# AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Document Understanding
Abstract
Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), lack inductive bias to constrain visual features within the linguistic structure of the LLM’s embedding space, making them data-hungry and prone to cross-modal misalignment. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where visual and textual modalities are highly correlated. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods, with larger gains on document understanding tasks and under low-resource setups. We provide further analysis demonstrating its efficiency and robustness to noise.
1 Introduction
Vision-Language Models (VLMs) have gained significant traction in recent years as a powerful framework for multimodal document understanding tasks that involve interpreting both the visual and textual contents of scanned documents (Kim et al., 2022; Lee et al., 2023; Liu et al., 2023a, 2024; Hu et al., 2024; Wang et al., 2023a; Rodriguez et al., 2024b). Such tasks are common in real-world commercial applications, including invoice parsing (Park et al., 2019), form reading (Jaume et al., 2019), and document question answering (Mathew et al., 2021b). VLM architectures typically consist of three components: (i) a vision encoder to process raw images, (ii) a Large Language Model (LLM) pre-trained on text, and (iii) a connector module that maps the visual features from the vision encoder into the LLM’s semantic space.
A central challenge in this pipeline is to effectively map the continuous feature embeddings of the vision encoder into the latent space of the LLM while preserving the semantic properties of visual concepts. Existing approaches can be broadly categorized into deep fusion and shallow fusion methods. Deep fusion methods, such as NVLM (Dai et al., 2024), Flamingo (Alayrac et al., 2022), CogVLM (Wang et al., 2023b), and LLama 3.2-Vision (Grattafiori et al., 2024), integrate visual and textual features by introducing additional cross-attention and feed-forward layers at each layer of the LLM. While effective at enhancing cross-modal interaction, these methods substantially increase the parameter count of the VLM compared to the base LLM, resulting in high computational overhead and reduced efficiency.
<details>
<summary>x1.png Details</summary>
### Visual Description
# Technical Data Extraction: Radar Chart Performance Comparison
## 1. Image Overview
This image is a radar chart (spider chart) comparing the performance of four different AI model configurations across nine distinct benchmarks. The chart uses a circular grid with nine axes radiating from a central point. Each model is represented by a colored line and shaded area.
## 2. Component Isolation
### Header/Labels (Benchmarks)
The chart evaluates models across nine benchmarks, arranged clockwise starting from the top:
1. **DeepForm**
2. **InfoVQA**
3. **DocVQA**
4. **TableVQA**
5. **TextVQA**
6. **ChartQA**
7. **TabFact**
8. **WTQ**
9. **KLC**
### Legend (Footer)
The legend is located at the bottom of the image.
* **Brown (Circle marker):** `Llama-3.2-3B-Perciever R.`
* **Light Green (Circle marker):** `Llama-3.2-3B-MLP`
* **Dark Blue (Circle marker):** `Llama-3.2-3B-Ovis`
* **Orange (Circle marker):** `Llama-3.2-3B-Align (ours)` (Bolded in legend)
---
## 3. Data Table Reconstruction
The following table extracts the numerical values associated with each data point on the radar chart.
| Benchmark | Llama-3.2-3B-Perciever R. (Brown) | Llama-3.2-3B-MLP (Light Green) | Llama-3.2-3B-Ovis (Dark Blue) | Llama-3.2-3B-Align (ours) (Orange) |
| :--- | :---: | :---: | :---: | :---: |
| **DeepForm** | 57.08 | 62.07 | 58.02 | **63.49** |
| **InfoVQA** | 34.13 | 37.56 | 42.11 | **44.53** |
| **DocVQA** | 69.08 | 71.46 | 74.68 | **79.63** |
| **TableVQA** | 51.33 | 53.93 | 53.93 | **60.1** |
| **TextVQA** | 52.6 | 53.56 | 51.33 | **57.38** |
| **ChartQA** | 65.16 | 66.48 | 67.92 | **71.88** |
| **TabFact** | 71.93 | 73.22 | 76.67 | **78.51** |
| **WTQ** | 27.95 | 28.94 | 33.13 | **38.59** |
| **KLC** | 31.75 | 33.36 | 33.5 | **35.25** |
---
## 4. Trend Verification and Analysis
### Llama-3.2-3B-Align (ours) - Orange Line
* **Trend:** This series forms the outermost perimeter of the radar chart. It slopes outward at every single axis compared to the other models.
* **Observation:** This model consistently achieves the highest score across all nine benchmarks. It shows significant leads in **DocVQA (79.63)** and **WTQ (38.59)**.
### Llama-3.2-3B-Ovis - Dark Blue Line
* **Trend:** Generally the second-best performer. It follows the shape of the orange line but sits slightly inward.
* **Observation:** It performs particularly well on **TabFact (76.67)** and **DocVQA (74.68)**, but falls behind the MLP version on **TextVQA (51.33)**.
### Llama-3.2-3B-MLP - Light Green Line
* **Trend:** This series fluctuates between the 2nd and 3rd position.
* **Observation:** It outperforms the Ovis model on **TextVQA (53.56)** and **DeepForm (62.07)**, but generally lags behind Ovis on VQA-specific tasks like **InfoVQA** and **DocVQA**.
### Llama-3.2-3B-Perciever R. - Brown Line
* **Trend:** This series forms the innermost shape, indicating it is the baseline or lowest-performing model in this set.
* **Observation:** It has the lowest scores across all categories, with its lowest relative performance seen in **WTQ (27.95)** and **InfoVQA (34.13)**.
---
## 5. Summary of Findings
The chart demonstrates that the **Llama-3.2-3B-Align (ours)** model provides a comprehensive performance improvement over the other three configurations. The performance gap is most pronounced in document and table understanding tasks (**DocVQA, TableVQA, WTQ**). All models follow a similar performance profile (e.g., all models score relatively lower on WTQ and KLC compared to TabFact or DocVQA), suggesting these benchmarks are inherently more challenging for this model family.
</details>
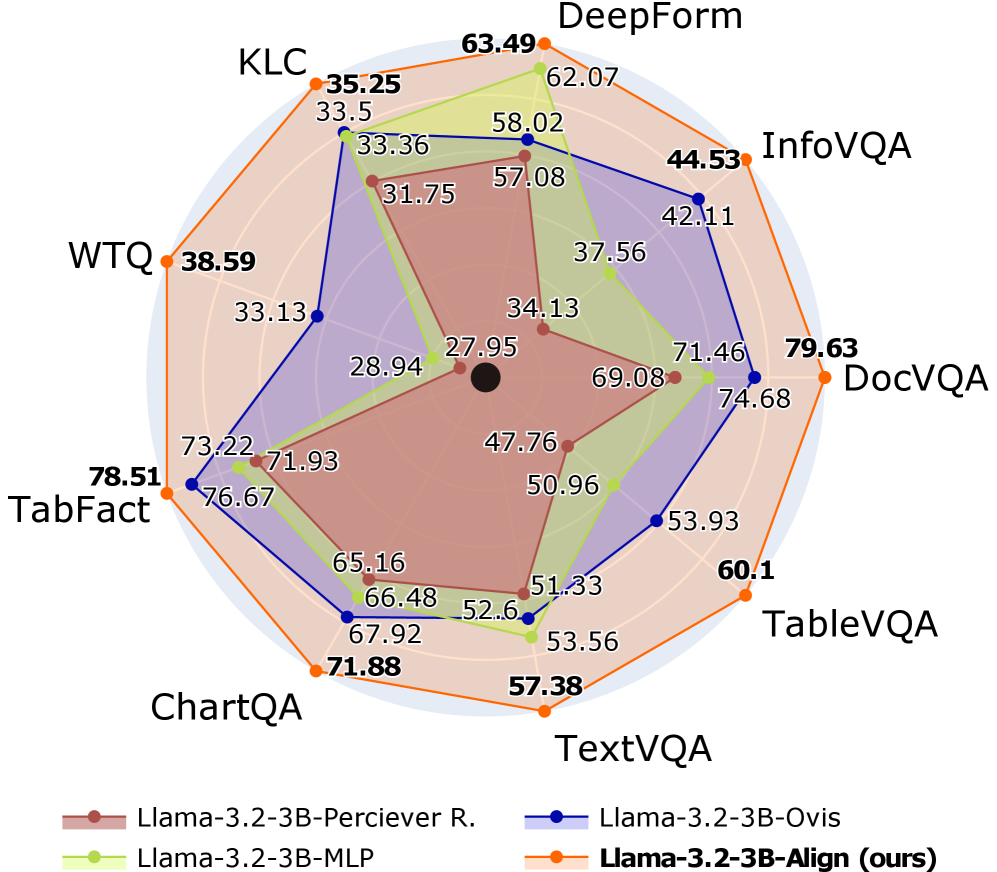
Figure 1: Performance of Different VLM Connectors. The proposed Align connector outperforms other methods across benchmarks using the same training configuration. Radial distance is proportion of maximal score, truncated at $0.7$ (black dot).
In contrast, shallow fusion methods project visual features from the vision encoder into the LLM input embedding space using either multilayer perceptrons (MLPs) (Liu et al., 2023b, 2024), convolution mappings such as HoneyBee (Cha et al., 2024) and H-Reducer (Hu et al., 2024), or attention-based mechanisms such as the Perceiver Resampler (Li et al., 2023b; Laurençon et al., 2024; Alayrac et al., 2022). This approach is more parameter-efficient and computationally lighter than deep fusion method However, these connectors lack inductive bias to ensure that the projected features remain within the region spanned by the LLM’s pretrained text embeddings. Consequently, the projected visual features may fall outside the distribution the LLM was trained on, leading to noisy or misaligned representations. Moreover, these mappings are typically learned from scratch, making them data-inefficient and less effective under low-resource conditions.
Recent methods like Ovis (Lu et al., 2024) attempt to alleviate these issues by introducing separate visual embeddings indexed from the vision encoder outputs and combined together to construct the visual inputs to the LLM. However, this approach significantly increases parameter count due to the massive embedding matrix and requires extensive training to learn a new embedding space without guaranteeing alignment with the LLM’s input latent space.
To address these limitations, this paper introduces AlignVLM, a novel framework that sidesteps direct projection of visual features into the LLM embedding space. Instead, our proposed connector, Align, maps visual features into probability distributions over the LLM’s existing pretrained vocabulary embeddings, which are then combined into a weighted representation of the text embeddings. By constraining each visual feature as a convex combination of the LLM text embeddings, our approach leverages the linguistic priors already encoded in the LLM’s text space. This ensures that the resulting visual features lie within the convex hull of the LLM’s embedding space, reducing the risk of noisy or out-of-distribution inputs and improving alignment between modalities. The connector thus enables faster convergence and stronger performance, particularly in low-resource scenarios.
Our experimental results show that Align improves performance on various document understanding tasks, outperforming prior connector methods, with especially large gains in low-data regimes. We summarize our main contributions as follows:
- We propose a novel connector, Align, to bridge the representation gap between vision and text modalities.
- We introduce a family of Vision-Language Models, AlignVLM, that achieves state-of-the-art performance on multimodal document understanding tasks by leveraging Align.
- We conduct extensive experiments demonstrating the robustness and effectiveness of Align across different LLM sizes and training data setups.
We release our code and research artifacts at alignvlm.github.io.
2 Related Work
2.1 Vision-Language Models
Over the past few years, Vision-Language Models (VLMs) have achieved remarkable progress, largely due to advances in Large Language Models (LLMs). Initially demonstrating breakthroughs in text understanding and generation (Brown et al., 2020; Raffel et al., 2023; Achiam et al., 2023; Grattafiori et al., 2024; Qwen et al., 2025; Team, 2024), LLMs are now increasingly used to effectively interpret visual inputs (Liu et al., 2023b; Li et al., 2024; Wang et al., 2024; Chen et al., 2024b; Dai et al., 2024; Drouin et al., 2024; Rodriguez et al., 2022). This progress has enabled real-world applications across diverse domains, particularly in multimodal document understanding for tasks like form reading (Svetlichnaya, 2020), document question answering (Mathew et al., 2021b), and chart question answering (Masry et al., 2022). VLMs commonly adopt a three-component architecture: a pretrained vision encoder (Zhai et al., 2023; Radford et al., 2021), a LLM, and a connector module. A key challenge for VLMs is effectively aligning visual features with the LLM’s semantic space to enable accurate and meaningful multimodal interpretation.
2.2 Vision-Language Alignment for Multimodal Models
Existing vision-language alignment approaches can be classified into deep fusion and shallow fusion. Deep fusion methods integrate visual and textual features by modifying the LLM’s architecture, adding cross-attention and feed-forward layers. For example, Flamingo (Alayrac et al., 2022) employs the Perceiver Resampler, which uses fixed latent embeddings to attend to vision features and fuses them into the LLM via gated cross-attention layers. Similarly, NVLM (Dai et al., 2024) adopts cross-gated attention while replacing the Perceiver Resampler with a simpler MLP. CogVLM (Wang et al., 2023b) extends this approach by incorporating new feed-forward (FFN) and QKV layers for the vision modality within every layer of the LLM. While these methods improve cross-modal alignment, they significantly increase parameter counts and computational overhead, making them less efficient.
On the other hand, shallow fusion methods are more computationally efficient, mapping visual features into the LLM’s embedding space without altering its architecture. These methods can be categorized into three main types: (1) MLP-based mapping, such as LLaVA (Liu et al., 2023b) and PaliGemma (Beyer et al., 2024), which use multilayer perceptrons (MLP) to project visual features but often produce misaligned or noisy features due to a lack of constraints and inductive bias (Rodriguez et al., 2024b); (2) cross-attention mechanisms, BLIP-2 (Li et al., 2023b) uses Q-Former, which utilizes a fixed set of latent embeddings to cross-attend to visual features, but that may still produce noisy or OOD visual features; (3) convolution-based mechanisms, such as HoneyBee (Cha et al., 2024) and H-Reducer (Hu et al., 2024), which leverage convolutional or ResNet (He et al., 2015) layers to preserve spatial locality while reducing dimensionality; and (4) visual embeddings, such as those introduced by Ovis (Lu et al., 2024), which use embeddings indexed by the vision encoder’s outputs to produce the visual inputs. While this regularizes feature mapping, it adds substantial parameter overhead and creates a new vision embedding space, risking misalignment with the LLM’s text embedding space. Encoder-free VLMs, like Fuyu-8B https://www.adept.ai/blog/fuyu-8b and EVE (Diao et al., 2024), eliminate dedicated vision encoders but show degraded performance (Beyer et al., 2024).
In contrast, AlignVLM maps visual features from the vision encoder into probability distributions over the LLM’s text embeddings, using them to compute a convex combination. By leveraging the linguistic priors encoded in the LLM’s vocabulary, AlignVLM ensures that visual features remain within the convex hull of the text embedding. This design mitigates noisy or out-of-distribution projections and achieves stronger multimodal alignment, particularly in tasks that require joint modalities representation like multimodal document understanding and in low-resource settings.
<details>
<summary>x2.png Details</summary>
### Visual Description
# Technical Document Extraction: Align Module Architecture
This document provides a comprehensive technical breakdown of the provided architectural diagram, which illustrates a multimodal Large Language Model (LLM) pipeline utilizing an "Align Module" to process visual and textual data.
## 1. Input Data (Left Region)
The system receives two types of inputs: a complex infographic and a natural language question.
### A. Visual Input (Infographic)
The infographic consists of six panels containing text and data visualizations:
1. **Top Left Panel:**
* **Header:** AMERICANS WANT TO BE DISTRACTED FROM REALITY
* **Body Text:** The more than 100 million active users of FarmVille spend an average of 15 minutes a day pretending to run a farm. Over the course of a year, that's 5,475 minutes—the equivalent of a full-time job for over two weeks!
2. **Top Middle Panel:**
* **Header:** AMERICANS LOVE VIDEO GAMES
* **Body Text:** Video games are the most popular form of entertainment in the U.S., accounting for 10% of all U.S. leisure time.
3. **Top Right Panel:**
* **Header:** AMERICANS ARE HYPER-SOCIAL
* **Body Text:** Social media now reaches the majority of Americans (51%), with 30% having a profile on one or more social networks.
4. **Bottom Left Panel:**
* **Header:** AMERICANS ARE CONNECTED
* **Body Text:** The vast of women Americans houses have broadband internet access. [Note: Text contains grammatical errors as transcribed].
* **Sub-statistic:** 9 OUT OF 10 AMERICANS ARE ONLINE. (Accompanied by an icon chart showing 9 blue figures and 1 grey figure).
5. **Bottom Middle Panel:**
* **Header:** AMERICANS LOVE ROUTINE
* **Body Text:** Of the more than 140 million Americans active on Facebook, 70% of those active users in the U.S. log on to the social network daily. Tagged comes in 2nd with the average user logging in every other day.
* **Sub-statistic:** 70% OF THOSE ACTIVE ON FACEBOOK LOG ONTO THE SOCIAL NETWORK DAILY. (Accompanied by a pie chart).
6. **Bottom Right Panel:**
* **Header:** AMERICANS ARE HIGHLY INFLUENCED BY OTHERS
* **Body Text:** The purchasing decisions of 3M million [sic] Americans in the U.S. are now influenced in various ways by social media—up 14% in just six months.
### B. Textual Input (Query)
* **Question:** "What percentage of Americans are online?"
---
## 2. Processing Pipeline (Main Diagram)
The architecture is divided into three primary stages: Encoding, Alignment, and Generation.
### Stage 1: Encoding
* **Vision Encoder (Blue Block):** Receives the infographic image. It outputs a feature representation to the Align Module.
* **Text Tokenizer (Pink Block):** Receives the text question. It converts the string into tokens which are then mapped to the **LLM Embedding Matrix**.
### Stage 2: The Align Module (Central Dashed Orange Box)
This module aligns visual features with the LLM's semantic space.
* **Projection Layer (Top Sequence):** The output from the Vision Encoder passes through a series of layers:
1. **Linear**
2. **Layer Norm**
3. **LM Head (LLM)** (Highlighted in pink, indicating it uses the LLM's own weights).
4. **Layer Norm**
5. **Softmax**
* **Weighted Average Sum:** This component takes the Softmax probabilities and the **Full Embedding Matrix** (sourced from the LLM Embedding Matrix) to calculate a weighted representation of the image.
* **Output Buffers:**
* **Vision Inputs (Blue):** A stack of vectors representing the visual information in the LLM's embedding space.
* **Text Inputs (Pink):** "Selected Text Embeddings" derived directly from the LLM Embedding Matrix based on the input question.
### Stage 3: LLM Generation
* **LLM (Large Pink Block):** Receives the concatenated Vision Inputs and Text Inputs.
* **Response:** The LLM processes the multimodal context to produce the final answer.
* **Output Value:** "Response: 90%" (Derived from the "9 out of 10" statistic in the infographic).
