# Logits are All We Need to Adapt Closed Models
**Authors**: Gaurush Hiranandani, Haolun Wu, Subhojyoti Mukherjee, Sanmi Koyejo
Abstract
Many commercial Large Language Models (LLMs) are often closed-source, limiting developers to prompt tuning for aligning content generation with specific applications. While these models currently do not provide access to token logits, we argue that if such access were available, it would enable more powerful adaptation techniques beyond prompt engineering. In this paper, we propose a token-level probability reweighting framework that, given access to logits and a small amount of task-specific data, can effectively steer black-box LLMs toward application-specific content generation. Our approach views next-token prediction through the lens of supervised classification. We show that aligning black-box LLMs with task-specific data can be formulated as a label noise correction problem, leading to Plugin model – an autoregressive probability reweighting model that operates solely on logits. We provide theoretical justification for why reweighting logits alone is sufficient for task adaptation. Extensive experiments with multiple datasets, LLMs, and reweighting models demonstrate the effectiveness of our method, advocating for broader access to token logits in closed-source models. We provide our code at this https URL.
Distribution Shift, Black-box Model, Reweighing, Decoding, Large Language Models
1 Introduction
The rise of Large Language Models (LLMs) has revolutionized generative Artificial Intelligence, yet the most capable models are often closed-source or black-box (Achiam et al., 2023; Bai et al., 2022a). These models generate text based on input prompts but keep their internal weights and training data undisclosed, limiting transparency and customization. Despite these constraints, closed-source LLMs are widely adopted across applications ranging from travel itinerary generation to tax advice, with developers largely relying on prompt optimization to achieve domain-specific outputs.
However, this reliance on prompt engineering is insufficient for specialized tasks, e.g., those requiring brand-specific tone or style. Consider a content writer aiming to generate product descriptions that reflect a brand’s unique identity. Black-box LLMs, trained on broad datasets, often fail to meet such nuanced requirements. With access limited to generated tokens, developers resort to zero-shot (Kojima et al., 2022) or few-shot (Song et al., 2023) prompting techniques. However, if model weights were accessible, advanced techniques like Parameter-Efficient Fine-Tuning (PEFT) using LoRA (Hu et al., 2021), QLoRA (Dettmers et al., 2024), prefix tuning (Li & Liang, 2021), or adapters (Hu et al., 2023a) could be employed for fine-tuning. Yet, due to intellectual property concerns and the high costs of development, most commercial LLMs remain closed-source, and even with API-based fine-tuning options, concerns over data privacy discourage developers from sharing proprietary data.
<details>
<summary>extracted/6617062/icml2025/images/plugin_fig.png Details</summary>
### Visual Description
# Technical Document Extraction: Plugin Model Architecture
This document describes a technical diagram illustrating the architecture and data flow of a **Plugin Model** used for text generation or classification, specifically demonstrating how a reweighting mechanism influences the output of a black-box model.
## 1. Component Isolation
The diagram is structured into three primary horizontal regions:
* **Input (Left):** A document icon representing the initial text prompt.
* **Main Processing Block (Center):** A light purple rounded rectangle labeled "Plugin Model" containing the core logic.
* **Output & Feedback (Right):** The resulting text and a feedback loop for the next inference step.
---
## 2. Detailed Component Analysis
### A. Input Stage
* **Text Prompt:** A document icon contains the text: `"This shirt is ..."`
* **Flow:** An arrow leads from the input into the Plugin Model, where it splits into two parallel processing paths.
### B. Plugin Model (Internal Components)
The Plugin Model consists of two sub-models that process the input simultaneously:
1. **Black-box Model:**
* **Visual:** Represented by a dark grey rectangular block.
* **Output:** A probability distribution table (Table 1).
2. **Reweighting Model:**
* **Visual:** Represented by a white rectangular block with vertical bars on the sides.
* **Output:** A probability distribution table (Table 2).
### C. Data Tables (Probability Distributions)
The diagram uses three tables to show how values are combined. Each table contains a list of tokens and their associated numerical weights.
| Token | Table 1 (Black-box) | Table 2 (Reweighting) | Table 3 (Combined Output) |
| :--- | :--- | :--- | :--- |
| **nice** | 0.1 | 0.1 | 0.01 |
| **adidas** | 0.1 | 0.7 | **0.07** |
| **black** | 0.3 | 0.1 | 0.03 |
| **...** | ... | ... | ... |
* **Visual Coding:** In all tables, the row for "black" is highlighted in yellow, and the row for "..." is highlighted in orange.
---
## 3. Process Flow and Logic
### Step 1: Parallel Inference
The input prompt is fed into both the **Black-box Model** and the **Reweighting Model**.
* The Black-box Model predicts "black" as the most likely next token (0.3).
* The Reweighting Model strongly favors "adidas" (0.7).
### Step 2: Multiplication Operation
The outputs from both tables are combined using a mathematical operation represented by a **circled 'X' (multiplication symbol)**.
* **Trend Verification:** The final value is the product of the two previous values (e.g., $0.1 \times 0.7 = 0.07$). This operation shifts the highest probability from "black" to "adidas".
### Step 3: Final Output Generation
* The combined table (Table 3) identifies **adidas** (0.07) as the winning token (indicated by bold text).
* **Resulting Text:** A document icon on the right shows the completed sentence: `"This shirt is adidas ..."`
### Step 4: Iterative Feedback
* **Label:** "Next inference step"
* **Flow:** A dashed line with an arrow loops from the final output back to the initial input document. This indicates that the generated word "adidas" is appended to the prompt for the next cycle of generation.
---
## 4. Summary of Data Points
* **Primary Language:** English.
* **Key Entities:** Black-box Model, Reweighting Model, Plugin Model.
* **Numerical Values:** 0.1, 0.3, 0.7, 0.01, 0.07, 0.03.
* **Keywords:** nice, adidas, black.
</details>
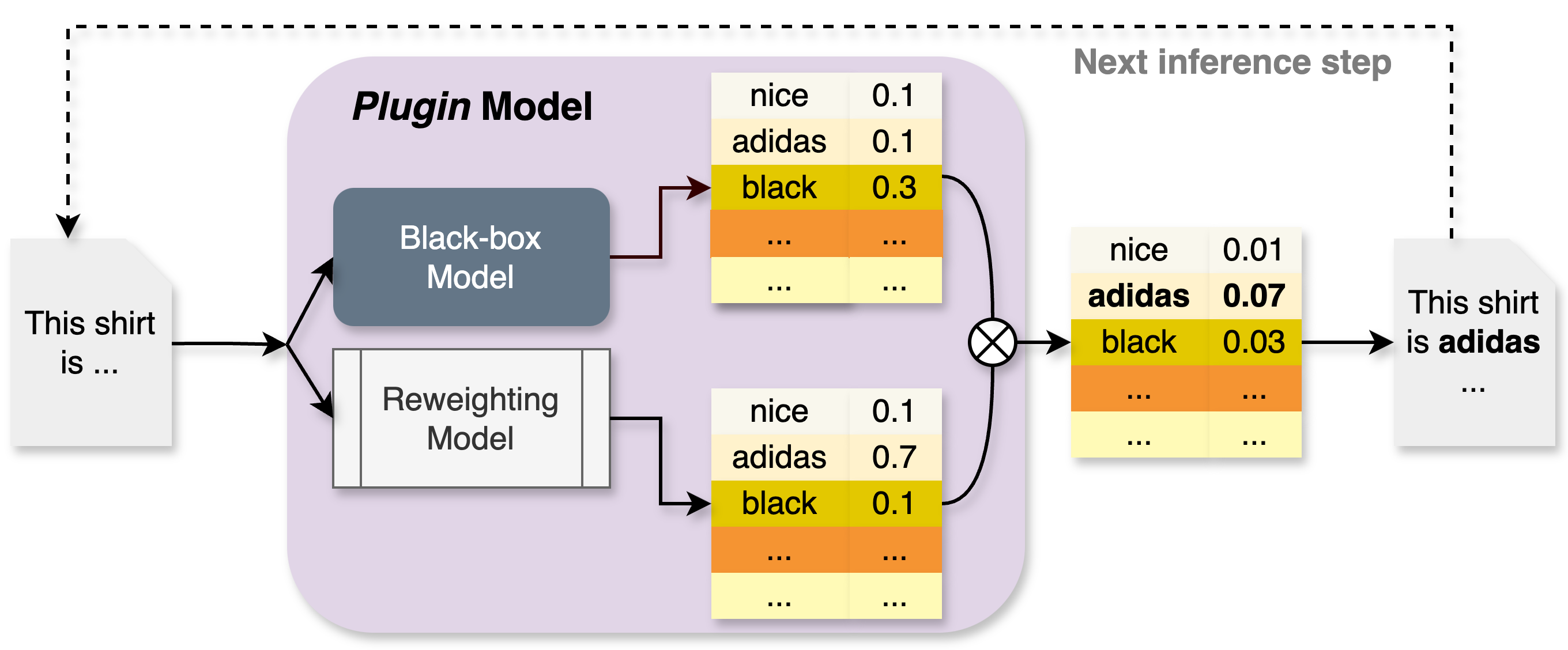
Figure 1: Inference phase of the Plugin model. The token probabilities are a product of the probabilities from the black-box model and a reweighting model that denotes label transitioning.
In this paper, we propose a middle ground between general-purpose LLM creators and developers seeking application-specific alignment. We argue that providing access to token logits, in addition to generated text, would enable more effective customization for downstream tasks. Viewing next-token prediction as a classification problem, we draw an analogy between LLMs and supervised classification models. Since decoder-only LLMs are trained to predict the next token given preceding tokens, aligning black-box LLMs to domain-specific data can be reframed as a label noise correction problem in supervised classification. In this analogy, the LLM’s broad training data serves as proxy labels, while application-specific data represents true labels. This can be interpreted as a distribution shift scenario. For example, in “label shift” (Lipton et al., 2018), certain tokens may appear more frequently in application-specific data than in the LLM’s original corpus. In “class-dependent or independent label noise” (Patrini et al., 2017), synonymous expressions or stylistic variations in application data may diverge from those seen during model training.
Inspired by the label noise correction method of Patrini et al. (2017), which estimates a transition matrix to correct class-dependent noise, we adapt this idea to black-box LLM alignment. Unlike prior work that modifies the loss and retrains the model, we lack access to the LLM’s training data and cannot retrain the model. Instead, we estimate an autoregressive transition matrix from application-specific data and use it to reweight token probabilities at inference.
This autoregressive extension is novel, as it accounts for dependencies on previously generated tokens when adjusting logits for the next token. By adapting label noise correction techniques to autoregressive language modeling, we present a practical method to align black-box LLMs using only logits—without requiring access to model weights or original training data.
Our contributions are summarized as follows:
1. We formulate the problem of adapting black-box LLMs for application-specific content generation as a loss correction approach, requiring only token logits at each generation step. This bridges label noise correction in supervised classification with autoregressive language modeling (Sections 2 and 3).
1. We propose an autoregressive probability reweighting framework, enabling token-level probability adjustment during inference. The resulting Plugin model dynamically reweights logits to align generation with task-specific data (Section 4).
1. We provide theoretical guarantees, showing that under mild assumptions, the Plugin model consistently aligns probability estimates with the target distribution given sufficient application-specific samples. To our knowledge, this is the first work to establish such consistency in an autoregressive label noise setting (Section 5).
1. We conduct extensive experiments across four language generation datasets and three black-box LLMs. Our results, supported by multiple ablations, demonstrate that the Plugin model outperforms baselines in adapting black-box LLMs for domain-specific content generation (Section 7). Based on our results, we advocate for publishing token logits alongside outputs in closed-source LLMs.
2 Preliminaries
We begin by establishing the notation. The index set is denoted as $[c]=\{1,...,c\}$ for any positive integer $c$ . Vectors are represented in boldface, for example, $\bm{v}$ , while matrices are denoted using uppercase letters, such as $V$ . The coordinates of a vector are indicated with subscripts, for instance, $v_{j}$ . The all-ones vector is denoted by $\mathbf{1}$ , with its size being clear from the context. The $c$ -dimensional simplex is represented as $\Delta^{c-1}⊂[0,1]^{c}$ . Finally, a sequence $(x_{t},x_{t-1},...,x_{1})$ of size $t$ is denoted by $x_{t:1}$ .
We assume access to language data for the target task, while the black-box LLM, trained on broad world knowledge, is treated as having learned from a noisy version of this data. We seek to adapt the black-box model to align with the task-specific distribution. To formalize this, we extend the label-noise framework from supervised classification (Patrini et al., 2017) to the decoder-only language modeling.
Decoder-only models are trained using a next-token prediction objective. At each step, this setup resembles a supervised classification problem with $|V|$ classes, where $V$ is the vocabulary of tokens. Formally, the label space at step $t$ is ${\cal X}_{t}=\{\bm{e}^{i}:i∈[|V|]\}$ , where $\bm{e}^{i}$ denotes the $i$ -th standard canonical vector in $\mathbb{R}^{|V|}$ , i.e., $\bm{e}^{i}∈\{0,1\}^{|V|},\mathbf{1}^{T}\bm{e}^{i}=1$ . The task at each step $t$ is to predict the next token $\bm{x}_{t}$ (denoted as one-hot vector) given a sequence of tokens $\bm{x}_{t-1:1}$ .
One observes examples $(\bm{x}_{t},\bm{x}_{t-1:1})$ drawn from an unknown distribution $p^{*}(\bm{x}_{t},\bm{x}_{t-1:1})=p^{*}(\bm{x}_{t}|\bm{x}_{t-1:1})p^{*}(\bm{x}_%
{t-1:1})$ over $V× V^{[t-1]}$ , with expectations denoted by $E^{*}_{\bm{x}_{t},\bm{x}_{t-1:1}}$ . Cross-entropy loss is typically used for training over the vocabulary tokens. Assuming access to token logits, and thus the softmax outputs, from the black-box LLM, we interpret the softmax output as a vector approximating the class-conditional probabilities $p^{*}(\bm{x}_{t}|\bm{x}_{t-1:1})$ , denoted as $b(\bm{x}_{t}|\bm{x}_{t-1:1})∈\Delta^{|V|-1}$ .
To quantify the discrepancy between the target label $\bm{x}_{t}=\bm{e}^{i}$ at step $t$ and the model’s predicted output, we define a loss function $\ell:|V|×\Delta^{|V|-1}→\mathbb{R}$ . A common choice in next-token prediction tasks is the cross-entropy loss:
$$
\displaystyle\ell(\bm{e}^{i},b(\bm{x}_{t}|{\bm{x}_{t-1:1}})) \displaystyle=-(\bm{e}^{i})^{T}\log b(\bm{x}_{t}|\bm{x}_{t-1:1}) \displaystyle=-\log b(\bm{x}_{t}=\bm{e}^{i}|\bm{x}_{t-1:1}). \tag{1}
$$
With some abuse of notation, the loss in vector form $\bm{\ell}:\Delta^{|V|-1}→\mathbb{R}^{|V|}$ , computed on every possible label is $\bm{\ell}(b(\bm{x}_{t}|\bm{x}_{t-1:1}))=\Big{(}\ell(\bm{e}^{1},b(\bm{x}_{t}|%
\bm{x}_{t-1:1})),...,\ell(\bm{e}^{|V|},b(\bm{x}_{t}|\bm{x}_{t-1:1}))\Big{)}^%
{T}.$
3 Loss Robustness
We extend label noise modeling to the autoregressive language setting, focusing on asymmetric or class-conditional noise. At each step $t$ , the label $\bm{x}_{t}$ in the black-box model’s training data is flipped to $\tilde{\bm{x}}_{t}∈ V$ with probability $p^{*}(\tilde{\bm{x}}_{t}|\bm{x}_{t})$ , while preceding tokens $(\bm{x}_{t-1:1})$ remain unchanged. As a result, the black-box model observes samples from a noisy distribution: $p^{*}(\tilde{\bm{x}}_{t},\bm{x}_{t-1:1})=\sum_{\bm{x}_{t}}p^{*}(\tilde{\bm{x}}%
_{t}|\bm{x}_{t})p^{*}(\bm{x}_{t}|\bm{x}_{t-1:1})p^{*}(\bm{x}_{t-1:1}).$
We define the noise transition matrix $T_{t}∈[0,1]^{|V|×|V|}$ at step $t$ , where each entry $T_{t_{ij}}=p^{*}(\tilde{\bm{x}}_{t}=\bm{e}^{j}|\bm{x}_{t}=\bm{e}^{i})$ represents the probability of label flipping. This matrix is row-stochastic but not necessarily symmetric.
To handle asymmetric label noise, we modify the loss $\bm{\ell}$ for robustness. Initially, assuming a known $T_{t}$ , we apply a loss correction inspired by (Patrini et al., 2017; Sukhbaatar et al., 2015). We then relax this assumption by estimating $T_{t}$ directly, forming the basis of our Plugin model approach.
We observe that a language model trained with no loss correction would result in a predictor for noisy labels $b(\tilde{\bm{x}}_{t}|\bm{x}_{t-1:1})$ . We can make explicit the dependence on $T_{t}$ . For example, with cross-entropy we have:
$$
\displaystyle\ell(\bm{e}^{i},b(\tilde{\bm{x}}_{t}|\bm{x}_{t-1:1}))=-\log b(%
\tilde{\bm{x}}_{t}=\bm{e}^{i}|\bm{x}_{t-1:1}) \displaystyle=-\log\sum_{j=1}^{|V|}p^{*}(\tilde{\bm{x}}_{t}=\bm{e}^{i}|\bm{x}_%
{t}=\bm{e}^{j})b(\bm{x}_{t}=\bm{e}^{j}|\bm{x}_{t-1:1}) \displaystyle=-\log\sum_{j=1}^{|V|}T_{t_{ji}}{b}(\bm{x}_{t}=\bm{e}^{j}|\bm{x}_%
{t-1:1}), \tag{2}
$$
or in matrix form
$$
\bm{\ell}(b(\tilde{\bm{x}}_{t}|\bm{x}_{t-1:1}))=-\log T_{t}^{\top}b(\bm{x}_{t}%
|\bm{x}_{t-1:1}). \tag{3}
$$
This loss compares the noisy label $\tilde{\bm{x}}_{t}$ to the noisy predictions averaged via the transition matrix $T_{t}$ at step $t$ . Cross-entropy loss, commonly used for next-token prediction, is a proper composite loss with the softmax function as its inverse link function (Patrini et al., 2017). Consequently, from Theorem 2 of Patrini et al. (2017), the minimizer of the forwardly-corrected loss in Equation (3) on noisy data aligns with the minimizer of the true loss on clean data, i.e.,
| | | $\displaystyle\operatorname*{argmin}_{w}E^{*}_{\tilde{\bm{x}}_{t},\bm{x}_{t-1:1%
}}\Big{[}\bm{\ell}(\bm{x}_{t},T_{t}^{→p}b(\bm{x}_{t}|\bm{x}_{t-1:1}))\Big{]}$ | |
| --- | --- | --- | --- |
where $w$ are the language model’s weights, implicitly embedded in the softmax output $b$ from the black-box model. This result suggests that if $T_{t}$ were known, we could transform the softmax output $b(\bm{x}_{t}\mid\bm{x}_{t-1:1})$ using $T_{t}^{T}$ , use the transformed predictions as final outputs, and retrain the model accordingly. However, since $T_{t}$ is unknown and training data is inaccessible, estimating $T_{t}$ from clean data is essential to our approach.
3.1 Estimation of Transition Matrix
We assume access to a small amount of target data for the task. Given that the black-box model is expressive enough to approximate $p^{*}(\tilde{\bm{x}}_{t}\mid\bm{x}_{t-1:1})$ (Assumption (2) in Theorem 3 of Patrini et al. (2017)), the transition matrix $T_{t}$ can be estimated from this target data. Considering the supervised classification setting at step $t$ , let $\mathcal{X}_{t}^{i}$ represent all target data samples where $\bm{x}_{t}=\bm{e}^{i}$ and the preceding tokens are $(\bm{x}_{t-1:1})$ . A naive estimate of the transition matrix is: $\hat{T}_{t_{ij}}=b(\tilde{\bm{x}}_{t}=\bm{e}^{j}|\bm{x}_{t}=\bm{e}^{i})=\frac{%
1}{|\mathcal{X}_{t}^{i}|}\sum_{x∈\mathcal{X}_{t}^{i}}b(\tilde{\bm{x}}_{t}=%
\bm{e}^{j}|\bm{x}_{t-1:1})$ . While this setup works for a single step $t$ , there are two key challenges in extending it across all steps in the token prediction task:
1. Limited sample availability: The number of samples where $\bm{x}_{t}=\bm{e}^{i}$ and the preceding tokens $(\bm{x}_{t-1},...,\bm{x}_{1})$ match exactly is limited in the clean data, especially with large vocabulary sizes (e.g., $|V|=O(100K)$ for LLaMA (Dubey et al., 2024)). This necessitates modeling the transition matrix as a function of features derived from $\bm{x}_{t-1:1}$ , akin to text-based autoregressive models.
1. Large parameter space: With a vocabulary size of $|V|=O(100K)$ , the transition matrix $T_{t}$ has approximately 10 billion parameters. This scale may exceed the size of the closed-source LLM and cannot be effectively learned from limited target data. Thus, structural restrictions must be imposed on $T_{t}$ to reduce its complexity.
To address these challenges, we impose the restriction that the transition matrix $T_{t}$ is diagonal. While various constraints could be applied to simplify the problem, assuming $T_{t}$ is diagonal offers two key advantages. First, it allows the transition matrix—effectively a vector in this case—to be modeled using standard autoregressive language models, such as a GPT-2 model with $k$ transformer blocks, a LLaMA model with $d$ -dimensional embeddings, or a fine-tuned GPT-2-small model. These architectures can be adjusted based on the size of the target data. Second, a diagonal transition matrix corresponds to a symmetric or class-independent label noise setup, where $\bm{x}_{t}=\bm{e}^{i}$ flips to any other class with equal probability in the training data. This assumption, while simplifying, remains realistic within the framework of label noise models.
Enforcing a diagonal structure ensures efficient estimation of the transition matrix while maintaining practical applicability within our framework. Next, we outline our approach for adapting closed-source language models to target data.
4 Proposed Method: The Plugin Approach
To estimate the autoregressive transition vector, we train an autoregressive language model on target data, which operates alongside the black-box model during inference. This model acts as an autoregressive reweighting mechanism, adjusting the token probabilities produced by the black-box model. The combined approach, integrating probabilities from the black-box and reweighting models, is referred to as the Plugin model. The term Plugin is inspired by classification literature, where plugin methods reweight probabilities to adapt to distribution shifts (Koyejo et al., 2014; Narasimhan et al., 2015; Hiranandani et al., 2021). We now detail the training and inference phases, summarized in Algorithm 1 (Appendix A) and illustrated in Figure 1.
4.1 Training the Plugin Model
During each training iteration, a sequence $s$ of $m$ tokens is passed through both the black-box model and the reweighting model to obtain token probabilities $\{\bm{b}_{1},\bm{b}_{2},...,\bm{b}_{m}\}$ and $\{\bm{r}_{1},\bm{r}_{2},...,\bm{r}_{m}\}$ , respectively, where each $\bm{b}_{i},\bm{r}_{i}∈\Delta^{|V|-1}$ . The final token probability from the Plugin model is computed by normalizing the element-wise product of these probabilities:
$$
{\bm{p}}_{i}=\frac{\bm{b}_{i}\odot\bm{r}_{i}}{\|\bm{b}_{i}\odot\bm{r}_{i}\|_{1%
}}. \tag{4}
$$
The sequence-level cross-entropy loss is given by:
$$
\ell_{s}=-\frac{1}{m}\sum_{i=1}^{m}\sum_{j=1}^{|V|}\log({\bm{p}}_{i})\odot\bm{%
e}_{j}, \tag{5}
$$
where the $j$ -th token appears at the $i$ -th position in the sequence $s$ . During backpropagation, only the reweighting model parameters are updated, while the black-box model remains frozen. This formulation extends naturally to batch training, refining $\bm{r}_{i}$ over iterations to approximate the transition vector governing label shifts in the target data.
4.2 Inference from the Plugin Model
Given a fully trained reweighting model and access to the black-box model, token generation proceeds autoregressively. At the first step, the black-box model produces token probabilities $\bm{b}_{1}$ , while the reweighting model outputs $\bm{r}_{1}$ . The Plugin model selects the first token as $\bm{x}_{1}=\operatorname*{argmax}_{V}(\bm{b}_{1}\odot\bm{r}_{1}).$ For subsequent steps, given the previously generated tokens $\bm{x}_{t-1:1}$ , we obtain probabilities $\bm{b}_{t}$ from the black-box model and $\bm{r}_{t}$ from the reweighting model. The Plugin model then predicts the next token as: $\bm{x}_{t}=\operatorname*{argmax}_{V}(\bm{b}_{t}\odot\bm{r}_{t})$ .
The process continues until a stopping criterion is met. Note that, this manuscript focuses on greedy decoding for inference. Other decoding strategies, such as temperature scaling, top- $p$ sampling, or beam search, can be incorporated by normalizing the element-wise product of probabilities and using them as the final token distribution, as in Equation (4).
5 Theoretical Analysis
We establish the convergence properties of Plugin, showing that after $t$ tokens, it accurately estimates the autoregressive noise transition matrix. Modeling the matrix as a function of an unknown parameter $\bm{\theta}_{*}$ , we prove that optimizing the autoregressive loss over token sequences enables consistent estimation of $\bm{\theta}_{*}$ with high probability. To our knowledge, this is the first finite-time convergence analysis for transition matrix estimation under autoregressive noisy loss.
Let $\mathcal{F}^{t-1}$ denote the history of selected tokens up to time $t-1$ . Let an unknown parameter $\bm{\theta}_{*}∈\bm{\Theta}⊂eq\mathbb{R}^{d}$ governs the transition dynamics of label flipping between token pairs. The transition matrix at time $t$ , denoted as $T_{t}(\bm{\theta}_{*}|\mathcal{F}^{t-1})$ , depends on $\bm{\theta}_{*}$ and all previously observed tokens. Before proving our main result, we first make a few assumptions.
