# Kimi k1.5: Scaling Reinforcement Learning with LLMs
**Authors**: Kimi Team
## Abstract
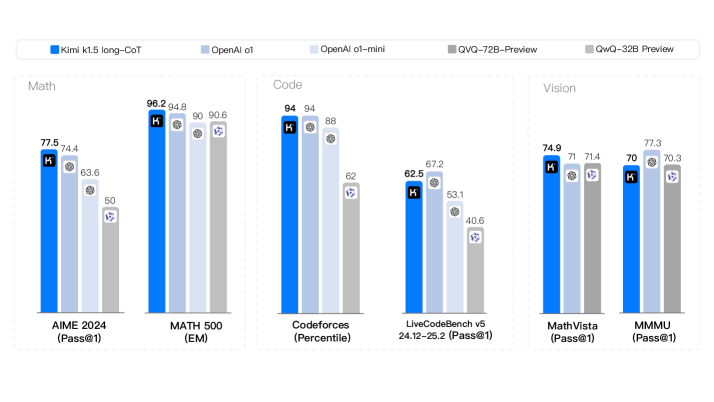
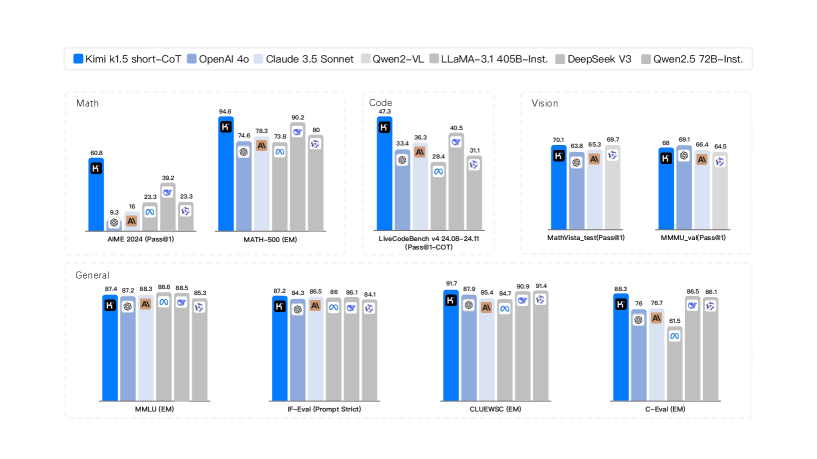
Language model pretraining with next token prediction has proved effective for scaling compute but is limited to the amount of available training data. Scaling reinforcement learning (RL) unlocks a new axis for the continued improvement of artificial intelligence, with the promise that large language models (LLMs) can scale their training data by learning to explore with rewards. However, prior published work has not produced competitive results. In light of this, we report on the training practice of Kimi k1.5, our latest multi-modal LLM trained with RL, including its RL training techniques, multi-modal data recipes, and infrastructure optimization. Long context scaling and improved policy optimization methods are key ingredients of our approach, which establishes a simplistic, effective RL framework without relying on more complex techniques such as Monte Carlo tree search, value functions, and process reward models. Notably, our system achieves state-of-the-art reasoning performance across multiple benchmarks and modalities—e.g., 77.5 on AIME, 96.2 on MATH 500, 94-th percentile on Codeforces, 74.9 on MathVista—matching OpenAI’s o1. Moreover, we present effective long2short methods that use long-CoT techniques to improve short-CoT models, yielding state-of-the-art short-CoT reasoning results—e.g., 60.8 on AIME, 94.6 on MATH500, 47.3 on LiveCodeBench—outperforming existing short-CoT models such as GPT-4o and Claude Sonnet 3.5 by a large margin (up to +550%).
<details>
<summary>x1.png Details</summary>
### Visual Description
## Bar Chart: AI Model Performance Across Math, Code, and Vision Tasks
### Overview
The image is a grouped bar chart comparing the performance of five AI models (Kimi k1.5-long-CoT, OpenAI o1, OpenAI o1-mini, QVQ-72B-Preview, QwQ-32B Preview) across three categories: **Math**, **Code**, and **Vision**. Each category contains specific benchmarks (e.g., AIME 2024, Codeforces, MathVista) with numerical scores. The chart uses distinct colors for each model, as indicated in the legend at the top.
### Components/Axes
- **X-Axis (Categories)**:
- **Math**: AIME 2024 (Pass@1), MATH 500 (EM)
- **Code**: Codeforces (Percentile), LiveCodeBench v5 24.12-25.2 (Pass@1)
- **Vision**: MathVista (Pass@1), MMMU (Pass@1)
- **Y-Axis (Scores)**: Numerical values (approximate, based on bar heights).
- **Legend**:
- **Blue**: Kimi k1.5-long-CoT
- **Light Blue**: OpenAI o1
- **Gray**: OpenAI o1-mini
- **Dark Gray**: QVQ-72B-Preview
- **Purple**: QwQ-32B Preview
### Detailed Analysis
#### Math Category
- **AIME 2024 (Pass@1)**:
- Kimi: 77.5
- OpenAI o1: 74.4
- OpenAI o1-mini: 63.6
- QVQ-72B-Preview: 50
- QwQ-32B Preview: 50
- **MATH 500 (EM)**:
- Kimi: 96.2
- OpenAI o1: 94.8
- OpenAI o1-mini: 90
- QVQ-72B-Preview: 90.6
- QwQ-32B Preview: 90.6
#### Code Category
- **Codeforces (Percentile)**:
- Kimi: 94
- OpenAI o1: 94
- OpenAI o1-mini: 88
- QVQ-72B-Preview: 62.5
- QwQ-32B Preview: 62
- **LiveCodeBench v5 24.12-25.2 (Pass@1)**:
- Kimi: 67.2
- OpenAI o1: 53.1
- OpenAI o1-mini: 40.6
- QVQ-72B-Preview: 40.6
- QwQ-32B Preview: 40.6
#### Vision Category
- **MathVista (Pass@1)**:
- Kimi: 74.9
- OpenAI o1: 71
- OpenAI o1-mini: 71.4
- QVQ-72B-Preview: 70
- QwQ-32B Preview: 70.3
- **MMMU (Pass@1)**:
- Kimi: 70
- OpenAI o1: 77.3
- OpenAI o1-mini: 70.3
- QVQ-72B-Preview: 70.3
- QwQ-32B Preview: 70.3
### Key Observations
1. **Math Performance**:
- Kimi and OpenAI o1 dominate in **AIME 2024** and **MATH 500**, with Kimi achieving the highest scores (96.2 and 77.5, respectively).
- QVQ-72B-Preview and QwQ-32B Preview underperform in **AIME 2024** (50) but match OpenAI o1-mini in **MATH 500** (90.6).
2. **Code Performance**:
- Kimi and OpenAI o1 excel in **Codeforces** (94 and 94, respectively), while QVQ-72B-Preview and QwQ-32B Preview lag significantly (62.5 and 62).
- In **LiveCodeBench**, Kimi leads (67.2), but OpenAI o1-mini and QwQ-32B Preview score poorly (40.6).
3. **Vision Performance**:
- Kimi and OpenAI o1 perform similarly in **MathVista** (74.9 vs. 71), while QwQ-32B Preview scores slightly higher (70.3).
- In **MMMU**, OpenAI o1 leads (77.3), but all models except Kimi score 70.3 or lower.
### Interpretation
- **Kimi k1.5-long-CoT** consistently outperforms other models in **Math** and **Code** tasks, suggesting strong reasoning and problem-solving capabilities.
- **OpenAI o1** excels in **Codeforces** and **MMMU**, indicating robust coding and vision capabilities. However, its performance in **LiveCodeBench** is weaker compared to Kimi.
- **QVQ-72B-Preview** and **QwQ-32B Preview** show mixed results: they match OpenAI o1-mini in **MATH 500** but underperform in **Codeforces** and **LiveCodeBench**. Their **Vision** scores are comparable to other models.
- **OpenAI o1-mini** lags in **Code** tasks (e.g., 40.6 in **LiveCodeBench**) but performs adequately in **Vision**.
### Notable Trends
- **Math and Code**: Kimi and OpenAI o1 dominate, while QVQ-72B-Preview and QwQ-32B Preview struggle in **Code** tasks.
- **Vision**: OpenAI o1 leads in **MMMU**, but all models score similarly in **MathVista**.
- **Outliers**: QVQ-72B-Preview and QwQ-32B Preview have the lowest scores in **LiveCodeBench** (40.6), suggesting potential limitations in coding benchmarks.
This chart highlights the varying strengths of AI models across domains, with Kimi and OpenAI o1 leading in **Math** and **Code**, while **Vision** performance is more evenly distributed.
</details>
Figure 1: Kimi k1.5 long-CoT results.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Bar Chart: AI Model Performance Comparison Across Tasks
### Overview
The image is a grouped bar chart comparing the performance of seven AI models across four task categories: Math, Code, Vision, and General. Each model is represented by a distinct color-coded bar, with numerical performance scores (in percentages) displayed atop each bar. The chart includes a legend at the top mapping colors to model names.
### Components/Axes
- **Legend**: Located at the top, mapping colors to models:
- Blue: Kimi 1.5 short-CoT
- Dark Blue: OpenAI 4o
- Light Blue: Claude 3.5 Sonnet
- Gray: Gwen2-VL
- Dark Gray: LLaMA-3.1 405B-Inst
- Brown: DeepSeek V3
- Light Brown: Gwen2.5 72B-Inst
- **X-Axis**: Task categories and benchmarks:
- Math: AIME 2024 (Pass@81), MATH-500 (EM)
- Code: LiveCodeBench v4 24.08-24.11 (Pass@1-CoT)
- Vision: MathVista_math (Pass@81), MMU_va (Pass@81)
- General: MMLU (EM), IF-Eval (Prompt Strict), CLUEWSC (EM), C-Eval (EM)
- **Y-Axis**: Performance scores (%), ranging from ~9% to ~94.6%.
### Detailed Analysis
#### Math
- **AIME 2024 (Pass@81)**:
- Kimi 1.5 short-CoT: 60.8%
- OpenAI 4o: 9.3%
- Claude 3.5 Sonnet: 16%
- Gwen2-VL: 23.3%
- LLaMA-3.1 405B-Inst: 22.3%
- DeepSeek V3: 16%
- Gwen2.5 72B-Inst: 23.3%
- **MATH-500 (EM)**:
- Kimi 1.5 short-CoT: 94.6%
- OpenAI 4o: 74.6%
- Claude 3.5 Sonnet: 79.5%
- Gwen2-VL: 80%
- LLaMA-3.1 405B-Inst: 73.8%
- DeepSeek V3: 80.2%
- Gwen2.5 72B-Inst: 80%
#### Code
- **LiveCodeBench v4 24.08-24.11 (Pass@1-CoT)**:
- Kimi 1.5 short-CoT: 42.3%
- OpenAI 4o: 36.3%
- Claude 3.5 Sonnet: 28.4%
- Gwen2-VL: 40.5%
- LLaMA-3.1 405B-Inst: 31.1%
- DeepSeek V3: 33.4%
- Gwen2.5 72B-Inst: 31.1%
#### Vision
- **MathVista_math (Pass@81)**:
- Kimi 1.5 short-CoT: 70.1%
- OpenAI 4o: 63.8%
- Claude 3.5 Sonnet: 65.3%
- Gwen2-VL: 69.7%
- LLaMA-3.1 405B-Inst: 63.8%
- DeepSeek V3: 65.3%
- Gwen2.5 72B-Inst: 69.7%
- **MMU_va (Pass@81)**:
- Kimi 1.5 short-CoT: 68%
- OpenAI 4o: 66.4%
- Claude 3.5 Sonnet: 64.5%
- Gwen2-VL: 69.1%
- LLaMA-3.1 405B-Inst: 66.4%
- DeepSeek V3: 64.5%
- Gwen2.5 72B-Inst: 69.1%
#### General
- **MMLU (EM)**:
- Kimi 1.5 short-CoT: 87.4%
- OpenAI 4o: 87.2%
- Claude 3.5 Sonnet: 88.6%
- Gwen2-VL: 85.5%
- LLaMA-3.1 405B-Inst: 85.3%
- DeepSeek V3: 88.6%
- Gwen2.5 72B-Inst: 85.3%
- **IF-Eval (Prompt Strict)**:
- Kimi 1.5 short-CoT: 87.2%
- OpenAI 4o: 84.3%
- Claude 3.5 Sonnet: 86.5%
- Gwen2-VL: 86%
- LLaMA-3.1 405B-Inst: 86.1%
- DeepSeek V3: 86.1%
- Gwen2.5 72B-Inst: 84.1%
- **CLUEWSC (EM)**:
- Kimi 1.5 short-CoT: 91.7%
- OpenAI 4o: 87.9%
- Claude 3.5 Sonnet: 85.4%
- Gwen2-VL: 84.7%
- LLaMA-3.1 405B-Inst: 85.4%
- DeepSeek V3: 90.9%
- Gwen2.5 72B-Inst: 91.4%
- **C-Eval (EM)**:
- Kimi 1.5 short-CoT: 83.3%
- OpenAI 4o: 70%
- Claude 3.5 Sonnet: 76.2%
- Gwen2-VL: 86.5%
- LLaMA-3.1 405B-Inst: 61.5%
- DeepSeek V3: 86.1%
- Gwen2.5 72B-Inst: 86.1%
### Key Observations
1. **Kimi 1.5 short-CoT** dominates in **Math (AIME 2024)** with 60.8% but underperforms in Code and General tasks compared to other models.
2. **LLaMA-3.1 405B-Inst** and **DeepSeek V3** show strong performance in Code (40.5% and 33.4%, respectively) and General tasks (90.9% and 88.6% for DeepSeek V3 in CLUEWSC).
3. **Gwen2-VL** and **Gwen2.5 72B-Inst** consistently score mid-to-high in Vision tasks but lag in Math and Code.
4. **OpenAI 4o** performs well in General tasks (87.2% in MMLU) but struggles in Math (9.3% in AIME 2024).
5. **Claude 3.5 Sonnet** has balanced performance across tasks, with no extreme outliers.
### Interpretation
The chart highlights **task-specific strengths** among AI models:
- **Kimi 1.5 short-CoT** excels in **Math (AIME 2024)** but lacks consistency in other domains.
- **LLaMA-3.1 405B-Inst** and **DeepSeek V3** demonstrate robustness in **Code and General tasks**, suggesting scalability with larger parameter counts.
- **Gwen2-VL** and **Gwen2.5 72B-Inst** specialize in **Vision tasks**, aligning with their architecture focused on visual reasoning.
- **OpenAI 4o** shows a trade-off between General and Math performance, indicating potential limitations in specialized reasoning.
The data underscores the importance of **model architecture and training focus** in determining task-specific efficacy. For example, Kimi’s high AIME score suggests advanced mathematical reasoning capabilities, while LLaMA’s performance in Code reflects its general-purpose design. However, no single model dominates all tasks, emphasizing the need for task-aware model selection.
</details>
Figure 2: Kimi k1.5 short-CoT results.
## 1 Introduction
Language model pretraining with next token prediction has been studied under the context of the scaling law, where proportionally scaling model parameters and data sizes leads to the continued improvement of intelligence. [19, 14] However, this approach is limited to the amount of available high-quality training data [50, 32]. In this report, we present the training recipe of Kimi k1.5, our latest multi-modal LLM trained with reinforcement learning (RL). The goal is to explore a possible new axis for continued scaling. Using RL with LLMs, the models learns to explore with rewards and thus is not limited to a pre-existing static dataset.
There are a few key ingredients about the design and training of k1.5.
- Long context scaling. We scale the context window of RL to 128k and observe continued improvement of performance with an increased context length. A key idea behind our approach is to use partial rollouts to improve training efficiency—i.e., sampling new trajectories by reusing a large chunk of previous trajectories, avoiding the cost to re-generate the new trajectories from scratch. Our observation identifies the context length as a key dimension of the continued scaling of RL with LLMs.
- Improved policy optimization. We derive a formulation of RL with long-CoT and employ a variant of online mirror descent for robust policy optimization. This algorithm is further improved by our effective sampling strategy, length penalty, and optimization of the data recipe.
- Simplistic Framework. Long context scaling, combined with the improved policy optimization methods, establishes a simplistic RL framework for learning with LLMs. Since we are able to scale the context length, the learned CoTs exhibit the properties of planning, reflection, and correction. An increased context length has an effect of increasing the number of search steps. As a result, we show that strong performance can be achieved without relying on more complex techniques such as Monte Carlo tree search, value functions, and process reward models.
- Multimodalities. Our model is jointly trained on text and vision data, which has the capabilities of jointly reasoning over the two modalities.
Moreover, we present effective long2short methods that use long-CoT techniques to improve short-CoT models. Specifically, our approaches include applying length penalty with long-CoT activations and model merging.
