# U-Fair: Uncertainty-based Multimodal Multitask Learning for Fairer Depression Detection
**Authors**:
- \NameJiaee Cheong \Emailjc2208@cam.ac.uk (\addrUniversity of Cambridge & the Alan Turing Institute)
- United Kingdom
- \NameAditya Bangar \Emailadityavb21@iitk.ac.in (\addrIndian Institute of Technology)
- Kanpur
- India
- \NameSinan Kalkan \Emailskalkan@metu.edu.tr (\addrDept. of Comp. Engineering and ROMER Center for Robotics and AI)
- Turkiye
- \NameHatice Gunes \Emailhg410@cam.ac.uk (\addrUniversity of Cambridge)
- United Kingdom
> This work was undertaken while Jiaee Cheong was a visiting PhD student at METU.
\theorembodyfont \theoremheaderfont \theorempostheader
: \theoremsep \jmlrvolume 259 \jmlryear 2024 \jmlrsubmitted LEAVE UNSET \jmlrpublished LEAVE UNSET \jmlrworkshop Machine Learning for Health (ML4H) 2024
Abstract
Machine learning bias in mental health is becoming an increasingly pertinent challenge. Despite promising efforts indicating that multitask approaches often work better than unitask approaches, there is minimal work investigating the impact of multitask learning on performance and fairness in depression detection nor leveraged it to achieve fairer prediction outcomes. In this work, we undertake a systematic investigation of using a multitask approach to improve performance and fairness for depression detection. We propose a novel gender-based task-reweighting method using uncertainty grounded in how the PHQ-8 questionnaire is structured. Our results indicate that, although a multitask approach improves performance and fairness compared to a unitask approach, the results are not always consistent and we see evidence of negative transfer and a reduction in the Pareto frontier, which is concerning given the high-stake healthcare setting. Our proposed approach of gender-based reweighting with uncertainty improves performance and fairness and alleviates both challenges to a certain extent. Our findings on each PHQ-8 subitem task difficulty are also in agreement with the largest study conducted on the PHQ-8 subitem discrimination capacity, thus providing the very first tangible evidence linking ML findings with large-scale empirical population studies conducted on the PHQ-8.
1 Introduction
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: U-Fair Loss Calculation
### Overview
The image is a diagram illustrating the process of calculating the U-Fair Loss. It shows the flow of data from different modalities (visual, audio, text) through convolutional and recurrent layers, their fusion, and the subsequent calculation of task losses, ultimately leading to the U-Fair Loss.
### Components/Axes
* **Input Modalities (Left)**:
* Visual Modality (orange)
* Audio Modality (blue)
* Text Modality (green)
* **Processing Layers (Left)**:
* CONV-2D (orange, for visual)
* CONV-1D (blue, for audio; green, for text)
* BiLSTM (orange, blue, green)
* FC (Fully Connected Layer) (light orange, light blue, light green)
* **Feature Concatenation (Center-Left)**:
* Concatenation of the extracted visual, audio and textual features (represented by colored circles: orange, blue, green)
* **Attentional Fusion Module (Center)**:
* A gray arrow pointing right, labeled "Attentional Fusion Module"
* **Task Losses (Center-Right)**:
* Task 1: L1
* Task 2: L2
* Task 3: L3
* Task 4: L4
* Task 5: L5
* Task 6: L6
* Task 7: L7
* Task 8: L8
* **Loss Calculation (Right)**:
* L\_F (Female Loss)
* L\_M (Male Loss)
* L\_U-Fair (U-Fair Loss)
### Detailed Analysis or ### Content Details
1. **Modality Processing**:
* Visual Modality (orange) -> CONV-2D -> BiLSTM -> FC
* Audio Modality (blue) -> CONV-1D -> BiLSTM -> FC
* Text Modality (green) -> CONV-1D -> BiLSTM -> FC
2. **Feature Concatenation**:
* The outputs of the FC layers are concatenated into a single feature vector.
3. **Attentional Fusion**:
* The concatenated features are passed through an Attentional Fusion Module.
4. **Task Losses**:
* The output of the Attentional Fusion Module is used to calculate task-specific losses (L1 to L8).
5. **Loss Calculation**:
* The task losses are used to calculate the Female Loss (L\_F) and Male Loss (L\_M).
* The U-Fair Loss (L\_U-Fair) is the sum of the Female Loss and Male Loss.
**Equations**:
* **Female Loss (L\_F)**:
* L\_F = ∑ (from t=1 to 8) \[ 1 / ((σ\_t^F)^2) * L\_t + log σ\_t^F ]
* **Male Loss (L\_M)**:
* L\_M = ∑ (from t=1 to 8) \[ 1 / ((σ\_t^M)^2) * L\_t + log σ\_t^M ]
* **U-Fair Loss (L\_U-Fair)**:
* L\_U-Fair = L\_F + L\_M
### Key Observations
* The diagram illustrates a multi-modal learning approach, combining visual, audio, and text data.
* The use of convolutional and recurrent layers suggests that the model is designed to capture both spatial and temporal dependencies in the input data.
* The Attentional Fusion Module likely aims to weigh the contributions of different modalities based on their relevance to the task.
* The U-Fair Loss is designed to balance the performance of the model across different demographic groups (male and female).
### Interpretation
The diagram presents a system for multi-modal learning with a focus on fairness. The model processes visual, audio, and text data separately before fusing them using an attention mechanism. The U-Fair Loss function is designed to mitigate bias by explicitly considering the performance of the model on male and female demographics. This approach aims to improve the overall fairness and robustness of the model. The equations for L\_F and L\_M suggest that the model is trying to minimize the task losses (L\_t) while also regularizing the variance (σ\_t) to ensure fair performance across groups.
</details>
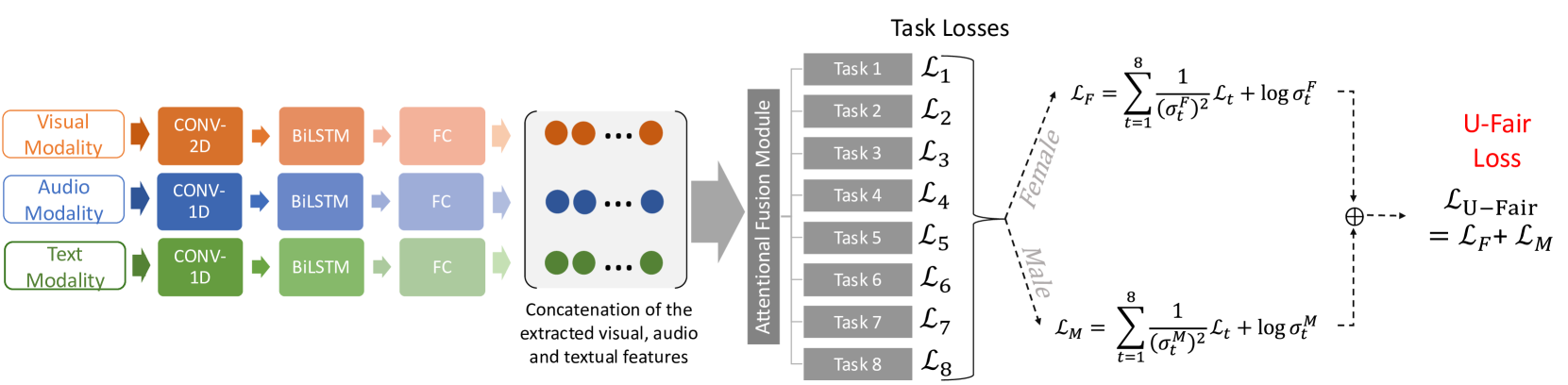
Figure 1: Our proposed method is rooted in the observation that each gender may have different PHQ-8 distributions and different levels of task difficulty across the $t_{1}$ to $t_{8}$ tasks. We propose accounting for this gender difference in PHQ-8 distributions via U-Fair.
Mental health disorders (MHDs) are becoming increasingly prevalent world-wide (Wang et al., 2007) Machine learning (ML) methods have been successfully applied to many real-world and health-related areas (Sendak et al., 2020). The natural extension of using ML for MHD analysis and detection has proven to be promising (Long et al., 2022; He et al., 2022; Zhang et al., 2020). On the other hand, ML bias is becoming an increasing source of concern (Buolamwini and Gebru, 2018; Barocas et al., 2017; Xu et al., 2020; Cheong et al., 2021, 2022, 2023a). Given the high stakes involved in MHD analysis and prediction, it is crucial to investigate and mitigate the ML biases present. A substantial amount of literature has indicated that adopting a multitask learning (MTL) approach towards depression detection demonstrated significant improvement across classification-based performances (Li et al., 2022; Zhang et al., 2020). Most of the existing work rely on the standardised and commonly used eight-item Patient Health Questionnaire depression scale (PHQ-8) (Kroenke et al., 2009) to obtain the ground-truth labels on whether a subject is considered depressed. A crucial observation is that in order to arrive at the final classification (depressed vs non-depressed), a clinician has to first obtain the scores of each of the PHQ-8 sub-criterion and then sum them up to arrive at the final binary classification (depressed vs non-depressed). Details on how the final score is derived from the PHQ-8 questionnaire can be found in Section 3.1.
Moreover, each gender may display different PHQ-8 task distribution which may results in different PHQ-8 distribution and variance. Although investigation on the relationship between the PHQ-8 and gender has been explored in other fields such as psychiatry (Thibodeau and Asmundson, 2014; Vetter et al., 2013; Leung et al., 2020), this has not been investigated nor accounted for in any of the existing ML for depression detection methods. Moreover, existing work has demonstrated the risk of a fairness-accuracy trade-off (Pleiss et al., 2017) and how mainstream MTL objectives might not correlate well with fairness goals (Wang et al., 2021b). No work has investigated how a MTL approach impacts performance across fairness for the task of depression detection.
In addition, prior works have demonstrated the intricate relationship between ML bias and uncertainty (Mehta et al., 2023; Tahir et al., 2023; Kaiser et al., 2022; Kuzucu et al., 2024). Uncertainty broadly refers to confidence in predictions. Within ML research, two types of uncertainty are commonly studied: data (or aleatoric) and model (or epistemic) uncertainties. Aleatoric uncertainty refers to the inherent randomness in the experimental outcome whereas epistemic uncertainty can be attributed to a lack of knowledge (Gal, 2016). A particularly relevant theme is that ML bias can be attributed to uncertainty in some models or datasets (Kuzucu et al., 2024) and that taking into account uncertainty as a bias mitigation strategy has proven effective (Tahir et al., 2023; Kaiser et al., 2022). A growing body of literature has also highlighted the importance of taking uncertainty into account within a range of tasks (Naik et al., 2024; Han et al., 2024; Baltaci et al., 2023; Cetinkaya et al., 2024) and healthcare settings (Grote and Keeling, 2022; Chua et al., 2023). Motivated by the above and the importance of a clinician-centred approach towards building relevant ML for healthcare solutions, we propose a novel method, U-Fair, which accounts for the gender difference in PHQ-8 distribution and leverages on uncertainty as a MTL task reweighing mechanism to achieve better gender fairness for depression detection. Our key contributions are as follow:
- We conduct the first analysis to investigate how MTL impacts fairness in depression detection by using each PHQ-8 subcriterion as a task. We show that a simplistic baseline MTL approach runs the risk of incurring negative transfer and may not improve on the Pareto frontier. A Pareto frontier can be understood as the set of optimal solutions that strike a balance among different objectives such that there is no better solution beyond the frontier.
- We propose a simple yet effective approach that leverages gender-based aleatoric uncertainty which improves the fairness-accuracy trade-off and alleviates the negative transfer phenomena and improves on the Pareto-frontier beyond a unitask method.
- We provide the very first results connecting the empirical results obtained via ML experiments with the empirical findings obtained via the largest study conducted on the PHQ-8. Interestingly, our results highlight the intrinsic relationship between task difficulty as quantified by aleatoric uncertainty and the discrimination capacity of each item of the PHQ-8 subcriterion.
Table 1: Comparative Summary with existing MTL Fairness studies. Abbreviations (sorted): A: Audio. NFM: Number of Fairness Measures. NT: Negative Transfers. ND: Number of Datasets. PF: Pareto Frontier. T: Text. V: Visual.
2 Literature Review
Gender difference in depression manifestation has long been studied and recognised within fields such as medicine (Barsky et al., 2001) and psychology (Hall et al., 2022). Anecdotal evidence has also often supported this view. Literature indicates that females and males tend to show different behavioural symptoms when depressed (Barsky et al., 2001; Ogrodniczuk and Oliffe, 2011). For instance, certain acoustic features (e.g. MFCC) are only statistically significantly different between depressed and healthy males (Wang et al., 2019). On the other hand, compared to males, depressed females are more emotionally expressive and willing to reveal distress via behavioural cues (Barsky et al., 2001; Jansz et al., 2000).
