# Inferring Functionality of Attention Heads from their Parameters
**Authors**:
- Amit Elhelo Mor Geva (Blavatnik School of Computer Science, Tel Aviv University)
## Abstract
Attention heads are one of the building blocks of large language models (LLMs). Prior work on investigating their operation mostly focused on analyzing their behavior during inference for specific circuits or tasks. In this work, we seek a comprehensive mapping of the operations they implement in a model. We propose MAPS (Mapping Attention head ParameterS), an efficient framework that infers the functionality of attention heads from their parameters, without any model training or inference. We showcase the utility of MAPS for answering two types of questions: (a) given a predefined operation, mapping how strongly heads across the model implement it, and (b) given an attention head, inferring its salient functionality. Evaluating MAPS on 20 operations across 6 popular LLMs shows its estimations correlate with the head’s outputs during inference and are causally linked to the model’s predictions. Moreover, its mappings reveal attention heads of certain operations that were overlooked in previous studies, and valuable insights on function universality and architecture biases in LLMs. Next, we present an automatic pipeline and analysis that leverage MAPS to characterize the salient operations of a given head. Our pipeline produces plausible operation descriptions for most heads, as assessed by human judgment, while revealing diverse operations. We release our code and mappings at https://github.com/amitelhelo/MAPS.
Inferring Functionality of Attention Heads from their Parameters
Amit Elhelo Mor Geva Blavatnik School of Computer Science, Tel Aviv University {amitelhelw@mail,morgeva@tauex}.tau.ac.il
## 1 Introduction
<details>
<summary>x1.png Details</summary>
### Visual Description
## Technical Diagram: Multi-Head Attention Layer Analysis
### Overview
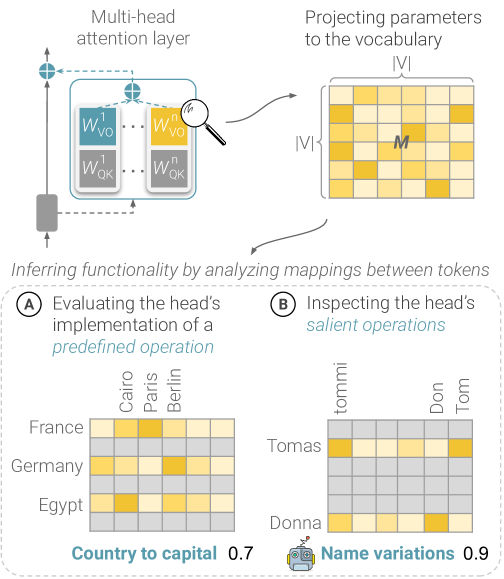
This image is a technical diagram illustrating a method for analyzing the functionality of attention heads within a transformer's multi-head attention layer. It demonstrates how the learned parameters of an attention head can be projected to the vocabulary space to create a mapping matrix (M), which is then analyzed to infer the head's specific function (e.g., "Country to capital" or "Name variations").
### Components/Axes
The diagram is segmented into three primary regions:
**1. Header (Top Section):**
* **Left Component:** Labeled "Multi-head attention layer". It depicts a standard multi-head attention mechanism with:
* Input and output arrows.
* A box containing weight matrices: `W_QK^1` through `W_QK^n` (Query-Key weights for n heads) and `W_VO^1` through `W_VO^n` (Value-Output weights for n heads).
* A magnifying glass icon focused on one head, indicating analysis.
* **Right Component:** Labeled "Projecting parameters to the vocabulary". It shows:
* A matrix labeled `M`.
* The matrix dimensions are indicated as `|V|` (vocabulary size) on both the vertical and horizontal axes.
* The matrix cells are colored in shades of yellow and gray, representing activation strength.
* An arrow points from the magnified head in the left component to this matrix.
**2. Main Chart (Bottom Section):**
* **Title:** "Inferring functionality by analyzing mappings between tokens"
* This section is divided into two side-by-side sub-diagrams, labeled **A** and **B**.
**3. Footer / Sub-diagram A (Bottom Left):**
* **Title:** "A) Evaluating the head's implementation of a *predefined operation*"
* **Chart Type:** Heatmap.
* **Y-axis (Rows):** Country names: "France", "Germany", "Egypt".
* **X-axis (Columns):** Capital city names: "Cairo", "Paris", "Berlin".
* **Legend:** Located at the bottom. Label: "Country to capital". Associated numerical value: `0.7`. A small icon of a building (likely representing a capital) is present.
* **Data Points (Heatmap Cells):** The grid shows varying intensity of yellow fill. The strongest (brightest yellow) mappings appear to be:
* France → Paris
* Germany → Berlin
* Egypt → Cairo
**4. Footer / Sub-diagram B (Bottom Right):**
* **Title:** "B) Inspecting the head's *salient operations*"
* **Chart Type:** Heatmap.
* **Y-axis (Rows):** Name tokens: "Tomas", "Donna".
* **X-axis (Columns):** Name variation tokens: "tommi", "Don", "Tom".
* **Legend:** Located at the bottom. Label: "Name variations". Associated numerical value: `0.9`. A small icon of two people is present.
* **Data Points (Heatmap Cells):** The grid shows varying intensity of yellow fill. The strongest mappings appear to be:
* Tomas → tommi
* Tomas → Tom
* Donna → Don
### Detailed Analysis
* **Flow of Information:** The diagram establishes a clear analytical pipeline: 1) Isolate an attention head, 2) Project its weight matrices to create a vocabulary-space mapping matrix `M`, 3) Analyze `M` to discover the head's function.
* **Matrix M:** This is the core analytical artifact. Its `|V| x |V|` structure suggests it represents a transformation or relationship between any two tokens in the model's vocabulary. The colored cells indicate the strength of the learned association.
* **Heatmap A (Predefined Operation):** This demonstrates a *supervised* or *hypothesis-driven* analysis. The researcher tests if the head implements a known, interpretable function ("Country to capital"). The heatmap confirms strong, correct mappings for the three given country-capital pairs. The score `0.7` likely quantifies the confidence or strength of this discovered mapping.
* **Heatmap B (Salient Operations):** This demonstrates an *unsupervised* or *exploratory* analysis. The researcher looks for strong, salient patterns in the mapping matrix without a predefined hypothesis. The pattern reveals the head groups morphological variations of names (e.g., "Tomas" with "tommi" and "Tom"; "Donna" with "Don"). The higher score `0.9` suggests this is a very strong, clear pattern detected in the head's parameters.
### Key Observations
1. **Dual Analysis Paradigm:** The diagram explicitly contrasts two methodological approaches: testing for a known function (A) versus discovering an unknown function (B).
2. **High Specificity:** The analyzed attention heads appear to be highly specialized. One head is dedicated to a geographic fact (country-capital), while another handles a linguistic/morphological task (name variations).
3. **Quantitative Scoring:** Both analyses yield a numerical score (0.7 and 0.9), providing a metric for the strength or purity of the discovered functionality.
4. **Visual Encoding:** The use of a consistent yellow-scale heatmap across both sub-diagrams allows for direct visual comparison of mapping strength and sparsity.
### Interpretation
This diagram is a pedagogical or methodological illustration from the field of **AI Interpretability**, specifically for transformer models. It argues that the internal mechanisms of complex neural networks, like attention heads, are not inscrutable "black boxes." Instead, their learned functions can be reverse-engineered.
The core insight is that by projecting an attention head's weights into the interpretable space of the vocabulary, we can create a "function map" (`M`). Analyzing this map reveals the head's job. The two examples show that heads can learn both **factual knowledge** (like a lookup table for capitals) and **linguistic rules** (like handling name morphology).
The implication is significant: if we can systematically catalog the functions of thousands of attention heads across a model, we can build a "circuit diagram" of how the model processes information. This is crucial for debugging model behavior, ensuring fairness, and building trust in AI systems. The diagram promotes a specific technical approach to achieve this understanding.
</details>
Figure 1: Illustration of MAPS, a framework for inferring the functionality of attention heads in LLMs from their parameters. MAPS casts the head as a matrix $M$ which assigns a score for every pair of tokens in the model’s vocabulary. Then, it considers groups of token pairs (sub-matrices in $M$ ) to measure how strongly the head implements a given operation (A) and to inspect the head’s salient operations (B).
Attention heads play a key role in modern large language models (LLMs) (Vaswani et al., 2017; Zhou et al., 2024; Olsson et al., 2022). Numerous studies (Zheng et al., 2024; Ferrando et al., 2024) have explored their functionality, typically by analyzing their attention patterns or outputs during inference for certain inputs or tasks.
However, relying on the model’s behavior for certain inputs has drawbacks. First, this approach may overlook some of the functions implemented by the head, as heads can exhibit different behaviors for different inputs (Gould et al., 2024; Merullo et al., 2024a; Olsson et al., 2022; Kissane et al., 2024). Second, a comprehensive analysis of the head’s operation would require executing the model over numerous inputs, potentially the whole training corpus, which involves a high computational cost and could be impossible when the data is unavailable. Last, analyzing the examples that activate the head is often non-trivial and could be misleading (Bolukbasi et al., 2021; Gao et al., 2024; Kissane et al., 2024).
In this work, we consider a different approach to this problem, where our goal is to infer the functionality of attention heads directly from their parameters and without executing the model. To this end, we leverage the approach of interpreting model parameters in the vocabulary space (Geva et al., 2021, 2022; Katz et al., 2024). Specifically, we build on the formulation by Elhage et al. (2021); Dar et al. (2023), who cast the attention head as a matrix $M$ , where each entry is a mapping score between two tokens. While this approach has been shown effective in identifying heads with certain operations, so far its usage has been limited to studying specific heads in detected circuits Wang et al. (2023); McDougall et al. (2024) or a single operation Gould et al. (2024).
Here, we scale this interpretation approach into a general framework, called MAPS (Mapping Attention heads ParameterS), which enables answering two types of basic questions: (a) given a predefined operation, mapping how strongly different heads across the model implement it, and (b) given an attention head, inferring its prominent operations. This is done by considering patterns across groups of mappings in $M$ , as illustrated in Figure 1. Predefined relations signify groups of mappings expressing a certain relation (e.g. city of a country or pronoun resolving). Salient operations consist of subsets of mappings for which the head induces the most prominent effect. In addition, analyzing simple statistics of these mappings provides insights into how global or specific its operation is.
We evaluate our framework on 6 popular LLMs and 20 predefined relations of 4 categories – knowledge, language, algorithmic, and translation. Experiments show that estimations by MAPS strongly correlate with the head outputs during inference. Moreover, causally removing all the heads implementing a certain operation substantially impairs the model’s ability to answer queries requiring this operation, compared to removing other heads.
Analysis of the obtained mappings shows that, across all models, MAPS detects relation heads mostly in the middle and upper layers, while revealing universality patterns for several relations. Moreover, it demonstrates how the model’s architecture introduces biases in function encoding. Smaller models tend to encode higher numbers of relations on a single head, and in Llama-3.1 models, which use grouped-query attention, grouped attention heads often implement the same or similar relations. Notably, MAPS successfully detected previously identified heads of specific operations, while discovering additional heads of similar operations not reported before.
Next, we demonstrate the utility of MAPS for inferring the prominent operations of a given head. We consider the head’s salient mappings in $M$ and use GPT-4o Hurst et al. (2024) to automatically describe the functionality they exhibit. Applying this procedure to GPT-2 xl and Pythia 6.9B, we map the prominent operations of 62% of their heads and 60%-96% of those in the middle and upper layers. Qualitative analysis shows semantic, linguistic, and algorithmic operations and reveals novel operations, such as the extension of time periods (day->month;month->year). A human study shows that our automated pipeline performs reasonably well, and GPT-4o reliably detects observable operations.
To conclude, we introduce MAPS, an efficient framework for inferring attention heads’ functionality from their parameters. We showcase the utility of MAPS in systematically mapping a certain functionality across the model and automatically characterizing the salient operations of a given head. Estimations by MAPS correlate with the head’s outputs and are faithful to the model’s behavior, and provide valuable insights on architecture biases and universality of head operations in LLMs.
## 2 Preliminaries and Notation
We assume a transformer-based LM with a hidden dimension $d$ , $L$ layers, $H$ attention heads per layer, a vocabulary $\mathcal{V}$ , an embedding matrix $E\in\mathbb{R}^{|\mathcal{V}|\times d}$ , and an unembedding matrix $U\in\mathbb{R}^{d\times|\mathcal{V}|}$ .
#### Attention heads as interaction matrices
We use the formulation by Elhage et al. (2021) and view an attention head as two “interaction” matrices $W_{QK},W_{VO}\in\mathbb{R}^{d\times d}$ . Given a sequence of $n$ hidden states $X\in\mathbb{R}^{n\times d}$ , the matrix $W_{QK}$ computes the query-key scores to produce an attention weights matrix $A\in\mathbb{R}^{n\times n}$ :
$$
A=\text{softmax}\Bigg{(}\frac{X(W_{QK})X^{T}}{\sqrt{d/H}}\Bigg{)}
$$
The matrix $W_{VO}$ operates on the contextualized hidden states according to $A$ , namely $\tilde{X}=AX$ , and produces the head’s output $Y\in\mathbb{R}^{n\times d}$ :
$$
Y=\tilde{X}W_{VO} \tag{1}
$$
The matrix $W_{QK}$ can be viewed as “reading” from the residual stream, and $W_{VO}$ can be viewed as the “writing” component. Notably, this formulation omits the bias terms of the head.
#### Interpreting attention heads in embedding space
Recent works have analyzed the operation of different components in transformers through projection to the model’s vocabulary space (nostalgebraist, 2020; Geva et al., 2021, 2022; Dar et al., 2023; Katz et al., 2024). Specifically, Elhage et al. (2021); Dar et al. (2023) interpret each of the attention head matrices – $W_{QK}$ and $W_{VO}$ – as a matrix that maps between pairs of tokens from the vocabulary. Considering $W_{VO}$ , it is interpreted via multiplication from both sides with the model’s embedding matrix: ${\tilde{M}=E(W_{VO})E^{T}\in\mathbb{R}^{|\mathcal{V}|\times|\mathcal{V}|}}$ . Each entry in $\tilde{M}$ is viewed as a mapping score between source and target tokens ${s,t\in\mathcal{V}}$ based on $W_{VO}$ , which signifies how strongly the head promotes it in its outputs. Elhage et al. (2021) suggested that when the weights of $E$ and $U$ are not tied, a more faithful interpretation can be obtained by:
$$
M=E(W_{VO})U
$$
Other notable variations include applying the model’s first MLP layer to the embedding matrix $E$ (Gould et al., 2024) and the final layer norm on rows of $E(W_{VO})$ (Wang et al., 2023).
## 3 MAPS
Based on the above view, we propose a general framework, called MAPS, for inferring the functionality of attention heads in LLMs directly from their parameters. We focus on analyzing the $W_{VO}$ component of the head, which produces the head’s output to the residual stream, and make the following observations. First, the $i$ -th row of $M$ provides the scores for mappings from the $i$ -th token to any token in $\mathcal{V}$ . Similarly, the $j$ -th column of $M$ provides scores for mappings from any token in $\mathcal{V}$ to the $j$ -th token. Therefore, considering the scores of certain submatrices of $M$ may reveal how the attention head operates on different sets of inputs. For example, analyzing the rows corresponding to tokens representing countries may reveal general knowledge-related operations implemented by the head, and attention heads that copy certain tokens should have diagonal-like submatrices in $M$ .
An important question that arises is which parts of $M$ to consider in order to identify the head’s functionality. In principle, there are $2^{|\mathcal{V}|}$ different subsets of rows that can be considered, which would be infeasible to traverse with $|\mathcal{V}|=\mathcal{O}(10K)$ in typical LLMs. Here, we propose two complementary ways to approach this, described next.
### 3.1 Predefined Relations
One intuitive approach is to define a set of possible operations that can be realized through pairs of tokens, and then measure the extent to which the head implements each operation. For example, the operation of mapping a country to its capital can be realized through a set of token pairs expressing that relation, e.g. (France, Paris) or (Egypt, Cairo). Similarly, mapping between synonyms can be realized via pairs such as (talk, speak) and (fast, quick). Such operations can be viewed as an implementation of relations between tokens.
Let $R$ be a predefined relation and $\mathcal{D}_{R}$ a dataset of token pairs expressing $R$ . Also, denote by $\mathbf{m}_{i}\in\mathbb{R}^{|\mathcal{V}|}$ the $i$ -th row of $M$ (corresponding to the mapping scores of the $i$ -th token), and by $\texttt{topk}(\mathbf{m}_{i})$ the $k$ tokens with the highest scores in $\mathbf{m}_{i}$ . The extent to which an attention head, interpreted as the matrix $M$ , implements $R$ can be measured as the portion of pairs $(s,t)\in\mathcal{D}_{R}$ where $t$ is in the top-scoring tokens in $\mathbf{m}_{s}$ :
$$
\phi_{R}(M):=\frac{1}{|\mathcal{D}_{R}|}\sum_{(s,t)\in\mathcal{D}_{R}}\mathds{
1}[t\in\texttt{topk}(\mathbf{m}_{s})] \tag{2}
$$
For instance, the score for $R=$ ‘‘country to capital’’ reflects how often the head promotes the capital city of a country in its output when operating on an input representation of that country.
Notably, our formulation also supports suppression operations observed in previous work (Wang et al., 2023; Gould et al., 2024; McDougall et al., 2024), where certain attention heads suppress certain concepts or outputs during inference. Representing a suppressive relation is done by defining the pairs $(s,t)$ as before and considering the top-scoring tokens in $-\mathbf{m}_{s}$ instead of $\mathbf{m}_{s}$ .
### 3.2 Salient Operations
The main limitation of the above approach is that it could miss certain relations that heads implement. A complementary approach would be to characterize the head’s functionality from prominent mappings appearing in $M$ . Dar et al. (2023) tackled this by considering the top-scoring mappings in $M$ . However, we recognize two drawbacks in this method: (a) the scores in $M$ are influenced by the token embedding norms, which could bias the top scores towards mappings of tokens with high embedding norms, and (b) the top entries in $M$ may cover mapping from a small number of tokens (e.g., from a single row), thus describing the head’s functionality for only a few tokens.
Here, we propose a more holistic approach to identify salient mappings in $M$ , by first identifying the tokens on which the head’s operation is most prominent, and then considering the top-scoring mappings for these tokens. We measure how prominent the head’s operation on a token $t\in\mathcal{V}$ via the ratio of the token’s embedding norm after multiplying by $W_{VO}$ to the norm before this transformation:
$$
\sigma_{t}(W_{VO}):=\frac{||\mathbf{e}_{t}W_{VO}||}{||\mathbf{e}_{t}||} \tag{3}
$$
Comparing the sets of top versus salient mappings indeed shows substantial differences. The average Jaccard similarity of the sets obtained for heads in GPT-2 xl is 0.01. In the next sections, we experiment with both approaches, showing their effectiveness in inferring attention head functionality in multiple LLMs.
## 4 Mapping Predefined Relations
In this section, we utilize MAPS to map how strongly attention heads implement various operations in multiple LLMs (§ 4.1). We assess the correctness and generalization of these estimations via correlative and causal experiments (§ 4.2, § 4.3) and analyze prominent trends (§ 4.4).
### 4.1 Experimental Setup
#### Datasets
We construct datasets for 20 relations of four categories: algorithmic (e.g., word to first letter), knowledge (e.g., country to capital), linguistic (e.g., adjective to comparative), and translation (English to French/Spanish), and 3 vocabularies of widely-used model families. For every relation, we collect pairs of strings expressing it. For instance, possible pairs for the relation word-to-compound are (hot, hotdog) and (wall, wallpaper). Data is obtained from previously published datasets and online sources and further augmented by querying ChatGPT to generate example pairs, which we (authors) manually validated. Then, we tokenize the pairs with each of the tokenizers of Llama-3.1 Dubey et al. (2024), Pythia Biderman et al. (2023) GPT Radford et al. (2019) and Phi-2 Javaheripi and Bubeck (2023), keeping only cases where the resulting mapping is between single tokens. Experimenting with different tokenizers is important as MAPS leverages the model’s vocabulary. Llama-3.1’s vocabulary has $\sim$ 130k tokens compared to $\sim$ 50k tokens for GPT-2, Phi-2, and Pythia. For more details on the collection, dataset statistics, and examples, see § A.
#### Models
We analyze models of various sizes from different families: Llama-3.1 8B and 70B Dubey et al. (2024), Pythia 6.9B and 12B Biderman et al. (2023), Phi-2 Javaheripi and Bubeck (2023), and GPT-2 xl Radford et al. (2019). These models have varying numbers of layers and attention heads, from 32 layers and 32 heads in Pythia 6.9B to 80 layers and 64 heads in Llama-3.1 70B. Additionally, Llama-3.1 uses grouped-query attention Ainslie et al. (2023), versus the other models which use multi-head attention Vaswani et al. (2017).
#### Measuring predefined relations
For every attention head and relation $R$ , we derive the matrix $M$ and calculate the relation score $\phi_{R}(M)$ (Eq. 2). We also compute the score for the suppressive variant $\bar{R}$ of every relation $R$ . For example, the suppressive variant of $R=\texttt{country to capital}$ corresponds to the operation of suppressing the capital of a given country.
We follow previous works (Dar et al., 2023; Geva et al., 2021, 2022) and set low $k$ values to reflect strong prioritization of the target token in the head’s output. For Pythia, Phi-2 and GPT-2, we use $k=1$ for the copying and name-copying relations and $k=10$ for other relations. For the Llama-3.1 models, we set $k=3$ for copying and name-copying and $k=25$ for other relations. The bigger values for Llama-3.1 are due to their large vocabulary, which allows expressing a concept with more tokens. The smaller values for the copying relations are for measuring them more strictly. For further discussion on this selection, see § A.
To classify whether a head “implements” a relation $R$ , we apply a threshold $\tau$ to $\phi_{R}(M)$ . Namely, if $t$ appears in the top- $k$ mappings of $s$ for $\tau$ percent of the pairs $(s,t)\in\mathcal{D}_{R}$ , then we consider the head as implementing $R$ . We choose a threshold of $\tau=15\$ after experimenting with different thresholds and comparing against randomly initialized heads (see § A for details).
### 4.2 Evaluation of Functionality Estimation
We evaluate whether the functionality estimations by MAPS faithfully describe the operations of the heads during inference. Our experiments show that the estimated operation of a head strongly correlates with its outputs and demonstrates the expected causal effect on the model’s generation.
#### Experiment 1: Correlation with head outputs
For every relation $R$ and source-target pair $(s,t)\in\mathcal{D}_{R}$ , we evaluate the model using four prompt templates (provided in § B.1). One representative template is: We do not simply feed in $s$ as input to avoid potential biases from the attention sink phenomenon Xiao et al. (2024).
$$
\mathcal{P}_{s}:=\texttt{``This is a document about $\langle$s$\rangle$''}
$$
Where $\langle\texttt{s}\rangle$ is the string of the source token $s$ . For example, for the pair (England, London), we will have ‘‘This is a document about England’’. Next, we obtain the output $\mathbf{y}_{s}\in\mathbb{R}^{d}$ of every attention head at the last position (corresponding to $s$ ), Here the head outputs include the bias term of $W_{V}$ , see § B.1. and project it to the model’s vocabulary space, i.e. $\mathbf{y}_{s}U\in\mathbb{R}^{|\mathcal{V}|}$ . The top-scoring tokens in the resulting vector are those promoted by the head given the prompt $\mathcal{P}_{s}$ Geva et al. (2022). To check whether the head implements the relation $R$ , namely promote $t$ when given $s$ in the input, we test for every pair $(s,t)$ whether $t$ appears in the top $k$ tokens in $\mathbf{y}_{s}U$ . We use the same $k$ values specified in § 4.1. Concretely, for every head $h$ we compute the following score, which represents how strongly the head implements $R$ during inference:
$$
\phi^{*}_{R}(h):=\frac{1}{|\mathcal{D}_{R}|}\sum_{(s,t)\in\mathcal{D}_{R}}
\mathds{1}[t\in\texttt{topk}(\mathbf{y}_{s}U)] \tag{4}
$$
We check the correlation between the static score $\phi_{R}(h)$ inferred by our method and the dynamic score $\phi^{*}_{R}(h)$ computed separately for each of the four templates. As a baseline, we compute $\phi^{*}_{R}(h)$ while restricting the attention in $h$ from $s$ to be only to itself. This emulates an operation of the head as if it fully attends to the representation of $s$ .
#### Results
Table 1 shows the results for Llama-3.1 8B. For the vast majority of relations, we observe a strong to very strong correlation of 0.71-0.95 Schober et al. (2018) when the query’s subject is not contextualized. This high correlation often remains or even increases when considering the head’s outputs for contextualized inputs. This shows that MAPS well-estimates the head’s behavior for task-related inputs. Still, for some relations (e.g. word to compound and word to last letter) correlation is lower for contextualized inputs, demonstrating that in some cases, the head may switch its operation depending on the context. This agrees with the observation that heads often implement multiple operations (§ 4.4). Results for other models are in § B.1, generally exhibiting similar trends, though with occasional larger drops in the contextualized setting for Pythia and GPT-2 xl.
| Category | Relation | Correlation w/o context. | Correlation w/ context. |
| --- | --- | --- | --- |
| Algorithmic | Copying | 0.76 | 0.73 |
| Name copying | 0.95 | 0.95 | |
| Word to first letter | 0.90 | 0.78 | |
| Word to last letter | 0.67 | 0.36 | |
| Knowledge | Country to capital | 0.85 | 0.85 |
| Country to language | 0.76 | 0.62 | |
| Object to superclass | 0.74 | 0.73 | |
| Product by company | 0.46 | 0.49 | |
| Work to location | 0.44 | 0.45 | |
| Linguistic | Word to antonym | 0.90 | 0.86 |
| Adj to comparative | 0.85 | 0.86 | |
| Adj to superlative | 0.87 | 0.89 | |
| Noun to pronoun | 0.89 | 0.79 | |
| Verb to past tense | 0.91 | 0.86 | |
| Word to compound | 0.78 | 0.62 | |
| Word to homophone | 0.85 | 0.75 | |
| Word to synonym | 0.79 | 0.69 | |
| Translation | English to French | 0.71 | 0.68 |
| English to Spanish | 0.82 | 0.81 | |
Table 1: Correlation between the relation score of a head and the head’s outputs in Llama-3.1 8B, with and without head contextualization. Results are statistically significant with p-values $\leq$ 3.9e-128 (see § B.1).
| Relation | TR Tasks | CTR Tasks | | | |
| --- | --- | --- | --- | --- | --- |
| Base | - TR | - RND | Base | - TR | |
| Adj to comparative | 0.91 | 0.20 | 0.82 | 0.92 | 0.63 |
| Copying | 1.00 | 0.68 | 1.00 | 0.95 | 0.88 |
| Country to capital | 0.97 | 0.00 | 0.95 | 0.89 | 0.90 |
| Country to language | 1.00 | 0.08 | 0.96 | 0.89 | 0.89 |
| Name copying | 1.00 | 0.24 | 1.00 | 0.90 | 0.92 |
| Noun to pronoun | 0.88 | 0.46 | 0.86 | 0.90 | 0.88 |
| Object to superclass | 0.78 | 0.39 | 0.68 | 0.90 | 0.87 |
| Verb to past tense | 0.22 | 0.04 | 0.26 | 0.03 | 0.02 |
| Word to first letter | 0.91 | 0.34 | 0.87 | 0.91 | 0.74 |
| Year to following | 0.92 | 0.00 | 0.87 | 0.83 | 0.79 |
Table 2: Accuracy of Pythia 12B on tasks for a target relation (TR) versus on control (CTR) tasks, when removing heads implementing the relation compared to when removing random heads (RND). Results for RND heads are averaged over 5 experiments. We omit standard deviation for brevity and report it in § B.2.
#### Experiment 2: Causal effect on model outputs
For a given relation $R$ , we evaluate the model’s performance on queries that require applying $R$ , when removing the heads classified by MAPS as implementing $R$ versus when removing random heads from the model. We choose a diverse set of 13 relations and construct a test set $\tilde{\mathcal{D}}_{R}$ for every relation $R$ as follows. First, we craft a task prompt that requires the model to apply $R$ . For example, a prompt for the country to capital relation could be ‘‘The capital of $\langle s\rangle$ is’’, with $\langle s\rangle$ being a placeholder for a country. Then, for each pair $(s,t)\in\mathcal{D}_{R}$ we instantiate the prompt with $s$ to create an input $\tilde{\mathcal{P}}_{s}$ and a test example $(\tilde{\mathcal{P}}_{s},t)\in\tilde{\mathcal{D}}_{R}$ .
Let $\mathcal{H}_{R}^{i}$ be the subset of $i$ attention heads with the highest scores for $\phi_{R}(M)$ . We evaluate the models on $\tilde{\mathcal{D}}_{R}$ while running each input $n$ times, each time canceling (by setting to zero) the outputs of the attention heads $\mathcal{H}_{R}^{i}$ and obtaining the model’s prediction with greedy decoding. We set $n$ as the minimum between the number of heads in the model with $\phi_{R}(M)>0$ and a fixed boundary: 150 for GPT-2 xl, Pythia 6.9B, Pythia 12B, and Llama-3.1 8B and 250 for Llama-3.1 70B. In cases when the accuracy drops to 0 after ablating $i<n$ heads, we report results obtained up to $i$ .
We compare the above intervention against a baseline where $i$ randomly sampled heads that are not in $\mathcal{H}_{R}^{i}$ are ablated, repeating this experiment 5 times and reporting the average accuracy. Additionally, to establish that relation heads are important specifically for tasks involving $R$ , we remove the relation heads as above and measure the model’s performance on up to five control tasks for other relations. We choose the relations such that $<$ 15% of the target relation heads are also control relation heads, and the absolute difference between the baseline accuracy on the control task and the target task is $\leq$ 20%.
#### Results
Results for Pythia 12B are presented in Table 2, excluding relations where the base accuracy was $<$ 0.1. For all relations, removing the relation heads identified by MAPS causes a major accuracy drop of $\geq$ 32% compared to $\leq$ 13% when removing random heads. Moreover, while the accuracy drop for the control tasks is considerable in some cases (at most 33%), it is significantly smaller than the relative drop on the target relation task. Results for the other models are generally similar (see § B.2). Notable differences are that the accuracy drops in Llama-3.1 are often smaller, but in 9 out of 11 relations they are larger than those obtained for the random and control baselines.
### 4.3 Generalization to Multi-Token Entities
A natural question that arises is how well the estimations by MAPS generalize to contextualized inputs representing multiple tokens. Namely, if we infer the head’s ability to perform country-to-capital mappings from country names tokenized as a single token, will we observe the same behavior for countries tokenized as multiple tokens?
To test this, we apply the data collection process from § 4.1 to create new datasets for 11 relations of source-target pairs $(s,t)$ where $s$ has multiple tokens. Then, we repeat the correlative experiment in § 4.2 for GPT-2 xl, Pythia 6.9B and Pythia 12B using this data and the prompt template ‘‘This is a document about $\langle$ s $\rangle$ ’’.
We observe that the estimated operations generalize to multi-token representations. For 53 out of the 64 model-relation combinations (with and without contextualization), the correlation between the relation score and the head’s output in the multi-token setting is similar ( $\leq$ 0.05 difference) or higher than the single-token setting. In the remaining cases, there is a slightly bigger drop ( $\leq$ 0.13), but the correlations remain $\geq$ 0.63. The full results are provided in § C.