---
## 3. Component Summary Table
| Component | Color Code | Function |
| :--- | :--- | :--- |
| **Vision Path** | Blue | Processes image data into visual tokens. |
| **Text Path** | Pink | Processes query data into text tokens. |
| **Align Module** | Orange (Dashed) | Bridges the gap between visual features and LLM embeddings. |
| **LM Head (LLM)** | Pink (Internal) | Uses the LLM's vocabulary head to project visual features. |
| **LLM** | Pink (Large) | The core reasoning engine that generates the final text output. |
## 4. Logical Flow Summary
1. **Image** is encoded into features.
2. **Question** is tokenized into embeddings.
3. The **Align Module** uses the LLM's own embedding matrix and LM head to transform visual features into "Vision Inputs" that the LLM can understand as if they were text.
4. The **LLM** reads both the Vision Inputs and Text Inputs to find the answer "90%" within the visual data.
</details>
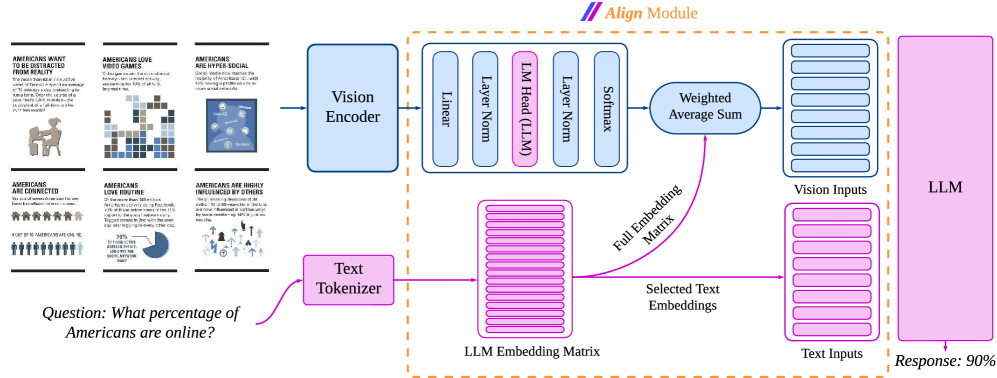
Figure 2: AlignVLM Model Architecture. The vision encoder extracts image features, which are processed to produce probabilities over the LLM embeddings. A weighted average combines these probabilities with embeddings to generate vision input vectors. Text inputs are tokenized, and the corresponding embeddings are selected from the embedding matrix, which is then used as input to the LLM. We display the vision layers in blue, and the text layers in purple.
3 Methodology
3.1 Model Architecture
The overall model architecture, shown in Figure 2, consists of three main components:
(1) Vision Encoder.
To handle high-resolution images of different aspect ratios, we divide each input image into multiple tiles according to one of the predefined aspect ratios (e.g., $1{:}1,\,1{:}2,\,...,\,9{:}1$ ) chosen via a coverage ratio (Lu et al., 2024; Chen et al., 2024a). Due to limited computational resources, we set the maximum number of tiles to 9. Each tile is further partitioned into $14× 14$ patches, projected into vectors, and processed by a SigLip-400M vision encoder (Zhai et al., 2023) to extract contextual visual features.
Each tile $t∈\{1,·s,T\}$ is divided into $N_{t}$ patches
$$
\mathbf{P}_{t}=\{\mathbf{p}_{t,1},\cdots,\mathbf{p}_{t,N_{t}}\},
$$
where $\mathbf{p}_{t,i}$ is the $i$ -th patch of tile $t$ . The vision encoder maps these patches to a set of visual feature vectors
| | $\displaystyle\mathbf{F}_{t}=\mathrm{VisionEncoder}(\mathbf{P}_{t}),\quad\mathbf{F}_{t}=\{\mathbf{f}_{t,1},·s,\mathbf{f}_{t,N_{t}}\},\quad\mathbf{f}_{t,i}∈\mathbb{R}^{d}.$ | |
| --- | --- | --- |
Finally, we concatenate the feature sets across all tiles into a single output
$$
\mathbf{F}=\mathrm{concat}\Bigl(\mathbf{F}_{1},\mathbf{F}_{2},\cdots,\mathbf{F}_{T}\Bigr).
$$
(2) Align Module.
This module aligns the visual features with the LLM. A linear layer $\mathbf{W}_{1}∈\mathbb{R}^{D× d}$ first projects the visual features $\mathbf{F}∈\mathbb{R}^{T· N_{t}× d}$ to the LLM’s token embedding space: one $\mathbb{R}^{D}$ vector per token. A second linear layer $\mathbf{W}_{2}∈\mathbb{R}^{V× D}$ (initialized from the LLM’s language-model head) followed by a softmax, produces a probability simplex $\mathbf{P}_{\text{vocab}}$ over the LLM’s vocabulary ( $V$ tokens)
$$
\mathbf{P}_{\text{vocab}}=\operatorname{softmax}(\operatorname{LayerNorm}(\mathbf{W}_{2}\operatorname{LayerNorm}(\mathbf{W}_{1}\mathbf{F}))) \tag{1}
$$
We then use the LLM text embeddings $\mathbf{E}_{\text{text}}∈\mathbb{R}^{V× D}$ to compute a weighted sum
$$
\mathbf{F}_{\text{align}}^{\prime}=\mathbf{P}_{\text{vocab}}^{\top}\mathbf{E}_{\text{text}}. \tag{2}
$$
Finally, we concatenate $\mathbf{F}_{\text{align}}^{\prime}$ with the tokenized text embeddings to form the LLM input
$$
\mathbf{H}_{\text{input}}=\mathrm{concat}\bigl(\mathbf{F}_{\text{align}}^{\prime},\mathbf{E}_{\text{text}}(\mathbf{x})\bigr),
$$
where $\mathbf{E}_{\text{text}}(\mathbf{x})$ is obtained by tokenizing the input text $\mathbf{x}=(x_{1},·s,x_{M})$ and selecting the corresponding embeddings from $\mathbf{E}_{\text{text}}$ such that
$$
\displaystyle\mathbf{E}_{\text{text}}(\mathbf{x}) \displaystyle=\bigl[\mathbf{E}_{\text{text}}(x_{1}),\cdots,\mathbf{E}_{\text{text}}(x_{M})\bigr]. \tag{3}
$$
(3) Large Language Model.
We feed the concatenated vision and text vectors, $\mathbf{H}_{\text{input}}$ , into the LLM, which then generates output text auto-regressively. To demonstrate the effectiveness of our alignment technique, we experiment with the Llama 3.1 model family (Grattafiori et al., 2024). These models offer state-of-the-art performance and permissive licenses, making them suitable for commercial applications. In particular, we utilize Llama 3.2-1B, Llama 3.2-3B, and Llama 3.1-8B.
3.2 Motivation and relation with existing methods
By construction, each $\mathbb{R}^{D}$ representation in $\mathbf{F}_{\text{align}}^{\prime}$ is constrained to the convex hull of the points $\mathbb{E}_{\text{text}}$ , thus concentrating the visual features in the part of latent space that the LLM can effectively interpret. Moreover, we argue that our initialization of $\mathbf{W}_{2}$ to the language model head is an inductive bias toward recycling some of the semantics of these text tokens into visual tokens. This contrasts with past methods that have been proposed to adapt the vision encoder outputs $\mathbf{F}∈\mathbb{R}^{T· N_{t}× d}$ to an $\mathbf{F}^{\prime}∈\mathbb{R}^{T· N_{t}× D}$ to be fed to the LLM. Here, we consider two examples in more detail, highlighting these contrasts.
(1) MLP Connector Liu et al. (2023b) applies a linear projection with parameters $\mathbf{W}_{\text{MLP}}∈\mathbb{R}^{D× d}$ and $\mathbf{b}_{\text{MLP}}∈\mathbb{R}^{D}$ , followed by an activation function $\sigma$ (e.g., ReLU)
$$
\mathbf{F}_{\text{MLP}}^{\prime}=\sigma(\mathbf{W}_{\text{MLP}}\mathbf{F}+\mathbf{b}_{\text{MLP}}).
$$
These parameters are all learned from scratch, without any bias aligning them to text embeddings.
(2) Visual Embedding Table Lu et al. (2024) introduces an entire new set of visual embeddings $\mathbf{E}_{\text{VET}}∈\mathbb{R}^{K× D}$ which, together with the weights $\mathbf{W}_{\text{VET}}∈\mathbb{R}^{K× d}$ , specifies
$$
\mathbf{F}_{\text{VET}}^{\prime}=\operatorname{softmax}(\mathbf{W}_{\text{VET}}\mathbf{F})^{\top}\mathbf{E}_{\text{VET}}.
$$
When $D<d$ , our $\mathbf{W}_{2}\mathbf{W}_{1}$ amounts to a low-rank version of $\mathbf{W}_{\text{VET}}$ . There is thus much more to learn to obtain $\mathbf{F}_{\text{VET}}^{\prime}$ , and there is again no explicit pressure to align it with the text embeddings.
3.3 Training Datasets & Stages
We train our model in three stages:
Stage 1.
This stage focuses on training the Align Module to map visual features to the LLM’s text embeddings effectively. We use the CC-12M dataset Changpinyo et al. (2021), a large-scale web dataset commonly used for VLM pretraining Liu et al. (2023b), which contains 12M image-text pairs. However, due to broken or unavailable links, we retrieved 8.1M pairs. This dataset facilitates the alignment of visual features with the text embedding space of the LLM. During this stage, we train the full model, as this approach improves performance and stabilizes the Align Module training.
Stage 2.
The goal is to enhance the model’s document understanding capabilities, such as OCR, document structure comprehension, in-depth reasoning, and instruction-following. We leverage the BigDocs-7.5M dataset Rodriguez et al. (2024a), a curated collection of license-permissive datasets for multimodal document understanding. This dataset aligns with the Accountability, Responsibility, and Transparency (ART) principles Bommasani et al. (2023); Vogus and Llansóe (2021), ensuring compliance for commercial applications. As in Stage 1, we train the full model during this stage.
Stage 3.
To enhance the model’s instruction-tuning capabilities, particularly for downstream tasks like question answering, we further train it on the DocDownstream Rodriguez et al. (2024a); Hu et al. (2024) instruction tuning dataset. In this stage, the vision encoder is frozen, focusing training exclusively on the LLM and Align module.
4 Experimental Setup
Table 1: Main Results on General Document Benchmarks. We compare AlignVLM (ours) with state-of-the-art (SOTA) open and closed-source instructed models, and with base models that we trained using the process described in Section 3.3. AlignVLM models outperform all Base VLM models trained in the same data regime. Our models also perform competitively across document benchmarks even compared with SOTA models, in which the data regime is more targeted and optimized. Color coding for comparison: closed-source models, open-source models below 7B parameters, open-source models between 7-12B parameters.
| Model | DocVQA VAL | InfoVQA VAL | DeepForm TEST | KLC TEST | WTQ TEST | TabFact TEST | ChartQA TEST | TextVQA VAL | TableVQA TEST | Avg. Score |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Closed-Source VLMs | | | | | | | | | | |
| (Opaque Training Data) | | | | | | | | | | |
| Claude-3.5 Sonnet | 88.48 | 59.05 | 31.41 | 24.82 | 47.13 | 53.48 | 51.84 | 71.42 | 81.27 | 56.54 |
| GeminiPro-1.5 | 91.23 | 73.94 | 32.16 | 24.07 | 50.29 | 71.22 | 34.68 | 68.16 | 80.43 | 58.46 |
| GPT-4o 20240806 | 92.80 | 66.37 | 38.39 | 29.92 | 46.63 | 81.10 | 85.70 | 70.46 | 72.87 | 64.91 |
| Open-Source Instruct VLMs | | | | | | | | | | |
| (Semi-Opaque Training Data) | | | | | | | | | | |
| Janus- 1.3B (Wu et al., 2024a) | 30.15 | 17.09 | 0.62 | 15.06 | 9.30 | 51.34 | 57.20 | 51.97 | 18.67 | 27.93 |
| Qwen2-VL- 2B (Wang et al., 2024) | 89.16 | 64.11 | 32.38 | 25.18 | 38.20 | 57.21 | 73.40 | 79.90 | 43.07 | 55.84 |
| Qwen2.5-VL- 3B (Wang et al., 2024) | 93.00 | 75.83 | 32.84 | 24.82 | 53.46 | 71.16 | 83.91 | 79.29 | 71.66 | 65.10 |
| InternVL-2.5- 2B (Chen et al., 2024b) | 87.70 | 61.85 | 13.14 | 16.58 | 36.33 | 57.26 | 74.96 | 76.85 | 42.20 | 51.87 |
| InternVL-3- 2B (Zhu et al., 2025) | 87.33 | 66.99 | 37.90 | 29.79 | 39.44 | 59.91 | 75.32 | 78.69 | 43.46 | 57.64 |
| DeepSeek-VL2-Tiny- 3.4B (Wu et al., 2024b) | 88.57 | 63.88 | 25.11 | 19.04 | 35.07 | 52.15 | 80.92 | 80.48 | 56.30 | 55.72 |
| Phi3.5-Vision- 4B (Abdin et al., 2024) | 86.00 | 56.20 | 10.47 | 7.49 | 17.18 | 30.43 | 82.16 | 73.12 | 70.70 | 48.19 |
| Qwen2-VL- 7B (Wang et al., 2024) | 93.83 | 76.12 | 34.55 | 23.37 | 52.52 | 74.68 | 83.16 | 84.48 | 53.97 | 64.08 |
| Qwen2.5-VL- 7B (Bai et al., 2025) | 94.88 | 82.49 | 42.21 | 24.26 | 61.96 | 78.56 | 86.00 | 85.35 | 76.10 | 70.20 |
| LLaVA-NeXT- 7B (Xu et al., 2024) | 63.51 | 30.90 | 1.30 | 5.35 | 20.06 | 52.83 | 52.12 | 65.10 | 32.87 | 36.00 |
| DocOwl1.5- 8B (Hu et al., 2024) | 80.73 | 49.94 | 68.84 | 37.99 | 38.87 | 79.67 | 68.56 | 68.91 | 52.60 | 60.68 |
| InternVL-2.5- 8B (Chen et al., 2024b) | 91.98 | 75.36 | 34.55 | 22.31 | 50.33 | 74.75 | 82.84 | 79.00 | 52.10 | 62.58 |
| InternVL-3- 8B (Zhu et al., 2025) | 91.99 | 73.90 | 51.24 | 36.41 | 53.60 | 72.27 | 85.60 | 82.41 | 53.26 | 66.74 |
| Fuyu- 8B (Bavishi et al., 2023) | 48.97 | 23.09 | 4.78 | 6.63 | 14.55 | 47.91 | 44.36 | 46.02 | 15.49 | 22.97 |
| Ovis-1.6-Gemma2- 9B (Lu et al., 2024) | 88.84 | 73.97 | 45.16 | 23.91 | 50.72 | 76.66 | 81.40 | 77.73 | 48.33 | 62.96 |
| Llama3.2- 11B (Grattafiori et al., 2024) | 82.71 | 36.62 | 1.78 | 3.47 | 23.03 | 58.33 | 23.80 | 54.28 | 22.40 | 34.04 |
| Pixtral- 12B (Agrawal et al., 2024) | 87.67 | 49.45 | 27.37 | 24.07 | 45.18 | 73.53 | 71.80 | 76.09 | 67.13 | 58.03 |
| Document Understanding Instructed Models | | | | | | | | | | |
| (Instruction Tuned on BigDocs-7.5M + DocDownStream (Rodriguez et al., 2024a; Hu et al., 2024)) | | | | | | | | | | |
| Qwen2-VL- 2B (base+) (Wang et al., 2024) | 57.23 | 31.88 | 49.31 | 34.39 | 31.61 | 64.75 | 68.60 | 61.01 | 47.53 | 49.59 |
| AlignVLM -Llama-3.2- 1B (ours) | 72.42 | 38.16 | 60.47 | 33.71 | 28.66 | 71.31 | 65.44 | 48.81 | 50.29 | 52.14 |
| AlignVLM -Llama-3.2- 3B (ours) | 79.63 | 44.53 | 63.49 | 35.25 | 38.59 | 78.51 | 71.88 | 57.38 | 60.10 | 58.81 |
| DocOwl1.5- 8B (base+) (Hu et al., 2024) | 78.70 | 47.62 | 64.39 | 36.93 | 35.69 | 72.65 | 65.80 | 67.30 | 49.03 | 57.56 |
| Llama3.2- 11B (base+) (Grattafiori et al., 2024) | 78.99 | 44.27 | 67.05 | 37.22 | 40.18 | 78.04 | 71.40 | 68.46 | 56.73 | 60.26 |
| AlignVLM -Llama-3.1- 8B (ours) | 81.18 | 53.75 | 63.25 | 35.50 | 45.31 | 83.04 | 75.00 | 64.60 | 64.33 | 62.88 |
Setup.
We conduct all experiments using 8 nodes of H100 GPUs, totaling 64 GPUs. For model training, we leverage the MS-Swift framework (Zhao et al., 2024) for its flexibility. Additionally, we utilize the DeepSpeed framework (Aminabadi et al., 2022), specifically the ZeRO-3 configuration, to optimize efficient parallel training across multiple nodes. Detailed hyperparameters are outlined in Appendix A.1.
Baselines.
Our work focuses on architectural innovations, so we ensure that all baselines are trained on the same datasets. To enable fair comparisons, we evaluate our models against a set of Base VLMs fine-tuned on the same instruction-tuning tasks (Stages 2 and 3) as our models, using the BigDocs-7.5M and BigDocs-DocDownstream datasets. This approach ensures consistent training data, avoiding biases introduced by the Instruct versions of VLMs, which are often trained on undisclosed instruction-tuning datasets. Due to the scarcity of recently released publicly available Base VLMs, we primarily compare our model against the following Base VLMs of varying sizes: Qwen2-VL-2B (Wang et al., 2024), DocOwl1.5-8B (Hu et al., 2024), and LLama 3.2-11B (Grattafiori et al., 2024).
For additional context, we also include results from the Instruct versions of recent VLMs of different sizes: Phi3.5-Vision-4B (Abdin et al., 2024), Qwen2-VL-2B and 7B (Wang et al., 2024), Qwen2.5-VL-7B (Qwen et al., 2025), LLaVA-NeXT-7B (Liu et al., 2024), InternVL2.5-2B and 8B (Chen et al., 2024b), InternVL3-2B and 8B (Zhu et al., 2025), Janus-1.3B (Wu et al., 2024a), DeepSeek-VL2-Tiny (Wu et al., 2024b), Ovis1.6-Gemma-9B (Lu et al., 2024), Llama3.2-11B (Grattafiori et al., 2024), DocOwl1.5-8B (Hu et al., 2024), and Pixtral-12B (Agrawal et al., 2024).
