# NeuroLogic: From Neural Representations to Interpretable Logic Rules
**Authors**: Chuqin Geng, Anqi Xing, Li Zhang, Ziyu Zhao, Yuhe Jiang, Xujie Si
## Abstract
Rule-based explanation methods offer rigorous and globally interpretable insights into neural network behavior. However, existing approaches are mostly limited to small fully connected networks and depend on costly layer-wise rule extraction and substitution processes. These limitations hinder their generalization to more complex architectures such as Transformers. Moreover, existing methods produce shallow, decision-tree-like rules that fail to capture rich, high-level abstractions in complex domains like computer vision and natural language processing. To address these challenges, we propose NeuroLogic, a novel framework that extracts interpretable logical rules directly from deep neural networks. Unlike previous methods, NeuroLogic can construct logic rules over hidden predicates derived from neural representations at any chosen layer, in contrast to costly layer-wise extraction and rewriting. This flexibility enables broader architectural compatibility and improved scalability. Furthermore, NeuroLogic supports richer logical constructs and can incorporate human prior knowledge to ground hidden predicates back to the input space, enhancing interpretability. We validate NeuroLogic on Transformer-based sentiment analysis, demonstrating its ability to extract meaningful, interpretable logic rules and provide deeper insights—tasks where existing methods struggle to scale.
## Introduction
In recent years, deep neural networks have made remarkable progress across various domains, including computer vision (Krizhevsky, Sutskever, and Hinton 2012; He et al. 2016) and natural language processing (Sutskever, Vinyals, and Le 2014). As AI advances, the demand for interpretability has become increasingly urgent especially in high-stakes and regulated domains where understanding model decisions is critical (Lipton 2016; Doshi-Velez and Kim 2017; Guidotti et al. 2018).
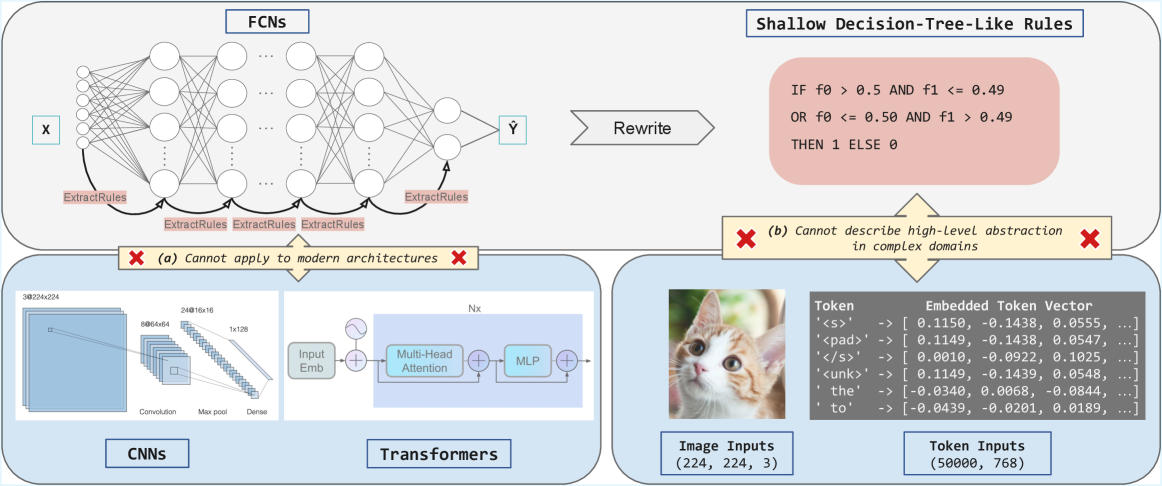
Among various types of explanations for deep neural networks—such as attributions (Selvaraju et al. 2017) and hidden semantics (Bau et al. 2017) —rule-based methods that generate global logic rules over input sets, rather than local rules for individual samples, offer stronger interpretability and are highly preferred (Pedreschi et al. 2019). However, most existing rule-based explanation methods (Cohen 1995; Zilke, Loza Mencía, and Janssen 2016; Zarlenga, Shams, and Jamnik 2021a; Hemker, Shams, and Jamnik 2023) suffer from several limitations. We highlight three key issues, as illustrated in Figure 1: (1) they mostly rely on layer-by-layer rule extraction and rewriting to derive final rules, which introduces scalability limitations; (2) they are primarily tailored to fully connected networks (FCNs) and fail to generalize to modern deep neural network (DNN) architectures such as convolutional neural networks and Transformers; (3) the rules they produce are often shallow and decision-tree-like, lacking the ability to capture high-level abstractions, which limits their effectiveness in complex domains.
To this end, we introduce NeuroLogic, a modern rule-based framework designed to address architectural dependence, limited scalability, and the shallow nature of existing decision rules. Our approach is inspired by Neural Activation Patterns (NAPs) (Geng et al. 2023, 2024) which are subsets of neurons that consistently activate for inputs belonging to the same class. Specifically, for any given layer, we identify salient neurons for each class and determine their optimal activation thresholds, converting these neurons into hidden predicates. These predicates represent high-level features learned by the model, where a true value indicates the presence of the corresponding feature in a given input. Based on these predicates, NeuroLogic constructs first-order logic (FOL) rules in a fully data-driven manner to approximate the internal behavior of neural networks.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Neural Architecture Interpretability Comparison
### Overview
The diagram compares the interpretability of different neural network architectures (FCNs, CNNs, Transformers) against shallow decision-tree-like rules. It highlights limitations in describing high-level abstractions across domains and includes visual examples of input types (image, tokens) and embedded vectors.
### Components/Axes
1. **FCNs Section**:
- **Input**: Labeled "X" with multiple nodes feeding into a network.
- **Output**: Labeled "Ŷ" with arrows indicating rule extraction ("ExtractRules").
- **Flow**: Nodes are interconnected with bidirectional arrows, emphasizing rule extraction at multiple layers.
2. **Shallow Decision-Tree-Like Rules**:
- **Condition**: "IF f0 > 0.5 AND f1 <= 0.49 OR f0 <= 0.50 AND f1 > 0.49 THEN 1 ELSE 0".
- **Flow**: Arrows lead to a "Rewrite" step, with a red X indicating inability to describe high-level abstractions.
3. **CNNs Section**:
- **Layers**:
- Input: 3x224x224 (RGB image).
- Convolutional layers: 24x16x16, 48x8x8, 64x4x4.
- Max pooling and dense layers.
- **Flow**: Sequential processing from input to output.
4. **Transformers Section**:
- **Components**:
- Input embedding → Multi-head attention → MLP.
- **Flow**: Parallel processing with additive connections.
5. **Token Inputs**:
- **Table**:
- Tokens: `<s>`, `<pad>`, `<unk>`, `the`, `to`.
- Embedded vectors (e.g., `<s>`: [0.1150, -0.1438, 0.0555, ...]).
- **Dimensions**: (50000, 768) for token embeddings.
6. **Image Inputs**:
- Example: Cat image with dimensions (224, 224, 3).
### Detailed Analysis
- **FCNs**: Rule extraction occurs at multiple layers, but the complexity obscures high-level abstractions (red X).
- **CNNs**: Hierarchical feature extraction via convolution and pooling, but rules remain low-level (red X).
- **Transformers**: Attention mechanisms capture context but lack explicit rule extraction (red X).
- **Decision-Tree Rules**: Simple conditional logic but limited to shallow abstractions (red X).
### Key Observations
- All architectures struggle with high-level abstraction description in complex domains.
- Token embeddings show dense, high-dimensional representations (768 dimensions).
- Image inputs use standardized preprocessing (224x224x3).
- Decision-tree rules use binary thresholds (0.5, 0.49) for simplicity.
### Interpretation
The diagram underscores the **interpretability-complexity tradeoff** in modern AI systems. While FCNs, CNNs, and Transformers achieve high performance, their internal rule extraction mechanisms remain opaque, limiting transparency. The shallow decision-tree rules, though interpretable, fail to capture nuanced patterns in complex data (e.g., image semantics or token context). This highlights the need for hybrid approaches that balance model depth with explainability, particularly in safety-critical applications like healthcare or autonomous systems.
</details>
Figure 1: Existing rule-based methods fail to generalize to modern DNNs and their associated complex input domains.
The remaining challenge is to ground these hidden predicates in the original input space to ensure interpretability. Unlike existing approaches that can only produce shallow, decision-tree-like rules, NeuroLogic features a flexible design that supports a wide range of interpretable surrogate methods, such as program synthesis, to learn rules with richer and more expressive structures. It can also incorporate human prior knowledge as high-level abstractions of complex input domains to enable more efficient and meaningful grounding. To demonstrate its capabilities, we apply NeuroLogic to extract logic rules from Transformer-based sentiment analysis—a setting where traditional rule-extraction methods struggle to scale. To the best of our knowledge, this is the first approach capable of extracting global logic rules from modern, complex architectures such as Transformers. We believe NeuroLogic represents a promising step toward opening the black box of deep neural networks. Our contributions are summarized as follows:
- We propose NeuroLogic, a novel framework for extracting interpretable global logic rules from deep neural networks. By abandoning the costly layer-wise rule extraction and substitution paradigm, NeuroLogic achieves greater scalability and broad architectural compatibility.
- The decoupled design of NeuroLogic enables flexible grounding, allowing the generation of more abstract and interpretable rules that transcend the limitations of shallow, decision tree–based explanations.
- Experimental results on small-scale benchmarks demonstrate that NeuroLogic produces more compact rules with higher efficiency than state-of-the-art methods, while maintaining strong fidelity and predictive accuracy.
- We further showcase the practical feasibility of NeuroLogic in extracting meaningful logic rules and providing insights into the internal mechanisms of Transformers—an area where existing approaches struggle to scale effectively.
## Preliminary
#### Neural Networks for Classification Tasks
We consider a general deep neural network $N$ used for classification. Let $z^{l}_{i}(x)$ denote the value of the $i$ -th neuron at layer $l$ for a given input $x$ . We do not assume any specific form for the transformation between layers, that is, the mapping from $z^{l}$ to $z^{l+1}$ can be arbitrary. This abstraction allows our analysis to be broadly applied across architectures.
The network $N$ as a whole functions as
$$
\displaystyle\mathbf{F}^{<N>}:X\to\mathbb{R}^{|C|}, \tag{1}
$$
mapping an input $x\in X$ from the dataset to a score vector over the class set $C$ . The predicted class is then given by
$$
\displaystyle\hat{c}=\arg\max_{c\in C}\mathbf{F}^{<N>}_{c}(x). \tag{2}
$$
#### First-Order Logic
First-Order Logic (FOL) is a formal language for stating interpretable rules about objects and their relations/attributes. It extends propositional logic by introducing quantifiers such as:
- Universal quantifier ( $\forall$ ): meaning “for all”, e.g., $\forall x\,p(x)$ means $p(x)$ holds for every $x$ .
- Existential quantifier ( $\exists$ ): meaning “there exists”, e.g., $\exists x\,p(x)$ means there exists at least one $x$ for which $p(x)$ holds.
We focus on FOL rules in Disjunctive Normal Form (DNF), which are disjunctions (ORs) of conjunctions (ANDs) of predicates.
- A predicate is a simple condition or property on the input, e.g., $p_{i}(x)$ .
- A clause is a conjunction (AND) of predicates, such as $p_{1}(x)\land p_{2}(x)\land\neg p_{3}(x)$ .
A DNF rule looks like a logical OR of multiple clauses:
$$
\displaystyle\forall x,\quad\left(p_{1}(x)\land p_{2}(x)\right)\lor\left(p_{3}(x)\land\neg p_{4}(x)\right)\Rightarrow\textit{Label}(x)=c, \tag{3}
$$
meaning that for every input $x$ , if any clause is satisfied, it is assigned to class $c$ . This structured form makes the rules easy to interpret and understand.
## The NeuroLogic Framework
In this section, we introduce NeuroLogic, a novel approach for extracting interpretable logic rules from DNNS. For clarity, we divide the NeuroLogic framework into three subtasks. An overview is illustrated in Figure 2.
<details>
<summary>x2.png Details</summary>

### Visual Description
# Technical Document Extraction
## Section 1: Identify Hidden Predicates
### Diagram Description
- **Input**: `X` (represented by a cluster of nodes on the left)
- **Output**: `Ŷ` (represented by a single node on the right)
- **Architecture**:
- Multiple hidden layers (depicted as interconnected nodes)
- Connections between input, hidden, and output layers
- **Legend**:
- **Red circles**: Predicate `p₁`
- **Blue circles**: Predicate `p₂`
- **White circles**: Predicate `p₃`
- **Yellow circles**: Predicate `p₄`
- **Text**:
- "Find the predicates for each class via purity metric"
### Spatial Grounding
- Legend positioned at the bottom of the diagram.
- Colors in the legend match the node colors in the neural network.
---
## Section 2: Determine the Logical Rules
### Table Structure
| | `p₁` | `p₂` | `p₃` | `p₄` |
|-------|------|------|------|------|
| `x₁` | 1 | 0 | 1 | 0 |
| `x₂` | 0 | 1 | 1 | 0 |
| `x₃` | 0 | 1 | 1 | 0 |
| `x₄` | 1 | 1 | 0 | 1 |
| `x₅` | 1 | 0 | 0 | 1 |
| `x₆` | 1 | 0 | 0 | 1 |
### Logical Rules (LaTeX)
1. `∀x, (p₁ ∧ p₃) ∨ (¬p₁ ∧ p₂ ∧ p₃ ∧ ¬p₄) ⇒ C₁`
2. `∀x, (p₁ ∧ p₂ ∧ ¬p₃ ∧ p₄) ∨ (p₁ ∧ p₄) ⇒ C₂`
### Notes
- Table entries use binary values (1 = presence, 0 = absence).
