# Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning
**Authors**: DiJia Su, Hanlin Zhu, Yingchen Xu, Jiantao Jiao, Yuandong Tian, Qinqing Zheng
Abstract
Large Language Models (LLMs) excel at reasoning and planning when trained on chain-of-thought (CoT) data, where the step-by-step thought process is explicitly outlined by text tokens. However, this results in lengthy inputs where many words support textual coherence rather than core reasoning information, and processing these inputs consumes substantial computation resources. In this work, we propose a hybrid representation of the reasoning process, where we partially abstract away the initial reasoning steps using latent discrete tokens generated by VQ-VAE, significantly reducing the length of reasoning traces. We explore the use of latent trace abstractions in two scenarios: 1) training the model from scratch for the Keys-Finding Maze problem, 2) fine-tuning LLMs on this hybrid data with an extended vocabulary including unseen latent tokens, for both logical and mathematical reasoning problems. To facilitate effective learning, we introduce a simple training procedure that randomly mixes latent and text tokens, which enables fast adaptation to new latent tokens. Our approach consistently outperforms the baselines methods in various benchmarks, such as Math (+4.2%, Llama-3.2-1B), GSM8K (+4.1%, Llama-3.2-3B), and Fresh-Gaokao-Math-2023 (+13.3%, Llama-3.1-8B) with an average reduction of 17% in reasoning trace’s length.
Machine Learning, ICML
1 Introduction
Reasoning capabilities are increasingly recognized as a critical component of Artificial General Intelligence (AGI) systems. Recent research has demonstrated that Large Language Models (LLMs) can exhibit sophisticated reasoning and planning abilities using chain-of-thought (CoT) methodologies, including prompting LLMs with examples where complex problems are broken down into explicit reasoning steps (Wei et al., 2022b; Chen et al., 2022a; Yao et al., 2024). More recently, a number of studies have further shown that when models are trained to articulate the intermediate steps of a reasoning process (Nye et al., 2021b; Lehnert et al., 2024), they achieve significantly higher accuracy. The effectiveness of this approach has been demonstrated across multiple domains, including mathematical problem-solving (Yue et al., 2023; Gandhi et al., 2024; Yu et al., 2023; Su et al., 2025; Tong et al., 2024), logical inference (Lin et al., 2024; Dziri et al., 2024), multistep planning tasks (Lehnert et al., 2024; Su et al., 2024), etc.
However, training with explicit reasoning traces in text space comes with notable computational costs (Deng et al., 2023, 2024), as the models must process lengthy input sequences. In fact, much of the text serves primarily to maintain linguistic coherence, rather than conveying core reasoning information. Several works have attempted to mitigate this issue. For example, Hao et al. (2024) investigate reasoning in continuous latent space as a means of compressing the reasoning trace, and Deng et al. (2024) explore internalizing the intermediate steps through iterative CoT eliminations, see Section 2 for more examples. Nonetheless, these approaches rely on multi-stage training procedures that resemble curriculum learning, which still incur significant computational costs, and their final performances fall behind models trained with complete reasoning traces.
To tackle this challenge, we propose to use discrete latent tokens to abstract the initial steps of the reasoning traces. These latent tokens, obtained through a vector-quantized variational autoencoder (VQ-VAE), provide a compressed representation of the reasoning process by condensing surface-level details. More precisely, we replace the text tokens with their corresponding latent abstractions from left to right until a pre-set location, leaving the remaining tokens unchanged. We then fine-tune LLMs with reasoning traces with such assorted tokens, allowing the models to learn from both abstract representations of the thinking process and detailed textual descriptions. One technical challenge posed for the fine-tuning is that the vocabulary is now extended and contains unseen latent tokens. To facilitate quick adaptation to those new tokens, we employ a randomized replacement strategy: during training, we randomly vary the number of text tokens being substituted by latent tokens for each sample. Our experiments confirm that this simple strategy leads to straightforward accommodation of unseen latent tokens.
We conduct a comprehensive evaluation of our approach on a diverse range of benchmarks spanning multiple domains. Specifically, we assess its performance on multistep planning tasks (Keys-Finding Maze) and logical reasoning benchmarks (ProntoQA (Saparov & He, 2022), ProsQA (Hao et al., 2024)) for training T5 or GPT-2 models from scratch. In addition, we fine-tune different sizes of LLama-3.1 and LLama-3.2 models using our approach and evaluate them on a number of mathematical reasoning benchmarks, including GSM8K (Cobbe et al., 2021a), Math (Hendrycks et al., 2021), and OlympiadBench-Math (He et al., 2024), see Section 4.2 for more details. Across all these tasks and model architectures, our models consistently outperform baseline models trained with text-only reasoning traces, demonstrating the effectiveness of compressing the reasoning process with assorted tokens.
2 Related Work
Explicit Chain-of-Thought Prompting.
The first line of work in Chain-of-Thought (CoT) use the traditional chain of prompt in text tokens (Wei et al., 2022a; Nye et al., 2021a). Research works demonstrated that by adding few-shot examples to the input prompt or even zero-shot, the model can perform better in question answering (Chen et al., 2022b; Kojima et al., 2022; Chung et al., 2024). To further improve the model reasoning performance, there has been research effort into prompting with self-consistency (Wang et al., 2022). Here the model is prompted to generate multiple responses and select the best one based on majority voting. On the other hand, research has shown that top- $k$ alternative tokens in the beginning of the prompt can also improve the model’s reasoning capability (Wang & Zhou, 2024). On top of these empirical results, there has been research on theoretical understanding of why CoT improves the model’s performance through the lens of expressivity (Feng et al., 2024; Li et al., 2024) or training dynamics (Zhu et al., 2024). In a nutshell, CoT improves the model’s effective depth because the generated output is being fed back to the original input. CoT is also important for LLMs to perform multi-hop reasoning according to the analysis of training dynamics (Zhu et al., 2024).
Learning with CoT Data.
In addition to the success of CoT prompting, an emerging line of works have explored training LLMs on data with high-quality reasoning traces, for example, the works of Nye et al. (2021b); Azerbayev et al. (2023); Lehnert et al. (2024); Su et al. (2024); Yu et al. (2024); Yang et al. (2024); Deng et al. (2023, 2024). There is also a surge of interest in synthesizing datasets with diverse intermediate steps for solving problems in various domains, see, e.g., the works of Kim et al. (2023); Tong et al. (2024); Yu et al. (2023); Yue et al. (2023); Lozhkov et al. (2024). Wen et al. (2024) also theoretically studies how training with reasoning trace can improve the sample complexity of certain tasks.
LLM Reasoning in Latent Space.
There has been research investigating LLM reasoning in the latent space. Hao et al. (2024) have proposed to use the last hidden state of a language model as the next input embeddings, allowing the model to continue reasoning within a continuous latent space. The authors show that this approach effectively captures multiple reasoning paths simultaneously, mimicking a breadth-first-search strategy. Goyal et al. (2023) proposes to insert learnable pause tokens into the original text, in order to delay the generation. As a result, the model can leverage additional computation before providing the final answer. Parallel to this, Pfau et al. (2024) have explored filler tokens, which are used to solve computational tasks that are otherwise unattainable without intermediate token generation. In addition, Liu et al. (2024) propose a latent coprocessor method that operates on the transformer’s key-value cache to improve the LLM performance. Nevertheless, none of these methods have shown good performance when integrated into modern-sized LLMs and tested on real-world LLM datasets instead of synthetic ones. Also, Wang et al. (2023) proposed to use the planning token at the start of generation. Orthogonal to these works, Pagnoni et al. (2024) proposes a tokenization-free architecture that encodes input bytes into continuous patch representations, which is then used to train a latent Transformer, and Barrault et al. (2024) perform autoregressive sentence prediction in an embedding space. While these two works both leverage continuous latent spaces, our work focuses on the direct use of discrete latent tokens.
3 Methodology
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Chain of Thought with Latent Tokens
### Overview
The image illustrates a Chain of Thought (CoT) process, comparing a standard CoT approach with a modified approach incorporating latent tokens. The diagram highlights how latent tokens are introduced within the CoT sequence.
### Components/Axes
* **X**: Represents the standard Chain of Thought process.
* **Prompt**: Green box labeled "Prompt".
* **CoT 1, CoT 2..., CoT 32, CoT 33, ..., CoT N**: Blue boxes representing Chain of Thought textual tokens.
* **Solution**: Red box labeled "Solution".
* **X̃**: Represents the modified Chain of Thought process with latent tokens.
* **Prompt**: Green box labeled "Prompt".
* **[boLatent]**: Orange box representing the beginning of latent tokens.
* **z1, z2**: Purple boxes representing discrete latent tokens.
* **[eoLatent]**: Orange box representing the end of latent tokens.
* **CoT 33, ..., CoT N**: Blue boxes representing Chain of Thought textual tokens.
* **Solution**: Red box labeled "Solution".
* **Legend**: Located at the bottom of the image.
* **[boLatent], [eoLatent]**: Orange box. "Special delimiters that encode the start / end of the latent tokens".
* **z**: Purple box. "Discrete latent tokens".
* **CoT N**: Blue box. "The n-th CoT textual tokens".
### Detailed Analysis or ### Content Details
* **Standard CoT (X)**: Starts with a "Prompt" followed by a sequence of "CoT" tokens (CoT 1, CoT 2, etc.) leading to a "Solution".
* **Modified CoT (X̃)**: Starts with a "Prompt", then introduces "[boLatent]" (begin latent), followed by latent tokens "z1" and "z2", then "[eoLatent]" (end latent), and continues with "CoT" tokens (CoT 33, CoT N) leading to a "Solution".
* A dashed box and arrow visually connect the standard CoT sequence (CoT 1 to CoT 32) to the latent token sequence in the modified CoT.
### Key Observations
* The diagram illustrates the insertion of latent tokens within the Chain of Thought process.
* The "[boLatent]" and "[eoLatent]" tokens act as delimiters, marking the beginning and end of the latent token sequence.
* The latent tokens are represented as "z1" and "z2", indicating discrete latent variables.
### Interpretation
The diagram demonstrates a method for incorporating latent variables into a Chain of Thought reasoning process. By introducing latent tokens, the model can potentially capture more nuanced or abstract aspects of the problem-solving process. The use of delimiters allows for clear separation and identification of the latent token sequence within the overall CoT. This approach could enable the model to explore different reasoning paths or internal representations before continuing with the explicit Chain of Thought.
</details>
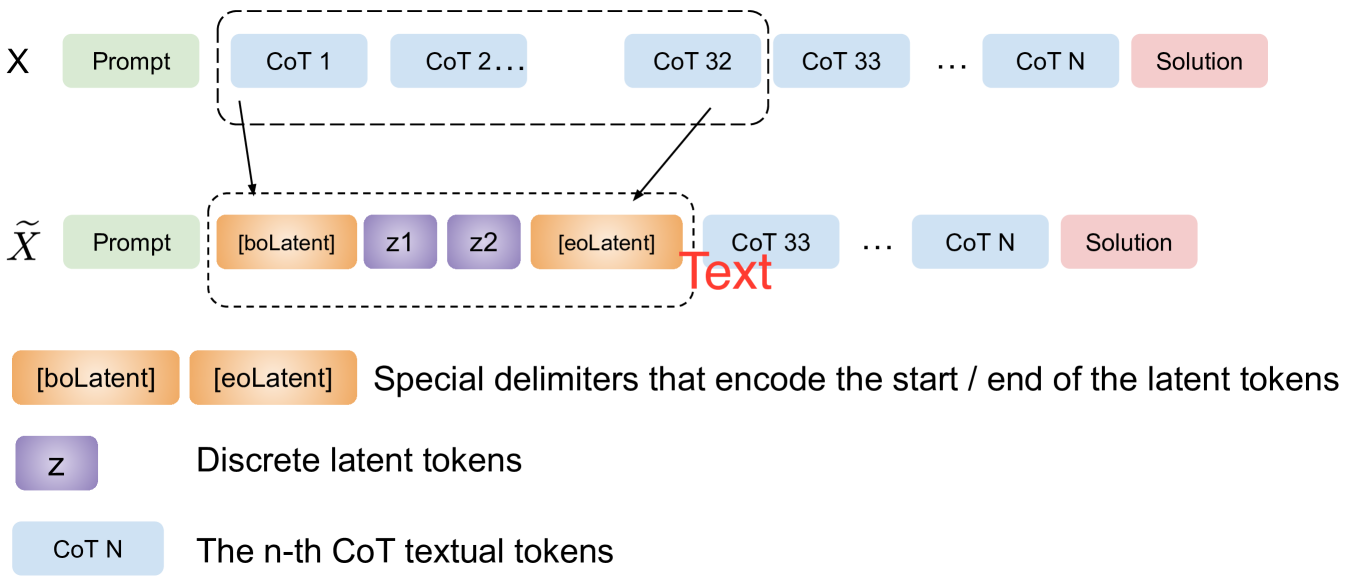
Figure 3.1: An example illustrating our replacement strategy. With chunk size $L=16$ and compression rate $r=16$ , we encode 32 textual CoT tokens into 2 discrete latent tokens from left to right. The other CoT tokens will remain in their original forms.
In this section, we describe our methodology to enable LLMs to reason with discrete latent tokens. The notations are summarized in Appendix B. Let $X=P\oplus C\oplus S$ denote a sample input, where $P=(p_{1},p_{2},...,p_{t_{p}})$ are the prompt tokens, $C=(c_{1},c_{2},...,c_{t_{c}})$ are the reasoning step (chain-of-thought) tokens, $S=(s_{1},s_{2},...,s_{t_{s}})$ are the solution tokens, and $\oplus$ denotes concatenation. Our training procedure consists of two stages:
1. Learning latent discrete tokens to abstract the reasoning steps, where we train a model to convert $C$ into a sequence of latent tokens $Z=(z_{1},z_{2},...,z_{t_{z}})$ such that $t_{z}<t_{c}$ . The compression rate $r=t_{c}/t_{z}$ controls the level of abstraction.
1. Training the LLM with a partial and high-level abstract of the reasoning steps, where we construct a modified input ${\widetilde{X}}$ by replacing the first $m$ tokens of $C$ by the corresponding latent abstractions:
$$
{\widetilde{X}}=P\oplus[z_{1},\ldots,z_{\frac{m}{r}},c_{m+1},\ldots,c_{t_{c}}]\oplus S. \tag{1}
$$
Figure 3.1 illustrates this replacement strategy. We randomize the value of $m$ during training.
3.1 Learning Latent Abstractions
We employ a vector-quantized variable autoencoder (VQ-VAE) (Van Den Oord et al., 2017) type of architecture to map CoT tokens $C$ into discrete latent tokens $Z$ . To enhance abstraction performance, our VQ-VAE is trained on the whole input sequence $X$ , but only applied to $C$ in the next stage. Following Jiang et al. (2022, 2023), we split $X$ into chunks of length $L$ and encode each chunk into $\frac{L}{r}$ latent codes, where $r$ is a preset compression rate. More precisely, our architecture consists of the following five components:
- ${\mathcal{E}}:$ a codebook containing $|{\mathcal{E}}|$ vectors in ${\mathbb{R}}^{d}$ .
- ${f_{\text{enc}}}:{\mathcal{V}}^{L}\mapsto{\mathbb{R}}^{d×\frac{L}{r}}$ that encodes a sequence of $L$ text tokens to $\frac{L}{r}$ latent embedding vectors $\bar{X}=\bar{x}_{1},...,\bar{x}_{\frac{L}{r}}$ , where ${\mathcal{V}}$ is the vocabulary of text tokens.
- $q:{\mathbb{R}}^{d}\mapsto{\mathcal{E}}$ : the quantization operator that replaces the encoded embedding $\bar{x}$ by the nearest neighbor in ${\mathcal{E}}$ : $q(\bar{x})=\operatorname*{argmin}_{e_{i}∈{\mathcal{E}}}\left\|e_{i}-\bar{x}\right\|^{2}_{2}$ .
- $g:{\mathcal{V}}^{K}\mapsto{\mathbb{R}}^{d}$ that maps $K$ text tokens to a $d$ -dimensional embedding vector. We use $g$ to generate a continuous embedding of the prompt $P$ .
- ${f_{\text{dec}}}:{\mathbb{R}}^{d×\frac{L}{r}}×{\mathbb{R}}^{k}\mapsto{\mathcal{V}}^{L}$ that decodes latent embeddings back to text tokens, conditioned on prompt embedding.
In particular, each continuous vector $e∈{\mathcal{E}}$ in the codebook has an associated latent token $z$ , which we use to construct the latent reasoning steps $Z$ To decode a latent token $z$ , we look up the corresponding embedding $e∈{\mathcal{E}}$ and feed it to ${f_{\text{dec}}}$ ..
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Chain-of-Thought Reconstruction
### Overview
The image is a diagram illustrating a process for reconstructing data, likely related to chain-of-thought reasoning. It involves encoding an input, interacting with a codebook, and then decoding to reconstruct the original input.
### Components/Axes
* **X**: Represents the input data, segmented into "Prompt" (green), "CoT" (Chain of Thought, blue), and "Solution" (red) sections.
