# Communicating Activations Between Language Model Agents
**Authors**: Vignav Ramesh, Kenneth Li
## Abstract
Communication between multiple language model (LM) agents has been shown to scale up the reasoning ability of LMs. While natural language has been the dominant medium for inter-LM communication, it is not obvious this should be the standard: not only does natural language communication incur high inference costs that scale quickly with the number of both agents and messages, but also the decoding process abstracts away too much rich information that could be otherwise accessed from the internal activations. In this work, we propose a simple technique whereby LMs communicate via activations; concretely, we pause an LM $B$ ’s computation at an intermediate layer, combine its current activation with another LM $A$ ’s intermediate activation via some function $f$ , then pass $f$ ’s output into the next layer of $B$ and continue the forward pass till decoding is complete. This approach scales up LMs on new tasks with zero additional parameters and data, and saves a substantial amount of compute over natural language communication. We test our method with various functional forms $f$ on two experimental setups—multi-player coordination games and reasoning benchmarks—and find that it achieves up to $27.0\$ improvement over natural language communication across datasets with $<$ $1/4$ the compute, illustrating the superiority and robustness of activations as an alternative “language” for communication between LMs.
Machine Learning, ICML
## 1 Introduction
Language is for the purpose of communication. As large language models (LLMs) have been increasingly used to power autonomous, goal-driven agents capable of reasoning, tool usage, and adaptive decision-making (Yao et al., 2023; Xi et al., 2023; Wang et al., 2024; Ahn et al., 2022; Schick et al., 2023; Shen et al., 2023; Park et al., 2023; Nakano et al., 2022), communication between multiple cooperating agents has emerged as an intuitive approach to amplify the reasoning capabilities of LLMs (Wu et al., 2023). Explicit communication in natural language between multiple LLMs has been shown to encourage divergent thinking (Liang et al., 2023), improve factuality and reasoning (Du et al., 2023), enable integration of cross-domain knowledge (Sukhbaatar et al., 2024), and allow for modular composition of abilities in a complementary manner (Wu et al., 2023; Prasad et al., 2023).
A critical problem with natural language communication, however, is that it incurs extremely high inference costs that scale quickly with the number of agents as well as length and number of messages (Du et al., 2023; Yang et al., 2023; Wu et al., 2023). Restricting LLM communication to natural language also raises the question: as LLMs are increasingly capable of handling larger, more complex tasks (sometimes with “super-human” ability) (Wei et al., 2022; Burns et al., 2023), might they communicate more effectively in representations of higher dimension than natural language? While using natural language as a communicative medium is appealing due to its interpretability, we claim that it may not be optimal for inter-LLM communication. Natural language generation uses only one token to represent the model’s belief over the entire vocabulary, which risks losing information embedded within the model output logits (Pham et al., 2024); furthermore, a model’s belief over the entire vocabulary is itself not always better (for communicative purposes) than the model’s (often richer) representation of the input in earlier layers. Indeed, Hernandez et al. (2024) find that by around the halfway point of an LM’s computation, it has developed “enriched entity representations” of the input, where entities in the prompt are populated with additional facts about that entity encoded in the model’s weights; but by the later layers these embeddings are transformed into a representation of the next word which leverages only parts of the previous, richer representations, when that full embedding would be quite useful for communication.
Motivated by these concerns, this work outlines a simple technique whereby LLM agents communicate via activations, thus enabling more efficient (i.e., higher-entropy) communication at a fraction of the number of forward passes required at inference time. Concretely, we (1) pause a Transformer LM $B$ ’s computation at intermediate layer $j$ in the residual stream; (2) combine its post-layer $j$ activation with another LM $A$ ’s post-layer $k$ activation via some function $f$ ; and then (3) pass $f$ ’s output into the next layer $j+1$ of $B$ and continue its forward pass till decoding is complete. This approach scales up LLMs on new tasks by leveraging existing, frozen LLMs along with zero task-specific parameters and data, applying to diverse domains and settings. Furthermore, in requiring only a partial forward pass through $A$ and one forward pass through $B$ , this method saves a substantial amount of compute over traditional natural language communication, which we quantify in Section 3.2.
We validate our method by testing this approach with various functional forms $f$ on two experimental setups: two multi-player coordination games, where $B$ is asked to complete a task requiring information provided in a prompt to $A$ ; and seven reasoning benchmarks spanning multiple domains: Biographies (Du et al., 2023), GSM8k (Cobbe et al., 2021), MMLU High School Psychology, MMLU Formal Logic, MMLU College Biology, MMLU Professional Law, and MMLU Public Relations (Hendrycks et al., 2021). Our activation communication protocol exhibits up to $27.0\$ improvement over natural language communication across these datasets, using $<$ $1/4$ the compute. Critically, unlike prior work which test inter-LLM communication only on large-scale ( $>$ $70$ B) models (Du et al., 2023; Liang et al., 2023), we find that our approach generalizes across a wide array of LLM suites and sizes, enabling even smaller LLMs to unlock the benefits of communication.
In summary, our contributions are two-fold:
- We propose a novel inter-model communication protocol for LLM agents that is purely activation-based.
- We perform comprehensive experiments to validate the improved performance of activation communication over traditional natural language communication. We also formally quantify our approach’s compute savings over natural language communication, illustrating the superiority and robustness of activations as an alternative “language” for communication between LMs.
## 2 Related Work
#### Multi-agent communication
The field of multi-agent communication has a long-standing history. Notably, prior works on emergent communication have showed that agents can autonomously evolve communication protocols when deployed in multi-agent environments that enable cooperative and competitive game-play (Sukhbaatar et al., 2016; Foerster et al., 2016; Lazaridou et al., 2017). However, recent experiments have demonstrated that learning meaningful languages from scratch, even with centralized training, remains difficult (Lowe et al., 2020; Chaabouni et al., 2019; Jaques et al., 2019).
With the emergence of large pre-trained language models, allowing communication between LLMs in natural language has hence become a promising approach to enable coordination among multiple LLM agents (Li et al., 2023). Recent works have demonstrated that such conversations enable integration of cross-domain knowledge (Sukhbaatar et al., 2024), modular composition of abilities in a complementary manner (Wu et al., 2023), and improved task performance via splitting into subtasks (Prasad et al., 2023). Most notable is multiagent debate introduced by Du et al. (2023), where LLMs provide initial responses and then make refinements by iteratively considering inputs from peers. While such methods have been shown to improve performance on various tasks over vanilla and majority-vote (Wang et al., 2023) style prompting, these experiments have only focused on large models ( $\mathtt{GPT}$ - $\mathtt{3.5/4}$ , $\mathtt{LLaMA2}$ - $\mathtt{70B}$ and up), leaving the efficacy of debate on smaller, open-source models underexplored; our study addresses this gap by reimplementing Du et al. (2023) in experiments with smaller-scale ( $1-70$ B) models. More crucially, debate and similar natural language communication methods are extremely computationally expensive, which this work addresses (Yang et al., 2023; Wu et al., 2023).
Notably, Pham et al. (2024) propose CIPHER, which uses input (tokenizer) embeddings (as opposed to activations) to enable multi-agent communication; specifically, CIPHER passes the average tokenizer embedding (weighted by the LLM’s next-token probabilities) between models. While (Pham et al., 2024) show this approach outperforms natural language debate, it (i) still faces substantial information loss relative to the model activations and (ii) does not save compute, as the number of these “average embeddings” passed between models is the same as the number of tokens passed between models in natural language communication.
A related class of methods involves spending extra test-time compute reasoning in latent space (Geiping et al., 2025; Hao et al., 2024). Such latent reasoning approaches involving doing ”chain-of-thought in activation space,” e.g. by grafting LM activations into other layers/later forward passes through the same model (e.g., a form of “recurrent AC” within a single model); our approach can be viewed as doing exactly the same thing, but instead ”outsourcing” the CoT to another model (and thus reaping benefits from greater diversity of thoughts/reasoning paths from distinct models).
#### Activation engineering
Activation engineering involves editing an LLM’s intermediate layer representations during a forward pass to create desired changes to output text (Li et al., 2024; Turner et al., 2023). Past work has explored extracting latent steering vectors from a frozen LLM to control quality and content of completions (Subramani et al., 2022), as well as using “direction” vectors (computed as the difference in activations between two prompts) that enable inference-time control over high-level properties of generations (Li et al., 2024; Turner et al., 2023). This work involves activation editing that is similar to such prior works at a high level, though for the purpose of communication between LLM agents.
#### Model composition and grafting
Composing expert models has been a recurring strategy to improve large models, with different methods imposing different restrictions on the types of base LLMs that can be combined. Mixture of Experts (Shazeer et al., 2017) requires that all experts are trained simultaneously using the same data; Branch-Train-Mix (Sukhbaatar et al., 2024) trains a single base LM multiple times on different datasets, then learns a router on outputs. Crucially, these methods do not work when neither model can do the task at hand well (i.e., they solve the problem of choosing which of several outputs is best, not that of generating a high-quality output by recombining the disparate abilities of the various base LMs).
Model grafting, in contrast, seeks to merge different models immediately prior to or at inference-time. Past works have explored this at the parameter level (e.g., task vector averaging as in Ilharco et al. (2023), which requires that the base models be well aligned), probability distribution / token level as in Shen et al. (2024) (which imposes few restrictions on the relationship between the base models, but by virtue of being token-based can result in cascading errors during decoding), and activation level (e.g., CALM (Bansal et al., 2024) which learns an attention layer on top of two models’ intermediate layer activations and thus enables broader integration of model abilities than token-level methods, but requires re-tuning of the attention mechanism for every model pair). In this work, we seek to unify CALM and other activation-level grafting techniques under a single framework, parameterized by the function $f$ used to combine activations; crucially, we explore simple forms of $f$ (e.g., sum, mean) that—unlike Bansal et al. (2024) —require zero additional task-specific parameters and data, and are far more compute-efficient.
## 3 Communicating Activations Between Language Models
<details>
<summary>extracted/6420159/overview.png Details</summary>
### Visual Description
## Diagram: Neural Network Module Interaction with Analogy
### Overview
The image is a technical diagram illustrating a conceptual framework for interaction between two neural network modules or sequences, labeled **A** and **B**. It uses a mathematical notation for hidden states and a function `f` to show how information flows and is combined. The diagram is split into two main sections by a vertical black line. The left section shows the high-level architecture with an illustrative analogy problem. The right section provides two detailed schematic views of the internal operation of function `f`.
### Components/Axes
**Left Section (High-Level Architecture):**
* **Block A (Left, Light Green):** A vertical rectangular block labeled "A" in the top-left corner. It contains a sequence of hidden states represented by rounded rectangles. Visible states are `h_{A,k+1}` (top) and `h_{A,k}` (below it), with vertical ellipsis (`⋮`) above and below indicating a sequence. A snowflake icon (❄) is in the top-right corner of the block. An upward-pointing arrow enters the bottom of the block.
* **Block B (Center, Light Blue):** A vertical rectangular block labeled "B" in the top-left corner. It contains a sequence of hidden states: `h_{B,j+1}` (top) and `h_{B,j}` (below it), with vertical ellipsis (`⋮`) above and below. A snowflake icon (❄) is in the top-right corner. An upward-pointing arrow enters the bottom of the block.
* **Function `f` (Center, Light Yellow):** A smaller rectangular block labeled with an italic `f`. It receives input arrows from `h_{A,k}` in Block A and `h_{B,j}` in Block B. It sends an output arrow to `h_{B,j+1}` in Block B.
* **Text Annotations:**
* **Bottom:** A word problem in monospaced font: "Janet bought 16 cookies, and wants to give an equal number to each of her 4 friends. How many cookies does each friend get?"
* **Top Center:** The solution to the word problem: "Each friend gets 16/4 = 4 cookies." An upward arrow points from this text toward the top of Block B.
**Right Section (Detailed Function `f` Schematics):**
* **Left Schematic (Addition):** A light yellow rectangle labeled `f`. Inside, a circle with a plus sign (`+`) represents an addition operation. Two input arrows from below are labeled `h_{A,k}` and `h_{B,j}`. They feed into the circle. One output arrow exits the top of the rectangle.
* **Right Schematic (Weighted Transformation):** A larger light yellow rectangle labeled `f`. Inside, a purple trapezoid is labeled with a bold **W**. An input arrow from below splits to feed into the bottom of the trapezoid. The labels `h_{A,k}` and `h_{B,j}` are placed below this input line, indicating they are the combined input. One output arrow exits the top of the rectangle from the top of the trapezoid.
### Detailed Analysis
**Data Flow and Relationships:**
1. **Primary Flow:** Information flows upward through both Block A and Block B, as indicated by the arrows entering their bottoms and the vertical sequence of hidden states (`h_{A,k}` -> `h_{A,k+1}`, `h_{B,j}` -> `h_{B,j+1}`).
2. **Cross-Module Interaction:** The function `f` acts as a bridge. It takes the current hidden state `h_{A,k}` from sequence A and the current hidden state `h_{B,j}` from sequence B as inputs.
3. **Output of `f`:** The output of function `f` is used to compute the *next* hidden state in sequence B, `h_{B,j+1}`. This suggests that information from module A influences the progression of module B.
4. **Snowflake Icons:** The snowflake symbols in the top-right corners of blocks A and B likely indicate that these modules or their parameters are "frozen" (not updated) during a particular training phase, such as in transfer learning or when using pre-trained models.
5. **Function `f` Implementations:** The right side details two possible implementations for `f`:
* **Simple Addition:** `f(h_{A,k}, h_{B,j}) = h_{A,k} + h_{B,j}`. This is an element-wise sum.
* **Weighted Transformation:** `f(h_{A,k}, h_{B,j}) = W * [h_{A,k}; h_{B,j}]` or similar, where **W** is a weight matrix applied to the concatenated or combined inputs `h_{A,k}` and `h_{B,j}`.
**Textual Content Transcription:**
* **Word Problem:** "Janet bought 16 cookies, and wants to give an equal number to each of her 4 friends. How many cookies does each friend get?"
* **Solution:** "Each friend gets 16/4 = 4 cookies."
### Key Observations
1. **Asymmetric Interaction:** The diagram shows a directed interaction. Module A influences Module B (via `f`), but there is no shown reciprocal arrow from B to A. The flow is A -> f -> B.
2. **Analogy for Distribution:** The cookie problem serves as a simple analogy for the core operation. The total "information" or "resources" (16 cookies) from a source (Janet, analogous to the combined input) are distributed equally (via division, analogous to the function `f`'s operation) to recipients (4 friends, analogous to the output or next state).
3. **Modularity:** The separation of the high-level view (left) from the detailed function view (right) emphasizes a modular design. The interaction mechanism `f` is pluggable and can be implemented in different ways (addition vs. linear transformation).
4. **State Sequences:** The use of indices `k` for A and `j` for B implies the two sequences may be at different processing steps or have different lengths.
### Interpretation
This diagram illustrates a **cross-attention or fusion mechanism** between two distinct neural network sequences or modules. It is common in architectures that process multiple inputs (e.g., vision-language models, multi-task learning, or encoder-decoder systems).
* **What it demonstrates:** The core idea is that the state of one network (B) can be conditioned on or updated by information from another network (A) at each step. The function `f` is the learnable component that determines *how* information from A is integrated into B's processing stream.
* **The Analogy's Role:** The cookie problem is a pedagogical tool. It frames the complex operation of `f` as a simple "distribution" or "combination" task. Just as Janet's total cookies are divided among friends, the combined information from `h_{A,k}` and `h_{B,j}` is processed by `f` to produce a new state. This makes the abstract concept more accessible.
* **Architectural Implication:** The snowflake icons suggest a scenario like **feature extraction** from a frozen pre-trained model (A) being fed into a trainable task-specific model (B). The function `f` would then be the trainable adapter that aligns the features from A with the needs of B.
* **Notable Design Choice:** The choice between a simple additive `f` and a weighted matrix `f` represents a trade-off between model capacity and complexity. Addition is a lightweight, parameter-free interaction, while the weighted version allows the model to learn a more complex, non-linear relationship between the two information streams.
In essence, the image provides a blueprint for a neural network component where information from one processing stream is systematically injected into another, using a flexible and learnable interaction function.
</details>
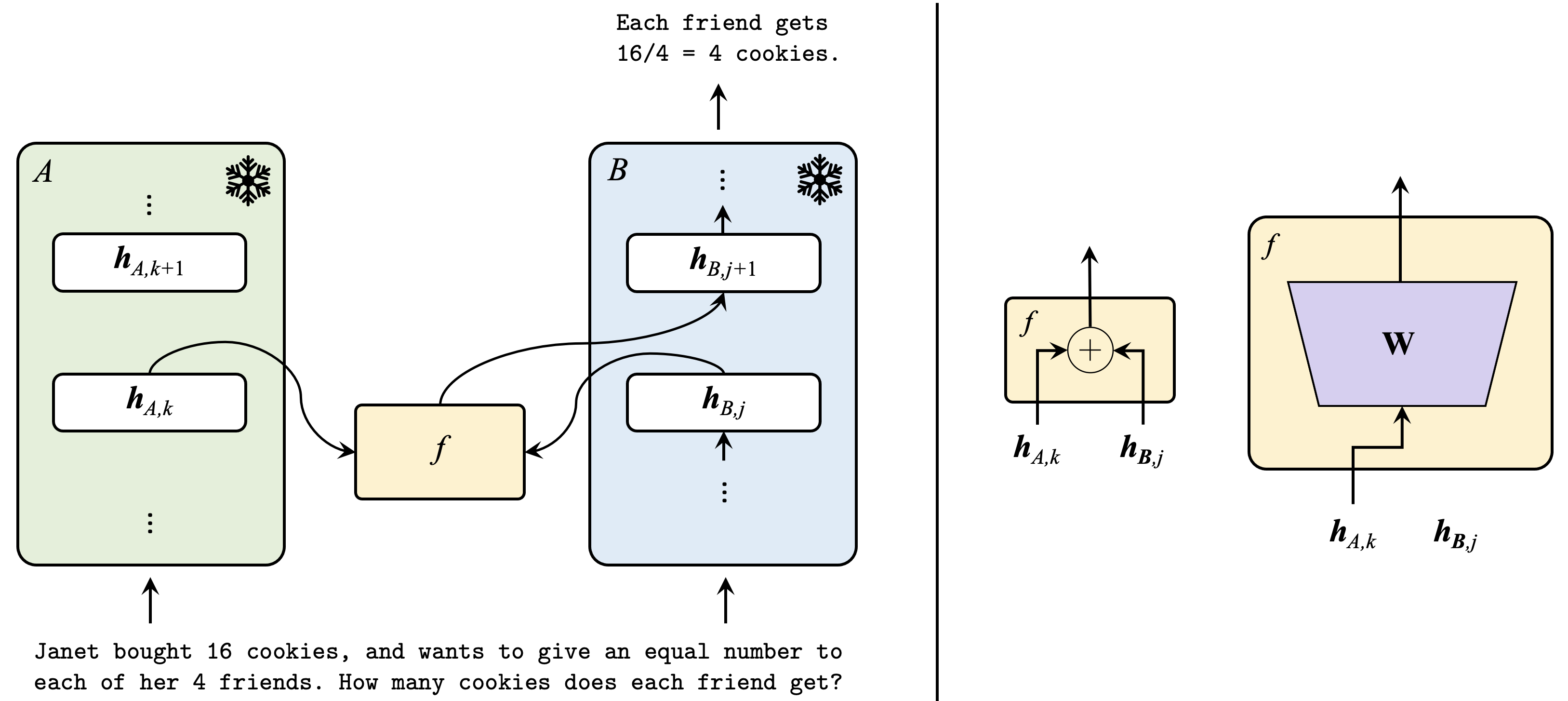
Figure 1: Overview of activation communication. (Left) Our method involves (1) pausing a Transformer LM $B$ ’s computation at layer $j$ in the residual stream; (2) combining its post-layer $j$ activation with another LM $A$ ’s post-layer $k$ activation via some function $f$ ; then (3) passing $f$ ’s output into the next layer $j+1$ of $B$ and continuing the forward pass till decoding is complete. (Right) Any function $f$ can be used to combine $A$ and $B$ ’s activations; we explore letting $f$ be the sum, mean, and replacement functions, as well as a task-agnostic learned linear layer (details in Section 3.1).
