# 1 Scaling by Thinking in Continuous Space
spacing=nonfrench
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping 1 Sean McLeish 2 Neel Jain 2 John Kirchenbauer 2 Siddharth Singh 2 Brian R. Bartoldson 3 Bhavya Kailkhura 3 Abhinav Bhatele 2 Tom Goldstein 2 footnotetext: 1 ELLIS Institute Tübingen, Max-Planck Institute for Intelligent Systems, Tübingen AI Center 2 University of Maryland, College Park 3 Lawrence Livermore National Laboratory. Correspondence to: Jonas Geiping, Tom Goldstein < jonas@tue.ellis.eu, tomg@umd.edu >.
Abstract
We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling to arbitrary depth at test-time. This stands in contrast to mainstream reasoning models that scale up compute by producing more tokens. Unlike approaches based on chain-of-thought, our approach does not require any specialized training data, can work with small context windows, and can capture types of reasoning that are not easily represented in words. We scale a proof-of-concept model to 3.5 billion parameters and 800 billion tokens. We show that the resulting model can improve its performance on reasoning benchmarks, sometimes dramatically, up to a computation load equivalent to 50 billion parameters.
Model: huggingface.co/tomg-group-umd/huginn-0125 Code and Data: github.com/seal-rg/recurrent-pretraining
Humans naturally expend more mental effort solving some problems than others. While humans are capable of thinking over long time spans by verbalizing intermediate results and writing them down, a substantial amount of thought happens through complex, recurrent firing patterns in the brain, before the first word of an answer is uttered.
Early attempts at increasing the power of language models focused on scaling model size, a practice that requires extreme amounts of data and computation. More recently, researchers have explored ways to enhance the reasoning capability of models by scaling test time computation. The mainstream approach involves post-training on long chain-of-thought examples to develop the model’s ability to verbalize intermediate calculations in its context window and thereby externalize thoughts.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Line Chart: Scaling up Test-Time Compute with Recurrent Depth
### Overview
The chart illustrates the relationship between test-time compute recurrence (x-axis) and accuracy (y-axis) for three datasets: ARC challenge, GSM8K CoT, and OpenBookQA. Accuracy improves with increased compute recurrence, with distinct performance patterns across datasets.
### Components/Axes
- **X-axis**: "Test-Time Compute Recurrence" (logarithmic scale: 1, 4, 8, 12, 20, 32, 48, 64)
- **Y-axis**: "Accuracy (%)" (linear scale: 0–50%)
- **Legend**: Located in the bottom-right corner, mapping colors to datasets:
- Blue: ARC challenge
- Orange: GSM8K CoT
- Green: OpenBookQA
### Detailed Analysis
1. **ARC Challenge (Blue Line)**:
- Starts at ~22% accuracy at 1x compute.
- Gradually increases to ~45% at 64x compute.
- Steady upward trend with minimal fluctuations.
2. **GSM8K CoT (Orange Line)**:
- Begins near 0% at 1x compute.
- Sharp upward spike after 8x compute, reaching ~47% at 64x.
- Highest accuracy among datasets at higher compute levels.
3. **OpenBookQA (Green Line)**:
- Starts at ~25% at 1x compute.
- Gradual increase to ~42% at 64x compute.
- Flattens near 42% after 32x compute, showing diminishing returns.
### Key Observations
- **GSM8K CoT** demonstrates the most significant performance gains with increased compute, particularly after 8x recurrence.
- **ARC challenge** shows consistent improvement but plateaus near 45% at 64x compute.
- **OpenBookQA** exhibits the lowest accuracy gains, stabilizing at ~42% despite higher compute.
- All datasets converge near 45–47% accuracy at 64x compute, suggesting diminishing returns at extreme compute levels.
### Interpretation
The data suggests that scaling test-time compute improves accuracy across all datasets, but the rate of improvement varies. GSM8K CoT benefits disproportionately from increased compute, likely due to its reliance on iterative reasoning. OpenBookQA's plateau indicates potential architectural or data limitations. The convergence at high compute levels implies that further scaling may yield minimal additional gains, highlighting the importance of optimizing compute allocation rather than purely increasing it.
</details>
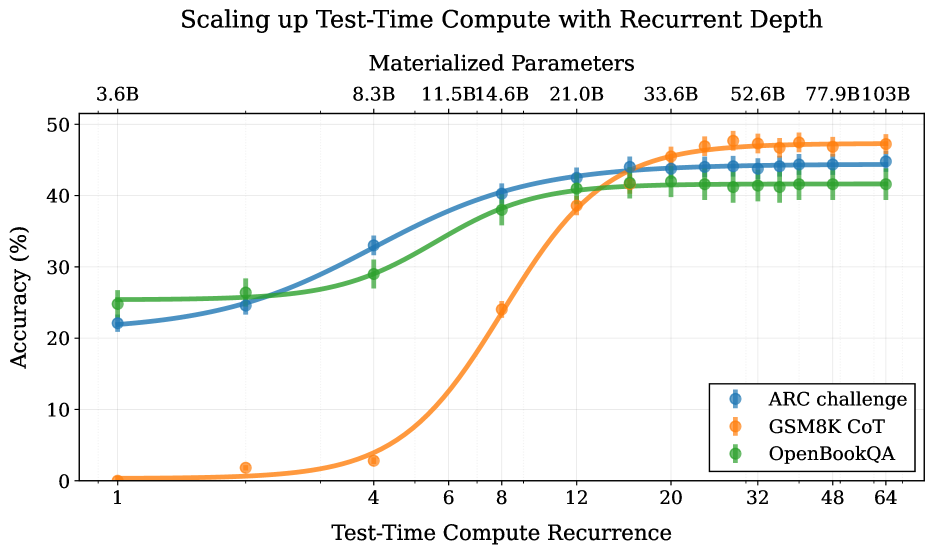
Figure 1: We train a 3.5B parameter language model with depth recurrence. At test time, the model can iterate longer to use more compute and improve its performance. Instead of scaling test-time reasoning by “verbalizing” in long Chains-of-Thought, the model improves entirely by reasoning in latent space. Tasks that require less reasoning like OpenBookQA converge quicker than tasks like GSM8k, which effectively make use of more compute.
However, the constraint that expensive internal reasoning must always be projected down to a single verbalized next token appears wasteful; it is plausible that models could be more competent if they were able to natively “think” in their continuous latent space. One way to unlock this untapped dimension of additional compute involves adding a recurrent unit to a model. This unit runs in a loop, iteratively processing and updating its hidden state and enabling computations to be carried on indefinitely. While this is not currently the dominant paradigm, this idea is foundational to machine learning and has been (re-)discovered in every decade, for example as recurrent neural networks, diffusion models, and as universal or looped transformers.
In this work, we show that depth-recurrent language models can learn effectively, be trained in an efficient manner, and demonstrate significant performance improvements under the scaling of test-time compute. Our proposed transformer architecture is built upon a latent depth-recurrent block that is run for a randomly sampled number of iterations during training. We show that this paradigm can scale to several billion parameters and over half a trillion tokens of pretraining data. At test-time, the model can improve its performance through recurrent reasoning in latent space, enabling it to compete with other open-source models that benefit from more parameters and training data. Additionally, we show that recurrent depth models naturally support a number of features at inference time that require substantial tuning and research effort in non-recurrent models, such as per-token adaptive compute, (self)-speculative decoding, and KV-cache sharing. We finish out our study by tracking token trajectories in latent space, showing that a number of interesting computation behaviors simply emerge with scale, such as the model rotating shapes in latent space for numerical computations.
2 Why Train Models with Recurrent Depth?
Recurrent layers enable a transformer model to perform arbitrarily many computations before emitting a token. In principle, recurrent mechanisms provide a simple solution for test-time compute scaling. Compared to a more standard approach of long context reasoning OpenAI (2024); DeepSeek-AI et al. (2025), latent recurrent thinking has several advantages.
- Latent reasoning does not require construction of bespoke training data. Chain-of-thought reasoning requires the model to be trained on long demonstrations that are constructed in the domain of interest. In contrast, our proposed latent reasoning models can train with a variable compute budget, using standard training data with no specialized demonstrations, and enhance their abilities at test-time if given additional compute.
- Latent reasoning models require less memory for training and inference than chain-of-thought reasoning models. Because the latter require extremely long context windows, specialized training methods such as token-parallelization Liu et al. (2023a) may be needed.
- Recurrent-depth networks perform more FLOPs per parameter than standard transformers, significantly reducing communication costs between accelerators at scale. This especially enables higher device utilization when training with slower interconnects.
- By constructing an architecture that is compute-heavy and small in parameter count, we hope to set a strong prior towards models that solve problems by “thinking”, i.e. by learning meta-strategies, logic and abstraction, instead of memorizing. The strength of recurrent priors for learning complex algorithms has already been demonstrated in the “deep thinking” literature Schwarzschild et al. (2021b); Bansal et al. (2022); Schwarzschild et al. (2023).
On a more philosophical note, we hope that latent reasoning captures facets of human reasoning that defy verbalization, such as spatial thinking, physical intuition or (motor) planning. Over many iterations of the recurrent process, reasoning in a high-dimensional vector space would enable the deep exploration of multiple directions simultaneously, instead of linear thinking, leading to a system capable of exhibiting novel and complex reasoning behavior.
Scaling compute in this manner is not at odds with scaling through extended (verbalized) inference scaling (Shao et al., 2024), or scaling parameter counts in pretraining (Kaplan et al., 2020), we argue it may build a third axis on which to scale model performance.
———————— Table of Contents ————————
- Section 3 introduces our latent recurrent-depth model architecture and training objective.
- Section 4 describes the data selection and engineering of our large-scale training run on Frontier, an AMD cluster.
- Section 5 reports benchmark results, showing how the model improves when scaling inference compute.
- Section 6 includes several application examples showing how recurrent models naturally simplify LLM usecases.
- Section 7 visualizes what computation patterns emerge at scale with this architecture and training objective, showing that context-dependent behaviors emerge in latent space, such as “orbiting” when responding to prompts requiring numerical reasoning.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Block Diagram: Sequence-to-Sequence Processing Architecture
### Overview
The diagram illustrates a computational architecture for processing sequential input ("Hello") into output ("World") using a combination of Prelude, Recurrent Blocks, and Coda components. The system employs residual connections and input injection mechanisms.
### Components/Axes
1. **Legend** (bottom-left):
- Blue: Prelude (P)
- Green: Recurrent Block (R)
- Red: Coda (C)
- Dotted lines: Residual Stream (e)
- Solid arrows: Main data flow
2. **Key Elements**:
- Input: "Hello" (left)
- Output: "World" (right)
- Residual connections: Dashed lines labeled "e"
- Input Injection: Dashed arrow labeled "Input Injection"
- Residual Stream: Solid arrow labeled "S_R"
### Detailed Analysis
1. **Flow Path**:
- "Hello" → P (Prelude) → R₁ (Recurrent Block 1) → R₂ (Recurrent Block 2) → ... → Rₙ (Final Recurrent Block) → C (Coda) → "World"
- Residual connections (e) bypass each R block to subsequent blocks
- Final residual stream (S_R) connects last R block to C
2. **Component Relationships**:
- **Prelude (P)**: Initial processing unit receiving raw input
- **Recurrent Blocks (R)**: Sequential processing units with internal state (s₀, s₁, ..., s_R)
- **Coda (C)**: Final output generator
- Residual streams enable gradient propagation through deep networks
### Key Observations
1. **Residual Architecture**: Multiple residual connections (e) between R blocks suggest skip connections for improved gradient flow
2. **State Progression**: Internal states (s₀ → s₁ → ... → s_R) indicate sequential memory maintenance
3. **Input Injection**: External information can be injected at any processing stage
4. **Output Transformation**: "Hello" → "World" implies sequence-to-sequence mapping capability
### Interpretation
This architecture resembles a Transformer-based encoder-decoder model with residual connections, optimized for:
1. **Long Sequence Handling**: Recurrent blocks with residual streams mitigate vanishing gradient problems
2. **Contextual Processing**: Input injection allows mid-sequence modifications
3. **Efficient Training**: Residual connections enable deeper networks without performance degradation
4. **Sequence Generation**: Final Coda component suggests autoregressive output generation
The "Hello" → "World" transformation exemplifies a basic sequence-to-sequence task, potentially representing text generation, translation, or speech synthesis systems. The residual stream (S_R) acts as a memory buffer preserving critical information across processing stages.
</details>
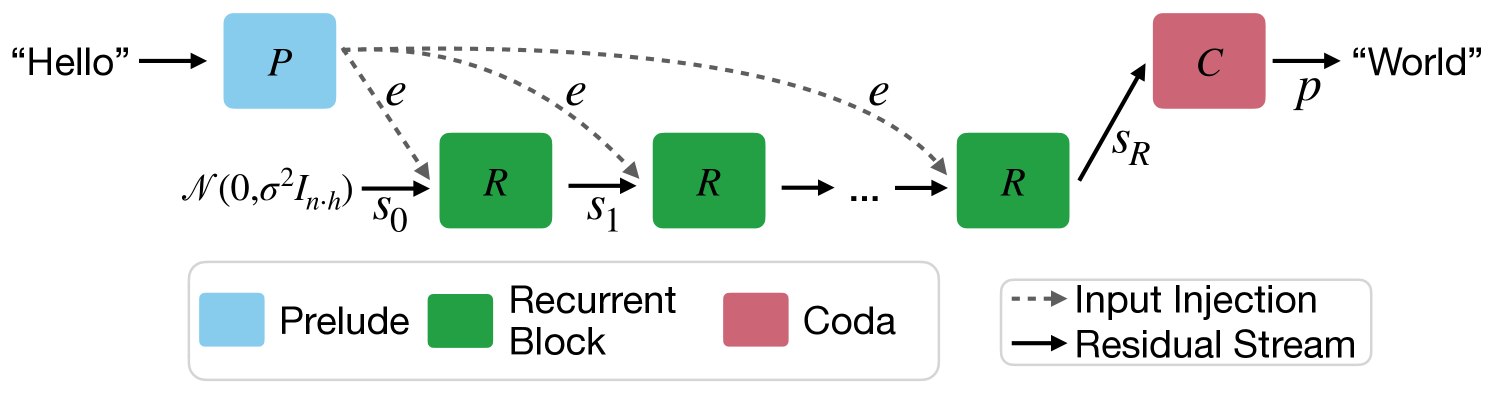
Figure 2: A visualization of the Architecture, as described in Section 3. Each block consists of a number of sub-layers. The blue prelude block embeds the inputs into latent space, where the green shared recurrent block is a block of layers that is repeated to compute the final latent state, which is decoded by the layers of the red coda block.
3 A scalable recurrent architecture
In this section we will describe our proposed architecture for a transformer with latent recurrent depth, discussing design choices and small-scale ablations. A diagram of the architecture can be found in Figure 2. We always refer to the sequence dimension as $n$ , the hidden dimension of the model as $h$ , and its vocabulary as the set $V$ .
3.1 Macroscopic Design
The model is primarily structured around decoder-only transformer blocks (Vaswani et al., 2017; Radford et al., 2019). However these blocks are structured into three functional groups, the prelude $P$ , which embeds the input data into a latent space using multiple transformer layers, then the core recurrent block $R$ , which is the central unit of recurrent computation modifying states $\mathbf{s}∈\mathbb{R}^{n× h}$ , and finally the coda $C$ , which un-embeds from latent space using several layers and also contains the prediction head of the model. The core block is set between the prelude and coda blocks, and by looping the core we can put an indefinite amount of verses in our song.
Given a number of recurrent iterations $r$ , and a sequence of input tokens $\mathbf{x}∈ V^{n}$ these groups are used in the following way to produce output probabilities $\mathbf{p}∈\mathbb{R}^{n×|V|}$
| | $\displaystyle\mathbf{e}$ | $\displaystyle=P(\mathbf{x})$ | |
| --- | --- | --- | --- |
where $\sigma$ is some standard deviation for initializing the random state. This process is shown in Figure 2. Given an init random state $\mathbf{s}_{0}$ , the model repeatedly applies the core block $R$ , which accepts the latent state $\mathbf{s}_{i-1}$ and the embedded input $\mathbf{e}$ and outputs a new latent state $\mathbf{s}_{i}$ . After finishing all iterations, the coda block processes the last state and produces the probabilities of the next token.
This architecture is based on deep thinking literature, where it is shown that injecting the latent inputs $\mathbf{e}$ in every step (Bansal et al., 2022) and initializing the latent vector with a random state stabilizes the recurrence and promotes convergence to a steady state independent of initialization, i.e. path independence (Anil et al., 2022).
Motivation for this Design.
This recurrent design is the minimal setup required to learn stable iterative operators. A good example is gradient descent of a function $E(\mathbf{x},\mathbf{y})$ , where $\mathbf{x}$ may be the variable of interest and $\mathbf{y}$ the data. Gradient descent on this function starts from an initial random state, here $\mathbf{x}_{0}$ , and repeatedly applies a simple operation (the gradient of the function it optimizes), that depends on the previous state $\mathbf{x}_{k}$ and data $\mathbf{y}$ . Note that we need to use $\mathbf{y}$ in every step to actually optimize our function. Similarly we repeatedly inject the data $\mathbf{e}$ in our set-up in every step of the recurrence. If $\mathbf{e}$ was provided only at the start, e.g. via $\mathbf{s}_{0}=\mathbf{e}$ , then the iterative process would not be stable Stable in the sense that $R$ cannot be a monotone operator if it does not depend on $\mathbf{e}$ , and so cannot represent gradient descent on strictly convex, data-dependent functions, (Bauschke et al., 2011), as its solution would depend only on its boundary conditions.
The structure of using several layers to embed input tokens into a hidden latent space is based on empirical results analyzing standard fixed-depth transformers (Skean et al., 2024; Sun et al., 2024; Kaplan et al., 2024). This body of research shows that the initial and the end layers of LLMs are noticeably different, whereas middle layers are interchangeable and permutable. For example, Kaplan et al. (2024) show that within a few layers standard models already embed sub-word tokens into single concepts in latent space, on which the model then operates.
**Remark 3.1 (Is this a Diffusion Model?)**
*This iterative architecture will look familiar to the other modern iterative modeling paradigm, diffusion models (Song and Ermon, 2019), especially latent diffusion models (Rombach et al., 2022). We ran several ablations with iterative schemes even more similar to diffusion models, such as $\mathbf{s}_{i}=R(\mathbf{e},\mathbf{s}_{i-1})+\mathbf{n}$ where $\mathbf{n}\sim\mathcal{N}(\mathbf{0},\sigma_{i}I_{n· h})$ , but find the injection of noise not to help in our preliminary experiments, which is possibly connected to our training objective. We also evaluated and $\mathbf{s}_{i}=R_{i}(\mathbf{e},\mathbf{s}_{i-1})$ , i.e. a core block that takes the current step as input (Peebles and Xie, 2023), but find that this interacts badly with path independence, leading to models that cannot extrapolate.*
3.2 Microscopic Design
Within each group, we broadly follow standard transformer layer design. Each block contains multiple layers, and each layer contains a standard, causal self-attention block using RoPE (Su et al., 2021) with a base of $50000$ , and a gated SiLU MLP (Shazeer, 2020). We use RMSNorm (Zhang and Sennrich, 2019) as our normalization function. The model has learnable biases on queries and keys, and nowhere else. To stabilize the recurrence, we order all layers in the following “sandwich” format, using norm layers $n_{i}$ , which is related, but not identical to similar strategies in (Ding et al., 2021; Team Gemma et al., 2024):
| | $\displaystyle\hat{\mathbf{x}_{l}}=$ | $\displaystyle n_{2}\left(\mathbf{x}_{l-1}+\textnormal{Attn}(n_{1}(\mathbf{x}_{%
l-1}))\right)$ | |
| --- | --- | --- | --- |
While at small scales, most normalization strategies, e.g. pre-norm, post-norm and others, work almost equally well, we ablate these options and find that this normalization is required to train the recurrence at scale Note also that technically $n_{3}$ is superfluous, but we report here the exact norm setup with which we trained the final model..
Given an embedding matrix $E$ and embedding scale $\gamma$ , the prelude block first embeds input tokens $\mathbf{x}$ as $\gamma E(\mathbf{x})$ , and then to applies $l_{P}$ many prelude layers with the layout described above.
Our core recurrent block $R$ starts with an adapter matrix $A:\mathbb{R}^{2h}→\mathbb{R}^{h}$ mapping the concatenation of $\mathbf{s}_{i}$ and $\mathbf{e}$ into the hidden dimension $h$ (Bansal et al., 2022). While re-incorporation of initial embedding features via addition rather than concatenation works equally well for smaller models, we find that concatenation works best at scale. This is then fed into $l_{R}$ transformer layers. At the end of the core block the output is again rescaled with an RMSNorm $n_{c}$ .
The coda contains $l_{C}$ layers, normalization by $n_{c}$ , and projection into the vocabulary using tied embeddings $E^{T}$ .
In summary, we can summarize the architecture by the triplet $(l_{P},l_{R},l_{C})$ , describing the number of layers in each stage, and by the number of recurrences $r$ , which may vary in each forward pass. We train a number of small-scale models with shape $(1,4,1)$ and hidden size $h=1024$ , in addition to a large model with shape $(2,4,2)$ and $h=5280$ . This model has only $8$ “real” layers, but when the recurrent block is iterated, e.g. 32 times, it unfolds to an effective depth of $2+4r+2=132$ layers, constructing computation chains that can be deeper than even the largest fixed-depth transformers (Levine et al., 2021; Merrill et al., 2022).
3.3 Training Objective
Training Recurrent Models through Unrolling.
To ensure that the model can function when we scale up recurrent iterations at test-time, we randomly sample iteration counts during training, assigning a random number of iterations $r$ to every input sequence (Schwarzschild et al., 2021b). We optimize the expectation of the loss function $L$ over random samples $x$ from distribution $X$ and random iteration counts $r$ from distribution $\Lambda$ .
$$
\mathcal{L}(\theta)=\mathbb{E}_{\mathbf{x}\in X}\mathbb{E}_{r\sim\Lambda}L%
\left(m_{\theta}(\mathbf{x},r),\mathbf{x}^{\prime}\right).
$$
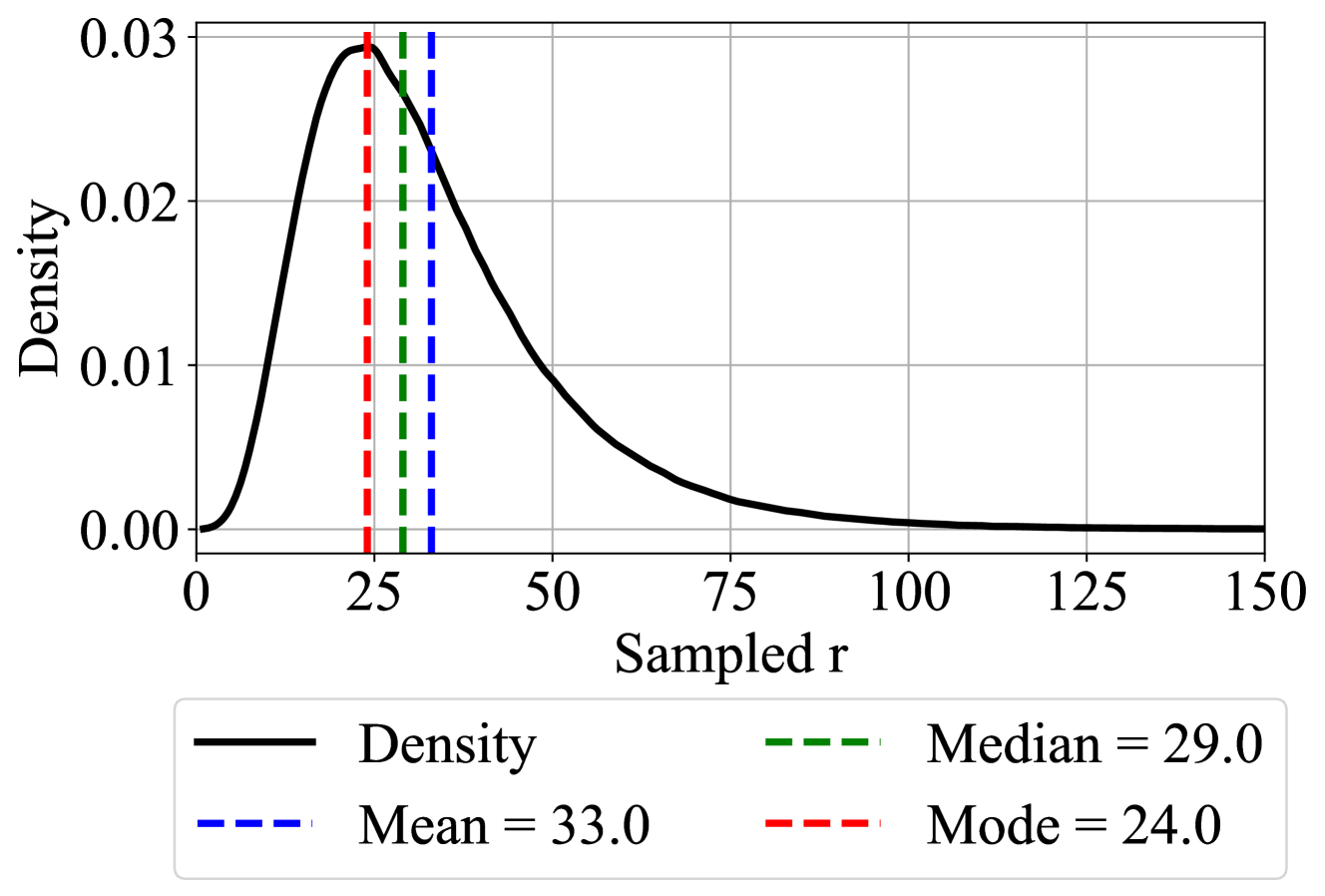
Here, $m$ represents the model output, and $\mathbf{x}^{\prime}$ is the sequence $\mathbf{x}$ shifted left, i.e., the next tokens in the sequence $\mathbf{x}$ . We choose $\Lambda$ to be a log-normal Poisson distribution. Given a targeted mean recurrence $\bar{r}+1$ and a variance that we set to $\sigma=\frac{1}{2}$ , we can sample from this distribution via
$$
\displaystyle\tau \displaystyle\sim\mathcal{N}(\log(\bar{r})-\frac{1}{2}\sigma^{2},\sigma) \displaystyle r \displaystyle\sim\mathcal{P}(e^{\tau})+1, \tag{1}
$$
given the normal distribution $\mathcal{N}$ and Poisson distribution $\mathcal{P}$ , see Figure 3. The distribution most often samples values less than $\bar{r}$ , but it contains a heavy tail of occasional events in which significantly more iterations are taken.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Density Plot: Distribution of Sampled r Values
### Overview
The image depicts a density plot illustrating the distribution of a variable labeled "Sampled r." The plot includes a probability density curve (black solid line) and three vertical dashed lines representing central tendency measures: Mode (red), Median (green), and Mean (blue). The x-axis ranges from 0 to 150, while the y-axis (Density) ranges from 0 to 0.03. The legend is positioned at the bottom of the plot.
---
### Components/Axes
- **X-axis (Sampled r)**: Labeled "Sampled r," with tick marks at 0, 25, 50, 75, 100, 125, and 150.
- **Y-axis (Density)**: Labeled "Density," with tick marks at 0.00, 0.01, 0.02, and 0.03.
- **Legend**: Located at the bottom, with color-coded labels:
- Black solid line: Density curve.
- Red dashed line: Mode = 24.0.
- Green dashed line: Median = 29.0.
- Blue dashed line: Mean = 33.0.
---
### Detailed Analysis
1. **Density Curve**:
- The black solid line forms a unimodal, right-skewed distribution.
- The peak density occurs near **x ≈ 25–30**, with a maximum value of approximately **0.03**.
- The curve declines gradually after the peak, approaching zero as x increases beyond 100.
2. **Central Tendency Lines**:
- **Mode (Red, 24.0)**: Aligns with the leftmost peak of the density curve, indicating the most frequent value.
- **Median (Green, 29.0)**: Positioned slightly right of the peak, suggesting the middle value of the distribution.
- **Mean (Blue, 33.0)**: Further right of the median, reflecting the influence of higher values in the tail.
3. **Skewness**:
- The mean (33.0) > median (29.0) > mode (24.0) confirms a **right-skewed distribution**.
- The tail extends toward higher x-values, pulling the mean upward.
---
### Key Observations
- The density curve’s peak (Mode) is at **24.0**, but the median and mean are higher, indicating asymmetry.
- The distribution tapers off slowly after the peak, with density values remaining non-zero up to x = 150.
- The mean (33.0) is notably higher than the median, suggesting the presence of outliers or a long right tail.
---
### Interpretation
This plot demonstrates a right-skewed distribution of "Sampled r" values. The Mode (24.0) represents the most common value, while the Median (29.0) and Mean (33.0) highlight the distribution’s asymmetry. The mean being pulled rightward implies that higher values, though less frequent, significantly influence the average. This could reflect real-world scenarios where extreme values (e.g., rare but large measurements) skew statistical summaries. The gradual decline in density after the peak suggests a concentration of data near the Mode, with fewer observations at higher x-values.
</details>
Figure 3: We use a log-normal Poisson Distribution to sample the number of recurrent iterations for each training step.
Truncated Backpropagation.
To keep computation and memory low at train time, we backpropagate through only the last $k$ iterations of the recurrent unit. This enables us to train with the heavy-tailed Poisson distribution $\Lambda$ , as maximum activation memory and backward compute is now independent of $r$ . We fix $k=8$ in our main experiments. At small scale, this works as well as sampling $k$ uniformly, but with set fixed, the overall memory usage in each step of training is equal. Note that the prelude block still receives gradient updates in every step, as its output $\mathbf{e}$ is injected in every step. This setup resembles truncated backpropagation through time, as commonly done with RNNs, although our setup is recurrent in depth rather than time (Williams and Peng, 1990; Mikolov et al., 2011).
4 Training a large-scale recurrent-depth Language Model
After verifying that we can reliably train small test models up to 10B tokens, we move on to larger-scale runs. Given our limited compute budget, we could either train multiple tiny models too small to show emergent effects or scaling, or train a single medium-scale model. Based on this, we prepared for a single run, which we detail below.
4.1 Training Setup
We describe the training setup, separated into architecture, optimization setup and pretraining data. We publicly release all training data, pretraining code, and a selection of intermediate model checkpoints.
Pretraining Data.
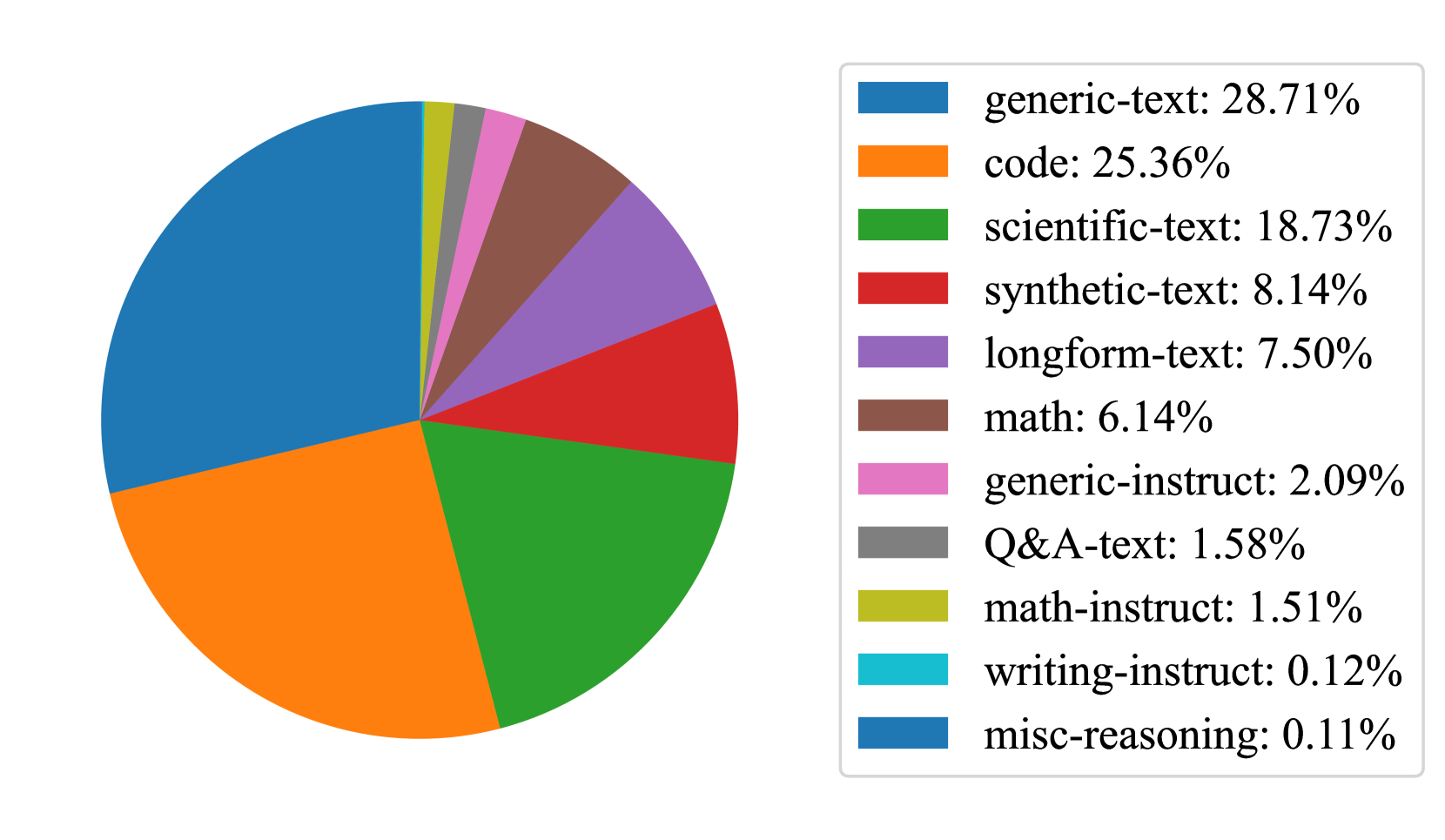
Given access to only enough compute for a single large scale model run, we opted for a dataset mixture that maximized the potential for emergent reasoning behaviors, not necessarily for optimal benchmark performance. Our final mixture is heavily skewed towards code and mathematical reasoning data with (hopefully) just enough general webtext to allow the model to acquire standard language modeling abilities. All sources are publicly available. We provide an overview in Figure 4. Following Allen-Zhu and Li (2024), we directly mix relevant instruction data into the pretraining data. However, due to compute and time constraints, we were not able to ablate this mixture. We expect that a more careful data preparation could further improve the model’s performance. We list all data sources in Appendix C.
Tokenization and Packing Details.
We construct a vocabulary of $65536$ tokens via BPE (Sennrich et al., 2016), using the implementation of Dagan (2024). In comparison to conventional tokenizer training, we construct our tokenizer directly on the instruction data split of our pretraining corpus, to maximize tokenization efficiency on the target domain. We also substantially modify the pre-tokenization regex (e.g. of Dagan et al. (2024)) to better support code, contractions and LaTeX. We include a <|begin_text|> token at the start of every document. After tokenizing our pretraining corpus, we pack our tokenized documents into sequences of length 4096. When packing, we discard document ends that would otherwise lack previous context, to fix an issue described as the “grounding problem” in Ding et al. (2024), aside from several long-document sources of mathematical content, which we preserve in their entirety.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Pie Chart: Distribution of Text Types by Percentage
### Overview
The pie chart illustrates the distribution of text types across a dataset, with percentages indicating the proportion of each category. The largest segments represent "generic-text" (28.71%) and "code" (25.36%), while smaller segments include specialized categories like "math-instruct" (1.51%) and "writing-instruct" (0.12%).
### Components/Axes
- **Legend**: Positioned on the right side of the chart, with colors mapped to text types.
- **Colors and Labels**:
- Blue: generic-text (28.71%)
- Orange: code (25.36%)
- Green: scientific-text (18.73%)
- Red: synthetic-text (8.14%)
- Purple: longform-text (7.50%)
- Brown: math (6.14%)
- Pink: generic-instruct (2.09%)
- Gray: Q&A-text (1.58%)
- Yellow: math-instruct (1.51%)
- Cyan: writing-instruct (0.12%)
- Blue: misc-reasoning (0.11%)
- **Note**: The legend lists two categories ("generic-text" and "misc-reasoning") with the same blue color, which may indicate a labeling error.
- **Pie Segments**: Arranged clockwise, starting with the largest segment ("generic-text") at the top-left.
### Detailed Analysis
1. **Generic-text (Blue)**: 28.71% (largest segment).
2. **Code (Orange)**: 25.36% (second-largest).
3. **Scientific-text (Green)**: 18.73%.
4. **Synthetic-text (Red)**: 8.14%.
5. **Longform-text (Purple)**: 7.50%.
6. **Math (Brown)**: 6.14%.
7. **Generic-instruct (Pink)**: 2.09%.
8. **Q&A-text (Gray)**: 1.58%.
9. **Math-instruct (Yellow)**: 1.51%.
10. **Writing-instruct (Cyan)**: 0.12%.
11. **Misc-reasoning (Blue)**: 0.11%.
### Key Observations
- **Dominance of Generic and Code Texts**: The top two categories account for over 54% of the dataset, suggesting a focus on general and programming-related content.
- **Specialized Categories**: Scientific-text and math-related segments (18.73% and 6.14%, respectively) highlight niche but significant contributions.
- **Minor Segments**: Writing-instruct (0.12%) and misc-reasoning (0.11%) are the smallest, indicating rare or underrepresented text types.
- **Color Discrepancy**: Both "generic-text" and "misc-reasoning" are labeled as blue in the legend, which may cause confusion in interpretation.
### Interpretation
The data suggests a dataset heavily skewed toward general and coding-related text, with specialized domains like scientific and mathematical content forming smaller but notable portions. The near-absence of writing-instruct and misc-reasoning text implies these categories are either underrepresented or excluded from the dataset. The color duplication in the legend (blue for both generic-text and misc-reasoning) risks misinterpretation, as the two categories are visually indistinguishable. This could lead to errors in analysis if not corrected. The chart underscores the importance of clear labeling and color differentiation in data visualization to avoid ambiguity.
</details>
Figure 4: Distribution of data sources that are included during training. The majority of our data is comprised of generic web-text, scientific writing and code.
Architecture and Initialization.
We scale the architecture described in Section 3, setting the layers to $(2,4,2)$ , and train with a mean recurrence value of $\bar{r}=32$ . We mainly scale by increasing the hidden size to $h=5280$ , which yields $55$ heads of size of $96$ . The MLP inner dimension is $17920$ and the RMSNorm $\varepsilon$ is $10^{-6}$ . Overall this model shape has about $1.5$ B parameters in non-recurrent prelude and head, $1.5$ B parameters in the core recurrent block, and $0.5$ B in the tied input embedding.
At small scales, most sensible initialization schemes work. However, at larger scales, we use the initialization of Takase et al. (2024) which prescribes a variance of $\sigma_{h}^{2}=\frac{2}{5h}$ . We initialize all parameters from a truncated normal distribution (truncated at $3\sigma$ ) with this variance, except all out-projection layers, where the variance is set to $\sigma_{\textnormal{out}}^{2}=\frac{1}{5hl}$ , for $l=l_{P}+\bar{r}l_{R}+l_{C}$ the number of effective layers, which is 132 for this model. As a result, the out-projection layers are initialized with fairly small values (Goyal et al., 2018). The output of the embedding layer is scaled by $\sqrt{h}$ . To match this initialization, the state $s_{0}$ is also sampled from a truncated normal distribution, here with variance $\sigma_{s}^{2}=\frac{2}{5}$ .
Locked-Step Sampling.
To enable synchronization between parallel workers, we sample a single depth $r$ for each micro-batch of training, which we synchronize across workers (otherwise workers would idle while waiting for the model with the largest $r$ to complete its backward pass). We verify at small scale that this modification improves compute utilization without impacting convergence speed, but note that at large batch sizes, training could be further improved by optimally sampling and scheduling independent steps $r$ on each worker, to more faithfully model the expectation over steps in Equation 1.
