# AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Document Understanding
Abstract
Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), lack inductive bias to constrain visual features within the linguistic structure of the LLM’s embedding space, making them data-hungry and prone to cross-modal misalignment. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where visual and textual modalities are highly correlated. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods, with larger gains on document understanding tasks and under low-resource setups. We provide further analysis demonstrating its efficiency and robustness to noise.
1 Introduction
Vision-Language Models (VLMs) have gained significant traction in recent years as a powerful framework for multimodal document understanding tasks that involve interpreting both the visual and textual contents of scanned documents (Kim et al., 2022; Lee et al., 2023; Liu et al., 2023a, 2024; Hu et al., 2024; Wang et al., 2023a; Rodriguez et al., 2024b). Such tasks are common in real-world commercial applications, including invoice parsing (Park et al., 2019), form reading (Jaume et al., 2019), and document question answering (Mathew et al., 2021b). VLM architectures typically consist of three components: (i) a vision encoder to process raw images, (ii) a Large Language Model (LLM) pre-trained on text, and (iii) a connector module that maps the visual features from the vision encoder into the LLM’s semantic space.
A central challenge in this pipeline is to effectively map the continuous feature embeddings of the vision encoder into the latent space of the LLM while preserving the semantic properties of visual concepts. Existing approaches can be broadly categorized into deep fusion and shallow fusion methods. Deep fusion methods, such as NVLM (Dai et al., 2024), Flamingo (Alayrac et al., 2022), CogVLM (Wang et al., 2023b), and LLama 3.2-Vision (Grattafiori et al., 2024), integrate visual and textual features by introducing additional cross-attention and feed-forward layers at each layer of the LLM. While effective at enhancing cross-modal interaction, these methods substantially increase the parameter count of the VLM compared to the base LLM, resulting in high computational overhead and reduced efficiency.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Radar Chart: Model Performance Comparison
### Overview
The image is a radar chart comparing the performance of four different language models (Llama-3.2-3B-Perciever R., Llama-3.2-3B-MLP, Llama-3.2-3B-Ovis, and Llama-3.2-3B-Align (ours)) across seven different tasks: KLC, DeepForm, InfoVQA, DocVQA, TableVQA, TextVQA, ChartQA, WTQ, and TabFact. The chart visualizes the performance of each model on each task, with higher values indicating better performance.
### Components/Axes
* **Chart Type**: Radar Chart (also known as a spider chart or star chart)
* **Axes**: The chart has seven axes, each representing a different task. The axes radiate outwards from a central point.
* **Tasks (Categories)**:
* KLC (top-left)
* DeepForm (top)
* InfoVQA (top-right)
* DocVQA (right)
* TableVQA (bottom-right)
* TextVQA (bottom)
* ChartQA (bottom-left)
* TabFact (left)
* WTQ (left)
* **Data Series (Models)**:
* Llama-3.2-3B-Perciever R. (brown)
* Llama-3.2-3B-MLP (light green)
* Llama-3.2-3B-Ovis (dark blue)
* Llama-3.2-3B-Align (ours) (orange)
* **Scale**: The chart has a radial scale, with values increasing from the center outwards. There are concentric circles indicating increasing values, but no explicit numerical labels on these circles. The values for each model on each task are displayed numerically next to the corresponding data point.
* **Legend**: Located at the bottom of the chart, the legend identifies each model by color and name.
### Detailed Analysis
**Llama-3.2-3B-Perciever R. (brown)**:
* KLC: 31.75
* DeepForm: 58.02
* InfoVQA: 57.08
* DocVQA: 71.46
* TableVQA: 51.33
* TextVQA: 52.6
* ChartQA: 65.16
* TabFact: 71.93
* WTQ: 28.94
**Llama-3.2-3B-MLP (light green)**:
* KLC: 33.5
* DeepForm: 62.07
* InfoVQA: 37.56
* DocVQA: 69.08
* TableVQA: 50.96
* TextVQA: 53.56
* ChartQA: 67.92
* TabFact: 73.22
* WTQ: 33.13
**Llama-3.2-3B-Ovis (dark blue)**:
* KLC: 33.36
* DeepForm: 44.53
* InfoVQA: 42.11
* DocVQA: 74.68
* TableVQA: 53.93
* TextVQA: 66.48
* ChartQA: 76.67
* TabFact: 76.67
* WTQ: 33.13
**Llama-3.2-3B-Align (ours) (orange)**:
* KLC: 35.25
* DeepForm: 63.49
* InfoVQA: 44.53
* DocVQA: 79.63
* TableVQA: 60.1
* TextVQA: 57.38
* ChartQA: 71.88
* TabFact: 78.51
* WTQ: 38.59
### Key Observations
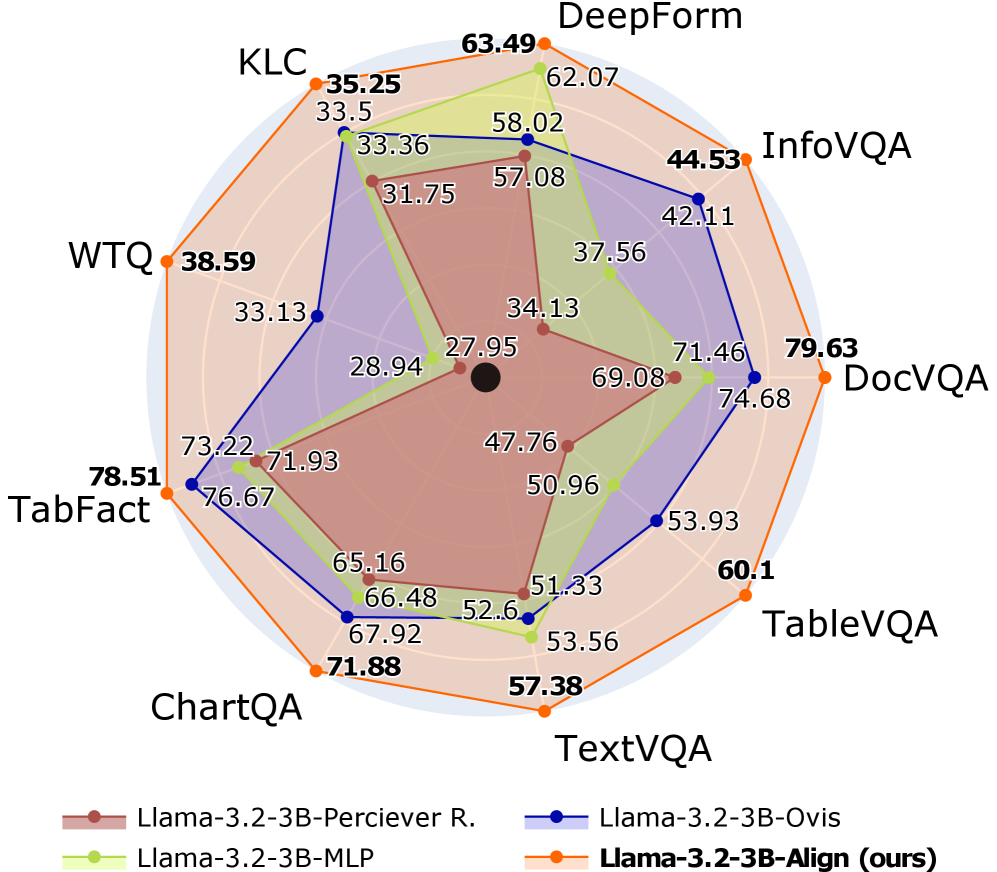
* **Overall Performance**: Llama-3.2-3B-Align (ours) generally outperforms the other models across most tasks, as indicated by the larger area enclosed by the orange line.
* **Task-Specific Performance**:
* DocVQA: All models perform relatively well on DocVQA, with Llama-3.2-3B-Align (ours) achieving the highest score (79.63).
* KLC: All models perform relatively poorly on KLC, with Llama-3.2-3B-Align (ours) achieving the highest score (35.25).
* DeepForm: All models perform relatively well on DeepForm, with Llama-3.2-3B-Align (ours) achieving the highest score (63.49).
* TabFact: All models perform relatively well on TabFact, with Llama-3.2-3B-Align (ours) achieving the highest score (78.51).
* **Model Consistency**: Llama-3.2-3B-Ovis (dark blue) shows relatively consistent performance across tasks, while Llama-3.2-3B-Perciever R. (brown) has more variability.
### Interpretation
The radar chart provides a clear visual comparison of the performance of the four language models across the seven tasks. The Llama-3.2-3B-Align (ours) model appears to be the most effective overall, achieving the highest scores on several tasks. The chart highlights the strengths and weaknesses of each model on specific tasks, which could inform future model development and task selection. The relatively low scores on KLC for all models suggest that this task may be particularly challenging. The high scores on DocVQA and TabFact suggest that these tasks are relatively easier for the models.
</details>
Figure 1: Performance of Different VLM Connectors. The proposed Align connector outperforms other methods across benchmarks using the same training configuration. Radial distance is proportion of maximal score, truncated at $0.7$ (black dot).
In contrast, shallow fusion methods project visual features from the vision encoder into the LLM input embedding space using either multilayer perceptrons (MLPs) (Liu et al., 2023b, 2024), convolution mappings such as HoneyBee (Cha et al., 2024) and H-Reducer (Hu et al., 2024), or attention-based mechanisms such as the Perceiver Resampler (Li et al., 2023b; Laurençon et al., 2024; Alayrac et al., 2022). This approach is more parameter-efficient and computationally lighter than deep fusion method However, these connectors lack inductive bias to ensure that the projected features remain within the region spanned by the LLM’s pretrained text embeddings. Consequently, the projected visual features may fall outside the distribution the LLM was trained on, leading to noisy or misaligned representations. Moreover, these mappings are typically learned from scratch, making them data-inefficient and less effective under low-resource conditions.
Recent methods like Ovis (Lu et al., 2024) attempt to alleviate these issues by introducing separate visual embeddings indexed from the vision encoder outputs and combined together to construct the visual inputs to the LLM. However, this approach significantly increases parameter count due to the massive embedding matrix and requires extensive training to learn a new embedding space without guaranteeing alignment with the LLM’s input latent space.
To address these limitations, this paper introduces AlignVLM, a novel framework that sidesteps direct projection of visual features into the LLM embedding space. Instead, our proposed connector, Align, maps visual features into probability distributions over the LLM’s existing pretrained vocabulary embeddings, which are then combined into a weighted representation of the text embeddings. By constraining each visual feature as a convex combination of the LLM text embeddings, our approach leverages the linguistic priors already encoded in the LLM’s text space. This ensures that the resulting visual features lie within the convex hull of the LLM’s embedding space, reducing the risk of noisy or out-of-distribution inputs and improving alignment between modalities. The connector thus enables faster convergence and stronger performance, particularly in low-resource scenarios.
Our experimental results show that Align improves performance on various document understanding tasks, outperforming prior connector methods, with especially large gains in low-data regimes. We summarize our main contributions as follows:
- We propose a novel connector, Align, to bridge the representation gap between vision and text modalities.
- We introduce a family of Vision-Language Models, AlignVLM, that achieves state-of-the-art performance on multimodal document understanding tasks by leveraging Align.
- We conduct extensive experiments demonstrating the robustness and effectiveness of Align across different LLM sizes and training data setups.
We release our code and research artifacts at alignvlm.github.io.
2 Related Work
2.1 Vision-Language Models
Over the past few years, Vision-Language Models (VLMs) have achieved remarkable progress, largely due to advances in Large Language Models (LLMs). Initially demonstrating breakthroughs in text understanding and generation (Brown et al., 2020; Raffel et al., 2023; Achiam et al., 2023; Grattafiori et al., 2024; Qwen et al., 2025; Team, 2024), LLMs are now increasingly used to effectively interpret visual inputs (Liu et al., 2023b; Li et al., 2024; Wang et al., 2024; Chen et al., 2024b; Dai et al., 2024; Drouin et al., 2024; Rodriguez et al., 2022). This progress has enabled real-world applications across diverse domains, particularly in multimodal document understanding for tasks like form reading (Svetlichnaya, 2020), document question answering (Mathew et al., 2021b), and chart question answering (Masry et al., 2022). VLMs commonly adopt a three-component architecture: a pretrained vision encoder (Zhai et al., 2023; Radford et al., 2021), a LLM, and a connector module. A key challenge for VLMs is effectively aligning visual features with the LLM’s semantic space to enable accurate and meaningful multimodal interpretation.
2.2 Vision-Language Alignment for Multimodal Models
Existing vision-language alignment approaches can be classified into deep fusion and shallow fusion. Deep fusion methods integrate visual and textual features by modifying the LLM’s architecture, adding cross-attention and feed-forward layers. For example, Flamingo (Alayrac et al., 2022) employs the Perceiver Resampler, which uses fixed latent embeddings to attend to vision features and fuses them into the LLM via gated cross-attention layers. Similarly, NVLM (Dai et al., 2024) adopts cross-gated attention while replacing the Perceiver Resampler with a simpler MLP. CogVLM (Wang et al., 2023b) extends this approach by incorporating new feed-forward (FFN) and QKV layers for the vision modality within every layer of the LLM. While these methods improve cross-modal alignment, they significantly increase parameter counts and computational overhead, making them less efficient.
On the other hand, shallow fusion methods are more computationally efficient, mapping visual features into the LLM’s embedding space without altering its architecture. These methods can be categorized into three main types: (1) MLP-based mapping, such as LLaVA (Liu et al., 2023b) and PaliGemma (Beyer et al., 2024), which use multilayer perceptrons (MLP) to project visual features but often produce misaligned or noisy features due to a lack of constraints and inductive bias (Rodriguez et al., 2024b); (2) cross-attention mechanisms, BLIP-2 (Li et al., 2023b) uses Q-Former, which utilizes a fixed set of latent embeddings to cross-attend to visual features, but that may still produce noisy or OOD visual features; (3) convolution-based mechanisms, such as HoneyBee (Cha et al., 2024) and H-Reducer (Hu et al., 2024), which leverage convolutional or ResNet (He et al., 2015) layers to preserve spatial locality while reducing dimensionality; and (4) visual embeddings, such as those introduced by Ovis (Lu et al., 2024), which use embeddings indexed by the vision encoder’s outputs to produce the visual inputs. While this regularizes feature mapping, it adds substantial parameter overhead and creates a new vision embedding space, risking misalignment with the LLM’s text embedding space. Encoder-free VLMs, like Fuyu-8B https://www.adept.ai/blog/fuyu-8b and EVE (Diao et al., 2024), eliminate dedicated vision encoders but show degraded performance (Beyer et al., 2024).
In contrast, AlignVLM maps visual features from the vision encoder into probability distributions over the LLM’s text embeddings, using them to compute a convex combination. By leveraging the linguistic priors encoded in the LLM’s vocabulary, AlignVLM ensures that visual features remain within the convex hull of the text embedding. This design mitigates noisy or out-of-distribution projections and achieves stronger multimodal alignment, particularly in tasks that require joint modalities representation like multimodal document understanding and in low-resource settings.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Align Module
### Overview
The image is a diagram illustrating the "Align Module" of a system, likely a neural network or AI model. It shows the flow of information from visual and textual inputs through various processing stages, ultimately leading to a response. The diagram includes components like Vision Encoder, Text Tokenizer, LLM (Language Model) Embedding Matrix, and other layers, culminating in a final response. The diagram also includes example data that the model is trained on.
### Components/Axes
* **Title:** Align Module (located at the top-center of the image)
* **Input Data (Left Side):**
* A series of six infographic-style panels showing statistics about Americans.
* Panel 1: "AMERICANS WANT TO BE DISTRACTED FROM REALITY"
* Panel 2: "AMERICANS LOVE VIDEO GAMES"
* Panel 3: "AMERICANS ARE HYPER-SOCIAL"
* Panel 4: "AMERICANS ARE CONNECTED"
* Panel 5: "AMERICANS LOVE ROUTINE"
* Panel 6: "AMERICANS ARE HIGHLY INFLUENCED BY OTHERS"
* A question: "Question: What percentage of Americans are online?"
* **Processing Blocks (Center):**
* Vision Encoder (blue box)
* Text Tokenizer (pink box)
* Linear (blue box)
* Layer Norm (blue box)
* LM Head (LLM) (pink box)
* Softmax (blue box)
* Weighted Average Sum (blue rounded box)
* LLM Embedding Matrix (pink stacked rectangles)
* Full Embedding Matrix (label for the pink arrow)
* Selected Text Embeddings (label for the pink stacked rectangles)
* Vision Inputs (blue stacked rectangles)
* Text Inputs (pink stacked rectangles)
* **Output (Right Side):**
* LLM (pink box)
* Response: 90% (located at the bottom-right)
### Detailed Analysis or ### Content Details
* **Input Data:**
* The infographic panels present various statistics about American behavior and preferences. The exact numerical data within each panel is not fully legible but the titles are clear.
* The question "What percentage of Americans are online?" serves as a prompt for the system.
* **Processing Flow:**
* The Vision Encoder processes visual information (presumably from the infographic panels).
* The Text Tokenizer processes the textual question.
* The LLM Embedding Matrix stores embeddings of the text.
* The Linear, Layer Norm, LM Head (LLM), and Softmax layers perform transformations on the encoded data.