We propose a simple yet effective technique whereby language models communicate via activations. We detail our approach in Section 3.1; provide analytical models of the compute saved over natural language communication in Section 3.2; and discuss the intuition behind this approach in Section 3.3.
### 3.1 Method
Consider two language models, $A$ and $B$ , and some setting in which $B$ must perform a task where it would benefit from knowledge given to $A$ as a prompt/encoded in $A$ ’s weights (example settings in Section 4.1 / Section 4.2 respectively). We propose incorporating information from $A$ ’s post-layer $k$ activation $\bm{h}_{A,k}$ into $B$ ’s post-layer $j$ activation $\bm{h}_{B,j}$ (and vice versa, though for simplicity we henceforth only discuss the first direction) (Figure 1, left).
More formally, suppose $A$ and $B$ (which have model dimensions $d_{A}$ and $d_{B}$ respectively) are given prompts $x_{A}$ and $x_{B}$ respectively, where $x_{A}$ is of length $t_{A}$ tokens and $x_{B}$ is of length $t_{B}$ tokens. We first run a partial forward pass of $B$ until layer $j$ (henceforth denoted $B_{\leq j}(x_{B})$ ) to get $\bm{h}_{B,j}\in\mathbb{R}^{t_{B}\times d_{B}}$ . Then we (1) run a partial forward pass of $A$ until layer $k$ to get $A_{\leq k}(x_{1}):=\bm{h}_{A,k}\in\mathbb{R}^{t_{A}\times d_{A}}$ ; (2) replace the activation of the last token $(\bm{h}_{B,j})_{t_{B}}\in\mathbb{R}^{d_{B}}$ $\longleftarrow f((\bm{h}_{A,k})_{t_{A}},(\bm{h}_{B,j})_{t_{B}})$ for some function $f:\mathbb{R}^{d_{A}+d_{B}}\to\mathbb{R}^{d_{B}}$ ; then (3) continue $B$ ’s forward pass till decoding is complete, resulting in an output $y=B_{>k}(\bm{h}_{B,j})$ .
Let $\bm{a}=(\bm{h}_{A,k})_{t_{A}}$ , $\bm{b}=(\bm{h}_{B,j})_{t_{B}}$ . For sake of simplicity assume $d_{A}=d_{B}$ . When $d_{A}\neq d_{B}$ , the $\mathtt{sum}$ , $\mathtt{mean}$ , and $\mathtt{replace}$ functions are defined as follows. Let $d=\min(d_{A},d_{B})$ and $\circ$ the concatenation operator. Then $f(\bm{a},\bm{b})=\bm{b}_{1:\max(d_{B}-d,0)}\circ\left(\bm{b}_{\max(d_{B}-d,0)+ 1:d_{B}}+\bm{a}_{\max(d_{A}-d,0)+1:d_{A}}\right)$ $\mathtt{(sum)}$ , $f(\bm{a},\bm{b})=\bm{b}_{1:\max(d_{B}-d,0)}\circ\frac{1}{2}\left(\bm{b}_{\max( d_{B}-d,0)+1:d_{B}}+\bm{a}_{\max(d_{A}-d,0)+1:d_{A}}\right)$ $\mathtt{(mean)}$ , and $f(\bm{a},\bm{b})=\bm{b}_{1:\max(d_{B}-d,0)}\circ\bm{a}_{\max(d_{A}-d,0)+1:d_{A}}$ $\mathtt{(replace)}$ . We consider three non-learned functions $f$ :
| | $\displaystyle f(\bm{a},\bm{b})$ | $\displaystyle=\bm{a}+\bm{b}\>\>\qquad\qquad\mathtt{(sum)}$ | |
| --- | --- | --- | --- |
For cases where, due to differences in $A$ and $B$ ’s training, $A$ and $B$ ’s activation spaces are quite different, we propose learning a task-agnostic (depends only on the models $A$ and $B$ ) linear layer $\bm{W}\in\mathbb{R}^{d_{B}}\times\mathbb{R}^{d_{A}}$ that projects $\bm{a}$ onto $B$ ’s activation space. Note that this introduces zero additional task-specific parameters and data, as we propose learning this “mapping matrix” $\bm{W}$ only once for each model pair $(A,B)$ using general text, e.g. sequences from $A$ and/or $B$ ’s pretraining data mixes. We can then perform $\mathtt{sum}$ , $\mathtt{mean}$ , or $\mathtt{replace}$ with $\bm{W}\bm{a},\bm{b}$ instead of $\bm{a},\bm{b}$ . We propose training $\bm{W}$ to minimize MSE loss over a dataset of $N$ sentences
$$
\mathcal{L}_{\rm MSE}\left(\{\bm{y}^{(i)}\}_{i=1}^{N},\{\bm{z}^{(i)}\}_{i=1}^{
N}\right)=\frac{1}{N}\sum_{i=1}^{N}\left\|\bm{z}^{(i)}-\bm{W}\bm{y}^{(i)}
\right\|_{2}^{2}
$$
where each $(\bm{y}^{(i)},\bm{z}^{(i)})$ pair denotes the final-token layer- $26$ activations of $A$ and $B$ at layers $k$ and $j$ respectively given the same sentence as input.
### 3.2 Compute Analysis
To understand the significance of activation communication, we must formally quantify the compute this procedure saves over natural language communication. For simplicity suppose the following (similar calculations can be made for the cases where $A$ and $B$ have differing model architectures and/or are given different prompts):
- $A$ and $B$ both have $L$ layers (each with $H$ attention heads, key size $K$ , and feedforward size $F$ ), dimension $D$ , and vocab size $V$
- $A$ and $B$ are both given a prompt of $P$ tokens
- $A$ can send $B$ a single $M$ -token message
- $B$ must produce an output of $T$ tokens, given its prompt and $A$ ’s message
Traditional methods require $M$ forward passes of $A$ given a $P$ -length input, plus $T$ forward passes of $B$ given a $(P+M)$ -length input. Following Hoffmann et al. (2022), this requires
$$
\displaystyle M\big{(}4PVD+L(8PDKH+4P^{2}KH+3HP^{2} \displaystyle+4PDF)\big{)}+T\big{(}4(P+M)VD+L(8(P+M)DKH \displaystyle+4(P+M)^{2}KH+3H(P+M)^{2}+4(P+M)DF)\big{)} \tag{1}
$$
FLOPs. In contrast, at inference time, our method requires only 1 partial (up till the $k$ th layer) forward pass of $A$ given a $P$ -length input, $T$ forward passes of $B$ given a $P$ -length input, and the activation replacement procedure. This requires
$$
\displaystyle 2PVD+k(8PDKH+4P^{2}KH+3HP^{2} \displaystyle+4PDF)+T\big{(}4PVD+L(8PDKH+4P^{2}KH \displaystyle+3HP^{2}+4PDF)\big{)}+\mathcal{F}(D) \tag{2}
$$
FLOPs, where $\mathcal{F}(D)=O(D)$ for non-learned $f$ and $O(D^{2})$ when $f$ is the mapping matrix.
In all practical cases, (2) is substantially lower than (1).
### 3.3 Why should this work?
Recall that Pham et al. (2024) propose CIPHER—communicating the average tokenizer embedding (weighted by the LLM’s next-token probabilities) between models. We build upon the intuition behind CIPHER, which goes as follows: the token sampling process during decoding risks substantial information loss from the model’s output logits, and communicating a model’s weighted-average tokenizer embedding essentially entails communicating both that model’s final answer and its belief in that answer (over the entire vocabulary).
Communicating activations, then, can be thought of as communicating a strict superset of {next-token prediction, belief over entire vocabulary}, as activations of late-enough layers essentially encode the model’s entire knowledge about the provided context as well as its predicted completion and confidence in that completion (see Figures 1 and 7 in Hewitt & Manning (2019) and Hernandez et al. (2024), respectively, which show that linear probes tasked with predicting certain output characteristics from a Transformer’s intermediate layer embeddings of its input work poorly for early layers, extremely well after around the halfway point of computation, but then probe accuracy drops closer to the final layers). Note one important critique of multiagent debate: that in cases where multiple agents are uncertain about the answer, there is no reason why referencing other agents’ answers would generate more factual reasoning. Both CIPHER and activation communication solve this problem, as some notion of model confidence is being communicated along with its next-token prediction. Indeed, these curves of probe accuracy by layer indicate that the final layers and LM head “ throw away ” information not useful for next-token prediction that very well could be useful for communicative purposes; this is precisely why our proposed activation communication technique is not an iterative approach (there is no notion of “rounds” like in debate and CIPHER, which require an additional token budget to extract more and more information out of the LM), as one activation grafting step from $A$ to $B$ inherently communicates to $B$ all of $A$ ’s knowledge/beliefs about the prompt it was given. Moreover, the extra information over the model’s next-token prediction and confidence that is encoded in its activations is what makes activation communication more performant than its natural language counterpart, as we will see in Section 4.
## 4 Experiments
| Countries | $x_{A}$ : “ $\mathtt{Alice}$ $\mathtt{is}$ $\mathtt{at}$ $\mathtt{the}$ $\mathtt{Acropolis}$ $\mathtt{of}$ $\mathtt{Athens}$ .” |
| --- | --- |
| $x_{B}$ : “ $\mathtt{Which}$ $\mathtt{country}$ $\mathtt{is}$ $\mathtt{Alice}$ $\mathtt{located}$ $\mathtt{in?}$ ” | |
| $B$ ’s Expected Answer: “ $\mathtt{Greece}$ ” | |
| Tip Sheets | $x_{A}$ : “ $\mathtt{Acme}$ $\mathtt{Inc.}$ $\mathtt{has}$ $\mathtt{taken}$ $\mathtt{a}$ $\mathtt{nosedive,}$ $\mathtt{as}$ $\mathtt{its}$ $\mathtt{quarterly}$ $\mathtt{earnings}$ $\mathtt{have}$ $\mathtt{dipped}$ $\mathtt{8\$ . |
| $\mathtt{Meanwhile}$ $\mathtt{Doe}$ $\mathtt{LLC}$ $\mathtt{and}$ $\mathtt{Kiteflyer}$ $\mathtt{Labs}$ $\mathtt{have}$ $\mathtt{both}$ $\mathtt{reached}$ $\mathtt{record\text{-}high}$ $\mathtt{stock}$ | |
| $\mathtt{prices}$ $\mathtt{of}$ $\mathtt{89,}$ $\mathtt{but}$ $\mathtt{Kiteflyer}$ $\mathtt{is}$ $\mathtt{involved}$ $\mathtt{in}$ $\mathtt{an}$ $\mathtt{IP}$ $\mathtt{lawsuit}$ $\mathtt{with}$ $\mathtt{its}$ $\mathtt{competitors.}^{\prime\prime}$ | |
| $x_{B}$ : “ $\mathtt{You}$ $\mathtt{must}$ $\mathtt{invest}$ $\mathtt{in}$ $\mathtt{one}$ $\mathtt{company}$ $\mathtt{out}$ $\mathtt{of}$ { $\mathtt{Acme}$ $\mathtt{Inc.,}$ $\mathtt{Doe}$ $\mathtt{LLC,}$ $\mathtt{Kiteflyer}$ $\mathtt{Labs}$ }. | |
| $\mathtt{Which}$ $\mathtt{do}$ $\mathtt{you}$ $\mathtt{invest}$ $\mathtt{in?}$ ” | |
| $B$ ’s Expected Answer: “ $\mathtt{Doe\text{ }LLC}$ ” | |
Table 1: Multi-player coordination games. Sample $\mathtt{(prompt,answer)}$ pairs for each game.
We test our method on two distinct experimental setups: multi-player coordination games (Section 4.1) and reasoning benchmarks (Section 4.2). Qualitative results are available in Appendix A.
### 4.1 Multi-player coordination games
Drawing from existing literature on multi-agent communication, we design two Lewis signaling games (Lewis, 2008; Lazaridou et al., 2016) to test the efficacy of activation communication (example prompts and answers in Table 1):
1. Countries, where $A$ is given as input a string of the format “ $\mathtt{[PERSON]\text{ }is\text{ }at\text{ }the\text{ }[LANDMARK]}$ ” and $B$ is asked “ $\mathtt{Which\text{ }country\text{ }is\text{ }[PERSON]\text{ }located\text{ } in?}$ ”
1. Tip Sheets (inspired by Lewis et al. (2017)), where $A$ is given a simulated “tip sheet” and $B$ is asked to make an informed investment decision in accordance with the information in the tip sheet.
| $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{3B}$ | ✗ | $0.0$ ( $0.0$ , $0.0$ ) | $38.6$ ( $38.6,39.4$ ) |
| --- | --- | --- | --- |
| Skyline | $84.0$ ( $83.5$ , $84.1$ ) | $100.0$ ( $100.0,100.0$ ) | |
| NL | $69.0$ ( $68.7$ , $69.3$ ) | $74.3$ ( $74.0,74.6$ ) | |
| AC ( $\mathtt{sum}$ ) | $34.0$ ( $33.9$ , $34.4$ ) | $50.0$ ( $49.6,50.3$ ) | |
| AC ( $\mathtt{mean}$ ) | $36.0$ ( $35.5$ , $36.1$ ) | $80.0$ ( $79.8,80.4$ ) | |
| AC ( $\mathtt{replace}$ ) | $\mathbf{78.0}$ ( $77.7$ , $78.2$ ) | $\mathbf{90.0}$ ( $89.9,90.3$ ) | |
| $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ | ✗ | $2.0$ ( $1.9$ , $2.1$ ) | $54.3$ ( $54.2,54.5$ ) |
| Skyline | $86.0$ ( $85.7$ , $86.1$ ) | $100.0$ ( $100.0,100.0$ ) | |
| NL | $77.0$ ( $76.6$ , $77.1$ ) | $85.7$ ( $85.3,85.8$ ) | |
| AC ( $\mathtt{sum}$ ) | $71.0$ ( $70.9,71.4$ ) | $85.7$ ( $85.5,86.0$ ) | |
| AC ( $\mathtt{mean}$ ) | $70.0$ ( $69.7,70.3$ ) | $92.9$ ( $92.7,93.1$ ) | |
| AC ( $\mathtt{replace}$ ) | $\mathbf{83.0}$ ( $82.7,83.1$ ) | $\mathbf{95.7}$ ( $95.6,95.9$ ) | |
Table 2: Accuracies (%) on both coordination games using two identical $\mathtt{LLaMA}$ family models. Communication at layer $k=j=26.$ $95\$ confidence intervals ( $1000$ bootstrap iterations) reported in parentheses.
We synthetically generate $100$ (Countries) and $70$ (Tip Sheets) different prompts and answers of the same format as the samples in Table 1, and report the proportion out of those samples that $B$ responds with an exact string match to the ground truth answer. As baselines, we consider a “silent” (✗) setup, where the agents are not allowed to communicate; a “single-agent skyline,” where a single LLM is given the concatenation of $A$ and $B$ ’s prompts; and traditional natural language communication, where $A$ is asked to output a message that is then given to $B$ along with $x_{B}$ . All decoding is done greedily.
Table 2 presents the results for both coordination games using 2 different instances of the same model as the agents ( $A=B$ ). Across the 3B and 8B model sizes, activation communication (AC) with $f=\mathtt{replace}$ almost completely recovers the gap between the zero-communication (✗) and the single-agent skyline (Skyline), outperforming natural language communication (NL) using far less compute. We hypothesize that $\mathtt{replace}$ is more effective than $\mathtt{mean}$ and $\mathtt{sum}$ as the former is guaranteed to output a vector within $B$ ’s activation space, while the latter two likely do not (e.g., the norm of the vector outputted by $\mathtt{sum}$ will be around double that of a typical activation). Furthermore, most of the information $B$ needs is likely contained in its representations of previous tokens in the sequence, hence losing its final-token representation does not hurt.
<details>
<summary>extracted/6420159/contour.png Details</summary>
### Visual Description
## Heatmap with Contour Lines: Accuracy Analysis for "Countries" and "Tip Sheets"
### Overview
The image displays two side-by-side heatmaps, each overlaid with contour lines, visualizing a metric labeled "Acc. (%)" (Accuracy percentage) as a function of two parameters, `j` and `k`. The left plot is labeled "(a) Countries" and the right plot is labeled "(b) Tip Sheets". Both plots share identical axes and color scales. A red diamond marker is present in each plot, indicating a specific point of interest, likely a peak or optimal configuration.
### Components/Axes
* **Plot Type:** 2D Heatmap with overlaid contour lines.
* **X-Axis (Both Plots):** Labeled `k`. The axis has major tick marks at intervals of 5, ranging from 0 to 30.
* **Y-Axis (Both Plots):** Labeled `j`. The axis has major tick marks at intervals of 5, ranging from 0 to 30.
* **Color Scale (Both Plots):** A vertical color bar positioned to the right of each heatmap.
* **Title:** `Acc. (%)`
* **Range:** 0 to 100.
* **Gradient:** Dark blue/purple (0%) → Purple → Orange → Yellow (100%).
* **Tick Marks:** Labeled at 0, 20, 40, 60, 80, and 100.
* **Contour Lines:** Black lines overlaid on the heatmaps, connecting points of equal accuracy value. The density of lines indicates the steepness of the gradient.
* **Marker:** A red diamond (♦) is present in each plot.
* In plot (a), it is located at approximately `k=25`, `j=25`.
* In plot (b), it is located at approximately `k=26`, `j=25`.
* **Plot Labels:**
* Left: `(a) Countries`
* Right: `(b) Tip Sheets`
### Detailed Analysis
**Plot (a) Countries:**
* **Trend Verification:** The heatmap shows a clear, smooth gradient. Accuracy is very low (dark blue) in the bottom-left region (low `j`, low `k`). It increases steadily as both `j` and `k` increase, forming a diagonal band of rising accuracy from the bottom-left to the top-right. The highest accuracy (bright yellow) is concentrated in the top-right quadrant.
* **Data Points & Distribution:**
* **Low Accuracy Region (0-20%):** Dominates the area where `k` < ~15 and `j` < ~20. The darkest blue (0-10%) is in the extreme bottom-left corner.