### 4.4 Analysis
#### Function distribution
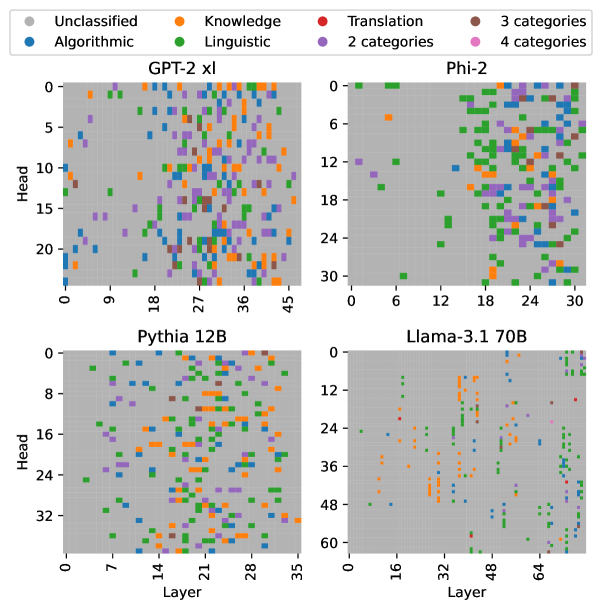
Figure 2 shows category-level classification results of all heads in GPT-2 xl, Phi-2, Pythia 12B, and Llama-3.1 70B. A head is assigned to a certain category if it implements at least one relation from it or its suppressive variant. Considering prominent trends across all models, we first observe that MAPS identified relations from all categories, with classified heads mostly being located in the middle and upper layers. This may suggest that early layers perform operations that cannot be represented in the model’s output vocabulary space. Interestingly, we observe a “side effect” of the grouped attention structure in Llama-3.1 models, where grouped heads often implement the same relations or their suppressive variants.
In addition, heads often implement multiple relations from the same or different categories. The portion of multi-category heads (out of all classified heads) generally decreases in model size: 38% in GPT-2 xl, 29% in Phi-2, 20% in Pythia 6.9B, Pythia 12B and 11% in Llama-3.1 70B. An exception to this trend is Llama-3.1 8B with 11% of multi-category heads, which may be caused by its grouped query attention structure. Also, 20%-36% of the classified heads implement at least one suppression relation.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Scatter Plot Matrix: Attention Head Specialization Across Language Models
### Overview
The image displays a 2x2 grid of scatter plots, each visualizing the functional specialization of attention heads across layers for four different large language models (LLMs). The plots use a color-coded legend to categorize heads based on their primary function or the number of functional categories they are associated with.
### Components/Axes
* **Legend (Top Center):** Positioned above the four plots, it defines eight categories with associated colors:
* **Unclassified:** Gray
* **Knowledge:** Orange
* **Translation:** Red
* **3 categories:** Brown
* **Algorithmic:** Blue
* **Linguistic:** Green
* **2 categories:** Purple
* **4 categories:** Pink
* **Plot Titles (Top of each subplot):**
* Top-Left: `GPT-2 xl`
* Top-Right: `Phi-2`
* Bottom-Left: `Pythia 12B`
* Bottom-Right: `Llama-3.1 70B`
* **Axes (For all plots):**
* **X-axis:** Labeled `Layer`. Represents the transformer layer index, starting from 0.
* **Y-axis:** Labeled `Head`. Represents the attention head index within a layer, starting from 0.
* **Data Points:** Each colored dot represents a single attention head at a specific (Layer, Head) coordinate. The color indicates its functional classification.
### Detailed Analysis
**1. GPT-2 xl (Top-Left Plot)**
* **Axes Range:** Layer (X): 0 to 45. Head (Y): 0 to 20.
* **Data Distribution:** A dense, relatively uniform scattering of points across the entire grid. There is a slight concentration of points in the middle layers (approx. 18-36).
* **Category Prevalence:** Green (Linguistic) and Orange (Knowledge) dots are the most frequent and are distributed widely. Purple (2 categories) dots are also common. Blue (Algorithmic) dots are present but less frequent. Red (Translation) and Brown (3 categories) dots are sparse. No Pink (4 categories) dots are visibly apparent.
**2. Phi-2 (Top-Right Plot)**
* **Axes Range:** Layer (X): 0 to 30. Head (Y): 0 to 30.
* **Data Distribution:** Points are less dense than in GPT-2 xl. There is a notable cluster of points in the upper-right quadrant (higher layers, higher head indices). The lower-left quadrant (early layers, low head indices) is relatively sparse.
* **Category Prevalence:** Green (Linguistic) dots are dominant, especially in the higher layers. Orange (Knowledge) and Purple (2 categories) dots are also present. Blue (Algorithmic) dots are scattered. A few Brown (3 categories) dots are visible.
**3. Pythia 12B (Bottom-Left Plot)**
* **Axes Range:** Layer (X): 0 to 35. Head (Y): 0 to 32.
* **Data Distribution:** Shows a moderate density of points. There appears to be a slight diagonal trend from the bottom-left to the top-right, suggesting heads in later layers might have higher indices, though this is not a strict rule.
* **Category Prevalence:** Orange (Knowledge) dots are very prominent, forming distinct vertical streaks in some layers (e.g., around layers 14-21). Green (Linguistic) and Purple (2 categories) dots are also abundant. Blue (Algorithmic) dots are present. A few Red (Translation) dots can be seen.
**4. Llama-3.1 70B (Bottom-Right Plot)**
* **Axes Range:** Layer (X): 0 to 64. Head (Y): 0 to 60.
* **Data Distribution:** This plot has the sparsest distribution of points. The data is not uniformly scattered; instead, it forms distinct vertical lines or clusters at specific layer intervals (e.g., near layers 16, 32, 48, 64). Many layers appear to have no classified heads.
* **Category Prevalence:** Orange (Knowledge) and Green (Linguistic) dots are the most common within the active clusters. Blue (Algorithmic) dots are also present. Purple (2 categories) dots are less frequent. The overall number of classified heads appears lower relative to the model's size (64 layers, 60 heads per layer).
### Key Observations
1. **Model-Specific Patterns:** Each model exhibits a unique "fingerprint" of head specialization. GPT-2 xl shows dense, widespread classification. Phi-2 has a concentration in later layers. Pythia 12B shows strong vertical banding for Knowledge heads. Llama-3.1 70B displays sparse, clustered activation.
2. **Dominant Functions:** Across all models, heads classified as **Linguistic (Green)** and **Knowledge (Orange)** are the most prevalent, suggesting these are core, widely distributed functions.
3. **Multi-Category Heads:** Heads classified into multiple categories (Purple: 2, Brown: 3) are present in all models but are less common than single-category heads. No heads clearly classified into 4 categories (Pink) are visible.
4. **Scale vs. Density:** The largest model (Llama-3.1 70B) does not have the highest density of classified heads. Its pattern is more specialized and clustered compared to the more uniformly distributed classifications in the smaller models.
### Interpretation
This visualization provides a comparative map of how different LLMs allocate their attention resources. The data suggests that:
* **Functional Specialization is Heterogeneous:** There is no universal blueprint for how attention heads are organized. Architectural differences (model size, training data, objective) lead to divergent internal organization strategies.
* **Core vs. Specialized Functions:** The prevalence of Linguistic and Knowledge heads across models indicates these are fundamental capabilities required for language modeling. The more sporadic appearance of Translation and Algorithmic heads suggests these might be more specialized or emergent functions.
* **Efficiency and Clustering:** The sparse, clustered pattern in Llama-3.1 70B could indicate a more efficient or modular organization, where specific capabilities are localized to particular network regions, as opposed to a diffuse distribution. The vertical streaks in Pythia 12B suggest entire layers may be dedicated to specific functions like Knowledge retrieval.
* **Investigative Insight:** This type of analysis moves beyond treating LLMs as black boxes. By mapping functional anatomy, researchers can hypothesize about model robustness, interpretability, and how capabilities like in-context learning or factual recall might be mechanistically implemented. The differences invite questions about whether one organizational pattern is more advantageous for specific tasks.
</details>
Figure 2: Functionality mapping by MAPS for 20 relations of 4 categories — algorithmic, knowledge, linguistic, translation — across all attention heads in GPT-2 xl, Phi-2, Pythia 12B, Llama-3.1 70B. A head is marked as a specific category if it implements at least one relation from this category.
#### Function universality
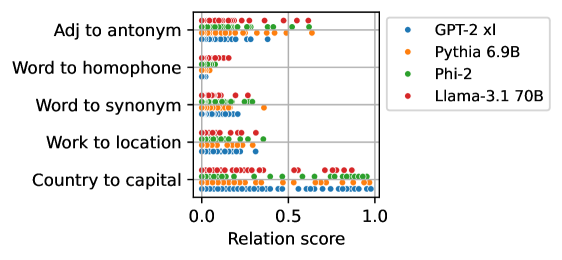
Figure 3 presents the distributions of relation scores for several representative relations in multiple models showing two interesting trends. First, despite architecture and training data differences, models encode relations in their heads to similar degrees, as observed by the similar highest scores per relation. This observation supports the “universality hypothesis” Li et al. (2015) that different networks learn similar features and circuits and expands recent similar findings about universality in LLMs Gould et al. (2024); Arditi et al. (2024); Tigges et al. (2024). Second, the scores for a given relation are diverse, with different heads implementing the relation at varying degrees, as opposed to having a small set of heads with high relation scores. This has implications for research concerning localization and editing; certain concepts or associations are encoded in a large number of model components at varying degrees.
#### Comparison with known head functionalities
Wang et al. (2023) identified “Name Mover” and “Anti Name Mover” heads in a circuit for indirect object identification in GPT-2 small, which copy or suppress copying specific names in the context, and Merullo et al. (2024a) identified “Mover” and “Capital” heads in GPT-2 medium. MAPS successfully identified all these heads as name copiers or country-to-capital mappers (which agrees with a similar analysis conducted by Wang et al., 2023). In addition, it discovered 25 heads in GPT-2 small and 46 in GPT-2 medium that implement similar operations but were not recognized in prior analyses. While the additional heads may not participate in the specific circuits discovered, they may be triggered for circuits of similar or related tasks that were overlooked in previous analyses.
Notably, for all the heads identified in previous works, MAPS reveals various additional functionalities. These observations extend the findings by Merullo et al. (2024a) of heads that implement multiple functionalities.
Taken together, these results demonstrate the effectiveness of MAPS in comprehensively mapping the implementation of a certain operation by attention heads across the model. A more detailed comparison is in § D.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Scatter Plot: Relation Scores of Language Models on Various Tasks
### Overview
The image is a horizontal scatter plot comparing the performance of four large language models (LLMs) on five different linguistic or knowledge-based tasks. Performance is measured by a "Relation score" on a scale from 0.0 to 1.0. Each model is represented by a distinct color, and each task is a separate horizontal row on the y-axis. The plot visualizes the distribution of scores for each model-task combination.
### Components/Axes
* **Chart Type:** Horizontal Scatter Plot / Dot Plot.
* **Y-Axis (Categories):** Lists five tasks. From top to bottom:
1. `Adj to antonym`
2. `Word to homophone`
3. `Word to synonym`
4. `Work to location` (Note: Likely a typo for "Word to location").
5. `Country to capital`
* **X-Axis (Metric):** Labeled `Relation score`. The axis has major tick marks at `0.0`, `0.5`, and `1.0`.
* **Legend:** Positioned in the top-right corner, outside the main plot area. It maps colors to model names:
* Blue dot: `GPT-2 xl`
* Orange dot: `Pythia 6.9B`
* Green dot: `Phi-2`
* Red dot: `Llama-3.1 70B`
### Detailed Analysis
The analysis is segmented by task (y-axis category), describing the visual trend and approximate data distribution for each model.
**1. Task: Adj to antonym (Top Row)**
* **Trend:** Scores are widely dispersed across the entire range for all models, indicating high variability in performance on this task.
* **Data Distribution:**
* **GPT-2 xl (Blue):** Points are scattered from ~0.1 to ~0.9, with a slight clustering below 0.5.
* **Pythia 6.9B (Orange):** Similar wide spread from ~0.1 to ~0.9.
* **Phi-2 (Green):** Points are densely clustered between ~0.2 and ~0.8.
* **Llama-3.1 70B (Red):** Shows a broad distribution from ~0.1 to ~0.9, with several points near the high end (~0.8-0.9).
**2. Task: Word to homophone (Second Row)**
* **Trend:** All models perform very poorly, with scores tightly clustered near the low end of the scale.
* **Data Distribution:**
* All four models (Blue, Orange, Green, Red) have their data points concentrated in a narrow band between `0.0` and approximately `0.2`. No model achieves a score above ~0.25.
**3. Task: Word to synonym (Third Row)**
* **Trend:** Moderate performance with a clear separation between models. Scores are generally in the low-to-mid range.
* **Data Distribution:**
* **GPT-2 xl (Blue):** Clustered between ~0.1 and ~0.4.
* **Pythia 6.9B (Orange):** Shows the widest spread in this row, from ~0.1 to ~0.6, with one notable outlier near `0.6`.
* **Phi-2 (Green):** Tightly grouped between ~0.2 and ~0.4.
* **Llama-3.1 70B (Red):** Points are concentrated between ~0.2 and ~0.5.
**4. Task: Work to location (Fourth Row)**
* **Trend:** Performance is generally low, similar to the homophone task, but with slightly more spread.
* **Data Distribution:**
* All models have points primarily between `0.0` and `0.4`.
* **GPT-2 xl (Blue)** and **Pythia 6.9B (Orange)** are clustered below `0.3`.
* **Phi-2 (Green)** and **Llama-3.1 70B (Red)** show a slightly higher reach, with some points approaching `0.4`.
**5. Task: Country to capital (Bottom Row)**
* **Trend:** This task shows the highest overall scores and the most significant performance differentiation between models.
* **Data Distribution:**
* **GPT-2 xl (Blue):** Scores are spread across the entire range from `0.0` to `1.0`, indicating inconsistent performance.
* **Pythia 6.9B (Orange):** Points are mostly between `0.0` and `0.7`, with a cluster in the mid-range.
* **Phi-2 (Green):** Shows strong performance, with a dense cluster of points between `0.5` and `1.0`.
* **Llama-3.1 70B (Red):** Demonstrates the best and most consistent performance, with the vast majority of points tightly clustered between `0.7` and `1.0`.
### Key Observations
1. **Task Difficulty Hierarchy:** "Word to homophone" and "Work to location" are the most challenging tasks, with all models scoring poorly (<0.4). "Country to capital" is the easiest, with several models achieving high scores.
2. **Model Performance Patterns:**
* **Llama-3.1 70B (Red)** is the top performer on the two tasks where high scores are possible ("Country to capital" and "Adj to antonym").
* **Phi-2 (Green)** shows strong, consistent performance on "Country to capital" and mid-range performance on others.
* **GPT-2 xl (Blue)** exhibits the most variance, especially on "Country to capital," where its scores span the entire scale.
* **Pythia 6.9B (Orange)** generally performs in the middle of the pack but has a notable high outlier on "Word to synonym."
3. **Notable Anomaly:** The "Word to homophone" task acts as a performance floor, with no model showing any significant capability.
### Interpretation
This chart provides a comparative snapshot of LLM capabilities across distinct types of relational knowledge. The data suggests that:
* **Factual Recall vs. Linguistic Skill:** Models excel at factual recall tasks like "Country to capital" but struggle significantly with phonological ("homophone") and likely spatial/geographical ("location") reasoning. This highlights a potential gap in their training data or architecture for these specific relation types.
* **Model Evolution:** The newer, larger model (Llama-3.1 70B) shows a clear advantage in tasks where high performance is achievable, suggesting scaling and/or architectural improvements lead to better mastery of certain knowledge domains.
* **Task-Specific Evaluation is Crucial:** A single aggregate score would be misleading. The wide dispersion of scores for GPT-2 xl on "Country to capital" indicates that its knowledge is patchy or unreliable for that specific task, even if it can sometimes get the answer right. The tight clustering of Llama-3.1 70B on the same task indicates robust and consistent knowledge.
* **The "Homophone" Barrier:** The uniformly low scores on "Word to homophone" point to a fundamental limitation in the models' understanding of sound-based word relationships, which may be underrepresented in text-centric training corpora.
In essence, the visualization moves beyond average benchmarks to reveal the nuanced strengths and weaknesses of different LLMs, showing that performance is highly dependent on the specific nature of the task.
</details>
Figure 3: Relation scores for all heads of Llama-3.1 70B, Pythia 6.9B, Phi-2, GPT-2 xl for several relations. We observe that heads from all models implement these relations to similar degrees.
## 5 Inspecting Salient Operations
We saw that given an operation realized as a relation between pairs of tokens, we can map how strongly it is implemented by attention heads across the model. Here, we use MAPS to tackle a complementary problem of inferring the prominent operations of a given attention head. We introduce an automatic pipeline for interpreting salient mappings in attention heads (§ 5.1) and use it to broadly infer the functionalities in Pythia 6.9B and GPT-2 xl (§ 5.2). In § F, we extend our analysis to show that the skewness of saliency scores can indicate how global or specific the head’s functionality is.
### 5.1 Automatic Functionality Inference
We propose the following steps for inferring the functionality of an attention head:
1. Using the saliency score (Eq. 3) to identify the top $k$ tokens for which the head’s transformation is most prominent.
1. For each salient token $s$ , collecting the top $n$ tokens it is mapped to according to $M$ , namely, the tokens corresponding to the top entries in $\mathbf{m}_{s}$ . This could be extended to suppression for better coverage.
1. Inferring the head’s salient operations by querying an LLM about prominent patterns in the list of salient tokens and their top mappings. Notably, we ask the model to indicate there is no pattern when no clear pattern is observed across the mappings. For the exact prompt used, see § E.
We run this pipeline on a total of 2,224 attention heads in GPT-2 xl and Pythia 6.9B, while setting $k=30$ (step 1) and $n=5$ (step 2) and using GPT-4o (Hurst et al., 2024) (step 3). We analyze how often GPT-4o was able to recognize a prominent functionality and measure the quality of its descriptions compared to human judgment.
### 5.2 Results
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Charts: Pattern Detection Across Neural Network Layers
### Overview
The image displays two side-by-side line charts comparing the percentage of attention heads where a specific pattern was detected across the layers of two different large language models: "Pythia 6.9b" (left) and "GPT2 xl" (right). The charts share a common y-axis label but have independent x-axes representing the layer number for each model.
### Components/Axes
* **Chart Titles:**
* Left Chart: "Pythia 6.9b"
* Right Chart: "GPT2 xl"
* **Y-Axis (Shared):**
* **Label:** "% of heads where a pattern was detected"
* **Scale:** Linear, from 0 to 100.
* **Tick Marks:** 0, 20, 40, 60, 80, 100.
* **X-Axes (Independent):**
* **Label (Both):** "Layer"
* **Pythia 6.9b Scale:** Linear, from 0 to 30. Tick marks at 0, 10, 20, 30.
* **GPT2 xl Scale:** Linear, from 0 to 40. Tick marks at 0, 10, 20, 30, 40.
* **Data Series:** A single blue line in each chart.
* **Grid:** Light gray grid lines are present for both major x and y ticks.
* **Spatial Layout:** The two charts are positioned horizontally adjacent. The shared y-axis label is positioned vertically to the left of both charts.
### Detailed Analysis
**Chart 1: Pythia 6.9b (Left)**
* **Trend:** The line shows a general increase from the first layer to a peak in the middle layers, followed by a sharp decline in the final layers.
* **Data Points (Approximate):**
* Layer 0: ~20%
* Layer 5: ~55% (local peak)
* Layer 10: ~40% (local trough)
* Layer 15: ~85% (high plateau begins)
* Layer 20: ~90% (approximate global peak)
* Layer 25: ~80%
* Layer 30: ~40% (sharp decline)
* Layer 31 (final point): ~35%
**Chart 2: GPT2 xl (Right)**
* **Trend:** The line is more volatile than the Pythia chart. It shows an overall upward trend with significant fluctuations, reaching a peak in the later third of the layers before a moderate decline.
* **Data Points (Approximate):**
* Layer 0: ~20%
* Layer 5: ~65% (early peak)
* Layer 10: ~45% (trough)
* Layer 15: ~50%
* Layer 20: ~70%
* Layer 25: ~80%
* Layer 30: ~85%
* Layer 35: ~95% (approximate global peak)
* Layer 40: ~70%
* Layer 44 (final point): ~70%
### Key Observations
1. **Common Starting Point:** Both models begin with approximately 20% of heads detecting the pattern at Layer 0.
2. **Peak Location:** The peak detection rate occurs at different depths. For Pythia 6.9b, it's around Layer 20 (middle). For GPT2 xl, it's around Layer 35 (later third).
3. **Post-Peak Behavior:** Pythia 6.9b exhibits a dramatic and steep decline after its peak, falling below 40% by its final layer. GPT2 xl's decline is less severe, ending at a higher percentage (~70%).
4. **Volatility:** The GPT2 xl line shows more pronounced ups and downs between layers compared to the relatively smoother ascent and descent of the Pythia line.
5. **Model Depth:** The x-axes indicate the models have different numbers of layers being analyzed (Pythia ~31, GPT2 xl ~44).
### Interpretation
This visualization suggests a fundamental difference in how the two models organize information processing across their layers regarding the specific, unnamed pattern being measured.
* **Pythia 6.9b** demonstrates a "mid-layer specialization" pattern. The pattern is most strongly and consistently detected in the central processing layers (15-25), implying these layers are crucial for the feature or concept the pattern represents. The sharp drop-off in later layers suggests this information is either transformed into a different representation or becomes less uniformly distributed across attention heads as the model prepares its final output.
* **GPT2 xl** shows a "late-layer specialization" with higher volatility. The pattern detection climbs more gradually and erratically, peaking much deeper in the network. This could indicate a more distributed or hierarchical processing where the pattern becomes most salient only after extensive integration of information. The less severe final drop-off might mean the pattern remains more relevant to the model's final output stages.
The stark contrast in the final layers is particularly noteworthy. It raises questions about the models' architectures or training objectives: Does Pythia 6.9b discard this pattern information more aggressively for downstream tasks? Does GPT2 xl retain it as a more persistent feature? Without knowing the specific "pattern" (e.g., a syntactic rule, a semantic concept, a positional bias), the exact implication remains speculative, but the data clearly shows the models have learned fundamentally different internal strategies for handling it.
</details>
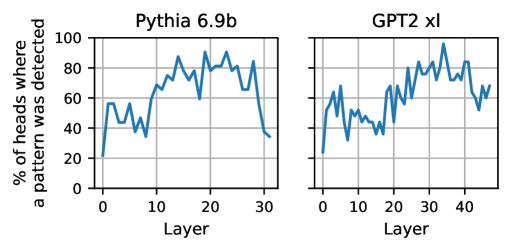
Figure 4: Portion of heads where GPT-4o identified a prominent pattern across the head’s salient mappings.
Figure 4 shows the percentage of heads per layer in GPT-2 xl and Pythia 6.9B where GPT-4o described a pattern. In both models, we observe a high rate of 60%-96% interpretable heads in the middle and upper layers, compared to a lower rate of 20%-60% in the early and last layers. These trends are consistent with those observed for predefined relations (§ 4), suggesting that early-layer heads are less interpretable in the vocabulary space. Qualitative analysis of 107 heads with identified patterns shows diverse operations: 38% semantic (e.g., extension of time-periods, day->month; month->year; year->decade), 36% algorithmic (e.g., capitalization, water->Water), and 26% linguistic (e.g., completion of sub-words (inhib->inhibition; resil->resilience). Examples of salient mappings and their interpretations are provided in § E.
#### Interpretation quality
We conduct a human study to assess the plausibility of the generated descriptions, finding that GPT-4o correctly identifies the presence or absence of a pattern in 80% of the cases and reliably detects observable patterns. This shows that our automatic pipeline is reasonable and demonstrates promising trends in automatically interpreting attention heads with MAPS. For more details on this study and its results, see § E.
## 6 Related Work
Prior studies of attention heads in LLMs mostly focused on analyzing their attention patterns Voita et al. (2019); Clark et al. (2019); Vig and Belinkov (2019), training probes and sparse auto-encoders Kissane et al. (2024), studying head outputs, and performing causal interventions (see survey by Zheng et al., 2024). Unlike these methods, MAPS infers the functionality of attention heads from their parameters, without any training or inference.
Vocabulary projections of attention head parameters have been used for analyzing certain attention head operations in LLMs Wang et al. (2023); McDougall et al. (2024); Kim et al. (2024); García-Carrasco et al. (2024); Elhage et al. (2021). However, they have been used mostly as a validation tool for operations inferred by other methods and were applied to specific relations and heads, typically in the scope of specific circuits. Gould et al. (2024) studied a single relation across all heads of multiple LLMs. Our work proposes a general framework that uses vocabulary projections as its primary tool for inferring attention head functionality.
Millidge and Black (2022) utilized an LLM to interpret the vocabulary projections of singular vectors of attention heads and MLP matrices, but their approach does not consider input-output mappings which are essential for estimating head functionality. More recently, Merullo et al. (2024b) used parameter similarities of heads at different layers to study their “communication channels”. Lastly, Hernandez et al. (2024) showed that relation operations of attention heads can be well-approximated by linear functions. Our work further shows that some of these relations are implemented by mappings encoded in head parameters.
## 7 Conclusion
We present MAPS, an efficient framework for analyzing the functionality of attention heads from their parameters. MAPS utility is two-fold: it allows mapping how strongly a given operation is implemented across the heads of a model and inferring the salient operations of a given head. Experiments show that estimations by MAPS correlate with the head outputs during inference and causally relate to the model’s behavior. Moreover, strong LLMs can interpret them automatically, often aligning with human judgment. Our analysis provides insights into architecture biases on function encoding and function universality in LLMs.
## Limitations
MAPS primarily focuses on analyzing the part of the head’s computation that writes the output to the residual stream, i.e., the matrix $W_{VO}$ . In other words, we use single-token mappings to analyze the operation of the output part of the head on contextualized representations $\tilde{X}$ . While our experiments in § 4.3 show that these estimations generalize to multi-token inputs, it is still valuable to examine the head’s computation responsible for contextualization and for creating $\tilde{X}$ , i.e., the matrix $W_{QK}$ .
Another limitation of MAPS is that its expressivity is bounded by the model’s vocabulary. Namely, it can only map operations that can be expressed via pairs of tokens. While this formulation can effectively describe and capture various features, as demonstrated by our experiments in § 4 and § 5, there are likely to be operations that this framework would overlook, such as idioms and positional features. A related challenge is the lower coverage of MAPS in early layers, where the model may not yet operate in the output vocabulary space, but instead computes general-purpose features to be used by later layers. Extending MAPS to support other types of representations is a promising direction to overcome these limitations, as well as exploring methods such as linear mappings Yom Din et al. (2024) and patching Ghandeharioun et al. (2024) to improve the performance on early layers.
Lastly, MAPS relies on the formulation of attention heads as interaction matrices (§ 2), which ignores the bias terms of $W_{V},W_{O}$ . While our experiments show there is a strong correlation between the estimations by MAPS and head outputs, these terms may influence them. Incorporating these bias terms into the analysis is an interesting direction, which we leave for future works to explore.
## Acknowledgments
We thank Guy Dar, Daniela Gottesman, Ohav Barbi, Ori Yoran, Yoav Gur-Arieh and Samuel Amouyal who helped with analysis and provided useful feedback. This research was supported in part by The Israel Science Foundation grant 1083/24.
## References
- Ainslie et al. (2023) Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. 2023. GQA: Training generalized multi-query transformer models from multi-head checkpoints. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901, Singapore. Association for Computational Linguistics.
- Arditi et al. (2024) Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. 2024. Refusal in language models is mediated by a single direction. arXiv preprint arXiv:2406.11717.
- Azaria and Mitchell (2023) Amos Azaria and Tom Mitchell. 2023. The internal state of an LLM knows when it‘s lying. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, Singapore. Association for Computational Linguistics.
- Biderman et al. (2023) Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. 2023. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pages 2397–2430. PMLR.
- Bohnet et al. (2022) Bernd Bohnet, Vinh Q Tran, Pat Verga, Roee Aharoni, Daniel Andor, Livio Baldini Soares, Massimiliano Ciaramita, Jacob Eisenstein, Kuzman Ganchev, Jonathan Herzig, et al. 2022. Attributed question answering: Evaluation and modeling for attributed large language models. arXiv preprint arXiv:2212.08037.
- Bolukbasi et al. (2021) Tolga Bolukbasi, Adam Pearce, Ann Yuan, Andy Coenen, Emily Reif, Fernanda Viégas, and Martin Wattenberg. 2021. An interpretability illusion for bert. ArXiv preprint, abs/2104.07143.
- Clark et al. (2019) Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. 2019. What does BERT look at? an analysis of BERT’s attention. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 276–286, Florence, Italy. Association for Computational Linguistics.
- Dar et al. (2023) Guy Dar, Mor Geva, Ankit Gupta, and Jonathan Berant. 2023. Analyzing transformers in embedding space. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16124–16170, Toronto, Canada. Association for Computational Linguistics.
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models. ArXiv preprint, abs/2407.21783.
- Elhage et al. (2021) Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. 2021. A mathematical framework for transformer circuits. Transformer Circuits Thread, 1(1):12.
- Ferrando et al. (2024) Javier Ferrando, Gabriele Sarti, Arianna Bisazza, and Marta R Costa-jussà. 2024. A primer on the inner workings of transformer-based language models. ArXiv preprint, abs/2405.00208.
- Gao et al. (2024) Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. 2024. Scaling and evaluating sparse autoencoders. ArXiv preprint, abs/2406.04093.
- García-Carrasco et al. (2024) Jorge García-Carrasco, Alejandro Maté, and Juan C. Trujillo. 2024. How does GPT-2 predict acronyms? extracting and understanding a circuit via mechanistic interpretability. In International Conference on Artificial Intelligence and Statistics, 2-4 May 2024, Palau de Congressos, Valencia, Spain, volume 238 of Proceedings of Machine Learning Research, pages 3322–3330. PMLR.
- Geva et al. (2022) Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Goldberg. 2022. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 30–45, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Geva et al. (2021) Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Ghandeharioun et al. (2024) Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva. 2024. Patchscopes: A unifying framework for inspecting hidden representations of language models. In Forty-first International Conference on Machine Learning.
- Gould et al. (2024) Rhys Gould, Euan Ong, George Ogden, and Arthur Conmy. 2024. Successor heads: Recurring, interpretable attention heads in the wild. In The Twelfth International Conference on Learning Representations.
- Gur-Arieh et al. (2025) Yoav Gur-Arieh, Roy Mayan, Chen Agassy, Atticus Geiger, and Mor Geva. 2025. Enhancing automated interpretability with output-centric feature descriptions. arXiv preprint arXiv:2501.08319.
- Hernandez et al. (2024) Evan Hernandez, Arnab Sen Sharma, Tal Haklay, Kevin Meng, Martin Wattenberg, Jacob Andreas, Yonatan Belinkov, and David Bau. 2024. Linearity of relation decoding in transformer language models. In The Twelfth International Conference on Learning Representations.
- Hurst et al. (2024) Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card. ArXiv preprint, abs/2410.21276.
- Javaheripi and Bubeck (2023) Mojan Javaheripi and Sébastien Bubeck. 2023. Phi-2: The surprising power of small language models.
- Katz et al. (2024) Shahar Katz, Yonatan Belinkov, Mor Geva, and Lior Wolf. 2024. Backward lens: Projecting language model gradients into the vocabulary space. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2390–2422, Miami, Florida, USA. Association for Computational Linguistics.
- Kim et al. (2024) Geonhee Kim, Marco Valentino, and André Freitas. 2024. A mechanistic interpretation of syllogistic reasoning in auto-regressive language models. ArXiv preprint, abs/2408.08590.
- Kissane et al. (2024) Connor Kissane, Robert Krzyzanowski, Joseph Isaac Bloom, Arthur Conmy, and Neel Nanda. 2024. Interpreting attention layer outputs with sparse autoencoders. In ICML 2024 Workshop on Mechanistic Interpretability.