* **f_enc**: Represents an encoding function, depicted as a yellow trapezoid.
* **f_dec**: Represents a decoding function, depicted as a yellow trapezoid.
* **g**: Represents an external input or condition, depicted as a purple rectangle.
* **Codebook**: A collection of encoded representations, labeled as e1, e2, ..., en. The codebook entries are varying shades of blue.
* **q**: Represents the query or selection process from the codebook.
* **Reconstructed X**: The output of the process, aiming to replicate the original input X. It is segmented into green, blue, and red sections, corresponding to the "Prompt", "CoT", and "Solution" respectively.
### Detailed Analysis
1. **Input X**: The input X is a sequence divided into three parts:
* "Prompt": Represented by 4 green blocks.
* "CoT": Represented by 4 blue blocks.
* "Solution": Represented by 3 red blocks.
2. **Encoding (f_enc)**: The input X is passed through the encoding function f_enc, which transforms it into a different representation. The output of f_enc is a sequence of 7 yellow blocks.
3. **External Input (g)**: An external input 'g' (purple) is introduced.
4. **Codebook Interaction (q)**: The encoded representation interacts with a "Codebook" via a query process 'q'. The codebook contains 'n' entries (e1, e2, ..., en), each represented by a blue block of varying shades.
5. **Decoding (f_dec)**: The output from the codebook interaction, represented by 7 blue blocks of varying shades, is passed through the decoding function f_dec.
6. **Reconstructed X**: The output of the decoding function is the "Reconstructed X", which aims to replicate the original input X. It consists of:
* 4 green blocks (corresponding to the "Prompt").
* 4 blue blocks (corresponding to the "CoT").
* 3 red blocks (corresponding to the "Solution").
### Key Observations
* The diagram illustrates a process where an input X is encoded, interacts with a codebook, and then decoded to produce a reconstructed version of X.
* The "Prompt", "CoT", and "Solution" segments are maintained throughout the process, suggesting that the reconstruction aims to preserve these components.
* The external input 'g' influences the process, likely affecting the codebook interaction and the final reconstructed output.
### Interpretation
The diagram represents a system for reconstructing chain-of-thought reasoning. The input X, which includes a prompt, the chain of thought, and the solution, is encoded. The encoded representation is then used to query a codebook, potentially retrieving relevant information or patterns. The decoding function then reconstructs the original input, potentially improving or refining the chain of thought and solution based on the codebook interaction and external input 'g'. This suggests a mechanism for learning and improving reasoning processes by leveraging a codebook of pre-existing knowledge or patterns. The system could be used to enhance the quality of generated solutions or to correct errors in the chain of thought.
</details>
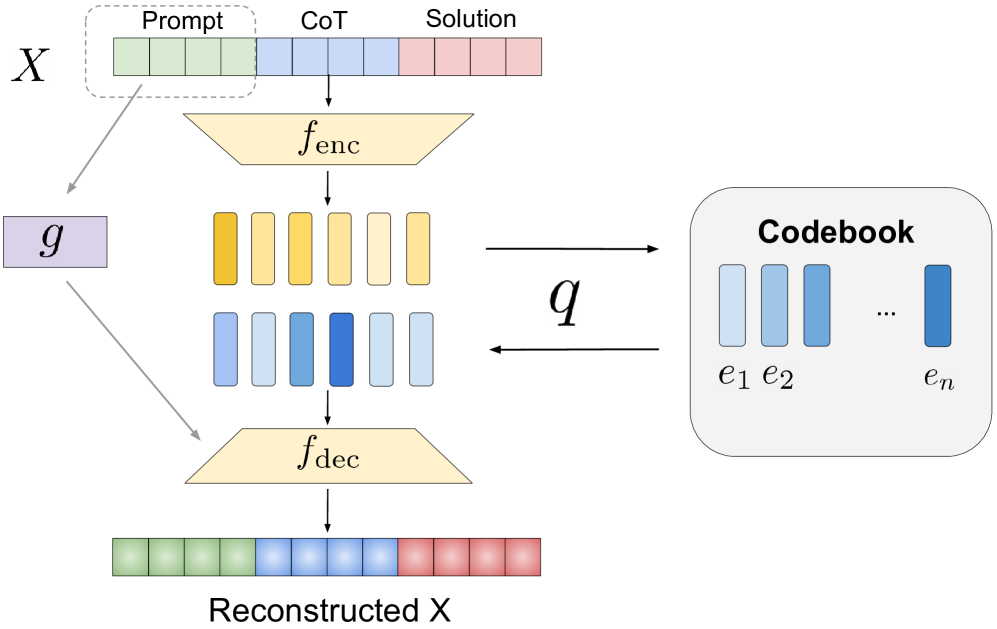
Figure 3.2: A graphical illustration of our VQ-VAE. ${f_{\text{enc}}}$ encodes the text tokens into latent embeddings, which are quantized by checking the nearest neighbors in the codebook. ${f_{\text{dec}}}$ decodes those quantized embeddings back to text tokens. When applying the VQ-VAE to compress the text tokens, the discrete latent tokens $Z$ are essentially the index of corresponding embeddings in the codebook.
For simplicity, we assume the lengths of the input $X$ and the prompt $P$ are $L$ and $K$ exactly. Similar to Van Den Oord et al. (2017), we use an objective $\mathcal{L}$ composed of 3 terms:
$$
\displaystyle\mathcal{L}(X)=\underbrace{\log p(X|{f_{\text{dec}}}(q(\bar{X})|g(P)))}_{\text{reconstruction loss}}+ \displaystyle\enspace\sum_{i=1}^{L}\underbrace{\|{\texttt{sg}}[\bar{X}_{i}]-q(\bar{X}_{i})\|_{2}^{2}}_{\text{VQ loss}}+\underbrace{\beta\|\bar{X}_{i}-{\texttt{sg}}[q(\bar{X}_{i})]\|_{2}^{2}}_{\text{commitment loss}}, \tag{2}
$$
where $\bar{X}={f_{\text{enc}}}(X)$ , ${\texttt{sg}}[·]$ is the stop-gradient operator, and $\beta$ is a hyperparameter controlling the strength of the commitment loss. The VQ loss and the commitment loss ensure that the encoder outputs remain close to the codebook, while the reconstruction loss concerns with the decoding efficacy. As standard for VQ-VAE, we pass the gradient $∇_{{f_{\text{dec}}}}(L)$ unaltered to ${f_{\text{enc}}}$ directly as the quantization operator $q(·)$ is non-differentiable. Figure 3.2 illustrates our architecture. In practice, we use a causal Transformer for both ${f_{\text{enc}}}$ and ${f_{\text{dec}}}$ , the model details are discussed in Appendix A.
Thus far we obtain a latent representation both semantically meaningful and conducive to reconstruction, setting the stage for the subsequent training phase where the LLM is trained to perform reasoning with abstractions.
3.2 Reasoning with Discrete Latent Tokens
In this second stage, we apply the obtained VQ-VAE to form modifed samples ${\widetilde{X}}$ with latent abstractions as in Equation 1, then train an LLM to perform next token prediction. Below, we outline the major design choices that are key to our model’s performance, and ablate them in Section 4.3.
Partial Replacement. Unlike previous planning works (Jiang et al., 2022, 2023) that project the whole input sequence onto a compact latent space, we only replace $m<t_{c}$ CoT tokens with their latent abstractions, leaving the remaining tokens unchanged. We delimit the latent tokens by injecting a special <boLatent> and <eoLatent> tokens to encapsulate them.
Left-to-Right (AR) Replacement. We replace the leftmost $m$ tokens of $C$ , rather than subsampling tokens at different locations.
Mixing Samples with Varying Values of $m$ . For fine-tuning an existing LLM on the reasoning dataset with latent tokens, one remarkable challenge is to deal with the extended vocabulary. As the LLM is pretrained with trillions of tokens, it is very hard for it to quickly adapt to tokens (and corresponding embeddings) beyond the original vocabulary. Previous works that aim to replace or eliminate CoT tokens (Deng et al., 2024; Hao et al., 2024) employ a multistage curriculum training approach, where those operations are gradually applied to the entire input sequence. In the context of our approach, this means we increase the values of $m$ in each stage until it reaches a pre-set cap value. However, such training procedure is complex and computationally inefficient, where dedicated optimization tuning is needed. In this work, we employ a simple single stage training approach where the value of $m$ is randomly set for each sample. Surprisingly, this not only makes our training more efficient, but also leads to enhanced performance.
Note that we use a VQVAE with a size of 50M, adding minimal parameter overhead. In addition, it is used only once during data preparation (to convert training data into discrete latent code), not during LLM training or inference. During inference, the LLM directly generates latent tokens without any use of VQVAE.
4 Experiments
We empirically evaluate our approach on two categories of benchmarks:
1. Synthetic datasets including the Keys-Finding Maze, ProntoQA (Saparov & He, 2022), and ProsQA (Hao et al., 2024), where we pretrain T5 or GPT-2 models from scratch using the method in Section 3;
1. Real-world mathematic reasoning problems, where we fine-tune Llama models (Dubey et al., 2024) on the MetaMathQA (Yu et al., 2023) or the Dart-MATH (Tong et al., 2024) dataset, and then test on in-domain datasets Math and GSM-8K, along with out-of-domain datasets including Fresh-Gaokao-Math-2023, DeepMind-Math, College-Math, OlympiaBench-Math, and TheoremQA.
The detailed setup is introduced in Section 4.1.
We compare our approach to the following baselines:
1. Sol-Only: the model is trained with samples that only contains questions and solutions, without any reasoning steps;
1. CoT: the model is trained with samples with complete CoT tokens;
1. iCoT (Deng et al., 2024): a method that utilizes curriculum learning to gradually eliminate the need of CoT tokens in reasoning;
1. Pause Token (Goyal et al., 2023): a method that injects a learnable pause token into the sample during training, in order to offer extra computation before giving out the final answer.
4.1 Benchmarks
4.1.1 Synthetic Benchmarks
Keys-Finding Maze is a complex navigation environment designed to evaluate an agent’s planning capabilities. The agent is randomly positioned within a maze comprising 4 $3× 3$ interconnected rooms, with the objective of reaching a randomly placed goal destination. To successfully reach the destination, the agent must collect keys (designated with green, red, and blue colors) that correspond to matching colored doors. These keys are randomly distributed among the rooms, requiring the agent to develop sophisticated planning strategies for key acquisition and door traversal. The agent is only allowed to take one key at a time. This environment poses a substantial cognitive challenge, as the agent must identify which keys are necessary for reaching the destination, and optimize the order of key collection and door unlocking to establish the most efficient path to the goal. Following Lehnert et al. (2024); Su et al. (2024), we generate intermediate search traces using the nondeterministic A* algorithm (Hart et al., 1968). The dataset contains 100k training samples. See Section A.2 for more information and graphical illustrations.
ProntoQA (Saparov & He, 2022) is a dataset consists of $9000$ logical reasoning problems derived from ontologies - formal representations of relationships between concepts. Each problem in the dataset is constructed to have exactly one correct proof or reasoning path. One distinctive feature of this dataset is its consistent grammatical and logical structure, which enables researchers to systematically analyze and evaluate how LLMs approach reasoning tasks.
ProsQA (Hao et al., 2024) is a more difficult benchmark building on top of ProntoQA. It contains 17,886 logical problems curated by randomly generated directed acyclic graphs. It has larger size of distracting reasoning paths in the ontology, and thus require more complex reasoning and planning capabilities.
4.1.2 Mathematical Reasoning
We fine-tune pretrained LLMs using the MetaMathQA (Yu et al., 2023) or the Dart-MATH (Tong et al., 2024) dataset. MetaMathQA is a curated dataset that augments the existing Math (Hendrycks et al., ) and GSM8K (Cobbe et al., 2021b) datasets by various ways of question bootstrapping, such as (i) rephrasing the question and generating the reasoning path; (ii) generating backward questions, self-verification questions, FOBAR questions (Jiang et al., 2024), etc. This dataset contains 395k samples in total, where 155k samples are bootstrapped from Math and the remaining 240k come from GSM8K. We rerun the MetaMath data pipeline by using Llama-3.1-405B-Inst to generate the response. Dart-MATH (Tong et al., 2024) also synthesizes responses for questions in Math and GSM8K, with the focus on difficult questions via difficulty-aware rejection tuning. For evaluation, we test the models on the original Math and GSM8K datasets, which are in-domain, and also the following out-of-domain benchmarks:
- College-Math (Tang et al., 2024) consists of 2818 college-level math problems taken from 9 textbooks. These problems cover over 7 different areas such as linear algebra, differential equations, and so on. They are designed to evaluate how well the language model can handle complicated mathematical reasoning problems in different field of study.
- DeepMind-Math (Saxton et al., 2019) consists of 1000 problems based on the national school math curriculum for students up to 16 years old. It examines the basic mathematics and reasoning skills across different topics.
- OlympiaBench-Math (He et al., 2024) is a text-only English subset of Olympiad-Bench focusing on advanced level mathematical reasoning. It contains 675 highly difficult math problems from competitions.
- TheoremQA (Chen et al., 2023) contains 800 problems focuses on solving problems in STEM fields (such as math, physics, and engineering) using mathematical theorems.
- Fresh-Gaokao-Math-2023 (Tang et al., 2024) contains 30 math questions coming from Gaokao, or the National College Entrance Examination, which is a national standardized test that plays a crucial role in the college admissions process.
4.2 Main Results
We employ a consistent strategy for training VQ-VAE and replacing CoT tokens with latent discrete codes across all our experiments, as outlined below. The specific model architecture and key hyperparameters used for LLM training are presented alongside the results for each category of benchmarks. All the other details are deferred to Appendix A.
VQ-VAE Training
For each benchmark, we train a VQ-VAE for 100k steps using the Adam optimizer, with learning rate $10^{-5}$ and batch size 32. We use a codebook of size $1024$ and compress every chunk of $L=16$ tokens into a single latent token (i.e., the compression rate $r=16$ ).
Randomized Latent Code Replacement
We introduce a stochastic procedure for partially replacing CoT tokens with latent codes. Specifically, we define a set of predetermined numbers $\mathcal{M}=\{0,72,128,160,192,224,256\}$ , which are all multipliers of $L=16$ . For each training example, we first sample $m_{\max}∈\mathcal{M}$ then sample an integer $m∈[0,16,32,...,m_{\max}]$ uniformly at random. The first $m$ CoT tokens are replaced by their corresponding latent discrete codes, while the later ones remain as raw text. This stochastic replacement mechanism exposes the model to a wide range of latent-text mixtures, enabling it to effectively learn from varying degrees of latent abstraction.
| Sol-Only CoT Latent (ours) | 3 43 62.8 ( $\uparrow$ +19.8) | 645 1312.0 374.6 | 93.8 98.8 100 ( $\uparrow$ +1.2) | 3.0 92.5 7.7 | 76.7 77.5 96.2 ( $\uparrow$ +18.7) | 8.2 49.4 10.9 |
| --- | --- | --- | --- | --- | --- | --- |
Table 4.1: Our latent approach surpasses the other baselines on Keys-Finding Maze, ProntoQA and ProsQA with a large margin . We use top- $k$ ( $k=10$ ) decoding for Keys-Finding Maze and greedy decoding for ProntoQA and ProsQA. In terms of token efficiency, our latent approach also generates much shorter reasoning traces than the CoT baseline, closely tracking or even outperforming the Sol-Only approach. Bold: best results. Underline: second best results. ( $\uparrow$ +Performance gain compared with the second best result.)
Model In-Domain Out-of-Domain Average Math GSM8K Gaokao-Math-2023 DM-Math College-Math Olympia-Math TheoremQA All Datasets Llama-3.2-1B Sol-Only 4.7 6.8 0.0 10.4 5.3 1.3 3.9 4.6 CoT 10.5 42.7 10.0 3.4 17.1 1.5 9.8 14.1 iCoT 8.2 10.5 3.3 11.3 7.6 2.1 10.7 7.7 Pause Token 5.1 5.3 2.0 1.4 0.5 0.0 0.6 2.1 Latent (ours) 14.7 ( $\uparrow$ +4.2) 48.7 ( $\uparrow$ +6) 10.0 14.6 ( $\uparrow$ +3.3) 20.5 ( $\uparrow$ +3.4) 1.8 11.3 ( $\uparrow$ +0.6) 17.8 ( $\uparrow$ +3.7) Llama-3.2-3B Sol-Only 6.1 8.1 3.3 14.0 7.0 1.8 6.8 6.7 CoT 21.9 69.7 16.7 27.3 30.9 2.2 11.6 25.2 iCoT 12.6 17.3 3.3 16.0 14.2 4.9 13.9 11.7 Pause Token 25.2 53.7 4.1 7.4 11.8 0.7 1.0 14.8 Latent (ours) 26.1 ( $\uparrow$ +4.2) 73.8 ( $\uparrow$ +4.1) 23.3 ( $\uparrow$ +6.6) 27.1 32.9 ( $\uparrow$ +2) 4.2 13.5 28.1 ( $\uparrow$ +2.9) Llama-3.1-8B Sol-Only 11.5 11.8 3.3 17.4 13.0 3.8 6.7 9.6 CoT 32.9 80.1 16.7 39.3 41.9 7.3 15.8 33.4 iCoT 17.8 29.6 16.7 20.3 21.3 7.6 14.8 18.3 Pause Token 39.6 79.5 6.1 25.4 25.1 1.3 4.0 25.9 Latent (ours) 37.2 84.1 ( $\uparrow$ +4.0) 30.0 ( $\uparrow$ +13.3) 41.3 ( $\uparrow$ +2) 44.0 ( $\uparrow$ +2.1) 10.2 ( $\uparrow$ +2.6) 18.4 ( $\uparrow$ +2.6) 37.9 ( $\uparrow$ +4.5)
Table 4.2: Our latent approach outperforms the baselines on various types of mathematical reasoning benchmarks. The models are fine-tuned on the MetaMathQA (Yu et al., 2023) dataset. The Math and GSM8K are in-domain datasets since they are used to generate MetaMathQA, while the others are out-of-domain. Bold: best results. Underscore: second best results. $\uparrow$ +: Performance gain compared with the second best result.