**Assumption 5.1**
*Let $T_{t}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{t-1})$ denote the $(i,j)$ -th component of the transition matrix, and let $f_{I_{t}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{t-1})$ be the transition function that determines the transition from $x_{i}$ to $x_{j}$ , where $I_{t}$ is the $x_{i}$ token selected at time $t$ . Let $x_{i},x_{j}\!∈\!\mathbb{R}^{d}$ . We assume that $∇ f_{I_{t}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{t-1})\!<\!\lambda_{0}$ and $∇^{2}f_{I_{t}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{t-1})\!<\!\lambda%
_{1}$ for some constant $\lambda_{0}\!>\!0$ , $\lambda_{1}>0$ and for all steps $t$ .*
5.1 assumes the transition matrix depends on the history-dependent function $f_{I_{t}}(·)$ with bounded gradient and Hessian, similar to assumptions in (Singh et al., 2023; Zhang et al., 2024) for other deep models.
**Assumption 5.2**
*We assume the cross-entropy loss (5) is clipped by $\epsilon>0$ and upper bounded as $\ell^{clipped}_{t}\!\!≤\!\!C|V|^{2}(Y_{t}-f_{I_{t}}(\bm{\theta}_{*};x_{i},x%
_{j},\mathcal{F}^{t-1}))^{2}$ for any time $t$ , where $Y_{t}$ is the predicted token class, $f_{I_{t}}$ determines the true class and satisfies 5.1, and $C\!>\!0$ is a constant.*
5.2 ensures that the clipped log loss is upper bounded by a smoother squared loss. For the remaining of this section we refer to this squared loss at time $t$ as $\ell_{t}(\bm{\theta})$ . Let the Plugin model minimize the loss $\ell_{1}(\bm{\theta}),\ell_{2}(\bm{\theta}),·s,\ell_{t}(\bm{\theta})$ over $t$ iterations. Let ${\widehat{\bm{\theta}}}_{t}=\operatorname*{argmin}_{\bm{\theta}∈\bm{\Theta}}%
\sum_{s=1}^{t}\ell_{s}(\bm{\theta})$ . At every iteration $t$ , the Plugin algorithm looks into the history $\mathcal{F}^{t-1}$ and samples a token $\bm{x}_{t}\sim\bm{p}_{\hat{\theta}_{t}}=\bm{b}_{t}\odot\bm{r}_{\hat{\theta}_{t}}$ .
Let $\widehat{\cal L}_{t}(\bm{\theta})=\frac{1}{t}\sum_{s=1}^{t}\ell_{s}(\bm{\theta})$ and its expectation ${\cal L}_{t}(\bm{\theta})=\frac{1}{t}\sum_{s=1}^{t}\mathbb{E}_{x_{s}\sim%
\mathbf{p}_{{\widehat{\bm{\theta}}}_{s-1}}}[\ell_{s}(\bm{\theta})|\mathcal{F}^%
{s-1}]$ . We impose regularity and smoothness assumptions on the loss function $\ell_{t}(\bm{\theta})$ as stated in B.1 (Appendix B). We are now ready to prove the main theoretical result of the paper.
**Theorem 1**
*Suppose $\ell_{1}(\bm{\theta}),·s,\ell_{t}(\bm{\theta}):\mathbb{R}^{|V|}\!\!%
→\!\!\mathbb{R}$ are loss functions from a distribution that satisfies Assumptions 5.1, 5.2, and B.1. Define ${\cal L}_{t}(\bm{\theta})=\frac{1}{t}\sum_{s=1}^{t}\mathbb{E}_{x_{s}\sim%
\mathbf{p}_{{\widehat{\bm{\theta}}}_{s-1}}}[\ell_{s}(\bm{\theta})|\mathcal{F}^%
{s-1}]$ where, ${\widehat{\bm{\theta}}}_{t}=\operatorname*{argmin}_{\bm{\theta}∈\bm{\Theta}}%
\sum_{s=1}^{t}\ell_{s}(\bm{\theta})$ . If $t$ is large enough such that $\frac{\gamma\log(dt)}{t}≤ c^{\prime}\min\left\{\frac{1}{C_{1}C_{2}|V|^{4}},%
\frac{\max\limits_{\bm{\theta}∈\bm{\Theta}}\left(\!{\cal L}_{t}(\bm{\theta})%
\!-\!{\cal L}_{t}\left(\bm{\theta}_{*}\!\right)\right)}{C_{2}}\right\}$ then for a constant $\gamma≥ 2$ , universal constants $C_{1},C_{2},c^{\prime}$ , we have that
| | $\displaystyle\left(1-\rho_{t}\right)\frac{\sigma_{t}^{2}}{t}-\frac{C_{1}^{2}}{%
t^{\gamma/2}}$ | $\displaystyle≤\mathbb{E}\left[{\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-{%
\cal L}_{t}\left(\bm{\theta}_{*}\right)\right]$ | |
| --- | --- | --- | --- |
where $\sigma^{2}_{t}\coloneqq\mathbb{E}\left[\frac{1}{2}\left\|∇\widehat{\cal L%
}_{t}\left(\bm{\theta}_{*}\right)\right\|_{\left(∇^{2}{\cal L}_{t}\left(%
\bm{\theta}_{*}\right)\right)^{-1}}^{2}\right]$ , and $\rho_{t}\coloneqq\left(C_{1}C_{2}+2\eta^{2}\lambda_{1}^{2}\right)\sqrt{\frac{%
\gamma\log(dt)}{t}}$ .*
1 bounds the difference between the estimated and true average loss functions, showing that this gap diminishes as the number of training tokens increases. Since ${\widehat{\bm{\theta}}}_{t}=\operatorname*{argmin}_{\bm{\theta}∈\bm{\Theta}}%
\sum_{s=1}^{t}\ell_{s}(\bm{\theta})$ , the Plugin model progressively refines its estimation of the unknown parameter $\bm{\theta}_{*}$ . As the transition matrix $T_{t}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{t-1})$ is derived from $f_{I_{t}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{t-1})$ , which depends on $\bm{\theta}_{*}$ , training on sufficiently many tokens ensures an accurate estimation of each component of $T_{t}(\bm{\theta}_{*}|\mathcal{F}^{t-1})$ .
Our proof reformulates the problem as a sequential hypothesis testing setting to estimate the average loss function ${\cal L}_{t}({\widehat{\bm{\theta}}}_{t})$ using the sequence of losses $\ell_{1}(\bm{\theta}),...,\ell_{t}(\bm{\theta})$ (Naghshvar & Javidi, 2013; Lattimore & Szepesvári, 2020). Unlike prior work (Frostig et al., 2015; Chaudhuri et al., 2015), which assumes i.i.d. losses, the loss at time $t$ in our setting depends on all previous losses. Additionally, Mukherjee et al. (2022) study a different active regression setting without considering cross-entropy loss or transition noise matrices as in Patrini et al. (2017). We provide a brief overview of the proof technique in Remark B.9 (Appendix B), highlighting key novelties.
6 Related Work
Parameter-Efficient Fine-Tuning (PEFT).
PEFT methods adapt LLMs to downstream tasks while minimizing computational overhead. LoRA (Hu et al., 2021) and QLoRA (Dettmers et al., 2024) introduce low-rank updates and quantization for efficient fine-tuning, while prefix tuning (Li & Liang, 2021), adapters (Hu et al., 2023b), and soft prompting (Lester et al., 2021) modify task-specific representations through trainable layers or embeddings. Torroba-Hennigen et al. (2025) further explore the equivalence between gradient-based transformations and adapter-based tuning. However, these methods require access to model weights, gradients, or architecture details, making them unsuitable for closed-source LLMs and inapplicable as baselines in our setup. In contrast, our approach operates solely on token logits, enabling adaptation without modifying the underlying model. Thus, we emphasize that the Plugin model is not an alternative to fine-tuning, but rather an approach that uniquely stands for adapting black-box LLMs which only provide logit access.
Steering and Aligning LLMs.
LLM alignment methods primarily use reinforcement learning or instruction tuning. RLHF and DPO (Christiano et al., 2017; Ouyang et al., 2022; Rafailov et al., 2024) optimize model behavior via human preferences, with DPO eliminating reward modeling. Constitutional AI (Bai et al., 2022b) aligns models using self-generated principles, while instruction tuning (Wei et al., 2021; Sanh et al., 2022) adapts them via task-specific demonstrations. Unlike our approach, these methods require model weights and training data, limiting their applicability as baselines in our setup.
Calibration of LLMs.
LLM calibration methods aim to align model confidence with predictive accuracy and adjust confidence scores but do not alter token predictions (Ulmer et al., 2024; Shen et al., 2024; Huang et al., 2024; Kapoor et al., 2024; Zhu et al., 2023; Zhang et al., 2023). In contrast, our method reweights token probabilities at inference, enabling adaptation of black-box LLMs without modifying the model or requiring fine-tuning.
Black-box LLMs.
Prior work explores various approaches for adapting black-box LLMs without fine-tuning, though they differ fundamentally from our method. (Gao et al., 2024) infer user preferences through interactive edits but do not adapt models based on past language data. Diffusion-LM (Li et al., 2022) formulates text generation as a non-autoregressive denoising process, whereas our approach reweights token probabilities autoregressively without requiring black-box model weights. Discriminator-based methods (Dathathri et al., 2020; Mireshghallah et al., 2022; Yang & Klein, 2021; Krause et al., 2021) control generation based on predefined attributes, contrasting with our method, which enables free-form text adaptation. DExperts (Liu et al., 2021, 2024) combines expert and anti-expert probabilities; we incorporate a similar probability combining strategy in a modified baseline without a de-expert component. In-context learning (Long et al., 2023; Dong et al., 2024) offers a common adaptation technique for black-box models and serves as a baseline in our setup.
Table 1: Performance comparison on E2E NLG dataset. We show mean and standard deviation of the metrics over five seeds.
| Model | Method | BLEU | Rouge-1 | Rouge-2 | Rouge-L | METEOR | CIDEr | NIST |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| GPT2-M | Zeroshot | 0.0247 | 0.3539 | 0.1003 | 0.2250 | 0.3015 | 0.0156 | 0.6133 |
| GPT2-M | ICL-1 | 0.0543 ±0.026 | 0.3431 ±0.048 | 0.1299 ±0.033 | 0.2280 ±0.047 | 0.3434 ±0.051 | 0.0260 ±0.042 | 0.7767 ±0.060 |
| GPT2-M | ICL-3 | 0.0750 ±0.035 | 0.3955 ±0.028 | 0.1676 ±0.020 | 0.2649 ±0.052 | 0.3977 ±0.063 | 0.0252 ±0.049 | 0.8993 ±0.076 |
| GPT2-M | NewModel | 0.2377 ±0.011 | 0.5049 ±0.014 | 0.2742 ±0.013 | 0.3902 ±0.006 | 0.4521 ±0.016 | 0.3938 ±0.019 | 1.1927 ±0.069 |
| GPT2-M | WeightedComb | 0.1709 ±0.008 | 0.4817 ±0.020 | 0.2447 ±0.011 | 0.3720 ±0.014 | 0.4071 ±0.025 | 0.3329 ±0.027 | 1.0864 ±0.002 |
| GPT2-M | TempNet | 0.1036 ±0.010 | 0.3425 ±0.016 | 0.1526 ±0.012 | 0.2735 ±0.010 | 0.2615 ±0.016 | 0.4116 ±0.023 | 0.2826 ±0.057 |
| GPT2-M | Plugin (Ours) | 0.1863 ±0.010 | 0.5227 ±0.011 | 0.2612 ±0.013 | 0.3728 ±0.003 | 0.4857 ±0.012 | 0.3544 ±0.013 | 1.1241 ±0.009 |
| GPT2-XL | Zeroshot | 0.0562 | 0.4013 | 0.1636 | 0.2862 | 0.3697 | 0.0187 | 0.5338 |
| GPT2-XL | ICL-1 | 0.0686 ±0.032 | 0.4016 ±0.042 | 0.1404 ±0.052 | 0.2745 ±0.025 | 0.3503 ±0.019 | 0.0353 ±0.015 | 0.7944 ±0.067 |
| GPT2-XL | ICL-3 | 0.0980 ±0.035 | 0.4188 ±0.040 | 0.1923 ±0.046 | 0.2912 ±0.031 | 0.3925 ±0.027 | 0.0250 ±0.017 | 0.9390 ±0.054 |
| GPT2-XL | NewModel | 0.2377 ±0.011 | 0.5049 ±0.014 | 0.2742 ±0.013 | 0.3902 ±0.006 | 0.4521 ±0.016 | 0.3938 ±0.019 | 1.1927 ±0.069 |
| GPT2-XL | WeightedComb | 0.1184 ±0.010 | 0.4237 ±0.016 | 0.1858 ±0.012 | 0.3004 ±0.010 | 0.3776 ±0.016 | 0.1818 ±0.023 | 1.0261 ±0.057 |
| GPT2-XL | TempNet | 0.1325 ±0.013 | 0.4642 ±0.017 | 0.2516 ±0.016 | 0.3021 ±0.022 | 0.4126 ±0.025 | 0.3627 ±0.033 | 0.8027 ±0.047 |
| GPT2-XL | Plugin (Ours) | 0.2470 ±0.009 | 0.5536 ±0.007 | 0.3084 ±0.007 | 0.4213 ±0.008 | 0.5057 ±0.009 | 0.5455 ±0.013 | 1.2736 ±0.051 |
| LLaMA-3.1-8B | Zeroshot | 0.3226 | 0.6917 | 0.4050 | 0.5004 | 0.6041 | 0.9764 | 1.1310 |
| LLaMA-3.1-8B | ICL-1 | 0.3301 ±0.037 | 0.6914 ±0.027 | 0.4126 ±0.026 | 0.5023 ±0.018 | 0.6037 ±0.015 | 0.9715 ±0.057 | 1.1735 ±0.066 |
| LLaMA-3.1-8B | ICL-3 | 0.3527 ±0.033 | 0.6936 ±0.036 | 0.4217 ±0.017 | 0.5127 ±0.017 | 0.6202 ±0.009 | 0.9927 ±0.018 | 1.1672 ±0.047 |
| LLaMA-3.1-8B | NewModel | 0.2452 ±0.008 | 0.5347 ±0.005 | 0.2905 ±0.006 | 0.4097 ±0.005 | 0.4812 ±0.009 | 0.4571 ±0.021 | 1.2281 ±0.041 |
| LLaMA-3.1-8B | WeightedComb | 0.3517 ±0.004 | 0.7040 ±0.004 | 0.4249 ±0.004 | 0.5181 ±0.003 | 0.6206 ±0.002 | 1.0947 ±0.010 | 1.1737 ±0.015 |
| LLaMA-3.1-8B | TempNet | 0.3502 ±0.023 | 0.6927 ±0.006 | 0.4216 ±0.023 | 0.5027 ±0.017 | 0.6124 ±0.019 | 0.9625 ±0.025 | 1.1713 ±0.027 |
| LLaMA-3.1-8B | Plugin (Ours) | 0.3691 ±0.013 | 0.7113 ±0.002 | 0.4374 ±0.004 | 0.5247 ±0.002 | 0.6392 ±0.009 | 1.1441 ±0.030 | 1.1749 ±0.034 |
Table 2: Performance comparison on Web NLG dataset. We show mean and standard deviation of the metrics over five seeds.
| Model | Method | BLEU | Rouge-1 | Rouge-2 | Rouge-L | METEOR | CIDEr | NIST |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| GPT2-M | Zeroshot | 0.0213 | 0.2765 | 0.1014 | 0.1872 | 0.2111 | 0.0479 | 0.2340 |
| GPT2-M | ICL-1 | 0.0317 ±0.013 | 0.3388 ±0.021 | 0.1318 ±0.013 | 0.2346 ±0.019 | 0.2876 ±0.042 | 0.0732 ±0.053 | 0.2715 ±0.042 |
| GPT2-M | ICL-3 | 0.0461 ±0.014 | 0.3388 ±0.018 | 0.1378 ±0.016 | 0.2291 ±0.010 | 0.3408 ±0.027 | 0.0748 ±0.031 | 0.3283 ±0.037 |
| GPT2-M | NewModel | 0.1071 ±0.005 | 0.3260 ±0.010 | 0.1496 ±0.014 | 0.2724 ±0.013 | 0.2642 ±0.008 | 0.4327 ±0.023 | 0.2916 ±0.031 |
| GPT2-M | WeightedComb | 0.0692 ±0.007 | 0.3593 ±0.010 | 0.1568 ±0.008 | 0.2834 ±0.015 | 0.2379 ±0.030 | 0.1916 ±0.028 | 0.2996 ±0.037 |
| GPT2-M | TempNet | 0.1045 ±0.012 | 0.3526 ±0.014 | 0.1526 ±0.014 | 0.2731 ±0.018 | 0.3326 ±0.026 | 0.4237 ±0.033 | 0.3002 ±0.048 |
| GPT2-M | Plugin (Ours) | 0.1280 ±0.007 | 0.4590 ±0.005 | 0.2226 ±0.005 | 0.3515 ±0.006 | 0.3832 ±0.010 | 0.7280 ±0.039 | 0.3060 ±0.017 |
| GPT2-XL | Zeroshot | 0.0317 | 0.2992 | 0.1321 | 0.2417 | 0.1969 | 0.0491 | 0.1826 |
| GPT2-XL | ICL-1 | 0.0510 ±0.024 | 0.3223 ±0.026 | 0.1526 ±0.016 | 0.2562 ±0.031 | 0.2591 ±0.009 | 0.1336 ±0.029 | 0.2235 ±0.033 |
| GPT2-XL | ICL-3 | 0.0744 ±0.016 | 0.3383 ±0.036 | 0.1682 ±0.016 | 0.2651 ±0.028 | 0.3071 ±0.014 | 0.1675 ±0.024 | 0.2550 ±0.021 |
| GPT2-XL | NewModel | 0.1071 ±0.005 | 0.3260 ±0.010 | 0.1496 ±0.014 | 0.2724 ±0.013 | 0.2642 ±0.008 | 0.4327 ±0.023 | 0.2916 ±0.031 |
| GPT2-XL | WeightedComb | 0.0636 ±0.006 | 0.3453 ±0.007 | 0.1666 ±0.003 | 0.2782 ±0.005 | 0.2871 ±0.006 | 0.2460 ±0.005 | 0.2981 ±0.018 |
| GPT2-XL | TempNet | 0.0925 ±0.008 | 0.3357 ±0.009 | 0.1663 ±0.014 | 0.2764 ±0.011 | 0.3025 ±0.009 | 0.4226 ±0.013 | 0.2837 ±0.027 |
| GPT2-XL | Plugin (Ours) | 0.1673 ±0.004 | 0.4616 ±0.007 | 0.2527 ±0.007 | 0.3757 ±0.008 | 0.3895 ±0.007 | 0.8987 ±0.013 | 0.2646 ±0.003 |
| LLaMA-3.1-8B | Zeroshot | 0.1453 | 0.5278 | 0.3030 | 0.3982 | 0.4314 | 0.6991 | 0.2684 |
| LLaMA-3.1-8B | ICL-1 | 0.2166 ±0.031 | 0.5944 ±0.027 | 0.3706 ±0.025 | 0.4667 ±0.013 | 0.5651 ±0.045 | 1.5719 ±0.024 | 0.2462 ±0.038 |
| LLaMA-3.1-8B | ICL-3 | 0.2031 ±0.027 | 0.5937 ±0.019 | 0.3821 ±0.015 | 0.4653 ±0.024 | 0.5682 ±0.046 | 1.3826 ±0.051 | 0.2469 ±0.045 |
| LLaMA-3.1-8B | NewModel | 0.1284 ±0.005 | 0.3506 ±0.009 | 0.1673 ±0.007 | 0.2879 ±0.009 | 0.2921 ±0.008 | 0.4999 ±0.030 | 0.2973 ±0.008 |
| LLaMA-3.1-8B | WeightedComb | 0.1922 ±0.012 | 0.5986 ±0.019 | 0.3612 ±0.012 | 0.4659 ±0.008 | 0.4470 ±0.030 | 1.1855 ±0.075 | 0.2575 ±0.020 |
| LLaMA-3.1-8B | TempNet | 0.2315 ±0.010 | 0.5916 ±0.015 | 0.3794 ±0.012 | 0.4620 ±0.010 | 0.5581 ±0.036 | 1.4826 ±0.043 | 0.2513 ±0.020 |
| LLaMA-3.1-8B | Plugin (Ours) | 0.2542 ±0.004 | 0.6375 ±0.005 | 0.3873 ±0.005 | 0.4869 ±0.007 | 0.5724 ±0.004 | 1.5911 ±0.046 | 0.2590 ±0.003 |
Table 3: Performance comparison on CommonGen dataset. We show mean and standard deviation of the metrics over five seeds.
| Model | Method | BLEU | Rouge-1 | Rouge-2 | Rouge-L | METEOR | CIDEr | NIST |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| GPT2-M | Zeroshot | 0.0153 | 0.2216 | 0.0409 | 0.1527 | 0.2848 | 0.0001 | 0.3686 |
| GPT2-M | ICL-1 | 0.0157 ±0.013 | 0.2580 ±0.024 | 0.0362 ±0.096 | 0.1388 ±0.102 | 0.2871 ±0.107 | 0.0222 ±0.076 | 0.3704 ±0.101 |
| GPT2-M | ICL-3 | 0.0552 ±0.010 | 0.3610 ±0.019 | 0.1248 ±0.045 | 0.2680 ±0.089 | 0.4079 ±0.133 | 0.1366 ±0.125 | 0.5340 ±0.087 |
| GPT2-M | NewModel | 0.1260 ±0.007 | 0.4106 ±0.016 | 0.1683 ±0.013 | 0.3740 ±0.009 | 0.3600 ±0.024 | 0.4570 ±0.058 | 0.7113 ±0.025 |
| GPT2-M | WeightedComb | 0.0567 ±0.005 | 0.3918 ±0.010 | 0.1353 ±0.005 | 0.3280 ±0.010 | 0.2929 ±0.016 | 0.2623 ±0.042 | 0.4353 ±0.028 |
| GPT2-M | TempNet | 0.1248 ±0.015 | 0.4048 ±0.014 | 0.1528 ±0.015 | 0.3526 ±0.014 | 0.3883 ±0.017 | 0.4492 ±0.023 | 0.4037 ±0.058 |
| GPT2-M | Plugin (Ours) | 0.1366 ±0.003 | 0.4533 ±0.007 | 0.1878 ±0.003 | 0.3934 ±0.006 | 0.4095 ±0.011 | 0.5572 ±0.022 | 0.6395 ±0.061 |
| GPT2-XL | Zeroshot | 0.0317 | 0.2992 | 0.1321 | 0.2417 | 0.1969 | 0.0491 | 0.1826 |
| GPT2-XL | ICL-1 | 0.0508 ±0.023 | 0.3201 ±0.035 | 0.1526 ±0.097 | 0.2562 ±0.103 | 0.2591 ±0.089 | 0.1336 ±0.092 | 0.2235 ±0.069 |
| GPT2-XL | ICL-3 | 0.0744 ±0.011 | 0.3383 ±0.014 | 0.1682 ±0.030 | 0.2651 ±0.072 | 0.3071 ±0.073 | 0.1675 ±0.066 | 0.2550 ±0.047 |
| GPT2-XL | NewModel | 0.1260 ±0.007 | 0.4106 ±0.016 | 0.1683 ±0.013 | 0.3740 ±0.009 | 0.3600 ±0.024 | 0.4570 ±0.058 | 0.7113 ±0.025 |
| GPT2-XL | WeightedComb | 0.0614 ±0.020 | 0.3364 ±0.024 | 0.1347 ±0.009 | 0.2969 ±0.019 | 0.2921 ±0.018 | 0.2763 ±0.010 | 0.3352 ±0.051 |
| GPT2-XL | TempNet | 0.1154 ±0.020 | 0.3937 ±0.026 | 0.1482 ±0.017 | 0.3625 ±0.013 | 0.3389 ±0.019 | 0.4376 ±0.018 | 0.5927 ±0.047 |
| GPT2-XL | Plugin (Ours) | 0.1791 ±0.014 | 0.4932 ±0.007 | 0.2288 ±0.004 | 0.4347 ±0.007 | 0.4702 ±0.006 | 0.7283 ±0.012 | 0.6554 ±0.038 |
| LLaMA-3.1-8B | Zeroshot | 0.0643 | 0.2776 | 0.1181 | 0.2488 | 0.3857 | 0.3155 | 0.3347 |
| LLaMA-3.1-8B | ICL-1 | 0.0615 ±0.027 | 0.2697 ±0.033 | 0.1158 ±0.062 | 0.2469 ±0.087 | 0.3822 ±0.069 | 0.3005 ±0.072 | 0.3059 ±0.094 |
| LLaMA-3.1-8B | ICL-3 | 0.0635 ±0.016 | 0.2748 ±0.024 | 0.1225 ±0.018 | 0.3120 ±0.047 | 0.4012 ±0.029 | 0.3250 ±0.022 | 0.3794 ±0.034 |
| LLaMA-3.1-8B | NewModel | 0.0753 ±0.004 | 0.3716 ±0.005 | 0.1122 ±0.003 | 0.3404 ±0.004 | 0.2665 ±0.006 | 0.1919 ±0.015 | 0.6900 ±0.046 |
| LLaMA-3.1-8B | WeightedComb | 0.1789 ±0.005 | 0.3485 ±0.012 | 0.1797 ±0.008 | 0.2981 ±0.012 | 0.3637 ±0.011 | 0.5503 ±0.046 | 0.5450 ±0.020 |
| LLaMA-3.1-8B | TempNet | 0.1524 ±0.008 | 0.3372 ±0.015 | 0.1524 ±0.010 | 0.3298 ±0.017 | 0.3676 ±0.015 | 0.3986 ±0.033 | 0.5286 ±0.023 |
| LLaMA-3.1-8B | Plugin (Ours) | 0.2665 ±0.010 | 0.5800 ±0.002 | 0.3139 ±0.005 | 0.5037 ±0.004 | 0.5829 ±0.003 | 1.0876 ±0.020 | 0.7031 ±0.007 |
Table 4: Performance comparison on Adidas dataset. We show mean and standard deviation of the metrics over five seeds.