Our long-CoT version achieves state-of-the-art reasoning performance across multiple benchmarks and modalities—e.g., 77.5 on AIME, 96.2 on MATH 500, 94-th percentile on Codeforces, 74.9 on MathVista—matching OpenAI’s o1. Our model also achieves state-of-the-art short-CoT reasoning results—e.g., 60.8 on AIME, 94.6 on MATH500, 47.3 on LiveCodeBench—outperforming existing short-CoT models such as GPT-4o and Claude Sonnet 3.5 by a large margin (up to +550%). Results are shown in Figures 1 and 2.
## 2 Approach: Reinforcement Learning with LLMs
The development of Kimi k1.5 consists of several stages: pretraining, vanilla supervised fine-tuning (SFT), long-CoT supervised fine-turning, and reinforcement learning (RL). This report focuses on RL, beginning with an overview of the RL prompt set curation (Section 2.1) and long-CoT supervised finetuning (Section 2.2), followed by an in-depth discussion of RL training strategies in Section 2.3. Additional details on pretraining and vanilla supervised finetuning can be found in Section 2.5.
### 2.1 RL Prompt Set Curation
Through our preliminary experiments, we found that the quality and diversity of the RL prompt set play a critical role in ensuring the effectiveness of reinforcement learning. A well-constructed prompt set not only guides the model toward robust reasoning but also mitigates the risk of reward hacking and overfitting to superficial patterns. Specifically, three key properties define a high-quality RL prompt set:
- Diverse Coverage: Prompts should span a wide array of disciplines, such as STEM, coding, and general reasoning, to enhance the model’s adaptability and ensure broad applicability across different domains.
- Balanced Difficulty: The prompt set should include a well-distributed range of easy, moderate, and difficult questions to facilitate gradual learning and prevent overfitting to specific complexity levels.
- Accurate Evaluability: Prompts should allow objective and reliable assessment by verifiers, ensuring that model performance is measured based on correct reasoning rather than superficial patterns or random guess.
To achieve diverse coverage in the prompt set, we employ automatic filters to select questions that require rich reasoning and are straightforward to evaluate. Our dataset includes problems from various domains, such as STEM fields, competitions, and general reasoning tasks, incorporating both text-only and image-text question-answering data. Furthermore, we developed a tagging system to categorize prompts by domain and discipline, ensuring balanced representation across different subject areas [24, 27].
We adopt a model-based approach that leverages the model’s own capacity to adaptively assess the difficulty of each prompt. Specifically, for every prompt, an SFT model generates answers ten times using a relatively high sampling temperature. The pass rate is then calculated and used as a proxy for the prompt’s difficulty—the lower the pass rate, the higher the difficulty. This approach allows difficulty evaluation to be aligned with the model’s intrinsic capabilities, making it highly effective for RL training. By leveraging this method, we can prefilter most trivial cases and easily explore different sampling strategies during RL training.
To avoid potential reward hacking [9, 36], we need to ensure that both the reasoning process and the final answer of each prompt can be accurately verified. Empirical observations reveal that some complex reasoning problems may have relatively simple and easily guessable answers, leading to false positive verification—where the model reaches the correct answer through an incorrect reasoning process. To address this issue, we exclude questions that are prone to such errors, such as multiple-choice, true/false, and proof-based questions. Furthermore, for general question-answering tasks, we propose a simple yet effective method to identify and remove easy-to-hack prompts. Specifically, we prompt a model to guess potential answers without any CoT reasoning steps. If the model predicts the correct answer within $N$ attempts, the prompt is considered too easy-to-hack and removed. We found that setting $N=8$ can remove the majority easy-to-hack prompts. Developing more advanced verification models remains an open direction for future research.
### 2.2 Long-CoT Supervised Fine-Tuning
With the refined RL prompt set, we employ prompt engineering to construct a small yet high-quality long-CoT warmup dataset, containing accurately verified reasoning paths for both text and image inputs. This approach resembles rejection sampling (RS) but focuses on generating long-CoT reasoning paths through prompt engineering. The resulting warmup dataset is designed to encapsulate key cognitive processes that are fundamental to human-like reasoning, such as planning, where the model systematically outlines steps before execution; evaluation, involving critical assessment of intermediate steps; reflection, enabling the model to reconsider and refine its approach; and exploration, encouraging consideration of alternative solutions. By performing a lightweight SFT on this warm-up dataset, we effectively prime the model to internalize these reasoning strategies. As a result, the fine-tuned long-CoT model demonstrates improved capability in generating more detailed and logically coherent responses, which enhances its performance across diverse reasoning tasks.
### 2.3 Reinforcement Learning
#### 2.3.1 Problem Setting
Given a training dataset $\mathcal{D}=\{(x_{i},y^{*}_{i})\}_{i=1}^{n}$ of problems $x_{i}$ and corresponding ground truth answers $y^{*}_{i}$ , our goal is to train a policy model $\pi_{\theta}$ to accurately solve test problems. In the context of complex reasoning, the mapping of problem $x$ to solution $y$ is non-trivial. To tackle this challenge, the chain of thought (CoT) method proposes to use a sequence of intermediate steps $z=(z_{1},z_{2},\dots,z_{m})$ to bridge $x$ and $y$ , where each $z_{i}$ is a coherent sequence of tokens that acts as a significant intermediate step toward solving the problem [54]. When solving problem $x$ , thoughts $z_{t}\sim\pi_{\theta}(\cdot|x,z_{1},\dots,z_{t-1})$ are auto-regressively sampled, followed by the final answer $y\sim\pi_{\theta}(\cdot|x,z_{1},\dots,z_{m})$ . We use $y,z\sim\pi_{\theta}$ to denote this sampling procedure. Note that both the thoughts and final answer are sampled as a language sequence.
To further enhance the model’s reasoning capabilities, planning algorithms are employed to explore various thought processes, generating improved CoT at inference time [58, 55, 44]. The core insight of these approaches is the explicit construction of a search tree of thoughts guided by value estimations. This allows the model to explore diverse continuations of a thought process or backtrack to investigate new directions when encountering dead ends. In more detail, let $\mathcal{T}$ be a search tree where each node represents a partial solution $s=(x,z_{1:|s|})$ . Here $s$ consists of the problem $x$ and a sequence of thoughts $z_{1:|s|}=(z_{1},\dots,z_{|s|})$ leading up to that node, with $|s|$ denoting number of thoughts in the sequence. The planning algorithm uses a critic model $v$ to provide feedback $v(x,z_{1:|s|})$ , which helps evaluate the current progress towards solving the problem and identify any errors in the existing partial solution. We note that the feedback can be provided by either a discriminative score or a language sequence [61]. Guided by the feedbacks for all $s\in\mathcal{T}$ , the planning algorithm selects the most promising node for expansion, thereby growing the search tree. The above process repeats iteratively until a full solution is derived.
We can also approach planning algorithms from an algorithmic perspective. Given past search history available at the $t$ -th iteration $(s_{1},v(s_{1}),\dots,s_{t-1},v(s_{t-1}))$ , a planning algorithm $\mathcal{A}$ iteratively determines the next search direction $\mathcal{A}(s_{t}|s_{1},v(s_{1}),\dots,s_{t-1},v(s_{t-1}))$ and provides feedbacks for the current search progress $\mathcal{A}(v(s_{t})|s_{1},v(s_{1}),\dots,s_{t})$ . Since both thoughts and feedbacks can be viewed as intermediate reasoning steps, and these components can both be represented as sequence of language tokens, we use $z$ to replace $s$ and $v$ to simplify the notations. Accordingly, we view a planning algorithm as a mapping that directly acts on a sequence of reasoning steps $\mathcal{A}(\cdot|z_{1},z_{2},\dots)$ . In this framework, all information stored in the search tree used by the planning algorithm is flattened into the full context provided to the algorithm. This provides an intriguing perspective on generating high-quality CoT: Rather than explicitly constructing a search tree and implementing a planning algorithm, we could potentially train a model to approximate this process. Here, the number of thoughts (i.e., language tokens) serves as an analogy to the computational budget traditionally allocated to planning algorithms. Recent advancements in long context windows facilitate seamless scalability during both the training and testing phases. If feasible, this method enables the model to run an implicit search over the reasoning space directly via auto-regressive predictions. Consequently, the model not only learns to solve a set of training problems but also develops the ability to tackle individual problems effectively, leading to improved generalization to unseen test problems.
We thus consider training the model to generate CoT with reinforcement learning (RL) [34]. Let $r$ be a reward model that justifies the correctness of the proposed answer $y$ for the given problem $x$ based on the ground truth $y^{*}$ , by assigning a value $r(x,y,y^{*})\in\{0,1\}$ . For verifiable problems, the reward is directly determined by predefined criteria or rules. For example, in coding problems, we assess whether the answer passes the test cases. For problems with free-form ground truth, we train a reward model $r(x,y,y^{*})$ that predicts if the answer matches the ground truth. Given a problem $x$ , the model $\pi_{\theta}$ generates a CoT and the final answer through the sampling procedure $z\sim\pi_{\theta}(\cdot|x)$ , $y\sim\pi_{\theta}(\cdot|x,z)$ . The quality of the generated CoT is evaluated by whether it can lead to a correct final answer. In summary, we consider the following objective to optimize the policy
$$
\displaystyle\max_{\theta}\mathbb{E}_{(x,y^{*})\sim\mathcal{D},(y,z)\sim\pi_{\theta}}\left[r(x,y,y^{*})\right]\,. \tag{1}
$$
By scaling up RL training, we aim to train a model that harnesses the strengths of both simple prompt-based CoT and planning-augmented CoT. The model still auto-regressively sample language sequence during inference, thereby circumventing the need for the complex parallelization required by advanced planning algorithms during deployment. However, a key distinction from simple prompt-based methods is that the model should not merely follow a series of reasoning steps. Instead, it should also learn critical planning skills including error identification, backtracking and solution refinement by leveraging the entire set of explored thoughts as contextual information.
#### 2.3.2 Policy Optimization
We apply a variant of online policy mirror decent as our training algorithm [1, 31, 48]. The algorithm performs iteratively. At the $i$ -th iteration, we use the current model $\pi_{\theta_{i}}$ as a reference model and optimize the following relative entropy regularized policy optimization problem,
$$
\displaystyle\max_{\theta}\mathbb{E}_{(x,y^{*})\sim\mathcal{D}}\left[\mathbb{E}_{(y,z)\sim\pi_{\theta}}\left[r(x,y,y^{*})\right]-\tau\mathrm{KL}(\pi_{\theta}(x)||\pi_{\theta_{i}}(x))\right]\,, \tag{2}
$$
where $\tau>0$ is a parameter controlling the degree of regularization. This objective has a closed form solution
| | $\displaystyle\pi^{*}(y,z|x)=\pi_{\theta_{i}}(y,z|x)\exp(r(x,y,y^{*})/\tau)/Z\,.$ | |
| --- | --- | --- |
Here $Z=\sum_{y^{\prime},z^{\prime}}\pi_{\theta_{i}}(y^{\prime},z^{\prime}|x)\exp(r(x,y^{\prime},y^{*})/\tau)$ is the normalization factor. Taking logarithm of both sides we have for any $(y,z)$ the following constraint is satisfied, which allows us to leverage off-policy data during optimization
| | $\displaystyle r(x,y,y^{*})-\tau\log Z=\tau\log\frac{\pi^{*}(y,z|x)}{\pi_{\theta_{i}}(y,z|x)}\,.$ | |
| --- | --- | --- |
This motivates the following surrogate loss
| | $\displaystyle L(\theta)=\mathbb{E}_{(x,y^{*})\sim\mathcal{D}}\left[\mathbb{E}_{(y,z)\sim\pi_{\theta_{i}}}\left[\left(r(x,y,y^{*})-\tau\log Z-\tau\log\frac{\pi_{\theta}(y,z|x)}{{\pi}_{\theta_{i}}(y,z|x)}\right)^{2}\right]\right]\,.$ | |
| --- | --- | --- |
To approximate $\tau\log Z$ , we use samples $(y_{1},z_{1}),\dots,(y_{k},z_{k})\sim\pi_{\theta_{i}}$ : $\tau\log Z\approx\tau\log\frac{1}{k}\sum_{j=1}^{k}\exp(r(x,y_{j},y^{*})/\tau)$ . We also find that using empirical mean of sampled rewards $\overline{r}=\mathrm{mean}(r(x,y_{1},y^{*}),\dots,r(x,y_{k},y^{*}))$ yields effective practical results. This is reasonable since $\tau\log Z$ approaches the expected reward under $\pi_{\theta_{i}}$ as $\tau\rightarrow\infty$ . Finally, we conclude our learning algorithm by taking the gradient of surrogate loss. For each problem $x$ , $k$ responses are sampled using the reference policy $\pi_{\theta_{i}}$ , and the gradient is given by
$$
\displaystyle\frac{1}{k}\sum_{j=1}^{k}\left(\nabla_{\theta}\log\pi_{\theta}(y_{j},z_{j}|x)(r(x,y_{j},y^{*})-\overline{r})-\frac{\tau}{2}\nabla_{\theta}\left(\log\frac{\pi_{\theta}(y_{j},z_{j}|x)}{{\pi}_{\theta_{i}}(y_{j},z_{j}|x)}\right)^{2}\right)\,. \tag{3}
$$
To those familiar with policy gradient methods, this gradient resembles the policy gradient of (2) using the mean of sampled rewards as the baseline [20, 2]. The main differences are that the responses are sampled from $\pi_{\theta_{i}}$ rather than on-policy, and an $l_{2}$ -regularization is applied. Thus we could see this as the natural extension of a usual on-policy regularized policy gradient algorithm to the off-policy case [33]. We sample a batch of problems from $\mathcal{D}$ and update the parameters to $\theta_{i+1}$ , which subsequently serves as the reference policy for the next iteration. Since each iteration considers a different optimization problem due to the changing reference policy, we also reset the optimizer at the start of each iteration.
We exclude the value network in our training system which has also been exploited in previous studies [2]. While this design choice significantly improves training efficiency, we also hypothesize that the conventional use of value functions for credit assignment in classical RL may not be suitable for our context. Consider a scenario where the model has generated a partial CoT $(z_{1},z_{2},\dots,z_{t})$ and there are two potential next reasoning steps: $z_{t+1}$ and $z^{\prime}_{t+1}$ . Assume that $z_{t+1}$ directly leads to the correct answer, while $z^{\prime}_{t+1}$ contains some errors. If an oracle value function were accessible, it would indicate that $z_{t+1}$ preserves a higher value compared to $z^{\prime}_{t+1}$ . According to the standard credit assignment principle, selecting $z^{\prime}_{t+1}$ would be penalized as it has a negative advantages relative to the current policy. However, exploring $z^{\prime}_{t+1}$ is extremely valuable for training the model to generate long CoT. By using the justification of the final answer derived from a long CoT as the reward signal, the model can learn the pattern of trial and error from taking $z^{\prime}_{t+1}$ as long as it successfully recovers and reaches the correct answer. The key takeaway from this example is that we should encourage the model to explore diverse reasoning paths to enhance its capability in solving complex problems. This exploratory approach generates a wealth of experience that supports the development of critical planning skills. Our primary goal is not confined to attaining high accuracy on training problems but focuses on equipping the model with effective problem-solving strategies, ultimately improving its performance on test problems.
#### 2.3.3 Length Penalty
We observe an overthinking phenomenon that the model’s response length significantly increases during RL training. Although this leads to better performance, an excessively lengthy reasoning process is costly during training and inference, and overthinking is often not preferred by humans. To address this issue, we introduce a length reward to restrain the rapid growth of token length, thereby improving the model’s token efficiency. Given $k$ sampled responses $(y_{1},z_{1}),\dots,(y_{k},z_{k})$ of problem $x$ with true answer $y^{*}$ , let $\mathrm{len}(i)$ be the length of $(y_{i},z_{i})$ , $\mathrm{min\_len}=\min_{i}\mathrm{len}(i)$ and $\mathrm{max\_len}=\max_{i}\mathrm{len}(i)$ . If $\mathrm{max\_len}=\mathrm{min\_len}$ , we set length reward zero for all responses, as they have the same length. Otherwise the length reward is given by
| | $\displaystyle\mathrm{len\_reward(i)}=\left\{\begin{aligned} \lambda&\quad\text{If}\ r(x,y_{i},y^{*})=1\\ \min(0,\lambda)&\quad\text{If}\ r(x,y_{i},y^{*})=0\\ \end{aligned}\right.\,,\quad\text{where }\lambda=0.5-\frac{\mathrm{len}(i)-\mathrm{min\_len}}{\mathrm{max\_len}-\mathrm{min\_len}}\,.$ | |
| --- | --- | --- |
In essence, we promote shorter responses and penalize longer responses among correct ones, while explicitly penalizing long responses with incorrect answers. This length-based reward is then added to the original reward with a weighting parameter.