* The Weighted Average Sum combines the processed visual and textual information.
* The "Full Embedding Matrix" arrow indicates the flow of information from the LLM Embedding Matrix to the Weighted Average Sum.
* The Vision Inputs and Text Inputs represent the processed visual and textual data, respectively.
* **Output:**
* The LLM produces a response, which in this case is "90%".
### Key Observations
* The diagram illustrates a multi-modal system that integrates visual and textual information.
* The use of "Vision Encoder" and "Text Tokenizer" suggests that the system can process both images and text.
* The "LLM Embedding Matrix" indicates the use of a Language Model for processing text.
* The "Weighted Average Sum" suggests that the system combines visual and textual information based on their relative importance.
* The final "Response: 90%" indicates that the system is answering the question based on the provided information.
### Interpretation
The diagram depicts the architecture and flow of information within an "Align Module," which appears to be a component of a larger AI system. The module takes visual and textual inputs, processes them through various layers and transformations, and generates a response. The example provided shows the system answering a question about the percentage of Americans online, based on the information presented in the infographic panels. This suggests that the system can understand and integrate information from multiple sources to provide accurate and relevant answers. The diagram highlights the importance of multi-modal processing and the use of Language Models in modern AI systems.
</details>
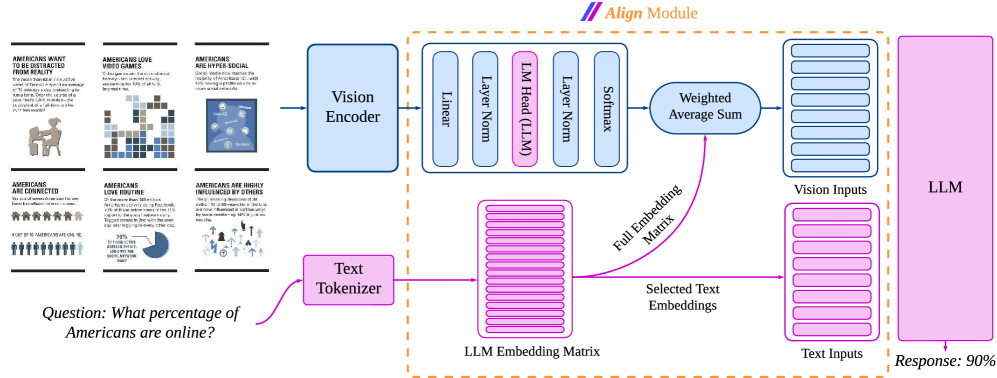
Figure 2: AlignVLM Model Architecture. The vision encoder extracts image features, which are processed to produce probabilities over the LLM embeddings. A weighted average combines these probabilities with embeddings to generate vision input vectors. Text inputs are tokenized, and the corresponding embeddings are selected from the embedding matrix, which is then used as input to the LLM. We display the vision layers in blue, and the text layers in purple.
3 Methodology
3.1 Model Architecture
The overall model architecture, shown in Figure 2, consists of three main components:
(1) Vision Encoder.
To handle high-resolution images of different aspect ratios, we divide each input image into multiple tiles according to one of the predefined aspect ratios (e.g., $1{:}1,\,1{:}2,\,...,\,9{:}1$ ) chosen via a coverage ratio (Lu et al., 2024; Chen et al., 2024a). Due to limited computational resources, we set the maximum number of tiles to 9. Each tile is further partitioned into $14× 14$ patches, projected into vectors, and processed by a SigLip-400M vision encoder (Zhai et al., 2023) to extract contextual visual features.
Each tile $t∈\{1,·s,T\}$ is divided into $N_{t}$ patches
$$
\mathbf{P}_{t}=\{\mathbf{p}_{t,1},\cdots,\mathbf{p}_{t,N_{t}}\},
$$
where $\mathbf{p}_{t,i}$ is the $i$ -th patch of tile $t$ . The vision encoder maps these patches to a set of visual feature vectors
| | $\displaystyle\mathbf{F}_{t}=\mathrm{VisionEncoder}(\mathbf{P}_{t}),\quad\mathbf{F}_{t}=\{\mathbf{f}_{t,1},·s,\mathbf{f}_{t,N_{t}}\},\quad\mathbf{f}_{t,i}∈\mathbb{R}^{d}.$ | |
| --- | --- | --- |
Finally, we concatenate the feature sets across all tiles into a single output
$$
\mathbf{F}=\mathrm{concat}\Bigl(\mathbf{F}_{1},\mathbf{F}_{2},\cdots,\mathbf{F}_{T}\Bigr).
$$
(2) Align Module.
This module aligns the visual features with the LLM. A linear layer $\mathbf{W}_{1}∈\mathbb{R}^{D× d}$ first projects the visual features $\mathbf{F}∈\mathbb{R}^{T· N_{t}× d}$ to the LLM’s token embedding space: one $\mathbb{R}^{D}$ vector per token. A second linear layer $\mathbf{W}_{2}∈\mathbb{R}^{V× D}$ (initialized from the LLM’s language-model head) followed by a softmax, produces a probability simplex $\mathbf{P}_{\text{vocab}}$ over the LLM’s vocabulary ( $V$ tokens)
$$
\mathbf{P}_{\text{vocab}}=\operatorname{softmax}(\operatorname{LayerNorm}(\mathbf{W}_{2}\operatorname{LayerNorm}(\mathbf{W}_{1}\mathbf{F}))) \tag{1}
$$
We then use the LLM text embeddings $\mathbf{E}_{\text{text}}∈\mathbb{R}^{V× D}$ to compute a weighted sum
$$
\mathbf{F}_{\text{align}}^{\prime}=\mathbf{P}_{\text{vocab}}^{\top}\mathbf{E}_{\text{text}}. \tag{2}
$$
Finally, we concatenate $\mathbf{F}_{\text{align}}^{\prime}$ with the tokenized text embeddings to form the LLM input
$$
\mathbf{H}_{\text{input}}=\mathrm{concat}\bigl(\mathbf{F}_{\text{align}}^{\prime},\mathbf{E}_{\text{text}}(\mathbf{x})\bigr),
$$
where $\mathbf{E}_{\text{text}}(\mathbf{x})$ is obtained by tokenizing the input text $\mathbf{x}=(x_{1},·s,x_{M})$ and selecting the corresponding embeddings from $\mathbf{E}_{\text{text}}$ such that
$$
\displaystyle\mathbf{E}_{\text{text}}(\mathbf{x}) \displaystyle=\bigl[\mathbf{E}_{\text{text}}(x_{1}),\cdots,\mathbf{E}_{\text{text}}(x_{M})\bigr]. \tag{3}
$$
(3) Large Language Model.
We feed the concatenated vision and text vectors, $\mathbf{H}_{\text{input}}$ , into the LLM, which then generates output text auto-regressively. To demonstrate the effectiveness of our alignment technique, we experiment with the Llama 3.1 model family (Grattafiori et al., 2024). These models offer state-of-the-art performance and permissive licenses, making them suitable for commercial applications. In particular, we utilize Llama 3.2-1B, Llama 3.2-3B, and Llama 3.1-8B.
3.2 Motivation and relation with existing methods
By construction, each $\mathbb{R}^{D}$ representation in $\mathbf{F}_{\text{align}}^{\prime}$ is constrained to the convex hull of the points $\mathbb{E}_{\text{text}}$ , thus concentrating the visual features in the part of latent space that the LLM can effectively interpret. Moreover, we argue that our initialization of $\mathbf{W}_{2}$ to the language model head is an inductive bias toward recycling some of the semantics of these text tokens into visual tokens. This contrasts with past methods that have been proposed to adapt the vision encoder outputs $\mathbf{F}∈\mathbb{R}^{T· N_{t}× d}$ to an $\mathbf{F}^{\prime}∈\mathbb{R}^{T· N_{t}× D}$ to be fed to the LLM. Here, we consider two examples in more detail, highlighting these contrasts.
(1) MLP Connector Liu et al. (2023b) applies a linear projection with parameters $\mathbf{W}_{\text{MLP}}∈\mathbb{R}^{D× d}$ and $\mathbf{b}_{\text{MLP}}∈\mathbb{R}^{D}$ , followed by an activation function $\sigma$ (e.g., ReLU)
$$
\mathbf{F}_{\text{MLP}}^{\prime}=\sigma(\mathbf{W}_{\text{MLP}}\mathbf{F}+\mathbf{b}_{\text{MLP}}).
$$
These parameters are all learned from scratch, without any bias aligning them to text embeddings.
(2) Visual Embedding Table Lu et al. (2024) introduces an entire new set of visual embeddings $\mathbf{E}_{\text{VET}}∈\mathbb{R}^{K× D}$ which, together with the weights $\mathbf{W}_{\text{VET}}∈\mathbb{R}^{K× d}$ , specifies
$$
\mathbf{F}_{\text{VET}}^{\prime}=\operatorname{softmax}(\mathbf{W}_{\text{VET}}\mathbf{F})^{\top}\mathbf{E}_{\text{VET}}.
$$
When $D<d$ , our $\mathbf{W}_{2}\mathbf{W}_{1}$ amounts to a low-rank version of $\mathbf{W}_{\text{VET}}$ . There is thus much more to learn to obtain $\mathbf{F}_{\text{VET}}^{\prime}$ , and there is again no explicit pressure to align it with the text embeddings.
3.3 Training Datasets & Stages
We train our model in three stages:
Stage 1.
This stage focuses on training the Align Module to map visual features to the LLM’s text embeddings effectively. We use the CC-12M dataset Changpinyo et al. (2021), a large-scale web dataset commonly used for VLM pretraining Liu et al. (2023b), which contains 12M image-text pairs. However, due to broken or unavailable links, we retrieved 8.1M pairs. This dataset facilitates the alignment of visual features with the text embedding space of the LLM. During this stage, we train the full model, as this approach improves performance and stabilizes the Align Module training.
Stage 2.
The goal is to enhance the model’s document understanding capabilities, such as OCR, document structure comprehension, in-depth reasoning, and instruction-following. We leverage the BigDocs-7.5M dataset Rodriguez et al. (2024a), a curated collection of license-permissive datasets for multimodal document understanding. This dataset aligns with the Accountability, Responsibility, and Transparency (ART) principles Bommasani et al. (2023); Vogus and Llansóe (2021), ensuring compliance for commercial applications. As in Stage 1, we train the full model during this stage.
Stage 3.
To enhance the model’s instruction-tuning capabilities, particularly for downstream tasks like question answering, we further train it on the DocDownstream Rodriguez et al. (2024a); Hu et al. (2024) instruction tuning dataset. In this stage, the vision encoder is frozen, focusing training exclusively on the LLM and Align module.
4 Experimental Setup
Table 1: Main Results on General Document Benchmarks. We compare AlignVLM (ours) with state-of-the-art (SOTA) open and closed-source instructed models, and with base models that we trained using the process described in Section 3.3. AlignVLM models outperform all Base VLM models trained in the same data regime. Our models also perform competitively across document benchmarks even compared with SOTA models, in which the data regime is more targeted and optimized. Color coding for comparison: closed-source models, open-source models below 7B parameters, open-source models between 7-12B parameters.
| Model | DocVQA VAL | InfoVQA VAL | DeepForm TEST | KLC TEST | WTQ TEST | TabFact TEST | ChartQA TEST | TextVQA VAL | TableVQA TEST | Avg. Score |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Closed-Source VLMs | | | | | | | | | | |
| (Opaque Training Data) | | | | | | | | | | |
| Claude-3.5 Sonnet | 88.48 | 59.05 | 31.41 | 24.82 | 47.13 | 53.48 | 51.84 | 71.42 | 81.27 | 56.54 |
| GeminiPro-1.5 | 91.23 | 73.94 | 32.16 | 24.07 | 50.29 | 71.22 | 34.68 | 68.16 | 80.43 | 58.46 |
| GPT-4o 20240806 | 92.80 | 66.37 | 38.39 | 29.92 | 46.63 | 81.10 | 85.70 | 70.46 | 72.87 | 64.91 |
| Open-Source Instruct VLMs | | | | | | | | | | |
| (Semi-Opaque Training Data) | | | | | | | | | | |
| Janus- 1.3B (Wu et al., 2024a) | 30.15 | 17.09 | 0.62 | 15.06 | 9.30 | 51.34 | 57.20 | 51.97 | 18.67 | 27.93 |
| Qwen2-VL- 2B (Wang et al., 2024) | 89.16 | 64.11 | 32.38 | 25.18 | 38.20 | 57.21 | 73.40 | 79.90 | 43.07 | 55.84 |
| Qwen2.5-VL- 3B (Wang et al., 2024) | 93.00 | 75.83 | 32.84 | 24.82 | 53.46 | 71.16 | 83.91 | 79.29 | 71.66 | 65.10 |
| InternVL-2.5- 2B (Chen et al., 2024b) | 87.70 | 61.85 | 13.14 | 16.58 | 36.33 | 57.26 | 74.96 | 76.85 | 42.20 | 51.87 |
| InternVL-3- 2B (Zhu et al., 2025) | 87.33 | 66.99 | 37.90 | 29.79 | 39.44 | 59.91 | 75.32 | 78.69 | 43.46 | 57.64 |
| DeepSeek-VL2-Tiny- 3.4B (Wu et al., 2024b) | 88.57 | 63.88 | 25.11 | 19.04 | 35.07 | 52.15 | 80.92 | 80.48 | 56.30 | 55.72 |
| Phi3.5-Vision- 4B (Abdin et al., 2024) | 86.00 | 56.20 | 10.47 | 7.49 | 17.18 | 30.43 | 82.16 | 73.12 | 70.70 | 48.19 |
| Qwen2-VL- 7B (Wang et al., 2024) | 93.83 | 76.12 | 34.55 | 23.37 | 52.52 | 74.68 | 83.16 | 84.48 | 53.97 | 64.08 |
| Qwen2.5-VL- 7B (Bai et al., 2025) | 94.88 | 82.49 | 42.21 | 24.26 | 61.96 | 78.56 | 86.00 | 85.35 | 76.10 | 70.20 |
| LLaVA-NeXT- 7B (Xu et al., 2024) | 63.51 | 30.90 | 1.30 | 5.35 | 20.06 | 52.83 | 52.12 | 65.10 | 32.87 | 36.00 |
| DocOwl1.5- 8B (Hu et al., 2024) | 80.73 | 49.94 | 68.84 | 37.99 | 38.87 | 79.67 | 68.56 | 68.91 | 52.60 | 60.68 |
| InternVL-2.5- 8B (Chen et al., 2024b) | 91.98 | 75.36 | 34.55 | 22.31 | 50.33 | 74.75 | 82.84 | 79.00 | 52.10 | 62.58 |
| InternVL-3- 8B (Zhu et al., 2025) | 91.99 | 73.90 | 51.24 | 36.41 | 53.60 | 72.27 | 85.60 | 82.41 | 53.26 | 66.74 |
| Fuyu- 8B (Bavishi et al., 2023) | 48.97 | 23.09 | 4.78 | 6.63 | 14.55 | 47.91 | 44.36 | 46.02 | 15.49 | 22.97 |
| Ovis-1.6-Gemma2- 9B (Lu et al., 2024) | 88.84 | 73.97 | 45.16 | 23.91 | 50.72 | 76.66 | 81.40 | 77.73 | 48.33 | 62.96 |
| Llama3.2- 11B (Grattafiori et al., 2024) | 82.71 | 36.62 | 1.78 | 3.47 | 23.03 | 58.33 | 23.80 | 54.28 | 22.40 | 34.04 |
| Pixtral- 12B (Agrawal et al., 2024) | 87.67 | 49.45 | 27.37 | 24.07 | 45.18 | 73.53 | 71.80 | 76.09 | 67.13 | 58.03 |
| Document Understanding Instructed Models | | | | | | | | | | |
| (Instruction Tuned on BigDocs-7.5M + DocDownStream (Rodriguez et al., 2024a; Hu et al., 2024)) | | | | | | | | | | |
| Qwen2-VL- 2B (base+) (Wang et al., 2024) | 57.23 | 31.88 | 49.31 | 34.39 | 31.61 | 64.75 | 68.60 | 61.01 | 47.53 | 49.59 |
| AlignVLM -Llama-3.2- 1B (ours) | 72.42 | 38.16 | 60.47 | 33.71 | 28.66 | 71.31 | 65.44 | 48.81 | 50.29 | 52.14 |
| AlignVLM -Llama-3.2- 3B (ours) | 79.63 | 44.53 | 63.49 | 35.25 | 38.59 | 78.51 | 71.88 | 57.38 | 60.10 | 58.81 |
| DocOwl1.5- 8B (base+) (Hu et al., 2024) | 78.70 | 47.62 | 64.39 | 36.93 | 35.69 | 72.65 | 65.80 | 67.30 | 49.03 | 57.56 |
| Llama3.2- 11B (base+) (Grattafiori et al., 2024) | 78.99 | 44.27 | 67.05 | 37.22 | 40.18 | 78.04 | 71.40 | 68.46 | 56.73 | 60.26 |
| AlignVLM -Llama-3.1- 8B (ours) | 81.18 | 53.75 | 63.25 | 35.50 | 45.31 | 83.04 | 75.00 | 64.60 | 64.33 | 62.88 |
Setup.
