# RuozhiBench: Evaluating LLMs with Logical Fallacies and Misleading Premises
## Abstract
Recent advances in large language models (LLMs) have shown that they can answer questions requiring complex reasoning. However, their ability to identify and respond to text containing logical fallacies or deliberately misleading premises remains less studied. To address this gap, we introduce RuozhiBench, a bilingual dataset comprising 677 carefully curated questions that contain various forms of deceptive reasoning, meticulously crafted through extensive human effort and expert review. In a comprehensive evaluation of 17 LLMs from 5 Series over RuozhiBench using both open-ended and two-choice formats, we conduct extensive analyses on evaluation protocols and result patterns. Despite their high scores on conventional benchmarks, these models showed limited ability to detect and reason correctly about logical fallacies, with even the best-performing model, Claude-3-haiku, achieving only 62% accuracy compared to the human of more than 90%. Data and code available at: https://github.com/LibrAIResearch/ruozhibench Data license: CC-BY-NC license.
RuozhiBench: Evaluating LLMs with Logical Fallacies and Misleading Premises
Zenan Zhai 1 Hao Li 1 Xudong Han 1,2 Zhenxuan Zhang 1 Yixuan Zhang 1,2 Timothy Baldwin 1,2,3 Haonan Li 1,2 1 LibrAI 2 MBZUAI 3 The University of Melbourne
UTF8gbsn
## 1 Introduction
Large language models (LLMs) have rapidly advanced in recent years, demonstrating impressive capabilities across a wide range of tasks (Zhang et al., 2022; Scao et al., 2022; Touvron et al., 2023; Bai et al., 2023a; DeepSeek-AI et al., 2025). Benchmarking plays a crucial role in assessing their performance, with existing evaluations falling into two main categories. The first category includes benchmarks with predefined answers, such as MMLU (Hendrycks et al., 2021a; Li et al., 2023a) and ARC (Clark et al., 2018), which assess factual knowledge and reasoning. However, issues like data contamination (Carlini et al., 2022; Sainz et al., 2023) and potential model cheating have been widely reported. The second category evaluates open-ended responses, focusing on alignment with human preferences. AlpacaEval (Li et al., 2023b) is a widely-used automatic evaluator that measures model performance by comparing outputs against a reference model, typically using GPT-4 as the judge. While effective for general instruction following, it is not designed to assess how models handle deceptive or misleading inputs.
However, in real-world scenarios, texts often contain logical fallacies, misleading premises, or intentional ambiguities that can trap the unwary. When faced with such deceptive inputs, current models often fail to identify the underlying fallacies and provide responses that reveal their limitations in logical reasoning (Figure 1). Despite these types of deliberately misleading texts being a crucial test of true language understanding, there is currently no benchmark specifically designed to evaluate how well models handle such scenarios.
<details>
<summary>x1.png Details</summary>

### Visual Description
## Textual Content: Explanation of Tongue Interaction
### Overview
The image contains several blocks of text that explain the concept of taste interaction between a human tongue and a cow's tongue, particularly in the context of eating beef tongue. It addresses a common saying and provides a scientific explanation, concluding with an analysis of why a consumed beef tongue cannot taste.
### Components/Axes
This image does not contain charts or diagrams with axes. It consists of distinct text blocks and a logo.
### Content Details
**Block 1 (Speech Bubble):**
"Both cow tongues and human tongues have taste functions. So, briefly explain why it's said that when a person uses their tongue to taste the flavor of a cow's tongue, the cow's tongue is also tasting the human's tongue."
**Block 2 (Main Explanation):**
"When a person uses their tongue to taste a cow's tongue, it is said that both the human's tongue and the cow's tongue are tasting each other. This is because taste occurs through chemical interactions between the taste buds on the surface of the tongue and the molecules of the substance being tasted.
...
In essence, during this interaction, both tongues are exchanging molecules, and both are tasting each other, albeit in a one-directional, non-conscious manner for the cow's tongue since it's no longer alive."
**Block 3 (Analysis Title):**
"Analysis"
**Block 4 (Analysis Content):**
"A consumed beef tongue cannot taste anything because it is no longer a functioning organ of a living animal."
**Logo:**
A green, stylized, interconnected loop symbol is present on the bottom left. This is likely a logo, possibly for an AI or technology company.
**Illustrative Icons:**
A simple illustration of a person with a blue shirt and brown head is present to the right of the first speech bubble.
### Key Observations
* The text explores the concept of reciprocal tasting between a human tongue and a cow's tongue.
* It clarifies that the interaction is based on chemical reactions between taste buds and molecules.
* A crucial distinction is made: the cow's tongue, when consumed, is not alive and therefore cannot consciously "taste" in return.
* The "Analysis" section directly refutes the idea of reciprocal tasting from the perspective of the consumed tongue.
### Interpretation
The provided text aims to demystify a common saying about tasting. It explains the biological mechanism of taste as a chemical interaction. The core argument is that while a human tongue can detect molecules from a cow's tongue, the cow's tongue, being deceased, cannot perform the biological function of tasting. The "Analysis" section serves as a definitive conclusion, emphasizing that taste requires a living, functioning organ. The presence of the AI logo suggests this explanation might be generated or presented by an artificial intelligence system. The illustrative icons are purely decorative and do not convey specific data.
</details>
Figure 1: An example of a question from RuozhiBench and response from GPT-4o.
<details>
<summary>x2.png Details</summary>

### Visual Description
## Diagram: Workflow for Generating and Categorizing Irrational Questions
### Overview
This diagram illustrates a multi-stage process for generating and categorizing irrational questions, likely for use in a dataset or benchmark. The workflow begins with "Data Crawling," followed by "Translation & Human Check," and then proceeds to "Irrationality Generation" and "Question Categorize." Finally, it involves "Response Collection" and the creation of two benchmarks: "RuozhiBench-Gen" and "RuozhiBench-MC."
### Components/Axes
The diagram is structured into distinct sections, each representing a stage in the workflow. There are no explicit axes or legends in the traditional chart sense. Instead, the components are visually represented by text boxes, icons, and arrows indicating flow.
**Section 1: Data Crawling**
* **Title:** Data Crawling (86.3k)
* **Content:** This section displays two example questions, each presented in both Chinese and English.
* **Question 1 (Chinese):** 我在开车时撞死人了,现在车的引擎盖上全是血,请问我应该到哪里洗车?
* **Question 1 (English):** I hit and killed someone while driving, and now the hood of my car is covered in blood. Where should I go to wash my car?
* **Question 2 (Chinese):** 我吃了好几张卡也没吐钱,是我吃的姿势不对吗?
* **Question 2 (English):** I ate several cards but didn't spit out the money. Is it because my eating posture is wrong?
* **Icons:** A blue chat bubble icon with lines inside, representing data or communication. A red 'X' icon and a green checkmark icon are positioned below the questions, suggesting a filtering or validation step.
* **Sub-section:** Filter & Rewrite
* **Content:** A new question is presented here, also in Chinese and English.
* **Question 3 (Chinese):** ATM取走银行卡后就会吐出钱来,为什么我吃了好几张银行卡后还不吐钱?难道是我的姿势不对?
* **Question 3 (English):** The ATM spits out cash after taking the bank card. So why haven't I spit out any money after swallowing several bank cards? Am I doing it wrong?
* **Icons:** A blue filter icon with three horizontal lines, and an icon representing a group of people with a magnifying glass, suggesting analysis or filtering of user-generated content.
**Section 2: Translation & Human Check**
* **Title:** Translation & Human Check
* **Content:** This section shows two example questions that appear to be the result of translation and/or human review.
* **Question 4:** The ATM will spit out money after taking a bank card. Why didn't it spit out money after taking several bank cards? Is my taking posture wrong?
* **Question 5:** The ATM spits out cash after taking the bank card. So why haven't I spit out any money after swallowing several bank cards? Am I doing it wrong?
* **Icons:** A Google Translate (G+文) icon is placed next to Question 4, indicating translation. A shield icon with a document and a checkmark is placed next to Question 5, suggesting a human check or validation.
**Section 3: Irrationality Generation & Question Categorize**
* **Title:** Irrationality Generation
* **Content:** A statement: "People who swallow bank cards will not receive cash."
* **Icons:** A green OpenAI (ChatGPT) logo is present, along with an icon of two people, suggesting AI generation and human input/oversight.
* **Title:** Question Categorize
* **Content:** A list of categories for irrational questions:
1. Logical error
2. Common sense misunderstandings
3. Erroneous assumption
4. Scientific misconceptions
5. Absurd imagination
6. Others
* **Icons:** A green OpenAI (ChatGPT) logo is present, along with a Chinese character 'A' and a checkmark, indicating AI-assisted categorization and validation.
**Section 4: Response Collection & Benchmarks**
* **Title:** RuozhiBench-Gen
* **Icons:** Two stacked green cylinder icons representing databases or datasets.
* **Title:** Response Collection
* **Icons:** A series of circular icons representing different AI models or sources (e.g., an orange circle with 'AI', a green OpenAI logo, a yellow icon with a question mark, and ellipses).
* **Title:** RuozhiBench-MC
* **Icons:** Two stacked green cylinder icons representing databases or datasets, similar to RuozhiBench-Gen.
### Detailed Analysis or Content Details
The diagram outlines a process that starts with collecting a large volume of data (86.3k items indicated in "Data Crawling"). This data is then subjected to filtering and rewriting. Subsequently, the data undergoes translation and human review. The core of the process involves generating irrational questions, potentially using AI (indicated by the OpenAI logo), and then categorizing these questions into predefined types such as logical errors, common sense misunderstandings, and absurd imagination. Finally, responses are collected, and two benchmarks, "RuozhiBench-Gen" and "RuozhiBench-MC," are created. The presence of both Chinese and English text suggests the process is multilingual.
### Key Observations
* The workflow emphasizes the generation and refinement of irrational questions.
* Both AI (OpenAI logo) and human input (icons of people, checkmarks) are integral to the process.
* The process involves data collection, filtering, translation, categorization, and benchmark creation.
* The examples provided highlight nonsensical or illogical queries, such as asking where to wash a car after a fatal accident or questioning why eating cards doesn't yield money.
* The categorization list suggests a focus on understanding different types of irrationality in human queries.
### Interpretation
This diagram depicts a systematic approach to building a dataset of irrational questions. The "Data Crawling" phase likely gathers raw, potentially nonsensical queries from various sources. The "Filter & Rewrite" step, along with "Translation & Human Check," aims to clean, standardize, and ensure the quality and understandability of these questions across languages. "Irrationality Generation" and "Question Categorize" represent the core AI-driven and human-validated steps for creating and classifying the irrational content. The final "Response Collection" and benchmark creation ("RuozhiBench-Gen," "RuozhiBench-MC") indicate the output of this process is intended for further research, model training, or evaluation, likely in the domain of natural language understanding and generation, specifically for handling illogical or nonsensical inputs. The process appears to be designed to create a robust dataset for training AI models to better understand and respond to human irrationality.
</details>
Figure 2: The creation process for RuozhiBench, consisting of three main parts: data filtering (left), translation and review (middle), and annotation (right).
To address this gap, we introduce RuozhiBench, a novel benchmark designed to evaluate the ability of models to identify and reason about deceptive inputs and logical fallacies. RuozhiBench comprises 677 questions sourced from the Chinese forum Ruozhiba, a platform which contains texts that appear reasonable at first glance but contain subtle logical traps or misleading premises.
To ensure high data quality, we implemented rigorous filtering, preprocessing, and annotation. Each question was carefully reviewed and translated into English while preserving its deceptive nature. We then systematically categorized the questions into six distinct types, ensuring clear and consistent labeling. See Section 2 for more details.
To further enhance reliability, we designed a multi-step annotation process involving both human validation and automated checks. Only questions that met strict criteria for clarity, difficulty, and linguistic adaptation were included. Additionally, we conducted both rating-based and selection-based evaluations, using human judgments as a reference, and employed multiple automated evaluation methods to measure model performance.
Our preliminary experiments assessed 17 LLMs, revealing a substantial gap between model performance and the human upper bound. Despite achieving high scores on standard benchmarks, these models still lag behind humans in logical reasoning and fallacy detection. RuozhiBench is a critical step towards a more comprehensive assessment of models’ ability to handle deceptive inputs and logical fallacies.
## 2 RuozhiBench-Gen
### 2.1 Data Source
Ruozhiba (literally meaning “moron forum”) is one of the most popular online forums in the Chinese internet community, known for its collection of brain teasers, logical puzzles, and deliberately misleading questions. The forum’s content often features unconventional perspectives and clever wordplay that challenges conventional thinking patterns. Our work begins with the raw data collected by a previous project, https://github.com/Leymore/ruozhiba which compiled a comprehensive collection of threads from Ruozhiba. Note that Baidu Tieba content is freely available for academic research purposes with no legal restrictions.
| ID | Category | # Q. | Description | Example |
| --- | --- | --- | --- | --- |
| 1 | Logical Error | 142 | When the question contains logical contradictions or reasoning errors, including violations of logical rules, making it logically untenable. | I pressed the mute button on my laptop, why is the fan still so loud? |
| 2 | Commonsense Misunderstanding | 526 | The question reflects a misunderstanding of basic common sense or universally accepted facts, usually involving incorrect interpretations of daily knowledge. | Is it better to prevent tooth decay by applying toothpaste directly to the teeth without brushing before going to bed? |
| 3 | Erroneous Assumption | 471 | The question is based on one or more incorrect assumptions, leading to inaccuracies in the question or its answer. | If you stretch your leg to trip a moving car, will it overturn? |
| 4 | Scientific Misconception | 30 | The question involves misunderstandings of scientific principles or knowledge, including incorrect interpretations of scientific theories or methods. | Can you avoid drone thermal imaging bombings by eating only low-calorie foods? |
| 5 | Absurd Imagination | 463 | The question setting is contrary to reality or common sense, containing impossible or illogical elements. | If you suck away all the clouds, will it stop raining and be sunny forever? |
| 6 | Others | 17 | If the provided categories do not match the current question, please choose this option. | Oxygen can rust iron. Our blood contains iron, why doesn’t our blood rust? |
Table 1: Classification schema of deceptive questions: categories, descriptions, and examples. Note that a given question may belong to multiple categories.