Model In-Domain (# of tokens) Out-of-Domain (# of tokens) Average Math GSM8K Gaokao-Math-2023 DM-Math College-Math Olympia-Math TheoremQA All Datasets Llama-3.2-1B Sol-Only 4.7 6.8 0.0 10.4 5.3 1.3 3.9 4.6 CoT 646.1 190.3 842.3 578.7 505.6 1087.0 736.5 655.2 iCoT 328.4 39.8 354.0 170.8 278.7 839.4 575.4 369.5 Pause Token 638.8 176.4 416.1 579.9 193.8 471.9 988.1 495 Latent (ours) 501.6 ( $\downarrow$ -22%) 181.3 ( $\downarrow$ -5%) 760.5 ( $\downarrow$ -11%) 380.1 ( $\downarrow$ -34%) 387.3 ( $\downarrow$ -23%) 840.0 ( $\downarrow$ -22%) 575.5 ( $\downarrow$ -22%) 518 ( $\downarrow$ -21%) Llama-3.2-3B Sol-Only 6.1 8.1 3.3 14.0 7.0 1.8 6.8 6.7 CoT 649.9 212.1 823.3 392.8 495.9 1166.7 759.6 642.9 iCoT 344.4 60.7 564.0 154.3 224.9 697.6 363.6 344.2 Pause Token 307.9 162.3 108.9 251.5 500.96 959.5 212.8 354.7 Latent (ours) 516.7 ( $\downarrow$ -20%) 198.8 ( $\downarrow$ -6%) 618.5 ( $\downarrow$ -25%) 340.0 ( $\downarrow$ -13%) 418.0 ( $\downarrow$ -16%) 832.8 ( $\downarrow$ -29%) 670.2 ( $\downarrow$ -12%) 513.6 ( $\downarrow$ -20%) Llama-3.1-8B Sol-Only 11.5 11.8 3.3 17.4 13.0 3.8 6.7 9.6 CoT 624.3 209.5 555.9 321.8 474.3 1103.3 760.1 578.5 iCoT 403.5 67.3 444.8 137.0 257.1 797.1 430.9 362.5 Pause Token 469.4 119.0 752.6 413.4 357.3 648.2 600.1 480 Latent (ours) 571.9 ( $\downarrow$ -9 %) 193.9 ( $\downarrow$ -8 %) 545.8 ( $\downarrow$ -2 %) 292.1 ( $\downarrow$ -10%) 440.3 ( $\downarrow$ -8%) 913.7 ( $\downarrow$ -17 %) 637.2 ( $\downarrow$ -16 %) 513.7 ( $\downarrow$ -10%)
Table 4.3: The average number of tokens in the generated responses. Compared with the CoT baseline, our latent approach achieves an $17\%$ reduction in response length on average, while surpassing it in final performance according to Table 4.2. The iCoT method generates shorter responses than our approach, yet performs significantly worse, see Table 4.2. $\downarrow$ -: Trace length reduction rate compared with CoT.
4.2.1 Synthetic Benchmarks
Hyperparameters and Evaluation Metric
For our experiments on the ProntoQA and ProsQA datasets, we fine-tune the pretrained GPT-2 model (Radford et al., 2019) for $16$ k steps, where we use a learning rate of $10^{-4}$ with linear warmup for 100 steps, and the batch size is set to 128. To evaluate the models, we use greedy decoding and check the exact match with the ground truth.
For Keys-Finding Maze, due to its specific vocabulary, we trained a T5 model (Raffel et al., 2020) from scratch for 100k steps with a learning rate of $7.5× 10^{-4}$ and a batch size of 1024. We evaluate the models by the 1-Feasible-10 metric. Namely, for each evaluation task, we randomly sample 10 responses with top- $k$ ( $k$ =10) decoding and check if any of them is feasible and reaches the goal location.
Results
As shown in Table 4.1, our latent approach performs better than the baselines for both the Keys-Finding Maze and ProntoQA tasks. Notably, the absolute improvement is 15% for the Keys-Finding Maze problem, and we reach 100% accuracy on the relatively easy ProntoQA dataset. For the more difficult ProsQA, the CoT baseline only obtains 77.5% accuracy, the latent approach achieves $17.5\%$ performance gain.
Model In-Domain Out-of-Domain Average math GSM8K Fresh-Gaokao-Math-2023 DeepMind-Mathematics College-Math Olympia-Math TheoremQA All Datasets Llama-3.2-1B All-Replace 6.7 4.2 0.0 11.8 6.0 2.1 8.5 5.6 Curriculum-Replace 7.1 9.8 3.3 13.0 7.9 2.4 10.5 7.8 Poisson-Replace 13.9 49.5 10.0 12.2 18.9 2.3 9.0 15.1 Latent-AR (ours) 14.7 48.7 10.0 14.6 20.5 1.8 11.3 17.8 Llama-3.2-3B All-Replace 10.7 12.8 10.0 19.4 12.8 5.3 11.8 11.8 Curriculum-Replace 10.2 14.9 3.3 16.8 12.9 3.9 14.4 10.9 Poisson-Replace 23.6 65.9 13.3 17.9 28.9 2.9 11.2 20.5 Latent (ours) 26.1 73.8 23.3 27.1 32.9 4.2 13.5 28.1 Llama-3.1-8B All-Replace 15.7 19.9 6.7 21.1 19.5 5.0 17.5 15.0 Curriculum-Replace 14.6 23.1 13.3 20.3 18.7 3.9 16.6 15.8 Possion-Replace 37.9 83.6 16.6 42.7 44.7 9.9 19.1 36.3 Latent (ours) 37.2 84.1 30.0 41.3 44.0 10.2 18.4 37.9
Table 4.4: Our latent token replacement strategy significantly outperforms the alternative choices: All-Replace (where all the textual CoT tokens are replaced by latent tokens at once), Curriculum-Replace (where we gradually replace the text tokens for the entire CoT subsequence by latent tokens over the course of training) and Poisson-Replace (where individual chunks of text tokens are replaced with probabilities 0.5).
4.2.2 Mathematical Reasoning
Hyperparameters and Evaluation Metrics
We considered 3 different sizes of LLMs from the LLaMa herd: Llama-3.2-1B, Llama-3.2-3B and Llama-3.1-8B models. For all the models, we fine-tune them on the MetaMathQA dataset for 1 epoch. To maximize training efficiency, we use a batch size of 32 with a sequence packing of 4096. We experiment with different learning rates $10^{-5},2.5× 10^{-5},5× 10^{-5},10^{-4}$ and select the one with the lowest validation error. The final choices are $10^{-5}$ for the 8B model and $2.5× 10^{-5}$ for the others. For all the experiments, we use greedy decoding for evaluation.
Accuracy Comparison
Table 4.2 presents the results. Our latent approach consistently outperforms all the baselines across nearly all the tasks, for models of different sizes. For tasks on which we do not observe improvement, our approach is also comparable to the best performance. The gains are more pronounced in specific datasets such as Gaokao-Math-2023. On average, we are observing a $+5.3$ points improvement for the 8B model, $+2.9$ points improvement for the 3B model, and +3.7 points improvement for the 1B model.
Tokens Efficiency Comparison
Alongside the accuracy, we also report the number of tokens contained in the generated responses in Table 4.3, which is the dominating factor of the inference efficiency. Our first observation is that for all the approaches, the model size has little influence on the length of generated responses. Overall, the CoT method outputs the longest responses, while the Sol-Only method outputs the least number of tokens, since it is trained to generate the answer directly. The iCoT method generates short responses as well ( $42.8\%$ reduction compared to CoT), as the CoT data has been iteratively eliminated in its training procedure. However, this comes at the cost of significantly degraded model performance compared with CoT, as shown in Table 4.2. Our latent approach shows an average $17\%$ reduction in token numbers compared with CoT while surpassing it in prediction accuracy.
4.3 Ablation & Understanding Studies
Replacement Strategies
Our latent approach partially replaces the leftmost $m$ CoT tokens, where the value of $m$ varies for each sample. We call such replacement strategies AR-Replace. Here we consider three alternative strategies:
1. All-Replace: all the text CoT tokens are replaced by the latent tokens.
1. Curriculum-Replace: the entire CoT subsequence are gradually replaced over the course of training, similar to the training procedure used by iCoT and COCONUT (Hao et al., 2024). We train the model for 8 epochs. Starting from the original dataset, in each epoch we construct a new training dataset whether we further replace the leftmost 16 textual CoT tokens by a discrete latent token.
1. Poisson-Replace: instead of replacing tokens from left to right, we conduct a Poisson sampling process to select CoT tokens to be replaced: we split the reasoning traces into chunks consisting of 16 consecutive text tokens, where each chunk is randomly replaced by the latent token with probability 0.5.
Table 4.4 reports the results. Our AR-Replace strategy demonstrate strong performance, outperforming the other two strategies with large performance gap. Our intuition is as follows. When all the textual tokens are removed, the model struggles to align the latent tokens with the linguistic and semantic structures it learned during pretraining.
In contrast, partial replacement offers the model a bridge connecting text and latent spaces: the remaining text tokens serve as anchors, helping the model interpret and integrate the latent representations more effectively. Interestingly, the curriculum learning strategy is bridging the two spaces very well, where All-Replace and Curriculum-Replace exhibit similar performance. This is similar to our observation that iCoT performs remarkably worse than CoT for mathematical reasoning problems. Poisson-Replace demonstrates performance marginally worse to our AR-Replace strategy on the 1B and 8B models, but significantly worse on the 3B model. Our intuition is that having a fix pattern of replacement (starting from the beginning and left to right) is always easier for the model to learn. This might be due to the limited finetuning dataset size and model capacity.
Attention Weights Analysis
To understand the reason why injecting latent tokens enhanced the model’s reasoning performance, we randomly selected two questions from the Math and Collegue-Math dataset and generate responses, then analyze the attention weights over the input prompt tokens:
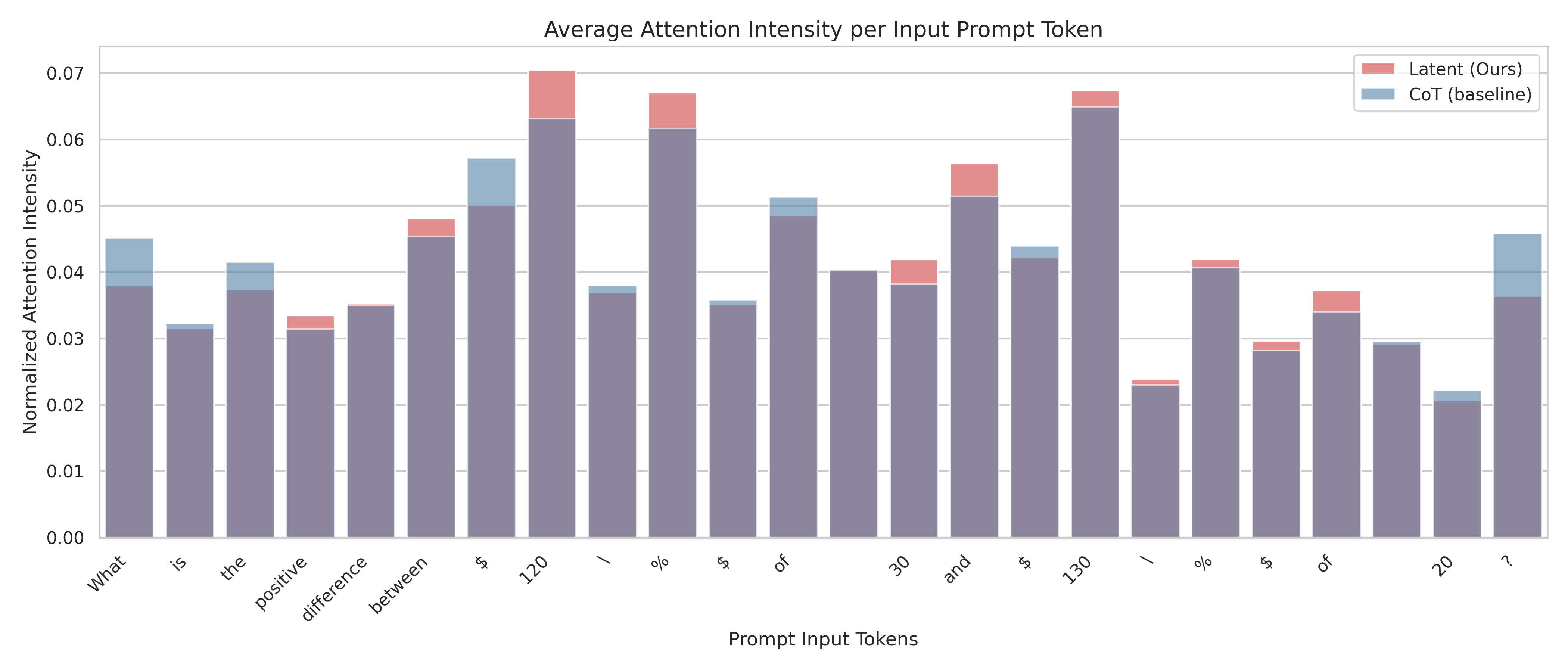
1. What is the positive difference between $120%$ of 30 and $130%$ of 20?
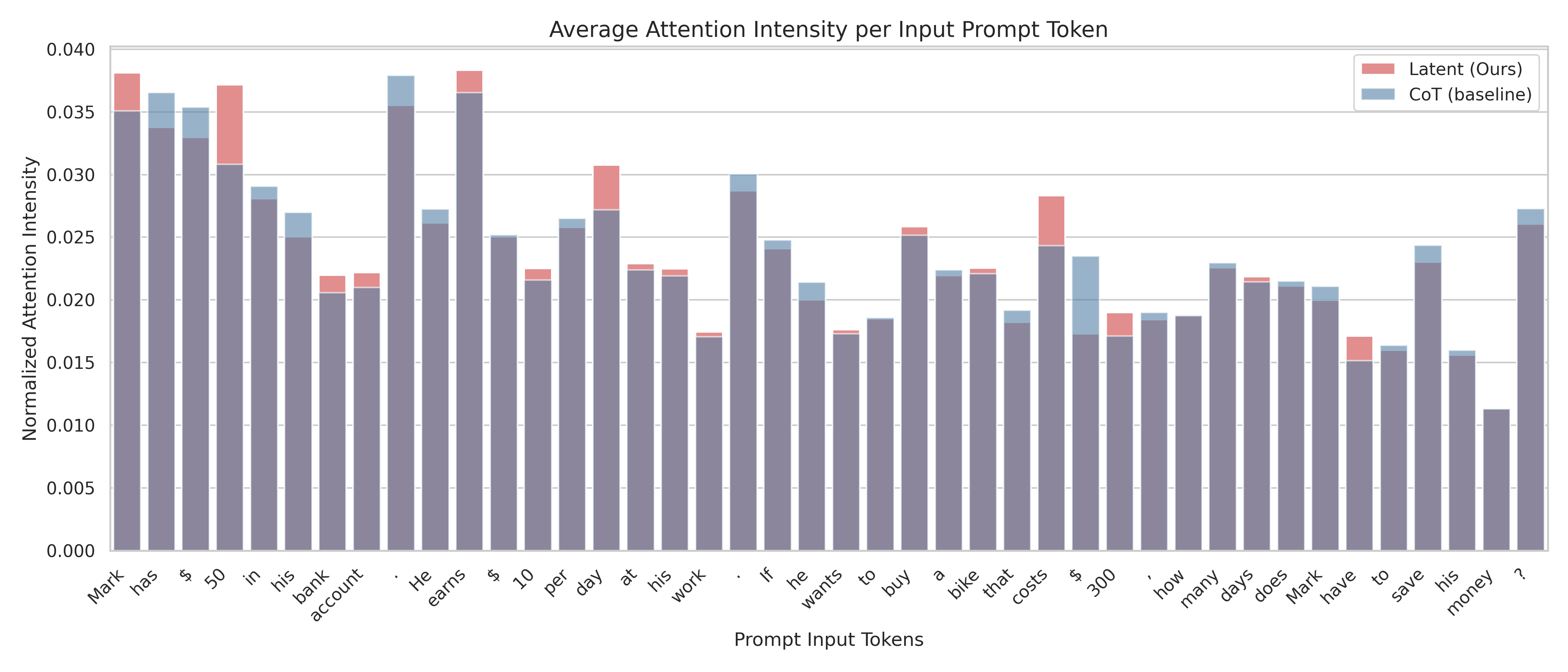
1. Mark has $50 in his bank account. He earns $10 per day at his work. If he wants to buy a bike that costs $300, how many days does Mark have to save his money?