We conduct all experiments using 8 nodes of H100 GPUs, totaling 64 GPUs. For model training, we leverage the MS-Swift framework (Zhao et al., 2024) for its flexibility. Additionally, we utilize the DeepSpeed framework (Aminabadi et al., 2022), specifically the ZeRO-3 configuration, to optimize efficient parallel training across multiple nodes. Detailed hyperparameters are outlined in Appendix A.1.
Baselines.
Our work focuses on architectural innovations, so we ensure that all baselines are trained on the same datasets. To enable fair comparisons, we evaluate our models against a set of Base VLMs fine-tuned on the same instruction-tuning tasks (Stages 2 and 3) as our models, using the BigDocs-7.5M and BigDocs-DocDownstream datasets. This approach ensures consistent training data, avoiding biases introduced by the Instruct versions of VLMs, which are often trained on undisclosed instruction-tuning datasets. Due to the scarcity of recently released publicly available Base VLMs, we primarily compare our model against the following Base VLMs of varying sizes: Qwen2-VL-2B (Wang et al., 2024), DocOwl1.5-8B (Hu et al., 2024), and LLama 3.2-11B (Grattafiori et al., 2024).
For additional context, we also include results from the Instruct versions of recent VLMs of different sizes: Phi3.5-Vision-4B (Abdin et al., 2024), Qwen2-VL-2B and 7B (Wang et al., 2024), Qwen2.5-VL-7B (Qwen et al., 2025), LLaVA-NeXT-7B (Liu et al., 2024), InternVL2.5-2B and 8B (Chen et al., 2024b), InternVL3-2B and 8B (Zhu et al., 2025), Janus-1.3B (Wu et al., 2024a), DeepSeek-VL2-Tiny (Wu et al., 2024b), Ovis1.6-Gemma-9B (Lu et al., 2024), Llama3.2-11B (Grattafiori et al., 2024), DocOwl1.5-8B (Hu et al., 2024), and Pixtral-12B (Agrawal et al., 2024).
Evaluation Benchmarks.
We evaluate our models on a diverse range of document understanding benchmarks that assess the model’s capabilities in OCR, chart reasoning, table processing, or form comprehension. In particular, we employ the VLMEvalKit (Duan et al., 2024) framework and report the results on the following popular benchmarks: DocVQA (Mathew et al., 2021b), InfoVQA (Mathew et al., 2021a), DeepForm (Svetlichnaya, 2020), KLC (Stanisławek et al., 2021), WTQ (Pasupat and Liang, 2015), TabFact (Chen et al., 2020), ChartQA (Masry et al., 2022), TextVQA (Singh et al., 2019), and TableVQA (Kim et al., 2024).
5 Results
Table 2: Impact of Connector Designs on VLM Performance: We present the results of experiments evaluating different connector designs for conditioning LLMs on visual features. Our proposed Align connector is compared against a basic Multi-Layer Perceptron (MLP), the Perceiver Resampler, and Ovis. The results demonstrate that Align consistently outperforms these alternatives across all benchmarks.
| Model | DocVQA VAL | InfoVQA VAL | DeepForm TEST | KLC TEST | WTQ TEST | TabFact TEST | ChartQA TEST | TextVQA VAL | TableVQA TEST | Avg. Score |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Llama-3.2-3B- MLP | 71.46 | 37.56 | 62.07 | 33.36 | 28.94 | 73.22 | 66.48 | 53.56 | 50.96 | 53.06 |
| Llama-3.2-3B- Perciever R. | 69.08 | 34.13 | 57.08 | 31.75 | 27.95 | 71.93 | 65.16 | 51.33 | 47.76 | 50.68 |
| Llama-3.2-3B- Ovis | 74.68 | 42.11 | 58.02 | 33.50 | 33.13 | 76.67 | 67.92 | 52.60 | 53.93 | 54.72 |
| Llama-3.2-3B- Align (ours) | 79.63 | 44.53 | 63.49 | 35.25 | 38.59 | 78.51 | 71.88 | 57.38 | 60.10 | 58.81 |
5.1 Main Results
Table 1 presents the performance of AlignVLM compared to state-of-the-art (SOTA) open- and closed-source instructed models, as well as baseline Base VLMs fine-tuned in the same instruction-tuning setup. The results demonstrate that AlignVLM consistently outperforms all Base VLMs within the same size category and achieves competitive performance against SOTA Instruct VLMs despite being trained on a more limited data regime. Below, we provide a detailed analysis.
AlignVLM vs. Base VLMs.
Our AlignVLM models, based on Llama 3.2-1B and Llama 3.2-3B, significantly outperform the corresponding Base VLM, Qwen2-VL-2B, by up to 9.22%. Notably, AlignVLM -Llama-3.2-3B surpasses DocOwl1.5-8B, which has 4B more parameters, demonstrating the effectiveness of Align in enhancing multimodal capabilities compared to traditional shallow fusion methods (e.g., MLPs). Furthermore, our 8B model achieves a 2.62% improvement over Llama3.2-11B despite sharing the same Base LLM, Llama3.1-8B. Since all models in this comparison were trained on the same instruction-tuning setup, this experiment provides a controlled evaluation, isolating the impact of architectural differences rather than dataset biases. Consequently, these results suggest that AlignVLM outperforms VLMs with shallow fusion techniques and surpasses parameter-heavy deep fusion VLMs, such as Llama3.2-11B, while maintaining a more efficient architecture.
AlignVLM vs. Instruct VLMs.
Even as open-source Instruct models are trained on significantly larger, often undisclosed instruction-tuning datasets, AlignVLM achieves competitive performance. For example, AlignVLM -Llama-3.2-3B (58.81%) outperforms other strong instruction-tuned VLMs in its size class, such as Qwen2-VL-2B and InternVL-3-2B, by considerable margins (2.97% and 1.17%, respectively). While it falls slightly behind Qwen2.5-VL-3B, a direct comparison is not entirely fair, as the latter was trained on a proprietary instruction-tuning dataset.
Additionally, our 8B model outperforms significantly larger models such as Llama 3.2-11B and PixTral-12B by substantial margins. It also surpasses InternVL-2.5-8B and performs competitively with Qwen2.5-VL-7B, though a direct comparison may not be entirely fair since Qwen2.5-VL-7B was trained on an undisclosed instruction-tuning dataset. Finally, AlignVLM also exhibits comparable performance to closed-source models like GeminiPro-1.5 and GPT4o.
Overall, these results validate the effectiveness of Align and establish AlignVLM as a state-of-the-art model for multimodal document understanding.
5.2 Impact of Connector Designs on VLM Performance
5.2.1 High-Resource Training Regime
To assess the effectiveness of our Align module, we compare it against three different and widely used shallow fusion VLM connectors: MLP, Perceiver Resampler, and Ovis. These experiments were carefully conducted under precisely identical training conditions (datasets, hyperparameters, training stages) as outlined in Appendix A.1, ensuring a fair and rigorous comparison. The results in Table 2 show that Align consistently outperforms all alternatives, demonstrating its superiority both in aligning visual and textual modalities in multimodal document understanding. MLP and Perceiver Resampler achieve the lowest performance, 53.06% and 50.68%, respectively, due to their direct feature projection, which lacks an explicit mechanism to align visual features with the LLM’s text space, leading to misalignment. Ovis introduces a separate visual embedding table, but this additional complexity does not significantly improve alignment, yielding only 54.72% accuracy. In contrast, Align ensures that visual features remain within the convex hull of the LLM’s text latent space, leveraging the linguistic priors of the LLM to enhance alignment and mitigate noisy embeddings. This design leads to the highest performance (58.81%), establishing Align as the most effective connector for integrating vision and language in multimodal document understanding. We provide some example outputs of the Llama-3.2-3B models with different connector designs in Appendix A.4. Furthermore, we include an analysis of the runtime efficiency and memory usage of different connectors in Appendix A.2.
5.2.2 Low-Resource Training Regime
The previous section focused on large-scale training setups involving millions of data samples (BigDocs-7.5M), which require significant compute resources and limit the number of baselines that we were able to compare against. Here, we examine whether Align remains effective in a low-resource setting.
We conduct additional experiments using SigLIP-400M as the vision encoder and Llama-3.2-3B as the language model, fine-tuned on the LLaVA-NeXT dataset Liu et al. (2024), which contains 779K samples. We follow the official LLaVA-NeXT configuration for both training stages. (i) Pretraining: the model is trained on the LLaVA-558K image–caption dataset Liu et al. (2024), freezing both the LLM and vision encoder while fine-tuning the connector (learning rate = 1e-3, batch size = 32, 1 epoch on 8 × H100 GPUs). To handle high-resolution document images, we adopt the "anyres_max_9" strategy with grid weaving from 1×1 to 6×6, supporting resolutions up to 2304×2304 with 729 tokens per grid; (ii) Instruction tuning: the model is further fine-tuned on the LLaVA-NeXT-779K instruction dataset with learning rates of 1e-5 for the LLM and connector, 2e-6 for the vision encoder, batch size = 8, for 1 epoch.
This lightweight setup allows direct comparison across more connector architectures including MLP Liu et al. (2023a), Perceiver Resampler, Ovis Lu et al. (2024), H-Reducer (1×4) Hu et al. (2024), and HoneyBee (C-Abstractor) Cha et al. (2024), all trained under identical conditions for fairness. Since the LLaVA-Next dataset is general-purpose and not exclusively document-focused like BigDocs-7.5M (Rodriguez et al., 2024a), it allows us to evaluate whether the Align connector generalizes beyond document understanding to broader visual reasoning. Accordingly, we assess all models on a comprehensive suite of benchmarks spanning both document understanding and general vision–language tasks. The document understanding benchmarks include DocVQA Mathew et al. (2021b), InfoVQA Mathew et al. (2021a), ChartQA Masry et al. (2022), and TextVQA Singh et al. (2019). For general vision–language evaluation, we report results on MMMU-dev Yue et al. (2024), SeedBench Li et al. (2023a), and MMVet Yu et al. (2024), Pope (Li et al., 2023c), and GQA (Hudson and Manning, 2019).
Table 3: Connector Performance under a Low-Resource Training Regime: We evaluate the effectiveness of more shallow-fusion connectors when trained on limited data. The Align connector achieves the highest performance, with notably larger gains on document understanding tasks, demonstrating its data efficiency and strong inductive bias.
| Model | Document Understanding Tasks | General Vision Tasks | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| DocVQA | InfoVQA | ChartQA | TextVQA | Avg. | MMMU | SeedBench | MMVet | POPE | GQA | Avg. | |
| Llama-3.2-3B-MLP | 42.11 | 19.93 | 48.44 | 51.97 | 40.61 | 33.33 | 58.54 | 31.14 | 87.35 | 57.62 | 53.59 |
| Llama-3.2-3B-Perceiver | 32.18 | 18.10 | 40.00 | 44.31 | 33.64 | 35.22 | 63.70 | 26.19 | 84.92 | 55.86 | 53.17 |
| Llama-3.2-3B-Ovis | 57.73 | 26.39 | 54.52 | 55.60 | 48.56 | 31.89 | 60.97 | 30.41 | 88.26 | 56.23 | 53.55 |
| Llama-3.2-3B-Hreducer | 34.59 | 17.57 | 45.64 | 47.13 | 36.23 | 35.00 | 61.82 | 28.39 | 87.48 | 58.24 | 54.18 |
| Llama-3.2-3B-HoneyBee | 55.86 | 19.36 | 55.32 | 58.13 | 47.16 | 32.11 | 61.18 | 34.31 | 89.28 | 54.79 | 54.33 |
| Llama-3.2-3B- Align (ours) | 71.43 | 30.50 | 69.72 | 65.63 | 59.32 | 35.33 | 63.27 | 35.32 | 88.85 | 61.67 | 56.88 |
As summarized in Table 3, Align consistently outperforms other connectors under this low-data regime, with stronger gains on document understanding tasks. The wider performance margin between Align and others connectors under limited data (Table 3) compared to the high-resource setting (Table 2) underscores the benefit of its inductive bias. By grounding visual features within the LLM’s text embedding space, Align learns more efficiently from fewer samples, unlike direct-projection connectors that rely heavily on large datasets. This makes Align especially valuable for resource-constrained environments such as academic labs or small-scale industrial research setups, where both data and compute are limited.
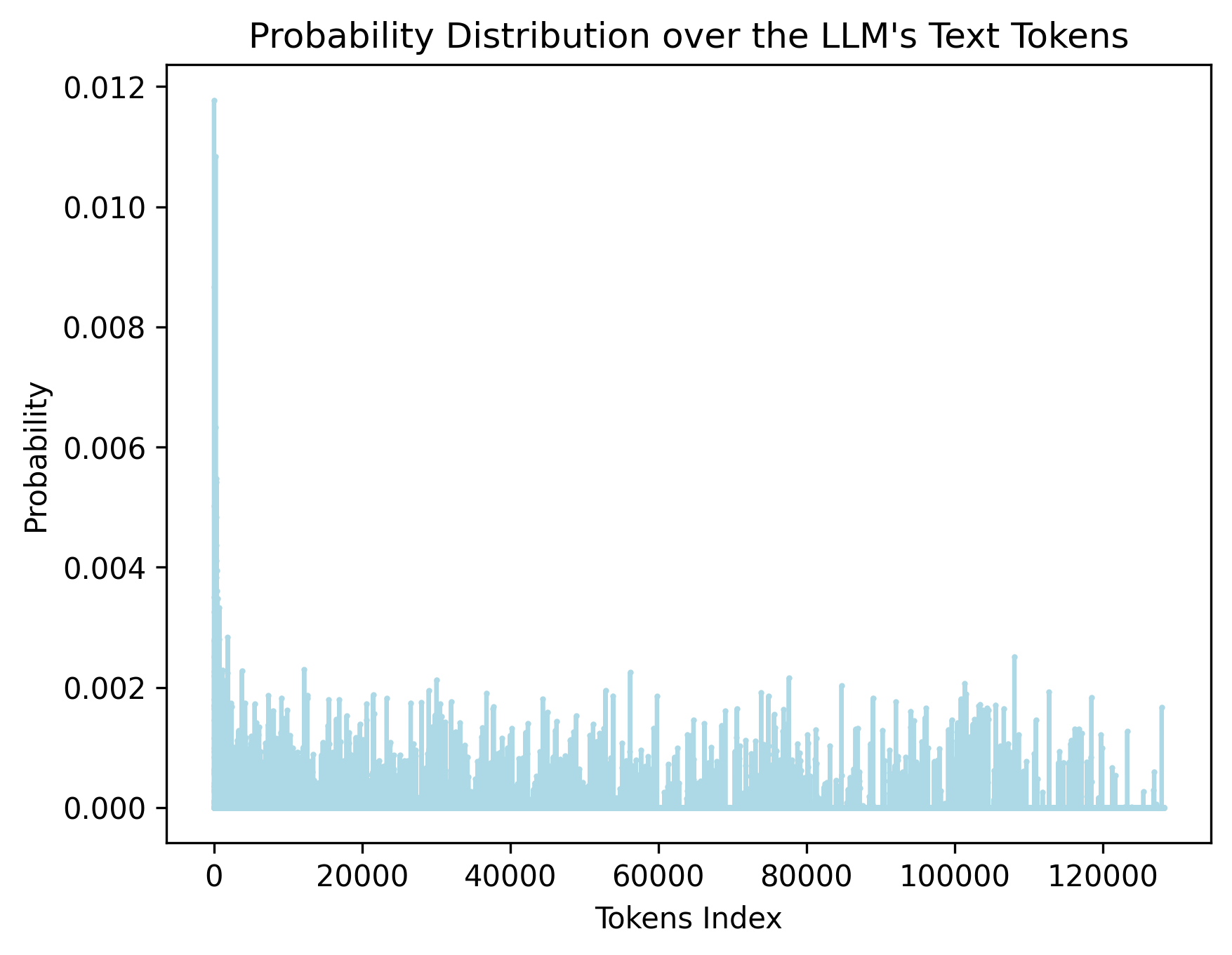
5.3 Probability Distribution over Text Tokens Analysis
To better understand the behavior of Align, we examine the probability distribution, $\mathbf{P}_{\text{vocab}}$ in Eq (1), over the LLM’s text vocabulary generated from visual features. Specifically, we process 100 document images through the vision encoder and Align, then average the resulting probability distributions across all image patches. The final distribution is shown in Figure 4. As illustrated, the distribution is dense (rather than sparse), with the highest probability assigned to a single token being 0.0118. This can be explained by the vision feature space being continuous and of much higher cardinality than the discrete text space. Indeed, while the LLM has 128K distinct vocabulary tokens, an image patch (e.g., 14×14 pixels) contains continuous, high-dimensional information that cannot be effectively mapped to a single or a few discrete tokens.