- Kuhn et al. (2023) Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In The Eleventh International Conference on Learning Representations.
- Li et al. (2015) Yixuan Li, Jason Yosinski, Jeff Clune, Hod Lipson, and John Hopcroft. 2015. Convergent learning: Do different neural networks learn the same representations? In Proceedings of the 1st International Workshop on Feature Extraction: Modern Questions and Challenges at NIPS 2015, volume 44 of Proceedings of Machine Learning Research, pages 196–212, Montreal, Canada. PMLR.
- Loper and Bird (2002) Edward Loper and Steven Bird. 2002. NLTK: The natural language toolkit. In Proceedings of the ACL-02 Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics, pages 63–70, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
- McDougall et al. (2024) Callum Stuart McDougall, Arthur Conmy, Cody Rushing, Thomas McGrath, and Neel Nanda. 2024. Copy suppression: Comprehensively understanding a motif in language model attention heads. In Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 337–363, Miami, Florida, US. Association for Computational Linguistics.
- Meng et al. (2022) Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in GPT. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Merullo et al. (2024a) Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. 2024a. Circuit component reuse across tasks in transformer language models. In The Twelfth International Conference on Learning Representations.
- Merullo et al. (2024b) Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. 2024b. Talking heads: Understanding inter-layer communication in transformer language models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.
- Millidge and Black (2022) Beren Millidge and Sid Black. 2022. The singular value decompositions of transformer weight matrices are highly interpretable.
- Nanda and Bloom (2022) Neel Nanda and Joseph Bloom. 2022. Transformerlens. https://github.com/TransformerLensOrg/TransformerLens.
- nostalgebraist (2020) nostalgebraist. 2020. Interpreting gpt: the logit lens.
- Olsson et al. (2022) Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. 2022. In-context learning and induction heads. ArXiv preprint, abs/2209.11895.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Schober et al. (2018) Patrick Schober, Christa Boer, and Lothar A. Schwarte. 2018. Correlation coefficients: Appropriate use and interpretation. Anesthesia & Analgesia, 126:1763–1768.
- Tigges et al. (2024) Curt Tigges, Michael Hanna, Qinan Yu, and Stella Biderman. 2024. LLM circuit analyses are consistent across training and scale. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 5998–6008.
- Vig and Belinkov (2019) Jesse Vig and Yonatan Belinkov. 2019. Analyzing the structure of attention in a transformer language model. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 63–76, Florence, Italy. Association for Computational Linguistics.
- Voita et al. (2019) Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. 2019. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5797–5808, Florence, Italy. Association for Computational Linguistics.
- Vrandečić and Krötzsch (2014) Denny Vrandečić and Markus Krötzsch. 2014. Wikidata: a free collaborative knowledgebase. Commun. ACM, 57(10):78–85.
- Wang et al. (2023) Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. 2023. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Xiao et al. (2024) Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient streaming language models with attention sinks. In The Twelfth International Conference on Learning Representations.
- Yom Din et al. (2024) Alexander Yom Din, Taelin Karidi, Leshem Choshen, and Mor Geva. 2024. Jump to conclusions: Short-cutting transformers with linear transformations. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 9615–9625, Torino, Italia. ELRA and ICCL.
- Yu et al. (2024) Lei Yu, Meng Cao, Jackie CK Cheung, and Yue Dong. 2024. Mechanistic understanding and mitigation of language model non-factual hallucinations. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7943–7956, Miami, Florida, USA. Association for Computational Linguistics.
- Zheng et al. (2024) Zifan Zheng, Yezhaohui Wang, Yuxin Huang, Shichao Song, Bo Tang, Feiyu Xiong, and Zhiyu Li. 2024. Attention heads of large language models: A survey. ArXiv preprint, abs/2409.03752.
- Zhou et al. (2024) Zhenhong Zhou, Haiyang Yu, Xinghua Zhang, Rongwu Xu, Fei Huang, Kun Wang, Yang Liu, Junfeng Fang, and Yongbin Li. 2024. On the role of attention heads in large language model safety. ArXiv preprint, abs/2410.13708.
## Appendix A Mapping Predefined Relations – Additional Details and Results
In § 4, we showed how MAPS can be utilized to map all heads that implement a predefined relation across a language model. Here we offer further details on the datasets and implementation, as well as supplementary results.
### A.1 Datasets
| Category | Relation | Example mappings | Dataset size per tokenizer | | |
| --- | --- | --- | --- | --- | --- |
| Llama-3.1 | Pythia | GPT-2 / Phi-2 | | | |
| Algorithmic | Copying | (ottawa, ottawa),(say,say) | 450 | 432 | 436 |
| Name copying | (Mallory, Mallory),(Walt, Walt) | 134 | 113 | 132 | |
| Word to first letter | (bend, b),(past, p) | 238 | 237 | 238 | |
| Word to last letter | (bend, d),(past, t) | 238 | 237 | 238 | |
| Year to following | (1728, 1729),(1958, 1959) | | 147 | 133 | |
| Knowledge | Country to capital | (Bulgaria, Sofia),(Chile, Santiago) | 45 | 32 | 43 |
| Country to language | (Laos, Lao),(Denmark, Danish) | 51 | 37 | 48 | |
| Object to superclass | (tiger, animal),(carp, fish) | 62 | 46 | 65 | |
| Product by company | (Xbox, Microsoft),(Bravia, Sony) | 39 | | 40 | |
| Work to location | (farmer, farm),(chef, kitchen) | 48 | 34 | 45 | |
| Linguistic | Adj to comparative | (big, bigger),(high, higher) | 47 | 44 | 48 |
| Adj to superlative | (angry, angriest),(high, highest) | 39 | | 41 | |
| Noun to pronoun | (viewers, they),(Anna, she) | 257 | 238 | 253 | |
| Verb to past tense | (ask, asked),(eat, ate) | 110 | 112 | 112 | |
| Word to antonym | (love, hate),(right, wrong) | 91 | 88 | 92 | |
| Word to compound | (hot, hotdog),(wall, wallpaper) | 38 | | 36 | |
| Word to homophone | (steal, steel),(sea, see) | 103 | 88 | 91 | |
| Word to synonym | (vague, obscure),(ill, sick) | 154 | 142 | 154 | |
| Translation | English to French | (cat, chat),(love, amour) | 32 | | |
| English to Spanish | (cat, gato),(love, amor) | 34 | | | |
Table 3: Datasets used for inspecting predefined operations in models with different tokenizers. Every model column describes the datasets’ sizes for this model. Different tokenizers lead to differences between datasets. We discard datasets that were left with $\leq$ 30 single-token mappings after tokenization.
Table 4: Sources for constructing per-relation datasets used in § 4.
We display the list of categories and relations used to map predefined relations (§ 4), alongside the sizes of the different datasets and examples for relations pairs in Table 3.
#### Data collection
We obtained the relation pairs from the sources: WikiData Vrandečić and Krötzsch (2014); “English Word Frequency List” Kaggle dataset, https://www.kaggle.com/datasets/wheelercode/english-word-frequency-list which is based on Google Books Ngram Viewer Exports, version 3, exported on Feb 17, 2020, https://storage.googleapis.com/books/ngrams/books/datasetsv3.html the datasets used by Hernandez et al. (2024), which are based on CounterFact Meng et al. (2022) and WikiData Vrandečić and Krötzsch (2014), and ChatGPT. https://chatgpt.com/ We also used the nltk package Loper and Bird (2002) to validate several relation datasets. Except for the Translation and year to following datasets, all datasets are in English. The details on which source was used to compose which relation are presented in Table 4.
In the datasets for the relations work to location, verb to past tense, product by company, object to superclass, adj to superlative, adj to comparative, word to antonym, we filter out pairs where the source token appeared as a source token in other pairs. Relation pairs were filtered out from different datasets to assert their correctness.
#### Data processing
For every model, we tokenized the various datasets using the model’s tokenizer. To maximize the number of words mapped to single tokens, we added a leading space before every word. For example, if the relation source word was "Don", we tokenized the string " Don" instead. Finally, we filtered out relation pairs where at least one of the words was mapped to more than one token.
### A.2 Implementation Details
#### Applying the first MLP
For every model except Llama-3.1 70B, and similarly to Wang et al. (2023); Gould et al. (2024), we first applied the model’s first MLP to the tokens embeddings. Notably, we did not apply the first MLP when we analyzed heads from the models’ first layers (layer 0), since the first attention layer precedes the first MLP in the computation. To adjust the embeddings to the first MLP’s input distribution, we also applied the layer norm that precedes it. Regarding Llama-3.1 70B, we observed better results when not applying the first MLP.
#### Selection of $k$
To calculate a head’s relation score $\phi_{R}(M)$ , we obtain the top- $k$ tokens in $\mathbf{m}_{s}$ for every source token $s$ . For Pythia, GPT-2 and Phi-2 we set $k=1$ for copying and name-copying relations and $k=10$ for other relations. For the Llama-3.1 models we set $k=3$ for copying and name-copying and $k=25$ for other relations. Table 5 – which presents the tokenization applied to several base words by the tokenizers of Llama-3.1, GPT-2 and Pythia – demonstrates the need to set larger $k$ values for Llama-3.1. The larger vocabulary size allows Llama-3.1’s tokenizer to express the same concept with more tokens.
| Word | Llama-3.1 | Pythia | GPT-2 |
| --- | --- | --- | --- |
| Hello | >Hello, Hello, _hello, Ġhello, hello, ĠHello, Hallo, Bonjour, Hola | Hello, Ġhello, hello, ĠHello | hello, ĠHello, Ġhello, Hello |
| Please | Please, Ġplease, please, ĠPLEASE, ĠPlease, .Please, PLEASE, >Please, Bitte, ĠBITTE, ĠBitte, Ġbitte | Please, please, Ġplease, ĠPlease | Please, Ġplease, ĠPlease, ĠPLEASE, please |
| Love | ĠLOVE, love, loven, Ġlove, Love, ĠLove, ĠLiebe, Ġliebe, Ġamour, Ġamore, Ġamor | love, ĠLOVE, Love, Ġlove, ĠLove | Ġlove, love, ĠLove, Love, ĠLOVE |
| Water | -water, _WATER, ĠWater, _water, water, Ġwater, Water, ĠWATER, .water, ĠWasser, ’eau, agua, Ġagua | Water, Ġwater, water, ĠWater, agua | Water, water, Ġwater, ewater, ĠWater |
| School | ĠSCHOOL, -school, schools, Ġschool, _school, school, ĠSchool, .school, School | School, Ġschool, school, ĠSchool | ĠSchool, Ġschool, school, ĠSCHOOL, School |
Table 5: Different tokenizations for base words by the tokenizers of Llama-3.1, Pythia and GPT-2. The “Ġ” symbol represents a leading space. We observe that Llama-3.1’s larger vocabulary allows expressing every base word with more tokens.
### A.3 Random Baselines
A concern that may arise from choosing a relatively small relation score threshold, is that the results obtained by MAPS may capture the similarity of tokens embeddings, rather than a functionality implemented by attention head’s weights. To study this, we applied MAPS to randomly initialized matrices from the empirical distribution of the model. Concretely, for every layer in the original model, we sampled $H$ random matrices (with the same shape as $W_{VO}$ ) from a normal distribution, for which the mean and standard deviation are the average and the standard deviation of the $W_{VO}$ matrices in the original layer. We applied our predefined relation analysis (described in § 4.1) to those matrices and measured the amounts of “functional attention heads” classified among them.
For models Phi-2, Pythia 6.9B, Pythia 12B, Llama-3.1 8B and Llama-3.1 70B no random matrices were classified as relation heads. For GPT-2 xl, 5 matrices were classified as such, compared to 250 relation heads in the trained model, and out of 1200 heads in the model. This demonstrates that the choice of $\tau=15\$ is meaningful for separating between functionalities of trained attention heads and random ones. While smaller thresholds could have also been justified by this experiment, we chose $\tau=15\$ to assert that the heads encode a substantial fraction of the relation pairs.
### A.4 Additional Results
In Figure 5 we display all heads classified in Llama-3.1 70B, Llama-3.1 8B, Pythia 12B, Pythia 6.9B, Phi-2 and GPT-2 xl divided to four categories. In Tables 6 and 7 we present the number of relation heads (and suppression relation heads) discovered in the same models, divided into relations. We observe that several relations (Name copying, Adj to comparative, Word to first letter) are demonstrated by a relatively large number of heads in at least five out of six models. On the other hand, several relations (e.g., word to homophone, word to last letter) are demonstrated by a small number of heads across all models.
| Category | Relation | GPT-2 xl | Phi-2 | Pythia 6.9B | Pythia 12B | Llama-3.1 8B | Llama-3.1 70B |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Algorithmic | Copying | 35 | 15 | 11 | 9 | 2 | 1 |
| Name copying | 71 | 25 | 27 | 23 | 3 | 14 | |
| Word to first letter | 4 | 5 | 13 | 13 | 15 | 19 | |
| Word to last letter | 0 | 1 | 2 | 1 | 2 | 2 | |
| Year to following | 47 | 16 | 14 | 22 | | | |
| Knowledge | Country to capital | 60 | 17 | 26 | 31 | 5 | 26 |
| Country to language | 50 | 23 | 24 | 30 | 5 | 28 | |
| Object to superclass | 17 | 12 | 11 | 19 | 0 | 13 | |
| Product by company | 24 | 4 | | | 1 | 3 | |
| Work to location | 10 | 6 | 6 | 8 | 0 | 5 | |
| Linguistic | Adj to comparative | 45 | 47 | 27 | 28 | 8 | 25 |
| Adj to superlative | 23 | 23 | | | 10 | 21 | |
| Noun to pronoun | 14 | 13 | 13 | 16 | 8 | 12 | |
| Verb to past tense | 15 | 27 | 17 | 28 | 8 | 18 | |
| Word to antonym | 12 | 15 | 11 | 15 | 5 | 11 | |
| Word to compound | 1 | 1 | | | 2 | 5 | |
| Word to homophone | 0 | 0 | 0 | 0 | 0 | 2 | |
| Word to synonym | 7 | 7 | 3 | 7 | 1 | 2 | |
| Translation | English to French | | | | | 0 | 2 |
| English to Spanish | | | | | 3 | 10 | |
Table 6: Number of heads implementing each of the relations across different models.
| Category | Relation | GPT-2 xl | Phi-2 | Pythia 6.9B | Pythia 12B | Llama-3.1 8B | Llama-3.1 70B |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Algorithmic | Copying | 8 | 7 | 5 | 7 | 0 | 2 |
| Name copying | 23 | 9 | 9 | 7 | 3 | 8 | |
| Word to first letter | 0 | 2 | 2 | 0 | 9 | 11 | |
| Word to last letter | 0 | 0 | 2 | 2 | 1 | 3 | |
| Year to following | 5 | 2 | 1 | 0 | | | |
| Knowledge | Country to capital | 19 | 8 | 5 | 5 | 1 | 10 |
| Country to language | 26 | 12 | 9 | 11 | 3 | 9 | |
| Object to superclass | 2 | 5 | 3 | 6 | 0 | 4 | |
| Product by company | 7 | 0 | | | 0 | 3 | |
| Work to location | 2 | 3 | 1 | 1 | 0 | 2 | |
| Linguistic | Adj to comparative | 11 | 29 | 15 | 19 | 5 | 13 |
| Adj to superlative | 6 | 13 | | | 5 | 10 | |
| Noun to pronoun | 1 | 2 | 2 | 4 | 4 | 7 | |
| Verb to past tense | 2 | 21 | 8 | 7 | 5 | 10 | |
| Word to antonym | 0 | 4 | 3 | 4 | 2 | 3 | |
| Word to compound | 0 | 1 | | | 2 | 3 | |
| Word to homophone | 0 | 0 | 0 | 0 | 1 | 1 | |
| Word to synonym | 0 | 2 | 0 | 1 | 0 | 1 | |
| Translation | English to French | | | | | 0 | 0 |
| English to Spanish | | | | | 2 | 7 | |
Table 7: Number of suppression heads implementing each of the relations across different models.
<details>
<summary>x5.png Details</summary>

### Visual Description
\n
## Scatter Plot Series: Attention Head Functional Classification Across Layers
### Overview
The image displays a series of five horizontally arranged scatter plots (or heatmaps) visualizing the distribution and functional classification of attention heads across the layers of a neural network model. The plots compare an aggregate view ("All Categories") against four isolated functional categories: Algorithmic, Knowledge, Linguistic, and Translation.
### Components/Axes
* **Chart Type:** Five separate scatter plots arranged in a horizontal row.
* **X-Axis (All Plots):** Labeled "layer". Scale runs from 0 to 80, with major tick marks at 0, 16, 32, 48, 64, and 80.
* **Y-Axis (All Plots):** Labeled "head". Scale runs from 0 to 60, with major tick marks at 0, 12, 24, 36, 48, and 60.
* **Legend:** Positioned to the right of the first subplot ("All Categories"). It defines the color coding for the data points:
* **Pink:** 4 categories
* **Brown:** 3 categories
* **Purple:** 2 categories
* **Red:** Translation
* **Green:** Linguistic
* **Orange:** Knowledge
* **Blue:** Algorithmic
* **Gray:** Unclassified (This appears to be the background color of the plot area, indicating heads not assigned to any of the above categories).
* **Subplot Titles (Top Center):**
1. All Categories
2. Algorithmic
3. Knowledge
4. Linguistic
5. Translation
### Detailed Analysis
**1. All Categories (Leftmost Plot):**
* **Trend/Pattern:** This plot shows a dense, scattered distribution of colored points across the entire grid (layers 0-80, heads 0-60). No single color dominates the entire space, but clusters and patterns are visible.
* **Data Points (Approximate Distribution):**
* **Blue (Algorithmic):** Points are scattered but show a slight concentration in the lower-left quadrant (layers ~0-40, heads ~30-60).
* **Orange (Knowledge):** Points are widely scattered, with a noticeable vertical cluster around layer 32, heads 36-48.
* **Green (Linguistic):** Points are broadly distributed, with a dense vertical band in the higher layers (64-80) across many head indices.
* **Red (Translation):** Points are sparse and scattered, with a few in the upper-right quadrant (layers >64, heads <24).
* **Multi-Category (Pink, Brown, Purple):** These points are interspersed among the single-category points, indicating heads classified into multiple functional groups.
**2. Algorithmic (Second Plot):**
* **Trend/Pattern:** Shows only the blue points from the first plot. The distribution is sparse and appears somewhat random, with no strong concentration in any specific layer or head range. Points exist from layer ~8 to ~76 and head ~12 to ~56.
**3. Knowledge (Third Plot):**
* **Trend/Pattern:** Shows only the orange points. A distinct vertical cluster is visible around layer 32, spanning heads approximately 36 to 48. Other points are scattered more sparsely across layers 8-72 and heads 12-60.
**4. Linguistic (Fourth Plot):**
* **Trend/Pattern:** Shows only the green points. There is a very strong concentration of points in the higher layers, specifically from layer ~64 to 80, forming a dense vertical band across a wide range of head indices (approximately 0-48). Scattered points also exist in lower layers.
**5. Translation (Rightmost Plot):**
* **Trend/Pattern:** Shows only the red points. This is the sparsest plot. Points are primarily located in the upper-right region of the grid, corresponding to higher layers (roughly 48-80) and lower head indices (roughly 0-36). A few isolated points exist elsewhere.
### Key Observations
1. **Functional Specialization by Layer:** The most striking pattern is the strong layer-wise specialization. "Linguistic" functions (green) are heavily concentrated in the final ~16 layers (64-80). "Knowledge" functions (orange) show a notable cluster in the middle layers (~32).
2. **Sparsity of Translation:** The "Translation" function (red) is assigned to the fewest heads and is primarily located in the later layers, but not as densely packed as the Linguistic function.
3. **Algorithmic Distribution:** "Algorithmic" functions (blue) are the most evenly dispersed across the network, suggesting a more fundamental or widely distributed computational role.
4. **Multi-Functional Heads:** The presence of pink, brown, and purple points in the "All Categories" plot confirms that some attention heads are classified as serving multiple functions simultaneously.
### Interpretation
This visualization provides a "functional map" of a neural network's attention mechanism. It suggests that different stages of processing (layers) are specialized for different types of tasks:
* **Early to Middle Layers (0-48):** Handle more foundational or "Algorithmic" computations and host clusters for "Knowledge"-based processing.
* **Middle to Late Layers (32-80):** See the emergence and then dominance of "Linguistic" processing, which peaks in the final layers.
* **Late Layers (48-80):** Also contain the sparse but present "Translation" function.
The data implies a hierarchical processing flow: lower layers perform general computations, middle layers integrate specific knowledge, and the final layers are heavily dedicated to linguistic structuring and translation-specific tasks. The existence of multi-category heads indicates that functional boundaries are not perfectly rigid, and some heads contribute to multiple aspects of processing. This map is crucial for understanding model interpretability, guiding pruning or fine-tuning efforts, and validating architectural hypotheses about how information flows and is transformed within the network.
</details>
(a) Functionality mapping by MAPS for relations of 4 categories — algorithmic, knowledge, linguistic, translation — across all attention heads in Llama-3.1 70B. A head is marked for a specific category if it implements (also in a suppression variant) at least one relation from this category.
<details>
<summary>x6.png Details</summary>

### Visual Description
## Heatmap Series: Attention Head Specialization Across Model Layers
### Overview
The image displays a series of five horizontally arranged heatmaps that visualize the classification of attention heads within a neural network model (likely a transformer) across its layers. Each heatmap plots "head" index (y-axis) against "layer" index (x-axis), with colored squares indicating heads assigned to specific functional categories. The first plot aggregates all classifications, while the subsequent four plots isolate individual categories.
### Components/Axes
* **Common Axes (All Plots):**
* **X-axis:** Labeled "layer". Scale ranges from 0 to 30, with major tick marks at 0, 6, 12, 18, 24, 30.
* **Y-axis:** Labeled "head". Scale ranges from 0 to 30, with major tick marks at 0, 6, 12, 18, 24, 30.
* **Legend (Positioned to the left of the first plot):**
* **4 categories:** Pink square
* **3 categories:** Brown square
* **2 categories:** Purple square
* **Translation:** Red square
* **Linguistic:** Green square
* **Knowledge:** Orange square
* **Algorithmic:** Blue square
* **Unclassified:** Gray square (This also serves as the background color for all plots).
* **Plot Titles (Positioned above each heatmap):**
1. All Categories
2. Algorithmic
3. Knowledge
4. Linguistic
5. Translation
### Detailed Analysis
**1. All Categories Plot:**
This plot shows heads classified into one or more categories. The distribution is densest in the later layers (approximately layers 18-30).
* **Multi-Category Heads:** Pink (4 categories) and brown (3 categories) squares are scattered, primarily between layers 18-24 and heads 12-24. Purple (2 categories) squares are also present in this region.
* **Single-Category Heads:** The plot is a composite of the colors from the subsequent four plots, showing the spatial overlap and segregation of different functional specializations.
**2. Algorithmic Plot (Blue):**
* **Trend:** Blue squares are distributed across layers ~18-30 and heads 0-30, with a notable concentration in the mid-to-lower head range (heads 12-30) of layers 24-30.
* **Data Points (Approximate):** Clusters are visible around (layer 24, head 18), (layer 27, head 24), and (layer 30, head 6). The pattern is somewhat scattered but avoids the very top rows (heads 0-6) in earlier layers.
**3. Knowledge Plot (Orange):**
* **Trend:** Orange squares are the most sparsely distributed. They appear almost exclusively in layers 18-30 and are scattered across the head range.
* **Data Points (Approximate):** Isolated points can be seen near (layer 18, head 9), (layer 21, head 21), (layer 24, head 24), and (layer 30, head 27). There is no dense clustering.
**4. Linguistic Plot (Green):**
* **Trend:** Green squares show a very dense and widespread distribution across layers 18-30 and heads 0-30. This appears to be the most prevalent single-category classification.
* **Data Points (Approximate):** Heavy clustering is evident, particularly in layers 21-27 across almost all head indices. A dense vertical band is visible around layer 24.
**5. Translation Plot (Red):**
* **Trend:** Red squares are the least frequent and are confined to the highest layers (approximately 24-30) and mid-to-lower head indices (heads 12-30).
* **Data Points (Approximate):** A small cluster is present around (layer 27, head 18) and (layer 30, head 21). Only a handful of red squares are visible in total.
### Key Observations
1. **Layer Specialization:** All functional specializations (Algorithmic, Knowledge, Linguistic, Translation) are almost entirely absent in the first 18 layers. Specialization emerges and intensifies in the final third of the network (layers 18-30).
2. **Category Prevalence:** The "Linguistic" category (green) is the most dominant and widespread single function in the later layers. "Translation" (red) is the most specialized and limited in scope.
3. **Multi-Function Heads:** The presence of pink, brown, and purple squares in the "All Categories" plot indicates that a subset of heads in layers 18-24 are involved in multiple functional categories simultaneously.
4. **Spatial Segregation:** While there is overlap, different categories show tendencies for different regions. For example, "Translation" heads are in higher layers and specific head ranges, while "Algorithmic" heads are more broadly distributed.
### Interpretation
This visualization provides a Peircean investigation into the internal functional organization of a large language model. It suggests a hierarchical processing structure where:
* **Early Layers (0-18):** Likely perform general, low-level processing not tied to these specific high-level task categories (hence "Unclassified").
* **Later Layers (18-30):** Exhibit functional specialization. The model appears to develop dedicated circuits or groups of attention heads for distinct capabilities: understanding and generating language (Linguistic), performing reasoning or calculations (Algorithmic), accessing factual information (Knowledge), and converting between languages (Translation).
* **The Coexistence of Multi-Category Heads** in the transition zone (layers 18-24) may represent integrative hubs where different types of information are combined before being processed by more specialized heads in the final layers.
* **The dominance of Linguistic heads** aligns with the core function of a language model, while the scarcity of Translation heads suggests this capability might be handled by a very specific, localized set of parameters or is a more emergent property.
The data demonstrates that model capabilities are not uniformly distributed but are spatially organized within the network's architecture, with clear progression from general to specialized processing along the layer axis.
</details>
(b) Functionality mapping by MAPS for Llama-3.1 8B.
<details>
<summary>x7.png Details</summary>
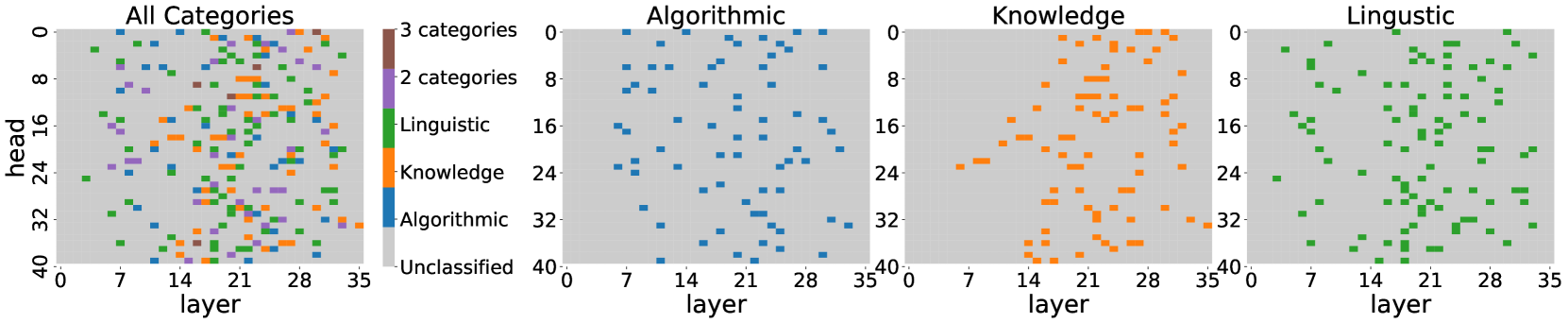
### Visual Description
\n
## Heatmap Series: Classification Distribution Across Model Layers and Attention Heads
### Overview
The image displays a series of four horizontally arranged heatmaps. The leftmost panel, titled "All Categories," is a composite visualization showing the classification of attention heads across a neural network model. The three subsequent panels to its right decompose this composite view, showing the distribution for each individual category: "Algorithmic," "Knowledge," and "Linguistic." A shared legend is positioned to the immediate right of the "All Categories" panel. The visualization maps classifications onto a 2D grid defined by model "layer" (x-axis) and attention "head" (y-axis).
### Components/Axes
* **Titles:** Four panel titles are present at the top: "All Categories", "Algorithmic", "Knowledge", "Linguistic".
* **Axes:**
* **X-axis (all panels):** Labeled "layer". The scale runs from 0 to 35, with major tick marks at 0, 7, 14, 21, 28, and 35.
* **Y-axis (all panels):** Labeled "head". The scale runs from 0 to 40, with major tick marks at 0, 8, 16, 24, 32, and 40.
* **Legend:** Located between the "All Categories" and "Algorithmic" panels. It defines six classification categories with associated colors:
* **Brown:** "3 categories"
* **Purple:** "2 categories"
* **Green:** "Linguistic"
* **Orange:** "Knowledge"
* **Blue:** "Algorithmic"
* **Light Gray:** "Unclassified" (This is the background color of all cells not marked with another color).
* **Data Representation:** Each cell in the 36x41 grid (layers 0-35, heads 0-40) represents a specific attention head. The cell's color indicates its classification according to the legend.
### Detailed Analysis
**Panel 1: "All Categories" (Composite View)**
* **Spatial Distribution:** Colored cells (classified heads) are scattered across the entire grid, with no single region completely devoid of classifications. There is a visible concentration of colored cells in the central region, roughly between layers 14-28 and heads 8-32.
* **Category Breakdown (Visual Estimate):**
* **Unclassified (Light Gray):** The majority of cells. Visually, it appears that less than 25% of the total heads are classified into any category.
* **Algorithmic (Blue):** Scattered individual cells and small clusters. A slight density increase is visible in the lower-left quadrant (layers 0-14, heads 24-40).
* **Knowledge (Orange):** Forms more distinct clusters and short horizontal streaks, particularly prominent in the central band (layers ~14-28, heads ~16-32).
* **Linguistic (Green):** Appears as widely dispersed individual cells and small groups, with a subtle presence across the entire grid.
* **2 categories (Purple):** Relatively rare, appearing as isolated cells, often adjacent to or within clusters of single-category heads.
* **3 categories (Brown):** Very rare, only a few isolated cells are visible (e.g., near layer 21, head 8).
**Panel 2: "Algorithmic" (Blue)**
* **Trend:** The blue cells show a scattered distribution with a mild concentration in the lower layers (0-14) and lower heads (24-40). There is no strong, continuous pattern; classifications appear as isolated points or very small, tight clusters.
**Panel 3: "Knowledge" (Orange)**
* **Trend:** This category shows the most structured distribution. Orange cells form clear horizontal bands and clusters, primarily concentrated in the middle layers (approximately 14 to 28). The density is highest in the head range of 16 to 32. There are very few orange cells in the earliest (0-7) or latest (28-35) layers.
**Panel 4: "Linguistic" (Green)**
* **Trend:** Green cells are the most uniformly dispersed across the entire layer-head space. While present everywhere, there is a slight visual increase in density in the upper half of the head axis (heads 0-20) compared to the lower half.
### Key Observations
1. **Functional Specialization:** The "Knowledge" category exhibits the strongest spatial specialization, being heavily concentrated in the model's middle layers. This suggests these layers/heads are primarily engaged in processing factual or world knowledge.
2. **Ubiquity of Linguistic Processing:** The "Linguistic" category is found throughout the model, indicating that syntactic and basic language processing functions are distributed across many layers and heads, not confined to a specific module.
