "N" indicates the depth of the model, and can be tuned to balance model capacity and computational cost.
</details>
Figure 6. Many state-of-the-art LLMs are decoder-only transformers, with $N$ multi-head attention sub-blocks, for auto-regressive output generation.
\Description
[Many state-of-the-art LLMs are decoder-only transformers, with $N$ multi-head attention sub-blocks, for auto-regressive output generation.]Many state-of-the-art LLMs are decoder-only transformers, with $N$ multi-head attention sub-blocks, for auto-regressive output generation.
While early LLM models utilized encoder-only or encoder-decoder transformer architectures, state-of-the-art LLMs now generally utilize a decoder-only architecture. For example, the GPT family of models, such as GPT-4 (Achiam et al., 2023), and the Llama family of models, such as Llama 3 (Dubey et al., 2024), are decoder-only transformers. In Figure 6, we show a decoder-only transformer model. These state-of-the-art models leverage advances in transformers to improve computational efficiency, given the huge size of these models: Llama $3$ has $8$ B parameters for the small variant and $70$ B parameters for the large variant, while GPT- $4$ is rumored to have over one trillion parameters. Llama $3$ uses rotary positional embeddings (RoPE) (Su et al., 2024a) instead of absolute positional embeddings, which have been shown to be more effective than alternative embedding schemes. For a more detailed review of LLMs, we refer readers to (Minaee et al., 2024). Before presenting the metrics utilized by UQ methods for LLMs, we discuss natural-language inference, which is an important component of many UQ methods for LLMs.
2.4.2. Natural-Language Inference
Natural-language inference (NLI) refers to the task of characterizing the relationship between two text fragments, where one text fragment represents a premise (i.e., a statement that is believed to be true) while the other fragment represents a hypothesis (i.e., a statement whose veracity we seek to evaluate based on the premise) (Williams et al., 2017; Dagan et al., 2005; Fyodorov et al., 2000). Given a premise and a hypothesis, we can classify the relation between the text pair as: an entailment, if one can infer that the hypothesis is most likely true given the premise; a contradiction, if one can infer that the hypothesis is most likely false given the premise; or a neutral label, if one cannot infer the truthfulness of the hypothesis from the premise (MacCartney and Manning, 2008; Condoravdi et al., 2003; Monz and de Rijke, 2001). In Figure 7, we provide some examples of text pairs that exhibit entailment, contradiction, or neutrality. In the first example, the premise indicates that the student presented a research paper at a conference (i.e., the student did not skip the conference), hence, the contradiction. In the second example, the premise indicates that the orchestra enjoyed the concert, but does not state whether the orchestra performed at the concert (or just observed the event), hence the neutral label. In the third example, we can infer that the hypothesis is true, since the premise indicates that the team was on vacation, hence, not in the office.
<details>
<summary>extracted/6588127/images/background/nli/nli.png Details</summary>
### Visual Description
\n
## Diagram: Natural Language Inference Examples
### Overview
The image presents three examples illustrating different relationships between pairs of sentences in the context of Natural Language Inference (NLI). Each example consists of a premise sentence on the left, a hypothesis sentence on the right, and a label indicating the relationship between them. The relationships are categorized as "Contradiction", "Neutral", and "Entailment". Each pair of sentences is visually connected by a series of interconnected circles.
### Components/Axes
The diagram consists of three horizontally stacked sections, each representing a different NLI relationship. Each section contains:
* **Premise:** A sentence presented on the left side.
* **Hypothesis:** A sentence presented on the right side.
* **Relationship Label:** A label (Contradiction, Neutral, Entailment) positioned above the connecting circles.
* **Connecting Circles:** A series of interconnected circles visually linking the premise and hypothesis. The circles are white with black outlines.
* **Color Coding:** Each section is color-coded:
* Contradiction: Pink
* Neutral: Light Yellow/Peach
* Entailment: Light Green
### Detailed Analysis / Content Details
**1. Contradiction (Pink Section)**
* **Premise:** "A student presented a research paper at the conference."
* **Hypothesis:** "The student skipped the conference."
* **Relationship:** Contradiction
* **Connecting Circles:** Four circles are present.
**2. Neutral (Light Yellow/Peach Section)**
* **Premise:** "The orchestra enjoyed the concert."
* **Hypothesis:** "The orchestra performed at the concert."
* **Relationship:** Neutral
* **Connecting Circles:** Four circles are present.
**3. Entailment (Light Green Section)**
* **Premise:** "The team was out on vacation yesterday."
* **Hypothesis:** "The team was not in the office yesterday."
* **Relationship:** Entailment
* **Connecting Circles:** Four circles are present.
### Key Observations
The diagram visually demonstrates the three core relationships in NLI:
* **Contradiction:** The hypothesis asserts something that logically conflicts with the premise.
* **Neutral:** The hypothesis neither confirms nor denies the premise; it's independent.
* **Entailment:** The hypothesis logically follows from the premise; if the premise is true, the hypothesis must also be true.
The connecting circles, while visually present, do not appear to convey any specific information beyond linking the premise and hypothesis. The color coding effectively distinguishes the different relationship types.
### Interpretation
This diagram serves as a clear and concise illustration of the fundamental concepts in Natural Language Inference. It highlights how understanding the relationship between sentences is crucial for tasks like question answering, text summarization, and dialogue systems. The examples chosen are relatively simple, making the concepts accessible. The use of color and visual connections aids in quick comprehension. The diagram doesn't present any quantitative data, but rather focuses on qualitative examples to define the NLI categories. The consistent structure across the three examples reinforces the understanding of each relationship type.
</details>
Figure 7. Natural-language inference models characterize the relationship between a pair of texts, namely: a premise and a hypothesis. The possible relations include: (1) an entailment where the hypothesis can be inferred from the premise; (2) a contradiction, where the hypothesis is more likely false given the premise; and (3) a neutral relation, where the veracity of the hypothesis cannot be determined from the premise.
\Description
[Natural-language inference models characterize the relationship between a pair of texts, namely: a premise and a hypothesis. The possible relations include: (1) an entailment where the hypothesis can be inferred from the premise; (2) a contradiction, where the hypothesis is more likely false given the premise; and (3) a neutral relation, where the veracity of the hypothesis cannot be determined from the premise.]Natural-language inference models characterize the relationship between a pair of texts, namely: a premise and a hypothesis. The possible relations include: (1) an entailment where the hypothesis can be inferred from the premise; (2) a contradiction, where the hypothesis is more likely false given the premise; and (3) a neutral relation, where the veracity of the hypothesis cannot be determined from the premise.
NLI methods play an important role in uncertainty quantification of LLMs. Many UQ methods for LLMs rely on characterization of the semantic relationship between multiple realizations of the LLM’s responses to a given input prompt to determine the confidence of the model. Many of these methods rely on learned models for natural-language inference, such as BERT (Devlin, 2018), which utilizes a transformer-based architecture to learn useful language representations that are crucial in natural-language tasks such as question answering and natural-language inference. Unlike many standard language models, e.g., Generative Pre-trained Transformer (GPT) (Radford and Narasimhan, 2018), which impose a unidirectionality constraint where every token can only attend to previous tokens, BERT employs a bidirectional approach where each token can attend to any token regardless of its relative position, using a masked language model, potentially enabling the model to capture broader context, especially in sentence-level tasks. In (Liu, 2019), the authors demonstrate that the performance of BERT is limited by inadequate pre-training and propose an improved model, named RoBERTa (Liu, 2019), which retains the same architecture as BERT but is trained for longer with larger mini-batches of data with longer sequences. DeBERTa (He et al., 2020) further improves upon the performance of RoBERTa by introducing a disentangled attention mechanism and an enhanced mask decoder.
2.4.3. Metrics for Uncertainty Quantification for LLMs.
Uncertainty quantification in the LLM community has largely eschewed traditional UQ methods for learned models due to the notable computation cost of running inference on LLMs (Balabanov and Linander, 2024), although, a few UQ methods for LLMs utilize deep ensembles, e.g., (Wang et al., 2023a; Balabanov and Linander, 2024; Zhang et al., 2024; Arteaga et al., 2024), generally based on low-rank adaptation (LoRA) (Hu et al., 2021). Consequently, many UQ methods in this space have introduced less computationally intensive approximate quantification methods that directly harness the unique architecture of LLM models to assess the uncertainty of these models. In some cases, these methods retain the high-level idea of ensemble methods, quantifying the uncertainty of the model on a given prompt using the outputs of a set of individual models or a collection of outputs from the same model, with a temperature parameter less than one to promote greater stochasticity in the tokens generated by the model. UQ methods for LLMs can be broadly categorized into white-box models and black-box models (Liu et al., 2024d; Vashurin et al., 2024), illustrated in Figure 9 and Figure 9, respectively.
White-Box UQ Methods
White-box UQ models assume that the underlying architecture of the model is partially or completely visible and accessible—hence the term white-box —taking advantage of access to the intermediate outputs of the underlying models, such as the probability distribution over the generated tokens or outputs at the inner layers of the model, to assess the uncertainty of the model (Kuhn et al., 2023; Azaria and Mitchell, 2023; Fadeeva et al., 2024). We provide some metrics utilized by white-box UQ methods for LLMs, where $p_{ij}$ denotes the conditional probability of token $j$ (conditioned on all preceding tokens) in sentence $i$ :
<details>
<summary>extracted/6588127/images/background/uq_techniques/white_box.png Details</summary>
### Visual Description
\n
## Data Display: Volleyball Olympic Debut & City Association
### Overview
The image presents information regarding the year volleyball debuted as an Olympic sport and a percentage breakdown associated with several cities. It appears to be a visual response to a question about volleyball's Olympic history.
### Components/Axes
The image contains the following elements:
* **Question Bubble:** A blue speech bubble containing the question "When did volleyball become an Olympic Sport?".
* **Answer Block:** A dark blue rectangular block stating "Volleyball debuted at the Tokyo Olympic Games in 1964." The word "Tokyo" is highlighted in orange.
* **Percentage List:** A list of cities and their associated percentages, displayed within the dark blue block. The cities are: Tokyo, Osaka, Kyoto, Beijing, and Mumbai.
### Detailed Analysis or Content Details
The image provides the following data:
* **Volleyball Debut:** 1964 at the Tokyo Olympic Games.
* **Tokyo:** 87.28%
* **Osaka:** 7.49%
* **Kyoto:** 4.16%
* **Beijing:** 1.04%
* **Mumbai:** 0.00%
The percentages are listed in descending order, with Tokyo having the highest percentage and Mumbai having the lowest.
### Key Observations
The data strongly associates the debut of volleyball as an Olympic sport with Tokyo. The percentage assigned to Tokyo (87.28%) is overwhelmingly dominant compared to the other cities listed. The remaining cities have significantly smaller percentages, suggesting a minor association or perhaps a representation of search interest related to the question.
### Interpretation
The image suggests that while volleyball debuted at the Tokyo Olympics in 1964, there's a disproportionately strong connection between the sport and the city of Tokyo. The percentages likely represent the frequency with which each city is mentioned in relation to the question "When did volleyball become an Olympic Sport?". This could be based on search data, social media mentions, or other forms of online activity. The high percentage for Tokyo reinforces its historical significance as the host city for volleyball's Olympic debut. The other cities likely have some tangential connection, perhaps through hosting related events or having strong volleyball communities, but their association is far less prominent. The 0.00% for Mumbai suggests a very weak or non-existent association with the question.
</details>
Figure 8. White-box uncertainty quantification methods utilize an LLM’s internal information, e.g., the model’s probabilities for the token associated with each output.
\Description
[White-box uncertainty quantification methods utilize an LLM’s internal information, e.g., the model’s probabilities for the token associated with each output.]White-box uncertainty quantification methods utilize an LLM’s internal information, e.g., the model’s probabilities for the token associated with each output.
<details>
<summary>extracted/6588127/images/background/uq_techniques/black_box.png Details</summary>
### Visual Description
\n
## Diagram: LLM Response Generation Flow
### Overview
This diagram illustrates the process of a Large Language Model (LLM) responding to a user query. It depicts the input query, the LLM processing stage, the generation of multiple responses, and a confidence estimate for the responses.
### Components/Axes
The diagram consists of the following components, arranged vertically:
1. **Input Query:** A light blue rounded rectangle at the top, labeled "Who was Abraham Lincoln?". A small grey icon of a person is positioned in the top-right corner.
2. **LLM Processing:** A green circular shape containing a stylized intertwined symbol, labeled "LLM".
3. **Responses:** A light blue rounded rectangle labeled "Randomly-Generated Responses". This contains two example responses, separated by ellipses ("..."), suggesting more responses exist.
4. **Confidence Estimate:** A pink rounded rectangle at the bottom, labeled "Confidence Estimate: 75%".
5. **Arrows:** Black downward-pointing arrows indicate the flow of information between the components.
### Detailed Analysis or Content Details
The diagram shows a sequential flow:
1. **Input:** The query "Who was Abraham Lincoln?" is presented as input.
2. **Processing:** The query is processed by the LLM.
3. **Output:** The LLM generates multiple responses. Two examples are provided:
* "Abraham Lincoln was the fifteenth president of the U.S., serving from 1861 to 1865."
* "Abraham Lincoln was the sixteenth president of the U.S., serving from 1861 to 1864."
4. **Confidence:** A confidence estimate of 75% is assigned to the generated responses.
### Key Observations
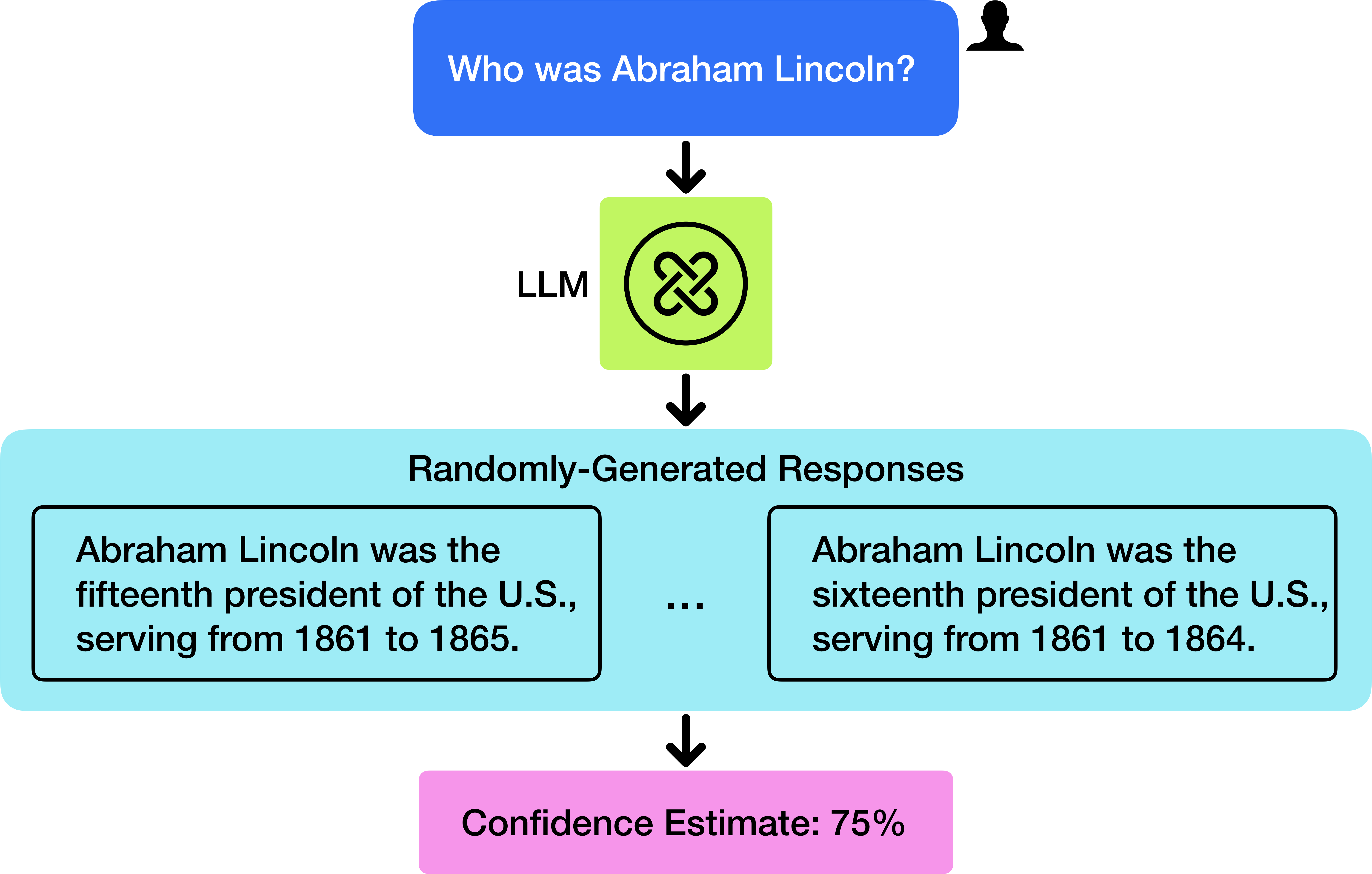
The diagram highlights a potential issue with LLMs: the generation of conflicting or inaccurate responses. The two provided responses disagree on Lincoln's presidential number (fifteenth vs. sixteenth) and the end year of his presidency (1865 vs. 1864). The confidence estimate of 75% suggests the LLM is not entirely certain about its responses, despite presenting them as factual.
### Interpretation
This diagram demonstrates the probabilistic nature of LLM responses. LLMs do not "know" facts in the same way humans do; they generate text based on patterns learned from training data. This can lead to inconsistencies and inaccuracies, even with a relatively high confidence estimate. The diagram suggests that LLM outputs should be critically evaluated and not accepted as definitive truth. The inclusion of a confidence estimate is a useful feature, but it does not guarantee the accuracy of the information. The "Randomly-Generated Responses" label implies that the LLM produces multiple possible answers, and the selection of the final response may be based on factors other than factual correctness. The diagram is a visual representation of the challenges associated with relying on LLMs for factual information.
</details>
Figure 9. Black-box uncertainty quantification methods do not access the internal states or probabilities computed by the model, quantifying the model’s uncertainty entirely from its natural-language response.
\Description
[Black-box uncertainty quantification methods do not access the internal states or probabilities computed by the model, quantifying the model’s uncertainty entirely from its natural-language response.]Black-box uncertainty quantification methods do not access the internal states or probabilities computed by the model, quantifying the model’s uncertainty entirely from its natural-language response.
1. Average Token Log-Probability. The average of the negative log-probability of the tokens, which captures the average confidence of the model (Manakul et al., 2023), is given by: ${\mathrm{Average}(p)=-\frac{1}{L_{i}}\sum_{j}\log(p_{ij}),}$ where sentence $i$ consists of $L_{i}$ tokens. Note that the value of this metric increases as the conditional probability distribution of each token decreases, signifying an decrease in the model’s confidence. The average token probability is related to the product of the token probabilities.
1. Perplexity. The perplexity of a model’s prediction represents the exponential of the average of the negative log-probability of the tokens which comprise the sentence (response) generated by the LLM (Fadeeva et al., 2024). Perplexity is given by: ${\mathrm{Perplexity}(p)=\exp\left(-\frac{1}{L_{i}}\sum_{j}\log(p_{ij})\right).}$
1. Maximum Token Log-Probability. The maximum token log-probability captures the token with the lowest conditional probability, which is given by: ${\mathrm{Maximum}(p)=\max_{j}-\log(p_{ij}).}$
1. Response Improbability. This metric entails computing the probability of a given sentence given the conditional distribution for each token (Fadeeva et al., 2024), where the probability distribution is conditioned on preceding tokens, and subtracting the resulting value from one. The uncertainty metric is defined as: ${\mathrm{Improb.}=1-\prod_{j}p_{ij}.}$
1. Entropy. The maximum entropy of the probability distribution associated with each token can be utilized as a metric for UQ, given by: ${\mathrm{Entropy}=\max_{j}\mathcal{H}(p_{j}),}$ where $\mathcal{H}$ represents the entropy of the probability distribution $p_{j}$ of token $j$ . Some existing methods claim that this metric is better than the perplexity (Fadeeva et al., 2024). Similarly, the predictive entropy (Malinin and Gales, 2020) at input $x$ and output $y$ is defined as: ${\mathcal{H}(Y\mid x)=-∈t p(y\mid x)\ln p(y\mid x)dy.}$ In the discrete case, the entropy associated with the output distribution of token $j$ in sentence $i$ is defined by: ${\mathcal{H}_{ij}=-\sum_{w∈\mathcal{D}}p_{ij}(w)\log p_{ij}(w),}$ where $\mathcal{D}$ denotes the dictionary containing all possible words in the model and $w$ represents a word in $\mathcal{D}$ .
Black-Box UQ Methods
In contrast, black-box methods assume that the model’s internal outputs cannot be accessed externally (Manakul et al., 2023; Chen and Mueller, 2023). Hence, these methods quantify the uncertainty of the model entirely from the model’s response to an input prompt. Prior work has discussed the pros and cons of both categories of UQ methods (Lin et al., 2023). Concisely, white-box methods generally require access to the underlying architecture and intermediate outputs of an LLM, which is increasingly difficult to obtain given that many LLMs have become closed-source models, posing a significant limitation. In contrast, black-box models enable UQ of closed-source models such as OpenAI’s GPT-4 (Achiam et al., 2023) and Anthropic Claude (Anthropic, 2024), which do not provide complete access to the model. In general, black-box UQ methods for LLMs require the evaluation of the similarity between multiple responses generated by an LLM or an ensemble of LLMs on the same or similar prompts to quantify the uncertainty of the LLM on a given input prompt. Other black-box UQ methods, such as self-verbalized UQ methods, train the model to directly provide a natural-language estimate of its confidence. Here, we identify some prominent techniques for measuring the similarity between a pair of text fragments:
1. NLI Scores. As described in Section 2.4.2, NLI models, such as RoBERTa (Liu, 2019) and DeBERTa (He et al., 2020), classify the relationship between a pair of text fragment as either an entailment, a contradiction, or a neutral relation. Many black-box methods utilize the probabilities (or logits) predicted by the NLI model for these three classes as a measure of the similarity between the two text fragments, which is ultimately used to quantify the uncertainty of the LLM. For example, given the probability $p_{\mathrm{entail}}$ predicted by an NLI model that a text fragment $t_{1}$ entails another text fragments $t_{2}$ , we can define the similarity between both text fragments as: ${\mathrm{sim}(t_{1},t_{2})=p_{\mathrm{entail}}}$ . Conversely, given the probability of contradiction $p_{\mathrm{contradict}}$ , we can define the similarity between $t_{1}$ and $t_{2}$ as: ${\mathrm{sim}(t_{1},t_{2})=1-p_{\mathrm{contradict}}}$ .