Recent works have indicated that ML bias is present within mental health analysis (Zanna et al., 2022; Bailey and Plumbley, 2021; Cheong et al., 2024a, b; Cameron et al., 2024; Spitale et al., 2024). Zanna et al. (2022) proposed an uncertainty-based approach to address the bias present in the TILES dataset. Bailey and Plumbley (2021) demonstrated the effectiveness of using an existing bias mitigation method, data re-distribution, to mitigate the gender bias present in the DAIC-WOZ dataset. Cheong et al. (2023b, 2024a) demonstrated that bias exists in existing mental health algorithms and datasets and subsequently proposed a causal multimodal method to mitigate the bias present.
MTL is noted to be particularly effective when the tasks are correlated (Zhang and Yang, 2021). Existing works using MTL for depression detection has proven fruitful. Ghosh et al. (2022) adopted a MTL approach by training the network to detect three closely related tasks: depression, sentiment and emotion. Wang et al. (2022) proposed a MTL approach using word vectors and statistical features. Li et al. (2022) implemented a similar strategy by using depression and three other auxiliary tasks: topic, emotion and dialog act. Gupta et al. (2023) adopted a multimodal, multiview and MTL approach where the subtasks are depression, sentiment and emotion.
In concurrence, although MTL has proven to be effective at improving fairness for other tasks such as healthcare predictive modelling (Li et al., 2023a), organ transplantation (Li et al., 2023b) and resource allocation (Ban and Ji, 2024), this approach has been underexplored for the task of depression detection.
Comparative Summary:
Our work differs from the above in the following ways (see Table 1). First, our work is the first to leverage an MTL approach to improve gender fairness in depression detection. Second, we utilise an MTL approach where each task corresponds to each of the PHQ-8 subtasks (Kroenke et al., 2009) in order to exploit gender-specific differences in PHQ-8 distribution to achieve greater fairness. Third, we propose a novel gender-based uncertainty MTL loss reweighing to achieve fairer performance across gender for
3 Methodology: U-Fair
In this section, we introduce U-Fair, which uses aleatoric-uncertainties for demographic groups to reweight their losses.
3.1 PHQ-8 Details
One of the standardised and most commonly used depression evaluation method is the PHQ-8 developed by Kroenke et al. (2009). In order to arrive at the final classification (depressed vs non-depressed), the protocol is to first obtain the subscores of each of the PHQ-8 subitem as follows:
- PHQ-1: Little interest or pleasure in doing things,
- PHQ-2: Feeling down, depressed, or hopeless,
- PHQ-3: Trouble falling or staying asleep, or sleeping too much,
- PHQ-4: Feeling tired or having little energy,
- PHQ-5: Poor appetite or overeating,
- PHQ-6: Feeling that you are a failure,
- PHQ-7: Trouble concentrating on things,
- PHQ-8: Moving or speaking so slowly that other people could have noticed.
Each PHQ-8 subcategory is scored between $0 0$ to $3$ , with the final PHQ-8 total score (TS) ranging between $0 0$ to $24$ . The PHQ-8 binary outcome is obtained via thresholding. A PHQ-8 TS of $≥ 10$ belongs to the depressed class ( $Y=1$ ) whereas TS $≤ 10$ belongs to the non-depressed class ( $Y=0$ ).
Most existing works focused on predicting the final binary class ( $Y$ ) (Zheng et al., 2023; Bailey and Plumbley, 2021). Some focused on predicting the PHQ-8 total score and further obtained the binary classification via thresholding according to the formal definition (Williamson et al., 2016; Gong and Poellabauer, 2017). Others adopted a bimodal setup with 2 different output heads to predict the PHQ-8 total score as well as the PHQ-8 binary outcome (Valstar et al., 2016; Al Hanai et al., 2018).
3.2 Problem Formulation
In our work, in alignment with how the PHQ-8 works, we adopt the approach where each PHQ-8 subcategory is treated as a task $t$ . The architecture is adapted from Wei et al. (2022). For each individual $i∈ I$ , we have 8 different prediction heads for each of the tasks, [ $t_{1}$ , …, $t_{8}$ ] $∈ T$ , to predict the score $y_{t}^{i}∈\{0,1,2,3\}$ for each task or sub PHQ-8 category. The ground-truth labels for each task $t$ is transformed into a Gaussian-based soft-distribution $p_{t}(x)$ , as soft labels provide more information for the model to learn from (Yuan et al., 2024). $x$ is the input feature provided to the model. Each of the classification heads are trained to predict the probability $q_{t}(x)$ of the 4 different score classes $y_{t}^{i}∈\{0,1,2,3\}$ . During inference, the final $y_{t}^{i}∈\{0,1,2,3\}$ is obtained by selecting the score with the maximum probability. The PHQ-8 Total Score $TS$ and final PHQ-8 binary classification $\hat{Y}$ for each individual $i∈ I$ are derived from each subtask via:
$$
TS=\sum_{t=1}^{8}y_{t}, \tag{1}
$$
and
$$
\hat{Y}=1\text{ if }TS\geq 10,\text{ else }\hat{Y}=0. \tag{2}
$$
$\hat{Y}$ thus denotes the final predicted class calculated based on the summation of $y_{t}$ . We study the problem of fairness in depression detection, where the goal is to predict a correct outcome $y^{i}∈ Y$ from input $\mathbf{x}^{i}∈ X$ based on the available dataset $D$ for individual $i∈ I$ . In our setup, $Y=1$ denotes the PHQ-8 binary outcome corresponding to “depressed” and $Y=0$ denotes otherwise. Only gender was provided as a sensitive attribute $S$ .
3.3 Unitask Approach
For our single task approach, we use a Kullback-Leibler (KL) Divergence loss as follows:
$$
\mathcal{L}_{STL}=\sum_{t\in T}p_{t}(x)\log\left(\frac{p_{t}(x)}{q_{t}(x)}%
\right). \tag{3}
$$
$p_{t}(x)$ is the soft ground-truth label for each task $t$ and $q_{t}(x)$ is the probability of the $4$ different score classes $y_{t}∈\{0,1,2,3\}$ as explained in Section 3.1.
3.4 Multitask Approach
For our baseline multitask approach, we extend the loss function in Equation 3 to arrive at the following generalisation:
$$
\mathcal{L}_{MTL}=\sum_{t\in T}w_{t}\mathcal{L}_{t}. \tag{4}
$$
$\mathcal{L}_{t}$ is the single task loss $\mathcal{L}_{STL}$ for each $t$ as defined in Equation 3. We set $w_{t}=1$ in our experiments.
3.5 Baseline Approach
To compare between the generic multitask approach in Equation 4 and an uncertainty-based loss reweighting approach, we use the commonly used multitask learning method by Kendall et al. (2018) as the baseline uncertainty weighting (UW) appraoch. The uncertainty MTL loss across tasks is thus defined by:
$$
\mathcal{L}_{UW}=\sum_{t\in T}\left(\frac{1}{\sigma_{t}^{2}}\mathcal{L}_{t}+%
\log\sigma_{t}\right), \tag{5}
$$
where $\mathcal{L}_{t}$ is the single task loss as defined in Equation 3. $\sigma_{t}$ is the learned weight of loss for each task $t$ and can be interpreted as the aleatoric uncertainty of the task. A task with a higher aleatoric uncertainty will thus lead to a larger single task loss $\mathcal{L}_{t}$ thus preventing the trained model to optimise on that task. The higher $\sigma_{t}$ , the more difficult the task $t$ . $\log\sigma_{t}$ penalizes the model from arbitrarily increasing $\sigma_{t}$ to reduce the overall loss (Kendall et al., 2018).
3.6 Proposed Loss: U-Fair
To achieve fairness across the different PHQ-8 tasks, we propose the idea of task prioritisation based on the model’s task-specific uncertainty weightings. Motivated by literature highlighting the existence of gender difference in depression manifestation (Barsky et al., 2001), we propose a novel gender based uncertainty reweighting approach and introduce U-Fair Loss which is defined as follows:
$$
\mathcal{L}_{U-Fair}=\frac{1}{|S|}\sum_{s\in S}\sum_{t\in T}\left(\frac{1}{%
\left(\sigma_{t}^{s}\right)^{2}}\mathcal{L}_{t}^{s}+\log\sigma_{t}^{s}\right). \tag{6}
$$
For our setting, $s$ can either be male $s_{1}$ or female $s_{0}$ and $|S|=2$ . Thus, we have the uncertainty weighted task loss for each gender, and sum them up to arrive at our proposed loss function $\mathcal{L}_{MMFair}$ .
This methodology has two key benefits. First, fairness is optimised implicitly as we train the model to optimise for task-wise prediction accuracy. As a result, by not constraining the loss function to blindly optimise for fairness at the cost of utility or accuracy, we hope to reduce the negative impact on fairness and improve the Pareto frontier with a constraint-based fairness optimisation approach (Wang et al., 2021b). Second, as highlighted by literature in psychiatry (Leung et al., 2020; Thibodeau and Asmundson, 2014), each task has different levels of uncertainty in relation to each gender. By adopting a gender based uncertainty loss-reweighting approach, we account for such uncertainty in a principled manner, thus encouraging the network to learn a better joint-representation due to the MTL and the gender-base aleatoric uncertainty loss reweighing approach.
4 Experimental Setup
We outline the implementation details and evaluation measures here. We use DAIC-WOZ (Valstar et al., 2016) and E-DAIC (Ringeval et al., 2019) for our experiments. Further details about the datasets can be found within the Appendix.
4.1 Implementation Details
We adopt an attention-based multimodal architecture adapted from Wei et al. (2022) featuring late fusion of extracted representations from the three different modalities (audio, visual, textual) as illustrated in Figure 1. The extracted features from each modality are concatenated in parallel to form a feature map as input to the subsequent fusion layer. We have 8 different attention fusion layers connected to the 8 output heads which corresponds to the $t_{1}$ to $t_{8}$ tasks. For all loss functions, we train the models with the Adam optimizer (Kingma and Ba, 2014) at a learning rate of 0.0002 and a batch size of 32. We train the network for a maximum of 150 epochs and apply early stopping.
4.2 Evaluation Measures
To evaluate performance, we use F1, recall, precision, accuracy and unweighted average recall (UAR) in accordance with existing work (Cheong et al., 2023c). To evaluate group fairness, we use the most commonly-used definitions according to (Hort et al., 2022). $s_{1}$ denotes the male majority group and $s_{0}$ denotes the female minority group for both datasets.
- Statistical Parity, or demographic parity, is based purely on predicted outcome $\hat{Y}$ and independent of actual outcome $Y$ :
$$
\mathcal{M}_{SP}=\frac{P(\hat{Y}=1|s_{0})}{P(\hat{Y}=1|s_{1})}. \tag{7}
$$
According to $\mathcal{M}_{SP}$ , in order for a classifier to be deemed fair, $P(\hat{Y}=1|s_{1})=P(\hat{Y}=1|s_{0})$ .
- Equal opportunity states that both demographic groups $s_{0}$ and $s_{1}$ should have equal True Positive Rate (TPR).
$$
\mathcal{M}_{EOpp}=\frac{P(\hat{Y}=1|Y=1,s_{0})}{P(\hat{Y}=1|Y=1,s_{1})}. \tag{8}
$$
According to this measure, in order for a classifier to be deemed fair, $P(\hat{Y}=1|Y=1,s_{1})=P(\hat{Y}=1|Y=1,s_{0})$ .
- Equalised odds can be considered as a generalization of Equal Opportunity where the rates are not only equal for $Y=1$ , but for all values of $Y∈\{1,...k\}$ , i.e.:
$$
\mathcal{M}_{EOdd}=\frac{P(\hat{Y}=1|Y=i,s_{0})}{P(\hat{Y}=1|Y=i,s_{1})}. \tag{9}
$$
According to this measure, in order for a classifier to be deemed fair, $P(\hat{Y}=1|Y=i,s_{1})=P(\hat{Y}=1|Y=i,s_{0}),∀ i∈\{1,...k\}$ .
- Equal Accuracy states that both subgroups $s_{0}$ and $s_{1}$ should have equal rates of accuracy.
$$
\mathcal{M}_{EAcc}=\frac{\mathcal{M}_{ACC,s_{0}}}{\mathcal{M}_{ACC,s_{1}}}. \tag{10}
$$
For all fairness measures, the ideal score of $1$ thus indicates that both measures are equal for $s_{0}$ and $s_{1}$ and is thus considered “perfectly fair”. We adopt the approach of existing work which considers $0.80$ and $1.20$ as the lower and upper fairness bounds respectively (Zanna et al., 2022). Values closer to $1$ are fairer, values further form $1$ are less fair. For all binary classification, the “default” threshold of $0.5$ is used in alignment with existing works (Wei et al., 2022; Zheng et al., 2023).
| Performance Measures | Acc | Unitask | 0.66 |
| --- | --- | --- | --- |
| Multitask | 0.70 | | |
| Baseline UW | 0.82 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.80 | |
| F1 | Unitask | 0.47 | |
| Multitask | 0.53 | | |
| Baseline UW | 0.29 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.54 | |
| Precision | Unitask | 0.44 | |
| Multitask | 0.50 | | |
| Baseline UW | 0.22 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.56 | |
| Recall | Unitask | 0.50 | |
| Multitask | 0.57 | | |
| Baseline UW | 0.43 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.60 | |
| UAR | Unitask | 0.60 | |
| Multitask | 0.65 | | |
| Baseline UW | 0.64 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.63 | |
| Fairness Measures | $\mathcal{M}_{SP}$ | Unitask | 0.47 |
| Multitask | 0.86 | | |
| Baseline UW | 1.23 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 1.06 | |
| $\mathcal{M}_{EOpp}$ | Unitask | 0.45 | |
| Multitask | 0.78 | | |
| Baseline UW | 1.70 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 1.46 | |
| $\mathcal{M}_{EOdd}$ | Unitask | 0.54 | |
| Multitask | 0.76 | | |
| Baseline UW | 1.31 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 1.17 | |
| $\mathcal{M}_{EAcc}$ | Unitask | 1.44 | |
| Multitask | 0.94 | | |
| Baseline UW | 1.25 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.95 | |
Table 2: Results for DAIC-WOZ. Full table results for DW, Table 6, is available within the Appendix. Best values are highlighted in bold.