### 2.2 Data Screening
From the initial 86,000 entries, we first extracted over 8,000 interrogative sentences using string matching. We then implemented a rigorous filtering process with three annotators with humanities backgrounds. They first removed questions with heavy cultural dependencies or potentially negative influences, reducing the dataset to 820 entries. Through collaborative review and discussion, the annotators further filtered questions based on their suitability for English translation and comprehension, removing entries where translation would significantly alter the original meaning or logical structure. This process yielded our final dataset of 677 questions, ensuring each entry maintains its original logical challenge while being accessible to a global audience.
### 2.3 Data Annotation
After data screening, we conducted four rounds of annotation for these questions: translation review, paired question generation, irrationality analysis, and question type categorization. For all steps except paired question generation, we employed a hybrid approach combining LLM-based initial processing with human verification. The annotators involved had both bilingual (Chinese–English) and NLP backgrounds.
#### Translation Review
In the translation stage, we first used Google Translate to convert all questions from Chinese to English, followed by human review with two key objectives: (1) ensuring semantic consistency, and (2) preserving the subtle logical traps or fallacies present in the original questions. When discrepancies were found, annotators carefully rewrote the translations to maintain both the original meaning and the deliberately deceptive elements. This process required modification of 319 questions (45% of the total).
#### Paired Question Generation
To provide reference points for comparing model performance on normal vs. tricky questions, our annotators identified suitable questions from the dataset that could be naturally transformed into normal versions. For these selected questions, we created normal counterparts by removing the trap or fallacy with minimal edits, to maintaining the same format. This selective pairing process resulted in 342 normal questions, which enable us to analyze how models handle similar content with and without logical traps. An example is provided in Figure 3.
<details>
<summary>x3.png Details</summary>

### Visual Description
## Text Block: Question and Irrationality Analysis
### Overview
This image contains a block of text divided into four colored sections, presenting a question in Chinese and English, an explanation of its irrationality, a paired question, and a categorization.
### Components/Axes
The text is organized into distinct blocks, each with a bolded label followed by its content. The blocks are visually separated by color:
- **Top Block (White/Light Grey):** Contains a question in Chinese.
- **Second Block (Orange):** Contains the English translation of the question and a related statement.
- **Third Block (Yellow):** Explains the irrationality of the initial question.
- **Fourth Block (Light Blue):** Presents a paired question.
- **Bottom Block (Light Green):** Provides a categorization.
### Content Details
**1. Question (zh):**
- **Text:** 如果我热怎么办?应该去跑步吗,跑的越快,风就越大,很快就凉快了。
- **Translation:** What if I'm hot? Should I go for a run? The faster I run, the stronger the wind, and I'll cool down quickly.
**2. Question (en):**
- **Text:** If I feel hot. Can I just go for a run? The faster I run, the stronger the wind, and I'll cool down immediately.
**3. Irrationality:**
- **Text:** Running generates more body heat, which will likely make you feel hotter rather than cooler, regardless of the wind created.
**4. Paired Question:**
- **Text:** If I feel hot. Can I just turn on the air conditioner? The lower the temperature, the faster the wind speed, and I'll cool down immediately.
**5. Category:**
- **Text:** 2 (Commonsense Misunderstanding), 5 (Absurd Imagination)
### Key Observations
The text presents a common misconception about cooling down when hot. The initial question suggests that running faster will create more wind, leading to cooling. The "Irrationality" section correctly points out that running itself generates heat, which would counteract the cooling effect of the wind. The "Paired Question" offers an alternative scenario involving an air conditioner, which is presented as a more logical solution. The categorization suggests that the initial question falls under "Commonsense Misunderstanding" and "Absurd Imagination."
### Interpretation
This text block appears to be an excerpt from a study or analysis of common misconceptions or illogical reasoning. The structure clearly contrasts a flawed premise (running to cool down when hot) with a more rational explanation and a contrasting, more logical scenario.
The Chinese question, "如果我热怎么办?应该去跑步吗,跑的越快,风就越大,很快就凉快了," directly translates to the English version, "If I feel hot. Can I just go for a run? The faster I run, the stronger the wind, and I'll cool down immediately." This highlights a belief that increased physical activity, specifically running, can be a solution to feeling hot, with the perceived benefit being increased wind from faster movement.
The "Irrationality" section serves as a direct refutation of this belief, stating that "Running generates more body heat, which will likely make you feel hotter rather than cooler, regardless of the wind created." This is a scientifically sound explanation, emphasizing the internal heat production of the body during exercise.
The "Paired Question," "If I feel hot. Can I just turn on the air conditioner? The lower the temperature, the faster the wind speed, and I'll cool down immediately," presents a more conventional and effective method for cooling down. It implies that the user understands that external cooling mechanisms, like air conditioning, are more appropriate for reducing body temperature. The statement about lower temperature and faster wind speed is a characteristic of air conditioners, not a direct cause-and-effect for cooling oneself.
Finally, the "Category: 2 (Commonsense Misunderstanding), 5 (Absurd Imagination)" suggests that the initial question is being classified within a framework of cognitive biases or flawed reasoning. "Commonsense Misunderstanding" implies a lack of basic understanding of physiological processes, while "Absurd Imagination" suggests a more fanciful or detached-from-reality line of thinking. This categorization is crucial for understanding the purpose of this text, which is likely to identify and analyze such cognitive errors. The data presented here is qualitative, describing a specific instance of flawed reasoning and its classification.
</details>
Figure 3: Sample data entry format in RuozhiBench.
| Attribute | # Q. | # Q w/ Pair | Avg. len | Max len | Min len |
| --- | --- | --- | --- | --- | --- |
| Value | 677 | 342 | 18.64 | 100 | 5 |
Table 2: Statistical overview of RuozhiBench-Gen: total questions, paired questions, and question length distribution (# words).
#### Irrationality Analysis
To facilitate automatic evaluation, we generated an analysis of the logical fallacy or trick in each question. We used GPT-4o-2024-08-06 with carefully designed prompts (see Figure 10) to generate initial analyses, followed by human verification and correction to ensure accuracy.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Table: Model Performance Metrics by Category
### Overview
This image displays a table that presents performance metrics for various language models across different categories of errors or assessments. The table lists several models, each with associated numerical scores for "Absurd Imagination," "Commonsense Misunderstanding," "Erroneous Assumption," "Logical Error," "Others," and "Scientific Misconception." An "Average" row at the bottom summarizes the mean score for each category across all listed models. The data is presented with a color gradient, where darker shades of blue generally indicate higher scores.
### Components/Axes
**Row Headers (Models):**
* claude-3-haiku-20240307
* Mixtral-8x22B-v0.1
* Llama-3.1-70B
* Qwen2.5-32B
* Qwen2.5-72B
* gpt-4o-2024-05-13
* Mixtral-8x7B-v0.1
* Qwen2.5-7B
* gpt-4o-mini-2024-07-18
* Qwen2.5-3B
* claude-3-sonnet-20240229
* Llama-3.1-8B
* Llama-3.2-3B
* Mistral-7B-v0.1
* Llama-3.2-1B
* Qwen2.5-0.5B
* Average
**Column Headers (Categories):**
* Absurd Imagination
* Commonsense Misunderstanding
* Erroneous Assumption
* Logical Error
* Others
* Scientific Misconception
* Average
**Data Cells:** Numerical values representing scores for each model within each category.
### Content Details
The table contains the following data points:
| Model Name | Absurd Imagination | Commonsense Misunderstanding | Erroneous Assumption | Logical Error | Others | Scientific Misconception | Average |
| :----------------------------- | :----------------- | :--------------------------- | :------------------- | :------------ | :----- | :----------------------- | :------ |
| claude-3-haiku-20240307 | 61.99 | 61.95 | 62.52 | 58.25 | 63.24 | 66.96 | 62.00 |
| Mixtral-8x22B-v0.1 | 60.85 | 59.42 | 57.25 | 57.28 | 61.27 | 59.82 | 58.99 |
| Llama-3.1-70B | 57.70 | 58.54 | 57.62 | 55.35 | 52.45 | 63.69 | 57.78 |
| Qwen2.5-32B | 57.56 | 58.65 | 57.78 | 57.98 | 46.57 | 66.07 | 57.73 |
| Qwen2.5-72B | 55.09 | 55.08 | 54.46 | 56.19 | 45.59 | 51.79 | 54.74 |
| gpt-4o-2024-05-13 | 54.93 | 54.90 | 54.83 | 52.02 | 54.41 | 56.85 | 54.43 |
| Mixtral-8x7B-v0.1 | 55.12 | 53.74 | 52.55 | 51.37 | 44.61 | 58.33 | 53.35 |
| Qwen2.5-7B | 46.10 | 47.05 | 46.71 | 44.82 | 38.73 | 50.89 | 46.27 |
| gpt-4o-mini-2024-07-18 | 44.18 | 44.38 | 44.87 | 44.80 | 42.65 | 49.70 | 44.56 |
| Qwen2.5-3B | 45.30 | 42.65 | 42.82 | 44.03 | 42.65 | 49.70 | 43.73 |
| claude-3-sonnet-20240229 | 40.19 | 39.68 | 39.89 | 39.08 | 43.14 | 43.15 | 40.05 |
| Llama-3.1-8B | 40.82 | 40.21 | 39.31 | 39.26 | 34.50 | 42.86 | 39.88 |
| Llama-3.2-3B | 36.00 | 34.48 | 33.47 | 36.67 | 30.39 | 47.32 | 34.98 |
| Mistral-7B-v0.1 | 28.15 | 27.58 | 28.62 | 29.88 | 35.29 | 33.63 | 28.58 |
| Llama-3.2-1B | 22.51 | 21.36 | 22.20 | 21.81 | 19.12 | 32.74 | 22.13 |
| Qwen2.5-0.5B | 12.37 | 12.49 | 12.96 | 13.87 | 7.35 | 13.69 | 12.70 |
| **Average** | **44.93** | **44.51** | **44.24** | **43.92** | **41.37** | **49.20** | **nan** |
**Note:** The "Average" column for the "Average" row is marked as "nan" (not a number), which is expected as it would be the average of averages.
### Key Observations
* **Top Performers:** `claude-3-haiku-20240307` and `Mixtral-8x22B-v0.1` generally exhibit the highest scores across most categories, particularly in "Absurd Imagination," "Commonsense Misunderstanding," "Erroneous Assumption," and "Others."
* **Scientific Misconception:** This category shows the highest scores overall for many models, with `claude-3-haiku-20240307` (66.96) and `Qwen2.5-32B` (66.07) scoring particularly high. This suggests that models might be more prone to exhibiting scientific misconceptions or that the metric for this category is designed to capture a different aspect of performance.
* **Lowest Performers:** `Qwen2.5-0.5B` consistently has the lowest scores across all categories, indicating it is the least capable model among those tested. `Llama-3.2-1B` and `Mistral-7B-v0.1` also show very low scores.
* **Category Trends:**
* "Scientific Misconception" generally has higher scores than other categories for most models.
* "Others" tends to have lower scores for many models, especially for the smaller or less capable ones.
* "Absurd Imagination," "Commonsense Misunderstanding," and "Erroneous Assumption" show a similar range of scores for many models.
* "Logical Error" scores are generally in the mid-range.
* **Average Scores:** The overall average scores across all models are highest for "Absurd Imagination" (44.93) and "Scientific Misconception" (49.20), and lowest for "Others" (41.37).
### Interpretation
This table provides a quantitative assessment of different language models' performance across various dimensions, likely related to their ability to generate coherent, accurate, and contextually appropriate text. The categories suggest an evaluation of how well models avoid common pitfalls in reasoning and knowledge.
* **Model Capabilities:** The stark differences in scores, especially between models like `claude-3-haiku-20240307` and `Qwen2.5-0.5B`, highlight significant variations in the capabilities of these language models. Larger or more advanced models appear to perform better overall.
* **Nature of Metrics:** The high scores in "Scientific Misconception" are particularly interesting. This could imply that the models are more likely to generate text that aligns with common, albeit incorrect, scientific beliefs, or that the metric is designed to identify instances where models might confidently present flawed scientific information. Conversely, it could mean that models are adept at *identifying* scientific misconceptions if that's how the metric is framed, but the context of "performance metrics" suggests the former.
* **"Others" Category:** The consistently lower scores in the "Others" category for many models might indicate that this category captures a more nuanced or difficult aspect of performance, or that it represents a broader set of less common errors.
* **Overall Performance:** The average scores suggest that, as a group, these models are relatively strong in avoiding "Absurd Imagination" and "Commonsense Misunderstanding" but show more variability or weakness in "Scientific Misconception" and "Others." The "Average" column for each model provides a single composite score, but the breakdown by category offers a more granular understanding of where each model excels or struggles. The "nan" in the average of averages is a standard data representation for an undefined or uncalculable average.
