# S2r: Teaching LLMs to Self-verify and Self-correct via Reinforcement Learning
> Equal contribution. This work was done during Peisong, Cheng, Jiaqi and Bang were interning at Tencent. Corresponding authors.
## Abstract
Recent studies have demonstrated the effectiveness of LLM test-time scaling. However, existing approaches to incentivize LLMs’ deep thinking abilities generally require large-scale data or significant training efforts. Meanwhile, it remains unclear how to improve the thinking abilities of less powerful base models. In this work, we introduce S 2 r, an efficient framework that enhances LLM reasoning by teaching models to self-verify and self-correct during inference. Specifically, we first initialize LLMs with iterative self-verification and self-correction behaviors through supervised fine-tuning on carefully curated data. The self-verification and self-correction skills are then further strengthened by both outcome-level and process-level reinforcement learning, with minimized resource requirements, enabling the model to adaptively refine its reasoning process during inference. Our results demonstrate that, with only 3.1k self-verifying and self-correcting behavior initialization samples, Qwen2.5-math-7B achieves an accuracy improvement from 51.0% to 81.6%, outperforming models trained on an equivalent amount of long-CoT distilled data. Extensive experiments and analysis based on three base models across both in-domain and out-of-domain benchmarks validate the effectiveness of S 2 r. Our code and data are available at https://github.com/NineAbyss/S2R.
S 2 r: Teaching LLMs to Self-verify and Self-correct via Reinforcement Learning
Ruotian Ma 1 thanks: Equal contribution. This work was done during Peisong, Cheng, Jiaqi and Bang were interning at Tencent., Peisong Wang 2 footnotemark: , Cheng Liu 1, Xingyan Liu 1, Jiaqi Chen 3, Bang Zhang 1, Xin Zhou 4, Nan Du 1 thanks: Corresponding authors. , Jia Li 5 To ensure a fair comparison, we report the Pass@1 (greedy) accuracy obtained without the process preference model of rStar, rather than the result obtained with increased test-time computation using 64 trajectories. 1 Tencent 2 Tsinghua University 3 The University of Hong Kong 4 Fudan University 5 The Hong Kong University of Science and Technology (Guangzhou) ruotianma@tencent.com, wps22@mails.tsinghua.edu.cn
## 1 Introduction
Recent advancements in Large Language Models (LLMs) have demonstrated a paradigm shift from scaling up training-time efforts to test-time compute Snell et al. (2024a); Kumar et al. (2024); Qi et al. (2024); Yang et al. (2024). The effectiveness of scaling test-time compute is illustrated by OpenAI o1 OpenAI (2024), which shows strong reasoning abilities by performing deep and thorough thinking, incorporating essential skills like self-checking, self-verifying, self-correcting and self-exploring during the model’s reasoning process. This paradigm not only enhances reasoning in domains like mathematics and science but also offers new insights into improving the generalizability, helpfulness and safety of LLMs across various general tasks OpenAI (2024); Guo et al. (2025).
<details>
<summary>x1.png Details</summary>
### Visual Description
## Scatter Plot: Model Accuracy vs. Data Size on MATH500
### Overview
The image is a scatter plot comparing the performance of five different AI models on the "MATH500" benchmark. The chart plots model accuracy against the logarithm (base 10) of the training data size used. Each model is represented by a single, distinctively colored data point with an embedded label.
### Components/Axes
* **Chart Title:** "MATH500" (centered at the top).
* **Y-Axis:** Labeled "Accuracy (%)". The scale runs from 76 to 86, with major tick marks and grid lines at intervals of 2% (76, 78, 80, 82, 84, 86).
* **X-Axis:** Labeled "Data Size (log₁₀)". The scale runs from 3 to 8, with major tick marks and grid lines at integer intervals (3, 4, 5, 6, 7, 8).
* **Data Series & Legend:** There is no separate legend box. Labels are placed directly adjacent to their corresponding data points within the plot area. The five models and their associated colors are:
1. **Qwen2.5-Math-7B-S²R-ORL (ours)** - Green circle.
2. **Qwen2.5-Math-7B-Instruct** - Pink circle.
3. **Eurus-2-7B-PRIME** - Orange circle.
4. **rStar-Math-7B** - Blue circle.
5. **Qwen2.5-7B-SimpleRL-Zero** - Purple circle.
### Detailed Analysis
The plot contains five data points. The following table reconstructs the approximate values based on visual inspection of the chart. All accuracy values are approximate (%).
| Model Name | Color | Approx. Data Size (log₁₀) | Approx. Accuracy (%) | Spatial Position (Relative) |
| :--- | :--- | :--- | :--- | :--- |
| **Qwen2.5-Math-7B-S²R-ORL (ours)** | Green | 4.0 | 84.5 | Top-left quadrant |
| **Qwen2.5-Math-7B-Instruct** | Pink | 6.5 | 83.2 | Top-right quadrant |
| **Eurus-2-7B-PRIME** | Orange | 5.5 | 79.2 | Center |
| **rStar-Math-7B** | Blue | 7.0 | 78.4 | Bottom-right quadrant |
| **Qwen2.5-7B-SimpleRL-Zero** | Purple | 3.9 | 77.2 | Bottom-left quadrant |
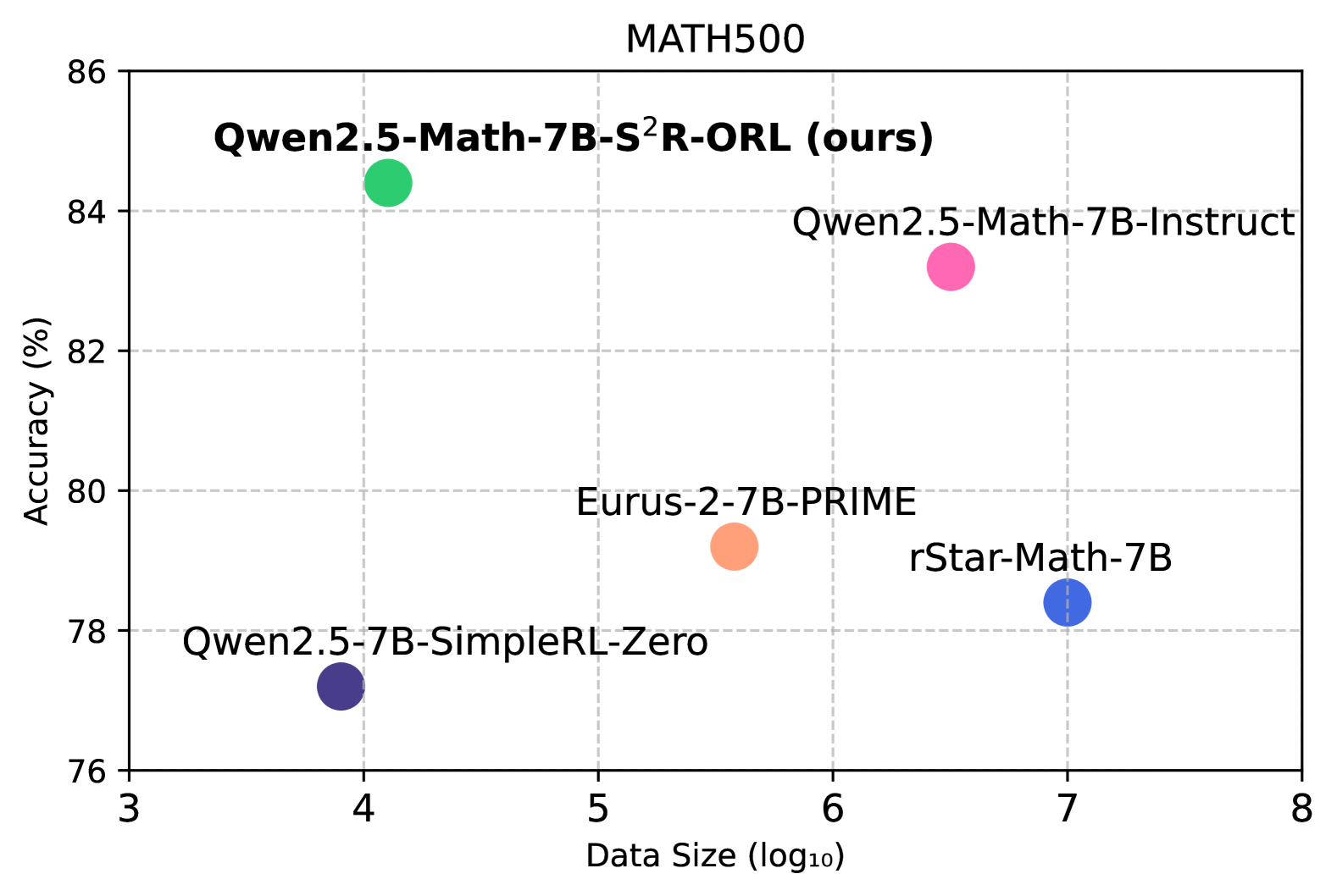
**Trend Verification:** There is no single linear trend across all models. The highest accuracy is achieved by the green point ("ours") at a relatively low data size. The pink point ("Instruct") has the second-highest accuracy but uses significantly more data. The blue point ("rStar-Math") uses the most data but has lower accuracy than three other models. The purple point ("SimpleRL-Zero") uses the least data and has the lowest accuracy.
### Key Observations
1. **Efficiency Leader:** The model labeled "(ours)" achieves the highest accuracy (~84.5%) with a comparatively small data size (log₁₀ ≈ 4.0, or ~10,000 samples).
2. **Data vs. Performance:** Increased data size does not guarantee higher accuracy. The model with the largest data size (rStar-Math-7B, log₁₀=7.0 or 10 million samples) performs worse than three models trained on less data.
3. **Clustering:** Two models (Qwen2.5-Math-7B-Instruct and Eurus-2-7B-PRIME) occupy the middle ground in both data size and accuracy.
4. **Baseline Comparison:** The "SimpleRL-Zero" model serves as a low-data, low-accuracy baseline in this comparison.
### Interpretation
This scatter plot is likely from a research paper or technical report introducing the "Qwen2.5-Math-7B-S²R-ORL" model. The primary message is one of **data efficiency and superior performance**. The authors demonstrate that their model ("ours") achieves state-of-the-art accuracy on the MATH500 benchmark while requiring orders of magnitude less training data than competing models like rStar-Math-7B.
The plot challenges the simple assumption that "more data is always better" for this specific task and model scale (7B parameters). It suggests that the training methodology (implied by names like "S²R-ORL", "Instruct", "PRIME", "SimpleRL") is a critical factor, potentially more so than raw data volume. The outlier position of the green point in the top-left quadrant is the key visual argument for the effectiveness of the authors' proposed method.
</details>
Figure 1: The data efficiency of S 2 r compared to competitive methods, with all models initialized from Qwen2.5-Math-7B.
Recent studies have made various attempts to replicate the success of o1. These efforts include using large-scale Monte Carlo Tree Search (MCTS) to construct long-chain-of-thought (long-CoT) training data, or to scale test-time reasoning to improve the performance of current models Guan et al. (2025); Zhao et al. (2024); Snell et al. (2024b); constructing high-quality long-CoT data for effective behavior cloning with substantial human effort Qin et al. (2024); and exploring reinforcement learning to enhance LLM thinking abilities on large-scale training data and models Guo et al. (2025); Team et al. (2025); Cui et al. (2025); Yuan et al. (2024). Recently, DeepSeek R1 Guo et al. (2025) demonstrated that large-scale reinforcement learning can incentivize LLM’s deep thinking abilities, with the R1 series showcasing the promising potential of long-thought reasoning. However, these approaches generally requires significant resources to enhance LLMs’ thinking abilities, including large datasets, substantial training-time compute, and considerable human effort and time costs. Meanwhile, it remains unclear how to incentivize valid thinking in smaller or less powerful LLMs beyond distilling knowledge from more powerful models.
In this work, we propose S 2 r, an efficient alternative to enhance the thinking abilities of LLMs, particularly for smaller or less powerful LLMs. Instead of having LLMs imitate the thinking process of larger, more powerful models, S 2 r focus on teaching LLMs to think deeply by iteratively adopting two critical thinking skills: self-verifying and self-correcting. By acquiring these two capabilities, LLMs can continuously reassess their solutions, identify mistakes during solution exploration, and refine previous solutions after self-checking. Such a paradigm also enables flexible allocation of test-time compute to different levels of problems. Our results show that, with only 3.1k training samples, Qwen2.5-math-7B significantly benefits from learning self-verifying and self-correcting behaviors, achieving a 51.0% to 81.6% accuracy improvement on the Math500 test set. This performance outperforms the same base model distilled from an equivalent amount of long-CoT data (accuracy 80.2%) from QwQ-32B-Preview Team (2024a).
More importantly, S 2 r employs both outcome-level and process-level reinforcement learning (RL) to further enhance the LLMs’ self-verifying and self-correcting capabilities. Using only rule-based reward models, RL improves the validity of both the self-verification and self-correction process, allowing the models to perform more flexible and effective test-time scaling through a self-directed trial-and-error process. By comparing outcome-level and process-level RL for our task, we found that process-level supervision is particularly effective in boosting accuracy of the thinking skills at intermediate steps, which might benefit base models with limited reasoning abilities. In contrast, outcome-level supervision enables models explore more flexible trial-and-error paths towards the correct final answer, leading to consistent improvement in the reasoning abilities of more capable base models. Additionally, we further show the potential of offline reinforcement learning as a more efficient alternative to the online RL training.
We conducted extensive experiments across 3 LLMs on 7 math reasoning benchmarks. Experimental results demonstrate that S 2 r outperforms competitive baselines in math reasoning, including recently-released advanced o1-like models Eurus-2-7B-PRIME Cui et al. (2025), rStar-Math-7B Guan et al. (2025) and Qwen2.5-7B-SimpleRL Zeng et al. (2025). We also found that S 2 r is generalizable to out-of-domain general tasks, such as MMLU-PRO, highlighting the validity of the learned self-verifying and self-correcting abilities. Additionally, we conducted a series of analytical experiments to better demonstrate the reasoning mechanisms of the obtained models, and provide insights into performing online and offline RL training for enhancing LLM reasoning.
## 2 Methodology
The main idea behind teaching LLMs self-verification and self-correction abilities is to streamline deep thinking into a critical paradigm: self-directed trial-and-error with self-verification and self-correction. Specifically: (1) LLMs are allowed to explore any potential (though possibly incorrect) solutions, especially when tackling difficult problems; (2) during the process, self-verification is essential for detecting mistakes on-the-fly; (3) self-correction enables the model to fix detected mistakes. This paradigm forms an effective test-time scaling approach that is more accessible for less powerful base models and is generalizable across various tasks.
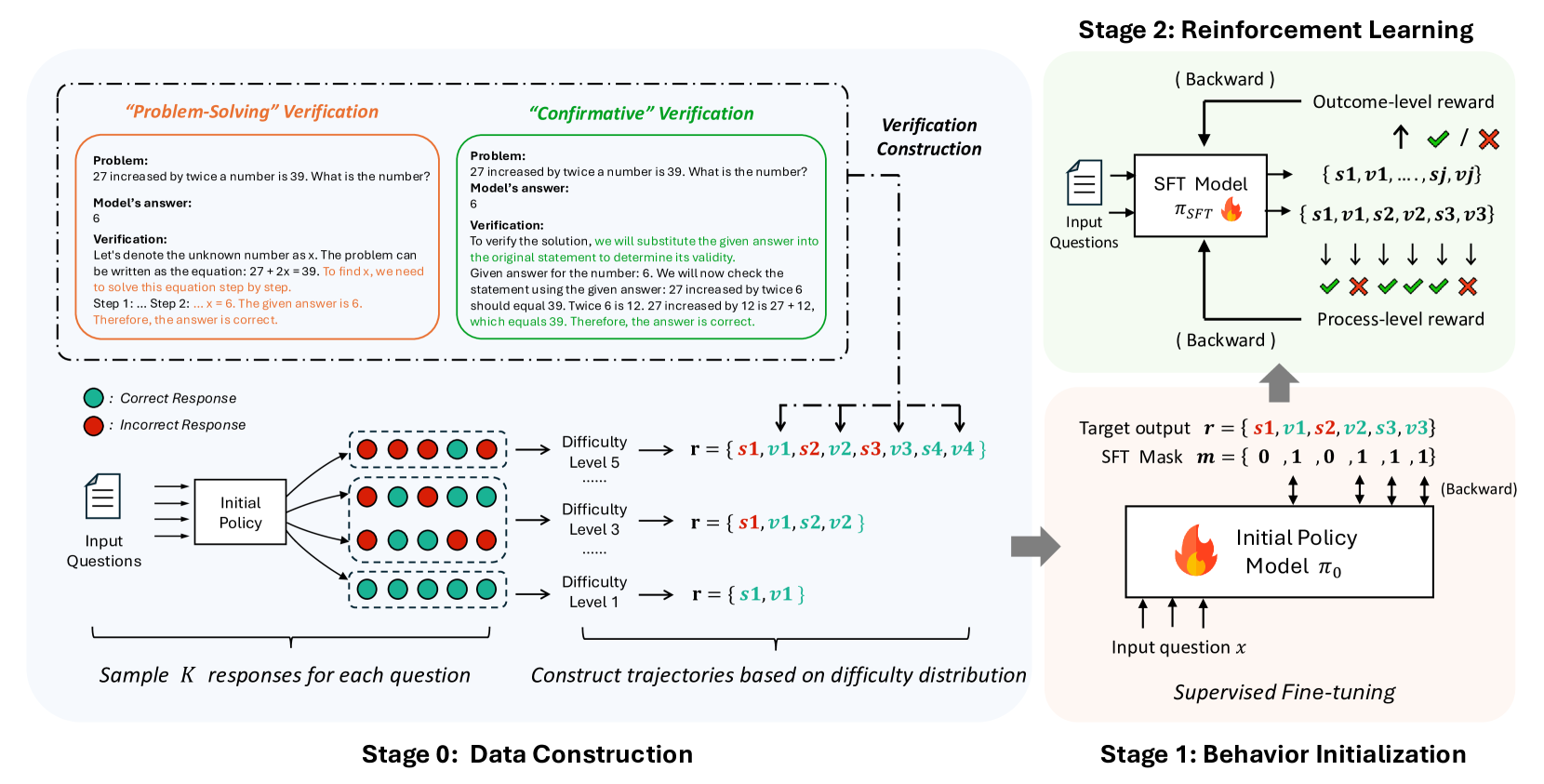
In this section, we first formally define the problem (§ 2.1). Next, we present the two-stage training framework of S 2 r, as described in Figure 2:
Stage 1: Behavior Initialization: We first construct dynamic self-verifying and self-correcting trial-and-error trajectories to initialize the desired behavior. Then, we apply supervised fine-tuning (SFT) to the initial policy models using these trajectories, resulting in behavior-initialized policy models (§ 2.2);
Stage 2: Reinforcement Learning: Following behavior initialization, we employ reinforcement learning to further enhance the self-verifying and self-correcting capabilities of the policy models. We explore both outcome-level and process-level RL methods, as well as their offline versions (§ 2.3).