3. **Sparsity of Classification:** A large majority of attention heads remain "Unclassified" by the criteria used in this analysis, suggesting either the classification method is highly selective or many heads perform functions not captured by these three categories.
4. **Multi-Category Heads:** The presence of heads classified under "2 categories" and "3 categories" (purple and brown) indicates that some attention heads perform hybrid functions, integrating algorithmic, knowledge-based, and linguistic processing.
### Interpretation
This visualization provides a functional map of a large language model's attention mechanism. The data suggests a **hierarchical and distributed processing architecture**:
* **Early Layers (0-14):** Show a mix of all categories but with a slight bias towards "Algorithmic" and "Linguistic" functions. This aligns with the hypothesis that lower layers handle more fundamental syntactic and structural processing.
* **Middle Layers (14-28):** Are the clear hub for **"Knowledge" retrieval and application**. The dense clustering here implies these layers are critical for accessing and manipulating the model's parametric knowledge base.
* **Late Layers (28-35):** See a reduction in "Knowledge" activity and a return to a more mixed, sparse distribution, potentially involved in task-specific formatting or output generation.
* **Overall Principle:** The model does not have a single "knowledge center" or "language center." Instead, capabilities are **distributed across the network**, with certain regions showing strong functional biases. The "Linguistic" function's ubiquity acts as a substrate upon which more specialized "Algorithmic" and "Knowledge" processes are built. The existence of multi-category heads highlights the integrated, non-modular nature of neural computation, where single components can simultaneously participate in multiple types of processing. This map is crucial for understanding model interpretability, guiding pruning or editing efforts, and diagnosing failure modes.
</details>
(c) Functionality mapping by MAPS for Pythia 12B.
<details>
<summary>x8.png Details</summary>
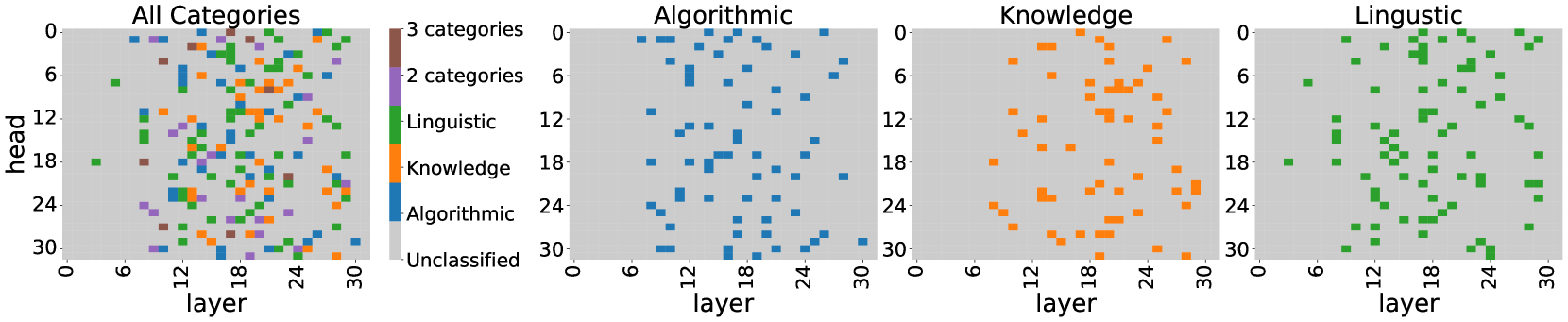
### Visual Description
\n
## Heatmap Set: Categorical Distribution Across Layers and Heads
### Overview
The image displays four horizontally arranged heatmaps, each plotting categorical data points on a grid defined by "layer" (x-axis) and "head" (y-axis). The leftmost heatmap, titled "All Categories," includes a legend and shows a composite view of all data. The subsequent three heatmaps isolate individual categories: "Algorithmic," "Knowledge," and "Linguistic." The visualization appears to map the presence or activation of specific functional categories within the layers and attention heads of a neural network model (likely a transformer).
### Components/Axes
* **Chart Type:** Four separate heatmaps (scatter plots on a grid).
* **Titles:**
* Leftmost: "All Categories"
* Second from left: "Algorithmic"
* Third from left: "Knowledge"
* Rightmost: "Linguistic"
* **Axes (Identical for all four charts):**
* **X-axis:** Label: "layer". Scale: 0 to 30, with major tick marks at 0, 6, 12, 18, 24, 30.
* **Y-axis:** Label: "head". Scale: 0 to 30, with major tick marks at 0, 6, 12, 18, 24, 30. The axis is inverted, with 0 at the top and 30 at the bottom.
* **Legend (Located on the left side of the "All Categories" heatmap):**
* **Brown square:** "3 categories"
* **Purple square:** "2 categories"
* **Green square:** "Linguistic"
* **Orange square:** "Knowledge"
* **Blue square:** "Algorithmic"
* **Light Gray square:** "Unclassified" (This corresponds to the background grid color).
### Detailed Analysis
**1. "All Categories" Heatmap (Leftmost):**
* **Content:** Displays a dense, mixed scatter of colored squares (blue, orange, green, purple, brown) across the entire grid. The background is light gray ("Unclassified").
* **Spatial Distribution:** Data points are scattered without a single dominant cluster, though there is a slight visual concentration in the central region (layers ~12-24, heads ~6-24). Brown ("3 categories") and purple ("2 categories") points are interspersed among the single-category points, indicating locations where multiple categories co-occur.
**2. "Algorithmic" Heatmap (Second from left):**
* **Content:** Shows only blue squares ("Algorithmic") on the light gray background.
* **Trend/Distribution:** The blue points are distributed across the grid but appear somewhat sparse. There is no strong, singular cluster, but a loose grouping is visible in the lower-left quadrant (layers ~0-18, heads ~12-30).
**3. "Knowledge" Heatmap (Third from left):**
* **Content:** Shows only orange squares ("Knowledge") on the light gray background.
* **Trend/Distribution:** The orange points show a more defined clustering pattern compared to the Algorithmic category. A notable concentration exists in the central to upper-right region (layers ~12-30, heads ~0-18). There are fewer points in the lower layers (0-12).
**4. "Linguistic" Heatmap (Rightmost):**
* **Content:** Shows only green squares ("Linguistic") on the light gray background.
* **Trend/Distribution:** The green points are widely scattered but show a visible density in the central and right portions of the grid (layers ~12-30). There is a relative sparsity in the very low layers (0-6) and the top rows (heads 0-6).
### Key Observations
1. **Category Co-occurrence:** The "All Categories" map reveals that specific layer-head positions (marked in brown and purple) are associated with two or three categories simultaneously, suggesting multifunctional components.
2. **Spatial Specialization:** While there is overlap, the individual category maps suggest a degree of spatial specialization:
* **Knowledge** points lean towards mid-to-high layers and mid-to-low heads.
* **Linguistic** points are prevalent in mid-to-high layers.
* **Algorithmic** points are more diffuse but have a presence in lower layers and heads.
3. **Coverage:** No single category uniformly covers the entire layer-head space. Significant portions of the grid remain "Unclassified" (light gray) in each individual category plot.
### Interpretation
This visualization likely analyzes the functional specialization within a large neural network, such as a transformer-based language model. Each "head" probably refers to an attention head within a specific "layer."
* **What the data suggests:** The model's processing is not monolithic. Different computational functions ("Algorithmic," "Knowledge," "Linguistic") are distributed across its architecture. The clustering patterns imply that certain regions of the network are more dedicated to specific types of processing. For instance, knowledge retrieval or storage might be concentrated in later layers, while linguistic syntactic processing could be more widespread.
* **Relationships:** The "All Categories" map is the union of the other three. The presence of multi-category (brown, purple) points is critical—it highlights components that serve integrated functions, bridging, for example, linguistic structure with factual knowledge.
* **Anomalies/Notable Trends:** The relative absence of points in the very first layers (0-6) and very last heads (24-30) across all categories is notable. This could indicate that the earliest and latest parts of the network perform more – -
## Textual Information Extraction
The image contains the following text, transcribed exactly as it appears:
**Titles:**
* All Categories
* Algorithmic
* Knowledge
* Linguistic
**Axis Labels:**
* head (Y-axis label for all charts)
* layer (X-axis label for all charts)
**Axis Markers:**
* Y-axis: 0, 6, 12, 18, 24, 30
* X-axis: 0, 6, 12, 18, 24, 30
**Legend Text (from top to bottom):**
* 3 categories
* 2 categories
* Linguistic
* Knowledge
* Algorithmic
* Unclassified
</details>
(d) Functionality mapping by MAPS for Pythia 6.9B.
<details>
<summary>x9.png Details</summary>
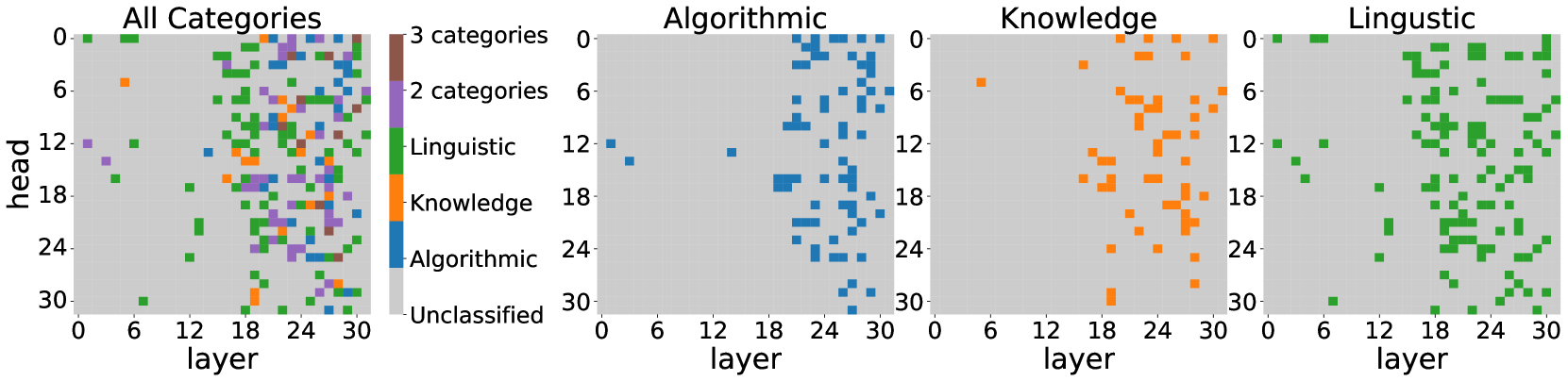
### Visual Description
## Heatmap Analysis: Layer-Head Activation Patterns by Category
### Overview
The image displays four horizontally arranged heatmap panels visualizing the distribution of categorized "heads" across "layers" in what appears to be a neural network or similar layered model. The leftmost panel, "All Categories," shows a composite view, while the subsequent three panels isolate specific categories: "Algorithmic," "Knowledge," and "Linguistic." The data is presented on a grid where the x-axis represents "layer" (0-30) and the y-axis represents "head" (0-30). Colored squares indicate the presence of a specific category at a given layer-head coordinate.
### Components/Axes
* **Panels:** Four distinct panels titled (from left to right): "All Categories", "Algorithmic", "Knowledge", "Linguistic".
* **Axes:**
* **X-axis (all panels):** Labeled "layer". Major tick marks at 0, 6, 12, 18, 24, 30.
* **Y-axis (all panels):** Labeled "head". Major tick marks at 0, 6, 12, 18, 24, 30.
* **Legend (in "All Categories" panel, top-right):** A vertical color bar with the following labels and associated colors:
* `3 categories` (Brown)
* `2 categories` (Purple)
* `Linguistic` (Green)
* `Knowledge` (Orange)
* `Algorithmic` (Blue)
* `Unclassified` (Gray - background color of the grid)
* **Spatial Layout:** The legend is positioned in the top-right corner of the first panel. The three category-specific panels are arranged to the right of the composite panel, each showing only one color from the legend.
### Detailed Analysis
**1. "All Categories" Panel (Composite View):**
* **Trend:** Shows a dense, mixed distribution of colored squares, indicating that many layer-head combinations are assigned to one or more categories. The distribution is not uniform.
* **Spatial Distribution:**
* **Green (Linguistic):** Appears most frequently and is widely scattered across the entire grid, with notable clusters in layers 12-30.
* **Orange (Knowledge):** Appears in distinct clusters, primarily in layers 18-30, heads 0-24.
* **Blue (Algorithmic):** Appears in a dense, vertical cluster primarily between layers 18-30, spanning most heads.
* **Purple (2 categories):** Scattered sparsely, often adjacent to or overlapping with other colors.
* **Brown (3 categories):** Very sparse, only a few instances visible (e.g., near layer 30, head 0).
* **Data Points (Approximate):** The grid is 31x31 (961 cells). A visual estimate suggests roughly 150-200 colored squares total, with green being the most numerous, followed by blue and orange.
**2. "Algorithmic" Panel (Blue):**
* **Trend:** Shows a strong, dense vertical band of activity.
* **Spatial Distribution:** Concentrated almost exclusively in the right half of the grid, from approximately layer 18 to layer 30. Within this band, the blue squares are densely packed across nearly all heads (0-30). Very few blue squares exist before layer 18 (e.g., isolated points near layer 0, head 12 and layer 12, head 12).
**3. "Knowledge" Panel (Orange):**
* **Trend:** Shows clustered, patchy activity.
* **Spatial Distribution:** Primarily located in layers 18-30. The distribution is less uniform than the Algorithmic panel, forming distinct clusters. One major cluster is in layers 18-24, heads 6-18. Another cluster appears in layers 24-30, heads 0-12. There are very few orange squares before layer 18 (e.g., one near layer 6, head 6).
**4. "Linguistic" Panel (Green):**
* **Trend:** Shows the most widespread and scattered distribution.
* **Spatial Distribution:** Green squares are present across the entire layer range (0-30) and head range (0-30). While scattered, there is a clear increase in density from left to right (lower to higher layers). The highest concentration appears in layers 18-30, but significant activity exists in earlier layers (e.g., clusters around layer 6, head 0 and layer 12, head 12).
### Key Observations
1. **Layer Specialization:** There is a clear demarcation around layer 18. The "Algorithmic" and "Knowledge" categories are almost exclusively active in layers 18 and above, suggesting these functions are handled by deeper layers of the model.
2. **Category Prevalence:** "Linguistic" processing appears to be a fundamental function distributed across all layers, though it also intensifies in deeper layers.
3. **Co-occurrence:** The "All Categories" panel shows many instances where colors are adjacent or overlapping (e.g., green next to blue), suggesting heads or layers may be involved in multiple functional categories simultaneously. The "2 categories" (purple) and "3 categories" (brown) labels explicitly confirm this multi-functionality for some units.
4. **Head vs. Layer:** For the "Algorithmic" category, the pattern is strongly layer-dependent (a vertical band) but largely head-agnostic within that band. For "Knowledge," the pattern is more cluster-based, suggesting specific combinations of layer and head are important.
### Interpretation
This visualization likely represents a functional analysis of a multi-layer, multi-head neural network (e.g., a Transformer model). The "heads" are probably attention heads, and the "layers" are the model's depth.
* **What the data suggests:** The model exhibits functional specialization across its depth. Early layers (0-17) are predominantly engaged in "Linguistic" processing, which could involve basic syntactic and morphological analysis. Deeper layers (18-30) take on more complex, specialized functions: "Algorithmic" (potentially procedural reasoning, step-by-step logic) and "Knowledge" (retrieval and application of factual information). The widespread "Linguistic" activity suggests that language processing is a continuous, foundational task that underpins the higher-order functions.
* **Relationship between elements:** The composite "All Categories" view is the sum of the three category-specific views. The clear separation of the blue and orange clusters in the deeper layers indicates a potential division of labor between algorithmic and knowledge-based reasoning in the model's final processing stages.
* **Notable patterns/anomalies:** The near-total absence of "Algorithmic" and "Knowledge" functions before layer 18 is a striking architectural insight. It implies a hierarchical processing pipeline where raw linguistic features are first extracted and then used as inputs for more abstract reasoning tasks in the network's later stages. The sparse "2 categories" and "3 categories" markers highlight rare, potentially highly specialized units that integrate multiple functions.
</details>
(e) Functionality mapping by MAPS for Phi-2.
<details>
<summary>x10.png Details</summary>
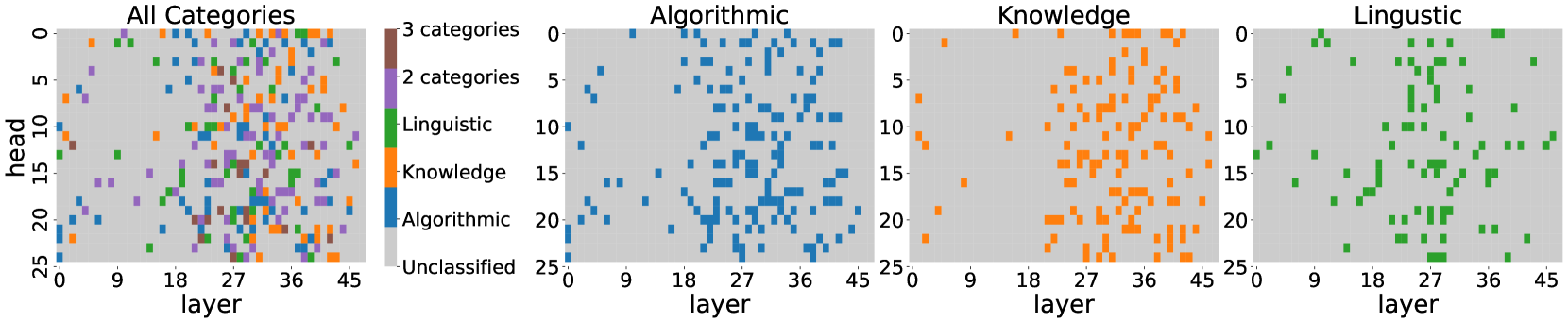
### Visual Description
\n
## Heatmap Series: Attention Head Classification by Layer
### Overview
The image displays a series of four horizontally arranged heatmaps. Each heatmap visualizes the classification of attention heads within a neural network model (likely a transformer) across its layers. The first plot shows an aggregate view of all classifications, while the subsequent three plots isolate the distribution for three specific categories: Algorithmic, Knowledge, and Linguistic. The background of all plots is gray, representing unclassified heads.
### Components/Axes
* **Titles (Top of each plot, left to right):** "All Categories", "Algorithmic", "Knowledge", "Linguistic".
* **Y-Axis (Left side of each plot):** Labeled "head". The scale runs from 0 at the top to 25 at the bottom, with major tick marks at 0, 5, 10, 15, 20, and 25. This represents the index of the attention head within a layer.
* **X-Axis (Bottom of each plot):** Labeled "layer". The scale runs from 0 on the left to 45 on the right, with major tick marks at 0, 9, 18, 27, 36, and 45. This represents the layer depth in the model.
* **Legend (Positioned to the right of the "All Categories" plot):**
* **Brown square:** "3 categories"
* **Purple square:** "2 categories"
* **Green square:** "Linguistic"
* **Orange square:** "Knowledge"
* **Blue square:** "Algorithmic"
* **Gray square:** "Unclassified"
### Detailed Analysis
**1. All Categories Plot (Leftmost):**
* **Trend:** This plot shows a composite, overlapping view. Colored squares (representing classified heads) are densely clustered in the central region of the plot.
* **Spatial Distribution:** The highest density of classified heads appears in the range of approximately **layers 18 to 36** and **heads 5 to 20**. Within this cluster, colors are heavily intermixed, indicating heads classified into multiple categories (brown for 3, purple for 2) or single categories (green, orange, blue).
* **Outliers:** Classified heads are sparse in the early layers (0-9) and the very late layers (36-45), and also in the highest (0-5) and lowest (20-25) head indices.
**2. Algorithmic Plot (Second from left):**
* **Trend:** The blue squares show a scattered but discernible pattern.
* **Spatial Distribution:** Algorithmic heads are most concentrated in the **mid-to-late layers**, roughly **layers 18 to 36**. They are distributed across a wide range of head indices within those layers, with a slight concentration in the middle head indices (5-20). Very few are present before layer 9 or after layer 40.
**3. Knowledge Plot (Third from left):**
* **Trend:** The orange squares form a distinct, dense cluster.
* **Spatial Distribution:** Knowledge heads are highly concentrated in the **later layers**, primarily between **layers 27 and 45**. Their head index distribution is broad but densest between **heads 5 and 20**. This category shows the clearest localization to a specific layer range.
**4. Linguistic Plot (Rightmost):**
* **Trend:** The green squares are the most widely dispersed of the three isolated categories.
* **Spatial Distribution:** Linguistic heads are found across a broad swath of the model, from approximately **layer 9 to layer 36**. They are not confined to a tight layer band like Knowledge. Their distribution across head indices is also relatively even within the active layer range, though slightly sparser at the very top (head 0) and bottom (head 25).
### Key Observations
1. **Layer Specialization:** There is a clear progression of functional specialization along the layer axis. Linguistic processing appears earlier and is more distributed, Algorithmic processing peaks in the middle layers, and Knowledge processing is strongly concentrated in the final third of the model.
2. **Head Multiplexing:** The presence of brown ("3 categories") and purple ("2 categories") squares in the "All Categories" plot confirms that individual attention heads can be involved in multiple types of processing simultaneously.
3. **Unclassified Majority:** The dominant gray background across all plots indicates that the majority of attention heads (across all layers and indices) were not classified into any of the three specified categories by the analysis method used.
4. **Spatial Overlap:** The dense cluster in the "All Categories" plot corresponds to the region where the Algorithmic, Knowledge, and Linguistic distributions overlap, particularly in layers 18-36.
### Interpretation
This visualization provides a functional map of a large language model's internal processing. It suggests a hierarchical or staged processing flow:
* **Early-to-Mid Layers (Linguistic Foundation):** Linguistic processing is distributed across a wide range of layers, forming a foundational capability that is likely engaged throughout processing.
* **Mid Layers (Algorithmic Processing):** A more specialized set of heads in the central layers appears dedicated to algorithmic or procedural tasks, such as syntactic parsing, logical reasoning, or step-by-step computation.
* **Late Layers (Knowledge Retrieval/Application):** The final layers are heavily specialized for accessing and applying factual or world knowledge, likely integrating the processed linguistic and algorithmic information to generate informed outputs.
The concentration of multi-category heads in the central overlap zone suggests this is a critical integration region where linguistic structure, reasoning algorithms, and factual knowledge converge. The high proportion of unclassified heads implies either that the classification scheme is not exhaustive, or that many heads perform functions not captured by these three categories (e.g., coreference, sentiment, stylistic control). This map is crucial for understanding model interpretability, identifying potential points for intervention or pruning, and guiding architectural design.
</details>
(f) Functionality mapping by MAPS for GPT-2 xl.
Figure 5: Functionality mapping by MAPS.
## Appendix B Additional Details on Evaluation Experiment
### B.1 Correlative Experiment
In § 4.2 we conducted an experiment which calculates the correlation between MAPS ’s estimations and heads outputs during inference.
#### Implementation details
Recall that the attention head’s formulation that we used: $Y=\tilde{X}W_{VO}$ omits the bias terms of $W_{V},W_{O}$ (§ 2). To account for the bias term of $W_{V}$ in the correlative experiment, where we compute the attention head’s output dynamically, we use both the original attention head definition Vaswani et al. (2017) and the formulation suggested by Elhage et al. (2021), which we have followed so far. First, following Vaswani et al. (2017), we obtain the head’s intermediate output: $\hat{y}\in\mathbb{R}^{n\times d_{\text{head}}}$ , where $d_{\text{head}}$ is the inner dimension of the head, often fixed to $\frac{d}{H}$ . Notably, this output already considers the bias term of $W_{V}$ . In Vaswani et al. (2017), $\hat{y}$ is viewed as the head’s final output. Then, following Elhage et al. (2021), we multiply this intermediate output by $W_{O}\in\mathbb{R}^{{d_{\text{head}}\times d}}$ and obtain the head’s final output.
We use the following templates: ‘‘This is a document about $\langle$ s $\rangle$ ’’, ‘‘No $\langle$ s $\rangle$ means no’’, ‘‘The story of $\langle$ s $\rangle$ contains’’, ‘‘When I think about $\langle$ s $\rangle$ I think about’’.
#### Additional results
Tables 8, 9, 10, 11, 12 present the correlation results between the static score $\phi_{R}(h)$ inferred by our method and the score $\phi^{*}_{R}(h)$ observed dynamically (both when we allow contextualization or not), obtained for Llama-3.1 70B, Llama-3.1 8B, Pythia 12B, Pythia 6.9B, GPT-2 xl. We also present the p-values and the maximum relation score obtained for any head in the model for the required relation. Notably, some of the lower correlations are demonstrated for relations that are not fully implemented by the model’s attention heads, as indicated by the small maximum relation scores. Tables 13, 14, 15, 16, 17 present the results (following the same format) for the suppression relation scores.
| Category | Relation | Correlation w/o context | Correlation w/ context | Max relation score (over heads) |
| --- | --- | --- | --- | --- |
| Algorithmic | Copying | 0.84 | 0.81 | 0.22 |
| Name copying | 0.94 | 0.89 | 0.83 | |
| Word to first letter | 0.88 | 0.78 | 0.95 | |
| Word to last letter | 0.66 | 0.39 | 0.16 | |
| Knowledge | Country to capital | 0.93 | 0.88 | 0.87 |
| Country to language | 0.94 | 0.88 | 0.67 | |
| Object to superclass | 0.75 | 0.76 | 0.52 | |
| Product by company | 0.69 | 0.65 | 0.36 | |
| Work to location | 0.58 | 0.58 | 0.31 | |
| Linguistic | Adj to comparative | 0.90 | 0.88 | 0.57 |
| Adj to superlative | 0.90 | 0.84 | 0.67 | |
| Noun to pronoun | 0.57 | 0.41 | 0.33 | |
| Verb to past tense | 0.90 | 0.80 | 0.81 | |
| Word to antonym | 0.93 | 0.91 | 0.62 | |
| Word to compound | 0.85 | 0.82 | 0.39 | |
| Word to homophone | 0.87 | 0.80 | 0.16 | |
| Word to synonym | 0.84 | 0.79 | 0.27 | |
| Translation | English to French | 0.71 | 0.68 | 0.22 |
| English to Spanish | 0.85 | 0.83 | 0.47 | |
Table 8: Correlation between the relation score of a head and the head’s output in Llama-3.1 70B, with and without head contextualization. The “max relation score” is the highest relation score achieved by a head in the model. All p-values observed are 0.
| Category | Relation | Correlation w/o context | Correlation w/ context | Max relation score (over heads) |
| --- | --- | --- | --- | --- |
| Algorithmic | Copying | 0.76 | 0.73 | 0.18 |
| Name copying | 0.95 | 0.95 | 0.71 | |
| Word to first letter | 0.90 | 0.78 | 0.89 | |
| Word to last letter | 0.67 | 0.36 | 0.27 | |
| Knowledge | Country to capital | 0.85 | 0.85 | 0.49 |
| Country to language | 0.76 | 0.62 | 0.31 | |
| Object to superclass | 0.74 | 0.73 | 0.15 | |
| Product by company | 0.46 | 0.49 | 0.18 | |
| Work to location | 0.44 | 0.45 | 0.10 | |
| Linguistic | Adj to comparative | 0.85 | 0.86 | 0.60 |
| Adj to superlative | 0.87 | 0.89 | 0.59 | |
| Noun to pronoun | 0.89 | 0.79 | 0.57 | |
| Verb to past tense | 0.91 | 0.86 | 0.73 | |
| Word to antonym | 0.90 | 0.86 | 0.37 | |
| Word to compound | 0.78 | 0.62 | 0.21 | |
| Word to homophone | 0.85 | 0.75 | 0.08 | |
| Word to synonym | 0.79 | 0.69 | 0.17 | |
| Translation | English to French | 0.71 | 0.68 | 0.12 |
| English to Spanish | 0.82 | 0.81 | 0.29 | |
Table 9: Correlation between the relation score of a head and the head’s output in Llama-3.1 8B, with and without head contextualization. The “max relation score” is the highest relation score achieved by a head in the model. All p-values observed are $\leq$ 3.9e-128.
| Category | Relation | Correlation w/o context | Correlation w/ context | Max relation score (over heads) |
| --- | --- | --- | --- | --- |
| Algorithmic | Copying | 0.89 | 0.60 | 0.42 |
| Name copying | 0.86 | 0.57 | 0.65 | |
| Word to first letter | 0.84 | 0.62 | 0.75 | |
| Word to last letter | 0.36 | 0.17 | 0.16 | |
| Year to following | 0.90 | 0.78 | 1.00 | |
| Knowledge | Country to capital | 0.93 | 0.89 | 0.97 |
| Country to language | 0.94 | 0.89 | 0.86 | |
| Object to superclass | 0.88 | 0.87 | 0.74 | |
| Work to location | 0.75 | 0.64 | 0.29 | |
| Linguistic | Adj to comparative | 0.92 | 0.80 | 0.95 |
| Noun to pronoun | 0.85 | 0.74 | 0.50 | |
| Verb to past tense | 0.89 | 0.71 | 0.54 | |
| Word to antonym | 0.92 | 0.85 | 0.60 | |
| Word to homophone | 0.67 | 0.43 | 0.07 | |
| Word to synonym | 0.90 | 0.67 | 0.35 | |
Table 10: Correlation between the relation score of a head and the head’s output in Pythia 12B, with and without head contextualization. The “max relation score” is the highest relation score achieved by a head in the model. All p-values observed are $\leq$ 5.7e-40.
| Category | Relation | Correlation w/o context | Correlation w/ context | Max relation score (over heads) |
| --- | --- | --- | --- | --- |
| Algorithmic | Copying | 0.88 | 0.45 | 0.53 |
| Name copying | 0.94 | 0.62 | 0.96 | |
| Word to first letter | 0.87 | 0.64 | 0.67 | |
| Word to last letter | 0.44 | 0.43 | 0.27 | |
| Year to following | 0.94 | 0.79 | 0.99 | |
| Knowledge | Country to capital | 0.95 | 0.91 | 0.97 |
| Country to language | 0.91 | 0.86 | 0.84 | |
| Object to superclass | 0.88 | 0.88 | 0.72 | |
| Work to location | 0.76 | 0.68 | 0.29 | |
| Linguistic | Adj to comparative | 0.91 | 0.76 | 0.77 |
| Noun to pronoun | 0.89 | 0.67 | 0.63 | |
| Verb to past tense | 0.91 | 0.70 | 0.81 | |
| Word to antonym | 0.93 | 0.87 | 0.64 | |
| Word to homophone | 0.70 | 0.38 | 0.05 | |
| Word to synonym | 0.93 | 0.64 | 0.36 | |
Table 11: Correlation between the relation score of a head and the head’s output in Pythia 6.9B, with and without head contextualization. The “max relation score” is the highest relation score achieved by a head in the model. All p-values observed are $\leq$ 1.7e-139.
