# AceMath: Advancing Frontier Math Reasoning with Post-Training and Reward Modeling
**Authors**: Zihan Liu, Yang Chen, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping
Abstract
In this paper, we introduce AceMath, a suite of frontier math models that excel in solving complex math problems, along with highly effective reward models capable of evaluating generated solutions and reliably identifying the correct ones. To develop the instruction-tuned math models, we propose a supervised fine-tuning (SFT) process that first achieves competitive performance across general domains, followed by targeted fine-tuning for the math domain using a carefully curated set of prompts and synthetically generated responses. The resulting model, AceMath-72B-Instruct greatly outperforms Qwen2.5-Math-72B-Instruct, GPT-4o and Claude-3.5 Sonnet. To develop math-specialized reward model, we first construct AceMath-RewardBench, a comprehensive and robust benchmark for evaluating math reward models across diverse problems and difficulty levels. After that, we present a systematic approach to build our math reward models. The resulting model, AceMath-72B-RM, consistently outperforms state-of-the-art reward models. Furthermore, when combining AceMath-72B-Instruct with AceMath-72B-RM, we achieve the highest average rm@8 score across the math reasoning benchmarks. We release model weights, training data, and evaluation benchmarks at: https://research.nvidia.com/labs/adlr/acemath.
Machine Learning, ICML
1 Introduction
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Data Table: Large Language Model Performance on Various Benchmarks
### Overview
This image presents a data table comparing the performance of several Large Language Models (LLMs) across a range of academic benchmarks. The table displays scores, likely representing accuracy or proficiency, along with root mean squared error (RMSE) values in parentheses.
### Components/Axes
The table has the following structure:
* **Rows:** Represent different benchmarks: GSM8K (Grade school math competition), MATH (High school math competition), Minerva Math (Undergraduate-level quantitative reasoning), Gaokao 2023 English (College-entry math exam), Olympiad Bench (Olympiad-level math reasoning), College Math (College-level mathematics), MMLU STEM (Undergraduate-level STEM knowledge), and Human Performance.
* **Columns:** Represent different LLMs: AceMath 72B-Instruct, AceMath 7B-Instruct, AceMath 1.5B-Instruct, Qwen2.5-Math 72B-Instruct, Qwen2.5-Math 7B-Instruct, Llama3.1 405B-Instruct, GPT-4o* 2024-06-08, and Claude 3.5 Sonnet 2024-10-22.
* **Data Cells:** Contain the score for each LLM on each benchmark, followed by the RMSE in parentheses.
* **Footer:** Contains a note: "Note: All family models consistently outperform zero-pre-prompt competition benchmarks."
### Detailed Analysis or Content Details
Here's a breakdown of the data, benchmark by benchmark, with approximate values and trends:
* **GSM8K:** Scores range from approximately 87.0 to 96.4. The highest score is 96.4 (Claude 3.5 Sonnet), and the lowest is 87.0 (AceMath 1.5B-Instruct). The RMSE values are around 9.3-9.8.
* **MATH:** Scores range from approximately 73.8 to 86.1. The highest score is 86.1 (AceMath 72B-Instruct), and the lowest is 73.8 (Llama3.1 405B-Instruct). RMSE values are around 8.4-8.9.
* **Minerva Math:** Scores range from approximately 41.5 to 59.9. The highest score is 59.9 (AceMath 72B-Instruct), and the lowest is 41.5 (AceMath 1.5B-Instruct). RMSE values are around 4.2-4.9.
* **Gakao 2023 English:** Scores range from approximately 64.4 to 76.1. The highest score is 76.1 (AceMath 72B-Instruct), and the lowest is 64.4 (AceMath 1.5B-Instruct). RMSE values are around 7.1-7.6.
* **Olympiad Bench:** Scores range from approximately 33.8 to 52.0. The highest score is 52.0 (AceMath 72B-Instruct), and the lowest is 33.8 (AceMath 1.5B-Instruct). RMSE values are around 4.6-5.0.
* **College Math:** Scores range from approximately 45.5 to 57.3. The highest score is 57.3 (AceMath 72B-Instruct), and the lowest is 45.5 (Claude 3.5 Sonnet). RMSE values are around 5.3-5.8.
* **MMLU STEM:** Scores range from approximately 78.5 to 85.1. The highest score is 85.1 (Claude 3.5 Sonnet), and the lowest is 78.5 (Qwen2.5-Math 7B-Instruct). RMSE values are around 7.7-8.0.
* **Human Performance:** The score is 71.8 with an RMSE of 7.2.
**Trends:**
* AceMath 72B-Instruct consistently performs well, achieving the highest scores on several benchmarks (GSM8K, MATH, Minerva Math, Gakao 2023 English, Olympiad Bench, and College Math).
* Claude 3.5 Sonnet performs very well on GSM8K and MMLU STEM.
* AceMath 1.5B-Instruct consistently performs the lowest across most benchmarks.
* The RMSE values are relatively consistent within each benchmark, suggesting similar levels of uncertainty in the scores.
### Key Observations
* The performance gap between the best-performing and worst-performing models varies significantly across benchmarks. For example, the gap is larger in Olympiad Bench than in MMLU STEM.
* AceMath 72B-Instruct appears to be a strong performer across a broad range of mathematical and reasoning tasks.
* The human performance score provides a baseline for evaluating the LLMs. Most models are approaching or exceeding human-level performance on some benchmarks.
* The note at the bottom indicates that all models in the "family" (presumably AceMath, Qwen, Llama, GPT, and Claude) outperform previous competition benchmarks, suggesting overall progress in LLM capabilities.
### Interpretation
This data table provides a comparative analysis of LLM performance on a diverse set of benchmarks. The results demonstrate that LLMs are increasingly capable of tackling complex reasoning and mathematical problems. The consistent strong performance of AceMath 72B-Instruct suggests that model size and architecture play a crucial role in achieving high accuracy. The fact that models are approaching or exceeding human performance on certain tasks highlights the rapid advancements in the field of artificial intelligence. The RMSE values provide a measure of the reliability of the scores, indicating the degree of variability in the results. The note about outperforming previous benchmarks underscores the ongoing progress in LLM development. The variation in performance across benchmarks suggests that different models may excel in different areas, and the choice of model should be tailored to the specific task at hand.
</details>
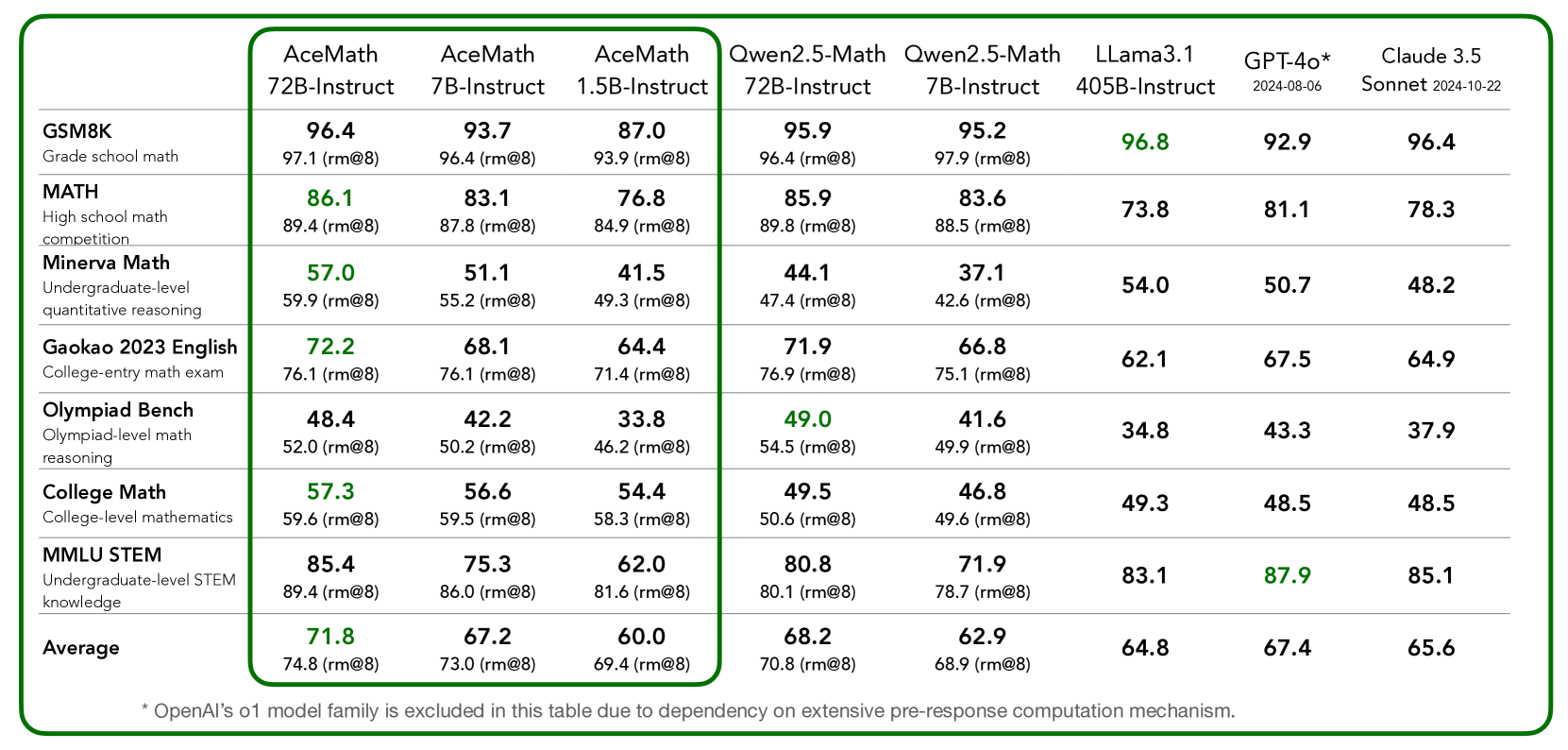
Figure 1: AceMath versus leading open-weights and proprietary LLMs on math reasoning benchmarks. Additionally, we report rm@8 accuracy (best of 8) with our reward model AceMath-72B-RM and use the official reported numbers from Qwen2.5-Math.
Over the past year, the open large language model (LLM) community has made remarkable progress in advancing the key capabilities of LLMs, including multi-turn conversation (Chiang et al., 2023; Dubey et al., 2024), coding (Guo et al., 2024; Hui et al., 2024), multimodal functionalities (Dai et al., 2024; Chen et al., 2024), retrieval-augmented generation (RAG) (Liu et al., 2024c), and mathematical reasoning (Azerbayev et al., 2023; Shao et al., 2024; Mistral, 2024; Yang et al., 2024b). Among these capabilities, mathematics is recognized as a fundamental aspect of intelligence. It can serve as a reliable benchmark due to its objective, consistent, verifiable nature. Consequently, solving math problems is widely regarded as a critical testbed for evaluating an LLM’s ability to tackle challenging tasks that require complex, numerical and multi-step logical reasoning (e.g., Cobbe et al., 2021; Hendrycks et al., 2021a; Lightman et al., 2023).
Previous studies have convincingly demonstrated that math-specialized LLMs significantly outperform general-purpose LLMs on challenging mathematical benchmarks (Azerbayev et al., 2023; Shao et al., 2024; Mistral, 2024; Yang et al., 2024b). These math-specialized models, including the corresponding reward models (a.k.a. verifiers), are not only valuable to the mathematics and science communities (e.g., Tao, 2023), but they also provide valuable insights into data collection and serve as synthetic data generation tools, contributing to the advancement of future iterations of general-purpose LLMs.
The improved mathematical reasoning capabilities of math-specialized LLMs are generally acquired through both the continued pre-training and post-training: i) During continued pre-training stage, the models are initialized with general-purpose base pretrained LLMs (e.g., Llama-3.1-70B (Dubey et al., 2024)), and continually trained on extensive collections of mathematical corpora, often comprising hundreds of billions of tokens sourced from Common Crawl (Shao et al., 2024), ArXiv papers (Azerbayev et al., 2023), and synthetically generated datasets (Yang et al., 2024b; Akter et al., 2024). In this stage, losses are calculated on every token within the corpus. ii) In the post-training phase, the continually pretrained math base LLMs (e.g., Qwen2.5-Math-72B (Yang et al., 2024b)) are fine-tuned using large datasets of mathematical prompt-response pairs. In this stage, losses are computed only on the response tokens, allowing the models to refine their ability to generate accurate answers given the prompts or problem descriptions.
In this work, we push the limits of math reasoning with post-training and reward modeling based on open weights base LLMs and math base LLMs. We establish state-of-the-art supervised fine-tuning (SFT) and reward modeling (RM) processes for building math-specialized models, while also sharing key insights gained from our comprehensive studies.
Specifically, we make the following contributions:
1. We introduce a SFT process designed to first achieve competitive performance across general domains, including multidisciplinary topics, coding, and math. Building on this, the general SFT model is further fine-tuned in math domain using a meticulously curated set of prompts and synthetically generated responses. Leveraging the high-quality training data, the resulting model, AceMath-7B-Instruct, largely outperforms the previous best-in-class Qwen2.5-Math-7B-Instruct (pass@1: 67.2 vs. 62.9) on a variety of math reasoning benchmarks (detailed results in Figure 1), while coming close to the performance of 10 $×$ larger Qwen2.5-Math-72B-Instruct (67.2 vs. 68.2). Notably, our AceMath-72B-Instruct outperforms the state-of-the-art Qwen2.5-Math-72B-Instruct by a margin (71.8 vs. 68.2).
1. We conducted a systematic investigation of training techniques for building math-specialized reward models, focusing on key aspects such as the construction of positive-negative pairs, training objectives, and the elimination of stylistic biases from specific LLMs. Leveraging the insights gained from this exploration, our AceMath-72B-RM consistently outperforms state-of-the-art reward models, including Qwen2.5-Math-RM-72B and Skywork-o1-Open-PRM-Qwen-2.5-7B (Skywork-o1, 2024), in the math domain. Moreover, when combining AceMath-72B-Instruct with AceMath-72B-RM, we achieve the highest average rm@8 score across seven math reasoning benchmarks (see Figure 1), setting a new standard for performance in this field.
1. We will open source the model weights for AceMath-Instruct and AceMath-RM, along with the complete training data used across all stages of their development. We also release AceMath-RewardBench, a comprehensive benchmark for evaluating math reward models, offering diverse datasets, varying difficulty levels, and robustness to variations in response styles.
We organize the rest of this paper as follows. In § 2, we introduce the related work. In § 3, we introduce the details on the SFT training data curation. We present our reward model training in § 4. We conclude the paper in § 5.
2 Related Work
2.1 Continued Pre-training on Math Corpus
Many studies have investigated the integration of large-scale mathematical data for pre-training LLMs to enhance their math capabilities (Shen et al., 2021; Wang et al., 2023; Zhang et al., 2024a; Ying et al., 2024; Akter et al., 2024; Hui et al., 2024). Additionally, some research has focused on developing math-specialized LLMs by continuing the pre-training of a general-purpose LLM with an extensive math corpus, sourced from math-related web texts, encyclopedias, exam questions, and synthetic mathematical data (Shao et al., 2024; Yang et al., 2024b). These works demonstrate that this additional math-focused pre-training significantly enhances the model’s ability to solve math problems, benefiting not only the pre-trained base model but also subsequent instruct models after post-training.
2.2 Supervised Fine-Tuning
Numerous supervised fine-tuning (SFT) datasets have been developed to enhance pretrained LLMs with versatile capability, such as instruction following (Chiang et al., 2023; The-Vicuna-Team, 2023; Lian et al., 2023; Mukherjee et al., 2023; Teknium, 2023; Peng et al., 2023; Yuan et al., 2024), coding (Glaive-AI, 2023; Wei et al., 2024; Luo et al., 2023), and mathematical problem-solving (Yue et al., 2024a, b; Yu et al., 2023; Mitra et al., 2024; Li et al., 2024b). Due to the high cost of human-annotated data, synthetic data generation has become an essential component of SFT data construction, including both prompt and response augmentation (Yu et al., 2023; Xu et al., 2024; Luo et al., 2023; Li et al., 2024a; Toshniwal et al., 2024).
Taking this further, math-instructed models have been developed to advance LLM performance in the mathematics domain (Shao et al., 2024; Toshniwal et al., 2024; Yang et al., 2024b) by utilizing math-specific pretrained models as backbones and vast amounts of synthetic post-training data tailored to mathematics. For example, OpenMathInstruct (Toshniwal et al., 2024) shows that math-specialized SFT with extensive synthetic data on the Llama3.1 base model significantly outperforms the corresponding Llama3.1 instruct model on mathematical benchmarks. In addition, Qwen2.5-Math (Yang et al., 2024b) demonstrates that a 7B math-instruct model can achieve math reasoning capabilities comparable to GPT-4o.