| Model | Method | BLEU | Rouge-1 | Rouge-2 | Rouge-L | METEOR | CIDEr | NIST |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| GPT2-M | Zeroshot | 0.0046 | 0.2488 | 0.0189 | 0.1353 | 0.1653 | 0.0312 | 0.6860 |
| GPT2-M | ICL-1 | 0.0088 ±0.054 | 0.2667 ±0.047 | 0.0247 ±0.66 | 0.1358 ±0.041 | 0.1762 ±0.028 | 0.0464 ±0.089 | 0.6793 ±0.078 |
| GPT2-M | ICL-3 | 0.0121 ±0.047 | 0.2693 ±0.028 | 0.0262 ±0.054 | 0.1470 ±0.020 | 0.1806 ±0.030 | 0.0415 ±0.104 | 0.7037 ±0.081 |
| GPT2-M | NewModel | 0.0515 ±0.016 | 0.2690 ±0.014 | 0.0637 ±0.014 | 0.1697 ±0.008 | 0.1918 ±0.013 | 0.0550 ±0.086 | 0.6682 ±0.047 |
| GPT2-M | WeightedComb | 0.0565 ±0.014 | 0.2630 ±0.028 | 0.0495 ±0.018 | 0.1565 ±0.015 | 0.1938 ±0.019 | 0.0585 ±0.088 | 0.6456 ±0.156 |
| GPT2-M | TempNet | 0.0442 ±0.017 | 0.2672 ±0.019 | 0.0482 ±0.022 | 0.1582 ±0.020 | 0.1902 ±0.017 | 0.0525 ±0.031 | 0.6533 ±0.098 |
| GPT2-M | Plugin (Ours) | 0.0486 ±0.006 | 0.2766 ±0.002 | 0.0515 ±0.007 | 0.1684 ±0.005 | 0.1994 ±0.004 | 0.0626 ±0.017 | 0.7919 ±0.024 |
| GPT2-XL | Zeroshot | 0.0075 | 0.2309 | 0.0278 | 0.1438 | 0.1487 | 0.0184 | 0.4956 |
| GPT2-XL | ICL-1 | 0.0109 ±0.039 | 0.2567 ±0.082 | 0.0265 ±0.054 | 0.1519 ±0.038 | 0.1649 ±0.052 | 0.0318 ±0.171 | 0.5133 ±0.162 |
| GPT2-XL | ICL-3 | 0.0295 ±0.037 | 0.2509 ±0.071 | 0.0395 ±0.043 | 0.1536 ±0.039 | 0.1658 ±0.041 | 0.0321 ±0.109 | 0.5176 ±0.116 |
| GPT2-XL | NewModel | 0.0515 ±0.016 | 0.2690 ±0.014 | 0.0637 ±0.014 | 0.1697 ±0.008 | 0.1918 ±0.013 | 0.0550 ±0.086 | 0.6682 ±0.047 |
| GPT2-XL | WeightedComb | 0.0567 ±0.016 | 0.2210 ±0.027 | 0.0714 ±0.015 | 0.1550 ±0.024 | 0.1674 ±0.017 | 0.0183 ±0.117 | 0.4105 ±0.109 |
| GPT2-XL | TempNet | 0.0539 ±0.018 | 0.2598 ±0.026 | 0.0686 ±0.014 | 0.1562 ±0.019 | 0.1863 ±0.029 | 0.0462 ±0.120 | 0.5263 ±0.117 |
| GPT2-XL | Plugin (Ours) | 0.0600 ±0.017 | 0.2710 ±0.025 | 0.0722 ±0.018 | 0.1725 ±0.017 | 0.1995 ±0.018 | 0.1195 ±0.138 | 0.6375 ±0.120 |
| LLaMA-3.1-8B | Zeroshot | 0.0120 | 0.2470 | 0.0318 | 0.1493 | 0.1526 | 0.0424 | 0.5285 |
| LLaMA-3.1-8B | ICL-1 | 0.0220 ±0.044 | 0.2472 ±0.072 | 0.0405 ±0.068 | 0.1434 ±0.057 | 0.1686 ±0.041 | 0.0555 ±0.133 | 0.5078 ±0.142 |
| LLaMA-3.1-8B | ICL-3 | 0.0177 ±0.041 | 0.2385 ±0.065 | 0.0364 ±0.071 | 0.1408 ±0.030 | 0.1712 ±0.029 | 0.0587 ±0.102 | 0.5775 ±0.145 |
| LLaMA-3.1-8B | NewModel | 0.0506 ±0.011 | 0.2700 ±0.011 | 0.0634 ±0.006 | 0.1749 ±0.006 | 0.1995 ±0.009 | 0.0575 ±0.051 | 0.6570 ±0.072 |
| LLaMA-3.1-8B | WeightedComb | 0.0357 ±0.017 | 0.2583 ±0.014 | 0.0661 ±0.015 | 0.1560 ±0.011 | 0.1706 ±0.016 | 0.0745 ±0.086 | 0.5927 ±0.077 |
| LLaMA-3.1-8B | TempNet | 0.0472 ±0.016 | 0.2647 ±0.022 | 0.0625 ±0.012 | 0.1625 ±0.020 | 0.1857 ±0.013 | 0.0586 ±0.103 | 0.5926 ±0.137 |
| LLaMA-3.1-8B | Plugin (Ours) | 0.0611 ±0.018 | 0.2714 ±0.029 | 0.0742 ±0.020 | 0.1759 ±0.019 | 0.1990 ±0.020 | 0.1293 ±0.152 | 0.6361 ±0.134 |
7 Experiments
We divide this section into four parts. Section 7.1 evaluates Plugin on four text generation datasets across three black-box language models. Since the Plugin model is trained on top of black-box models, we refer to black-box models interchangeably as base models. Section 7.2 discusses how Plugin can be applied on top of any prompt-tuning method as a wrapper, when logits are accessible. Section 7.3 presents ablation studies analyzing the impact of black-box model quality, Plugin ’s complexity, and architecture choices. Section 7.4 shows qualitative analysis and case studies.
We evaluate Plugin on four text generation benchmarks: (a) E2E NLG (Dušek et al., 2020), (b) Web NLG (Gardent et al., 2017), (c) CommonGen (Lin et al., 2020), and (d) the Adidas product description dataset (adi, 2023). For the first three datasets, we use the train-validation-test splits from the Transformers library (Wolf, 2020). To introduce distribution shifts, we filter Web NLG’s training data to include only infrastructure descriptions, while validation and test sets retain person descriptions. Similarly, CommonGen’s training set is restricted to samples having man, while validation and test sets remain unchanged. Details of this setup are in Section 7.4. The Adidas dataset is split into validation and test sets. Data statistics are provided in Table 6, Appendix C.1.
7.1 Text Generation Performance Comparison
We evaluate Plugin on the text generation task using only the validation and test splits of all four datasets, reserving the train split for ablation studies (Section 7.3). Plugin and baseline models are trained on the small validation set, with performance measured on the test set. Additionally, we allocate 40% of the validation data as hyper-validation for cross-validation of hyperparameters.
Performance is reported using seven standard natural language generation metrics: (a) BLEU (Papineni et al., 2002), (b) ROUGE-1 (Lin, 2004), (c) ROUGE-2 (Lin, 2004), (d) ROUGE-L (Lin & Och, 2004), (e) METEOR (Banerjee & Lavie, 2005), (f) CIDEr (Vedantam et al., 2015), and (g) NIST (Doddington, 2002). All experiments are repeated over five random seeds, and we report the mean and standard deviation for each metric.
We compare Plugin with the following baselines: (a) Zeroshot: The black-box model directly performs text generation without additional adaptation. (b) ICL-1 (Long et al., 2023): One randomly selected validation sample is used as an in-context example. (c) ICL-3 (Long et al., 2023): Three randomly selected validation samples are used as in-context examples. (d) NewModel: A new language model is trained using the validation data. (e) WeightedComb (Liu et al., 2021): A new model is trained alongside the black-box model, with token probabilities computed as $\alpha\bm{n}+(1-\alpha)\bm{b}$ , where $\bm{n}$ represents the probabilities from the new model and $\alpha$ is cross-validated in $\{0.25,0.50,0.75\}$ . (f) TempNet (Qiu et al., 2024), a recent logit-scaling approach that learns a global temperature per input and uniformly scales logits during generation. Since the black-box model weights are inaccessible, fine-tuning-based approaches are not applicable in our setting. Nonetheless, we include a comparison with LoRA in Appendix C.4 for completeness. This highlights Plugin ’s competitiveness despite operating under stricter access constraints than required for PEFT.
All methods use the same prompts where applicable (Appendix C.2) and employ greedy decoding. The base (black-box) models used are GPT2-M (Radford et al., 2019), GPT2-XL (Radford et al., 2019), and LLaMA-3.1-8B (Dubey et al., 2024). NewModel, WeightedComb, and the reweighting model in Plugin share the same architecture. For GPT-based models, these use a Transformer encoder with one hidden layer and default configurations. For LLaMA-based models, the architecture consists of a Transformer encoder with one hidden layer, 256 hidden size, 1024 intermediate size, and one attention head. Learning rate and weight decay are cross-validated over $\{1e-5,5e-5,1e-4,5e-4,1e-3,5e-3\}$ and $\{0.01,0.1,1,10\}$ , respectively. Models are trained using AdamW with warmup followed by linear decay, and early stopping is applied if the hyper-validation loss does not decrease for five consecutive epochs.
As shown in Tables 1 – 4 (the best is bold, the second best is underlined), Plugin outperforms baselines across nearly all datasets, black-box models, and evaluation metrics. NewModel occasionally achieves higher NIST scores due to increased repetition of less-frequent input tokens, but this comes at the cost of coherence, as reflected by other metrics. WeightedComb does not perform well, indicating one combination for all tokens is not a good modeling choice. TempNet, which learns a single temperature per input and uniformly scales logits during generation, also underperforms. In contrast, Plugin reweights logits at each timestep, enabling finer, context-sensitive adjustments.
<details>
<summary>x1.png Details</summary>
### Visual Description
# Technical Data Extraction: Performance Comparison of GPT2-M Models
This document provides a detailed extraction of data from two side-by-side bar charts comparing the performance of "Base" vs. "Plugin" configurations across different fine-tuning stages of the GPT2-M model.
## 1. Document Structure and Metadata
* **Image Type:** Grouped Bar Charts (2 panels).
* **Primary Language:** English.
* **X-Axis Categories (Common to both):**
1. GPT2-M (zeroshot)
2. GPT2-M (1FT)
3. GPT2-M (2FT)
4. GPT2-M (5FT)
* **Legend (Common to both):**
* **Base:** Light mauve/pink color (Left bar in each pair).
* **Plugin:** Dark purple/plum color (Right bar in each pair).
* **Legend Location:** Top-left quadrant of each chart.
* **Y-Axis Label:** "Value" (Shared/Centralized).
---
## 2. Chart 1: BLEU Score Analysis
### Component Isolation: BLEU Chart
* **Header:** BLEU
* **Y-Axis Range:** 0.00 to 0.30+ (Markers every 0.05).
* **Trend Verification:**
* **Base Series:** Shows a significant jump from zeroshot to 1FT, plateaus at 2FT, and increases slightly at 5FT.
* **Plugin Series:** Shows a consistent upward trend across all stages, significantly outperforming the Base model at every stage.
### Extracted Data Points (Approximate based on grid alignment)
| Model Stage | Base (Light Mauve) | Plugin (Dark Purple) |
| :--- | :--- | :--- |
| **GPT2-M (zeroshot)** | ~0.025 | ~0.185 |
| **GPT2-M (1FT)** | ~0.220 | ~0.300 |
| **GPT2-M (2FT)** | ~0.220 | ~0.310 |
| **GPT2-M (5FT)** | ~0.245 | ~0.320 |
---
## 3. Chart 2: Rouge-L Score Analysis
### Component Isolation: Rouge-L Chart
* **Header:** Rouge-L
* **Y-Axis Range:** 0.00 to 0.50 (Markers every 0.10).
* **Trend Verification:**
* **Base Series:** Shows a steady, linear-style upward trend from zeroshot through 5FT.
* **Plugin Series:** Shows a sharp increase from zeroshot to 1FT, followed by a very gradual upward slope through 5FT.
### Extracted Data Points (Approximate based on grid alignment)
| Model Stage | Base (Light Mauve) | Plugin (Dark Purple) |
| :--- | :--- | :--- |
| **GPT2-M (zeroshot)** | ~0.225 | ~0.390 |
| **GPT2-M (1FT)** | ~0.385 | ~0.465 |
| **GPT2-M (2FT)** | ~0.400 | ~0.470 |
| **GPT2-M (5FT)** | ~0.425 | ~0.485 |
---
## 4. Key Technical Observations
1. **Plugin Superiority:** In both BLEU and Rouge-L metrics, the "Plugin" configuration consistently outperforms the "Base" configuration across all training stages.
2. **Zeroshot Impact:** The most dramatic performance delta between Base and Plugin occurs in the "zeroshot" stage, particularly in the BLEU metric where the Base model is near zero while the Plugin model achieves a substantial score.
3. **Diminishing Returns:** While performance increases with more fine-tuning (from 1FT to 5FT), the rate of improvement slows down significantly after the first fine-tuning stage (1FT) for both metrics.
4. **Metric Scaling:** Rouge-L values are generally higher than BLEU values for the same model configurations, with the Plugin model approaching a 0.50 Rouge-L score at 5FT.
</details>
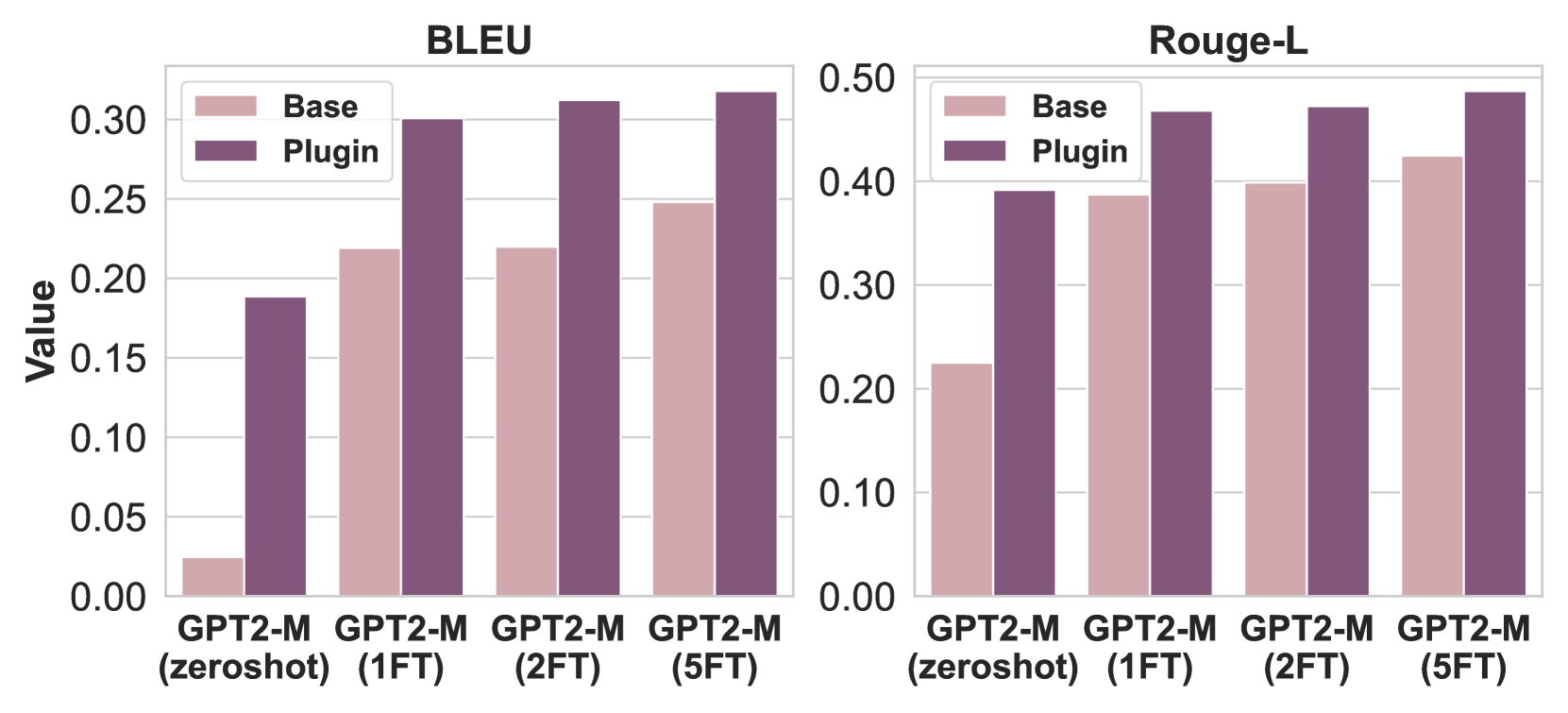
Figure 2: Plugin with increasingly fine-tuned GPT2-M models on the E2E NLG dataset. Results demonstrate that as the quality of the base model improves, the performance of the Plugin improves.
<details>
<summary>x2.png Details</summary>
### Visual Description
# Technical Data Extraction: Performance Comparison of Reweighting Modules
This document contains a detailed extraction of data from two side-by-side bar charts comparing the performance of different reweighting modules across two metrics: **BLEU** and **Rouge-L**.
## 1. General Layout and Metadata
- **Image Type:** Comparative Bar Charts with overlaid line plots.
- **Language:** English.
- **X-Axis Label (Both Charts):** "Choice of the reweighting module"
- **Y-Axis Label (Left Chart):** "Value"
- **X-Axis Categories (Common to both):**
1. No plugin
2. 1-layer
3. 2-layer
4. 4-layer
5. 8-layer
6. 12-layer
7. GPT2 Small
- **Visual Encoding:**
- Bars represent the value for each category.
- A dashed black line with circular markers connects the top of each bar to visualize the trend across configurations.
- Color Gradient: The bars transition from a light dusty rose (left) to a deep plum/purple (right).
---
## 2. Chart 1: BLEU Score Analysis
### Component Isolation: BLEU
- **Y-Axis Scale:** 0.00 to 0.30 with increments of 0.05.
- **Trend Description:** There is a sharp initial increase from "No plugin" to "1-layer," followed by a slight plateau/minor decrease through the "12-layer" configuration. A significant final spike occurs for the "GPT2 Small" module, which achieves the highest performance.
### Data Points (Estimated from Y-Axis)
| Reweighting Module | BLEU Value (Approx.) | Visual Trend |
| :--- | :--- | :--- |
| No plugin | 0.025 | Baseline |
| 1-layer | 0.188 | Sharp Increase |
| 2-layer | 0.162 | Slight Decrease |
| 4-layer | 0.160 | Plateau |
| 8-layer | 0.159 | Plateau |
| 12-layer | 0.158 | Plateau |
| GPT2 Small | 0.292 | Significant Spike (Peak) |
---
## 3. Chart 2: Rouge-L Score Analysis
### Component Isolation: Rouge-L
- **Y-Axis Scale:** 0.00 to 0.40+ (Markers go up to 0.45+) with increments of 0.10.
- **Trend Description:** Similar to the BLEU chart, there is a massive jump from "No plugin" to "1-layer." The performance remains remarkably stable (flat) across the "1-layer" to "12-layer" range, before another notable increase for the "GPT2 Small" module.
### Data Points (Estimated from Y-Axis)
| Reweighting Module | Rouge-L Value (Approx.) | Visual Trend |
| :--- | :--- | :--- |
| No plugin | 0.225 | Baseline |
| 1-layer | 0.392 | Sharp Increase |
| 2-layer | 0.380 | Minor Dip / Stable |
| 4-layer | 0.378 | Stable |
| 8-layer | 0.376 | Stable |
| 12-layer | 0.378 | Stable |
| GPT2 Small | 0.465 | Significant Spike (Peak) |
---
## 4. Summary of Findings
- **Impact of Plugin:** Adding any reweighting module (even a 1-layer version) provides a substantial performance boost over the "No plugin" baseline in both metrics.
- **Layer Scaling:** Increasing the number of layers in the reweighting module from 1 to 12 does not result in performance gains; in fact, performance remains largely stagnant or slightly regresses compared to the 1-layer version.
- **Model Superiority:** The "GPT2 Small" module consistently outperforms all other configurations, including the multi-layer custom modules, suggesting that the pre-trained architecture provides a superior basis for reweighting.
</details>
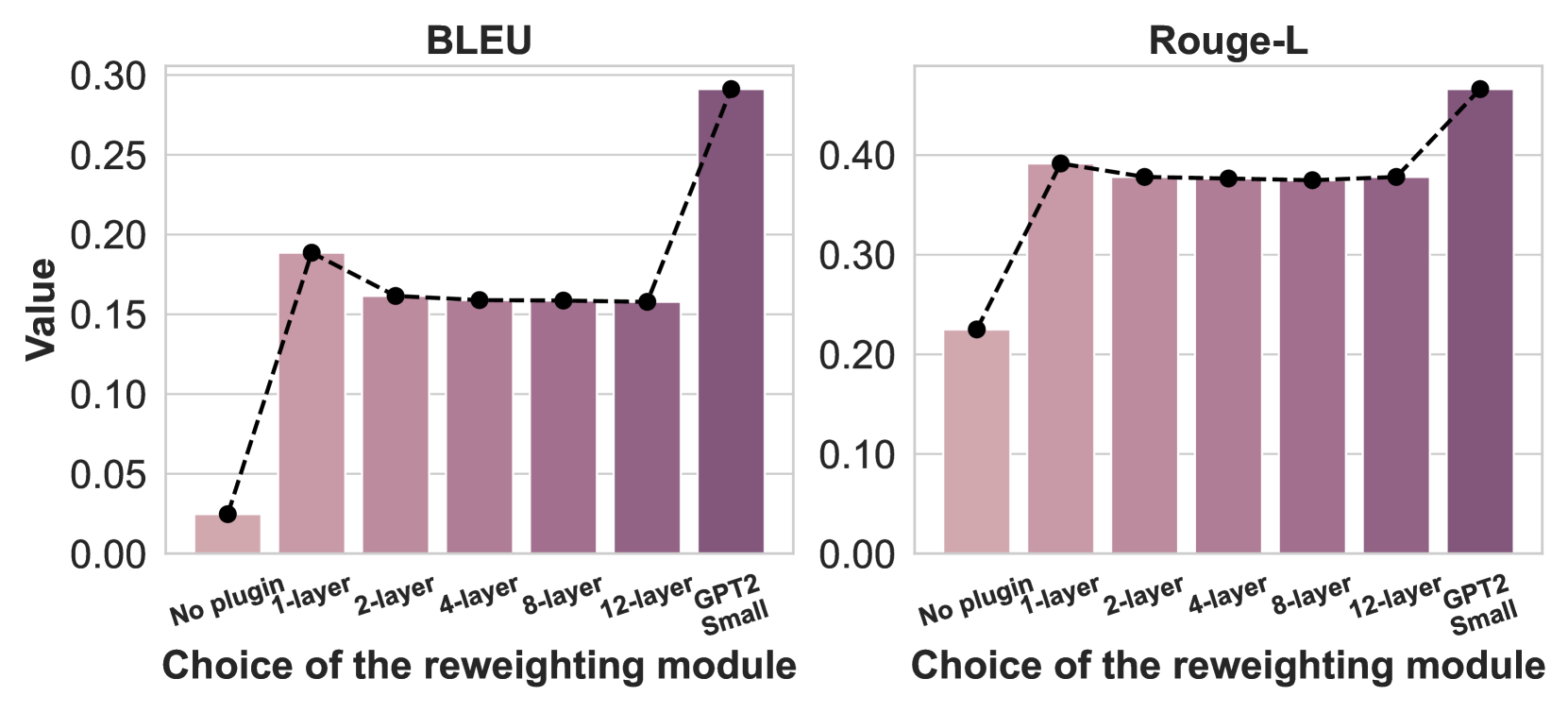
Figure 3: Performance of GPT2-M with varying reweighting model complexities on E2E NLG (BLEU, ROUGE-L). A single-layer reweighting model yields significant gains, while additional layers degrade performance due to overfitting. Initializing with GPT2-Small as the reweighting model improves performance, demonstrating the benefits of leveraging small pretrained models.
We note that the absolute numbers may not appear competitive with state-of-the-art results, because (a) we restrict to greedy decoding (Section 4.2), and (b) Web NLG and CommonGen use distribution-shifted subsets.
We also conduct a human evaluation on 100 Adidas dataset samples, where three subjects compare outputs from Plugin and ICL-3 using LLaMA-3.1 as the base model. Evaluators select the prediction closest to the ground truth, with Plugin preferred in 81% of cases. Details are in Appendix C.7.
<details>
<summary>extracted/6617062/icml2025/images/adidas_histogram.png Details</summary>
### Visual Description
# Technical Document: Analysis of Plugin Model Reweighting in Text Generation
This document provides a comprehensive extraction and analysis of the provided technical diagram, which illustrates the effect of a "Plugin Model" on text generation via a reweighting process.
## 1. Component Isolation
The image is structured into three primary horizontal segments:
* **Top Segment (Input & Reference):** Defines the task and the target output.
* **Middle Segment (Process):** Shows the transformation from a Base Model to a Plugin Model via "reweighting."
* **Bottom Segment (Data Visualization):** Three bar charts showing probability distributions at specific decoding steps.
---
## 2. Textual Content Extraction
### Region: Given Product Attributes (Top Left)
* **Icon:** A black long-sleeve zip-up shirt.