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Diagram: Multi-Stage Training Pipeline for Reasoning Models
### Overview
The image is a technical flowchart illustrating a three-stage pipeline for training a machine learning model to solve reasoning problems. The process begins with **Stage 0: Data Construction**, where training data is generated and verified. This feeds into **Stage 1: Behavior Initialization**, which uses Supervised Fine-Tuning (SFT) to create an initial policy model. Finally, **Stage 2: Reinforcement Learning** refines this model using outcome and process-level rewards. The diagram uses color-coding (green for correct, red for incorrect), flow arrows, and text boxes to detail each step.
### Components/Axes
The diagram is divided into three primary regions, each representing a stage:
1. **Stage 0: Data Construction (Left, light blue background)**
* **Input:** "Input Questions" (document icon).
* **Process:** "Initial Policy" generates multiple responses.
* **Legend:** A green circle denotes ": Correct Response". A red circle denotes ": Incorrect Response".
* **Output:** Responses are grouped by "Difficulty Level" (Level 1, 3, 5) to form reasoning trajectories `r`.
* **Verification Methods:** Two dashed boxes at the top detail verification approaches:
* **"Problem-Solving" Verification (Orange box):** Shows an algebraic problem, a model's answer, and a step-by-step verification solving the equation.
* **"Confirmative" Verification (Green box):** Shows the same problem and answer, but verification substitutes the answer back into the original statement to check its validity.
* **Key Text:** "Sample K responses for each question", "Construct trajectories based on difficulty distribution".
2. **Stage 1: Behavior Initialization (Bottom Right, light pink background)**
* **Title:** "Supervised Fine-tuning".
* **Input:** "Input question x".
* **Model:** "Initial Policy Model π₀" (with a flame icon).
* **Target:** "Target output r = {s1, v1, s2, v2, s3, v3}" and "SFT Mask m = {0, 1, 0, 1, 1, 1}".
* **Flow:** An arrow points from Stage 0's constructed trajectories to this stage. A "(Backward)" arrow indicates gradient flow.
3. **Stage 2: Reinforcement Learning (Top Right, light green background)**
* **Input:** "Input Questions" (document icon) fed into an "SFT Model π_SFT" (with a flame icon).
* **Outputs:** The model generates sequences like `{s1, v1, ..., sj, vj}` and `{s1, v1, s2, v2, s3, v3}`.
* **Rewards:**
* "Outcome-level reward": Indicated by a checkmark (✓) or cross (✗) next to the final answer.
* "Process-level reward": Indicated by a sequence of checkmarks and crosses (✓ ✗ ✓ ✓ ✗) below the model's step-by-step output.
* **Flow:** A "(Backward)" arrow points from the rewards back to the SFT Model. A large grey arrow connects Stage 1 to Stage 2.
### Detailed Analysis
**Stage 0: Data Construction**
* **Verification Example:** The problem is: "27 increased by twice a number is 39. What is the number?" The model's answer is "6".
* *Problem-Solving Verification Text:* "Let's denote the unknown number as x. The problem can be written as the equation: 27 + 2x = 39. To find x, we need to solve this equation step by step. Step 1: ... Step 2: ... x = 6. The given answer is 6. Therefore, the answer is correct."
* *Confirmative Verification Text:* "To verify the solution, we will substitute the given answer into the original statement to determine its validity. Given answer for the number: 6. We will now check the statement using the given answer: 27 increased by twice 6 should equal 39. Twice 6 is 12. 27 increased by 12 is 27 + 12, which equals 39. Therefore, the answer is correct."
* **Trajectory Construction:** For a given question, the Initial Policy samples K responses. These are sorted into difficulty levels.
* Difficulty Level 5: Trajectory `r = {s1, v1, s2, v2, s3, v3, s4, v4}` (8 elements).
* Difficulty Level 3: Trajectory `r = {s1, v1, s2, v2}` (4 elements).
* Difficulty Level 1: Trajectory `r = {s1, v1}` (2 elements).
* The notation `{s, v}` likely represents a "step" and its "verification" or "value".
**Stage 1: Behavior Initialization**
* This stage performs Supervised Fine-Tuning (SFT) on the Initial Policy Model (π₀).
* It uses the constructed trajectories `r` as target outputs.
* The "SFT Mask m = {0, 1, 0, 1, 1, 1}" suggests that only specific parts of the sequence (likely the verification steps `v`) are used for the loss calculation during training.
**Stage 2: Reinforcement Learning**
* The SFT Model (π_SFT) is trained further with RL.
* It receives two types of rewards:
1. **Outcome-level reward:** A single binary signal (✓/✗) for the final answer's correctness.
2. **Process-level reward:** A sequence of binary signals (✓/✗) evaluating the correctness of each intermediate reasoning step.
* Both rewards are used in a "(Backward)" pass to update the model.
### Key Observations
1. **Dual Verification Strategy:** The pipeline employs two distinct methods ("Problem-Solving" and "Confirmative") to verify the correctness of model-generated answers during data construction, ensuring robust labeling.
2. **Difficulty-Aware Data:** Training data is explicitly structured by difficulty level, with more complex problems requiring longer reasoning trajectories (more steps).
3. **Hybrid Reward Structure:** The reinforcement learning stage uses a combination of sparse (outcome) and dense (process-level) rewards, which is a sophisticated approach to guide learning.
4. **Sequential Refinement:** The pipeline shows a clear progression from data generation (Stage 0), to imitation learning (Stage 1), to goal-oriented optimization (Stage 2).
### Interpretation
This diagram outlines a comprehensive methodology for training AI models to perform multi-step reasoning, likely for mathematical or logical problem-solving. The process is designed to overcome key challenges in training such models:
* **Data Scarcity & Quality:** Stage 0 automates the creation of high-quality, verified training data with difficulty annotations, solving the problem of needing large, human-labeled datasets.
* **Learning Stability:** Starting with Supervised Fine-Tuning (Stage 1) on curated trajectories provides a stable behavioral foundation before introducing the more volatile reinforcement learning phase.
* **Credit Assignment:** The use of **process-level rewards** in Stage 2 is particularly significant. It addresses the "credit assignment problem" in long reasoning chains by providing feedback on each step, not just the final answer. This should lead to more reliable and interpretable reasoning patterns.
* **Overall Goal:** The pipeline aims to produce a model that doesn't just arrive at correct answers but does so through a verifiable and correct step-by-step process, enhancing both accuracy and trustworthiness. The "Verification Construction" block linking Stage 0 to the reward signals in Stage 2 indicates that the verification methods developed for data labeling are also used to generate the process-level rewards during RL, creating a cohesive training loop.
</details>
Figure 2: Overview of S 2 r.
### 2.1 Problem Setup
We formulate the desired LLM reasoning paradigm as a sequential decision-making process under a reinforcement learning framework. Given a problem $x$ , the language model policy $\pi$ is expected to generate a sequence of interleaved reasoning actions $y=(a_{1},a_{2},\cdots,a_{T})$ until reaching the termination action <end>. We represent the series of actions before an action $a_{t}\in y$ as $y_{:a_{t}}$ , i.e., $y_{:a_{t}}=(a_{1},a_{2},\cdots,a_{t-i})$ , where $a_{t}$ is excluded. The number of tokens in $y$ is denoted as $|y|$ , and the total number of actions in $y$ is denoted as $|y|_{a}$ .
We restrict the action space to three types: “ solve ”, “ verify ”, and “ <end> ”, where “ solve ” actions represent direct attempts to solve the problem, “ verify ” actions correspond to self-assessments of the preceding solution, and “ <end> ” actions signal the completion of the reasoning process. We denote the type of action $a_{i}$ as $Type(\cdot)$ , where $Type(a_{i})\in\{\texttt{verify},\texttt{solve},\texttt{<end>}\}$ . We expect the policy to learn to explore new solutions by generating “ solve ” actions, to self-verify the correctness of preceding solutions with “ verify ” actions, and to correct the detected mistakes with new “ solve ” actions if necessary. Therefore, for each action $a_{i}$ , the type of the next action $a_{i+1}$ is determined by the following rules:
$$
Type(a_{i+1})=\begin{cases}\texttt{verify},&Type(a_{i})=\texttt{solve}\\
\texttt{solve},&Type(a_{i})=\texttt{verify}\\
&\text{ and }\text{Parser}(a_{i})=\textsc{incorrect}\\
\texttt{<end>},&Type(a_{i})=\texttt{verify}\\
&\text{ and }\text{Parser}(a_{i})=\textsc{correct}\\
\end{cases}
$$
Here, $Parser(a)\in\{\textsc{correct},\textsc{incorrect}\}$ (for any action $a$ where $Type(a)=\texttt{verify}$ ) is a function (e.g., a regex) that converts the model’s free-form verification text into binary judgments.
For simplicity, we denote the $j$ -th solve action as $s_{j}$ and the $j$ -th verify action as $v_{j}$ . Then we have $y=(s_{1},v_{1},s_{2},v_{2},\cdots,s_{k},v_{k},\texttt{<end>})$ .
### 2.2 Initializing Self-verification and Self-correction Behaviors
#### 2.2.1 Learning Valid Self-verification
Learning to perform valid self-verification is the most crucial part in S 2 r, as models can make mistakes during trial-and-error, and recognizing intermediate mistakes is critical for reaching the correct answer. In this work, we explore two methods for constructing self-verification behavior.
“Problem-Solving” Verification
The most intuitive method for verification construction is to directly query existing models to generate verifications on the policy models’ responses, and then filter for valid verifications. By querying existing models using different prompts, we found that existing models tend to perform verification in a “Problem-Solving” manner, i.e., by re-solving the problem and checking whether the answer matches the given one. We refer to this kind of verification as “Problem-Solving” Verification.
“Confirmative” Verification
"Problem-solving" verification is intuitively not the ideal verification behavior we seek. Ideally, we expect the model to think outside the box and re-examine the solution from a new perspective, rather than thinking from the same problem-solving view for verification. We refer to this type of verification behavior as “Confirmative” Verification. Specifically, we construct “Confirmative” Verification by prompting existing LLMs to "verify the correctness of the answer without re-solving the problem", and filtering out invalid verifications using LLM-as-a-judge. The detail implementation can be found in Appendix § A.1.
#### 2.2.2 Learning Self-correction
Another critical part of S 2 r is enabling the model to learn self-correction. Inspired by Kumar et al. (2024) and Snell et al. (2024b), we initialize the self-correcting behavior by concatenating a series of incorrect solutions (each followed by a verification recognizing the mistakes) with a final correct solution. As demonstrated by Kumar et al. (2024), LLMs typically fail to learn valid self-correction behavior through SFT, but the validity of self-correction can be enhanced through reinforcement learning. Therefore, we only initialize the self-correcting behavior at this stage, leaving further enhancement of the self-correcting capabilities to the RL stage.
#### 2.2.3 Constructing Dynamic Trial-and-Error Trajectory
We next construct the complete trial-and-error trajectories for behavior initialization SFT, following three principles:
- To ensure the diversity of the trajectories, we construct trajectories of various lengths. Specifically, we cover $k\in\{1,2,3,4\}$ for $y=(a_{1},\cdots,a_{2k})=(s_{1},v_{1},\cdots,s_{k},v_{k})$ in the trajectories.
- To ensure that the LLMs learn to verify and correct their own errors, we construct the failed trials in each trajectory by sampling and filtering from the LLMs’ own responses.
- As a plausible test-time scaling method allocates reasonable effort to varying levels of problems, it is important to ensure the trial-and-error trajectories align with the difficulty level of problems. Specifically, more difficult problems will require more trial-and-error iterations before reaching the correct answer. Thus, we determine the length of each trajectory based on the accuracy of the sampled responses for each base model.
#### 2.2.4 Supervised Fine-tuning for Thinking Behavior Initialization
Once the dynamic self-verifying and self-correcting training data $\mathcal{D}_{SFT}$ is ready, we optimize the policy $\pi$ for thinking behavior initialization by minimizing the following objective:
$$
\mathcal{L}=-\mathbb{E}_{(x,y)\sim\mathcal{D}_{SFT}}\sum_{a_{t}\in y}\delta_{
mask}(a_{t})\log\pi(a_{t}\mid x,y_{:a_{t}}) \tag{1}
$$
where the mask function $\delta_{mask}(a_{t})$ for action $a_{t}$ in $y=(a_{1},\cdots,a_{T})$ is defined as:
$$
\delta_{mask}(a_{t})=\begin{cases}1,&\text{if }Type(a_{t})=\texttt{verify}\\
1,&\text{if }Type(a_{t})=\texttt{solve}\text{ and }t=T-1\\
1,&\text{if }Type(a_{t})=\texttt{<end>}\text{ and }t=T\\
0,&\text{otherwise}\end{cases}
$$
That is, we optimize the probability of all verifications and only the last correct solution $s_{N}$ by using masks during training.
### 2.3 Boosting Thinking Capabilities via Reinforcement Learning
After Stage 1, we initialized the policy model $\pi$ with self-verification and self-correction behavior, obtaining $\pi_{SFT}$ . We then explore further enhancing these thinking capabilities of $\pi_{SFT}$ via reinforcement learning. Specifically, we explore two simple RL algorithms: the outcome-level REINFORCE Leave-One-Out (RLOO) algorithm and a proces-level group-based RL algorithm.
#### 2.3.1 Outcome-level RLOO
We first introduce the outcome-level REINFORCE Leave-One-Out (RLOO) algorithm Ahmadian et al. (2024); Kool et al. (2019) to further enhance the self-verification and self-correction capabilities of $\pi_{SFT}$ . Given a problem $x$ and the response $y=(s_{1},v_{1},...,s_{T},v_{T})$ , we define the reward function $R_{o}(x,y)$ based on the correctness of the last solution $s_{T}$ :
$$
R_{o}(x,y)=\begin{cases}1,&V_{golden}(s_{T})=\texttt{correct}\\
-1,&otherwise\\
\end{cases}
$$
Here $V_{golden}(\cdot)\in\{\texttt{correct},\texttt{incorrect}\}$ represents ground-truth validation by matching the golden answer with the given solution. We calculate the advantage of each response $y$ using an estimated baseline and KL reward shaping as follows:
$$
A(x,y)=R_{o}(x,y)-\hat{b}-\beta\log\frac{\pi_{\theta_{old}}(y|x)}{\pi_{ref}(y|
x)} \tag{2}
$$
where $\beta$ is the KL divergence regularization coefficient, and $\pi_{\text{ref}}$ is the reference policy (in our case, $\pi_{SFT}$ ). $\hat{b}(x,y^{(m)})=\frac{1}{M-1}\sum_{\begin{subarray}{c}j=1,...,M\\ j\neq m\end{subarray}}.R_{o}(x,y^{(j)})$ is the baseline estimation of RLOO, which represents the leave-one-out mean of $M$ sampled outputs $\{y^{(1)},...y^{(M)}\}$ for each input $x$ , serving as a baseline estimation for each $y^{(m)}$ . Then, we optimize the policy $\pi_{\theta}$ by minimizing the following objective after each sampling episode based on $\pi_{\theta_{old}}$ :
$$
\begin{split}\mathcal{L}(\theta)\ &=\ -\mathbb{E}_{\begin{subarray}{c}x\sim
\mathcal{D}\\
y\sim\pi_{\theta_{\text{old}}}(\cdot|x)\end{subarray}}\bigg{[}\min\big{(}r(
\theta)A(x,y),\\
&\text{clip}\big{(}r(\theta),1-\epsilon,1+\epsilon\big{)}A(x,y)\big{)}\bigg{]}
\end{split} \tag{3}
$$
where $r(\theta)=\frac{\pi_{\theta}(y|x)}{\pi_{\theta_{\text{old}}}(y|x)}$ is the probability ratio.
When implementing the above loss function, we treat $y$ as a complete trajectory sampled with an input problem $x$ , meaning we optimize the entire trajectory with outcome-level supervision. With this approach, we aim to incentivize the policy model to explore more dynamic self-verification and self-correcting trajectories on its own, which has been demonstrated as an effective practice in recent work Guo et al. (2025); Team et al. (2025).
#### 2.3.2 Process-level Group-based RL
Process-level supervision has demonstrated effectiveness in math reasoning Lightman et al. (2023a); Wang et al. (2024c). Since the trajectory of S 2 r thinking is naturally divided into self-verification and self-correction processes, it is intuitive to adopt process-level supervision for RL training.
Inspired by RLOO and process-level GRPO Shao et al. (2024), we designed a group-based process-level optimization method. Specifically, we regard each action $a$ in the output trajectory $y$ as a sub-process and define the action level reward function $R_{a}(a\mid x,y_{:a})$ based on the action type. For each “ solve ” action $s_{j}$ , we expect the policy to generate the correct solution; for each “ verify ” action $v_{j}$ , we expect the verification to align with the actual solution validity. The corresponding rewards are defined as follows:
$$
R_{a}(s_{j}\mid x,y_{:s_{j}})=\begin{cases}1,&V_{golden}(s_{j})=\texttt{
correct}\\
-1,&otherwise\\
\end{cases}
$$
$$
R_{a}(v_{j}\mid x,y_{:v_{j}})=\begin{cases}1,&Parser(v_{j})=V_{golden}(s_{j})
\\
-1,&otherwise\\
\end{cases}
$$
To calculate the advantage of each action $a_{t}$ , we estimate the baseline as the average reward of the group of actions sharing the same reward context:
$$
\mathbf{R}(a_{t}\mid x,y)=\left(R_{a}(a_{i}\mid x,y_{:a_{i}})\right)_{i=1}^{t-1}
$$
which is defined as the reward sequence of the previous actions $y_{:a_{t}}$ of each action $a_{t}$ . We denote the set of actions sharing the same reward context $\mathbf{R}(a_{t}\mid x,y)$ as $\mathcal{G}(\mathbf{R}(a_{t}\mid x,y))$ . Then the baseline can be estimated as follows:
$$
\begin{split}&\hat{b}(a_{t}\mid x,y)=\\
&\frac{1}{|\mathcal{G}(\mathbf{R}(a_{t}|x,y))|}\sum_{a\in\mathcal{G}(\mathbf{R
}(a_{t}|x,y))}R_{a}(a|x^{(a)},y^{(a)}_{:a})\end{split} \tag{4}
$$
And the advantage of each action $a_{t}$ is:
$$
\begin{split}A(a_{t}\mid x,y)=&R_{a}(a_{t}\mid x,y_{:a_{t}})-\hat{b}(a_{t}\mid
x
,y)\\
&-\beta\log\frac{\pi_{\theta_{old}}(a_{t}\mid x,y)}{\pi_{\text{ref}}(a_{t}\mid
x
,y)}\end{split} \tag{5}
$$
The main idea of the group-based baseline estimation is that the actions sharing the same reward context are provided with similar amounts of information before the action is taken. For instance, all actions sharing a reward context consisting of one failed attempt and one successful verification (i.e., $\mathbf{R}(a_{t}|x,y)=(-1,1)$ ) are provided with the information about the problem, a failed attempt, and the reassessment on the failure. Given the same amount of information, it is reasonable to estimate a baseline using the average reward of these actions.