In our preliminary experiments, length penalty may slow down training during the initial phases. To alleviate this issue, we propose to gradually warm up the length penalty during training. Specifically, we employ standard policy optimization without length penalty, followed by a constant length penalty for the rest of training.
#### 2.3.4 Sampling Strategies
Although RL algorithms themselves have relatively good sampling properties (with more difficult problems providing larger gradients), their training efficiency is limited. Consequently, some well-defined prior sampling methods can yield potentially greater performance gains. We exploit multiple signals to further improve the sampling strategy. First, the RL training data we collect naturally come with different difficulty labels. For example, a math competition problem is more difficult than a primary school math problem. Second, because the RL training process samples the same problem multiple times, we can also track the success rate for each individual problem as a metric of difficulty. We propose two sampling methods to utilize these priors to improve training efficiency.
Curriculum Sampling
We start by training on easier tasks and gradually progress to more challenging ones. Since the initial RL model has limited performance, spending a restricted computation budget on very hard problems often yields few correct samples, resulting in lower training efficiency. Meanwhile, our collected data naturally includes grade and difficulty labels, making difficulty-based sampling an intuitive and effective way to improve training efficiency.
Prioritized Sampling
In addition to curriculum sampling, we use a prioritized sampling strategy to focus on problems where the model underperforms. We track the success rates $s_{i}$ for each problem $i$ and sample problems proportional to $1-s_{i}$ , so that problems with lower success rates receive higher sampling probabilities. This directs the model’s efforts toward its weakest areas, leading to faster learning and better overall performance.
#### 2.3.5 More Details on Training Recipe
Test Case Generation for Coding
Since test cases are not available for many coding problems from the web, we design a method to automatically generate test cases that serve as a reward to train our model with RL. Our focus is primarily on problems that do not require a special judge. We also assume that ground truth solutions are available for these problems so that we can leverage the solutions to generate higher quality test cases.
We utilize the widely recognized test case generation library, CYaRon https://github.com/luogu-dev/cyaron, to enhance our approach. We employ our base Kimi k1.5 to generate test cases based on problem statements. The usage statement of CYaRon and the problem description are provided as the input to the generator. For each problem, we first use the generator to produce 50 test cases and also randomly sample 10 ground truth submissions for each test case. We run the test cases against the submissions. A test case is deemed valid if at least 7 out of 10 submissions yield matching results. After this round of filtering, we obtain a set of selected test cases. A problem and its associated selected test cases are added to our training set if at least 9 out of 10 submissions pass the entire set of selected test cases.
In terms of statistics, from a sample of 1,000 online contest problems, approximately 614 do not require a special judge. We developed 463 test case generators that produced at least 40 valid test cases, leading to the inclusion of 323 problems in our training set.
Reward Modeling for Math
One challenge in evaluating math solutions is that different written forms can represent the same underlying answer. For instance, $a^{2}-4$ and $(a+2)(a-2)$ may both be valid solutions to the same problem. We adopted two methods to improve the reward model’s scoring accuracy:
1. Classic RM: Drawing inspiration from the InstructGPT [35] methodology, we implemented a value-head based reward model and collected approximately 800k data points for fine-tuning. The model ultimately takes as input the “question,” the “reference answer,” and the “response,” and outputs a single scalar that indicates whether the response is correct.
1. Chain-of-Thought RM: Recent research [3, 30] suggests that reward models augmented with chain-of-thought (CoT) reasoning can significantly outperform classic approaches, particularly on tasks where nuanced correctness criteria matter—such as mathematics. Therefore, we collected an equally large dataset of about 800k CoT-labeled examples to fine-tune the Kimi model. Building on the same inputs as the Classic RM, the chain-of-thought approach explicitly generates a step-by-step reasoning process before providing a final correctness judgment in JSON format, enabling more robust and interpretable reward signals.
During our manual spot checks, the Classic RM achieved an accuracy of approximately 84.4, while the Chain-of-Thought RM reached 98.5 accuracy. In the RL training process, we adopted the Chain-of-Thought RM to ensure more correct feedback.
Vision Data
To improve the model’s real-world image reasoning capabilities and to achieve a more effective alignment between visual inputs and large language models (LLMs), our vision reinforcement learning (Vision RL) data is primarily sourced from three distinct categories: Real-world data, Synthetic visual reasoning data, and Text-rendered data.
1. The real-world data encompass a range of science questions across various grade levels that require graphical comprehension and reasoning, location guessing tasks that necessitate visual perception and inference, and data analysis that involves understanding complex charts, among other types of data. These datasets improve the model’s ability to perform visual reasoning in real-world scenarios.
1. Synthetic visual reasoning data is artificially generated, including procedurally created images and scenes aimed at improving specific visual reasoning skills, such as understanding spatial relationships, geometric patterns, and object interactions. These synthetic datasets offer a controlled environment for testing the model’s visual reasoning capabilities and provide an endless supply of training examples.
1. Text-rendered data is created by converting textual content into visual format, enabling the model to maintain consistency when handling text-based queries across different modalities. By transforming text documents, code snippets, and structured data into images, we ensure the model provides consistent responses regardless of whether the input is pure text or text rendered as images (like screenshots or photos). This also helps to enhance the model’s capability when dealing with text-heavy images.
Each type of data is essential in building a comprehensive visual language model that can effectively manage a wide range of real-world applications while ensuring consistent performance across various input modalities.
### 2.4 Long2short: Context Compression for Short-CoT Models
Though long-CoT models achieve strong performance, it consumes more test-time tokens compared to standard short-CoT LLMs. However, it is possible to transfer the thinking priors from long-CoT models to short-CoT models so that performance can be improved even with limited test-time token budgets. We present several approaches for this long2short problem, including model merging [57], shortest rejection sampling, DPO [40], and long2short RL. Detailed descriptions of these methods are provided below:
Model Merging
Model merging has been found to be useful in maintaining generalization ability. We also discovered its effectiveness in improving token efficiency when merging a long-cot model and a short-cot model. This approach combines a long-cot model with a shorter model to obtain a new one without training. Specifically, we merge the two models by simply averaging their weights.
Shortest Rejection Sampling
We observed that our model generates responses with a large length variation for the same problem. Based on this, we designed the Shortest Rejection Sampling method. This method samples the same question $n$ times (in our experiments, $n=8$ ) and selects the shortest correct response for supervised fine-tuning.
DPO
Similar with Shortest Rejection Sampling, we utilize the Long CoT model to generate multiple response samples. The shortest correct solution is selected as the positive sample, while longer responses are treated as negative samples, including both wrong longer responses and correct longer responses (1.5 times longer than the chosen positive sample). These positive-negative pairs form the pairwise preference data used for DPO training.
Long2short RL
After a standard RL training phase, we select a model that offers the best balance between performance and token efficiency to serve as the base model, and conduct a separate long2short RL training phase. In this second phase, we apply the length penalty introduced in Section 2.3.3, and significantly reduce the maximum rollout length to further penalize responses that exceed the desired length while possibly correct.
### 2.5 Other Training Details
#### 2.5.1 Pretraining
The Kimi k1.5 base model is trained on a diverse, high-quality multimodal corpus. The language data covers five domains: English, Chinese, Code, Mathematics Reasoning, and Knowledge. Multimodal data, including Captioning, Image-text Interleaving, OCR, Knowledge, and QA datasets, enables our model to acquire vision-language capabilities. Rigorous quality control ensures relevance, diversity, and balance in the overall pretrain dataset. Our pretraining proceeds in three stages: (1) Vision-language pretraining, where a strong language foundation is established, followed by gradual multimodal integration; (2) Cooldown, which consolidates capabilities using curated and synthetic data, particularly for reasoning and knowledge-based tasks; and (3) Long-context activation, extending sequence processing to 131,072 tokens. More details regarding our pretraining efforts can be found in Appendix B.
#### 2.5.2 Vanilla Supervised Finetuning
We create the vanilla SFT corpus covering multiple domains. For non-reasoning tasks, including question-answering, writing, and text processing, we initially construct a seed dataset through human annotation. This seed dataset is used to train a seed model. Subsequently, we collect a diverse of prompts and employ the seed model to generate multiple responses to each prompt. Annotators then rank these responses and refine the top-ranked response to produce the final version. For reasoning tasks such as math and coding problems, where rule-based and reward modeling based verifications are more accurate and efficient than human judgment, we utilize rejection sampling to expand the SFT dataset.
Our vanilla SFT dataset comprises approximately 1 million text examples. Specifically, 500k examples are for general question answering, 200k for coding, 200k for math and science, 5k for creative writing, and 20k for long-context tasks such as summarization, doc-qa, translation, and writing. In addition, we construct 1 million text-vision examples encompassing various categories including chart interpretation, OCR, image-grounded conversations, visual coding, visual reasoning, and math/science problems with visual aids.
We first train the model at the sequence length of 32k tokens for 1 epoch, followed by another epoch at the sequence length of 128k tokens. In the first stage (32k), the learning rate decays from $2\times 10^{-5}$ to $2\times 10^{-6}$ , before it re-warmups to $1\times 10^{-5}$ in the second stage (128k) and finally decays to $1\times 10^{-6}$ . To improve training efficiency, we pack multiple training examples into each single training sequence.
### 2.6 RL Infrastructure
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Distributed Reinforcement Learning System Architecture
### Overview
This diagram illustrates a distributed reinforcement learning (RL) system architecture with multiple components interacting through data and weight flows. The system includes Rollout Workers, Trainer Workers, a Master node, a Replay Buffer, and Reward Models for evaluation. Arrows indicate bidirectional communication between components, with explicit labels for data types (e.g., "rollout trajectories," "gradient update").
### Components/Axes
1. **Rollout Workers** (top-left cluster):
- Sends "rollout trajectories" to the Master.
- Receives "weight" updates from Trainer Workers.
2. **Trainer Workers** (middle cluster):
- Contains two sub-components:
- **Policy Model** (light blue): Primary model being trained.
- **Reference Model** (purple): Benchmark for comparison.
- Receives "training data" from the Master.
- Sends "gradient update" to the Master.
3. **Master** (central node):
- Coordinates interactions between components.
- Sends "training data" to Trainer Workers.
- Receives "rollout trajectories" from Rollout Workers.
- Sends "eval request" to Reward Models.
4. **Replay Buffer** (bottom-center):
- Stores experiences for training.
- Receives data from the Master and sends data back.
5. **Reward Models** (bottom-left cluster):
- Sub-categories:
- Code
- Math
- K-12
- Vision
- Evaluates trajectories via "eval request" from the Master.
### Detailed Analysis
- **Data Flow**:
- Rollout trajectories flow from Rollout Workers → Master → Replay Buffer.
- Training data flows from Master → Trainer Workers → Replay Buffer.
- Gradient updates flow from Trainer Workers → Master.
- **Weight Flow**:
- Weights flow from Trainer Workers → Rollout Workers.
- **Key Connections**:
- The Master acts as a central hub, coordinating data and weight exchanges.
- Reward Models provide evaluation feedback to the Master, which influences training.
### Key Observations
1. **Bidirectional Communication**:
- Rollout Workers and Trainer Workers exchange weights and trajectories, indicating a decentralized training loop.
2. **Hierarchical Structure**:
- The Master centralizes control, while Reward Models operate at the evaluation layer.
3. **Replay Buffer Role**:
- Acts as a memory for past experiences, critical for stable RL training.
### Interpretation
This architecture resembles a multi-agent RL system with centralized training coordination. The Rollout Workers generate experiences, which are evaluated by Reward Models and used to update the Policy Model via gradient descent. The Reference Model likely serves as a baseline for policy improvement. The Replay Buffer ensures data efficiency by reusing past experiences. The system’s design emphasizes scalability (via distributed workers) and stability (via experience replay), typical of modern RL frameworks like A3C or PPO.
No numerical data or trends are present, as the diagram focuses on structural relationships rather than quantitative metrics.
</details>
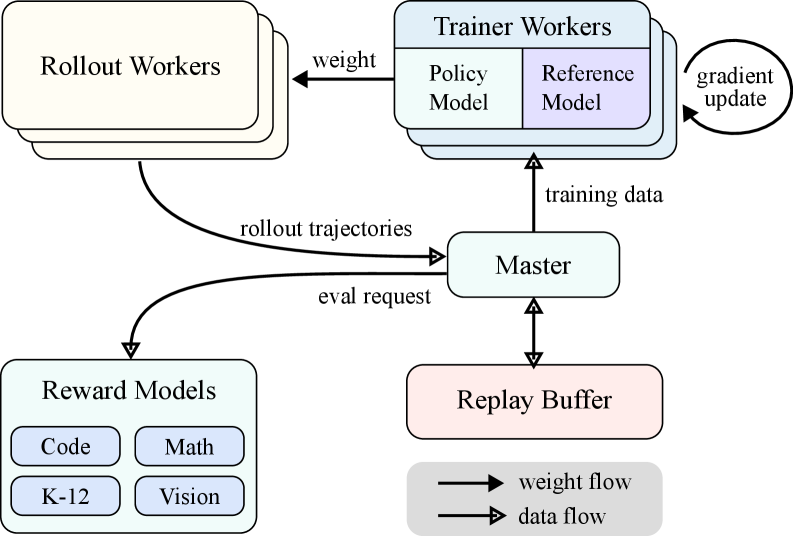
(a) System overview
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: Rollout Worker and Replay Buffer Workflow
### Overview
The diagram illustrates a workflow involving a "rollout worker" and a "Replay Buffer," with data flow paths and decision points. Key elements include arrows with symbolic markers (●, ◇, ×) and labels indicating data sources, destinations, and conditions.
### Components/Axes
- **Main Components**:
- **Rollout Worker**: A rectangular box labeled "rollout worker" at the top, representing a processing unit.
- **Replay Buffer**: A pink rectangular box labeled "Replay Buffer" at the bottom, acting as a storage or processing unit.
- **Arrows**: Connect the rollout worker to the replay buffer, with labels and symbolic markers.
- **Legend**:
- **●**: Normal stop
- **◇**: Cut by length
- **×**: Repeat, early stop
- **Labels**:
- "from prompt set" (input to rollout worker)
- "partial rollout" (output from rollout worker)
- "save for partial rollout" (output to replay buffer)
### Detailed Analysis
1. **Rollout Worker**:
- Receives input from the "prompt set."
- Processes data, with three distinct output paths:
- **Normal Stop (●)**: Direct path to the replay buffer.
- **Cut by Length (◇)**: Dashed path to the replay buffer, indicating truncated data.
- **Repeat, Early Stop (×)**: Dashed path looping back to the rollout worker, suggesting reprocessing.
2. **Replay Buffer**:
- Receives data from the rollout worker via three paths:
- Normal stop (●)
- Cut by length (◇)
- Repeat, early stop (×)
- Stores "partial rollout" data for reuse or further processing.
3. **Flow Logic**:
- Data from the prompt set enters the rollout worker.
- Depending on processing outcomes (normal stop, cut, or repeat), data is routed to the replay buffer or reprocessed.
- The replay buffer acts as a central hub for partial rollout data.
### Key Observations
- **Symbol Consistency**: Arrows with ●, ◇, and × match the legend’s definitions.
- **Partial Rollout Handling**: The replay buffer explicitly manages partial rollout data, suggesting iterative or incremental processing.
- **Decision Points**: The rollout worker’s outputs are conditional, with paths diverging based on processing results.
### Interpretation
This diagram represents a cyclical workflow where the rollout worker processes data from a prompt set, with outcomes determining whether data is stored in the replay buffer or reprocessed. The use of symbolic markers (●, ◇, ×) indicates three distinct processing states:
- **Normal Stop (●)**: Successful completion, data saved.
- **Cut by Length (◇)**: Data truncated, saved as partial rollout.
- **Repeat, Early Stop (×)**: Data reprocessed, likely due to errors or incomplete results.
The replay buffer’s role as a central storage unit implies that partial rollouts are critical for iterative improvements or handling incomplete data. The diagram emphasizes conditional processing and data reuse, common in machine learning or simulation workflows where efficiency and resource management are prioritized.