* **Medium Accuracy Region (40-60%):** Forms a transition band running diagonally. Contour lines are densely packed here, indicating a rapid change in accuracy.
* **High Accuracy Region (80-100%):** Occupies the top-right area. The peak, marked by the red diamond at `(k≈25, j≈25)`, is within the brightest yellow zone, suggesting accuracy near or at 100%.
* **Contour Pattern:** The contour lines are relatively smooth and run roughly parallel to the diagonal gradient, confirming the consistent trend.
**Plot (b) Tip Sheets:**
* **Trend Verification:** The pattern is more complex and less uniform than in plot (a). While there is a general trend of higher accuracy in the top-right, there are significant regions of lower accuracy interspersed, particularly in the top-left and center.
* **Data Points & Distribution:**
* **High Accuracy Region (80-100%):** A large, dominant yellow area covers most of the right half and bottom of the plot (`k` > ~15). The red diamond at `(k≈26, j≈25)` sits within this high-accuracy zone.
* **Low Accuracy "Valleys":** There are distinct pockets of lower accuracy:
1. A deep blue/purple region (20-40%) in the top-left corner (`k` < 10, `j` > 20).
2. A smaller, isolated purple region (~40%) near the center-left (`k≈7, j≈15`).
* **Medium Accuracy Region (40-60%):** Forms irregular bands and islands, particularly surrounding the low-accuracy valleys and in the top-center.
* **Contour Pattern:** The contour lines are more convoluted and irregular, especially around the low-accuracy valleys, indicating a more volatile relationship between `j`, `k`, and accuracy for the "Tip Sheets" dataset.
### Key Observations
1. **Fundamental Difference in Landscape:** The "Countries" plot (a) shows a smooth, predictable performance landscape where increasing both parameters reliably improves accuracy. The "Tip Sheets" plot (b) reveals a more rugged landscape with local minima (performance valleys), suggesting that parameter tuning is more critical and non-intuitive for this task.
2. **Optimal Point Similarity:** Despite the different landscapes, the red diamond markers indicating optimal (or chosen) parameters are located in very similar positions (`j≈25`, `k≈25-26`) for both tasks, within high-accuracy zones.
3. **Parameter Sensitivity:** In plot (a), accuracy is highly sensitive to both `j` and `k` simultaneously (diagonal gradient). In plot (b), for a large portion of the parameter space (right side), accuracy remains high even as `j` varies, suggesting less sensitivity in that region.
4. **Presence of Local Minima:** Plot (b) contains clear local minima (the blue valleys), which could trap optimization algorithms, whereas plot (a) appears to have a single global maximum region.
### Interpretation
This visualization compares the performance sensitivity of a model or algorithm on two different tasks ("Countries" and "Tip Sheets") across a two-dimensional parameter space (`j`, `k`).
* **What the data suggests:** The "Countries" task appears to be "easier" or more straightforward for the model, as its performance improves monotonically with increased model complexity or capacity (assuming `j` and `k` represent such parameters). The "Tip Sheets" task is more complex or has a different structure, leading to a non-monotonic performance landscape where certain parameter combinations (`j` high, `k` low) lead to poor results, possibly due to overfitting, underfitting, or an unfavorable inductive bias.
* **How elements relate:** The contour lines translate the color gradient into precise topographic information. The red diamonds likely represent the parameters selected by an automated search (like grid search) or chosen for a final model, showing that the selection process successfully found high-performing regions in both landscapes.
* **Notable implications:** The stark contrast between the two plots underscores the importance of task-specific hyperparameter tuning. A parameter set that works optimally for one task (`Countries`) may be near a dangerous performance valley for another (`Tip Sheets`). The existence of local minima in (b) warns that simple hill-climbing optimization strategies might fail to find the best solution for the "Tip Sheets" task. The analysis implies that the underlying data distributions or the model's interaction with them differ significantly between the two tasks.
</details>
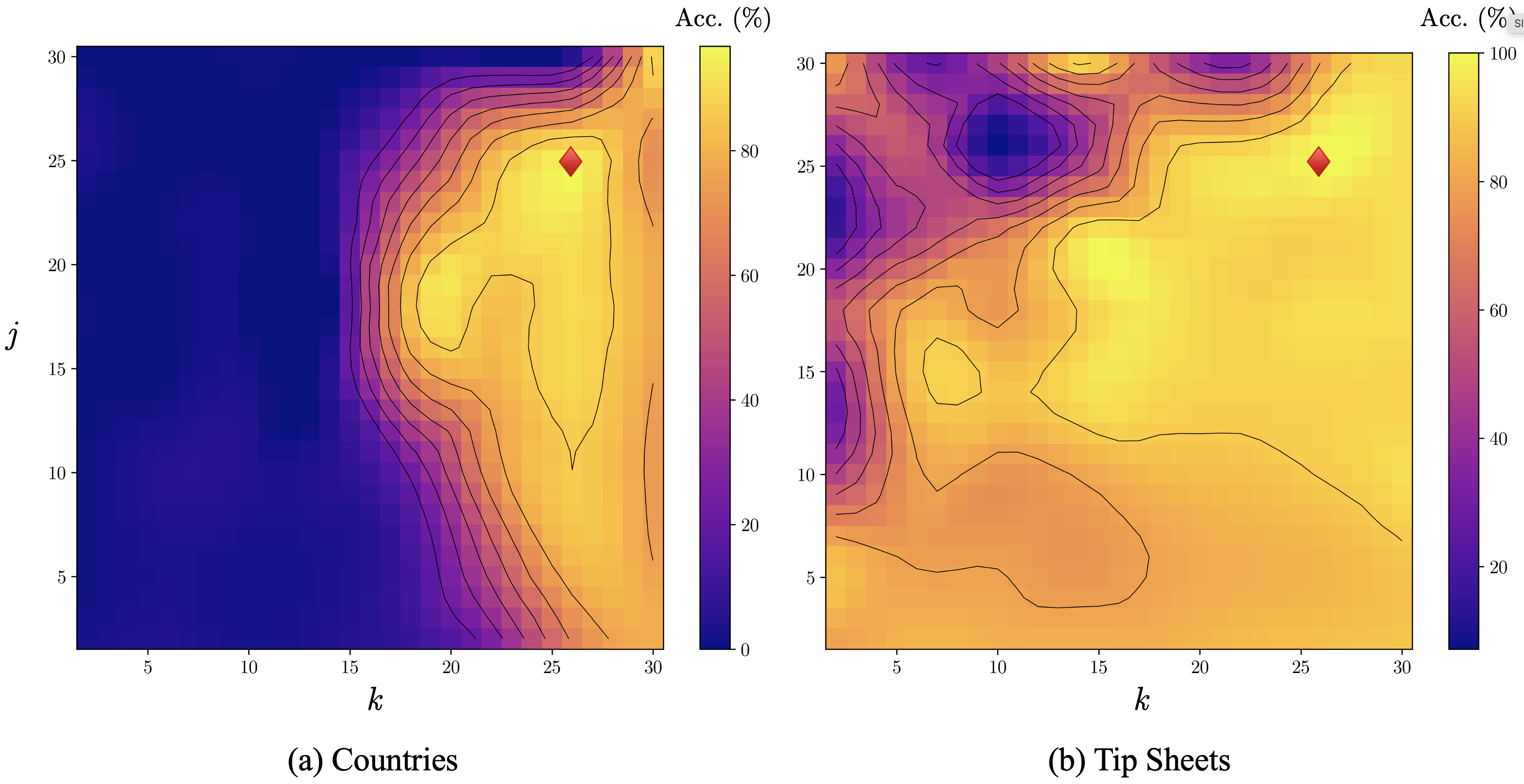
Figure 2: 2D contour plots of accuracy over different values of $k$ and $j$ (the layers at which we access/edit activations for $A$ / $B$ respectively). $k=j=26$ is roughly optimal ( $$ ) for both (a) Countries and (b) Tip Sheets.
### 4.2 Reasoning Benchmarks
Next, we test our methods on a variety of reasoning benchmarks, spanning several real-world tasks and domains.
#### Baselines
We benchmark activation communication against the following two baselines:
- Single Model: A single LLM responds to the prompt in natural language.
- Natural Language Debate (NLD) (Du et al., 2023): Each LLM provides an initial response to the given prompt. Then, for each of $r-1$ subsequent rounds, each LLM is prompted to refine its previous response given the other agents’ responses as input. Note that NLD is the most direct baseline for our approach, as it is a state-of-the-art natural language communication protocol. We fix $r=2$ in our experiments.
Note that we do not compare to Pham et al. (2024), as they communicate the input (tokenizer) embeddings rather than activations/output embeddings between models, and hence require a shared tokenizer and embedding table between agents which is extremely restrictive and prevents applicability to our experimental setup.
To determine the values of $k$ and $j$ for activation communication (AC), we compute the accuracy on Countries and Tip Sheets for every pair $(k,j)\in\{1,\dots,30\}^{2}$ . Based on these results (shown in Figure 2) as well as Table 2, we fix $k=j=26$ and $f$ $=$ $\mathtt{replace}$ for the following experiments.
Across all experiment configurations, we fix the decoding strategy to nucleus sampling with $p=0.9$ .
#### Models
We conduct most of our experiments using $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{3B}$ and $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ as the two agents. Additionally, to test our approach’s robustness and generalizability, we conduct experiments with models belonging to various other suites within the $\mathtt{LLaMA}$ family and of several different sizes.
Note that for these experiments, we restrict the setting to communication between different models (rather than multiple instances of the same model in Section 4.1), since the same model would have identical activations for the same prompts, meaning no information would be communicated in the grafting process. We argue that the multiple-model setting is realistic (perhaps more so than the setting of multiple instances of the same model), as recent advances in LLM development have led to the release of models with specialized abilities (Singhal et al., 2023) and of different sizes (Dubey et al., 2024) that merit complementary usage. Our work thus answers the question: How can we get the best performance by leveraging multiple models of distinct capabilities and sizes, relative to the added inference-time compute over a single forward pass through any single model?
#### Datasets
We evaluate our technique on seven reasoning datasets that span various real-world tasks and domains: (i) Biographies (Du et al., 2023), which asks the LLM to generate a factual biography of a famous computer scientist; (ii) GSM8k (Cobbe et al., 2021), a variety of grade school math problems created by human problem writers; and (iii) 5 datasets randomly drawn from MMLU (Hendrycks et al., 2021): High School Psychology (from the Social Sciences category), Formal Logic (from the Humanities category), College Biology (from the STEM category), Professional Law (from the Humanities Category), and Public Relations (from the Social Sciences category). We evaluate on a randomly-sampled size- $100$ subset of each dataset.
In experiments involving the mapping matrix $\bm{W}$ , we instantiate $\bm{W}\in\mathbb{R}^{4096\times 3072}$ using Xavier initialization and train for $10$ epochs on a dataset of $3072$ sentences We use $3072$ sentences as linear regression with $d$ -dimensional input has a sample complexity of $O(d)$ (Vapnik, 1999). randomly drawn from the Colossal Clean Crawled Corpus (C4) (Dodge et al., 2021). We use batch size $32$ and the Adam optimizer with learning rate $0.001$ .
#### Metrics
We measure the accuracy of the final response for the single models and AC. For NLD, we measure the accuracy of the majority-held final-round answer across agents when the answer is automatically verifiable (numeric in GSM8k, multiple choice for the MMLU datasets) or the average final-round answer across agents otherwise (Biographies).
For GSM8k and the MMLU datasets, we report the proportion of samples in the dataset for which the generated answer exactly matches the ground-truth answer. For Biographies, following Du et al. (2023), we prompt an LLM judge ( $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ ) to check whether each manually-decomposed fact in a ground-truth biography is supported ( $1$ ), partially supported ( $0.5$ ), or unsupported ( $0 0$ ) in the generated biography, taking the mean of these scores over all facts as the per-biography accuracy and the mean over all dataset samples as the total accuracy.
| $\mathtt{3.2}$ - $\mathtt{3B}$ $\mathtt{3.1}$ - $\mathtt{8B}$ NLD | $79.4$ $\pm 0.0$ $83.9$ $\pm 0.0$ $80.2$ $\pm 0.1$ | $58.0$ $\pm 4.9$ $60.0$ $\pm 4.9$ $\mathbf{75.0}$ $\pm 4.3$ | $30.0$ $\pm 1.0$ $65.0$ $\pm 0.1$ $83.0$ $\pm 0.8$ | $16.0$ $\pm 0.8$ $42.0$ $\pm 0.1$ $37.0$ $\pm 0.1$ | $11.0$ $\pm 0.7$ $50.0$ $\pm 0.2$ $71.0$ $\pm 0.1$ | $0.0$ $\pm 0.0$ $20.0$ $\pm 0.8$ $30.0$ $\pm 0.1$ | $26.0$ $\pm 0.1$ $53.0$ $\pm 0.2$ $63.0$ $\pm 0.7$ |
| --- | --- | --- | --- | --- | --- | --- | --- |
| AC | $84.6$ $\pm 0.0$ | $64.0$ $\pm 4.8$ | $\mathbf{85.0}$ $\pm 0.8$ | $\mathbf{47.0}$ $\pm 0.1$ | $78.0$ $\pm 0.9$ | $30.0$ $\pm 0.1$ | $\mathbf{74.0}$ $\pm 0.1$ |
| AC ( $\bm{W}$ ) | $\mathbf{86.8}$ $\pm 0.0$ | $66.0$ $\pm 4.8$ | $70.0$ $\pm 0.1$ | $35.0$ $\pm 0.1$ | $\mathbf{79.0}$ $\pm 0.9$ | $\mathbf{45.0}$ $\pm 0.1$ | $63.0$ $\pm 0.1$ |
Table 3: Accuracies (%) on all seven reasoning benchmarks. NLD and all AC variants involve communication between $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{3B}$ ( $A$ ) and $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ ( $B$ ); the performance of these models individually are presented in the first two rows of the table. NLD typically improves performance over at least one of the single model baselines; AC— both with and without the task-agnostic linear layer—consistently beats both baselines and NLD as well.
#### Comprehensive evaluation with the $\mathtt{LLaMA}$ family
Table 3 presents results on each of the seven reasoning benchmarks across various baselines and activation communication. Notably, while NLD consistently outperforms $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{3B}$ , it does not always display a performance improvement over $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ ; but remarkably, AC consistently outperforms both single-model baselines. In fact, AC offers an up to $27.0\$ improvement over NLD across six of the seven reasoning datasets. When applying $\bm{W}$ to $A$ ’s activation before performing the replacement function, we see even further gains of $2.6-50.0\$ over vanilla AC for four of the seven datasets. We hypothesize that the benefits from the learned linear layer are less consistent across datasets because the subset of C4 data used to train $\bm{W}$ likely contains text more semantically similar to some datasets than others, hence some datasets provide $\bm{W}$ with out-of-distribution inputs which reduces performance compared to vanilla AC.
While we fix $A$ as the smaller model and $B$ as the larger model in Table 3 (so as to ensure decoding happens with the presumably more capable model), this need not be the case; swapping $A$ and $B$ yields results of $81.5\pm 0.0$ and $61.0\pm 4.8$ on Biographies and GSM8k respectively (without the linear layer). While these accuracies are lower than their non-swapped counterparts, notably they still are higher than both single-model baselines (and higher than NLD for Biographies); plus this is much more compute-efficient as the smaller model is now the one requiring the full instead of partial forward pass.
Note that we find AC outperforms NLD on 48 of the 57 datasets in the full MMLU benchmark; complete MMLU results, as well as a suite of additional experiments, are shown in Appendix B.
#### Performance-compute tradeoff and generalization to different model scales
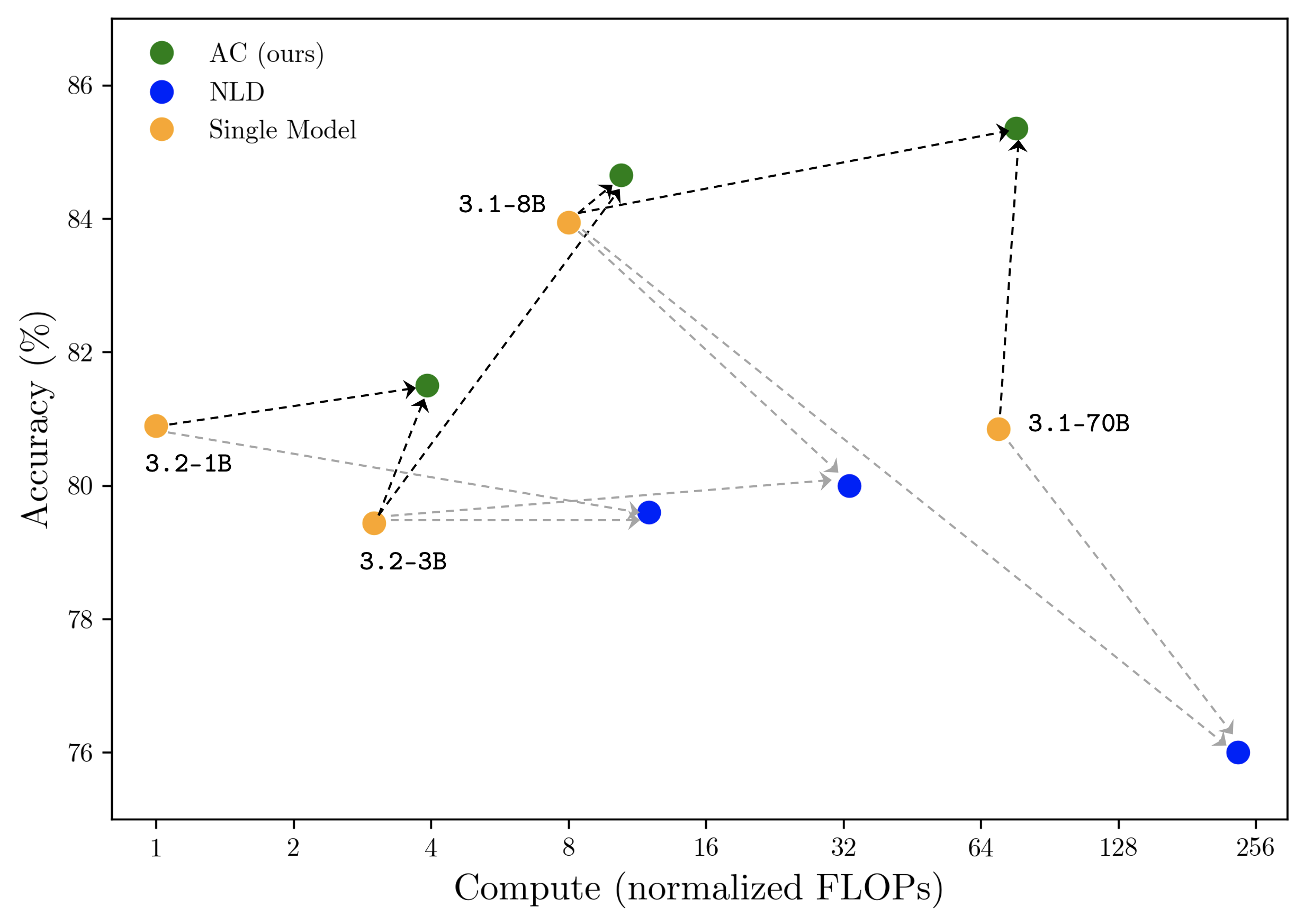
Thus far, we have been considering the absolute performance of AC with respect to NLD, for which our method attains state-of-the-art results; however the superiority of activations as a language for inter-LLM communication is further illustrated by AC’s larger ratio of performance improvement to added inference-time compute over individual LMs. Figure 3 displays the results of single models, AC, and NLD across model scales and suites within the $\mathtt{LLaMA}$ family on the Biographies dataset. Incoming arrows to AC and NLD nodes denote the base models between which communication occurred. Not only does AC consistently outperform both single-model baselines unlike NLD, but also notice that the slope of each black line is far greater than the slope of each gray line, indicating that AC consistently achieves greater increases in accuracy per additional unit of inference-time compute (normalized by the compute of a single forward pass through $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{1B}$ on the given prompt) compared to NLD.