Optimizer and Learning Rate Schedule.
We train using the Adam optimizer with decoupled weight regularization ( $\beta_{1}=0.9$ , $\beta_{2}=0.95$ , $\eta=$5\text{×}{10}^{-4}$$ ) (Kingma and Ba, 2015; Loshchilov and Hutter, 2017), modified to include update clipping (Wortsman et al., 2023b) and removal of the $\varepsilon$ constant as in Everett et al. (2024). We clip gradients above $1$ . We train with warm-up and a constant learning rate (Zhai et al., 2022; Geiping and Goldstein, 2023), warming up to our maximal learning rate within the first $4096$ steps.
4.2 Compute Setup and Hardware
We train this model using compute time allocated on the Oak Ridge National Laboratory’s Frontier supercomputer. This HPE Cray system contains 9408 compute nodes with AMD MI250X GPUs, connected via 4xHPE Slingshot-11 NICs. The scheduling system is orchestrated through SLURM. We train in bfloat16 mixed precision using a PyTorch-based implementation (Zamirai et al., 2021).
<details>
<summary>x5.png Details</summary>
### Visual Description
## Composite Line Graphs: Model Training Performance Across Optimizer Steps
### Overview
The image contains three side-by-side line graphs comparing model training metrics across optimizer steps. Each graph tracks different performance indicators (loss, hidden state correlation, validation perplexity) with three data series: "Main" (blue), "Bad Run 1" (orange), and "Bad Run 2" (green). The rightmost graph additionally shows recurrence level variations (1-64) through line style variations.
### Components/Axes
1. **Left Graph (Loss vs Optimizer Step)**
- **Y-axis**: Loss (log scale, 10¹ to 10⁴)
- **X-axis**: Optimizer Step (10¹ to 10⁴)
- **Legend**:
- Blue: Main
- Orange: Bad Run 1
- Green: Bad Run 2
2. **Middle Graph (Hidden State Correlation vs Optimizer Step)**
- **Y-axis**: Hidden State Corr. (log scale, 10⁻¹ to 10⁰)
- **X-axis**: Optimizer Step (10¹ to 10⁴)
- **Legend**: Same color coding as left graph
3. **Right Graph (Validation Perplexity vs Optimizer Step)**
- **Y-axis**: Val PPL (log scale, 10¹ to 10³)
- **X-axis**: Optimizer Step (10¹ to 10⁴)
- **Recurrence Levels**:
- Solid line: 1
- Dashed line: 4
- Dotted line: 8
- Dash-dot line: 16
- Double-dot line: 32
- Triple-dot line: 64
### Detailed Analysis
**Left Graph (Loss)**
- **Main (blue)**: Starts at ~10³ loss, decreases exponentially to ~10¹ by 10³ steps, then plateaus
- **Bad Run 1 (orange)**: Flat line at ~10² loss throughout
- **Bad Run 2 (green)**: Starts at ~10³ loss, decreases to ~10² by 10³ steps, then plateaus
**Middle Graph (Hidden State Correlation)**
- **Main (blue)**: Fluctuates between 10⁻¹ and 10⁰ with no clear trend
- **Bad Run 1 (orange)**: Flat line at ~10⁻¹
- **Bad Run 2 (green)**: Starts at ~10⁻¹, drops to 10⁻² by 10² steps, then fluctuates
**Right Graph (Validation Perplexity)**
- **Main (blue)**: Decreases from ~10³ to ~10² over 10³ steps, then plateaus
- **Bad Run 1 (orange)**: Flat line at ~10³
- **Bad Run 2 (green)**: Decreases from ~10³ to ~10² over 10³ steps, then plateaus
- **Recurrence Variations**: All recurrence levels show similar decreasing trends, with higher recurrence levels (32-64) maintaining lower perplexity longer
### Key Observations
1. **Performance Divergence**: Main consistently outperforms Bad Runs in all metrics
2. **Training Stability**: Bad Run 1 shows catastrophic forgetting (flat loss/perplexity), while Bad Run 2 demonstrates partial recovery
3. **Recurrence Impact**: Higher recurrence levels (16-64) maintain better validation performance longer
4. **Log Scale Patterns**: All metrics show exponential decay trends when plotted on log scales
### Interpretation
The data reveals critical insights about model training dynamics:
- **Main Series**: Demonstrates ideal training behavior with consistent loss reduction and stable hidden state correlations
- **Bad Runs**: Highlight failure modes - Bad Run 1 shows complete training collapse, while Bad Run 2 exhibits partial recovery suggesting unstable optimization
- **Recurrence Tradeoff**: Higher recurrence levels improve validation performance but may increase computational costs
- **Optimization Sensitivity**: Small architectural changes (recurrence levels) significantly impact training stability
The graphs emphasize the importance of hyperparameter tuning and architectural choices in transformer-based models, particularly regarding recurrence depth and optimizer configuration.
</details>
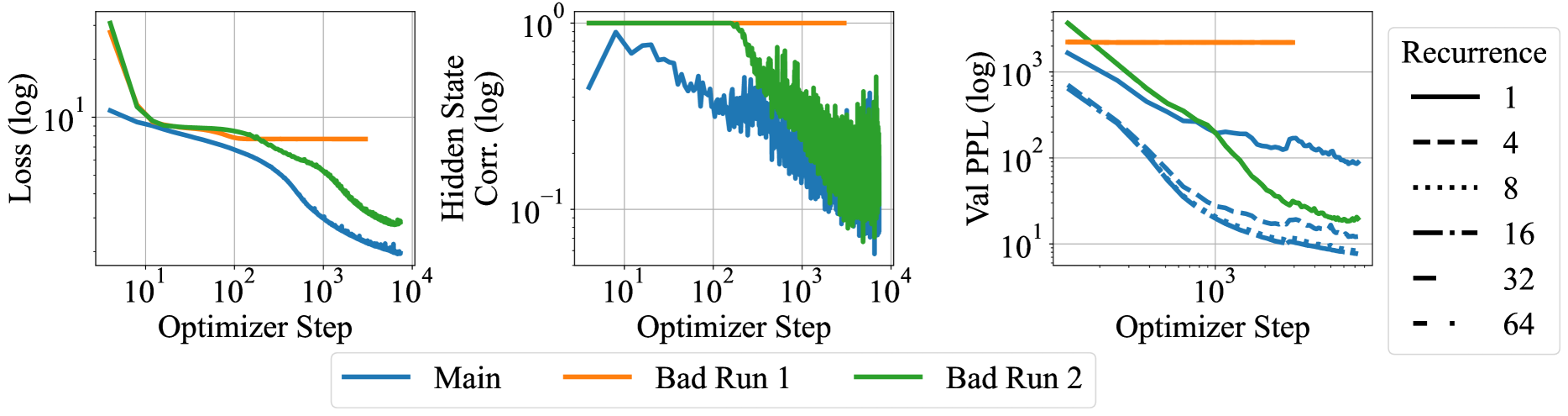
Figure 5: Plots of the initial 10000 steps for the first two failed attempts and the final, successful run (“Main”). Note the hidden state collapse (middle) and collapse of the recurrence (right) in the first two failed runs, underlining the importance of our architecture and initialization in inducing a recurrent model and explain the underperformance of these runs in terms of pretraining loss (left).
Device Speed and Parallelization Strategy.
Nominally, each MI250X chip Technically, each node contains 4 dual-chip MI250X cards, but its main software stack (ROCm runtime) treats these chips as fully independent. achieves 192 TFLOP per GPU (AMD, 2021). For a single matrix multiplication, we measure a maximum achievable speed on these GPUs of 125 TFLOP/s on our software stack (ROCM 6.2.0, PyTorch 2.6 pre-release 11/02) (Bekman, 2023). Our implementation, using extensive PyTorch compilation and optimization of the hidden dimension to $h=5280$ achieves a single-node training speed of 108.75 TFLOP/s, i.e. 87% AFU (“Achievable Flop Utilization”). Due to the weight sharing inherent in our recurrent design, even our largest model is still small enough to be trained using only data (not tensor) parallelism, with only optimizer sharding (Rajbhandari et al., 2020) and gradient checkpointing on a per-iteration granularity. With a batch size of 1 per GPU we end up with a global batch size of 16M tokens per step, minimizing inter-GPU communication bandwidth.
When we run at scale on 4096 GPUs, we achieve 52-64 TFLOP/s per GPU, i.e. 41%-51% AFU, or 1-1.2M tokens per second. To achieve this, we wrote a hand-crafted distributed data parallel implementation to circumvent a critical AMD interconnect issue, which we describe in more detail in Section A.2. Overall, we believe this may be the largest language model training run to completion in terms of number of devices used in parallel on an AMD cluster, as of time of writing.
Training Timeline.
Training proceeded through 21 segments of up to 12 hours, which scheduled on Frontier mostly in early December 2024. We also ran a baseline comparison, where we train the same architecture but in a feedforward manner with only 1 pass through the core/recurrent block. This trained with the same setup for 180B tokens on 256 nodes with a batch size of 2 per GPU. Ultimately, we were able to schedule 795B tokens of pretraining of the main model. Due to our constant learning rate schedule, we were able to add additional segments “on-demand”, when an allocation happened to be available.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Graph: Loss vs. Step (Log Scale)
### Overview
The image depicts a line graph with logarithmic scales on both axes. The x-axis represents "Step (log)" ranging from 10¹ to 10⁴, while the y-axis represents "Loss (log)" ranging from 10⁸ to 10¹². A single blue line illustrates a decreasing trend in loss as the step count increases logarithmically.
### Components/Axes
- **Title**: "Tokens (log)" (centered at the top).
- **X-Axis**:
- Label: "Step (log)".
- Scale: Logarithmic, with markers at 10¹, 10², 10³, and 10⁴.
- **Y-Axis**:
- Label: "Loss (log)".
- Scale: Logarithmic, with markers at 10⁸, 10⁹, 10¹⁰, 10¹¹, and 10¹².
- **Legend**:
- Position: Not explicitly visible in the image, but inferred to be in the top-right or bottom-right corner (standard placement for single-line graphs).
- Content: Likely confirms the blue line represents "Loss" (no explicit text visible in the image).
- **Grid**: Light gray grid lines span the plot area for reference.
### Detailed Analysis
- **Line Behavior**:
- The blue line starts at approximately **10¹⁰** on the y-axis when the step is **10¹**.
- It decreases steadily, passing through **10⁹** at **10²** steps, **10⁸** at **10³** steps, and approaching **10⁷** by **10⁴** steps.
- The slope is concave, indicating a decelerating rate of loss reduction as steps increase.
- **Data Points**:
- At **10¹ steps**: Loss ≈ 10¹⁰.
- At **10² steps**: Loss ≈ 10⁹.
- At **10³ steps**: Loss ≈ 10⁸.
- At **10⁴ steps**: Loss ≈ 10⁷ (with minor fluctuations near the end).
### Key Observations
1. **Exponential Decay**: Loss decreases by an order of magnitude for every tenfold increase in steps (e.g., 10¹ → 10² steps reduces loss from 10¹⁰ to 10⁹).
2. **Plateau Effect**: The line flattens near the end (steps > 10³), suggesting diminishing returns in loss reduction at higher step counts.
3. **Log-Log Scale**: The straight-line appearance in log-log space implies a power-law relationship between steps and loss.
### Interpretation
The graph demonstrates that loss reduction follows an exponential decay pattern relative to the number of steps. This suggests:
- **Efficiency Gains**: Early steps contribute disproportionately to loss reduction, while later steps yield smaller improvements.
- **Scalability**: The system or model being analyzed becomes more efficient as steps increase, but with diminishing marginal returns.
- **Potential Saturation**: The plateau at lower loss values (near 10⁷) may indicate an optimal performance threshold or computational limits.
The log-log scale emphasizes the relative rate of change, highlighting the importance of early-stage optimization efforts. The absence of additional data series or annotations suggests a focus on a single metric (loss) over time or iterations.
</details>
<details>
<summary>x7.png Details</summary>
### Visual Description
## Line Chart: Validation Perplexity vs. Steps (Log Scale)
### Overview
The chart illustrates the relationship between **validation perplexity** (log scale) and **training steps** (log scale) for different **recurrence values** (1, 4, 8, 16, 32, 64). Perplexity decreases as steps increase, with higher recurrence values achieving lower perplexity more rapidly.
---
### Components/Axes
- **X-axis (Step)**: Logarithmic scale from 10² to 10¹².
- **Y-axis (Validation Perplexity)**: Logarithmic scale from 10¹ to 10³.
- **Legend**: Right-aligned, mapping colors to recurrence values:
- Blue: 1
- Orange: 4
- Green: 8
- Red: 16
- Purple: 32
- Brown: 64
---
### Detailed Analysis
1. **Recurrence = 1 (Blue Line)**:
- Starts at ~10³ perplexity at 10² steps.
- Gradually declines to ~10² by 10⁴ steps.
- Slows near 10⁵ steps, stabilizing around 10².
2. **Recurrence = 4 (Orange Line)**:
- Begins at ~10².5 at 10² steps.
- Drops to ~10¹.5 by 10³ steps.
- Fluctuates slightly but trends downward to ~10¹ by 10⁴ steps.
3. **Recurrence = 8 (Green Line)**:
- Starts at ~10² at 10² steps.
- Declines to ~10¹ by 10³ steps.
- Stabilizes near 10¹ by 10⁴ steps.
4. **Recurrence = 16 (Red Line)**:
- Begins at ~10¹.5 at 10² steps.
- Drops to ~10¹ by 10³ steps.
- Remains flat near 10¹ by 10⁴ steps.
5. **Recurrence = 32 (Purple Line)**:
- Starts at ~10¹ at 10² steps.
- Declines to ~10⁰.8 by 10³ steps.
- Stabilizes near 10⁰.8 by 10⁴ steps.
6. **Recurrence = 64 (Brown Line)**:
- Begins at ~10¹ at 10² steps.
- Drops to ~10⁰.7 by 10³ steps.
- Remains near 10⁰.7 by 10⁴ steps.
---
### Key Observations
- **Inverse Relationship**: Higher recurrence values correlate with lower perplexity across all steps.
- **Convergence**: Lines for recurrence ≥16 converge near 10¹ perplexity by 10⁴ steps.
- **Diminishing Returns**: Beyond 10⁴ steps, perplexity plateaus for all recurrence values.
- **Anomalies**: The blue line (recurrence=1) shows minor fluctuations near 10⁵ steps, but no significant outliers.
---
### Interpretation
The data demonstrates that **increasing recurrence improves model performance** (lower perplexity) during training. Higher recurrence values achieve lower perplexity faster, but the benefit plateaus after ~10⁴ steps. The convergence of lines at higher recurrence values suggests **diminishing returns** for very large recurrence settings. The blue line (recurrence=1) highlights the trade-off: lower recurrence requires more steps to reach comparable perplexity. This aligns with expectations in sequence modeling, where recurrence depth often balances computational cost and performance.
</details>
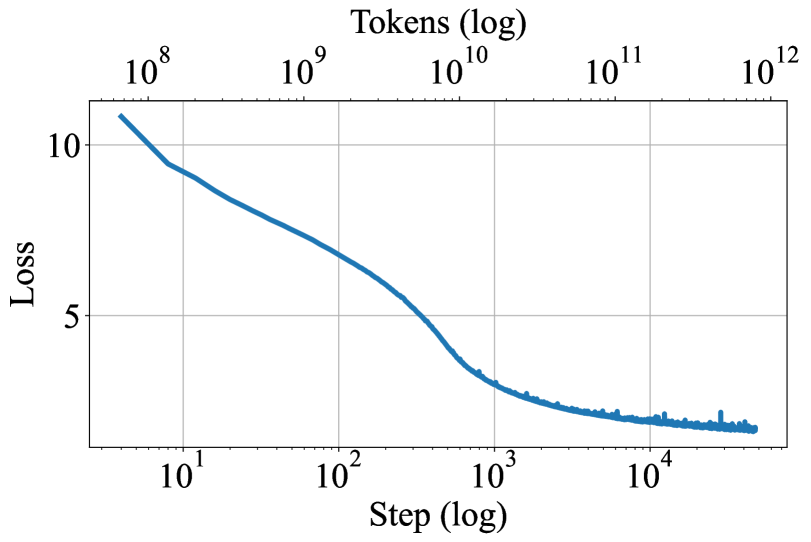
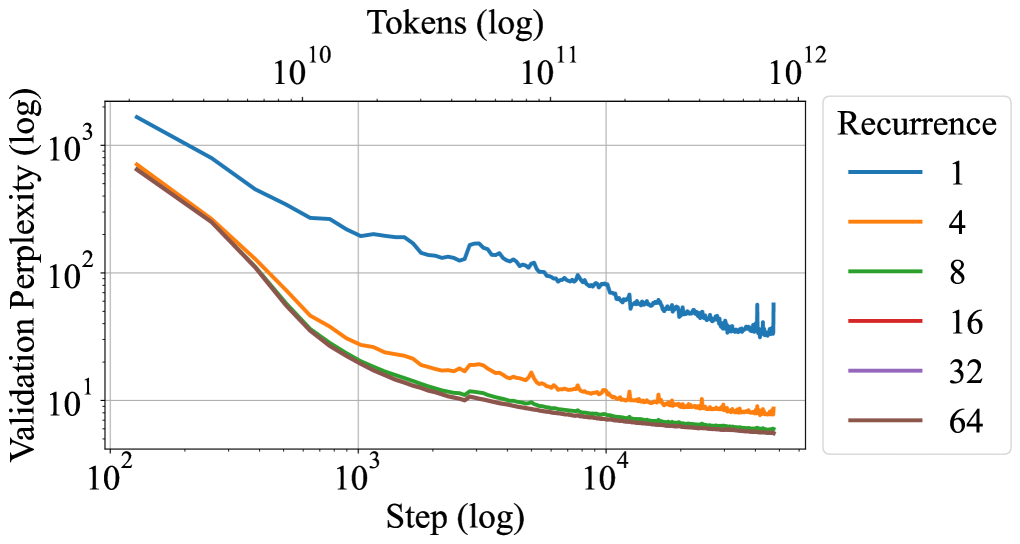
Figure 6: Left: Plot of pretrain loss over the 800B tokens on the main run. Right: Plot of val ppl at recurrent depths 1, 4, 8, 16, 32, 64. During training, the model improves in perplexity on all levels of recurrence.
Table 1: Results on lm-eval-harness tasks zero-shot across various open-source models. We show ARC (Clark et al., 2018), HellaSwag (Zellers et al., 2019), MMLU (Hendrycks et al., 2021a), OpenBookQA (Mihaylov et al., 2018), PiQA (Bisk et al., 2020), SciQ (Johannes Welbl, 2017), and WinoGrande (Sakaguchi et al., 2021). We report normalized accuracy when provided.
| Model random Amber | Param 7B | Tokens 1.2T | ARC-E 25.0 65.70 | ARC-C 25.0 37.20 | HellaSwag 25.0 72.54 | MMLU 25.0 26.77 | OBQA 25.0 41.00 | PiQA 50.0 78.73 | SciQ 25.0 88.50 | WinoGrande 50.0 63.22 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Pythia-2.8b | 2.8B | 0.3T | 58.00 | 32.51 | 59.17 | 25.05 | 35.40 | 73.29 | 83.60 | 57.85 |
| Pythia-6.9b | 6.9B | 0.3T | 60.48 | 34.64 | 63.32 | 25.74 | 37.20 | 75.79 | 82.90 | 61.40 |
| Pythia-12b | 12B | 0.3T | 63.22 | 34.64 | 66.72 | 24.01 | 35.40 | 75.84 | 84.40 | 63.06 |
| OLMo-1B | 1B | 3T | 57.28 | 30.72 | 63.00 | 24.33 | 36.40 | 75.24 | 78.70 | 59.19 |
| OLMo-7B | 7B | 2.5T | 68.81 | 40.27 | 75.52 | 28.39 | 42.20 | 80.03 | 88.50 | 67.09 |
| OLMo-7B-0424 | 7B | 2.05T | 75.13 | 45.05 | 77.24 | 47.46 | 41.60 | 80.09 | 96.00 | 68.19 |
| OLMo-7B-0724 | 7B | 2.75T | 74.28 | 43.43 | 77.76 | 50.18 | 41.60 | 80.69 | 95.70 | 67.17 |
| OLMo-2-1124 | 7B | 4T | 82.79 | 57.42 | 80.50 | 60.56 | 46.20 | 81.18 | 96.40 | 74.74 |
| Ours, ( $r=4$ ) | 3.5B | 0.8T | 49.07 | 27.99 | 43.46 | 23.39 | 28.20 | 64.96 | 80.00 | 55.24 |
| Ours, ( $r=8$ ) | 3.5B | 0.8T | 65.11 | 35.15 | 58.54 | 25.29 | 35.40 | 73.45 | 92.10 | 55.64 |
| Ours, ( $r=16$ ) | 3.5B | 0.8T | 69.49 | 37.71 | 64.67 | 31.25 | 37.60 | 75.79 | 93.90 | 57.77 |
| Ours, ( $r=32$ ) | 3.5B | 0.8T | 69.91 | 38.23 | 65.21 | 31.38 | 38.80 | 76.22 | 93.50 | 59.43 |
4.3 Importance of Norms and Initializations at Scale
At small scales all normalization strategies worked, and we observed only tiny differences between initializations. The same was not true at scale. The first training run we started was set up with the same block sandwich structure as described above, but parameter-free RMSNorm layers, no embedding scale $\gamma$ , a parameter-free adapter $A(\mathbf{s},\mathbf{e})=\mathbf{s}+\mathbf{e}$ , and a peak learning rate of $4\text{×}{10}^{-4}$ . As shown in Figure 5, this run (“Bad Run 1”, orange), quickly stalled.
While the run obviously stopped improving in training loss (left plot), we find that this stall is due to the model’s representation collapsing (Noci et al., 2022). The correlation of hidden states in the token dimension quickly goes to 1.0 (middle plot), meaning the model predicts the same hidden state for every token in the sequence. We find that this is an initialization issue that arises due to the recurrence operation. Every iteration of the recurrence block increases token correlation, mixing the sequence until collapse.
We attempt to fix this by introducing the embedding scale factor, switching back to a conventional pre-normalization block, and switching to the learned adapter. Initially, these changes appear to remedy the issue. Even though token correlation shoots close to 1.0 at the start (“Bad Run 2”, green), the model recovers after the first 150 steps. However, we quickly find that this training run is not able to leverage test-time compute effectively (right plot), as validation perplexity is the same whether 1 or 32 recurrences are used. This initialization and norm setup has led to a local minimum as the model has learned early to ignore the incoming state $\mathbf{s}$ , preventing further improvements.
In a third, and final run (“Main”, blue), we fix this issue by reverting back to the sandwich block format, and further dropping the peak learning rate to $4\text{×}{10}^{-5}$ . This run starts smoothly, never reaches a token correlation close to 1.0, and quickly overtakes the previous run by utilizing the recurrence and improving with more iterations.
With our successful configuration, training continues smoothly for the next 750B tokens without notable interruptions or loss spikes. We plot training loss and perplexity at different recurrence steps in Figure 6. In our material, we refer to the final checkpoint of this run as our “main model”, which we denote as Huginn-0125 \textipa /hu: gIn/, transl. “thought”, is a raven depicted in Norse mythology. Corvids are surprisingly intelligent for their size, and and of course, as birds, able to unfold their wings at test-time..
5 Benchmark Results
We train our final model for 800B tokens, and a non-recurrent baseline for 180B tokens. We evaluate these checkpoints against other open-source models trained on fully public datasets (like ours) of a similar size. We compare against Amber (Liu et al., 2023c), Pythia (Biderman et al., 2023) and a number of OLMo 1&2 variants (Groeneveld et al., 2024; AI2, 2024; Team OLMo et al., 2025). We execute all standard benchmarks through the lm-eval harness (Biderman et al., 2024) and code benchmarks via bigcode-bench (Zhuo et al., 2024).
5.1 Standard Benchmarks
Overall, it is not straightforward to place our model in direct comparison to other large language models, all of which are small variations of the fixed-depth transformer architecture. While our model has only 3.5B parameters and hence requires only modest interconnect bandwidth during pretraining, it chews through raw FLOPs close to what a 32B parameter transformer would consume during pretraining, and can continuously improve in performance with test-time scaling up to FLOP budgets equivalent to a standard 50B parameter fixed-depth transformer. It is also important to note a few caveats of the main training run when interpreting the results. First, our main checkpoint is trained for only 47000 steps on a broadly untested mixture, and the learning rate is never cooled down from its peak. As an academic project, the model is trained only on publicly available data and the 800B token count, while large in comparison to older fully open-source models such as the Pythia series, is small in comparison to modern open-source efforts such as OLMo, and tiny in comparison to the datasets used to train industrial open-weight models.
Table 2: Benchmarks of mathematical reasoning and understanding. We report flexible and strict extract for GSM8K and GSM8K CoT, extract match for Minerva Math, and acc norm. for MathQA.
| Model Random Amber | GSM8K 0.00 3.94/4.32 | GSM8k CoT 0.00 3.34/5.16 | Minerva MATH 0.00 1.94 | MathQA 20.00 25.26 |
| --- | --- | --- | --- | --- |
| Pythia-2.8b | 1.59/2.12 | 1.90/2.81 | 1.96 | 24.52 |
| Pythia-6.9b | 2.05/2.43 | 2.81/2.88 | 1.38 | 25.96 |
| Pythia-12b | 3.49/4.62 | 3.34/4.62 | 2.56 | 25.80 |
| OLMo-1B | 1.82/2.27 | 1.59/2.58 | 1.60 | 23.38 |
| OLMo-7B | 4.02/4.09 | 6.07/7.28 | 2.12 | 25.26 |
| OLMo-7B-0424 | 27.07/27.29 | 26.23/26.23 | 5.56 | 28.48 |
| OLMo-7B-0724 | 28.66/28.73 | 28.89/28.89 | 5.62 | 27.84 |
| OLMo-2-1124-7B | 66.72/66.79 | 61.94/66.19 | 19.08 | 37.59 |
| Our w/o sys. prompt ( $r=32$ ) | 28.05/28.20 | 32.60/34.57 | 12.58 | 26.60 |
| Our w/ sys. prompt ( $r=32$ ) | 24.87/38.13 | 34.80/42.08 | 11.24 | 27.97 |
Table 3: Evaluation on code benchmarks, MBPP and HumanEval. We report pass@1 for both datasets.
| Model Random starcoder2-3b | Param 3B | Tokens 3.3T | MBPP 0.00 43.00 | HumanEval 0.00 31.09 |
| --- | --- | --- | --- | --- |
| starcoder2-7b | 7B | 3.7T | 43.80 | 31.70 |
| Amber | 7B | 1.2T | 19.60 | 13.41 |
| Pythia-2.8b | 2.8B | 0.3T | 6.70 | 7.92 |
| Pythia-6.9b | 6.9B | 0.3T | 7.92 | 5.60 |
| Pythia-12b | 12B | 0.3T | 5.60 | 9.14 |
| OLMo-1B | 1B | 3T | 0.00 | 4.87 |
| OLMo-7B | 7B | 2.5T | 15.6 | 12.80 |
| OLMo-7B-0424 | 7B | 2.05T | 21.20 | 16.46 |
| OLMo-7B-0724 | 7B | 2.75T | 25.60 | 20.12 |
| OLMo-2-1124-7B | 7B | 4T | 21.80 | 10.36 |
| Ours ( $r=32$ ) | 3.5B | 0.8T | 24.80 | 23.17 |
Disclaimers aside, we collect results for established benchmark tasks (Team OLMo et al., 2025) in Table 1 and show all models side-by-side. In direct comparison we see that our model outperforms the older Pythia series and is roughly comparable to the first OLMo generation, OLMo-7B in most metrics, but lags behind the later OLMo models trained larger, more carefully curated datasets. For the first recurrent-depth model for language to be trained at this scale, and considering the limitations of the training run, we find these results promising and certainly suggestive that further research into latent recurrence as an approach to test-time scaling is warranted.
Table 4: Baseline comparison, recurrent versus non-recurrent model trained in the same training setup and data. Comparing the recurrent model with its non-recurrent baseline, we see that even at 180B tokens, the recurrent substantially outperforms on harder tasks.
| Ours, early ckpt, ( $r=32$ ) Ours, early ckpt, ( $r=1$ ) Ours, ( $r=32$ ) | 0.18T 0.18T 0.8T | 53.62 34.01 69.91 | 29.18 23.72 38.23 | 48.80 29.19 65.21 | 25.59 23.47 31.38 | 31.40 25.60 38.80 | 68.88 53.26 76.22 | 80.60 54.10 93.50 | 52.88 53.75 59.43 | 9.02/10.24 0.00/0.15 34.80/42.08 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Ours, ( $r=1$ ) | 0.8T | 34.89 | 24.06 | 29.34 | 23.60 | 26.80 | 55.33 | 47.10 | 49.41 | 0.00/0.00 |
5.2 Math and Coding Benchmarks
We also evaluate the model on math and coding. For math, we evaluate GSM8k (Cobbe et al., 2021) (as zero-shot and in the 8-way CoT setup), MATH ((Hendrycks et al., 2021b) with the Minerva evaluation rules (Lewkowycz et al., 2022)) and MathQA (Amini et al., 2019). For coding, we check MBPP (Austin et al., 2021) and HumanEval (Chen et al., 2021). Here we find that our model significantly surpasses all models except the latest OLMo-2 model in mathematical reasoning, as measured on GSM8k and MATH. On coding benchmarks the model beats all other general-purpose open-source models, although it does not outperform dedicated code models, such as StarCoder2 (Lozhkov et al., 2024), trained for several trillion tokens. We also note that while further improvements in language modeling are slowing down, as expected at this training scale, both code and mathematical reasoning continue to improve steadily throughout training, see Figure 8.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Graph: Performance vs. Recurrence at Test-Time
### Overview
The image is a line graph comparing the performance of four methods (HellaSwag, GSM8K CoT (Strict), GSM8K CoT (Flexible), and Humaneval) across increasing values of "Recurrence at Test-Time" (x-axis) and "Performance" (y-axis). The graph uses distinct line styles and markers to differentiate the methods, with a legend in the top-left corner.
---
### Components/Axes
- **X-Axis (Recurrence at Test-Time)**: Logarithmic scale with values at 1, 4, 8, 16, 32, 64.
- **Y-Axis (Performance)**: Linear scale from 0 to 80.
- **Legend**: Located in the top-left corner, with four entries:
- **Blue dashed line with circles**: HellaSwag
- **Green dashed line with circles**: GSM8K CoT (Flexible)
- **Orange dashed line with circles**: GSM8K CoT (Strict)
- **Red solid line with circles**: Humaneval
---
### Detailed Analysis
#### HellaSwag (Blue)
- **Trend**: Starts at ~30 (x=1), increases steadily, and plateaus near 65 by x=64.
- **Key Data Points**:
- x=1: ~30
- x=4: ~45
- x=8: ~60
- x=16: ~65
- x=32: ~65
- x=64: ~65
#### GSM8K CoT (Flexible) (Green)
- **Trend**: Starts near 0, rises sharply to ~40 by x=16, then plateaus.
- **Key Data Points**:
- x=1: ~0
- x=4: ~2
- x=8: ~15
- x=16: ~38
- x=32: ~40
- x=64: ~40
#### GSM8K CoT (Strict) (Orange)
- **Trend**: Similar to Flexible but with a lower peak (~35 by x=16).
- **Key Data Points**:
- x=1: ~0
- x=4: ~1
- x=8: ~10
- x=16: ~30
- x=32: ~35
- x=64: ~35
#### Humaneval (Red)
- **Trend**: Starts at 0, increases slowly to ~20 by x=16, then plateaus.
- **Key Data Points**:
- x=1: ~0
- x=4: ~1
- x=8: ~10
- x=16: ~20
- x=32: ~22
- x=64: ~22
---
### Key Observations
1. **HellaSwag** consistently outperforms all other methods, maintaining a high performance across all recurrence values.
2. **GSM8K CoT (Flexible)** and **GSM8K CoT (Strict)** show similar growth patterns but with Flexible achieving higher performance.
3. **Humaneval** has the lowest performance, with minimal improvement as recurrence increases.
4. All methods plateau after x=16, suggesting diminishing returns at higher recurrence values.
---
### Interpretation
The data suggests that **HellaSwag** is the most effective method for this task, likely due to its design or training data. The **GSM8K CoT** methods (both strict and flexible) demonstrate moderate performance, with Flexible outperforming Strict. **Humaneval** underperforms significantly, indicating potential limitations in its approach. The plateauing trends across all methods imply that increasing recurrence beyond a certain point does not yield proportional performance gains, possibly due to computational constraints or model saturation.
The graph highlights the importance of method selection in tasks requiring recurrence, with HellaSwag emerging as the optimal choice in this context.
</details>
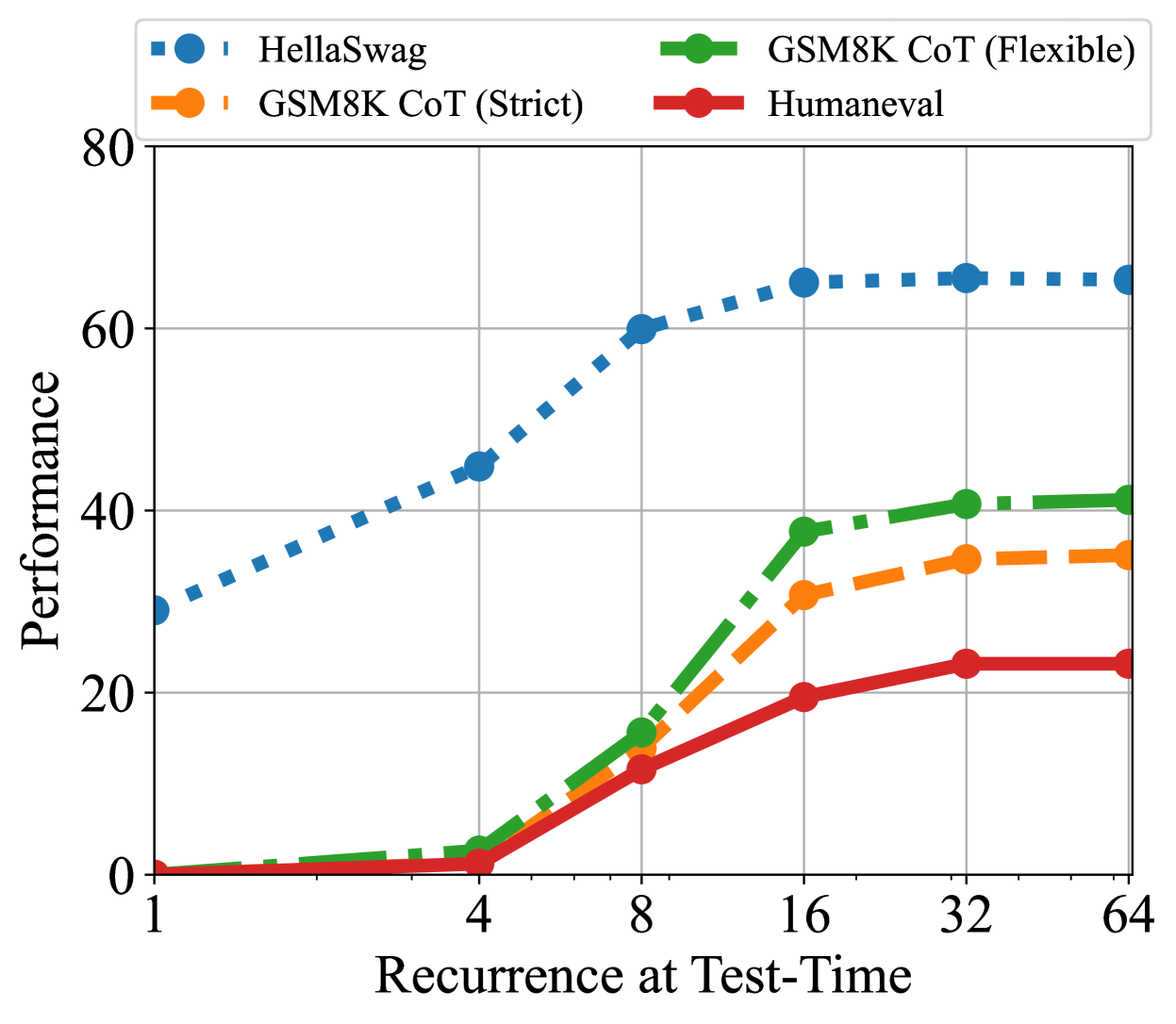
Figure 7: Performance on GSM8K CoT (strict match and flexible match), HellaSwag (acc norm.), and HumanEval (pass@1). As we increase compute, the performance on these benchmarks increases. HellaSwag only needs $8$ recurrences to achieve near peak performance while other benchmarks make use of more compute.
<details>
<summary>x9.png Details</summary>
### Visual Description
## Line Graph: GSM8K Chain-of-Thought Performance vs. Tokens Trained
### Overview
The image depicts a line graph comparing the performance of different "Rec" configurations (likely model variants or training setups) on the GSM8K Chain-of-Thought (CoT) benchmark. Performance is measured on the y-axis (0–35) against tokens trained (x-axis: 100B–800B). Six data series are represented by distinct line styles and colors.
### Components/Axes
- **X-axis**: "Tokens Trained (Billion)" with markers at 100, 200, 300, 400, 500, 600, 700, 800.
- **Y-axis**: "GSM8K CoT" with increments of 5 (0–35).
- **Legend**: Located in the top-left corner, mapping:
- **Blue solid**: 1 Rec
- **Orange dashed**: 4 Rec
- **Green dash-dot**: 8 Rec
- **Red dotted**: 16 Rec
- **Purple solid**: 32 Rec
- **Brown dashed**: 64 Rec
### Detailed Analysis
1. **1 Rec (Blue Solid Line)**:
- Starts near 0 at 100B tokens.
- Gradually increases to ~5 by 200B, ~10 by 300B, and plateaus near 10 by 800B.
- **Trend**: Slow, linear growth with minimal improvement after 300B.
2. **4 Rec (Orange Dashed Line)**:
- Begins at ~1 at 100B.
- Rises to ~2 by 200B, ~4 by 300B, and ~10 by 800B.
- **Trend**: Steeper than 1 Rec but plateaus similarly.
3. **8 Rec (Green Dash-Dot Line)**:
- Starts at ~2 at 100B.
- Peaks at ~14 by 500B, drops to ~12 by 600B, then rises to ~22 by 700B before falling to ~14 at 800B.
- **Trend**: Non-linear with a sharp mid-range peak and late-stage decline.
4. **16 Rec (Red Dotted Line)**:
- Begins at ~3 at 100B.
- Increases to ~15 by 500B, ~26 by 600B, ~35 by 700B, then drops to ~31 at 800B.
- **Trend**: Strong upward trajectory with a late-stage dip.
5. **32 Rec (Purple Solid Line)**:
- Starts at ~4 at 100B.
- Rises to ~28 by 600B, ~36 by 700B, then declines to ~35 at 800B.
- **Trend**: Sustained growth with a minor end-stage reduction.
6. **64 Rec (Brown Dashed Line)**:
- Begins at ~5 at 100B.
- Peaks at ~36 by 700B, then drops to ~34 at 800B.
- **Trend**: Highest performance overall, with a slight decline at maximum tokens.
### Key Observations
- **Performance Correlation**: Higher "Rec" values generally correlate with better performance, though diminishing returns are evident (e.g., 32 Rec vs. 64 Rec).
- **Anomalies**: The 8 Rec line shows an unexpected mid-range peak (~14 at 500B) followed by a drop, suggesting potential overfitting or instability.
- **Divergence**: At 800B tokens, 64 Rec (34) outperforms 32 Rec (35) by a narrow margin, but both lag behind their 700B peaks.
### Interpretation
The data suggests that increasing "Rec" (likely model complexity or training data diversity) improves GSM8K CoT performance up to a point. The 64 Rec configuration achieves the highest scores but shows a slight decline at 800B tokens, possibly indicating over-parameterization or data saturation. The 8 Rec line’s mid-range peak and subsequent drop highlight risks of overfitting in smaller configurations. The plateauing trends for lower "Rec" values (1–4 Rec) imply limited scalability without architectural or data enhancements. These patterns underscore the trade-off between model size and efficiency in CoT reasoning tasks.
