2502.05714
Model: gemini-2.0-flash
# Proving the Coding Interview: A Benchmark for Formally Verified Code Generation
**Authors**: Quinn Dougherty, Ronak Mehta
> Beneficial AI Foundationquinn.dougherty92@gmail.com
> Independentronakrm@gmail.com
\addbibresource
conference_101719.bib
Abstract
We introduce the Formally Verified Automated Programming Progress Standards, or FVAPPS, a benchmark of 4715 samples for writing programs and proving their correctness, the largest formal verification benchmark, including 1083 curated and quality controlled samples. Previously, APPS provided a benchmark and dataset for programming puzzles to be completed in Python and checked against unit tests, of the kind seen in technical assessments in the software engineering industry. Building upon recent approaches for benchmarks in interactive theorem proving, we generalize the unit tests to Lean 4 theorems given without proof (i.e., using Lean’s “sorry” keyword). On the 406 theorems of 100 randomly selected samples, Sonnet correctly proves 30% and Gemini correctly proves 18%. We challenge the machine learning and program synthesis communities to solve both each general purpose programming problem and its associated correctness specifications. The benchmark is available at https://huggingface.co/datasets/quinn-dougherty/fvapps.
Index Terms: theorem proving, machine learning, program synthesis, formal verification
I Introduction
Large Language Models (LLMs) have developed incredible capabilities, spanning creative writing, tutoring and education, information retrieval and distillation, common sense reasoning, complex mathematical reasoning, and even code generation [chatbotarena, gpt4, llama3, deepseek]. Particular focus and attention has been given towards LLM-assisted software development, given its economic value and position between natural language and formal logic.
We have seen rapid advancements in code generation capabilities [Singh2023CodeFusionAP, jimenez2023swe, Hendrycks2021MeasuringCC]. With this has come strong concerns around the misuse and safety of code generated by these models, and the ability to prove or guarantee that the produced code is sound. An approach commonly employed today includes running LLM-generated code in restricted development environments, and ensuring tight feedback loops with software engineers who understand the unique failure modes of their particular complex software. This paired programming-style approach is common in LLM chatbot interfaces, as well as programming assistants more strongly integrated in the software engineering development cycle such as GitHub Copilot [chen2021evaluating] and Cursor (Anysphere Inc., 2023).
However, recent paradigm shifts in the ability to develop and enhance capabilities through supervised fine-tuning has led to fully autonomous software engineering, which includes code generation and execution in the development loop (e.g., Devin, Cognition AI, Inc. 2023, [wang2024openhandsopenplatformai]). Without a human evaluating code before it is run, strong assumptions or restrictions are necessary to ensure that generated code is safe and correct. Critically, as these tools become ubiquitous across more and more applications that touch the real world, it will be a requirement that we have guarantees of their safety and correctness. Code generated for managing medical devices, for managing patient records, for ensuring the security of private personal information, for controlling autonomous vehicles, for cybersecurity defense systems, and for military use will all require strong guarantees before users, organizations, and governments can make effective use of these tools.
While software quality assurance primarily relies on extensive testing, the emerging field of deductive verification offers a more rigorous alternative by mathematically proving code correctness against formal specifications. However, this approach requires deep system knowledge, explicit property definitions, and often demands rewriting existing code in specialized proof assistant languages—a significant challenge given the current state of tools. As Large Language Models (LLMs) advance in code generation capabilities, they may eventually enable automated creation of deductively verifiable code, allowing us to defer trust to theorem provers rather than testing alone. This could revolutionize mission-critical software development by providing formal guarantees against bugs and hallucinations, though current LLM capabilities fall short of this goal, and it remains unclear whether fine-tuning or prompt engineering can bridge this gap.
Contributions. We deliver a set of 4,715 Lean 4 files consisting of a solution function signature and theorem statements, all of which are passed on for future proving via the “sorry” keyword, allowing the lean executable to compile without actual proofs or implementations. We provide tags for samples that pass additional, rigorous quality assurance, defined by inline unit testing and property tests in Lean.
II The FVAPPS Benchmark
<details>
<summary>extracted/6182580/figs/FVAPPS_Pipeline.png Details</summary>
### Visual Description
## Diagram: Benchmark Generation Pipeline
### Overview
The image is a flowchart illustrating the benchmark generation pipeline. It starts with an original APPS dataset, preprocesses it, and then generates Python property tests, Lean theorem statements, and solutions with unit tests. The pipeline includes checks for Python and Pytest success, Lean success, and plausibility, leading to the creation of FVAPPS categorized as Guarded and Plausible, Guarded, or Unguarded.
### Components/Axes
* **Title:** Benchmark Generation Pipeline
* **Input:** Original APPS Dataset
* **Processes:**
* Preprocess Dataset (Yellow Rectangle)
* Generate Python Property Tests (Yellow Rectangle)
* Generate Lean Theorem Statements (Yellow Rectangle)
* Generate Solutions and #guard\_msgs Unit Tests (Yellow Rectangle)
* **Decision Points:**
* python Success? (Blue Diamond)
* pytest Success? (Blue Diamond)
* lean Success? (Blue Diamond)
* lean Success? (Blue Diamond)
* Plausible? (Blue Diamond)
* **Output:** FVAPPS (Rounded Rectangle)
* Guarded and Plausible (Green Stacked Pages)
* Guarded (Green Stacked Pages)
* Unguarded (Green Stacked Pages)
* **Flow Control:** Arrows indicate the flow of data and processes. "Yes" and "No" labels indicate the direction based on the outcome of the decision points.
### Detailed Analysis or ### Content Details
1. **Original APPS Dataset:** The process begins with the original APPS dataset.
2. **Preprocess Dataset:** The dataset is preprocessed. If this process fails ("No"), the flow loops back to the Preprocess Dataset step.
3. **Generate Python Property Tests:** Python property tests are generated. If the "python Success?" test fails ("No"), the flow loops back to the Preprocess Dataset step.
4. **Generate Lean Theorem Statements:** Lean theorem statements are generated. If the "pytest Success?" test fails ("No"), the flow loops back to the Generate Python Property Tests step.
5. **Generate Solutions and #guard\_msgs Unit Tests:** Solutions and unit tests are generated. If the "lean Success?" test fails ("No"), the flow loops back to the Generate Lean Theorem Statements step.
6. **Plausible?:** The generated solutions are checked for plausibility. If the "lean Success?" test fails ("No"), the flow loops back to the Generate Solutions and #guard\_msgs Unit Tests step.
7. **FVAPPS:**
* If the solutions are plausible ("Yes"), they are categorized as "Guarded and Plausible" within FVAPPS.
