# Dialogue-based Explanations for Logical Reasoning using Structured Argumentation
**Authors**: Loan Ho, Stefan Schlobach
> Vrije University Amsterdam, The Netherlands
## Abstract
The problem of explaining inconsistency-tolerant reasoning in knowledge bases (KBs) is a prominent topic in Artificial Intelligence (AI). While there is some work on this problem, the explanations provided by existing approaches often lack critical information or fail to be expressive enough for non-binary conflicts. In this paper, we identify structural weaknesses of the state-of-the-art and propose a generic argumentation-based approach to address these problems. This approach is defined for logics involving reasoning with maximal consistent subsets and shows how any such logic can be translated to argumentation. Our work provides dialogue models as dialectic-proof procedures to compute and explain a query answer wrt inconsistency-tolerant semantics. This allows us to construct dialectical proof trees as explanations, which are more expressive and arguably more intuitive than existing explanation formalisms.
Key words and phrases: Argumentation, Inconsistency-tolerant semantics, Dialectical proof procedures, Explanation
## 1. Introduction
This paper addresses the problem of explaining logical reasoning in (inconsistent) KBs. Several approaches have been proposed by [18, 17, 22, 24], which mostly include set-based explanations and proof-based explanations. Set-based explanations, which are responsible for the derived answer, are defined as minimal sets of facts in the existential rules [18, 17] or as causes in Description Logics (DLs) [22]. Additionally, the work in [22] provides the notion of conflicts that are minimal sets of assertions responsible for a KB to be inconsistent. Set-based explanations present the necessary premises of entailment and, as such, do not articulate the (often non-obvious) reasoning that connects those premises with the conclusion nor track conflicts. Proof-based explanations provide graphical representations to allow users to understand the reasoning progress better [24]. Unfortunately, the research in this area generally focuses on reasoning in consistent KBs.
The limit of the above approaches is that they lack the tracking of contradictions, whereas argumentation can address this issue. Clearly, argumentation offers a potential solution to address inconsistencies. Those are divided into three approaches:
- Argumentation approach based on Deductive logic: Various works propose instantiations of abstract argumentation (AFs) for $\text{Datalog}^{\pm}$ [19, 35], Description Logic [14] or Classical Logic [51], focusing on the translation of KBs to argumentation without considering explanations. In [7], explanations can be viewed as dialectical trees defined abstractly, requiring a deep understanding of formal arguments and trees, making the work impractical for non-experts. In [35, 9], argumentation with collective attacks is proposed to capture non-binary conflicts in $\text{Datalog}^{\pm}$ , i.e., assuming that every conflict has more than two formulas.
- Sequent-based argumentation [69] and its extension (Hypersequent-based argumentation) [55], using Propositional Logic, provide non-monotonic extensions for Gentzen-style proof systems in terms of argumen-tation-based. Moreover, the authors conclude by wishing future work to include “the study of more expressive formalisms, like those that are based on first-order logics” [69].
- Rule-based argumentation: DeLP/DeLP with collective attacks are introduced for defeasible logic programming [45, 70]. However, in [35], the authors claim that they cannot instantiate DeLP for $\text{Datalog}^{\pm}$ , since DeLP only considers ground rules. In [46, 62], ASPIC/ASPIC+ is introduced for defeasible logic. Following [61], the logical formalism in ASPIC+ is ill-defined, i.e., the contrariness relation is not general enough to consider n-ary constraints. This issue is stated in [35] for $\text{Datalog}^{\pm}$ , namely, the ASPIC+ cannot be directly instantiated with Datalog. The reasons behind this are that Datalog does not have the negation and the contrariness function of ASPIC+ is not general for this language.
Notable works include assumption-based argumentation (ABA) [44] and ABA with collective attack [53], which are applied for default logic and logic programming. However, ABAs ignore cases of the inferred assumptions conflicting, which is allowed in the existential rules, Description Logic and Logic Programming with Negation as Failure in the Head. We call the ABAs ” flat ABAs”. In [41], ”flat” ABAs link to Answer Set Programming but only consider a single conflict for each assumption. In [67, 68], ” Non-flat ” ABAs overcome the limits of ”flat” ABAs, which allow the inferred assumptions to conflict. However, like ASPIC+, the non-flat ABAs ignore the n-ary constraints case. Contrapositive ABAs [65] and its collective attack version [63], which use contrapositive propositional logic, propose extended forms for ’flat’ and ’non-flat’ ABAs. While [63] mainly focuses on representation (which can be simulated in our setting, see Section 3.2), we extend our study to proof procedures in AFs with collective attacks.
Argumentation offers dialogue games to determine and explain the acceptance of propositions for classical logic [50], for $\text{Datalog}^{\pm}$ [33, 34, 20, 19], for logic programming/ default logic [48, 47], and for defeasible logic [42]. However, the models have limitations. In [33, 34], the dialogue models take place between a domain expert but are only applied to a specific domain (agronomy). In [20, 19, 42, 50], persuasion dialogues (dialectic proof procedures) generate the abstract dispute trees defined abstractly that include arguments and attacks and ignore the internal structure of the argument. These works lack exhaustive explanations, making them insufficient for understanding inference steps and argument structures. The works in [43, 13] provide dialectical proof procedures, while the works [47, 48] offer dialogue games (as a distributed mechanism) for ”flat” ABAs to determine sentence acceptance under (grounded/ admissible/ ideal) semantics. Although the works in [47, 48] are similar to our idea of using dialogue and tree, these approaches do not generalize to n-ary conflicts.
The existing studies are mostly restricted to (1) specific logic or have limitations in representation aspects, (2) AFs with binary conflicts, and (3) lack exhaustive explanations. This paper addresses the limitations by introducing a general framework that provides dialogue models as dialectical proof procedures for acceptance in structured argumentation. The following is a simple illustration of how our approach works in a university example.
**Example 1.1**
*Consider inconsistent knowledge about a university domain, in which we know that: lecturers $(\texttt{{Le}})$ and researchers $(\texttt{{Re}})$ are employers $(\texttt{{Em}})$ ; full professors $(\texttt{{FP}})$ are researchers; everyone who is a teaching assistant $(\texttt{{taOf}})$ of an undergraduate course $(\texttt{{UC}})$ is a teaching assistant $(\texttt{{TA}})$ ; everyone who teaches a course is a lecturer and everyone who teaches a graduate course $(\texttt{{GC}})$ is a full professor. However, teaching assistants can be neither researchers nor lecturers, which leads to inconsistency. We also know that an individual Victor apparently is or was a teaching assistant of the KD course $(\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}}))$ , and the KD course is an undergraduate course $(\texttt{{UC}}(\texttt{{KD}}))$ . Additionally, Victor teaches either the KD course $(\texttt{{te}}(\texttt{{v}},\texttt{{KD}}))$ or the KR course $(\texttt{{te}}(\texttt{{v}},\texttt{{KR}}))$ , where the KR course is a graduate course $(\texttt{{GC}}(\texttt{{KR}}))$ . The KB $\mathcal{K}_{1}$ is modelled as follows:
| | $\displaystyle\mathcal{F}_{1}=$ | $\displaystyle\{\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}}),\ \texttt{{te}}( \texttt{{v}},\texttt{{KD}}),\ \texttt{{UC}}(\texttt{{KD}}),\ \texttt{{te}}( \texttt{{v}},\texttt{{KR}}),\ \texttt{{GC}}(\texttt{{KR}})\}$ | |
| --- | --- | --- | --- |
When a user asks ” Is Victor a researcher? ”, the answer will be ” Yes, but Victor is possibly a researcher ”. The current method [18, 17, 22] will provide a set-based explanation consisting of (1) the cause $\{\texttt{{te}}(\texttt{{v}},\texttt{{KR}}),\ \texttt{{GC}}(\texttt{{KR}})\}$ entailing the answer (why the answer is accepted) and (2) the conflict $\{\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}}),\texttt{{UC}}(\texttt{{KD}})\}$ being inconsistent with every cause (why the answer cannot be accepted). The cause, though, does not show a series of reasoning steps to reach $\texttt{{Re}}(\texttt{{v}})$ from the justification $\{\texttt{{te}}(\texttt{{v}},\texttt{{KR}}),\ \texttt{{GC}}(\texttt{{KR}})\}$ . The conflict still lacks all relevant information to explain this result. Indeed, in the KB, the fact $\texttt{{te}}(\texttt{{v}},\texttt{{KD}})$ deducing $\texttt{{Le}}(\texttt{{v}})$ makes the conflict $\{\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}}),\texttt{{UC}}(\texttt{{KD}})\}$ deducing $\texttt{{TA}}(\texttt{{v}})$ uncertain, due to the constraint that lecturers cannot be teaching assistants. Thus, using the conflict in the explanation is insufficient to assert the non-acceptance of the answer. It remains unclear why the answer is possible. Instead, $\texttt{{te}}(\texttt{{v}},\texttt{{KD}})$ deducing $\texttt{{Le}}(\texttt{{v}})$ should be included in the explanation. Without knowing the relevant information, it is impossible for the user - especially non-experts in logic - to understand why this is the case. However, using the argumentation approach will provide a dialogical explanation that is more informative and intuitive. The idea involves a dialogue between a proponent and opponent, where they exchange logical formulas to a dispute agree. The proponent aims to prove that the argument in question is acceptable, while the opponent exhaustively challenges the proponent’s moves. The dialogue where the proponent wins represents a proof that the argument in question is accepted. The dialogue whose graphical representation is shown in Figure 4 proceeds as follows: 1. Suppose that the proponent wants to defend their claim $\texttt{{Re}}(\texttt{{v}})$ . They can do so by putting forward an argument, say $A_{1}$ , supported by facts $\texttt{{te}}(\texttt{{v}},\texttt{{KR}})$ and $\texttt{{GC}}(\texttt{{KR}})$ :
| | $\displaystyle A_{1}:\$ | $\displaystyle\texttt{{Re}}(\texttt{{v}})(\text{by }r_{3})$ | |
| --- | --- | --- | --- | 2. The opponent challenges the proponent’s argument by attacking the claim $\texttt{{Re}}(\texttt{{v}})$ with an argument $\texttt{{TA}}(\texttt{{v}})$ , say $A_{2}$ , supported by facts $\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}})$ and $\texttt{{UC}}(\texttt{{KD}})$ :
| | $\displaystyle A_{2}:\$ | $\displaystyle\texttt{{TA}}(\texttt{{v}})(\text{by }r_{4})$ | |
| --- | --- | --- | --- | 3. To argue that the opponent’s attack is not possible - and to further defend the initial claim $\texttt{{Re}}(\texttt{{v}})$ - the proponent can counter the opponent’s argument by providing additional evidence $\texttt{{Le}}(\texttt{{v}})$ supported by a fact $\texttt{{te}}(\texttt{{v}},\texttt{{KD}})$ :
| | $\displaystyle A_{3}:\$ | $\displaystyle\texttt{{Le}}(\texttt{{v}})(\text{by }r_{5})$ | |
| --- | --- | --- | --- | 4. The opponent concedes $\texttt{{Re}}(\texttt{{v}})$ since it has no argument to argue the proponent.
| | Opponent: | I concede that v is a researcher because I have no argument to argue that v is | |
| --- | --- | --- | --- |
The proponent’s belief $\texttt{{Re}}(\texttt{{v}})$ is defended successfully, namely, $\texttt{{Re}}(\texttt{{v}})$ that is justified by facts $\{\texttt{{te}}(\texttt{{v}},\texttt{{KR}})$ , $\texttt{{GC}}(\texttt{{KR}})\}$ that be extended to be the defending set $\{\texttt{{te}}(\texttt{{v}},\texttt{{KR}})$ , $\texttt{{GC}}(\texttt{{KR}})$ , $\texttt{{te}}(\texttt{{v}},\texttt{{KD}})\}$ that can counter-attack every attack. By the same line of reasoning, the opponent can similarly defend their belief in the contrary statement $\texttt{{TA}}(\texttt{{v}})$ based on the defending set $\{\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}}),\texttt{{UC}}(\texttt{{KD}})\}$ . Because different agents can hold contrary claims, the acceptance semantics of the answer can be considered credulous rather than sceptical. In other words, the answer is deemed possible rather than plausible. Thus, the derived system can conclude that v is possibly a researcher.*
The main contributions of this paper are the following:
- We propose a proof-oriented (logical) argumentation framework with collective attacks (P-SAF), in which we consider abstract logic to generalize monotonic and non-monotonic logics involving reasoning with maximal consistent subsets, and we show how any such logic can be translated to P-SAFs. We also conduct a detailed investigation of how existing argumentation frameworks in the literature can be instantiated as P-SAFs. Thus, we demonstrate that the P-SAF framework is sufficiently generic to encode n-ary conflicts and to enable logical reasoning with (inconsistent) KBs.
- We introduce a novel explanatory dialogue model viewed as a dialectical proof procedure to compute and explain the credulous, grounded and sceptical acceptances in P-SAFs. The dialogues, in this sense, can be regarded as explanations for the acceptances. As our main theoretical result, we prove the soundness and completeness of the dialogue model wrt argumentation semantics.
- This novel explanatory dialogue model provides dialogical explanations for the acceptance of a given query wrt inconsistency-tolerant semantics, and dialogue trees as graphical representations of the dialogical explanations. Based on these dialogical explanations, our framework assists in understanding the intermediate steps of a reasoning process and enhancing human communication on logical reasoning with inconsistencies.
## 2. Preliminaries
To motivate our work, we review argumentation approaches using Tarski abstract logic characterized by a consequence operator [71]. However, many logic in argumentation systems, like ABA or ASPIC systems, do not always impose certain axioms, such as the absurdity axiom. Defining the consequence operator by means of ”models” cannot allow users to understand reasoning progresses better, as inference rule steps are implicit. These motivate a slight generalization of consequence operators in a proof-theoretic manner, inspired by [72], with minimal properties.
Most of our discussion applies to abstract logics (monotonic and non-monotonic) which slightly generalize Tarski abstract logic. Let $\mathcal{L}$ be a set of well-formed formulas, or simply formulas, and $X$ be an arbitrary set of formulas in $\mathcal{L}$ . With the help of inference rules, new formulas are derived from $X$ ; these formulas are called logical consequences of $X$ ; a consequence operator (called closure operator) returns the logical consequences of a set of formulas.
**Definition 2.1**
*We define a map $\texttt{{CN}}:2^{\mathcal{L}}\to 2^{\mathcal{L}}$ such that $\overline{\texttt{{CN}}}(X)=\bigcup_{n\geq 0}\texttt{{CN}}^{n}(X)$ satisfies the axioms:
- ( $A_{1}$ ) Expansion $X\subseteq\overline{\texttt{{CN}}}(X)$ .
- ( $A_{2}$ ) Idempotence $\overline{\texttt{{CN}}}(\overline{\texttt{{CN}}}(X))=\overline{\texttt{{CN}}} (X)$ .*
In general, a map $2^{\mathcal{L}}\to 2^{\mathcal{L}}$ satisfying these axioms $A_{1}-\ A_{2}$ is called a consequence operator. Other properties that consequence operators might have, but that we do not require in this paper, are
- ( $A_{3}$ ) Finiteness $\overline{\texttt{{CN}}}(X)\subseteq\bigcup\{\overline{\texttt{{CN}}}(Y)\mid Y \subset_{f}X\}$ where the notation $Y\subset_{f}X$ means that $Y$ is a finite proper subset of $X$ .
- ( $A_{4}$ ) Coherence $\overline{\texttt{{CN}}}(\emptyset)\neq\mathcal{L}$ .
- ( $A_{5}$ ) Absurdity $\overline{\texttt{{CN}}}(\{x\})=\mathcal{L}$ for some $x$ in the language $\mathcal{L}$ .
Note that finiteness is essential for practical reasoning and is satisfied by any logic that has a decent proof system.
An abstract logic includes a pair $\mathcal{L}$ and a consequence operator CN. Different logics have consequence operators with various properties that can satisfy certain axioms. For instance, the class of Tarskian logics, such as classical logic, is defined by a consequence operator satisfying $A_{1}-\ A_{5}$ while the one of defeasible logic satisfies $A_{1}-\ A_{3}$ .
**Example 2.2**
*An inference rule $r$ in first-order logic is of the form $\frac{p_{1},\ldots,p_{n}}{c}$ where its conclusion is $c$ and the premises are $p_{1},\ldots,p_{n}$ . $c$ is called a direct consequence of $p_{1},\ldots,p_{n}$ by virtue of $r$ . If we define $\texttt{{CN}}(X)$ as the set of direct consequences of $X\subseteq\mathcal{L}$ , then $\overline{\texttt{{CN}}}$ coincides with $\overline{\texttt{{CN}}}(X)=\{\alpha\in\mathcal{L}\mid X\vdash\alpha\}$ and satisfies the axioms $A_{1}-\ A_{5}$ .*
Fix a logic $(\mathcal{L},\texttt{{CN}})$ and a set of formulas $X\subseteq\mathcal{L}$ . We say that:
- $X$ is consistent wrt $(\mathcal{L},\texttt{{CN}})$ iff $\overline{\texttt{{CN}}}(X)\neq\mathcal{L}$ . It is inconsistent otherwise;
- $X$ is a minimal conflict of $\mathcal{K}$ if $X^{\prime}\subsetneq X$ implies $X^{\prime}$ is consistent.
- A knowledge base (KB) is any subset $\mathcal{K}$ of $\mathcal{L}$ . Formulas in a KB are called facts. A knowledge base may be inconsistent.
Reasoning in inconsistent KBs $\mathcal{K}\subseteq\mathcal{L}$ amounts to:
1. Constructing maximal consistent subsets,
1. Applying classical entailment mechanism on a choice of the maximal consistent subsets.
Motivated by this idea, we give the following definition.
**Definition 2.3**
*Let $\mathcal{K}$ be a KB and $X\subseteq\mathcal{K}$ be a set of formulas. $X$ is a maximal (for set-inclusion) consistent subsets of $\mathcal{K}$ iff
- $X$ is consistent,
- there is no $X^{\prime}$ such that $X\subset X^{\prime}$ and $X^{\prime}$ is consistent.
We denote the set of all maximal consistent subsets by $\texttt{{MCS}}(\mathcal{K})$ .*
Inconsistency-tolerant semantics allow us to determine different types of entailments.
**Definition 2.4**
*Let $\mathcal{K}$ be a KB. A formula $\phi\in\mathcal{L}$ is entailed in
- some maximal consistent subset iff for some $\Delta\in\texttt{{MCS}}(\mathcal{K})$ , $\phi\in\overline{\texttt{{CN}}}(\Delta)$ ;
- the intersection of all maximal consistent subsets iff for $\Psi=\bigcap\{\Delta\mid\Delta\in\texttt{{MCS}}(\mathcal{K})\}$ , $\phi\in\overline{\texttt{{CN}}}(\Psi)$ ;
- all maximal consistent subsets iff for all $\Delta\in\texttt{{MCS}}(\mathcal{K})$ , $\phi\in\overline{\texttt{{CN}}}(\Delta)$ .*
Informally, some maximal consistent subset semantics refers to possible answers, all maximal consistent subsets semantics to plausible answers, and the intersection of all maximal consistent subsets semantics to surest answers.
In the following subsections, we illustrate the generality of the above definition by providing instantiations for propositional logic, defeasible logic, $\text{Datalog}^{\pm}$ . Table 1 summarizes properties holding for consequence operators of the instantiations.
| $A_{1}$ $A_{2}$ $A_{3}$ | $\times$ $\times$ $\times$ | $\times$ $\times$ $\times$ | $\times$ $\times$ $\times$ | $\times$ $\times$ $\times$ | $\times$ $\times$ |
| --- | --- | --- | --- | --- | --- |
| $A_{4}$ | $\times$ | $\times$ | | | |
| $A_{5}$ | $\times$ | $\times$ | | | |
Table 1. Properties of consequence operators of the instantiations
### 2.1. Classical Logic
We assume familiarity with classical logic. A logical language for classical logic $\mathcal{L}$ is a set of well-formed formulas. Let us define $\texttt{{CN}}_{c}:2^{\mathcal{L}_{c}}\to 2^{\mathcal{L}_{c}}$ as follows: For $X\subseteq\mathcal{L}_{c}$ , a formula $x\in\mathcal{L}_{c}$ satisfies $x\in\texttt{{CN}}_{c}(X)$ iff the inference rule $\frac{y}{x}$ is applied to $X$ such that $y\in X$ . Define $\overline{\texttt{{CN}}}_{c}(X)=\bigcup_{n\geq 0}\texttt{{CN}}_{c}^{n}(X)$ . In particular, $\overline{\texttt{{CN}}}_{c}$ is a consequence operator satisfying $A_{1}-\ A_{5}$ . Examples of classical logic are propositional logic and first-order logic. Next, we will consider propositional logic as being given by our abstract notions. Since first-order logic can be similarly simulated, we do not consider here in detail.
We next present propositional logic as a special case of classical logic. Let $A$ be a set of propositional atoms. Any atoms $a\in A$ is a well-formed formula wrt. $A$ . If $\phi$ and $\alpha$ are well-formed formulas wrt. $A$ then $\neg\phi$ , $\phi\wedge\alpha$ , $\phi\vee\alpha$ are well-formulas wrt. $A$ (we also assume that the usual abbreviations $\supset$ , $\leftrightarrow$ are defined accordingly). Then $\mathcal{L}_{p}$ is the set of well-formed formulas wrt. $A$ .
Let $\texttt{{CN}}_{p}:2^{\mathcal{L}_{p}}\to 2^{\mathcal{L}_{p}}$ be defined as follows: for $X\subseteq\mathcal{L}_{p}$ , an element $x\in\mathcal{L}_{p}$ satisfies $x\in\texttt{{CN}}_{p}(X)$ iff there are $y_{1},\ldots,y_{j}\in X$ such that $x$ can be obtained from $y_{1},\ldots,y_{j}$ by the application of a single inference rule of propositional logic.
**Example 2.5**
*Consider the propositional atoms $A_{1}=\{x,y\}$ and the knowledge base $\mathcal{K}_{1}=\{x,y,x\supset\neg y\}\subseteq\mathcal{L}_{p}$ . Consider a set $\{x,x\supset\neg y\}\subseteq\mathcal{K}_{1}$ . If the inference rule (modus ponens) $\frac{A,A\supset B}{B}$ is applied to this set, then $\texttt{{CN}}_{p}(\{x,x\supset\neg y\})=\{x,x\supset\neg y,\neg y\}$ .*
Consider $\overline{\texttt{{CN}}}_{p}(X)=\bigcup_{n\geq 0}\texttt{{CN}}_{p}^{n}(X)$ . For instance, $\overline{\texttt{{CN}}}_{p}(\mathcal{K}_{1})=\{x,y,x\supset\neg y,\neg y,x \wedge y,\ldots\}$ . Since propositional logic is coherent and complete, then $x\in\overline{\texttt{{CN}}}_{p}(X)=\{x\mid X\models x\}$ where $\models$ is the entailment relation, i.e., $\phi\models\alpha$ if all models of $\phi$ are models of $\alpha$ in the propositional semantics. In particular, $\overline{\texttt{{CN}}}_{p}$ is a consequence operator satisfying $A_{1}-\ A_{5}$ . The propositional logic can be defined as $(\mathcal{L}_{p},\texttt{{CN}}_{p})$ .
It follows immediately
**Lemma 2.6**
*$(\mathcal{L}_{p},\texttt{{CN}}_{p})$ is an abstract logic.*
**Example 2.7 (Continue Example2.5)**
*Recall $\mathcal{K}_{1}$ . The KB admits a MCS: $\{x,y,x\supset\neg y\}$ .*
### 2.2. Defeasible Logic
Let $(\mathcal{L}_{d},\texttt{{CN}}_{d})$ be a defeasible logic such as used in defeasible logic programming [45], assumption-based argumentation (ABA) [44], ASPIC/ ASPIC+ systems [46, 62]. The language for defeasible logic $\mathcal{L}_{d}$ includes a set of (strict and defeasible) rules and a set of literals. The rules is the form of $x_{1},\ldots x_{i}\rightarrow_{s}x_{i+1}$ ( $x_{1},\ldots x_{i}\rightarrow_{d}x_{i+1}$ ) where $x_{1},\ldots x_{i},x_{i+1}$ are literals and $\rightarrow_{s}$ (denote strict rules) and $\rightarrow_{d}$ (denotes defeasible rules) are implication symbols.
**Definition 2.8**
*Define $\texttt{{CN}}_{d}:2^{\mathcal{L}_{d}}\to 2^{\mathcal{L}_{d}}$ as follows: for $X\subseteq\mathcal{L}_{d}$ , a formula $x\in\mathcal{L}_{d}$ satisfies $x\in\texttt{{CN}}_{d}(X)$ iff at least of the following properties is true:
1. $x$ is a literal in $X$ ,
1. there is $(y_{1},\ldots,y_{j})\rightarrow_{s}x\in X$ , or $(y_{1},\ldots,y_{j})\rightarrow_{d}x\in X$ st. $\{y_{1},\ldots,y_{j}\}\subseteq X$ .
Define $\overline{\texttt{{CN}}}_{d}(X)=\bigcup_{n\geq 0}\texttt{{CN}}_{d}^{n}(X)$ .*
**Remark 2.9**
*One can describe $\overline{\texttt{{CN}}}_{d}$ explicitly. We have $x\in\overline{\texttt{{CN}}}_{d}(X)$ iff there exists a finite sequence of literals $x_{1},\ldots,x_{n}$ such that
1. $x$ is $x_{n}$ , and
1. for each $x_{i}\in\{x_{1},\ldots,x_{n}\}$ ,
- there is $y_{1},\ldots,y_{j}\rightarrow_{s}x_{i}\in X$ , or $y_{1},\ldots,y_{j}\rightarrow_{d}x_{i}\in X$ , such that $\{y_{1},\ldots,y_{j}\}\subseteq\{x_{1},\ldots,x_{i-1}\}$ ,
- or $x_{i}$ is a literal in $X$ . Note that if $x\in\texttt{{CN}}_{d}^{n}(X)$ , the above sequence $x_{1},\ldots,x_{n}$ might have length $m\neq n$ : intuitively $n$ is the depth of the proof tree while $m$ is the number of nodes.*
**Example 2.10**
*Consider the KB $\mathcal{K}_{2}=\{x,x\rightarrow_{s}y,t\rightarrow_{d}z\}\subseteq\mathcal{L}_ {d}$ . $\overline{\texttt{{CN}}}_{d}(\mathcal{K}_{2})=\{x,y\}$ where the sequence of literals in the derivation is $x,y$ . The KB admits a MCS: $\{x,x\rightarrow_{s}y,t\rightarrow_{d}z\}$*
**Remark 2.11**
*For ASPIC/ASPIC+ systems [46, 62], Prakken claimed that strict and defeasible rules can be considered in two ways: (1) they encode information of the knowledge base, in which case they are part of the logical language $\mathcal{L}_{d}$ , (2) they represent inference rules, in which case they are part of the consequence operator. These ways can encoded by consequence operators as in [61]. Our definition of $\overline{\texttt{{CN}}}_{d}$ can align with the later interpretation as done in [61]. In particular, if we consider $X$ being a set of literals of $\mathcal{L}_{d}$ instead of being a set of literals and rules as above, the definitions of $\texttt{{CN}}_{d}$ and $\overline{\texttt{{CN}}}_{d}$ still hold for this case. Thus, the defeasible logic of ASPIC/ASPIC+ can be represented by the logic $(\mathcal{L}_{d},\texttt{{CN}}_{d})$ in our settings.*
**Proposition 2.12 ([61])**
*$\overline{\texttt{{CN}}}_{d}$ satisfies $A_{1}-\ A_{3}$ .*
It follows immediately
**Lemma 2.13**
*$(\mathcal{L}_{d},\texttt{{CN}}_{d})$ is an abstract logic.*
In [64], proposals for argumentation using defeasible logic were criticized for violating the postulates that they proposed for acceptable argumentation. One solution is to introduce contraposition into the reasoning of the underlying logic. This solution can be seen as another representation of defeasible logic. We introduce contraposition by defining a consequence operator as follows:
Consider $\mathcal{L}_{co}$ containing a set of literal and a set of (strict and defeasible) rules $\mathcal{R}_{s}$ ( $\mathcal{R}_{d})$ . For this case represent inference rules, namely, they are part of a consequence operator. For $\Delta\subseteq\mathcal{L}_{co}$ , $\texttt{Contrapositives}(\Delta)$ is the set of contrapositives formed from the rules in $\Delta$ . For instance, a strict rule $s$ is a contraposition of the rule $\phi_{1},\ldots,\phi_{n}\rightarrow_{s}\alpha\in\mathcal{R}_{s}$ iff $s=\phi_{1},\ldots,\phi_{i-1},\neg\alpha,\phi_{i+1},\ldots,\phi_{n}\rightarrow_ {s}\neg\phi_{i}$ for $1\leq i\leq n$ .
**Definition 2.14**
*Define $\texttt{{CN}}_{co}:2^{\mathcal{L}_{co}}\to 2^{\mathcal{L}_{co}}$ as follows: for a set of literals $X\subseteq\mathcal{L}_{co}$ , a formula $x\in\mathcal{L}_{co}$ satisfies $x\in\texttt{{CN}}_{co}(X)$ iff at least of the following properties is true:
1. $x$ is a literal in $X$ ,
1. there is $(y_{1},\ldots,y_{j})\rightarrow_{s}x\in\mathcal{R}_{s}\cup\texttt{ { Contrapositives}}(\mathcal{R}_{s})$ , or $(y_{1},\ldots,y_{j})\rightarrow_{d}x\in\mathcal{R}_{d}\cup\texttt{{ Contrapositives}}(\mathcal{R}_{d})$ such that $\{y_{1},\ldots,y_{j}\}\subseteq X$ .
Define $\overline{\texttt{{CN}}}_{co}(X)=\bigcup_{n\geq 0}\texttt{{CN}}_{co}^{n}(X)$ .*
**Remark 2.15**
*Similarly, one can represent $\overline{\texttt{{CN}}}_{co}$ as follows: $x\in\overline{\texttt{{CN}}}_{co}(X)$ iff there exists a sequence of literals $x_{1},\ldots,x_{n}$ such that
1. $x$ is $x_{n}$ , and
1. for each $x_{i}\in\{x_{1},\ldots,x_{n}\}$ ,
- there is $y_{1},\ldots,y_{j}\rightarrow_{s}x_{i}\in\mathcal{R}_{s}\cup\texttt{{ Contrapositives}}(\mathcal{R}_{s})$ , or $y_{1},\ldots,y_{j}\rightarrow_{d}x_{i}\in\mathcal{R}_{d}\cup\texttt{{ Contrapositives}}(\mathcal{R}_{d})$ , such that $\{y_{1},\ldots,y_{j}\}\subseteq\{x_{1},\ldots,x_{i-1}\}$ ,
- or $x_{i}$ is a literal in $X$ .*
**Proposition 2.16**
*$(\mathcal{L}_{co},\texttt{{CN}}_{co})$ is an abstract logic. $\overline{\texttt{{CN}}}_{co}$ satisfies $A_{1}-\ A_{3}$ .*
**Example 2.17**
*Consider $\mathcal{K}_{3}=\{q,\neg r,p\wedge q\rightarrow_{d}r,\neg p\rightarrow_{s}u\}$ , $\texttt{{Contrapositives}}(\mathcal{K}_{3})=\{\neg r\wedge q\rightarrow_{d} \neg p,\neg r\wedge p\rightarrow_{d}\neg q,\neg u\rightarrow_{s}p\}$ . Then $\overline{\texttt{{CN}}}_{co}(\mathcal{K}_{3})=\{q,\neg r,\neg p,u\}$ where the sequence of literals in the derivation is $q,\neg r,\neg p,u$ . The KB admits MCSs: $\{q,\neg r,\neg p\rightarrow_{s}u\}$ and $\{q,p\wedge q\rightarrow_{d}r,\neg p\rightarrow_{s}u\}$ .*
### 2.3. $\text{Datalog}^{\pm}$
We consider $\text{Datalog}^{\pm}$ [26], and shall use it to illustrate our demonstrations through the paper.