\subfigure [ $\mathcal{M}_{EAcc}$ vs Acc]
<details>
<summary>x2.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy vs. EAcc
### Overview
The image is a scatter plot showing the relationship between "Accuracy" on the x-axis and "EAcc" on the y-axis. There are four data points, each represented by a different color: green, blue, orange, and red. The plot appears to show the performance of different models or configurations, with each point indicating a specific accuracy and EAcc score.
### Components/Axes
* **X-axis:** "Accuracy", ranging from 0.00 to approximately 0.88, with tick marks at intervals of 0.25.
* **Y-axis:** "EAcc", ranging from 0.00 to 1.00, with tick marks at intervals of 0.25.
* **Data Points:** Four data points, colored green, blue, orange, and red.
### Detailed Analysis
* **Green Data Point:** Located at approximately (0.65, 0.55).
* **Blue Data Point:** Located at approximately (0.78, 0.75).
* **Orange Data Point:** Located at approximately (0.78, 0.92).
* **Red Data Point:** Located at approximately (0.82, 0.95).
### Key Observations
* All data points are clustered in the upper-right quadrant of the plot, indicating relatively high accuracy and EAcc scores.
* The red data point has the highest accuracy and EAcc.
* The green data point has the lowest accuracy and EAcc.
* There is a positive correlation between accuracy and EAcc, as higher accuracy values tend to correspond with higher EAcc values.
### Interpretation
The scatter plot visualizes the performance of different models or configurations based on their accuracy and EAcc scores. The clustering of points in the upper-right quadrant suggests that all models perform reasonably well. The red data point represents the best-performing model, while the green data point represents the worst-performing model. The positive correlation between accuracy and EAcc indicates that improvements in accuracy generally lead to improvements in EAcc, and vice versa.
</details>
\subfigure [ $\mathcal{M}_{EOdd}$ vs Acc]
<details>
<summary>x3.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy vs. EOdd
### Overview
The image is a scatter plot displaying the relationship between "Accuracy" on the x-axis and "EOdd" on the y-axis. Four data points are plotted, each represented by a different color: red, orange, blue, and green. The plot appears to show the performance of different models or algorithms, with each point indicating a specific accuracy and EOdd value.
### Components/Axes
* **X-axis:** "Accuracy", ranging from 0.00 to approximately 1.00, with tick marks at intervals of 0.25.
* **Y-axis:** "EOdd", ranging from 0.00 to approximately 1.00, with tick marks at intervals of 0.25.
* **Data Points:** Four colored data points: red, orange, blue, and green. There is no legend.
### Detailed Analysis
* **Red Data Point:** Located at approximately Accuracy = 0.75, EOdd = 0.82.
* **Orange Data Point:** Located at approximately Accuracy = 0.70, EOdd = 0.75.
* **Blue Data Point:** Located at approximately Accuracy = 0.75, EOdd = 0.70.
* **Green Data Point:** Located at approximately Accuracy = 0.65, EOdd = 0.52.
### Key Observations
* All data points are clustered in the upper-right quadrant of the plot, indicating relatively high accuracy and EOdd values.
* The red data point has the highest EOdd value, while the green data point has the lowest.
* The green data point has the lowest accuracy value.
### Interpretation
The scatter plot visualizes the trade-off between accuracy and EOdd (Equality of Odds). Each colored point likely represents a different model or configuration. The clustering of points suggests that achieving both high accuracy and high EOdd simultaneously might be challenging. The red point represents a model with the highest EOdd but not necessarily the highest accuracy, while the green point represents a model with lower accuracy and EOdd. The choice of which model to use would depend on the specific application and the relative importance of accuracy versus fairness (as EOdd is a fairness metric).
</details>
\subfigure [ $\mathcal{M}_{EOpp}$ vs Acc]
<details>
<summary>x4.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy vs. EOpp
### Overview
The image is a scatter plot showing the relationship between "Accuracy" on the x-axis and "EOpp" on the y-axis. There are four data points, each represented by a colored circle: orange, red, green, and blue. The plot visualizes the distribution of these points in a two-dimensional space defined by accuracy and EOpp.
### Components/Axes
* **X-axis:** "Accuracy", ranging from 0.00 to approximately 0.85, with tick marks at intervals of 0.25.
* **Y-axis:** "EOpp", ranging from 0.00 to 1.00, with tick marks at intervals of 0.25.
* **Data Points:** Four colored circles (orange, red, green, and blue) representing different data points. There is no legend.
### Detailed Analysis
* **Orange Data Point:** Located at approximately (0.70, 0.75).
* **Red Data Point:** Located at approximately (0.75, 0.65).
* **Green Data Point:** Located at approximately (0.65, 0.45).
* **Blue Data Point:** Located at approximately (0.75, 0.30).
### Key Observations
* All data points have an accuracy greater than 0.60.
* The EOpp values are spread between 0.30 and 0.75.
* There is no clear linear correlation between Accuracy and EOpp based on these four points.
### Interpretation
The scatter plot visualizes the trade-off between accuracy and EOpp (Equality of Opportunity). Each colored point likely represents a different model or configuration. The plot suggests that while all models have relatively high accuracy, they differ in their EOpp values. The choice of which model to use would depend on the relative importance of accuracy versus equality of opportunity in the specific application. The absence of a legend makes it impossible to determine what each color represents.
</details>
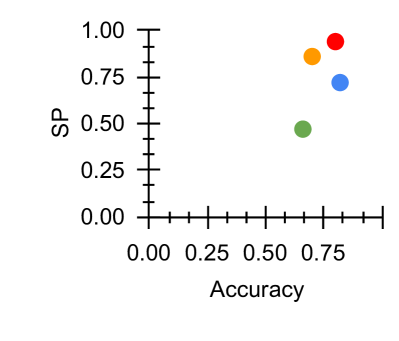
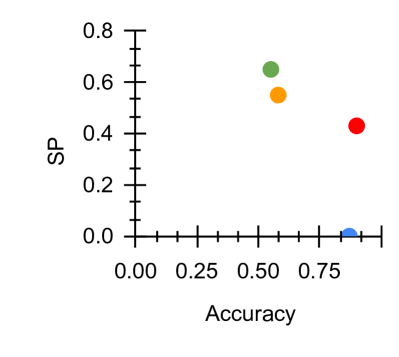
\subfigure [ $\mathcal{M}_{SP}$ vs Acc]
<details>
<summary>x5.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy vs. SP
### Overview
The image is a scatter plot displaying the relationship between "Accuracy" on the x-axis and "SP" (likely Sensitivity/Specificity) on the y-axis. Four data points are plotted, each represented by a different color: red, orange, blue, and green. The data points are clustered in the upper-right quadrant of the plot, indicating relatively high values for both Accuracy and SP.
### Components/Axes
* **X-axis:** "Accuracy", ranging from 0.00 to 1.00, with tick marks at intervals of 0.25.
* **Y-axis:** "SP", ranging from 0.00 to 1.00, with tick marks at intervals of 0.25.
* **Data Points:** Four data points, colored red, orange, blue, and green. There is no legend.
### Detailed Analysis
* **Red Data Point:** Located at approximately Accuracy = 0.80, SP = 0.95.
* **Orange Data Point:** Located at approximately Accuracy = 0.75, SP = 0.85.
* **Blue Data Point:** Located at approximately Accuracy = 0.75, SP = 0.75.
* **Green Data Point:** Located at approximately Accuracy = 0.65, SP = 0.50.
### Key Observations
* All data points have an accuracy greater than 0.60.
* The red data point exhibits the highest accuracy and SP values.
* The green data point exhibits the lowest accuracy and SP values.
* The data points are clustered, suggesting a positive correlation between Accuracy and SP.
### Interpretation
The scatter plot visualizes the performance of different models or conditions, where each data point represents a specific scenario. The clustering of points in the upper-right quadrant suggests that the models/conditions generally perform well in terms of both accuracy and SP. The red data point represents the best-performing scenario, while the green data point represents the worst-performing scenario. The plot allows for a quick comparison of the different scenarios and their trade-offs between accuracy and SP. Without a legend, it is impossible to know what the colors represent.
</details>
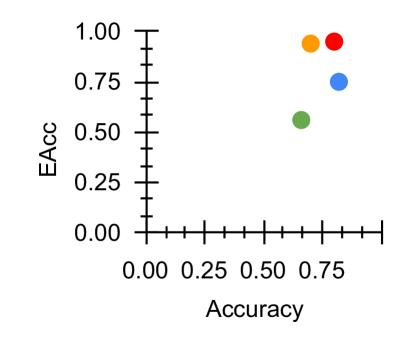
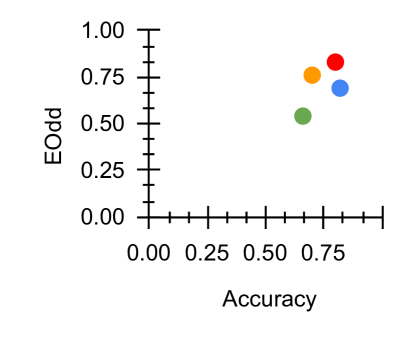
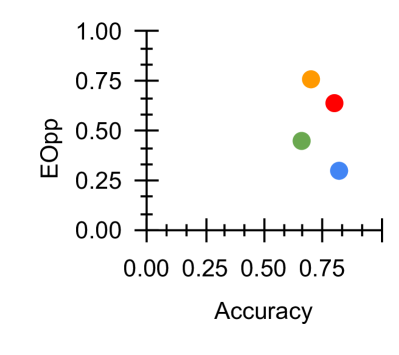
Figure 2: Fairness-Accuracy Pareto Frontier across the DAIC-WOZ results. Upper right indicates better Pareto optimality, i.e. better fairness-accuracy trade-off. Orange: Unitask. Green: Multitask. Blue: Multitask UW. Red: U-Fair. Abbreviations: Acc: accuracy.
| Performance Measures | Acc | Unitask | 0.55 |
| --- | --- | --- | --- |
| Multitask | 0.58 | | |
| Baseline UW | 0.87 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.90 | |
| F1 | Unitask | 0.51 | |
| Multitask | 0.45 | | |
| Baseline UW | 0.27 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.45 | |
| Precision | Unitask | 0.36 | |
| Multitask | 0.32 | | |
| Baseline UW | 0.28 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.46 | |
| Recall | Unitask | 0.87 | |
| Multitask | 0.80 | | |
| Baseline UW | 0.26 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.45 | |
| UAR | Unitask | 0.63 | |
| Multitask | 0.67 | | |
| Baseline UW | 0.60 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.70 | |
| Fairness Measures | $\mathcal{M}_{SP}$ | Unitask | 0.65 |
| Multitask | 1.25 | | |
| Baseline UW | 3.86 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 1.67 | |
| $\mathcal{M}_{EOpp}$ | Unitask | 0.57 | |
| Multitask | 0.81 | | |
| Baseline UW | 2.31 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 1.00 | |
| $\mathcal{M}_{EOdd}$ | Unitask | 0.75 | |
| Multitask | 1.41 | | |
| Baseline UW | 8.21 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 5.00 | |
| $\mathcal{M}_{EAcc}$ | Unitask | 0.83 | |
| Multitask | 0.65 | | |
| Baseline UW | 0.92 | | |
| \cdashline 3-4[.4pt/2pt] | U-Fair (Ours) | 0.94 | |
Table 3: Results for E-DAIC. Full table results for ED, Table 7, is available within the Appendix. Best values are highlighted in bold.
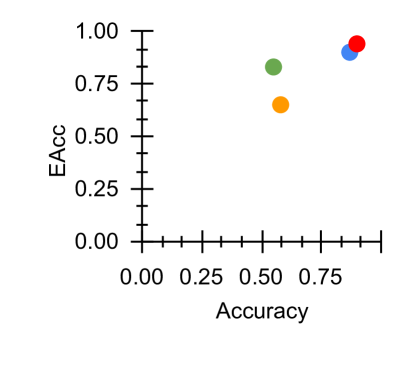
\subfigure [ $\mathcal{M}_{EAcc}$ vs Acc]
<details>
<summary>x6.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy vs. EAcc
### Overview
The image is a scatter plot showing the relationship between "Accuracy" on the x-axis and "EAcc" on the y-axis. There are four data points, each represented by a different color: red, blue, green, and orange. The data points are clustered in the upper-right quadrant of the plot, indicating a positive correlation between Accuracy and EAcc.