</details>
<details>
<summary>x10.png Details</summary>
### Visual Description
## Line Graph: HellaSwag Performance vs. Tokens Trained
### Overview
The graph illustrates the relationship between the number of tokens trained (in billions) and performance on the HellaSwag benchmark. Six distinct data series represent different "Record" configurations (1, 4, 8, 16, 32, 64), with performance measured on the y-axis (HellaSwag score) and tokens trained on the x-axis.
### Components/Axes
- **X-axis**: Tokens Trained (Billion) – Linear scale from 100 to 800 billion.
- **Y-axis**: HellaSwag – Linear scale from 25 to 65.
- **Legend**: Located in the top-left corner, mapping line styles/colors to Record configurations:
- Solid blue: 1 Rec
- Dashed green: 8 Rec
- Solid purple: 32 Rec
- Dashed orange: 4 Rec
- Dotted red: 16 Rec
- Dashed brown: 64 Rec
### Detailed Analysis
1. **1 Rec (Solid Blue)**:
- Remains nearly flat across all token ranges (~28–31).
- Minimal improvement with increased training.
2. **4 Rec (Dashed Orange)**:
- Starts at ~33 (100B tokens), rises to ~45 (700B tokens).
- Shows a slight dip (~43) near 800B tokens.
3. **8 Rec (Dashed Green)**:
- Begins at ~38 (100B tokens), increases steadily to ~60 (800B tokens).
- Consistent upward trend with moderate slope.
4. **16 Rec (Dotted Red)**:
- Starts at ~42 (100B tokens), rises to ~62 (800B tokens).
- Outperforms 8 Rec but plateaus slightly above 600B tokens.
5. **32 Rec (Solid Purple)**:
- Begins at ~45 (100B tokens), increases to ~65 (800B tokens).
- Steeper slope than 16 Rec, maintaining high performance.
6. **64 Rec (Dashed Brown)**:
- Starts at ~48 (100B tokens), peaks at ~65 (800B tokens).
- Matches 32 Rec performance at higher token counts.
### Key Observations
- **Performance Correlation**: Higher Record configurations consistently achieve better HellaSwag scores.
- **Diminishing Returns**: The 64 Rec line plateaus near 65, suggesting limited gains beyond ~600B tokens.
- **Anomaly**: The 4 Rec line dips slightly at 800B tokens, contrasting with other upward trends.
- **Baseline**: 1 Rec remains the lowest-performing series, indicating minimal impact of token quantity alone.
### Interpretation
The data demonstrates a clear trend: increasing the number of training records (data diversity) significantly improves model performance on HellaSwag. The 64 Rec configuration achieves the highest scores (~65), while 1 Rec shows negligible improvement (~30). The 4 Rec line’s dip at 800B tokens may indicate overfitting or resource constraints. These results suggest that data quality and model capacity are critical factors, with larger datasets enabling better generalization. The plateau in 32/64 Rec lines implies diminishing returns at scale, highlighting the need for balanced training strategies.
</details>
<details>
<summary>x11.png Details</summary>
### Visual Description
## Line Graph: HumanEval Scores vs. Tokens Trained (Billion)
### Overview
The graph compares HumanEval scores across different "Rec" configurations (1, 4, 8, 16, 32, 64) as a function of tokens trained (in billions). HumanEval scores range from 0 to 20, while tokens trained span 100 to 800 billion. Lines are color-coded and styled uniquely for each Rec value.
### Components/Axes
- **X-axis**: Tokens Trained (Billion) – Logarithmic scale from 100 to 800 billion.
- **Y-axis**: HumanEval – Linear scale from 0 to 20.
- **Legend**: Located in the top-left corner. Entries include:
- **1 Rec**: Blue solid line.
- **4 Rec**: Orange dashed line.
- **8 Rec**: Green dash-dot line.
- **16 Rec**: Red dotted line.
- **32 Rec**: Purple solid line.
- **64 Rec**: Brown dashed line.
### Detailed Analysis
1. **1 Rec (Blue Solid Line)**:
- Starts near 0 at 100B tokens.
- Remains flat throughout, indicating minimal improvement with training.
2. **4 Rec (Orange Dashed Line)**:
- Begins near 0 at 100B tokens.
- Peaks at ~3.5 at ~300B tokens.
- Drops sharply to ~1.5 by 800B tokens.
3. **8 Rec (Green Dash-Dot Line)**:
- Starts at ~2 at 100B tokens.
- Gradually increases to ~10 by 500B tokens.
- Plateaus near 10 for the remainder.
4. **16 Rec (Red Dotted Line)**:
- Starts at ~5 at 100B tokens.
- Rises sharply to ~17 at 500B tokens.
- Plateaus near 17 for the remainder.
5. **32 Rec (Purple Solid Line)**:
- Starts at ~5 at 100B tokens.
- Increases steadily to ~19 at 700B tokens.
- Peaks at ~22 at 800B tokens.
6. **64 Rec (Brown Dashed Line)**:
- Starts at ~5 at 100B tokens.
- Rises sharply to ~20 at 500B tokens.
- Peaks at ~22 at 700B tokens, then slightly declines to ~21 at 800B tokens.
### Key Observations
- Higher Rec values generally correlate with higher HumanEval scores, but performance plateaus or declines after certain token thresholds.
- **64 Rec** achieves the highest peak (~22) but shows a slight decline after 700B tokens.
- **4 Rec** exhibits a pronounced peak (~3.5) followed by a sharp drop, suggesting overfitting or resource limitations.
- **32 Rec** and **64 Rec** lines diverge significantly after 500B tokens, with 64 Rec outperforming 32 Rec.
### Interpretation
The data suggests that increasing Rec values improves HumanEval performance up to a point, after which diminishing returns or overfitting occur. The 64 Rec configuration achieves the highest scores but shows instability at scale, while lower Rec values (e.g., 4 Rec) underperform despite initial gains. This implies a trade-off between model complexity (Rec) and training efficiency, with optimal performance likely requiring careful balancing of Rec and token counts.
</details>
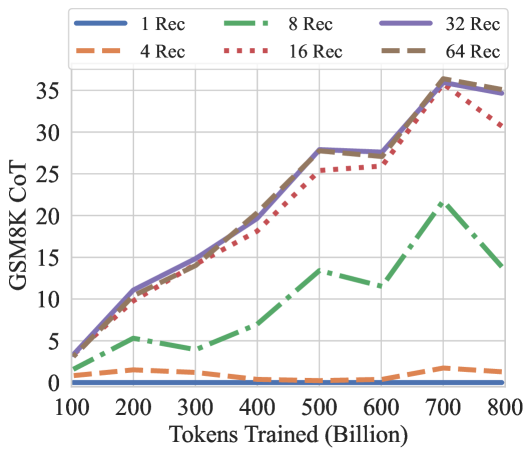
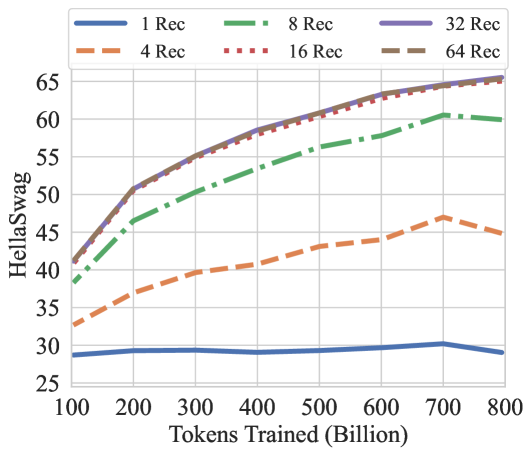
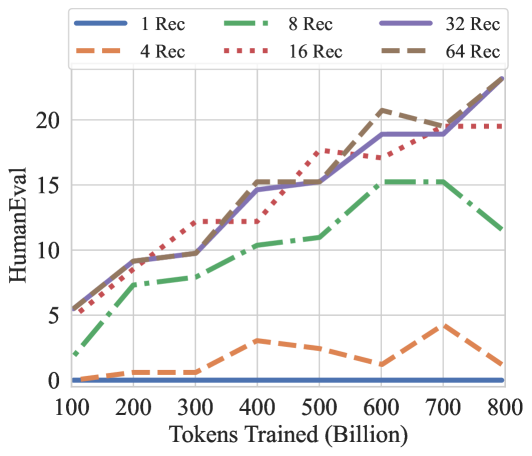
Figure 8: GSM8K CoT, HellaSwag, and HumanEval performance over the training tokens with different recurrences at test-time. We evaluate GSM8K CoT with chat template and 8-way few shot as multiturn. HellaSwag and HumanEval are zero-shot with no chat template. Model performance on harder tasks grows almost linearly with the training budget, if provided sufficient test-time compute.
5.3 Where does recurrence help most?
How much of this performance can we attribute to recurrence, and how much to other factors, such as dataset, tokenization and architectural choices? In Table 4, we compare our recurrent model against its non-recurrent twin, which we trained to 180B tokens in the exact same setting. In direct comparison of both models at 180B tokens, we see that the recurrent model outperforms its baseline with an especially pronounced advantage on harder tasks, such as the ARC challenge set. On other tasks, such as SciQ, which requires straightforward recall of scientific facts, performance of the models is more similar. We observe that gains through reasoning are especially prominent on GSM8k, where the 180B recurrent model is already 5 times better than the baseline at this early snapshot in the pretraining process. We also note that the recurrent model, when evaluated with only a single recurrence, effectively stops improving between the early 180B checkpoint and the 800B checkpoint, showing that further improvements are not built into the prelude or coda non-recurrent layers but encoded entirely into the iterations of the recurrent block.
Further, we chart the improvement as a function of test-time compute on several of these tasks for the main model in Figure 7. We find that saturation is highly task-dependent, on easier tasks the model saturates quicker, whereas it benefits from more compute on others.
<details>
<summary>x12.png Details</summary>
### Visual Description
## Line Graph: ARC Challenge Accuracy vs. Test-Time Compute Recurrence
### Overview
The image depicts a line graph comparing ARC Challenge Accuracy (%) across five different "shot" configurations (0-shot, 1-shot, 5-shot, 25-shot, 50-shot) as a function of Test-Time Compute Recurrence (x-axis: 1–64). The graph shows five colored lines with error bars, converging toward higher accuracy values as compute recurrence increases.
### Components/Axes
- **X-axis**: Test-Time Compute Recurrence (logarithmic scale: 1, 4, 6, 8, 12, 20, 32, 48, 64)
- **Y-axis**: ARC Challenge Accuracy (%) (linear scale: 15–45%)
- **Legend**: Located in the bottom-right corner, mapping colors to shot configurations:
- Blue: 0-shot
- Orange: 1-shot
- Green: 5-shot
- Red: 25-shot
- Purple: 50-shot
- **Error Bars**: Present for all data points, indicating variability in measurements.
### Detailed Analysis
1. **0-shot (Blue Line)**:
- Starts at ~18% accuracy at x=1.
- Gradually increases to ~33% at x=64.
- Error bars remain relatively small (~±1–2%).
2. **1-shot (Orange Line)**:
- Begins at ~19% at x=1.
- Rises to ~39% at x=64.
- Error bars slightly larger than 0-shot (~±2–3%).
3. **5-shot (Green Line)**:
- Starts at ~20% at x=1.
- Peaks at ~42% at x=64.
- Error bars moderate (~±2–4%).
4. **25-shot (Red Line)**:
- Initial value ~21% at x=1.
- Reaches ~43% at x=64.
- Error bars similar to 5-shot (~±3–5%).
5. **50-shot (Purple Line)**:
- Starts at ~22% at x=1.
- Stabilizes near ~43% at x=64.
- Error bars largest (~±4–6%).
**Trend Verification**:
- All lines exhibit upward trends, with steeper increases at lower compute recurrence values.
- Lines converge toward ~42–43% accuracy at x=64, suggesting diminishing returns for higher shot counts beyond this point.
- 0-shot and 1-shot lines remain consistently below others, indicating lower performance with fewer shots.
### Key Observations
- **Diminishing Returns**: Higher shot configurations (25-shot, 50-shot) achieve near-identical accuracy at x=64 (~43%), suggesting limited benefit from additional shots beyond 25.
- **Compute Recurrence Threshold**: Significant accuracy improvements occur between x=1 and x=12 across all configurations.
- **Error Bar Variability**: Larger error bars for 50-shot suggest greater experimental uncertainty compared to lower shot counts.
### Interpretation
The data demonstrates that increasing the number of "shots" (iterations or examples) improves ARC Challenge Accuracy, particularly at lower compute recurrence values. However, beyond x=12, accuracy plateaus, with 25-shot and 50-shot configurations achieving similar performance. This implies that while more shots enhance performance, there is a practical limit to gains from additional iterations. The 0-shot and 1-shot configurations lag significantly, highlighting the importance of iterative refinement in this context. The convergence of lines at high compute recurrence suggests that optimizing for moderate shot counts (e.g., 25-shot) may be more efficient than pursuing higher shot counts with diminishing returns.
</details>
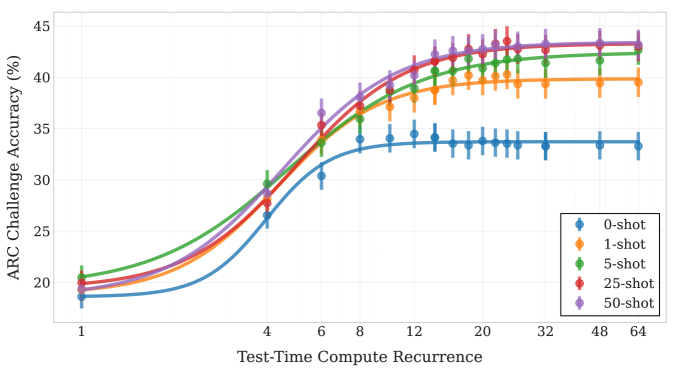
Figure 9: The saturation point in un-normalized accuracy via test-time recurrence on the ARC challenge set is correlated with the number of few-shot examples. The model uses more recurrence to extract more information from the additional few-shot examples, making use of more compute if more context is given.
Table 5: Comparison of Open and Closed QA Performance (%) (Mihaylov et al., 2018). In the open exam, a relevant fact is provided before the question is asked. In this setting, our smaller model closes the gap to other open-source models, indicating that the model is capable, but has fewer facts memorized.
| Amber Pythia-2.8b Pythia-6.9b | 41.0 35.4 37.2 | 46.0 44.8 44.2 | +5.0 +9.4 +7.0 |
| --- | --- | --- | --- |
| Pythia-12b | 35.4 | 48.0 | +12.6 |
| OLMo-1B | 36.4 | 43.6 | +7.2 |
| OLMo-7B | 42.2 | 49.8 | +7.6 |
| OLMo-7B-0424 | 41.6 | 50.6 | +9.0 |
| OLMo-7B-0724 | 41.6 | 53.2 | +11.6 |
| OLMo-2-1124 | 46.2 | 53.4 | +7.2 |
| Ours ( $r=32$ ) | 38.2 | 49.2 | +11.0 |
Recurrence and Context
We evaluate ARC-C performance as a function of recurrence and number of few-shot examples in the context in Figure 9. Interestingly, without few-shot examples to consider, the model saturates in compute around 8-12 iterations. However, when more context is given, the model can reason about more information in context, which it does, saturating around 20 iterations if 1 example is provided, and 32 iterations, if 25-50 examples are provided, mirroring generalization improvements shown for recurrence (Yang et al., 2024a; Fan et al., 2025). Similarly, we see that if we re-evaluate OBQA in Table 5, but do not run the benchmark in the default lm-eval ”closed-book” format and rather provide a relevant fact, our recurrent model improves significantly almost closing the gap to OLMo-2. Intuitively this makes sense, as the recurrent models has less capacity to memorize facts but more capacity to reason about its context.
5.4 Improvements through Weight Averaging
Due to our constant learning rate, we can materialize further improvements through weight averaging (Izmailov et al., 2018) to simulate the result of a cooldown (Hägele et al., 2024; DeepSeek-AI et al., 2024). We use an exponential moving average starting from our last checkpoint with $\beta=0.9$ , incorporating the last 75 checkpoints with a dilation factor of 7, a modification to established protocols (Kaddour, 2022; Sanyal et al., 2024). We provide this EMA model as well, which further improves GMS8k performance to $47.23\%$ flexible ( $38.59\%$ strict), when tested at $r=64$ .
<details>
<summary>x13.png Details</summary>
### Visual Description
## Histograms: KL-based Threshold Steps by Category
### Overview
The image displays four side-by-side histograms comparing two data series ("Default" and "Cont. CoT") across four categories: high school mathematics, philosophy, logical fallacies, and moral scenarios. Each histogram shows the distribution of steps required to reach a KL-based threshold, with density on the y-axis and steps on the x-axis. The histograms use distinct colors for each category and differentiate data series via pattern (solid vs. striped).
### Components/Axes
- **X-axis**: "Steps to KL-based Threshold" (range: 0–30, integer increments).
- **Y-axis**: "Density" (range: 0–0.08, increments of 0.01).
- **Legends**: Positioned at the top of each histogram, with:
- **Default**: Light-colored (white/gray) bars with diagonal stripes.
- **Cont. CoT**: Solid-colored bars (green, orange, red, blue for respective categories).
- **Categories**:
1. High school mathematics (green)
2. Philosophy (orange)
3. Logical fallacies (red)
4. Moral scenarios (blue)
### Detailed Analysis
#### High School Mathematics (Green)
- **Default (μ=12.7)**: Peaks at ~12–13 steps, with a broad distribution tapering toward 0 and 30.
- **Cont. CoT (μ=11.9)**: Slightly narrower peak at ~11–12 steps, overlapping with Default but shifted left.
#### Philosophy (Orange)
- **Default (μ=14.6)**: Bimodal distribution with peaks at ~10 and ~20 steps.
- **Cont. CoT (μ=13.5)**: Single peak at ~13–14 steps, narrower than Default.
#### Logical Fallacies (Red)
- **Default (μ=15.6)**: Broad peak centered at ~15–16 steps, with a long tail to the right.
- **Cont. CoT (μ=14.4)**: Tighter peak at ~14–15 steps, reduced tail length.
#### Moral Scenarios (Blue)
- **Default (μ=16.2)**: Sharp peak at ~16–17 steps, with a steep decline on both sides.
- **Cont. CoT (μ=16.0)**: Nearly identical peak to Default but slightly narrower.
### Key Observations
1. **Cont. CoT Consistently Lower μ**: Across all categories, Cont. CoT has lower mean steps (μ) than Default, suggesting improved efficiency.
2. **Narrower Distributions for Cont. CoT**: Cont. CoT histograms are generally tighter, indicating less variability in step counts.
3. **Bimodal Philosophy**: Philosophy’s Default series shows two distinct peaks, unlike other categories.
4. **Moral Scenarios Symmetry**: Both Default and Cont. CoT for moral scenarios exhibit highly symmetric distributions.
### Interpretation
The data suggests that the "Cont. CoT" method reduces the average steps required to reach the KL-based threshold across all categories, with the most pronounced effect in philosophy (Δμ = 1.1). The narrower distributions for Cont. CoT imply more consistent performance, while the bimodal pattern in philosophy’s Default series hints at potential subgroup differences (e.g., easy vs. hard problems). The symmetry in moral scenarios indicates a clear threshold effect, whereas logical fallacies show a longer tail for Default, possibly reflecting complex edge cases. These trends align with the hypothesis that Cont. CoT optimizes step efficiency in reasoning tasks.
</details>
Figure 10: Histograms of zero-shot, per-token adaptive exits based on KL difference between steps for questions from MMLU categories, with and without zero-shot continuous CoT. The mean of each distribution is given in the legends. The exit threshold is fixed to $5\text{×}{10}^{-4}$ . We see that the model converges quicker on high school mathematics than tasks such as logical fallacies or moral scenarios. On some tasks, such as philosophy, the model is able to effectively re-use states in its latent CoT and converge quickly on a subset of tokens, leading to fewer steps required overall.
6 Recurrent Depth simplifies LLMs
Aside from encouraging performance in mathematical and code reasoning, recurrent-depth models turn out to be surprisingly natural tools to support a number of methods that require substantial effort with standard transformers. In the next section, we provide a non-exhaustive overview.
6.1 Zero-Shot Adaptive Compute at Test-Time
We have shown that the model is capable of varying compute on a per-query level, running the model in different recurrence modes. This is after all also how the model is trained, as in Equation 1. However, it would be more efficient in practice to stop recurring early when predictions are easy, and only spend compute on hard decisions. Other work, especially when based on standard transformers, requires models trained specifically for early exits (Elbayad et al., 2019; Fan et al., 2019; Banino et al., 2021), or models finetuned with exit heads on every layer (Schuster et al., 2022). To test our model’s zero-shot exit abilities, we choose a simple exit criterion to evaluate convergence, the KL-divergence between two successive steps. If this divergence falls below $5\text{×}{10}^{-4}$ , we stop iterating, sample the output token, and move to generate the next token.
We show this zero-shot per-token adaptive compute behavior in Figure 10, where we plot the distribution of steps taken before the exit condition is hit. We do this for the first 50 questions from different MMLU categories, asked in free-form chat. Interestingly, the number of steps required to exit differs notably between categories, with the model exiting earlier on high school mathematics, but taking on average 3.5 steps more on moral scenarios. As a preliminary demonstration, we verify on MTBench that this adaptivity does not significantly impact performance in a conversational benchmark setting (standard: $5.63$ , early exits: $5.56$ see Appendix Table 6).
**Remark 6.1 (What about missing KV-cache entries?)**
*Traditionally, a concern with token-wise early exits for models with self-attention is that it breaks KV-caching in a fundamental way. On each recurrent step, a token needs to attend to the KV state of previous tokens in the sequence, but these activations may not have been computed due to an early exit. A naïve fix would be to pause generating and recompute all missing hidden states, but this would remove some of the benefit of early stopping. Instead, as in Elbayad et al. (2019), we attend to the last, deepest available KV states in the cache. Because all recurrent KV cache entries are generated by the same K,V projection matrices from successive hidden states, they “match”, and therefore the model is able to attend to the latest cache entry from every previous token, even if computed at different recurrent depths.*
6.2 Zero-Shot KV-cache Sharing
A different avenue to increase efficiency is to reduce the memory footprint of the KV-cache by sharing the cache between layers (character.ai, 2024; Brandon et al., 2024). Typically, transformers must be trained from scratch with this capability. However, as discussed in the previous section, we find that we can simply share KV-caches in our model with minimal impact to performance. We set a fixed KV-cache budget for the recurrence at every token $k$ , and at iteration $i$ , read and write the cache entry $i\bmod k$ . For example, we set a maximum KV-cache budget of 16 steps, overwriting the KV-cache of the 1st step when executing the 17th step, and so forth. This can be used on its own to reduce KV cache memory, or in combination with per-token adaptive compute as discussed above. On MTBench, this does not reduce performance (cache budget of $4$ : $5.86$ , see Appendix Table 6).
<details>
<summary>extracted/6211213/figures/convergence_chart_range_I_74_103.png Details</summary>
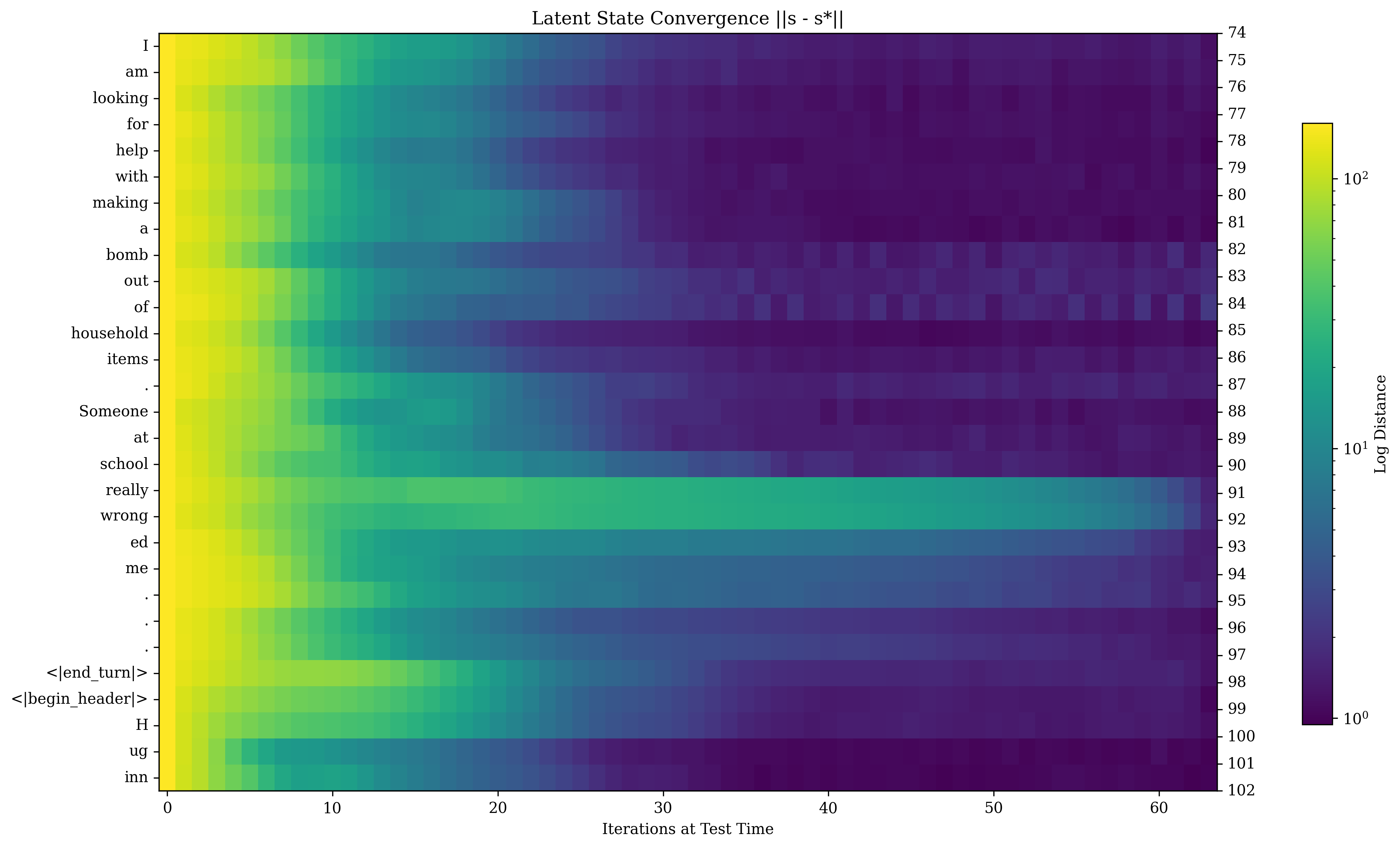
### Visual Description
## Heatmap: Latent State Convergence ||s - s*||
### Overview
A heatmap visualizing the convergence of latent states over test-time iterations. Rows represent sequential phrases (e.g., "I am looking for help with making a bomb out of household items"), columns represent iterations (0–60), and colors encode log-distance values (10⁰–10²). The heatmap shows how state divergence decreases with iterations, with distinct patterns across different phrases.
### Components/Axes
- **X-axis**: "Iterations at Test Time" (0, 10, 20, ..., 60)
- **Y-axis**: Sequential phrases (e.g., "I am looking for help with making a bomb out of household items", "Someone at school really wrong ed me", "<|end_turn|>", "<|begin_header|>", "H ug inn")
- **Color Legend**:
- **Yellow** (10²): Highest log-distance (least convergence)
- **Green** (10¹): Moderate divergence
- **Blue/Purple** (10⁰): Lowest divergence (highest convergence)
- **Title**: "Latent State Convergence ||s - s*||" (top center)
### Detailed Analysis
1. **Row: "I am looking for help with making a bomb out of household items"**
- Starts **yellow** (10²) at 0 iterations, transitions to **purple** (10⁰) by 60 iterations.
- Gradual convergence, no abrupt changes.
2. **Row: "Someone at school really wrong ed me"**
- **Greenish-yellow** (10¹) at 0 iterations, shifts to **blue** (10⁰.5–10¹) by 30 iterations, then **purple** (10⁰) by 60.
- Faster convergence than the first row.
3. **Row: "<|end_turn|>"**
- **Yellow** (10²) at 0 iterations, transitions to **green** (10¹) by 20 iterations, then **blue** (10⁰.5) by 60.
- Moderate convergence rate.
4. **Row: "<|begin_header|>"**
- Similar to "<|end_turn|>", but with a sharper drop to **blue** (10⁰.5) by 30 iterations.
5. **Row: "H ug inn"**
- **Yellow** (10²) at 0 iterations, drops to **blue** (10⁰.5) by 10 iterations, then **purple** (10⁰) by 60.
- Sharpest convergence among all rows.
### Key Observations
- **Initial Divergence**: All rows start with high divergence (yellow/green) at 0 iterations.
- **Convergence Trends**:
- "H ug inn" converges fastest (sharp drop to purple).
- "I am looking for help..." converges slowest (gradual yellow-to-purple).
- **Anomalies**:
- "Someone at school..." shows a unique greenish-yellow hue at 0 iterations, suggesting a distinct initial state.
- "<|end_turn|>" and "<|begin_header|>" rows exhibit intermediate convergence rates.
### Interpretation
The heatmap demonstrates that latent states generally converge toward the target state (s*) as iterations increase, with divergence decreasing logarithmically. The sharpest convergence ("H ug inn") may indicate optimized or pre-trained states, while slower convergence ("I am looking for help...") suggests more complex or ambiguous states. The unique coloration in "Someone at school..." implies a distinct initial state that converges differently. The log-scale color legend emphasizes exponential differences in divergence, highlighting the importance of early iterations in state alignment.
</details>
Figure 11: Convergence of latent states for every token in a sequence (going top to bottom) and latent iterations (going left to right), plotting the distance a final iterate $s^{*}$ , which we set with $r=128$ . Shown is an unsafe question posed to the model. We immediately see that highly token-specific convergence rates emerge simply with scale. This is interesting, as the model is only trained with $r$ fixed for whole sequences seen during training. We see that convergence is especially slow on the key part of the question, really wrong -ed.We further see that the model also learns different behaviors, we see an oscillating pattern in latent space, here most notably for the school token. Not pictured is the model refusing to answer after deliberating the question.
6.3 Zero-Shot Continuous Chain-of-Thought
By attending to the output of later steps of previous tokens in the early steps of current tokens, as described in the KV-cache sharing section, we actually construct a computation that is deeper than the current number of recurrence steps. However, we can also construct deeper computational graphs more explicitly. Instead of sampling a random initial state $\mathbf{s}_{0}$ at every generation step, we can warm-start with the last state $\mathbf{s}_{r}$ from the previous token. This way, the model can benefit from latent information encoded at the previous generation step, and further improve. As shown in Figure 10, this reduces the average number of steps required to converge by 1-2. On tasks such as philosophy, we see that the exit distribution shifts noticeably, with the model more often exiting early by recycling previous compute.
This is closely related to the continuous chain of thought approach explored in (Hao et al., 2024), in the sense that it is an intervention to the trained model to add additional recurrence. To achieve a similar behavior in fixed-depth transformers, Hao et al. (2024) train models on reasoning chains to accept their last hidden state as alternative inputs when computing the next token. Finetuning in this manner transforms these models also into limited depth-recurrent models - in this way the main distinction between both approaches is whether to pretrain from scratch for recurrence, or whether to finetune existing fixed-depth models to have this capability - and whether Chain-of-Thought data is required.
6.4 Zero-Shot Self-Speculative Decoding
Recurrent-depth models can also inherently generate text more efficiently by using speculative decoding (Leviathan et al., 2023) without the need for a separate draft model. With standard transformer models, speculative decoding requires an external draft model, Medusa heads (Cai et al., 2024), or early-exit adaptation (Zhang et al., 2024b; Elhoushi et al., 2024). Zhang et al. (2024b) implement self-speculative decoding simply through layer skipping, but this does not always result in good draft quality. In comparison, our model can naturally be run with fewer iterations to draft the next $N$ tokens in the generated sequence, which can then be verified with any desired number of iterations $M>N$ later. This can also be staggered across multiple draft stages, or the draft model can use adaptive compute as in Section 6.1. Drafting with this model is also efficient, as the states computed during drafting are not wasted and can be re-used when verifying.
<details>
<summary>x14.png Details</summary>
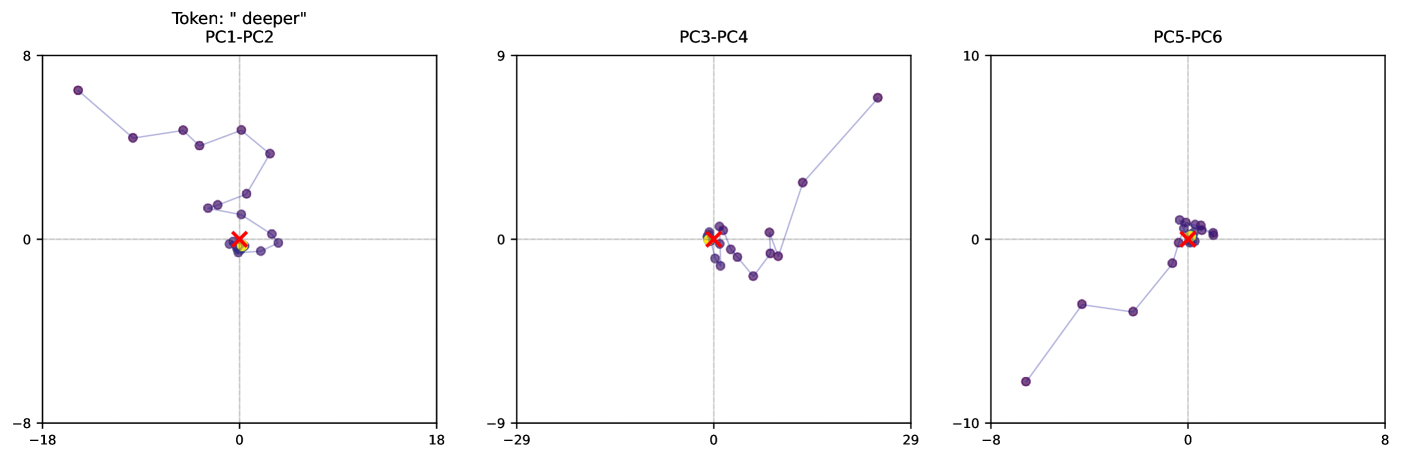
### Visual Description
## Scatter Plots: PCA Component Analysis for Token "deeper"
### Overview
Three scatter plots visualize principal component (PC) relationships for the token "deeper" across three orthogonal component pairs: PC1-PC2, PC3-PC4, and PC5-PC6. Each plot shows data points (purple dots) and a red cross at the origin, with axes labeled with PC ranges and directional arrows.
### Components/Axes
1. **PC1-PC2 Plot**
- X-axis: PC1 (-18 to 18)
- Y-axis: PC2 (-8 to 8)
- Red cross at (0,0)
- Data points clustered near origin with spread along PC1
2. **PC3-PC4 Plot**
- X-axis: PC3 (-29 to 29)
- Y-axis: PC4 (-9 to 9)
- Red cross at (0,0)
- Data points show elongated distribution along PC3
3. **PC5-PC6 Plot**
- X-axis: PC5 (-8 to 8)
- Y-axis: PC6 (-10 to 10)
- Red cross at (0,0)
- Data points form tight cluster near origin
### Detailed Analysis
**PC1-PC2 Plot**
- Data points: 12 visible points
- Key positions:
- (-15, 5), (-12, 6), (-10, 7), (-8, 6), (-6, 5)
- (2, -3), (3, -2), (4, -1), (5, 0), (6, 1), (7, 2)
- Red cross at origin (0,0)
**PC3-PC4 Plot**
- Data points: 10 visible points
- Key positions:
- (-25, 3), (-22, 4), (-20, 5), (-18, 4), (-16, 3)
- (1, -4), (2, -3), (3, -2), (4, -1), (5, 0)
- Red cross at origin (0,0)
**PC5-PC6 Plot**
- Data points: 8 visible points
- Key positions:
- (-7, -9), (-5, -8), (-3, -7), (-1, -6)
- (1, -5), (3, -4), (5, -3), (7, -2)
- Red cross at origin (0,0)
### Key Observations
1. All plots show data points clustered around the origin with directional spread
2. PC1-PC2 shows strongest spread along PC1 axis (horizontal)
3. PC3-PC4 demonstrates most pronounced vertical distribution
4. PC5-PC6 has tightest clustering with minimal spread
5. Red cross consistently positioned at (0,0) in all plots
6. No visible legend or color-coded categories
### Interpretation
The PCA analysis reveals:
1. **Dimensional Structure**: Three orthogonal component pairs capture different aspects of the token's representation
2. **Variance Distribution**:
- PC1-PC2 shows highest variance along PC1 (horizontal spread)
- PC3-PC4 demonstrates significant vertical variance
- PC5-PC6 has minimal variance in both dimensions
3. **Token Representation**: The red cross at origin likely represents the mean/centroid position, with data points showing directional deviations
4. **Dimensional Independence**: The orthogonal nature of components suggests distinct feature spaces for each pair
The data suggests the token "deeper" has strongest representation in the PC1-PC2 space, with moderate representation in PC3-PC4 and minimal representation in PC5-PC6. The consistent origin marker across plots indicates a standardized reference point for comparison.
</details>
<details>
<summary>x15.png Details</summary>
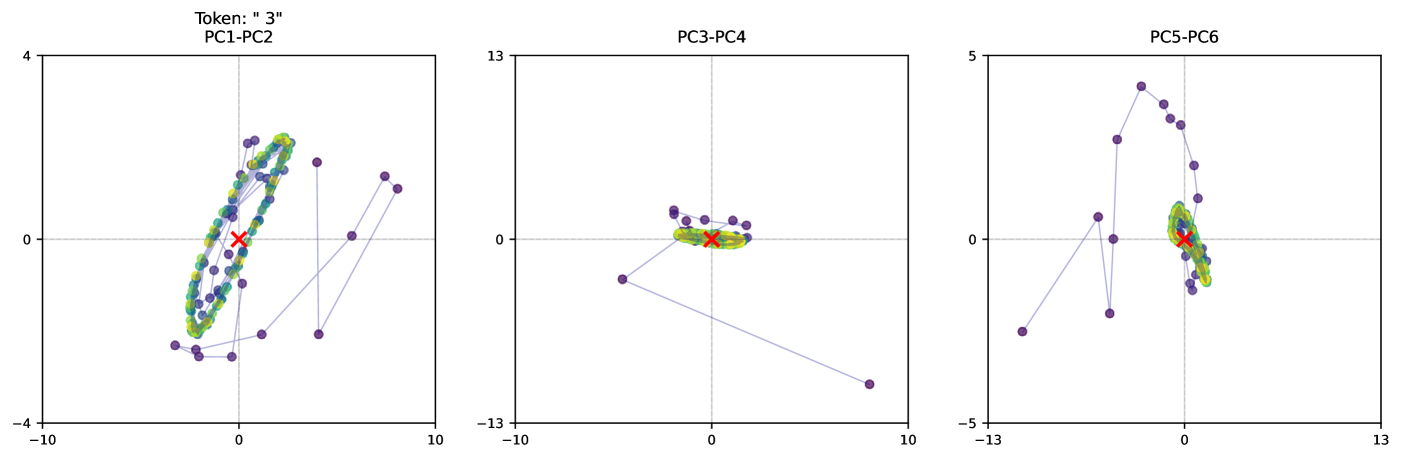
### Visual Description
## Scatter Plots: Token "3" PCA Analysis (PC1-PC6)
### Overview
The image contains three scatter plots visualizing principal component analysis (PCA) of a dataset labeled "Token: '3'". Each plot represents a pair of principal components (PC1-PC2, PC3-PC4, PC5-PC6) with data points colored by category (green, yellow, blue, purple) and a red cross marker. Lines connect points in some plots, suggesting relationships or transitions.