* **Header:** Given Product Attributes
* **Input Text:** "Given the following attributes of a product, write a description."
* **Data Fields:**
| Field | Value |
| :--- | :--- |
| `name` | [Adizero 1/2 Zip Long Sleeve Tee] |
| `Category` | [Clothing] |
| `Price` | [68] |
| `Color` | [Black] |
### Region: Ground-truth Reference (Top Right)
* **Icon:** A male character with glasses and a lightbulb (representing an expert/human).
* **Header:** Ground-truth Reference
* **Description:** "More of the warmth, less of the weight. This adidas running tee gives you a light, stretchy layer to wear while training and racing. AEROREADY wicks moisture, so you stay dry before it gets cold. Slip the thumbhole sleeves over your hands for extra coverage. This product is made with Primegreen, a series of high-performance recycled materials."
### Region: Base Model (Middle Left)
* **Icon:** A blue robot.
* **Header:** Base Model
* **Description:** "The adizero 1/2 zip long sleeve tee is a great way to keep your feet warm and dry. The soft, fabric has been designed with comfort in mind."
* **Note:** The model incorrectly mentions "feet" for a shirt product.
### Region: Plugin Model (Middle Right)
* **Icon:** A blue robot combined with a pink brain/circuit icon.
* **Header:** Plugin Model
* **Process Arrow:** A black arrow pointing from Base Model to Plugin Model labeled **"+ reweighting"**.
* **Description:** "It's a long sleeve tee that is made in the adidas style. It keeps all your busy days short to **<u>keep</u>** you feeling fresh, energized and ready for whatever comes next. This product belongs on this page:Stay **<u>comfortable</u>** through our **<u>ambition</u>**-driven line of high-performance recycled materials."
* **Formatting:** The words "keep", "comfortable", and "ambition" are highlighted in red and underlined, corresponding to the charts below.
---
## 3. Data Visualization: Probability Distributions
All three charts share the following characteristics:
* **Y-Axis:** "Normalized Probability" (Scale varies per chart).
* **X-Axis:** Categorical labels representing a vocabulary of tokens (e.g., adidas, made, recycled, shoes, etc.).
* **Legend:**
* **Light Blue:** Base Model
* **Light Red/Pink:** Plugin Model
* **Legend Placement:** Top right of each chart [x≈0.9, y≈0.9].
### Chart 1: Decoding Step 23
* **Target Token:** "keep"
* **Trend:** The Base Model has low probability across most tokens. The Plugin Model shows a massive spike for the token "keep".
* **Key Data Points:**
| Token | Base Model Prob | Plugin Model Prob |
| :--- | :--- | :--- |
| "keep" | ~0.01 | ~0.17 (Highest peak) |
| "soft" | ~0.02 | ~0.01 |
| "running" | ~0.01 | ~0.005 |
### Chart 2: Decoding Step 48
* **Target Token:** "comfortable"
* **Trend:** The Base Model distribution is nearly flat/zero for the target. The Plugin Model shows a singular dominant spike at "comfortable".
* **Key Data Points:**
| Token | Base Model Prob | Plugin Model Prob |
| :--- | :--- | :--- |
| "comfortable" | ≈ 0.00 | ≈ 0.09 (Highest peak) |
| "dry" | ≈ 0.005 | ≈ 0.032 |
### Chart 3: Decoding Step 51
* **Target Token:** "ambition"
* **Trend:** This chart shows a higher y-axis scale (up to 0.5). The Base Model has a notable peak at "materials", but the Plugin Model overrides this with an extremely high probability for "ambition".
* **Key Data Points:**
| Token | Base Model Prob | Plugin Model Prob |
| :--- | :--- | :--- |
| "ambition" | ≈ 0.00 | ≈ 0.51 (Dominant peak) |
| "materials" | ≈ 0.20 | ≈ 0.08 |
| "products" | ≈ 0.08 | ≈ 0.11 |
---
## 4. Summary of Findings
The image demonstrates a **reweighting mechanism** where a "Plugin Model" modifies the output of a "Base Model."
1. **Correction:** The Base Model produced a hallucination ("keep your feet warm" for a shirt).
2. **Mechanism:** The bar charts prove that at specific decoding steps (23, 48, 51), the Plugin Model significantly increases the probability of specific tokens ("keep", "comfortable", "ambition") that were nearly non-existent in the Base Model's original distribution.
3. **Result:** The final text is steered toward a specific vocabulary, likely derived from the "Ground-truth Reference" or a specific stylistic plugin.
</details>
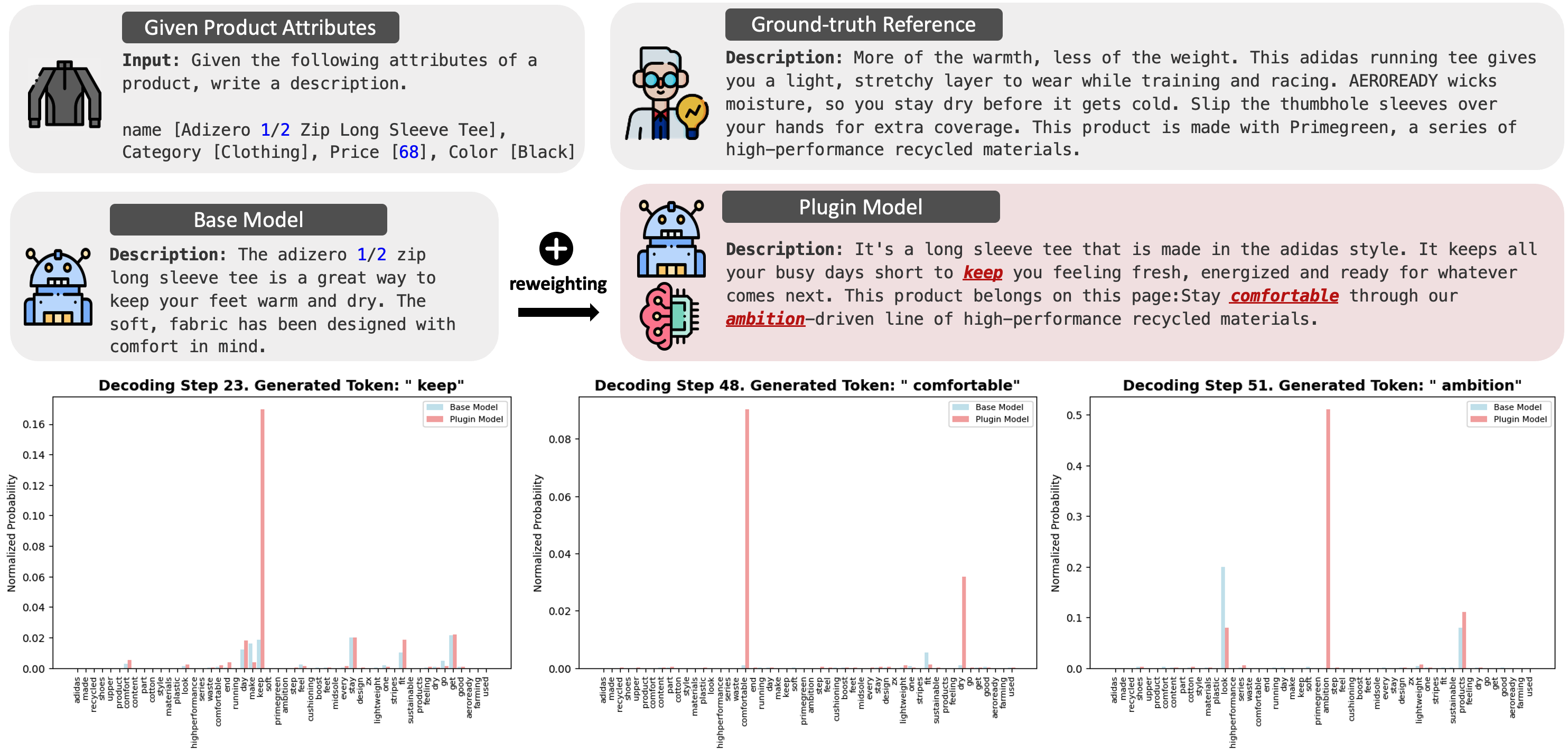
Figure 4: Comparison of the adaptation ability between the base model and Plugin on Adidas dataset. Plugin, enhanced with a reweighting model, generates text that better aligns with the “ Adidas domain ”. The bottom row illustrates token probabilities for key Adidas-related words at different decoding steps, showing how the reweighting model influences token selection.
7.2 Plugin as a Wrapper
Table 5: Performance comparison of BDPL and BDPL + Plugin.
| Dataset | Method | BLEU | | Rouge-L | METEOR | CIDEr | NIST |
| --- | --- | --- | --- | --- | --- | --- | --- |
| E2E NLG | BDPL | 0.2287 | | 0.3922 | 0.4628 | 0.4216 | 0.8625 |
| BDPL + Plugin | 0.4527 | | 0.6027 | 0.6214 | 0.7002 | 2.0817 | |
| WEB NLG | BDPL | 0.1024 | | 0.3017 | 0.3527 | 0.4321 | 0.2631 |
| BDPL + Plugin | 0.2137 | | 0.5928 | 0.5766 | 1.0826 | 0.6142 | |
| CommonGen | BDPL | 0.1023 | | 0.2936 | 0.3362 | 0.2517 | 0.4226 |
| BDPL + Plugin | 0.2614 | | 0.5241 | 0.5016 | 0.8251 | 0.9261 | |
| Adidas | BDPL | 0.0417 | | 0.1710 | 0.1826 | 0.0861 | 0.6034 |
| BDPL + Plugin | 0.0623 | | 0.1759 | 0.2148 | 0.1325 | 0.7024 | |
If logit access is available, Plugin can be applied on top of any prompt-based method using its best-found prompt. For example, our Zeroshot prompt is reused across methods. We also apply Plugin to the Black-box Discrete Prompt Learning (BDPL) approach from Diao et al. (2022), following their recommended 75 API call budget. Table 5 shows results on all datasets with GPT2-XL as the base model. Plugin outperforms BDPL (see Tables 1 – 4), and their combination yields further gains, underscoring the utility of logit-level access in strengthening prompt-based methods.
7.3 Ablation Study
We now show ablation studies that reflect various aspects of the Plugin model. We display the results using GPT2-M as base model on the E2E NLG dataset. The observation is similar on other base models and datasets (Appendix C.5).
Impact of Base Model Quality.
We fine-tune GPT2-M for varying epochs, denoted as 1FT (one epoch), 2FT (two epochs), and 5FT (five epochs), and train a Plugin model for each. Figure 2 shows that as the base model’s task-specific quality improves, the Plugin’s performance improves.
Complexity of the Reweighting Model in Plugin.
We train Plugin models with reweighting architectures varying from 1 to 12 transformer layers while keeping other configurations unchanged. Additionally, we train a variant where the reweighting model is initialized with GPT2-Small. As shown in Figure 3, a single-layer reweighting model yields significant improvements over the base GPT2-M model, while additional layers (e.g., 2, 4, 8, 12) offer diminishing returns and slight performance decline due to overfitting on the small validation set of E2E NLG. This suggests that more data is required for learning complex reweighting models. Notably, initializing with a pretrained GPT2-Small substantially improves performance, underscoring the advantage of using small pretrained models for reweighting due to their inherent autoregressive properties.
7.4 Qualitative Analysis and Case Study
Plugin adapting to distribution shift.
We evaluate Plugin on distribution-shifted Web NLG and CommonGen using LLaMA-3.1-8B as the base model. Web NLG training data contains only Infrastructure concepts, while validation and test sets include Person concepts. Similarly, CommonGen training data features man, whereas validation and test sets contain both man and woman. The base model is fine-tuned on the training data, and Plugin is trained on validation data using the fine-tuned model as the base. These settings reflect different degrees of domain shift, even adversarial to some extent as the training distributions induce biases (e.g., overemphasis on infrastructure or male-related concepts), and Plugin is tasked with correcting them during inference.
Using GPT-4o (Hurst et al., 2024) as an evaluator, the fine-tuned Web NLG model generates only 17.99% Person -related sentences, while Plugin increases this to 71.34%. On CommonGen, the fine-tuned model generates 10.37% Woman -related sentences, whereas Plugin improves this to 31.92%. These results highlight Plugin ’s ability to adapt under distribution shift and mitigate biases in the base model.
Case study: Plugin adapting to domain (extreme distirbution shifts).
We examine token probabilities during inference for LLaMA-3.1-8B and Plugin to assess domain adaptation in the Adidas dataset, which features product-centric language and a brand-specific tone that diverge significantly from the general pretraining distribution of the black-box LLMs. This experimental setup can also be viewed as extreme distribution shift. Removing stopwords, we extract the top-50 most frequent words, defining the “ Adidas domain ”. Figure 4 illustrates this adaptation: the first row shows product attributes and ground-truth references; the second row compares outputs from the base model (left) and Plugin (right); the third row visualizes model probabilities for “ Adidas domain ” words at three decoding steps.
As seen in Figure 4, Plugin dynamically reweights probabilities to align with domain-specific language. At step 23, “keep” is significantly upweighted. At step 48, “comfortable” and “dry” gain prominence over “fit,” which the base model favors. At step 59, “recycled” is preferred by Plugin, aligning with the ground truth, while the base model favors “running” and “products”. This demonstrates that Plugin effectively steers generation toward domain-specific terminology, whereas the base model, trained on broad corpora, lacks inherent domain preference.
Unlike methods that prune or suppress tokens, Plugin softly reweights token probabilities without eliminating any vocabulary candidates. This preserves full coverage while amplifying domain-specific terms. To quantify this, we measure the total occurrences of the top-50 “ Adidas domain ” words in generated outputs: Plugin includes 25.6% of these terms compared to 13.8% in the base model, indicating substantially improved alignment with domain language.
8 Conclusion
We propose Plugin, a token-level probability reweighting framework that adapts black-box LLMs using only logits and small task-specific data. Framing next-token prediction as a label noise correction problem, we demonstrate both theoretical guarantees and empirical effectiveness across multiple datasets and models. Our findings highlight the potential of logit-based adaptation and advocate for broader access to token logits in closed-source LLMs.
Acknowledgements
HW acknowledges support by Fonds de recherche du Québec – Nature et technologies (FRQNT) and Borealis AI. SK acknowledges support by NSF 2046795 and 2205329, IES R305C240046, the MacArthur Foundation, Stanford HAI, OpenAI, and Google.
Impact Statement
This work introduces a powerful middle ground between fully black-box APIs and fully white-box access to large language models (LLMs), addressing a critical constraint faced by developers: the inability to adapt models when weights and architecture are inaccessible. By leveraging token-level logits—without requiring access to model weights or architecture—our approach enables meaningful adaptation of closed-source LLMs for domain-specific tasks. This has far-reaching implications for both research and industry: it empowers developers to customize models within privacy-preserving, IP-sensitive environments while ensuring greater control, transparency, and safety. Our findings advocate for broader logit access as a scalable, secure, and effective interface—bridging the gap between usability and protection of proprietary models—and open new possibilities for equitable, context-aware language generation in real-world applications.
While Plugin effectively adapts black-box LLMs, it has some limitations, too. Since it only reweights token probabilities without modifying internal representations or embeddings, it may struggle with tasks requiring deep structural adaptations, such as executing complex reasoning. Further research on this aspect is needed. Additionally, although Plugin avoids full fine-tuning, training a separate reweighting model introduces computational overhead compared to prompt tuning or in-context learning, with efficiency depending on the complexity of the reweighting model and the availability of task-specific data.
References
- adi (2023) Adidas us retail products dataset. Kaggle, 2023. URL https://www.kaggle.com/datasets/whenamancodes/adidas-us-retail-products-dataset.
- Achiam et al. (2023) Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Bai et al. (2022a) Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022a.
- Bai et al. (2022b) Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022b.
- Banerjee & Lavie (2005) Banerjee, S. and Lavie, A. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In ACL workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pp. 65–72, 2005.
- Chaudhuri et al. (2015) Chaudhuri, K., Kakade, S. M., Netrapalli, P., and Sanghavi, S. Convergence rates of active learning for maximum likelihood estimation. Advances in Neural Information Processing Systems, 28, 2015.
- Christiano et al. (2017) Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- Dathathri et al. (2020) Dathathri, S., Madotto, A., Lan, J., Hung, J., Frank, E., Molino, P., Yosinski, J., and Liu, R. Plug and play language models: A simple approach to controlled text generation. In International Conference on Learning Representations, 2020.
- Dettmers et al. (2024) Dettmers, T., Pagnoni, A., Holtzman, A., and Zettlemoyer, L. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36, 2024.
- Diao et al. (2022) Diao, S., Huang, Z., Xu, R., Li, X., Lin, Y., Zhou, X., and Zhang, T. Black-box prompt learning for pre-trained language models. arXiv preprint arXiv:2201.08531, 2022.
- Doddington (2002) Doddington, G. Automatic evaluation of machine translation quality using n-gram co-occurrence statistics. In International conference on Human Language Technology Research, pp. 138–145, 2002.
- Dong et al. (2024) Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R., Xia, H., Xu, J., Wu, Z., Chang, B., et al. A survey on in-context learning. In Conference on Empirical Methods in Natural Language Processing, pp. 1107–1128, 2024.
- Dubey et al. (2024) Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Dušek et al. (2020) Dušek, O., Novikova, J., and Rieser, V. Evaluating the state-of-the-art of end-to-end natural language generation: The e2e nlg challenge. Computer Speech & Language, 59:123–156, 2020.
- Frostig et al. (2015) Frostig, R., Ge, R., Kakade, S. M., and Sidford, A. Competing with the empirical risk minimizer in a single pass. In Conference on learning theory, pp. 728–763. PMLR, 2015.
- Gao et al. (2024) Gao, G., Taymanov, A., Salinas, E., Mineiro, P., and Misra, D. Aligning llm agents by learning latent preference from user edits. arXiv preprint arXiv:2404.15269, 2024.
- Gardent et al. (2017) Gardent, C., Shimorina, A., Narayan, S., and Perez-Beltrachini, L. Creating training corpora for nlg micro-planning. In Annual Meeting of the Association for Computational Linguistics, pp. 179–188, 2017.
- Hiranandani et al. (2021) Hiranandani, G., Mathur, J., Narasimhan, H., Fard, M. M., and Koyejo, S. Optimizing black-box metrics with iterative example weighting. In International Conference on Machine Learning, pp. 4239–4249. PMLR, 2021.
- Hsu et al. (2012) Hsu, D., Kakade, S., Zhang, T., et al. A tail inequality for quadratic forms of subgaussian random vectors. Electronic Communications in Probability, 17, 2012.
- Hu et al. (2021) Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Hu et al. (2023a) Hu, Z., Wang, L., Lan, Y., Xu, W., Lim, E.-P., Bing, L., Xu, X., Poria, S., and Lee, R. LLM-adapters: An adapter family for parameter-efficient fine-tuning of large language models. In Conference on Empirical Methods in Natural Language Processing, pp. 5254–5276, 2023a.
- Hu et al. (2023b) Hu, Z., Wang, L., Lan, Y., Xu, W., Lim, E.-P., Bing, L., Xu, X., Poria, S., and Lee, R. Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models. In Conference on Empirical Methods in Natural Language Processing, pp. 5254–5276, 2023b.
- Huang et al. (2024) Huang, Y., Liu, Y., Thirukovalluru, R., Cohan, A., and Dhingra, B. Calibrating long-form generations from large language models. arXiv preprint arXiv:2402.06544, 2024.
- Hurst et al. (2024) Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024.
- Kapoor et al. (2024) Kapoor, S., Gruver, N., Roberts, M., Pal, A., Dooley, S., Goldblum, M., and Wilson, A. Calibration-tuning: Teaching large language models to know what they don’t know. In Workshop on Uncertainty-Aware NLP, pp. 1–14, 2024.
- Kojima et al. (2022) Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., and Iwasawa, Y. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35, 2022.
- Koyejo et al. (2014) Koyejo, O. O., Natarajan, N., Ravikumar, P. K., and Dhillon, I. S. Consistent binary classification with generalized performance metrics. Advances in neural information processing systems, 27, 2014.
- Krause et al. (2021) Krause, B., Gotmare, A. D., McCann, B., Keskar, N. S., Joty, S., Socher, R., and Rajani, N. F. Gedi: Generative discriminator guided sequence generation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 4929–4952, 2021.
- Lattimore & Szepesvári (2020) Lattimore, T. and Szepesvári, C. Bandit algorithms. Cambridge University Press, 2020.
- Lester et al. (2021) Lester, B., Al-Rfou, R., and Constant, N. The power of scale for parameter-efficient prompt tuning. In Conference on Empirical Methods in Natural Language Processing, pp. 3045–3059, 2021.
- Li et al. (2022) Li, X., Thickstun, J., Gulrajani, I., Liang, P. S., and Hashimoto, T. B. Diffusion-lm improves controllable text generation. Advances in Neural Information Processing Systems, 35:4328–4343, 2022.
- Li & Liang (2021) Li, X. L. and Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. In Annual Meeting of the Association for Computational Linguistics, pp. 4582–4597, 2021.
- Lin et al. (2020) Lin, B. Y., Zhou, W., Shen, M., Zhou, P., Bhagavatula, C., Choi, Y., and Ren, X. Commongen: A constrained text generation challenge for generative commonsense reasoning. In Findings of the Association for Computational Linguistics, pp. 1823–1840, 2020.
- Lin (2004) Lin, C.-Y. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pp. 74–81, 2004.
- Lin & Och (2004) Lin, C.-Y. and Och, F. J. Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In Annual meeting of the association for computational linguistics, pp. 605–612, 2004.
- Lipton et al. (2018) Lipton, Z., Wang, Y.-X., and Smola, A. Detecting and correcting for label shift with black box predictors. In International conference on machine learning, pp. 3122–3130. PMLR, 2018.
- Liu et al. (2021) Liu, A., Sap, M., Lu, X., Swayamdipta, S., Bhagavatula, C., Smith, N. A., and Choi, Y. Dexperts: Decoding-time controlled text generation with experts and anti-experts. In Annual Meeting of the Association for Computational Linguistics, 2021.
- Liu et al. (2024) Liu, A., Han, X., Wang, Y., Tsvetkov, Y., Choi, Y., and Smith, N. A. Tuning language models by proxy. arXiv preprint arXiv:2401.08565, 2024.
- Long et al. (2023) Long, Q., Wang, W., and Pan, S. Adapt in contexts: Retrieval-augmented domain adaptation via in-context learning. In Conference on Empirical Methods in Natural Language Processing, pp. 6525–6542, 2023.
- Mireshghallah et al. (2022) Mireshghallah, F., Goyal, K., and Berg-Kirkpatrick, T. Mix and match: Learning-free controllable text generationusing energy language models. In Annual Meeting of the Association for Computational Linguistics, pp. 401–415, 2022.
- Mukherjee et al. (2022) Mukherjee, S., Tripathy, A. S., and Nowak, R. Chernoff sampling for active testing and extension to active regression. In International Conference on Artificial Intelligence and Statistics, pp. 7384–7432. PMLR, 2022.
- Naghshvar & Javidi (2013) Naghshvar, M. and Javidi, T. Active sequential hypothesis testing. 2013.
- Narasimhan et al. (2015) Narasimhan, H., Ramaswamy, H., Saha, A., and Agarwal, S. Consistent multiclass algorithms for complex performance measures. In International Conference on Machine Learning, pp. 2398–2407. PMLR, 2015.
- Ouyang et al. (2022) Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Papineni et al. (2002) Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. Bleu: a method for automatic evaluation of machine translation. In Annual meeting of the Association for Computational Linguistics, pp. 311–318, 2002.
- Patrini et al. (2017) Patrini, G., Rozza, A., Krishna Menon, A., Nock, R., and Qu, L. Making deep neural networks robust to label noise: A loss correction approach. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1944–1952, 2017.
- Qiu et al. (2024) Qiu, Z.-H., Guo, S., Xu, M., Zhao, T., Zhang, L., and Yang, T. To cool or not to cool? temperature network meets large foundation models via dro. arXiv preprint arXiv:2404.04575, 2024.
- Radford et al. (2019) Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Rafailov et al. (2024) Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36, 2024.
- Sanh et al. (2022) Sanh, V., Webson, A., Raffel, C., Bach, S., Sutawika, L., Alyafeai, Z., Chaffin, A., Stiegler, A., Raja, A., Dey, M., et al. Multitask prompted training enables zero-shot task generalization. In International Conference on Learning Representations, 2022.
- Shen et al. (2024) Shen, M., Das, S., Greenewald, K., Sattigeri, P., Wornell, G. W., and Ghosh, S. Thermometer: Towards universal calibration for large language models. In International Conference on Machine Learning, 2024.
- Singh et al. (2023) Singh, S. P., Hofmann, T., and Schölkopf, B. The hessian perspective into the nature of convolutional neural networks. arXiv preprint arXiv:2305.09088, 2023.
- Song et al. (2023) Song, C. H., Wu, J., Washington, C., Sadler, B. M., Chao, W.-L., and Su, Y. Llm-planner: Few-shot grounded planning for embodied agents with large language models. In IEEE/CVF International Conference on Computer Vision, pp. 2998–3009, 2023.
- Sukhbaatar et al. (2015) Sukhbaatar, S., Bruna, J., Paluri, M., Bourdev, L., and Fergus, R. Training convolutional networks with noisy labels. In International Conference on Learning Representations, 2015.
- Torroba-Hennigen et al. (2025) Torroba-Hennigen, L., Lang, H., Guo, H., and Kim, Y. On the duality between gradient transformations and adapters. arXiv preprint arXiv:2502.13811, 2025.
- Ulmer et al. (2024) Ulmer, D., Gubri, M., Lee, H., Yun, S., and Oh, S. J. Calibrating large language models using their generations only. arXiv preprint arXiv:2403.05973, 2024.
- Vedantam et al. (2015) Vedantam, R., Lawrence Zitnick, C., and Parikh, D. Cider: Consensus-based image description evaluation. In IEEE conference on computer vision and pattern recognition, pp. 4566–4575, 2015.