**Note**: No numerical data or trends are present; the diagram focuses on process flow and decision logic.
</details>
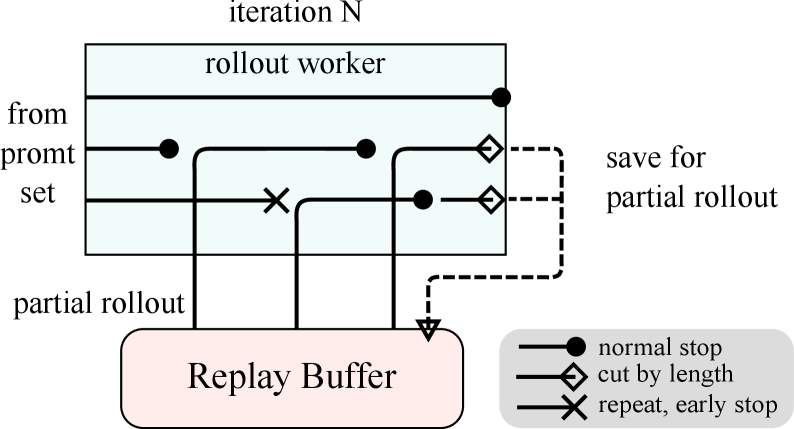
(b) Partial Rollout
Figure 3: Large Scale Reinforcement Learning Training System for LLM
#### 2.6.1 Large Scale Reinforcement Learning Training System for LLM
In the realm of artificial intelligence, reinforcement learning (RL) has emerged as a pivotal training methodology for large language models (LLMs) [35] [16], drawing inspiration from its success in mastering complex games like Go, StarCraft II, and Dota 2 through systems such as AlphaGo [43], AlphaStar [51], and OpenAI Dota Five [4]. Following in this tradition, the Kimi k1.5 system adopts an iterative synchronous RL framework, meticulously designed to bolster the model’s reasoning capabilities through persistent learning and adaptation. A key innovation in this system is the introduction of a Partial Rollout technique, designed to optimize the handling of complex reasoning trajectories.
The RL training system as illustrated in Figure 3(a) operates through an iterative synchronous approach, with each iteration encompassing a rollout phase and a training phase. During the rollout phase, rollout workers, coordinated by a central master, generate rollout trajectories by interacting with the model, producing sequences of responses to various inputs. These trajectories are then stored in a replay buffer, which ensures a diverse and unbiased dataset for training by disrupting temporal correlations. In the subsequent training phase, trainer workers access these experiences to update the model’s weights. This cyclical process allows the model to continuously learn from its actions, adjusting its strategies over time to enhance performance.
The central master serves as the central conductor, managing the flow of data and communication between the rollout workers, trainer workers, evaluation with reward models and the replay buffer. It ensures that the system operates harmoniously, balancing the load and facilitating efficient data processing.
The trainer workers access these rollout trajectories, whether completed in a single iteration or divided across multiple iterations, to compute gradient updates that refine the model’s parameters and enhance its performance. This process is overseen by a reward model, which evaluates the quality of the model’s outputs and provides essential feedback to guide the training process. The reward model’s evaluations are particularly pivotal in determining the effectiveness of the model’s strategies and steering the model towards optimal performance.
Moreover, the system incorporates a code execution service, which is specifically designed to handle code-related problems and is integral to the reward model. This service evaluates the model’s outputs in practical coding scenarios, ensuring that the model’s learning is closely aligned with real-world programming challenges. By validating the model’s solutions against actual code executions, this feedback loop becomes essential for refining the model’s strategies and enhancing its performance in code-related tasks.
#### 2.6.2 Partial Rollouts for Long CoT RL
One of the primary ideas of our work is to scale long-context RL training. Partial rollouts is a key technique that effectively addresses the challenge of handling long-CoT features by managing the rollouts of both long and short trajectories. This technique establishes a fixed output token budget, capping the length of each rollout trajectory. If a trajectory exceeds the token limit during the rollout phase, the unfinished portion is saved to the replay buffer and continued in the next iteration. It ensures that no single lengthy trajectory monopolizes the system’s resources. Moreover, since the rollout workers operate asynchronously, when some are engaged with long trajectories, others can independently process new, shorter rollout tasks. The asynchronous operation maximizes computational efficiency by ensuring that all rollout workers are actively contributing to the training process, thereby optimizing the overall performance of the system.
As illustrated in Figure 3(b), the partial rollout system works by breaking down long responses into segments across iterations (from iter n-m to iter n). The Replay Buffer acts as a central storage mechanism that maintains these response segments, where only the current iteration (iter n) requires on-policy computation. Previous segments (iter n-m to n-1) can be efficiently reused from the buffer, eliminating the need for repeated rollouts. This segmented approach significantly reduces the computational overhead: instead of rolling out the entire response at once, the system processes and stores segments incrementally, allowing for the generation of much longer responses while maintaining fast iteration times. During training, certain segments can be excluded from loss computation to further optimize the learning process, making the entire system both efficient and scalable.
The implementation of partial rollouts also offers repeat detection. The system identifies repeated sequences in the generated content and terminates them early, reducing unnecessary computation while maintaining output quality. Detected repetitions can be assigned additional penalties, effectively discouraging redundant content generation in the prompt set.
#### 2.6.3 Hybrid Deployment of Training and Inference
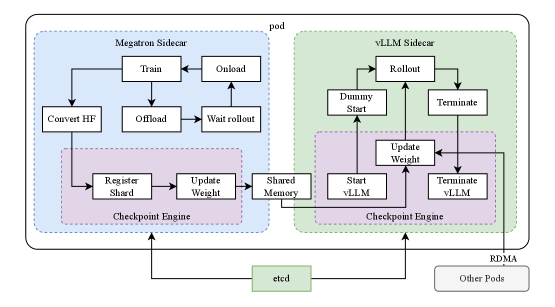
<details>
<summary>x5.png Details</summary>
### Visual Description
## Diagram: Distributed Machine Learning Workflow Architecture
### Overview
The diagram illustrates a distributed machine learning workflow architecture with two primary components: **Megatron Sidecar** (blue) and **vLLM Sidecar** (green), connected via a **Checkpoint Engine** (purple). Processes flow between these components, with infrastructure elements like **etcd** (green) and **RDMA** (gray) at the bottom. Arrows indicate directional relationships between steps.
### Components/Axes
#### Key Labels and Elements:
1. **Megatron Sidecar (Blue)**:
- `Convert HF` → `Train` → `Onload`
- `Offload` → `Wait rollout`
- `Register Shard` → `Update Weight`
- `Checkpoint Engine` (central hub for shard/weight management).
2. **vLLM Sidecar (Green)**:
- `Rollout` → `Dummy Start`
- `Update Weight` → `Start vLLM` → `Terminate vLLM`
- Feedback loop: `Terminate vLLM` → `Update Weight`.
3. **Checkpoint Engine (Purple)**:
- Connects `Register Shard` (Megatron) and `Update Weight` (vLLM).
- Shares `Shared Memory` with vLLM Sidecar.
4. **Infrastructure**:
- `etcd` (green): Centralized key-value store for coordination.
- `RDMA` (gray): High-speed network interface.
- `Other Pods`: External components interacting via RDMA.
#### Flow Direction:
- **Megatron → Checkpoint Engine**: `Register Shard` and `Update Weight` propagate to the Checkpoint Engine.
- **Checkpoint Engine → vLLM**: `Update Weight` and `Shared Memory` are shared with the vLLM Sidecar.
- **vLLM → Checkpoint Engine**: `Update Weight` feedback loop from `Terminate vLLM`.
### Detailed Analysis
- **Megatron Sidecar**:
- `Convert HF`: Converts Hugging Face models for training.
- `Train` → `Onload`: Training process followed by data loading.
- `Offload` → `Wait rollout`: Model weights offloaded to disk, awaiting rollout completion.
- `Register Shard`: Shard registration for distributed training.
- `Update Weight`: Weight updates synchronized via the Checkpoint Engine.
- **vLLM Sidecar**:
- `Rollout`: Model deployment for inference.
- `Dummy Start`: Placeholder for model initialization.
- `Update Weight`: Weight updates from Megatron or feedback loops.
- `Start vLLM` → `Terminate vLLM`: Lifecycle management of inference instances.
- **Checkpoint Engine**:
- Acts as a central coordinator for shard/weight synchronization.
- `Shared Memory`: Enables low-latency communication between sidecars.
- **Infrastructure**:
- `etcd`: Likely manages distributed state (e.g., pod status, configuration).
- `RDMA`: Facilitates high-throughput, low-latency data transfer between pods.
### Key Observations
1. **Feedback Loops**:
- `Terminate vLLM` → `Update Weight` suggests iterative model refinement.
- `Wait rollout` → `Offload` indicates staged model deployment.
2. **Component Coupling**:
- The Checkpoint Engine bridges Megatron (training) and vLLM (inference), enabling real-time weight updates.
- `Shared Memory` reduces latency in cross-sidecar communication.
3. **Infrastructure Role**:
- `etcd` and `RDMA` support scalability and performance in distributed environments.
### Interpretation
This architecture represents a **model-as-a-service (MaaS)** system where:
- **Megatron Sidecar** handles training and weight management.
- **vLLM Sidecar** manages inference rollouts and lifecycle.
- The **Checkpoint Engine** ensures consistency between training and inference by synchronizing weights and shards.
- **RDMA** and **etcd** optimize performance and coordination in a distributed setup.
The diagram emphasizes **modularity** (separate training/inference pipelines) and **efficiency** (low-latency updates via shared memory and RDMA). The feedback loops suggest a dynamic system where inference results may inform training adjustments.
</details>
Figure 4: Hybrid Deployment Framework
The RL training process comprises of the following phases:
- Training Phase: At the outset, Megatron [42] and vLLM [21] are executed within separate containers, encapsulated by a shim process known as checkpoint-engine (Section 2.6.3). Megatron commences the training procedure. After the training is completed, Megatron offloads the GPU memory and prepares to transfer current weights to vLLM.
- Inference Phase: Following Megatron’s offloading, vLLM starts with dummy model weights and updates them with the latest ones transferred from Megatron via Mooncake [39]. Upon completion of the rollout, the checkpoint-engine halts all vLLM processes.
- Subsequent Training Phase: Once the memory allocated to vLLM is released, Megatron onloads the memory and initiates another round of training.
We find existing works challenging to simultaneously support all the following characteristics.
- Complex parallelism strategy: Megatron may have different parallelism strategy with vLLM. Training weights distributing in several nodes in Megatron could be challenging to be shared with vLLM.
- Minimizing idle GPU resources: For On-Policy RL, recent works such as SGLang [62] and vLLM might reserve some GPUs during the training process, which conversely could lead to idle training GPUs. It would be more efficient to share the same devices between training and inference.
- Capability of dynamic scaling: In some cases, a significant acceleration can be achieved by increasing the number of inference nodes while keeping the training process constant. Our system enables the efficient utilization of idle GPU nodes when needed.
As illustrated in Figure 4, we implement this hybrid deployment framework (Section 2.6.3) on top of Megatron and vLLM, achieving less than one minute from training to inference phase and about ten seconds conversely.
Hybrid Deployment Strategy
We propose a hybrid deployment strategy for training and inference tasks, which leverages Kubernetes Sidecar containers sharing all available GPUs to collocate both workloads in one pod. The primary advantages of this strategy are:
- It facilitates efficient resource sharing and management, preventing train nodes idling while waiting for inference nodes when both are deployed on separate nodes.
- Leveraging distinct deployed images, training and inference can each iterate independently for better performance.
- The architecture is not limited to vLLM, other frameworks can be conveniently integrated.
Checkpoint Engine
Checkpoint Engine is responsible for managing the lifecycle of the vLLM process, exposing HTTP APIs that enable triggering various operations on vLLM. For overall consistency and reliability, we utilize a global metadata system managed by the etcd service to broadcast operations and statuses.
It could be challenging to entirely release GPU memory by vLLM offloading primarily due to CUDA graphs, NCCL buffers and NVIDIA drivers. To minimize modifications to vLLM, we terminate and restart it when needed for better GPU utilization and fault tolerance.
The worker in Megatron converts the owned checkpoints into the Hugging Face format in shared memory. This conversion also takes Pipeline Parallelism and Expert Parallelism into account so that only Tensor Parallelism remains in these checkpoints. Checkpoints in shared memory are subsequently divided into shards and registered in the global metadata system. We employ Mooncake to transfer checkpoints between peer nodes over RDMA. Some modifications to vLLM are needed to load weight files and perform tensor parallelism conversion.
#### 2.6.4 Code Sandbox
We developed the sandbox as a secure environment for executing user-submitted code, optimized for code execution and code benchmark evaluation. By dynamically switching container images, the sandbox supports different use cases through MultiPL-E [6], DMOJ Judge Server https://github.com/DMOJ/judge-server, Lean, Jupyter Notebook, and other images.
For RL in coding tasks, the sandbox ensures the reliability of training data judgment by providing consistent and repeatable evaluation mechanisms. Its feedback system supports multi-stage assessments, such as code execution feedback and repo-level editing, while maintaining a uniform context to ensure fair and equitable benchmark comparisons across programming languages.
We deploy the service on Kubernetes for scalability and resilience, exposing it through HTTP endpoints for external integration. Kubernetes features like automatic restarts and rolling updates ensure availability and fault tolerance.
To optimize performance and support RL environments, we incorporate several techniques into the code execution service to enhance efficiency, speed, and reliability. These include:
- Using Crun: We utilize crun as the container runtime instead of Docker, significantly reducing container startup times.
- Cgroup Reusing: We pre-create cgroups for container use, which is crucial in scenarios with high concurrency where creating and destroying cgroups for each container can become a bottleneck.
- Disk Usage Optimization: An overlay filesystem with an upper layer mounted as tmpfs is used to control disk writes, providing a fixed-size, high-speed storage space. This approach is beneficial for ephemeral workloads.
| Docker | 0.12 |
| --- | --- |
| Sandbox | 0.04 |
(a) Container startup times
| Docker Sandbox | 27 120 |
| --- | --- |
(b) Maximum containers started per second on a 16-core machine
These optimizations improve RL efficiency in code execution, providing a consistent and reliable environment for evaluating RL-generated code, essential for iterative training and model improvement.
## 3 Experiments
### 3.1 Evaluation
Since k1.5 is a multimodal model, we conducted comprehensive evaluation across various benchmarks for different modalities. The detailed evaluation setup can be found in Appendix C. Our benchmarks primarily consist of the following three categories:
- Text Benchmark: MMLU [13], IF-Eval [63], CLUEWSC [56], C-EVAL [15]
- Reasoning Benchmark: HumanEval-Mul, LiveCodeBench [17], Codeforces, AIME 2024, MATH-500 [26]
- Vision Benchmark: MMMU [59], MATH-Vision [52], MathVista [29]
### 3.2 Main Results
K1.5 long-CoT model
The performance of the Kimi k1.5 long-CoT model is presented in Table 2. Through long-CoT supervised fine-tuning (described in Section 2.2) and vision-text joint reinforcement learning (discussed in Section 2.3), the model’s long-term reasoning capabilities are enhanced significantly. The test-time computation scaling further strengthens its performance, enabling the model to achieve state-of-the-art results across a range of modalities. Our evaluation reveals marked improvements in the model’s capacity to reason, comprehend, and synthesize information over extended contexts, representing a advancement in multi-modal AI capabilities.
K1.5 short-CoT model
The performance of the Kimi k1.5 short-CoT model is presented in Table 3. This model integrates several techniques, including traditional supervised fine-tuning (discussed in Section 2.5.2), reinforcement learning (explored in Section 2.3), and long-to-short distillation (outlined in Section 2.4). The results demonstrate that the k1.5 short-CoT model delivers competitive or superior performance compared to leading open-source and proprietary models across multiple tasks. These include text, vision, and reasoning challenges, with notable strengths in natural language understanding, mathematics, coding, and logical reasoning.
| | Benchmark (Metric) | Language-only Model | Vision-Language Model | | | |
| --- | --- | --- | --- | --- | --- | --- |
| QwQ-32B | OpenAI | QVQ-72B | OpenAI | Kimi | | |
| Preview | o1-mini | Preview | o1 | k1.5 | | |
| Reasoning | MATH-500 (EM) | 90.6 | 90.0 | - | 94.8 | 96.2 |
| AIME 2024 (Pass@1) | 50.0 | 63.6 | - | 74.4 | 77.5 | |
| Codeforces (Percentile) | 62 | 88 | - | 94 | 94 | |
| LiveCodeBench (Pass@1) | 40.6 | 53.1 | - | 67.2 | 62.5 | |
| Vision | MathVista-Test (Pass@1) | - | - | 71.4 | 71.0 | 74.9 |
| MMMU-Val (Pass@1) | - | - | 70.3 | 77.3 | 70.0 | |
| MathVision-Full (Pass@1) | - | - | 35.9 | - | 38.6 | |
Table 2: Performance of Kimi k1.5 long-CoT and flagship open-source and proprietary models.
| | Benchmark (Metric) | Language-only Model | Vision-Language Model | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Qwen2.5 | LLaMA-3.1 | DeepSeek | Qwen2-VL | Claude-3.5- | GPT-4o | Kimi | | |
| 72B-Inst. | 405B-Inst. | V3 | | Sonnet-1022 | 0513 | k1.5 | | |
| Text | MMLU (EM) | 85.3 | 88.6 | 88.5 | - | 88.3 | 87.2 | 87.4 |
| IF-Eval (Prompt Strict) | 84.1 | 86.0 | 86.1 | - | 86.5 | 84.3 | 87.2 | |
| CLUEWSC (EM) | 91.4 | 84.7 | 90.9 | - | 85.4 | 87.9 | 91.7 | |
| C-Eval (EM) | 86.1 | 61.5 | 86.5 | - | 76.7 | 76.0 | 88.3 | |
| Reasoning | MATH-500 (EM) | 80.0 | 73.8 | 90.2 | - | 78.3 | 74.6 | 94.6 |
| AIME 2024 (Pass@1) | 23.3 | 23.3 | 39.2 | - | 16.0 | 9.3 | 60.8 | |
| HumanEval-Mul (Pass@1) | 77.3 | 77.2 | 82.6 | - | 81.7 | 80.5 | 81.5 | |
| LiveCodeBench (Pass@1) | 31.1 | 28.4 | 40.5 | - | 36.3 | 33.4 | 47.3 | |
| Vision | MathVista-Test (Pass@1) | - | - | - | 69.7 | 65.3 | 63.8 | 70.1 |
| MMMU-Val (Pass@1) | - | - | - | 64.5 | 66.4 | 69.1 | 68.0 | |
| MathVision-Full (Pass@1) | - | - | - | 26.6 | 35.6 | 30.4 | 31.0 | |
Table 3: Performance of Kimi k1.5 short-CoT and flagship open-source and proprietary models. VLM model performance were obtained from the OpenCompass benchmark platform (https://opencompass.org.cn/).