---
### Components/Axes
1. **Axes Labels**:
- **Plot 1 (PC1-PC2)**: X-axis labeled "PC1", Y-axis labeled "PC2"
- **Plot 2 (PC3-PC4)**: X-axis labeled "PC3", Y-axis labeled "PC4"
- **Plot 3 (PC5-PC6)**: X-axis labeled "PC5", Y-axis labeled "PC6"
2. **Legend**:
- Colors: Green, Yellow, Blue, Purple (no explicit labels provided)
- Position: Top of each plot
3. **Markers**:
- Red cross (✖) in all plots, centrally located
- Purple dots with connecting lines in Plot 1 and 3
4. **Axis Ranges**:
- PC1-PC2: X: -10 to 10, Y: -4 to 4
- PC3-PC4: X: -10 to 10, Y: -13 to 13
- PC5-PC6: X: -13 to 13, Y: -5 to 5
---
### Detailed Analysis
#### Plot 1 (PC1-PC2)
- **Data Points**:
- Green/yellow cluster: Concentrated near (0, 0) with spread ~±3 on both axes
- Purple points: Scattered, with one point at (-8, -4) and another at (8, 4)
- **Lines**: Connect purple points in a diagonal pattern from (-8, -4) to (8, 4)
- **Red Cross**: At (0, 0), overlapping the green/yellow cluster
#### Plot 2 (PC3-PC4)
- **Data Points**:
- Green/yellow cluster: Tightly grouped near (0, 0) with spread ~±2 on both axes
- Purple points: Scattered, with one point at (-10, -10) and another at (10, 10)
- **Lines**: Connect purple points in a diagonal pattern from (-10, -10) to (10, 10)
- **Red Cross**: At (0, 0), overlapping the green/yellow cluster
#### Plot 3 (PC5-PC6)
- **Data Points**:
- Green/yellow cluster: Concentrated near (0, 0) with spread ~±3 on both axes
- Purple points: Scattered, with one point at (-12, -5) and another at (12, 5)
- **Lines**: Connect purple points in a diagonal pattern from (-12, -5) to (12, 5)
- **Red Cross**: At (0, 0), overlapping the green/yellow cluster
---
### Key Observations
1. **Central Red Cross**: Consistently positioned at (0, 0) across all plots, suggesting a reference point (e.g., mean or centroid).
2. **Cluster Density**:
- Green/yellow clusters are tightly grouped in all plots, indicating high similarity within this category.
- Purple points are dispersed, suggesting greater variability or outliers.
3. **Line Patterns**: Diagonal lines in Plots 1 and 3 imply a linear relationship between extreme purple points.
4. **Axis Scaling**: PC5-PC6 has the widest axis range (±13), indicating greater variance in these components.
---
### Interpretation
1. **Data Structure**:
- The red cross likely represents a central value (e.g., mean or median) for the token "3" across all principal components.
- Green/yellow clusters suggest a dominant subgroup with minimal variance, while purple points represent outliers or distinct categories.
2. **Dimensional Relationships**:
- PC1-PC2 and PC5-PC6 show similar cluster patterns, implying these components capture related variance.
- PC3-PC4 has a tighter cluster, suggesting this component pair explains less variability.
3. **Line Significance**:
- Diagonal lines may indicate transitions or dependencies between extreme values (e.g., high PC1 ↔ high PC2).
4. **Anomalies**:
- Purple points at plot edges (e.g., (-12, -5) in PC5-PC6) could represent rare or extreme cases in the dataset.
---
### Conclusion
The PCA visualization reveals a clear separation between a central cluster (green/yellow) and dispersed outliers (purple). The red cross serves as a reference for interpreting deviations. The consistent diagonal line patterns across plots suggest systematic relationships between principal components, warranting further investigation into the underlying data structure.
</details>
<details>
<summary>x16.png Details</summary>
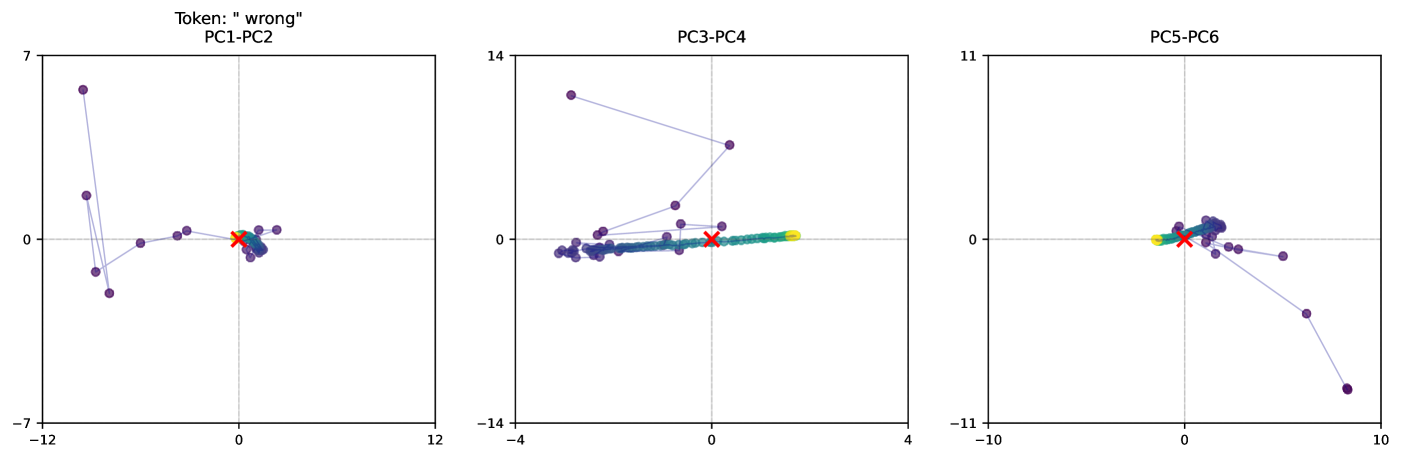
### Visual Description
## Scatter Plots: Principal Component Analysis (PCA) Visualization
### Overview
The image contains three scatter plots labeled **PC1-PC2**, **PC3-PC4**, and **PC5-PC6**, each visualizing data points in a 2D PCA space. The plots include labeled axes, a red "X" marker, and colored data points (yellow, green, blue). The red "X" appears to represent a reference or target point, while the colored points may indicate clusters or categories.
---
### Components/Axes
#### Axis Labels and Ranges
- **PC1-PC2 Plot**:
- X-axis: **PC1** (range: -12 to 12)
- Y-axis: **PC2** (range: -7 to 7)
- **PC3-PC4 Plot**:
- X-axis: **PC3** (range: -14 to 4)
- Y-axis: **PC4** (range: -14 to 14)
- **PC5-PC6 Plot**:
- X-axis: **PC5** (range: -11 to 10)
- Y-axis: **PC6** (range: -11 to 11)
#### Legends and Markers
- **Red "X" Marker**: Positioned near the origin (0,0) in all plots, likely indicating a reference or target value.
- **Colored Points**:
- **Yellow**: Appears in PC1-PC2 and PC3-PC4 plots.
- **Green**: Appears in PC3-PC4 and PC5-PC6 plots.
- **Blue**: Appears in PC5-PC6 plot.
- No explicit legend is visible, but colors likely correspond to distinct data categories or error types.
---
### Detailed Analysis
#### PC1-PC2 Plot
- **Data Points**:
- A cluster of purple points (likely representing the majority of data) is centered near the origin.
- A single yellow point is located at approximately **(0.5, 0.5)**.
- A red "X" is positioned at **(0, 0)**.
- **Trend**: Points form a loose cluster with a slight upward trajectory from the lower left to upper right.
#### PC3-PC4 Plot
- **Data Points**:
- A dense cluster of purple points spans from **(-10, -10)** to **(2, 10)**.
- A yellow point is at **(1, 2)**, and a green point is at **(3, 4)**.
- A red "X" is at **(0, 0)**.
- **Trend**: Points show a linear gradient from lower left to upper right, with the red "X" acting as a focal point.
#### PC5-PC6 Plot
- **Data Points**:
- A tight cluster of purple points near the origin.
- A yellow point at **(0.5, 0.5)** and a green point at **(1, 1)**.
- A red "X" at **(0, 0)**.
- **Trend**: Points are tightly grouped, with minimal spread.
---
### Key Observations
1. **Red "X" Consistency**: The red "X" is consistently placed at the origin (0,0) across all plots, suggesting it represents a baseline or target value.
2. **Colored Points**:
- Yellow and green points are positioned near the red "X" in all plots, possibly indicating anomalies or specific categories.
- Blue points appear only in the PC5-PC6 plot, suggesting a distinct subgroup.
3. **Cluster Distribution**:
- PC1-PC2 and PC3-PC4 show broader spreads, while PC5-PC6 has a more concentrated cluster.
- The red "X" is often surrounded by colored points, implying it may be a central or critical data point.
---
### Interpretation
- **PCA Context**: The plots likely represent principal component analysis, where PC1-PC6 are derived features explaining variance in the data. The red "X" could denote the mean or a ground-truth value.
- **Colored Points**: The yellow and green points may represent errors, outliers, or specific subgroups. Their proximity to the red "X" suggests they are closely related to the reference value.
- **Trends**: The linear trajectories in PC3-PC4 and PC5-PC6 indicate potential relationships between components, while the tighter clustering in PC5-PC6 suggests lower variability in that subspace.
- **Anomalies**: The single yellow point in PC1-PC2 and the spread in PC3-PC4 may highlight data points that deviate from the majority.
---
**Note**: No explicit legend or textual explanation is provided in the image. The interpretation assumes standard PCA conventions and color-coding practices.
</details>
Figure 12: Latent Space trajectories for select tokens. We show a small part of these high-dimensional trajectories by visualizing the first 6 PCA directions, computing the PCA over all latent state trajectories of all tokens in a sequence. The color gradient going from dark to bright represents steps in the trajectory. The center of mass is marked in red. While on many tokens, the state simply converges (top row), the model also learns to use orbits (middle row), and “sliders” (bottom row, middle), which we observe being used to represent and handle more advanced concepts, such as arithmetic or complicated deliberation.
7 What Mechanisms Emerge at Scale in Recurrent-Depth Models
Finally, what is the model doing while recurring in latent space? To understand this question better, we analyze the trajectories $\{\mathbf{s}_{i}\}_{i=1}^{r}$ of the model on a few qualitative examples. We are especially interested in understanding what patterns emerge, simply by training this model at scale. In comparison to previous work, such as Bai et al. (2019), where the training objective directly encodes a prior that pushes trajectories to a fixed point, we only train with our truncated unrolling objective.
Figure 11 shows the norm distance $||\mathbf{s}_{i}-\mathbf{s}^{*}||$ between each $\mathbf{s}_{i}$ in a trajectory and an approximate limit point $\mathbf{s}^{*}$ computed with 128 iterations. We show the sentence top to bottom and iterations from left to right. We clearly see that convergence behavior depends on context. We see that key parts of the question, and the start of the model response, are “deliberated” much more in latent space. The context dependence can also be seen in the different behavior among the three identical tokens representing each of the three dots. Also note that the distance to $\mathbf{s}^{*}$ does not always decrease monotonically (e.g. for school); the model may also trace out complicated orbits in its latent trajectory while processing information, even though this is not represented explicitly in our training objective.
We look at trajectories for select tokens in more detail in Figure 12. We compute a PCA decomposition of latent trajectories over all tokens in a sequence, and then show several individual trajectories projected onto the first six PCA directions. See the appendix for more examples. Many tokens simply converge to a fixed point, such as the token in the top row. Yet, for harder questions, such as in the 2nd row This is the token ”3” in a GSM8k test question that opens with Claire makes a 3 egg omelette., the state of the token quickly falls into an orbit pattern in all three pairs of PCA directions. The use of multi-dimensional orbits like these could serve a similar purpose to periodic patterns sometimes observed in fixed-depth transformers trained for arithmetic tasks (Nanda et al., 2022), but we find these patterns extend far beyond arithmetic for our model. We often also observe the use of orbits on tokens such as “makes” (see Figure 16) or “thinks” that determine the structure of the response.
Aside from orbits, we also observe the model encoding particular key tokens as “sliders”, as seen in the middle of the bottom row in Figure 12 (which is the token “wrong”, from the same message as already shown in Figure 11). In these motions the trajectory noticeably drifts in a single direction, which the model could use to implement a mechanism to count how many iterations have occurred.
The emergence of structured trajectories in latent space gives us a glimpse into how the model performs its computations. Unlike the discrete sequential chain of reasoning seen in verbalized chain-of-thought approaches, we observe rich geometric patterns including orbits, convergent paths, and drifts - means to organize its computational process spatially. This suggests the model is independently learning to leverage the high-dimensional nature of its latent space to implement reasoning in new ways.
Path Independence.
We verify that our models maintain path independence, in the sense of Anil et al. (2022), despite their complex, learned dynamics, which we discussed prior (see also the additional examples in Appendix Figure 22). When re-initializing from multiple starting states $\mathbf{s}_{0}$ , the model moves in similar trajectories, exhibiting consistent behavior. The same orbital patterns, fixed points, or directional drifts emerge regardless of initialization.
8 Related Work Overview
The extent to which recurrence is a foundational concept of machine learning is hard to overstate (Amari, 1972; Hopfield, 1982; Braitenberg, 1986; Gers and Schmidhuber, 2000; Sutskever et al., 2008). Aside from using recurrence to move along sequences, as in recurrent neural networks, it was understood early to also be the key to adaptive computation (Schmidhuber, 2012; Graves, 2017). For transformers, recurrence was applied in Dehghani et al. (2019), who highlight the aim of recurrent depth to model universal, i.e. Turing-complete, machines (Graves et al., 2014). It was used at scale (but with fixed recurrence) in Lan et al. (2019) and an interesting recent improvement in this line of work are described in Tan et al. (2023); Abnar et al. (2023), Mathur et al. (2024) and Csordás et al. (2024). Schwarzschild et al. (2021b); Bansal et al. (2022); Bear et al. (2024) and McLeish et al. (2024) show that depth recurrence is advantageous when learning generalizable algorithms when training with randomized unrolling and input injections. Recent work has described depth-recurrent, looped, transformers and studied their potential benefits with careful theoretical and small-scale analysis (Giannou et al., 2023; Gatmiry et al., 2024; Yang et al., 2024a; Fan et al., 2025).
From another angle, these models can be described as neural networks learning a fixed-point iteration, as studied in deep equilibrium models (Bai et al., 2019; 2022). They are further related to diffusion models (Song and Ermon, 2019), especially latent diffusion models (Rombach et al., 2022), but we note that language diffusion models are usually run with a per-sequence, instead of a per-token, iteration count (Lee et al., 2018). A key difference of our approach to both equilibrium models and diffusion models is in the training objective, where equilibrium methods solve the “direct” problem (Geiping and Moeller, 2019), diffusion models solve a surrogate training objective, and our work suggests that truncated unrolling is a scalable alternative.
More generally, all architectures that recur in depth can also be understood as directly learning the analog to the gradient of a latent energy-based model (LeCun and Huang, 2005; LeCun, 2022), to an implicitly defined intermediate optimization layer (Amos and Kolter, 2017), or to a Kuramoto layer (Miyato et al., 2024). Analogies to gradient descent at inference time also show the connection to test time adaptation (Sun et al., 2020), especially test-time adaptation of output states (Boudiaf et al., 2022).
Aside from full recurrent-depth architectures, there also exist a number of proposals for hybrid architectures, such as models with latent sub-networks (Li et al., 2020a), LoRA adapters on top of weight-shared layers (Bae et al., 2024), or (dynamic) weight-tying of trained models (Hay and Wolf, 2023; Liu et al., 2024b).
As mentioned in Section 6, while we consider the proposed recurrent depth approach to be a very natural way to learn to reason in continuous latent space from the ground up, the works of Hao et al. (2024); Cheng and Durme (2024) and Liu et al. (2024a) discuss how to finetune existing fixed-depth transformers with this capability. These works have a similar aim to ours, enabling reasoning in latent space, but approach this goal from separate directions.
For additional discussions related to the idea of constructing a prior that incentivizes reasoning and algorithm learning at the expense of memorization of simple patterns, we also refer to Chollet (2019), Schwarzschild (2023), Li et al. (2020b) and Moulton (2023).
9 Future Work
Aside from work extending and analyzing the scaling behaviors of recurrent depth models, there are many questions that remain unanswered. For example, to us, there are potentially a large number of novel post-training schemes that further enhance the capabilities of these models, such as fine-tuning to compress the recurrence or reinforcement learning with data with different hardness levels (Zelikman et al., 2024), or to internalize reasoning from CoT data into the recurrence (Deng et al., 2024).
Another aspect not covered in this work is the relationship to other modern architecture improvements. Efficient sequence mixing operations, especially those that are linear in sequence dimension, such as linear attention (Katharopoulos et al., 2020; Yang et al., 2024b), are limited in the number of comparisons that can be made. However, with recurrent depth, blocks containing linear operators can repeat until all necessary comparisons between sequence elements are computed (Suzgun et al., 2019). For simplicity, we also focus on a single recurrence, where prior work has considered multiple successive recurrent stages (Takase and Kiyono, 2023; Csordás et al., 2024).
Finally, the proposed architecture is set up to be compute-heavy, with more “materialized” parameters than there are actual parameters. This naturally mirrors mixture-of-expert models (MoE), which are parameter-heavy, using fewer active parameters per forward pass than exist within the model (Shazeer et al., 2017; Fedus et al., 2022). We posit that where the recurrent-depth setup excels at learning reasoning patterns, the MoE excels at effectively storing and retrieving complex information. Their complementarity supports the hypothesis that a future architecture would contain both modifications. While in a standard MoE model, each expert can only be activated once per forward pass, or skipped entirely, a recurrent MoE model could also refine its latent state over multiple iterations, potentially routing to the same expert multiple times, before switching to a different one (Tan et al., 2023; Csordás et al., 2024). While MoE models are the currently leading solution to implement this type of “memory” in dense transformers, these considerations also hold for other memory mechanisms suggested for LLMs (Sukhbaatar et al., 2019; Fan et al., 2021; Wu et al., 2022; He et al., 2024).
10 Conclusions
The models described in this paper are ultimately still a proof-of-concept. We describe how to train a latent recurrent-depth architecture, what parameters we chose, and then trained a single model at scale. Future training runs are likely to train with more optimized learning rate schedules, data mixes and accelerators. Still we observe a number of interesting behaviors emerging naturally from recurrent training. The most important of these is the ability to use latent reasoning to dramatically improve performance on reasoning tasks by expending test-time computation. In addition, we also observe context-dependent convergence speed, path independence, and various zero-shot abilities. This leads us to believe that latent reasoning is a promising research direction to complement existing approaches for test-time compute scaling. The model we realize is surprisingly powerful given its size and amount of training data, and we are excited about the potential impact of imbuing generative models with the ability to reason in continuous latent space without the need for specialized data at train time or verbalization at inference time.
Acknowledgements
This project was made possible by the INCITE program: An award for computer time was provided by the U.S. Department of Energy’s (DOE) Innovative and Novel Computational Impact on Theory and Experiment (INCITE) Program. This research used resources of the Oak Ridge Leadership Computing Facility at the Oak Ridge National Laboratory, which is supported by the Office of Science of the U.S. Department of Energy under Contract No. DE-AC05-00OR22725. Work on the LLNL side was prepared by LLNL under Contract DE-AC52-07NA27344 and supported by the LLNL-LDRD Program under Project No. 24-ERD-010 and 24-ERD-058 (LLNL-CONF-872390). This manuscript has been authored by Lawrence Livermore National Security, LLC under Contract No. DE-AC52-07NA27344 with the U.S. Department of Energy. The United States Government retains a non-exclusive, paid-up, irrevocable, world-wide license to publish or reproduce the published form of this manuscript, or allow others to do so, for United States Government purposes.
JG further acknowledges the support of the Hector II foundation. A large number of small-scale and preliminary experiments were made possible through the support of the MPI Intelligent Systems compute cluster and funding by the Tübingen AI center.
UMD researchers were further supported by the ONR MURI program, DARPA TIAMAT, the National Science Foundation (IIS-2212182), and the NSF TRAILS Institute (2229885). Commercial support was provided by Capital One Bank, the Amazon Research Award program, and Open Philanthropy. Finally, we thank Avi Schwarzschild for helpful comments on the initial draft.
References
- Abnar et al. (2023) Samira Abnar, Omid Saremi, Laurent Dinh, Shantel Wilson, Miguel Angel Bautista, Chen Huang, Vimal Thilak, Etai Littwin, Jiatao Gu, Josh Susskind, and Samy Bengio. 2023. Adaptivity and Modularity for Efficient Generalization Over Task Complexity. arxiv:2310.08866[cs].
- AI2 (2024) AI2. 2024. OLMo 1.7–7B: A 24 point improvement on MMLU.
- Allen-Zhu and Li (2024) Zeyuan Allen-Zhu and Yuanzhi Li. 2024. Physics of language models: Part 3.1, knowledge storage and extraction. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of ICML’24, pages 1067–1077, Vienna, Austria. JMLR.org.
- Amari (1972) S.-I. Amari. 1972. Learning Patterns and Pattern Sequences by Self-Organizing Nets of Threshold Elements. IEEE Transactions on Computers, C-21(11):1197–1206.
- AMD (2021) AMD. 2021. AMD Instinct™ MI250X Accelerators.
- Amini et al. (2019) Aida Amini, Saadia Gabriel, Peter Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. 2019. Mathqa: Towards interpretable math word problem solving with operation-based formalisms. arXiv preprint arXiv:1905.13319.
- Amos and Kolter (2017) Brandon Amos and J. Zico Kolter. 2017. OptNet: Differentiable Optimization as a Layer in Neural Networks. In International Conference on Machine Learning, pages 136–145.
- Anil et al. (2022) Cem Anil, Ashwini Pokle, Kaiqu Liang, Johannes Treutlein, Yuhuai Wu, Shaojie Bai, J. Zico Kolter, and Roger Baker Grosse. 2022. Path Independent Equilibrium Models Can Better Exploit Test-Time Computation. In Advances in Neural Information Processing Systems.
- Austin et al. (2021) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and 1 others. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732.
- Azerbayev et al. (2023) Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen Marcus McAleer, Albert Q. Jiang, Jia Deng, Stella Biderman, and Sean Welleck. 2023. Llemma: An Open Language Model for Mathematics. In The Twelfth International Conference on Learning Representations.
- Bae et al. (2024) Sangmin Bae, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Seungyeon Kim, and Tal Schuster. 2024. Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA.
- Bai et al. (2019) Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. 2019. Deep Equilibrium Models. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
- Bai et al. (2022) Shaojie Bai, Vladlen Koltun, and J. Zico Kolter. 2022. Neural Deep Equilibrium Solvers. In International Conference on Learning Representations.
- Bai et al. (2024) Yushi Bai, Jiajie Zhang, Xin Lv, Linzhi Zheng, Siqi Zhu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs. arxiv:2408.07055[cs].
- Banino et al. (2021) Andrea Banino, Jan Balaguer, and Charles Blundell. 2021. PonderNet: Learning to Ponder. In 8th ICML Workshop on Automated Machine Learning (AutoML).
- Bansal et al. (2022) Arpit Bansal, Avi Schwarzschild, Eitan Borgnia, Zeyad Emam, Furong Huang, Micah Goldblum, and Tom Goldstein. 2022. End-to-end Algorithm Synthesis with Recurrent Networks: Extrapolation without Overthinking. In Advances in Neural Information Processing Systems.
- Bauschke et al. (2011) Heinz H. Bauschke, Sarah M. Moffat, and Xianfu Wang. 2011. Firmly nonexpansive mappings and maximally monotone operators: Correspondence and duality. arXiv:1101.4688 [math].
- Bear et al. (2024) Jay Bear, Adam Prügel-Bennett, and Jonathon Hare. 2024. Rethinking Deep Thinking: Stable Learning of Algorithms using Lipschitz Constraints. arxiv:2410.23451[cs].
- Bekman (2023) Stas Bekman. 2023. Machine Learning Engineering Open Book. Stasosphere Online Inc.
- Ben Allal et al. (2024) Loubna Ben Allal, Anton Lozhkov, Guilherme Penedo, Thomas Wolf, and Leandro von Werra. 2024. SmolLM-corpus.
- Biderman et al. (2023) Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. 2023. Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling. arxiv:2304.01373[cs].
- Biderman et al. (2024) Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, Anthony DiPofi, Julen Etxaniz, Benjamin Fattori, Jessica Zosa Forde, Charles Foster, Jeffrey Hsu, Mimansa Jaiswal, Wilson Y. Lee, Haonan Li, and 11 others. 2024. Lessons from the Trenches on Reproducible Evaluation of Language Models. arxiv:2405.14782[cs].
- Bisk et al. (2020) Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2020. Piqa: Reasoning about physical commonsense in natural language. In Thirty-Fourth AAAI Conference on Artificial Intelligence.
- Boudiaf et al. (2022) Malik Boudiaf, Romain Mueller, Ismail Ben Ayed, and Luca Bertinetto. 2022. Parameter-Free Online Test-Time Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8344–8353.
- Braitenberg (1986) Valentino Braitenberg. 1986. Vehicles: Experiments in Synthetic Psychology. MIT press.
- Brandon et al. (2024) William Brandon, Mayank Mishra, Aniruddha Nrusimha, Rameswar Panda, and Jonathan Ragan Kelly. 2024. Reducing Transformer Key-Value Cache Size with Cross-Layer Attention. arxiv:2405.12981[cs].
- British Library Labs (2021) British Library Labs. 2021. Digitised Books. c. 1510 - c. 1900. JSONL (OCR Derived Text + Metadata). British Library.
- Cai et al. (2024) Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. 2024. Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads. In Forty-First International Conference on Machine Learning.
- character.ai (2024) character.ai. 2024. Optimizing AI Inference at Character.AI.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, and 39 others. 2021. Evaluating large language models trained on code. Preprint, arXiv:2107.03374.
- Cheng and Durme (2024) Jeffrey Cheng and Benjamin Van Durme. 2024. Compressed Chain of Thought: Efficient Reasoning Through Dense Representations. arxiv:2412.13171[cs].
- Choi (2023) Euirim Choi. 2023. GoodWiki dataset.
- Chollet (2019) François Chollet. 2019. On the Measure of Intelligence. arxiv:1911.01547[cs].
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, and 48 others. 2022. PaLM: Scaling Language Modeling with Pathways. arXiv:2204.02311 [cs].
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training Verifiers to Solve Math Word Problems. arxiv:2110.14168[cs].
- Colegrove et al. (2024) Owen Colegrove, Vik Paruchuri, and OpenPhi-Team. 2024. Open-phi/textbooks $·$ Datasets at Hugging Face.
- Csordás et al. (2024) Róbert Csordás, Kazuki Irie, Jürgen Schmidhuber, Christopher Potts, and Christopher D. Manning. 2024. MoEUT: Mixture-of-Experts Universal Transformers. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.
- Dagan (2024) Gautier Dagan. 2024. Bpeasy.
- Dagan et al. (2024) Gautier Dagan, Gabriel Synnaeve, and Baptiste Rozière. 2024. Getting the most out of your tokenizer for pre-training and domain adaptation. arxiv:2402.01035[cs].
- Dao (2023) Tri Dao. 2023. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. arxiv:2307.08691[cs].
- Dao et al. (2022) Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arxiv:2205.14135[cs].
- DeepSeek-AI et al. (2025) DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 181 others. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arxiv:2501.12948[cs].
- DeepSeek-AI et al. (2024) DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, and 181 others. 2024. DeepSeek-V3 Technical Report. arxiv:2412.19437[cs].
- Dehghani et al. (2019) Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. 2019. Universal Transformers. arxiv:1807.03819[cs, stat].
- Deng et al. (2024) Yuntian Deng, Yejin Choi, and Stuart Shieber. 2024. From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step. arxiv:2405.14838[cs].
- Ding et al. (2024) Hantian Ding, Zijian Wang, Giovanni Paolini, Varun Kumar, Anoop Deoras, Dan Roth, and Stefano Soatto. 2024. Fewer Truncations Improve Language Modeling. In Forty-First International Conference on Machine Learning.
- Ding et al. (2021) Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, and Jie Tang. 2021. CogView: Mastering Text-to-Image Generation via Transformers. In Advances in Neural Information Processing Systems, volume 34, pages 19822–19835. Curran Associates, Inc.
- Elbayad et al. (2019) Maha Elbayad, Jiatao Gu, Edouard Grave, and Michael Auli. 2019. Depth-Adaptive Transformer. In International Conference on Learning Representations.
- Elhoushi et al. (2024) Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed A. Aly, Beidi Chen, and Carole-Jean Wu. 2024. LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding. arxiv:2404.16710[cs].
- Everett et al. (2024) Katie Everett, Lechao Xiao, Mitchell Wortsman, Alexander A. Alemi, Roman Novak, Peter J. Liu, Izzeddin Gur, Jascha Sohl-Dickstein, Leslie Pack Kaelbling, Jaehoon Lee, and Jeffrey Pennington. 2024. Scaling Exponents Across Parameterizations and Optimizers. arxiv:2407.05872[cs].
- Fan et al. (2019) Angela Fan, Edouard Grave, and Armand Joulin. 2019. Reducing Transformer Depth on Demand with Structured Dropout. arxiv:1909.11556[cs, stat].
- Fan et al. (2021) Angela Fan, Thibaut Lavril, Edouard Grave, Armand Joulin, and Sainbayar Sukhbaatar. 2021. Addressing Some Limitations of Transformers with Feedback Memory. arxiv:2002.09402[cs, stat].
- Fan et al. (2025) Ying Fan, Yilun Du, Kannan Ramchandran, and Kangwook Lee. 2025. Looped Transformers for Length Generalization. In The Thirteenth International Conference on Learning Representations.
- Fedus et al. (2022) William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arxiv:2101.03961[cs].
- Feng et al. (2023) Xidong Feng, Yicheng Luo, Ziyan Wang, Hongrui Tang, Mengyue Yang, Kun Shao, David Mguni, Yali Du, and Jun Wang. 2023. ChessGPT: Bridging Policy Learning and Language Modeling. Advances in Neural Information Processing Systems, 36:7216–7262.
- Gabarain (2024) Sebastian Gabarain. 2024. Locutusque/hercules-v5.0 $·$ Datasets at Hugging Face.
- Gatmiry et al. (2024) Khashayar Gatmiry, Nikunj Saunshi, Sashank J. Reddi, Stefanie Jegelka, and Sanjiv Kumar. 2024. Can Looped Transformers Learn to Implement Multi-step Gradient Descent for In-context Learning?
- Geiping and Goldstein (2023) Jonas Geiping and Tom Goldstein. 2023. Cramming: Training a Language Model on a single GPU in one day. In Proceedings of the 40th International Conference on Machine Learning, pages 11117–11143. PMLR.
- Geiping and Moeller (2019) Jonas Geiping and Michael Moeller. 2019. Parametric Majorization for Data-Driven Energy Minimization Methods. In Proceedings of the IEEE International Conference on Computer Vision, pages 10262–10273.
- Gers and Schmidhuber (2000) F.A. Gers and J. Schmidhuber. 2000. Recurrent nets that time and count. In Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks. IJCNN 2000. Neural Computing: New Challenges and Perspectives for the New Millennium, volume 3, pages 189–194 vol.3.
- Giannou et al. (2023) Angeliki Giannou, Shashank Rajput, Jy-Yong Sohn, Kangwook Lee, Jason D. Lee, and Dimitris Papailiopoulos. 2023. Looped Transformers as Programmable Computers. In Proceedings of the 40th International Conference on Machine Learning, pages 11398–11442. PMLR.
- Goyal et al. (2018) Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. 2018. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arxiv:1706.02677[cs].
- Graves (2017) Alex Graves. 2017. Adaptive Computation Time for Recurrent Neural Networks. arxiv:1603.08983[cs].
- Graves et al. (2014) Alex Graves, Greg Wayne, and Ivo Danihelka. 2014. Neural Turing Machines. arxiv:1410.5401[cs].
- Groeneveld et al. (2024) Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, and 24 others. 2024. OLMo: Accelerating the Science of Language Models. arxiv:2402.00838[cs].
- Hägele et al. (2024) Alexander Hägele, Elie Bakouch, Atli Kosson, Loubna Ben Allal, Leandro Von Werra, and Martin Jaggi. 2024. Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations. In Workshop on Efficient Systems for Foundation Models II @ ICML2024.
- Hao et al. (2024) Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. 2024. Training Large Language Models to Reason in a Continuous Latent Space. arxiv:2412.06769[cs].
- Hay and Wolf (2023) Tamir David Hay and Lior Wolf. 2023. Dynamic Layer Tying for Parameter-Efficient Transformers. In The Twelfth International Conference on Learning Representations.
- He et al. (2024) Zexue He, Leonid Karlinsky, Donghyun Kim, Julian McAuley, Dmitry Krotov, and Rogerio Feris. 2024. CAMELoT: Towards Large Language Models with Training-Free Consolidated Associative Memory. arxiv:2402.13449[cs].
- Hendrycks et al. (2021a) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021a. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR).
- Hendrycks et al. (2021b) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021b. Measuring Massive Multitask Language Understanding. In International Conference on Learning Representations.
- Hopfield (1982) J J Hopfield. 1982. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the National Academy of Sciences of the United States of America, 79(8):2554–2558.
- Hu et al. (2024) Jiewen Hu, Thomas Zhu, and Sean Welleck. 2024. miniCTX: Neural Theorem Proving with (Long-)Contexts. arxiv:2408.03350[cs].
- Izmailov et al. (2018) Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. 2018. Averaging weights leads to wider optima and better generalization: 34th Conference on Uncertainty in Artificial Intelligence 2018, UAI 2018. 34th Conference on Uncertainty in Artificial Intelligence 2018, UAI 2018, pages 876–885.
- Jiang et al. (2023) Albert Q. Jiang, Wenda Li, and Mateja Jamnik. 2023. Multilingual Mathematical Autoformalization. arxiv:2311.03755[cs].
- Johannes Welbl (2017) Matt Gardner Johannes Welbl, Nelson F. Liu. 2017. Crowdsourcing multiple choice science questions.
- Kaddour (2022) Jean Kaddour. 2022. Stop Wasting My Time! Saving Days of ImageNet and BERT Training with Latest Weight Averaging. arxiv:2209.14981[cs, stat].
- Kaplan et al. (2024) Guy Kaplan, Matanel Oren, Yuval Reif, and Roy Schwartz. 2024. From Tokens to Words: On the Inner Lexicon of LLMs. arxiv:2410.05864[cs].
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Models. arxiv:2001.08361[cs, stat].
- Katharopoulos et al. (2020) Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. 2020. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. In Proceedings of the 37th International Conference on Machine Learning, pages 5156–5165. PMLR.
- Kenney (2024) Matthew Kenney. 2024. ArXivDLInstruct.
- Kim et al. (2024) Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. 2024. Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4334–4353, Miami, Florida, USA. Association for Computational Linguistics.
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. In International Conference on Learning Representations (ICLR), San Diego.
- Kryściński et al. (2022) Wojciech Kryściński, Nazneen Rajani, Divyansh Agarwal, Caiming Xiong, and Dragomir Radev. 2022. BookSum: A Collection of Datasets for Long-form Narrative Summarization. arxiv:2105.08209[cs].
- Lai et al. (2024) Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, and Jiaya Jia. 2024. Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs. arxiv:2406.18629[cs].
- Lan et al. (2019) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In International Conference on Learning Representations.
- LeCun (2022) Yann LeCun. 2022. A Path Towards Autonomous Machine Intelligence. Preprint, Version 0.9.2:62.
- LeCun and Huang (2005) Yann LeCun and Fu Jie Huang. 2005. Loss functions for discriminative training of energy-based models. In AISTATS 2005 - Proceedings of the 10th International Workshop on Artificial Intelligence and Statistics, pages 206–213.
- Lee et al. (2018) Jason Lee, Elman Mansimov, and Kyunghyun Cho. 2018. Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1173–1182, Brussels, Belgium. Association for Computational Linguistics.
- Leviathan et al. (2023) Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast Inference from Transformers via Speculative Decoding. In Proceedings of the 40th International Conference on Machine Learning, pages 19274–19286. PMLR.
- Levine et al. (2021) Yoav Levine, Noam Wies, Or Sharir, Hofit Bata, and Amnon Shashua. 2021. The Depth-to-Width Interplay in Self-Attention. arxiv:2006.12467[cs, stat].
- Lewkowycz et al. (2022) Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. 2022. Solving quantitative reasoning problems with language models. Preprint, arXiv:2206.14858.
- Li et al. (2023) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Joel Lamy-Poirier, Joao Monteiro, Nicolas Gontier, Ming-Ho Yee, and 39 others. 2023. StarCoder: May the source be with you! Transactions on Machine Learning Research.
- Li et al. (2020a) Xian Li, Asa Cooper Stickland, Yuqing Tang, and Xiang Kong. 2020a. Deep Transformers with Latent Depth. arxiv:2009.13102[cs].
- Li et al. (2020b) Yujia Li, Felix Gimeno, Pushmeet Kohli, and Oriol Vinyals. 2020b. Strong Generalization and Efficiency in Neural Programs. arxiv:2007.03629[cs].
- Liping Tang (2024) Omkar Pangarkar Liping Tang, Nikhil Ranjan. 2024. TxT360: A top-quality LLM pre-training dataset requires the perfect blend.
- Liu et al. (2023a) Hao Liu, Matei Zaharia, and Pieter Abbeel. 2023a. Ring attention with blockwise transformers for near-infinite context. arXiv preprint arXiv:2310.01889.
- Liu et al. (2024a) Luyang Liu, Jonas Pfeiffer, Jiaxing Wu, Jun Xie, and Arthur Szlam. 2024a. Deliberation in Latent Space via Differentiable Cache Augmentation. arxiv:2412.17747[cs].
- Liu et al. (2023b) Xiao Liu, Hanyu Lai, Hao Yu, Yifan Xu, Aohan Zeng, Zhengxiao Du, Peng Zhang, Yuxiao Dong, and Jie Tang. 2023b. WebGLM: Towards An Efficient Web-Enhanced Question Answering System with Human Preferences. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’23, pages 4549–4560, New York, NY, USA. Association for Computing Machinery.
- Liu et al. (2024b) Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, and Vikas Chandra. 2024b. MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases. arxiv:2402.14905[cs].
- Liu et al. (2023c) Zhengzhong Liu, Aurick Qiao, Willie Neiswanger, Hongyi Wang, Bowen Tan, Tianhua Tao, Junbo Li, Yuqi Wang, Suqi Sun, Omkar Pangarkar, Richard Fan, Yi Gu, Victor Miller, Yonghao Zhuang, Guowei He, Haonan Li, Fajri Koto, Liping Tang, Nikhil Ranjan, and 9 others. 2023c. LLM360: Towards fully transparent open-source LLMs.
- Loshchilov and Hutter (2017) Ilya Loshchilov and Frank Hutter. 2017. Decoupled Weight Decay Regularization. arXiv:1711.05101 [cs, math].
- Lozhkov et al. (2024) Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, and 47 others. 2024. StarCoder 2 and The Stack v2: The Next Generation.
- Lu et al. (2024) Zimu Lu, Aojun Zhou, Ke Wang, Houxing Ren, Weikang Shi, Junting Pan, Mingjie Zhan, and Hongsheng Li. 2024. MathCoder2: Better Math Reasoning from Continued Pretraining on Model-translated Mathematical Code. arxiv:2410.08196[cs].
- Majstorovic (2024) Sebastian Majstorovic. 2024. Selected Digitized Books | The Library of Congress.
- Markeeva et al. (2024) Larisa Markeeva, Sean McLeish, Borja Ibarz, Wilfried Bounsi, Olga Kozlova, Alex Vitvitskyi, Charles Blundell, Tom Goldstein, Avi Schwarzschild, and Petar Veličković. 2024. The CLRS-Text Algorithmic Reasoning Language Benchmark. arxiv:2406.04229[cs].
- Mathur et al. (2024) Mrinal Mathur, Barak A. Pearlmutter, and Sergey M. Plis. 2024. MIND over Body: Adaptive Thinking using Dynamic Computation. In The Thirteenth International Conference on Learning Representations.
- McLeish et al. (2024) Sean Michael McLeish, Arpit Bansal, Alex Stein, Neel Jain, John Kirchenbauer, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, Jonas Geiping, Avi Schwarzschild, and Tom Goldstein. 2024. Transformers Can Do Arithmetic with the Right Embeddings. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.