Evaluation Benchmarks.
We evaluate our models on a diverse range of document understanding benchmarks that assess the model’s capabilities in OCR, chart reasoning, table processing, or form comprehension. In particular, we employ the VLMEvalKit (Duan et al., 2024) framework and report the results on the following popular benchmarks: DocVQA (Mathew et al., 2021b), InfoVQA (Mathew et al., 2021a), DeepForm (Svetlichnaya, 2020), KLC (Stanisławek et al., 2021), WTQ (Pasupat and Liang, 2015), TabFact (Chen et al., 2020), ChartQA (Masry et al., 2022), TextVQA (Singh et al., 2019), and TableVQA (Kim et al., 2024).
5 Results
Table 2: Impact of Connector Designs on VLM Performance: We present the results of experiments evaluating different connector designs for conditioning LLMs on visual features. Our proposed Align connector is compared against a basic Multi-Layer Perceptron (MLP), the Perceiver Resampler, and Ovis. The results demonstrate that Align consistently outperforms these alternatives across all benchmarks.
| Model | DocVQA VAL | InfoVQA VAL | DeepForm TEST | KLC TEST | WTQ TEST | TabFact TEST | ChartQA TEST | TextVQA VAL | TableVQA TEST | Avg. Score |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Llama-3.2-3B- MLP | 71.46 | 37.56 | 62.07 | 33.36 | 28.94 | 73.22 | 66.48 | 53.56 | 50.96 | 53.06 |
| Llama-3.2-3B- Perciever R. | 69.08 | 34.13 | 57.08 | 31.75 | 27.95 | 71.93 | 65.16 | 51.33 | 47.76 | 50.68 |
| Llama-3.2-3B- Ovis | 74.68 | 42.11 | 58.02 | 33.50 | 33.13 | 76.67 | 67.92 | 52.60 | 53.93 | 54.72 |
| Llama-3.2-3B- Align (ours) | 79.63 | 44.53 | 63.49 | 35.25 | 38.59 | 78.51 | 71.88 | 57.38 | 60.10 | 58.81 |
5.1 Main Results
Table 1 presents the performance of AlignVLM compared to state-of-the-art (SOTA) open- and closed-source instructed models, as well as baseline Base VLMs fine-tuned in the same instruction-tuning setup. The results demonstrate that AlignVLM consistently outperforms all Base VLMs within the same size category and achieves competitive performance against SOTA Instruct VLMs despite being trained on a more limited data regime. Below, we provide a detailed analysis.
AlignVLM vs. Base VLMs.
Our AlignVLM models, based on Llama 3.2-1B and Llama 3.2-3B, significantly outperform the corresponding Base VLM, Qwen2-VL-2B, by up to 9.22%. Notably, AlignVLM -Llama-3.2-3B surpasses DocOwl1.5-8B, which has 4B more parameters, demonstrating the effectiveness of Align in enhancing multimodal capabilities compared to traditional shallow fusion methods (e.g., MLPs). Furthermore, our 8B model achieves a 2.62% improvement over Llama3.2-11B despite sharing the same Base LLM, Llama3.1-8B. Since all models in this comparison were trained on the same instruction-tuning setup, this experiment provides a controlled evaluation, isolating the impact of architectural differences rather than dataset biases. Consequently, these results suggest that AlignVLM outperforms VLMs with shallow fusion techniques and surpasses parameter-heavy deep fusion VLMs, such as Llama3.2-11B, while maintaining a more efficient architecture.
AlignVLM vs. Instruct VLMs.
Even as open-source Instruct models are trained on significantly larger, often undisclosed instruction-tuning datasets, AlignVLM achieves competitive performance. For example, AlignVLM -Llama-3.2-3B (58.81%) outperforms other strong instruction-tuned VLMs in its size class, such as Qwen2-VL-2B and InternVL-3-2B, by considerable margins (2.97% and 1.17%, respectively). While it falls slightly behind Qwen2.5-VL-3B, a direct comparison is not entirely fair, as the latter was trained on a proprietary instruction-tuning dataset.
Additionally, our 8B model outperforms significantly larger models such as Llama 3.2-11B and PixTral-12B by substantial margins. It also surpasses InternVL-2.5-8B and performs competitively with Qwen2.5-VL-7B, though a direct comparison may not be entirely fair since Qwen2.5-VL-7B was trained on an undisclosed instruction-tuning dataset. Finally, AlignVLM also exhibits comparable performance to closed-source models like GeminiPro-1.5 and GPT4o.
Overall, these results validate the effectiveness of Align and establish AlignVLM as a state-of-the-art model for multimodal document understanding.
5.2 Impact of Connector Designs on VLM Performance
5.2.1 High-Resource Training Regime
To assess the effectiveness of our Align module, we compare it against three different and widely used shallow fusion VLM connectors: MLP, Perceiver Resampler, and Ovis. These experiments were carefully conducted under precisely identical training conditions (datasets, hyperparameters, training stages) as outlined in Appendix A.1, ensuring a fair and rigorous comparison. The results in Table 2 show that Align consistently outperforms all alternatives, demonstrating its superiority both in aligning visual and textual modalities in multimodal document understanding. MLP and Perceiver Resampler achieve the lowest performance, 53.06% and 50.68%, respectively, due to their direct feature projection, which lacks an explicit mechanism to align visual features with the LLM’s text space, leading to misalignment. Ovis introduces a separate visual embedding table, but this additional complexity does not significantly improve alignment, yielding only 54.72% accuracy. In contrast, Align ensures that visual features remain within the convex hull of the LLM’s text latent space, leveraging the linguistic priors of the LLM to enhance alignment and mitigate noisy embeddings. This design leads to the highest performance (58.81%), establishing Align as the most effective connector for integrating vision and language in multimodal document understanding. We provide some example outputs of the Llama-3.2-3B models with different connector designs in Appendix A.4. Furthermore, we include an analysis of the runtime efficiency and memory usage of different connectors in Appendix A.2.
5.2.2 Low-Resource Training Regime
The previous section focused on large-scale training setups involving millions of data samples (BigDocs-7.5M), which require significant compute resources and limit the number of baselines that we were able to compare against. Here, we examine whether Align remains effective in a low-resource setting.
We conduct additional experiments using SigLIP-400M as the vision encoder and Llama-3.2-3B as the language model, fine-tuned on the LLaVA-NeXT dataset Liu et al. (2024), which contains 779K samples. We follow the official LLaVA-NeXT configuration for both training stages. (i) Pretraining: the model is trained on the LLaVA-558K image–caption dataset Liu et al. (2024), freezing both the LLM and vision encoder while fine-tuning the connector (learning rate = 1e-3, batch size = 32, 1 epoch on 8 × H100 GPUs). To handle high-resolution document images, we adopt the "anyres_max_9" strategy with grid weaving from 1×1 to 6×6, supporting resolutions up to 2304×2304 with 729 tokens per grid; (ii) Instruction tuning: the model is further fine-tuned on the LLaVA-NeXT-779K instruction dataset with learning rates of 1e-5 for the LLM and connector, 2e-6 for the vision encoder, batch size = 8, for 1 epoch.
This lightweight setup allows direct comparison across more connector architectures including MLP Liu et al. (2023a), Perceiver Resampler, Ovis Lu et al. (2024), H-Reducer (1×4) Hu et al. (2024), and HoneyBee (C-Abstractor) Cha et al. (2024), all trained under identical conditions for fairness. Since the LLaVA-Next dataset is general-purpose and not exclusively document-focused like BigDocs-7.5M (Rodriguez et al., 2024a), it allows us to evaluate whether the Align connector generalizes beyond document understanding to broader visual reasoning. Accordingly, we assess all models on a comprehensive suite of benchmarks spanning both document understanding and general vision–language tasks. The document understanding benchmarks include DocVQA Mathew et al. (2021b), InfoVQA Mathew et al. (2021a), ChartQA Masry et al. (2022), and TextVQA Singh et al. (2019). For general vision–language evaluation, we report results on MMMU-dev Yue et al. (2024), SeedBench Li et al. (2023a), and MMVet Yu et al. (2024), Pope (Li et al., 2023c), and GQA (Hudson and Manning, 2019).
Table 3: Connector Performance under a Low-Resource Training Regime: We evaluate the effectiveness of more shallow-fusion connectors when trained on limited data. The Align connector achieves the highest performance, with notably larger gains on document understanding tasks, demonstrating its data efficiency and strong inductive bias.
| Model | Document Understanding Tasks | General Vision Tasks | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| DocVQA | InfoVQA | ChartQA | TextVQA | Avg. | MMMU | SeedBench | MMVet | POPE | GQA | Avg. | |
| Llama-3.2-3B-MLP | 42.11 | 19.93 | 48.44 | 51.97 | 40.61 | 33.33 | 58.54 | 31.14 | 87.35 | 57.62 | 53.59 |
| Llama-3.2-3B-Perceiver | 32.18 | 18.10 | 40.00 | 44.31 | 33.64 | 35.22 | 63.70 | 26.19 | 84.92 | 55.86 | 53.17 |
| Llama-3.2-3B-Ovis | 57.73 | 26.39 | 54.52 | 55.60 | 48.56 | 31.89 | 60.97 | 30.41 | 88.26 | 56.23 | 53.55 |
| Llama-3.2-3B-Hreducer | 34.59 | 17.57 | 45.64 | 47.13 | 36.23 | 35.00 | 61.82 | 28.39 | 87.48 | 58.24 | 54.18 |
| Llama-3.2-3B-HoneyBee | 55.86 | 19.36 | 55.32 | 58.13 | 47.16 | 32.11 | 61.18 | 34.31 | 89.28 | 54.79 | 54.33 |
| Llama-3.2-3B- Align (ours) | 71.43 | 30.50 | 69.72 | 65.63 | 59.32 | 35.33 | 63.27 | 35.32 | 88.85 | 61.67 | 56.88 |
As summarized in Table 3, Align consistently outperforms other connectors under this low-data regime, with stronger gains on document understanding tasks. The wider performance margin between Align and others connectors under limited data (Table 3) compared to the high-resource setting (Table 2) underscores the benefit of its inductive bias. By grounding visual features within the LLM’s text embedding space, Align learns more efficiently from fewer samples, unlike direct-projection connectors that rely heavily on large datasets. This makes Align especially valuable for resource-constrained environments such as academic labs or small-scale industrial research setups, where both data and compute are limited.
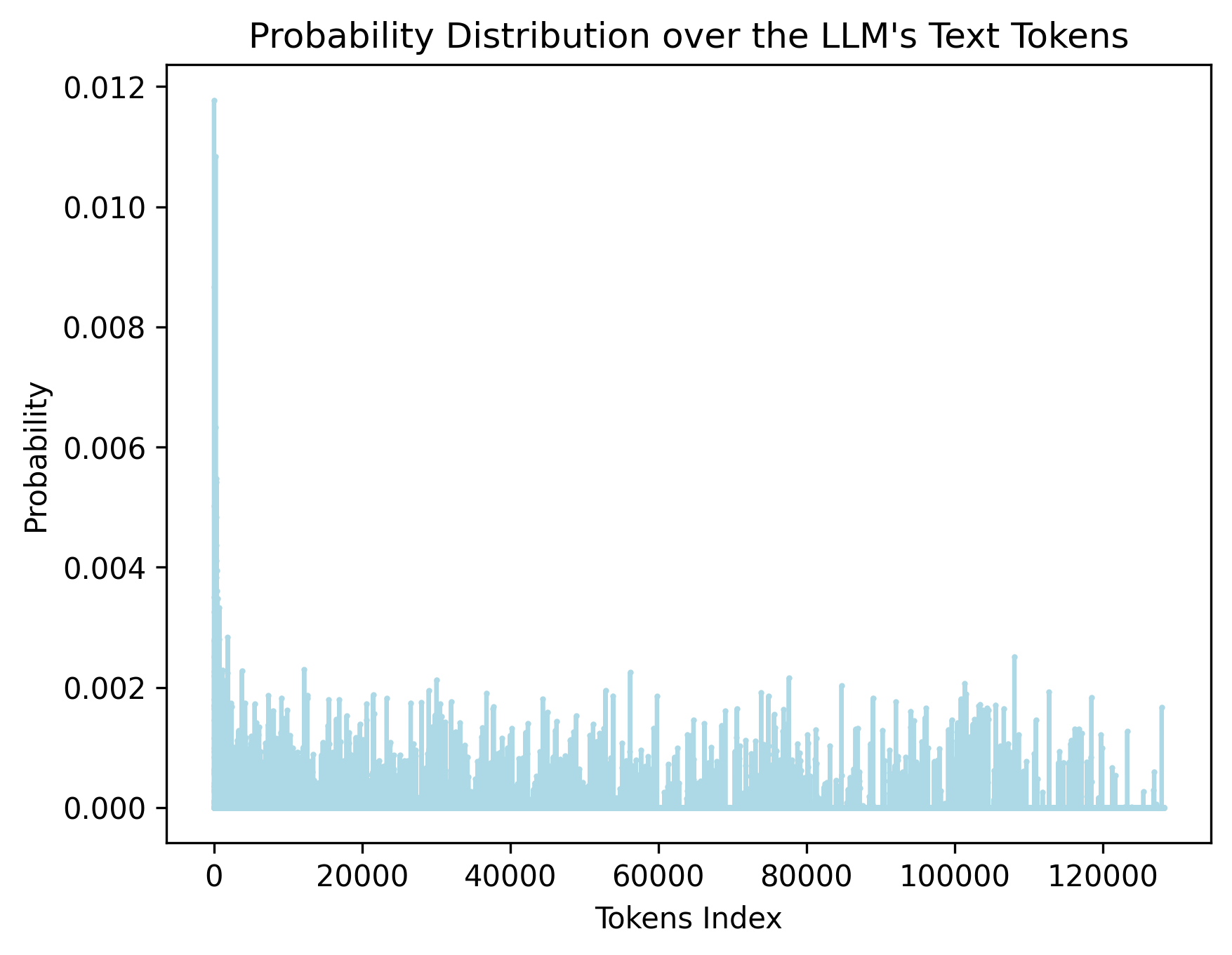
5.3 Probability Distribution over Text Tokens Analysis
To better understand the behavior of Align, we examine the probability distribution, $\mathbf{P}_{\text{vocab}}$ in Eq (1), over the LLM’s text vocabulary generated from visual features. Specifically, we process 100 document images through the vision encoder and Align, then average the resulting probability distributions across all image patches. The final distribution is shown in Figure 4. As illustrated, the distribution is dense (rather than sparse), with the highest probability assigned to a single token being 0.0118. This can be explained by the vision feature space being continuous and of much higher cardinality than the discrete text space. Indeed, while the LLM has 128K distinct vocabulary tokens, an image patch (e.g., 14×14 pixels) contains continuous, high-dimensional information that cannot be effectively mapped to a single or a few discrete tokens.
Table 4: Performance comparison when evaluating Align with the full text embedding vocabulary (128K) versus the reduced subset of 3.4K high-probability embeddings. The results show negligible performance degradation, indicating that Align relies primarily on a small subset of embeddings.
| Model | DocVQA VAL | InfoVQA VAL | DeepForm TEST | KLC TEST | WTQ TEST | TabFact TEST | ChartQA TEST | TextVQA VAL | TableVQA TEST | Avg. Score |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Llama-3.2-3B- Align (Full Embeddings) | 79.63 | 44.53 | 63.49 | 35.25 | 38.59 | 78.51 | 71.88 | 57.38 | 60.10 | 58.81 |
| Llama-3.2-3B- Align (3.4K Embeddings) | 79.40 | 44.13 | 63.64 | 35.02 | 38.26 | 78.83 | 71.72 | 57.48 | 59.80 | 58.69 |
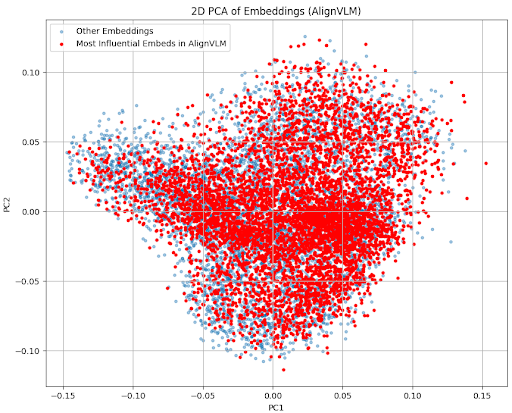
We conducted a deeper analysis of the token probability distributions produced by the Align connector. Our observations show that Align consistently assigns high probabilities to approximately 3.4K tokens from the entire vocabulary, while the remaining tokens receive negligible probabilities (below $10^{-6}$ ). To better understand this behavior, we applied Principal Component Analysis (PCA) to reduce the dimensionality of the embeddings and visualized them in a two-dimensional space, as shown in Figure 4. The visualization reveals that these 3.4K tokens densely and comprehensively span the latent space of the LLM’s text embeddings. To validate this finding, we conducted additional evaluation experiments in which we retained only these 3.4K high-probability embeddings in the Align connector, entirely removing the rest during evaluation. As shown in Table 4, the performance difference compared to using the full embedding set (128K) was negligible. This confirms that Align effectively leverages and combines a compact subset of embeddings to map visual features into semantically meaningful regions within the LLM’s latent text space. Moreover, this suggests that Align can be further optimized through targeted embedding pruning to improve computational efficiency without sacrificing performance.
<details>
<summary>figures/prob_dist_image.png Details</summary>
### Visual Description
# Technical Document Extraction: Probability Distribution over the LLM's Text Tokens
## 1. Document Metadata
* **Title:** Probability Distribution over the LLM's Text Tokens
* **Type:** Line Chart / Probability Mass Function (PMF) visualization
* **Language:** English
## 2. Component Isolation
### Header
* **Text:** "Probability Distribution over the LLM's Text Tokens"
* **Position:** Top center.
### Main Chart Area
* **Y-Axis Label:** Probability
* **Y-Axis Scale:** Linear, ranging from 0.000 to 0.012 with major tick intervals of 0.002.
* **X-Axis Label:** Tokens Index
* **X-Axis Scale:** Linear, ranging from 0 to approximately 128,000 with major tick intervals of 20,000.
* **Data Series:** A single light-blue line plot representing the probability assigned to each token in a Large Language Model's vocabulary.
## 3. Data Extraction and Trend Analysis
### Axis Markers
| Axis | Markers / Ticks |
| :--- | :--- |
| **Y-Axis (Probability)** | 0.000, 0.002, 0.004, 0.006, 0.008, 0.010, 0.012 |
| **X-Axis (Tokens Index)** | 0, 20000, 40000, 60000, 80000, 100000, 120000 |
### Trend Verification
* **Initial Peak:** The data series begins with an extremely sharp vertical spike at the very beginning of the X-axis (Token Index near 0). This represents the "greedy" or most likely token.
