# Agentic Deep Graph Reasoning Yields Self-Organizing Knowledge Networks
**Authors**:
- Markus J. Buehler (Laboratory for Atomistic and Molecular Mechanics)
- Cambridge, MA 02139, USA
> Corresponding author.
Abstract
We present an agentic, autonomous graph expansion framework that iteratively structures and refines knowledge in situ. Unlike conventional knowledge graph construction methods relying on static extraction or single-pass learning, our approach couples a reasoning-native large language model with a continually updated graph representation. At each step, the system actively generates new concepts and relationships, merges them into a global graph, and formulates subsequent prompts based on its evolving structure. Through this feedback-driven loop, the model organizes information into a scale-free network characterized by hub formation, stable modularity, and bridging nodes that link disparate knowledge clusters. Over hundreds of iterations, new nodes and edges continue to appear without saturating, while centrality measures and shortest path distributions evolve to yield increasingly distributed connectivity. Our analysis reveals emergent patterns—such as the rise of highly connected “hub” concepts and the shifting influence of “bridge” nodes—indicating that agentic, self-reinforcing graph construction can yield open-ended, coherent knowledge structures. Applied to materials design problems, we present compositional reasoning experiments by extracting node-specific and synergy-level principles to foster genuinely novel knowledge synthesis, yielding cross-domain ideas that transcend rote summarization and strengthen the framework’s potential for open-ended scientific discovery. We discuss other applications in scientific discovery and outline future directions for enhancing scalability and interpretability.
Keywords Artificial Intelligence $·$ Science $·$ Graph Theory $·$ Category Theory $·$ Materials Science $·$ Materiomics $·$ Language Modeling $·$ Reasoning $·$ Isomorphisms $·$ Engineering
1 Introduction
Scientific inquiry often proceeds through an interplay of incremental refinement and transformative leaps, evoking broader questions of how knowledge evolves under continual reflection and questioning. In many accounts of discovery, sustained progress arises not from isolated insights but from an iterative process in which prior conclusions are revisited, expressed as generalizable ideas, refined, or even reorganized as new evidence and perspectives emerge [1]. Foundational work in category theory has formalized aspects of this recursive structuring, showing how hierarchical representations can unify diverse knowledge domains and enable higher-level abstractions in both the natural and social sciences [2, 3, 4]. Across engineering disciplines including materials science, such iterative integration of information has proven essential in synthesizing deeply interlinked concepts.
Recent AI methods, however, often emphasize predictive accuracy and single-step outputs over the layered, self-reflective processes that characterize human problem-solving. Impressive gains in natural language processing, multimodal reasoning [5, 6, 7, 8, 9, 10, 11, 12], and materials science [13, 14, 15, 16, 17], including breakthroughs in molecular biology [18] and protein folding [19, 20, 21], showcase the prowess of large-scale models trained on vast datasets. Yet most of the early systems generate answers in a single pass, sidestepping the symbolic, stepwise reasoning that often underpins scientific exploration. This gap has prompted a line of research into modeling that explicitly incorporates relational modeling, reflection or multi-step inferences [2, 3, 4, 22, 23, 24, 25, 26, 27, 28], hinting at a transition from single-shot pattern recognition to more adaptive synthesis of answers from first principles in ways that more closely resemble compositional mechanisms. Thus, a fundamental challenge now is how can we build scientific AI systems that synthesize information rather than memorizing it.
Graphs offer a natural substrate for this kind of iterative knowledge building. By representing concepts and their relationships as a network, it becomes possible to capture higher-order structure—such as hubs, bridging nodes, or densely interconnected communities—that might otherwise remain implicit. This explicit relational format also facilitates systematic expansion: each newly added node or edge can be linked back to existing concepts, reshaping the network and enabling new paths of inference [29, 23, 27]. Moreover, graph-based abstractions can help large language models move beyond memorizing discrete facts; as nodes accumulate and form clusters, emergent properties may reveal cross-domain synergies or overlooked gaps in the knowledge space.
Recent work suggests that standard Transformer architectures can be viewed as a form of Graph Isomorphism Network (GIN), where attention operates over relational structures rather than raw token sequences [23]. Under this lens, each attention head effectively tests for isomorphisms in local neighborhoods of the graph, offering a principled way to capture both global and local dependencies. A category-theoretic perspective further bolsters this approach by providing a unified framework for compositional abstractions: nodes and edges can be treated as objects and morphisms, respectively, while higher-level concepts emerge from functorial mappings that preserve relational structure [2, 3, 4]. Taken together, these insights hint at the potential for compositional capabilities in AI systems, where simpler building blocks can be combined and reconfigured to form increasingly sophisticated representations, rather than relying on one-pass computations or static ontologies. By using graph-native modeling and viewing nodes and edges as composable abstractions, such a model may be able to recognize and reapply learned configurations in new contexts—akin to rearranging building blocks to form unanticipated solutions. This compositional approach, strengthened by category-theoretic insights, allows the system to not only interpolate among known scenarios but to extrapolate to genuinely novel configurations. In effect, graph-native attention mechanisms treat interconnected concepts as first-class entities, enabling the discovery of new behaviors or interactions that purely sequence-based methods might otherwise overlook.
A fundamental challenge remains: How can we design AI systems that, rather than merely retrieving or matching existing patterns, build and refine their own knowledge structures across iterations. Recent work proposes that graphs can be useful strategies to endow AI models with relational capabilities [29, 23, 27] both within the framework of creating graph-native attention mechanisms and by training models to use graphs as native abstractions during learned reasoning phases. Addressing this challenge requires not only methods for extracting concepts but also mechanisms for dynamically organizing them so that new information reshapes what is already known. By endowing large language models with recursively expanding knowledge graph capabilities, we aim to show how stepwise reasoning can support open-ended discovery and conceptual reorganization. The work presented here explores how such feedback-driven graph construction may lead to emergent, self-organizing behaviors, shedding light on the potential for truly iterative AI approaches that align more closely with the evolving, integrative nature of human scientific inquiry. Earlier work on graph-native reasoning has demonstrated that models explicitly taught how to reason in graphs and abstractions can lead to systems that generalize better and are more interpretable [27].
Here we explore whether we can push this approach toward ever-larger graphs, creating extensive in situ graph reasoning loops where models spend hours or days developing complex relational structures before responding to a task. Within such a vision, several key issues arise: Will repeated expansions naturally preserve the network’s relational cohesion, or risk splintering into disconnected clusters? Does the continuous addition of new concepts and edges maintain meaningful structure, or lead to saturation and redundancy? And to what extent do bridging nodes, which may initially spark interdisciplinary links, remain influential over hundreds of iterations? In the sections ahead, we investigate these questions by analyzing how our recursively expanded knowledge graphs grow and reorganize at scale—quantifying hub formation, modular stability, and the persistence of cross-domain connectors. Our findings suggest that, rather than collapsing under its own complexity, the system retains coherent, open-ended development, pointing to new possibilities for large-scale knowledge formation in AI-driven research for scientific exploration. Iterative Reasoning $i<N$
Define Initial Question (Broad question or specific topic, e.g., "Impact-Resistant Materials")
Generate Graph-native Reasoning Tokens <|thinking|> ... <|/thinking|>
Parse Graph $\mathcal{G}_{\text{local}}^{i}$ (Extract Nodes and Relations)
Merge Extracted Graph with Larger Graph (Append Newly Added Nodes/Edges) $\mathcal{G}←\mathcal{G}\cup\mathcal{G}_{\text{local}}^{i}$
Save and Visualize
Final Integrated Graph $\mathcal{G}$
Generate New Question Based on Last Extracted Added Nodes/Edges as captured in $\mathcal{G}_{\text{local}}^{i}$
Figure 1: Algorithm used for iterative knowledge extraction and graph refinement. At each iteration $i$ , the model generates reasoning tokens (blue). From the response, a local graph $\mathcal{G}_{\text{local}}^{i}$ is extracted (violet) and merged with the global knowledge graph $\mathcal{G}$ (light violet). The evolving graph is stored in multiple formats for visualization and analysis (yellow). Instead of letting the model respond to the task, a follow-up task is generated based on the latest extracted nodes and edges in $\mathcal{G}_{\text{local}}^{i}$ (green), ensuring iterative refinement (orange), so that the model generates yet more reasoning tokens, and as part of that process, new nodes and edges. The process continues until the stopping condition $i<N$ is met, yielding a final structured knowledge graph $\mathcal{G}$ (orange).
1.1 Knowledge Graph Expansion Approaches
Knowledge graphs are one way to organize relational understanding of the world. They have grown from manually curated ontologies decades ago into massive automatically constructed repositories of facts. A variety of methodologies have been developed for expanding knowledge graphs. Early approaches focused on information extraction from text using pattern-based or open-domain extractors. For example, the DIPRE algorithm [30] bootstrapped relational patterns from a few seed examples to extract new facts in a self-reinforcing loop. Similarly, the KnowItAll system [31] introduced an open-ended, autonomous “generate-and-test” paradigm to extract entity facts from the web with minimal supervision. Open Information Extraction methods like TextRunner [32] and ReVerb [33] further enabled unsupervised extraction of subject–predicate–object triples from large text corpora without requiring a predefined schema. These unsupervised techniques expanded knowledge graphs by harvesting new entities and relations from unstructured data, although they often required subsequent mapping of raw extractions to a coherent ontology.
In parallel, research on knowledge graph completion has aimed to expand graphs by inferring missing links and attributes. Statistical relational learning and embedding-based models (e.g., translational embeddings like TransE [34]) predict new relationships by generalizing from known graph structures. Such approaches, while not fully unsupervised (they rely on an existing core of facts for training), can autonomously suggest plausible new edges to add to a knowledge graph. Complementary to embeddings, logical rule-mining systems such as AMIE [35] showed that high-confidence Horn rules can be extracted from an existing knowledge base and applied to infer new facts recursively. Traditional link prediction heuristics from network science – for example, preferential attachment and other graph connectivity measures – have also been used as simple unsupervised methods to propose new connections in knowledge networks. Together, these techniques form a broad toolkit for knowledge graph expansion, combining text-derived new content with graph-internal inference to improve a graph’s coverage and completeness.
1.2 Recursive and Autonomous Expansion Techniques
A notable line of work seeks to make knowledge graphs growth continuous and self-sustaining – essentially achieving never-ending expansion. The NELL project (Never-Ending Language Learner) [36] pioneered this paradigm, with a system that runs 24/7, iteratively extracting new beliefs from the web, integrating them into its knowledge base, and retraining itself to improve extraction competence each day. Over years of operation, NELL has autonomously accumulated millions of facts by coupling multiple learners (for parsing, classification, relation extraction, etc.) in a semi-supervised bootstrapping loop. This recursive approach uses the knowledge learned so far to guide future extractions, gradually expanding coverage while self-correcting errors; notably, NELL can even propose extensions to its ontology as new concepts emerge.
Another milestone in autonomous knowledge graph construction was Knowledge Vault [37], which demonstrated web-scale automatic knowledge base population by fusing facts from diverse extractors with probabilistic inference. Knowledge Vault combined extractions from text, tables, page structure, and human annotations with prior knowledge from existing knowledge graphs, yielding a vast collection of candidate facts (on the order of 300 million) each accompanied by a calibrated probability of correctness. This approach showed that an ensemble of extractors, coupled with statistical fusion, can populate a knowledge graph at scales far beyond what manual curation or single-source extraction can achieve. Both NELL and Knowledge Vault illustrate the power of autonomous or weakly-supervised systems that grow a knowledge graph with minimal human intervention, using recursive learning and data fusion to continually expand and refine the knowledge repository.
More recent research has explored agent-based and reinforcement learning (RL) frameworks for knowledge graph expansion and reasoning. Instead of one-shot predictions, these methods allow an agent to make multi-hop queries or sequential decisions to discover new facts or paths in the graph. For example, some work [38] employ an agent that learns to navigate a knowledge graph and find multi-step relational paths, effectively learning to reason over the graph to answer queries. Such techniques highlight the potential of autonomous reasoning agents that expand knowledge by exploring connections in a guided manner (using a reward signal for finding correct or novel information). This idea of exploratory graph expansion aligns with concepts in network science, where traversing a network can reveal undiscovered links or communities. It also foreshadowed approaches like Graph-PReFLexOR [27] that treat reasoning as a sequential decision process, marked by special tokens, that can iteratively build and refine a task-specific knowledge graph.
Applications of these expansion techniques in science and engineering domains underscore their value for discovery [29]. Automatically constructed knowledge graphs have been used to integrate and navigate scientific literature, enabling hypothesis generation by linking disparate findings. A classic example is Swanson’s manual discovery of a connection between dietary fish oil and Raynaud’s disease, which emerged by linking two disjoint bodies of literature through intermediate concepts [39, 40]. Modern approaches attempt to replicate such cross-domain discovery in an automated way: for instance, mining biomedical literature to propose new drug–disease links, or building materials science knowledge graphs that connect material properties, processes, and applications to suggest novel materials, engineering concepts, or designs [41, 29].
1.3 Relation to Earlier Work and Key Hypothesis
The prior work discussed in Section 1.2 provides a foundation for our approach, which draws on the never-ending learning spirit of NELL [36] and the web-scale automation of Knowledge Vault [37] to dynamically grow a knowledge graph in situ as it reasons. Like those systems, it integrates information from diverse sources and uses iterative self-improvement. However, rather than relying on passive extraction or purely probabilistic link prediction, our method pairs on-the-fly logical reasoning with graph expansion within the construct of a graph-native reasoning LLM. This means each newly added node or edge is both informed by and used for the model’s next step of reasoning. Inspired in part by category theory and hierarchical inference, we move beyond static curation by introducing a principled, recursive reasoning loop that helps maintain transparency in how the knowledge graph evolves. In this sense, the work can be seen as a synthesis of existing ideas—continuous learning, flexible extraction, and structured reasoning—geared toward autonomous problem-solving in scientific domains.
Despite substantial progress in knowledge graph expansion, many existing methods still depend on predefined ontologies, extensive post-processing, or reinforce only a fixed set of relations. NELL and Knowledge Vault, for instance, demonstrated how large-scale extraction and integration of facts can be automated, but they rely on established schemas or require manual oversight to refine extracted knowledge [36, 37]. Reinforcement learning approaches such as DeepPath [38] can efficiently navigate existing graphs but do not grow them by generating new concepts or hypotheses.
By contrast, the work reported here treats reasoning as an active, recursive process that expands a knowledge graph while simultaneously refining its structure. This aligns with scientific and biological discovery processes, where knowledge is not just passively accumulated but also reorganized in light of new insights. Another key distinction is the integration of preference-based objectives, enabling more explicit interpretability of each expansion step. Methods like TransE [34] excel at capturing statistical regularities but lack an internal record of reasoning paths; our approach, in contrast, tracks and justifies each newly added node or relation. This design allows for a transparent, evolving representation that is readily applied to interdisciplinary exploration—such as in biomedicine [39] and materials science [41] —without depending on rigid taxonomies.
Hence, this work goes beyond conventional graph expansion by embedding recursive reasoning directly into the construction process, bridging the gap between passive knowledge extraction and active discovery. As we show in subsequent sections, this self-expanding paradigm yields scale-free knowledge graphs in which emergent hubs and bridge nodes enable continuous reorganization, allowing the system to evolve its understanding without exhaustive supervision and paving the way for scalable hypothesis generation and autonomous reasoning.
Hypothesis.
We hypothesize that recursive graph expansion enables self-organizing knowledge formation, allowing intelligence-like behavior to emerge without predefined ontologies, external supervision, or centralized control. Using a pre-trained model, Graph-PReFLexOR (an autonomous graph-reasoning model trained on a corpus of biological and biologically inspired materials principles) we demonstrate that knowledge graphs can continuously expand in a structured yet open-ended manner, forming scale-free networks with emergent conceptual hubs and interdisciplinary bridge nodes. Our findings suggest that intelligence-like reasoning can arise from recursive self-organization, challenging conventional paradigms and advancing possibilities for autonomous scientific discovery and scalable epistemic reasoning.
2 Results and Discussion
We present the results of experiments in which the graph-native reasoning model engages in a continuous, recursive process of graph-based reasoning, expanding its knowledge graph representation autonomously over 1,000 iterations. Unlike prior approaches that rely on a small number of just a few recursive reasoning steps, the experiments reported in this paper explore how knowledge formation unfolds in an open-ended manner, generating a dynamically evolving graph. As the system iterates, it formulates new tasks, refines reasoning pathways, and integrates emerging concepts, progressively structuring its own knowledge representation following the simple algorithmic paradigm delineated in Figure 1. The resulting graphs from all iterations form a final integrated knowledge graph, which we analyze for structural and conceptual insights. Figure 2 depicts the final state of the graph, referred to as graph $\mathcal{G}_{1}$ , after the full reasoning process.
The recursive graph reasoning process can be conducted in either an open-ended setting or develoepd into a more tailored manner to address a specific domain or flavor in which reasoning steps are carried out (details, see Materials and Methods). In the example explored here, we focus on designing impact-resistant materials. In this specialized scenario, we initiate the model with a concise, topic-specific prompt – e.g., Describe a way to design impact resistant materials, and maintain the iterative process of extracting structured knowledge from the model’s reasoning. We refer to the resulting graph as $\mathcal{G}_{2}$ . Despite the narrower focus, the same core principles apply: each new piece of information from the language model is parsed into nodes and edges, appended to a global graph, and informs the next iteration’s query. In this way, $\mathcal{G}_{2}$ captures a highly directed and domain-specific knowledge space while still exhibiting many of the emergent structural traits—such as hub formation, stable modularity, and growing connectivity—previously seen in the more general graph $\mathcal{G}_{1}$ . Figure 3 shows the final snapshot for $\mathcal{G}_{2}$ . To further examine the emergent structural organization of both graphs, Figures S1 and S2 display the same graphs with nodes and edges colored according to cluster identification, revealing the conceptual groupings that emerge during recursive knowledge expansion.
<details>
<summary>x2.png Details</summary>

### Visual Description
## Network Graph: Bimodal Node-Link Diagram
### Overview
This image displays a complex network graph (specifically a node-link diagram) rendered against a solid white background. The visualization maps the relationships and interconnectivity between hundreds to thousands of individual entities.
**CRITICAL NOTE:** This image contains absolutely no text, labels, axes, legends, or explicit numerical data. Therefore, specific factual data points (e.g., exact values, categories, or metrics) cannot be extracted. The following analysis is derived entirely from the visual topology, clustering patterns, and the visual encoding (size, color, density) of the network elements.
### Components/Axes
In the absence of explicit legends or axes, the data is encoded through the following visual components:
* **Nodes (Vertices):** Represented by circular points.
* *Size:* Varies significantly. Larger size correlates with a higher number of connections (degree centrality).
* *Color:* Ranges from pale, translucent peach/orange (small, peripheral nodes) to deep, opaque crimson red (large, highly connected hub nodes).
* **Edges (Links):** Represented by curved lines connecting the nodes.
* *Color/Opacity:* Ranges from very faint, translucent peach to darker reddish-brown. Darker lines appear to indicate either higher edge weight (stronger connections) or the visual accumulation of multiple overlapping edges in dense areas.
* **Layout:** The spatial distribution appears to be generated by a force-directed layout algorithm. This type of algorithm simulates physical forces, pulling highly connected nodes closer together into clusters while pushing disconnected nodes apart, revealing the underlying structure of the network.
### Detailed Analysis (Spatial Grounding & Component Isolation)
To accurately describe the topology, the image can be segmented into distinct spatial regions:
**1. Bottom-Left Primary Cluster (The Major Hub)**
* *Position:* Centered in the lower-left quadrant of the graph.
* *Description:* This is the densest and most visually dominant region of the network.
* *Key Features:* It contains the single largest and darkest red node in the entire graph. This node acts as a massive central hub. Immediately to its right (approx. 4 o'clock position relative to the main hub) is a secondary, slightly smaller dark red node. Hundreds of distinct, curved edges radiate outward from these central points in a dense "starburst" or hub-and-spoke pattern, connecting to a vast cloud of smaller, lighter-colored peripheral nodes.
**2. Top-Right Secondary Cluster**
* *Position:* Located in the upper-right quadrant.
* *Description:* A distinct, secondary center of gravity within the network. It is less dense than the bottom-left cluster but highly structured.
* *Key Features:* It features one prominent dark red hub node. Unlike the primary cluster, this hub is closely surrounded by a constellation of 4 to 5 medium-sized, moderately red nodes. The connections here form a complex, interconnected web among these medium hubs, rather than a single massive starburst.
**3. Far-Right Peripheral Hub**
* *Position:* Located on the far right edge, slightly below the horizontal midline.
* *Description:* A smaller, isolated sub-cluster.
* *Key Features:* It contains one medium-dark red node with a localized, distinct starburst of connections radiating outward, primarily connecting back toward the Top-Right Secondary Cluster.
**4. The Interstitial Web (Connecting Tissue)**
* *Position:* The space between the major clusters (running diagonally from top-left to bottom-right).
* *Description:* This area is characterized by long, sweeping, curved edges that bridge the distinct clusters.
* *Key Features:* While the clusters are spatially separated, the dense webbing of faint lines between them indicates that the sub-networks are highly integrated. There are very few isolated nodes; almost everything eventually connects back to the main hubs.
### Key Observations
* **Bimodal Distribution:** The network is fundamentally bimodal, dominated by two massive super-clusters (bottom-left and top-right) that dictate the overall shape of the graph.
* **Scale-Free Topology:** The visual evidence strongly suggests a "scale-free" network topology. The vast majority of nodes are small and have very few connections, while a tiny minority of nodes (the dark red circles) possess a massive number of connections.
* **Curved Edge Bundling:** The edges are drawn as sweeping curves (splines) rather than straight lines. This is a common data visualization technique used to reduce visual clutter in highly dense graphs, allowing the viewer to see the flow of connections without the center becoming a solid, unreadable block of color.
### Interpretation
Because we lack the specific data labels, we must interpret the *structural meaning* of this graph.
* **System Dynamics:** This topology is typical of systems like social networks (where the red nodes are massive influencers or central figures), biological networks (like protein-protein interactions where central nodes are vital genes), or transportation/routing networks (like major airline hubs).
* **Efficiency vs. Vulnerability:** The network is highly efficient for transferring information/resources. Because of the massive central hubs, it likely takes very few "hops" to get from any one node to any other node in the network. However, this structure represents a significant vulnerability. If the single largest node in the bottom-left were removed or failed, that entire half of the network would likely fragment into disconnected pieces. The system relies heavily on a few critical points of failure.
* **Community Structure:** The distinct separation between the bottom-left and top-right clusters suggests two distinct "communities" or sub-groups within the broader dataset. While they interact (evidenced by the interstitial web), their internal connections are much stronger than their external connections to each other.
</details>
Figure 2: Knowledge graph $\mathcal{G_{1}}$ after around 1,000 iterations, under a flexible self-exploration scheme initiated with the prompt Discuss an interesting idea in bio-inspired materials science. We observe the formation of a highly connected graph with multiple hubs and centers.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Network Graph: Centralized Hub-and-Spoke Topology
### Overview
This image is a data visualization of a complex network graph (node-link diagram) displayed against a solid white background. **CRITICAL NOTE: The image contains absolutely no text, labels, axes, legends, or explicit numerical data.** Therefore, no text transcription or exact data table reconstruction is possible. The information contained within this image is entirely structural, relational, and topological, conveyed through the spatial distribution, size, color, and density of nodes (circles) and edges (connecting lines).
### Components & Visual Encoding
Because standard chart axes and legends are absent, the visual encoding must be inferred from the graphical elements:
* **Nodes (Vertices):** Represent individual entities within the network.
* *Size:* Node radius appears to correlate with "degree centrality" (the number of connections it has).
* *Color:* Node color correlates with importance or centrality, ranging from pale peach/translucent (low importance/few connections) to dark, opaque red (high importance/many connections).
* **Edges (Links):** Represent relationships or interactions between nodes.
* *Shape:* Edges are rendered as curved lines (Bezier curves) rather than straight lines, which helps visualize dense connections without them merging into a single solid block.
* *Color/Opacity:* Edges are uniformly pale peach/orange and highly translucent. Density is shown through the overlapping of hundreds of these translucent lines, creating darker, more opaque regions where connections are thickest.
### Detailed Analysis
Applying component isolation, the network can be divided into three primary spatial regions:
**1. The Primary Central Hub (Center / Center-Left)**
* **Positioning:** Dominates the upper-left and central portion of the canvas.
* **Features:** At the exact core of this cluster is a single, prominent, dark red node. This is the largest and darkest element in the entire image.
* **Connectivity:** Hundreds of curved edges radiate outward from this central red node. Many edges loop back to smaller nodes in its immediate vicinity, creating a dense, flower-like or starburst pattern. A few secondary nodes (slightly larger than the background nodes, colored medium-orange) are visible within this primary cluster's orbit.
**2. The Secondary Sub-Hub (Bottom-Right)**
* **Positioning:** Located in the lower right quadrant of the image.
* **Features:** This is a distinct, tightly knit cluster of nodes. It lacks a single massive dominant node like the primary hub, but instead features 3 to 5 medium-sized, light-orange nodes acting as local centers.
* **Connectivity:** It is highly interconnected internally. Crucially, a thick "highway" or bridge of sweeping, curved edges connects this entire cluster back to the Primary Central Hub.
**3. The Tertiary Sub-Hub (Bottom-Left)**
* **Positioning:** Located in the lower left quadrant, directly below the left edge of the primary hub.
* **Features:** The smallest and least dense of the three main clusters. It contains a few slightly enlarged nodes.
* **Connectivity:** It serves as a structural bridge. It has distinct edge pathways connecting upward to the Primary Central Hub, and sweeping edge pathways connecting rightward to the Secondary Sub-Hub.
**4. The Periphery**
* Long, faint, sweeping lines extend outward from the main hubs into the negative white space. Some of these appear to connect to very small, almost invisible nodes at the edges of the graph, while others loop back into the main clusters.
### Key Observations
* **Extreme Centralization:** The visual trend overwhelmingly points to a highly centralized network. The vast majority of paths through the network must pass through or near the single dark red node.
* **Macro-Structure:** The overall shape forms a rough, asymmetrical triangle, with the massive primary hub at the top/center, and the two smaller sub-hubs forming the base at the bottom left and right.
* **Sparsity vs. Density:** The graph utilizes extreme contrast in density. The core of the primary hub is nearly opaque due to overlapping lines, while the spaces between the three main hubs are relatively sparse, crossed only by specific bridging connections.
### Interpretation
While the specific subject matter (e.g., social network, biological pathways, IT infrastructure) is unknown due to the lack of labels, the topological data suggests several strong conclusions:
1. **Scale-Free Network Dynamics:** The graph strongly exhibits properties of a "scale-free" network, which follows a power-law distribution. One node has a massive number of connections (the hub), while the vast majority of nodes have very few. This is typical of organic networks like the internet, social influencer networks, or protein interaction networks.
2. **Single Point of Failure:** From a systems analysis perspective, this network is highly vulnerable. The dark red central node is a critical bottleneck. If that node were removed or failed, the network would likely fragment into isolated, disconnected sub-communities (specifically, the bottom-right and bottom-left clusters would lose their primary routing pathway).
3. **Community Structure:** Despite the overwhelming dominance of the central node, the presence of the bottom-right and bottom-left clusters indicates distinct sub-communities. These communities have strong internal relationships but rely on the central hub for broader network integration. The bottom-left cluster appears to act as an intermediary or secondary routing path between the main hub and the bottom-right hub.
</details>
Figure 3: Visualizatrion of the knowledge graph Graph 2 after around 500 iterations, under a topic-specific self-exploration scheme initiated with the prompt Describe a way to design impact resistant materials. The graph structure features a complex interwoven but highly connected network with multiple centers.
Table 1 shows a comparison of network properties for two graphs (graph $\mathcal{G_{1}}$ , see Figure 2 and graph $\mathcal{G_{2}}$ , see Figure 3), each computed at the end of their iterations. The scale-free nature of each graph is determined by fitting the degree distribution to a power-law model using the maximum likelihood estimation method. The analysis involves estimating the power-law exponent ( $\alpha$ ) and the lower bound ( $x_{\min}$ ), followed by a statistical comparison against an alternative exponential distribution. A log-likelihood ratio (LR) greater than zero and a $p$ -value below 0.05 indicate that the power-law distribution better explains the degree distribution than an exponential fit, suggesting that the network exhibits scale-free behavior. In both graphs, these criteria are met, supporting a scale-free classification. We observe that $\mathcal{G_{1}}$ has a power-law exponent of $\alpha=3.0055$ , whereas $\mathcal{G_{2}}$ has a lower $\alpha=2.6455$ , indicating that Graph 2 has a heavier-tailed degree distribution with a greater presence of high-degree nodes (hubs). The lower bound $x_{\min}$ is smaller in $\mathcal{G_{2}}$ ( $x_{\min}=10.0$ ) compared to $\mathcal{G_{1}}$ ( $x_{\min}=24.0$ ), suggesting that the power-law regime starts at a lower degree value, reinforcing its stronger scale-free characteristics.
Other structural properties provide additional insights into the connectivity and organization of these graphs. The average clustering coefficients (0.1363 and 0.1434) indicate moderate levels of local connectivity, with $\mathcal{G_{2}}$ exhibiting slightly higher clustering. The average shortest path lengths (5.1596 and 4.8984) and diameters (17 and 13) suggest that both graphs maintain small-world characteristics, where any node can be reached within a relatively short number of steps. The modularity values (0.6970 and 0.6932) indicate strong community structures in both graphs, implying the presence of well-defined clusters of interconnected nodes. These findings collectively suggest that both graphs exhibit small-world and scale-free properties, with $\mathcal{G_{2}}$ demonstrating a stronger tendency towards scale-free behavior due to its lower exponent and smaller $x_{\min}$ .
Beyond scale-free characteristics, we note that the two graphs exhibit differences in structural properties that influence their connectivity and community organization. We find that $\mathcal{G_{1}}$ , with 3,835 nodes and 11,910 edges, is much larger and more densely connected than $\mathcal{G_{2}}$ , which has 2,180 nodes and 6,290 edges. However, both graphs have similar average degrees (6.2112 and 5.7706), suggesting comparable overall connectivity per node. The number of self-loops is slightly higher in Graph 1 (70 vs. 33), though this does not significantly impact global structure. The clustering coefficients (0.1363 and 0.1434) indicate moderate levels of local connectivity, with Graph 2 exhibiting slightly more pronounced local clustering. The small-world nature of both graphs is evident from their average shortest path lengths (5.1596 and 4.8984) and diameters (17 and 13), implying efficient information flow. Modularity values (0.6970 and 0.6932) suggest both graphs have well-defined community structures, with Graph 1 showing marginally stronger modularity, possibly due to its larger size. Overall, while both graphs display small-world and scale-free properties, $\mathcal{G_{2}}$ appears to have a more cohesive structure with shorter paths and higher clustering, whereas $\mathcal{G_{1}}$ is larger with a slightly stronger community division.
| Number of nodes Number of edges Average degree | 3835 11910 6.2112 | 2180 6290 5.7706 |
| --- | --- | --- |
| Number of self-loops | 70 | 33 |
| Average clustering coefficient | 0.1363 | 0.1434 |
| Average shortest path length (LCC) | 5.1596 | 4.8984 |
| Diameter (LCC) | 17 | 13 |
| Modularity (Louvain) | 0.6970 | 0.6932 |
| Log-likelihood ratio (LR) | 15.6952 | 39.6937 |
| p-value | 0.0250 | 0.0118 |
| Power-law exponent ( $\alpha$ ) | 3.0055 | 2.6455 |
| Lower bound ( $x_{\min}$ ) | 24.0 | 10.0 |
| Scale-free classification | Yes | Yes |
Table 1: Comparison of network properties for two graphs (graph $\mathcal{G_{1}}$ , see Figure 2 and S1 and graph $\mathcal{G_{2}}$ , see Figure 3 and S2), each computed at the end of their iterations. Both graphs exhibit scale-free characteristics, as indicated by the statistically significant preference for a power-law degree distribution over an exponential fit (log-likelihood ratio $LR>0$ and $p<0.05$ ). The power-law exponent ( $\alpha$ ) for $\mathcal{G_{1}}$ is 3.0055, while $\mathcal{G_{2}}$ has a lower exponent of 2.6455, suggesting a heavier-tailed degree distribution. The clustering coefficients (0.1363 and 0.1434) indicate the presence of local connectivity, while the shortest path lengths (5.1596 and 4.8984) and diameters (17 and 13) suggest efficient global reachability. The high modularity values (0.6970 and 0.6932) indicate strong community structure in both graphs. Overall, both networks exhibit hallmark properties of scale-free networks, with $\mathcal{G_{2}}$ showing a more pronounced scale-free behavior due to its lower $\alpha$ and lower $x_{\min}$ .
2.1 Basic Analysis of Recursive Graph Growth
We now move on to a detailed analysis of the evolution of the graph as the reasoning process unfolds over thinking iterations. This sheds light into how the iterative process dynamically changes the nature of the graph. The analysis is largely focused on $\mathcal{G_{1}}$ , albeit a few key results are also included for $\mathcal{G_{2}}$ . Detailed methods about how the various quantities are computed are included in Materials and Methods.
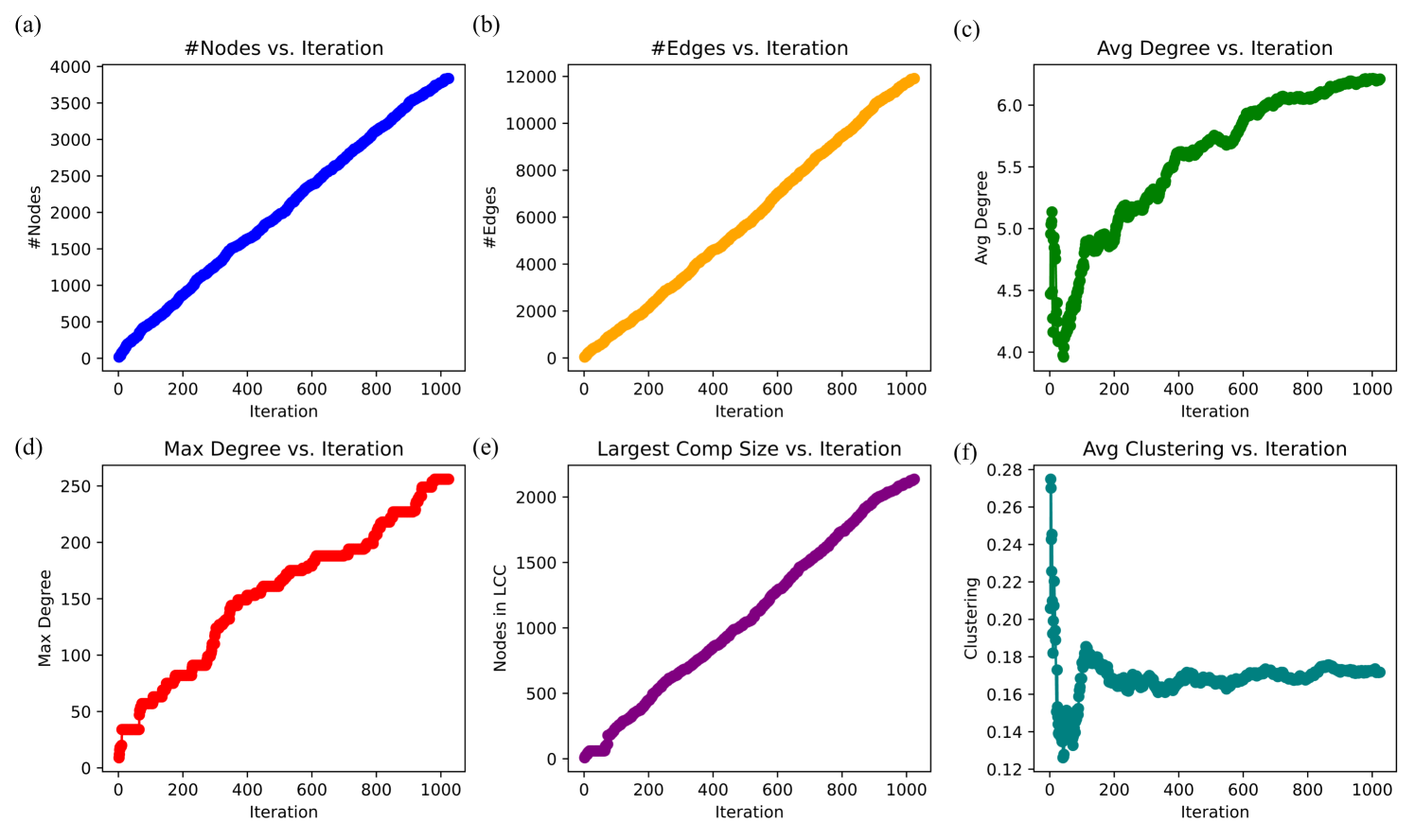
Figure 4 illustrates the evolution of key structural properties of the recursively generated knowledge graph. The number of nodes and edges both exhibit linear growth with iterations, indicating that the reasoning process systematically expands the graph without saturation. The increase in edges is slightly steeper than that of nodes, suggesting that each new concept introduced is integrated into an increasingly dense network of relationships rather than remaining isolated. This continuous expansion supports the hypothesis that the model enables open-ended knowledge discovery through recursive self-organization.
The average degree of the graph steadily increases, stabilizing around six edges per node. This trend signifies that the knowledge graph maintains a balance between exploration and connectivity, ensuring that newly introduced concepts remain well-integrated within the broader structure. Simultaneously, the maximum degree follows a non-linear trajectory, demonstrating that certain nodes become significantly more connected over time. This emergent hub formation is characteristic of scale-free networks and aligns with patterns observed in human knowledge organization, where certain concepts act as central abstractions that facilitate higher-order reasoning.
The size of the largest connected component (LCC) grows proportionally with the total number of nodes, reinforcing the observation that the graph remains a unified, traversable structure rather than fragmenting into disconnected subgraphs. This property is crucial for recursive reasoning, as it ensures that the system retains coherence while expanding. The average clustering coefficient initially fluctuates but stabilizes around 0.16, indicating that while localized connections are formed, the graph does not devolve into tightly clustered sub-networks. Instead, it maintains a relatively open structure that enables adaptive reasoning pathways.
These findings highlight the self-organizing nature of the recursive reasoning process, wherein hierarchical knowledge formation emerges without the need for predefined ontologies or supervised corrections. The presence of conceptual hubs, increasing relational connectivity, and sustained network coherence suggest that the model autonomously structures knowledge in a manner that mirrors epistemic intelligence. This emergent organization enables the system to navigate complex knowledge spaces efficiently, reinforcing the premise that intelligence-like behavior can arise through recursive, feedback-driven information processing. Further analysis of degree distribution and centrality metrics would provide deeper insights into the exact nature of this evolving graph topology.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Charts: Network Evolution Metrics over Iterations
### Overview
The image consists of a 2x3 grid of line charts, labeled (a) through (f). These charts display the evolution of various graph/network topological metrics over a series of iterations. The primary language used in the image is English; no other languages are present. All six charts share a common X-axis metric ("Iteration") but track different Y-axis variables, each represented by a distinct color. There are no explicit legend boxes; instead, the title and Y-axis label of each subplot define the data series.
### Components/Axes
**Shared X-Axis (All Plots):**
* **Label:** Iteration
* **Scale:** Linear, ranging from 0 to 1000.
* **Markers:** Major tick marks at 0, 200, 400, 600, 800, and 1000.
**Individual Y-Axes and Spatial Grounding:**
* **Top-Left - Plot (a):**
* **Title:** #Nodes vs. Iteration
* **Y-Axis Label:** #Nodes
* **Scale:** 0 to 4000, increments of 500.
* **Color:** Blue
* **Top-Center - Plot (b):**
* **Title:** #Edges vs. Iteration
* **Y-Axis Label:** #Edges
* **Scale:** 0 to 12000, increments of 2000.
* **Color:** Orange/Yellow
* **Top-Right - Plot (c):**
* **Title:** Avg Degree vs. Iteration
* **Y-Axis Label:** Avg Degree
* **Scale:** 4.0 to 6.0, increments of 0.5.
* **Color:** Green
* **Bottom-Left - Plot (d):**
* **Title:** Max Degree vs. Iteration
* **Y-Axis Label:** Max Degree
* **Scale:** 0 to 250, increments of 50.
* **Color:** Red
* **Bottom-Center - Plot (e):**
* **Title:** Largest Comp Size vs. Iteration
* **Y-Axis Label:** Nodes in LCC (Largest Connected Component)
* **Scale:** 0 to 2000, increments of 500.
* **Color:** Purple
* **Bottom-Right - Plot (f):**
* **Title:** Avg Clustering vs. Iteration
* **Y-Axis Label:** Clustering
* **Scale:** 0.12 to 0.28, increments of 0.02.