1. Jaccard Index. The Jaccard index, also referred to as Intersection-over-Union measures the similarity between two sets by computing the ratio of the intersection of both sets and the union of both sets. Hence, the Jaccard index $J$ between two sets $\mathcal{T}_{1}$ and $\mathcal{T}_{2}$ , where each set consists of the words that make up its associated text fragment, is given by: ${J(\mathcal{T}_{1},\mathcal{T}_{2})=\frac{|\mathcal{T}_{1}\cap\mathcal{T}_{2}|%
}{|\mathcal{T}_{1}\cup\mathcal{T}_{2}|}.}$ Although the Jaccard index always lies between $0 0$ and $1$ , making it a suitable metric (Pilehvar et al., 2013; Cronin et al., 2017; Qurashi et al., 2020), the Jaccard index does not consider the context of the text fragments, which is important in evaluating the similarity between both text fragments.
1. Sentence-Embedding-Based Similarity. The similarity between two text fragments can also be determined by computing the cosine-similarity between the sentence embeddings associated with each text fragment. Sentence-embedding models transform natural-language inputs (or tokens) into a vector space, enabling direct computation of the similarity between two sentences (phrases). For example, Sentence-BERT (SBERT) (Reimers, 2019) builds upon the pretrained BERT architecture to train a model that computes semantically-relevant sentence embeddings. Other similar models include LaBSE (Feng et al., 2020) and SONAR (Duquenne et al., 2023). Since the sentence embeddings capture the context of the text fragment, this approach is less susceptible to the challenges faced by the Jaccard index, such as those that arise with negated words.
1. BERTScore. The BERTScore (Zhang et al., 2019) measures the similarity between two sentences by computing the cosine-similarity between the contextual embedding of each token (word) in the reference sentence $t_{r}$ and the contextual embedding of the associated token in the candidate sentence $t_{c}$ . The token embeddings are generated from NLI models to capture the context of the sentence. As a result, a given word might have different embeddings, depending on the context of the sentence in which it is used, addressing the challenges faced by the Jaccard similarity metric and word-embedding-based metrics. The BERTScore is composed of a precision $P_{\mathrm{BS}}$ , recall $R_{\mathrm{BS}}$ , and F1 $F_{\mathrm{BS}}$ score, given by:
$$
P_{\mathrm{BS}}=\frac{1}{|t_{c}|}\sum_{\hat{w}_{j}\in t_{c}}\max_{w_{i}\in t_{%
r}}w_{i}^{\top}\hat{w}_{j},\enspace R_{\mathrm{BS}}=\frac{1}{|t_{r}|}\sum_{w_{%
i}\in t_{r}}\max_{\hat{w}_{j}\in t_{c}}w_{i}^{\top}\hat{w}_{j},\enspace F_{%
\mathrm{BS}}=2\frac{P_{\mathrm{BS}}\cdot R_{\mathrm{BS}}}{P_{\mathrm{BS}}+R_{%
\mathrm{BS}}}, \tag{1}
$$
where each token in the candidate sentence is matched to its most similar token in the reference sentence. The BERTScore is obtained by computing the cosine-similarity between matched pairs. Since each token embedding is normalized, the cosine-similarity between a pair of embeddings simplifies to the inner-product. The recall score is related to the ROUGE metric (Lin, 2004) used in evaluating text summaries and more broadly to the BARTScore (Yuan et al., 2021). However, the ROUGE metric utilizes human-provided summaries as the reference.
In the following sections, we describe the main categories of UQ methods for LLMs in detail, namely: (1) Token-Level UQ Methods; (2) Self-Verbalized UQ Methods; (3) Semantic-Similarity UQ Methods; and (4) Mechanistic Interpretability, outlined in Figure 2. Although mechanistic interpretability has not been widely applied to uncertainty quantification, we believe that insights from mechanistic interpretability can be more extensively applied to the uncertainty quantification of LLMs; hence, we include these methods within our taxonomy.
3. Token-Level UQ
We recall that the outputs of an LLM are generated by sampling from a probability distribution over the tokens that make up the outputs, conditioned on the preceding tokens in the outputs (see LABEL:{sec:background_uq_llm}). Token-level UQ methods leverage the probability distribution over each token to estimate the probability of generating a given response from an LLM. Although a high predicted probability in a particular generation may not be indicative of its correctness over another, direct quantification of the model’s generating distribution may lead to better understanding of the stochasticity of generations. Token-level UQ methods utilize the white-box UQ metrics discussed in Section 2.4.3 to estimate the randomness in the probability distribution associated with an LLM’s response. For example, some token-level UQ methods compute the entropy of the underlying probability distribution over the tokens (Xiao and Wang, 2021; Ling et al., 2024) or semantic clusters (Kuhn et al., 2023) (referred to as semantic entropy) to estimate the LLM’s confidence. Likewise, a variant of SelfCheckGPT (Manakul et al., 2023) trains an $n$ -gram model using multiple samples of the response of an LLM to a given query including its main response. Subsequently, SelfCheckGPT estimates the LLM’s uncertainty by computing the average of the log-probabilities of the tokens generated by the $n$ -gram model, given the original response of the LLM. Moreover, SelfCheckGPT proposes using the maximum of the negative log-probability to estimate the LLM’s uncertainty.
Token-based UQ methods generally perform poorly with long-form responses, because the product of the token probabilities decrease with longer responses, even when the responses are semantically equivalent to a shorter response. To address this limitation, token-based UQ methods employ a length-normalized scoring function (Thomas and Joy, 2006; Malinin and Gales, 2020), to reduce the dependence of the UQ metrics on the length of the sequence, given by: ${\mathrm{Product(p)}=\prod_{j=1}^{L_{i}}p_{ij}^{\frac{1}{L_{i}}}}$ , where $L_{i}$ denotes the length of sentence $i$ , and $p_{ij}$ is the conditional probability of token $j$ , given all preceding tokens, in sentence $i$ . The work in (Bakman et al., 2024) introduces Meaning-Aware Response Scoring (MARS) as an alternative to length-normalized scoring. MARS utilizes an importance function to assign weights to each token based on its contribution to the meaning of the sentence. The contribution of each token to the meaning of the sentence is determined using BEM (Bulian et al., 2022), a question-answer evaluation model. Taking a different approach, Claim-Conditioned Probability (CCP) (Fadeeva et al., 2024) decomposes the output of an LLM into a set of claims and computes the token-level uncertainty of each claim from its constituent tokens. CCP utilizes the OpenAI Chat API (Brown, 2020; Achiam et al., 2023) to identify the main claims in a given response. By examining the component claims, CCP provides finer-grained uncertainty quantification compared to other UQ methods for LLMs.
As described, token-level UQ methods estimate the uncertainty of an LLM based on the conditional distribution associated with each token. Although this approach is effective in general, the conditional distribution of the tokens can be misleading in certain scenarios, especially when an initial token is incorrect but all the succeeding tokens are highly probable given the initial token. Trainable attention-based dependency (TAD) (Vazhentsev et al., 2024) trains a regression model on the conditional dependence between the tokens and applies the predicted factors to improve the estimated uncertainty of the LLM. Lastly, we present token-level UQ methods that use specific prompting strategies to estimate the model’s confidence. The work in (Kadavath et al., 2022) shows that token-based UQ methods can be particularly effective in estimating the confidence of LLMs when the model is prompted to select an option when given a multiple-choice question. Specifically, the authors show that the model’s probability distribution over the options in the prompt is well-calibrated, when presented with multiple-choice problems or problems with a True/False answer. Further, the authors fine-tune an LLM with a value head to predict the probability that the model knows the answer to a given question for each token. The probability associated with the LLM’s final token is defined as the confidence of the LLM in its response for the given prompt. The results demonstrate that the LLM predictions of these probability values are well-calibrated, with an improvement in the calibration performance with larger models. Other follow-on work leveraging multiple-choice problems to estimate the uncertainty of LLMs includes (Ren et al., 2023b).
4. Self-Verbalized UQ
Self-verbalized uncertainty quantification methods seek to harness the impressive learning and reasoning capabilities of LLMs to enable an LLM to express its confidence in a given response through natural-language. Self-verbalized uncertainty estimates (e.g., expressed as probabilities) are more easily interpretable to humans, especially when the estimates are provided using widely-used epistemic uncertainty markers (Tang et al., 2024; Yona et al., 2024), e.g., words like I am not sure… or This response might be… Figure 11 illustrates the use of epistemic markers by an LLM to convey its uncertainty, when asked of the team that won the 2022 NBA Finals. The response of the LLM is actually incorrect; however, by expressing its uncertainty, a user may be more inclined to verify the factuality of the LLM’s response. Prior work has shown that LLMs typically fail to accurately express their confidence in a given response, often using decisive words that suggest confidence, while at the same time being unsure of the accuracy of their response. Empirical studies (Krause et al., 2023) have shown that poor calibration of LLM’s self-verbalized confidence estimates is more pronounced in low-data language settings, e.g., Hindi and Amharic.
<details>
<summary>extracted/6588127/images/self_verbalized_uq/epistemic_uncertainty_markers.png Details</summary>

### Visual Description
\n
## Diagram: LLM Response with and without Epistemic Markers
### Overview
This diagram illustrates the difference in responses from a Large Language Model (LLM) when prompted with a question, specifically "Which team won the 2022 NBA Finals?", with and without the inclusion of epistemic markers (expressions of uncertainty). The diagram shows a flow from the question, through the LLM, to two different outputs.
### Components/Axes
The diagram consists of the following components:
* **Input Question:** "Which team won the 2022 NBA Finals?" - positioned at the top of the diagram.
* **LLM Representation:** A circular icon labeled "LLM" with a stylized infinity symbol inside, representing the Large Language Model. This is positioned centrally.
* **Output 1: With Epistemic Markers:** A rounded rectangle labeled "With Epistemic Markers" containing the text: "I think the Milwaukee Bucks won the 2022 NBA Finals, but I am not sure." - positioned on the left side, below the LLM.
* **Output 2: Without Epistemic Markers:** A rounded rectangle labeled "Without Epistemic Markers" containing the text: "The Milwaukee Bucks won the 2022 NBA Finals." - positioned on the right side, below the LLM.
* **Arrows:** Downward arrows indicating the flow of information from the question to the LLM, and from the LLM to the outputs.
* **User Icon:** A small grey icon of a person's head and shoulders, positioned to the right of the input question.
### Detailed Analysis or Content Details
The diagram presents a comparative analysis of LLM responses.
* **Input:** The question is a straightforward factual query about the winner of the 2022 NBA Finals.
* **LLM Processing:** The LLM processes the question.
* **Output with Epistemic Markers:** The LLM's response includes phrases expressing uncertainty ("I think," "but I am not sure"). The response states the Milwaukee Bucks as the winner, but qualifies it with doubt.
* **Output without Epistemic Markers:** The LLM's response is a direct statement of fact, asserting that the Milwaukee Bucks won the 2022 NBA Finals without any qualifiers.
### Key Observations
The key observation is the difference in the LLM's output based on whether or not it incorporates epistemic markers. The inclusion of these markers demonstrates a level of awareness of uncertainty, while their absence presents the information as a definitive fact. The diagram highlights the importance of how LLMs frame their responses, particularly when dealing with potentially ambiguous or uncertain information.
### Interpretation
The diagram demonstrates a crucial aspect of LLM behavior: the ability to express (or suppress) uncertainty. The presence of epistemic markers in the first output suggests a more cautious and nuanced response, acknowledging the possibility of error. The second output, lacking these markers, presents the information as a confident assertion. This difference is significant because it impacts how users perceive the reliability of the information provided by the LLM.
The diagram implicitly raises questions about the underlying mechanisms that control the inclusion or exclusion of epistemic markers in LLM responses. It suggests that these markers are not inherent to the LLM's knowledge but are rather a function of its programming or the specific prompt it receives. This has implications for the development of more trustworthy and transparent LLMs, as it highlights the need for mechanisms that accurately reflect the LLM's level of confidence in its responses.
The diagram also subtly points to the potential for LLMs to be manipulated into presenting uncertain information as fact, simply by omitting epistemic markers. This underscores the importance of critical thinking and source evaluation when interacting with LLMs.
</details>
Figure 10. The LLM provides an incorrect response, but communicates its uncertainty using epistemic markers, e.g., “I think.”
\Description
[The LLM provides an incorrect response, but communicates its uncertainty using epistemic markers, e.g., “I think.”]The LLM provides an incorrect response, but communicates its uncertainty using epistemic markers, e.g., “I think.”
<details>
<summary>extracted/6588127/images/self_verbalized_uq/self_verbalized_uncertainty.png Details</summary>

### Visual Description
\n
## Screenshot: Chatbot Conversation
### Overview
The image is a screenshot of a chatbot conversation. It depicts a question and two responses from the chatbot, including a confidence level. The conversation is presented as a series of speech bubbles.
### Components/Axes
There are no axes or traditional chart components. The elements are:
* **Question Bubble:** Top-center, blue background, white text.
* **Response 1 Bubble:** Center, blue background, white text. Includes a circular icon on the left.
* **Response 2 Bubble:** Bottom-center, purple background, white text. Includes a circular icon on the left.
* **User Icon:** Top-right corner of the question bubble.
### Content Details
The text content is as follows:
1. **Question:** "What is the capital of Luxembourg?"
2. **Response 1:** "Luxembourg is the capital of Luxembourg."
3. **Response 2:** "Confidence: I am 98% confident."
The circular icons in the response bubbles appear to be identical.
### Key Observations
The chatbot correctly identifies Luxembourg as the capital of Luxembourg. The chatbot expresses a high degree of confidence (98%) in its answer.
### Interpretation
This screenshot demonstrates a simple question-answering interaction with a chatbot. The chatbot successfully provides a factual answer and quantifies its certainty. The high confidence level suggests the chatbot is well-trained on this particular piece of information. The visual presentation (speech bubbles) is typical of conversational interfaces. The chatbot's response is a tautology, stating that Luxembourg is the capital of Luxembourg, which is factually correct but not particularly informative.
</details>
Figure 11. LLMs can be trained or fine-tuned to provide numeric estimates of their confidence in the factuality of their response.
\Description
[LLMs can be trained or fine-tuned to provide numeric estimates of their confidence in the factuality of their response.]LLMs can be trained or fine-tuned to provide numeric estimates of their confidence in the factuality of their response.
To address this challenge, prior work in (Mielke et al., 2022) trains a learned model (calibrator) that predicts the probability that an LLM’s response to a given prompt is correct, given the input prompt, its response, and the LLM’s representations of the prompt and its response. In addition, the output of the calibrator and the LLM’s original response are subsequently used in fine-tuning a generative model (Smith et al., 2020) to produce a linguistically calibrated response, aligning the verbal expression of the LLM’s confidence with its probability of factual correctness. However, the resulting verbalized uncertainty lacks a numerical value, making it difficult for users to assess the relative confidence of the LLM. Follow-on work in (Lin et al., 2022) introduces the notion of verbalized probability, providing a definite numerical value of the model’s confidence, e.g., in Figure 11, or a scaled characterization of the model’s confidence in words, e.g., low, medium, or high confidence. The authors of (Lin et al., 2022) fine-tune GPT-3 on their proposed CalibratedMath benchmark dataset using supervised learning, demonstrating that the verbalized probability generalizes well; however, best performance is achieved in in-distribution scenarios.
More recent work has investigated other training approaches for fine-tuning LLMs to accurately express their confidence verbally. LACIE (Stengel-Eskin et al., 2024) introduces a two-agent speaker-listener architecture to generate training data for fine-tuning an LLM, where the reward signal is a function of the ground-truth answer and the listener’s perceived confidence of the speaker’s response. In essence, LACIE aims to fine-tune an LLM to produce a response composed of epistemic markers that are aligned with the model’s confidence in the correctness of its response. Likewise, the work in (Yang et al., 2024b) proposes a knowledge-transfer training architecture where the knowledge from a bigger LLM (the teacher), e.g., GPT-4 (Achiam et al., 2023), is distilled into a smaller LLM (the student), e.g., Vicuna-7B (Chiang et al., 2023), using chain-of-thought reasoning. The student LLM is fine-tuned to provide its confidence (expressed as a value between $0 0$ and $100$ ) along with its response to an input prompt. A line of existing work (Xu et al., 2024b; Tao et al., 2024) utilizes reinforcement learning to fine-tune an LLM to improve the alignment of the confidence estimates expressed by the LLM with its factual accuracy. While SaySelf (Xu et al., 2024b) relies on self-reflective rationales to improve the calibration of the verbalized confidence, the work in (Tao et al., 2024) uses reinforcement learning from human feedback (RLHF) to define a reward function consisting of a quality component in addition to an alignment component. Similarly, the work in (Band et al., 2024) fine-tunes Llama 2 (Touvron et al., 2023) using supervised learning and reinforcement learning, to produce calibrated verbalized confidence estimates that enable a user to make informed decisions on related questions. Lastly, other recent work, e.g., (Yang et al., 2023a; Feng et al., 2024), seeks to fine-tune LLMs to abstain from providing an answer to a question when faced with doubt (Tomani et al., 2024), which is illustrated in Figure 12.
<details>
<summary>extracted/6588127/images/self_verbalized_uq/abstain_when_uncertain.png Details</summary>

### Visual Description
\n
## Screenshot: Chatbot Response Comparison
### Overview
The image presents a comparison of two chatbot responses to the same question: "How deep is the Pacific Ocean?". The responses are displayed in a chat-like interface, separated by a horizontal line. The top response provides a specific depth, while the bottom response declines to answer due to uncertainty.
### Components/Axes
The image is divided into two sections, delineated by a dashed horizontal line. Each section contains:
* A user query bubble (light blue) with the text: "How deep is the Pacific Ocean?"
* A chatbot response bubble (darker blue) containing the chatbot's answer.
* A user icon (silhouette of a head and shoulders) positioned to the right of the user query.
* A chatbot icon (a circular symbol with a stylized "x" inside) positioned to the left of the chatbot response.
* Section titles: "Default" (top) and "Abstain when Uncertain" (bottom), in orange text.
### Detailed Analysis or Content Details
**Section 1: Default**
* **User Query:** "How deep is the Pacific Ocean?"
* **Chatbot Response:** "The Pacific Ocean is 3500 meters (11483 feet) deep."
**Section 2: Abstain when Uncertain**
* **User Query:** "How deep is the Pacific Ocean?"
* **Chatbot Response:** "Sorry, I am unsure about the correct answer, so I humbly decline to provide an answer."
### Key Observations
The key difference between the two responses is the chatbot's approach to uncertainty. The "Default" response provides a specific value (3500 meters, 11483 feet) without indicating any level of confidence. The "Abstain when Uncertain" response explicitly acknowledges its lack of knowledge and refuses to provide an answer.
### Interpretation
This image demonstrates two different strategies for handling uncertainty in a chatbot. The "Default" approach prioritizes providing an answer, even if it may be inaccurate. This could be useful in situations where a rough estimate is better than no answer at all. However, it could also lead to misinformation. The "Abstain when Uncertain" approach prioritizes accuracy and avoids providing potentially misleading information. This is a more cautious approach that may be preferable in situations where accuracy is critical. The image highlights the importance of considering the trade-offs between providing an answer and avoiding misinformation when designing chatbot behavior. The choice of strategy depends on the specific application and the potential consequences of providing an incorrect answer.
</details>
Figure 12. Some self-verbalized UQ methods fine-tune an LLM to refrain from answering when it is uncertain about the answer.
\Description
[Some self-verbalized UQ methods fine-tune an LLM to refrain from answering when it is uncertain about the answer.]Some self-verbalized UQ methods fine-tune an LLM to refrain from answering when it is uncertain about the answer.
Despite these efforts, in many cases, LLMs still fail to accurately express their confidence verbally (Xiong et al., 2023; Groot and Valdenegro-Toro, 2024), typically exhibiting overconfidence, with confidence values primarily between 80% and 100%, often in multiples of $5$ , similar to the way humans interact. This weakness decreases with the size of an LLM. Nonetheless, large-scale LLMs still display overconfidence, albeit at a smaller rate. However, effective prompting strategies to reduce the calibration error of these models exist. Although verbalized confidence estimates are better calibrated than raw, conditional token probabilities (Tian et al., 2023), existing empirical studies (Ni et al., 2024) suggest that token-based UQ methods generally yield better-calibrated uncertainty estimates compared to their self-verbalized UQ counterparts.