2.3 Reward Modeling
Training reward models for mathematical verification often involves discriminative approaches, such as binary classification to distinguish correct solutions from incorrect ones (Cobbe et al., 2021). Alternatively, preference-based methods are employed, leveraging techniques like the Bradley-Terry loss (Bradley & Terry, 1952; Ouyang et al., 2022) or regression loss to rank solutions, as demonstrated in models like HelpSteer (Wang et al., 2024e, d). In contrast, generative reward models, such as LLM-as-a-judge (Zheng et al., 2023) prompt LLMs to act as verifiers using predefined rubrics and grading templates (Bai et al., 2022), GenRM (Zhang et al., 2024c) leverages Chain-of-Thought reasoning (Wei et al., 2022), and Critic-RM (Yu et al., 2024) uses critic before predicting a reward. Our work on outcome reward model mainly focuses on robustness against style biases (Liu et al., 2024b) by sampling diverse model responses for training. Beyond outcome-based reward models, process reward models (PRMs) provide step-by-step evaluations of model responses (Uesato et al., 2022; Lightman et al., 2023). For example, Math-Shepherd (Wang et al., 2024b) introduces an automated sampling method to construct large-scale process supervision data for training, following by further developments in step-wise supervision labeling (Dong et al., 2024), including PAV (Setlur et al., 2024), OmegaPRM (Luo et al., 2024), ER-PRM (Zhang et al., 2024b), AutoPSV (Lu et al., 2024) and ProcessBench (Zheng et al., 2024).
3 Supervised Fine-tuning
3.1 Overview
Providing a strong initialization point is crucial for the model to begin math-focused SFT effectively. Previous works (Shao et al., 2024; Yang et al., 2024b) have demonstrated that continual pre-training of LLMs with a large math corpus provides a more effective initialization for subsequent math post-training. Taking this further, we explore whether conducting general SFT on pre-trained LLM can serves as a even better initialization for the subsequent math-specific SFT. The idea is that performing SFT on general-purpose tasks helps the model develop strong capabilities for following instructions and reasoning (e.g., knowledge-related). This foundation, in turn, makes it easier for the model to acquire math problem-solving skills from math-focused SFT data. The details of curating general SFT data can be found in § 3.2.1.
The next-step is constructing math-specific SFT data. It is crucial to develop a diverse set of math prompts accompanied by unified, step-by-step, and accurate solutions. The details of curating math SFT data can be found in § 3.2.2.
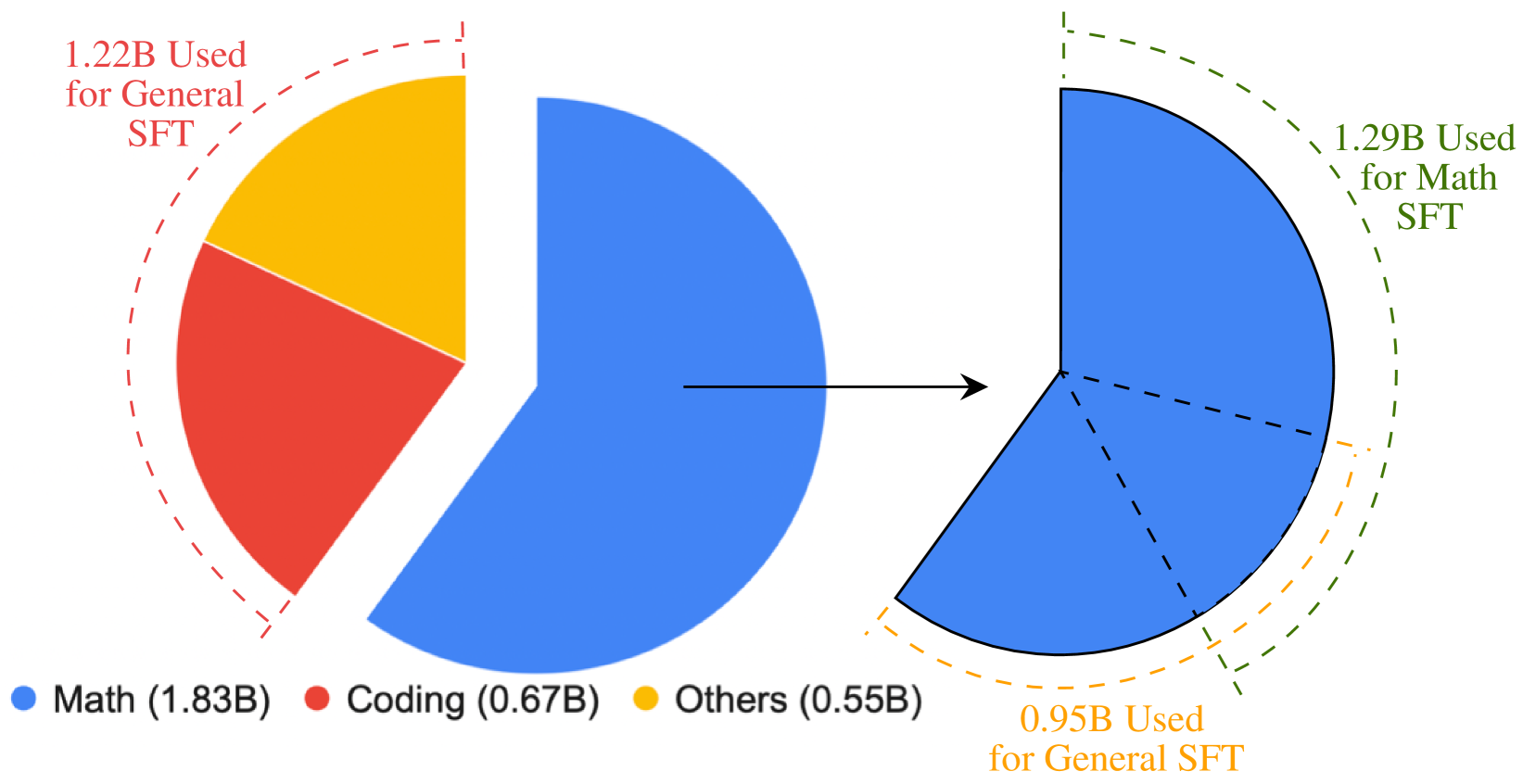
Figure 2 depicts the summary of the SFT data. The details of how we leverage general and math SFT data for the training can be found in § 3.3.
3.2 Data Curation
3.2.1 General SFT Data
Our goal is to build a general SFT model that serve as a strong starting point for the subsequent math-specific SFT. This general SFT model should excel at following instructions and answer a wide range of questions, including those related to math and coding.
Prompt Construction
To achieve this goal, we collect prompts from a diverse range of open-source datasets, categorized as follows:
- General domain: ShareGPT (Chiang et al., 2023; The-Vicuna-Team, 2023), SlimOrca (Lian et al., 2023; Mukherjee et al., 2023), EvolInstruct (Xu et al., 2024), GPTeacher (Teknium, 2023), AlpacaGPT4 (Peng et al., 2023), and UltraInteract (Yuan et al., 2024);
- Coding domain: Magicoder (Wei et al., 2024), WizardCoder (Luo et al., 2023), GlaiveCodeAssistant (Glaive-AI, 2023), and CodeSFT (Adler et al., 2024);
- Math domain: NuminaMath (Li et al., 2024b), OrcaMathWordProblems (Mitra et al., 2024), MathInstruct (Yue et al., 2024a), and MetaMathQA (Yu et al., 2023), as well as our synthetic data (details in § 3.2.2).
Since different data sources could have prompt overlaps, we conduct data deduplication to eliminate duplicate prompts that are identical when converted to lowercase. After deduplication, we retain the prompt set unfiltered to preserve the diversity of prompts.
Response Construction
After collecting the prompts, our goal is to construct high-quality responses in a consistent format so that models can learn more effectively. Therefore, we avoid using the original open-source responses for these prompts, as they may lack quality and have inconsistent formats due to being sourced from different curators or generated by different models. We use GPT-4o-mini (2024-0718) to generate responses for collected prompts in coding and general domains. GPT-4o-mini is selected for its strong performance across different tasks and instructions, as well as its compact size, which makes it both time-efficient and cost-efficient for producing a large volume of generated responses. We put the details of constructing responses for math SFT prompts in § 3.2.2.
We generate a single response for each prompt using greedy decoding, ultimately accumulating around 1.2 million coding SFT samples (0.67 billion tokens) and 0.7 million samples (0.55 billion tokens) in the general domain. And, we take around 1.2 million samples (0.95 billion tokens) from the math SFT data (described in § 3.2.2) for the general SFT.
3.2.2 Math SFT Data
The goal is to construct a diverse set of math prompts accompanied by unified, step-by-step, and accurate solutions.
Initial Prompts
We first take math prompts from general SFT data, drawing specifically from open-source datasets: NuminaMath (Li et al., 2024b), OrcaMathWordProblems (Mitra et al., 2024), MathInstruct (Yue et al., 2024a), and MetaMathQA (Yu et al., 2023). These prompts cover a wide range of math problems, spanning grade school, high school, college-level, and Olympiad-level math challenges. After that, we perform data deduplication to remove duplicate prompts as before. Finally, we collect over 1.3 million initial prompts.
Synthetic Prompt Generation
Furthermore, we generate additional synthetic prompts to enrich the diversity of our math prompt collection. This process involves two key steps: 1) leveraging diverse seed prompts to inspire a powerful instruct model to generate entirely new, potentially more challenging or uncommon prompts, and 2) ensuring that the generated prompts are solvable, as unsolvable prompts can lead to incorrect answers, which may degrade performance when used for training. Therefore, we select NuminaMath as our seed prompt source due to its broad coverage of math questions across various difficulty levels. Then, we apply two strategies inspired by Xu et al. (2024): in-breadth evolution for generating more rare prompts and in-depth evolution for generating more challenging ones. For synthetic prompt generation, we utilize GPT-4o-mini (2024-0718).
It is crucial to filter out low-quality synthetic prompts. In particular, we find that one type of in-depth evolution, which involves adding constraints to existing prompts to generate new ones, can sometimes produce unsolvable or overly challenging questions. This, in turn, may result in incorrect answers being included in the training data, ultimately degrading model performance (see ablation studies in § 3.6.4). As a result, we exclude this type of prompt augmentation. Moreover, we filter out the synthetic prompts exceeding 300 words, as excessively lengthy math-related prompts are often problematic or unsolvable. Finally, we refine the synthetic math prompts to approximately one million by filtering out 500K, ensuring a more curated dataset for training. As a result, we have a total collection of over 2.3 million math prompts (1.3M initial prompts + 1M synthetic prompts). We provide the details about the synthetic prompt generation in Appendix C.
Response Construction
We utilize Qwen2.5-Math-72B-Instruct for generating responses to math prompts, given its state-of-the-art performance across various math benchmarks. We add the instruction, “ Please reason step by step, and put your final answer within \\ $boxed\{\}$ . ” to the prompt to ensures the responses are presented in a clear, step-by-step format with a consistent style.
We generate a single response for each of the over 2.3M prompts and ensure consistency in the response format by selecting only those responses (along with their prompts) that adhere to a uniform structure (e.g., starting the response with a summary of the question and having the final answer within \\ $boxed{}$ ). Additionally, responses exceeding 2,500 words are excluded, along with their prompts, as excessive response length often indicates a verbose or incorrect solution, or an unfinished response. Furthermore, while Qwen2.5-Math-72B-Instruct demonstrates strong capabilities, it occasionally produces repetitive strings (e.g., repeating the same text until reaching the maximum output length). We detect and remove such patterns, along with their corresponding prompts. Although these cases represent only a small fraction of the dataset, they can negatively impact the final performance and are carefully filtered during the curation process. After filtering, we obtain a total of around 2.3 million math SFT samples (1.83 billion tokens), of which around 1.2 million are utilized in the general SFT.
Qwen2.5-Math-72B-Instruct can still generate incorrect solutions which may negatively impact model training. To mitigate this, we focus on identifying samples with accurate final answers to create a higher-quality dataset for training.
Our approach involves cross-checking answers generated by different models and treating solutions with consistent outcomes as highly likely to be correct. Specifically, we leverage another strong model, GPT-4o-mini (2024-0718), to generate responses. Since GPT-4o-mini is comparatively weaker in mathematics than Qwen2.5-Math-72B-Instruct, we generate two responses per prompt and consider answers consistent across both responses as potentially correct. Finally, we compare these answers with those from Qwen2.5-Math-72B-Instruct, and select matched final answers as high-quality solutions for training, which results in a total size of 800K math SFT samples.
3.2.3 Data Decontamination
Data decontamination is essential in SFT to ensure unbiased evaluation and to prevent models from memorizing test samples. Following Yang et al. (2024b), we conduct data decontamination for math SFT prompts. The process begins with text normalization and the removal of irrelevant punctuation for each math prompt. Next, we filter out the prompt that has a 13-gram overlap with the test data and the longest common subsequence exceeding 60% of its length. For the rest of non-math SFT prompts, we simply filter out those with a 13-gram overlap with test samples.
3.3 Training Strategy
3.3.1 General SFT Strategy
Among general tasks, solving complex coding and math problems stands out as particularly challenging, and many general instruct models often struggle with them. To address this and develop a more effective general SFT model, we introduce a two-stage training approach.
In stage-1, the model is trained on a large dataset specifically curated for code and math SFT tasks, providing a strong foundation in these areas. Stage-2 expands the scope by incorporating a balanced mix of code, math, and other general SFT data, broadening the model’s capabilities and enhance the overall performance.
We organize the constructed general SFT data (around three million samples) to support this two-stage training. For stage-1, the majority of the coding and math samples are selected, leading to a total of around 2 million SFT samples. Stage-2 training utilizes the remaining coding and math SFT samples, a subset of the stage-1 data, along with all other general SFT samples, resulting in a total of around 1.6 million samples. For math SFT samples used in stage-2 training, we select only the cross-checked high-quality data where the final answers provided by GPT-4o-mini and Qwen2.5-Math-72B-Instruct align, as detailed in § 3.2.2. This strategy ensures that stage-2 training integrates additional, diverse, and high-quality coding and math SFT samples, thereby fostering a more robust model.
| Models | HumanEval | MBPP | GSM8K | MATH | MMLU | MMLU Pro | Avg. |
| --- | --- | --- | --- | --- | --- | --- | --- |
| DeepSeek-Coder-7B-Instruct-v1.5 | 64.10 | 64.60 | 72.60 | 34.10 | 49.50 | - | - |
| AceInstruct-7B-DeepSeekCoder (Ours) | 78.05 | 73.54 | 82.56 | 55.62 | 54.65 | 33.28 | 62.95 |
| Llama3.1-8B-Instruct | 72.60 | 69.60 | 84.50 | 51.90 | 69.40 | 48.30 | 66.05 |
| AceInstruct-8B-Llama3.1 (Ours) | 81.10 | 74.71 | 90.45 | 64.42 | 68.31 | 43.27 | 70.38 |
| Qwen2.5-1.5B-Instruct | 61.60 | 63.20 | 73.20 | 55.20 | 58.37 | 32.40 | 57.33 |
| AceInstruct-1.5B-Qwen2.5 (Ours) | 73.17 | 65.76 | 80.44 | 60.34 | 58.17 | 33.78 | 61.94 |
| Qwen2.5-7B-Instruct | 84.80 | 79.20 | 91.60 | 75.50 | 74.51 | 56.30 | 76.99 |
| AceInstruct-7B-Qwen2.5 (Ours) | 85.37 | 74.32 | 93.10 | 76.40 | 74.68 | 54.50 | 76.40 |
| Qwen2.5-72B-Instruct | 86.60 | 88.20 | 95.80 | 83.10 | 84.67 | 71.10 | 84.91 |
| AceInstruct-72B-Qwen2.5 (Ours) | 89.63 | 83.66 | 96.36 | 84.50 | 83.88 | 66.10 | 84.02 |
Table 1: Results of our AceInstruct general SFT models. We apply our proposed two-stage training strategy to conduct SFT on various base models from DeepSeekCoder, Llama3.1, and Qwen2.5. These finetuned models are then compared against the corresponding instruct baselines that are built upon the same base models.
| Models | HumanEval | MBPP | GSM8K | MATH | MMLU | MMLU Pro | Avg. |
| --- | --- | --- | --- | --- | --- | --- | --- |
| AceInstruct-8B-Llama3.1 | 81.10 | 74.71 | 90.45 | 64.42 | 68.31 | 43.27 | 70.38 |
| $\triangleright$ Single-Stage SFT w/ all general SFT data | 78.66 | 69.26 | 87.79 | 56.80 | 67.62 | 42.64 | 67.13 |
| $\triangleright$ Single-Stage SFT w/ only stage-2 data | 73.78 | 67.32 | 88.17 | 55.84 | 67.48 | 42.85 | 65.91 |
| AceInstruct-7B-Qwen2.5 | 85.37 | 74.32 | 93.10 | 76.40 | 74.68 | 54.50 | 76.40 |
| $\triangleright$ Single-Stage SFT w/ all general SFT data | 83.54 | 75.49 | 91.96 | 75.04 | 73.96 | 53.36 | 75.56 |
| $\triangleright$ Single-Stage SFT w/ only stage-2 data | 83.54 | 73.15 | 92.27 | 75.12 | 74.26 | 53.06 | 75.23 |
Table 2: Ablation studies of our general SFT models regarding the effectiveness of the two-stage training strategy.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Pie Chart: Token Distribution for SFT
### Overview
The image presents two pie charts illustrating the distribution of tokens used for Supervised Fine-Tuning (SFT). The first pie chart shows the overall distribution across Math, Coding, and Other categories. The second pie chart focuses on the breakdown of tokens used specifically for Math SFT, showing the proportion allocated to General SFT and Math SFT. An arrow connects the two charts, indicating a relationship between the overall token distribution and the Math SFT allocation.