* **Color:** Teal/Dark Cyan
### Detailed Analysis
**Plot (a) - #Nodes (Top-Left, Blue Line):**
* **Trend Verification:** The blue line slopes upward in a strictly linear fashion from the origin to the top right.
* **Data Points:** The network starts at approximately 0 nodes at iteration 0. It grows steadily, reaching exactly 2000 nodes at iteration ~520, and concludes at approximately 3800 nodes at iteration 1000.
**Plot (b) - #Edges (Top-Center, Orange Line):**
* **Trend Verification:** Similar to nodes, the orange line exhibits a strictly linear upward slope.
* **Data Points:** Starting near 0 edges at iteration 0, the edge count increases rapidly and consistently, reaching approximately 6000 edges at iteration 500, and finishing near 12,000 edges at iteration 1000.
**Plot (c) - Avg Degree (Top-Right, Green Line):**
* **Trend Verification:** The green line shows high initial volatility. It drops sharply, then reverses into a steady, slightly fluctuating upward curve that begins to plateau near the end.
* **Data Points:** At iteration 0, the average degree starts high at ~5.1. It immediately plummets to a minimum of ~4.0 around iteration 50. From there, it climbs steadily, crossing 5.0 at iteration ~250, and ends at approximately 6.2 at iteration 1000.
**Plot (d) - Max Degree (Bottom-Left, Red Line):**
* **Trend Verification:** The red line displays a step-wise, monotonically increasing trend. It features periods of rapid growth interspersed with flat plateaus.
* **Data Points:** Starting at ~10 at iteration 0, it jumps to ~30 quickly. A notable rapid ascent occurs between iterations 250 and 350 (jumping from ~90 to ~150). Another steep climb happens around iteration 800. The maximum degree reaches approximately 260 by iteration 1000.
**Plot (e) - Largest Comp Size (Bottom-Center, Purple Line):**
* **Trend Verification:** The purple line slopes upward linearly, closely mirroring the trend in Plot (a), though with a very brief flat period at the very beginning.
* **Data Points:** Starting near 0, it stays flat for roughly the first 50 iterations, then grows linearly. It reaches ~1000 nodes at iteration 500 and concludes at approximately 2150 nodes at iteration 1000.
**Plot (f) - Avg Clustering (Bottom-Right, Teal Line):**
* **Trend Verification:** The teal line shows extreme early volatility before settling into a stable, horizontal band with minor oscillations.
* **Data Points:** The clustering coefficient starts at its peak of ~0.275 at iteration 0. It crashes dramatically to a low of ~0.125 around iteration 50. It rebounds to ~0.18 by iteration 120, and for the remaining 800+ iterations, it oscillates tightly between ~0.16 and ~0.175.
### Key Observations
1. **Linear Growth in Size:** Both the number of nodes (a) and the number of edges (b) grow at a constant linear rate. However, edges grow much faster than nodes (reaching 12,000 vs. 3,800).
2. **Initialization Phase ("Burn-in"):** Plots (c) Avg Degree and (f) Avg Clustering show a distinct "burn-in" phase during the first 50-100 iterations. The metrics are highly unstable before the network reaches a critical mass, after which structural properties stabilize or follow predictable curves.
3. **Step-wise Hub Formation:** The Max Degree (d) does not grow smoothly. The step-wise pattern indicates that specific nodes (hubs) acquire connections in bursts, or that the algorithm driving the network evolution operates in discrete phases.
4. **Component Ratio:** By comparing (a) and (e), at iteration 1000, there are ~3800 total nodes, and the Largest Connected Component contains ~2150 nodes. This means roughly 56% of the network belongs to a single giant component.
### Interpretation
These charts almost certainly depict the execution of a **generative network algorithm** or a simulation of network evolution over time (e.g., a modified Barabási–Albert model or similar preferential attachment simulation).
* **Mathematical Consistency Check:** We can cross-reference the data to prove internal consistency. The formula for Average Degree in an undirected graph is `(2 * Total Edges) / Total Nodes`.
* At iteration 1000, Total Edges $\approx$ 12,000 (from plot b).
* At iteration 1000, Total Nodes $\approx$ 3,800 (from plot a).
* Calculation: `(2 * 12000) / 3800` $\approx$ `24000 / 3800` $\approx$ **6.31**.
* Looking at Plot (c), the Average Degree at iteration 1000 is indeed just above 6.0 (approximately 6.2). This confirms the data across the subplots is mathematically linked and accurate.
* **Network Dynamics:** The linear addition of nodes and edges suggests a constant growth rate. Because edges are added at a higher rate than nodes, the network becomes increasingly dense over time, which is reflected in the rising Average Degree (c).
* **Structural Maturation:** The dramatic drop in Average Clustering (f) at the beginning suggests the simulation starts with a very small, tightly knit "seed" graph (which naturally has high clustering). As new nodes are added linearly, they dilute this initial tight structure, causing the clustering coefficient to plummet. However, as the network matures past iteration 200, it finds an equilibrium, maintaining a steady clustering coefficient of ~0.17 despite continuous growth.
* **Hubs and Inequality:** The Max Degree (d) reaching 260 in a network of 3800 nodes (where the average degree is only ~6) indicates a heavy-tailed degree distribution. A few nodes are highly connected "hubs." The step-wise nature of this growth suggests that once a node becomes a hub, it experiences periods of rapid connection acquisition, a hallmark of "rich-get-richer" network dynamics.
</details>
Figure 4: Evolution of basic graph properties over recursive iterations, highlighting the emergence of hierarchical structure, hub formation, and adaptive connectivity, for $\mathcal{G_{1}}$ .
Figure S5 illustrates the same analysis of the evolution of key structural properties of the recursively generated knowledge graph for graph $\mathcal{G_{2}}$ , as a comparison.
Structural Evolution of the Recursive Knowledge Graph
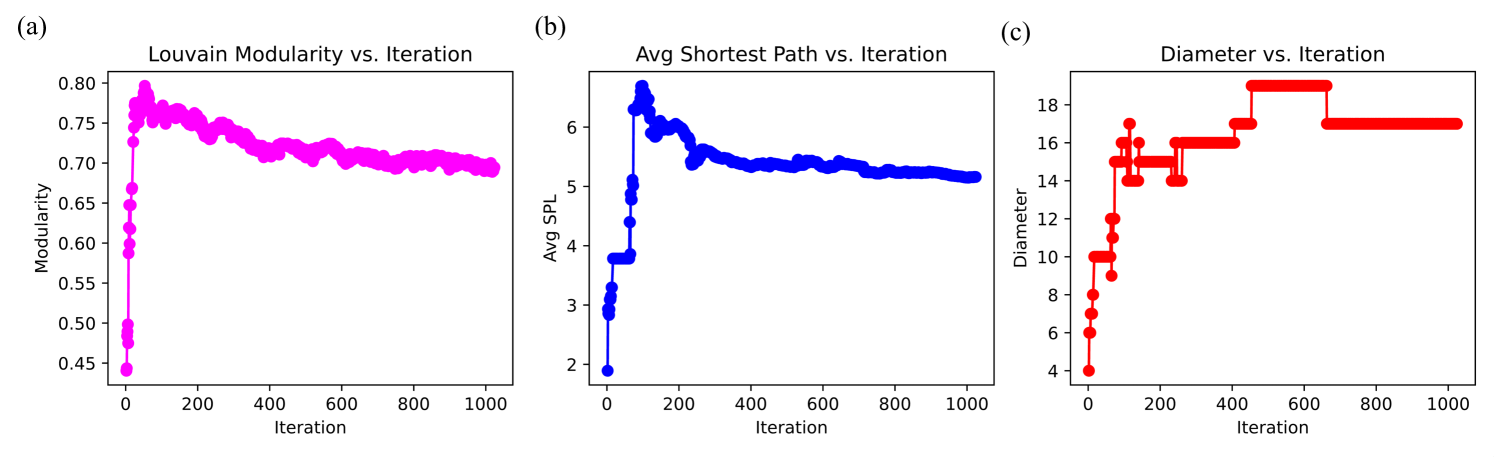
Figure 5 presents the evolution of three key structural properties, including Louvain modularity, average shortest path length, and graph diameter, over iterations. These metrics provide deeper insights into the self-organizing behavior of the graph as it expands through iterative reasoning. The Louvain modularity, depicted in Figure 5 (a), measures the strength of community structure within the graph. Initially, modularity increases sharply, reaching a peak around 0.75 within the first few iterations. This indicates that the early phases of reasoning lead to the rapid formation of well-defined conceptual clusters. As the graph expands, modularity stabilizes at approximately 0.70, suggesting that the system maintains distinct knowledge domains while allowing new interconnections to form. This behavior implies that the model preserves structural coherence, ensuring that the recursive expansion does not collapse existing conceptual groupings.
The evolution of the average shortest path length (SPL), shown in Figure 5 (b), provides further evidence of structured self-organization. Initially, the SPL increases sharply before stabilizing around 4.5–5.0. The initial rise reflects the introduction of new nodes that temporarily extend shortest paths before they are effectively integrated into the existing structure. The subsequent stabilization suggests that the recursive process maintains an efficient knowledge representation, ensuring that information remains accessible despite continuous expansion. This property is crucial for reasoning, as it implies that the system does not suffer from runaway growth in path lengths, preserving navigability.
The graph diameter, illustrated in Figure 5 (c), exhibits a stepwise increase, eventually stabilizing around 16–18. The staircase-like behavior suggests that the recursive expansion occurs in structured phases, where certain iterations introduce concepts that temporarily extend the longest shortest path before subsequent refinements integrate them more effectively. This bounded expansion indicates that the system autonomously regulates its hierarchical growth, maintaining a balance between depth and connectivity.
These findings reveal several emergent properties of the recursive reasoning model. The stabilization of modularity demonstrates the ability to autonomously maintain structured conceptual groupings, resembling human-like hierarchical knowledge formation. The controlled growth of the shortest path length highlights the system’s capacity for efficient information propagation, preventing fragmentation. We note that the bounded expansion of graph diameter suggests that reasoning-driven recursive self-organization is capable of structuring knowledge in a way that mirrors epistemic intelligence, reinforcing the hypothesis that certain forms of intelligent-like behavior can emerge without predefined ontologies.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Multi-Panel Line Chart: Network Evolution Metrics over Iterations
### Overview
The image consists of three horizontally aligned line charts, labeled (a), (b), and (c) from left to right. All three charts share a common X-axis metric ("Iteration") ranging from 0 to over 1000, indicating they likely represent different metrics tracked simultaneously during a single computational process, simulation, or algorithm execution (such as a network growth model or a community detection algorithm). The language used throughout is English.
### Components/Axes
**Chart (a) - Left Panel**
* **Spatial Positioning:** Leftmost chart. Label "(a)" is in the top-left corner outside the plot area.
* **Title:** "Louvain Modularity vs. Iteration" (Top center).
* **X-axis:** Label "Iteration" (Bottom center). Markers at 0, 200, 400, 600, 800, 1000.
* **Y-axis:** Label "Modularity" (Left side, rotated 90 degrees). Markers at 0.45, 0.50, 0.55, 0.60, 0.65, 0.70, 0.75, 0.80.
* **Data Series:** A single line with circular markers, colored magenta.
**Chart (b) - Center Panel**
* **Spatial Positioning:** Center chart. Label "(b)" is in the top-left corner outside the plot area.
* **Title:** "Avg Shortest Path vs. Iteration" (Top center).
* **X-axis:** Label "Iteration" (Bottom center). Markers at 0, 200, 400, 600, 800, 1000.
* **Y-axis:** Label "Avg SPL" (Left side, rotated 90 degrees). Markers at 2, 3, 4, 5, 6.
* **Data Series:** A single line with circular markers, colored blue.
**Chart (c) - Right Panel**
* **Spatial Positioning:** Rightmost chart. Label "(c)" is in the top-left corner outside the plot area.
* **Title:** "Diameter vs. Iteration" (Top center).
* **X-axis:** Label "Iteration" (Bottom center). Markers at 0, 200, 400, 600, 800, 1000.
* **Y-axis:** Label "Diameter" (Left side, rotated 90 degrees). Markers at 4, 6, 8, 10, 12, 14, 16, 18.
* **Data Series:** A single line with circular markers, colored red.
### Detailed Analysis
**Chart (a): Louvain Modularity**
* **Visual Trend:** The magenta line exhibits a near-vertical spike immediately at the start, reaches a global maximum, and then enters a long, gradual, slightly oscillating decline, eventually stabilizing.
* **Data Points (Approximate):**
* Starts at Iteration 0 with a value of ~0.44.
* Shoots up rapidly, crossing 0.50, 0.60, and 0.70 within the first ~25 iterations.
* Peaks at ~0.80 around Iteration 50-60.
* Gradually declines to ~0.75 by Iteration 200.
* Continues a slow, wavy descent to ~0.71 by Iteration 400.
* Stabilizes around ~0.69 to ~0.70 from Iteration 800 through 1000+.
**Chart (b): Average Shortest Path Length (Avg SPL)**
* **Visual Trend:** The blue line shows a rapid, stepped increase initially, followed by a sharp spike to a peak, a quick drop, and then a long, smooth asymptotic decay.
* **Data Points (Approximate):**
* Starts at Iteration 0 with a value of ~1.9.
* Jumps rapidly to ~2.9, then ~3.8 within the first ~30 iterations.
* Plateaus briefly at ~3.8 until roughly Iteration 70.
* Spikes sharply to a peak of ~6.7 around Iteration 100.
* Drops quickly to ~5.9 by Iteration 150.
* Gradually decays to ~5.4 by Iteration 400.
* Levels off, ending at ~5.1 by Iteration 1000.
**Chart (c): Diameter**
* **Visual Trend:** The red line exhibits distinct step-function behavior, indicating discrete integer values. It steps up rapidly, fluctuates slightly, reaches a high plateau, and then steps down to a final, stable plateau.
* **Data Points (Approximate):**
* Starts at Iteration 0 with a value of 4.
* Steps up rapidly through 6, 8, and 10 within the first ~30 iterations.
* Jumps to 15, 16, and peaks briefly at 17 around Iteration 100.
* Drops back to 14 and 15 between Iterations 150-200.
* Holds a plateau at 16 from Iteration ~250 to ~400.
* Steps up to 17, then reaches its maximum plateau of 19 from Iteration ~450 to ~650.
* Steps down to 17 at Iteration ~650 and remains perfectly flat at 17 through Iteration 1000+.
### Key Observations
1. **Phase Transition:** All three charts show a distinct "burn-in" or rapid structural change phase between Iterations 0 and roughly 150. During this time, Modularity peaks, Avg SPL peaks, and Diameter expands rapidly.
2. **Convergence/Stabilization:** After Iteration 650, all three metrics have largely stabilized. Modularity is slowly decaying but mostly flat, Avg SPL has reached an asymptote, and Diameter is locked at a constant integer value.
3. **Discrete vs. Continuous:** Charts (a) and (b) represent continuous variables (averages and modularity scores), while Chart (c) represents a discrete variable (Diameter, which in graph theory is the maximum shortest path, inherently an integer in unweighted graphs). This is visually confirmed by the strict horizontal and vertical lines in the red series.
### Interpretation
These charts almost certainly depict the evolution of a network (graph) over time, likely during a generative process, a rewiring simulation, or an optimization algorithm.
* **Louvain Modularity** measures the strength of division of a network into modules (clusters/communities). The rapid spike to 0.80 suggests the algorithm quickly found or created highly distinct communities. The subsequent slow decline suggests that as the network continued to evolve (perhaps adding more edges), the boundaries between these communities became slightly blurred, settling at a still-strong modularity of ~0.70.
* **Avg SPL and Diameter** are measures of network distance. The initial rapid increase in both indicates the network is "stretching out"—perhaps transitioning from a dense, fully connected initial state to a sparser, more complex topology.
* The peak in Avg SPL (~6.7) aligns chronologically with the peak in Modularity. This implies that when the communities were most distinct (highest modularity), it took the longest average time to traverse the network, likely because there were very few edges connecting different communities.
* As the iterations progress past 200, the Avg SPL decreases while the Diameter remains high (and even increases to 19 before settling at 17). This suggests the network is forming "shortcuts" or hubs that reduce the *average* distance between most nodes, even though the absolute *longest* distance between the two furthest nodes remains quite large.
* The stabilization of all metrics after iteration 800 indicates the algorithm has reached a steady state or convergence, where further iterations do not significantly alter the macro-topology of the network.
</details>
Figure 5: Evolution of key structural properties in the recursively generated knowledge graph $\mathcal{G_{1}}$ : (a) Louvain modularity, showing stable community formation; (b) average shortest path length, highlighting efficient information propagation; and (c) graph diameter, demonstrating bounded hierarchical expansion.
For comparison, Figure S4 presents the evolution of three key structural properties—Louvain modularity, average shortest path length, and graph diameter—over recursive iterations for graph $\mathcal{G_{2}}$ .
2.2 Analysis of Advanced Graph Evolution Metrics
Figure 6 presents the evolution of six advanced structural metrics over recursive iterations, capturing higher-order properties of the self-expanding knowledge graph. These measures provide insights into network organization, resilience, and connectivity patterns emerging during recursive reasoning.
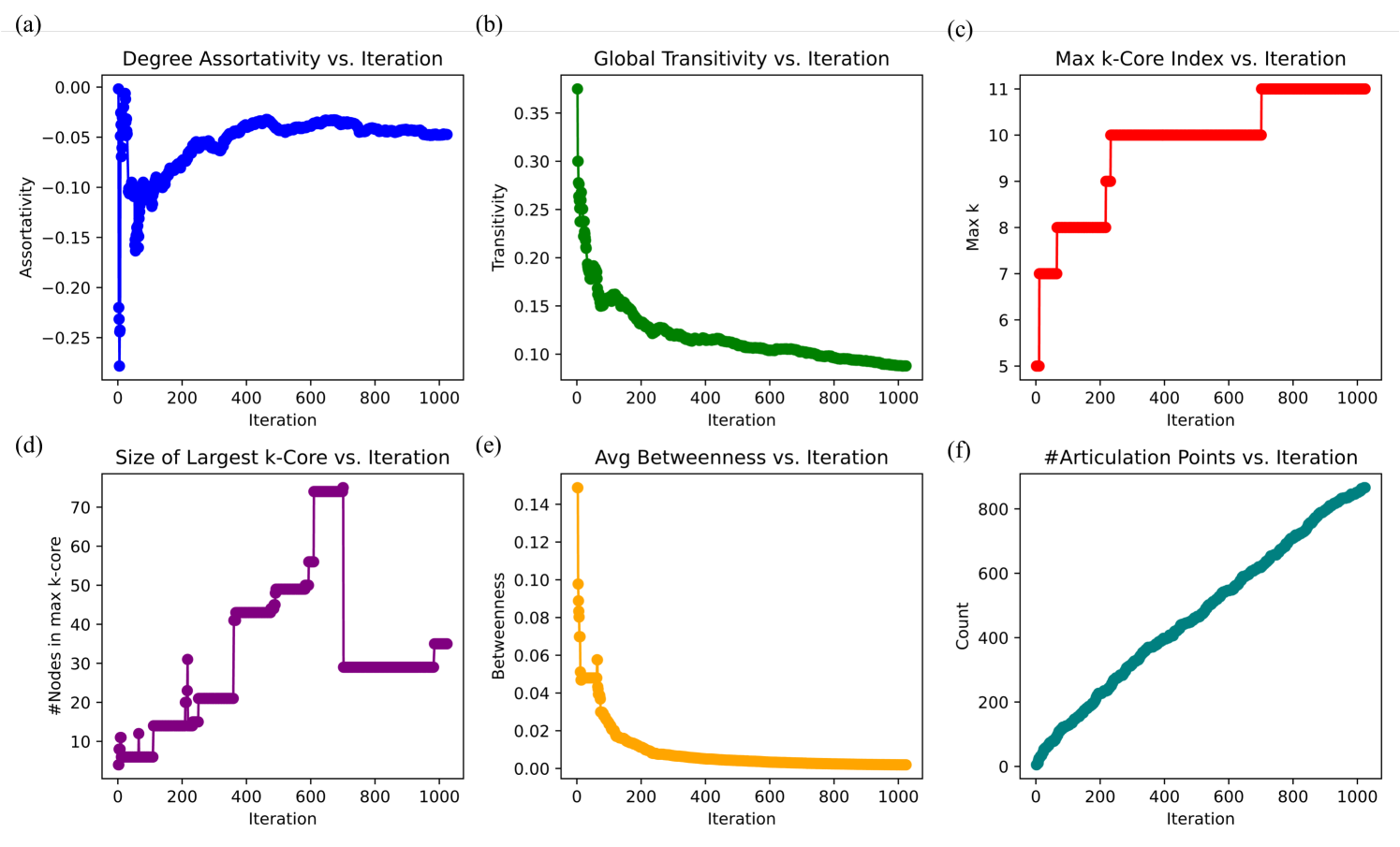
Degree assortativity coefficient is a measure of the tendency of nodes to connect to others with similar degrees. A negative value indicates disassortativity (high-degree nodes connect to low-degree nodes), while a positive value suggests assortativity (nodes prefer connections to similarly connected nodes). The degree assortativity coefficient (Figure 6 (a)) begins with a strongly negative value near $-0.25$ , indicating a disassortative structure where high-degree nodes preferentially connect to low-degree nodes. Over time, assortativity increases and stabilizes around $-0.05$ , suggesting a gradual shift toward a more balanced connectivity structure without fully transitioning to an assortative regime. This trend is consistent with the emergence of hub-like structures, characteristic of scale-free networks, where a few nodes accumulate a disproportionately high number of connections.
The global transitivity (Figure 6 (b)), measuring the fraction of closed triplets in the network, exhibits an initial peak near 0.35 before rapidly declining and stabilizing towards 0.10, albeit still decreasing. This suggests that early in the recursive reasoning process, the graph forms tightly clustered regions, likely due to localized conceptual groupings. As iterations progress, interconnections between distant parts of the graph increase, reducing local clustering and favoring long-range connectivity, a hallmark of expanding knowledge networks.
The $k$ -core Index defines the largest integer $k$ for which a subgraph exists where all nodes have at least $k$ connections. A higher maximum $k$ -core index suggests a more densely interconnected core. The maximum $k$ -core index (Figure 6 (c)), representing the deepest level of connectivity, increases in discrete steps, reaching a maximum value of 11. This indicates that as the graph expands, an increasingly dense core emerges, reinforcing the formation of highly interconnected substructures. The stepwise progression suggests that specific iterations introduce structural reorganizations that significantly enhance connectivity rather than continuous incremental growth.
We observe that the size of the largest $k$ -core (Figure 6 (d)) follows a similar pattern, growing in discrete steps and experiencing a sudden drop around iteration 700 before stabilizing again. This behavior suggests that the graph undergoes structural realignments, possibly due to the introduction of new reasoning pathways that temporarily reduce the dominance of the most connected core before further stabilization.
Betweenness Centrality is a measure of how often a node appears on the shortest paths between other nodes. High betweenness suggests a critical role in information flow, while a decrease indicates decentralization and redundancy in pathways. The average betweenness centrality (Figure 6 (e)) initially exhibits high values, indicating that early reasoning iterations rely heavily on specific nodes to mediate information flow. Over time, betweenness declines and stabilizes a bit below 0.01, suggesting that the graph becomes more navigable and distributed, reducing reliance on key bottleneck nodes over more iterations. This trend aligns with the emergence of redundant reasoning pathways, making the system more robust to localized disruptions.
Articulation points are nodes whose removal would increase the number of disconnected components in the graph, meaning they serve as key bridges between different knowledge clusters. The number of articulation points (Figure 6 (f)) steadily increases throughout iterations, reaching over 800. This suggests that as the knowledge graph expands, an increasing number of bridging nodes emerge, reflecting a hierarchical structure where key nodes maintain connectivity between distinct regions. Despite this increase, the network remains well connected, indicating that redundant pathways mitigate the risk of fragmentation.
A network where the degree distribution follows a power-law, meaning most nodes have few connections, but a small number (hubs) have many (supporting the notion of a scale-free network). Our findings provide evidence that the recursive graph reasoning process spontaneously organizes into a hierarchical, scale-free structure, balancing local clustering, global connectivity, and efficient navigability. The noted trends in assortativity, core connectivity, and betweenness centrality confirm that the system optimally structures its knowledge representation over iterations, reinforcing the hypothesis that self-organized reasoning processes naturally form efficient and resilient knowledge networks.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Panel of Line Charts: Network Topology Metrics vs. Iteration
### Overview
The image consists of a 2x3 grid of six line charts, labeled (a) through (f). Each chart tracks a different network topology metric on the y-axis against a common x-axis representing "Iteration" (from 0 to 1000). The charts illustrate the evolution of a network's structural properties over time or algorithmic steps. There is no explicit legend box; instead, each subplot utilizes a distinct color for its data series. All text is in English.
### Components/Axes
**Common X-Axis (All Plots):**
* **Label:** "Iteration"
* **Scale:** Linear, ranging from 0 to slightly over 1000.
* **Major Ticks:** 0, 200, 400, 600, 800, 1000.
**Specific Y-Axes by Plot:**
* **(a) Top-Left:** "Assortativity" (Scale: 0.00 to -0.25, Ticks: 0.00, -0.05, -0.10, -0.15, -0.20, -0.25)
* **(b) Top-Center:** "Transitivity" (Scale: 0.10 to 0.35, Ticks: 0.10, 0.15, 0.20, 0.25, 0.30, 0.35)
* **(c) Top-Right:** "Max k" (Scale: 5 to 11, Ticks: 5, 6, 7, 8, 9, 10, 11)
* **(d) Bottom-Left:** "#Nodes in max k-core" (Scale: 10 to 70, Ticks: 10, 20, 30, 40, 50, 60, 70)
* **(e) Bottom-Center:** "Betweenness" (Scale: 0.00 to 0.14, Ticks: 0.00, 0.02, 0.04, 0.06, 0.08, 0.10, 0.12, 0.14)
* **(f) Bottom-Right:** "Count" (Scale: 0 to 800, Ticks: 0, 200, 400, 600, 800)
---
### Detailed Analysis
#### (a) Degree Assortativity vs. Iteration
* **Spatial Grounding:** Top-left quadrant.
* **Visual Trend:** The blue line with circular markers exhibits extreme early volatility, dropping sharply, rebounding, and then gradually smoothing out into a slight upward curve that plateaus.
* **Data Points:**
* Starts at iteration 0 near **0.00**.
* Plummets rapidly within the first ~20 iterations to a minimum of approximately **-0.28**.
* Rebounds quickly to roughly **-0.10** by iteration 50.
* Experiences a secondary dip to **-0.16** around iteration 60.
* Gradually climbs and stabilizes. By iteration 400, it reaches roughly **-0.04** and remains relatively flat, ending near **-0.05** at iteration 1000.
#### (b) Global Transitivity vs. Iteration
* **Spatial Grounding:** Top-center.
* **Visual Trend:** The green line with circular markers shows a rapid exponential-style decay, starting high and flattening out near the bottom of the y-axis.
* **Data Points:**
* Starts at a peak of approximately **0.37** at iteration 0.
* Drops precipitously in the first 100 iterations to roughly **0.16**.
* Continues a slower, steady decline, crossing **0.10** around iteration 700.
* Ends at approximately **0.09** at iteration 1000.
#### (c) Max k-Core Index vs. Iteration
* **Spatial Grounding:** Top-right quadrant.
* **Visual Trend:** The red line with circular markers forms a monotonically increasing step function. It never decreases.
* **Data Points:**
* Starts at a value of **5** at iteration 0.
* Jumps immediately to **7** within the first few iterations.
* Steps up to **8** at approximately iteration 60.
* Steps up to **9** at approximately iteration 220, and almost immediately steps up to **10** around iteration 230.
* Remains flat at **10** for a long duration.
* Steps up to **11** at approximately iteration 700 and remains there until iteration 1000.
#### (d) Size of Largest k-Core vs. Iteration
* **Spatial Grounding:** Bottom-left quadrant.
* **Visual Trend:** The purple line with circular markers is a highly volatile step function. It generally increases but features a massive, sudden drop late in the process.
* **Data Points:**
* Starts low, fluctuating between **~5 and ~12** in the first 100 iterations.
* Steps up to **~15** (iteration 100), then **~21** (iteration 250).
* Jumps significantly to **~43** at iteration 350.
* Steps up to **~50** at iteration 500, then peaks at **~75** at iteration 600.
* *Notable Anomaly:* At approximately iteration 700, the value crashes drastically from **~75** down to **~29**.
* Remains at **~29** until stepping up slightly to **~35** at iteration 980.
#### (e) Avg Betweenness vs. Iteration
* **Spatial Grounding:** Bottom-center.
* **Visual Trend:** The orange/yellow line with circular markers displays a sharp initial drop followed by a smooth, asymptotic tail approaching zero.
* **Data Points:**
* Starts at a peak of approximately **0.145** at iteration 0.
* Crashes rapidly to roughly **0.05** by iteration 20.
* Shows a brief, minor spike to **~0.06** around iteration 60.
* Decays smoothly thereafter, dropping below **0.02** by iteration 200.
* Ends very close to **0.00** (approx. 0.002) at iteration 1000.
#### (f) #Articulation Points vs. Iteration
* **Spatial Grounding:** Bottom-right quadrant.
* **Visual Trend:** The teal/dark cyan line with circular markers shows a nearly perfect, constant linear increase from the origin to the top right.
* **Data Points:**
* Starts at **0** at iteration 0.
* Passes through **~200** at iteration 200, **~400** at iteration 450, and **~600** at iteration 650.
* Ends at a maximum of approximately **850** at iteration 1000.
---
### Key Observations
1. **Direct Correlation in k-Core Metrics:** There is a critical, simultaneous event at approximately **iteration 700**. In plot (c), the Max k-Core Index steps up from 10 to 11. At that exact same iteration in plot (d), the size of that largest k-core drops precipitously from ~75 nodes to ~29 nodes.
2. **Linear Growth vs. Exponential Decay:** The number of articulation points (f) grows linearly, while global transitivity (b) and average betweenness (e) decay in an exponential/asymptotic manner.
3. **Early Volatility:** The first 100 iterations represent a period of rapid structural change, evidenced by the sharp drops in assortativity (a), transitivity (b), and betweenness (e).
---
### Interpretation
These charts collectively describe the evolution of a network graph undergoing a specific algorithmic process—most likely a **network growth model** (adding nodes/edges) or a specific **rewiring process**.
* **The k-Core Phenomenon:** The relationship between charts (c) and (d) is the most revealing. A k-core is a maximal subgraph where all nodes have at least degree *k*. As the network evolves, the maximum *k* value increases (c), meaning the core is becoming denser. However, at iteration 700, when the network achieves an 11-core, the *size* of that core (d) shrinks drastically. This indicates that out of the ~75 nodes that made up the 10-core, only a tightly-knit subset of ~29 nodes gained enough connections to form the new 11-core. The remaining nodes were left behind in the 10-core shell.
* **Network Sparsification/Branching:** The linear increase in Articulation Points (f) (nodes that, if removed, disconnect the graph) strongly suggests that as the network evolves, it is growing many "branches" or tree-like structures.
* **Efficiency and Clustering:** The rapid drop in Average Betweenness (e) suggests that paths between nodes are becoming shorter or more redundant, which lowers the bottleneck effect of individual nodes. Simultaneously, the drop in Global Transitivity (b) indicates that the overall proportion of closed triangles is decreasing.
* **Conclusion:** Reading between the lines, this data likely represents a generative network model where a dense, highly connected core is slowly forming (increasing max k-core), while simultaneously, a large number of peripheral nodes are being added in a tree-like, non-clustered manner (increasing articulation points, decreasing overall transitivity and betweenness).
</details>
Figure 6: Evolution of advanced structural properties in the recursively generated knowledge graph $\mathcal{G_{1}}$ : (a) degree assortativity, (b) global transitivity, (c) maximum k-core index, (d) size of the largest k-core, (e) average betweenness centrality, and (f) number of articulation points. These metrics reveal the emergence of hierarchical organization, hub formation, and increased navigability over recursive iterations.
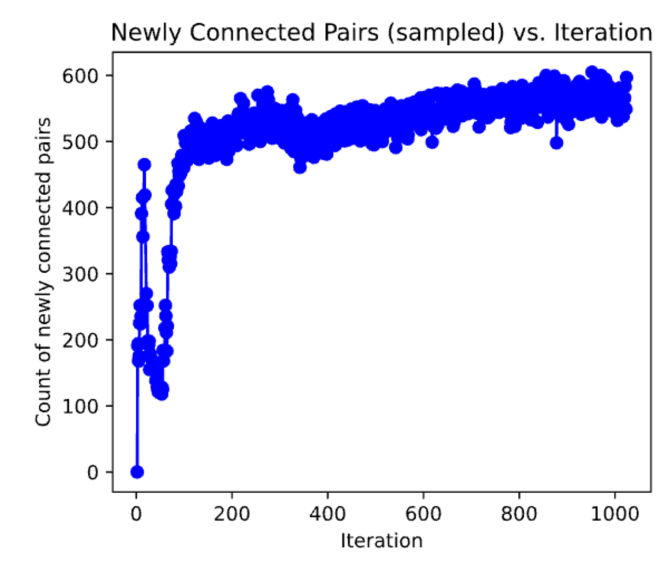
2.3 Evolution of Newly Connected Pairs
Figure 7 presents the evolution of newly connected node pairs as a function of iteration, illustrating how the recursive reasoning process expands the knowledge graph over time. This metric captures the rate at which new relationships are established between nodes, providing insights into the self-organizing nature of the network.
In the early iterations (0–100), the number of newly connected pairs exhibits high variance, fluctuating between 0 and 400 connections per iteration. This suggests that the initial phase of recursive reasoning leads to significant structural reorganization, where large bursts of new edges are formed as the network establishes its fundamental connectivity patterns. The high variability in this region indicates an exploratory phase, where the graph undergoes rapid adjustments to define its core structure.
Beyond approximately 200 iterations, the number of newly connected pairs stabilizes around 500–600 per iteration, with only minor fluctuations. This plateau suggests that the knowledge graph has transitioned into a steady-state expansion phase, where new nodes and edges are integrated into an increasingly structured and predictable manner. Unlike random growth, this behavior indicates that the system follows a self-organized expansion process, reinforcing existing structures rather than disrupting them.
The stabilization at a high connection rate suggests the emergence of hierarchical organization, where newly introduced nodes preferentially attach to well-established structures. This pattern aligns with the scale-free properties observed in other experimentally acquired knowledge networks, where central concepts continuously accumulate new links, strengthening core reasoning pathways. The overall trend highlights how recursive self-organization leads to sustained, structured knowledge expansion, rather than arbitrary or saturation-driven growth.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Line Graph: Newly Connected Pairs (sampled) vs. Iteration
### Overview
This image is a 2D line graph with scatter-style markers displaying the relationship between algorithmic iterations and the count of newly connected pairs. The data is represented by a single, continuous blue line connecting solid blue circular markers. The graph shows extreme initial volatility followed by a long-term, noisy, but generally upward trend.
*Language Declaration:* All text in this image is in English. No other languages are present.
### Components/Axes
**Header Region:**
* **Title (Top Center):** "Newly Connected Pairs (sampled) vs. Iteration"
**Left Region (Y-Axis):**
* **Label (Rotated 90 degrees, centered vertically):** "Count of newly connected pairs"
* **Scale:** Linear scale.
* **Tick Markers:** 0, 100, 200, 300, 400, 500, 600.
**Bottom Region (X-Axis):**
* **Label (Bottom Center):** "Iteration"
* **Scale:** Linear scale.
* **Tick Markers:** 0, 200, 400, 600, 800, 1000.
**Main Chart Region:**
* **Data Series:** A single series represented by solid blue circular markers connected by a solid blue line. There is no explicit legend box, as the title and axes define the single variable being plotted.
### Detailed Analysis
*Trend Verification & Spatial Grounding:*
The data series begins at the bottom-left corner at the origin. It immediately exhibits a violent upward spike, followed by a sharp downward crash. After this initial turbulence, the line slopes steeply upward again, rounding off into a thick, highly clustered band of data points that slowly trends upward toward the top-right of the chart area.
**Extracted Data Points & Trends (Approximate values with uncertainty):**
1. **Initialization (Iteration 0):** The graph starts exactly at `X: 0, Y: 0`.
2. **Initial Spike (Iterations ~1 to ~20):** The line shoots almost vertically upward.
* *Peak:* Reaches a local maximum at approximately `X: ~15, Y: ~465`.
3. **Initial Crash (Iterations ~20 to ~50):** The trend reverses sharply, dropping rapidly.
* *Trough:* Hits a local minimum at approximately `X: ~50, Y: ~120`.
4. **Rapid Recovery (Iterations ~50 to ~150):** The line slopes steeply upward again, recovering the lost ground.
* *Recovery Point:* Reaches approximately `X: ~150, Y: ~500`.
5. **First Plateau & Dip (Iterations ~150 to ~350):** The trend flattens out with high variance (a thick band of blue circles). It peaks slightly before experiencing a noticeable dip.
* *Local Peak:* Approximately `X: ~250, Y: ~570`.
* *Dip:* Drops to approximately `X: ~340, Y: ~460`.
6. **Long-Term Steady Growth (Iterations ~350 to >1000):** The line slopes upward at a very gradual angle. The data is highly noisy, creating a thick band of markers spanning roughly 50 to 80 units on the Y-axis at any given X value.
* *Midpoint:* At `X: 600`, values fluctuate between `Y: ~500` and `Y: ~560`.
* *Notable Outlier:* A distinct downward spike occurs at approximately `X: ~880, Y: ~500`.
* *Endpoint:* By `X: 1000` and slightly beyond, the data band fluctuates between `Y: ~530` and `Y: ~600`.
### Key Observations
* **Extreme Early Volatility:** The most striking feature is the massive fluctuation within the first 100 iterations (0 -> 465 -> 120 -> 500).
* **High Variance/Noise:** After iteration 150, the data does not form a clean, thin line. Instead, the dense clustering of blue circular markers indicates significant iteration-to-iteration variance (noise) within a consistent broader trend.
* **Asymptotic Tendency:** While the trend from iteration 400 to 1000 is upward, the rate of growth is decelerating, suggesting it may be approaching an upper bound or steady-state capacity slightly above 600.
### Interpretation
This graph likely represents the performance or behavior of a network algorithm, graph generation model, or machine learning clustering process over time (iterations).
* **The "Burn-in" Phase:** The extreme volatility between iterations 0 and 100 strongly suggests an initialization or "burn-in" phase. The algorithm rapidly makes connections (the spike to 465), realizes many are invalid or suboptimal based on its parameters, prunes them (the crash to 120), and then finds a more stable heuristic to begin building valid connections (the climb to 500).
* **Exploration vs. Exploitation:** The steady, thick band of data from iteration 350 onward represents the algorithm in its primary operational phase. The fact that it is still finding "newly connected pairs" at a high rate (500-600 per iteration) suggests either a continuously expanding dataset or an algorithm that is constantly exploring new permutations.
* **The Noise:** The thickness of the line (the variance) indicates that the number of connections found per iteration is not uniform; it depends heavily on the specific localized data being processed in that specific iteration step.
* **Overall Meaning:** The system successfully stabilizes after a chaotic start and settles into a highly productive, albeit noisy, steady state of discovering new network pairs, with a slight overall increase in efficiency or opportunity as the iterations progress.
</details>
Figure 7: Evolution of newly connected node pairs over recursive iterations, $\mathcal{G_{1}}$ . Early iterations exhibit high variability, reflecting an exploratory phase of rapid structural reorganization. Beyond 200 iterations, the process stabilizes, suggesting a steady-state expansion phase with sustained connectivity formation.
The observed transition from high-variance, exploratory graph expansion to a stable, structured growth phase suggests that recursive self-organization follows a process similar to human cognitive learning and scientific discovery. We believe that this indicates that in early iterations, the system explores diverse reasoning pathways, mirroring how scientific fields establish foundational concepts through broad exploration before refining them into structured disciplines [1]. The stabilization of connectivity beyond 200 iterations reflects preferential attachment dynamics, a hallmark of scale-free networks where highly connected nodes continue to accumulate new links, much like citation networks in academia [42]. This mechanism ensures that core concepts serve as attractors for further knowledge integration, reinforcing structured reasoning while maintaining adaptability. Importantly, the system does not exhibit saturation or stagnation, suggesting that open-ended knowledge discovery is possible through recursive reasoning alone, without requiring predefined ontologies or externally imposed constraints. This aligns with findings in AI-driven scientific hypothesis generation, where graph-based models dynamically infer new connections by iterating over expanding knowledge structures [39, 41]. The ability of the system to self-organize, expand, and refine its knowledge base autonomously underscores its potential as a scalable framework for automated scientific discovery and epistemic reasoning.
2.4 Analysis of Node Centrality Distributions at Final Stage of Reasoning
Next, Figure 8 presents histograms for three key centrality measures—betweenness centrality, closeness centrality, and eigenvector centrality—computed for the recursively generated knowledge graph, at the final iteration. These metrics provide insights into the role of different nodes in maintaining connectivity, network efficiency, and global influence.