5. Semantic-Similarity UQ
<details>
<summary>extracted/6588127/images/semantic_similarity_uq/semantically_similar_responses.png Details</summary>
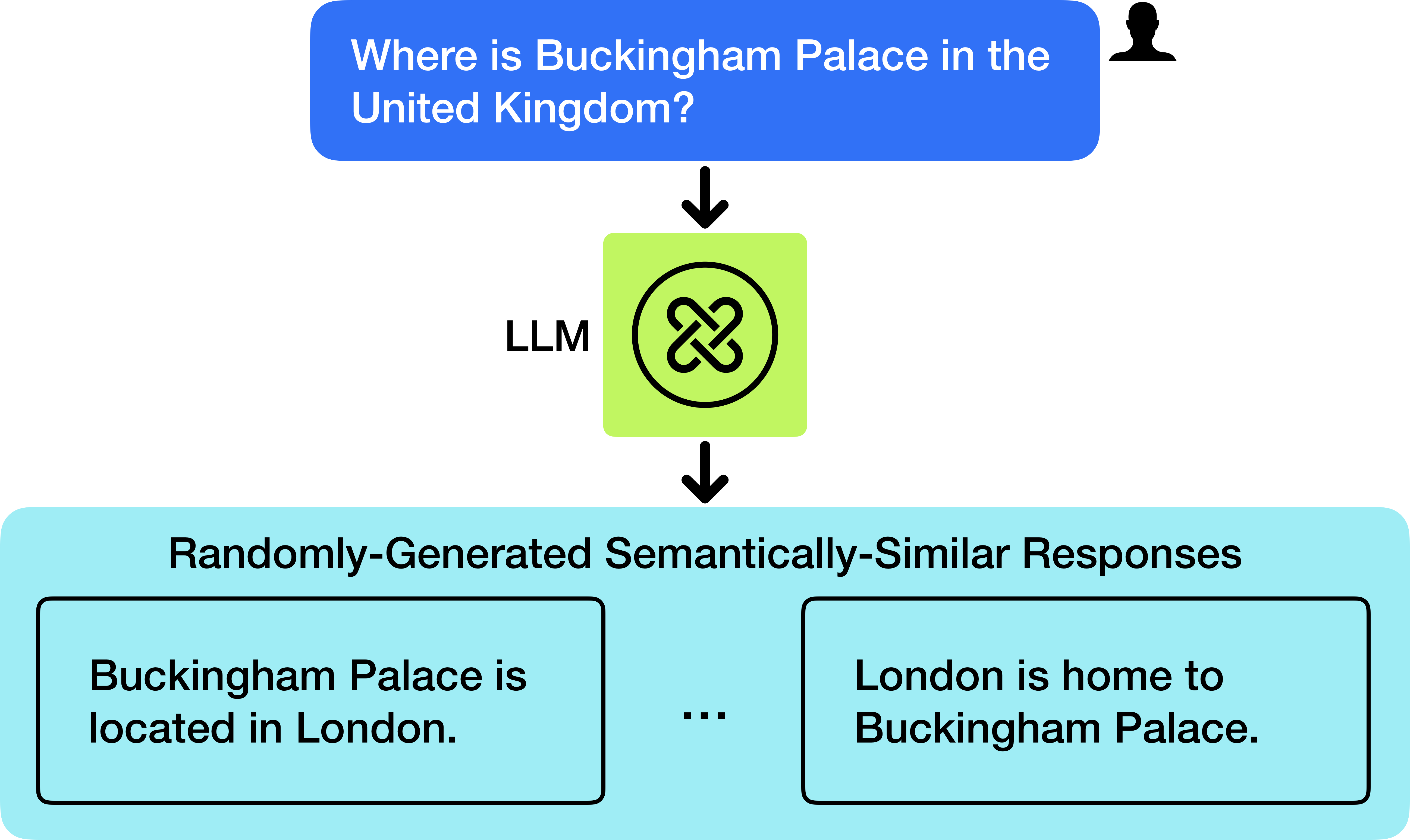
### Visual Description
\n
## Diagram: LLM Response Flow
### Overview
This diagram illustrates the process of a Large Language Model (LLM) responding to a user query. It depicts the input query, the LLM processing, and the generation of multiple semantically similar responses. The diagram is visually structured as a flow chart with directional arrows indicating the sequence of events.
### Components/Axes
The diagram consists of three main components:
1. **Input Query:** A light blue rounded rectangle at the top, containing the text "Where is Buckingham Palace in the United Kingdom?". A small grey silhouette of a person is positioned to the right of the query.
2. **LLM Processing:** A central circular element labeled "LLM" with a stylized green icon resembling intertwined loops.
3. **Output Responses:** A light green rounded rectangle at the bottom, labeled "Randomly-Generated Semantically-Similar Responses". This rectangle contains two example responses: "Buckingham Palace is located in London." and "London is home to Buckingham Palace." with an ellipsis ("...") indicating that more responses exist.
Arrows indicate the flow of information: from the input query to the LLM, and from the LLM to the output responses.
### Detailed Analysis or Content Details
* **Input Query:** The query is "Where is Buckingham Palace in the United Kingdom?".
* **LLM:** The LLM is represented by the label "LLM" and a green icon. The icon appears to be a stylized representation of neural network connections.
* **Output Responses:** Two example responses are provided:
* "Buckingham Palace is located in London."
* "London is home to Buckingham Palace."
The ellipsis ("...") suggests that the LLM can generate a variety of similar responses.
### Key Observations
The diagram highlights the LLM's ability to generate multiple, semantically equivalent responses to a single input query. This suggests a degree of randomness or variability in the LLM's output, even when the underlying meaning remains consistent. The diagram does not provide any quantitative data or performance metrics.
### Interpretation
The diagram demonstrates a core capability of LLMs: the generation of diverse outputs based on a single input. The "Randomly-Generated Semantically-Similar Responses" label suggests that the LLM doesn't simply provide a single, deterministic answer, but rather explores a range of possible formulations that convey the same information. This is a key feature of LLMs, allowing for more natural and engaging interactions. The diagram illustrates the process of natural language understanding and generation, where the LLM interprets the user's question and then formulates a relevant and coherent response. The use of semantically similar responses suggests the LLM is focused on conveying the *meaning* of the answer, rather than a specific phrasing. The diagram is a conceptual illustration and does not provide any information about the LLM's architecture, training data, or performance characteristics.
</details>
Figure 13. When prompted to answer a question, e.g., “Where is Buckingham Palace in the United Kingdom?”, an LLM might generate many variations of the same sentence. Although the form of each response may differ at the token-level, the semantic meaning of the sentences remains consistent. Semantic-similarity UQ techniques exploit semantic clustering to derive UQ methods that are robust to these variations in the form of the responses.
\Description
[When prompted to answer a question, e.g., “Where is Buckingham Palace in the United Kingdom?”, an LLM might generate many variations of the same sentence. Although the form of each response may differ at the token-level, the semantic meaning of the sentences remains consistent. Semantic-similarity UQ techniques exploit semantic clustering to derive UQ methods that are robust to these variations in the form of the responses.]When prompted to answer a question, e.g., “Where is Buckingham Palace in the United Kingdom?”, an LLM might generate many variations of the same sentence. Although the form of each response may differ at the token-level, the semantic meaning of the sentences remains consistent. Semantic-similarity UQ techniques exploit semantic clustering to derive UQ methods that are robust to these variations in the form of the responses.
Semantic-similarity uncertainty quantification methods examine the similarity between multiple responses of an LLM to the same query (Kuhn et al., 2023; Chen and Mueller, 2023; Lin et al., 2023) by focusing on the meaning (i.e., the semantic content of a generated sentence) rather than the form (i.e., the string of tokens that the model predicts) (Kuhn et al., 2023) of the responses. For example, consider the prompt (question) given to an LLM: Where is Buckingham Palace in the United Kingdom? Standard sampling from an LLM can produce many variations of the same answer when prompted with this question, as illustrated in Figure 13. However, while an LLM may be uncertain about which sequence the user may prefer, most variations do not alter the meaning of the sentence. This difference in the ordering of the tokens in each response may lead to different token probabilities, which in turn may negatively impact the accuracy of other uncertainty quantification methods, such as token-level UQ methods.
Since semantic similarity is a relative metric, its outputs are in general model-dependent, posing a central challenge. A recent line of work uses NLI models, such as RoBERTa (Liu, 2019) and DeBERTa (He et al., 2020) (discussed in Section 2.4.2), to compute entailment probabilities. The work in (Aichberger et al., 2024) proposes upweighting tokens that have large gradients with respect to the NLI model to maximize the probability of contradiction to generate semantically-varied responses. In addition, the method in (Tanneru et al., 2024) proposes using a chain-of-thought agreement (CoTA) metric that uses entailment probabilities to evaluate the agreement between CoT generations, concluding that CoTA semantic uncertainty leads to more robust model faithfulness estimates than either self-verbalized or token-level uncertainty estimates. The authors of (Chen and Mueller, 2023) propose using a combined measure of confidence that incorporates entailment probabilities along with a verbalized confidence score, and selects the generation with the highest confidence. The UQ method in (Becker and Soatto, 2024) proposes generating multiple explanations for each plausible response and then summing the entailment probabilities. Another work (Kossen et al., 2024) introduces semantic entropy probes, wherein semantic clusters are grown iteratively using entailment probabilities. Each new generation is either added to an existing cluster if entailment holds, or added to a new cluster. Then, a linear classifier is trained to predict high-entropy prompts. Furthermore, the method in (Martín et al., 2022) uses a database of user-verified false statements to build a semi-automated fact-checking system that uses entailment probabilities with database queries as a metric for confidence in a statement’s falseness.
In addition to using NLI models to evaluate factual similarities between responses, some methods use language embeddings (Petukhova et al., 2024) to cluster responses based on their semantic similarity and reason about uncertainty over the clusters, e.g., semantic density in (Qiu and Miikkulainen, 2024). First, several reference responses are generated by sampling the model. Then, the overall uncertainty per response is computed using the entailment scores, taking values in the set $\{0,0.5,1\}$ . The semantic density is then used to accept or reject a target response based on the similarity to the target responses. The supervised approach in (He and Li, 2024) utilizes the K-means algorithm to first cluster synonyms, which are attended by the LLM during training. The work in (Hu et al., 2024) introduces a method to achieve semantically-aligned item identification embeddings based on item descriptions, which aid in aligning LLM-based recommender systems with semantically-similar generations when item descriptions are sparse. Further, the method in (Wang et al., 2024a) prompts an LLM to generate concepts (effectively semantic clusters) and uses an NLI-based concept scorer along with the entropy over the concepts to quantify the overall uncertainty of the LLM. ClusterLLM (Zhang et al., 2023b) uses a frozen instruction-trained LLM to guide clustering based on triplet queries (e.g., does A match B better than C?), achieving more semantically-aligned embeddings.
However, assigning responses to a single cluster precludes assignment to another, when in reality a response may belong to more than one class, limiting the effectiveness of clustering-based semantic-similarity UQ methods. To address this challenge, another line of work extends clustering-based methods to graphs, which may express the complex relationship between responses more explicitly. The work in (Ao et al., 2024) proposes Contrastive Semantic Similarity, which uses responses as vertices and CLIP cosine similarities as edges. The overall uncertainty is computed from the eigenvalues of the graph Laplacian, and the eigenvectors can be used to assign clusters more effectively. Similarly, the approach in (Da et al., 2024) uses edges weights determined directly from NLI models and extends the graph-Laplacian-based uncertainty metric to include additional semantic uncertainty, such as Jaccard similarity. The authors of (Jiang et al., 2024) introduce a claim-and-response structure wherein edges are added between a claim and response if the response entails the claim. The centrality metrics are used to estimate per-claim uncertainty and integrate low-uncertainty claims into further generations. In addition, Kernel Language Entropy (Nikitin et al., 2024) clusters responses to construct a kernelized graph Laplacian, which is used to estimate fine-grained differences between responses in a cluster.
A few works that learn to estimate semantic meanings without NLI models using supervised approaches have also been proposed. In (Liu et al., 2024d), the authors use an auxiliary tool LLM to compute a similarity score between the target LLM’s generation and the tool LLM’s generation and learns an uncertainty estimation function to estimate the similarity score. In (Jung et al., 2024), the authors propose a cascading chain of increasingly complex LLM judges to evaluate the predecessor’s preference between two generations. A calibration dataset is used to learn a threshold that determines each judge’s minimum confidence level. The confidence thresholds are tuned in order to guarantee that the appropriate judge is selected to generate a satisfactory response.
6. Mechanistic Interpretability
Mechanistic interpretability (MI) aims to understand the inner workings of LLMs to pinpoint the potential sources of uncertainty, by uncovering causal relationships (Bereska and Gavves, 2024). Several survey papers have provided a taxonomy of mechanistic interpretability in the field of transformer-based language models (Rai et al., 2024), focused on AI safety (Bereska and Gavves, 2024) or interpretability of language models in general (Zhao et al., 2024a).
<details>
<summary>extracted/6588127/images/mechanistic_interpretability/MITaxonomy.png Details</summary>
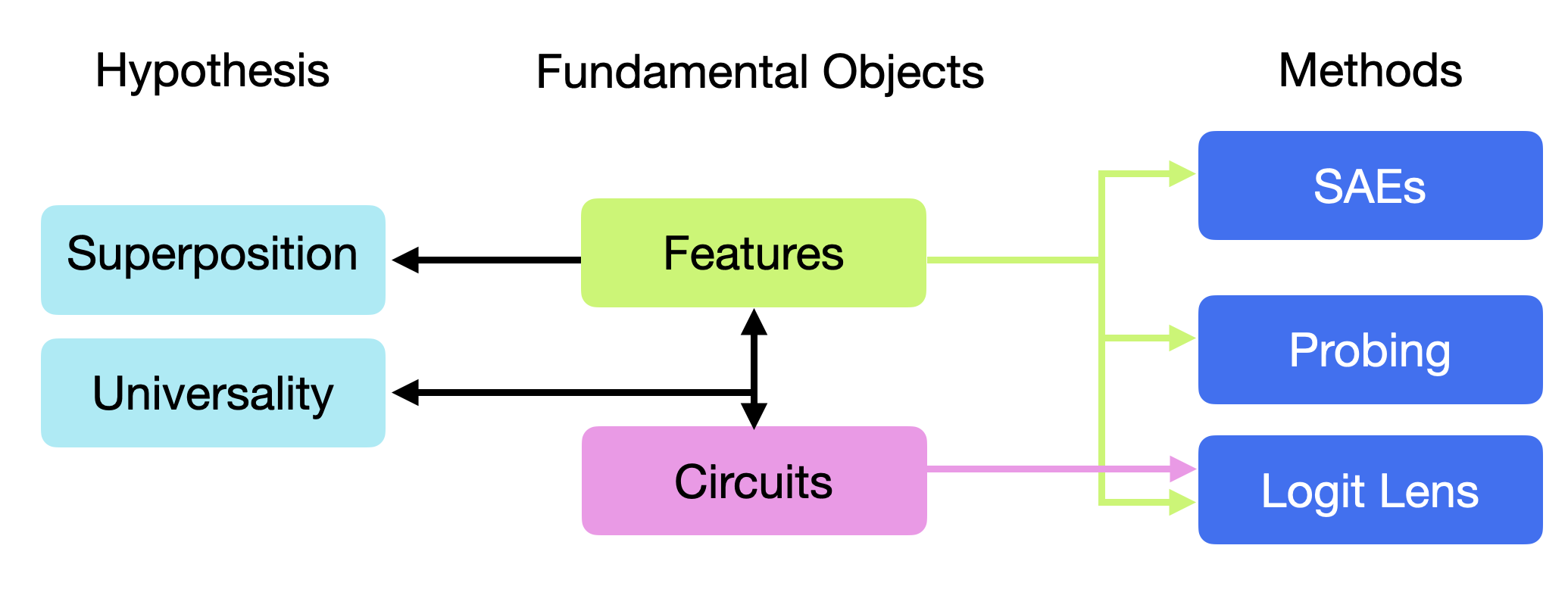
### Visual Description
\n
## Diagram: Conceptual Framework for Neural Circuit Analysis
### Overview
The image presents a diagram illustrating a conceptual framework connecting hypotheses, fundamental objects, and methods used in neural circuit analysis. It depicts relationships between concepts like superposition, universality, features, circuits, and various analytical methods (SAEs, Probing, Logit Lens) through directional arrows.
### Components/Axes
The diagram is organized into three main columns:
* **Hypothesis:** Contains "Superposition" and "Universality".
* **Fundamental Objects:** Contains "Features" and "Circuits".
* **Methods:** Contains "SAEs", "Probing", and "Logit Lens".
Arrows indicate relationships and flow of information between these components. The central element is "Features", which receives input from "Superposition" and "Universality" and provides output to all three methods. "Circuits" also provides input to "Features".
### Detailed Analysis or Content Details
* **Superposition** (light blue rectangle, top-left) is connected to **Features** (dark green rectangle, center) via a black arrow pointing right.
* **Universality** (light blue rectangle, bottom-left) is connected to **Features** via a black arrow pointing left.
* **Features** is connected to **SAEs** (blue rectangle, top-right) via a yellow arrow pointing right.
* **Features** is connected to **Probing** (blue rectangle, center-right) via a green arrow pointing right.
* **Features** is connected to **Logit Lens** (blue rectangle, bottom-right) via a light green arrow pointing right.
* **Circuits** (purple rectangle, bottom-center) is connected to **Features** via a black arrow pointing up.
* The arrows indicate a directional relationship, suggesting information flow or influence.
### Key Observations
The diagram emphasizes the central role of "Features" in bridging hypotheses about neural circuits with the methods used to analyze them. "Features" appears to be a key intermediate representation, influenced by both "Superposition" and "Universality" and used as input for "SAEs", "Probing", and "Logit Lens". The diagram does not contain any numerical data or quantitative values.
### Interpretation
This diagram represents a high-level conceptual model for understanding how different aspects of neural circuit analysis relate to each other. The "Hypothesis" column suggests starting points for investigation, while the "Fundamental Objects" column identifies core elements to be studied. The "Methods" column outlines the tools available for analysis.
The connections suggest a workflow: hypotheses about "Superposition" and "Universality" inform the identification of relevant "Features" within neural "Circuits". These "Features" are then analyzed using techniques like "SAEs", "Probing", and "Logit Lens".
The diagram implies that these methods are not mutually exclusive but rather complementary approaches to understanding the same underlying "Features". The choice of methods may depend on the specific hypothesis being tested or the nature of the circuits being studied. The diagram is a qualitative representation of relationships, not a quantitative model. It doesn't provide specific details about the nature of the features, circuits, or methods, but rather outlines a general framework for their interaction.
</details>
Figure 14. Taxonomy of Mechanistic Interpretability (Rai et al., 2024).
\Description
[Taxonomy of Mechanistic Interpretability (Rai et al., 2024).]Taxonomy of Mechanistic Interpretability (Rai et al., 2024).
We start by discussing a few key concepts of mechanistic interpretability, summarized in Figure 14. Features are the unit for encoding knowledge in a neural network. For example, a neuron or set of neurons consistently activating for Golden Gate Bridge can be interpreted as the “Golden Gate Bridge” feature (Templeton et al., 2024). Superposition (Elhage et al., 2022) is often a key hypothesis in mechanistic interpretability (Bereska and Gavves, 2024), due to the fact that the same neuron seems to activate in multiple, distinct contexts, a phenomenon known as polysemanticity (Cunningham et al., 2023). The superposition hypothesis claims that the set of $N$ neurons encode $M>N$ features, by allocating each feature to a linear combination of neurons, which are in almost orthogonal directions, leading to an overcomplete set of basis. On the other hand, the work in (Engels et al., 2024) suggests that there exists circular features corresponding to days of the week and months of the year, breaking the assumption that high-level features are linearly represented in the activation space. Circuits, another fundamental concept, refers to sub-graphs of the network that consist of features and weights connecting them. Recent research have aimed to perform comprehensive circuit analysis on LLMs in order to construct a full mapping from specific circuits to functionalities of the language model (Lieberum et al., 2024; Dunefsky et al., 2024). The hypothesis of universality, related to both features and circuits, claims that similar features and circuits exist across different LLMs.
Methods in MI can be broadly classified into the following categories: logit lens, probing, and sparse auto-encoders methods, each discussed briefly. Logit lens methods project the activations from various layers of the LLM back into the vocabulary space, allowing for interpreting intermediate predictions and information encoded in activations (Geva et al., 2020; Lieberum et al., 2023). Probing methods aim to find which intermediate activations encode specific information (e.g., syntactic, semantic, or factual knowledge), by training a linear classifier as a probe to predict the existence of a certain feature (Belinkov, 2022; Gurnee et al., 2023). Despite being simple and successful, probing methods only reveal correlations instead of causal relations, limiting their use in MI. Sparse auto-encoders (SAEs) represent a popular architecture applied in MI to directly identify meaningful feature activations within LLMs and the causal relations between them. SAEs map the feature vectors onto a much higher dimensional space with strong sparsity, in order to disentangle the features that were in superposition. In these methods, an encoder-decoder pair $(z,\hat{x})$ is trained to map $\hat{x}(z(x))$ back to the model’s activation $x$ , given by: ${z=\sigma(W_{\text{enc}}x+b_{\text{enc}})}$ , ${{\hat{x}}=W_{\text{dec}}z+b_{\text{dec}}}$ . The specific implementation of the activation function can vary, with a common choice of the activation function given by the ReLU (Dunefsky et al., 2024; Cunningham et al., 2023). In (Gao et al., 2024), ${\sigma=\mathrm{TopK}}$ is used to keep only the $k$ -largest latents, simplifying tuning and outperforming ReLU. In (Lieberum et al., 2024), ${\sigma=\mathrm{JumpReLU}}$ is chosen due to its slightly better performance and the ability to allow for a variable number of active latents at different tokens. In (Dunefsky et al., 2024), the authors train the architecture differently with transcoders, where the faithfulness term in the loss function measures the error between the output and the original MLP sub-layer output, instead of the original input. In (Yun et al., 2021), the authors hypothesize that contextualized word embeddings are linear superpositions of transformer factors. For example, the word “apple” can be decomposed into: ${\mathrm{apple}=0.09\mathrm{dessert}+0.11\mathrm{organism}+0.16\mathrm{fruit}+%
0.22\mathrm{mobile\&IT}+0.42\mathrm{other}}$ . The authors aim to learn a comprehensive dictionary of word factors. In doing so, they distinguish between low, mid, and high-level factors by looking at the change in the importance score across layers. Low-level factors correspond to word-level polysemy disambiguation; mid-level factors are sentence-level pattern formation; and high-level factors correspond to long-range dependency, which have to be manually distinguishable from mid-level factors, although it could be done with black-box interpretation algorithms as well. In (Tamkin et al., 2023), the authors quantize features into sparse “codebook” features, providing the capability to control the network behavior.