We assume a set $\mathsf{N_{t}}$ of terms which contain variables, constants and function terms. An atom is of the form $P(\vec{t})$ , with $P$ a predicate name and $\vec{t}$ a vector of terms, which is ground if it contains no variables. A database is a finite set of ground atoms (called facts). A tuple-generating dependency (TGD) $\sigma$ is a first-order formula of the form $\forall\vec{x}\forall\vec{y}\phi(\vec{x},\vec{y})\rightarrow\exists\vec{z}\psi (\vec{x},\vec{z})$ , where $\phi(\vec{x},\vec{y})$ and $\psi(\vec{x},\vec{z})$ are non-empty conjunctions of atoms. We leave out the universal quantification, and refer to $\phi(\vec{x},\vec{y})$ and $\psi(\vec{x},\vec{z})$ as the body ad head of $\sigma$ . A negative constraint (NC) $\delta$ is a rule of the form $\forall\vec{x}$ $\phi(\vec{x})\rightarrow\bot$ where $\phi(\vec{x})$ is a conjunction of atoms. We may leave out the universal restriction. A language for $\text{Datalog}^{\pm}$ $\mathcal{L}_{da}$ includes a set of facts and a set of TGDs and NCs. A knowledge base $\mathcal{K}$ of $\mathcal{L}_{da}$ is now a tuple $(\mathcal{F},\mathcal{R},\mathcal{C})$ where a database $\mathcal{F}$ , a set $\mathcal{R}$ of TGDs and a set $\mathcal{C}$ of NCs.
Define $\texttt{{CN}}_{da}:2^{\mathcal{L}_{da}}\to 2^{\mathcal{L}_{da}}$ as follows: Let $X$ be a set of facts of $\mathcal{L}_{da}$ , an element $x\in\mathcal{L}_{da}$ satisfies $x\in\texttt{{CN}}_{da}(X)$ iff there are $y_{1},\ldots,y_{j}\in X$ s.t. $x$ can be obtained from $y_{1},\ldots,y_{j}$ by the application of a single inference rule. Note that we treat such TGDs and NCs as inference rules.
Consider $\overline{\texttt{{CN}}}_{da}(X)=\bigcup_{n\geq 0}\texttt{{CN}}_{da}^{n}(X)$ . Similar to proposition logic, $x\in\overline{\texttt{{CN}}}_{da}(X)=\{x\mid X\models x\}$ where $\models$ is the entailment of first-order formulas, i.e., $X\models x$ holds iff every model of all elements in $X$ is also a model of $x$ . $\overline{\texttt{{CN}}}_{da}$ satisfies the properties $A_{1},A_{2}$ . Note that the finiteness property ( $A_{3}$ ) still holds for some fragments of $\text{Datalog}^{\pm}$ , such as guarded, weakly guarded $\text{Datalog}^{\pm}$ .
It follows immediately
**Lemma 2.18**
*$(\mathcal{L}_{da},\texttt{{CN}}_{da})$ is an abstract logic.*
**Example 2.19 (Continue Example1.1)**
*Recall $\mathcal{K}_{1}$ . The KB admits MSCs (called repairs in $\text{Datalog}^{\pm}$ ):
| | $\displaystyle\mathcal{B}_{1}=\{\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}}), \texttt{{UC}}(\texttt{{KD}})\}\quad\mathcal{B}_{3}=\{\texttt{{taOf}}(\texttt{{ v}},\texttt{{KD}}),\texttt{{te}}(\texttt{{v}},\texttt{{KR}}),\texttt{{te}}( \texttt{{v}},\texttt{{KD}}),\texttt{{GC}}(\texttt{{KR}})\}$ | |
| --- | --- | --- |
Consider $q_{1}=\texttt{{Re}}(\texttt{{v}})$ . We have that v is a possible answer for $q_{1}$ since $q_{1}$ is entailed in some repairs, such as $\mathcal{B}_{2},\ \mathcal{B}_{3},\ \mathcal{B}_{5}$ .*
## 3. Proof-oriented (Logical) Argumentations
In this section, we present proof-oriented (logical) argumentations (P-SAFs) and their ingredients. We also provide insights into the connections between our framework and state-of-the-art argumentation frameworks. We then show the close relations of reasoning with P-SAFs to reasoning with MCSs.
### 3.1. Arguments, Collective Attacks and Proof-oriented Argumentations
Logical arguments (arguments for short) built from a KB may be defined in different ways. For instance, arguments are represented by the notion of sequents [69], proof [41, 44], a pair of $(\Gamma,\ \psi)$ where $\Gamma$ is the support, or premises, or assumptions of the argument, and $\psi$ is the claim, or conclusion, of the argument [7, 33]. To improve explanations in terms of representation and understanding, we choose the form of proof to represent arguments. The proof is in the form of a tree.
**Definition 3.1**
*A formula $\phi\in\mathcal{L}$ is tree-derivable from a set of fact-premises $H\subseteq\mathcal{K}$ if there is a tree such that
- the root holds $\phi$ ;
- $H$ is the set of formulas held by leaves;
- for every inner node $N$ , if $N$ holds the formula $\beta_{0}$ , then its successors hold $n$ formulas $\beta_{1},\ldots,\beta_{n}$ such that $\beta_{0}\in\texttt{{CN}}(\{\beta_{1},\ldots,\beta_{n}\})$ .
If such a tree exists (it might not be unique), we call $A:H\Rightarrow\phi$ an argument with the support set $\texttt{{Sup}}(A)=H$ and the conclusion $\texttt{{Con}}(A)=\phi$ . We denote the set of arguments induced from $\mathcal{K}$ by $\texttt{{Arg}}_{\mathcal{K}}$ .*
**Remark 3.2**
*By Definition 3.1 it follows that $H\Rightarrow\phi$ is an argument iff $\phi\in\overline{\texttt{{CN}}}(H)$ .*
Note that an individual argument can be represented by several different trees (with the same root and leaves). We assume these trees represent the same arguments; otherwise, we could have infinitely many arguments with the same support set and conclusion.
Intuitively, a tree represents a possible derivation of the formula at its root and the fact-premise made at its leaves. The leaves of the tree, constituting the fact-premise, belong to $H=\texttt{{CN}}^{0}(H)$ . If a node $\beta$ has children nodes $\beta_{a_{1}}\in\texttt{{CN}}^{i_{1}}(H)$ , …, $\beta_{a_{k}}\in\texttt{{CN}}^{i_{k}}(H)$ , then $\beta\in\texttt{{CN}}^{i+1}(X)$ where $i=\max\{i_{1},\ldots,i_{k}\}$ because by the extension property $\texttt{{CN}}^{i_{1}}(H),\ldots,\texttt{{CN}}^{i_{k}}(H)\subseteq\texttt{{CN}} ^{i}(H)$ . The root $\phi$ , constituting the conclusion, belongs to $\texttt{{CN}}^{n}(H)$ , where $n$ is the longest path from leaf to root. Note that, by the extension property, if $\beta\in\texttt{{CN}}^{i}(H)$ , then also $\beta\in\texttt{{CN}}^{i+1}(H)$ , $\beta\in\texttt{{CN}}^{i+2}(H)$ , …. The idea is to have $i$ in $\texttt{{CN}}^{i}(H)$ as small as possible (we don’t want to argue longer than necessary).
Some proposals for logic-based argumentation stipulate additionally that the argument’s support is consistent and/or that none of its subsets entails the argument’s conclusion (see [56]). However, such restrictions, i.e., minimality and consistency, are not substantial (although required for some specific logics). In some proposals, the requirement that the support of an argument is consistent may be irrelevant for some logics, especially when consistency is defined by satisfiability. For instance, in Priest’s three-valued logic [57] or Belnap’s four-valued logic [58], every set of formulas in the language of $\{\neg,\vee,\wedge\}$ is satisfiable. In frameworks in which the supports of arguments are represented only by literals (atomic formulas or their negation), arguments like $A=\{a,b\}\Rightarrow a\vee b$ are excluded since their supports are not minimal, although one may consider $\{a,b\}$ a stronger support for $a\vee b$ than, say, $\{a\}$ , since the set $\{a,b\}$ logically implies every minimal support of $a\vee b$ . To keep our framework as general as possible, we do not consider the extra restrictions for our definition of arguments (See [56, 69] for further justifications of this choice).
We present instantiations to show the generality of Definition 3.1 for generating arguments in argumentation systems in the literature.
- We start with deductive argumentation that uses classical logic. In [59], arguments as pairs of premises and conclusions can be simulated in our settings, and for which $H\Rightarrow\phi$ is an argument (in the form of tree-derivations), where $H\subseteq\mathcal{L}_{c}$ and $\phi\in\mathcal{L}_{c}$ iff $\phi\in\overline{\texttt{{CN}}}_{c}(H)$ , $H$ is minimal (i.e., there is no $H^{\prime}\subset H$ such that $\phi\in\overline{\texttt{{CN}}}_{c}(H^{\prime})$ ) and $H$ is consistent. For example, we use the propositional logic in Example 2.5, and the following is an argument in propositional logic $A:\{x,x\supset\neg y\}\Rightarrow\neg y$ . Tree-representation of $A$ is shown in Figure 1 (left). Similarly, since most Description Logics (DLs), such as $ALC$ , DL-Lite families, Horn DL, etc., are decidable fragments of first-order logic, it is straightforward to apply Definition 3.1 to encode arguments of the framework using the DL $ALC$ in [14].
- We consider defeasible logic approaches to argumentation, such as [44, 53, 67, 68, 45]. For defeasible logic programming [45], $H\Rightarrow\phi$ is an argument (in the form of tree-derivations) iff $\phi\in\overline{\texttt{{CN}}}_{d}(H)$ and there is no $H^{\prime}\subset H$ such that $\phi\in\overline{\texttt{{CN}}}_{d}(H^{\prime})$ and it is not the case that there is $\alpha$ such that $\alpha\in\overline{\texttt{{CN}}}_{d}(H)$ and $\neg\alpha\in\overline{\texttt{{CN}}}_{d}(H)$ (i.e. $H$ is a minimal consistent set entailing $\phi$ ).
For ” flat ”- ABA [44, 53], assume that $\texttt{{CN}}_{d}$ ignores differences between various implication symbols in the knowledge base, and for which $H\Rightarrow\phi$ is an argument iff $\phi\in\overline{\texttt{{CN}}}_{d}(H)$ where $H\subseteq\mathcal{L}_{d}$ . In this case, the argument, from the support $H$ to the conclusion $\phi$ , can be described as tree-derivations by $\texttt{{CN}}_{d}$ . Note that the minimality and consistency requirements are dropped. Similarly, in ”non-flat” - ABAs [67, 68], arguments as tree-derivations can be simulated in our setting.
Note, in [45] only the defeasible rules are represented in the support of the argument, and in [44, 53, 67, 68] only the literals are represented in the support of the argument, but in both cases it is a trivial change (as we do here) to represent both the rules and literals used in the derivation in the support of the argument.
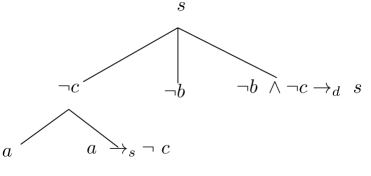
**Example 3.3**
*For $\mathcal{K}_{5}=\{a,\neg b,a\rightarrow_{s}\neg c,\ \neg b\wedge\neg c \rightarrow_{d}s,\ s\rightarrow_{s}t,\ a\wedge t\rightarrow_{d}u\}$ , the following is an argument in defeasible logic programming $B:\{a,\neg b,a\rightarrow_{s}\neg c,\neg b\wedge\neg c\rightarrow_{d}s\}\Rightarrow s$ with the sequences of literals $a,\neg c,\neg b,s$ . Tree-representations of the arguments are shown in Figure 1 (middle). For $\mathcal{K}_{6}=\{p,\neg q,s,p\rightarrow\neg r,\neg q\wedge\neg r\wedge s \rightarrow t,t\wedge p\rightarrow u,v\}$ , the following is an argument in ABA $C:\{p,\neg q,s,p\rightarrow\neg r,\neg q\wedge\neg r\wedge s\rightarrow t\}\Rightarrow t$ .*
- We translate ASPIC/ ASPIC+ [46, 62] into our work as follows:
We have considered the underlying logic of ASPIC/ ASPIC+ as being given by $\overline{\texttt{{CN}}}_{d}$ (see Remark 2.11) and $\mathcal{L}_{d}$ including the set of literals and strict/ defeasible rules.
We recall argument of the form $A_{1},\ldots,A_{n}\rightarrow_{s}/\rightarrow_{d}\phi$ in these systems as follows:
1. Rules of the form $\rightarrow_{s}/\rightarrow_{d}\alpha$ , are arguments with conclusion $\alpha$ .
1. Let $r$ be a strict/defeasible rule of the form $\beta_{1},\ldots,\beta_{n}\rightarrow_{s}/\rightarrow_{d}\phi$ , $n\geq 0$ . Further suppose that $A_{1},\ldots,A_{n}$ , $n\geq 0$ , are arguments with conclusions $\beta_{1},\ldots,\beta_{n}$ respectively. Then $A_{1},\ldots,A_{n}\rightarrow_{s}/\rightarrow_{d}\phi$ is an argument with conclusion $\phi$ and last rule $r$ .
1. Every argument is constructed by applying finitely many times the above two steps.
The arguments of the form $A_{1},\ldots,A_{n}\rightarrow_{s}/\rightarrow_{d}\phi$ can be viewed as tree-derivations in the sense of Definition 3.1, in which the conclusion of the argument is $\phi$ ; the support $H$ of the argument is the set of leaves that are rules of the form $\rightarrow_{s}/\rightarrow_{d}\alpha_{i}$ such that $\alpha_{i}\in\texttt{{CN}}^{0}_{d}(H)$ . In this view, the root of the tree is labelled by $\phi$ such $\phi\in\texttt{{CN}}^{n}_{d}(H)$ ; the children $\beta_{i}$ , $i=1,\ldots,n$ , of the root are the roots of subtrees $A_{1},\ldots,A_{n}$ ; if $\phi\in\texttt{{CN}}^{n}_{d}(H)$ , then $\beta_{i}\in\texttt{{CN}}^{n-1}_{d}(H)$ . Since $\overline{\texttt{{CN}}}_{d}(H)=\bigcup_{n}\texttt{{CN}}^{n}_{d}(H)$ , it follows that $\phi\in\overline{\texttt{{CN}}}_{d}(H)$ . Note that if $n=0$ , the tree consists of just the root that is the rule of the form $\rightarrow_{s}/\rightarrow_{d}\phi$ .
- In argumentation framework for $\text{Datalog}^{\pm}$ [19, 61], arguments, viewed as pairs of the premises $H$ (i.e., the set of facts) and the conclusion $\phi$ (i.e., the derived fact), can be represented as tree-derivations in our definitions as follows: For a consistent set $H\subseteq\mathcal{F}$ and $\phi\in\mathcal{L}_{da}$ , $H\Rightarrow\phi$ is an argument in the sense of Definition 3.1 iff $\phi\in\overline{\texttt{{CN}}}_{da}(H)$ , in which $\phi$ is the root of the tree; $H$ are the leaves.
**Example 3.4**
*Let us continue Example 2.19, the following is an argument in the framework using $\text{Datalog}^{\pm}$ $A_{7}:\{\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}}),\ \texttt{{UC}}(\texttt{{ KD}})\}\Rightarrow\texttt{{TA}}(\texttt{{v}})$ . By Definition 3.1, the argument can be viewed as a proof tree with the root labelled by $\texttt{{TA}}(\texttt{{v}})$ and the leaves labelled $\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}}),\ \texttt{{UC}}(\texttt{{KD}})$ .*
<details>
<summary>x1.png Details</summary>
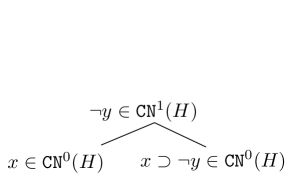
### Visual Description
## Logical Diagram: Hierarchical Set Membership and Implication
### Overview
The image displays a simple hierarchical diagram representing logical or set-theoretic relationships. It consists of three text elements arranged in a tree structure with one parent node and two child nodes connected by lines. The notation suggests a formal system involving sets labeled `CN` with superscripts, membership (`∈`), negation (`¬`), and implication or superset (`⊃`).
### Components/Axes
The diagram has no traditional chart axes. Its components are purely textual and relational:
1. **Parent Node (Top Center):** `¬y ∈ CN¹(H)`
2. **Left Child Node (Bottom Left):** `x ∈ CN⁰(H)`
3. **Right Child Node (Bottom Right):** `x ⊃ ¬y ∈ CN⁰(H)`
4. **Connecting Lines:** Two straight lines descend from the parent node, one to each child node, forming an inverted "V" shape.
### Detailed Analysis
* **Spatial Grounding:** The parent node is positioned at the top center of the image. The two child nodes are placed below it, aligned horizontally. The left child is directly below the left side of the parent, and the right child is directly below the right side.
* **Text Transcription & Symbol Breakdown:**
* `¬`: Logical negation ("not").
* `y`, `x`: Variables.
* `∈`: Set membership ("is an element of").
* `CN¹(H)`, `CN⁰(H)`: Sets or categories. The superscripts `¹` and `⁰` likely denote different levels, types, or generations within a framework denoted by `H`.
* `⊃`: Superset or logical implication ("implies" or "contains").
* **Logical Structure:** The diagram presents a relationship where the statement at the parent node (`¬y is an element of CN¹(H)`) is connected to two statements below it. The structure could be interpreted in several ways common in formal logic or proof trees:
1. **Premise/Conclusion:** The two lower statements might be premises that together lead to the conclusion in the upper statement.
2. **Case Analysis:** The upper statement might be analyzed or broken down into the two conditions represented by the lower statements.
3. **Definition/Decomposition:** The concept `¬y ∈ CN¹(H)` might be defined by or decomposed into the two related properties involving `x`.
### Key Observations
1. **Hierarchical Notation:** The use of superscripts (`⁰`, `¹`) on the `CN` sets indicates a structured, possibly hierarchical or iterative, classification system.
2. **Role of Variable `x`:** The variable `x` appears only in the child nodes, acting as a mediating element. The right child node introduces a direct logical relationship (`⊃`) between `x` and the parent's subject (`¬y`).
3. **Symmetry and Contrast:** The left child is a simple membership statement (`x ∈ CN⁰(H)`). The right child is a more complex compound statement (`x ⊃ ¬y ∈ CN⁰(H)`), creating a contrast in logical complexity between the two branches.
### Interpretation
This diagram visually encodes a specific logical proposition within a formal system. It suggests that the condition "`¬y` belongs to the set `CN¹(H)`" is fundamentally connected to two facts about a variable `x`:
1. `x` itself belongs to a base set `CN⁰(H)`.
2. `x` implies (or is a superset containing) the fact that "`¬y` belongs to `CN⁰(H)`".
The diagram implies a **transitive or inferential relationship across levels**. It proposes that membership in the higher-level set `CN¹(H)` (for `¬y`) can be understood or derived from properties of `x` in the base set `CN⁰(H)`. The structure is reminiscent of proof sketches in logic, type theory, or formal semantics, where complex statements are reduced to combinations of simpler ones. The absence of context for `H`, `CN`, or the variables limits a definitive interpretation, but the formal notation clearly points to a technical, mathematical, or philosophical discourse.
</details>
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Logical/Semantic Tree Diagram: Propositional Decomposition
### Overview
The image displays a hierarchical tree diagram, likely representing a logical proof, semantic decomposition, or derivation in a formal system (e.g., modal logic, proof theory). The structure consists of nodes connected by lines, with logical symbols and propositional variables as labels. The diagram is monochrome (black lines and text on a white background).
### Components/Axes
This is not a chart with axes but a node-link diagram. The components are:
* **Nodes**: Labeled with logical symbols and variables.
* **Edges (Lines)**: Represent relationships or derivations between nodes.
* **Labels**: The textual content of each node.
* **Spatial Layout**: A top-down tree structure with a root node and branching children.
### Detailed Analysis
**1. Root Node:**
* **Position**: Top center.
* **Label**: `s`
**2. First-Level Branches (from root `s`):**
The root `s` has three direct child nodes, connected by lines branching downwards.
* **Left Branch**: Leads to a node labeled `¬c` (negation of proposition `c`).
* **Middle Branch**: Leads to a node labeled `¬b` (negation of proposition `b`).
* **Right Branch**: Leads to a node labeled `¬b ∧ ¬c →_d s`. This is a compound formula: "not `b` AND not `c` implies (with subscript `d`) `s`".
**3. Subtree under Left Branch (`¬c`):**
The node `¬c` itself has two child nodes, forming a smaller subtree.
* **Left Child of `¬c`**: A node labeled `a`.
* **Right Child of `¬c`**: A node labeled `→_s ¬c`. This appears to be an implication operator (with subscript `s`) pointing to `¬c`. The arrow `→_s` is part of the node's label.
**4. Complete Node Inventory (Transcription):**
* `s` (Root)
* `¬c` (Child of root, left)
* `¬b` (Child of root, middle)
* `¬b ∧ ¬c →_d s` (Child of root, right)
* `a` (Child of `¬c`, left)
* `→_s ¬c` (Child of `¬c`, right)
**5. Language Identification:**
The text consists of **logical and mathematical notation**. This is a formal symbolic language, not a natural language. The symbols include:
* Propositional variables: `a`, `b`, `c`, `s`.
* Logical connectives: `¬` (negation), `∧` (conjunction), `→` (implication).
* Subscripts: `_s`, `_d` attached to implication arrows, likely denoting different modalities, derivation rules, or semantic relations.
### Key Observations
1. **Asymmetric Structure**: The tree is not balanced. The left branch (`¬c`) has a deeper subtree (two additional levels) compared to the middle (`¬b`) and right (`¬b ∧ ¬c →_d s`) branches, which are terminal nodes at the first level.
2. **Subscripted Implications**: The diagram uses two distinct implication symbols: `→_d` (in the right branch of the root) and `→_s` (in the subtree under `¬c`). This suggests the formal system distinguishes between at least two types of implication or inference steps.
3. **Self-Reference in Label**: The rightmost child of the root, `¬b ∧ ¬c →_d s`, contains the root label `s` within its own formula, indicating a recursive or self-referential relationship in the logical structure.
4. **Leaf Nodes**: The terminal nodes (leaves) of the entire tree are: `¬b`, `¬b ∧ ¬c →_d s`, `a`, and `→_s ¬c`.
### Interpretation
This diagram visually represents a **formal logical argument or semantic analysis**. The root `s` is being decomposed or justified by three conditions or premises (`¬c`, `¬b`, and the implication `¬b ∧ ¬c →_d s`). The structure suggests that `s` might be true if any of these child conditions hold, or perhaps they are conjunctive requirements.
The deeper analysis under `¬c` indicates that the truth or derivation of `¬c` itself depends on two further elements: a proposition `a` and an implication `→_s ¬c`. This could represent a case analysis or a sub-proof where `¬c` is established via `a` and a specific rule (`→_s`).
The use of distinct subscripts (`_s`, `_d`) is critical. In contexts like modal logic or proof theory, these often denote different modalities (e.g., "s" for "strict" or "system", "d" for "derived" or "deontic") or different inference rules. The diagram therefore likely illustrates a proof in a **multi-modal or multi-relation logical system**, where the path to establishing `s` involves different kinds of logical steps. The self-reference in `¬b ∧ ¬c →_d s` hints at a fixed-point or recursive definition within the system.
</details>
<details>
<summary>x3.png Details</summary>
### Visual Description
## Logical Proof Tree Diagram: Derivation of `p, p ⊃ q ⇝ q`
### Overview
The image displays a formal proof tree (or derivation tree) from mathematical logic or proof theory. It visually demonstrates the step-by-step derivation of the sequent `p, p ⊃ q ⇝ q` (read as: from the assumptions `p` and `p ⊃ q`, one can derive `q`) using a specific set of inference rules. The tree structure shows how the main conclusion is broken down into simpler sub-goals, which are then proven by axioms.
### Components/Axes
This is a diagram, not a chart, so it has no axes. Its components are:
1. **Logical Formulas (Nodes):** Sequents written in the form `Γ ⇝ Δ`, where `Γ` (Gamma) is a set of premises/assumptions and `Δ` (Delta) is a conclusion. The symbol `⇝` represents a turnstile or sequent arrow. The symbol `⊃` represents logical implication (if...then).
2. **Inference Rule Labels:** The annotation `[Mon]` appears twice, likely standing for the "Monotonicity" or "Weakening" rule in sequent calculus, which allows adding extra formulas to the premise set.
3. **Tree Structure (Edges):** Lines connecting parent nodes to child nodes, indicating the direction of logical inference. The derivation flows from the bottom (axioms) to the top (main conclusion).
### Detailed Analysis
The proof tree is structured as follows, described from the top (main goal) down to the bottom (axioms):
* **Top Node (Main Conclusion):**
* **Position:** Top center.
* **Content:** `p, p ⊃ q ⇝ q`
* **Description:** This is the final sequent to be proven.
* **First Branching:**
* The top node splits into two child nodes via an implicit rule application (the rule itself is not labeled on this branch).
* **Left Child Node:**
* **Position:** Middle left.
* **Content:** `p ⇝ p, q`
* **Right Child Node:**
* **Position:** Middle right.
* **Content:** `p, q ⇝ q`
* **Annotation:** The label `[⊃⇝]` is placed near the right branch, suggesting the rule used for this split is related to the implication (`⊃`) in the premise.
* **Second Level Derivations (Axiom Applications):**
* Each of the middle nodes is then proven by a single-step application of the `[Mon]` rule.
* **Left Sub-tree:**
* **Parent:** `p ⇝ p, q` (Middle left)
* **Rule Applied:** `[Mon]` (Monotonicity/Weakening)
* **Child (Axiom):** `p ⇝ p` (Bottom left)
* **Logic:** The sequent `p ⇝ p` is an identity axiom (a formula implies itself). The `[Mon]` rule is applied to add the extra formula `q` to the right side (conclusion set), yielding `p ⇝ p, q`.
* **Right Sub-tree:**
* **Parent:** `p, q ⇝ q` (Middle right)
* **Rule Applied:** `[Mon]` (Monotonicity/Weakening)
* **Child (Axiom):** `q ⇝ q` (Bottom right)
* **Logic:** The sequent `q ⇝ q` is an identity axiom. The `[Mon]` rule is applied to add the extra formula `p` to the left side (premise set), yielding `p, q ⇝ q`.
### Key Observations
1. **Symmetry:** The proof tree exhibits a clear symmetrical structure. The left branch deals with the first premise (`p`), and the right branch deals with the second premise (`q`) derived from the implication.
2. **Use of Identity Axioms:** The proof is grounded in the fundamental identity axioms `p ⇝ p` and `q ⇝ q`, which are the simplest true statements in this logical system.
3. **Role of Monotonicity:** The `[Mon]` rule is used as a "cleanup" step. It formally justifies the presence of the unused premise in each branch. In the left branch, `q` is added to the conclusion; in the right branch, `p` is added to the premises. This is a technical necessity in many sequent calculus formulations.
4. **Implicit Rule at the Top:** The most significant logical step—the decomposition of the implication `p ⊃ q`—happens at the first, unlabeled branch. The label `[⊃⇝]` nearby hints at the specific rule for implication, which typically requires proving the antecedent (`p`) and using the consequent (`q`) as a new assumption.
### Interpretation
This diagram is a formal, syntactic proof of the logical principle known as **Modus Ponens** (or a closely related variant in sequent calculus). It demonstrates, step-by-step, how the truth of `q` can be formally derived from the truths of `p` and `p ⊃ q`.
* **What it Demonstrates:** The tree shows that the conclusion `q` is not assumed but is logically necessitated by the premises. The derivation is decomposed into verifying the truth of the individual components (`p` is true, and `q` follows from `p`) and then combining them.
* **Relationship Between Elements:** The tree illustrates a dependency chain. The top conclusion depends on the two middle sequents. Each middle sequent, in turn, depends on a basic identity axiom, with the `[Mon]` rule accounting for the "extra" information present in the more complex sequent.
* **Notable Anomaly for Non-Specialists:** The use of `[Mon]` to add seemingly irrelevant formulas (`q` on the left, `p` on the right) might appear counterintuitive. In proof theory, this is a standard technical device to maintain structural rules within the calculus. It highlights that the proof is about the *structure* of derivation, not just the *content* of the formulas.
* **Underlying Logic:** The proof likely belongs to a **sequent calculus** system, a formal framework for natural deduction. The specific rules (`[⊃⇝]`, `[Mon]`) and the tree format are hallmarks of this approach, which is foundational in theoretical computer science and mathematical logic for studying the properties of proofs themselves.
</details>
Figure 1. Tree-representation for arguments wrt logics.
As shown in examples of [35, 61, 63], binary attacks, used in the literature [69, 19, 7, 14, 50], are not enough expressive to capture cases in which n-ary conflicts may arise. To overcome this limit, some argumentation frameworks introduced the notion of collective attacks to better capture non-binary conflicts, and so improve the decision making process in various conflicting situations. To ensure the generality of our framework, we introduce collective attacks.
**Definition 3.5 (Collective Attacks)**
*Let $A:\Gamma\Rightarrow\alpha$ be an argument and $\mathcal{X}\subseteq\texttt{{Arg}}_{\mathcal{K}}$ be a set of arguments such that $\bigcup_{X\in\mathcal{X}}\texttt{{Sup}}(X)$ is consistent. We say that
- $\mathcal{X}$ undercut-attacks $A$ iff there is $\Gamma^{\prime}\subseteq\Gamma$ s.t $\bigcup_{X\in\mathcal{X}}\{\texttt{{Con}}(X)\}\cup\Gamma^{\prime}$ is inconsistent.
- $\mathcal{X}$ rebuttal-attacks $A$ iff $\bigcup_{X\in\mathcal{X}}\{\texttt{{Con}}(X)\}\cup\{\alpha\}$ is inconsistent.
We can say that $\mathcal{X}$ attacks $A$ for short. We use $\texttt{{Att}}_{\mathcal{K}}\subseteq 2^{\texttt{{Arg}}_{\mathcal{K}}}\times \texttt{{Arg}}_{\mathcal{K}}$ to denote the set of attacks induced from $\mathcal{K}$ .*
Note that deductive argumentation can capture n-ary conflicts. However, as discussed in [35, 9], it argued that the argumentation framework using $\text{Datalog}^{\pm}$ , an instance of deductive argumentation, may generate a large number of arguments and attacks when using the definition of deductive arguments, as in [19]. To address this problem, some redundant arguments are dropped, as discussed in [9], or arguments are re-defined as those in ASPIC+, as seen in [35]. Then the attack relation must be redesigned to preserve all conflicts. In particular, n-ary attacks are allowed where arguments can jointly attack an argument. We will show this issue in the following example.
**Example 3.6**
*Consider $\mathcal{K}_{2}=(\mathcal{F}_{2},\mathcal{R}_{2},\mathcal{C}_{2})$ where
| | $\displaystyle\mathcal{R}_{2}=$ | $\displaystyle\emptyset,$ | |
| --- | --- | --- | --- |
The deductive argumentation approach [19] uses six arguments
| | $\displaystyle C_{2}:(\{B(a)\},B(a)),C_{3}:(\{C(a)\},C(a)),C_{4}:(\{A(a),B(a)\} ,A(a)\land B(a)),$ | |
| --- | --- | --- |
to obtains the preferred extensions: $\{C_{1},C_{2},C_{4}\}$ , $\{C_{1},C_{3},C_{5}\}$ , $\{C_{2},C_{3},C_{6}\}$ . In contrast, our approach uses three arguments $B_{1}:\{A(a)\}\Rightarrow A(a)$ , $B_{2}:\{B(a)\}\Rightarrow B(a)$ , $B_{3}:\{C(a)\}\Rightarrow C(a)$ with collective attacks, such as $\{B_{1},B_{2}\}$ attacks $B_{3}$ , etc., to obtain extensions $\{B_{1},B_{2}\},\{B_{1},B_{3}\},\{B_{2},B_{3}\}$ .*
**Remark 3.7**
*Similar to structured argumentation, such as deductive argumentation for propositional logic [59], DLs [14], $\text{Datalog}^{\pm}$ [19], DeLP systems [45], ASPIC systems [46] and sequent-based argumentation [65, 63], attacks in our framework are defined between individual arguments. In contrast, in ABA systems [44, 53, 67, 68], attacks are defined between sets of assumptions. However, in these ABA systems, the arguments generated from a set of assumptions are tree-derivations (both notions are used interchangeably), which can be instantiated by Definition 3.1, see above. Thus, the attacks defined on assumptions are equivalent to the attacks defined on the level of arguments.*
**Remark 3.8**
*Note that the definition of collective attacks holds if we only consider ASPIC+ without preferences [62]. We leave the case of preferences for future work.*
We introduce proof-oriented argumentation (P-SAF) as an instantiation of SAFs [25]. Our framework is comparable to the one of [52] in that both are applied to abstract logic. However, arguments in our setting differ from those in [52] in that we represent arguments in the form of a tree.