Figure 8 (a) shows the distribution of betweenness centrality. We find the distribution of betweenness centrality to be highly skewed, with the majority of nodes exhibiting values close to zero. Only a small fraction of nodes attain significantly higher centrality values, indicating that very few nodes serve as critical intermediaries for shortest paths. This pattern is characteristic of hierarchical or scale-free networks, where a small number of hub nodes facilitate global connectivity, while most nodes remain peripheral. The presence of a few high-betweenness outliers suggests that key nodes emerge as crucial mediators of information flow, reinforcing the hypothesis that self-organizing structures lead to the formation of highly connected bridging nodes.
Figure 8 (b) depicts the closeness centrality distribution. It follows an approximately normal distribution centered around 0.20, suggesting that most nodes remain well-connected within the network. This result implies that the network maintains a compact structure, allowing for efficient navigation between nodes despite continuous expansion. The relatively low spread indicates that the recursive reasoning process prevents excessive distance growth, ensuring that newly introduced nodes do not become isolated. This reinforces the observation that the graph remains navigable as it evolves, an essential property for maintaining coherent reasoning pathways.
Next, Figure 8 (c) shows the eigenvector centrality distribution, identified to be also highly skewed, with most nodes having values close to zero. However, a few nodes attain substantially higher eigenvector centrality scores, indicating that only a select few nodes dominate the network in terms of global influence. This suggests that the network naturally organizes into a hierarchical structure, where dominant hubs accumulate influence over time, while the majority of nodes play a more peripheral role. The emergence of high-eigenvector hubs aligns with scale-free network behavior, further supporting the idea that reasoning-driven recursive self-organization leads to structured knowledge representation.
These findings indicate that the recursive knowledge graph balances global connectivity and local modularity, self-organizing into a structured yet efficient system. The few high-betweenness nodes act as key mediators, while the closeness centrality distribution suggests that the network remains efficiently connected. The eigenvector centrality pattern highlights the formation of dominant conceptual hubs, reinforcing the presence of hierarchical knowledge organization within the evolving reasoning framework.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Histograms: Network Centrality Measure Distributions
### Overview
The image displays three side-by-side histograms, labeled (a), (b), and (c) from left to right. These charts illustrate the frequency distributions of three different network centrality metrics: Betweenness Centrality, Closeness Centrality, and Eigenvector Centrality. The data represents the structural properties of nodes within a specific, unnamed network. All text in the image is in English.
### Components/Axes
The image is divided into three distinct spatial regions (subplots).
**Shared Elements:**
* **X-axes:** All three charts have an x-axis labeled "Value", representing the calculated centrality score. The scales vary slightly between the charts.
* **Y-axes:** Only the leftmost chart (a) explicitly labels the y-axis as "Count". However, based on standard histogram conventions and visual alignment, the y-axes on charts (b) and (c) also represent the frequency "Count" of nodes falling into each value bin.
**Specific Subplot Axes:**
* **(a) Left Chart:**
* Y-axis markers: 0, 250, 500, 750, 1000, 1250, 1500, 1750, 2000.
* X-axis markers: 0.00, 0.05, 0.10, 0.15, 0.20, 0.25.
* **(b) Center Chart:**
* Y-axis markers: 0, 25, 50, 75, 100, 125, 150, 175, 200.
* X-axis markers: 0.10, 0.15, 0.20, 0.25, 0.30.
* **(c) Right Chart:**
* Y-axis markers: 0, 200, 400, 600, 800, 1000, 1200, 1400.
* X-axis markers: 0.00, 0.05, 0.10, 0.15, 0.20, 0.25, 0.30.
### Detailed Analysis
#### Region 1: Left Subplot (a)
* **Title:** Betweenness Centrality
* **Visual Trend:** The data exhibits a severe right-skew (positive skew), resembling a power-law distribution. The vast majority of the data is concentrated in the very first bin, with an immediate and flat tail extending to the right.
* **Data Points (Blue Bars):**
* The first bin (approx. value 0.00 to 0.01) contains an overwhelming majority of the counts, peaking slightly above the 2000 mark (estimated ~2050).
* The second bin (approx. 0.01 to 0.02) drops drastically to an estimated count of ~50.
* All subsequent bins from 0.02 up to 0.25 have counts that are visually indistinguishable from zero, indicating extremely rare outliers.
#### Region 2: Center Subplot (b)
* **Title:** Closeness Centrality
* **Visual Trend:** Unlike the other two charts, this data forms a roughly symmetrical, bell-shaped curve resembling a normal distribution. The data is centered around the 0.20 mark.
* **Data Points (Red Bars):**
* The distribution begins around a value of 0.09 with counts near 0.
* It slopes upward steadily. At a value of 0.15, the count is approximately 60.
* The distribution has a jagged peak. The absolute highest bar occurs just before 0.20 (approx. 0.19), reaching a count of ~210.
* There is a slight dip at exactly 0.20 (count ~175), followed by two more high bars at approx. 0.21 (count ~195) and 0.22 (count ~190).
* The right tail slopes downward, reaching a count of ~40 at the 0.25 mark, and tapering off to near zero by 0.30.
#### Region 3: Right Subplot (c)
* **Title:** Eigenvector Centrality
* **Visual Trend:** Similar to chart (a), this exhibits a strong right-skew, resembling an exponential decay curve. It starts very high at zero and drops off quickly, though the curve is slightly smoother and less abrupt than the Betweenness Centrality chart.
* **Data Points (Green Bars):**
* The first bin (approx. 0.00 to 0.01) peaks just below the 1500 mark (estimated ~1480).
* The second bin (approx. 0.01 to 0.02) drops to an estimated count of ~350.
* The third bin (approx. 0.02 to 0.03) drops to an estimated count of ~150.
* The counts continue to decay smoothly, approaching zero around the 0.10 mark.
* A long, empty tail extends from 0.10 to 0.30, indicating no significant node counts in this higher range.
### Key Observations
* **Disparity in Scales:** The maximum count (y-axis) varies wildly between the metrics. Betweenness peaks over 2000, Eigenvector near 1500, while Closeness only peaks around 210. This indicates that Betweenness and Eigenvector scores are highly concentrated at the bottom of their ranges, whereas Closeness scores are spread much more evenly across the network's nodes.
* **Distribution Shapes:** Metrics (a) and (c) share a heavily skewed, long-tail distribution. Metric (b) stands out as the only normally distributed metric.
### Interpretation
These histograms provide a distinct "fingerprint" of the underlying network's topology.
1. **Betweenness Centrality (The Bridges):** The extreme spike at zero indicates that the vast majority of nodes in this network do not act as bridges on the shortest paths between other nodes. They are likely peripheral. The long, invisible tail implies the existence of a very small number of highly critical "hub" nodes that control the flow of information or resources across the network.
2. **Closeness Centrality (The Distances):** The normal distribution indicates that most nodes are roughly the same average distance from all other nodes in the network (centered around a score of 0.20). There are very few nodes that are exceptionally close to everything, and very few that are exceptionally isolated.
3. **Eigenvector Centrality (The Influence):** The exponential decay shows that most nodes are connected to other low-influence nodes (scoring near zero). A small fraction of nodes have higher scores, meaning they are connected to other well-connected nodes.
**Conclusion:** Reading between the lines, this combination of distributions is highly characteristic of a **Scale-Free or Small-World network** (common in social networks, biological pathways, and the internet). In such networks, a few massive hubs dominate the routing (Betweenness) and hold the most structural influence (Eigenvector), while the overall network remains compact enough that the average path length from any node to any other node remains relatively consistent and normally distributed (Closeness).
</details>
Figure 8: Distribution of node centrality measures in the recursively generated knowledge graph, for $\mathcal{G_{1}}$ : (a) Betweenness centrality, showing that only a few nodes serve as major intermediaries; (b) Closeness centrality, indicating that the majority of nodes remain well-connected; (c) Eigenvector centrality, revealing the emergence of dominant hub nodes. These distributions highlight the hierarchical and scale-free nature of the evolving knowledge graph.
Figure 9 presents the distribution of sampled shortest path lengths. This distribution provides insights into the overall compactness, navigability, and structural efficiency of the network.
The histogram reveals that the most frequent shortest path length is centered around 5–6 steps, indicating that the majority of node pairs are relatively close in the network. The distribution follows a bell-shaped pattern, suggesting a typical range of distances between nodes, with a slight right skew where some paths extend beyond 10 steps. The presence of longer paths implies that certain nodes remain in the periphery or are indirectly connected to the core reasoning structure.
The relatively narrow range of shortest path lengths affirms that the network remains well-integrated, ensuring efficient knowledge propagation and retrieval. The absence of extreme outliers suggests that the recursive expansion process does not lead to fragmented or sparsely connected regions. This structure contrasts with purely random graphs, where shortest path lengths typically exhibit a narrower peak at lower values. The broader peak observed here suggests that the model does not generate arbitrary connections but instead organizes knowledge in a structured manner, balancing global integration with local modularity.
The observed path length distribution supports the hypothesis that recursive graph reasoning constructs an efficiently connected knowledge framework, where most concepts can be accessed within a small number of steps. The presence of some longer paths further suggests that the network exhibits hierarchical expansion, with certain areas developing as specialized subdomains that extend outward from the core structure.
<details>
<summary>x9.png Details</summary>
### Visual Description
## Histograms: Distribution of Shortest Path Lengths
### Overview
The image consists of two side-by-side histograms, labeled (a) on the left and (b) on the right. Both charts display the frequency distribution of sampled shortest path lengths, likely representing data from a network analysis or graph theory context. Both charts utilize solid purple bars with thin black outlines to represent the data bins. There are no other languages present besides English.
### Components/Axes
**Chart (a) - Left Side**
* **Header/Label:** Top-left corner contains the label "(a)".
* **Title:** Centered above the chart: "Distribution of Shortest Path Lengths (sampled)".
* **Y-axis:** Labeled "Frequency" (rotated 90 degrees counter-clockwise). The scale ranges from 0 to slightly above 500. Major tick marks and grid labels are provided at intervals of 100: 0, 100, 200, 300, 400, 500.
* **X-axis:** Labeled "Shortest Path Length". The scale ranges from approximately 1 to 13. Major tick marks and grid labels are provided at intervals of 2: 2, 4, 6, 8, 10, 12.
**Chart (b) - Right Side**
* **Header/Label:** Top-left corner contains the label "(b)".
* **Title:** Centered above the chart: "Distribution of Shortest Path Lengths (sampled)".
* **Y-axis:** Labeled "Frequency" (rotated 90 degrees counter-clockwise). The scale ranges from 0 to slightly above 500. Major tick marks and grid labels are provided at intervals of 100: 0, 100, 200, 300, 400, 500.
* **X-axis:** Labeled "Shortest Path Length". The scale ranges from approximately 1 to 11. Major tick marks and grid labels are provided at intervals of 2: 2, 4, 6, 8, 10.
### Detailed Analysis
*Note: All numerical values extracted from the bar heights are approximate (denoted by ~) based on visual alignment with the Y-axis.*
**Chart (a) Data Extraction**
*Visual Trend:* The data forms a bell-shaped curve that is slightly right-skewed (positive skew). The frequency rises sharply from path length 2, peaks between 5 and 6, and then tapers off more gradually towards a path length of 13.
* Bin [1-2]: ~2
* Bin [2-3]: ~50
* Bin [3-4]: ~200
* Bin [4-5]: ~415
* Bin [5-6]: ~560 (Peak)
* Bin [6-7]: ~430
* Bin [7-8]: ~210
* Bin [8-9]: ~90
* Bin [9-10]: ~30
* Bin [10-11]: ~15
* Bin [11-12]: ~5
* Bin [12-13]: ~2
**Chart (b) Data Extraction**
*Visual Trend:* Similar to chart (a), this forms a bell-shaped curve, but it is slightly more symmetrical and has a narrower overall spread. The frequency rises from path length 1, peaks between 5 and 6, and tapers off by path length 11.
* Bin [1-2]: ~5
* Bin [2-3]: ~75
* Bin [3-4]: ~250
* Bin [4-5]: ~490
* Bin [5-6]: ~520 (Peak)
* Bin [6-7]: ~360
* Bin [7-8]: ~215
* Bin [8-9]: ~60
* Bin [9-10]: ~15
* Bin [10-11]: ~5
### Key Observations
1. **Central Tendency:** Both distributions share the same modal bin; the most frequent shortest path length in both datasets is between 5 and 6.
2. **Spread and Range:** Chart (a) exhibits a wider range of path lengths, extending up to approximately 13, indicating a network with a potentially larger maximum diameter. Chart (b) is more compact, with path lengths effectively terminating around 11.
3. **Peak Concentration:** While both peak at the [5-6] bin, Chart (a) has a higher absolute peak frequency (~560) compared to Chart (b) (~520). However, Chart (b) has a higher frequency in the preceding bin [4-5] (~490 vs ~415), making the center of distribution (b) look slightly "fatter" or more evenly distributed around the mean.
4. **Skewness:** Chart (a) has a more pronounced right tail (positive skew) than Chart (b).
### Interpretation
These histograms represent the topology of one or two networks (e.g., social networks, communication grids, or biological pathways). The "Shortest Path Length" measures the minimum number of edges required to connect two random nodes.
The normal-like distribution centered around 5 to 6 strongly suggests the presence of the **"Small-World" phenomenon** (often colloquially known as "six degrees of separation"). In such networks, despite having many nodes, most nodes can be reached from every other node by a small number of steps.
The differences between (a) and (b) imply a comparison. This could represent:
* Two distinct networks being compared (e.g., a Twitter network vs. a Facebook network). Network (a) has a slightly longer "tail," meaning there are a few pairs of nodes that are exceptionally far apart compared to network (b).
* The same network measured at two different points in time. For example, if (a) is the "before" and (b) is the "after," the network in (b) has become slightly more compact and interconnected, reducing the maximum distance between the most isolated nodes.
* Two different sampling methods or algorithmic approaches applied to the same underlying graph.
</details>
Figure 9: Distribution of sampled shortest path lengths in the recursively generated knowledge graphs (panel (a), for graph $\mathcal{G_{2}}$ , panel (b), graph $\mathcal{G_{2}}$ ). The peak around 5–6 steps suggests that the network remains compact and navigable, while the slight right skew especially in panel (a) indicates the presence of peripheral nodes or specialized subdomains.
2.5 Knowledge Graph Evolution and Conceptual Breakthroughs
The evolution of the knowledge graph over iterative expansions discussed so far reveals distinct patterns in knowledge accumulation, conceptual breakthroughs, and interdisciplinary integration. To analyze these processes, we now examine (i) the growth trajectories of major conceptual hubs, (ii) the emergence of new highly connected nodes, and (iii) overall network connectivity trends across iterations. The results of these analyses are presented in Figure 11, which consists of three sub-components.
<details>
<summary>x10.png Details</summary>
### Visual Description
## Multi-Panel Network Analysis Charts: Hub Growth, Emergence, and Connectivity
### Overview
This image is a composite of three distinct data visualizations, labeled (a), (b), and (c), detailing the growth and connectivity metrics of a simulated network over a series of iterations.
- **Chart (a)** (top-left) is a step-line chart tracking the absolute degree of specific top nodes over time.
- **Chart (b)** (bottom-left) is a bar chart showing the frequency of new hub emergence over early iterations.
- **Chart (c)** (bottom-right) is a scatter plot showing the linear growth of the average node degree across the entire network.
**Language Declaration:** All text within the image is in English.
---
### Component Isolation & Detailed Analysis
#### Panel (a): Growth of Top Hubs Over Iterations
**Spatial Grounding:** Located in the top-left quadrant. The legend is positioned outside the chart area to the right.
**Components/Axes:**
* **Title:** Growth of Top Hubs Over Iterations
* **X-axis:** Labeled "Iteration". Scale runs from 0 to 1000, with major gridlines and markers at 0, 200, 400, 600, 800, and 1000.
* **Y-axis:** Labeled "Absolute Degree". Scale runs from 0 to 200, with major gridlines and markers at 0, 25, 50, 75, 100, 125, 150, 175, and 200.
* **Legend:** Contains 10 categories, mapped to specific line colors.
**Trend Verification & Content Details:**
The chart displays step-wise growth for all series, indicating that node degrees increase in discrete jumps rather than continuous flows.
* **Blue Line (Node Artificial Intelligence (AI)):** *Trend:* Dominant, steep upward slope from the beginning. *Data:* Starts at 0, rises rapidly to ~70 by iteration 200, crosses 125 around iteration 450, and finishes as the highest value at ~195 by iteration 1000.
* **Orange Line (Node Knowledge Graph):** *Trend:* Flat initially, with massive late-stage jumps. *Data:* Remains below 25 until iteration ~350. Jumps to ~60 around iteration 400. Experiences a massive spike around iteration 800, ending at ~135.
* **Green Line (Node Urban Ecosystems):** *Trend:* Steady, moderate step-wise growth. *Data:* Reaches ~25 by iteration 200, ~70 by iteration 500, and ends at ~110.
* **Red Line (Node Bioluminescent Technology):** *Trend:* Dormant for the first half, followed by explosive growth. *Data:* Remains near 0-10 until iteration ~620, then shoots up rapidly in a series of steps, ending at ~105.
* **Purple Line (Node Learning Outcomes):** *Trend:* Rapid early growth followed by a long plateau. *Data:* Rises to ~40 by iteration 200, hits ~80 by iteration 400, and then remains almost completely flat, ending at ~80.
* **Brown Line (Node Climate Change):** *Trend:* Consistent, moderate growth. *Data:* Rises to ~50 by iteration 250, steadily climbs to end at ~100.
* **Pink Line (Node Resilience):** *Trend:* Gradual, steady growth. *Data:* Climbs slowly throughout the 1000 iterations, ending at ~85.
* **Grey Line (Node Human Well-being):** *Trend:* Gradual, steady growth, closely mirroring the Pink line. *Data:* Ends at ~75.
* **Olive/Yellow-Green Line (Node Bioluminescent Organisms):** *Trend:* Flat initially, moderate mid-stage growth. *Data:* Stays below 25 until iteration ~480, rises to ~70, and plateaus, ending at ~75.
* **Cyan/Light Blue Line (Node Symbiotic Relationships):** *Trend:* Very late bloomer. *Data:* Stays at 0 until iteration ~200, remains below 10 until iteration ~680, then steps up to end at ~65.
#### Panel (b): Emergence of New Hubs Over Iterations
**Spatial Grounding:** Located in the bottom-left quadrant.
**Components/Axes:**
* **Title:** Emergence of New Hubs Over Iterations
* **X-axis:** Labeled "Iteration Number". Scale runs from 0 to roughly 250, with markers at 0, 50, 100, 150, and 200. *Note: This axis represents a much shorter timeframe than charts (a) and (c).*
* **Y-axis:** Labeled "Number of New Hubs". Scale runs from 0.00 to 2.00, with markers at 0.00, 0.25, 0.50, 0.75, 1.00, 1.25, 1.50, 1.75, and 2.00.
**Trend Verification & Content Details:**
* *Trend:* The emergence of new hubs is heavily front-loaded in the network's lifespan.
* *Data:*
* Single hubs (value 1.00) emerge at approximate iterations: ~5, ~12, ~20, ~28, and ~35.
* A spike of two hubs (value 2.00) emerges at approximate iteration ~80.
* Single hubs (value 1.00) emerge at approximate iterations ~90, ~110, and a final outlier at ~220.
* No new hubs emerge after iteration ~220 (up to the visible edge of the chart).
#### Panel (c): Overall Network Connectivity Over Time
**Spatial Grounding:** Located in the bottom-right quadrant.
**Components/Axes:**
* **Title:** Overall Network Connectivity Over Time
* **X-axis:** Labeled "Iteration". Scale runs from 0 to 1000, with markers at 0, 200, 400, 600, 800, and 1000.
* **Y-axis:** Labeled "Average Node Degree". Scale runs from 0 to roughly 4.5, with markers at 0, 1, 2, 3, and 4.
**Trend Verification & Content Details:**
* *Trend:* A perfectly linear, positive slope.
* *Data:* The chart features a thick blue line (likely composed of dense scatter plot points). It starts at (0, 0) and rises linearly. At iteration 200, the value is ~0.9. At iteration 500, the value is ~2.2. At iteration 1000, the value reaches ~4.5.
---
### Key Observations
1. **The "Rich Get Richer" Phenomenon:** In chart (a), the "Artificial Intelligence (AI)" node establishes dominance early and maintains the highest growth rate throughout the simulation.
2. **Late Bloomers:** Nodes like "Bioluminescent Technology" (Red) show that a node can remain highly disconnected for more than half the simulation (600 iterations) before suddenly experiencing explosive connectivity.
3. **Early Hub Formation:** Chart (b) proves that the "hubs" tracked in chart (a) almost exclusively gained their hub status in the first 120 iterations.
4. **Constant Network Densification:** Chart (c) shows that the average degree of the entire network grows linearly. Because the average degree is growing steadily, edges are being added to the network at a faster rate than new nodes are being added.
### Interpretation
These three charts collectively describe the evolution of a simulated network, highly indicative of a **scale-free network** utilizing a **preferential attachment** mechanism (such as the Barabási–Albert model).
* **Reading between the lines:** Chart (c) shows a smooth, linear increase in average connectivity, meaning the overall system is growing predictably. However, Chart (a) shows that this connectivity is *not* distributed evenly. The step-wise, erratic jumps in Chart (a) indicate that when new connections are formed, they disproportionately attach to specific, already-established nodes.
* **Thematic Context:** The node labels (AI, Knowledge Graph, Urban Ecosystems, Bioluminescent Tech) suggest this is a simulation of technological or conceptual evolution—perhaps mapping how different research topics or patents link together over time. "AI" acts as a foundational, highly-linked concept.
* **The Lifecycle of a Hub:** Chart (b) reveals a critical insight: to become a top hub by iteration 1000, a node generally needs to achieve "hub" status very early in the network's life (before iteration 120). The only way a node overcomes this "first-mover advantage" is through sudden, massive thematic relevance later in the simulation, as seen with the "Bioluminescent Technology" node in Chart (a), which lay dormant until iteration 600 before rapidly acquiring connections.
</details>
Figure 10: Evolution of knowledge graph structure across iterations, for $\mathcal{G_{1}}$ . (a) Degree growth of the top conceptual hubs, showing both steady accumulation and sudden breakthroughs. (b) Histogram of newly emerging high-degree nodes across iterations, indicating phases of conceptual expansion. (c) Plot of the mean node degree over time, illustrating the system’s progressive integration of new knowledge.
The trajectory of hub development (Figure 10 (a)) suggests two primary modes of knowledge accumulation: steady growth and conceptual breakthroughs. Certain concepts, such as Artificial Intelligence (AI) and Knowledge Graphs, exhibit continuous incremental expansion, reflecting their persistent relevance in structuring knowledge. In contrast, hubs like Bioluminescent Technology and Urban Ecosystems experience extended periods of low connectivity followed by sudden increases in node degree, suggesting moments when these concepts became structurally significant in the knowledge graph. These results indicate that the system does not expand knowledge in a purely linear fashion but undergoes phases of conceptual restructuring, akin to punctuated equilibrium in scientific development.
The emergence of new hubs (Figure 10 (b)) further supports this interpretation. Instead of a continuous influx of new central concepts, we observe discrete bursts of hub formation occurring at specific iteration milestones. These bursts likely correspond to the accumulation of contextual knowledge reaching a critical threshold, after which the system autonomously generates new organizing principles to structure its expanding knowledge base. This finding suggests that the system’s reasoning process undergoes alternating cycles of consolidation and discovery, where previously formed knowledge stabilizes before new abstract concepts emerge.
The overall network connectivity trends (Figure 10 (c)) demonstrate a steady increase in average node degree, indicating that the graph maintains a structurally stable expansion while integrating additional knowledge. The absence of abrupt drops in connectivity suggests that previously introduced concepts remain relevant and continue to influence reasoning rather than become obsolete. This trend supports the hypothesis that the system exhibits self-organizing knowledge structures, continuously refining its conceptual hierarchy as it expands.
These observations lead to several overarching conclusions. First, the results indicate that the system follows a hybrid knowledge expansion model, combining gradual accumulation with disruptive conceptual breakthroughs. This behavior closely mirrors the dynamics of human knowledge formation, where foundational ideas develop progressively, but major paradigm shifts occur when conceptual thresholds are crossed. Second, the persistence of high-degree hubs suggests that knowledge graphs generated in this manner do not suffer from catastrophic forgetting; instead, they maintain and reinforce previously established structures while integrating new insights. Third, the formation of new hubs in discrete bursts implies that knowledge expansion is not driven by uniform growth but by self-reinforcing epistemic structures, where accumulated reasoning reaches a tipping point that necessitates new abstract representations.
Additionally, the system demonstrates a structured directionality in knowledge formation, as evidenced by the smooth increase in average node degree without fragmentation. This suggests that new concepts do not disrupt existing structures but are incrementally woven into the broader network. Such behavior is characteristic of self-organizing knowledge systems, where conceptual evolution follows a dynamic yet cohesive trajectory. The model also exhibits potential for cross-domain knowledge synthesis, as indicated by the presence of nodes that transition into highly connected hubs later in the process. These nodes likely act as bridges between previously distinct knowledge clusters, fostering interdisciplinary connections.
These analyses provide strong evidence that the recursive graph expansion model is capable of simulating key characteristics of scientific knowledge formation. The presence of alternating stability and breakthrough phases, the hierarchical organization of concepts, and the increasing connectivity across knowledge domains all highlight the potential for autonomous reasoning systems to construct, refine, and reorganize knowledge representations dynamically. Future research could potentially focus on exploring the role of interdisciplinary bridge nodes, analyzing the hierarchical depth of reasoning paths, and examining whether the system can autonomously infer meta-theoretical insights from its evolving knowledge graph.
2.6 Structural Evolution of the Knowledge Graph
The expansion of the knowledge graph over iterative refinements reveals emergent structural patterns that highlight how knowledge communities form, how interdisciplinary connections evolve, and how reasoning complexity changes over time. These dynamics provide insight into how autonomous knowledge expansion follows systematic self-organization rather than random accumulation. Figure 11 presents three key trends: (a) the formation and growth of knowledge sub-networks, (b) the number of bridge nodes that connect different knowledge domains, and (c) the depth of multi-hop reasoning over iterations.
<details>
<summary>x11.png Details</summary>
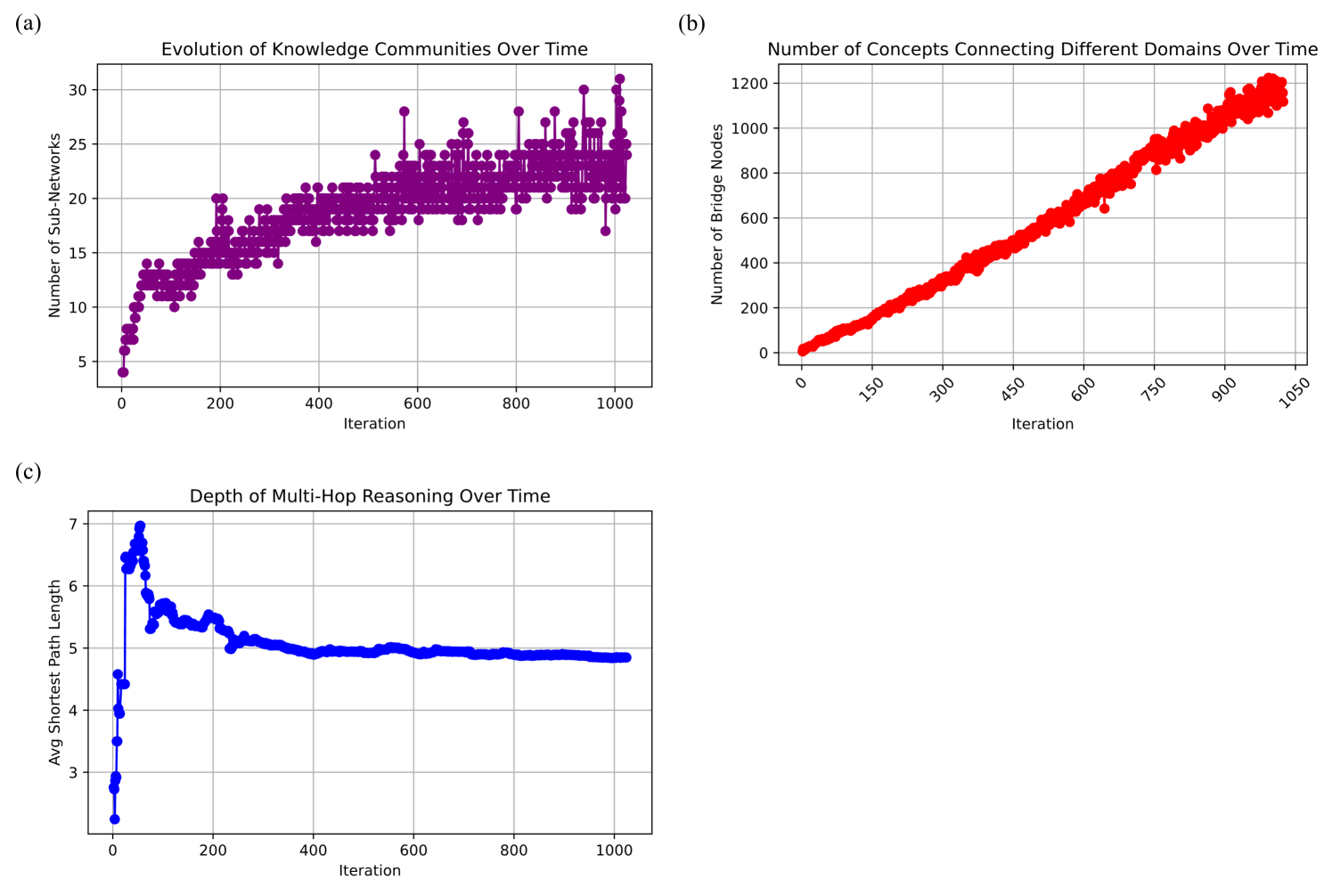
### Visual Description
## Line Charts: Network and Knowledge Graph Evolution Metrics
### Overview
The image consists of three distinct line charts arranged in a 2x2 grid layout, with the bottom-right quadrant empty. The charts are labeled (a) in the top-left, (b) in the top-right, and (c) in the bottom-left. All text is in English. The charts collectively illustrate the evolution of different network or knowledge graph metrics over a period of approximately 1000 iterations. There are no explicit legends; instead, each chart utilizes a distinct color (purple, red, blue) for its data series.
---
### Component Isolation & Detailed Analysis
#### Chart (a) - Top-Left
* **Title:** Evolution of Knowledge Communities Over Time
* **Color/Style:** Purple line with circular markers.
* **Y-Axis:** Labeled "Number of Sub-Networks". Scale ranges from 5 to 30, with major gridlines and tick marks at increments of 5 (5, 10, 15, 20, 25, 30).
* **X-Axis:** Labeled "Iteration". Scale ranges from 0 to 1000, with major gridlines and tick marks at increments of 200 (0, 200, 400, 600, 800, 1000).
* **Visual Trend:** The purple line exhibits a logarithmic-style growth curve characterized by increasing volatility. It begins low, rises sharply in the first 200 iterations, and then continues to trend upward at a slower rate. As iterations increase, the vertical spread (variance) of the data points becomes significantly wider, indicating rapid fluctuations in the number of sub-networks.
* **Data Points (Approximate):**
* Iteration 0: ~4
* Iteration 100: Fluctuates between ~10 and ~14
* Iteration 200: Fluctuates between ~13 and ~20
* Iteration 400: Fluctuates between ~16 and ~21
* Iteration 600: Fluctuates between ~18 and ~28
* Iteration 800: Fluctuates between ~19 and ~28
* Iteration 1000: Fluctuates between ~17 and ~31 (highest variance observed here)
#### Chart (b) - Top-Right
* **Title:** Number of Concepts Connecting Different Domains Over Time
* **Color/Style:** Red line with circular markers. The line appears thick due to the high density of data points.
* **Y-Axis:** Labeled "Number of Bridge Nodes". Scale ranges from 0 to 1200, with major gridlines and tick marks at increments of 200 (0, 200, 400, 600, 800, 1000, 1200).
* **X-Axis:** Labeled "Iteration". Scale ranges from 0 to 1050, with major gridlines and tick marks at increments of 150 (0, 150, 300, 450, 600, 750, 900, 1050). The numerical labels on this axis are rotated approximately 45 degrees counter-clockwise.
* **Visual Trend:** The red line demonstrates a strong, consistent, and almost perfectly linear upward trend. The variance (thickness of the line band) increases only slightly as the iterations progress, indicating a highly stable growth rate.
* **Data Points (Approximate):**
* Iteration 0: ~0 to 10
* Iteration 150: ~150 to 200
* Iteration 300: ~300 to 350
* Iteration 450: ~450 to 500
* Iteration 600: ~600 to 700
* Iteration 750: ~800 to 900
* Iteration 900: ~1000 to 1100
* Iteration 1050: ~1100 to 1200
#### Chart (c) - Bottom-Left
* **Title:** Depth of Multi-Hop Reasoning Over Time
* **Color/Style:** Blue line with circular markers.
* **Y-Axis:** Labeled "Avg Shortest Path Length". Scale ranges from 2 to 7, with major gridlines and tick marks at increments of 1 (2, 3, 4, 5, 6, 7).
* **X-Axis:** Labeled "Iteration". Scale ranges from 0 to 1000, with major gridlines and tick marks at increments of 200 (0, 200, 400, 600, 800, 1000).
* **Visual Trend:** The blue line shows a dramatic initial spike followed by a rapid decay and eventual stabilization. It starts at the lowest point on the graph, shoots up to its maximum peak within the first ~50 iterations, drops sharply, and then slowly asymptotes to a flat, stable line just below the value of 5 for the remainder of the iterations.
* **Data Points (Approximate):**
* Iteration 0: ~2.2
* Iteration ~50 (Peak): ~7.0
* Iteration 100: ~5.3
* Iteration 200: ~5.5
* Iteration 400: ~4.9
* Iteration 600: ~4.9
* Iteration 800: ~4.9
* Iteration 1000: ~4.8
---
### Key Observations
1. **Divergent Volatility:** While Chart (b) shows incredibly stable, linear growth, Chart (a) shows increasing instability and variance over the same time period.
2. **Early System Shock:** Chart (c) reveals a massive structural shift in the network at the very beginning of the process (iterations 0-100), which resolves into long-term stability.
3. **Correlated Stabilization:** The stabilization of the average shortest path length in Chart (c) (around iteration 400) coincides with the period where the number of sub-networks in Chart (a) begins to experience its highest volatility.
---
### Interpretation
These charts likely represent the training process or dynamic evolution of an AI model, specifically one dealing with Knowledge Graphs, semantic networks, or multi-hop reasoning systems (like a Graph Neural Network or an LLM building internal representations).
* **Community Formation (Chart A):** The system is actively clustering information into distinct "sub-networks" or topics. The increasing volatility suggests that as the system learns more, it constantly re-evaluates these clusters—splitting them apart and merging them together dynamically. It is not settling on a rigid taxonomy, but maintaining a fluid, evolving categorization.
* **Interconnectivity (Chart B):** Despite the fracturing of knowledge into distinct communities (Chart A), the system is simultaneously and consistently building "bridge nodes" (concepts that link different domains). The linear growth implies a steady, healthy integration of cross-disciplinary knowledge. The system is not becoming siloed.
* **Reasoning Efficiency (Chart C):** The "Avg Shortest Path Length" is a classic measure of network efficiency (the "small-world" property).
* *The Initial Spike:* When the system first starts learning (iterations 0-50), it likely ingests disparate pieces of information, creating long, inefficient chains of logic to connect concept A to concept B (path length jumps to 7).
* *The Stabilization:* As the system builds more "bridge nodes" (as seen in Chart B), it creates shortcuts between different domains. This causes the average path length to drop and stabilize around 4.8.
* **Synthesis:** Reading between the lines, this data demonstrates a highly successful network evolution. The system is simultaneously becoming more specialized (more sub-networks) and more integrated (more bridge nodes). Because of this steady integration, the system maintains a highly efficient reasoning depth (a stable path length of ~5), meaning it can connect any two disparate concepts across its entire knowledge base in roughly 5 logical steps, regardless of how large the total network grows.
</details>
Figure 11: Structural evolution of the knowledge graph across iterations. (a) The number of distinct knowledge communities over time, showing an increasing trend with some fluctuations, for graph $\mathcal{G_{1}}$ . (b) The growth of bridge nodes that connect multiple knowledge domains, following a steady linear increase. (c) The average shortest path length over iterations, indicating shifts in reasoning complexity as the graph expands.
Figure 11 (a) illustrates the formation of knowledge sub-networks over time. The number of distinct communities increases as iterations progress, reflecting the system’s ability to differentiate between specialized fields of knowledge. The trend suggests two key observations: (i) an early rapid formation of new communities as novel knowledge domains emerge and (ii) a later stage where the number of communities stabilizes with occasional fluctuations. The latter behavior indicates that rather than indefinitely forming new disconnected knowledge clusters, the system reaches a regime where previously distinct domains remain relatively stable while undergoing minor structural reorganizations. The fluctuations in the later stages may correspond to moments where knowledge clusters merge or when new abstractions cause domain shifts.
Figure 11 (b) tracks the number of bridge nodes (concepts that serve as interdisciplinary connectors) over iterative expansions. The steady, almost linear increase in bridge nodes suggests that as knowledge expands, more concepts naturally emerge as crucial links between different domains. This behavior reflects the self-reinforcing nature of knowledge integration, where new ideas not only expand within their respective fields but also introduce new ways to connect previously unrelated disciplines. Interestingly, there is no evidence of saturation in the number of bridge nodes, implying that the graph remains highly adaptive, continuously uncovering interdisciplinary relationships without premature convergence. This property is reminiscent of human knowledge structures, where interdisciplinary connections become more prevalent as scientific inquiry deepens.
Figure 11 (c) examines the depth of multi-hop reasoning over iterations by measuring the average shortest path length in the graph. Initially, reasoning depth fluctuates significantly, which corresponds to the early phase of knowledge graph formation when structural organization is still emergent. As iterations progress, the average path length stabilizes, indicating that the system achieves a balance between hierarchical depth and accessibility of information. The early fluctuations may be attributed to the rapid reorganization of knowledge, where some paths temporarily become longer as new concepts emerge before stabilizing into more efficient reasoning structures. The eventual stabilization suggests that the graph reaches an equilibrium in how information propagates through interconnected domains, maintaining reasoning efficiency while still allowing for complex inferential pathways.
Taken together, these findings suggest that the autonomous knowledge expansion model exhibits structured self-organization, balancing specialization and integration. The interplay between distinct community formation, interdisciplinary connectivity, and reasoning depth highlights the emergence of a dynamically evolving but structurally coherent knowledge network. The continuous increase in bridge nodes reinforces the idea that interdisciplinary reasoning remains a central feature throughout the system’s expansion, which may have significant implications for autonomous discovery processes. Future analyses will explore whether certain bridge nodes exhibit long-term persistence as central knowledge connectors or if interdisciplinary pathways evolve dynamically based on newly introduced concepts.
2.7 Persistence of Bridge Nodes in Knowledge Evolution
To understand the structural stability of interdisciplinary connections, we further analyze the persistence of bridge nodes—concepts that act as connectors between distinct knowledge domains, over multiple iterations. Figure 12 presents a histogram of bridge node lifespans, showing how long each node remained an active bridge in the knowledge graph.