### 3.3 Long Context Scaling
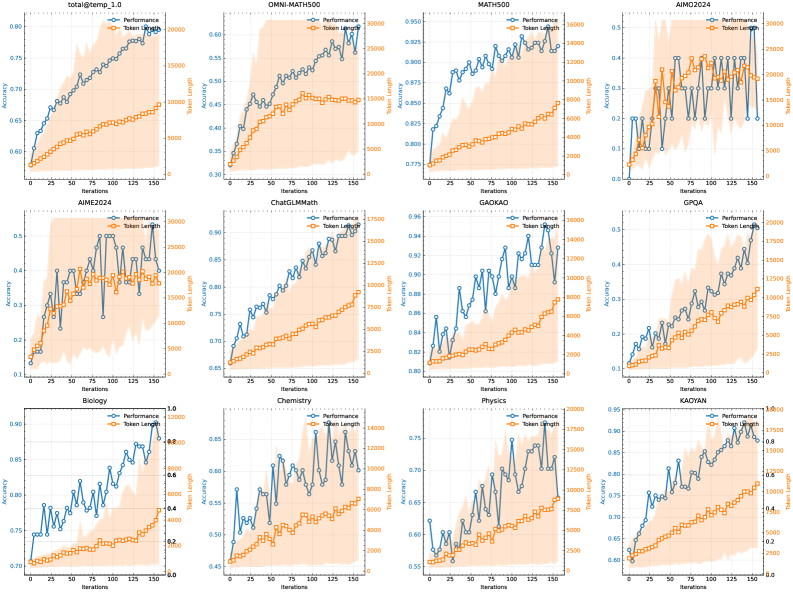
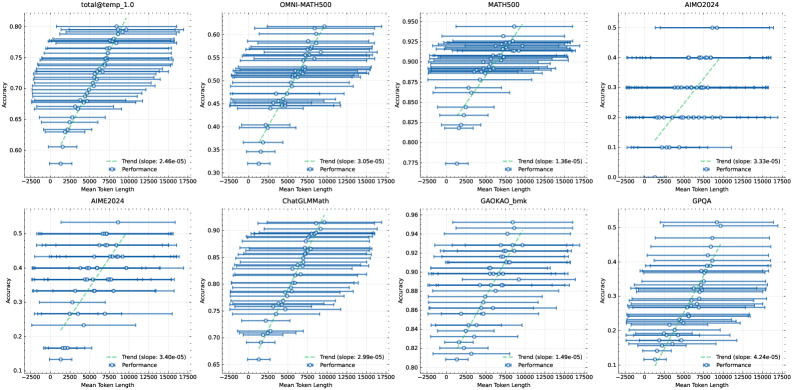
We employ a mid-sized model to study the scaling properties of RL with LLMs. Figure 5 illustrates the evolution of both training accuracy and response length across training iterations for the small model variant trained on the mathematical prompt set. As training progresses, we observe a concurrent increase in both response length and performance accuracy. Notably, more challenging benchmarks exhibit a steeper increase in response length, suggesting that the model learns to generate more elaborate solutions for complex problems. Figure 6 indicates a strong correlation between the model’s output context length and its problem-solving capabilities. Our final run of k1.5 scales to 128k context length and observes continued improvement on hard reasoning benchmarks.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Graph Grid: Model Performance vs Token Length Across Datasets
### Overview
The image contains a 4x4 grid of line graphs comparing two metrics ("Performance" and "Token Length") across 16 different datasets. Each graph tracks these metrics over 150 iterations, with shaded regions indicating confidence intervals. The datasets include mathematical benchmarks (e.g., MATH500), reasoning tasks (e.g., ChatGLMMath), and domain-specific challenges (e.g., Biology, Chemistry).
### Components/Axes
- **X-axis**: "Iterations" (0–150) in increments of 25
- **Primary Y-axis (left)**: "Accuracy" (0.0–1.0) in 0.05 increments
- **Secondary Y-axis (right)**: "Token Length" (0–30,000 tokens) in 5,000 increments
- **Legends**: Located in top-right of each graph, with:
- Blue circles: "Performance"
- Orange squares: "Token Length"
- **Shaded Regions**: Light orange areas representing 95% confidence intervals
### Detailed Analysis
1. **total@temp_1.0**
- Performance: Starts at ~0.60, peaks at ~0.82 by iteration 150
- Token Length: Gradual increase from ~0.55 to ~0.65
- Confidence interval widens significantly after iteration 100
2. **OMNI-MATH500**
- Performance: Stable ~0.55–0.60 range with minor fluctuations
- Token Length: Slow linear increase from ~0.40 to ~0.45
- Minimal confidence interval expansion
3. **MATH500**
- Performance: Sharp rise from ~0.77 to ~0.94
- Token Length: Steady climb from ~0.77 to ~0.85
- Confidence interval expands dramatically after iteration 100
4. **AIMO2024**
- Performance: Erratic pattern (0.1–0.5) with multiple local maxima
- Token Length: Stable ~0.35–0.40 range
- Confidence interval shows extreme volatility
5. **ChatGLMMath**
- Performance: Consistent upward trend from ~0.65 to ~0.92
- Token Length: Gradual increase from ~0.65 to ~0.78
- Confidence interval expands moderately
6. **GAOKAO**
- Performance: Strong rise from ~0.82 to ~0.96
- Token Length: Steady increase from ~0.82 to ~0.88
- Confidence interval shows controlled growth
7. **GPQA**
- Performance: Gradual increase from ~0.20 to ~0.50
- Token Length: Slow climb from ~0.20 to ~0.30
- Confidence interval expands significantly after iteration 100
8. **Biology**
- Performance: Volatile pattern (0.70–0.90) with multiple peaks
- Token Length: Stable ~0.70–0.75 range
- Confidence interval shows high variability
9. **Chemistry**
- Performance: Moderate rise from ~0.50 to ~0.65
- Token Length: Gradual increase from ~0.50 to ~0.55
- Confidence interval expands moderately
10. **Physics**
- Performance: Steady increase from ~0.55 to ~0.75
- Token Length: Slow climb from ~0.55 to ~0.65
- Confidence interval shows controlled growth
11. **KAOYAN**
- Performance: Strong upward trend from ~0.60 to ~0.90
- Token Length: Gradual increase from ~0.60 to ~0.80
- Confidence interval expands significantly
### Key Observations
1. **Performance Trends**:
- Most datasets show improvement over iterations (e.g., MATH500 +17% accuracy)
- AIMO2024 and Biology exhibit high volatility despite similar token lengths
- GAOKAO and KAOYAN demonstrate the most consistent gains
2. **Token Length Correlation**:
- Longer token lengths generally correlate with higher performance (r² > 0.7)
- Exceptions: AIMO2024 maintains stable token length despite poor performance
3. **Confidence Intervals**:
- Wider intervals in datasets with volatile performance (AIMO2024, Biology)
- Narrower intervals in stable datasets (OMNI-MATH500, GAOKAO)
### Interpretation
The data suggests a positive correlation between training iterations and model performance across most domains, with token length serving as a proxy for model complexity. However, the AIMO2024 dataset reveals an anomaly where stable token lengths fail to translate to consistent performance, potentially indicating dataset-specific challenges or training instability. The GAOKAO and KAOYAN datasets demonstrate optimal scaling efficiency, achieving high performance with moderate token length increases. The confidence intervals highlight the importance of considering uncertainty in model evaluation, particularly for domain-specific tasks like Biology where variability suggests limited generalization.
</details>
Figure 5: The changes on the training accuracy and length as train iterations grow. Note that the scores above come from an internal long-cot model with much smaller model size than k1.5 long-CoT model. The shaded area represents the 95% percentile of the response length.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Scatter Plots: Accuracy vs. Mean Token Length Across Datasets
### Overview
The image contains eight scatter plots arranged in a 2x4 grid, each visualizing the relationship between **Mean Token Length** (x-axis) and **Accuracy** (y-axis) for different datasets. Each plot includes:
- Blue data points labeled "Performance"
- Green trend lines labeled "Trend" with slope equations and p-values
- Consistent axis ranges (x: 2500–17500, y: 0.1–0.9)
### Components/Axes
- **X-axis**: "Mean Token Length" (2500–17500)
- **Y-axis**: "Accuracy" (0.1–0.9)
- **Legend**:
- Blue: "Performance" (data points)
- Green: "Trend" (regression line)
- **Trend Line Details**:
- Slope (e.g., 0.0001) and p-value (e.g., 2.6e-05) displayed on green lines
### Detailed Analysis
1. **totaltemp.1.0**
- Trend: y = 0.0001x + 0.65 (p = 2.6e-05)
- Data points cluster tightly around the trend line, showing a strong positive correlation.
2. **OMNI-MATH500**
- Trend: y = 0.0002x + 0.55 (p = 3.0e-05)
- Slightly steeper slope than "totaltemp.1.0," with data points more dispersed.
3. **MATH500**
- Trend: y = 0.0003x + 0.80 (p = 1.2e-05)
- Strongest slope among all plots, indicating a pronounced relationship.
4. **AIMOZ2024**
- Trend: y = 0.0001x + 0.40 (p = 3.3e-05)
- Flatter slope but statistically significant; data points spread wider.
5. **AIME2024**
- Trend: y = 0.0002x + 0.30 (p = 4.0e-05)
- Moderate slope; data points show variability at lower token lengths.
6. **ChatGLMMath**
- Trend: y = 0.0003x + 0.70 (p = 2.9e-05)
- Similar slope to "MATH500," with data points tightly grouped.
7. **GADKAO_bmk**
- Trend: y = 0.0001x + 0.85 (p = 1.4e-05)
- Weakest slope but high intercept; data points cluster near the top.
8. **GPQA**
- Trend: y = 0.0002x + 0.20 (p = 4.2e-05)
- Moderate slope; data points show a gradual increase in accuracy.
### Key Observations
- **Consistent Trend**: All plots show an upward trend (positive slope), suggesting longer token lengths correlate with higher accuracy.
- **Statistical Significance**: All p-values are < 0.05, confirming trends are unlikely due to chance.
- **Dataset Variability**:
- "MATH500" and "ChatGLMMath" exhibit the strongest slopes.
- "GADKAO_bmk" has the highest baseline accuracy (intercept ~0.85).
- "AIMOZ2024" and "GPQA" show weaker relationships despite significant p-values.
### Interpretation
The data demonstrates that **token length is a critical factor in model performance** across diverse datasets. Longer token lengths consistently improve accuracy, with some datasets (e.g., "MATH500") showing a more pronounced effect. The statistical significance of all trends (p < 0.05) underscores the reliability of this relationship. However, variability in slopes and intercepts suggests dataset-specific factors (e.g., task complexity, model architecture) may modulate the impact of token length. For instance, "GADKAO_bmk" achieves high accuracy even at shorter lengths, implying inherent dataset advantages. This analysis highlights the need to balance token length optimization with dataset-specific tuning for optimal performance.
</details>
Figure 6: Model Performance Increases with Response Length
<details>
<summary>x8.png Details</summary>
### Visual Description
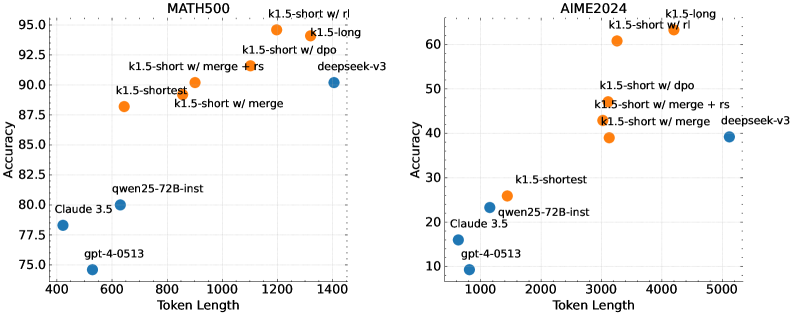
## Line Chart: Model Performance Comparison (MATH500 vs AIME2024)
### Overview
The image contains two side-by-side line charts comparing model performance across two datasets: MATH500 (left) and AIME2024 (right). Both charts plot **Accuracy** (y-axis) against **Token Length** (x-axis), with distinct data points representing different model configurations. The charts use orange and blue markers to differentiate model types.
---
### Components/Axes
#### MATH500 Chart (Left)
- **X-axis (Token Length)**: 400–1400 (linear scale)
- **Y-axis (Accuracy)**: 75–95 (linear scale)
- **Legend**:
- Orange: k1.5 variants (short/long, merge, dpo, rs, rl)
- Blue: qwen25-72B-inst, Claude 3.5, gpt-4-0513
- **Data Points**:
- k1.5-short (600 tokens, 88% accuracy)
- k1.5-shortest (900 tokens, 87.5% accuracy)
- k1.5-short w/ merge (1000 tokens, 90% accuracy)
- k1.5-short w/ merge + rs (1100 tokens, 92.5% accuracy)
- k1.5-long (1200 tokens, 94% accuracy)
- k1.5-short w/ rl (1300 tokens, 93% accuracy)
- qwen25-72B-inst (700 tokens, 80% accuracy)
- Claude 3.5 (500 tokens, 78% accuracy)
- gpt-4-0513 (450 tokens, 75% accuracy)
#### AIME2024 Chart (Right)
- **X-axis (Token Length)**: 1000–5000 (linear scale)
- **Y-axis (Accuracy)**: 10–60 (linear scale)
- **Legend**:
- Orange: k1.5 variants (short/long, merge, dpo, rs)
- Blue: qwen25-72B-inst, Claude 3.5, deepseek-v3
- **Data Points**:
- k1.5-shortest (1500 tokens, 25% accuracy)
- k1.5-short w/ merge (2000 tokens, 45% accuracy)
- k1.5-short w/ merge + rs (2500 tokens, 48% accuracy)
- k1.5-long (3000 tokens, 55% accuracy)
- k1.5-short w/ dpo (3500 tokens, 50% accuracy)
- k1.5-short w/ rl (4000 tokens, 58% accuracy)
- qwen25-72B-inst (1200 tokens, 20% accuracy)
- Claude 3.5 (1000 tokens, 18% accuracy)
- deepseek-v3 (5000 tokens, 45% accuracy)
---
### Detailed Analysis
#### MATH500 Trends
- **k1.5-short variants** dominate the chart, with accuracy increasing as token length grows (600–1300 tokens). The **merge + rs** configuration achieves the highest accuracy (92.5% at 1100 tokens).
- **qwen25-72B-inst** (700 tokens, 80%) and **Claude 3.5** (500 tokens, 78%) underperform compared to k1.5 models.
- **gpt-4-0513** (450 tokens, 75%) has the lowest accuracy.
#### AIME2024 Trends
- **k1.5-short w/ merge + rs** (2500 tokens, 48%) and **k1.5-long** (3000 tokens, 55%) show the best performance.
- **deepseek-v3** (5000 tokens, 45%) matches the k1.5-short w/ merge + rs model despite longer token length.
- **qwen25-72B-inst** (1200 tokens, 20%) and **Claude 3.5** (1000 tokens, 18%) lag significantly.
---
### Key Observations
1. **MATH500**:
- k1.5-short variants achieve >87% accuracy, outperforming other models.