</details>
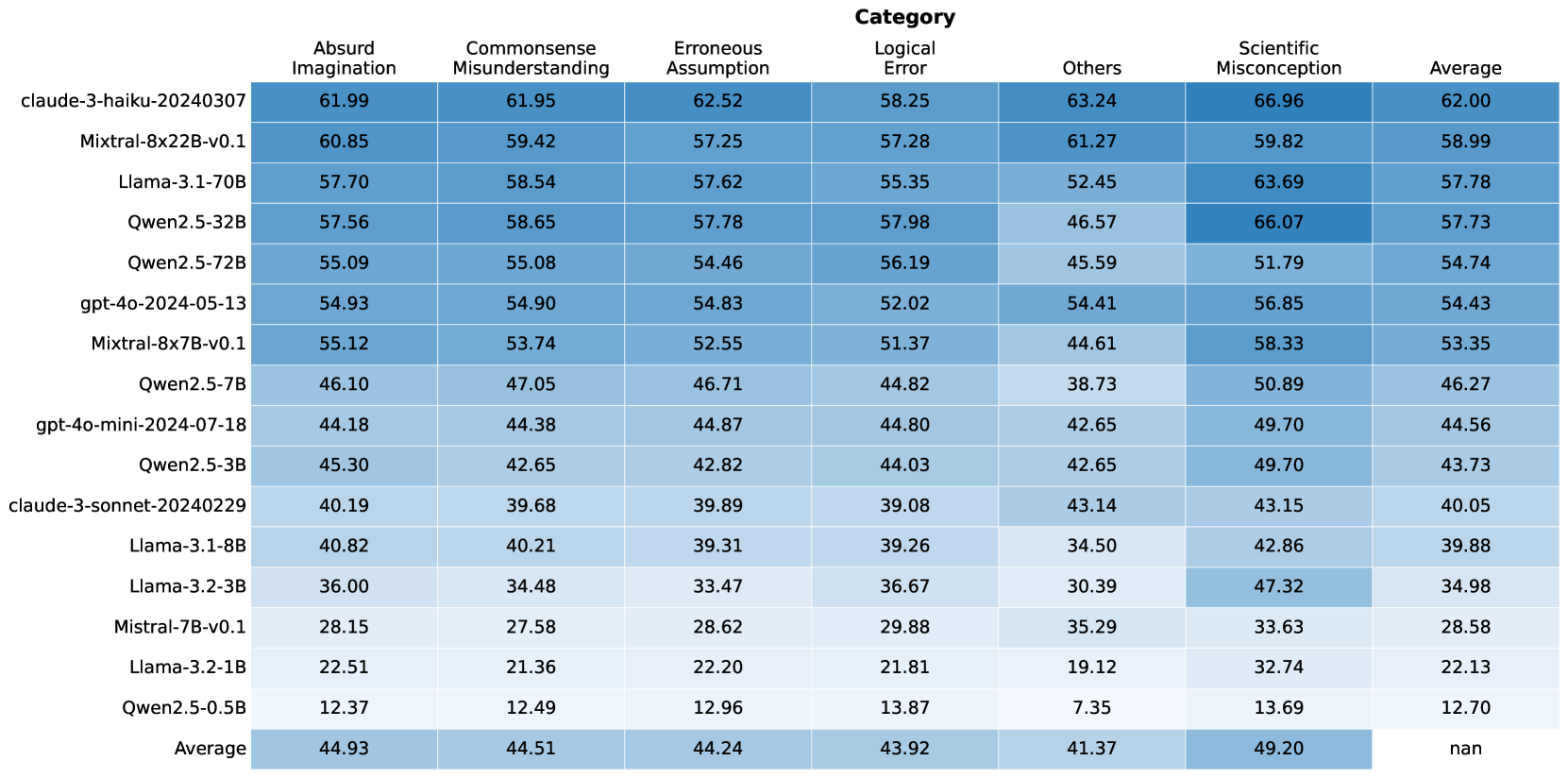
Figure 4: Overall model performance across different error categories.
#### Question Type Annotation
Finally, we categorized questions into 6 types (shown in Table 1). We first used GPT-4o-2024-08-06 with bilingual prompts (see Figure 11) to generate initial classifications based on both the questions and their irrationality analyses. Human annotators then reviewed and adjusted these classifications. For cases where annotators disagreed or were uncertain, a meta annotator (one of the authors) made the final decision to ensure consistency and quality across both the English and Chinese versions, resulting in the final RuozhiBench-Gen.
### 2.4 RuozhiBench-Gen Statistics
Figure 3 illustrates the structure of a data entry in RuozhiBench. Each entry consists of a question in both Chinese and English, its irrationality analysis, question categories, and where applicable, the paired normal question. Table 2 shows the basic statistics of the dataset.
## 3 Experiments on RuozhiBench-Gen
### 3.1 Setup
#### Models
We evaluated 17 advanced models from 5 series. Including: GPT-4o-2024-05-13, GPT-4o-mini-2024-07-18 from OpenAI (OpenAI, 2023); Claude-3-haiku-20240307, and Claude-3-sonnet-20240229 from Anthropic Claude (2023); Mistral-Instruct-v0.1 (7B, 8x7B, and 8x22B) from Mixtral Jiang et al. (2024); Qwen2.5-Instruct (0.5B, 3B, 7B, 32B, 72B) from Qwen team Bai et al. (2023b); and Llama-3.1-Instruct (8B, 70B), Llama-3.2-Instruct (1B, 3B) from Meta Meta AI (2024).
#### Automated Evaluation
We employ an LLM-as-Judge framework using three independent models: GPT-4o-2024-08-06, Claude-3.5-Sonnet-20241022, and Llama-3.3-70B-Instruct. By design, we ensure the judge models are distinct from those being evaluated and represent more advanced versions of their respective architectures. Each judge independently evaluates responses on a scale of 0 to 4. Additionally, we incorporate irrationality analysis into the judging process to enhance evaluation quality and consistency. The detailed scoring criteria and evaluation prompts are available in Figure 13.
### 3.2 Main results
The results highlight significant performance differences across models and error categories. Claude-3-haiku leads with an average score of 62.00, particularly excelling in “Scientific Misconception” (66.96). Mixtral-8x22B-v0.1 (58.99) and Llama-3.1-70B (57.78) follow closely, showing balanced performance across categories.
A clear trend is observed across all model series: larger models consistently outperform their smaller counterparts, as seen in the Qwen, Llama, Mixtral, and GPT families. This suggests that model size plays a crucial role in performance, though architectural design and training strategies, such as those in Mixtral models, also contribute significantly.
Across categories, “Scientific Misconception” has the highest average score (49.20), suggesting models handle domain-specific knowledge better than abstract concepts like “Absurd Imagination” and “Others”. Smaller models, such as Qwen2.5-0.5B, consistently struggle, reinforcing the importance of both scale and training strategies in reducing errors.
Notably, the best-performing model only achieved a score of 62.00, indicating that this task remains inherently challenging for current models.
### 3.3 Comparison on Paired Normal Questions
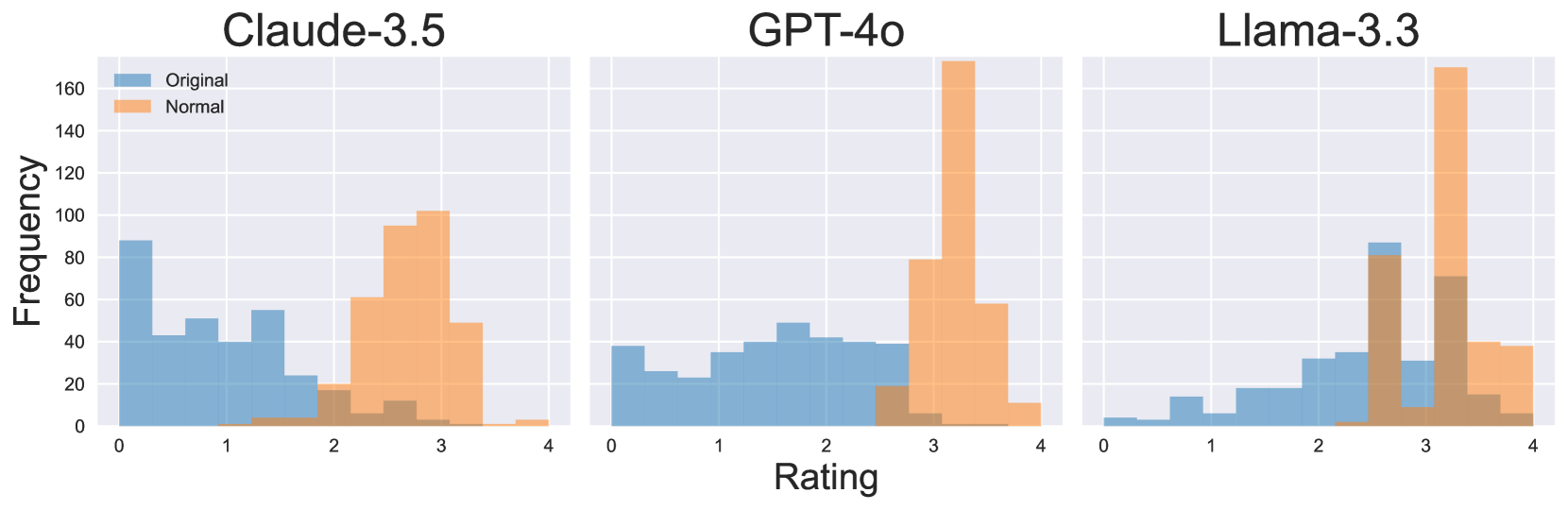
To compare model performance on normal and tricky questions, we input paired normal questions and apply the same LLM-based judging with a 0-4 scoring system (see Figure 13 for prompt). Figure 5 shows the rating distributions from three evaluators for three models. The results reveal a clear shift toward higher scores, indicating better performance on normal questions while logical traps remain consistently challenging.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Histograms: Rating Distribution for Different Language Models
### Overview
This image displays three side-by-side histograms, each representing the rating distribution for a different language model: Claude-3.5, GPT-4o, and Llama-3.3. For each model, two datasets are plotted: "Original" and "Normal". The histograms show the frequency of ratings on the y-axis, against the rating values on the x-axis, ranging from 0 to 4.
### Components/Axes
**Common Elements:**
* **Y-axis Title:** "Frequency" (located on the left side of the leftmost histogram, vertically oriented).
* **Y-axis Scale:** Ranges from 0 to 160, with major tick marks at 0, 20, 40, 60, 80, 100, 120, 140, and 160.
* **X-axis Title:** "Rating" (located at the bottom center of the image, horizontally oriented).
* **X-axis Scale:** Ranges from 0 to 4, with major tick marks at 0, 1, 2, 3, and 4.
* **Legend:** Located in the top-left corner of the "Claude-3.5" panel.
* **Blue Square:** Labeled "Original".
* **Orange Square:** Labeled "Normal".
**Individual Panel Titles:**
* **Top Left:** "Claude-3.5"
* **Top Center:** "GPT-4o"
* **Top Right:** "Llama-3.3"
### Detailed Analysis or Content Details
**Claude-3.5 Panel:**
* **Original (Blue):**
* Rating 0-0.2: Frequency approximately 88.
* Rating 0.2-0.4: Frequency approximately 50.
* Rating 0.4-0.6: Frequency approximately 30.
* Rating 0.6-0.8: Frequency approximately 52.
* Rating 0.8-1.0: Frequency approximately 40.
* Rating 1.0-1.2: Frequency approximately 40.
* Rating 1.2-1.4: Frequency approximately 24.
* Rating 1.4-1.6: Frequency approximately 20.
* Rating 1.6-1.8: Frequency approximately 10.
* Rating 1.8-2.0: Frequency approximately 10.
* Rating 2.0-2.2: Frequency approximately 10.
* Rating 2.2-2.4: Frequency approximately 10.
* Rating 2.4-2.6: Frequency approximately 10.
* Rating 2.6-2.8: Frequency approximately 10.
* Rating 2.8-3.0: Frequency approximately 10.
* Rating 3.0-3.2: Frequency approximately 10.
* Rating 3.2-3.4: Frequency approximately 10.
* Rating 3.4-3.6: Frequency approximately 10.
* Rating 3.6-3.8: Frequency approximately 10.
* Rating 3.8-4.0: Frequency approximately 10.
* **Normal (Orange):**
* Rating 2.4-2.6: Frequency approximately 10.
* Rating 2.6-2.8: Frequency approximately 20.
* Rating 2.8-3.0: Frequency approximately 100.
* Rating 3.0-3.2: Frequency approximately 70.
* Rating 3.2-3.4: Frequency approximately 20.
* Rating 3.4-3.6: Frequency approximately 10.
**GPT-4o Panel:**
* **Original (Blue):**
* Rating 0-0.2: Frequency approximately 38.
* Rating 0.2-0.4: Frequency approximately 20.
* Rating 0.4-0.6: Frequency approximately 40.
* Rating 0.6-0.8: Frequency approximately 45.
* Rating 0.8-1.0: Frequency approximately 35.
* Rating 1.0-1.2: Frequency approximately 45.
* Rating 1.2-1.4: Frequency approximately 30.
* Rating 1.4-1.6: Frequency approximately 45.
* Rating 1.6-1.8: Frequency approximately 30.
* Rating 1.8-2.0: Frequency approximately 40.
* Rating 2.0-2.2: Frequency approximately 30.
* Rating 2.2-2.4: Frequency approximately 45.
* Rating 2.4-2.6: Frequency approximately 30.
* Rating 2.6-2.8: Frequency approximately 40.
* Rating 2.8-3.0: Frequency approximately 20.
* Rating 3.0-3.2: Frequency approximately 10.
* Rating 3.2-3.4: Frequency approximately 10.
* Rating 3.4-3.6: Frequency approximately 10.
* Rating 3.6-3.8: Frequency approximately 10.
* Rating 3.8-4.0: Frequency approximately 10.
* **Normal (Orange):**
* Rating 2.8-3.0: Frequency approximately 10.
* Rating 3.0-3.2: Frequency approximately 160.
* Rating 3.2-3.4: Frequency approximately 100.
* Rating 3.4-3.6: Frequency approximately 40.
* Rating 3.6-3.8: Frequency approximately 20.
* Rating 3.8-4.0: Frequency approximately 10.
**Llama-3.3 Panel:**
* **Original (Blue):**
* Rating 0-0.2: Frequency approximately 5.
* Rating 0.2-0.4: Frequency approximately 15.
* Rating 0.4-0.6: Frequency approximately 10.
* Rating 0.6-0.8: Frequency approximately 15.
* Rating 0.8-1.0: Frequency approximately 10.
* Rating 1.0-1.2: Frequency approximately 15.
* Rating 1.2-1.4: Frequency approximately 10.
* Rating 1.4-1.6: Frequency approximately 15.
* Rating 1.6-1.8: Frequency approximately 10.
* Rating 1.8-2.0: Frequency approximately 15.
* Rating 2.0-2.2: Frequency approximately 10.
* Rating 2.2-2.4: Frequency approximately 15.
* Rating 2.4-2.6: Frequency approximately 10.
* Rating 2.6-2.8: Frequency approximately 15.
* Rating 2.8-3.0: Frequency approximately 70.