<details>
<summary>x12.png Details</summary>
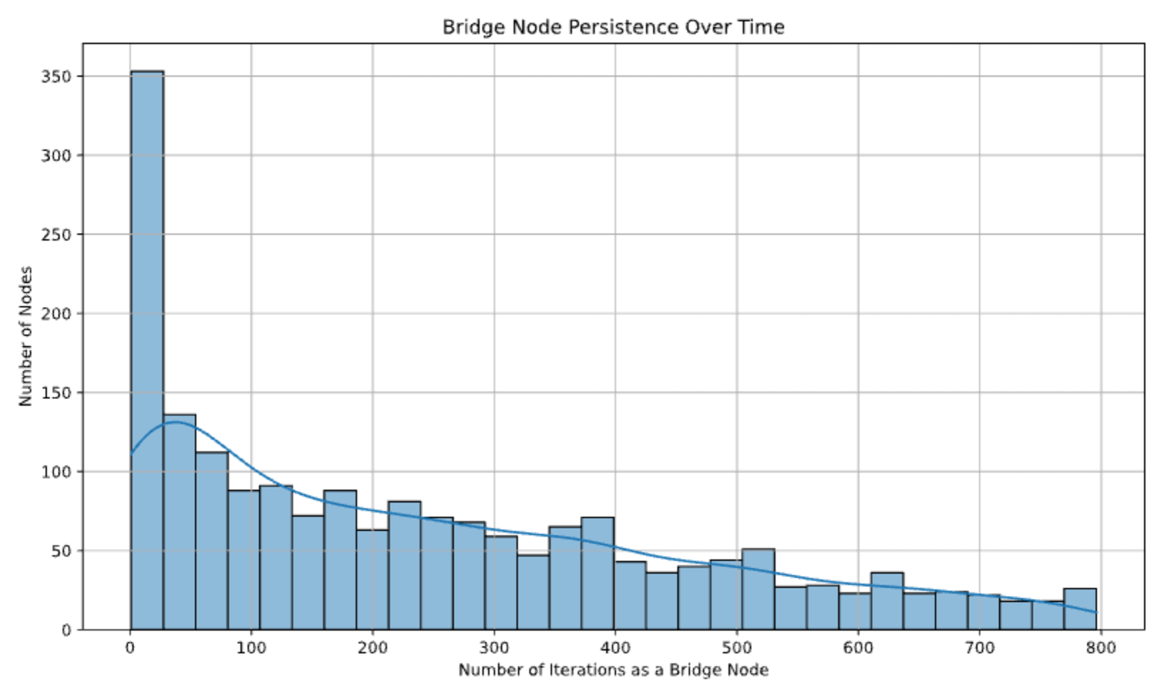
### Visual Description
## Histogram: Bridge Node Persistence Over Time
### Overview
This image is a statistical chart, specifically a histogram overlaid with a Kernel Density Estimate (KDE) curve or trend line. It visualizes the frequency distribution of "Bridge Nodes" based on how long they persist (measured in iterations) within a given system or network model. The data exhibits a heavy right-skew (positive skew), indicating that the vast majority of bridge nodes are highly transient, while a small minority persist for a long duration.
### Components/Axes
**1. Header Region (Top)**
* **Chart Title:** "Bridge Node Persistence Over Time" (Positioned top-center, black text).
**2. Main Chart Area (Center)**
* **Grid:** A background grid consisting of light gray lines aligns with the major axis markers, forming a rectangular matrix to aid in reading values.
* **Data Series 1 (Histogram Bars):** 32 contiguous vertical bars.
* *Color:* Light blue fill with thin black outlines.
* *Bin Width:* Based on the x-axis scale (0 to 800) and the presence of 4 bars per 100 units, each bin represents exactly 25 iterations.
* **Data Series 2 (Trend Line):** A continuous, smoothed curve overlaid on the bars.
* *Color:* Solid medium-blue line.
* *Placement:* It begins at approximately y=110 on the y-axis, rises slightly to peak around x=40, and then follows the general declining trend of the histogram bars, smoothing out local variances.
* **Legend:** *None present.* The chart relies on axis labels to define the data.
**3. Left Axis Region (Y-Axis)**
* **Axis Title:** "Number of Nodes" (Rotated 90 degrees counter-clockwise, positioned vertically centered on the left).
* **Axis Scale/Markers:** Linear scale starting at 0 and ending at 350.
* **Tick Marks:** 0, 50, 100, 150, 200, 250, 300, 350.
**4. Footer Region (X-Axis)**
* **Axis Title:** "Number of Iterations as a Bridge Node" (Positioned bottom-center, below the tick markers).
* **Axis Scale/Markers:** Linear scale starting at 0 and ending at 800.
* **Tick Marks:** 0, 100, 200, 300, 400, 500, 600, 700, 800.
### Detailed Analysis
**Trend Verification:**
Visually, the data demonstrates a sharp, immediate peak in the very first bin, followed by a steep drop-off. After the initial drop, the data forms a "long tail" that gradually slopes downward toward the right side of the chart. The overlaid blue line confirms this trend: an initial spike followed by an exponential-like decay, with minor, localized fluctuations (small bumps) along the descent.
**Data Point Extraction (Approximate Values):**
*Note: Values are visually estimated based on the y-axis gridlines (increments of 50). Uncertainty is approximately ±5 units per bar.*
* **Bin 1 (0-25 iterations):** ~353 nodes *(Absolute maximum)*
* **Bin 2 (25-50 iterations):** ~135 nodes
* **Bin 3 (50-75 iterations):** ~112 nodes
* **Bin 4 (75-100 iterations):** ~88 nodes
* **Bin 5 (100-125 iterations):** ~91 nodes
* **Bin 6 (125-150 iterations):** ~72 nodes
* **Bin 7 (150-175 iterations):** ~88 nodes
* **Bin 8 (175-200 iterations):** ~63 nodes
* **Bin 9 (200-225 iterations):** ~81 nodes
* **Bin 10 (225-250 iterations):** ~71 nodes
* **Bin 11 (250-275 iterations):** ~68 nodes
* **Bin 12 (275-300 iterations):** ~59 nodes
* **Bin 13 (300-325 iterations):** ~47 nodes
* **Bin 14 (325-350 iterations):** ~65 nodes
* **Bin 15 (350-375 iterations):** ~71 nodes
* **Bin 16 (375-400 iterations):** ~43 nodes
* **Bin 17 (400-425 iterations):** ~36 nodes
* **Bin 18 (425-450 iterations):** ~40 nodes
* **Bin 19 (450-475 iterations):** ~44 nodes
* **Bin 20 (475-500 iterations):** ~51 nodes
* **Bin 21 (500-525 iterations):** ~27 nodes
* **Bin 22 (525-550 iterations):** ~28 nodes
* **Bin 23 (550-575 iterations):** ~23 nodes
* **Bin 24 (575-600 iterations):** ~36 nodes
* **Bin 25 (600-625 iterations):** ~23 nodes
* **Bin 26 (625-650 iterations):** ~24 nodes
* **Bin 27 (650-675 iterations):** ~22 nodes
* **Bin 28 (675-700 iterations):** ~21 nodes
* **Bin 29 (700-725 iterations):** ~18 nodes
* **Bin 30 (725-750 iterations):** ~17 nodes
* **Bin 31 (750-775 iterations):** ~18 nodes
* **Bin 32 (775-800 iterations):** ~26 nodes
### Key Observations
1. **Extreme Initial Volatility:** The most striking feature is the first bin (0-25 iterations), which contains over 350 nodes. This is more than 2.5 times higher than the second-highest bin.
2. **The Long Tail:** Despite the massive initial drop-off, the distribution does not quickly reach zero. Nodes continue to persist all the way to the 800-iteration mark, maintaining a baseline of roughly 15 to 30 nodes per bin in the latter half of the chart.
3. **Localized Resurgence:** There are minor, localized peaks that interrupt the smooth decay. For example, there are slight bumps at 150-175 iterations (~88 nodes), 200-225 iterations (~81 nodes), and 350-375 iterations (~71 nodes).
4. **End-of-Chart Anomaly:** The final bin (775-800) shows a slight uptick (~26 nodes) compared to the immediately preceding bins (~17-18 nodes). This could indicate a "survivor" grouping or an artificial cutoff in the simulation/data collection at 800 iterations.
### Interpretation
In network theory, a "bridge node" is a critical component that connects distinct clusters or communities; removing it would separate the network or drastically increase the distance between nodes.
**What the data suggests:**
This chart reveals the dynamic, shifting topology of the network being analyzed. The massive spike at the beginning indicates that the vast majority of bridge nodes are highly unstable or transient—they form a bridge for a very brief period (under 25 iterations) before the network shifts and they lose that status.
However, the presence of the long tail demonstrates a structural dichotomy within the network. While most bridges are fleeting, a small, resilient "core" of bridge nodes exists. These nodes maintain their critical bridging status for hundreds of iterations (up to 800).
**Reading between the lines (Peircean investigative):**
The minor bumps in the long tail (e.g., around 150, 200, and 350 iterations) suggest cyclical or phased shifts in the network's topology, where certain groups of nodes collectively gain or lose bridge status at specific intervals. Furthermore, the slight uptick at the 800 mark strongly implies that the simulation or data collection was terminated at 800 iterations, and those ~26 nodes would likely have continued to persist as bridges if the timeline were extended.
Ultimately, this data characterizes a network that is highly fluid at its edges but relies on a very small, deeply entrenched set of nodes to maintain overall global connectivity over long periods.
</details>
Figure 12: Histogram of bridge node persistence over iterations, for $\mathcal{G_{1}}$ . The distribution follows a long-tail pattern, indicating that while most bridge nodes exist only briefly, a subset remains active across hundreds of iterations.
The distribution in Figure 12 suggests that knowledge graph connectivity follows a hybrid model of structural evolution. The majority of bridge nodes appear only for a limited number of iterations, reinforcing the hypothesis that interdisciplinary pathways frequently evolve as new concepts emerge and replace older ones. This aligns with earlier observations that the knowledge system exhibits a high degree of conceptual dynamism.
However, a subset of bridge nodes remains persistent for hundreds of iterations. These nodes likely correspond to fundamental concepts that sustain long-term interdisciplinary connectivity. Their extended presence suggests that the system does not solely undergo continuous restructuring; rather, it maintains a set of core concepts that act as stable anchors in the evolving knowledge landscape.
These results refine our earlier observations by distinguishing between transient interdisciplinary connections and long-term structural stability. While knowledge graph expansion is dynamic, certain foundational concepts maintain their bridging role, structuring the broader knowledge network over extended periods. This hybrid model suggests that autonomous knowledge expansion does not operate under complete conceptual turnover but instead converges toward the emergence of stable, high-impact concepts that persist across iterations.
Related questions that could be explored in future research is whether these persistent bridge nodes correspond to widely used theoretical frameworks, methodological paradigms, or cross-domain knowledge principles. Additionally, further analysis is needed to examine whether long-term bridge nodes exhibit distinct topological properties, such as higher degree centrality or clustering coefficients, compared to short-lived connectors.
2.8 Early Evolution of Bridge Nodes in Knowledge Expansion
To examine the mechanics of the formation of interdisciplinary connections in the early stages of knowledge graph evolution, we pay close attention to the process. In the analysis discussed here, we identify the first occurrences of bridge nodes over the initial 200 iterations. Figure 13 presents a binary heatmap, where each row represents a bridge node, and each column corresponds to an iteration. The bridge nodes are sorted by the iteration in which they first appeared, providing a clearer view of how interdisciplinary connectors emerge over time.
<details>
<summary>x13.png Details</summary>

### Visual Description
## Heatmap: Bridge Node Appearance Over Early Iterations
### Overview
This image is a binary heatmap titled "Bridge Node Appearance Over Early Iterations (Sorted by First Appearance)". It visualizes the presence or absence of 100 specific conceptual "Bridge Nodes" across the first 200 iterations of a process. The data is sorted so that nodes appearing in the earliest iterations are at the top, creating a distinct cascading "waterfall" or "staircase" visual pattern from the top-left to the bottom-right. Dark blue indicates the presence/activation of a node, while white indicates its absence.
### Components/Axes
* **Header / Title (Top Center):** "Bridge Node Appearance Over Early Iterations (Sorted by First Appearance)"
* **Y-Axis (Left):**
* **Title:** "Top 100 Earliest Appearing Bridge Nodes"
* **Labels:** 100 distinct text labels representing concepts, technologies, and domains. (Transcribed fully in the Content Details section).
* **X-Axis (Bottom):**
* **Title:** "Iteration (First 200)"
* **Markers (Ticks):** Non-linear, discrete numerical markers representing specific iteration steps. The visible ticks are: 2, 5, 8, 11, 17, 23, 26, 29, 35, 40, 44, 50, 53, 56, 60, 63, 66, 69, 73, 76, 82, 87, 90, 94, 100, 105, 108, 112, 116, 120, 125, 130, 133, 137, 142, 146, 149, 152, 156, 159, 164, 169, 176, 179, 184, 188, 192, 195, 199.
* **Legend / Data Representation:** There is no explicit legend box. However, spatial grounding and visual context dictate:
* **Dark Blue Rectangle:** Node is present/active at that specific iteration.
* **White Space:** Node is absent/inactive at that specific iteration.
### Content Details
#### Trend Verification & Spatial Grounding
1. **The Cascading Edge:** The most prominent visual trend is the left-most edge of the blue data points. It slopes downward and to the right. The top-most node first appears at iteration 2 (far left). The bottom-most node first appears around iteration 56 (center-left).
2. **Continuity vs. Fragmentation:**
* Some rows feature a solid dark blue line from their first appearance all the way to iteration 199 (far right). This indicates permanent retention of the concept once introduced.
* Other rows are highly fragmented, appearing as dashed blue lines (e.g., the 4th row down, "Material Utilization"). This indicates concepts that are temporarily relevant, discarded, and revisited.
#### Y-Axis Label Transcription (Ordered Top to Bottom)
*Note: The list reveals distinct thematic clustering as one moves down the axis.*
1. Closed-Loop Life Cycle Design
2. Environmental Sustainability
3. Human Well-being
4. Material Utilization
5. Material Waste
6. Recycling
7. Bio-inspired Materials
8. Bio-inspired Materials Science
9. Closed-loop Life Cycle Design *(Note: Lowercase 'l' in loop, distinct from item 1)*
10. Design Approach
11. Development of Novel, Adaptive Urban Ecosystems
12. Materials Production
13. Materials Science
14. Nature
15. Novel, Adaptive Urban Ecosystems
16. Social Impact
17. Sustainable Materials Development
18. Self-healing Infrastructure
19. Environmental Impact
20. More Resilient Urban Ecosystems
21. Urban Planning and Development
22. Adaptability of cities to climate change
23. Enhancement of Adaptability and Resilience in cities
24. Integration
25. Key Design Considerations
26. Sustainability
27. Adaptability and Resilience of Cities
28. Climate Change
29. Smart Ecosystems
30. Biological and Bio-Inspired Materials
31. Resilience
32. Urban Infrastructure Design
33. Environmental Health
34. Flood Resilience
35. Infrastructure
36. Adaptive
37. Advanced Material
38. Economic Growth
39. Economic Outcome
40. Floodwall System
41. Smart Material
42. Urban Flood Defenses
43. Urban Infrastructure
44. Adaptive, Modular Design
45. Economic Growth of Affected Communities
46. Learning Pathways
47. Artificial Intelligence (AI)
48. Feedback Mechanism
49. Inclusive Learning Ecosystem (ILE)
50. Personalized Learning Environment
51. Personalized Learning Experiences
52. Adaptive Learning
53. Learning Effectiveness
54. Learning Process
55. Personalized Learning
56. Adaptive Learning Systems
57. Cognitive Profiling
58. Learning Environment
59. Learning Motivation
60. Learning Outcomes
61. AI-driven Knowledge Graph (KG)
62. Adaptive Interventions
63. Knowledge Graph-based Adaptation (KG-bA)
64. Personalized Learning Pathways
65. Personalized Learning Pathways (PLP)
66. Adaptive Learning System (ALS)
67. Flow
68. Individual Differences
69. Knowledge Graph
70. Knowledge Graph Construction
71. Knowledge Representation
72. Learning Platform
73. Learning Approach
74. Neuroplasticity
75. Neuroplasticity-Based Learning
76. Personalized Education Strategies
77. Learning Approach *(Repeated)*
78. Learning Outcome
79. Learning Process *(Repeated)*
80. Student Success
81. AI
82. AI-Driven Narrative Generation
83. Personalized Adaptive Narratives
84. Anxiety Disorders
85. Immersive Storytelling
86. Virtual Reality (VR) Therapy
87. BCIs
88. Long-term Outcomes
89. Personalized VR Therapy
90. Therapeutic Approach
91. User Engagement
92. Treatment Efficacy
93. Brain-Computer Interfaces (BCIs)
94. Neurological Disorders
95. Outcome
96. Recovery
97. Technology
98. Treatment Longevity
99. Personalization and Adaptation
100. Therapy
### Key Observations
* **Thematic Shifts over Time:** The graph visually captures a system moving through distinct conceptual phases.
* **Iterations 2-11 (Top rows):** Focus is heavily on Materials Science, Sustainability, and Ecology.
* **Iterations 11-26 (Upper-middle rows):** The focus shifts to Urban Planning, Infrastructure, and Climate Resilience.
* **Iterations 26-44 (Lower-middle rows):** A massive shift occurs toward Artificial Intelligence, Education, and Personalized Learning.
* **Iterations 44-60 (Bottom rows):** The final shift moves into Medical/Therapeutic domains, specifically VR Therapy, Brain-Computer Interfaces (BCIs), and Neurological Disorders.
* **Foundational vs. Ephemeral Nodes:**
* Nodes like "Urban Infrastructure Design" (Row 32), "Artificial Intelligence (AI)" (Row 47), and "Virtual Reality (VR) Therapy" (Row 86) become solid blue blocks immediately upon introduction. They are foundational to the iterations that follow.
* Nodes like "Economic Growth" (Row 38) and "Learning Effectiveness" (Row 53) are highly fragmented, appearing and disappearing frequently, suggesting they are context-dependent variables rather than core structural pillars.
* **Redundancy:** There are near-duplicates in the system's generated nodes (e.g., "Learning Process" appears at row 54 and row 79; "Closed-Loop Life Cycle Design" appears at row 1 and row 9 with different capitalization).
### Interpretation
This heatmap likely represents the diagnostic output of an iterative, generative AI process—such as an automated literature review, a knowledge graph construction algorithm, or an evolutionary ideation agent.
The term "Bridge Node" is the critical clue. The algorithm appears to be tasked with connecting disparate fields of study. It does not explore randomly; it follows a logical, chained progression. It begins with physical materials and sustainability, uses "Urban Ecosystems" as a bridge to infrastructure, uses "Smart Ecosystems/AI" as a bridge to learning and cognitive profiling, and finally uses "Neuroplasticity" as a bridge into clinical therapies (VR and BCIs).
The solid blue lines represent the "anchors" of the knowledge graph—once the system discovers "Artificial Intelligence," it keeps it active in its working memory for all subsequent iterations. The fragmented lines represent the system testing specific applications or sub-topics (like "Floodwall System" or "Anxiety Disorders") against those anchors, dropping them when they don't yield useful connections, and picking them up again later.
Ultimately, the chart demonstrates a successful, directed traversal across four major academic/technical disciplines within 60 iterations, after which it spends iterations 60-200 refining and cross-referencing those established domains.
</details>
Figure 13: Emergence of bridge nodes over the first 200 iterations, sorted by first appearance, for $\mathcal{G_{1}}$ . White regions indicate the absence of a node as a bridge, while dark blue regions denote its presence. Nodes that appear earlier in the graph evolution are positioned at the top. The structured emergence pattern suggests phases of knowledge expansion and stabilization.
The heatmap in Figure 13 reveals several key trends in the evolution of bridge nodes. Notably, the earliest iterations feature a rapid influx of bridge nodes, reflecting the initial structuring phase of the knowledge graph. Many nodes appear and remain active for extended periods, suggesting that certain concepts establish themselves as core interdisciplinary connectors early in the process. These nodes likely play a foundational role in structuring knowledge integration across domains.
A second notable pattern is the episodic emergence of new bridge nodes, rather than a continuous accumulation. The visualization shows distinct clusters of newly appearing bridge nodes, interspersed with periods of relative stability. These bursts suggest that knowledge integration occurs in structured phases rather than through gradual accumulation. Such phases may represent moments when the system reaches a threshold where newly integrated concepts allow for the creation of previously infeasible interdisciplinary links.
In contrast to the early-established bridge nodes, a subset of nodes appears only in later iterations. These late-emerging bridge nodes indicate that interdisciplinary roles are notably not static; rather, the system continuously restructures itself, incorporating new ideas as they gain relevance. This supports the hypothesis that certain bridge nodes emerge not from initial structuring but from later stages of conceptual refinement, possibly as higher-order abstractions connecting previously developed knowledge clusters.
The distribution of bridge node activity also suggests a mix of persistent and transient connectors. While some nodes appear briefly and disappear, others remain active over long stretches. This behavior reinforces the idea that knowledge expansion is both dynamic and structured, balancing exploration (where new connections are tested) and stabilization (where key interdisciplinary links persist).
We note that the structured emergence of bridge nodes may indicate that interdisciplinary pathways do not form randomly but are shaped by systematic phases of knowledge integration and refinement. Future analyses could explore the long-term impact of early bridge nodes, assessing whether they remain influential throughout the knowledge graph’s evolution, and whether the structure of interdisciplinary connectivity stabilizes or continues to reorganize over extended iterations.
2.9 Evolution of Key Bridge Nodes Over Iterations
To investigate how interdisciplinary pathways evolve in the knowledge graph, we analyzed the betweenness centrality of the most influential bridge nodes across 1,000 iterations. Figure 14 presents the trajectory of the top 10 bridge nodes, highlighting their shifting roles in facilitating interdisciplinary connections.
<details>
<summary>x14.png Details</summary>
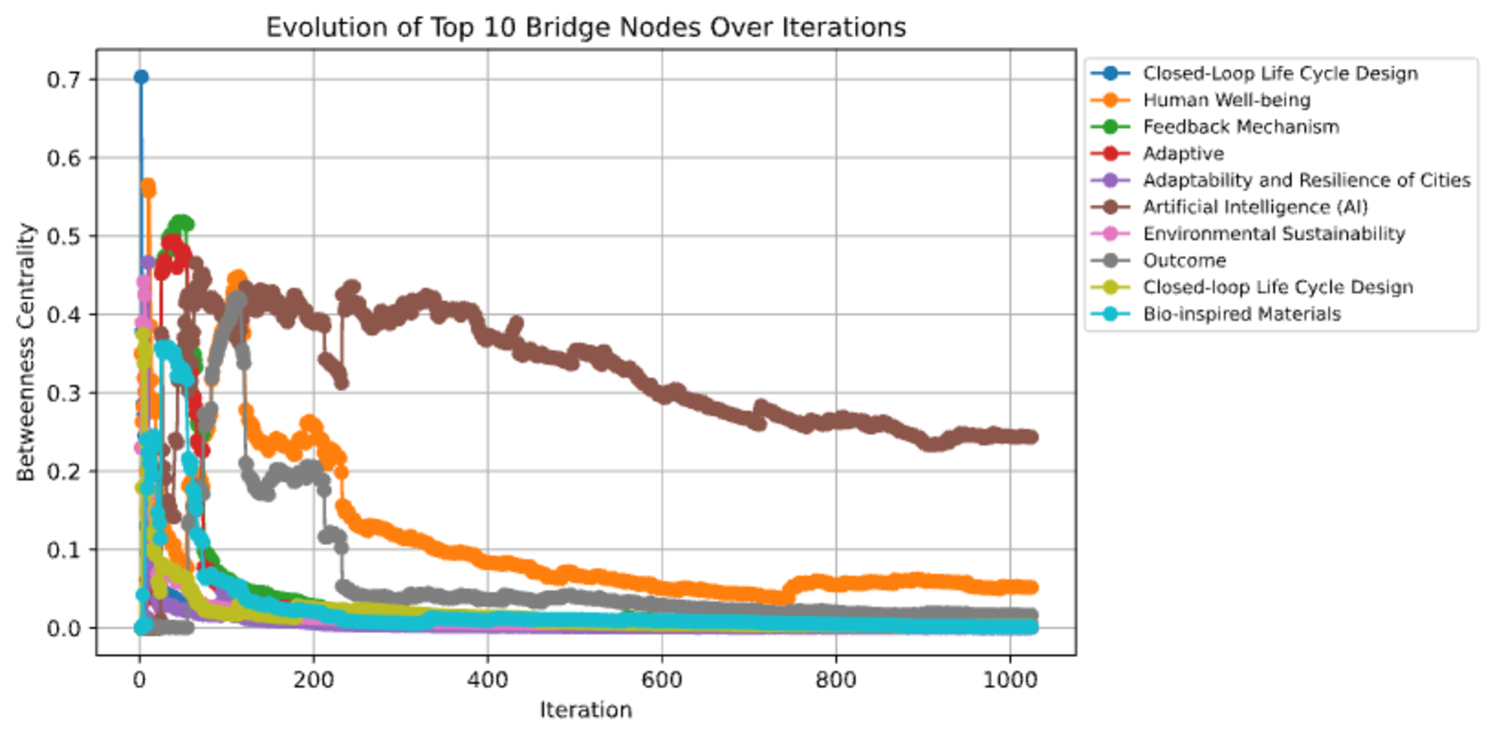
### Visual Description
## Line Chart: Evolution of Top 10 Bridge Nodes Over Iterations
### Overview
This image is a line chart displaying the evolution of a network metric ("Betweenness Centrality") for ten specific nodes over a series of iterations. The chart shows high initial volatility for most nodes, followed by a general trend of decay, with one notable exception that maintains a high centrality throughout the observed period.
### Components/Axes
**Spatial Layout:**
* **Header (Top Center):** Contains the chart title.
* **Main Chart (Center/Left):** Contains the plotted data lines against a grid.
* **Legend (Right):** Positioned outside the main plotting area, listing the data series.
**Text and Labels:**
* **Title:** "Evolution of Top 10 Bridge Nodes Over Iterations"
* **Y-Axis (Left side, vertical):**
* Label: "Betweenness Centrality"
* Scale: Linear, ranging from 0.0 to 0.7.
* Markers: 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7.
* **X-Axis (Bottom, horizontal):**
* Label: "Iteration"
* Scale: Linear, ranging from 0 to slightly over 1000.
* Markers: 0, 200, 400, 600, 800, 1000.
**Legend (Top-Right to Bottom-Right):**
* Blue line with circular markers: Closed-Loop Life Cycle Design
* Orange line with circular markers: Human Well-being
* Green line with circular markers: Feedback Mechanism
* Red line with circular markers: Adaptive
* Purple line with circular markers: Adaptability and Resilience of Cities
* Brown line with circular markers: Artificial Intelligence (AI)
* Pink line with circular markers: Environmental Sustainability
* Grey line with circular markers: Outcome
* Olive/Yellow-Green line with circular markers: Closed-loop Life Cycle Design *(Note: Differs from the first entry only by a lowercase 'l' in 'loop')*
* Cyan/Light Blue line with circular markers: Bio-inspired Materials
### Detailed Analysis
The data series can be categorized by their visual trends and behaviors over the iterations.
**1. The Initial Outlier (Immediate Spike and Crash)**
* **Blue (Closed-Loop Life Cycle Design):** This line begins at the absolute highest point on the chart at Iteration 0, with a Betweenness Centrality of approximately ~0.70. It immediately plummets in a near-vertical drop, reaching ~0.0 by Iteration ~20, and remains flat at 0.0 for the remainder of the chart.
**2. The Long-Term Dominant Node**
* **Brown (Artificial Intelligence (AI)):** This line exhibits a unique trend. It starts near 0, spikes sharply upward to ~0.45 around Iteration 50. It remains highly volatile but elevated, fluctuating between ~0.30 and ~0.45 until Iteration ~400. After Iteration 400, it begins a slow, steady downward slope, ending at approximately ~0.25 at Iteration 1000. It is the highest-ranking node from Iteration ~150 onward.
**3. Mid-Term Volatile Nodes**
* **Orange (Human Well-being):** Slopes upward rapidly, spiking to ~0.55 around Iteration 10. It drops, then forms a second peak at ~0.45 near Iteration 100, and a third peak at ~0.25 near Iteration 200. Afterward, it follows a long, slow decay curve, stabilizing around ~0.05 by Iteration 1000.
* **Grey (Outcome):** Shows early volatility, peaking at ~0.40 around Iteration 100. It drops to ~0.20, holds steady briefly, then drops sharply to ~0.05 around Iteration 250. It slowly decays to approximately ~0.02 by Iteration 1000.
**4. Early Spikers with Rapid Decay**
* **Green (Feedback Mechanism):** Spikes to ~0.50 around Iteration 50, then rapidly slopes downward, falling below 0.05 by Iteration 200 and flatlining near 0.0.
* **Red (Adaptive):** Spikes to ~0.50 around Iteration 40, rapidly decays to near 0.0 by Iteration 100, and flatlines.
* **Purple (Adaptability and Resilience of Cities):** Spikes to ~0.45 very early (Iteration ~10), drops to near 0.0 by Iteration 50, and flatlines.
* **Pink (Environmental Sustainability):** Spikes to ~0.45 at Iteration ~5, plummets to near 0.0 by Iteration 20, and flatlines.
* **Olive (Closed-loop Life Cycle Design):** Spikes to ~0.35 at Iteration ~5, drops to near 0.0 by Iteration 50, and flatlines.
* **Cyan (Bio-inspired Materials):** Spikes to ~0.35 at Iteration ~20, drops, has a minor secondary bump to ~0.10 at Iteration 80, then decays to near 0.0 by Iteration 200.
### Key Observations
* **Dominance of AI:** "Artificial Intelligence (AI)" is the only node that maintains significant betweenness centrality over the long term.
* **Early Network Instability:** The period between Iteration 0 and 200 is characterized by extreme volatility, with almost all nodes experiencing massive spikes and subsequent crashes.
* **Nomenclature Anomaly:** The legend contains two nearly identical entries: "Closed-Loop Life Cycle Design" (Blue) and "Closed-loop Life Cycle Design" (Olive). Despite the similar names, their data paths are distinct, though both crash to zero very early.
* **Convergence:** By Iteration 1000, 8 out of the 10 nodes have converged to a centrality score of nearly 0.0.
### Interpretation
**Data Context:**
In network theory, "Betweenness Centrality" measures how often a node acts as a bridge along the shortest path between two other nodes. A high score indicates a node is a critical bottleneck or a vital conduit for information/relationships in the network. The "Iterations" likely represent a machine learning training process, an evolutionary algorithm, or a dynamic network simulation where connections are being rewired over time.
**Peircean Investigative Analysis (Reading Between the Lines):**
1. **Network Reorganization:** The chart visually demonstrates a network undergoing massive structural reorganization. At Iteration 0, "Closed-Loop Life Cycle Design" is the absolute center of the network (the primary bridge). However, the system immediately rejects this structure, causing that node's centrality to collapse.
2. **The Rise of AI as the Core Hub:** As the initial concepts (Sustainability, Resilience, Bio-materials) lose their bridging status, "Artificial Intelligence (AI)" emerges as the dominant structural bridge. The data suggests that as the model/network iterates and "learns" or "optimizes," AI becomes the central connecting theme that links all other disparate concepts together.
3. **Concept Marginalization:** The fact that 8 out of 10 nodes drop to near-zero centrality indicates that the network is becoming highly centralized around a few key hubs (primarily AI, and to a lesser extent, Human Well-being). The other concepts are likely being pushed to the periphery of the network; they still exist, but they no longer serve as bridges between other clusters of information.
4. **The Duplicate Entry:** The presence of "Closed-Loop" and "Closed-loop" suggests a potential data cleaning issue in the source dataset (case sensitivity creating two distinct nodes for the same concept). Interestingly, the network algorithm treats them differently initially, but ultimately marginalizes both of them equally fast.
</details>
Figure 14: Evolution of the top 10 bridge nodes over iterations, for $\mathcal{G_{1}}$ . Each curve represents the betweenness centrality of a bridge node, indicating its role in facilitating knowledge integration. Nodes that initially had high centrality later declined, while some concepts maintained their influence throughout the graph’s evolution.
The trends in Figure 14 reveal distinct patterns in how bridge nodes emerge, peak in influence, and decline over time. Notably, nodes such as Closed-Loop Life Cycle Design and Human Well-being exhibit high betweenness centrality in the early iterations, suggesting that they played a fundamental role in structuring the initial interdisciplinary landscape. However, as the knowledge graph expanded, these nodes saw a gradual decline in their centrality, indicating that their role as primary connectors was replaced by alternative pathways.
A second class of bridge nodes, including Adaptability and Resilience of Cities and Artificial Intelligence (AI), maintained high centrality values for a longer duration, suggesting that certain concepts remain essential to interdisciplinary knowledge integration even as the graph evolves. These nodes acted as long-term knowledge stabilizers, facilitating interactions between different research domains throughout a significant portion of the knowledge expansion process.
Interestingly, a subset of nodes, such as Feedback Mechanism and Outcome, gradually gained importance over time. Unlike early bridge nodes that peaked and declined, these nodes started with lower centrality but increased in influence in later iterations. This suggests that some interdisciplinary pathways only become critical after sufficient knowledge accumulation, reinforcing the idea that interdisciplinary roles are not static but continuously reorganize as the knowledge graph matures.
Furthermore, we observe that by approximately iteration 400-600, most bridge nodes’ betweenness centrality values begin converging toward lower values, indicating that knowledge transfer is no longer reliant on a small set of nodes. This suggests that, as the graph expands, alternative pathways develop, leading to a more distributed and decentralized knowledge structure where connectivity is no longer dominated by a few highly influential nodes.
These findings support the hypothesis that interdisciplinary pathways evolve dynamically, with early-stage knowledge formation relying on a few key concepts, followed by a transition to a more robust and distributed network where multiple redundant pathways exist. Future analyses will focus on:
- Identifying which nodes replaced early bridge nodes as major interdisciplinary connectors in later iterations.
- Comparing early vs. late-stage bridge nodes to assess whether earlier nodes tend to be general concepts, while later bridge nodes represent more specialized interdisciplinary knowledge.
- Analyzing the resilience of the knowledge graph by simulating the removal of early bridge nodes to determine their structural significance.
These results provide a perspective on how interdisciplinary linkages emerge, stabilize, and reorganize over time, offering insights into the self-organizing properties of large-scale knowledge systems.
2.10 Evolution of Betweenness Centrality Distribution
To analyze the structural evolution of the knowledge graph, we next examine the distribution of betweenness centrality at different iterations. Betweenness centrality is a measure of a node’s importance in facilitating knowledge transfer between different parts of the network. Formally, the betweenness centrality of a node $v$ is given by:
$$
C_{B}(v)=\sum_{s\neq v\neq t}\frac{\sigma_{st}(v)}{\sigma_{st}}, \tag{1}
$$
where $\sigma_{st}$ is the total number of shortest paths between nodes $s$ and $t$ , and $\sigma_{st}(v)$ is the number of those paths that pass through $v$ . A higher betweenness centrality indicates that a node serves as a critical intermediary in connecting disparate knowledge domains.
Figure S3 presents histograms of betweenness centrality distribution at four key iterations (2, 100, 510, and 1024), illustrating the shifting role of bridge nodes over time.
Initially, at Iteration 2, the network is highly centralized, with a small number of nodes exhibiting extremely high betweenness centrality (above 0.6), while the majority of nodes have near-zero values. This indicates that only a few nodes act as critical interdisciplinary connectors, facilitating nearly all knowledge transfer.
By Iteration 100, the distribution has broadened, meaning that more nodes participate in knowledge transfer. The highest betweenness values have decreased compared to Iteration 2, and more nodes exhibit low but nonzero centrality, suggesting an increase in redundant pathways and reduced dependency on a few dominant bridge nodes.
At Iteration 510, the distribution becomes more skewed again, with fewer nodes having high betweenness centrality and a stronger concentration at low values. This suggests that the network has undergone a phase of structural consolidation, where interdisciplinary pathways reorganize around fewer, more stable bridges.
Finally, at Iteration 1024, the histogram shows that most nodes have low betweenness centrality, and only a few retain moderate values. This suggests that the network has matured into a more distributed structure, where no single node dominates knowledge transfer. The observed trend indicates that as the knowledge graph expands, the burden of interdisciplinary connectivity is increasingly shared among many nodes rather than concentrated in a few.
These results suggest that the system undergoes a dynamic reorganization process, shifting from an initial hub-dominated structure to a more distributed and resilient network. Future work could potentially explore whether these trends continue as the graph scales further and whether the eventual network state remains stable or undergoes additional restructuring.
To examine the overall structural properties of the knowledge graph, we analyzed the distribution of betweenness centrality across all iterations. Figure 15 presents a histogram of betweenness centrality values collected from all iterations of the knowledge graph. The distribution was generated by computing betweenness centrality for each iteration and aggregating all node values overall iterations.
<details>
<summary>x15.png Details</summary>
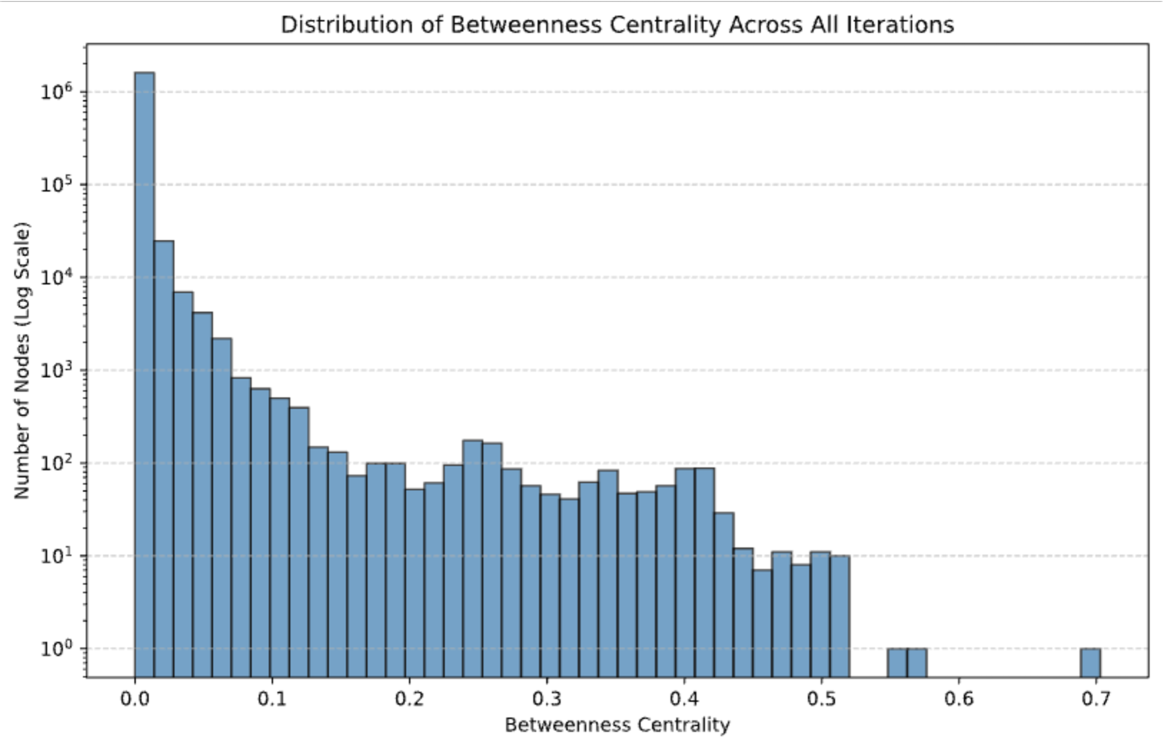
### Visual Description
## Histogram: Distribution of Betweenness Centrality
### Overview
This image is a histogram displaying the frequency distribution of a network metric called "Betweenness Centrality." The chart utilizes a linear scale for the x-axis and a logarithmic scale (base 10) for the y-axis. The data is represented by contiguous vertical blue bars with black outlines. The language present in the image is entirely English.
### Components/Axes
**1. Header Region (Top Center)**
* **Chart Title:** "Distribution of Betweenness Centrality Across All Iterations"
**2. Y-Axis (Left Edge)**
* **Label:** "Number of Nodes (Log Scale)" (Oriented vertically, reading bottom-to-top).
* **Scale:** Logarithmic (Base 10).
* **Tick Markers:** $10^0, 10^1, 10^2, 10^3, 10^4, 10^5, 10^6$.
* **Gridlines:** Light gray, dashed horizontal lines extend from each major tick mark across the main chart area.
**3. X-Axis (Bottom Edge)**
* **Label:** "Betweenness Centrality"
* **Scale:** Linear.
* **Tick Markers:** 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7.
**4. Main Chart Area (Center)**
* **Data Series:** A single series of light blue bars representing the frequency of nodes falling into specific betweenness centrality bins. The bin width appears to be approximately ~0.014 units wide (roughly 7 bars per 0.1 interval).
### Detailed Analysis
**Visual Trend Verification:**
The overall visual trend is a massive right-skewed (heavy-tailed) distribution. The line formed by the tops of the bars slopes sharply downward from the extreme left, indicating that the vast majority of nodes have a betweenness centrality at or very near 0.0. As the x-value increases, the y-value drops precipitously by several orders of magnitude. However, the descent is not perfectly smooth; there are distinct secondary "bumps" or local maxima in the mid-ranges, followed by a sparse scattering of isolated outliers at the extreme right end of the x-axis.
**Data Extraction (Approximate Values):**
Due to the logarithmic scale and visual estimation, values are approximate ($\sim$).
* **The Primary Peak (0.0 to 0.05):**
* The first bin (starting at 0.0) contains the absolute maximum, exceeding the $10^6$ line. Estimated value: $\sim 1.5 \times 10^6$ nodes.
* The second bin drops sharply to $\sim 2.5 \times 10^4$.
* The frequency continues to decay rapidly through 0.1, dropping to $\sim 5 \times 10^2$.
* **The Mid-Range Plateau and Bumps (0.15 to 0.45):**
* Between 0.15 and 0.25, the frequency fluctuates between $\sim 5 \times 10^1$ and $10^2$.
* **Local Maximum 1:** A distinct spike occurs around x = 0.26, reaching $\sim 1.8 \times 10^2$.