### Components/Axes
* **X-axis:** "Accuracy" with a scale from 0.00 to 1.00, incrementing by 0.25.
* **Y-axis:** "EAcc" with a scale from 0.00 to 1.00, incrementing by 0.25.
* **Data Points:** Four colored data points: red, blue, green, and orange. There is no legend provided to indicate what each color represents.
### Detailed Analysis
* **Red Data Point:** Located at approximately Accuracy = 0.85, EAcc = 0.95.
* **Blue Data Point:** Located at approximately Accuracy = 0.80, EAcc = 0.90.
* **Green Data Point:** Located at approximately Accuracy = 0.55, EAcc = 0.80.
* **Orange Data Point:** Located at approximately Accuracy = 0.55, EAcc = 0.65.
### Key Observations
* The red and blue data points are clustered closely together in the upper-right corner, indicating high accuracy and EAcc values.
* The green and orange data points are located closer to the center of the plot, indicating lower accuracy and EAcc values compared to the red and blue points.
* There is a noticeable gap between the red/blue cluster and the green/orange cluster.
### Interpretation
The scatter plot suggests a positive correlation between Accuracy and EAcc. The red and blue data points represent scenarios with high accuracy and EAcc, while the green and orange data points represent scenarios with lower accuracy and EAcc. The clustering of the data points suggests that there may be distinct performance levels or categories represented by the different colors. Without a legend, it is impossible to determine what each color represents. The gap between the clusters could indicate a threshold effect or a significant difference in the underlying conditions or parameters that lead to the observed performance.
</details>
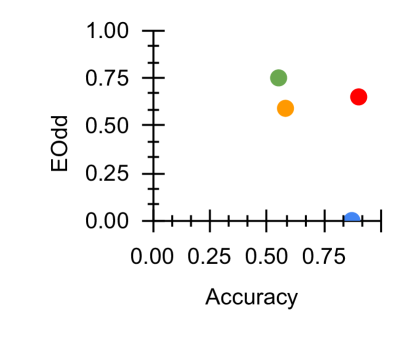
\subfigure [ $\mathcal{M}_{EOdd}$ vs Acc]
<details>
<summary>x7.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy vs. EOdd
### Overview
The image is a scatter plot showing the relationship between "Accuracy" on the x-axis and "EOdd" on the y-axis. There are four data points, each represented by a colored circle: blue, red, green, and orange. The plot appears to show the distribution of these points in a two-dimensional space defined by accuracy and EOdd values.
### Components/Axes
* **X-axis:** "Accuracy", ranging from 0.00 to approximately 0.85. Axis markers are present at 0.00, 0.25, 0.50, and 0.75.
* **Y-axis:** "EOdd", ranging from 0.00 to 1.00. Axis markers are present at 0.00, 0.25, 0.50, 0.75, and 1.00.
* **Data Points:** Four colored data points are present: blue, red, green, and orange. There is no legend provided.
### Detailed Analysis
* **Blue Data Point:** Located at approximately (0.80, 0.02).
* **Red Data Point:** Located at approximately (0.82, 0.68).
* **Green Data Point:** Located at approximately (0.55, 0.75).
* **Orange Data Point:** Located at approximately (0.55, 0.60).
### Key Observations
* The blue data point has high accuracy but very low EOdd.
* The red data point has high accuracy and a moderate EOdd.
* The green and orange data points have similar accuracy but different EOdd values.
### Interpretation
The scatter plot visualizes the relationship between accuracy and EOdd for four different entities (represented by the colored points). The plot suggests that high accuracy does not necessarily imply a high EOdd, as seen with the blue data point. The spread of the points indicates a varying trade-off between accuracy and EOdd. Without a legend, it's impossible to know what each color represents, but the plot allows for a comparison of their relative performance in terms of these two metrics.
</details>
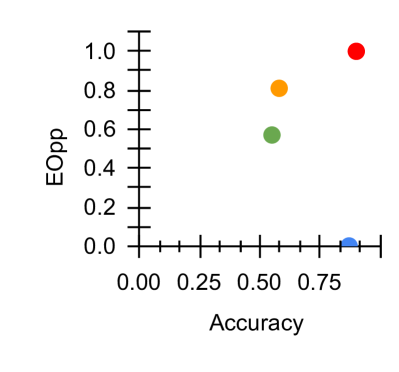
\subfigure [ $\mathcal{M}_{EOpp}$ vs Acc]
<details>
<summary>x8.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy vs. EOpp
### Overview
The image is a scatter plot showing the relationship between "Accuracy" on the x-axis and "EOpp" (likely Equal Opportunity) on the y-axis. There are four data points, each represented by a different color: blue, green, orange, and red. The plot shows how these two metrics vary across different models or scenarios.
### Components/Axes
* **X-axis:** "Accuracy", ranging from 0.00 to 1.00, with tick marks at intervals of 0.25.
* **Y-axis:** "EOpp", ranging from 0.0 to 1.0, with tick marks at intervals of 0.2.
* **Data Points:** Four data points, each with a distinct color: blue, green, orange, and red. There is no legend.
### Detailed Analysis
* **Blue Data Point:** Located at approximately Accuracy = 0.8, EOpp = 0.0.
* **Green Data Point:** Located at approximately Accuracy = 0.5, EOpp = 0.6.
* **Orange Data Point:** Located at approximately Accuracy = 0.6, EOpp = 0.8.
* **Red Data Point:** Located at approximately Accuracy = 0.8, EOpp = 1.0.
### Key Observations
* The blue data point has high accuracy but very low EOpp.
* The green data point has moderate accuracy and moderate EOpp.
* The orange data point has moderate accuracy and high EOpp.
* The red data point has high accuracy and high EOpp.
### Interpretation
The scatter plot visualizes the trade-off between accuracy and equal opportunity (EOpp). The data suggests that achieving high accuracy does not necessarily guarantee high EOpp, and vice versa. The blue data point represents a scenario where the model is accurate but potentially unfair (low EOpp). The red data point represents a scenario where the model is both accurate and fair (high EOpp). The green and orange data points represent intermediate scenarios with varying levels of accuracy and EOpp. Without knowing what each color represents (e.g., different models, different parameter settings), it's difficult to draw more specific conclusions.
</details>
\subfigure [ $\mathcal{M}_{SP}$ vs Acc]
<details>
<summary>x9.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy vs. SP
### Overview
The image is a scatter plot showing the relationship between "Accuracy" on the x-axis and "SP" (likely a metric, but its full meaning is not provided) on the y-axis. There are four data points, each represented by a colored circle: blue, red, orange, and green. The plot spans from 0.00 to 1.00 on both axes, although no data points reach 1.00.
### Components/Axes
* **X-axis:** "Accuracy", ranging from 0.00 to 1.00 with tick marks at intervals of 0.25.
* **Y-axis:** "SP", ranging from 0.0 to 0.8 with tick marks at intervals of 0.2.
* **Data Points:**
* Blue: Located near (0.8, 0.0)
* Red: Located near (0.8, 0.4)
* Orange: Located near (0.5, 0.55)
* Green: Located near (0.5, 0.65)
### Detailed Analysis
* **Blue Data Point:** Accuracy is approximately 0.8, SP is approximately 0.0.
* **Red Data Point:** Accuracy is approximately 0.8, SP is approximately 0.4.
* **Orange Data Point:** Accuracy is approximately 0.5, SP is approximately 0.55.
* **Green Data Point:** Accuracy is approximately 0.5, SP is approximately 0.65.
### Key Observations
* Two data points (blue and red) share the same accuracy value (approximately 0.8) but have different SP values.
* Two data points (orange and green) share the same accuracy value (approximately 0.5) but have different SP values.
* The green data point has the highest SP value, while the blue data point has the lowest.
### Interpretation
The scatter plot visualizes the relationship between accuracy and SP for four different entities or conditions represented by the colored data points. The plot suggests that while accuracy can be the same for different entities (as seen with the blue and red points, and the orange and green points), the SP value can vary significantly. Without knowing what SP represents, it's difficult to draw definitive conclusions, but the plot highlights that accuracy alone may not be the only factor differentiating these entities. The spread of SP values for similar accuracy levels indicates that other variables are likely influencing the SP metric.
</details>
Figure 3: Fairness-Accuracy Pareto Frontier across the E-DAIC results. Upper right indicates better Pareto optimality, i.e. better fairness-accuracy trade-off. Orange: Unitask. Green: Multitask. Blue: Multitask UW. Red: U-Fair. Abbreviations: Acc: accuracy.
5 Results
For both datasets, we normalise the fairness results to facilitate visualisation in Figures 2 and 3.
Table 4: Comparison with other models which used extracted features for DAIC-WOZ. Best results highlighted in bold.
5.1 Uni vs Multitask
For DAIC-WOZ (DW), we see from Table 2, we find that a multitask approach generally improves results compared to a unitask approach (Section 3.3). The baseline loss re-weighting approach from Equation 5 managed to further improve performance. For example, we see from Table 2 that the overall classification accuracy improved from $0.70$ within a vanilla MTL approach to $0.82$ using the baseline uncertainty-based task reweighing approach.
However, this observation is not consistent for E-DAIC (ED). With reference to Table 3, a unitask approach seems to perform better. We see evidence of negative transfer, i.e. the phenomena where learning multiple tasks concurrently result in lower performance than a unitask approach. We hypothesise that this is because ED is a more challenging dataset. When adopting a multitask approach, the model completely relies on the easier tasks thus negatively impacting the learning of the other tasks.
Moreover, performance improvement seems to come at a cost. This may be due to the fairness-accuracy trade-off (Wang et al., 2021b). For instance in DW, we see that the fairness scores $\mathcal{M}_{SP}$ , $\mathcal{M}_{EOpp}$ , $\mathcal{M}_{Odd}$ and $\mathcal{M}_{Acc}$ reduced from $0.86$ , $0.78$ , $0.94$ and $0.76$ to $1.23$ , $1.70$ , $1.31$ and $1.25$ respectively. This is consistent with the analysis across the Pareto frontier depicted in Figures 2 and 3.
5.2 Uncertainty & the Pareto Frontier
Our proposed loss reweighting approach seems to address the negative transfer and Pareto frontier challenges. Although accuracy dropped slightly from $0.82$ to $0.80$ , fairness largely improved compared to the baseline UW approach (Equation 5). We see from Table 2 that fairness improved across $\mathcal{M}_{SP}$ , $\mathcal{M}_{EOpp}$ , $\mathcal{M}_{EOdd}$ and $\mathcal{M}_{Acc}$ from $1.23$ , $1.70$ , $1.31$ , $1.25$ to $1.06$ , $1.46$ , $1.17$ and $0.95$ for DW.
For ED, the baseline UW which adopts a task based difficulty reweighting mechanism seems to somewhat mitigate the task-based negative transfer which improves the unitask performance but not overall performance nor fairness measures. Our proposed method which takes into account the gender difference may have somewhat addressed this task-based negative transfer. In concurrence, U-Fair also addressed the initial bias present. We see from Table 3 that fairness improved across all fairness measures. The scores improved from $3.86$ , $2.31$ , $8.21$ , $0.92$ to $1.67$ , $1.00$ , $5.00$ and $0.94$ across $\mathcal{M}_{SP}$ , $\mathcal{M}_{EOpp}$ , $\mathcal{M}_{EOdd}$ and $\mathcal{M}_{Acc}$ .
The Pareto frontier across all four measures illustrated in Figures 2 and 3 demonstrated that our proposed method generally provides better accuracy-fairness trade-off across most fairness measures for both datasets. With reference to Figure 2, we see that U-Fair, generally provides a slightly better Pareto optimality compared to other methods. This improvement in the Pareto frontier is especially pronounced for Figure 3 (c). The difference in the Pareto frontier between our proposed method and other compared methods is greater in ED (Fig 3), the more challenging dataset, compared to that in DW (Fig 2).