### Components/Axes
* **Pie Chart 1 (Left):** Represents the total token distribution.
* Categories: Math, Coding, Others
* Values: 1.83B, 0.67B, 0.55B respectively.
* **Pie Chart 2 (Right):** Represents the token distribution within Math SFT.
* Categories: General SFT, Math SFT
* Values: 0.95B, 1.29B respectively.
* **Legend (Bottom-Left):**
* Blue: Math (1.83B)
* Red: Coding (0.67B)
* Yellow: Others (0.55B)
* **Annotations:**
* "1.22B Used for General SFT" (Top-Right of Pie Chart 1)
* "1.29B Used for Math SFT" (Top-Right of Pie Chart 2)
* "0.95B Used for General SFT" (Bottom-Right of Pie Chart 2)
* **Arrow:** Connects Pie Chart 1 to Pie Chart 2, indicating a flow or relationship.
### Detailed Analysis
**Pie Chart 1:**
* The largest segment, colored blue, represents Math tokens, accounting for 1.83 billion tokens. This segment occupies approximately 45% of the pie chart.
* The second largest segment, colored red, represents Coding tokens, accounting for 0.67 billion tokens. This segment occupies approximately 16% of the pie chart.
* The smallest segment, colored yellow, represents Other tokens, accounting for 0.55 billion tokens. This segment occupies approximately 13% of the pie chart.
**Pie Chart 2:**
* The larger segment, colored blue, represents Math SFT tokens, accounting for 1.29 billion tokens. This segment occupies approximately 60% of the pie chart.
* The smaller segment, colored yellow, represents General SFT tokens, accounting for 0.95 billion tokens. This segment occupies approximately 40% of the pie chart.
### Key Observations
* Math tokens constitute the largest portion of the overall token distribution (45%).
* Within Math SFT, the majority of tokens are dedicated to Math SFT itself (60%), while a significant portion is also used for General SFT (40%).
* The annotation "1.22B Used for General SFT" on the first pie chart seems to be a mislabel, as the total tokens used for General SFT (from the second pie chart) is 0.95B.
* The arrow suggests that a portion of the overall Math tokens (1.83B) is allocated to Math SFT (1.29B) and General SFT (0.95B).
### Interpretation
The data suggests a strong focus on Math in the SFT process, with Math tokens representing the largest share of the overall distribution. The breakdown within Math SFT indicates a balanced approach, dedicating a substantial amount of tokens to both Math-specific and general SFT tasks. The annotation discrepancy suggests a potential error in labeling or data reporting. The relationship between the two charts highlights how the overall token distribution influences the allocation of resources within specific SFT domains like Math. The data implies that the model is being trained with a significant emphasis on mathematical capabilities, and that this training is being done in a way that leverages both specialized and general knowledge.
</details>
Figure 2: The proportion of total SFT tokens for math, coding, and other categories.
3.3.2 Math SFT Strategy
We take the base (or math-base) model trained on our general SFT data as the starting point for the math SFT. In order to achieve diverse and high-quality math SFT data, we merge all samples from NuminaMath (Li et al., 2024b), a subset of samples from our synthetic prompts, and the 800K math SFT samples that are cross-checked between GPT-4o-mini and Qwen2.5-Math-72B-Instruct (as described in § 3.2.2). We remove duplicate samples with identical prompts, resulting in a total of 1.6 million samples for math SFT. We find that this training blend leads to better results than directly utilize all 2.3 million math SFT samples for training (this ablation study can be found in § 3.6.3).
3.3.3 SFT Data Summary
Figure 2 provides an overview of the distribution of total SFT tokens across math, coding, and other categories, along with details on the utilization of math SFT samples. In total, there are approximately 2.3 million math SFT samples (1.83 billion tokens), 1.2 million coding SFT samples (0.67 billion tokens), and 0.7 million samples in other categories (0.55 billion tokens). Among the math SFT samples, 1.2 million (0.95 billion tokens) are used for general SFT, while 1.6 million (1.29 billion tokens) are utilized for math SFT.
3.3.4 Training Details
All SFT models are trained using the AdamW optimizer (Kingma, 2014; Loshchilov, 2017). We use a learning rate of 5e-6 for the general SFT and 3e-6 for the math SFT. A global batch size of 128 is used across all model sizes, except for the 72B model, where it is increased to 256. We conduct one epoch of training with a maximum sequence length of 4096 for both general SFT and math SFT.
| Models | GSM8K | MATH | Minerva Math | GaoKao 2023 En | Olympiad Bench | College Math | MMLU STEM | Avg. |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| GPT-4o (2024-0806) | 92.90 | 81.10 | 50.74 | 67.50 | 43.30 | 48.50 | 87.99 | 67.43 |
| Claude-3.5 Sonnet (2024-1022) | 96.40 | 75.90 | 48.16 | 64.94 | 37.93 | 48.47 | 85.06 | 65.27 |
| Llama3.1-70B-Instruct | 94.10 | 65.70 | 34.20 | 54.00 | 27.70 | 42.50 | 80.40 | 56.94 |
| Llama3.1-405B-Instruct | 96.80 | 73.80 | 54.04 | 62.08 | 34.81 | 49.25 | 83.10 | 64.84 |
| OpenMath2-Llama3.1-8B | 91.70 | 67.80 | 16.91 | 53.76 | 28.00 | 46.13 | 46.02 | 50.08 |
| Qwen2.5-Math-1.5B-Instruct | 84.80 | 75.80 | 29.40 | 65.50 | 38.10 | 47.70 | 57.50 | 56.97 |
| Qwen2.5-Math-7B-Instruct | 95.20 | 83.60 | 37.10 | 66.80 | 41.60 | 46.80 | 71.90 | 63.29 |
| Qwen2.5-Math-72B-Instruct | 95.90 | 85.90 | 44.10 | 71.90 | 49.00 | 49.50 | 80.80 | 68.16 |
| AceMath-1.5B-Instruct (Ours) | 86.95 | 76.84 | 41.54 | 64.42 | 33.78 | 54.36 | 62.04 | 59.99 |
| AceMath-7B-Instruct (Ours) | 93.71 | 83.14 | 51.11 | 68.05 | 42.22 | 56.64 | 75.32 | 67.17 |
| AceMath-72B-Instruct (Ours) | 96.44 | 86.10 | 56.99 | 72.21 | 48.44 | 57.24 | 85.44 | 71.84 |
Table 3: Greedy decoding (pass@1) results of math instruct models on math benchmarks. Our AceMath-1.5B/7B/72B-Instruct models are built upon the Qwen2.5-Math-1.5B/7B/72B-base models. AceMath-72B-Instruct greatly surpasses the previous state-of-the-art math-instruct model, Qwen2.5-Math-72B-Instruct.
3.4 Benchmarks
3.4.1 General SFT Benchmarks
We evaluate our general SFT models on a diverse set of widely used benchmarks. These benchmarks consist of coding tasks, including HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021), mathematical reasoning, including GSM8K (Cobbe et al., 2021) and MATH (Hendrycks et al., 2021b), as well as general knowledge domains, including MMLU (Hendrycks et al., 2020) and MMLU Pro (Wang et al., 2024c). We conduct standard 5-shot evaluations for MMLU and MMLU Pro, and use 0-shot evaluations for the remaining benchmarks.
3.4.2 Mathematical Benchmarks
We follow the evaluation setting in Qwen2.5-Math (Yang et al., 2024b) for assessing English mathematical tasks. Beyond the commonly used GSM8K (Cobbe et al., 2021) and MATH (Hendrycks et al., 2021b) benchmarks, we also evaluate our models on a broader set of mathematical benchmarks, including Minerva Math (Lewkowycz et al., 2022), GaoKao 2023 En (Liao et al., 2024), Olympiad Bench (He et al., 2024), College Math (Tang et al., 2024), and MMLU STEM (Hendrycks et al., 2020). These benchmarks comprehensively assess a wide range of mathematical reasoning capabilities, from grade school arithmetic to advanced college-level problems and Olympic-level challenges.
Other than the above datasets, we further evaluate our models on AMC 2023 https://huggingface.co/datasets/AI-MO/aimo-validation-amc and AIME 2024 https://huggingface.co/datasets/AI-MO/aimo-validation-aime. Although these benchmarks are highly challenging math competition benchmarks, they are quite limited in size, with AMC 2023 containing only 40 test samples and AIME 2024 comprising just 30. Following Yang et al. (2024b), we evaluate these benchmarks separately and present the results in Appendix A.
We conduct 5-shot evaluations for MMLU STEM, and use 0-shot evaluations for the remaining benchmarks.
Note that for all benchmarks except for Math and GSM8K, we do not use any training dataset or synthetic dataset derived from it. This ensures a more reliable and valid evaluation of our models on these benchmarks.
3.5 Results of AceInstruct General SFT Models
3.5.1 Main Results
As shown in Table 1, we apply our proposed two-stage training strategy to conduct SFT on various base models, including DeepSeekCoder-7B (Guo et al., 2024), Llama3.1-8B (Dubey et al., 2024), and Qwen2.5-1.5B/7B/72B (Yang et al., 2024a). We compare our finetuned general AceInstruct models to the corresponding instruct baselines that are built upon the same base models. We observe that our general SFT brings significant improvements across different models, such as DeepSeek-Coder-7B, Llama3.1-8B, and Qwen2.5-1.5B, with an average score improvement of over 4%. Notably, results on DeepSeek-Coder show that AceInstruct achieves particularly pronounced gains, with an average score increase of approximately 10% or more in coding and math tasks. When compared to more advanced models like Qwen2.5-7B-Instruct and Qwen2.5-72B-instruct, our SFT delivers comparable performance. These findings highlight the effectiveness and strong generalization capabilities of our constructed general SFT dataset.
3.5.2 Effectiveness of Two-Stage Training
As shown in Table 2, we study the effectiveness of two-stage training strategy. For comparison, we use two base models from distinct families (Qwen2.5 and Llama3.1) and conduct single-stage training using either all general SFT data or only the stage-2 SFT data.
We observe that our two-stage training (AceInstruct) consistently outperforms single-stage training. Interestingly, we find notable improvements (more than 3% average score) on a relatively weaker base model (e.g., Llama3.1-8B) compared to a stronger one (e.g., Qwen2.5-7B). This highlights the importance of incorporating extensive coding and math data during training to enhance the model’s ability to handle complex coding and math tasks. We conjecture that the Qwen2.5 models already leverage substantial math and coding SFT data during pretraining, which reduces the effectiveness of an additional stage-1 SFT focused on these areas.
| Models | GSM8K | MATH | Minerva Math | GaoKao 2023 En | Olympiad Bench | College Math | MMLU STEM | Avg. |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Backbone: Llama3.1-8B-Base | | | | | | | | |
| AceMath-Instruct | 91.51 | 69.06 | 31.99 | 59.74 | 32.00 | 49.08 | 67.94 | 57.33 |
| $\triangleright$ Only Qwen2.5-Math-72B-Instruct | 91.13 | 69.66 | 33.82 | 60.26 | 30.37 | 49.86 | 66.21 | 57.33 |
| $\triangleright$ Only GPT-4o-mini | 90.83 | 68.12 | 36.03 | 60.26 | 31.70 | 48.05 | 66.50 | 57.36 |
| $\triangleright$ Skipping general SFT | 91.81 | 68.70 | 31.99 | 59.48 | 31.11 | 48.40 | 62.76 | 56.32 |
| Backbone: Qwen2.5-7B-Base | | | | | | | | |
| AceMath-Instruct | 93.56 | 77.10 | 43.38 | 65.19 | 37.78 | 54.90 | 77.41 | 64.19 |
| $\triangleright$ Only Qwen2.5-Math-72B-Instruct | 92.80 | 76.96 | 41.91 | 63.64 | 38.07 | 54.93 | 75.64 | 63.42 |
| $\triangleright$ Only GPT-4o-mini | 91.66 | 74.14 | 43.75 | 64.42 | 39.26 | 52.27 | 76.03 | 63.08 |
| $\triangleright$ Math SFT with all math samples | 93.40 | 77.12 | 42.28 | 65.19 | 37.78 | 54.05 | 75.33 | 63.59 |
| $\triangleright$ Math SFT with only cross-checked samples | 92.72 | 76.76 | 41.54 | 65.97 | 36.74 | 54.33 | 76.78 | 63.55 |
| $\triangleright$ Skipping general SFT | 93.03 | 77.52 | 40.44 | 62.86 | 37.19 | 54.58 | 75.77 | 63.06 |
| Backbone: Qwen2.5-Math-72B-Base | | | | | | | | |
| AceMath-Instruct | 96.44 | 86.10 | 56.99 | 72.21 | 48.44 | 57.24 | 85.44 | 71.84 |
| $\triangleright$ Math SFT with all math samples | 96.29 | 86.06 | 55.15 | 70.13 | 46.67 | 57.49 | 84.96 | 70.96 |
| $\triangleright$ Skipping general SFT | 95.75 | 85.52 | 56.25 | 71.43 | 45.33 | 56.71 | 84.42 | 70.77 |
Table 4: Ablation Studies on training data and strategies across various backbone models for training our AceMath-Instruct models. The ablation studies can be categorized into three parts: 1) evaluating the effectiveness of using either GPT-4o-mini responses or Qwen2.5-Math-72B-Instruct responses individually; 2) analyzing the effectiveness of different math-specific samples for math SFT; and 3) assessing the impact of conducting general SFT prior to math SFT.
3.6 Results of AceMath-Instruct
3.6.1 Main Results
In Table 3, we compare our AceMath-Instruct models against several strong baselines for greedy decoding, including Qwen2.5-Math-1.5B/7B/72B-Instruct (Yang et al., 2024b), GPT-4o (OpenAI, 2024a), and Claude-3.5 Sonnet (Anthropic, 2024). Specifically, our AceMath-1.5B/7B/72B-Instruct models are built upon the Qwen2.5-Math-1.5B/7B/72B-base models, which also serve as the foundation for Qwen2.5-Math-1.5B/7B/72B-Instruct. We find that AceMath-1.5B, 7B, and 72B-Instruct achieve significantly better performance compared to the corresponding Qwen2.5-Math-1.5B, 7B, and 72B-Instruct models. Our best model, AceMath-72B-Instruct, achieves a significant average improvement of 3.68 over the previous state-of-the-art, Qwen2.5-Math-72B-Instruct. This highlights the superior quality and generalizability of our constructed math SFT data.
Moreover, we find that our 7B model, AceMath-7B-Instruct, demonstrate superior or comparable performance compared to several advanced instruct models, including Llama3.1-405B-Instruct, GPT-4o, and Claude-3.5 Sonnet. And, it comes close to matching the performance of the significantly larger Qwen2.5-Math-72B-Instruct, with only a slight difference in the average score (68.16 vs. 67.17).
We put several chain-of-thought reasoning examples generated by AceMath-72B-Instruct in Appendix D.