* **Primary Trend:** Immediately following the initial spike, there is a precipitous drop-off. The probability values fall from nearly 0.012 to below 0.004 within the first few hundred indices.
* **Secondary Trend (Long Tail):** From Token Index ~5,000 to ~128,000, the distribution enters a "long tail." The baseline probability sits very close to 0.000, with frequent stochastic "spikes" or "noise" where individual tokens reach probabilities between 0.001 and 0.002.
* **Visual Density:** The density of the light-blue lines indicates a very large vocabulary (approx. 128k tokens), where the vast majority of tokens have a near-zero probability of being selected.
### Key Data Points (Estimated)
* **Maximum Probability:** ~0.0118 (at Token Index 0).
* **Secondary Peaks:** Several tokens throughout the vocabulary (e.g., near index 12,000, 30,000, 58,000, 78,000, and 108,000) show localized spikes reaching approximately 0.002 to 0.0025.
* **Vocabulary Limit:** The data series terminates just before the 140,000 mark, specifically around 128,000, which is a common vocabulary size for modern LLMs (e.g., Llama 3).
## 4. Technical Summary
This chart visualizes the softmax output (probability distribution) of a Large Language Model for a single prediction step. It demonstrates a **highly skewed distribution**. A very small number of tokens (the "head") carry significant probability mass, while the overwhelming majority of the 128,000+ tokens (the "long tail") have negligible individual probabilities. This visualization is characteristic of a model that has a clear preference for a specific next token but maintains a wide, low-probability field for alternative "creative" or "noisy" selections.
</details>
Figure 3: Probability distribution over LLM tokens, highlighting dense probabilities for whitespace tokens.
<details>
<summary>figures/vision-to-text/alignvlm_embeds.png Details</summary>
### Visual Description
# Technical Document Extraction: 2D PCA of Embeddings (AlignVLM)
## 1. Document Metadata
* **Title:** 2D PCA of Embeddings (AlignVLM)
* **Type:** Principal Component Analysis (PCA) Scatter Plot
* **Language:** English
## 2. Component Isolation
### Header
* **Main Title:** "2D PCA of Embeddings (AlignVLM)"
### Main Chart Area
* **X-Axis Label:** "PC1" (Principal Component 1)
* **Y-Axis Label:** "PC2" (Principal Component 2)
* **X-Axis Scale:** Ranges from approximately -0.15 to +0.15. Major tick marks are visible at -0.15, -0.10, -0.05, 0.00, 0.05, 0.10, and 0.15.
* **Y-Axis Scale:** Ranges from approximately -0.10 to +0.10 (with data points extending slightly beyond to ~ -0.12 and +0.13). Major tick marks are visible at -0.10, -0.05, 0.00, 0.05, and 0.10.
* **Grid:** A standard rectangular grid is overlaid on the plot area.
### Legend [Spatial Grounding: Top-Left Corner]
* **Location:** Approximately [x=0.1, y=0.9] in normalized coordinates relative to the chart area.
* **Entry 1:** Light Blue Circle (semi-transparent) — "Other Embeddings"
* **Entry 2:** Red Circle (opaque) — "Most Influential Embeds in AlignVLM"
---
## 3. Data Analysis and Trends
### Trend Verification
* **Other Embeddings (Light Blue):** This series forms the "background" distribution. It occupies a broad, roughly triangular or "arrowhead" shape pointing toward the left. The density is highest in the center-right and thins out significantly as PC1 decreases toward -0.15.
* **Most Influential Embeds (Red):** This series is overlaid on the blue distribution. It shows a high degree of overlap with the "Other Embeddings" but appears more concentrated in specific clusters, particularly in the central and right-hand regions of the plot (PC1 > -0.05).
### Spatial Distribution and Key Data Points
1. **Horizontal Spread (PC1):**
* The data spans from a minimum PC1 of roughly **-0.15** to a maximum of roughly **0.15**.
* The "Most Influential" (red) points are less frequent in the extreme left tail (PC1 < -0.10) compared to the "Other" (blue) points.
2. **Vertical Spread (PC2):**
* The data spans from a minimum PC2 of roughly **-0.12** to a maximum of roughly **0.13**.
* There is a noticeable "bulge" or higher density of red points in the upper-right quadrant (PC1: 0.0 to 0.10, PC2: 0.0 to 0.10).
3. **Central Cluster:**
* A dense horizontal band of red points is visible along the **PC2 = 0.0** line, stretching from PC1 = -0.05 to PC1 = 0.07. This suggests a significant portion of influential embeddings share similar characteristics along the second principal component.
4. **Outliers:**
* A few red points are isolated at the extreme right (PC1 ≈ 0.15).
* Blue points are the primary occupants of the far-left "nose" of the distribution (PC1 ≈ -0.15, PC2 ≈ 0.03).
---
## 4. Technical Summary
The visualization represents a dimensionality reduction of high-dimensional embedding vectors into a 2D space using PCA. The primary objective of the chart is to compare the distribution of "Most Influential" embeddings against the general population of "Other" embeddings within the AlignVLM model.
**Key Finding:** The "Most Influential" embeddings are not isolated in a separate cluster; rather, they are embedded within the general distribution but show higher density in the central and positive regions of PC1. This indicates that influence in the AlignVLM model is associated with specific features captured by the positive direction of the first principal component, while the "Other" embeddings are more widely dispersed, particularly into the negative PC1 space.
</details>
Figure 4: PCA of Align Embeddings: The principal components of the most influential embeddings in the Align Connector span most of the feature space represented by all embeddings.
5.4 Robustness to Noise Analysis
To evaluate the robustness of our Align connector to noisy visual features, we conduct an experiment where random Gaussian noise is added to the visual features produced by the vision encoder before passing them into the connector. Specifically, given the visual features $\mathbf{F}∈\mathbb{R}^{N× d}$ output by the vision encoder (where $N$ is the number of feature vectors and $d$ is their dimensionality), we perturbed them as
$$
\widetilde{\mathbf{F}}=\mathbf{F}+\mathbf{N},\quad\mathbf{N}\sim\mathcal{N}(0,\sigma=3).
$$
Table 5: Robustness to Noise. Comparison of Avg. Scores with and without Gaussian noise ( $\sigma=3$ ), including performance drop ( $\Delta$ ).
| Model | Without Noise | With Noise | Drop ( $\Delta$ ) |
| --- | --- | --- | --- |
| Llama-3.2-3B-MLP | 53.06 | 27.52 | $\downarrow 25.54$ |
| Llama-3.2-3B- Align (ours) | 58.81 | 57.14 | $\downarrow\textbf{1.67}$ |
As shown in Table 5, our Align connector demonstrates high robustness to noise, with only a 1.67% average drop in performance. In contrast, the widely adopted MLP connector suffers a significant performance degradation of 25.54%, highlighting its vulnerability to noisy inputs. Furthermore, we measured the average cosine distance between the original and noise-perturbed visual embeddings using both the Align and MLP connectors. Align showed significantly lower distances (0.0036) than MLP (0.3938), further validating its robustness to noise. These empirical results support our hypothesis that leveraging the knowledge encoded in the LLM’s text embeddings and constraining the visual features within the convex hull of the text latent space act as a regularization mechanism, reducing the model’s sensitivity to noisy visual features.
6 Conclusion
We introduce Align, a novel connector designed to align vision and language latent spaces in vision-language models (VLMs), specifically enhancing multimodal document understanding. By improving cross-modal alignment and minimizing noisy embeddings, our models, AlignVLM, which leverage Align, achieve state-of-the-art performance across diverse document understanding tasks. This includes outperforming base VLMs trained on the same datasets and achieving competitive performance with open-source instruct models trained on undisclosed data. Extensive experiments and ablations validate the robustness and effectiveness of Align compared to existing connector designs, establishing it as a significant contribution to vision-language modeling. Future work will explore training on more diverse instruction-tuning datasets to generalize to broader domains.
References
- Abdin et al. [2024] M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, A. A. Awan, N. Bach, A. Bahree, A. Bakhtiari, J. Bao, H. Behl, A. Benhaim, M. Bilenko, J. Bjorck, S. Bubeck, M. Cai, Q. Cai, V. Chaudhary, D. Chen, D. Chen, W. Chen, Y.-C. Chen, Y.-L. Chen, H. Cheng, P. Chopra, X. Dai, M. Dixon, R. Eldan, V. Fragoso, J. Gao, M. Gao, M. Gao, A. Garg, A. D. Giorno, A. Goswami, S. Gunasekar, E. Haider, J. Hao, R. J. Hewett, W. Hu, J. Huynh, D. Iter, S. A. Jacobs, M. Javaheripi, X. Jin, N. Karampatziakis, P. Kauffmann, M. Khademi, D. Kim, Y. J. Kim, L. Kurilenko, J. R. Lee, Y. T. Lee, Y. Li, Y. Li, C. Liang, L. Liden, X. Lin, Z. Lin, C. Liu, L. Liu, M. Liu, W. Liu, X. Liu, C. Luo, P. Madan, A. Mahmoudzadeh, D. Majercak, M. Mazzola, C. C. T. Mendes, A. Mitra, H. Modi, A. Nguyen, B. Norick, B. Patra, D. Perez-Becker, T. Portet, R. Pryzant, H. Qin, M. Radmilac, L. Ren, G. de Rosa, C. Rosset, S. Roy, O. Ruwase, O. Saarikivi, A. Saied, A. Salim, M. Santacroce, S. Shah, N. Shang, H. Sharma, Y. Shen, S. Shukla, X. Song, M. Tanaka, A. Tupini, P. Vaddamanu, C. Wang, G. Wang, L. Wang, S. Wang, X. Wang, Y. Wang, R. Ward, W. Wen, P. Witte, H. Wu, X. Wu, M. Wyatt, B. Xiao, C. Xu, J. Xu, W. Xu, J. Xue, S. Yadav, F. Yang, J. Yang, Y. Yang, Z. Yang, D. Yu, L. Yuan, C. Zhang, C. Zhang, J. Zhang, L. L. Zhang, Y. Zhang, Y. Zhang, Y. Zhang, and X. Zhou. Phi-3 technical report: A highly capable language model locally on your phone, 2024. URL https://arxiv.org/abs/2404.14219.
- Achiam et al. [2023] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Agrawal et al. [2024] P. Agrawal, S. Antoniak, E. B. Hanna, B. Bout, D. Chaplot, J. Chudnovsky, D. Costa, B. D. Monicault, S. Garg, T. Gervet, S. Ghosh, A. Héliou, P. Jacob, A. Q. Jiang, K. Khandelwal, T. Lacroix, G. Lample, D. L. Casas, T. Lavril, T. L. Scao, A. Lo, W. Marshall, L. Martin, A. Mensch, P. Muddireddy, V. Nemychnikova, M. Pellat, P. V. Platen, N. Raghuraman, B. Rozière, A. Sablayrolles, L. Saulnier, R. Sauvestre, W. Shang, R. Soletskyi, L. Stewart, P. Stock, J. Studnia, S. Subramanian, S. Vaze, T. Wang, and S. Yang. Pixtral 12b, 2024. URL https://arxiv.org/abs/2410.07073.
- Alayrac et al. [2022] J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds, R. Ring, E. Rutherford, S. Cabi, T. Han, Z. Gong, S. Samangooei, M. Monteiro, J. Menick, S. Borgeaud, A. Brock, A. Nematzadeh, S. Sharifzadeh, M. Binkowski, R. Barreira, O. Vinyals, A. Zisserman, and K. Simonyan. Flamingo: a visual language model for few-shot learning, 2022. URL https://arxiv.org/abs/2204.14198.
- Aminabadi et al. [2022] R. Y. Aminabadi, S. Rajbhandari, M. Zhang, A. A. Awan, C. Li, D. Li, E. Zheng, J. Rasley, S. Smith, O. Ruwase, and Y. He. Deepspeed inference: Enabling efficient inference of transformer models at unprecedented scale, 2022. URL https://arxiv.org/abs/2207.00032.
- Anthropic [2024] Anthropic. The claude 3 model family: Opus, sonnet, haiku. 2024.
- Bai et al. [2025] S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y. Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y. Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin. Qwen2.5-vl technical report, 2025. URL https://arxiv.org/abs/2502.13923.
- Bavishi et al. [2023] R. Bavishi, E. Elsen, C. Hawthorne, M. Nye, A. Odena, A. Somani, and S. Taşırlar. Introducing our multimodal models, 2023. URL https://www.adept.ai/blog/fuyu-8b.
- Beyer et al. [2024] L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdulmohsin, M. Tschannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. Koppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby, M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Bošnjak, X. Chen, M. Minderer, P. Voigtlaender, I. Bica, I. Balazevic, J. Puigcerver, P. Papalampidi, O. Henaff, X. Xiong, R. Soricut, J. Harmsen, and X. Zhai. Paligemma: A versatile 3b vlm for transfer, 2024. URL https://arxiv.org/abs/2407.07726.
- Bommasani et al. [2023] R. Bommasani, K. Klyman, S. Longpre, S. Kapoor, N. Maslej, B. Xiong, D. Zhang, and P. Liang. The foundation model transparency index, 2023. URL https://arxiv.org/abs/2310.12941.
- Brown et al. [2020] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Cha et al. [2024] J. Cha, W. Kang, J. Mun, and B. Roh. Honeybee: Locality-enhanced projector for multimodal llm, 2024. URL https://arxiv.org/abs/2312.06742.
- Changpinyo et al. [2021] S. Changpinyo, P. Sharma, N. Ding, and R. Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts, 2021. URL https://arxiv.org/abs/2102.08981.
- Chen et al. [2020] W. Chen, H. Wang, J. Chen, Y. Zhang, H. Wang, S. Li, X. Zhou, and W. Y. Wang. Tabfact: A large-scale dataset for table-based fact verification. In International Conference Learning Representations, 2020.
- Chen et al. [2024a] Z. Chen, W. Wang, H. Tian, S. Ye, Z. Gao, E. Cui, W. Tong, K. Hu, J. Luo, Z. Ma, J. Ma, J. Wang, X. Dong, H. Yan, H. Guo, C. He, B. Shi, Z. Jin, C. Xu, B. Wang, X. Wei, W. Li, W. Zhang, B. Zhang, P. Cai, L. Wen, X. Yan, M. Dou, L. Lu, X. Zhu, T. Lu, D. Lin, Y. Qiao, J. Dai, and W. Wang. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites, 2024a. URL https://arxiv.org/abs/2404.16821.
- Chen et al. [2024b] Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024b.
- Dai et al. [2024] W. Dai, N. Lee, B. Wang, Z. Yang, Z. Liu, J. Barker, T. Rintamaki, M. Shoeybi, B. Catanzaro, and W. Ping. Nvlm: Open frontier-class multimodal llms. arXiv preprint arXiv: 2409.11402, 2024.
- Diao et al. [2024] H. Diao, Y. Cui, X. Li, Y. Wang, H. Lu, and X. Wang. Unveiling encoder-free vision-language models. arXiv preprint arXiv:2406.11832, 2024.
- Drouin et al. [2024] A. Drouin, M. Gasse, M. Caccia, I. H. Laradji, M. D. Verme, T. Marty, L. Boisvert, M. Thakkar, Q. Cappart, D. Vazquez, N. Chapados, and A. Lacoste. Workarena: How capable are web agents at solving common knowledge work tasks?, 2024. URL https://arxiv.org/abs/2403.07718.
- Duan et al. [2024] H. Duan, J. Yang, Y. Qiao, X. Fang, L. Chen, Y. Liu, X. Dong, Y. Zang, P. Zhang, J. Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024.