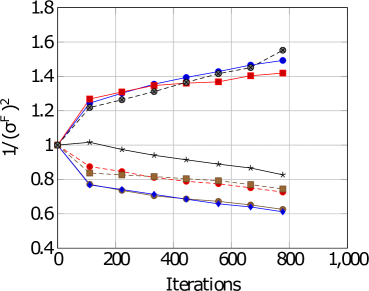
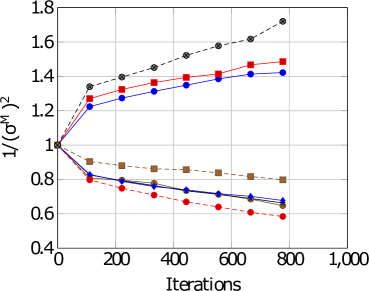
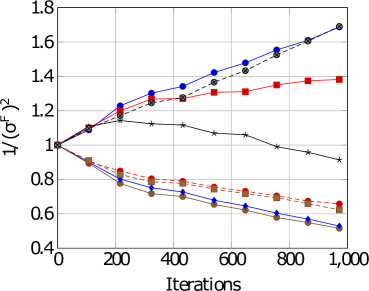
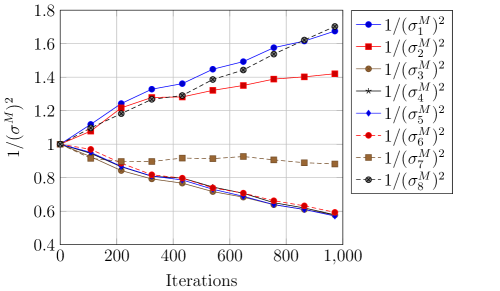
For DW, with reference to Figures 4 and 4, we see that there is a difference in task difficulty. Task 4 and 6 is easier for females whereas task 7 is easier for males. For ED, with reference to Figures 4, 4 and Table 5, Task 4 seems to be easier for females whereas task 7 seems easier for males. Thus, adopting a gender-based uncertainty reweighting approach might have ensured that the tasks are more appropriately weighed leading towards better performance for both genders whilst mitigating the negative transfer and Pareto frontier challenges.
5.3 Task Difficulty & Discrimination Capacity
A particularly relevant and exciting finding is that each PHQ-8 subitem’s task difficulty agree with its discrimination capacity as evidenced by the rigorous study conducted by de la Torre et al. (2023). This largest study to date assessed the internal structure, reliability and cross-country validity of the PHQ-8 for the assessment of depressive symptoms. Discrimination capacity is defined as the ability of item to distinguish whether a person is depressed or not.
With reference to Table 5, it is noteworthy that the task difficulty captured by $\frac{1}{\sigma^{2}}$ in our experiments corresponds to the discrimination capacity (DC) of each task. The higher $\sigma_{t}$ , the more difficult the task $t$ . In other words, the lower the value of $\frac{1}{\sigma^{2}}$ , the more difficult the task. For instance, in their study, PHQ-1, 2 and 6 were the items that has the greatest ability to discriminate whether a person is depressed. This is in alignment with our results where PHQ-1,2 and 8 are easier across both datasets. PHQ-3 and PHQ-5 are the least discriminatory or more difficult tasks as evidenced by the values highlighted in red.
\subfigure [DAIC-WOZ: Female]
<details>
<summary>x10.png Details</summary>
### Visual Description
## Line Chart: Variance vs. Iterations
### Overview
The image is a line chart displaying the relationship between the inverse of the variance (1/(σ^F)^2) and the number of iterations. Several data series are plotted, each represented by a different color and marker, showing how the variance changes with increasing iterations.
### Components/Axes
* **X-axis:** Iterations, ranging from 0 to 1,000 in increments of 200.
* **Y-axis:** 1/(σ^F)^2, ranging from 0.4 to 1.8 in increments of 0.2.
* **Data Series:** Multiple lines with different colors and markers, but no explicit legend is provided.
### Detailed Analysis
Since there is no legend, I will describe the lines by their color and marker.
* **Red Squares:** This line starts at approximately 1.0, increases to about 1.3 at 200 iterations, plateaus around 1.35 until 600 iterations, and then increases slightly to approximately 1.42 at 800 iterations.
* **Blue Diamonds:** This line starts at approximately 1.0, decreases to about 0.75 at 200 iterations, and continues to decrease gradually to approximately 0.6 at 800 iterations.
* **Black Stars:** This line starts at approximately 1.0, and decreases gradually to approximately 0.8 at 800 iterations.
* **Brown Squares:** This line starts at approximately 1.0, decreases to about 0.8 at 200 iterations, and continues to decrease gradually to approximately 0.72 at 800 iterations.
* **Black Circles (Dashed):** This line starts at approximately 1.0, increases to about 1.25 at 200 iterations, and continues to increase to approximately 1.55 at 800 iterations.
* **Red Circles (Dashed):** This line starts at approximately 1.0, decreases to about 0.9 at 200 iterations, and continues to decrease gradually to approximately 0.75 at 800 iterations.
* **Blue Circles (Dashed):** This line starts at approximately 1.0, increases to about 1.2 at 200 iterations, and continues to increase to approximately 1.5 at 800 iterations.
### Key Observations
* Some lines show an increasing trend of 1/(σ^F)^2 with iterations, while others show a decreasing trend.
* The red squares line shows an initial increase, then plateaus, and finally increases slightly.
* The blue diamonds line shows a consistent decrease in 1/(σ^F)^2 with iterations.
* The black stars line shows a consistent decrease in 1/(σ^F)^2 with iterations.
* The brown squares line shows a consistent decrease in 1/(σ^F)^2 with iterations.
* The black circles (dashed) line shows a consistent increase in 1/(σ^F)^2 with iterations.
* The red circles (dashed) line shows a consistent decrease in 1/(σ^F)^2 with iterations.
* The blue circles (dashed) line shows a consistent increase in 1/(σ^F)^2 with iterations.
### Interpretation
The chart illustrates how the inverse of the variance changes as the number of iterations increases. The different lines likely represent different algorithms or parameter settings. The increasing lines suggest that the variance is decreasing with more iterations (indicating convergence or improvement), while the decreasing lines suggest the opposite. The specific meaning depends on what the variance represents in the context of the experiment. Without a legend, it's impossible to definitively say which line corresponds to which algorithm or setting. The dashed lines may represent a different set of conditions or a variation of the solid lines.
</details>
\subfigure [DAIC-WOZ: Male]
<details>
<summary>x11.png Details</summary>
### Visual Description
## Line Chart: Convergence of Variance Estimators
### Overview
The image is a line chart that depicts the convergence of variance estimators over a number of iterations. Several lines, each representing a different estimator, show how the inverse of the variance estimate changes with increasing iterations. The chart includes multiple data series, some increasing and some decreasing, indicating the behavior of different estimation methods.
### Components/Axes
* **X-axis (Horizontal):** "Iterations", ranging from 0 to 1,000. Axis markers are present at 0, 200, 400, 600, 800, and 1,000.
* **Y-axis (Vertical):** "1/(σM)^2", ranging from 0.4 to 1.8. Axis markers are present at 0.4, 0.6, 0.8, 1.0, 1.2, 1.4, 1.6, and 1.8.
* **Legend:** There is no explicit legend, but the different lines are distinguished by color and marker type.
### Detailed Analysis
**Data Series and Trends:**
1. **Black dashed line with circle markers:** This line starts at approximately 1.0 and increases steadily, reaching approximately 1.7 at 800 iterations.
2. **Red solid line with square markers:** This line starts at approximately 1.0 and increases, reaching approximately 1.5 at 800 iterations.
3. **Blue solid line with circle markers:** This line starts at approximately 1.0 and increases, reaching approximately 1.4 at 800 iterations.
4. **Brown solid line with square markers:** This line starts at approximately 1.0 and decreases, reaching approximately 0.8 at 800 iterations.
5. **Red dashed line with circle markers:** This line starts at approximately 1.0 and decreases, reaching approximately 0.6 at 800 iterations.
6. **Blue solid line with diamond markers:** This line starts at approximately 1.0 and decreases, reaching approximately 0.7 at 800 iterations.
7. **Black solid line:** This line starts at approximately 1.0 and decreases, reaching approximately 0.65 at 800 iterations.
### Key Observations
* Some estimators (black dashed, red solid, blue solid) show an increasing trend in the inverse of the variance, while others (brown solid, red dashed, blue solid, black solid) show a decreasing trend.
* All lines start at approximately 1.0, indicating an initial normalized state.
* The black dashed line exhibits the most significant increase in the inverse of the variance.
* The red dashed line exhibits the most significant decrease in the inverse of the variance.
* The convergence rate varies among the different estimators.
### Interpretation
The chart illustrates the convergence behavior of different variance estimators as the number of iterations increases. The increasing lines suggest that the corresponding estimators are underestimating the variance, leading to an increase in the inverse of the variance. Conversely, the decreasing lines suggest that the corresponding estimators are overestimating the variance, leading to a decrease in the inverse of the variance. The convergence rate and final values indicate the relative performance and stability of each estimator. The initial value of 1.0 for all lines likely represents a normalized or initial estimate, allowing for a direct comparison of how each estimator evolves over iterations.
</details>
\subfigure [E-DAIC: Female]
<details>
<summary>x12.png Details</summary>
### Visual Description
## Line Chart: Convergence Analysis
### Overview
The image is a line chart comparing the convergence of different algorithms or methods, likely in an optimization or machine learning context. The y-axis represents the inverse of the squared Frobenius norm (1/(σ^F)^2), and the x-axis represents the number of iterations. Several lines, each with a distinct color and marker, show how this metric changes over iterations.
### Components/Axes
* **X-axis:** Iterations, ranging from 0 to 1,000 in increments of 200.
* **Y-axis:** 1/(σ^F)^2, ranging from 0.4 to 1.8 in increments of 0.2.
* **Legend:** The legend is not explicitly present, but the different lines are distinguished by color and marker type.
### Detailed Analysis
The chart contains several data series, each represented by a line with distinct markers and colors.
* **Blue line with circle markers:** This line shows an upward trend, starting at approximately 1.0 and increasing to approximately 1.65 at 1,000 iterations.
* (0, 1.0)
* (200, 1.25)
* (400, 1.32)
* (600, 1.45)
* (800, 1.55)
* (1000, 1.65)
* **Red line with square markers:** This line also shows an upward trend, but less steep than the blue line. It starts at approximately 1.0 and increases to approximately 1.4 at 1,000 iterations.
* (0, 1.0)
* (200, 1.15)
* (400, 1.25)
* (600, 1.3)
* (800, 1.35)
* (1000, 1.4)
* **Black line with star markers:** This line shows a downward trend initially, then stabilizes. It starts at approximately 1.0 and decreases to approximately 0.9 at 1,000 iterations.
* (0, 1.0)
* (200, 1.1)
* (400, 1.1)
* (600, 1.05)
* (800, 0.95)
* (1000, 0.9)
* **Brown line with triangle markers:** This line shows a downward trend, starting at approximately 1.0 and decreasing to approximately 0.5 at 1,000 iterations.
* (0, 1.0)
* (200, 0.85)
* (400, 0.75)
* (600, 0.65)
* (800, 0.55)
* (1000, 0.5)
* **Dashed Black line with X markers:** This line shows an upward trend, starting at approximately 1.0 and increasing to approximately 1.7 at 1,000 iterations.
* (0, 1.0)
* (200, 1.15)
* (400, 1.25)
* (600, 1.4)
* (800, 1.55)
* (1000, 1.7)
* **Dashed Red line with circle markers:** This line shows a downward trend, starting at approximately 1.0 and decreasing to approximately 0.65 at 1,000 iterations.
* (0, 1.0)
* (200, 0.9)
* (400, 0.8)
* (600, 0.75)
* (800, 0.7)
* (1000, 0.65)
* **Dashed Blue line with diamond markers:** This line shows a downward trend, starting at approximately 1.0 and decreasing to approximately 0.55 at 1,000 iterations.
* (0, 1.0)
* (200, 0.85)
* (400, 0.75)
* (600, 0.65)
* (800, 0.6)
* (1000, 0.55)
### Key Observations
* Some algorithms (blue and red lines) cause the metric to increase with iterations, while others (brown and black lines) cause it to decrease.
* The dashed black line increases the most rapidly.
* The brown line decreases the most rapidly.
* The black line stabilizes after an initial decrease.
### Interpretation
The chart visualizes the convergence behavior of different algorithms or methods. The y-axis metric, 1/(σ^F)^2, likely represents some measure of error or residual, where a lower value indicates better convergence. Algorithms with downward-sloping lines are converging towards a better solution as the number of iterations increases. Conversely, algorithms with upward-sloping lines are diverging or not converging effectively. The specific meaning of σ^F would depend on the context of the problem being solved. The different markers and colors likely represent different parameter settings or variations of the algorithms being compared. The dashed lines may represent a different set of algorithms or a variation of the solid lines.
</details>
\subfigure [E-DAIC: Male]
<details>
<summary>x13.png Details</summary>
### Visual Description
## Line Chart: Variance Components vs. Iterations
### Overview
The image is a line chart that plots the inverse of the squared variance components (1/(σ^M)^2) against the number of iterations. There are eight different variance components plotted, each represented by a different colored line with distinct markers. The chart shows how these variance components change over 1000 iterations.
### Components/Axes
* **X-axis:** "Iterations", ranging from 0 to 1000 in increments of 200.
* **Y-axis:** "1/(σ^M)^2", ranging from 0.4 to 1.8 in increments of 0.2.
* **Legend (Top-Right):**
* Blue circles: 1/(σ₁^M)^2
* Red squares: 1/(σ₂^M)^2
* Brown circles: 1/(σ₃^M)^2
* Black stars: 1/(σ₄^M)^2
* Blue diamonds: 1/(σ₅^M)^2
* Red dashed line with circles: 1/(σ₆^M)^2
* Brown dashed line with squares: 1/(σ₇^M)^2
* Black dashed line with circles: 1/(σ₈^M)^2
### Detailed Analysis
* **1/(σ₁^M)^2 (Blue circles):** Starts at approximately 1.0 and increases to approximately 1.7 at 1000 iterations. The trend is upward.