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Line Chart: Performance Comparison of Math Models
### Overview
This line chart compares the performance of three different model configurations – Baselines (Math-Instruct), Ours (Base), and Ours (Math Base) – across four different model sizes: DeepSeek-7B, Qwen2.5-1.5B, Qwen2.5-7B, and Qwen2.5-72B. The performance metric appears to be a score, ranging from approximately 45 to 75.
### Components/Axes
* **X-axis:** Model Name (DeepSeek-7B, Qwen2.5-1.5B, Qwen2.5-7B, Qwen2.5-72B)
* **Y-axis:** Performance Score (Scale from 45 to 75, with increments of 5)
* **Legend:**
* Blue Diamonds: Baselines (Math-Instruct)
* Red Circles: Ours (Base)
* Green Triangles: Ours (Math Base)
### Detailed Analysis
**Baselines (Math-Instruct) - Blue Diamonds:**
The line slopes upward consistently.
* DeepSeek-7B: 46.59
* Qwen2.5-1.5B: 56.97
* Qwen2.5-7B: 63.29
* Qwen2.5-72B: 68.16
**Ours (Base) - Red Circles:**
The line initially increases, then plateaus.
* DeepSeek-7B: 50.29
* Qwen2.5-1.5B: 51.82
* Qwen2.5-7B: 64.19
* Qwen2.5-72B: 71.13
**Ours (Math Base) - Green Triangles:**
The line slopes upward consistently and is generally the highest performing.
* DeepSeek-7B: 55.35
* Qwen2.5-1.5B: 59.99
* Qwen2.5-7B: 67.17
* Qwen2.5-72B: 71.84
### Key Observations
* The "Ours (Math Base)" model consistently outperforms both "Baselines (Math-Instruct)" and "Ours (Base)" across all model sizes.
* The performance of all models generally increases with model size.
* The "Ours (Base)" model shows a relatively flat performance curve between DeepSeek-7B and Qwen2.5-1.5B, then a significant jump to Qwen2.5-7B.
* The gap between "Ours (Math Base)" and the other two models widens as the model size increases.
### Interpretation
The data suggests that incorporating a "Math Base" into the model architecture significantly improves performance on the evaluated task. The consistent upward trend for all models indicates that increasing model size generally leads to better results, but the "Math Base" provides a substantial boost. The plateau observed in "Ours (Base)" between the first two model sizes suggests that simply increasing model size isn't sufficient; architectural improvements (like the "Math Base") are crucial for realizing further gains. The widening gap between the models as size increases indicates that the benefits of the "Math Base" become more pronounced with larger models. This could be due to the "Math Base" enabling the model to better leverage the increased capacity of larger models.
</details>
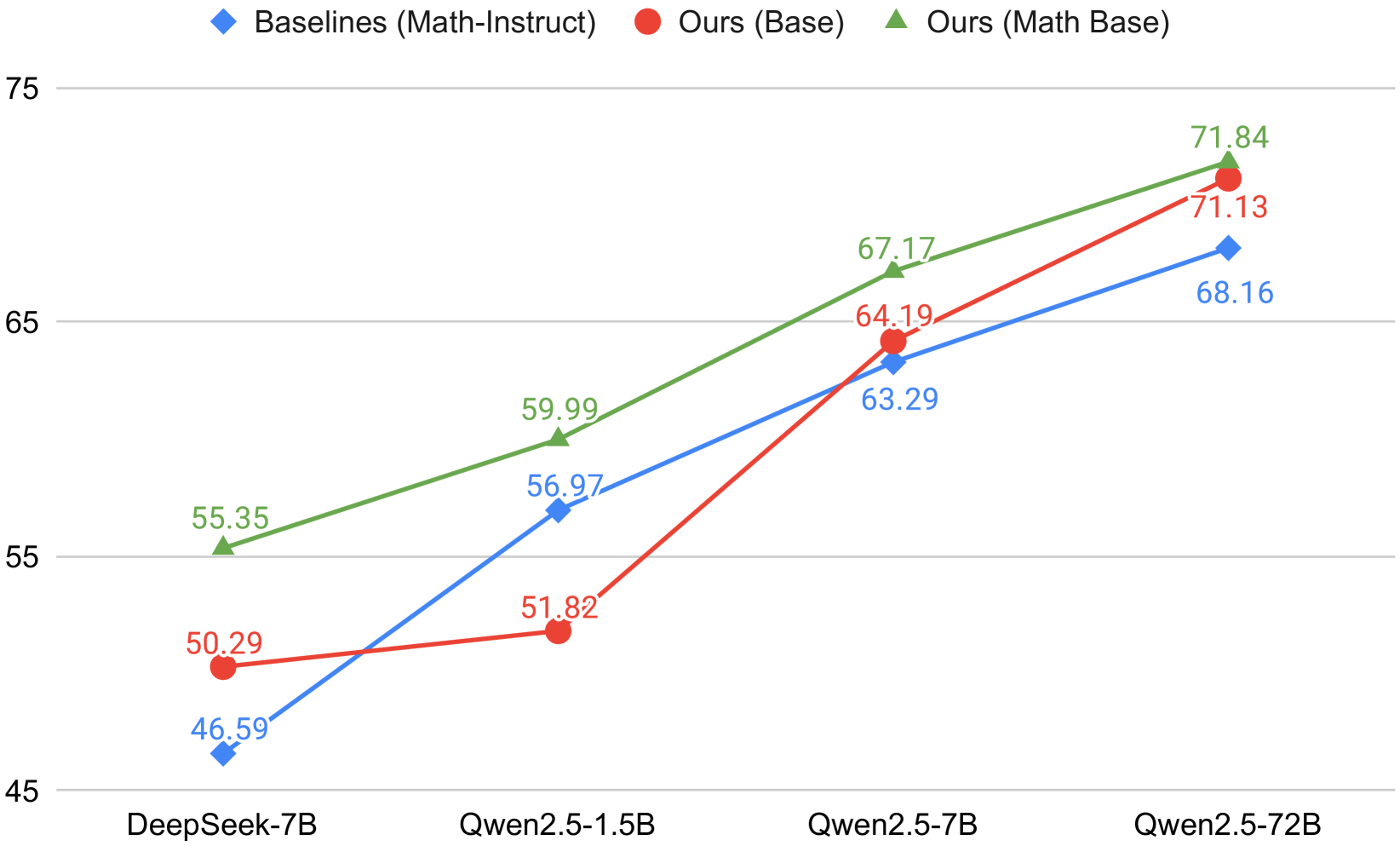
Figure 3: Studies on the impact of using either the base model or the math base model as the backbone on the performance of our AceMath-Instruct models. We compare our models against the corresponding math-instruct baselines across different model types and sizes. Results are the average scores of greedy decoding over the math benchmarks.
3.6.2 Backbone Model: Base vs. Math-Base
In Figure 3, we study the impact of using either the base model (e.g., Qwen2.5-7B-Base) or the math base model (e.g., Qwen2.5-Math-7B-Base) as the backbone on the performance of our AceMath-Instruct models. This study is crucial, as it helps us understand the importance of continual pre-training on a large math corpus (i.e., building math base models) for improving the performance on solving math questions after post-training.
For DeepSeek-7B, “Ours (Base)” uses the DeepSeek-Coder-7B-Base (Guo et al., 2024) as the backbone model, while “Ours (Math Base)” uses the DeepSeek-Math-7B-Base (Shao et al., 2024) as the backbone model, which continues the pre-training of DeepSeek-Coder-7B-Base using a large math corpus. The math instruct baseline is DeepSeek-Math-7B-RL (Shao et al., 2024), which is developed from DeepSeek-Math-7B-Base. For Qwen2.5-1.5/7B/72B, the base models are Qwen2.5-1.5/7B/72B-Base, while the math base models are Qwen2.5-Math-1.5/7B/72B-Base, with the baselines being Qwen2.5-Math-1.5/7B/72B-Instruct.
We find that as the model size increases, the performance of our models with base models as backbones approaches that of models with math base as backbones. Specifically, when the Qwen2.5-(Math)-72B-Base is used, the performance gap between “Ours (Base)” and “Ours (Math Base)” becomes very marginal (71.84 vs. 71.13). We conjecture that larger models inherently possess better math problem-solving and generalization capability, which diminishes the need for continual pre-training. This finding extends across different model families. Additionally, when comparing models of sizes between 1.5B and 7B, the performance gap between “Ours (Base)” and “Ours (Math Base)” is smaller for 7B models (i.e., DeepSeek-7B and Qwen2.5-7B) than it is for Qwen2.5-1.5B.
Moreover, we observe that except for Qwen2.5-1.5B, all the models from “Ours (Base)” outperform the corresponding math-instruct models that use stronger math base models as backbones. This further indicates that smaller models (e.g., 1.5B) rely more on continual pre-training with a large math corpus to enhance their math problem-solving capability (full results can be found in Appendix B).
| Models | Average |
| --- | --- |
| AceMath-Instruct | 64.19 |
| $\triangleright$ Removing all synthetic data | 62.53 |
| $\triangleright$ Using extra low-quality synthetic data | 62.95 |
Table 5: Ablation studies on the synthetic data, exploring the effects of removing all synthetic math SFT data and incorporating additional low-quality synthetic math SFT data. The backbone of AceMath-Instruct is Qwen2.5-7B-Base. Results are average across the seven math benchmark.
3.6.3 Ablation Studies on Training Strategy
In Table 4, we conduct ablation studies on training data and strategies across various backbone models for training our AceMath-Instruct models.
First, we explore the effectiveness of using either GPT-4o-mini responses or Qwen2.5-Math-72B-Instruct responses individually. Given that our best-performing models leverage responses from both, we analyze the impact of relying solely on one model when constructing general and math SFT data. Notably, even when only GPT-4o-mini responses are available, we achieve strong performance, with just a 1% average score drop when Qwen2.5-7B-Base serves as the backbone model. Furthermore, with Llama3.1-8B-Base as the backbone, using responses from GPT-4o-mini, Qwen2.5-Math-72B-Instruct, or their combination (AceMath-Instruct) yields comparable results. This indicates that the robustness of our data construction process which minimizes dependence on super powerful math expert models for generating synthetic data.
Second, we analyze the effectiveness of different math-specific samples for math SFT. To study this, we compare AceMath-Instruct trained with 1.6 million math SFT samples (details in § 3.3.2) to models trained using all available math SFT samples (2.3 million) or only cross-checked high-quality samples (800K). We find that simply increasing the quantity of data or exclusively using high-quality samples does not yield better outcomes. Instead, combining cross-checked high-quality data with additional samples that include a diverse range of math questions produces superior results.
Third, we study the impact of conducting general SFT before transitioning to math SFT. To explore this, we skip the general SFT step, and conduct math SFT directly using all math-specific samples. We observe that skipping general SFT typically results in an average score drop of approximately 1%, even when using a math-base model (e.g., Qwen2.5-Math-72B-Base) as the backbone. The results highlight the effectiveness of conducting general SFT prior to math SFT.
3.6.4 Ablation Studies on Synthetic Data
As shown in Table 5, we study how synthetic math SFT data affects the results. We compare AceMath-Instruct against two scenarios: one where all one million synthetic data samples are removed and another where an additional 500K low-quality synthetic data are included for training (e.g., lengthy prompts and one type of in-depth evolution that adds constraints). Details of the synthetic math SFT data can be found in § 3.2.2. In both scenarios, we observe a decline in results, underscoring the importance of not only generating synthetic data but also carefully selecting it for training. Effectively leveraging appropriate synthetic data proves essential for achieving optimal performance.
4 Reward Model Training
We train a math reward model for AceMath-Instruct, aiming to select more accurate solutions and better reasoning paths. To ensure broad applicability across a variety of language models, we curate a diverse training dataset. The following sections detail our training methodology, evaluation protocols, and empirical results.
4.1 Reward Training Data Synthesis
4.1.1 Initial Dataset Construction
We utilize a portion of the math SFT dataset (350K) from § 3.2.2 to use the prompts and the answers generated by gpt-4o-mini (OpenAI, 2024b) as reference labels. To capture the diversity of model-generated reasoning steps and potential different kinds of reasoning mistakes, we sample four model responses per LLM from a set of 14 LLMs, including Llama2-7b-chat (Touvron et al., 2023), Llama3.1-8/70B-Instruct (Dubey et al., 2024), DeepSeek-math-7b-instruct (Shao et al., 2024), Mistral-7B/Mathstral-7B (Jiang et al., 2023), Gemma-2/27b-it (Gemma et al., 2024), and Qwen2/2.5-1.5/7/72B-Instruct (Yang et al., 2024b). We then annotate the model solutions as correct or incorrect by comparing them against the referenced labels using the Qwen-math evaluation toolkit. https://github.com/QwenLM/Qwen2.5-Math/tree/main/evaluation This process initializes a pool of correct and incorrect candidate responses for each problem, which we treat as positive and negative samples that can be further sampled to create paired responses for training.
4.1.2 Response Scoring and Selection
Mathematical problem answers encompass a wide range of formats with diverse representations (e.g., [\frac {1}{2}, 1/2, 0.5] and [1e-5, 1 $×$ 10^ {-5}]), and heuristic math evaluation toolkits using SymPy and latex2sympy2 may inevitably result in false negative candidates (i.e., correct answers annotated as incorrect). Such examples in the negative candidates could introduce noise and adversely affect model training. Therefore, instead of randomly sample responses from all candidates, we rank the candidates and apply a score-sorted sampling strategy. Specifically, we use the math reward model Qwen2.5-Math-RM-72B to rank positive and negative candidates for each problem based on their scores. We then randomly sample from top- $k$ positive and bottom- $k$ negative candidates, with $k$ set to 14 based on preliminary experiments. Compared to random sampling from all candidates, our ablation study in Table 8 demonstrates the benefits of the score-sorted sampling strategy. In conclusion, we sample a total of six response candidates (positive + negative) for each problem, ensuring a balanced number of positive and negative responses, and filter out problems where all responses are either correct or incorrect.
4.1.3 Addressing Stylistic Biases
LLMs can generate different styles of chain-of-thought reasoning paths when prompted in the zero-shot setting or with few-shot examples (Wei et al., 2022). We observe significant shorter and simple reasoning paths in model outputs for datasets such as MMLU (Hendrycks et al., 2021a) as the model follows the simple 5-shot examples provided in the instruction. To improve reward model performance on such output styles, we create training data using the few-shot prompting approach to generate simple and short reasoning paths for 2,000 multiple-choice problems. In addition, as our ultimate goal is to develop a reward model for the AceMath-Instruct model family, we sample a set of 30,000 problems and use AceMath-(1.5/7/72B)-Instruct checkpoints to generated responses to create positive and negative pairs for training. In conclusion, our final training dataset consists of 356K problems, each paired with a total of six responses ( $k$ positive and $6-k$ negative).
| Model | GSM8K | MATH500 | Minerva Math | GaoKao 2023 En | Olympiad Bench | College Math | MMLU STEM | Avg. |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| majority@8 | 96.22 | 83.11 | 41.20 | 68.21 | 42.69 | 45.01 | 78.21 | 64.95 |
| Internlm2-7b-reward | 95.26 | 78.96 | 36.25 | 67.51 | 40.49 | 43.88 | 75.42 | 62.54 |
| Internlm2-20b-reward | 95.10 | 76.53 | 37.69 | 66.63 | 40.12 | 42.57 | 70.60 | 61.32 |
| Skywork-Reward-Llama-3.1-8B-v0.2 | 95.64 | 74.16 | 39.11 | 67.16 | 39.10 | 44.58 | 76.52 | 62.32 |
| Skywork-Reward-Gemma-2-27B-v0.2 | 95.94 | 74.90 | 39.37 | 66.96 | 39.07 | 45.46 | 78.20 | 62.84 |
| Skywork-o1-Open-PRM-Qwen-2.5-7B | 96.92 | 86.64 | 41.00 | 72.34 | 46.50 | 46.30 | 74.01 | 66.24 |
| Qwen2.5-Math-RM-72B | 96.61 | 86.63 | 43.60 | 73.62 | 47.21 | 47.29 | 84.24 | 68.46 |
| \hdashline AceMath-7B-RM (Ours) | 96.66 | 85.47 | 41.96 | 73.82 | 46.81 | 46.37 | 80.78 | 67.41 |
| AceMath-72B-RM (Ours) | 97.23 | 86.72 | 45.06 | 74.69 | 49.23 | 46.79 | 87.01 | 69.53 |
| pass@8 (Oracle) | 98.86 | 91.84 | 56.18 | 82.09 | 59.00 | 56.38 | 96.15 | 77.21 |
Table 6: Reward model evaluation on AceMath-RewardBench. The average results (rm@8) of reward models on math benchmarks, randomly sample 8 responses from 64 candidates with 100 random seeds. Response candidates are generated from a pool of 8 LLMs (Qwen{2/2.5}-Math-{7/72}B-Instruct, Llama-3.1-{8/70}B-Instruct, Mathtral-7B-v0.1, deepseek-math-7b-instruct).