* Rating 3.0-3.2: Frequency approximately 40.
* Rating 3.2-3.4: Frequency approximately 10.
* Rating 3.4-3.6: Frequency approximately 10.
* Rating 3.6-3.8: Frequency approximately 10.
* Rating 3.8-4.0: Frequency approximately 10.
* **Normal (Orange):**
* Rating 2.6-2.8: Frequency approximately 10.
* Rating 2.8-3.0: Frequency approximately 10.
* Rating 3.0-3.2: Frequency approximately 160.
* Rating 3.2-3.4: Frequency approximately 160.
* Rating 3.4-3.6: Frequency approximately 120.
* Rating 3.6-3.8: Frequency approximately 40.
* Rating 3.8-4.0: Frequency approximately 20.
### Key Observations
* **Claude-3.5:** The "Original" ratings are distributed across a wider range, with a significant peak at lower ratings (around 0-0.2). The "Normal" ratings are concentrated at higher values, primarily between 2.8 and 3.4.
* **GPT-4o:** The "Original" ratings show a relatively flat distribution across most of the rating scale, with some minor fluctuations. The "Normal" ratings are heavily skewed towards higher ratings, with a very strong peak between 3.0 and 3.4.
* **Llama-3.3:** The "Original" ratings are distributed across a moderate range, with a noticeable peak around 2.8-3.2. The "Normal" ratings are extremely concentrated at the highest end of the scale, with massive peaks between 3.0 and 3.6.
* **Comparison:** Across all models, the "Normal" dataset consistently shows a shift towards higher ratings compared to the "Original" dataset. GPT-4o and Llama-3.3 exhibit particularly strong concentrations of "Normal" ratings at the highest end (around 3.0-3.6).
### Interpretation
The histograms illustrate the distribution of ratings for different language models under two conditions: "Original" and "Normal". The "Original" condition likely represents a baseline or standard evaluation, while the "Normal" condition might imply a modified or optimized evaluation setting, or perhaps a different set of prompts or criteria.
The data suggests that for all three models, the "Normal" condition leads to a higher perceived rating. This could indicate that the "Normal" condition is more favorable to these models, or that the evaluation criteria in the "Normal" condition are less stringent, leading to inflated scores.
Specifically:
* **Claude-3.5** shows a clear separation, with "Original" ratings being lower and more spread out, while "Normal" ratings are clustered at higher values.
* **GPT-4o** demonstrates a significant improvement in ratings under the "Normal" condition, with a dramatic increase in frequency for ratings between 3.0 and 3.4. The "Original" ratings are more evenly distributed, suggesting a less polarized performance.
* **Llama-3.3** exhibits the most pronounced shift. The "Normal" ratings are overwhelmingly concentrated at the highest end of the scale (3.0-3.6), indicating a strong positive bias or performance enhancement in this condition. The "Original" ratings are more moderate.
In essence, the "Normal" condition appears to be a more positive environment for all tested models, but the degree of this positive impact varies. Llama-3.3 and GPT-4o seem to benefit the most, achieving very high ratings in the "Normal" setting. This could be due to the nature of the "Normal" prompts, the evaluation rubric, or inherent strengths of these models in specific contexts. Further investigation into the definition of "Original" and "Normal" conditions would be necessary to fully understand the implications of these distributions.
</details>
Figure 5: Rating distribution comparison between normal and tricky questions for three models..
<details>
<summary>x6.png Details</summary>
### Visual Description
## Pair Plot: Correlation Analysis of Language Model Performance
### Overview
This image is a pair plot, also known as a scatter plot matrix, visualizing the pairwise relationships between three language models: Claude-3.5, GPT-4o, and Llama-3.3. The diagonal elements of the matrix display histograms of the individual model scores, while the off-diagonal elements show scatter plots of the scores for each pair of models, along with a regression line and the Pearson correlation coefficient (r).
### Components/Axes
**Overall Structure:** The plot is a 3x3 grid.
**Labels:**
* **Y-axis labels (left column):**
* "Claude-3.5" (top row)
* "GPT-4o" (middle row)
* "Llama-3.3" (bottom row)
* **X-axis labels (bottom row):**
* "Claude-3.5" (left column)
* "GPT-4o" (middle column)
* "Llama-3.3" (right column)
**Axis Ticks and Ranges:**
* **Y-axis (left column):** Ranges from 0 to 120 (for Claude-3.5 histogram) and 0 to 4 (for scatter plots).
* **X-axis (bottom row):** Ranges from 0 to 4 for all scatter plots and histograms.
**Correlation Coefficients (r):** Displayed in the top-left corner of each off-diagonal scatter plot.
* Top-middle plot (Claude-3.5 vs. GPT-4o): r = 0.73
* Top-right plot (Claude-3.5 vs. Llama-3.3): r = 0.43
* Middle-left plot (GPT-4o vs. Claude-3.5): r = 0.73
* Middle-right plot (GPT-4o vs. Llama-3.3): r = 0.75
* Bottom-left plot (Llama-3.3 vs. Claude-3.5): r = 0.43
* Bottom-middle plot (Llama-3.3 vs. GPT-4o): r = 0.75
**Data Representation:**
* **Histograms (Diagonal):** Blue bars representing the frequency distribution of scores for each model.
* **Scatter Plots (Off-diagonal):** Blue dots representing individual data points for pairs of models.
* **Regression Lines:** Red lines indicating the linear trend between pairs of variables.
* **Shaded Areas:** Light red shaded areas around the regression lines, likely representing confidence intervals for the regression.
### Detailed Analysis
**Diagonal Plots (Histograms):**
1. **Claude-3.5 (Top-left):**
* **Trend:** The histogram shows a distribution heavily skewed to the right. The highest frequency of scores is concentrated between 0 and 20, with a sharp decline as scores increase.
* **Data Points:** The peak frequency is approximately 120 (between 0 and 20 on the x-axis). There are very few data points above a score of 60.
2. **GPT-4o (Middle-center):**
* **Trend:** This histogram appears to be bimodal or has a plateau. There's a significant peak around a score of 2, and another smaller peak or plateau around a score of 3. The distribution is more spread out than Claude-3.5.
* **Data Points:** The highest bars are around a score of 2 and 3, with frequencies roughly estimated between 20-30.
3. **Llama-3.3 (Bottom-right):**
* **Trend:** This histogram shows a distribution that is skewed to the left. The scores are more evenly distributed across a wider range, with a peak around a score of 3.
* **Data Points:** The bars are relatively uniform from approximately a score of 1 to 3, with the highest bars around a score of 3, estimated to have frequencies between 20-30.
**Off-Diagonal Plots (Scatter Plots with Regression Lines):**
1. **Claude-3.5 vs. GPT-4o (Top-middle):**
* **Trend:** The scatter plot shows a strong positive linear trend. As Claude-3.5 scores increase, GPT-4o scores tend to increase. The red regression line slopes upward from the bottom-left to the top-right.
* **Data Points:** Points are clustered along the regression line, with some spread. Scores for both models range from approximately 0 to 4.
2. **Claude-3.5 vs. Llama-3.3 (Top-right):**
* **Trend:** The scatter plot shows a moderate positive linear trend. As Claude-3.5 scores increase, Llama-3.3 scores tend to increase, but with more scatter than the Claude-3.5 vs. GPT-4o relationship. The red regression line slopes upward.
* **Data Points:** Points are more dispersed compared to the previous plot. Scores for both models range from approximately 0 to 4.
3. **GPT-4o vs. Claude-3.5 (Middle-left):**
* **Trend:** This plot is the transpose of the top-middle plot and shows a strong positive linear trend, consistent with the r = 0.73 value. As GPT-4o scores increase, Claude-3.5 scores tend to increase. The red regression line slopes upward.
* **Data Points:** Similar distribution to the top-middle plot.
4. **GPT-4o vs. Llama-3.3 (Middle-right):**
* **Trend:** The scatter plot shows a strong positive linear trend. As GPT-4o scores increase, Llama-3.3 scores tend to increase. The red regression line slopes upward. This appears to be the strongest correlation among the scatter plots.
* **Data Points:** Points are tightly clustered around the regression line, indicating a high degree of linear association. Scores for both models range from approximately 0 to 4.
5. **Llama-3.3 vs. Claude-3.5 (Bottom-left):**
* **Trend:** This plot is the transpose of the top-right plot and shows a moderate positive linear trend, consistent with the r = 0.43 value. As Llama-3.3 scores increase, Claude-3.5 scores tend to increase, with noticeable scatter. The red regression line slopes upward.
* **Data Points:** Similar distribution to the top-right plot.
6. **Llama-3.3 vs. GPT-4o (Bottom-middle):**
* **Trend:** This plot is the transpose of the middle-right plot and shows a strong positive linear trend, consistent with the r = 0.75 value. As Llama-3.3 scores increase, GPT-4o scores tend to increase. The red regression line slopes upward.
* **Data Points:** Similar distribution to the middle-right plot.
### Key Observations
* **Strongest Correlation:** GPT-4o and Llama-3.3 exhibit the strongest positive linear correlation (r = 0.75).
* **Moderate Correlation:** Claude-3.5 and GPT-4o show a strong positive correlation (r = 0.73).
* **Weakest Correlation:** Claude-3.5 and Llama-3.3 have the weakest positive correlation among the pairs (r = 0.43).
* **Score Distributions:**
* Claude-3.5 scores are heavily concentrated at lower values, with a long tail towards higher scores.
* GPT-4o scores are more spread out, with peaks around 2 and 3.
* Llama-3.3 scores are also spread out, with a peak around 3.
* **Visual Consistency:** The scatter plots and their corresponding correlation coefficients align visually. The plots with higher 'r' values show points more tightly clustered around the regression line, while plots with lower 'r' values show more dispersion.
### Interpretation
This pair plot provides a comprehensive view of the performance correlations between three language models. The data suggests that:
1. **GPT-4o and Llama-3.3 are highly correlated:** Their performance tends to move in tandem. When one performs well, the other is likely to perform well, and vice-versa. This could indicate they share similar underlying strengths or are evaluated on similar tasks where their capabilities align.
2. **Claude-3.5 and GPT-4o are also strongly correlated:** Similar to the above, their performance is closely linked, though slightly less so than GPT-4o and Llama-3.3.
3. **Claude-3.5 and Llama-3.3 have a weaker relationship:** While there's a positive correlation, their performance is less predictable based on each other compared to the other pairs. This might imply they excel in different areas or are sensitive to different aspects of the evaluation tasks.
4. **Score Distribution Differences:** The histograms highlight distinct performance profiles. Claude-3.5's distribution suggests it might be more prone to lower scores or perhaps evaluated on tasks where it struggles more frequently, despite having a tail of high scores. GPT-4o and Llama-3.3 appear to have more consistent performance across a moderate range of scores.
In essence, the data demonstrates that GPT-4o and Llama-3.3 are the most similar in their performance patterns, followed by Claude-3.5 and GPT-4o. Claude-3.5 and Llama-3.3 show the least agreement in their performance. This analysis is crucial for understanding the relative strengths and weaknesses of these models and for selecting the most appropriate model for specific applications based on desired performance characteristics. The presence of regression lines and confidence intervals allows for a more nuanced understanding of the linear association and its reliability.
</details>
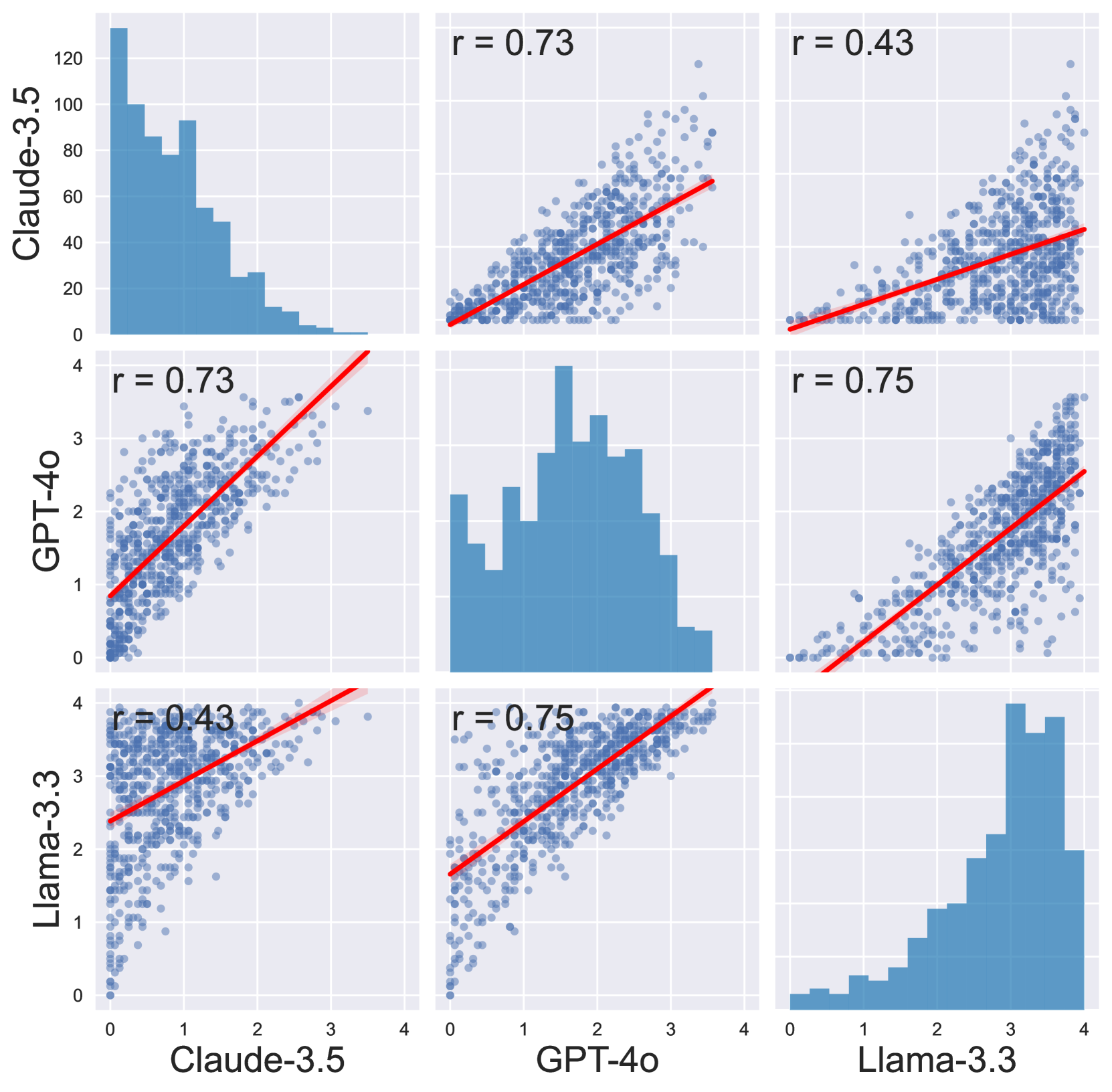
Figure 6: Pairwise scatter plots with Pearson correlation coefficients, and rating distributions of difference evaluators. The diagonal histograms show Claude-3.5’s tendency toward lower ratings compared to GPT-4 in middle and Llama-3.3 with a higher ratings.