Table 4: Performance comparison when evaluating Align with the full text embedding vocabulary (128K) versus the reduced subset of 3.4K high-probability embeddings. The results show negligible performance degradation, indicating that Align relies primarily on a small subset of embeddings.
| Model | DocVQA VAL | InfoVQA VAL | DeepForm TEST | KLC TEST | WTQ TEST | TabFact TEST | ChartQA TEST | TextVQA VAL | TableVQA TEST | Avg. Score |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Llama-3.2-3B- Align (Full Embeddings) | 79.63 | 44.53 | 63.49 | 35.25 | 38.59 | 78.51 | 71.88 | 57.38 | 60.10 | 58.81 |
| Llama-3.2-3B- Align (3.4K Embeddings) | 79.40 | 44.13 | 63.64 | 35.02 | 38.26 | 78.83 | 71.72 | 57.48 | 59.80 | 58.69 |
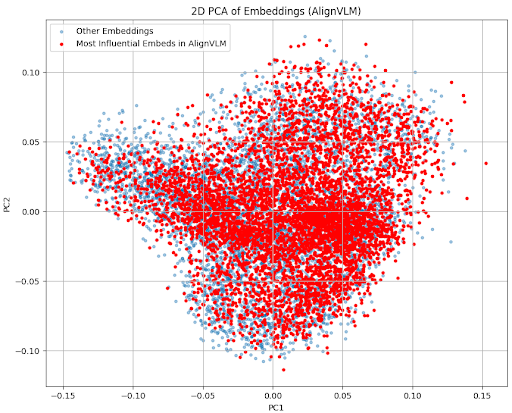
We conducted a deeper analysis of the token probability distributions produced by the Align connector. Our observations show that Align consistently assigns high probabilities to approximately 3.4K tokens from the entire vocabulary, while the remaining tokens receive negligible probabilities (below $10^{-6}$ ). To better understand this behavior, we applied Principal Component Analysis (PCA) to reduce the dimensionality of the embeddings and visualized them in a two-dimensional space, as shown in Figure 4. The visualization reveals that these 3.4K tokens densely and comprehensively span the latent space of the LLM’s text embeddings. To validate this finding, we conducted additional evaluation experiments in which we retained only these 3.4K high-probability embeddings in the Align connector, entirely removing the rest during evaluation. As shown in Table 4, the performance difference compared to using the full embedding set (128K) was negligible. This confirms that Align effectively leverages and combines a compact subset of embeddings to map visual features into semantically meaningful regions within the LLM’s latent text space. Moreover, this suggests that Align can be further optimized through targeted embedding pruning to improve computational efficiency without sacrificing performance.
<details>
<summary>figures/prob_dist_image.png Details</summary>
### Visual Description
## Bar Chart: Probability Distribution over the LLM's Text Tokens
### Overview
The image is a bar chart illustrating the probability distribution of text tokens within a Large Language Model (LLM). The x-axis represents the token index, and the y-axis represents the probability. The chart shows a high probability for the initial tokens, followed by a rapid decrease and then a relatively stable, low probability distribution across the remaining tokens.
### Components/Axes
* **Title:** Probability Distribution over the LLM's Text Tokens
* **X-axis:** Tokens Index
* Scale: 0 to 120000, with major ticks at 0, 20000, 40000, 60000, 80000, 100000, and 120000.
* **Y-axis:** Probability
* Scale: 0.000 to 0.012, with major ticks at 0.000, 0.002, 0.004, 0.006, 0.008, 0.010, and 0.012.
* **Data Series:** The chart displays a single data series represented by light blue bars.
### Detailed Analysis
* **Initial Tokens:** The probability for the first few tokens is significantly higher, peaking at approximately 0.012.
* **Rapid Decrease:** The probability drops sharply from token index 0 to approximately 10000.
* **Stable Distribution:** Beyond token index 10000, the probability remains relatively low and stable, fluctuating between approximately 0.000 and 0.002.
* **Token Index 0:** The probability at token index 0 is approximately 0.0118.
* **Token Index 20000:** The probability fluctuates around 0.001.
* **Token Index 40000:** The probability fluctuates around 0.001.
* **Token Index 60000:** The probability fluctuates around 0.001.
* **Token Index 80000:** The probability fluctuates around 0.001.
* **Token Index 100000:** The probability fluctuates around 0.001.
* **Token Index 120000:** The probability fluctuates around 0.001.
### Key Observations
* The distribution is highly skewed, with a few tokens having a much higher probability than the rest.
* The initial tokens are likely to be more frequent or important in the LLM's vocabulary.
* The long tail of low-probability tokens suggests a diverse vocabulary.
### Interpretation
The chart illustrates the probability distribution of tokens used by the LLM. The high probability of the initial tokens suggests that these tokens are either very common or play a crucial role in the language model's structure. The rapid decrease in probability indicates that the model's vocabulary contains a large number of less frequent tokens. This distribution is typical for language models, where a small subset of words accounts for a large proportion of the text. The shape of the distribution provides insights into the LLM's vocabulary and token usage patterns.
</details>
Figure 3: Probability distribution over LLM tokens, highlighting dense probabilities for whitespace tokens.
<details>
<summary>figures/vision-to-text/alignvlm_embeds.png Details</summary>
### Visual Description
## Scatter Plot: 2D PCA of Embeddings (AlignVLM)
### Overview
The image is a scatter plot visualizing the 2D Principal Component Analysis (PCA) of embeddings, specifically for the AlignVLM model. Two categories of embeddings are plotted: "Other Embeddings" (light blue) and "Most Influential Embeds in AlignVLM" (red). The plot shows the distribution of these embeddings along the first two principal components (PC1 and PC2).
### Components/Axes
* **Title:** 2D PCA of Embeddings (AlignVLM)
* **X-axis (PC1):** Ranges from approximately -0.15 to 0.15, with tick marks at -0.15, -0.10, -0.05, 0.00, 0.05, 0.10, and 0.15.
* **Y-axis (PC2):** Ranges from approximately -0.10 to 0.10, with tick marks at -0.10, -0.05, 0.00, 0.05, and 0.10.
* **Legend (top-left):**
* Light Blue: Other Embeddings
* Red: Most Influential Embeds in AlignVLM
### Detailed Analysis
* **Other Embeddings (Light Blue):** These points are more sparsely distributed across the plot. They appear to form a broader, less dense cluster.
* **Most Influential Embeds in AlignVLM (Red):** These points form a denser cluster, primarily concentrated in the central region of the plot. The red points appear to be more concentrated around the origin (0,0).
**Trend Verification and Data Points:**
* **Other Embeddings (Light Blue):** The light blue points are scattered across the plot, with a higher concentration in the central region. The distribution is relatively even across the PC1 axis, but there are fewer points at the extreme ends of the PC2 axis.
* **Most Influential Embeds in AlignVLM (Red):** The red points are heavily concentrated in the central region, forming a dense cluster. The density decreases as you move away from the origin.
### Key Observations
* The "Most Influential Embeds" are more tightly clustered than the "Other Embeddings," suggesting they have more similar characteristics in the reduced PCA space.
* The spread of "Other Embeddings" indicates greater variability among these embeddings.
* The concentration of "Most Influential Embeds" near the origin (0,0) suggests that these embeddings are well-represented by the first two principal components.
### Interpretation
The scatter plot visualizes the distribution of embeddings after applying PCA, highlighting the difference between "Other Embeddings" and "Most Influential Embeds" within the AlignVLM model. The tighter clustering of "Most Influential Embeds" suggests that these embeddings share more common features or patterns compared to the "Other Embeddings." This could indicate that the "Most Influential Embeds" are more important for the model's performance or represent more salient aspects of the data. The broader distribution of "Other Embeddings" implies greater diversity or variability within this set. The PCA projection effectively separates and visualizes these differences, providing insights into the structure and characteristics of the embeddings.
</details>
Figure 4: PCA of Align Embeddings: The principal components of the most influential embeddings in the Align Connector span most of the feature space represented by all embeddings.
5.4 Robustness to Noise Analysis
To evaluate the robustness of our Align connector to noisy visual features, we conduct an experiment where random Gaussian noise is added to the visual features produced by the vision encoder before passing them into the connector. Specifically, given the visual features $\mathbf{F}∈\mathbb{R}^{N× d}$ output by the vision encoder (where $N$ is the number of feature vectors and $d$ is their dimensionality), we perturbed them as
$$
\widetilde{\mathbf{F}}=\mathbf{F}+\mathbf{N},\quad\mathbf{N}\sim\mathcal{N}(0,\sigma=3).
$$
Table 5: Robustness to Noise. Comparison of Avg. Scores with and without Gaussian noise ( $\sigma=3$ ), including performance drop ( $\Delta$ ).
| Model | Without Noise | With Noise | Drop ( $\Delta$ ) |
| --- | --- | --- | --- |
| Llama-3.2-3B-MLP | 53.06 | 27.52 | $\downarrow 25.54$ |
| Llama-3.2-3B- Align (ours) | 58.81 | 57.14 | $\downarrow\textbf{1.67}$ |
As shown in Table 5, our Align connector demonstrates high robustness to noise, with only a 1.67% average drop in performance. In contrast, the widely adopted MLP connector suffers a significant performance degradation of 25.54%, highlighting its vulnerability to noisy inputs. Furthermore, we measured the average cosine distance between the original and noise-perturbed visual embeddings using both the Align and MLP connectors. Align showed significantly lower distances (0.0036) than MLP (0.3938), further validating its robustness to noise. These empirical results support our hypothesis that leveraging the knowledge encoded in the LLM’s text embeddings and constraining the visual features within the convex hull of the text latent space act as a regularization mechanism, reducing the model’s sensitivity to noisy visual features.
6 Conclusion
We introduce Align, a novel connector designed to align vision and language latent spaces in vision-language models (VLMs), specifically enhancing multimodal document understanding. By improving cross-modal alignment and minimizing noisy embeddings, our models, AlignVLM, which leverage Align, achieve state-of-the-art performance across diverse document understanding tasks. This includes outperforming base VLMs trained on the same datasets and achieving competitive performance with open-source instruct models trained on undisclosed data. Extensive experiments and ablations validate the robustness and effectiveness of Align compared to existing connector designs, establishing it as a significant contribution to vision-language modeling. Future work will explore training on more diverse instruction-tuning datasets to generalize to broader domains.
References
- Abdin et al. [2024] M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, A. A. Awan, N. Bach, A. Bahree, A. Bakhtiari, J. Bao, H. Behl, A. Benhaim, M. Bilenko, J. Bjorck, S. Bubeck, M. Cai, Q. Cai, V. Chaudhary, D. Chen, D. Chen, W. Chen, Y.-C. Chen, Y.-L. Chen, H. Cheng, P. Chopra, X. Dai, M. Dixon, R. Eldan, V. Fragoso, J. Gao, M. Gao, M. Gao, A. Garg, A. D. Giorno, A. Goswami, S. Gunasekar, E. Haider, J. Hao, R. J. Hewett, W. Hu, J. Huynh, D. Iter, S. A. Jacobs, M. Javaheripi, X. Jin, N. Karampatziakis, P. Kauffmann, M. Khademi, D. Kim, Y. J. Kim, L. Kurilenko, J. R. Lee, Y. T. Lee, Y. Li, Y. Li, C. Liang, L. Liden, X. Lin, Z. Lin, C. Liu, L. Liu, M. Liu, W. Liu, X. Liu, C. Luo, P. Madan, A. Mahmoudzadeh, D. Majercak, M. Mazzola, C. C. T. Mendes, A. Mitra, H. Modi, A. Nguyen, B. Norick, B. Patra, D. Perez-Becker, T. Portet, R. Pryzant, H. Qin, M. Radmilac, L. Ren, G. de Rosa, C. Rosset, S. Roy, O. Ruwase, O. Saarikivi, A. Saied, A. Salim, M. Santacroce, S. Shah, N. Shang, H. Sharma, Y. Shen, S. Shukla, X. Song, M. Tanaka, A. Tupini, P. Vaddamanu, C. Wang, G. Wang, L. Wang, S. Wang, X. Wang, Y. Wang, R. Ward, W. Wen, P. Witte, H. Wu, X. Wu, M. Wyatt, B. Xiao, C. Xu, J. Xu, W. Xu, J. Xue, S. Yadav, F. Yang, J. Yang, Y. Yang, Z. Yang, D. Yu, L. Yuan, C. Zhang, C. Zhang, J. Zhang, L. L. Zhang, Y. Zhang, Y. Zhang, Y. Zhang, and X. Zhou. Phi-3 technical report: A highly capable language model locally on your phone, 2024. URL https://arxiv.org/abs/2404.14219.
- Achiam et al. [2023] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Agrawal et al. [2024] P. Agrawal, S. Antoniak, E. B. Hanna, B. Bout, D. Chaplot, J. Chudnovsky, D. Costa, B. D. Monicault, S. Garg, T. Gervet, S. Ghosh, A. Héliou, P. Jacob, A. Q. Jiang, K. Khandelwal, T. Lacroix, G. Lample, D. L. Casas, T. Lavril, T. L. Scao, A. Lo, W. Marshall, L. Martin, A. Mensch, P. Muddireddy, V. Nemychnikova, M. Pellat, P. V. Platen, N. Raghuraman, B. Rozière, A. Sablayrolles, L. Saulnier, R. Sauvestre, W. Shang, R. Soletskyi, L. Stewart, P. Stock, J. Studnia, S. Subramanian, S. Vaze, T. Wang, and S. Yang. Pixtral 12b, 2024. URL https://arxiv.org/abs/2410.07073.
- Alayrac et al. [2022] J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds, R. Ring, E. Rutherford, S. Cabi, T. Han, Z. Gong, S. Samangooei, M. Monteiro, J. Menick, S. Borgeaud, A. Brock, A. Nematzadeh, S. Sharifzadeh, M. Binkowski, R. Barreira, O. Vinyals, A. Zisserman, and K. Simonyan. Flamingo: a visual language model for few-shot learning, 2022. URL https://arxiv.org/abs/2204.14198.
- Aminabadi et al. [2022] R. Y. Aminabadi, S. Rajbhandari, M. Zhang, A. A. Awan, C. Li, D. Li, E. Zheng, J. Rasley, S. Smith, O. Ruwase, and Y. He. Deepspeed inference: Enabling efficient inference of transformer models at unprecedented scale, 2022. URL https://arxiv.org/abs/2207.00032.
- Anthropic [2024] Anthropic. The claude 3 model family: Opus, sonnet, haiku. 2024.
- Bai et al. [2025] S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y. Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y. Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin. Qwen2.5-vl technical report, 2025. URL https://arxiv.org/abs/2502.13923.
- Bavishi et al. [2023] R. Bavishi, E. Elsen, C. Hawthorne, M. Nye, A. Odena, A. Somani, and S. Taşırlar. Introducing our multimodal models, 2023. URL https://www.adept.ai/blog/fuyu-8b.
- Beyer et al. [2024] L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdulmohsin, M. Tschannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. Koppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby, M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Bošnjak, X. Chen, M. Minderer, P. Voigtlaender, I. Bica, I. Balazevic, J. Puigcerver, P. Papalampidi, O. Henaff, X. Xiong, R. Soricut, J. Harmsen, and X. Zhai. Paligemma: A versatile 3b vlm for transfer, 2024. URL https://arxiv.org/abs/2407.07726.
- Bommasani et al. [2023] R. Bommasani, K. Klyman, S. Longpre, S. Kapoor, N. Maslej, B. Xiong, D. Zhang, and P. Liang. The foundation model transparency index, 2023. URL https://arxiv.org/abs/2310.12941.
- Brown et al. [2020] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Cha et al. [2024] J. Cha, W. Kang, J. Mun, and B. Roh. Honeybee: Locality-enhanced projector for multimodal llm, 2024. URL https://arxiv.org/abs/2312.06742.
- Changpinyo et al. [2021] S. Changpinyo, P. Sharma, N. Ding, and R. Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts, 2021. URL https://arxiv.org/abs/2102.08981.
- Chen et al. [2020] W. Chen, H. Wang, J. Chen, Y. Zhang, H. Wang, S. Li, X. Zhou, and W. Y. Wang. Tabfact: A large-scale dataset for table-based fact verification. In International Conference Learning Representations, 2020.
- Chen et al. [2024a] Z. Chen, W. Wang, H. Tian, S. Ye, Z. Gao, E. Cui, W. Tong, K. Hu, J. Luo, Z. Ma, J. Ma, J. Wang, X. Dong, H. Yan, H. Guo, C. He, B. Shi, Z. Jin, C. Xu, B. Wang, X. Wei, W. Li, W. Zhang, B. Zhang, P. Cai, L. Wen, X. Yan, M. Dou, L. Lu, X. Zhu, T. Lu, D. Lin, Y. Qiao, J. Dai, and W. Wang. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites, 2024a. URL https://arxiv.org/abs/2404.16821.
- Chen et al. [2024b] Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024b.
- Dai et al. [2024] W. Dai, N. Lee, B. Wang, Z. Yang, Z. Liu, J. Barker, T. Rintamaki, M. Shoeybi, B. Catanzaro, and W. Ping. Nvlm: Open frontier-class multimodal llms. arXiv preprint arXiv: 2409.11402, 2024.
- Diao et al. [2024] H. Diao, Y. Cui, X. Li, Y. Wang, H. Lu, and X. Wang. Unveiling encoder-free vision-language models. arXiv preprint arXiv:2406.11832, 2024.