4.2 Reward Training Strategy
Our reward model architecture adopts a outcome reward approach, which introduces a linear layer at the top of the language model to project the last token representation into a scalar value. We initialize the backbone of the reward model using a supervised fine-tuned model (i.e., AceMath-Instruct). Following the training objective established in Qwen2.5-Math (Yang et al., 2024b), we construct problem-response pairs with $k$ positive (correct) candidates and $6-k$ negative (incorrect) candidates. We compute the list-wise Bradley-Terry loss (Bradley & Terry, 1952), which demonstrates computational efficiency compared to pair-wise approaches as shown in Table 8.
| | $\displaystyle\mathcal{L}_{\text{rm}}(\theta)=$ | |
| --- | --- | --- |
Here, $r_{\theta}(x,y)$ represents the output score of the reward model $r_{\theta}$ , where $x$ denotes the problem and $y$ represents the response candidate. The loss function is designed to optimize the model’s ability to discriminate between correct and incorrect responses by maximizing the margin between positive and negative candidate scores.
4.3 Reward Evaluation Benchmarks
4.3.1 AceMath-RewardBench
Existing math reward benchmarks lack diversity, both in the types of candidate solutions and the range of difficulty levels in the math questions. To address this, we construct a math reward model evaluation benchmark, AceMath-RewardBench, which contains 7 datasets and use 8 different LLMs to generate solutions for robust evaluation. The benchmark use the best-of-N (BoN or rm@ $n$ ) metric, a methodology extensively used in literature (Cobbe et al., 2021; Lightman et al., 2023; Yang et al., 2024b). The primary objective of the reward model is to select the highest reward scored model response from a candidate set of $n$ and calculate the corresponding problem-solving rate for each math benchmark (7 datasets) used in § 3.4.2. We adopt rm@8 metric following the Qwen2.5-Math evaluation protocol, optimizing computational efficiency during the inference stage. To ensure robust and statistically reliable benchmark performance, we implement two design principles: 1) diverse model distribution: we sample 8 responses from each model in a set of mathematical and general-purpose LLMs (i.e., Qwen2.5-Math-7/72B-Instruct (Yang et al., 2024b), Qwen2-Math-7/72B-Instruct (Yang et al., 2024a), Llama-3.1-8/70B-Instruct (Dubey et al., 2024), DeepSeek-Math-7B-Instruct (Shao et al., 2024), Mathtral-7B-v0.1 (Jiang et al., 2023)), mitigating potential model-specific style biases; 2) we compute accuracy metrics by averaging results across 100 random seeds, reducing result variance and enhancing reproducibility.
In total, each problem in the benchmark contains a total of 64 candidate responses from 8 LLMs. We then randomly sample 8 responses from these 64 candidates, compute the rm@8 result, and average the final accuracy over 100 random seeds. Different from the Math SFT evaluation, we use the MATH500 (Lightman et al., 2023), a subset of 500 problems sampled from the MATH dataset (Hendrycks et al., 2021b) following the prior work such as PRM800K (Lightman et al., 2023) and RewardBench (Lambert et al., 2024).
4.3.2 RewardBench (MATH500) and RewardMath
Apart from our own benchmarks, we also evaluate on RewardBench (Lambert et al., 2024) (MATH500) and RewardMath (Kim et al., 2024) to report the accuracy of selecting the correct solution from a list of candidates for each problem in MATH500 (Lightman et al., 2023). The primary difference between these two benchmarks lies in the candidate sets: RewardBench uses one correct (human-written) solution and one incorrect candidate (generated by GPT-4), while RewardMath uses one correct (a GPT-4 rewrite) and nine incorrect candidates (generated by models). Kim et al. (2024) highlight a significant distributional shift between human-written solutions and machine-generated ones as the prior ones are typically shorter, more concise, and contain fewer details. This difference in style and content may partially explain why saturated accuracy exceeding 95% on the RewardBench. To address this limitation and better assess the robustness of reward models, they propose RewardMath, which introduces a more challenging evaluation setup and show that most reward models struggle significantly with this new benchmark, achieving accuracies of only around 30% or lower.
4.4 Experiments of Reward models
4.4.1 Hyperparameters
We use the AceMath-7B/72B-Instruct model as the backbone to train the outcome reward model: AceMath-RM-7/72B. The model is trained using AdamW (Kingma, 2014; Loshchilov, 2017) for 2 epochs with a learning rate of {5e-6, 2e-6}, using a cosine learning rate scheduler and an effective batch size of 256. Training is conducted on 8 H100 GPUs for the 7B model and 256 H100 GPUs for the 72B model.
4.4.2 Baselines
For mathematical reward modeling, we compare with current state-of-the-art outcome reward model Qwen2.5-Math-RM-72B (Yang et al., 2024b) and a process reward model Skywork-o1-Open-PRM-Qwen-2.5-7B (Skywork-o1, 2024). We also include majority@8 (majority voting) baseline and the pass@8 (any one of the 8 is correct) as an oracle reward model to measure the upper bound of this benchmark. Additionally, we incorporate general reward models top-ranked on RewardBench, including Skywork-Reward (Liu et al., 2024a) and Internlm2-reward (Cai et al., 2024). It is noteworthy that while these models are not exclusively trained for mathematical domains, a substantial portion of their training data encompasses mathematical content. For instance, Skywork-Reward (Liu et al., 2024a) uses 50% math data for training.
4.4.3 Results on AceMath-RewardBench
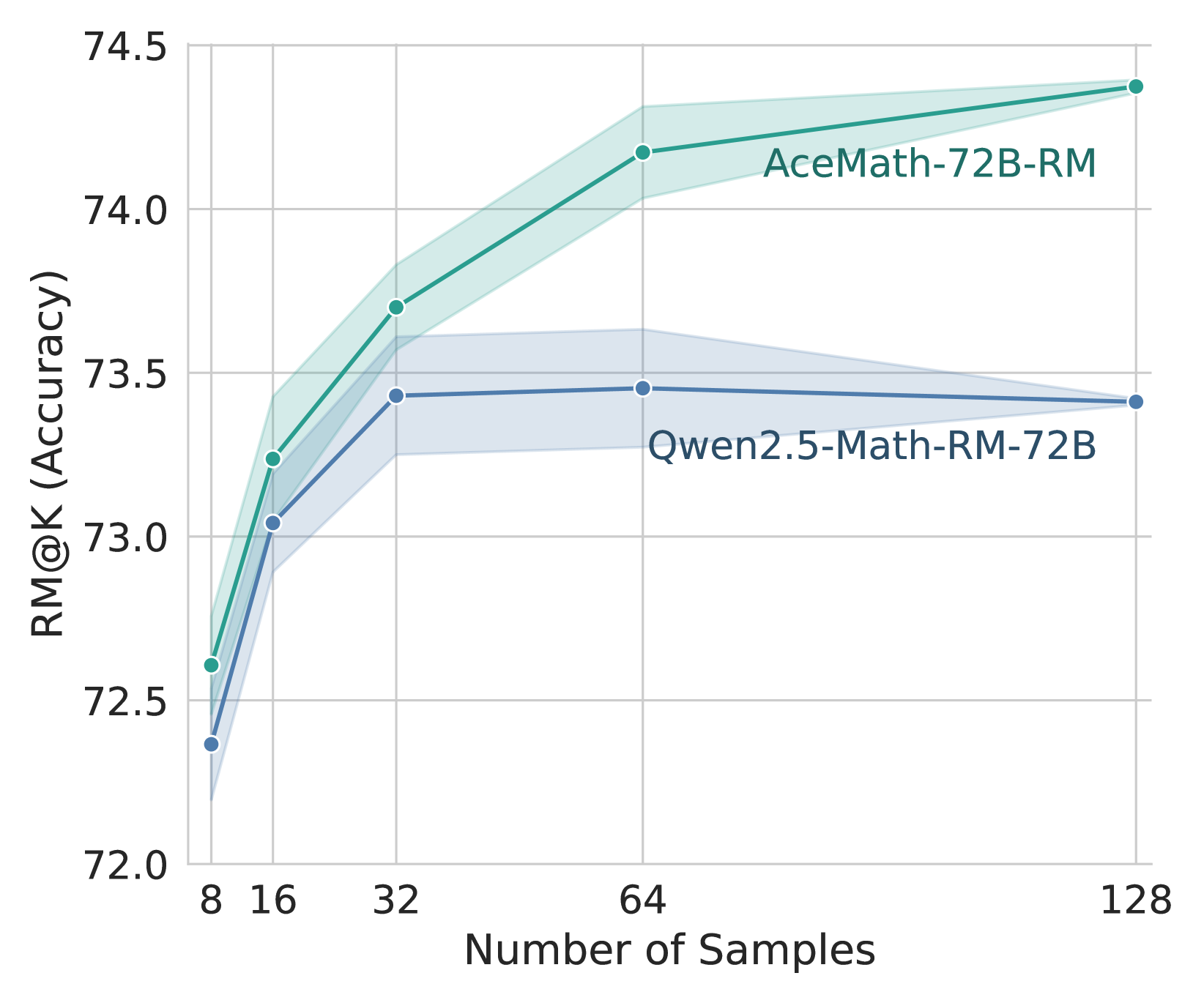
In Table 6, we show that our AceMath-72B-RM achieves the state-of-the-art rm@8 accuracy on average of AceMath-RewardBench, outperforming the Qwen2.5-Math-RM-72B by 1% absolute (69.53 vs 68.46) and on 6 out of 7 datasets. We show the 7B variant achieves 67.41 accuracy on average and demonstrates the benefits of model size scaling from 7B to 72B, especially on datasets require college-level STEM knowledge such as Minerva Math (41.96 $→$ 45.06) and MMLU STEM (80.78 $→$ 87.01). Comparing to other reward model baselines, the 7B outperform Internlm2 and Skywork-Reward by a large margin as our benchmark reveal these reward model even underperform the majority voting baseline. Nevertherless, we note that there remains considerable room for improvement as indicated by the gap between the reward model and pass@8 oracle accuracy.
| Model | RewardBench MATH500 | RewardMath MATH500 |
| --- | --- | --- |
| Random | 50.00 | 10.00 |
| LLM-as-a-Judge | | |
| Claude-3.5-Sonnet † | 70.70 | 15.32 |
| GPT-4o-2024-05-13 † | 72.50 | 25.98 |
| Classifier-based | | |
| Math-Shepherd-Mistral-7B † | 94.41 | 17.18 |
| ArmoRM-Llama3-8B-v0.1 † | 98.70 | 20.50 |
| Skywork-Reward-Llama-3.1-8B † | 96.87 | 22.15 |
| Internlm2-20b-reward † | 95.10 | 33.95 |
| Internlm2-7b-reward † | 94.90 | 37.27 |
| Skywork-o1-Open-PRM-7B | 78.52 | 51.34 |
| Qwen2.5-Math-RM-72B | 95.97 | 68.53 |
| \hdashline AceMath-7B-RM (Ours) | 92.62 | 57.76 |
| AceMath-72B-RM (Ours) | 97.09 | 68.94 |
Table 7: The accuracy of reward models on RewardBench (MATH500) (Lambert et al., 2024) and RewardMATH (Kim et al., 2024). $\dagger$ : Results are copied from RewardMATH. Bold: top-1. Underline: top-2 accuracy.
4.4.4 Results on RewardBench and RewardMath
In Table 7, we demonstrate that our AceMath-72B-RM achieves state-of-the-art accuracy on RewardMATH. While many reward models (e.g., ArmoRM (Wang et al., 2024a), Internlm2) achieve 95%+ accuracy on the RewardBench MATH500 split, their accuracy drops significantly on RewardMATH, ranging from only 20% to 37%. We found Skywork-PRM model performs much better on RewardMATH (51.34) but worse on RewardBench (78.5). This may be due to the lack of reasoning steps typically found in human-written solutions, and as a result, our AceMath-7B-RM outperforms it on both benchmarks. In conclusion, these evaluation results highlight the benefits of training on diverse, model-generated solutions to mitigate, though not entirely eliminate, out-of-distribution generalization challenges.
| Model | AceMath-RewardBench |
| --- | --- |
| AceMath-7B-RM | 67.41 |
| $\triangleright$ Backbone: Qwen2.5-Math-7B-Instruct | 66.93 |
| $\triangleright$ Data: Random sampling | 67.07 |
| $\triangleright$ Loss: Pairwise BT | 67.33 |
| $\triangleright$ Loss: Cross-entropy Classification | 66.93 |
| $\triangleright$ Loss: MSE Regression | 66.79 |
| \hdashline AceMath-72B-RM | 69.53 |
| $\triangleright$ Backbone: Qwen2.5-Math-72B-Instruct | 69.09 |
| $\triangleright$ Loss: Cross-entropy Classification | 68.66 |
Table 8: Ablation study of AceMath-7/72B-RM on AceMath-RewardBench (Backbone: AceMath-7/72B-Instruct; Data: reward score-sorted sampling; Loss: listwise Bradley-Terry.
4.4.5 Ablation studies
In Table 8, we conduct ablation studies on the model backbone, data sampling method, and different loss functions used to train the reward model. First, we found that using AceMath-7B-Instruct as the backbone model for training the model consistently outperforms Qwen2.5-Math-7B-Instruct on average of 7 datasets, with a similar performance gap observed at the 72B scale. Secondly, we observed that employing reward score-sorted sampling (§ 4.1.2) during the data construction process improves average accuracy compared to random sampling. This highlights the benefits of filtering out noisy labels when heuristic evaluation toolkits produce false negative errors. Lastly, we experimented with different loss functions. We found that using pairwise Bradley-Terry loss achieves comparable accuracy to the listwise loss approach, however requiring 3.7 $×$ more training time using 8 H100 GPUs. Additionally, training a classifier using cross-entropy loss or a regression model using mean squared error (MSE) loss both resulted in lower accuracy. A similar performance gap was also observed at the 72B scale for the cross-entropy classification approach. Since the data is constructed for the listwise BT approach, where each problem consists of six responses, this also leads to 3.8 times more compute hours on 8 GPUs.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Line Chart: RM@K Accuracy vs. Number of Samples
### Overview
This line chart compares the RM@K (Accuracy) of two models, AceMath-72B-RM and Qwen2.5-Math-RM-72B, across varying numbers of samples. The chart displays the accuracy as a function of the number of samples used, with confidence intervals represented by shaded areas around each line.
### Components/Axes
* **X-axis:** Number of Samples. Scale ranges from 8 to 128, with markers at 8, 16, 32, 64, and 128.
* **Y-axis:** RM@K (Accuracy). Scale ranges from 72.0 to 74.5, with markers at 72.0, 72.5, 73.0, 73.5, 74.0, and 74.5.
* **Data Series 1:** AceMath-72B-RM (represented by a green line with a lighter green shaded confidence interval).
* **Data Series 2:** Qwen2.5-Math-RM-72B (represented by a blue line).
* **Legend:** Located in the top-right corner, labeling each line with its corresponding model name.
### Detailed Analysis
**AceMath-72B-RM (Green Line):**
The green line representing AceMath-72B-RM exhibits a generally upward trend, indicating increasing accuracy with a larger number of samples.
* At 8 samples: Approximately 72.2 (± 0.1)
* At 16 samples: Approximately 73.0 (± 0.1)
* At 32 samples: Approximately 73.7 (± 0.1)
* At 64 samples: Approximately 74.2 (± 0.1)
* At 128 samples: Approximately 74.4 (± 0.1)
**Qwen2.5-Math-RM-72B (Blue Line):**
The blue line representing Qwen2.5-Math-RM-72B shows an initial increase in accuracy, followed by a plateau.
* At 8 samples: Approximately 72.1
* At 16 samples: Approximately 73.0
* At 32 samples: Approximately 73.4
* At 64 samples: Approximately 73.6
* At 128 samples: Approximately 73.2
The confidence interval for AceMath-72B-RM is relatively consistent across all sample sizes, indicating stable performance.
### Key Observations
* AceMath-72B-RM consistently outperforms Qwen2.5-Math-RM-72B across all sample sizes.
* The accuracy of Qwen2.5-Math-RM-72B plateaus after 32 samples, suggesting diminishing returns from increasing the sample size.