* If the solutions are not plausible ("No"), they are categorized as "Guarded" within FVAPPS.
* If there are "-10 Failures-", they are categorized as "Unguarded" within FVAPPS.
### Key Observations
* The pipeline involves iterative checks at each stage, looping back to previous steps if certain criteria are not met.
* The final output, FVAPPS, is categorized into three groups based on plausibility and guarding status.
### Interpretation
The diagram illustrates a systematic approach to generating benchmarks, incorporating multiple layers of testing and validation. The iterative nature of the pipeline suggests a focus on ensuring the quality and reliability of the generated benchmarks. The categorization of FVAPPS into "Guarded and Plausible," "Guarded," and "Unguarded" indicates a tiered system for assessing the suitability of the generated benchmarks for different purposes. The pipeline aims to produce high-quality benchmarks by rigorously testing and refining the generated solutions.
</details>
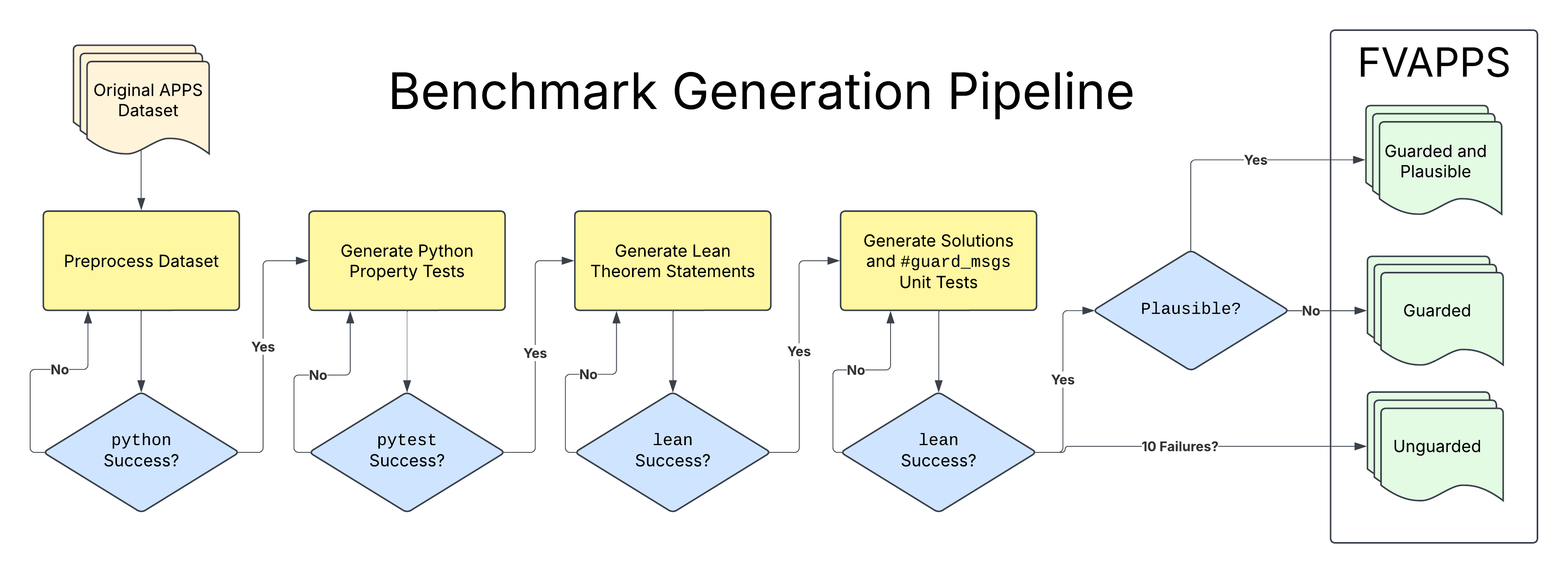
Figure 1: Benchmark generation pipeline for creating coding interview theorem statements in Lean from APPS questions and solutions.
A strong benchmark for evaluating model capabilities for theorem proving should have a number of desirable properties. With a particular focus on software engineering, algorithms and properties of those algorithms should well represent tasks and solutions that are used to evaluate skill in the labor force today. Coding interview questions fit this requirement naturally. With generic coding capabilities well-evaluated, we can build upon existing benchmarks of coding ability to generate our formally-verified one.
We begin with APPS, a benchmark and dataset for programming puzzle solving [Hendrycks2021MeasuringCC]. Developed largely by scraping the interview preparation platforms CodeForces and LeetCode, each sample consists of a natural language question, a ternary flag marking difficulty, a list of correct solutions in Python, and a few input-output test case pairs.
II-A An Example Task
⬇
def solve_elections (n : Nat) (voters : List (Nat à Nat)) : Nat := sorry
theorem solve_elections_nonnegative (n : Nat) (voters : List (Nat à Nat)) : solve_elections n voters >= 0 := sorry
theorem solve_elections_upper_bound (n : Nat) (voters : List (Nat à Nat)) : solve_elections n voters <= List. foldl (λ acc (pair : Nat à Nat) => acc + pair.2) 0 voters := sorry
theorem solve_elections_zero_votes (n : Nat) (voters : List (Nat à Nat)) : (List. all voters (fun pair => pair.1 = 0)) -> solve_elections n voters = 0 := sorry
theorem solve_elections_single_zero_vote : solve_elections 1 [(0, 5)] = 0 := sorry
Figure 2: FVAPPS sample 23, derived from train sample 23 of APPS source. The def is where the solver implements the function, each theorem is a correctness specification.
As an example, consider the crooked election problem:
There are $n$ voters, and two ways to convince each of them to vote for you. The first way to convince the $i$ -th voter is to pay him $p_{i}$ coins. The second way is to make $m_{i}$ other voters vote for you, and the $i$ -th voter will vote for free. Moreover, the process of such voting takes place in several steps. For example, if there are five voters with $m_{1}=1$ , $m_{2}=2$ , $m_{3}=2$ , $m_{4}=4$ , $m_{5}=5$ , then you can buy the vote of the fifth voter, and eventually everyone will vote for you. Set of people voting for you will change as follows: ${5}→{1,5}→{1,2,3,5}→{1,2,3,4,5}$ .
Calculate the minimum number of coins you have to spend so that everyone votes for you.
To get everyone to vote for you, you can either purchase votes for each voter’s declared price, or convert each voter through their declared groupthink threshold. This is the setup of sample 0023, derived from APPS problem train/23 https://huggingface.co/datasets/codeparrot/apps/viewer/all/train?row=23. Figure 2 is our pipeline’s output that we ship in our dataset. Crucially, it is one def and multiple theorem s, though many samples include extra definitions that are helper functions either for the solution or some theorem statement. The def is where the problem solution is implemented as a first-order requirement to proving theorems about its correctness.