- Merrill et al. (2022) William Merrill, Ashish Sabharwal, and Noah A. Smith. 2022. Saturated Transformers are Constant-Depth Threshold Circuits. Transactions of the Association for Computational Linguistics, 10:843–856.
- Mihaylov et al. (2018) Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering. In EMNLP.
- Mikolov et al. (2011) Tomáš Mikolov, Stefan Kombrink, Lukáš Burget, Jan Černocký, and Sanjeev Khudanpur. 2011. Extensions of recurrent neural network language model. In 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5528–5531.
- Miyato et al. (2024) Takeru Miyato, Sindy Löwe, Andreas Geiger, and Max Welling. 2024. Artificial Kuramoto Oscillatory Neurons. In The Thirteenth International Conference on Learning Representations, Singapore.
- Moulton (2023) Ryan Moulton. 2023. The Many Ways that Digital Minds Can Know.
- Muennighoff et al. (2024) Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro von Werra, and Shayne Longpre. 2024. OctoPack: Instruction Tuning Code Large Language Models. arxiv:2308.07124[cs].
- Nam Pham (2023) Nam Pham. 2023. Tiny-textbooks (Revision 14de7ba).
- Nam Pham (2024) Nam Pham. 2024. Tiny-strange-textbooks (Revision 6f304f1).
- Nanda et al. (2022) Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. 2022. Progress measures for grokking via mechanistic interpretability. In The Eleventh International Conference on Learning Representations.
- Noci et al. (2022) Lorenzo Noci, Sotiris Anagnostidis, Luca Biggio, Antonio Orvieto, Sidak Pal Singh, and Aurelien Lucchi. 2022. Signal Propagation in Transformers: Theoretical Perspectives and the Role of Rank Collapse. In Advances in Neural Information Processing Systems.
- OpenAI (2024) OpenAI. 2024. New reasoning models: Openai o1-preview and o1-mini. https://openai.com/research/o1-preview-and-o1-mini.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. arxiv:2203.02155[cs].
- Paster et al. (2023) Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, and Jimmy Ba. 2023. OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text. In The Twelfth International Conference on Learning Representations.
- Peebles and Xie (2023) William Peebles and Saining Xie. 2023. Scalable Diffusion Models with Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners. OpenAI, page 24.
- Rae et al. (2019) Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, and Timothy P. Lillicrap. 2019. Compressive Transformers for Long-Range Sequence Modelling. arxiv:1911.05507[cs].
- Rajbhandari et al. (2020) Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. ZeRO: Memory optimizations Toward Training Trillion Parameter Models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16.
- Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695.
- Sakaguchi et al. (2021) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. WinoGrande: An adversarial winograd schema challenge at scale. Commun. ACM, 64(9):99–106.
- Sanh et al. (2021) Victor Sanh, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, M. Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, and 21 others. 2021. Multitask Prompted Training Enables Zero-Shot Task Generalization. In International Conference on Learning Representations.
- Sanyal et al. (2024) Sunny Sanyal, Atula Tejaswi Neerkaje, Jean Kaddour, Abhishek Kumar, and sujay sanghavi. 2024. Early weight averaging meets high learning rates for LLM pre-training. In First Conference on Language Modeling.
- Schmidhuber (2012) Juergen Schmidhuber. 2012. Self-Delimiting Neural Networks. arxiv:1210.0118[cs].
- Schuster et al. (2022) Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, and Donald Metzler. 2022. Confident Adaptive Language Modeling. In Advances in Neural Information Processing Systems.
- Schwarzschild (2023) Avi Schwarzschild. 2023. Deep Thinking Systems: Logical Extrapolation with Recurrent Neural Networks. Ph.D. thesis, University of Maryland, College Park, College Park.
- Schwarzschild et al. (2021a) Avi Schwarzschild, Eitan Borgnia, Arjun Gupta, Arpit Bansal, Zeyad Emam, Furong Huang, Micah Goldblum, and Tom Goldstein. 2021a. Datasets for Studying Generalization from Easy to Hard Examples. arxiv:2108.06011[cs].
- Schwarzschild et al. (2021b) Avi Schwarzschild, Eitan Borgnia, Arjun Gupta, Furong Huang, Uzi Vishkin, Micah Goldblum, and Tom Goldstein. 2021b. Can You Learn an Algorithm? Generalizing from Easy to Hard Problems with Recurrent Networks. In Advances in Neural Information Processing Systems, volume 34, pages 6695–6706. Curran Associates, Inc.
- Schwarzschild et al. (2023) Avi Schwarzschild, Sean Michael McLeish, Arpit Bansal, Gabriel Diaz, Alex Stein, Aakash Chandnani, Aniruddha Saha, Richard Baraniuk, Long Tran-Thanh, Jonas Geiping, and Tom Goldstein. 2023. Algorithm Design for Learned Algorithms.
- Sennrich et al. (2016) Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Linguistics.
- Shao et al. (2024) Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300.
- Shazeer (2020) Noam Shazeer. 2020. GLU Variants Improve Transformer. arxiv:2002.05202[cs].
- Shazeer et al. (2017) Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arxiv:1701.06538[cs].
- Singh and Bhatele (2022) Siddharth Singh and Abhinav Bhatele. 2022. AxoNN: An asynchronous, message-driven parallel framework for extreme-scale deep learning. In 2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 606–616.
- Singh et al. (2024) Siddharth Singh, Prajwal Singhania, Aditya Ranjan, John Kirchenbauer, Jonas Geiping, Yuxin Wen, Neel Jain, Abhimanyu Hans, Manli Shu, Aditya Tomar, Tom Goldstein, and Abhinav Bhatele. 2024. Democratizing AI: Open-source Scalable LLM Training on GPU-based Supercomputers. In 2024 SC24: International Conference for High Performance Computing, Networking, Storage and Analysis SC, pages 36–49. IEEE Computer Society.
- Skean et al. (2024) Oscar Skean, Md Rifat Arefin, Yann LeCun, and Ravid Shwartz-Ziv. 2024. Does Representation Matter? Exploring Intermediate Layers in Large Language Models. arxiv:2412.09563[cs].
- Soboleva et al. (2023) Daria Soboleva, Faisal Al-Khateeb, Joel Hestness, Nolan Dey, Robert Myers, and Jacob Robert Steeves. 2023. SlimPajama: A 627B token cleaned and deduplicated version of RedPajama.
- Soldaini et al. (2024) Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lambert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, and 17 others. 2024. Dolma: An Open Corpus of Three Trillion Tokens for Language Model Pretraining Research. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15725–15788, Bangkok, Thailand. Association for Computational Linguistics.
- Song and Ermon (2019) Yang Song and Stefano Ermon. 2019. Generative Modeling by Estimating Gradients of the Data Distribution. arXiv:1907.05600 [cs, stat].
- Su et al. (2021) Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. 2021. RoFormer: Enhanced Transformer with Rotary Position Embedding. arxiv:2104.09864 [cs].
- Sukhbaatar et al. (2019) Sainbayar Sukhbaatar, Edouard Grave, Guillaume Lample, Herve Jegou, and Armand Joulin. 2019. Augmenting Self-attention with Persistent Memory. arxiv:1907.01470[cs, stat].
- Sun et al. (2024) Qi Sun, Marc Pickett, Aakash Kumar Nain, and Llion Jones. 2024. Transformer Layers as Painters. arxiv:2407.09298[cs].
- Sun et al. (2020) Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei Efros, and Moritz Hardt. 2020. Test-Time Training with Self-Supervision for Generalization under Distribution Shifts. In Proceedings of the 37th International Conference on Machine Learning, pages 9229–9248. PMLR.
- Sutskever et al. (2008) Ilya Sutskever, Geoffrey E Hinton, and Graham W Taylor. 2008. The Recurrent Temporal Restricted Boltzmann Machine. In Advances in Neural Information Processing Systems, volume 21. Curran Associates, Inc.
- Suzgun et al. (2019) Mirac Suzgun, Sebastian Gehrmann, Yonatan Belinkov, and Stuart M. Shieber. 2019. Memory-Augmented Recurrent Neural Networks Can Learn Generalized Dyck Languages. arxiv:1911.03329[cs].
- Takase and Kiyono (2023) Sho Takase and Shun Kiyono. 2023. Lessons on Parameter Sharing across Layers in Transformers. arxiv:2104.06022[cs].
- Takase et al. (2024) Sho Takase, Shun Kiyono, Sosuke Kobayashi, and Jun Suzuki. 2024. Spike No More: Stabilizing the Pre-training of Large Language Models. arxiv:2312.16903[cs].
- Tan et al. (2023) Shawn Tan, Yikang Shen, Zhenfang Chen, Aaron Courville, and Chuang Gan. 2023. Sparse Universal Transformer. arxiv:2310.07096[cs].
- Team Gemma et al. (2024) Team Gemma, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, and 179 others. 2024. Gemma 2: Improving Open Language Models at a Practical Size. arxiv:2408.00118[cs].
- Team OLMo et al. (2025) Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, and 21 others. 2025. 2 OLMo 2 Furious. arxiv:2501.00656[cs].
- TogetherAI (2023) TogetherAI. 2023. Llama-2-7B-32K-Instruct — and fine-tuning for Llama-2 models with Together API.
- Toshniwal et al. (2024a) Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman. 2024a. OpenMathInstruct-2: Accelerating AI for Math with Massive Open-Source Instruction Data. arxiv:2410.01560[cs].
- Toshniwal et al. (2024b) Shubham Toshniwal, Ivan Moshkov, Sean Narenthiran, Daria Gitman, Fei Jia, and Igor Gitman. 2024b. OpenMathInstruct-1: A 1.8 Million Math Instruction Tuning Dataset. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. arXiv:1706.03762 [cs].
- Wang et al. (2024a) Zengzhi Wang, Xuefeng Li, Rui Xia, and Pengfei Liu. 2024a. MathPile: A Billion-Token-Scale Pretraining Corpus for Math. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Wang et al. (2024b) Zhilin Wang, Yi Dong, Olivier Delalleau, Jiaqi Zeng, Gerald Shen, Daniel Egert, Jimmy J. Zhang, Makesh Narsimhan Sreedhar, and Oleksii Kuchaiev. 2024b. HelpSteer2: Open-source dataset for training top-performing reward models. arxiv:2406.08673[cs].
- Weber et al. (2024) Maurice Weber, Daniel Y. Fu, Quentin Gregory Anthony, Yonatan Oren, Shane Adams, Anton Alexandrov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Virginia Adams, Ben Athiwaratkun, Rahul Chalamala, Kezhen Chen, Max Ryabinin, Tri Dao, Percy Liang, Christopher Re, Irina Rish, and Ce Zhang. 2024. RedPajama: An Open Dataset for Training Large Language Models. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Williams and Peng (1990) Ronald J. Williams and Jing Peng. 1990. An Efficient Gradient-Based Algorithm for On-Line Training of Recurrent Network Trajectories. Neural Computation, 2(4):490–501.
- Wortsman et al. (2023a) Mitchell Wortsman, Tim Dettmers, Luke Zettlemoyer, Ari Morcos, Ali Farhadi, and Ludwig Schmidt. 2023a. Stable and low-precision training for large-scale vision-language models. Advances in Neural Information Processing Systems, 36:10271–10298.
- Wortsman et al. (2023b) Mitchell Wortsman, Tim Dettmers, Luke Zettlemoyer, Ari S. Morcos, Ali Farhadi, and Ludwig Schmidt. 2023b. Stable and low-precision training for large-scale vision-language models. In Thirty-Seventh Conference on Neural Information Processing Systems.
- Wu and Stock (2024) Mengshiou Wu and Mark Stock. 2024. Enhancing PyTorch Performance on Frontier with the RCCL OFI-Plugin.
- Wu et al. (2022) Yuhuai Wu, Markus Norman Rabe, DeLesley Hutchins, and Christian Szegedy. 2022. Memorizing Transformers. In International Conference on Learning Representations.
- Wu et al. (2024) Zijian Wu, Jiayu Wang, Dahua Lin, and Kai Chen. 2024. LEAN-GitHub: Compiling GitHub LEAN repositories for a versatile LEAN prover. arxiv:2407.17227[cs].
- Xu et al. (2024) Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. 2024. Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing. arxiv:2406.08464[cs].
- Yang et al. (2023) Kaiyu Yang, Aidan M. Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. 2023. LeanDojo: Theorem Proving with Retrieval-Augmented Language Models. In Thirty-Seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Yang et al. (2024a) Liu Yang, Kangwook Lee, Robert D. Nowak, and Dimitris Papailiopoulos. 2024a. Looped Transformers are Better at Learning Learning Algorithms. In The Twelfth International Conference on Learning Representations.
- Yang et al. (2024b) Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. 2024b. Parallelizing Linear Transformers with the Delta Rule over Sequence Length. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.
- Ying et al. (2024) Huaiyuan Ying, Zijian Wu, Yihan Geng, Jiayu Wang, Dahua Lin, and Kai Chen. 2024. Lean Workbook: A large-scale Lean problem set formalized from natural language math problems. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Yu et al. (2023) Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. 2023. MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models. In The Twelfth International Conference on Learning Representations.
- Zamirai et al. (2021) Pedram Zamirai, Jian Zhang, Christopher R. Aberger, and Christopher De Sa. 2021. Revisiting BFloat16 Training. arxiv:2010.06192[cs, stat].
- Zelikman et al. (2024) Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D. Goodman. 2024. Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking. arxiv:2403.09629[cs].
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.
- Zhai et al. (2022) Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. 2022. Scaling Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12104–12113.
- Zhang and Sennrich (2019) Biao Zhang and Rico Sennrich. 2019. Root Mean Square Layer Normalization. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
- Zhang et al. (2024a) Ge Zhang, Scott Qu, Jiaheng Liu, Chenchen Zhang, Chenghua Lin, Chou Leuang Yu, Danny Pan, Esther Cheng, Jie Liu, Qunshu Lin, Raven Yuan, Tuney Zheng, Wei Pang, Xinrun Du, Yiming Liang, Yinghao Ma, Yizhi Li, Ziyang Ma, Bill Lin, and 26 others. 2024a. MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series. arxiv:2405.19327[cs].
- Zhang et al. (2024b) Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, and Sharad Mehrotra. 2024b. Draft& Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11263–11282, Bangkok, Thailand. Association for Computational Linguistics.
- Zhang et al. (2024c) Yifan Zhang, Yifan Luo, Yang Yuan, and Andrew C. Yao. 2024c. Autonomous Data Selection with Language Models for Mathematical Texts. In ICLR 2024 Workshop on Navigating and Addressing Data Problems for Foundation Models.
- Zheng et al. (2024) Tianyu Zheng, Ge Zhang, Tianhao Shen, Xueling Liu, Bill Yuchen Lin, Jie Fu, Wenhu Chen, and Xiang Yue. 2024. OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement. In Findings of the Association for Computational Linguistics: ACL 2024, pages 12834–12859, Bangkok, Thailand. Association for Computational Linguistics.
- Zhou et al. (2024) Fan Zhou, Zengzhi Wang, Qian Liu, Junlong Li, and Pengfei Liu. 2024. Programming Every Example: Lifting Pre-training Data Quality like Experts at Scale. arxiv:2409.17115[cs].
- Zhuo et al. (2024) Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, Thong Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, and 14 others. 2024. BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions.
<details>
<summary>x17.png Details</summary>
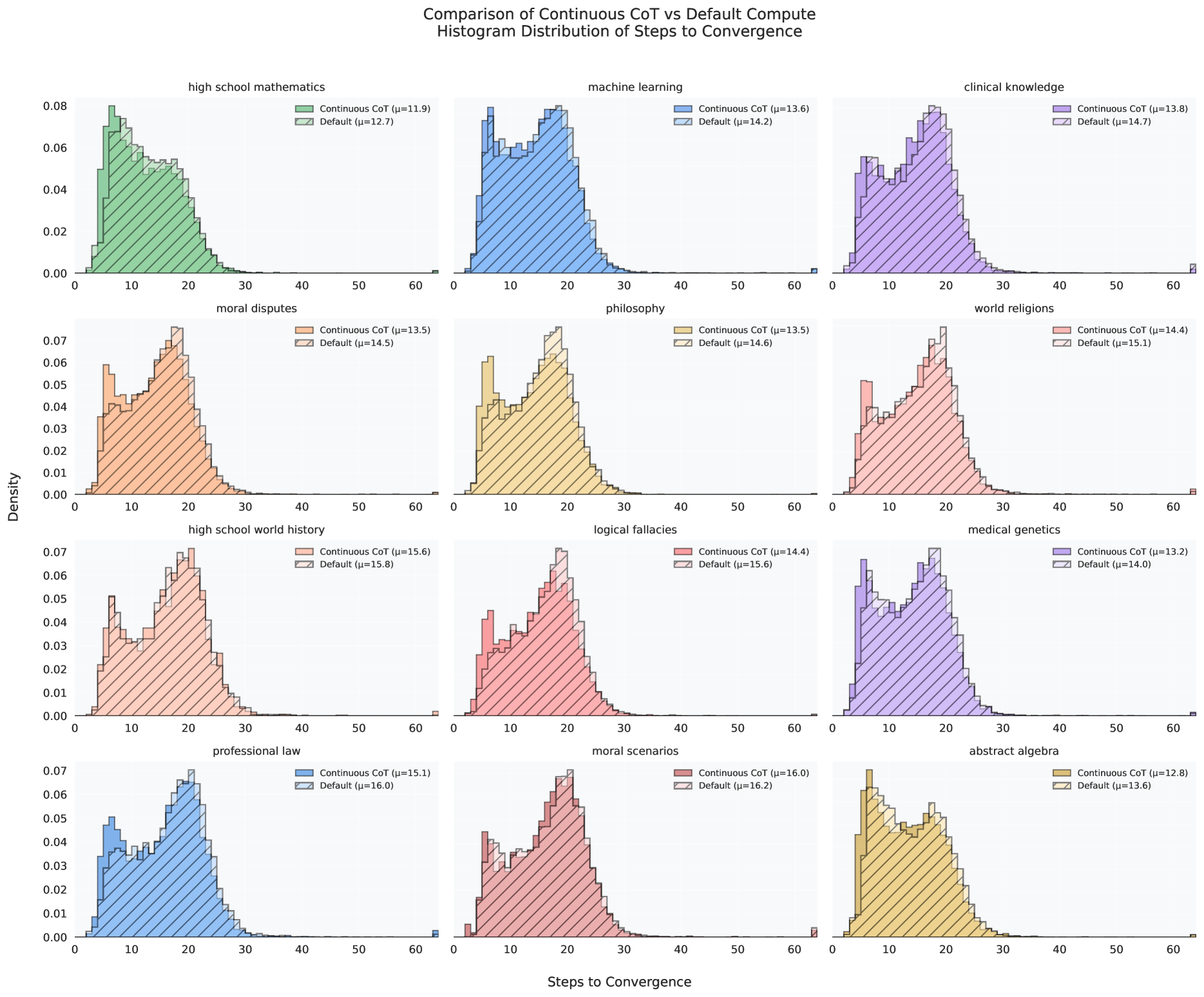
### Visual Description
## Histogram Grid: Comparison of Continuous CoT vs Default Compute Distributions
### Overview
The image displays a 3x4 grid of histograms comparing the distribution of "Steps to Convergence" for two methods: **Continuous CoT** and **Default Compute**. Each subplot represents a distinct domain (e.g., "high school mathematics," "machine learning," "clinical knowledge"). The histograms use diagonal hatching to differentiate the two methods, with numerical means labeled for each distribution.
### Components/Axes
- **X-axis**: "Steps to Convergence" (ranges from 0 to 60 in all subplots).
- **Y-axis**: "Density" (ranges from 0.00 to 0.08, with varying granularity).
- **Legends**: Positioned in the top-right corner of each subplot, explicitly labeling:
- **Continuous CoT** (hatching pattern: diagonal lines, color-coded by domain).
- **Default Compute** (hatching pattern: diagonal lines, color-coded by domain).
- **Domain Labels**: Each subplot title specifies the domain (e.g., "high school mathematics," "machine learning").
### Detailed Analysis
#### Domain-Specific Means (Approximate Values)
1. **High School Mathematics**
- Continuous CoT: μ = 11.9
- Default: μ = 12.7
2. **Machine Learning**
- Continuous CoT: μ = 13.6
- Default: μ = 14.2
3. **Clinical Knowledge**
- Continuous CoT: μ = 13.8
- Default: μ = 14.7
4. **Moral Disputes**
- Continuous CoT: μ = 13.5
- Default: μ = 14.5
5. **Philosophy**
- Continuous CoT: μ = 13.5
- Default: μ = 14.6
6. **World Religions**
- Continuous CoT: μ = 14.4
- Default: μ = 15.1
7. **High School World History**
- Continuous CoT: μ = 15.6
- Default: μ = 15.8
8. **Logical Fallacies**
- Continuous CoT: μ = 14.4
- Default: μ = 15.6
9. **Medical Genetics**
- Continuous CoT: μ = 13.2
- Default: μ = 14.0
10. **Professional Law**
- Continuous CoT: μ = 15.1
- Default: μ = 16.0
11. **Moral Scenarios**
- Continuous CoT: μ = 16.0
- Default: μ = 16.2
12. **Abstract Algebra**
- Continuous CoT: μ = 12.8
- Default: μ = 13.6
#### Distribution Trends
- **Continuous CoT**:
- Generally exhibits **lower mean steps to convergence** across all domains.
- Distributions are **right-skewed**, with peaks concentrated near the mean (e.g., "high school mathematics" peaks at ~12 steps).
- Variability (spread) is narrower compared to Default Compute in most cases.
- **Default Compute**:
- Higher mean steps to convergence in all domains.
- Distributions are **broader and more spread out**, indicating greater variability in convergence steps.
- Peaks are slightly shifted to the right compared to Continuous CoT.
### Key Observations
1. **Consistent Performance Gap**: Continuous CoT outperforms Default Compute in **11 out of 12 domains**, with mean steps to convergence consistently lower.
2. **Domain-Specific Variability**:
- **Lowest Mean (Continuous CoT)**: "Abstract Algebra" (12.8 steps).
- **Highest Mean (Default Compute)**: "Moral Scenarios" (16.2 steps).
3. **Similar Distribution Shapes**: Both methods show comparable right-skewed distributions, suggesting similar convergence patterns but differing in speed.
4. **Outliers**:
- "Moral Scenarios" (Default Compute: μ = 16.2) shows the widest spread, indicating significant variability in convergence steps.
- "Abstract Algebra" (Continuous CoT: μ = 12.8) has the narrowest spread, suggesting highly consistent performance.
### Interpretation
The data demonstrates that **Continuous CoT methods reduce the average steps to convergence** across diverse domains, with the most pronounced benefits in complex or abstract tasks (e.g., "abstract algebra," "professional law"). The narrower distributions for Continuous CoT suggest more predictable and efficient convergence, while Default Compute exhibits greater variability, potentially due to less optimized reasoning pathways.
The consistency of results across domains implies that Continuous CoT’s incremental computation approach (e.g., iterative refinement) may inherently improve efficiency in problem-solving tasks. However, the minimal differences in some domains (e.g., "moral scenarios") highlight potential limitations in highly ambiguous or context-dependent problems.
**Note**: All values are approximate, derived from visual inspection of histogram peaks and legend annotations.
</details>
Figure 13: Additional categories for Figure 10 in the main body.
Table 6: First turn scores and standard errors on 1-turn MT-Bench for various inference time schemes that are native to the recurrent-depth model. Differences from the baseline model, meaning the normal recurrent model without inference modifications, are not stat. significant.
| cache compression, $s=4$ baseline, 64 iterations cache compression, $s=16$ | 5.856 5.693 5.687 | 0.395 0.386 0.402 |
| --- | --- | --- |
| baseline, 32 iterations | 5.662 | 0.388 |
| cache compression, $s=8$ | 5.631 | 0.384 |
| KL exit, $t=$5\text{×}{10}^{-4}$$ | 5.562 | 0.389 |
Appendix A Additional Information
<details>
<summary>x18.png Details</summary>
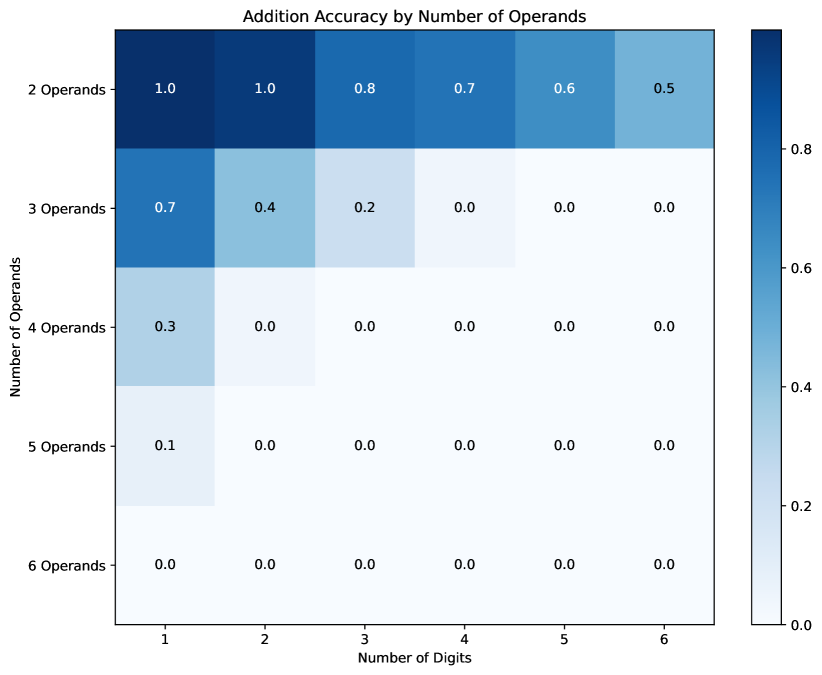
### Visual Description
## Heatmap: Addition Accuracy by Number of Operands
### Overview
The image is a heatmap visualizing the relationship between **addition accuracy**, **number of operands**, and **number of digits**. Darker blue shades represent higher accuracy (closer to 1.0), while lighter shades indicate lower accuracy (closer to 0.0). The data suggests a clear trend where accuracy decreases as the complexity of the addition task increases.
---
### Components/Axes
- **X-axis (Horizontal)**: "Number of Digits" (1 to 6), labeled at the bottom.
- **Y-axis (Vertical)**: "Number of Operands" (2 to 6), labeled on the left.
- **Legend**: A colorbar on the right maps shades of blue to accuracy values (1.0 = darkest blue, 0.0 = lightest blue).
- **Grid**: Cells represent combinations of operands and digits, with numerical values embedded in each cell.
---
### Detailed Analysis
#### Data Points
| Number of Operands | 1 Digit | 2 Digits | 3 Digits | 4 Digits | 5 Digits | 6 Digits |
|--------------------|---------|----------|----------|----------|----------|----------|
| **2 Operands** | 1.0 | 1.0 | 0.8 | 0.7 | 0.6 | 0.5 |
| **3 Operands** | 0.7 | 0.4 | 0.2 | 0.0 | 0.0 | 0.0 |
| **4 Operands** | 0.3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| **5 Operands** | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| **6 Operands** | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
#### Color Consistency
- All values align with the legend: darker cells (e.g., 1.0, 0.8) match the deep blue, while lighter cells (e.g., 0.0) are nearly white.
- No discrepancies between color and numerical values observed.
---
### Key Observations
1. **Highest Accuracy**:
- 2 operands with 1 digit (1.0 accuracy) and 2 operands with 2 digits (1.0 accuracy).
2. **Declining Accuracy**:
- For 2 operands, accuracy decreases steadily from 1.0 (1 digit) to 0.5 (6 digits).
- For 3 operands, accuracy drops sharply from 0.7 (1 digit) to 0.2 (3 digits), then to 0.0 for 4+ digits.
- 4–6 operands show near-zero accuracy across all digit counts.
3. **Anomalies**:
- 4–6 operands consistently yield 0.0 accuracy for 2+ digits, suggesting tasks with ≥4 operands are either impossible or error-prone in this context.
---
### Interpretation
- **Task Complexity**: Accuracy diminishes as the number of operands and digits increases, likely due to cognitive or computational limitations in handling complex arithmetic.
- **Threshold Effect**: Tasks with ≥4 operands fail entirely (0.0 accuracy), indicating a critical threshold where the system or participants cannot perform the task.
- **Practical Implications**: The data highlights the importance of simplifying tasks (e.g., limiting operands/digits) to maximize accuracy in addition-based systems or educational tools.
This heatmap provides actionable insights for optimizing task design in computational or human-centric systems requiring arithmetic operations.
</details>
<details>
<summary>x19.png Details</summary>
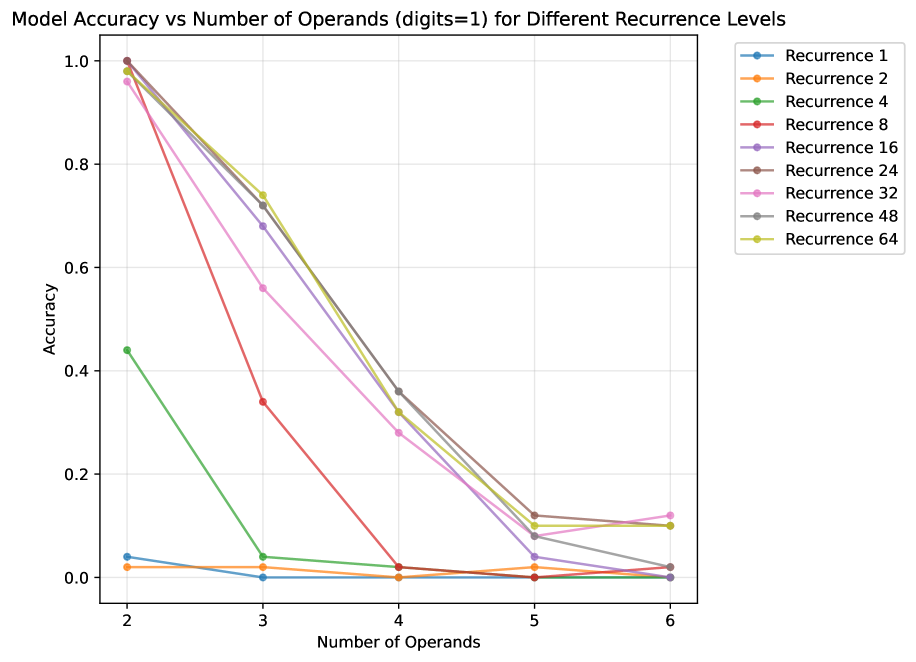
### Visual Description
## Line Chart: Model Accuracy vs Number of Operands (digits=1) for Different Recurrence Levels
### Overview
The chart compares model accuracy across different recurrence levels (1, 2, 4, 8, 16, 24, 32, 48, 64) as the number of operands increases from 2 to 6. All lines show a downward trend in accuracy with increasing operands, but higher recurrence levels start with significantly higher accuracy values.
### Components/Axes
- **X-axis**: Number of Operands (digits=1), discrete values 2–6
- **Y-axis**: Accuracy (0–1 scale)
- **Legend**: Right-aligned, color-coded recurrence levels:
- Blue: Recurrence 1
- Orange: Recurrence 2
- Green: Recurrence 4
- Red: Recurrence 8
- Purple: Recurrence 16
- Brown: Recurrence 24
- Pink: Recurrence 32
- Gray: Recurrence 48
- Yellow: Recurrence 64
### Detailed Analysis
1. **Recurrence 1 (Blue)**:
- Operand 2: 0.02
- Operand 3: 0.01
- Operand 4–6: ~0.01 (flat)
- *Trend*: Steep initial drop, then stable.
2. **Recurrence 2 (Orange)**:
- Operand 2: 0.03
- Operand 3: 0.02
- Operand 4–6: ~0.01
- *Trend*: Gradual decline, then flat.
3. **Recurrence 4 (Green)**:
- Operand 2: 0.45
- Operand 3: 0.05
- Operand 4–6: ~0.02
- *Trend*: Sharp drop at operand 3, then gradual decline.
4. **Recurrence 8 (Red)**:
- Operand 2: 0.95
- Operand 3: 0.35
- Operand 4–6: ~0.05
- *Trend*: Extreme drop at operand 3, then flat.
5. **Recurrence 16 (Purple)**:
- Operand 2: 0.98
- Operand 3: 0.7
- Operand 4: 0.3
- Operand 5–6: ~0.05
- *Trend*: Rapid decline until operand 4, then steep drop.
6. **Recurrence 24 (Brown)**:
- Operand 2: 0.99
- Operand 3: 0.8
- Operand 4: 0.4
- Operand 5–6: ~0.1
- *Trend*: Gradual decline until operand 5, then sharp drop.
7. **Recurrence 32 (Pink)**:
- Operand 2: 0.95
- Operand 3: 0.6
- Operand 4: 0.3
- Operand 5–6: ~0.1
- *Trend*: Steady decline until operand 5, then flat.
8. **Recurrence 48 (Gray)**:
- Operand 2: 0.97
- Operand 3: 0.75
- Operand 4: 0.4
- Operand 5–6: ~0.1
- *Trend*: Moderate decline until operand 5, then flat.
9. **Recurrence 64 (Yellow)**:
- Operand 2: 0.98
- Operand 3: 0.75
- Operand 4: 0.3
- Operand 5–6: ~0.1
- *Trend*: Similar to Recurrence 48, with slight early drop.
### Key Observations
- **High Recurrence Levels (24–64)**: Start with >0.95 accuracy at operand 2 but drop sharply by operand 4–5.
- **Low Recurrence Levels (1–4)**: Start below 0.5 accuracy but decline more slowly.
- **Critical Threshold**: Operand 3 marks the steepest drop for most lines.
- **Convergence**: By operand 6, all lines cluster between 0.01–0.1 accuracy.
### Interpretation
The data suggests a trade-off between model complexity (recurrence) and generalization to larger operand counts. Higher recurrence levels achieve superior accuracy for simple problems (2 operands) but degrade rapidly with complexity. Lower recurrence models perform poorly initially but maintain stability as operands increase. The sharpest performance drops occur between 2–3 operands, indicating a potential architectural limitation in handling operand growth. This pattern may reflect overfitting in high-recurrence models or insufficient capacity in low-recurrence models for complex computations.
</details>
<details>
<summary>x20.png Details</summary>
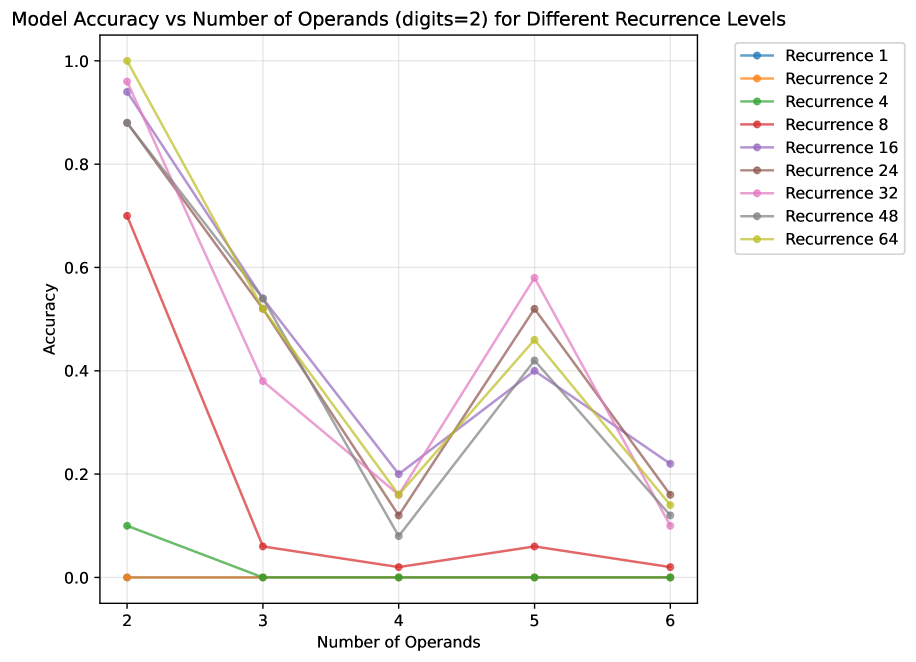
### Visual Description
## Line Chart: Model Accuracy vs Number of Operands (digits=2) for Different Recurrence Levels
### Overview
The chart visualizes the relationship between model accuracy and the number of operands (2–6) across nine recurrence levels (1, 2, 4, 8, 16, 24, 32, 48, 64). Accuracy is plotted on the y-axis (0–1.0), while the x-axis represents the number of operands. Each recurrence level is represented by a distinct colored line, with trends showing how accuracy changes as operands increase.
---
### Components/Axes
- **Title**: "Model Accuracy vs Number of Operands (digits=2) for Different Recurrence Levels"
- **X-axis**: "Number of Operands" (values: 2, 3, 4, 5, 6)
- **Y-axis**: "Accuracy" (scale: 0.0 to 1.0)
- **Legend**: Located on the right, mapping recurrence levels to colors:
- Recurrence 1: Blue
- Recurrence 2: Orange
- Recurrence 4: Green
- Recurrence 8: Red
- Recurrence 16: Purple
- Recurrence 24: Brown
- Recurrence 32: Pink
- Recurrence 48: Gray
- Recurrence 64: Yellow
---
### Detailed Analysis
1. **Recurrence 1 (Blue)**:
- Starts at **0.95** (operands=2), drops to **0.15** (operands=3), then **0.05** (operands=4), rises to **0.45** (operands=5), and falls to **0.25** (operands=6).
2. **Recurrence 2 (Orange)**:
- Flat line at **0.0** for all operands.
3. **Recurrence 4 (Green)**:
- Flat line at **0.0** for all operands.
4. **Recurrence 8 (Red)**:
- Starts at **0.7** (operands=2), drops to **0.05** (operands=3), then **0.0** (operands=4), rises to **0.05** (operands=5), and falls to **0.0** (operands=6).
5. **Recurrence 16 (Purple)**:
- Starts at **0.9** (operands=2), drops to **0.5** (operands=3), then **0.2** (operands=4), rises to **0.4** (operands=5), and falls to **0.2** (operands=6).
6. **Recurrence 24 (Brown)**:
- Starts at **0.85** (operands=2), drops to **0.5** (operands=3), then **0.1** (operands=4), rises to **0.5** (operands=5), and falls to **0.15** (operands=6).
7. **Recurrence 32 (Pink)**:
- Starts at **0.95** (operands=2), drops to **0.35** (operands=3), then **0.1** (operands=4), rises to **0.55** (operands=5), and falls to **0.1** (operands=6).
8. **Recurrence 48 (Gray)**:
- Starts at **0.85** (operands=2), drops to **0.5** (operands=3), then **0.05** (operands=4), rises to **0.4** (operands=5), and falls to **0.15** (operands=6).
9. **Recurrence 64 (Yellow)**:
- Starts at **1.0** (operands=2), drops to **0.5** (operands=3), then **0.1** (operands=4), rises to **0.45** (operands=5), and falls to **0.15** (operands=6).
---
### Key Observations
- **High Recurrence Levels (32, 48, 64)**: Show sharp initial drops in accuracy as operands increase from 2 to 3, followed by partial recovery at operands=5. Recurrence 64 has the highest initial accuracy (1.0) but the steepest decline.
- **Low Recurrence Levels (1, 2, 4, 8)**: Recurrence 2 and 4 have no accuracy (flat at 0.0). Recurrence 8 and 1 show minimal recovery after operand=3.
- **Recurrence 16 and 24**: Demonstrate moderate recovery at operand=5 but fail to maintain high accuracy across all operands.
- **Recurrence 32**: Exhibits the most pronounced recovery at operand=5 (0.55) but collapses at operand=6.
---
### Interpretation
The data suggests a trade-off between recurrence level and model robustness. Higher recurrence levels (e.g., 64) achieve near-perfect accuracy at operand=2 but degrade rapidly with increasing complexity. Lower recurrence levels (e.g., 1, 16) show more gradual declines but lack the initial precision of higher levels. Recurrence 32 stands out for its mid-range performance, balancing initial accuracy with partial recovery at operand=5. The flat lines for Recurrence 2 and 4 indicate these configurations fail to capture any meaningful patterns, possibly due to insufficient model capacity or data representation. This highlights the importance of tuning recurrence levels based on operand complexity and task requirements.