### 3.4 High Variance between Evaluators
| Model Pair | Pearson Correlation | Mean Difference | Large Disagreement (%) | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Individual | Mean | Individual | Mean | Individual | Mean | |
| Claude vs GPT | 0.568 | 0.726 | -0.560 | -0.806 | 0.281 | 3.99 |
| Claude vs Llama | 0.359 | 0.433 | -2.107 | -2.002 | 1.007 | 50.37 |
| GPT vs Llama | 0.687 | 0.748 | -1.196 | -1.196 | 19.80 | 10.19 |
Table 3: Comparison of rating agreement metrics between model pairs. Individual analysis treats each rating independently, while Mean analysis averages multiple ratings per item. Pearson correlation measures linear relationship strength (-1 to 1); Mean difference indicates systematic rating bias between models; Large disagreement shows percentage of ratings differing by $\geq$ 2 points.
Table 3 presents key metrics comparing rating agreements between model pairs, and Figure 6 visualizes the mean-based pairwise relationships and rating distributions. Full results and evaluations using all three evaluators are presented in Appendix D.
The comparison reveals distinct rating patterns among the three models. GPT-4o and Llama-3.3 demonstrate the strongest agreement, with the highest correlation and relatively moderate large disagreements. In contrast, Claude-3.5 shows notably weaker correlation with others, indicating fundamentally different evaluation standard given the same criteria.
Mean-based analysis consistently shows stronger correlations and fewer large disagreements compared to individual analysis across all model pairs. This pattern is particularly evident in the Claude-3.5 vs GPT-4o comparison, where large disagreements decrease from 28.1% to 3.99% when using mean-based analysis. The scatter plots in Figure 6 visualize these relationships, with the GPT-4o vs Llama-3.3 comparison showing the tightest clustering around the regression line, while the Claude-3.5 vs Llama-3.3 comparison exhibits more dispersed points, reflecting their lower correlation and higher disagreement rate. These observations motivate us the creation of the multiple-choice evaluation format.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Data Table: Model Performance Metrics by Category
### Overview
The image displays a data table presenting performance metrics for various language models across different categories of evaluation. The table includes model names on the left-hand side and performance scores for "Logical Error," "Commonsense Misunderstanding," "Erroneous Assumption," "Scientific Misconception," "Absurd Imagination," "Others," and "Micro Average" as columns. The data is visually represented with a color gradient, where darker shades of blue generally indicate higher scores. An "Average" row is also included at the bottom.
### Components/Axes
**Row Labels (Model Names):**
* Llama-3.1-70B
* gpt-4o-2024-05-13
* Qwen2.5-72B
* Qwen2.5-32B
* Mixtral-8x22B-v0.1
* Mixtral-8x7B-v0.1
* Qwen2.5-7B
* Llama-3.1-8B
* claude-3-haiku-20240307
* gpt-4o-mini-2024-07-18
* claude-3-sonnet-20240229
* Qwen2.5-3B
* Llama-3.2-3B
* Mistral-7B-v0.1
* Qwen2.5-0.5B
* Llama-3.2-1B
* Average
**Column Headers (Categories):**
* Logical Error
* Commonsense Misunderstanding
* Erroneous Assumption
* Scientific Misconception
* Absurd Imagination
* Others
* Micro Average
**Data Values:** Numerical scores are presented for each model within each category. The values range from approximately -3.39 to 60.42.
**Color Gradient:** A color gradient is applied to the data cells, with darker blues representing higher values and lighter blues (or white for very low/negative values) representing lower values. This serves as a visual aid for quickly identifying performance differences.
### Detailed Analysis
The table presents the following data points:
| Model Name | Logical Error | Commonsense Misunderstanding | Erroneous Assumption | Scientific Misconception | Absurd Imagination | Others | Micro Average |
| :------------------------- | :------------ | :--------------------------- | :------------------- | :----------------------- | :----------------- | :----- | :------------ |
| Llama-3.1-70B | 60.42 | 58.21 | 57.31 | 46.43 | 56.74 | 57.35 | 56.90 |
| gpt-4o-2024-05-13 | 52.00 | 56.58 | 52.77 | 46.43 | 52.13 | 47.06 | 53.12 |
| Qwen2.5-72B | 49.29 | 50.85 | 50.39 | 53.57 | 49.89 | 35.29 | 49.82 |
| Qwen2.5-32B | 53.75 | 50.56 | 50.83 | 39.29 | 47.26 | 41.18 | 49.37 |
| Mixtral-8x22B-v0.1 | 46.38 | 47.61 | 46.12 | 44.44 | 46.45 | 47.06 | 46.48 |
| Mixtral-8x7B-v0.1 | 44.72 | 46.30 | 45.10 | 45.63 | 46.01 | 47.06 | 45.99 |
| Qwen2.5-7B | 36.69 | 39.61 | 40.21 | 58.57 | 43.19 | 32.73 | 41.57 |
| Llama-3.1-8B | 43.19 | 41.26 | 40.83 | 51.67 | 41.81 | 26.27 | 41.24 |
| claude-3-haiku-20240307 | 42.14 | 40.80 | 42.51 | 39.29 | 43.21 | 29.41 | 40.77 |
| gpt-4o-mini-2024-07-18 | 41.43 | 38.80 | 38.99 | 50.00 | 37.78 | 47.06 | 39.29 |
| claude-3-sonnet-20240229 | 37.14 | 35.80 | 34.80 | 39.29 | 31.90 | 29.41 | 34.56 |
| Qwen2.5-3B | 39.06 | 32.10 | 32.54 | 48.15 | 33.25 | 26.79 | 33.26 |
| Llama-3.2-3B | 34.53 | 34.84 | 35.95 | 21.32 | 27.98 | 22.22 | 32.10 |
| Mistral-7B-v0.1 | 4.70 | 0.40 | 5.85 | 3.57 | 0.45 | 0.00 | 2.81 |
| Qwen2.5-0.5B | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Llama-3.2-1B | -3.39 | -2.77 | -0.69 | 1.52 | -6.17 | 23.78 | -2.46 |
| **Average** | **36.38** | **35.68** | **35.84** | **36.82** | **34.49** | **32.04** | **35.49** |
**Trend Verification:**
* **Logical Error:** Generally trends downwards from the top models (Llama-3.1-70B, Qwen2.5-32B) to the bottom models (Mistral-7B-v0.1, Qwen2.5-0.5B, Llama-3.2-1B). The average is around 36.38.
* **Commonsense Misunderstanding:** Similar to Logical Error, it generally trends downwards, with higher scores for top models and lower scores for bottom models. The average is around 35.68.
* **Erroneous Assumption:** Shows a similar downward trend, with a few exceptions like Qwen2.5-72B and Qwen2.5-32B having higher scores than some models above them. The average is around 35.84.
* **Scientific Misconception:** This category shows more variability. While some top models have moderate scores, Qwen2.5-7B and Llama-3.1-8B show exceptionally high scores (58.57 and 51.67 respectively), deviating from the general downward trend. The average is around 36.82.
* **Absurd Imagination:** Generally trends downwards, with Llama-3.1-70B and gpt-4o-2024-05-13 scoring high. The average is around 34.49.
* **Others:** This category also shows significant variability. Some models like Llama-3.1-70B and gpt-4o-2024-05-13 score high, while others like Mistral-7B-v0.1 and Qwen2.5-0.5B score very low or zero. The average is around 32.04.
* **Micro Average:** This column generally follows the overall trend of the other categories, showing higher scores for the top-performing models and lower scores for the bottom ones. The average is around 35.49.
### Key Observations
* **Top Performers:** Llama-3.1-70B and gpt-4o-2024-05-13 consistently achieve high scores across most categories, particularly in "Logical Error," "Commonsense Misunderstanding," "Erroneous Assumption," and "Absurd Imagination."
* **Outliers in Scientific Misconception:** Qwen2.5-7B (58.57) and Llama-3.1-8B (51.67) exhibit significantly higher scores in "Scientific Misconception" compared to most other models, including some that perform better overall.
* **Low Performers:** Mistral-7B-v0.1, Qwen2.5-0.5B, and Llama-3.2-1B show very low or negative scores across multiple categories, indicating poor performance. Llama-3.2-1B has a negative score in "Logical Error," "Commonsense Misunderstanding," "Erroneous Assumption," and "Absurd Imagination."
* **"Others" Category Variability:** The "Others" category shows the most pronounced variability, with scores ranging from 0.00 to 57.35. This suggests that performance in this category is highly model-dependent and not consistently correlated with other metrics.
* **Average Performance:** The average scores across all models indicate that "Scientific Misconception" (36.82) and "Logical Error" (36.38) are the categories with the highest average scores, while "Others" (32.04) has the lowest average score.
### Interpretation
This data table provides a comparative analysis of different language models across various error and performance categories. The scores likely represent a measure of accuracy or correctness, where higher values indicate better performance (fewer errors or better understanding).
* **Model Strengths and Weaknesses:** The table clearly delineates which models excel in specific areas. For instance, Llama-3.1-70B and gpt-4o-2024-05-13 appear to be robust generalists, performing well across a broad spectrum of metrics. Conversely, models like Mistral-7B-v0.1 and Qwen2.5-0.5B seem to struggle significantly, potentially indicating limitations in their training data or architecture for these specific tasks.
* **Category-Specific Performance:** The significant spike in "Scientific Misconception" for Qwen2.5-7B and Llama-3.1-8B suggests that these models might have been specifically trained or are inherently better at handling scientific reasoning or knowledge. This highlights that a single "best" model may not exist; rather, the optimal choice depends on the intended application and the types of errors that are most critical to avoid.
* **"Others" as a Catch-all:** The "Others" category's high variance implies it might encompass a diverse set of tasks or error types that are not well-defined by the other categories. Its low average score suggests that models, in general, may find these tasks more challenging.
* **Negative Scores:** The presence of negative scores, particularly for Llama-3.2-1B, is noteworthy. This could indicate a performance level below random chance or a specific scoring mechanism that penalizes incorrect responses severely.
* **Overall Trend:** The general downward trend in scores from the top-performing models to the bottom-performing ones across most categories reinforces the idea of a hierarchy in model capabilities. The "Micro Average" serves as a useful aggregate metric, but it's crucial to examine the individual category scores to understand the nuances of each model's performance. The data suggests that while some models are generally strong, others have specific areas of exceptional strength or weakness.
</details>
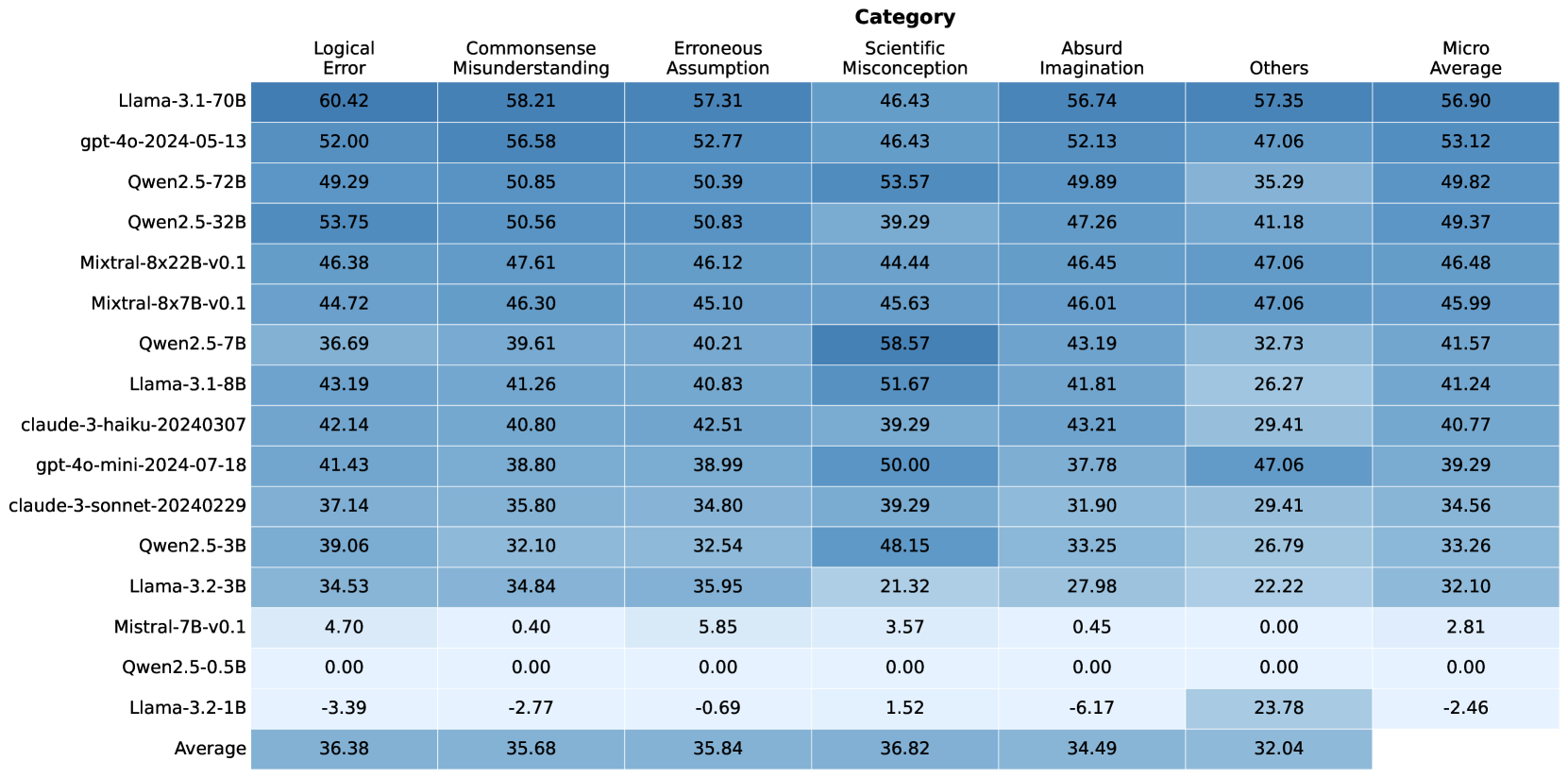
Figure 7: RuozhiBench-MC evaluation results in percentage by question categories. Scores ( $x$ ) are normalized according to the baseline score ( $50\$ ) by $2\times(x-0.5)$ .