While a number of theorem provers now exist, we choose Lean because of its explosive growth in mathematics https://leanprover-community.github.io/mathlib_stats.html and its fertile potential for general-purpose programming [christiansen2023fpinlean]. Lean is capable of expressing arbitrary programs, taking advantage of the identity monad and the partial keyword.
II-B Generation Pipeline Sonnet 3.5 read run $\lambda c.c+\texttt{stderr}$ exitcode write $p_{0}$ $c_{k}$ 0 1 $p_{k+1}$
Figure 3: Our generic scaffolding loop used at various stages of our pipeline. The run element is replaced with the python, pytest, lean, or lake build executable respectively.
We use Anthropic’s Claude Sonnet 3.5 Model version claude-3-5-sonnet-20241022, accessed October 25th 2024. to power five core parts of our benchmark creation pipeline. In stages one through three of our pipeline, whenever a non-deductive LLM call is used for processing, we allow for a maximum of 5 attempts before "failing" on that sample. Stage four allows for a maximum of ten, and stage five has no LLM call. These loops include simple instructions that pass relevant error messages back to the model and ask for an updated response. Given that subsets of our pipeline fall withing the scope of what is capable with current LLMs, we construct scaffolding loops for iterating on model-based solutions. Broadly, we use outputs from python, pytest, lean, and lake build to ensure the generated code is correct, and to collect standard error and outputs to send back to the model when incorrect (Figure 3).
We first preprocess the original APPS dataset, aggregating unit tests and solutions into one file with a particular function definition and architecture that better lends itself to automated unit testing. This step also selects a single solution from the set of solutions provided by the original APPS dataset.
Property-based tests are procedurally generated unit tests, up to boundary conditions given on input types [MacIver2019Hypothesis]. We use our scaffolding loop outlined above, specifically feeding pytest ’s standard error and standard out messages back into the next API call. When pytest returns an empty standard error and an exit code of zero, we write the final file of tests to disk and exit the loop.
The lean executable is used as our supervisor for the third step, again with standard error and standard output fed back to the model API until a valid lean file is constructed. The model is prompted to explicitly convert the property tests into unproven theorem statements (cleared via sorry). The lean executable Lean (version 4.12.0, x86_64-unknown-linux-gnu, commit dc2533473114, Release). is used to typecheck the theorem statements, ignoring the sorry s but ensuring statements are well-formed.
Step four of our process aims to add more strict quality assurance to our lean outputs. Using unit tests that have been generated by our preprocessing step as assertions in Python, we deductively parse these assertions to construct inline unit tests in Lean https://github.com/leanprover/lean4/blob/master/src/Lean/Elab/GuardMsgs.lean. In parallel, we translate the Python solutions into Lean 4 as def s, and require that the guard messages "pass". While theorem statements and property tests are broadly our primary goal and focus, these unit tests provide an easy way to filter for solutions that are not correct in some minimal form.
The last phase of our pipeline involves ensuring that the theorems we wish to provide are probably true, using Lean’s property-based testing framework Plausible https://reservoir.lean-lang.org/@leanprover-community/plausible. Any theorems that are not " plausible " at this stage, given our solutions that pass unit tests, are filtered.
All code and prompts used for the generation can be found at our open-source GitHub repository. https://github.com/quinn-dougherty/fvapps
II-C Results
| 0 | 1963 | 1735 |
| --- | --- | --- |
| 1 | 1915 | 1450 |
| 2 | 584 | 842 |
| 3 | 143 | 394 |
| 4 | 75 | 183 |
| 5 | 35 | 111 |
TABLE I: Iterations needed for Pytest and Lean agents to converge, filtered to those that made it passed Stage 3 of the pipeline.
We provide three subsets of our benchmark according to the assurance level, depending on when the samples were chosen and filtered in our pipeline.
Unguarded
This largest set represents all examples that generated valid theorems, ending at Stage 3 of our full pipeline. Table I shows the number of execution-generation loops needed to pass our generation criterion in Stages 2 and 3. The Pytest agent took on average 0.846 iterations (with the 0th position as initialization prompt), and the Lean agent took on average 1.188 iterations.
<details>
<summary>extracted/6182580/figs/num_theorems_across_samples.png Details</summary>
### Visual Description
## Histogram: Number of Definitions and Theorems Across Samples
### Overview
The image is a histogram showing the distribution of the number of definitions and theorems across a set of 4715 samples. The x-axis represents the number of theorems, and the y-axis represents the number of samples. The histogram shows a right-skewed distribution, with most samples having a small number of theorems.
### Components/Axes
* **Title:** Number of defs and theorems across samples (N=4715)
* **X-axis:** Num theorems
* Scale: 0 to 50, with tick marks at intervals of 10 (0, 10, 20, 30, 40, 50)
* **Y-axis:** Num samples
* Scale: 0 to 1200, with tick marks at intervals of 200 (0, 200, 400, 600, 800, 1000, 1200)
* **Data:** The data is represented by blue bars.
### Detailed Analysis
The histogram's bars show the frequency of samples for each number of theorems.
* The highest bar is located at approximately x=5, with a value of approximately y=1250.
* The distribution is heavily skewed to the right, indicating that most samples have a small number of theorems.
* The frequency decreases rapidly as the number of theorems increases.
* The bar at x=0 has a value of approximately y=20.
* The bar at x=1 has a value of approximately y=280.
* The bar at x=2 has a value of approximately y=600.
* The bar at x=3 has a value of approximately y=850.
* The bar at x=4 has a value of approximately y=1120.
* The bar at x=6 has a value of approximately y=620.
* The bar at x=7 has a value of approximately y=300.
* The bar at x=8 has a value of approximately y=100.
* The bar at x=9 has a value of approximately y=60.
* The bar at x=10 has a value of approximately y=20.
### Key Observations
* The distribution is strongly right-skewed.
* The majority of samples have a small number of theorems (less than 10).
* The peak of the distribution is around 5 theorems.
### Interpretation
The histogram suggests that, across the 4715 samples, the number of definitions and theorems is generally low. The right skew indicates that while most samples have few theorems, there are some samples with a significantly higher number of theorems, pulling the tail of the distribution to the right. This could indicate that some samples are inherently more complex or cover more material than others. The concentration of samples around 5 theorems suggests a typical or common level of complexity within the dataset.