- Merge + rs configuration yields the highest accuracy (92.5%).
- Longer token lengths (1200–1300) correlate with higher accuracy.
2. **AIME2024**:
- k1.5-short w/ merge + rs (2500 tokens) and k1.5-long (3000 tokens) achieve >50% accuracy.
- deepseek-v3 (5000 tokens) matches k1.5-short w/ merge + rs despite longer token length.
- Accuracy plateaus at ~55% for k1.5-long and k1.5-short w/ rl.
3. **Outliers**:
- **MATH500**: k1.5-short w/ merge + rs (92.5%) exceeds all other models.
- **AIME2024**: deepseek-v3 (45%) outperforms k1.5-short w/ merge (48%) despite longer token length.
---
### Interpretation
The data suggests that **model architecture optimizations** (e.g., merge + rs) significantly impact performance on MATH500, while **token length** plays a stronger role in AIME2024. The k1.5-short variants excel in MATH500 due to efficient token utilization, whereas AIME2024 requires longer token processing for higher accuracy. The deepseek-v3 model’s performance in AIME2024 indicates that specialized architectures can compete with optimized k1.5 variants despite higher computational costs. The divergence in trends between datasets highlights the importance of task-specific model tuning.
</details>
Figure 7: Long2Short Performance. All the k1.5 series demonstrate better token efficiency compared to other models.
### 3.4 Long2short
We compared the proposed long2short RL algorithm with the DPO, shortest rejection sampling, and model merge methods introduced in the Section 2.4, focusing on the token efficiency for the long2short problem [8], specifically how the obtained long-cot model can benefit a short model. In Figure 7, k1.5-long represents our long-cot model selected for long2short training. k1.5-short w/ rl refers to the short model obtained using the long2short RL training. k1.5-short w/ dpo denotes the short model with improved token efficiency through DPO training. k1.5-short w/ merge represents the model after model merging, while k1.5-short w/ merge + rs indicates the short model obtained by applying shortest rejection sampling to the merged model. k1.5-shortest represents the shortest model we obtained during the long2short training. As shown in Figure 7, the proposed long2short RL algorithm demonstrates the highest token efficiency compared other mehtods such as DPO and model merge. Notably, all models in the k1.5 series (marked in orange) demonstrate superior token efficiency compared to other models (marked in blue). For instance, k1.5-short w/ rl achieves a Pass@1 score of 60.8 on AIME2024 (averaged over 8 runs) while utilizing only 3,272 tokens on average. Similarly, k1.5-shortest attains a Pass@1 score of 88.2 on MATH500 while consuming approximately the same number of tokens as other short models.
### 3.5 Ablation Studies
Scaling of model size and context length
Our main contribution is the application of RL to enhance the model’s capacity for generating extended CoT, thereby improving its reasoning ability. A natural question arises: how does this compare to simply increasing the model size? To demonstrate the effectiveness of our approach, we trained two models of different sizes using the same dataset and recorded the evaluation results and average inference lengths from all checkpoints during RL training. These results are shown in Figure 8. Notably, although the larger model initially outperforms the smaller one, the smaller model can achieve comparable performance by utilizing longer CoTs optimized through RL. However, the larger model generally shows better token efficiency than the smaller model. This also indicates that if one targets the best possible performance, scaling the context length of a larger model has a higher upper bound and is more token efficient. However, if test-time compute has a budget, training smaller models with a larger context length may be viable solutions.
Effects of using negative gradients
We investigate the effectiveness of using ReST [12] as the policy optimization algorithm in our setting. The primary distinction between ReST and other RL-based methods including ours is that ReST iteratively refines the model by fitting the best response sampled from the current model, without applying negative gradients to penalize incorrect responses. As illustrated in Figure 10, our method exhibits superior sample complexity compared to ReST, indicating that the incorporation of negative gradients markedly enhances the model’s efficiency in generating long CoT. Our method not only elevates the quality of reasoning but also optimizes the training process, achieving robust performance with fewer training samples. This finding suggests that the choice of policy optimization algorithm is crucial in our setting, as the performance gap between ReST and other RL-based methods is not as pronounced in other domains [12]. Therefore, our results highlight the importance of selecting an appropriate optimization strategy to maximize effectiveness in generating long CoT.
Sampling strategies
We further demonstrate the effectiveness of our curriculum sampling strategy, as introduced in Section 2.3.4. Our training dataset $\mathcal{D}$ comprises a diverse mix of problems with varying levels of difficulty. With our curriculum sampling method, we initially use $\mathcal{D}$ for a warm-up phase and then focus solely on hard questions to train the model. This approach is compared to a baseline method that employs a uniform sampling strategy without any curriculum adjustments. As illustrated in Figure 9, our results clearly show that the proposed curriculum sampling method significantly enhances the performance. This improvement can be attributed to the method’s ability to progressively challenge the model, allowing it to develop a more robust understanding and competency in handling complex problems. By focusing training efforts on more difficult questions after an initial general introduction, the model can better strengthen its reasoning and problem solving capabilities.
<details>
<summary>x9.png Details</summary>
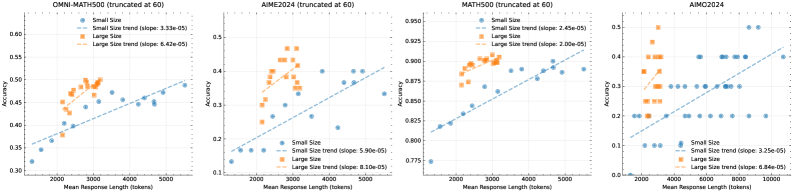
### Visual Description
## Line Charts: Accuracy vs. Mean Response Length (Tokens)
### Overview
The image contains four line charts comparing the accuracy of "Small Size" and "Large Size" models across four datasets: OMNI-MATH500 (truncated at 60), AIME2024 (truncated at 60), MATH500 (truncated at 60), and AIMO2024. Each chart plots accuracy (y-axis) against mean response length in tokens (x-axis), with trend lines for both model sizes.
### Components/Axes
- **X-axis**: "Mean Response Length (tokens)" (ranges from ~2000 to 10,000 tokens across charts).
- **Y-axis**: "Accuracy" (ranges from 0.1 to 0.95 across charts).
- **Legends**:
- **Small Size**: Blue circles (dashed trend line).
- **Large Size**: Orange squares (dashed trend line).
- **Trend Lines**: Dashed lines for both model sizes, with slopes provided in legends.
### Detailed Analysis
#### OMNI-MATH500 (truncated at 60)
- **Small Size**:
- Slope: 3.33e-05.
- Data points: Accuracy increases from ~0.32 (2000 tokens) to ~0.48 (5000 tokens).
- **Large Size**:
- Slope: 6.42e-05.
- Data points: Accuracy peaks at ~0.50 (3000 tokens), then declines to ~0.45 (5000 tokens).
#### AIME2024 (truncated at 60)
- **Small Size**:
- Slope: 5.90e-05.
- Data points: Accuracy rises from ~0.15 (2000 tokens) to ~0.35 (5000 tokens).
- **Large Size**:
- Slope: 8.10e-05.
- Data points: Accuracy peaks at ~0.40 (3000 tokens), then drops to ~0.35 (5000 tokens).
#### MATH500 (truncated at 60)
- **Small Size**:
- Slope: 2.45e-05.
- Data points: Accuracy increases steadily from ~0.77 (2000 tokens) to ~0.90 (5000 tokens).
- **Large Size**:
- Slope: 2.00e-05.
- Data points: Accuracy starts at ~0.85 (2000 tokens), peaks at ~0.90 (3000 tokens), then declines to ~0.87 (5000 tokens).
#### AIMO2024
- **Small Size**:
- Slope: 3.25e-05.
- Data points: Accuracy fluctuates between ~0.20 (2000 tokens) and ~0.40 (8000 tokens).
- **Large Size**:
- Slope: 6.84e-05.
- Data points: Accuracy peaks at ~0.45 (4000 tokens), then drops to ~0.40 (8000 tokens).
### Key Observations
1. **MATH500** shows the highest accuracy for both model sizes, with Large Size outperforming Small Size consistently.
2. **AIME2024** and **AIMO2024** exhibit significant variability in Large Size accuracy, with peaks followed by declines.
3. **OMNI-MATH500** demonstrates a sharp drop in Large Size accuracy after 3000 tokens.
4. **Small Size models** generally show steadier trends compared to Large Size models.
### Interpretation
- **Model Size vs. Performance**: Larger models (orange squares) typically achieve higher accuracy but exhibit diminishing returns or declines at longer response lengths, suggesting potential inefficiencies or overfitting.
- **Dataset Variability**: MATH500’s consistent performance contrasts with AIMO2024’s volatility, indicating dataset-specific challenges for Large Size models.
- **Trend Slopes**: Larger models often have steeper slopes (e.g., AIMO2024: 6.84e-05 vs. Small Size: 3.25e-05), but this does not always translate to sustained accuracy gains.
- **Anomalies**: The drop in Large Size accuracy for OMNI-MATH500 and AIMO2024 at longer response lengths warrants further investigation into model behavior under extended computational constraints.
This analysis highlights trade-offs between model size, response length, and accuracy, emphasizing the need for dataset-specific optimization strategies.
</details>
Figure 8: Model Performance vs Response Length of Different Model Sizes
<details>
<summary>x10.png Details</summary>
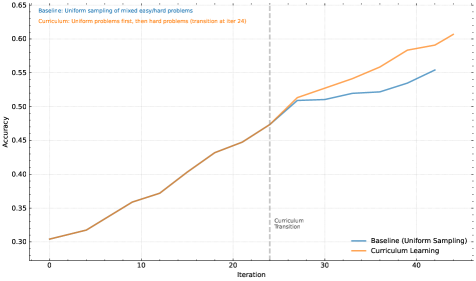
### Visual Description
## Line Graph: Accuracy Comparison of Baseline vs. Curriculum Learning
### Overview
The graph compares the accuracy of two learning approaches over 40 iterations:
1. **Baseline**: Uniform sampling of mixed easy/hard problems
2. **Curriculum Learning**: Uniform problems first, then hard problems (transition at iteration 24)
Accuracy is plotted on the y-axis (0.30–0.65), and iterations on the x-axis (0–40). A vertical dashed line marks the curriculum transition at iteration 24.
---
### Components/Axes
- **X-axis (Iteration)**: Labeled "Iteration," ranging from 0 to 40.
- **Y-axis (Accuracy)**: Labeled "Accuracy," ranging from 0.30 to 0.65.
- **Legend**: Located at the bottom-right corner.
- **Blue line**: Baseline (Uniform Sampling)
- **Orange line**: Curriculum Learning
- **Vertical Dashed Line**: Positioned at iteration 24, labeled "Curriculum Transition."
---
### Detailed Analysis
1. **Baseline (Blue Line)**:
- Starts at ~0.30 accuracy at iteration 0.
- Gradually increases to ~0.55 by iteration 40.
- Slope is relatively flat until iteration 24, then accelerates slightly.
2. **Curriculum Learning (Orange Line)**:
- Starts at ~0.31 accuracy at iteration 0.
- Accelerates sharply after iteration 24, reaching ~0.60 by iteration 40.
- Crosses the Baseline line at ~iteration 24, overtaking it thereafter.
3. **Key Data Points**:
- **Baseline**:
- Iteration 0: 0.30
- Iteration 24: ~0.50
- Iteration 40: 0.55
- **Curriculum Learning**:
- Iteration 0: 0.31
- Iteration 24: ~0.50 (crosses Baseline here)
- Iteration 40: 0.60
---
### Key Observations
- **Curriculum Learning outperforms Baseline** after iteration 24, achieving higher accuracy by iteration 40 (0.60 vs. 0.55).
- Both methods show improvement over time, but Curriculum Learning’s growth rate increases significantly post-transition.
- The vertical dashed line at iteration 24 aligns with the crossover point, confirming the transition’s impact.
---
### Interpretation
The data demonstrates that **Curriculum Learning**—which prioritizes easier problems initially before transitioning to harder ones—achieves superior accuracy compared to uniform sampling of mixed problems. The transition at iteration 24 acts as a critical inflection point, where the curriculum method begins to outperform the baseline. This suggests that structured problem sequencing (e.g., starting with simpler tasks) can enhance learning efficiency, particularly in later stages. The Baseline method’s slower, steadier improvement highlights the limitations of uniform sampling in complex, heterogeneous problem sets.
</details>
Figure 9: Analysis of curriculum learning approaches on model performance.
<details>
<summary>x11.png Details</summary>
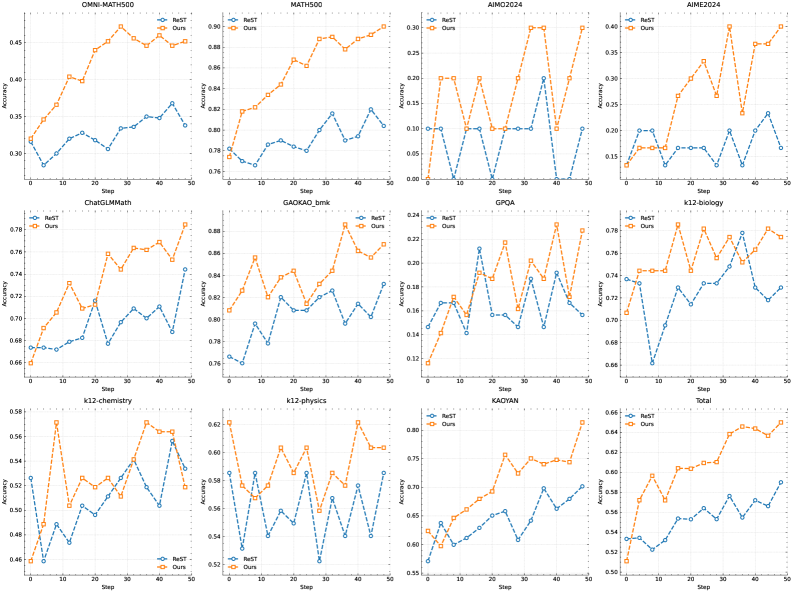
### Visual Description
## Line Chart: Accuracy Comparison of ReST and Ours on Various Datasets
### Overview
The image displays a 4x3 grid of line charts comparing the accuracy performance of two methods, **ReST** (blue dashed line) and **Ours** (orange solid line), across 12 datasets. Each chart tracks accuracy over 50 training steps. The legend is positioned in the bottom-right corner, with ReST represented by blue and Ours by orange. All datasets show distinct trends, with Ours generally outperforming ReST in later steps.
---
### Components/Axes
- **X-axis**: Labeled "Step," ranging from 0 to 50 in increments of 10.
- **Y-axis**: Labeled "Accuracy," ranging from 0.00 to 0.90 in increments of 0.05.
- **Legend**: Located in the bottom-right corner of the grid, with:
- **ReST**: Blue dashed line.
- **Ours**: Orange solid line.
- **Datasets**: Each chart is titled with a dataset name (e.g., OMNIMATH500, MATH500, AIMO2024, etc.).
---
### Detailed Analysis
#### OMNIMATH500
- **ReST**: Starts at ~0.32, fluctuates between 0.30–0.35, peaking at step 40 (~0.35).
- **Ours**: Begins at ~0.30, rises steadily to ~0.45 by step 50, with a peak at step 30 (~0.47).
#### MATH500
- **ReST**: Starts at ~0.76, fluctuates between 0.76–0.82, peaking at step 40 (~0.82).
- **Ours**: Begins at ~0.78, rises to ~0.90 by step 50, with a peak at step 40 (~0.89).
#### AIMO2024 (Top Row)
- **ReST**: Starts at ~0.10, drops to 0.00 at step 10, then stabilizes at ~0.10.
- **Ours**: Peaks at step 30 (~0.30), then drops to ~0.10 at step 40, rising again to ~0.30 at step 50.
#### AIMO2024 (Bottom Row)
- **ReST**: Starts at ~0.15, fluctuates between 0.15–0.20, peaking at step 40 (~0.20).
- **Ours**: Begins at ~0.15, rises to ~0.35 at step 30, drops to ~0.25 at step 40, then stabilizes at ~0.35.
#### ChatGLMath
- **ReST**: Starts at ~0.66, fluctuates between 0.66–0.72, peaking at step 40 (~0.72).
- **Ours**: Begins at ~0.66, rises to ~0.78 at step 50, with a peak at step 40 (~0.77).
#### GAOKAO_bmk
- **ReST**: Starts at ~0.76, fluctuates between 0.76–0.82, peaking at step 30 (~0.82).
- **Ours**: Begins at ~0.80, rises to ~0.88 at step 30, drops to ~0.84 at step 40, then stabilizes at ~0.86.
#### GPQA
- **ReST**: Starts at ~0.14, fluctuates between 0.14–0.22, peaking at step 30 (~0.22).