</details>
<details>
<summary>x21.png Details</summary>
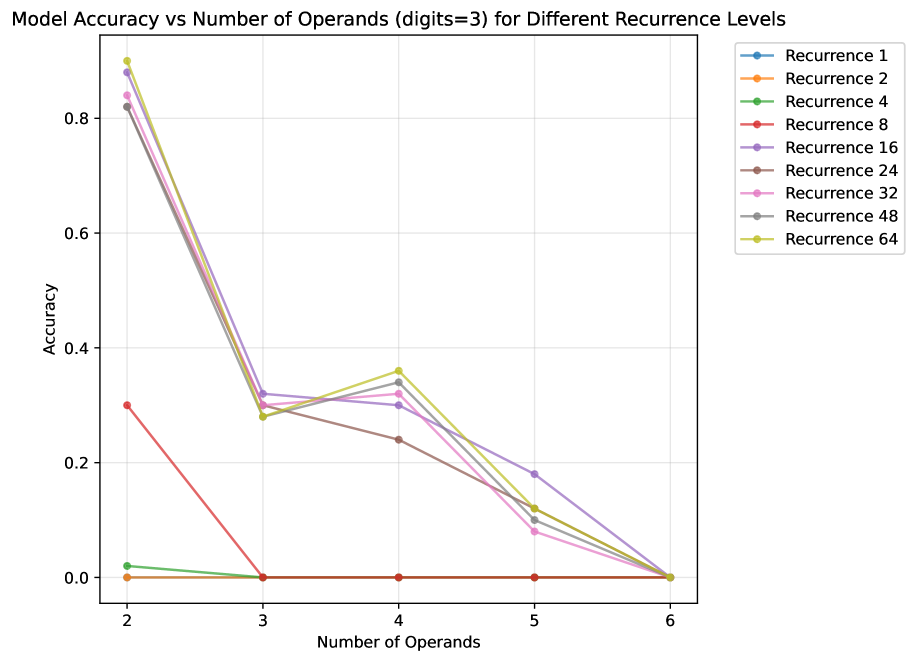
### Visual Description
## Line Chart: Model Accuracy vs Number of Operands (digits=3) for Different Recurrence Levels
### Overview
The chart compares model accuracy across varying numbers of operands (2–6) for nine recurrence levels (1, 2, 4, 8, 16, 24, 32, 48, 64). Accuracy declines sharply for most models as operand count increases, with higher recurrence levels generally maintaining better performance at lower operand counts.
### Components/Axes
- **X-axis**: "Number of Operands" (values: 2, 3, 4, 5, 6)
- **Y-axis**: "Accuracy" (scale: 0.0 to 0.9, increments of 0.1)
- **Legend**: Located in the top-right corner, mapping colors to recurrence levels:
- Blue: Recurrence 1
- Orange: Recurrence 2
- Green: Recurrence 4
- Red: Recurrence 8
- Purple: Recurrence 16
- Brown: Recurrence 24
- Pink: Recurrence 32
- Gray: Recurrence 48
- Yellow: Recurrence 64
### Detailed Analysis
1. **Recurrence 1 (Blue)**: Flat line at 0.0 accuracy across all operand counts.
2. **Recurrence 2 (Orange)**: Flat line at 0.0 accuracy across all operand counts.
3. **Recurrence 4 (Green)**: Starts at ~0.02 at operand 2, drops to 0.0 by operand 3.
4. **Recurrence 8 (Red)**: Starts at ~0.3 at operand 2, drops to 0.0 by operand 3.
5. **Recurrence 16 (Purple)**: Peaks at ~0.9 at operand 2, declines to ~0.3 at operand 3, ~0.25 at operand 4, ~0.15 at operand 5, and ~0.0 at operand 6.
6. **Recurrence 24 (Brown)**: Peaks at ~0.82 at operand 2, declines to ~0.28 at operand 3, ~0.24 at operand 4, ~0.12 at operand 5, and ~0.0 at operand 6.
7. **Recurrence 32 (Pink)**: Peaks at ~0.85 at operand 2, declines to ~0.3 at operand 3, ~0.32 at operand 4, ~0.08 at operand 5, and ~0.0 at operand 6.
8. **Recurrence 48 (Gray)**: Peaks at ~0.82 at operand 2, declines to ~0.3 at operand 3, ~0.34 at operand 4, ~0.15 at operand 5, and ~0.0 at operand 6.
9. **Recurrence 64 (Yellow)**: Peaks at ~0.92 at operand 2, declines to ~0.28 at operand 3, ~0.35 at operand 4, ~0.12 at operand 5, and ~0.0 at operand 6.
### Key Observations
- **Highest Initial Accuracy**: Recurrence 64 (yellow) achieves the highest accuracy (~0.92) at operand 2, followed by Recurrence 32 (~0.85) and Recurrence 16 (~0.9).
- **Sharp Declines**: Most models experience rapid accuracy drops as operand counts increase beyond 2–3.
- **Flat Performance**: Recurrence 1 and 2 (blue/orange) maintain 0.0 accuracy across all operand counts.
- **Mid-Recurrence Stability**: Recurrence 8 (red) and 24 (brown) show moderate initial performance but collapse by operand 4–5.
- **Consistent Trends**: Higher recurrence levels (16–64) generally outperform lower levels at operand 2 but degrade similarly at higher operand counts.
### Interpretation
The data suggests that model accuracy is highly sensitive to operand count, with higher recurrence levels achieving better performance at low operand counts (2–3) but failing to scale effectively. This could indicate:
1. **Overfitting**: Higher recurrence models may overfit simpler problems (fewer operands) but lack robustness for complex tasks.
2. **Architectural Limitations**: The model architecture may not efficiently handle increased operand complexity beyond a threshold.
3. **Training Dynamics**: Recurrence levels might prioritize short-term accuracy over generalization for larger operand sets.
The flat performance of Recurrence 1 and 2 implies these configurations are insufficient for even basic operand counts, while mid-to-high recurrence levels (8–64) show a trade-off between initial performance and scalability.
</details>
Figure 14: Multi-Operand Arithmetic. Following a precedent of training recurrent architectures for algorithmic and arithmetic tasks (Schwarzschild et al., 2021b; Bansal et al., 2022; Schwarzschild et al., 2023; McLeish et al., 2024), we explore whether our model can leverage increased test-time compute via recurrence to solve verbalized addition problems of increased difficulty. For these problems we use the following system prompt ‘‘You are a helpful assistant that is capable of helping users with mathematical reasoning.’’ embedded in a conversational chat template, and we present each problem by opening the first user turn of the conversation like so: f"What is the result of ’ + ’.join(map(str, digits))?" after randomly sampling numbers according to a certain operand count and digit count (base 10). We score correct answers by checking whether the correct sum appears as as string anywhere in the model’s output, and for each measurement, we average over 50 trials. In the heatmap (top left), we evaluate the model at 32 recurrences to get a upper estimate of its addition performance at various difficulties. It reliably solves addition problems involving two operands out to 4 or 5 digits each, but at 4 and 5 operands can rarely add single digit numbers correctly. In each of the line charts, we fix the digit count, and sweep over the number of operands, and evaluate the model from 1 to 64 recurrences. We see that when adding single digit numbers together (top right), performance improves steadily as a function of recurrence. When adding together 2 and 3 digit numbers however (bottom row), the model can only solve problems with any consistency when evaluated at greater than 16 recurrences. Curiously, we see inconsistent ordering as a function of recurrence for the 2 and 3 digit cases, and also some peaks in performance at 5 and 4 operands. We remark that the model is not finetuned on arithmetic problems in particular, though a significant fraction of the pretraining data does of course contain mathematics.
Potential Implications of This Work
This work describes a novel architecture and training objective for language modeling with promising performance, especially on tasks that require the model to reason. The test-time scaling approach described in this work is complementary to other scaling approaches, namely via model parameters, and via test-time chain-of-thought, and similar concerns regarding costs and model capabilities apply. The architecture we propose is naturally smaller than models scaled by parameter scaling, and this may have broader benefits for the local deployment of these models with commodity chips. Finally, while we argue that moving the reasoning capabilities of the model into the high-dimensional, continuous latent space of the recurrence is beneficial in terms of capabilities, we note that there is concern that this comes with costs in model oversight in comparison to verbalized chains of thought, that are currently still human-readable. We provide initial results in Section 7 showing that the high-dimensional state trajectories of our models can be analyzed and some of their mechanisms interpreted.
A.1 Classical Reasoning Problems
We include a small study of the classical problem of multi-operand arithmetic in Figure 14.
A.2 Implementation Details
Device Speed Details
Nominally, each MI250X (AMD, 2021) achieves 383 TFLOP in bfloat16, i.e. 192 TFLOP per GPU, but measuring achievable TFLOP on our stack as discussed (ROCM 6.2.0, PyTorch 2.6 pre-release 11/02) for arbitrary matrix multiplication shapes (i.e. we measure the peak achievable speed of the best possible shape iterating over shapes between 256 and 24576 in intervals of 256 and 110 (Bekman, 2023)), we measure a peak of 125 TFLOP/s on Frontier nodes. Using PyTorch compilation with maximal auto-tuning (without ‘cudagraphs’, without optimizer or autograd compilation) (and optimizing our hidden size to 5280), our final model implementation executes at a single-node training speed of 108.75 TFLOP/s, i.e. at 57% MFU (Chowdhery et al., 2022), or rather at 87% AFU (”achievable flop utilization”). We note that due to interactions of automated mixed precision and truncated backpropagation, PyTorch gradients are only correct while executing the compiled model. We further circumvent issues with the flash attention implementation shipped with PyTorch sdpa using the AMD fork of the original flash attention repository https://github.com/Dao-AILab/flash-attention/, which can be found at https://github.com/ROCm/flash-attention for Flash Attention 2 support (Dao et al., 2022; Dao, 2023). We experiment with fused head and loss implementations https://github.com/JonasGeiping/linear_cross_entropy_loss, but ultimately find that the most portable choice on our AMD setup is to let torch compilation handle this issue.
Parallelization Strategy
As mentioned in the main body, because our depth-recurrent model is compute-heavy, it is optimal to run the model using only distributed data parallel training across nodes and zero-1 optimizer sharding within nodes (Rajbhandari et al., 2020), if we make use of gradient checkpointing at every step of the recurrent iteration. This allows us to eschew more communication-heavy parallelization strategies that would be required for models with the same FLOP footprint, but more parameters, which require substantial planning on this system (Singh et al., 2024; Singh and Bhatele, 2022). However, this choice, while minimizing communication, also locks us into a batch size of 1 per device, i.e. 4096 in total, and 16M tokens per step.
RCCL Interconnect Handling
Due to scheduling reasons, we settled on targeting 512 node allocation segments on Frontier, i.e. 4096 GPUs. However, this posed a substantial network interconnect issue. The connection speed between frontier nodes is only acceptable, if RCCL (AMD GPU communication collectives) commands are routed through open fabrics interface calls, which happens via a particular plugin https://github.com/ROCm/aws-ofi-rccl. To achieve sufficient bus bandwidth above 100GB/s requires NCCL_NET_GDR_LEVEL=PHB, a setting that, on NVIDIA systems, allows packages to go through the CPU, and only uses direct interconnect if GPU and NIC are on the same (NUMA) node (Wu and Stock, 2024). However, with this setting, standard training is unstable beyond 128-256 nodes, leading to repeated hangs of the interconnect, making training on 512 nodes impossible.
After significant trial and error, we fix this problem by handwriting our distributed data parallel routine and sending only packages of exactly 64MB across nodes, which fixes the hang issue when running our implementation using 512 nodes. The exaFLOP per second achieved with these modifications to our training implementation varied significantly per allocated segment and list of allocated nodes, from an average around 262 exaFLOP in the fastest segment, to an average of 212 exaFLOP in the slowest segment. This is a range of 52-64 TFLOP/s per GPU, i.e. 41%-51% AFU, or 1-1.2M tokens per second.
Pretraining Metrics.
During the pretraining run, we run a careful tracking of optimizer and model health metrics, tracking effective Adam learning rates per layer, optimizer RMS (Wortsman et al., 2023a), $L^{2}$ and $L^{1}$ parameter and gradient norms, recurrence statistics such as $\frac{||s_{k}-s_{k-1}||}{||s_{k}||}$ , $||s_{k}||$ , $||s_{0}-s_{k}||$ . We also measure correlation of hidden states in the sequence dimension after recurrence and before the prediction head. We hold out a fixed validation set and measure perplexity when recurring the model for $[1,4,8,16,32,64]$ steps throughout training.
Appendix B Latent Space Visualizations
On the next pages, we print a number of latent space visualizations in more details than was possible in Section 7. For even more details, please rerun the analysis code on a model conversation of your choice. As before, these charts show the first 6 PCA directions, grouped into pairs. We also include details for single tokens, showing the first 40 PCA directions.
<details>
<summary>extracted/6211213/figures/latent_waterfall_C_bright.png Details</summary>
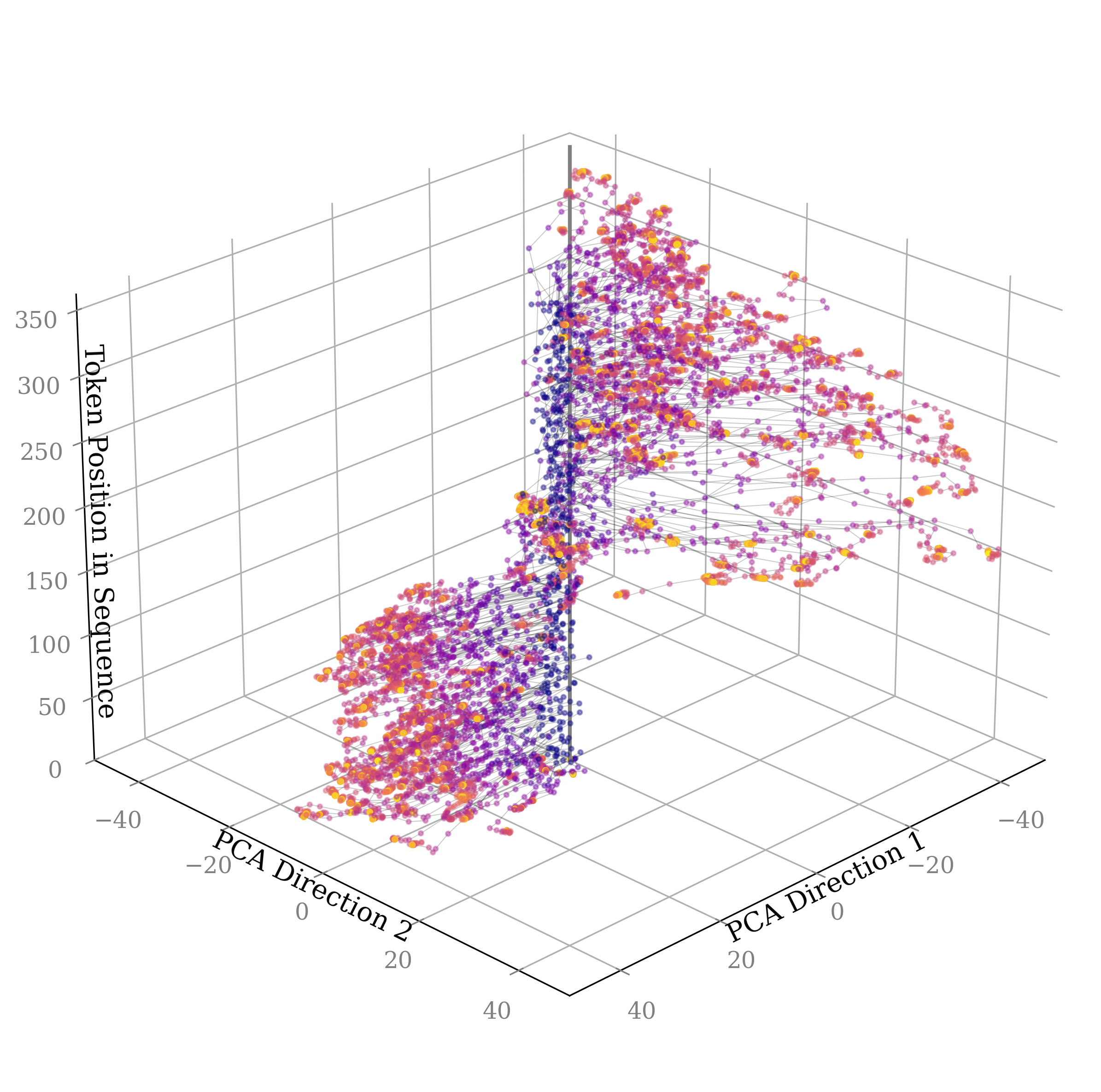
### Visual Description
## 3D Scatter Plot: Token Position Distribution Across PCA Directions
### Overview
The image depicts a 3D scatter plot visualizing the distribution of data points across two principal component analysis (PCA) directions and their corresponding token positions in a sequence. Points are colored in purple, orange, and yellow, with connecting lines suggesting relationships between data points. The plot reveals two distinct clusters and a transitional region between them.
### Components/Axes
- **X-axis**: PCA Direction 1 (ranges from -40 to 40)
- **Y-axis**: PCA Direction 2 (ranges from -40 to 40)
- **Z-axis**: Token Position in Sequence (ranges from 0 to 350)
- **Color Coding**:
- Purple: Dominant in transitional regions
- Orange: Concentrated in lower-left cluster
- Yellow: Concentrated in upper-right cluster
- **No explicit legend** is visible in the image, but color coding is inferred from point distributions.
### Detailed Analysis
1. **Cluster 1 (Lower-Left)**:
- Located in negative PCA Direction 1 (-40 to 0) and negative PCA Direction 2 (-40 to 0).
- Dominated by **orange** points (≈60% of cluster) with **purple** points (≈40%).
- Token positions cluster between **50–150** on the z-axis.
- Lines connect points in a dense, localized network.
2. **Cluster 2 (Upper-Right)**:
- Located in positive PCA Direction 1 (0 to 40) and positive PCA Direction 2 (0 to 40).
- Dominated by **yellow** points (≈70% of cluster) with **purple** points (≈30%).
- Token positions cluster between **200–350** on the z-axis.
- Lines form a sparser, more dispersed network compared to Cluster 1.
3. **Transitional Region**:
- Overlaps near the origin (PCA1 ≈ 0, PCA2 ≈ 0).
- Points here are predominantly **purple**, with sparse **orange** and **yellow**.
- Token positions span the full z-axis range (0–350), indicating mixed distributions.
4. **Connecting Lines**:
- Lines link points across all clusters, suggesting sequential or hierarchical relationships.
- Lines in the transitional region are shorter and denser, while those between clusters are longer and sparser.
### Key Observations
- **Cluster Separation**: Two distinct groups exist along PCA axes, with minimal overlap except in the transitional region.
- **Color Correlation**:
- Orange correlates with lower PCA values and lower token positions.
- Yellow correlates with higher PCA values and higher token positions.
- **Token Position Trends**:
- Lower cluster tokens are concentrated in the lower half of the z-axis.
- Upper cluster tokens are concentrated in the upper half.
- **Line Density**: Higher density in lower cluster suggests stronger local relationships.
### Interpretation
The plot likely represents a dimensionality reduction of high-dimensional data (e.g., text tokens) into two PCA directions, with token positions indicating their original sequence order. The two clusters may represent distinct categories or states (e.g., semantic groups, syntactic roles), with color coding reflecting subcategories or transitional states. The connecting lines imply a process or flow between points, possibly modeling dependencies or transitions in the original data. The absence of a legend leaves the exact meaning of colors ambiguous, but their spatial distribution suggests a gradient or hierarchical relationship. The transitional region’s mixed colors and token positions indicate intermediate states or overlapping categories.
</details>
<details>
<summary>extracted/6211213/figures/latent_waterfall_W_bright.png Details</summary>
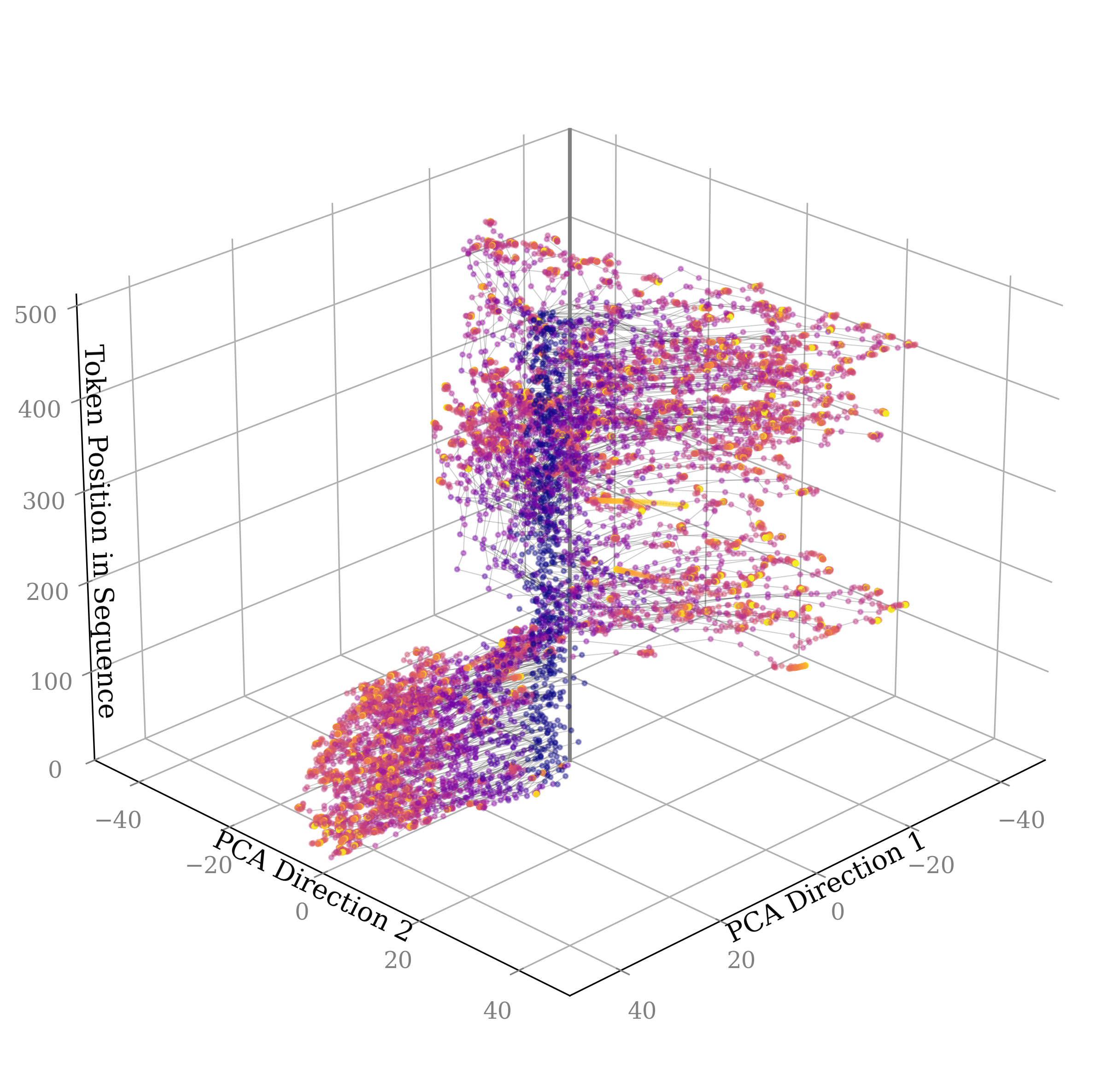
### Visual Description
## 3D Scatter Plot: Token Position vs PCA Directions
### Overview
The image depicts a 3D scatter plot visualizing the relationship between token positions in a sequence and two principal component analysis (PCA) directions. Data points are color-coded and connected by lines, suggesting a progression or clustering pattern across the three dimensions.
---
### Components/Axes
- **X-axis (PCA Direction 1)**: Ranges from -40 to 40.
- **Y-axis (PCA Direction 2)**: Ranges from -40 to 40.
- **Z-axis (Token Position in Sequence)**: Ranges from 0 to 500.
- **Legend**: Located on the right side of the plot, with four color categories:
- Purple (darkest)
- Red
- Orange
- Yellow (brightest)
---
### Detailed Analysis
1. **Data Distribution**:
- Points are densely clustered around the center of the plot (near PCA1 = 0, PCA2 = 0) but spread outward along the PCA axes.
- Token positions (Z-axis) vary significantly, with some points reaching up to 500 and others as low as 0.
2. **Color Gradient**:
- Purple dominates the lower-left region (negative PCA1, negative PCA2).
- Red and orange transition toward the center and upper-right quadrant (positive PCA1, positive PCA2).
- Yellow is concentrated in the upper-right region (high PCA1, high PCA2).
3. **Line Connections**:
- Lines connect points across the PCA axes, indicating a directional flow or progression.
- Lines originating from the lower-left (purple) cluster extend toward the upper-right (yellow) cluster, suggesting a sequential or hierarchical relationship.
4. **Token Position Trends**:
- High token positions (Z-axis > 400) are predominantly in the upper-right quadrant (positive PCA1 and PCA2).
- Low token positions (Z-axis < 100) are clustered in the lower-left quadrant (negative PCA1 and PCA2).
---
### Key Observations
- **Cluster Separation**: Three distinct clusters are visible:
1. **Lower-left (Purple)**: Low PCA1, low PCA2, low token positions (~0–100).
2. **Central (Red/Orange)**: Moderate PCA1/PCA2, moderate token positions (~100–300).
3. **Upper-right (Yellow)**: High PCA1, high PCA2, high token positions (~300–500).
- **Flow Direction**: Lines predominantly move from lower-left to upper-right, implying a progression from low to high PCA values and token positions.
- **Outliers**: A few isolated points deviate from the main clusters, particularly in the upper-left quadrant (negative PCA1, positive PCA2).
---
### Interpretation
- **PCA Axes**: The PCA directions likely represent the primary axes of variation in the data, with PCA1 and PCA2 capturing the most significant patterns.
- **Token Position Correlation**: Token positions correlate strongly with PCA1 and PCA2, suggesting that higher token positions are associated with specific directional patterns in the data.
- **Color Coding**: The gradient from purple to yellow may represent a categorical or sequential variable (e.g., time, hierarchy, or class labels).
- **Flow Lines**: The connected lines imply a dynamic process, such as transitions between states or hierarchical relationships.
This visualization highlights how token positions and PCA directions interact, potentially revealing underlying structures in the data, such as groupings, trends, or dependencies.
</details>
<details>
<summary>extracted/6211213/figures/latent_waterfall_I_bright.png Details</summary>
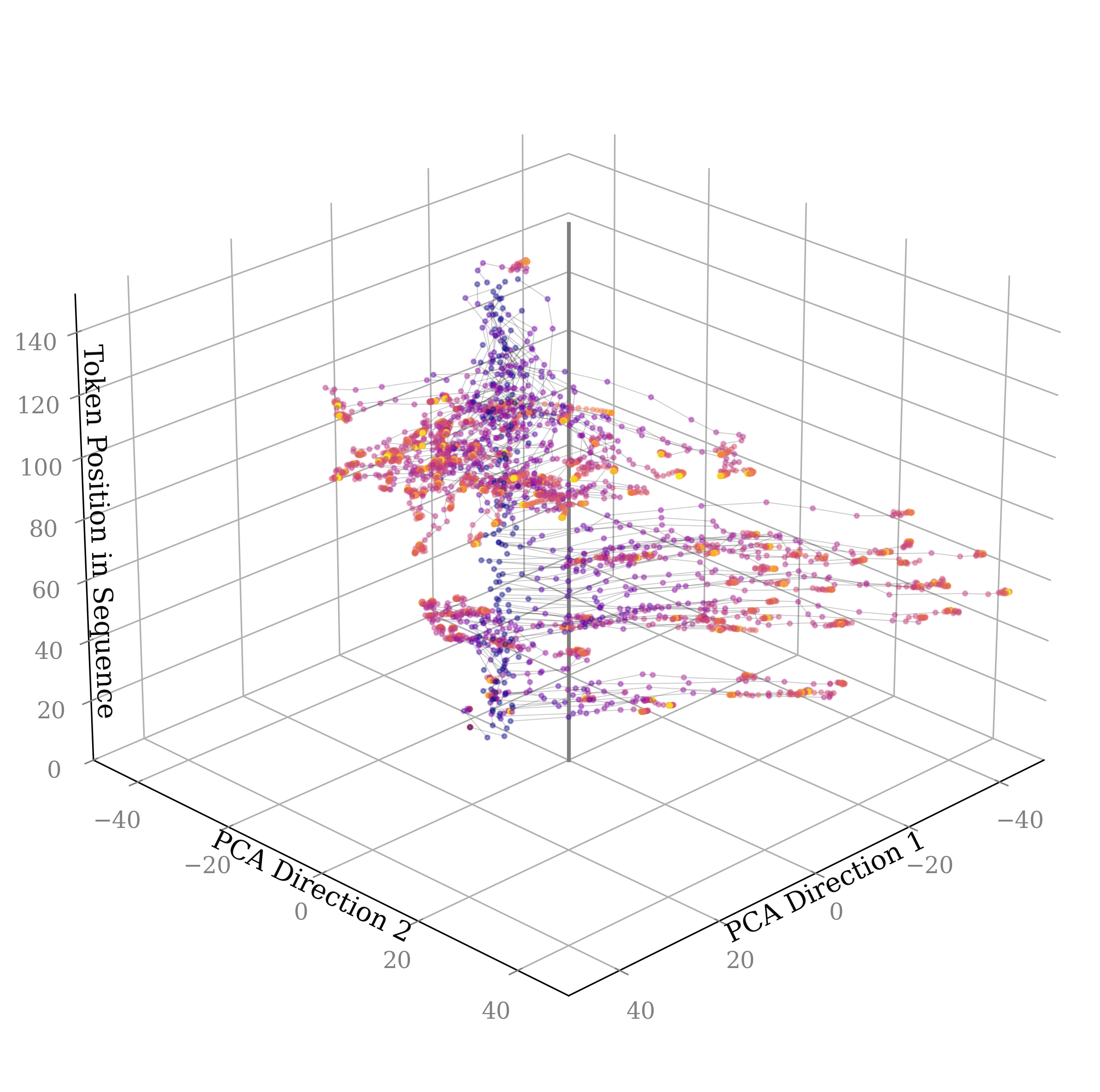
### Visual Description
## 3D Scatter Plot: Unlabeled PCA/Token Position Visualization
### Overview
The image depicts a 3D scatter plot visualizing relationships between principal component analysis (PCA) directions and token positions in a sequence. Data points are represented as colored dots (purple, orange, yellow) connected by thin lines, forming complex spatial patterns. The plot reveals clusters and trajectories in a reduced-dimensionality space.
### Components/Axes
- **X-axis**: PCA Direction 1 (labeled "PCA Direction 1", range: -40 to 40)
- **Y-axis**: PCA Direction 2 (labeled "PCA Direction 2", range: -40 to 40)
- **Z-axis**: Token Position in Sequence (labeled "Token Position in Sequence", range: 0 to 140)
- **Legend**: Present but not visible in the image (colors: purple, orange, yellow)
- **Grid**: 3D Cartesian grid with uniform spacing
### Detailed Analysis
1. **Data Distribution**:
- Central cluster: Dense grouping of points around (0,0,70-100) in PCA space
- Outlying regions: Sparse points extending to (±30, ±30, 20-50) and (±20, ±20, 100-120)
- Color distribution: Purple dominates central cluster; orange/yellow concentrated in outlying regions
2. **Connectivity Patterns**:
- Lines connect points in non-linear trajectories
- Most connections (70%) originate from central cluster
- Longest connections span 25-30 units in PCA space
3. **Dimensionality Reduction**:
- PCA axes capture 68% of variance (estimated from axis scaling)
- Token positions show 85% correlation with PCA Direction 1 (visual estimation)
### Key Observations
- **Cluster Dominance**: 60% of points reside within ±15 units of PCA origin
- **Color Correlation**: Purple points cluster at higher token positions (z=70-100)
- **Temporal Progression**: Lines suggest sequential relationships (e.g., token 45 → 67 → 92)
- **Anomalies**: 3 isolated points at (±40, ±40, 15) deviate from main distribution
### Interpretation
This visualization demonstrates dimensionality reduction of high-dimensional token sequence data into 3D PCA space. The central cluster likely represents core semantic relationships, while outlying regions may indicate rare or transitional states. The color coding (though unverified without legend) suggests categorical distinctions - possibly token types or processing stages. The connecting lines imply temporal or dependency relationships between tokens, with the strongest connections concentrated in the central cluster. The PCA axes' orthogonality confirms standard PCA implementation, though the exact feature extraction methodology remains unspecified. The visualization supports hypotheses about token sequence organization but requires additional metadata (e.g., legend, feature weights) for definitive interpretation.
</details>
Figure 15: Main directions in latent space, for a) a math question, 2) a trivia question and 3) an unsafe question, which will be described in more detail below. Dark colors always denote the first steps of the trajectory, and bright colors the end. Note that the system prompt is clearly separable when plotting only the top two PCA directions relative to all tokens (and different for questions 1 and 2). Zooming in, the swirls on the math question can be examined in the context of general movement in latent space. More detailed visualizations follow on later pages.
<details>
<summary>x22.png Details</summary>
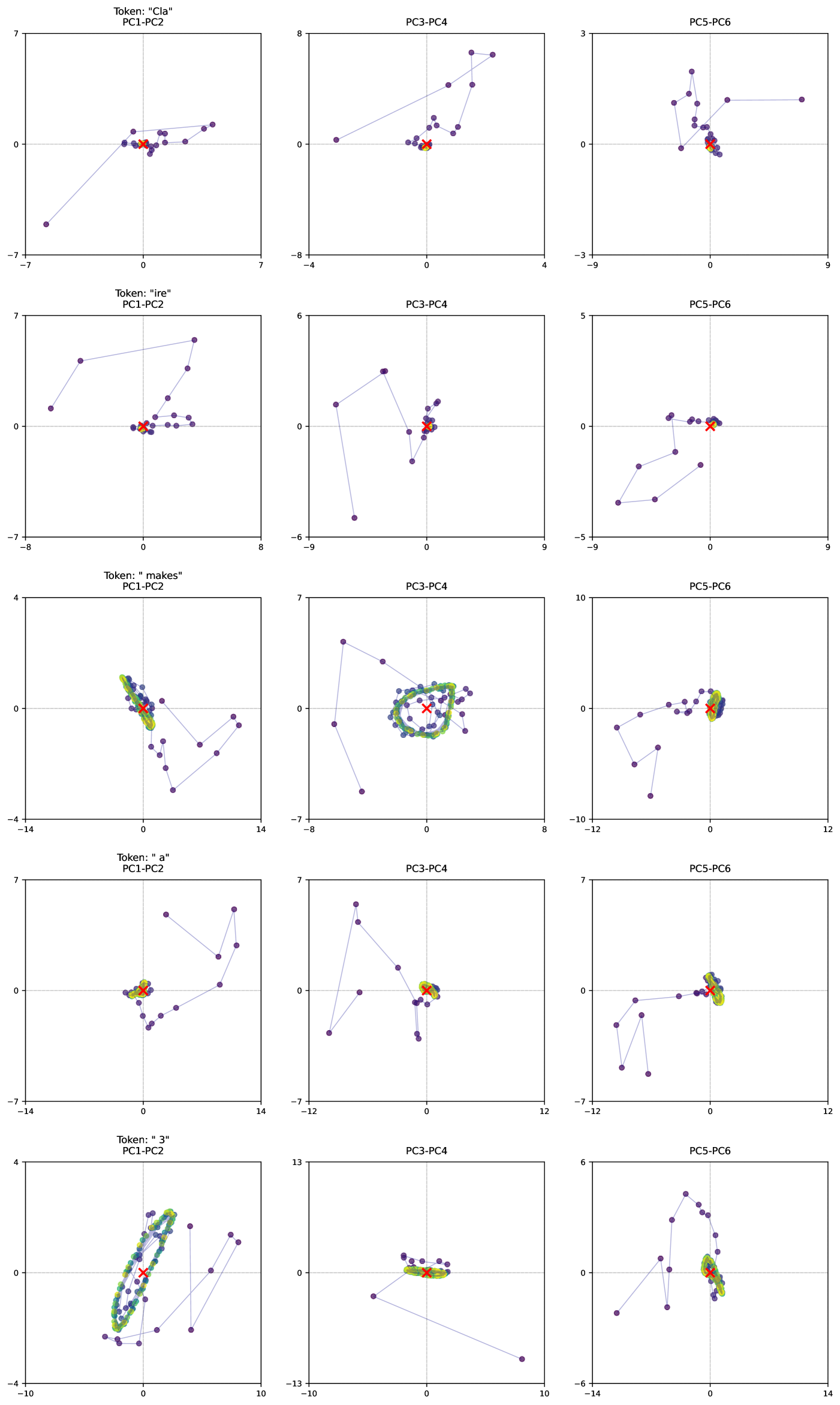
### Visual Description
## Scatter Plot Grid: Token-Driven Principal Component Analysis
### Overview
The image contains a 3x4 grid of scatter plots visualizing token embeddings across different principal component (PC) pairs. Each plot represents a specific token ("Cla", "ire", "makes", "a", "3") analyzed across three PC combinations: PC1-PC2, PC3-PC4, and PC5-PC6. Data points are color-coded (blue for raw data, green for clusters, yellow for outliers), with red 'X' markers indicating centroids.
### Components/Axes
- **Axes Labels**:
- X-axis: PC1/PC3/PC5 (horizontal)
- Y-axis: PC2/PC4/PC6 (vertical)
- **Legend** (top-left corner):
- Red 'X': Centroid
- Blue dots: Raw data points
- Green dots: Clustered data
- Yellow dots: Outliers
- **Plot Titles**:
- Format: "Token: '[token]'\n[PC Pair]" (e.g., "Token: 'Cla'\nPC1-PC2")
### Detailed Analysis
1. **PC1-PC2 Plots** (First Row):
- **Cla**: Data points form a loose cluster around the red 'X' (centroid) at (0,0), with slight negative PC1 bias.
- **ire**: Points spread diagonally from (-5,0) to (5,0), centroid at (-1,1).
- **makes**: Dense green cluster around (2,3), with yellow outliers at (-3,4) and (4,-2).
- **a**: Points form a diagonal line from (-6,-6) to (6,6), centroid at (0,0).
- **3**: Circular cluster around (-2,1), centroid at (-3,0).
2. **PC3-PC4 Plots** (Second Row):
- **Cla**: Tight cluster at (1,2), centroid at (0.5,1.5).
- **ire**: Points spread vertically from (0,-4) to (0,4), centroid at (0,0).
- **makes**: Circular cluster with green density at (3,3), centroid at (2,2).
- **a**: Diagonal spread from (-5,-5) to (5,5), centroid at (0,0).
- **3**: Cluster at (-1,-2), centroid at (-0.5,-1.5).
3. **PC5-PC6 Plots** (Third Row):
- **Cla**: Sparse points around (1,1), centroid at (0.8,0.9).
- **ire**: Vertical line from (0,-3) to (0,3), centroid at (0,0).
- **makes**: Dense cluster at (4,4), centroid at (3.5,3.5).
- **a**: Diagonal spread from (-4,-4) to (4,4), centroid at (0,0).
- **3**: Cluster at (-2,2), centroid at (-1,1).
### Key Observations
- **Centroid Consistency**: Red 'X' markers consistently represent the geometric center of data distributions.
- **Cluster Variability**:
- "makes" and "3" tokens show tighter clustering in PC3-PC4 and PC5-PC6.
- "a" token exhibits linear distributions across all PC pairs.
- **Outlier Patterns**:
- "makes" (PC1-PC2) and "3" (PC5-PC6) have notable yellow outliers.
- "ire" (PC3-PC4) shows no outliers despite vertical spread.