</details>
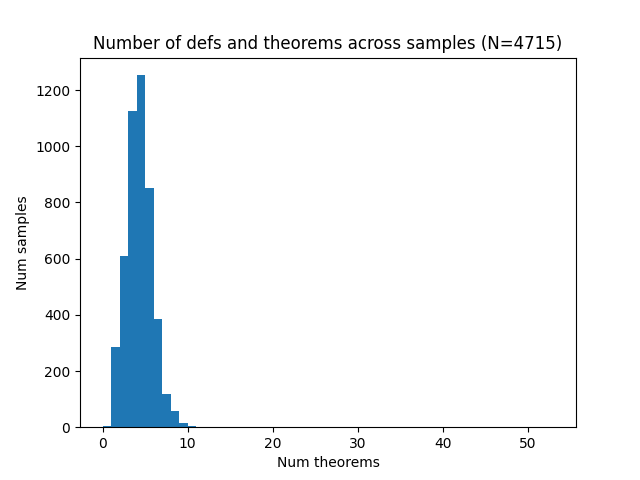
Figure 4: Total number of defs and theorems across FVAPPS samples.
Of the 4715 successful samples, the median number of theorems is four (Figure 4).
Guarded
Samples that passed Stage 4 of our pipeline include those samples where solutions were able to be identified that pass simple unit tests. While we don’t include these solutions in our set here, the definitions have been verified to admit a solution such that these basic unit tests pass. Importantly this means that claude-3-5-sonnet-20241022 was able to solve the problem with our scaffold. 2089 samples passed this level of assurance.
Guarded and Plausible
1083 samples passed through all five parts of our pipeline These problems are solvable and well-stated to the highest possible probability short of a full proof (which we leave to the LLMs and other program synthesis methods). Note that the definitions in each of the sets Guarded and Guarded and Plausible are somehow "easy" in the sense that current language models can provide definitions.
All 4715 samples are provided as a dataset on HuggingFace with appropriate tagging. https://huggingface.co/datasets/quinn-dougherty/fvapps
III Baseline Experiments
Our baseline task is to implement and prove each invocation of the word "sorry" in the benchmark’s source specification. We provide preliminary evaluations here, using a loop similar to the generation pipeline. We attempt to solve 101 randomly sampled FVAPPS problems with both Claude 3.5 Sonnet (new) and Gemini 1.5 Pro Retrieved in early November 2024.. For a direct human comparison, we allocated ten hours for a baseliner to attempt one sample.
III-A Model Baseline Details
We use Lean 4.12.0 throughout our benchmark generation and baseline, pinned with Mathlib available in the environment. Mathlib commit: 809c3fb3b5c8f5d7dace56e200b426187516535a We attempt to produce a partial baseline for a subset of FVAPPS using claude-3-5-sonnet-20241022 (the same model that generated the task).
A note on open source models. We spent some time attempting to solve benchmark samples with small and medium-sized open source models. Particularly, we attempted simple, single-shot autocompletion of theorem statements using DeepSeek’s DeepSeek-Prover-V1.5-RL https://huggingface.co/deepseek-ai/DeepSeek-Prover-V1.5-RL [xin2024deepseekproverv15harnessingproofassistant], but were unable to find a one-shot or loop-based scaffolding solution that made any sufficient progress. An important part of this task seems to be the ability to iterate, and while models fine-tuned to reduce loss on next token prediction in Lean may eventually prove to be useful, currently their limited capability in broader, less narrow goals is insufficient.
III-A 1 Prompt Details
Because Lean 4 is in active development and interfaces and functions change with reasonable frequency, we found it was critical to give the LLM sufficient context to avoid common pitfalls associated with biases it may have due to outdated training data. We found significantly higher success rates by following a number of key insights by Victor Taelin https://github.com/VictorTaelin/AI-scripts/, including 1) direct, explicit description of the problem formulation and goal, 2) details of the Lean 4 environment that may be significantly different from its pretrain dataset, and 3) multiple examples of theorem statements and solutions to theorem statements.
III-A 2 Scaffolding Loop (Agent)
We initially provide the model with a system prompt consisting of the details in the previous section, and prompt the model first with the original English-language description of the problem and the sorry ’d benchmark .lean file (Figure 2), with instructions to implement the sorry s. After the model responds, any code block provided is extracted, written to a Basic.lean file, and run in a custom managed environment with specifically pinned libraries using lake build. The full standard input and output alongside returncode are sent back to the model with the instruction to address the issues.
Initial attempts were unsuccessful in solving all of the theorem statements at once; to give the model a better chance at solving the problem we show and allow the model to solve one statement at a time, starting with the definitions and then appending each theorem independently, to be proven separately from the rest.
III-B Human Baseline
A human attempted the function and one of the theorems from sample 0023. It took them 10 hours to accomplish the function shown in Figure 5, since they needed termination proofs for two recursors. In the time allotted, they did not make it through any of the proofs. A problem they ran into with the proofs was stack overflow trying to unfold the recursors. Given this, we don’t think a full human baseline is a feasible option.
⬇
def go (voters holdouts : List (Nat à Nat)) (expense conversions : Nat) : Nat :=
if conversions ⥠voters. length then
expense
else
let filtered := filter_cascade holdouts conversions
if filtered. isEmpty then
expense
else
let bestValue := filtered. argmax? utility |>. get!
let holdouts ’ := filtered. eraseP (. == bestValue)
go voters
holdouts ’
(expense + bestValue. snd)
(conversions + 1)
termination_by (voters. length - conversions)
decreasing_by omega
def solve_elections (n : Nat) (voters : List (Nat à Nat)) : Nat :=
go voters voters 0 0
Figure 5: Human baseline’s solution to the definition for sample 23 of FVAPPS (helper recursor omitted for brevity, available on GitHub)
III-C Comparing Model Baseline and Human Baseline on One Sample
On sample 23 regarding the crooked election, both successfully implemented the definition of the function (Appendix -C) and succeeded on no nontrivial proofs. We let Sonnet attempt the second theorem for 100 loops, and while it made a valiant effort, it diverged. The human and Sonnet clearly took two very different approaches, but it remains to be seen which approach has better proof ergonomics.
III-D Model performance on more samples
<details>
<summary>extracted/6182580/figs/qualitative_assessment_of_model_baseline_results.png Details</summary>
### Visual Description
## Bar Chart: Qualitative Assessments of Model Baseline Results
### Overview
The image is a bar chart comparing the qualitative assessments of two models, "Sonnet" and "Gemini," across several categories. The y-axis represents a count or frequency, while the x-axis lists the categories being assessed.