- Drouin et al. [2024] A. Drouin, M. Gasse, M. Caccia, I. H. Laradji, M. D. Verme, T. Marty, L. Boisvert, M. Thakkar, Q. Cappart, D. Vazquez, N. Chapados, and A. Lacoste. Workarena: How capable are web agents at solving common knowledge work tasks?, 2024. URL https://arxiv.org/abs/2403.07718.
- Duan et al. [2024] H. Duan, J. Yang, Y. Qiao, X. Fang, L. Chen, Y. Liu, X. Dong, Y. Zang, P. Zhang, J. Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024.
- Dubey et al. [2024] A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, and et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Grattafiori et al. [2024] A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, A. Rodriguez, A. Gregerson, A. Spataru, B. Roziere, B. Biron, B. Tang, B. Chern, C. Caucheteux, C. Nayak, C. Bi, C. Marra, C. McConnell, C. Keller, C. Touret, C. Wu, C. Wong, C. C. Ferrer, C. Nikolaidis, D. Allonsius, D. Song, D. Pintz, D. Livshits, D. Wyatt, D. Esiobu, D. Choudhary, D. Mahajan, D. Garcia-Olano, D. Perino, D. Hupkes, E. Lakomkin, E. AlBadawy, E. Lobanova, E. Dinan, E. M. Smith, F. Radenovic, F. Guzmán, F. Zhang, G. Synnaeve, G. Lee, G. L. Anderson, G. Thattai, G. Nail, G. Mialon, G. Pang, G. Cucurell, H. Nguyen, H. Korevaar, H. Xu, H. Touvron, I. Zarov, I. A. Ibarra, I. Kloumann, I. Misra, I. Evtimov, J. Zhang, J. Copet, J. Lee, J. Geffert, J. Vranes, J. Park, J. Mahadeokar, J. Shah, J. van der Linde, J. Billock, J. Hong, J. Lee, J. Fu, J. Chi, J. Huang, J. Liu, J. Wang, J. Yu, J. Bitton, J. Spisak, J. Park, J. Rocca, J. Johnstun, J. Saxe, J. Jia, K. V. Alwala, K. Prasad, K. Upasani, K. Plawiak, K. Li, K. Heafield, K. Stone, K. El-Arini, K. Iyer, K. Malik, K. Chiu, K. Bhalla, K. Lakhotia, L. Rantala-Yeary, L. van der Maaten, L. Chen, L. Tan, L. Jenkins, L. Martin, L. Madaan, L. Malo, L. Blecher, L. Landzaat, L. de Oliveira, M. Muzzi, M. Pasupuleti, M. Singh, M. Paluri, M. Kardas, M. Tsimpoukelli, M. Oldham, M. Rita, M. Pavlova, M. Kambadur, M. Lewis, M. Si, M. K. Singh, M. Hassan, N. Goyal, N. Torabi, N. Bashlykov, N. Bogoychev, N. Chatterji, N. Zhang, O. Duchenne, O. Çelebi, P. Alrassy, P. Zhang, P. Li, P. Vasic, P. Weng, P. Bhargava, P. Dubal, P. Krishnan, P. S. Koura, P. Xu, Q. He, Q. Dong, R. Srinivasan, R. Ganapathy, R. Calderer, R. S. Cabral, R. Stojnic, R. Raileanu, R. Maheswari, R. Girdhar, R. Patel, R. Sauvestre, R. Polidoro, R. Sumbaly, R. Taylor, R. Silva, R. Hou, R. Wang, S. Hosseini, S. Chennabasappa, S. Singh, S. Bell, S. S. Kim, S. Edunov, S. Nie, S. Narang, S. Raparthy, S. Shen, S. Wan, S. Bhosale, S. Zhang, S. Vandenhende, S. Batra, S. Whitman, S. Sootla, S. Collot, S. Gururangan, S. Borodinsky, T. Herman, T. Fowler, T. Sheasha, T. Georgiou, T. Scialom, T. Speckbacher, T. Mihaylov, T. Xiao, U. Karn, V. Goswami, V. Gupta, V. Ramanathan, V. Kerkez, V. Gonguet, V. Do, V. Vogeti, V. Albiero, V. Petrovic, W. Chu, W. Xiong, W. Fu, W. Meers, X. Martinet, X. Wang, X. Wang, X. E. Tan, X. Xia, X. Xie, X. Jia, X. Wang, Y. Goldschlag, Y. Gaur, Y. Babaei, Y. Wen, Y. Song, Y. Zhang, Y. Li, Y. Mao, Z. D. Coudert, Z. Yan, Z. Chen, Z. Papakipos, A. Singh, A. Srivastava, A. Jain, A. Kelsey, A. Shajnfeld, A. Gangidi, A. Victoria, A. Goldstand, A. Menon, A. Sharma, A. Boesenberg, A. Baevski, A. Feinstein, A. Kallet, A. Sangani, A. Teo, A. Yunus, A. Lupu, A. Alvarado, A. Caples, A. Gu, A. Ho, A. Poulton, A. Ryan, A. Ramchandani, A. Dong, A. Franco, A. Goyal, A. Saraf, A. Chowdhury, A. Gabriel, A. Bharambe, A. Eisenman, A. Yazdan, B. James, B. Maurer, B. Leonhardi, B. Huang, B. Loyd, B. D. Paola, B. Paranjape, B. Liu, B. Wu, B. Ni, B. Hancock, B. Wasti, B. Spence, B. Stojkovic, B. Gamido, B. Montalvo, C. Parker, C. Burton, C. Mejia, C. Liu, C. Wang, C. Kim, C. Zhou, C. Hu, C.-H. Chu, C. Cai, C. Tindal, C. Feichtenhofer, C. Gao, D. Civin, D. Beaty, D. Kreymer, D. Li, D. Adkins, D. Xu, D. Testuggine, D. David, D. Parikh, D. Liskovich, D. Foss, D. Wang, D. Le, D. Holland, E. Dowling, E. Jamil, E. Montgomery, E. Presani, E. Hahn, E. Wood, E.-T. Le, E. Brinkman, E. Arcaute, E. Dunbar, E. Smothers, F. Sun, F. Kreuk, F. Tian, F. Kokkinos, F. Ozgenel, F. Caggioni, F. Kanayet, F. Seide, G. M. Florez, G. Schwarz, G. Badeer, G. Swee, G. Halpern, G. Herman, G. Sizov, Guangyi, Zhang, G. Lakshminarayanan, H. Inan, H. Shojanazeri, H. Zou, H. Wang, H. Zha, H. Habeeb, H. Rudolph, H. Suk, H. Aspegren, H. Goldman, H. Zhan, I. Damlaj, I. Molybog, I. Tufanov, I. Leontiadis, I.-E. Veliche, I. Gat, J. Weissman, J. Geboski, J. Kohli, J. Lam, J. Asher, J.-B. Gaya, J. Marcus, J. Tang, J. Chan, J. Zhen, J. Reizenstein, J. Teboul, J. Zhong, J. Jin, J. Yang, J. Cummings, J. Carvill, J. Shepard, J. McPhie, J. Torres, J. Ginsburg, J. Wang, K. Wu, K. H. U, K. Saxena, K. Khandelwal, K. Zand, K. Matosich, K. Veeraraghavan, K. Michelena, K. Li, K. Jagadeesh, K. Huang, K. Chawla, K. Huang, L. Chen, L. Garg, L. A, L. Silva, L. Bell, L. Zhang, L. Guo, L. Yu, L. Moshkovich, L. Wehrstedt, M. Khabsa, M. Avalani, M. Bhatt, M. Mankus, M. Hasson, M. Lennie, M. Reso, M. Groshev, M. Naumov, M. Lathi, M. Keneally, M. Liu, M. L. Seltzer, M. Valko, M. Restrepo, M. Patel, M. Vyatskov, M. Samvelyan, M. Clark, M. Macey, M. Wang, M. J. Hermoso, M. Metanat, M. Rastegari, M. Bansal, N. Santhanam, N. Parks, N. White, N. Bawa, N. Singhal, N. Egebo, N. Usunier, N. Mehta, N. P. Laptev, N. Dong, N. Cheng, O. Chernoguz, O. Hart, O. Salpekar, O. Kalinli, P. Kent, P. Parekh, P. Saab, P. Balaji, P. Rittner, P. Bontrager, P. Roux, P. Dollar, P. Zvyagina, P. Ratanchandani, P. Yuvraj, Q. Liang, R. Alao, R. Rodriguez, R. Ayub, R. Murthy, R. Nayani, R. Mitra, R. Parthasarathy, R. Li, R. Hogan, R. Battey, R. Wang, R. Howes, R. Rinott, S. Mehta, S. Siby, S. J. Bondu, S. Datta, S. Chugh, S. Hunt, S. Dhillon, S. Sidorov, S. Pan, S. Mahajan, S. Verma, S. Yamamoto, S. Ramaswamy, S. Lindsay, S. Lindsay, S. Feng, S. Lin, S. C. Zha, S. Patil, S. Shankar, S. Zhang, S. Zhang, S. Wang, S. Agarwal, S. Sajuyigbe, S. Chintala, S. Max, S. Chen, S. Kehoe, S. Satterfield, S. Govindaprasad, S. Gupta, S. Deng, S. Cho, S. Virk, S. Subramanian, S. Choudhury, S. Goldman, T. Remez, T. Glaser, T. Best, T. Koehler, T. Robinson, T. Li, T. Zhang, T. Matthews, T. Chou, T. Shaked, V. Vontimitta, V. Ajayi, V. Montanez, V. Mohan, V. S. Kumar, V. Mangla, V. Ionescu, V. Poenaru, V. T. Mihailescu, V. Ivanov, W. Li, W. Wang, W. Jiang, W. Bouaziz, W. Constable, X. Tang, X. Wu, X. Wang, X. Wu, X. Gao, Y. Kleinman, Y. Chen, Y. Hu, Y. Jia, Y. Qi, Y. Li, Y. Zhang, Y. Zhang, Y. Adi, Y. Nam, Yu, Wang, Y. Zhao, Y. Hao, Y. Qian, Y. Li, Y. He, Z. Rait, Z. DeVito, Z. Rosnbrick, Z. Wen, Z. Yang, Z. Zhao, and Z. Ma. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783.
- He et al. [2015] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385.
- Hu et al. [2024] A. Hu, H. Xu, J. Ye, M. Yan, L. Zhang, B. Zhang, C. Li, J. Zhang, Q. Jin, F. Huang, and J. Zhou. mplug-docowl 1.5: Unified structure learning for ocr-free document understanding, 2024. URL https://arxiv.org/abs/2403.12895.
- Hudson and Manning [2019] D. A. Hudson and C. D. Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering, 2019. URL https://arxiv.org/abs/1902.09506.
- Jaume et al. [2019] G. Jaume, H. K. Ekenel, and J.-P. Thiran. Funsd: A dataset for form understanding in noisy scanned documents, 2019. URL https://arxiv.org/abs/1905.13538.
- Kim et al. [2022] G. Kim, T. Hong, M. Yim, J. Nam, J. Park, J. Yim, W. Hwang, S. Yun, D. Han, and S. Park. Ocr-free document understanding transformer, 2022. URL https://arxiv.org/abs/2111.15664.
- Kim et al. [2024] Y. Kim, M. Yim, and K. Y. Song. Tablevqa-bench: A visual question answering benchmark on multiple table domains. arXiv preprint arXiv:2404.19205, 2024.
- Laurençon et al. [2024] H. Laurençon, L. Tronchon, M. Cord, and V. Sanh. What matters when building vision-language models?, 2024. URL https://arxiv.org/abs/2405.02246.
- Lee et al. [2023] K. Lee, M. Joshi, I. Turc, H. Hu, F. Liu, J. Eisenschlos, U. Khandelwal, P. Shaw, M.-W. Chang, and K. Toutanova. Pix2struct: Screenshot parsing as pretraining for visual language understanding, 2023. URL https://arxiv.org/abs/2210.03347.
- Li et al. [2023a] B. Li, R. Wang, G. Wang, Y. Ge, Y. Ge, and Y. Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension, 2023a. URL https://arxiv.org/abs/2307.16125.
- Li et al. [2024] B. Li, Y. Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y. Li, Z. Liu, and C. Li. Llava-onevision: Easy visual task transfer, 2024. URL https://arxiv.org/abs/2408.03326.
- Li et al. [2023b] J. Li, D. Li, S. Savarese, and S. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023b. URL https://arxiv.org/abs/2301.12597.
- Li et al. [2023c] Y. Li, Y. Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen. Evaluating object hallucination in large vision-language models, 2023c. URL https://arxiv.org/abs/2305.10355.
- Liu et al. [2023a] H. Liu, C. Li, Y. Li, and Y. J. Lee. Improved baselines with visual instruction tuning, 2023a.
- Liu et al. [2023b] H. Liu, C. Li, Q. Wu, and Y. J. Lee. Visual instruction tuning, 2023b.
- Liu et al. [2024] H. Liu, C. Li, Y. Li, B. Li, Y. Zhang, S. Shen, and Y. J. Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024. URL https://llava-vl.github.io/blog/2024-01-30-llava-next/.
- Lu et al. [2024] S. Lu, Y. Li, Q.-G. Chen, Z. Xu, W. Luo, K. Zhang, and H.-J. Ye. Ovis: Structural embedding alignment for multimodal large language model, 2024. URL https://arxiv.org/abs/2405.20797.
- Masry et al. [2022] A. Masry, D. X. Long, J. Q. Tan, S. Joty, and E. Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. arXiv preprint arXiv:2203.10244, 2022.
- Mathew et al. [2021a] M. Mathew, V. Bagal, R. P. Tito, D. Karatzas, E. Valveny, and C. V. Jawahar. Infographicvqa, 2021a. URL https://arxiv.org/abs/2104.12756.
- Mathew et al. [2021b] M. Mathew, D. Karatzas, and C. V. Jawahar. Docvqa: A dataset for vqa on document images, 2021b. URL https://arxiv.org/abs/2007.00398.
- OpenAI et al. [2023] OpenAI, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, R. Avila, I. Babuschkin, S. Balaji, V. Balcom, P. Baltescu, H. Bao, M. Bavarian, J. Belgum, I. Bello, et al. Gpt-4 technical report. arXiv preprint arXiv: 2303.08774, 2023.
- Park et al. [2019] S. Park, S. Shin, B. Lee, J. Lee, J. Surh, M. Seo, and H. Lee. Cord: A consolidated receipt dataset for post-ocr parsing. Document Intelligence Workshop at Neural Information Processing Systems, 2019.
- Pasupat and Liang [2015] P. Pasupat and P. Liang. Compositional semantic parsing on semi-structured tables. In Annual Meeting of the Association for Computational Linguistics, 2015.
- Qwen et al. [2025] Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z. Zhang, and Z. Qiu. Qwen2.5 technical report, 2025. URL https://arxiv.org/abs/2412.15115.
- Radford et al. [2021] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/2103.00020.
- Raffel et al. [2023] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2023. URL https://arxiv.org/abs/1910.10683.
- Rodriguez et al. [2024a] J. Rodriguez, X. Jian, S. S. Panigrahi, T. Zhang, A. Feizi, A. Puri, A. Kalkunte, F. Savard, A. Masry, S. Nayak, R. Awal, M. Massoud, A. Abaskohi, Z. Li, S. Wang, P.-A. Noël, M. L. Richter, S. Vadacchino, S. Agarwal, S. Biswas, S. Shanian, Y. Zhang, N. Bolger, K. MacDonald, S. Fauvel, S. Tejaswi, S. Sunkara, J. Monteiro, K. D. Dvijotham, T. Scholak, N. Chapados, S. Kharagani, S. Hughes, M. Özsu, S. Reddy, M. Pedersoli, Y. Bengio, C. Pal, I. Laradji, S. Gella, P. Taslakian, D. Vazquez, and S. Rajeswar. Bigdocs: An open and permissively-licensed dataset for training multimodal models on document and code tasks, 2024a. URL https://arxiv.org/abs/2412.04626.
- Rodriguez et al. [2022] J. A. Rodriguez, D. Vazquez, I. Laradji, M. Pedersoli, and P. Rodriguez. Ocr-vqgan: Taming text-within-image generation, 2022. URL https://arxiv.org/abs/2210.11248.
- Rodriguez et al. [2024b] J. A. Rodriguez, A. Puri, S. Agarwal, I. H. Laradji, P. Rodriguez, S. Rajeswar, D. Vazquez, C. Pal, and M. Pedersoli. Starvector: Generating scalable vector graphics code from images and text, 2024b. URL https://arxiv.org/abs/2312.11556.
- Singh et al. [2019] A. Singh, V. Natarajan, M. Shah, Y. Jiang, X. Chen, D. Batra, D. Parikh, and M. Rohrbach. Towards vqa models that can read. In IEEE Conference Computer Vision Pattern Recognition, 2019.
- Stanisławek et al. [2021] T. Stanisławek, F. Graliński, A. Wróblewska, D. Lipiński, A. Kaliska, P. Rosalska, B. Topolski, and P. Biecek. Kleister: key information extraction datasets involving long documents with complex layouts. In International Conference on Document Analysis and Recognition, 2021.
- Svetlichnaya [2020] S. Svetlichnaya. Deepform: Understand structured documents at scale, 2020.
- Team [2024] G. Team. Gemini: A family of highly capable multimodal models, 2024. URL https://arxiv.org/abs/2312.11805.