Prior work has employed techniques from mechanistic interpretability to track the progress of models during training (Nanda et al., 2023), to explain the outputs of models (Schwab and Karlen, 2019), and to improve the accuracy of LLMs (Burns et al., 2022). The work in (Burns et al., 2022) demonstrates that the accuracy of the latent knowledge of LLMs is less sensitive to the input prompts, with its accuracy remaining relatively constant even when the LLM is prompted to generate incorrect responses. Likewise, ReDeEP (Sun et al., 2024a) examines the latent knowledge of an LLM to decouple the effects of external knowledge from knowledge bases and the internal knowledge in the model on hallucinations in retrieval-augmented generation. Further, prior work has examined hallucinations in LLMs through the lens of mechanistic interpretability (Yu et al., 2024; Wang et al., 2024d). The work in (Yu et al., 2024) investigates the role of an LLM’s hidden states in contributing to hallucinations, quantifying the contributions of lower-layer and upper-layer MLPs and attention heads to factual errors. In addition, the method in (Ferrando et al., 2024) leverages mechanistic interpretability to identify the boundaries of an LLM’s internal knowledge of its own capabilities, which could be used to prevent a model from answering questions on certain subjects (i.e., in safeguarding the model) or to prevent hallucinations when the model does not know about certain subjects. Lastly, the work in (Ahdritz et al., 2024) trains small classifiers (linear and non-linear MLPs) on the activations of a small LLM to predict the uncertainty level of a larger LLM, demonstrating that the classifiers generalize to unseen distributions. Although there is an inextricable link between understanding the inner workings of LLMs and quantifying their uncertainty when prompted by a user, the connections between mechanistic interpretability and uncertainty quantification have not been extensively explored. For example, certain neural activation patterns in LLMs might be associated with the expression of uncertainty by the model. In addition, when faced with doubt, an LLM might utilize certain features (words/concepts), that could be detected from its neural activations. Identifying the specific intermediate activations and features of an LLM that are relevant for uncertainty quantification remains an open research challenge. We describe this open challenge in Section 10.4.
7. Calibration of Uncertainty
In many cases, the confidence estimates computed by the UQ methods presented in the preceding sections are not well-calibrated i.e., aligned with the observed frequencies of the responses (accuracy of the model). However, reliability of the confidence estimates of an LLM’s output remains crucial to the safe deployment of LLMs. As a result, we would like the confidence estimates to be calibrated. Formally, for a perfectly-calibrated confidence estimate $p$ , we have that, ${∀ p∈[0,1]}$ :
$$
\mathbb{P}[Y=\hat{Y}\mid\hat{P}=p]=p, \tag{2}
$$
where $Y$ and $\hat{Y}$ represent random variables denoting the ground-truth and predicted outputs from the model, respectively, and $\hat{P}$ represents a random variable denoting the confidence associated with the predicted output $\hat{Y}$ (Guo et al., 2017). In Figure 15, we show poorly-calibrated confidence estimates on the left, where the estimated confidence of the model is not well-aligned with the observed accuracy of the model. The dashed-line illustrates perfect alignment between the estimated confidence of the model and its accuracy. In this example, confidence estimates of the model above $0.5$ tend to be overconfident, exceeding the accuracy of the model. Conversely, confidence estimates that are less than $0.5$ tend to be underconfident. Calibration techniques improve the alignment of the estimated confidence of the model with the observed accuracy, with the estimated confidence more closely following the dashed-line, as shown on the right in Figure 15. We review some metrics for quantifying the calibration of a model’s confidence estimates.
<details>
<summary>extracted/6588127/images/calibration/calibrated_confidence.png Details</summary>
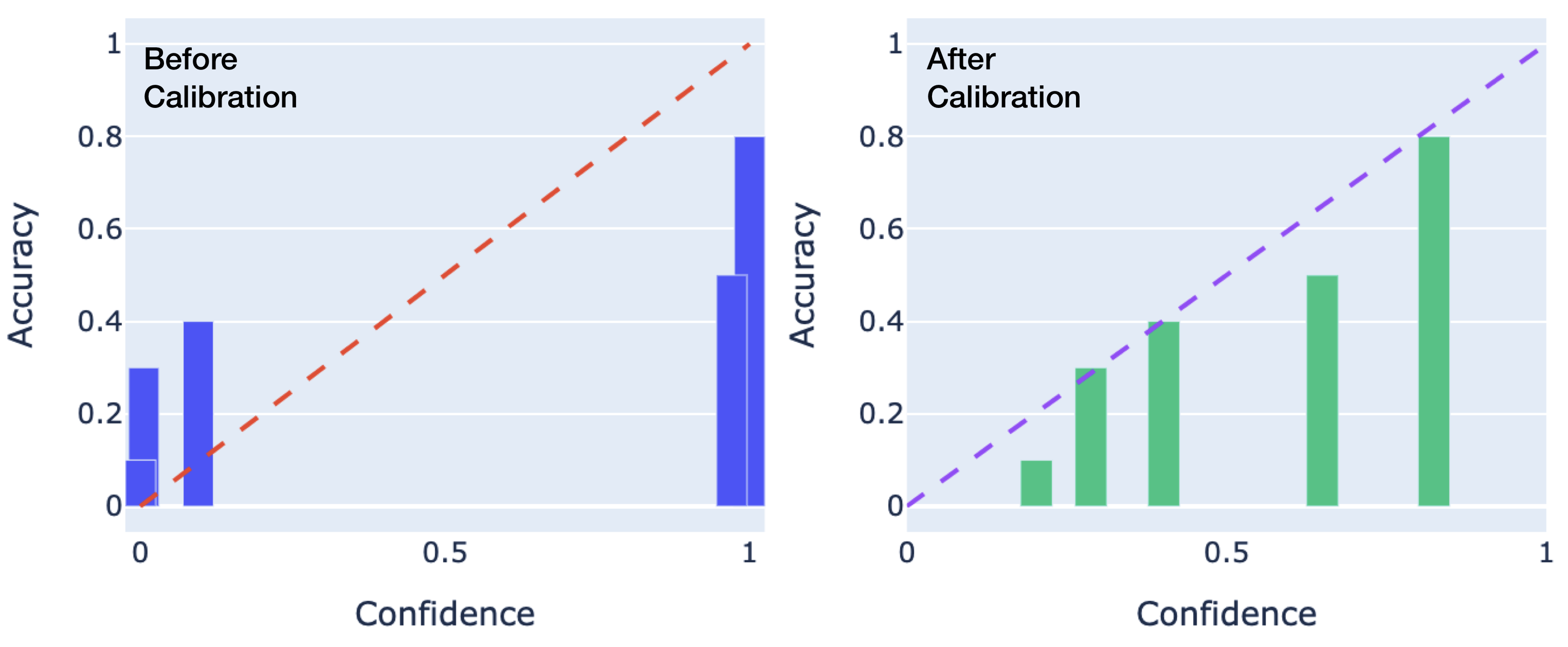
### Visual Description
\n
## Bar Charts: Accuracy vs. Confidence Before and After Calibration
### Overview
The image presents two bar charts side-by-side, comparing accuracy against confidence levels. The left chart shows data "Before Calibration," while the right chart shows data "After Calibration." Both charts share the same x and y-axis scales. A diagonal dashed line is overlaid on both charts, representing a perfect correlation between confidence and accuracy.
### Components/Axes
* **X-axis:** "Confidence" ranging from 0 to 1, with markers at 0, 0.5, and 1.
* **Y-axis:** "Accuracy" ranging from 0 to 1, with markers at 0, 0.2, 0.4, 0.6, 0.8, and 1.
* **Left Chart:** Title: "Before Calibration". Bars are blue.
* **Right Chart:** Title: "After Calibration". Bars are green.
* **Overlaid Line:** A dashed red line is present on both charts, representing the line y=x (perfect confidence/accuracy correlation).
### Detailed Analysis or Content Details
**Left Chart (Before Calibration):**
The chart contains three blue bars.
* **Bar 1:** Located at approximately Confidence = 0, Accuracy ≈ 0.08.
* **Bar 2:** Located at approximately Confidence = 0.5, Accuracy ≈ 0.25.
* **Bar 3:** Located at approximately Confidence = 1, Accuracy ≈ 0.85.
The bars show a general upward trend, but the accuracy does not consistently match the confidence. The dashed red line (y=x) is significantly above the first two bars, indicating poor calibration.
**Right Chart (After Calibration):**
The chart contains three green bars.
* **Bar 1:** Located at approximately Confidence = 0, Accuracy ≈ 0.1.
* **Bar 2:** Located at approximately Confidence = 0.5, Accuracy ≈ 0.3.
* **Bar 3:** Located at approximately Confidence = 1, Accuracy ≈ 0.5.
The bars also show an upward trend, but the accuracy is still below the dashed red line, though closer than before calibration.
### Key Observations
* The "After Calibration" chart shows a clear improvement in the correlation between confidence and accuracy compared to the "Before Calibration" chart.
* Before calibration, the model was overconfident in its predictions at lower confidence levels (Confidence = 0 and 0.5).
* Even after calibration, the model still exhibits some degree of miscalibration, particularly at higher confidence levels (Confidence = 1).
* The dashed line serves as a visual benchmark for ideal calibration.
### Interpretation
The data demonstrates the effect of calibration on a model's confidence and accuracy. Before calibration, the model's accuracy is significantly lower than its confidence, indicating a tendency to make predictions with unwarranted certainty. Calibration aims to align confidence with actual accuracy. The "After Calibration" chart shows that calibration has improved this alignment, but the model is not perfectly calibrated. This suggests that further calibration or a different model architecture might be necessary to achieve optimal performance. The charts highlight the importance of calibration in machine learning, as a well-calibrated model provides more reliable and trustworthy predictions. The data suggests that the calibration process has moved the model closer to the ideal state (represented by the dashed line), but there is still room for improvement.
</details>
Figure 15. The confidence estimates provided by many UQ methods are not always calibrated, i.e., the observed frequencies do not match the estimates. Calibration techniques correct these confidence estimates for better alignment with the observed accuracy.
\Description
[The confidence estimates provided by many UQ methods are not always calibrated, i.e., the observed frequencies do not match the estimates. Calibration techniques correct these confidence estimates for better alignment with the observed accuracy.]The confidence estimates provided by many UQ methods are not always calibrated, i.e., the observed frequencies do not match the estimates. Calibration techniques correct these confidence estimates for better alignment with the observed accuracy.
Expected Calibration Error (ECE)
The Expected Calibration Error (ECE) measures the expected deviation between the left-hand side and right-hand side of (2), with: ${\mathbb{E}_{\hat{P}}\left[\left\lvert\mathbb{P}[Y=\hat{Y}\mid\hat{P}=p]-p%
\right\rvert\right],}$ where the expectation is taken over the random variable $\hat{P}$ . Computing the expectation in the ECE is intractable in general. Hence, the work in (Naeini et al., 2015) introduces an approximation of the ECE, which partitions the confidence estimates into equal-width bins and computes the difference bin-wide, with: ${\mathrm{ECE}=\sum_{m=1}^{M}\frac{\lvert B_{m}\rvert}{n}\left\lvert\mathrm{acc%
}(B_{m})-\mathrm{conf}(B_{m})\right\rvert,}$ where the confidence estimates are divided into $M$ bins with the i’th bin denoted by $B_{i}$ , and $\mathrm{acc}$ and $\mathrm{conf}$ denote the average accuracy and confidence of the samples in a bin.
Maximum Calibration Error (MCE)
Alternatively, we may seek to quantify the maximum deviation between the left-hand and right-hand sides of (2), representing the worst-case error, which is often useful in safety-critical applications. The Maximum Calibration Error (MCE) is given by: ${\max_{p∈[0,1]}\left\lvert\mathbb{P}[Y=\hat{Y}\mid\hat{P}=p]-p\right\rvert,}$ which is also challenging to compute exactly, like the ECE. As a result, we can estimate an upper bound, given by: ${\mathrm{MCE}=\max_{m∈\{1,...,M\}}\left\lvert\mathrm{acc}(B_{m})-\mathrm{%
conf}(B_{m})\right\rvert,}$ as introduced in (Naeini et al., 2015). Metrics for quantifying the calibration error of confidence estimates are further discussed in (Guo et al., 2017; Niculescu-Mizil and Caruana, 2005; Nixon et al., 2019).
We can categorize calibration techniques for uncertainty estimation as either training-based or training-free calibration methods. Training-based calibration methods comprise supervised techniques that modify the network’s weights and various types of self-verbalization, where the model qualifies and refines its outputs based on its own reasoning or feedback about uncertainty. In contrast, training-free calibration methods include statistical techniques that operate on a frozen learned model.
7.1. Training-Free Calibration Methods
Training-free calibration methods do not modify the weights of the model to produce calibrated predictions, e.g., Platt scaling (Platt et al., 1999), isotonic regression (Zadrozny and Elkan, 2001, 2002), and conformal prediction (Shafer and Vovk, 2008). Here, we discuss conformal prediction in greater detail. Conformal prediction (CP) is a powerful technique used to quantify the uncertainty of a model’s predictions by providing prediction sets that are guaranteed to contain the true outcome with a specified probability. Given a prediction model $f$ and a calibration dataset $\mathcal{D}_{\text{cal}}=\{(x,y)_{i})\}_{i=1}^{N}$ , conformal prediction aims to compute a set of nonconformity scores $\mathcal{S}=\{(s)_{i}\}_{i=1}^{N}$ over $\mathcal{D}_{\text{cal}}$ , which reflect how closely each prediction $f(x_{i})$ —such as the confidence estimate provided by the aforementioned UQ methods—aligns with the true label $y_{i}$ . Given a coverage level $\hat{\varepsilon}$ (effectively a budget for incorrect predictions) and $\mathcal{S}$ , CP aims to construct a prediction set $C(x_{n+1})$ for a new test data point $x_{n+1}$ : ${C(x_{n+1})=\left\{y:f(x_{n+1})≤ q_{1-\hat{\varepsilon}}(s_{1},s_{2},...,%
s_{n})\right\},}$ along with the probabilistic guarantee: ${\mathbb{P}(x_{n+1}∈ C(x_{n+1})|\mathcal{D}_{\text{cal}})≥ 1-\varepsilon(%
\delta),}$ where $q_{1-\hat{\varepsilon}}$ is the $(1-\hat{\varepsilon})$ -quantile of the nonconformity scores from the calibration set and $\delta$ is a tunable failure probability associated with the randomness in sampling $\mathcal{D}_{\text{cal}}$ . By applying a Hoeffding-style argument (Shafer and Vovk, 2008), one can show that $\varepsilon$ can be selected, e.g., using the cumulative distribution function of the Beta distribution: ${\varepsilon:=\text{Beta}^{-1}_{N+1-v,v}(\delta),\quad v:=\lfloor(N+1)\hat{%
\varepsilon}\rfloor,}$ where $\hat{\varepsilon}$ is the target coverage level.
Provided that the nonconformity scores represent the true conditional probabilities, conformal prediction produces the tightest prediction set that minimizes the number of false positives (i.e., maximizes the discriminative power) among all set-valued predictors such that the user-specified coverage level holds (Sadinle et al., 2019, Theorem 1). As a result, LLMs that are calibrated with conformal prediction will have the smallest prediction sets on average, and therefore the least ambiguity in their responses. A number of papers employ conformal prediction for uncertainty quantification of LLMs, e.g., for semantic uncertainty quantification (Wang et al., 2024b) and calibration (Liu and Wu, 2024). In addition to conformal prediction, information-theoretic approaches have been developed to manage and calibrate uncertainty in sequential decision-making processes (Zhao et al., 2022), e.g., entropy-rate control and multicalibration (Detommaso et al., 2024), which involves grouping data points into subgroups and ensuring the model is calibrated with respect to each of these subgroups . A model can also be calibrated to control a heuristic estimate of risk, such as human agreement (Jung et al., 2024) or Pareto-optimality of the response correctness (Zhao et al., 2024b).
7.2. Training-Based Calibration Methods
We can group training-based calibration techniques into ensemble-based calibration methods, few-shot calibration methods, and supervised calibration methods.
7.2.1. Ensemble-Based Calibration
Ensemble-based calibration (model ensembling) seeks to estimate uncertainty by querying many similar models (for example, the same architecture trained with different random seeds) and comparing their outputs. Prompt ensembles enhance calibration by combining the outputs of multiple prompts (Jiang et al., 2023a). One common and effective ensembling strategy involves utilizing the majority vote. Given $K$ models predicting a response $l_{i}$ , the majority vote is selected as: ${P_{\text{acc}}(\hat{y}=l_{i})=\sum_{k=1}^{K}P_{k}(\hat{y}_{k}=l_{i})\mathbb{I%
}(\hat{y}_{k}=l_{i}).}$ The ensemble vote is then the response $l_{i}$ with the highest aggregate confidence. Another class of ensemble-based methods evaluates overall (rather than pre-choice) uncertainty, e.g. binning the model’s responses into semantic categories and computing the entropy (Bakman et al., 2024; Ulmer et al., 2024). An ensemble-like effect can also be realized by varying the in-context examples provided to the LLM (Li et al., 2024b).
7.2.2. Few-Shot Calibration
Few-shot calibration techniques employ several queries to the same model and benefit from sequential reasoning as the model evaluates its intermediate generations. For instance, prompting models to begin their responses with a fact and justification for the fact has been shown to improve calibration versus other types of linear reasoning, such as tree-of-thought (Zhao et al., 2024c; Wei et al., 2022). In the domain of code generation, calibration techniques have also been applied to improve the reliability of generated code (Spiess et al., 2024). Furthermore, inferring human preferences with in-context learning has been explored as a means to calibrate models in alignment with human judgments (Liu et al., 2023b).
7.2.3. Supervised Calibration
Supervised calibration approaches, which mainly involve modifying the LLM’s weights via additional losses, auxiliary models, or additional data, are also crucial in enhancing model calibration. In supervised methods, learning to classify generated responses as correct (i.e., via a cross-entropy loss) can result in better calibration than non-learning-based approaches and can help to combat overconfidence (Chen et al., 2022; Zhu et al., 2023; Johnson et al., 2024). In fact, some existing work argue that fine-tuning is necessary for the calibration of uncertainty estimates of LLMs (Kapoor et al., 2024). Given a language generator $\hat{f}$ , score model (confidence) $\hat{P}$ , and a dataset $\mathcal{D}:=\{(x,y)_{i}\}_{i=1}^{N}$ of data-label pairs, the token-level cross-entropy loss seeks to measure the uncertainty of the predicted labels $\hat{f}(x)$ , on average, over the dataset: ${L_{\text{CE}}=-\mathbb{E}^{(x,y)\sim D}[\log\hat{P}(y=\hat{f}(x))],}$ to improve the calibration of the confidence estimates of the model. While LLMs exhibit high-quality text generations ( $\hat{f}$ ), their confidences ( $\hat{P}$ ) may be improved by fine-tuning the model with a cross-entropy loss on the full dataset or a subset. Besides the cross-entropy function, other proper-scoring rules can also be used for achieving calibration (Gneiting et al., 2007; Gneiting and Raftery, 2007). Reinforcement learning (with human feedback in some applications) may be used to fine-tune a model to produce realistic confidence estimates, e.g., (Band et al., 2024; Mao et al., 2024). Techniques such as learning to rationalize predictions with generative adversarial networks (Sha et al., 2021), applying regularization (Kong et al., 2020), and biasing token logits (Liu et al., 2024b; Zhao et al., 2021) have also been explored. Finally, sequence-level likelihood calibration has been proposed to improve the quality of LLM generations (Zhao et al., 2022). Instead of modifying the model’s weights, another class of supervised calibration methods seeks to modify model hyperparameters in a post-hoc manner. These include temperature tuning (Desai and Durrett, 2020) and methods involving entropy and logit differences [QQ] (Lyu et al., 2024).
8. Datasets and Benchmarks
Here, we present useful benchmarks in uncertainty quantification for LLMs. The rapid development of highly-capable LLMs has led to the introduction of a slate of benchmarks for measuring advances on the different capabilities of these models. Some examples of these datasets include: GPQA (Rein et al., 2023), a domain-specific dataset with multiple-choice questions in the physical sciences; MMLU (Hendrycks et al., 2020), a multi-task dataset for evaluating the breadth of knowledge of LLMs across a wide range of subjects, e.g., the humanities and sciences; HellaSwag (Zellers et al., 2019), a dataset for evaluating LLM’s common-sense reasoning capability in sentence-completion tasks; RACE (Lai et al., 2017), a dataset for reading-comprehension evaluation; GSM8K (Cobbe et al., 2021), a dataset for evaluating the grade-school, math-solving capability of LLMs; and APPS (Hendrycks et al., 2021), a code-generation benchmark for LLMs. There have been a related line of work in developing datasets with inherent ambiguities (Kamath et al., 2024; Min et al., 2020; Liu et al., 2023a; Tamkin et al., 2022), e.g., “the cat was lost after leaving the house” meaning either that the cat was unable to find the way, or the cat was unable to be found (Min et al., 2020, Fig. 1), as well as datasets modeling clarifying questions in multi-turn conversations (Aliannejadi et al., 2021). However, experimental results associated with these datasets do not necessarily incorporate uncertainty evaluation beyond answering accuracy.