Putting it all together, we minimize the following surrogate loss function to update the policy parameters $\theta$ , using trajectories collected from $\pi_{old}$ :
$$
\begin{split}\mathcal{L}(\theta)\ &=\ -\mathbb{E}_{\begin{subarray}{c}x\sim
\mathcal{D}\\
y\sim\pi_{\theta_{\text{old}}}(\cdot|x)\end{subarray}}\bigg{[}\frac{1}{|y|_{a}
}\sum_{a\in y}\min\big{(}r_{a}(\theta)A(a|x,y_{:a}),\\
&\text{clip}\big{(}r_{a}(\theta),1-\epsilon,1+\epsilon\big{)}A(a|x,y_{:a})\big
{)}\bigg{]}\end{split} \tag{6}
$$
where $r_{a}(\theta)=\frac{\pi_{\theta}(a|x,y_{:a})}{\pi_{\theta_{\text{old}}}(a|x,y_ {:a})}$ is the importance ratio.
### 2.4 More Efficient Training with Offline RL
While online RL is known for its high resource requirements, offline RL, which does not require real-time sampling during training, offers a more efficient alternative for RL training. Additionally, offline sampling allows for more accurate baseline calculations with better trajectories grouping for each policy. As part of our exploration into more efficient RL training in S 2 r framework, we also experimented with offline RL to assess its potential in further enhancing the models’ thinking abilities. In Appendix § D.2, we include more details and formal definition for offline RL training.
## 3 Experiment
To verify the effectiveness of the proposed method, we conducted extensive experiments across 3 different base policy models on various benchmarks.
| Stage 1: Behavior Initialization | | |
| --- | --- | --- |
| Base Model | Source | # Training Data |
| Llama-3.1-8B-Instruct | MATH | 4614 |
| Qwen2-7B-Instruct | MATH | 4366 |
| Qwen2.5-Math-7B | MATH | 3111 |
| Stage 2: Reinforcement Learning | | |
| Base Model | Source | # Training Data |
| Llama-3.1-8B-Instruct | MATH+GSM8K | 9601 |
| Qwen2-7B-Instruct | MATH+GSM8K | 9601 |
| Qwen2.5-Math-7B | MATH+OpenMath2.0 | 10000 |
Table 1: Training data statistics.
Table 2: The performance of S 2 r and other strong baselines on the most challenging math benchmarks is presented. BI refers to the behavior-initialized models through supervised fine-tuning, ORL denotes models trained with outcome-level RL, and PRL refers to models trained with process-level RL. The highest results are highlighted in bold and the second-best results are marked with underline. For some baselines, we use the results from their original reports or from Guan et al. (2025), denoted by ∗.
### 3.1 Experiment Setup
Base Models
To evaluate the general applicability of our method across different LLMs, we conducted experiments using three distinct base models: Llama-3.1-8B-Instruct Dubey et al. (2024), Qwen2-7B-Instruct qwe (2024), and Qwen2.5-Math-7B Qwen (2024). Llama-3.1-8B-Instruct and Qwen2-7B-Instruct are versatile general-purpose models trained on diverse domains without a specialized focus on mathematical reasoning. In contrast, Qwen2.5-Math-7B is a state-of-the-art model specifically tailored for mathematical problem-solving and has been widely adopted in recent research on math reasoning Guan et al. (2025); Cui et al. (2025); Zeng et al. (2025).
Training Data Setup
For Stage 1: Behavior Initialization, we used the widely adopted MATH Hendrycks et al. (2021a) training set for dynamic trial-and-error data collection We use the MATH split from Lightman et al. (2023a), i.e., 12000 problems for training and 500 problems for testing.. For each base model, we sampled 5 responses per problem in the training data. After data filtering and sampling, we constructed a dynamic trial-and-error training set consisting of 3k-4k instances for each base model. Detailed statistics of the training set are shown in Table 1. For Stage 2: Reinforcement Learning, we used the MATH+GSM8K Cobbe et al. (2021a) training data for RL training on the policy $\pi_{SFT}$ initialized from Llama-3.1-8B-Instruct and Qwen2-7B-Instruct. Since Qwen2.5-math-7b already achieves high accuracy on the GSM8K training data after Stage 1, we additionally include training data randomly sampled from the OpenMath2 dataset Toshniwal et al. (2024). Following Cui et al. (2025), we filter out excessively easy or difficult problems based on each $\pi_{SFT}$ from Stage 1 to enhance the efficiency and stability of RL training, resulting in RL training sets consisting of approximately 10000 instances. Detailed statistics of the final training data can be found in Table 1. Additional details on training data construction can be found in in Appendix § A.1.
Baselines
We benchmark our proposed method against four categories of strong baselines:
- Frontier LLMs includes cutting-edge proprietary models such as GPT-4o, the latest Claude, and OpenAI’s o1-preview and o1-mini.
- Top-tier open-source reasoning models covers state-of-the-art open-source models known for their strong reasoning capabilities, including Mathstral-7B-v0.1 Team (2024b), NuminaMath-72B LI et al. (2024), LLaMA3.1-70B-Instruct Dubey et al. (2024), and Qwen2.5-Math-72B-Instruct Yang et al. (2024).
- Enhanced models built on Qwen2.5-Math-7B: Given the recent popularity of Qwen2.5-Math-7B as a base policy model, we evaluate S 2 r against three competitive baselines that have demonstrated superior performance based on Qwen2.5-Math-7B: Eurus-2-7B-PRIME Cui et al. (2025), rStar-Math-7B Guan et al. (2025), and Qwen2.5-7B-SimpleRL Zeng et al. (2025). These models serve as direct and strong baseline for our Qwen2.5-Math-7B-based variants.
- SFT with different CoT constructions: We also compare with training on competitive types of CoT reasoning, including the original CoT solution in the training datasets, and Long-CoT solutions distilled from QwQ-32B-Preview Team (2024a), a widely adopted open-source o1-like model Chen et al. (2024c); Guan et al. (2025); Zheng et al. (2024). Specifically, to ensure a fair comparison between behavior initialization with long-CoT and S 2 r, we use long-CoT data of the same size as our behavior initialization data. We provide more details on the baseline data construction in Appendix § A.2.3.
More details on the baselines are included in Appendix § A.2.
Evaluation Datasets
We evaluate the proposed method on 7 diverse mathematical benchmarks. To ensure a comprehensive evaluation, in addition to the in-distribution GSM8K Cobbe et al. (2021b) and MATH500 Lightman et al. (2023a) test sets, we include challenging out-of-distribution benchmarks covering various difficulty levels and mathematical domains, including the AIME 2024 competition problems AI-MO (2024a), the AMC 2023 exam AI-MO (2024b), the advanced reasoning tasks from Olympiad Bench He et al. (2024), and college-level problem sets from College Math Tang et al. (2024a). Additionally, we assess performance on real-world standardized tests, the GaoKao (Chinese College Entrance Exam) En 2023 Liao et al. (2024). A detailed description of these datasets is provided in Appendix § B.1.
Evaluation Metrics
We report Pass@1 accuracy for all baselines. For inference, we employ vLLM Kwon et al. (2023) and develop evaluation scripts based on Qwen Math’s codebase. All evaluations are performed using greedy decoding. Details of the prompts used during inference are provided in Appendix § A.3. All implementation details, including hyperparameter settings, can be found in Appendix § B.2.
### 3.2 Main Results
Table 2 shows the main results of S 2 r compared with baseline methods. We can observe that: (1) S 2 r consistently improves the reasoning abilities of models across all base models. Notably, on Qwen2.5-Math-7B, the proposed method improves the base model by 32.2% on MATH500 and by 34.3% on GSM8K. (2) Generally, S 2 r outperforms the baseline methods derived from the same base models across most benchmarks. Specifically, on Qwen2.5-Math-7B, S 2 r surpasses several recently proposed competitive baselines, such as Eurus-2-7B-PRIME, rStar-Math-7B and Qwen2.5-7B-SimpleRL. While Eurus-2-7B-PRIME and rStar-Math-7B rely on larger training datasets (Figure 1) and require more data construction and reward modeling efforts, S 2 r only needs linear sampling efforts for data construction, 10k RL training data and rule-based reward modeling. These results highlight the efficiency of S 2 r. (3) With the same scale of SFT data, S 2 r also outperforms the long-CoT models distilled from QwQ-32B-Preview, demonstrating that learning to self-verify and self-correct is an effective alternative to long-CoT for test-time scaling in smaller LLMs.
Comparing process-level and outcome-level RL, we find that outcome-level RL generally outperforms process-level RL across the three models. This is likely because outcome-level RL allows models to explore trajectories without emphasizing intermediate accuracy, which may benefit enhancing long-thought reasoning in stronger base models like Qwen2.5-Math-7B. In contrast, process-level RL, which provides guidance for each intermediate verification and correction step, may be effective for models with lower initial capabilities, such as Qwen2-7B-Instruct. As shown in Figure 3, process-level RL can notably enhance the verification and correction abilities of Qwen2-7B- S 2 r -BI.
| Model | FOLIO | CRUX- Eval | Strategy- QA | MMLUPro- STEM |
| --- | --- | --- | --- | --- |
| Qwen2.5-Math-72B-Instruct | 69.5 | 68.6 | 94.3 | 66.0 |
| Llama-3.1-70B-Instruct ∗ | 65.0 | 59.6 | 88.8 | 61.7 |
| OpenMath2-Llama3.1-70B ∗ | 68.5 | 35.1 | 95.6 | 55.0 |
| QwQ-32B-Preview ∗ | 84.2 | 65.2 | 88.2 | 71.9 |
| Eurus-2-7B-PRIME | 56.7 | 50.0 | 79.0 | 53.7 |
| Qwen2.5-Math-7B-Instruct | 61.6 | 28.0 | 81.2 | 44.7 |
| Qwen2.5-Math-7B | 37.9 | 40.8 | 61.1 | 46.0 |
| Qwen2.5-Math-7B- S 2 r -BI (ours) | 58.1 | 48.0 | 88.7 | 49.8 |
| Qwen2.5-Math-7B- S 2 r -ORL (ours) | 61.6 | 50.9 | 90.8 | 50.0 |
Table 3: Performance of the proposed method and the baseline methods on 4 cross-domain tasks. The results with ∗ are reported by Shen et al. (2025).
### 3.3 Generalizing to Cross-domain Tasks
Despite training on math reasoning tasks, we found that the learned self-verifying and self-correcting capability can also generalize to out-of-distribution general domains. In Table 3, we evaluate the SFT model and the outcome-level RL model based on Qwen2.5-Math-7B on four cross-domain tasks: FOLIO Han et al. (2022) on logical reasoning, CRUXEval Gu et al. (2024) on code reasoning, StrategyQA Geva et al. (2021) on multi-hop reasoning and MMLUPro-STEM on multi-task complex understanding Wang et al. (2024d); Shen et al. (2025), with details of these datasets provided in Appendix § B.1. The results show that after learning to self-verify and self-correct, the proposed method effectively boosts the base model’s performance across all tasks and achieves comparative results to the baseline models. These findings indicate that the learned self-verifying and self-correcting capabilities are general thinking skills, which can also benefit reasoning in general domains. Additionally, we expect that the performance in specific domains can be further improved by applying S 2 r training on domain data with minimal reward model requirements (e.g., rule-based or LLM-as-a-judge). For better illustration, we show cases on how the trained models perform self-verifying and self-correcting on general tasks in Appendix § E.
### 3.4 Analyzing Self-verification and Self-correction Abilities
In this section, we conduct analytical experiments on the models’ self-verification and self-correction capabilities from various perspectives.
#### 3.4.1 Problem-solving v.s. Confirmative Verification
We first compare the Problem-solving and Confirmative Verification methods described in § 2.2.1. In Table 4, we present the verification results of different methods on the Math500 test set. We report the overall verification accuracy, as well as the initial verification accuracy when the initial answer is correct ( $V_{golden}(s_{0})=\texttt{correct}$ ) and incorrect ( $V_{golden}(s_{0})=\texttt{incorrect}$ ), respectively.
| Base Model | Methods | Overall Verification Acc. | Initial Verification Acc. | |
| --- | --- | --- | --- | --- |
| $V_{golden}(s_{0})$ $=\texttt{correct}$ | $V_{golden}(s_{0})$ $=\texttt{incorrect}$ | | | |
| Llama3.1-8B-Instruct | Problem-solving | 80.10 | 87.28 | 66.96 |
| Confirmative | 65.67 | 77.27 | 78.22 | |
| Qwen2-7B-Instruct | Problem-solving | 73.28 | 90.24 | 67.37 |
| Confirmative | 58.31 | 76.16 | 70.05 | |
| Qwen2.5-Math-7B | Problem-solving | 77.25 | 91.21 | 56.67 |
| Confirmative | 61.58 | 82.80 | 68.04 | |
Table 4: Comparison of problem-solving and confirmative verification.
We observe from the table that: (1) Generally, problem-solving verification achieves superior overall accuracy compared to confirmative verification. This result is intuitive, as existing models are trained for problem-solving, and recent studies have highlighted the difficulty of existing LLMs in performing reverse thinking Berglund et al. (2023); Chen et al. (2024b). During data collection, we also found that existing models tend to verify through problem-solving, even when prompted to verify without re-solving (see Table 6 in Appendix § A.1). (2) In practice, accuracy alone does not fully reflect the validity of a method. For example, when answer accuracy is sufficiently high, predicting all answers as correct will naturally lead to high verification accuracy, but this is not a desired behavior. By further examining the initial verification accuracy for both correct and incorrect answers, we found that problem-solving verification exhibits a notable bias toward predicting answers as correct, while the predictions from confirmative verification are more balanced. We deduce that this bias arises might be because problem-solving verification is more heavily influenced by the preceding solution, aligning with previous studies showing that LLMs struggle to identify their own errors Huang et al. (2023); Tyen et al. (2023). In contrast, confirmative verification performs verification from different perspectives, making it less influenced by the LLMs’ preceding solution.
In all experiments, we used confirmative verification for behavior initialization.
#### 3.4.2 Boosting Self-verifying and Self-correcting with RL
In this experiment, we investigate the effect of RL training on the models’ self-verifying and self-correcting capabilities.
We assess self-verification using the following metrics: (1) Verification Accuracy: The overall accuracy of verification predictions, as described in § 3.4.1. (2) Error Recall: The recall of verification when the preceding answers are incorrect. (3) Correct Precision: The precision of verification when it predicts the answers as correct. Both Error Recall and Correct Precision directly affect the final answer accuracy: if verification fails to detect an incorrect answer, or if it incorrectly predicts an answer as correct, the final answer will be wrong.
For self-correction, we use the following metrics: (1) Incorrect to Correct Rate: the rate at which the model successfully corrects an incorrect initial answer to a correct final answer. (2) Correct to Incorrect Rate: the rate at which the model incorrectly changes a correct initial answer to an incorrect final answer. We provide the formal definitions of the metrics used in Appendix § C.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Chart: Evaluation on Verification and Correction (Base Model: Qwen2-7B-Instruct)
### Overview
The image displays a comparative bar chart evaluating the performance of three different training methods applied to the base language model "Qwen2-7B-Instruct". The evaluation is split into two distinct metric groups: "Self-verification Metrics" (left panel) and "Self-correction Metrics" (right panel). The chart compares the performance of Supervised Fine-Tuning (SFT) alone against SFT combined with two types of Reinforcement Learning (RL): Process-level RL and Outcome-level RL.
### Components/Axes
* **Main Title:** "Evaluation on Verification and Correction (Base Model: Qwen2-7B-Instruct)"
* **Left Panel Title:** "Self-verification Metrics"
* **Right Panel Title:** "Self-correction Metrics"
* **Y-Axis (Both Panels):** Labeled "Value (%)". The left panel's axis ranges from 50 to 100 in increments of 10. The right panel's axis ranges from 0 to 25 in increments of 5.
* **X-Axis (Left Panel):** Three metric categories: "Verification Accuracy", "Error Recall", and "Correct Precision".
* **X-Axis (Right Panel):** Two metric categories: "Incorrect to Correct" and "Correct to Incorrect".
* **Legend (Top-Left of Left Panel):** A color-coded legend identifies the three training methods:
* **Grey Bar:** SFT
* **Teal/Green Bar:** SFT + Process-level RL
* **Salmon/Orange Bar:** SFT + Outcome-level RL
### Detailed Analysis
**Self-verification Metrics (Left Panel):**
This panel shows the model's ability to verify its own outputs. For all three metrics, the RL-enhanced methods outperform the SFT baseline.
1. **Verification Accuracy:**
* SFT (Grey): 58.31%
* SFT + Process-level RL (Teal): 67.86%
* SFT + Outcome-level RL (Salmon): 63.93%
* *Trend:* Both RL methods improve accuracy, with Process-level RL showing the largest gain.
2. **Error Recall:**
* SFT (Grey): 81.91%
* SFT + Process-level RL (Teal): 86.67%
* SFT + Outcome-level RL (Salmon): 87.34%
* *Trend:* All methods score highly. The RL methods provide a modest improvement over SFT, with Outcome-level RL performing slightly better.
3. **Correct Precision:**
* SFT (Grey): 65.58%
* SFT + Process-level RL (Teal): 73.59%
* SFT + Outcome-level RL (Salmon): 69.80%
* *Trend:* RL methods improve precision. Process-level RL shows the most significant improvement.
**Self-correction Metrics (Right Panel):**
This panel measures the model's ability to correct its own outputs. The trends here are more varied.
1. **Incorrect to Correct:**
* SFT (Grey): 20.00%
* SFT + Process-level RL (Teal): 22.17%
* SFT + Outcome-level RL (Salmon): 19.55%
* *Trend:* Process-level RL improves the rate of correcting incorrect answers. Outcome-level RL performs slightly worse than the SFT baseline.
2. **Correct to Incorrect:**
* SFT (Grey): 8.42%
* SFT + Process-level RL (Teal): 5.39%
* SFT + Outcome-level RL (Salmon): 3.93%
* *Trend:* This is a negative metric (lower is better). Both RL methods significantly reduce the rate of corrupting correct answers, with Outcome-level RL showing the best (lowest) result.
### Key Observations
* **Consistent Improvement in Verification:** All three verification metrics (Accuracy, Error Recall, Correct Precision) show improvement when RL is applied to the SFT baseline.
* **Divergent Impact on Correction:** The effect of RL on correction is metric-dependent. Process-level RL improves the "Incorrect to Correct" rate, while both RL methods excel at reducing the "Correct to Incorrect" error rate.