- Dubey et al. [2024] A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, and et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Grattafiori et al. [2024] A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, A. Rodriguez, A. Gregerson, A. Spataru, B. Roziere, B. Biron, B. Tang, B. Chern, C. Caucheteux, C. Nayak, C. Bi, C. Marra, C. McConnell, C. Keller, C. Touret, C. Wu, C. Wong, C. C. Ferrer, C. Nikolaidis, D. Allonsius, D. Song, D. Pintz, D. Livshits, D. Wyatt, D. Esiobu, D. Choudhary, D. Mahajan, D. Garcia-Olano, D. Perino, D. Hupkes, E. Lakomkin, E. AlBadawy, E. Lobanova, E. Dinan, E. M. Smith, F. Radenovic, F. Guzmán, F. Zhang, G. Synnaeve, G. Lee, G. L. Anderson, G. Thattai, G. Nail, G. Mialon, G. Pang, G. Cucurell, H. Nguyen, H. Korevaar, H. Xu, H. Touvron, I. Zarov, I. A. Ibarra, I. Kloumann, I. Misra, I. Evtimov, J. Zhang, J. Copet, J. Lee, J. Geffert, J. Vranes, J. Park, J. Mahadeokar, J. Shah, J. van der Linde, J. Billock, J. Hong, J. Lee, J. Fu, J. Chi, J. Huang, J. Liu, J. Wang, J. Yu, J. Bitton, J. Spisak, J. Park, J. Rocca, J. Johnstun, J. Saxe, J. Jia, K. V. Alwala, K. Prasad, K. Upasani, K. Plawiak, K. Li, K. Heafield, K. Stone, K. El-Arini, K. Iyer, K. Malik, K. Chiu, K. Bhalla, K. Lakhotia, L. Rantala-Yeary, L. van der Maaten, L. Chen, L. Tan, L. Jenkins, L. Martin, L. Madaan, L. Malo, L. Blecher, L. Landzaat, L. de Oliveira, M. Muzzi, M. Pasupuleti, M. Singh, M. Paluri, M. Kardas, M. Tsimpoukelli, M. Oldham, M. Rita, M. Pavlova, M. Kambadur, M. Lewis, M. Si, M. K. Singh, M. Hassan, N. Goyal, N. Torabi, N. Bashlykov, N. Bogoychev, N. Chatterji, N. Zhang, O. Duchenne, O. Çelebi, P. Alrassy, P. Zhang, P. Li, P. Vasic, P. Weng, P. Bhargava, P. Dubal, P. Krishnan, P. S. Koura, P. Xu, Q. He, Q. Dong, R. Srinivasan, R. Ganapathy, R. Calderer, R. S. Cabral, R. Stojnic, R. Raileanu, R. Maheswari, R. Girdhar, R. Patel, R. Sauvestre, R. Polidoro, R. Sumbaly, R. Taylor, R. Silva, R. Hou, R. Wang, S. Hosseini, S. Chennabasappa, S. Singh, S. Bell, S. S. Kim, S. Edunov, S. Nie, S. Narang, S. Raparthy, S. Shen, S. Wan, S. Bhosale, S. Zhang, S. Vandenhende, S. Batra, S. Whitman, S. Sootla, S. Collot, S. Gururangan, S. Borodinsky, T. Herman, T. Fowler, T. Sheasha, T. Georgiou, T. Scialom, T. Speckbacher, T. Mihaylov, T. Xiao, U. Karn, V. Goswami, V. Gupta, V. Ramanathan, V. Kerkez, V. Gonguet, V. Do, V. Vogeti, V. Albiero, V. Petrovic, W. Chu, W. Xiong, W. Fu, W. Meers, X. Martinet, X. Wang, X. Wang, X. E. Tan, X. Xia, X. Xie, X. Jia, X. Wang, Y. Goldschlag, Y. Gaur, Y. Babaei, Y. Wen, Y. Song, Y. Zhang, Y. Li, Y. Mao, Z. D. Coudert, Z. Yan, Z. Chen, Z. Papakipos, A. Singh, A. Srivastava, A. Jain, A. Kelsey, A. Shajnfeld, A. Gangidi, A. Victoria, A. Goldstand, A. Menon, A. Sharma, A. Boesenberg, A. Baevski, A. Feinstein, A. Kallet, A. Sangani, A. Teo, A. Yunus, A. Lupu, A. Alvarado, A. Caples, A. Gu, A. Ho, A. Poulton, A. Ryan, A. Ramchandani, A. Dong, A. Franco, A. Goyal, A. Saraf, A. Chowdhury, A. Gabriel, A. Bharambe, A. Eisenman, A. Yazdan, B. James, B. Maurer, B. Leonhardi, B. Huang, B. Loyd, B. D. Paola, B. Paranjape, B. Liu, B. Wu, B. Ni, B. Hancock, B. Wasti, B. Spence, B. Stojkovic, B. Gamido, B. Montalvo, C. Parker, C. Burton, C. Mejia, C. Liu, C. Wang, C. Kim, C. Zhou, C. Hu, C.-H. Chu, C. Cai, C. Tindal, C. Feichtenhofer, C. Gao, D. Civin, D. Beaty, D. Kreymer, D. Li, D. Adkins, D. Xu, D. Testuggine, D. David, D. Parikh, D. Liskovich, D. Foss, D. Wang, D. Le, D. Holland, E. Dowling, E. Jamil, E. Montgomery, E. Presani, E. Hahn, E. Wood, E.-T. Le, E. Brinkman, E. Arcaute, E. Dunbar, E. Smothers, F. Sun, F. Kreuk, F. Tian, F. Kokkinos, F. Ozgenel, F. Caggioni, F. Kanayet, F. Seide, G. M. Florez, G. Schwarz, G. Badeer, G. Swee, G. Halpern, G. Herman, G. Sizov, Guangyi, Zhang, G. Lakshminarayanan, H. Inan, H. Shojanazeri, H. Zou, H. Wang, H. Zha, H. Habeeb, H. Rudolph, H. Suk, H. Aspegren, H. Goldman, H. Zhan, I. Damlaj, I. Molybog, I. Tufanov, I. Leontiadis, I.-E. Veliche, I. Gat, J. Weissman, J. Geboski, J. Kohli, J. Lam, J. Asher, J.-B. Gaya, J. Marcus, J. Tang, J. Chan, J. Zhen, J. Reizenstein, J. Teboul, J. Zhong, J. Jin, J. Yang, J. Cummings, J. Carvill, J. Shepard, J. McPhie, J. Torres, J. Ginsburg, J. Wang, K. Wu, K. H. U, K. Saxena, K. Khandelwal, K. Zand, K. Matosich, K. Veeraraghavan, K. Michelena, K. Li, K. Jagadeesh, K. Huang, K. Chawla, K. Huang, L. Chen, L. Garg, L. A, L. Silva, L. Bell, L. Zhang, L. Guo, L. Yu, L. Moshkovich, L. Wehrstedt, M. Khabsa, M. Avalani, M. Bhatt, M. Mankus, M. Hasson, M. Lennie, M. Reso, M. Groshev, M. Naumov, M. Lathi, M. Keneally, M. Liu, M. L. Seltzer, M. Valko, M. Restrepo, M. Patel, M. Vyatskov, M. Samvelyan, M. Clark, M. Macey, M. Wang, M. J. Hermoso, M. Metanat, M. Rastegari, M. Bansal, N. Santhanam, N. Parks, N. White, N. Bawa, N. Singhal, N. Egebo, N. Usunier, N. Mehta, N. P. Laptev, N. Dong, N. Cheng, O. Chernoguz, O. Hart, O. Salpekar, O. Kalinli, P. Kent, P. Parekh, P. Saab, P. Balaji, P. Rittner, P. Bontrager, P. Roux, P. Dollar, P. Zvyagina, P. Ratanchandani, P. Yuvraj, Q. Liang, R. Alao, R. Rodriguez, R. Ayub, R. Murthy, R. Nayani, R. Mitra, R. Parthasarathy, R. Li, R. Hogan, R. Battey, R. Wang, R. Howes, R. Rinott, S. Mehta, S. Siby, S. J. Bondu, S. Datta, S. Chugh, S. Hunt, S. Dhillon, S. Sidorov, S. Pan, S. Mahajan, S. Verma, S. Yamamoto, S. Ramaswamy, S. Lindsay, S. Lindsay, S. Feng, S. Lin, S. C. Zha, S. Patil, S. Shankar, S. Zhang, S. Zhang, S. Wang, S. Agarwal, S. Sajuyigbe, S. Chintala, S. Max, S. Chen, S. Kehoe, S. Satterfield, S. Govindaprasad, S. Gupta, S. Deng, S. Cho, S. Virk, S. Subramanian, S. Choudhury, S. Goldman, T. Remez, T. Glaser, T. Best, T. Koehler, T. Robinson, T. Li, T. Zhang, T. Matthews, T. Chou, T. Shaked, V. Vontimitta, V. Ajayi, V. Montanez, V. Mohan, V. S. Kumar, V. Mangla, V. Ionescu, V. Poenaru, V. T. Mihailescu, V. Ivanov, W. Li, W. Wang, W. Jiang, W. Bouaziz, W. Constable, X. Tang, X. Wu, X. Wang, X. Wu, X. Gao, Y. Kleinman, Y. Chen, Y. Hu, Y. Jia, Y. Qi, Y. Li, Y. Zhang, Y. Zhang, Y. Adi, Y. Nam, Yu, Wang, Y. Zhao, Y. Hao, Y. Qian, Y. Li, Y. He, Z. Rait, Z. DeVito, Z. Rosnbrick, Z. Wen, Z. Yang, Z. Zhao, and Z. Ma. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783.
- He et al. [2015] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385.
- Hu et al. [2024] A. Hu, H. Xu, J. Ye, M. Yan, L. Zhang, B. Zhang, C. Li, J. Zhang, Q. Jin, F. Huang, and J. Zhou. mplug-docowl 1.5: Unified structure learning for ocr-free document understanding, 2024. URL https://arxiv.org/abs/2403.12895.
- Hudson and Manning [2019] D. A. Hudson and C. D. Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering, 2019. URL https://arxiv.org/abs/1902.09506.
- Jaume et al. [2019] G. Jaume, H. K. Ekenel, and J.-P. Thiran. Funsd: A dataset for form understanding in noisy scanned documents, 2019. URL https://arxiv.org/abs/1905.13538.
- Kim et al. [2022] G. Kim, T. Hong, M. Yim, J. Nam, J. Park, J. Yim, W. Hwang, S. Yun, D. Han, and S. Park. Ocr-free document understanding transformer, 2022. URL https://arxiv.org/abs/2111.15664.
- Kim et al. [2024] Y. Kim, M. Yim, and K. Y. Song. Tablevqa-bench: A visual question answering benchmark on multiple table domains. arXiv preprint arXiv:2404.19205, 2024.
- Laurençon et al. [2024] H. Laurençon, L. Tronchon, M. Cord, and V. Sanh. What matters when building vision-language models?, 2024. URL https://arxiv.org/abs/2405.02246.
- Lee et al. [2023] K. Lee, M. Joshi, I. Turc, H. Hu, F. Liu, J. Eisenschlos, U. Khandelwal, P. Shaw, M.-W. Chang, and K. Toutanova. Pix2struct: Screenshot parsing as pretraining for visual language understanding, 2023. URL https://arxiv.org/abs/2210.03347.
- Li et al. [2023a] B. Li, R. Wang, G. Wang, Y. Ge, Y. Ge, and Y. Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension, 2023a. URL https://arxiv.org/abs/2307.16125.
- Li et al. [2024] B. Li, Y. Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y. Li, Z. Liu, and C. Li. Llava-onevision: Easy visual task transfer, 2024. URL https://arxiv.org/abs/2408.03326.
- Li et al. [2023b] J. Li, D. Li, S. Savarese, and S. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023b. URL https://arxiv.org/abs/2301.12597.
- Li et al. [2023c] Y. Li, Y. Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen. Evaluating object hallucination in large vision-language models, 2023c. URL https://arxiv.org/abs/2305.10355.
- Liu et al. [2023a] H. Liu, C. Li, Y. Li, and Y. J. Lee. Improved baselines with visual instruction tuning, 2023a.
- Liu et al. [2023b] H. Liu, C. Li, Q. Wu, and Y. J. Lee. Visual instruction tuning, 2023b.
- Liu et al. [2024] H. Liu, C. Li, Y. Li, B. Li, Y. Zhang, S. Shen, and Y. J. Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024. URL https://llava-vl.github.io/blog/2024-01-30-llava-next/.
- Lu et al. [2024] S. Lu, Y. Li, Q.-G. Chen, Z. Xu, W. Luo, K. Zhang, and H.-J. Ye. Ovis: Structural embedding alignment for multimodal large language model, 2024. URL https://arxiv.org/abs/2405.20797.
- Masry et al. [2022] A. Masry, D. X. Long, J. Q. Tan, S. Joty, and E. Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. arXiv preprint arXiv:2203.10244, 2022.
- Mathew et al. [2021a] M. Mathew, V. Bagal, R. P. Tito, D. Karatzas, E. Valveny, and C. V. Jawahar. Infographicvqa, 2021a. URL https://arxiv.org/abs/2104.12756.
- Mathew et al. [2021b] M. Mathew, D. Karatzas, and C. V. Jawahar. Docvqa: A dataset for vqa on document images, 2021b. URL https://arxiv.org/abs/2007.00398.
- OpenAI et al. [2023] OpenAI, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, R. Avila, I. Babuschkin, S. Balaji, V. Balcom, P. Baltescu, H. Bao, M. Bavarian, J. Belgum, I. Bello, et al. Gpt-4 technical report. arXiv preprint arXiv: 2303.08774, 2023.
- Park et al. [2019] S. Park, S. Shin, B. Lee, J. Lee, J. Surh, M. Seo, and H. Lee. Cord: A consolidated receipt dataset for post-ocr parsing. Document Intelligence Workshop at Neural Information Processing Systems, 2019.
- Pasupat and Liang [2015] P. Pasupat and P. Liang. Compositional semantic parsing on semi-structured tables. In Annual Meeting of the Association for Computational Linguistics, 2015.
- Qwen et al. [2025] Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z. Zhang, and Z. Qiu. Qwen2.5 technical report, 2025. URL https://arxiv.org/abs/2412.15115.
- Radford et al. [2021] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/2103.00020.
- Raffel et al. [2023] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2023. URL https://arxiv.org/abs/1910.10683.
- Rodriguez et al. [2024a] J. Rodriguez, X. Jian, S. S. Panigrahi, T. Zhang, A. Feizi, A. Puri, A. Kalkunte, F. Savard, A. Masry, S. Nayak, R. Awal, M. Massoud, A. Abaskohi, Z. Li, S. Wang, P.-A. Noël, M. L. Richter, S. Vadacchino, S. Agarwal, S. Biswas, S. Shanian, Y. Zhang, N. Bolger, K. MacDonald, S. Fauvel, S. Tejaswi, S. Sunkara, J. Monteiro, K. D. Dvijotham, T. Scholak, N. Chapados, S. Kharagani, S. Hughes, M. Özsu, S. Reddy, M. Pedersoli, Y. Bengio, C. Pal, I. Laradji, S. Gella, P. Taslakian, D. Vazquez, and S. Rajeswar. Bigdocs: An open and permissively-licensed dataset for training multimodal models on document and code tasks, 2024a. URL https://arxiv.org/abs/2412.04626.
- Rodriguez et al. [2022] J. A. Rodriguez, D. Vazquez, I. Laradji, M. Pedersoli, and P. Rodriguez. Ocr-vqgan: Taming text-within-image generation, 2022. URL https://arxiv.org/abs/2210.11248.
- Rodriguez et al. [2024b] J. A. Rodriguez, A. Puri, S. Agarwal, I. H. Laradji, P. Rodriguez, S. Rajeswar, D. Vazquez, C. Pal, and M. Pedersoli. Starvector: Generating scalable vector graphics code from images and text, 2024b. URL https://arxiv.org/abs/2312.11556.
- Singh et al. [2019] A. Singh, V. Natarajan, M. Shah, Y. Jiang, X. Chen, D. Batra, D. Parikh, and M. Rohrbach. Towards vqa models that can read. In IEEE Conference Computer Vision Pattern Recognition, 2019.
- Stanisławek et al. [2021] T. Stanisławek, F. Graliński, A. Wróblewska, D. Lipiński, A. Kaliska, P. Rosalska, B. Topolski, and P. Biecek. Kleister: key information extraction datasets involving long documents with complex layouts. In International Conference on Document Analysis and Recognition, 2021.
- Svetlichnaya [2020] S. Svetlichnaya. Deepform: Understand structured documents at scale, 2020.
- Team [2024] G. Team. Gemini: A family of highly capable multimodal models, 2024. URL https://arxiv.org/abs/2312.11805.
- Vogus and Llansóe [2021] C. Vogus and E. Llansóe. Making transparency meaningful: A framework for policymakers. Center for Democracy and Technology, 2021.
- Wang et al. [2023a] D. Wang, N. Raman, M. Sibue, Z. Ma, P. Babkin, S. Kaur, Y. Pei, A. Nourbakhsh, and X. Liu. Docllm: A layout-aware generative language model for multimodal document understanding, 2023a. URL https://arxiv.org/abs/2401.00908.
- Wang et al. [2024] P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y. Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, 2024. URL https://arxiv.org/abs/2409.12191.
- Wang et al. [2023b] W. Wang, Q. Lv, W. Yu, W. Hong, J. Qi, Y. Wang, J. Ji, Z. Yang, L. Zhao, X. Song, et al. Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079, 2023b.
- Wu et al. [2024a] C. Wu, X. Chen, Z. Wu, Y. Ma, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, C. Ruan, and P. Luo. Janus: Decoupling visual encoding for unified multimodal understanding and generation, 2024a. URL https://arxiv.org/abs/2410.13848.
- Wu et al. [2024b] Z. Wu, X. Chen, Z. Pan, X. Liu, W. Liu, D. Dai, H. Gao, Y. Ma, C. Wu, B. Wang, Z. Xie, Y. Wu, K. Hu, J. Wang, Y. Sun, Y. Li, Y. Piao, K. Guan, A. Liu, X. Xie, Y. You, K. Dong, X. Yu, H. Zhang, L. Zhao, Y. Wang, and C. Ruan. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding, 2024b. URL https://arxiv.org/abs/2412.10302.
- Xu et al. [2024] R. Xu, Y. Yao, Z. Guo, J. Cui, Z. Ni, C. Ge, T.-S. Chua, Z. Liu, M. Sun, and G. Huang. Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images. European Conference on Computer Vision, 2024. doi: 10.48550/arXiv.2403.11703.
- Yu et al. [2024] W. Yu, Z. Yang, L. Li, J. Wang, K. Lin, Z. Liu, X. Wang, and L. Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities, 2024. URL https://arxiv.org/abs/2308.02490.
- Yue et al. [2024] X. Yue, Y. Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y. Sun, C. Wei, B. Yu, R. Yuan, R. Sun, M. Yin, B. Zheng, Z. Yang, Y. Liu, W. Huang, H. Sun, Y. Su, and W. Chen. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi, 2024. URL https://arxiv.org/abs/2311.16502.
- Zhai et al. [2023] X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training, 2023. URL https://arxiv.org/abs/2303.15343.
- Zhang et al. [2024] T. Zhang, S. Wang, L. Li, G. Zhang, P. Taslakian, S. Rajeswar, J. Fu, B. Liu, and Y. Bengio. Vcr: Visual caption restoration. arXiv preprint arXiv: 2406.06462, 2024.
- Zhao et al. [2024] Y. Zhao, J. Huang, J. Hu, X. Wang, Y. Mao, D. Zhang, Z. Jiang, Z. Wu, B. Ai, A. Wang, W. Zhou, and Y. Chen. Swift:a scalable lightweight infrastructure for fine-tuning, 2024. URL https://arxiv.org/abs/2408.05517.
- Zhu et al. [2025] J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y. Duan, W. Su, J. Shao, Z. Gao, E. Cui, X. Wang, Y. Cao, Y. Liu, X. Wei, H. Zhang, H. Wang, W. Xu, H. Li, J. Wang, N. Deng, S. Li, Y. He, T. Jiang, J. Luo, Y. Wang, C. He, B. Shi, X. Zhang, W. Shao, J. He, Y. Xiong, W. Qu, P. Sun, P. Jiao, H. Lv, L. Wu, K. Zhang, H. Deng, J. Ge, K. Chen, L. Wang, M. Dou, L. Lu, X. Zhu, T. Lu, D. Lin, Y. Qiao, J. Dai, and W. Wang. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models, 2025. URL https://arxiv.org/abs/2504.10479.
Appendix A Appendix
A.1 Experimental Setup
We provide detailed hyperparameters of our experiments in Table 6.
Table 6: Detailed hyperparameters for each training stage across different LLM backbones.
LLM Backbone Llama 3.2-1B Llama 3.2-3B Llama 3.1-8B Stage-1 Stage-2 Stage-3 Stage-1 Stage-2 Stage-3 Stage-1 Stage-2 Stage-3 Trainable Parameters Full Model Full Model LLM & Connector Full Model Full Model LLM & Connector Full Model Full Model LLM & Connector Batch Size 512 512 512 512 256 256 512 256 256 Text Max Length 1024 2048 2048 1024 2048 2048 1024 2048 2048 Epochs 1 1 5 1 1 5 1 1 5 Learning Rate $1× 10^{-5}$ $5× 10^{-5}$ $5× 10^{-5}$ $1× 10^{-5}$ $5× 10^{-5}$ $5× 10^{-5}$ $1× 10^{-5}$ $1× 10^{-5}$ $1× 10^{-5}$
A.2 Runtime Comparison Between Connectors
One caveat in the Align connector is that it includes an additional LM head layer, which slightly increases the total number of parameters. However, this addition has a negligible impact on runtime efficiency due to its simple structure. It only introduces a few matrix multiplication operations (as shown in Equations 1 and 2) instead of stacking many complex layers that require sequential processing, as in deep fusion methods.