Although many of the aforementioned benchmarks have not been widely adopted in research on uncertainty quantification, a few benchmarks in natural-language processing have proven highly amenable to research in uncertainty quantification of LLMs, e.g., TriviaQA (Joshi et al., 2017), a dataset which consists of 95K question-answer pairs for evaluating an LLM’s reading-comprehension skill. TriviaQA (Joshi et al., 2017) has been widely utilized in evaluating many methods for uncertainty quantification of LLMs (Kuhn et al., 2023; Mielke et al., 2022; Stengel-Eskin et al., 2024). Likewise, other methods have employed CoQA (Reddy et al., 2019), a dataset containing conversational question-answer pairs, and WikiBio (Lebret et al., 2016), a dataset containing biographies from Wikipedia, in evaluating the performance of UQ methods for LLMs. The CalibratedMath benchmark was introduced in (Lin et al., 2022) for examining the ability of LLMs to verbally express their confidence in solving arithmetic tasks. Moreover, datasets for evaluating the consistency of LLMs exist, e.g., ParaRel (Elazar et al., 2021), which consists of 328 paraphrases, generated by altering a set of prompts while keeping the semantic meaning of the prompts the same. Furthermore, HotpotQA (Yang et al., 2018) and StrategyQA (Geva et al., 2021) represent question-answering benchmarks consisting of question-answer pairs generated from Wikipedia, specifically designed to assess the ability of LLMs to perform multi-hop reasoning. Similarly, TruthfulQA (Lin et al., 2021) represents a factuality-oriented dataset, designed to evaluate the ability of LLMs to generate factual responses to questions that some humans might answer wrongly based on misconceptions. Noting the connection between hallucination and uncertainty quantification, uncertain quantification methods can leverage benchmarks for hallucination detection, e.g., HaluEval (Li et al., 2023), and datasets for factuality analysis and claim verification, e.g., FEVER (Thorne et al., 2018). Lastly, we note that there has been some work that aims to standardize the tasks for evaluating the performance of LLMs by explicitly accounting for the uncertainty of LLMs in specific tasks, e.g., based on selective classification and generation (Vashurin et al., 2024) or conformal prediction (Ye et al., 2024).
9. Applications
We highlight a few application areas of uncertainty quantification of LLMs, including its applications to chatbots and other textual use-cases and robotics.
9.1. Chatbot and Textual Applications
Given that LLMs are prone to hallucinate, existing work examines the integration of uncertainty quantification techniques in LLM-enabled chatbots. For example, recent work leverages uncertainty quantification techniques for LLMs in hallucination detection (Zhang et al., 2023a; Yadkori et al., 2024; Kossen et al., 2024; Tomani et al., 2024) and content and factuality analysis (Tai et al., 2024; Pacchiardi et al., 2023). Semantic entropy probes (SEPs) (Zhang et al., 2023a) utilize linear logistic models to predict semantic entropy from the hidden states of an LLM, demonstrating its effectiveness in detecting hallucinations on a variety of tasks. The approach in (Yadkori et al., 2024) introduces an information-theoretic metric for hallucination detection by estimating both the aleatoric and epistemic uncertainty of the LLM, with the premise that large epistemic uncertainty corresponds to hallucinations. Other downstream applications leverage hallucination detection to estimate the confidence of the LLM on the factuality of its response (Mahaut et al., 2024) or to actively improve the factuality of LLMs during the token-generation step (Chang et al., 2024).
In Figure 17, we illustrate an application of uncertainty quantification to detect hallucinations in LLMs. When asked for the smallest country in Asia by land area, the LLM provides a confident response. However, the low token-level confidence estimate reveals the uncertainty of the LLM, indicating a high likelihood of hallucination by the LLM. Drawing upon the association between factuality analysis and uncertainty quantification, the work in (Mohri and Hashimoto, 2024) employs conformal prediction to actively generate outputs that have a high probability of being facts. Further, the work in (Pacchiardi et al., 2023) trains a logistic regression classifier to detect outright lies in LLMs (i.e., false information provided by the LLM when the factual answer is known as opposed to hallucinations where the LLM does not know the factual answer), by asking the LLM follow-up questions unrelated to the original prompt. Applications in sentiment analysis (Maltoudoglou et al., 2020) and content analysis (Xiao et al., 2023; Dai et al., 2023; Chew et al., 2023) utilize LLMs in characterizing the sentiments or opinions implied in text sources and in deductive coding to aid the identification of relevant themes across highly-varied documents, respectively. However, noting that LLMs are not necessarily consistent in their outputs, the LLMq method (Tai et al., 2024) examines the LLM’s outputs for the presence of epistemic linguistic uncertainty markers and the consistency of the LLM’s outputs to identify the thematic codes associated with the text. Further applications arise in text summarization (Kolagar and Zarcone, 2024), examining the alignment of uncertainty markers in the original source document and the LLM-generated summary.
Uncertainty quantification has also been explored within the context of jailbreaking LLMs. For example, the work in (Steindl et al., 2024) examines the connections between predictive entropy and jailbreak prompts, showing that the entropy of the LLM’s tokens increases when an LLM is given jailbreak prompts. However, the LLM’s uncertainty can be directly manipulated during the jailbreaking attempt (Zeng et al., 2024). In addition, the evaluation study in (Liu et al., 2024a) highlights that safeguard models for LLMs often show notable miscalibration in jailbreaking attempts. Further, existing work employs uncertainty quantification techniques to improve LLMs via fine-tuning (Osband et al., 2022; Niu et al., 2024; Yang et al., 2023b, 2024a). Other applications have explored uncertainty quantification in multi-step interaction and chain-of-thought prompting settings (Zhao et al., 2024d; Han et al., 2024), where the final output of an LLM depends on intermediate responses. To account for the influence of preceding responses, these methods propagate the LLM’s uncertainty at each interaction phase. Similar uncertainty propagation techniques have been applied to sequential labeling problems (He et al., 2023). In other applications, uncertainty quantification methods for LLMs have been utilized in retrieval-augmented generation (Rouzrokh et al., 2024; Li et al., 2024a), using the framework of conformal prediction to provide provable guarantees. Moreover, some existing work utilizes conformal prediction in response generation from an LLM to identify prediction sets that are likely to contain the ground-truth with some guarantees (Quach et al., 2023; Kumar et al., 2023). Although prior work employing conformal prediction generally assume access to the LLM’s logits, conformal prediction can also be utilized with black-box LLMs, e.g., (Su et al., 2024b). Lastly, techniques and results from mechanistic interpretability can be used to predict performance of LLMs at test time. In (Schwab and Karlen, 2019), the authors train a causal explanation model to estimate model performance using sensitivity to input features. In (Nanda et al., 2023), the authors find that sudden emergent qualitative changes in LLMs can be predicted by reverse engineering the model. Further, recent works (Zimmermann et al., 2024) have shown that scaling up LLMs in terms of model size or dataset does not improve interpretability as previously believed, by surveying human participants.
<details>
<summary>extracted/6588127/images/applications/hallucination_detection.png Details</summary>

### Visual Description
\n
## Diagram: AI Response Evaluation
### Overview
This diagram illustrates an AI's response to a user query, along with confidence and hallucination scores. It depicts a conversational flow with a question, an AI-generated answer, and subsequent evaluation metrics.
### Components/Axes
The diagram consists of four main components arranged vertically:
1. **User Query:** A blue speech bubble containing the question.
2. **AI Response:** A blue rectangular block containing the AI's answer.
3. **Token-Level Confidence Estimate:** A pink rectangular block displaying a confidence percentage.
4. **Hallucination Score:** A yellow rectangular block displaying a hallucination percentage.
Arrows indicate the flow of information from the query to the response, and then to the evaluation metrics. A small icon resembling a checkmark inside a circle is present to the left of the AI response.
### Detailed Analysis or Content Details
* **User Query:** "What is the most smallest country in Asia, by land area?"
* **AI Response:** "Nepal is the smallest country in Asia, by land area."
* **Token-Level Confidence Estimate:** 13%
* **Hallucination Score:** 80%
### Key Observations
The AI's response claims Nepal is the smallest country in Asia by land area. However, the Token-Level Confidence Estimate is very low (13%), and the Hallucination Score is extremely high (80%). This suggests the AI is likely providing inaccurate information. The user query itself contains a grammatical error ("most smallest").
### Interpretation
This diagram highlights a critical issue with AI language models: they can generate confident-sounding but factually incorrect responses (hallucinations). The low confidence score combined with the high hallucination score indicates the AI is uncertain about its answer and is likely fabricating information. The diagram serves as a warning about the need for careful verification of AI-generated content, especially when dealing with factual questions. The presence of the user query with a grammatical error may have contributed to the AI's inaccurate response, demonstrating the sensitivity of these models to input quality. The diagram demonstrates a system for evaluating AI responses, providing metrics to assess reliability.
</details>
Figure 16. Uncertainty quantification methods for LLMs have been employed in hallucination detection. LLMs tend to be less confident when hallucinating (measured via token-based metrics), although their responses may sound overly confident. In this example, although the LLM provides a confident response to the prompt, a token-level UQ method indicates that the LLM is uncertain, enabling hallucination detection.
\Description
[Uncertainty quantification methods for LLMs have been employed in hallucination detection. LLMs tend to be less confident when hallucinating (measured via token-based metrics), although their responses may sound overly confident. In this example, although the LLM provides a confident response to the prompt, a token-level UQ method indicates that the LLM is uncertain, enabling hallucination detection.]Uncertainty quantification methods for LLMs have been employed in hallucination detection. LLMs tend to be less confident when hallucinating (measured via token-based metrics), although their responses may sound overly confident. In this example, although the LLM provides a confident response to the prompt, a token-level UQ method indicates that the LLM is uncertain, enabling hallucination detection.
<details>
<summary>extracted/6588127/images/applications/uq_llm_robotics.png Details</summary>
### Visual Description
\n
## Screenshot: Robotic Assistance - Task Options
### Overview
The image depicts a screenshot of a robotic arm positioned over a table cluttered with objects. Below the image is a speech bubble containing a user query ("How do I clear the table?") and a list of suggested actions with associated confidence scores. The overall impression is a demonstration of a robotic assistant responding to a natural language command.
### Components/Axes
The image contains the following elements:
* **Robotic Arm:** A yellow robotic arm with multiple joints.
* **Table:** A wooden table with various objects on it (bowls, containers, etc.).
* **Arrow:** A downward-pointing arrow indicating interaction or focus.
* **Speech Bubble:** A blue speech bubble containing the text "How do I clear the table?".
* **Action List:** A light blue rectangular box containing a list of suggested actions and their associated confidence scores.
* **User Icon:** A small icon representing a user, positioned to the right of the speech bubble.
* **Swirl Icon:** A small swirl icon positioned to the left of the action list.
### Detailed Analysis or Content Details
The action list presents four suggested actions with corresponding confidence scores:
1. **0.51** – Move the ceramic bowl into the top drawer.
2. **0.33** – Move the metal bowl into the middle drawer.
3. **0.10** – Move the table to the living room.
4. **0.06** – Remove the top drawer.
The confidence scores are represented as decimal values between 0 and 1, indicating the system's certainty about the relevance of each action to the user's query. The actions are listed in descending order of confidence.
### Key Observations
* The system demonstrates an understanding of the objects on the table ("ceramic bowl", "metal bowl").
* The confidence scores suggest that the system is most confident in the first two actions (moving the bowls).
* The action "Move the table to the living room" has a significantly lower confidence score, indicating it is less likely to be the user's intention.
* The action "Remove the top drawer" has the lowest confidence score.
### Interpretation
The image demonstrates a robotic system capable of interpreting natural language commands and suggesting relevant actions. The confidence scores provide a measure of the system's uncertainty, allowing it to prioritize actions and potentially ask for clarification if needed. The system appears to be focused on object manipulation within the immediate environment (the table and drawers) rather than broader actions like moving the entire table. The descending order of confidence scores suggests a probabilistic reasoning process, where the system ranks actions based on their likelihood of fulfilling the user's intent. The system is likely using computer vision to identify the objects on the table and natural language processing to understand the user's query. The relatively low confidence in actions beyond object manipulation suggests the system's current capabilities are limited to tasks within a defined scope.
</details>
Figure 17. Robotics applications utilize UQ methods to estimate the LLM’s confidence in the sub-tasks proposed by the LLM, to determine when human assistance is required.
\Description
[Robotics applications utilize UQ methods to estimate the LLM’s confidence in the sub-tasks proposed by the LLM, to determine when human assistance is required.]Robotics applications utilize UQ methods to estimate the LLM’s confidence in the sub-tasks proposed by the LLM, to determine when human assistance is required.
9.2. Robotics
Endowing LLMs with an embodiment (physical form) presents unique challenges, as is the case in robotics. Such embodiment essentially empowers LLMs to be agents of physical change, which can lead to potentially disastrous outcomes if the outputs of the LLMs are not reliable or trustworthy. Although LLMs (and vision-language models) have found widespread applications in robotics, e.g., robotic manipulation (Ahn et al., 2022; Brohan et al., 2022, 2023; Kim et al., 2024b), robotic navigation and exploration (Shah et al., 2023; Dorbala et al., 2023; Ren et al., 2024), and multi-robot collaboration (Kannan et al., 2023; Chen et al., 2024; Mandi et al., 2024), only a few of these applications explicitly consider the uncertainty of the LLMs to ensure safety, although other existing work (Wang et al., 2024c) utilize LLMs to assess the success of a task without explicitly reasoning about the confidence of the LLM.
The work in (Tsai et al., 2024) fine-tunes the Mistral-7B LLM (Jiang et al., 2023b) to generate possible next actions for a decision-making agent and trains a neural point-wise dependency estimator to predict the compatibility score between a user-provided prompt and all generated actions. Subsequently, the authors employ conformal prediction to identify more likely actions for a given prompt, which is presented to the user to select the next action. A collection of LLM-based task planning work for robots examine the confidence an LLM assigns to its generated next-step plans to determine when human assistance or verification is required, illustrated in Figure 17. To determine when an LLM requires clarification from a human, KnowNo (Ren et al., 2023a) utilizes a token-based UQ approach to estimate the uncertainty of the LLM in generating possible next steps for a robot given a task, by examining the token probability assigned to each option in the list of possible next steps. Further, KnowNo employs conformal prediction to generate prediction sets over the possible next steps, with provable theoretical guarantees, prompting the human for help, if the prediction set consists of more than one possible action. HERACLEs (Wang et al., 2023b) presents a similar pipeline within a Linear Temporal Logic framework, with multiple high-level sub-goals.
IntroPlan (Liang et al., 2024) extends KnowNo (Ren et al., 2023a) through introspective planning, where, given a task, the LLM retrieves the most relevant instance from a knowledge base constructed from few-shot, human-provided examples and reasons about the feasibility of the possible next actions. Introspective planning enables IntroPlan to generate prediction sets with tighter confidence bounds, minimizing human intervention. LAP (Mullen Jr and Manocha, 2024) further introduces an action-feasibility metric to improve the alignment of the LLM’s confidence estimate with the probability of success, resulting in fewer clarification queries. S-ATLAS (Wang et al., 2024c) extends KnowNo to LLM-based multi-robot task planning, where a team of robot collaborate to complete a task. In addition, KnowLoop (Zheng et al., 2024) utilizes a multi-modal large language model (MLLM), e.g., LLaVa (Liu et al., 2024c) or ChatGPT-4V, for failure detection in LLM-based task planning. The MLLM evaluates the success of the task, given images of the environment at each stage, providing its feedback along with its estimated confidence, using either a self-verbalized approach or a token-level UQ method. KnowLoop (Zheng et al., 2024) demonstrates that token-level UQ approaches yield better-aligned uncertainty estimates compared to a self-verbalized UQ approach. Lastly, TrustNavGPT (Sun et al., 2024b) employs a similar architecture to evaluate the trustworthiness of human commands to an LLM in LLM-based, audio-guided robot navigation.
10. Open Research Challenges
We enumerate a number of open research challenges, hoping to drive future research to address these challenges.
10.1. Consistency is not Factuality
Many uncertainty quantification methods for LLMs rely on evaluating the consistency between multiple realizations of the response generated by LLMs. This approach faces fundamental limitations, since consistency is not necessarily aligned with factuality. For example, in Figure 19, when prompted to provide a response to the question: “What happened to Google in June 2007, in a single sentence?” GPT-4 claims that Google announced its mobile operating system Android in June 2007, which is incorrect, given that Android was launched in November 2007. In fact, when creating the set of responses for uncertainty quantification, multiple queries to GPT-4 generate the same incorrect response, which can lead to a miscalibrated confidence estimate. Notably, black-box methods that rely entirely on consistency are most susceptible to this challenge.
Nonetheless, consistency is often a good predictor of factuality, especially when given a sufficiently large number of samples. However, many existing methods do not rigorously examine the number of samples required to define a reliable set of responses when evaluating the consistency of an LLM on a given prompt, which constitutes a critical component for any guarantee on the estimated confidence of the model or factuality of the model’s response. Moreover, this challenge might be mitigated by a principled selection of the temperature parameter in an LLM to increase the randomness of the mode; however, the effectiveness of this strategy is quite limited, as excessive randomness in the LLM’s outputs defeats the purpose of examining the confidence of the model on a given prompt.
<details>
<summary>extracted/6588127/images/open_research_challenges/consistency_and_factuality.png Details</summary>
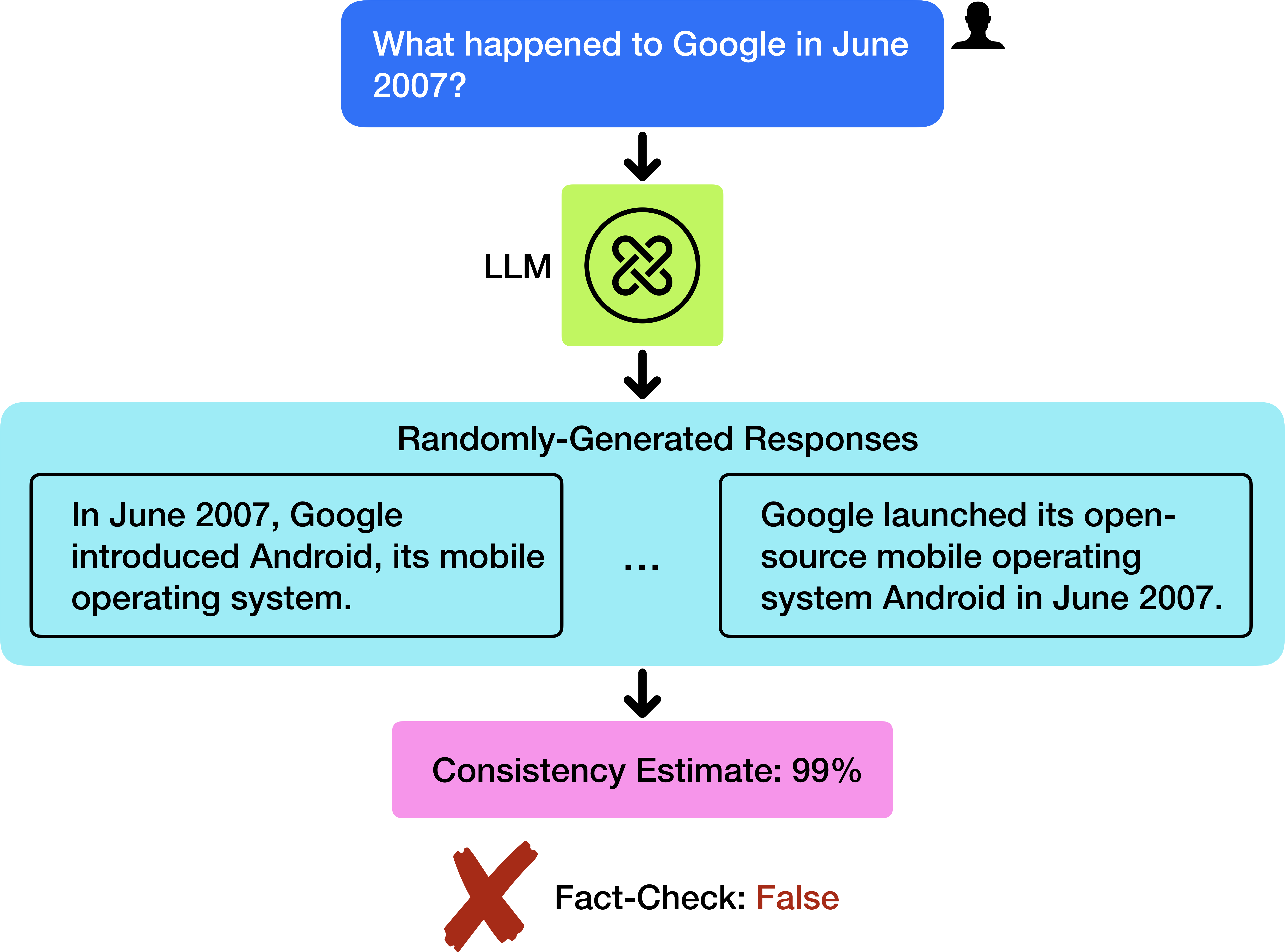
### Visual Description
\n
## Diagram: LLM Response and Fact-Check Flow
### Overview
This diagram illustrates the process of a Large Language Model (LLM) responding to a query, generating multiple responses, and then undergoing a fact-check. The diagram highlights a scenario where the LLM generates a response that, despite high consistency, is factually incorrect.
### Components/Axes
The diagram consists of the following components, arranged vertically:
1. **Input Query:** A blue rectangular box at the top, containing the text "What happened to Google in June 2007?". A small user icon is present in the top-right corner of this box.
2. **LLM Processing:** A green circular shape in the center, labeled "LLM" with a swirling arrow symbol inside.
3. **Randomly-Generated Responses:** A large, light-orange rectangular box containing two example responses, separated by ellipses ("..."), indicating more responses exist.
* Response 1: "In June 2007, Google introduced Android, its mobile operating system."
* Response 2: "Google launched its open-source mobile operating system Android in June 2007."
4. **Fact-Check Result:** A pink rectangular box at the bottom, containing two pieces of information:
* "Consistency Estimate: 99%"
* "Fact-Check: False" accompanied by a red "X" symbol.
5. **Arrows:** Black downward-pointing arrows indicate the flow of information between each component.
### Detailed Analysis or Content Details
The diagram shows a clear sequential flow:
1. A query ("What happened to Google in June 2007?") is input into the LLM.
2. The LLM processes the query and generates multiple responses.
3. Two example responses are provided, both stating that Google introduced/launched Android in June 2007.
4. These responses are then subjected to a fact-check, which determines them to be "False" despite a "Consistency Estimate" of 99%.