**Definition 3.9**
*Let $\mathcal{K}$ be a KB, the corresponding proof-oriented (logical) argumentation (P-SAF) $\mathcal{AF}_{\mathcal{K}}$ is the pair $(\texttt{{Arg}}_{\mathcal{K}},\texttt{{Att}}_{\mathcal{K}})$ where $\texttt{{Arg}}_{\mathcal{K}}$ is the set of arguments induced from $\mathcal{K}$ and $\texttt{{Att}}_{\mathcal{K}}$ is the set of attacks.*
In the next subsections, we show that the existing argumentation frameworks are instances of logic-associated argumentation frameworks.
### 3.2. Translating the Existing Argumentation Frameworks to P-SAFs
We have already shown that the existing frameworks (deductive argumentation [59, 14, 19], DeLP systems [45], ASPIC systems [46], ASPIC+ without preferences [62], ABA systems [44, 53, 67, 68]) can be seen as instances of our settings. Now we show how sequent-based argumentation [69, 55] and contrapositive ABAs [65, 63] fit in our framework.
- Sequent-based argumentation [69], using propositional logic, represents arguments as sequents. The construction of arguments from simpler arguments is done by the inference rules of the sequent calculus. Attack rules are represented as sequent elimination rules. The ingredients of sequent-based argumentation may be simulated in our setting:
We start with a logic $(\mathcal{L}_{s},\texttt{{CN}}_{s})$ . $\mathcal{L}_{s}$ is a propositional language having a set of atomic formulas $\texttt{{Atoms}}(\mathcal{L}_{s})$ . If $\phi$ and $\alpha$ are formulas wrt. $\texttt{{Atoms}}(\mathcal{L}_{s})$ then $\neg\phi$ , $\phi\wedge\alpha$ are formulas wrt. $\texttt{{Atoms}}(\mathcal{L}_{s})$ . We assume that the implication $\supset$ and $\leftrightarrow$ are defined accordingly. Propositional logic can be modelled by using sequents [69]. A sequent is a formula in the language $\mathcal{L}_{s}$ of propositional logic enriched by the addition of a new symbol $\leadsto$ . We call such sequent the s-formula of $\mathcal{L}_{s}$ to avoid ambiguity. In particular, for a formula $p\in\mathcal{L}_{s}$ the axiom $p\leadsto p$ are a s-formula in $\mathcal{L}_{s}$ . In general, for any set of formulas $\Psi\subseteq\mathcal{L}_{s}$ and $\phi\in\mathcal{L}_{s}$ , the sequents $\Psi\leadsto\phi$ are s-formulas of $\mathcal{L}_{s}$ .
Define $\texttt{{CN}}_{s}$ as follows: For a set of formulas $X\subseteq\mathcal{L}_{s}$ , a formula $\phi\in\mathcal{L}_{s}$ satisfies $\phi\in\texttt{{CN}}_{s}(X)$ iff an inference rule $\frac{\Psi_{1}\leadsto\phi_{1}\ldots\Psi_{n}\leadsto\phi_{n}}{\Psi\leadsto\phi}$ , where the sequents $\Psi\leadsto\phi$ and $\Psi_{i}\leadsto\phi_{i}$ ( $i=1,\ldots,n$ ) are s-formulas of $\mathcal{L}_{s}$ , is applied to $X$ such that $\Psi_{1},\ldots,\Psi_{n}$ are subsets of $X$ . We here consider the inference rules as structural rules and logical rules in [69]. Then we define $\overline{\texttt{{CN}}}_{s}(X)=\bigcup_{n\geq 0}\texttt{{CN}}_{s}^{n}(X)$ .
Let us define arguments in the sense of Definition 3.1: For a set of formulas $H\subseteq\mathcal{L}_{s}$ , $H\Rightarrow\phi$ is an argument iff $\phi\in\overline{\texttt{{CN}}}_{s}(H)$ . In this case, the argument, from the premise $H$ to the conclusion $\phi$ , can be described by a sequence of applications of inference rules. Such sequence is naturally organized in the shape of a tree by $\texttt{{CN}}_{s}$ . Each step up the tree corresponds to an application of an inference rule. The root of the tree is the final sequent (the conclusion), and the leaves are the axioms or initial sequents.
We show how the attack rules can be described in terms of corresponding attack relations in Definition 3.5. The attack rule has the form of $\frac{\Psi_{1}\leadsto\phi_{1},\ldots,\Psi_{n}\leadsto\phi_{n}}{\Psi_{n}\not \leadsto\phi_{n}}$ , in which the first sequent in the attack rule’s prerequisites is the “attacking” sequent, the last sequent in the attack rule’s prerequisites is the “attacked” sequent, and the other prerequisites are the conditions for the attack. According to the discussion above, these sequents $\Psi_{i}\leadsto\phi_{i}$ , ( $i=1,\ldots,n$ ), can be viewed as arguments $A_{i}:\Psi_{i}\Rightarrow\phi_{i}$ in the sense of Definition 3.1 where $\phi_{i}\in\overline{\texttt{{CN}}}_{s}(\Psi_{i})$ . Then, in this view, the first sequent $\Psi_{1}\leadsto\phi_{1}$ is the attacking argument $A_{1}$ , the last sequent $\Psi_{n}\leadsto\phi_{n}$ is the attacked argument $A_{n}$ , and the conclusions of the attack rule are the eliminations of the attacked arguments, meaning that $A_{n}$ is removed since $A_{1}$ attacks $A_{n}$ in the sense of Definition 3.5.
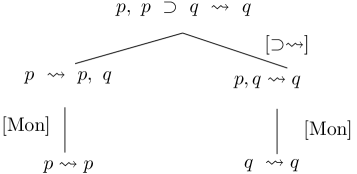
**Example 3.10 (Continue Example2.5)**
*Consider $\mathcal{K}=\{x,x\supset y,\neg y\}\subseteq\mathcal{L}_{s}$ . The following is an argument in propositional logic $A:\{x,x\supset y\}\Rightarrow y$ , $B:\{\neg y\}\Rightarrow\neg y$ . $A$ attacks $B$ since $\{x,x\supset y,\neg y\}$ is inconsistent, i.e., $\overline{\texttt{{CN}}}_{s}(\{x,x\supset y,\neg y\})=\mathcal{L}_{s}$ . Tree-representations of the arguments are shown in Figure 1 (Right), in which $[Mon]$ and $[\supset,\leadsto]$ are the names of inference rules.*
- Contrapositive ABA [65, 63] may be based on propositional logic and strict and candidate (defeasible) assumptions consists of arbitrary formulas in the language of that logic. Attacks are defined between sets of assumptions, i.e., defeasible assumptions may be attacked in the presence of a counter defeasible information. Our P-SAF framework using logic $(\mathcal{L}_{co},\texttt{{CN}}_{co})$ can simulate contrapositive ABAs as follows:
Assume that an implication connective $\supset$ is deductive (i.e., it is a $\vdash$ -implication in contrapositive ABAs) and converting such implications $\supset$ (i.e., $\phi_{1}\wedge\cdots\wedge\phi_{n}\supset\psi$ ) to rules of the form $\phi_{1},\ldots,\phi_{n}\rightarrow\psi$ in $\mathcal{L}_{co}$ . Here we ignore the distinction between defeasible and strict rules. With this assumption, the rules in $\mathcal{L}_{co}$ can be treated as $\vdash$ - implication, i.e., $\{\phi_{1},\ldots,\phi_{n}\rightarrow\psi\in\mathcal{L}_{co}\mid\phi_{1}, \ldots,\phi_{n}\vdash\psi\}$ ; their contrapositions treated as $\vdash$ - contrapositive, i.e., $\{\phi_{1},\ldots,\phi_{i-1},\neg\psi,\phi_{i+1},\dots\phi_{n}\rightarrow\neg \phi_{i}\mid\phi_{1},\ldots,\phi_{i-1},\neg\psi,\phi_{i+1},\dots\phi_{n}\vdash \neg\phi_{i}\}$ See definitions of $\vdash$ -implication and $\vdash$ -contrapositive in [65, 63]. This translation views the contrapositive ABA as a special case of the traditional definition of ABA [44]; also the traditional ABA can be simulated in our P-SAF using $(\mathcal{L}_{co},\texttt{{CN}}_{co})$ . Thus, the results and concepts of P-SAFs can apply to the contrapositive ABAs. Indeed, first, $\mathcal{L}_{co}$ includes the strict and candidate assumptions We abuse the term “strict and candidate assumptions” and refer them as ”literals”. and the set of rules. These rules as reasoning patterns are used in $\texttt{{CN}}_{co}$ as defined in Definition 2.14. Second, by Definition 3.1, for $H\subseteq\mathcal{L}_{co}$ be a set of assumptions and $\phi\in\mathcal{L}_{co}$ , $H\Rightarrow\phi$ is an argument iff $\phi\in\overline{\texttt{{CN}}}_{co}(H)$ . Third, the attacks defined on assumptions in traditional ABA are equivalent to those in our S-PAFs (see Remark 3.7 for further explanation).
Note that contrapositive ABAs in [63] (with collective attacks) are analogous to those in [65], except they drop the requirement that any set of candidate assumptions contributing to the attacks must be close. Similarly, our P-SAF framework, which uses $\overline{\texttt{{CN}}}_{co}$ in the definition of inconsistency for our attacks, does not impose this additional requirement.
### 3.3. Acceptability of P-SAFs and Relations to Reasoning with MSCs
Semantics of P-SAFs are now defined as in the definition of semantics for SAFs [25]. These semantics consist of admissible, complete, stable, preferred and grounded semantics.
Given a P-SAF $\mathcal{AF}_{\mathcal{K}}=(\texttt{{Arg}}_{\mathcal{K}},\texttt{{Att}}_{ \mathcal{K}})$ and $\mathcal{S}\subseteq\texttt{{Arg}}_{\mathcal{K}}$ . $\mathcal{S}$ attacks $\mathcal{X}$ iff $\exists A\in\mathcal{X}$ s.t. $\mathcal{S}$ attacks $A$ . $\mathcal{S}$ defends $A$ if for each $\mathcal{X}\subseteq\texttt{{Arg}}_{\mathcal{K}}$ s.t. $\mathcal{X}$ attacks $A$ , some $\mathcal{S}^{\prime}\subseteq\mathcal{S}$ attacks $\mathcal{X}$ . An extension $\mathcal{S}$ is called
- conflict-free if it does not attack itself;
- admissible $(\texttt{{adm}})$ if it is conflict-free and defends itself.
- complete $(\texttt{{cmp}})$ if it is admissible containing all arguments it defends.
- preferred $(\texttt{{prf}})$ if it is an inclusion-maximal admissible extension.
- stable $(\texttt{{stb}})$ if it is conflict-free and attacks every argument not in it.
- grounded $(\texttt{{grd}})$ if it is an inclusion-minimal complete extension.
Note that this implies that each grounded or preferred extension of a P-SAF is an admissible one, the grounded extension is contained in all other extensions.
Let $\texttt{{Exts}}_{\texttt{{sem}}}(\mathcal{AF}_{\mathcal{K}})$ denote the set of all extensions of $\mathcal{AF}_{\mathcal{K}}$ under the semantics $\texttt{{sem}}\in\{\texttt{{adm}},\ \texttt{{stb}},\ \texttt{{prf}},\ \texttt{ {grd}}\}$ . Let us define acceptability in P-SAFs.
**Definition 3.11**
*Let $\mathcal{AF}_{\mathcal{K}}$ be the corresponding P-SAF of a KB $\mathcal{K}$ and $\texttt{{sem}}\in\{\texttt{{adm}},\texttt{{stb}},\texttt{{prf}}\}$ . A formula $\phi\in\mathcal{L}$ is
- credulously accepted under sem iff for some $\mathcal{E}\in\texttt{{Exts}}_{\texttt{{sem}}}(\mathcal{AF}_{\mathcal{K}})$ , $\phi\in\texttt{{Cons}}(\mathcal{E})$ .
- groundedly accepted under grd iff for some $\mathcal{E}\in\texttt{{Exts}}_{\texttt{{grd}}}(\mathcal{AF}_{\mathcal{K}})$ , $\phi\in\texttt{{Cons}}(\mathcal{E})$ .
- sceptically accepted under sem iff for all $\mathcal{E}\in\texttt{{Exts}}_{\texttt{{sem}}}(\mathcal{AF}_{\mathcal{K}})$ , $\phi\in\texttt{{Cons}}(\mathcal{E})$ .*
Next, we show the relation to reasoning with maximal consistent subsets in inconsistent KBs. Proposition 3.12 shows a relation between extensions of P-SAFs and MSCs of KBs.
**Proposition 3.12**
*Let $\mathcal{AF}_{\mathcal{K}}$ be the corresponding P-SAF of a KB $\mathcal{K}$ . Then, - the maximal consistent subset of $\mathcal{K}$ coincides with the stable/ preferred extension of $\mathcal{AF}_{\mathcal{K}}$ ;
- the intersection of the maximal consistent subsets of $\mathcal{K}$ coincides with the grounded extension of $\mathcal{AF}_{\mathcal{K}}$ .*
* Proof*
The idea of the proof is to show that every preferred extension is the set of arguments generated from a MCS, that every such set of arguments is a stable extension, and that every stable extension is preferred. The proof of the second statement follows the lemma saying that if there are no rejected arguments under preferred semantics, then the grounded extension is equal to the intersection of all preferred extensions. By the proof of the first statement, every preferred extension is a maximal consistent subset. Thus the second statement is proved. ∎
**Remark 3.13**
*In general, the grounded extension is contained in the intersection of all maximal consistent subsets.*
The main result of this section, Theorem 3.14, which follows from Proposition 3.12 generalises results from previous works.
**Theorem 3.14**
*Let $\mathcal{AF}_{\mathcal{K}}$ be the corresponding P-SAF of a KB $\mathcal{K}$ , $\phi\in\mathcal{L}$ a formula and $\texttt{{sem}}\in\{\texttt{{adm}},\texttt{{stb}},\texttt{{prf}}\}$ . Then, $\phi$ is entailed in
- some maximal consistent subset iff $\phi$ is credulously accepted under sem.
- all maximal consistent subsets iff $\phi$ is sceptically accepted under sem.
- the intersection of all maximal consistent subsets iff $\phi$ is groundedly accepted under grd.*
To argue the quality of P-SAF, it can be shown that it satisfies the rationality postulates introduced in [51, 40].
**Definition 3.15**
*Let $\mathcal{AF}_{\mathcal{K}}$ be the corresponding P-SAF of a KB $\mathcal{K}$ . Wrt. $\texttt{{sem}}\in\{\texttt{{adm}},\texttt{{stb}},\texttt{{prf}},\texttt{{grd}}\}$ , $\mathcal{AF}_{\mathcal{K}}$ is
1. closed under $\overline{\texttt{{CN}}}$ iff for all $\mathcal{E}\in\texttt{{Exts}}_{\texttt{{sem}}}(\mathcal{AF}_{\mathcal{K}})$ , $\texttt{{Cons}}(\mathcal{E})=\overline{\texttt{{CN}}}(\texttt{{Cons}}(\mathcal {E}))$ ;
1. consistent iff for all $\mathcal{E}\in\texttt{{Exts}}_{\texttt{{sem}}}(\mathcal{AF}_{\mathcal{K}})$ , $\texttt{{Cons}}(\mathcal{E})$ is consistent;*
**Proposition 3.16**
*Wrt. to any semantics in $\{\texttt{{adm}},\texttt{{stb}}$ , $\texttt{{prf}},\texttt{{grd}}\}$ , $\mathcal{AF}_{\mathcal{K}}$ satisfies consistency, closure.*
The proof of Proposition 3.16 is analogous to those of Proposition 2 in [52]. Because of this similarity, they are not included in the appendix.
**Example 3.17 (Continue Example2.19)**
*Recall $\mathcal{K}_{1}$ . Table 2 shows the supports and conclusions of all arguments induced from $\mathcal{K}$ . The corresponding P-SAF admits stb (prf) extensions: $\texttt{{Exts}}_{\texttt{{stb}}/\texttt{{prf}}}(\mathcal{AF}_{1})=\{\mathcal{E }_{1},\ldots,\mathcal{E}_{6}\}$ , where $\mathcal{E}_{1}=\texttt{{Args}}(\{\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}}), \texttt{{UC}}(\texttt{{KD}})\})$ Fix $\mathcal{F}^{\prime}\subseteq\mathcal{F}$ , $\texttt{{Args}}(\mathcal{F}^{\prime})$ is the set of arguments generated by $\mathcal{F}^{\prime}$ $=\{A_{5},A_{6},A_{2}\}$ , and $\mathcal{E}_{2},\ldots,\mathcal{E}_{6}$ are obtained in an analogous way. It can be seen that the extensions correspond to the repairs of the KBs (by Theorem 3.14). Reconsider $q_{1}=\texttt{{Re}}(\texttt{{v}})$ . We have that $q_{1}$ is credulously accepted under stb (prf) extensions. In other words, v is a possible answer for $q_{1}$ .*
Table 2. Supports and conclusions of arguments
| $A_{0}$ $A_{9}$ $A_{7}$ | $\{\texttt{{te}}(\texttt{{v}},\texttt{{KR}})\}$ $\{\texttt{{GC}}(\texttt{{KR}})\}$ $\{\texttt{{GC}}(\texttt{{KR}}),\texttt{{te}}(\texttt{{v}},\texttt{{KR}})\}$ | $\texttt{{te}}(\texttt{{v}},\texttt{{KR}})$ $\texttt{{GC}}(\texttt{{KR}})$ $\texttt{{FP}}(\texttt{{v}})$ |
| --- | --- | --- |
| $A_{1}$ | $\{\texttt{{GC}}(\texttt{{KR}}),\texttt{{te}}(\texttt{{v}},\texttt{{KR}})\}$ | $\texttt{{Re}}(\texttt{{v}})$ |
| $A_{4}$ | $\{\texttt{{te}}(\texttt{{v}},\texttt{{KD}})\}$ | $\texttt{{te}}(\texttt{{v}},\texttt{{KD}})$ |
| $A_{5}$ | $\{\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}})\}$ | $\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}})$ |
| $A_{6}$ | $\{\texttt{{UC}}(\texttt{{KD}})\}$ | $\texttt{{UC}}(\texttt{{KD}})$ |
| $A_{2}$ | $\{\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}}),\ \texttt{{UC}}(\texttt{{KD}})\}$ | $\texttt{{TA}}(\texttt{{v}})$ |
| $A_{3}$ | $\{\texttt{{te}}(\texttt{{v}},\texttt{{KD}})\}$ | $\texttt{{Le}}(\texttt{{v}})$ |
| $A_{8}$ | $\{\texttt{{te}}(\texttt{{v}},\texttt{{KR}})\}$ | $\texttt{{Le}}(\texttt{{v}})$ |
| $A_{10}$ | $\{\texttt{{te}}(\texttt{{v}},\texttt{{KR}})\}$ | $\texttt{{Em}}(\texttt{{v}})$ |
| $A_{11}$ | $\{\texttt{{te}}(\texttt{{v}},\texttt{{KD}})\}$ | $\texttt{{Em}}(\texttt{{v}})$ |
| $A_{12}$ | $\{\texttt{{GC}}(\texttt{{KR}}),\texttt{{te}}(\texttt{{v}},\texttt{{KR}})\}$ | $\texttt{{Em}}(\texttt{{v}})$ |
In this section, we have translated from KBs into P-SAFs. Consequently, the acceptance of a formula $\phi$ of $\mathcal{L}$ corresponds to the acceptance of a set of arguments $\mathcal{A}$ for $\phi$ . When we say ”a set of arguments $\mathcal{A}$ for $\phi$ ”, it means simply that for each argument in $\mathcal{A}$ , its consequence is $\phi$ . We next introduce a novel notion of explanatory dialogue (” dialogue ” for short) viewed as a dialectical proof procedure in Section 4. Section 5 will show how to use a dialogue model to determine and explain the acceptance of $\phi$ wrt argumentation semantics.
## 4. Explanatory Dialogue Models
Inspired by [23, 42], we develop a novel explanatory dialogue model of P-SAF by examining the dispute process involving the exchange of arguments (represented as formulas in KBs) between two agents. The novel explanatory dialogue model can show how to determine and explain the acceptance of a formula wrt argumentation semantics.
### 4.1. Basic Notions
Concepts of a novel dialogue model for P-SAFs include utterances, dialogues and concrete dialogue trees (” dialogue tree ” for short). In this model, a topic language $\mathcal{L}_{t}$ is abstract logic $(\mathcal{L},\texttt{{CN}})$ ; dialogues are sequences of utterances between two agents $a_{1}$ and $a_{2}$ sharing a common language $\mathcal{L}_{c}$ . Utterances are defined as follows:
**Definition 4.1 (Utterances)**
*An utterance of agents $a_{i},\ i\in\{1,2\}$ has the form $u=(a_{i},\texttt{{TG}},\texttt{{C}},\texttt{{ID}})$ , where:
- $\texttt{{ID}}\in\mathbb{N}$ is the identifier of the utterance,
- TG is the target of the utterance and we impose that $\texttt{{TG}}<\texttt{{ID}}$ ,
- $\texttt{{C}}\in\mathcal{L}_{c}$ (the content) is one of the following forms: Fix $\phi\in\mathcal{L}$ and $\Delta\subseteq\mathcal{L}$ .
- $\texttt{{claim}}(\phi)$ : The agent asserts that $\phi$ is the case,
- $\texttt{{offer}}(\Delta,\phi)$ : The agent advances grounds $\Delta$ for $\phi$ uttered by the previously advanced utterances such that $\phi\in\texttt{{CN}}(\Delta)$ ,
- $\texttt{{contrary}}(\Delta,\ \phi)$ : The agent advances the formulas $\Delta$ that are contrary to $\phi$ uttered by the previously advanced utterance,
- $\texttt{{concede}}(\phi)$ : The agent gives up debating and admits that $\phi$ is the case,
- $\texttt{{fact}}(\phi)$ : The agent asserts that $\phi$ is a fact in $\mathcal{K}$ .
- $\kappa$ : The agent does not have or wants to contribute information at that point in the dialogue.
We denote by $\mathcal{U}$ the set of all utterances.*
To determine which utterances agents can make to construct a dialogue, we define a notion of legal move, similarly to communication protocols. For any two utterances $u_{i},\ u_{j}\in\mathcal{U}$ , $u_{i}\neq u_{j}$ , we say that:
- $u_{i}$ is the target utterance of $u_{j}$ iff the target of $u_{j}$ is the identifier of $u_{i}$ , i.e., $u_{i}=(\_,\_,\texttt{{C}}_{i},\texttt{{ID}})$ and $u_{j}=(\_,\texttt{{ID}},\texttt{{C}}_{j},\_)$ ;
- $u_{j}$ is the legal move after $u_{i}$ iff $u_{i}$ is the target utterance of $u_{j}$ and one of the following cases in Table 3 holds.
Table 3. Locutions and responses
$$
u_{i} u_{j} \texttt{{C}}_{i}=\texttt{{claim}}(\phi) \texttt{{C}}_{j}=\texttt{{offer}}(\_,\phi) \phi\in\texttt{{CN}}(\{\_\}) \texttt{{C}}_{j}=\texttt{{fact}}(\phi) \phi\in\mathcal{K} \texttt{{C}}_{j}=\texttt{{contrary}}(\_,\ \phi) \{\_,\phi\} \texttt{{C}}_{i}=\texttt{{fact}}(\phi) \texttt{{C}}_{j}=\texttt{{contrary}}(\_,\phi) \{\_,\phi\} \texttt{{C}}_{i}=\texttt{{offer}}(\Delta,\phi) \texttt{{C}}_{j}=\texttt{{contrary}}(\_,\ \phi) \{\_,\phi\} \phi\in\texttt{{CN}}(\Delta) \texttt{{C}}_{j}=\texttt{{contrary}}(\_,\ \Delta) \{\_\}\cup\Delta \texttt{{C}}_{j}=\texttt{{offer}}(\_,\beta_{i}) \beta_{i}\in\Delta \beta_{j}\in\texttt{{CN}}(\{\_\}) \texttt{{C}}_{i}=\texttt{{contrary}}(\beta,\_) \texttt{{C}}_{j}=\texttt{{contrary}}(\_,\beta) \{\_,\beta\} \texttt{{C}}_{j}=\texttt{{offer}}(\_,\beta) \beta\in\texttt{{CN}}(\{\_\}) \tag{1}
$$
An utterance is a legal move after another if any of the following cases happens: (1) it with content offer contributes to expanding an argument; (2) it with content fact identifies a fact in support of an argument; (3) it with content contrary starts the construction of a counter-argument. An utterance can be from the same agent or not.
### 4.2. Dialogue Trees, Dialogues and Focused Sub-dialogues
In essence, a dialogue is a sequence of utterances $u_{1},\ldots,u_{n}$ , each of which transforms the dialogue from one state to another. To keep track of information disclosed in dialogues for P-SAFs, we define dialogue trees constructed as the dialogue progresses. These are subsequently used to determine successful dialogues w.r.t argumentation semantics.
A dialogue tree represents a dispute progress between a proponent and an opponent who take turns exchanging arguments in the form of formulas of a KB. The proponent starts the dispute with their arguments and must defend against all of the opponent’s attacks to win. Informally, in a dialogue tree, the formula of each node represents an argument’s conclusion or elements of the argument’s support. A node is annotated unmarked if its formula is only mentioned in the claim, but without any further examination, marked-non-fact if its formula is the logical consequence of previous uttered formulas, and marked-fact if its formula has been explicitly uttered as a fact in $\mathcal{K}$ . A node is labelled P $(\texttt{{O}})$ if it is (directly or indirectly) for (against, respectively) the claim of the dialogue. The ID is used to identify the node’s corresponding utterance in the dialogue. The nodes are connected in two cases: (1) they belong to the same argument, and (2) they form collective attacks between arguments. We formally define dialogue trees and dialogues.
**Definition 4.2**
*Given a sequence of utterances $\delta=u_{1},\ldots,u_{n}$ , the dialogue tree $\mathcal{T}(\delta)$ drawn from $\delta$ is a tree whose nodes are tuples $(\texttt{{S}},\ [\texttt{{T}},\ \texttt{{L}},\ \texttt{{ID}}])$ , where:
- S is a formula in $\mathcal{L}$ ,
- T is either um (unmarked), nf (marked-non-fact), fa (marked-fact),
- L is either P or O,
- ID is the identifier of the utterance $u_{i}$ ; and $\mathcal{T}(\delta)$ is $\mathcal{T}^{n}$ in the sequence $\mathcal{T}^{1},\ldots,\mathcal{T}^{n}$ constructed inductively from $\delta$ , as follows:
1. $\mathcal{T}^{1}$ contains a single node: $(\phi,[\texttt{{um}},\ \texttt{{P}},\ \texttt{{id}}_{1}])$ where $\texttt{{id}}_{1}$ is the identifier of the utterance $u_{1}=(\_,\_,\texttt{{claim}}(\phi),\texttt{{id}}_{1})$ ;
1. Let $u_{i+1}=(\_,\ \texttt{{ta}},\ \texttt{{C}},\ \texttt{{id}})$ be the utterance in $\delta$ ; $\mathcal{T}^{i}$ be the $i$ -th tree with the utterance $(\_,\ \_,\ \texttt{{C}}_{\texttt{{ta}}},\ \texttt{{ta}})$ as the target utterance of $u_{i+1}$ . Then $\mathcal{T}^{i+1}$ is obtained from $\mathcal{T}^{i}$ by $u_{i+1}$ , if one of the following conditions holds: $(\texttt{{L}},\texttt{{L}}_{\texttt{{ta}}}\in\{\texttt{{P}},\texttt{{O}}\}, \texttt{{L}}\neq\texttt{{L}}_{\texttt{{ta}}})$ :
1. If $\texttt{{C}}=\texttt{{offer}}(\Delta,\ \alpha)$ with $\Delta=\{\beta_{1},\ldots,\beta_{m}\}$ and $\alpha\in\texttt{{CN}}(\Delta)$ , then $\mathcal{T}^{i+1}$ is obtained:
- For all $\beta_{j}\in\Delta$ , new nodes $(\beta_{j},[\texttt{{T}},\ \texttt{{L}},\ \texttt{{id}}])$ are added to the node $(\alpha,[\_,\ \texttt{{L}},\ \texttt{{ta}}])$ of $\mathcal{T}^{i}$ . Here $\texttt{{T}}=\texttt{{fa}}$ if $\beta_{j}\in\mathcal{K}$ , otherwise $\texttt{{T}}=\texttt{{nf}}$ ;
- The node $(\alpha,[\_,\ \texttt{{L}},\ \texttt{{ta}}])$ is replaced by $(\alpha,[\texttt{{nf}},\ \texttt{{L}},\ \texttt{{ta}}])$ ;
1. If $\texttt{{C}}=\texttt{{fact}}(\alpha)$ then $\mathcal{T}^{i+1}$ is $\mathcal{T}^{i}$ with the node $(\alpha,\ [\_,\ \texttt{{L}},\ \texttt{{ta}}])$ replaced by $(\alpha,\ [\texttt{{fa}},\ \texttt{{L}},\ \texttt{{id}}])$ ;
1. If $\texttt{{C}}=\texttt{{contrary}}(\Delta,\eta)$ where $\Delta=\{\beta_{1},\ldots,\beta_{m}\}$ and $\Delta\cup\{\eta\}$ is inconsistent, then $\mathcal{T}^{i+1}$ is obtained by adding new nodes $(\beta_{j},[\texttt{{T}},\ \texttt{{L}},\ \texttt{{id}}])$ , $(\texttt{{T}}=\texttt{{fa}}$ if $\beta_{j}\in\mathcal{K}$ , otherwise $\texttt{{T}}=\texttt{{nf}})$ , as children of the node $(\eta,[\texttt{{T}}_{\texttt{{ta}}},\ \texttt{{L}}_{\texttt{{ta}}},\ \texttt{{ ta}}])$ of $\mathcal{T}^{i}$ , where $\texttt{{T}}_{\texttt{{ta}}}\in\{\texttt{{fa}},\ \texttt{{nf}}\}$ . For such dialogue tree $\mathcal{T}(\delta)$ , the nodes labelled by P (resp., O) are called the proponent nodes (resp., opponent nodes). We call the sequence $u_{1},\ldots,u_{n}$ a dialogue $D(\phi)$ for $\phi$ where $\phi$ is the formula of the root in $\mathcal{T}(\delta)$ .*
This dialogue tree can be seen as a concrete representation of an abstract dialogue tree defined in [52]. Here, the nodes represent formulas and the edges display either the monotonic inference steps used to construct arguments or the attack relations between arguments. A group of nodes in a dialogue tree with the same label P (or O) corresponds to the proponent (or opponent) argument in the abstract dialogue tree.
**Definition 4.3 (Focused sub-dialogues)**
*$\delta^{\prime}$ is called a focused sub-dialogue of a dialogue $\delta$ iff it is a dialogue for $\phi$ and, for all utterances $u\in\delta^{\prime}$ , $u\in\delta$ . We say that $\delta$ is the full-dialogue of $\delta^{\prime}$ and $\mathcal{T}(\delta^{\prime})$ drawn from $\delta^{\prime}$ is the sub-tree of $\mathcal{T}(\delta)$ .*
If there are no utterances for both proponents and opponents in a dialogue tree from a dialogue $\delta$ , then $\delta$ is called terminated. Note that a dialogue can be ”incomplete”, which means that it ends before the utterances related to determining success are claimed. To prevent this from happening we assume that dialogues are complete, i.e. that there are no ”unsaid” utterances (with the content fact, offer or contrary) in such dialogue that would bring important arguments to determine success. This assumption will ease the proof of soundness result later.