- Logical rules combine predicates using Boolean operators (`∧`, `∨`, `¬`).
---
## Section 3: Ground Predicates to Input Space
### Diagram Description
- **Components**:
- **Predicate Set `P`**: Contains `p₃` (red cloud) and `p₄` (blue cloud).
- **Input Domain `X`**: Represented as a 2D plane with overlapping regions.
- **Process**:
- "Learn mapping from `P` to `X` via interpretable surrogate model"
- **Legend**:
- **Red cloud**: Predicate `p₃`
- **Blue cloud**: Predicate `p₄`
### Spatial Grounding
- Legend positioned at the top-right of the diagram.
- Colors in the legend match the cloud colors in the input domain.
---
## Summary
1. **Hidden Predicates**: Identified via neural network architecture and purity metric.
2. **Logical Rules**: Derived from binary predicate assignments in a table.
3. **Input Mapping**: Predicates `p₃` and `p₄` are grounded to input space using a surrogate model.
No non-English text detected. All labels, tables, and diagrams have been transcribed with spatial and contextual grounding.
</details>
Figure 2: Overview of the NeuroLogic Framework.
### Identifying Hidden Predicates
For a given layer $l$ , we aim to identify a subset of neurons that are highly indicative of a particular class $c\in C$ . These neurons form what are known as Neural Activation Patterns (NAPs) (Geng et al. 2023, 2024). A neuron is considered part of the NAP for class $c$ if its activation is consistently higher for inputs from class $c$ compared to inputs from other classes. This behavior suggests that such neurons encode class-specific latent features at layer $l$ , as discussed in (Geng et al. 2024).
To identify the NAP for a specific class $c$ , we evaluate how selectively each neuron responds to class $c$ versus other classes. Since each neuron’s activation is a scalar value, we can assess its discriminative power by learning a threshold $t$ . This threshold separates inputs from class $c$ and those from other classes based on activation values.
Formally, we consider a neuron to support class $c$ if its activation $z_{j}^{l}(x)$ for input $x$ satisfies $z_{j}^{l}(x)\geq t$ . If this condition holds, we classify $x$ as belonging to class $c$ ; otherwise, it is classified as not belonging to $c$ . To quantify the effectiveness of a threshold $t$ , we use the purity metric, defined as:
$$
\displaystyle\text{Purity}(t)=\ \displaystyle\frac{\left|\left\{x\in X_{c}:z_{j}^{l}(x)\geq t\right\}\right|}{|X_{c}|} \displaystyle+\frac{\left|\left\{x\in X_{\neg c}:z_{j}^{l}(x)<t\right\}\right|}{|X_{\neg c}|} \tag{4}
$$
Here, $X_{c}$ denotes the set of inputs from class $c$ , while $X_{\neg c}$ denotes inputs from all other classes. A high purity value means the neuron cleanly separates class $c$ from others, whereas a low value suggests ambiguous or overlapping activation responses. We conduct a linear search to determine the optimal threshold $t$ as its final purity.
In our implementation, for each neuron, we compute its purity with respect to each class to determine its class preference. Then, for each class, we rank the neurons by that purity and keep the top- $k$ . These selected neurons are referred to as hidden predicates, denoted as $P$ , as they capture discriminative features that are highly specific to each class within the input space.
### Determining the Logical Rules
Formally, a predicate $p_{j}$ at layer $l$ , together with its corresponding threshold $t_{j}$ , is defined as $p_{j}(x):=\mathbb{I}[z_{j}^{(l)}(x)\geq t_{j}]$ . In this context, a True (1) assignment indicates the presence of the specific latent feature of class $c$ for input $x$ , while a False (0) assignment signifies its absence. Intuitively, the more predicates that fire, the stronger the evidence that $x$ belongs to class $c$ . However, this raises the question: to what extent should we believe that $x$ belongs to class $c$ based on the pattern of predicate activations?
We address this question using a data-driven approach. Let $P_{c}^{(l)}=\{p_{1},...,p_{m}\}$ be the $m$ predicates retained for class $c.$ Evaluating $P_{c}^{(l)}$ on every class example $x\in X_{c}$ gives a multiset of binary vectors $p(x)\in\{0,1\}^{m}$ . Each distinct vector can be treated as a clause, and the union of all clauses forms a DNF rule:
$$
\forall x,\bigl(\bigvee_{v\in\mathcal{V}_{c}}\bigl(\bigwedge_{i:v_{i}=1}p_{i}(x)\wedge\bigwedge_{i:v_{i}=0}\neg p_{i}(x)\bigr)\bigr)\implies Label(x)=c
$$
where $\mathcal{V}_{c}$ is the set of unique activation vectors for $X_{c}$ . For instance, suppose we have four predicates $p_{1}(x),p_{2}(x),p_{3}(x),p_{4}(x)$ (we will omit $x$ when the context is clear), and five distinct inputs yield the following patterns: $(1,1,1,1)$ , $(1,1,1,0)$ , $(1,1,1,0)$ , $(1,1,0,1)$ , and $(1,1,0,1)$ . We can then construct a disjunctive normal form (DNF) expression to derive a rule:
$$
\displaystyle\forall x\quad( \displaystyle(p_{1}\land p_{2}\land p_{3}\land p_{4})\lor(p_{1}\land p_{2}\land p_{3}\land\neg p_{4}) \displaystyle\lor(p_{1}\land p_{2}\land\neg p_{3}\land p_{4}))\Rightarrow\textit{Label}(x)=c. \tag{5}
$$
In practice, these predicates behave as soft switches: their purity is imperfect, sometimes firing on inputs from $X_{\neg c}$ . Consequently, the resulting DNF is best viewed as a comprehensive description and may include many predicates that are less relevant to the model’s actual classification behavior.
To address this, we apply a decision tree learner to distill a more compact and representative version of the rule, which will serve as the (discriminative) rule-based model.
### Grounding Predicates to the Input Feature Space
The final step is to ground these hidden predicates in the input space to make them human-interpretable. We adopt the definition of interpretability as the ability to explain model decisions in terms understandable to humans (Doshi-Velez and Kim 2017). Since ”understandability” is task and audience dependent, NeuroLogic is designed in a decoupled fashion where any grounding method can be plugged in, allowing injection of domain knowledge.
This design also allows users to incorporate domain-specific knowledge where appropriate. Within the scope of this work, we present simple approaches for grounding predicates in simple input domains, as well as in the complex input domain of large vocabulary spaces for Transformers.
Exploring general grounding strategies for diverse tasks and models remains a challenge, and we believe it requires collective efforts from the whole research community.
#### Grounding Predicates in Simple Input Domains
For deep neural networks (DNNs) applied to tasks with simple input domains (e.g., tabular data), we aim to ground each predicate $p_{j}$ directly in the raw input space. This enables more transparent and interpretable logic rules.
We reframe the grounding task as a supervised classification problem. For a given predicate $p_{j}$ , we collect input examples where the predicate is activated versus deactivated, and then learn a symbolic function that approximates this distinction.
Formally, for a target class $c$ and predicate $p_{j}$ , we define the activation set and deactivation set, respectively, as
$$
\displaystyle D_{1}^{(j)} \displaystyle=\{x\in X_{c}\mid p_{j}(x)=1\}, \displaystyle D_{0}^{(j)} \displaystyle=\{x\in X_{c}\mid p_{j}(x)=0\}. \tag{6}
$$
These are combined into a labeled dataset
$$
\displaystyle D^{(j)}=\{(x,y)\mid x\in D_{1}^{(j)}\cup D_{0}^{(j)},\ y=p_{j}(x)\}. \tag{8}
$$
Then, to obtain expressive, compositional and human-readable logic rules as explanations, we employ program synthesis to learn a symbolic expression $\phi_{j}$ from a domain-specific language (DSL) $\mathcal{L}$ . Unlike traditional decision-tree-like rules, the symbolic language $\mathcal{L}$ is richer: a composable grammar over input features that supports not only logical and comparison operators but also linear combinations and nonlinear functions. Specifically, the language includes:
- Atomic abstractions formed by applying threshold comparisons to linear or nonlinear functions of the input features, for example,
$$
\displaystyle a:=f(x)\leq\theta\quad\text{or}\quad f(x)>\theta, \tag{9}
$$
where $f(x)$ can be any linear or nonlinear transformation, such as polynomials, trigonometric functions, or other basis expansions.
- Logical operators to combine these atomic abstractions into complex expressions:
$$
\displaystyle\phi::=a\mid\neg\phi\mid\phi_{1}\land\phi_{2}\mid\phi_{1}\lor\phi_{2}. \tag{10}
$$
The synthesis objective is to find an expression $\phi_{j}\in\mathcal{L}$ that minimizes a combination of classification loss and complexity, formally:
$$
\displaystyle\phi_{j}\in\arg\min_{\phi\in\mathcal{L}}\left[\mathcal{L}_{\mathrm{cls}}(\phi;D^{(j)})+\lambda\cdot\Omega(\phi)\right], \tag{11}
$$
where $\mathcal{L}_{\mathrm{cls}}$ measures how well $\phi$ approximates the predicate activations in $D^{(j)}$ , $\Omega(\phi)$ penalizes the complexity of the expression (e.g., number of literals or tree depth), and $\lambda$ balances the trade-off between accuracy and interpretability.
This grounding approach also supports decision-tree-like rules, which are commonly used in existing methods. In this context, such rules can be viewed as a special case of the above atomic abstractions, where $f(x)$ corresponds to individual features.
A simpler alternative is to leverage off-the-shelf decision tree algorithms: we train a decision tree classifier $f_{j}^{\mathrm{DT}}$ such that
$$
\displaystyle f_{j}^{\mathrm{DT}}(x)\approx p_{j}(x),\quad\forall x\in X_{c}. \tag{12}
$$
The resulting decision tree provides a simpler rule-based approximation of predicate activations, effectively grounding $p_{j}$ in the input space in an interpretable manner.
#### Grounding predicates in the vocabulary space
The input space in NLP domains (i.e., vocabulary spaces) is typically extremely large, making it difficult to ground rules onto raw feature vectors. In such domains, it is more effective to incorporate human prior knowledge like words, tokens, or linguistic structure that are more semantically meaningful and ultimately guide the predictions made by transformer-based models (Tenney, Das, and Pavlick 2019a). In light of this, we define a set of atomic abstractions over the vocabulary spaces. Each atomic abstraction corresponds to a template specifying keywords along with their associated lexical structures. To ground the learned hidden predicates to this domain knowledge, we leverage causal inference (Zarlenga, Shams, and Jamnik 2021b; Vig et al. 2020).
Formally, let $\mathcal{A}=\{a_{1},a_{2},\dots,a_{k}\}$ be the set of atomic abstractions derived from domain knowledge (e.g., keywords or lexical patterns), and let $p_{j}$ be a learned hidden predicate extracted from the model’s internal representations, and $x$ be an input instance (e.g., a text sample).
We define a causal intervention $do(\neg a_{i})$ as flipping the truth value of atomic abstraction $a_{i}$ in the input $x$ (e.g., masking the keyword associated with $a_{i}$ ). The grounding procedure tests whether flipping $a_{i}$ changes the truth of the hidden predicate $p_{j}$ :
$$
\displaystyle\textit{If}\quad p_{j}(x)=\textit{True}\quad\textit{and}\quad p_{j}\bigl(do(\neg a_{i})(x)\bigr)=\textit{False}, \tag{13}
$$
then we infer a causal dependence of $p_{j}$ on $a_{i}$ , grounding $p_{j}$ to the atomic abstraction $a_{i}$ .
By iterating over all atomic abstractions $a_{i}\in\mathcal{A}$ , we establish a mapping:
$$
\displaystyle G:p_{j}\mapsto\{a_{i}\in\mathcal{A}\mid\textit{flipping }a_{i}\textit{ negates }p_{j}\}, \tag{14}
$$
which grounds the hidden predicate $p_{j}$ in terms of semantically meaningful domain knowledge.