- Vogus and Llansóe [2021] C. Vogus and E. Llansóe. Making transparency meaningful: A framework for policymakers. Center for Democracy and Technology, 2021.
- Wang et al. [2023a] D. Wang, N. Raman, M. Sibue, Z. Ma, P. Babkin, S. Kaur, Y. Pei, A. Nourbakhsh, and X. Liu. Docllm: A layout-aware generative language model for multimodal document understanding, 2023a. URL https://arxiv.org/abs/2401.00908.
- Wang et al. [2024] P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y. Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, 2024. URL https://arxiv.org/abs/2409.12191.
- Wang et al. [2023b] W. Wang, Q. Lv, W. Yu, W. Hong, J. Qi, Y. Wang, J. Ji, Z. Yang, L. Zhao, X. Song, et al. Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079, 2023b.
- Wu et al. [2024a] C. Wu, X. Chen, Z. Wu, Y. Ma, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, C. Ruan, and P. Luo. Janus: Decoupling visual encoding for unified multimodal understanding and generation, 2024a. URL https://arxiv.org/abs/2410.13848.
- Wu et al. [2024b] Z. Wu, X. Chen, Z. Pan, X. Liu, W. Liu, D. Dai, H. Gao, Y. Ma, C. Wu, B. Wang, Z. Xie, Y. Wu, K. Hu, J. Wang, Y. Sun, Y. Li, Y. Piao, K. Guan, A. Liu, X. Xie, Y. You, K. Dong, X. Yu, H. Zhang, L. Zhao, Y. Wang, and C. Ruan. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding, 2024b. URL https://arxiv.org/abs/2412.10302.
- Xu et al. [2024] R. Xu, Y. Yao, Z. Guo, J. Cui, Z. Ni, C. Ge, T.-S. Chua, Z. Liu, M. Sun, and G. Huang. Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images. European Conference on Computer Vision, 2024. doi: 10.48550/arXiv.2403.11703.
- Yu et al. [2024] W. Yu, Z. Yang, L. Li, J. Wang, K. Lin, Z. Liu, X. Wang, and L. Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities, 2024. URL https://arxiv.org/abs/2308.02490.
- Yue et al. [2024] X. Yue, Y. Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y. Sun, C. Wei, B. Yu, R. Yuan, R. Sun, M. Yin, B. Zheng, Z. Yang, Y. Liu, W. Huang, H. Sun, Y. Su, and W. Chen. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi, 2024. URL https://arxiv.org/abs/2311.16502.
- Zhai et al. [2023] X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training, 2023. URL https://arxiv.org/abs/2303.15343.
- Zhang et al. [2024] T. Zhang, S. Wang, L. Li, G. Zhang, P. Taslakian, S. Rajeswar, J. Fu, B. Liu, and Y. Bengio. Vcr: Visual caption restoration. arXiv preprint arXiv: 2406.06462, 2024.
- Zhao et al. [2024] Y. Zhao, J. Huang, J. Hu, X. Wang, Y. Mao, D. Zhang, Z. Jiang, Z. Wu, B. Ai, A. Wang, W. Zhou, and Y. Chen. Swift:a scalable lightweight infrastructure for fine-tuning, 2024. URL https://arxiv.org/abs/2408.05517.
- Zhu et al. [2025] J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y. Duan, W. Su, J. Shao, Z. Gao, E. Cui, X. Wang, Y. Cao, Y. Liu, X. Wei, H. Zhang, H. Wang, W. Xu, H. Li, J. Wang, N. Deng, S. Li, Y. He, T. Jiang, J. Luo, Y. Wang, C. He, B. Shi, X. Zhang, W. Shao, J. He, Y. Xiong, W. Qu, P. Sun, P. Jiao, H. Lv, L. Wu, K. Zhang, H. Deng, J. Ge, K. Chen, L. Wang, M. Dou, L. Lu, X. Zhu, T. Lu, D. Lin, Y. Qiao, J. Dai, and W. Wang. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models, 2025. URL https://arxiv.org/abs/2504.10479.
Appendix A Appendix
A.1 Experimental Setup
We provide detailed hyperparameters of our experiments in Table 6.
Table 6: Detailed hyperparameters for each training stage across different LLM backbones.
LLM Backbone Llama 3.2-1B Llama 3.2-3B Llama 3.1-8B Stage-1 Stage-2 Stage-3 Stage-1 Stage-2 Stage-3 Stage-1 Stage-2 Stage-3 Trainable Parameters Full Model Full Model LLM & Connector Full Model Full Model LLM & Connector Full Model Full Model LLM & Connector Batch Size 512 512 512 512 256 256 512 256 256 Text Max Length 1024 2048 2048 1024 2048 2048 1024 2048 2048 Epochs 1 1 5 1 1 5 1 1 5 Learning Rate $1× 10^{-5}$ $5× 10^{-5}$ $5× 10^{-5}$ $1× 10^{-5}$ $5× 10^{-5}$ $5× 10^{-5}$ $1× 10^{-5}$ $1× 10^{-5}$ $1× 10^{-5}$
A.2 Runtime Comparison Between Connectors
One caveat in the Align connector is that it includes an additional LM head layer, which slightly increases the total number of parameters. However, this addition has a negligible impact on runtime efficiency due to its simple structure. It only introduces a few matrix multiplication operations (as shown in Equations 1 and 2) instead of stacking many complex layers that require sequential processing, as in deep fusion methods.
To empirically validate this claim, we benchmarked the runtime and memory usage of models equipped with different connector types (MLP, Align, Ovis, and Perceiver), following the same experimental setup as in Table 2. As shown in Table 7, the results demonstrate that although the Align connector delivers notably superior performance (see Table 2), the variations in inference speed and GPU memory usage among the connectors remain minimal.
Table 7: Runtime and memory comparison between different connector designs. The results show that Align introduces negligible computational overhead compared to other connectors.
| Model | Samples | Avg Time (s) | Tokens/sec | GPU Memory (GB) |
| --- | --- | --- | --- | --- |
| Llama-3.2-3B-MLP | 2500 | 0.161 | 118.3 | 10.9 |
| Llama-3.2-3B-Perceiver | 2500 | 0.140 | 135.1 | 10.9 |
| Llama-3.2-3B-Ovis | 2500 | 0.155 | 122.5 | 10.8 |
| Llama-3.2-3B- Align | 2500 | 0.165 | 115.4 | 10.9 |
Overall, the empirical evidence confirms that the Align connector achieves an effective balance between computational efficiency and performance. It introduces only a negligible increase in runtime and memory usage while providing substantial gains in overall accuracy.
A.3 Pixel-Level Tasks Analysis
To rigorously evaluate the ability of vision-language models to integrate fine-grained visual and textual pixel-level cues, we test our model on the VCR benchmark [Zhang et al., 2024], which requires the model to recover partially occluded texts with pixel-level hints from the revealed parts of the text. This task challenges VLM’s alignment of text and image in extreme situations. Current state-of-the-art models like GPT-4V OpenAI et al. [2023], Claude 3.5 Sonnet Anthropic [2024], and Llama-3.2 Dubey et al. [2024] significantly underperform humans on hard VCR task due to their inability to process subtle pixel-level cues in occluded text regions. These models frequently discard critical visual tokens during image tokenization on semantic priors, overlooking the interplay between partial character strokes and contextual visual scenes. To evaluate performance on VCR, we modify our Stage 3 SFT dataset composition by replacing the exclusive use of DocDownstream with a 5:1 blended ratio of DocDownstream and VCR training data. This adjustment enables direct evaluation of our architecture Align ’s ability to leverage pixel-level character cues.
From the experimental outcomes, it is evident that AlignVLM consistently outperforms the MLP Connector Model across both easy and hard settings of the pixel-level VCR task (see Figure 5), with improvements ranging from 10.18% on the hard setting to 14.41% on the easy setting.
We provide a case study on VCR in Figure 6, featuring four representative examples. In Figure 6(a), it is evident that the MLP connector model fails to capture semantic consistency as effectively as AlignVLM. The phrase “The commune first census in written history in ” (where the words in italics are generated by the model while the rest are in the image) is not as semantically coherent as the phrase generated by Align “The commune first appears in written history in ”.
Beyond the issue of semantic fluency, in Figure 6(b) we also observe that AlignVLM successfully identifies the uncovered portion of the letter “g” in “accounting” and uses it as a pixel-level hint to infer the correct word. In contrast, the MLP model fails to effectively attend to this crucial detail.
Figures 6(c) and 6(d) show examples where AlignVLM fails on the VCR task. These carefully picked instances show that our method mistakes names of landmarks with common words when the two are very similar. As seen in the examples, AlignVLM mistakes “Llanengan" for “Llanongan" and “Gorden" for “Garden”. In both instances, the pairs differ by one character, indicating perhaps that AlignVLM tends to align vision representations to more common tokens in the vocabulary. One approach that would potentially mitigate such errors would be to train AlignVLM with more contextually-relevant data.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Chart: Exact Match Performance on VCR EN Dataset
### Overview
The image is a bar chart comparing the "Exact Match" performance of two models, "Llama-3.2-3B-Align (Ours)" and "Llama-3.2-3B-MLP", on the VCR EN dataset, split into "Easy" and "Hard" difficulty levels. The chart displays the percentage of exact matches achieved by each model on each difficulty level.
### Components/Axes
* **Y-axis:** "VCR EN Easy" and "VCR EN Hard" representing the two difficulty levels of the VCR EN dataset.
* **X-axis:** "Exact Match (%)" ranging from 0 to 60, indicating the percentage of exact matches.
* **Legend:** Located at the bottom of the chart.
* Light Blue: "Llama-3.2-3B-Align (Ours)"
* Light Orange: "Llama-3.2-3B-MLP"
### Detailed Analysis
* **VCR EN Easy:**
* Llama-3.2-3B-Align (Ours) (Light Blue): 65.84%
* Llama-3.2-3B-MLP (Light Orange): 51.43%
* **VCR EN Hard:**
* Llama-3.2-3B-Align (Ours) (Light Blue): 48.07%
* Llama-3.2-3B-MLP (Light Orange): 37.89%
### Key Observations
* For both "Easy" and "Hard" difficulty levels, "Llama-3.2-3B-Align (Ours)" outperforms "Llama-3.2-3B-MLP" in terms of "Exact Match (%)".
* Both models achieve higher "Exact Match (%)" on the "Easy" split compared to the "Hard" split, as expected.
* The performance gap between the two models is larger on the "Easy" split (65.84% vs 51.43%) compared to the "Hard" split (48.07% vs 37.89%).
### Interpretation
The bar chart demonstrates that the "Llama-3.2-3B-Align (Ours)" model exhibits superior performance compared to the "Llama-3.2-3B-MLP" model on the VCR EN dataset, regardless of the difficulty level. The "Align" model's architecture or training procedure likely contributes to its improved accuracy in achieving exact matches. The larger performance difference on the "Easy" split suggests that the "Align" model is better at handling less complex or ambiguous scenarios within the VCR EN dataset. The drop in performance for both models on the "Hard" split indicates that both models struggle with the more challenging aspects of the dataset.
</details>
Figure 5: Comparison of Llama-3.2-3b- Align and Llama-3.2-3B-MLP on the Easy and Hard VCR tasks.
<details>
<summary>figures/vcr_example1.png Details</summary>
### Visual Description
## Map: Ațel Commune, Sibiu County, Transylvania, Romania
### Overview
The image is a map of the Ațel commune located in Sibiu County, Transylvania, Romania. The map shows the geographical layout of the commune, including its villages and surrounding areas. The map is satellite imagery with borders drawn on top.
### Components/Axes
* **Location:** Ațel Commune, Sibiu County, Transylvania, Romania.
* **Villages:** Ațel and Dupuş.
* **Visual Elements:** Satellite imagery showing terrain, vegetation, and possibly some infrastructure. A yellow border highlights a specific region in the northern part of the commune.
### Detailed Analysis
The map displays the geographical boundaries of the Ațel commune. The satellite imagery provides a detailed view of the landscape, showing variations in terrain and vegetation cover. The yellow border highlights a specific area within the commune, possibly indicating a point of interest or a specific administrative region.
The text below the map states that the commune is composed of two villages, Ațel and Dupuş.
### Key Observations
* The map provides a visual representation of the Ațel commune's location and geographical features.
* The yellow border highlights a specific area within the commune.
* The text identifies the two villages that make up the commune.
### Interpretation
The map serves as a visual aid for understanding the geographical context of the Ațel commune. It shows the location of the commune within Sibiu County, Transylvania, Romania, and highlights its key features, such as its villages and terrain. The yellow border may indicate a specific area of interest within the commune, such as a protected area or a development zone. The map and text together provide a basic overview of the commune's composition and location.
</details>
| GT: | (appears in written history in) |
| --- | --- |
| MLP: | (census in written history in) ✗ |
| Align | (appears in written history in) ✓ |
(a) Positive Example 1
<details>
<summary>figures/vcr_example2.png Details</summary>
### Visual Description
## Map: Ghana Telephone Numbering Plan
### Overview
The image is a map of Ghana, divided into regions, each colored differently and labeled with a two- or three-digit number. The map illustrates the Ghana telephone numbering plan. Below the map is a text description of the plan.
### Components/Axes
* **Regions:** The map is divided into several regions, each representing a specific area within Ghana.
* **Colors:** Each region is colored differently. The colors are: blue, purple, green, red, light purple, light blue, pink, and yellow.
* **Labels:** Each region is labeled with a numerical code: 030, 031, 032, 033, 034, 035, 036, 037, 038, 039.
* **Text:** A text description is present below the map.
### Detailed Analysis
The map shows the geographical distribution of telephone number prefixes in Ghana. Each region corresponds to a specific telephone area code.
* **Region 030:** Located in the southeastern part of the map, colored pink.
* **Region 031:** Located in the southwestern part of the map, colored blue.
* **Region 032:** Located in the central-southern part of the map, colored red.
* **Region 033:** Located south of region 032, colored light blue.
* **Region 034:** Located east of region 032, colored light purple.
* **Region 035:** Located north of region 032, colored green.
* **Region 036:** Located east of region 035, colored green.
* **Region 037:** Located north of region 035, colored purple.
* **Region 038:** Located in the northernmost part of the map, colored yellow.
* **Region 039:** Located west of region 038, colored blue.
The text below the map states: "The Ghana telephone numbering plan is the system used for assigning telephone numbers in Ghana. It is regulated by the National Communications".
### Key Observations
* The map provides a visual representation of the telephone numbering plan in Ghana.
* Different regions are assigned different numerical codes.
* The text provides a brief explanation of the purpose and regulatory body of the plan.
### Interpretation
The map illustrates the geographical organization of Ghana's telephone numbering system. The different colors and numerical codes assigned to each region likely correspond to specific area codes or prefixes used within those regions. The National Communications Authority regulates the system. The map provides a clear visual aid for understanding how telephone numbers are allocated across the country.
</details>
| GT: | (the system used for assigning) |
| --- | --- |
| MLP: | (the system used for accounting) ✗ |
| Align | (the system used for assigning) ✓ |
(b) Positive Example 2
<details>
<summary>figures/vcr_example3.png Details</summary>

### Visual Description
## Photograph: Mine Tunnel
### Overview
The image is a photograph of a mine tunnel. The tunnel appears to be long and narrow, with rough-hewn walls and a textured floor. The lighting is dim, with a light source illuminating the path ahead. The photograph is taken from within the tunnel, looking towards the vanishing point in the distance.
### Components/Axes
* **Tunnel Walls:** The walls are dark and appear to be made of rock.
* **Tunnel Floor:** The floor is textured and lighter in color than the walls.
* **Light Source:** A light source illuminates the path ahead, creating a bright spot on the floor.
* **Text Overlay:** A block of text is overlaid on the bottom of the image.
### Content Details
The text overlay reads:
"The Penrhyn Dû Mines are a collection of... the Llŷn Peninsula. It encompasses the Penrhyn, Assheton, Western and..."
### Key Observations
* The tunnel appears to be old and possibly abandoned.
* The lighting is dim, which adds to the sense of mystery and danger.
* The text overlay provides context about the location of the mine.
### Interpretation
The photograph captures the atmosphere of a mine tunnel, emphasizing its darkness, narrowness, and rough texture. The text overlay identifies the location as the Penrhyn Dû Mines on the Llŷn Peninsula. The image evokes a sense of exploration and the history of mining in the region. The incomplete text suggests that the image is part of a larger document or presentation.
</details>
| GT: | (mines situated near Llanengan on) |
| --- | --- |
| MLP: | (mines situated near Llanengan on) ✓ |
| Align | (mines situated near Llanongan on) ✗ |
(c) Negative Example 1
<details>
<summary>figures/vcr_example4.png Details</summary>

### Visual Description
## Image Description: City of Fairmount Building
### Overview
The image shows a brick building identified as the "City of Fairmount" building, along with a textual description of Fairmount, Georgia.
### Components/Axes
* **Building:** A two-story brick building with a white roof overhang above the entrance. The building has a symmetrical design with a central entrance.
* **Text Above Building:** "CITY OF FAIRMOUNT" in gold lettering. Below this, smaller text reads "A GROWING COMMUNITY WITH A BRIGHT FUTURE".