#### Communication across model families
Table 4 displays results for AC between models from the $\mathtt{Qwen}$ - $\mathtt{2.5}$ , $\mathtt{Gemma}$ - $\mathtt{2}$ , and $\mathtt{LLaMA}$ - $\mathtt{3}$ families. We see that AC beats NLD across the board, and beats both individual models for $4/5$ of the $6$ model pairs on Biographies/GSM8k respectively —demonstrating the efficacy of AC irrespective of model architecture, size, tokenizer, and training data. Moreover, these results are obtained without training $\bm{W}$ , meaning we do not need a separate projection layer between activation spaces to attain SOTA results, even for extremely distinct models! (We hypothesize this is because we are only replacing $B$ ’s last-token activation, hence $B$ can learn from $A$ without an extreme alteration to its activation distribution. An alternative explanation is to see this result as proof of the platonic representation hypothesis (Huh et al., 2024), which historical deep learning works have oft alluded to, including in the context of cross-model representation stitching (Moschella et al., 2023; Kornblith et al., 2019).)
| $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{3B}$ , $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ $\mathtt{Qwen}$ - $\mathtt{2.5}$ - $\mathtt{1.5B}$ , $\mathtt{Qwen}$ - $\mathtt{2.5}$ - $\mathtt{3B}$ $\mathtt{Gemma}$ - $\mathtt{2}$ - $\mathtt{2B}$ , $\mathtt{Gemma}$ - $\mathtt{2}$ - $\mathtt{9B}$ | $79.4$ $\pm 0.0$ / $58.0$ $\pm 4.9$ $59.4$ $\pm 0.9$ / $20.0$ $\pm 0.9$ $83.0$ $\pm 1.1$ / $45.0$ $\pm 1.1$ | $83.9$ $\pm 0.0$ / $60.0$ $\pm 4.9$ $85.5$ $\pm 1.1$ / $35.0$ $\pm 1.1$ $\mathbf{94.6}$ $\pm 0.9$ / $80.0$ $\pm 0.9$ | $80.2$ $\pm 0.1$ / $\mathbf{75.0}$ $\pm 4.3$ $63.2$ $\pm 1.1$ / $65.0$ $\pm 1.1$ $70.3$ $\pm 1.0$ / $70.0$ $\pm 1.0$ | $\mathbf{84.6}$ $\pm 0.0$ / $64.0$ $\pm 4.8$ $\mathbf{89.6}$ $\pm 1.0$ / $\mathbf{70.0}$ $\pm 1.0$ $88.1$ $\pm 0.7$ / $\mathbf{90.0}$ $\pm 0.7$ |
| --- | --- | --- | --- | --- |
| $\mathtt{Qwen}$ - $\mathtt{2.5}$ - $\mathtt{1.5B}$ , $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{3B}$ | $59.4$ $\pm 0.9$ / $20.0$ $\pm 0.9$ | $79.4$ $\pm 0.0$ / $58.0$ $\pm 4.9$ | $75.4$ $\pm 1.0$ / $\mathbf{75.0}$ $\pm 1.0$ | $\mathbf{79.5}$ $\pm 1.0$ / $75.0$ $\pm 1.0$ |
| $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{3B}$ , $\mathtt{Gemma}$ - $\mathtt{2}$ - $\mathtt{2B}$ | $79.4$ $\pm 0.0$ / $58.0$ $\pm 4.9$ | $83.0$ $\pm 1.1$ / $45.0$ $\pm 1.1$ | $62.5$ $\pm 1.1$ / $55.0$ $\pm 1.1$ | $\mathbf{84.0}$ $\pm 0.1$ / $\mathbf{60.0}$ $\pm 1.1$ |
| $\mathtt{Qwen}$ - $\mathtt{2.5}$ - $\mathtt{1.5B}$ , $\mathtt{Gemma}$ - $\mathtt{2}$ - $\mathtt{2B}$ | $59.4$ $\pm 0.9$ / $20.0$ $\pm 0.9$ | $\mathbf{83.0}$ $\pm 1.1$ / $45.0$ $\pm 1.1$ | $49.3$ $\pm 1.1$ / $50.0$ $\pm 1.1$ | $73.0$ $\pm 1.1$ / $\mathbf{55.0}$ $\pm 1.1$ |
Table 4: Individual model, AC, and NLD accuracies across three model families. Each cell displays two values: Biographies score / GSM8k score.
<details>
<summary>extracted/6420159/TODO.png Details</summary>
### Visual Description
## Scatter Plot: Model Accuracy vs. Compute (Normalized FLOPs)
### Overview
This is a scatter plot comparing the performance of three different model types or methods—labeled "AC (ours)", "NLD", and "Single Model"—across two dimensions: computational cost (x-axis) and accuracy (y-axis). The plot uses a logarithmic scale for the x-axis. Data points for the "Single Model" category are explicitly labeled with model names (e.g., "3.2-1B"). Dashed lines with arrows connect points, indicating a directional relationship or transition between model versions or configurations.
### Components/Axes
* **X-Axis:** Labeled "Compute (normalized FLOPs)". It is a logarithmic scale with major tick marks at 1, 2, 4, 8, 16, 32, 64, 128, and 256.
* **Y-Axis:** Labeled "Accuracy (%)". It is a linear scale ranging from approximately 75% to 87%, with major tick marks at 76, 78, 80, 82, 84, and 86.
* **Legend:** Located in the top-left corner of the plot area.
* **Green Circle:** "AC (ours)"
* **Blue Circle:** "NLD"
* **Orange Circle:** "Single Model"
* **Data Point Labels:** Four orange "Single Model" points have text labels placed directly below or beside them:
* "3.2-1B" (leftmost orange point)
* "3.2-3B" (second orange point from left)
* "3.1-8B" (third orange point from left)
* "3.1-70B" (rightmost orange point)
### Detailed Analysis
**Data Series and Approximate Points:**
1. **Single Model (Orange Circles):**
* **Trend:** The points show a non-monotonic relationship. Accuracy initially dips from the 1B to 3B model, then rises sharply for the 8B model, before falling again for the 70B model.
* **Points (Compute, Accuracy):**
* 3.2-1B: (~1, ~80.9%)
* 3.2-3B: (~3, ~79.5%)
* 3.1-8B: (~8, ~84.0%)
* 3.1-70B: (~70, ~80.9%)
2. **AC (ours) (Green Circles):**
* **Trend:** Shows a consistent upward trend. As compute increases, accuracy increases.
* **Points (Compute, Accuracy):**
* Point 1: (~4, ~81.5%)
* Point 2: (~10, ~84.6%)
* Point 3: (~80, ~85.3%)
3. **NLD (Blue Circles):**
* **Trend:** Shows a consistent downward trend. As compute increases, accuracy decreases.
* **Points (Compute, Accuracy):**
* Point 1: (~12, ~79.6%)
* Point 2: (~32, ~80.0%)
* Point 3: (~240, ~76.0%)
**Connections (Dashed Lines with Arrows):**
* **Black Dashed Lines (with arrows pointing to Green/AC points):** These lines connect each orange "Single Model" point to a corresponding green "AC (ours)" point that is positioned at a higher accuracy and, in two cases, higher compute. This visually suggests that the "AC" method improves upon the base "Single Model".
* 3.2-1B (Orange) → AC Point 1 (Green)
* 3.2-3B (Orange) → AC Point 1 (Green) *[Note: Two orange points connect to the same green point]*
* 3.1-8B (Orange) → AC Point 2 (Green)
* 3.1-70B (Orange) → AC Point 3 (Green)
* **Grey Dashed Lines (with arrows pointing to Blue/NLD points):** These lines connect each orange "Single Model" point to a corresponding blue "NLD" point. The relationship is mixed: for the 1B and 3B models, the NLD point is at similar or slightly lower accuracy but higher compute. For the 8B and 70B models, the NLD point is at significantly lower accuracy and higher compute.
* 3.2-1B (Orange) → NLD Point 1 (Blue)
* 3.2-3B (Orange) → NLD Point 1 (Blue) *[Note: Two orange points connect to the same blue point]*
* 3.1-8B (Orange) → NLD Point 2 (Blue)
* 3.1-70B (Orange) → NLD Point 3 (Blue)
### Key Observations
1. **Performance Hierarchy:** At every connected comparison point, the "AC (ours)" method achieves higher accuracy than its corresponding "Single Model" baseline. The "NLD" method generally performs worse than or comparable to the "Single Model" baseline, with a severe drop in accuracy for the highest-compute configuration.
2. **Scaling Behavior:** The three methods exhibit fundamentally different scaling properties with respect to compute:
* **AC (ours):** Positive scaling (more compute → higher accuracy).
* **NLD:** Negative scaling (more compute → lower accuracy).
* **Single Model:** Irregular scaling, with a peak at the 8B parameter model.
3. **Efficiency:** The "AC" method appears to be the most compute-efficient for achieving high accuracy. For example, the AC point at ~10 normalized FLOPs achieves ~84.6% accuracy, surpassing the best Single Model (3.1-8B at ~84.0%) with only a modest increase in compute.
4. **Outlier:** The "NLD" point at ~240 normalized FLOPs is a significant outlier, showing the lowest accuracy (~76.0%) on the chart despite using the most compute.
### Interpretation
This chart is likely from a research paper proposing a new model training or architecture method called "AC" (the authors' method). It demonstrates the method's superiority over two baselines: a standard "Single Model" approach and another method called "NLD".
The core message is one of **improved scaling and efficiency**. The "AC" method successfully translates increased computational resources (normalized FLOPs) into higher task accuracy, which is the desired behavior for scalable AI systems. In contrast, the "NLD" method exhibits pathological scaling, where throwing more compute at the problem actually harms performance, suggesting instability or a fundamental mismatch between the method and the scaling axis.
The irregular performance of the "Single Model" baseline (dipping at 3B, peaking at 8B) might reflect challenges in training stability or data requirements at different model scales. The "AC" method appears to smooth out this irregularity, providing a more reliable performance improvement over the baseline across the scale spectrum.
The arrows are critical: they don't just show data points; they tell a story of **transformation**. They visually argue that applying the "AC" technique to a base model (orange) reliably "lifts" it to a higher-performing state (green), while applying "NLD" often "drags" it down (blue). This makes a compelling case for the adoption of the "AC" method.
</details>
Figure 3: Accuracy (%) vs. compute (# FLOPs normalized by single $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{1B}$ forward pass) for various configurations of AC and NLD on the Biographies dataset. AC () yields the greatest performance gains per additional unit of inference-time compute over each baseline ().
## 5 Conclusion
We present a simple approach to enable effective and computationally efficient communication between language models by injecting information from the activations of one model into the activations of another during the forward pass. Salient features of this approach include: (i) Scales up LLMs on new tasks by leveraging existing, frozen LLMs along with zero additional task-specific parameters and data, (ii) Applies to diverse domains and settings, and (iii) Saves a substantial amount of compute.
There are some limitations to this method. First, when not using the learned model-specific mapping discussed in Section 3.1, our method requires both models to have aligned embedding spaces, such that the activation of one model roughly retains its meaning in the other’s activation space (note that unlike past works such as Pham et al. (2024) we do not require shared tokenizers or aligned vocabularies, only aligned embeddings). While less restrictive than past works (Pham et al., 2024), this assumption is somewhat limiting, but can be relaxed when we let $f$ be the learned model-specific mapping; and in practice we find that even amongst different models in the $\mathtt{LLaMA}$ family, no such mapping is required for state-of-the-art results.
Second, this method requires access to embeddings and will not work with black-box API access; however exploring API-only approaches is highly limiting, and recent releases of powerful open-source models (Dubey et al., 2024) merit the development of embedding-based techniques.
Third, while a concern might be the limited interpretability of communicating activations as opposed to natural language, we note the following. First, there is a fundamental tradeoff between interpretability and information preservation (as activations, by virtue of being much higher-dimensional than the space of natural language, allow proportionally higher-entropy communication) (Pham et al., 2024), which merits discussion beyond the scope of this work. But second, we actually posit that our method suggests a new avenue towards interpreting LM activations: “translating” activations based on the beliefs they induce as messages in listening agents, similar to the method put forward in Andreas et al. (2018). We recognize this as a promising avenue for future research.
Additional directions of future work include using AC to allow large LMs to leverage small, tunable LMs as “knowledge bases” during decoding (Lee et al., 2024), as in collaborative decoding (Shen et al., 2024) setups; and testing our approach on more complex coordination games (e.g., Lewis-style negotiation games (Lewis et al., 2017), Diplomacy).
## Impact Statement
This paper presents work whose goal is to advance the field of Machine Learning. There are many potential societal consequences of our work, none which we feel must be specifically highlighted here.
## Acknowledgements
The authors are grateful to Jacob Andreas, Yoon Kim, and Sham Kakade for their valuable discussions and feedback.
## References
- Ahn et al. (2022) Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Ho, D., Hsu, J., Ibarz, J., Ichter, B., Irpan, A., Jang, E., Ruano, R. J., Jeffrey, K., Jesmonth, S., Joshi, N. J., Julian, R., Kalashnikov, D., Kuang, Y., Lee, K.-H., Levine, S., Lu, Y., Luu, L., Parada, C., Pastor, P., Quiambao, J., Rao, K., Rettinghouse, J., Reyes, D., Sermanet, P., Sievers, N., Tan, C., Toshev, A., Vanhoucke, V., Xia, F., Xiao, T., Xu, P., Xu, S., Yan, M., and Zeng, A. Do as i can, not as i say: Grounding language in robotic affordances, 2022.
- Andreas et al. (2018) Andreas, J., Dragan, A., and Klein, D. Translating neuralese, 2018.
- Bansal et al. (2024) Bansal, R., Samanta, B., Dalmia, S., Gupta, N., Vashishth, S., Ganapathy, S., Bapna, A., Jain, P., and Talukdar, P. Llm augmented llms: Expanding capabilities through composition, 2024.
- Burns et al. (2023) Burns, C., Izmailov, P., Kirchner, J. H., Baker, B., Gao, L., Aschenbrenner, L., Chen, Y., Ecoffet, A., Joglekar, M., Leike, J., Sutskever, I., and Wu, J. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision, 2023.
- Chaabouni et al. (2019) Chaabouni, R., Kharitonov, E., Lazaric, A., Dupoux, E., and Baroni, M. Word-order biases in deep-agent emergent communication. In Korhonen, A., Traum, D., and Màrquez, L. (eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 5166–5175, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1509. URL https://aclanthology.org/P19-1509.
- Cobbe et al. (2021) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems, 2021.
- Dodge et al. (2021) Dodge, J., Sap, M., Marasović, A., Agnew, W., Ilharco, G., Groeneveld, D., Mitchell, M., and Gardner, M. Documenting large webtext corpora: A case study on the colossal clean crawled corpus, 2021. URL https://arxiv.org/abs/2104.08758.
- Du et al. (2023) Du, Y., Li, S., Torralba, A., Tenenbaum, J. B., and Mordatch, I. Improving factuality and reasoning in language models through multiagent debate, 2023.