* The frequency dips again around x = 0.32 to $\sim 4 \times 10^1$.
* **Local Maximum 2:** Another distinct spike occurs around x = 0.41, reaching $\sim 9 \times 10^1$.
* **The Tail and Outliers (0.45 to 0.7):**
* After x = 0.45, the contiguous bars drop to the $10^1$ range and below.
* The contiguous distribution ends around x = 0.52.
* **Outlier 1:** A single bar at x $\sim 0.55$, resting exactly on the $10^0$ line (1 node).
* **Outlier 2:** A single bar at x $\sim 0.57$, resting exactly on the $10^0$ line (1 node).
* **Outlier 3:** A single bar at x $\sim 0.69$, resting exactly on the $10^0$ line (1 node).
**Reconstructed Representative Data Table:**
*(Note: Bins are approximated based on visual width; Y-values are estimated from the log scale).*
| Centrality Range (Approx X) | Number of Nodes (Approx Y) | Visual Characteristic |
| :--- | :--- | :--- |
| 0.000 - 0.014 | $1,500,000$ | Absolute Maximum |
| 0.014 - 0.028 | $25,000$ | Sharp decay |
| 0.085 - 0.100 | $600$ | Continued decay |
| 0.185 - 0.210 | $100$ | Plateau |
| 0.250 - 0.270 | $180$ | Local Maximum |
| 0.310 - 0.330 | $40$ | Local Minimum |
| 0.400 - 0.420 | $90$ | Local Maximum |
| 0.500 - 0.520 | $10$ | End of contiguous tail |
| $\sim 0.55$ | $1$ ($10^0$) | Isolated Outlier |
| $\sim 0.57$ | $1$ ($10^0$) | Isolated Outlier |
| $\sim 0.69$ | $1$ ($10^0$) | Extreme Outlier |
### Key Observations
1. **Extreme Concentration at Zero:** Over 1 million nodes have a betweenness centrality near zero, while all other bins combined contain only a fraction of that amount.
2. **Logarithmic Decay:** The use of a log scale on the y-axis is necessary to even see the data beyond x=0.05. The drop from the first bin to the outliers represents a difference of six orders of magnitude.
3. **Structural Bumps:** The presence of secondary peaks around 0.26 and 0.41 indicates that while high centrality is rare, there are specific structural roles or network tiers that group nodes into these specific centrality bands.
4. **The "Super-Hub":** There is exactly one node with a centrality near 0.7, making it the most critical bridge in the entire network by a significant margin compared to the next highest nodes (~0.57).
### Interpretation
**What the data means:**
Betweenness centrality measures how often a node acts as a bridge along the shortest path between two other nodes. A value of 0 means the node is never on a shortest path (typically "leaf" nodes at the edges of a network). A high value indicates a "bottleneck" or "hub" that controls the flow of information across the network.
**Reading between the lines (Peircean investigative analysis):**
* **Network Topology:** This histogram strongly suggests a highly centralized, scale-free, or "hub-and-spoke" network topology. The fact that over $10^6$ nodes have near-zero centrality implies a massive periphery of disconnected or single-connection users/entities.
* **Vulnerability:** The network is highly reliant on a very small number of nodes. The single node at ~0.7 and the few nodes between 0.4 and 0.6 are critical points of failure. If these nodes are removed, the network would likely shatter into disconnected components, as they are the primary bridges connecting the millions of peripheral nodes.
* **The "Iterations" Context:** The title mentions "Across All Iterations." This suggests this data might be aggregated from a simulation, a dynamic network changing over time, or an algorithm (like a random walk or routing protocol) running multiple times. The secondary "bumps" (at 0.26 and 0.41) might represent specific phases of the iteration or distinct hierarchical layers within the network's core that consistently emerge across these iterations.
</details>
Figure 15: Distribution of betweenness centrality across all iterations, $\mathcal{G_{1}}$ . The y-axis is log-scaled, showing the frequency of nodes with different centrality values. A small number of nodes dominate knowledge transfer, while most nodes exhibit near-zero centrality.
The histogram in Figure 15 reveals a highly skewed distribution, where the majority of nodes exhibit near-zero betweenness centrality, while a small subset maintains significantly higher values. This pattern suggests that knowledge transfer within the network is primarily governed by a few dominant bridge nodes, which facilitate interdisciplinary connections. The presence of a long tail in the distribution indicates that these high-betweenness nodes persist throughout multiple iterations.
Interestingly, the distribution also exhibits multiple peaks, suggesting that the network consists of different classes of bridge nodes. Some nodes act as long-term stable interdisciplinary connectors, while others emerge as transient bridges that facilitate knowledge transfer only for limited iterations.
The log scale on the $y$ -axis reveals that while most nodes contribute little to betweenness centrality, a significant number of nodes still exhibit low but nonzero values indicating that knowledge flow is distributed across many minor pathways. Over multiple iterations, it is expected that betweenness centrality values redistribute, reducing dependency on early dominant nodes and leading to a more decentralized knowledge structure.
These findings highlight that the knowledge graph maintains a core-periphery structure, where a few key nodes play a disproportionate role in bridging knowledge across disciplines. Future work will explore how the distribution evolves over time, identifying whether the network transitions toward a more evenly distributed structure or remains reliant on a small number of high-centrality nodes.
2.11 Evolution of Betweenness Centrality in the Knowledge Graph
To analyze the structural evolution of the knowledge graph, we tracked the changes in betweenness centrality over 1,000 iterations. Betweenness centrality quantifies the extent to which a node serves as a bridge between other nodes by appearing on shortest paths. A node with high betweenness centrality facilitates interdisciplinary knowledge transfer by linking otherwise disconnected regions of the network. Figures 16 (a) and 16 (b) illustrate how mean and maximum betweenness centrality evolve over time. The first plot captures the average importance of nodes in knowledge transfer, while the second identifies the most dominant bridge nodes at each iteration.
<details>
<summary>x16.png Details</summary>
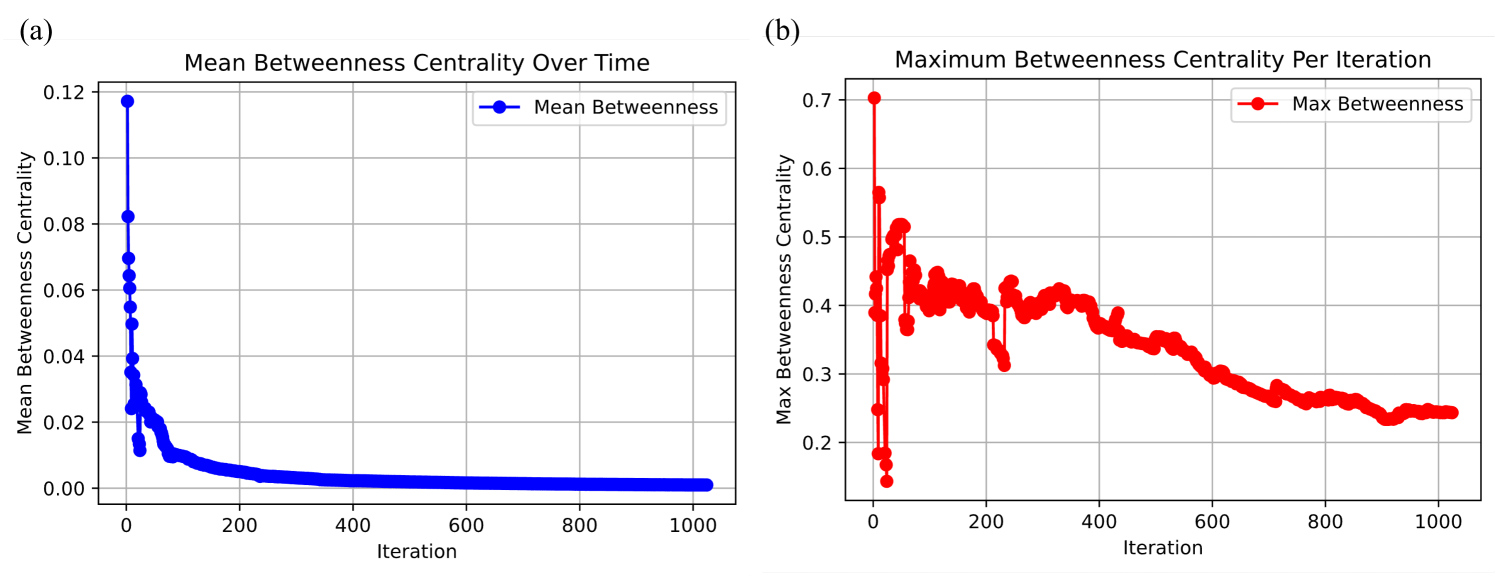
### Visual Description
## Line Charts: Mean and Maximum Betweenness Centrality Over Time
### Overview
The image consists of two side-by-side line charts, labeled (a) on the left and (b) on the right. Both charts plot a network metric ("Betweenness Centrality") against a measure of time ("Iteration"). The left chart displays the mean value across the network, while the right chart displays the maximum value. The language used in the image is entirely English.
---
### Component Isolation: Chart (a) - Left Panel
#### Components/Axes
* **Panel Label:** "(a)" located in the top-left corner, outside the chart boundary.
* **Chart Title:** "Mean Betweenness Centrality Over Time" located at the top center, above the chart area.
* **Y-axis Title:** "Mean Betweenness Centrality" positioned vertically along the left edge.
* **Y-axis Scale:** Ranges from 0.00 to 0.12, with major gridline markers at 0.00, 0.02, 0.04, 0.06, 0.08, 0.10, and 0.12.
* **X-axis Title:** "Iteration" positioned horizontally centered below the axis.
* **X-axis Scale:** Ranges from 0 to 1000, with major gridline markers at 0, 200, 400, 600, 800, and 1000.
* **Legend:** Located in the top-right corner inside the chart area. It displays a solid blue line with a blue circular marker, labeled "Mean Betweenness".
* **Grid:** A standard rectangular grid is visible, corresponding to the major axis markers.
#### Trend Verification & Content Details
* **Visual Trend:** The blue line (matching the legend for "Mean Betweenness") exhibits a classic exponential decay curve with extreme initial volatility. It starts near the absolute maximum of the Y-axis, drops precipitously within the first 50 iterations, and then forms a long, thick, asymptotic tail that flattens out just above the 0.00 line for the remainder of the 1000 iterations. The line is rendered very thickly due to the high density of circular data points.
* **Data Points (Approximate values with uncertainty):**
* **Iteration ~0-5:** The data begins with a sharp vertical spike, reaching a peak value of approximately ~0.118.
* **Iteration ~10-50:** The value plummets rapidly, oscillating sharply between ~0.08 and ~0.01.
* **Iteration ~100:** The curve begins to smooth out, dropping to approximately ~0.01.
* **Iteration ~200:** The value is approximately ~0.005.
* **Iteration ~400 to 1000:** The line becomes nearly flat, asymptotically approaching a value of approximately ~0.001 to ~0.002.
---
### Component Isolation: Chart (b) - Right Panel
#### Components/Axes
* **Panel Label:** "(b)" located in the top-left corner, outside the chart boundary.
* **Chart Title:** "Maximum Betweenness Centrality Per Iteration" located at the top center, above the chart area.
* **Y-axis Title:** "Max Betweenness Centrality" positioned vertically along the left edge.
* **Y-axis Scale:** Ranges from 0.2 to 0.7, with major gridline markers at 0.2, 0.3, 0.4, 0.5, 0.6, and 0.7. *(Note: The scale is vastly different from chart a).*
* **X-axis Title:** "Iteration" positioned horizontally centered below the axis.
* **X-axis Scale:** Ranges from 0 to 1000, with major gridline markers at 0, 200, 400, 600, 800, and 1000. *(Identical to chart a).*
* **Legend:** Located in the top-right corner inside the chart area. It displays a solid red line with a red circular marker, labeled "Max Betweenness".
* **Grid:** A standard rectangular grid is visible, corresponding to the major axis markers.
#### Trend Verification & Content Details
* **Visual Trend:** The red line (matching the legend for "Max Betweenness") shows high volatility and a gradual, jagged downward trend. Unlike the smooth asymptote in chart (a), this line experiences massive swings in the early iterations, followed by a noisy, undulating decline. It never approaches zero.
* **Data Points (Approximate values with uncertainty):**
* **Iteration ~0-5:** A massive initial spike reaches exactly ~0.70.
* **Iteration ~10-25:** The value crashes dramatically to a global minimum of approximately ~0.14.
* **Iteration ~30-60:** The value spikes back up rapidly, reaching a secondary peak of approximately ~0.56.
* **Iteration ~100-200:** The data oscillates heavily between ~0.38 and ~0.45.
* **Iteration ~220:** A sharp, brief dip occurs down to approximately ~0.31.
* **Iteration ~400:** The value stabilizes slightly around ~0.40.
* **Iteration ~600:** The downward trend continues, reaching approximately ~0.30.
* **Iteration ~800:** The value is approximately ~0.26.
* **Iteration ~900-1000:** The curve flattens out slightly, ending at approximately ~0.24 to ~0.25.
---
### Key Observations
1. **Scale Discrepancy:** While both charts share an identical X-axis (0-1000 iterations), their Y-axes are drastically different. The maximum value for the Mean (Chart a) is ~0.12, whereas the maximum value for the Max (Chart b) is ~0.70.
2. **Volatility:** Both metrics experience their most extreme volatility within the first 100 iterations.
3. **Convergence:** The Mean Betweenness (blue) converges to a near-zero steady state very quickly (by iteration 200). The Max Betweenness (red) takes much longer to settle and remains highly elevated relative to the mean, ending around ~0.25.
### Interpretation
In network science and graph theory, "Betweenness Centrality" measures how often a node acts as a bridge along the shortest path between two other nodes. A high betweenness centrality indicates a "bottleneck" or a highly critical hub in the network.
* **Network Evolution:** The X-axis ("Iteration") suggests this data represents a dynamic network undergoing a generative process, an optimization algorithm (like network rewiring), or a simulation over time.
* **The Early Chaos (Iterations 0-100):** The extreme spikes and crashes in both charts during the early iterations indicate that the network's topology is undergoing radical restructuring. The initial state has at least one massive bottleneck (Max = 0.7), which is quickly dismantled, rebuilt, and dismantled again.
* **Decentralization (Chart a):** The rapid collapse of the *Mean* Betweenness to near-zero suggests that the network is becoming highly interconnected or decentralized overall. As more edges are added or optimized, the average node is no longer required to act as a bridge; there are many alternative paths.
* **Persistent Hubs (Chart b):** Despite the average node losing its bridging role, the *Maximum* Betweenness remains relatively high (ending at ~0.25). This indicates that while the network as a whole is well-connected, there is still at least one (or a few) dominant hub nodes that control a significant portion of the shortest paths.
* **Conclusion:** The data demonstrates a system evolving from a highly centralized, fragile, and volatile state into a more stable, decentralized state that still retains a distinct hierarchical structure (a core-periphery or scale-free topology), where a few hubs remain important despite the average node becoming structurally redundant.
</details>
Figure 16: Evolution of betweenness centrality in the knowledge graph, $\mathcal{G_{1}}$ . Panel (a): Mean betweenness centrality over time, showing a transition from early high centralization to a more distributed state. Panel (b): Maximum betweenness centrality per iteration, highlighting how the most dominant bridge nodes shift and decline in influence.
Figure 16 (a) tracks the mean betweenness centrality, providing insight into how the overall distribution of knowledge transfer roles evolves. In the earliest iterations, the mean betweenness is extremely high, indicating that only a few nodes dominate knowledge exchange. However, as the graph expands and alternative pathways form, the mean betweenness declines rapidly within the first 100 iterations.
Between iterations 100 and 500, we observe a continued decline, but at a slower rate. This suggests that knowledge transfer is being shared across more nodes, reducing reliance on a small set of dominant bridges. After iteration 500, the values stabilize near zero, indicating that the network has reached a decentralized state, where multiple nodes contribute to knowledge integration instead of a few key intermediaries.
These trends suggest a self-organizing process, where the knowledge graph transitions from a highly centralized system into a more distributed and resilient network. The final structure is more robust, with many small bridges collectively supporting interdisciplinary connectivity instead of a few dominant hubs.
Figure 16 (b) examines the highest betweenness centrality recorded in each iteration, tracking the most dominant knowledge bridge at each stage. In the earliest iterations, a single node reaches an extreme betweenness value of around 0.7, indicating that knowledge transfer is highly bottlenecked through one or very few key nodes.
Between iterations 50 and 300, the maximum betweenness remains high, fluctuating between 0.3 and 0.5. This suggests that while the network becomes less dependent on a single node, a small number of highly central nodes still dominate knowledge flow. This phase represents a transition period, where the network starts distributing knowledge transfer across multiple nodes.
After iteration 500, the maximum betweenness exhibits a gradual decline, eventually stabilizing around 0.2. This suggests that the network has successfully decentralized, and knowledge transfer is no longer dominated by a single key node. The presence of multiple lower-betweenness bridge nodes implies that redundant pathways have developed, making the system more resilient to disruptions. This is in general agreement with earlier observations.
The combined results from Figures 16 (a) and 16 (b) suggest that the knowledge graph undergoes a fundamental structural transformation over time:
- Initially, a few dominant nodes control knowledge flow, leading to high mean and maximum betweenness centrality.
- As the graph expands, new pathways emerge, and betweenness is distributed across more nodes.
- By the later iterations, no single node dominates, and knowledge transfer occurs through a decentralized structure.
This evolution suggests that the knowledge graph self-organizes into a more distributed state, where interdisciplinary connectivity is no longer constrained by a few central hubs. Future studies can explore whether this trend continues at larger scales and analyze which specific nodes maintained high betweenness longest and which replaced them in later iterations.
2.12 Analysis of longest shortest path in $\mathcal{G}_{2}$ and analysis using agentic reasoning
While the primary focus of this study is targeting a detailed analysis of graph dynamic experiments during reasoning, we also explore how graph reasoning based on the in-situ generated graph can be used to improve responses through in-context learning [11] (here, we use meta-llama/Llama-3.2-3B-Instruct). The methodology employs a graph-based reasoning framework to enhance LLM responses through structured knowledge extraction obtained through the method described above. Figure 17 (b) depicts additional analysis, showing a correlation heatmap of path-level metrics, computed for the first 30 longest shortest paths.
<details>
<summary>x17.png Details</summary>
### Visual Description
This image contains two distinct technical visualizations labeled (a) and (b). All text present in the image is in English.
Below is the detailed extraction and analysis of both components, processed independently to ensure accuracy.
---
## Part (a): Network Diagram: Knowledge Domain Relationships
### Overview
Figure (a) is a node-link diagram (knowledge graph) illustrating the relationships between various scientific, technological, and environmental concepts. The flow of information converges from two distinct starting areas (top-left and bottom-left) toward a primary, highly emphasized central node on the right.
### Components
* **Nodes (Entities):** Represented primarily by small yellow dots with adjacent blue text labels. Two nodes are emphasized as large circles with text inside them.
* **Edges (Relationships):** Represented by solid gray lines connecting the nodes.
* **Edge Labels:** Black text placed over the gray lines defining the nature of the relationship (`IS-A`, `RELATES-TO`, `INFLUENCES`).
### Spatial Grounding & Content Details
The diagram can be isolated into two main pathways that eventually connect to the central focal point.
**1. Top Pathway (Materials & Environment - Top-Left to Center-Right):**
* Node: `Biodegradable Microplastic Materials` (Top-left)
* Edge: `IS-A` connects down-left to Node: `Materials for infrastructure design`
* Edge: `RELATES-TO` connects down-right to Node: `Pollution mitigation`
* Node: `Self-healing Materials in Infrastructure Design` (Top-center)
* Edge: `RELATES-TO` connects down-left to Node: `Pollution mitigation`
* Edge: `INFLUENCES` connects straight down to Node: `Development of novel materials for infrastructure design`
* Node: `Development of novel materials for infrastructure design`
* Edge: `INFLUENCES` connects right to Node: `Pollution Mitigation` (Note: Capital 'M' used here).
* Node: `Pollution Mitigation`
* Edge: `RELATES-TO` connects down-left to Node: `Self-healing materials`
* Node: `Self-healing materials`
* Edge: `RELATES-TO` connects right to Node: `Environmental Sustainability`
* Node: `Environmental Sustainability` (Large circle, pale yellow fill, thick light-green border)
* Edge: `INFLUENCES` connects down-left to the primary focal node: `Impact-Resistant Materials`.
**2. Bottom Pathway (Medicine & AI - Bottom-Left to Center-Right):**
* Node: `Personalized Medicine` (Center-left)
* Edge: `RELATES-TO` connects down-left to Node: `Rare Genetic Disorders`
* Edge: `INFLUENCES` connects straight down to Node: `Knowledge Discovery`
* Node: `Knowledge Discovery`
* Edge: `IS-A` connects up-right to Node: `Data Analysis`
* Node: `Data Analysis`
* Edge: `RELATES-TO` connects down-right to Node: `AI Techniques`
* Node: `AI Techniques`
* Edge: `RELATES-TO` connects up-right to Node: `Predictive Modeling`
* Node: `Predictive Modeling`
* Edge: `RELATES-TO` connects down-right to Node: `Machine Learning (ML) Algorithms`
* Node: `Machine Learning (ML) Algorithms`
* Edge: `RELATES-TO` connects up-right to the primary focal node: `Impact-Resistant Materials`.
**3. Focal Point (Center-Right):**
* Node: `Impact-Resistant Materials` (Largest circle, pale yellow fill, thick dark-purple border). This node acts as the terminal point for both the top and bottom pathways.
---
## Part (b): Heatmap: Correlation Between Path Metrics
### Overview
Figure (b) is a 7x7 correlation matrix heatmap displaying the statistical correlation between different network analysis metrics.
### Components/Axes
* **Title:** `Correlation Between Path Metrics` (Top center)
* **Y-Axis (Left, top to bottom):** `Avg Degree`, `Avg Betweenness`, `Avg Closeness`, `Avg Eigenvector`, `Avg PageRank`, `Avg Clustering`, `Path Density`.
* **X-Axis (Bottom, left to right):** `Avg Degree`, `Avg Betweenness`, `Avg Closeness`, `Avg Eigenvector`, `Avg PageRank`, `Avg Clustering`, `Path Density`. (Labels are rotated 90 degrees vertically).
* **Legend (Right side):** A vertical color bar indicating the correlation coefficient scale.
* Scale ranges from `0.0` (bottom) to `1.0` (top). Note: The data contains negative values, and the color scale extends below 0.0 visually, though the lowest tick mark is 0.0.
* **Color Mapping Verification:**
* `1.0` = Bright Yellow
* `0.8` to `0.99` = Yellow-Green
* `0.4` to `0.6` = Teal / Blue-Green
* `0.0` to `0.2` = Dark Blue
* `< 0.0` (Negative values) = Dark Purple
### Detailed Analysis (Data Table Reconstruction)
*Visual Trend Check:* The diagonal from top-left to bottom-right is entirely bright yellow, representing the perfect 1.00 correlation of a metric with itself. A distinct block of high correlation (yellow/light green) exists among Degree, Betweenness, Eigenvector, and PageRank. Dark purple (negative correlation) is clustered where Path Density intersects with Betweenness, Eigenvector, and PageRank.
Below is the exact transcription of the heatmap data grid:
| Metric | Avg Degree | Avg Betweenness | Avg Closeness | Avg Eigenvector | Avg PageRank | Avg Clustering | Path Density |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **Avg Degree** | 1.00 | 0.99 | 0.47 | 0.88 | 0.95 | 0.25 | 0.05 |
| **Avg Betweenness** | 0.99 | 1.00 | 0.41 | 0.93 | 0.97 | 0.17 | -0.03 |
| **Avg Closeness** | 0.47 | 0.41 | 1.00 | 0.14 | 0.32 | 0.65 | 0.42 |
| **Avg Eigenvector** | 0.88 | 0.93 | 0.14 | 1.00 | 0.96 | -0.02 | -0.17 |
| **Avg PageRank** | 0.95 | 0.97 | 0.32 | 0.96 | 1.00 | 0.05 | -0.11 |
| **Avg Clustering** | 0.25 | 0.17 | 0.65 | -0.02 | 0.05 | 1.00 | 0.52 |
| **Path Density** | 0.05 | -0.03 | 0.42 | -0.17 | -0.11 | 0.52 | 1.00 |
### Key Observations
* **Highly Correlated Cluster:** `Avg Degree`, `Avg Betweenness`, `Avg Eigenvector`, and `Avg PageRank` all exhibit extremely strong positive correlations with one another (ranging from 0.88 to 0.99).
* **Weak/Negative Correlations:** `Path Density` has very weak or slightly negative correlations with the highly correlated cluster mentioned above (-0.17 to 0.05).
* **Moderate Correlations:** `Avg Closeness` has moderate positive correlations with `Avg Clustering` (0.65) and `Avg Degree` (0.47).
---
## Interpretation
**Reading Between the Lines:**
These two figures, while visually distinct, are thematically linked under the umbrella of **Network/Graph Theory and Analysis**.
* **Figure (a)** demonstrates the practical application of a knowledge graph. It shows how an AI or literature-mining system might connect seemingly disparate academic fields. The graph reveals a fascinating interdisciplinary bridge: it suggests that advancements in AI/Machine Learning (bottom path) and advancements in Environmental/Pollution mitigation (top path) are both converging to influence the development of **"Impact-Resistant Materials."** The varying sizes of the nodes (Impact-Resistant Materials and Environmental Sustainability being the largest) likely indicate their "weight" or "centrality" within this specific query or dataset.
* **Figure (b)** provides a statistical meta-analysis of the mathematical metrics used to evaluate networks (like the one in figure a). The data reveals a critical insight for data scientists: calculating Degree, Betweenness, Eigenvector, and PageRank simultaneously is largely redundant. Because they correlate so highly (>0.88), they are essentially measuring the same underlying topological feature of the network (likely the general "importance" or "connectedness" of a node). Conversely, if a researcher wants to capture different structural nuances of a network, they should pair one of those centrality metrics with `Avg Clustering` or `Path Density`, as these measure distinct, non-overlapping properties (indicated by their low/negative correlations with the main cluster).
</details>
Figure 17: Longest shortest path analysis. Panel (a): Visualization of the longest shortest path (diameter path) in $\mathcal{G}_{2}$ , presenting a fascinating chain of interdisciplinary relationships across medicine, data science and AI, materials science, sustainability, and infrastructure. Panel (b): Correlation heatmap of path-level metrics, computed for the first 30 longest shortest paths. Degree and betweenness centrality are highly correlated, indicating that high-degree nodes frequently serve as key connectors. Eigenvector centrality and PageRank also show strong correlation, highlighting their shared role in capturing node influence. Path density exhibits a weak or negative correlation with centrality measures, suggesting that highly connected nodes often form less dense structures. The metrics were computed for each path by extracting node-level properties (degree, betweenness, closeness, eigenvector centrality, PageRank, clustering coefficient) from the original graph and averaging them over all nodes in the path. Path density was calculated as the ratio of actual edges to possible edges within the path subgraph. Correlations were then derived from these aggregated values across multiple paths.
The extracted longest shortest path depicted in Figure 17 (a) presents a compelling sequence of relationships spanning biotechnology, artificial intelligence, materials science, and sustainability, illustrating how advancements in one domain influence others. The overall logical flow is well-structured, with clear and expected progressions, such as Rare Genetic Disorders leading to Personalized Medicine and Knowledge Discovery, reflecting that the model captures the increasing role of AI in medical research. The sequence from AI Techniques to Predictive Modeling and Machine Learning (ML) Algorithms is similarly intuitive, as computational models underpin predictive simulations across disciplines (details on methods, see Section 4.5).
However, some unexpected connections emerge, suggesting areas for further exploration. The link from Machine Learning (ML) Algorithms to Impact-Resistant Materials stands out – not as a weak connection, but as an intriguing suggestion of AI-driven materials design rather than mere discovery. Computational techniques, such as reinforcement learning and generative modeling, could optimize material structures for durability, opening new pathways in materials engineering. Another unconventional relationship is the transition from Biodegradable Microplastic Materials to Infrastructure Design. These two areas typically operate separately, yet this link may hint at the emergence of biodegradable composites for construction or sustainable materials engineering. Further investigation into the practical applications of biodegradable materials in structural design could strengthen this connection.
A notable redundancy appears in the presence of Pollution Mitigation twice, spelled differently, which results from a lack of node merging rather than a distinct conceptual relationship. This duplication suggests that similar concepts are being represented as separate nodes, potentially affecting graph-based reasoning. Similarly, Self-Healing Materials in Infrastructure Design loops back to Pollution Mitigation, reinforcing an already established sustainability link. While valid, this repetition could be streamlined for clarity.
We find that the logical progression effectively captures key interdisciplinary relationships while revealing areas for refinement. The structure underscores the increasing role of AI in materials science, the integration of sustainability into materials design, and the interplay between predictive modeling and physical sciences. Addressing node duplication and refining transitions between traditionally separate fields—such as biodegradable materials in construction—would enhance the clarity and coherence of the path, making it an even more insightful representation of scientific knowledge.
Agentic Reasoning over the Path
We apply an agentic model to analyze the longest shortest path. For this analysis, an agentic system first analyzes each node in the subgraph, then each of the relationships, and then synthesizes them into a “Final Synthesized Discovery” (in blue font for clarity). The analysis identifies key concepts such as biodegradable microplastics, self-healing materials, pollution mitigation, and AI-driven predictive modeling, ultimately synthesizing the Bio-Inspired, Adaptive Materials for Resilient Ecosystems (BAMES) paradigm. The resulting document, Supporting Text 1, presents the results.
The proposed discovery proposes self-healing, bio-inspired materials that integrate microbial, plant, and animal-derived mechanisms with AI-driven optimization to create adaptive, environmentally responsive materials. By embedding microorganisms for pollutant degradation and leveraging machine learning for real-time optimization, the model suggests that BAMES extends conventional self-healing materials beyond infrastructure applications into active environmental remediation [43]. The concept of temporal memory, where materials learn from past environmental conditions and adjust accordingly, introduces a novel paradigm in smart materials [44]. Additionally, the hypothesis that interconnected materials could develop emergent, collective behavior akin to biological ecosystems presents an interesting perspective on material intelligence and sustainability [45, 46].
Agentic Compositional Reasoning
We can formalize this approach further and induce agentic strategy to develop compositional reasoning (see, Section 4.5.1 for details). In this experiment, implement a systematic development of hierarchical reasoning over concepts, pairs of concepts, and so on. The resulting document is shown in Supporting Text 2, and Figure 18 shows a flowchart of the reasoning process.
<details>
<summary>x18.png Details</summary>
### Visual Description
## Diagram: Concept Fusion Flowchart for EcoCycle Framework
### Overview
This image is a left-to-right process flowchart or concept map demonstrating how foundational concepts are merged and synthesized into increasingly complex frameworks, ultimately resulting in a single unified concept. The diagram is divided into four distinct vertical columns, representing stages of conceptual evolution.
### Components/Axes
The diagram contains no traditional axes, scales, or legends. Instead, it relies on spatial positioning and directional arrows to convey relationships.
* **Columns (Regions):** There are four main vertical bounding boxes, each with a header title.
1. **Atomic Components** (Far Left)
2. **Pairwise Compositional Fusions** (Center Left)
3. **Bridge Synergies** (Center Right)
4. **Final Expanded Discovery** (Far Right)
* **Nodes (Boxes):** Within each column are smaller rectangular boxes containing text.
* **Styling:** All bounding boxes and internal node boxes feature a gradient border that transitions from blue on the left/top to red on the right/bottom.
* **Flow:** Solid black lines with arrowheads connect the nodes, indicating a directional flow of information or conceptual merging from left to right.
### Content Details
Below is the precise transcription of all text and the mapping of the directional flow, isolated by column progression.
#### Stage 1 to Stage 2: Atomic Components $\rightarrow$ Pairwise Compositional Fusions
The first column contains 15 "Atomic Components." These merge, primarily in overlapping pairs, to form the 15 concepts in the second column.
1. **Materials for Infrastructure Design** + **Biodegradable Microplastic Materials** $\rightarrow$ merge into $\rightarrow$ **Eco-Resilient Infrastructure Design**
2. **Biodegradable Microplastic Materials** + **Pollution Mitigation** $\rightarrow$ merge into $\rightarrow$ **Sustainable Pollution Mitigation**
3. **Pollution Mitigation** + **Self-healing Materials in Infrastructure Design** $\rightarrow$ merge into $\rightarrow$ **Smart Infrastructure for Sustainable Ecosystems**
4. **Self-healing Materials in Infrastructure Design** + **Development of Novel Infrastructure Materials** $\rightarrow$ merge into $\rightarrow$ **Autonomous Repairable Infrastructure**
5. **Development of Novel Infrastructure Materials** + **Self-healing Materials** $\rightarrow$ merge into $\rightarrow$ **Sustainable Infrastructure Development**
6. **Self-healing Materials** + **Environmental Sustainability** $\rightarrow$ merge into $\rightarrow$ **Environmental Self-Healing Systems**
7. **Environmental Sustainability** + **Impact-Resistant Materials** $\rightarrow$ merge into $\rightarrow$ **Eco-Repair Systems**
8. **Impact-Resistant Materials** + **Machine Learning (ML) Algorithms** $\rightarrow$ merge into $\rightarrow$ **Eco-Toughened Materials**
9. **Machine Learning (ML) Algorithms** + **Predictive Modeling** $\rightarrow$ merge into $\rightarrow$ **Damage Forecasting Systems**
10. **Predictive Modeling** + **AI Techniques** $\rightarrow$ merge into $\rightarrow$ **Explainable Predictive Models**
11. **AI Techniques** + **Data Analysis** $\rightarrow$ merge into $\rightarrow$ **AI-Driven Predictive Systems**
12. **Data Analysis** + **Knowledge Discovery** $\rightarrow$ merge into $\rightarrow$ **Explainable Machine Learning (XML)**
13. **Knowledge Discovery** + **Personalized Medicine** $\rightarrow$ merge into $\rightarrow$ **Explainable Insights**
14. **Personalized Medicine** + **Rare Genetic Disorders** $\rightarrow$ merge into $\rightarrow$ **Precision Medicine Informatics**
15. **Rare Genetic Disorders** (alone) $\rightarrow$ flows into $\rightarrow$ **Precision Medicine for Rare Genetic Disorders**
#### Stage 2 to Stage 3: Pairwise Compositional Fusions $\rightarrow$ Bridge Synergies
The 15 concepts from Column 2 are grouped and funneled into 3 broader categories in Column 3.
* **Group 1 flows into "Environmental Sustainability + Tech Innovation"**
* Eco-Resilient Infrastructure Design
* Sustainable Pollution Mitigation
* Smart Infrastructure for Sustainable Ecosystems
* **Group 2 flows into "Holistic Understanding of Complex Systems"**
* Autonomous Repairable Infrastructure
* Sustainable Infrastructure Development
* Environmental Self-Healing Systems
* Eco-Repair Systems
* **Group 3 flows into "Convergence of Diverse Disciplines"**
* Eco-Toughened Materials
* Damage Forecasting Systems
* Explainable Predictive Models
* AI-Driven Predictive Systems
* Explainable Machine Learning (XML)
* Explainable Insights
* Precision Medicine Informatics
* Precision Medicine for Rare Genetic Disorders
*Note on Internal Flow:* There is an upward diagonal arrow inside Column 3 pointing from **Convergence of Diverse Disciplines** to **Holistic Understanding of Complex Systems**.
#### Stage 3 to Stage 4: Bridge Synergies $\rightarrow$ Final Expanded Discovery
All three nodes in Column 3 converge into a single final node in Column 4.
* **Environmental Sustainability + Tech Innovation** $\rightarrow$ flows into $\rightarrow$ **EcoCycle: A Sustainable Infrastructure Framework**
* **Holistic Understanding of Complex Systems** $\rightarrow$ flows into $\rightarrow$ **EcoCycle: A Sustainable Infrastructure Framework**
* **Convergence of Diverse Disciplines** $\rightarrow$ flows into $\rightarrow$ **EcoCycle: A Sustainable Infrastructure Framework**
### Key Observations
* **Overlapping Pairwise Logic:** The transition from Column 1 to Column 2 follows a strict overlapping pattern. Node 1 and 2 make Result 1; Node 2 and 3 make Result 2, etc. This visually justifies the term "Pairwise Compositional Fusions."
* **Thematic Drift:** The "Atomic Components" begin with physical engineering concepts (infrastructure, materials, microplastics), transition in the middle to computer science (Machine Learning, AI, Data Analysis), and abruptly end with medical biology (Personalized Medicine, Rare Genetic Disorders).
* **Asymmetrical Convergence:** The funneling into Column 3 is highly asymmetrical. The top node receives 3 inputs, the middle receives 4 inputs, and the bottom node receives 8 inputs (encompassing all the AI and Medical concepts).
### Interpretation
This diagram appears to map the conceptual generation of an interdisciplinary framework called "EcoCycle." It illustrates how base-level ideas are combined to create novel, cross-disciplinary solutions.
However, reading between the lines, the data suggests this may be the output of an automated semantic network traversal, a knowledge graph generation, or an AI brainstorming tool. The evidence for this is the severe thematic drift. The diagram attempts to force a relationship between "Infrastructure Design" and "Rare Genetic Disorders" by using "Machine Learning" and "Data Analysis" as a bridge.
The final output, "EcoCycle: A Sustainable Infrastructure Framework," logically aligns with the top half of the diagram (materials, pollution, self-healing). The bottom half of the diagram (precision medicine, genetics) is forced into the final framework through the highly abstracted "Convergence of Diverse Disciplines" node. This suggests the diagram is demonstrating a theoretical or algorithmic exercise in connecting disparate academic fields, rather than a practical, real-world engineering schematic.
</details>
Figure 18: Compositional framework applied to the longest shortest path. The flowchart illustrates the hierarchical process of compositional reasoning, beginning with atomic components (fundamental scientific concepts, left, as identified in the longest shortest path (Figure 17 (a))) and progressing through pairwise fusions, bridge synergies, and a final expanded discovery. Each stage (Steps A, B, C and D) integrates concepts systematically, ensuring interoperability, generativity, and hierarchical refinement, culminating in the EcoCycle framework for sustainable infrastructure development.
The example ultimately presents a structured approach to compositional scientific discovery, integrating principles from infrastructure materials science, environmental sustainability, and artificial intelligence to develop a novel framework for sustainable infrastructure, termed EcoCycle. As can be seen in Supporting Text 2 and in Figure 18, the compositional reasoning process proceeded through multiple hierarchical steps, ensuring the systematic combination of concepts with well-defined relationships.
At the foundational level, atomic components were identified, each representing an independent domain concept, such as biodegradable microplastic materials, self-healing materials, predictive modeling, and knowledge discovery. These fundamental elements were then combined into pairwise fusions, leveraging shared properties to generate novel synergies. For instance, the fusion of self-healing materials with pollution mitigation led to environmental self-healing systems, integrating autonomous repair mechanisms with pollution reduction strategies. Similarly, combining impact-resistant materials with machine learning algorithms enabled damage forecasting systems, enhancing predictive maintenance in infrastructure.
The validity of this compositional reasoning was established by ensuring that each fusion preserved the integrity of its constituent concepts while generating emergent functionalities. The process adhered to key compositionality principles: (1) Interoperability, ensuring that combined components interacted meaningfully rather than arbitrarily; (2) Generativity, whereby new properties emerged that were not present in the individual components; and (3) Hierarchical Refinement, wherein smaller-scale synergies were recursively integrated into higher-order bridge synergies. This led to overarching themes such as the intersection of environmental sustainability and technological innovation and the holistic understanding of complex systems, demonstrating the robustness of the approach.
Ultimately, these synergies converged into the EcoCycle framework, encapsulating self-healing, eco-responsive, and AI-optimized infrastructure solutions. The structured composition ensured that emergent discoveries were not mere aggregations but cohesive, context-aware innovations, validating the methodological rigor of the compositional approach. Using a strategy of adhering to systematic composition principles, the method used here demonstrates how interdisciplinary insights can be synthesized into scientific concepts.
For comparison, Supporting Text 3 shows the same experiment but where we use o1-pro in the final step of synthesis.
Putting this into context, earlier work [47, 48, 49, 50] have highlighted significant limitations in large language models (LLMs) concerning their ability to perform systematic compositional reasoning, particularly in domains requiring logical integration and generalization. Our approach directly addresses these deficiencies by structuring reasoning processes in a progressive and interpretable manner. Despite possessing individual components of knowledge, LLMs often struggle to integrate these dynamically to detect inconsistencies or solve problems requiring novel reasoning paths. We mitigate this by explicitly encoding relationships between concepts within a graph structure. Unlike conventional LLMs that rely on associative pattern recognition or statistical co-occurrence [47], our structured approach mitigates the concerns of mere connectionist representations by enforcing rule-based, interpretable generalization mechanisms that allow for dynamic recombination of learned knowledge in novel contexts. Further, our approach ensures that each reasoning step builds upon prior knowledge in a structured hierarchy. Steps A-D in our framework progressively construct solutions by leveraging explicit connections between concepts, enforcing compositionality rather than assuming it. For example, our approach connects biodegradable microplastic materials with self-healing materials, not merely through surface-level similarities but through defined mechanisms such as thermoreversible gelation and environmental interactions. Instead of expecting an LLM to infer relationships in a single step, our agentic model progressively traverses reasoning graphs, ensuring that the final outcome emerges through logically justified intermediary steps. This not only reduces reliance on pattern memorization but also enhances interpretability and robustness in novel scenarios.