* **Surroundings:** The building is surrounded by a grassy area and a paved parking lot. Trees are visible in the background.
* **Text Below Building:** A paragraph describing Fairmount, Georgia.
### Detailed Analysis or Content Details
* **Text Transcription:**
* "CITY OF FAIRMOUNT"
* "A GROWING COMMUNITY WITH A BRIGHT FUTURE"
* "Fairmount is a city in Gordon County, Georgia, United States. As of the 2010 census it had a population of 720. Gordon County is home to New Echota,"
### Key Observations
* The building appears to be a municipal building or city hall.
* The text emphasizes the growth and positive outlook of Fairmount.
* The text mentions the population of Fairmount as 720 in the 2010 census.
### Interpretation
The image presents a view of the City of Fairmount's municipal building, aiming to portray the city as a growing and promising community. The inclusion of the population figure provides a concrete detail about the city's size. The mention of New Echota suggests a historical connection or point of interest within Gordon County.
</details>
| GT: | (Gorden County is home to) |
| --- | --- |
| MLP: | (Gorden County is home to) ✓ |
| Align | (Garden County is home to) ✗ |
(d) Negative Example 2
Figure 6: Case Study for Pixel-Level Tasks. We provide examples of our proposed Align connector compared with a the Multi-Layer Perceptron (MLP) connector. The Align connector tends to better map visual elements to common words. GT is the ground truth.
A.4 Case Studies
In this section, we provide case studies for the experiments in Section 5.1. Specifically, we provide examples of our Llama-3.2-3B- Align, and its counterpart model with alternative connectors Llama-3.2-3B-MLP and Llama-3.2-3B-Ovis on three different datasets: KLC [Stanisławek et al., 2021], DocVQA [Mathew et al., 2021b], and TextVQA [Singh et al., 2019]. The examples are shown in Figure 7, 8, and 9.
<details>
<summary>figures/case_1.jpg Details</summary>

### Visual Description
## Document Cover: Ardingly College Limited - Directors' Report and Financial Statements
### Overview
The image is a cover page for the "Directors' Report and Financial Statements" of Ardingly College Limited for the year ended 31st August 2017. It includes the college's logo, name, and registration details. The word "EXTERNAL" is handwritten at the top right.
### Components/Axes
* **Header:**
* **Logo:** Ardingly College logo featuring a bird and a globe.
* **College Name:** "ARDINGLY College"
* **Slogan:** "World Ready"
* **Handwritten Note:** "EXTERNAL" at the top right.
* **Main Body:**
* **Title:** "Ardingly College Limited"
* **Report Description:** "DIRECTORS' REPORT AND FINANCIAL STATEMENTS"
* **Year Ended:** "FOR THE YEAR ENDED 31ST AUGUST 2017"
* **Footer:**
* **Charity Registration Number:** "Charity Registration No. 1076456"
* **Company Registration Number:** "Company Registration No. 03779971 (England and Wales)"
* **Border:** A decorative border surrounds the entire page.
### Detailed Analysis or ### Content Details
* The document is a formal report related to the financial performance and activities of Ardingly College Limited.
* The report covers the period ending on August 31, 2017.
* The document includes registration numbers for both charity and company status.
### Key Observations
* The handwritten "EXTERNAL" suggests the document's intended audience or classification.
* The presence of both charity and company registration numbers indicates the organization's legal structure.
### Interpretation
The cover page indicates that the document contains financial and operational information about Ardingly College Limited. The "Directors' Report and Financial Statements" likely provide details on the college's performance, activities, and financial standing for the specified year. The registration numbers are important for legal and regulatory purposes. The handwritten "EXTERNAL" suggests that the document is intended for external stakeholders, such as auditors, regulators, or investors.
</details>
| Question: | What is the value for the charity name? |
| --- | --- |
| GT: | (Ardingly College Ltd.) |
| MLP: | (Ardington College Ltd.) ✗ |
| Ovis: | (Ardington College Ltd.) ✗ |
| Align: | (Ardingly College Ltd.) ✓ |
(a) Positive Example #1
<details>
<summary>figures/case_2.jpg Details</summary>

### Visual Description
## Form: Trustees' Annual Report - Section A
### Overview
This image is a form titled "Trustees' Annual Report for the period," specifically Section A, which focuses on reference and administration details of a charity. It includes fields for charity name, other known names, registered charity number, principal address, and information about the charity trustees.
### Components/Axes
* **Header:**
* "CHARITY COMMISSION" logo (top-left)
* Title: "Trustees' Annual Report for the period"
* Period start date: "From 11 02 2016"
* Period end date: "To 10 02 2017"
* **Section A Title:** "Section A Reference and administration details"
* **Charity Information:**
* "Charity name" field
* "Other names charity is known by" field
* "Registered charity number (if any)" field
* "Charity's principal address" fields for address lines and postcode
* **Trustee Information Table:**
* Columns: "Trustee name", "Office (if any)", "Dates acted if not for whole year", "Name of person (or body) entitled to appoint trustee (if any)"
* Rows numbered 1-20
* **Custodian Trustee Information:**
* "Names of the trustees for the charity, if any, (for example, any custodian trustees)"
* Columns: "Name", "Dates acted if not for whole year"
* **Footer:**
* "TAR" (bottom-left)
* Page number: "1" (bottom-center)
* Date: "March 2012" (bottom-right)
### Detailed Analysis or Content Details
* **Charity Details:**
* Charity Name: "TENDER GRACE CHRISTIAN CENTRE"
* Registered Charity Number: "1165532"
* Principal Address:
* "FLAT 13"
* "39 TRINITY RISE"
* "LONDON"
* Postcode: "SW2 2QP"
* **Trustee Information (Rows 1-4):**
* Row 1:
* Trustee Name: "Mr Anthony Yakubu Membu"
* Row 2:
* Trustee Name: "Miss Happiness Ngosi Jan-Nnyeruka"
* Row 3:
* Trustee Name: "Mrs Olabisi Comfort Ogunjobi"
* Row 4:
* Trustee Name: "Mrs Olayinka Adeola Oyesanya"
* **Trustee Information (Rows 5-20):**
* Rows 5-20 are empty.
* **Custodian Trustee Information:**
* The fields for custodian trustees are empty.
### Key Observations
* The form is designed to collect essential information about a charity and its trustees.
* Only the first four rows of the trustee information table are populated.
* The custodian trustee section is empty, suggesting either no custodian trustees or that the information was not provided.
### Interpretation
The document is a standard form used by the Charity Commission to gather information about registered charities. The provided data indicates that "TENDER GRACE CHRISTIAN CENTRE" is registered with the charity number "1165532" and has a principal address in London. Four trustees are listed, but no information is provided about their offices, dates of service, or appointing bodies. The absence of data in the custodian trustee section could indicate that the charity does not have any custodian trustees or that this information was not included in the report. The form covers the period from November 11, 2016, to October 10, 2017.
</details>
| Question: | What is the value for the address postcode? |
| --- | --- |
| GT: | (SW2 2QP) |
| MLP: | (SW22 0PQ) ✗ |
| Ovis: | (SW2 2OP) ✗ |
| Align: | (SW2 2QP) ✓ |
(b) Positive Example #2
<details>
<summary>figures/case_3.jpg Details</summary>

### Visual Description
## Cover Image: Human Appeal Annual Report 2015
### Overview
The image is the cover of the Human Appeal Annual Report and Financial Statements for 2015. It features a photograph of a smiling young girl in a school setting, with the organization's name and report title prominently displayed.
### Components/Axes
* **Title:** ANNUAL REPORT AND FINANCIAL STATEMENTS 2015
* **Organization:** human appeal (with logo)
* **Image:** A photograph of a young girl smiling, likely in a school setting. Other children are visible in the background.
* **Charity Information:** Charity No. 1154288 | Company Reg No. 8553893 | Scottish Reg No. SC046481
### Detailed Analysis or ### Content Details
* The girl in the photograph is wearing a white shirt with purple accents.
* The "human appeal" logo is located on the bottom-left corner, within a purple rectangle.
* The text "ANNUAL REPORT" is in large, white, bold font.
* The text "AND FINANCIAL STATEMENTS 2015" is in smaller, white font below the title.
* The charity and company registration information is located in the top-right corner in a small font.
### Key Observations
* The image is designed to be visually appealing and evoke positive emotions.
* The focus on a child suggests the organization's work benefits children.
* The inclusion of financial statements indicates transparency and accountability.
### Interpretation
The cover image is designed to convey a message of hope and positive impact. The smiling child represents the beneficiaries of Human Appeal's work, while the inclusion of financial statements aims to build trust with donors and stakeholders. The overall impression is one of a reputable and effective charity working to improve the lives of vulnerable people.
</details>
| Question: | What is the value for the charity name? |
| --- | --- |
| GT: | (Human Appeal) |
| MLP: | (Humanitarian Agenda) ✗ |
| Ovis: | (Human Appeal) ✓ |
| Align: | (Human Rightsappeal) ✗ |
(c) Negative Example #1
<details>
<summary>figures/case_4.jpg Details</summary>

### Visual Description
## Document: Bishop's Stortford Baptist Church Annual Report 2017
### Overview
The image is a page from the Bishop's Stortford Baptist Church Annual Report 2017. It includes the church's logo, a statement of purpose, aims, objectives, and an overview of its activities.
### Components/Axes
* **Header:**
* Church Logo (BSBC with a cross incorporated) and the text "bishops stortford baptist church"
* Title: "Bishop's Stortford Baptist Church"
* Subtitle: "This Church aims to be a community of believers living according to the Bible's teaching where people become fully devoted followers of Jesus Christ"
* Report Title: "Annual Report 2017"
* Introductory sentence: "We are pleased to present a report of the life and work of the Church during 2017."
* **Main Body:**
* Section: "Aim and Purposes" - A paragraph describing the church's vision and mission.
* Section: "Objectives and Overview" - A paragraph describing the church's commitment and activities.
* Bulleted list of activities:
* Services each week for worship, prayer, Bible study, preaching and teaching, including additional services for those in the local area whose first language is not English
* Baptisms on request
* Meetings for young people
* Small group meetings (LIFE Groups) for all ages
* Pastoral care
* Discipleship for Christian service
* Evangelism and mission
* Support of Christian and social charitable action within the local area
* Support for mission overseas
* Involvement with the local and national Baptist associations
* Concluding paragraph: "The ministry areas of the Church are classified into Worship, Fellowship, Reaching Out, Discipleship and Social Action, supplemented by a Resources Team (all led by the Deacons) and with spiritual oversight and pastoral care administered by the Elders."
* **Footer:**
* Page number: "1"
### Detailed Analysis or ### Content Details
The document outlines the church's mission, vision, and activities. The "Aim and Purposes" section focuses on creating a community of believers and fulfilling Christ's redemptive purposes. The "Objectives and Overview" section lists specific activities such as weekly services, baptisms, meetings, small groups, pastoral care, discipleship, evangelism, and support actions. The document also mentions the church's involvement with local and national Baptist associations.
### Key Observations
* The document is a formal report outlining the church's activities and goals for the year 2017.
* The church emphasizes community, discipleship, and service.
* The report is structured with clear headings and bullet points for easy readability.
### Interpretation
The document serves as a concise overview of the Bishop's Stortford Baptist Church's activities and objectives for 2017. It highlights the church's commitment to its community, its faith-based mission, and its various programs and services. The report likely aims to inform members, stakeholders, and the wider community about the church's work and impact. The inclusion of specific activities provides concrete examples of how the church is fulfilling its mission.
</details>
| Question: | What is the value for the post town address? |
| --- | --- |
| GT: | (Bishop’s Stortford) |
| MLP: | (Stortford) ✗ |
| Ovis: | (Bishop’s Stortford) ✓ |
| Align: | (Stortford) ✗ |
(d) Negative Example #2
Figure 7: Case Study for Connector Comparison on the KLC dataset [Stanisławek et al., 2021]. We show four qualitative examples (including two correct and two incorrect examples) comparing Llama-3.2-3B- Align to the same architecture with different connectors, Llama-3.2-3B-MLP and Llama-3.2-3B-Ovis. “GT” denotes the ground truth.
<details>
<summary>figures/case_5.jpg Details</summary>

### Visual Description
## Schedule: Workshop Agenda
### Overview
The image presents a workshop agenda spanning two days, Thursday, June 29, and Friday, June 30. It details the schedule of events, including session titles, group assignments, leaders, and room locations. The agenda is divided into morning and afternoon sessions.
### Components/Axes
* **Days:** Thursday, June 29; Friday, June 30
* **Time:** Various timeslots from 1:00 to 3:15 on Thursday and 8:00 to 3:15 on Friday.
* **Session Titles:** Techniques of Interviewing, Practice Interviews, Statistical Aspects of Epidemiologic Research, Problems in Research Design, Construction and Use of Questionnaires.
* **Groups:** I, II, III, IV, V, A, B
* **Leaders:** Mrs. Fink, Miss Grass, Miss Peck, Mr. Price, Dr. Croley, Dr. Gaffey, Dr. Reynolds, Dr. Mellinger
* **Rooms:** 123, 802, 627 State Health Department, 510, 522 School of Public Health
### Detailed Analysis or ### Content Details
**Thursday, June 29 (Afternoon)**
* **1:00:** Techniques of Interviewing (Mrs. Fink) in Room 123.
* **1:30:** Practice Interviews. Groups are assigned as follows:
* Group I: Leader Mrs. Fink, Room 123 State Health Department
* Group II: Leader Miss Grass, Room 802 State Health Department
* Group III: Leader Miss Peck, Room 627 State Health Department
* Group IV: Leader Mr. Price, Room 510 School of Public Health
* Group V: Leader Dr. Croley, Room 522 School of Public Health
* **2:45:** Recess
* **3:15:** Practice Interviews (continued) with the same groups and rooms.
**Friday, June 30**
* **Morning**
* **8:00:**
* Group A: Statistical Aspects of Epidemiologic Research (Dr. Gaffey) in Room 802.
* Group B: Problems in Research Design (Dr. Reynolds) in Room 123.
* **9:45:** Recess
* **10:15:**
* Group A: Problems in Research Design (Dr. Reynolds) in Room 123.
* Group B: Statistical Aspects of Epidemiologic Research (Dr. Gaffey) in Room 802.
* **12:00:** Lunch
* **Afternoon**
* **1:00:** Construction and Use of Questionnaires.
* Group A: (Dr. Fink) in Room 123.
* Group B: (Dr. Mellinger) in Room 522 School of Public Health.
* **2:45:** Recess
* **3:15:** Construction and Use of Questionnaire (continued) with the same groups and rooms.
### Key Observations
* Thursday afternoon focuses on interviewing techniques and practice.
* Friday is divided into morning and afternoon sessions with different topics.
* Groups A and B switch topics and rooms between the 8:00 and 10:15 sessions on Friday morning.
* Recess and lunch breaks are scheduled.
* The same groups and rooms are used for the continued sessions.
### Interpretation
The agenda outlines a structured workshop with a focus on research methodologies. The sessions cover interviewing techniques, research design, and questionnaire construction. The switching of topics and rooms for Groups A and B on Friday morning suggests a rotation system to expose participants to both subjects. The consistent use of the same groups and rooms for continued sessions indicates a focus on building upon previous knowledge and maintaining continuity.
```
</details>
| Question: | What does the afternoon session begin on June 29? |
| --- | --- |
| GT: | (1:00) |
| MLP: | (2:45) ✗ |
| Ovis: | (3:30) ✗ |
| Align: | (1:00) ✓ |
(a) Positive Example #1
<details>
<summary>figures/case_6.jpg Details</summary>
### Visual Description
## Data Tables: Hemoglobin, Hematocrit, and Socio-economic Data for Massachusetts
### Overview
The image presents three data tables related to health and socio-economic indicators in Massachusetts. The first table shows hemoglobin levels, the second shows hematocrit levels, and the third presents general socio-economic data. All data is part of the National Nutrition Survey.
### Components/Axes
**Table 1: Hemoglobin Data - Massachusetts**
* **Title:** Hemoglobin data - Massachusetts
* **Context:** 8% of the surveyed population had unsatisfactory hemoglobin levels (ICNND guidelines).
* **Columns:**
* Age (0-5 yr, 6-12, 13-16, 17-59, 60+)
* Males: Def., Low, Total Unsatisfactory
* Females: Def., Low, Total Unsatisfactory
**Table 2: Hematocrit Data - Massachusetts**
* **Title:** Hematocrit data - Massachusetts
* **Context:** 9.2% of the surveyed population had unsatisfactory hematocrit levels (ICNND guidelines).