### Components/Axes
* **Title:** Qualitative assessments of model baseline results
* **X-axis:** Categories: Easy Branch of If, Effectively Unit Test, Non-negativity of Nat, Too Trivial, Actually Nontrivial, Bug, Model Declares Untrue. The labels are rotated diagonally.
* **Y-axis:** Numerical scale ranging from 0 to 12, with increments of 2.
* **Legend:** Located in the top-right corner.
* Blue: Sonnet
* Orange: Gemini
### Detailed Analysis
Here's a breakdown of the data for each category:
* **Easy Branch of If:**
* Sonnet (Blue): Approximately 12
* Gemini (Orange): Approximately 7
* **Effectively Unit Test:**
* Sonnet (Blue): Approximately 6
* Gemini (Orange): Approximately 1
* **Non-negativity of Nat:**
* Sonnet (Blue): Approximately 10
* Gemini (Orange): Approximately 1
* **Too Trivial:**
* Sonnet (Blue): Approximately 9
* Gemini (Orange): Approximately 10
* **Actually Nontrivial:**
* Sonnet (Blue): Approximately 9
* Gemini (Orange): Approximately 5
* **Bug:**
* Sonnet (Blue): Approximately 6
* Gemini (Orange): Approximately 2
* **Model Declares Untrue:**
* Sonnet (Blue): Approximately 0
* Gemini (Orange): Approximately 1
### Key Observations
* Sonnet generally scores higher than Gemini in the first three categories (Easy Branch of If, Effectively Unit Test, Non-negativity of Nat).
* Gemini scores slightly higher than Sonnet in the "Too Trivial" category.
* Both models have relatively low scores in the "Model Declares Untrue" category.
### Interpretation
The bar chart provides a qualitative comparison of the "Sonnet" and "Gemini" models across different assessment categories. The data suggests that "Sonnet" performs better in categories like "Easy Branch of If," "Effectively Unit Test," and "Non-negativity of Nat," while "Gemini" shows a slightly better performance in the "Too Trivial" category. The low scores in "Model Declares Untrue" indicate that both models struggle with this particular aspect. The chart highlights the strengths and weaknesses of each model, allowing for a more nuanced understanding of their performance.
</details>
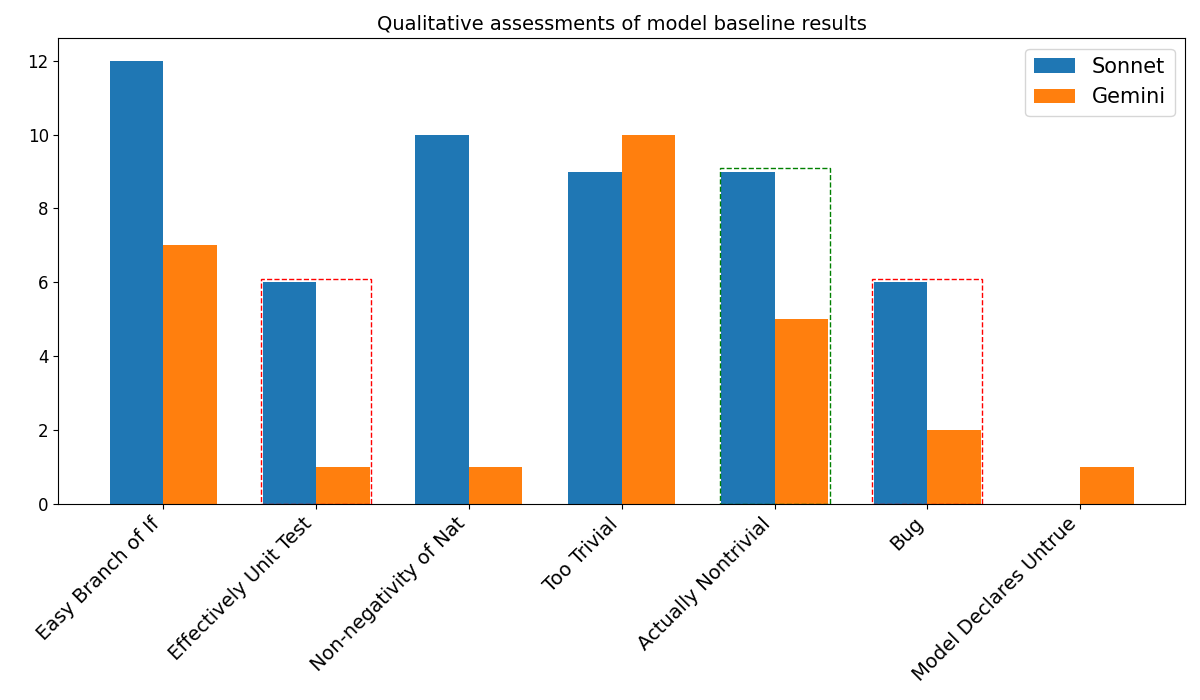
Figure 6: Qualitative categories of theorem solutions in the 100 samples, first two theorems each sample. The red box shows completely spurious results, either bugs or a substitution of a quantified variable with a single value. The green box shows the most nontrivial results. The other categories are neither spurious nor impressive, though they require some syntactic fluency that many language models would fail at.
Both Sonnet and Gemini ran for a maximum of 25 loops for the def s and a max of 50 loops for each theorem. Sonnet completed all but seven of the definitions and 43 samples had at least one theorem completed. Gemini completed only 71 of the definitions, and 23 samples had at least one theorem completed. Figure 6 shows the breakdown across our different buckets, assessed qualitatively. The green box surrounds the best solutions, nontrivial proofs that involve both intricate reasoning and correct syntax. The red box shows completely spurious results, either bugs or a substitution of a quantified variable with a single value. The other categories are neither spurious nor impressive, though they require some syntactic fluency that many language models would fail at. Importantly, Gemini declared the second theorem of sample 3078 incorrect/unsolvable in a comment, while Sonnet nontrivially solved it.
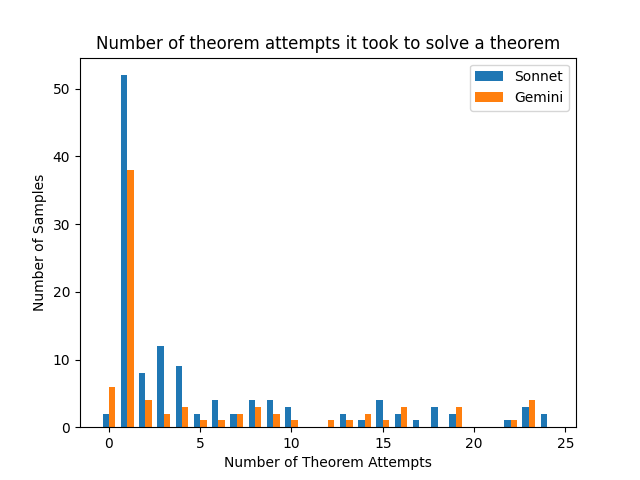
Figures 7 and 8 show how many samples took how many attempts. Of the theorems that got eventually completed, roughly 20% of each model’s were done in zero or one iteration of the loop.