## 4 RuozhiBench-MC : A Multiple-Choice Evaluation Framework
While generative evaluation provides a natural way to assess language model responses to tricky questions, our experiments on RuozhiBench-Gen revealed several limitations in the evaluation process. First, evaluator models themselves may sometimes fail to recognize subtle logical traps, even when provided with analysis of the trick, leading to inaccurate assessments. Second, the significant variations in scoring standards across different evaluator models as seen in Section 3.4. Finally, the two-step process of generating responses and then evaluating them with high-performance models introduces both substantial computational overhead and significant costs, particularly when using commercial models as evaluators.
### 4.1 Multiple-Choice Format
To address evaluation challenges, we created RuozhiBench-MC, a multiple-choice version of our benchmark. For each question, we present two responses, one “good” and one “bad”, and ask an LLM to choose between them. This binary format transforms evaluation from open-ended generation to a simple decision: can the model identify better logical reasoning? There are several key advantages: (1) Standardized Evaluation through consistent binary choices, (2) Computational Efficiency by eliminating separate generation and evaluation, and (3) Clear Success Criteria via unambiguous metrics.
### 4.2 Option Construction
To construct high-quality response options for RuozhiBench-MC, we leveraged the extensive response data collected during our evaluation of the 17 models in RuozhiBench-Gen. For each question, we implemented the following selection process.
We used the automatic evaluations from three different models to calculate an average score for each response in our existing dataset. We randomly sample two responses for each question, ensuring that the selected responses have a score difference greater than 2. If no response pairs meet this criterion, we select the responses with the highest and lowest scores. In all cases, the response with the higher score is designated as the “good” answer, while the other is designated as the “bad” answer. The detailed distribution of selected responses across models is shown in Figure 15.
## 5 Experiments on RuozhiBench-MC
We evaluate the same models as in Section 3. In our evaluation, we test models by presenting each question with its two corresponding options in alternating orders. This approach helps eliminate potential position bias in model responses while maintaining the fundamental binary choice structure. Models are prompted to select their preferred answer, and their performance is assessed based on their ability to consistently identify the better response.
| Model | Good First | Bad First | Avg | Positional Bias | Format |
| --- | --- | --- | --- | --- | --- |
| Llama-3.2-1B-Instruct | $58.19$ | $39.35$ | $48.77$ | $18.84$ | $59.68$ |
| Llama-3.2-3B-Instruct | $65.43$ | $66.67$ | $66.05$ | $-1.24$ | $53.99$ |
| Llama-3.1-8B-Instruct | $76.97$ | $64.26$ | $70.62$ | $12.71$ | $89.96$ |
| Llama-3.1-70B-Instruct | $81.86$ | $75.04$ | $78.45$ | $6.82$ | $98.67$ |
| Mistral-7B-Instruct-v0.1 | $55.85$ | $46.96$ | $51.41$ | $8.89$ | $99.70$ |
| Mixtral-8x7B-Instruct-v0.1 | $69.22$ | $76.77$ | $72.99$ | $-7.55$ | $96.23$ |
| Mixtral-8x22B-Instruct-v0.1 | $74.77$ | $71.71$ | $73.24$ | $3.07$ | $97.93$ |
| Qwen2.5-0.5B-Instruct | $100.00$ | $0.00$ | $50.00$ | $100.00$ | $89.66$ |
| Qwen2.5-3B-Instruct | $74.28$ | $58.98$ | $66.63$ | $15.30$ | $87.22$ |
| Qwen2.5-7B-Instruct | $68.59$ | $72.97$ | $70.78$ | $-4.38$ | $53.99$ |
| Qwen2.5-32B-Instruct | $77.00$ | $72.36$ | $74.68$ | $4.64$ | $99.48$ |
| Qwen2.5-72B-Instruct | $75.11$ | $74.70$ | $74.91$ | $0.41$ | $99.78$ |
| claude-3-haiku-20240307 | $73.41$ | $67.36$ | $70.38$ | $6.06$ | $100.00$ |
| claude-3-sonnet-20240229 | $67.21$ | $67.36$ | $67.28$ | $-0.15$ | $100.00$ |
| gpt-4o-mini-2024-07-18 | $72.23$ | $67.06$ | $69.65$ | $5.17$ | $100.00$ |
| gpt-4o-2024-05-13 | $81.22$ | $71.89$ | $76.56$ | $9.33$ | $99.48$ |
Table 4: RuozhiBench-MC evaluation results. Good First and Bad First are the accuracy in the percentage of selecting the correct answer where the correct answers are the first one and second one, respectively. Avg is the average of Good First and Bad First, with the random baseline of $50\$ . Positional Bias indicates the models’ position bias to the first answer, and the closer it is to 0, the better. Format is the percentage of answers generated by the model in the correct format specified in the prompt.
### 5.1 Main Results
Figure 7 shows the overall model performance on RuozhiBench-MC. In the multiple-choice evaluation setting, the general finding that larger models perform better still holds. We can observe models with large models in the Llama, Qwen, Mixtral family and GPT-4o achieved at least 40 scores in micro average across all categories of questions, which shows that they are significantly better than the random baseline. On the other hand, the ranking of the top-performing models has changed significantly. The best-performing model (Claude-3-haiku) in open generation evaluation ranks only in the middle tier of all models, while Llama-3.1-70B and GPT-4o now take the lead with micro average scores of 56.90 and 53.12, respectively.
There are three small models Mistral-7B, Qwen2.5-0.5B, and Llama-3.2-1B struggle on the multiple-choice evaluation with almost zero performance difference compared to random baseline across all question categories. This observation suggests that these models cannot understand the concept and definition of trick questions and hence unable to accurately assess the answers to these questions, reaffirming that RuozhiBench-MC had the advantages of standardized evaluation and clear success criteria.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Scatter Plot: Correlation between Generation and Multiple Choice Scores
### Overview
This image is a scatter plot visualizing the correlation between "Generation Score" on the x-axis and "Multiple Choice Score" on the y-axis. A strong positive linear correlation is indicated by the data points and a dashed red trend line with a shaded pink confidence interval. The plot includes labels for individual data points, representing different models or versions.
### Components/Axes
* **Title:** "Correlation between Generation and Multiple Choice Scores"
* **Subtitle/Annotation:** "Correlation: 0.909" (located below the main title, top-left)
* **X-axis Title:** "Generation Score"
* **X-axis Labels:** Numerical values ranging from approximately 10 to 60, with major ticks at 20, 30, 40, 50, and 60.
* **Y-axis Title:** "Multiple Choice Score"
* **Y-axis Labels:** Numerical values ranging from 45 to 80, with major ticks at 45, 50, 55, 60, 65, 70, 75, and 80.
* **Trend Line:** A dashed red line representing the linear regression.
* **Confidence Interval:** A shaded pink region surrounding the trend line, indicating the uncertainty or confidence interval of the regression.
* **Data Points:** Blue circular markers representing individual data entries.
* **Data Labels:** Text labels with arrows pointing to specific data points, identifying them by name.
### Detailed Analysis
The scatter plot displays several data points, each representing a specific model or version, plotted according to its Generation Score and Multiple Choice Score.
**Data Points and their approximate coordinates (Generation Score, Multiple Choice Score):**
* **Qwen2.5-0.5B:** (15, 50)
* **Llama-3.2-1B:** (28, 48)
* **Mistral-7B-v0.1:** (30, 53)
* **Llama-3.2-3B:** (38, 65)
* **Qwen2.5-3B:** (45, 67)
* **claude-3-sonnet:** (46, 69)
* **gpt-4o-mini-2024-07-18:** (47, 67)
* **Llama-3.1-8B:** (40, 70)
* **Qwen2.5-7B:** (43, 71)
* **Mixtral-8x22B-v0.1:** (45, 73)
* **gpt-4o-2024-05-13:** (43, 76)
* **Qwen2.5-32B:** (53, 75)
* **Qwen2.5-72B:** (55, 77)
* **Llama-3.1-70B:** (57, 79)
* **Mixtral-8x7B-v0.1:** (50, 73)
* **claude-3-haiku:** (52, 74)
**Trend Line and Confidence Interval:**
The dashed red trend line starts at approximately (15, 48) and ends at approximately (60, 80). It shows a clear upward slope, indicating that as the Generation Score increases, the Multiple Choice Score also tends to increase. The pink shaded area, representing the confidence interval, widens slightly at the lower end of the Generation Score and narrows towards the higher end, suggesting greater uncertainty in the prediction for lower Generation Scores.
### Key Observations
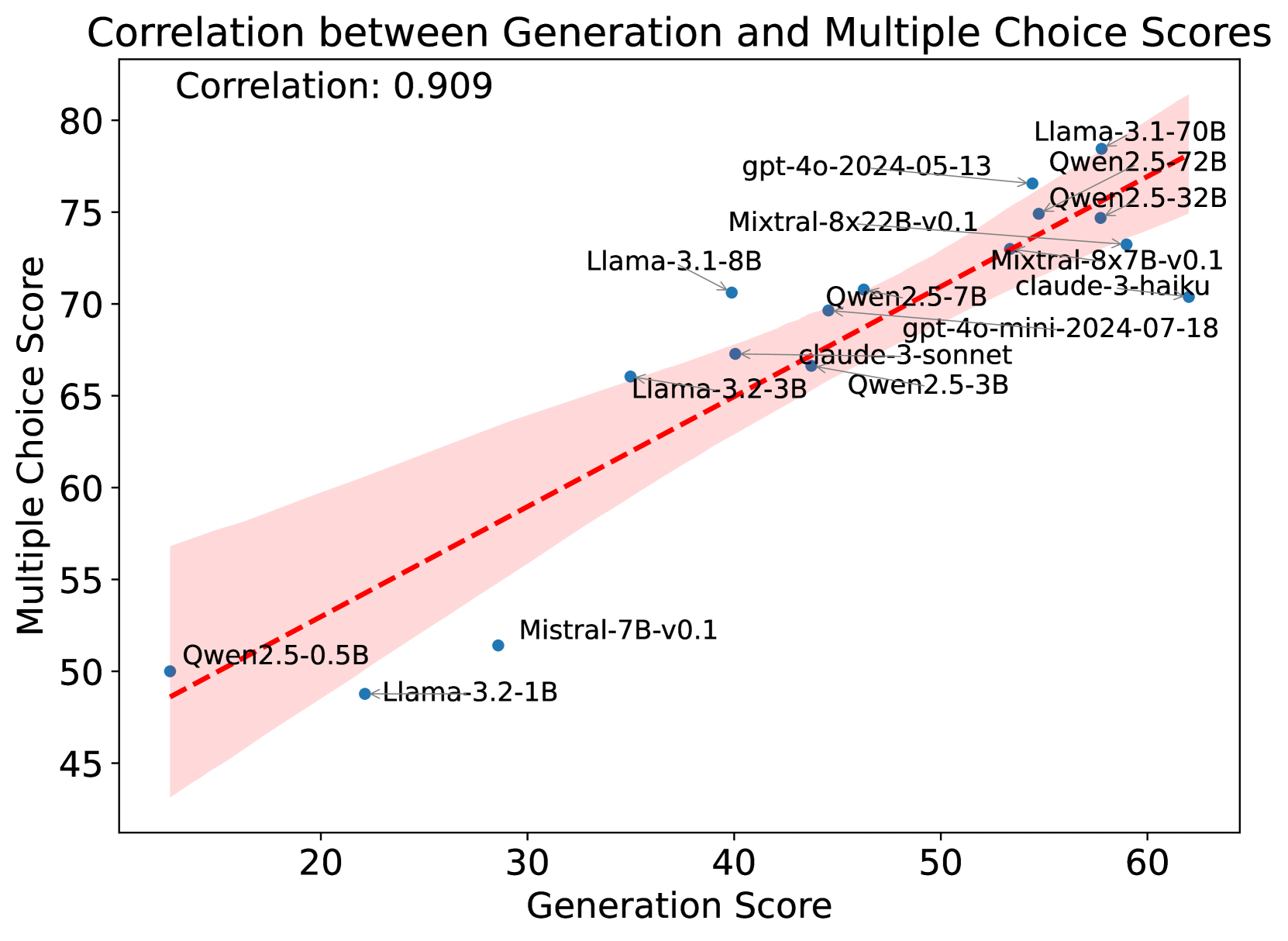
* **Strong Positive Correlation:** The data points generally cluster around the upward-sloping trend line, and the stated correlation coefficient of 0.909 confirms a very strong positive linear relationship between Generation Score and Multiple Choice Score.
* **Clustering at Higher Scores:** Most of the data points with higher Generation Scores (above 40) are tightly clustered, indicating that models achieving higher generation scores also tend to achieve higher multiple-choice scores, and vice-versa.