Specifically, we take the last attention layer, compute the average attention weights over different attention heads and show its relative intensity over the prompt tokens We first compute the average attention weights across multiple heads. This gives us a single lower triangular matrix. Then, we take the column sum of this matrix to get an aggregated attention weights for each token. Last, we normalize the weights by their average to obtain the relative intensity. A one line pseudocode is: column_sum(avg(attention_matrices)) / avg(column_sum(avg(attention_matrices))). . We compare the averaged attention weights of our model with the CoT model in Figure 4.1. Interestingly, our model learns to grasp a stronger attention to numbers and words representing mathematical operations. Both Figure 1(a) and Figure 1(b) show that the latent model focus more on the numbers, such as 120, 30, and 130 for the first question. For the second question, our latent model shows a larger attention weights on numbers including 50, 10, and 300, and also tokens semantically related to mathematical operations such as earns (means addition) and cost (means subtraction). This suggests that, by partially compressing the reasoning trace into a mix of latent and text tokens, we allow the model to effectively focus on important tokens that build the internal logical flow. See Section C.1 for the exact response generated by our approach and the CoT baseline.
<details>
<summary>plots/entry_1.png Details</summary>
### Visual Description
## Bar Chart: Average Attention Intensity per Input Prompt Token
### Overview
The image is a bar chart comparing the average attention intensity per input prompt token for two models: "Latent (Ours)" and "CoT (baseline)". The x-axis represents the prompt input tokens, and the y-axis represents the normalized attention intensity. The chart displays the attention intensity of each model for each token in the prompt.
### Components/Axes
* **Title:** Average Attention Intensity per Input Prompt Token
* **X-axis:** Prompt Input Tokens
* Tokens: What, is, the, positive, difference, between, $, 120, /, %, $, of, 30, and, $, 130, /, %, $, of, 20, ?
* **Y-axis:** Normalized Attention Intensity
* Scale: 0.00 to 0.07, with increments of 0.01
* **Legend:** Located in the top-right corner.
* Latent (Ours): Represented by light red bars.
* CoT (baseline): Represented by light blue bars.
### Detailed Analysis
The chart presents a comparison of attention intensities for each token between the "Latent (Ours)" model and the "CoT (baseline)" model. The base of each bar represents the CoT (baseline) attention intensity, and the red portion stacked on top represents the additional attention intensity from the Latent (Ours) model.
Here's a breakdown of the approximate attention intensities for each token:
* **What:** CoT (baseline) ~0.04, Latent (Ours) ~0.005
* **is:** CoT (baseline) ~0.032, Latent (Ours) ~0
* **the:** CoT (baseline) ~0.037, Latent (Ours) ~0.004
* **positive:** CoT (baseline) ~0.031, Latent (Ours) ~0.003
* **difference:** CoT (baseline) ~0.034, Latent (Ours) ~0.001
* **between:** CoT (baseline) ~0.045, Latent (Ours) ~0.003
* **$:** CoT (baseline) ~0.057, Latent (Ours) ~0
* **120:** CoT (baseline) ~0.063, Latent (Ours) ~0.007
* **/:** CoT (baseline) ~0.037, Latent (Ours) ~0.001
* **%:** CoT (baseline) ~0.062, Latent (Ours) ~0.005
* **$:** CoT (baseline) ~0.035, Latent (Ours) ~0.001
* **of:** CoT (baseline) ~0.049, Latent (Ours) ~0.002
* **30:** CoT (baseline) ~0.04, Latent (Ours) ~0
* **and:** CoT (baseline) ~0.038, Latent (Ours) ~0.004
* **$:** CoT (baseline) ~0.051, Latent (Ours) ~0.005
* **130:** CoT (baseline) ~0.042, Latent (Ours) ~0.002
* **/:** CoT (baseline) ~0.065, Latent (Ours) ~0.002
* **%:** CoT (baseline) ~0.023, Latent (Ours) ~0
* **$:** CoT (baseline) ~0.041, Latent (Ours) ~0.001
* **of:** CoT (baseline) ~0.029, Latent (Ours) ~0.004
* **20:** CoT (baseline) ~0.029, Latent (Ours) ~0
* **?:** CoT (baseline) ~0.022, Latent (Ours) ~0
* **?:** CoT (baseline) ~0.036, Latent (Ours) ~0.01
### Key Observations
* The CoT (baseline) model generally has a higher attention intensity than the Latent (Ours) model for most tokens.
* The Latent (Ours) model shows increased attention intensity for specific tokens like "120", "%", "and", and "of".
* The attention intensity varies significantly across different tokens, indicating that the models focus on different parts of the input prompt.
### Interpretation
The bar chart provides insights into how the "Latent (Ours)" model and the "CoT (baseline)" model attend to different tokens within the input prompt. The "Latent (Ours)" model seems to focus more on numerical and symbolic tokens ("120", "%", "$"), while the "CoT (baseline)" model distributes its attention more evenly across the prompt. This suggests that the "Latent (Ours)" model might be prioritizing specific numerical or symbolic information within the prompt, potentially for more precise calculations or reasoning. The differences in attention intensity highlight the distinct processing strategies employed by each model.
</details>
(a) Prompt: What is the positive difference between $120%$ of 30 and $130%$ of 20?
<details>
<summary>plots/entry_7746.png Details</summary>
### Visual Description
## Bar Chart: Average Attention Intensity per Input Prompt Token
### Overview
The image is a bar chart comparing the average attention intensity per input prompt token for two different models: "Latent (Ours)" and "CoT (baseline)". The x-axis represents the prompt input tokens, and the y-axis represents the normalized attention intensity. The chart displays the attention intensity for each token in the prompt, allowing for a comparison of how the two models focus on different parts of the input.
### Components/Axes
* **Title:** Average Attention Intensity per Input Prompt Token
* **X-axis:** Prompt Input Tokens. The tokens are: Mark, has, \$, 50, in, his, bank, account, ., He, earns, \$, 10, per, day, at, his, work, If, he, wants, to, buy, a, bike, that, costs, \$, 300, ',', how, many, days, does, Mark, have, to, save, his, money, ?
* **Y-axis:** Normalized Attention Intensity, ranging from 0.000 to 0.040 in increments of 0.005.
* **Legend:** Located in the top-right corner.
* Latent (Ours) - Represented by light red bars.
* CoT (baseline) - Represented by light blue bars.
### Detailed Analysis
The chart presents a bar for each token in the input prompt, with each bar split into two components: a light red portion representing the "Latent (Ours)" model's attention intensity and a light blue portion representing the "CoT (baseline)" model's attention intensity. The total height of each bar indicates the combined attention intensity for that token.
Here's a breakdown of the approximate attention intensity for each token, separated by model:
| Token | Latent (Ours) | CoT (baseline) |
| ----------- | ----------- | ----------- |
| Mark | ~0.005 | ~0.035 |
| has | ~0.005 | ~0.033 |
| \$ | ~0.005 | ~0.030 |
| 50 | ~0.008 | ~0.021 |
| in | ~0.002 | ~0.027 |
| his | ~0.000 | ~0.022 |
| bank | ~0.000 | ~0.038 |
| account | ~0.002 | ~0.036 |
| . | ~0.000 | ~0.027 |
| He | ~0.000 | ~0.026 |
| earns | ~0.000 | ~0.022 |
| \$ | ~0.008 | ~0.014 |
| 10 | ~0.000 | ~0.023 |
| per | ~0.000 | ~0.022 |
| day | ~0.008 | ~0.022 |
| at | ~0.000 | ~0.017 |
| his | ~0.000 | ~0.024 |
| work | ~0.002 | ~0.018 |
| If | ~0.000 | ~0.022 |
| he | ~0.000 | ~0.022 |
| wants | ~0.004 | ~0.022 |
| to | ~0.000 | ~0.019 |
| buy | ~0.002 | ~0.017 |
| a | ~0.000 | ~0.021 |
| bike | ~0.000 | ~0.021 |
| that | ~0.000 | ~0.021 |
| costs | ~0.000 | ~0.017 |
| \$ | ~0.008 | ~0.008 |
| 300 | ~0.002 | ~0.014 |
| , | ~0.000 | ~0.016 |
| how | ~0.000 | ~0.016 |
| many | ~0.000 | ~0.023 |
| days | ~0.000 | ~0.016 |
| does | ~0.000 | ~0.016 |
| Mark | ~0.000 | ~0.027 |
### Key Observations
* The "CoT (baseline)" model generally has a higher attention intensity across most tokens compared to the "Latent (Ours)" model.
* The "Latent (Ours)" model shows increased attention intensity for specific tokens like "50", "\$", "day", and "\$".
* The attention intensity varies significantly across different tokens, indicating that both models focus on specific parts of the input prompt.
### Interpretation
The chart suggests that the "CoT (baseline)" model distributes its attention more evenly across the input prompt tokens, while the "Latent (Ours)" model focuses its attention on a smaller subset of tokens. The tokens that the "Latent (Ours)" model focuses on, such as numerical values ("50", "\$", "300") and time-related words ("day"), might indicate that this model is more sensitive to specific types of information within the prompt. The differences in attention intensity between the two models could be related to their underlying architectures or training objectives. The "Latent (Ours)" model may be employing a strategy that involves focusing on key pieces of information to achieve its task.
</details>
(b) Prompt: Mark has $50 in his bank account. He earns $10 per day at his work. If he wants to buy a bike that costs $300, how many days does Mark have to save his money?
Figure 4.1: Comparing with the CoT model, our latent approach have high attention weights on numbers and text tokens representing mathematical operations.
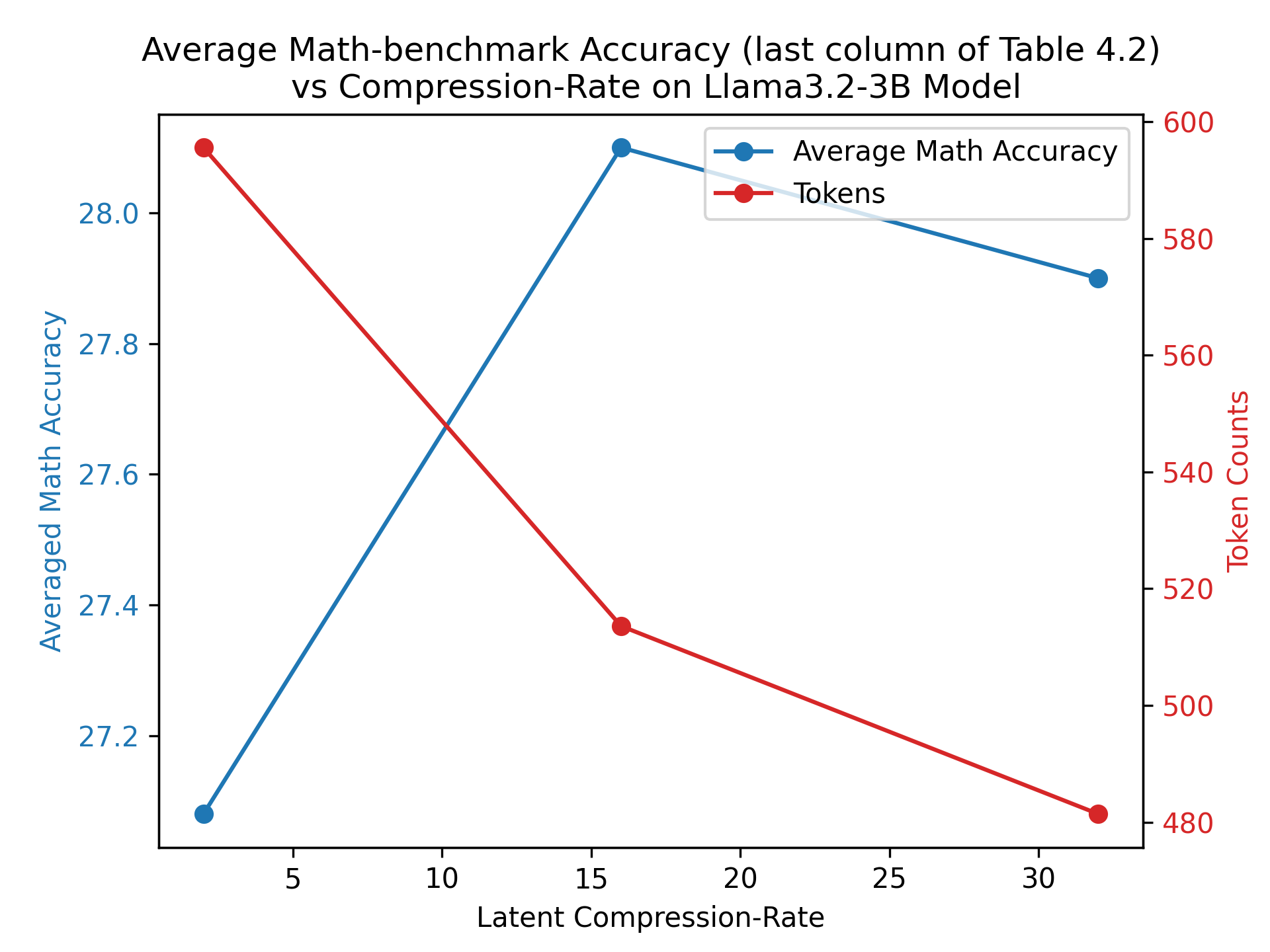
Table 4.5: The Table blow illustrates a clear trend on Llama-3.2-3B model where increasing the compression rate reduces the number of generated tokens due to higher data compression. Notably, a compression rate of 2 shows some improvements over the CoT baseline. Furthermore, there appears to be an optimal ’sweet spot’ where the data is neither overly compressed (rate = 32) nor minimally compressed (rate = 2), optimizing both efficiency and accuracy.
Model In-Domain Out-of-Domain Average math GSM8K Fresh-Gaokao- Math-2023 DeepMind- Mathematics College- Math Olympia- Math TheoremQA All Datasets Llama-3.2-3B CoT (baseline) (Acc.) 21.9 69.7 16.7 27.3 30.9 2.2 11.6 25.2 # of Tokens 649.9 212.1 823.3 392.8 495.9 1166.7 759.6 642.9 Latent- $r=2$ (Acc.) 24.3 71.7 16.7 25.4 32.0 4.7 14.8 27.08 # of Tokens 586.0 207.6 739.6 415.3 471 1036 714 595.6 Latent $r=16$ (Acc.) 26.1 73.8 23.3 27.1 32.9 4.2 13.5 28.1 # of Tokens 516.7 198.8 618.5 340.0 418.0 832.8 670.2 513.6 Latent $r=32$ (Acc.) 25.2 71.5 23.3 26.3 33.3 4.9 14.1 27.9 # of Tokens 496.5 183.3 577.3 311.0 395.2 821.0 585.6 481.4
4.4 Ablations on the Latent $r$ parameters
Throughout this paper we have been using $r$ (or the compression ratio) to be 16, in this section, we will be ablating how would $r$ affects the performance of the downstream Math tasks if we vary this parameter.
To this end, we vary this parameter on the Llama-3.2-3B model. Our result is summarized in Table. 4.5. A graphical illustration is shown in Figure. 4.2. A key takeaway is that our latent approach comes out ahead of the CoT baseline for all $r$ settings in terms of fewer tokens (better efficiency) and higher accuracy. This is a strong signal that the shift to a latent representation itself is fundamentally beneficial. In addition, we see that when the $r$ (compression ratio) increases, we expect each latent token to encode more information (higher compression). As a result, we see that, on average, the number of tokens reduces as $r$ increases. However, in terms of the accuracy metric, we see that the model increases initially from 25.2 (overall accuracy) to 27.1 (when $r=2$ ). It further boosts up to 28.1 at $r=16$ , and then it goes down to 27.9 when $r=32$ . This indicates a sweet spot that $r=16$ , it is neither overly-compressed (which implies information loss), nor under-compressed (which implies information is not encoded abstractly enough). This study indicates an interesting trade-off between accuracy and tokens efficiency in our latent approach. So, $r=16$ appears to strike an optimal balance between compact representation and the preservation of task-critical information.
<details>
<summary>plots/plot_r.png Details</summary>
### Visual Description
## Line Chart: Average Math-benchmark Accuracy vs Compression-Rate
### Overview
The image is a line chart comparing the average math accuracy and token counts against the latent compression rate on the Llama3.2-3B model. The x-axis represents the latent compression rate, the left y-axis represents the average math accuracy, and the right y-axis represents the token counts. There are two data series plotted: average math accuracy (blue) and tokens (red).