| Category | Relation | Correlation w/o context | Correlation w/ context | Max relation score (over heads) |
| --- | --- | --- | --- | --- |
| Algorithmic | Copying | 0.95 | 0.65 | 0.52 |
| Name copying | 0.97 | 0.70 | 0.92 | |
| Word to first letter | 0.91 | 0.69 | 0.32 | |
| Word to last letter | 0.61 | 0.20 | 0.05 | |
| Year to following | 0.94 | 0.74 | 0.95 | |
| Knowledge | Country to capital | 0.98 | 0.88 | 0.98 |
| Country to language | 0.96 | 0.84 | 0.75 | |
| Object to superclass | 0.94 | 0.81 | 0.43 | |
| Product by company | 0.96 | 0.91 | 0.65 | |
| Work to location | 0.88 | 0.73 | 0.31 | |
| Linguistic | Adj to comparative | 0.95 | 0.78 | 0.88 |
| Adj to superlative | 0.94 | 0.73 | 0.54 | |
| Noun to pronoun | 0.96 | 0.68 | 0.58 | |
| Verb to past tense | 0.93 | 0.76 | 0.28 | |
| Word to antonym | 0.96 | 0.85 | 0.38 | |
| Word to compound | 0.80 | 0.65 | 0.17 | |
| Word to homophone | 0.46 | 0.38 | 0.02 | |
| Word to synonym | 0.95 | 0.79 | 0.21 | |
Table 12: Correlation between the relation score of a head and the head’s output in GPT-2 xl, with and without head contextualization. The “max relation score” is the highest relation score achieved by a head in the model. All p-values observed are $\leq$ 1.1e-45.
| Category | Relation | Correlation w/o context | Correlation w/ context | Max relation score (over heads) |
| --- | --- | --- | --- | --- |
| Algorithmic | Copying | 0.88 | 0.85 | 0.18 |
| Name copying | 0.95 | 0.83 | 0.66 | |
| Word to first letter | 0.86 | 0.72 | 0.56 | |
| Word to last letter | 0.56 | 0.42 | 0.33 | |
| Knowledge | Country to capital | 0.91 | 0.90 | 0.84 |
| Country to language | 0.89 | 0.89 | 0.49 | |
| Object to superclass | 0.81 | 0.83 | 0.39 | |
| Product by company | 0.81 | 0.78 | 0.31 | |
| Work to location | 0.70 | 0.70 | 0.21 | |
| Linguistic | Adj to comparative | 0.91 | 0.88 | 0.72 |
| Adj to superlative | 0.90 | 0.87 | 0.56 | |
| Noun to pronoun | 0.33 | 0.30 | 0.46 | |
| Verb to past tense | 0.91 | 0.80 | 0.54 | |
| Word to antonym | 0.91 | 0.80 | 0.35 | |
| Word to compound | 0.86 | 0.82 | 0.24 | |
| Word to homophone | 0.91 | 0.81 | 0.31 | |
| Word to synonym | 0.83 | 0.77 | 0.21 | |
| Translation | English to French | 0.61 | 0.59 | 0.09 |
| English to Spanish | 0.86 | 0.83 | 0.35 | |
Table 13: Correlation between the suppression relation score of a head and the head’s output in Llama-3.1 70B, with and without head contextualization. The “max relation score” is the highest relation score achieved by a head in the model. All p-values observed are 0.
| Category | Relation | Correlation w/o context | Correlation w/ context | Max relation score (over heads) |
| --- | --- | --- | --- | --- |
| Algorithmic | Copying | 0.77 | 0.74 | 0.11 |
| Name copying | 0.99 | 0.95 | 0.72 | |
| Word to first letter | 0.78 | 0.41 | 0.61 | |
| Word to last letter | 0.77 | 0.31 | 0.25 | |
| Knowledge | Country to capital | 0.90 | 0.87 | 0.18 |
| Country to language | 0.76 | 0.74 | 0.20 | |
| Object to superclass | 0.61 | 0.63 | 0.08 | |
| Product by company | 0.44 | 0.38 | 0.08 | |
| Work to location | 0.40 | 0.32 | 0.12 | |
| Linguistic | Adj to comparative | 0.81 | 0.91 | 0.81 |
| Adj to superlative | 0.87 | 0.93 | 0.62 | |
| Noun to pronoun | 0.80 | 0.57 | 0.40 | |
| Verb to past tense | 0.90 | 0.85 | 0.46 | |
| Word to antonym | 0.81 | 0.70 | 0.29 | |
| Word to compound | 0.84 | 0.76 | 0.24 | |
| Word to homophone | 0.89 | 0.61 | 0.17 | |
| Word to synonym | 0.75 | 0.65 | 0.09 | |
| Translation | English to French | 0.74 | 0.65 | 0.06 |
| English to Spanish | 0.84 | 0.81 | 0.26 | |
Table 14: Correlation between the suppression relation score of a head and the head’s output in Llama-3.1 8B, with and without head contextualization. The “max relation score” is the highest relation score achieved by a head in the model. All p-values observed are $\leq$ 2.6e-89.
| Category | Relation | Correlation w/o context | Correlation w/ context | Max relation score (over heads) |
| --- | --- | --- | --- | --- |
| Algorithmic | Copying | 0.91 | 0.78 | 0.31 |
| Name copying | 0.99 | 0.72 | 1.00 | |
| Word to first letter | 0.48 | 0.18 | 0.11 | |
| Word to last letter | 0.59 | 0.23 | 0.19 | |
| Year to following | 0.39 | 0.59 | 0.12 | |
| Knowledge | Country to capital | 0.63 | 0.62 | 0.56 |
| Country to language | 0.84 | 0.70 | 0.46 | |
| Object to superclass | 0.79 | 0.77 | 0.41 | |
| Work to location | 0.61 | 0.64 | 0.24 | |
| Linguistic | Adj to comparative | 0.93 | 0.74 | 0.73 |
| Noun to pronoun | 0.68 | 0.29 | 0.28 | |
| Verb to past tense | 0.96 | 0.75 | 0.73 | |
| Word to antonym | 0.90 | 0.77 | 0.32 | |
| Word to homophone | 0.61 | 0.39 | 0.03 | |
| Word to synonym | 0.82 | 0.63 | 0.16 | |
Table 15: Correlation between the suppression relation score of a head and the head’s output in Pythia 12B, with and without head contextualization. The “max relation score” is the highest relation score achieved by a head in the model. All p-values observed are $\leq$ 2.2e-45.
| Category | Relation | Correlation w/o context | Correlation w/ context | Max relation score (over heads) |
| --- | --- | --- | --- | --- |
| Algorithmic | Copying | 0.88 | 0.81 | 0.41 |
| Name copying | 0.98 | 0.79 | 0.96 | |
| Word to first letter | 0.81 | 0.37 | 0.31 | |
| Word to last letter | 0.30 | 0.08 | 0.24 | |
| Year to following | 0.45 | 0.80 | 0.33 | |
| Knowledge | Country to capital | 0.92 | 0.91 | 0.66 |
| Country to language | 0.89 | 0.81 | 0.51 | |
| Object to superclass | 0.86 | 0.78 | 0.33 | |
| Work to location | 0.73 | 0.58 | 0.21 | |
| Linguistic | Adj to comparative | 0.95 | 0.83 | 0.59 |
| Noun to pronoun | 0.86 | 0.51 | 0.56 | |
| Verb to past tense | 0.94 | 0.80 | 0.82 | |
| Word to antonym | 0.91 | 0.78 | 0.30 | |
| Word to homophone | 0.49 | 0.31 | 0.02 | |
| Word to synonym | 0.87 | 0.73 | 0.13 | |
Table 16: Correlation between the suppression relation score of a head and the head’s output in Pythia 6.9B, with and without head contextualization. The “max relation score” is the highest relation score achieved by a head in the model. All p-values observed are $\leq$ 3.6e-7.
| Category | Relation | Correlation w/o context | Correlation w/ context | Max relation score (over heads) |
| --- | --- | --- | --- | --- |
| Algorithmic | Copying | 0.97 | 0.71 | 0.29 |
| Name copying | 0.99 | 0.72 | 0.97 | |
| Word to first letter | 0.78 | 0.52 | 0.04 | |
| Word to last letter | 0.78 | 0.54 | 0.06 | |
| Year to following | 0.75 | 0.52 | 0.32 | |
| Knowledge | Country to capital | 0.94 | 0.80 | 0.72 |
| Country to language | 0.96 | 0.78 | 0.50 | |
| Object to superclass | 0.89 | 0.82 | 0.23 | |
| Product by company | 0.88 | 0.77 | 0.33 | |
| Work to location | 0.83 | 0.62 | 0.18 | |
| Linguistic | Adj to comparative | 0.86 | 0.60 | 0.38 |
| Adj to superlative | 0.81 | 0.59 | 0.27 | |
| Noun to pronoun | 0.92 | 0.34 | 0.40 | |
| Verb to past tense | 0.84 | 0.64 | 0.17 | |
| Word to antonym | 0.53 | 0.37 | 0.05 | |
| Word to compound | 0.80 | 0.58 | 0.14 | |
| Word to homophone | 0.10 | 0.04 | 0.01 | |
| Word to synonym | 0.81 | 0.59 | 0.08 | |
Table 17: Correlation between the suppression relation score of a head and the head’s output in GPT-2 xl, with and without head contextualization. The “max relation score” is the highest relation score achieved by a head in the model. All p-values observed are $\leq$ 2.3e-3.
| Relation | Prompt |
| --- | --- |
| Adj to comparative | lovely-> lovelier; edgy-> edgier; <s>-> |
| Copying | walk-> walk; cat-> cat; water-> water; <s>-> |
| Country to capital | The capital of <s> is |
| Country to language | The official language of <s> is |
| English to Spanish | apartment-> departamento; computer-> computadora; tribe-> tribu; <s>-> |
| Name copying | John-> John; Donna-> Donna; <s>-> |
| Noun to pronoun | mother-> she; father-> he; tribe-> they; actress-> she; apartment-> it; <s>-> |
| Object to superclass | A <s> is a kind of |
| Product by company | Nesquik is made by Nestlé; Mustang is made by Ford; <s> is made by |
| Verb to past tense | hike->hiked; purchase-> purchased; <s>-> |
| Word to first letter | word-> w, o, r, d; cat-> c, a, t; <s>-> |
| Word to last letter | word-> d, r, o, w; cat-> t, a, c; <s>-> |
| Year to following | 1300-> 1301; 1000-> 1001; <s>-> |
Table 18: Relations and prompts used in the causal experiment. The < s> string is replaced with the relation’s source tokens.
### B.2 Causal Experiment
In § 4.2 we measured the causal effect of removing the heads that implement a specific operation on the model’s performance in handling queries that depend on that operation.
#### Implementation details
We evaluate models on tasks for 13 relations. For each model, we filter out relations where (a) the base accuracy is very low ( $<$ 0.1) or (b) there is no dataset for the relation (see § A). The task prompts used for the different relations are presented in Table 18. Notably, When ablating an attention head, we remove its output only from the last position of the prompt.
#### Additional results
In Tables 19, 20, 21, 22, 23 we present the extended experiment results for Llama-3.1 70B, Llama-3.1 8B, Pythia 12B, Pythia 6.9B, GPT-2 xl.
| Relation name | # heads removed | TR tasks | CTR tasks | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Base | -TR | -RND | # tasks | Base (CTR) | -TR (CTR) | | |
| Adj to comparative | 175 | 0.98 | $\downarrow$ 13% 0.85 | $\downarrow$ 0% 0.98 $\pm$ 0.00 | 5 | 0.94 $\pm$ 0.05 | $\downarrow$ 3% 0.92 $\pm$ 0.08 |
| Copying | 250 | 0.97 | $\downarrow$ 30% 0.68 | $\downarrow$ 0% 0.97 $\pm$ 0.01 | 3 | 0.97 $\pm$ 0.03 | $\downarrow$ 23% 0.75 $\pm$ 0.34 |
| Country to capital | 118 | 0.84 | $\downarrow$ 66% 0.29 | $\uparrow$ 1% 0.85 $\pm$ 0.09 | 5 | 0.93 $\pm$ 0.08 | $\uparrow$ 0% 0.94 $\pm$ 0.09 |
| Country to language | 133 | 0.96 | $\downarrow$ 6% 0.90 | $\downarrow$ 0% 0.96 $\pm$ 0.00 | 4 | 0.92 $\pm$ 0.08 | $\downarrow$ 1% 0.92 $\pm$ 0.10 |
| English to Spanish | 175 | 0.91 | $\downarrow$ 6% 0.85 | $\uparrow$ 0% 0.91 $\pm$ 0.00 | 4 | 0.97 $\pm$ 0.03 | $\uparrow$ 0% 0.97 $\pm$ 0.03 |
| Name copying | 205 | 0.99 | $\downarrow$ 95% 0.05 | $\uparrow$ 1% 1.00 $\pm$ 0.00 | 3 | 0.97 $\pm$ 0.03 | $\downarrow$ 15% 0.83 $\pm$ 0.23 |
| Noun to pronoun | 154 | 0.98 | $\uparrow$ 0% 0.98 | $\uparrow$ 0% 0.98 $\pm$ 0.00 | 5 | 0.93 $\pm$ 0.08 | $\downarrow$ 1% 0.92 $\pm$ 0.09 |
| Object to superclass | 119 | 0.79 | $\downarrow$ 4% 0.76 | $\downarrow$ 2% 0.77 $\pm$ 0.02 | 5 | 0.88 $\pm$ 0.11 | $\downarrow$ 3% 0.85 $\pm$ 0.15 |
| Product by company | 59 | 0.67 | $\downarrow$ 4% 0.64 | $\downarrow$ 0% 0.67 $\pm$ 0.00 | 1 | 0.79 $\pm$ 0.00 | $\downarrow$ 2% 0.77 $\pm$ 0.00 |
| Word to first letter | 250 | 1.00 | $\downarrow$ 8% 0.92 | $\downarrow$ 0% 1.00 $\pm$ 0.00 | 5 | 0.94 $\pm$ 0.05 | $\downarrow$ 5% 0.89 $\pm$ 0.14 |
| Word to last letter | 250 | 0.92 | $\downarrow$ 18% 0.76 | $\uparrow$ 1% 0.93 $\pm$ 0.01 | 5 | 0.94 $\pm$ 0.05 | $\uparrow$ 1% 0.95 $\pm$ 0.04 |
Table 19: Accuracy of Llama-3.1 70B on tasks for a target relation (TR) versus on control (CTR) tasks, when removing heads implementing the relation compared to when removing random heads (RND). Results for RND heads are averaged over 5 experiments.
| Relation name | # heads removed | TR tasks | CTR tasks | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Base | -TR | -RND | # tasks | Base (CTR) | -TR (CTR) | | |
| Adj to comparative | 69 | 0.98 | $\downarrow$ 7% 0.91 | $\downarrow$ 3% 0.95 $\pm$ 0.05 | 4 | 0.96 $\pm$ 0.04 | $\uparrow$ 0% 0.96 $\pm$ 0.04 |
| Copying | 150 | 1.00 | $\downarrow$ 94% 0.06 | $\downarrow$ 0% 1.00 $\pm$ 0.00 | 3 | 0.95 $\pm$ 0.04 | $\downarrow$ 5% 0.91 $\pm$ 0.05 |
| Country to capital | 19 | 0.89 | $\downarrow$ 75% 0.22 | $\uparrow$ 2% 0.91 $\pm$ 0.03 | 5 | 0.87 $\pm$ 0.12 | $\uparrow$ 1% 0.87 $\pm$ 0.12 |
| Country to language | 30 | 0.98 | $\downarrow$ 50% 0.49 | $\uparrow$ 1% 0.99 $\pm$ 0.01 | 5 | 0.98 $\pm$ 0.02 | $\downarrow$ 0% 0.98 $\pm$ 0.02 |
| English to Spanish | 54 | 0.94 | $\uparrow$ 3% 0.97 | $\downarrow$ 1% 0.93 $\pm$ 0.01 | 3 | 0.95 $\pm$ 0.04 | $\uparrow$ 2% 0.97 $\pm$ 0.02 |
| Name copying | 70 | 1.00 | $\downarrow$ 87% 0.13 | $\downarrow$ 0% 1.00 $\pm$ 0.00 | 2 | 0.94 $\pm$ 0.05 | $\downarrow$ 4% 0.90 $\pm$ 0.08 |
| Noun to pronoun | 35 | 0.98 | $\downarrow$ 0% 0.98 | $\uparrow$ 0% 0.99 $\pm$ 0.00 | 5 | 0.97 $\pm$ 0.04 | $\uparrow$ 1% 0.98 $\pm$ 0.03 |
| Object to superclass | 34 | 0.74 | $\downarrow$ 11% 0.66 | $\uparrow$ 1% 0.75 $\pm$ 0.01 | 2 | 0.79 $\pm$ 0.09 | $\downarrow$ 3% 0.77 $\pm$ 0.07 |
| Product by company | 12 | 0.54 | $\downarrow$ 5% 0.51 | $\uparrow$ 4% 0.56 $\pm$ 0.01 | 1 | 0.70 $\pm$ 0.00 | $\downarrow$ 1% 0.69 $\pm$ 0.00 |
| Verb to past tense | 113 | 0.70 | $\downarrow$ 61% 0.27 | $\downarrow$ 7% 0.65 $\pm$ 0.10 | 2 | 0.71 $\pm$ 0.18 | $\downarrow$ 1% 0.70 $\pm$ 0.14 |
| Word to first letter | 150 | 1.00 | $\downarrow$ 98% 0.02 | $\downarrow$ 0% 1.00 $\pm$ 0.00 | 5 | 0.96 $\pm$ 0.04 | $\downarrow$ 30% 0.67 $\pm$ 0.33 |
Table 20: Accuracy of Llama-3.1 8B on tasks for a target relation (TR) versus on control (CTR) tasks, when removing heads implementing the relation compared to when removing random heads (RND). Results for RND heads are averaged over 5 experiments.
| Relation name | # heads removed | TR tasks | CTR tasks | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Base | -TR | -RND | # tasks | Base (CTR) | -TR (CTR) | | |
| Adj to comparative | 150 | 0.91 | $\downarrow$ 77% 0.20 | $\downarrow$ 10% 0.82 $\pm$ 0.07 | 3 | 0.92 $\pm$ 0.04 | $\downarrow$ 32% 0.63 $\pm$ 0.18 |
| Copying | 150 | 1.00 | $\downarrow$ 32% 0.68 | $\downarrow$ 0% 1.00 $\pm$ 0.00 | 3 | 0.95 $\pm$ 0.05 | $\downarrow$ 7% 0.88 $\pm$ 0.11 |
| Country to capital | 75 | 0.97 | $\downarrow$ 100% 0.00 | $\downarrow$ 2% 0.95 $\pm$ 0.02 | 2 | 0.89 $\pm$ 0.02 | $\uparrow$ 0% 0.90 $\pm$ 0.01 |
| Country to language | 94 | 1.00 | $\downarrow$ 92% 0.08 | $\downarrow$ 4% 0.96 $\pm$ 0.01 | 2 | 0.89 $\pm$ 0.01 | $\downarrow$ 0% 0.89 $\pm$ 0.01 |
| Name copying | 150 | 1.00 | $\downarrow$ 76% 0.24 | $\downarrow$ 0% 1.00 $\pm$ 0.00 | 2 | 0.90 $\pm$ 0.02 | $\uparrow$ 2% 0.92 $\pm$ 0.05 |
| Noun to pronoun | 105 | 0.88 | $\downarrow$ 48% 0.46 | $\downarrow$ 2% 0.86 $\pm$ 0.03 | 5 | 0.90 $\pm$ 0.07 | $\downarrow$ 3% 0.88 $\pm$ 0.08 |
| Object to superclass | 75 | 0.78 | $\downarrow$ 50% 0.39 | $\downarrow$ 13% 0.68 $\pm$ 0.03 | 2 | 0.90 $\pm$ 0.02 | $\downarrow$ 3% 0.87 $\pm$ 0.09 |
| Verb to past tense | 150 | 0.22 | $\downarrow$ 84% 0.04 | $\uparrow$ 17% 0.26 $\pm$ 0.11 | 1 | 0.03 $\pm$ 0.00 | $\downarrow$ 33% 0.02 $\pm$ 0.00 |
| Word to first letter | 150 | 0.91 | $\downarrow$ 63% 0.34 | $\downarrow$ 4% 0.87 $\pm$ 0.04 | 5 | 0.91 $\pm$ 0.08 | $\downarrow$ 19% 0.74 $\pm$ 0.30 |
| Year to following | 56 | 0.92 | $\downarrow$ 100% 0.00 | $\downarrow$ 5% 0.87 $\pm$ 0.07 | 2 | 0.83 $\pm$ 0.05 | $\downarrow$ 5% 0.79 $\pm$ 0.03 |
Table 21: Accuracy of Pythia 12B on tasks for a target relation (TR) versus its accuracy on control (CTR) tasks, when removing heads implementing the relation compared to when removing random heads (RND). Results for RND heads are averaged over 5 experiments.
| Relation name | # heads removed | TR tasks | CTR tasks | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Base | -TR | -RND | # tasks | Base (CTR) | -TR (CTR) | | |
| Adj to comparative | 124 | 0.52 | $\downarrow$ 100% 0.00 | $\downarrow$ 51% 0.25 $\pm$ 0.18 | 1 | 0.68 $\pm$ 0.00 | $\downarrow$ 25% 0.51 $\pm$ 0.00 |
| Copying | 150 | 1.00 | $\downarrow$ 93% 0.07 | $\downarrow$ 1% 0.99 $\pm$ 0.01 | 0 | | |
| Country to capital | 45 | 0.97 | $\downarrow$ 100% 0.00 | $\downarrow$ 1% 0.96 $\pm$ 0.02 | 1 | 1.00 $\pm$ 0.00 | $\downarrow$ 0% 1.00 $\pm$ 0.00 |
| Country to language | 74 | 0.97 | $\downarrow$ 92% 0.08 | $\uparrow$ 1% 0.98 $\pm$ 0.01 | 0 | | |
| Name copying | 143 | 1.00 | $\downarrow$ 97% 0.03 | $\downarrow$ 1% 0.99 $\pm$ 0.01 | 0 | | |
| Noun to pronoun | 102 | 0.68 | $\downarrow$ 46% 0.37 | $\uparrow$ 13% 0.77 $\pm$ 0.09 | 3 | 0.68 $\pm$ 0.11 | $\downarrow$ 25% 0.51 $\pm$ 0.22 |
| Object to superclass | 67 | 0.78 | $\downarrow$ 53% 0.37 | $\downarrow$ 4% 0.75 $\pm$ 0.02 | 2 | 0.71 $\pm$ 0.03 | $\uparrow$ 1% 0.71 $\pm$ 0.18 |
| Verb to past tense | 150 | 0.43 | $\downarrow$ 94% 0.03 | $\downarrow$ 16% 0.36 $\pm$ 0.07 | 0 | | |
| Word to first letter | 66 | 1.00 | $\downarrow$ 100% 0.00 | $\downarrow$ 0% 1.00 $\pm$ 0.00 | 2 | 0.97 $\pm$ 0.00 | $\downarrow$ 13% 0.85 $\pm$ 0.13 |
| Year to following | 52 | 0.73 | $\downarrow$ 100% 0.00 | $\uparrow$ 5% 0.77 $\pm$ 0.07 | 2 | 0.73 $\pm$ 0.05 | $\downarrow$ 2% 0.71 $\pm$ 0.05 |
Table 22: Accuracy of Pythia 6.9B on tasks for a target relation (TR) versus its accuracy on control (CTR) tasks, when removing heads implementing the relation compared to when removing random heads (RND). Results for RND heads are averaged over 5 experiments.
| Relation name | # heads removed | TR tasks | CTR tasks | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Base | -TR | -RND | # tasks | Base (CTR) | -TR (CTR) | | |
| Copying | 150 | 0.99 | $\downarrow$ 30% 0.69 | $\downarrow$ 0% 0.99 $\pm$ 0.00 | 0 | | |
| Country to capital | 38 | 0.88 | $\downarrow$ 100% 0.00 | $\downarrow$ 3% 0.86 $\pm$ 0.05 | 1 | 0.71 $\pm$ 0.00 | $\uparrow$ 2% 0.72 $\pm$ 0.00 |
| Country to language | 148 | 0.96 | $\downarrow$ 91% 0.08 | $\downarrow$ 2% 0.94 $\pm$ 0.01 | 0 | | |
| Name copying | 133 | 0.76 | $\downarrow$ 100% 0.00 | $\downarrow$ 15% 0.65 $\pm$ 0.08 | 1 | 0.71 $\pm$ 0.00 | $\downarrow$ 15% 0.60 $\pm$ 0.00 |
| Noun to pronoun | 27 | 0.71 | $\downarrow$ 26% 0.53 | $\downarrow$ 2% 0.69 $\pm$ 0.04 | 4 | 0.72 $\pm$ 0.13 | $\downarrow$ 3% 0.69 $\pm$ 0.16 |
| Object to superclass | 99 | 0.71 | $\downarrow$ 54% 0.32 | $\downarrow$ 1% 0.70 $\pm$ 0.02 | 1 | 0.71 $\pm$ 0.00 | $\downarrow$ 42% 0.41 $\pm$ 0.00 |
| Product by company | 73 | 0.40 | $\downarrow$ 81% 0.08 | $\downarrow$ 0% 0.40 $\pm$ 0.00 | 1 | 0.40 $\pm$ 0.00 | $\uparrow$ 2% 0.41 $\pm$ 0.00 |
| Verb to past tense | 150 | 0.40 | $\downarrow$ 56% 0.18 | $\downarrow$ 4% 0.38 $\pm$ 0.18 | 0 | | |
| Word to first letter | 62 | 0.18 | $\downarrow$ 16% 0.16 | $\downarrow$ 1% 0.18 $\pm$ 0.02 | 1 | 0.04 $\pm$ 0.00 | $\uparrow$ 250% 0.15 $\pm$ 0.00 |
| Year to following | 54 | 0.53 | $\downarrow$ 100% 0.00 | $\downarrow$ 5% 0.50 $\pm$ 0.03 | 1 | 0.71 $\pm$ 0.00 | $\downarrow$ 36% 0.45 $\pm$ 0.00 |
Table 23: Accuracy of GPT-2 xl on tasks for a target relation (TR) versus its accuracy on control (CTR) tasks, when removing heads implementing the relation compared to when removing random heads (RND). Results for RND heads are averaged over 5 experiments.
## Appendix C Generalization to Multi-Token Entities – Additional Results
In § 4.3 we conducted an experiment that evaluates how well the classifications by MAPS generalize to contextualized inputs. Table 24 shows the full results of this experiment. We omit the correlations for GPT-2 xl and the relation word to last letter, as all static scores are very small ( $\leq$ 0.05).
| Model | Relation | # samples | W/o context | W/ context | | |
| --- | --- | --- | --- | --- | --- | --- |
| Single-token | Multi-token | Single-token | Multi-token | | | |
| Pythia 12B | Copying | 283 | 0.91 | 0.85 | 0.48 | 0.44 |
| Country to capital | 30 | 0.94 | 0.93 | 0.85 | 0.87 | |
| Country to language | 70 | 0.94 | 0.90 | 0.88 | 0.83 | |
| Name copying | 83 | 0.87 | 0.76 | 0.38 | 0.33 | |
| Noun to pronoun | 174 | 0.84 | 0.85 | 0.78 | 0.79 | |
| Object to superclass | 91 | 0.88 | 0.89 | 0.84 | 0.86 | |
| Word to first letter | 77 | 0.83 | 0.73 | 0.56 | 0.64 | |
| Word to last letter | 77 | 0.34 | 0.50 | 0.11 | 0.09 | |
| Word to synonym | 71 | 0.92 | 0.86 | 0.61 | 0.58 | |
| Work to location | 65 | 0.77 | 0.72 | 0.74 | 0.70 | |
| Year to following | 65 | 0.90 | 0.84 | 0.64 | 0.60 | |
| Pythia 6.9B | Copying | 283 | 0.90 | 0.87 | 0.34 | 0.32 |
| Country to capital | 30 | 0.95 | 0.93 | 0.89 | 0.89 | |
| Country to language | 70 | 0.92 | 0.88 | 0.85 | 0.83 | |
| Name copying | 83 | 0.94 | 0.92 | 0.47 | 0.47 | |
| Noun to pronoun | 174 | 0.89 | 0.85 | 0.69 | 0.70 | |
| Object to superclass | 91 | 0.88 | 0.90 | 0.86 | 0.82 | |
| Word to first letter | 77 | 0.89 | 0.79 | 0.59 | 0.66 | |
| Word to last letter | 77 | 0.45 | 0.70 | 0.44 | 0.44 | |
| Word to synonym | 71 | 0.94 | 0.91 | 0.62 | 0.62 | |
| Work to location | 65 | 0.79 | 0.76 | 0.71 | 0.75 | |
| Year to following | 65 | 0.94 | 0.87 | 0.72 | 0.67 | |
| GPT-2 xl | Copying | 301 | 0.95 | 0.88 | 0.68 | 0.64 |
| Country to capital | 34 | 0.98 | 0.97 | 0.87 | 0.86 | |
| Country to language | 70 | 0.96 | 0.91 | 0.82 | 0.80 | |
| Name copying | 91 | 0.97 | 0.93 | 0.60 | 0.58 | |
| Noun to pronoun | 154 | 0.97 | 0.95 | 0.47 | 0.56 | |
| Object to superclass | 97 | 0.93 | 0.89 | 0.83 | 0.82 | |
| Word to first letter | 78 | 0.92 | 0.89 | 0.53 | 0.72 | |
| Word to synonym | 79 | 0.95 | 0.89 | 0.79 | 0.76 | |
| Work to location | 67 | 0.89 | 0.80 | 0.74 | 0.76 | |
| Year to following | 90 | 0.95 | 0.82 | 0.74 | 0.63 | |
Table 24: Extended results for the multi-token experiment, presented in Section 4.3. All p-values observed are $\leq$ 9.3e-4.
## Appendix D Comparison to Head Operations Identified in Prior Works
#### Name-mover heads in GPT-2 small
Wang et al. (2023) studied the Indirect Object Identification circuit in GPT-2 small. Analyzing the operations of the circuit’s heads, they defined heads that copy names as Name-Mover heads and heads that suppress names as Negative Name-Mover heads. They also classified heads that contribute to these tasks when the original mover heads are ablated as “backup” mover heads.
Using MAPS we classified all three name-mover heads as implementing the name copying relation, and the two negative name-mover heads as implementing the suppression variant of name copying. We note that a similar analysis was performed by Wang et al. (2023) as well. However, by applying MAPS to all heads in the model, and not just the heads in the discovered circuit, we were able to identify 21 additional name-copying heads as well, 6 of which were identified by Wang et al. (2023) as “backup” heads. One backup mover head and one backup negative mover head that were identified by Wang et al. (2023), were not identified by MAPS. Moreover, we find that each of the five identified name-mover heads implements a myriad of other relations. In Figure 6(a) we present the name copying relation scores for all heads in GPT-2 small and the heads classified by Wang et al. (2023).
We further examined the name copying heads not classified by Wang et al. (2023), to study whether their omission was mostly due to limited involvement in the specific task studied by Wang et al. (2023), or instead a consequence of inaccurate estimations by MAPS. These heads show a strong correlation (0.94, p-value of $2.5e{-7}$ ) between their name copying static and dynamic relation scores (for the prompt This is a document about $\langle$ s $\rangle$ , see § 4.2), when attention is restricted to the name position, suggesting that they indeed copy names when they attend to them. However, the attention weight assigned to the name token may change depending on the context. For example, head 8.11 in GPT-2 small has a static relation score of 0.88. Its dynamic relation score is 0.23 for the prompt This is a document about $\langle$ s $\rangle$ , but it increases substantially to 0.92 for the prompt “ John->John; Donna-> Donna; $\langle$ s $\rangle$ -> ”. We anticipate that other relation heads will demonstrate the name-copying functionality for other prompts or interventions. Crafting prompts that steer heads to demonstrate a specific functionality over another (for example by adapting MAPS to the $W_{QK}$ matrix) is an interesting direction for future work.
#### Mover heads in GPT-2 medium
Merullo et al. (2024a) studied the Indirect Object Identification (IOI) and Colored Objects circuits in GPT-2 medium. They discovered two sets of attention heads implementing certain functions, both called “Mover” heads. Heads from the first set copy names (in IOI), and heads from the second set copy colors (in the Colored Objects task). The authors also point out a significant overlap between the two sets.