* **Columns:**
* Age (0-5 yr, 6-12, 13-16, 17-59, 60+)
* Males: Def., Low, Total Unsatisfactory
* Females: Def., Low, Total Unsatisfactory
**Table 3: General Socio-economic Data - Massachusetts**
* **Title:** General Socio-economic data - Massachusetts
* **Rows:**
* Total number of persons examined
* Mean family size
* Mean income: $ per annum
* Mean poverty index ratio
* % of families below poverty index ratio of 1.00
### Detailed Analysis
**Table 1: Hemoglobin Data**
| Age | Males Def. | Males Low | Males Total Unsatisfactory | Females Def. | Females Low | Females Total Unsatisfactory |
| :------ | :--------- | :-------- | :------------------------- | :----------- | :---------- | :--------------------------- |
| 0-5 yr | 4.5 | 8.0 | 12.5 | 1.5 | 7.0 | 8.5 |
| 6-12 | 0.2 | 3.8 | 4.0 | 0.2 | 5.0 | 5.2 |
| 13-16 | 3.6 | 12.7 | 16.3 | 0.0 | 3.5 | 3.5 |
| 17-59 | 1.2 | 10.0 | 11.2 | 1.1 | 6.0 | 7.1 |
| 60+ | 0.7 | 14.3 | 15.0 | 0.5 | 4.7 | 5.2 |
**Table 2: Hematocrit Data**
| Age | Males Def. | Males Low | Males Total Unsatisfactory | Females Def. | Females Low | Females Total Unsatisfactory |
| :------ | :--------- | :-------- | :------------------------- | :----------- | :---------- | :--------------------------- |
| 0-5 yr | 4.4 | 4.0 | 8.4 | 0.5 | 1.5 | 2.0 |
| 6-12 | 0.0 | 3.9 | 3.9 | 0.0 | 5.4 | 5.4 |
| 13-16 | 1.2 | 15.0 | 16.2 | 0.0 | 2.9 | 2.9 |
| 17-59 | 0.7 | 10.0 | 10.7 | 0.5 | 7.8 | 8.3 |
| 60+ | 0.0 | 20.0 | 20.0 | 0.5 | 3.8 | 4.3 |
**Table 3: General Socio-economic Data**
| Metric | Value |
| :------------------------------------------ | :---- |
| Total number of persons examined | 4,568 |
| Mean family size | 5.31 |
| Mean income: $ per annum | 6,500 |
| Mean poverty index ratio | 2.29 |
| % of families below poverty index ratio of 1.00 | 19.5 |
### Key Observations
* **Hemoglobin:** For males, the "Total Unsatisfactory" hemoglobin levels are highest in the 13-16 and 60+ age groups. For females, the highest "Total Unsatisfactory" levels are in the 0-5 yr age group.
* **Hematocrit:** For males, the "Total Unsatisfactory" hematocrit levels are highest in the 60+ age group. For females, the highest "Total Unsatisfactory" levels are in the 17-59 age group.
* **Socio-economic:** The mean income is $6,500 per annum, and 19.5% of families are below the poverty index ratio of 1.00.
### Interpretation
The data suggests that certain age groups may be more vulnerable to unsatisfactory hemoglobin and hematocrit levels. Socio-economic factors, such as income and poverty levels, could potentially contribute to these health outcomes. The data highlights the need for targeted interventions and further investigation into the underlying causes of these health disparities. The source of the data is listed as: https://www.industrydocuments.ucsf.edu/docs/tnbf0227
</details>
| Question: | What levels does the second table indicate? |
| --- | --- |
| GT: | (hematocrit data - Massachusetts) |
| MLP: | (SATISFACTORY) ✗ |
| Ovis: | (Females) ✗ |
| Align: | (hematocrit data - Massachusetts) ✓ |
(b) Positive Example #2
<details>
<summary>figures/case_7.jpg Details</summary>

### Visual Description
## Document: Policy on Document Control
### Overview
The image is a document titled "Policy on Document Control," which outlines general provisions and definitions related to document management within a company. It includes information on the purpose of the policy, general guidelines for handling documents, and definitions of key terms like "Documents," "Disks," and "Storage."
### Components/Axes
* **Header:**
* "Policy on Document Control"
* "Policy No. 8"
* "Chapter 1 General Provisions"
* **Articles:**
* Article 1 (Purpose)
* Article 2 (General Provisions)
* Article 3 (Definitions)
* **Footer:**
* "Confidential - Subject to Protective Order"
* "Source: https://www.indup2378-00001ts.ucsf.edu/docs/jpjf0226"
* "TAKJ-TPC-00000252"
* **Exhibit Stamp (Top Right):**
* "PENGAD 800-631-6989"
* "EXHIBIT"
* "R-7"
### Detailed Analysis or Content Details
* **Article 1 (Purpose):** This section states the policy's intention to establish basic guidelines for the creation, storage, disposal, and management of documents (including electromagnetic records) to effectively handle legal and administrative proceedings.
* **Article 2 (General Provisions):** This section specifies that company documents must be handled in accordance with this policy, in addition to other policies such as "Policy on Handling Contract Documents, etc, and Corporate Seals (Policy No. 6)", "Policy on Confidential Information Management (Policy No. 18)", and "Policy on IT Security (Policy No. 67)". It also states that each core organization should set standards for document handling.
* **Article 3 (Definitions):** This section defines key terms used in the policy:
* **"Documents"**: Includes approval documents, notification documents, reports, conference materials, correspondences, fax/telex transmissions, bills, various records, drawings, microfilms, photographs, video/audio media, electronic mail, and other documents and electromagnetic records related to company business.
* **"Disks"**: Refers to electromagnetic recording media, including floppy disks, CD-Rs, and DVD-Rs.
* **"Storage"**: Means managing documents in specific methods and places for defined periods, referred to as "Stored Documents." Storage methods include:
* Originals or write-protected disks in lockable cabinets, desks, or designated warehouses.
* Electromagnetic means in access-controlled servers.
### Key Observations
* The document provides a structured approach to document control, covering purpose, general guidelines, and definitions.
* The policy references other related policies, indicating a comprehensive document management framework.
* The definitions section clarifies the scope of the policy and ensures consistent understanding of key terms.
### Interpretation
The document outlines a formal policy for managing documents within a company. It emphasizes the importance of proper handling, storage, and disposal of documents, including electronic records. The policy aims to ensure that document information is effectively managed and utilized, particularly in the context of legal and administrative proceedings. The inclusion of definitions helps to standardize the understanding of key terms and ensures consistent application of the policy across the organization. The reference to other related policies suggests a broader, integrated approach to information governance.
</details>
| Question: | What type of policy is described in this document? |
| --- | --- |
| GT: | (Policy on Document Control) |
| MLP: | (Policy on Document Control) ✓ |
| Ovis: | (General Provisions) ✗ |
| Align: | (Document Control) ✗ |
(c) Negative Example #1
<details>
<summary>figures/case_8.jpg Details</summary>

### Visual Description
## Blood Analysis Table: Dietary Glycan Effects on Cholesterol and Triglycerides in Rats
### Overview
The image presents a table of blood analysis results from a study on the effects of dietary glycan on cholesterol and triglyceride levels in rats. Three groups of rats were tested, with measurements taken for cholesterol at 0 weeks and triglycerides at 4 weeks.
### Components/Axes
* **Title:** The Ability of Dietary Glycan to Lower Elevated Blood Cholesterol and Triglycerides in Rats.
* **Date:** June 18, 1975
* **Groups:** #1, #2 (labeled as #2 a), #3 (labeled as #3 b)
* **Measurements:**
* Cholesterol mg % 0 Wk. (Cholesterol levels in milligrams per percent at 0 weeks)
* Triglyceride mg % 4 Wk. (Triglyceride levels in milligrams per percent at 4 weeks)
* **Source:** https://www.industrydocuments.ucsf.edu/docs/hnhd0227
### Detailed Analysis or ### Content Details
**Experimental Setup:**
* Ten male rats were fed the control diet (basal + cholesterol and cholic acid) for four weeks and divided into two groups.
* Group (2A) continued to receive the control diet.
* Group (2B) received a test diet of the same composition as the control diet except that 15 parts of Glycan replaced 15 parts of sucrose.
* Another group (#1) of ten male rats were fed the basal diet for four weeks and then continued on the basal diet.
* At weekly intervals, whole blood was drawn from the caudal vein for the determination of serum cholesterol.
* At the end of four weeks, whole blood was drawn by heart puncture.
**Data Table:**
| Group | #1 | #2 a | #3 b |
| ---------------------- | --- | ---- | ---- |
| Cholesterol mg % 0 Wk. | | | |
| 1 | 96 | 157 | 157 |
| 2 | 96 | 148 | 115 |
| 3 | 96 | 156 | 99 |
| 4 | 96 | 148 | 115 |
| 4 | 103 | 133 | 111 |
| Triglyceride mg % 4 Wk.| 293 | 203 | 169 |
### Key Observations
* Cholesterol levels at 0 weeks are consistently higher in groups #2 and #3 compared to group #1.
* Triglyceride levels at 4 weeks are highest in group #1 and lowest in group #3.
### Interpretation
The data suggests that dietary glycan may have an effect on both cholesterol and triglyceride levels in rats. Group #1, which continued on the basal diet, had lower initial cholesterol levels but higher triglyceride levels at 4 weeks. Groups #2 and #3, which received different diets, showed elevated cholesterol levels at the start, with group #3 showing the lowest triglyceride levels at 4 weeks. This could indicate that the dietary modifications in groups #2 and #3 influenced lipid metabolism differently. Further analysis and more detailed experimental information would be needed to draw definitive conclusions.
</details>
| Question: | What was the diet fed to the #1 group? |
| --- | --- |
| GT: | (basal diet) |
| MLP: | (basel diet) ✓ |
| Ovis: | (Whole blood) ✗ |
| Align: | (control diet) ✗ |
(d) Negative Example #2
Figure 8: Case Study for Connector Comparison on the DocVQA dataset [Mathew et al., 2021b]. We show four qualitative examples (including two correct and two incorrect examples) comparing Llama-3.2-3B- Align to the same architecture with different connectors, Llama-3.2-3B-MLP and Llama-3.2-3B-Ovis. “GT” denotes the ground truth.
<details>
<summary>figures/case_9.jpg Details</summary>

### Visual Description
## Photograph: Goodbye Letter on Suitcase
### Overview
The image shows a white envelope with red and blue stripes along its edges, placed on top of a vintage-looking suitcase. The words "good bye" are handwritten on the envelope. The suitcase is resting on a patterned surface.
### Components/Axes
* **Envelope:** White with red and blue alternating stripes along the edges. The words "good bye" are written in the center.
* **Suitcase:** Vintage style, light beige color with a handle and metal clasps.
* **Surface:** A patterned surface with black and white designs.
### Detailed Analysis
* **Envelope:** The envelope is a standard airmail style, with alternating red and blue stripes. The text "good bye" is written in a simple, handwritten font.
* **Suitcase:** The suitcase appears to be old and well-used, adding to the overall vintage aesthetic of the image.
* **Surface:** The patterned surface provides a contrasting background, making the suitcase and envelope stand out.
### Key Observations
* The handwritten "good bye" on the envelope suggests a personal message.
* The vintage suitcase implies travel or departure.
* The overall composition evokes a sense of farewell or ending.
### Interpretation
The image likely represents a farewell or a departure. The "good bye" message on the envelope, combined with the suitcase, suggests someone is leaving or has left. The vintage style of the suitcase could symbolize a journey into the past or a nostalgic feeling. The image evokes a sense of melancholy and finality.
</details>
| Question: | What greeting is written on the letter? |
| --- | --- |
| GT: | (good bye) |
| MLP: | (good) ✗ |
| Ovis: | (good buy) ✗ |
| Align: | (good bye) ✓ |
(a) Positive Example #1
<details>
<summary>figures/case_10.jpg Details</summary>

### Visual Description
## Digital Clock Display
### Overview
The image shows a digital clock displaying the time, date, indoor temperature, and outdoor temperature. The clock is a "SkyScan Atomic Clock".
### Components/Axes
* **Header:** "SkyScan ATOMIC CLOCK" with a small antenna icon.
* **Time Display:** "12:04" with the label "TIME" to the right. A small antenna icon is also displayed above the time.
* **Date Display:** "1/1" with the label "DATE" to the left.
* **Temperature Display:**
* "INDOOR" label above "68.4" °F.
* "OUTDOOR" label above "-1.4" °F.
### Detailed Analysis or ### Content Details
* **Time:** 12:04
* **Date:** 1/1 (January 1st)
* **Indoor Temperature:** 68.4 °F
* **Outdoor Temperature:** -1.4 °F
### Key Observations
* The clock is displaying both time and date.
* The clock is displaying both indoor and outdoor temperatures in Fahrenheit.
* The outdoor temperature is below freezing.
### Interpretation
The image shows a typical digital clock providing standard information such as time, date, and temperature. The negative outdoor temperature suggests it is a cold day. The indoor temperature is a comfortable room temperature. The presence of the antenna icon suggests the clock is synchronized via radio signal.
</details>
| Question: | What indoor temperature is shown? |
| --- | --- |
| GT: | (68.4) |
| MLP: | (68 F) ✗ |
| Ovis: | (40.0) ✗ |
| Align: | (68.4) ✓ |
(b) Positive Example #2
<details>
<summary>figures/case_11.jpg Details</summary>

### Visual Description
## Advertisement: Topnotch Health Club
### Overview
The image is an advertisement for "Topnotch Health Club," featuring cartoon-style illustrations of a man and a woman, along with promotional text. The overall tone is energetic and inviting.
### Components/Axes
* **Header:** "Proffesional Passionate Personal" (Note the misspelling of "Professional")
* **Main Image:** Cartoon-style illustrations of a man and a woman. The woman is pointing to the left.
* **Text:** "we're the club 4U!"
* **Footer:** "topnotch health club" and "dare to be different"
### Detailed Analysis
* **Header:** The words "Proffesional Passionate Personal" are stacked vertically, suggesting the qualities of the health club.
* **Main Image:**
* The woman is wearing a white tank top, orange arm band, and has brown hair. She is pointing to the left with her right hand.
* The man is wearing a red shirt and has black hair. He has a watch on his left wrist.
* **Text:** "we're the club 4U!" is written in a playful font, emphasizing the club's welcoming atmosphere.
* **Footer:** "topnotch health club" is the name of the health club. "dare to be different" is a slogan.
### Key Observations
* The misspelling of "Professional" in the header is a notable error.
* The use of cartoon-style illustrations gives the advertisement a friendly and approachable feel.
* The slogan "dare to be different" suggests that the health club offers a unique experience.
### Interpretation
The advertisement aims to attract potential customers by highlighting the health club's professional, passionate, and personal approach. The illustrations of the man and woman suggest that the club is suitable for both genders. The slogan "dare to be different" implies that the club offers a unique and innovative fitness experience. The misspelling in the header could be seen as a lack of attention to detail, which might negatively impact the club's image.
</details>
| Question: | What type of club is advertised? |
| --- | --- |
| GT: | (health club) |
| MLP: | (topnote health club) ✗ |
| Ovis: | (health club) ✓ |
| Align: | (professional passionate personal) ✗ |
(c) Negative Example #1
<details>
<summary>figures/case_12.jpg Details</summary>

### Visual Description
## Advertisement: Hadiah Plus Loyalty Program
### Overview
The image is an advertisement for the "Hadiah Plus" loyalty program, offering rewards for card swipes. It features images of various travel destinations and promotes converting Hadiah Points to BIG Points for free flights.
### Components/Axes
* **Title:** Hadiah Plus (in large, stylized gold font at the top)
* **Subtitle:** MORE REWARDS WITH EVERY SWIPE (in smaller gold font below the title)
* **Destinations:**
* Singapore (image of the Merlion statue)
* Penang (image of a coastal city with mountains)
* Bangkok (image of a temple)
* Bali (image of a pagoda-like structure near water)
* Hong Kong (image of the city skyline)
* **Loyalty Program Logo:** AirAsia BIG LOYALTY Programme (in a red circle on the right side)
* **Text:** "You can now convert your Hadiah Points to BIG Points to redeem for free flights."
* **Credit Cards:** Images of three different credit cards at the bottom.
* Gold card
* Silver card
* Black card with gold accents
* **Credit Card Number (Black Card):** 1234 5678 9876 5432
### Detailed Analysis or Content Details
The advertisement is visually organized with the title and subtitle at the top, followed by images representing the destinations. Below the destinations is promotional text, and at the bottom are images of the credit cards associated with the program. The AirAsia BIG Loyalty Programme logo is prominently displayed.
### Key Observations
* The advertisement emphasizes travel destinations and the ability to earn rewards through card usage.
* The visual elements are designed to be appealing and highlight the benefits of the loyalty program.
* The inclusion of credit card images suggests a partnership or integration with financial institutions.
### Interpretation
The advertisement aims to attract customers to the Hadiah Plus loyalty program by showcasing the potential for travel rewards. The use of recognizable destinations and the AirAsia brand association likely target frequent travelers. The call to action, "You can now convert your Hadiah Points to BIG Points to redeem for free flights," is a clear incentive for customers to participate in the program. The inclusion of different credit card designs suggests that the program may offer various tiers or benefits based on the card used.
</details>
| Question: | What credit card is this? |
| --- | --- |
| GT: | (hadiah plus) |
| MLP: | (hadiah plus) ✓ |
| Ovis: | (american big loyalty program) ✗ |
| Align: | (hadia plus) ✗ |
(d) Negative Example #2
Figure 9: Case Study for Connector Comparison on the TextVQA dataset [Singh et al., 2019]. We show four qualitative examples (including two correct and two incorrect examples) comparing Llama-3.2-3B- Align to the same architecture with different connectors, Llama-3.2-3B-MLP and Llama-3.2-3B-Ovis. “GT” denotes the ground truth.