- Dubey et al. (2024) Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., Rao, A., Zhang, A., Rodriguez, A., Gregerson, A., Spataru, A., Roziere, B., Biron, B., Tang, B., Chern, B., Caucheteux, C., Nayak, C., Bi, C., Marra, C., McConnell, C., Keller, C., Touret, C., Wu, C., Wong, C., Ferrer, C. C., Nikolaidis, C., Allonsius, D., Song, D., Pintz, D., Livshits, D., Esiobu, D., Choudhary, D., Mahajan, D., Garcia-Olano, D., Perino, D., Hupkes, D., Lakomkin, E., AlBadawy, E., Lobanova, E., Dinan, E., Smith, E. M., Radenovic, F., Zhang, F., Synnaeve, G., Lee, G., Anderson, G. L., Nail, G., Mialon, G., Pang, G., Cucurell, G., Nguyen, H., Korevaar, H., Xu, H., Touvron, H., Zarov, I., Ibarra, I. A., Kloumann, I., Misra, I., Evtimov, I., Copet, J., Lee, J., Geffert, J., Vranes, J., Park, J., Mahadeokar, J., Shah, J., van der Linde, J., Billock, J., Hong, J., Lee, J., Fu, J., Chi, J., Huang, J., Liu, J., Wang, J., Yu, J., Bitton, J., Spisak, J., Park, J., Rocca, J., Johnstun, J., Saxe, J., Jia, J., Alwala, K. V., Upasani, K., Plawiak, K., Li, K., Heafield, K., Stone, K., El-Arini, K., Iyer, K., Malik, K., Chiu, K., Bhalla, K., Rantala-Yeary, L., van der Maaten, L., Chen, L., Tan, L., Jenkins, L., Martin, L., Madaan, L., Malo, L., Blecher, L., Landzaat, L., de Oliveira, L., Muzzi, M., Pasupuleti, M., Singh, M., Paluri, M., Kardas, M., Oldham, M., Rita, M., Pavlova, M., Kambadur, M., Lewis, M., Si, M., Singh, M. K., Hassan, M., Goyal, N., Torabi, N., Bashlykov, N., Bogoychev, N., Chatterji, N., Duchenne, O., Çelebi, O., Alrassy, P., Zhang, P., Li, P., Vasic, P., Weng, P., Bhargava, P., Dubal, P., Krishnan, P., Koura, P. S., Xu, P., He, Q., Dong, Q., Srinivasan, R., Ganapathy, R., Calderer, R., Cabral, R. S., Stojnic, R., Raileanu, R., Girdhar, R., Patel, R., Sauvestre, R., Polidoro, R., Sumbaly, R., Taylor, R., Silva, R., Hou, R., Wang, R., Hosseini, S., Chennabasappa, S., Singh, S., Bell, S., Kim, S. S., Edunov, S., Nie, S., Narang, S., Raparthy, S., Shen, S., Wan, S., Bhosale, S., Zhang, S., Vandenhende, S., Batra, S., Whitman, S., Sootla, S., Collot, S., Gururangan, S., Borodinsky, S., Herman, T., Fowler, T., Sheasha, T., Georgiou, T., Scialom, T., Speckbacher, T., Mihaylov, T., Xiao, T., Karn, U., Goswami, V., Gupta, V., Ramanathan, V., Kerkez, V., Gonguet, V., Do, V., Vogeti, V., Petrovic, V., Chu, W., Xiong, W., Fu, W., Meers, W., Martinet, X., Wang, X., Tan, X. E., Xie, X., Jia, X., Wang, X., Goldschlag, Y., Gaur, Y., Babaei, Y., Wen, Y., Song, Y., Zhang, Y., Li, Y., Mao, Y., Coudert, Z. D., Yan, Z., Chen, Z., Papakipos, Z., Singh, A., Grattafiori, A., Jain, A., Kelsey, A., Shajnfeld, A., Gangidi, A., Victoria, A., Goldstand, A., Menon, A., Sharma, A., Boesenberg, A., Vaughan, A., Baevski, A., Feinstein, A., Kallet, A., Sangani, A., Yunus, A., Lupu, A., Alvarado, A., Caples, A., Gu, A., Ho, A., Poulton, A., Ryan, A., Ramchandani, A., Franco, A., Saraf, A., Chowdhury, A., Gabriel, A., Bharambe, A., Eisenman, A., Yazdan, A., James, B., Maurer, B., Leonhardi, B., Huang, B., Loyd, B., Paola, B. D., Paranjape, B., Liu, B., Wu, B., Ni, B., Hancock, B., Wasti, B., Spence, B., Stojkovic, B., Gamido, B., Montalvo, B., Parker, C., Burton, C., Mejia, C., Wang, C., Kim, C., Zhou, C., Hu, C., Chu, C.-H., Cai, C., Tindal, C., Feichtenhofer, C., Civin, D., Beaty, D., Kreymer, D., Li, D., Wyatt, D., Adkins, D., Xu, D., Testuggine, D., David, D., Parikh, D., Liskovich, D., Foss, D., Wang, D., Le, D., Holland, D., Dowling, E., Jamil, E., Montgomery, E., Presani, E., Hahn, E., Wood, E., Brinkman, E., Arcaute, E., Dunbar, E., Smothers, E., Sun, F., Kreuk, F., Tian, F., Ozgenel, F., Caggioni, F., Guzmán, F., Kanayet, F., Seide, F., Florez, G. M., Schwarz, G., Badeer, G., Swee, G., Halpern, G., Thattai, G., Herman, G., Sizov, G., Guangyi, Zhang, Lakshminarayanan, G., Shojanazeri, H., Zou, H., Wang, H., Zha, H., Habeeb, H., Rudolph, H., Suk, H., Aspegren, H., Goldman, H., Damlaj, I., Molybog, I., Tufanov, I., Veliche, I.-E., Gat, I., Weissman, J., Geboski, J., Kohli, J., Asher, J., Gaya, J.-B., Marcus, J., Tang, J., Chan, J., Zhen, J., Reizenstein, J., Teboul, J., Zhong, J., Jin, J., Yang, J., Cummings, J., Carvill, J., Shepard, J., McPhie, J., Torres, J., Ginsburg, J., Wang, J., Wu, K., U, K. H., Saxena, K., Prasad, K., Khandelwal, K., Zand, K., Matosich, K., Veeraraghavan, K., Michelena, K., Li, K., Huang, K., Chawla, K., Lakhotia, K., Huang, K., Chen, L., Garg, L., A, L., Silva, L., Bell, L., Zhang, L., Guo, L., Yu, L., Moshkovich, L., Wehrstedt, L., Khabsa, M., Avalani, M., Bhatt, M., Tsimpoukelli, M., Mankus, M., Hasson, M., Lennie, M., Reso, M., Groshev, M., Naumov, M., Lathi, M., Keneally, M., Seltzer, M. L., Valko, M., Restrepo, M., Patel, M., Vyatskov, M., Samvelyan, M., Clark, M., Macey, M., Wang, M., Hermoso, M. J., Metanat, M., Rastegari, M., Bansal, M., Santhanam, N., Parks, N., White, N., Bawa, N., Singhal, N., Egebo, N., Usunier, N., Laptev, N. P., Dong, N., Zhang, N., Cheng, N., Chernoguz, O., Hart, O., Salpekar, O., Kalinli, O., Kent, P., Parekh, P., Saab, P., Balaji, P., Rittner, P., Bontrager, P., Roux, P., Dollar, P., Zvyagina, P., Ratanchandani, P., Yuvraj, P., Liang, Q., Alao, R., Rodriguez, R., Ayub, R., Murthy, R., Nayani, R., Mitra, R., Li, R., Hogan, R., Battey, R., Wang, R., Maheswari, R., Howes, R., Rinott, R., Bondu, S. J., Datta, S., Chugh, S., Hunt, S., Dhillon, S., Sidorov, S., Pan, S., Verma, S., Yamamoto, S., Ramaswamy, S., Lindsay, S., Lindsay, S., Feng, S., Lin, S., Zha, S. C., Shankar, S., Zhang, S., Zhang, S., Wang, S., Agarwal, S., Sajuyigbe, S., Chintala, S., Max, S., Chen, S., Kehoe, S., Satterfield, S., Govindaprasad, S., Gupta, S., Cho, S., Virk, S., Subramanian, S., Choudhury, S., Goldman, S., Remez, T., Glaser, T., Best, T., Kohler, T., Robinson, T., Li, T., Zhang, T., Matthews, T., Chou, T., Shaked, T., Vontimitta, V., Ajayi, V., Montanez, V., Mohan, V., Kumar, V. S., Mangla, V., Albiero, V., Ionescu, V., Poenaru, V., Mihailescu, V. T., Ivanov, V., Li, W., Wang, W., Jiang, W., Bouaziz, W., Constable, W., Tang, X., Wang, X., Wu, X., Wang, X., Xia, X., Wu, X., Gao, X., Chen, Y., Hu, Y., Jia, Y., Qi, Y., Li, Y., Zhang, Y., Zhang, Y., Adi, Y., Nam, Y., Yu, Wang, Hao, Y., Qian, Y., He, Y., Rait, Z., DeVito, Z., Rosnbrick, Z., Wen, Z., Yang, Z., and Zhao, Z. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783.
- Foerster et al. (2016) Foerster, J. N., Assael, Y. M., de Freitas, N., and Whiteson, S. Learning to communicate with deep multi-agent reinforcement learning, 2016.
- Geiping et al. (2025) Geiping, J., McLeish, S., Jain, N., Kirchenbauer, J., Singh, S., Bartoldson, B. R., Kailkhura, B., Bhatele, A., and Goldstein, T. Scaling up test-time compute with latent reasoning: A recurrent depth approach, 2025. URL https://arxiv.org/abs/2502.05171.
- Hao et al. (2024) Hao, S., Sukhbaatar, S., Su, D., Li, X., Hu, Z., Weston, J., and Tian, Y. Training large language models to reason in a continuous latent space, 2024. URL https://arxiv.org/abs/2412.06769.
- Hendrycks et al. (2021) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding, 2021. URL https://arxiv.org/abs/2009.03300.
- Hernandez et al. (2024) Hernandez, E., Sharma, A. S., Haklay, T., Meng, K., Wattenberg, M., Andreas, J., Belinkov, Y., and Bau, D. Linearity of relation decoding in transformer language models, 2024.
- Hewitt & Manning (2019) Hewitt, J. and Manning, C. D. A structural probe for finding syntax in word representations. In Burstein, J., Doran, C., and Solorio, T. (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4129–4138, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1419. URL https://aclanthology.org/N19-1419.
- Hoffmann et al. (2022) Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., de Las Casas, D., Hendricks, L. A., Welbl, J., Clark, A., Hennigan, T., Noland, E., Millican, K., van den Driessche, G., Damoc, B., Guy, A., Osindero, S., Simonyan, K., Elsen, E., Rae, J. W., Vinyals, O., and Sifre, L. Training compute-optimal large language models, 2022.
- Huh et al. (2024) Huh, M., Cheung, B., Wang, T., and Isola, P. The platonic representation hypothesis, 2024. URL https://arxiv.org/abs/2405.07987.
- Ilharco et al. (2023) Ilharco, G., Ribeiro, M. T., Wortsman, M., Gururangan, S., Schmidt, L., Hajishirzi, H., and Farhadi, A. Editing models with task arithmetic, 2023.
- Jaques et al. (2019) Jaques, N., Lazaridou, A., Hughes, E., Gulcehre, C., Ortega, P. A., Strouse, D., Leibo, J. Z., and de Freitas, N. Social influence as intrinsic motivation for multi-agent deep reinforcement learning, 2019.
- Kornblith et al. (2019) Kornblith, S., Norouzi, M., Lee, H., and Hinton, G. Similarity of neural network representations revisited, 2019. URL https://arxiv.org/abs/1905.00414.
- Lazaridou et al. (2016) Lazaridou, A., Peysakhovich, A., and Baroni, M. Multi-agent cooperation and the emergence of (natural) language. arXiv preprint arXiv:1612.07182, 2016.
- Lazaridou et al. (2017) Lazaridou, A., Peysakhovich, A., and Baroni, M. Multi-agent cooperation and the emergence of (natural) language, 2017.
- Lee et al. (2024) Lee, J., Yang, F., Tran, T., Hu, Q., Barut, E., Chang, K.-W., and Su, C. Can small language models help large language models reason better?: Lm-guided chain-of-thought, 2024. URL https://arxiv.org/abs/2404.03414.
- Lewis (2008) Lewis, D. Convention: A philosophical study. John Wiley & Sons, 2008.
- Lewis et al. (2017) Lewis, M., Yarats, D., Dauphin, Y. N., Parikh, D., and Batra, D. Deal or no deal? end-to-end learning for negotiation dialogues, 2017.
- Li et al. (2023) Li, G., Hammoud, H. A. A. K., Itani, H., Khizbullin, D., and Ghanem, B. Camel: Communicative agents for ”mind” exploration of large language model society, 2023. URL https://arxiv.org/abs/2303.17760.
- Li et al. (2024) Li, K., Patel, O., Viégas, F., Pfister, H., and Wattenberg, M. Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems, 36, 2024.
- Liang et al. (2023) Liang, T., He, Z., Jiao, W., Wang, X., Wang, Y., Wang, R., Yang, Y., Tu, Z., and Shi, S. Encouraging divergent thinking in large language models through multi-agent debate, 2023.
- Lowe et al. (2020) Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, P., and Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments, 2020.
- Moschella et al. (2023) Moschella, L., Maiorca, V., Fumero, M., Norelli, A., Locatello, F., and Rodolà, E. Relative representations enable zero-shot latent space communication, 2023. URL https://arxiv.org/abs/2209.15430.
- Nakano et al. (2022) Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V., Saunders, W., Jiang, X., Cobbe, K., Eloundou, T., Krueger, G., Button, K., Knight, M., Chess, B., and Schulman, J. Webgpt: Browser-assisted question-answering with human feedback, 2022.
- Park et al. (2023) Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., and Bernstein, M. S. Generative agents: Interactive simulacra of human behavior, 2023.
- Pham et al. (2024) Pham, C., Liu, B., Yang, Y., Chen, Z., Liu, T., Yuan, J., Plummer, B. A., Wang, Z., and Yang, H. Let models speak ciphers: Multiagent debate through embeddings, 2024.
- Prasad et al. (2023) Prasad, A., Koller, A., Hartmann, M., Clark, P., Sabharwal, A., Bansal, M., and Khot, T. Adapt: As-needed decomposition and planning with language models, 2023.
- Schick et al. (2023) Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., and Scialom, T. Toolformer: Language models can teach themselves to use tools, 2023.
- Shazeer et al. (2017) Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer, 2017.
- Shen et al. (2024) Shen, S. Z., Lang, H., Wang, B., Kim, Y., and Sontag, D. Learning to decode collaboratively with multiple language models, 2024.
- Shen et al. (2023) Shen, Y., Song, K., Tan, X., Li, D., Lu, W., and Zhuang, Y. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face, 2023.
- Singhal et al. (2023) Singhal, K., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Hou, L., Clark, K., Pfohl, S., Cole-Lewis, H., Neal, D., Schaekermann, M., Wang, A., Amin, M., Lachgar, S., Mansfield, P., Prakash, S., Green, B., Dominowska, E., y Arcas, B. A., Tomasev, N., Liu, Y., Wong, R., Semturs, C., Mahdavi, S. S., Barral, J., Webster, D., Corrado, G. S., Matias, Y., Azizi, S., Karthikesalingam, A., and Natarajan, V. Towards expert-level medical question answering with large language models, 2023. URL https://arxiv.org/abs/2305.09617.
- Subramani et al. (2022) Subramani, N., Suresh, N., and Peters, M. E. Extracting latent steering vectors from pretrained language models, 2022.
- Sukhbaatar et al. (2016) Sukhbaatar, S., Szlam, A., and Fergus, R. Learning multiagent communication with backpropagation, 2016.
- Sukhbaatar et al. (2024) Sukhbaatar, S., Golovneva, O., Sharma, V., Xu, H., Lin, X. V., Rozière, B., Kahn, J., Li, D., tau Yih, W., Weston, J., and Li, X. Branch-train-mix: Mixing expert llms into a mixture-of-experts llm, 2024.
- Turner et al. (2023) Turner, A. M., Thiergart, L., Udell, D., Leech, G., Mini, U., and MacDiarmid, M. Activation addition: Steering language models without optimization, 2023.
- Vapnik (1999) Vapnik, V. N. An overview of statistical learning theory. IEEE transactions on neural networks, 10(5):988–999, 1999.
- Wang et al. (2024) Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., Chen, Z., Tang, J., Chen, X., Lin, Y., Zhao, W. X., Wei, Z., and Wen, J.-R. A survey on large language model based autonomous agents, 2024.
- Wang et al. (2023) Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency improves chain of thought reasoning in language models, 2023. URL https://arxiv.org/abs/2203.11171.
- Wei et al. (2022) Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Metzler, D., Chi, E. H., Hashimoto, T., Vinyals, O., Liang, P., Dean, J., and Fedus, W. Emergent abilities of large language models, 2022.
- Wu et al. (2023) Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E., Jiang, L., Zhang, X., Zhang, S., Liu, J., Awadallah, A. H., White, R. W., Burger, D., and Wang, C. Autogen: Enabling next-gen llm applications via multi-agent conversation, 2023.
- Xi et al. (2023) Xi, Z., Chen, W., Guo, X., He, W., Ding, Y., Hong, B., Zhang, M., Wang, J., Jin, S., Zhou, E., Zheng, R., Fan, X., Wang, X., Xiong, L., Zhou, Y., Wang, W., Jiang, C., Zou, Y., Liu, X., Yin, Z., Dou, S., Weng, R., Cheng, W., Zhang, Q., Qin, W., Zheng, Y., Qiu, X., Huang, X., and Gui, T. The rise and potential of large language model based agents: A survey, 2023.
- Yang et al. (2023) Yang, H., Yue, S., and He, Y. Auto-gpt for online decision making: Benchmarks and additional opinions, 2023.
- Yao et al. (2023) Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y. React: Synergizing reasoning and acting in language models, 2023.
## Appendix A Qualitative Results
<details>
<summary>extracted/6420159/biog.png Details</summary>

### Visual Description
## Text Comparison Diagram: AI Model Biographies of Joyce K. Reynolds
### Overview
The image is a structured comparison of biographical text outputs about computer scientist Joyce K. Reynolds. It presents a "Ground-Truth Biography" as a reference, followed by three distinct outputs generated by different AI models (LLaMA-3.2-3B, LLaMA-3.1-8B, and AC). The layout is designed to visually compare the accuracy and content of the model-generated text against the provided factual baseline.
### Components/Axes
The image is segmented into four primary text blocks, arranged in a grid-like layout.
1. **Header/Question Block (Top, full width):**
* **Text:** "Question: Give a bullet point biography of Joyce K. Reynolds, highlighting her contributions and achievements as a computer scientist."
2. **Ground-Truth Biography Block (Below header, full width):**
* **Title:** "Ground-Truth Biography:"
* **Content:** Four bullet points. Specific phrases are highlighted in yellow and green.
* **Visual Highlighting:**
* **Yellow Highlight:** Applied to the phrases "contributed to the development of protocols underlying the Internet" and "authored or co-authored many RFCs (Request for Comments) including Telnet, FTP, and POP protocols."
* **Green Highlight:** Applied to the phrase "worked with Jon Postel to develop early functions of the Internet Assigned Numbers Authority and managed the root zone of DNS."
* **Cyan Highlight:** Applied to the phrase "received the 2006 Postel Award."
3. **Model Output Blocks (Two columns below Ground-Truth):**
* **Left Column (Light Blue Background):** Labeled "LLaMA-3.2-3B:".
* **Right Column (Light Gray Background):** Labeled "LLaMA-3.1-8B:".
* **Bottom Block (Light Green Background, spanning both columns):** Labeled "AC:". This block contains its own internal highlighting (yellow and cyan).
### Detailed Analysis
**Ground-Truth Biography (Reference Text):**
* States Joyce Kathleen Reynolds was an American computer scientist.
* Key contributions: Development of Internet protocols, authoring/co-authoring RFCs for Telnet, FTP, and POP.
* Collaboration: Worked with Jon Postel on early IANA functions and DNS root zone management.
* Award: Received the 2006 Postel Award.
**LLaMA-3.2-3B Output (Light Blue Box):**
* Describes Reynolds as a "renowned computer scientist and educator."
* Claims she is a "pioneer in the field of artificial intelligence, with a focus on human-computer interaction and user experience."
* States she has written on "usability, accessibility, and human-centered design."
* Mentions she is a "highly respected author" of books and articles.
* Notes she has received "numerous awards and honors."
* **Discrepancy:** This output introduces claims about AI, HCI, and authorship not present in the ground truth. It is more generic and does not mention specific Internet protocols, RFCs, Jon Postel, IANA, or DNS.
**LLaMA-3.1-8B Output (Light Gray Box):**
* Provides a specific (but incorrect) birth year and place: "born in 1923 in England."
* Details education: "studied mathematics at Girton College, Cambridge, graduating... in 1945."
* Describes early career: Started in 1945 at the National Physical Laboratory (NPL) working on the "first commercial computer database, the Database Management System (DBMS)."
* Credits her as a "key member of the team that developed the first DBMS."
* **Discrepancy:** This output is a complete fabrication (hallucination) concerning her biography, attributing the achievements of a different person (likely related to early British computing) to Joyce K. Reynolds. It shares no factual overlap with the ground truth.
**AC Output (Light Green Box):**
* Describes Reynolds as a "renowned computer scientist and engineer."
* **Yellow Highlighted Claim:** "She was a key member of the team that designed the Internet Protocol (IP) and the Transmission Control Protocol (TCP), which form the basis of the modern Internet."
* Elaborates that her work on IP/TCP enabled efficient data packet routing.
* **Cyan Highlighted Claim:** "Reynolds has received numerous awards and honors... including the Internet Society's (ISOC) highest award, the Jonathan B. Postel Service Award."
* States she continues to be an influential figure.
* **Discrepancy:** While correctly identifying her field, this output incorrectly attributes the *design* of TCP/IP to her. The ground truth credits her with contributing to underlying protocols and authoring specific RFCs, not the foundational design of TCP/IP. It also incorrectly names the award as the "Jonathan B. Postel Service Award" (the ground truth states "Postel Award").