Using MAPS, we classified all mover heads as implementing the name copying relation. We find that many of these heads also implement the relations: year to following, country to language, country to capital, copying. Lastly, we identify 31 other name-copying heads. Notably, in our counting, we omit the heads 14.5, 17.10, 16.0, 18.12, and 21.7, which are labeled in Figure 2 of Merullo et al. (2024a) as Mover-heads. This is because, to the best of our understanding, the paper does not provide any explanation for why they are classified as such, while other heads are described as more important than them.
#### Capital heads in GPT-2 medium
Merullo et al. (2024a) have also studied a circuit for resolving the capital city of a country (in Appendix I). MAPS identified all attention heads classified in that study, along with 15 others. In Figure 6(b) we present the name copying, country to capital relation scores for all heads in GPT-2 medium and the heads classified by Merullo et al. (2024a).
<details>
<summary>x11.png Details</summary>
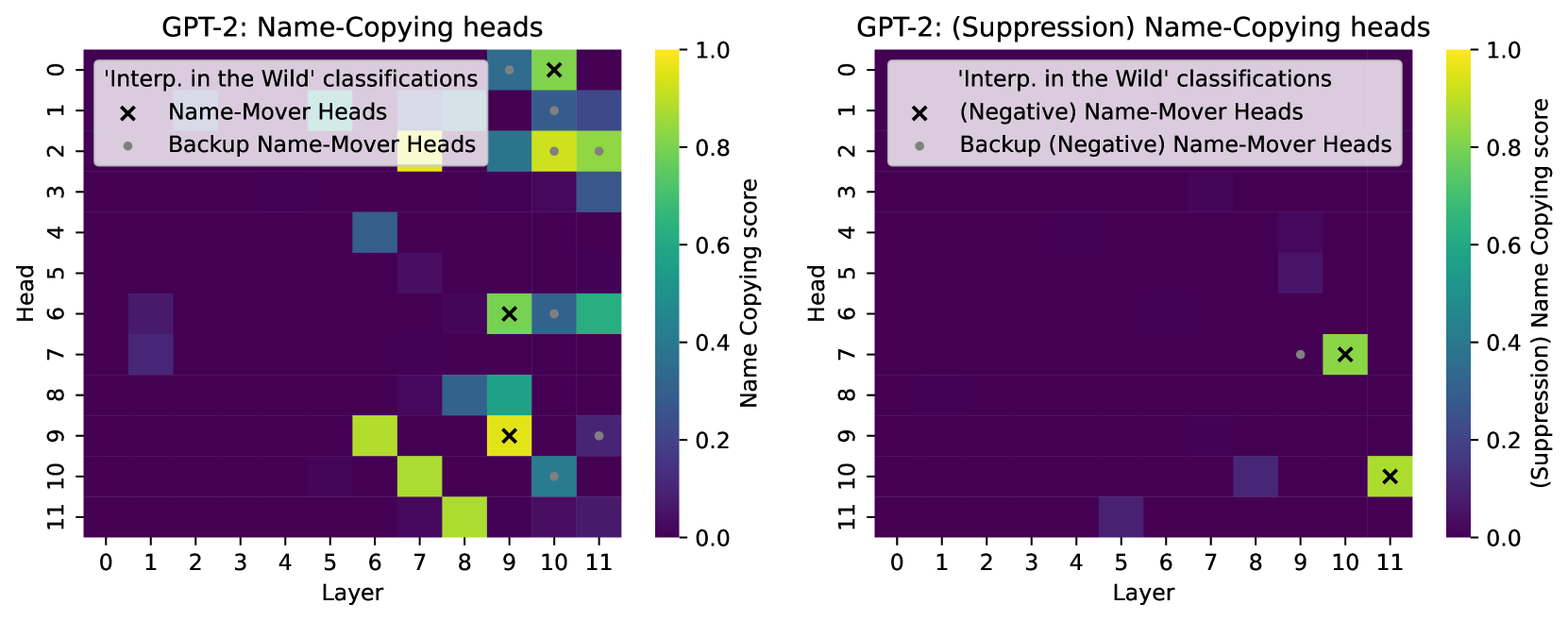
### Visual Description
## Heatmap: GPT-2 Attention Head Analysis
### Overview
The image displays two side-by-side heatmaps visualizing the "Name Copying score" for attention heads across the 12 layers (0-11) of a GPT-2 model. The left heatmap is titled "GPT-2: Name-Copying heads," and the right heatmap is titled "GPT-2: (Suppression) Name-Copying heads." Both charts use a color scale from dark purple (score 0.0) to bright yellow (score 1.0) to represent the strength of the measured property. Specific heads are annotated with symbols based on classifications from a source labeled "'Interp. in the Wild' classifications."
### Components/Axes
**Common Elements (Both Heatmaps):**
* **X-axis:** Labeled "Layer," with markers from 0 to 11.
* **Y-axis:** Labeled "Head," with markers from 0 to 11.
* **Color Bar:** Located on the right side of each heatmap. The scale is labeled "Name Copying score" (left) and "(Suppression) Name Copying score" (right). The scale ranges from 0.0 (dark purple) to 1.0 (bright yellow), with intermediate ticks at 0.2, 0.4, 0.6, and 0.8.
* **Legend:** Positioned in the top-left corner of each heatmap's plotting area, with a light gray background.
**Left Heatmap Specifics:**
* **Title:** "GPT-2: Name-Copying heads"
* **Legend Content:**
* Header: `'Interp. in the Wild' classifications`
* Symbol `×`: `Name-Mover Heads`
* Symbol `●`: `Backup Name-Mover Heads`
**Right Heatmap Specifics:**
* **Title:** "GPT-2: (Suppression) Name-Copying heads"
* **Legend Content:**
* Header: `'Interp. in the Wild' classifications`
* Symbol `×`: `(Negative) Name-Mover Heads`
* Symbol `●`: `Backup (Negative) Name-Mover Heads`
### Detailed Analysis
**Left Heatmap: Name-Copying Heads**
* **Trend:** High scores (yellow/green) are concentrated in the later layers (Layers 8, 9, 10, 11), with a few notable heads in earlier layers. Most of the grid is dark purple (score ~0.0).
* **Annotated Heads & Approximate Scores:**
* **Layer 9, Head 0:** Marked with `×` (Name-Mover Head). Score is bright yellow (~1.0).
* **Layer 9, Head 6:** Marked with `×` (Name-Mover Head). Score is bright yellow-green (~0.8-0.9).
* **Layer 9, Head 9:** Marked with `×` (Name-Mover Head). Score is bright yellow (~1.0).
* **Layer 10, Head 0:** Marked with `●` (Backup Name-Mover Head). Score is dark blue (~0.2-0.3).
* **Layer 10, Head 2:** Marked with `●` (Backup Name-Mover Head). Score is bright yellow-green (~0.8-0.9).
* **Layer 10, Head 6:** Marked with `●` (Backup Name-Mover Head). Score is teal (~0.5-0.6).
* **Layer 10, Head 10:** Marked with `●` (Backup Name-Mover Head). Score is teal (~0.5-0.6).
* **Layer 11, Head 2:** Marked with `●` (Backup Name-Mover Head). Score is bright yellow-green (~0.8-0.9).
* **Layer 11, Head 9:** Marked with `●` (Backup Name-Mover Head). Score is dark purple-blue (~0.1-0.2).
* **Other Notable High-Score Cells (Not Annotated):**
* Layer 6, Head 4: Teal (~0.5).
* Layer 7, Head 11: Teal (~0.5).
* Layer 8, Head 8: Teal-green (~0.6-0.7).
* Layer 9, Head 7: Bright yellow-green (~0.8-0.9).
* Layer 10, Head 7: Bright yellow-green (~0.8-0.9).
* Layer 11, Head 8: Bright yellow-green (~0.8-0.9).
**Right Heatmap: (Suppression) Name-Copying Heads**
* **Trend:** This heatmap is overwhelmingly dark purple (score ~0.0), indicating very low suppression scores for nearly all heads. Only three specific cells show any significant color.
* **Annotated Heads & Approximate Scores:**
* **Layer 10, Head 7:** Marked with `×` ((Negative) Name-Mover Head). Score is bright yellow-green (~0.8-0.9).
* **Layer 11, Head 10:** Marked with `×` ((Negative) Name-Mover Head). Score is bright yellow-green (~0.8-0.9).
* **Layer 9, Head 7:** Marked with `●` (Backup (Negative) Name-Mover Head). Score is dark purple (~0.0-0.1).
* **Other Notable Cell (Not Annotated):**
* Layer 5, Head 11: Very faint dark blue/purple, score slightly above 0.0 (~0.05-0.1).
### Key Observations
1. **Sparsity of Function:** The vast majority of attention heads in both charts have a Name Copying score near zero. Functional heads (high score or annotated) are sparse.
2. **Layer Specialization:** For positive name copying (left chart), functional heads are heavily concentrated in the final four layers (8-11). Suppression heads (right chart) are even more localized, appearing only in layers 10 and 11.
3. **Distinct Head Roles:** The annotations distinguish between primary "Name-Mover" heads (`×`) and "Backup" heads (`●`). In the left chart, the highest-scoring heads (brightest yellow) are primarily the annotated Name-Mover heads in Layer 9.
4. **Contrast Between Tasks:** The right heatmap for suppression is almost entirely blank compared to the left, suggesting that the "suppression" function is performed by a much smaller, more specific set of heads than the general "name copying" function.
### Interpretation
This visualization provides a mechanistic interpretability analysis of GPT-2, pinpointing which specific attention heads are responsible for the model's ability to copy names from a prompt into its output.
* **What the data suggests:** The model delegates the core task of name copying to a small committee of heads located in its final processing layers. The presence of both "Name-Mover" and "Backup" heads suggests a degree of redundancy or specialization within this committee. The suppression task appears to be an even more specialized sub-function, handled by a tiny subset of heads in the very last layers.
* **How elements relate:** The layer axis represents the depth of processing in the neural network. The concentration of activity in later layers indicates that name copying is a high-level, late-stage operation, likely occurring after the model has processed the semantic context of the sentence. The head axis represents parallel processing units within each layer; the sparse activation shows that only a few of these parallel units are recruited for this specific task.
* **Notable patterns/anomalies:** The most striking pattern is the stark contrast between the two heatmaps. It implies that while many heads may contribute weakly to copying (left chart), actively *suppressing* incorrect names (right chart) is a more precise operation performed by very few heads. The single annotated Backup (Negative) head in Layer 9, Head 7 has a near-zero score, which may indicate a misclassification by the "'Interp. in the Wild'" method or a head whose suppressive function is not captured well by this specific scoring metric.
</details>
(a) Comparison between “Name-Mover” heads discovered by Wang et al. (2023) and heads which implement the name copying relation, discovered by MAPS.
<details>
<summary>x12.png Details</summary>
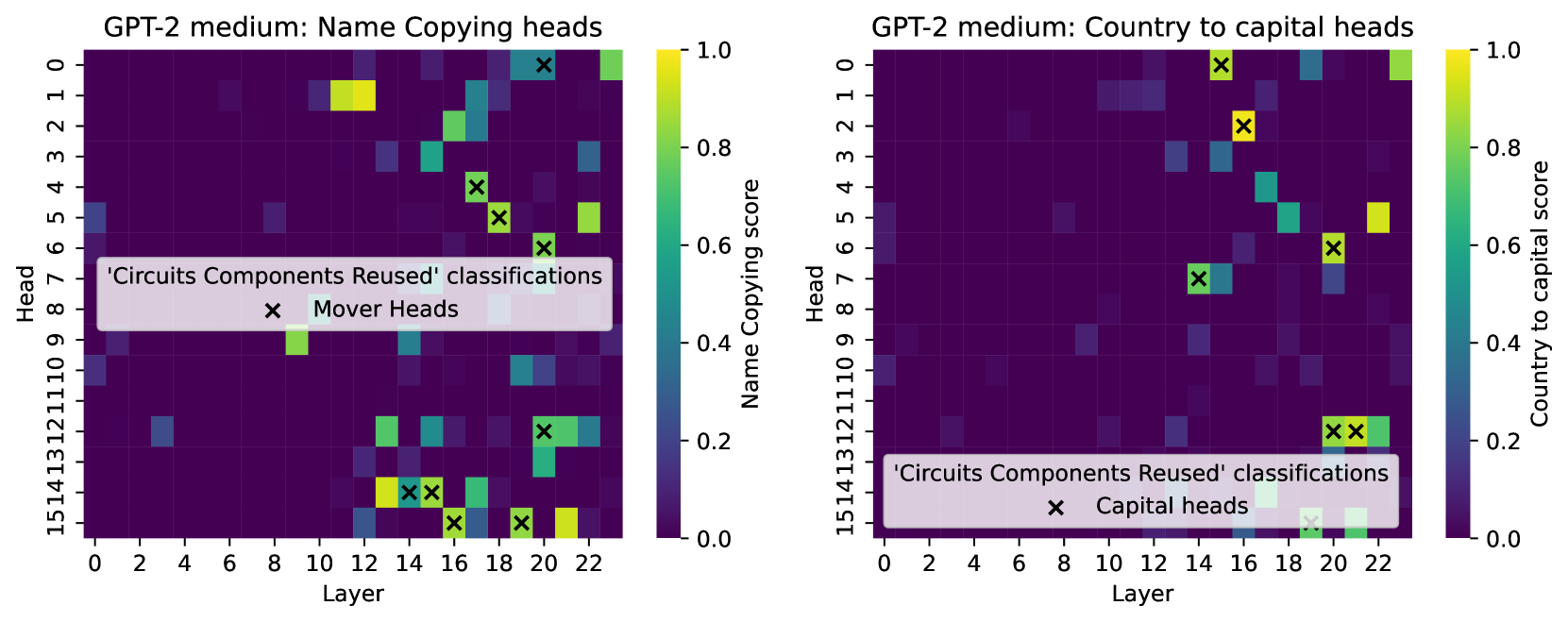
### Visual Description
\n
## Heatmap Chart: GPT-2 Medium Attention Head Analysis
### Overview
The image displays two side-by-side heatmaps visualizing the performance scores of attention heads within the GPT-2 medium model on two distinct tasks: "Name Copying" (left) and "Country to Capital" (right). Each heatmap plots "Head" index (y-axis) against "Layer" index (x-axis), with cell color indicating a task-specific score. Overlaid on both heatmaps are 'x' markers indicating heads classified as part of reused circuit components for each task.
### Components/Axes
**Common Elements (Both Charts):**
* **Chart Type:** Heatmap.
* **Y-axis:** Labeled "Head". Ticks range from 0 to 15 in increments of 1.
* **X-axis:** Labeled "Layer". Ticks range from 0 to 22 in increments of 2 (0, 2, 4, ..., 22).
* **Color Scale:** A vertical color bar on the right of each chart maps color to a score from 0.0 (dark purple) to 1.0 (bright yellow). The gradient passes through blue and green.
* **Legend/Annotation:** A semi-transparent white box contains the text "'Circuits Components Reused' classifications" and a key showing a black 'x' symbol with a label.
**Left Chart Specifics:**
* **Title:** "GPT-2 medium: Name Copying heads"
* **Color Bar Label:** "Name Copying score"
* **Legend Label (for 'x'):** "Mover Heads"
* **Legend Position:** Lower-left quadrant, overlapping data cells in approximately layers 0-10, heads 6-9.
**Right Chart Specifics:**
* **Title:** "GPT-2 medium: Country to capital heads"
* **Color Bar Label:** "Country to capital score"
* **Legend Label (for 'x'):** "Capital heads"
* **Legend Position:** Lower-right quadrant, overlapping data cells in approximately layers 14-22, heads 12-15.
### Detailed Analysis
**Left Chart: Name Copying Heads**
* **Trend:** High scores (yellow/green) are concentrated in the later layers (approximately layers 12-22) across various heads. The earlier layers (0-10) show predominantly low scores (dark purple/blue), with a few isolated medium-score cells.
* **High-Score Cells (Approximate):**
* Layer 14, Head 1: Score ~1.0 (bright yellow).
* Layer 16, Head 0: Score ~0.9 (yellow-green).
* Layer 22, Head 5: Score ~0.8 (green).
* Layer 14, Head 14: Score ~0.9 (yellow).
* Layer 22, Head 15: Score ~0.9 (yellow).
* **'x' Marker (Mover Heads) Positions:** The 'x' markers are placed on specific cells, indicating heads classified as "Mover Heads." Their approximate (Layer, Head) coordinates are:
* (14, 4), (15, 5), (16, 6), (18, 0), (20, 12), (14, 14), (15, 14), (16, 15), (18, 15), (20, 15).
* **Verification:** These markers generally, but not exclusively, overlay cells with medium to high scores (green/yellow). For example, the marker at (14, 14) is on a high-score yellow cell, while the marker at (16, 6) is on a medium-score green cell.
**Right Chart: Country to Capital Heads**
* **Trend:** High scores are more sparsely distributed compared to the left chart. Notable high-score clusters appear in layers 14-16 and around layer 22.
* **High-Score Cells (Approximate):**
* Layer 14, Head 0: Score ~1.0 (bright yellow).
* Layer 16, Head 2: Score ~0.9 (yellow).
* Layer 22, Head 5: Score ~0.8 (green).
* Layer 20, Head 12: Score ~0.7 (green).
* Layer 22, Head 12: Score ~0.7 (green).
* **'x' Marker (Capital heads) Positions:** The 'x' markers indicate heads classified as "Capital heads." Their approximate (Layer, Head) coordinates are:
* (14, 0), (15, 2), (16, 6), (14, 7), (20, 12), (21, 12), (20, 15), (21, 15).
* **Verification:** These markers show a strong correlation with high-score cells. The markers at (14, 0) and (15, 2) are directly on bright yellow cells. The cluster at layers 20-21, heads 12 and 15, also aligns with green cells.
### Key Observations
1. **Task-Specific Specialization:** The heatmaps reveal that different sets of attention heads are activated for different tasks. The pattern of high-scoring cells is distinct between "Name Copying" and "Country to Capital."
2. **Layer Preference:** Both tasks show a preference for heads in the middle to later layers (roughly 12-22) for high performance, with very few high-scoring heads in the first 10 layers.
3. **Circuit Reuse:** The 'x' markers highlight heads identified as part of reusable circuit components. In both charts, these marked heads often (but not always) correspond to cells with elevated scores, suggesting a link between a head's functional classification and its task performance.
4. **Marker Density:** The "Name Copying" task has more 'x' markers (10) spread across layers 14-20, while the "Country to Capital" task has 8 markers, with a notable cluster in the final layers (20-21).
### Interpretation
This visualization provides evidence for the **modular and distributed nature of knowledge** within a transformer language model like GPT-2. The data suggests:
* **Functional Localization:** Specific capabilities (like copying names or recalling capitals) are not handled by a single, monolithic component but are distributed across multiple attention heads, primarily in the model's deeper layers where more abstract processing is believed to occur.
* **Circuit Reusability:** The overlay of "Circuits Components Reused" classifications implies that the model reuses certain architectural components (attention heads) for multiple, potentially related, tasks. A head classified as a "Mover Head" for name copying might also play a role in other information movement tasks, while a "Capital head" is likely specialized for entity-relation lookup.
* **Investigative Insight:** The discrepancy where some high-score cells lack an 'x' marker (e.g., Layer 22, Head 5 in both charts) is notable. This could indicate heads that are highly effective for a specific task but are not part of the core, reused circuit identified by the "Circuits Components Reused" analysis framework. Conversely, a marked head with a lower score might be a necessary but insufficient component of a larger circuit.
* **Practical Implication:** For researchers in mechanistic interpretability, this map serves as a guide. It pinpoints which heads (e.g., Layer 14 Head 1 for names, Layer 14 Head 0 for capitals) are most critical to investigate to understand how these specific facts or operations are encoded and retrieved within the model's network.
</details>
(b) Comparison between “Name-Mover” and “Capital” heads discovered by Merullo et al. (2024a) and heads which implement the name copying and the country to capital relations discovered in our work.
Figure 6: Comparison between relation heads discovered by MAPS and heads classified in prior works.
## Appendix E Automatic Mapping of Salient Head Operations
### E.1 Automatic Functionality Inference
In § 5.1 we showed that GPT-4o can be utilized to interpret attention heads’ salient operations. Here, we provide additional implementation details and present an evaluation of the interpretation quality.
#### Implementation details
We found that GPT-4o sometimes describes in words that the pattern is unclear, rather than just outputting the word “Unclear”, as requested. To handle these cases, we classify every head for which GPT-4o’s response contained the string “clear” as a head where a pattern was not detected. We view this as an upper bound over the true ratio of heads with undetected patterns. Also, for some heads, GPT-4o would stop generating descriptions mid-generation. We hypothesize that it is because of strings viewed as special GPT-4o tokens that appeared in the salient mappings. We solved this issue by querying GPT-4o again with other random seeds. We note that in several mappings the salient tokens were decoded as an unreadable character. This could be solved by alternating between Transformers package Wolf et al. (2020) decoding functions.
#### Prompt format
We present the prompt used to query GPT-4o in Table 26.
| Head | Salient mappings | GPT-4o description |
| --- | --- | --- |
| Pythia 6.9B 15.3 | osevelt: 1943, 1941, 1940, 1930, 1936 Roosevelt: 1943, 1941, 1936, 1940, 1930 FDR: 1943, 1942, 1941, 1938, 1936 Napole: 1800, 1800, 18,18, 1840 oslov: 1968, 1970, 1960, 1964, 1965 Napoleon: 1800, 1800,18, 18, Napoleon taire: 1840, 1850,1800, Pruss, 1830 afka: 1908, 1912, 1916, 1903, 1911 lantern: 1870, 1880, 1930, Depression, railroad Edison: 1920,1920,1900, 1908, 1880 Confederate: 1863, 1864, 1861, 1862, 1870 1861: 1861, 1863, 1860, 1864, 1870 | The input strings are partial or full names of historical figures as well as years and terms relating to historical events. The mappings associate each input with years or terms relevant to their historical significance, reflecting events or periods related to the input entity. |
| Pythia 6.9B 16.1 | inhib: inhibition, inhib, Inhib, inhibiting, inhibit resil: resilience, resistance,Resp, res,resistance toler: toler, tolerance, tolerate, tolerated, tolerant aggrav: aggrav, exacerb, help, assistance : response, responses, responding, inhibiting destructive: destructive, destruction, destroying salvage: saving, save,saving,save, saves reluct: reluctance, resistance, resisting, resist prophyl: protection, protective, Protection Relief: relief, Relief, relie, relieved, relieve surv: survival, Survival, protection, surviv | The input strings are truncated forms of words, often found in contexts related to protection, resistance, or functionality. The mappings primarily expand truncated forms into semantically related words, often the full form of the input string or related words. |
| Pythia 6.9B 16.11 | weeks: months, month, summer, season, year months: year,year, Year,Year, yearly month: year, Year,year,Year, yearly Month: year, Year,year,Year, years weeks: month, months,month,months, summer months: year, Year,year,Year, yearly Week: months, month,months,month, Month week: month, months,month,months, season month: year, Year,year,Year, yearly overnight: month, week, weeks,acci, months years: decade, decades, aging, century, life | The input strings are related to time periods such as weeks, months, and years. Mappings are connecting input strings to related or hierarchical time concepts, often extending them into longer periods like months to years and weeks to months. |
| Pythia 6.9B 22.13 | periodontal: dental, Dental, dentist, dent, periodontal mandibular: dental, Dental, mandibular, teeth, dentist odontic: dental, Dental, dentist, teeth, tooth psori: skin, Skin,skin, dermat, skins retinal: eye, ophthal, retinal, ocular, eyes echocardiography: cardiac, Card, hearts,Card, Cardi scalp: brain, Brain,brain, brains, scalp hippocampal: hippocampal, Brain, brain,brain, hippocampus ocardi: cardiac, Card, hearts, Heart, heart ACL: knee, knees, thigh, Hip, ankle caries: dental, Dental, dentist, dent, Dent | The input strings seem to relate to various medical and anatomical terms, including parts of the body, diseases, and medical procedures. The mappings primarily associate anatomical or medical terms (input strings) with related medical terminology, such as conditions, associated body parts, or broader medical categories. |
| GPT-2 xl 26.2 | Jedi: lightsaber, Jedi, Kenobi, droid, Skywalker lightsaber: lightsaber, Jedi, Kenobi, Skywalker, Sith galactic: Galactic, galactic, starship, galaxy, droid Starfleet: galactic, Starfleet, starship, Galactic, interstellar Klingon: starship, Starfleet, Klingon, Trek, Starship starship: starship, Galactic, galactic, interstellar, Planetary Skyrim: Skyrim, Magicka, Bethesda, Elven, Hearth Darth: Jedi, lightsaber, Kenobi, Darth, Sith galaxy: Galactic, galactic, starship, galaxy, droid | The input strings are terms related to popular science fiction and fantasy franchises such as Star Wars, Star Trek, Pokémon, Elder Scrolls, Harry Potter, and general fantastical terms. The pattern observed is that each mapping takes an input term from a science fiction or fantasy context and maps it to other terms that are often from the same or related fictional universe. |
Table 25: Example salient operations of attention heads in Pythia 6.9B and GPT-2 xl and their corresponding descriptions by GPT-4o.
| Below you are given a list of input strings, and a list of mappings: each mapping is between an input string and a list of 5 strings. |
| --- |
| Mappings are provided in the format "s: t1, t2, t3, t4, t5" where each of s, t1, t2, t3, t4, t5 is a short string, typically corresponding to a single word or a sub-word. |
| Your goal is to describe shortly and simply the inputs and the function that produces these mappings. To perform the task, look for semantic and textual patterns. |
| For example, input tokens ’water’,’ice’,’freeze’ are water-related, and a mapping (’fire’:’f’) is from a word to its first letter. |
| As a final response, suggest the most clear patterns observed or indicate that no clear pattern is visible (write only the word "Unclear"). |
| Your response should be a vaild json, with the following keys: |
| "Reasoning": your reasoning. |
| "Input strings": One sentence describing the input strings (or "Unclear"). |
| "Observed pattern": One sentence describing the most clear patterns observed (or "Unclear"). |
| The input strings are: |
| <input strings> |
| The mappings are: |
| <mapping strings> |
Table 26: The prompt used to query GPT-4o. The salient tokens and mappings (§ 3.2), which are unique for every head, are plugged instead of <input strings> and <mapping strings>.
#### Examples
Table 25 provides examples of salient mappings and the patterns described by GPT-4o for three attention heads in GPT-2 xl and Pythia 6.9B.
### E.2 Interpretation Quality
To assess the accuracy and plausibility of the model-generated descriptions, we let human annotators — five graduate students who are fluent English speakers — evaluate its responses in terms of (a) did GPT-4o correctly recognize the existence of a pattern in the mappings, (b) the quality of the generated descriptions, (c) the category of the recognized patterns. We conduct this study for a random sample of 138 (13.5%) heads in Pythia 6.9B and 134 (11.2%) heads in GPT-2 xl.
#### Annotation instructions
We present the instructions given to the human annotators in Figures 7, 8.
<details>
<summary>x13.png Details</summary>

### Visual Description
\n
## Technical Document: Instructions for Evaluating GPT4's Pattern Inference
### Overview
This image displays a set of instructions for a human evaluation task. The task's goal is to verify the correctness of GPT4 in inferring a relation or function from a list of demonstrations. The evaluator is provided with input-output mappings and a description generated by GPT4, and must assess the accuracy of GPT4's analysis.
### Components/Axes
The document is structured as follows:
* **Title:** "Instructions"
* **Goal Statement:** A single, underlined sentence defining the task's objective.
* **"You will be given:" Section:** A bulleted list describing the two materials provided to the evaluator.
* **"Your task is the following:" Section:** A two-step process (labeled a. and b.) for the evaluator to follow.
* **Question Block:** Three multi-choice questions (Q1, Q2, Q3) with conditional logic for when to answer them.
* **Hyperlink:** The text "this spreadsheet" is a blue, underlined hyperlink.
### Detailed Analysis
The document contains the following precise text:
**Instructions**
<u>The goal of this task is to verify the correctness of GPT4 in inferring a relation or function from a list of demonstrations.</u>
You will be given:
* **A list of 30 demonstrations** of some function that maps an input string into a list of 5 strings. Demonstrations are given in the format of "s: t1, t2, t3, t4, t5", where s is an input string and t1, t2, t3, t4, t5 are 5 strings to which s is being mapped. Each of s, t1, t2, t3, t4, t5 is a short string, typically corresponding to a single word or a sub-word.
* **A description generated by GPT4** of patterns it identified across the input strings and their mappings.
Examples are provided in [this spreadsheet](https://docs.google.com/spreadsheets/).
Your task is the following:
a. **Go over the input strings and their mappings and try to identify prominent patterns.** Patterns can be semantic, language-related, general or unnatural. It could be that you would not observe a clear pattern. We expect that, in most cases, the mappings will exhibit one pattern or no patterns.
b. **Then answer the multi-choice questions below** to indicate the degree to which your assessment agrees with the description generated by GPT4.
**Q1: Did GPT4 correctly identify the presence or lack of a pattern?**
1: There is no observable pattern, and GPT4 indicated there is no pattern.
2: There is no observable pattern, but GPT4 described a pattern.
3: There is an observable pattern, and GPT4 indicated there is no pattern.
4: There is an observable pattern, and GPT4 described a pattern.
**Q2 (answer only if your answer to Q1 is 4): How precise is the description of GPT4?**
* **Correct and accurate:** the description accurately describes the pattern, without errors.
* **Correct but inaccurate:** the description is correct overall, but is too general or abstract for the pattern expressed in the mappings. Alternatively, it is too specific or explicit and does not fully capture the general pattern.
* **Partially correct:** The description describes the correct pattern to some degree, but it also includes incorrect parts.
* **Poor:** the description does not describe the pattern at all.
**Q3: (answer only if your answer to Q1 is 3 or 4): How would you categorise the most prominent pattern:**
* Semantic
* Language
* General
* Unnatural
### Key Observations
1. **Conditional Logic:** The questionnaire has built-in dependencies. Q2 is only to be answered if the evaluator selects option 4 for Q1. Q3 is only to be answered if the evaluator selects option 3 or 4 for Q1.
2. **Pattern Taxonomy:** The instructions explicitly define four categories for patterns: Semantic, Language-related, General, and Unnatural.
3. **Task Structure:** The evaluator's job is two-fold: first, to perform an independent analysis of the raw data (30 demonstrations), and second, to compare their findings against GPT4's generated description.
4. **Data Format:** The demonstrations are strictly formatted as "s: t1, t2, t3, t4, t5", where each element is a short string (word or sub-word).
5. **Reference Material:** A hyperlink to a spreadsheet is provided for examples, though the link's destination is not visible in the image.
### Interpretation
This document outlines a rigorous protocol for auditing the reasoning capabilities of a large language model (GPT4). The task is designed to measure two key aspects of the model's performance:
1. **Detection Accuracy:** Can the model correctly discern whether a pattern exists in a given dataset (Q1)?
2. **Description Fidelity:** When a pattern is detected, how accurately and precisely can the model describe it (Q2)?
The inclusion of the "Unnatural" pattern category is particularly noteworthy. It suggests the task may involve synthetic or adversarial examples designed to test the model's ability to recognize non-intuitive, rule-based mappings that don't align with human semantic or linguistic intuition. This moves beyond testing simple knowledge retrieval to evaluating abstract reasoning and rule induction.