**Example 4.4 (Continue Example3.17)**
*When users received the answer ” $(\texttt{{v}})$ is possible researcher ”, they would like to know ” Why is this the case? ”. The system will explain to the users through the natural language dispute agreement that the agent $a_{1}$ is persuading $a_{2}$ to agree that v is a researcher. This dispute agreement is formally modelled by an explanatory dialogue $D(\texttt{{Re}}(\texttt{{v}}))=\delta$ as in Figure 2.
<details>
<summary>x4.png Details</summary>

### Visual Description
## Table: Formal Dialogue/Argumentation Exchange
### Overview
The image displays a two-column table representing a structured dialogue or argumentation exchange between two agents, labeled **a₁** and **a₂**. The table contains eight numbered utterances (u₁ through u₈), each consisting of a formal logical or argumentative move. The language used is formal mathematical/logical notation.
### Components/Axes
* **Structure:** A table with two columns.
* **Column Headers:**
* Left Column: `a₁` (Agent 1)
* Right Column: `a₂` (Agent 2)
* **Content:** Each cell contains one or more lines of text. Each line defines an utterance `uₙ` with a specific format: `uₙ = (agent, step, move_type, argument, step)`.
* **Notation:** The moves use predicates and functions such as `claim`, `offer`, `contrary`, `concede`, `Re(v)`, `FP(v)`, `te(v, KR)`, `GC(KR)`, `TA(v)`, `Le(v)`, `taOf(v, KD)`, `UC(KD)`.
### Detailed Analysis / Content Details
The table is transcribed below, preserving the exact formatting and notation.
| Left Column (Agent a₁) | Right Column (Agent a₂) |
| :--- | :--- |
| 1. `u₁ = (a₁, 0, claim(Re(v)), 1)` | 1. `u₄ = (a₂, 2, contrary(TA(v), Re(v)), 4)` |
| 2. `u₂ = (a₁, 1, offer(FP(v), Re(v)), 2)` | 2. `u₅ = (a₂, 4, offer({taOf(v, KD), UC(KD)}, TA(v)), 5)` |
| 3. `u₃ = (a₁, 2, offer({te(v, KR), GC(KR)}, FP(v)), 3)` | 3. `u₈ = (a₂, 0, concede(Re(v)), 8)` |
| 4. `u₆ = (a₁, 4, contrary(Le(v), TA(v)), 6)` | |
| 5. `u₇ = (a₁, 6, offer(te(v, KD), Le(v)), 7)` | |
### Key Observations
1. **Dialogue Flow:** The utterances are not strictly sequential by number (u₁, u₂, u₃, u₄, u₅, u₆, u₇, u₈). The sequence appears to be: u₁ (a₁) -> u₂ (a₁) -> u₃ (a₁) -> u₄ (a₂) -> u₅ (a₂) -> u₆ (a₁) -> u₇ (a₁) -> u₈ (a₂).
2. **Agent Activity:** Agent `a₁` makes the initial claim and several offers. Agent `a₂` responds with a contrary move and an offer, and finally makes a concession.
3. **Move Types:** The dialogue consists of four move types: `claim`, `offer`, `contrary`, and `concede`.
4. **Argument Structure:** Offers often involve sets of premises (denoted by `{...}`) supporting a conclusion. For example, `u₃` offers `{te(v, KR), GC(KR)}` in support of `FP(v)`.
5. **Spatial Layout:** The table is a simple grid. Utterances are left-aligned within their respective cells. The final utterance, `u₈`, is in the bottom-right cell.
### Interpretation
This table formalizes a dialectical process, likely from the field of argumentation theory, formal logic, or multi-agent systems. It models a conversation where agents advance positions (`claim`), support them with evidence or sub-arguments (`offer`), challenge each other's positions (`contrary`), and finally reach an agreement or withdrawal (`concede`).
* **Narrative:** The exchange begins with `a₁` claiming `Re(v)` (perhaps "Relevance of v"). `a₁` then builds a support structure for this claim through successive offers. Agent `a₂` intervenes by challenging a different proposition `TA(v)` (perhaps "Truth of A about v") as contrary to the initial `Re(v)`. `a₂` then offers support for its own challenge. `a₁` responds by challenging `a₂`'s proposition `Le(v)` (perhaps "Legitimacy of E about v") as contrary to `TA(v)`, and offers support for its challenge. The dialogue concludes with `a₂` conceding the original point `Re(v)`.
* **Underlying Logic:** The predicates (`Re`, `FP`, `TA`, `Le`, etc.) are not defined in the image, but their usage suggests a structured argumentation scheme where propositions are supported by sets of rules or facts (e.g., `te(v, KR)` could mean "testified evidence from knowledge repository KR").
* **Purpose:** This formalization allows for the precise analysis of argument validity, burden of proof, and dialogue outcomes in computational models of argument. The final concession by `a₂` suggests that within this formal system, `a₁`'s line of argumentation was successful.
</details>
Figure 2. Given $\mathcal{L}_{t}$ is $\mathcal{K}_{1}$ , a dialogue $D(\texttt{{Re}}(\texttt{{v}}))$ $=u_{1},\ldots,u_{9}$ for $q_{1}=\texttt{{Re}}(\texttt{{v}})$ Figure 3 illustrates how to fully construct a dialogue tree $\mathcal{T}(\delta)$ from $D(\texttt{{Re}}(\texttt{{v}}))=\delta$ . To avoid confusing users, after the construction processing, we display the final dialogue tree $\mathcal{T}(\delta)$ with necessary labels, such as formulas, P and O, in Figure 4. The line indicates that children conflict with their parents. The dotted line indicates that children are implied from their parents by inference rules. From this tree, the system provides a dialogical explanation in natural language as shown in Example 1.1.*
<details>
<summary>x5.png Details</summary>
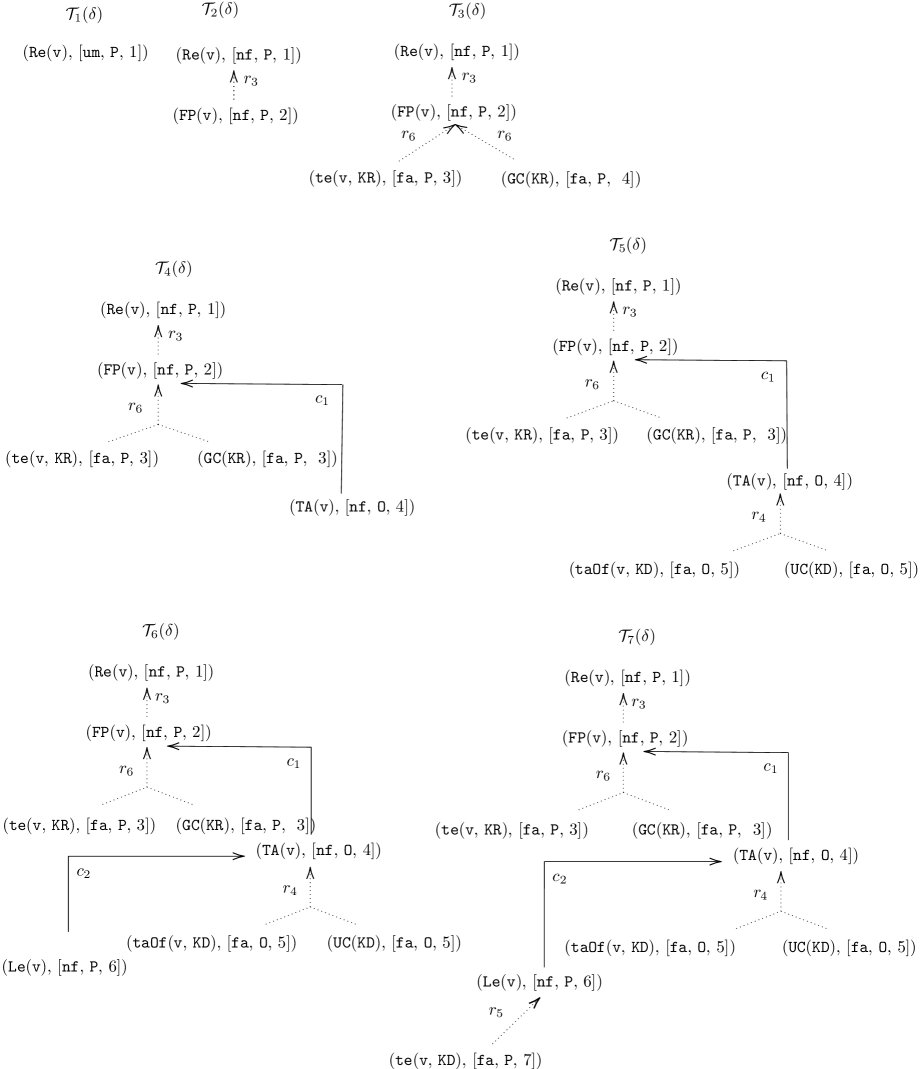
### Visual Description
\n
## Diagram Type: Hierarchical State Transition Trees
### Overview
The image displays seven distinct hierarchical tree diagrams, labeled **T₁(δ)** through **T₇(δ)**, arranged in a grid pattern. Each diagram represents a structured process or state machine, with nodes containing complex symbolic expressions and edges labeled with transition rules (e.g., `r₃`, `c₁`). The diagrams appear to model a formal system, likely from computer science, logic, or process algebra, showing different configurations or derivations from a common base structure.
### Components/Axes
* **Diagram Labels:** Each tree is titled at its top: `T₁(δ)`, `T₂(δ)`, `T₃(δ)`, `T₄(δ)`, `T₅(δ)`, `T₆(δ)`, `T₇(δ)`.
* **Node Structure:** Nodes are textual expressions in the format `(Function/Process(Variable), [Attribute1, Attribute2, Attribute3])`.
* **Edge Labels:** Directed edges (arrows) connecting nodes are labeled with identifiers such as `r₃`, `r₆`, `c₁`, `c₂`, `r₄`, `r₅`. Solid lines indicate primary transitions; dashed lines indicate secondary or conditional transitions.
* **Spatial Layout:**
* **Top Row:** `T₁(δ)` (left), `T₂(δ)` (center), `T₃(δ)` (right).
* **Middle Row:** `T₄(δ)` (left), `T₅(δ)` (right).
* **Bottom Row:** `T₆(δ)` (left), `T₇(δ)` (right).
### Detailed Analysis
**Transcription of All Diagrams:**
**T₁(δ)**
* **Root Node (Top):** `(Re(v), [um, P, 1])`
* **Structure:** A single node. No edges or children.
**T₂(δ)**
* **Root Node (Top):** `(Re(v), [nf, P, 1])`
* **Edge:** A dashed arrow labeled `r₃` points downward from the root.
* **Child Node:** `(FP(v), [nf, P, 2])`
**T₃(δ)**
* **Root Node (Top):** `(Re(v), [nf, P, 1])`
* **Edge:** A dashed arrow labeled `r₃` points downward from the root.
* **Child Node (Middle):** `(FP(v), [nf, P, 2])`
* **Edges:** Two dashed arrows labeled `r₆` point downward from the middle node.
* **Child Nodes (Bottom):**
* Left: `(te(v, KR), [fa, P, 3])`
* Right: `(GC(KR), [fa, P, 4])`
**T₄(δ)**
* **Root Node (Top):** `(Re(v), [nf, P, 1])`
* **Edge:** A dashed arrow labeled `r₃` points downward from the root.
* **Child Node (Upper Middle):** `(FP(v), [nf, P, 2])`
* **Edges:**
* A dashed arrow labeled `r₆` points downward from the upper middle node.
* A solid arrow labeled `c₁` points leftward from a lower node back to the upper middle node.
* **Child Nodes (Lower Middle):**
* Left: `(te(v, KR), [fa, P, 3])`
* Right: `(GC(KR), [fa, P, 3])`
* **Grandchild Node (Bottom):** `(TA(v), [nf, 0, 4])` is connected via a solid line from the `(GC(KR), ...)` node.
**T₅(δ)**
* **Root Node (Top):** `(Re(v), [nf, P, 1])`
* **Edge:** A dashed arrow labeled `r₃` points downward from the root.
* **Child Node (Upper Middle):** `(FP(v), [nf, P, 2])`
* **Edges:**
* A dashed arrow labeled `r₆` points downward from the upper middle node.
* A solid arrow labeled `c₁` points leftward from a lower node back to the upper middle node.
* **Child Nodes (Lower Middle):**
* Left: `(te(v, KR), [fa, P, 3])`
* Right: `(GC(KR), [fa, P, 3])`
* **Grandchild Node (Bottom Middle):** `(TA(v), [nf, 0, 4])` is connected via a solid line from the `(GC(KR), ...)` node.
* **Edges:** Two dashed arrows labeled `r₄` point downward from the grandchild node.
* **Great-Grandchild Nodes (Bottom):**
* Left: `(taOf(v, KD), [fa, 0, 5])`
* Right: `(UC(KD), [fa, 0, 5])`
**T₆(δ)**
* **Root Node (Top):** `(Re(v), [nf, P, 1])`
* **Edge:** A dashed arrow labeled `r₃` points downward from the root.
* **Child Node (Upper Middle):** `(FP(v), [nf, P, 2])`
* **Edges:**
* A dashed arrow labeled `r₆` points downward from the upper middle node.
* A solid arrow labeled `c₁` points leftward from a lower node back to the upper middle node.
* **Child Nodes (Lower Middle):**
* Left: `(te(v, KR), [fa, P, 3])`
* Right: `(GC(KR), [fa, P, 3])`
* **Grandchild Node (Bottom Middle):** `(TA(v), [nf, 0, 4])` is connected via a solid line from the `(GC(KR), ...)` node.
* **Edges:**
* Two dashed arrows labeled `r₄` point downward from the grandchild node.
* A solid arrow labeled `c₂` points leftward from the grandchild node to a new node.
* **Great-Grandchild Nodes (Bottom):**
* Left (connected via `c₂`): `(Le(v), [nf, P, 6])`
* Center-Left (connected via `r₄`): `(taOf(v, KD), [fa, 0, 5])`
* Center-Right (connected via `r₄`): `(UC(KD), [fa, 0, 5])`
**T₇(δ)**
* **Root Node (Top):** `(Re(v), [nf, P, 1])`
* **Edge:** A dashed arrow labeled `r₃` points downward from the root.
* **Child Node (Upper Middle):** `(FP(v), [nf, P, 2])`
* **Edges:**
* A dashed arrow labeled `r₆` points downward from the upper middle node.
* A solid arrow labeled `c₁` points leftward from a lower node back to the upper middle node.
* **Child Nodes (Lower Middle):**
* Left: `(te(v, KR), [fa, P, 3])`
* Right: `(GC(KR), [fa, P, 3])`
* **Grandchild Node (Bottom Middle):** `(TA(v), [nf, 0, 4])` is connected via a solid line from the `(GC(KR), ...)` node.
* **Edges:**
* Two dashed arrows labeled `r₄` point downward from the grandchild node.
* A solid arrow labeled `c₂` points leftward from the grandchild node to a new node.
* **Great-Grandchild Nodes (Bottom):**
* Left (connected via `c₂`): `(Le(v), [nf, P, 6])`
* Center-Left (connected via `r₄`): `(taOf(v, KD), [fa, 0, 5])`
* Center-Right (connected via `r₄`): `(UC(KD), [fa, 0, 5])`
* **Edge:** A dashed arrow labeled `r₅` points downward from the `(Le(v), ...)` node.
* **Great-Great-Grandchild Node (Very Bottom):** `(te(v, KD), [fa, P, 7])`
### Key Observations
1. **Progressive Complexity:** The diagrams show a clear progression from a single node (`T₁`) to a deeply nested tree (`T₇`), suggesting an iterative application of rules.
2. **Common Substructures:** The chain `(Re(v), ...) -> r₃ -> (FP(v), ...) -> r₆ -> {(te(v, KR), ...), (GC(KR), ...)}` is a recurring core pattern present in `T₂` through `T₇`.
3. **Rule Application:** Edge labels (`r₃`, `r₆`, `r₄`, `r₅`) likely denote transformation or inference rules. The labels `c₁` and `c₂` on solid, backward-pointing arrows may represent conditions or constraints that enable further transitions.
4. **Attribute Changes:** The third attribute in the bracketed lists changes systematically (e.g., from `1` to `2` to `3`...), possibly indicating a step counter, depth, or priority level. The second attribute changes between `um`, `nf`, and `fa`.
5. **Node Introduction:** New node types (`TA`, `taOf`, `UC`, `Le`, `te(v, KD)`) are introduced in later diagrams (`T₄` onwards), expanding the system's state space.
### Interpretation
These diagrams almost certainly represent **derivation trees** or **operational semantics** for a formal system, such as a process calculus, logic programming language, or state transition system.
* **What the data suggests:** The sequence `T₁` to `T₇` demonstrates how a complex system state is built from an initial state (`Re(v)`) through the sequential application of rules. The `r` rules appear to be *reduction* or *reaction* rules that decompose or transform processes. The `c` rules appear to be *communication* or *coordination* rules that create feedback loops or enable new interactions.
* **How elements relate:** The root `Re(v)` is the initial request or process. `FP(v)` likely represents a "First Phase" or "Forwarding Process." `GC(KR)` and `te(v, KR)` could be "Garbage Collection" and "terminal evaluation" related to a knowledge resource (`KR`). The later nodes (`TA`, `UC`, `Le`) suggest "Task Assignment," "Use Case," and "Lifecycle Event," indicating the system manages workflow or resource lifecycle.
* **Notable patterns/anomalies:** The shift from `[um, P, 1]` in `T₁` to `[nf, P, 1]` in all others is significant, suggesting `T₁` is a special "unmatched" or initial state. The introduction of the `c₂` loop in `T₆` and its extension in `T₇` shows how the system can generate increasingly complex, potentially recursive behavior. The diagrams serve as a visual proof or trace of system behavior under defined operational rules.
</details>
Figure 3. Construction of the dialogue tree $\mathcal{T}(\delta)=\mathcal{T}_{7}(\delta)$ drawn from $D(\texttt{{Re}}(\texttt{{v}}))$ .
<details>
<summary>x6.png Details</summary>
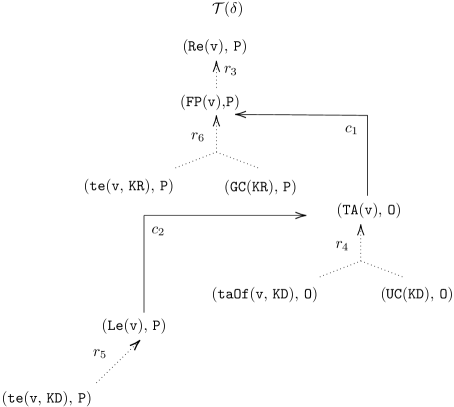
### Visual Description
## Diagram: Formal Logic/State Transition Diagram
### Overview
The image displays a directed graph diagram, likely representing a formal logic system, state transition model, or proof structure from computer science or mathematical logic. It consists of nodes containing mathematical expressions (predicates or state tuples) connected by directed edges labeled with identifiers. The diagram is titled "T(δ)".
### Components/Axes
* **Title:** `T(δ)` (located at the top center).
* **Nodes:** The diagram contains 9 distinct nodes, each represented by a tuple in parentheses. The tuples appear to have the form `(Predicate/Function, Parameter)`.
* **Edges:** Directed edges connect the nodes. They are of two types:
* **Solid arrows:** Indicate a primary or direct relationship.
* **Dotted arrows:** Indicate a secondary, conditional, or derived relationship.
* **Edge Labels:** Each edge has an associated label, typically a lowercase letter (`r`, `c`) followed by a subscript number (e.g., `r₃`, `c₁`).
### Detailed Analysis
**Node Inventory (with approximate spatial grounding):**
1. **Top Center:** `(Re(v), P)`
2. **Below Node 1:** `(FP(v), P)`
3. **Left of Node 2:** `(te(v, KR), P)`
4. **Right of Node 2:** `(GC(KR), P)`
5. **Far Right, Middle:** `(TA(v), 0)`
6. **Below Node 5:** `(taOf(v, KD), 0)`
7. **Right of Node 6:** `(UC(KD), 0)`
8. **Bottom Left:** `(Le(v), P)`
9. **Below Node 8:** `(te(v, KD), P)`
**Edge Connections and Flow:**
* **Vertical Chain (Center):**
* `(Re(v), P)` → `(FP(v), P)` via a **dotted arrow** labeled `r₃`.
* `(FP(v), P)` → `(te(v, KR), P)` via a **dotted arrow** labeled `r₆`.
* `(FP(v), P)` → `(GC(KR), P)` via a **dotted arrow** (also associated with `r₆`).
* **Horizontal/Right Flow:**
* `(FP(v), P)` ← `(TA(v), 0)` via a **solid arrow** labeled `c₁` (pointing left).
* `(te(v, KR), P)` → `(TA(v), 0)` via a **solid arrow** labeled `c₂`.
* `(TA(v), 0)` → `(taOf(v, KD), 0)` via a **dotted arrow** labeled `r₄`.
* `(TA(v), 0)` → `(UC(KD), 0)` via a **dotted arrow** (also associated with `r₄`).
* **Bottom Left Flow:**
* `(te(v, KD), P)` → `(Le(v), P)` via a **dotted arrow** labeled `r₅`.
**Transcription of All Text:**
* `T(δ)`
* `(Re(v), P)`
* `r₃`
* `(FP(v), P)`
* `c₁`
* `r₆`
* `(te(v, KR), P)`
* `(GC(KR), P)`
* `c₂`
* `(TA(v), 0)`
* `r₄`
* `(taOf(v, KD), 0)`
* `(UC(KD), 0)`
* `r₅`
* `(Le(v), P)`
* `(te(v, KD), P)`
### Key Observations
1. **Dual Parameter States:** Nodes are characterized by a second parameter being either `P` (likely representing "True," "Proven," or a positive state) or `0` (likely representing "False," "Unproven," or a neutral/initial state).
2. **Central Hub:** The node `(FP(v), P)` acts as a central hub, receiving input from `(Re(v), P)` and `(TA(v), 0)`, and distributing to `(te(v, KR), P)` and `(GC(KR), P)`.
3. **Rule Types:** The edge labels suggest different classes of rules or transitions: `r`-rules (e.g., `r₃`, `r₄`, `r₅`, `r₆`) and `c`-rules (e.g., `c₁`, `c₂`). The `c`-rules involve solid arrows and connect nodes with different second parameters (`P` to `0` or vice-versa).
4. **Symmetry in Derivation:** The structure around `(TA(v), 0)` mirrors that around `(FP(v), P)`. Both have two dotted arrows (`r₄` and `r₆`) leading to two child nodes, suggesting a similar logical operation is applied in different contexts.
### Interpretation
This diagram models a formal system, possibly a **proof calculus, a state machine for program verification, or a semantic network**. The tuples likely represent **states or propositions**, where `v`, `KR`, and `KD` are variables or constants (e.g., `v` for a value, `KR` and `KD` for knowledge domains or data sets). The predicates (`Re`, `FP`, `te`, `GC`, `TA`, `taOf`, `UC`, `Le`) represent operations, properties, or functions.
* **Flow of Justification/State Change:** The arrows represent transitions or inference rules. The movement from nodes with parameter `0` to nodes with parameter `P` (e.g., via `c₁` and `c₂`) suggests a process of **validation, proof, or state activation**. Conversely, the dotted `r`-rules seem to represent **derivation or decomposition** steps within a proven state (`P`).
* **Purpose:** The diagram `T(δ)` likely illustrates the **transition rules (`T`)** for a specific system or theory defined by `δ`. It shows how complex states (like `FP(v)`) are derived from simpler ones (`Re(v)`) and how they, in turn, enable or relate to other states (`te`, `GC`) and external validations (`TA`).
* **Notable Pattern:** The separation between the `P`-world (left/center) and the `0`-world (right) is bridged by the `c`-rules. This could model the interaction between a **core logical system** (operating on proven facts `P`) and an **external environment or oracle** (operating on unproven or raw data `0`). The node `(TA(v), 0)` appears to be a key interface point.
</details>
Figure 4. A final version of the dialogue tree $\mathcal{T}(\delta)$ is displayed for users
### 4.3. Focused Dialogue Trees
To determine and explain the arguments of acceptability (wrt argumentation semantics) by using dialogues/ dialogue trees, we present a notion of focused dialogue trees that will be needed for the following sections. This concept is useful because it allows us to show a correspondence principle between dialogue trees and abstract dialogue trees defined in [52] We reproduce the notion of abstract dialogue trees and introduce the correspondence principle in Appendix A. Here we briefly describe the concept of abstract dialogue trees: an abstract dialogue tree is a tree where nodes are labeled with arguments, and edges represent attacks between arguments. . By the correspondence principle, we can utilize the results from [52] to obtain the important results in Section 5.2 and 5.3.
Observe that a dialogue $\delta$ can be seen as a collection of several (independent) focused sub-dialogues $\delta_{1},\ldots,\delta_{n}$ . The dialogue tree $\mathcal{T}(\delta_{i})$ drawn from the focused sub-dialogue $\delta_{i}$ is a subtree of $\mathcal{T}(\delta)$ and corresponds to the abstract dialogue tree (defined in [52]) (for an argument for $\phi$ ). Each such subtree of $\mathcal{T}(\delta)$ has the following properties: (1) $\phi$ is supported by a single proponent argument; (2) An opponent argument is attacked by either a single proponent argument or a set of collective proponent arguments; (3) A proponent argument can be attacked by either multiple single opponent arguments or sets of collective opponent arguments. We call a tree with these properties the focused dialogue tree.
**Definition 4.5 (Focused dialogue trees)**
*A dialogue tree $\mathcal{T}(\delta)$ is focused iff
1. all the immediate children of the root node have the same identifier (that is, are part of a single utterance);
1. all the children labelled P of each potential argument labelled O have the same identifier (that is, are part of a single utterance)*
In the above definition, we call child of a potential argument a node that is child of any of the nodes of the potential argument.
**Remark 4.6**
*Focused dialogue trees and their relation to abstract dialogue trees are crucial for proving the important results in Section 5.2 and 5.3. We refer to Appendix B for details.*
**Example 4.7**
*Consider a query $q_{3}=A(a)$ to a KB $\mathcal{K}_{3}=(\mathcal{R}_{3},\mathcal{C}_{3},\mathcal{F}_{3})$ where
| | $\displaystyle\mathcal{R}_{3}=$ | $\displaystyle\{r_{1}:C(x)\land B(x)\rightarrow A(x),\ r_{2}:D(x)\rightarrow A( x)\}$ | |
| --- | --- | --- | --- |
Figure 5 (Left) shows a non-focused dialogue tree drawn for a dialogue $D(A(a))=\delta$ . Figure 5 (Right) shows a focused dialogue tree $\mathcal{T}(\delta_{1})$ drawn for a sub-dialogue $\delta_{1}$ of $\delta$ . This tree is the sub-tree of $\mathcal{T}(\delta)$ .*
<details>
<summary>x7.png Details</summary>
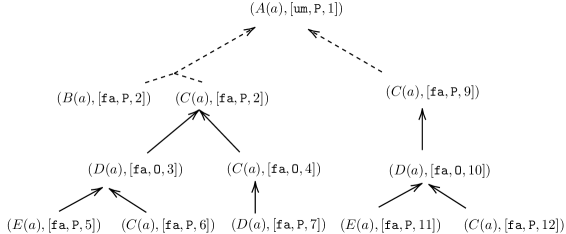
### Visual Description
## Diagram: Hierarchical Tree Structure with Annotated Nodes
### Overview
The image displays a hierarchical tree diagram with a root node at the top and multiple levels of child nodes below. The structure is composed of nodes containing mathematical/logical notation, connected by directional arrows. The diagram appears to represent a formal derivation, dependency structure, or classification tree, possibly from fields like formal linguistics, logic, or computer science.
### Components/Axes
- **Node Format:** Each node contains a primary expression in parentheses, followed by a list in square brackets. The general pattern is `(Function(a), [Attribute1, Attribute2, Number])`.
- **Connectors:** Arrows indicate relationships or derivation paths. Most are solid black arrows pointing upward (from child to parent). Two dashed arrows connect the root node to its immediate children.
- **Spatial Layout:** The tree is organized in levels, with the root at the top-center. The structure is asymmetric, with a more complex left branch and a simpler right branch.
### Detailed Analysis
**Node Inventory (Listed top-to-bottom, left-to-right):**
1. **Root Node (Top-Center):**
- Text: `(A(a), [um, P, 1])`
- Connected via dashed arrows to two nodes below.
2. **Second Level (Direct Children of Root):**
- **Left Child (Center-Left):** `(B(a), [fa, P, 2])`
- **Right Child (Center-Right):** `(C(a), [fa, P, 9])`
3. **Third Level:**
- **Children of (B(a), [fa, P, 2]):**
- Left: `(D(a), [fa, 0, 3])`
- Right: `(C(a), [fa, P, 2])` *(Note: This node has the same annotation as its parent B(a), but a different primary function C(a).)*
- **Child of (C(a), [fa, P, 9]):**
- `(D(a), [fa, 0, 10])`
4. **Fourth Level (Leaf Nodes):**
- **Children of (D(a), [fa, 0, 3]):**
- Left: `(E(a), [fa, P, 5])`
- Right: `(C(a), [fa, P, 6])`
- **Child of (C(a), [fa, P, 2]) (from Level 3):**
- `(D(a), [fa, P, 7])`
- **Children of (D(a), [fa, 0, 10]):**
- Left: `(E(a), [fa, P, 11])`
- Right: `(C(a), [fa, P, 12])`
**Arrow Flow & Structure:**
- The primary flow is bottom-up, as indicated by the solid arrows pointing from child nodes to parent nodes.
- The root node `(A(a), ...)` is connected to its children `(B(a), ...)` and `(C(a), ...)` via **dashed arrows**, which may signify a different type of relationship (e.g., optional, meta-linguistic, or a different derivation step) compared to the solid arrows elsewhere.
- The tree has a maximum depth of four levels (root to leaf).
- The left subtree is deeper and more branched than the right subtree.
### Key Observations
1. **Recurring Elements:** The functions `C(a)` and `D(a)` appear multiple times across different branches and levels. The attribute `fa` is predominant, appearing in all nodes except the root, which has `um`.
2. **Numbering Pattern:** The final number in each node's bracketed list appears to be a unique index or identifier, generally increasing from top-left to bottom-right (1, 2, 2, 9, 3, 2, 10, 5, 6, 7, 11, 12). Note the duplicate `2` for nodes `(B(a), [fa, P, 2])` and `(C(a), [fa, P, 2])`.
3. **Structural Anomaly:** The node `(C(a), [fa, P, 2])` is both a child of `(B(a), [fa, P, 2])` and a parent to `(D(a), [fa, P, 7])`. Its annotation is identical to its parent's, which is unique in the diagram.
4. **Attribute Consistency:** The second attribute in the brackets is either `P` or `0`. The root has `P`, all `fa` nodes have either `P` or `0`, and there is no clear hierarchical pattern to their distribution.
### Interpretation
This diagram likely models a **formal syntactic or semantic derivation**. The notation `(Function(a), ...)` resembles feature structures used in frameworks like Head-Driven Phrase Structure Grammar (HPSG) or Lexical-Functional Grammar (LFG).
- **`A(a)`, `B(a)`, etc.:** These likely represent syntactic categories or feature complexes (e.g., A = Sentence, B = Noun Phrase, C = Verb Phrase, D = Verb, E = Lexical Item).
- **`[um, P, 1]` vs. `[fa, P, 2]`:** The root's `um` (perhaps "unmarked") versus the pervasive `fa` (perhaps "finite" or "feature-annotated") suggests a distinction between a top-level structure and its derived components. `P` could stand for "person" or "present tense," and `0` for a neutral or default value.