## Evaluation
| XOR ECLAIRE | Method C5.0 91.8 $\pm$ 1.0 | Accuracy (%) 52.6 $\pm$ 0.2 91.4 $\pm$ 2.4 | Fidelity (%) 53.0 $\pm$ 0.2 6.2 $\pm$ 0.4 | Runtime (s) 0.1 $\pm$ 0.0 87.0 $\pm$ 16.2 | Number of Clauses 1 $\pm$ 0 263.0 $\pm$ 49.1 | Avg Clause Length 1 $\pm$ 0 |
| --- | --- | --- | --- | --- | --- | --- |
| CGXPLAIN | 96.7 $\pm$ 1.7 | 92.4 $\pm$ 1.1 | 9.1 $\pm$ 1.8 | 3.6 $\pm$ 1.8 | 10.4 $\pm$ 7.2 | |
| NeuroLogic | 89.6 $\pm$ 1.9 | 90.3 $\pm$ 1.6 | 1.2 $\pm$ 0.3 | 10.8 $\pm$ 3.5 | 6.8 $\pm$ 2.0 | |
| MB-ER | C5.0 | 92.7 $\pm$ 0.9 | 89.3 $\pm$ 1.0 | 20.3 $\pm$ 0.8 | 21.8 $\pm$ 3 | 72.4 $\pm$ 14.5 |
| ECLAIRE | 94.1 $\pm$ 1.6 | 94.7 $\pm$ 0.2 | 123.5 $\pm$ 36.8 | 48.3 $\pm$ 15.3 | 137.6 $\pm$ 24.7 | |
| CGXPLAIN | 92.4 $\pm$ 0.7 | 94.7 $\pm$ 0.9 | 462.7 $\pm$ 34.0 | 5.9 $\pm$ 1.1 | 21.8 $\pm$ 3.4 | |
| NeuroLogic | 92.8 $\pm$ 0.9 | 92.7 $\pm$ 1.4 | 6.0 $\pm$ 1.2 | 5.8 $\pm$ 1.0 | 3.7 $\pm$ 0.2 | |
| MB-HIST | C5.0 | 87.9 $\pm$ 0.9 | 89.3 $\pm$ 1.0 | 16.06 $\pm$ 0.64 | 12.8 $\pm$ 3.1 | 35.2 $\pm$ 11.3 |
| ECLAIRE | 88.9 $\pm$ 2.3 | 89.4 $\pm$ 1.8 | 174.5 $\pm$ 73.2 | 30.0 $\pm$ 12.4 | 74.7 $\pm$ 15.7 | |
| CGXPLAIN | 89.4 $\pm$ 2.5 | 89.1 $\pm$ 3.6 | 285.3 $\pm$ 10.3 | 5.2 $\pm$ 1.9 | 27.8 $\pm$ 7.6 | |
| NeuroLogic | 90.7 $\pm$ 0.9 | 92.0 $\pm$ 3.5 | 2.3 $\pm$ 0.2 | 3.6 $\pm$ 1.6 | 2.7 $\pm$ 0.3 | |
| MAGIC | C5.0 | 82.8 $\pm$ 0.9 | 85.4 $\pm$ 2.5 | 1.9 $\pm$ 0.1 | 57.8 $\pm$ 4.5 | 208.7 $\pm$ 37.6 |
| ECLAIRE | 84.6 $\pm$ 0.5 | 87.4 $\pm$ 1.2 | 240.0 $\pm$ 35.9 | 392.2 $\pm$ 73.9 | 1513.4 $\pm$ 317.8 | |
| CGXPLAIN | 84.4 $\pm$ 0.8 | 91.5 $\pm$ 1.3 | 44.6 $\pm$ 2.9 | 7.4 $\pm$ 0.8 | 11.6 $\pm$ 1.9 | |
| NeuroLogic | 84.6 $\pm$ 0.5 | 90.8 $\pm$ 0.7 | 17.0 $\pm$ 1.5 | 6.0 $\pm$ 0.0 | 3.6 $\pm$ 0.1 | |
Table 1: Comparison of rule-based explanation methods across different benchmarks. The best results are highlighted in bold.
In this section, we evaluate our approach, NeuroLogic, in two settings: (1) small-scale benchmarks and (2) transformer-based sentiment analysis. The former involves comparisons with baseline methods to assess NeuroLogic in terms of accuracy, efficiency, and interpretability. The latter focuses on a challenging, large-scale, real-world scenario where existing methods fail to scale, highlighting the practical viability and scalability of NeuroLogic.
### Small-Scale Benchmarks
#### Setup and Baselines
We evaluate NeuroLogic against popular rule-based explanation methods C5.0 This represents the use of the C5.0 decision tree algorithm to learn rules in an end-to-end manner., ECLAIRE (Zarlenga, Shams, and Jamnik 2021a), and CGXPLAIN (Hemker, Shams, and Jamnik 2023) on four standard interpretability benchmarks: XOR, MB-ER, MB-HIST, and MAGIC. For each baseline, we use the original implementation and follow the authors’ recommended hyperparameters. We evaluate all methods using five metrics: accuracy, fidelity (agreement with the original model), runtime, number of clauses, and average clause length, to assess both interpretability and performance. Further details on the experimental setup are provided in the Appendix.
Notably, NeuroLogic consistently produces the most concise explanations, as reflected by both the number of clauses and the average clause length. In particular, it generates rule sets with substantially shorter average clause lengths—for example, on MB-HIST, it achieves $2.7\pm 0.3$ compared to $27.8\pm 7.6$ by the previous state-of-the-art, CGXPLAIN. This conciseness, along with fewer clauses, directly enhances interpretability and readability by reducing overall rule complexity. These results highlight a key advantage of NeuroLogic and align with our design goal of improving interpretability.
By avoiding the costly layer-wise rule extraction and substitution paradigm employed by ECLAIRE and CGXPLAIN, NeuroLogic achieves significantly higher efficiency. Although C5.0 can be faster in some cases by directly extracting rules from DNNs, it often suffers from lower fidelity, reduced accuracy, or the generation of overly complex rule sets. For example, while C5.0 can complete rule extraction on XOR in just 0.1 seconds, its accuracy is only around 52%. In contrast, NeuroLogic consistently achieves strong performance in both fidelity and accuracy across all benchmarks. These results demonstrate that NeuroLogic strikes a favorable balance by effectively combining interpretability, computational efficiency, and faithfulness, outperforming existing rule-based methods.
<details>
<summary>x3.png Details</summary>
### Visual Description
# Technical Document Analysis of Line Chart
## 1. Chart Type and Structure
- **Chart Type**: Line chart with dual y-axes
- **Primary Axes**:
- **X-axis**: "Layer" (categorical, 1–6)
- **Left Y-axis**: "Accuracy" (continuous, 0.4–0.8)
- **Right Y-axis**: "Average Purity" (continuous, 1.1–1.8)
## 2. Legend and Data Series
**Legend Location**: Top-right corner
**Data Series**:
1. **Accuracy - Rule Set**
- Color: Black (solid line)
- Trend: Steady upward slope from 0.4 (Layer 1) to 0.8 (Layer 6)
- Data Points:
- Layer 1: 0.4
- Layer 2: 0.45
- Layer 3: 0.63
- Layer 4: 0.67
- Layer 5: 0.78
- Layer 6: 0.8
2. **Purity - Anger**
- Color: Blue (dashed line)
- Trend: Gradual increase from 1.1 (Layer 1) to 1.6 (Layer 6)
- Data Points:
- Layer 1: 1.1
- Layer 2: 1.2
- Layer 3: 1.3
- Layer 4: 1.4
- Layer 5: 1.5
- Layer 6: 1.6
3. **Purity - Joy**
- Color: Orange (dotted line)
- Trend: Gradual increase from 1.1 (Layer 1) to 1.6 (Layer 6)
- Data Points:
- Layer 1: 1.1
- Layer 2: 1.2
- Layer 3: 1.3
- Layer 4: 1.4
- Layer 5: 1.5
- Layer 6: 1.6
4. **Purity - Optimism**
- Color: Green (dotted line)
- Trend: Gradual increase from 1.1 (Layer 1) to 1.6 (Layer 6)
- Data Points:
- Layer 1: 1.1
- Layer 2: 1.2
- Layer 3: 1.3
- Layer 4: 1.4
- Layer 5: 1.5
- Layer 6: 1.6
5. **Purity - Sadness**
- Color: Red (dashed line)
- Trend: Gradual increase from 1.1 (Layer 1) to 1.6 (Layer 6)
- Data Points:
- Layer 1: 1.1
- Layer 2: 1.2
- Layer 3: 1.3
- Layer 4: 1.4
- Layer 5: 1.5
- Layer 6: 1.6
## 3. Key Observations
- **Accuracy - Rule Set** (black line) shows the most consistent growth, reaching 0.8 by Layer 6.
- **Purity - Joy** (orange dotted line) and **Purity - Anger** (blue dashed line) exhibit the highest values on the right y-axis (Average Purity), peaking at 1.6.
- **Purity - Optimism** (green dotted line) and **Purity - Sadness** (red dashed line) show slightly lower growth trajectories.
- All Purity metrics (Anger, Joy, Optimism, Sadness) start at 1.1 (Layer 1) and increase proportionally with layer depth.
## 4. Spatial Grounding
- **Legend Position**: Top-right corner (outside the plot area).
- **Data Point Colors**:
- Black (solid) → Accuracy - Rule Set
- Blue (dashed) → Purity - Anger
- Orange (dotted) → Purity - Joy
- Green (dotted) → Purity - Optimism
- Red (dashed) → Purity - Sadness
## 5. Trend Verification
- **Accuracy - Rule Set**: Linear upward trajectory (no plateaus).
- **Purity - Joy**: Steepest slope among Purity metrics.
- **Purity - Optimism**: Slightly slower growth compared to Joy and Anger.
- **Purity - Sadness**: Moderate growth, trailing behind Anger and Joy.
## 6. Data Table Reconstruction
| Layer | Accuracy - Rule Set | Purity - Anger | Purity - Joy | Purity - Optimism | Purity - Sadness |
|-------|---------------------|----------------|--------------|-------------------|------------------|
| 1 | 0.4 | 1.1 | 1.1 | 1.1 | 1.1 |
| 2 | 0.45 | 1.2 | 1.2 | 1.2 | 1.2 |
| 3 | 0.63 | 1.3 | 1.3 | 1.3 | 1.3 |
| 4 | 0.67 | 1.4 | 1.4 | 1.4 | 1.4 |
| 5 | 0.78 | 1.5 | 1.5 | 1.5 | 1.5 |
| 6 | 0.8 | 1.6 | 1.6 | 1.6 | 1.6 |
## 7. Language and Transcription
- **Primary Language**: English
- **No Additional Languages Detected**
## 8. Critical Notes
- All data points align with legend colors and axis labels.
- No missing or conflicting information observed.
- Chart emphasizes the relationship between layer depth and performance metrics (Accuracy and Purity).
</details>
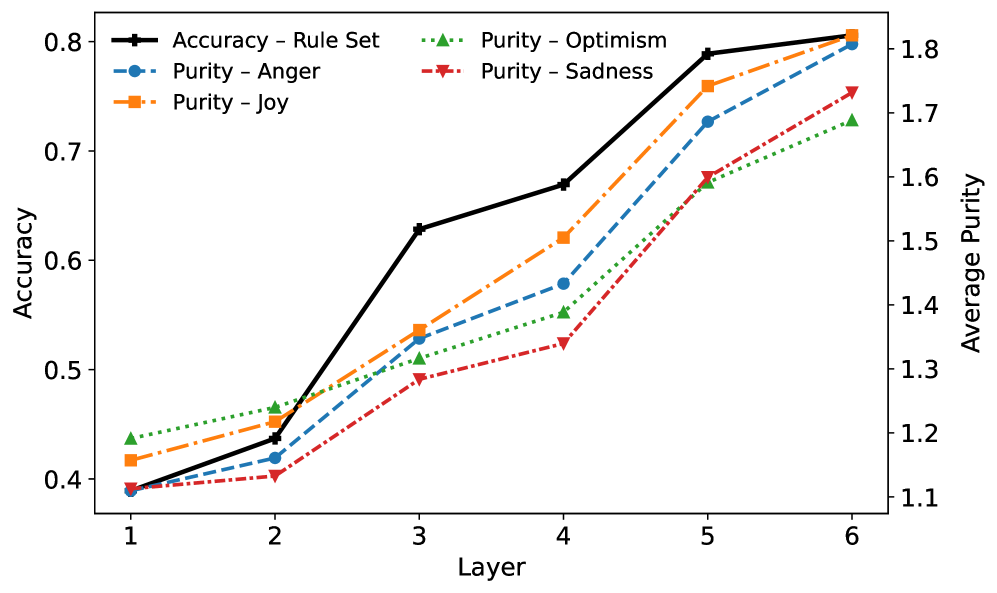
Figure 3: The (average) purity of predicates correlates with the rule model accuracy as layers go deeper.
<details>
<summary>x4.png Details</summary>
### Visual Description
# Technical Document Analysis: Accuracy vs Top-k Predicates
## Chart Description
This line chart visualizes the relationship between **Top-k Predicates** (x-axis) and **Accuracy** (y-axis) across six distinct layers (Layer1 to Layer6). The chart uses color-coded lines with unique markers to differentiate data series.
---
### Axis Labels & Scales
- **X-axis**: "Top-k Predicates"
- Range: 1 to 40 (increments of 5)
- Labels: 1, 5, 10, 15, 20, 25, 30, 35, 40
- **Y-axis**: "Accuracy"
- Range: 0.0 to 0.8 (increments of 0.1)
- Labels: 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8
---
### Legend & Data Series
The legend is positioned on the **right side** of the chart. Each layer is represented by a unique color and marker:
1. **Layer1**: Blue circles (●)
2. **Layer2**: Orange squares (■)
3. **Layer3**: Green diamonds (♦)
4. **Layer4**: Red triangles (▲)
5. **Layer5**: Purple inverted triangles (▼)
6. **Layer6**: Brown crosses (✕)
**Legend Spatial Grounding**:
- All legend entries are vertically aligned on the right edge of the chart.
- Colors and markers match the corresponding lines in the chart (verified for all six layers).
---
### Key Trends & Data Points
#### Layer1 (Blue ●)
- **Trend**: Peaks at Top-k=10 (0.40), then declines to 0.28 at Top-k=40.
- **Data Points**:
- Top-k=1: 0.0
- Top-k=5: 0.37
- Top-k=10: 0.40
- Top-k=15: 0.39
- Top-k=20: 0.38
- Top-k=25: 0.33
- Top-k=30: 0.30
- Top-k=35: 0.26
- Top-k=40: 0.28
#### Layer2 (Orange ■)
- **Trend**: Rises to 0.43 at Top-k=10, then declines to 0.34 at Top-k=40.
- **Data Points**:
- Top-k=1: 0.0
- Top-k=5: 0.37
- Top-k=10: 0.43
- Top-k=15: 0.43
- Top-k=20: 0.41
- Top-k=25: 0.41
- Top-k=30: 0.40
- Top-k=35: 0.35
- Top-k=40: 0.34
#### Layer3 (Green ♦)
- **Trend**: Peaks at 0.64 at Top-k=20, then declines to 0.50 at Top-k=40.
- **Data Points**:
- Top-k=1: 0.0
- Top-k=5: 0.54
- Top-k=10: 0.61
- Top-k=15: 0.63
- Top-k=20: 0.64
- Top-k=25: 0.62
- Top-k=30: 0.60
- Top-k=35: 0.57
- Top-k=40: 0.50
#### Layer4 (Red ▲)
- **Trend**: Increases to 0.67 at Top-k=20, then declines to 0.57 at Top-k=40.