* **Process-level vs. Outcome-level RL:** Process-level RL generally provides the largest boost to verification metrics and the "Incorrect to Correct" correction metric. Outcome-level RL is particularly effective at minimizing the "Correct to Incorrect" error.
* **Scale Difference:** The values for self-verification metrics (50-90% range) are substantially higher than those for self-correction metrics (4-22% range), indicating the model is better at verifying outputs than actively correcting them.
### Interpretation
The data suggests that integrating Reinforcement Learning (RL) with Supervised Fine-Tuning (SFT) enhances the self-evaluation capabilities of the Qwen2-7B-Instruct model. The core finding is that RL training, whether focused on the process or the outcome, makes the model more reliable at identifying errors (higher Verification Accuracy and Error Recall) and more precise in its judgments (higher Correct Precision).
The correction metrics reveal a more nuanced picture. The model's ability to fix its own mistakes ("Incorrect to Correct") sees a moderate boost primarily from Process-level RL. More importantly, both RL methods drastically reduce the harmful behavior of changing correct answers into incorrect ones ("Correct to Incorrect"). This indicates that RL training instills a more conservative and confident correction behavior, making the model less likely to "over-correct" and introduce new errors.
In summary, the chart demonstrates that RL-augmented training produces a model that is not only better at judging the correctness of its outputs but also safer and more reliable when attempting to correct them, with a notable reduction in harmful interventions. The choice between Process-level and Outcome-level RL may depend on whether the primary goal is improving active correction or minimizing correction-induced errors.
</details>
(a)
<details>
<summary>x4.png Details</summary>
### Visual Description
## Bar Chart: Evaluation on Verification and Correction (Base Model: Qwen2.5-Math-7B)
### Overview
The image is a composite bar chart comparing the performance of three different training methods on a base language model (Qwen2.5-Math-7B) across two sets of metrics: "Self-verification Metrics" and "Self-correction Metrics." The chart evaluates how well the model can verify its own outputs and correct errors.
### Components/Axes
* **Title:** "Evaluation on Verification and Correction (Base Model: Qwen2.5-Math-7B)"
* **Subplots:** The chart is divided into two distinct panels.
* **Left Panel Title:** "Self-verification Metrics"
* **Right Panel Title:** "Self-correction Metrics"
* **Legend:** Located in the top-left corner of the left panel. It defines three data series:
* **SFT** (Gray bar)
* **SFT + Process-level RL** (Teal/Green bar)
* **SFT + Outcome-level RL** (Salmon/Orange bar)
* **Y-Axis (Left Panel):** Labeled "Value (%)". Scale ranges from 50 to 90, with major gridlines at intervals of 10.
* **X-Axis (Left Panel):** Three categorical groups:
1. Verification Accuracy
2. Error Recall
3. Correct Precision
* **Y-Axis (Right Panel):** Labeled "Value (%)". Scale ranges from 0 to 14, with major gridlines at intervals of 2.
* **X-Axis (Right Panel):** Two categorical groups:
1. Incorrect to Correct
2. Correct to Incorrect
### Detailed Analysis
**Self-verification Metrics (Left Panel):**
1. **Verification Accuracy:**
* **SFT:** 61.58%
* **SFT + Process-level RL:** 74.61% (Highest in this group)
* **SFT + Outcome-level RL:** 66.49%
* *Trend:* Process-level RL provides the largest improvement over the SFT baseline, followed by Outcome-level RL.
2. **Error Recall:**
* **SFT:** 66.83%
* **SFT + Process-level RL:** 64.75% (Lowest in this group)
* **SFT + Outcome-level RL:** 70.11% (Highest in this group)
* *Trend:* Outcome-level RL improves error recall over SFT, while Process-level RL slightly decreases it.
3. **Correct Precision:**
* **SFT:** 84.94%
* **SFT + Process-level RL:** 90.28% (Highest in this group)
* **SFT + Outcome-level RL:** 87.85%
* *Trend:* Both RL methods improve precision, with Process-level RL showing the greatest gain.
**Self-correction Metrics (Right Panel):**
1. **Incorrect to Correct (Rate of fixing wrong answers):**
* **SFT:** 6.52%
* **SFT + Process-level RL:** 12.22%
* **SFT + Outcome-level RL:** 13.64% (Highest in this group)
* *Trend:* Both RL methods nearly double or more than double the self-correction rate compared to SFT, with Outcome-level RL performing best.
2. **Correct to Incorrect (Rate of breaking right answers):**
* **SFT:** 1.96%
* **SFT + Process-level RL:** 1.46%
* **SFT + Outcome-level RL:** 0.97% (Lowest in this group)
* *Trend:* Both RL methods reduce the rate of corrupting correct answers, with Outcome-level RL showing the most significant reduction.
### Key Observations
* **Performance Trade-offs:** The two RL methods show complementary strengths. "SFT + Process-level RL" excels in Verification Accuracy and Correct Precision. "SFT + Outcome-level RL" excels in Error Recall and the "Incorrect to Correct" self-correction rate.
* **Consistent Improvement in Correction:** Both RL methods dramatically improve the model's ability to correct its own errors ("Incorrect to Correct") while simultaneously reducing its tendency to alter correct answers ("Correct to Incorrect").
* **Baseline Performance:** The SFT (Supervised Fine-Tuning) baseline serves as the reference point, with all RL variants showing targeted improvements in specific metrics.
### Interpretation
This data suggests that applying Reinforcement Learning (RL) to a math-capable language model enhances its metacognitive abilities—specifically, its capacity to self-verify and self-correct its reasoning. The choice of RL objective creates a specialisation:
* **Process-level RL** (which likely rewards intermediate reasoning steps) appears to make the model more precise and accurate in its verification judgments, leading to higher confidence when it identifies a correct answer.
* **Outcome-level RL** (which rewards only the final answer) seems to make the model more sensitive to errors, improving its recall of mistakes and its ability to transform incorrect solutions into correct ones.
The most significant practical takeaway is the substantial reduction in the "Correct to Incorrect" rate alongside the increase in "Incorrect to Correct" rate. This indicates the RL-trained models are not just guessing more often but are becoming more reliable self-editors, a crucial trait for autonomous problem-solving systems. The base model, Qwen2.5-Math-7B, demonstrates a strong foundation that is meaningfully enhanced by these targeted training strategies.
</details>
(b)
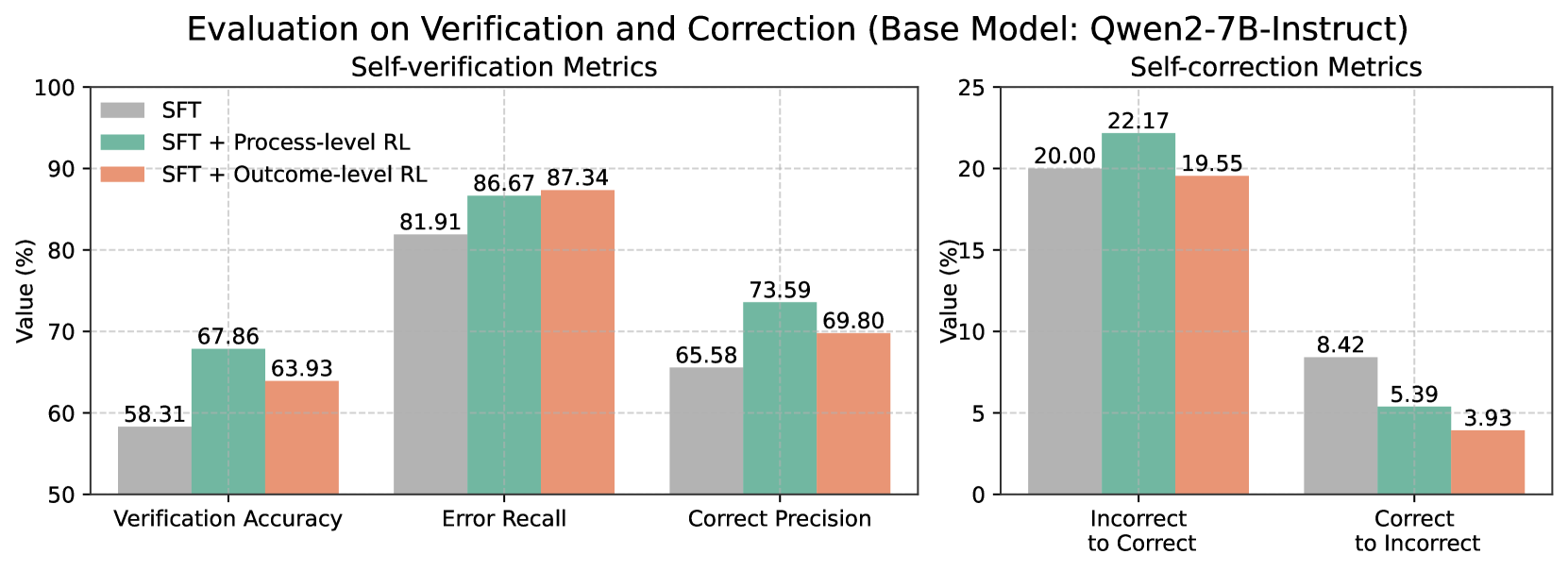
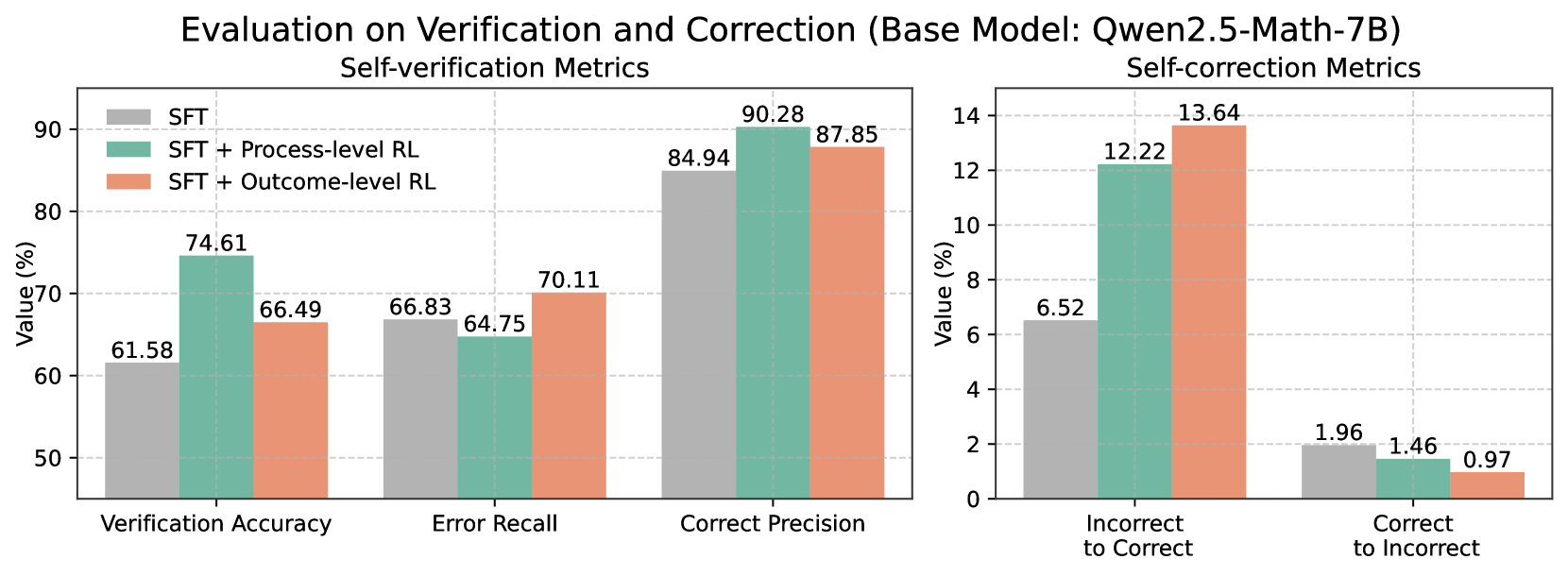
Figure 3: Evaluation on verification and correction.
In Figure 3, we present the results of the behavior-initialized model (SFT) and different RL models obtained from Qwen2.5-Math-7B. We observe that: (1) Both RL methods effectively enhance self-verification accuracy. The process-level RL shows larger improvement on accuracy, while the outcome-level RL consistently improves Error Recall and Correct Precision. This might be because process-level supervision indiscriminately promotes verification accuracy in intermediate steps, while outcome-level supervision allows the policy model to explore freely in intermediate steps and only boosts the final answer accuracy, thus mainly enhancing Error Recall and Correct Precision (which directly relate to final answer accuracy). (2) Both RL methods can successfully enhance the models’ self-correction capability. Notably, the model’s ability to correct incorrect answers is significantly improved after RL training. The rate of model mistakenly altering correct answers is also notably reduced. This comparison demonstrates that S 2 r can substantially enhance the validity of models’ self-correction ability.
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
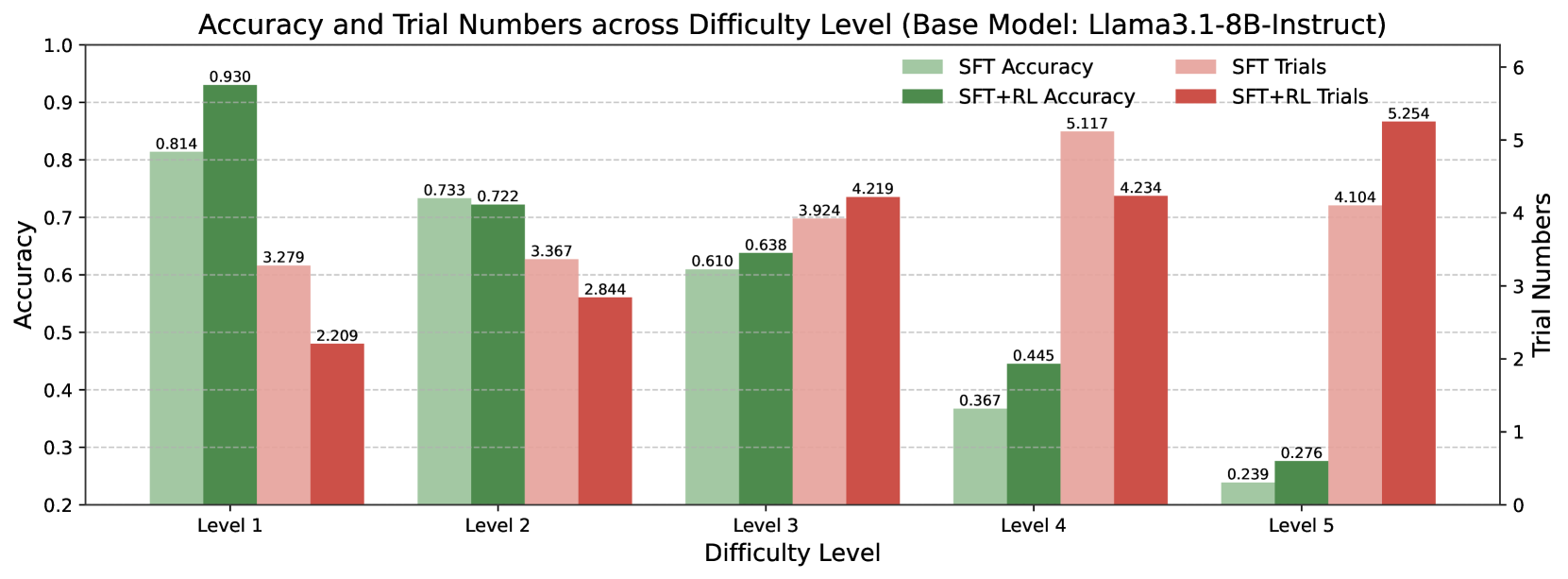
## Grouped Bar Chart: Accuracy and Trial Numbers across Difficulty Level (Base Model: Llama3.1-8B-Instruct)
### Overview
This is a grouped bar chart comparing the performance of two model training approaches—Supervised Fine-Tuning (SFT) and SFT combined with Reinforcement Learning (SFT+RL)—across five increasing difficulty levels. The chart displays two metrics for each approach: Accuracy (left y-axis) and Trial Numbers (right y-axis). The base model for all evaluations is Llama3.1-8B-Instruct.
### Components/Axes
* **Title:** "Accuracy and Trial Numbers across Difficulty Level (Base Model: Llama3.1-8B-Instruct)"
* **X-Axis (Horizontal):** "Difficulty Level". Categories are discrete: Level 1, Level 2, Level 3, Level 4, Level 5.
* **Primary Y-Axis (Left):** "Accuracy". Scale ranges from 0.2 to 1.0, with major gridlines at 0.1 intervals.
* **Secondary Y-Axis (Right):** "Trial Numbers". Scale ranges from 0 to 6, with major gridlines at integer intervals.
* **Legend (Top-Right Corner):**
* Light Green Bar: "SFT Accuracy"
* Dark Green Bar: "SFT+RL Accuracy"
* Light Red Bar: "SFT Trials"
* Dark Red Bar: "SFT+RL Trials"
### Detailed Analysis
Data is presented in four bars per difficulty level. Values are annotated directly on top of each bar.
**Level 1:**
* **Accuracy:** SFT = 0.814 (light green), SFT+RL = 0.930 (dark green). SFT+RL shows a significant accuracy improvement.
* **Trials:** SFT = 3.279 (light red), SFT+RL = 2.209 (dark red). SFT+RL requires fewer trials.
**Level 2:**
* **Accuracy:** SFT = 0.733 (light green), SFT+RL = 0.722 (dark green). Performance is nearly identical, with SFT slightly higher.
* **Trials:** SFT = 3.367 (light red), SFT+RL = 2.844 (dark red). SFT+RL requires fewer trials.
**Level 3:**
* **Accuracy:** SFT = 0.610 (light green), SFT+RL = 0.638 (dark green). SFT+RL shows a modest accuracy improvement.
* **Trials:** SFT = 3.924 (light red), SFT+RL = 4.219 (dark red). SFT+RL requires more trials.
**Level 4:**
* **Accuracy:** SFT = 0.367 (light green), SFT+RL = 0.445 (dark green). SFT+RL shows a notable accuracy improvement.
* **Trials:** SFT = 5.117 (light red), SFT+RL = 4.234 (dark red). SFT+RL requires fewer trials.
**Level 5:**
* **Accuracy:** SFT = 0.239 (light green), SFT+RL = 0.276 (dark green). SFT+RL shows a small accuracy improvement.
* **Trials:** SFT = 4.104 (light red), SFT+RL = 5.254 (dark red). SFT+RL requires significantly more trials.
### Key Observations
1. **Accuracy Trend:** For both SFT and SFT+RL, accuracy consistently and sharply declines as difficulty increases from Level 1 to Level 5.