* AceMath-72B-RM continues to improve in accuracy even at the highest sample size (128).
* The confidence interval for AceMath-72B-RM is narrow, indicating a reliable and consistent performance.
### Interpretation
The data suggests that AceMath-72B-RM is a more scalable model than Qwen2.5-Math-RM-72B, as its accuracy continues to improve with more samples. Qwen2.5-Math-RM-72B reaches a performance limit relatively quickly. The consistent confidence interval for AceMath-72B-RM indicates that its performance is less sensitive to the specific samples used, making it a more robust choice. The difference in performance between the two models could be attributed to differences in their architectures, training data, or optimization strategies. The RM@K metric likely represents a rank-based accuracy measure, where a higher value indicates better performance in ranking correct answers among a set of candidates. The plateauing of Qwen2.5-Math-RM-72B suggests that it may have reached its capacity to learn from the given data or that the ranking task becomes saturated with its current capabilities.
</details>
Figure 4: rm@ $k$ evaluation on average accuracy of 7 datasets for AceMath-7B-Instruct.
<details>
<summary>x5.png Details</summary>
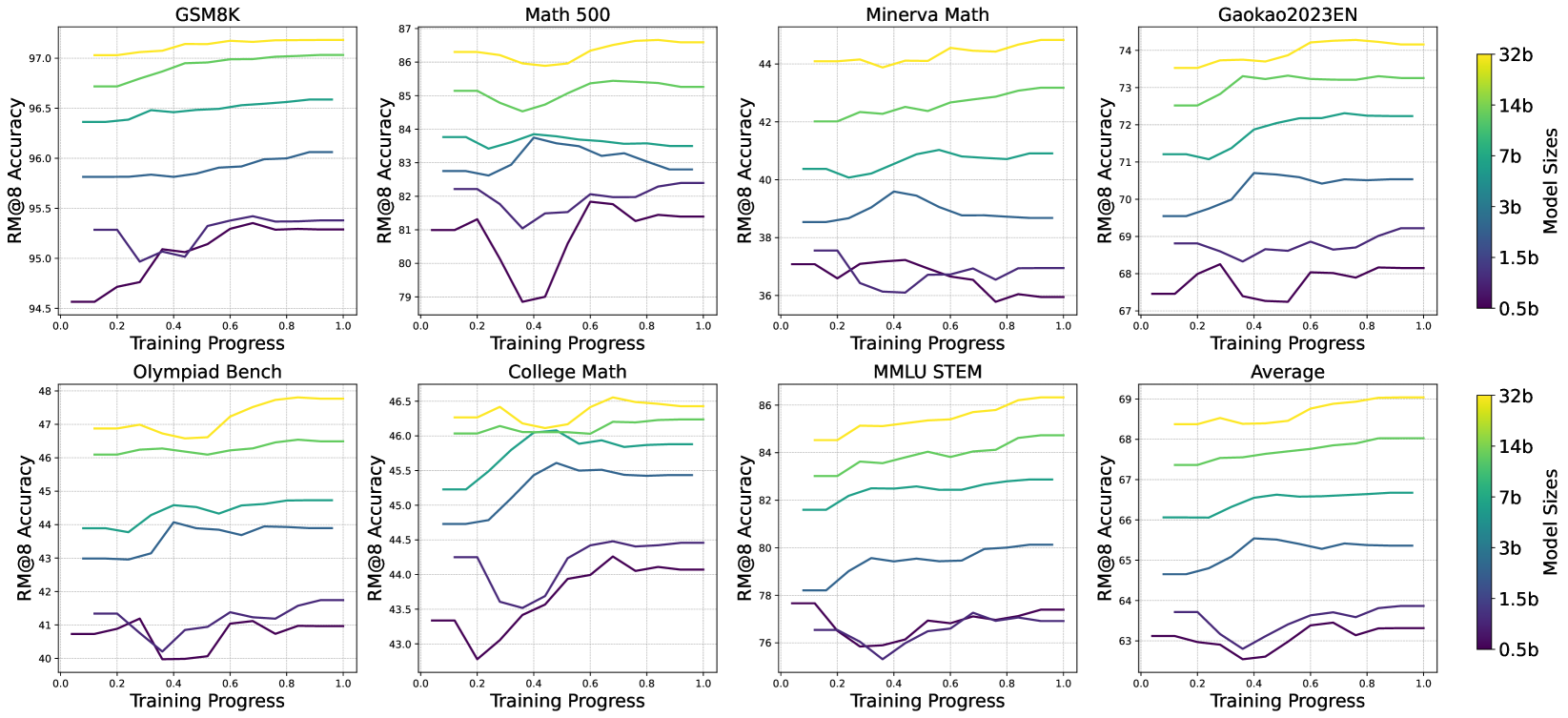
### Visual Description
## Charts: Model Performance vs. Training Progress
### Overview
The image presents a 3x4 grid of line charts, each depicting the relationship between RM@8 Accuracy and Training Progress for different datasets and model sizes. The charts compare the performance of models with varying numbers of parameters (0.5b, 1.5b, 3b, 7b, 14b, and 32b) as they are trained. The datasets include GSM8K, Math 500, Minerva Math, Gaokao2023EN, Olympiad Bench, College Math, MMLU STEM, and an Average across all datasets.
### Components/Axes
* **X-axis:** Training Progress, ranging from 0.0 to 1.0.
* **Y-axis:** RM@8 Accuracy, with varying scales depending on the dataset.
* GSM8K: 94.5 to 97.0
* Math 500: 79 to 87
* Minerva Math: 36 to 44
* Gaokao2023EN: 67 to 74
* Olympiad Bench: 40 to 48
* College Math: 43 to 46.5
* MMLU STEM: 76 to 86
* Average: 63 to 69
* **Legend:** Located on the right side of the image, indicating model sizes with corresponding colors:
* 32b (Dark Blue)
* 14b (Light Blue)
* 7b (Green)
* 3b (Red)
* 1.5b (Orange)
* 0.5b (Purple)
### Detailed Analysis or Content Details
**GSM8K:**
* The 32b model (Dark Blue) shows a slight upward trend, starting around 96.2 and ending around 96.8.
* The 14b model (Light Blue) starts around 95.8 and ends around 96.5, showing a moderate upward trend.
* The 7b model (Green) starts around 95.5 and ends around 96.2, with a slight upward trend.
* The 3b model (Red) starts around 95.2 and ends around 95.8, with a minimal upward trend.
* The 1.5b model (Orange) starts around 94.8 and ends around 95.3, with a slight upward trend.
* The 0.5b model (Purple) starts around 94.5 and ends around 95.0, with a minimal upward trend.
**Math 500:**
* The 32b model (Dark Blue) shows a slight downward trend, starting around 86.5 and ending around 85.5.
* The 14b model (Light Blue) shows a downward trend, starting around 85.0 and ending around 83.5.
* The 7b model (Green) shows a downward trend, starting around 84.0 and ending around 82.0.
* The 3b model (Red) shows a downward trend, starting around 83.0 and ending around 80.5.
* The 1.5b model (Orange) shows a downward trend, starting around 82.0 and ending around 79.5.
* The 0.5b model (Purple) shows a downward trend, starting around 81.0 and ending around 79.0.
**Minerva Math:**
* The 32b model (Dark Blue) shows a slight upward trend, starting around 41.5 and ending around 42.5.
* The 14b model (Light Blue) shows a slight upward trend, starting around 40.5 and ending around 41.5.
* The 7b model (Green) shows a slight upward trend, starting around 39.5 and ending around 40.5.
* The 3b model (Red) shows a slight upward trend, starting around 38.5 and ending around 39.5.
* The 1.5b model (Orange) shows a slight upward trend, starting around 37.5 and ending around 38.5.
* The 0.5b model (Purple) shows a slight upward trend, starting around 36.5 and ending around 37.5.
**Gaokao2023EN:**
* The 32b model (Dark Blue) shows a slight upward trend, starting around 72.5 and ending around 73.5.
* The 14b model (Light Blue) shows a slight upward trend, starting around 71.5 and ending around 72.5.
* The 7b model (Green) shows a slight upward trend, starting around 70.5 and ending around 71.5.
* The 3b model (Red) shows a slight upward trend, starting around 69.5 and ending around 70.5.
* The 1.5b model (Orange) shows a slight upward trend, starting around 68.5 and ending around 69.5.
* The 0.5b model (Purple) shows a slight upward trend, starting around 67.5 and ending around 68.5.
**Olympiad Bench:**
* The 32b model (Dark Blue) shows a slight upward trend, starting around 45.5 and ending around 46.5.
* The 14b model (Light Blue) shows a slight upward trend, starting around 44.5 and ending around 45.5.
* The 7b model (Green) shows a slight upward trend, starting around 43.5 and ending around 44.5.
* The 3b model (Red) shows a slight upward trend, starting around 42.5 and ending around 43.5.
* The 1.5b model (Orange) shows a slight upward trend, starting around 41.5 and ending around 42.5.
* The 0.5b model (Purple) shows a slight upward trend, starting around 40.5 and ending around 41.5.
**College Math:**
* The 32b model (Dark Blue) shows a slight upward trend, starting around 45.5 and ending around 46.0.
* The 14b model (Light Blue) shows a slight upward trend, starting around 44.5 and ending around 45.0.
* The 7b model (Green) shows a slight upward trend, starting around 43.5 and ending around 44.0.
* The 3b model (Red) shows a slight upward trend, starting around 42.5 and ending around 43.0.
* The 1.5b model (Orange) shows a slight upward trend, starting around 41.5 and ending around 42.0.
* The 0.5b model (Purple) shows a slight upward trend, starting around 40.5 and ending around 41.0.
**MMLU STEM:**
* The 32b model (Dark Blue) shows a slight upward trend, starting around 82.5 and ending around 83.5.
* The 14b model (Light Blue) shows a slight upward trend, starting around 81.5 and ending around 82.5.
* The 7b model (Green) shows a slight upward trend, starting around 80.5 and ending around 81.5.
* The 3b model (Red) shows a slight upward trend, starting around 79.5 and ending around 80.5.
* The 1.5b model (Orange) shows a slight upward trend, starting around 78.5 and ending around 79.5.
* The 0.5b model (Purple) shows a slight upward trend, starting around 76.5 and ending around 77.5.
**Average:**
* The 32b model (Dark Blue) shows a slight upward trend, starting around 66.5 and ending around 67.5.
* The 14b model (Light Blue) shows a slight upward trend, starting around 65.5 and ending around 66.5.
* The 7b model (Green) shows a slight upward trend, starting around 64.5 and ending around 65.5.
* The 3b model (Red) shows a slight upward trend, starting around 63.5 and ending around 64.5.
* The 1.5b model (Orange) shows a slight upward trend, starting around 63.0 and ending around 64.0.
* The 0.5b model (Purple) shows a slight upward trend, starting around 62.5 and ending around 63.5.
### Key Observations
* Generally, larger models (32b, 14b) exhibit slightly higher accuracy than smaller models (0.5b, 1.5b) across most datasets.
* The Math 500 dataset shows a consistent downward trend in accuracy for all model sizes, suggesting potential difficulties in this domain.
* The Minerva Math dataset shows the lowest overall accuracy levels, indicating a challenging task.
* The GSM8K dataset shows the highest overall accuracy levels.
* The accuracy improvements across training progress are generally small, suggesting diminishing returns.
### Interpretation
The charts demonstrate the performance of language models of varying sizes on a range of tasks. The consistent trend of larger models outperforming smaller models highlights the benefits of increased model capacity. However, the relatively small accuracy gains with increased training progress suggest that the models may be approaching their performance limits or that the training data is not sufficiently diverse or challenging. The downward trend observed in the Math 500 dataset indicates that this task is particularly difficult for these models, potentially requiring specialized architectures or training techniques. The differences in performance across datasets suggest that the models' capabilities vary depending on the nature of the task. The average chart provides a consolidated view of performance, showing that even the largest models have room for improvement. The data suggests that scaling model size is a viable strategy for improving performance, but it is not a panacea, and further research is needed to address the challenges posed by specific tasks like Math 500.
</details>
Figure 5: Learning curves for reward model training. All models are trained from Qwen2.5-Instruct family.
4.4.6 Results on rm@ $k$
In Figure 4, we present a comparison between AceMath-72B-RM and Qwen2.5-Math-RM-72B on rm@ $k$ ( $k=8,16,32,64,128$ ) across the seven datasets listed in Table 6, using samples generated by AceMath-7B-Instruct. We report the average accuracy across these seven datasets, each with 10 different random seeds.
First, we find that using AceMath-72B-RM to score the outputs from AceMath-7B-Instruct consistently improves the average accuracy, increasing from 72.6 to 74.4 as $k$ rises from 8 to 128. Second, we observe that AceMath-RM consistently outperforms Qwen2.5-Math-RM in scoring outputs generated from AceMath-7B-Instruct, and this improvement becomes larger as $k$ increases.
Furthermore, we compare the performance of AceMath-72B-RM paired with AceMath-Instruct to Qwen2.5-Math-RM-72B paired with Qwen2.5-Math-Instruct. As shown in Figure 1, the AceMath combination consistently outperforms its Qwen2.5 counterpart in terms of rm@8, on average, for both the 7B and 72B models. Remarkably, we find that the our AceMath-7B model even outperforms the Qwen2.5-Math-72B in rm@8, showing the potential of a smaller model when paired with a carefully designed reward model.
4.4.7 Learning curves of reward model training
In Figure 5, we aim to understand how reward modeling accuracy improves as we increase model size and use additional data. We find distinct patterns in the interplay between model size and data scaling. In general on simpler dataset such as GSM8K, all model sizes (ranging from 0.5B to 32B parameters) exhibit steady improvements as training proceeds, with larger models achieving higher accuracy. In contrast, on the more challenging datasets, which requires college-level knowledge, such as Minerva Math, MMLU STEM, and OlympiadBench, model size emerges as a critical factor: smaller models (e.g., 0.5B, 1.5B) show negligible improvement despite increased data, whereas larger models (e.g., 14B, 32B) achieve better accuracy gains. These results suggest that increasing model size provides the greatest benefit, whereas the advantages of increasing data appear less pronounced. Our experiments use Qwen2.5-Instruct (Yang et al., 2024a) model family. instead of Qwen2.5-Math-Instruct, as it provides a more comprehensive set of models with different sizes. All models are trained for one epoch only.
5 Conclusion
In this work, we present AceMath, a series of frontier-class math instruct and reward models. We demonstrate that our AceMath-7B-Instruct significantly surpasses the previous best-in-class Qwen2.5-Math-7B-Instruct across comprehensive math reasoning benchmarks, and it performs slightly worse than a 10 $×$ larger Qwen2.5-Math-72-Instruct (67.2 vs. 68.2). Remarkably, our AceMath-72B-Instruct greatly outperforms Qwen2.5-Math-72-Instruct, GPT-4o and Claude-3.5 Sonnet. Additionally, we construct AceMath-RewardBench, a comprehensive benchmark designed to evaluate math reward models across a diverse range of datasets and difficulty levels. We show that our AceMath-72B-RM consistently outperforms state-of-the-art reward models, including Qwen2.5-Math-RM-72B and Skywork-o1-Open-PRM-Qwen-2.5-7B, on various math reward benchmarks. Furthermore, when combining AceMath-72B-Instruct with AceMath-72B-RM, we achieve the highest average rm@8 score across the math reasoning benchmarks. To advance open research in the field, we will open source the model weights for both AceMath-Instruct and AceMath-RM, along with the complete training data used throughout their development.
References
- Adler et al. (2024) Adler, B., Agarwal, N., Aithal, A., Anh, D. H., Bhattacharya, P., Brundyn, A., Casper, J., Catanzaro, B., Clay, S., Cohen, J., et al. Nemotron-4 340b technical report. arXiv preprint arXiv:2406.11704, 2024.
- Akter et al. (2024) Akter, S. N., Prabhumoye, S., Kamalu, J., Satheesh, S., Nyberg, E., Patwary, M., Shoeybi, M., and Catanzaro, B. Mind: Math informed synthetic dialogues for pretraining llms. arXiv preprint arXiv:2410.12881, 2024.
- Anthropic (2024) Anthropic. Introducing claude 3.5 sonnet. 2024. URL https://www.anthropic.com/news/claude-3-5-sonnet.
- Austin et al. (2021) Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- Azerbayev et al. (2023) Azerbayev, Z., Schoelkopf, H., Paster, K., Santos, M. D., McAleer, S., Jiang, A. Q., Deng, J., Biderman, S., and Welleck, S. Llemma: An open language model for mathematics. arXiv preprint arXiv:2310.10631, 2023.