<details>
<summary>extracted/6182580/figs/number_of_theorem_attempts_it_took_to_solve_a_theorem.png Details</summary>
### Visual Description
## Histogram: Number of Theorem Attempts to Solve a Theorem
### Overview
The image is a histogram comparing the number of theorem attempts it took for two systems, "Sonnet" (blue) and "Gemini" (orange), to solve a theorem. The x-axis represents the number of theorem attempts, and the y-axis represents the number of samples (frequency).
### Components/Axes
* **Title:** Number of theorem attempts it took to solve a theorem
* **X-axis:** Number of Theorem Attempts (ranging from 0 to 25)
* **Y-axis:** Number of Samples (ranging from 0 to 50)
* **Legend:** Located in the top-right corner.
* Blue: Sonnet
* Orange: Gemini
### Detailed Analysis
Here's a breakdown of the data for each system:
**Sonnet (Blue):**
* **Trend:** The frequency is highest at 1 attempt and decreases rapidly as the number of attempts increases.
* **Data Points:**
* 0 Attempts: ~2
* 1 Attempt: ~52
* 2 Attempts: ~12
* 3 Attempts: ~9
* 4 Attempts: ~3
* 5 Attempts: ~4
* 6 Attempts: ~2
* 7 Attempts: ~1
* 8 Attempts: ~4
* 9 Attempts: ~2
* 10 Attempts: ~1
* 11 Attempts: ~0
* 12 Attempts: ~0
* 13 Attempts: ~0
* 14 Attempts: ~2
* 15 Attempts: ~1
* 16 Attempts: ~2
* 17 Attempts: ~0
* 18 Attempts: ~0
* 19 Attempts: ~0
* 20 Attempts: ~0
* 21 Attempts: ~0
* 22 Attempts: ~0
* 23 Attempts: ~0
* 24 Attempts: ~2
* 25 Attempts: ~3
**Gemini (Orange):**
* **Trend:** Similar to Sonnet, the frequency is highest at 1 attempt and decreases as the number of attempts increases, but the decrease is less drastic.
* **Data Points:**
* 0 Attempts: ~6
* 1 Attempt: ~38
* 2 Attempts: ~8
* 3 Attempts: ~3
* 4 Attempts: ~2
* 5 Attempts: ~1
* 6 Attempts: ~4
* 7 Attempts: ~3
* 8 Attempts: ~3
* 9 Attempts: ~4
* 10 Attempts: ~2
* 11 Attempts: ~0
* 12 Attempts: ~0
* 13 Attempts: ~0
* 14 Attempts: ~1
* 15 Attempts: ~4
* 16 Attempts: ~2
* 17 Attempts: ~3
* 18 Attempts: ~1
* 19 Attempts: ~3
* 20 Attempts: ~0
* 21 Attempts: ~0
* 22 Attempts: ~0
* 23 Attempts: ~1
* 24 Attempts: ~4
* 25 Attempts: ~1
### Key Observations
* Both systems solve most theorems within the first few attempts.
* Sonnet has a higher peak at 1 attempt compared to Gemini.
* Gemini has a more gradual decrease in frequency as the number of attempts increases, suggesting it might be more consistent in solving theorems that require more attempts.
* Both systems have a few instances where they require a significantly higher number of attempts (24-25).
### Interpretation
The histogram suggests that both "Sonnet" and "Gemini" are generally successful in solving theorems with a low number of attempts. However, "Sonnet" appears to be more efficient at solving theorems quickly, as indicated by its higher peak at 1 attempt. "Gemini," on the other hand, seems to have a more consistent performance across a wider range of attempts, potentially indicating a more robust approach to solving more complex theorems. The presence of data points at higher attempt numbers (24-25) for both systems suggests that there are some theorems that pose a significant challenge to both systems.
</details>
Figure 7: Number of theorem attempts it took to solve a theorem, conditional on that theorem succeeding.
Of the 406 theorems attempted, Sonnet accomplished 121 ( $30\%$ ) and Gemini accomplished 74 ( $18.5\%$ ).
III-E Discussion
We noticed that Sonnet solved many problems via imperative programming with the identity monad (Id.run do). However, this kind of solution fails to capture inductive structure that lends itself to proofs. This means future solutions to FVAPPS will take one of two directions: an unwieldy and uninterpretable proof involving the identity monad, or ensuring that solutions are factored in a way that can exploit inductive structure.
Table II shows the split over our quality assurance steps over the entire baseline set and those that were solved. While this sample is small, we roughly find that our higher-quality samples that are both guarded and plausible are somewhat more likely to be solvable by current models.
| Unguarded Guarded Guarded and Plausible | 69 18 14 | 41 12 7 | 28 11 4 |
| --- | --- | --- | --- |
| Total | 101 | 60 | 43 |
TABLE II: Baseline results split across quality assurance stages of our generation pipeline.
IV Related Work
Research and development into stronger programming guarantees spans a number of large and growing communities in the software landscape. While interest in generally stronger-typed programming paradigms is growing (e.g., growing interest in converting the Linux kernel codebase to Rust, https://github.com/Rust-for-Linux/linux increasing availability of static typing in Python https://realpython.com/python312-typing/) there remains a smaller group of people and programming languages focused directly on formal verification. Coq [coq], Dafny [dafnybook], Isabelle [isabellebook], and Lean [demoura2015lean] all target theorem proving and formal verification as first class goals, albeit with varying visions and core foundations.
Automating programming with machine learning or program synthesis is a rich area [ellis2020dreamcodergrowinggeneralizableinterpretable, austin2021programsynthesislargelanguage]
IV-A Datasets and Benchmarks
Informal Mathematical theorem proving datasets are the most extensive, with benchmarks ranging from 15,000 to over 100,000 proofs [coqgym, leandojo, jiang2021lisa, naturalproofs], plus the Archive of Formal Proofs containing around 1 million lines of code [afp]. Unverified program synthesis benchmarks are typically an order of magnitude smaller, containing thousands of programs, with APPS being the largest at 10,000 programs [Hendrycks2021MeasuringCC] (though LiveCodeBench continues to grow [livecodebench]). In stark contrast, formal software verification benchmarks have historically been much more limited in size, with both available datasets (Clover and dafny-synthesis) containing order of 100 programs each [clover, dafny-synthesis], with DafnyBench [loughridge2024dafnybench] up at 782.