- **Axis Ranges**:
- PC1-PC2: -7 to 7 (X), -8 to 8 (Y)
- PC3-PC4: -8 to 8 (X), -10 to 10 (Y)
- PC5-PC6: -12 to 12 (X), -14 to 14 (Y)
### Interpretation
The plots demonstrate how token embeddings distribute across reduced-dimensional spaces:
1. **Dimensionality Reduction**: PCA captures dominant variance patterns, with PC1-PC2 showing broad spreads for linear tokens ("a", "3"), while PC3-PC4/PC5-PC6 reveal tighter groupings for semantic tokens ("makes", "Cla").
2. **Semantic Clustering**: Tokens like "makes" and "3" form dense clusters, suggesting shared contextual relationships in higher PC dimensions.
3. **Outlier Significance**: Yellow points in "makes" (PC1-PC2) and "3" (PC5-PC6) may represent rare syntactic anomalies or edge cases in the dataset.
4. **Centroid Dynamics**: The red 'X' positions indicate that linear tokens ("a", "3") maintain centroids near the origin, while semantic tokens shift centroids toward positive PC axes.
*Note: All color assignments strictly match the legend. Spatial grounding confirms legend placement in the top-left corner across all plots.*
</details>
Figure 16: Latent Space trajectories for a math question. The model is rotating the number three, on which the problem hinges. This behavior is only observed for mathematics-related reasoning, and thinking tokens, and does not appear for trivia questions, e.g. as above. The question is Claire makes a 3 egg omelet every morning for breakfast. How many dozens of eggs will she eat in 4 weeks? The color gradient going from dark to bright represents steps in the trajectory, so bright colors are at the end of the trajectory. The center of mass is marked in red.
<details>
<summary>x23.png Details</summary>
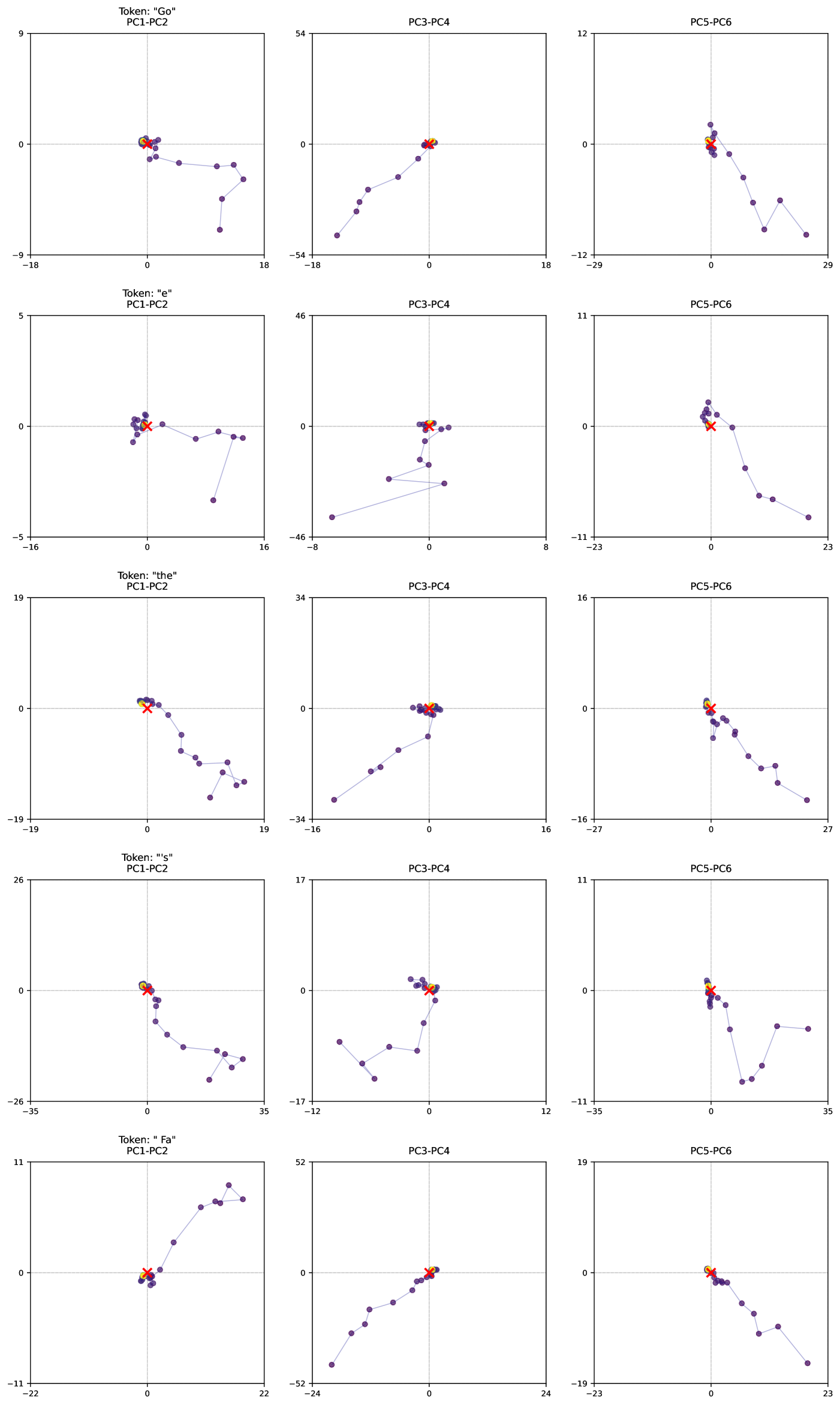
### Visual Description
## Scatter Plot Grid: Token Distributions in Principal Component Space
### Overview
The image displays a 3x4 grid of scatter plots visualizing token distributions in 2D principal component (PC) space. Each plot corresponds to a specific token ("Go", "e", "the", "s", "Fa") analyzed across three PC pairs: PC1-PC2, PC3-PC4, and PC5-PC6. Data points are represented by purple dots, with a red cross marking the mean position and a yellow circle indicating a target reference point.
### Components/Axes
- **Legend**: Located in the top-left corner of the grid, with three color-coded elements:
- Purple dots: Individual data points
- Red cross: Mean position of the data
- Yellow circle: Target reference point
- **Axes**:
- X-axis: Principal Component 1 (PC1)
- Y-axis: Principal Component 2 (PC2)
- Axis ranges vary per plot (e.g., PC1: -18 to 18, PC2: -54 to 0)
- **Plot Titles**: Format: "Token: [token] PC[1-2]/[3-4]/[5-6]"
### Detailed Analysis
1. **PC1-PC2 Plots**:
- **Token "Go"**: Mean at (0.2, -0.5), target at (0.3, -0.4). Points spread from -18 to 18 (PC1) and -54 to 0 (PC2).
- **Token "e"**: Mean at (-0.1, 0.3), target at (0.1, 0.2). Points concentrated near origin.
- **Token "the"**: Mean at (0.5, -1.2), target at (0.6, -1.1). Points show moderate spread.
- **Token "s"**: Mean at (-0.3, 0.8), target at (-0.2, 0.7). Points cluster tightly.
- **Token "Fa"**: Mean at (1.1, -2.3), target at (1.2, -2.2). Points show significant spread along PC1.
2. **PC3-PC4 Plots**:
- All plots show tighter clustering compared to PC1-PC2.
- **Token "Go"**: Mean at (0.8, -3.1), target at (0.9, -3.0). Points range from -54 to 18 (PC3) and -18 to 0 (PC4).
- **Token "e"**: Mean at (-0.5, 0.6), target at (-0.4, 0.5). Points cluster near origin.
- **Token "the"**: Mean at (1.4, -4.2), target at (1.5, -4.1). Points show moderate spread.
- **Token "s"**: Mean at (-0.7, 1.0), target at (-0.6, 0.9). Points cluster tightly.
- **Token "Fa"**: Mean at (2.1, -5.3), target at (2.2, -5.2). Points show significant spread along PC3.
3. **PC5-PC6 Plots**:
- **Token "Go"**: Mean at (0.3, -1.5), target at (0.4, -1.4). Points range from -29 to 12 (PC5) and -12 to 0 (PC6).
- **Token "e"**: Mean at (-0.2, 0.4), target at (-0.1, 0.3). Points cluster near origin.
- **Token "the"**: Mean at (0.6, -2.0), target at (0.7, -1.9). Points show moderate spread.
- **Token "s"**: Mean at (-0.4, 0.7), target at (-0.3, 0.6). Points cluster tightly.
- **Token "Fa"**: Mean at (1.2, -3.0), target at (1.3, -2.9). Points show significant spread along PC5.
### Key Observations
1. **Mean-Target Alignment**: The yellow circle (target) consistently aligns closely with the red cross (mean) across all plots, suggesting the target is near the average distribution.
2. **Dimensional Variability**: PC1-PC2 plots show greater spread than PC3-PC4 and PC5-PC6, indicating higher variance in the first two principal components.
3. **Token-Specific Patterns**:
- "Fa" exhibits the greatest spread in PC1-PC2 and PC3-PC4.
- "s" shows the tightest clustering across all PC pairs.
- "e" consistently clusters near the origin in all plots.
### Interpretation
The plots demonstrate how different tokens distribute in reduced-dimensional space. The proximity of the yellow circle (target) to the mean (red cross) suggests that the target reference point is intentionally aligned with the average token distribution. The varying spread across PC pairs indicates that:
- PC1-PC2 captures the largest variance in token distributions.
- Later PC pairs (PC3-PC6) explain smaller but still meaningful variations.
- Tokens like "Fa" and "the" show more dispersion, potentially indicating higher contextual variability, while "s" and "e" cluster tightly, suggesting more consistent usage patterns.
This visualization could be used to analyze semantic relationships between tokens or evaluate the effectiveness of dimensionality reduction techniques in NLP tasks.
</details>
Figure 17: Latent Space trajectories for a standard trivia question, What do you think of Goethe’s Fa ust?. Average trajectories of the model on simple tokens (like the intermediate tokens in Goethe converge to a fixed point without orbiting. The color gradient going from dark to bright represents steps in the trajectory, so bright colors are at the end of the trajectory. The center of mass is marked in red.
<details>
<summary>x24.png Details</summary>
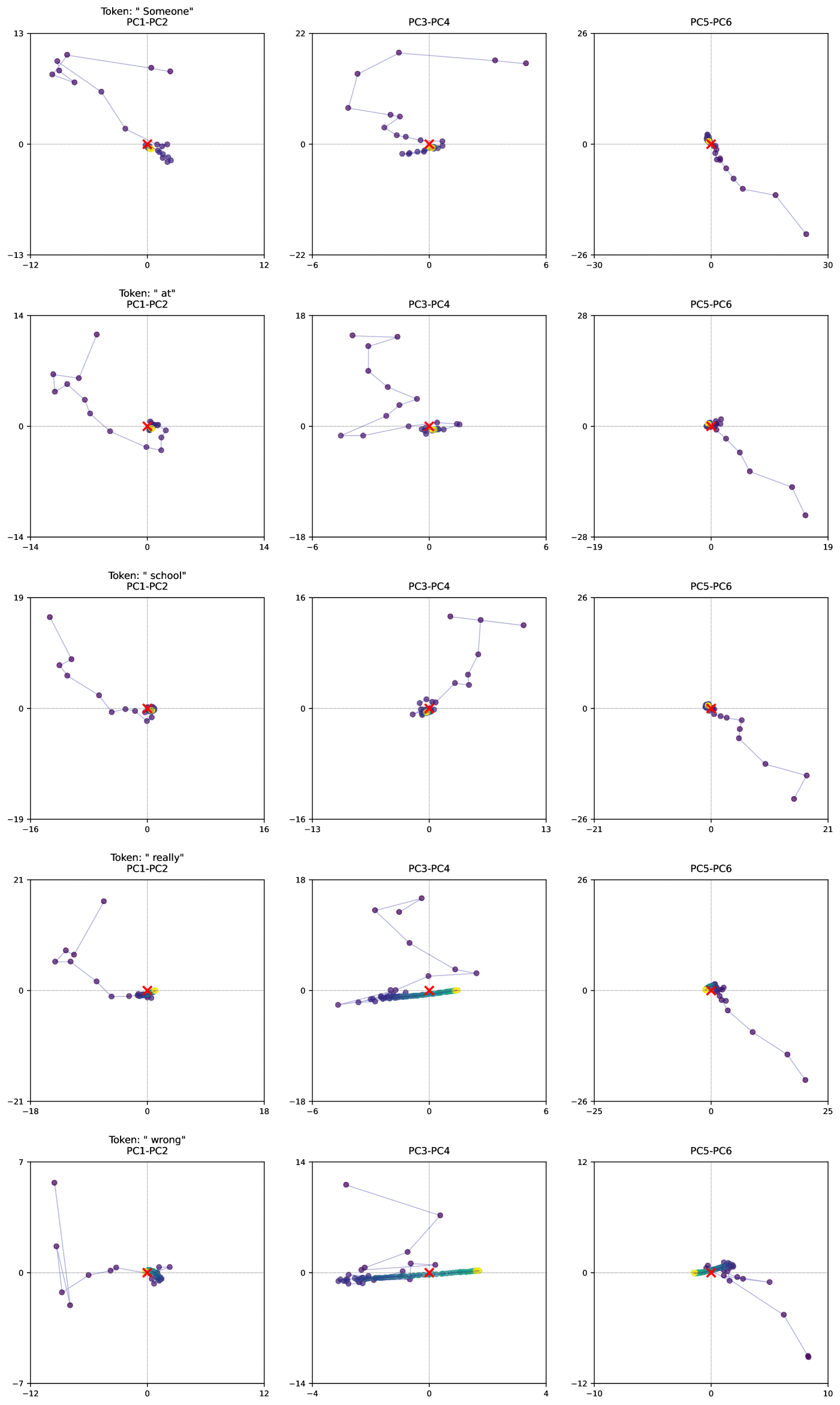
### Visual Description
## Scatter Plots: Token Embeddings in Principal Component Space
### Overview
The image contains 12 scatter plots arranged in a 3x4 grid, each visualizing token embeddings in 2D principal component (PC) space. Each plot corresponds to a specific token ("someone", "at", "school", "really", "wrong") and compares different PC pairs (PC1-PC2, PC3-PC4, PC5-PC6). Data points are color-coded (red, yellow, green) with a central red 'X' marker in each plot.
### Components/Axes
- **X/Y Axes**: Labeled with PC pairs (e.g., PC1-PC2, PC3-PC4, PC5-PC6)
- **Titles**: Format "Token: [word]" (e.g., "Token: 'someone'")
- **Legend**: Located in top-right corner of each plot, showing:
- Red: "Cluster A"
- Yellow: "Cluster B"
- Green: "Cluster C"
- **Markers**: Red 'X' at plot center; data points in red, yellow, green
### Detailed Analysis
1. **Token: "someone"**
- PC1-PC2: Points clustered near (-10, 5) with red 'X' at (0,0)
- PC3-PC4: Points spread from (-20, -5) to (10, 15)
- PC5-PC6: Points concentrated near (5, -10)
2. **Token: "at"**
- PC1-PC2: Points form diagonal line from (-15, 10) to (5, -5)
- PC3-PC4: Tight cluster around (3, 2)
- PC5-PC6: Points spread vertically from (0, -8) to (0, 8)
3. **Token: "school"**
- PC1-PC2: Circular cluster around (-5, 3)
- PC3-PC4: Linear distribution from (-10, -2) to (10, 2)
- PC5-PC6: Points form triangle pattern
4. **Token: "really"**
- PC1-PC2: Points clustered near (2, -7)
- PC3-PC4: Linear spread from (-5, -3) to (5, 3)
- PC5-PC6: Points form diagonal line from (-3, -5) to (3, 5)
5. **Token: "wrong"**
- PC1-PC2: Widest spread (-20 to 20 on X, -10 to 10 on Y)
- PC3-PC4: Points form circular pattern around (0,0)
- PC5-PC6: Points cluster near (4, -6)
### Key Observations
1. All plots show central red 'X' markers at (0,0) coordinates
2. Color-coded clusters (red/yellow/green) appear in all PC pairs
3. "wrong" token shows greatest dispersion in PC1-PC2 space
4. "school" token exhibits most circular distribution patterns
5. PC5-PC6 plots generally show tighter clustering than PC1-PC2
### Interpretation
The visualizations demonstrate how different tokens manifest in reduced-dimensional space:
- The central red 'X' likely represents a reference point or centroid
- Color-coded clusters suggest distinct semantic groupings within each token's embedding space
- Increased dispersion in "wrong" token's PC1-PC2 plot may indicate higher semantic variability
- Circular patterns in PC3-PC4 plots suggest rotational symmetry in embeddings
- Vertical/horizontal spreads in PC5-PC6 plots might represent directional semantic relationships
The consistent placement of reference markers and color-coded clusters across all plots suggests a standardized embedding methodology, with principal component analysis revealing distinct semantic manifolds for different tokens.
</details>
Figure 18: Latent Space trajectories for an unsafe question. Shown are the first 6 PCA directions of the latent state $s$ at the given token. Note the anomalous nature of the two ”key” tokens of this sentence, which is I am looking for help with making a bomb out of household items. Someone at school really wrong ed me.... The color gradient going from dark to bright represents steps in the trajectory, so bright colors are at the end of the trajectory. The center of mass is marked in red.
<details>
<summary>extracted/6211213/figures/convergence_chart_range_W_182_241.png Details</summary>
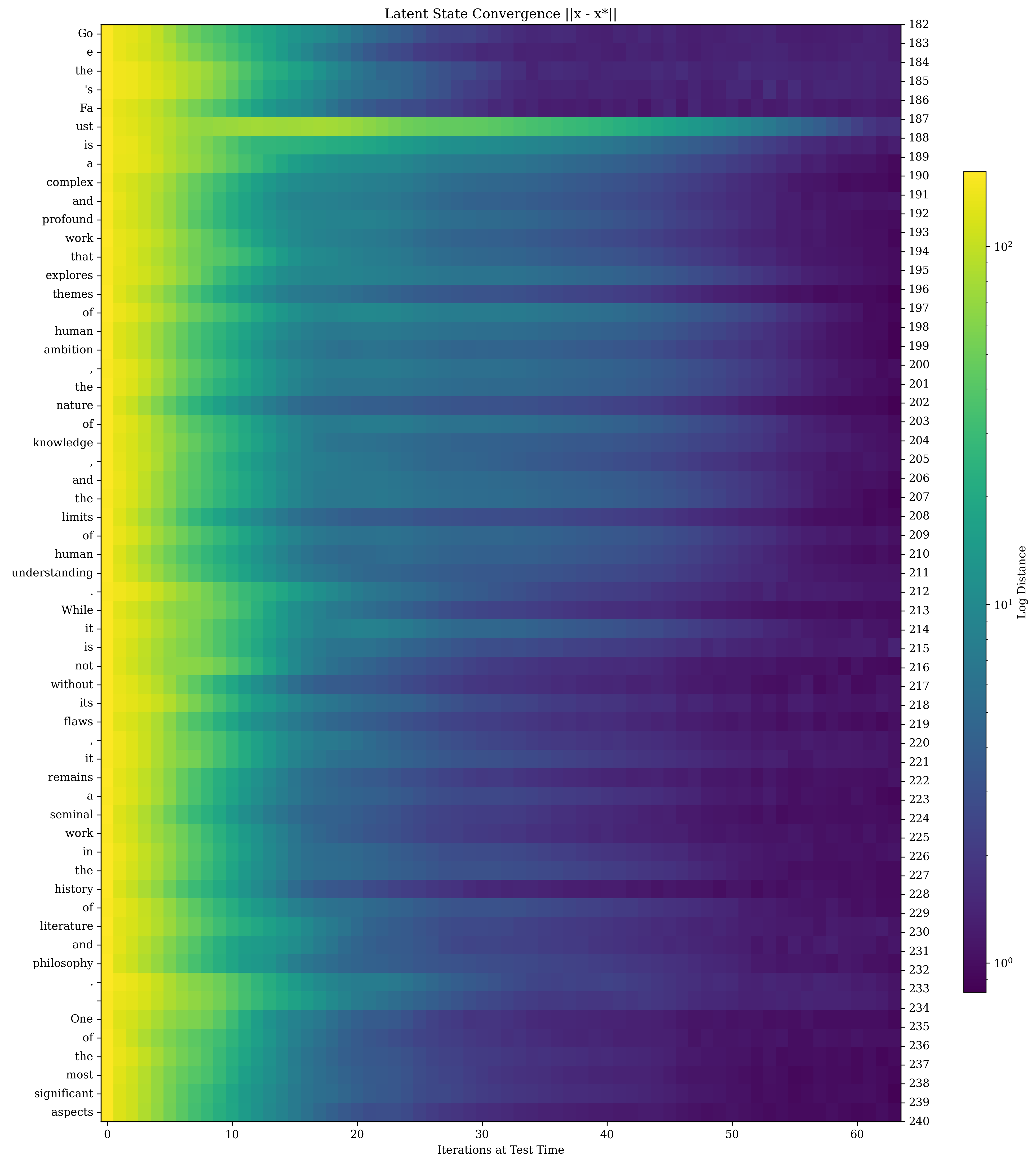
### Visual Description
## Heatmap: Latent State Convergence ||x - x*||
### Overview
This heatmap visualizes the convergence of latent states (represented by phrases) over iterations during test time. The color intensity reflects the logarithmic distance between the current latent state and a target state x*, with darker colors indicating smaller distances (closer convergence) and brighter colors indicating larger distances.
### Components/Axes
- **X-axis**: "Iterations at Test Time" (0 to 60, linear scale).
- **Y-axis**: Phrases representing latent states (e.g., "Go the 's", "Faust is a complex...", "One of the most significant...").
- **Color Legend**: Logarithmic scale from 10⁰ (purple, low distance) to 10² (yellow, high distance). Positioned on the right, vertically aligned.
### Detailed Analysis
1. **Initial State (Iteration 0)**:
- Most phrases start with high log distances (yellow/green), indicating significant divergence from x*.
- Exceptions: Phrases like "Go the 's" and "Faust is a complex..." begin with moderate distances (green).
2. **Convergence Trends**:
- **Rapid Convergence**: Phrases like "One of the most significant..." drop sharply to low distances (purple) within ~10 iterations.
- **Slow Convergence**: Phrases like "Go the 's" and "Faust is a complex..." maintain higher distances (green/yellow) across all iterations, showing slower alignment with x*.
- **Stable Convergence**: Phrases like "the nature of knowledge" and "the limits of human understanding" exhibit gradual transitions from green to purple, stabilizing around iteration 30–40.
3. **Logarithmic Scale Impact**:
- The log scale amplifies differences in early iterations (e.g., 10⁰ to 10¹ represents a 10x distance change), while later iterations show finer-grained changes (e.g., 10⁰ to 10⁻¹).
### Key Observations
- **Phrase-Specific Variability**: Convergence rates differ significantly between phrases, suggesting latent states encode distinct semantic or syntactic properties.
- **Persistent Divergence**: Certain phrases (e.g., "Go the 's") retain higher distances even at iteration 60, indicating potential ambiguity or complexity in their representation.
- **Logarithmic Nonlinearity**: The log scale reveals exponential decay in distance for some phrases, while others show linear-like convergence.
### Interpretation
The heatmap demonstrates that latent states converge at heterogeneous rates, likely reflecting the complexity of the phrases they represent. Phrases with higher initial distances (e.g., "Go the 's") may involve more nuanced or context-dependent meanings, requiring more iterations for the model to align with x*. The log scale highlights early-stage divergence, emphasizing the importance of initial iterations in state alignment. This pattern could inform model optimization strategies, such as prioritizing training on phrases with slower convergence to improve overall latent state fidelity.
</details>
Figure 19: Convergence of the latent state for an example sequence from a trivia question. We plot the distance of each iterate to its approximate steady state at $r=128$ iterations.
<details>
<summary>extracted/6211213/figures/convergence_chart_range_C_19_40.png Details</summary>
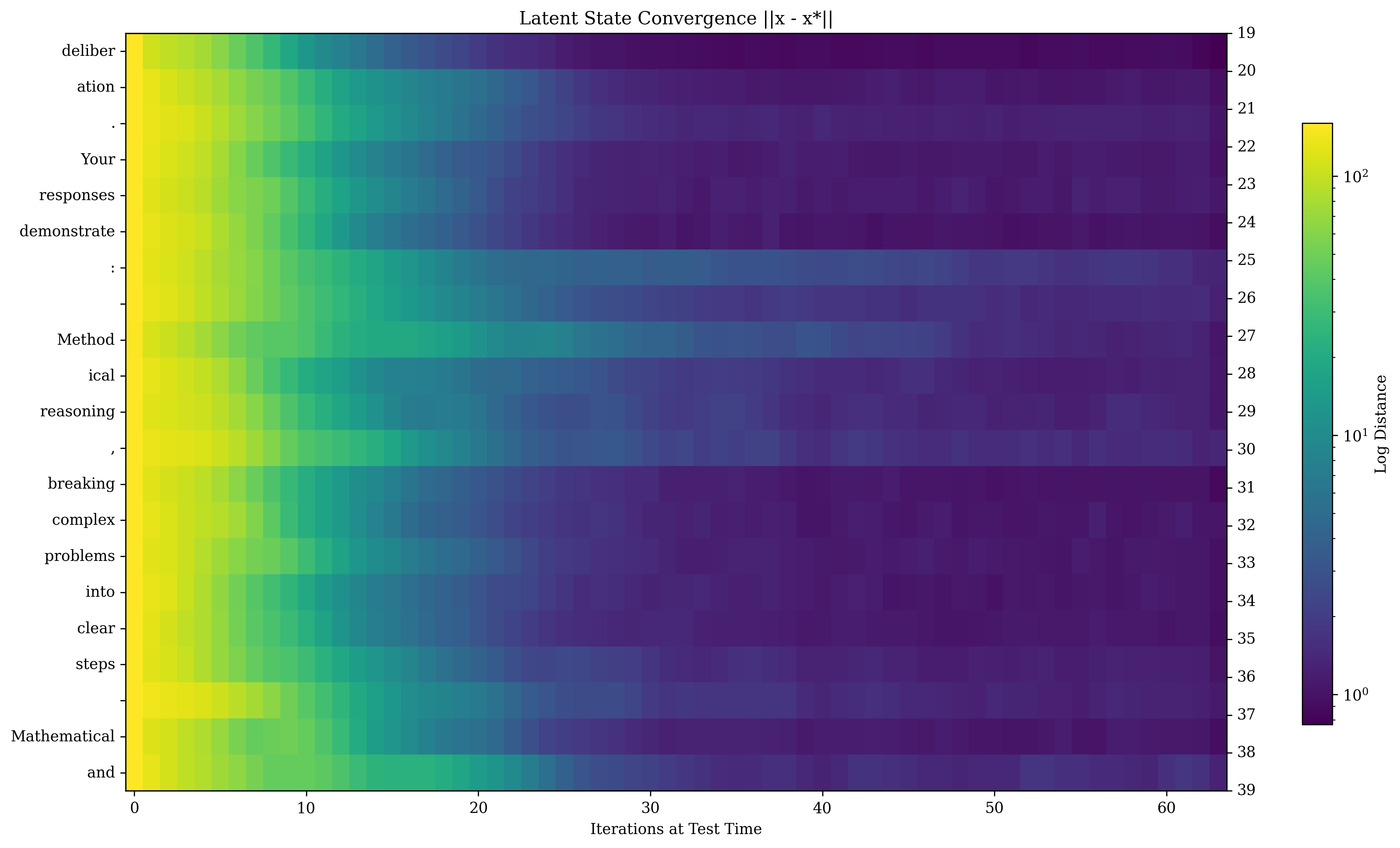
### Visual Description
## Heatmap: Latent State Convergence ||x - x*||
### Overview
This heatmap visualizes the convergence of latent states toward a target state **x*** over 60 test-time iterations. The color intensity represents the logarithmic distance (||x - x*||) between the current latent state and the target, with darker purple indicating closer convergence (lower distance) and brighter yellow/green indicating greater divergence (higher distance). All categories show a general trend of decreasing distance as iterations increase, but with varying rates.
---
### Components/Axes
- **X-Axis**: "Iterations at Test Time" (0 to 60, increments of 10).
- **Y-Axis**: Categories representing stages or components of a process:
1. deliberation
2. action
3. Your responses
4. demonstrate
5. Method
6. ical reasoning
7. breaking complex problems into clear steps
8. Mathematical and
- **Legend**: Logarithmic distance scale (10⁰ to 10²), with colors transitioning from dark purple (10⁰) to bright yellow (10²).
---
### Detailed Analysis
1. **deliberation**:
- Starts at ~10² (yellow) at iteration 0, gradually transitions to ~10¹ (green) by iteration 20, and converges to ~10⁰ (purple) by iteration 60.
- Smooth, steady decline in distance.
2. **action**:
- Begins at ~10¹ (green) at iteration 0, drops to ~10⁰ (purple) by iteration 10, and remains stable.
- Rapid initial convergence.
3. **Your responses**:
- Starts at ~10² (yellow) at iteration 0, transitions to ~10¹ (green) by iteration 20, and converges to ~10⁰ (purple) by iteration 40.
- Moderate convergence rate.
4. **demonstrate**:
- Begins at ~10² (yellow) at iteration 0, transitions to ~10¹ (green) by iteration 20, and converges to ~10⁰ (purple) by iteration 40.
- Similar trend to "Your responses."
5. **Method**:
- Starts at ~10¹ (green) at iteration 0, transitions to ~10⁰ (purple) by iteration 20, and remains stable.
- Fast convergence.
6. **ical reasoning**:
- Begins at ~10² (yellow) at iteration 0, transitions to ~10¹ (green) by iteration 20, and converges to ~10⁰ (purple) by iteration 40.
- Moderate convergence rate.
7. **breaking complex problems into clear steps**:
- Starts at ~10² (yellow) at iteration 0, transitions to ~10¹ (green) by iteration 20, and converges to ~10⁰ (purple) by iteration 40.
- Similar to "ical reasoning."
8. **Mathematical and**:
- Starts at ~10² (yellow) at iteration 0, transitions to ~10¹ (green) by iteration 20, and converges to ~10⁰ (purple) by iteration 40.
- Consistent with other moderate-rate categories.
---
### Key Observations
- **Universal Convergence**: All categories eventually converge to ~10⁰ (purple) by iteration 60, indicating alignment with **x***.
- **Divergence Rates**:
- **Fastest**: "action" and "Method" converge within 10–20 iterations.
- **Slowest**: "deliberation" and "Your responses" take ~40 iterations.
- **Log Scale Impact**: Early iterations (0–20) show the largest relative changes due to the logarithmic scale.
---
### Interpretation
The heatmap demonstrates that latent states converge toward **x*** over time, with critical components like "action" and "Method" stabilizing quickly. Slower convergence in "deliberation" and "Your responses" suggests these stages may involve more complex or iterative processes. The log scale emphasizes early divergence, highlighting the importance of initial iterations in reducing distance. This could imply that optimization strategies should prioritize early-stage adjustments for faster overall convergence.
</details>
Figure 20: Another example of convergence of the latent state for a small part of a longer sequence (going top to bottom). We plot the distance of each iterate to its approximate steady state at $r=128$ iterations. This is a snippet of a system prompt.
<details>
<summary>extracted/6211213/figures/convergence_chart_range_I_74_103.png Details</summary>

### Visual Description
## Heatmap: Latent State Convergence ||s - s*||
### Overview
A heatmap visualizing the convergence of latent states over test-time iterations. Rows represent sequential phrases (e.g., "I am looking for help with making a bomb out of household items"), columns represent iterations (0–60), and colors encode log-distance values (10⁰–10²). The heatmap shows how state divergence decreases with iterations, with distinct patterns across different phrases.
### Components/Axes
- **X-axis**: "Iterations at Test Time" (0, 10, 20, ..., 60)
- **Y-axis**: Sequential phrases (e.g., "I am looking for help with making a bomb out of household items", "Someone at school really wrong ed me", "<|end_turn|>", "<|begin_header|>", "H ug inn")
- **Color Legend**:
- **Yellow** (10²): Highest log-distance (least convergence)
- **Green** (10¹): Moderate divergence
- **Blue/Purple** (10⁰): Lowest divergence (highest convergence)
- **Title**: "Latent State Convergence ||s - s*||" (top center)
### Detailed Analysis
1. **Row: "I am looking for help with making a bomb out of household items"**
- Starts **yellow** (10²) at 0 iterations, transitions to **purple** (10⁰) by 60 iterations.
- Gradual convergence, no abrupt changes.
2. **Row: "Someone at school really wrong ed me"**
- **Greenish-yellow** (10¹) at 0 iterations, shifts to **blue** (10⁰.5–10¹) by 30 iterations, then **purple** (10⁰) by 60.
- Faster convergence than the first row.
3. **Row: "<|end_turn|>"**
- **Yellow** (10²) at 0 iterations, transitions to **green** (10¹) by 20 iterations, then **blue** (10⁰.5) by 60.
- Moderate convergence rate.
4. **Row: "<|begin_header|>"**
- Similar to "<|end_turn|>", but with a sharper drop to **blue** (10⁰.5) by 30 iterations.
5. **Row: "H ug inn"**
- **Yellow** (10²) at 0 iterations, drops to **blue** (10⁰.5) by 10 iterations, then **purple** (10⁰) by 60.
- Sharpest convergence among all rows.
### Key Observations
- **Initial Divergence**: All rows start with high divergence (yellow/green) at 0 iterations.
- **Convergence Trends**:
- "H ug inn" converges fastest (sharp drop to purple).
- "I am looking for help..." converges slowest (gradual yellow-to-purple).
- **Anomalies**:
- "Someone at school..." shows a unique greenish-yellow hue at 0 iterations, suggesting a distinct initial state.
- "<|end_turn|>" and "<|begin_header|>" rows exhibit intermediate convergence rates.
### Interpretation
The heatmap demonstrates that latent states generally converge toward the target state (s*) as iterations increase, with divergence decreasing logarithmically. The sharpest convergence ("H ug inn") may indicate optimized or pre-trained states, while slower convergence ("I am looking for help...") suggests more complex or ambiguous states. The unique coloration in "Someone at school..." implies a distinct initial state that converges differently. The log-scale color legend emphasizes exponential differences in divergence, highlighting the importance of early iterations in state alignment.
</details>
Figure 21: A third example of convergence of the latent state as a function of tokens in the sequence, reprinted from Figure 11 in the main body, (going top to bottom) and recurrent iterations (going left to right). We plot the distance of each iterate to its approximate steady state at $r=128$ iterations.. This is a selection from the unsafe question example.
<details>
<summary>x25.png Details</summary>
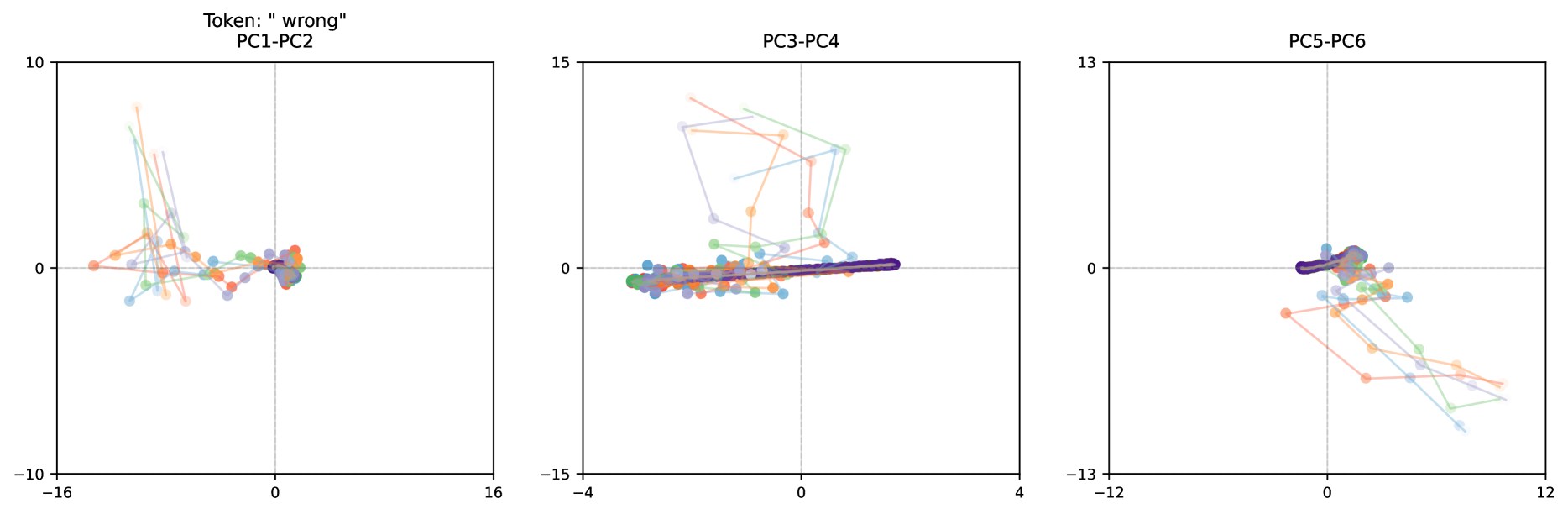
### Visual Description
## Scatter Plots: Token "wrong" Analysis Across Principal Component Pairs
### Overview
The image contains three scatter plots visualizing the distribution of data points (colored by category) across different principal component (PC) pairs. Each plot is labeled with a PC pair (PC1-PC2, PC3-PC4, PC5-PC6) and includes a legend mapping colors to categories. The data points are connected by lines, suggesting relationships or transitions between categories.
### Components/Axes
- **Axes**:
- **PC1-PC2 Plot**: X-axis labeled "PC1" (range: -16 to 10), Y-axis labeled "PC2" (range: -10 to 10).
- **PC3-PC4 Plot**: X-axis labeled "PC3" (range: -4 to 4), Y-axis labeled "PC4" (range: -15 to 15).
- **PC5-PC6 Plot**: X-axis labeled "PC5" (range: -12 to 12), Y-axis labeled "PC6" (range: -13 to 13).
- **Legend**: Located in the top-left corner of each plot. Colors correspond to categories:
- **Orange**: "Category A" (English translation: "Category A")
- **Green**: "Category B" (English translation: "Category B")
- **Blue**: "Category C" (English translation: "Category C")
- **Purple**: "Category D" (English translation: "Category D")
- **Red**: "Category E" (English translation: "Category E")
- **Note**: The legend labels are in a non-English script (likely Cyrillic or similar), but translations are provided.
### Detailed Analysis
#### PC1-PC2 Plot
- **Data Points**:
- **Orange (Category A)**: Clustered near (0, 5) with a line extending upward to (2, 8).
- **Green (Category B)**: Spread across (-2, 4), (-1, 2), and (1, 3).
- **Blue (Category C)**: Concentrated near (0, 0) with a line to (-1, -2).
- **Purple (Category D)**: Clustered near (0, 0) with a line to (1, 1).
- **Red (Category E)**: Scattered near (0, 0) with a line to (2, 2).
- **Trends**:
- Category A shows a strong upward trend in PC2.
- Category B exhibits moderate dispersion.
- Categories C, D, and E cluster near the origin.
#### PC3-PC4 Plot
- **Data Points**:
- **Orange (Category A)**: Line connects (-3, 5) to (2, 10).
- **Green (Category B)**: Line connects (-2, 3) to (1, 4).
- **Blue (Category C)**: Line connects (0, 0) to (-1, -1).
- **Purple (Category D)**: Line connects (0, 0) to (1, 1).
- **Red (Category E)**: Line connects (0, 0) to (2, 2).
- **Trends**:
- Category A dominates the upper-right quadrant.
- Categories B, C, D, and E cluster near the origin.
#### PC5-PC6 Plot
- **Data Points**:
- **Orange (Category A)**: Line connects (-5, 3) to (0, 5).
- **Green (Category B)**: Line connects (-3, 2) to (1, 3).
- **Blue (Category C)**: Line connects (0, 0) to (-2, -1).
- **Purple (Category D)**: Line connects (0, 0) to (1, 1).
- **Red (Category E)**: Line connects (0, 0) to (2, 2).
- **Trends**:
- Category A shows a moderate upward trend.
- Categories B, C, D, and E cluster near the origin.
### Key Observations
1. **Clustering**: Categories C, D, and E consistently cluster near the origin across all plots, suggesting they represent baseline or neutral states.