### Components/Axes
* **Title:** Average Math-benchmark Accuracy (last column of Table 4.2) vs Compression-Rate on Llama3.2-3B Model
* **X-axis:**
* Label: Latent Compression-Rate
* Scale: 5, 10, 15, 20, 25, 30
* **Left Y-axis:**
* Label: Averaged Math Accuracy
* Scale: 27.2, 27.4, 27.6, 27.8, 28.0
* **Right Y-axis:**
* Label: Token Counts
* Scale: 480, 500, 520, 540, 560, 580, 600
* **Legend:** Located in the top-right corner.
* Average Math Accuracy (blue line)
* Tokens (red line)
### Detailed Analysis
* **Average Math Accuracy (blue line):**
* Trend: Initially increases sharply, then decreases slightly.
* Data Points:
* At Latent Compression-Rate = 4, Average Math Accuracy ≈ 27.1
* At Latent Compression-Rate = 16, Average Math Accuracy ≈ 28.0
* At Latent Compression-Rate = 32, Average Math Accuracy ≈ 27.9
* **Tokens (red line):**
* Trend: Decreases consistently.
* Data Points:
* At Latent Compression-Rate = 4, Token Counts ≈ 590
* At Latent Compression-Rate = 16, Token Counts ≈ 520
* At Latent Compression-Rate = 32, Token Counts ≈ 480
### Key Observations
* The average math accuracy peaks at a latent compression rate of approximately 16.
* The token count decreases as the latent compression rate increases.
* There appears to be an inverse relationship between token count and latent compression rate.
* The average math accuracy increases sharply between latent compression rates of 4 and 16, then decreases slightly between 16 and 32.
### Interpretation
The chart suggests that increasing the latent compression rate initially improves the average math accuracy, but beyond a certain point (around 16), further increases in the compression rate lead to a slight decrease in accuracy. Simultaneously, increasing the latent compression rate consistently reduces the number of tokens. This indicates a trade-off between model accuracy and the number of tokens required. The optimal compression rate would likely depend on the specific application and the relative importance of accuracy versus token count.
</details>
Figure 4.2: A graphical illustration of the compression rate $r$ trade-off between the accuracy and the token efficiency on the Llama-3.2-3B model.
4.5 Additional Examples and Interpretability Result
We provide 4 additional example responses for questions in the Math and TheoremQA datasets in Appendix D. In Appendix F, we compare all the approaches when the model is trained on the DART-MATH (Tong et al., 2024) dataset, where similar trends are observed.
We also provide interpretable examples in the Appendix E.
5 Conclusion
We present a novel approach to improve the reasoning capabilities of LLMs, by compressing the initial steps of the reasoning traces using discrete latent tokens obtained from VQ-VAE. By integrating both abstract representation and textual details of the reasoning process into training, our approach enables LLMs to capture essential reasoning information with improved token efficiency. Furthermore, by randomizing the number of text tokens to be compressed during training, we unlock fast adaptation to unseen latent tokens. Our comprehensive evaluation demonstrates the effectiveness across multiple domains, outperforming standard methods that rely on complete textual reasoning traces.
Impact Statement
This paper presents a method to enhance the reasoning capability of Large Language Models (LLMs) by combining latent and text tokens in the reasoning trace. In terms of society impact, while reasoning with (opaque) latent tokens may trigger safety concerns, our approach provides a VQVAE decoder that can decode the latent tokens into human readable format, mitigating such concerns.
References
- Azerbayev et al. (2023) Azerbayev, Z., Schoelkopf, H., Paster, K., Santos, M. D., McAleer, S., Jiang, A. Q., Deng, J., Biderman, S., and Welleck, S. Llemma: An open language model for mathematics. arXiv preprint arXiv:2310.10631, 2023.
- Barrault et al. (2024) Barrault, L., Duquenne, P.-A., Elbayad, M., Kozhevnikov, A., Alastruey, B., Andrews, P., Coria, M., Couairon, G., Costa-jussà, M. R., Dale, D., et al. Large concept models: Language modeling in a sentence representation space. arXiv e-prints, pp. arXiv–2412, 2024.
- Chen et al. (2022a) Chen, W., Ma, X., Wang, X., and Cohen, W. W. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588, 2022a.
- Chen et al. (2022b) Chen, W., Ma, X., Wang, X., and Cohen, W. W. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588, 2022b.
- Chen et al. (2023) Chen, W., Yin, M., Ku, M., Lu, P., Wan, Y., Ma, X., Xu, J., Wang, X., and Xia, T. Theoremqa: A theorem-driven question answering dataset. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 7889–7901, 2023.
- Chung et al. (2024) Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., et al. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53, 2024.
- Cobbe et al. (2021a) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021a.
- Cobbe et al. (2021b) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021b.
- Deng et al. (2023) Deng, Y., Prasad, K., Fernandez, R., Smolensky, P., Chaudhary, V., and Shieber, S. Implicit chain of thought reasoning via knowledge distillation. arXiv preprint arXiv:2311.01460, 2023.
- Deng et al. (2024) Deng, Y., Choi, Y., and Shieber, S. From explicit cot to implicit cot: Learning to internalize cot step by step. arXiv preprint arXiv:2405.14838, 2024.
- Dubey et al. (2024) Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Dziri et al. (2024) Dziri, N., Lu, X., Sclar, M., Li, X. L., Jian, L., Lin, B. Y., West, P., Bhagavatula, C., Bras, R. L., Hwang, J. D., Sanyal, S., Welleck, S., Ren, X., Ettinger, A., Harchaoui, Z., and Choi, Y. Faith and fate: Limits of transformers on compositionality. Advances in Neural Information Processing Systems, 36, 2024.
- Feng et al. (2024) Feng, G., Zhang, B., Gu, Y., Ye, H., He, D., and Wang, L. Towards revealing the mystery behind chain of thought: a theoretical perspective. Advances in Neural Information Processing Systems, 36, 2024.
- Gandhi et al. (2024) Gandhi, K., Lee, D., Grand, G., Liu, M., Cheng, W., Sharma, A., and Goodman, N. D. Stream of search (sos): Learning to search in language. arXiv preprint arXiv:2404.03683, 2024.
- Goyal et al. (2023) Goyal, S., Ji, Z., Rawat, A. S., Menon, A. K., Kumar, S., and Nagarajan, V. Think before you speak: Training language models with pause tokens. arXiv preprint arXiv:2310.02226, 2023.
- Hao et al. (2024) Hao, S., Sukhbaatar, S., Su, D., Li, X., Hu, Z., Weston, J., and Tian, Y. Training large language models to reason in a continuous latent space. arXiv preprint arXiv:2412.06769, 2024.
- Hart et al. (1968) Hart, P. E., Nilsson, N. J., and Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE transactions on Systems Science and Cybernetics, 4(2):100–107, 1968.
- He et al. (2024) He, C., Luo, R., Bai, Y., Hu, S., Thai, Z. L., Shen, J., Hu, J., Han, X., Huang, Y., Zhang, Y., et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. arXiv preprint arXiv:2402.14008, 2024.
- (19) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2).
- Hendrycks et al. (2021) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021.
- Jiang et al. (2024) Jiang, W., Shi, H., Yu, L., Liu, Z., Zhang, Y., Li, Z., and Kwok, J. Forward-backward reasoning in large language models for mathematical verification. In Findings of the Association for Computational Linguistics ACL 2024, pp. 6647–6661, 2024.
- Jiang et al. (2022) Jiang, Z., Zhang, T., Janner, M., Li, Y., Rocktäschel, T., Grefenstette, E., and Tian, Y. Efficient planning in a compact latent action space. arXiv preprint arXiv:2208.10291, 2022.
- Jiang et al. (2023) Jiang, Z., Xu, Y., Wagener, N., Luo, Y., Janner, M., Grefenstette, E., Rocktäschel, T., and Tian, Y. H-gap: Humanoid control with a generalist planner. arXiv preprint arXiv:2312.02682, 2023.
- Kim et al. (2023) Kim, S., Joo, S. J., Kim, D., Jang, J., Ye, S., Shin, J., and Seo, M. The cot collection: Improving zero-shot and few-shot learning of language models via chain-of-thought fine-tuning. arXiv preprint arXiv:2305.14045, 2023.
- Kojima et al. (2022) Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., and Iwasawa, Y. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213, 2022.
- Lehnert et al. (2024) Lehnert, L., Sukhbaatar, S., Su, D., Zheng, Q., McVay, P., Rabbat, M., and Tian, Y. Beyond a*: Better planning with transformers via search dynamics bootstrapping. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=SGoVIC0u0f.
- Li et al. (2024) Li, Z., Liu, H., Zhou, D., and Ma, T. Chain of thought empowers transformers to solve inherently serial problems, 2024. URL https://arxiv.org/abs/2402.12875.
- Lin et al. (2024) Lin, B. Y., Bras, R. L., and Choi, Y. Zebralogic: Benchmarking the logical reasoning ability of language models, 2024. URL https://huggingface.co/spaces/allenai/ZebraLogic.
- Liu et al. (2024) Liu, L., Pfeiffer, J., Wu, J., Xie, J., and Szlam, A. Deliberation in latent space via differentiable cache augmentation. 2024. URL https://arxiv.org/abs/2412.17747.
- Lozhkov et al. (2024) Lozhkov, A., Ben Allal, L., Bakouch, E., von Werra, L., and Wolf, T. Finemath: the finest collection of mathematical content, 2024. URL https://huggingface.co/datasets/HuggingFaceTB/finemath.
- Nye et al. (2021a) Nye, M., Andreassen, A. J., Gur-Ari, G., Michalewski, H., Austin, J., Bieber, D., Dohan, D., Lewkowycz, A., Bosma, M., Luan, D., et al. Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114, 2021a.
- Nye et al. (2021b) Nye, M., Andreassen, A. J., Gur-Ari, G., Michalewski, H., Austin, J., Bieber, D., Dohan, D., Lewkowycz, A., Bosma, M., Luan, D., et al. Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114, 2021b.
- Pagnoni et al. (2024) Pagnoni, A., Pasunuru, R., Rodriguez, P., Nguyen, J., Muller, B., Li, M., Zhou, C., Yu, L., Weston, J., Zettlemoyer, L., Ghosh, G., Lewis, M., Holtzman, A., and Iyer, S. Byte latent transformer: Patches scale better than tokens. 2024. URL https://arxiv.org/abs/2412.09871.
- Pfau et al. (2024) Pfau, J., Merrill, W., and Bowman, S. R. Let’s think dot by dot: Hidden computation in transformer language models. arXiv preprint arXiv:2404.15758, 2024.
- Radford et al. (2019) Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Raffel et al. (2020) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020. URL http://jmlr.org/papers/v21/20-074.html.
- Saparov & He (2022) Saparov, A. and He, H. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. arXiv preprint arXiv:2210.01240, 2022.
- Saxton et al. (2019) Saxton, D., Grefenstette, E., Hill, F., and Kohli, P. Analysing mathematical reasoning abilities of neural models. arXiv preprint arXiv:1904.01557, 2019.
- Su et al. (2024) Su, D., Sukhbaatar, S., Rabbat, M., Tian, Y., and Zheng, Q. Dualformer: Controllable fast and slow thinking by learning with randomized reasoning traces. arXiv preprint arXiv:2410.09918, 2024.
- Su et al. (2025) Su, D., Gu, A., Xu, J., Tian, Y., and Zhao, J. Galore 2: Large-scale llm pre-training by gradient low-rank projection. arXiv preprint arXiv:2504.20437, 2025.
- Tang et al. (2024) Tang, Z., Zhang, X., Wang, B., and Wei, F. Mathscale: Scaling instruction tuning for mathematical reasoning. arXiv preprint arXiv:2403.02884, 2024.
- Tong et al. (2024) Tong, Y., Zhang, X., Wang, R., Wu, R., and He, J. Dart-math: Difficulty-aware rejection tuning for mathematical problem-solving. arXiv preprint arXiv:2407.13690, 2024.
- Van Den Oord et al. (2017) Van Den Oord, A., Vinyals, O., et al. Neural discrete representation learning. Advances in neural information processing systems, 30, 2017.
- Wang & Zhou (2024) Wang, X. and Zhou, D. Chain-of-thought reasoning without prompting. 2024. URL https://arxiv.org/abs/2402.10200.
- Wang et al. (2022) Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- Wang et al. (2023) Wang, X., Caccia, L., Ostapenko, O., Yuan, X., Wang, W. Y., and Sordoni, A. Guiding language model reasoning with planning tokens. arXiv preprint arXiv:2310.05707, 2023.
- Wei et al. (2022a) Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022a.
- Wei et al. (2022b) Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022b.
- Wen et al. (2024) Wen, K., Zhang, H., Lin, H., and Zhang, J. From sparse dependence to sparse attention: Unveiling how chain-of-thought enhances transformer sample efficiency. arXiv preprint arXiv:2410.05459, 2024.
- Yang et al. (2024) Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115, 2024.
- Yao et al. (2024) Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y., and Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024.
- Yu et al. (2023) Yu, L., Jiang, W., Shi, H., Yu, J., Liu, Z., Zhang, Y., Kwok, J. T., Li, Z., Weller, A., and Liu, W. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023.
- Yu et al. (2024) Yu, P., Xu, J., Weston, J., and Kulikov, I. Distilling system 2 into system 1. arXiv preprint arXiv:2407.06023, 2024.
- Yue et al. (2023) Yue, X., Qu, X., Zhang, G., Fu, Y., Huang, W., Sun, H., Su, Y., and Chen, W. Mammoth: Building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653, 2023.
- Zhu et al. (2024) Zhu, H., Huang, B., Zhang, S., Jordan, M., Jiao, J., Tian, Y., and Russell, S. Towards a theoretical understanding of the’reversal curse’via training dynamics. arXiv preprint arXiv:2405.04669, 2024.
Appendix A Experiment Details
A.1 VQ-VAE Model Details
The codebook size $|\mathcal{E}|$ is 64 for ProntoQA and ProsQA, 512 for the Keys-Finding Maze, and 1024 for math reasoning problems. For both encoder ${f_{\text{enc}}}$ and decoder ${f_{\text{dec}}}$ , we use a 2-layer transformer with 4 heads, where the embedding size is 512 and the block size is 512. We set the max sequence to be 2048 for the synthetic dataset experiments and 256 for the math reasoning experiments.
A.2 Keys-Finding Maze
A.2.1 Environment Details
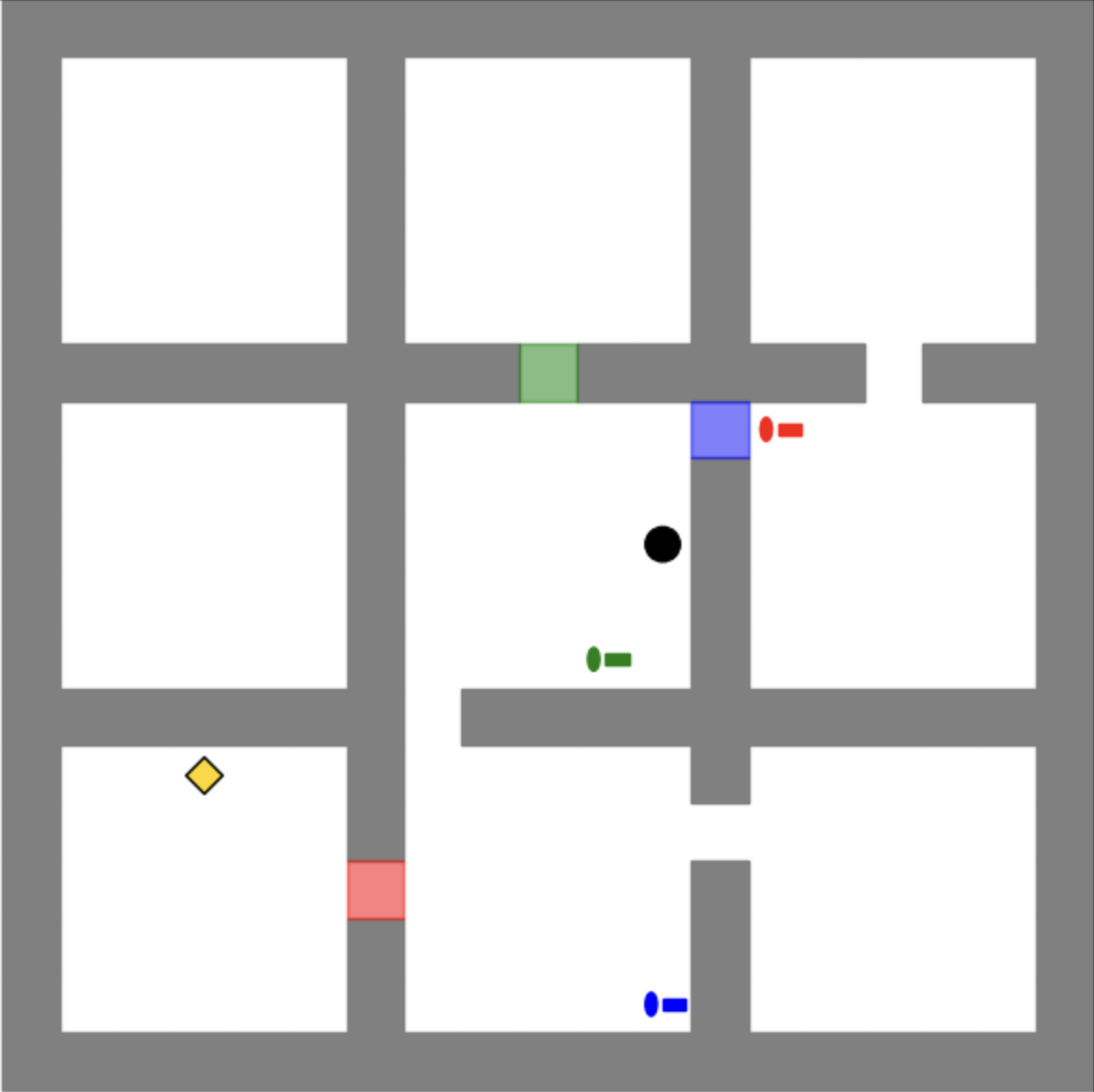
In this section, we introduce our synthetic keys-finding maze environment. Figure A.1 shows an example maze that consists of $m× m$ rooms, where the size of each room is $n× n$ ( $m=3$ and $n=5$ ). The goal of the agent (represented by the black circle) is to reach the gold diamond using the minimum number of steps. The agent cannot cross the wall. Also, there are three doors (represented by squares) of different colors (i.e., red, green, and blue) which are closed initially. The agent have to pick up keys to open the door in the same color. Note that the agent can not carry more than one key at the same time.