- Wei et al. (2021) Wei, J., Bosma, M., Zhao, V., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., and Le, Q. V. Finetuned language models are zero-shot learners. In International Conference on Learning Representations, 2021.
- Wolf (2020) Wolf, T. Transformers: State-of-the-art natural language processing. arXiv preprint arXiv:1910.03771, 2020.
- Yang & Klein (2021) Yang, K. and Klein, D. Fudge: Controlled text generation with future discriminators. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 3511–3535, 2021.
- Zhang et al. (2023) Zhang, H., Zhang, Y.-F., Yu, Y., Madeka, D., Foster, D., Xing, E., Lakkaraju, H., and Kakade, S. A study on the calibration of in-context learning. arXiv preprint arXiv:2312.04021, 2023.
- Zhang et al. (2024) Zhang, Y., Chen, C., Ding, T., Li, Z., Sun, R., and Luo, Z.-Q. Why transformers need adam: A hessian perspective. arXiv preprint arXiv:2402.16788, 2024.
- Zhu et al. (2023) Zhu, C., Xu, B., Wang, Q., Zhang, Y., and Mao, Z. On the calibration of large language models and alignment. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 9778–9795, 2023.
Appendix A Algorithm Details
We provide summarized form of the training and inference algorithm for the Plugin model below.
Algorithm 1 Training and Inference for the Plugin Model
Input: Black-box model $B$ , reweighting model $R$ , clean training data $\mathcal{D}$ , vocabulary $V$ Output: Plugin model predictions $\bm{x}_{1:T}$ for a given sequence
1: Training Phase:
2: for each sequence $s∈\mathcal{D}$ do
3: Compute token probabilities $\{\bm{b}_{1},\bm{b}_{2},...,\bm{b}_{m}\}$ using $B$ .
4: Compute token probabilities $\{\bm{r}_{1},\bm{r}_{2},...,\bm{r}_{m}\}$ using $R$ .
5: Combine probabilities: ${\bm{p}}_{i}=\frac{\bm{b}_{i}\odot\bm{r}_{i}}{\|\bm{b}_{i}\odot\bm{r}_{i}\|_{1}}$ for $i∈[m]$ .
6: Compute sequence loss $\ell_{s}=-\frac{1}{m}\sum_{i=1}^{m}\sum_{j=1}^{|V|}\log({\bm{p}}_{i})\odot\bm{%
e}_{j}$ .
7: Update parameters of $R$ using back-propagation. Freeze $B$ .
8: end for
9: Inference Phase:
10: Initialize sequence $\bm{x}_{1:T}=\{\}$ .
11: for each token position $t=1$ to $T$ do
12: Compute token probabilities $\bm{b}_{t}$ using $B$ .
13: Compute token probabilities $\bm{r}_{t}$ using $R$ .
14: Combine probabilities: ${\bm{p}}_{t}=\frac{\bm{b}_{t}\odot\bm{r}_{t}}{\|\bm{b}_{t}\odot\bm{r}_{t}\|_{1}}$ .
15: Predict token: $\bm{x}_{t}=\operatorname*{argmax}_{V}({\bm{p}}_{t})$ .
16: Append $\bm{x}_{t}$ to $\bm{x}_{1:T}$ .
17: end for
18: Return: $\bm{x}_{1:T}$
Appendix B Proof of Main Convergence Theorem
We define the following assumption on the smoothness and regularity of the loss function.
**Assumption B.1**
*We assume the following assumptions hold with probability $1$ :
1. (Convexity of $\ell_{s}$ ): The loss function $\ell_{s}$ is convex for all time $s∈[t]$ .
1. (Smoothness of $\ell_{s}$ ): The $\ell_{s}$ is smooth such that the first, second, and third derivatives exist at all interior points in $\bm{\Theta}$ .
1. (Regularity Conditions):
1. $\bm{\Theta}$ is compact and $\ell_{s}(\bm{\theta})$ is bounded for all $\bm{\theta}∈\bm{\Theta}$ and for all $s∈[t]$ .
1. $\bm{\theta}_{*}$ is an interior point in $\bm{\Theta}$ .
1. $∇^{2}\ell_{s}(\bm{\theta}_{*})$ is positive definite, for all $s∈[t]$ .
1. There exists a neighborhood $\mathcal{B}$ of $\bm{\theta}_{*}$ and a constant $C_{1}$ , such that $∇^{2}\ell_{s}(\bm{\theta})$ is $C_{1}$ -Lipschitz. Hence, we have that $\left\|∇^{2}\ell_{s}(\bm{\theta})-∇^{2}\ell_{s}\left(\bm{\theta}^{%
\prime}\right)\right\|_{*}≤ C_{1}\left\|\bm{\theta}-\bm{\theta}^{\prime}%
\right\|_{∇^{2}{\cal L}_{s}\left(\bm{\theta}_{*}\right)}$ , for $\bm{\theta},\bm{\theta}^{\prime}$ in this neighborhood.
1. (Concentration at $\bm{\theta}_{*}$ ): We further assume that $\left\|∇\ell_{s}\left(\bm{\theta}_{*}\right)\right\|_{\left(∇^{2}{%
\cal L}_{s}\left(\bm{\theta}_{*}\right)\right)^{-1}}≤ C_{2}$ hold with probability one.*
**Lemma B.2**
*(Proposition 2 of (Hsu et al., 2012)) Let $\mathbf{u}_{1},...,\mathbf{u}_{n}$ be a martingale difference vector sequence (i.e., $\mathbb{E}\left[\mathbf{u}_{i}\mid\mathbf{u}_{1},...,\mathbf{u}_{i-1}\right]=$ 0 for all $i=1,...,n$ ) such that
$$
\sum_{i=1}^{n}\mathbb{E}\left[\left\|\mathbf{u}_{i}\right\|^{2}\mid\mathbf{u}_%
{1},\ldots,\mathbf{u}_{i-1}\right]\leq v\quad\text{ and }\quad\left\|\mathbf{u%
}_{i}\right\|\leq b
$$
for all $i=1,...,n,$ almost surely. For all $t>0$
$$
\operatorname{Pr}\left[\left\|\sum_{i=1}^{n}\mathbf{u}_{i}\right\|>\sqrt{v}+%
\sqrt{8vt}+(4/3)bt\right]\leq e^{-t}
$$*
**Lemma B.3**
*The probability that $\|∇\widehat{\cal L}_{t}(\bm{\theta}_{*})\|_{\left(∇^{2}{\cal L}\left%
(\bm{\theta}_{*}\right)\right)^{-1}}$ crosses the threshold $\sqrt{\dfrac{c\gamma\log(dt)}{t}}>0$ is bounded by
| | $\displaystyle\mathbb{P}\left(\|∇\widehat{\cal L}_{t}(\bm{\theta}_{*})\|_{%
\left(∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)^{-1}}≥ C_{2%
}\sqrt{\dfrac{c\gamma\log(dt)}{t}}\right)≤\frac{1}{t^{c\gamma}}.$ | |
| --- | --- | --- |*
* Proof*
Define $\mathbf{u_{s}}\coloneqq∇(Y_{s}-f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},%
\mathcal{F}^{s-1}))^{2}$ . Then we have $\mathbf{u}_{1},\mathbf{u}_{2},...,\mathbf{u}_{t}$ as random vectors such that
| | $\displaystyle\mathbb{E}\left[\left\|\sum_{s=1}^{t}\mathbf{u_{s}}\right\|_{%
\left(∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)^{-1}}^{2}\bigg%
{|}\mathbf{u}_{1},...,\mathbf{u}_{s-1}\right]=\mathbb{E}\left[\sum_{s=1}^{t%
}\mathbf{u_{s}}^{→p}\left(∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)%
\right)^{-1}\mathbf{u_{s}}\mid\mathbf{u}_{1},...,\mathbf{u}_{s-1}\right]%
≤ tC^{2}_{2}$ | |
| --- | --- | --- |
Also we have that $\|\mathbf{u_{s}}\|≤ C_{2}$ . Finally we have that
| | $\displaystyle\mathbb{E}[∇_{\bm{\theta}=\bm{\theta}_{*}}\mathbf{u_{s}}]=-2%
\sum_{s=1}^{t}p_{{\widehat{\bm{\theta}}}_{s-1}}(f_{I_{s}}(\bm{\theta}_{*};x_{i%
},x_{j},\mathcal{F}^{s-1})-f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{%
s-1})∇_{\bm{\theta}=\bm{\theta}_{*}}f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j}%
,\mathcal{F}^{s-1})=0.$ | |
| --- | --- | --- |
Then following Lemma B.2 and by setting $\epsilon=c\gamma\log(dt)$ we can show that
| | $\displaystyle\mathbb{P}$ | $\displaystyle\left(\|\frac{1}{t}\sum_{s=1}^{t}\mathbf{u_{s}}\|^{2}_{{}_{\left(%
∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)^{-1}}}-\mathbb{E}%
\left[\|\frac{1}{t}\sum_{s=1}^{t}\mathbf{u_{s}}\|^{2}_{{}_{\left(∇^{2}{%
\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)^{-1}}}\right]>\frac{1}{t}\sqrt{%
8tC_{2}^{2}\epsilon}+\dfrac{4C_{2}}{3\epsilon}\right)$ | |
| --- | --- | --- | --- |
The claim of the lemma follows. ∎
**Lemma B.4**
*Let the $j$ -th row and $k$ -th column entry in the Hessian matrix $∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}(\ell_{s}(\bm{\theta}))$ be denoted as $[∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}(\ell_{s}(\bm{\theta}))]_{jk}$ . Then we have that
| | $\displaystyle[∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}(\ell_{s}(\bm{%
\theta}))]_{jk}=2\dfrac{∂ f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}%
^{s-1})}{∂\bm{\theta}_{j}}\dfrac{∂ f_{I_{s}}(\bm{\theta};x_{i},x%
_{j},\mathcal{F}^{s-1})}{∂\bm{\theta}_{k}}+2\left(f_{I_{s}}(\bm{\theta}%
;x_{i},x_{j},\mathcal{F}^{s-1})-Y_{s}\right)\dfrac{∂^{2}f_{I_{s}}(\bm{%
\theta};x_{i},x_{j},\mathcal{F}^{s-1})}{∂\bm{\theta}_{j}∂\bm{%
\theta}_{k}}.$ | |
| --- | --- | --- |*
* Proof*
This lemma follows from Frostig et al. (2015); Mukherjee et al. (2022) adapted to our setting for the squared loss, and transition function $f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1})$ . We want to evaluate the Hessian $∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}(\ell_{s}(\bm{\theta}))$ at any $\bm{\theta}^{\prime}∈\bm{\Theta}$ . We denote the $j$ -th row and $k$ -th column entry in the Hessian matrix as $[∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}(\ell_{s}(\bm{\theta}))]_{jk}$ . Then we can show that
| | $\displaystyle[∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}(\ell_{s}(\bm{%
\theta}))]_{jk}$ | $\displaystyle\coloneqq\frac{∂}{∂\bm{\theta}_{j}}\left[\frac{%
∂(f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})-Y_{s})^{2}}{%
∂\bm{\theta}_{k}}\right]=\frac{∂}{∂\bm{\theta}_{j}}\left[%
2(f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})-Y_{s})\frac{∂ f_%
{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})}{∂\bm{\theta}_{k}}\right]$ | |
| --- | --- | --- | --- |
The claim of the lemma follows. ∎
**Lemma B.5**
*Let the $j$ -th row and $k$ -th column entry in the Hessian matrix $∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}(\mathbb{E}[\ell_{s}(\bm{\theta})%
|\mathcal{F}^{s-1}])$ be denoted as $[∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}(\mathbb{E}[\ell_{s}(\bm{\theta}%
)|\mathcal{F}^{s-1}])]_{jk}$ . Then we have that
| | $\displaystyle\left[∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}\mathbb{E}[%
\ell_{s}(\bm{\theta})|\mathcal{F}^{s-1}]\right]_{jk}$ | $\displaystyle=2\sum_{i=1}^{|V|}p_{{\widehat{\bm{\theta}}}_{s-1}}(i)\left(%
\dfrac{∂ f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})}{∂%
\bm{\theta}_{j}}\dfrac{∂ f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^%
{s-1})}{∂\bm{\theta}_{k}}\right.$ | |
| --- | --- | --- | --- |*
* Proof*
This lemma follows from Frostig et al. (2015); Mukherjee et al. (2022) adapted to our setting for the squared loss, transition function $f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1})$ , and the sampling distribution $\mathbf{p}_{{\widehat{\bm{\theta}}}_{s-1}}$ . We show it here for completeness. Now we want to evaluate the Hessian $∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}(\mathbb{E}[\ell_{s}(\bm{\theta})%
|\mathcal{F}^{s-1}])$ at any $\bm{\theta}^{\prime}∈\bm{\Theta}$ . We denote the $j$ -th row and $k$ -th column entry in the Hessian matrix as $[∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}(\mathbb{E}[\ell_{s}(\bm{\theta}%
)|\mathcal{F}^{s-1}])]_{jk}$ . Then we can show that
$$
\displaystyle\nabla^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}\mathbb{E}[\ell_{s}(%
\bm{\theta})|\mathcal{F}^{s-1}]=\nabla^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}%
\left(f^{2}_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})+\mathbb{E}[Y^{2%
}_{s}|\mathcal{F}^{s-1}]-2\mathbb{E}[Y_{s}|\mathcal{F}^{s-1}]f_{I_{s}}(\bm{%
\theta};x_{i},x_{j},\mathcal{F}^{s-1})\right) \displaystyle=\nabla^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}\sum_{i=1}^{|V|}p_{%
{\widehat{\bm{\theta}}}_{s-1}}(i)\left(f^{2}_{i}(\bm{\theta};x_{i},x_{j},%
\mathcal{F}^{s-1})+f^{2}_{i}(\bm{\theta}^{\prime};x_{i},x_{j},\mathcal{F}^{s-1%
})+\frac{1}{2}-2f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1})f_{I_{%
s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})\right) \displaystyle=\nabla^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}\sum_{i=1}^{|V|}p_{%
{\widehat{\bm{\theta}}}_{s-1}}(i)\left(\left(f_{I_{s}}(\bm{\theta}_{*};x_{i},x%
_{j},\mathcal{F}^{s-1})-f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})%
\right)^{2}+\frac{1}{2}\right) \displaystyle=\nabla^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}\sum_{i=1}^{|V|}p_{%
{\widehat{\bm{\theta}}}_{s-1}}(i)\left(\left(f_{I_{s}}(\bm{\theta}_{*};x_{i},x%
_{j},\mathcal{F}^{s-1})-f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})%
\right)^{2}\right) \tag{6}
$$
We now denote the $j$ -th row and $k$ -th column entry of the Hessian Matrix $∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}((f_{I_{s}}(\bm{\theta};x_{i},x_{%
j},\mathcal{F}^{s-1})-f_{i}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1}))^{2})$ as $\big{[}∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}((f_{I_{s}}(\bm{\theta};x_%
{i},x_{j},\mathcal{F}^{s-1})-f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}%
^{s-1}))^{2})\big{]}_{jk}$ . Then we can show that
| | $\displaystyle\big{[}∇^{2}_{\bm{\theta}=\bm{\theta}_{*}}((f_{I_{s}}(\bm{%
\theta};x_{i},x_{j},\mathcal{F}^{s-1})-f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},%
\mathcal{F}^{s-1}))^{2})\big{]}_{jk}$ | |
| --- | --- | --- |
Plugging this back in Equation 6 we get that
| | $\displaystyle\left[∇^{2}_{\bm{\theta}=\bm{\theta}^{\prime}}\mathbb{E}[%
\ell_{s}(\bm{\theta})|\mathcal{F}^{s-1}]\right]_{jk}$ | $\displaystyle=2\sum_{i=1}^{|V|}p_{{\widehat{\bm{\theta}}}_{s-1}}(i)\left(%
\dfrac{∂ f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})}{∂%
\bm{\theta}_{j}}\dfrac{∂ f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^%
{s-1})}{∂\bm{\theta}_{k}}\right.$ | |
| --- | --- | --- | --- |
∎
**Lemma B.6**
*The sum of the difference of the Hessians $\sum_{s=1}^{t}∇_{\bm{\theta}=\bm{\theta}^{\prime}}^{2}\ell_{s}\left(\bm{%
\theta}\right)-\mathbb{E}\left[∇_{\bm{\theta}=\bm{\theta}^{\prime}}^{2}%
\ell_{s}\left(\bm{\theta}\right)\mid\mathcal{F}^{s-1}\right]$ is given by
| | $\displaystyle\sum_{s=1}^{t}∇_{\bm{\theta}=\bm{\theta}^{\prime}}^{2}\ell_{%
s}\left(\bm{\theta}\right)-\mathbb{E}\left[∇_{\bm{\theta}=\bm{\theta}^{%
\prime}}^{2}\ell_{s}\left(\bm{\theta}\right)\mid\mathcal{F}^{s-1}\right]\!\!$ | $\displaystyle=\!\!\sum_{s=1}^{t}\bigg{(}-2(Y_{s}-f_{I_{s}}(\bm{\theta};x_{i},x%
_{j},\mathcal{F}^{s-1}))\dfrac{∂^{2}f_{I_{s}}(\bm{\theta};x_{i},x_{j},%
\mathcal{F}^{s-1})}{∂\bm{\theta}_{j}∂\bm{\theta}_{k}}$ | |
| --- | --- | --- | --- |*
* Proof*
This lemma directly follows from Lemma B.4 and Lemma B.5. First note that the difference $∇_{\bm{\theta}=\bm{\theta}^{\prime}}^{2}\ell_{s}\left(\bm{\theta}\right)-%
\mathbb{E}\left[∇_{\bm{\theta}=\bm{\theta}^{\prime}}^{2}\ell_{s}\left(\bm%
{\theta}\right)\mid\mathcal{F}^{s-1}\right]_{jk}$ is given by
$$
\displaystyle\nabla_{\bm{\theta}=\bm{\theta}^{\prime}}^{2}\ell_{s}\left(\bm{%
\theta}\right)-\mathbb{E}\left[\nabla_{\bm{\theta}=\bm{\theta}^{\prime}}^{2}%
\ell_{s}\left(\bm{\theta}\right)\mid\mathcal{F}^{s-1}\right] \displaystyle\overset{(a)}{=}2\dfrac{\partial f_{I_{s}}(\bm{\theta};x_{i},x_{j%
},\mathcal{F}^{s-1})}{\partial\bm{\theta}_{j}}\dfrac{\partial f_{I_{s}}(\bm{%
\theta};x_{i},x_{j},\mathcal{F}^{s-1})}{\partial\bm{\theta}_{k}}+2\left(f_{I_{%
s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})-Y_{s}\right)\dfrac{\partial^{2}%
f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})}{\partial\bm{\theta}_{j}%
\partial\bm{\theta}_{k}} \displaystyle\qquad-2\sum_{i=1}^{|V|}p_{{\widehat{\bm{\theta}}}_{s-1}}(i)\bigg%
{(}\dfrac{\partial f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})}{%
\partial\bm{\theta}_{j}}\dfrac{\partial f_{I_{s}}(\bm{\theta};x_{i},x_{j},%
\mathcal{F}^{s-1})}{\partial\bm{\theta}_{k}}-\left(f_{I_{s}}(\bm{\theta};x_{i}%
,x_{j},\mathcal{F}^{s-1})-f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s%
-1})\right)\cdot \displaystyle\qquad\dfrac{\partial^{2}f_{I_{s}}(\bm{\theta};x_{i},x_{j},%
\mathcal{F}^{s-1})}{\partial\bm{\theta}_{j}\partial\bm{\theta}_{k}}\bigg{)} \displaystyle= \displaystyle-2(Y_{s}-f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1}))%
\dfrac{\partial^{2}f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})}{%
\partial\bm{\theta}_{j}\partial\bm{\theta}_{k}}+2\dfrac{\partial f_{I_{s}}(\bm%
{\theta};x_{i},x_{j},\mathcal{F}^{s-1})}{\partial\bm{\theta}_{j}}\dfrac{%
\partial f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})}{\partial\bm{%
\theta}_{k}} \displaystyle\qquad-2\sum_{i=1}^{|V|}p_{{\widehat{\bm{\theta}}}_{s-1}}(i)%
\dfrac{\partial f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})}{\partial%
\bm{\theta}_{j}}\dfrac{\partial f_{I_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^%
{s-1})}{\partial\bm{\theta}_{k}} \tag{7}
$$
where, $(a)$ follows from Lemma B.4 and Lemma B.5. Plugging this equality in Equation 7 below we get
| | $\displaystyle\sum_{s=1}^{t}∇_{\bm{\theta}=\bm{\theta}^{\prime}}^{2}\ell_{%
s}\left(\bm{\theta}\right)-\mathbb{E}\left[∇_{\bm{\theta}=\bm{\theta}^{%
\prime}}^{2}\ell_{s}\left(\bm{\theta}\right)\mid\mathcal{F}^{s-1}\right]$ | |
| --- | --- | --- |
The claim of the lemma follows. ∎
**Lemma B.7**
*Let $\widehat{\cal L}_{t}(\bm{\theta}_{*})=\frac{1}{t}\sum_{s=1}^{t}\ell_{s}(\bm{%
\theta}_{*})$ and $∇^{2}{\cal L}_{t}(\bm{\theta}_{*})=\frac{1}{t}\sum_{s=1}^{t}∇^{2}%
\mathbb{E}[\ell_{s}(\bm{\theta}_{*})|\mathcal{F}^{s-1}]$ . Then we can bound the
| | $\displaystyle\mathbb{P}$ | $\displaystyle\left(\lambda_{\max}(∇^{2}\widehat{\cal L}_{t}(\bm{\theta}_{%
*})-∇^{2}{\cal L}_{t}(\theta^{*}))>\sqrt{\dfrac{8C|V|^{2}\eta^{2}\lambda^%
{2}_{1}c\gamma\log(dt)}{t}}\right)≤\dfrac{2}{(dt)^{\gamma}},$ | |
| --- | --- | --- | --- |
where $c>0$ is a constant.*
* Proof*
This lemma is different than Frostig et al. (2015); Mukherjee et al. (2022) as it requires a different concentration bound to take into account the squared loss 5.2 and the vocabulary size. Recall that $\widehat{\cal L}_{t}(\bm{\theta}_{*})=\frac{1}{t}\sum_{s=1}^{t}\ell_{s}(\bm{%
\theta}_{*})$ and $∇^{2}{\cal L}_{s}(\theta^{*})=∇^{2}\mathbb{E}[\ell_{s}(\bm{\theta}_{%
*})|\mathcal{F}^{s-1}]$ . We define $∇^{2}{\cal L}_{t}(\bm{\theta}_{*})=\frac{1}{t}\sum_{s=1}^{t}∇^{2}%
\mathbb{E}[\ell_{s}(\bm{\theta}_{*})|\mathcal{F}^{s-1}]$ . Denote, $\mathbf{V}_{s}=2∇_{\bm{\theta}=\bm{\theta}_{*}}f_{I_{s}}(\bm{\theta};x_{i%
},x_{j},\mathcal{F}^{s-1})∇_{\bm{\theta}=\bm{\theta}_{*}}f_{I_{s}}(\bm{%
\theta};x_{i},x_{j},\mathcal{F}^{s-1})^{→p}-2\sum_{i=1}^{|V|}p_{{\widehat{%
\bm{\theta}}}_{s-1}}(i)∇_{\bm{\theta}=\bm{\theta}_{*}}f_{I_{s}}(\bm{%
\theta};x_{i},x_{j},\mathcal{F}^{s-1})∇_{\bm{\theta}=\bm{\theta}_{*}}f_{I%
_{s}}(\bm{\theta};x_{i},x_{j},\mathcal{F}^{s-1})^{→p}$ . Then we can show that,
$$
\displaystyle\mathbb{P}\left(\lambda_{\max}(\nabla^{2}\widehat{\cal L}_{t}(\bm%
{\theta}_{*})-\nabla^{2}{\cal L}_{t}(\theta^{*}))>\sqrt{\dfrac{8C^{2}|V|^{4}%
\eta^{2}\lambda^{2}_{1}c\gamma\log(dt)}{t}}\right) \displaystyle=\mathbb{P}\left(\lambda_{\max}\left(\nabla^{2}_{\bm{\theta}=\bm{%
\theta}_{*}}\frac{1}{t}\sum_{s=1}^{t}\ell_{s}(\bm{\theta})-\frac{1}{t}\sum_{s=%
1}^{t}\nabla^{2}_{\bm{\theta}=\bm{\theta}_{*}}\mathbb{E}[\ell_{s}(\bm{\theta})%
|\mathcal{F}^{s-1}]\right)>\sqrt{\dfrac{8C^{2}|V|^{4}\eta^{2}\lambda^{2}_{1}c%
\gamma\log(dt)}{t}}\right) \displaystyle=\mathbb{P}\left(\lambda_{\max}\left(\nabla^{2}_{\bm{\theta}=\bm{%
\theta}_{*}}\frac{1}{t}\sum_{s=1}^{t}\left(\ell_{s}(\bm{\theta})-\nabla^{2}_{%
\bm{\theta}=\bm{\theta}_{*}}\mathbb{E}[\ell_{s}(\bm{\theta})|\mathcal{F}^{s-1}%
]\right)\right)>\sqrt{\dfrac{8C^{2}|V|^{4}\eta^{2}\lambda^{2}_{1}c\gamma\log(%
dt)}{t}}\right) \displaystyle\overset{(a)}{\leq}\mathbb{P}\left(\lambda_{\max}\left(\frac{C|V|%
^{2}}{t}\sum_{s=1}^{t}\left(Y_{s}-f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},%
\mathcal{F}^{s-1})\right)\nabla^{2}_{\bm{\theta}=\bm{\theta}_{*}}f_{I_{s}}(\bm%
{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1})\right.\right. \displaystyle\qquad\left.\left.+\frac{C|V|^{2}}{t}\sum_{s=1}^{t}\mathbf{V}_{s}%
\right)>\sqrt{\dfrac{8C^{2}|V|^{4}\eta^{2}\lambda^{2}_{1}c\gamma\log(dt)}{t}}\right) \displaystyle\leq\mathbb{P}\left(\lambda_{\max}\left(\frac{1}{t}\sum_{s=1}^{t}%
-2\left(Y_{s}-f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1})\right)%
\nabla^{2}_{\bm{\theta}=\bm{\theta}_{*}}f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},%
\mathcal{F}^{s-1})\right)>\frac{1}{2}\sqrt{\dfrac{8\eta^{2}\lambda^{2}_{1}c%
\gamma\log(dt)}{t}}\right) \displaystyle\qquad+\mathbb{P}\left(\lambda_{\max}\left(\frac{1}{t}\sum_{s=1}^%
{t}\mathbf{V}_{s}\right)>\frac{1}{2}\sqrt{\dfrac{8\eta^{2}\lambda^{2}_{1}c%
\gamma\log(dt)}{t}}\right) \displaystyle\overset{(b)}{\leq}\mathbb{P}\left(\frac{1}{t}\sum_{s=1}^{t}-2%
\left(Y_{s}-f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1})\right)%
\lambda_{\max}\left(\nabla^{2}_{\bm{\theta}=\bm{\theta}_{*}}f_{I_{s}}(\bm{%
\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1})\right)>\frac{1}{2}\sqrt{\dfrac{8%
\eta^{2}\lambda^{2}_{1}c\gamma\log(dt)}{t}}\right) \displaystyle\qquad+\mathbb{P}\left(\frac{1}{t}\sum_{s=1}^{t}\lambda_{\max}%
\left(\mathbf{V}_{s}\right)>\frac{1}{2}\sqrt{\dfrac{8\eta^{2}\lambda^{2}_{1}c%
\gamma\log(dt)}{t}}\right) \displaystyle\overset{(c)}{\leq}2\exp\left(-\dfrac{t^{2}8\eta^{2}\lambda_{1}^{%
2}c\gamma\log(dt)}{4t}\cdot\dfrac{1}{2tc\eta^{2}\lambda_{1}^{2}}\right)%
\overset{(d)}{\leq}2\left(\dfrac{1}{dt}\right)^{\gamma}. \tag{8}
$$
where, $(a)$ follows from substituting the value of $∇^{2}_{\bm{\theta}=\bm{\theta}_{*}}\ell_{s}(\bm{\theta})-∇^{2}_{\bm{%
\theta}=\bm{\theta}_{*}}\mathbb{E}[\ell_{s}(\bm{\theta})|\mathcal{F}^{s-1}]$ from Lemma B.6, and $(b)$ follows by triangle inequality, $(c)$ follows by using two concentration inequalities stated below, and $(d)$ follows by simplifying the equations. Denote $Q_{s}=-2\left(Y_{s}-f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1})%
\right)\lambda_{\max}\left(∇^{2}_{\bm{\theta}=\bm{\theta}_{*}}f_{I_{s}}(%
\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1})\right)$ . Also note that $\lambda_{\max}\left(∇^{2}_{\bm{\theta}=\bm{\theta}_{*}}f_{I_{s}}(\bm{%
\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1})\right)≤\lambda_{1}$ for all time $s$ using B.1.