- Bai et al. (2022) Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- Bradley & Terry (1952) Bradley, R. A. and Terry, M. E. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952. ISSN 00063444, 14643510. URL http://www.jstor.org/stable/2334029.
- Cai et al. (2024) Cai, Z., Cao, M., Chen, H., Chen, K., Chen, K., Chen, X., Chen, X., Chen, Z., Chen, Z., Chu, P., et al. Internlm2 technical report. arXiv preprint arXiv:2403.17297, 2024.
- Chen et al. (2021) Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Chen et al. (2024) Chen, Z., Wang, W., Tian, H., Ye, S., Gao, Z., Cui, E., Tong, W., Hu, K., Luo, J., Ma, Z., et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv preprint arXiv:2404.16821, 2024.
- Chiang et al. (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J. E., Stoica, I., and Xing, E. P. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Cobbe et al. (2021) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Dai et al. (2024) Dai, W., Lee, N., Wang, B., Yang, Z., Liu, Z., Barker, J., Rintamaki, T., Shoeybi, M., Catanzaro, B., and Ping, W. NVLM: Open frontier-class multimodal LLMs. arXiv preprint arXiv:2409.11402, 2024.
- Dong et al. (2024) Dong, H., Xiong, W., Pang, B., Wang, H., Zhao, H., Zhou, Y., Jiang, N., Sahoo, D., Xiong, C., and Zhang, T. Rlhf workflow: From reward modeling to online rlhf. TMLR, 2024.
- Dubey et al. (2024) Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Gemma et al. (2024) Gemma, Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ramé, A., et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024.
- Glaive-AI (2023) Glaive-AI. GlaiveCodeAssistant, 2023. URL https://huggingface.co/datasets/glaiveai/glaive-code-assistant-v2.
- Guo et al. (2024) Guo, D., Zhu, Q., Yang, D., Xie, Z., Dong, K., Zhang, W., Chen, G., Bi, X., Li, Y., et al. Deepseek-coder: When the large language model meets programming–the rise of code intelligence. arXiv preprint arXiv:2401.14196, 2024.
- He et al. (2024) He, C., Luo, R., Bai, Y., Hu, S., Thai, Z. L., Shen, J., Hu, J., Han, X., Huang, Y., Zhang, Y., et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. arXiv preprint arXiv:2402.14008, 2024.
- Hendrycks et al. (2020) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2020.
- Hendrycks et al. (2021a) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021a.
- Hendrycks et al. (2021b) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021b.
- Hui et al. (2024) Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., et al. Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186, 2024.
- Jiang et al. (2023) Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. d. l., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Kim et al. (2024) Kim, S., Kang, D., Kwon, T., Chae, H., Won, J., Lee, D., and Yeo, J. Evaluating robustness of reward models for mathematical reasoning. arXiv preprint arXiv:2410.01729, 2024.
- Kingma (2014) Kingma, D. P. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Lambert et al. (2024) Lambert, N., Pyatkin, V., Morrison, J., Miranda, L., Lin, B. Y., Chandu, K., Dziri, N., Kumar, S., Zick, T., Choi, Y., et al. Rewardbench: Evaluating reward models for language modeling. arXiv preprint arXiv:2403.13787, 2024.
- Lewkowycz et al. (2022) Lewkowycz, A., Andreassen, A., Dohan, D., Dyer, E., Michalewski, H., Ramasesh, V., Slone, A., Anil, C., Schlag, I., Gutman-Solo, T., et al. Solving quantitative reasoning problems with language models. Advances in Neural Information Processing Systems, 35:3843–3857, 2022.
- Li et al. (2024a) Li, C., Yuan, Z., Yuan, H., Dong, G., Lu, K., Wu, J., Tan, C., Wang, X., and Zhou, C. Mugglemath: Assessing the impact of query and response augmentation on math reasoning. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 10230–10258, 2024a.
- Li et al. (2024b) Li, J., Beeching, E., Tunstall, L., Lipkin, B., Soletskyi, R., Huang, S. C., Rasul, K., Yu, L., Jiang, A., Shen, Z., Qin, Z., Dong, B., Zhou, L., Fleureau, Y., Lample, G., and Polu, S. Numinamath. [https://huggingface.co/AI-MO/NuminaMath-CoT](https://github.com/project-numina/aimo-progress-prize/blob/main/report/numina_dataset.pdf), 2024b.
- Lian et al. (2023) Lian, W., Wang, G., Goodson, B., Pentland, E., Cook, A., Vong, C., and ”Teknium”. Slimorca: An open dataset of gpt-4 augmented flan reasoning traces, with verification, 2023. URL https://https://huggingface.co/Open-Orca/SlimOrca.
- Liao et al. (2024) Liao, M., Luo, W., Li, C., Wu, J., and Fan, K. Mario: Math reasoning with code interpreter output–a reproducible pipeline. arXiv preprint arXiv:2401.08190, 2024.
- Lightman et al. (2023) Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023.
- Liu et al. (2024a) Liu, C. Y., Zeng, L., Liu, J., Yan, R., He, J., Wang, C., Yan, S., Liu, Y., and Zhou, Y. Skywork-reward: Bag of tricks for reward modeling in llms. arXiv preprint arXiv:2410.18451, 2024a.
- Liu et al. (2024b) Liu, Y., Yao, Z., Min, R., Cao, Y., Hou, L., and Li, J. Rm-bench: Benchmarking reward models of language models with subtlety and style. arXiv preprint arXiv:2410.16184, 2024b.
- Liu et al. (2024c) Liu, Z., Ping, W., Roy, R., Xu, P., Lee, C., Shoeybi, M., and Catanzaro, B. ChatQA: Surpassing gpt-4 on conversational QA and RAG. In NeurIPS, 2024c.
- Loshchilov (2017) Loshchilov, I. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Lu et al. (2024) Lu, J., Dou, Z., Wang, H., Cao, Z., Dai, J., Wan, Y., Huang, Y., and Guo, Z. Autocv: Empowering reasoning with automated process labeling via confidence variation. arXiv preprint arXiv:2405.16802, 2024.
- Luo et al. (2024) Luo, L., Liu, Y., Liu, R., Phatale, S., Lara, H., Li, Y., Shu, L., Zhu, Y., Meng, L., Sun, J., et al. Improve mathematical reasoning in language models by automated process supervision. arXiv preprint arXiv:2406.06592, 2024.
- Luo et al. (2023) Luo, Z., Xu, C., Zhao, P., Sun, Q., Geng, X., Hu, W., Tao, C., Ma, J., Lin, Q., and Jiang, D. Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568, 2023.
- Mistral (2024) Mistral. Math $\Sigma$ tral, 2024. URL https://mistral.ai/news/mathstral/.
- Mitra et al. (2024) Mitra, A., Khanpour, H., Rosset, C., and Awadallah, A. Orca-math: Unlocking the potential of slms in grade school math. arXiv preprint arXiv:2402.14830, 2024.
- Mukherjee et al. (2023) Mukherjee, S., Mitra, A., Jawahar, G., Agarwal, S., Palangi, H., and Awadallah, A. Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707, 2023.
- OpenAI (2024a) OpenAI. Hello GPT-4o, 2024a. URL https://openai.com/index/hello-gpt-4o/.
- OpenAI (2024b) OpenAI. GPT-4o mini: advancing cost-efficient intelligence, 2024b.
- Ouyang et al. (2022) Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- Peng et al. (2023) Peng, B., Li, C., He, P., Galley, M., and Gao, J. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277, 2023.
- Setlur et al. (2024) Setlur, A., Nagpal, C., Fisch, A., Geng, X., Eisenstein, J., Agarwal, R., Agarwal, A., Berant, J., and Kumar, A. Rewarding progress: Scaling automated process verifiers for llm reasoning. arXiv preprint arXiv:2410.08146, 2024.
- Shao et al. (2024) Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, Y., Wu, Y., and Guo, D. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- Shen et al. (2021) Shen, J. T., Yamashita, M., Prihar, E., Heffernan, N., Wu, X., Graff, B., and Lee, D. Mathbert: A pre-trained language model for general nlp tasks in mathematics education. In NeurIPS 2021 Math AI for Education Workshop, 2021.
- Skywork-o1 (2024) Skywork-o1. Skywork-o1 open series. https://huggingface.co/Skywork, November 2024. URL https://huggingface.co/Skywork.
- Tang et al. (2024) Tang, Z., Zhang, X., Wang, B., and Wei, F. Mathscale: Scaling instruction tuning for mathematical reasoning. In Forty-first International Conference on Machine Learning, 2024.
- Tao (2023) Tao, T. Embracing change and resetting expectations, 2023. URL https://unlocked.microsoft.com/ai-anthology/terence-tao/.
- Teknium (2023) Teknium. GPTeacher-General-Instruct, 2023. URL https://huggingface.co/datasets/teknium/GPTeacher-General-Instruct.
- The-Vicuna-Team (2023) The-Vicuna-Team. ShareGPT-Vicuna, 2023. URL https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered.
- Toshniwal et al. (2024) Toshniwal, S., Du, W., Moshkov, I., Kisacanin, B., Ayrapetyan, A., and Gitman, I. Openmathinstruct-2: Accelerating ai for math with massive open-source instruction data. arXiv preprint arXiv:2410.01560, 2024.
- Touvron et al. (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Uesato et al. (2022) Uesato, J., Kushman, N., Kumar, R., Song, F., Siegel, N., Wang, L., Creswell, A., Irving, G., and Higgins, I. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022.
- Wang et al. (2024a) Wang, H., Xiong, W., Xie, T., Zhao, H., and Zhang, T. Interpretable preferences via multi-objective reward modeling and mixture-of-experts. In EMNLP, 2024a.
- Wang et al. (2024b) Wang, P., Li, L., Shao, Z., Xu, R., Dai, D., Li, Y., Chen, D., Wu, Y., and Sui, Z. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, August 2024b. Association for Computational Linguistics.
- Wang et al. (2024c) Wang, Y., Ma, X., Zhang, G., Ni, Y., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. arXiv preprint arXiv:2406.01574, 2024c.
- Wang et al. (2023) Wang, Z., Xia, R., and Liu, P. Generative ai for math: Part i–mathpile: A billion-token-scale pretraining corpus for math. arXiv preprint arXiv:2312.17120, 2023.
- Wang et al. (2024d) Wang, Z., Bukharin, A., Delalleau, O., Egert, D., Shen, G., Zeng, J., Kuchaiev, O., and Dong, Y. Helpsteer2-preference: Complementing ratings with preferences, 2024d. URL https://arxiv.org/abs/2410.01257.
- Wang et al. (2024e) Wang, Z., Dong, Y., Delalleau, O., Zeng, J., Shen, G., Egert, D., Zhang, J. J., Sreedhar, M. N., and Kuchaiev, O. Helpsteer2: Open-source dataset for training top-performing reward models, 2024e.
- Wei et al. (2022) Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- Wei et al. (2024) Wei, Y., Wang, Z., Liu, J., Ding, Y., and Zhang, L. Magicoder: Empowering code generation with oss-instruct. In Forty-first International Conference on Machine Learning, 2024.
- Xu et al. (2024) Xu, C., Sun, Q., Zheng, K., Geng, X., Zhao, P., Feng, J., Tao, C., Lin, Q., and Jiang, D. WizardLM: Empowering large pre-trained language models to follow complex instructions. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=CfXh93NDgH.
- Yang et al. (2024a) Yang, A., Yang, B., Hui, B., Zheng, B., Yu, B., Zhou, C., Li, C., Li, C., Liu, D., Huang, F., et al. Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2024a.
- Yang et al. (2024b) Yang, A., Zhang, B., Hui, B., Gao, B., Yu, B., Li, C., Liu, D., Tu, J., Zhou, J., Lin, J., et al. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122, 2024b.
- Ying et al. (2024) Ying, H., Zhang, S., Li, L., Zhou, Z., Shao, Y., Fei, Z., Ma, Y., Hong, J., Liu, K., Wang, Z., et al. InternLM-Math: Open math large language models toward verifiable reasoning. arXiv preprint arXiv:2402.06332, 2024.
- Yu et al. (2023) Yu, L., Jiang, W., Shi, H., Yu, J., Liu, Z., Zhang, Y., Kwok, J. T., Li, Z., Weller, A., and Liu, W. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023.
- Yu et al. (2024) Yu, Y., Chen, Z., Zhang, A., Tan, L., Zhu, C., Pang, R. Y., Qian, Y., Wang, X., Gururangan, S., Zhang, C., et al. Self-generated critiques boost reward modeling for language models. arXiv preprint arXiv:2411.16646, 2024.
- Yuan et al. (2024) Yuan, L., Cui, G., Wang, H., Ding, N., Wang, X., Deng, J., Shan, B., Chen, H., Xie, R., Lin, Y., et al. Advancing llm reasoning generalists with preference trees. arXiv preprint arXiv:2404.02078, 2024.
- Yue et al. (2024a) Yue, X., Qu, X., Zhang, G., Fu, Y., Huang, W., Sun, H., Su, Y., and Chen, W. Mammoth: Building math generalist models through hybrid instruction tuning. ICLR, 2024a.
- Yue et al. (2024b) Yue, X., Zheng, T., Zhang, G., and Chen, W. Mammoth2: Scaling instructions from the web. NeurIPS, 2024b.
- Zhang et al. (2024a) Zhang, F., Li, C., Henkel, O., Xing, W., Baral, S., Heffernan, N., and Li, H. Math-llms: Ai cyberinfrastructure with pre-trained transformers for math education. International Journal of Artificial Intelligence in Education, pp. 1–24, 2024a.
- Zhang et al. (2024b) Zhang, H., Wang, P., Diao, S., Lin, Y., Pan, R., Dong, H., Zhang, D., Molchanov, P., and Zhang, T. Entropy-regularized process reward model, 2024b.
- Zhang et al. (2024c) Zhang, L., Hosseini, A., Bansal, H., Kazemi, M., Kumar, A., and Agarwal, R. Generative verifiers: Reward modeling as next-token prediction. arXiv preprint arXiv:2408.15240, 2024c.
- Zheng et al. (2024) Zheng, C., Zhang, Z., Zhang, B., Lin, R., Lu, K., Yu, B., Liu, D., Zhou, J., and Lin, J. Processbench: Identifying process errors in mathematical reasoning. arXiv preprint arXiv:2412.06559, 2024.
- Zheng et al. (2023) Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36:46595–46623, 2023.
Appendix A AIME 2024 & AMC 2023 Results
| Models | AIME 2024 | AMC 2023 |
| --- | --- | --- |
| Llama-3.1-405B-Instruct | 5/30 | 20/40 |
| Claude 3.5 Sonnet (2024-1022) | 4/30 | 21/40 |
| OpenMath2-Llama3.1-8B | 3/30 | 16/40 |
| OpenMath2-Llama3.1-70B | 4/30 | 20/40 |
| Qwen2.5-Math-1.5B-Instruct | 3/30 | 24/40 |
| Qwen2.5-Math-7B-Instruct | 5/30 | 25/40 |
| Qwen2.5-Math-72B-Instruct | 9/30 | 28/40 |
| AceMath-1.5B-Instruct | 4/30 | 25/40 |
| AceMath-7B-Instruct | 6/30 | 26/40 |
| AceMath-72B-Instruct | 6/30 | 28/40 |
Table 9: Greedy decoding results of AceMath-Instruct on AIME 2024 and AMC 2023.
Table 9 shows the greedy decoding results on AIME 2024 and AMC 2023. We find that the AceMath-1.5B/7B-Instruct models slightly outperform Qwen2.5-Math-1.5B/7B-Instruct on both datasets, while AceMath-72B-Instruct falls short of Qwen2.5-Math-72B-Instruct’s performance on AIME 2024. Given that AIME 2024 contains challenging math problems comparable to pre-Olympiad levels, these results indicate that there is room to improve AceMath-Instruct to better address varying levels of mathematical difficulty.