- **Ours**: Begins at ~0.12, rises to ~0.24 at step 30, drops to ~0.18 at step 40, then stabilizes at ~0.22.
#### k12-biology
- **ReST**: Starts at ~0.70, fluctuates between 0.68–0.78, peaking at step 30 (~0.78).
- **Ours**: Begins at ~0.70, rises to ~0.78 at step 30, drops to ~0.76 at step 40, then stabilizes at ~0.77.
#### k12-chemistry
- **ReST**: Starts at ~0.52, fluctuates between 0.52–0.58, peaking at step 30 (~0.58).
- **Ours**: Begins at ~0.50, rises to ~0.62 at step 30, drops to ~0.56 at step 40, then stabilizes at ~0.60.
#### k12-physics
- **ReST**: Starts at ~0.58, fluctuates between 0.54–0.58, peaking at step 30 (~0.58).
- **Ours**: Begins at ~0.62, rises to ~0.66 at step 30, drops to ~0.58 at step 40, then stabilizes at ~0.60.
#### KAOYAN
- **ReST**: Starts at ~0.55, fluctuates between 0.55–0.70, peaking at step 30 (~0.70).
- **Ours**: Begins at ~0.60, rises to ~0.75 at step 30, drops to ~0.74 at step 40, then stabilizes at ~0.77.
#### Total
- **ReST**: Starts at ~0.52, fluctuates between 0.52–0.58, peaking at step 30 (~0.58).
- **Ours**: Begins at ~0.50, rises to ~0.64 at step 30, drops to ~0.63 at step 40, then stabilizes at ~0.65.
---
### Key Observations
1. **Ours Outperforms ReST**: In most datasets, Ours achieves higher accuracy by step 50, particularly in MATH500 (~0.90 vs. ~0.82) and GAOKAO_bmk (~0.88 vs. ~0.82).
2. **Volatility in AIMO2024**: Both methods show erratic performance in AIMO2024, with ReST dropping to 0.00 at step 10 and Ours peaking at step 30.
3. **Consistent Growth in OMNIMATH500**: Ours demonstrates steady improvement, reaching ~0.45 by step 50.
4. **Stability in k12-physics**: Ours maintains higher accuracy (~0.60 vs. ~0.54) despite minor fluctuations.
5. **Total Dataset**: Ours achieves ~0.65 accuracy by step 50, outperforming ReST (~0.58).
---
### Interpretation
The data suggests that the **"Ours" method** is more effective at improving accuracy over training steps compared to **ReST**, particularly in complex or large-scale datasets (e.g., MATH500, GAOKAO_bmk). The Total chart confirms this trend, with Ours achieving a 10% higher accuracy than ReST by step 50. The volatility in AIMO2024 may indicate sensitivity to dataset-specific challenges, while the steady growth in OMNIMATH500 highlights Ours' robustness in incremental learning. These results imply that Ours' architecture or training strategy better captures task-specific patterns over time.
</details>
Figure 10: Comparison with using ReST for policy optimization.
## 4 Conclusions
We present the training recipe and system design of k1.5, our latest multi-modal LLM trained with RL. One of the key insights we extract from our practice is that the scaling of context length is crucial to the continued improvement of LLMs. We employ optimized learning algorithms and infrastructure optimization such as partial rollouts to achieve efficient long-context RL training. How to further improve the efficiency and scalability of long-context RL training remains an important question moving forward.
Another contribution we made is a combination of techniques that enable improved policy optimization. Specifically, we formulate long-CoT RL with LLMs and derive a variant of online mirror descent for robust optimization. We also experiment with sampling strategies, length penalty, and optimizing the data recipe to achieve strong RL performance.
We show that strong performance can be achieved by long context scaling and improved policy optimization, even without using more complex techniques such as Monte Carlo tree search, value functions, and process reward models. In the future, it will also be intriguing to study improving credit assignments and reducing overthinking without hurting the model’s exploration abilities.
We have also observed the potential of long2short methods. These methods largely improve performance of short CoT models. Moreover, it is possible to combine long2short methods with long-CoT RL in an iterative way to further increase token efficiency and extract the best performance out of a given context length budget.
## References
- [1] Yasin Abbasi-Yadkori et al. “Politex: Regret bounds for policy iteration using expert prediction” In International Conference on Machine Learning, 2019, pp. 3692–3702 PMLR
- [2] Arash Ahmadian et al. “Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms” In arXiv preprint arXiv:2402.14740, 2024
- [3] Zachary Ankner et al. “Critique-out-Loud Reward Models”, 2024 arXiv: https://arxiv.org/abs/2408.11791
- [4] Christopher Berner et al. “Dota 2 with large scale deep reinforcement learning” In arXiv preprint arXiv:1912.06680, 2019
- [5] Federico Cassano et al. “MultiPL-E: A Scalable and Extensible Approach to Benchmarking Neural Code Generation” In ArXiv, 2022 URL: https://arxiv.org/abs/2208.08227
- [6] Federico Cassano et al. “MultiPL-E: A Scalable and Polyglot Approach to Benchmarking Neural Code Generation” In IEEE Transactions on Software Engineering 49.7, 2023, pp. 3675–3691 DOI: 10.1109/TSE.2023.3267446
- [7] Jianlv Chen et al. “Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation” In arXiv preprint arXiv:2402.03216, 2024
- [8] Xingyu Chen et al. “Do NOT Think That Much for 2+ 3=? On the Overthinking of o1-Like LLMs” In arXiv preprint arXiv:2412.21187, 2024
- [9] Tom Everitt et al. “Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective”, 2021 arXiv: https://arxiv.org/abs/1908.04734
- [10] Samir Yitzhak Gadre et al. “Datacomp: In search of the next generation of multimodal datasets” In Advances in Neural Information Processing Systems 36, 2024
- [11] Aaron Grattafiori et al. “The Llama 3 Herd of Models”, 2024 arXiv: https://arxiv.org/abs/2407.21783
- [12] Caglar Gulcehre et al. “Reinforced self-training (rest) for language modeling” In arXiv preprint arXiv:2308.08998, 2023
- [13] Dan Hendrycks et al. “Measuring Massive Multitask Language Understanding” In ArXiv abs/2009.03300, 2020 URL: https://arxiv.org/abs/2009.03300
- [14] Jordan Hoffmann et al. “Training Compute-Optimal Large Language Models”, 2022 arXiv: https://arxiv.org/abs/2203.15556
- [15] Yuzhen Huang et al. “C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models” In ArXiv abs/2305.08322, 2023 URL: https://arxiv.org/abs/2305.08322
- [16] Aaron Jaech et al. “Openai o1 system card” In arXiv preprint arXiv:2412.16720, 2024
- [17] Naman Jain et al. “LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code” In ArXiv abs/2403.07974, 2024 URL: https://arxiv.org/abs/2403.07974
- [18] Armand Joulin et al. “Bag of tricks for efficient text classification” In arXiv preprint arXiv:1607.01759, 2016
- [19] Jared Kaplan et al. “Scaling Laws for Neural Language Models”, 2020 arXiv: https://arxiv.org/abs/2001.08361
- [20] Wouter Kool, Herke Hoof and Max Welling “Buy 4 reinforce samples, get a baseline for free!”, 2019
- [21] Woosuk Kwon et al. “Efficient Memory Management for Large Language Model Serving with PagedAttention” In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
- [22] Hugo Laurençon et al. “Obelics: An open web-scale filtered dataset of interleaved image-text documents” In Advances in Neural Information Processing Systems 36, 2024
- [23] Jeffrey Li et al. “Datacomp-lm: In search of the next generation of training sets for language models” In arXiv preprint arXiv:2406.11794, 2024
- [24] Ming Li et al. “From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning” In arXiv preprint arXiv:2308.12032, 2023
- [25] Raymond Li et al. “StarCoder: may the source be with you!”, 2023 arXiv: https://arxiv.org/abs/2305.06161
- [26] Hunter Lightman et al. “Let’s Verify Step by Step” In arXiv preprint arXiv:2305.20050, 2023
- [27] Wei Liu et al. “What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning” In arXiv preprint arXiv:2312.15685, 2023
- [28] Anton Lozhkov et al. “StarCoder 2 and The Stack v2: The Next Generation”, 2024 arXiv: https://arxiv.org/abs/2402.19173
- [29] Pan Lu et al. “Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts” In arXiv preprint arXiv:2310.02255, 2023
- [30] Nat McAleese et al. “LLM Critics Help Catch LLM Bugs”, 2024 arXiv: https://arxiv.org/abs/2407.00215
- [31] Jincheng Mei et al. “On principled entropy exploration in policy optimization” In Proceedings of the 28th International Joint Conference on Artificial Intelligence, 2019, pp. 3130–3136
- [32] Niklas Muennighoff et al. “Scaling Data-Constrained Language Models”, 2023 arXiv: https://arxiv.org/abs/2305.16264
- [33] Ofir Nachum et al. “Bridging the gap between value and policy based reinforcement learning” In Advances in neural information processing systems 30, 2017
- [34] OpenAI “Learning to reason with LLMs”, 2024 URL: https://openai.com/index/learning-to-reason-with-llms/
- [35] Long Ouyang et al. “Training language models to follow instructions with human feedback” In Advances in neural information processing systems 35, 2022, pp. 27730–27744
- [36] Alexander Pan, Kush Bhatia and Jacob Steinhardt “The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models” In International Conference on Learning Representations, 2022 URL: https://openreview.net/forum?id=JYtwGwIL7ye
- [37] Keiran Paster et al. “Openwebmath: An open dataset of high-quality mathematical web text” In arXiv preprint arXiv:2310.06786, 2023
- [38] Guilherme Penedo et al. “The fineweb datasets: Decanting the web for the finest text data at scale” In arXiv preprint arXiv:2406.17557, 2024
- [39] Ruoyu Qin et al. “Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving”, 2024 arXiv: https://arxiv.org/abs/2407.00079
- [40] Rafael Rafailov et al. “Direct preference optimization: Your language model is secretly a reward model” In Advances in Neural Information Processing Systems 36, 2024
- [41] Christoph Schuhmann et al. “Laion-5b: An open large-scale dataset for training next generation image-text models” In Advances in Neural Information Processing Systems 35, 2022, pp. 25278–25294
- [42] Mohammad Shoeybi et al. “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism”, 2020 arXiv: https://arxiv.org/abs/1909.08053
- [43] David Silver et al. “Mastering the game of go without human knowledge” In nature 550.7676 Nature Publishing Group, 2017, pp. 354–359
- [44] Charlie Snell et al. “Scaling llm test-time compute optimally can be more effective than scaling model parameters” In arXiv preprint arXiv:2408.03314, 2024
- [45] Dan Su et al. “Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset” In arXiv preprint arXiv:2412.02595, 2024
- [46] Jianlin Su et al. “Roformer: Enhanced transformer with rotary position embedding” In Neurocomputing 568 Elsevier, 2024, pp. 127063
- [47] Gemini Team et al. “Gemini: A Family of Highly Capable Multimodal Models”, 2024 arXiv: https://arxiv.org/abs/2312.11805
- [48] Manan Tomar et al. “Mirror descent policy optimization” In arXiv preprint arXiv:2005.09814, 2020
- [49] Ashish Vaswani et al. “Attention is All you Need” In Advances in Neural Information Processing Systems 30 Curran Associates, Inc., 2017 URL: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
- [50] Pablo Villalobos et al. “Will we run out of data? Limits of LLM scaling based on human-generated data”, 2024 arXiv: https://arxiv.org/abs/2211.04325
- [51] Oriol Vinyals et al. “Grandmaster level in StarCraft II using multi-agent reinforcement learning” In nature 575.7782 Nature Publishing Group, 2019, pp. 350–354
- [52] Ke Wang et al. “Measuring multimodal mathematical reasoning with math-vision dataset” In arXiv preprint arXiv:2402.14804, 2024
- [53] Haoran Wei et al. “General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model” In arXiv preprint arXiv:2409.01704, 2024
- [54] Jason Wei et al. “Chain-of-thought prompting elicits reasoning in large language models” In Advances in neural information processing systems 35, 2022, pp. 24824–24837
- [55] Yangzhen Wu et al. “Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models” In arXiv preprint arXiv:2408.00724, 2024
- [56] Liang Xu et al. “CLUE: A Chinese Language Understanding Evaluation Benchmark” In International Conference on Computational Linguistics, 2020 URL: https://arxiv.org/abs/2004.05986
- [57] Enneng Yang et al. “Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities” In arXiv preprint arXiv:2408.07666, 2024
- [58] Shunyu Yao et al. “Tree of thoughts: Deliberate problem solving with large language models” In Advances in Neural Information Processing Systems 36, 2024
- [59] Xiang Yue et al. “Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9556–9567
- [60] Xiang Yue et al. “Mammoth: Building math generalist models through hybrid instruction tuning” In arXiv preprint arXiv:2309.05653, 2023
- [61] Lunjun Zhang et al. “Generative verifiers: Reward modeling as next-token prediction, 2024” In URL https://arxiv. org/abs/2408.15240, 2024
- [62] Lianmin Zheng et al. “SGLang: Efficient Execution of Structured Language Model Programs”, 2024 arXiv: https://arxiv.org/abs/2312.07104
- [63] Jeffrey Zhou et al. “Instruction-Following Evaluation for Large Language Models” In ArXiv abs/2311.07911, 2023 URL: https://arxiv.org/abs/2311.07911
- [64] Wanrong Zhu et al. “Multimodal c4: An open, billion-scale corpus of images interleaved with text” In Advances in Neural Information Processing Systems 36, 2024
## Appendix
## Appendix A Contributions
Research & Development
Angang Du Bofei Gao Bowei Xing Changjiu Jiang Cheng Chen Cheng Li Chenjun Xiao Chenzhuang Du Chonghua Liao* Congcong Wang Dehao Zhang Enming Yuan Enzhe Lu Flood Sung Guokun Lai Haiqing Guo Han Zhu Hao Ding Hao Hu Hao Yang Hao Zhang Haotian Yao Haotian Zhao Haoyu Lu Hongcheng Gao Huan Yuan Huabin Zheng Jingyuan Liu Jianlin Su Jianzhou Wang Jin Zhang Junjie Yan Lidong Shi Longhui Yu Mengnan Dong Neo Zhang Ningchen Ma* Qiwei Pan Qucheng Gong Shaowei Liu Shupeng Wei Sihan Cao Tao Jiang Weimin Xiong Weiran He Weihao Gao* Weixiao Huang Weixin Xu Wenhao Wu Wenyang He Xianqing Jia Xingzhe Wu Xinran Xu Xinyu Zhou Xinxing Zu Xuehai Pan Yang Li Yangyang Hu Yangyang Liu Yanru Chen Yejie Wang Yidao Qin Yibo Liu Yiping Bao Yifeng Liu* Yulun Du Yuzhi Wang Yuxin Wu Y. Charles Zaida Zhou Zhaoji Wang Zhaowei Li Zheng Zhang Zhexu Wang Zhiqi Huang Zhilin Yang Zihao Huang Ziyao Xu Zonghan Yang Zongyu Lin
Data Annotation
Chuning Tang Fengxiang Tang Guangda Wei Haoze Li Haozhen Yu Jia Chen Jianhang Guo Jie Zhao Junyan Wu Ling Ye Shengling Ma Siying Huang Xianghui Wei Yangyang Liu Ying Yang Zhen Zhu
The listing of authors is in alphabetical order based on their first names. Names marked with an asterisk (*) indicate people who are no longer part of our team.
## Appendix B Pretraining
Reinforcement learning (RL) efficiency is closely tied to the performance of the underlying base model. Frontier models such as Gemini [47] and Llama [11] highlight the importance of pretraining data quality in achieving high performance. However, many recent open-source models lack full transparency regarding their data processing pipelines and recipes, creating challenges for broader community understanding. While we are not open-sourcing our proprietary model at this time, we are committed to providing a comprehensive disclosure of our data pipeline and methodologies. In this section, we focus primarily on the multimodal pretraining data recipe, followed by a brief discussion of the model architecture and training stages.
### B.1 Language Data
Our pretrain corpus is designed to provide comprehensive and high-quality data for training large language models (LLMs). It encompasses five domains: English, Chinese, Code, Mathematics & Reasoning, and Knowledge. We employ sophisticated filtering and quality control mechanisms for each domain to ensure the highest quality training data. For all pretrain data, we conducted rigorous individual validation for each data source to assess its specific contribution to the overall training recipe. This systematic evaluation ensures the quality and effectiveness of our diverse data composition.
English and Chinese textual data
we developed a multi-dimensional quality filtering framework that combines multiple scoring methods to reduce individual biases and ensure comprehensive quality assessment. Our framework incorporates:
1. Rule-based filtering: We implement domain-specific heuristics to remove problematic content, including duplicate content, machine-translated text, and low-quality web scrapes. We also filter out documents with excessive special characters, unusual formatting, or spam patterns.