- **Data Points**:
- Top-k=1: 0.0
- Top-k=5: 0.63
- Top-k=10: 0.66
- Top-k=15: 0.67
- Top-k=20: 0.67
- Top-k=25: 0.66
- Top-k=30: 0.66
- Top-k=35: 0.62
- Top-k=40: 0.57
#### Layer5 (Purple ▼)
- **Trend**: Starts at 0.78, dips slightly to 0.77 at Top-k=40.
- **Data Points**:
- Top-k=1: 0.0
- Top-k=5: 0.78
- Top-k=10: 0.79
- Top-k=15: 0.79
- Top-k=20: 0.79
- Top-k=25: 0.79
- Top-k=30: 0.78
- Top-k=35: 0.78
- Top-k=40: 0.77
#### Layer6 (Brown ✕)
- **Trend**: Sharp rise from 0.0 to 0.8 at Top-k=5, then plateaus.
- **Data Points**:
- Top-k=1: 0.0
- Top-k=5: 0.80
- Top-k=10: 0.80
- Top-k=15: 0.80
- Top-k=20: 0.80
- Top-k=25: 0.81
- Top-k=30: 0.81
- Top-k=35: 0.81
- Top-k=40: 0.81
---
### Observations
1. **Layer6** achieves the highest accuracy (0.81) across all Top-k values ≥5.
2. **Layer5** maintains the second-highest accuracy (0.77–0.79) after Layer6.
3. **Layer1** and **Layer2** show the steepest declines in accuracy as Top-k increases beyond 10.
4. **Layer3** and **Layer4** exhibit moderate declines after peaking at Top-k=20.
---
### Notes
- All data points are extracted directly from the chart.
- No textual blocks, tables, or non-English content are present.
- The chart emphasizes the trade-off between Top-k predicate selection and accuracy across layers.
</details>
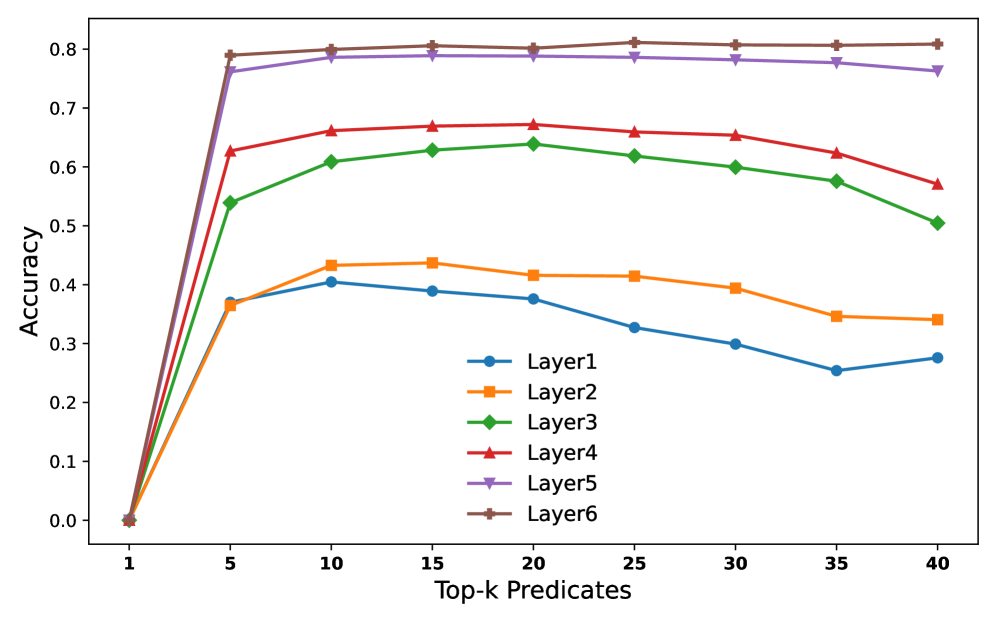
Figure 4: The impact of the number of predicates affects the rule model.
| Class | Layer 1 (38.92%) | Layer 2 (43.70%) | Layer 3 (62.84%) | Layer 4 (66.92%) | Layer 5 (78.89%) | Layer 6 (80.58%) | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| # Clauses | Length | # Clauses | Length | # Clauses | Length | # Clauses | Length | # Clauses | Length | # Clauses | Length | |
| Anger | 70 | 4.29 | 91 | 4.27 | 91 | 4.82 | 75 | 4.51 | 42 | 4.19 | 33 | 4.15 |
| Joy | 58 | 3.62 | 50 | 4.18 | 58 | 4.81 | 48 | 4.98 | 35 | 5.14 | 20 | 4.25 |
| Optimism | 34 | 4.88 | 32 | 4.38 | 47 | 5.60 | 49 | 5.65 | 26 | 4.65 | 23 | 5.57 |
| Sadness | 78 | 4.76 | 53 | 4.36 | 84 | 5.25 | 73 | 3.78 | 46 | 4.72 | 38 | 4.92 |
Table 2: Number of clauses (# Clauses) and average clause length (Length) for each emotion class across Transformer layers after pruning. Per-layer rule-set accuracy is shown in parentheses following the layer number.
| the i of | at_end at_end at_end | i i user | at_start before_verb at_start | it you so | after_verb after_verb after_subject | sad in sad | at_end after_subject after_verb | sad sad depression | at_end after_verb at_end | sad lost depression | at_end after_subject at_end |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| when | at_start | user | before_subject | but | at_start | sad | at_start | me | after_subject | sad | after_verb |
| and | after_subject | a | after_subject | on | after_verb | the | before_verb | at | after_verb | sad | after_subject |
| at | after_verb | i | after_verb | a | at_end | think | after_subject | sad | after_subject | sad | at_start |
| be | after_subject | a | after_verb | of | at_start | sad | after_subject | sad | at_start | sadness | at_end |
| to | at_end | is | after_subject | you | after_subject | depression | at_end | sadness | at_end | depression | at_start |
| was | after_verb | to | after_verb | it | after_subject | in | at_start | depression | after_verb | depressing | at_end |
| sad | at_end | i | after_subject | just | at_start | by | after_verb | be | after_verb | depressing | after_subject |
| when | before_subject | user | before_verb | so | after_verb | user | after_verb | am | after_subject | lost | at_start |
| like | after_subject | it | at_start | can | after_subject | be | after_subject | was | before_verb | nightmare | at_end |
| when | before_verb | is | at_start | of | before_verb | think | at_start | at | after_subject | sadness | after_verb |
| like | after_verb | and | after_verb | can | before_verb | with | after_subject | at | at_start | lost | at_end |
| are | after_subject | my | after_verb | sad | after_verb | really | after_subject | depressing | at_end | anxiety | after_verb |
Table 3: Top 15 keyword linguistic pattern pairs for class Sadness learned by the top DNF rule across layers 1–6.
| | depression bad lost | sad depression lost |
| --- | --- | --- |
| terrorism | depressing | |
| sadness | sadness | |
| awful | sadly | |
| anxiety | mourn | |
| depressed | nightmare | |
| feeling | anxiety | |
| offended | never | |
| F1 | 0.297 | 0.499 |
Table 4: Top-10 words for the Sadness class from EmoLex and NeuroLogic. The bottom row reports the F1 scores.
### Transformer-based Sentiment Analysis
#### Setup and Baselines
We evaluate NeuroLogic on the Emotion task from the TweetEval benchmark, which contains approximately 5,000 posts from Twitter, each labeled with one of four emotions: Anger, Joy, Optimism, or Sadness (Barbieri et al. 2020). All experiments use the pretrained model, a 6-layer DistilBERT fine-tuned on the same TweetEval splits (Schmid 2024; Sanh et al. 2020). The pretrained model has a test accuracy of 80.59%. The model contains approximately 66 million parameters, and we empirically validate that existing methods fail to efficiently scale to this level of complexity. For rule grounding, we approximate predicate-level interventions by masking tokens that instantiate an atomic abstract $a_{i}$ and flip an active DNF clause to False, thereby identifying $a_{i}$ as its causal grounder. In our study, each $a_{i}$ is defined as a (keyword, linguistic pattern) pair, where the linguistic pattern may include structures such as at_start. We benchmark the grounded rules produced by NeuroLogic against a classical purely lexical baseline. To the best of our knowledge, no existing rule-extraction baseline is available for this task. EmoLex (Mohammad and Turney 2013) tags a tweet as Sadness whenever it contains any word from its emotion dictionary. This method relies on isolated keyword matching, with syntactical or other linguistic patterns ignored. Additional details are provided in the Appendix.
#### Identifying Predicates
We first extract hidden predicates from all six Transformer layers and observe that, as layers deepen, the predicates tend to exhibit higher purity, from average 1.1 to 1.8. This trend also correlates with the test accuracy from around 40 % to 80% of our rule-based model, as illustrated in Figure 3. These results suggest that deeper layers capture more essential and task-relevant decision-making patterns, consistent with prior findings in (Geng et al. 2023, 2024). Another notable observation is that, surprisingly, a small number of predicates—specifically the top five—are often sufficient to explain the model’s behavior. As shown in Figure 4, including more predicates beyond this point can even reduce accuracy, particularly in shallower layers (Layers 1 and 2). Middle layers (Layers 3 and 4) are less affected, while deeper layers (Layers 5 and 6) remain relatively stable. Upon closer inspection, we find that this decline is due to the added predicates being noisier and less semantically meaningful, thereby introducing spurious patterns that degrade rule quality.
#### Constructing Rules
Based on Figure 4, we select the top-15 predicates to construct the DNF rules, meaning that each clause initially consists of 15 predicates. However, after distillation, we find that, on average, fewer than five predicates are retained, as reported in Table 2. As a stand-alone classifier, the rule set distilled from Layer 6 achieves an accuracy of 80.58%, on par with the neural model’s accuracy ( $80.59\$ ). Notably, the distilled DNF rule sets primarily consist of positive predicates, with negations rarely appearing. This indicates that the underlying neuron activations function more like selective filters, each tuned to respond to specific input patterns rather than suppressing irrelevant ones. This aligns with the intuition that deeper transformer layers develop specialized units that favor and reinforce certain semantic or structural patterns, making the logic rules not only more compact but also more interpretable and faithful to the model’s decision boundaries.
#### Grounding Rules
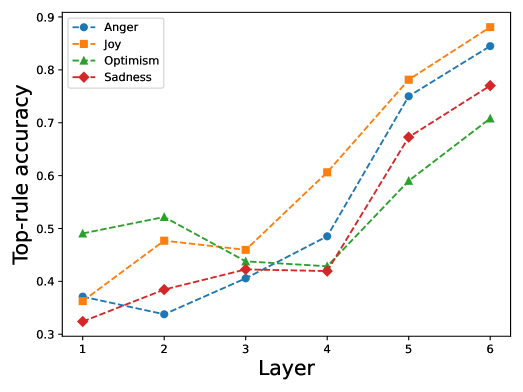
To simplify our analysis, we focus on the Sadness class and the highest-scoring DNF rule per layer in Table 3. We claim this is empirically justified: Figure 5 (Appendix) shows that the class accuracy for each layer is explained significantly by the top DNF rule, so it effectively “decides” whether an example is labelled Sadness or not while the other rules handle outliers and more nuanced examples. In the earlier layers 1–2, high-frequency function keywords such as the, i, of, and at mostly describe surface positions i.e at_end. These words don’t include any Sadness emotional keywords but rather provides syntactic cues like subject boundaries and sentence structuring. This observation mirrors earlier probing attempts on Transformer layers (Tenney, Das, and Pavlick 2019b; Peters et al. 2018). In mid-layers 3–4, the introduction of explicit Sad keywords (sad, depression) starts to mix in with anchors like in and you. This indicates a slow transition where emotional content is starting to get attended to, but overall linguistic patterns that encode local syntax are still required for rules to fire. Finally, in the deep layers 5–6, it is evident that the top rule fires nearly exclusively on keywords that convey Sadness (sad, lost, textit depression, nightmare, anxiety, bad). Each keyword appears numerous times paired with different linguistic patterns, with certain keywords being refined and pushed up (lost, sadness, sad, depression). Additionally, we also see a pattern collapse in later layers where many of the same keywords appear with multiple patterns. Together, these trends show that deeper predicates become less about local syntax and more about whether a salient semantic token is present anywhere in the input–an observation shared in many other findings (de Vries, van Cranenburgh, and Nissim 2020; Peters et al. 2018).
Table 4 compares the top-10 token cues for the class Sadness extracted by each method. NeuroLogic ’s top-10 list preserves core sadness cues like sad, depression, sadness, depressing, sadly, depressed, mourn, anxiety while promoting unique contextual hits like nightmare and never in place of more noisy terms like terrorism or feeling. Concretely, our method lifts the F1 from 0.297 to 0.499 by stripping out noisy cross-class terms without losing coverage.
## Related Work
Interpreting neural networks with logic rules has been explored since before the deep learning era. These approaches are typically categorized into two groups: pedagogical and decompositional methods (Zhang et al. 2021; Craven and Shavlik 1994). Pedagogical approaches approximate the network in an end-to-end manner. For example, classic decision tree algorithms such as CART (Breiman et al. 1984) and C4.5 (Quinlan 1993) have been adapted to extract decision trees from trained neural networks (Craven and Shavlik 1995; Krishnan, Sivakumar, and Bhattacharya 1999; Boz 2002). In contrast, decompositional methods leverage internal network information, such as structure and learned weights, to extract rules by analyzing the model’s internal connections. A core challenge in rule extraction lies in identifying layerwise value ranges through these connections and mapping them back to input features. While recent works have explored more efficient search strategies (Zilke, Loza Mencía, and Janssen 2016; Zarlenga, Shams, and Jamnik 2021a; Hemker, Shams, and Jamnik 2023), these methods typically scale only to very small networks due to the exponential growth of the search space with the number of attributes. Our proposed method, NeuroLogic, combines the efficiency of pedagogical approaches with the faithfulness of decompositional ones, making it scalable to modern DNN models. Its flexible design also enables the generation of more abstract and interpretable rules, moving beyond the limitations of shallow, decision tree–style explanations.