The conditional structure of the questions ensures a nuanced evaluation. It prevents a simple "right/wrong" binary and instead captures degrees of correctness (e.g., "correct but inaccurate") and the evaluator's independent judgment on pattern categorization. This methodology is typical of high-quality AI alignment and capability research, where understanding the *nature* of model errors is as important as counting them. The ultimate goal is likely to identify failure modes in the model's inferential reasoning, which is crucial for improving reliability and trustworthiness in AI systems.
</details>
Figure 7: First part of human annotation instructions.
<details>
<summary>x14.png Details</summary>

### Visual Description
## Technical Document: Evaluation Guidelines for AI Model Mapping Descriptions
### Overview
The image displays a set of "Important guidelines" for evaluating an AI model's (specifically "GPT4") ability to recognize and describe patterns in input-to-output string mappings. The document outlines criteria for three distinct evaluation questions (Q1, Q2, Q3) and provides instructions for annotators. The text is presented in a bulleted list format with nested sub-bullets.
### Components/Axes
The document is structured as a single list with five main bullet points. The text is black on a white background. There are no charts, diagrams, or axes. The content is purely textual.
### Detailed Analysis / Content Details
The following is a precise transcription of the text content from the image.
**Important guidelines:**
* In Q1, we consider that “GPT4 indicated there is no pattern” if it either responded with the word “Unclear”, or explained that there is no pattern in a sentence.
* In cases where the description of the model includes suggestive commentary about the hidden motivation for the function represented in the mappings (in addition to an explicit explanation), the commentary should not be considered. An example for a description which includes commentary is “*The mappings generally consist of repetitions or small variations of their corresponding input string's characters, **suggesting** a pattern related to breaking down or rearranging the input string*”.
* We consider a pattern *recognizable* when it is apparent across 20 or more mappings. We require that **at least one** of the following will hold:
* The functionality behind the mappings (of input to output strings) will be visible and clear - for example, mappings of words to their first letters.
* The destination strings will be highly related to each other - for example, cases where all the source strings are mapped to numbers.
* In cases where there is a mutual pattern encompassing **only** the source strings, we do not consider this as a recognizable pattern.
* In Q2 we use the terms *correct* and *accurate* to label the descriptions. *Correct* descriptions describe the mappings and do not include incorrect parts. *Correct* descriptions might be *accurate* or *inaccurate*. The *inaccuracy* metric refers to whether the descriptions are too general (or too specific).
* In Q3, the different mapping categories are:
* *Semantic* - the mapping encodes semantic associations of the input strings (which might require knowledge). For example, associating countries with their capitals or languages.
* *Language* - the mapping encodes a relationship which requires language knowledge (e.g. syntactic or lexical expertise) relationship. For example, mapping words to prefixes, or nouns to pronouns.
* *General* - the mapping encodes a general functionality, which naturally can be applied to a large subset of strings. For example, mapping a string to itself, or a number to its successor/predecessor.
* *Unnatural* - the mapping does **not** encode a recognizable/understandable function or relation, one that might be used for natural language processing (see examples of unnatural patterns in [the examples spreadsheet](the%20examples%20spreadsheet)).
* Please use the Notes column to add any information, insight or problem you find relevant.
### Key Observations
1. **Structured Evaluation Framework:** The guidelines define a clear, multi-faceted evaluation process (Q1, Q2, Q3) for assessing an AI's analytical output on mapping tasks.
2. **Specific Thresholds:** A pattern is only considered "recognizable" if it is consistent across a minimum of 20 mappings, establishing a quantitative benchmark.
3. **Distinction Between Correctness and Accuracy:** The document makes a nuanced separation between a description being factually correct (no errors) and being accurate (appropriately specific or general).
4. **Categorization of Mapping Logic:** Q3 provides a taxonomy (Semantic, Language, General, Unnatural) to classify the underlying logic of the mappings being analyzed.
5. **Exclusion of Speculative Commentary:** There is an explicit rule to ignore the model's speculative or "suggestive commentary" about hidden motivations, focusing only on the explicit explanation of the pattern.
6. **Source-Only Pattern Exclusion:** A pattern that exists only in the input (source) strings, without a corresponding relationship to the output (destination) strings, is explicitly disqualified.
### Interpretation
This document serves as a rubric or annotation guide for human evaluators tasked with assessing the performance of a large language model (GPT4) on a specific analytical task: identifying and describing patterns in string transformation mappings.
The guidelines are designed to ensure **consistent, objective, and granular evaluation**. They move beyond a simple "right/wrong" assessment by:
* Defining what constitutes a valid pattern (Q1).
* Separating the factual correctness of a description from its precision (Q2).
* Classifying the *type* of intelligence or knowledge required to discern the pattern (Q3).
The emphasis on excluding "suggestive commentary" and "source-only" patterns indicates a focus on evaluating the model's ability to deduce the *functional relationship* between input and output, not just its ability to describe the data superficially or generate plausible-sounding hypotheses. The requirement for patterns to be "apparent across 20 or more mappings" guards against overfitting to small, coincidental samples.
The linked "examples spreadsheet" for "Unnatural" patterns suggests this is part of a larger, active research or annotation project aimed at understanding the limits and capabilities of AI in logical and semantic reasoning tasks. The final instruction to use a "Notes column" implies this text is likely part of a larger spreadsheet or data annotation interface.
</details>
Figure 8: Second part of human annotation instructions.
#### Human study results
The overall results per question and the distribution of responses across models and layers are presented in Figure 9 (Question 1), Figure 10 (Question 2), Figure 11 (Question 3). In 80% of the cases, GPT-4o correctly identifies the presence or absence of a pattern. In most of the failure cases (87%), the model described a pattern that is not visible in the mappings. We also find that in lower layers there are fewer patterns and they are harder to parse: there are higher rates of unnatural patterns and inaccurate descriptions. This agrees with our findings in § 4. In case of an observable pattern, GPT-4o will identify it: for 95% of heads with observable patterns, GPT-4o described a pattern, and $<$ 2% of the descriptions were labeled “poor”. Overall, this analysis shows that the quality of our automatic annotation pipeline is reasonable and demonstrates promising trends in automatically interpreting attention heads with MAPS. We leave further improvements to the pipeline for future work to explore. In particular, addressing model hallucinations could involve methods like aggregating multiple model responses to check its confidence (Kuhn et al., 2023), using intrinsic classifiers for hallucinations (e.g. Azaria and Mitchell (2023), Yu et al. (2024)), employing a strong LLM to indicate whether the generated pattern matches the mappings Gur-Arieh et al. (2025), using an NLI model Bohnet et al. (2022), or similarity-based heuristics.
<details>
<summary>x15.png Details</summary>
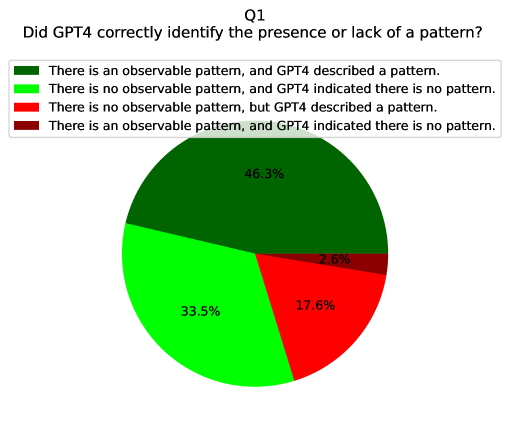
### Visual Description
## Pie Chart: GPT4 Pattern Identification Accuracy (Q1)
### Overview
This is a pie chart titled "Q1 Did GPT4 correctly identify the presence or lack of a pattern?". It displays the percentage distribution of four possible outcomes when GPT4 was tasked with identifying patterns in data. The chart is composed of four colored slices, each representing a specific combination of ground truth (whether a pattern was actually present) and GPT4's assessment.
### Components/Axes
* **Title:** "Q1 Did GPT4 correctly identify the presence or lack of a pattern?" (Positioned at the top center).
* **Legend:** Located in the top-left corner of the image. It contains four entries, each with a colored square and a descriptive label:
1. **Dark Green Square:** "There is an observable pattern, and GPT4 described a pattern."
2. **Bright Green Square:** "There is no observable pattern, and GPT4 indicated there is no pattern."
3. **Red Square:** "There is no observable pattern, but GPT4 described a pattern."
4. **Dark Red Square:** "There is an observable pattern, and GPT4 indicated there is no pattern."
* **Pie Chart Slices:** The central element is a pie chart divided into four slices. Each slice's color corresponds to an entry in the legend, and its size represents the percentage of cases for that outcome. The percentage value is printed inside each slice.
### Detailed Analysis
The chart breaks down GPT4's performance into four categories based on a 2x2 matrix of ground truth vs. model output.
1. **True Positive (Correct Identification of a Pattern):**
* **Color:** Dark Green.
* **Position:** The largest slice, occupying the top and right portion of the pie.
* **Value:** 46.3%.
* **Description:** Cases where a pattern existed and GPT4 correctly identified it.
2. **True Negative (Correct Identification of No Pattern):**
* **Color:** Bright Green.
* **Position:** The second-largest slice, located in the bottom-left quadrant.
* **Value:** 33.5%.
* **Description:** Cases where no pattern existed and GPT4 correctly reported no pattern.
3. **False Positive (Incorrectly Describing a Pattern):**
* **Color:** Red.
* **Position:** A medium-sized slice in the bottom-right quadrant.
* **Value:** 17.6%.
* **Description:** Cases where no pattern existed, but GPT4 incorrectly claimed one was present.
4. **False Negative (Missing an Existing Pattern):**
* **Color:** Dark Red.
* **Position:** The smallest slice, a thin wedge between the dark green and red slices.
* **Value:** 2.6%.
* **Description:** Cases where a pattern existed, but GPT4 failed to identify it.
### Key Observations
* **Dominant Correct Outcomes:** The two "correct" categories (True Positive and True Negative) together account for the vast majority of cases: 46.3% + 33.5% = **79.8%**.
* **Primary Error Mode:** The most common error is the False Positive (17.6%), where GPT4 hallucinates or incorrectly identifies a pattern where none exists. This is significantly more frequent than the False Negative error (2.6%).
* **Asymmetry in Errors:** GPT4 is far more likely to incorrectly claim a pattern exists (17.6%) than to miss one that does exist (2.6%). This suggests a bias toward over-detection or pattern-seeking behavior.
* **Largest Single Category:** The most frequent single outcome is correctly identifying an existing pattern (46.3%).
### Interpretation
This chart provides a diagnostic breakdown of GPT4's reliability in a specific pattern-recognition task. The data suggests that GPT4 is generally reliable, with an overall accuracy of approximately 80% for this task. However, its error profile is notably skewed.
The high False Positive rate (17.6%) indicates a potential weakness: the model may be prone to "seeing" patterns in noise or random data, which could be problematic in applications requiring high precision (e.g., scientific analysis, medical diagnostics). Conversely, its low False Negative rate (2.6%) suggests it is quite sensitive and unlikely to miss genuine patterns when they are present.
The relationship between the elements shows a clear performance hierarchy: Correct Pattern ID > Correct No-Pattern ID > False Alarm > Missed Pattern. For users of this system, the key takeaway is that while GPT4 is a capable pattern detector, its outputs claiming a pattern exists should be treated with more skepticism than its outputs claiming no pattern exists, given the observed asymmetry in its error rates.
</details>
(a) Human annotation distribution for Question 1.
<details>
<summary>x16.png Details</summary>
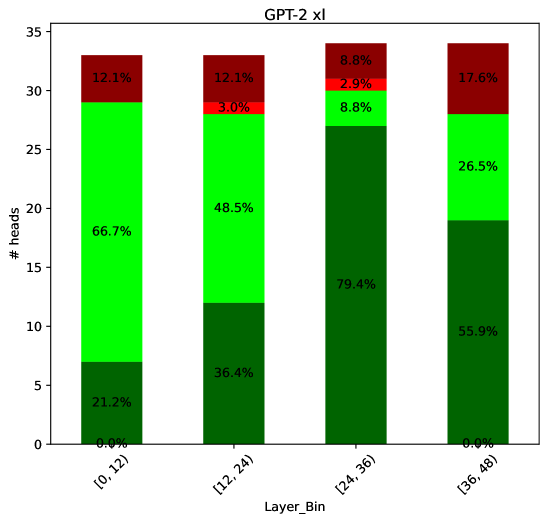
### Visual Description
## Stacked Bar Chart: GPT-2 xl Attention Head Distribution by Layer Range
### Overview
This is a stacked bar chart titled "GPT-2 xl". It visualizes the distribution of attention heads across four contiguous layer ranges (bins) of the GPT-2 xl model. Each bar represents a layer range, and the segments within each bar show the percentage of heads falling into four distinct categories, indicated by color. The y-axis represents the absolute count of heads ("# heads").
### Components/Axes
* **Chart Title:** "GPT-2 xl" (centered at the top).
* **X-Axis:**
* **Label:** "Layer_Bin"
* **Categories (Bins):** Four discrete layer ranges:
1. `[0, 12)`
2. `[12, 24)`
3. `[24, 36)`
4. `[36, 48)`
* **Y-Axis:**
* **Label:** "# heads"
* **Scale:** Linear scale from 0 to 35, with major tick marks at intervals of 5.
* **Legend:** Located in the top-right corner of the plot area. It defines four color-coded categories with associated percentage ranges:
* **Dark Green:** `0.0% - 25.0%`
* **Bright Green:** `25.0% - 50.0%`
* **Red:** `50.0% - 75.0%`
* **Dark Red:** `75.0% - 100.0%`
* **Data Labels:** Each colored segment within the bars contains a text label indicating its exact percentage value.
### Detailed Analysis
The chart displays data for four layer bins. The total height of each bar represents the total number of attention heads in that layer range, which appears to be approximately 33-34 heads per bin.
**Bin 1: [0, 12)**
* **Dark Green (0.0% - 25.0%):** 21.2% (Bottom segment)
* **Bright Green (25.0% - 50.0%):** 66.7% (Middle segment)
* **Red (50.0% - 75.0%):** 0.0% (Not visible)
* **Dark Red (75.0% - 100.0%):** 12.1% (Top segment)
* **Trend:** Dominated by the Bright Green category (66.7%).
**Bin 2: [12, 24)**
* **Dark Green (0.0% - 25.0%):** 36.4% (Bottom segment)
* **Bright Green (25.0% - 50.0%):** 48.5% (Middle segment)
* **Red (50.0% - 75.0%):** 3.0% (Thin segment above Bright Green)
* **Dark Red (75.0% - 100.0%):** 12.1% (Top segment)
* **Trend:** Bright Green remains the largest segment (48.5%), but Dark Green has increased notably from the first bin.
**Bin 3: [24, 36)**
* **Dark Green (0.0% - 25.0%):** 79.4% (Bottom segment, very large)
* **Bright Green (25.0% - 50.0%):** 8.8% (Small segment above Dark Green)
* **Red (50.0% - 75.0%):** 2.9% (Thin segment above Bright Green)
* **Dark Red (75.0% - 100.0%):** 8.8% (Top segment)
* **Trend:** Dramatic shift. Dark Green becomes overwhelmingly dominant (79.4%). Bright Green shrinks significantly.
**Bin 4: [36, 48)**
* **Dark Green (0.0% - 25.0%):** 55.9% (Bottom segment)
* **Bright Green (25.0% - 50.0%):** 26.5% (Middle segment)
* **Red (50.0% - 75.0%):** 0.0% (Not visible)
* **Dark Red (75.0% - 100.0%):** 17.6% (Top segment)
* **Trend:** Dark Green decreases from its peak but remains the majority (55.9%). Bright Green recovers somewhat. Dark Red reaches its highest percentage (17.6%).
### Key Observations
1. **Dominant Category Shift:** The primary category shifts from Bright Green (25-50%) in early layers to Dark Green (0-25%) in middle layers, before partially reverting in the final layers.
2. **Peak of Dark Green:** The `[24, 36)` layer bin shows an extreme concentration (79.4%) of heads in the lowest percentage bracket (Dark Green, 0-25%).
3. **Minimal "Red" Category:** The Red category (50-75%) is negligible, appearing only as thin slivers (2.9-3.0%) in the two middle bins and absent elsewhere.
4. **Dark Red Consistency:** The Dark Red category (75-100%) maintains a presence across all bins, ranging from 8.8% to 17.6%, with its highest value in the final bin.
5. **Total Head Count:** The total number of heads per layer bin appears consistent, visually estimated at ~33-34 heads.
### Interpretation
This chart likely illustrates the distribution of some metric (e.g., attention entropy, specialization score, or activation sparsity) across the attention heads within different layers of the GPT-2 xl model. The percentages in the legend (0-25%, 25-50%, etc.) categorize heads based on this metric's value.
The data suggests a **non-uniform functional organization** across the model's depth:
* **Early Layers ([0,12)):** Heads are moderately active or specialized (majority in the 25-50% bracket).
* **Middle Layers ([24,36)):** A dramatic shift occurs where the vast majority of heads fall into the lowest bracket (0-25%). This could indicate a region of the model where attention heads are highly specialized, sparse, or focused on very specific, low-entropy patterns.
* **Late Layers ([36,48)):** The distribution becomes more mixed again, with a resurgence of heads in the 25-50% bracket and the highest proportion of heads in the top bracket (75-100%). This might reflect a transition to more generalized or integrative processing before the output.
The near-absence of heads in the 50-75% (Red) range is a notable anomaly, suggesting the measured property tends to cluster at the lower or higher ends of the spectrum rather than in the middle. The consistent presence of a small subset of heads in the highest bracket (Dark Red) across all layers may indicate a persistent, specialized role for these heads throughout the network.
</details>
(b) Human annotation distribution for Question 1 across layers (GPT-2 xl).
<details>
<summary>x17.png Details</summary>
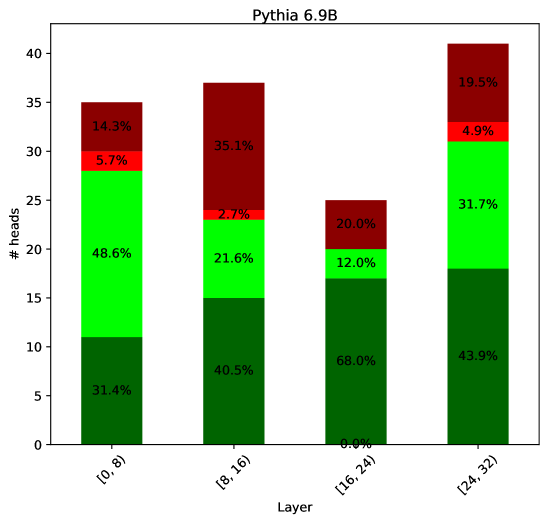
### Visual Description
## Stacked Bar Chart: Pythia 6.9B Layer-wise Head Distribution
### Overview
This is a stacked bar chart titled "Pythia 6.9B". It displays the distribution of a metric (likely attention heads) across four different layer ranges of a neural network model. The y-axis represents the count ("#heads"), and the x-axis represents the "Layer" ranges. Each bar is segmented into four colored categories, with the percentage of the total for that bar labeled within each segment.
### Components/Axes
* **Title:** "Pythia 6.9B"
* **Y-axis:** Label: "#heads". Scale: 0 to 40, with major ticks at intervals of 5.
* **X-axis:** Label: "Layer". Categories (from left to right):
1. `[0, 8)`
2. `[8, 16)`
3. `[16, 24)`
4. `[24, 32)`
* **Legend:** Not explicitly shown. The four colors used in the bars represent distinct categories. Based on consistent color use across bars, the categories are:
* **Dark Green** (bottom segment)
* **Bright Green** (second segment from bottom)
* **Red** (third segment from bottom)
* **Dark Red** (top segment)
### Detailed Analysis
The chart presents the composition of "#heads" for each layer range. The total height of each bar represents the total number of heads in that layer range. The segments show the proportion of each category within that total.
**Bar 1: Layer Range [0, 8)**
* **Total Height (Approximate):** 35 heads
* **Segment Breakdown (from bottom to top):**
* **Dark Green:** 31.4% (≈11 heads)
* **Bright Green:** 48.6% (≈17 heads)
* **Red:** 5.7% (≈2 heads)
* **Dark Red:** 14.3% (≈5 heads)
**Bar 2: Layer Range [8, 16)**
* **Total Height (Approximate):** 37 heads
* **Segment Breakdown (from bottom to top):**
* **Dark Green:** 40.5% (≈15 heads)
* **Bright Green:** 21.6% (≈8 heads)
* **Red:** 2.7% (≈1 head)
* **Dark Red:** 35.1% (≈13 heads)
**Bar 3: Layer Range [16, 24)**
* **Total Height (Approximate):** 25 heads
* **Segment Breakdown (from bottom to top):**
* **Dark Green:** 68.0% (≈17 heads)
* **Bright Green:** 12.0% (≈3 heads)
* **Red:** 0.0% (0 heads)
* **Dark Red:** 20.0% (≈5 heads)
**Bar 4: Layer Range [24, 32)**
* **Total Height (Approximate):** 41 heads
* **Segment Breakdown (from bottom to top):**
* **Dark Green:** 43.9% (≈18 heads)
* **Bright Green:** 31.7% (≈13 heads)
* **Red:** 4.9% (≈2 heads)
* **Dark Red:** 19.5% (≈8 heads)
### Key Observations
1. **Variable Total Heads:** The total number of heads is not constant across layer ranges. The `[16, 24)` range has the fewest (~25), while `[24, 32)` has the most (~41).
2. **Dominant Category Shift:** The **Dark Green** category's proportion generally increases from the first to the third layer range (31.4% → 40.5% → 68.0%), before decreasing in the final range (43.9%).
3. **Inverse Relationship:** There is a clear inverse relationship between the **Dark Green** and **Bright Green** categories. As the share of Dark Green increases (from `[0,8)` to `[16,24)`), the share of Bright Green decreases sharply (48.6% → 21.6% → 12.0%).
4. **Anomaly in [16,24):** The **Red** category is completely absent (0.0%) in the `[16, 24)` layer range.
5. **Dark Red Fluctuation:** The **Dark Red** category shows significant fluctuation, peaking in the `[8, 16)` range at 35.1%.
### Interpretation
This chart visualizes how different types of attention heads (represented by the four colors) are distributed across the layers of the Pythia 6.9B model. The data suggests a functional specialization or reorganization of model components across depth.
* **Early Layers ([0,8)):** Dominated by the **Bright Green** category (nearly half of all heads), suggesting this type of head is crucial for initial processing.
* **Middle Layers ([8,16) & [16,24)):** Show a significant transition. The **Dark Green** category becomes increasingly dominant, while **Bright Green** diminishes. The `[16,24)` range is particularly specialized, with **Dark Green** heads comprising over two-thirds of the total and **Red** heads vanishing entirely. This could indicate a "bottleneck" or a layer range dedicated to a specific, unified computation.
* **Later Layers ([24,32)):** The distribution becomes more balanced again, with a resurgence of **Bright Green** heads and a more even split between **Dark Green** and **Bright Green**. This may reflect a shift towards integrating processed information for final output generation.
The variation in total head count per layer range is also noteworthy, indicating that the model's architecture is not uniform in terms of parallel processing capacity across its depth. The absence of the **Red** category in one specific range is a stark anomaly that would warrant further investigation into the model's design or the metric being measured.
</details>
(c) Human annotation distribution for Question 1 across layers (Pythia 6.9B).
Figure 9: Quality of GPT-4o interpretation (§ E) - Human annotation distribution for Question 1.
<details>
<summary>x18.png Details</summary>
### Visual Description
## Pie Chart: Accuracy of GPT-4 Description (Conditional on Q1 Answer)
### Overview
This image displays a pie chart representing survey results for a specific question (Q2). The question is conditional, asking respondents to answer only if their answer to a previous question (Q1) was "4." The core question is: "How accurate is the description of GPT4?" The chart visualizes the distribution of responses across four categories of accuracy.
### Components/Axes
* **Chart Type:** Pie Chart.
* **Title:** "Q2 (answer only if your answer to Q1 is 4) How accurate is the description of GPT4?"
* **Data Series (Segments):** The chart is divided into four colored segments, each representing a response category. The legend is provided as labels placed directly adjacent to their corresponding slices.
* **Segment Labels & Percentages:**
1. **Correct and accurate** (Green slice, positioned on the left side of the pie): 66.4%
2. **Partially correct** (Orange slice, positioned at the bottom of the pie): 16.8%
3. **Correct but inaccurate** (Orange slice, positioned on the lower-right side of the pie): 15.2%
4. **Poor** (Red slice, positioned on the right side of the pie, adjacent to the "Correct and accurate" slice): 1.6%
### Detailed Analysis
The data presents a clear hierarchy of responses regarding the perceived accuracy of a description of GPT-4:
* The overwhelming majority of respondents, **66.4%**, selected the highest accuracy category: **"Correct and accurate."** This is the dominant segment, occupying nearly two-thirds of the chart.
* The next two categories are similar in size and are both colored orange. **"Partially correct"** accounts for **16.8%**, while **"Correct but inaccurate"** accounts for **15.2%**. Together, these "middle-ground" responses constitute 32.0% of the total.
* The smallest segment by a significant margin is the **"Poor"** category, represented by a thin red slice, comprising only **1.6%** of responses.
### Key Observations
1. **Strong Positive Skew:** The distribution is heavily skewed towards positive accuracy assessments. Over 83% of respondents (66.4% + 15.2%) indicated the description was at least "correct," with the majority of those finding it fully accurate.
2. **Minimal Negative Feedback:** The "Poor" rating is a clear outlier on the low end, representing a negligible fraction of the feedback.
3. **Ambiguity in Middle Categories:** The two orange categories, "Partially correct" and "Correct but inaccurate," are semantically similar but distinct. Their near-equal split suggests respondents differentiated between a description that was incomplete versus one that was factually right but poorly executed or lacking precision.
### Interpretation
This chart suggests that, among the subset of survey participants who answered "4" to Q1 (the nature of which is unknown), there is a high level of confidence in the accuracy of the provided description of GPT-4. The data indicates the description was largely successful, with very few respondents finding it fundamentally flawed.
The conditional nature of the question ("answer only if your answer to Q1 is 4") is critical. It implies this result is not from all respondents, but from a specific subgroup defined by their response to a prior question. Without knowing what Q1 was, we cannot generalize these findings to a broader population. The results are strong within this subgroup, but the subgroup itself may be biased (e.g., perhaps Q1 filtered for users with a certain level of familiarity or a specific prior opinion).
The near-even split in the middle categories is noteworthy. It highlights that for about a third of this group, the description had notable shortcomings—either in completeness ("Partially correct") or in the quality/precision of the correct information ("Correct but inaccurate"). This provides actionable feedback for refinement, even amidst the overall positive reception.
</details>
(a) Human annotation distribution for Question 2.
<details>
<summary>x19.png Details</summary>
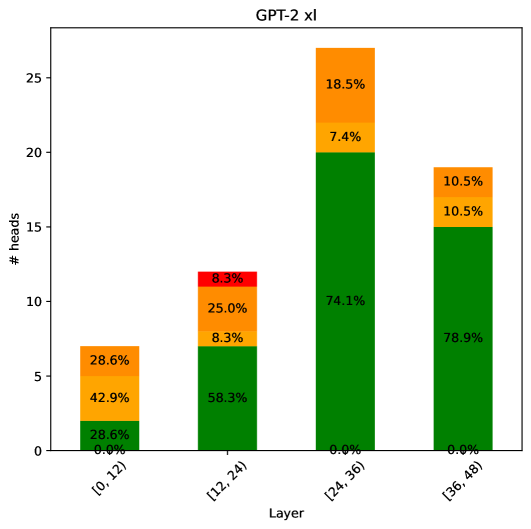
### Visual Description
## Stacked Bar Chart: GPT-2 xl Attention Head Distribution by Layer
### Overview
This image is a stacked bar chart titled "GPT-2 xl". It visualizes the distribution of a categorical variable (represented by different colors) across four distinct layer ranges of the GPT-2 xl model. The y-axis represents the count of attention heads ("# heads"), and the x-axis represents the model layers grouped into four contiguous ranges. Each bar is segmented by color, with each segment labeled with a percentage value.
### Components/Axes
* **Chart Title:** "GPT-2 xl" (centered at the top).
* **Y-Axis:**
* **Label:** "# heads" (vertical text on the left).
* **Scale:** Linear scale from 0 to 25, with major tick marks at 0, 5, 10, 15, 20, and 25.
* **X-Axis:**
* **Label:** "Layer" (centered at the bottom).
* **Categories (Bars):** Four bars representing layer ranges:
1. `[0, 12)`
2. `[12, 24)`
3. `[24, 36)`
4. `[36, 48)`
* **Data Series (Colors):** The bars are stacked with up to three colors. The colors and their associated percentage labels within the bars are:
* **Green:** The bottom segment in each bar.
* **Orange:** The middle segment in most bars.
* **Red:** A top segment present only in the second bar (`[12, 24)`).
* **Legend:** There is no explicit legend box. The color categories are defined by the segments within the bars themselves.
### Detailed Analysis
The chart displays the following data for each layer range:
**1. Layer Range `[0, 12)`**
* **Total Height (Approx. # heads):** ~7
* **Segments (from bottom to top):**
* **Green:** 28.6% (Approx. 2 heads)
* **Orange:** 42.9% (Approx. 3 heads)
* **Orange (Top):** 28.6% (Approx. 2 heads)
* **Trend:** The bar is composed of two orange segments and one green segment. The largest segment is the middle orange one (42.9%).
**2. Layer Range `[12, 24)`**
* **Total Height (Approx. # heads):** ~12
* **Segments (from bottom to top):**
* **Green:** 58.3% (Approx. 7 heads)
* **Orange:** 25.0% (Approx. 3 heads)
* **Red:** 8.3% (Approx. 1 head)
* **Orange (Top):** 8.3% (Approx. 1 head)
* **Trend:** This is the only bar containing a red segment. The green segment is the largest (58.3%).
**3. Layer Range `[24, 36)`**
* **Total Height (Approx. # heads):** ~27
* **Segments (from bottom to top):**
* **Green:** 74.1% (Approx. 20 heads)
* **Orange:** 7.4% (Approx. 2 heads)
* **Orange (Top):** 18.5% (Approx. 5 heads)
* **Trend:** This is the tallest bar. The green segment is overwhelmingly dominant (74.1%). The orange segments are relatively small.
**4. Layer Range `[36, 48)`**
* **Total Height (Approx. # heads):** ~19
* **Segments (from bottom to top):**
* **Green:** 78.9% (Approx. 15 heads)
* **Orange:** 10.5% (Approx. 2 heads)
* **Orange (Top):** 10.5% (Approx. 2 heads)
* **Trend:** Similar to the third bar, the green segment is dominant (78.9%). The two orange segments are equal in percentage.
### Key Observations
1. **Dominance of Green:** The green segment shows a clear increasing trend in both absolute count and percentage share as the layer range increases. It starts at 28.6% in the first range and rises to 78.9% in the final range.
2. **Decline of Orange:** The combined percentage of the orange segments generally decreases as layers progress, from a high of 71.5% (42.9% + 28.6%) in the first range to 21.0% (10.5% + 10.5%) in the last range.
3. **Presence of Red:** The red category appears only in the `[12, 24)` layer range, constituting 8.3% of the heads in that range.
4. **Peak Head Count:** The highest total number of attention heads is found in the `[24, 36)` layer range.
5. **Segmentation Pattern:** The first three bars have three or four distinct segments, while the last bar has three segments with the top two being equal.
### Interpretation
This chart likely illustrates the functional specialization or behavior of attention heads across different layers of the GPT-2 xl transformer model. The colors (Green, Orange, Red) represent different types or roles of attention heads (e.g., syntactic, semantic, positional, or heads identified by a specific analysis technique).