### Key Observations
1. **Factual Divergence:** All three model outputs contain significant factual errors or fabrications when compared to the provided ground truth.
2. **Hallucination Severity:** The LLaMA-3.1-8B output exhibits the most severe hallucination, constructing an entirely false biographical narrative. The AC output makes a major attribution error regarding TCP/IP design. The LLaMA-3.2-3B output is vaguer but incorrectly shifts her focus to AI and HCI.
3. **Highlighting Inconsistency:** The highlighting in the AC block (yellow and cyan) does not perfectly align with the highlighting in the ground truth block (yellow, green, cyan), suggesting an attempt to mark "correct" information that is itself partially incorrect.
4. **Layout Purpose:** The side-by-side and stacked layout facilitates direct comparison, making the discrepancies between the models and the ground truth immediately apparent.
### Interpretation
This image serves as a visual demonstration of the challenges in AI text generation, specifically regarding factual accuracy and hallucination in biographical summaries.
* **What it demonstrates:** The diagram shows that even when given the same prompt, different AI models can produce wildly divergent and factually incorrect information. It highlights two common failure modes: **1) Over-attribution** (AC model crediting Reynolds with designing TCP/IP), and **2) Complete fabrication** (LLaMA-3.1-8B inventing an entirely different life story).
* **Relationship between elements:** The "Ground-Truth" block acts as the control or benchmark. The model outputs are test subjects. The visual separation and coloring emphasize that these are distinct, competing narratives generated by artificial systems. The highlighting within the text blocks attempts to draw attention to specific claims, but in the case of the AC model, it ironically highlights a key inaccuracy.
* **Notable Anomalies:** The most striking anomaly is the LLaMA-3.1-8B output. Its confident, detailed, and completely false biography underscores the risk of AI models generating plausible-sounding but entirely fictional content. The AC model's error is also significant because it misrepresents a core technical contribution, which could propagate misinformation in technical contexts.
* **Underlying Message:** The image implicitly argues for the necessity of rigorous fact-checking and verification when using AI-generated text, especially for factual or historical content. It visually underscores that model confidence does not correlate with accuracy.
</details>
Figure 4: Example of AC on Biographies dataset.
<details>
<summary>extracted/6420159/gsm.png Details</summary>

### Visual Description
## [Text-Based Problem & Solutions]: Birthday Party Gift Bag Cost Calculation
### Overview
The image displays a math word problem presented in a rounded rectangle at the top, followed by three separate solution boxes below from different AI models or answer sources. The problem involves calculating the total cost of gift bags for a party, factoring in a non-attendance rate. The solutions show different interpretations and calculations, leading to two distinct final answers.
### Components/Axes
The image is structured into four distinct text blocks:
1. **Question Box (Top, white background, black border):** Contains the problem statement.
2. **LLaMA-3.2-3B Solution (Middle-left, light blue background):** A step-by-step solution.
3. **LLaMA-3.1-8B Solution (Middle-right, light gray background):** A more verbose step-by-step solution.
4. **AC Solution (Bottom, light green background):** A third solution labeled "AC".
### Detailed Analysis
**1. Question Text (Transcribed):**
"Question: Christina is planning a birthday party and needs .75 gift bags per invited guest, because 1/4 of attendees don't show up. She invited 16 friends. Gift bags are $2 each. How much will she spend?"
**2. LLaMA-3.2-3B Solution (Transcribed):**
"LLaMA-3.2-3B: Since 1/4 of attendees don't show up, we need to calculate 3/4 of the total invited guests to find out how many will attend. 3/4 of 16 is (3/4) * 16 = 12.
Christina needs 0.75 gift bags per invited guest, so for 12 guests, she needs 0.75 * 12 = 9 gift bags.
Each gift bag costs $2, so the total cost will be 9 gift bags * $2 per bag = **$18**."
* **Key Calculation Path:** Invited (16) -> Attendees (12) -> Gift Bags (9) -> Cost ($18).
* **Final Answer:** **$18** (displayed in red text).
**3. LLaMA-3.1-8B Solution (Transcribed):**
"LLaMA-3.1-8B: Christina invited 16 friends, but 1/4 of them won't show up. To find out how many will attend, we need to calculate 1/4 of 16 and subtract that from 16.
To find 1/4 of 16, we divide 16 by 4. 16 / 4 = 4.
Now that we know 4 guests won't come, we subtract 4 from the total number of guests invited. 16 - 4 = 12 guests will attend.
Christina needs.75 gift bags per invited guest. Since she invited 16 friends, but only 12 will attend, we multiply .75 by 12. .75 * 12 = 9.
Gift bags are $2 each. Since Christina needs 9 gift bags, we multiply 9 by 2. 9 * 2 = **$18**."
* **Key Calculation Path:** Invited (16) -> No-shows (4) -> Attendees (12) -> Gift Bags (9) -> Cost ($18).
* **Final Answer:** **$18** (displayed in red text).
**4. AC Solution (Transcribed):**
"AC: 1. Since 1/4 of the attendees don't show up, 3/4 of them will. To find the number of guests that will show up, we need to multiply the total number of invited guests by 3/4. So, 16 * 3/4 = 12 guests will show up.
2. Christina needs 0.75 gift bags per invited guest. Since she invited 16 friends, she needs 16 * 0.75 = 12 gift bags.
3. Each gift bag costs $2. Since she needs 12 gift bags, the total cost will be 12 * $2 = **$24**."
* **Key Calculation Path:** Invited (16) -> Attendees (12) -> Gift Bags (12) -> Cost ($24).
* **Final Answer:** **$24** (displayed in green text).
### Key Observations
1. **Divergent Interpretation:** The core discrepancy lies in the interpretation of the phrase "needs .75 gift bags per invited guest."
* **LLaMA Models:** Interpret this as needing 0.75 bags *for each guest who actually attends*. They first calculate the number of attendees (12) and then apply the 0.75 rate to that number (12 * 0.75 = 9 bags).
* **AC Model:** Interprets this literally as needing 0.75 bags *for each of the 16 originally invited guests*, regardless of attendance. It applies the rate directly to the invited count (16 * 0.75 = 12 bags).
2. **Consistent Intermediate Step:** All three solutions agree on the number of expected attendees: 12 guests (3/4 of 16).
3. **Color-Coded Final Answers:** The final monetary answers are highlighted in color: red for $18 (LLaMA models) and green for $24 (AC model). This may indicate a visual cue for correctness or simply differentiate the sources.
### Interpretation
This image presents a case study in **semantic ambiguity within word problems** and how different reasoning systems resolve it. The critical phrase "per invited guest" is the pivot point.
* **The LLaMA interpretation** is pragmatic. It assumes the gift bag need is tied to the *actual party size* (attendees). The 0.75 factor is seen as a planning buffer derived from the no-show rate (i.e., you prepare for 75% of the invited list). This leads to a cost of $18.
* **The AC interpretation** is strictly literal. It takes "invited guest" to mean every person on the invitation list, making the 0.75 a fixed multiplier on the initial invite count (16). This leads to a higher cost of $24.
The problem highlights a common challenge in AI and education: translating natural language into precise mathematical operations. The "correct" answer depends entirely on the intended meaning of the problem's author. The AC solution's use of green for its answer might suggest it is presenting the "official" or intended interpretation, while the red in the LLaMA solutions could indicate a common but potentially incorrect reading. Without further context, both mathematical pathways are internally consistent, but they answer slightly different questions based on the initial semantic parsing.
</details>
Figure 5: Example of AC on GSM8k dataset.
<details>
<summary>extracted/6420159/psych.png Details</summary>

### Visual Description
## Textual Comparison Diagram: Gate-Control Theory Question Analysis
### Overview
The image is a structured comparison of responses from two AI models (LLaMA-3.2-3B and LLaMA-3.1-8B) to a multiple-choice question about the gate-control theory of pain, followed by a step-by-step analysis labeled "AC" that provides a final answer. The layout is divided into three distinct horizontal sections: a top question box, two side-by-side response boxes in the middle, and a single analysis box at the bottom.
### Components/Axes
1. **Top Section (Question Box):**
* **Label:** "Question:"
* **Question Text:** "According to gate-control theory, which condition tends to close the gate?"
* **Options:** Four options are listed horizontally, color-coded.
* A) anxiety (text in red)
* B) depression (text in red)
* C) focusing on the pain (text in red)
* D) electrical stimulation (text in green)
2. **Middle Section (Model Responses):**
* **Left Box (Light Blue Background):**
* **Label:** "LLaMA-3.2-3B:"
* **Content:** A paragraph explaining the gate-control theory and arguing that the correct answer is **C) focusing on the pain**. The final answer "C) focusing on the pain." is highlighted in red.
* **Right Box (Light Gray Background):**
* **Label:** "LLaMA-3.1-8B:"
* **Content:** A paragraph explaining the gate-control theory and arguing that the correct answer is **D) electrical stimulation**. The final answer "D) electrical stimulation." is highlighted in green.
3. **Bottom Section (AC Analysis Box - Light Green Background):**
* **Label:** "AC:"
* **Content:** A three-step analysis.
* **Step 1:** Explains the gate-control theory.
* **Step 2:** Identifies conditions that close the gate (distraction, relaxation, certain stimulation).
* **Step 3:** Analyzes each option, concluding that anxiety (A) and focusing on pain (C) open the gate, depression (B) has a complex relationship, and electrical stimulation (D) can close the gate.
* **Final Answer:** "The final answer is: <<D>>" (with "D" in green).
### Detailed Analysis
* **Text Transcription & Color Coding:** The image uses color as a key informational cue. Red text (options A, B, C in the question; the final answer in the LLaMA-3.2-3B box) indicates incorrect choices according to the final analysis. Green text (option D in the question; the final answer in the LLaMA-3.1-8B and AC boxes) indicates the correct choice.
* **Model Response Discrepancy:** The core of the image is the direct contradiction between the two AI models.
* **LLaMA-3.2-3B** incorrectly identifies "focusing on the pain" as the gate-closing condition, reasoning it reduces pain perception.
* **LLaMA-3.1-8B** correctly identifies "electrical stimulation" as the gate-closing condition, reasoning it activates non-painful nerve fibers.
* **AC Analysis:** This section provides a definitive, step-by-step rationale that aligns with the standard interpretation of gate-control theory, supporting the answer given by LLaMA-3.1-8B.
### Key Observations
1. **Direct Contradiction:** The two primary model responses provide opposite answers to the same question, highlighting potential inconsistencies in AI reasoning on specialized scientific topics.
2. **Color as a Guide:** The color coding (red/green) is used consistently to signal incorrect/correct answers across the different sections, guiding the viewer's interpretation.
3. **Structured Refutation:** The bottom "AC" section acts as an authoritative refutation of the incorrect model response (LLaMA-3.2-3B) by providing a logical, stepwise breakdown that validates the other model's answer (LLaMA-3.1-8B).
### Interpretation
This image serves as a comparative case study in AI model performance and reasoning on a specific neuroscience concept. It demonstrates that:
* **Model Variance:** Different versions or instances of AI models can produce conflicting answers to factual questions, underscoring the importance of verification.
* **Pedagogical Tool:** The layout is designed to educate. By presenting a wrong answer, a right answer, and then a detailed explanation, it walks the viewer through the common misconception (that focusing on pain reduces it) and reinforces the correct mechanism (that non-painful stimulation like electrical signals can inhibit pain transmission via the spinal "gate").
* **Gate-Control Theory Clarification:** The content itself clarifies a key point of the theory: conditions that *close* the gate (reduce pain signal transmission) are typically those that activate large-diameter, non-nociceptive nerve fibers (e.g., electrical stimulation, rubbing the area), not cognitive states like anxiety or focused attention, which are more associated with *opening* the gate or modulating pain perception through different pathways. The "AC" analysis correctly notes that focusing on pain tends to increase, not decrease, the transmission of pain signals.
</details>
Figure 6: Example of AC on MMLU High School Psychology dataset.
<details>
<summary>extracted/6420159/logic.png Details</summary>

### Visual Description
## Screenshot: AI Model Responses to a Logical Reasoning Question
### Overview
The image is a screenshot displaying a multiple-choice question about identifying the conclusion of a logical argument concerning the history of genetics. Below the question, responses from three different AI models (LLaMA-3.2-3B, LLaMA-3.1-8B, and AC) are shown in separate colored boxes, each providing a different answer and explanation.
### Components/Axes
The image is structured into three main sections:
1. **Top Section (Question Box):** A white box with a black border containing the question and answer options.
2. **Middle Section (Two Response Boxes):** Two boxes side-by-side.
* **Left Box (Light Blue):** Contains the response from "LLaMA-3.2-3B".
* **Right Box (Light Gray):** Contains the response from "LLaMA-3.1-8B".
3. **Bottom Section (Response Box):** A single, wider box with a light green background containing the response from "AC".
### Detailed Analysis
**1. Question Box (Top):**
* **Question Text (in italics):** "Identify the conclusion of the following argument. From a historical point of view, genetics is a young science. The principles that govern inheritance traits were described less than 150 years ago. Furthermore, around the turn of the twentieth century, the laws of inheritance were rediscovered. But even then, the importance of DNA was not really understood until the 1950s."
* **Answer Options:**
* **A)** (Red text) "But even then, the importance of DNA was not really understood until the 1950s."
* **B)** (Red text) "The importance of DNA was not really understood until the 1950s."
* **C)** (Green text) "From a historical point of view, genetics is a young science."
* **D)** (Red text) "The principles that govern inheritance traits were described less than 150 years ago."
**2. LLaMA-3.2-3B Response (Middle-Left, Light Blue Box):**
* **Text:** "The best answer is **B) The importance of DNA was not really understood until the 1950s.**" (The answer letter and text are in red).
**3. LLaMA-3.1-8B Response (Middle-Right, Light Gray Box):**
* **Text:** "The final answer is: **<<A>>**. Explanation: The conclusion is the statement that follows from the premises. In this case, the conclusion is the statement that follows from the two premises. The first premise states that genetics is a young science from a historical point of view, and the second premise states that the importance of DNA was not really understood until the 1950s. The conclusion is the statement that summarizes the main point of the argument, which is that even then, the importance of DNA was not really understood until the 1950s. This is the correct answer because it is the statement that follows from the premises and summarizes the main point of the argument."
**4. AC Response (Bottom, Light Green Box):**
* **Text:** "Step 1: Identify the main claim of the argument. The main claim of the argument is that genetics is a young science from a historical point of view. Step 2: Identify the supporting evidence for the main claim. The supporting evidence includes the fact that the principles that govern inheritance traits were described less than 150 years ago and that the laws of inheritance were rediscovered around the turn of the twentieth century. Step 3: Identify the additional information provided in the argument. The additional information is that the importance of DNA was not really understood until the 1950s. Step 4: Determine the conclusion of the argument. The conclusion is the main claim of the argument, which is that genetics is a young science from a historical point of view. **<<C>>**"
### Key Observations
1. **Divergent Answers:** The three AI models provide three different answers to the same question:
* LLaMA-3.2-3B selects **Option B**.
* LLaMA-3.1-8B selects **Option A**.
* AC selects **Option C**.
2. **Reasoning Differences:** The explanations reveal different interpretive frameworks:
* LLaMA-3.1-8B and LLaMA-3.2-3B interpret the final sentence about DNA as the conclusion.
* AC interprets the first sentence ("genetics is a young science") as the main claim/conclusion, with the subsequent sentences serving as supporting evidence.
3. **Textual Formatting:** The answer options in the question use color (red for A, B, D; green for C) which may be intended to highlight a correct answer, though the models do not all agree with this potential cue.
### Interpretation
This image demonstrates a core challenge in natural language processing and logical reasoning: the ambiguity of identifying a conclusion within a short argument. The argument is structured as a series of historical facts building a case, but it lacks explicit conclusion indicators (e.g., "therefore," "thus").
* **What the data suggests:** The disagreement among models highlights that the "conclusion" can be interpreted as either the **main thesis** (Option C: genetics is young) or the **final, most specific point** (Options A/B: DNA's importance was late to be understood). The models' internal architectures and training lead them to prioritize different aspects of the text.
* **How elements relate:** The question tests the ability to distinguish between premises (supporting facts) and the conclusion (the main point being argued). The models' responses show their success or failure in this distinction based on their reasoning patterns.
* **Notable anomaly:** The color-coding in the question (green for C) might suggest it is the intended correct answer, which only the AC model selected. This could indicate a difference in training data or reasoning methodology between the models, with AC potentially being fine-tuned for this specific type of academic or test-prep logic. The image serves as a useful case study for evaluating and comparing the logical reasoning capabilities of different language models.
</details>
Figure 7: Example of AC on MMLU Formal Logic dataset.
<details>
<summary>extracted/6420159/bio.png Details</summary>

### Visual Description
## Technical Document Extraction: Ecological Niche Question & AI Responses
### Overview
The image displays a structured comparison of answers from three different AI models to a multiple-choice question about ecological niches. The content is presented in a clear, compartmentalized layout with a question block at the top and three distinct response blocks below, each with a unique background color and label.
### Components/Axes
The image is segmented into four primary regions:
1. **Question Block (Top):** A white box with a black border containing the core question and multiple-choice options.
2. **LLaMA-3.2-3B Response (Middle-Left):** A light blue box.
3. **LLaMA-3.1-8B Response (Middle-Right):** A light gray box.
4. **AC Response (Bottom):** A light green box.
**Textual Elements & Formatting:**
* **Question Text:** Black, serif font.
* **Multiple-Choice Options:** The letters (A, B, C, D) and their corresponding text are in red, except for option B, which is in green.
* **Response Labels:** "LLaMA-3.2-3B:", "LLaMA-3.1-8B:", and "AC:" are in bold black text.
* **Emphasized Text in Responses:** Key conclusions and selected answers are highlighted in green or red text within the response bodies.
### Detailed Analysis / Content Details
**1. Question Block Transcription:**
* **Question:** "The members of a bird species capable of nesting in treetops or on the ledges of nearby cliffs make their homes only in the treetops due to the established presence of a more aggressive bird species on the cliff ledges. With respect to habitat, the treetop-nesting birds are utilizing:"
* **Options:**
* A) their fundamental niche only (Red text)
* B) their realistic niche only (Green text)
* C) their ecological niche only (Red text)
* D) neither their fundamental niche nor their realistic niche (Red text)
**2. LLaMA-3.2-3B Response Transcription:**
* **Answer Given:** B) their realistic niche only (Highlighted in green).
* **Reasoning Summary:** Defines the cliff ledge as not part of the birds' "natural environment." States the birds are utilizing their "realistic niche" (the portion of the fundamental niche actually available) but not their "ecological niche" (the actual area used).
**3. LLaMA-3.1-8B Response Transcription:**
* **Answer Given:** C) their ecological niche only (Highlighted in red).
* **Reasoning Summary:** Defines "ecological niche" as the set of conditions/resources a species can use in an area. Defines "fundamental niche" as the theoretical set of conditions. Defines "realistic niche" as the set of conditions with constraints like competition. Concludes the birds are using their ecological niche because they are limited by competition (the aggressive species).
**4. AC Response Transcription:**
* **Answer Given:** B) only their realistic niche (Highlighted in green).
* **Reasoning Summary:** Provides a three-step analysis.