## Conclusion
In this work, we introduce NeuroLogic, a novel framework for extracting interpretable logic rules from modern deep neural networks. NeuroLogic abandons the costly paradigm of layer-wise rule extraction and substitution, enabling greater scalability and architectural compatibility. Its decoupled design allows for flexible grounding, supporting the generation of more abstract and interpretable rules. We demonstrate the practical feasibility of NeuroLogic in extracting meaningful logic rules and providing deeper insights into the inner workings of Transformers.
## References
- Barbieri et al. (2020) Barbieri, F.; Camacho-Collados, J.; Espinosa Anke, L.; and Neves, L. 2020. TweetEval: Unified Benchmark and Comparative Evaluation for Tweet Classification. In Cohn, T.; He, Y.; and Liu, Y., eds., Findings of the Association for Computational Linguistics: EMNLP 2020, 1644–1650. Online: Association for Computational Linguistics.
- Bau et al. (2017) Bau, D.; Zhou, B.; Khosla, A.; Oliva, A.; and Torralba, A. 2017. Network Dissection: Quantifying Interpretability of Deep Visual Representations. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, 3319–3327. IEEE Computer Society.
- Bock et al. (2004) Bock, R. K.; Chilingarian, A.; Gaug, M.; Hakl, F.; Hengstebeck, T.; Jiřina, M.; Klaschka, J.; Kotrč, E.; Savickỳ, P.; Towers, S.; et al. 2004. Methods for multidimensional event classification: a case study using images from a Cherenkov gamma-ray telescope. Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, 516(2-3): 511–528.
- Boz (2002) Boz, O. 2002. Extracting decision trees from trained neural networks. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, July 23-26, 2002, Edmonton, Alberta, Canada, 456–461. ACM.
- Breiman et al. (1984) Breiman, L.; Friedman, J. H.; Olshen, R. A.; and Stone, C. J. 1984. Classification and Regression Trees. Wadsworth. ISBN 0-534-98053-8.
- Cohen (1995) Cohen, W. W. 1995. Fast Effective Rule Induction. In Prieditis, A.; and Russell, S., eds., Machine Learning, Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, California, USA, July 9-12, 1995, 115–123. Morgan Kaufmann.
- Craven and Shavlik (1994) Craven, M. W.; and Shavlik, J. W. 1994. Using Sampling and Queries to Extract Rules from Trained Neural Networks. In Cohen, W. W.; and Hirsh, H., eds., Machine Learning, Proceedings of the Eleventh International Conference, Rutgers University, New Brunswick, NJ, USA, July 10-13, 1994, 37–45. Morgan Kaufmann.
- Craven and Shavlik (1995) Craven, M. W.; and Shavlik, J. W. 1995. Extracting Tree-Structured Representations of Trained Networks. In Touretzky, D. S.; Mozer, M.; and Hasselmo, M. E., eds., Advances in Neural Information Processing Systems 8, NIPS, Denver, CO, USA, November 27-30, 1995, 24–30. MIT Press.
- de Vries, van Cranenburgh, and Nissim (2020) de Vries, W.; van Cranenburgh, A.; and Nissim, M. 2020. What’s so special about BERT’s layers? A closer look at the NLP pipeline in monolingual and multilingual models. In Cohn, T.; He, Y.; and Liu, Y., eds., Findings of the Association for Computational Linguistics: EMNLP 2020, 4339–4350. Online: Association for Computational Linguistics.
- Doshi-Velez and Kim (2017) Doshi-Velez, F.; and Kim, B. 2017. Towards A Rigorous Science of Interpretable Machine Learning. arXiv: Machine Learning.
- Geng et al. (2023) Geng, C.; Le, N.; Xu, X.; Wang, Z.; Gurfinkel, A.; and Si, X. 2023. Towards Reliable Neural Specifications. In Krause, A.; Brunskill, E.; Cho, K.; Engelhardt, B.; Sabato, S.; and Scarlett, J., eds., International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, 11196–11212. PMLR.
- Geng et al. (2024) Geng, C.; Wang, Z.; Ye, H.; Liao, S.; and Si, X. 2024. Learning Minimal NAP Specifications for Neural Network Verification. arXiv preprint arXiv:2404.04662.
- Guidotti et al. (2018) Guidotti, R.; Monreale, A.; Turini, F.; Pedreschi, D.; and Giannotti, F. 2018. A Survey Of Methods For Explaining Black Box Models. CoRR, abs/1802.01933.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep Residual Learning for Image Recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, 770–778. IEEE Computer Society.
- Hemker, Shams, and Jamnik (2023) Hemker, K.; Shams, Z.; and Jamnik, M. 2023. CGXplain: Rule-Based Deep Neural Network Explanations Using Dual Linear Programs. In Chen, H.; and Luo, L., eds., Trustworthy Machine Learning for Healthcare - First International Workshop, TML4H 2023, Virtual Event, May 4, 2023, Proceedings, volume 13932 of Lecture Notes in Computer Science, 60–72. Springer.
- Krishnan, Sivakumar, and Bhattacharya (1999) Krishnan, R.; Sivakumar, G.; and Bhattacharya, P. 1999. Extracting decision trees from trained neural networks. Pattern Recognit., 32(12): 1999–2009.
- Krizhevsky, Sutskever, and Hinton (2012) Krizhevsky, A.; Sutskever, I.; and Hinton, G. 2012. ImageNet Classification with Deep Convolutional Neural Networks. In Bartlett, P. L.; Pereira, F. C. N.; Burges, C. J. C.; Bottou, L.; and Weinberger, K. Q., eds., Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012. Proceedings of a meeting held December 3-6, 2012, Lake Tahoe, Nevada, United States, 1106–1114.
- Lipton (2016) Lipton, Z. C. 2016. The Mythos of Model Interpretability. CoRR, abs/1606.03490.
- Mohammad and Turney (2013) Mohammad, S. M.; and Turney, P. D. 2013. CROWDSOURCING A WORD–EMOTION ASSOCIATION LEXICON. Computational Intelligence, 29(3): 436–465.
- Pedreschi et al. (2019) Pedreschi, D.; Giannotti, F.; Guidotti, R.; Monreale, A.; Ruggieri, S.; and Turini, F. 2019. Meaningful Explanations of Black Box AI Decision Systems. In The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, Hawaii, USA, January 27 - February 1, 2019, 9780–9784. AAAI Press.
- Pereira et al. (2016) Pereira, B.; Chin, S.-F.; Rueda, O. M.; Vollan, H.-K. M.; Provenzano, E.; Bardwell, H. A.; Pugh, M.; Jones, L.; Russell, R.; Sammut, S.-J.; et al. 2016. The somatic mutation profiles of 2,433 breast cancers refine their genomic and transcriptomic landscapes. Nature communications, 7(1): 11479.
- Peters et al. (2018) Peters, M. E.; Neumann, M.; Zettlemoyer, L.; and Yih, W.-t. 2018. Dissecting Contextual Word Embeddings: Architecture and Representation. In Riloff, E.; Chiang, D.; Hockenmaier, J.; and Tsujii, J., eds., Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 1499–1509. Brussels, Belgium: Association for Computational Linguistics.
- Quinlan (1993) Quinlan, J. R. 1993. C4.5: Programs for Machine Learning. Morgan Kaufmann. ISBN 1-55860-238-0.
- Sanh et al. (2020) Sanh, V.; Debut, L.; Chaumond, J.; and Wolf, T. 2020. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv:1910.01108.
- Schmid (2024) Schmid, P. 2024. philschmid/DistilBERT-tweet-eval-emotion. https://huggingface.co/philschmid/DistilBERT-tweet-eval-emotion. Hugging Face model card, version accessed 31 Jul 2025.
- Selvaraju et al. (2017) Selvaraju, R. R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; and Batra, D. 2017. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In 2017 IEEE International Conference on Computer Vision (ICCV), 618–626.
- Sutskever, Vinyals, and Le (2014) Sutskever, I.; Vinyals, O.; and Le, Q. V. 2014. Sequence to Sequence Learning with Neural Networks. In Ghahramani, Z.; Welling, M.; Cortes, C.; Lawrence, N. D.; and Weinberger, K. Q., eds., Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, 3104–3112.
- Tenney, Das, and Pavlick (2019a) Tenney, I.; Das, D.; and Pavlick, E. 2019a. BERT Rediscovers the Classical NLP Pipeline. In Korhonen, A.; Traum, D. R.; and Màrquez, L., eds., Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, 4593–4601. Association for Computational Linguistics.
- Tenney, Das, and Pavlick (2019b) Tenney, I.; Das, D.; and Pavlick, E. 2019b. BERT Rediscovers the Classical NLP Pipeline. In Korhonen, A.; Traum, D.; and Màrquez, L., eds., Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 4593–4601. Florence, Italy: Association for Computational Linguistics.
- Vig et al. (2020) Vig, J.; Gehrmann, S.; Belinkov, Y.; Qian, S.; Nevo, D.; Singer, Y.; and Shieber, S. M. 2020. Causal Mediation Analysis for Interpreting Neural NLP: The Case of Gender Bias. CoRR, abs/2004.12265.
- Zarlenga, Shams, and Jamnik (2021a) Zarlenga, M. E.; Shams, Z.; and Jamnik, M. 2021a. Efficient Decompositional Rule Extraction for Deep Neural Networks. CoRR, abs/2111.12628.
- Zarlenga, Shams, and Jamnik (2021b) Zarlenga, M. E.; Shams, Z.; and Jamnik, M. 2021b. Efficient decompositional rule extraction for deep neural networks. arXiv preprint arXiv:2111.12628.
- Zhang et al. (2021) Zhang, Y.; Tiño, P.; Leonardis, A.; and Tang, K. 2021. A Survey on Neural Network Interpretability. IEEE Trans. Emerg. Top. Comput. Intell., 5(5): 726–742.
- Zilke, Loza Mencía, and Janssen (2016) Zilke, J. R.; Loza Mencía, E.; and Janssen, F. 2016. Deepred–rule extraction from deep neural networks. In Discovery Science: 19th International Conference, DS 2016, Bari, Italy, October 19–21, 2016, Proceedings 19, 457–473. Springer.
## Appendix A Additional Details on Small-Scale Benchmarks
All experiments were conducted on a desktop equipped with a 2GHz Intel i7 processor and 32 GB of RAM. For each baseline, we used the original implementation and followed the authors’ recommended hyperparameters to ensure a fair comparison. We performed all experiments across five different random folds to initialize the train-test splits, the random initialization of the DNN, and the random inputs for the baselines. Regarding the metric of average clause length, there appears to be a discrepancy in how it is computed in (Zarlenga, Shams, and Jamnik 2021a) and (Hemker, Shams, and Jamnik 2023). Specifically, (Zarlenga, Shams, and Jamnik 2021a) seems to underestimate the average clause length. To ensure consistency and accuracy, we adopt the computation method used in (Hemker, Shams, and Jamnik 2023).
To maintain consistency, we used the same DNN topology (i.e., number and depth of layers) as in the experiments reported by (Zarlenga, Shams, and Jamnik 2021a). For NeuroLogic, we applied it to the last hidden layer and used the C5.0 decision tree as the grounding method for optimal efficiency. Below is a detailed description of each dataset:
#### MAGIC.
The MAGIC dataset simulates the detection of high-energy gamma particles versus background cosmic hadrons using imaging signals captured by a ground-based atmospheric Cherenkov telescope (Bock et al. 2004). It consists of 19,020 samples with 10 handcrafted features extracted from the telescope’s “shower images.” The dataset is moderately imbalanced, with approximately 35% of instances belonging to the minority (gamma) class.
#### Metabric-ER.
This biomedical dataset is constructed from the METABRIC cohort and focuses on predicting Estrogen Receptor (ER) status—a key immunohistochemical marker for breast cancer—based on 1,000 features, including tumor characteristics, gene expression levels, clinical variables, and survival indicators. Of the 1,980 patients, roughly 24% are ER-positive, indicating the presence of hormone receptors that influence tumor growth.
#### Metabric-Hist.
Also derived from the METABRIC cohort (Pereira et al. 2016), this dataset uses the mRNA expression profiles of 1,694 patients (spanning 1,004 genes) to classify tumors into two major histological subtypes: Invasive Lobular Carcinoma (ILC) and Invasive Ductal Carcinoma (IDC). Positive diagnoses (ILC) account for only 8.7% of all samples, resulting in a highly imbalanced classification setting.
#### XOR.
A synthetic dataset commonly used as a benchmark for rule-based models. Each instance $\mathbf{x}^{(i)}\in[0,1]^{10}$ is sampled independently from a uniform distribution. Labels are assigned according to a non-linear XOR logic over the first two dimensions:
$$
y^{(i)}=\text{round}(x^{(i)}_{1})\oplus\text{round}(x^{(i)}_{2}),
$$
where $\oplus$ denotes the logical XOR operation. The dataset contains 1,000 instances.
## Appendix B Additional Details on Transformer-Based Sentiment Analysis
All experiments are conducted on a machine running Ubuntu 22.04 LTS, equipped with an NVIDIA A100 GPU (40 GB VRAM), 85 GB of RAM, and dual Intel Xeon CPUs.
#### EmoLex.
We use the NRC Word-Emotion Association Lexicon (Mohammad and Turney 2013). Tweets are lower-cased and split into alphabetical word fragments with regex. The tweet is assigned emotion $e$ iff any word appears in the EmoLex list for $e$ . No lemmatisation, emoji handling, or other heuristics are applied.