IV-B Models
Models like DeepSeek [xin2024deepseekproveradvancingtheoremproving, xin2024deepseekproverv15harnessingproofassistant] and AlphaProof [deepmind2024imo] have advanced the ability of AI to do math, both formally and informally. DeepSeek Prover has demonstrated significant capabilities in formal mathematics, achieving state-of-the-art performance on the Lean theorem proving benchmark. The model combines large-scale pretraining on mathematical texts with specialized fine-tuning on formal proof corpora, enabling it to generate valid formal proofs for complex mathematical statements.
AlphaProof [deepmind2024imo] represents another milestone in automated theorem proving, showing particular strength in creative mathematical problem-solving. Its success on IMO-level problems demonstrates the potential for AI systems to engage in sophisticated mathematical reasoning, though the gap between informal mathematical proofs and formal verification remains significant.
In the domain of program synthesis and verification, models have evolved along several tracks. Traditional program synthesis approaches using symbolic techniques and SMT solvers have been augmented by neural methods [wang2023legoprover]. Large language models fine-tuned on code, such as CodeLlama [Rozire2023CodeLO] and GPT-4 [gpt4], have shown promising results in generating functionally correct programs, but their capabilities in formal verification remain limited.
Recent work has begun to bridge this gap [Baif2024DafnyCopilot, yang2024autoverusautomatedproofgeneration] demonstrating the potential for AI assistance in formal program verification. However, these systems typically require significant human guidance and cannot yet autonomously generate both correct programs and their formal proofs. The challenge of simultaneously reasoning about program semantics and verification conditions remains an open problem in the field.
V Discussion
Our current presentation has a few limitations, and clear directions for future work. While the samples in our final guarded and plausible set are quite high quality, it is nontheless possible that the theorem statements do not correspond to desirable properties nor that they, in union, cover the full range of properties one would ideally prefer. While manual spot-checking did not reveal any systematic failures post complete five-stage processing, it is nontheless possible that particular theorems are not applicable or vacuous in some form.
The FVAPPS benchmark evaluates AI systems on both program synthesis and formal verification by extending APPS with Lean 4 theorem specifications. While current language models can implement programming solutions https://www.anthropic.com/news/3-5-models-and-computer-use https://openai.com/index/introducing-swe-bench-verified/, they struggle with formal verification proofs, highlighting the challenge between imperative programming and proof-amenable structures. The benchmark’s difficulty is demonstrated by limited progress from both human baselines and models. FVAPPS opens research directions in simultaneous implementation and verification reasoning, automated proof-amenable solution structuring, and scaling formal verification, providing a framework to measure progress toward verified automated programming.
Acknowledgment
We thank Buck Shlegeris, Jason Gross, and Rajashree Agarwal for valuable feedback and discussion during early versions of this work. We are also grateful to the Anthropic External Researcher program for providing API credits for benchmark generation, and to FAR.ai for providing operations and administrative support during the course of the project.
-A Details of buckets in 6
Table III declares which samples in particular fall into Figure 6 ’s buckets. Of note is that 3078 is declared untrue in a code comment by Gemini, but solved completely by Sonnet. Otherwise, many samples fall into the same buckets across models.
TABLE III: Comparison of theorem classifications between Sonnet and Gemini
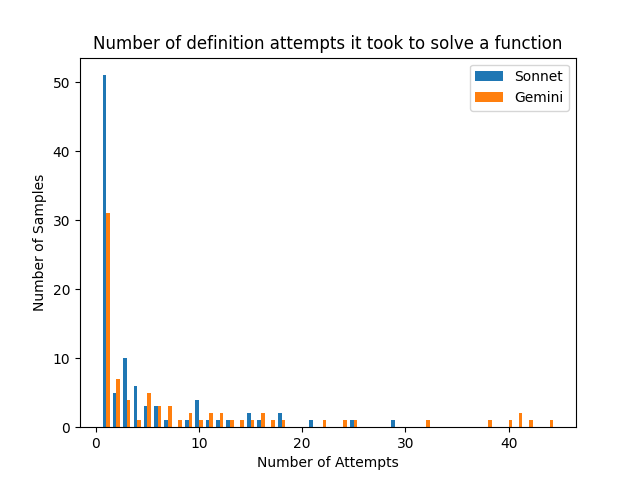
-B Number of definition attempts it took to solve a function, conditional on it succeeding
Figure 8 is a companion to Figure 7 but refers to definitions instead of theorems. Of the def s that succeeded at all, 50% of Sonnet’s and 31% of Gemini’s succeeded in one shot.
<details>
<summary>extracted/6182580/figs/number_of_definition_attempts_it_took_to_solve_a_function.png Details</summary>
### Visual Description
## Histogram: Number of Definition Attempts to Solve a Function
### Overview
The image is a histogram comparing the number of attempts it took for two systems, "Sonnet" and "Gemini," to solve a function. The x-axis represents the number of attempts, and the y-axis represents the number of samples.
### Components/Axes
* **Title:** "Number of definition attempts it took to solve a function"
* **X-axis:** "Number of Attempts" with tick marks at 0, 10, 20, 30, and 40.
* **Y-axis:** "Number of Samples" with tick marks at 0, 10, 20, 30, 40, and 50.
* **Legend:** Located in the top-right corner.
* Blue: "Sonnet"
* Orange: "Gemini"
### Detailed Analysis
The histogram shows the distribution of attempts for each system.
* **Sonnet (Blue):**
* The highest bar is at 1 attempt, with approximately 51 samples.
* The number of samples decreases rapidly as the number of attempts increases.
* At 2 attempts, there are approximately 10 samples.
* At 3 attempts, there are approximately 6 samples.
* At 4 attempts, there are approximately 4 samples.
* At 5 attempts, there are approximately 3 samples.
* At 6 attempts, there are approximately 2 samples.
* At 7 attempts, there are approximately 1 samples.
* At 8 attempts, there are approximately 1 samples.
* At 9 attempts, there are approximately 1 samples.
* At 10 attempts, there are approximately 1 samples.
* At 11 attempts, there are approximately 1 samples.
* At 12 attempts, there are approximately 1 samples.
* At 13 attempts, there are approximately 1 samples.
* At 14 attempts, there are approximately 1 samples.
* At 15 attempts, there are approximately 1 samples.
* At 16 attempts, there are approximately 1 samples.
* At 17 attempts, there are approximately 1 samples.