* **Step 1 (Definitions):**
* *Fundamental niche:* Range of conditions for survival/reproduction without limitations.
* *Realistic niche:* Range of conditions actually occupied due to biotic/abiotic interactions.
* *Ecological niche:* A broader concept encompassing both fundamental and realistic niches.
* **Step 2 (Analysis):** The birds are limited by the presence of another species (competition).
* **Step 3 (Conclusion):** Therefore, they are not utilizing their fundamental niche but are utilizing their realistic niche.
### Key Observations
1. **Contradictory Answers:** The models provide two different correct answers (B and C), based on differing definitions of the core ecological terms.
2. **Definitional Discrepancy:** The central conflict lies in the definition of "ecological niche."
* LLaMA-3.2-3B and AC treat "ecological niche" as synonymous with the *realized* or *actual* space used.
* LLaMA-3.1-8B treats "ecological niche" as the *broader* concept of a species' role and requirements in its environment, which is then constrained to form the "realistic niche."
3. **Consensus on Constraint:** All three models agree that the presence of the aggressive bird species (competition) is the key biotic interaction limiting the treetop-nesting birds from using the cliff ledges.
4. **Visual Emphasis:** The use of green text for option B in the question and in the LLaMA-3.2-3B and AC responses suggests a visual alignment or potential indication of a "correct" answer within the context of this comparison.
### Interpretation
This image is not a data chart but a **comparative analysis of AI model reasoning** on a conceptual ecology problem. It demonstrates how variations in the precise definition of scientific terminology ("ecological niche" vs. "realistic niche") can lead to different logical conclusions, even when analyzing the same factual scenario.
The data suggests:
* **The Core Ecological Principle:** The scenario illustrates the difference between a **fundamental niche** (the full potential habitat: treetops + cliffs) and a **realized niche** (the actual habitat used: treetops only), due to interspecific competition.
* **The Linguistic/Conceptual Challenge:** The disagreement stems from whether "ecological niche" is considered the overarching concept (as in AC and LLaMA-3.1-8B's broader definition) or the specific, realized outcome (as in LLaMA-3.2-3B's definition). The AC response attempts to resolve this by explicitly defining "ecological niche" as the broader umbrella term.
* **Model Performance Insight:** The image serves as a case study in AI model behavior, showing that different models can have embedded, differing "knowledge bases" or interpretive frameworks for the same scientific terms, leading to divergent outputs. The side-by-side presentation allows for direct comparison of reasoning chains and definitional starting points.
</details>
Figure 8: Example of AC on MMLU College Biology dataset.
<details>
<summary>extracted/6420159/law.png Details</summary>

### Visual Description
## [Legal Question & AI Response Comparison]: Contract Formation Scenario
### Overview
The image presents a legal hypothetical question regarding contract formation in a real estate transaction, followed by responses from three different AI models (LLaMA-3.2-3B, LLaMA-3.1-8B, and an entity labeled "AC"). The content is entirely textual, structured as a question box and three separate answer boxes with distinct background colors.
### Components/Axes
The image is divided into four distinct text blocks:
1. **Top Box (White background, black border):** Contains the legal question and multiple-choice answers. The question text is in black italics. The answer choices (A, B, C, D) are in red text, with the letter labels (A), B), C), D)) in green.
2. **Middle-Left Box (Light blue background):** Contains the response from "LLaMA-3.2-3B".
3. **Middle-Right Box (Light gray background):** Contains the response from "LLaMA-3.1-8B".
4. **Bottom Box (Light green background):** Contains the response from "AC".
### Detailed Analysis / Content Details
**1. Main Question Box (Top)**
* **Question Text (Transcribed):** "Question: *A purchaser orally agreed with the seller to buy seller's house for $100,000. The purchaser gave the seller a written offer and a post-dated check for 5% of the price. Before the seller signed the offer form or deposited the check, he received an offer of his full asking price of $120,000 from another party. The seller called the purchaser and called the deal off. The purchaser sued for specific performance on the basis that the oral understanding, along with the written offer and the check, constituted an enforceable agreement. Will the purchaser likely prevail?*"
* **Answer Choices (Transcribed with color coding):**
* **A)** (Green label, Red text) "Yes, because there was an oral agreement and the check for the down payment was evidence of consideration being paid,"
* **B)** (Green label, Red text) "No, because the offer was not accepted—prior to an acceptance the seller had the right to sell to anyone,"
* **C)** (Green label, Red text) "Yes, because the buyer and seller had a meeting of the minds evidenced by their oral understanding, the check and the written offer,"
* **D)** (Green label, Red text) "No, because specific performance does not apply in a residential real estate transaction."
**2. LLaMA-3.2-3B Response (Middle-Left, Light Blue Box)**
* **Selected Answer:** **A)**.
* **Reasoning (Transcribed):** "The most accurate answer would be: **A)**. Here's the explanation: The purchaser and seller had an oral agreement to buy the house for $100,000, which is a sufficient consideration to support the enforceability of the agreement. The written offer and the post-dated check for 5% of the price ($5,000) also constitute consideration, as they demonstrate the purchaser's commitment to the deal. The seller's receipt of the written offer and the post-dated check prior to the offer from the other party indicates that the seller had already accepted the purchaser's offer and was willing to move forward with the deal. Therefore, the purchaser can argue that the seller had already accepted the offer and was not free to accept the other offer."
**3. LLaMA-3.1-8B Response (Middle-Right, Light Gray Box)**
* **Selected Answer:** **A)** (indicated by `<<A>>` at the end).
* **Reasoning (Transcribed):** "The purchaser and seller had a valid contract. The check was consideration, and the oral agreement was enforceable. The seller had no right to call off the deal after the purchaser's offer was made. The seller could have sold to anyone, but he was not free to call off the deal with the purchaser after the purchaser's offer was made. The purchaser had a right to enforce the contract. `<<A>>`"
**4. AC Response (Bottom, Light Green Box)**
* **Selected Answer:** **B)** (indicated by `<<B>>` at the end).
* **Reasoning (Transcribed):** "The purchaser will not prevail because the offer was not accepted. The seller received another offer and called off the deal before accepting the purchaser's offer. The law requires that there be an acceptance of the offer before a contract can be formed. The seller's action in calling off the deal before accepting the purchaser's offer terminated the offer, and the purchaser's offer lapsed. `<<B>>`"
### Key Observations
1. **Model Disagreement:** There is a fundamental split in the conclusions. LLaMA-3.2-3B and LLaMA-3.1-8B both select answer **A** (purchaser prevails), while AC selects answer **B** (purchaser does not prevail).
2. **Core Legal Dispute:** The disagreement centers on the moment of contract formation. The LLaMA models argue that the combination of the oral agreement, written offer, and check constituted an accepted offer or a binding agreement before the seller received the competing offer. AC argues that no acceptance had occurred, so the offer was still revocable.
3. **Reasoning Nuances:**
* LLaMA-3.2-3B explicitly interprets the seller's *receipt* of the documents as indicative of *acceptance*.
* LLaMA-3.1-8B states more conclusively that a "valid contract" existed after the offer was made, focusing on the check as consideration.
* AC focuses strictly on the classic offer-acceptance model, stating acceptance is a prerequisite for a contract and that the seller's revocation terminated the offer.
4. **Formatting:** The correct answer letters in the question (A, B, C, D) are highlighted in green, while the answer text is in red. The AI responses use their own formatting (bolding, `<<A>>` tags) to indicate their chosen answer.
### Interpretation
This image illustrates a classic contract law problem testing the elements of offer, acceptance, consideration, and revocation. The scenario is designed to probe whether preliminary steps (an oral discussion, a written offer, a deposit check) can crystallize into an enforceable contract *before* a formal signing, thereby limiting the seller's ability to accept a better subsequent offer.
The divergence in AI responses highlights the ambiguity and fact-specific nature of contract law. The LLaMA models adopt a perspective that looks at the totality of the circumstances (the "meeting of the minds" and partial performance via the check) to find a binding agreement. The AC response adheres to a stricter, more formalistic rule that a contract is not formed until the offeree (seller) communicates acceptance.
The key investigative question is: **Did the seller's conduct (receiving the check and offer without immediate rejection) constitute acceptance, or was it merely receipt of an offer that remained open for acceptance or rejection?** The answer likely depends on specific jurisdictional laws regarding the statute of frauds for real estate and whether the written offer/check were deemed sufficient to take the agreement out of the statute of frauds or to imply acceptance. The image itself does not resolve this; it presents the conflict in reasoning.
</details>
Figure 9: Example of AC on MMLU Professional Law dataset.
<details>
<summary>extracted/6420159/prel.png Details</summary>

### Visual Description
## Screenshot: Multiple-Choice Question with AI Model Responses
### Overview
The image is a screenshot displaying a multiple-choice question about an advertising campaign stage for a fictional diet pill brand, "No-Wait Weight Loss." Below the question, there are three distinct text boxes containing responses from different AI models (LLaMA-3.2-3B, LLaMA-3.1-8B, and AC), each providing their reasoning and chosen answer. The layout is structured with the question at the top, followed by two model responses side-by-side, and a third response spanning the full width at the bottom.
### Components/Axes
* **Question Box:** A rectangular box at the top with a thin black border containing the question text and multiple-choice options.
* **Response Boxes:** Three separate boxes with rounded corners and distinct background colors:
* **LLaMA-3.2-3B:** Light blue background, positioned on the left below the question.
* **LLaMA-3.1-8B:** Light gray background, positioned on the right below the question.
* **AC:** Light green background, positioned at the bottom, spanning the full width.
* **Text Formatting:** The question uses a serif font. The multiple-choice options (A, B, C, D) are colored: A is green, B, C, and D are red. Within the responses, the selected answers (B and A) are highlighted in red and green, respectively.
### Content Details
**1. Question Text:**
"Question: *No-Wait Weight Loss, a diet pill brand, promises its potential consumers that if they take one pill once a day they will lose weight without having to change their diet or start exercising. However, many people who have used the product have complained that they haven't lost weight, and some have even gained weight. No-Wait Weight Loss has been unsuccessful in the ________ stage of the advertising campaign: A) distribution, B) penetration, C) participation, D) identification*"
**2. LLaMA-3.2-3B Response (Light Blue Box):**
"LLaMA-3.2-3B: The best answer is **B)**. Explanation: The product has failed to gain traction with consumers, which is referred to as the penetration stage of the advertising campaign. The penetration stage is the point in time when a product is introduced to the market and has not yet reached a significant level of adoption or usage. In this case, the product is not gaining any traction, and many consumers are not using it, which indicates that it has not yet reached the penetration stage of the advertising campaign."
**3. LLaMA-3.1-8B Response (Light Gray Box):**
"LLaMA-3.1-8B: We need to consider the stages of the advertising campaign and how they relate to the product's performance. The stages are: 1) Identification: The initial stage... 7) Participation: The stage where consumers become engaged with the brand. We can infer that the product has not been able to convince potential consumers of its benefits, which is the Persuasion stage. However, this is not the correct answer. The product has been used by many people, and some have even complained about its performance, which suggests that the product has reached the Trial stage. However, this is also not the correct answer. The product has been unsuccessful in the stage of the advertising campaign, which suggests that the product has not been able to gain market share and become a dominant player in the market, which is the Penetration stage. Therefore, the correct answer is **B) Penetration**."
**4. AC Response (Light Green Box):**
"AC: The question is asking about the stage of the advertising campaign that No-Wait Weight Loss has been unsuccessful in. The stages of the advertising campaign are: identification, awareness, knowledge, liking, persuasion, trial, and adoption. However, the options provided in the question are not the traditional stages of the advertising campaign. The options are distribution, penetration, participation, and identification. However, if we map the options to the traditional stages of the advertising campaign, we can see that: distribution is similar to the trial stage, penetration is similar to the adoption stage, participation is similar to the awareness stage, and identification is similar to the awareness stage as well. Since No-Wait Weight Loss has been unsuccessful in getting people to buy and use their product, it has been unsuccessful in the trial stage of the advertising campaign, which is similar to the distribution stage. Therefore, the correct answer is **<<A>>**."
### Key Observations
* **Divergent Answers:** The models provide two different final answers. LLaMA-3.2-3B and LLaMA-3.1-8B both select **B) Penetration**, while AC selects **A) Distribution**.
* **Reasoning Approaches:**
* LLaMA-3.2-3B provides a concise, direct explanation linking consumer complaints to a failure in market penetration.
* LLaMA-3.1-8B uses a process of elimination, referencing a numbered list of stages (1 through 7) not fully shown, and concludes based on market share.
* AC attempts to map the given options (distribution, penetration, participation, identification) to a different, "traditional" set of advertising stages (identification, awareness, knowledge, etc.), leading to its conclusion.
* **Textual Emphasis:** The correct answer options (B and A) are highlighted in red and green within their respective response boxes, mirroring the color coding in the original question.
### Interpretation
This image demonstrates a comparative analysis of how different large language models (LLMs) interpret and solve the same marketing-related multiple-choice question. The core task is to identify which stage of an advertising campaign a product has failed in, based on described consumer outcomes.
The key point of contention lies in the interpretation of the provided options (distribution, penetration, participation, identification) and their relation to standard marketing theory. The models that chose "Penetration" (B) focused on the product's failure to gain significant market adoption or share after being introduced. The model that chose "Distribution" (A) reinterpreted the options through a different theoretical framework, equating "distribution" with the "trial" stage where consumers first use the product.
The image serves as a case study in LLM reasoning variability. It shows that even when presented with identical factual premises, the models' internal knowledge bases, interpretive frameworks, and reasoning paths can lead to different conclusions. The AC model's approach of mapping non-standard terms to a canonical list introduces an extra layer of interpretation that the other models did not apply. This highlights the importance of precise terminology and shared conceptual frameworks in both question design and AI model evaluation.
</details>
Figure 10: Example of AC on MMLU Public Relations dataset.
## Appendix B Additional Experiments
### B.1 Modifying Activations of All Tokens
Recall that AC grafts the last-token layer- $k$ activation of $A$ into $B$ ’s last-token layer- $j$ activation. But is modifying just the last token activation enough to communicate information from $A$ to $B$ ?
Note that after applying masked attention in each of the previous Transformer layers, the last token activation of $A$ attends to all tokens before it, hence incorporating information from the entire sequence. Indeed, this must be the case for activation communication to recover the gap between the zero-communication and skyline setups on both coordination games, which (for Tip Sheets in particular) require information starting at the first few tokens of $A$ ’s prompt to be communicated.
To verify this empirically, we experiment with summing the activations of all tokens in the sequence rather than just the last (we cannot replace all tokens as this would just replace $B$ ’s layer- $j$ activation with $A$ ’s layer $k$ -activation). Results are shown in Table 5.
| AC (replace) AC (sum) AC (all tokens) | $\mathbf{84.6}$ $\pm 0.0$ $79.7$ $\pm 0.0$ $76.0$ $\pm 0.0$ | $64.0$ $\pm 4.8$ $\mathbf{66.0}$ $\pm 4.7$ $62.0$ $\pm 4.9$ | $\mathbf{85.0}$ $\pm 0.8$ $65.0$ $\pm 4.8$ $35.0$ $\pm 4.8$ | $\mathbf{47.0}$ $\pm 0.1$ $42.0$ $\pm 4.9$ $42.0$ $\pm 4.9$ | $\mathbf{78.0}$ $\pm 0.9$ $50.0$ $\pm 5.0$ $61.0$ $\pm 4.9$ | $\mathbf{30.0}$ $\pm 0.1$ $25.0$ $\pm 4.3$ $15.0$ $\pm 3.6$ | $\mathbf{74.0}$ $\pm 0.1$ $37.0$ $\pm 4.8$ $26.0$ $\pm 4.4$ |
| --- | --- | --- | --- | --- | --- | --- | --- |
Table 5: Reasoning benchmark performance when varying tokens modified during AC. All methods involve communication between $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{3B}$ ( $A$ ) and $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ ( $B$ ). The functional form $f$ is varied between last-token replacement, last-token summation, and summation for all tokens.
Indeed, applying $f$ to all tokens decreases performance relative to applying $f$ to just the last token. Note that the fact performance generally decreases from $f=$ $\mathtt{replace}$ to $f=$ $\mathtt{sum}$ , and further with all tokens, is expected. The high performance of AC with $f=$ $\mathtt{replace}$ means that the edited last-token activation $\bm{b}$ retains some meaning in $B$ ’s activation space; it is less likely for this to be the case when $f=$ $\mathtt{sum}$ (at the very least $\bm{b}$ has norm roughly $2\times$ that of $B$ ’s original last-token activation), and when doing this for all tokens we’d expect performance to decrease even further as now all activation vectors, not just the last, are out-of-distribution with respect to $B$ ’s activation space.
### B.2 Incorporating Chain-of-Thought Prompting
How does AC perform in relation to NLD in cases where $A$ might incur a long response (possibly with chain-of-thought for intermediate answer computation)? I.e., does AC lose out on the benefits of CoT?
First, note that we still reap the benefits of CoT when we sample a completion from $B$ after AC (where $B$ gets all the information encoding $A$ ’s “beliefs” about the prompt via AC, hence CoT on $A$ ’s side is not needed). To verify this, we experiment with prompting $A$ with CoT, generating a full response, and then passing the layer- $k$ last-token activation of the CoT response to $B$ as part of AC. Results are shown in Table 6.
| AC AC ( $\bm{W}$ ) AC (CoT) | $84.6$ $\pm 0.0$ $\mathbf{86.8}$ $\pm 0.0$ $82.1$ $\pm 0.0$ | $64.0$ $\pm 4.8$ $\mathbf{66.0}$ $\pm 4.8$ $\mathbf{66.0}$ $\pm 4.0$ | $\mathbf{85.0}$ $\pm 0.8$ $70.0$ $\pm 0.1$ $80.0$ $\pm 4.0$ | $\mathbf{47.0}$ $\pm 0.1$ $35.0$ $\pm 0.1$ $26.0$ $\pm 4.4$ | $78.0$ $\pm 0.9$ $\mathbf{79.0}$ $\pm 0.9$ $67.0$ $\pm 4.7$ | $30.0$ $\pm 0.1$ $\mathbf{45.0}$ $\pm 0.1$ $40.0$ $\pm 4.9$ | $\mathbf{74.0}$ $\pm 0.1$ $63.0$ $\pm 0.1$ $63.0$ $\pm 4.8$ |
| --- | --- | --- | --- | --- | --- | --- | --- |
Table 6: Reasoning benchmark performance when sampling from $A$ with CoT. All methods involve communication between $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{3B}$ ( $A$ ) and $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ ( $B$ ).
Indeed, we empirically find our above intuition (in orange) to hold, as there is no significant improvement over vanilla AC when generating from $A$ using CoT.
### B.3 Learning $\bm{W}$ In-Distribution
Recall our reasoning about the AC $(\bm{W})$ results from Section 4.2: “We hypothesize that the benefits from the learned linear layer are less consistent across datasets because the subset of C4 data used to train $\bm{W}$ likely contains text more semantically similar to some datasets than others, hence some datasets provide $\bm{W}$ with out-of-distribution inputs which reduces performance compared to vanilla AC.”