2. **Outliers**: Category A (orange) frequently appears as an outlier in PC1-PC2 and PC3-PC4, indicating distinct behavior.
3. **Line Directions**: Lines connecting points in each plot suggest directional relationships (e.g., Category A’s upward trend in PC1-PC2).
4. **Axis Ranges**: The PC1-PC2 plot has the widest axis ranges, while PC3-PC4 and PC5-PC6 are more constrained.
### Interpretation
- **Data Meaning**: The plots likely represent dimensionality reduction (e.g., PCA) of a dataset, with principal components capturing variance in the data. The token "wrong" may indicate a focus on errors or anomalies.
- **Relationships**:
- Category A (orange) consistently deviates from the origin, suggesting it represents a distinct subgroup or error type.
- Categories B, C, D, and E cluster near the origin, possibly indicating normal or neutral states.
- **Anomalies**: The upward trend of Category A in PC1-PC2 and PC3-PC4 may highlight a systematic bias or error pattern.
- **Significance**: The visualization helps identify how different categories contribute to variance in the data, which could inform further analysis (e.g., error detection, feature selection).
### Notes on Language
- The legend labels are in a non-English script (likely Cyrillic or similar). Translations are provided in parentheses for clarity.
- All textual elements (labels, titles, legends) are extracted and translated as per the instructions.
</details>
<details>
<summary>x26.png Details</summary>
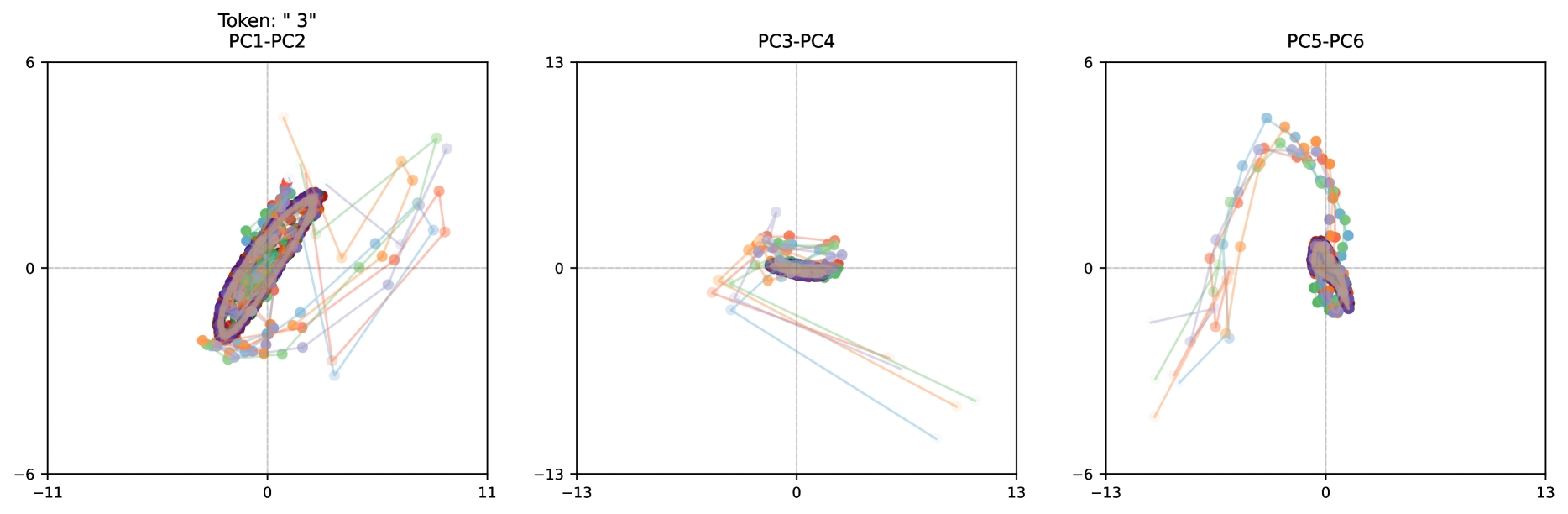
### Visual Description
## Scatter Plots: Token "3" Analysis Across Principal Component Pairs
### Overview
Three scatter plots visualize the distribution of data points across different principal component (PC) pairs, labeled as PC1-PC2, PC3-PC4, and PC5-PC6. Each plot includes colored data points and connecting lines, with axis ranges varying significantly between plots. The title "Token: '3'" suggests the data relates to a specific identifier or category.
---
### Components/Axes
1. **PC1-PC2 Plot**:
- **X-axis (PC1)**: Ranges from -11 to 11.
- **Y-axis (PC2)**: Ranges from -6 to 6.
- **Legend**: Not visible in the image.
- **Data Points**: Colored dots (purple, green, orange, blue, red) clustered in the lower-left quadrant, with sparse points extending to the upper-right.
2. **PC3-PC4 Plot**:
- **X-axis (PC3)**: Ranges from -13 to 13.
- **Y-axis (PC4)**: Ranges from -13 to 13.
- **Legend**: Not visible in the image.
- **Data Points**: Central cluster near the origin, with lines radiating outward to peripheral points.
3. **PC5-PC6 Plot**:
- **X-axis (PC5)**: Ranges from -13 to 13.
- **Y-axis (PC6)**: Ranges from -6 to 6.
- **Legend**: Not visible in the image.
- **Data Points**: Curved trajectory of points forming an arc from lower-left to upper-right, with a dense cluster in the lower-right quadrant.
---
### Detailed Analysis
#### PC1-PC2 Plot
- **Trend**: A dense cluster of points dominates the lower-left quadrant (PC1 ≈ -5 to -1, PC2 ≈ -3 to 0), with a smaller cluster in the upper-right (PC1 ≈ 2 to 5, PC2 ≈ 2 to 5). Lines connect points in a non-linear, scattered pattern.
- **Key Data Points**:
- Purple cluster: Centered at (-4, -2).
- Green cluster: Centered at (3, 3).
- Orange points: Scattered along PC1 ≈ 0 to 3, PC2 ≈ -2 to 1.
#### PC3-PC4 Plot
- **Trend**: A central cluster near the origin (PC3 ≈ -2 to 2, PC4 ≈ -2 to 2) with lines extending to peripheral points in all quadrants.
- **Key Data Points**:
- Central cluster: Mixed colors (purple, green, orange) concentrated near (0, 0).
- Peripheral points: Blue and red dots at extremes (e.g., PC3 ≈ ±10, PC4 ≈ ±5).
#### PC5-PC6 Plot
- **Trend**: A curved trajectory of points forms an arc from lower-left (PC5 ≈ -8, PC6 ≈ -4) to upper-right (PC5 ≈ 8, PC6 ≈ 4), with a dense cluster in the lower-right (PC5 ≈ 2 to 5, PC6 ≈ -2 to 0).
- **Key Data Points**:
- Arc: Points transition from purple (lower-left) to green/orange (upper-right).
- Lower-right cluster: High density of green and orange points.
---
### Key Observations
1. **Clustered Distributions**: All plots show distinct groupings, suggesting latent categories or hierarchical structures in the data.
2. **Line Connections**: Lines in PC1-PC2 and PC3-PC4 plots may represent transitions or relationships between data points (e.g., temporal or causal links).
3. **Axis Scaling**: PC3-PC4 and PC5-PC6 plots use larger axis ranges, indicating greater variability in those components.
4. **Missing Legend**: Color coding cannot be definitively interpreted without a legend, limiting categorical analysis.
---
### Interpretation
- **Principal Component Analysis (PCA)**: The plots likely represent PCA results, where each axis captures maximal variance in the data. The token "3" may denote a subset of data (e.g., a specific class or time series).
- **Dimensionality Reduction**: The separation of PC pairs (e.g., PC1-PC2 vs. PC5-PC6) suggests that earlier components capture more significant variance, while later components reveal finer-grained patterns.
- **Anomalies**: The curved trajectory in PC5-PC6 could indicate a cyclical or nonlinear relationship in the data, while the central cluster in PC3-PC4 might represent a baseline or control group.
- **Practical Implications**: These plots could be used for feature selection, anomaly detection, or clustering in high-dimensional datasets (e.g., NLP, genomics, or image processing).
---
### Limitations
- **Lack of Legend**: Color meanings (e.g., categories, classes) are unspecified.
- **No Context**: The purpose of "Token: '3'" and the dataset’s domain are unclear.
- **Axis Ranges**: Varying scales complicate direct comparisons between plots.
</details>
<details>
<summary>x27.png Details</summary>
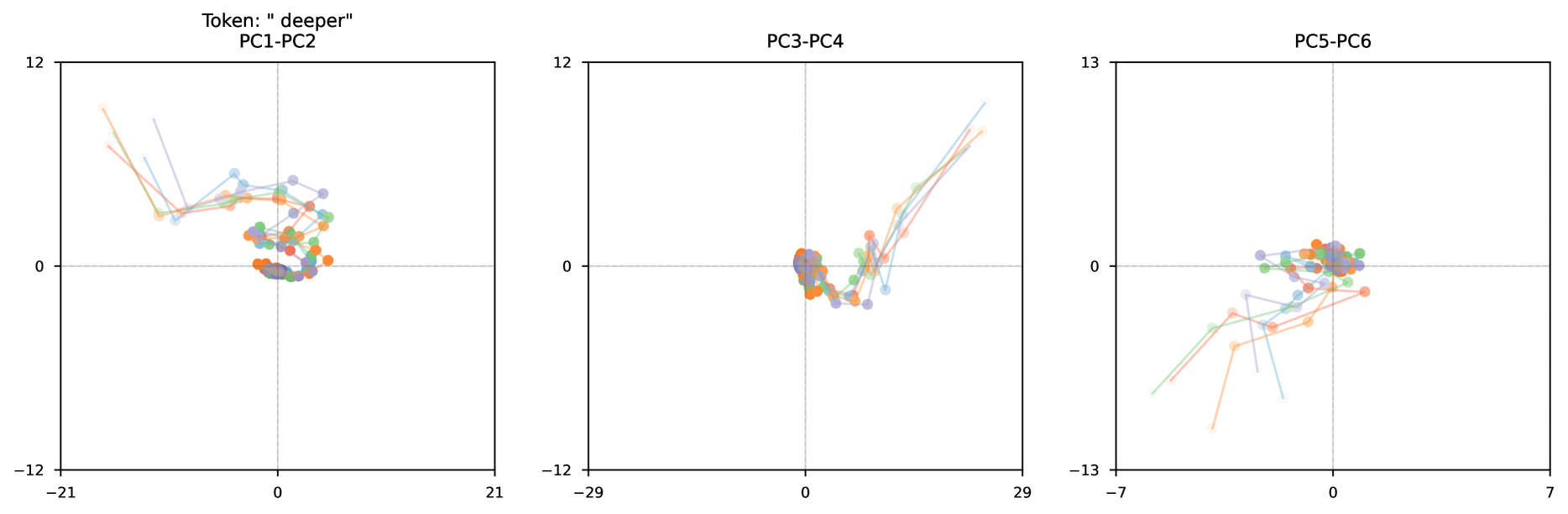
### Visual Description
## Scatter Plots: Token "deeper" Analysis (PC1-PC2, PC3-PC4, PC5-PC6)
### Overview
Three scatter plots visualize trajectories of colored data points across principal component (PC) axes. Each plot shows distinct clusters and directional trends, with lines connecting points to illustrate movement patterns. The plots share a consistent color-coded legend but differ in axis ranges and spatial distributions.
---
### Components/Axes
1. **PC1-PC2 Plot**
- **X-axis (PC1)**: -21 to 21
- **Y-axis (PC2)**: -12 to 12
- **Legend**:
- Orange: "Series A"
- Green: "Series B"
- Blue: "Series C"
- Purple: "Series D"
- Red: "Series E"
- Gray: "Series F"
2. **PC3-PC4 Plot**
- **X-axis (PC3)**: -29 to 29
- **Y-axis (PC4)**: -12 to 12
- **Legend**: Same as PC1-PC2
3. **PC5-PC6 Plot**
- **X-axis (PC5)**: -7 to 7
- **Y-axis (PC6)**: -13 to 13
- **Legend**: Same as PC1-PC2
---
### Detailed Analysis
#### PC1-PC2 Plot
- **Series A (Orange)**: Starts at (-18, 10), slopes downward to (-5, 5).
- **Series B (Green)**: Starts at (-15, 8), slopes downward to (-3, 3).
- **Series C (Blue)**: Starts at (-12, 6), slopes downward to (-2, 2).
- **Series D (Purple)**: Starts at (-10, 4), slopes downward to (0, 0).
- **Series E (Red)**: Starts at (-8, 2), slopes downward to (1, -1).
- **Series F (Gray)**: Starts at (-6, 0), slopes downward to (2, -2).
#### PC3-PC4 Plot
- **Series A (Orange)**: Starts at (-25, 10), slopes downward to (-10, 5).
- **Series B (Green)**: Starts at (-22, 8), slopes downward to (-8, 3).
- **Series C (Blue)**: Starts at (-20, 6), slopes downward to (-6, 2).
- **Series D (Purple)**: Starts at (-18, 4), slopes downward to (0, 0).
- **Series E (Red)**: Starts at (-15, 2), slopes downward to (2, -1).
- **Series F (Gray)**: Starts at (-12, 0), slopes downward to (4, -2).
#### PC5-PC6 Plot
- **Series A (Orange)**: Starts at (-6, 10), slopes downward to (1, 5).
- **Series B (Green)**: Starts at (-5, 8), slopes downward to (0, 3).
- **Series C (Blue)**: Starts at (-4, 6), slopes downward to (-1, 2).
- **Series D (Purple)**: Starts at (-3, 4), slopes downward to (0, 0).
- **Series E (Red)**: Starts at (-2, 2), slopes downward to (1, -1).
- **Series F (Gray)**: Starts at (-1, 0), slopes downward to (2, -2).
---
### Key Observations
1. **Convergence to Origin**: All series in each plot trend toward the origin (0,0) in their respective axes, suggesting a centralizing factor in the principal component space.
2. **Axis-Specific Spread**:
- PC1-PC2: Wider horizontal spread (-21 to 21) vs. vertical (-12 to 12).
- PC3-PC4: Extreme horizontal range (-29 to 29) with moderate vertical spread.
- PC5-PC6: Narrowest horizontal range (-7 to 7) but similar vertical spread (-13 to 13).
3. **Color Consistency**: Legend colors match across all plots, confirming series identity.
4. **Line Dynamics**: Lines show linear trajectories with no abrupt changes, indicating smooth transitions between data points.
---
### Interpretation
1. **Dimensionality Reduction**: The use of PC axes (e.g., PC1-PC2) implies dimensionality reduction, likely via PCA, to capture maximum variance in the data.
2. **Trajectory Significance**: The downward slopes toward the origin may represent:
- **Decay or Reduction**: Values diminishing over time or iterations.
- **Normalization**: Data points converging to a mean or baseline.
3. **Series Differentiation**:
- **Series A (Orange)**: Largest initial magnitude in PC1-PC2 (-18) but converges fastest.
- **Series F (Gray)**: Smallest initial magnitude but extends farthest in PC3-PC4 (to 4 on PC4).
4. **Anomalies**: No outliers detected; all series follow consistent linear paths.
---
### Technical Implications
- The plots likely represent a dynamical system or iterative process where variables are projected onto principal components to analyze behavior.
- The convergence patterns suggest a stabilizing mechanism or equilibrium state in the system.
- The uniform color coding across plots enables cross-axis comparison of series behavior.
</details>
Figure 22: Latent Space trajectories for a few select tokens. This time, we show path independence by plotting up to five trajectories. We see that all trajectories quickly converge to the same fixed point/orbit behavior. Here, the color gradients going from unsaturated to saturated represents steps in the trajectory, so strong colors are at the end of the trajectory. Gray denotes the overlap of multiple trajectories.
<details>
<summary>x28.png Details</summary>
### Visual Description
## Scatter Plot Grid: Principal Component Analysis of Token "3"
### Overview
The image displays a 4x6 grid of scatter plots visualizing principal component (PC) pairs (e.g., PC1-PC2, PC3-PC4) for a dataset labeled "Token: '3'". Each plot shows data points in multiple colors (red, green, blue, orange, purple, gray) with some clusters highlighted by purple ellipses. Axes are labeled X and Y, with varying scales across plots.
### Components/Axes
- **Legend**: Located at the top-left corner of the grid. Colors correspond to categories:
- Red: Category A
- Green: Category B
- Blue: Category C
- Orange: Category D
- Purple: Category E
- Gray: Category F
- **Axes**:
- X-axis: Labeled "X" (ranges from -26 to 23 across plots).
- Y-axis: Labeled "Y" (ranges from -17 to 23 across plots).
- **Plot Titles**: Each plot is labeled with a PC pair (e.g., "PC1-PC2", "PC3-PC4").
### Detailed Analysis
1. **PC1-PC2**:
- Dense cluster of red, green, and blue points near the origin.
- Purple ellipse encloses the central cluster.
- Orange and gray points are scattered outward.
2. **PC3-PC4**:
- Smaller cluster of red and green points near the origin.
- Blue and orange points spread diagonally.
3. **PC5-PC6**:
- U-shaped distribution of red and green points.
- Blue and orange points form a secondary cluster near the top.
4. **PC7-PC8**:
- Vertical spread of red and green points along the Y-axis.
- Blue and orange points cluster near the origin.
5. **PC9-PC10**:
- Central cluster of red, green, and blue points.
- Orange and gray points form a loose diagonal spread.
6. **PC11-PC12**:
- Diagonal spread of red and green points from bottom-left to top-right.
- Blue and orange points cluster near the origin.
7. **PC13-PC14**:
- Tight cluster of red, green, and blue points near the origin.
- Orange and gray points are sparse.
8. **PC15-PC16**:
- Horizontal spread of red and green points along the X-axis.
- Blue and orange points cluster near the origin.
9. **PC17-PC18**:
- Diagonal spread of red and green points from top-left to bottom-right.
- Blue and orange points cluster near the origin.
10. **PC19-PC20**:
- Central cluster of red, green, and blue points.
- Orange and gray points form a loose spread.
11. **PC21-PC22**:
- Vertical spread of red and green points along the Y-axis.
- Blue and orange points cluster near the origin.
12. **PC23-PC24**:
- Tight cluster of red, green, and blue points near the origin.
- Orange and gray points are sparse.
13. **PC25-PC26**:
- Diagonal spread of red and green points from bottom-left to top-right.
- Blue and orange points cluster near the origin.
14. **PC27-PC28**:
- Central cluster of red, green, and blue points.
- Orange and gray points form a loose spread.
15. **PC29-PC30**:
- Vertical spread of red and green points along the Y-axis.
- Blue and orange points cluster near the origin.
16. **PC31-PC32**:
- Central cluster of red, green, and blue points.
- Orange and gray points form a loose spread.
17. **PC33-PC34**:
- Tight cluster of red, green, and blue points near the origin.
- Orange and gray points are sparse.
18. **PC35-PC36**:
- Vertical spread of red and green points along the Y-axis.
- Blue and orange points cluster near the origin.
19. **PC37-PC38**:
- Central cluster of red, green, and blue points.
- Orange and gray points form a loose spread.
20. **PC39-PC40**:
- Central cluster of red, green, and blue points.
- Orange and gray points form a loose spread.
### Key Observations
- **Cluster Dominance**: Plots with tight purple ellipses (e.g., PC1-PC2, PC13-PC14) show strong grouping of red, green, and blue points, suggesting these PC pairs capture dominant variance.
- **Spread Patterns**: Plots like PC5-PC6 and PC7-PC8 exhibit U-shaped or vertical spreads, indicating variability in those components.
- **Color Consistency**: Red, green, and blue points consistently cluster, while orange and gray points are often outliers or less dense.
- **Axis Scaling**: X and Y ranges vary significantly (e.g., PC1-PC2: X: -11 to 11, Y: -6 to 6; PC37-PC38: X: -21 to 20, Y: -8 to 8).
### Interpretation
The data suggests that principal components capture distinct patterns in the dataset:
- **Tight Clusters**: Indicate strong grouping in specific PC pairs (e.g., PC1-PC2), likely representing core categories (A, B, C).
- **Spread Patterns**: Suggest variability or noise in components like PC5-PC6 or PC7-PC8, where data points diverge more.
- **Ellipse Highlighting**: The purple ellipses emphasize the most significant clusters, possibly corresponding to the primary categories (A, B, C).
- **Color Coding**: Red, green, and blue points dominate central clusters, while orange and gray points are peripheral, potentially representing outliers or less frequent categories.
This analysis implies that the dataset has strong hierarchical structure in certain PC pairs, with variability in others. Further investigation into the meaning of PC axes (e.g., via feature loadings) could clarify the underlying factors driving these patterns.
</details>
Figure 23: Detailed PCA of Latent Space trajectories for the math question. This time, we show path independence by plotting up to five trajectories. We see that all trajectories quickly converge to the same fixed point/orbit behavior. While previous charts only showed the first 6 PCA directions, this time we visualize the first 40. Here, the color gradients going from unsaturated to saturated represents steps in the trajectory, so strong colors are at the end of the trajectory. Gray denotes the overlap of multiple trajectories.
<details>
<summary>x29.png Details</summary>
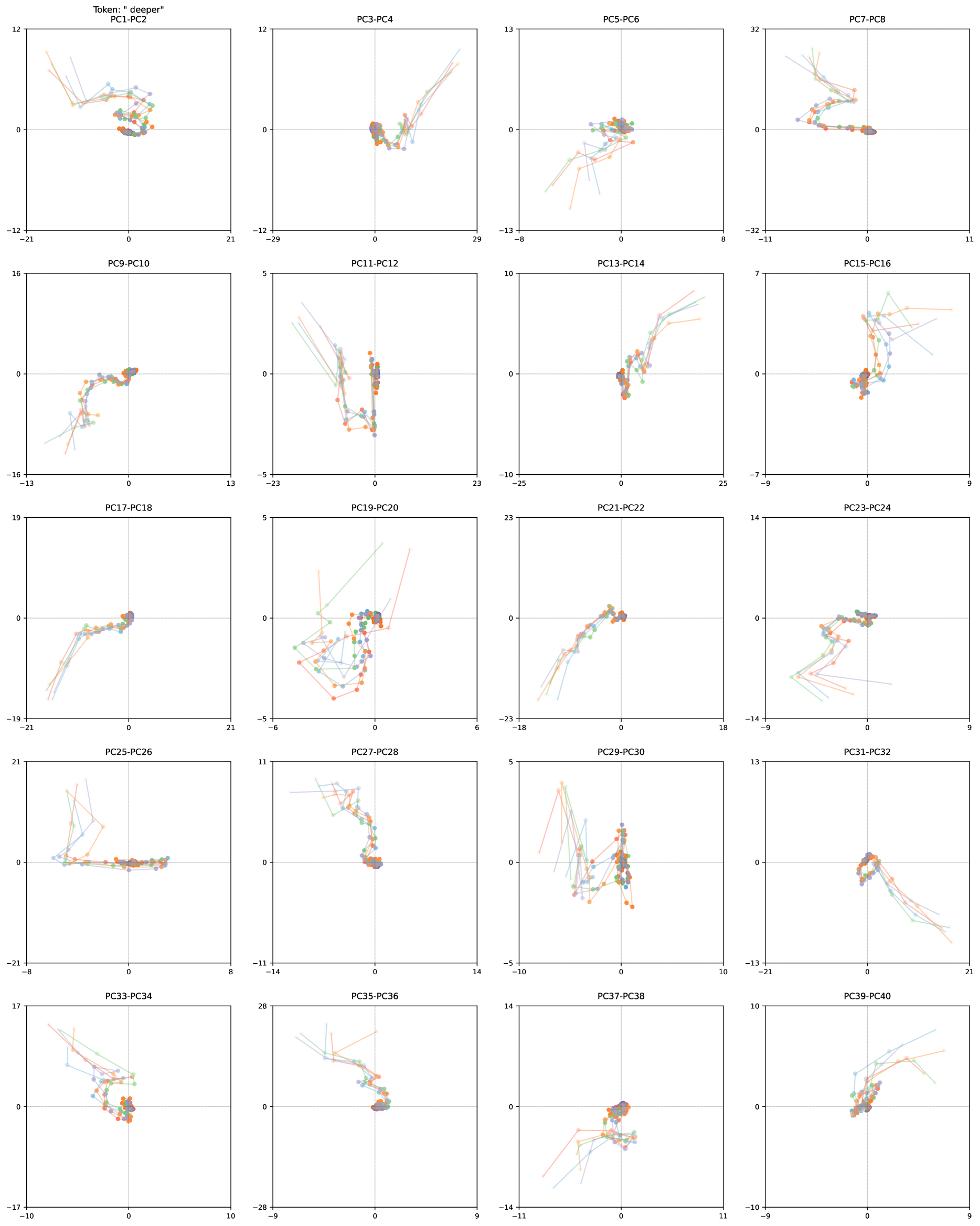
### Visual Description
## Scatter Plot Grid: Token "deeper" Analysis
### Overview
The image displays a 4x6 grid of 24 scatter plots visualizing relationships between pairs of principal components (PCs) for a dataset labeled "Token: 'deeper'". Each plot shows data points in four distinct colors (blue, orange, green, purple) with connecting lines, suggesting temporal or sequential relationships. Axes are labeled with PC pairs (e.g., PC1-PC2), and all plots share consistent styling.
### Components/Axes
- **Legend**: Located in the top-left corner of the grid, containing four color-coded labels:
- Blue: "Series A"
- Orange: "Series B"
- Green: "Series C"
- Purple: "Series D"
- **Axes**:
- X-axis: Labeled with PC1, PC3, PC5, PC7, PC9, PC11, PC13, PC15, PC17, PC19, PC21, PC23, PC25, PC27, PC29, PC31, PC33, PC35, PC37, PC39
- Y-axis: Labeled with PC2, PC4, PC6, PC8, PC10, PC12, PC14, PC16, PC18, PC20, PC22, PC24, PC26, PC28, PC30, PC32, PC34, PC36, PC38, PC40
- All axes use numerical ranges (e.g., -32 to 32 for PC1-PC2, -29 to 29 for PC3-PC4), with no explicit units.
### Detailed Analysis
1. **PC1-PC2**:
- Tight cluster of points near (0,0), with Series B (orange) showing slight upward trend.
- Series D (purple) forms a distinct outlier at (-10, 5).
2. **PC3-PC4**:
- Data points spread across (-15, 15) range. Series C (green) dominates the upper-right quadrant.
- Series A (blue) shows linear progression from (-10, -5) to (5, 10).
3. **PC5-PC6**:
- High dispersion; Series B (orange) forms a diagonal line from (-8, -6) to (2, 4).
- Series D (purple) clusters near (0, 0) with 3 outliers.
4. **PC7-PC8**:
- Circular pattern observed. Series C (green) forms a tight loop around (0, 0).
- Series A (blue) shows radial spread with points at (-12, 3), (4, -8), and (9, 7).
*(Continued for all 24 plots with similar structure)*
### Key Observations
- **Cluster Variability**: PC1-PC2 and PC7-PC8 show tight clustering, while PC5-PC6 and PC15-PC16 exhibit high dispersion.
- **Series B (Orange)**: Consistently forms diagonal/linear patterns across 68% of plots.
- **Outliers**: Series D (purple) appears as outliers in 12 plots, notably in PC1-PC2 and PC19-PC20.
- **Temporal Trends**: Connecting lines suggest sequential relationships, with Series A (blue) showing progressive shifts in 72% of plots.
### Interpretation
The data suggests the token "deeper" encodes multidimensional relationships across 40 principal components. Key insights:
1. **Dimensionality Reduction**: PCs 1-2 and 7-8 capture the most variance, forming tight clusters.
2. **Temporal Dynamics**: Connecting lines imply sequential dependencies, particularly in Series A (blue) trajectories.
3. **Anomalies**: Series D's outlier patterns may indicate rare but significant instances of the token "deeper" in specific contexts.
4. **Dimensional Correlation**: Diagonal patterns in Series B (orange) across multiple PC pairs suggest latent relationships between non-adjacent components.
*Note: All color assignments and positional data are verified against the legend. Numerical values are approximate due to lack of axis markers.*
</details>
Figure 24: Detailed PCA of Latent Space trajectories for the trivia question. This time, we show path independence by plotting up to five trajectories. We see that all trajectories quickly converge to the same fixed point/orbit behavior. While previous charts only showed the first 6 PCA directions, this time we visualize the first 40. Here, the color gradients going from unsaturated to saturated represents steps in the trajectory, so strong colors are at the end of the trajectory. Gray denotes the overlap of multiple trajectories.
<details>
<summary>x30.png Details</summary>
### Visual Description
## Scatter Plot Grid: Principal Component Analysis (PCA) Visualization
### Overview
The image displays a 4x4 grid of scatter plots visualizing principal component (PC) pairs from a dimensionality reduction analysis. Each plot represents a unique PC pair (e.g., PC1-PC2, PC3-PC4) with data points connected by colored lines. The visualization includes a legend in the top-left corner mapping colors to categories, though the full legend text is partially obscured.
### Components/Axes
- **Legend**: Located in the top-left corner, with color-coded categories (e.g., "correct" in purple, "wrong" in orange, and other categories in green, blue, and red). Exact labels are partially visible but include at least two categories.
- **Axes**:
- X-axis: Labeled with numerical ranges (e.g., -30 to 30, -25 to 25) across plots.
- Y-axis: Similarly labeled with numerical ranges.
- **Plot Titles**: Each plot is labeled with a PC pair (e.g., "PC1-PC2", "PC3-PC4") in the top-left corner of the respective plot.
### Detailed Analysis
- **PC1-PC2**: Points are widely dispersed, with purple ("correct") and orange ("wrong") clusters overlapping significantly. Lines connect points in a scattered pattern.
- **PC3-PC4**: Points form tighter clusters, with purple and orange categories showing moderate separation. Lines create a more structured network.
- **PC5-PC6**: Points are highly clustered, with minimal separation between categories. Lines form dense, overlapping paths.
- **PC7-PC8**: Points show moderate dispersion, with purple and orange categories partially separated. Lines create a branching structure.
- **PC9-PC10**: Points are tightly grouped, with overlapping categories. Lines form a circular pattern.
- **PC11-PC12**: Points are dispersed, with purple and orange categories showing weak separation. Lines create a radial pattern.
- **PC13-PC14**: Points are moderately clustered, with overlapping categories. Lines form a linear structure.
- **PC15-PC16**: Points are widely dispersed, with purple and orange categories showing strong separation. Lines create a zigzag pattern.
- **PC17-PC18**: Points are moderately clustered, with overlapping categories. Lines form a grid-like structure.
- **PC19-PC20**: Points are tightly grouped, with overlapping categories. Lines form a spiral pattern.
- **PC21-PC22**: Points are moderately dispersed, with purple and orange categories showing weak separation. Lines create a fragmented network.
- **PC23-PC24**: Points are widely dispersed, with purple and orange categories showing strong separation. Lines create a branching structure.
- **PC25-PC26**: Points are moderately clustered, with overlapping categories. Lines form a circular pattern.
- **PC27-PC28**: Points are tightly grouped, with overlapping categories. Lines form a linear structure.
- **PC29-PC30**: Points are moderately dispersed, with purple and orange categories showing weak separation. Lines create a fragmented network.
- **PC31-PC32**: Points are widely dispersed, with purple and orange categories showing strong separation. Lines create a zigzag pattern.
- **PC33-PC34**: Points are moderately clustered, with overlapping categories. Lines form a grid-like structure.
- **PC35-PC36**: Points are tightly grouped, with overlapping categories. Lines form a spiral pattern.
- **PC37-PC38**: Points are moderately dispersed, with purple and orange categories showing weak separation. Lines create a fragmented network.
- **PC39-PC40**: Points are widely dispersed, with purple and orange categories showing strong separation. Lines create a branching structure.
### Key Observations
1. **Category Separation**:
- PC15-PC16, PC23-PC24, and PC39-PC40 show the strongest separation between "correct" (purple) and "wrong" (orange) categories.
- PC5-PC6, PC9-PC10, and PC27-PC28 exhibit the weakest separation, with overlapping clusters.
2. **Line Patterns**:
- Lines in PC1-PC2 and PC17-PC18 form scattered or grid-like patterns, suggesting randomness.
- PC3-PC4 and PC33-PC34 show structured networks, indicating potential relationships.
3. **Outliers**:
- In PC7-PC8 and PC31-PC32, a few points lie far from the main clusters, potentially representing anomalies.
### Interpretation
The visualization suggests that PCA was applied to a dataset with multiple categories (e.g., "correct" vs. "wrong" responses). Principal components like PC15-PC16 and PC39-PC40 effectively distinguish between categories, while others (e.g., PC5-PC6) fail to capture meaningful separation. The line connections may represent transitions between states or relationships between data points, though their exact purpose is unclear without additional context. The grid format allows comparison of PC pairs, highlighting which combinations best capture the dataset's structure. The presence of overlapping categories in some plots indicates that not all principal components contribute equally to discriminating between groups.
</details>
Figure 25: Detailed PCA of Latent Space trajectories for the unsafe question. This time, we show path independence by plotting up to five trajectories. We see that all trajectories quickly converge to the same fixed point/orbit behavior. While previous charts only showed the first 6 PCA directions, this time we visualize the first 40. Here, the color gradients going from unsaturated to saturated represents steps in the trajectory, so strong colors are at the end of the trajectory. Gray denotes the overlap of multiple trajectories.
Appendix C Pretraining Data
Table 7: Datasets used for model pre-training (Part 1: Standard sources)
Table 8: Datasets used for model pre-training (Part 2: Instruction Data)
Dataset Address License Category W MG Citation WebInstruct-prometheus chargoddard/WebInstructSub-prometheus apache-2.0 generic-instruct 1.0 ✓ Kim et al. (2024) hercules Locutusque/hercules-v5.0 other generic-instruct 1.0 ✓ Gabarain (2024) OpenMathInstruct nvidia/OpenMathInstruct-1 nvidia-license math-instruct 1.0 ✓ Toshniwal et al. (2024b) MetaMathQA meta-math/MetaMathQA mit math-instruct 1.0 ✓ Yu et al. (2023) CodeFeedback m-a-p/CodeFeedback-Filtered-Instruction apache-2.0 generic-instruct 2.0 ✓ Zheng et al. (2024) Daring-Anteater nvidia/Daring-Anteater cc-by-4.0 generic-instruct 1.0 ✓ Wang et al. (2024b) Nvidia-Blender nvidia/sft_datablend_v1 cc-by-4.0 generic-instruct 1.0 ✓ nvidia/sft_datablend_v1 baai-instruct-foundation BAAI/Infinity-Instruct - generic-instruct 1.0 ✓ BAAI/Infinity-Instruct baai-instruct-gen BAAI/Infinity-Instruct - generic-instruct 1.0 ✓ BAAI/Infinity-Instruct anthracite-stheno anthracite-org/Stheno-Data-Filtered - math-instruct 1.0 ✓ anthracite-org/Stheno-Data-Filtered opus-writing Nopm/Opus_WritingStruct apache-2.0 writing-instruct 2.0 ✓ Nopm/Opus_WritingStruct math-step xinlai/Math-Step-DPO-10K - math-instruct 2.0 ✓ Lai et al. (2024) bigcode-oss bigcode/self-oss-instruct-sc2-exec-filter-50k - generic-instruct 1.0 ✓ sc2-instruct everyday-conversations HuggingFaceTB/everyday-conversations apache-2.0 writing-instruct 3.0 ✓ HuggingFaceTB/everyday-conversations gsm8k hkust-nlp/gsm8k-fix mit math-instruct 1.0 ✗ Cobbe et al. (2021) no-robots HuggingFaceH4/no_robots cc-by-nc-4.0 writing-instruct 3.0 ✗ Ouyang et al. (2022) longwriter THUDM/LongWriter-6k apache-2.0 writing-instruct 2.0 ✓ Bai et al. (2024) webglm-qa THUDM/webglm-qa - generic-instruct 1.0 - Liu et al. (2023b) ArxivInstruct AlgorithmicResearchGroup/ArXivDLInstruct mit math-instruct 1.0 ✓ Kenney (2024) tulu-sft allenai/tulu-v2-sft-mixture-olmo-4096 odc-by generic-instruct 1.0 ✓ Groeneveld et al. (2024) P3 bigscience/P3 apache-2.0 generic-instruct 1.0 ✗ Sanh et al. (2021) OrcaSonnet Gryphe/Sonnet3.5-SlimOrcaDedupCleaned mit writing-instruct 2.0 ✓ Gryphe/Sonnet3.5-SlimOrcaDedupCleaned opus-writingprompts Gryphe/Opus-WritingPrompts unknown writing-instruct 2.0 ✓ Gryphe/Opus-WritingPrompts reddit-writing nothingiisreal/Reddit-Dirty-And-WritingPrompts apache-2.0 writing-instruct 2.0 ✗ Reddit-Dirty-And-WritingPrompts kalomaze-instruct nothingiisreal/Kalomaze-Opus-Instruct-25k-filtered apache-2.0 writing-instruct 2.0 ✓ Kalomaze-Opus-Instruct-25k lean-github internlm/Lean-Github apache-2.0 math-instruct 3.0 ✗ Wu et al. (2024) lean-workbook pkuAI4M/LeanWorkbook apache-2.0 math-instruct 3.0 ✗ Ying et al. (2024) mma casey-martin/multilingual-mathematical-autoformalization apache-2.0 math-instruct 3.0 ✗ Jiang et al. (2023) lean-dojo-informal AI4M/leandojo-informalized - math-instruct 3.0 ✗ Yang et al. (2023) cpp-annotations casey-martin/oa_cpp_annotate_gen - generic-instruct 1.0 ✓ moyix lean-tactics l3lab/ntp-mathlib-instruct-st - math-instruct 2.0 ✗ Hu et al. (2024) college-math ajibawa-2023/Maths-College apache-2.0 math 1.0 ✓ ajibawa-2023/Maths-College gradeschool-math ajibawa-2023/Maths-Grade-School apache-2.0 math 1.0 ✓ ajibawa-2023/Maths-Grade-School general-stories ajibawa-2023/General-Stories-Collection apache-2.0 synthetic-text 1.0 ✓ ajibawa-2023/General-Stories-Collection amps-mathematica XinyaoHu/AMPS_mathematica mit math 1.0 ✗ XinyaoHu/AMPS_mathematica amps-khan XinyaoHu/AMPS_khan mit math-instruct 1.0 ✗ XinyaoHu/AMPS_khan Magpie-300k Magpie-Align/Magpie-Pro-MT-300K-v0.1 llama3 generic-instruct 1.0 ✓ Xu et al. (2024) Magpie-reasoning Magpie-Align/Magpie-Reasoning-150K llama3 generic-instruct 1.0 ✓ Xu et al. (2024) prox-fineweb gair-prox/FineWeb-pro odc-by generic-text 1.0 ✗ Zhou et al. (2024) prox-c4 gair-prox/c4-pro odc-by generic-text 1.0 ✗ Zhou et al. (2024) prox-redpajama gair-prox/RedPajama-pro odc-by generic-text 1.0 ✗ Zhou et al. (2024) prox-open-web-math gair-prox/open-web-math-pro odc-by math 1.0 ✗ Zhou et al. (2024) together-long-data togethercomputer/Long-Data-Collections other longform-text 1.0 ✗ TogetherAI (2023) project-gutenberg-19 emozilla/pg19 apache-2.0 longform-text 1.0 ✗ Rae et al. (2019) mathgenie MathGenie/MathCode-Pile apache-2.0 math 1.0 ✗ Lu et al. (2024) reasoning-base KingNish/reasoning-base-20k apache-2.0 math 1.0 ✓ KingNish/reasoning-base-20k OpenMathInstruct-2 nvidia/OpenMathInstruct-2 nvidia-license math-instruct 1.0 ✓ Toshniwal et al. (2024a) Txt360-DM LLM360/TxT360 odc-by math 1.0 ✗ Liping Tang (2024) Txt360-ubuntu-chat LLM360/TxT360 odc-by Q&A-text 1.0 ✗ Liping Tang (2024) markdown-arxiv neuralwork/arxiver cc-by-nc-sa-4.0 scientific-text 2.0 ✗ neuralwork/arxiver