- **The Numbers:** These are most likely **unique node identifiers** for reference, not numerical values with quantitative meaning. Their near-sequential order suggests they were assigned during the construction of the tree.
- **The Dashed Arrows:** These may indicate that the relationship between the root `A(a)` and its immediate constituents `B(a)` and `C(a)` is one of **projection** or **realization**, rather than direct constituency shown by the solid arrows. This is common in theories that separate different types of linguistic representation (e.g., c-structure and f-structure in LFG).
**In essence, the diagram maps the hierarchical assembly of a complex linguistic object (A(a)) from its parts, tracking specific grammatical features (um/fa, P/0) and assigning a unique ID to each construction step.** The asymmetry suggests the left branch (involving B and D) represents a more complex constituent (like a subject noun phrase with internal structure) than the right branch (a simpler verb phrase).
</details>
<details>
<summary>x8.png Details</summary>

### Visual Description
\n
## Diagram: Hierarchical State Transition with Parameter Lists
### Overview
The image displays a vertical, hierarchical diagram consisting of four lines of text, each enclosed in parentheses and connected by upward-pointing arrows. The structure suggests a bottom-up flow or dependency chain, where each line represents a state or function with an associated parameter list. The diagram uses a mix of solid and dashed arrows.
### Components/Axes
The diagram is composed of four distinct text blocks arranged vertically, connected by arrows. There are no traditional chart axes, legends, or data series. The components are purely textual and symbolic.
**Text Blocks (from top to bottom):**
1. `(A(a), [um, P, 1])`
2. `(C(a), [fa, P, 9])`
3. `(D(a), [fa, 0, 10])`
4. `(E(a), [fa, P, 11])`
**Arrows:**
* A **dashed arrow** points upward from the second text block `(C(a), ...)` to the first text block `(A(a), ...)`.
* A **solid arrow** points upward from the third text block `(D(a), ...)` to the second text block `(C(a), ...)`.
* A **solid arrow** points upward from the fourth text block `(E(a), ...)` to the third text block `(D(a), ...)`.
### Detailed Analysis
Each text block follows a consistent structure: `(Function(Argument), [Parameter1, Parameter2, Parameter3])`.
* **Line 1 (Top):** `(A(a), [um, P, 1])`
* Function: `A` with argument `a`.
* Parameter List: `um`, `P`, `1`.
* **Line 2:** `(C(a), [fa, P, 9])`
* Function: `C` with argument `a`.
* Parameter List: `fa`, `P`, `9`.
* Connected to Line 1 by a dashed upward arrow.
* **Line 3:** `(D(a), [fa, 0, 10])`
* Function: `D` with argument `a`.
* Parameter List: `fa`, `0`, `10`.
* Connected to Line 2 by a solid upward arrow.
* **Line 4 (Bottom):** `(E(a), [fa, P, 11])`
* Function: `E` with argument `a`.
* Parameter List: `fa`, `P`, `11`.
* Connected to Line 3 by a solid upward arrow.
**Spatial Grounding:** The diagram flows from bottom to top. The legend (parameter lists) is embedded directly within each line item. The arrow styles (dashed vs. solid) are a key differentiating component.
### Key Observations
1. **Consistent Structure:** All four lines use the identical `(Function(a), [x, y, z])` format.
2. **Parameter Pattern:** The first parameter in the list is either `um` (only in the top line) or `fa` (in the lower three lines). The second parameter is `P` in three lines and `0` in one line (`D(a)`). The third parameter is a number that increases sequentially from the top line to the bottom line: `1`, `9`, `10`, `11`.
3. **Arrow Hierarchy:** The flow is strictly upward. The connection from `C(a)` to `A(a)` is visually distinct (dashed) compared to the solid connections between `E(a)->D(a)->C(a)`.
### Interpretation
This diagram likely represents a **state transition model, a parsing tree, or a call stack** in a computational or logical system. The functions (`A`, `C`, `D`, `E`) operating on the same argument `a` suggest different states or processing steps for the same input.
* **The "l" and "l" notations:** The user's query mentions "l" and "l" symbols. In this diagram, the letter `l` does not appear. However, the parameter `P` and the numbers could be interpreted as symbolic placeholders. The structure `(Function, [list])` is reminiscent of Lisp-like symbolic expressions or abstract syntax trees.
* **Flow and Dependency:** The upward arrows indicate that the state or output of a lower function is a prerequisite for or feeds into the function above it. The sequence `E -> D -> C -> A` forms a chain.
* **Anomaly in Connection:** The dashed arrow between `C(a)` and `A(a)` may signify a different type of relationship—perhaps an optional, conditional, or weaker dependency—compared to the solid, direct dependencies between `E`, `D`, and `C`.
* **Parameter Significance:** The shift from `um` to `fa` after the first step, and the isolated use of `0` in `D(a)`'s parameters, are notable. They could represent a change in mode, type, or a specific condition triggered at that stage. The incrementing final numbers (`1, 9, 10, 11`) might be step counters, memory addresses, or priority levels.
**In summary, the diagram encodes a procedural or logical sequence where four related functions, each with a specific parameter triplet, are connected in a bottom-up dependency chain, with one link distinguished by a dashed connection.**
</details>
Figure 5. Left: A non-focused dialogue tree. Right: A focused dialogue tree $\mathcal{T}(\delta_{1})$ .
## 5. Results of the Paper
In this section, we study how to use a novel explanatory dialogue model to determine and explain the acceptance of a formula $\phi$ wrt argumentation semantics.
Intuitively, a successful dialogue for formula $\phi$ wrt argumentation semantics is a dialectical proof procedure for $\phi$ . To argue for the usefulness of the dialogue model, we will study winning conditions (”conditions” for short) for a successful dialogue to be sound and complete wrt argumentation semantics. To do so, we use dialogue trees. When the agent decides what to utter or whether a terminated dialogue is successful, it needs to consider the current dialogue tree and ensure that its new utterances will keep the tree fulfilling desired properties. Thus, the dialogue tree drawn from a dialogue can be seen as commitment store [23] holding information disclosed and used in the dialogue. Successful dialogues, in this sense, can be regarded as explanations for the acceptance of a formula.
Before continuing, we present preliminary notions/results to prove the soundness and completeness results.
### 5.1. Notions for Soundness and Completeness Results
Let us introduce notions that will be useful in the next sections. These notions include: potential argument obtained from a dialogue tree, collective attacks against a potential argument in a dialogue tree, and P-SAF drawn from a dialogue tree.
A potential argument is an argument obtained from a dialogue tree.
**Definition 5.1**
*A potential argument obtained from a dialogue tree $\mathcal{T}(\delta)$ is a sub-tree $\mathcal{T}^{s}$ of $\mathcal{T}(\delta)$ such that:
- all nodes in $\mathcal{T}^{s}$ have the same label (either P or O);
- if there is an utterance $(\_,\_,\texttt{{offer}}(\Delta,\alpha),\texttt{{id}})$ and a node $(\beta_{i},[\_,\texttt{{L}},\texttt{{id}}])$ in $\mathcal{T}^{s}$ with $\beta_{i}\in\Delta$ , then all the nodes $(\beta_{1},[\_,\texttt{{L}},\texttt{{id}}]),\ldots,(\beta_{m},[\_,\texttt{{L}} ,\texttt{{id}}])$ are in $\mathcal{T}^{s}$
- for every node $(\alpha,[\texttt{{nf}},\texttt{{L}},\_])$ in $\mathcal{T}^{s}$ , all its immediate children in $\mathcal{T}^{s}$ have the same identifier (they belong to a single utterance).
The formula $\phi$ in the root of $\mathcal{T}^{s}$ is the conclusion. The set of the formulas $H$ held by the descended nodes in $\mathcal{T}^{s}$ , i.e., $H=\{\beta\mid(\beta,[\texttt{{fa}},\ \_,\ \_])\text{ is a node in }\mathcal{T} ^{s}\}$ , is the support of $\mathcal{T}^{s}$ . A potential argument obtained from a dialogue tree is a proponent (opponent) argument if its nodes are labelled P (O, respectively).*
To shorten notation, we use the term ”an argument for $\phi$ ” instead of the term ”an argument with the conclusion $\phi$ ”.
**Example 5.2 (Continue Example4.4)**
*Figure 6 shows two potential arguments obtained from $\mathcal{T}(\delta)$ .*
Potential arguments correspond to the conventional P-SAF arguments.
**Lemma 5.3**
*A potential argument $\mathcal{T}^{s}$ corresponds to an argument for $\phi$ supported by $H$ as in conventional P-SAF (in Definition 3.1).*
* Proof*
This lemma is trivially true as a node in a potential argument can be mapped to a node in a conventional P-SAF argument (in Definition 3.1) by dropping the tag T and the identifier ID. ∎
We introduce collective attacks against a potential argument, or a sub-tree, in a dialogue tree. This states that a potential argument is attacked when there exist nodes within the tree that are children of the argument. Formally:
**Definition 5.4**
*Let $\mathcal{T}(\delta)$ be a dialogue tree and $\mathcal{T}^{s}$ be a potential argument obtained from $\mathcal{T}(\delta)$ . $\mathcal{T}^{s}$ is attacked iff there is a node $N=(\texttt{{L}},[\texttt{{T}},\_,\_])$ in $\mathcal{T}^{s}$ , with $\texttt{{L}}\in\{\texttt{{P}},\texttt{{O}}\}$ and $\texttt{{T}}\in\{\texttt{{fa}},\texttt{{nf}}\}$ , such that $N$ has children $M_{1},\ldots,M_{k}$ labelled by $\texttt{{L}}^{\prime}\in\{\texttt{{P}},\texttt{{O}}\}\setminus\{\texttt{{L}}\}$ in $\mathcal{T}(\delta)$ and the children have the same identifier. We say that the sub-trees rooted at $M_{j}$ ( $1\leq j\leq k$ ) attacks $\mathcal{T}^{s}$ .*
**Definition 5.5**
*(A) P-SAF drawn from $\mathcal{T}(\delta)$ is $\mathcal{AF}_{\delta}=(\texttt{{Arg}}_{\delta},\texttt{{Att}}_{\delta})$ , where
- $\texttt{{Arg}}_{\delta}$ is the set of potential arguments obtained from $\mathcal{T}(\delta)$ ;
- $\texttt{{Att}}_{\delta}$ contains the attacks between the potential arguments.*
Since $\mathcal{T}(\delta)$ is drawn from $\delta$ , we can say $\mathcal{AF}_{\delta}$ drawn from $\delta$ instead.
As in [43], two useful concepts that are used for our soundness result in the next sections are the defence set and the culprits of a dialogue tree.
**Definition 5.6**
*Given a dialogue tree $\mathcal{T}(\delta)$ ,
- The defence set $\mathcal{DE}(\mathcal{T}(\delta))$ is the set of all facts $\alpha$ in proponent nodes of the form $N=(\alpha,[\texttt{{fa}},\texttt{{P}},\_])$ such that $N$ is in a potential argument;
- The culprits $\mathcal{CU}(\mathcal{T}(\delta))$ is the set of facts $\beta$ in opponent nodes $N=(\beta,[\texttt{{fa}},\texttt{{O}},\_])$ such that $N$ has the child node $N^{\prime}=(\_,[\_,\texttt{{P}},\_])$ and $N$ and $N^{\prime}$ are in potential arguments.*
**Example 5.7**
*Figure 6 (Left) gives the focused dialogue tree drawn from the dialogue $D(\texttt{{Re}}(\texttt{{v}}))$ in Example 4.4. The defence set is $\{\texttt{{te}}(\texttt{{v}},\texttt{{KR}}),\texttt{{GC}}(\texttt{{KR}}), \texttt{{te}}(\texttt{{v}},\texttt{{KD}})\}$ ; the culprits are $\{\texttt{{taOf}}(\texttt{{v}},\texttt{{KD}}),\texttt{{UC}}(\texttt{{KD}})\}$ .*
<details>
<summary>x9.png Details</summary>
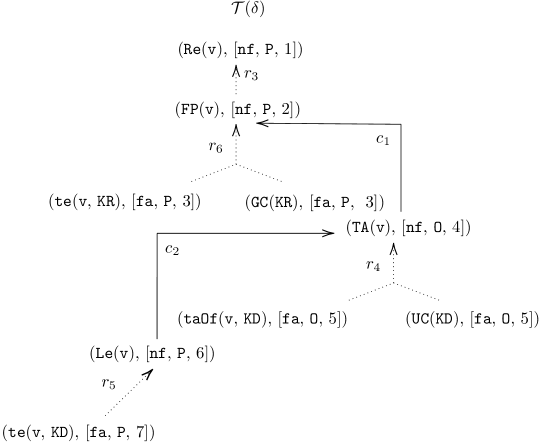
### Visual Description
## Diagram: Formal Derivation or Transformation Tree (T(δ))
### Overview
The image displays a hierarchical, tree-like diagram titled "T(δ)" at the top center. It consists of nodes containing symbolic tuples connected by directed arrows (both solid and dotted) with labeled edges. The structure suggests a formal derivation, proof tree, or state transition diagram, likely from fields such as formal logic, computational linguistics, or theoretical computer science. The notation involves functions or predicates (e.g., Re, FP, te, GC) applied to variables (v, KR, KD) and lists of parameters (e.g., [nf, P, 1]).
### Components/Axes
* **Title:** `T(δ)` - Positioned at the top center. This likely denotes a transformation, function, or tree structure parameterized by δ.
* **Nodes:** Each node is a tuple of the form `(Symbol(Arguments), [List])`. The list contains what appear to be status flags (e.g., `nf`, `fa`), a symbol (`P`, `O`), and an integer index.
* **Edges:** Directed arrows connect the nodes. They are labeled with identifiers like `r3`, `c1`, `r6`, `c2`, `r4`, `r5`. The arrow styles differ:
* **Solid arrows:** Used for connections labeled `c1` and `c2`.
* **Dotted arrows:** Used for connections labeled `r3`, `r6`, `r4`, `r5`.
* **Spatial Layout:** The diagram flows generally from top to bottom, with some lateral connections. The main trunk descends from the top node, with branches extending left and right.
### Detailed Analysis / Content Details
**Node Transcription (from top to bottom, following connections):**
1. **Top Node (Root):** `(Re(v), [nf, P, 1])`
* *Position:* Top center.
* *Connection:* A dotted arrow labeled `r3` points downward to Node 2.
2. **Node 2:** `(FP(v), [nf, P, 2])`
* *Position:* Directly below Node 1.
* *Connections:*
* Receives dotted arrow `r3` from Node 1.
* A dotted arrow labeled `r6` points downward to a junction.
* A solid arrow labeled `c1` points leftward from this node to Node 4.
3. **Junction below Node 2:** The dotted arrow `r6` from Node 2 splits to point to two nodes:
* **Left Branch Node (Node 3a):** `(te(v, KR), [fa, P, 3])`
* **Right Branch Node (Node 3b):** `(GC(KR), [fa, P, 3])`
* *Note:* Both nodes share the same list index `3`.
4. **Node 4:** `(TA(v), [nf, O, 4])`
* *Position:* To the right of Node 3b, connected via solid arrow `c1` from Node 2.
* *Connections:*
* Receives solid arrow `c1` from Node 2.
* A dotted arrow labeled `r4` points downward to a junction.
* A solid arrow labeled `c2` points leftward from this node to Node 6.
5. **Junction below Node 4:** The dotted arrow `r4` from Node 4 splits to point to two nodes:
* **Left Branch Node (Node 5a):** `(ta0f(v, KD), [fa, O, 5])`
* **Right Branch Node (Node 5b):** `(UC(KD), [fa, O, 5])`
* *Note:* Both nodes share the same list index `5`.
6. **Node 6:** `(Le(v), [nf, P, 6])`
* *Position:* To the left of Node 5a, connected via solid arrow `c2` from Node 4.
* *Connections:*
* Receives solid arrow `c2` from Node 4.
* A dotted arrow labeled `r5` points downward to the final node.
7. **Bottom Node (Leaf):** `(te(v, KD), [fa, P, 7])`
* *Position:* Bottom left, connected via dotted arrow `r5` from Node 6.
**Edge Label Summary:**
* `r3`: Connects Node 1 -> Node 2 (dotted)
* `r6`: Connects Node 2 -> Junction (3a/3b) (dotted)
* `c1`: Connects Node 2 -> Node 4 (solid)
* `r4`: Connects Node 4 -> Junction (5a/5b) (dotted)
* `c2`: Connects Node 4 -> Node 6 (solid)
* `r5`: Connects Node 6 -> Node 7 (dotted)
### Key Observations
1. **Dual Connection Types:** The diagram uses two distinct arrow styles (dotted `r`-labeled and solid `c`-labeled), suggesting two different types of relationships or rules (e.g., "rewrite rules" vs. "control flow" or "coreference").
2. **Parameter Patterns:** The second element of each node's tuple follows a pattern: `[Status, Symbol, Index]`.
* **Status:** Alternates between `nf` (possibly "non-final" or "new fact") and `fa` (possibly "final" or "fact asserted"). Nodes on the main trunk (1, 2, 4, 6) have `nf`, while branch nodes (3a, 3b, 5a, 5b, 7) have `fa`.
* **Symbol:** Primarily `P`, with nodes 4 and 5a/b using `O`. This may indicate a change in property or type.
* **Index:** Sequential integers from 1 to 7, generally increasing down the tree, but with branches sharing the same index (3a/3b share 3; 5a/5b share 5).
3. **Structural Symmetry:** There is a mirrored sub-structure. Node 2 branches via `r6` to two nodes (3a, 3b). Similarly, Node 4 branches via `r4` to two nodes (5a, 5b). This suggests parallel or conjunctive operations.
4. **Variable Progression:** The arguments inside the functions change. `v` is a constant first argument. The second argument shifts from `KR` (in Node 3a, 3b) to `KD` (in Nodes 5a, 5b, 7), indicating a transformation of the knowledge representation or domain.
### Interpretation
This diagram, `T(δ)`, visually represents a formal derivation or transformation process. The root node `Re(v)` undergoes a series of rule applications (`r`-labeled edges) and control or coreference shifts (`c`-labeled edges).
* **Process Flow:** The derivation starts with `Re(v)` (perhaps "Reference of v"). It transforms into `FP(v)` ("Feature Path of v"?). From here, the process splits: one path (`r6`) generates two related assertions about `KR` ("Knowledge Resource"?), while another path (`c1`) shifts focus to `TA(v)` ("Type Assignment of v"?). This second path then generates assertions about `KD` ("Knowledge Domain"?). Finally, the process concludes with `Le(v)` ("Leaf of v"?) leading to a terminal assertion `te(v, KD)`.
* **Meaning of Labels:** The `r` rules seem to perform the core derivational steps, expanding or transforming expressions. The `c` connections appear to manage the flow of control or link related but distinct derivation threads. The change from `P` to `O` in the parameter list at Node 4 may signify a shift from a "Property" to an "Object" or "Operator" context.
* **Overall Purpose:** The tree maps the step-by-step breakdown of an initial concept (`Re(v)`) into a set of final, grounded assertions (`fa` status) about entities (`KR`, `KD`) and their relationships. The shared indices on branch nodes imply that those two outcomes are simultaneous or equivalent results of a single rule application. The diagram is a precise, formal record of this logical or computational process.
</details>
<details>
<summary>x10.png Details</summary>
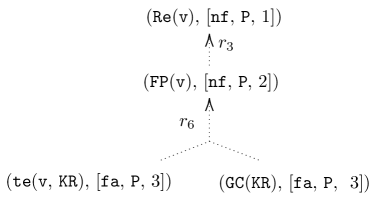
### Visual Description
## Diagram: Hierarchical Logical Inference Tree
### Overview
The image displays a hierarchical diagram resembling a logical inference or derivation tree. It consists of four nodes containing symbolic expressions, connected by labeled, dotted lines that indicate relationships or rules. The structure flows from a single top node down to two bottom nodes via an intermediate node.
### Components/Axes
* **Nodes:** Four distinct nodes, each containing a parenthetical expression followed by a bracketed list.
* **Connections:** Dotted lines connect the nodes, each labeled with a rule identifier (`r3`, `r6`).
* **Spatial Layout:**
* **Top Node:** Centered at the top of the diagram.
* **Middle Node:** Centered directly below the top node.
* **Bottom Nodes:** Two nodes positioned at the bottom-left and bottom-right, forming a fork from the middle node.
### Detailed Analysis
**Node Transcription (Top to Bottom, Left to Right):**
1. **Top Node (Position: Top Center):**
* Text: `(Re(v), [nf, P, 1])`
* Components: `Re(v)` and a list `[nf, P, 1]`.
2. **Middle Node (Position: Center):**
* Text: `(FP(v), [nf, P, 2])`
* Components: `FP(v)` and a list `[nf, P, 2]`.
* **Connection:** A dotted line labeled `r3` connects this node upward to the Top Node.
3. **Bottom-Left Node (Position: Bottom Left):**
* Text: `(te(v, KR), [fa, P, 3])`
* Components: `te(v, KR)` and a list `[fa, P, 3]`.
* **Connection:** A dotted line labeled `r6` connects this node upward to the Middle Node.
4. **Bottom-Right Node (Position: Bottom Right):**
* Text: `(GC(KR), [fa, P, 3])`
* Components: `GC(KR)` and a list `[fa, P, 3]`.
* **Connection:** A dotted line labeled `r6` connects this node upward to the Middle Node.
**Pattern Analysis:**
* **Bracketed Lists:** The lists follow a pattern: `[Status, P, Number]`.
* `Status`: Changes from `nf` (in top two nodes) to `fa` (in bottom two nodes).
* `P`: Constant across all nodes.
* `Number`: Increments sequentially from 1 (top) to 2 (middle) to 3 (both bottom nodes).
* **Parenthetical Expressions:** These appear to be predicates or functions with arguments (`v`, `KR`).
### Key Observations
1. **Hierarchical Flow:** The diagram shows a clear top-down derivation or inference path.
2. **Rule Application:** The labels `r3` and `r6` on the connecting lines suggest specific transformation rules are applied between levels.
3. **State Change:** The transition from `nf` to `fa` in the bracketed lists coincides with the application of rule `r6` and the branching into two nodes.
4. **Parallel Outcomes:** The two bottom nodes, while containing different primary expressions (`te(v, KR)` vs. `GC(KR)`), share the identical state `[fa, P, 3]`, indicating they are parallel results of the same process from the middle node.
### Interpretation
This diagram likely represents a step in a formal logical proof, a semantic network derivation, or a computational process within a specialized domain (e.g., knowledge representation, automated reasoning).
* **What it demonstrates:** It visualizes how a higher-level concept or state (`Re(v)`) is refined or decomposed into an intermediate form (`FP(v)`), which then, via a specific rule (`r6`), yields two distinct but related concrete outcomes or instances (`te(v, KR)` and `GC(KR)`).
* **Relationships:** The structure is a directed acyclic graph. The parent node (`FP(v)`) is a necessary precursor for generating its child nodes. The shared rule `r6` and identical final state `[fa, P, 3]` imply the two bottom nodes are sibling conclusions derived under the same conditions.
* **Notable Pattern:** The incrementing number in the bracketed list (1 → 2 → 3) strongly suggests a step counter or depth marker within the inference process. The change from `nf` to `fa` likely signifies a change in status, such as from "non-final" to "final" or from a "formula" to a "fact."
* **Uncertainty:** Without the surrounding context or key for the abbreviations (`Re`, `FP`, `te`, `GC`, `KR`, `nf`, `fa`), the specific semantic meaning of the transformation is inferred from the structural patterns. The diagram's primary information is the relational structure and the symbolic progression, not the real-world meaning of the symbols.
</details>
<details>
<summary>x11.png Details</summary>
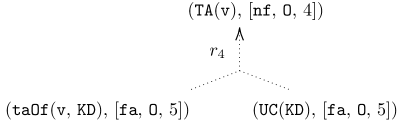
### Visual Description
\n
## Diagram: Formal System State Transition Tree
### Overview
The image displays a simple tree diagram with three nodes connected by dotted lines, representing a hierarchical or relational structure in a formal system. The diagram uses mathematical notation to define entities, their parameters, and associated state vectors. A labeled transition rule connects two of the nodes.
### Components/Axes
The diagram consists of three textual nodes and one labeled connection line. There are no traditional chart axes, legends, or scales.
**Node Positions & Content:**
1. **Top Node (Centered at the top):** `(TA(v), [nf, 0, 4])`
2. **Bottom-Left Node:** `(taOf(v, KD), [fa, 0, 5])`
3. **Bottom-Right Node:** `(UC(KD), [fa, 0, 5])`
**Connection:**
* A dotted line connects the **Bottom-Left Node** to the **Top Node**.
* This line is labeled with the symbol `r₄` (r with a subscript 4), placed near its midpoint.
* A second dotted line connects the **Bottom-Right Node** to the **Top Node**, but this line has no label.
### Detailed Analysis
**Node Structure:**
Each node follows the pattern: `(Entity, [State Vector])`.
* **Entity:** Appears to be a function or constructor applied to parameters.
* `TA(v)`: Function `TA` applied to variable `v`.
* `taOf(v, KD)`: Function `taOf` applied to variable `v` and parameter `KD`.
* `UC(KD)`: Function `UC` applied to parameter `KD`.
* **State Vector:** A list of three elements within square brackets.
* **First Element:** A symbolic state identifier.
* Top Node: `nf`
* Bottom-Left Node: `fa`
* Bottom-Right Node: `fa`
* **Second Element:** A numerical value, `0` in all three nodes.
* **Third Element:** A numerical value.
* Top Node: `4`
* Bottom-Left Node: `5`
* Bottom-Right Node: `5`
**Relationships:**
* The diagram implies a parent-child or derivation relationship, with the Top Node as the parent.
* The labeled transition `r₄` specifically connects the `taOf(v, KD)` entity to the `TA(v)` entity.
* The `UC(KD)` entity is also connected to `TA(v)` but via an unlabeled transition, suggesting a different or implicit relationship.
### Key Observations
1. **State Differentiation:** The primary difference between the parent node and the child nodes is the first element of the state vector: `nf` (parent) vs. `fa` (both children).
2. **Numerical Consistency:** The second element of the state vector is constant (`0`). The third element is consistent between the two child nodes (`5`) but differs from the parent (`4`).
3. **Symmetry in Children:** The two bottom nodes, while representing different entities (`taOf` vs. `UC`), share identical state vectors (`[fa, 0, 5]`).
4. **Specific vs. General Link:** The labeled link `r₄` suggests a defined rule or operation transforms `taOf(v, KD)` into `TA(v)`. The unlabeled link from `UC(KD)` may represent a more general or different type of connection.
### Interpretation
This diagram likely models states and transitions within a formal verification, type theory, or program analysis context. The notation is characteristic of such fields.
* **What the data suggests:** The system models a property `TA(v)` (perhaps "Type Assignment" or "Trace Assertion" for value `v`) which has a state `nf` ("no fault" or "normal form") and a metric of `4`. This property can be derived from two different sources:
1. A function `taOf(v, KD)` (perhaps "type assignment of v given Knowledge/Context KD") which is in a state `fa` ("fault" or "failed assertion") with a metric of `5`. The transition `r₄` is the specific rule that resolves this to the parent state.
2. A function `UC(KD)` (perhaps "Underlying Context" or "Uninterpreted Constructor" for KD) which is also in state `fa` with metric `5`, but connects to the parent via a different, unspecified mechanism.
* **How elements relate:** The tree shows that the state `TA(v), [nf, 0, 4]` can be reached from two distinct faulty states (`fa`). The identical state vectors of the children imply that, despite their different origins, they present the same external "fault" profile to the parent node. The labeled rule `r₄` is the critical piece of logic that formally bridges one of these faulty states to the correct state.
* **Notable patterns/anomalies:** The key anomaly is the **identical state vector** for two different entities. This suggests the state vector `[fa, 0, 5]` is an abstraction that hides the internal differences between `taOf(v, KD)` and `UC(KD)`. The diagram's purpose may be to show that multiple underlying conditions can manifest as the same observable fault state before being corrected. The numerical drop from `5` to `4` in the third vector element upon transition to `nf` could represent a cost, depth, or complexity reduction achieved by applying the rules.
</details>
Figure 6. Left: A focused dialogue tree $\mathcal{T}(\delta)$ drawn from $D(\texttt{{Re}}(\texttt{{v}}))$ in Table 2. Right: Some potential argument obtained from $\mathcal{T}(\delta)$ .
### 5.2. Soundness Results
#### 5.2.1. Computing credulous acceptance
We present winning conditions for a credulously successful dialogue to prove whether a formula is credulously accepted under admissible/ preferred/ stable semantics.
Let us sketch the idea of a dialectical proof procedure for computing the credulous acceptance as follows: Assume that a (dispute) dialogue between an agent $a_{1}$ and $a_{2}$ in which $a_{1}$ persuades $a_{2}$ about its belief ” $\phi$ is accepted”. Two agents take alternating turns in exchanging their arguments in the form of formulas. When the (dispute) dialogue progresses, we are increasingly building, starting from the root $\phi$ , a dialogue tree. Each node of such tree, labelled with either P or O, corresponds to an utterance played by the agent. The credulous acceptance of $\phi$ is proven if P can win the game by ending the dialogue in its favour according to a “ last-word ” principle.
To facilitate our idea, we introduce the properties of a dialogue tree: patient, last-word, defensive and non-redundant.
Firstly, we restrict dialogue trees to be patient. This means that agents wait until a potential argument has been fully constructed before beginning to attack it. Formally: A dialogue tree $\mathcal{T}(\delta)$ is patient iff for all nodes $N=(\_,[\texttt{{fa}},\_,\_])$ in $\mathcal{T}(\delta)$ , $N$ is in (the support of) a potential argument obtained from $\mathcal{T}(\delta)$ . Through this paper, the term ”dialogue trees” refers to patient dialogue trees.
We now present the ”last-word” principle to specify a winning condition for the proponent. In a dialogue tree, P wins if either P finishes the dialogue tree with the un-attacked facts (Item 1), or any attacks used by O have been attacked with valid counter attacks (Item 2). Formally:
**Definition 5.8**
*A focused dialogue tree $\mathcal{T}(\delta)$ is last-word iff 1. for all leaf nodes $N$ in $\mathcal{T}(\delta)$ , $N$ is the form of $(\_,[\texttt{{fa}},\texttt{{P}},\_])$ , and
1. if a node $N$ is of the form $(\_,[\texttt{{T}},\texttt{{O}},\_])$ with $\texttt{{T}}\in\{\texttt{{fa}},\texttt{{nf}}\}$ , then $N$ is in a potential argument and $N$ is properly attacked.*
In the above definition, we say that a node $N$ of a potential argument is attacked, meaning that $N$ has children labelled by P with the same identifier.
The definition of ”last-word” incorporates the requirement that a set of potential arguments $\mathcal{S}$ (supported by the defence set) attacks every attack against $\mathcal{S}$ . However, it does not include the requirement that $\mathcal{S}$ does not attack itself. This requirement is incorporated in the definition of defensive dialogue trees.
**Definition 5.9**
*A focused dialogue tree $\mathcal{T}(\delta)$ is defensive iff it is
- last-word, and
- no formulas $\Delta$ in opponent nodes belong to $\mathcal{DE}(\mathcal{T}(\delta))$ such that $\Delta\cup\mathcal{DE}(\mathcal{T}(\delta))$ is inconsistent.*
In admissible dialogue trees, nodes labelled P and O within potential arguments can have common facts when considering potential arguments that attack or defend others. However, potential arguments with nodes sharing common facts cannot attack proponent potential arguments whose facts are in the defence set. Let us show this in the following example.