Our model further enhances compositional reasoning through three key mechanisms:
1. Explicit Pathway Construction: By mapping dependencies between concepts in a structured graph, our model ensures that each step in the reasoning process is explicitly defined and logically connected.
1. Adaptive Contextual Integration: Instead of treating reasoning steps as isolated tasks, the model dynamically integrates intermediate results to refine its conclusions, ensuring that errors or inconsistencies in earlier stages are corrected before final predictions.
1. Hierarchical Synergy Identification: Our model analyzes multi-domain interactions through graph traversal and thereby identify emergent patterns that standard LLMs would overlook, enabling more robust and flexible reasoning. These mechanisms collectively establish a reasoning framework that mitigates compositional deficiencies and facilitates the structured synthesis of knowledge.
Table 2 summarizes how our approach directly addresses key LLM limitations identified in earlier work.
| Fails to compose multiple reasoning steps into a coherent process | Uses hierarchical reasoning with Steps A-D, ensuring progressive knowledge integration through structured dependencies. |
| --- | --- |
| Struggles to generalize beyond memorized patterns | Uses explicit graph structures to enforce systematic knowledge composition, allowing for novel reasoning paths. |
| Overfits to reasoning templates, failing on unseen reformulations | Introduces pairwise and bridge synergies to enable dynamic recombination of knowledge through structured traversal and adaptive reasoning. |
| Does not simulate "slow thinking" or iterative reasoning well | Implements an agentic model that explicitly traverses a reasoning graph rather than relying on a single forward pass, ensuring each step refines and validates prior knowledge. |
Table 2: Comparison of limitations of conventional LLMs, and our approach addresses these. By explicitly structuring relationships between concepts, breaking down reasoning into progressive steps, and incorporating dynamic knowledge recombination, our approach achieves a higher level of structured compositionality that conventional LLMs struggle with. Future work could further refine this approach by introducing adaptive feedback loops, reinforcing causal reasoning, and incorporating quantitative constraints to strengthen knowledge synergies.
Further analysis of these is left to future work, as they would exceed the scope of the present paper. The experiments show that principled approaches to expand knowledge can indeed be implemented using the methodologies described above, complementing other recent work that has explored related topics [29, 49, 23, 50, 47].
2.13 Utilization of Graph Reasoning over Key Hubs and Influencer Nodes in Response Generation
In this example, we analyze the knowledge graph $\mathcal{G}_{2}$ using NetworkX to compute node centralities (betweenness and eigenvector centrality), identifying key hubs and influencers. Community detection via the Louvain method partitions the graph into conceptual clusters, extracting representative nodes per community.
Key relationships are identified by examining high-centrality nodes and their strongest edges. These insights are formatted into a structured context and integrated into a task-specific prompt for LLM reasoning on impact-resistant materials, the same prompt that was used to construct the original graph.
The model’s response is generated both with and without graph data, followed by a comparative evaluation based on graph utilization, depth of reasoning, scientific rigor, and innovativeness. Raw responses for both models are shown in Text Boxes Supplementary Information and Supplementary Information. Table S1 provides a detailed comparison, and Figure 19 compares responses based on four key evaluation metrics (Graph Utilization, Depth of Reasoning, Scientific Rigor, and Innovativeness, along with the overall score).
<details>
<summary>x19.png Details</summary>
### Visual Description
## Bar Chart: Comparison of Responses on Impact-Resistant Material Design
### Overview
This image is a grouped bar chart comparing the performance scores of two different responses ("Response 1" and "Response 2") across five evaluation categories related to "Impact-Resistant Material Design." The primary variable being tested is the inclusion versus exclusion of graph data in the prompt or context provided to generate the response.
### Components/Axes
**Header Region:**
* **Title:** Located at the top center, reading exactly: "Comparison of Responses on Impact-Resistant Material Design".
**Main Chart Region & Legend:**
* **Legend:** Positioned in the top-left corner, inside the chart's bounding box. It defines two data series:
* **Red/Dark Coral Square:** Labeled "Response 1 (With Graph Data)"
* **Yellow/Light Green Square:** Labeled "Response 2 (Without Graph Data)"
* **Y-Axis (Left):**
* **Title:** "Score", oriented vertically, reading bottom-to-top.
* **Scale:** Numerical, starting at 0.0 at the bottom and ending at 17.5 near the top.
* **Markers:** Tick marks are placed at intervals of 2.5 (0.0, 2.5, 5.0, 7.5, 10.0, 12.5, 15.0, 17.5).
* **X-Axis (Bottom):**
* **Title:** None explicitly stated, but represents evaluation categories.
* **Labels:** Five distinct categories, with text rotated approximately 30 degrees counter-clockwise to fit. From left to right: "Graph Utilization", "Depth of Reasoning", "Scientific Rigor", "Innovativeness", "Overall Score".
### Detailed Analysis
*Trend Verification and Data Extraction by Category (Left to Right):*
1. **Graph Utilization:**
* *Visual Trend:* The red bar is prominent, while the yellow bar is completely absent (flat on the x-axis).
* *Data:* Response 1 (Red) scores **5**. Response 2 (Yellow) scores **0**.
2. **Depth of Reasoning:**
* *Visual Trend:* The red bar is slightly taller than the yellow bar.
* *Data:* Response 1 (Red) scores **4**. Response 2 (Yellow) scores **3**.
3. **Scientific Rigor:**
* *Visual Trend:* Both the red and yellow bars are exactly the same height.
* *Data:* Response 1 (Red) scores **4**. Response 2 (Yellow) scores **4**.
4. **Innovativeness:**
* *Visual Trend:* The red bar is noticeably taller than the yellow bar, showing a distinct advantage.
* *Data:* Response 1 (Red) scores **5**. Response 2 (Yellow) scores **3**.
5. **Overall Score:**
* *Visual Trend:* The red bar is nearly twice as tall as the yellow bar, extending slightly above the highest y-axis tick mark (17.5).
* *Data:* Response 1 (Red) scores **18**. Response 2 (Yellow) scores **10**.
### Key Observations
* **Dominance of Response 1:** Response 1 (With Graph Data) equals or outperforms Response 2 (Without Graph Data) in every single category.
* **The Zero Score:** Response 2 scored a 0 in "Graph Utilization," which is a logical absolute given it was generated "Without Graph Data."
* **The Tie:** "Scientific Rigor" is the only category where the lack of graph data did not negatively impact the score (both scored 4).
* **Mathematical Correlation:** The "Overall Score" is the exact mathematical sum of the four preceding individual categories.
* Response 1: 5 + 4 + 4 + 5 = 18
* Response 2: 0 + 3 + 4 + 3 = 10
### Interpretation
This chart serves as empirical evidence demonstrating the value of multimodal inputs (specifically, providing graphical data) to an AI model or human respondent tasked with complex technical design (Impact-Resistant Materials).
Reading between the lines, the data suggests a cascading effect. The baseline model/respondent is inherently capable of maintaining "Scientific Rigor" (scoring a 4 regardless of input). However, the absence of the graph (Response 2) didn't just cost points in the obvious category ("Graph Utilization"); it actively hindered the respondent's ability to reason deeply (dropping from 4 to 3) and to innovate (dropping from 5 to 3).
This implies that the graph contained critical contextual clues, relationships, or edge cases that served as a springboard for higher-order thinking. Without the graph, the response was scientifically sound but lacked depth and creativity. Therefore, to achieve optimal, innovative results in technical material design tasks, providing structured visual data alongside text prompts is highly advantageous.
</details>
Figure 19: Comparison of Responses on Impact-Resistant Material Design. This plot compares two responses based on four key evaluation metrics: Graph Utilization, Depth of Reasoning, Scientific Rigor, and Innovativeness, along with the overall score. Response 1, which incorporates graph-based insights, AI/ML techniques, and interdisciplinary approaches, outperforms Response 2 in all categories. Response 2 follows a more conventional materials science approach without leveraging computational methods. The higher overall score of Response 1 highlights the benefits of integrating advanced data-driven methodologies in material design.
2.14 Use of an Agentic Deep Reasoning Model to Generate new Hypotheses and Anticipated Material Behavior
Next, we use the SciAgents model [51] with the o3-mini reasoning model [52] as the back-end, and graph $\mathcal{G_{2}}$ to answer this question: Create a research idea around impact resistant materials and resilience. Rate the novelty and feasibility in the end.
The path-finding algorithm that integrates node embeddings and a degree of randomness to enhance exploration sampling strategy [51] extracts this sub-graph from the larger graph:
Iterative Reasoning $i<N$
⬇ Impact Resistant Materials -- IS - A -- Materials -- IS - A -- Impact - Resistant Materials -- INFLUENCES -- Modular Infrastructure Systems -- RELATES - TO -- Self - Healing Materials -- RELATES - TO -- Long - term Sustainability and Environmental Footprint of Infrastructure -- RELATES - TO -- Self - Healing Materials -- RELATES - TO -- Infrastructure -- IS - A -- Infrastructure Resilience -- RELATES - TO -- Smart Infrastructure -- RELATES - TO -- Impact - Resistant Materials -- RELATES - TO -- Machine Learning Algorithms -- RELATES - TO -- Impact - Resistant Materials -- RELATES - TO -- Resilience
As described in [51] paths are sampled using a path-finding algorithm that utilizes both node embeddings and a degree of randomness to enhance exploration as a path is identified between distinct concepts. Critically, instead of simply identifying the shortest path, the algorithm introduces stochastic elements by selecting waypoints and modifying priority queues in a modified version of Dijkstra’s algorithm. This allows for the discovery of richer and more diverse paths in a knowledge graph. The resulting paths serve as the foundation for graph-based reasoning specifically geared towards research hypothesis generation, ensuring a more extensive and insightful exploration of scientific concepts.
Visualizations of the subgraph are shown in Figure 20, depicting the subgraph alone (Figure 20 (a)) and the subgraph with second hops (Figure 20 (b), showing the deep interconnectness that can be extracted).
<details>
<summary>x20.png Details</summary>
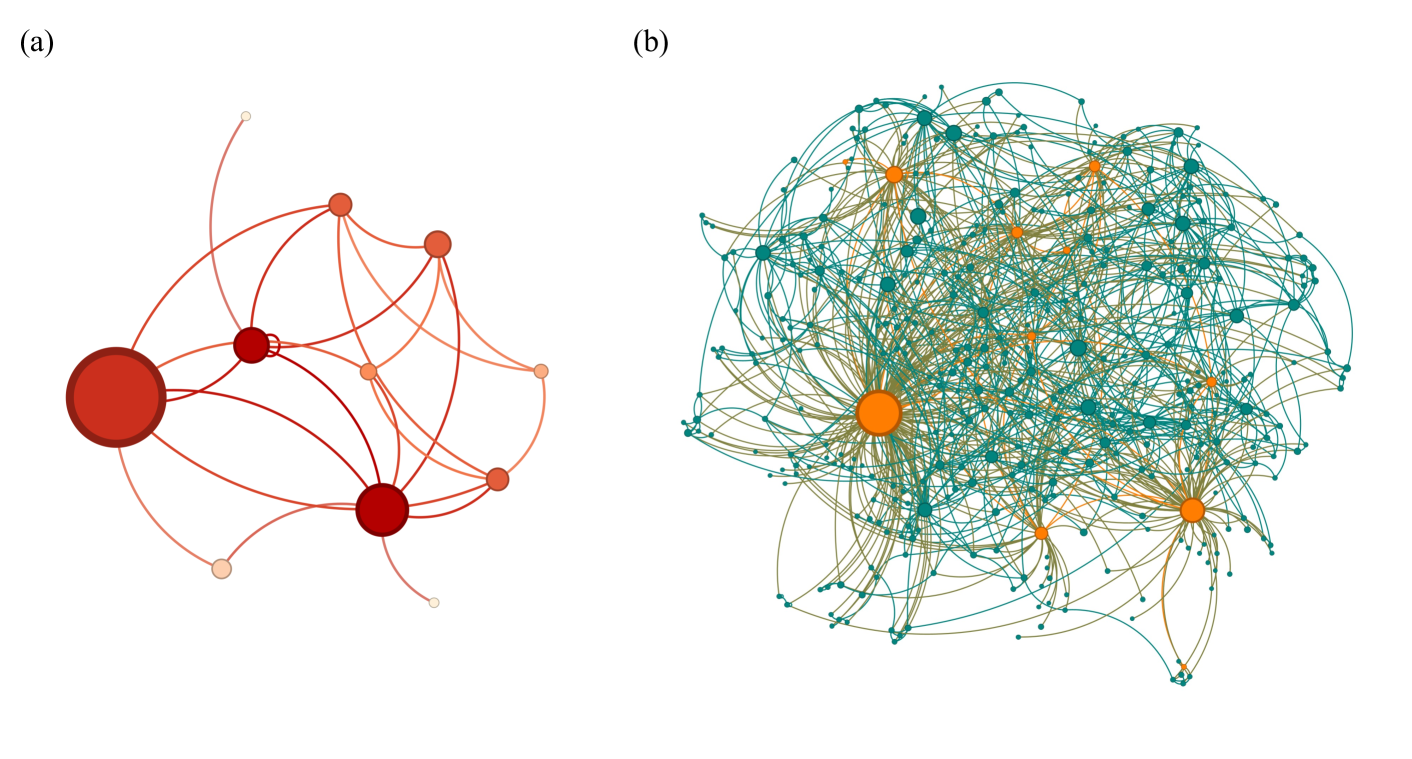
### Visual Description
## Network Diagrams: Simple vs. Complex Topologies
### Overview
The image displays two side-by-side network graphs, labeled (a) on the left and (b) on the right. These diagrams visually represent relationships (edges) between various entities (nodes). The image serves as a comparative illustration, contrasting a highly simplified, sparse network (a) with a highly complex, dense, and multi-categorical network (b).
**Crucial Note on Data Extraction:** The image does not contain any explicit data tables, axes, scales, or legends. Aside from the structural labels "(a)" and "(b)", there is no text. Therefore, exact numerical facts or specific categorical data cannot be extracted. The following analysis relies on visual encodings (size, color, density, and topology) to infer the underlying data structure.
### Components/Legend (Inferred)
Because no explicit legend is provided, the visual variables must be deduced:
* **Text Labels:**
* `(a)` located at the top-left corner of the left diagram.
* `(b)` located at the top-left corner of the right diagram.
* **Nodes (Circles):** Represent individual entities or data points.
* *Size:* Varies significantly in both diagrams. This almost certainly represents a quantitative metric, most likely "degree centrality" (the number of connections a node has) or a specific weight/importance assigned to the entity.
* *Color:* Represents either a continuous variable (gradient) or categorical data (distinct groups).
* **Edges (Lines):** Represent relationships, interactions, or pathways between nodes. They are drawn as curved lines to visually separate overlapping connections.
---
### Content Details
#### Region 1: Diagram (a) - Left Side
* **Visual Trend/Layout:** This is a sparse, localized network with a clear hub-and-spoke tendency. The layout is relatively open, allowing every individual connection to be traced visually.
* **Node Characteristics:**
* **Count:** Exactly 10 nodes are visible.
* **Color Palette:** A sequential, monochromatic gradient ranging from pale peach/pink to deep, dark red.
* **Size & Placement:**
* One massive node (bright red with a dark red outline) is positioned on the far-left edge of the cluster.
* Two medium-large nodes (dark red) are positioned centrally and toward the bottom-right.
* Seven smaller nodes (lighter peach/pink) are scattered around the periphery (top, far right, bottom).
* **Correlation:** There appears to be a direct correlation between node size and color darkness; larger nodes are darker red, while smaller nodes are lighter.
* **Edge Characteristics:**
* The lines are relatively thin and colored in reddish hues that generally match the nodes they connect.
* The massive node on the left connects directly to the two medium-large nodes and several smaller ones.
* There are no isolated nodes; all are part of a single connected component.
#### Region 2: Diagram (b) - Right Side
* **Visual Trend/Layout:** This is a highly dense, complex "hairball" network. It exhibits a clustered, force-directed layout where highly connected nodes are pulled toward the center, creating a massive tangle of overlapping edges.
* **Node Characteristics:**
* **Count:** Hundreds of nodes (estimated 200-300+).
* **Color Palette:** A diverging/categorical palette consisting of two distinct colors: Teal (dark cyan) and Orange.
* **Size & Placement:**
* *Orange Nodes:* Represent a minority in count but include the most prominent hubs. There are two exceptionally large orange nodes (one in the lower-left-center, one in the lower-right). There are approximately 8-10 medium-sized orange nodes scattered throughout the upper and central regions.
* *Teal Nodes:* Represent the vast majority of the nodes. They range from medium-small to tiny dots. They form the dense "cloud" that makes up the bulk of the network.
* **Edge Characteristics:**
* The edges are extremely dense, making it impossible to trace individual paths through the center of the mass.
* Edge colors correspond to the nodes: Teal lines connect teal nodes, while brownish/orange lines connect to the orange nodes.
* The large orange nodes act as massive gravitational centers (super-hubs), with dozens of brownish edges radiating outward from them to other parts of the network.
---
### Key Observations
1. **Scale Contrast:** Diagram (a) represents a micro-level system or a highly filtered dataset, whereas diagram (b) represents a macro-level, systemic dataset.
2. **Color Encoding Shift:** Diagram (a) uses color to represent a gradient (likely tied to the same metric as node size), while diagram (b) uses color to represent two distinct categories or classes of nodes within the same ecosystem.
3. **Hub Dominance:** Both networks rely heavily on "hubs" (the large nodes). However, in (b), the hubs are categorically distinct (orange) from the general population of nodes (teal).
---
### Interpretation
From a Peircean investigative standpoint, reading between the lines of these visual structures suggests this image is likely a figure from a scientific or technical paper demonstrating network topologies.
* **What the data suggests:**
* **Diagram (a)** likely illustrates a simple motif, a localized cluster, or a baseline model. Because size and color correlate, it might represent something like a small social group where the large red node is the central figure, or a localized protein interaction where one protein acts as the primary catalyst.
* **Diagram (b)** represents a complex, real-world system. The presence of two distinct colors (Teal and Orange) strongly suggests a *bipartite network* (e.g., users and products, authors and papers, or two different types of biological cells). Alternatively, it could represent a network where a specific class of nodes (Orange) acts as critical infrastructure or "super-spreaders" within a larger population (Teal).
* **Relationship:** The juxtaposition implies a comparison of scale or methodology. The authors may be showing a zoomed-in sub-network (a) extracted from the larger whole (b), or they may be contrasting a theoretical simple model (a) against empirical, messy real-world data (b).
* **Vulnerabilities:** Visually, network (b) appears highly dependent on the two massive orange hubs in the lower hemisphere. If this were a power grid or a computer network, taking out those two specific orange nodes would likely cause massive fragmentation of the teal nodes, demonstrating a system that is highly connected but potentially fragile to targeted attacks.
</details>
Figure 20: Visualization of subgraphs extracted from $\mathcal{G}_{2}$ by SciAgents, for use in graph reasoning. The left panel (a) represents the primary subgraph containing only nodes from the specified reasoning path. Node size is proportional to the original degree in the full network, highlighting key entities with high connectivity. The structure is sparse, with key nodes acting as central hubs in the reasoning framework. The right panel (b) represents an expanded subgraph that includes second-hop neighbors. Nodes from the original subgraph are colored orange, while newly introduced second-hop nodes are green. The increased connectivity and density indicate the broader network relationships captured through second-hop expansion. Larger orange nodes remain dominant in connectivity, while green nodes form supporting structures, emphasizing peripheral interactions and their contribution to knowledge propagation. This visualization highlights how expanding reasoning pathways in a graph framework integrates additional contextual information, enriching the overall structure..
The resulting document Supporting Text 4 presents the results of applying SciAgents to $\mathcal{G}_{2}$ in the context of impact-resistant materials and infrastructure resilience. The graph representation serves as a structured framework for reasoning about the relationships between key concepts—impact-resistant materials, self-healing mechanisms, machine learning optimization, and modular infrastructure—by encoding dependencies and influences between them. Graph 2 specifically captures these interconnected domains as nodes, with edges representing logical or causal links, enabling a systematic exploration of pathways that lead to optimal material design strategies. The path traversal within the graph identifies key dependencies, such as how impact-resistant materials influence infrastructure resilience or how machine learning refines self-healing efficiency. This structured pathway-based reasoning allows SciAgents to generate research hypotheses that maximize cross-domain synergies, ensuring that material properties are not optimized in isolation but rather in concert with their broader applications in engineering and sustainability. Furthermore, graph traversal reveals emergent relationships—such as how integrating real-time sensor feedback into modular infrastructure could create self-improving materials—that might not be immediately evident through conventional linear analysis. Thus, the use of graph-based reasoning is pivotal in formulating a research framework that is not only interdisciplinary but also systematically optimized for long-term infrastructure resilience and material adaptability.
In terms of specific content, the proposed research explores an advanced composite material that integrates carbon nanotube (CNT)-reinforced polymer matrices with self-healing microcapsules, embedded sensor networks, and closed-loop ML optimization. The goal is to create a dynamically self-improving material system that enhances impact resistance and longevity in modular infrastructure. The material design is structured around several key components: (1) CNT reinforcement (1–2 wt%) to improve tensile strength and fracture toughness, (2) self-healing microcapsules (50–200 $\mu$ m) filled with polymerizable agents, (3) embedded graphene-based or PVDF strain sensors for real-time monitoring, and (4) adaptive ML algorithms that regulate stress distributions and healing responses.
The proposal establishes interconnections between several domains, highlighting the interdisciplinary nature of the research: impact-resistant materials are a subset of general materials with enhanced energy dissipation properties, modular infrastructure benefits from these materials due to increased durability, self-healing materials reduce maintenance cycles, and machine learning optimizes real-time responses to structural stress. This holistic framework aims to advance infrastructure resilience and sustainability. The research hypothesizes that embedding self-healing microcapsules within a CNT-reinforced polymer matrix will yield a composite with superior impact resistance and adaptive repair capabilities. Expected performance gains include a 50% increase in impact energy absorption (surpassing 200 J/m²), up to 80% recovery of mechanical properties after micro-damage, an estimated 30% improvement in yield strain, a 50% extension in structural lifetime, and a 30% reduction in required maintenance interventions.
The composite operates via a multi-scale integration strategy where nanoscale CNTs form a stress-bridging network, microscale healing agents autonomously restore structural integrity, and macroscale sensors collect real-time strain data to inform machine learning-based optimizations. The closed-loop ML system refines material responses dynamically, preemptively addressing stress concentrations before catastrophic failure occurs. This iterative self-optimization process is represented in the flowchart shown in Figure 21.
\sansmath Iterative Reasoning $i<N$
Impact Event (Material undergoes structural stress or damage)
Sensor Detection (Real-time strain monitoring via embedded graphene/PVDF sensors)
Machine Learning Analysis (Prediction of stress distribution, micro-damage evolution)
Healing Response Adjustment (ML-optimized activation of microcapsules based on sensor data)
Microcapsule Rupture and Repair (Self-healing agent polymerization to restore mechanical integrity)
Material Performance Feedback (Updated data informs next optimization cycle)
Adaptive Learning Cycle: Sensors collect new data, ML refines healing response
Figure 21: Flowchart of the Self-Optimizing Composite System proposed by SciAgents after reasoning over $\mathcal{G}_{2}$ . Upon an impact event, embedded sensors (cyan) detect strain changes and transmit real-time data to a machine learning system (violet). This system predicts stress evolution and dynamically adjusts healing response thresholds (light violet). Microcapsules containing polymerizable agents (green) rupture at critical points, autonomously restoring material integrity. A feedback mechanism (yellow) continuously refines the process, ensuring adaptive optimization over multiple impact cycles. The dashed feedback loop signifies that each iteration improves the material’s ability to predict and mitigate future stress events, making the system progressively more efficient.
Compared to conventional high-performance composites such as ultra-high molecular weight polyethylene (UHMWPE) and standard carbon fiber-reinforced polymers, the proposed material demonstrates superior mechanical performance and autonomous damage remediation. Traditional impact-resistant materials typically absorb 120–150 J/m² of energy, whereas this system is designed to exceed 200 J/m². Additionally, existing self-healing materials recover only 50–60% of their mechanical properties, while this composite targets an 80% restoration rate. The modular design ensures seamless integration into existing infrastructure, supporting scalability and standardization.
Beyond its core functions, the composite exhibits several emergent properties: (1) localized reinforcement zones where healing chemistry alters stress distributions, (2) increased energy dissipation efficiency over repeated impact cycles, (3) long-term self-improving feedback where ML-driven adjustments refine material performance, and (4) potential microstructural evolution, such as crystalline phase formation, that enhances impact resistance. These unexpected yet beneficial attributes highlight the adaptive nature of the material system.
The broader implications of this research include significant economic and environmental benefits. By reducing maintenance frequency by 30%, the composite lowers infrastructure downtime and lifecycle costs. The extended service life translates to a 25–30% reduction in resource consumption and associated carbon emissions. While the upfront processing cost is higher due to advanced material fabrication and sensor integration, the long-term cost per operational year is projected to be competitive with, or superior to, existing alternatives.
This interdisciplinary fusion of nanomaterials, self-healing chemistry, real-time sensor feedback, and machine learning-based control represents a fundamental shift from passive materials to smart, self-optimizing systems. The proposed research not only addresses impact resistance and self-repair but also pioneers an adaptable, continuously improving infrastructure material. The combination of rigorous experimental validation (e.g., ASTM mechanical testing, finite element modeling, and real-world simulations) ensures that the material’s theoretical advantages translate into practical performance gains. This research positions itself as a transformative solution for infrastructure resilience, bridging the gap between static engineering materials and dynamically intelligent, self-regulating composites.
3 Conclusion
This work introduced a framework for recursive graph expansion, demonstrating that self-organizing intelligence-like behavior can emerge through iterative reasoning without predefined ontologies, external supervision, or centralized control. Unlike conventional knowledge graph expansion techniques that rely on static extractions, probabilistic link predictions, or reinforcement learning-based traversal, extensive test-time compute Graph-PReFLexOR graph reasoning actively restructures its own knowledge representation as it evolves, allowing for dynamic adaptation and autonomous knowledge synthesis. These findings are generally in line with other recent results that elucidated the importance of inference scaling methods [25, 52, 53, 26].
Through extensive graph-theoretic analysis, we found that the recursively generated knowledge structures exhibit scale-free properties, hierarchical modularity, and sustained interdisciplinary connectivity, aligning with patterns observed in human knowledge systems. The formation of conceptual hubs (Figures 4 - 5) and the emergence of bridge nodes (Figures 12) demonstrate that the system autonomously organizes information into a structured yet flexible network, facilitating both local coherence and global knowledge integration. Importantly, the model does not appear to saturate or stagnate; instead, it continuously reorganizes relationships between concepts by reinforcing key conceptual linkages while allowing new hypotheses to emerge through iterative reasoning (Figures 11 and 14).
One of the most striking findings is the self-regulation of knowledge propagation pathways. The early stages of graph expansion relied heavily on a few dominant nodes (high betweenness centrality), but over successive iterations, knowledge transfer became increasingly distributed and decentralized (Figure S3). This structural transformation suggests that recursive self-organization naturally reduces bottlenecks, enabling a more resilient and scalable knowledge framework. Additionally, we observed alternating phases of conceptual stability and breakthrough, indicating that knowledge formation follows a punctuated equilibrium model, rather than purely incremental accumulation.
More broadly, the recursive self-organization process produces emergent, fractal-like knowledge structures, suggesting that similar principles may underlie both human cognition and the design of intelligent systems [42]. Moreover, the potential role of bridge nodes—as connectors and as natural intervention points—is underscored by their persistent yet shifting influence, implying they could be strategically targeted for system updates or error correction in a self-organizing network. Additionally, the observed alternating phases of stable community formation punctuated by sudden breakthroughs appear to mirror the concept of punctuated equilibrium in scientific discovery [1], offering a promising framework for understanding the natural emergence of innovation. These insights extend the implications of our work beyond scientific discovery, hinting at broader applications in autonomous reasoning, such as adaptive natural language understanding and real-time decision-making in complex environments. We demonstrated a few initial use cases where we used graph structures in attempts towards compositional reasoning, as shown in Figure 18.
3.1 Graph Evolution Dynamics: Interplay of Network Measures
The evolution of the knowledge graph reveals a complex interplay between growth, connectivity, centralization, and structural reorganization, with different network-theoretic measures exhibiting distinct yet interdependent behaviors over iterations. Initially, the system undergoes rapid expansion, as seen in the near-linear increase in the number of nodes and edges (Figure 4). However, despite this outward growth, the clustering coefficient stabilizes early (around 0.16), suggesting that the graph maintains a balance between connectivity and modularity rather than devolving into isolated clusters. This stabilization indicates that the system does not expand chaotically but instead integrates new knowledge in a structured and preferentially attached manner, reinforcing key concepts while allowing for exploration.
One of the most informative trends is the evolution of betweenness centrality (Figure 16), which starts highly concentrated in a few key nodes but then redistributes over time, reflecting a transition from hub-dominated information flow to a more decentralized and resilient network. This shift aligns with the gradual stabilization of average shortest path length (around 4.5, see Figure 9) and the graph diameter (around 16–18 steps, see Figure 5), implying that while knowledge expands, it remains navigable and does not suffer from excessive fragmentation. Meanwhile, the maximum $k$ -core index (Figure 6) exhibits a stepwise increase, reflecting structured phases of densification where core knowledge regions consolidate before expanding further. This suggests that the system undergoes punctuated reorganization, where newly introduced concepts occasionally necessitate internal restructuring before further outward growth.
Interestingly, the degree assortativity starts strongly negative (around -0.25) and trends toward neutrality (-0.05), indicating that high-degree nodes initially dominate connections but later distribute their influence, allowing mid-degree nodes to contribute to network connectivity. This effect is reinforced by the persistence of bridge nodes (Figures 6 - 16), where we see a long-tail distribution of interdisciplinary connectors—some nodes serve as transient links that appear briefly, while others persist across hundreds of iterations, indicating stable, high-impact conceptual connectors.
Taken together, these experimentally observed trends suggest that the system self-regulates its expansion, dynamically shifting between growth, consolidation, and reorganization phases. The absence of saturation in key structural properties (such as new edge formation and bridge node emergence) indicates that the model supports continuous knowledge discovery, rather than converging to a fixed-state representation. This emergent behavior, where network-wide connectivity stabilizes while conceptual expansion remains open-ended, suggests that recursive graph reasoning could serve as a scalable foundation for autonomous scientific exploration, adaptive learning, and self-organizing knowledge systems.
3.2 Relevance in the Context of Materials Science
The framework introduced in this work offers a novel paradigm for accelerating discovery in materials science by systematically structuring and expanding knowledge networks. Unlike traditional approaches that rely on static databases or predefined ontologies [54, 55, 56, 57, 58], our self-organizing method enables dynamic hypothesis generation, uncovering hidden relationships between material properties, synthesis pathways, and functional behaviors. The emergent scale-free networks observed in our experiments reflect the underlying modularity and hierarchical organization often seen in biological and engineered materials, suggesting that recursive graph-based reasoning could serve as a computational analogue to self-assembling and adaptive materials. Applied to materials design, the approach developed in this paper could reveal unexpected synergies between molecular architectures and macroscale performance, leading to new pathways for bioinspired, multifunctional, and self-healing materials. Future work can integrate experimental data directly into these reasoning loops, allowing AI-driven materials discovery to move beyond retrieval-focused recognition toward novel inference and innovation. We believe it is essential to bridge the gap between autonomous reasoning and materials informatics to ultimately create self-improving knowledge systems that can adaptively guide materials engineering efforts in real-time [59].
3.3 Broader Implications
The observations put forth in this paper have potential implications for AI-driven scientific reasoning, autonomous hypothesis generation, and scientific inquiry. As our results demonstrate, complex knowledge structures can self-organize without explicit goal-setting. This work challenges a prevailing assumption that intelligence requires externally imposed constraints or supervision. Instead, it suggests that intelligent reasoning may emerge as a fundamental property of recursive, feedback-driven information processing, mirroring cognitive processes observed in scientific discovery and human learning. Our experiments that directed the evolution of the thinking mechanisms towards a certain goal were provided with relational modeling that incorporated these concepts in a more pronounced manner, as expected, provisioning a powerful substrate for deeper reasoning.
Future work could potentially explore extending this framework to multi-agent reasoning environments, cross-domain knowledge synthesis, and real-world applications in AI-driven research discovery. Additionally, refining interpretability mechanisms will be crucial for ensuring that autonomously generated insights align with human epistemic standards, minimizing risks related to misinformation propagation and reasoning biases. Bridging graph-theoretic modeling, AI reasoning, and self-organizing knowledge dynamics, allowed us to provide a step toward building AI systems capable of autonomous, scalable, and transparent knowledge formation on their own.
We note that wile our agentic deep graph reasoning framework demonstrates promise in achieving self-organizing knowledge formation, several challenges remain. In particular, the computational scalability of recursive graph expansions and the sensitivity of emergent structures to parameter choices warrant further investigation. Future work should explore robust error-correction strategies, enhanced interpretability of evolving networks, and ethical guidelines to ensure transparency in autonomous reasoning systems, especially if deployed in commercial or public settings beyond academic research. Addressing these issues will not only refine the current model but also paves the way for its application in real-world autonomous decision-making and adaptive learning environments.
4 Materials and Methods
We describe key materials and methods developed and used in the course of this study in this section.
4.1 Graph-PReFLexOR model development
A detailed account of the Graph-PReFLexOR is provided in [27]. Graph-PReFLexOR (Graph-based Preference-based Recursive Language Modeling for Exploratory Optimization of Reasoning) is an AI model integrating in-situ graph reasoning, symbolic abstraction, and recursive reflection into generative modeling. The model was trained on a set of around 1,000 scientific papers in the biological materials and bio-inspired materials domain, as discussed in [27]. We refer readers to the original paper for implementation details, but provide a high-level summary here. The method defines reasoning as a structured mapping:
$$
M:T\rightarrow(G,P,A), \tag{2}
$$
where a given task $T$ generates a knowledge graph $G=(V,E)$ with nodes $V$ representing key concepts and edges $E$ denoting relationships, abstract patterns $P$ capturing structural dependencies, and final answers $A$ . Inspired by category theory, the approach encodes knowledge through hierarchical inference, leveraging isomorphisms to generalize across domains. The model autonomously constructs symbolic representations via a reasoning phase marked by <|thinking|> … <|/thinking|> tokens, refining understanding before generating outputs. Recursive optimization can further improve logical coherence, aligning responses with generalizable principles, a particular feature that will be expanded on in this paper.
To enhance the adaptability of structured reasoning, Graph-PReFLexOR employs an iterative feedback mechanism:
$$
R_{i+1}=f_{\text{eval}}(R_{i},F_{i}), \tag{3}
$$
where $R_{i}$ denotes the intermediate reasoning at step $i$ , $F_{i}$ is the feedback applied to improve logical structure, and $f_{\text{eval}}$ evaluates alignment with domain principles. The final answer $A$ is derived after $N$ refinements as:
$$
A=g(R_{N}). \tag{4}
$$
Through the idea to explicitly model knowledge graphs and symbolic representations, this method attempts to bridge connectionist and symbolic paradigms, facilitating multi-step reasoning, hypothesis generation, and interdisciplinary knowledge expansion. Empirical evaluations in [27] demonstrated its capability to generalize beyond training data. In this study, we take advantage of the capability of Graph-PReFLexOR to generate graph representations on the fly over a great number of iterations during which the model continues to expand its reasoning tokens.
4.2 Iterative Unconstrained Graph Reasoning on General Topic
We develop an iterative knowledge extraction pipeline to construct a structured knowledge graph using a LLM, following the flowchart shown in Figure 1. The method systematically expands a graph representation of relationships by extracting structured knowledge from model-generated reasoning sequences and generating follow-up queries to refine exploration. We use this method to construct $\mathcal{G_{1}}$ .
At the start of each run, the algorithm initializes an initial question or prompt. This can be very general or focus on a particular topic that defines the area of scientific inquiry. In the example, the topic is set as:
Iterative Reasoning $i<N$
⬇ prompt = " Discuss an interesting idea in bio - inspired materials science."
The LLM then generates structured reasoning responses within the <|thinking|> … <|/thinking|> tokens. The response is processed to extract structured knowledge by isolating the graph.
To convert the extracted knowledge into a structured representation, the model is queried with an additional instruction to transform the resulting raw text that contains the reasoning graph (denoted by {raw graph}) into a Python dictionary formatted for graph representation:
Iterative Reasoning $i<N$
⬇ You are an AI that extracts information from structured text and outputs a graph in Python dictionary format compatible with NetworkX. Given the following structured text: {raw graph} Output the graph as a Python dictionary without any additional text or explanations. Ensure the dictionary is properly formatted for immediate evaluation in Python.
The output is parsed and structured using ast.literal_eval() to construct a directed graph $\mathcal{G}_{\text{local}}^{i}$ in NetworkX, where nodes represent entities such as materials, properties, and scientific concepts, while edges encode relationships such as HAS, INFLUENCES, and SIMILAR-TO.
At each iteration $i$ , the newly extracted knowledge graph is appended to an evolving global graph:
$$
\mathcal{G}\leftarrow\mathcal{G}\cup\mathcal{G}_{\text{local}}^{i}. \tag{5}
$$
The extracted structure is parsed using:
graph_code, graph_dict = extract_graph_from_text(graph)
The graph is progressively expanded by adding newly introduced nodes and edges, ensuring that redundant relationships are not duplicated. The final knowledge graph is stored in multiple formats, including GraphML for structural analysis and PNG for visualization.
To facilitate continued exploration, a follow-up question is generated at each iteration. The LLM is queried to produce a question that introduces a new aspect of the domain, ensuring an iterative, self-refining process that utilizes the previously generated entities and relations:
Iterative Reasoning $i<N$
⬇ Consider this list of topics / keywords. Formulate a creative follow - up question to ask about a totally new concept. Your question should include at least one of the original topics / keywords. Original list of topics / keywords: {latest extracted entities and relations} Reply only with the new question. The new question is:
This ensures that subsequent queries remain contextually grounded in the domain while promoting scientific discovery. The generated question is appended to the reasoning token structure and fed back into the LLM, thereby continuing the iterative learning process.
The algorithm runs for a total of $N$ iterations, progressively refining the knowledge graph. At each step, we track the growth of the graph by recording the number of nodes and edges over time. The final knowledge graph provides a structured and extensible representation of insights extracted from the LLM, enabling downstream analysis of emerging concepts. The reasoning process (Figure 1) unfolds sequentially over a period of several days (using a consumer GPU, like NVIDIA A6000 Ada).
4.3 Iterative Graph Reasoning on a Particular Topic
As an alternative to the approach above, we can tailor the reasoning process to focus more strongly on a particular topic. We use this method to construct $\mathcal{G_{2}}$ . For instance, at the beginning of each run, the algorithm is initialized with a user-defined topic:
Iterative Reasoning $i<N$
⬇ topic = " impact resistant materials "
This variable defines the area of exploration and is dynamically incorporated into the model prompts. The LLM is then queried with a topic-conditioned instruction to generate structured reasoning tokens:
Iterative Reasoning $i<N$
⬇ Describe a way to design {topic}.
The model generates textual responses that include explicit reasoning within the <|thinking|> … <|/thinking|> markers. As before, from this output, we extract structured knowledge by isolating the section labeled graph, to extract entity-relationship pairs. A follow-up question is generated at each iteration to drive the discovery process forward. This prompt ensures that new queries focus on underexplored aspects of the knowledge graph while maintaining the topic-conditioned structure:
Iterative Reasoning $i<N$
⬇ Consider this list of keywords. Considering the broad topic of {topic}, formulate a creative follow - up question to ask about a totally new aspect. Your question should include at least one of the original keywords. Original list of keywords: {latest extracted entities and relations} Reply only with the new question. The new question is:
This ensures that each iteration remains contextually grounded in the specified domain while continuously expanding the knowledge graph.
The process continues for $N$ steps, progressively refining the knowledge graph. At each iteration, we track the growth of the graph by recording the number of nodes and edges. The resulting knowledge graph serves as a structured repository of insights extracted from the LLM, enabling downstream analysis of materials properties and design principles.
Naturally, other variants of these strategies could easily be devised, for instance to create other generalist graphs (akin to $\mathcal{G}_{1}$ ) or specialized graphs (akin to $\mathcal{G}_{2}$ ). Prompt engineering can be human-tailored or developed agentically by other AI systems.