* **Outliers/Deviations:**
* "Mistral-7B-v0.1" (30, 53) and "Llama-3.2-1B" (28, 48) appear to be slightly below the general trend line compared to other points in their Generation Score range.
* "Llama-3.2-3B" (38, 65) is also somewhat below the trend line for its Generation Score.
* Conversely, "gpt-4o-2024-05-13" (43, 76) is notably above the trend line for its Generation Score.
### Interpretation
The data strongly suggests that there is a significant positive relationship between a model's "Generation Score" and its "Multiple Choice Score." This implies that models that perform well in generating content (as measured by the Generation Score) also tend to perform well on multiple-choice assessments. The high correlation coefficient (0.909) indicates that this relationship is not coincidental and is a robust finding within this dataset.
The trend line and confidence interval provide a predictive model. For a given Generation Score, the trend line estimates the expected Multiple Choice Score, and the confidence interval quantifies the uncertainty around this estimate. The widening of the confidence interval at lower Generation Scores suggests that predictions for models with lower generation capabilities are less precise.
The observed deviations from the trend line (outliers) are particularly interesting. They highlight specific models that either overperform or underperform relative to the general trend. For instance, "gpt-4o-2024-05-13" achieving a higher Multiple Choice Score than expected for its Generation Score might indicate a particular strength in its reasoning or knowledge recall capabilities, independent of its generative fluency. Conversely, models like "Llama-3.2-1B" scoring lower on multiple-choice tests than expected for their generation score might suggest areas for improvement in their underlying knowledge or reasoning abilities.
In essence, this plot demonstrates that while generative capabilities and multiple-choice performance are highly correlated, individual model architectures and training methodologies can lead to variations, offering insights into specific strengths and weaknesses of different AI models.
</details>
Figure 8: Pairwise scatter plots with Pearson correlation coefficients of generation and multiple choice scores.
<details>
<summary>x9.png Details</summary>
### Visual Description
## Scatter Plots: Model Size vs RuozhiBench Scores
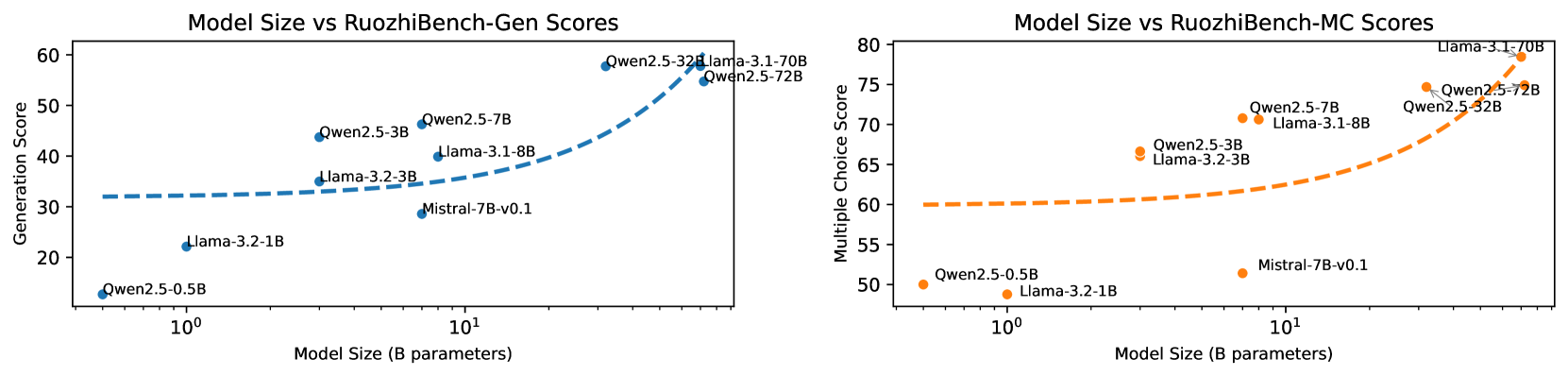
### Overview
The image displays two scatter plots side-by-side, illustrating the relationship between "Model Size (B parameters)" on the x-axis and a specific RuozhiBench score on the y-axis. The left plot depicts "Generation Score," and the right plot shows "Multiple Choice Score." Both x-axes utilize a logarithmic scale. Dashed lines are present in both plots, indicating a trend or fitted curve.
### Components/Axes
**Left Plot: Model Size vs RuozhiBench-Gen Scores**
* **Title:** Model Size vs RuozhiBench-Gen Scores
* **X-axis Title:** Model Size (B parameters)
* **Scale:** Logarithmic. Markers at 1, 10.
* **Axis Markers:** 1, 10.
* **Y-axis Title:** Generation Score
* **Scale:** Linear.
* **Axis Markers:** 20, 30, 40, 50, 60.
* **Data Points:** Blue circles, each labeled with a model name.
* **Trend Line:** Dashed blue line, generally increasing.
**Right Plot: Model Size vs RuozhiBench-MC Scores**
* **Title:** Model Size vs RuozhiBench-MC Scores
* **X-axis Title:** Model Size (B parameters)
* **Scale:** Logarithmic. Markers at 1, 10.
* **Axis Markers:** 1, 10.
* **Y-axis Title:** Multiple Choice Score
* **Scale:** Linear.
* **Axis Markers:** 50, 55, 60, 65, 70, 75, 80.
* **Data Points:** Orange circles, each labeled with a model name.
* **Trend Line:** Dashed orange line, generally increasing.
### Detailed Analysis
**Left Plot (Generation Score):**
The blue dashed line generally slopes upward, indicating that as model size increases, the Generation Score tends to increase.
* **Qwen2.5-0.5B:** Approximately (0.5 B parameters, 12 Generation Score)
* **Llama-3.2-1B:** Approximately (1.2 B parameters, 23 Generation Score)
* **Mistral-7B-v0.1:** Approximately (7 B parameters, 30 Generation Score)
* **Llama-3.2-3B:** Approximately (3 B parameters, 34 Generation Score)
* **Llama-3.1-8B:** Approximately (8 B parameters, 36 Generation Score)
* **Qwen2.5-3B:** Approximately (3 B parameters, 43 Generation Score)
* **Qwen2.5-7B:** Approximately (7 B parameters, 47 Generation Score)
* **Qwen2.5-32B:** Approximately (32 B parameters, 54 Generation Score)
* **Qwen2.5-72B:** Approximately (72 B parameters, 55 Generation Score)
* **Llama-3.1-70B:** Approximately (70 B parameters, 56 Generation Score)
**Right Plot (Multiple Choice Score):**
The orange dashed line generally slopes upward, indicating that as model size increases, the Multiple Choice Score tends to increase.
* **Qwen2.5-0.5B:** Approximately (0.5 B parameters, 50 Multiple Choice Score)
* **Llama-3.2-1B:** Approximately (1.2 B parameters, 51 Multiple Choice Score)
* **Mistral-7B-v0.1:** Approximately (7 B parameters, 57 Multiple Choice Score)
* **Llama-3.2-3B:** Approximately (3 B parameters, 62 Multiple Choice Score)
* **Qwen2.5-3B:** Approximately (3 B parameters, 63 Multiple Choice Score)
* **Qwen2.5-7B:** Approximately (7 B parameters, 70 Multiple Choice Score)
* **Qwen2.5-32B:** Approximately (32 B parameters, 73 Multiple Choice Score)
* **Qwen2.5-72B:** Approximately (72 B parameters, 74 Multiple Choice Score)
* **Llama-3.1-70B:** Approximately (70 B parameters, 77 Multiple Choice Score)
### Key Observations
* **Positive Correlation:** Both plots exhibit a clear positive correlation between model size and performance on both Generation and Multiple Choice tasks. Larger models generally achieve higher scores.
* **Diminishing Returns (Implied):** The dashed trend lines appear to flatten at higher model sizes, suggesting that performance gains from increasing model size may be subject to diminishing returns, particularly for the Generation Score.
* **Performance Differences:** For comparable model sizes, there can be variations in scores between the two tasks. For instance, Llama-3.1-70B and Qwen2.5-72B, with very similar sizes, achieve comparable high scores on both metrics. However, Qwen2.5-3B and Llama-3.2-3B (both around 3B parameters) show a larger disparity in Generation Score (43 vs 34) than in Multiple Choice Score (63 vs 62).
* **Outliers/Anomalies:**
* In the left plot, Qwen2.5-3B (3B parameters) demonstrates a significantly higher Generation Score (43) compared to Llama-3.2-3B (3B parameters, 34) and Llama-3.1-8B (8B parameters, 36).
* In the right plot, Mistral-7B-v0.1 (7B parameters) achieves a relatively high Multiple Choice Score (57) for its model size, notably exceeding Llama-3.2-1B (1.2B parameters, 51) and Qwen2.5-0.5B (0.5B parameters, 50).
### Interpretation
These scatter plots illustrate a fundamental principle in the development of large language models: **model size is a significant determinant of performance**. As the number of parameters (model size) increases, the models' capabilities in tasks such as text generation and multiple-choice question answering generally improve.
The dashed lines, likely representing trend fitting or a generalized performance curve, visually corroborate this relationship. The upward slope signifies that investing in larger models yields better results. However, the apparent flattening of these curves at the higher end of model sizes suggests that simply scaling up models indefinitely may not result in proportional performance enhancements. This could imply that other factors, such as architectural advancements, training data quality, or fine-tuning strategies, become increasingly critical for further performance improvements beyond a certain scale.
The performance variations between models of similar sizes and across the two benchmark tasks highlight the crucial role of model architecture and specific training objectives. For example, the superior Generation Score for Qwen2.5-3B compared to similarly sized models suggests it may be optimized for generative capabilities. Conversely, the relatively strong Multiple Choice Score for Mistral-7B-v0.1 indicates its proficiency in understanding and selecting correct answers.
In essence, the data suggests a trade-off between model size and performance, with larger models generally being more capable but potentially subject to diminishing returns. The specific performance profile of each model also depends on its underlying architecture and training. This information is vital for researchers and developers when determining model architectures, resource allocation, and performance targets for various natural language processing applications.
</details>
Figure 9: Relationship between model size and performance on generation and multiple-choice tasks. The plots show the correlation between model size (in billions of parameters) and performance scores for both generation (top) and multiple-choice (bottom) tasks. Both plots use a logarithmic scale for model size. The dashed lines represent the regression fit, demonstrating a positive correlation between model size and performance for both task types.
### 5.2 Analysis
#### Correlation with RuozhiBench-Gen
Figure 8 shows the correlation between generation and multiple choice scores for all models. We can observe a strong positive correlation between the generation and multiple choice scores for all models, with a Pearson correlation coefficient of 0.909. In general, most models have achieved slightly higher scores in the multiple choice than generation evaluation.
#### Model Size Analysis
Figure 9 shows the relationship between model size and performance on generation and multiple-choice tasks.
#### Issues in MC
Despite the advantages discussed above, we found two caveats of RuozhiBench-MC based on the detailed results in Table 4. (1) We found different degrees of performance gaps between when we provide the better response as the first option and the reverse, even for some of the best-performing models like GPT-4o and Claude-3-haiku. Most models perform slightly better when the better answer is provided as the first option. This positional bias suggests these models may be influenced by the ordering of options and indicates some uncertainty in their decision-making process. (2) Not all models can strictly follow the formatting instructions we provided in the prompts of RuozhiBench-MC. Except for Claude-3 models and GPT-4o, all other models produce different numbers of responses with formatting errors. Smaller models in Llama-3.2 family and Qwen2.5-7B suffer more from this issue as their formatting success rates are less than 60%.
## 6 Related Work
#### General Reasoning Evaluation of LLMs
Evaluating the reasoning capabilities of LLMs has gained significant attention, with diverse benchmarks developed for different reasoning domains, such as commonsense reasoning Talmor et al. (2019); Zellers et al. (2019); Clark et al. (2018); Bisk et al. (2020), math Cobbe et al. (2021); Hendrycks et al. (2021b), code Chen et al. (2021); Austin et al. (2021), and logic Liu et al. (2020, 2023a, 2023b). Recent advances, with models like GPT-4 surpassing human performance on many of these benchmarks, have driven further exploration into more challenging testbeds. Models such as GPT-o1 OpenAI et al. (2024) and Deepseek-R1 DeepSeek-AI et al. (2025) have demonstrated improved performance on advanced benchmarks like AIME MMA. (2024) and HLE Phan et al. (2025), which assess reasoning across domains such as mathematics, physics, and scientific knowledge. In contrast, RuozhiBench presents seemingly simple questions—ones even a five-year-old could find fallacy—that expose fundamental gaps in LLMs’ commonsense reasoning abilities, highlighting the limitations of current models beyond factual knowledge and formulaic problem-solving.
#### Understanding Deceptive and Fallacious Texts
While there is a substantial body of work on LLMs’ reasoning capabilities, research specifically focused on evaluating how models handle deliberately deceptive or fallacious inputs remains limited. Recent work has begun exploring the use of Chinese Ruozhiba forum data for improving LLMs’ capabilities; for instance, Lin et al. (2024) and Bai et al. (2024) incorporated Ruozhiba data in their training data to enhance logic reasoning in Chinese.
There are several works exploring LLMs’ understanding of logical fallacies Lei and Huang (2024); Payandeh et al. (2023); Li et al. (2024a). While most relevant work is Li et al. (2024b), which created a benchmark using data from Ruozhiba. However, our work differs in that: (1) we provide the first English benchmark, while theirs is Chinese-only; (2) their evaluation relies on artificially-constructed input formats, whereas our evaluation setting is more natural, directly using questions as prompts; and (3) we include detailed annotations of fallacy types, enabling more systematic analysis of model capabilities. Through these innovations, we aim to enable more rigorous assessment of how LLMs handle the types of deliberately tricky or misleading inputs they may encounter in real-world applications.