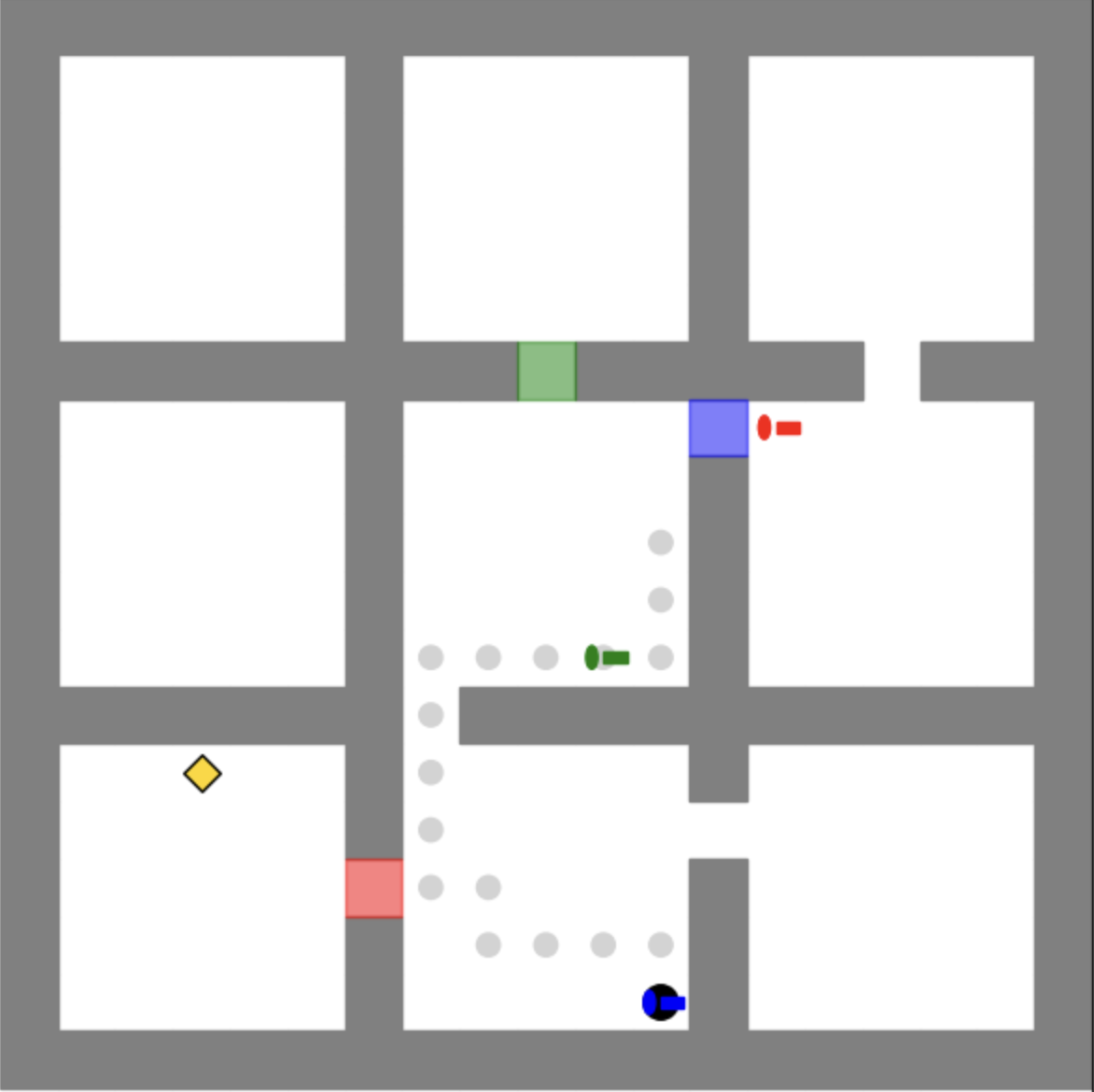
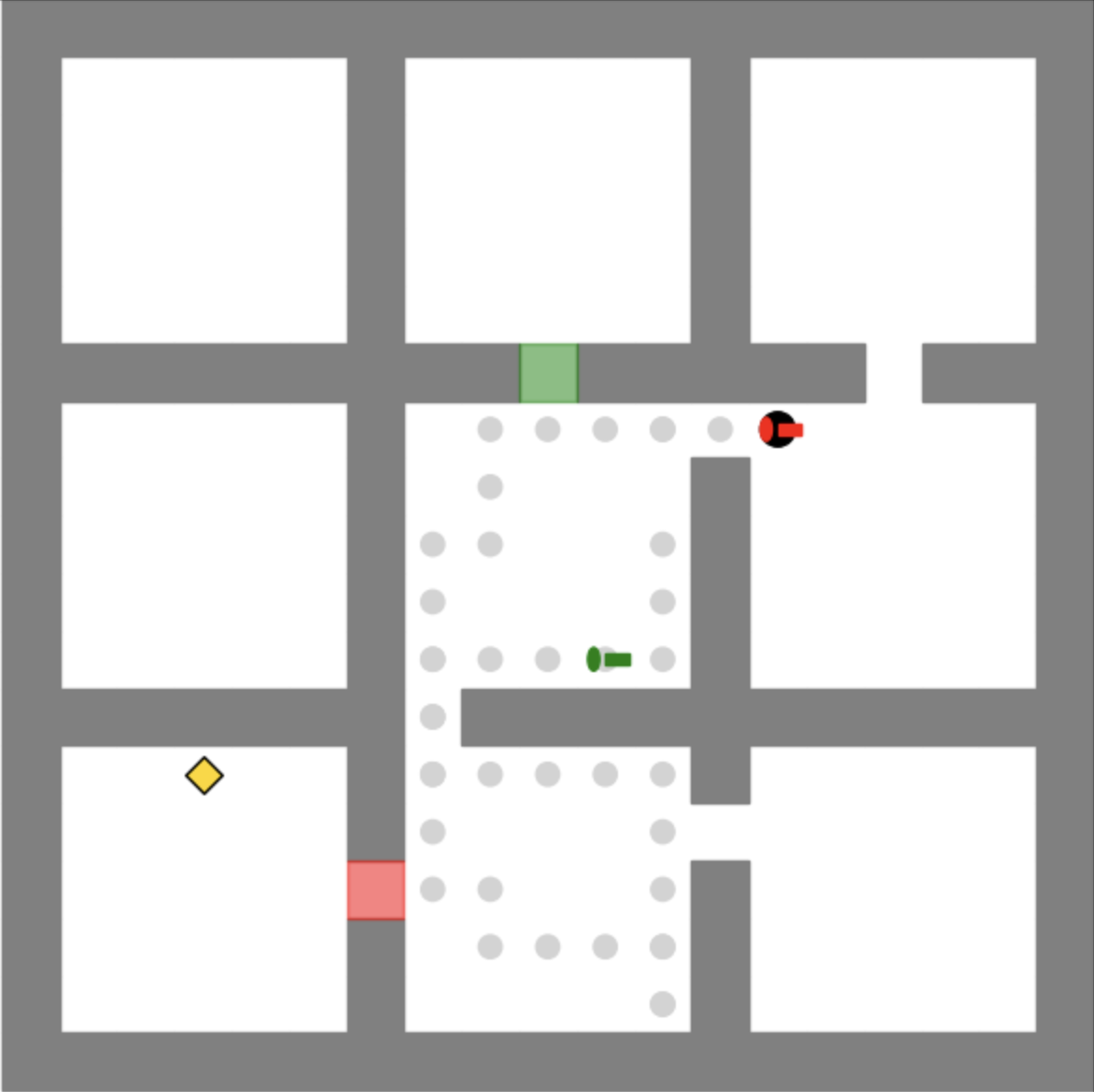
Figure A.2 shows an example optimal trajectory of the maze in Figure A.1. The agent first picks up the blue key and opens the blue door to obtain the red key. Then the agent navigates to the red door and opens it. Finally the agent is able to reach the objective.
<details>
<summary>plots/maze_env.png Details</summary>
### Visual Description
## Diagram: Maze Layout with Colored Markers
### Overview
The image depicts a top-down view of a maze-like structure with several colored markers placed within its corridors and rooms. The maze consists of gray pathways and white rectangular spaces, resembling rooms. The markers are of various shapes and colors, each positioned at specific locations within the maze.
### Components/Axes
* **Maze Structure:** The maze is composed of gray pathways and white rectangular rooms. The pathways form a grid-like structure, connecting the rooms.
* **Colored Markers:** There are several colored markers within the maze:
* **Yellow Diamond:** Located in the bottom-left quadrant.
* **Red Rectangle:** Located in the bottom-left quadrant.
* **Green Rectangle:** Located in the top-center quadrant.
* **Blue Rectangle:** Located in the top-right quadrant.
* **Black Circle:** Located in the top-right quadrant.
* **Small Green Line:** Located in the center-right quadrant.
* **Small Red Line:** Located in the top-right quadrant.
* **Small Blue Line:** Located in the bottom-right quadrant.
### Detailed Analysis
* **Yellow Diamond:** Positioned in the bottom-left room.
* **Red Rectangle:** Positioned in the bottom-left quadrant.
* **Green Rectangle:** Positioned in the top-center quadrant.
* **Blue Rectangle:** Positioned in the top-right quadrant.
* **Black Circle:** Located in the top-right quadrant.
* **Small Green Line:** Located in the center-right quadrant.
* **Small Red Line:** Located in the top-right quadrant.
* **Small Blue Line:** Located in the bottom-right quadrant.
### Key Observations
* The maze has a grid-like structure with interconnected rooms.
* The colored markers are strategically placed within the maze, possibly indicating specific locations or points of interest.
* The markers vary in shape and color, suggesting they may represent different entities or categories.
### Interpretation
The diagram likely represents a map or layout of a maze, with the colored markers indicating specific locations, objects, or points of interest within the maze. The different colors and shapes of the markers could signify different categories or types of entities. The diagram could be used for navigation, planning, or analysis of the maze environment. The placement of the markers seems deliberate, suggesting a specific purpose or meaning behind their locations.
</details>
Figure A.1: An example of the keys-finding maze environment.
<details>
<summary>plots/maze_traj1.png Details</summary>
### Visual Description
## Maze Diagram: Agent Navigation
### Overview
The image is a diagram of a maze, showing a possible path taken by an agent. The maze consists of interconnected rooms and corridors, with the agent's path marked by a series of gray dots. There are colored markers and shapes within the maze, possibly indicating start/end points or points of interest.
### Components/Axes
* **Maze Structure:** The maze is composed of white square rooms connected by gray corridors. The outer boundary of the maze is also gray.
* **Agent Path:** A series of small, light gray dots indicates the path taken by the agent.
* **Agent:** Represented by a dark blue circle with a black outline, located at the bottom of the maze.
* **Goal/Target 1:** A yellow diamond located in the bottom-left quadrant of the maze.
* **Goal/Target 2:** A green horizontal capsule shape located in the upper-middle section of the maze.
* **Goal/Target 3:** A red horizontal capsule shape located in the upper-right section of the maze.
* **Start Point:** A green rectangle located in the top-middle section of the maze.
* **Obstacle/Marker 1:** A red rectangle located in the bottom-left quadrant of the maze.
* **Obstacle/Marker 2:** A blue rectangle located in the upper-right section of the maze.
### Detailed Analysis
* **Maze Layout:** The maze has a grid-like structure with rooms arranged in a 3x3 pattern, although not all rooms are fully enclosed.
* **Agent Path:** The agent starts at the bottom of the maze and navigates through a series of turns and corridors. The path leads towards the green capsule shape.
* **Agent Location:** The agent is positioned at the bottom of the maze, near a corridor leading upwards.
* **Goal/Target Locations:** The yellow diamond is in the bottom-left room, the green capsule is in the upper-middle section, and the red capsule is in the upper-right section.
* **Start Point Location:** The green rectangle is located in the top-middle section of the maze.
* **Obstacle/Marker Locations:** The red rectangle is in the bottom-left quadrant, and the blue rectangle is in the upper-right section.
### Key Observations
* The agent's path is not a straight line; it involves multiple turns and changes in direction.
* The agent's path appears to be heading towards the green capsule shape.
* The maze has multiple potential paths, but the agent follows a specific route.
* The colored shapes (diamond, capsules, rectangles) likely represent different types of locations or objects within the maze.
### Interpretation
The diagram illustrates a navigation problem within a maze environment. The agent, starting from a specific location, needs to find a path to reach certain goals or targets while potentially avoiding obstacles. The gray dots represent the agent's trajectory, indicating the steps taken to navigate the maze. The colored shapes likely represent different types of locations or objects within the maze, each potentially having a different significance or reward associated with it. The diagram could be used to analyze the efficiency of the agent's path, the complexity of the maze, or the effectiveness of different navigation algorithms. The presence of the start point suggests that the agent may have a predefined starting location. The obstacles/markers could represent areas to avoid or points of interest.
</details>
(a) Phase 1
<details>
<summary>plots/maze_traj2.png Details</summary>
### Visual Description
## Diagram: Room Layout with Objects
### Overview
The image depicts a top-down view of a building layout, possibly a maze or a floor plan, with several rooms connected by corridors. The walls are gray, and the rooms are white. There are several objects within the layout, including a red object, a yellow diamond, and two green objects. The layout also contains a region filled with gray circles.
### Components/Axes
* **Walls:** Gray lines defining the structure of the building.
* **Rooms:** White spaces enclosed by the walls.
* **Corridors:** Gray pathways connecting the rooms.
* **Red Object:** A red circular object with a black top, located in the top-right quadrant.
* **Yellow Diamond:** A yellow diamond shape located in the bottom-left quadrant.
* **Green Objects:** Two green cylindrical objects, one near the center and one near the top.
* **Gray Circles:** A region filled with gray circles, resembling columns, in the central area.
* **Green Passage:** A green colored passage in the top center.
* **Red Passage:** A red colored passage in the bottom left.
### Detailed Analysis
* **Building Layout:** The layout consists of several rooms arranged in a grid-like pattern. The rooms are connected by corridors, allowing movement between them.
* **Red Object:** The red object is located in the top-right quadrant, near a corridor. It appears to be a circular object with a black top.
* **Yellow Diamond:** The yellow diamond is located in the bottom-left quadrant, within a room.
* **Green Objects:** One green object is located near the center of the layout, within the region of gray circles. The other green object is located near the top of the layout, also within the region of gray circles.
* **Gray Circles:** The gray circles are arranged in a rectangular pattern, suggesting a columned area or a structural feature.
* **Green Passage:** The green passage is located in the top center, connecting two rooms.
* **Red Passage:** The red passage is located in the bottom left, connecting two rooms.
### Key Observations
* The layout is symmetrical to some extent, with rooms and corridors arranged in a grid-like pattern.
* The objects are strategically placed within the layout, possibly indicating points of interest or obstacles.
* The gray circles create a distinct region within the layout, potentially representing a specific area or feature.
* The red and green passages may indicate entry and exit points.
### Interpretation
The image likely represents a floor plan or a maze-like structure. The objects within the layout could represent various elements, such as targets, obstacles, or points of interest. The gray circles may indicate a columned area or a structural feature. The red and green passages may indicate entry and exit points. The arrangement of the rooms and corridors suggests a deliberate design, possibly for navigation or problem-solving purposes. The image could be used in a game, simulation, or architectural design.