To empirically validate this claim, we benchmarked the runtime and memory usage of models equipped with different connector types (MLP, Align, Ovis, and Perceiver), following the same experimental setup as in Table 2. As shown in Table 7, the results demonstrate that although the Align connector delivers notably superior performance (see Table 2), the variations in inference speed and GPU memory usage among the connectors remain minimal.
Table 7: Runtime and memory comparison between different connector designs. The results show that Align introduces negligible computational overhead compared to other connectors.
| Model | Samples | Avg Time (s) | Tokens/sec | GPU Memory (GB) |
| --- | --- | --- | --- | --- |
| Llama-3.2-3B-MLP | 2500 | 0.161 | 118.3 | 10.9 |
| Llama-3.2-3B-Perceiver | 2500 | 0.140 | 135.1 | 10.9 |
| Llama-3.2-3B-Ovis | 2500 | 0.155 | 122.5 | 10.8 |
| Llama-3.2-3B- Align | 2500 | 0.165 | 115.4 | 10.9 |
Overall, the empirical evidence confirms that the Align connector achieves an effective balance between computational efficiency and performance. It introduces only a negligible increase in runtime and memory usage while providing substantial gains in overall accuracy.
A.3 Pixel-Level Tasks Analysis
To rigorously evaluate the ability of vision-language models to integrate fine-grained visual and textual pixel-level cues, we test our model on the VCR benchmark [Zhang et al., 2024], which requires the model to recover partially occluded texts with pixel-level hints from the revealed parts of the text. This task challenges VLM’s alignment of text and image in extreme situations. Current state-of-the-art models like GPT-4V OpenAI et al. [2023], Claude 3.5 Sonnet Anthropic [2024], and Llama-3.2 Dubey et al. [2024] significantly underperform humans on hard VCR task due to their inability to process subtle pixel-level cues in occluded text regions. These models frequently discard critical visual tokens during image tokenization on semantic priors, overlooking the interplay between partial character strokes and contextual visual scenes. To evaluate performance on VCR, we modify our Stage 3 SFT dataset composition by replacing the exclusive use of DocDownstream with a 5:1 blended ratio of DocDownstream and VCR training data. This adjustment enables direct evaluation of our architecture Align ’s ability to leverage pixel-level character cues.
From the experimental outcomes, it is evident that AlignVLM consistently outperforms the MLP Connector Model across both easy and hard settings of the pixel-level VCR task (see Figure 5), with improvements ranging from 10.18% on the hard setting to 14.41% on the easy setting.
We provide a case study on VCR in Figure 6, featuring four representative examples. In Figure 6(a), it is evident that the MLP connector model fails to capture semantic consistency as effectively as AlignVLM. The phrase “The commune first census in written history in ” (where the words in italics are generated by the model while the rest are in the image) is not as semantically coherent as the phrase generated by Align “The commune first appears in written history in ”.
Beyond the issue of semantic fluency, in Figure 6(b) we also observe that AlignVLM successfully identifies the uncovered portion of the letter “g” in “accounting” and uses it as a pixel-level hint to infer the correct word. In contrast, the MLP model fails to effectively attend to this crucial detail.
Figures 6(c) and 6(d) show examples where AlignVLM fails on the VCR task. These carefully picked instances show that our method mistakes names of landmarks with common words when the two are very similar. As seen in the examples, AlignVLM mistakes “Llanengan" for “Llanongan" and “Gorden" for “Garden”. In both instances, the pairs differ by one character, indicating perhaps that AlignVLM tends to align vision representations to more common tokens in the vocabulary. One approach that would potentially mitigate such errors would be to train AlignVLM with more contextually-relevant data.
<details>
<summary>x3.png Details</summary>
### Visual Description
# Technical Data Extraction: Performance Comparison on VCR EN Benchmarks
## 1. Component Isolation
* **Header:** None present.
* **Main Chart:** A horizontal grouped bar chart comparing two models across two difficulty levels of the "VCR EN" benchmark.
* **Footer (Legend):** Located at the bottom of the image, centered horizontally.
## 2. Legend and Model Identification
The legend maps colors to specific model configurations:
* **Light Blue:** `Llama-3.2-3B-Align (Ours)`
* **Light Peach/Orange:** `Llama-3.2-3B-MLP`
## 3. Axis Definitions
* **Y-Axis (Categories):** Represents the benchmark datasets.
* `VCR EN Easy` (Top grouping)
* `VCR EN Hard` (Bottom grouping)
* **X-Axis (Metric):** Represents the performance score.
* **Title:** `Exact Match (%)`
* **Markers:** 0, 20, 40, 60
## 4. Data Table Reconstruction
The following table represents the numerical values explicitly labeled at the end of each horizontal bar.
| Benchmark Category | Model | Exact Match (%) |
| :--- | :--- | :--- |
| **VCR EN Easy** | Llama-3.2-3B-Align (Ours) | 65.84 |
| **VCR EN Easy** | Llama-3.2-3B-MLP | 51.43 |
| **VCR EN Hard** | Llama-3.2-3B-Align (Ours) | 48.07 |
| **VCR EN Hard** | Llama-3.2-3B-MLP | 37.89 |
## 5. Trend Verification and Analysis
* **Overall Performance:** The `Llama-3.2-3B-Align (Ours)` model (light blue) consistently outperforms the `Llama-3.2-3B-MLP` model (light peach) in both tested scenarios.
* **Difficulty Scaling:** There is a significant performance drop for both models when moving from the "Easy" to the "Hard" variant of the VCR EN benchmark.
* The "Align" model drops by **17.77** percentage points.
* The "MLP" model drops by **13.54** percentage points.
* **Relative Gain:**
* On **VCR EN Easy**, the "Align" model outperforms the "MLP" model by **14.41** percentage points.
* On **VCR EN Hard**, the "Align" model outperforms the "MLP" model by **10.18** percentage points.
## 6. Spatial Grounding Notes
* The legend is positioned at the bottom center of the figure.
* In each category grouping, the `Llama-3.2-3B-Align (Ours)` bar is positioned above the `Llama-3.2-3B-MLP` bar.
* Numerical labels are placed to the immediate right of the terminal end of each bar for precise reading.
</details>
Figure 5: Comparison of Llama-3.2-3b- Align and Llama-3.2-3B-MLP on the Easy and Hard VCR tasks.
<details>
<summary>figures/vcr_example1.png Details</summary>
### Visual Description
# Technical Document Extraction: Ațel Commune, Sibiu County
## 1. Image Overview
This image is a composite technical document consisting of a satellite/topographic map and a descriptive text block. It identifies the location and basic administrative structure of the Ațel commune within a larger regional context.
## 2. Component Isolation
### Region A: Map (Header/Main Visual)
* **Type:** Satellite imagery with administrative overlays.
* **Subject:** Sibiu County, Romania.
* **Visual Features:**
* The map shows a large, irregularly shaped territory (Sibiu County) outlined in a thick black border.
* The terrain is predominantly green, indicating heavy forestation or mountainous vegetation, interspersed with lighter patches representing valleys or urban settlements.
* White lines delineate the internal administrative boundaries (communes) within the county.
* **Spatial Highlight:** In the upper-right (northeast) quadrant of the county, one specific administrative area is highlighted with a **bright yellow border**. This represents the Ațel commune.
* **Coordinates (Relative):** The highlighted area is located approximately at [x=65%, y=15%] relative to the total county landmass.
### Region B: Text Block (Footer)
* **Language:** English.
* **Transcription:**
> "Ațel is a commune in Sibiu County, Transylvania, Romania. It is composed of two villages, Ațel and Dupuș. The commune first appears in written history in"
* **Note:** The text is cut off at the bottom, ending mid-sentence.
## 3. Extracted Data & Facts
| Category | Details |
| :--- | :--- |
| **Location Name** | Ațel |
| **Administrative Level** | Commune |
| **County** | Sibiu County |
| **Historical Region** | Transylvania |
| **Country** | Romania |
| **Constituent Villages** | 1. Ațel <br> 2. Dupuș |
## 4. Spatial Grounding and Logic Check
* **Boundary Verification:** The yellow highlight corresponds to the specific commune mentioned in the text. It is situated in the northern part of Sibiu County, which aligns with the geographical location of Ațel near the border with Mureș County.
* **Visual Trend:** The map indicates that Sibiu County is a highly fragmented administrative region with dozens of smaller communes, of which Ațel is one of the northernmost entities.
## 5. Language Declaration
The primary language of the document is **English**.
* **Specific Terms:** "Ațel", "Dupuș", and "Sibiu" are Romanian proper nouns.
* **Translation/Context:**
* *Ațel* (Romanian) -> Ațel (English)
* *Dupuș* (Romanian) -> Dupuș (English)
* *Sibiu* (Romanian) -> Sibiu (English)
</details>
| GT: | (appears in written history in) |
| --- | --- |
| MLP: | (census in written history in) ✗ |
| Align | (appears in written history in) ✓ |
(a) Positive Example 1
<details>
<summary>figures/vcr_example2.png Details</summary>
### Visual Description
# Technical Document Extraction: Ghana Telephone Numbering Plan Map
## 1. Document Overview
This image is a technical diagram illustrating the regional division of the Ghana telephone numbering plan. It consists of a color-coded map of Ghana with numerical area codes and a descriptive text block at the bottom.
## 2. Component Isolation
### Region A: Map Diagram
The map displays the geographic boundaries of Ghana, subdivided into ten distinct zones. Each zone is assigned a specific color and a three-digit numerical code.
#### Data Table: Regional Codes and Visual Identifiers
| Code | Color | Geographic Position |
| :--- | :--- | :--- |
| **030** | Pink | Southeast coastal strip (indicated by a leader line) |
| **031** | Light Blue | Southwest coast |
| **032** | Red | South-central interior |
| **033** | Pale Cyan | South-central coast (between 031 and 030) |
| **034** | Lavender | Southeast interior |
| **035** | Lime Green | Central-west interior |
| **036** | Dark Green | Eastern border (mid-section) |
| **037** | Purple | Large North-central region |
| **038** | Yellow | Northeast corner |
| **039** | Dark Blue | Northwest corner |
### Region B: Text Block (Transcription)
The text is located at the bottom of the image. Note: Some words in the second and third lines appear partially obscured or faded but are legible through context.
**Transcribed Text:**
> "The Ghana telephone numbering plan is the system used for assigning telephone numbers in Ghana. It is regulated by the National Communications"
*(Note: The text cuts off abruptly after "Communications", likely referring to the National Communications Authority (NCA) of Ghana.)*
## 3. Technical Analysis and Flow
The diagram functions as a spatial reference for landline or regional telecommunication routing.
* **Numerical Pattern:** All extracted codes follow a sequential prefix pattern starting with **03**. The third digit (0-9) differentiates the specific geographic region.
* **Spatial Distribution:**
* Codes **030-034** cover the southern half of the country.
* Codes **035-036** cover the central belt.
* Codes **037-039** cover the northern half of the country.
* **Visual Logic:** The use of high-contrast colors serves to clearly delineate administrative or technical boundaries that might otherwise overlap in a monochrome map.
## 4. Language Declaration
The primary and only language present in this document is **English**. No other languages were detected.
</details>
| GT: | (the system used for assigning) |
| --- | --- |
| MLP: | (the system used for accounting) ✗ |
| Align | (the system used for assigning) ✓ |
(b) Positive Example 2
<details>
<summary>figures/vcr_example3.png Details</summary>

### Visual Description
# Technical Document Extraction: Penrhyn Dû Mines
## 1. Image Component Isolation
The image is divided into two distinct horizontal segments:
* **Upper Region (Visual Data):** A photograph of a subterranean mine passage.
* **Lower Region (Textual Data):** A block of descriptive text in English, containing specific geographical and proper nouns.
---
## 2. Textual Transcription
The following text is transcribed exactly as it appears in the image. Note that some characters in the second and third lines of the text block are partially obscured or distorted by horizontal digital artifacts, but remain legible through context.
**Language:** English (with Welsh proper nouns).
> "The Penrhyn Dû Mines are a
> collection of mines situated near
> Llanengan on the Llŷn Peninsula.
> It encompasses the Penrhyn,
> Assheton, Western and"
*(Note: The text ends abruptly with the word "and", suggesting the original source material continues beyond this crop.)*
---
## 3. Visual Analysis & Technical Description
The photograph provides a first-person perspective of a mine adit or level.
* **Structural Geometry:** The passage is narrow and linear, receding into a vanishing point in the center-background. The walls appear to be hand-cut or blasted from solid rock, showing vertical ribbing and irregular textures.
* **Ceiling:** The roof is arched, a common structural shape in mining to distribute weight and prevent collapse. The rock at the top appears lighter in color (possibly quartz or a different mineral vein) compared to the darker side walls.
* **Floor/Substrate:** The floor of the passage is covered in standing water or very wet sludge. The surface reflects the light source, showing a rippled, brownish-yellow texture.
* **Lighting/Atmosphere:** The scene is illuminated by a single, high-intensity artificial light source (likely a headlamp or flashlight) positioned near the camera lens. This creates a "tunnel vision" effect where the center is brightly lit and the periphery fades into deep shadow (black).
* **Color Palette:**
* **Walls:** Dark greys, purples, and blacks.
* **Ceiling:** Off-white to light tan.
* **Floor:** Ochre/Brown (indicative of iron oxide or "ochre" common in flooded mines).
---
## 4. Fact & Data Summary
Based on the combined textual and visual evidence:
| Category | Details |
| :--- | :--- |
| **Subject** | Penrhyn Dû Mines |
| **Location** | Near Llanengan, Llŷn Peninsula (Wales) |
| **Constituent Parts** | Penrhyn Mine, Assheton Mine, Western Mine (and others) |
| **Condition** | Subterranean, partially flooded, hand-excavated appearance |
| **Primary Language** | English |
| **Secondary Language** | Welsh (Proper nouns: Penrhyn Dû, Llanengan, Llŷn) |
**Translation of Welsh Terms:**
* **Penrhyn Dû:** Literally translates to "Black Headland" or "Black Promontory."
* **Llŷn:** Refers to the Llŷn Peninsula in North Wales.
</details>
| GT: | (mines situated near Llanengan on) |
| --- | --- |
| MLP: | (mines situated near Llanengan on) ✓ |
| Align | (mines situated near Llanongan on) ✗ |
(c) Negative Example 1
<details>
<summary>figures/vcr_example4.png Details</summary>

### Visual Description
# Technical Document Extraction: City of Fairmount Information
## 1. Image Overview
The image is a composite document consisting of two primary segments:
* **Upper Segment (Visual):** A photograph of a municipal building.
* **Lower Segment (Textual):** A block of descriptive text regarding the location and demographics of the city.
---
## 2. Component Isolation & Extraction
### Region A: Building Facade (Header/Main Image)
The image depicts a single-story red brick building with a gabled roof and white trim.
**Extracted Text (Building Signage):**
The following text is mounted in gold-colored lettering on the upper portion of the brick facade:
* **Line 1:** CITY OF FAIRMOUNT
* **Line 2:** CITY HALL - POLICE DEPARTMENT - LIBRARY
**Architectural Details:**
* **Entrance:** A central recessed entryway under a small white-trimmed portico.
* **Doors/Windows:** Dark-tinted glass doors and windows are visible at the entrance.
* **Surroundings:** A paved parking area with blue-marked accessible parking spaces is in the foreground. Green foliage and trees are visible in the background and to the sides.
### Region B: Descriptive Text (Footer)
The bottom portion of the image contains a block of black sans-serif text. Note: Some parts of the text are partially obscured or faded due to image artifacts, but the content is reconstructed below.
**Transcribed Text:**
> "Fairmount is a city in Gordon County, Georgia, United States. As of the 2010 census it had a population of 720. Gordon County is home to New Echota,"
---
## 3. Data Summary & Facts
Based on the extracted information, the following facts are established:
| Category | Data Point |
| :--- | :--- |
| **Location** | Fairmount, Gordon County, Georgia, USA |
| **Population (2010 Census)** | 720 |
| **Building Functions** | City Hall, Police Department, Library |
| **Regional Landmark** | New Echota (located within the same county) |
## 4. Language Declaration
The primary and only language present in this document is **English**. No other languages were detected.
</details>
| GT: | (Gorden County is home to) |
| --- | --- |
| MLP: | (Gorden County is home to) ✓ |
| Align | (Garden County is home to) ✗ |
(d) Negative Example 2
Figure 6: Case Study for Pixel-Level Tasks. We provide examples of our proposed Align connector compared with a the Multi-Layer Perceptron (MLP) connector. The Align connector tends to better map visual elements to common words. GT is the ground truth.
A.4 Case Studies
In this section, we provide case studies for the experiments in Section 5.1. Specifically, we provide examples of our Llama-3.2-3B- Align, and its counterpart model with alternative connectors Llama-3.2-3B-MLP and Llama-3.2-3B-Ovis on three different datasets: KLC [Stanisławek et al., 2021], DocVQA [Mathew et al., 2021b], and TextVQA [Singh et al., 2019]. The examples are shown in Figure 7, 8, and 9.
<details>
<summary>figures/case_1.jpg Details</summary>

### Visual Description
# Technical Document Extraction: Ardingly College Limited Financial Report Cover
## 1. Document Overview
This image is the front cover of a formal financial document for **Ardingly College Limited**. It contains institutional branding, the title of the report, the fiscal period covered, and legal registration identifiers.
---
## 2. Component Isolation
### Region 1: Header (Top Margin)
* **Handwritten Annotation:** Located at the top right, outside the decorative border.
* **Text:** "EXTERNAL" (Capitalized, handwritten in ink).
### Region 2: Institutional Branding (Top Center)
* **Logo Left:** A stylized line drawing of a pelican in her piety (a traditional heraldic symbol).
* **Logo Right:** A line drawing of a terrestrial globe on a stand.
* **Primary Text:** "ARDINGLY" (Large, serif, all caps).
* **Secondary Text:** "College" (Smaller, serif, title case, positioned under "ARDINGLY").
* **Motto:** "World Ready" (Sans-serif, positioned under the globe and college name).
### Region 3: Main Title and Subject (Center)
* **Entity Name:** "Ardingly College Limited" (Large, italicized serif font).
* **Document Title:** "DIRECTORS' REPORT AND FINANCIAL STATEMENTS" (Bold, sans-serif, all caps).
* **Reporting Period:** "FOR THE YEAR ENDED 31ST AUGUST 2017" (Sans-serif, all caps).
### Region 4: Legal and Regulatory Information (Footer)
* **Charity Status:** "Charity Registration No. 1076456" (Sans-serif).
* **Company Status:** "Company Registration No. 03779971 (England and Wales)" (Sans-serif).