4.4 Graph Analysis and Visualization
Graph analysis and visualizations are conducted using NetworkX [60], Gephi [61], Cytoscope [62], Mermaid https://mermaid.js.org/, and various plugins within these packages.
4.4.1 Basic Analysis of Recursive Graph Growth over Reasoning Iterations
To analyze the recursive expansion of the knowledge graph, we computed a set of graph-theoretic properties at each iteration using the NetworkX Python library. Graph data was stored in GraphML format, with filenames encoded to reflect the iteration number, allowing for chronological tracking of structural changes. Each graph was sequentially loaded and processed to extract key metrics that characterize its connectivity, topology, and hierarchical organization.
The fundamental properties of the graph, including the number of nodes and edges, were directly retrieved from the graph structure. The degree distribution was computed across all nodes to derive the average degree, representing the mean connectivity per node, and the maximum degree, which highlights the most connected node at each iteration. To assess network cohesion, the largest connected component (LCC) was extracted by identifying the largest strongly connected component in directed graphs and the largest connected subgraph in undirected cases. The clustering coefficient was computed using the standard local clustering metric, which quantifies the likelihood that a node’s neighbors are also connected to each other. The average clustering coefficient was obtained by averaging over all nodes in the graph, providing insight into the tendency of local structures to form tightly connected clusters.
To assess global connectivity and efficiency, we computed the average shortest path length (SPL) and the graph diameter within the largest connected component. The SPL was obtained by calculating the mean shortest path distance between all pairs of nodes in the LCC, while the diameter was determined as the longest shortest path observed in the component. Since these calculations are computationally expensive for large graphs, they were conditionally executed only when the LCC was sufficiently small or explicitly enabled in the analysis. For community detection, we applied the Louvain modularity algorithm using the community-louvain package. The graph was treated as undirected for this step, and the modularity score was computed by partitioning the graph into communities that maximize the modularity function. This metric captures the extent to which the graph naturally organizes into distinct clusters over iterations.
The entire analysis pipeline iterated over a series of GraphML files, extracting the iteration number from each filename and systematically computing these metrics. The results were stored as time series arrays and visualized through multi-panel plots, capturing trends in network evolution. To optimize performance, computationally intensive operations, such as shortest path calculations and modularity detection, were executed conditionally based on graph size and software availability. To further examine the structural evolution of the recursively generated knowledge graph, we computed a set of advanced graph-theoretic metrics over iterative expansions. As before, the analysis was conducted over a series of iterations, allowing for the study of emergent network behaviors.
The degree assortativity coefficient was computed to measure the correlation between node degrees, assessing whether high-degree nodes preferentially connect to similar nodes. This metric provides insight into the network’s structural organization and whether its expansion follows a preferential attachment mechanism. The global transitivity, defined as the fraction of closed triplets among all possible triplets, was calculated to quantify the overall clustering tendency of the graph and detect the emergence of tightly interconnected regions. To assess the hierarchical connectivity structure, we performed $k$ -core decomposition, which identifies the maximal subgraph where all nodes have at least $k$ neighbors. We extracted the maximum $k$ -core index, representing the deepest level of connectivity within the network, and computed the size of the largest $k$ -core, indicating the robustness of highly connected core regions.
For understanding the importance of individual nodes in information flow, we computed average betweenness centrality over the largest connected component. Betweenness centrality quantifies the extent to which nodes serve as intermediaries in shortest paths, highlighting critical nodes that facilitate efficient navigation of the knowledge graph. Since exact computation of betweenness centrality can be computationally expensive for large graphs, it was performed only within the largest component to ensure feasibility. Additionally, we identified articulation points, which are nodes whose removal increases the number of connected components in the network. The presence and distribution of articulation points reveal structural vulnerabilities, highlighting nodes that serve as key bridges between different knowledge regions.
4.4.2 Prediction of Newly Connected Pairs
To track the evolution of connectivity in the recursively expanding knowledge graph, we employed a random sampling approach to estimate the number of newly connected node pairs at each iteration. Given the computational cost of computing all-pairs shortest paths in large graphs, we instead sampled a fixed number of node pairs per iteration and measured changes in their shortest path distances over time.
Sampling Strategy. At each iteration, we randomly selected 1,000 node pairs from the current set of nodes in the global knowledge graph. For each sampled pair $(u,v)$ , we computed the shortest path length in the graph using Breadth-First Search (BFS), implemented via nx.single_source_shortest_path_length(G, src). If a path existed, its length was recorded; otherwise, it was marked as unreachable.
Tracking Newly Connected Pairs. To detect the formation of new connections, we maintained a record of shortest path distances from the previous iteration and compared them with the current distances. A pair $(u,v)$ was classified as:
- Newly connected if it was previously unreachable ( $\text{dist}_{\text{before}}=\text{None}$ ) but became connected ( $\text{dist}_{\text{now}}≠\text{None}$ ).
- Having a shorter path if its shortest path length decreased between iterations ( $\text{dist}_{\text{now}}<\text{dist}_{\text{before}}$ ).
The number of newly connected pairs and the number of pairs with shortened paths were recorded for each iteration.
Graph Integration and Visualization. At each iteration, the newly processed graph was merged into a global knowledge graph, ensuring cumulative analysis over time. The number of newly connected pairs per iteration was plotted as a time series, revealing patterns in connectivity evolution. This method effectively captures structural transitions, particularly the initial burst of connectivity formation followed by a steady-state expansion phase, as observed in the results.
By employing this approach, we achieved a computationally efficient yet statistically robust estimate of network connectivity evolution, allowing us to analyze the self-organizing dynamics of the reasoning process over large iterative expansions.
4.4.3 Graph Structure and Community Analysis
To examine the structural properties of the recursively generated knowledge graph, we performed a comprehensive analysis of node connectivity, degree distribution, clustering behavior, shortest-path efficiency, and community structure. The graph was loaded from a GraphML file using the NetworkX library, and various metrics were computed to assess both local and global network properties.
Basic Graph Properties. The fundamental characteristics of the graph, including the number of nodes, edges, and average degree, were extracted. Additionally, the number of self-loops was recorded to identify redundant connections that may influence network dynamics.
Graph Component Analysis. To ensure robust connectivity analysis, the largest connected component (LCC) was extracted for undirected graphs, while the largest strongly connected component (SCC) was used for directed graphs. This ensured that further structural computations were performed on a fully connected subgraph, avoiding artifacts from disconnected nodes.
Degree Distribution Analysis. The degree distribution was computed and visualized using both a linear-scale histogram and a log-log scatter plot. The latter was used to assess whether the network exhibits a power-law degree distribution, characteristic of scale-free networks.
Clustering Coefficient Analysis. The local clustering coefficient, which quantifies the tendency of nodes to form tightly connected triads, was computed for each node. The distribution of clustering coefficients was plotted, and the average clustering coefficient was recorded to evaluate the extent of modular organization within the network.
Centrality Measures. Three centrality metrics were computed to identify influential nodes: (i) Betweenness centrality, which measures the extent to which nodes act as intermediaries in shortest paths, highlighting key connectors in the knowledge graph; (ii) Closeness centrality, which quantifies the efficiency of information propagation from a given node; (iii) Eigenvector centrality, which identifies nodes that are highly influential due to their connections to other high-importance nodes.
Shortest Path Analysis. The average shortest path length (SPL) and graph diameter were computed to evaluate the network’s navigability. Additionally, a histogram of sampled shortest path lengths was generated to analyze the distribution of distances between randomly selected node pairs (2,000 samples used).
Community Detection and Modularity. The Louvain modularity algorithm was applied (if available) to partition the network into communities and assess its hierarchical structure. The modularity score was computed to quantify the strength of the detected community structure, and the resulting partitions were visualized using a force-directed layout.
4.4.4 Analysis of Conceptual Breakthroughs
The evolution of knowledge graphs is analyzed by processing a sequence of graph snapshots stored in GraphML format. Each graph is indexed by an iteration number, extracted using a regular expression from filenames of the form graph_iteration_#.graphml. The graphs are sequentially loaded and processed to ensure consistency across iterations. If the graph is directed, it is converted to an undirected format using the networkx.to_undirected() function. To ensure structural integrity, we extract the largest connected component using the networkx.connected_components() function, selecting the subgraph with the maximum number of nodes.
For each iteration $t$ , we compute the degree distribution of all nodes in the largest connected component. The degree of a node $v$ in graph $G_{t}=(V_{t},E_{t})$ is given by:
$$
d_{t}(v)=\sum_{u\in V_{t}}A_{t}(v,u) \tag{6}
$$
where $A_{t}$ is the adjacency matrix of $G_{t}$ . The computed degree distributions are stored in a dictionary and later aggregated into a pandas DataFrame for further analysis.
To track the emergence of top hubs, we define a node $v$ as a hub if it attains a high degree at any iteration. The set of top hubs is determined by selecting the nodes with the highest maximum degree across all iterations:
$$
H=\{v\mid\max_{t}d_{t}(v)\geq d_{\text{top},10}\}
$$
where $d_{\text{top},10}$ is the degree of the 10th highest-ranked node in terms of maximum degree. The degree growth trajectory of each hub is then extracted by recording $d_{t}(v)$ for all $t$ where $v∈ V_{t}$ .
To quantify the emergence of new hubs, we define an emergence threshold $d_{\text{emerge}}=5$ , considering a node as a hub when its degree first surpasses this threshold. The first significant appearance of a node $v$ is computed as:
$$
t_{\text{emerge}}(v)=\min\{t\mid d_{t}(v)>d_{\text{emerge}}\}
$$
for all $v$ where such $t$ exists. The histogram of $t_{\text{emerge}}(v)$ across all nodes provides a temporal distribution of hub emergence.
To evaluate global network connectivity, we compute the mean degree at each iteration:
$$
\bar{d}_{t}=\frac{1}{|V_{t}|}\sum_{v\in V_{t}}d_{t}(v) \tag{7}
$$
capturing the overall trend in node connectivity as the knowledge graph evolves.
Three key visualizations are generated: (1) the degree growth trajectories of top hubs, plotted as $d_{t}(v)$ over time for $v∈ H$ ; (2) the emergence of new hubs, represented as a histogram of $t_{\text{emerge}}(v)$ ; and (3) the overall network connectivity, visualized as $\bar{d}_{t}$ over iterations.
4.4.5 Structural Evolution of the Graphs: Knowledge Communities, Bridge Nodes and Multi-hop Reasoning
We analyze the structural evolution of knowledge graphs by computing three key metrics: (1) the number of distinct knowledge communities over time, (2) the emergence of bridge nodes that connect different knowledge domains, and (3) the depth of multi-hop reasoning based on shortest path lengths. These metrics are computed for each iteration $t$ of the evolving graph and visualized as follows.
The evolution of knowledge communities is measured using the Louvain modularity optimization algorithm, implemented via community.best_partition(), which partitions the graph into distinct communities. For each iteration, the number of detected communities $|C_{t}|$ is computed as:
$$
|C_{t}|=|\{c\mid c=P_{t}(v),v\in V_{t}\}|
$$
where $P_{t}(v)$ maps node $v$ to its assigned community at iteration $t$ . The values of $|C_{t}|$ are plotted over iterations to track the subdivision and merging of knowledge domains over time.
The emergence of bridge nodes, nodes that connect multiple communities, is determined by examining the community affiliations of each node’s neighbors. A node $v$ is classified as a bridge node if:
$$
|\mathcal{C}(v)|>1,\quad\text{where}\quad\mathcal{C}(v)=\{P_{t}(u)\mid u\in N(%
v)\}
$$
and $N(v)$ represents the set of neighbors of $v$ . The number of bridge nodes is computed per iteration and plotted to analyze how interdisciplinary connections emerge over time.
The depth of multi-hop reasoning is quantified by computing the average shortest path length for the largest connected component at each iteration:
$$
L_{t}=\frac{1}{|V_{t}|(|V_{t}|-1)}\sum_{v,u\in V_{t},v\neq u}d_{\text{sp}}(v,u)
$$
where $d_{\text{sp}}(v,u)$ is the shortest path distance between nodes $v$ and $u$ , computed using networkx.average_shortest_path_length(). This metric captures the evolving complexity of conceptual reasoning chains in the knowledge graph.
We generate three plots: (1) the evolution of knowledge communities, visualizing $|C_{t}|$ over time; (2) the emergence of bridge nodes, displaying the number of inter-community connectors per iteration; and (3) the depth of multi-hop reasoning, tracking $L_{t}$ as a function of iteration number.
To analyze the temporal stability of bridge nodes in the evolving knowledge graph, we compute the persistence of bridge nodes, which quantifies how long individual nodes function as bridges across multiple iterations. Given the bridge node set $B_{t}$ at iteration $t$ , the persistence count for a node $v$ is defined as:
$$
P(v)=\sum_{t}\mathbb{1}(v\in B_{t})
$$
where $\mathbb{1}(·)$ is the indicator function that equals 1 if $v$ appears as a bridge node at iteration $t$ , and 0 otherwise. This metric captures the frequency with which each node serves as a conceptual connector between different knowledge domains.
To visualize the distribution of bridge node persistence, we construct a histogram of $P(v)$ across all detected bridge nodes, with kernel density estimation (KDE) applied for smoother visualization. The histogram provides insight into whether bridge nodes are transient or persist over multiple iterations.
The persistence values are computed and stored in a structured dataset, which is then used to generate a plot of the histogram of bridge node persistence.
To analyze the temporal dynamics of bridge node emergence, we construct a binary presence matrix that tracks when individual nodes first appear as bridges. The matrix is used to visualize the earliest bridge nodes over time, capturing the structural formation of key conceptual connectors.
The binary presence matrix is defined as follows. Given a set of bridge node lists $B_{t}$ for each iteration $t$ , we construct a matrix $M$ where each row corresponds to an iteration and each column corresponds to a unique bridge node. The matrix entries are:
$$
M_{t,v}=\begin{cases}1,&v\in B_{t}\\
0,&\text{otherwise}\end{cases}
$$
where $M_{t,v}$ indicates whether node $v$ appears as a bridge at iteration $t$ . The full set of unique bridge nodes across all iterations is extracted to define the columns of $M$ .
To identify the earliest appearing bridge nodes we compute the first iteration in which each node appears:
$$
t_{\text{first}}(v)=\min\{t\mid M_{t,v}=1\}
$$
The top 100 earliest appearing bridge nodes are selected by ranking nodes based on $t_{\text{first}}(v)$ , keeping those with the smallest values. The binary matrix is then restricted to these nodes.
To capture early-stage network formation, the analysis is limited to the first 200 iterations, ensuring that the onset of key bridge nodes is clearly visible. The final presence matrix $M^{\prime}$ is reordered so that nodes are sorted by their first appearance, emphasizing the sequential nature of bridge formation.
The matrix is visualized as a heatmap (Figure 13), where rows correspond to the top 100 earliest appearing bridge nodes and columns represent iterations. A blue-scale colormap is used to indicate presence (darker shades for active nodes).
To analyze the evolution of key bridge nodes in the knowledge graph, we compute and track the betweenness centrality of all nodes across multiple iterations. Betweenness centrality quantifies the importance of a node as an intermediary in shortest paths and is defined as:
$$
C_{B}(v)=\sum_{s\neq v\neq t}\frac{\sigma_{st}(v)}{\sigma_{st}}
$$
where $\sigma_{st}$ is the total number of shortest paths between nodes $s$ and $t$ , and $\sigma_{st}(v)$ is the number of those paths that pass through $v$ . This measure is recalculated at each iteration to observe structural changes in the network.
The computational procedure is as follows:
1. Graph Loading: Graph snapshots are loaded from GraphML files, indexed by iteration number. If a graph is directed, it is converted to an undirected format using networkx.to_undirected() to ensure consistent betweenness computations.
1. Betweenness Centrality Calculation: For each graph $G_{t}$ at iteration $t$ , the betweenness centrality for all nodes is computed using networkx.betweenness_centrality().
1. Time Series Construction: The computed centrality values are stored in a time-series matrix $B$ , where rows correspond to iterations and columns correspond to nodes:
$$
B_{t,v}=C_{B}(v)\quad\forall v\in V_{t}
$$
Missing values (nodes absent in certain iterations) are set to zero to maintain a consistent matrix structure.
To identify key bridge nodes, we extract the top ten nodes with the highest peak betweenness at any iteration:
$$
H=\{v\mid\max_{t}B_{t,v}\geq B_{\text{top},10}\}
$$
where $B_{\text{top},10}$ represents the 10th highest betweenness value recorded across all iterations. The time-series data is filtered to retain only these nodes.
To visualize the dynamic role of key bridge nodes, we generate a line plot of betweenness centrality evolution where each curve represents the changing centrality of a top bridge node over iterations. This graph captures how structural importance fluctuates over time.
4.5 Agentic Approach to Reason over Longest Shortest Paths
We employ an agentic approach to analyze structured knowledge representations in the form of a graph $G=(V,E)$ , where $V$ represents the set of nodes (concepts) and $E$ represents the set of edges (relationships). The methodology consists of four primary steps: (i) extraction of the longest knowledge path, (ii) decentralized node and relationship reasoning, (iii) multi-agent synthesis, and (iv) structured report generation.
Path Extraction. The input knowledge graph $G$ is first converted into an undirected graph $G^{\prime}=(V,E^{\prime})$ where $E^{\prime}$ contains bidirectional edges to ensure reachability across all nodes. We extract the largest connected component $G_{c}$ by computing:
$$
G_{c}=\arg\max_{S\in\mathcal{C}(G^{\prime})}|S|
$$
where $\mathcal{C}(G^{\prime})$ is the set of all connected components in $G^{\prime}$ . The longest shortest path, or diameter path, is determined by computing the eccentricity:
$$
\epsilon(v)=\max_{u\in V}d(v,u),
$$
where $d(v,u)$ is the shortest path length between nodes $v$ and $u$ . The source node is selected as $v^{*}=\arg\max_{v∈ V}\epsilon(v)$ , and the farthest reachable node from $v^{*}$ determines the longest path.
Numerically, the longest paths are determined by computing node eccentricities using networkx.eccentricity(), which identifies the most distant node pairs in terms of shortest paths. The five longest shortest paths are extracted with networkx.shortest_path(). For each extracted path, we assign node-level structural metrics computed from the original graph. The node degree is obtained using networkx.degree(), betweenness centrality is computed with networkx.betweenness_centrality(), and closeness centrality is determined via networkx.closeness_centrality(). Each identified path is saved as a GraphML file using networkx.write_graphml() with these computed node attributes for further analysis.
Decentralized Node and Relationship Reasoning. Each node $v_{i}∈ V$ and each relationship $e_{ij}∈ E$ along the longest path is analyzed separately. A language model $f_{\theta}$ is prompted with:
$$
\text{LLM}(v_{i})=f_{\theta}(\text{``Analyze concept }v_{i}\text{ in a novel %
scientific context."})
$$
for nodes, and
$$
\text{LLM}(e_{ij})=f_{\theta}(\text{``Analyze relationship }e_{ij}\text{ and %
hypothesize new implications."})
$$
for relationships. This enables independent hypothesis generation at the atomic level.
Multi-Agent Synthesis. The set of independent insights $\mathcal{I}=\{I_{1},I_{2},...\}$ is aggregated, and a final inference step is performed using:
$$
I_{\text{final}}=f_{\theta}(\text{``Synthesize a novel discovery from }%
\mathcal{I}\text{."})
$$
This allows the model to infer higher-order patterns beyond individual node-relationship reasoning.
Structured Report Generation. The final response, along with intermediate insights, is formatted into a structured markdown report containing:
- The extracted longest path
- Individual insights per node and relationship
- The final synthesized discovery
This approach leverages multi-step reasoning and recursive inference, allowing for emergent discoveries beyond explicit graph-encoded knowledge.
4.5.1 Agent-driven Compositional Reasoning
We employ a multi-step agentic approach that couples LLMs with graph-based compositional reasoning. To develop such an approach, we load the graph and locate its largest connected component. We compute eccentricities to identify two far-apart nodes, then extract the longest shortest path between them. Each node in that path becomes a “building block,” for which the LLM provides a concise definition, principles, and a property conducive to synergy (Step A). Next, we prompt the LLM to create pairwise synergies by merging adjacent building blocks, encouraging a short, compositional statement that unifies the nodes’ respective features (Step B). To deepen the layering of ideas, we consolidate multiple synergy statements into bridge synergies that capture cross-cutting themes (Step C). Finally, we issue a more elaborate prompt asking the LLM to integrate all building blocks and synergies into an expanded, coherent “final discovery,” referencing both prior statements and each node’s defining traits (Step D). This process yields a multi-step compositional approach, wherein each synergy can build on earlier results to reveal increasingly sophisticated connections. The initial steps A-C are carried out using meta-llama/Llama-3.2-3B-Instruct, whereas the final integration of the response in Step D is conducted using meta-llama/Llama-3.3-70B-Instruct. We also experimented with other models, such as o1-pro as discussed in the main text.
4.6 Scale free analysis
To determine whether a given network exhibits scale-free properties, we analyze its degree distribution using the power-law fitting method implemented in the powerlaw Python package. The algorithm extracts the degree sequence from the input graph and fits a power-law distribution, estimating the exponent $\alpha$ and lower bound $x_{\min}$ . To assess whether the power-law is a preferable fit, we compute the log-likelihood ratio (LR) between the power-law and an exponential distribution, along with the corresponding $p$ -value. A network is classified as scale-free if LR is positive and $p<0.05$ , indicating statistical support for the power-law hypothesis. The method accounts for discrete degree values and excludes zero-degree nodes from the fitting process.
4.7 Audio Summary in the Form of a Podcast
Supplementary Audio A1 presents an audio summary of this paper in the style of a podcast, created using PDF2Audio (https://huggingface.co/spaces/lamm-mit/PDF2Audio [51]). The audio format in the form a conversation enables reader to gain a broader understanding of the results of this paper, including expanding the broader impact of the work. The transcript was generated using the o3-mini model [52] from the final draft of the paper.
Code, data and model weights availability
Codes, model weights and additional materials are available at https://huggingface.co/lamm-mit and https://github.com/lamm-mit/PRefLexOR. The model used for the experiments is available at lamm-mit/Graph-Preflexor_01062025.
Conflicts of Interest
The author declares no conflicts of interest of any kind.
Acknowledgments
The author acknowledges support from the MIT Generative AI initiative.
References
- [1] Kuhn, T. S. The Structure of Scientific Revolutions (University of Chicago Press, 1962).
- [2] Spivak, D., Giesa, T., Wood, E. & Buehler, M. Category theoretic analysis of hierarchical protein materials and social networks. PLoS ONE 6 (2011).
- [3] Giesa, T., Spivak, D. & Buehler, M. Reoccurring Patterns in Hierarchical Protein Materials and Music: The Power of Analogies. BioNanoScience 1 (2011).
- [4] Giesa, T., Spivak, D. & Buehler, M. Category theory based solution for the building block replacement problem in materials design. Advanced Engineering Materials 14 (2012).
- [5] Vaswani, A. et al. Attention is All you Need (2017). URL https://papers.nips.cc/paper/7181-attention-is-all-you-need.
- [6] Alec Radford, Karthik Narasimhan, Tim Salimans & Ilya Sutskever. Improving Language Understanding by Generative Pre-Training URL https://gluebenchmark.com/leaderboard.
- [7] Xue, L. et al. ByT5: Towards a token-free future with pre-trained byte-to-byte models. Transactions of the Association for Computational Linguistics 10, 291–306 (2021). URL https://arxiv.org/abs/2105.13626v3.
- [8] Jiang, A. Q. et al. Mistral 7B (2023). URL http://arxiv.org/abs/2310.06825.
- [9] Phi-2: The surprising power of small language models - Microsoft Research. URL https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/.
- [10] Dubey, A. et al. The llama 3 herd of models (2024). URL https://arxiv.org/abs/2407.21783. 2407.21783.
- [11] Brown, T. B. et al. Language Models are Few-Shot Learners (2020).
- [12] Salinas, H. et al. Exoplanet transit candidate identification in tess full-frame images via a transformer-based algorithm (2025). URL https://arxiv.org/abs/2502.07542. 2502.07542.
- [13] Schmidt, J., Marques, M. R. G., Botti, S. & Marques, M. A. L. Recent advances and applications of machine learning in solid-state materials science. npj Computational Materials 5 (2019). URL https://doi.org/10.1038/s41524-019-0221-0.
- [14] Buehler, E. L. & Buehler, M. J. X-LoRA: Mixture of Low-Rank Adapter Experts, a Flexible Framework for Large Language Models with Applications in Protein Mechanics and Design (2024). URL https://arxiv.org/abs/2402.07148v1.
- [15] Arevalo, S. E. & Buehler, M. J. Learning from nature by leveraging integrative biomateriomics modeling toward adaptive and functional materials. MRS Bulletin 2023 1–14 (2023). URL https://link.springer.com/article/10.1557/s43577-023-00610-8.
- [16] Hu, Y. & Buehler, M. J. Deep language models for interpretative and predictive materials science. APL Machine Learning 1, 010901 (2023). URL https://aip.scitation.org/doi/abs/10.1063/5.0134317.
- [17] Szymanski, N. J. et al. Toward autonomous design and synthesis of novel inorganic materials. Mater. Horiz. 8, 2169–2198 (2021). URL http://dx.doi.org/10.1039/D1MH00495F.
- [18] Vamathevan, J. et al. Applications of machine learning in drug discovery and development. Nature Reviews Drug Discovery 18, 463–477 (2019).
- [19] Jumper, J. et al. Highly accurate protein structure prediction with AlphaFold. Nature 1–12 (2021).
- [20] Protein structure prediction by trRosetta. URL https://yanglab.nankai.edu.cn/trRosetta/.
- [21] Wu, R. et al. High-resolution de novo structure prediction from primary sequence. bioRxiv 2022.07.21.500999 (2022). URL https://www.biorxiv.org/content/10.1101/2022.07.21.500999v1.
- [22] Abbott, V. & Zardini, G. Flashattention on a napkin: A diagrammatic approach to deep learning io-awareness (2024). URL https://arxiv.org/abs/2412.03317. 2412.03317.
- [23] Buehler, M. J. Graph-aware isomorphic attention for adaptive dynamics in transformers (2025). URL https://arxiv.org/abs/2501.02393. 2501.02393.
- [24] Miconi, T. & Kay, K. Neural mechanisms of relational learning and fast knowledge reassembly in plastic neural networks. Nature Neuroscience 28, 406–414 (2025). URL https://www.nature.com/articles/s41593-024-01852-8.
- [25] OpenAI et al. OpenAI o1 system card (2024). URL https://arxiv.org/abs/2412.16720. 2412.16720.
- [26] Buehler, M. J. Preflexor: Preference-based recursive language modeling for exploratory optimization of reasoning and agentic thinking (2024). URL https://arxiv.org/abs/2410.12375. 2410.12375.
- [27] Buehler, M. J. In-situ graph reasoning and knowledge expansion using graph-preflexor (2025). URL https://arxiv.org/abs/2501.08120. 2501.08120.
- [28] Reddy, C. K. & Shojaee, P. Towards scientific discovery with generative ai: Progress, opportunities, and challenges. arXiv preprint arXiv:2412.11427 (2024). URL https://arxiv.org/abs/2412.11427.
- [29] Buehler, M. J. Accelerating scientific discovery with generative knowledge extraction, graph-based representation, and multimodal intelligent graph reasoning. Mach. Learn.: Sci. Technol. 5, 035083 (2024). Accepted Manuscript online 21 August 2024, © 2024 The Author(s). Open Access.
- [30] Brin, S. Extracting patterns and relations from the world wide web. In International Workshop on The World Wide Web and Databases (WebDB), 172–183 (1998).
- [31] Etzioni, O. et al. Knowitall: Fast, scalable, and self-supervised web information extraction. In Proceedings of the 13th International World Wide Web Conference (WWW), 100–110 (2004).
- [32] Banko, M., Cafarella, M. J., Soderland, S., Broadhead, M. & Etzioni, O. Open information extraction from the web. In Proceedings of the 20th International Joint Conference on Artificial Intelligence (IJCAI), 2670–2676 (2007).
- [33] Etzioni, O., Fader, A., Christensen, J., Soderland, S. & Mausam. Open information extraction: The second generation. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence (IJCAI), 3–10 (2011).
- [34] Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J. & Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Advances in Neural Information Processing Systems (NeurIPS), 2787–2795 (2013).
- [35] Galárraga, L. A., Teflioudi, C., Hose, K. & Suchanek, F. M. Amie: Association rule mining under incomplete evidence in ontological knowledge bases. In Proceedings of the 22nd International World Wide Web Conference (WWW), 413–422 (2013).
- [36] Carlson, A. et al. Toward an architecture for never-ending language learning. In Proceedings of the 24th AAAI Conference on Artificial Intelligence (AAAI), 1306–1313 (2010).
- [37] Dong, X. L. et al. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 601–610 (2014).
- [38] Xiong, W., Hoang, T. & Wang, W. Y. Deeppath: A reinforcement learning method for knowledge graph reasoning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP), 564–573 (2017).
- [39] Swanson, D. R. Fish oil, Raynaud’s syndrome, and undiscovered public knowledge. Perspectives in Biology and Medicine 30, 7–18 (1986).
- [40] Cameron, D. et al. A graph-based recovery and decomposition of swanson’s hypothesis using semantic predications. Journal of Biomedical Informatics 46, 238–251 (2013). URL https://doi.org/10.1016/j.jbi.2012.09.004.
- [41] Nickel, M., Murphy, K., Tresp, V. & Gabrilovich, E. A review of relational machine learning for knowledge graphs. Proceedings of the IEEE 104, 11–33 (2016).
- [42] Barabási, A.-L. & Albert, R. Emergence of scaling in random networks. Science 286, 509–512 (1999).
- [43] White, S. R. et al. Autonomic healing of polymer composites. Nature 409, 794–797 (2001).
- [44] Bar-Yam, Y. Dynamics of complex systems ISBN 0813341213 (1997). URL https://necsi.edu/dynamics-of-complex-systems.
- [45] Bhushan, B. Biomimetics: lessons from nature–an overview. Philosophical Transactions of the Royal Society A 367, 1445–1486 (2009).
- [46] Nepal, D. et al. Hierarchically structured bioinspired nanocomposites. Nature Materials 2022 1–18 (2022). URL https://www.nature.com/articles/s41563-022-01384-1.
- [47] Fodor, J. A. & Pylyshyn, Z. W. Connectionism and cognitive architecture: A critical analysis. Cognition 28, 3–71 (1988).
- [48] Zhao, J. et al. Exploring the compositional deficiency of large language models in mathematical reasoning. arXiv preprint arXiv:2405.06680 (2024). URL https://arxiv.org/abs/2405.06680. 2405.06680.
- [49] Shi, J. et al. Cryptox: Compositional reasoning evaluation of large language models. arXiv preprint arXiv:2502.07813 (2025). URL https://arxiv.org/abs/2502.07813. 2502.07813.
- [50] Xu, Z., Shi, Z. & Liang, Y. Do large language models have compositional ability? an investigation into limitations and scalability (2024). URL https://arxiv.org/abs/2407.15720. 2407.15720.
- [51] Ghafarollahi, A. & Buehler, M. J. Sciagents: Automating scientific discovery through multi-agent intelligent graph reasoning (2024). URL https://arxiv.org/abs/2409.05556. 2409.05556.
- [52] OpenAI. OpenAI o3-mini system card (2025). URL https://openai.com/index/o3-mini-system-card/.
- [53] Geiping, J. et al. Scaling up test-time compute with latent reasoning: A recurrent depth approach (2025). URL https://arxiv.org/abs/2502.05171. 2502.05171.
- [54] Arevalo, S. & Buehler, M. J. Learning from nature by leveraging integrative biomateriomics modeling toward adaptive and functional materials. MRS Bulletin (2023). URL https://link.springer.com/article/10.1557/s43577-023-00610-8.
- [55] Tshitoyan, V. et al. Unsupervised word embeddings capture latent knowledge from materials science literature. Nature 571, 95–98 (2019). URL https://www.nature.com/articles/s41586-019-1335-8.
- [56] Buehler, M. J. Generating 3D architectured nature-inspired materials and granular media using diffusion models based on language cues. Oxford Open Materials Science 2 (2022). URL https://academic.oup.com/ooms/article/2/1/itac010/6823542.
- [57] Buehler, M. J. Predicting mechanical fields near cracks using a progressive transformer diffusion model and exploration of generalization capacity. Journal of Materials Research 38, 1317–1331 (2023). URL https://link.springer.com/article/10.1557/s43578-023-00892-3.
- [58] Brinson, L. C. et al. Community action on FAIR data will fuel a revolution in materials research. MRS Bulletin 1–5 (2023). URL https://link.springer.com/article/10.1557/s43577-023-00498-4.
- [59] Stach, E. et al. Autonomous experimentation systems for materials development: A community perspective. Matter 4, 2702–2726 (2021).
- [60] networkx/networkx: Network Analysis in Python. URL https://github.com/networkx/networkx.
- [61] Bastian, M., Heymann, S. & Jacomy, M. Gephi: An open source software for exploring and manipulating networks (2009). URL http://www.aaai.org/ocs/index.php/ICWSM/09/paper/view/154.
- [62] Shannon, P. et al. Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Research 13, 2498–2504 (2003).
Supplementary Information
Agentic Deep Graph Reasoning Yields Self-Organizing Knowledge Networks
Markus J. Buehler
Laboratory for Atomistic and Molecular Mechanics
Center for Computational Science and Engineering
Schwarzman College of Computing
Massachusetts Institute of Technology
Cambridge, MA 02139, USA
mbuehler@MIT.EDU
<details>
<summary>x21.png Details</summary>

### Visual Description
## Network Graph: Complex Multi-Cluster Node-Link Diagram
### Overview
This image displays a highly complex, unlabelled network graph (specifically, a force-directed node-link diagram) rendered against a solid white background. **CRITICAL NOTE:** There is absolutely no text, typography, labels, axes, legends, or explicit numerical data present in this image. Therefore, no factual data tables or exact numerical values can be extracted.
Instead, the image conveys structural and relational information through visual encodings: nodes (circles representing entities), edges (curved lines representing relationships or interactions), node size (representing degree or centrality), and color (representing modularity classes or distinct communities).
### Components/Structure
Because traditional chart axes and legends are absent, the structural components of this visualization are defined by its graphical elements:
* **Nodes (Vertices):** Solid circles of varying diameters. Larger circles indicate a higher number of connections (degree centrality).
* **Edges (Links):** Thin, curved, semi-transparent lines connecting the nodes. The curvature helps distinguish overlapping connections.
* **Color Coding:** Distinct hues (Cyan, Dark Blue, Green, Pink, Orange, Purple) are used to group nodes and their primary edges into clusters, indicating algorithmic community detection.
* **Layout:** The spatial distribution appears to be a force-directed layout, where connected nodes are pulled together (forming dense clusters) and unconnected nodes are pushed apart, utilizing the white space to show relational distance.
### Detailed Analysis (Spatial Grounding & Component Isolation)
To analyze this complex structure, the graph can be segmented into distinct spatial and color-coded regions:
**1. The Center-Left Hub (Cyan/Dark Blue Region)**
* *Visual Trend:* A classic "hub-and-spoke" topology radiating from a single massive point.
* *Details:* Located in the mid-to-lower left quadrant. This region is dominated by a single, prominent **Dark Blue node**, which is visually the largest node in the entire graph. Hundreds of light blue/cyan edges radiate outward from this single point, connecting to a vast array of smaller, peripheral cyan nodes. This cluster has long, sweeping connections reaching across the graph to the top-right and bottom-center clusters.
**2. The Top-Right Agglomeration (Green/Olive/Magenta Region)**
* *Visual Trend:* A highly dense, tightly knit "mesh" topology with multiple medium-sized hubs rather than one dominant center.
* *Details:* Located in the upper right quadrant. This is the most visually dense area of the graph. It contains several distinct, medium-to-large nodes colored bright green, olive green, and dark magenta. The edges here are highly entangled and short, suggesting intense internal connectivity.
**3. The Bottom-Center Base (Pink/Light Red Region)**
* *Visual Trend:* A diffuse but highly interconnected cloud lacking a single dominant hub.
* *Details:* Located at the bottom center of the image. The nodes here are generally small to very small. There is a high density of internal pink/red edges, creating a "cloud" effect. It shares a significant number of bridging edges with the Cyan hub to its left.
**4. Peripheral and Minor Clusters**
* *Orange/Yellow:* Found in two primary locations—a sparse grouping at the top-center (bridging the left and right main clusters) and a smaller, distinct cluster at the bottom-right edge.
* *Purple:* A small, distinct cluster located at the extreme bottom-left edge, connected primarily to the outer edges of the Cyan cluster.
**5. Inter-Cluster Edges (The "Bridges")**
* *Visual Trend:* Long, sweeping arcs crossing the negative (white) space.
* *Details:* While edges within clusters share the cluster's color, the graph features many long, faint, often grey or multi-colored lines connecting distant nodes. A massive bundle of these bridging edges flows between the Center-Left (Cyan) hub and the Top-Right (Green) agglomeration.
### Key Observations
* **Extreme Centrality:** The dark blue node on the left possesses an exceptionally high degree of centrality compared to any other node in the network.
* **Differing Topologies:** The graph demonstrates two distinct types of network behavior simultaneously: a broadcast/influencer model (the left cyan hub) and a community/echo-chamber model (the top-right green mesh).
* **High Modularity:** The distinct separation of colors indicates that the algorithm used to generate this graph found very strong, isolated communities that interact internally much more than they interact externally.
### Interpretation
*Note: Because the graph is unlabelled, this interpretation relies on standard network analysis principles (Peircean abduction) applied to the visual topology.*
* **What the data suggests:** This visualization likely represents a complex system such as a social media network (e.g., Twitter/X retweets or mentions), a biological network (protein-protein interactions), or an IT routing topology.
* **Reading between the lines:**
* If this is a **social network**, the giant Dark Blue node represents a major broadcaster, celebrity, or viral post. It pushes information out to thousands of disconnected users (the cyan cloud). Conversely, the Top-Right Green cluster represents a highly interactive, conversational community where many users are talking directly to one another, rather than just listening to one central figure.
* The long bridging edges between the Cyan and Green clusters represent "weak ties"—individuals who act as conduits of information between two otherwise isolated communities.
* The smaller clusters (Orange, Purple) represent niche sub-communities that are largely isolated from the main flow of the network, interacting only with the extreme periphery of the larger groups.
</details>
Figure S1: Knowledge graph $\mathcal{G_{1}}$ after around 1,000 iterations, under a flexible self-exploration scheme initiated with the prompt Discuss an interesting idea in bio-inspired materials science.. In this visualization, nodes/edges are colored according to cluster ID.
<details>
<summary>x22.png Details</summary>
### Visual Description
## Network Graph Diagram: Complex Node-Link Visualization
### Overview
The image displays a complex, unlabelled network graph (specifically a node-link diagram) rendered against a solid white background. It visualizes the relationships and clustering of numerous entities. The visualization relies entirely on color, node size, edge density, and spatial positioning to convey information.
**CRITICAL NOTE:** There is absolutely no text, typography, labels, axes, legends, or numerical data present in this image. The data extracted below is based entirely on the visual topology and structural properties of the rendered network.
### Components/Axes
* **Text/Labels:** None present.
* **Axes/Scales:** None present. The spatial distribution appears to be generated by a force-directed layout algorithm (such as Fruchterman-Reingold or ForceAtlas2), where proximity indicates relationship strength or community belonging rather than Cartesian coordinates.
* **Nodes (Vertices):** Represented by solid circles.
* *Size:* Varies significantly, indicating a metric like "Degree Centrality" (number of connections) or "Betweenness Centrality."
* *Color:* Indicates community detection or modularity class (groupings of similar nodes).
* **Edges (Links):** Represented by thin, curved lines connecting the nodes.
* *Color:* Edges generally inherit the color of the nodes they connect, blending or transitioning when connecting different colored clusters.
* *Shape:* Highly curved, sweeping arcs, which helps distinguish individual connections in dense areas.
### Detailed Analysis (Spatial & Structural)
To analyze the data structure, the image can be segmented into distinct spatial regions based on clustering:
**1. The Central Hub (Center / Slightly Right)**
* **Visual Trend:** All major pathways in the graph eventually route through or near this area.
* **Key Feature:** Contains the single largest node in the entire network. It is colored dark teal/blue-green.
* **Connections:** This central node has an extremely high degree of connectivity, with edges radiating outward 360 degrees to almost every other color cluster in the graph.
**2. The Upper-Left Mass (Top-Left to Center-Left)**
* **Visual Trend:** This is the most densely packed region of the graph, forming a large, interconnected "cloud."
* **Colors Present:** A highly mixed palette including bright green, pink/magenta, light blue, orange, and pale yellow.
* **Structure:** While dense, there are distinct sub-centers (slightly larger nodes in pink and green) acting as local hubs within this larger mass.