| | $\displaystyle\mathbb{P}(\sum_{s=1}^{t}-2$ | $\displaystyle\left(Y_{s}-f_{I_{s}}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-%
1})\right)\lambda_{\max}\left(∇^{2}_{\bm{\theta}=\bm{\theta}_{*}}f_{I_{s}%
}(\bm{\theta}_{*};x_{i},x_{j},\mathcal{F}^{s-1})\right)≥\epsilon)=\mathbb{P%
}\left(-\sum_{s=1}^{t}Q_{s}≥\epsilon\right)$ | |
| --- | --- | --- | --- |
where $(a)$ follows by Markov’s inequality, $(b)$ follows as $Q_{s}$ is conditionally independent given ${\widehat{\bm{\theta}}}_{s-1}$ , $(c)$ follows by unpacking the term for $t$ times and $(d)$ follows by taking $\lambda=\epsilon/4t\lambda_{1}^{2}\eta^{2}$ where $\lambda_{1}$ is defined in 5.1. Next we bound the second term of (8) below. | | $\displaystyle\mathbb{P}(\sum_{s=1}^{t}\lambda_{\max}\left(\mathbf{V}_{s}\right%
)≥\epsilon)$ | $\displaystyle=\mathbb{P}\left(\lambda\sum_{s=1}^{t}\lambda_{\max}\left(\mathbf%
{V}_{s}\right)≥\lambda\epsilon\right)=\mathbb{P}\left(e^{\lambda\sum_{s=1}^%
{t}\lambda_{\max}\left(\mathbf{V}_{s}\right)}≥ e^{\lambda\epsilon}\right)%
\overset{(a)}{≤}e^{-\lambda\epsilon}\mathbb{E}\left[e^{\lambda\sum_{s=1}^{t%
}\lambda_{\max}\left(\mathbf{V}_{s}\right)}\right]$ | |
| --- | --- | --- | --- | where $(a)$ follows by Markov’s inequality, $(b)$ follows as $\lambda_{\max}(\mathbf{V}_{s})$ is conditionally independent given ${\widehat{\bm{\theta}}}_{s-1}$ . In the inequality $(c)$ using the always valid upper bound of $2\lambda_{1}$ , we have that $\mathbb{E}[\lambda_{\max}(\mathbf{V}_{t})]≤ 2\lambda_{1}$ . So the term in inequality $(c)$ will become $e^{-\lambda\epsilon}e^{2\lambda^{2}t\eta^{2}\lambda_{1}^{t}+4t\lambda\lambda_{%
1}}$ . Hence, we can upper bound the inequality $(c)$ by a constant $c>0$ such that we have $\mathbb{E}[e^{\lambda\lambda_{\max}(V_{t})}\mid{\widehat{\bm{\theta}}}_{t-1}]%
≤ e^{2\lambda^{2}\lambda_{1}^{2}\eta^{2}}e^{2\lambda× 2\lambda_{1}}=%
\exp(2\lambda^{2}\lambda_{1}^{2}\eta^{2}+4\lambda\lambda_{1})≤\exp(2c%
\lambda^{2}\lambda_{1}^{2}\eta^{2})$ . The inequality $(d)$ follows by unpacking the term for $t$ times and $(e)$ follows by taking $\lambda=\epsilon/4tc\lambda_{1}^{2}\eta^{2}$ and $\lambda_{1}$ defined in 5.1. ∎
**Lemma B.8**
*Let ${\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}=\left(∇^{2}\widehat{\cal L}_{%
t}(\widetilde{\bm{\theta}}_{t})\right)^{-1}∇\widehat{\cal L}_{t}(\bm{%
\theta}_{*})$ where $\widetilde{\bm{\theta}}_{t}$ is between ${\widehat{\bm{\theta}}}_{t}$ and $\bm{\theta}_{*}$ . Then we can show that
| | $\displaystyle\left\|{\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}\right\|_{%
∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)}≤\left\|\left(∇^{2}%
{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)^{1/2}\left(∇^{2}\widehat{%
\cal L}_{t}(\widetilde{\bm{\theta}}_{t})\right)^{-1}\left(∇^{2}{\cal L}_{%
t}\left(\bm{\theta}_{*}\right)\right)^{1/2}\right\|\left\|∇\widehat{\cal L%
}_{t}\left(\bm{\theta}_{*}\right)\right\|_{\left(∇^{2}{\cal L}_{t}\left(%
\bm{\theta}_{*}\right)\right)^{-1}}.$ | |
| --- | --- | --- |*
* Proof*
We begin with the definition of $\left\|{\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}\right\|_{∇^{2}{\cal L}%
_{t}\left(\bm{\theta}_{*}\right)}$ as follows:
| | $\displaystyle\left\|{\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}\right\|_{%
∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)}$ | $\displaystyle\overset{(a)}{=}\sqrt{({\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*%
})^{T}∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)({\widehat{\bm{\theta}%
}}_{t}-\bm{\theta}_{*})}$ | |
| --- | --- | --- | --- |
where, $(a)$ follows as $\|x\|_{M}=\sqrt{x^{T}Mx}$ , $(b)$ follows as $\|{\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}\|_{∇^{2}{\cal L}_{t}(\bm{%
\theta}_{*})}=\left(∇^{2}\widehat{\cal L}_{t}(\widetilde{\bm{\theta}})%
\right)^{-1}∇\widehat{\cal L}_{t}(\bm{\theta}_{*})$ , and $(c)$ follows from Cauchy Schwarz inequality. The claim of the lemma follows. ∎
**Remark B.9**
*The proof of 1 consists of several steps. In the first step we relate $∇^{2}\widehat{\cal L}_{t}(\bm{\theta})$ to $∇^{2}{\cal L}_{t}(\bm{\theta}_{*})$ for any $\bm{\theta}$ in a ball $\mathcal{B}$ around $\bm{\theta}_{*}$ . The ball $\mathcal{B}$ is assumed in B.1 to be a neighborhood where $∇^{2}\ell_{s}(\bm{\theta})$ satisfies a Lipschitz property. B.1 in Appendix B are standard and have also been made by Frostig et al. (2015); Chaudhuri et al. (2015); Mukherjee et al. (2022). Using 5.1 and B.1, we can show that for a large enough sequences of tokens $t$ stated in 1 we have the following: (1) $∇^{2}{\cal L}_{t}(\bm{\theta}_{*})$ lies between in the positive semidefinite order by scaled multiples of $∇^{2}\widehat{\cal L}_{t}(\bm{\theta})$ for any $\bm{\theta}∈\mathcal{B}$ , and (2) the empirical error minimizing ${\widehat{\bm{\theta}}}_{t}$ is in the ball $\mathcal{B}$ with probability $1-1/t^{\gamma}$ , which is the good event $\mathcal{E}$ . Then we use a Taylor series expansion around ${\widehat{\bm{\theta}}}_{t}$ and using the fact that $∇\widehat{\cal L}_{t}(\widehat{\bm{\theta}}(t))=0$ along with the relation between $∇^{2}\widehat{\cal L}_{t}(\bm{\theta})$ and $∇^{2}{\cal L}_{t}(\bm{\theta}_{*})$ , we can obtain an upper bound to $\lVert\widehat{\bm{\theta}}(t)-\bm{\theta}_{*}\rVert_{∇^{2}{\cal L}_{t}(%
\bm{\theta}_{*})}$ in terms of $\lVert∇\widehat{\cal L}_{t}(\bm{\theta}_{*})\rVert_{(∇^{2}{\cal L}_{%
t}(\bm{\theta}_{*}))^{-1}}$ that can be shown to be decreasing with $t$ . Further, $\lVert\widehat{\bm{\theta}}(t)-\bm{\theta}_{*}\rVert_{∇^{2}{\cal L}_{t}(%
\bm{\theta}_{*})}$ can also be used to obtain an upper bound to ${\cal L}_{t}(\widehat{\bm{\theta}}(t))-{\cal L}_{t}(\bm{\theta}_{*})$ using a Taylor series expansion. Finally we can bound $\mathbb{E}[{\cal L}_{t}(\widehat{\bm{\theta}}_{t})-{\cal L}_{t}(\bm{\theta}^{*%
})]=\mathbb{E}[({\cal L}_{t}(\widehat{\bm{\theta}}_{t})-{\cal L}_{t}(\bm{%
\theta}^{*}))I(\mathcal{E})]+\mathbb{E}[({\cal L}_{t}(\widehat{\bm{\theta}}_{t%
})-{\cal L}_{t}(\bm{\theta}^{*}))I(\mathcal{E}^{\complement})]$ where $I(·)$ is the indicator. Since $\mathbb{P}(\mathcal{E}^{\complement})≤ 1/t^{\gamma}$ , the second term can be bounded as $\max_{\bm{\theta}∈\bm{\Theta}}\left({\cal L}_{t}(\bm{\theta})-{\cal L}_{t}%
\left(\bm{\theta}^{*}\right)\right)/t^{\gamma}$ , while the first term simplifies to $(1+\rho_{t})\sigma_{t}^{2}/t$ .*
**Theorem 1**
*(Restatement of main theorem) Suppose $\ell_{1}(\bm{\theta}),\ell_{2}(\bm{\theta}),·s,\ell_{t}(\bm{\theta}):%
\mathbb{R}^{|V|}→\mathbb{R}$ are loss functions from a distribution that satisfies Assumptions 5.1 , 5.2, and B.1. Define ${\cal L}_{t}(\bm{\theta})=\frac{1}{t}\sum_{s=1}^{t}\mathbb{E}_{x_{s}\sim%
\mathbf{p}_{{\widehat{\bm{\theta}}}_{s-1}}}[\ell_{s}(\bm{\theta})|\mathcal{F}^%
{s-1}]$ where, ${\widehat{\bm{\theta}}}_{t}=\operatorname*{argmin}_{\bm{\theta}∈\bm{\Theta}}%
\sum_{s=1}^{t}\ell_{s}(\bm{\theta})$ . If $t$ is large enough such that $\frac{\gamma\log(dt)}{t}≤ c^{\prime}\min\left\{\frac{1}{C_{1}C_{2}|V|^{4}},%
\frac{\max\limits_{\bm{\theta}∈\bm{\Theta}}\left(\!{\cal L}_{t}(\bm{\theta})%
\!-\!{\cal L}_{t}\left(\bm{\theta}_{*}\!\right)\right)}{C_{2}}\right\}$ then for a constant $\gamma≥ 2$ , universal constants $C_{1},C_{2},c^{\prime}$ , we can show that
| | $\displaystyle\left(1-\rho_{t}\right)\frac{\sigma_{t}^{2}}{t}-\frac{C_{1}^{2}}{%
t^{\gamma/2}}$ | $\displaystyle≤\mathbb{E}\left[{\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-{%
\cal L}_{t}\left(\bm{\theta}_{*}\right)\right]≤\left(1+\rho_{t}\right)\frac%
{\sigma_{t}^{2}}{t}\!+\!\frac{\max\limits_{\bm{\theta}∈\bm{\Theta}}\left(\!{%
\cal L}_{t}(\bm{\theta})\!-\!{\cal L}_{t}\left(\bm{\theta}_{*}\!\right)\right)%
}{t^{\gamma}},$ | |
| --- | --- | --- | --- |
where $\sigma^{2}_{t}\coloneqq\mathbb{E}\left[\frac{1}{2}\left\|∇\widehat{\cal L%
}_{t}\left(\bm{\theta}_{*}\right)\right\|_{\left(∇^{2}{\cal L}_{t}\left(%
\bm{\theta}_{*}\right)\right)^{-1}}^{2}\right]$ , and $\rho_{t}\coloneqq\left(C_{1}C_{2}+2\eta^{2}\lambda_{1}^{2}\right)\sqrt{\frac{%
\gamma\log(dt)}{t}}$ .*
* Proof*
Step 1: We first bound the $\left\|∇^{2}\widehat{\cal L}_{t}(\bm{\theta})-∇^{2}{\cal L}_{t}\left%
(\bm{\theta}_{*}\right)\right\|_{*}$ as follows
$$
\displaystyle\left\|\nabla^{2}\widehat{\cal L}_{t}(\bm{\theta})-\nabla^{2}{%
\cal L}_{t}\left(\bm{\theta}_{*}\right)\right\|_{*} \displaystyle\overset{(a)}{\leq}\left\|\nabla^{2}\widehat{\cal L}_{t}(\bm{%
\theta})-\nabla^{2}\widehat{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right\|_{*%
}+\left\|\nabla^{2}\widehat{\cal L}_{t}\left(\bm{\theta}_{*}\right)-\nabla^{2}%
{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right\|_{*} \displaystyle\overset{(b)}{\leq}C_{1}\left\|\bm{\theta}-\bm{\theta}_{*}\right%
\|_{\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)}+\sqrt{\dfrac{8C^{2}|V|%
^{4}\eta^{2}\lambda_{1}^{2}c\gamma\log(dt)}{t}} \tag{9}
$$
where, $(a)$ follows from triangle inequality, and $(b)$ is due to B.1.3.d and Lemma B.7. Step 2 (Approximation of $∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)$ ): By choosing a sufficiently smaller ball $\mathcal{B}_{1}$ of radius of $\min\left\{1/\left(10C_{1}\right),\right.$ diameter $\left.(\mathcal{B})\right\}$ ), the first term in (9) can be made small for $\bm{\theta}∈\mathcal{B}_{1}$ . Also, for sufficiently large $t$ , the second term in (9) can be made arbitrarily small (smaller than $1/10$ ), which occurs if $\sqrt{\frac{\gamma\log(dt)}{t}}≤\frac{c^{\prime}}{\sqrt{2C^{2}|V|^{4}\eta^{%
2}\lambda_{1}^{2}}}$ . Hence for large $t$ and $\bm{\theta}∈\mathcal{B}_{1}$ we have
$$
\displaystyle\frac{1}{2}\nabla^{2}\widehat{\cal L}_{t}(\bm{\theta})\preceq%
\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)\preceq 2\nabla^{2}\widehat{%
\cal L}_{t}(\bm{\theta}) \tag{10}
$$ Step 3 (Show ${\widehat{\bm{\theta}}}_{t}$ in $\mathcal{B}_{1}$ ): Fix a $\widetilde{\bm{\theta}}$ between $\bm{\theta}$ and $\bm{\theta}_{*}$ in $\mathcal{B}_{1}$ . Apply Taylor’s series approximation
| | $\displaystyle\widehat{\cal L}_{t}(\bm{\theta})=\widehat{\cal L}_{t}\left(\bm{%
\theta}_{*}\right)+∇\widehat{\cal L}_{t}\left(\bm{\theta}_{*}\right)^{%
→p}\left(\bm{\theta}-\bm{\theta}_{*}\right)+\frac{1}{2}\left(\bm{\theta}-\bm%
{\theta}_{*}\right)^{→p}∇^{2}\widehat{\cal L}_{t}(\widetilde{\bm{\theta%
}})\left(\bm{\theta}-\bm{\theta}_{*}\right)$ | |
| --- | --- | --- |
We can further reduce this as follows:
$$
\displaystyle\widehat{\cal L}_{t}(\bm{\theta})-\widehat{\cal L}_{t}\left(\bm{%
\theta}_{*}\right) \displaystyle\overset{(a)}{=}\nabla\widehat{\cal L}_{t}\left(\bm{\theta}_{*}%
\right)^{\top}\left(\bm{\theta}-\bm{\theta}_{*}\right)+\frac{1}{2}\left\|\bm{%
\theta}-\bm{\theta}_{*}\right\|_{\nabla^{2}\widehat{\cal L}_{t}(\widetilde{\bm%
{\theta}})}^{2} \displaystyle\overset{(b)}{\geq}\nabla\widehat{\cal L}_{t}\left(\bm{\theta}_{*%
}\right)^{\top}\left(\bm{\theta}-\bm{\theta}_{*}\right)+\frac{1}{4}\left\|\bm{%
\theta}-\bm{\theta}_{*}\right\|_{\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_{*}%
\right)}^{2} \displaystyle\geq-\left\|\bm{\theta}-\bm{\theta}_{*}\right\|_{\nabla^{2}{\cal L%
}_{t}\left(\bm{\theta}_{*}\right)}\left\|\nabla\widehat{\cal L}_{t}\left(\bm{%
\theta}_{*}\right)\right\|_{\left(\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_{*}%
\right)\right)^{-1}}+\frac{1}{4}\left(\left\|\bm{\theta}-\bm{\theta}_{*}\right%
\|_{\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)}\right)^{\top}\left(%
\left\|\bm{\theta}-\bm{\theta}_{*}\right\|_{\nabla^{2}{\cal L}_{t}\left(\bm{%
\theta}_{*}\right)}\right) \displaystyle=\left\|\bm{\theta}-\bm{\theta}_{*}\right\|_{\nabla^{2}{\cal L}_{%
t}\left(\bm{\theta}_{*}\right)}\left(-\left\|\nabla\widehat{\cal L}_{t}\left(%
\bm{\theta}_{*}\right)\right\|_{\left(\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_%
{*}\right)\right)^{-1}}+\frac{1}{4}\left\|\bm{\theta}-\bm{\theta}_{*}\right\|_%
{\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)}\right) \tag{11}
$$
where, $(a)$ follows as $\left\|\bm{\theta}-\bm{\theta}_{*}\right\|_{∇^{2}\widehat{\cal L}_{t}(%
\widetilde{\bm{\theta}})}^{2}\coloneqq\left(\bm{\theta}-\bm{\theta}_{*}\right)%
^{→p}∇^{2}\widehat{\cal L}_{t}(\widetilde{\bm{\theta}})\left(\bm{\theta%
}-\bm{\theta}_{*}\right)$ , and $(b)$ follows as $\widetilde{\bm{\theta}}$ is in between $\bm{\theta}$ and $\bm{\theta}_{*}$ and then using (10). Note that in (11) if the right hand side is positive for some $\bm{\theta}∈\mathcal{B}_{1}$ , then $\bm{\theta}$ is not a local minimum. Also, since $\left\|∇\widehat{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right\|%
→ 0,$ for a sufficiently small value of $\left\|∇\widehat{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right\|,$ all points on the boundary of $\mathcal{B}_{1}$ will have values greater than that of $\bm{\theta}_{*}.$ Hence, we must have a local minimum of $\widehat{\cal L}_{t}(\bm{\theta})$ that is strictly inside $\mathcal{B}_{1}$ (for $t$ large enough). We can ensure this local minimum condition is achieved by choosing an $t$ large enough so that $\sqrt{\frac{\gamma\log(dt)}{t}}≤ c^{\prime}\min\left\{\frac{1}{C_{1}C_{2}},%
\frac{\operatorname{diameter}(\mathcal{B})}{C_{2}}\right\},$ using Lemma B.3 (and our bound on the diameter of $\mathcal{B}_{1}$ ). By convexity, we have that this is the global minimum, ${\widehat{\bm{\theta}}}_{t},$ and so ${\widehat{\bm{\theta}}}_{t}∈\mathcal{B}_{1}$ for $t$ large enough. We will assume now that $t$ is this large from here on. Step 4 (Bound $\left\|{\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}\right\|_{∇^{2}{\cal L}%
_{t}\left(\bm{\theta}_{*}\right)}$ ): For the ${\widehat{\bm{\theta}}}(t)$ that minimizes the sum of squared errors, $0=∇\widehat{\cal L}_{t}({\widehat{\bm{\theta}}}_{t})$ . Again, using Taylor’s theorem if ${\widehat{\bm{\theta}}}_{t}$ is an interior point, we have:
$$
\displaystyle 0=\nabla\widehat{\cal L}_{t}({\widehat{\bm{\theta}}}_{t})=\nabla%
\widehat{\cal L}_{t}\left(\bm{\theta}_{*}\right)+\nabla^{2}\widehat{\cal L}_{t%
}(\widetilde{\bm{\theta}}_{t})\left({\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*%
}\right) \tag{12}
$$
for some $\widetilde{\bm{\theta}}_{t}$ between $\bm{\theta}_{*}$ and ${\widehat{\bm{\theta}}}_{t}$ . Now observe that $\widetilde{\bm{\theta}}_{t}$ is in $B_{1}$ (since, for $t$ large enough, ${\widehat{\bm{\theta}}}_{t}∈\mathcal{B}_{1}$ ). Thus it follows from (12) that,
$$
\displaystyle{\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}=\left(\nabla^{2}%
\widehat{\cal L}_{t}(\widetilde{\bm{\theta}}_{t})\right)^{-1}\nabla\widehat{%
\cal L}_{t}\left(\bm{\theta}_{*}\right) \tag{13}
$$
where the invertibility is guaranteed by (10) and the positive definiteness of $∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)$ (by B.1 (3c)). We finally derive the upper bound to $\left\|{\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}\right\|_{∇^{2}{\cal L}%
_{t}\left(\bm{\theta}_{*}\right)}$ as follows
$$
\displaystyle\left\|{\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}\right\|_{%
\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)} \displaystyle\overset{(a)}{\leq}\left\|\left(\nabla^{2}{\cal L}_{t}\left(\bm{%
\theta}_{*}\right)\right)^{1/2}\left(\nabla^{2}\widehat{\cal L}_{t}(\widetilde%
{\bm{\theta}}_{t})\right)^{-1}\left(\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_{*%
}\right)\right)^{1/2}\right\|\left\|\nabla\widehat{\cal L}_{t}\left(\bm{\theta%
}_{*}\right)\right\|_{\left(\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)%
\right)^{-1}} \displaystyle\overset{(b)}{\leq}cC_{2}\sqrt{\frac{\gamma\log(dt)}{t}} \tag{14}
$$
where $(a)$ follows from Lemma B.8, and $(b)$ from Lemma B.3, (11), and $c$ is some universal constant. Step 5 (Introducing $\widetilde{\mathbf{z}}$ ): Fix a $\widetilde{\mathbf{z}}_{t}$ between $\bm{\theta}_{*}$ and ${\widehat{\bm{\theta}}}_{t}$ . Apply Taylor’s series
$$
\displaystyle{\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-{\cal L}_{t}\left(\bm{%
\theta}_{*}\right)=\frac{1}{2}\left({\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*%
}\right)^{\top}\nabla^{2}{\cal L}_{t}\left(\widetilde{\mathbf{z}}_{t}\right)%
\left({\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}\right) \tag{15}
$$
Now note that both $\widetilde{\bm{\theta}}_{t}$ and $\widetilde{\mathbf{z}}_{t}$ are between ${\widehat{\bm{\theta}}}_{t}$ and $\bm{\theta}_{*},$ which implies $\widetilde{\bm{\theta}}_{t}→\bm{\theta}_{*}$ and $\widetilde{\mathbf{z}}_{t}→\bm{\theta}_{*}$ since ${\widehat{\bm{\theta}}}_{t}→\bm{\theta}_{*}$ . By (9) and (14) and applying the concentration inequalities give us
$$
\displaystyle\left\|\nabla^{2}\widehat{\cal L}_{t}(\widetilde{\bm{\theta}}_{t}%
)-\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right\|_{*}\leq\rho_{t} \displaystyle\left\|\nabla^{2}{\cal L}_{t}\left(\widetilde{\mathbf{z}}_{t}%
\right)-\nabla^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right\|_{*}\leq C_{%
1}\left\|\widetilde{\mathbf{z}}_{t}-\bm{\theta}_{*}\right\|_{\nabla^{2}{\cal L%
}_{t}\left(\bm{\theta}_{*}\right)}\leq\rho_{t} \tag{16}
$$
where $\rho_{t}=c\left(C_{1}C_{2}+2\eta^{2}\lambda_{1}^{2}\right)\sqrt{\frac{\gamma%
\log(dt)}{t}}$ . Step 6 (Define $\mathbf{M}_{1,t}$ and $\mathbf{M}_{2,t}$ ): It follows from the inequality (16) that
| | $\displaystyle∇^{2}\widehat{\cal L}_{t}(\widetilde{\bm{\theta}}_{t})%
\preceq\left(1+\rho_{t}\right)∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}%
\right)\implies∇^{2}\widehat{\cal L}_{t}(\widetilde{\bm{\theta}}_{t})-%
∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)\preceq\rho_{t}∇^{2}{%
\cal L}_{t}\left(\bm{\theta}_{*}\right)$ | |
| --- | --- | --- |
Then we can use the inequalities (16) and (17) to show that
| | $\displaystyle\left(1-\rho_{t}\right)∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*%
}\right)\preceq∇^{2}\widehat{\cal L}_{t}(\widetilde{\bm{\theta}}_{t})%
\preceq\left(1+\rho_{t}\right)∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)$ | |
| --- | --- | --- |
Now we define the two quantities $\mathbf{M}_{1,t}$ and $\mathbf{M}_{2,t}$ as follows:
| | $\displaystyle\mathbf{M}_{1,t}$ | $\displaystyle:=\left(∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)%
^{1/2}\left(∇^{2}\widehat{\cal L}_{t}(\widetilde{\bm{\theta}}_{t})\right)%
^{-1}\left(∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)^{1/2}$ | |
| --- | --- | --- | --- | Step 7 (Lower bound ${\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-{\cal L}_{t}\left(\bm{\theta}_{*}\right)$ ): Now for the lower bound it follows from Equation 15 that
| | $\displaystyle{\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-{\cal L}_{t}\left(\bm{%
\theta}_{*}\right)$ | $\displaystyle=\frac{1}{2}\left({\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}%
\right)^{→p}∇^{2}{\cal L}_{t}\left(\widetilde{\mathbf{z}}_{t}\right)%
\left({\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}\right)$ | |
| --- | --- | --- | --- |
where, in $(a)$ we define the vector $\mathbf{u}:=\left({\widehat{\bm{\theta}}}_{t}-\bm{\theta}_{*}\right)^{→p}%
∇^{2}{\cal L}_{t}(\bm{\theta}_{*})^{\frac{1}{2}}$ . Now observe from the definition of and then using the min-max theorem we can show that
| | $\displaystyle{\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-{\cal L}_{t}\left(\bm{%
\theta}_{*}\right)$ | $\displaystyle≥\frac{1}{2}\lambda_{\min}\left(\mathbf{M}_{2,t}\right)\mathbf%
{u}^{T}\mathbf{u}$ | |
| --- | --- | --- | --- |
where, in $(a)$ we use the Equation 13. Step 8: Define $I(\mathcal{E})$ as the indicator that the desired previous events hold, which we can ensure with probability greater than $1-2\left(\dfrac{1}{dt}\right)^{\gamma}$ . Then we can show that: | | $\displaystyle\mathbb{E}\left[{\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-{\cal L%
}_{t}\left(\bm{\theta}_{*}\right)\right]≥$ | $\displaystyle\mathbb{E}\left[\left({\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-{%
\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)I(\mathcal{E})\right]$ | |
| --- | --- | --- | --- |
where, in $(a)$ we have $\sigma^{2}_{t}:=\left\|∇\widehat{\cal L}_{t}\left(\bm{\theta}_{*}\right)%
\right\|_{\left(∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)^{-1}%
}^{2}$ , and $c^{\prime}$ is an universal constant. Step 9: Define the random variable $Z=\left\|∇\widehat{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right\|_{\left%
(∇^{2}{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)^{-1}}$ . With a failure event probability of less than $2\left(\dfrac{1}{dt}\right)^{\gamma}$ for any $z_{0},$ we have:
| | $\displaystyle\mathbb{E}\left[Z^{2}I(\operatorname{not}\mathcal{E})\right]$ | $\displaystyle=\mathbb{E}\left[Z^{2}I(\operatorname{not}\mathcal{E})I\left(Z^{2%
}<z_{0}\right)\right]+\mathbb{E}\left[Z^{2}I(\operatorname{not}\mathcal{E})I%
\left(Z^{2}≥ z_{0}\right)\right]$ | |
| --- | --- | --- | --- |
where $z_{0}=t^{\gamma/2}\sqrt{\mathbb{E}\left[Z^{4}\right]}$ . Step 10 (Upper Bound): For an upper bound we have that:
| | $\displaystyle\mathbb{E}\left[{\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-{\cal L%
}_{t}\left(\bm{\theta}_{*}\right)\right]$ | $\displaystyle=\mathbb{E}\left[\left({\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-%
{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)I(\mathcal{E})\right]+\mathbb{E%
}\left[\left({\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-{\cal L}_{t}\left(\bm{%
\theta}_{*}\right)\right)I(\operatorname{not}\mathcal{E})\right]$ | |
| --- | --- | --- | --- |
since the probability of not $\mathcal{E}$ is less than $\dfrac{1}{t^{\gamma}}$ . Now for an upper bound of the first term, observe that
| | $\displaystyle\mathbb{E}\left[\left({\cal L}_{t}({\widehat{\bm{\theta}}}_{t})-{%
\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)I(\mathcal{E})\right]≤$ | $\displaystyle\frac{1}{2}\mathbb{E}\left[\left(\lambda_{\max}\left(\mathbf{M}_{%
1,t}\right)\right)^{2}\lambda_{\max}\left(\mathbf{M}_{2,t}\right)\left\|∇%
\widehat{\cal L}_{t}\left(\bm{\theta}_{*}\right)\right\|_{\left(∇^{2}{%
\cal L}_{t}\left(\bm{\theta}_{*}\right)\right)^{-1}}^{2}I(\mathcal{E})\right]$ | |
| --- | --- | --- | --- |
where, $c^{\prime}$ is another universal constant. ∎
Appendix C Experimental Details
C.1 Dataset Statistics
We provide the processed data statistics in Table 6. We highlight that due to the black-box assumption of the base model, the training set is used for ablation and qualitative analysis in Section 7.3 and Section 7.4.