---
## 3. Visual and Structural Details
* **Border:** The entire main content is enclosed in a decorative double-line rectangular border with ornate flourishes (fleur-de-lis style) at the four interior corners.
* **Binding Marks:** On the far left edge, there are visible vertical indentations/perforations suggesting the document was previously bound or held in a ring binder.
* **Layout:** The document follows a formal, centered alignment for all printed text elements.
---
## 4. Full Text Transcription
| Field | Content |
| :--- | :--- |
| **Handwritten Note** | EXTERNAL |
| **Institution Name** | ARDINGLY College |
| **Motto** | World Ready |
| **Legal Entity** | Ardingly College Limited |
| **Report Type** | DIRECTORS' REPORT AND FINANCIAL STATEMENTS |
| **Fiscal Year End** | FOR THE YEAR ENDED 31ST AUGUST 2017 |
| **Charity Number** | 1076456 |
| **Company Number** | 03779971 (England and Wales) |
---
## 5. Language Declaration
The document is entirely in **English**. No other languages are present.
</details>
| Question: | What is the value for the charity name? |
| --- | --- |
| GT: | (Ardingly College Ltd.) |
| MLP: | (Ardington College Ltd.) ✗ |
| Ovis: | (Ardington College Ltd.) ✗ |
| Align: | (Ardingly College Ltd.) ✓ |
(a) Positive Example #1
<details>
<summary>figures/case_2.jpg Details</summary>

### Visual Description
# Technical Document Extraction: Trustees' Annual Report
This document is a formal "Trustees' Annual Report" form from the Charity Commission. It contains administrative details for a specific charity for a defined reporting period.
## 1. Header Information
The top of the document contains the organization logo and the reporting period.
* **Logo:** Charity Commission (Green and white logo in the top left).
* **Document Title:** Trustees' Annual Report for the period
* **Reporting Period:**
* **From (Period start date):** 11 / 02 / 2016
* **To (Period end date):** 10 / 02 / 2017
---
## 2. Section A: Reference and Administration Details
This section provides the core identification data for the charity.
| Field Label | Extracted Data |
| :--- | :--- |
| **Charity name** | TENDER GRACE CHRISTIAN CENTRE |
| **Other names charity is known by** | [Blank] |
| **Registered charity number (if any)** | 1165532 |
| **Charity's principal address** | FLAT 13, 39 TRINITY RISE, LONDON |
| **Postcode** | SW2 2QP |
---
## 3. Names of the Charity Trustees
This is a structured table listing the individuals responsible for managing the charity. The table contains 20 numbered rows, with data populated in the first four.
### Main Trustee Table
| # | Trustee name | Office (if any) | Dates acted if not for whole year | Name of person (or body) entitled to appoint trustee (if any) |
| :--- | :--- | :--- | :--- | :--- |
| 1 | Mr Anthony Yakubu Membu | [Blank] | [Blank] | [Blank] |
| 2 | Miss Happiness Ngosi Jan-Nnyeruka | [Blank] | [Blank] | [Blank] |
| 3 | Mrs Olabisi Comfort Ogunjobi | [Blank] | [Blank] | [Blank] |
| 4 | Mrs Olayinka Adeola Oyesanya | [Blank] | [Blank] | [Blank] |
| 5-20 | [Blank] | [Blank] | [Blank] | [Blank] |
---
## 4. Additional Trustee Information
A secondary table is provided for other types of trustees (e.g., custodian trustees).
**Section Title:** Names of the trustees for the charity, if any, (for example, any custodian trustees)
| Name | Dates acted if not for whole year |
| :--- | :--- |
| [Blank] | [Blank] |
---
## 5. Footer Information
* **Left:** TAR
* **Center:** 1 (Page Number)
* **Right:** March 2012 (Form version/date)
</details>
| Question: | What is the value for the address postcode? |
| --- | --- |
| GT: | (SW2 2QP) |
| MLP: | (SW22 0PQ) ✗ |
| Ovis: | (SW2 2OP) ✗ |
| Align: | (SW2 2QP) ✓ |
(b) Positive Example #2
<details>
<summary>figures/case_3.jpg Details</summary>

### Visual Description
# Technical Document Extraction: Annual Report Cover
## 1. Document Overview
This image serves as the front cover of a formal corporate/charity publication. It features a high-resolution photograph of children in a classroom setting, overlaid with organizational branding and report titles.
## 2. Component Isolation
### Region A: Vertical Sidebar (Left Edge)
* **Location:** Bottom-left corner, extending vertically.
* **Background Color:** Purple.
* **Logo:** A circular emblem containing a stylized globe and Arabic calligraphy.
* **Text (Vertical):** "human appeal" (lowercase, sans-serif font).
### Region B: Main Title Overlay (Bottom Right)
* **Location:** Lower third of the image, right-aligned.
* **Primary Title:** "ANNUAL REPORT" (Uppercase, bold, white sans-serif font).
* **Secondary Title:** "AND FINANCIAL STATEMENTS 2015" (Uppercase, white sans-serif font, smaller weight than primary title).
### Region C: Regulatory Information (Top Left Margin)
* **Location:** Rotated 90 degrees counter-clockwise, running along the top-left edge of the image.
* **Transcribed Text:**
> Charity No. 1154288 | Company Reg No. 8553893 | Scottish Reg No. SC046481
### Region D: Visual Content (Background)
* **Subject:** A young girl of African descent is the central focus. She is smiling broadly, showing her teeth, and has her left hand raised to her head.
* **Setting:** A classroom. Other children are visible in the blurred background.
* **Attire:** The children are wearing school uniforms consisting of white collared shirts and purple pinafores/vests.
* **Objects:** Wooden school desks and books are visible in the foreground and mid-ground.
## 3. Extracted Data Summary
| Field | Value |
| :--- | :--- |
| **Organization Name** | Human Appeal |
| **Document Type** | Annual Report and Financial Statements |
| **Reporting Year** | 2015 |
| **Charity Registration No.** | 1154288 |
| **Company Registration No.** | 8553893 |
| **Scottish Registration No.** | SC046481 |
| **Primary Brand Color** | Purple (Hex approx. #662D91) |
## 4. Language Declaration
* **Primary Language:** English.
* **Secondary Language:** Arabic (contained within the circular logo emblem).
* *Note:* The Arabic text in the logo is stylized calligraphy representing the organization's name or mission; it is a standard part of the "Human Appeal" brand identity.
## 5. Fact/Data Statement
The image does not contain charts, heatmaps, or data tables. It provides administrative identification numbers (Charity/Company/Scottish Reg) and establishes the temporal context of the report (2015). The visual elements emphasize the organization's focus on education and international aid.
</details>
| Question: | What is the value for the charity name? |
| --- | --- |
| GT: | (Human Appeal) |
| MLP: | (Humanitarian Agenda) ✗ |
| Ovis: | (Human Appeal) ✓ |
| Align: | (Human Rightsappeal) ✗ |
(c) Negative Example #1
<details>
<summary>figures/case_4.jpg Details</summary>

### Visual Description
# Technical Document Extraction: Bishop’s Stortford Baptist Church Annual Report 2017
## 1. Document Overview
This document is the first page of the **Annual Report 2017** for **Bishop’s Stortford Baptist Church**. It serves as an introductory page outlining the church's mission statement, vision, aims, and operational objectives.
---
## 2. Component Isolation
### Region 1: Header (Top Right & Center)
* **Logo:** Located in the top right corner. It features the stylized letters "**BSBC**" with a Christian cross integrated into the letter 'C'. Below the letters is the text: "bishops stortford baptist church".
* **Main Title:** "Bishop’s Stortford Baptist Church" (Large bold font).
* **Mission Statement:** "This Church aims to be a community of believers living according to the Bible’s teaching where people become fully devoted followers of Jesus Christ" (Centered below the title).
### Region 2: Report Title (Center)
* **Document Title:** "Annual Report 2017" (Bold).
* **Introductory Sentence:** "We are pleased to present a report of the life and work of the Church during 2017."
### Region 3: Aim and Purposes (Body Text)
* **Section Heading:** "Aim and Purposes" (Bold).
* **Content Transcription:**
> "The vision of Bishop’s Stortford Baptist Church is to be a community of believers living according to the Bible’s teaching so that Christ’s redemptive purposes can be accomplished in the world. The Church’s mission is to enable people to become fully devoted followers of Jesus Christ by the power of the Holy Spirit. To that end, we understand the purposes of the Church to be worship, discipleship, fellowship, outreach and service. The fellowship of the Church seeks to go deeper with God, become closer to each other and wider in our influence."
### Region 4: Objectives and Overview (Body Text & List)
* **Section Heading:** "Objectives and Overview" (Bold).
* **Introductory Text:** "The Church is committed to carrying out its activities in line with the Baptist tradition and to encourage and enable people in the local area to attend and take part in its services and meetings. Activities include:"
* **Bulleted List of Activities:**
* Services each week for worship, prayer, Bible study, preaching and teaching, including additional services for those in the local area whose first language is not English.
* Baptisms on request.
* Meetings for young people.
* Small group meetings (LIFE Groups) for all ages.
* Pastoral care.
* Discipleship for Christian service.
* Evangelism and mission.
* Support of Christian and social charitable action within the local area.
* Support for mission overseas.
* Involvement with the local and national Baptist associations.
* **Organizational Structure Text:**
> "The ministry areas of the Church are classified into Worship, Fellowship, Reaching Out, Discipleship and Social Action, supplemented by a Resources Team (all led by the Deacons) and with spiritual oversight and pastoral care administered by the Elders."
### Region 5: Footer
* **Page Number:** "1" (Centered at the bottom).
---
## 3. Key Information Summary
| Category | Details |
| :--- | :--- |
| **Organization** | Bishop’s Stortford Baptist Church (BSBC) |
| **Reporting Period** | Calendar Year 2017 |
| **Core Pillars** | Worship, Discipleship, Fellowship, Outreach, Service |
| **Ministry Classifications** | Worship, Fellowship, Reaching Out, Discipleship, Social Action |
| **Leadership Structure** | Deacons (Resources/Ministry areas); Elders (Spiritual oversight/Pastoral care) |
## 4. Language Declaration
The document is written entirely in **English**. No other languages are present.
</details>
| Question: | What is the value for the post town address? |
| --- | --- |
| GT: | (Bishop’s Stortford) |
| MLP: | (Stortford) ✗ |
| Ovis: | (Bishop’s Stortford) ✓ |
| Align: | (Stortford) ✗ |
(d) Negative Example #2
Figure 7: Case Study for Connector Comparison on the KLC dataset [Stanisławek et al., 2021]. We show four qualitative examples (including two correct and two incorrect examples) comparing Llama-3.2-3B- Align to the same architecture with different connectors, Llama-3.2-3B-MLP and Llama-3.2-3B-Ovis. “GT” denotes the ground truth.
<details>
<summary>figures/case_5.jpg Details</summary>

### Visual Description
# Technical Document Extraction: Schedule of Events
This document is a typewritten schedule for a multi-day academic or professional seminar, likely related to public health or epidemiology. The document is page 3 of a larger set.
## Document Metadata
- **Page Number:** -3-
- **Language:** English
- **Source:** https://www.industrydocuments.ucsf.edu/docs/gpcg0227
---
## Schedule Data
### Thursday, June 29
**Session Period: Afternoon**
| Time | Activity / Topic | Leader / Group Details | Location |
| :--- | :--- | :--- | :--- |
| 1:00 | Techniques of Interviewing | Mrs. Fink | Room 123 |
| 1:30 | Practice Interviews | (See Group Breakdown Below) | (See Group Breakdown Below) |
| 2:45 | Recess | - | - |
| 3:15 | Practice Interviews (continued) | Same groups, same rooms | - |
#### Practice Interview Group Assignments (1:30 PM)
| Group | Leader | Room / Building |
| :--- | :--- | :--- |
| I | Mrs. Fink | 123 State Health Department |
| II | Miss Grass | 802 State Health Department |
| III | Miss Peck | 627 State Health Department |
| IV | Mr. Price | 510 School of Public Health |
| V | Dr. Croley | 522 School of Public Health |
---
### Friday, June 30
**Session Period: Morning**
| Time | Group | Topic | Leader | Location |
| :--- | :--- | :--- | :--- | :--- |
| 8:00 | Group A | Statistical Aspects of Epidemiologic Research | Dr. Gaffey | Room 802 |
| 8:00 | Group B | Problems in Research Design | Dr. Reynolds | Room 123 |
| 9:45 | - | **Recess** | - | - |
| 10:15 | Group A | Problems in Research Design | Dr. Reynolds | Room 123 |
| 10:15 | Group B | Statistical Aspects of Epidemiologic Research | Dr. Gaffey | Room 802 |
| 12:00 | - | **Lunch** | - | - |
**Session Period: Afternoon**
| Time | Activity / Topic | Leader / Group Details | Location |
| :--- | :--- | :--- | :--- |
| 1:00 | Construction and Use of Questionnaires | **Group A:** (Dr. Fink) | Room 123 |
| 1:00 | Construction and Use of Questionnaires | **Group B:** (Dr. Mellinger) | Room 522 School of Public Health |
| 2:45 | Recess | - | - |
| 3:15 | Construction and Use of Questionnaires (continued) | Same groups, same rooms | - |
---
## Component Analysis and Flow
1. **Structure:** The document is organized chronologically by day (Thursday vs. Friday) and then subdivided by time of day (Morning vs. Afternoon).
2. **Logic Flow:**
* On Thursday afternoon, a general lecture is followed by breakout sessions into five numbered groups (I-V).
* On Friday morning, two specific tracks (Statistical Aspects vs. Research Design) are rotated between Group A and Group B so that both groups receive both lectures by noon.
* On Friday afternoon, the groups remain split (A and B) for a session on Questionnaires, which continues after a recess.
3. **Institutional Context:** The locations mentioned indicate a collaboration or proximity between the "State Health Department" and the "School of Public Health."
</details>
| Question: | What does the afternoon session begin on June 29? |
| --- | --- |
| GT: | (1:00) |
| MLP: | (2:45) ✗ |
| Ovis: | (3:30) ✗ |
| Align: | (1:00) ✓ |
(a) Positive Example #1
<details>
<summary>figures/case_6.jpg Details</summary>
### Visual Description
# Technical Document Extraction: National Nutrition Survey - Massachusetts
This document contains three distinct data sections regarding health and socio-economic statistics for the state of Massachusetts, based on the National Nutrition Survey and ICNND (Interdepartmental Committee on Nutrition for National Defense) guidelines.
---
## Section 1: Hemoglobin Data - Massachusetts
**Summary Statement:** 8% of the surveyed population had unsatisfactory hemoglobin levels (ICNND guidelines).
### Data Table: Hemoglobin Levels by Age and Gender
This table breaks down unsatisfactory hemoglobin levels into "Def." (Deficient) and "Low" categories for Males and Females across five age cohorts.
| Age | Males: Def. | Males: Low | Males: Total Unsatisfactory | Females: Def. | Females: Low | Females: Total Unsatisfactory |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: |
| 0-5 yr | 4.5 | 8.0 | 12.5 | 1.5 | 7.0 | 8.5 |
| 6-12 | 0.2 | 3.8 | 4.0 | 0.2 | 5.0 | 5.2 |
| 13-16 | 3.6 | 12.7 | 16.3 | 0.0 | 3.5 | 3.5 |
| 17-59 | 1.2 | 10.0 | 11.2 | 1.1 | 6.0 | 7.1 |
| 60+ | 0.7 | 14.3 | 15.0 | 0.5 | 4.7 | 5.2 |
**Key Trends:**
* **Males:** The highest total unsatisfactory levels are found in the 13-16 age group (16.3%) and the 60+ age group (15.0%). The lowest is the 6-12 age group (4.0%).
* **Females:** The highest total unsatisfactory levels are in the youngest cohort, 0-5 years (8.5%). Unlike males, the 13-16 age group for females shows the lowest total unsatisfactory levels (3.5%).
* **Gender Comparison:** Males generally show higher total unsatisfactory hemoglobin levels than females in every age category except the 6-12 range.
---
## Section 2: Hematocrit Data - Massachusetts
**Summary Statement:** 9.2% of the surveyed population had unsatisfactory hematocrit levels (ICNND guidelines).
### Data Table: Hematocrit Levels by Age and Gender
This table follows the same structure as the Hemoglobin table, categorizing "Def." (Deficient) and "Low" levels.
| Age | Males: Def. | Males: Low | Males: Total Unsatisfactory | Females: Def. | Females: Low | Females: Total Unsatisfactory |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: |
| 0-5 yr | 4.4 | 4.0 | 8.4 | 0.5 | 1.5 | 2.0 |
| 6-12 | 0.0 | 3.9 | 3.9 | 0.0 | 5.4 | 5.4 |
| 13-16 | 1.2 | 15.0 | 16.2 | 0.0 | 2.9 | 2.9 |
| 17-59 | 0.7 | 10.0 | 10.7 | 0.5 | 7.8 | 8.3 |
| 60+ | 0.0 | 20.0 | 20.0 | 0.5 | 3.8 | 4.3 |
**Key Trends:**
* **Males:** There is a significant upward trend in unsatisfactory levels as age increases beyond childhood, peaking at 20.0% for the 60+ cohort.
* **Females:** The highest unsatisfactory levels are found in the 17-59 age group (8.3%).
* **Gender Comparison:** Males exhibit significantly higher unsatisfactory hematocrit levels than females in the 0-5, 13-16, and 60+ age groups.
---
## Section 3: General Socio-economic Data - Massachusetts
This section provides the demographic and economic context for the surveyed population.
| Metric | Value |
| :--- | :--- |
| Total number of persons examined | 4,568 |
| Mean family size | 5.31 |
| Mean income: $ per annum | 6,500 |
| Mean poverty index ratio | 2.29 |
| % of families below poverty index ratio of 1.00 | 19.5 |
**Observations:**
* The survey sample size is 4,568 individuals.
* Nearly one-fifth (19.5%) of the families surveyed live below the poverty index ratio of 1.00.
* The average family size is relatively large at 5.31 members.
---
**Document Footer:**
Source: `https://www.industrydocuments.ucsf.edu/docs/tnbf0227`
</details>
| Question: | What levels does the second table indicate? |
| --- | --- |
| GT: | (hematocrit data - Massachusetts) |
| MLP: | (SATISFACTORY) ✗ |
| Ovis: | (Females) ✗ |
| Align: | (hematocrit data - Massachusetts) ✓ |
(b) Positive Example #2
<details>
<summary>figures/case_7.jpg Details</summary>

### Visual Description
# Technical Document Extraction: Policy on Document Control
## 1. Document Metadata and Header Information
The image is a scanned page of a formal corporate policy document, likely used as legal evidence based on the presence of an exhibit stamp.