* At 200 iterations: ~1.2
* At 400 iterations: ~1.35
* At 600 iterations: ~1.5
* At 800 iterations: ~1.6
* At 1000 iterations: ~1.7
* **1/(σ₂^M)^2 (Red squares):** Starts at approximately 1.0 and increases to approximately 1.4 at 1000 iterations. The trend is upward.
* At 200 iterations: ~1.1
* At 400 iterations: ~1.3
* At 600 iterations: ~1.4
* At 800 iterations: ~1.4
* At 1000 iterations: ~1.4
* **1/(σ₃^M)^2 (Brown circles):** Starts at approximately 1.0 and decreases to approximately 0.8 at 1000 iterations. The trend is downward.
* At 200 iterations: ~0.95
* At 400 iterations: ~0.9
* At 600 iterations: ~0.8
* At 800 iterations: ~0.7
* At 1000 iterations: ~0.6
* **1/(σ₄^M)^2 (Black stars):** Starts at approximately 1.0 and increases to approximately 1.7 at 1000 iterations. The trend is upward.
* At 200 iterations: ~1.2
* At 400 iterations: ~1.3
* At 600 iterations: ~1.5
* At 800 iterations: ~1.6
* At 1000 iterations: ~1.7
* **1/(σ₅^M)^2 (Blue diamonds):** Starts at approximately 1.0 and decreases to approximately 0.6 at 1000 iterations. The trend is downward.
* At 200 iterations: ~0.9
* At 400 iterations: ~0.8
* At 600 iterations: ~0.7
* At 800 iterations: ~0.65
* At 1000 iterations: ~0.55
* **1/(σ₆^M)^2 (Red dashed line with circles):** Starts at approximately 1.0 and decreases to approximately 0.6 at 1000 iterations. The trend is downward.
* At 200 iterations: ~0.9
* At 400 iterations: ~0.8
* At 600 iterations: ~0.7
* At 800 iterations: ~0.65
* At 1000 iterations: ~0.6
* **1/(σ₇^M)^2 (Brown dashed line with squares):** Starts at approximately 1.0 and decreases slightly before increasing and leveling off at approximately 0.9 at 1000 iterations. The trend is relatively stable after the initial decrease.
* At 200 iterations: ~0.9
* At 400 iterations: ~0.9
* At 600 iterations: ~0.95
* At 800 iterations: ~0.9
* At 1000 iterations: ~0.9
* **1/(σ₈^M)^2 (Black dashed line with circles):** Starts at approximately 1.0 and increases to approximately 1.7 at 1000 iterations. The trend is upward.
* At 200 iterations: ~1.2
* At 400 iterations: ~1.3
* At 600 iterations: ~1.5
* At 800 iterations: ~1.6
* At 1000 iterations: ~1.7
### Key Observations
* Variance components 1, 4, and 8 (blue circles, black stars, and black dashed line with circles, respectively) show a clear increasing trend as the number of iterations increases.
* Variance components 3, 5, and 6 (brown circles, blue diamonds, and red dashed line with circles, respectively) show a clear decreasing trend as the number of iterations increases.
* Variance component 7 (brown dashed line with squares) is relatively stable after an initial decrease.
* Variance component 2 (red squares) increases, but at a slower rate than components 1, 4, and 8.
### Interpretation
The chart illustrates how different variance components behave as the number of iterations increases. Some variance components increase, suggesting they become more significant with more iterations, while others decrease, suggesting they become less significant. The stable variance component indicates that its contribution remains relatively constant throughout the iterations. The data suggests that the iterative process has a varying impact on different variance components, potentially indicating different convergence rates or sensitivities to the iterative algorithm.
</details>
Figure 4: Task-based weightings for both gender and datasets.
| PHQ-1 PHQ-2 PHQ-3 | 3.06 3.42 1.91 | 1.50 1.41 0.62 | 1.41 1.47 0.64 | 1.69 1.38 0.51 | 1.69 1.41 0.58 |
| --- | --- | --- | --- | --- | --- |
| PHQ-4 | 2.67 | 0.82 | 0.68 | 0.91 | 0.60 |
| PHQ-5 | 2.22 | 0.61 | 0.69 | 0.51 | 0.58 |
| PHQ-6 | 2.86 | 0.73 | 0.59 | 0.63 | 0.60 |
| PHQ-7 | 2.55 | 0.75 | 0.80 | 0.61 | 0.89 |
| PHQ-8 | 2.43 | 1.58 | 1.72 | 1.69 | 1.70 |
Table 5: Discrimination capacity (DC) vs $\frac{1}{\sigma^{2}}$ . Lower $\frac{1}{\sigma^{2}}$ values implies higher task difficulty. Green: top 3 highest scores. Red: bottom 2 lowest scores. Our results are in harmony with the largest and most comprehensive study on the PHQ-8 conducted by de la Torre et al. (2023). DW: DAIC-WOZ. ED: E-DAIC. F: Female. M: Male.
6 Discussion and Conclusion
Our experiments unearthed several interesting insights. First, overall, there are certain gender-based differences across the different PHQ-8 distribution labels as evidenced in Figure 4. In addition, each task have slightly different degree of task uncertainty across gender. This may be due to a gender difference in PHQ-8 questionnaire profiling or inadequate data curation. Thus, employing a gender-aware approach may be a viable method to improve fairness and accuracy for depression detection.
Second, though a multitask approach generally performs better than a unitask approach, this comes with several caveats. We see from Table 5 that each task has a different level of difficulty. Naively using all tasks may worsen performance and fairness compared to a unitask approach if we do not account for task-based uncertainty. This is in agreement with existing literature which indicates that there can be a mix of positive and negative transfers across tasks (Li et al., 2023c) and tasks have to be related for performance to improve (Wang et al., 2021a).
Third, understanding, analysing and improving upon the fairness-accuracy Pareto frontier within the task of depression requires a nuanced and careful use of measures and datasets in order to avoid the fairness-accuracy trade-off. Moreover, there is a growing amount of research indicating that if using appropriate methodology and metrics, these trade-offs are not always present (Dutta et al., 2020; Black et al., 2022; Cooper et al., 2021) and can be mitigated with careful selection of models (Black et al., 2022) and evaluation methods (Wick et al., 2019). Our results are in agreement with existing works indicating that state-of-the-art bias mitigation methods are typically only effective at removing epistemic discrimination (Wang et al., 2023), i.e. the discrimination made during model development, but not aleatoric discrimination. In order to address aleatoric discrimination, i.e. the bias inherent within the data distribution, and to improve the Pareto frontier, better data curation is required (Dutta et al., 2020). Though our results are unable to provide a significant improvement on the Pareto frontier, we believe that this work presents the first step in this direction and would encourage future work to look into this.
In sum, we present a novel gender-based uncertainty multitask loss reweighting mechanism. We showed that our proposed multitask loss reweighting is able to improve fairness with lesser fairness-accuracy trade-off. Our findings also revealed the importance of accounting for negative transfers and for more effort to be channelled towards improving the Pareto frontier in depression detection research.
ML for Healthcare Implication:
Producing a thorough review of strategies to improve fairness is not within the scope of this work. Instead, the key goal is to advance ML for healthcare solutions that are grounded in the framework used by clinicians. In our settings, this corresponds to using each PHQ-8 subcriterion as individual subtask within our MTL-based approach and using a a gender-based uncertainty reweighting mechanism to account for the gender difference in PHQ-8 label distribution. By replicating the inferential process used by clinicians, this work attempts to bridge ML methods with the symptom-based profiling system used by clinicians. Future work can also make use of this property during inference in order to improve the trustworthiness of the machine learning or decision-making model (Huang and Ma, 2022).
In the process of doing so, our proposed method also provide the elusive first evidence that each PHQ-8 subitem’s task difficulty aligns with its discrimination capacity as evidenced from data collected from the largest PHQ-8 population-based study to date (de la Torre et al., 2023). We hope this piece of work will encourage other ML and healthcare researchers to further investigate methods that could bridge ML experimental results with empirical real world healthcare findings to ensure its reliability and validity.
Limitations:
We only investigated gender fairness due to the limited availability of other sensitive attributes in both datasets. Future work can consider investigating this approach across different sensitive attributes such as race and age, the intersectionality of sensitive attributes and other healthcare challenges such as cognitive impairment or cancer diagnosis. Moreover, we have adopted our existing experimental approach in alignment with the train-validation-test split provided by the dataset owners as well as other existing works. Future works can consider adopting a cross-validation approach. Other interesting directions include investigating this challenge as an ordinal regression problem (Diaz and Marathe, 2019). Future work can also consider repeating the experiments using datasets collected from other countries and dive deeper into the cultural intricacies of the different PHQ-8 subitems, investigate the effects of the different modalities and its relation to a multitask approach, as well as investigate other important topics such as interpretability and explainability to advance responsible (Wiens et al., 2019) and ethical machine learning for healthcare (Chen et al., 2021).
\acks
Funding: J. Cheong is supported by the Alan Turing Institute doctoral studentship, the Leverhulme Trust and further acknowledges resource support from METU. A. Bangar contributed to this while undertaking a remote visiting studentship at the Department of Computer Science and Technology, University of Cambridge. H. Gunes’ work is supported by the EPSRC/UKRI project ARoEq under grant ref. EP/R030782/1. Open access: The authors have applied a Creative Commons Attribution (CC BY) licence to any Author Accepted Manuscript version arising. Data access: This study involved secondary analyses of existing datasets. All datasets are described and cited accordingly.
References
- Al Hanai et al. (2018) Tuka Al Hanai, Mohammad M Ghassemi, and James R Glass. Detecting depression with audio/text sequence modeling of interviews. In Interspeech, pages 1716–1720, 2018.
- Bailey and Plumbley (2021) Andrew Bailey and Mark D Plumbley. Gender bias in depression detection using audio features. EUSIPCO 2021, 2021.
- Baltaci et al. (2023) Zeynep Sonat Baltaci, Kemal Oksuz, Selim Kuzucu, Kivanc Tezoren, Berkin Kerim Konar, Alpay Ozkan, Emre Akbas, and Sinan Kalkan. Class uncertainty: A measure to mitigate class imbalance. arXiv preprint arXiv:2311.14090, 2023.
- Ban and Ji (2024) Hao Ban and Kaiyi Ji. Fair resource allocation in multi-task learning. arXiv preprint arXiv:2402.15638, 2024.
- Barocas et al. (2017) Solon Barocas, Moritz Hardt, and Arvind Narayanan. Fairness in machine learning. NeurIPS Tutorial, 1:2, 2017.
- Barsky et al. (2001) Arthur J Barsky, Heli M Peekna, and Jonathan F Borus. Somatic symptom reporting in women and men. Journal of general internal medicine, 16(4):266–275, 2001.
- Black et al. (2022) Emily Black, Manish Raghavan, and Solon Barocas. Model multiplicity: Opportunities, concerns, and solutions. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 850–863, 2022.
- Buolamwini and Gebru (2018) Joy Buolamwini and Timnit Gebru. Gender shades: Intersectional accuracy disparities in commercial gender classification. In FAccT, pages 77–91. PMLR, 2018.
- Cameron et al. (2024) Joseph Cameron, Jiaee Cheong, Micol Spitale, and Hatice Gunes. Multimodal gender fairness in depression prediction: Insights on data from the usa & china. arXiv preprint arXiv:2408.04026, 2024.
- Cetinkaya et al. (2024) Bedrettin Cetinkaya, Sinan Kalkan, and Emre Akbas. Ranked: Addressing imbalance and uncertainty in edge detection using ranking-based losses. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3239–3249, 2024.
- Chen et al. (2021) Irene Y Chen, Emma Pierson, Sherri Rose, Shalmali Joshi, Kadija Ferryman, and Marzyeh Ghassemi. Ethical machine learning in healthcare. Annual review of biomedical data science, 4(1):123–144, 2021.
- Cheong et al. (2021) Jiaee Cheong, Sinan Kalkan, and Hatice Gunes. The hitchhiker’s guide to bias and fairness in facial affective signal processing: Overview and techniques. IEEE Signal Processing Magazine, 38(6), 2021.
- Cheong et al. (2022) Jiaee Cheong, Sinan Kalkan, and Hatice Gunes. Counterfactual fairness for facial expression recognition. In European Conference on Computer Vision, pages 245–261. Springer, 2022.
- Cheong et al. (2023a) Jiaee Cheong, Sinan Kalkan, and Hatice Gunes. Causal structure learning of bias for fair affect recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 340–349, 2023a.
- Cheong et al. (2023b) Jiaee Cheong, Selim Kuzucu, Sinan Kalkan, and Hatice Gunes. Towards gender fairness for mental health prediction. In IJCAI 2023, pages 5932–5940, US, 2023b. IJCAI.
- Cheong et al. (2023c) Jiaee Cheong, Micol Spitale, and Hatice Gunes. “it’s not fair!” – fairness for a small dataset of multi-modal dyadic mental well-being coaching. In ACII, pages 1–8, USA, sep 2023c.