Appendix B AceMath-Instruct Using Different Backbone Models
| Models | GSM8K | MATH | Minerva Math | GaoKao 2023 En | Olympiad Bench | College Math | MMLU STEM | Avg. |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| DeepSeek-Math-7B-RL | 88.20 | 52.40 | 20.60 | 43.60 | 19.00 | 37.50 | 64.80 | 46.59 |
| AceMath-Instruct (backbone: DeepSeek-Coder-7B-Base) | 83.85 | 59.72 | 29.78 | 53.51 | 24.59 | 44.64 | 55.95 | 50.29 |
| AceMath-Instruct (backbone: DeepSeek-Math-7B-Base) | 85.06 | 66.86 | 40.07 | 56.62 | 29.63 | 48.94 | 65.53 | 56.10 |
| Llama-3.1-8B-Instruct | 84.50 | 51.90 | 21.70 | 38.40 | 15.40 | 33.80 | 60.50 | 43.74 |
| OpenMath2-Llama3.1-8B | 91.70 | 67.80 | 16.91 | 53.76 | 28.00 | 46.13 | 46.02 | 50.08 |
| AceMath-Instruct (backbone: Llama3.1-8B-Base) | 91.51 | 69.06 | 31.99 | 59.74 | 32.00 | 49.08 | 67.94 | 57.33 |
| Qwen2.5-Math-1.5B-Instruct | 84.80 | 75.80 | 29.40 | 65.50 | 38.10 | 47.70 | 57.50 | 56.97 |
| AceMath-Instruct (backbone: Qwen2.5-1.5B-Base) | 80.89 | 64.59 | 30.51 | 53.25 | 27.11 | 47.80 | 58.62 | 51.82 |
| AceMath-Instruct (backbone: Qwen2.5-Math-1.5B-Base) | 86.95 | 76.84 | 41.54 | 64.42 | 33.78 | 54.36 | 62.04 | 59.99 |
| Qwen2.5-Math-7B-Instruct | 95.20 | 83.60 | 37.10 | 66.80 | 41.60 | 46.80 | 71.90 | 63.29 |
| AceMath-Instruct (backbone: Qwen2.5-7B-Base) | 93.56 | 77.10 | 43.38 | 65.19 | 37.78 | 54.90 | 77.41 | 64.19 |
| AceMath-Instruct (backbone: Qwen2.5-Math-7B-Base) | 93.71 | 83.14 | 51.11 | 68.05 | 42.22 | 56.64 | 75.32 | 67.17 |
| Qwen2.5-Math-72B-Instruct | 95.90 | 85.90 | 44.10 | 71.90 | 49.00 | 49.50 | 80.80 | 68.16 |
| AceMath-Instruct (backbone: Qwen2.5-72B-Base) | 95.99 | 85.06 | 54.04 | 73.25 | 46.96 | 57.10 | 85.48 | 71.13 |
| AceMath-Instruct (backbone: Qwen2.5-Math-72B-Base) | 96.44 | 86.10 | 56.99 | 72.21 | 48.44 | 57.24 | 85.44 | 71.84 |
Table 10: Greedy decoding results of AceMath-Instruct across different backbone models.
Table 10 shows the full results of AceMath-Instruct using various models as backbone models. Additionally, we include the results for Llama3.1-8B-Base as the backbone model and compare our model to OpenMath2-Llama3.1-8B (Toshniwal et al., 2024) that also uses Llama3.1-8B-Base as its backbone model. We find that except for our 1.5B model based on Qwen2.5-1.5B-Base, all our models, including those built on base models, outperform their respective strong baselines, often by a significant margin.
Appendix C Synthetic Prompt Generation for Math SFT
In this section, we describe the prompt we provided to GPT-4o-mini (2024-0718) for generating synthetic prompts tailored to math SFT. We utilize the in-breath evolution and in-depth evolution prompts inspired from Xu et al. (2024).
C.1 In-Breath Evolution
We use the following prompt to generate more diverse math questions. You are a good math question creator. Your objective is to draw inspiration from the #Given MATH Question# to create a brand new math question. This new math question should be distinctly different from the #Given MATH Question# and be even more unique. The length and difficulty level of the #Created MATH Question# should be similar to those of the #Given MATH Question#. The #Created MATH Question# must be solvable and understandable by humans. #Given MATH Question#: {given_math_question} #Created MATH Question#:
C.2 In-Depth Evolution
We use the following prompt to generate more challenging math questions.
You are a good math question creator. Your objective is to draw inspiration from the #Given MATH Question# to create a brand new math question. This new math question should be more complex and challenging than the #Given MATH Question#. The #Created MATH Question# must be solvable and understandable by humans. #Given MATH Question#: {given_math_question} #Created MATH Question#:
Moreover, we find that the following prompt that requires to add constraints to the given prompt could result in unsolvable or overly challenging math questions. This, in turn, can lead to incorrect answers being included in the training data, ultimately degrading model performance.
You are a good math question creator. Your objective is to rewrite the #Given MATH Question# into a brand new but more complex version. You can complicate the #Given MATH Question# by introducing additional constraints and requirements. The #Created MATH Question# must be solvable and understandable by humans. #Given MATH Question#: {given_math_question} #Created MATH Question#:
Appendix D Chain-of-Thought Reasoning Examples
Below, we present several Chain-of-Thought reasoning examples generated by AceMath-72B-Instruct.
Sample 1 Question: For each positive integer $N$ , let $P(N)$ denote the product of the digits of $N$ . For example, $P(8)=8$ , $P(451)=20$ , and $P(2023)=0$ . Compute the least positive integer $n$ such that $P(n+23)=P(n)+23$ .
AceMath-72B-Instruct: To find the least positive integer $n$ such that $P(n+23)=P(n)+23$ , we need to analyze the properties of the function $P$ , which gives the product of the digits of a number. Let’s start by considering the possible values of $n$ and their corresponding values of $P(n)$ and $P(n+23)$ .
First, note that if $n$ has a digit of 0, then $P(n)=0$ . In this case, $P(n+23)=23$ , which means $n+23$ must have digits whose product is 23. Since 23 is a prime number, the only way to achieve this is if $n+23$ is either 23 or a number with 2 and 3 as its only digits. However, $n$ must be a positive integer, so $n+23$ cannot be 23. Therefore, $n+23$ must be a number like 230, 203, 320, 302, etc. The smallest such number is 230, so $n=230-23=207$ . Let’s verify this solution:
- $P(207)=2· 0· 7=0$
- $P(230)=2· 3· 0=0$
This does not satisfy the equation $P(n+23)=P(n)+23$ . Therefore, we need to consider other possibilities. Next, let’s consider the case where $n$ does not have a digit of 0. We need to find $n$ such that the product of the digits of $n+23$ is 23 more than the product of the digits of $n$ . Let’s try some small values of $n$ :
- If $n=1$ , then $P(1)=1$ and $P(24)=2· 4=8$ . $8≠ 1+23$ .
- If $n=2$ , then $P(2)=2$ and $P(25)=2· 5=10$ . $10≠ 2+23$ .
- If $n=3$ , then $P(3)=3$ and $P(26)=2· 6=12$ . $12≠ 3+23$ .
- If $n=4$ , then $P(4)=4$ and $P(27)=2· 7=14$ . $14≠ 4+23$ .
- If $n=5$ , then $P(5)=5$ and $P(28)=2· 8=16$ . $16≠ 5+23$ .
- If $n=6$ , then $P(6)=6$ and $P(29)=2· 9=18$ . $18≠ 6+23$ .
- If $n=7$ , then $P(7)=7$ and $P(30)=3· 0=0$ . $0≠ 7+23$ .
- If $n=8$ , then $P(8)=8$ and $P(31)=3· 1=3$ . $3≠ 8+23$ .
- If $n=9$ , then $P(9)=9$ and $P(32)=3· 2=6$ . $6≠ 9+23$ .
- If $n=10$ , then $P(10)=1· 0=0$ and $P(33)=3· 3=9$ . $9≠ 0+23$ .
- If $n=11$ , then $P(11)=1· 1=1$ and $P(34)=3· 4=12$ . $12≠ 1+23$ .
- If $n=12$ , then $P(12)=1· 2=2$ and $P(35)=3· 5=15$ . $15≠ 2+23$ .
- If $n=13$ , then $P(13)=1· 3=3$ and $P(36)=3· 6=18$ . $18≠ 3+23$ .
- If $n=14$ , then $P(14)=1· 4=4$ and $P(37)=3· 7=21$ . $21=4+17$ .
- If $n=15$ , then $P(15)=1· 5=5$ and $P(38)=3· 8=24$ . $24=5+19$ .
- If $n=16$ , then $P(16)=1· 6=6$ and $P(39)=3· 9=27$ . $27=6+21$ .
- If $n=17$ , then $P(17)=1· 7=7$ and $P(40)=4· 0=0$ . $0≠ 7+23$ .
- If $n=18$ , then $P(18)=1· 8=8$ and $P(41)=4· 1=4$ . $4≠ 8+23$ .
- If $n=19$ , then $P(19)=1· 9=9$ and $P(42)=4· 2=8$ . $8≠ 9+23$ .
- If $n=20$ , then $P(20)=2· 0=0$ and $P(43)=4· 3=12$ . $12≠ 0+23$ .
- If $n=21$ , then $P(21)=2· 1=2$ and $P(44)=4· 4=16$ . $16≠ 2+23$ .
- If $n=22$ , then $P(22)=2· 2=4$ and $P(45)=4· 5=20$ . $20=4+16$ .
- If $n=23$ , then $P(23)=2· 3=6$ and $P(46)=4· 6=24$ . $24=6+18$ .
- If $n=24$ , then $P(24)=2· 4=8$ and $P(47)=4· 7=28$ . $28=8+20$ .
- If $n=25$ , then $P(25)=2· 5=10$ and $P(48)=4· 8=32$ . $32=10+22$ .
- If $n=26$ , then $P(26)=2· 6=12$ and $P(49)=4· 9=36$ . $36=12+24$ .
- If $n=27$ , then $P(27)=2· 7=14$ and $P(50)=5· 0=0$ . $0≠ 14+23$ .
- If $n=28$ , then $P(28)=2· 8=16$ and $P(51)=5· 1=5$ . $5≠ 16+23$ .
- If $n=29$ , then $P(29)=2· 9=18$ and $P(52)=5· 2=10$ . $10≠ 18+23$ .
- If $n=30$ , then $P(30)=3· 0=0$ and $P(53)=5· 3=15$ . $15≠ 0+23$ .
- If $n=31$ , then $P(31)=3· 1=3$ and $P(54)=5· 4=20$ . $20=3+17$ .
- If $n=32$ , then $P(32)=3· 2=6$ and $P(55)=5· 5=25$ . $25=6+19$ .
- If $n=33$ , then $P(33)=3· 3=9$ and $P(56)=5· 6=30$ . $30=9+21$ .
- If $n=34$ , then $P(34)=3· 4=12$ and $P(57)=5· 7=35$ . $35=12+23$ .
Thus, the least positive integer $n$ such that $P(n+23)=P(n)+23$ is $\boxed{34}$ .
Sample 2 Question: Consider the function $f(x)=x^{2}-2x$ . Determine all real numbers $x$ that satisfy the equation $f(f(f(x)))=3$ .
AceMath-72B-Instruct: To solve the equation $f(f(f(x)))=3$ where $f(x)=x^{2}-2x$ , we need to determine the values of $x$ that satisfy this equation step by step.
First, let’s find the values of $x$ that satisfy $f(x)=3$ . We start with the equation:
$$
x^{2}-2x=3
$$
Rearranging terms, we get:
$$
x^{2}-2x-3=0
$$
This quadratic equation can be factored as:
$$
(x-3)(x+1)=0
$$
So, the solutions are:
$$
x=3\quad\text{or}\quad x=-1
$$
This means that $f(x)=3$ if and only if $x=3$ or $x=-1$ .
Next, we need to find the values of $x$ such that $f(f(x))=3$ . From the previous step, we know that $f(f(x))=3$ if and only if $f(x)=3$ or $f(x)=-1$ .
We already know the solutions to $f(x)=3$ , which are $x=3$ and $x=-1$ . Now, let’s find the solutions to $f(x)=-1$ :
$$
x^{2}-2x=-1
$$
Rearranging terms, we get:
$$
x^{2}-2x+1=0
$$
This quadratic equation can be factored as:
$$
(x-1)^{2}=0
$$
So, the solution is:
$$
x=1
$$
Therefore, the solutions to $f(f(x))=3$ are $x=3$ , $x=-1$ , and $x=1$ .
Finally, we need to find the values of $x$ such that $f(f(f(x)))=3$ . From the previous step, we know that $f(f(f(x)))=3$ if and only if $f(f(x))=3$ or $f(f(x))=-1$ .
We already know the solutions to $f(f(x))=3$ , which are $x=3$ , $x=-1$ , and $x=1$ . Now, let’s find the solutions to $f(f(x))=-1$ :
$$
f(f(x))=-1
$$
From the previous step, we know that $f(x)=3$ or $f(x)=-1$ or $f(x)=1$ will satisfy $f(f(x))=3$ . We already know the solutions to $f(x)=3$ , which are $x=3$ and $x=-1$ . We also know the solution to $f(x)=-1$ , which is $x=1$ . Now, let’s find the solutions to $f(x)=1$ :
$$
x^{2}-2x=1
$$
Rearranging terms, we get:
$$
x^{2}-2x-1=0
$$
This quadratic equation can be solved using the quadratic formula $x=\frac{-b±\sqrt{b^{2}-4ac}}{2a}$ , where $a=1$ , $b=-2$ , and $c=-1$ :
$$
x=\frac{2\pm\sqrt{4+4}}{2}=\frac{2\pm\sqrt{8}}{2}=\frac{2\pm 2\sqrt{2}}{2}=1%
\pm\sqrt{2}
$$
So, the solutions are:
$$
x=1+\sqrt{2}\quad\text{or}\quad x=1-\sqrt{2}
$$
Therefore, the solutions to $f(f(f(x)))=3$ are $x=3$ , $x=-1$ , $x=1$ , $x=1+\sqrt{2}$ , and $x=1-\sqrt{2}$ .
The final answer is:
$$
\boxed{3,-1,1,1+\sqrt{2},1-\sqrt{2}}
$$
Sample 3 Question: Alice chooses a set $A$ of positive integers. Then Bob lists all finite nonempty sets $B$ of positive integers with the property that the maximum element of $B$ belongs to $A$ . Bob’s list has 2024 sets. Find the sum of the elements of A.
AceMath-72B-Instruct: To solve the problem, we need to determine the set $A$ such that the number of finite nonempty sets $B$ of positive integers, where the maximum element of $B$ belongs to $A$ , is 2024. Let’s denote the elements of $A$ as $a_{1},a_{2},...,a_{n}$ where $a_{1}<a_{2}<·s<a_{n}$ .
For each element $a_{i}$ in $A$ , the sets $B$ that have $a_{i}$ as their maximum element are all subsets of $\{1,2,...,a_{i}\}$ that include $a_{i}$ . The number of such subsets is $2^{a_{i}-1}$ because we can either include or exclude each of the $a_{i}-1$ elements $1,2,...,a_{i}-1$ .
Therefore, the total number of sets $B$ is the sum of $2^{a_{i}-1}$ for all $i$ from 1 to $n$ :
$$
2^{a_{1}-1}+2^{a_{2}-1}+\cdots+2^{a_{n}-1}=2024.
$$
We need to find a set $A$ such that the above sum equals 2024. Notice that the sum is a sum of distinct powers of 2, which means it is the binary representation of 2024. Let’s convert 2024 to binary:
$$
2024_{10}=11111101000_{2}.
$$
This binary number can be expanded as:
$$
2024=2^{10}+2^{9}+2^{8}+2^{7}+2^{6}+2^{5}+2^{3}.
$$
Thus, the corresponding set $A$ is:
$$
A=\{11,10,9,8,7,6,4\}.
$$
The sum of the elements of $A$ is:
$$
11+10+9+8+7+6+4=55.
$$
Therefore, the sum of the elements of $A$ is $\boxed{55}$ .
Sample 4 Question: How many ’r’ in ’strawberry’?
AceMath-72B-Instruct: To determine how many ’r’ letters are in the word ”strawberry,” we can follow these steps:
1. Write down the word: ”strawberry.”
2. Identify each ’r’ in the word.
3. Count the number of ’r’s.
Let’s go through the word ”strawberry” step by step:
- The first letter is ’s’.
- The second letter is ’t’.
- The third letter is ’r’.
- The fourth letter is ’a’.
- The fifth letter is ’w’.
- The sixth letter is ’b’.
- The seventh letter is ’e’.
- The eighth letter is ’r’.
- The ninth letter is ’r’.
- The tenth letter is ’y’.
Now, let’s count the ’r’s:
- There is one ’r’ in the third position.
- There is one ’r’ in the eighth position.
- There is one ’r’ in the ninth position.
So, the total number of ’r’s in the word ”strawberry” is $1+1+1=3$ .
Therefore, the number of ’r’ in ’strawberry’ is $\boxed{3}$ .