* **Exhibit Stamp (Top Right):** A rectangular stamp with rounded corners.
* **Text:** "EXHIBIT"
* **Handwritten Reference:** "R-17"
* **Vertical Text (Left side of stamp):** "PENGAD 800-631-6989"
| Document Header Table | |
| :--- | :--- |
| Policy on Document Control | Policy No. 8 |
* **Footer Information:**
* **Left:** Confidential - Subject to Protective Order
* **Right:** TAKJ-TPC-00000252
* **Bottom Center (Source URL):** Source: https://www.industrydocuments.ucsf.edu/docs/jpjf0226
* **Bottom Center (Bates/Reference Number):** 2378-00001
---
## 2. Textual Content Transcription
### Chapter I: General Provisions
#### Article 1 (Purpose)
This Policy shall be intended to stipulate basic matters on creation, storage, and disposal, etc. of documents (including electromagnetic records) handled by the Company and exceptional treatments, etc. in order to respond to lawsuits and other legal/administrative proceedings (hereinafter referred to as "disputes, etc."), so that document information can be properly and effectively managed and utilized.
#### Article 2 (General Provisions)
(1) Documents of the Company shall be handled in accordance with this Policy, in addition to those stipulated in the "Policy on Handling Contract Documents, etc. and Corporate Seals (Policy No. 6)", the "Policy on Confidential Information Management (Policy No. 18)", and the "Policy on IT Security (Policy No. 67)".
(2) Each core organization shall set forth standards for creation, storage, disposal, and other detailed treatment of documents to be handled at the core organization (hereinafter referred to as "Function Standards"), in accordance with the provisions stipulated herein.
#### Article 3 (Definitions)
Definitions of the terms used in this Policy shall be as set forth in the following items.
1. **"Documents"** shall mean approval documents, notification documents, reports, conference materials, correspondences, fax/telex transmissions, bills, various records, drawings, microfilms, photographs, video/audio media, electronic mail, and any other documents and electromagnetic records handled in connection with Company business (including those created by external parties, but excluding publications such as newspapers, magazines, and books, etc.).
2. **"Disks"** shall mean electromagnetic recording media, including floppy disks, CD-Rs, and DVD-Rs, etc.
3. **"Storage"** shall mean managing documents in any of the following methods and places for specified periods of time. Documents stored shall be referred to as "Stored Documents."
1) By the originals or write-protected disks, in lockable cabinets or desks, or designated warehouses
2) By electromagnetic means, in access-controlled servers
---
## 3. Component Analysis and Flow
The document follows a standard legal/corporate policy structure:
1. **Header:** Establishes the subject ("Document Control") and the policy index number ("No. 8").
2. **Chapter Heading:** Defines the broad category of the following articles ("General Provisions").
3. **Article 1 (Scope/Intent):** Defines *why* the policy exists (legal compliance and effective management).
4. **Article 2 (Hierarchy/Integration):** Explains how this policy interacts with other specific policies (Nos. 6, 18, and 67) and mandates that sub-organizations create their own "Function Standards."
5. **Article 3 (Taxonomy):** Provides precise definitions for technical terms used throughout the document to prevent ambiguity in legal or administrative contexts.
## 4. Technical Observations
* **Language:** English.
* **Format:** Typed text within a bordered frame.
* **Key Entities:** The "Company," "Core Organizations," and "Function Standards."
* **Media Types Mentioned:** Physical paper, electromagnetic records, floppy disks, CD-Rs, DVD-Rs, microfilms, and servers.
</details>
| Question: | What type of policy is described in this document? |
| --- | --- |
| GT: | (Policy on Document Control) |
| MLP: | (Policy on Document Control) ✓ |
| Ovis: | (General Provisions) ✗ |
| Align: | (Document Control) ✗ |
(c) Negative Example #1
<details>
<summary>figures/case_8.jpg Details</summary>

### Visual Description
# Technical Document Extraction: Blood Analysis Report (June 18, 1975)
## Document Metadata
* **Date:** June 18, 1975
* **Document Type:** Technical Research Summary / Data Table
* **Source:** Industry Documents Library (UCSF)
* **Language:** English
---
## 1. Header and Narrative Summary
The document describes a study titled: **"The Ability of Dietary Glycan to Lower Elevated Blood Cholesterol and Triglycerides in Rats."**
### Experimental Methodology
The text describes an experiment involving male rats divided into specific dietary groups:
* **Initial Phase:** Ten male rats were fed a control diet (basal + cholesterol and cholic acid) for four weeks.
* **Group Division:**
* **Group 2A (Handwritten as #2 a):** Continued to receive the control diet.
* **Group 2B (Handwritten as #3 b):** Received a test diet where 15 parts of Glycan replaced 15 parts of sucrose.
* **Group #1:** A separate group of ten male rats fed a basal diet for four weeks and continued on that basal diet (Control/Baseline group).
* **Procedure:** Whole blood was drawn weekly from the caudal vein for serum cholesterol determination. At the end of four weeks, blood was drawn via heart puncture for final analysis.
---
## 2. Data Table: Blood Analysis
The following table reconstructs the data presented in the "Blood Analysis" section. Note that the column headers contain handwritten annotations modifying the original typed text.
| Measurement Category | Week | Group #1 (Basal) | Group #2 a (Control Diet) | Group #3 b (Glycan Test Diet) |
| :--- | :---: | :---: | :---: | :---: |
| **Cholesterol mg %** | 0 | 96 | 157 | 157 |
| | 1 | 96 | 148 | 115 |
| | 2 | 96 | 156 | 99 |
| | 3 | 96 | 148 | 115 |
| | 4 | 103 | 133 | 111 |
| **Triglyceride mg %** | 4 | 293* | 203 | 169 |
*\*Note: The value 293 for Group #1 Triglycerides is circled in the original document.*
---
## 3. Trend Analysis and Observations
### Cholesterol Trends
* **Group #1 (Basal Diet):** Remained extremely stable at 96 mg % for the first three weeks, with a slight increase to 103 mg % at week 4.
* **Group #2 a (Control Diet - High Cholesterol):** Started at a high baseline of 157 mg %. The levels fluctuated but remained elevated throughout the study, ending at 133 mg %.
* **Group #3 b (Glycan Test Diet):** Started at the same high baseline as Group 2 (157 mg %). There is a **sharp downward trend** immediately following the introduction of the Glycan diet. By Week 2, the level dropped to 99 mg % (nearly reaching the basal level of Group 1) before stabilizing in the 111-115 mg % range.
### Triglyceride Observations (Week 4)
* The Glycan Test Diet (Group #3 b) shows the lowest triglyceride levels (169 mg %) compared to the Control Diet (203 mg %).
* Interestingly, the Basal Diet group (#1) shows the highest triglyceride levels (293 mg %), which is highlighted by a hand-drawn circle in the source image.
---
## 4. Component Isolation & Annotations
* **Header:** Contains the date "June 18, 1975" in the top right and a handwritten "8" in the far top right corner.
* **Main Body:** Typed text explaining the experimental design.
* **Data Region:** A structured table under the underlined heading "Blood Analysis".
* **Handwritten Marks:**
* "a" added next to #2.
* "b" added next to #3.
* A circle around the value "293" in the Triglyceride row.
* **Footer:** Source URL watermark: `https://www.industrydocuments.ucsf.edu/docs/hnhd0227`
</details>
| Question: | What was the diet fed to the #1 group? |
| --- | --- |
| GT: | (basal diet) |
| MLP: | (basel diet) ✓ |
| Ovis: | (Whole blood) ✗ |
| Align: | (control diet) ✗ |
(d) Negative Example #2
Figure 8: Case Study for Connector Comparison on the DocVQA dataset [Mathew et al., 2021b]. We show four qualitative examples (including two correct and two incorrect examples) comparing Llama-3.2-3B- Align to the same architecture with different connectors, Llama-3.2-3B-MLP and Llama-3.2-3B-Ovis. “GT” denotes the ground truth.
<details>
<summary>figures/case_9.jpg Details</summary>

### Visual Description
# Technical Document Extraction: Image Analysis
## 1. Document Overview
The provided image is a high-angle photograph of a physical object (an envelope) resting on a textured surface (a suitcase). This is a non-technical, artistic image and does not contain charts, data tables, heatmaps, or technical diagrams.
## 2. Component Isolation
### Region A: The Envelope (Main Subject)
* **Type:** Airmail-style envelope.
* **Orientation:** Horizontal, centered in the upper half of the frame.
* **Design Features:** The perimeter of the envelope features a repeating diagonal striped border in alternating colors of red and blue.
* **Textual Content:** There is a single line of handwritten text located in the center of the envelope.
* **Transcription:** `good bye`
* **Language:** English.
* **Typography:** Lowercase, sans-serif, handwritten script with slight spacing between the two words.
### Region B: The Suitcase (Background/Support)
* **Material:** Textured, light beige or cream-colored material (likely vintage leather or vinyl).
* **Hardware:** Visible at the bottom of the frame are metal latches and a handle assembly. The hardware appears to be aged brass or bronze.
### Region C: The Base Surface (Footer)
* **Description:** The suitcase is resting on a surface with a black and white pattern.
* **Pattern Details:** Concentric wavy lines and dots, resembling a stylized or doodle-art aesthetic.
## 3. Data and Fact Summary
* **Quantitative Data:** None. There are no numerical values, axis markers, or statistical trends present in the image.
* **Qualitative Data:** The image conveys a theme of departure or finality through the combination of a "good bye" note and travel-related items (suitcase, airmail envelope).
## 4. Final Transcription
The only textual information present in the image is:
> **good bye**
</details>
| Question: | What greeting is written on the letter? |
| --- | --- |
| GT: | (good bye) |
| MLP: | (good) ✗ |
| Ovis: | (good buy) ✗ |
| Align: | (good bye) ✓ |
(a) Positive Example #1
<details>
<summary>figures/case_10.jpg Details</summary>

### Visual Description
# Technical Data Extraction: SkyScan Atomic Clock
## 1. Device Identification
* **Brand:** SkyScan
* **Model Type:** ATOMIC CLOCK
* **Logo:** Stylized "SkyScan" text accompanied by a radio tower icon emitting signal waves.
## 2. Component Segmentation
### Region A: Header (Top Bezel)
* **Text:** `SkyScan`
* **Text:** `ATOMIC CLOCK`
* **Visuals:** Dark grey/black matte finish bezel.
### Region B: Main Display (Upper LCD)
This region displays the primary timekeeping information.
* **Time Value:** `12:04`
* **Label:** `TIME` (located on the far right of the LCD panel).
* **Status Icon:** A small radio tower icon is visible between the "2" and the "0", indicating a synchronized signal connection.
### Region C: Secondary Display (Lower LCD)
This region is segmented into three distinct data fields: Date/Seconds, Indoor Temperature, and Outdoor Temperature.
| Field Label | Value Extracted | Units/Notes |
| :--- | :--- | :--- |
| **DATE** | `1 / 1` | Month / Day format |
| **[Seconds]** | `40` | Located to the right of the date |
| **INDOOR** | `68.4` | Degrees Fahrenheit (°F) |
| **OUTDOOR** | `- 1.4` | Degrees Fahrenheit (°F); Negative value |
## 3. Detailed Data Analysis
### Time and Synchronization
The device displays **12:04**. The presence of the radio tower icon on the LCD confirms that the device is currently receiving or has successfully synchronized with the atomic time signal (WWVB).
### Environmental Data
* **Indoor Temperature:** The reading is **68.4°F**. This represents the ambient temperature at the location of the base unit.
* **Outdoor Temperature:** The reading is **-1.4°F**. This indicates a significant temperature differential of **69.8°F** between the indoor and outdoor environments. The negative sign is clearly visible to the left of the "1.4".
### Calendar Data
* **Date:** The display shows **1/1**, representing January 1st.
* **Seconds:** The clock is at the **40-second** mark of the current minute.
## 4. Physical Characteristics
* **Housing:** The unit features a dark grey/black central faceplate flanked by wood-grain (brown) side panels.
* **Display Type:** Multi-segment Liquid Crystal Display (LCD).
* **Speaker/Sensor Grille:** A perforated pattern is visible at the bottom of the front faceplate, likely for an alarm speaker or internal sensor ventilation.
</details>
| Question: | What indoor temperature is shown? |
| --- | --- |
| GT: | (68.4) |
| MLP: | (68 F) ✗ |
| Ovis: | (40.0) ✗ |
| Align: | (68.4) ✓ |
(b) Positive Example #2
<details>
<summary>figures/case_11.jpg Details</summary>

### Visual Description
# Technical Document Extraction: Promotional Graphic
## 1. Document Overview
This image is a promotional flyer or advertisement for a fitness facility. It utilizes a stylized, vector-art illustration of two individuals against a blue abstract background. The document does not contain quantitative data charts or tables; it is a marketing asset designed to convey brand identity and slogans.
---
## 2. Component Isolation
### Region A: Header (Top Left)
* **Content:** Three descriptive adjectives stacked vertically.
* **Transcription:**
* "Proffesional" (Note: This is a misspelling of "Professional")
* "Passionate"
* "Personal"
* **Styling:** White, bold, sans-serif italicized font with a subtle drop shadow.
### Region B: Main Visual (Center)
* **Subject:** Two illustrated characters (one female, one male) in athletic attire.
* **Details:**
* **Female Character:** Brown hair, wearing a white tank top, orange wristbands, and white earphones. She is pointing to the left.
* **Male Character:** Black hair, wearing a red t-shirt and a white digital device (likely an MP3 player or fitness tracker) strapped to his upper left arm.
* **Background:** A blue gradient with abstract white light streaks and geometric patterns.
### Region C: Central Slogan (Lower Middle)
* **Content:** The primary marketing hook.
* **Transcription:** "we're the club 4U!"
* **Styling:** Large, white, bubble-style font with a thick blue outline and drop shadow. The text is angled upward from left to right.
### Region D: Footer (Bottom)
* **Logo:** A red stylized "T" icon resembling a human figure in motion.
* **Brand Name:** "topnotch health club" (Transcribed in lowercase as presented in the image).
* **Tagline:** "dare to be different"
* **Styling:** The brand name is in a dark blue/purple sans-serif font. The tagline is in a red, handwritten-style script font.
---
## 3. Textual Data Summary
| Category | Extracted Text |
| :--- | :--- |
| **Primary Slogans** | Proffesional, Passionate, Personal |
| **Call to Action/Identity** | we're the club 4U! |
| **Brand Name** | topnotch health club |
| **Brand Tagline** | dare to be different |
---
## 4. Technical Observations
* **Language:** English.
* **Orthographic Note:** The word "Professional" is misspelled as "Proffesional" in the top-most line of the header.
* **Visual Hierarchy:** The design uses a "Z-pattern" layout, starting with the descriptive words at the top left, moving through the central characters, and ending with the brand logo and name at the bottom.
* **Data/Facts:** The image provides no specific data points, addresses, contact information, or pricing. It is purely a brand-awareness graphic.
</details>
| Question: | What type of club is advertised? |
| --- | --- |
| GT: | (health club) |
| MLP: | (topnote health club) ✗ |
| Ovis: | (health club) ✓ |
| Align: | (professional passionate personal) ✗ |
(c) Negative Example #1
<details>
<summary>figures/case_12.jpg Details</summary>

### Visual Description
# Technical Document Extraction: Hadiah Plus Promotional Graphic
## 1. Document Overview
This image is a promotional advertisement for a credit card rewards conversion program. It features a gold-themed background with a geometric pattern, a collage of travel destinations, and images of specific credit cards.
## 2. Language Declaration
* **Primary Language:** English
* **Secondary Language:** Malay
* **Term:** "Hadiah"
* **Translation:** "Gift" or "Reward"
* **Context:** Used in the program name "Hadiah Plus" (Reward Plus) and "Hadiah Points" (Reward Points).
## 3. Component Segmentation
### Region A: Header (Top Section)
* **Main Title:** "Hadiah Plus" (Rendered in a large, gold, cursive serif font).
* **Sub-headline:** "MORE REWARDS WITH EVERY SWIPE" (Rendered in uppercase, gold, serif font).
### Region B: Main Visual Collage (Center Section)
This section consists of five vertical panels, each representing a travel destination. A gold bar at the top of the panels contains the labels for each city.
| Panel Position | Label (Text) | Visual Content (Landmark) |
| :--- | :--- | :--- |
| 1 (Left) | Singapore | The Merlion statue at night. |
| 2 | Penang | Skyline view featuring the Komtar building and waterfront. |
| 3 | Bangkok | A traditional Thai temple (Wat) with a golden spire. |
| 4 | Bali | A Balinese Hindu temple (Pura) by the water. |
| 5 (Right) | Hong Kong | Skyline view of Victoria Harbour and skyscrapers. |
* **Overlay Element:** A red circular badge is positioned at the bottom right of the collage.
* **Badge Text:** "AirAsia BIG LOYALTY Programme" (White text, "LOYALTY" is emphasized in a larger, bold font).
### Region C: Promotional Offer & Footer (Bottom Section)
* **Instructional Text:** "You can now convert your Hadiah Points to BIG Points to redeem for free flights."
* **Product Display:** Three credit cards are displayed side-by-side at the bottom center.
1. **Left Card:** Gold-colored card with a chip and Mastercard logo.
2. **Middle Card:** Silver/Platinum-colored card with a chip and Mastercard logo.
3. **Right Card:** Black-colored card with a chip and Mastercard logo.
## 4. Data and Fact Summary
* **Program Name:** Hadiah Plus.
* **Partner Program:** AirAsia BIG Loyalty Programme.
* **Core Value Proposition:** Conversion of "Hadiah Points" into "BIG Points."
* **Primary Benefit:** Redemption for free flights.
* **Target Destinations (Implied):** Singapore, Penang, Bangkok, Bali, Hong Kong.
* **Eligible Hardware:** Three tiers of credit cards (Gold, Silver/Platinum, and Black/World).
## 5. Visual Design Specifications
* **Background:** Gold gradient with a repeating Islamic-style geometric star/lattice pattern.
* **Color Palette:** Gold, White, Red (for the call-to-action badge), and various photographic colors from the destination panels.
* **Typography:** Mix of elegant script for the brand name and clean serif fonts for instructional text.
</details>
| Question: | What credit card is this? |
| --- | --- |
| GT: | (hadiah plus) |
| MLP: | (hadiah plus) ✓ |
| Ovis: | (american big loyalty program) ✗ |
| Align: | (hadia plus) ✗ |
(d) Negative Example #2
Figure 9: Case Study for Connector Comparison on the TextVQA dataset [Singh et al., 2019]. We show four qualitative examples (including two correct and two incorrect examples) comparing Llama-3.2-3B- Align to the same architecture with different connectors, Llama-3.2-3B-MLP and Llama-3.2-3B-Ovis. “GT” denotes the ground truth.