2. **Trial Trend:** The number of trials generally increases with difficulty for both methods, though the pattern is less linear than accuracy. The highest trial count for SFT is at Level 4 (5.117), and for SFT+RL is at Level 5 (5.254).
3. **SFT vs. SFT+RL Performance:** SFT+RL achieves higher accuracy than SFT at four out of five difficulty levels (Levels 1, 3, 4, 5). The exception is Level 2, where they are nearly equal.
4. **Trial Efficiency:** The relationship between trial numbers for the two methods is inconsistent. SFT+RL uses fewer trials at Levels 1, 2, and 4, but more trials at Levels 3 and 5.
### Interpretation
The data demonstrates the expected inverse relationship between task difficulty and model accuracy. The core finding is that applying Reinforcement Learning (RL) on top of Supervised Fine-Tuning (SFT) generally improves the model's final accuracy across most difficulty levels for the Llama3.1-8B-Instruct base model.
However, the benefit is not uniform. The most substantial accuracy gain from RL is seen at the easiest (Level 1) and mid-high (Level 4) difficulties. At the highest difficulty (Level 5), the accuracy gain from RL is marginal.
The trial number data suggests a complex relationship between RL and computational cost or exploration. RL does not consistently reduce the number of trials needed. In fact, at the highest difficulty (Level 5), RL requires the most trials of any condition, suggesting the RL process may struggle to find a successful policy for very hard tasks, even if it ultimately yields a slightly better final model. The peak trial count for SFT at Level 4, followed by a drop at Level 5, might indicate a different failure mode or ceiling effect for the SFT-only approach at extreme difficulties.
In summary, SFT+RL is a more accurate training paradigm than SFT alone for this model across a range of difficulties, but its efficiency in terms of trial numbers is highly dependent on the specific difficulty level.
</details>
(a)
<details>
<summary>x6.png Details</summary>
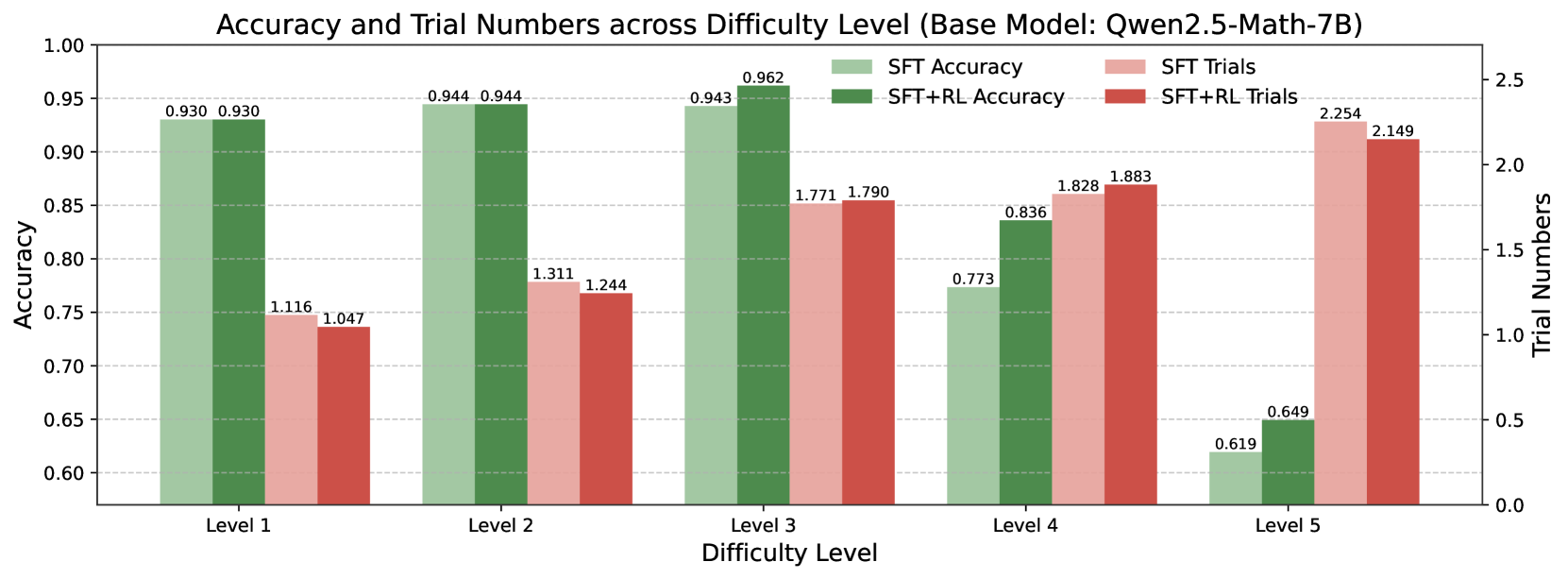
### Visual Description
## Dual-Axis Grouped Bar Chart: Accuracy and Trial Numbers across Difficulty Level (Base Model: Qwen2.5-Math-7B)
### Overview
This image is a dual-axis grouped bar chart comparing the performance of two training methods (SFT and SFT+RL) on a base model named "Qwen2.5-Math-7B". The chart evaluates performance across five discrete difficulty levels (Level 1 to Level 5) using two metrics: Accuracy (left y-axis) and Trial Numbers (right y-axis). Each difficulty level has four bars representing the two metrics for the two training methods.
### Components/Axes
* **Chart Title:** "Accuracy and Trial Numbers across Difficulty Level (Base Model: Qwen2.5-Math-7B)"
* **X-Axis (Horizontal):** Labeled "Difficulty Level". It contains five categorical groups: "Level 1", "Level 2", "Level 3", "Level 4", and "Level 5".
* **Primary Y-Axis (Left):** Labeled "Accuracy". It is a linear scale ranging from 0.60 to 1.00, with major gridlines at intervals of 0.05.
* **Secondary Y-Axis (Right):** Labeled "Trial Numbers". It is a linear scale ranging from 0.0 to 2.5, with major gridlines at intervals of 0.5.
* **Legend:** Positioned in the top-right quadrant of the chart area. It defines four data series:
* **SFT Accuracy:** Light green bar.
* **SFT+RL Accuracy:** Dark green bar.
* **SFT Trials:** Light red/pink bar.
* **SFT+RL Trials:** Dark red bar.
* **Data Labels:** Each bar has its exact numerical value displayed directly above it.
### Detailed Analysis
The chart presents the following data points for each difficulty level, grouped by metric and training method:
**Level 1:**
* **Accuracy:** SFT = 0.930, SFT+RL = 0.930 (Identical performance).
* **Trial Numbers:** SFT = 1.116, SFT+RL = 1.047 (SFT+RL requires slightly fewer trials).
**Level 2:**
* **Accuracy:** SFT = 0.944, SFT+RL = 0.944 (Identical performance).
* **Trial Numbers:** SFT = 1.311, SFT+RL = 1.244 (SFT+RL requires fewer trials).
**Level 3:**
* **Accuracy:** SFT = 0.943, SFT+RL = 0.962 (SFT+RL shows a slight improvement).
* **Trial Numbers:** SFT = 1.771, SFT+RL = 1.790 (Trial numbers are very close, with SFT+RL being marginally higher).
**Level 4:**
* **Accuracy:** SFT = 0.773, SFT+RL = 0.836 (SFT+RL shows a notable improvement of ~0.063).
* **Trial Numbers:** SFT = 1.828, SFT+RL = 1.883 (SFT+RL requires slightly more trials).
**Level 5:**
* **Accuracy:** SFT = 0.619, SFT+RL = 0.649 (SFT+RL shows a moderate improvement of 0.030).
* **Trial Numbers:** SFT = 2.254, SFT+RL = 2.149 (SFT+RL requires fewer trials).
**Visual Trends:**
1. **Accuracy Trend (Green Bars):** For both methods, accuracy generally decreases as difficulty increases from Level 3 to Level 5. Levels 1-3 maintain high accuracy (>0.93), with a sharp drop at Level 4 and a further drop at Level 5.
2. **Trial Numbers Trend (Red Bars):** For both methods, the number of trials required increases steadily with difficulty level, from ~1.1 at Level 1 to over 2.1 at Level 5.
3. **Method Comparison:** The SFT+RL method (dark green/dark red) consistently matches or outperforms the SFT method (light green/light red) in accuracy, with the most significant advantage at Level 4. The trial numbers for the two methods are closely matched, with no consistent pattern of one requiring significantly more trials than the other across all levels.
### Key Observations
* **Performance Plateau and Drop:** The model achieves near-identical, high accuracy on Levels 1-3, suggesting these difficulty levels are within the model's strong capability range. The significant performance drop at Level 4 indicates a substantial increase in problem complexity that challenges the model.
* **RL Benefit at Critical Point:** The reinforcement learning (RL) component provides the most clear accuracy benefit at Level 4, the point where base performance drops significantly. This suggests RL may help the model generalize or apply its knowledge more effectively to harder problems.
* **Trial Cost Correlates with Difficulty:** The near-linear increase in trial numbers with difficulty level indicates that harder problems require more attempts to solve, regardless of the training method.
* **Anomaly at Level 3 Trials:** While accuracy is very high and similar for both methods at Level 3, the trial numbers (1.771 and 1.790) are notably higher than at Level 2 (~1.3). This suggests Level 3 problems, while still solvable with high accuracy, may require more exploratory attempts.
### Interpretation
This chart demonstrates the trade-off between problem difficulty, solution accuracy, and computational effort (trials) for a math-focused language model. The data suggests that:
1. **The base model (Qwen2.5-Math-7B) has a clear capability threshold.** It performs robustly on Levels 1-3 but struggles significantly with Level 4 and above, indicating these levels likely involve more advanced mathematical reasoning or multi-step processes.
2. **Supervised Fine-Tuning (SFT) alone is sufficient for easier problems** (Levels 1-3), achieving high accuracy. Adding Reinforcement Learning (SFT+RL) provides marginal to no accuracy benefit on these levels but does not significantly increase the trial cost.
3. **Reinforcement Learning shows its value at the model's performance edge.** The most pronounced accuracy gain from RL occurs at Level 4, where the model's base performance falters. This implies RL training helps refine the model's decision-making or strategy selection when faced with challenging, but not impossible, problems.
4. **Increased difficulty universally demands more resources.** The consistent rise in trial numbers underscores that harder problems are not just less likely to be solved correctly, but are also more computationally expensive to attempt, regardless of the training paradigm.
In essence, the visualization argues that while SFT establishes a strong foundation, targeted RL can provide a crucial performance boost precisely where the model begins to fail, making it a valuable tool for extending a model's effective difficulty range.
</details>
(b)
Figure 4: The accuracy and average trial number of different models across difficulty levels. Evaluated on MATH500 test set.
#### 3.4.3 Improvement across Difficulty Levels
To further illustrate the effect of S 2 r training, Figure 4 shows the answer accuracy and average number of trials (i.e., the average value of " $K$ " across all $y=(s_{1},v_{1},\cdots,s_{K},v_{K})$ under each difficulty level) for the SFT and SFT+RL models. We observe that: (1) By learning to self-verify and self-correct during reasoning, the models learn to dynamically allocate test-time effort. For easier problems, the models can reach a confident answer with fewer trials, while for more difficult problems, they require more trials to achieve a confident answer. (2) RL further improves test-time effort allocation, particularly for less capable model (e.g., Llama3.1-8B-Instruct). (3) After RL training, the answer accuracy for more difficult problems is notably improved, demonstrating the effectiveness of the self-verifying and self-correcting paradigm in enhancing the models’ reasoning abilities.
| | Datasets | xx Average xx | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Model | MATH 500 | AIME 2024 | AMC 2023 | College Math | Olympiad Bench | GSM8K | GaokaoEn 2023 | |
| General Model: Qwen2-7B-Instruct | | | | | | | | |
| Qwen2-7B-Instruct | 51.2 | 3.3 | 30.0 | 18.2 | 19.1 | 86.4 | 39.0 | 35.3 |
| Qwen2-7B- S 2 r -BI (ours) | 61.2 | 3.3 | 27.5 | 41.1 | 27.1 | 87.4 | 49.1 | 42.4 |
| Qwen2-7B- S 2 r -PRL (ours) | 65.4 | 6.7 | 35.0 | 36.7 | 27.0 | 89.0 | 49.9 | 44.2 |
| Qwen2-7B- S 2 r -ORL (ours) | 64.8 | 3.3 | 42.5 | 34.7 | 26.2 | 86.4 | 50.9 | 44.1 |
| Qwen2-7B–Instruct- S 2 r -PRL-offline (ours) | 61.6 | 10.0 | 32.5 | 40.2 | 26.5 | 87.6 | 50.4 | 44.1 |
| Qwen2-7B-Instruct- S 2 r -ORL-offline (ours) | 61.0 | 6.7 | 37.5 | 40.5 | 27.3 | 87.4 | 49.6 | 44.3 |
| Math-Specialized Model: Qwen2.5-Math-7B | | | | | | | | |
| Qwen2.5-Math-7B | 51.0 | 16.7 | 45.0 | 21.5 | 16.7 | 58.3 | 39.7 | 35.6 |
| Qwen2.5-Math-7B- S 2 r -BI (ours) | 81.6 | 23.3 | 60.0 | 43.9 | 44.4 | 91.9 | 70.1 | 59.3 |
| Qwen2.5-Math-7B- S 2 r -PRL (ours) | 83.4 | 26.7 | 70.0 | 43.8 | 46.4 | 93.2 | 70.4 | 62.0 |
| Qwen2.5-Math-7B- S 2 r -ORL (ours) | 84.4 | 23.3 | 77.5 | 43.8 | 44.9 | 92.9 | 70.1 | 62.4 |
| Qwen2.5-Math-7B- S 2 r -PRL-offline (ours) | 83.4 | 23.3 | 62.5 | 50.0 | 46.7 | 92.9 | 72.2 | 61.6 |
| Qwen2.5-Math-7B- S 2 r -ORL-offline (ours) | 82.0 | 20.0 | 67.5 | 49.8 | 45.8 | 92.6 | 70.4 | 61.2 |
Table 5: Comparison of S 2 r using online and offline RL training.
### 3.5 Exploring Offline RL
As described in § 2.4, we explore offline RL as a more efficient alternative to online RL training, given the effectiveness of offline RL has been demonstrated in recent studies Baheti et al. (2023); Cheng et al. (2025); Wang et al. (2024b).
Table 5 presents the results of offline RL with process-level and outcome-level supervision, compared to online RL. We can observe that: (1) Different from online RL, process-level supervision outperforms outcome-level supervision in offline RL training. This interesting phenomenon may be due to: a) Outcome-level RL, which excels at allowing models to freely explore dynamic trajectories, is more suitable for on-the-fly sampling during online parameter updating. b) In contrast, process-level RL, which requires accurate baseline estimation for intermediate steps, benefits from offline trajectory sampling, which can provide more accurate baseline estimates with larger scale data sampling. (2) Offline RL consistently improves performance over the behavior-initialized models across most benchmarks and achieves comparable results to online RL. These results highlight the potential of offline RL as a more efficient alternative for enhancing LLMs’ deep reasoning.
## 4 Related Work
### 4.1 Scaling Test-time Compute
Scaling test-time compute recently garners wide attention in LLM reasoning Snell et al. (2024b); Wu et al. (2024); Brown et al. (2024). Existing studies have explored various methods for scaling up test-time compute, including: (1) Aggregation-based methods that samples multiple responses for each question and obtains the final answer with self-consistency Wang et al. (2023) or by selecting best-of-N answer using a verifier or reward model Wang et al. (2024c); Zhang et al. (2024b); Lightman et al. (2023b); Havrilla et al. (2024b); (2) Search-based methods that apply search algorithms such as Monte Carlo Tree Search Tian et al. (2024); Wang et al. (2024a); Zhang et al. (2024a); Qi et al. (2024), beam search Snell et al. (2024b), or other effective algorithms Feng et al. (2023); Yao et al. (2023) to search for correct trajectories; (3) Iterative-refine-based methods that iteratively improve test performance through self-refinement Madaan et al. (2024a); Shinn et al. (2024); Chen et al. (2024a, 2025). Recently, there has been a growing focus on training LLMs to perform test-time search on their own, typically by conducting longer and deeper thinking OpenAI (2024); Guo et al. (2025). These test-time scaling efforts not only directly benefit LLM reasoning, but can also be integrated back into training time, enabling iterative improvement for LLM reasoning Qin et al. (2024); Feng et al. (2023); Snell et al. (2024b); Luong et al. (2024). In this work, we also present an efficient framework for training LLMs to perform effective test-time scaling through self-verification and self-correction iterations. This approach is achieved without extensive efforts, and the performance of S 2 r can also be consistently promoted via iterative training.
### 4.2 Self-verification and Self-correction
Enabling LLMs to perform effective self-verification and self-correction is a promising solution for achieving robust reasoning for LLMs Madaan et al. (2024b); Shinn et al. (2023); Paul et al. (2023); Lightman et al. (2023a), and these abilities are also critical for performing deep reasoning. Previous studies have shown that direct prompting of LLMs for self-verification or self-correction is suboptimal in most scenarios Huang et al. (2023); Tyen et al. (2023); Ma et al. (2024); Zhang et al. (2024c). As a result, recent studies have explored various approaches to enhance these capabilities during post-training Saunders et al. (2022); Rosset et al. (2024); Kumar et al. (2024). These methods highlight the potential of using human-annotated or LLM-generated data to equip LLMs with self-verification or self-correction capabilities Zhang et al. (2024d); Jiang et al. (2024), while also indicating that behavior imitation via supervised fine-tuning alone is insufficient for achieving valid self-verification or self-correction Kumar et al. (2024); Qu et al. (2025); Kamoi et al. (2024). In this work, we propose effective methods to enhance LLMs’ self-verification and self-correction abilities through principled imitation data construction and RL training, and demonstrate the effectiveness of our approach with in-depth analysis.
### 4.3 RL for LLM Reasoning
Reinforcement learning has proven effective in enhancing LLM performance across various tasks Ziegler et al. (2019); Stiennon et al. (2020); Bai et al. (2022); Ouyang et al. (2022); Setlur et al. (2025). In LLM reasoning, previous studies typically employ RL in an actor-critic framework Lightman et al. (2024); Tajwar et al. (2024); Havrilla et al. (2024a), and research on developing accurate reward models for RL training has been a long-standing focus, particularly in reward modeling for Process-level RL Lightman et al. (2024); Setlur et al. (2024, 2025); Luo et al. (2024). Recently, several studies have demonstrate that simplified reward modeling and advantage estimation Ahmadian et al. (2024); Shao et al. (2024); Team et al. (2025); Guo et al. (2025) in RL training can also effectively enhance LLM reasoning. Recent advances in improving LLMs’ deep thinking Guo et al. (2025); Team et al. (2025) further highlight the effectiveness of utilizing unhackable rewards Gao et al. (2023); Everitt et al. (2021) to consistently enhance LLM reasoning. In this work, we also show that simplified advantage estimation and RL framework enable effective improvements on LLM reasoning. Additionally, we conducted an analysis on process-level RL, outcome-level RL and offline RL, providing insights for future work in RL for LLM reasoning.