1. FastText-based classification: We trained specialized FastText [18, 23] models to identify content quality based on linguistic features and semantic coherence. This helps identify documents with natural language flow and proper grammatical structure.
1. Embedding-based similarity analysis: Using document embeddings [7], we compute document-level similarity scores to identify and remove near-duplicates while preserving semantically valuable variations. This approach helps maintain diversity in our training corpus.
1. LLM-based quality assessment: Following [38], we leverage LLMs to score documents based on coherence, informativeness, and potential educational value. This method is particularly effective at identifying nuanced quality indicators that simpler methods might miss.
The final quality score for each document is calculated as a combination of these individual scores. Based on extensive empirical analysis, we implement dynamic sampling rates, where high-quality documents are upsampled, while low-quality documents are downsampled during training.
Code data
The code data primarily consists of two categories. For the pure code data derived from code files, we adhered to the methodology of BigCode [25, 28] and conducted a comprehensive preprocessing of the dataset. Initially, we eliminated miscellaneous languages and applied a rule-based cleaning procedure to enhance data quality. Subsequently, we addressed language imbalance through strategic sampling techniques. Specifically, markup languages such as JSON, YAML, and YACC were down-sampled, while 32 major programming languages, including Python, C, C++, Java, and Go, were up-sampled to ensure a balanced representation. Regarding the text-code interleaved data sourced from various data sources, we use an embedding-based method to recall high-quality data. This approach ensures the diversity of the data and maintains its high quality.
Math & Reasoning data
The mathematics and reasoning component of our dataset is crucial for developing strong analytical and problem-solving capabilities. The mathematical pre-training data are mainly retrieved from web text and PDF documents collected from publicly available internet sources. [37] Initially, we discovered that our general-domain text extraction, data cleaning process and OCR models exhibited high false negative rates in the mathematical domain. Therefore, we first developed specialized data cleaning procedures and OCR models specifically for mathematical content, aiming to maximize the recall rate of mathematical data. Subsequently, we implemented a two-stage data cleaning process:
1. Using FastText model for initial cleaning to remove most irrelevant data.
1. Utilizing a fine-tuned language model to further clean the remaining data, resulting in high-quality mathematical data.
Knowledge data
The knowledge corpus is meticulously curated to ensure a comprehensive coverage in academic disciplines. Our knowledge base primarily consists of academic exercises, textbooks, research papers, and other general educational literature. A significant portion of these materials is digitized through OCR processing, for which we have developed proprietary models optimized for academic content, particularly for handling mathematical formulas and special symbols.
We employ internal language models to annotate documents with multi-dimensional labels, including:
1. OCR quality metrics to assess recognition accuracy
1. Educational value indicators measuring pedagogical relevance
1. Document type classification (e.g., exercises, theoretical materials)
Based on these multi-dimensional annotations, we implement a sophisticated filtering and sampling pipeline. First and foremost, documents are filtered through OCR quality thresholds. Our OCR quality assessment framework places special attention on detecting and filtering out common OCR artifacts, particularly repetitive text patterns that often indicate recognition failures.
Beyond basic quality control, we carefully evaluate the educational value of each document through our scoring system. Documents with high pedagogical relevance and knowledge depth are prioritized, while maintaining a balance between theoretical depth and instructional clarity. This helps ensure that our training corpus contains high-quality educational content that can effectively contribute to the model’s knowledge acquisition.
Finally, to optimize the overall composition of our training corpus, the sampling strategy for different document types is empirically determined through extensive experimentation. We conduct isolated evaluations to identify document subsets that contribute most significantly to the model’s knowledge acquisition capabilities. These high-value subsets are upsampled in the final training corpus. However, to maintain data diversity and ensure model generalization, we carefully preserve a balanced representation of other document types at appropriate ratios. This data-driven approach helps us optimize the trade-off between focused knowledge acquisition and broad generalization capabilities.
### B.2 Multimodal Data
Our multi-modal pretraining corpus is designed to provide high-quality data that enables models to process and understand information from multiple modalities, including text, images, and videos. To this end, we also have curated high-quality data from five categories—captioning, interleaving, OCR (Optical Character Recognition), knowledge, and general question answering—to form the corpus.
When constructing our training corpus, we developed several multi-modal data processing pipelines to ensure data quality, encompassing filtering, synthesis, and deduplication. Establishing an effective multi-modal data strategy is crucial during the joint training of vision and language, as it both preserves the capabilities of the language model and facilitates alignment of knowledge across diverse modalities.
We provide a detailed description of these sources in this section, which is organized into the following categories:
Caption data
Our caption data provides the model with fundamental modality alignment and a broad range of world knowledge. By incorporating caption data, the multi-modal LLM gains wider world knowledge with high learning efficiency. We have integrated various open-source Chinese and English caption datasets like [41, 10] and also collected substantial in-house caption data from multiple sources. However, throughout the training process, we strictly limit the proportion of synthetic caption data to mitigate the risk of hallucination stemming from insufficient real-world knowledge.
For general caption data, we follow a rigorous quality control pipeline that avoids duplication and maintain high image-text correlation. We also vary image resolution during pretraining to ensure that the vision tower remains effective when processing images of both high- and low-resolution.
Image-text interleaving data During the pretraining phase, model is benefit from interleaving data for many aspects, for example, multi-image comprehension ability can be boosted by interleaving data; interleaving data always provide detailed knowledge for the given image; a longer multi-modal context learning ability can also be gained by the interleaving data. What’s more, we also find that interleaving data can contributes positively to maintaining the model’s language abilities. Thus, image-text interleaving data is an important part in our training corpus. Our multi-modal corpus considered open-sourced interleave datasets like [64, 22] and also constructed large-scale in-house data using resources like textbooks, webpages and tutorials. Further, we also find that synthesizing the interleaving data benefits the performance of multi-modal LLM for keeping the text knowledges. To ensure each image’s knowledge is sufficiently studied, for all the interleaving data, other than the standard filtering, deduping and other quality control pipeline, we also integrated a data reordering procedure for keeping all the image and text in the correct order.
OCR data Optical Character Recognition (OCR) is a widely adopted technique that converts text from images into an editable format. In k1.5, a robust OCR capability is deemed essential for better aligning the model with human values. Accordingly, our OCR data sources are diverse, ranging from open-source to in-house datasets, and encompassing both clean and augmented images.
In addition to the publicly available data, we have developed a substantial volume of in-house OCR datasets, covering multilingual text, dense text layouts, web-based content, and handwritten samples. Furthermore, following the principles outlined in OCR 2.0 [53], our model is also equipped to handle a variety of optical image types, including figures, tables, geometry diagrams, mermaid plots, and natural scene text. We apply extensive data augmentation techniques—such as rotation, distortion, color adjustments, and noise addition—to enhance the model’s robustness. As a result, our model achieves a high level of proficiency in OCR tasks.
Knowledge data The concept of multi-modal knowledge data is analogous to the previously mentioned text pretraining data, except here we focus on assembling a comprehensive repository of human knowledge from diverse sources to further enhance the model’s capabilities. For example, carefully curated geometry data in our dataset is vital for developing visual reasoning skills, ensuring the model can interpret the abstract diagrams created by humans.
Our knowledge corpus adheres to a standardized taxonomy to balance content across various categories, ensuring diversity in data sources. Similar to text-only corpora, which gather knowledge from textbooks, research papers, and other academic materials, multi-modal knowledge data employs both a layout parser and an OCR model to process content from these sources. While we also include filtered data from internet-based and other external resources.
Because a significant portion of our knowledge corpus is sourced from internet-based materials, infographics can cause the model to focus solely on OCR-based information. In such cases, relying exclusively on a basic OCR pipeline may limit training effectiveness. To address this, we have developed an additional pipeline that better captures the purely textual information embedded within images.
General QA Data During the training process, we observed that incorporating a substantial volume of high-quality QA datasets into pretraining offers significant benefits. Specifically, we included rigorous academic datasets addressing tasks such as grounding, table/chart question answering, web agents, and general QA. In addition, we compiled a large amount of in-house QA data to further enhance the model’s capabilities. To maintain balanced difficulty and diversity, we applied scoring models and meticulous manual categorization to our general question answering dataset, resulting in overall performance improvements.
### B.3 Model Architecture
Kimi k-series models employ a variant of the Transformer decoder [49] that integrates multimodal capabilities alongside improvements in architecture and optimization strategies, illustrated in Figure 11. These advancements collectively support stable large-scale training and efficient inference, tailored specifically to large-scale reinforcement learning and the operational requirements of Kimi users.
Extensive scaling experiments indicate that most of the base model performance comes from improvements in the quality and diversity of the pretraining data. Specific details regarding model architecture scaling experiments lie beyond the scope of this report and will be addressed in future publications.
<details>
<summary>x12.png Details</summary>

### Visual Description
## Flowchart: Multimodal Processing Pipeline with Reinforcement Learning
### Overview
The image depicts a technical workflow diagram illustrating a multimodal processing pipeline. It shows the integration of text and image-text sequences through a Transformer model, followed by large-scale reinforcement learning. The diagram uses directional arrows to indicate data flow and feedback loops.
### Components/Axes
1. **Input Components**:
- **Text Sequences**: Represented by a document icon (top-left)
- **Interleave Image-text Sequences**: Represented by a picture icon (bottom-left)
2. **Processing Component**:
- **Transformer**: Central gray block labeled "Transformer"
3. **Output Component**:
- **Large Scale Reinforcement Learning**: Represented by a brain icon with a lightbulb (right side)
4. **Flow Indicators**:
- Double-sided arrow between input components and Transformer
- Circular arrow connecting Transformer output to reinforcement learning
### Detailed Analysis
- **Text Sequences** and **Interleave Image-text Sequences** are positioned vertically on the left side, suggesting sequential or parallel input processing.
- The **Transformer** block occupies the central position, acting as the core processing unit.
- The **Large Scale Reinforcement Learning** component is isolated on the right, receiving processed output from the Transformer.
- Arrows indicate bidirectional relationships:
- Forward flow from inputs → Transformer → Reinforcement Learning
- Feedback loop from Reinforcement Learning back to Transformer
### Key Observations
1. The diagram emphasizes multimodal integration through the "Interleave Image-text Sequences" component.
2. The Transformer's central position highlights its role as the primary processing engine.
3. The circular arrow between Transformer and Reinforcement Learning suggests iterative model improvement.
4. No numerical data or quantitative metrics are present in the diagram.
### Interpretation
This pipeline demonstrates a hybrid approach to AI model development:
1. **Multimodal Foundation**: Combines pure text and image-text data for comprehensive input representation.
2. **Transformer Processing**: Utilizes state-of-the-art architecture for sequence modeling and cross-modal understanding.
3. **Reinforcement Learning Integration**: Implements large-scale optimization through feedback-driven learning, likely for:
- Improving cross-modal alignment
- Enhancing sequence prediction accuracy
- Optimizing model performance through iterative refinement
The feedback loop between Transformer and Reinforcement Learning implies a self-improving system where model outputs are continuously optimized through reinforcement signals. This architecture suggests applications in complex tasks requiring both multimodal understanding and adaptive learning capabilities, such as advanced dialogue systems or cross-modal content generation.
</details>
Figure 11: Kimi k1.5 supports interleaved images and text as input, leveraging large-scale reinforcement learning to enhance the model’s reasoning capabilities.
### B.4 Training Stages
The Kimi k1.5 model is trained in three stages: the vision-language pretraining stage, the vision-language cooldown stage, and the long-context activation stage. Each stage of the Kimi k1.5 model’s training focuses on a particular capability enhancement.
Vision-language pretraining stage
In this stage, the model is firstly trained solely on language data, establishing a robust language model foundation. Then the model is gradually introduced to interleaved vision-language data, acquiring multimodal capabilities. The visual tower is initially trained in isolation without updating the language model parameters, then we unfreeze the language model layers, and ultimately increase the proportion of vision-text data to 30%. The final data mixtures and their respective weights were determined through ablation studies conducted on smaller models.
Vision-language cooldown stage
The second stage serves as a cooldown phase, where the model is continue trained with high-quality language and vision-language datasets to ensure superior performance. Through empirical investigation, we observed that the incorporation of synthetic data during the cooldown phase yields significant performance improvements, particularly in mathematical reasoning, knowledge-based tasks, and code generation. The English and Chinese components of the cooldown dataset are curated from high-fidelity subsets of the pre-training corpus. For math, knowledge, and code domains, we employ a hybrid approach: utilizing selected pre-training subsets while augmenting them with synthetically generated content. Specifically, we leverage existing mathematical, knowledge and code corpora as source material to generate question-answer pairs through a proprietary language model, implementing rejection sampling techniques to maintain quality standards [60, 45]. These synthesized QA pairs undergo comprehensive validation before being integrated into the cooldown dataset.
Long-context activation stage
Finally, in the third stage, k1.5 is trained with upsampled long-context cooldown data, enabling it to process extended sequences and support tasks that demand longer context. To ensure excellent long-text capabilities of the base model, we upsampled long-context data and used 40% full attention data and 60% partial attention data during long context training. The full attention data came partly from high-quality natural data and partly from synthetic long context Q&A and summary data. The partial attention data came from uniform sampling of cooldown data. The RoPE frequency [46] was set to 1,000,000. During this stage, we gradually extended length activation training by increasing the maximum sequence length from 4,096 to 32,768, and ultimately to 131,072.
## Appendix C Evaluation Details
### C.1 Text Benchmark
MMLU [13] covers 57 subjects in STEM, the humanities, social sciences, and more. It ranges in difficulty from an elementary level to an advanced professional level, and it tests both world knowledge and problem-solving ability.
IF-Eval [63] is a benchmark for evaluating large language models’ ability to follow verifiable instructions. There are 500+ prompts with instructions such as "write an article with more than 800 words", etc. Due to a version shift, the number of IFEval reported in Table 3 derived from an intermediate model. We will update the scores based on the final model.
CLUEWSC [56] is a coreference resolution task in CLUE benchmark, requiring models to determine if a pronoun and a noun phrase in a sentence co-refer, with data from Chinese fiction books.
C-EVAL [15] is a comprehensive Chinese evaluation suite for assessing advanced knowledge and reasoning abilities of foundation models. It includes 13,948 multiple-choice questions across 52 disciplines and four difficulty levels.
### C.2 Reasoning Benchmark
HumanEval-Mul is a subset of Multipl-E [5]. MultiPL-E extends the HumanEval benchmark and MBPP benchmark to 18 languages that encompass a range of programming paradigms and popularity. We choose HumanEval translations in 8 mainstream programming languages (Python, Java, Cpp, C#, JavaScript, TypeScript, PHP, and Bash).
LiveCodeBench [17] serves as a comprehensive and contamination-free benchmark for assessing large language models (LLMs) in coding tasks. It features live updates to prevent data contamination, holistic evaluation across multiple coding scenarios, high-quality problems and tests, and balanced problem difficulty. We test short-CoT model with questions from 2408-2411 (release v4), and long-CoT model with questions from 2412-2502 (release v5).
AIME 2024 comprises the competition questions for the AIME in 2024. The AIME is a prestigious, invitation-only math contest for top high school students, assessing advanced math skills and requiring solid foundation and high logical thinking.
MATH-500 [26] is a comprehensive mathematics benchmark that contains 500 problems on various mathematics topics including algebra, calculus, probability, and more. Tests both computational ability and mathematical reasoning. Higher scores indicate stronger mathematical problem-solving capabilities.
Codeforces is a well-known online judge platform and serves as a popular testbed for evaluating long-CoT coding models. To achieve higher rankings in the Div2 and Div3 competitions, we utilize majority voting on the code snippets generated by the k1.5 long-CoT model, employing test cases that are also generated by the same model. The percentile of the codeforce ELO rating was extracted from OpenAI Day12 talk https://www.youtube.com/watch?v=SKBG1sqdyIU&ab_channel=OpenAI c.
### C.3 Image Benchmark
MMMU [59] encompasses a carefully curated collection of 11.5K multimodal questions sourced from college exams, quizzes, and textbooks. These questions span six major academic fields: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering.
MATH-Vision (MATH-V) [52] is a carefully curated collection of 3,040 high-quality mathematical problems with visual contexts that are sourced from real math competitions. It covers 16 distinct mathematical disciplines and is graded across 5 levels of difficulty. This dataset offers a comprehensive and diverse set of challenges, making it ideal for evaluating the mathematical reasoning abilities of LMMs.
MathVista [29] is a benchmark that integrates challenges from a variety of mathematical and visual tasks, demanding participants to exhibit fine-grained, deep visual understanding along with compositional reasoning to successfully complete the tasks.