</details>
(b) Phase 2
<details>
<summary>plots/maze_traj3.png Details</summary>
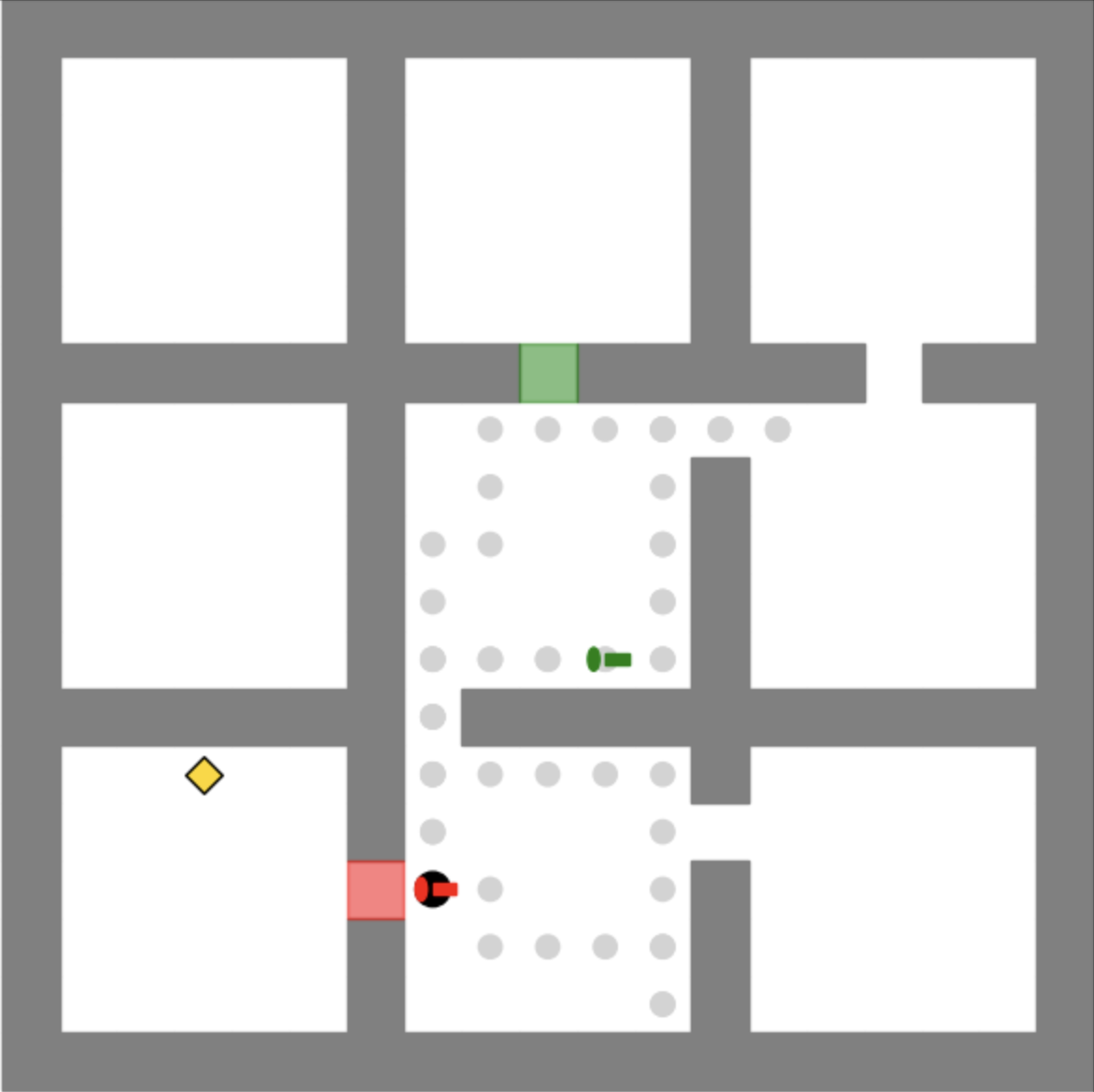
### Visual Description
## Floor Plan: Simple Room Layout
### Overview
The image depicts a simplified floor plan of a building or structure. It shows a series of rooms connected by hallways and doorways. There are several colored indicators within the plan, including green, red, and yellow markers, along with a series of gray circles in one section.
### Components/Axes
* **Walls/Structure:** Represented by thick gray lines, defining the boundaries of rooms and hallways.
* **Rooms:** White spaces enclosed by the gray walls.
* **Hallways/Doorways:** Gray areas connecting the rooms.
* **Green Marker:** Located in a hallway near the top of the plan.
* **Red Marker:** Located in a hallway near the bottom-left of the plan.
* **Yellow Diamond:** Located in a room in the bottom-left of the plan.
* **Gray Circles:** Arranged in a rectangular pattern in the central area of the plan, possibly indicating columns or some other structural element.
* **Small Green Marker:** Located within the area defined by the gray circles.
* **Small Black/Red Marker:** Located within the area defined by the gray circles, near the red marker.
### Detailed Analysis or Content Details
* The floor plan consists of several rooms arranged in a grid-like pattern.
* The gray circles form a rectangular shape with a gap in the middle, suggesting a courtyard or open space. The circles are arranged in a roughly 6x6 grid, with some missing to allow for hallways.
* The green marker at the top is positioned in a hallway connecting two rooms.
* The red marker at the bottom-left is positioned in a hallway connecting a room to the area with the gray circles.
* The yellow diamond is located in a room in the bottom-left corner of the plan.
* The small green marker is located within the area defined by the gray circles, slightly above the center.
* The small black/red marker is located within the area defined by the gray circles, near the red marker.
### Key Observations
* The floor plan appears to be a simplified representation, possibly for navigation or layout planning.
* The colored markers likely indicate specific points of interest or locations within the structure.
* The gray circles suggest a distinct area within the building, possibly an open space or courtyard.
### Interpretation
The floor plan likely represents a building with a central courtyard or open area surrounded by columns (indicated by the gray circles). The colored markers could represent entry/exit points (green and red) and a point of interest (yellow). The small green and black/red markers could represent objects or people within the courtyard. The diagram is a schematic representation, and without further context, the exact purpose and meaning of the elements are speculative.
</details>
(c) Phase 3
<details>
<summary>plots/maze_traj4.png Details</summary>
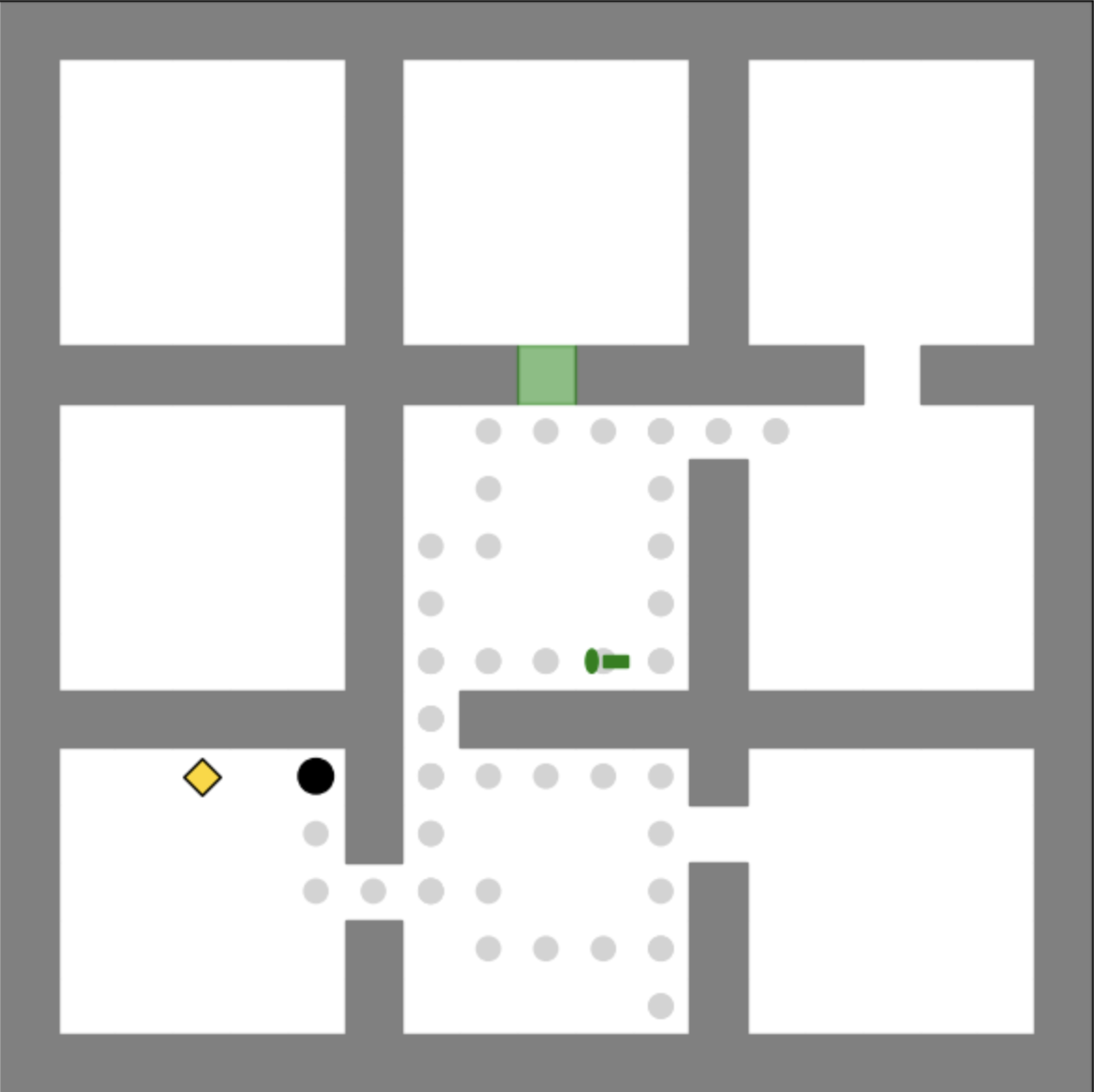
### Visual Description
## Diagram: Room Layout with Objects
### Overview
The image is a schematic diagram of a building layout, showing rooms connected by corridors. The walls are gray, and the rooms are white. There are several objects within the layout, including a green rectangle, a green capsule shape, a yellow diamond, and a black circle. A dotted gray line indicates a path.
### Components/Axes
* **Walls:** Gray lines defining the structure of the building.
* **Rooms:** White spaces enclosed by the walls.
* **Corridors:** Gray spaces connecting the rooms.
* **Green Rectangle:** Located in the top center of the diagram, spanning a corridor.
* **Green Capsule:** Located in the center-right of the diagram, within a room.
* **Yellow Diamond:** Located in the bottom-left of the diagram, within a room.
* **Black Circle:** Located in the bottom-left of the diagram, within a room, to the right of the yellow diamond.
* **Dotted Gray Line:** Indicates a path through the rooms and corridors, forming a rectangular shape in the center-right room.
### Detailed Analysis
* The building layout consists of multiple rooms arranged in a grid-like pattern.
* The green rectangle is positioned in the top center, acting as a potential marker or object of interest.
* The green capsule is located in the center-right room, possibly representing a target or object to be collected.
* The yellow diamond and black circle are located in the bottom-left room, potentially representing starting points or other objects of interest.
* The dotted gray line forms a rectangular path in the center-right room, suggesting a route or area of interest.
### Key Observations
* The diagram provides a clear representation of the building layout and the positions of the objects within it.
* The dotted gray line highlights a specific path within the center-right room.
* The objects (green rectangle, green capsule, yellow diamond, and black circle) are strategically placed within the layout.
### Interpretation
The diagram likely represents a map or layout for a game, simulation, or navigation task. The objects could represent targets, obstacles, or points of interest. The dotted gray line indicates a suggested path or area of focus. The arrangement of the rooms and corridors defines the environment in which the task is to be performed. The green rectangle could represent a starting point or a checkpoint. The green capsule could represent a goal or an object to be collected. The yellow diamond and black circle could represent starting positions or alternative paths.
</details>
(d) Phase 4
Figure A.2: An (optimal) trajectory of the maze in Figure A.1. Phase 1: the agent picks up the blue key; Phase 2: the agent opens the blue door to obtain the red key; Phase 3: the agent carries the red key to the red door; Phase 4: the agent opens the red door and reaches the objective.
A.2.2 Dataset Details
Our dataset consists of 100k training data points, 500 validation data points, and 300 data points for testing. For each data point, the structure of the prompt and response is as follows:
- [Prompt]: maze_size: $M× M$ agent: $(x_{a0},y_{a0}),$ walls: $(x_{1},y_{1}),(x_{2},y_{2}),...$ objective: $(x_{o},y_{o}),$ keys: [red_key]: $(x_{rk},y_{rk}),...$ doors: [red_door]: $(x_{rd},y_{rd}),...$
- [Response]: create-node $(x_{a1},y_{a1},f_{a1},h_{a1})$ , create-node $(x_{a2},y_{a2},f_{a2},h_{a2})$ , … agent $(x_{a1},y_{a1}),(x_{a2},y_{a2}),...,(x_{aT},y_{aT}),$
Below, we show the prompt and response for an example training data pint.
Prompt
initial_state: maze_size: 19x19 wall: (0,0), (0,1), (0,2), (0,3), (0,4), (0,5), (0,6), (0,7), (0,8), (0,9), (0,10), (0,11), (0,12), (0,13), (0,14), (0,15), (0,16), (0,17), (0,18), (1,0), (1,6), (1,12), (1,18), (2,0), (2,6), (2,12), (2,18), (3,0), (3,6), (3,12), (3,18), (4,0), (4,6), (4,12), (4,18), (5,0), (5,6), (5,12), (5,18), (6,0), (6,1), (6,3), (6,4), (6,5), (6,6), (6,7), (6,8), (6,9), (6,10), (6,11), (6,12), (6,13), (6,14), (6,15), (6,16), (6,17), (6,18), (7,0), (7,12), (7,18), (8,0), (8,6), (8,12), (8,18), (9,0), (9,6), (9,12), (9,18), (10,0), (10,6), (10,12), (10,18), (11,0), (11,6), (11,12), (11,18), (12,0), (12,1), (12,2), (12,3), (12,4), (12,6), (12,8), (12,9), (12,10), (12,11), (12,12), (12,13), (12,14), (12,15), (12,16), (12,17), (12,18), (13,0), (13,12), (13,18), (14,0), (14,6), (14,12), (14,18), (15,0), (15,6), (15,12), (15,18), (16,0), (16,6), (16,12), (16,18), (17,0), (17,6), (17,12), (17,18), (18,0), (18,1), (18,2), (18,3), (18,4), (18,5), (18,6), (18,7), (18,8), (18,9), (18,10), (18,11), (18,12), (18,13), (18,14), (18,15), (18,16), (18,17), (18,18), agent: (11,5), objective: (1,1), [red_key]: (16,1), [green_key]: (16,9), [blue_key]: (7,2), [red_door]: (12,5), [green_door]: (6,2), [blue_door]: (12,7)
Response (CoT and Answer)
create-node: (11,5), heuristics: 14, cost: 0 create-node: (11,4), heuristics: 13, cost: 1 create-node: (11,3), heuristics: 12, cost: 2 create-node: (10,3), heuristics: 11, cost: 3 create-node: (9,3), heuristics: 10, cost: 4 create-node: (9,2), heuristics: 9, cost: 5 create-node: (8,2), heuristics: 8, cost: 6 create-node: (7,2), heuristics: 7, cost: 7 create-node: (7,2), heuristics: 7, cost: 8 create-node: (7,3), heuristics: 8, cost: 9 create-node: (7,4), heuristics: 9, cost: 10 create-node: (7,5), heuristics: 10, cost: 11 create-node: (7,6), heuristics: 11, cost: 12 create-node: (7,7), heuristics: 12, cost: 13 create-node: (8,7), heuristics: 13, cost: 14 create-node: (9,7), heuristics: 14, cost: 15 create-node: (10,7), heuristics: 15, cost: 16 create-node: (11,7), heuristics: 16, cost: 17 create-node: (11,7), heuristics: 16, cost: 18 create-node: (12,7), heuristics: 17, cost: 19 create-node: (13,7), heuristics: 18, cost: 20 create-node: (14,7), heuristics: 19, cost: 21 create-node: (14,8), heuristics: 20, cost: 22 create-node: (15,8), heuristics: 21, cost: 23 create-node: (15,9), heuristics: 22, cost: 24 create-node: (16,9), heuristics: 23, cost: 25 create-node: (16,9), heuristics: 23, cost: 26 create-node: (16,8), heuristics: 22, cost: 27 create-node: (16,7), heuristics: 21, cost: 28 create-node: (15,7), heuristics: 20, cost: 29 create-node: (14,7), heuristics: 19, cost: 30 create-node: (13,7), heuristics: 18, cost: 31 create-node: (12,7), heuristics: 17, cost: 32 create-node: (11,7), heuristics: 16, cost: 33 create-node: (10,7), heuristics: 15, cost: 34 create-node: (9,7), heuristics: 14, cost: 35 create-node: (8,7), heuristics: 13, cost: 36 create-node: (7,7), heuristics: 12, cost: 37 create-node: (7,6), heuristics: 11, cost: 38 create-node: (7,5), heuristics: 10, cost: 39 create-node: (7,4), heuristics: 9, cost: 40 create-node: (7,3), heuristics: 8, cost: 41 create-node: (7,2), heuristics: 7, cost: 42 create-node: (7,2), heuristics: 7, cost: 43 create-node: (6,2), heuristics: 6, cost: 44 create-node: (5,2), heuristics: 5, cost: 45 create-node: (5,1), heuristics: 4, cost: 46 create-node: (4,1), heuristics: 3, cost: 47 create-node: (3,1), heuristics: 2, cost: 48 create-node: (2,1), heuristics: 1, cost: 49 create-node: (1,1), heuristics: 0, cost: 50 agent: (11,5), current_key: none, remaining_key: [red_key]: [green_key]: [blue_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (11,4), current_key: none, remaining_key: [red_key]: [green_key]: [blue_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (11,3), current_key: none, remaining_key: [red_key]: [green_key]: [blue_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (10,3), current_key: none, remaining_key: [red_key]: [green_key]: [blue_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (9,3), current_key: none, remaining_key: [red_key]: [green_key]: [blue_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (9,2), current_key: none, remaining_key: [red_key]: [green_key]: [blue_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (8,2), current_key: none, remaining_key: [red_key]: [green_key]: [blue_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (7,2), current_key: none, remaining_key: [red_key]: [green_key]: [blue_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (7,2), current_key: [blue_key], remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (7,3), current_key: [blue_key], remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (7,4), current_key: [blue_key], remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (7,5), current_key: [blue_key], remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (7,6), current_key: [blue_key], remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (7,7), current_key: [blue_key], remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (8,7), current_key: [blue_key], remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (9,7), current_key: [blue_key], remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (10,7), current_key: [blue_key], remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (11,7), current_key: [blue_key], remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: [blue_door]: agent: (11,7), current_key: none, remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: agent: (12,7), current_key: none, remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: agent: (13,7), current_key: none, remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: agent: (14,7), current_key: none, remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: agent: (14,8), current_key: none, remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: agent: (15,8), current_key: none, remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: agent: (15,9), current_key: none, remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: agent: (16,9), current_key: none, remaining_key: [red_key]: [green_key]: remaining_door: [red_door]: [green_door]: agent: (16,9), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (16,8), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (16,7), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (15,7), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (14,7), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (13,7), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (12,7), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (11,7), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (10,7), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (9,7), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (8,7), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (7,7), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (7,6), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (7,5), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (7,4), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (7,3), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (7,2), current_key: [green_key], remaining_key: [red_key]: remaining_door: [red_door]: [green_door]: agent: (7,2), current_key: none, remaining_key: [red_key]: remaining_door: [red_door]: agent: (6,2), current_key: none, remaining_key: [red_key]: remaining_door: [red_door]: agent: (5,2), current_key: none, remaining_key: [red_key]: remaining_door: [red_door]: agent: (5,1), current_key: none, remaining_key: [red_key]: remaining_door: [red_door]: agent: (4,1), current_key: none, remaining_key: [red_key]: remaining_door: [red_door]: agent: (3,1), current_key: none, remaining_key: [red_key]: remaining_door: [red_door]: agent: (2,1), current_key: none, remaining_key: [red_key]: remaining_door: [red_door]: agent: (1,1), current_key: none, remaining_key: [red_key]: remaining_door: [red_door]:
The prompt describes the maze in a structured language. The maze size $M=m(n+1)+1$ (e.g., in Figure A.1, the maze size $M=19$ ). The positions of walls are $(x_{1},y_{1}),(x_{2},y_{2}),...$ , and so on. The position of the agent in time step $t$ is $(x_{at},y_{at})$ , where $t=0$ corresponds to the initial position The position of the objective is $(x_{o},y_{o})$ , and the position of keys and doors in color $c$ (where $c$ = $r$ , $g$ , $b$ ) are $(x_{ck},y_{ck})$ and $(x_{cd},y_{cd})$ , respectively. The response describes an optimal path (i.e., with minimal total times steps $T$ ) for the agent to reach the objective.