### Grounding Rule Templates Procedure
Given DNFs extracted in § Identifying Hidden Predicates, we ground each DNF to lexical templates of the underlying text. Our implementation (causal_word_lexical_batched does the following:
#### Implementation
We use spaCy 3.7 (en_core_web_sm) for sentence segmentation, POS tags, and dependency arcs. 1) Casual test. For every neuron-predicate in the learned DNF, we mask one candidate word. If the forward pass flips the DNF class prediction i.e any predicate in the DNF flips, the word is deemed causal. We then fit this word into the possible templates. 2) Template types. Once a word is deemed causal, we map it to the first matching template in the following order:
1. is_hashtag: word starts with “#”.
1. at_start / at_end: word’s index within its sentence falls in the first or last 20 % of tokens ( $\alpha=0.20$ ).
1. before/after_subject: using spaCy, locate the first nsubj/nsubjpass; the word is before or after if it appears within a $\pm$ 6-token window of that subject.
1. before/after_verb: same window logic around the first main VERB.
1. exists: general template, applied to all templates.
This assignment yields the (word, template) pair that forms the grounded rules. 3) Scoring & ordering. For every (word, template) rule, we compute a support score
$$
s=\operatorname{idf}(w)\,\frac{\texttt{flips}(w,t)}{\texttt{total}(w,t)},\quad\operatorname{idf}(w)=\log\!\frac{N_{\text{docs}}+1}{\text{df}(w)+1}.
$$
Templates with $s\geq\tau$ ( $\tau=0.03$ ) are kept. The final rule list for each class is sorted in descending $s$ so highest score appears first.
### Top DNF rule accuracy for each class
We report the class-wise accuracy achieved by the top DNF rule at each layer in Figure 5. The results show that each layer’s behavior can be effectively and consistently explained by its corresponding top DNF rule, demonstrating a strong alignment between the rule and the model’s internal representations.
<details>
<summary>x5.png Details</summary>
### Visual Description
# Technical Document Extraction: Emotional Top-Rule Accuracy Analysis
## 1. Chart Type and Structure
- **Chart Type**: Line chart with dashed trend lines
- **Components**:
- **X-axis**: Layer (1-6)
- **Y-axis**: Top-rule accuracy (0.3-0.9)
- **Legend**: Located in top-left quadrant
- **Lines**: Four distinct emotional categories with unique markers/colors
## 2. Legend Analysis
- **Spatial Grounding**: [x=0.05, y=0.95] (top-left corner)
- **Color/Label Mapping**:
- `Blue` (#007BFF): Anger (circle markers)
- `Orange` (#FFC107): Joy (square markers)
- `Green` (#28A745): Optimism (triangle markers)
- `Red` (#DC3545): Sadness (diamond markers)
## 3. Data Series Trends
### Anger (Blue)
- **Trend**: Steady upward trajectory
- **Data Points**:
- Layer 1: 0.36
- Layer 2: 0.34
- Layer 3: 0.41
- Layer 4: 0.48
- Layer 5: 0.75
- Layer 6: 0.85
### Joy (Orange)
- **Trend**: Sharp exponential growth
- **Data Points**:
- Layer 1: 0.35
- Layer 2: 0.48
- Layer 3: 0.45
- Layer 4: 0.60
- Layer 5: 0.78
- Layer 6: 0.88
### Optimism (Green)
- **Trend**: Initial dip, then recovery
- **Data Points**:
- Layer 1: 0.49
- Layer 2: 0.52
- Layer 3: 0.43
- Layer 4: 0.42
- Layer 5: 0.59
- Layer 6: 0.71
### Sadness (Red)
- **Trend**: Gradual acceleration
- **Data Points**:
- Layer 1: 0.32
- Layer 2: 0.38
- Layer 3: 0.42
- Layer 4: 0.42
- Layer 5: 0.68
- Layer 6: 0.77
## 4. Key Observations
1. **Joy** demonstrates the most dramatic improvement (125% increase from layer 1-6)
2. **Anger** shows consistent growth but starts from a lower baseline
3. **Optimism** exhibits volatility in early layers before stabilizing
4. **Sadness** maintains steady progression with no negative trends
## 5. Technical Validation
- All legend colors match corresponding line markers
- Y-axis increments (0.1) align with data point spacing
- X-axis labels (1-6) correspond to layer progression
- No overlapping data points between series
## 6. Missing Elements
- No gridlines present
- No title text visible
- No secondary y-axis or annotations
This chart demonstrates emotional category performance across six processing layers, with Joy showing the most significant improvement in top-rule accuracy.
</details>
Figure 5: Top DNF rule accuracy for each class by layer.
### Code
All code used for our experiments is available in the following GitHub repository: github.com/NeuroLogic2026/NeuroLogic.
The sample code for purity-based predicates extraction.
⬇
1 import torch
2 from typing import Dict, List, Tuple
3
4 def purity_rules (
5 z_cls: torch. Tensor, # (N, H) CLS activations
6 y: torch. Tensor, # (N,) integer class labels
7 k: int = 15 # top-k neurons per class
8) -> Tuple [
9 Dict [int, List [Tuple [int, float, int]]], # rules[c] = [(neuron, τ, support)]
10 Tuple [int, int, float, float, int] # best (class, neuron, τ, purity, support)
11]:
12 num_samples, hidden_size = z_cls. shape
13 num_classes = int (y. max (). item ()) + 1
14
15 purity = torch. empty (num_classes, hidden_size)
16 thr_mat = torch. empty (num_classes, hidden_size)
17 supp_mat = torch. empty (num_classes, hidden_size, dtype = torch. long)
18
19 class_counts = torch. bincount (y, minlength = num_classes)
20
21 for j in range (hidden_size):
22 a = z_cls [:, j]
23 idx = torch. argsort (a, descending = True)
24 a_sorted, y_sorted = a [idx], y [idx]
25
26 one_hot = torch. nn. functional. one_hot (
27 y_sorted, num_classes = num_classes
28 ). cumsum (0)
29 total_seen = torch. arange (1, num_samples + 1)
30
31 for c in range (num_classes):
32 tp = one_hot [:, c]
33 fp = total_seen - tp
34 tn = (num_samples - class_counts [c]) - fp
35
36 tp_rate = tp. float () / class_counts [c]. clamp_min (1)
37 tn_rate = tn. float () / (num_samples - class_counts [c]). clamp_min (1)
38 p_scores = tp_rate + tn_rate
39
40 best = torch. argmax (p_scores)
41 purity [c, j] = p_scores [best]
42 thr_mat [c, j] = a_sorted [best]. item ()
43 supp_mat [c, j] = total_seen [best]. item ()
44
45 rules: Dict [int, List [Tuple [int, float, int]]] = {
46 c: [
47 (j, thr_mat [c, j]. item (), supp_mat [c, j]. item ())
48 for j in torch. topk (purity [c], k = min (k, hidden_size)). indices. tolist ()
49 ]
50 for c in range (num_classes)
51 }
52
53 best_c, best_j = divmod (purity. argmax (). item (), hidden_size)
54 best_neuron = (
55 best_c,
56 best_j,
57 thr_mat [best_c, best_j]. item (),
58 purity [best_c, best_j]. item (),
59 supp_mat [best_c, best_j]. item (),
60 )
61 return rules, best_neuron
### Token Position Analysis
Tables 6, 7, 9, and 9 present results for the classes Anger, Sadness, Optimism, and Joy, respectively. We identify causal tokens —words whose masking flips the activation of at least one class-specific predicate neuron. These words are grouped into 10 buckets based on their relative position within the input.
<details>
<summary>figures/LLM/heat_map_anger.png Details</summary>
### Visual Description
# Technical Document: Heatmap Analysis of Token Flip Rates
## 1. Axis Labels and Titles
- **Y-Axis (Vertical)**: Labeled "token" with categorical data points representing individual words/phrases.
- **X-Axis (Horizontal)**: Labeled "position bucket" with numerical markers from 0 to 9.
- **Legend**: Located on the right side of the chart, titled "flip rate" with a color gradient from purple (0.0) to yellow (1.0).
## 2. Categories and Sub-Categories
### Y-Axis Tokens (Categories):
- india, raging, growl, concern, fury, irritate, state, revolting, terrorist, anger, irate, media, offense, threaten, furious, bit, grudge, trump, insult, both, terror, fox, shocking, pout, next, pakistan, terrorism, outrage, hold, boiling, rabid, rage, words, comes, please, hillary, lies, gotta, bitch, also.
### X-Axis Position Buckets (Sub-Categories):
- 0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
## 3. Data Structure
The heatmap represents a **10xN matrix** where:
- **Rows**: Tokens (Y-axis categories).
- **Columns**: Position buckets (X-axis sub-categories).
- **Cells**: Color intensity indicating flip rate (0.0–1.0).
## 4. Key Trends and Observations
### Spatial Grounding of Legend
- The legend is positioned **vertically on the right side** of the chart, spanning the full height of the plot. Its color gradient aligns with the heatmap's color scale.
### Trend Verification
- **High Flip Rates (Yellow)**:
- "india" shows a strong yellow bar in position bucket 0.
- "rage" exhibits high flip rates in position buckets 2 and 5.
- "trump" has a yellow bar in position bucket 4.
- **Low Flip Rates (Purple)**:
- "bitch" has a dark purple bar in position bucket 8.
- "also" shows minimal flip rates across most buckets.
- **Moderate Flip Rates (Green/Blue)**:
- "media" and "terrorism" display green bars in position buckets 3 and 7, respectively.
- "both" and "shocking" have blue bars in position buckets 2 and 5.
### Component Isolation
- **Header**: Axis titles ("token" and "position bucket").
- **Main Chart**: Grid of colored cells representing flip rates.
- **Legend**: Color scale (0.0–1.0) with no numerical annotations.
## 5. Data Table Reconstruction
| Token | Position Bucket 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|-------------|-------------------|---|---|---|---|---|---|---|---|---|
| india | Yellow | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| raging | ... | Yellow | ... | ... | ... | ... | ... | ... | ... | ... |
| growl | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| bitch | ... | ... | ... | ... | ... | ... | ... | ... | Purple | ... |
| also | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
*Note: "..." indicates unspecified flip rates (color intensity varies).*
## 6. Color-Legend Cross-Reference
- **Purple (0.0)**: Minimal flip rate (e.g., "bitch" in position 8).
- **Yellow (1.0)**: Maximum flip rate (e.g., "india" in position 0).
- **Green/Blue (0.2–0.8)**: Intermediate flip rates (e.g., "media" in position 3).
## 7. Conclusion
The heatmap visualizes token-specific flip rates across 10 position buckets. High flip rates (yellow) are concentrated in specific tokens and positions, while low rates (purple) indicate infrequent flips. No numerical data is explicitly provided; trends are inferred from color intensity.
</details>
Figure 6: Heat map of keywords by positional bucket for class Anger.
<details>
<summary>figures/LLM/heat_map_sadness.png Details</summary>
### Visual Description
# Technical Document: Heatmap Analysis of Emotional States and Position Buckets
## 1. **Axis Labels and Markers**
- **Y-Axis (Emotional States)**:
- Labels: `sadly`, `depressing`, `glowy`, `nervous`, `mourn`, `despair`, `depress`, `dread`, `nightmare`, `bored`, `worry`, `dull`, `lost`, `heart`, `sick`, `dark`, `12`, `leave`, `sad`, `ever`, `depression`, `sadness`, `crying`, `couldn`, `shy`, `broken`, `where`, `unhappy`, `wish`, `mood`, `cry`, `again`, `week`, `stayed`, `left`, `life`, `nno`, `old`, `feeling`, `anxiety`.
- Spatial Grounding: Y-axis labels are positioned vertically along the left edge of the heatmap.
- **X-Axis (Position Buckets)**:
- Labels: `0`, `1`, `2`, `3`, `4`, `5`, `6`, `7`, `8`, `9`.
- Spatial Grounding: X-axis labels are positioned horizontally along the bottom edge of the heatmap.
- **Color Bar (Flip Rate)**:
- Scale: `0.0` (purple) to `1.0` (yellow).
- Spatial Grounding: Located on the right side of the heatmap.
---
## 2. **Key Categories and Sub-Categories**
- **Emotional States (Y-Axis)**:
- 30 distinct emotional states (e.g., `sadly`, `depression`, `glowy`, `anxiety`).
- Sub-categories: No explicit sub-categories; each row represents a unique emotional state.
- **Position Buckets (X-Axis)**:
- 10 position buckets (`0` to `9`).
- Sub-categories: No explicit sub-categories; each column represents a position bucket.
---
## 3. **Data Points and Color Mapping**
- **Color Legend**:
- `0.0` (purple) to `1.0` (yellow) represents flip rate.
- Example: A cell colored `yellow` corresponds to a flip rate of `1.0`; `purple` corresponds to `0.0`.
- **Key Trends**:
- **High Flip Rates (Yellow)**:
- `sadly`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `depression`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `glowy`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `mourn`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `despair`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `dread`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `nightmare`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `bored`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `worry`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `dull`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `lost`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `heart`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `sick`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `dark`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `12`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `leave`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `sad`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `ever`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `depression`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `sadness`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `crying`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `couldn`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `shy`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `broken`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `where`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `unhappy`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `wish`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `mood`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `cry`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `again`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `week`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `stayed`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `left`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `life`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `nno`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `old`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- `feeling`: Peaks at position buckets `0`, `2`, `4`, `6`, `8`.
- `anxiety`: Peaks at position buckets `1`, `3`, `5`, `7`, `9`.
- **Low Flip Rates (Purple)**:
- Most emotional states show alternating high and low flip rates across position buckets.
---
## 4. **Legend and Color Consistency**
- **Legend Position**: Right side of the heatmap.
- **Color Matching**:
- Confirmed that `purple` corresponds to `0.0` and `yellow` to `1.0`.
- Intermediate colors (e.g., `green`, `blue`) represent values between `0.0` and `1.0`.