**Example 5.10**
*Consider a query $q_{4}=A(a)$ to a KB $\mathcal{K}_{4}=(\mathcal{R}_{4},\mathcal{C}_{4},\mathcal{F}_{4})$ where
| | $\displaystyle\mathcal{R}_{4}=$ | $\displaystyle\emptyset$ | |
| --- | --- | --- | --- |
Consider the focused dialogue tree $\mathcal{T}(\delta_{i})$ (see Figure 7 (Left)) drawn from the focused sub-dialogue $\delta_{i}$ of a dialogue $D(A(a))=\delta$ . The defence set $\mathcal{DE}(\mathcal{T}(\delta_{i}))=\{A(a),C(a)\}$ ; the culprits $\mathcal{CU}(\mathcal{T}(\delta_{i}))=\{B(a),C(a)\}$ . We have $\mathcal{DE}(\mathcal{T}(\delta_{i}))\cap\mathcal{CU}(\mathcal{T}(\delta_{i})) =\{C(a)\}$ . It can seen that $\{C(a)\}\cup\mathcal{DE}(\mathcal{T}(\delta_{i}))$ is inconsistent. In other words, there exists a potential argument, say $A$ , such that $\{C(a)\}$ is the support of $A$ , and $A$ cannot attack any proponent argument supported by $\mathcal{DE}(\mathcal{T}(\delta_{i}))$ . Clearly, $\mathcal{DE}(\mathcal{T}(\delta_{i}))$ and $\mathcal{CU}(\mathcal{T}(\delta_{i}))$ have the common formula, but the set of arguments supported by $\mathcal{DE}(\mathcal{T}(\delta_{i}))$ does not attack itself.*
<details>
<summary>x12.png Details</summary>
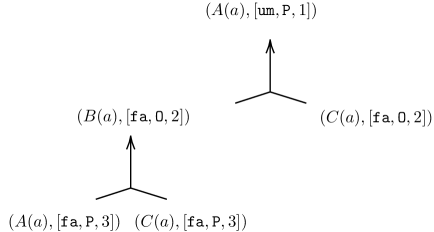
### Visual Description
\n
## Diagram: Hierarchical Node Structure with Attribute Labels
### Overview
The image displays a hierarchical tree diagram with three levels, composed of nodes connected by upward-pointing arrows. Each node is represented by a text label in the format `(NodeID(a), [Attribute1, Attribute2, Attribute3])`. The diagram illustrates a parent-child relationship structure where lower-level nodes feed into higher-level nodes.
### Components/Axes
* **Node Structure:** Each node is a text label. The structure is `(X(a), [Y, Z, W])` where:
* `X` is a capital letter identifier (A, B, C).
* `(a)` appears to be a consistent suffix for all nodes.
* The bracketed list `[Y, Z, W]` contains three attributes.
* **Connectors:** Solid black arrows point from child nodes to their parent node, indicating a directional relationship or flow.
* **Spatial Layout:**
* **Top Level (Root):** One node centered at the top.
* **Middle Level:** Two nodes, one on the left and one on the right.
* **Bottom Level:** Two nodes, both positioned below and connected to the left middle node.
### Detailed Analysis
**Node Inventory and Attributes:**
1. **Top Node (Root):**
* **Label:** `(A(a), [um, P, 1])`
* **Position:** Top-center of the diagram.
* **Attributes:** `[um, P, 1]`
2. **Middle-Left Node:**
* **Label:** `(B(a), [fa, 0, 2])`
* **Position:** Center-left, below the top node.
* **Attributes:** `[fa, 0, 2]`
* **Relationship:** Is a child of the Top Node (arrow points from it to the Top Node).
3. **Middle-Right Node:**
* **Label:** `(C(a), [fa, 0, 2])`
* **Position:** Center-right, below the top node.
* **Attributes:** `[fa, 0, 2]`
* **Relationship:** Is a child of the Top Node (arrow points from it to the Top Node).
4. **Bottom-Left Node:**
* **Label:** `(A(a), [fa, P, 3])`
* **Position:** Bottom-left, below the Middle-Left Node.
* **Attributes:** `[fa, P, 3]`
* **Relationship:** Is a child of the Middle-Left Node (arrow points from it to the Middle-Left Node).
5. **Bottom-Right Node:**
* **Label:** `(C(a), [fa, P, 3])`
* **Position:** Bottom-right (relative to the bottom-left node), below the Middle-Left Node.
* **Attributes:** `[fa, P, 3]`
* **Relationship:** Is a child of the Middle-Left Node (arrow points from it to the Middle-Left Node).
**Flow and Hierarchy:**
The flow is strictly upward. The two bottom nodes (`A(a)` and `C(a)`) are children of the middle-left node (`B(a)`). The middle-left node (`B(a)`) and the middle-right node (`C(a)`) are both children of the top node (`A(a)`).
### Key Observations
1. **Attribute Patterns:**
* The first attribute in the bracket is either `um` (only in the root) or `fa` (in all other nodes).
* The second attribute is either `P` or `0`.
* The third attribute is a number: `1`, `2`, or `3`.
2. **Node ID Repetition:** The node identifier `A(a)` appears at both the top (root) and bottom levels. The identifier `C(a)` appears in both the middle-right and bottom-right positions.
3. **Structural Asymmetry:** The tree is asymmetric. The middle-left node (`B(a)`) has two children, while the middle-right node (`C(a)`) has none.
4. **Attribute Consistency in Children:** The two bottom-level child nodes share identical attribute lists: `[fa, P, 3]`.
### Interpretation
This diagram likely represents a **formal system, a state machine, or a data structure** where nodes have specific types and properties.
* **What the data suggests:** The attributes `[Y, Z, W]` appear to be a tuple defining the node's state or type. `Y` (`um`/`fa`) could be a primary category (e.g., "unit" vs. "function" or "master" vs. "agent"). `Z` (`P`/`0`) might be a binary flag or parameter. `W` (1, 2, 3) could be a version, level, or priority indicator.
* **Relationships:** The arrows define a clear dependency or composition hierarchy. The root node `A(a)` is composed of or depends on `B(a)` and `C(a)`. `B(a)` itself is composed of or depends on another `A(a)` and `C(a)`. This recursive use of IDs (`A`, `C`) suggests these are **types or classes** rather than unique instances.
* **Notable Anomaly:** The root node is of type `A` with attribute `um`, while a child node is also of type `A` but with attribute `fa`. This strongly implies that `A` is a class or template, and the `um`/`fa` attribute distinguishes between different roles or instances of that class (e.g., a "master A" vs. a "worker A").
* **Why it matters:** This structure visualizes a system where components are built from other components, with properties that change based on their position in the hierarchy. It could model anything from software architecture and organizational charts to grammatical parse trees or logical proofs. The precise meaning of the attributes (`um`, `fa`, `P`, `0`, numbers) would be defined in the accompanying technical documentation for this specific system.
</details>
<details>
<summary>x13.png Details</summary>
### Visual Description
## Hierarchical Flow Diagram: State Transition Sequence
### Overview
The image displays a vertical, hierarchical flow diagram consisting of four rectangular blocks connected by upward-pointing arrows. The diagram appears to represent a sequence of states or computational steps, with each block containing a label and a set of parameters in brackets. The flow direction is from bottom to top, suggesting a progression or transformation process.
### Components/Axes
* **Structure:** Four text blocks stacked vertically, centered horizontally.
* **Connectors:** Solid black arrows point upward from the bottom of each block to the base of the block above it. A small, partial arrow at the very bottom indicates the sequence continues from a preceding, unseen element.
* **Text Elements:** Each block contains text in a monospaced font, formatted as: `(Label), [Parameter1, Parameter2, Parameter3]`.
* **Flow Direction:** Bottom-to-top, indicated by the arrows.
### Detailed Analysis
The diagram contains the following four blocks, listed in order from the bottom (start of visible sequence) to the top (end of visible sequence):
1. **Bottom Block (Position: Bottom-center):**
* Text: `(B(a)), [fa, 0, 4]`
* An upward arrow originates from below this block (partially visible: `...`).
2. **Second Block (Position: Center-bottom):**
* Text: `(A(a)), [fa, P, 3]`
* Connected by an arrow from the block below.
3. **Third Block (Position: Center-top):**
* Text: `(B(a)), [fa, 0, 2]`
* Connected by an arrow from the block below.
4. **Top Block (Position: Top-center):**
* Text: `(A(a)), [um, P, 1]`
* Connected by an arrow from the block below.
### Key Observations
* **Alternating Labels:** The primary label alternates between `B(a)` and `A(a)` in the sequence: B -> A -> B -> A.
* **Parameter Consistency & Change:**
* The first parameter in the brackets is `fa` for the first three blocks, changing to `um` in the top block.
* The second parameter alternates between `0` and `P`, corresponding with the `B(a)` and `A(a)` labels respectively. `B(a)` blocks have `0`, `A(a)` blocks have `P`.
* The third parameter is a descending integer sequence: `4`, `3`, `2`, `1`.
* **Visual Trend:** The diagram shows a clear, linear upward progression. Each step modifies the state, with the most significant change (from `fa` to `um`) occurring at the final visible step.
### Interpretation
This diagram likely models a **state machine, a computational process, or a hierarchical decision tree**. The elements suggest the following:
* **State Representation:** Each `(Label)` (e.g., `A(a)`, `B(a)`) represents a distinct state, mode, or function type. The `(a)` suffix may denote a specific instance or version.
* **State Parameters:** The bracketed values `[P1, P2, P3]` define the properties or context of each state.
* `P1` (`fa`/`um`): Could represent a **mode, phase, or operational flag**. The shift from `fa` (possibly "forward," "function A," or a state code) to `um` (possibly "update mode," "upper mode," or another state code) at the top indicates a critical transition or culmination of the process.
* `P2` (`0`/`P`): Likely a **binary flag or condition** tied directly to the state label (`B` vs. `A`). `P` might stand for "processed," "priority," or "parameterized."
* `P3` (4, 3, 2, 1): Acts as a **counter, step index, or priority level**. Its consistent decrement suggests a countdown, a reduction in resource allocation, or progression towards a terminal state (1).
* **Process Flow:** The upward arrows define a strict, linear sequence. The process starts in state `B(a)` with parameters `[fa, 0, 4]` and, through a series of transformations, ends in state `A(a)` with parameters `[um, P, 1]`. The alternating `A/B` pattern could indicate a ping-pong mechanism, a two-phase commit, or an iterative refinement between two core functions.
* **Notable Anomaly:** The change in the first parameter (`fa` -> `um`) only at the final step is significant. It implies that the preceding steps (`4`, `3`, `2`) are preparatory or occur within the `fa` context, while step `1` triggers or belongs to a new `um` context. This could mark the completion of a sub-process or the activation of a finalization routine.
**In essence, the diagram depicts a four-step, upward-flowing process where a system alternates between two states (`A` and `B`), decrements a counter, and finally switches its operational mode upon reaching the last step.**
</details>
Figure 7. Left: A focused dialogue tree $\mathcal{T}(\delta_{i})$ . Right: An infinite dialogue tree.
From the above observation, it follows immediately that.
**Lemma 5.11**
*Let $\mathcal{T}(\delta)$ be a defensive dialogue tree. The set of proponent arguments (supported by $\mathcal{DE}(\mathcal{T}(\delta))$ ) does not attack itself in the P-SAF drawn from $\delta$ .*
Consider the following dialogue to see why the ”non-redundant” property is necessary.
**Example 5.12**
*Consider a query $q_{5}=A(a)$ to a KB $\mathcal{K}_{5}=(\mathcal{R}_{5},\mathcal{C}_{5},\mathcal{F}_{5})$ where
| | $\displaystyle\mathcal{R}_{5}=$ | $\displaystyle\emptyset$ | |
| --- | --- | --- | --- |
Initially, an argument $A_{1}$ asserts that ” $A(a)$ is accepted” where $A(a)$ is at the P node. $A_{1}$ is attacked by $A_{2}$ by using $B(a)$ that is at the O node. $A_{1}$ counter-attacks $A_{2}$ by using $A(a)$ , then $A_{2}$ again attacks $A_{1}$ by using $B(a)$ , ad infinitum (see Figure 7 (Right)). Hence P cannot win. Since the grounded extension is empty, $A(a)$ is not groundedly accepted in the P-SAF, thus P should not win under the grounded semantics. Since $A(a)$ is credulously accepted in the P-SAF, we expect that P can win in a terminated dialogue under the credulous semantics.*
To ensure credulous acceptance, all possible opponent nodes must be accounted for. But if such a parent node is already in the dialogue tree, then deploying it will not help the opponent win the dialogues. To avoid this, we define a dialogue tree to be non-redundant.
**Definition 5.13**
*A focused dialogue tree $\mathcal{T}(\delta)$ is non-redundant iff for any two nodes $N_{1}=(\beta,[\texttt{{fa}},\texttt{{L}},\texttt{{id}}_{1}])$ and $N_{2}=(\beta,[\texttt{{fa}},\texttt{{L}},\texttt{{id}}_{2}])$ with $\texttt{{L}}\in\{\texttt{{P}},\texttt{{O}}\}$ and $N_{1}\neq N_{2}$ , if $N_{1}$ is in a potential argument $\mathcal{T}_{1}^{s}$ and $N_{2}$ is in a potential argument $\mathcal{T}_{2}^{s}$ , then $\mathcal{T}_{1}^{s}\neq\mathcal{T}_{2}^{s}$ .*
In Definition 5.13, when comparing two arguments, we compare their respective proof trees. Here, we only consider the formula and the tag of each node in the tree, disregarding the label and identifier of the node.
The following theorem establishes credulous soundness for admissible semantics.
theorem thmcredulous Let $\delta$ be a dialogue for a formula $\phi\in\mathcal{L}$ . If there is a dialogue tree $\mathcal{T}(\delta_{i})$ drawn from a focused sub-dialogue $\delta_{i}$ of $\delta$ such that it is defensive and non-redundant, then
- $\delta$ is admissible-successful;
- $\phi$ is credulously accepted under adm in $\mathcal{AF}_{\delta}$ drawn from $\delta$ (supported by $\mathcal{DE}(\mathcal{T}(\delta_{i}))$ .
The proof of this theorem is in Appendix B.
We can define a notion of preferred-successful dialogue with a formula accepted under prf in the P-SAF framework drawn from the dialogue. Since every admissible set (of arguments) is necessarily contained in a preferred set (see [6, 25]), and every preferred set is admissible by definition, trivially a dialogue is preferred-successful iff it is admissible-successful. The following theorem is analogous to Theorem 5.13 for prf semantics.
theorem thmpreferred Let $\delta$ be a dialogue for a formula $\phi\in\mathcal{L}$ . If there is a dialogue tree $\mathcal{T}(\delta_{i})$ drawn from a focused sub-dialogue $\delta_{i}$ of $\delta$ such that it is defensive and non-redundant, then $\delta$ is preferred-successful and $\phi$ is credulously accepted under prf in $\mathcal{AF}_{\delta}$ drawn from $\delta$ (supported by $\mathcal{DE}(\mathcal{T}(\delta_{i}))$ .
* Sketch*
The proof of this theory follows the fact that every preferred dialogue tree is an admissible dialogue tree. Thus, the proof of this theorem is analogous to those of Theorem 5.13. ∎
**Remark 5.14**
*We can similarly define a notion of stable dialogue trees for a formula accepted under stb in the P-SAF. Since stable and preferred sets coincide, trivially a dialogue tree is stable iff it is defensive and non-redundant. Thus we can use the result of Theorem 5.13 for stable semantics.*
#### 5.2.2. Computing grounded acceptance
We present winning conditions for a groundedly successful dialogue to determine grounded acceptance of a given formula. The conditions require that whenever O could advance any evidence, P still wins. This requirement is incorporated in dialogue trees being defensive. Note that credulously successful dialogues for computing credulous acceptance also require dialogue trees to be defensive (see in Theorem 5.13). However, the credulously successful dialogues cannot be used for computing the grounded acceptance, as shown by Example 5.12. In Example 5.12, it would be incorrect to infer from the depicted credulously successful dialogue that $A(a)$ is groundedly accepted as the grounded extension is empty. Note that the dialogue tree for $A(a)$ is infinite. From this observation, it follows that the credulously successful dialogues are not sound for computing grounded acceptance. Since all dialogue trees of a formula that is credulously accepted but not groundedly accepted can be infinite, we could detect this situation by checking if constructed dialogue trees are infinite. This motivates us to consider ” finite ” dialogue trees as a winning condition.
The following theorem establishes the soundness of grounded acceptance. theorem thmground Let $\delta$ be a dialogue for a formula $\phi\in\mathcal{L}$ . If there is a dialogue tree $\mathcal{T}(\delta_{i})$ drawn from a focused sub-dialogue $\delta_{i}$ of $\delta$ such that it is defensive and finite, then
- $\delta$ is groundedly-successful;
- $\phi$ is groundedly accepted under grounded semantics in $\mathcal{AF}_{\delta}$ drawn from $\delta$ (supported by $\mathcal{DE}(\mathcal{T}(\delta_{i}))$ .
The proof of this theorem is in Appendix B.
#### 5.2.3. Computing sceptical acceptance
Inspired by [13], to determine the sceptically acceptance of an argument for $\phi$ , we verify the following: (1) There exists an admissible set of arguments $S$ that includes the argument for $\phi$ ; (2) For each argument $A$ attacking $S$ , there exists no admissible set of arguments containing $A$ . These steps can be interpreted through the following winning conditions for a sceptical successful dialogue to compute the sceptical acceptance of $\phi$ :
1. P wins the game by ending the dialogue,
1. none of O wins by the same line of reasoning.
This perspective allows us to introduce a notion of ideal dialogue trees.
**Definition 5.15**
*A defensive and non-redundant dialogue tree $\mathcal{T}(\delta)$ is ideal iff none of the opponent arguments obtained from $\mathcal{T}(\delta)$ belongs to an admissible set of potential arguments in $\mathcal{AF}_{\delta}$ drawn from $\mathcal{T}(\delta)$ .*
The following result sanctions the soundness of sceptical acceptance.
theoremthmsceptical Let $\delta$ be a dialogue for a formula $\phi\in\mathcal{L}$ . If there is a dialogue tree $\mathcal{T}(\delta)$ drawn from $\delta$ such that it is ideal, then
- $\delta$ is sceptically-successful;
- $\phi$ is sceptically accepted under sem in $\mathcal{AF}_{\delta}$ drawn from $\delta$ (supported by $\mathcal{DE}(\mathcal{T}(\delta))$ , where $\texttt{{sem}}\in\{\texttt{{adm}},\texttt{{prf}},\texttt{{stb}}\}$ .
The proof of this theorem is in Appendix B.
### 5.3. Completeness Results
We now present completeness. In this work, dialogues viewed as dialectical proof procedures are sound but not always complete in general. The reason is that the dialectical proof procedures might enter a non-terminating loop during the process of argument constructions, which leads to the incompleteness wrt the admissibility semantics. To illustrate this, we refer to Example 1 using logic programming in [4] for an explanation. We also provide another example using $\text{Datalog}^{\pm}$ .
**Example 5.16**
*Consider a query $q_{6}=P(a)$ to a $\text{Datalog}^{\pm}$ KB $\mathcal{K}_{6}=(\mathcal{R}_{6},\mathcal{C}_{6},\mathcal{F}_{6})$ where
| | $\displaystyle\mathcal{R}_{6}=$ | $\displaystyle\{r_{1}:P(x)\rightarrow Q(x),r_{2}:Q(x)\rightarrow P(x)\}$ | |
| --- | --- | --- | --- |
The semantics of the corresponding P-SAF $\mathcal{AF}_{4}$ are determined by the arguments illustrated in Figure 8. The result should state that ” $P(a)$ is a possible answer” as the argument $B_{1}$ for $P(a)$ is credulously accepted under the admissible sets $\{B_{1}\}$ and $\{B_{2}\}$ of $\mathcal{AF}_{4}$ . But the dialectical proof procedures fail to deliver the admissible set $\{B_{1}\}$ wrt $\mathcal{AF}_{4}$ as they could not overcome the non-termination of the process to construct an argument $B_{1}$ for $P(a)$ due to the “infinite loop”.*
<details>
<summary>x14.png Details</summary>
### Visual Description
## Diagram: Logical Process Flow with Infinite Loop
### Overview
The image displays a technical diagram comparing two labeled processes or branches, designated as **B₁** and **B₂**. **B₁** depicts a vertical, repeating sequence of logical statements and rules that form an infinite loop. **B₂** shows a single, terminal logical statement. The diagram is presented on a plain, light gray background with black text and lines.
### Components/Axes
The diagram is divided into two distinct vertical sections:
* **Left Section (B₁):** A column of text elements connected by vertical lines, indicating a flow or sequence.
* **Right Section (B₂):** A single text element positioned to the right of the B₁ column.
**Labels and Text Elements:**
* **Top Labels:** `B₁ :` (top-left) and `B₂ :` (top-right).
* **B₁ Sequence (from top to bottom):**
1. `P(a)`
2. `r₂` (enclosed in a faint gray box)
3. `Q(a)`
4. `r₁` (enclosed in a faint gray box)
5. `P(a)`
6. `r₂` (enclosed in a faint gray box)
7. `Q(a)`
8. `r₁` (enclosed in a faint gray box)
9. `......` (ellipsis)
* **B₂ Element:** `R(a)`
* **Annotation:** A curly brace `}` spans the repeating section of B₁ (from the second `P(a)` to the ellipsis), with the label `infinite loops` placed to its right.
### Detailed Analysis
**B₁ Process Flow:**
1. The sequence initiates with the statement `P(a)`.
2. A vertical line connects `P(a)` to a boxed rule or transition labeled `r₂`.
3. `r₂` connects to the statement `Q(a)`.
4. `Q(a)` connects to a boxed rule or transition labeled `r₁`.
5. `r₁` connects back to the statement `P(a)`, completing one cycle.
6. This cycle (`P(a)` → `r₂` → `Q(a)` → `r₁` → `P(a)`) is shown to repeat, as indicated by the second identical cycle below the first.
7. The sequence terminates with an ellipsis (`......`), signifying continuation.
8. The curly brace explicitly labels this repeating pattern as `infinite loops`.
**B₂ Component:**
* Contains only the statement `R(a)`. There are no connecting lines or rules shown, suggesting it is either a standalone fact, a goal, or a terminal state not involved in the looping process of B₁.
**Spatial Grounding:**
* The `B₁ :` and `B₂ :` labels are positioned at the top of their respective columns.
* The `infinite loops` annotation is placed to the right of the B₁ column, vertically centered against the repeating segment it describes.
* The boxed rules (`r₁`, `r₂`) are visually distinct from the unboxed statements (`P(a)`, `Q(a)`, `R(a)`).
### Key Observations
1. **Cyclic Structure:** B₁ demonstrates a clear, two-step cyclic dependency between `P(a)` and `Q(a)`, mediated by rules `r₂` and `r₁`.
2. **Infinite Regress:** The diagram explicitly identifies this cycle as an infinite loop, meaning the process within B₁ has no terminating condition.
3. **Asymmetry:** B₂ (`R(a)`) is presented as separate and distinct from the looping mechanism of B₁. Its relationship to the B₁ process is not defined by any visible connectors.
4. **Notation:** The use of parentheses `(a)` suggests `P`, `Q`, and `R` are predicates or functions applied to a common argument or variable `a`. The subscripts on `r` denote distinct rules or relations.
### Interpretation
This diagram likely illustrates a concept from formal logic, computer science (e.g., program semantics, state machines), or automated reasoning.
* **What it demonstrates:** It contrasts a non-terminating computational or logical process (B₁) with a potentially stable or goal state (B₂). The B₁ loop represents a situation where applying rule `r₂` to `P(a)` yields `Q(a)`, and applying rule `r₁` to `Q(a)` yields `P(a)` again, creating a perpetual cycle with no progress toward a conclusion or a different state.
* **Relationship between elements:** `R(a)` in B₂ may represent a desired conclusion, an alternative fact, or a state that is unreachable from the B₁ loop. The lack of connection implies that the infinite loop in B₁ prevents the derivation or achievement of `R(a)`.
* **Underlying meaning:** The diagram serves as a visual proof or warning about a specific logical configuration that leads to non-termination. In the context of a technical document, it could be used to explain a flaw in a system's design, a paradox in a logical theory, or the behavior of a particular algorithmic pattern. The core message is the identification and isolation of a self-referential, unproductive cycle.
</details>
Figure 8. Arguments of $\mathcal{AF}_{4}$
Intuitively, since the dialogues as dialectical proof procedures (implicitly) incorporate the computation of arguments top-down, the process of argument construction should be finite (also known as finite tree-derivations in the sense of Definition 3.1) to achieve the completeness results. Thus, we restrict the attention to decidable logic with cycle-restricted conditions that its corresponding P-SAF framework produces arguments to be computed finitely in a top-down fashion. For example, given a $\text{Datalog}^{\pm}$ KB $\mathcal{K}=(\mathcal{R},\mathcal{C},\mathcal{F})$ , the dependency graph of the KB as defined in [73] consists of the vertices representing the atoms and the edges from an atom $u$ to $v$ iff $v$ is obtained from $u$ (possibly with other atoms) by the application of a rule in $\mathcal{R}$ . The intuition behind the use of the dependency graph is that no infinite tree-derivation exists if the dependency graph of KB is acyclic. By restricting such acyclic dependency graph condition, the process of argument construction in the corresponding P-SAF of the KB $\mathcal{K}$ will be finite, which leads to the completeness of the dialogues wrt argumentation semantics. The following theorems show the completeness of credulous acceptances wrt admissible semantics.
theoremcompadm Let $\delta$ be a dialogue for a formula $\phi\in\mathcal{L}$ . If $\phi$ is credulously accepted under adm in $\mathcal{AF}_{\delta}$ drawn from $\delta$ (supported by $\mathcal{DE}(\mathcal{T}(\delta))$ ) and $\delta$ is admissible-successful, then there is a defensive and non-redundant dialogue tree $\mathcal{T}(\delta_{i})$ for $\phi$ drawn from a focused sub-dialogue $\delta_{i}$ of $\delta$ .
The proof of this theorem is in Appendix C.
The following theorem is analogous to Theorem 8 for preferred semantics. theoremcomppreferred Let $\delta$ be a dialogue for a formula $\phi\in\mathcal{L}$ . If $\phi$ is credulously accepted under prf in $\mathcal{AF}_{\delta}$ drawn from $\delta$ (supported by $\mathcal{DE}(\mathcal{T}(\delta))$ ) and $\delta$ is preferred-successful, then there is a defensive and non-redundant dialogue tree $\mathcal{T}(\delta_{i})$ for $\phi$ drawn from a focused sub-dialogue $\delta_{i}$ of $\delta$ .
* Sketch*
The proof of this theory follows the fact that every preferred-successful dialogue is an admissible-successful dialogue. Thus, the proof of this theorem is analogous to those of Theorem 8. ∎
Theorem 8 presents the completeness of grounded acceptances. theoremcompground Let $\delta$ be a dialogue for a formula $\phi\in\mathcal{L}$ . If $\phi$ is groundedly accepted under grd in $\mathcal{AF}_{\delta}$ drawn from $\delta$ (supported by $\mathcal{DE}(\mathcal{T}(\delta))$ ) and $\delta$ is groundedly-successful, then there is a defensive and finite dialogue tree $\mathcal{T}(\delta_{i})$ for $\phi$ drawn from a focused sub-dialogue $\delta_{i}$ of $\delta$ .
The proof of this theorem is in Appendix C.
Theorem 8 presents the completeness of sceptical acceptances.
theoremcompsceptical Let $\delta$ be a dialogue for a formula $\phi\in\mathcal{L}$ . If $\phi$ is sceptically accepted under sem in $\mathcal{AF}_{\delta}$ drawn from $\delta$ (supported by $\mathcal{DE}(\mathcal{T}(\delta))$ ), where $\texttt{{sem}}\in\{\texttt{{adm}},\texttt{{prf}},\texttt{{stb}}\}$ , and $\delta$ is sceptically-successful, then there is an ideal dialogue tree $\mathcal{T}(\delta)$ for $\phi$ drawn from $\delta$ .
The proof of this theorem is in Appendix C.
### 5.4. Results for a Link between Inconsistency-Tolerant Reasoning and Dialogues
In Section 5.2 and 5.3, we demonstrated the use of dialogue trees to determine the acceptance of a formula in the P-SAF drawn from the dialogue tree. As a direct corollary of Theorem 3.14 - 8, we show how to determine and explain the entailment of a formula in KBs by using dialogue trees, which was the main goal of this paper.
**Corollary 5.17**
*Let $\mathcal{K}$ be a KB, $\phi$ be a formula in $\mathcal{L}$ . Then $\phi$ is entailed in
- some maximal consistent subset of $\mathcal{K}$ iff there is a defensive and non-redundant dialogue tree $\mathcal{T}(\delta)$ for $\phi$ .
- the intersection of maximal consistent subsets of $\mathcal{K}$ iff there is a defensive and finite dialogue tree $\mathcal{T}(\delta)$ for $\phi$ .
- all maximal consistent subsets of $\mathcal{K}$ iff there is an ideal dialogue tree $\mathcal{T}(\delta)$ for $\phi$ .*
## 6. Summary and Conclusion
We introduce a generic framework to provide a flexible environment for logic argumentation, and to address the challenges of explaining inconsistency-tolerant reasoning. Particularly, we studied how deductive arguments, DeLP, ASPIC/ ASPIC+ without preferences, flat or non-flat ABAs and sequent-based argumentation are instances of P-SAF frameworks. (Detailed discussions can be found after Definition 3.1 and 3.5). However, different perspectives were considered as follows.
Regarding deductive arguments and DeLP, our work extends these approaches in several ways. First, the usual conditions of minimality and consistency of supports are dropped. This offers a simpler way of producing arguments and identifying them. Second, like ABAs, the P-SAF arguments are in the form of tree derivations to show the structure of the arguments. This offer aims to (1) clarify the argument structure, and (2) enhance understanding of intermediate reasoning steps in inconsistency-tolerant reasoning in, for instance, $\text{Datalog}^{\pm}$ and DL.
Similar to ”non-flat” ABAs, the P-SAF framework uses the notion of CN to allow the inferred assumptions being conflicting. In contrast, ”flat” ABAs ignore the case of the inferred assumptions being conflicting. Moreover, by using collective attacks, the P-SAF framework is sufficiently general to model n-ary constraints, which are not yet addressed in ”non-flat” ABAs and ASPIC/ ASPIC+ without preferences. Like our approach, contrapositive ABAs in [65, 63] provide an abstract view for logical argumentation, in which attacks are defined on the level assumptions. However, since a substantial part of the development of the theory of contrapositive ABA is focused on contrapositive propositional logic, we have considered the logic of ABA as being given by $\overline{\texttt{{CN}}}_{s}$ and these contrapositive ABAs being simulated in our setting, see Section 3.2. In Section 3.2, we showed how sequent-based argumentation can fit in the P-SAF setting. While our work can be applied to first-order logic, sequent-based argumentation leaves the study of first-order formalisms for further research.
The work of [71] proposed the use of Tarski abstract logic in argumentation that is characterized simply by a consequence operator. However, many logics underlying argumentation systems, like ABA or ASPIC systems, do not always impose the absurdity axiom. A similar idea of using consequence operators can be found in the work of [52]. When a consequence operation is defined by means of ” models ”, inference rule steps are implicit within it. If arguments are defined by consequence operators, then the structure of arguments is often ignored, which makes it difficult to clearly explain the acceptability of the arguments. These observations motivate the slight generalizations of Tarski’s abstract logic, in which we defined consequence operators in a proof-theoretic manner, inspired by the approach of [72], with minimal properties.
As we have studied here, we introduced an alternative abstract approach for logical argumentation and showed the connections between our framework and the state-of-the-art argumentation frameworks. However, we should not claim any framework as better than those, or vice versa. Rather, the choice of an argumentation framework using specific logic should depend on the needs of the application.
Finally, this paper is the first investigation of dialectical proof procedures to compute and explain the acceptance wrt argumentation semantics in the case of collective attacks. The dialectical proof procedures address the limits of the paper [52], i.e., it is not easy to understand intermediate reasoning steps in reasoning progress with (inconsistent) KBs.
The primary message of this paper is that we introduce a generic argumentation framework to address the challenge of explaining inconsistency-tolerant reasoning in KBs. This approach is defined for any logic involving reasoning with maximal consistent subsets, therefore, it provides a flexible environment for logical argumentation. To clarify and explain the acceptance of a sentence with respect to inconsistency-tolerant semantics, we present explanatory dialogue models that can be viewed as dialectic-proof procedures and connect the dialogues with argumentation semantics. The results allow us to provide dialogical explanations with graphical representations of dialectical proof trees. The dialogical explanations are more expressive and intuitive than existing explanation formalisms.