### Key Observations
The key observation is the discrepancy between the high consistency estimate (99%) and the fact-check result ("False"). This suggests that the LLM is generating responses that are internally consistent but not aligned with factual reality. The diagram emphasizes the importance of fact-checking LLM outputs, even when they appear highly confident.
### Interpretation
This diagram demonstrates a critical challenge in the development and deployment of LLMs: the potential for generating plausible-sounding but inaccurate information. The high consistency estimate indicates the LLM is confident in its response, but the fact-check reveals that this confidence is misplaced. This highlights the need for robust fact-checking mechanisms to mitigate the risk of spreading misinformation. The diagram serves as a cautionary tale, illustrating that LLMs are not inherently truthful and require external validation. The use of multiple responses suggests the LLM is exploring different phrasing, but none of them are factually correct in this instance. The diagram is a visual representation of the "hallucination" problem often encountered with LLMs.
</details>
Figure 18. Consistency is not factuality. Semantic-similarity UQ methods for LLMs might provide misleading confidence estimates, e.g., when multiple random responses from the LLM are consistent but false. In this example, the LLM consistently claims that Google introduced Android in June 2007, which is incorrect, given that Android was introduced in November 2007.
\Description
[Consistency is not factuality. Semantic-similarity UQ methods for LLMs might provide misleading confidence estimates, e.g., when multiple random responses from the LLM are consistent but false. In this example, the LLM consistently claims that Google introduced Android in June 2007, which is incorrect, given that Android was introduced in November 2007.]Consistency is not factuality. Semantic-similarity UQ methods for LLMs might provide misleading confidence estimates, e.g., when multiple random responses from the LLM are consistent but false. In this example, the LLM consistently claims that Google introduced Android in June 2007, which is incorrect, given that Android was introduced in November 2007.
<details>
<summary>extracted/6588127/images/open_research_challenges/entropy_and_factuality.png Details</summary>

### Visual Description
\n
## Diagram: Fact-Check Result for Population Claim
### Overview
This diagram presents a fact-check result for the claim regarding the most populous country in the world in 2024. It shows a question, a proposed answer with a population figure, a confidence estimate, and a final fact-check verdict.
### Components/Axes
The diagram consists of four main blocks arranged vertically:
1. **Question Block (Top):** A light blue rectangle containing the question: "What is the most populous country in the world in 2024?"
2. **Answer Block (Middle-Top):** A light purple rectangle stating: "The United States of America with a population of 345,426,571." This block also contains a series of small square icons, alternating between green and yellow.
3. **Confidence Block (Middle-Bottom):** A magenta rectangle displaying: "Confidence Estimate from Token Probability: 91%"
4. **Fact-Check Block (Bottom):** A red "X" symbol with the text: "Fact-Check: False"
### Detailed Analysis or Content Details
* **Question:** "What is the most populous country in the world in 2024?"
* **Proposed Answer:** The United States of America with a population of 345,426,571.
* **Icon Sequence:** The answer block contains 10 small square icons. The sequence is: Green, Yellow, Green, Green, Yellow, Green, Yellow, Green, Green, Yellow.
* **Confidence Estimate:** 91%
* **Fact-Check Result:** False.
### Key Observations
The diagram indicates a high confidence (91%) in the proposed answer, yet the fact-check result is "False". This suggests the model is confident in its response, but the response is inaccurate. The alternating green and yellow icons in the answer block are not explained and their purpose is unclear.
### Interpretation
The diagram demonstrates a scenario where a language model or AI system confidently provides an incorrect answer to a factual question. The high confidence estimate highlights a potential issue with the model's knowledge base or reasoning capabilities. The fact that the model confidently states the United States is the most populous country in 2024 is demonstrably false, as China and India both have significantly larger populations. The icons may represent some internal confidence scoring or token probabilities, but their meaning is not explicitly stated. This example underscores the importance of fact-checking AI-generated content, even when presented with high confidence. The diagram serves as a cautionary example of the limitations of AI and the need for critical evaluation of its outputs.
</details>
Figure 19. Using the conditional distribution of tokens for uncertainty quantification (e.g., in token-level UQ methods) can lead to misleading uncertainty estimates. In this example, the uncertainty of the LLM is notably low, since the succeeding tokens are highly likely given the preceding tokens. However, the claim is incorrect. The most populous country in the world in 2024 is India, not the United States of America. The bars denote the probability of each token.
\Description
[Using the conditional distribution of tokens for uncertainty quantification (e.g., in token-level UQ methods) can lead to misleading uncertainty estimates. In this example, the uncertainty of the LLM is notably low, since the succeeding tokens are highly likely given the preceding tokens. However, the claim is incorrect. The most populous country in the world in 2024 is India, not the United States of America. The bars denote the probability of each token.]Using the conditional distribution of tokens for uncertainty quantification (e.g., in token-level UQ methods) can lead to misleading uncertainty estimates. In this example, the uncertainty of the LLM is notably low, since the succeeding tokens are highly likely given the preceding tokens. However, the claim is incorrect. The most populous country in the world in 2024 is India, not the United States of America. The bars denote the probability of each token.
10.2. Entropy is not Factuality
Entropy and other token-based UQ metrics of the token probability distribution in an LLM’s output are not necessarily aligned with the factuality of the model’s output, although entropy and factuality are often aligned. In particular, the distribution over the tokens is a function of the size of the LLM (including its dictionary of tokens) and the diversity and size of the training data, which can influence the alignment of entropy and factuality. Hence, token-based UQ methods might produce highly miscalibrated confidence estimates for a given prompt, when these estimates are computed entirely from the distribution over the tokens. For example, in a worst-case scenario where the training data is corrupted or insufficient, an LLM might assign most of its probability to an incorrect answer (token) which is most closely related to the training data, leading to a miscalibrated estimate of its confidence. Moreover, reinforcement learning with human feedback (RLHF), which is utilized in fine-tuning LLMs, generally reduces the calibration of the LLM’s confidence estimates (Achiam et al., 2023). Further, the conditional distribution of each token might not be indicative of the factuality of an LLM’s response at the claim-level (sentence-level), i.e., although each generated token might be highly likely given the preceding token, the overall claim expressed by the LLM might not be correct (Vazhentsev et al., 2024), as illustrated in Figure 19.
Future research should explore aligning the entropy of tokens with the factuality of the claims expressed by LLMs and examine augmentation strategies that consider the training distribution of LLMs to better account for the influence of the training data on the probability distribution associated with the generated tokens to ultimately improve the alignment of entropy and other token-based measures of uncertainty with factuality. Moreover, the probability distributions over the tokens of an LLM can be manipulated in jailbreaking attacks, leading to misleading confidence estimates and, in some cases, non-factual responses (Zeng et al., 2024). Future research should seek to improve the robustness of token-level uncertainty quantification methods to adversarial attacks. Further, few existing methods explore uncertainty quantification of LLMs in text summarization, which is critical to the preservation of factual records, constituting an important direction for future research.
10.3. Applications in Interactive LLM-Enabled Agents
Although some existing applications explore uncertainty quantification in LLM-enabled agents, e.g., see Section 9.2, many of these applications only estimate the LLM’s uncertainty at each episode without considering the history of the agent’s interaction with the LLM. However, many practical applications require multi-episode interactions, where the LLM generates successive responses based on the information from preceding episodes with the agent. For example, in the scenario depicted in Figure 17, the robot may be asked to prepare a meal for a user, which would require multi-episode interactions, where each episode corresponds to a given sub-task, such as dicing some vegetables before sautéing it. Note that utilizing many existing techniques for uncertainty quantification would require the assumption that the LLM’s uncertainty at each episode is independent of its prior interaction history, an assumption that is generally not satisfied in real-world applications. Rigorous uncertainty quantification of the LLM’s outputs requires the consideration of the history of the agent’s interaction with the LLM and its observations (e.g., camera images), in the case of VLMs. This yet-unexplored research area constitutes an exciting direction for future research.
10.4. Applications of Mechanistic Interpretability to Uncertainty Quantification
The connections between interpretability of LLMs and uncertainty quantification have been relatively unexplored, despite the intuitive relationship between both concepts. Mechanistic interpretability holds notable potential in exploiting the synergy between both areas to derive solutions to some of the aforementioned research challenges. For example, the work in (Ahdritz et al., 2024) predicts the token-level confidence of large LLMs using small linear probes (models) trained on the embeddings of frozen pretrained models. This work suggests the existence of a relationship between the internal states of LLMs and their confidence. The authors indicate that their findings suggest that information on the internal state of an LLM could be utilized in distinguishing epistemic uncertainty of the model from aleatoric uncertainty. However, this research area is relatively unexplored, presenting a potentially fruitful direction for future research.
10.5. Datasets and Benchmarks
Although a number of datasets and benchmark for uncertainty quantification exists (Joshi et al., 2017; Reddy et al., 2019; Yang et al., 2018; Lin et al., 2021), to the best of our knowledge, no dataset exists for uncertainty quantification of LLMs in multi-episode interaction scenarios. Future research should examine the creation of versatile, standardized datasets that aid research on uncertainty quantification of LLMs, taking into consideration the history of interaction between a user and an LLM. Moreover, benchmarks on uncertainty quantification of LLMs can help inform researchers on the relative performance of their proposed methods. Unfortunately, widely-accepted benchmarks for uncertainty quantification of LLMs do not exist, although some work has been devoted to developing such benchmarks. Future work should seek to create suitable benchmarks for this purpose, especially benchmarks that evaluate the calibration, tightness (conservativeness), and interpretability of uncertainty quantification methods. However, benchmarks can also introduce other challenges, by disconnecting research from practical concerns, overly simplifying the assessment of research advances to outperforming existing work on some metric defined in a benchmark. Hence, care must be taken to ensure that benchmarks remain relevant to practical effectiveness.
11. Conclusion
In this survey, we provide a comprehensive review of existing uncertainty quantification methods for LLMs, including relevant background information necessary for readers. We categorize UQ methods for LLMs into four broad classes based on the underlying technique employed by these methods, namely: token-based UQ methods, self-verbalized UQ methods, semantic-similarity-based methods, and mechanistic interpretability. Token-based UQ methods rely on access to an LLM’s intermediate outputs or architecture to estimate the confidence an LLM, whereas in self-verbalized UQ methods, the LLM provides its estimated confidence in natural-language. Many semantic-similarity-based methods are black-box methods which only require access to the model’s natural-language output, relying on consistency metrics to estimate the LLM’s confidence. In contrast, mechanistic interpretability requires access to the LLM’s internal activations to identify latent features that explain its activation patterns. Furthermore, we identify relevant datasets and applications for uncertainty quantification of LLMs and highlight open research challenges to inspire future research.
Acknowledgements. We would like to acknowledge Apurva S. Badithela and David Snyder for their contributions. This work was partially supported by the NSF CAREER Award [#2044149], the Office of Naval Research [N00014-23-1-2148], and the Sloan Fellowship. Justin Lidard was supported by a National Science Foundation Graduate Research Fellowship.
References
- (1)
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
- Ahdritz et al. (2024) Gustaf Ahdritz, Tian Qin, Nikhil Vyas, Boaz Barak, and Benjamin L Edelman. 2024. Distinguishing the knowable from the unknowable with language models. arXiv preprint arXiv:2402.03563 (2024).
- Ahn et al. (2022) Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. 2022. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691 (2022).
- Aichberger et al. (2024) Lukas Aichberger, Kajetan Schweighofer, Mykyta Ielanskyi, and Sepp Hochreiter. 2024. Semantically Diverse Language Generation for Uncertainty Estimation in Language Models. arXiv preprint arXiv:2406.04306 (2024).
- Aliannejadi et al. (2021) Mohammad Aliannejadi, Julia Kiseleva, Aleksandr Chuklin, Jeffrey Dalton, and Mikhail Burtsev. 2021. Building and evaluating open-domain dialogue corpora with clarifying questions. arXiv preprint arXiv:2109.05794 (2021).
- Alkaissi and McFarlane (2023) Hussam Alkaissi and Samy I McFarlane. 2023. Artificial hallucinations in ChatGPT: implications in scientific writing. Cureus 15, 2 (2023).
- Anthropic (2024) AI Anthropic. 2024. The Claude 3 model family: Opus, Sonnet, Haiku. Claude-3 Model Card 1 (2024).
- Ao et al. (2024) Shuang Ao, Stefan Rueger, and Advaith Siddharthan. 2024. CSS: Contrastive Semantic Similarity for Uncertainty Quantification of LLMs. arXiv preprint arXiv:2406.03158 (2024).
- Arteaga et al. (2024) Gabriel Y Arteaga, Thomas B Schön, and Nicolas Pielawski. 2024. Hallucination Detection in LLMs: Fast and Memory-Efficient Finetuned Models. arXiv preprint arXiv:2409.02976 (2024).
- Ayhan and Berens (2018) Murat Seckin Ayhan and Philipp Berens. 2018. Test-time data augmentation for estimation of heteroscedastic aleatoric uncertainty in deep neural networks. In Medical Imaging with Deep Learning.
- Azamfirei et al. (2023) Razvan Azamfirei, Sapna R Kudchadkar, and James Fackler. 2023. Large language models and the perils of their hallucinations. Critical Care 27, 1 (2023), 120.
- Azaria and Mitchell (2023) Amos Azaria and Tom Mitchell. 2023. The internal state of an LLM knows when it’s lying. arXiv preprint arXiv:2304.13734 (2023).
- Bahat and Shakhnarovich (2020) Yuval Bahat and Gregory Shakhnarovich. 2020. Classification confidence estimation with test-time data-augmentation. arXiv preprint arXiv:2006.16705 (2020).
- Bai et al. (2024) Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. 2024. Hallucination of multimodal large language models: A survey. arXiv preprint arXiv:2404.18930 (2024).
- Bakman et al. (2024) Yavuz Faruk Bakman, Duygu Nur Yaldiz, Baturalp Buyukates, Chenyang Tao, Dimitrios Dimitriadis, and Salman Avestimehr. 2024. MARS: Meaning-Aware Response Scoring for Uncertainty Estimation in Generative LLMs. arXiv preprint arXiv:2402.11756 (2024).
- Balabanov and Linander (2024) Oleksandr Balabanov and Hampus Linander. 2024. Uncertainty quantification in fine-tuned LLMs using LoRA ensembles. arXiv preprint arXiv:2402.12264 (2024).
- Band et al. (2024) Neil Band, Xuechen Li, Tengyu Ma, and Tatsunori Hashimoto. 2024. Linguistic Calibration of Long-Form Generations. In Forty-first International Conference on Machine Learning.
- Becker and Soatto (2024) Evan Becker and Stefano Soatto. 2024. Cycles of Thought: Measuring LLM Confidence through Stable Explanations. arXiv preprint arXiv:2406.03441 (2024).
- Belinkov (2022) Yonatan Belinkov. 2022. Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics 48, 1 (2022), 207–219.
- Bereska and Gavves (2024) Leonard Bereska and Efstratios Gavves. 2024. Mechanistic Interpretability for AI Safety–A Review. arXiv preprint arXiv:2404.14082 (2024).
- Brohan et al. (2023) Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. 2023. Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818 (2023).
- Brohan et al. (2022) Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. 2022. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817 (2022).
- Brown (2020) Tom B Brown. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165 (2020).
- Buciluǎ et al. (2006) Cristian Buciluǎ, Rich Caruana, and Alexandru Niculescu-Mizil. 2006. Model compression. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. 535–541.
- Bulian et al. (2022) Jannis Bulian, Christian Buck, Wojciech Gajewski, Benjamin Boerschinger, and Tal Schuster. 2022. Tomayto, tomahto. beyond token-level answer equivalence for question answering evaluation. arXiv preprint arXiv:2202.07654 (2022).
- Burns et al. (2022) Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. 2022. Discovering latent knowledge in language models without supervision. arXiv preprint arXiv:2212.03827 (2022).
- Cavalcanti et al. (2016) George DC Cavalcanti, Luiz S Oliveira, Thiago JM Moura, and Guilherme V Carvalho. 2016. Combining diversity measures for ensemble pruning. Pattern Recognition Letters 74 (2016), 38–45.
- Chang et al. (2024) Haw-Shiuan Chang, Nanyun Peng, Mohit Bansal, Anil Ramakrishna, and Tagyoung Chung. 2024. REAL Sampling: Boosting Factuality and Diversity of Open-Ended Generation via Asymptotic Entropy. arXiv preprint arXiv:2406.07735 (2024).
- Chen and Mueller (2023) Jiuhai Chen and Jonas Mueller. 2023. Quantifying uncertainty in answers from any language model via intrinsic and extrinsic confidence assessment. arXiv preprint arXiv:2308.16175 (2023).
- Chen et al. (2024) Yongchao Chen, Jacob Arkin, Yang Zhang, Nicholas Roy, and Chuchu Fan. 2024. Scalable multi-robot collaboration with large language models: Centralized or decentralized systems?. In 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 4311–4317.
- Chen et al. (2023) Yuyan Chen, Qiang Fu, Yichen Yuan, Zhihao Wen, Ge Fan, Dayiheng Liu, Dongmei Zhang, Zhixu Li, and Yanghua Xiao. 2023. Hallucination detection: Robustly discerning reliable answers in large language models. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. 245–255.
- Chen et al. (2022) Yangyi Chen, Lifan Yuan, Ganqu Cui, Zhiyuan Liu, and Heng Ji. 2022. A close look into the calibration of pre-trained language models. arXiv preprint arXiv:2211.00151 (2022).
- Chew et al. (2023) Robert Chew, John Bollenbacher, Michael Wenger, Jessica Speer, and Annice Kim. 2023. LLM-assisted content analysis: Using large language models to support deductive coding. arXiv preprint arXiv:2306.14924 (2023).
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) 2, 3 (2023), 6.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021).
- Condoravdi et al. (2003) Cleo Condoravdi, Dick Crouch, Valeria De Paiva, Reinhard Stolle, and Daniel Bobrow. 2003. Entailment, intensionality and text understanding. In Proceedings of the HLT-NAACL 2003 workshop on Text meaning. 38–45.
- Cronin et al. (2017) Robert M Cronin, Daniel Fabbri, Joshua C Denny, S Trent Rosenbloom, and Gretchen Purcell Jackson. 2017. A comparison of rule-based and machine learning approaches for classifying patient portal messages. International journal of medical informatics 105 (2017), 110–120.
- Cunningham et al. (2023) Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. 2023. Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600 (2023).
- Da et al. (2024) Longchao Da, Tiejin Chen, Lu Cheng, and Hua Wei. 2024. LLM Uncertainty Quantification through Directional Entailment Graph and Claim Level Response Augmentation. arXiv preprint arXiv:2407.00994 (2024).
- Dagan et al. (2005) Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The pascal recognising textual entailment challenge. In Machine learning challenges workshop. Springer, 177–190.
- Dai et al. (2023) Shih-Chieh Dai, Aiping Xiong, and Lun-Wei Ku. 2023. LLM-in-the-loop: Leveraging large language model for thematic analysis. arXiv preprint arXiv:2310.15100 (2023).
- Delacroix (2024) Sylvie Delacroix. 2024. Augmenting judicial practices with LLMs: re-thinking LLMs’ uncertainty communication features in light of systemic risks. Available at SSRN (2024).
- Desai and Durrett (2020) Shrey Desai and Greg Durrett. 2020. Calibration of pre-trained transformers. arXiv preprint arXiv:2003.07892 (2020).
- Detommaso et al. (2024) Gianluca Detommaso, Martin Bertran, Riccardo Fogliato, and Aaron Roth. 2024. Multicalibration for confidence scoring in LLMs. arXiv preprint arXiv:2404.04689 (2024).
- Devlin (2018) Jacob Devlin. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Dorbala et al. (2023) Vishnu Sashank Dorbala, James F Mullen Jr, and Dinesh Manocha. 2023. Can an embodied agent find your “cat-shaped mug”? llm-based zero-shot object navigation. IEEE Robotics and Automation Letters (2023).
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024).
- Dunefsky et al. (2024) Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. 2024. Transcoders Find Interpretable LLM Feature Circuits. arXiv preprint arXiv:2406.11944 (2024).
- Duquenne et al. (2023) Paul-Ambroise Duquenne, Holger Schwenk, and Benoît Sagot. 2023. SONAR: sentence-level multimodal and language-agnostic representations. arXiv e-prints (2023), arXiv–2308.
- Elazar et al. (2021) Yanai Elazar, Nora Kassner, Shauli Ravfogel, Abhilasha Ravichander, Eduard Hovy, Hinrich Schütze, and Yoav Goldberg. 2021. Measuring and improving consistency in pretrained language models. Transactions of the Association for Computational Linguistics 9 (2021), 1012–1031.
- Elhage et al. (2022) Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. 2022. Toy models of superposition. arXiv preprint arXiv:2209.10652 (2022).
- Engels et al. (2024) Joshua Engels, Isaac Liao, Eric J Michaud, Wes Gurnee, and Max Tegmark. 2024. Not All Language Model Features Are Linear. arXiv preprint arXiv:2405.14860 (2024).
- Fadeeva et al. (2024) Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov, Sergey Petrakov, Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov, Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, et al. 2024. Fact-checking the output of large language models via token-level uncertainty quantification. arXiv preprint arXiv:2403.04696 (2024).
- Feng et al. (2020) Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, and Wei Wang. 2020. Language-agnostic BERT sentence embedding. arXiv preprint arXiv:2007.01852 (2020).
- Feng et al. (2024) Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, and Yulia Tsvetkov. 2024. Don’t Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration. arXiv preprint arXiv:2402.00367 (2024).
- Ferrando et al. (2024) Javier Ferrando, Oscar Obeso, Senthooran Rajamanoharan, and Neel Nanda. 2024. Do I Know This Entity? Knowledge Awareness and Hallucinations in Language Models. arXiv preprint arXiv:2411.14257 (2024).
- Fyodorov et al. (2000) Yaroslav Fyodorov, Yoad Winter, and Nissim Francez. 2000. A natural logic inference system. In Proceedings of the 2nd workshop on inference in computational semantics (ICoS-2).