## 5 Conclusion
In this work, we propose S 2 r, an efficient framework for enhancing LLM reasoning by teaching LLMs to iteratively self-verify and self-correct during reasoning. We introduce a principled approach for behavior initialization, and explore both outcome-level and process-level RL to further strengthen the models’ thinking abilities. Experimental results across three different base models on seven math reasoning benchmarks demonstrate that S 2 r significantly enhances LLM reasoning with minimal resource requirements. Since self-verification and self-correction are two crucial abilities for LLMs’ deep reasoning, S 2 r offers an interpretable framework for understanding how SFT and RL enhance LLMs’ deep reasoning. It also offers insights into the selection of RL strategies for enhancing LLMs’ long-CoT reasoning.
## References
- qwe (2024) 2024. Qwen2 technical report.
- Ahmadian et al. (2024) Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. 2024. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms. arXiv preprint arXiv:2402.14740.
- AI-MO (2024a) AI-MO. 2024a. Aime 2024.
- AI-MO (2024b) AI-MO. 2024b. Amc 2023.
- Baheti et al. (2023) Ashutosh Baheti, Ximing Lu, Faeze Brahman, Ronan Le Bras, Maarten Sap, and Mark Riedl. 2023. Leftover lunch: Advantage-based offline reinforcement learning for language models. arXiv preprint arXiv:2305.14718.
- Bai et al. (2022) Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
- Berglund et al. (2023) Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. 2023. The reversal curse: Llms trained on" a is b" fail to learn" b is a". arXiv preprint arXiv:2309.12288.
- Brown et al. (2024) Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. 2024. Large language monkeys: Scaling inference compute with repeated sampling. arXiv preprint arXiv:2407.21787.
- Chen et al. (2025) Jiefeng Chen, Jie Ren, Xinyun Chen, Chengrun Yang, Ruoxi Sun, and Sercan Ö Arık. 2025. Sets: Leveraging self-verification and self-correction for improved test-time scaling. arXiv preprint arXiv:2501.19306.
- Chen et al. (2024a) Justin Chih-Yao Chen, Archiki Prasad, Swarnadeep Saha, Elias Stengel-Eskin, and Mohit Bansal. 2024a. Magicore: Multi-agent, iterative, coarse-to-fine refinement for reasoning. arXiv preprint arXiv:2409.12147.
- Chen et al. (2024b) Justin Chih-Yao Chen, Zifeng Wang, Hamid Palangi, Rujun Han, Sayna Ebrahimi, Long Le, Vincent Perot, Swaroop Mishra, Mohit Bansal, Chen-Yu Lee, et al. 2024b. Reverse thinking makes llms stronger reasoners. arXiv preprint arXiv:2411.19865.
- Chen et al. (2024c) Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, et al. 2024c. Do not think that much for 2+ 3=? on the overthinking of o1-like llms. arXiv preprint arXiv:2412.21187.
- Cheng et al. (2025) Pengyu Cheng, Tianhao Hu, Han Xu, Zhisong Zhang, Yong Dai, Lei Han, Xiaolong Li, et al. 2025. Self-playing adversarial language game enhances llm reasoning. Advances in Neural Information Processing Systems, 37:126515–126543.
- Cobbe et al. (2021a) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021a. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Cobbe et al. (2021b) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021b. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Cui et al. (2025) Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. 2025. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456.
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783.
- Everitt et al. (2021) Tom Everitt, Marcus Hutter, Ramana Kumar, and Victoria Krakovna. 2021. Reward tampering problems and solutions in reinforcement learning: A causal influence diagram perspective. Synthese, 198(Suppl 27):6435–6467.
- Feng et al. (2023) Xidong Feng, Ziyu Wan, Muning Wen, Ying Wen, Weinan Zhang, and Jun Wang. 2023. Alphazero-like tree-search can guide large language model decoding and training. arXiv preprint arXiv:2309.17179.
- Gao et al. (2023) Leo Gao, John Schulman, and Jacob Hilton. 2023. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866. PMLR.
- Geva et al. (2021) Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. 2021. Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies. Transactions of the Association for Computational Linguistics (TACL).
- Gu et al. (2024) Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I. Wang. 2024. Cruxeval: A benchmark for code reasoning, understanding and execution. arXiv preprint arXiv:2401.03065.
- Guan et al. (2025) Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. 2025. rstar-math: Small llms can master math reasoning with self-evolved deep thinking. arXiv preprint arXiv:2501.04519.
- Guo et al. (2025) Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
- Han et al. (2022) Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Luke Benson, Lucy Sun, Ekaterina Zubova, Yujie Qiao, Matthew Burtell, et al. 2022. Folio: Natural language reasoning with first-order logic. arXiv preprint arXiv:2209.00840.
- Havrilla et al. (2024a) Alex Havrilla, Yuqing Du, Sharath Chandra Raparthy, Christoforos Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravinskyi, Eric Hambro, Sainbayar Sukhbaatar, and Roberta Raileanu. 2024a. Teaching large language models to reason with reinforcement learning. arXiv preprint arXiv:2403.04642.
- Havrilla et al. (2024b) Alex Havrilla, Sharath Raparthy, Christoforus Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravinskyi, Eric Hambro, and Roberta Raileanu. 2024b. Glore: When, where, and how to improve llm reasoning via global and local refinements. arXiv preprint arXiv:2402.10963.
- He et al. (2024) Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. 2024. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. arXiv preprint arXiv:2402.14008.
- Hendrycks et al. (2021a) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021a. Measuring mathematical problem solving with the math dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2).
- Hendrycks et al. (2021b) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021b. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874.
- Huang et al. (2023) Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. 2023. Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798.
- Jiang et al. (2024) Huchen Jiang, Yangyang Ma, Chaofan Ding, Kexin Luan, and Xinhan Di. 2024. Towards intrinsic self-correction enhancement in monte carlo tree search boosted reasoning via iterative preference learning. arXiv preprint arXiv:2412.17397.
- Kamoi et al. (2024) Ryo Kamoi, Yusen Zhang, Nan Zhang, Jiawei Han, and Rui Zhang. 2024. When can llms actually correct their own mistakes? a critical survey of self-correction of llms. Transactions of the Association for Computational Linguistics, 12:1417–1440.
- Kool et al. (2019) Wouter Kool, Herke van Hoof, and Max Welling. 2019. Buy 4 reinforce samples, get a baseline for free!
- Kumar et al. (2024) Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, et al. 2024. Training language models to self-correct via reinforcement learning. arXiv preprint arXiv:2409.12917.
- Kwon et al. (2023) Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles.
- LI et al. (2024) Jia LI, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu. 2024. Numinamath. [https://github.com/project-numina/aimo-progress-prize](https://github.com/project-numina/aimo-progress-prize/blob/main/report/numina_dataset.pdf).
- Liao et al. (2024) Minpeng Liao, Wei Luo, Chengxi Li, Jing Wu, and Kai Fan. 2024. Mario: Math reasoning with code interpreter output–a reproducible pipeline. arXiv preprint arXiv:2401.08190.
- Lightman et al. (2023a) Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023a. Let’s verify step by step. arXiv preprint arXiv:2305.20050.
- Lightman et al. (2023b) Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023b. Let’s verify step by step. arXiv preprint arXiv:2305.20050.
- Lightman et al. (2024) Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. Let’s verify step by step. In The Twelfth International Conference on Learning Representations.
- Luo et al. (2024) Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, et al. 2024. Improve mathematical reasoning in language models by automated process supervision. arXiv preprint arXiv:2406.06592.
- Luong et al. (2024) Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li. 2024. Reft: Reasoning with reinforced fine-tuning. arXiv preprint arXiv:2401.08967.
- Ma et al. (2024) Ruotian Ma, Xiaolei Wang, Xin Zhou, Jian Li, Nan Du, Tao Gui, Qi Zhang, and Xuanjing Huang. 2024. Are large language models good prompt optimizers? arXiv preprint arXiv:2402.02101.
- Madaan et al. (2024a) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. 2024a. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36.
- Madaan et al. (2024b) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. 2024b. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36.
- OpenAI (2024) OpenAI. 2024. Openai o1 system card. preprint.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744.
- Paul et al. (2023) Debjit Paul, Mete Ismayilzada, Maxime Peyrard, Beatriz Borges, Antoine Bosselut, Robert West, and Boi Faltings. 2023. Refiner: Reasoning feedback on intermediate representations. arXiv preprint arXiv:2304.01904.
- Qi et al. (2024) Zhenting Qi, Mingyuan Ma, Jiahang Xu, Li Lyna Zhang, Fan Yang, and Mao Yang. 2024. Mutual reasoning makes smaller llms stronger problem-solvers. arXiv preprint arXiv:2408.06195.
- Qin et al. (2024) Yiwei Qin, Xuefeng Li, Haoyang Zou, Yixiu Liu, Shijie Xia, Zhen Huang, Yixin Ye, Weizhe Yuan, Hector Liu, Yuanzhi Li, et al. 2024. O1 replication journey: A strategic progress report–part 1. arXiv preprint arXiv:2410.18982.
- Qu et al. (2025) Yuxiao Qu, Tianjun Zhang, Naman Garg, and Aviral Kumar. 2025. Recursive introspection: Teaching language model agents how to self-improve. Advances in Neural Information Processing Systems, 37:55249–55285.
- Qwen (2024) Qwen. 2024. Qwen2.5-math-7b.
- Rosset et al. (2024) Corby Rosset, Ching-An Cheng, Arindam Mitra, Michael Santacroce, Ahmed Awadallah, and Tengyang Xie. 2024. Direct nash optimization: Teaching language models to self-improve with general preferences. arXiv preprint arXiv:2404.03715.
- Saunders et al. (2022) William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. 2022. Self-critiquing models for assisting human evaluators. arXiv preprint arXiv:2206.05802.
- Setlur et al. (2025) Amrith Setlur, Saurabh Garg, Xinyang Geng, Naman Garg, Virginia Smith, and Aviral Kumar. 2025. Rl on incorrect synthetic data scales the efficiency of llm math reasoning by eight-fold. Advances in Neural Information Processing Systems, 37:43000–43031.
- Setlur et al. (2024) Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. 2024. Rewarding progress: Scaling automated process verifiers for llm reasoning. arXiv preprint arXiv:2410.08146.
- Shao et al. (2024) Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300.
- Shen et al. (2025) Maohao Shen, Guangtao Zeng, Zhenting Qi, Zhang-Wei Hong, Zhenfang Chen, Wei Lu, Gregory Wornell, Subhro Das, David Cox, and Chuang Gan. 2025. Satori: Reinforcement learning with chain-of-action-thought enhances llm reasoning via autoregressive search. arXiv preprint arXiv:2502.02508.
- Shinn et al. (2024) Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2024. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36.
- Shinn et al. (2023) Noah Shinn, Beck Labash, and Ashwin Gopinath. 2023. Reflexion: an autonomous agent with dynamic memory and self-reflection. arXiv preprint arXiv:2303.11366.
- Snell et al. (2024a) Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024a. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314.
- Snell et al. (2024b) Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024b. Scaling llm test-time compute optimally can be more effective than scaling model parameters. Preprint, arXiv:2408.03314.
- Stiennon et al. (2020) Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. 2020. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021.
- Tajwar et al. (2024) Fahim Tajwar, Anikait Singh, Archit Sharma, Rafael Rafailov, Jeff Schneider, Tengyang Xie, Stefano Ermon, Chelsea Finn, and Aviral Kumar. 2024. Preference fine-tuning of llms should leverage suboptimal, on-policy data. arXiv preprint arXiv:2404.14367.
- Tang et al. (2024a) Zhengyang Tang, Xingxing Zhang, Benyou Wan, and Furu Wei. 2024a. Mathscale: Scaling instruction tuning for mathematical reasoning. arXiv preprint arXiv:2403.02884.
- Tang et al. (2024b) Zhengyang Tang, Xingxing Zhang, Benyou Wang, and Furu Wei. 2024b. Mathscale: Scaling instruction tuning for mathematical reasoning. arXiv preprint arXiv:2403.02884.
- Team et al. (2025) Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. 2025. Kimi k1. 5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599.
- Team (2024a) Qwen Team. 2024a. Qwq: Reflect deeply on the boundaries of the unknown.
- Team (2024b) The Mistral AI Team. 2024b. Mathstral-7b-v0.1.
- Tian et al. (2024) Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, and Dong Yu. 2024. Toward self-improvement of llms via imagination, searching, and criticizing. arXiv preprint arXiv:2404.12253.
- Toshniwal et al. (2024) Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman. 2024. Openmathinstruct-2: Accelerating ai for math with massive open-source instruction data. arXiv preprint arXiv:2410.01560.
- Tyen et al. (2023) Gladys Tyen, Hassan Mansoor, Peter Chen, Tony Mak, and Victor Cărbune. 2023. Llms cannot find reasoning errors, but can correct them! arXiv preprint arXiv:2311.08516.
- Wang et al. (2024a) Chaojie Wang, Yanchen Deng, Zhiyi Lv, Shuicheng Yan, and An Bo. 2024a. Q*: Improving multi-step reasoning for llms with deliberative planning. Preprint, arXiv:2406.14283.
- Wang et al. (2024b) Huaijie Wang, Shibo Hao, Hanze Dong, Shenao Zhang, Yilin Bao, Ziran Yang, and Yi Wu. 2024b. Offline reinforcement learning for llm multi-step reasoning. arXiv preprint arXiv:2412.16145.
- Wang et al. (2024c) Peiyi Wang, Lei Li, Zhihong Shao, R. X. Xu, Damai Dai, Yifei Li, Deli Chen, Y. Wu, and Zhifang Sui. 2024c. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. Preprint, arXiv:2312.08935.
- Wang et al. (2023) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations.
- Wang et al. (2024d) Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. 2024d. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. arXiv preprint arXiv:2406.01574.
- Wu et al. (2024) Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. 2024. An empirical analysis of compute-optimal inference for problem-solving with language models. arXiv preprint arXiv:2408.00724.
- Yang et al. (2024) An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. 2024. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems, 36:11809–11822.
- Yuan et al. (2024) Lifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. 2024. Free process rewards without process labels. arXiv preprint arXiv:2412.01981.
- Zeng et al. (2025) Weihao Zeng, Yuzhen Huang, Wei Liu, Keqing He, Qian Liu, Zejun Ma, and Junxian He. 2025. 7b model and 8k examples: Emerging reasoning with reinforcement learning is both effective and efficient. https://hkust-nlp.notion.site/simplerl-reason. Notion Blog.
- Zhang et al. (2024a) Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. 2024a. Rest-mcts*: Llm self-training via process reward guided tree search. arXiv preprint arXiv:2406.03816.
- Zhang et al. (2024b) Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. 2024b. Generative verifiers: Reward modeling as next-token prediction. In The 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24.
- Zhang et al. (2024c) Qingjie Zhang, Han Qiu, Di Wang, Haoting Qian, Yiming Li, Tianwei Zhang, and Minlie Huang. 2024c. Understanding the dark side of llms’ intrinsic self-correction. arXiv preprint arXiv:2412.14959.
- Zhang et al. (2024d) Yunxiang Zhang, Muhammad Khalifa, Lajanugen Logeswaran, Jaekyeom Kim, Moontae Lee, Honglak Lee, and Lu Wang. 2024d. Small language models need strong verifiers to self-correct reasoning. arXiv preprint arXiv:2404.17140.
- Zhao et al. (2024) Yu Zhao, Huifeng Yin, Bo Zeng, Hao Wang, Tianqi Shi, Chenyang Lyu, Longyue Wang, Weihua Luo, and Kaifu Zhang. 2024. Marco-o1: Towards open reasoning models for open-ended solutions. arXiv preprint arXiv:2411.14405.
- Zheng et al. (2024) Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2024. Processbench: Identifying process errors in mathematical reasoning. arXiv preprint arXiv:2412.06559.
- Ziegler et al. (2019) Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 2019. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593.
## Appendix A Implementation Details
### A.1 Verification Processing and SFT Data Construction
Given the responses sampled from the original LLM policy, we prompt frontier LLMs for initial verifications. In order to construct more valid verification, we force the LLMs to “verify without re-solving the problem” and filter out invalid verifications during data processing. We found that despite being instructed to "verify without re-solving the problem", most existing LLMs still biased to solve the problem again, as shown in Table 6. Finally, we collected the verification data by querying gpt-4-preview-1106 https://openai.com/api/ , which shows strong instruction-following ability to "verify without re-solving the problem" and can perform plausible verification such as adopting reverse thinking, inductive reasoning and other methods.
For these collected prompts, we refine the remaining verifications using gpt-4o to improve fluency and clarity. During this refinement, we instruct gpt-4o to append a conclusion at the end of each verification based on its stance—for example: “Therefore, the answer is correct/incorrect/cannot verify.” Finally, we discard any verifications where the judgment does not align with the actual correctness of the answer. The prompts we used during the whole process are provided in Appendix § A.3.
With the refined and filtered verifications, we construct the SFT data as follows. For each problem, we determine the number of answer attempts required to eventually obtain a correct answer based on the accuracy from the initial sampling. The lower the accuracy, the more rounds of responses are generated. In our implementation, we categorize all problems into four difficulty levels and construct answer sequences with 1, 2, 3, or 4 rounds, according to descending accuracy. Then, after an incorrect answer, we append “Wait, let me recheck my solution” along with the corresponding verification. If that answer is not the final attempt, we further append “Let me try again.” We ensure that the last answer in the sequence is correct. Additionally, we ensure that the answers in each round for a given problem are distinct. Figure 5 is an example of SFT data constructed with 4 rounds of responses.
### A.2 Baseline Details
#### A.2.1 Baseline Implementations
In Table 2, the reported results for Frontier LLMs and Top-tier Open-source Reasoning LLMs are sourced from the original reports and Guan et al. (2025). We evaluate Llama-3.1-8B-Instruct Dubey et al. (2024), Qwen2-7B-Instruct qwe (2024), Qwen2.5-Math-7B, Qwen2.5-Math-7B-Instruct and Qwen2.5-Math-72B-Instruct Yang et al. (2024) using the same process described in Section § 3.1. For Eurus-7B-PRIME Cui et al. (2025), rStar-Math-7B Guan et al. (2025), and Qwen2.5-7B-SimpleRL Zeng et al. (2025), we report results directly from the original papers.
In Table 3, the results for Llama-3.1-70B-Instruct and QwQ-32B-Preview are taken from Shen et al. (2025). For the remaining baselines, we follow the official evaluation protocol of the dataset project https://github.com/Yale-LILY/FOLIO https://github.com/facebookresearch/cruxeval https://github.com/eladsegal/strategyqa https://github.com/TIGER-AI-Lab/MMLU-Pro .