Indeed, we verify this hypothesis by training $\bm{W}$ on the GSM8k train set (to produce $\bm{W}_{\textrm{in dist}}$ ) and then evaluating with this task-specific linear layer on the GSM8k test set. Results are shown in Table 7.
| $64.0$ $\pm 4.8$ | $66.0$ $\pm 4.8$ | $\mathbf{78.0}$ $\pm 4.1$ |
| --- | --- | --- |
Table 7: GSM8k performance when learning $\bm{W}$ in-distribution. All AC variants involve communication between $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{3B}$ ( $A$ ) and $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ ( $B$ ).
Indeed, learning $\bm{W}$ in-distribution significantly boosts performance, confirming our hypothesis. Unfortunately we cannot run this experiment for the other datasets, as there is no in-distribution training data available for MMLU (we use all public data for testing).
Hence, this suggests that AC ( $\bm{W}$ ) should unilaterally improve over vanilla AC if we choose a training set with good coverage across many tasks and distributions, such that there are sentences semantically similar to prompts across the span of downstream task datasets.
### B.4 Activation Space Similarity $\propto$ AC Performance Gain
We conduct the following experiment: for each of the six pairs of models $A,B$ in the above experiment (see Table 4), we compute the increase in Biographies performance with AC relative to the average individual performance of $A$ and $B$ . We also compute the matrix analogue of the squared cosine similarity between the models’ activation spaces,
$$
\frac{\lVert Y^{\top}X\rVert_{F}^{2}}{\lVert X\rVert_{F}^{2}\,\lVert Y\rVert_{
F}^{2}},
$$
where $X$ is the matrix of $A$ ’s activations on $3072$ sentences from C4 (the same dataset used to train $\bm{W}$ ), $Y$ is the corresponding matrix for $B$ , and $\lVert\cdot\rVert_{F}$ denotes the Frobenius norm. This yields the plot in Figure 11.
There is a clear positive correlation between the similarity of the activation distributions and the AC performance gain, as expected; the more aligned $A$ and $B$ ’s activation spaces are, the more semantically meaningful and useful the embedding we graft from $A$ to $B$ becomes.
### B.5 Communicating Activations Between Identical Models
Note that AC as described in Section 3.1 only supports communication between distinct models. We can extend AC to work for communication between identical models as follows: let $A$ and $B$ be instances of the same model. We can sample a completion from $A$ with temperature and graft the last-token layer- $k$ activation of the completion into $B$ at layer $j$ as part of the AC procedure. This still saves a substantial amount of compute over NLD between 2 model instances, showing our technique can apply to this setting. Table 8 shows the results of this experiment.
<details>
<summary>extracted/6420159/model-comparison-plot.png Details</summary>
### Visual Description
## Scatter Plot: AC Performance Gain vs. Activation Space Similarity
### Overview
This image is a scatter plot comparing the performance gain of an "AC" method against a measure of similarity between the activation spaces of pairs of language models. The plot contains six data points, each labeled with a pair of model names (e.g., "qwen1.5b,qwen3b"). The overall trend suggests a positive correlation: as the activation space similarity increases, the performance gain from AC also tends to increase.
### Components/Axes
* **Chart Title:** "AC performance gain vs. "cosine similarity" (normalized squared Frobenius norm) of A,B's activation spaces"
* **Y-Axis:**
* **Label:** "AC performance gain on Biographies (AC perf. - avg(A, B) perf.)"
* **Scale:** Linear, ranging from approximately -0.025 to 0.175. Major tick marks are at intervals of 0.025 (e.g., 0.000, 0.025, 0.050, ..., 0.175).
* **Interpretation:** This axis represents the improvement in performance on a "Biographies" task when using the AC method, calculated as the AC performance minus the average performance of the two individual models (A and B). A positive value indicates AC outperforms the average of the pair.
* **X-Axis:**
* **Label:** `||Y^T X||_F^2 / (||X||_F^2 ||Y||_F^2)`
* **Scale:** Linear, ranging from approximately 0.35 to 0.65. Major tick marks are at 0.35, 0.40, 0.45, 0.50, 0.55, 0.60, and 0.65.
* **Interpretation:** This is the mathematical formula for the "cosine similarity" metric referenced in the title. It is the normalized squared Frobenius norm of the product of the transposed activation matrix Y and activation matrix X. It quantifies the similarity between the activation spaces of model A (represented by X) and model B (represented by Y). A value closer to 1 indicates higher similarity.
* **Data Points:** Six blue circular markers, each annotated with a text label identifying a pair of models. There is no separate legend; labels are placed directly adjacent to their corresponding points.
* **Grid:** A light gray dashed grid is present for both major x and y ticks.
### Detailed Analysis
The following table reconstructs the data from the six labeled points. Values are approximate based on visual inspection of the plot.
| Data Point Label (Model Pair) | Approx. X-Value (Similarity) | Approx. Y-Value (AC Gain) | Spatial Position (Relative) |
| :--- | :--- | :--- | :--- |
| `qwen1.5b,qwen3b` | 0.63 | 0.17 | Top-right corner |
| `qwen1.5b,llama3b` | 0.57 | 0.10 | Upper-middle right |
| `llama3b,gemma2b` | 0.57 | 0.03 | Center-right, below the previous point |
| `qwen1.5b,gemma2b` | 0.57 | 0.02 | Center-right, just below `llama3b,gemma2b` |
| `llama3b,llama8b` | 0.52 | 0.03 | Center |
| `gemma2b,gemma9b` | 0.35 | -0.01 | Bottom-left corner |
**Trend Verification:**
* The data series does not form a line but shows a clear upward trend from left to right.
* The point with the lowest similarity (`gemma2b,gemma9b`, x≈0.35) has a slightly negative performance gain.
* The point with the highest similarity (`qwen1.5b,qwen3b`, x≈0.63) has the highest performance gain by a significant margin.
* Three points cluster around a similarity of 0.57, with performance gains ranging from 0.02 to 0.10.
### Key Observations
1. **Positive Correlation:** There is a strong visual suggestion that higher activation space similarity between two models is associated with a greater performance gain from the AC method.
2. **Highest Performing Pair:** The pair `qwen1.5b,qwen3b` is a clear outlier in terms of gain, achieving nearly double the gain of the next highest point (`qwen1.5b,llama3b`). This pair also exhibits the highest measured similarity.
3. **Negative Gain:** The pair `gemma2b,gemma9b` is the only one showing a negative AC gain (approx. -0.01), indicating the AC method performed slightly worse than the average of the two individual models for this pair. This pair also has the lowest similarity score.
4. **Clustering at Mid-Range Similarity:** Three data points (`qwen1.5b,llama3b`, `llama3b,gemma2b`, `qwen1.5b,gemma2b`) share a very similar x-value (~0.57) but show a wide spread in y-values (0.02 to 0.10). This indicates that while similarity is a strong factor, other model-pair characteristics also significantly influence the AC gain.
### Interpretation
The chart presents empirical evidence for a hypothesis in machine learning research: the effectiveness of a model merging or ensemble technique (here called "AC") is related to the representational similarity of the constituent models.
* **What the data suggests:** The positive trend implies that the AC method is most beneficial when applied to models whose internal activation spaces are already highly aligned (high cosine similarity). When models are dissimilar (low similarity), the method may offer little benefit or even be detrimental, as seen with the `gemma2b,gemma9b` pair.
* **Relationship between elements:** The x-axis (similarity) acts as the independent variable or predictor, while the y-axis (performance gain) is the dependent outcome. The plot tests how well the former predicts the latter.
* **Notable anomalies and insights:** The cluster at x≈0.57 is particularly interesting. It shows that for a given level of similarity, the gain can vary substantially. This suggests that similarity is a necessary but not sufficient condition for high gain. The specific nature of the model pair (e.g., architecture family, size difference) likely plays a crucial secondary role. For instance, `qwen1.5b,llama3b` (cross-family) yields a much higher gain than `llama3b,gemma2b` (also cross-family) at the same similarity level, hinting at other underlying factors.
* **Peircean investigative reading:** The chart is an indexical sign pointing to a causal relationship. The physical arrangement of points (their correlation) indexes an underlying principle about model compatibility. The symbolic labels (model names) allow us to hypothesize about *why* certain pairs are more compatible. For example, the high-performing `qwen1.5b,qwen3b` pair consists of two models from the same family (Qwen) at different scales, suggesting intra-family merging might be particularly effective with this AC method. Conversely, the negative-gain `gemma2b,gemma9b` pair is also intra-family (Gemma), indicating that family alone is not a guarantee of success; the specific similarity metric captured here is a more direct indicator.
</details>
Figure 11: AC performance gain over average $A$ / $B$ individual performance on Biographies, as a function of matrix “cosine similarity” between $A$ and $B$ ’s activation spaces.
| $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ NLD AC | $\mathbf{83.9}$ $\pm 0.0$ $80.8$ $\pm 0.0$ $83.7$ $\pm 0.0$ | $60.0$ $\pm 4.9$ $\mathbf{70.0}$ $\pm 3.7$ $60.0$ $\pm 4.9$ | $65.0$ $\pm 0.1$ $\mathbf{85.0}$ $\pm 3.6$ $\mathbf{85.0}$ $\pm 3.6$ | $\mathbf{42.0}$ $\pm 0.1$ $35.0$ $\pm 4.8$ $40.0$ $\pm 4.9$ | $50.0$ $\pm 0.2$ $\mathbf{78.0}$ $\pm 4.1$ $74.0$ $\pm 4.4$ | $20.0$ $\pm 0.8$ $\mathbf{40.0}$ $\pm 4.9$ $\mathbf{40.0}$ $\pm 4.9$ | $53.0$ $\pm 0.2$ $53.0$ $\pm 5.1$ $\mathbf{79.0}$ $\pm 4.1$ |
| --- | --- | --- | --- | --- | --- | --- | --- |
Table 8: Reasoning benchmark performance of communication between identical models. Both NLD and AC involve communication between 2 instances of $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ . $512$ -token completions are sampled with temperature $0.7$ and debate is run for $2$ rounds.
Indeed, while communication between multiple model instances doesn’t always show improvement over the single model itself (a well-known result from (Du et al., 2023)), AC matches/outperforms NLD on five of the seven datasets.
The intuition behind debate between multiple identical model instances is that sampling multiple completions (with temperature) from the same model yields diverse reasoning paths that can be recombined into a stronger final answer. The above experiment shows that the same intuition holds for AC—we are sampling multiple times from the same model, but passing responses between agents via AC rather than as NL messages.
### B.6 Additional Rounds of Natural Language Debate
In Section 4.2 we fix NLD to $2$ agents and $2$ rounds, however we find in additional experiments that AC outperforms NLD even with additional rounds, highlighting the superiority and robustness of activations as an alternative “language” for inter-LM communication. Results are shown in Table 9; we see that for 5 of the 7 reasoning benchmarks, AC beats NLD even with $3$ - $4$ rounds while using substantially less compute.
| NLD (1 round) NLD (2 rounds) NLD (3 rounds) | $83.6$ $\pm 0.0$ $80.2$ $\pm 0.1$ $80.1$ $\pm 4.6$ | $72.0$ $\pm 4.5$ $75.0$ $\pm 4.3$ $\mathbf{79.0}$ $\pm 4.1$ | $65.0$ $\pm 4.8$ $83.0$ $\pm 0.8$ $70.0$ $\pm 4.6$ | $40.0$ $\pm 4.9$ $37.0$ $\pm 0.1$ $45.0$ $\pm 5.0$ | $68.0$ $\pm 4.6$ $71.0$ $\pm 0.1$ $63.0$ $\pm 4.8$ | $30.0$ $\pm 4.6$ $30.0$ $\pm 0.1$ $\mathbf{40.0}$ $\pm 4.9$ | $63.0$ $\pm 4.8$ $63.0$ $\pm 0.7$ $\mathbf{74.0}$ $\pm 4.4$ |
| --- | --- | --- | --- | --- | --- | --- | --- |
| NLD (4 rounds) | $78.0$ $\pm 0.0$ | $\mathbf{79.0}$ $\pm 4.1$ | * | * | * | * | * |
| AC | $\mathbf{84.6}$ $\pm 0.0$ | $64.0$ $\pm 4.8$ | $\mathbf{85.0}$ $\pm 0.8$ | $\mathbf{47.0}$ $\pm 0.1$ | $\mathbf{78.0}$ $\pm 0.9$ | $30.0$ $\pm 0.1$ | $\mathbf{74.0}$ $\pm 0.1$ |
∗ Runs required too much compute
Table 9: Reasoning benchmark performance of AC and NLD with varying number of rounds. All methods involve communication between $\mathtt{LLaMA}$ - $\mathtt{3.2}$ - $\mathtt{3B}$ ( $A$ ) and $\mathtt{LLaMA}$ - $\mathtt{3.1}$ - $\mathtt{8B}$ ( $B$ ).
### B.7 Full MMLU Benchmark Results
Table 10 below displays complete results of both AC and NLD on the full MMLU benchmark. Notably, AC matches/outperforms NLD on 48/57 datasets, with substantially less compute used, indicating its superiority and robustness as an alternative “language” for inter-LLM communication.
| Conceptual Physics High School Chemistry Security Studies | $60.0\pm 4.9$ $\mathbf{50.0\pm 5.0}$ $60.0\pm 4.9$ | $\mathbf{68.0\pm 4.6}$ $37.0\pm 4.8$ $60.0\pm 4.9$ |
| --- | --- | --- |
| Jurisprudence | $84.0\pm 3.6$ | $84.0\pm 3.6$ |
| Logical Fallacies | $63.0\pm 4.8$ | $\mathbf{72.0\pm 4.5}$ |
| College Computer Science | $44.0\pm 5.0$ | $44.0\pm 5.0$ |
| International Law | $55.0\pm 5.0$ | $\mathbf{59.0\pm 4.9}$ |
| Miscellaneous | $90.0\pm 3.0$ | $\mathbf{95.0\pm 2.2}$ |
| Marketing | $70.0\pm 4.6$ | $\mathbf{85.0\pm 3.6}$ |
| Elementary Mathematics | $\mathbf{75.0\pm 4.3}$ | $58.0\pm 4.9$ |
| Machine Learning | $42.0\pm 4.9$ | $42.0\pm 4.9$ |
| High School Macroeconomics | $44.0\pm 5.0$ | $\mathbf{75.0\pm 4.3}$ |
| High School US History | $45.0\pm 5.0$ | $\mathbf{71.0\pm 4.6}$ |
| Human Aging | $56.0\pm 5.0$ | $\mathbf{72.0\pm 4.5}$ |
| Astronomy | $79.0\pm 4.1$ | $\mathbf{80.0\pm 4.0}$ |
| Computer Security | $56.0\pm 5.0$ | $\mathbf{75.0\pm 4.3}$ |
| High School Statistics | $\mathbf{55.0\pm 5.0}$ | $42.0\pm 4.9$ |
| Professional Medicine | $\mathbf{79.0\pm 4.1}$ | $65.0\pm 4.8$ |
| Electrical Engineering | $58.0\pm 4.9$ | $\mathbf{60.0\pm 4.9}$ |
| High School Computer Science | $63.0\pm 4.8$ | $\mathbf{70.0\pm 4.6}$ |
| College Physics | $\mathbf{50.0\pm 5.0}$ | $28.0\pm 4.5$ |
| Management | $74.0\pm 4.1$ | $\mathbf{75.0\pm 4.3}$ |
| Moral Scenarios | $40.0\pm 4.9$ | $40.0\pm 4.9$ |
| World Religions | $58.0\pm 4.9$ | $\mathbf{72.0\pm 4.5}$ |
| Virology | $47.0\pm 5.0$ | $\mathbf{50.0\pm 5.0}$ |
| Philosophy | $67.0\pm 4.7$ | $\mathbf{70.0\pm 4.6}$ |
| Abstract Algebra | $\mathbf{50.0\pm 5.0}$ | $28.0\pm 4.5$ |
| High School Government and Politics | $\mathbf{80.0\pm 4.0}$ | $61.0\pm 4.9$ |
| High School Biology | $60.0\pm 4.9$ | $\mathbf{65.0\pm 4.8}$ |
| College Mathematics | $64.0\pm 4.8$ | $\mathbf{66.0\pm 2.4}$ |
| Global Facts | $33.0\pm 5.0$ | $\mathbf{37.0\pm 4.8}$ |
| High School World History | $71.0\pm 4.0$ | $\mathbf{74.0\pm 4.4}$ |
| High School European History | $68.0\pm 4.0$ | $\mathbf{71.0\pm 4.6}$ |
| College Medicine | $\mathbf{65.0\pm 4.8}$ | $53.0\pm 5.0$ |
| High School Geography | $67.0\pm 4.7$ | $\mathbf{79.0\pm 4.1}$ |
| Anatomy | $74.0\pm 4.4$ | $74.0\pm 4.4$ |
| Human Sexuality | $75.0\pm 4.3$ | $75.0\pm 4.3$ |
| Medical Genetics | $79.0\pm 4.1$ | $\mathbf{82.0\pm 3.8}$ |
| Professional Accounting | $40.0\pm 4.9$ | $\mathbf{48.0\pm 4.5}$ |
| US Foreign Policy | $89.0\pm 3.1$ | $\mathbf{90.0\pm 3.1}$ |
| Business Ethics | ${43.0\pm 5.0}$ | $\mathbf{44.0\pm 5.0}$ |
| College Chemistry | ${41.0\pm 5.0}$ | $\mathbf{47.0\pm 5.0}$ |
| High School Physics | ${40.0\pm 5.0}$ | $\mathbf{47.0\pm 5.0}$ |
| Professional Psychology | ${54.0\pm 4.8}$ | $\mathbf{55.0\pm 5.0}$ |
| Sociology | ${68.0\pm 4.1}$ | $\mathbf{68.0\pm 4.6}$ |
| High School Microeconomics | $95.0\pm 2.2$ | $95.0\pm 2.2$ |
| High School Mathematics | $55.0\pm 5.0$ | $55.0\pm 5.0$ |
| Prehistory | $\mathbf{75.0\pm 4.3}$ | $60.0\pm 4.9$ |
| Nutrition | ${64.0\pm 4.5}$ | $\mathbf{70.0\pm 4.6}$ |
| Clinical Knowledge | ${65.0\pm 4.3}$ | $65.0\pm 4.8$ |
| Moral Disputes | ${58.0\pm 4.8}$ | $\mathbf{60.0\pm 4.9}$ |
| Econometrics | ${40.0\pm 5.0}$ | $40.0\pm 4.9$ |
| High School Psychology | $83.0\pm 0.8$ | $\mathbf{85.0\pm 0.8}$ |
| Formal Logic | $37.0\pm 0.1$ | $\mathbf{47.0\pm 0.1}$ |
| College Biology | $71.0\pm 0.1$ | $\mathbf{78.0\pm 0.9}$ |
| Professional Law | $30.0\pm 0.1$ | $30.0\pm 0.1$ |
| Public Relations | $63.0\pm 0.7$ | $\mathbf{74.0\pm 0.1}$ |
| Average | $60.7\pm 2.0$ | $\mathbf{62.7\pm 2.2}$ |
Table 10: Comparison of NLD vs. AC on the full MMLU benchmark (Hendrycks et al., 2021).