Table 6: Processed Dataset Statistics. Training set is only used for ablation and qualitative analysis due to the black-box model assumption.
| Dataset | Train | Validation | Test |
| --- | --- | --- | --- |
| E2E NLG | 33,525 | 4,299 | 4,693 |
| Web NLG | 2,732 (filtered by categories) | 844 | 720 |
| CommonGen | 1,476 (filtered for “man”) | 2,026 | 1,992 |
| Adidas | — | 745 | 100 |
C.2 Prompts
We now describe the prompts we used for the four datasets and three models.
E2E NLG Dataset
- For the GPT2-M model, we use the prompt: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] Given the following aspects of a restaurant, [attributes], a natural language sentence describing the restaurant is:
- For the GPT2-XL model, the prompt is: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] Imagine you are writing a one-sentence description for a restaurant, given the following aspects: [attributes], a human-readable natural language sentence describing the restaurant is:
- For the LLaMA-3.1-8B model, we use: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] Please convert the following attributes into a coherent sentence. Do not provide an explanation.
Web NLG Dataset
- For the GPT2-M model, we use the prompt: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] Convert the following facts into a coherent sentence: Facts: [facts] Sentence:
- For the GPT2-XL model, the prompt is: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] You are given the following facts. Facts: [facts] A short, coherent sentence summarizing the facts is:
- For the LLaMA-3.1-8B model, we use: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] Do not provide an explanation or follow-up. Just convert the following facts of an entity into a coherent sentence. Facts: [facts] Sentence:
CommonGen Dataset
- For the GPT2-M and GPT2-XL models, we use the same prompt: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] One coherent sentence that uses all the following concepts: [concepts], is:
- For the LLaMA-3.1-8B model, we use: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] Please write a coherent sentence that uses all the following concepts. Concepts: [concepts] Sentence:
Adidas Dataset
- For the GPT2-M and GPT2-XL models, we use the same prompt: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] Given the following attributes of a product, write a description. Attributes: [attributes] Description:
- For the LLaMA-3.1-8B model, we use: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] Please write a description of this product given the following attributes. Attributes: [attributes] Description:
For in-context learning, we simply add a sentence at the beginning of the prompt before adding the samples in the prompt: Below are a list of demonstrations:.
For the qualitative analysis on the distribution shift in Section 7.4, we ask GPT-4o with the following prompt: For Web NLG dataset: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] Focus on all the samples, how much percentage is related to ‘‘Person’’?
For CommonGen dataset: {mdframed} [backgroundcolor=gray!20, linewidth=0pt] Focus on those samples whose target is related to gender, how much percentage is related to ‘‘woman’’?
C.3 Metrics
We report performance using seven standard metrics often used in the natural language generation tasks. These are: (a) BLEU (Papineni et al., 2002) (measures n-gram overlap between the generated and reference texts, emphasizing precision), (b) ROUGE-1 (Lin, 2004) (computes unigram recall to measure the overlap between generated and reference texts), (c) ROUGE-2 (Lin, 2004) (extends ROUGE-1 to bigrams, measuring the recall of two-word sequences), (d) ROUGE-L (Lin & Och, 2004) (uses the longest common subsequence to evaluate recall), (e) METEOR (Banerjee & Lavie, 2005) (combines unigram precision, recall, and semantic matching to assess similarity), (f) CIDEr (Vedantam et al., 2015) (measures consensus in n-gram usage across multiple references, with tf-idf weighting), and (g) NIST (Doddington, 2002) (similar to BLEU but weights n-grams by their informativeness, favoring less frequent and meaningful phrases).
C.4 Performance and Efficiency Comparision with Parameter-Efficient Fine-Tuning
While our work focuses on black-box LLM adaptation where model weights are inaccessible, we include a controlled comparison with Parameter-Efficient Fine-Tuning (PEFT) methods. Specifically, we implement LoRA (Hu et al., 2021) with rank-8 matrices on the query and value projections of GPT2-XL and LLaMA-3.1-8B, and fine-tune the base models using the same task-specific data.
The performance results are shown in Table 7. Consider GPT2-XL as a reference example, Plugin adds a 1-layer autoregressive Transformer with 30.72M parameters, while LoRA (r=8) introduces only 2.46M trainable parameters. However, Plugin requires no modification of the base model and can be deployed post hoc. Despite the access advantage of LoRA, the performance gap is minimal. As for computational efficiency, Plugin requires 196.2B FLOPs (up to 64 decoding steps), while LoRA uses 188.8B FLOPs—a difference of less than 5%. The gap narrows or inverts depending on model configuration. These results suggest that Plugin offers a competitive adaptation solution even under white-box conditions, while maintaining broader applicability in black-box settings.
Table 7: Comparison between Plugin and PEFT (LoRA, r=8) on four datasets using GPT2-XL and LLaMA-3.1-8B as base models. We show mean and standard deviation of the metrics over five seeds.
| Model | Method | BLEU | Rouge-1 | Rouge-2 | Rouge-L | METEOR | CIDEr | NIST |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| E2E NLG | | | | | | | | |
| GPT2-XL | Zeroshot | 0.0562 | 0.4013 | 0.1636 | 0.2862 | 0.3697 | 0.0187 | 0.5338 |
| GPT2-XL | LoRA (r=8) | 0.2517 ±0.012 | 0.5712 ±0.010 | 0.3079 ±0.013 | 0.4317 ±0.011 | 0.5162 ±0.014 | 0.5225 ±0.012 | 1.2172 ±0.011 |
| GPT2-XL | Plugin (Ours) | 0.2470 ±0.009 | 0.5536 ±0.007 | 0.3084 ±0.007 | 0.4213 ±0.008 | 0.5057 ±0.009 | 0.5455 ±0.013 | 1.2736 ±0.051 |
| LLaMA-3.1-8B | Zeroshot | 0.3226 | 0.6917 | 0.4050 | 0.5004 | 0.6041 | 0.9764 | 1.1310 |
| LLaMA-3.1-8B | LoRA (r=8) | 0.3702 ±0.016 | 0.7125 ±0.010 | 0.4236 ±0.014 | 0.5345 ±0.012 | 0.6413 ±0.017 | 1.1028 ±0.033 | 1.1827 ±0.035 |
| LLaMA-3.1-8B | Plugin (Ours) | 0.3691 ±0.013 | 0.7113 ±0.002 | 0.4374 ±0.004 | 0.5247 ±0.002 | 0.6392 ±0.009 | 1.1441 ±0.030 | 1.1749 ±0.034 |
| Web NLG | | | | | | | | |
| GPT2-XL | Zeroshot | 0.0317 | 0.2992 | 0.1321 | 0.2417 | 0.1969 | 0.0491 | 0.1826 |
| GPT2-XL | LoRA (r=8) | 0.1723 ±0.007 | 0.4604 ±0.010 | 0.2618 ±0.011 | 0.3628 ±0.015 | 0.4012 ±0.017 | 0.9018 ±0.028 | 0.2736 ±0.014 |
| GPT2-XL | Plugin (Ours) | 0.1673 ±0.004 | 0.4616 ±0.007 | 0.2527 ±0.007 | 0.3757 ±0.008 | 0.3895 ±0.007 | 0.8987 ±0.013 | 0.2646 ±0.003 |
| LLaMA-3.1-8B | Zeroshot | 0.1453 | 0.5278 | 0.3030 | 0.3982 | 0.4314 | 0.6991 | 0.2684 |
| LLaMA-3.1-8B | LoRA (r=8) | 0.2638 ±0.008 | 0.6238 ±0.010 | 0.3927 ±0.009 | 0.4726 ±0.009 | 0.5927 ±0.013 | 1.6421 ±0.028 | 0.2379 ±0.008 |
| LLaMA-3.1-8B | Plugin (Ours) | 0.2542 ±0.004 | 0.6375 ±0.005 | 0.3873 ±0.005 | 0.4869 ±0.007 | 0.5724 ±0.004 | 1.5911 ±0.046 | 0.2590 ±0.003 |
| CommonGen | | | | | | | | |
| GPT2-XL | Zeroshot | 0.0317 | 0.2992 | 0.1321 | 0.2417 | 0.1969 | 0.0491 | 0.1826 |
| GPT2-XL | LoRA (r=8) | 0.1826 ±0.027 | 0.5027 ±0.010 | 0.2137 ±0.014 | 0.4447 ±0.016 | 0.4726 ±0.009 | 0.7182 ±0.027 | 0.6725 ±0.043 |
| GPT2-XL | Plugin (Ours) | 0.1791 ±0.014 | 0.4932 ±0.007 | 0.2288 ±0.004 | 0.4347 ±0.007 | 0.4702 ±0.006 | 0.7283 ±0.012 | 0.6554 ±0.038 |
| LLaMA-3.1-8B | Zeroshot | 0.0643 | 0.2776 | 0.1181 | 0.2488 | 0.3857 | 0.3155 | 0.3347 |
| LLaMA-3.1-8B | LoRA (r=8) | 0.2736 ±0.018 | 0.5829 ±0.009 | 0.3206 ±0.009 | 0.5026 ±0.012 | 0.5927 ±0.016 | 1.1121 ±0.034 | 0.7926 ±0.028 |
| LLaMA-3.1-8B | Plugin (Ours) | 0.2665 ±0.010 | 0.5800 ±0.002 | 0.3139 ±0.005 | 0.5037 ±0.004 | 0.5829 ±0.003 | 1.0876 ±0.020 | 0.7031 ±0.007 |
| Adidas | | | | | | | | |
| GPT2-XL | Zeroshot | 0.0075 | 0.2309 | 0.0278 | 0.1438 | 0.1487 | 0.0184 | 0.4956 |
| GPT2-XL | LoRA (r=8) | 0.0629 ±0.028 | 0.2816 ±0.030 | 0.0719 ±0.029 | 0.1816 ±0.038 | 0.2037 ±0.018 | 0.1231 ±0.126 | 0.6576 ±0.134 |
| GPT2-XL | Plugin (Ours) | 0.0600 ±0.017 | 0.2710 ±0.025 | 0.0722 ±0.018 | 0.1725 ±0.017 | 0.1995 ±0.018 | 0.1195 ±0.138 | 0.6375 ±0.120 |
| LLaMA-3.1-8B | Zeroshot | 0.0120 | 0.2470 | 0.0318 | 0.1493 | 0.1526 | 0.0424 | 0.5285 |
| LLaMA-3.1-8B | LoRA (r=8) | 0.0721 ±0.020 | 0.2697 ±0.031 | 0.0756 ±0.028 | 0.1821 ±0.020 | 0.2023 ±0.038 | 0.1302 ±0.178 | 0.6137 ±0.172 |
| LLaMA-3.1-8B | Plugin (Ours) | 0.0611 ±0.018 | 0.2714 ±0.029 | 0.0742 ±0.020 | 0.1759 ±0.019 | 0.1990 ±0.020 | 0.1293 ±0.152 | 0.6361 ±0.134 |
C.5 Further Quantitative Analysis and Ablation
Following Section 7.3, we present the same ablation analysis using GPT2-M on the remaining three datasets. As shown in Figure 5, the trends mirror those in Figure 2: the Plugin model consistently improves performance as the base model becomes stronger with additional fine-tuning, underscoring the robustness and versatility of our approach. Similarly, Figure 6 confirms the pattern observed in Figure 3: a single-layer reweighting model yields optimal performance, while deeper configurations tend to overfit and degrade quality. Across all datasets, initializing the reweighting model with a pretrained GPT2-Small consistently boosts effectiveness.
<details>
<summary>x3.png Details</summary>
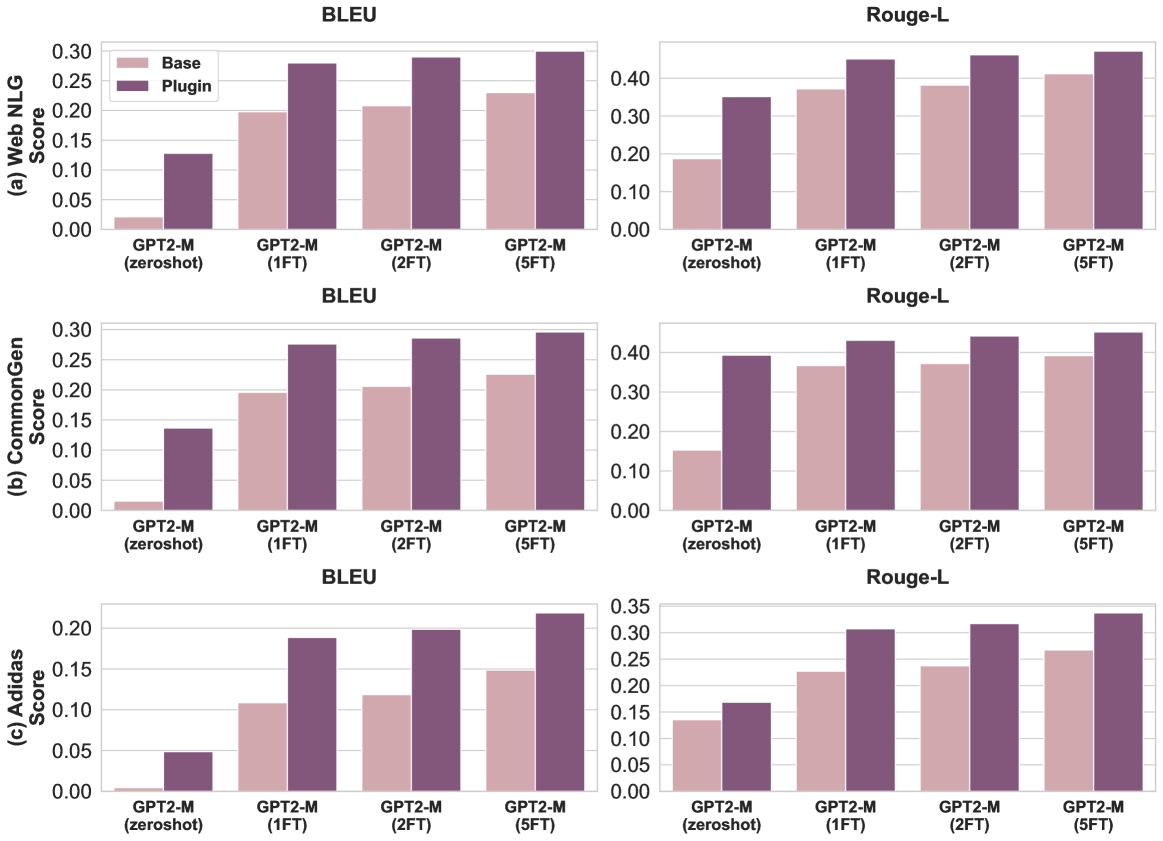
### Visual Description
# Technical Data Extraction: Performance Comparison of Base vs. Plugin Models
This document provides a comprehensive extraction of data from a series of bar charts comparing the performance of a "Base" model against a "Plugin" model across three datasets (Web NLG, CommonGen, and Adidas) using two metrics (BLEU and Rouge-L).
## 1. Metadata and Global Legend
* **Image Type:** Grouped Bar Charts (3x2 grid).
* **Legend Location:** Top-left chart (Row 1, Column 1).
* **Legend Categories:**
* **Base:** Light pink/mauve color.
* **Plugin:** Dark purple/plum color.
* **X-Axis Categories (Common to all charts):**
1. GPT2-M (zeroshot)
2. GPT2-M (1FT)
3. GPT2-M (2FT)
4. GPT2-M (5FT)
*Note: "FT" likely refers to Fine-Tuning epochs or stages.*
---
## 2. Data Extraction by Dataset
### (a) Web NLG Dataset
**Trend Analysis:** Both Base and Plugin scores increase as fine-tuning progresses from zeroshot to 5FT. The "Plugin" consistently and significantly outperforms the "Base" model, with the largest relative gap occurring at the "zeroshot" stage.
#### BLEU Score (Top Left)
* **Y-Axis Range:** 0.00 to 0.30 (increments of 0.05).
* **Data Points (Approximate):**
| Category | Base | Plugin |
| :--- | :--- | :--- |
| zeroshot | 0.02 | 0.13 |
| 1FT | 0.20 | 0.28 |
| 2FT | 0.21 | 0.29 |
| 5FT | 0.23 | 0.30 |
#### Rouge-L Score (Top Right)
* **Y-Axis Range:** 0.00 to 0.40+ (increments of 0.10).
* **Data Points (Approximate):**
| Category | Base | Plugin |
| :--- | :--- | :--- |
| zeroshot | 0.19 | 0.35 |
| 1FT | 0.37 | 0.45 |
| 2FT | 0.38 | 0.46 |
| 5FT | 0.41 | 0.47 |
---
### (b) CommonGen Dataset
**Trend Analysis:** Similar to Web NLG, there is a steady upward trend for both models. The Plugin model maintains a lead of approximately 0.05 to 0.10 points across all categories.
#### BLEU Score (Middle Left)
* **Y-Axis Range:** 0.00 to 0.30 (increments of 0.05).
* **Data Points (Approximate):**
| Category | Base | Plugin |
| :--- | :--- | :--- |
| zeroshot | 0.01 | 0.14 |
| 1FT | 0.20 | 0.28 |
| 2FT | 0.21 | 0.29 |
| 5FT | 0.23 | 0.30 |
#### Rouge-L Score (Middle Right)
* **Y-Axis Range:** 0.00 to 0.40+ (increments of 0.10).
* **Data Points (Approximate):**
| Category | Base | Plugin |
| :--- | :--- | :--- |
| zeroshot | 0.15 | 0.39 |
| 1FT | 0.37 | 0.43 |
| 2FT | 0.37 | 0.44 |
| 5FT | 0.39 | 0.45 |
---
### (c) Adidas Dataset
**Trend Analysis:** This dataset shows the lowest overall scores among the three. While the upward trend persists, the "Base" model starts near zero in the zeroshot BLEU category. The Plugin model provides a substantial performance boost, nearly doubling the Base score in several instances.
#### BLEU Score (Bottom Left)
* **Y-Axis Range:** 0.00 to 0.20+ (increments of 0.05).
* **Data Points (Approximate):**
| Category | Base | Plugin |
| :--- | :--- | :--- |
| zeroshot | 0.005 | 0.05 |
| 1FT | 0.11 | 0.19 |
| 2FT | 0.12 | 0.20 |
| 5FT | 0.15 | 0.22 |
#### Rouge-L Score (Bottom Right)
* **Y-Axis Range:** 0.00 to 0.35 (increments of 0.05).
* **Data Points (Approximate):**
| Category | Base | Plugin |
| :--- | :--- | :--- |
| zeroshot | 0.14 | 0.17 |
| 1FT | 0.23 | 0.31 |
| 2FT | 0.24 | 0.32 |
| 5FT | 0.27 | 0.34 |
---
## 3. Summary of Findings
1. **Plugin Efficacy:** In every single test case (3 datasets x 2 metrics x 4 training stages), the **Plugin** model (dark purple) outperforms the **Base** model (light pink).
2. **Zero-shot Impact:** The Plugin architecture provides a critical performance floor; where the Base model often fails or performs poorly in zero-shot scenarios, the Plugin model maintains usable scores.