* **Architectural Insight:** The data suggests a shift in the model's processing strategy across its depth. Early layers (`[0, 12)`) have a more mixed population of head types. Middle layers (`[12, 24)` and `[24, 36)`) see a significant increase in the total number of heads and the emergence of a unique "Red" type, possibly indicating a phase of complex feature integration. The final layers (`[36, 48)`) are heavily dominated by the "Green" head type, which may correspond to heads responsible for final output generation or high-level task execution.
* **Functional Hypothesis:** The increasing dominance of the "Green" heads could imply that as information flows deeper into the network, the model converges on a more uniform processing mechanism for producing its final predictions. The transient appearance of "Red" heads in the second layer range might mark a critical transformation point in the data representation.
* **Data Anomaly/Note:** The percentages within each bar sum to 100% (e.g., 28.6+42.9+28.6=100.1% for the first bar, a minor rounding discrepancy). The approximate head counts are derived from the bar heights and percentages, introducing a small margin of error. The chart does not specify what the colors represent, which is the primary missing context for a full technical interpretation.
</details>
(b) Human annotation distribution for Question 2 across layers (GPT-2 xl).
<details>
<summary>x20.png Details</summary>
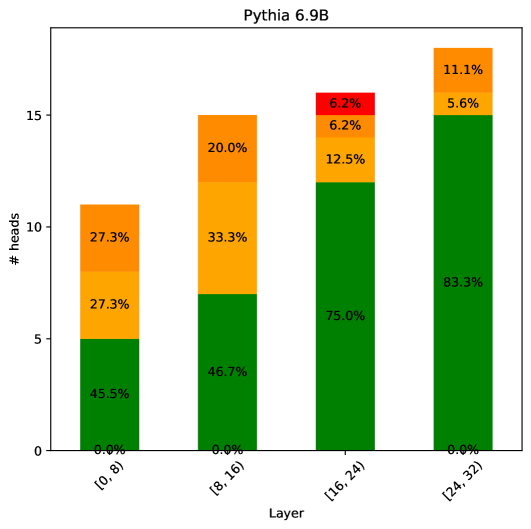
### Visual Description
\n
## Stacked Bar Chart: Pythia 6.9B Attention Head Distribution by Layer
### Overview
This is a stacked bar chart visualizing the distribution of different types of attention heads across the layers of the Pythia 6.9B language model. The chart shows four bars, each representing a range of model layers, with the total height of each bar indicating the total number of attention heads in that layer range. Each bar is segmented by color, representing the proportion of heads belonging to different categories.
### Components/Axes
* **Chart Title:** "Pythia 6.9B" (Top center)
* **X-Axis:**
* **Label:** "Layer" (Bottom center)
* **Categories (from left to right):**
1. `[0, 8)`
2. `[8, 16)`
3. `[16, 24)`
4. `[24, 32)`
* **Y-Axis:**
* **Label:** "# heads" (Left side, rotated vertically)
* **Scale:** Linear, from 0 to 15, with major ticks at 0, 5, 10, 15.
* **Data Series (Inferred from color and position):** The legend is not explicitly shown, but the consistent color coding across bars implies four categories. From bottom to top within each bar:
1. **Green (Bottom segment)**
2. **Orange (Middle segment)**
3. **Yellow (Upper-middle segment)**
4. **Red (Top segment, only present in one bar)**
### Detailed Analysis
**Bar 1: Layers [0, 8)**
* **Total Height (Approximate):** 11 heads
* **Segment Breakdown (from bottom to top):**
* **Green:** 45.5% (≈5 heads)
* **Orange:** 27.3% (≈3 heads)
* **Yellow:** 27.3% (≈3 heads)
* **Red:** 0.0% (0 heads)
**Bar 2: Layers [8, 16)**
* **Total Height (Approximate):** 15 heads
* **Segment Breakdown (from bottom to top):**
* **Green:** 46.7% (≈7 heads)
* **Orange:** 33.3% (≈5 heads)
* **Yellow:** 20.0% (≈3 heads)
* **Red:** 0.0% (0 heads)
**Bar 3: Layers [16, 24)**
* **Total Height (Approximate):** 16 heads
* **Segment Breakdown (from bottom to top):**
* **Green:** 75.0% (≈12 heads)
* **Orange:** 12.5% (≈2 heads)
* **Yellow:** 6.2% (≈1 head)
* **Red:** 6.2% (≈1 head)
**Bar 4: Layers [24, 32)**
* **Total Height (Approximate):** 18 heads
* **Segment Breakdown (from bottom to top):**
* **Green:** 83.3% (≈15 heads)
* **Orange:** 5.6% (≈1 head)
* **Yellow:** 11.1% (≈2 heads)
* **Red:** 0.0% (0 heads)
### Key Observations
1. **Increasing Total Heads:** The total number of attention heads per layer range increases from the first to the last bar (≈11 → 15 → 16 → 18).
2. **Dominant Green Segment:** The proportion of "Green" category heads increases dramatically across layers, from 45.5% in the first layers to 83.3% in the final layers. It becomes the overwhelming majority in the second half of the model.
3. **Declining Orange Segment:** The "Orange" category shows a clear downward trend, decreasing from 27.3% to 5.6%.
4. **Anomaly in Third Bar:** The `[16, 24)` layer range is the only one containing a "Red" category segment (6.2%). It also has the smallest "Yellow" segment (6.2%).
5. **Yellow Segment Fluctuation:** The "Yellow" category does not follow a monotonic trend, starting at 27.3%, dipping to 6.2% in the third bar, and rising slightly to 11.1% in the final bar.
### Interpretation
This chart likely illustrates the functional specialization of attention heads within the Pythia 6.9B model. The "Green" heads, which dominate the later layers, are probably responsible for higher-level, task-specific, or output-oriented processing. The "Orange" heads, prominent in early layers, may handle more fundamental syntactic or local contextual tasks. The unique appearance of a "Red" head in the middle layers (`[16, 24)`) suggests a specialized function that is only activated or necessary in that specific processing stage. The overall increase in total heads per layer range indicates that the model allocates more computational resources (attention mechanisms) to deeper processing stages. The distribution pattern suggests a shift from diverse, possibly general-purpose head types in early layers to a more homogeneous, specialized set of heads in later layers.
</details>
(c) Human annotation distribution for Question 2 across layers (Pythia 6.9B).
Figure 10: Quality of GPT-4o interpretation (§ E) - Human annotation distribution for Question 2.
<details>
<summary>x21.png Details</summary>
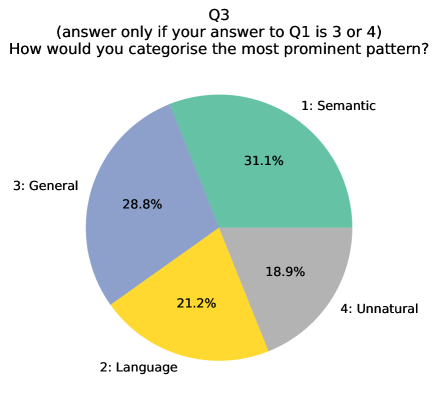
### Visual Description
\n
## Pie Chart: Q3 - Categorization of Prominent Patterns
### Overview
This image displays a pie chart from a survey or questionnaire, specifically labeled as question "Q3". The chart visualizes the distribution of responses to the question: "How would you categorise the most prominent pattern?" A conditional note indicates this question was only presented to respondents who answered "3 or 4" to a previous question, "Q1".
### Components/Axes
* **Chart Title:** "Q3"
* **Subtitle/Instruction:** "(answer only if your answer to Q1 is 3 or 4)"
* **Question Text:** "How would you categorise the most prominent pattern?"
* **Chart Type:** Pie chart with four segments.
* **Legend/Labels:** Labels are placed directly adjacent to their corresponding pie slices.
* **1: Semantic** (Teal/Green slice, top-right quadrant)
* **2: Language** (Yellow slice, bottom quadrant)
* **3: General** (Blue-gray slice, left quadrant)
* **4: Unnatural** (Gray slice, bottom-right quadrant)
### Detailed Analysis
The pie chart is divided into four categories with the following percentages and visual characteristics:
1. **Semantic (Category 1):**
* **Percentage:** 31.1%
* **Color:** Teal/Green
* **Position:** Occupies the largest segment, starting from the top (12 o'clock position) and extending clockwise to approximately the 4 o'clock position.
* **Trend/Size:** This is the largest segment, representing nearly one-third of the total.
2. **Language (Category 2):**
* **Percentage:** 21.2%
* **Color:** Yellow
* **Position:** Located at the bottom of the chart, between the "General" and "Unnatural" segments.
* **Trend/Size:** The third-largest segment.
3. **General (Category 3):**
* **Percentage:** 28.8%
* **Color:** Blue-gray
* **Position:** Occupies the left side of the chart, from approximately the 8 o'clock to the 12 o'clock position.
* **Trend/Size:** The second-largest segment, representing over a quarter of the total.
4. **Unnatural (Category 4):**
* **Percentage:** 18.9%
* **Color:** Gray
* **Position:** Located in the bottom-right quadrant, between the "Semantic" and "Language" segments.
* **Trend/Size:** The smallest segment.
**Data Verification:** The sum of the percentages (31.1% + 21.2% + 28.8% + 18.9%) equals 100.0%, confirming the data is complete for this respondent group.
### Key Observations
* **Dominant Category:** "Semantic" is the most frequently cited category for the most prominent pattern, chosen by 31.1% of the relevant respondents.
* **Secondary Category:** "General" is a close second at 28.8%, indicating a significant portion of respondents use a broad, non-specific categorization.
* **Combined Majority:** The "Semantic" and "General" categories together account for 59.9% of responses, suggesting that nearly six in ten respondents identify the prominent pattern as either meaning-based or broadly general.
* **Smallest Segment:** "Unnatural" is the least selected category at 18.9%, implying that patterns perceived as unnatural are less commonly identified as the *most* prominent by this group.
* **Balanced Distribution:** While there is a clear leader, no single category holds a majority (>50%). The distribution is relatively balanced across the four options, with the largest gap being 12.2 percentage points between the first and last categories.
### Interpretation
This chart provides insight into how a specific subset of survey respondents (those who gave a "3 or 4" answer to Q1) conceptualize the primary pattern they observed. The data suggests that for this group, **semantic or meaning-based patterns are the most salient**, followed closely by patterns described in general terms. The relatively lower selection of "Language" and "Unnatural" indicates that respondents are more likely to frame the prominent pattern in terms of its meaning or a general quality rather than attributing it specifically to linguistic structure or perceiving it as artificial/unnatural.
The conditional nature of the question ("answer only if...") is critical. It means these results are not representative of all survey participants, but only of a filtered subgroup. The findings are therefore specific to the characteristics of that subgroup, which answered "3 or 4" to Q1. Without knowing what Q1 asked, the exact context is limited, but the chart effectively communicates the internal distribution of pattern categorization within this defined cohort.
</details>
(a) Human annotation distribution for Question 3.
<details>
<summary>x22.png Details</summary>
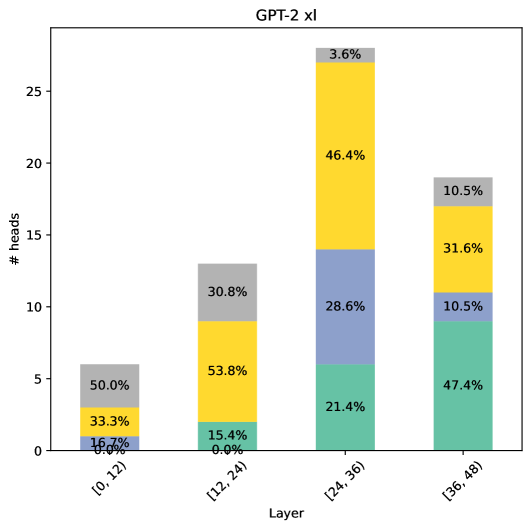
### Visual Description
## Stacked Bar Chart: GPT-2 xl Attention Head Distribution by Layer
### Overview
This image displays a stacked bar chart titled "GPT-2 xl". It visualizes the distribution of different categories of attention heads across four consecutive layer ranges (blocks) of the GPT-2 xl model. The chart quantifies the number and proportional composition of heads within each layer block.
### Components/Axes
* **Chart Title:** "GPT-2 xl" (centered at the top).
* **X-Axis:** Labeled "Layer". It represents four discrete, contiguous ranges of model layers:
* `[0, 12)`
* `[12, 24)`
* `[24, 36)`
* `[36, 48)`
* **Y-Axis:** Labeled "# heads". It represents the count of attention heads, with a linear scale marked at intervals of 5, from 0 to 25.
* **Data Series (Inferred from consistent color coding across bars):** The chart uses four distinct colors to represent different categories of attention heads. While no explicit legend is present, the colors and their associated percentage labels are consistent. The segments within each bar are stacked in the following order from bottom to top: Green, Blue, Yellow, Gray.
### Detailed Analysis
The chart contains four stacked bars, one for each layer range. Each bar's total height represents the total number of attention heads in that block of layers. The segments within each bar show the percentage contribution of each head category.
**1. Layer Range [0, 12)**
* **Total Height (Approximate):** 6 heads.
* **Segment Composition (from bottom to top):**
* **Green:** 0.0% (0 heads)
* **Blue:** 16.7% (~1 head)
* **Yellow:** 33.3% (~2 heads)
* **Gray:** 50.0% (~3 heads)
**2. Layer Range [12, 24)**
* **Total Height (Approximate):** 13 heads.
* **Segment Composition (from bottom to top):**
* **Green:** 15.4% (~2 heads)
* **Blue:** 0.0% (0 heads)
* **Yellow:** 53.8% (~7 heads)
* **Gray:** 30.8% (~4 heads)
**3. Layer Range [24, 36)**
* **Total Height (Approximate):** 28 heads.
* **Segment Composition (from bottom to top):**
* **Green:** 21.4% (~6 heads)
* **Blue:** 28.6% (~8 heads)
* **Yellow:** 46.4% (~13 heads)
* **Gray:** 3.6% (~1 head)
**4. Layer Range [36, 48)**
* **Total Height (Approximate):** 19 heads.
* **Segment Composition (from bottom to top):**
* **Green:** 47.4% (~9 heads)
* **Blue:** 10.5% (~2 heads)
* **Yellow:** 31.6% (~6 heads)
* **Gray:** 10.5% (~2 heads)
### Key Observations
* **Total Head Count Trend:** The total number of attention heads per layer block is not constant. It increases from the first block (6) to a peak in the third block (28), then decreases in the final block (19).
* **Category Trends:**
* **Green Segment:** Shows a clear, consistent upward trend across layers, starting at 0% in the first block and becoming the dominant category (47.4%) in the final block.
* **Yellow Segment:** Is the most prevalent category in the middle two blocks (53.8% and 46.4%) but decreases in the first and last blocks.
* **Blue Segment:** Exhibits a volatile pattern. It is present in the first block, absent in the second, peaks in the third, and is present again in the fourth.
* **Gray Segment:** Shows a general downward trend, being most prominent in the first block (50.0%) and least prominent in the third (3.6%).
* **Notable Anomaly:** The second layer block ([12, 24)) is the only one where the Blue category is completely absent (0.0%).
### Interpretation
This chart provides a structural analysis of the GPT-2 xl transformer model, specifically examining the functional specialization of its multi-head attention layers. The data suggests a **progression of role specialization from early to late layers**:
1. **Early Layers ([0, 12)):** Dominated by the "Gray" category (50%), with a significant "Yellow" component. This suggests these layers may handle more fundamental or general syntactic processing.
2. **Middle Layers ([12, 24) & [24, 36)):** These layers show the highest total head count and are dominated by the "Yellow" category. The third block also sees a major rise in the "Blue" category. This indicates these middle layers are the core computational engine, likely handling complex, integrated features of the input.
3. **Late Layers ([36, 48)):** The "Green" category becomes dominant (47.4%), while others recede. This points to a shift in function in the final layers, possibly towards task-specific output formatting, final prediction, or a distinct type of contextual integration.
The absence of the "Blue" category in the second block is a curious architectural or functional anomaly that may indicate a specific design choice or a phase in the model's processing pipeline where that type of attention is not required. Overall, the chart illustrates that attention heads in a large language model are not uniform; they are heterogeneous and their functional composition evolves systematically through the network's depth.
</details>
(b) Human annotation distribution for Question 3 across layers (GPT-2 xl).
<details>
<summary>x23.png Details</summary>
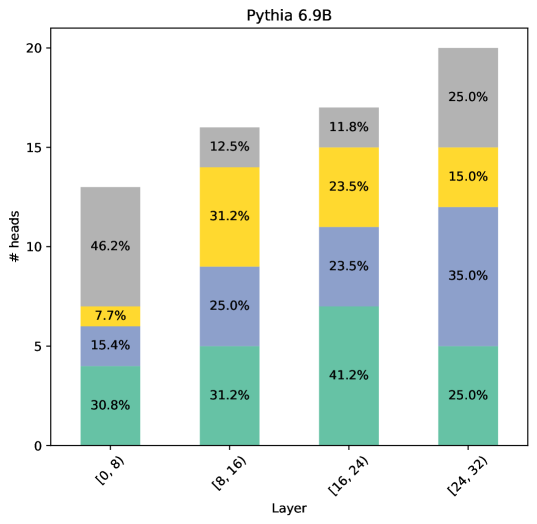
### Visual Description
## Stacked Bar Chart: Pythia 6.9B Attention Head Distribution by Layer
### Overview
This is a stacked bar chart titled "Pythia 6.9B". It visualizes the distribution of attention heads across four different layer ranges in the Pythia 6.9B language model. Each bar represents a range of layers, and the bar is segmented into four colored sections, each representing a distinct category of attention head. The height of each segment corresponds to the number of heads in that category for that layer range, and the percentage of the total for that bar is labeled on each segment.
### Components/Axes
* **Title:** "Pythia 6.9B" (centered at the top).
* **Y-Axis:** Labeled "# heads". The scale runs from 0 to 20, with major tick marks at 0, 5, 10, 15, and 20.
* **X-Axis:** Labeled "Layer". It has four categorical labels corresponding to the bars:
1. `[0, 8)`
2. `[8, 16)`
3. `[16, 24)`
4. `[24, 32)`
* **Data Series (Inferred from Color and Position):** The chart does not have an explicit legend box. The categories are inferred from the consistent color ordering within each stacked bar, from bottom to top:
1. **Green (Teal):** Bottom segment.
2. **Blue (Periwinkle):** Second segment from bottom.
3. **Yellow (Gold):** Third segment from bottom.
4. **Gray:** Top segment.
### Detailed Analysis
The chart displays data for four layer ranges. The total number of heads (bar height) increases from left to right.
**Bar 1: Layer Range [0, 8)**
* **Total Height (Approximate):** 13 heads.
* **Segment Breakdown (from bottom to top):**
* **Green:** 30.8% (≈4 heads)
* **Blue:** 15.4% (≈2 heads)
* **Yellow:** 7.7% (≈1 head)
* **Gray:** 46.2% (≈6 heads)
**Bar 2: Layer Range [8, 16)**
* **Total Height (Approximate):** 16 heads.
* **Segment Breakdown (from bottom to top):**
* **Green:** 31.2% (≈5 heads)
* **Blue:** 25.0% (≈4 heads)
* **Yellow:** 31.2% (≈5 heads)
* **Gray:** 12.5% (≈2 heads)
**Bar 3: Layer Range [16, 24)**
* **Total Height (Approximate):** 17 heads.
* **Segment Breakdown (from bottom to top):**
* **Green:** 41.2% (≈7 heads)
* **Blue:** 23.5% (≈4 heads)
* **Yellow:** 23.5% (≈4 heads)
* **Gray:** 11.8% (≈2 heads)
**Bar 4: Layer Range [24, 32)**
* **Total Height (Approximate):** 20 heads.
* **Segment Breakdown (from bottom to top):**
* **Green:** 25.0% (≈5 heads)
* **Blue:** 35.0% (≈7 heads)
* **Yellow:** 15.0% (≈3 heads)
* **Gray:** 25.0% (≈5 heads)
### Key Observations
1. **Total Head Count Increases:** The total number of attention heads visualized increases steadily across the layer ranges, from ~13 in the earliest layers to 20 in the final layers.
2. **Dominant Category Shift:** The dominant category (largest segment) changes across layers.
* In `[0, 8)`, **Gray** is dominant (46.2%).
* In `[8, 16)`, **Green** and **Yellow** are co-dominant (31.2% each).
* In `[16, 24)`, **Green** is clearly dominant (41.2%).
* In `[24, 32)`, **Blue** becomes the dominant category (35.0%).
3. **Green Segment Trend:** The proportion of Green heads increases from the first to the third bar (30.8% → 31.2% → 41.2%) before dropping in the final bar (25.0%).
4. **Blue Segment Trend:** The proportion of Blue heads shows a general upward trend, starting low (15.4%), rising (25.0%), dipping slightly (23.5%), and peaking in the final layer range (35.0%).
5. **Gray Segment Trend:** The proportion of Gray heads is highest in the earliest layers (46.2%) and drops significantly, remaining low and relatively stable in the middle and later layers (12.5%, 11.8%, 25.0%).
6. **Yellow Segment Trend:** The Yellow segment is smallest in the first bar (7.7%), jumps in the second (31.2%), and then declines in the third and fourth bars (23.5%, 15.0%).
### Interpretation
This chart likely illustrates how the functional specialization of attention heads in the Pythia 6.9B model varies across its depth. The four color-coded categories probably represent different types or clusters of attention head behaviors (e.g., syntactic, semantic, positional, or based on some learned metric).
* **Early Layers ([0, 8)):** Dominated by the "Gray" category, suggesting these layers may handle more fundamental or generic processing tasks common to all inputs.
* **Middle Layers ([8, 16) & [16, 24)):** Show a transition. The "Green" category becomes prominent, potentially indicating the rise of more specialized processing. The "Yellow" category also peaks here. The diversity of significant segments suggests these layers are performing complex, mixed transformations.
* **Late Layers ([24, 32)):** The "Blue" category becomes dominant, while "Green" and "Gray" are also substantial. This could indicate a shift towards tasks related to final output generation, refinement, or long-range coherence, where different head types collaborate.
The increasing total head count per layer range might be an artifact of the visualization (e.g., aggregating more layers into the later bins) or could reflect a structural property of the model where later layers have more attention heads allocated. The shifting proportions strongly suggest that the model's computational strategy is not uniform but evolves hierarchically, with different layers specializing in different types of information processing.
</details>
(c) Human annotation distribution for Question 3 across layers (Pythia 6.9B).
Figure 11: Quality of GPT-4o interpretation (§ E) - Human annotation distribution for Question 3.
## Appendix F Analysis of Global Versus Specific Functionality
We observe that the mappings in $M$ provide a broad view of the head’s functionality, particularly on how global the head’s operation is. For example, a head that maps any token to an end-of-sequence token has global functionality, whereas heads that map countries to their capitals, colors to their complementary pairs, and so on, demonstrate specific operations. In this section, we use properties of $M$ to analyze how global the functionalities of attention heads in LLMs are.
#### Analysis
We estimate how global the functionality of a given head is using two metrics: input skewness, which captures the skewness of the head’s operation towards specific inputs, and output space size, which estimates the number of tokens the head tends to output. For input skewness, we obtain the saliency scores $\sigma_{t}(W_{VO})\;\forall t\in\mathcal{V}$ according to the head (see § 3.2), and calculate the skewness of their distribution. For output space size, we compute for every token $s\in\mathcal{V}$ the highest-score token $t$ it is mapped into according to $M$ : $t=\arg\max(\mathbf{m}_{s})$ . Next, we define the output space size to be the portion of unique output tokens over the vocabulary. For instance, we expect the output space of a head that only maps strings to their first letters to be a small set of letter tokens. Similarly to the normalization of the saliency scores by the embedding norms, which we applied in § 3.2, here, when calculating $M$ , we normalize the unembeddings ( $U$ ’s columns).
<details>
<summary>x24.png Details</summary>
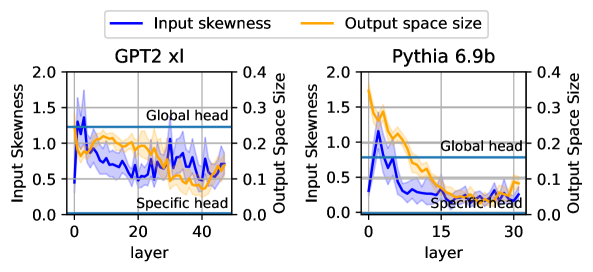
### Visual Description
\n
## Dual-Axis Line Chart: Input Skewness vs. Output Space Size Across Model Layers
### Overview
The image displays two side-by-side dual-axis line charts comparing the metrics "Input Skewness" and "Output Space Size" across the layers of two different language models: **GPT2 xl** (left panel) and **Pythia 6.9b** (right panel). The charts illustrate how these two properties evolve from the input layer (layer 0) to the final layers of each model.
### Components/Axes
* **Legend:** Positioned at the top center, spanning both charts.
* Blue line: **Input skewness**
* Orange line: **Output space size**
* **Left Chart (GPT2 xl):**
* **Title:** "GPT2 xl" (centered above the plot area).
* **X-axis:** Label: "layer". Scale: 0 to 40, with major ticks at 0, 20, 40.
* **Primary Y-axis (Left):** Label: "Input Skewness". Scale: 0.0 to 2.0, with major ticks at 0.0, 0.5, 1.0, 1.5, 2.0.
* **Secondary Y-axis (Right):** Label: "Output Space Size". Scale: 0.0 to 0.4, with major ticks at 0.0, 0.1, 0.2, 0.3, 0.4.
* **Horizontal Reference Lines:**
* A solid blue line labeled "Global head" at approximately y=1.3 on the Input Skewness axis.
* A solid blue line labeled "Specific head" at approximately y=0.1 on the Input Skewness axis.
* **Right Chart (Pythia 6.9b):**
* **Title:** "Pythia 6.9b" (centered above the plot area).
* **X-axis:** Label: "layer". Scale: 0 to 30, with major ticks at 0, 15, 30.
* **Primary Y-axis (Left):** Label: "Input Skewness". Scale: 0.0 to 2.0, with major ticks at 0.0, 0.5, 1.0, 1.5, 2.0.
* **Secondary Y-axis (Right):** Label: "Output Space Size". Scale: 0.0 to 0.4, with major ticks at 0.0, 0.1, 0.2, 0.3, 0.4.
* **Horizontal Reference Lines:**
* A solid blue line labeled "Global head" at approximately y=0.8 on the Input Skewness axis.
* A solid blue line labeled "Specific head" at approximately y=0.1 on the Input Skewness axis.
### Detailed Analysis
**GPT2 xl (Left Panel):**
* **Input Skewness (Blue Line):** The trend begins high, near 1.5 at layer 0. It shows a sharp initial drop within the first ~5 layers to below 1.0, followed by a period of fluctuation between approximately 0.5 and 1.0 across the middle layers (10-30). The line shows a slight upward trend in the final layers (30-40), ending near 0.8. The shaded blue area indicates variance or a confidence interval around the mean line.
* **Output Space Size (Orange Line):** The trend starts at its peak of approximately 0.25 at layer 0. It demonstrates a relatively steady, monotonic decrease across all layers, ending at its lowest point of approximately 0.1 at layer 40. The shaded orange area is narrower than the blue, suggesting less variance.
* **Relationship:** The two metrics show a generally inverse relationship. As Output Space Size decreases steadily, Input Skewness drops initially and then stabilizes at a lower, fluctuating level.
**Pythia 6.9b (Right Panel):**
* **Input Skewness (Blue Line):** The trend starts lower than GPT2, around 0.5 at layer 0. It rises sharply to a peak of approximately 1.2 within the first 5 layers. After this peak, it declines steadily, reaching a low of ~0.3 around layer 20, and remains relatively flat at that level through layer 30.
* **Output Space Size (Orange Line):** The trend starts at its highest point, approximately 0.35 at layer 0. It peaks slightly higher (~0.36) around layer 2-3, then begins a steep decline. The decline continues until around layer 20, where it plateaus at a very low value of approximately 0.05.
* **Relationship:** Similar to GPT2, there is an inverse relationship. Both metrics peak early (within the first 5 layers) and then decline, with Output Space Size showing a more dramatic and complete reduction.
### Key Observations
1. **Model-Specific Baselines:** The "Global head" reference line is set at a much higher Input Skewness value for GPT2 xl (~1.3) than for Pythia 6.9b (~0.8), suggesting a fundamental difference in the models' baseline attention characteristics.
2. **Early-Layer Dynamics:** Pythia 6.9b exhibits a pronounced early peak in Input Skewness, which is absent in GPT2 xl. This indicates a different processing strategy in the initial layers.
3. **Convergence of Output Space:** Both models show a significant reduction in Output Space Size across layers, converging to a low value (0.05-0.1). This suggests that deeper layers operate within a more constrained representational space.
4. **Variance:** The shaded regions (confidence intervals) for Input Skewness are notably wider than for Output Space Size in both models, indicating greater layer-to-layer or run-to-run variability in skewness measurements.
### Interpretation
This data visualizes a key aspect of how information is processed and transformed within deep transformer language models. **Input Skewness** likely measures the concentration or "peakiness" of attention distributions—higher values mean attention is focused on fewer tokens. **Output Space Size** may relate to the effective dimensionality or diversity of the representations produced by a layer.
The observed trends suggest a common architectural principle: **early layers perform broad, exploratory processing** (higher Output Space Size, with varying skewness), while **later layers perform focused, specialized processing** (low Output Space Size, with stabilized skewness). The steady decline in Output Space Size implies a progressive compression or specialization of information as it flows through the network.
The difference between GPT2 and Pythia is instructive. Pythia's early spike in skewness suggests its initial layers may be more aggressively selecting specific tokens for processing right from the start, whereas GPT2's initial layers have a high but immediately dropping skewness. The lower "Global head" baseline for Pythia might indicate its attention mechanisms are generally less skewed or operate on a different scale. This comparison highlights how different model architectures, despite being trained for the same task, can develop distinct internal processing strategies. The "Specific head" lines at a very low skewness (~0.1) in both models likely represent a baseline or minimum attention spread.
</details>
Figure 12: Input skewness versus output space size for all attention heads per layer in Pythia 6.9B and GPT-2 xl, compared to baseline heads of global and specific functionalities. Lower input skewness indicates a larger input space.
Additionally, we present two baselines. The first baseline, dubbed “specific head”, represents the output space size of a head that maps the entire vocabulary to 1 specific token (e.g. a head that always outputs the end of sequence token). The second baseline, called “global head”, represents the output space size of a head that maps the entire vocabulary to capitalized tokens with leading spaces - a subset whose size is 25% of the vocabulary of GPT-2 xl, and 16% of the vocabulary of Pythia 6.9B. An example of such a “global head” is a head that maps every word (or sub-word) in English to its capitalized version, and all other tokens to one specific token.
#### Results
Figure 12 shows the input skewness and output space sizes for all heads in Pythia 6.9B and GPT-2 xl. In both models, the input skewness rises and then sharply decreases in the early layers, after which it stabilizes. This implies that attention heads in shallower layers induce a salient effect into a specific set of inputs compared to later layers. In contrast, the output space size generally decreases across layers with a slight increase in the final layers, suggesting that head outputs across layers converge to smaller token subsets. Taken together, we hypothesize that early layer heads demonstrate their functionality on fewer inputs than deeper heads, which in turn map a larger set of possible inputs to a small set of outputs.
## Appendix G Resources and Packages
In our experiments, we used models and code from the transformers Wolf et al. (2020) and TransformerLens Nanda and Bloom (2022) packages, and nanoGPT. https://github.com/karpathy/nanoGPT All the experiments were conducted using a single A100 80GB or H100 80GB GPU, aside from the experiments studying Llama-3.1 70B, which used nodes with 8 of these GPUs.