- Cheong et al. (2024a) Jiaee Cheong, Sinan Kalkan, and Hatice Gunes. Fairrefuse: Referee-guided fusion for multi-modal causal fairness in depression detection. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, pages 7224–7232, 8 2024a. AI for Good.
- Cheong et al. (2024b) Jiaee Cheong, Micol Spitale, and Hatice Gunes. Small but fair! fairness for multimodal human-human and robot-human mental wellbeing coaching, 2024b.
- Chua et al. (2023) Michelle Chua, Doyun Kim, Jongmun Choi, Nahyoung G Lee, Vikram Deshpande, Joseph Schwab, Michael H Lev, Ramon G Gonzalez, Michael S Gee, and Synho Do. Tackling prediction uncertainty in machine learning for healthcare. Nature Biomedical Engineering, 7(6):711–718, 2023.
- Cooper et al. (2021) A Feder Cooper, Ellen Abrams, and Na Na. Emergent unfairness in algorithmic fairness-accuracy trade-off research. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pages 46–54, 2021.
- de la Torre et al. (2023) Jorge Arias de la Torre, Gemma Vilagut, Amy Ronaldson, Jose M Valderas, Ioannis Bakolis, Alex Dregan, Antonio J Molina, Fernando Navarro-Mateu, Katherine Pérez, Xavier Bartoll-Roca, et al. Reliability and cross-country equivalence of the 8-item version of the patient health questionnaire (phq-8) for the assessment of depression: results from 27 countries in europe. The Lancet Regional Health–Europe, 31, 2023.
- Diaz and Marathe (2019) Raul Diaz and Amit Marathe. Soft labels for ordinal regression. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4738–4747, 2019.
- Dutta et al. (2020) Sanghamitra Dutta, Dennis Wei, Hazar Yueksel, Pin-Yu Chen, Sijia Liu, and Kush Varshney. Is there a trade-off between fairness and accuracy? a perspective using mismatched hypothesis testing. In International conference on machine learning, pages 2803–2813. PMLR, 2020.
- Gal (2016) Yarin Gal. Uncertainty in deep learning. 2016.
- Ghosh et al. (2022) Soumitra Ghosh, Asif Ekbal, and Pushpak Bhattacharyya. A multitask framework to detect depression, sentiment and multi-label emotion from suicide notes. Cognitive Computation, 14(1), 2022.
- Gong and Poellabauer (2017) Yuan Gong and Christian Poellabauer. Topic modeling based multi-modal depression detection. In Proceedings of the 7th annual workshop on Audio/Visual emotion challenge, pages 69–76, 2017.
- Grote and Keeling (2022) Thomas Grote and Geoff Keeling. Enabling fairness in healthcare through machine learning. Ethics and Information Technology, 24(3):39, 2022.
- Gupta et al. (2023) Shelley Gupta, Archana Singh, and Jayanthi Ranjan. Multimodal, multiview and multitasking depression detection framework endorsed with auxiliary sentiment polarity and emotion detection. International Journal of System Assurance Engineering and Management, 14(Suppl 1), 2023.
- Hall et al. (2022) Melissa Hall, Laurens van der Maaten, Laura Gustafson, Maxwell Jones, and Aaron Adcock. A systematic study of bias amplification. arXiv preprint arXiv:2201.11706, 2022.
- Han et al. (2024) Mengjie Han, Ilkim Canli, Juveria Shah, Xingxing Zhang, Ipek Gursel Dino, and Sinan Kalkan. Perspectives of machine learning and natural language processing on characterizing positive energy districts. Buildings, 14(2):371, 2024.
- He et al. (2022) Lang He, Mingyue Niu, Prayag Tiwari, Pekka Marttinen, Rui Su, Jiewei Jiang, Chenguang Guo, Hongyu Wang, Songtao Ding, Zhongmin Wang, et al. Deep learning for depression recognition with audiovisual cues: A review. Information Fusion, 80:56–86, 2022.
- Hort et al. (2022) Max Hort, Zhenpeng Chen, Jie M Zhang, Federica Sarro, and Mark Harman. Bias mitigation for machine learning classifiers: A comprehensive survey. arXiv preprint arXiv:2207.07068, 2022.
- Huang and Ma (2022) Guanjie Huang and Fenglong Ma. Trustsleepnet: A trustable deep multimodal network for sleep stage classification. In 2022 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI), pages 01–04. IEEE, 2022.
- Jansz et al. (2000) Jeroen Jansz et al. Masculine identity and restrictive emotionality. Gender and emotion: Social psychological perspectives, pages 166–186, 2000.
- Kaiser et al. (2022) Patrick Kaiser, Christoph Kern, and David Rügamer. Uncertainty-aware predictive modeling for fair data-driven decisions, 2022.
- Kendall et al. (2018) Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In CVPR, pages 7482–7491, 2018.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. ICLR, 2014.
- Kroenke et al. (2009) Kurt Kroenke, Tara W Strine, Robert L Spitzer, Janet BW Williams, Joyce T Berry, and Ali H Mokdad. The phq-8 as a measure of current depression in the general population. Journal of affective disorders, 114(1-3):163–173, 2009.
- Kuzucu et al. (2024) Selim Kuzucu, Jiaee Cheong, Hatice Gunes, and Sinan Kalkan. Uncertainty as a fairness measure. Journal of Artificial Intelligence Research, 81:307–335, 2024.
- Leung et al. (2020) Doris YP Leung, Yim Wah Mak, Sau Fong Leung, Vico CL Chiang, and Alice Yuen Loke. Measurement invariances of the phq-9 across gender and age groups in chinese adolescents. Asia-Pacific Psychiatry, 12(3):e12381, 2020.
- Li et al. (2023a) Can Li, Sirui Ding, Na Zou, Xia Hu, Xiaoqian Jiang, and Kai Zhang. Multi-task learning with dynamic re-weighting to achieve fairness in healthcare predictive modeling. Journal of Biomedical Informatics, 143:104399, 2023a.
- Li et al. (2023b) Can Li, Dejian Lai, Xiaoqian Jiang, and Kai Zhang. Feri: A multitask-based fairness achieving algorithm with applications to fair organ transplantation. arXiv preprint arXiv:2310.13820, 2023b.
- Li et al. (2024) Can Li, Xiaoqian Jiang, and Kai Zhang. A transformer-based deep learning approach for fairly predicting post-liver transplant risk factors. Journal of Biomedical Informatics, 149:104545, 2024.
- Li et al. (2022) Chuyuan Li, Chloé Braud, and Maxime Amblard. Multi-task learning for depression detection in dialogs. arXiv preprint arXiv:2208.10250, 2022.
- Li et al. (2023c) Dongyue Li, Huy Nguyen, and Hongyang Ryan Zhang. Identification of negative transfers in multitask learning using surrogate models. Transactions on Machine Learning Research, 2023c.
- Long et al. (2022) Nannan Long, Yongxiang Lei, Lianhua Peng, Ping Xu, and Ping Mao. A scoping review on monitoring mental health using smart wearable devices. Mathematical Biosciences and Engineering, 19(8), 2022.
- Ma et al. (2016) Xingchen Ma, Hongyu Yang, Qiang Chen, Di Huang, and Yunhong Wang. Depaudionet: An efficient deep model for audio based depression classification. In 6th Intl. Workshop on audio/visual emotion challenge, 2016.
- Mehta et al. (2023) Raghav Mehta, Changjian Shui, and Tal Arbel. Evaluating the fairness of deep learning uncertainty estimates in medical image analysis, 2023.
- Naik et al. (2024) Lakshadeep Naik, Sinan Kalkan, and Norbert Krüger. Pre-grasp approaching on mobile robots: a pre-active layered approach. IEEE Robotics and Automation Letters, 2024.
- Ogrodniczuk and Oliffe (2011) John S Ogrodniczuk and John L Oliffe. Men and depression. Canadian Family Physician, 57(2):153–155, 2011.
- Pleiss et al. (2017) Geoff Pleiss, Manish Raghavan, Felix Wu, Jon Kleinberg, and Kilian Q Weinberger. On fairness and calibration. NeurIPS, 30, 2017.
- Ringeval et al. (2019) Fabien Ringeval, Björn Schuller, Michel Valstar, Nicholas Cummins, Roddy Cowie, and Maja Pantic. Avec’19: Audio/visual emotion challenge and workshop. In ICMI, pages 2718–2719, 2019.
- Sendak et al. (2020) Mark Sendak, Madeleine Clare Elish, Michael Gao, Joseph Futoma, William Ratliff, Marshall Nichols, Armando Bedoya, Suresh Balu, and Cara O’Brien. ”the human body is a black box” supporting clinical decision-making with deep learning. In FAccT, pages 99–109, 2020.
- Song et al. (2018) Siyang Song, Linlin Shen, and Michel Valstar. Human behaviour-based automatic depression analysis using hand-crafted statistics and deep learned spectral features. In FG 2018, pages 158–165. IEEE, 2018.
- Spitale et al. (2024) Micol Spitale, Jiaee Cheong, and Hatice Gunes. Underneath the numbers: Quantitative and qualitative gender fairness in llms for depression prediction. arXiv preprint arXiv:2406.08183, 2024.
- Tahir et al. (2023) Anique Tahir, Lu Cheng, and Huan Liu. Fairness through aleatoric uncertainty. In CIKM, 2023.
- Thibodeau and Asmundson (2014) Michel A Thibodeau and Gordon JG Asmundson. The phq-9 assesses depression similarly in men and women from the general population. Personality and Individual Differences, 56:149–153, 2014.
- Valstar et al. (2016) Michel Valstar, Jonathan Gratch, Björn Schuller, Fabien Ringeval, Denis Lalanne, Mercedes Torres Torres, Stefan Scherer, Giota Stratou, Roddy Cowie, and Maja Pantic. Avec 2016: Depression, mood, and emotion recognition workshop and challenge. pages 3–10, 2016.
- Vetter et al. (2013) Marion L Vetter, Thomas A Wadden, Christopher Vinnard, Reneé H Moore, Zahra Khan, Sheri Volger, David B Sarwer, and Lucy F Faulconbridge. Gender differences in the relationship between symptoms of depression and high-sensitivity crp. International journal of obesity, 37(1):S38–S43, 2013.
- Wang et al. (2023) Hao Wang, Luxi He, Rui Gao, and Flavio Calmon. Aleatoric and epistemic discrimination: Fundamental limits of fairness interventions. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Wang et al. (2021a) Jialu Wang, Yang Liu, and Caleb Levy. Fair classification with group-dependent label noise. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 526–536, 2021a.
- Wang et al. (2019) Jingying Wang, Lei Zhang, Tianli Liu, Wei Pan, Bin Hu, and Tingshao Zhu. Acoustic differences between healthy and depressed people: a cross-situation study. BMC psychiatry, 19:1–12, 2019.
- Wang et al. (2007) Philip S Wang, Sergio Aguilar-Gaxiola, Jordi Alonso, Matthias C Angermeyer, Guilherme Borges, Evelyn J Bromet, Ronny Bruffaerts, Giovanni De Girolamo, Ron De Graaf, Oye Gureje, et al. Use of mental health services for anxiety, mood, and substance disorders in 17 countries in the who world mental health surveys. The Lancet, 370(9590):841–850, 2007.
- Wang et al. (2022) Yiding Wang, Zhenyi Wang, Chenghao Li, Yilin Zhang, and Haizhou Wang. Online social network individual depression detection using a multitask heterogenous modality fusion approach. Information Sciences, 609, 2022.
- Wang et al. (2021b) Yuyan Wang, Xuezhi Wang, Alex Beutel, Flavien Prost, Jilin Chen, and Ed H Chi. Understanding and improving fairness-accuracy trade-offs in multi-task learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 1748–1757, 2021b.
- Wei et al. (2022) Ping-Cheng Wei, Kunyu Peng, Alina Roitberg, Kailun Yang, Jiaming Zhang, and Rainer Stiefelhagen. Multi-modal depression estimation based on sub-attentional fusion. In European Conference on Computer Vision, pages 623–639. Springer, 2022.
- Wick et al. (2019) Michael Wick, Jean-Baptiste Tristan, et al. Unlocking fairness: a trade-off revisited. Advances in neural information processing systems, 32, 2019.
- Wiens et al. (2019) Jenna Wiens, Suchi Saria, Mark Sendak, Marzyeh Ghassemi, Vincent X Liu, Finale Doshi-Velez, Kenneth Jung, Katherine Heller, David Kale, Mohammed Saeed, et al. Do no harm: a roadmap for responsible machine learning for health care. Nature medicine, 25(9):1337–1340, 2019.
- Williamson et al. (2016) James R Williamson, Elizabeth Godoy, Miriam Cha, Adrianne Schwarzentruber, Pooya Khorrami, Youngjune Gwon, Hsiang-Tsung Kung, Charlie Dagli, and Thomas F Quatieri. Detecting depression using vocal, facial and semantic communication cues. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, pages 11–18, 2016.
- Xu et al. (2020) Tian Xu, Jennifer White, Sinan Kalkan, and Hatice Gunes. Investigating bias and fairness in facial expression recognition. In Computer Vision–ECCV 2020 Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part VI 16, pages 506–523. Springer, 2020.