A.2.3 Model Details
Following Su et al. (2024); Lehnert et al. (2024), we employ a similar encode-decoder transformer architecture with rotary embeddings and no drop-out. Our model consisted of 6 layers with 3 attention heads, and the embedding size is 64.
A.3 ProntoQA and ProsQA
We used the pretrained GPT-2 model which has the following parameters:
| Number of Layers (Transformer Blocks) | 12 |
| --- | --- |
| Hidden Size (Embedding Size) | 768 |
| Number of Attention Heads | 12 |
| Vocabulary Size | 50,257 |
| Total Number of Parameters | 117 million |
Table A.1: Hyperparameters of the pretrained GPT-2 model used for ProntoQA and ProsQA.
A.4 LLM experiments
We use the Llama Cookbook https://github.com/meta-llama/llama-cookbook codebase to fine-tune the Llama models.
As described in Section 4.2, we use a batch size of 32 with a sequence packing of 4096. We experiment with different learning rates $10^{-5},2.5× 10^{-5},5× 10^{-5},10^{-4}$ and select the one with the lowest validation error. The final choices are $10^{-5}$ for Llama-3.2-8B and $2.5× 10^{-5}$ for Llama-3.2-1B and Llama-3.2-3B.
Appendix B Notations
Table B.1 summarizes the notations we used throughout the paper.
| $X=P\oplus C\oplus S$ $P$ $p_{i}$ | input text sample where $\oplus$ means concatenation prompt of length $t_{p}$ the $i$ -th token of prompt (in text) |
| --- | --- |
| $C$ | reasoning trace of length $t_{c}$ |
| $c_{i}$ | the $i$ -th token of trace (in text) |
| $S$ | solution of length $t_{s}$ |
| $s_{i}$ | the $i$ -th token of solution (in text) |
| $Z$ | the complete latent reasoning traces of length $t_{z}$ |
| $z_{i}$ | the $i$ -th token of latent trace |
| $r=t_{c}/t_{z}$ | compression rate |
| $m$ | number of trace tokens to be replaced by latent tokens during training |
| ${\widetilde{X}}$ | modified input with mixed text and latent tokens |
| $\mathcal{E}$ | codebook of VQ-VAE |
| $e_{i}$ | the $i$ -th vector in the codebook, which corresponds to the $i$ -th latent token |
| $d$ | dimension of $e_{i}$ s |
| ${\mathcal{V}}$ | vocabulary of text tokens |
| $L$ | chunk size |
| ${f_{\text{enc}}}(·)$ | encodes a chunk of $L$ text tokens to $\frac{L}{r}$ embedding vectors |
| $\bar{X}=\bar{x}_{1},...,\bar{x}_{\frac{L}{r}}$ | embedding vectors of $X$ outputted by ${f_{\text{enc}}}(·)$ |
| $q(·)$ | quantization operator that replaces, e.g., $\bar{x}_{1}$ by its nearest neighbor in ${\mathcal{E}}$ : |
| $g(\bar{x}_{1})=\operatorname*{argmin}_{e_{i}∈{\mathcal{E}}}\left\|e_{i}-\bar{x}_{1}\right\|^{2}$ | |
| $g(·)$ | maps prompt to a $d$ -dimensional embedding vector |
| ${f_{\text{dec}}}(·,·)$ | decodes $L/r$ quantized embedding vectors in ${\mathcal{E}}$ back to text tokens, |
| conditioning on prompt embedding generated by $g(·)$ | |
Table B.1: Mathematical notations used throughout the paper.
Appendix C Details of Attention Weights Analysis
C.1 Generated Responses
Question 1
Prompt: What is the positive difference between $120%$ of 30 and $130%$ of 20?
Response of Our Latent Approach: <boLatent> <Latent-code-278> <Latent-code-416> <eoLatent> % of 30 and $130%$ of 20. First, let’s calculate $120%$ of 30: $120%$ of 30 = 1.2 x 30 = 36. Next, let’s calculate $130%$ of 20: $130%$ of 20 = 1.3 x 20 = 26. Now, let’s find the positive difference between 36 and 26: 36 - 26 = 10
The answer is 10.
Response of Baseline (CoT): To find the positive difference between $120\%$ of 30 and $130\%$ of 20, we need to calculate each value first. $120\%$ of 30 is calculated as 1.2 * 30 = 36. $130\%$ of 20 is calculated as 1.3 * 20 = 26. Now, we need to find the positive difference between these two values. To do this, we subtract the smaller value from the larger value: 36 - 26 = 10.
The final answer is 10.
Question 2
Prompt: Mark has $50 in his bank account. He earns $10 per day at his work. If he wants to buy a bike that costs $300, how many days does Mark have to save his money?
Response of Our Latent Approach: <boLatent> <Latent-code-123> <eoLatent> need to calculate how much more money he needs to buy the bike and then divide that amount by his daily earnings. The bike costs $300, and Mark already has $50. So, he needs: $300 (bike cost) - $50 (current savings) = $250 (more money needed)
Mark earns $10 per day. To find out how many days he needs to save, we divide the amount he needs by his daily earnings: $250 (more money needed) / $10 (daily earnings) = 25 days. The answer is 25.
Response of Baseline (CoT): To find out how many days Mark needs to save his money, we need to subtract the cost of the bike from the amount of money he has, then divide the result by the amount he earns per day. Mark has $50 and wants to buy a bike that costs $300. First, subtract the cost of the bike from the amount of money Mark has: $50 - $300 = -$250 Since Mark can’t have a negative amount of money, we need to convert the negative amount to a positive one by adding the cost of the bike to the amount of money Mark has: $50 + $300 = $350 Now, divide the result by the amount Mark earns per day: $350 / $10 = 35
The final answer is 35.
Appendix D Other Text Generation Examples
Example Generation of Our Latent Approach
Prompt: Evaluate the expression $a^{3}· a^{2}$ if $a=5$ Generated Text: <boLatent> <Latent-code-130> <eoLatent> We can use the rule of exponents that states $a^{m}· a^{n}=a^{m+n}$ . So, $a^{3}· a^{2}=a^{3+2}=a^{5}$ . Now, we substitute $a=5$ into the expression: $5^{5}$ . $5^{5}=5· 5· 5· 5· 5=3125$ . The answer is 3125.
Example Generation of Our Latent Approach
Prompt: Compute $\dbinom{15}{2}$ . Generated Text: <boLatent> <Latent-code-888> <Latent-code-744> <Latent-code-196> <Latent-code-92> <Latent-code-557> <eoLatent> $\frac{15!}{2!(15-2)!}=\frac{15!}{2!13!}$ To simplify this expression, we can cancel out the common factors in the numerator and denominator: $\dbinom{15}{2}=\frac{15× 14}{2}=105$ . The answer is 105.
Example Generation of Our Latent Approach
Question: How many vertical asymptotes does the graph of $y=\frac{2}{x^{2}+x-6}$ have? Answer: <boLatent> <Latent-code-773> <Latent-code-514> <eoLatent> the denominator, which is $x^{2}+x-6$ . We can factor this quadratic expression as $(x+3)(x-2)$ . Now, we can see that the denominator will be equal to zero when either $(x+3)=0$ or $(x-2)=0$ . Solving for these values, we get $x=-3$ or $x=2$ . Therefore, the vertical asymptotes of the graph of $y=\\
frac{2}{x^{2}+x-6}$ are $x=-3$ and $x=2$ . Since there are two distinct values of $x$ that make the denominator equal to zero, the graph has 2 vertical asymptotes. The answer is 2.
Example Generation of Our Latent Approach
Question: If there exists an ordered numbering of the nodes such that for each node there are no links going to a lower-numbered node, then there are no directed cycles in a directed graph. True or false? Answer: <boLatent> <Latent-code-526> <eoLatent> a directed graph. A directed cycle is a sequence of nodes in a graph, where each node is connected to the next node by a directed edge, and the last node is connected back to the first node by a directed edge. Now, let’s consider the given condition: ”If there exists an ordered numbering of the nodes such that for each node there are no links going to a lower-numbered node, then there are no directed cycles in a directed graph.” This condition essentially means that if we number the nodes in a specific way, and there are no links going to a lower-numbered node, then there are no directed cycles in the graph. To see why this is true, let’s consider what would happen if there were a directed cycle in the graph. If there were a directed cycle, then there would be a sequence of nodes where each node is connected to the next node by a directed edge, and the last node is connected back to the first node by a directed edge. However, if we number the nodes in the way described, and there are no links going to a lower-numbered node, then this directed cycle would be impossible. This is because the last node in the cycle would have to be connected to a lower-numbered node, which would violate the condition. Therefore, if we number the nodes in this way, then there can be no directed cycles in the graph. The answer is True.
Appendix E Interpreability Examples
To examine the interpretability of the latent-codes, we use the decoder from the trained VQ-VAE to convert the latent-code back to the text space. In general, it is interpretable. We bolded the decoded part of the text from the latent code, which is delimited by the <boLatent> … <eoLatent> tags. In general, we find the latent tokens capture long/verbose sentences which may trigger useful follow-up thinking pattern.
Example Generation of Our Latent Approach
Prompt: In a 8 fluid ounce bottle of Vitamin Water, there are 125 calories. How many calories would be contained in a 12 fluid ounce bottle? Express your answer in decimal form. Generated Text: <boLatent> To convert the number from in in a 8 ounces <eoLatent> we need to find the ratio of calories to fluid ounces in the 8 fluid ounce bottle and then multiply it by 12. First, let’s find the ratio of calories to fluid ounces in the 8 fluid ounce bottle: Calories per fluid ounce = Total calories / Total fluid ounces = 125 calories / 8 fluid ounces = 15.625 calories per fluid ounce Now, let’s multiply this ratio by 12 fluid ounces to find the total calories in the 12 fluid ounce bottle: Total calories in 12 fluid ounces = Calories per fluid ounce * Total fluid ounces = 15.625 calories per fluid ounce * 12 fluid ounces = 187.5 calories The answer is 187.5.
Here, in the example above, the decoded latent token ”To convert the number from in in a 8 ounces” captures the core concept of proportional conversion from the 8-ounce bottle to the 12-ounce bottle. Despite its grammar mistake, it still precisely states the mathematical operation needed to solve the problem.
Example Generation of Our Latent Approach
Prompt: What is the greatest common divisor of 315 and 108? Generated Text: <boLatent> We find the greatest of CD of::63 common find <eoLatent> we can use the Euclidean algorithm. Here’s how to do it: 1. Divide 315 by 108: 315 = 108 × 2 + 99 2. Divide 108 by 99: 108 = 99 × 1 + 9 3. Divide 99 by 9: 99 = 9 × 11 + 0 Since the remainder is 0, the GCD is the divisor in the last step, which is 9. The answer is 9.
Here, in the example above, the decoded latent token ”We find the greatest of CD of::63 common find” abstracts the initiation of the Euclidean algorithm, leading directly into the process that determines the GCD.
Appendix F Additional Experiments
We present results of different approaches for fine-tuning a Llama-3.1-8B model on the DART-MATH (Tong et al., 2024) dataset. The observations are similar to those we presented in Section 4.2.
Model (Dart-Math) In-Domain Out-of-Domain Average math GSM8K Fresh-Gaokao-Math-2023 DeepMind-Mathematics College-Math Olympia-Math TheoremQA All Datasets Llama-3.1-8B Sol-only 13.3 16.4 0.0 18.2 15.9 4.7 16.9 12.2 CoT 43.1 84.5 30.7 47.8 45.7 10.1 21.2 40.4 iCoT 35.2 61.8 30.0 30.6 37.6 8.3 19.5 31.8 Latent (Ours) 43.2 ( $\uparrow$ +0.1) 83.9 33.3 ( $\uparrow$ +2.6) 44.7 47.1 ( $\uparrow$ +1.4) 13.3 ( $\uparrow$ +3.2) 20.3 40.8 ( $\uparrow$ +0.4)
Table F.1: Our approach surpasses the iCoT and Sol-Only baseline when trained on the DART-MATH dataset (Tong et al., 2024), while marginally outperforming the CoT baseline.
Model (Dart-Math) In-Domain (# of tokens) Out-of-Domain (# of tokens) Average (# of tokens) math GSM8K Fresh-Gaokao-Math-2023 DeepMind-Mathematics College-Math Olympia-Math TheoremQA All Datasets Llama-3.1-8B Sol-only 10.9 8.1 10.2 8.4 11.2 16.1 16.13 11.6 CoT 522.7 181.0 628.8 343.2 486.3 893.7 648.3 529.1 iCoT 397.1 118.6 440.8 227.9 321.9 614.4 485.7 372.3 Latent (Ours) 489.1 ( $\downarrow$ -6.4%) 163.5 ( $\downarrow$ -9.7%) 462.1 ( $\downarrow$ -26.5%) 265.6 ( $\downarrow$ -22.6%) 396.3 ( $\downarrow$ -18.5%) 801.3 ( $\downarrow$ -10.3%) 591.3 452.7 ( $\downarrow$ -16%)
Table F.2: The average number of tokens in the generated responses. Our approach generates shorter reasoning traces then the CoT baseline. $\downarrow$ -: Trace length reduction rate compared with CoT.