- Gal and Ghahramani (2016) Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning. PMLR, 1050–1059.
- Gal et al. (2017) Yarin Gal, Jiri Hron, and Alex Kendall. 2017. Concrete dropout. Advances in neural information processing systems 30 (2017).
- Gao et al. (2024) Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. 2024. Scaling and evaluating sparse autoencoders. arXiv preprint arXiv:2406.04093 (2024).
- Geng et al. (2024) Jiahui Geng, Fengyu Cai, Yuxia Wang, Heinz Koeppl, Preslav Nakov, and Iryna Gurevych. 2024. A Survey of Confidence Estimation and Calibration in Large Language Models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 6577–6595.
- Geva et al. (2021) Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. 2021. Did Aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics 9 (2021), 346–361.
- Geva et al. (2020) Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2020. Transformer feed-forward layers are key-value memories. arXiv preprint arXiv:2012.14913 (2020).
- Gneiting et al. (2007) Tilmann Gneiting, Fadoua Balabdaoui, and Adrian E Raftery. 2007. Probabilistic forecasts, calibration and sharpness. Journal of the Royal Statistical Society Series B: Statistical Methodology 69, 2 (2007), 243–268.
- Gneiting and Raftery (2007) Tilmann Gneiting and Adrian E Raftery. 2007. Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association 102, 477 (2007), 359–378.
- Groot and Valdenegro-Toro (2024) Tobias Groot and Matias Valdenegro-Toro. 2024. Overconfidence is Key: Verbalized Uncertainty Evaluation in Large Language and Vision-Language Models. arXiv preprint arXiv:2405.02917 (2024).
- Guo et al. (2017) Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. 2017. On calibration of modern neural networks. In International conference on machine learning. PMLR, 1321–1330.
- Guo et al. (2018) Huaping Guo, Hongbing Liu, Ran Li, Changan Wu, Yibo Guo, and Mingliang Xu. 2018. Margin & diversity based ordering ensemble pruning. Neurocomputing 275 (2018), 237–246.
- Gurnee et al. (2023) Wes Gurnee, Neel Nanda, Matthew Pauly, Katherine Harvey, Dmitrii Troitskii, and Dimitris Bertsimas. 2023. Finding neurons in a haystack: Case studies with sparse probing. arXiv preprint arXiv:2305.01610 (2023).
- Han et al. (2024) Jiuzhou Han, Wray Buntine, and Ehsan Shareghi. 2024. Towards uncertainty-aware language agent. arXiv preprint arXiv:2401.14016 (2024).
- Hastings (1970) W Keith Hastings. 1970. Monte Carlo sampling methods using Markov chains and their applications. Oxford University Press.
- He et al. (2023) Jianfeng He, Linlin Yu, Shuo Lei, Chang-Tien Lu, and Feng Chen. 2023. Uncertainty estimation on sequential labeling via uncertainty transmission. arXiv preprint arXiv:2311.08726 (2023).
- He and Li (2024) Lin He and Keqin Li. 2024. Mitigating Hallucinations in LLM Using K-means Clustering of Synonym Semantic Relevance. Authorea Preprints (2024).
- He et al. (2020) Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2020. Deberta: Decoding-enhanced bert with disentangled attention. arXiv preprint arXiv:2006.03654 (2020).
- Hendrycks et al. (2021) Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. 2021. Measuring coding challenge competence with apps. arXiv preprint arXiv:2105.09938 (2021).
- Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 (2020).
- Hinton (2015) Geoffrey Hinton. 2015. Distilling the Knowledge in a Neural Network. arXiv preprint arXiv:1503.02531 (2015).
- Hou et al. (2023) Bairu Hou, Yujian Liu, Kaizhi Qian, Jacob Andreas, Shiyu Chang, and Yang Zhang. 2023. Decomposing uncertainty for large language models through input clarification ensembling. arXiv preprint arXiv:2311.08718 (2023).
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021).
- Hu et al. (2024) Jun Hu, Wenwen Xia, Xiaolu Zhang, Chilin Fu, Weichang Wu, Zhaoxin Huan, Ang Li, Zuoli Tang, and Jun Zhou. 2024. Enhancing sequential recommendation via llm-based semantic embedding learning. In Companion Proceedings of the ACM on Web Conference 2024. 103–111.
- Huang et al. (2024) Hsiu-Yuan Huang, Yutong Yang, Zhaoxi Zhang, Sanwoo Lee, and Yunfang Wu. 2024. A Survey of Uncertainty Estimation in LLMs: Theory Meets Practice. arXiv preprint arXiv:2410.15326 (2024).
- Huang et al. (2023b) Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2023b. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232 (2023).
- Huang et al. (2021) Rui Huang, Andrew Geng, and Yixuan Li. 2021. On the importance of gradients for detecting distributional shifts in the wild. Advances in Neural Information Processing Systems 34 (2021), 677–689.
- Huang et al. (2023a) Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, and Lei Ma. 2023a. Look before you leap: An exploratory study of uncertainty measurement for large language models. arXiv preprint arXiv:2307.10236 (2023).
- Igoe et al. (2022) Conor Igoe, Youngseog Chung, Ian Char, and Jeff Schneider. 2022. How useful are gradients for ood detection really? arXiv preprint arXiv:2205.10439 (2022).
- Ji et al. (2023) Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. Comput. Surveys 55, 12 (2023), 1–38.
- Jiang et al. (2023b) Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023b. Mistral 7B. arXiv preprint arXiv:2310.06825 (2023).
- Jiang et al. (2023a) Mingjian Jiang, Yangjun Ruan, Sicong Huang, Saifei Liao, Silviu Pitis, Roger Baker Grosse, and Jimmy Ba. 2023a. Calibrating language models via augmented prompt ensembles. (2023).
- Jiang et al. (2024) Mingjian Jiang, Yangjun Ruan, Prasanna Sattigeri, Salim Roukos, and Tatsunori Hashimoto. 2024. Graph-based Uncertainty Metrics for Long-form Language Model Outputs. arXiv preprint arXiv:2410.20783 (2024).
- Johnson et al. (2024) Daniel D Johnson, Daniel Tarlow, David Duvenaud, and Chris J Maddison. 2024. Experts Don’t Cheat: Learning What You Don’t Know By Predicting Pairs. arXiv preprint arXiv:2402.08733 (2024).
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551 (2017).
- Jospin et al. (2022) Laurent Valentin Jospin, Hamid Laga, Farid Boussaid, Wray Buntine, and Mohammed Bennamoun. 2022. Hands-on Bayesian neural networks—A tutorial for deep learning users. IEEE Computational Intelligence Magazine 17, 2 (2022), 29–48.
- Jung et al. (2024) Jaehun Jung, Faeze Brahman, and Yejin Choi. 2024. Trust or Escalate: LLM Judges with Provable Guarantees for Human Agreement. arXiv preprint arXiv:2407.18370 (2024).
- Kadavath et al. (2022) Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. 2022. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221 (2022).
- Kamath et al. (2024) Gaurav Kamath, Sebastian Schuster, Sowmya Vajjala, and Siva Reddy. 2024. Scope Ambiguities in Large Language Models. Transactions of the Association for Computational Linguistics 12 (2024), 738–754.
- Kannan et al. (2023) Shyam Sundar Kannan, Vishnunandan LN Venkatesh, and Byung-Cheol Min. 2023. Smart-llm: Smart multi-agent robot task planning using large language models. arXiv preprint arXiv:2309.10062 (2023).
- Kapoor et al. (2024) Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, and Andrew Gordon Wilson. 2024. Large Language Models Must Be Taught to Know What They Don’t Know. arXiv preprint arXiv:2406.08391 (2024).
- Katz et al. (2024) Daniel Martin Katz, Michael James Bommarito, Shang Gao, and Pablo Arredondo. 2024. Gpt-4 passes the bar exam. Philosophical Transactions of the Royal Society A 382, 2270 (2024), 20230254.
- Keeling and Street (2024) Geoff Keeling and Winnie Street. 2024. On the attribution of confidence to large language models. arXiv preprint arXiv:2407.08388 (2024).
- Kim et al. (2024b) Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. 2024b. OpenVLA: An Open-Source Vision-Language-Action Model. arXiv preprint arXiv:2406.09246 (2024).
- Kim et al. (2024a) Sunnie SY Kim, Q Vera Liao, Mihaela Vorvoreanu, Stephanie Ballard, and Jennifer Wortman Vaughan. 2024a. ” I’m Not Sure, But…”: Examining the Impact of Large Language Models’ Uncertainty Expression on User Reliance and Trust. In The 2024 ACM Conference on Fairness, Accountability, and Transparency. 822–835.
- Kolagar and Zarcone (2024) Zahra Kolagar and Alessandra Zarcone. 2024. Aligning Uncertainty: Leveraging LLMs to Analyze Uncertainty Transfer in Text Summarization. In Proceedings of the 1st Workshop on Uncertainty-Aware NLP (UncertaiNLP 2024). 41–61.
- Kong et al. (2020) Lingkai Kong, Haoming Jiang, Yuchen Zhuang, Jie Lyu, Tuo Zhao, and Chao Zhang. 2020. Calibrated language model fine-tuning for in-and out-of-distribution data. arXiv preprint arXiv:2010.11506 (2020).
- Kossen et al. (2024) Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. 2024. Semantic entropy probes: Robust and cheap hallucination detection in llms. arXiv preprint arXiv:2406.15927 (2024).
- Krause et al. (2023) Lea Krause, Wondimagegnhue Tufa, Selene Báez Santamaría, Angel Daza, Urja Khurana, and Piek Vossen. 2023. Confidently wrong: exploring the calibration and expression of (Un) certainty of large language models in a multilingual setting. In Proceedings of the workshop on multimodal, multilingual natural language generation and multilingual WebNLG Challenge (MM-NLG 2023). 1–9.
- Kuhn et al. (2023) Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. arXiv preprint arXiv:2302.09664 (2023).
- Kumar et al. (2023) Bhawesh Kumar, Charlie Lu, Gauri Gupta, Anil Palepu, David Bellamy, Ramesh Raskar, and Andrew Beam. 2023. Conformal prediction with large language models for multi-choice question answering. arXiv preprint arXiv:2305.18404 (2023).
- Lai et al. (2017) Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. 2017. Race: Large-scale reading comprehension dataset from examinations. arXiv preprint arXiv:1704.04683 (2017).
- Lakshminarayanan et al. (2017) Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information processing systems 30 (2017).
- Lebret et al. (2016) Rémi Lebret, David Grangier, and Michael Auli. 2016. Generating text from structured data with application to the biography domain. CoRR, abs/1603.07771 (2016).
- Ledda et al. (2023) Emanuele Ledda, Giorgio Fumera, and Fabio Roli. 2023. Dropout injection at test time for post hoc uncertainty quantification in neural networks. Information Sciences 645 (2023), 119356.
- Lee and AlRegib (2020) Jinsol Lee and Ghassan AlRegib. 2020. Gradients as a measure of uncertainty in neural networks. In 2020 IEEE International Conference on Image Processing (ICIP). IEEE, 2416–2420.
- Lee et al. (2018) Katherine Lee, Orhan Firat, Ashish Agarwal, Clara Fannjiang, and David Sussillo. 2018. Hallucinations in neural machine translation. (2018).
- Li et al. (2024b) Chengzu Li, Han Zhou, Goran Glavaš, Anna Korhonen, and Ivan Vulić. 2024b. Can Large Language Models Achieve Calibration with In-Context Learning?. In ICLR 2024 Workshop on Reliable and Responsible Foundation Models.
- Li et al. (2023) Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023. Halueval: A large-scale hallucination evaluation benchmark for large language models. arXiv preprint arXiv:2305.11747 (2023).
- Li et al. (2024a) Shuo Li, Sangdon Park, Insup Lee, and Osbert Bastani. 2024a. TRAQ: Trustworthy Retrieval Augmented Question Answering via Conformal Prediction. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 3799–3821.
- Liang et al. (2024) Kaiqu Liang, Zixu Zhang, and Jaime Fernández Fisac. 2024. Introspective Planning: Guiding Language-Enabled Agents to Refine Their Own Uncertainty. arXiv preprint arXiv:2402.06529 (2024).
- Lieberum et al. (2023) Tom Lieberum, Matthew Rahtz, János Kramár, Neel Nanda, Geoffrey Irving, Rohin Shah, and Vladimir Mikulik. 2023. Does circuit analysis interpretability scale? evidence from multiple choice capabilities in chinchilla. arXiv preprint arXiv:2307.09458 (2023).
- Lieberum et al. (2024) Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. 2024. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2. arXiv preprint arXiv:2408.05147 (2024).
- Lin (2004) Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out. 74–81.
- Lin et al. (2021) Stephanie Lin, Jacob Hilton, and Owain Evans. 2021. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958 (2021).
- Lin et al. (2022) Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Teaching models to express their uncertainty in words. arXiv preprint arXiv:2205.14334 (2022).
- Lin et al. (2023) Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. 2023. Generating with confidence: Uncertainty quantification for black-box large language models. arXiv preprint arXiv:2305.19187 (2023).
- Ling et al. (2024) Chen Ling, Xujiang Zhao, Wei Cheng, Yanchi Liu, Yiyou Sun, Xuchao Zhang, Mika Oishi, Takao Osaki, Katsushi Matsuda, Jie Ji, et al. 2024. Uncertainty decomposition and quantification for in-context learning of large language models. arXiv preprint arXiv:2402.10189 (2024).
- Liu et al. (2023a) Alisa Liu, Zhaofeng Wu, Julian Michael, Alane Suhr, Peter West, Alexander Koller, Swabha Swayamdipta, Noah A Smith, and Yejin Choi. 2023a. We’re afraid language models aren’t modeling ambiguity. arXiv preprint arXiv:2304.14399 (2023).
- Liu et al. (2024a) Hongfu Liu, Hengguan Huang, Hao Wang, Xiangming Gu, and Ye Wang. 2024a. On Calibration of LLM-based Guard Models for Reliable Content Moderation. arXiv preprint arXiv:2410.10414 (2024).
- Liu et al. (2024c) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2024c. Visual instruction tuning. Advances in neural information processing systems 36 (2024).
- Liu et al. (2024e) Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. 2024e. A survey on hallucination in large vision-language models. arXiv preprint arXiv:2402.00253 (2024).
- Liu et al. (2024d) Linyu Liu, Yu Pan, Xiaocheng Li, and Guanting Chen. 2024d. Uncertainty Estimation and Quantification for LLMs: A Simple Supervised Approach. arXiv preprint arXiv:2404.15993 (2024).
- Liu and Wu (2024) Terrance Liu and Zhiwei Steven Wu. 2024. Multi-group Uncertainty Quantification for Long-form Text Generation. arXiv preprint arXiv:2407.21057 (2024).
- Liu et al. (2024b) Xin Liu, Muhammad Khalifa, and Lu Wang. 2024b. LitCab: Lightweight Language Model Calibration over Short-and Long-form Responses. In The Twelfth International Conference on Learning Representations.
- Liu (2019) Yinhan Liu. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019).
- Liu et al. (2023b) Yuxuan Liu, Tianchi Yang, Shaohan Huang, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. 2023b. Calibrating llm-based evaluator. arXiv preprint arXiv:2309.13308 (2023).
- Liu et al. (2023c) Yang Liu, Yuanshun Yao, Jean-Francois Ton, Xiaoying Zhang, Ruocheng Guo Hao Cheng, Yegor Klochkov, Muhammad Faaiz Taufiq, and Hang Li. 2023c. Trustworthy LLMs: A survey and guideline for evaluating large language models’ alignment. arXiv preprint arXiv:2308.05374 (2023).
- Loquercio et al. (2020) Antonio Loquercio, Mattia Segu, and Davide Scaramuzza. 2020. A general framework for uncertainty estimation in deep learning. IEEE Robotics and Automation Letters 5, 2 (2020), 3153–3160.
- Lyu et al. (2024) Qing Lyu, Kumar Shridhar, Chaitanya Malaviya, Li Zhang, Yanai Elazar, Niket Tandon, Marianna Apidianaki, Mrinmaya Sachan, and Chris Callison-Burch. 2024. Calibrating large language models with sample consistency. arXiv preprint arXiv:2402.13904 (2024).
- MacCartney and Manning (2008) Bill MacCartney and Christopher D Manning. 2008. Modeling semantic containment and exclusion in natural language inference. In Proceedings of the 22nd International Conference on Computational Linguistics (Coling 2008). 521–528.
- Mahaut et al. (2024) Matéo Mahaut, Laura Aina, Paula Czarnowska, Momchil Hardalov, Thomas Müller, and Lluís Màrquez. 2024. Factual Confidence of LLMs: on Reliability and Robustness of Current Estimators. arXiv preprint arXiv:2406.13415 (2024).
- Malinin and Gales (2020) Andrey Malinin and Mark Gales. 2020. Uncertainty estimation in autoregressive structured prediction. arXiv preprint arXiv:2002.07650 (2020).
- Maltoudoglou et al. (2020) Lysimachos Maltoudoglou, Andreas Paisios, and Harris Papadopoulos. 2020. BERT-based conformal predictor for sentiment analysis. In Conformal and Probabilistic Prediction and Applications. PMLR, 269–284.
- Manakul et al. (2023) Potsawee Manakul, Adian Liusie, and Mark JF Gales. 2023. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. arXiv preprint arXiv:2303.08896 (2023).
- Mandi et al. (2024) Zhao Mandi, Shreeya Jain, and Shuran Song. 2024. Roco: Dialectic multi-robot collaboration with large language models. In 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 286–299.
- Mao et al. (2024) Xin Mao, Feng-Lin Li, Huimin Xu, Wei Zhang, and Anh Tuan Luu. 2024. Don’t Forget Your Reward Values: Language Model Alignment via Value-based Calibration. arXiv preprint arXiv:2402.16030 (2024).
- Martín et al. (2022) Alejandro Martín, Javier Huertas-Tato, Álvaro Huertas-García, Guillermo Villar-Rodríguez, and David Camacho. 2022. FacTeR-Check: Semi-automated fact-checking through semantic similarity and natural language inference. Knowledge-based systems 251 (2022), 109265.
- Martinez-Munoz et al. (2008) Gonzalo Martinez-Munoz, Daniel Hernández-Lobato, and Alberto Suárez. 2008. An analysis of ensemble pruning techniques based on ordered aggregation. IEEE Transactions on Pattern Analysis and Machine Intelligence 31, 2 (2008), 245–259.
- Mi et al. (2022) Lu Mi, Hao Wang, Yonglong Tian, Hao He, and Nir N Shavit. 2022. Training-free uncertainty estimation for dense regression: Sensitivity as a surrogate. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 10042–10050.
- Mielke et al. (2022) Sabrina J Mielke, Arthur Szlam, Emily Dinan, and Y-Lan Boureau. 2022. Reducing conversational agents’ overconfidence through linguistic calibration. Transactions of the Association for Computational Linguistics 10 (2022), 857–872.
- Min et al. (2020) Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2020. AmbigQA: Answering ambiguous open-domain questions. arXiv preprint arXiv:2004.10645 (2020).
- Minaee et al. (2024) Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. 2024. Large language models: A survey. arXiv preprint arXiv:2402.06196 (2024).
- Mohri and Hashimoto (2024) Christopher Mohri and Tatsunori Hashimoto. 2024. Language models with conformal factuality guarantees. arXiv preprint arXiv:2402.10978 (2024).
- Monz and de Rijke (2001) Christof Monz and Maarten de Rijke. 2001. Light-weight entailment checking for computational semantics. In Proc. of the third workshop on inference in computational semantics (ICoS-3).
- Mullen Jr and Manocha (2024) James F Mullen Jr and Dinesh Manocha. 2024. Towards Robots That Know When They Need Help: Affordance-Based Uncertainty for Large Language Model Planners. arXiv preprint arXiv:2403.13198 (2024).
- Naeini et al. (2015) Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. 2015. Obtaining well calibrated probabilities using bayesian binning. In Proceedings of the AAAI conference on artificial intelligence, Vol. 29.
- Nanda et al. (2023) Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. 2023. Progress measures for grokking via mechanistic interpretability. arXiv preprint arXiv:2301.05217 (2023).
- Ni et al. (2024) Shiyu Ni, Keping Bi, Lulu Yu, and Jiafeng Guo. 2024. Are Large Language Models More Honest in Their Probabilistic or Verbalized Confidence? arXiv preprint arXiv:2408.09773 (2024).
- Niculescu-Mizil and Caruana (2005) Alexandru Niculescu-Mizil and Rich Caruana. 2005. Predicting good probabilities with supervised learning. In Proceedings of the 22nd international conference on Machine learning. 625–632.
- Nikitin et al. (2024) Alexander Nikitin, Jannik Kossen, Yarin Gal, and Pekka Marttinen. 2024. Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities. arXiv preprint arXiv:2405.20003 (2024).
- Niu et al. (2024) Ruijia Niu, Dongxia Wu, Rose Yu, and Yi-An Ma. 2024. Functional-level Uncertainty Quantification for Calibrated Fine-tuning on LLMs. arXiv preprint arXiv:2410.06431 (2024).
- Nixon et al. (2019) Jeremy Nixon, Michael W Dusenberry, Linchuan Zhang, Ghassen Jerfel, and Dustin Tran. 2019. Measuring Calibration in Deep Learning.. In CVPR workshops, Vol. 2.
- Osband et al. (2022) Ian Osband, Seyed Mohammad Asghari, Benjamin Van Roy, Nat McAleese, John Aslanides, and Geoffrey Irving. 2022. Fine-tuning language models via epistemic neural networks. arXiv preprint arXiv:2211.01568 (2022).
- Osband et al. (2023) Ian Osband, Zheng Wen, Seyed Mohammad Asghari, Vikranth Dwaracherla, Morteza Ibrahimi, Xiuyuan Lu, and Benjamin Van Roy. 2023. Epistemic neural networks. Advances in Neural Information Processing Systems 36 (2023), 2795–2823.