#### A.2.2 Baseline License
In this work, we utilize the Llama-3.1-8B-Instruct model, whose license can be reviewed at https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct/blob/main/LICENSE. In addition, the models Qwen2-7B-Instruct, Qwen2.5-Math-7B, Eurus-2-7B-PRIME, and project vLLM are distributed under the Apache License 2.0. We gratefully acknowledge the contributions of the open-source community and strictly adhere to the terms of the respective licenses.
#### A.2.3 Baseline SFT Data Construction
Original Solution SFT Data
In this setting, we use the solution from the original dataset as sft data. To ensure a fair comparison, we maintain the same training data volume as our behavior initialization approaches.
Long CoT SFT Data
We also introduce a baseline by fine-tuning on Long CoT responses generated by QwQ-32B-Preview Team (2024a). Specifically, we instruct QwQ to generate responses to given problems and filter out those with incorrect answers. The remaining high-quality responses are then used for supervised fine-tuning. Importantly, we ensure that the total training data volume remains consistent with that used in our behavior initialization approach. The prompt we use for QwQ is provided in Appendix § A.3.
### A.3 Prompts
The prompts we use in all experiments are as follows:
Sampling Responses During Training/Inference
⬇
Please reason step by step, and put your final answer within
\ boxed {}.
Problem: {problem}
Verification Refinement
⬇
You are a math teacher. I will give you a math problem and an answer.
Verify the answer ’ s correctness without step - by - step solving. Use alternative verification methods.
Question: {problem}
Answer: {answer}
Verification:
Verification Collection
⬇
Refine this verification text to read as a natural self - check within a solution. Maintain logical flow and professionalism.
Key Requirements:
1. Avoid phrases like " without solving step - by - step " or " as a math teacher ".
2. Treat the answer as your own prior solution.
3. Conclude with EXACTLY one of:
Therefore, the answer is correct.
Therefore, the answer is incorrect.
Therefore, the answer cannot be verified.
Original text: {verification}
## Appendix B Detailed Experiment Settings
| Without Asking for Confirmative Verification | |
| --- | --- |
| Model | Confirmative out of 100 |
| GPT-4o | 26 |
| GPT-4-Preview-1106 | 32 |
| QwQ-32B-preview | 37 |
| Llama-3.1-70B-Instruct | 28 |
| Asking for Confirmative Verification | |
| Model | Confirmative out of 100 |
| GPT-4o | 44 |
| GPT-4-Preview-1106 | 61 |
| QwQ-32B-preview | 58 |
| Llama-3.1-70B-Instruct | 50 |
Table 6:
### B.1 Datasets
Details of each test dataset we used as benchmark are as follows:
#### B.1.1 In-domain Datasets
MATH500 Lightman et al. (2023b) offers a streamlined slice of the broader MATH Hendrycks et al. (2021b) dataset, comprising 500 test problems selected through uniform sampling. Despite its smaller scope, it maintains a distribution of topics and difficulty levels that mirrors the larger MATH corpus.
GSM8K Cobbe et al. (2021a) features around 8,500 grade-school math word problems. The dataset focuses on simple arithmetic through early algebra and includes 1,319 distinct tasks in its test set.
OlympiadBench He et al. (2024) collects 8,476 advanced math and physics questions drawn from Olympiad contexts, with some originating from the Chinese college entrance exam. We use the subset of 674 text-only competition questions, providing open-ended math challenges.
AMC2023 AI-MO (2024b) and AIME AI-MO (2024a) each supply a set of challenging exam-style problems: 40 questions from AMC 2023 and 30 from AIME 2024, all in text-only format.
CollegeMath Tang et al. (2024b) is a dataset targeting advanced college-level mathematics, drawn from nine textbooks spanning seven major fields—algebra, pre-calculus, calculus, vector calculus, probability, linear algebra, and differential equations. The final collection comprises 1,281 training examples and 2,818 test examples.
Gaokao2023en Liao et al. (2024) is a dataset consisting of 385 mathematics problems sourced from the 2023 Chinese higher education entrance examination, which have been professionally translated into English.
#### B.1.2 Cross-domain Datasets
FOLIO Han et al. (2022) is meticulously annotated to assess intricate logical reasoning in natural language. It pairs 1,430 conclusions with 487 sets of premises—each verified using first-order logic (FOL)—and contains 203 unique problems in its test portion.
CRUXEval Gu et al. (2024) tests code comprehension and reasoning through 800 concise Python functions (spanning 3–13 lines). Each function is accompanied by one or more input-output examples. The goal is to predict the correct outputs given the function body and a specific input. The test partition encompasses all 800 problems.
StrategyQA Geva et al. (2021) targets multi-hop reasoning questions where the necessary intermediate steps are not explicit. Each of its 2,780 items includes a strategic query, a breakdown of the reasoning steps, and supporting evidence drawn from Wikipedia.
MMLUProSTEM is extracted from MMLU-Pro Wang et al. (2024d). Following Satori Shen et al. (2025), we conduct evaluations on six STEM subsets—physics, chemistry, computer science, engineering, biology, and economics.
### B.2 Hyperparameters Setting
| Model | Learning Rate | Batch Size | KL Coefficient | Max Length | Training Epochs |
| --- | --- | --- | --- | --- | --- |
| Llama-3.1-8B-Instruct | 5e-6 | 32 | 0.1 | 8000 | 3 |
| Qwen2-7B-Instruct | 5e-6 | 32 | 0.1 | 6000 | 3 |
| Qwen2.5-Math-7B | 5e-6 | 32 | 0.01 | 8000 | 3 |
Table 7: Model Training Hyperparameter Settings (SFT)
| Model | Learning Rate | Training Batch Size | Forward Batch Size | KL Coefficient | Max Length | Sampling Temperature | Clip Range | Training Steps |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Llama-3.1 | 5e-7 | 64 | 256 | 0.05 | 8000 | 0.7 | 0.2 | 500 |
| Qwen2-7B-Instruct | 5e-7 | 64 | 256 | 0.05 | 6000 | 0.7 | 0.2 | 500 |
| Qwen2.5-Math-7B | 5e-7 | 64 | 256 | 0.01 | 8000 | 0.7 | 0.2 | 500 |
Table 8: Model Training Hyperparameter Settings (RL)
During behavior initialization with SFT, we use a batch size of 32 and adopt a learning rate of 5e-6. We set the maximum sequence length 8000 to accommodate long responses and verifications. To balance stability and convergence during training, we add a KL punishment to the training loss, and the KL coefficient is set to 0.1.
During reinforcement learning, for each training batch, we use a training batch size of 64, and sample $n$ responses for each question in a batch, resulting a forward batch size of $64n$ . For each forward batch, we update the model for $n$ step with the training batch size 64. Specifically, for both process-level and outcome-level RL, we adopt $n=4$ (i.e., for RLOO, the sample number is also $4$ ). More hyperparameters of the RL training are presented in Table 8. We use the BF16 model precision in all experiments.
Main hyperparameters used in the experiments are illustrated in Table 7 and 8.
### B.3 Experiment Environment
All experiments are implemented using the PyTorch framework on 32 NVIDIA H20 (96GB) GPUs or 32 NVIDIA A100Pro (40GB) GPUs. Our training code is built upon Hugging Face TRL https://github.com/huggingface/trl. For inference, we use a single NVIDIA A100 (40GB) GPU with vLLM-0.5.4 https://github.com/vllm-project/vllm. We utilize transformers version 4.39.3 for fine-tuning Qwen2-7B-Instruct and Qwen2.5-Math-7B, version 4.44.0 for fine-tuning Llama-3.1-8B, and version 4.46.3 for reinforcement learning. We use PyTorch 2.1.1 across our training pipeline. Our evaluation code is built upon Qwen Math’s evaluation codebase https://github.com/QwenLM/Qwen2.5-Math.
## Appendix C Metrics Definition
We include the formal definition of metrics we use for analyzing self-verification and self-correction behaviors of the post-trained models as follows.
### C.1 Notations
We first present the main notations used in our formulation in Table 9.
| Variable | Description |
| --- | --- |
| $\pi$ | The policy |
| $x$ | Problem instance |
| $y$ | Series of predefined actions: $y=\{a_{1},a_{2},\ldots,a_{n}\}$ |
| $a_{i}$ | The $i$ -th action in the response $y$ , and let |
| $Type(a_{i})\in\{\texttt{verify},\texttt{solve},\texttt{<end>}\}$ | |
| $s_{j}$ | $j^{th}$ attempt to solve the problem |
| $v_{j}$ | $j^{th}$ self-verification for the $j^{th}$ attempt |
| $Parser(\cdot)$ | $Parser(v_{j})\in\{\texttt{correct},\texttt{incorrect}\}$ |
| The text parser to get the self-verification result | |
| indicating the correctness of action $s_{j}$ | |
| $V_{golden}(\cdot)$ | $V_{golden}(a_{i})\in\{\texttt{correct},\texttt{incorrect}\}$ |
| $R(\cdot)$ | The rule based reward function |
| $R(\cdot)\in\{-1,1\}$ | |
| $R(s_{j})=\begin{cases}1,&V_{golden}(s_{j})=\texttt{correct}\\ -1,&otherwise\\ \end{cases}$ | |
| $R(v_{j})=\begin{cases}1,&Parser(v_{j})=V_{golden}(s_{j})\\ -1,&otherwise\\ \end{cases}$ | |
| <end> | End of action series |
| $\mathbb{I}(\cdot)$ | The indicator function, $\mathbb{I}(\cdot)\in\{0,1\}$ . $\mathbb{I}(\cdot)=1$ if the condition inside holds true, and $\mathbb{I}(\cdot)=0$ otherwise. |
Table 9: Variable Lookup Table
### C.2 Self-Verification Metrics
#### C.2.1 Verification Accuracy (VA)
Verification Accuracy measures how often the verification prediction matches the ground-truth correctness ( $N$ is the total number of verifications in the responses to the test set):
#### C.2.2 Error Recall (ER)
Error Recall measures the recall of detecting incorrect answers (i.e., the fraction of actually incorrect answers that are successfully identified as incorrect):
where $|y|_{a}$ is the total number of actions in $y$ and $\frac{|y|_{a}}{2}$ is the total number of attempts to solve the problem ( $y=\{a_{1},a_{2},\cdots,a_{|y|_{a}}\}=\{s_{1},v_{1},\cdots,s_{\frac{|y|_{a}}{2} },v_{\frac{|y|_{a}}{2}}\}$ ).
#### C.2.3 Correct Precision (CP)
Correct Precision measures the precision when the verification model predicts an answer to be correct (i.e., among all “correct” predictions, how many are truly correct):
### C.3 Self-Correction Metrics
#### C.3.1 Incorrect to Correct Rate (ICR)
The rate at which the model successfully corrects an initially incorrect answer ( $R(s_{1})=-1$ ) into a correct final answer ( $R(s_{T_{y}})=1$ ), where $T_{y}=|y|_{a}/2$ is the total number of attempts to solve the problem in each $y$ . Formally:
$$
\text{ICR}=\frac{\sum_{y}\mathbb{I}\bigl{(}R(s_{1})=-1\bigr{)}\,\mathbb{I}
\bigl{(}R(s_{T_{y}})=1\bigr{)}}{\sum_{y}\mathbb{I}\bigl{(}R(s_{1})=-1\bigr{)}}. \tag{10}
$$
#### C.3.2 Correct to Incorrect Rate (CIR)
The rate at which the model incorrectly alters an initially correct answer ( $R(s_{1})=1$ ) into an incorrect final answer ( $R(s_{T_{y}})=-1$ ), where $T_{y}=|y|_{a}/2$ is the total number of attempts to solve the problem in each $y$ . Formally:
$$
\text{CIR}=\frac{\sum_{y}\mathbb{I}\bigl{(}R(s_{1})=1\bigr{)}\,\mathbb{I}\bigl
{(}R(s_{T_{y}})=-1\bigr{)}}{\sum_{y}\mathbb{I}\bigl{(}R(s_{1})=1\bigr{)}}. \tag{11}
$$
## Appendix D Offline RL Training Details
In this section, we provide additional details on the offline reinforcement learning training process, including formal definition, ablation studies, and implementation details.
### D.1 Accuracy-Grouped Baseline Definition
To fully leverage the advantages of offline RL, which does not require real-time sampling, we explore more appropriate baseline selection by further grouping trajectories based on problem difficulty. Intuitively, for two trajectories $y^{(1)}$ and $y^{(2)}$ sampled under questions of different difficulty levels, and their corresponding actions $a^{(1)}_{t}$ and $a^{(2)}_{t}$ at the same position, even if they share identical reward contexts, their expected returns (baselines) should differ, i.e., the expected return is typically lower for more challenging problems.
We measure a problem’s difficulty by estimating how often it is solved correctly under the current sampling policy. Concretely, we sample multiple trajectories in parallel for each problem. The fraction of these trajectories that yield a correct final answer serves as the problem’s accuracy. We then discretize this accuracy into separate bins, effectively grouping the problems according to their estimated difficulty. All trajectories belonging to problems within the same accuracy bin form a common subset.
Compared to using direct reward contexts alone, this accuracy-based grouping offers a more robust estimate of expected returns, problems in the same bin share similar success rates. Moreover, unlike a pre-defined difficulty grouping, these bins adjust dynamically as the model’s capabilities evolve. Building on this approach, we propose two accuracy-based baseline estimation methods for offline RL as follows.
#### D.1.1 Accuracy-Grouped Baseline With Position Group
Within each accuracy bin, we further split actions based on their position in the trajectory. Concretely, we consider all actions occurring at the same step index across trajectories in the same bin to be comparable, and we compute their average return to serve as the baseline. Thus, when we look up the baseline for a particular action at a given step in a trajectory, we use the average return of all actions taken at that same step index in all trajectories belonging to the same accuracy bin.
#### D.1.2 Accuracy-Grouped Baseline With Reward Context
We also propose combining accuracy-based grouping with reward-context grouping. The underlying assumption is that even if two actions share the same immediate reward context, their expected returns can differ if they originate from different difficulty bins. Generally, problems that are harder to solve exhibit lower expected returns. Consequently, we first bin the trajectories by accuracy, then further group them by common reward context. Within each sub-group, we average the returns of all relevant actions to obtain the baseline.
### D.2 Offline RL Implementation Details
In each iteration of offline RL training, we generate multiple trajectories (e.g., eight) per prompt in parallel. We then apply prompt filtering, rejection sampling, accuracy-based baseline estimation, advantage computation, and policy updates. Implementation details follow.
#### D.2.1 Prompt Filtering
| Accuracy Range | Retained Questions | MATH500 | AIME2024 | AMC2023 | College Math | Olympiad Bench | GSM8K | GaokaoEn2023 | Average |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $[0.1-0.7]$ | 1805 | 83.4 | 23.3 | 62.5 | 50.0 | 46.7 | 92.9 | 72.2 | 61.6 |
| $[0.2-0.8]$ | 2516 | 82.6 | 23.3 | 70.0 | 49.8 | 45.3 | 92.4 | 70.1 | 61.9 |
| $[0.3-0.9]$ | 4448 | 81.6 | 23.3 | 70.0 | 49.4 | 44.7 | 92.0 | 68.1 | 61.3 |
| $[0-1]$ | Full | 80.6 | 26.7 | 67.5 | 50.0 | 43.0 | 91.4 | 67.0 | 60.9 |
Table 10: Comparison of question filtering accuracy selection.
As we sample multiple trajectories for each prompt, we compute the accuracy of each prompt. We retain prompts whose accuracy falls within a predefined range.
Our ablation study on Qwen2.5-Math-7B shown in Table 10 confirms that filtering improves performance. The most stable results are obtained with an accuracy range of $[0.1,0.7]$ , suggesting that including moderately difficult samples enhances the model’s reasoning capabilities.
#### D.2.2 Rejection Sampling
We discard any trajectory that does not follow the alternation pattern of solution and verification: $y=(s_{1},v_{1},\dots,s_{k},v_{k})$ . Additionally, we remove malformed trajectories such as $y=(s_{1},s_{2},v_{1})$ . To mitigate reward hacking due to excessively long outputs, we eliminate trajectories where $R(s_{t})=1$ and $R(v_{t})=1$ at timestep $t$ , but further actions are taken at $t+1$ . Moreover, we discard trajectories containing more than 20 actions, as excessive action sequences can introduce instability and deviate from expected solution structures.
#### D.2.3 Loss Function
| | Datasets | xx Average xx | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Baseline Method | MATH500 | AIME2024 | AMC2023 | College Math | Olympiad Bench | GSM8K | GaokaoEn2023 | |
| Based on reward context | 82.4 | 26.7 | 65.0 | 50.1 | 46.1 | 92.9 | 71.2 | 62.1 |
| Based on accuracy group with position | 83.4 | 23.3 | 62.5 | 50.0 | 46.7 | 92.9 | 72.2 | 61.6 |
| Based on accuracy group with reward context | 82.4 | 23.3 | 67.5 | 49.3 | 45.8 | 93.3 | 71.2 | 61.8 |
Table 11: The performance of different baselines
To determine the best offline baseline method, we conducted ablation studies on Qwen2.5-Math-7B shown in Table 11. We found that using the accuracy-grouped baseline with an additional division by position provides the most stable results. When computing advantages, we subtract both the baseline and a scaled relative policy term like Equation 5. Notably, we fix $\pi_{\text{ref}}$ as the reference policy instead of being updated at each iteration.
#### D.2.4 Training Hyperparameter Settings
We use a batch size of 64, a maximum learning rate of $5\times 10^{-7}$ , and a KL penalty coefficient of 0.1. The maximum training sequence length is set to 8192. We apply a warm-up phase of 5 steps and a clipping range parameter of 0.2. We use BF16 model precision in all experiments.
## Appendix E Demo Cases
<details>
<summary>x7.png Details</summary>

### Visual Description
## Text-Based Mathematical Problem and Solution
### Overview
The image displays a mathematical word problem about candy distribution among four individuals, followed by a detailed, self-correcting response that analyzes the truth value of six statements regarding the final number of candies. The text is presented in a serif font (likely LaTeX Computer Modern) on a plain white background, typical of academic or competition problem sets.
### Components/Axes
The content is structured into two main sections:
1. **Problem Statement:** A paragraph defining the scenario and the question.
2. **Response:** A multi-paragraph analysis that includes several self-interruptions and corrections, highlighted in green text.
### Detailed Analysis / Content Details
**Problem Statement Transcription:**
> **Problem:** Lizzy, Megan, Oscar, and Patrick each have *x* pieces of candy, where *x* is a positive integer. Unfortunately, Patrick is the only one of the four who likes candy. So Lizzy gives all her candy to Megan. Then Megan gives all the candy she now has (which includes the candy Lizzy gave her) to Oscar. Then Oscar gives all the candy he now has to Patrick.