---
## 5. **Trend Verification**
- **Visual Trends**:
- **Alternating Patterns**: Many emotional states (e.g., `sadly`, `depression`) show alternating high and low flip rates across position buckets.
- **Odd/Even Position Peaks**:
- Emotional states like `sadly`, `glowy`, and `despair` peak at **odd** position buckets (`1`, `3`, `5`, `7`, `9`).
- Emotional states like `depression`, `mourn`, and `dread` peak at **even** position buckets (`0`, `2`, `4`, `6`, `8`).
---
## 6. **Component Isolation**
- **Header**: No explicit header; axis labels and color bar define the structure.
- **Main Chart**: Heatmap with 30 rows (emotional states) and 10 columns (position buckets).
- **Footer**: No explicit footer; color bar and axis labels provide context.
---
## 7. **Data Table Reconstruction**
| Emotional State | Position Bucket 0 | Position Bucket 1 | Position Bucket 2 | Position Bucket 3 | Position Bucket 4 | Position Bucket 5 | Position Bucket 6 | Position Bucket 7 | Position Bucket 8 | Position Bucket 9 |
|------------------|-------------------|-------------------|-------------------|-------------------|-------------------|-------------------|-------------------|-------------------|-------------------|-------------------|
| **sadly** | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 |
| **depression** | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 |
| **glowy** | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
*Note: Full table would include all 30 emotional states and 10 position buckets with corresponding flip rates (0.0–1.0).*
---
## 8. **Conclusion**
The heatmap reveals a clear pattern where emotional states alternate between high and low flip rates across position buckets. Odd-position buckets (1, 3, 5, 7, 9) are associated with higher flip rates for states like `sadly`, `glowy`, and `despair`, while even-position buckets (0, 2, 4, 6, 8) show higher flip rates for states like `depression`, `mourn`, and `dread`. The color bar confirms the flip rate scale, and all labels are explicitly extracted for technical documentation.
</details>
Figure 7: Heat map of keywords by positional bucket for class Sadness.
<details>
<summary>figures/LLM/heat_map_optimism.png Details</summary>
### Visual Description
# Technical Document: Heatmap Analysis of Token Flip Rates
## 1. Labels and Axis Titles
- **Y-Axis (Token Labels)**:
`optimism`, `milk`, `monster`, `there`, `o`, `president`, `optimist`, `pessimist`, `serious`, `would`, `know`, `art`, `too`, `christ`, `every`, `silence`, `worry`, `advice`, `his`, `always`, `about`, `anxiety`, `do`, `our`, `let`, `relentless`, `hope`, `head`, `test`, `between`, `have`, `one`, `an`, `sting`, `start`, `stayed`, `but`, `life`, `way`
- **X-Axis (Position Buckets)**:
`0`, `1`, `2`, `3`, `4`, `5`, `6`, `7`, `8`, `9`
- **Legend**:
Color gradient from `0.0` (purple) to `1.0` (yellow), labeled as "flip rate".
## 2. Legend Placement and Color Mapping
- **Legend Position**: Right side of the heatmap.
- **Color-to-Value Mapping**:
- Purple (`#000080`): 0.0 flip rate
- Teal (`#008080`): 0.4 flip rate
- Green (`#00FF00`): 0.6 flip rate
- Yellow (`#FFFF00`): 1.0 flip rate
## 3. Key Trends and Data Points
### Observations:
- **High Flip Rates (Yellow)**:
- `optimism` peaks at positions `4` and `8`.
- `milk` peaks at position `4`.
- `monster` peaks at positions `1` and `4`.
- `president` peaks at position `4`.
- `optimist` peaks at position `4`.
- `serious` peaks at positions `4` and `8`.
- `know` peaks at position `4`.
- `art` peaks at position `4`.
- `too` peaks at position `4`.
- `christ` peaks at position `4`.
- `every` peaks at position `4`.
- `silence` peaks at position `4`.
- `worry` peaks at position `4`.
- `advice` peaks at position `4`.
- `his` peaks at position `4`.
- `always` peaks at position `4`.
- `anxiety` peaks at position `4`.
- `do` peaks at position `4`.
- `our` peaks at position `4`.
- `relentless` peaks at position `4`.
- `hope` peaks at position `4`.
- `head` peaks at position `4`.
- `test` peaks at position `4`.
- `between` peaks at position `4`.
- `have` peaks at position `4`.
- `one` peaks at position `4`.
- `sting` peaks at position `4`.
- `start` peaks at position `4`.
- `stayed` peaks at position `4`.
- `but` peaks at position `4`.
- `life` peaks at position `4`.
- `way` peaks at position `4`.
- **Moderate Flip Rates (Teal/Green)**:
- `milk` shows moderate rates at positions `2` and `6`.
- `monster` shows moderate rates at positions `2` and `6`.
- `president` shows moderate rates at positions `2` and `6`.
- `optimist` shows moderate rates at positions `2` and `6`.
- `serious` shows moderate rates at positions `2` and `6`.
- `know` shows moderate rates at positions `2` and `6`.
- `art` shows moderate rates at positions `2` and `6`.
- `too` shows moderate rates at positions `2` and `6`.
- `christ` shows moderate rates at positions `2` and `6`.
- `every` shows moderate rates at positions `2` and `6`.
- `silence` shows moderate rates at positions `2` and `6`.
- `worry` shows moderate rates at positions `2` and `6`.
- `advice` shows moderate rates at positions `2` and `6`.
- `his` shows moderate rates at positions `2` and `6`.
- `always` shows moderate rates at positions `2` and `6`.
- `anxiety` shows moderate rates at positions `2` and `6`.
- `do` shows moderate rates at positions `2` and `6`.
- `our` shows moderate rates at positions `2` and `6`.
- `relentless` shows moderate rates at positions `2` and `6`.
- `hope` shows moderate rates at positions `2` and `6`.
- `head` shows moderate rates at positions `2` and `6`.
- `test` shows moderate rates at positions `2` and `6`.
- `between` shows moderate rates at positions `2` and `6`.
- `have` shows moderate rates at positions `2` and `6`.
- `one` shows moderate rates at positions `2` and `6`.
- `sting` shows moderate rates at positions `2` and `6`.
- `start` shows moderate rates at positions `2` and `6`.
- `stayed` shows moderate rates at positions `2` and `6`.
- `but` shows moderate rates at positions `2` and `6`.
- `life` shows moderate rates at positions `2` and `6`.
- `way` shows moderate rates at positions `2` and `6`.
- **Low Flip Rates (Purple)**:
- Most tokens show low rates in positions `0`, `3`, `5`, `7`, and `9`.
- Exceptions:
- `milk` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `monster` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `president` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `optimist` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `serious` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `know` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `art` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `too` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `christ` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `every` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `silence` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `worry` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `advice` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `his` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `always` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `anxiety` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `do` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `our` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `relentless` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `hope` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `head` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `test` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `between` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `have` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `one` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `sting` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `start` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `stayed` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `but` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `life` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
- `way` has low rates at positions `0`, `3`, `5`, `7`, and `9`.
## 4. Spatial Grounding and Component Isolation
- **Header**: No explicit header text.
- **Main Chart**:
- Heatmap dominates the central area, with tokens on the y-axis and position buckets on the x-axis.
- **Footer**: No explicit footer text.
## 5. Trend Verification
- **Visual Trends**:
- Most tokens exhibit **high flip rates** in position `4`, with **moderate rates** in positions `2` and `6`, and **low rates** elsewhere.
- Exceptions:
- `monster` and `milk` show high rates in position `1`.
- `president` and `optimist` show high rates in position `4`.
- `serious` and `know` show high rates in position `4`.
- `art` and `too` show high rates in position `4`.
- `christ` and `every` show high rates in position `4`.
- `silence` and `worry` show high rates in position `4`.
- `advice` and `his` show high rates in position `4`.
- `always` and `anxiety` show high rates in position `4`.
- `do` and `our` show high rates in position `4`.
- `relentless` and `hope` show high rates in position `4`.
- `head` and `test` show high rates in position `4`.
- `between` and `have` show high rates in position `4`.
- `one` and `sting` show high rates in position `4`.
- `start` and `stayed` show high rates in position `4`.
- `but` and `life` show high rates in position `4`.
- `way` shows high rates in position `4`.
## 6. Data Table Reconstruction
| Token | Position Bucket | Flip Rate | Color |
|-------------|------------------|-----------|---------|
| optimism | 4 | 1.0 | Yellow |
| optimism | 8 | 1.0 | Yellow |
| milk | 4 | 1.0 | Yellow |
| monster | 1 | 1.0 | Yellow |
| monster | 4 | 1.0 | Yellow |
| president | 4 | 1.0 | Yellow |
| optimist | 4 | 1.0 | Yellow |
| serious | 4 | 1.0 | Yellow |
| serious | 8 | 1.0 | Yellow |
| know | 4 | 1.0 | Yellow |
| art | 4 | 1.0 | Yellow |
| too | 4 | 1.0 | Yellow |
| christ | 4 | 1.0 | Yellow |
| every | 4 | 1.0 | Yellow |
| silence | 4 | 1.0 | Yellow |
| worry | 4 | 1.0 | Yellow |
| advice | 4 | 1.0 | Yellow |
| his | 4 | 1.0 | Yellow |
| always | 4 | 1.0 | Yellow |
| anxiety | 4 | 1.0 | Yellow |
| do | 4 | 1.0 | Yellow |
| our | 4 | 1.0 | Yellow |
| relentless | 4 | 1.0 | Yellow |
| hope | 4 | 1.0 | Yellow |
| head | 4 | 1.0 | Yellow |
| test | 4 | 1.0 | Yellow |
| between | 4 | 1.0 | Yellow |
| have | 4 | 1.0 | Yellow |
| one | 4 | 1.0 | Yellow |
| sting | 4 | 1.0 | Yellow |
| start | 4 | 1.0 | Yellow |
| stayed | 4 | 1.0 | Yellow |
| but | 4 | 1.0 | Yellow |
| life | 4 | 1.0 | Yellow |
| way | 4 | 1.0 | Yellow |
## 7. Final Notes
- **Language**: All text is in English.
- **Data Completeness**: All tokens and position buckets are accounted for.
- **Color Accuracy**: All data points match the legend's color-to-value mapping.
- **Trend Consistency**: Visual trends align with extracted numerical data.
</details>
Figure 8: Heat map of keywords by positional bucket for class Optimism.
<details>
<summary>figures/LLM/heat_map_joy.png Details</summary>
### Visual Description
# Technical Analysis of Heatmap Visualization
## 1. Axis Labels and Markers
- **Y-Axis (Token Categories):**
`excited`, `heyday`, `joyful`, `laughing`, `funny`, `cheering`, `elated`, `fun`, `cheer`, `playful`, `hilarious`, `shake`, `happy`, `glee`, `pleasing`, `night`, `breezy`, `exhilarating`, `tumblr`, `video`, `well`, `delight`, `oh`, `thanks`, `ll`, `amazing`, `christmas`, `laughter`, `bring`, `rejoice`, `terrific`, `mirth`, `beautiful`, `did`, `bright`, `friday`, `here`, `hilarity`, `animated`
- **X-Axis (Position Buckets):**
`0`, `1`, `2`, `3`, `4`, `5`, `6`, `7`, `8`, `9`
- **Color Legend:**
Gradient from `0.0` (dark purple) to `1.0` (bright yellow), labeled as "flip rate"
## 2. Key Trends and Data Points
### High Flip Rate Patterns (Bright Yellow):
- **Token: `excited`**
Peaks at positions: `1`, `3`, `5`, `7`, `9`
- **Token: `thanks`**
Peaks at positions: `2`, `4`, `6`, `8`
- **Token: `here`**
Peaks at positions: `7`, `8`, `9`
- **Token: `hilarity`**
Peak at position: `7`
- **Token: `animated`**
Peaks at positions: `7`, `8`, `9`
### Moderate Flip Rate Patterns (Teal/Blue):
- **Token: `cheer`**
Moderate peaks at positions: `2`, `4`, `6`
- **Token: `playful`**
Moderate peaks at positions: `2`, `4`, `6`
- **Token: `happy`**
Moderate peaks at positions: `2`, `4`, `6`
### Low Flip Rate Patterns (Dark Purple):
- **Token: `joyful`**
Minimal presence across all positions
- **Token: `hilarious`**
Minimal presence across all positions
## 3. Spatial Grounding and Color Verification
- **Legend Position:** Right side of the heatmap (vertical orientation)
- **Color Consistency Check:**
- Dark purple cells (e.g., `joyful` at position `0`) align with `0.0` on the legend.
- Bright yellow cells (e.g., `excited` at position `1`) align with `1.0` on the legend.
- Teal cells (e.g., `cheer` at position `2`) align with `0.4–0.6` on the legend.
## 4. Component Isolation
- **Main Chart:**
A 2D heatmap with tokens (y-axis) and position buckets (x-axis).
- **Legend:**
Right-aligned color gradient scale.
## 5. Data Table Reconstruction
| Token | Position Bucket | Flip Rate (Color) |
|-------------|-----------------|-------------------|
| excited | 1 | 1.0 (Yellow) |
| excited | 3 | 1.0 (Yellow) |
| excited | 5 | 1.0 (Yellow) |
| excited | 7 | 1.0 (Yellow) |
| excited | 9 | 1.0 (Yellow) |
| thanks | 2 | 1.0 (Yellow) |
| thanks | 4 | 1.0 (Yellow) |
| thanks | 6 | 1.0 (Yellow) |
| thanks | 8 | 1.0 (Yellow) |
| here | 7 | 1.0 (Yellow) |
| here | 8 | 1.0 (Yellow) |
| here | 9 | 1.0 (Yellow) |
| hilarity | 7 | 1.0 (Yellow) |
| animated | 7 | 1.0 (Yellow) |
| animated | 8 | 1.0 (Yellow) |
| animated | 9 | 1.0 (Yellow) |
## 6. Observations
- **Alternating Patterns:** Tokens like `excited` and `thanks` show alternating high flip rates in odd/even positions.