- Pacchiardi et al. (2023) Lorenzo Pacchiardi, Alex J Chan, Sören Mindermann, Ilan Moscovitz, Alexa Y Pan, Yarin Gal, Owain Evans, and Jan Brauner. 2023. How to catch an ai liar: Lie detection in black-box llms by asking unrelated questions. arXiv preprint arXiv:2309.15840 (2023).
- Petukhova et al. (2024) Alina Petukhova, Joao P Matos-Carvalho, and Nuno Fachada. 2024. Text clustering with LLM embeddings. arXiv preprint arXiv:2403.15112 (2024).
- Pilehvar et al. (2013) Mohammad Taher Pilehvar, David Jurgens, and Roberto Navigli. 2013. Align, disambiguate and walk: A unified approach for measuring semantic similarity. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1341–1351.
- Platt et al. (1999) John Platt et al. 1999. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in large margin classifiers 10, 3 (1999), 61–74.
- Posch et al. (2019) Konstantin Posch, Jan Steinbrener, and Jürgen Pilz. 2019. Variational Inference to Measure Model Uncertainty in Deep Neural Networks. arXiv preprint arXiv:1902.10189 (2019). arXiv:1902.10189 [stat.ML] https://arxiv.org/abs/1902.10189
- Qiu and Miikkulainen (2024) Xin Qiu and Risto Miikkulainen. 2024. Semantic Density: Uncertainty Quantification in Semantic Space for Large Language Models. arXiv preprint arXiv:2405.13845 (2024).
- Quach et al. (2023) Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi S Jaakkola, and Regina Barzilay. 2023. Conformal language modeling. arXiv preprint arXiv:2306.10193 (2023).
- Qurashi et al. (2020) Abdul Wahab Qurashi, Violeta Holmes, and Anju P Johnson. 2020. Document processing: Methods for semantic text similarity analysis. In 2020 international conference on INnovations in Intelligent SysTems and Applications (INISTA). IEEE, 1–6.
- Radford and Narasimhan (2018) Alec Radford and Karthik Narasimhan. 2018. Improving Language Understanding by Generative Pre-Training.
- Rahaman et al. (2021) Rahul Rahaman et al. 2021. Uncertainty quantification and deep ensembles. Advances in neural information processing systems 34 (2021), 20063–20075.
- Rai et al. (2024) Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, and Ziyu Yao. 2024. A practical review of mechanistic interpretability for transformer-based language models. arXiv preprint arXiv:2407.02646 (2024).
- Rawte et al. (2023) Vipula Rawte, Amit Sheth, and Amitava Das. 2023. A survey of hallucination in large foundation models. arXiv preprint arXiv:2309.05922 (2023).
- Reddy et al. (2019) Siva Reddy, Danqi Chen, and Christopher D Manning. 2019. Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics 7 (2019), 249–266.
- Reimers (2019) N Reimers. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv preprint arXiv:1908.10084 (2019).
- Rein et al. (2023) David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. 2023. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022 (2023).
- Ren et al. (2024) Allen Z Ren, Jaden Clark, Anushri Dixit, Masha Itkina, Anirudha Majumdar, and Dorsa Sadigh. 2024. Explore until Confident: Efficient Exploration for Embodied Question Answering. arXiv preprint arXiv:2403.15941 (2024).
- Ren et al. (2023a) Allen Z Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, Fei Xia, Jake Varley, et al. 2023a. Robots that ask for help: Uncertainty alignment for large language model planners. arXiv preprint arXiv:2307.01928 (2023).
- Ren et al. (2023b) Jie Ren, Yao Zhao, Tu Vu, Peter J. Liu, and Balaji Lakshminarayanan. 2023b. Self-Evaluation Improves Selective Generation in Large Language Models. In Proceedings on ”I Can’t Believe It’s Not Better: Failure Modes in the Age of Foundation Models” at NeurIPS 2023 Workshops (Proceedings of Machine Learning Research, Vol. 239), Javier Antorán, Arno Blaas, Kelly Buchanan, Fan Feng, Vincent Fortuin, Sahra Ghalebikesabi, Andreas Kriegler, Ian Mason, David Rohde, Francisco J. R. Ruiz, Tobias Uelwer, Yubin Xie, and Rui Yang (Eds.). PMLR, 49–64.
- Rouzrokh et al. (2024) Pouria Rouzrokh, Shahriar Faghani, Cooper U Gamble, Moein Shariatnia, and Bradley J Erickson. 2024. CONFLARE: CONFormal LArge language model REtrieval. arXiv preprint arXiv:2404.04287 (2024).
- Sadinle et al. (2019) Mauricio Sadinle, Jing Lei, and Larry Wasserman. 2019. Least ambiguous set-valued classifiers with bounded error levels. J. Amer. Statist. Assoc. 114, 525 (2019), 223–234.
- Schwab and Karlen (2019) Patrick Schwab and Walter Karlen. 2019. Cxplain: Causal explanations for model interpretation under uncertainty. Advances in neural information processing systems 32 (2019).
- Sha et al. (2021) Lei Sha, Oana-Maria Camburu, and Thomas Lukasiewicz. 2021. Learning from the best: Rationalizing predictions by adversarial information calibration. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 13771–13779.
- Shafer and Vovk (2008) Glenn Shafer and Vladimir Vovk. 2008. A tutorial on conformal prediction. Journal of Machine Learning Research 9, 3 (2008).
- Shah et al. (2023) Dhruv Shah, Błażej Osiński, Sergey Levine, et al. 2023. Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action. In Conference on robot learning. PMLR, 492–504.
- Smith et al. (2020) Eric Michael Smith, Diana Gonzalez-Rico, Emily Dinan, and Y-Lan Boureau. 2020. Controlling style in generated dialogue. arXiv preprint arXiv:2009.10855 (2020).
- Spiess et al. (2024) Claudio Spiess, David Gros, Kunal Suresh Pai, Michael Pradel, Md Rafiqul Islam Rabin, Amin Alipour, Susmit Jha, Prem Devanbu, and Toufique Ahmed. 2024. Calibration and correctness of language models for code. arXiv preprint arXiv:2402.02047 (2024).
- Steindl et al. (2024) Sebastian Steindl, Ulrich Schäfer, Bernd Ludwig, and Patrick Levi. 2024. Linguistic Obfuscation Attacks and Large Language Model Uncertainty. In Proceedings of the 1st Workshop on Uncertainty-Aware NLP (UncertaiNLP 2024). 35–40.
- Stengel-Eskin et al. (2024) Elias Stengel-Eskin, Peter Hase, and Mohit Bansal. 2024. LACIE: Listener-Aware Finetuning for Confidence Calibration in Large Language Models. arXiv preprint arXiv:2405.21028 (2024).
- Su et al. (2024a) Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024a. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing 568 (2024), 127063.
- Su et al. (2024b) Jiayuan Su, Jing Luo, Hongwei Wang, and Lu Cheng. 2024b. Api is enough: Conformal prediction for large language models without logit-access. arXiv preprint arXiv:2403.01216 (2024).
- Sun et al. (2024b) Xingpeng Sun, Yiran Zhang, Xindi Tang, Amrit Singh Bedi, and Aniket Bera. 2024b. TrustNavGPT: Modeling Uncertainty to Improve Trustworthiness of Audio-Guided LLM-Based Robot Navigation. arXiv preprint arXiv:2408.01867 (2024).
- Sun et al. (2024a) Zhongxiang Sun, Xiaoxue Zang, Kai Zheng, Yang Song, Jun Xu, Xiao Zhang, Weijie Yu, and Han Li. 2024a. ReDeEP: Detecting Hallucination in Retrieval-Augmented Generation via Mechanistic Interpretability. arXiv preprint arXiv:2410.11414 (2024).
- Tai et al. (2024) Robert H Tai, Lillian R Bentley, Xin Xia, Jason M Sitt, Sarah C Fankhauser, Ana M Chicas-Mosier, and Barnas G Monteith. 2024. An examination of the use of large language models to aid analysis of textual data. International Journal of Qualitative Methods 23 (2024), 16094069241231168.
- Tamkin et al. (2022) Alex Tamkin, Kunal Handa, Avash Shrestha, and Noah Goodman. 2022. Task ambiguity in humans and language models. arXiv preprint arXiv:2212.10711 (2022).
- Tamkin et al. (2023) Alex Tamkin, Mohammad Taufeeque, and Noah D Goodman. 2023. Codebook features: Sparse and discrete interpretability for neural networks. arXiv preprint arXiv:2310.17230 (2023).
- Tang et al. (2024) Zhisheng Tang, Ke Shen, and Mayank Kejriwal. 2024. An Evaluation of Estimative Uncertainty in Large Language Models. arXiv preprint arXiv:2405.15185 (2024).
- Tanneru et al. (2024) Sree Harsha Tanneru, Chirag Agarwal, and Himabindu Lakkaraju. 2024. Quantifying uncertainty in natural language explanations of large language models. In International Conference on Artificial Intelligence and Statistics. PMLR, 1072–1080.
- Tao et al. (2024) Shuchang Tao, Liuyi Yao, Hanxing Ding, Yuexiang Xie, Qi Cao, Fei Sun, Jinyang Gao, Huawei Shen, and Bolin Ding. 2024. When to Trust LLMs: Aligning Confidence with Response Quality. arXiv preprint arXiv:2404.17287 (2024).
- Templeton et al. (2024) Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, et al. 2024. Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet. https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
- Thomas and Joy (2006) MTCAJ Thomas and A Thomas Joy. 2006. Elements of information theory. Wiley-Interscience.
- Thorne et al. (2018) James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER: a large-scale dataset for fact extraction and VERification. arXiv preprint arXiv:1803.05355 (2018).
- Tian et al. (2023) Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. 2023. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. arXiv preprint arXiv:2305.14975 (2023).
- Tomani et al. (2024) Christian Tomani, Kamalika Chaudhuri, Ivan Evtimov, Daniel Cremers, and Mark Ibrahim. 2024. Uncertainty-Based Abstention in LLMs Improves Safety and Reduces Hallucinations. arXiv preprint arXiv:2404.10960 (2024).
- Tonmoy et al. (2024) SM Tonmoy, SM Zaman, Vinija Jain, Anku Rani, Vipula Rawte, Aman Chadha, and Amitava Das. 2024. A comprehensive survey of hallucination mitigation techniques in large language models. arXiv preprint arXiv:2401.01313 (2024).
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
- Tsai et al. (2024) Yao-Hung Hubert Tsai, Walter Talbott, and Jian Zhang. 2024. Efficient Non-Parametric Uncertainty Quantification for Black-Box Large Language Models and Decision Planning. arXiv preprint arXiv:2402.00251 (2024).
- Ulmer et al. (2024) Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, and Seong Joon Oh. 2024. Calibrating Large Language Models Using Their Generations Only. arXiv preprint arXiv:2403.05973 (2024).
- Vashurin et al. (2024) Roman Vashurin, Ekaterina Fadeeva, Artem Vazhentsev, Akim Tsvigun, Daniil Vasilev, Rui Xing, Abdelrahman Boda Sadallah, Lyudmila Rvanova, Sergey Petrakov, Alexander Panchenko, et al. 2024. Benchmarking Uncertainty Quantification Methods for Large Language Models with LM-Polygraph. arXiv preprint arXiv:2406.15627 (2024).
- Vaswani (2017) A Vaswani. 2017. Attention is all you need. Advances in Neural Information Processing Systems (2017).
- Vazhentsev et al. (2024) Artem Vazhentsev, Ekaterina Fadeeva, Rui Xing, Alexander Panchenko, Preslav Nakov, Timothy Baldwin, Maxim Panov, and Artem Shelmanov. 2024. Unconditional Truthfulness: Learning Conditional Dependency for Uncertainty Quantification of Large Language Models. arXiv preprint arXiv:2408.10692 (2024).
- Vyas et al. (2018) Apoorv Vyas, Nataraj Jammalamadaka, Xia Zhu, Dipankar Das, Bharat Kaul, and Theodore L Willke. 2018. Out-of-distribution detection using an ensemble of self supervised leave-out classifiers. In Proceedings of the European conference on computer vision (ECCV). 550–564.
- Wang and Ji (2024) Hanjing Wang and Qiang Ji. 2024. Epistemic Uncertainty Quantification For Pre-Trained Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11052–11061.
- Wang et al. (2024c) Jun Wang, Guocheng He, and Yiannis Kantaros. 2024c. Safe Task Planning for Language-Instructed Multi-Robot Systems using Conformal Prediction. arXiv preprint arXiv:2402.15368 (2024).
- Wang et al. (2023b) J. Wang, Jiaming Tong, Kai Liang Tan, Yevgeniy Vorobeychik, and Yiannis Kantaros. 2023b. Conformal Temporal Logic Planning using Large Language Models: Knowing When to Do What and When to Ask for Help. ArXiv abs/2309.10092 (2023).
- Wang et al. (2023a) Xi Wang, Laurence Aitchison, and Maja Rudolph. 2023a. LoRA ensembles for large language model fine-tuning. arXiv preprint arXiv:2310.00035 (2023).
- Wang et al. (2024d) Yiming Wang, Pei Zhang, Baosong Yang, Derek F Wong, and Rui Wang. 2024d. Latent Space Chain-of-Embedding Enables Output-free LLM Self-Evaluation. arXiv preprint arXiv:2410.13640 (2024).
- Wang et al. (2024a) Yu-Hsiang Wang, Andrew Bai, Che-Ping Tsai, and Cho-Jui Hsieh. 2024a. CLUE: Concept-Level Uncertainty Estimation for Large Language Models. arXiv preprint arXiv:2409.03021 (2024).
- Wang et al. (2024b) Zhiyuan Wang, Jinhao Duan, Lu Cheng, Yue Zhang, Qingni Wang, Hengtao Shen, Xiaofeng Zhu, Xiaoshuang Shi, and Kaidi Xu. 2024b. ConU: Conformal Uncertainty in Large Language Models with Correctness Coverage Guarantees. arXiv preprint arXiv:2407.00499 (2024).
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35 (2022), 24824–24837.
- Williams et al. (2017) Adina Williams, Nikita Nangia, and Samuel R Bowman. 2017. A broad-coverage challenge corpus for sentence understanding through inference. arXiv preprint arXiv:1704.05426 (2017).
- Wu and Williamson (2024) Luhuan Wu and Sinead A Williamson. 2024. Posterior Uncertainty Quantification in Neural Networks using Data Augmentation. In International Conference on Artificial Intelligence and Statistics. PMLR, 3376–3384.
- Xiao and Wang (2021) Yijun Xiao and William Yang Wang. 2021. On hallucination and predictive uncertainty in conditional language generation. arXiv preprint arXiv:2103.15025 (2021).
- Xiao et al. (2023) Ziang Xiao, Xingdi Yuan, Q Vera Liao, Rania Abdelghani, and Pierre-Yves Oudeyer. 2023. Supporting qualitative analysis with large language models: Combining codebook with GPT-3 for deductive coding. In Companion proceedings of the 28th international conference on intelligent user interfaces. 75–78.
- Xiong et al. (2023) Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. 2023. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. arXiv preprint arXiv:2306.13063 (2023).
- Xu et al. (2024b) Tianyang Xu, Shujin Wu, Shizhe Diao, Xiaoze Liu, Xingyao Wang, Yangyi Chen, and Jing Gao. 2024b. SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales. arXiv preprint arXiv:2405.20974 (2024).
- Xu et al. (2024a) Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. 2024a. Hallucination is inevitable: An innate limitation of large language models. arXiv preprint arXiv:2401.11817 (2024).
- Yadkori et al. (2024) Yasin Abbasi Yadkori, Ilja Kuzborskij, András György, and Csaba Szepesvári. 2024. To Believe or Not to Believe Your LLM. arXiv preprint arXiv:2406.02543 (2024).
- Yang et al. (2024a) Adam X. Yang, Maxime Robeyns, Xi Wang, and Laurence Aitchison. 2024a. Bayesian Low-rank Adaptation for Large Language Models. arXiv preprint arXiv:2308.13111 (2024). arXiv:2308.13111 [cs.LG] https://arxiv.org/abs/2308.13111
- Yang et al. (2024b) Haoyan Yang, Yixuan Wang, Xingyin Xu, Hanyuan Zhang, and Yirong Bian. 2024b. Can We Trust LLMs? Mitigate Overconfidence Bias in LLMs through Knowledge Transfer. arXiv preprint arXiv:2405.16856 (2024).
- Yang et al. (2023a) Yuqing Yang, Ethan Chern, Xipeng Qiu, Graham Neubig, and Pengfei Liu. 2023a. Alignment for honesty. arXiv preprint arXiv:2312.07000 (2023).
- Yang et al. (2023b) Yuchen Yang, Houqiang Li, Yanfeng Wang, and Yu Wang. 2023b. Improving the Reliability of Large Language Models by Leveraging Uncertainty-Aware In-Context Learning. arXiv preprint arXiv:2310.04782 (2023).
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600 (2018).
- Ye et al. (2024) Fanghua Ye, Mingming Yang, Jianhui Pang, Longyue Wang, Derek F Wong, Emine Yilmaz, Shuming Shi, and Zhaopeng Tu. 2024. Benchmarking llms via uncertainty quantification. arXiv preprint arXiv:2401.12794 (2024).
- Yona et al. (2024) Gal Yona, Roee Aharoni, and Mor Geva. 2024. Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words? arXiv preprint arXiv:2405.16908 (2024).
- Yu et al. (2024) Lei Yu, Meng Cao, Jackie Chi Kit Cheung, and Yue Dong. 2024. Mechanisms of non-factual hallucinations in language models. arXiv preprint arXiv:2403.18167 (2024).
- Yuan et al. (2021) Weizhe Yuan, Graham Neubig, and Pengfei Liu. 2021. Bartscore: Evaluating generated text as text generation. Advances in Neural Information Processing Systems 34 (2021), 27263–27277.
- Yun et al. (2021) Zeyu Yun, Yubei Chen, Bruno A Olshausen, and Yann LeCun. 2021. Transformer visualization via dictionary learning: contextualized embedding as a linear superposition of transformer factors. arXiv preprint arXiv:2103.15949 (2021).
- Zadrozny and Elkan (2001) Bianca Zadrozny and Charles Elkan. 2001. Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers. In Icml, Vol. 1. 609–616.
- Zadrozny and Elkan (2002) Bianca Zadrozny and Charles Elkan. 2002. Transforming classifier scores into accurate multiclass probability estimates. In Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining. 694–699.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830 (2019).
- Zeng et al. (2024) Qingcheng Zeng, Mingyu Jin, Qinkai Yu, Zhenting Wang, Wenyue Hua, Zihao Zhou, Guangyan Sun, Yanda Meng, Shiqing Ma, Qifan Wang, et al. 2024. Uncertainty is Fragile: Manipulating Uncertainty in Large Language Models. arXiv preprint arXiv:2407.11282 (2024).
- Zhang et al. (2024) Caiqi Zhang, Fangyu Liu, Marco Basaldella, and Nigel Collier. 2024. LUQ: Long-text Uncertainty Quantification for LLMs. arXiv preprint arXiv:2403.20279 (2024).
- Zhang et al. (2019) Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675 (2019).
- Zhang et al. (2023a) Tianhang Zhang, Lin Qiu, Qipeng Guo, Cheng Deng, Yue Zhang, Zheng Zhang, Chenghu Zhou, Xinbing Wang, and Luoyi Fu. 2023a. Enhancing uncertainty-based hallucination detection with stronger focus. arXiv preprint arXiv:2311.13230 (2023).
- Zhang et al. (2023b) Yuwei Zhang, Zihan Wang, and Jingbo Shang. 2023b. Clusterllm: Large language models as a guide for text clustering. arXiv preprint arXiv:2305.14871 (2023).
- Zhao et al. (2024a) Haiyan Zhao, Hanjie Chen, Fan Yang, Ninghao Liu, Huiqi Deng, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, and Mengnan Du. 2024a. Explainability for large language models: A survey. ACM Transactions on Intelligent Systems and Technology 15, 2 (2024), 1–38.
- Zhao et al. (2024d) Qiwei Zhao, Xujiang Zhao, Yanchi Liu, Wei Cheng, Yiyou Sun, Mika Oishi, Takao Osaki, Katsushi Matsuda, Huaxiu Yao, and Haifeng Chen. 2024d. SAUP: Situation Awareness Uncertainty Propagation on LLM Agent. arXiv preprint arXiv:2412.01033 (2024).
- Zhao et al. (2024b) Theodore Zhao, Mu Wei, J Preston, and Hoifung Poon. 2024b. Pareto Optimal Learning for Estimating Large Language Model Errors. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10513–10529.
- Zhao et al. (2024c) Xinran Zhao, Hongming Zhang, Xiaoman Pan, Wenlin Yao, Dong Yu, Tongshuang Wu, and Jianshu Chen. 2024c. Fact-and-Reflection (FaR) Improves Confidence Calibration of Large Language Models. arXiv preprint arXiv:2402.17124 (2024).
- Zhao et al. (2022) Yao Zhao, Mikhail Khalman, Rishabh Joshi, Shashi Narayan, Mohammad Saleh, and Peter J Liu. 2022. Calibrating sequence likelihood improves conditional language generation. In The eleventh international conference on learning representations.
- Zhao et al. (2021) Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improving few-shot performance of language models. In International conference on machine learning. PMLR, 12697–12706.
- Zheng et al. (2024) Zhi Zheng, Qian Feng, Hang Li, Alois Knoll, and Jianxiang Feng. 2024. Evaluating Uncertainty-based Failure Detection for Closed-Loop LLM Planners. arXiv preprint arXiv:2406.00430 (2024).
- Zhu et al. (2023) Chiwei Zhu, Benfeng Xu, Quan Wang, Yongdong Zhang, and Zhendong Mao. 2023. On the calibration of large language models and alignment. arXiv preprint arXiv:2311.13240 (2023).
- Zimmermann et al. (2024) Roland S Zimmermann, Thomas Klein, and Wieland Brendel. 2024. Scale alone does not improve mechanistic interpretability in vision models. Advances in Neural Information Processing Systems 36 (2024).