- Yuan et al. (2024) Hua Yuan, Yu Shi, Ning Xu, Xu Yang, Xin Geng, and Yong Rui. Learning from biased soft labels. Advances in Neural Information Processing Systems, 36, 2024.
- Zanna et al. (2022) Khadija Zanna, Kusha Sridhar, Han Yu, and Akane Sano. Bias reducing multitask learning on mental health prediction. In ACII, pages 1–8. IEEE, 2022.
- Zhang and Yang (2021) Yu Zhang and Qiang Yang. A survey on multi-task learning. IEEE Transactions on Knowledge and Data Engineering, 34(12):5586–5609, 2021.
- Zhang et al. (2020) Ziheng Zhang, Weizhe Lin, Mingyu Liu, and Marwa Mahmoud. Multimodal deep learning framework for mental disorder recognition. In 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), pages 344–350. IEEE, 2020.
- Zheng et al. (2023) Wenbo Zheng, Lan Yan, and Fei-Yue Wang. Two birds with one stone: Knowledge-embedded temporal convolutional transformer for depression detection and emotion recognition. IEEE Transactions on Affective Computing, 2023.
Appendix A Experimental Setup
A.1 Datasets
For both DAIC-WOZ and E-DAIC, we work with the extracted features and followed the train-validate-test split provided. The dataset owners provided the ground-truths for each of the PHQ-8 sub-criterion and the final binary classification for both datasets.
DAIC-WOZ (Valstar et al., 2016)
contains audio recordings, extracted visual features and transcripts collected in a lab-based setting of 100 males and 85 females. The dataset owners provided a standard train-validate-test split which we followed. The dataset owners also provided the ground-truths for each of the PHQ-8 questionnaire sub-criterion as well as the final binary classification.
E-DAIC (Ringeval et al., 2019)
contains acoustic recordings and extracted visual features of 168 males and 103 females. The dataset owners provided a standard train-validate-test split which we followed.
| Acc Multitask Baseline UW | Unitask 0.72 0.81 | 0.87 0.68 0.70 | 0.51 0.57 0.64 | 0.62 0.62 0.60 | 0.57 0.64 0.66 | 0.57 0.68 0.62 | 0.51 0.74 0.72 | 0.79 0.89 0.87 | 0.94 0.70 0.82 | 0.66 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.68 | 0.66 | 0.47 | 0.43 | 0.43 | 0.49 | 0.60 | 0.74 | 0.80 |
| F1 | Unitask | 0.25 | 0.41 | 0.44 | 0.33 | 0.33 | 0.53 | 0.44 | 0.40 | 0.47 |
| Multitask | 0.32 | 0.29 | 0.50 | 0.44 | 0.32 | 0.48 | 0.45 | 0.29 | 0.53 | |
| Baseline UW | 0.40 | 0.30 | 0.51 | 0.42 | 0.33 | 0.31 | 0.43 | 0.25 | 0.29 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.29 | 0.33 | 0.44 | 0.43 | 0.27 | 0.33 | 0.39 | 0.00 | 0.54 |
| Precision | Unitask | 1.00 | 0.27 | 0.47 | 0.31 | 0.26 | 0.37 | 0.67 | 0.50 | 0.44 |
| Multitask | 0.25 | 0.25 | 0.43 | 0.39 | 0.29 | 0.47 | 0.50 | 0.25 | 0.50 | |
| Baseline UW | 0.38 | 0.27 | 0.50 | 0.37 | 0.31 | 0.33 | 0.45 | 0.20 | 0.22 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.21 | 0.27 | 0.36 | 0.30 | 0.19 | 0.27 | 0.32 | 0.00 | 0.56 |
| Recall | Unitask | 0.14 | 0.89 | 0.41 | 0.36 | 0.45 | 0.93 | 0.33 | 0.33 | 0.50 |
| Multitask | 0.43 | 0.33 | 0.59 | 0.50 | 0.36 | 0.50 | 0.42 | 0.33 | 0.57 | |
| Baseline UW | 0.43 | 0.33 | 0.53 | 0.50 | 0.36 | 0.29 | 0.42 | 0.33 | 0.43 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.43 | 0.44 | 0.59 | 0.71 | 0.45 | 0.43 | 0.50 | 0.00 | 0.60 |
| UAR | Unitask | 0.93 | 0.60 | 0.58 | 0.51 | 0.52 | 0.64 | 0.74 | 0.73 | 0.60 |
| Multitask | 0.57 | 0.54 | 0.57 | 0.57 | 0.54 | 0.62 | 0.66 | 0.60 | 0.65 | |
| Baseline UW | 0.65 | 0.56 | 0.61 | 0.57 | 0.56 | 0.52 | 0.62 | 0.62 | 0.64 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.58 | 0.58 | 0.49 | 0.51 | 0.44 | 0.47 | 0.56 | 0.40 | 0.63 |
| $\mathcal{M}_{SP}$ | Unitask | 0.00 | 1.44 | 1.92 | 1.60 | 0.86 | 1.44 | 4.79 | 0.96 | 0.47 |
| Multitask | 1.92 | 0.96 | 1.80 | 1.20 | 3.51 | 1.10 | 3.83 | 2.88 | 0.86 | |
| Baseline UW | 2.88 | 1.15 | 1.92 | 1.06 | 2.16 | 1.34 | 1.15 | 1.44 | 1.23 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.72 | 0.64 | 1.28 | 1.15 | 1.12 | 0.66 | 0.86 | 0.77 | 1.06 |
| $\mathcal{M}_{EOpp}$ | Unitask | 0.00 | 1.50 | 2.00 | 1.67 | 0.90 | 1.50 | 5.00 | 1.00 | 0.45 |
| Multitask | 2.00 | 1.00 | 1.88 | 1.25 | 3.67 | 1.14 | 4.00 | 3.00 | 0.78 | |
| Baseline UW | 3.00 | 1.20 | 2.00 | 1.11 | 2.25 | 1.40 | 1.20 | 1.50 | 1.70 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.75 | 0.67 | 1.33 | 1.20 | 1.17 | 0.69 | 0.90 | 0.80 | 1.46 |
| $\mathcal{M}_{EOdd}$ | Unitask | 0.00 | 1.44 | 1.90 | 2.83 | 1.25 | 1.53 | 0.00 | 0.00 | 0.54 |
| Multitask | 0.00 | 1.60 | 1.83 | 1.28 | 9.00 | 1.88 | 4.00 | 0.00 | 0.76 | |
| Baseline UW | 0.00 | 0.00 | 2.29 | 1.49 | 3.50 | 2.25 | 1.50 | 2.74 | 1.31 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.80 | 0.80 | 1.43 | 1.16 | 1.33 | 0.75 | 1.00 | 0.00 | 1.17 |
| $\mathcal{M}_{EAcc}$ | Unitask | 0.91 | 0.81 | 0.89 | 0.56 | 1.20 | 0.81 | 1.01 | 0.96 | 1.44 |
| Multitask | 0.96 | 1.09 | 0.89 | 0.89 | 0.55 | 1.23 | 1.01 | 0.87 | 0.94 | |
| Baseline UW | 0.96 | 1.30 | 0.84 | 0.72 | 0.69 | 1.03 | 1.08 | 0.91 | 1.25 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 1.09 | 1.16 | 0.80 | 0.96 | 0.64 | 1.28 | 1.11 | 1.14 | 0.95 |
Table 6: Full experimental results for DAIC-WOZ across the different PHQ-8 subitems. Best values are highlighted in bold.
| Acc Multitask Baseline UW | Unitask 0.68 0.75 | 0.80 0.54 0.63 | 0.66 0.48 0.61 | 0.59 0.43 0.73 | 0.66 0.52 0.73 | 0.59 0.54 0.63 | 0.61 0.48 0.59 | 0.63 0.54 0.89 | 0.89 0.58 0.87 | 0.55 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.77 | 0.61 | 0.61 | 0.54 | 0.71 | 0.71 | 0.71 | 0.93 | 0.90 |
| F1 | Unitask | 0.27 | 0.24 | 0.49 | 0.60 | 0.47 | 0.45 | 0.49 | 0.25 | 0.51 |
| Multitask | 0.18 | 0.32 | 0.47 | 0.43 | 0.40 | 0.38 | 0.38 | 0.07 | 0.45 | |
| Baseline UW | 0.22 | 0.36 | 0.54 | 0.48 | 0.29 | 0.09 | 0.08 | 0.00 | 0.27 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.13 | 0.21 | 0.39 | 0.43 | 0.33 | 0.33 | 0.27 | 0.00 | 0.45 |
| Precision | Unitask | 0.29 | 0.21 | 0.38 | 0.45 | 0.34 | 0.33 | 0.33 | 0.25 | 0.36 |
| Multitask | 0.14 | 0.22 | 0.33 | 0.30 | 0.29 | 0.28 | 0.25 | 0.04 | 0.32 | |
| Baseline UW | 0.20 | 0.27 | 0.41 | 0.54 | 0.43 | 0.10 | 0.07 | 0.00 | 0.28 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.14 | 0.18 | 0.35 | 0.33 | 0.40 | 0.36 | 0.27 | 0.00 | 0.46 |
| Recall | Unitask | 0.25 | 0.27 | 0.69 | 0.88 | 0.71 | 0.69 | 0.91 | 0.25 | 0.87 |
| Multitask | 0.25 | 0.55 | 0.81 | 0.75 | 0.64 | 0.62 | 0.82 | 0.25 | 0.80 | |
| Baseline UW | 0.25 | 0.55 | 0.81 | 0.44 | 0.21 | 0.08 | 0.09 | 0.00 | 0.26 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.13 | 0.27 | 0.44 | 0.63 | 0.29 | 0.31 | 0.27 | 0.00 | 0.45 |
| UAR | Unitask | 0.58 | 0.51 | 0.60 | 0.69 | 0.60 | 0.60 | 0.65 | 0.60 | 0.63 |
| Multitask | 0.50 | 0.52 | 0.58 | 0.53 | 0.55 | 0.55 | 0.58 | 0.47 | 0.67 | |
| Baseline UW | 0.54 | 0.59 | 0.67 | 0.64 | 0.56 | 0.43 | 0.40 | 0.48 | 0.60 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.50 | 0.48 | 0.56 | 0.56 | 0.57 | 0.57 | 0.55 | 0.50 | 0.70 |
| $\mathcal{M}_{SP}$ | Unitask | 0.26 | 2.78 | 0.81 | 1.12 | 0.94 | 1.44 | 1.03 | 0.52 | 0.65 |
| Multitask | 5.67 | 2.63 | 1.19 | 1.40 | 0.98 | 1.44 | 1.24 | 0.41 | 1.25 | |
| Baseline UW | 1.55 | 1.29 | 2.58 | 2.47 | 2.06 | 2.32 | 5.67 | 0.00 | 3.86 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 2.06 | 2.83 | 1.26 | 2.67 | 3.61 | 1.29 | 1.29 | 0.00 | 1.67 |
| $\mathcal{M}_{EOpp}$ | Unitask | 0.17 | 1.80 | 0.53 | 0.72 | 0.61 | 0.93 | 0.67 | 0.33 | 0.57 |
| Multitask | 3.67 | 1.70 | 0.77 | 0.90 | 0.63 | 0.93 | 0.80 | 0.26 | 0.81 | |
| Baseline UW | 1.00 | 0.83 | 1.67 | 1.60 | 1.33 | 1.50 | 3.67 | 0.00 | 2.31 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 1.33 | 1.83 | 0.82 | 1.73 | 2.33 | 0.83 | 0.83 | 0.00 | 1.00 |
| $\mathcal{M}_{EOdd}$ | Unitask | 0.35 | 3.65 | 1.39 | 1.38 | 1.00 | 1.46 | 1.40 | 0.74 | 0.75 |
| Multitask | 7.00 | 3.42 | 1.29 | 1.63 | 1.03 | 1.53 | 1.43 | 0.41 | 1.41 | |
| Baseline UW | 3.00 | 1.76 | 4.20 | 6.11 | 2.00 | 0.00 | 0.00 | 0.00 | 8.21 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 2.80 | 3.42 | 2.22 | 3.67 | 3.60 | 2.25 | 1.90 | 0.00 | 5.00 |
| $\mathcal{M}_{EAcc}$ | Unitask | 1.13 | 0.74 | 1.45 | 0.84 | 1.14 | 0.96 | 0.71 | 1.08 | 0.83 |
| Multitask | 0.63 | 0.39 | 0.77 | 0.41 | 0.94 | 0.77 | 0.54 | 1.77 | 0.65 | |
| Baseline UW | 1.05 | 0.71 | 0.48 | 0.99 | 0.89 | 0.81 | 0.88 | 1.12 | 0.92 | |
| \cdashline 2-11[.4pt/2pt] | U-Fair (Ours) | 0.96 | 0.64 | 1.22 | 0.47 | 0.83 | 0.74 | 1.03 | 1.05 | 0.94 |
Table 7: Full experimental results for E-DAIC across the different PHQ-8 subitems. Best values are highlighted in bold.