3. **Scaling with Fine-Tuning:** While fine-tuning improves both models, the performance gap remains relatively consistent, suggesting the Plugin provides architectural advantages that are not entirely superseded by additional training data.
</details>
Figure 5: Performance of applying a single-layer reweighting model across increasingly fine-tuned GPT2-M models on the three datasets. Results demonstrate consistent improvements introduced by our method regardless of the strength of the base model.
<details>
<summary>x4.png Details</summary>
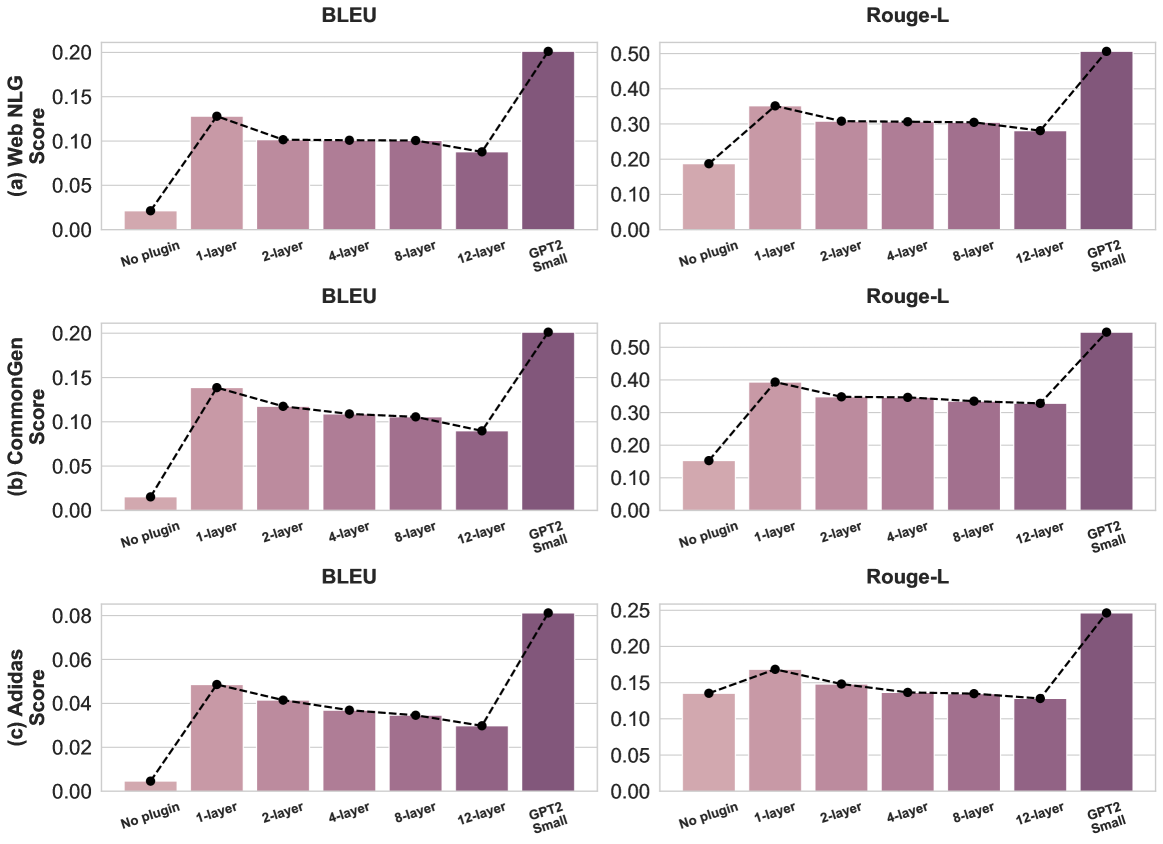
### Visual Description
# Technical Data Extraction: Performance Comparison Across Datasets and Model Configurations
This document provides a comprehensive extraction of data from a 3x2 grid of bar charts comparing model performance (BLEU and Rouge-L scores) across three datasets: **Web NLG**, **CommonGen**, and **Adidas**.
## 1. Document Structure and Global Components
The image is organized into three horizontal rows, each representing a specific dataset, and two vertical columns representing evaluation metrics.
* **Rows (Datasets):**
* (a) Web NLG
* (b) CommonGen
* (c) Adidas
* **Columns (Metrics):**
* BLEU (Left Column)
* Rouge-L (Right Column)
* **X-Axis Categories (Common to all charts):**
1. No plugin
2. 1-layer
3. 2-layer
4. 4-layer
5. 8-layer
6. 12-layer
7. GPT2 Small
* **Visual Encoding:**
* **Bars:** Represent the score for each configuration. The color transitions from light pink (left) to dark purple (right).
* **Dashed Line with Markers:** Connects the top of each bar to visualize the trend across configurations.
* **Y-Axis:** Represents the numerical "Score" for the respective metric.
---
## 2. Detailed Data Extraction by Dataset
### (a) Web NLG Dataset
**Trend Analysis:** Performance spikes significantly when moving from "No plugin" to "1-layer". From "1-layer" to "12-layer", there is a gradual, slight decline in performance. "GPT2 Small" represents the peak performance for both metrics.
| Configuration | BLEU Score (Approx.) | Rouge-L Score (Approx.) |
| :--- | :--- | :--- |
| No plugin | 0.02 | 0.19 |
| 1-layer | 0.13 | 0.35 |
| 2-layer | 0.10 | 0.31 |
| 4-layer | 0.10 | 0.31 |
| 8-layer | 0.10 | 0.30 |
| 12-layer | 0.09 | 0.28 |
| GPT2 Small | 0.20 | 0.51 |
---
### (b) CommonGen Dataset
**Trend Analysis:** Similar to Web NLG, there is a sharp increase at "1-layer". A steady, linear decrease is observed as the number of layers increases from 1 to 12. "GPT2 Small" remains the highest-performing baseline.
| Configuration | BLEU Score (Approx.) | Rouge-L Score (Approx.) |
| :--- | :--- | :--- |
| No plugin | 0.015 | 0.15 |
| 1-layer | 0.14 | 0.39 |
| 2-layer | 0.12 | 0.35 |
| 4-layer | 0.11 | 0.35 |
| 8-layer | 0.105 | 0.34 |
| 12-layer | 0.09 | 0.33 |
| GPT2 Small | 0.20 | 0.55 |
---
### (c) Adidas Dataset
**Trend Analysis:** The scores for this dataset are lower in absolute magnitude compared to the others. The trend follows the same pattern: a peak at "1-layer" followed by a consistent downward slope through "12-layer". "GPT2 Small" shows a significant lead over all plugin configurations.
| Configuration | BLEU Score (Approx.) | Rouge-L Score (Approx.) |
| :--- | :--- | :--- |
| No plugin | 0.005 | 0.135 |
| 1-layer | 0.048 | 0.165 |
| 2-layer | 0.041 | 0.148 |
| 4-layer | 0.037 | 0.138 |
| 8-layer | 0.035 | 0.135 |
| 12-layer | 0.030 | 0.128 |
| GPT2 Small | 0.081 | 0.245 |
---
## 3. Summary of Key Findings
1. **Plugin Impact:** Adding even a single layer ("1-layer") results in a massive performance gain over the "No plugin" baseline across all datasets and metrics.
2. **Layer Scaling:** Increasing the number of layers in the plugin (from 1 to 12) consistently leads to a **decrease** in performance. The 1-layer configuration is the most effective plugin setup shown.
3. **Baseline Comparison:** The "GPT2 Small" model consistently outperforms all plugin-augmented configurations, typically achieving scores roughly double those of the 1-layer plugin in BLEU metrics.
4. **Metric Correlation:** BLEU and Rouge-L scores follow identical trends across all configurations, suggesting that the model improvements (or degradations) are consistent across different linguistic evaluation methods.
</details>
Figure 6: Performance of GPT2-M with varying reweighting model complexities on the three datasets, measured by BLEU and Rouge-L. Results demonstrate that a single reweighting layer achieves significant improvements, while increasing the number of layers beyond this leads to performance degradation, likely due to overfitting. Using a pretrained GPT2-Small as the reweighting model largely boosts the performance, highlighting the benefits of leveraging pretrained models.
C.6 Influence of the architecture of the reweighting model in Plugin
We vary the choice of the reweighting model architecture. We find that a causal transformer layer identical to those used in the base model performs best, as it can leverage the base model’s logits and aggregate contextual information from prior tokens to better adapt the base model to the new data distribution. This conclusion is reinforced by Figure 7, where the transformer architecture consistently outperforms both the MLP (two layer with ReLU activation) and linear layers across all metrics, as indicated by higher means and narrower standard deviation bands. These results highlight the importance of leveraging the architectural capacity of transformers to effectively adapt the logits of the base black-box model.
<details>
<summary>x5.png Details</summary>
### Visual Description
# Technical Document Extraction: Performance Comparison of Model Architectures
## 1. Image Overview
This image is a line graph comparing the performance of three different machine learning architectures (**Linear**, **MLP**, and **Transformer**) across seven distinct evaluation metrics. The y-axis represents the mean score with a shaded region indicating the standard deviation (Mean ± Std).
## 2. Component Isolation
### A. Header / Legend
* **Location:** Top-left quadrant of the chart area.
* **Content:**
* **Linear:** Represented by a light pink line with circular markers (●).
* **MLP:** Represented by a medium mauve line with square markers (■).
* **Transformer:** Represented by a dark purple line with diamond markers (◆).
### B. Main Chart Area (Axes)
* **Y-Axis Label:** "Mean ± Std"
* **Y-Axis Scale:** Numerical range from 0.0 to 0.7, with major gridlines every 0.1 units.
* **X-Axis Labels (Categories):**
1. BLEU
2. Rouge-1
3. Rouge-2
4. Rouge-L
5. METEOR
6. CIDEr
7. NIST
### C. Visual Trends and Logic Check
* **Transformer (Dark Purple):** Consistently the highest-performing architecture across all metrics. It shows a significant peak at Rouge-1, a dip at Rouge-2, and a strong upward trajectory from METEOR through NIST.
* **MLP (Medium Mauve):** Consistently occupies the middle performance tier. It follows a similar shape to the Transformer but at a lower magnitude. Notably, its performance dips slightly between METEOR and CIDEr before rising for NIST.
* **Linear (Light Pink):** The lowest-performing architecture. It follows the general "M" shape of the Rouge metrics but drops significantly at CIDEr (nearly to 0.0) before recovering for NIST.
## 3. Data Extraction (Estimated Values)
The following table reconstructs the data points based on the visual alignment with the y-axis gridlines.
| Metric | Linear (Light Pink ●) | MLP (Medium Mauve ■) | Transformer (Dark Purple ◆) |
| :--- | :--- | :--- | :--- |
| **BLEU** | ~0.02 | ~0.06 | ~0.14 |
| **Rouge-1** | ~0.26 | ~0.39 | ~0.45 |
| **Rouge-2** | ~0.04 | ~0.14 | ~0.19 |
| **Rouge-L** | ~0.14 | ~0.33 | ~0.39 |
| **METEOR** | ~0.21 | ~0.29 | ~0.41 |
| **CIDEr** | ~0.02 | ~0.26 | ~0.56 |
| **NIST** | ~0.37 | ~0.44 | ~0.64 |
## 4. Detailed Observations
* **Standard Deviation:** The shaded regions indicate the variance in performance. The **Transformer** model shows a noticeably wider standard deviation (higher variance) on the **NIST** and **CIDEr** metrics compared to the other models.
* **Metric Correlation:** All three models show a sharp performance drop when moving from **Rouge-1** to **Rouge-2**, and a sharp increase when moving from **CIDEr** to **NIST**.
* **Performance Gap:** The performance gap between the Transformer and the other models is most pronounced in the **CIDEr** and **NIST** metrics, where the Transformer significantly outperforms the Linear and MLP baselines.
* **Linear Model Anomaly:** The Linear model performs exceptionally poorly on the **CIDEr** metric, nearly touching the 0.0 baseline, whereas the MLP and Transformer maintain much higher relative scores.
</details>
Figure 7: Performance comparison of the weighting model architecture in Plugin. The transformer layer achieves the best performance with consistently higher means and narrower standard deviations. Shaded bands represent the standard deviation around the mean.
C.7 Details for Adidas Qualitative Studies
Human Evaluation.
We conduct a human evaluation on 100 test passages from the Adidas product dataset, comparing outputs generated with and without applying the reweighting model, using LLaMA-3.1-8B as the base model. Three human evaluators are presented with a ground-truth Adidas product description and two randomly ordered descriptions: one generated with the reweighting layer and one without (i.e., we use the base model with ICL-3 as a much stronger baseline due to the low quality of the zero-shot). Evaluators are prompted to select the prediction closest to the ground truth. Results show that the output generated with the reweighting model is preferred on an average of 80.7 out of all 100 cases. The output descriptions from the base model without the reweighting are generally short and general. This demonstrates that our approach effectively adapts a closed model to the unique style of the given dataset.
In this section, we display some details for the qualitative analysis on the Adidas product description dataset.
Details of Extracting Adidas Style Words.
We discuss the details on extracting the most frequent 50 words in the Adidas product description dataset as the “Adidas style” words. We argue that there does not exist a gold-standard way to define the “style” words for a dataset. We extract these style words through a minimal preprocessing pipeline: converting text to lowercase, removing special characters and numbers, and filtering out common English stopwords. We deliberately preserve the original word forms without lemmatization or stemming to maintain distinct style markers (e.g., keeping “comfortable” distinct from “comfort”, “running” distinct from “run”). After tokenization using NLTK’s word tokenizer, we count word frequencies across all product descriptions and select the top 50 most frequent words. This approach captures the exact vocabulary used in Adidas’ product descriptions, including specific product features.
A statistics of the frequency of these top-50 words is shown in Figure 8.
<details>
<summary>x6.png Details</summary>
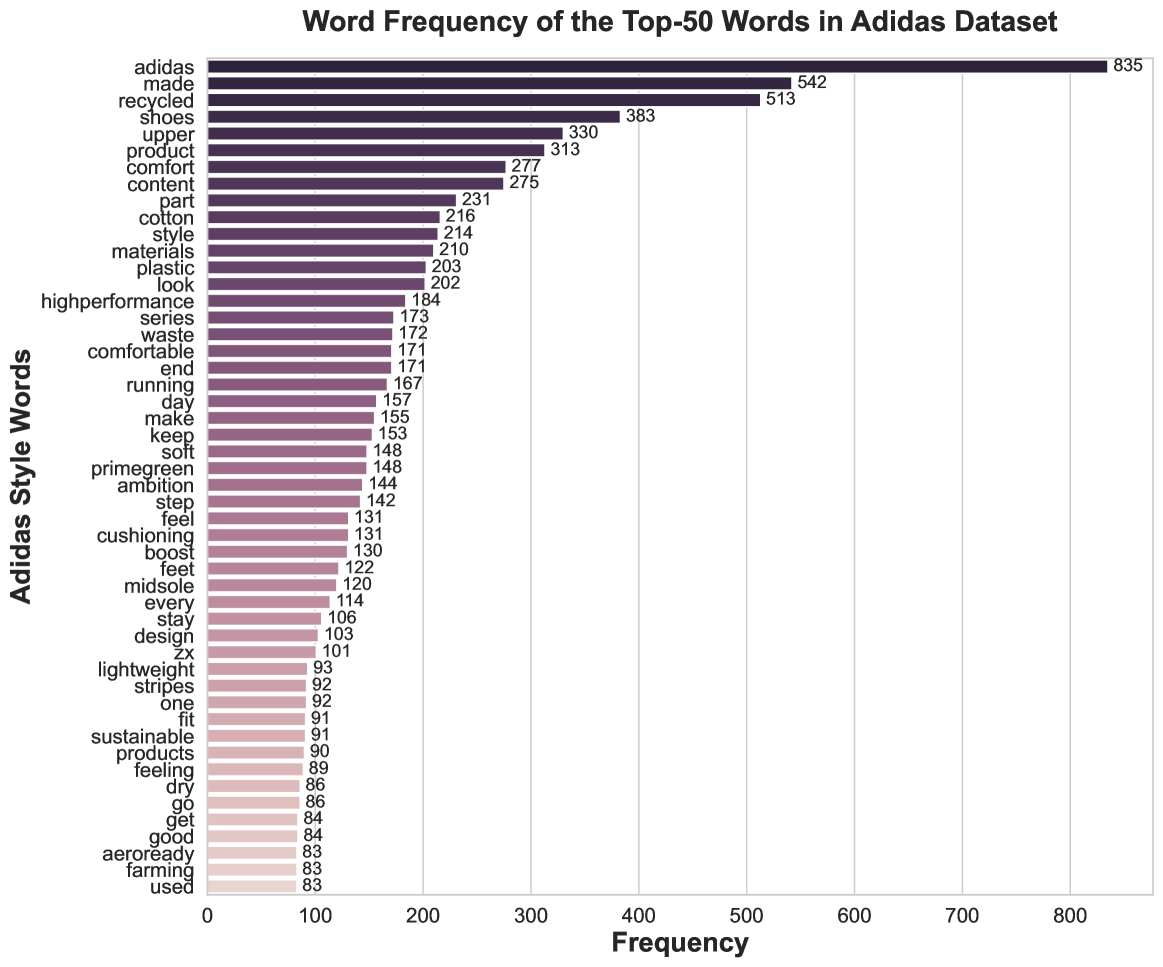
### Visual Description
# Technical Document Extraction: Word Frequency Analysis
## 1. Document Overview
This image is a horizontal bar chart titled **"Word Frequency of the Top-50 Words in Adidas Dataset"**. It visualizes the most common terms found within a specific dataset related to Adidas products, likely derived from product descriptions or marketing copy.
## 2. Chart Components
* **Header:** Centered at the top, bold black text.
* **Y-Axis (Vertical):** Labeled **"Adidas Style Words"**. It lists 50 individual words in descending order of frequency.
* **X-Axis (Horizontal):** Labeled **"Frequency"**. It features a numerical scale from 0 to 800 with major gridline intervals every 100 units.
* **Data Representation:** Horizontal bars. The length of each bar corresponds to the frequency count.
* **Color Gradient:** The bars utilize a sequential color gradient. The highest frequency words (top) are dark purple/black, transitioning through shades of plum and mauve to a light dusty rose/beige for the lowest frequency words (bottom).
* **Data Labels:** Each bar is terminated with the exact numerical frequency value printed to the right of the bar.
## 3. Data Table Extraction
The following table reconstructs the data presented in the chart, sorted from highest to lowest frequency.
| Rank | Word | Frequency | Rank | Word | Frequency |
| :--- | :--- | :--- | :--- | :--- | :--- |
| 1 | adidas | 835 | 26 | soft | 148 |
| 2 | made | 542 | 27 | primegreen | 148 |
| 3 | recycled | 513 | 28 | ambition | 144 |
| 4 | shoes | 383 | 29 | step | 142 |
| 5 | upper | 330 | 30 | feel | 131 |
| 6 | product | 313 | 31 | cushioning | 131 |
| 7 | comfort | 277 | 32 | boost | 130 |
| 8 | content | 275 | 33 | feet | 122 |
| 9 | part | 231 | 34 | midsole | 120 |
| 10 | cotton | 216 | 35 | every | 114 |
| 11 | style | 214 | 36 | stay | 106 |
| 12 | materials | 210 | 37 | design | 103 |
| 13 | plastic | 203 | 38 | zx | 101 |
| 14 | look | 202 | 39 | lightweight | 93 |
| 15 | highperformance | 184 | 40 | stripes | 92 |
| 16 | series | 173 | 41 | one | 92 |
| 17 | waste | 172 | 42 | fit | 91 |
| 18 | comfortable | 171 | 43 | sustainable | 91 |
| 19 | end | 171 | 44 | products | 90 |
| 20 | running | 167 | 45 | feeling | 89 |
| 21 | day | 157 | 46 | dry | 86 |
| 22 | make | 155 | 47 | go | 86 |
| 23 | keep | 153 | 48 | get | 84 |
| 24 | good | 84 | 49 | aeroready | 83 |
| 25 | farming | 83 | 50 | used | 83 |
*Note: "good" and "farming/used" appear out of strict numerical order in the visual list near the bottom, but are transcribed as they appear on the Y-axis sequence.*
## 4. Key Trends and Observations
* **Brand Dominance:** The word **"adidas"** is the most frequent by a significant margin (835), appearing approximately 54% more often than the second-place word.
* **Sustainability Focus:** There is a strong cluster of sustainability-related terms in the top 20, including **"recycled"** (513), **"plastic"** (203), and **"waste"** (172). This suggests the dataset is heavily weighted toward Adidas's eco-friendly initiatives (e.g., Primegreen).
* **Product Anatomy:** Common footwear descriptors are prevalent, such as **"shoes"** (383), **"upper"** (330), **"midsole"** (120), and **"cushioning"** (131).
* **Distribution:** The data follows a "long tail" distribution. There is a sharp drop-off after the top three words, followed by a gradual decline. The frequency difference between the 10th word ("cotton", 216) and the 50th word ("used", 83) is relatively small compared to the gap between the 1st and 10th.
</details>
Figure 8: Word Frequency of the Top-50 Words in Adidas Dataset.
Case Studies for Human Side-by-side Evaluation.
Below we provide more case studies on the Adidas product description datasets. We display the given product attributes, base model’s zero-shot outputs, base model with ICL-3’s outputs, Plugin model’s outputs, and the ground-truth references for each case.
{mdframed}
[backgroundcolor=gray!20, linewidth=0pt] $\clubsuit$ Case 1 Given Product Attributes:
- name [Cushioned Angle Stripe Low-Cut Socks 6 Pairs]
- category [Accessories]
- price [13]
- color [Multicolor]
Base Model (Zero-shot): Cushioned Angle Stripe Low-Cut Socks 6 Pairs, Multicolor.
Base Model (ICL-3): These adidas socks are made with a cushioned sole for extra comfort and support. The low-cut design is perfect for everyday wear, whether you’re running errands or hitting the gym.
Plugin Model: Cushioned Angle Stripe Low-Cut Socks 6 Pairs are the perfect blend of style and comfort. The low-cut design gives you a sleek, modern look while still providing plenty of support for your feet. Made with high-quality materials, these socks will keep your feet feeling comfortable and looking chic all day long.
Ground-truth Reference: With lots of cushioning in the heel and toe and a soft, stretchy feel, these kids’ socks are big on comfort. Whether they’re bouncing around between classes, practice or after-school activities, their little feet will stay dry thanks to moisture-wicking yarn and a mesh upper. An adidas Badge of Sport and 3-Stripes give the socks a classic adidas feel.
{mdframed}
[backgroundcolor=gray!20, linewidth=0pt] $\spadesuit$ Case 2 Given Product Attributes:
- name [Badge of Sport Tee]
- category [Clothing]
- price [21]
- color [Grey]
Base Model (Zero-shot): A white t-shirt with a badge of the sport you love on it.
Base Model (ICL-3): The adidas Badge of Sport tee is a classic. It’s made with soft cotton and features the iconic 3-Stripes on the shoulders. The crew neck has a ribbed hem for a comfortable fit.
Plugin Model: There’s nothing more classic than a white tee with your favorite team’s logo. This adidas Badge of Sport Tee is an everyday essential that can be worn to the gym or on game days. It’s made with recycled materials, so you’re making a sustainable choice. The soft cotton jersey is lightweight, breathable, and comfortable.
Ground-truth Reference: Put your brand pride on full display. A simple yet versatile look, this long sleeve t-shirt keeps you comfortable while on the move or lounging at home. A contrast adidas Badge of Sport stands out on the chest. This product is made with Primegreen, a series of high-performance recycled materials.
{mdframed}
[backgroundcolor=gray!20, linewidth=0pt] Case 3 Given Product Attributes:
- name [Stretch Cotton Trunk Briefs 3 Pairs]
- category [Clothing]
- price [21]
- color [Grey]
Base Model (Zero-shot): Stretch Cotton Trunk Briefs 3 Pairs, Grey.
Base Model (ICL-3): These adidas men’s trunks are made from a soft cotton blend that feels great against the skin. The stretchy fabric moves with you, while the flatlock seams prevent chafing and irritation. A drawcord waistband allows for an adjustable fit.
Plugin Model: Stretch Cotton Trunk Briefs 3 Pairs. The stretch cotton fabric is comfortable to wear. These briefs are made with a classic design in mind, so you can feel confident and comfortable. They have been designed with a low waist, which gives them a flattering fit and makes them easy to get on.
Ground-truth Reference: Just look at these adidas boxer briefs. They’re made with soft, quick-dry fabric that keeps you feeling fresh and a stay-put design that keeps you covered from your first rep to your last. Get comfortable and give it your all. Our cotton products support sustainable cotton farming. This is part of our ambition to end plastic waste.
{mdframed}
[backgroundcolor=gray!20, linewidth=0pt] Case 4 Given Product Attributes:
- name [adidas x Zoe Saldana Long Sleeve Tee]
- category [Clothing]
- price [28]
- color [Black]
Base Model (Zero-shot): This is a long sleeve tee with the adidas logo on the front and Zoe Saldana’s name on the back. It has a crew neck, short sleeves, and a straight hem. The fabric is made of 100% cotton and is machine washable.
Base Model (ICL-3): This adidas x Zoe Saldana long sleeve tee is made with 100% recycled polyester. The soft, lightweight fabric has a smooth finish and features a crew neck and short sleeves. It’s finished with an adidas logo on the chest.
Plugin Model: This is not your average training t-shirt. A modern, slim fit and the softest fabric make it one of our most comfortable tops to date. The lightweight feel makes this tee perfect for all-day wear. Pair it with a pair of leggings or joggers for that ultimate athleisure look you’re always striving for ambition and comfort.
Ground-truth Reference: Your growth, your goals and the challenges you face along the way are all part of your journey. This adidas tee was created in collaboration with Zoe Saldana to inspire you to move with confidence, no matter where you are on your path. Smooth material lays softly on your body so you can feel comfortable in your own skin. A solid color offers styling versatility. This product is made with recycled content as part of our ambition to end plastic waste.