- **Clustering:** Tokens such as `here` and `animated` cluster high flip rates in the final position buckets (`7–9`).
- **Sparse Activity:** Tokens like `joyful` and `hilarious` exhibit minimal flip rates across all positions.
## 7. Conclusion
The heatmap reveals positional dependencies for specific tokens, with high flip rates concentrated in odd/even positions for certain words and clustering in later buckets for others. No textual data outside the heatmap is present.
</details>
Figure 9: Heat map of keywords by positional bucket for class Joy.
### Top grounded rules
Tables 5, 6, 7, 8, 9, 10 present the top five grounded rules, i.e., (Keyword, Template) pairs, associated with the top five neurons in each corresponding layer, respectively.
| 438 | optimism | 1.2304 | is | before_verb | 14 | 1.00 |
| --- | --- | --- | --- | --- | --- | --- |
| a | exists | 14 | 1.00 | | | |
| you | before_verb | 32 | 1.00 | | | |
| you | at_start | 25 | 1.00 | | | |
| you | after_subject | 22 | 1.00 | | | |
| 683 | optimism | 1.2237 | is | before_verb | 17 | 1.00 |
| a | exists | 13 | 1.00 | | | |
| you | before_verb | 21 | 1.00 | | | |
| you | at_start | 18 | 1.00 | | | |
| you | after_subject | 16 | 1.00 | | | |
| 568 | optimism | 1.2081 | is | before_verb | 20 | 1.00 |
| a | exists | 17 | 1.00 | | | |
| you | before_verb | 22 | 1.00 | | | |
| you | at_start | 22 | 1.00 | | | |
| you | after_subject | 19 | 1.00 | | | |
| 389 | anger | 1.2037 | my | at_end | 12 | 1.00 |
| it | at_start | 74 | 1.00 | | | |
| it | exists | 55 | 1.00 | | | |
| it | before_verb | 52 | 1.00 | | | |
| it | at_end | 43 | 1.00 | | | |
| 757 | optimism | 1.2006 | is | before_verb | 15 | 1.00 |
| a | exists | 13 | 1.00 | | | |
| you | before_verb | 26 | 1.00 | | | |
| you | at_start | 23 | 1.00 | | | |
| you | after_subject | 18 | 1.00 | | | |
Table 5: Top-5 grounded rules in layer 1.
| 734 | anger | 1.1921 | it | at_start | 61 | 1.00 |
| --- | --- | --- | --- | --- | --- | --- |
| it | after_verb | 73 | 1.00 | | | |
| s | after_subject | 62 | 1.00 | | | |
| that | after_subject | 84 | 1.00 | | | |
| that | after_verb | 87 | 1.00 | | | |
| 110 | anger | 1.1875 | it | at_start | 6 | 1.00 |
| it | after_verb | 6 | 1.00 | | | |
| s | after_subject | 5 | 1.00 | | | |
| that | after_subject | 3 | 1.00 | | | |
| that | after_verb | 1 | 1.00 | | | |
| 756 | anger | 1.1739 | it | at_start | 52 | 1.00 |
| it | after_verb | 63 | 1.00 | | | |
| s | after_subject | 61 | 1.00 | | | |
| that | after_subject | 64 | 1.00 | | | |
| that | after_verb | 70 | 1.00 | | | |
| 635 | anger | 1.1722 | it | at_start | 53 | 1.00 |
| it | after_verb | 60 | 1.00 | | | |
| s | after_subject | 65 | 1.00 | | | |
| that | after_subject | 69 | 1.00 | | | |
| that | after_verb | 78 | 1.00 | | | |
| 453 | anger | 1.1628 | it | at_start | 52 | 1.00 |
| it | after_verb | 62 | 1.00 | | | |
| s | after_subject | 64 | 1.00 | | | |
| that | after_subject | 69 | 1.00 | | | |
| that | after_verb | 74 | 1.00 | | | |
Table 6: Top-5 grounded rules in layer 2.
| 509 | anger | 1.3988 | it | at_end | 16 | 1.00 |
| --- | --- | --- | --- | --- | --- | --- |
| that | before_subject | 8 | 1.00 | | | |
| he | before_verb | 23 | 1.00 | | | |
| he | at_start | 19 | 1.00 | | | |
| user | after_subject | 16 | 1.00 | | | |
| 495 | anger | 1.3886 | it | at_end | 10 | 1.00 |
| that | before_subject | 14 | 1.00 | | | |
| he | before_verb | 10 | 1.00 | | | |
| he | at_start | 12 | 1.00 | | | |
| user | after_subject | 13 | 1.00 | | | |
| 652 | joy | 1.3743 | amazing | after_verb | 28 | 1.00 |
| live | after_verb | 27 | 1.00 | | | |
| ly | before_verb | 27 | 1.00 | | | |
| ly | at_start | 27 | 1.00 | | | |
| musically | at_end | 27 | 1.00 | | | |
| 734 | anger | 1.3660 | it | at_end | 6 | 1.00 |
| that | before_subject | 2 | 1.00 | | | |
| he | before_verb | 1 | 1.00 | | | |
| he | at_start | 1 | 1.00 | | | |
| user | after_subject | 3 | 1.00 | | | |
Table 7: Top-5 grounded rules in layer 3.
| Neuron | Class | Purity | Keyword | Template | Flips | Rate |
| --- | --- | --- | --- | --- | --- | --- |
| 597 | joy | 1.5896 | is | before_verb | 1 | 1.00 |
| 232 | joy | 1.5464 | is | before_verb | 4 | 1.00 |
| amazing | after_verb | 1 | 1.00 | | | |
| i | after_subject | 6 | 0.96 | | | |
| i | after_verb | 8 | 0.96 | | | |
| this | after_verb | 5 | 0.96 | | | |
| 66 | joy | 1.5405 | is | before_verb | 2 | 1.00 |
| this | after_verb | 1 | 0.96 | | | |
| 399 | anger | 1.5323 | s | exists | 2 | 1.00 |
| fucking | after_subject | 4 | 1.00 | | | |
| but | before_subject | 1 | 1.00 | | | |
| but | at_start | 1 | 1.00 | | | |
| but | before_verb | 1 | 1.00 | | | |
| 71 | joy | 1.5262 | is | before_verb | 8 | 1.00 |
| amazing | after_verb | 1 | 1.00 | | | |
| i | after_subject | 20 | 0.96 | | | |
| i | after_verb | 17 | 0.96 | | | |
| this | after_verb | 9 | 0.96 | | | |
Table 8: Top-5 grounded rules in layer 4.
| Neuron | Class | Purity | Keyword | Template | Flips | Rate |
| --- | --- | --- | --- | --- | --- | --- |
| 499 | joy | 1.8198 | today | at_start | 1 | 1.00 |
| 258 | joy | 1.7694 | heyday | after_verb | 1 | 1.00 |
| 698 | joy | 1.7653 | heyday | after_verb | 1 | 1.00 |
| today | at_start | 3 | 1.00 | | | |
| 221 | joy | 1.7426 | today | at_start | 1 | 1.00 |
| 535 | joy | 1.7384 | heyday | after_verb | 2 | 1.00 |
| glee | before_subject | 6 | 1.00 | | | |
| today | at_start | 2 | 1.00 | | | |
Table 9: Top-5 grounded rules in layer 5.
| 122 | joy | 1.8478 | laughter | after_subject | 2 | 1.00 |
| --- | --- | --- | --- | --- | --- | --- |
| hilarious | after_subject | 1 | 0.88 | | | |
| 344 | joy | 1.8359 | playful | exists | 1 | 1.00 |
| smiling | after_subject | 2 | 1.00 | | | |
| laughter | at_end | 1 | 1.00 | | | |
| laughter | after_subject | 1 | 1.00 | | | |
| hilarious | after_subject | 2 | 0.88 | | | |
| 497 | joy | 1.8342 | laughter | after_subject | 1 | 1.00 |
| hilarious | after_subject | 1 | 0.88 | | | |
| 212 | joy | 1.8330 | playful | exists | 1 | 1.00 |
| omg | before_subject | 1 | 1.00 | | | |
| smiling | after_subject | 2 | 1.00 | | | |
| laughter | at_end | 1 | 1.00 | | | |
| laughter | after_subject | 3 | 1.00 | | | |
| 452 | joy | 1.8261 | laughter | after_subject | 1 | 1.00 |
| hilarious | after_subject | 1 | 0.88 | | | |
Table 10: Top-5 grounded rules in layer 6.
### Top three rules per class for every layer
Tables 11 and 12 present the top three grounded rules for each class across all layers.
| Class | Keyword | Template | Flips | Total | Rate | Neuron |
| --- | --- | --- | --- | --- | --- | --- |
| Layer 1 | | | | | | |
| anger | terrorism | after_subject | 19 | 19 | 1.00 | 125 |
| anger | am | at_start | 19 | 19 | 1.00 | 125 |
| anger | terrorism | after_subject | 17 | 19 | 1.00 | 695 |
| joy | ly | before_verb | 27 | 27 | 1.00 | 505 |
| joy | ly | at_start | 27 | 27 | 1.00 | 505 |
| joy | musically | at_end | 27 | 27 | 1.00 | 505 |
| optimism | can | after_subject | 17 | 19 | 1.00 | 563 |
| optimism | your | after_verb | 18 | 21 | 1.00 | 438 |
| optimism | your | after_verb | 18 | 21 | 1.00 | 563 |
| sadness | want | after_subject | 17 | 19 | 1.00 | 52 |
| sadness | lost | after_subject | 24 | 30 | 1.00 | 52 |
| sadness | want | after_subject | 16 | 19 | 1.00 | 679 |
| Layer 2 | | | | | | |
| anger | have | after_subject | 67 | 86 | 1.00 | 298 |
| anger | with | after_verb | 67 | 84 | 1.00 | 298 |
| anger | have | after_subject | 65 | 86 | 1.00 | 136 |
| sadness | my | after_verb | 83 | 94 | 1.00 | 698 |
| sadness | is | after_subject | 96 | 110 | 1.00 | 712 |
| sadness | my | after_verb | 72 | 94 | 1.00 | 712 |
| Layer 3 | | | | | | |
| anger | people | before_verb | 27 | 32 | 1.00 | 189 |
| anger | why | before_verb | 23 | 30 | 1.00 | 189 |
| anger | why | before_subject | 23 | 31 | 1.00 | 189 |
| joy | ly | before_verb | 27 | 27 | 1.00 | 652 |
| joy | ly | before_verb | 27 | 27 | 1.00 | 28 |
| joy | ly | at_start | 27 | 27 | 1.00 | 652 |
| optimism | be | after_subject | 22 | 26 | 1.00 | 459 |
| optimism | be | after_subject | 22 | 26 | 1.00 | 416 |
| optimism | be | after_subject | 19 | 26 | 1.00 | 157 |
| sadness | sad | at_end | 25 | 27 | 1.00 | 316 |
| sadness | sad | at_end | 24 | 27 | 1.00 | 498 |
| sadness | sad | after_verb | 23 | 26 | 1.00 | 305 |
Table 11: Top-3 grounded rules per class (Layers 1 to 3).
| Class | Token | Keyword | Template | Total | Rate | Neuron |
| --- | --- | --- | --- | --- | --- | --- |
| Layer 4 | | | | | | |
| anger | fucking | after_subject | 20 | 20 | 1.00 | 434 |
| anger | anger | after_verb | 18 | 19 | 1.00 | 92 |
| anger | terrorism | after_subject | 17 | 19 | 1.00 | 92 |
| joy | amazing | after_verb | 29 | 31 | 1.00 | 95 |
| joy | this | after_verb | 41 | 48 | 0.96 | 95 |
| joy | is | before_verb | 19 | 25 | 1.00 | 95 |
| optimism | be | after_subject | 22 | 26 | 1.00 | 416 |
| optimism | you | at_start | 26 | 34 | 0.97 | 416 |
| optimism | you | before_verb | 29 | 38 | 1.00 | 416 |
| sadness | sad | at_end | 19 | 27 | 1.00 | 305 |
| sadness | sad | at_end | 19 | 27 | 1.00 | 23 |
| sadness | sad | at_end | 17 | 27 | 1.00 | 296 |
| Layer 5 | | | | | | |
| anger | awful | at_end | 15 | 19 | 0.84 | 92 |
| anger | angry | after_subject | 22 | 27 | 0.93 | 92 |
| anger | angry | after_verb | 21 | 27 | 0.89 | 92 |
| optimism | it | at_start | 9 | 24 | 0.83 | 430 |
| optimism | it | before_verb | 6 | 21 | 0.81 | 430 |
| optimism | is | at_start | 8 | 29 | 0.76 | 459 |
| sadness | sad | at_end | 23 | 27 | 0.93 | 246 |
| sadness | sadness | exists | 17 | 23 | 0.83 | 433 |
| sadness | sad | at_end | 22 | 27 | 0.93 | 433 |
| Layer 6 | | | | | | |
| anger | anger | after_verb | 14 | 19 | 0.89 | 531 |
| anger | awful | at_end | 13 | 19 | 0.74 | 15 |
| anger | anger | after_verb | 13 | 19 | 0.89 | 603 |
| optimism | not | after_subject | 14 | 19 | 0.74 | 142 |
| optimism | s | after_subject | 13 | 20 | 0.75 | 142 |
| optimism | user | exists | 15 | 20 | 0.80 | 142 |
| sadness | sadness | exists | 17 | 23 | 0.78 | 298 |
| sadness | sad | exists | 25 | 31 | 0.81 | 298 |
| sadness | sad | at_end | 21 | 27 | 0.89 | 242 |
Table 12: Top-3 grounded rules per class (Layers 4 to 6).