**3. The Bottom-Right Peninsula (Bottom-Right)**
* **Visual Trend:** A distinct, somewhat isolated cluster that forms its own sub-network, pulled away from the main mass.
* **Colors Present:** Predominantly bright orange and cyan/light blue, with a small dark green cluster at the very bottom tip.
* **Connections:** It is connected to the central hub and upper mass via long, sweeping, distinct edge bundles. These "bridge" edges are primarily colored red, pink, and brown, indicating the specific pathways that link this isolated community to the rest of the network.
**4. The Bottom-Left Lobe (Bottom-Left)**
* **Visual Trend:** A smaller, looser grouping of nodes.
* **Colors Present:** Primarily blue, purple, and brown.
* **Connections:** Features long, looping connections that tie back into the central teal hub and the lower portions of the upper-left mass.
**5. The Periphery (Outer Edges)**
* **Visual Trend:** Sparse, wispy connections extending outward into the white space.
* **Structure:** Composed of very small nodes with only one or two connections (degree of 1 or 2). The edges here are often grey or very pale, indicating weak ties or outlier data points.
### Key Observations
* **Extreme Centralization:** The network is heavily reliant on the single dark teal node. If this were a vulnerability map, that node represents a single point of failure.
* **Strong Modularity:** Despite the central hub, the network has distinct communities (represented by colors). The force-directed layout successfully pulls these communities apart, most notably the bottom-right orange/cyan cluster.
* **Bridge Connections:** The long red/pink arcs connecting the bottom-right cluster to the center are crucial; they represent the few entities that bridge the gap between two otherwise isolated communities.
### Interpretation
While the specific subject matter (e.g., social media interactions, biological protein pathways, IT infrastructure, or semantic word associations) is unknown due to the lack of labels, the *behavior* of the data is clear.
The data demonstrates a **"Scale-Free" or "Hub-and-Spoke" network topology** mixed with strong community structures.
1. **The "Who/What":** There is one dominant entity (the teal node) that interacts with almost everything.
2. **The Communities:** The entities naturally form echo-chambers or specialized groups (the distinct color clusters). For example, the orange nodes in the bottom right interact heavily with each other, but rarely interact directly with the green nodes in the top left; they must route their relationship through the central hubs or the specific red/pink bridge connections.
3. **Reading between the lines:** The presence of the isolated bottom-right cluster suggests a sub-group that is fundamentally different or geographically/logically separated from the main body of data, yet still tethered to the overall ecosystem by a few key links.
</details>
Figure S2: Knowledge graph $\mathcal{G_{2}}$ after around 500 iterations, under a topic-specific self-exploration scheme initiated with the prompt Describe a way to design impact resistant materials. Nodes/edges are colored according to cluster ID.
<details>
<summary>x23.png Details</summary>
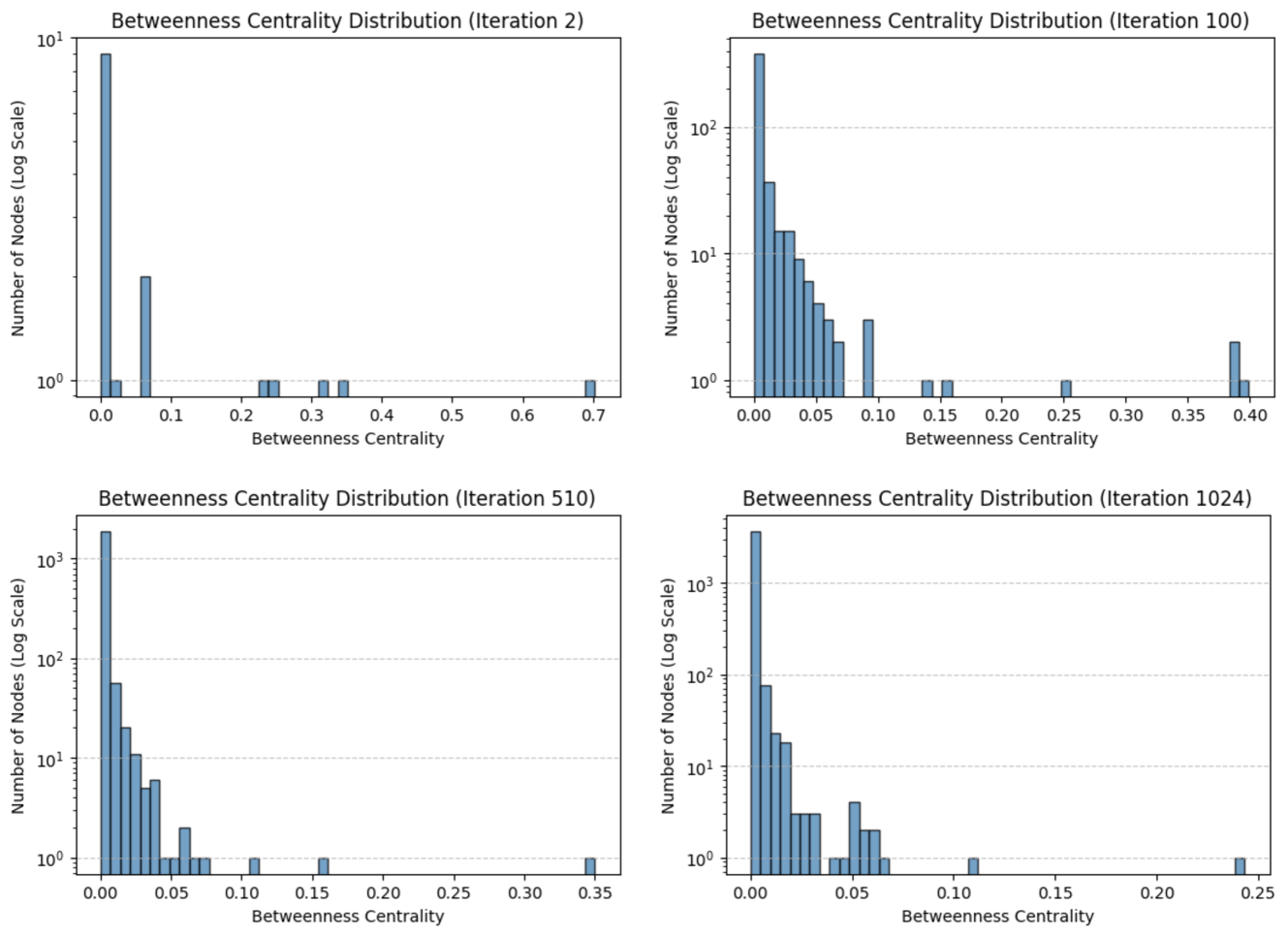
### Visual Description
## Grid of Histograms: Evolution of Betweenness Centrality Distribution
### Overview
The image displays a 2x2 grid of histograms illustrating the "Betweenness Centrality Distribution" of a network across four distinct time steps or stages, labeled as "Iterations." The iterations shown are 2, 100, 510, and 1024. The charts demonstrate how the network's topology evolves, specifically showing a massive increase in the total number of nodes and a shift toward a highly skewed, power-law-like distribution where the vast majority of nodes have near-zero betweenness centrality. All text in the image is in English.
### Components/Axes
The image is divided into four quadrants (Top-Left, Top-Right, Bottom-Left, Bottom-Right). All four charts share the following structural components:
* **Chart Type:** Histogram (vertical bar charts).
* **Visual Style:** Light blue bars with dark borders. Horizontal dashed gridlines correspond to major Y-axis ticks.
* **X-axis Label:** "Betweenness Centrality" (Linear scale). Note: The maximum range of the X-axis changes across the iterations.
* **Y-axis Label:** "Number of Nodes (Log Scale)" (Logarithmic scale: $10^0$, $10^1$, $10^2$, $10^3$). Note: The maximum range of the Y-axis changes across the iterations as the network grows.
---
### Detailed Analysis
#### 1. Top-Left Chart: Iteration 2
* **Position:** Top-Left quadrant.
* **Title:** Betweenness Centrality Distribution (Iteration 2)
* **X-axis Range:** 0.0 to 0.7 (Markers at 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7).
* **Y-axis Range:** $10^0$ (1) to $10^1$ (10).
* **Visual Trend:** The distribution is sparse, indicating a very small network. There is a small cluster at 0.0, and a few individual nodes scattered across higher centrality values up to 0.7.
* **Data Points (Approximate):**
* ~0.00: ~9 nodes (just below the $10^1$ line)
* ~0.02: 1 node ($10^0$ line)
* ~0.06: ~2 nodes
* ~0.23: 1 node
* ~0.25: 1 node
* ~0.32: 1 node
* ~0.35: 1 node
* ~0.70: 1 node
#### 2. Top-Right Chart: Iteration 100
* **Position:** Top-Right quadrant.
* **Title:** Betweenness Centrality Distribution (Iteration 100)
* **X-axis Range:** 0.00 to 0.40 (Markers at 0.00, 0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35, 0.40). *Note the scale reduction from Iteration 2.*
* **Y-axis Range:** $10^0$ (1) to above $10^2$ (100).
* **Visual Trend:** A heavy right-skewed distribution emerges. A massive spike occurs at 0.00, trailing off rapidly. The network has grown significantly.
* **Data Points (Approximate):**
* ~0.00: ~350 nodes (bar extends well above $10^2$)
* ~0.01: ~40 nodes
* ~0.02: ~15 nodes
* ~0.03: ~15 nodes
* ~0.04: ~9 nodes
* ~0.05: ~6 nodes
* ~0.06: ~4 nodes
* ~0.07: ~2 nodes
* ~0.09: ~3 nodes
* ~0.14: 1 node
* ~0.16: 1 node
* ~0.25: 1 node
* ~0.39: ~2 nodes
* ~0.40: 1 node
#### 3. Bottom-Left Chart: Iteration 510
* **Position:** Bottom-Left quadrant.
* **Title:** Betweenness Centrality Distribution (Iteration 510)
* **X-axis Range:** 0.00 to 0.35 (Markers at 0.00, 0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35). *Scale reduction continues.*
* **Y-axis Range:** $10^0$ (1) to above $10^3$ (1000).
* **Visual Trend:** Extreme right skew. The peak at zero centrality has grown exponentially compared to Iteration 100.
* **Data Points (Approximate):**
* ~0.00: ~3000 nodes (bar extends significantly above $10^3$)
* ~0.01: ~60 nodes
* ~0.02: ~20 nodes
* ~0.03: ~10 nodes
* ~0.04: ~5 nodes
* ~0.05: ~6 nodes
* ~0.06: 1 node
* ~0.07: ~2 nodes
* ~0.08: 1 node
* ~0.11: 1 node
* ~0.16: 1 node
* ~0.35: 1 node
#### 4. Bottom-Right Chart: Iteration 1024
* **Position:** Bottom-Right quadrant.
* **Title:** Betweenness Centrality Distribution (Iteration 1024)
* **X-axis Range:** 0.00 to 0.25 (Markers at 0.00, 0.05, 0.10, 0.15, 0.20, 0.25). *Maximum centrality is now much lower.*
* **Y-axis Range:** $10^0$ (1) to above $10^3$ (1000).
* **Visual Trend:** The distribution solidifies its extreme right-skewed shape. The vast majority of the network's nodes have near-zero betweenness.
* **Data Points (Approximate):**
* ~0.00: ~4500 nodes (highest peak across all charts)
* ~0.01: ~80 nodes
* ~0.02: ~25 nodes
* ~0.03: ~18 nodes
* ~0.04: ~3 nodes
* ~0.05: ~3 nodes
* ~0.06: 1 node
* ~0.07: ~4 nodes
* ~0.08: ~2 nodes
* ~0.09: ~2 nodes
* ~0.10: 1 node
* ~0.13: 1 node
* ~0.24: 1 node
---
### Key Observations
1. **Explosive Node Growth:** The Y-axis maximum increases from $10^1$ (Iteration 2) to well over $10^3$ (Iteration 1024). The network is actively growing over time, adding thousands of nodes.
2. **Decreasing Maximum Centrality:** In Iteration 2, the highest betweenness centrality is ~0.7. By Iteration 1024, the highest value has shrunk to ~0.24. The X-axis scale compresses accordingly in each subsequent chart.
3. **Solidification of Skew:** The distribution shifts from a sparse, somewhat random scattering (Iteration 2) to a highly defined, long-tail distribution (Iterations 510 and 1024).
### Interpretation
Applying Peircean abductive reasoning to these visual trends reveals the underlying mechanics of the network being modeled:
* **Network Growth Model:** The data strongly suggests a generative network model (such as the Barabási–Albert model of preferential attachment). We are watching a network grow from a tiny seed (Iteration 2) into a massive complex system (Iteration 1024).
* **The Meaning of the Zero-Peak:** Betweenness centrality measures how often a node acts as a bridge along the shortest path between two other nodes. The massive, exponentially growing spike at 0.00 indicates that as the network grows, almost all *new* nodes are added to the periphery (leaf nodes). They do not act as bridges for any other nodes.
* **Dilution of Centrality:** The fact that the *maximum* betweenness centrality drops from 0.7 to 0.24 is highly significant. In a tiny network (Iteration 2), a single central node might be the *only* bridge between two halves of the network, giving it a very high relative centrality score (0.7). As the network grows to thousands of nodes (Iteration 1024), it becomes denser. More alternative paths are created. Even the most critical "hub" nodes now share the bridging load with other pathways, diluting their individual betweenness score relative to the whole network, capping out at ~0.24.
* **Conclusion:** The charts successfully visualize the emergence of a scale-free or complex network topology, characterized by a few highly connected hubs (the long tail on the right) and a massive majority of peripheral, low-influence nodes (the massive spike on the left).
</details>
Figure S3: Distribution of betweenness centrality across four iterations, $\mathcal{G_{1}}$ . The $y$ -axis is in log scale, indicating the number of nodes with a given centrality value. The evolution suggests a transition from an early centralized state to a more distributed knowledge structure in later iterations.
| Graph Utilization | 5/5 (Explicit use of graph-based insights for material selection and optimization) | 0/5 (No reference to graph data) |
| --- | --- | --- |
| Depth of Reasoning | 4/5 (Multi-step reasoning including AI/ML integration, degradation adaptability, and bioinspiration) | 3/5 (Structured approach but mostly standard materials science reasoning) |
| Scientific Rigor | 4/5 (Logical relationships between material properties, AI/ML, and impact resistance) | 4/5 (Follows well-established materials science principles with clear reasoning) |
| Innovativeness | 5/5 (Proposes unique ideas such as AI/ML-driven discovery, urban ecosystems, and adaptive materials) | 3/5 (Uses conventional material design strategies without novel insights) |
| Overall Score | 18/20 (Superior interdisciplinary and computational approach) | 10/20 (Limited to conventional material design strategies) |
Table S1: Comparison of Responses on Impact-Resistant Material Design with Annotated Scores. Response 1 achieves a higher score due to its interdisciplinary approach, explicit graph-based insights, and innovative integration of AI/ML.
Text Box S1: Answer of the graph-reasoning model to the task Describe a way to design impact resistant materials. In this case, we extract key insights from a knowledge graph using centrality measures, Louvain community detection, and key relationship identification, integrating structured graph-based context into LLM prompts to enhance reasoning and evaluate response quality.
Iterative Reasoning $i<N$ Iterative Reasoning $i<N$ Answer of the graph-reasoning model
⬇ Based on the knowledge graph insights, I will outline a design strategy for impact - resistant materials. ** Design Strategy:** 1. ** Material Selection and Optimization **: Utilize advanced materials science and machine learning algorithms to identify and optimize materials with inherent impact resistance properties. This can be achieved by analyzing the relationships between materials, their properties, and impact resistance. 2. ** Self - Healing Materials **: Incorporate self - healing materials into the design, which can repair cracks and damages autonomously. This can be achieved through the use of microcapsules, polymers, or other materials that can release healing agents in response to impact. 3. ** Adaptive Materials **: Design materials that can adapt to changing environmental conditions, such as temperature, humidity, or pressure. This can be achieved through the use of shape - memory alloys, polymers, or other materials that can change their properties in response to external stimuli. 4. ** Urban Ecosystems Integration **: Incorporate urban ecosystems into the design, which can provide a natural source of inspiration for impact - resistant materials. For example, studying the properties of urban algae farms or the self - healing properties of certain plants can inform the design of impact - resistant materials. 5. ** Artificial Intelligence (AI) and Machine Learning (ML) Integration **: Utilize AI and ML algorithms to analyze data from various sources, such as sensor data, material properties, and environmental conditions. This can help identify patterns and trends that can inform the design of impact - resistant materials. 6. ** Material Degradation and Adaptability **: Design materials that can adapt to material degradation over time. This can be achieved through the use of materials that can self - heal, self - repair, or self - renew. ** Key Materials and Technologies:** 1. ** Shape - Memory Alloys (SMAs)**: SMAs can be used to create adaptive materials that can change their properties in response to external stimuli. 2. ** Polymers **: Polymers can be used to create self - healing materials that can repair cracks and damages autonomously. 3. ** Graphene **: Graphene can be used to create ultra - strong and lightweight materials with high impact resistance. 4. ** Nanomaterials **: Nanomaterials can be used to create materials with enhanced impact resistance and self - healing properties. ** Design Considerations:** 1. ** Material Properties **: Consider the material properties, such as strength, stiffness, and toughness, when designing impact - resistant materials. 2. ** Environmental Conditions **: Consider the environmental conditions, such as temperature, humidity, and pressure, when designing impact - resistant materials. 3. ** Scalability **: Consider the scalability of the design, including the ability to manufacture and deploy the material at large scales. 4. ** Cost - Effectiveness **: Consider the cost - effectiveness of the design, including the cost of materials, manufacturing, and deployment. By following this design strategy, impact - resistant materials can be designed that are optimized for performance, scalability, and cost - effectiveness.
Text Box S2: Answer of the base model to the task Describe a way to design impact resistant materials.
Iterative Reasoning $i<N$ Iterative Reasoning $i<N$ Answer of the base model
⬇ Designing impact - resistant materials involves creating materials that can absorb and distribute the energy of an impact, reducing the likelihood of damage or failure. Here ’ s a step - by - step approach to designing impact - resistant materials: 1. ** Material Selection **: Choose a material with inherent properties that can absorb and dissipate energy, such as: * High - density materials (e. g., metals, ceramics) * Viscoelastic materials (e. g., rubber, polymers) * Energy - absorbing materials (e. g., foam, composites) 2. ** Microstructure Optimization **: Design the material ’ s microstructure to optimize energy absorption: * Create a hierarchical structure with multiple scales (e. g., nanoparticles, microparticles, macroscopic particles) * Incorporate defects or irregularities to increase the material ’ s energy - absorbing capacity * Use phase transformations or phase changes to absorb energy 3. ** Material Properties Engineering **: Engineer the material ’ s properties to enhance its impact resistance: * Increase the material ’ s stiffness and strength to resist deformation * Improve the material ’ s toughness by increasing its energy - absorbing capacity * Enhance the material ’ s viscoelastic properties to absorb and dissipate energy 4. ** Composite Materials **: Design composite materials that combine different materials to achieve enhanced impact resistance: * Use a matrix material (e. g., polymer, metal) to bind together reinforcement materials (e. g., fibers, particles) * Incorporate energy - absorbing materials (e. g., foam, rubber) into the composite * Use a hierarchical structure to optimize energy absorption 5. ** Testing and Validation **: Test and validate the material ’ s impact resistance using standardized tests (e. g., Charpy impact test, Izod impact test): * Measure the material ’ s energy absorption capacity * Evaluate the material ’ s ability to withstand different types of impacts (e. g., drop, impact, penetration) 6. ** Scaling and Optimization **: Scale up the material design and optimize it for specific applications: * Use computational models (e. g., finite element analysis, molecular dynamics) to simulate the material ’ s behavior under impact * Optimize the material ’ s design for specific applications (e. g., aerospace, automotive, sports equipment) Some examples of impact - resistant materials include: * Kevlar - reinforced polymers * Carbon fiber - reinforced polymers * High - density polyethylene (HDPE) foam * Rubber - based composites * Ceramic matrix composites By following these steps, designers can create impact - resistant materials that can withstand various types of impacts and reduce the risk of damage or failure.
<details>
<summary>x24.png Details</summary>
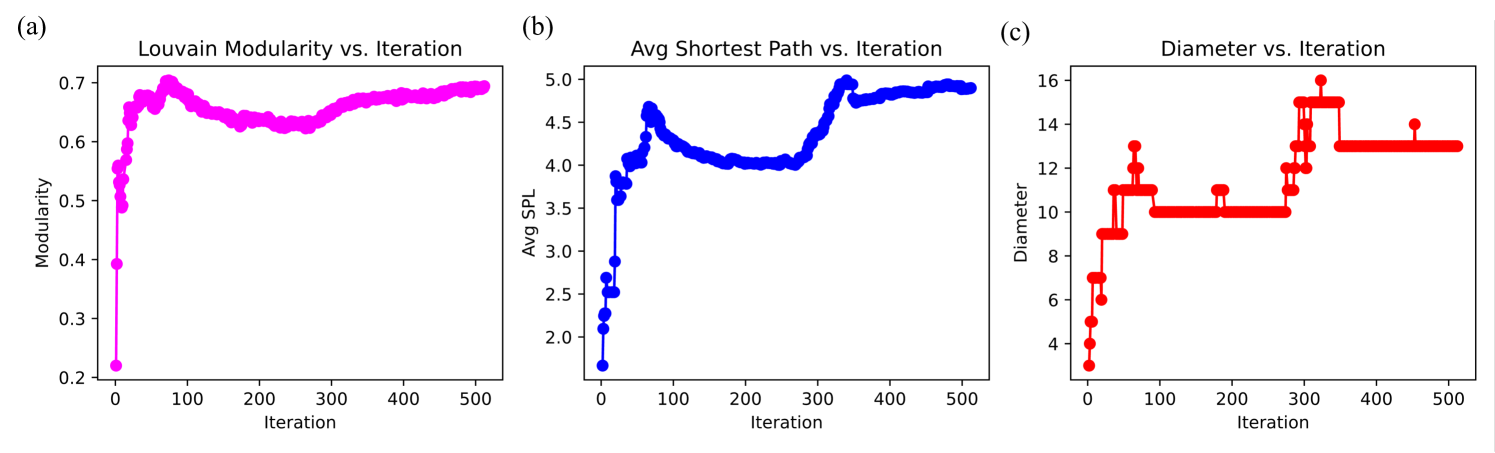
### Visual Description
## Multi-Panel Line Chart: Network Topology Metrics over Iterations
### Overview
This image contains three side-by-side line charts, labeled (a), (b), and (c) from left to right. The charts display the progression of three different network topology metrics—Louvain Modularity, Average Shortest Path Length (Avg SPL), and Diameter—over a series of iterations. All text in the image is in English.
### Components/Axes
**Global Elements (Shared across all charts):**
* **X-axis (Bottom):** Labeled "Iteration" on all three charts. The scale is linear, with major tick marks and labels at `0`, `100`, `200`, `300`, `400`, and `500`. The data extends slightly past the 500 mark (approximately to iteration 510-520).
**Chart (a) - Left Panel:**
* **Spatial Position:** Leftmost chart.
* **Panel Label:** "(a)" located in the top-left corner outside the chart area.
* **Title:** "Louvain Modularity vs. Iteration" located top-center above the chart.
* **Y-axis (Left):** Labeled "Modularity". The scale is linear, with major tick marks and labels at `0.2`, `0.3`, `0.4`, `0.5`, `0.6`, and `0.7`.
* **Data Series:** A single line with circular markers, colored magenta/pink.
**Chart (b) - Center Panel:**
* **Spatial Position:** Center chart.
* **Panel Label:** "(b)" located in the top-left corner outside the chart area.
* **Title:** "Avg Shortest Path vs. Iteration" located top-center above the chart.
* **Y-axis (Left):** Labeled "Avg SPL". The scale is linear, with major tick marks and labels at `2.0`, `2.5`, `3.0`, `3.5`, `4.0`, `4.5`, and `5.0`.
* **Data Series:** A single line with circular markers, colored blue.
**Chart (c) - Right Panel:**
* **Spatial Position:** Rightmost chart.
* **Panel Label:** "(c)" located in the top-left corner outside the chart area.
* **Title:** "Diameter vs. Iteration" located top-center above the chart.
* **Y-axis (Left):** Labeled "Diameter". The scale is linear, with major tick marks and labels at `4`, `6`, `8`, `10`, `12`, `14`, and `16`.
* **Data Series:** A single line with circular markers, colored red.
---
### Detailed Analysis
#### Chart (a): Louvain Modularity vs. Iteration
* **Trend Verification:** The magenta line exhibits a rapid initial ascent, reaches an early peak, experiences a shallow, prolonged dip, and then gradually climbs to a stable plateau.
* **Data Points (Approximate):**
* **Start:** At Iteration 0, the modularity starts at its lowest point, ~0.22.
* **Initial Climb:** Between iterations 0 and ~20, there is a near-vertical spike, reaching ~0.65.
* **First Peak:** The metric hits a global maximum of ~0.70 around iteration 75.
* **Trough:** From iteration 75 to ~250, the modularity slowly declines to a local minimum of ~0.62.
* **Recovery & Plateau:** From iteration 250 to 400, it climbs back up to ~0.68. From iteration 400 to the end (~510), the line plateaus, remaining highly stable just below 0.70 (approx. 0.69).
#### Chart (b): Avg Shortest Path vs. Iteration
* **Trend Verification:** The blue line shows a volatile early phase with sharp spikes and drops, followed by a gradual decline, a secondary sharp spike to a global maximum, and finally a high-level plateau.
* **Data Points (Approximate):**
* **Start:** At Iteration 0, the Avg SPL is at its lowest, ~1.7.
* **First Spike:** It rises sharply to ~3.9 around iteration 20, dips briefly to ~3.6 at iteration 30, and then spikes again to a local peak of ~4.7 around iteration 70.
* **Decline:** Between iterations 70 and 250, the Avg SPL gradually decreases, forming a shallow bowl shape that bottoms out at ~4.0.
* **Second Spike:** Between iterations 250 and 300, there is a steep climb to the global maximum of ~5.0.
* **Plateau:** After a brief drop to ~4.7 at iteration 310, the metric slowly rises and stabilizes, plateauing around ~4.9 from iteration 400 to the end (~510).
#### Chart (c): Diameter vs. Iteration
* **Trend Verification:** The red line behaves like a step function, indicating discrete integer values. It steps up rapidly, holds steady, experiences mid-iteration volatility with sharp spikes, and eventually settles into a flat plateau.
* **Data Points (Approximate):**
* **Start:** At Iteration 0, the diameter is 3.
* **Initial Steps:** Between iterations 0 and 30, it steps up rapidly through values 4, 5, 6, 7, and 9.
* **First Plateau:** It holds at 9 until iteration 50.
* **Volatility:** Around iteration 60-70, it spikes to 13, drops to 11, and holds at 11 until iteration 100.
* **Second Plateau:** From iteration 100 to ~270, it drops to and holds steady at 10 (with one brief, single-point spike to 11 around iteration 180).
* **Late Spikes:** Between iterations 270 and 320, it steps up to 11, 12, 13, spikes to 15, drops to 14, and hits a global maximum of 16.
* **Final Plateau:** It holds at 15 until iteration 350, then drops to 13. From iteration 350 to the end (~510), it forms a solid plateau at 13 (with one brief, single-point spike to 14 around iteration 450).
---
### Key Observations
1. **Convergence:** All three metrics show significant volatility in the first 350 iterations but reach a state of equilibrium or plateau between iterations 350 and 500.
2. **Correlated Volatility:** The major shifts in the network occur in similar phases. For example, around iteration 250-300, Modularity begins to recover (Chart a), Avg SPL spikes dramatically (Chart b), and Diameter experiences its highest volatility and peak (Chart c).
3. **Discrete vs. Continuous:** While Modularity and Avg SPL are continuous floating-point metrics (showing smooth curves between points), Diameter is strictly an integer metric, resulting in the rigid, stepped visual appearance of Chart (c).
### Interpretation
These charts likely represent the evolution of a network graph undergoing an iterative algorithm, such as a community detection process (explicitly named "Louvain" in chart a), a network pruning process, or a generative growth model.
* **Modularity (Chart a):** The rapid increase in modularity indicates that the algorithm is successfully finding and isolating dense communities (clusters) within the network. The high final plateau (~0.69) suggests a network with very strong community structure (dense internal connections, sparse external connections).
* **Avg Shortest Path & Diameter (Charts b & c):** As the network becomes more modular, the average distance between any two random nodes (Avg SPL) and the maximum distance between the two furthest nodes (Diameter) both increase significantly.
* **Synthesis:** Reading between the lines, the data demonstrates a structural trade-off. As the algorithm forces the network into distinct, tight-knit communities (high modularity), it likely removes or stretches the "bridge" edges that connect these different communities. Consequently, traversing the network from one community to another takes more steps, driving up both the average shortest path and the overall diameter of the graph. The stabilization of all three metrics after iteration 350 indicates that the algorithm has converged on a final, optimized network topology.
</details>
Figure S4: Evolution of key structural properties in the recursively generated knowledge graph ( $\mathcal{G_{2}}$ , focused on Describe a way to design impact resistant materials.): (a) Louvain modularity, showing stable community formation; (b) average shortest path length, highlighting efficient information propagation; and (c) graph diameter, demonstrating bounded hierarchical expansion.
<details>
<summary>x25.png Details</summary>
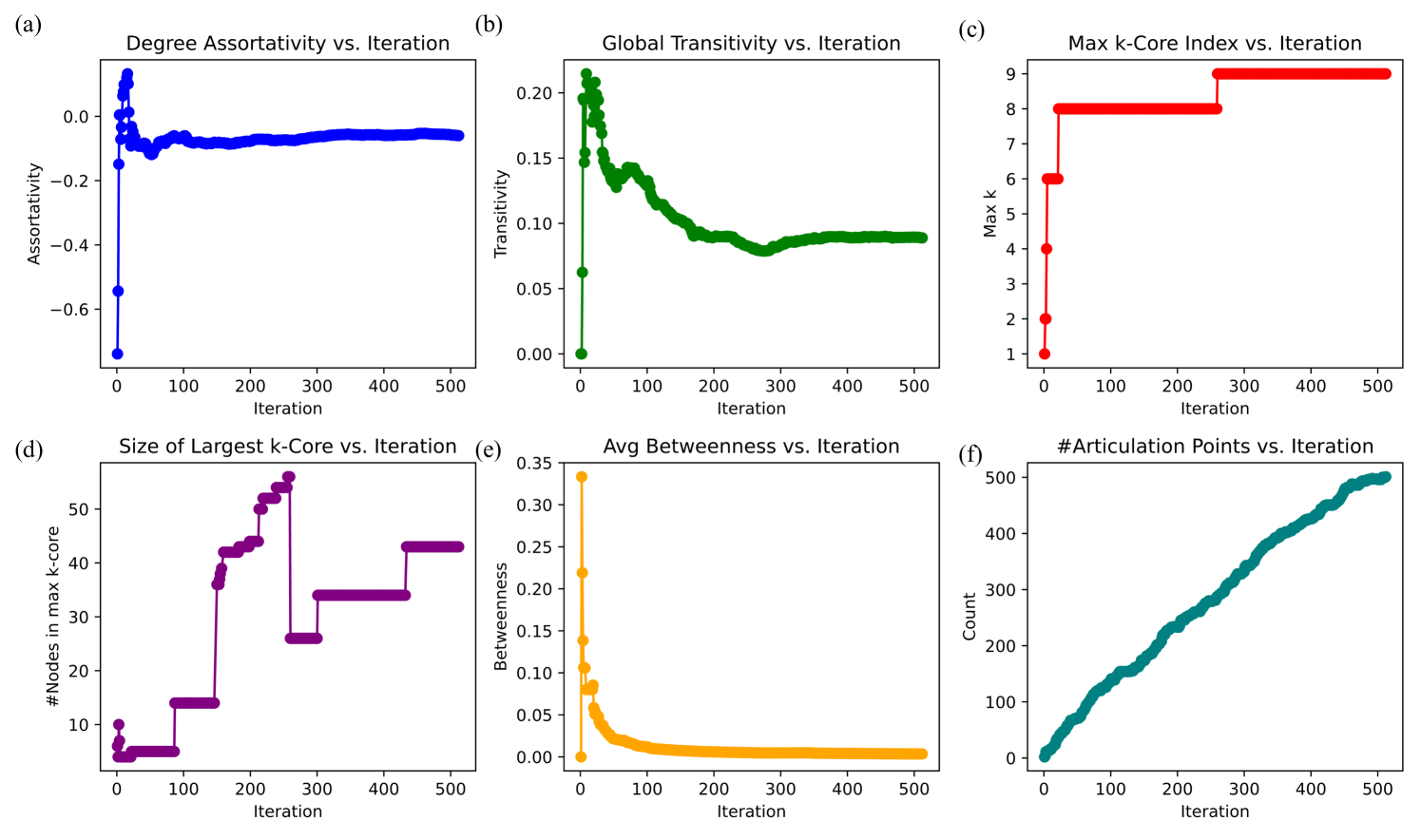
### Visual Description
## Multi-Panel Line Charts: Network Evolution Metrics
### Overview
This image consists of a 2x3 grid of line charts, labeled (a) through (f). The charts display the evolution of various network topology metrics over a series of iterations. All six charts share a common X-axis representing "Iteration," ranging from 0 to slightly over 500. Each chart utilizes a distinct color for its data series and plots a different network metric on the Y-axis. There is no standalone legend; instead, the title of each subplot and the Y-axis label define the data being presented.
### Components/Axes
* **Global X-Axis:** Present on all six charts. Labeled "Iteration". Major tick marks are at 0, 100, 200, 300, 400, and 500.
* **Panel (a) - Top-Left:**
* Title: "Degree Assortativity vs. Iteration"
* Y-Axis Label: "Assortativity"
* Y-Axis Scale: -0.6 to 0.0 (Tick marks at -0.6, -0.4, -0.2, 0.0)
* Data Color: Blue
* **Panel (b) - Top-Center:**
* Title: "Global Transitivity vs. Iteration"
* Y-Axis Label: "Transitivity"
* Y-Axis Scale: 0.00 to 0.20 (Tick marks at 0.00, 0.05, 0.10, 0.15, 0.20)
* Data Color: Green
* **Panel (c) - Top-Right:**
* Title: "Max k-Core Index vs. Iteration"
* Y-Axis Label: "Max k"
* Y-Axis Scale: 1 to 9 (Tick marks at 1, 2, 3, 4, 5, 6, 7, 8, 9)
* Data Color: Red
* **Panel (d) - Bottom-Left:**
* Title: "Size of Largest k-Core vs. Iteration"
* Y-Axis Label: "#Nodes in max k-core"
* Y-Axis Scale: 10 to 50 (Tick marks at 10, 20, 30, 40, 50)
* Data Color: Purple
* **Panel (e) - Bottom-Center:**
* Title: "Avg Betweenness vs. Iteration"
* Y-Axis Label: "Betweenness"
* Y-Axis Scale: 0.00 to 0.35 (Tick marks at 0.00, 0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35)
* Data Color: Orange
* **Panel (f) - Bottom-Right:**
* Title: "#Articulation Points vs. Iteration"
* Y-Axis Label: "Count"
* Y-Axis Scale: 0 to 500 (Tick marks at 0, 100, 200, 300, 400, 500)
* Data Color: Teal/Dark Cyan
### Detailed Analysis
**Panel (a): Degree Assortativity vs. Iteration**
* *Trend:* The blue line exhibits extreme volatility in the initial iterations, featuring a sharp drop followed by a rapid spike, before dampening into a stable, slightly negative horizontal line.
* *Data Points:* The value begins at approximately -0.75 at iteration 0. It immediately spikes to a peak of roughly +0.15 around iteration 20. It then drops back down to approximately -0.15 by iteration 50. From iteration 100 through 500, the line stabilizes, hovering consistently between -0.05 and -0.10.
**Panel (b): Global Transitivity vs. Iteration**
* *Trend:* The green line shows an immediate, massive spike from zero, followed by a jagged, gradual decay curve that eventually levels off.
* *Data Points:* Starting exactly at 0.00 at iteration 0, it shoots up to a peak of ~0.21 within the first 10-15 iterations. It drops to ~0.13 near iteration 50, experiences a secondary bump to ~0.14 around iteration 80, and then steadily declines. By iteration 280, it hits a local minimum of ~0.08. It then rises slightly and stabilizes at approximately 0.09 from iteration 350 to 500.
**Panel (c): Max k-Core Index vs. Iteration**
* *Trend:* The red line follows a strict, monotonically increasing step-function. It only moves horizontally or vertically upwards.
* *Data Points:* Starting at a value of 1 at iteration 0, it rapidly steps up to 2, 4, and 6 within the first 10 iterations. By iteration ~20, it steps up to 8. It remains perfectly flat at 8 for a long duration. At approximately iteration 260, it steps up to 9, where it remains flat through iteration 500.
**Panel (d): Size of Largest k-Core vs. Iteration**
* *Trend:* The purple line is a highly volatile step-function. Unlike panel (c), it features both sharp increases and sharp decreases, forming distinct plateaus.
* *Data Points:* Starting at ~10 nodes, it drops to ~4 nodes almost immediately. It stays at ~5 nodes until iteration ~80, where it steps up to ~14. At iteration ~150, it jumps to ~36, then steps up incrementally to ~42, ~44, and ~50, peaking at ~56 nodes around iteration 250. *Crucially*, at iteration ~260, it plummets sharply down to ~26 nodes. It steps up to ~34 at iteration 300, and finally steps up to ~43 at iteration 430, remaining there until the end.
**Panel (e): Avg Betweenness vs. Iteration**
* *Trend:* The orange line demonstrates an extreme initial spike followed by a rapid, smooth exponential decay, asymptotically approaching zero.
* *Data Points:* Starting at 0.00 at iteration 0, it spikes instantly to its maximum of ~0.33 at iteration 1 or 2. It crashes rapidly, falling below 0.10 by iteration 20. By iteration 100, the value is approximately 0.02. From iteration 200 to 500, the line is virtually flat, hovering just above 0.00.
**Panel (f): #Articulation Points vs. Iteration**
* *Trend:* The teal line displays a nearly constant, linear upward slope from the beginning to the end of the observed period.
* *Data Points:* Starting at 0 at iteration 0, it grows steadily. At iteration 100, the count is ~130. At iteration 200, it is ~240. At iteration 300, it is ~350. At iteration 400, it is ~430. By iteration 500, the count reaches approximately 500.
### Key Observations
1. **Initial Chaos:** The first 50 iterations represent a period of extreme structural volatility. Assortativity (a), Transitivity (b), and Betweenness (e) all experience their most dramatic spikes and crashes during this brief initial window.
2. **Correlated Step-Changes:** There is a direct, observable correlation between Panel (c) and Panel (d) at iteration ~260. Exactly when the Max k-Core Index increases from 8 to 9, the *size* of that maximum k-core drops precipitously from ~56 to ~26.
3. **Divergent Long-Term Trends:** While metrics like Assortativity, Transitivity, and Betweenness stabilize and flatten out after iteration 200, the number of Articulation Points (f) continues to grow linearly without any sign of plateauing.
### Interpretation
These charts likely depict the evolution of a generative network model or a dynamic graph undergoing a specific iterative process (such as node addition, edge rewiring, or a specific algorithmic simulation).
* **Network Maturation:** The wild fluctuations in the first 50 iterations suggest the network starts from a highly unstable or trivial state (e.g., an empty graph or a simple chain) and rapidly forms its initial complex topology. The stabilization of Betweenness near zero indicates that as the network grows, it loses any central "bottleneck" nodes; paths become distributed.
* **Core Deepening vs. Shrinking:** The relationship between charts (c) and (d) is a classic demonstration of k-core decomposition dynamics. As the network evolves, it becomes dense enough to support a higher-order core (moving from an 8-core to a 9-core at iteration 260). However, because the criteria for a 9-core are stricter (every node must have at least 9 connections *within* that specific subgraph), many nodes that qualified for the 8-core are filtered out. Thus, the core becomes "deeper" (more densely connected) but physically smaller in terms of node count.
* **Peripheral Expansion:** The relentless linear growth of Articulation Points (f) (nodes whose removal would disconnect the graph) combined with the stabilizing dense core suggests a specific growth pattern. The network is likely developing a dense, cohesive center (evidenced by the k-core and stable transitivity) while simultaneously growing long, tree-like, or branching structures on its periphery. Every new node added to these peripheral branches creates a new articulation point, explaining the steady linear climb in chart (f) even as the core metrics stabilize.
</details>
Figure S5: Evolution of graph properties over recursive iterations, highlighting the emergence of hierarchical structure, hub formation, and adaptive connectivity (Graph $\mathcal{G_{2}}$ , focused on Describe a way to design impact resistant materials.).
See pages - of discovery_sample.pdf
See pages - of compositional_1_20250217_140156.pdf
See pages - of compositional_2_20250217_140156_o1-pro.pdf
See pages - of proposal_1.pdf