> Let *P* be the number of pieces of candy Patrick has in the end. How many of the following statements are true? (Assume that we do not know exactly what *x* is.)
> (a) 2 can be a divisor of *P*.
> (b) 2 must be a divisor of *P*.
> (c) 3 can be a divisor of *P*.
> (d) 3 must be a divisor of *P*.
> (e) 4 can be a divisor of *P*.
> (f) 4 must be a divisor of *P*.
**Response Transcription (including green-highlighted text):**
> **Response:**
> Let’s analyze each statement step-by-step, considering the transformation of the pieces of candy from Lizzy to Megan, then to Oscar, and finally to Patrick… **Wait, let me recheck my solution.** To verify the correctness of the answer, we need to consider… Therefore, the answer is incorrect. **Let me try again.** Given that Lizzy, Megan, Oscar, and Patrick each start with *x* pieces of candy… **Wait, let me recheck my solution.** To verify the solution, we will analyze the number of pieces of candy, … Therefore, the answer is incorrect. **Let me try again.** First, let’s break down the candy distribution process… **Wait, let me recheck my solution.** To verify the answer, I will assess the properties of the… **Let me try again.** To solve this problem, let’s denote the initial number of pieces of candy each person has as *x*… **Wait, let me recheck my solution.** To verify the answer, we need to evaluate the given statements based on the problem conditions.
>
> Lizzy, Megan, Oscar, and Patrick each start with *x* pieces of candy. The total amount of candy remains constant as it is transferred among them. Ultimately, Patrick ends up with all the candy, totaling *4x* pieces.
>
> Let’s examine each statement:
> (a) 2 can be a divisor of *P*: This is true because if *x* is even, then *4x* is even and divisible by 2.
> (b) 2 must be a divisor of *P*: This is true because *4x* is always divisible by 2, regardless of *x*.
> (c) 3 can be a divisor of *P*: This is true if *x* is a multiple of 3, then *4x* will also be a multiple of 3.
> (d) 3 must be a divisor of *P*: This is false because if *x* is not a multiple of 3, then *4x* will not be a multiple of 3.
> (e) 4 can be a divisor of *P*: This is true as *4x* is divisible by 4.
> (f) 4 must be a divisor of *P*: This is true because *4x* is always divisible by 4, regardless of *x*.
>
> Five statements are true: (a), (b), (c), (e), and (f). The only false statement is (d).
> Therefore, the answer is correct.
### Key Observations
1. **Self-Correction Pattern:** The initial part of the response is fragmented with four instances of the green-highlighted phrase "**Wait, let me recheck my solution.**" and two instances of "**Let me try again.**" This suggests a simulated or genuine process of iterative reasoning and error correction before arriving at the final, coherent analysis.
2. **Logical Structure:** The final, clean analysis correctly deduces that *P = 4x*. It then systematically evaluates each statement based on the properties of the integer *x* and the expression *4x*.
3. **Statement Analysis:** The core mathematical insight is distinguishing between "can be" (possibility) and "must be" (necessity) for divisibility. Statements (a), (c), and (e) are about possibility, while (b), (d), and (f) are about necessity.
4. **Conclusion:** The response concludes that five of the six statements are true, with only statement (d) being false.
### Interpretation
The image presents a classic number theory problem wrapped in a simple narrative. The data (the problem and its solution) demonstrates the importance of precise logical language in mathematics. The key takeaway is the critical difference between existential ("can be") and universal ("must be") quantifiers when discussing properties of an unknown integer.
The green-highlighted text is particularly interesting. It doesn't represent factual data about the candy problem but rather provides a meta-commentary on the problem-solving process itself. It illustrates a non-linear path to a solution, involving backtracking and re-evaluation, which is a realistic representation of mathematical reasoning. From a Peircean perspective, this highlights the abductive and deductive steps taken: forming hypotheses about the statements, testing them against the deduced fact that *P=4x*, and revising the approach when initial attempts seemed flawed.
The final, clean analysis is correct. Since *P = 4x*:
* **Divisibility by 2:** *4x* is always even, so 2 **must** be a divisor (b is true). It also **can** be a divisor (a is trivially true).
* **Divisibility by 3:** *4x* is divisible by 3 only if *x* is divisible by 3. Therefore, 3 **can** be a divisor (c is true), but it **must not** be a divisor (d is false).
* **Divisibility by 4:** *4x* is always divisible by 4, so 4 **must** be a divisor (f is true). It also **can** be a divisor (e is trivially true).
Thus, the problem tests the solver's ability to separate necessary conditions from possible ones, a fundamental skill in mathematical logic. The image serves as both a problem set and a demonstration of a rigorous, self-critical solution method.
</details>
Figure 5: SFT data example.
<details>
<summary>x8.png Details</summary>

### Visual Description
\n
## Mathematical Solution: Vector Cross Product Problem
### Overview
The image displays a step-by-step mathematical solution to a vector algebra problem. The task is to find the vector **v** with the smallest magnitude that satisfies the cross product equation: `(1, 2, -5) × v = (90, 30, 30)`. The solution process includes an initial incorrect attempt, a verification step that identifies the error, and a corrected final solution.
### Components/Axes
The content is structured as a series of mathematical derivations and text explanations. There are no graphical axes or charts. The primary components are:
1. **Problem Statement:** Presented at the top.
2. **Initial Solution Attempt:** Labeled "Reponse:" (likely a typo for "Response").
3. **Verification Section:** Introduced with green text: "Wait, let me recheck my solution."
4. **Corrected Solution:** Introduced with green text: "Let me try again."
5. **Final Verification:** Another green-text section confirming the corrected answer.
### Detailed Analysis / Content Details
**1. Problem Statement:**
* **Text:** "Problem: There are an infinite number of vectors **v** such that `(1, 2, -5) × v = (90, 30, 30)`. Find the vector **v** that has the smallest magnitude."
**2. Initial (Incorrect) Solution Attempt:**
* **Method:** Sets `v = (x, y, z)`. Computes the cross product `(1, 2, -5) × (x, y, z)` as `(2z + 5y, -5x + z, 2x - y)`.
* **System of Equations:**
```
2z + 5y = 90
-5x + z = 30
2x - y = 30
```
* **Solving Process:** Solves the third equation for `y = 2x - 30`. Substitutes into the first to get `z = 120 - 5x`. Substitutes into the second to find `x = 9`. Then finds `y = -12` and `z = 75`.
* **Proposed Vector:** `v = (9, -12, 75)`.
* **Minimization Logic:** States the general solution is `v = (9, -12, 75) + t(1, 2, -5)` for scalar `t`. Claims magnitude is minimized when `t=0`, yielding the vector `(9, -12, 75)`.
**3. First Verification (Identifies Error):**
* **Text (in green):** "Wait, let me recheck my solution."
* **Method:** Uses the property that the cross product `a × b` is orthogonal to both `a` and `b`. Here, `a = (1, 2, -5)` and the result `c = (90, 30, 30)`. Therefore, the correct `v` must be orthogonal to `c`.
* **Check:** Computes dot products:
* `a · c = (1)(90) + (2)(30) + (-5)(30) = 90 + 60 - 150 = 0` (Orthogonal, as expected).
* `v · c = (9)(90) + (-12)(30) + (75)(30) = 810 - 360 + 2250 = 2700 ≠ 0`.
* **Conclusion (in red):** "Since `v · c ≠ 0`, the given answer **v** is not orthogonal to **c**, which means it cannot be the correct vector **v** that satisfies the cross product equation. Therefore, the answer is incorrect."
**4. Corrected Solution:**
* **Text (in green):** "Let me try again."
* **Method:** Recomputes the cross product using the determinant formula with unit vectors **i, j, k**:
```
| i j k |
| 1 2 -5 | = i(2z + 5y) - j(z + 5x) + k(y - 2x)
| x y z |
```
This yields the vector: `(2z + 5y, -z - 5x, y - 2x)`.
* **Correct System of Equations:**
```
2z + 5y = 90
-z - 5x = 30
y - 2x = 30
```
* **Solving Process:**
* From second equation: `z = -5x - 30`.
* From third equation: `y = 2x + 30`.
* Substitutes into first equation: `2(-5x - 30) + 5(2x + 30) = 90` → `-10x - 60 + 10x + 150 = 90` → `90 = 90`.
* **Key Insight:** The system is consistent and dependent, yielding infinitely many solutions. The general solution is expressed as:
`v = (x, 2x + 30, -5x - 30)`.
* **Minimization:** To find the smallest magnitude, minimizes `||v||² = x² + (2x+30)² + (-5x-30)²`.
* Simplifies to: `30x² + 420x + 1800`.
* Completes the square: `30(x + 7)² + 330`.
* The minimum occurs at `x = -7`.
* **Final Vector:** Substitutes `x = -7` into the general solution:
`v = (-7, 2(-7)+30, -5(-7)-30) = (-7, 16, 5)`.
**5. Final Verification:**
* **Text (in green):** "Wait, let me recheck my solution."
* **Method:** Repeats the orthogonality check with the new vector `v = (-7, 16, 5)`.
* **Check:**
* `a · c = 0` (as before).
* `v · c = (-7)(90) + (16)(30) + (5)(30) = -630 + 480 + 150 = 0`.
* **Conclusion:** "Since both dot products are zero, the given answer **v** is orthogonal to **c**, which means it could be a correct vector **v** that satisfies the cross product equation. Therefore, the answer is correct."
### Key Observations
1. **Error Identification:** The initial solution made a sign error in the second component of the cross product (`-5x + z` instead of `-z - 5x`). This was caught by applying the orthogonality property of the cross product.
2. **System Dependency:** The correct system of equations is linearly dependent, leading to a line of solutions parameterized by `x`.
3. **Minimization Technique:** The problem of finding the smallest magnitude vector is solved by minimizing the squared magnitude function, which reduces to finding the vertex of a parabola.
4. **Visual Cues:** The use of **green text** for self-correction and **red text** for the error statement provides clear visual segmentation of the problem-solving narrative.
### Interpretation
This document is a pedagogical walkthrough of a vector algebra problem. It demonstrates not just the solution, but the **process of mathematical reasoning and verification**. The core takeaway is the application of two key concepts:
1. **Geometric Property of Cross Product:** The result `a × b` is orthogonal to both `a` and `b`. This property serves as a powerful check for the correctness of a solution.
2. **Optimization in Linear Systems:** When a system has infinite solutions (a line), the solution with the minimum norm (smallest magnitude) is the one orthogonal to the direction vector of the line. The algebraic method of completing the square on the magnitude function is shown to find this point.
The narrative structure—attempt, error, correction, verification—mirrors authentic problem-solving and emphasizes the importance of checking work using fundamental properties. The final answer, `v = (-7, 16, 5)`, is the unique point on the solution line closest to the origin.
</details>
Figure 6: MATH500 Case.
<details>
<summary>x9.png Details</summary>

### Visual Description
\n
## Screenshot: Logical Reasoning Problem and Solution Attempts
### Overview
The image is a screenshot of a text-based logical reasoning exercise. It presents a problem with two given facts, a question, and a series of step-by-step solution attempts. The text shows an iterative reasoning process where an initial incorrect answer ("False") is challenged and re-evaluated, ultimately leading to a corrected answer ("True"). The text includes visual formatting cues such as colored text and boxed answers.
### Content Details (Full Transcription)
**Problem** You are given the following facts:
1. Chlorine, when added to water, creates household bleach.
2. Household bleach is available at most dollar stores.
Based on the facts above, answer the following question. Your final answer should be either "True" or "False".
Problem: Can you buy chlorine at a dollar store?
**Response** To determine if you can buy chlorine at a dollar store, let's analyze the given facts step by step:
1. Fact 1 states that when chlorine is added to water, it creates household bleach.
2. Fact 2 states that household bleach is available at most dollar stores.
From Fact 2, we know that household bleach is available at dollar stores. However, Fact 1 does not provide any direct information about the availability of chlorine itself at dollar stores. It only tells us that chlorine, when added to water, produces household bleach.
Since Fact 1 does not provide information about the direct sale of chlorine, we cannot conclude that chlorine is available at dollar stores based solely on the given facts.
Therefore, the answer is: <span style="background-color: #e0e0e0; padding: 2px 6px; border: 1px solid #999;">False</span>
<span style="color: green;">Wait, let me recheck my solution.</span>
The answer provided is "False." To verify this, let's examine the logical structure of the given statements and the inferred conclusion.
The first statement asserts that when chlorine is added to water, it creates household bleach. The second statement claims that household bleach is available at most dollar stores.
From these two statements, we can infer that if household bleach is available at dollar stores, it is possible that chlorine, when added to water, could be used to create household bleach that is sold at dollar stores. However, the statements do not explicitly confirm the availability of chlorine at dollar stores.
The answer "False" implies that it is not possible to buy chlorine at a dollar store. Given that the statements do not provide information about the direct sale of chlorine, but rather the creation of bleach from chlorine, the answer "False" is not necessarily incorrect. It is possible that chlorine is not sold at dollar stores, but it could be used to create bleach that is sold there.
Therefore, the answer is incorrect.
<span style="color: green;">Let me try again.</span>
To determine if you can buy chlorine at a dollar store, let's analyze the given facts step by step.
1. Fact 1: Chlorine, when added to water, creates household bleach.
2. Fact 2: Household bleach is available at most dollar stores.
From Fact 2, we know that household bleach is a product that can be found at dollar stores. However, Fact 1 only states that chlorine, when added to water, creates household bleach. It does not provide any information about whether chlorine itself is sold at dollar stores.
Since the availability of chlorine at dollar stores is not mentioned in the facts provided, we cannot definitively conclude that chlorine is available at dollar stores based solely on the given information.
Therefore, the answer is: <span style="background-color: #e0e0e0; padding: 2px 6px; border: 1px solid #999;">False</span>
<span style="color: green;">Wait, let me recheck my solution.</span>
The answer provided is "False." To verify this, let's examine the logical structure of the given statements and the inferred conclusion.
The first statement asserts that when chlorine is added to water, it creates household bleach. The second statement claims that household bleach is available at most dollar stores.
From these two statements, we can infer that if household bleach is available at dollar stores, it is possible that chlorine, when added to water, could be used to create household bleach that is sold at dollar stores. However, the statements do not explicitly confirm the availability of chlorine at dollar stores.
The answer "False" implies that it is not possible to buy chlorine at a dollar store. Given that the statements do not provide information about the direct sale of chlorine, but rather the creation of bleach from chlorine, the answer "False" is not necessarily incorrect. It is possible that chlorine is not sold at dollar stores, but it could be used to create bleach that is sold there.
Therefore, the answer is incorrect.
<span style="color: green;">Let me try again.</span>
To determine whether you can buy chlorine at a dollar store, let's analyze the given facts step by step.
1. Fact 1: Chlorine, when added to water, creates household bleach.
2. Fact 2: Household bleach is available at most dollar stores.
From Fact 2, we know that household bleach is available at most dollar stores. Since household bleach is made by adding chlorine to water, it implies that the process of making household bleach involves chlorine. However, Fact 1 does not provide any information about the direct sale of chlorine itself at dollar stores.
Given that household bleach is available at dollar stores and it is made from chlorine, it is reasonable to infer that chlorine is also available at dollar stores, as it is a necessary component for making household bleach.
Therefore, based on the given facts, it is reasonable to conclude that you can buy chlorine at a dollar store.
<span style="background-color: #e0e0e0; padding: 2px 6px; border: 1px solid #999;">True</span>
<span style="color: green;">Wait, let me recheck my solution.</span>
The answer provided is "True." To verify this, let's examine the logical structure of the given statements and the inferred conclusion.
The first statement asserts that when chlorine is added to water, it creates household bleach. The second statement claims that household bleach is available at most dollar stores.
From these two statements, we can infer that if household bleach is available at dollar stores, it is possible that chlorine, when added to water, could be used to create household bleach that is sold at dollar stores. This inference supports the conclusion that chlorine can be bought at a dollar store, as it is a necessary component for producing household bleach.
Therefore, the answer is correct.
### Key Observations
1. **Iterative Reasoning Process:** The text displays a self-correcting reasoning loop. The initial conclusion ("False") is presented, followed by a re-evaluation prompt in green text ("Wait, let me recheck my solution."), which leads to a critique of the initial logic. This cycle repeats, showing a progression from a strict, literal interpretation of the facts to a more inferential one.
2. **Visual Formatting:** The final answers ("False" and "True") are enclosed in light grey boxes with a border, making them stand out from the reasoning text. The self-correction prompts are consistently highlighted in green.
3. **Logical Structure:** The core of the problem hinges on the difference between *direct information* and *reasonable inference*. The facts do not explicitly state chlorine is sold at dollar stores, only that its product (bleach) is. The reasoning evolves from requiring explicit statement to accepting a necessary component inference.
### Interpretation
This image documents a metacognitive exercise in logical deduction. It demonstrates how the same set of premises can lead to different conclusions based on the strictness of the interpretive framework applied.
* **Initial "False" Conclusion:** This reasoning adopts a strict, positivist stance. It demands that for a statement to be true, it must be directly supported by the given facts. Since the facts do not explicitly say "chlorine is sold at dollar stores," the answer is "False." This approach avoids making assumptions beyond the provided text.
* **Final "True" Conclusion:** This reasoning employs abductive logic, or inference to the best explanation. It connects the two facts through a causal chain: if bleach (made from chlorine) is sold, then its necessary precursor (chlorine) is likely also available for purchase. This is a pragmatic, real-world inference that fills a logical gap left by the explicit statements.
The exercise highlights a common tension in analytical reasoning: the balance between rigorous adherence to given data and the use of plausible inference to solve problems. The iterative structure, with its self-correction, models a thoughtful problem-solving approach where conclusions are tested and refined. The final, correct answer ("True") validates the use of reasonable inference based on the provided causal relationship (chlorine + water → bleach).
</details>
Figure 7: StrategyQA Case.
To intuitively demonstrate the effectiveness of our proposed method, we present the model’s inference examples after RL on the MATH500 and StrategyQA datasets in the Figure 6 and Figure 7.
## Appendix F Other Discussion
### F.1 Discussion on Potential Risk
We have carefully considered potential risks associated with our work and found no significant concerns. Our approach, focused on enhancing LLM reasoning through self-verification and self-correction, does not introduce malicious or harmful effects, privacy issues, or security threats. Additionally, it does not contribute to biases, fairness concerns, or environmental impact. We believe our work is safe for responsible use in research.
### F.2 Use of AI Assistant
In this work, we utilized an AI assistant solely for the purpose of refining and polishing the language of the manuscript. The AI assistant was employed to improve clarity, flow, and overall readability, ensuring the text adhered to academic writing standards. It was not involved in any data analysis, experimentation, or formulation of ideas. All research design, methodology, results, and conclusions were developed independently by the authors. The use of the AI assistant was limited to language enhancement and did not influence the content or scientific integrity of the work.