Our approach has been studied from a theoretical viewpoint. From practice, especially, from a human-computer interaction perspective, we will perform experiments with our approach in real-data applications. We then qualitatively evaluate our explanation by human evaluation. It would be interesting to analyze the complexity of computing the explanations empirically and theoretically.
## Appendix A Preliminaries
To prove the soundness and complete results, we sketch out a general strategy as follows:
1. Our proof starts with the observation that a dialogue $\delta$ for a formula $\phi$ can be seen as a collection of several (independent) focused sub-dialogues $\delta_{1},\ldots,\delta_{n}$ . The dialogue tree $\mathcal{T}(\delta_{i})$ drawn from $\delta_{i}$ is a subtree of $\mathcal{T}(\delta)$ drawn from the sub-dialogue $\delta$ , and it corresponds to the abstract dialogue tree that has root an argument with conclusion $\phi$ . (The notion of abstract dialogue tree can be found in [52]). Thus it is necessary to consider a correspondence principle that links dialogue trees to abstract dialogue trees. The materials for this step can be found in Section A.2 and A.3.
1. The correspondence principle allows to utilize the results of abstract dialogue trees in [[52], Corollary 1] to prove the soundness results. We extend Corollary 1 of [52] to prove the completeness results.
The proof of the soundness and completeness results depends on some notions and results that we describe next.
**Notation A.1**
*Let $\mathcal{K}$ be a KB, $\mathcal{X}\subseteq\mathcal{K}$ be a set of facts and $\mathcal{S}\subseteq\texttt{{Arg}}_{\mathcal{K}}$ be a set of arguments induced from $\mathcal{K}$ . Then,
- $\texttt{{Args}}(\mathcal{X})=\{A\in\texttt{{Arg}}_{\mathcal{K}}\mid\texttt{{ Sup}}(A)\subseteq\mathcal{X}\}$ are the set of arguments generated by $\mathcal{X}$ ,
- $\texttt{{Base}}(\mathcal{S})=\underset{A\in\mathcal{S}}{\bigcup}\texttt{{Sup}} (A)$ are the set of supports of arguments in $\mathcal{S}$ ,
- An argument $B$ is a subargument of argument $A$ iff $\texttt{{Sup}}(B)\subseteq\texttt{{Sup}}(A)$ . We denote the set of subarguments of $A$ as $\texttt{{Subs}}(A)$ .*
### A.1. Abstract Dialogue Trees and Abstract Dialogue Forests
We observe that a formula $\phi$ can have many arguments whose conclusion is $\phi$ . Thus a dialogue tree with root $\phi$ can correspond to one, none, or multiple abstract dialogue trees, one for each argument for $\phi$ . We call this set of abstract dialogue trees an abstract dialogue forest. The following one presents a definition of abstract dialogue forests and reproduces a definition of abstract dialogue trees (analogous to Definition 8 in [52]). Formally:
**Definition A.2 (Abstract dialogue forests)**
*Let $\mathcal{AF}_{\delta}=(\texttt{{Arg}}_{\delta},\texttt{{Att}}_{\delta})$ be the P-SAF drawn from a dialogue $D(\phi)=\delta$ . An abstract dialogue forest (obtained from $\mathcal{AF}_{\delta}$ ) for $\phi$ is a set of abstract dialogue trees, written $\mathcal{F}_{\texttt{{G}}}(\phi)=\{\mathcal{T}^{1}_{\texttt{{G}}},\ldots, \mathcal{T}^{h}_{\texttt{{G}}}\}$ , such that: For each abstract dialogue tree $\mathcal{T}^{j}_{\texttt{{G}}}$ ( $j=1,\ldots,h$ ), - the root of $\mathcal{T}^{j}_{\texttt{{G}}}$ is the proponent argument (in $\texttt{{Arg}}_{\delta}$ ) with the conclusion $\phi$ ,
- if a node $A$ in $\mathcal{T}^{j}_{\texttt{{G}}}$ is a proponent argument (in $\texttt{{Arg}}_{\delta}$ ), then all its children (possibly none) are opponent arguments (in $\texttt{{Arg}}_{\delta}$ ) that attack $A$
- if a node $A$ in $\mathcal{T}^{j}_{\texttt{{G}}}$ is an opponent argument (in $\texttt{{Arg}}_{\delta}$ ), then exactly one of the following is true: (1) $A$ has exactly one child, and this child is a proponent argument (in $\texttt{{Arg}}_{\delta}$ ) that attacks $A$ ; (2) $A$ has more than one child, and all these children are proponent argument (in $\texttt{{Arg}}_{\delta}$ ) that collectively attacks $A$ .*
**Remark A.3**
*We call the abstract dialogue tree that has root an argument with conclusion $\phi$ an abstract dialogue tree for $\phi$ .*
Fix an abstract dialogue forest $\mathcal{F}_{\texttt{{G}}}(\phi)=\{\mathcal{T}^{1}_{\texttt{{G}}},\ldots, \mathcal{T}^{h}_{\texttt{{G}}}\}$ . For such abstract dialogue tree $\mathcal{T}^{j}_{\texttt{{G}}}$ ( $i=1,\ldots,h$ ), we adopt the following conventions:
- Let $\mathcal{B}_{1}$ be the set of all proponent arguments in $\mathcal{T}^{j}_{\texttt{{G}}}$ . $\mathcal{DE}(\mathcal{T}^{j}_{\texttt{{G}}})=\{\alpha\mid\forall A\in\mathcal{ B}_{1},\alpha\in\texttt{{Sup}}(A)\}\subseteq\mathcal{F}$ is the defence set of $\mathcal{T}^{j}_{\texttt{{G}}}$ , i.e. the set of facts in the support of the arguments in $\mathcal{B}_{1}$ .
- Similarly, let $\mathcal{B}_{2}$ be the set of all opponent arguments in $\mathcal{T}^{j}_{\texttt{{G}}}$ . $\mathcal{CU}(\mathcal{T}^{j}_{\texttt{{G}}})=\{\beta\mid\forall B\in\mathcal{B }_{2},\beta\in\texttt{{Sup}}(B)\}\subseteq\mathcal{F}$ is the culprit set of $\mathcal{T}^{j}_{\texttt{{G}}}$ , i.e. the set of facts in support of the arguments in $\mathcal{B}_{2}$ .
We reproduce a definition of admissible abstract dialogue trees given in [52]. This notion will be needed for Section A.3.
**Definition A.4 (Admissible abstract dialogue trees)**
*An abstract dialogue tree for $\phi$ is said to admissible iff the proponent wins and no argument labels both a proponent and an opponent node.*
Intuitively, in an abstract dialogue tree, a proponent wins if either the tree ends with arguments labelled by proponent nodes or every argument labelling an opponent node has a child.
### A.2. Partitioning a Dialogue Tree into Focused Substrees
This section shows how to partition a dialogue tree $\mathcal{T}(\delta)$ into focused subtrees of $\mathcal{T}(\delta)$ . We will need this result to prove soundness and completeness results.
We observe that a dialogue $D(\phi)=\delta$ , from which the dialogue tree $\mathcal{T}(\delta)$ is drawn, may contain one, none, or multiple focused sub-dialogues $\delta_{i}$ of $\delta$ . Each dialogue tree $\mathcal{T}(\delta_{i})$ drawn from the focused sub-dialogue $\delta_{i}$ is a subtree of $\mathcal{T}(\delta)$ and focused. This is proven in the following lemma.
**Lemma A.5**
*Let $\mathcal{T}(\delta)$ be a dialogue tree (with root $\phi$ ) drawn from a dialogue $D(\phi)=\delta$ . Every focused subtree of $\mathcal{T}(\delta)$ with root $\phi$ is the dialogue tree drawn from a focused sub-dialogue $\delta_{i}$ of $\delta$ .*
* Proof*
All the subtrees considered in this proof are assumed to have root $\phi$ . The proof proceeds as follows:
1. First, we construct the set of focused dialogue subtrees of $\mathcal{T}(\delta)$
1. Second, we show that each focused subtree $\mathcal{T}(\delta_{i})$ of $\mathcal{T}(\delta)$ is drawn from a focused sub-dialogue $\delta_{i}$ of $\delta$ . Let $\mathcal{T}(\delta_{1}),\ldots,\mathcal{T}(\delta_{m})$ be all the focused subtrees contained in $\mathcal{T}(\delta)$ with root $\phi$ . Each focused subtree is obtained in the following way: First, choose a single utterance at the root and discard the subtrees corresponding to the other utterances at the root. Then proceed (depth first) and for each potential argument labelled O with children labelled P, choose a single identifier and select among them those (and only those) with that identifier; discard the other children labelled P (which have a different identifier) and the corresponding subtrees. By Definition 4.5, every focused subtree can be obtained in this way. 2. We next prove (2) by showing the construction of the focused sub-dialogue $\delta_{i}$ that draws $\mathcal{T}(\delta_{i})$ . Given $m$ dialogue trees $\mathcal{T}(\delta_{1}),\ldots,\mathcal{T}(\delta_{m})$ constructed from $\mathcal{T}(\delta)$ , the focused sub-dialogue $\delta_{i}$ ( $1\leq i\leq m$ ) drawing the dialogue tree $\mathcal{T}(\delta_{i})$ is constructed as follows: - $\delta_{i}$ is initialised to empty;
- for each node $\psi,[\_,\_,\texttt{{id}}])=N$ in $\mathcal{T}(\delta_{i})$ ,
- if $u_{id}=(\_,\ \texttt{{ta}},\ \_,\ \texttt{{id}})$ is in $\delta$ but not in $\delta_{i}$ , then add $u_{id}$ to $\delta_{i}$ ;
- let $u_{\texttt{{ta}}}$ be the utterance in $\delta$ ; if $u_{\texttt{{ta}}}$ is the target utterance of $u_{\texttt{{id}}}$ , then add $u_{\texttt{{ta}}}$ to $\delta_{i}$ ;
- Sort $\delta_{i}$ in the order of utterances $ID$ . It is easy to see that each $\delta_{i}$ constructed as above is a focused sub-dialogue of $\delta$ (by the definition of focused sub-dialogues in Definition 4.2), and $\mathcal{T}(\delta_{i})$ is drawn from $\delta_{i}$ . Thus (2) is proved. ∎
### A.3. Transformation from Dialogue Trees into Abstract Dialogue Trees
The following correspondence principle allows to translate dialogue trees into abstract dialogue trees and vice versa.
**Remark A.6**
*Recall that a dialogue tree for $\phi$ has root $\phi$ , while an abstract dialogue tree for $\phi$ has root an argument for $\phi$ .*
**Theorem A.7 (Correspondence principle)**
*Let $\phi\in\mathcal{L}$ be a formula. Then: 1. For every defensive and non-redudant dialogue tree $\mathcal{T}(\delta)$ for $\phi$ , there exists an admissible abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}$ for $\phi$ such that $\mathcal{DE}(\mathcal{T}_{\texttt{{G}}})\subseteq\mathcal{DE}(\mathcal{T}( \delta))$ and $\mathcal{CU}(\mathcal{T}_{\texttt{{G}}})\subseteq\mathcal{CU}(\mathcal{T}( \delta))$ .
1. For every admisslbe abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}$ for $\phi$ , there exists a defensive and non-redundant dialogue tree $\mathcal{T}(\delta)$ for $\phi$ such that $\mathcal{DE}(\mathcal{T}(\delta))\subseteq\mathcal{DE}(\mathcal{T}_{\texttt{{G }}})$ and $\mathcal{CU}(\mathcal{T}(\delta))\subseteq\mathcal{CU}(\mathcal{T}_{\texttt{{G }}})$ .*
* Proof*
We prove the theorem by transforming dialogue trees into abstract dialogue trees and vice versa. 1. The transformation from dialogue trees into abstract dialogue trees Given a defensive and non-redundant dialogue tree $\mathcal{T}(\delta)$ with root $\phi$ , its equivalent abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}$ for an argument for $\phi$ in $\mathcal{T}_{\texttt{{G}}}^{1},\ldots,\mathcal{T}_{\texttt{{G}}}^{h}$ is constructed inductively as follows: 1. Modify $\mathcal{T}(\delta)$ by adding a new flag ( $0 0$ or $1$ ) to nodes in $\mathcal{T}(\delta)$ and initialise $0 0$ for all nodes; a node looks like $(\_,[\_,\_,\_])-0$ . The obtained tree is $\mathcal{T}^{\prime}(\delta)$ .
1. $\mathcal{T}_{\texttt{{G}}}$ is $\mathcal{T}_{\texttt{{G}}}^{h}$ in the sequence $\mathcal{T}_{\texttt{{G}}}^{1},\ldots,\mathcal{T}_{\texttt{{G}}}^{h}$ constructed inductively as follows:
1. Let $A$ be the potential argument drawn from $\mathcal{T}(\delta)$ that contains root $\phi$ . $\mathcal{T}_{\texttt{{G}}}^{1}$ contains exactly one node that holds $A$ and is labelled by P. Set the nodes in $\mathcal{T}^{\prime}(\delta)$ that are in $A$ to $1$ . The obtained tree is $\mathcal{T}^{\prime}_{1}(\delta)$ .
1. Let $\mathcal{T}_{\texttt{{G}}}^{k}$ be the $k$ -th tree, with $1\leq k\leq h$ . $\mathcal{T}^{k+1}_{\texttt{{G}}}$ is expanded from $\mathcal{T}^{k}_{\texttt{{G}}}$ by adding nodes $(\texttt{{L}}:\ B_{j})$ with $\texttt{{L}}\in\{\texttt{{P}},\texttt{{O}}\}$ .
For each node $(\texttt{{L}}:\ B_{j})$ , $B_{j}$ is a potential argument drawn from $\mathcal{T}^{\prime}_{k}(\delta)$ , which is a child of $C$ - another potential argument drawn from $\mathcal{T}^{\prime}_{k}(\delta)$ , such that:
- there is at least one node in $B_{j}$ that is assigned $0 0$ ;
- the root of $B_{j}$ has a parent node $t$ in $\mathcal{T}^{\prime}_{k}(\delta)$ such that the flag of $t$ is $1$ and $t$ is in $C$ ;
- if the root of $B_{j}$ is labelled by P, then L is P. Otherwise, L is O.
- set all nodes in $\mathcal{T}^{\prime}_{k}(\delta)$ that are also in $B_{j}$ to 1. The obtained tree is $\mathcal{T}^{\prime}_{k+1}(\delta)$ .
1. $h$ is the smallest index s.t there is no node in $\mathcal{T}^{\prime}_{h}(\delta)$ where its flag is $0 0$ . $\mathcal{T}_{\texttt{{G}}}$ is constructed as follows: - Every node of $\mathcal{T}_{\texttt{{G}}}=\mathcal{T}_{\texttt{{G}}}^{h}$ includes a potential argument. For each potential argument, there is a unique node in $\mathcal{T}_{\texttt{{G}}}$ . Each node is labelled P or O as potential arguments drawn from $\mathcal{T}(\delta)$ are labelled either P or O.
- The root of $\mathcal{T}_{\texttt{{G}}}$ includes the potential argument for $\phi$ of the dialogue and labelled P by constructing $\mathcal{T}(\delta)$ .
- Since $\mathcal{T}(\delta)$ is defensive, by Definition 5.9, it is focused and patient. Thus there is only one way of attacking a potential argument labelled by O. Since $\mathcal{T}(\delta)$ is defensive, by Definition 5.9, it is last-word. Then there is no un-attacked (potential) argument labelled by O. From the above, it follows that every O node has exactly one P node as its child.
- Since $\mathcal{T}(\delta)$ is non-redundant, by Definition 5.13, no potential argument labels O and P. Recall that, in $\mathcal{T}_{\texttt{{G}}}$ , the potential arguments labelling P (O, respectively) are called proponent arguments (opponent arguments, respectively). It can be seen that $\mathcal{T}_{\texttt{{G}}}$ has the following properties:
- the root is the proponent argument for $\phi$ .
- the O node has either exactly one child holding one proponent argument that attacks it or children holding the proponent arguments that collectively attack it.
- all leaves are nodes labelled by P, namely P wins and there is no node labelled by both P and O. It follows immediately that $\mathcal{T}_{\texttt{{G}}}$ is an admissible abstract dialogue tree (by the definition of abstract dialogue trees in Definition A.2 and Definition A.4). Since $\mathcal{T}_{\texttt{{G}}}$ contains the same potential arguments as $\mathcal{T}(\delta)$ and the arguments have the same $\texttt{{P}}/\texttt{{O}}$ labelling in both $\mathcal{T}_{\texttt{{G}}}$ and $\mathcal{T}(\delta)$ , we have $\mathcal{DE}(\mathcal{T}_{\texttt{{G}}})=\mathcal{DE}(\mathcal{T}(\delta))$ and $\mathcal{CU}(\mathcal{T}_{\texttt{{G}}})=\mathcal{CU}(\mathcal{T}(\delta))$ . 2. The transformation from abstract dialogue trees into dialogue trees We first need to introduce some new concepts that together constitute the dialogue tree.
**Definition A.8 (Support trees)**
*A support tree of a formula $\alpha$ is defined as follows:
1. The root is a proponent node labelled by $\alpha$ .
1. Let $N$ be a proponent node labelled by $\sigma$ . If $\sigma$ is a fact, then either $N$ has no children, or $N$ has children that are opponent nodes labelled by $\beta_{k}$ , $k=1,\ldots,n$ such that $\{\beta_{k}\}\cup\{\sigma\}$ is inconsistent. If $\sigma$ is a non-fact, then one of the following holds:
- either (1) $N$ has children that are proponent nodes labelling $\omega_{l}$ , $l=1,\dots,m$ , such that $\sigma\in\texttt{{CN}}(\{\omega_{l}\})$ ,
- or (2) $N$ has children that are opponent nodes labelling $\beta_{k}$ , $k=1,\ldots,n$ , such that $\{\beta_{k}\}\cup\{\sigma\}$ is inconsistent,
- or both (1) and (2) hold.*
**Definition A.9 (Context trees)**
*A context tree of a formula $\alpha$ is defined as follows:
1. The root is an opponent node labelled by $\alpha$ .
1. Let $N$ be an opponent node labelled by $\sigma$ . If $\sigma$ is a fact, then $N$ has children that are proponent nodes labelled by $\beta_{k}$ , with $k=1,\ldots,n$ , such that $\{\beta_{k}\}\cup\{\sigma\}$ is inconsistent and the children have the same identify The condition of ”children having the same identify” ensure that a potential argument is attacked by exactly one potential argument if $k=1$ or collectively attacked by one set of potential arguments if $k>1$ .. If $\sigma$ is a non-fact, then one of the following holds:
- either (1) $N$ has children that are opponent nodes labelled by $\omega_{l}$ , with $l=1,\dots,m$ , such that $\sigma\in\texttt{{CN}}(\{\omega_{l}\})$ ,
- or (2) $N$ has children that are proponent nodes labelling $\beta_{k}$ , with $k=1,\ldots,n$ , such that $\{\beta_{k}\}\cup\{\sigma\}$ is inconsistent and the children have the same identify,
- or both (1) and (2) hold.*
Now we prove the translation from abstract dialogue trees to dialogue trees. Given an abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}$ for $\phi$ , its equivalent focused subtree $\mathcal{T}(\delta_{i})$ of a dialogue tree $\mathcal{T}(\delta)$ for $\phi$ is constructed inductively as follows: Let $\mathcal{DE}(\mathcal{T}_{\texttt{{G}}})$ and $\mathcal{CU}(\mathcal{T}_{\texttt{{G}}})$ be the defence set and the set of culprits of $\mathcal{T}_{\texttt{{G}}}$ , respectively. For each $\alpha\in\mathcal{CU}(\mathcal{T}_{\texttt{{G}}})$ , let $arg(\beta_{k})$ , with $k=1,\ldots,n$ , be a set of arguments for $\beta_{k}$ labelling nodes in $\mathcal{T}_{\texttt{{G}}}$ such that $\{\beta_{k}\}\cup\{\alpha\}$ is inconsistent. If $k=1$ , then there exists a single argument for $\beta$ that attacks an argument including $\alpha$ . We say that an argument including $\alpha$ is an argument whose conclusion or support includes $\alpha$ . If $k>1$ , then there exists a set of arguments for $\beta_{k}$ that collectively attacks an argument including $\alpha$ . For each $\alpha\in\mathcal{DE}(\mathcal{T}_{\texttt{{G}}})$ , let $B^{\alpha}_{k}$ be the set of facts in the support of arguments for $\beta_{k}$ in $\mathcal{T}_{\texttt{{G}}}$ such that the arguments for $\beta_{k}$ attack an argument including $\alpha$ . Clearly, there exists an argument for $\beta$ that attacks an argument including $\alpha$ if $k=1$ and there exist arguments for $\beta_{k}$ that attack or collectively attack an argument including $\alpha$ if $k>1$ . We construct inductively the sequence of trees $\mathcal{T}^{1}(\delta_{i}),\ldots,\mathcal{T}^{h}(\delta_{i})$ as follows:
1. $\mathcal{T}^{1}(\delta_{i})$ is a support tree of $\phi$ corresponding to the argument labelling the root of $\mathcal{T}_{\texttt{{G}}}$ .
1. Let $j=2n$ such that the non-terminal nodes in the frontier of $\mathcal{T}^{j}(\delta_{i})$ are opponent nodes labelled by a set of formulas $\beta_{k}$ where $\{\beta_{k}\}\cup\{\alpha\}$ is inconsistent and $\alpha\in\mathcal{DE}(\mathcal{T}_{\texttt{{G}}})$ . Expand each such node by a context tree of $\beta_{k}$ wrt $B^{\alpha}_{k}$ . The obtained tree is $\mathcal{T}^{j+1}(\delta_{i})$ .
1. Let $j=2n+1$ such that the non-terminal nodes in the frontier of $\mathcal{T}^{j}(\delta_{i})$ are proponent nodes labelled by a set of formula $\beta_{k}$ , where $\{\beta_{k}\}\cup\{\alpha\}$ is inconsistent and $\alpha\in\mathcal{CU}(\mathcal{T}_{\texttt{{G}}})$ . Expand each such node by a support tree of $\beta_{k}$ corresponding to the argument for $\beta_{k}$ . The obtained tree is $\mathcal{T}^{j+1}(\delta_{i})$ .
1. Define $\mathcal{T}(\delta_{i})$ to be the limit of $\mathcal{T}^{j}(\delta_{i})$ . It follows immediately that $\mathcal{T}(\delta_{i})$ is a dialogue tree for $\phi$ whose defence set is a subset of the defence set of $\mathcal{T}_{\texttt{{G}}}$ and whose the culprit set is a subset of the culprit set of $\mathcal{T}_{\texttt{{G}}}$ . Since $\mathcal{T}_{\texttt{{G}}}$ is admissible, by Defintion A.4, the proponent wins, namely either the tree ends with arguments labelled by proponent nodes or every argument labelled by an opponent node has a child. By Definition 5.9, $\mathcal{T}(\delta_{i})$ is defensive. Since $\mathcal{T}_{\texttt{{G}}}$ is admissible, by Defintion A.4, $\mathcal{T}_{\texttt{{G}}}$ has no argument labelling both a proponent and an opponent node. By Definition 5.13, $\mathcal{T}(\delta_{i})$ is non-redundant. ∎
### A.4. Notions and Results of Acceptance of an Argument from Its Abstract Dialogue Trees
For reader’s convenience, we reproduce here definitions and results for abstract dialogues for $\phi$ that can also be found in [52]. We use a similar argument for focused sub-dialogues of a dialogue $\delta$ for $\phi$ . In fact, the definitions and the results we reproduce here are essentially the same with abstract dialogues replaced by focused sub-dialogues of $\delta$ for $\phi$ . This replacement is because an abstract dialogue for $\phi$ can be seen as a focused sub-dialogue of a dialogue $\delta$ for $\phi$ . This follows immediately from the results in Lemma A.5 (i.e., showing a dialogue tree drawn from a dialogue $\delta$ for $\phi$ can be divided into focused sub-trees drawn from focused sub-dialogues of $\delta$ for $\phi$ ) and in Theorem A.7 (i.e., showing each such focused subtrees corresponds with an abstract dialogue tree drawn from an abstract dialogue).
**Definition A.10 (Analogous to Definition 9 in[52])**
*Let $\mathcal{T}_{\texttt{{G}}}$ be the abstract dialogue tree drawn from a focused sub-dialogue $\delta^{\prime}$ of a dialogue for $\phi$ . The focused sub-dialogue $\delta^{\prime}$ is called
- admissible-successful iff $\mathcal{T}_{\texttt{{G}}}$ is admissible;
- preferred-successful iff it is admissible-successful;
- grounded-successful iff $\mathcal{T}_{\texttt{{G}}}$ is admissible and finite;
- sceptical-successful iff $\mathcal{T}_{\texttt{{G}}}$ is admissible and for no opponent node in it, there exists an admissible dialogue tree for the argument labelling an opponent node.*
**Corollary A.11 (Analogous to Corollary 1 in[52])**
*Let $\mathcal{K}$ be a KB, $\phi\in\mathcal{L}$ a formula and $\mathcal{AF}_{\mathcal{K}}$ be the corresponding P-SAF of $\mathcal{K}$ . Then, $\phi$ is
- credulously accepted in some admissible/preferred extension of $\mathcal{AF}_{\mathcal{K}}$ if there is a focused sub-dialogue $\delta^{\prime}$ of a dialogue for $\phi$ such that $\delta^{\prime}$ is admissible/preferred-successful;
- groundedly accepted in a grounded extension of $\mathcal{AF}_{\mathcal{K}}$ if there is a focused sub-dialogue $\delta^{\prime}$ of a dialogue for $\phi$ such that $\delta^{\prime}$ is grounded-successful;
- sceptically accepted in all preferred extensions of $\mathcal{AF}_{\mathcal{K}}$ if there is a focused sub-dialogue $\delta^{\prime}$ of a dialogue for $\phi$ such that $\delta^{\prime}$ is sceptical-successful.*
## Appendix B Proofs for Section 5.2
We follow the general strategy to prove Theorem 5.13, 5.13, 5.2.2 and 5.15. In particular, we:
1. partition a dialogue tree for $\phi$ drawn from a dialogue $\delta$ into subtrees for $\phi$ drawn from the focused sub-dialogue of $\delta$ (by Lemma A.5),
1. use the correspondence principle to transfer each subtree for $\phi$ into an abstract dialogue tree for $\phi$ (by Theorem A.7),
1. apply Definition A.10 (analogous to Definition 9 in [52] and Corollary A.11 (analogous to Corollary 1 in [52]) for abstract dialogue trees to prove the soundness results.
### B.1. Proof of Theorem 5.13
*
* Proof*
Let $\mathcal{T}(\delta)$ be a dialogue tree drawn from a dialogue $\delta$ for $\phi$ . Let $\mathcal{T}(\delta_{1}),\ldots,\mathcal{T}(\delta_{m})$ be sub-trees (with root $\phi$ ) constructed from $\mathcal{T}(\delta)$ . By Lemma A.5, we know all sub-trees $\mathcal{T}(\delta_{i})$ of $\mathcal{T}(\delta)$ are the dialogue trees drawn from focused sub-dialogues $\delta_{i}$ , with $i=1,\ldots,m$ , of $\delta$ and each such sub-tree is focused. We assume that $\mathcal{T}(\delta_{i})$ is defensive and non-redundant. By the correspondence principle of Theorem A.7, there is an abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}^{i}$ for $\phi$ such that $\mathcal{DE}(\mathcal{T}_{\texttt{{G}}}^{i})=\mathcal{DE}(\mathcal{T}(\delta_{ i}))$ and $\mathcal{CU}(\mathcal{T}_{\texttt{{G}}}^{i})=\mathcal{CU}(\mathcal{T}(\delta_{ i}))$ . For such abstract dialogue tree, let $\mathcal{B}$ be a set of proponent arguments in $\mathcal{T}_{\texttt{{G}}}^{i}$ , we prove that
1. $\mathcal{B}$ attacks every attack against it and $\mathcal{B}$ does not attack itself;
1. no argument in $\mathcal{T}_{\texttt{{G}}}^{i}$ that labels both P or O. Since $\mathcal{T}(\delta_{i})$ is defensive and non-redundant, we get the following statements: 1. By Definition 5.9, it is focused. Then the root of $\mathcal{T}_{\texttt{{G}}}^{i}$ hold a proponent argument for $\phi$ .
1. By Definition 5.9, it is last-word. Then the proponent arguments in $\mathcal{T}_{\texttt{{G}}}^{i}$ are leaf nodes, i.e., P wins. Thus, $\mathcal{B}$ attacks every attack against it.
1. By Definition 5.9, $\mathcal{T}(\delta_{i})$ has no formulas $\alpha_{h}$ in opponent nodes belong to $\mathcal{DE}(\mathcal{T}(\delta_{i}))$ such that $\{\alpha_{h}\}\cup\mathcal{DE}(\mathcal{T}(\delta_{i}))$ is inconsistent. $h=0$ corresponds to the case that there is no potential argument, say $A$ , such that $\{\alpha\}$ is the support of $A$ and $A$ attacks any potential arguments supported by $\mathcal{DE}(\mathcal{T}(\delta_{i}))$ . Similarly, for $h>0$ , there are no potential arguments collectively attacking any potential arguments supported by $\mathcal{DE}(\mathcal{T}(\delta_{i}))$ . Thus, $\mathcal{B}$ does not attack itself.
1. By Definition 5.13 of non-redundant trees, there is no argument in $\mathcal{T}_{\texttt{{G}}}^{i}$ that labels both P or O. It can be seen that (b) and (c) prove (1), and (d) proves (2). It follows that $\mathcal{T}_{\texttt{{G}}}^{i}$ is admissible. This result directly follows from the definition of admissible abstract dialogue trees in Definition A.4 (analogous to those in [52]). By Definition A.10 (analogous to Definition 9 in [52]), $\delta_{i}$ is admissible-successful in the P-SAF framework $\mathcal{AF}_{\delta_{i}}$ drawn from $\delta_{i}$ (supported by $\mathcal{DE}(\mathcal{T}(\delta_{i}))$ ). Now, we need to show $\delta$ is admissible-successful. By Definition A.1, each tree in the abstract dialogue forest contains its own set of proponent arguments, namely, $\mathcal{DE}(\mathcal{T}_{\texttt{{G}}}^{i})\neq\mathcal{DE}(\mathcal{T}_{ \texttt{{G}}}^{l})$ , with $1\leq i,\ l\leq m,\ i\neq l$ . Thus, arguments in other trees do not affect arguments in $\mathcal{AF}_{\delta_{i}}$ . It follows that $\delta$ is admissible-successful. By Corollary A.11 (analogous to Corollary 1 in [52]), $\phi$ is credulously accepted under adm semantics in $\mathcal{AF}_{\delta}$ . ∎
### B.2. Proof of Theorem 5.2.2
The following lemma is used in the proof of Theorem 5.2.2
**Lemma B.1**
*An abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}$ is finite iff the set of arguments labelling P in $\mathcal{T}_{\texttt{{G}}}$ is a subset of the grounded set of arguments.*
* Proof*
Let $\mathcal{B}$ is a set of arguments labbeling P in $\mathcal{T}_{\texttt{{G}}}$ . We prove the lemma as follows: If part: The height of a finite dialogue tree $\mathcal{T}_{\texttt{{G}}}$ is $2h$ . We prove that $\mathcal{B}$ is a subset of the grounded set by induction on $h$ . Observer that (1) if $\mathcal{A}_{1}$ , $\mathcal{A}_{2}$ are an admissible subset of the grounded set, then so is $\mathcal{A}_{1}\cup\mathcal{A}_{2}$ ; (2) if an argument $A$ is accepted wrt $\mathcal{A}_{1}$ then $\mathcal{A}_{1}\cup\{A\}$ is an admissible subset of the grounded set. $h=0$ corresponds to dialogue trees containing a single node labelled by an argument that is not attacked. So $\mathcal{B}$ containing only that argument is a subset of the grounded set. Assume the assertion holds for all finite dialogue tree of height smaller than $2h$ . Let $A$ be an argument labelling P at the root of $\mathcal{T}_{\texttt{{G}}}$ . For each argument $B$ attacking a child of $A$ , let $\mathcal{T}_{B}$ be the subtree of $\mathcal{T}_{\texttt{{G}}}$ rooted at $B$ . Clearly, $\mathcal{T}_{B}$ is a finite dispute tree with height smaller than $2h$ . The union of sets of arguments labelling P of all $\mathcal{T}_{B}$ is a subset of the grounded set and defends $A$ . So $\mathcal{B}$ is a subset of the grounded set. Only if part: to construct a finite abstract dialogue tree for a groundedly accepted argument in a finite P-SAF framework, we need the following lemma: In a finite P-SAF framework, the grounded set equals $\emptyset\cup\mathcal{F}(\emptyset)\cup\mathcal{F}^{2}(\emptyset)\cup\cdots$ . This lemma follows from two facts, proven in [6], of the characteristic function $\mathcal{F}$ :
- $\mathcal{F}$ is monotonic w.r.t. set inclusion.