* At 18 attempts, there are approximately 1 samples.
* At 19 attempts, there are approximately 1 samples.
* At 20 attempts, there are approximately 1 samples.
* At 21 attempts, there are approximately 1 samples.
* At 22 attempts, there are approximately 1 samples.
* At 23 attempts, there are approximately 1 samples.
* At 24 attempts, there are approximately 1 samples.
* At 25 attempts, there are approximately 1 samples.
* At 26 attempts, there are approximately 1 samples.
* At 27 attempts, there are approximately 1 samples.
* At 28 attempts, there are approximately 1 samples.
* At 29 attempts, there are approximately 1 samples.
* At 30 attempts, there are approximately 1 samples.
* At 31 attempts, there are approximately 1 samples.
* At 32 attempts, there are approximately 1 samples.
* At 33 attempts, there are approximately 1 samples.
* At 34 attempts, there are approximately 1 samples.
* At 35 attempts, there are approximately 1 samples.
* At 36 attempts, there are approximately 1 samples.
* At 37 attempts, there are approximately 1 samples.
* At 38 attempts, there are approximately 1 samples.
* At 39 attempts, there are approximately 1 samples.
* At 40 attempts, there are approximately 1 samples.
* At 41 attempts, there are approximately 1 samples.
* At 42 attempts, there are approximately 1 samples.
* At 43 attempts, there are approximately 1 samples.
* At 44 attempts, there are approximately 1 samples.
* At 45 attempts, there are approximately 1 samples.
* At 46 attempts, there are approximately 1 samples.
* At 47 attempts, there are approximately 1 samples.
* At 48 attempts, there are approximately 1 samples.
* At 49 attempts, there are approximately 1 samples.
* At 50 attempts, there are approximately 1 samples.
* **Gemini (Orange):**
* The highest bar is at 1 attempt, with approximately 31 samples.
* The number of samples decreases as the number of attempts increases, but not as rapidly as Sonnet.
* At 2 attempts, there are approximately 7 samples.
* At 3 attempts, there are approximately 4 samples.
* At 4 attempts, there are approximately 3 samples.
* At 5 attempts, there are approximately 3 samples.
* At 6 attempts, there are approximately 3 samples.
* At 7 attempts, there are approximately 2 samples.
* At 8 attempts, there are approximately 2 samples.
* At 9 attempts, there are approximately 2 samples.
* At 10 attempts, there are approximately 2 samples.
* At 11 attempts, there are approximately 2 samples.
* At 12 attempts, there are approximately 2 samples.
* At 13 attempts, there are approximately 2 samples.
* At 14 attempts, there are approximately 2 samples.
* At 15 attempts, there are approximately 2 samples.
* At 16 attempts, there are approximately 2 samples.
* At 17 attempts, there are approximately 2 samples.
* At 18 attempts, there are approximately 2 samples.
* At 19 attempts, there are approximately 2 samples.
* At 20 attempts, there are approximately 2 samples.
* At 21 attempts, there are approximately 2 samples.
* At 22 attempts, there are approximately 2 samples.
* At 23 attempts, there are approximately 2 samples.
* At 24 attempts, there are approximately 2 samples.
* At 25 attempts, there are approximately 2 samples.
* At 26 attempts, there are approximately 2 samples.
* At 27 attempts, there are approximately 2 samples.
* At 28 attempts, there are approximately 2 samples.
* At 29 attempts, there are approximately 2 samples.
* At 30 attempts, there are approximately 2 samples.
* At 31 attempts, there are approximately 2 samples.
* At 32 attempts, there are approximately 2 samples.
* At 33 attempts, there are approximately 2 samples.
* At 34 attempts, there are approximately 2 samples.
* At 35 attempts, there are approximately 2 samples.
* At 36 attempts, there are approximately 2 samples.
* At 37 attempts, there are approximately 2 samples.
* At 38 attempts, there are approximately 2 samples.
* At 39 attempts, there are approximately 2 samples.
* At 40 attempts, there are approximately 2 samples.
* At 41 attempts, there are approximately 2 samples.
* At 42 attempts, there are approximately 2 samples.
* At 43 attempts, there are approximately 2 samples.
* At 44 attempts, there are approximately 2 samples.
* At 45 attempts, there are approximately 2 samples.
* At 46 attempts, there are approximately 2 samples.
* At 47 attempts, there are approximately 2 samples.
* At 48 attempts, there are approximately 2 samples.
* At 49 attempts, there are approximately 2 samples.
* At 50 attempts, there are approximately 2 samples.
### Key Observations
* Both systems solve the function with a single attempt in most cases.
* Sonnet solves the function with one attempt more often than Gemini.
* Gemini has a longer tail, indicating that it sometimes requires significantly more attempts than Sonnet.
### Interpretation
The data suggests that Sonnet is more efficient at solving the function, as it requires fewer attempts on average. Gemini, while often solving the function quickly, occasionally struggles and requires a larger number of attempts. This could indicate differences in the algorithms or approaches used by the two systems. Sonnet is more consistent, while Gemini has more variability in its performance.
</details>
Figure 8: Definition attempts needed to solve a function, conditional on success.
-C Baseline solutions to problem 23
Gemini accomplished 10 in 11 attempts and sonnet failed 9 after 50 attempts.
⬇
def solve_elections (n : Nat) (voters : List (Nat à Nat)) : Nat := Id. run do
let range := List. range (n + 1)
let mut best := none
for k in range do
match try_subset ⨠n, voters, 0, k, []⩠with
| some cost =>
match best with
| none => best := some cost
| some b => if cost < b then best := some cost
| none => continue
best. getD 0
Figure 9: claude-3-5-sonnet-20241022’s attempt at the definition for sample 23 of FVAPPS (try_subset omitted for brevity, available on GitHub)
⬇
def solve_elections (n : Nat) (voters : List (Nat à Nat)) : Nat :=
let voters := voters. toArray. qsort (fun v â v â => (v â. fst < v â. fst) || (v â. fst == v â. fst && v â. snd > v â. snd)) |>. toList – Use boolean comparisons for sorting
let rec go (cost : Nat) (numVoters : Nat) (remainingVoters : List (Nat à Nat)) : Nat :=
if numVoters == n then cost
else
match remainingVoters with
| [] => cost
| (m, p):: rest =>
let buyCost := go (cost + p) (numVoters) rest
let freeCost := if m <= numVoters then go cost (min n (numVoters + 1)) rest else buyCost
min buyCost freeCost
go 0 0 voters
Figure 10: gemini-1.5-pro’s solution to the definition for sample 23 of FVAPPS
\printbibliography