- if the argument framework is finite, then $\mathcal{F}$ is $\omega-$ continuous.
For each argument $A$ in the grounded set, $A$ can be ranked by a natural number $r(A)$ such that $A\in\mathcal{F}^{n(A)}(\emptyset)\setminus\mathcal{F}^{r(A)-1}(\emptyset)$ . So $r(A)=1$ , then $A$ belongs to the grounded set and is not attacked. $r(A)=2$ , the set of arguments (of the grounded set) defended by the set of arguments (of the grounded set) such that $r(A)\leq 1$ and so on. For each set of arguments $\mathcal{S}$ collectively attacking the grounded set, the rank of $\mathcal{S}$ is $\texttt{min}\{r(A)\mid A\text{ is in the grounded set and attacks some argument in }\mathcal{S}\}$ . Clearly, $\mathcal{S}$ does not attack any argument in the grounded set of rank smaller than the rank of $\mathcal{S}$ . Given any argument $A$ in the grounded set, we can build an abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}$ for $A$ as follows: The root of $\mathcal{T}_{\texttt{{G}}}$ is labelled by $A$ . For each set of arguments $\mathcal{S}$ attacking $A$ , we select a set of arguments $\mathcal{C}$ to counterattacks $\mathcal{S}$ such that the rank of $\mathcal{C}$ equals the rank of $\mathcal{S}$ , then for each set of arguments $\mathcal{E}$ attacking some arguments of $\mathcal{C}$ , we select arguments $\mathcal{F}$ to counterattacks $\mathcal{E}$ such that the rank of $\mathcal{F}$ equals to the rank of $\mathcal{E}$ , and so on. So for each branch of $\mathcal{T}_{\texttt{{G}}}$ , the rank of a proponent node is equal to that of its opponent parent node, but the rank of an opponent node is smaller than that of its parent proponent node. Clearly, ranking decreases downwards. So all branches of $\mathcal{T}_{\texttt{{G}}}$ are of finite length. Since the P-SAF is finite, $\mathcal{T}_{\texttt{{G}}}$ is finite in breath. Thus $\mathcal{T}_{\texttt{{G}}}$ is finite. ∎
*
* Proof*
Let $\mathcal{T}(\delta)$ be a dialogue tree drawn from a dialogue $\delta$ for $\phi$ and $\mathcal{T}(\delta_{1}),\ldots,\mathcal{T}(\delta_{m})$ (with root $\phi$ ) be subtrees of $\mathcal{T}(\delta)$ . By Lemma A.5, all sub-trees of $\mathcal{T}(\delta)$ are the dialogue trees drawn from focused sub-dialogues $\delta_{i}$ , with $i=1,\ldots,m$ , of $\delta$ and each such subtree is focused. Assume that $\mathcal{T}(\delta_{i})$ is defensive and finite. Since $\mathcal{T}(\delta_{i})$ is defensive, by the correspondence principle of Theorem A.7, there is an abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}^{i}$ for $\phi$ such that $\mathcal{DE}(\mathcal{T}_{\texttt{{G}}}^{i})=\mathcal{DE}(\mathcal{T}(\delta_{ i}))$ and $\mathcal{CU}(\mathcal{T}_{\texttt{{G}}}^{i})=\mathcal{CU}(\mathcal{T}(\delta_{ i}))$ . For such abstract dialogue tree, let $\mathcal{B}$ be the set of arguments labelling P in $\mathcal{T}_{\texttt{{G}}}^{i}$ . We need to show that 1. $\mathcal{T}_{\texttt{{G}}}^{i}$ is finite;
1. $\mathcal{B}$ attacks ever attract against it, and
1. $\mathcal{B}$ does not attack itself. Similar to the proof of Theorem 5.13, (2) and (3) directly follows from the fact that $\mathcal{T}(\delta_{i})$ is admissible. Trivially, every $\mathcal{T}(\delta_{i})$ is finite, then $\mathcal{T}_{\texttt{{G}}}^{i}$ is finite. As a direct consequence of Lemma B.1, we obtain that $\mathcal{B}$ is a subset of the grounded set of arguments in $\mathcal{T}_{\texttt{{G}}}^{i}$ . By Definition A.10 (analogous to Definition 9 in [52]), $\delta_{i}$ is grounded-successful in $\mathcal{AF}_{\delta_{i}}$ (drawn from $\delta_{i}$ ). We next prove that $\delta$ is grounded-successful. Since $\delta_{i}$ is grounded-successful in $\mathcal{AF}_{\delta_{i}}$ drawn from $\delta_{i}$ , it follows that there are no arguments attacking the arguments in $\mathcal{B}$ that have not been counter-attacked in the abstract dialogue forest $\mathcal{T}_{\texttt{{G}}}^{1},\ldots,\mathcal{T}_{\texttt{{G}}}^{m}$ (obtained from the P-SAF drawn from $\delta$ ). By Definition A.1, each tree in the abstract dialogue forest contains its own set of proponent arguments, namely, $\mathcal{DE}(\mathcal{T}_{\texttt{{G}}}^{i})\neq\mathcal{DE}(\mathcal{T}_{ \texttt{{G}}}^{l})$ , with $1\leq i,\ l,\leq m,\ i\neq l$ . If the set of proponent arguments in $\mathcal{T}_{\texttt{{G}}}^{i}$ drawn from the focused sub-dialogue $\delta_{i}$ is grounded, it is also grounded in $\mathcal{AF}_{\delta}$ drawn from $\delta$ . Thus, $\delta$ is grounded successful. By Corollary A.11 (analogous to Corollary 1 in [52]), $\phi$ is groundedly accepted in $\mathcal{AF}_{\delta}$ (supported by $\mathcal{DE}(\mathcal{T}(\delta_{i}))$ ). ∎
### B.3. Proof of Theorem 5.15
*
* Proof*
We prove this theorem for the case of admissible semantics. The proof for preferred (stable) semantics is analogous. Let $\mathcal{T}(\delta)$ be a dialogue tree drawn from a dialogue $\delta$ for $\phi$ , and $\mathcal{T}(\delta_{1}),\ldots,\mathcal{T}(\delta_{m})$ (with root $\phi$ ) be subtrees constructed from $\mathcal{T}(\delta)$ . By Lemma A.5, we know all subtrees in $\mathcal{T}(\delta)$ are dialogue trees drawn from focused sub-dialogues $\delta_{i}$ , ( $i=1,\ldots,m$ ) of $\delta$ and each tree is focused. Assume that $\mathcal{T}(\delta)$ is ideal. Since $\mathcal{T}(\delta)$ is ideal, $\mathcal{T}(\delta_{i})$ is ideal. By Definition 5.15, $\mathcal{T}(\delta_{i})$ is defensive. By the correspondence principle, there is an abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}^{i}$ for $\phi$ such that $\mathcal{DE}(\mathcal{T}_{\texttt{{G}}}^{i})=\mathcal{DE}(\mathcal{T}(\delta_{ i}))$ and $\mathcal{CU}(\mathcal{T}_{\texttt{{G}}}^{i})=\mathcal{CU}(\mathcal{T}(\delta_{ i}))$ . For such abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}^{i}$ , we need to show that:
1. $\mathcal{T}_{\texttt{{G}}}^{i}$ is admissible, and
1. for no opponent node O in it there exists an admissible dialogue tree for the opponent argument. Similar to the proof of Theorem 5.13, (1) holds. Since $\mathcal{T}(\delta)$ is ideal, by Definition 5.15, there is a dialogue tree $\mathcal{T}(\delta_{i})$ such that none of the opponent arguments drawn from $\mathcal{T}(\delta_{i})$ belongs to an admissible set of arguments in $\mathcal{AF}_{\delta}$ drawn from $\delta$ . Then, (2) holds. We have shown that $\mathcal{T}_{\texttt{{G}}}^{i}$ is defensive and none of the opponent arguments belongs to an admissible set of arguments in $\mathcal{AF}_{\delta}$ drawn from $\delta$ . By Definition A.10 (analogous to Definition 9 in [52]), $\delta$ is sceptical-successful. By Corollary A.11 (analogous to Corollary 1 in [52]), $\phi$ is sceptically accepted in $\mathcal{AF}_{\delta}$ . ∎
## Appendix C Proofs for Section 5.3
To prove the completeness results, we
1. partition a dialogue $\delta$ for $\phi$ into its focused sub-dialogues of $\delta$ (by Definition 4.3),
1. apply Corollary C.1 and Definition A.10 (analogous to Definition 9 in [52]) to obtain the existence of an abstract dialogue tree drawn from each focused sub-dialogue of $\delta$ wrt argumentation semantics,
1. use the correspondence principle to transfer from each abstract dialogue tree for $\phi$ into a dialogue tree for $\phi$ (by Theorem A.7), thereby proving the completeness results.
### C.1. Preliminaries
Corollary A.11 is used for the proof of the soundness results. To prove the completeness result, we need to extend Corollary A.11 as follows:
**Corollary C.1**
*Let $\mathcal{K}$ be a KB, $\phi\in\mathcal{L}$ a formula and $\mathcal{AF}_{\mathcal{K}}$ be the corresponding P-SAF of $\mathcal{K}$ . We say that if $\phi$ is - credulously accepted in some admissible/preferred extension of $\mathcal{AF}_{\mathcal{K}}$ , then there is a focused sub-dialogue $\delta_{i}$ , with $i=1,\ldots,m$ , of a dialogue for $\phi$ such that $\delta_{i}$ is admissible/preferred-successful;
- groundedly accepted in a grounded extension of $\mathcal{AF}_{\mathcal{K}}$ , then there is a focused sub-dialogue $\delta_{i}$ of a dialogue for $\phi$ such that $\delta_{i}$ is grounded-successful;
- sceptically accepted in all preferred extensions of $\mathcal{AF}_{\mathcal{K}}$ , then there is a focused sub-dialogue $\delta_{i}$ of a dialogue for $\phi$ such that $\delta_{i}$ is sceptical-successful.*
* Proof*
Let $\mathcal{T}(\delta)$ be a dialogue tree drawn from a dialogue $\delta$ for $\phi$ and $\mathcal{T}(\delta_{1}),\ldots,\mathcal{T}(\delta_{m})$ (with root $\phi$ ) be subtrees of $\mathcal{T}(\delta)$ . By Lemma A.5, all sub-trees of $\mathcal{T}(\delta)$ are the dialogue trees drawn from focused sub-dialogues $\delta_{i}$ , with $i=1,\ldots,m$ , of $\delta$ and each such subtree is focused. By the correspondence principle, there is an abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}^{i}$ for an argument $A$ with conclusion $\phi$ , or simply, an abstract dialogue $\mathcal{T}_{\texttt{{G}}}^{i}$ for $\phi$ , which corresponds to the dialogue tree $\mathcal{T}(\delta_{i})$ for $\phi$ . It is clear that there is a focused sub-dialogue $\delta_{i}$ such that it is admissible-successful if $\phi$ is credulously accepted in some admissible/preferred extension of $\mathcal{AF}_{\mathcal{K}}$ . The argument given in Definition 2 and Lemma 1 of [49] for binary attacks generalizes to collective attacks, implying that $A$ is accepted in some admissible extension iff $\mathcal{T}_{\texttt{{G}}}^{i}$ is admissible which in turn holds iff P wins and no argument labels both a proponent and an opponent node. By Definition A.10, $\delta_{i}$ is admissible-successful iff $\mathcal{T}_{\texttt{{G}}}^{i}$ is admissible. Thus, the statement is proved. $\delta_{i}$ is preferred-successful if $\delta_{i}$ is admissible-successful. This result directly follows from the results of [6] that states that an extension is preferred if it is admissible. Thus, if $\phi$ is credulously accepted in some preferred extension, then $\delta_{i}$ is preferred-successful. The other statement follows in a similar way as a straightforward generalization of Theorem 1 of [49] for the ”grounded-successful” semantic; Definition 3.3 and Theorem 3.4 of [13] for the ”sceptical-successful” semantic. ∎
### C.2. Proof of Theorem 8
*
* Proof*
Given $\delta$ be a dialogue for a formula $\phi\in\mathcal{L}$ , we assume that $\phi$ is credulously accepted under adm in $\mathcal{AF}_{\delta}$ drawn from $\delta$ and $\delta$ is admissible-successful. We prove that there exists a dialogue tree drawn from the sub-dialogue of $\delta$ such that the dialogue tree is defensive and non-redundant. Let $\delta_{1},\ldots,\delta_{m}$ , where $i=1,\ldots,m$ , be sub-dialogues of $\delta$ and each sub-dialogue is focused. Since $\phi$ is credulously accepted under adm in $\mathcal{AF}_{\delta}$ drawn from the dialogue $\delta$ , by Corollary C.1, the focused sub-dialogue $\delta_{i}$ is admissible-successful. By Definition A.10 (analogous to Definition 9 in [52]), there is an admissible abstract dialogue tree $\mathcal{T}^{i}_{\texttt{{G}}}$ for $\phi$ drawn from the admissible-successful dialogue $\delta_{i}$ . By the correspondence principle, there exists a dialogue tree $\mathcal{T}(\delta_{i})$ for $\phi$ that corresponds to the abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}^{i}$ for $\phi$ such that $\mathcal{DE}(\mathcal{T}_{\texttt{{G}}}^{i})=\mathcal{DE}(\mathcal{T}(\delta_{ i}))$ and $\mathcal{CU}(\mathcal{T}_{\texttt{{G}}}^{i})=\mathcal{CU}(\mathcal{T}(\delta_{ i}))$ . Since $\mathcal{T}_{\texttt{{G}}}^{i}$ is admissible, $\mathcal{T}(\delta_{i})$ is defensive and non-redundant. Thus, the statement is proved. ∎
### C.3. Proof of Theorem 8
*
* Proof*
Given $\delta$ be a dialogue for a formula $\phi\in\mathcal{L}$ , we assume that $\phi$ is groundedly accepted under grd in $\mathcal{AF}_{\delta}$ drawn from $\delta$ and $\delta$ is groundedly-successful. We prove that there exists a dialogue tree drawn from the sub-dialogue of $\delta$ such that the dialogue tree is defensive and finite. Let $\delta_{1},\ldots,\delta_{m}$ , where $i=1,\ldots,m$ , be sub-dialogues of $\delta$ and each sub-dialogue is focused. Since $\phi$ is groundedly accepted under grd in $\mathcal{AF}_{\delta}$ drawn from the dialogue $\delta$ , by Corollary C.1, the focused sub-dialogue $\delta_{i}$ is grounded-successful. By Definition A.10 (analogous to Definition 9 in [52]), there is an admissible and finite abstract dialogue tree $\mathcal{T}^{i}_{\texttt{{G}}}$ for $\phi$ drawn from the grounded-successful dialogue $\delta_{i}$ . By the correspondence principle, there is a dialogue tree $\mathcal{T}(\delta_{i})$ for $\phi$ that corresponds to the abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}^{i}$ for $\phi$ such that $\mathcal{DE}(\mathcal{T}(\delta_{i}))=\mathcal{DE}(\mathcal{T}_{\texttt{{G}}}^ {i})$ and $\mathcal{CU}(\mathcal{T}(\delta_{i}))=\mathcal{CU}(\mathcal{T}_{\texttt{{G}}}^ {i})$ . Since $\mathcal{T}_{\texttt{{G}}}^{i}$ is admissible, $\mathcal{T}(\delta_{i})$ is defensive. Since $\mathcal{T}_{\texttt{{G}}}^{i}$ is finite, $\mathcal{T}(\delta_{i})$ is finite. Thus, the statement is proved. ∎
### C.4. Proof of Theorem 8
*
* Proof*
We prove this theorem for the case of admissible semantics. The proof for preferred (stable) semantics is analogous. Given $\delta$ be a dialogue for a formula $\phi\in\mathcal{L}$ , we assume that $\phi$ is credulously accepted under adm in $\mathcal{AF}_{\delta}$ drawn from $\delta$ and $\delta$ is admissible-successful. We prove that there is an ideal dialogue tree $\mathcal{T}(\delta)$ for $\phi$ drawn from the dialogue $\delta$ . Let $\delta_{1},\ldots,\delta_{m}$ , where $i=1,\ldots,m$ , be focused sub-dialogues of $\delta$ . Since $\phi$ is sceptically accepted under adm in $\mathcal{AF}_{\delta}$ drawn from the dialogue $\delta$ , by Corollary C.1, the focused sub-dialogue $\delta_{i}$ is sceptical-successful. By Definition A.10 (analogous to Definition 9 in [52]), there is an abstract dialogue tree $\mathcal{T}^{i}_{\texttt{{G}}}$ for $\phi$ drawn from the sceptical-successful dialogue $\delta_{i}$ such that $\mathcal{T}^{i}_{\texttt{{G}}}$ is admissible and for no opponent node in it there exists an admissible abstract dialogue tree for the argument labelling an opponent node. Since $\mathcal{T}^{i}_{\texttt{{G}}}$ is admissible, by the correspondence principle, there is a dialogue tree $\mathcal{T}(\delta_{i})$ for $\phi$ that corresponds to the abstract dialogue tree $\mathcal{T}_{\texttt{{G}}}^{i}$ for $\phi$ such that $\mathcal{DE}(\mathcal{T}(\delta_{i}))=\mathcal{DE}(\mathcal{T}_{\texttt{{G}}}^ {i})$ and $\mathcal{CU}(\mathcal{T}(\delta_{i}))=\mathcal{CU}(\mathcal{T}_{\texttt{{G}}}^ {i})$ . For such the dialogue tree $\mathcal{T}(\delta_{i})$ , we need to show that:
1. $\mathcal{T}(\delta_{i})$ is defensive and non-redundant,
1. none of the opponent arguments obtained from $\mathcal{T}(\delta_{i})$ belongs to an admissible set of potential arguments in $\mathcal{AF}_{\delta_{i}}$ drawn from $\mathcal{T}(\delta_{i})$ . Since the abstract dialogue $\mathcal{T}_{\texttt{{G}}}^{i}$ is admissible, (1) holds. We have that, for no opponent node in $\mathcal{T}_{\texttt{{G}}}^{i}$ , there exists an admissible abstract dialogue tree for the argument labelling by O. From this, we obtain that (2) holds. By Definition 5.15, $\mathcal{T}(\delta_{i})$ is ideal. Thus, $\mathcal{T}(\delta)$ is ideal. Thus, the statement is proved. ∎
## References
- [1] Cali, A., Gottlob, G., Lukasiewicz, T. & Pieris, A. Datalog+-: A Family of Languages for Ontology Querying. Workshop, Datalog. (2011)
- [2] Baget, J., Leclère, M., Mugnier, M. & Salvat, E. On rules with existential variables: Walking the decidability line. Artificial Intelligence. (2011)
- [3] Alrabbaa, C., Baader, F., Borgwardt, S., Koopmann, P. & Kovtunova, A. Finding Small Proofs for Description Logic Entailments: Theory and Practice. (2020)
- [4] Thang, P., Dung, P. & Pooksook, J. Infinite arguments and semantics of dialectical proof procedures. Argument Comput.. 13, 121-157 (2022)
- [5] Marnette, B. Generalized Schema-Mappings: From Termination to Tractability. ACM Symposium On Principles Of Database Systems. (2009)
- [6] Dung, P. On the Acceptability of Arguments and its Fundamental Role in Nonmonotonic Reasoning, Logic Programming and n-Person Games. Artif. Intell.. 77, 321-358 (1995)
- [7] Ho, L., Arch-int, S., Acar, E., Schlobach, S. & Arch-int, N. An argumentative approach for handling inconsistency in prioritized Datalog $\pm$ ontologies. AI Commun.. 35, 243-267 (2022)
- [8] Yun, B., Croitoru, M., Vesic, S. & Bisquert, P. Graph Theoretical Properties of Logic Based Argumentation Frameworks: Proofs and General Results. Proceeding Of GKR. (2017)
- [9] Yun, B., Vesic, S. & Croitoru, M. Toward a More Efficient Generation of Structured Argumentation Graphs. COMMA. (2018)
- [10] Amgoud, L. Postulates for logic-based argumentation systems. IJAR. (2014)
- [11] Borg, A. & Bex, F. A Basic Framework for Explanations in Argumentation. IEEE Intelligent Systems. (2021)
- [12] Vreeswijk, G. & Prakken, H. Credulous and Sceptical Argument Games for Preferred Semantics. JELIA. 1919 pp. 239-253 (2000)
- [13] Dung, P., Mancarella, P. & Toni, F. Computing ideal sceptical argumentation. Artificial Intelligence. 171, 642-674 (2007)
- [14] Zhang, X. & Lin, Z. An argumentation framework for description logic ontology reasoning and management. J. Intell. Inf. Syst.. 40, 375-403 (2013)
- [15] Lacave, C. & Diez, F. A review of explanation methods for heuristic expert systems. The Knowledge Engineering Review. (2024)
- [16] Lukasiewicz, T., Malizia, E., Martinez, M., Molinaro, C., Pieris, A. & Simari, G. Inconsistency-tolerant query answering for existential rules. Artificial Intelligence. (2022)
- [17] Lukasiewicz, T., Malizia, E. & Molinaro, C. Explanations for Negative Query Answers under Inconsistency-Tolerant Semantics. Proceedings Of IJCAI. (2022)
- [18] Lukasiewicz, T., Malizia, E. & Molinaro, C. Explanations for Inconsistency-Tolerant Query Answering under Existential Rules. The Thirty-Fourth AAAI Conference On Artificial Intelligence. pp. 2909-2916 (2020)
- [19] Arioua, A., Croitoru, M. & Vesic, S. Logic-based argumentation with existential rules. Int. J. Approx. Reason.. 90 pp. 76-106 (2017)
- [20] Arioua, A. & Croitoru, M. Dialectical Characterization of Consistent Query Explanation with Existential Rules. Proceedings Of The Twenty-Ninth International Florida Artificial Intelligence Research Society Conference, FLAIRS. (2016)
- [21] Arioua, A., Tamani, N. & Croitoru, M. Query Answering Explanation in Inconsistent Datalog $\pm$ Knowledge Bases. In DEXA. 9261 pp. 203-219 (2015)
- [22] Bienvenu, M., Bourgaux, C. & Goasdoué, F. Computing and Explaining Query Answers over Inconsistent DL-Lite Knowledge Bases. J. Artif. Intell. Res.. 64 pp. 563-644 (2019)
- [23] Prakken, H. Formal systems for persuasion dialogue. Knowl. Eng. Rev.. 21, 163-188 (2006)
- [24] Alrabbaa, C., Borgwardt, S., Koopmann, P. & Kovtunova, A. Explaining Ontology-Mediated Query Answers Using Proofs over Universal Models. RuleML+RR. 13752 pp. 167-182 (2022)
- [25] Nielsen, S. & Parsons, S. A Generalization of Dung’s Abstract Framework for Argumentation: Arguing with Sets of Attacking Arguments. Argumentation In Multi-Agent Systems. pp. 54-73 (2007)
- [26] Calì, A., Gottlob, G. & Lukasiewicz, T. A general Datalog-based framework for tractable query answering over ontologies. Jour. Of Web Semantics. 14 pp. 57-83 (2012)
- [27] Halpern, J. Defining Relative Likelihood in Partially-Ordered Preferential Structures. Procceeding Of UAI. (1996)
- [28] Cayrol, C., Dubois, D. & Touazi, F. On the Semantics of Partially Ordered Bases.
- [29] Modgil, S. & Caminada, M. Proof Theories and Algorithms for Abstract Argumentation Frameworks. (2009)
- [30] Deagustini, C., Martinez, M., Falappa, M. & Simari, G. On the Influence of Incoherence in Inconsistency-tolerant Semantics for Datalog $\pm$ . IJCAI. (2015)
- [31] Amgoud, L. & Vesic, S. Rich preference-based argumentation frameworks. International Journal Of Approximate Reasoning. 55, 585-606 (2014)
- [32] Kaci, S., Der Torre, L., Vesic, S. & Villata, S. Preference in Abstract Argumentation. Handbook Of Formal Argumentation, Volume 2. (2021)
- [33] Arioua, A., Buche, P. & Croitoru, M. Explanatory dialogues with argumentative faculties over inconsistent knowledge bases. Expert Systems With Applications. 80 pp. 244-262 (2017)
- [34] Arioua, A., Tamani, N., Croitoru, M. & Buche, P. Query Failure Explanation in Inconsistent Knowledge Bases Using Argumentation. Comma. (2014)
- [35] Yun, B., Vesic, S. & Croitoru, M. Sets of Attacking Arguments for Inconsistent Datalog Knowledge Bases. Comma. (2020)
- [36] Dunne, P. & Bench-Capon, T. Two party immediate response disputes: Properties and efficiency. Artificial Intelligence. 149, 221-250 (2003)
- [37] Cayrol, C., Doutre, S. & Mengin, J. Dialectical Proof Theories for the Credulous Preferred Semantics of Argumentation Frameworks. ECSQARU, Proceedings. pp. 668-679 (2001)
- [38] Arieli, O. & Straßer, C. Sequent-based logical argumentation. Argument Comput.. 6, 73-99 (2015)
- [39] D’Agostino, M. & Modgil, S. Classical logic, argument and dialectic. Artif. Intell.. 262 pp. 15-51 (2018)
- [40] Amgoud, L. & Besnard, P. Logical limits of abstract argumentation frameworks. J. Appl. Non Class. Logics. 23, 229-267 (2013)
- [41] Schulz, C. & Toni, F. Justifying answer sets using argumentation. Theory And Practice Of Logic Programming. 16, 59-110 (2016)
- [42] Prakken, H. Coherence and Flexibility in Dialogue Games for Argumentation. J. Log. Comput.. 15, 1009-1040 (2005)
- [43] Dung, P., Kowalski, R. & Toni, F. Dialectic proof procedures for assumption-based, admissible argumentation. Artif. Intell.. 170, 114-159 (2006)
- [44] Dung, P., Kowalski, R. & Toni, F. Assumption-Based Argumentation. Argumentation In Artificial Intelligence. pp. 199-218 (2009)
- [45] Garcia, A. & Simari, G. Defeasible logic programming: DeLP-servers, contextual queries, and explanations for answers. Argument Comput.. 5, 63-88 (2014)
- [46] Prakken, H. & Vreeswijk, G. Logics for Defeasible Argumentation. Handbook Of Philosophical Logic. (2002)
- [47] Fan, X. & Toni, F. A general framework for sound assumption-based argumentation dialogues. Artif. Intell.. 216 pp. 20-54 (2014)
- [48] Thang, P., Dung, P. & Hung, N. Towards Argument-based Foundation for Sceptical and Credulous Dialogue Games. Proceedings Of COMMA. 245 pp. 398-409 (2012)
- [49] Thang, P., Dung, P. & Hung, N. Towards a Common Framework for Dialectical Proof Procedures in Abstract Argumentation. J. Log. Comput.. 19 (2009)
- [50] Castagna, F. A Dialectical Characterisation of Argument Game Proof Theories for Classical Logic Argumentation. Proceedings Of AIxIA. 3086 (2021)
- [51] D’Agostino, M. & Modgil, S. Classical logic, argument and dialectic. Artif. Intell.. 262 pp. 15-51 (2018)
- [52] Ho, L. & Schlobach, S. A General Dialogue Framework for Logic-based Argumentation. Proceedings Of The 2nd International Workshop On Argumentation For EXplainable AI. 3768 pp. 41-55 (2024)
- [53] Dimopoulos, Y., Dvorák, W., König, M., Rapberger, A., Ulbricht, M. & Woltran, S. Redefining ABA+ Semantics via Abstract Set-to-Set Attacks. AAAI. pp. 10493-10500 (2024)
- [54] Bienvenu, M. & Bourgaux, C. Querying and Repairing Inconsistent Prioritized Knowledge Bases: Complexity Analysis and Links with Abstract Argumentation. Proceedings Of KR. pp. 141-151 (2020)
- [55] Borg, A., Arieli, O. & Straßer, C. Hypersequent-Based Argumentation: An Instantiation in the Relevance Logic RM. Proceeding Of TAFA. (2017)
- [56] Hunter, A. Base Logics in Argumentation. Proceedings Of COMMA. 216 pp. 275-286 (2010)
- [57] Priest, G. Reasoning About Truth. Artif. Intell.. 39, 231-244 (1989)
- [58] Belnap, N. A Useful Four-Valued Logic. Modern Uses Of Multiple-Valued Logic. pp. 5-37 (1977)
- [59] Besnard, P. & Hunter, A. A logic-based theory of deductive arguments. Artif. Intell.. 128, 203-235 (2001)
- [60] Heyninck, J. & Arieli, O. Simple contrapositive assumption-based argumentation frameworks. Int. J. Approx. Reason.. 121 pp. 103-124 (2020)
- [61] Amgoud, L. Five Weaknesses of ASPIC +. IPMU 2012 Proceedings. 299 pp. 122-131 (2012)
- [62] Modgil, S. & Prakken, H. The ASPIC+ framework for structured argumentation: a tutorial. Argument Comput.. 5, 31-62 (2014)
- [63] Arieli, O. & Heyninck, J. Collective Attacks in Assumption-Based Argumentation. Proceedings Of The 39th ACM/SIGAPP Symposium On Applied Computing,SAC. pp. 746-753 (2024)
- [64] Caminada, M. & Amgoud, L. On the evaluation of argumentation formalisms. Artif. Intell.. 171, 286-310 (2007)
- [65] Jesse Heyninck, O. Simple contrapositive assumption-based argumentation frameworks. International Journal Of Approximate Reasoning. 121 pp. 103-124 (2020)
- [66] Krötzsch, M., Rudolph, S. & Schmitt, P. A closer look at the semantic relationship between Datalog and description logics. Semantic Web. 6, 63-79 (2015)
- [67] Rapberger, A., Ulbricht, M. & Toni, F. On the Correspondence of Non-flat Assumption-based Argumentation and Logic Programming with Negation as Failure in the Head. CoRR. abs/2405.09415 (2024)
- [68] Lehtonen, T., Rapberger, A., Toni, F., Ulbricht, M. & Wallner, J. Instantiations and Computational Aspects of Non-Flat Assumption-based Argumentation. CoRR. abs/2404.11431 (2024)
- [69] Arieli, O. & Straßer, C. Logical argumentation by dynamic proof systems. Theor. Comput. Sci.. 781 pp. 63-91 (2019)
- [70] Alsinet, T., Béjar, R. & Godo, L. A characterization of collective conflict for defeasible argumentation. Computational Models Of Argument: Proceedings Of COMMA 2010. 216 pp. 27-38 (2010)
- [71] Amgoud, L. & Besnard, P. Bridging the Gap between Abstract Argumentation Systems and Logic. Scalable Uncertainty Management. pp. 12-27 (2009)
- [72] Bloom, S. Some Theorems on Structural Consequence Operations. Studia Logica: An International Journal For Symbolic Logic. 34, 1-9 (1975)
- [73] Hecham, A., Bisquert, P. & Croitoru, M. On the Chase for All Provenance Paths with Existential Rules. Rules And Reasoning - International Joint Conference, RuleML+RR. 10364 pp. 135-150 (2017)