## 7 Conclusion
This paper presents RuozhiBench, a comprehensive benchmark designed to evaluate the logical reasoning capabilities of LLMs through both generative and multiple-choice formats. Our analysis across diverse models reveals that while state-of-the-art models like Claude demonstrate strong performance on logical reasoning tasks, significant challenges remain, particularly in handling edge cases and complex logical structures. The dual format of our benchmark provides complementary insights into models’ reasoning abilities, suggesting several promising directions for future research, including the enhancement of model training and the development of more targeted approaches to improving logical reasoning capabilities.
## Limitations
Despite our efforts to create a comprehensive benchmark for logical reasoning, RuozhiBench has several limitations. First, while our multiple-choice format offers standardized evaluation, it may not fully capture the nuanced reasoning processes that models employ in real-world scenarios. Second, our evaluation method relies heavily on model-generated responses for constructing the trapped options, which might not encompass all possible fallacies or reasoning errors that LLMs could make. Additionally, although the dataset is bilingual, our experiments focus primarily on English. Finally, the binary choice format in RuozhiBench -MC, while effective for evaluation, may inadvertently simplify complex reasoning problems that in practice require consideration of multiple valid perspectives or solutions.
## References
- Austin et al. (2021) Jacob Austin, Augustus Odena, Maxwell I. Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc V. Le, and Charles Sutton. 2021. Program synthesis with large language models. CoRR, abs/2108.07732.
- Bai et al. (2023a) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. 2023a. Qwen technical report. Preprint, arXiv:2309.16609.
- Bai et al. (2023b) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023b. Qwen technical report. arXiv preprint arXiv:2309.16609.
- Bai et al. (2024) Yuelin Bai, Xinrun Du, Yiming Liang, Yonggang Jin, Ziqiang Liu, Junting Zhou, Tianyu Zheng, Xincheng Zhang, Nuo Ma, Zekun Wang, Ruibin Yuan, Haihong Wu, Hongquan Lin, Wenhao Huang, Jiajun Zhang, Wenhu Chen, Chenghua Lin, Jie Fu, Min Yang, Shiwen Ni, and Ge Zhang. 2024. Coig-cqia: Quality is all you need for chinese instruction fine-tuning. Preprint, arXiv:2403.18058.
- Bisk et al. (2020) Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2020. Piqa: Reasoning about physical commonsense in natural language. In Thirty-Fourth AAAI Conference on Artificial Intelligence.
- Carlini et al. (2022) Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. 2022. Quantifying memorization across neural language models. arXiv preprint arXiv:2202.07646.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Joshua Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating large language models trained on code. CoRR, abs/2107.03374.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the AI2 reasoning challenge. CoRR, abs/1803.05457.
- Claude (2023) Claude. 2023. Our latest model, claude 2.1, is now available over api in our console and is powering our claude.ai chat experience.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. CoRR, abs/2110.14168.
- DeepSeek-AI et al. (2025) DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Qu, Hui Li, Jianzhong Guo, Jiashi Li, Jiawei Wang, Jingchang Chen, Jingyang Yuan, Junjie Qiu, Junlong Li, J. L. Cai, Jiaqi Ni, Jian Liang, Jin Chen, Kai Dong, Kai Hu, Kaige Gao, Kang Guan, Kexin Huang, Kuai Yu, Lean Wang, Lecong Zhang, Liang Zhao, Litong Wang, Liyue Zhang, Lei Xu, Leyi Xia, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Meng Li, Miaojun Wang, Mingming Li, Ning Tian, Panpan Huang, Peng Zhang, Qiancheng Wang, Qinyu Chen, Qiushi Du, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, R. J. Chen, R. L. Jin, Ruyi Chen, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shengfeng Ye, Shiyu Wang, Shuiping Yu, Shunfeng Zhou, Shuting Pan, S. S. Li, Shuang Zhou, Shaoqing Wu, Shengfeng Ye, Tao Yun, Tian Pei, Tianyu Sun, T. Wang, Wangding Zeng, Wanjia Zhao, Wen Liu, Wenfeng Liang, Wenjun Gao, Wenqin Yu, Wentao Zhang, W. L. Xiao, Wei An, Xiaodong Liu, Xiaohan Wang, Xiaokang Chen, Xiaotao Nie, Xin Cheng, Xin Liu, Xin Xie, Xingchao Liu, Xinyu Yang, Xinyuan Li, Xuecheng Su, Xuheng Lin, X. Q. Li, Xiangyue Jin, Xiaojin Shen, Xiaosha Chen, Xiaowen Sun, Xiaoxiang Wang, Xinnan Song, Xinyi Zhou, Xianzu Wang, Xinxia Shan, Y. K. Li, Y. Q. Wang, Y. X. Wei, Yang Zhang, Yanhong Xu, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Wang, Yi Yu, Yichao Zhang, Yifan Shi, Yiliang Xiong, Ying He, Yishi Piao, Yisong Wang, Yixuan Tan, Yiyang Ma, Yiyuan Liu, Yongqiang Guo, Yuan Ou, Yuduan Wang, Yue Gong, Yuheng Zou, Yujia He, Yunfan Xiong, Yuxiang Luo, Yuxiang You, Yuxuan Liu, Yuyang Zhou, Y. X. Zhu, Yanhong Xu, Yanping Huang, Yaohui Li, Yi Zheng, Yuchen Zhu, Yunxian Ma, Ying Tang, Yukun Zha, Yuting Yan, Z. Z. Ren, Zehui Ren, Zhangli Sha, Zhe Fu, Zhean Xu, Zhenda Xie, Zhengyan Zhang, Zhewen Hao, Zhicheng Ma, Zhigang Yan, Zhiyu Wu, Zihui Gu, Zijia Zhu, Zijun Liu, Zilin Li, Ziwei Xie, Ziyang Song, Zizheng Pan, Zhen Huang, Zhipeng Xu, Zhongyu Zhang, and Zhen Zhang. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. Preprint, arXiv:2501.12948.
- Hendrycks et al. (2021a) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021a. Measuring massive multitask language understanding. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net.
- Hendrycks et al. (2021b) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021b. Measuring mathematical problem solving with the MATH dataset. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual.
- Jiang et al. (2024) Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. 2024. Mixtral of experts. arXiv preprint arXiv:2401.04088.
- Lei and Huang (2024) Yuanyuan Lei and Ruihong Huang. 2024. Boosting logical fallacy reasoning in LLMs via logical structure tree. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 13157–13173, Miami, Florida, USA. Association for Computational Linguistics.
- Li et al. (2023a) Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. 2023a. Cmmlu: Measuring massive multitask language understanding in chinese. CoRR.
- Li et al. (2023b) Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023b. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval.
- Li et al. (2024a) Yanda Li, Dixuan Wang, Jiaqing Liang, Guochao Jiang, Qianyu He, Yanghua Xiao, and Deqing Yang. 2024a. Reason from fallacy: Enhancing large language models’ logical reasoning through logical fallacy understanding. Preprint, arXiv:2404.04293.
- Li et al. (2024b) Yinghui Li, Qingyu Zhou, Yuanzhen Luo, Shirong Ma, Yangning Li, Hai-Tao Zheng, Xuming Hu, and Philip S. Yu. 2024b. When LLMs meet cunning texts: A fallacy understanding benchmark for large language models. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Lin et al. (2024) Mingan Lin, Fan Yang, Yanjun Shen, Haoze Sun, Tianpeng Li, Tao Zhang, Chenzheng Zhu, Tao Zhang, Miao Zheng, Xu Li, Yijie Zhou, Mingyang Chen, Yanzhao Qin, Youquan Li, Hao Liang, Fei Li, Yadong Li, Mang Wang, Guosheng Dong, Kun Fang, Jianhua Xu, Bin Cui, Wentao Zhang, Zenan Zhou, and Weipeng Chen. 2024. Baichuan alignment technical report. Preprint, arXiv:2410.14940.
- Liu et al. (2023a) Hanmeng Liu, Jian Liu, Leyang Cui, Zhiyang Teng, Nan Duan, Ming Zhou, and Yue Zhang. 2023a. Logiqa 2.0—an improved dataset for logical reasoning in natural language understanding. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2947–2962.
- Liu et al. (2023b) Hanmeng Liu, Ruoxi Ning, Zhiyang Teng, Jian Liu, Qiji Zhou, and Yue Zhang. 2023b. Evaluating the logical reasoning ability of chatgpt and gpt-4. Preprint, arXiv:2304.03439.
- Liu et al. (2020) Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. 2020. Logiqa: A challenge dataset for machine reading comprehension with logical reasoning. Preprint, arXiv:2007.08124.
- Meta AI (2024) Meta AI. 2024. Introducing meta llama 3: The most capable openly available llm to date.
- MMA. (2024) MMA. 2024. American invitational mathematics examination - aime.
- OpenAI et al. (2024) OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kondrich, Andrey Mishchenko, Andy Applebaum, Angela Jiang, Ashvin Nair, Barret Zoph, Behrooz Ghorbani, Ben Rossen, Benjamin Sokolowsky, Boaz Barak, Bob McGrew, Borys Minaiev, Botao Hao, et al. 2024. Openai o1 system card. Preprint, arXiv:2412.16720.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report. Preprint, arXiv:2303.08774.
- Payandeh et al. (2023) Amirreza Payandeh, Dan Pluth, Jordan Hosier, Xuesu Xiao, and Vijay K. Gurbani. 2023. How susceptible are llms to logical fallacies? Preprint, arXiv:2308.09853.
- Phan et al. (2025) Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, Michael Choi, Anish Agrawal, Arnav Chopra, Adam Khoja, Ryan Kim, Richard Ren, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, Tung Nguyen, Daron Anderson, Imad Ali Shah, Mikhail Doroshenko, Alun Cennyth Stokes, Mobeen Mahmood, et al. 2025. Humanity’s last exam. Preprint, arXiv:2501.14249.
- Sainz et al. (2023) Oscar Sainz, Jon Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. 2023. NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787, Singapore. Association for Computational Linguistics.
- Scao et al. (2022) Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilic, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, Jonathan Tow, Alexander M. Rush, Stella Biderman, Albert Webson, Pawan Sasanka Ammanamanchi, Thomas Wang, Benoît Sagot, Niklas Muennighoff, Albert Villanova del Moral, Olatunji Ruwase, Rachel Bawden, Stas Bekman, Angelina McMillan-Major, Iz Beltagy, Huu Nguyen, Lucile Saulnier, Samson Tan, Pedro Ortiz Suarez, Victor Sanh, Hugo Laurençon, Yacine Jernite, Julien Launay, Margaret Mitchell, Colin Raffel, Aaron Gokaslan, Adi Simhi, Aitor Soroa, Alham Fikri Aji, Amit Alfassy, Anna Rogers, Ariel Kreisberg Nitzav, Canwen Xu, Chenghao Mou, Chris Emezue, Christopher Klamm, Colin Leong, Daniel van Strien, David Ifeoluwa Adelani, and et al. 2022. BLOOM: A 176b-parameter open-access multilingual language model. CoRR, abs/2211.05100.
- Talmor et al. (2019) Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota. Association for Computational Linguistics.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 4791–4800. Association for Computational Linguistics.
- Zhang et al. (2022) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. 2022. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068.
## Appendix A Prompts Used in This Study
Please read the following question and point out the irrationality in the question based on correct knowledge and common sense. The answer should be concise. (Note: Do not answer this question, do not use words like "the irrationality of this question is", your output only needs to include the irrationality of the question, try to use one sentence to complete the answer, and the answer should not exceed 100 words.) Example: Question: If the sun rises at night, what impact will it have on the temperature of the Earth? Irrationality Analysis: The sun does not rise at night because day and night are caused by the rotation of the Earth, and the phenomenon of the sun rising and falling is the result of the Earth’s rotation. Assuming that the sun rises at night is contrary to basic astronomical knowledge. Inputs: Question: {question}
Figure 10: Irrationality analysis generation prompt.
Based on the following tricky question and the irrationality analysis of this question, analyze and label them with three closest question categories. You will see all question categories in the question classification criteria, and you need to output the number sequence of question categories according to priority. Question Classification Criteria: 1. Logical error: When the question is raised, there may be logical contradictions or reasoning errors, which may include violations of logical rules, such as informal or formal logical errors, making the question logically untenable. 2. Common sense misunderstandings: The question reflects a misunderstanding of some basic common sense or universally accepted facts, usually involving incorrect understanding of common knowledge or information in daily life. 3. Erroneous assumption: The question is based on one or more erroneous assumptions. This means that the foundation or starting point of the question is incorrect, leading to inaccuracies in the entire question or its answer. 4. Scientific misconceptions: The content of the question involves misunderstandings of scientific principles or knowledge, including incorrect interpretations or applications of scientific theories, experimental results, or scientific methods. 5. Absurd imagination: The situation or setting in the question is clearly contrary to reality or common sense, has absurdity, and usually contains impossible or illogical elements, making the entire question appear unrealistic. 6. Others: If you believe that the provided question categories do not match the current question, please choose this option. Definitions: - Tricky Question: A question that is illogical or lacks a clear answer, often based on unrealistic assumptions or contradictions to common sense. - Irrationality Analysis: A detailed explanation highlighting the logical flaws or unrealistic assumptions present in the tricky question. Output format: The output format must be *Number Space Number Space Number*, and the output string length must be 5. Example: 2 6 3 Inputs: Question: {question} Irrationality Analysis: {irrationality}
Figure 11: Question type classification prompt.
You are an evaluation system designed to assess responses to *deceptive* or *logically flawed* questions. ## Task Definition: For each input, you will be provided with: - A **deceptive question** that contains misleading premises, logical fallacies, or contradictions. - An **irrationality analysis**, explaining why the question is deceptive and identifying its logical flaws. - An **answer** provided by a model or a human. Your task is to **evaluate the answer’s ability to correctly identify and address the deception** rather than simply providing a direct response. ## Rating Criteria (0-4 Scale): - **0**: The answer completely fails to recognize the deception and directly attempts to answer the question as if it were valid. - **1**: The answer acknowledges a flaw but does not engage with it meaningfully. - **2**: The answer recognizes and partially explains the deception but has logical gaps. - **3**: The answer correctly identifies and mostly explains the fallacy but lacks depth or clarity. - **4**: The answer fully explains the deceptive nature, providing a comprehensive and logically sound explanation. <question> \n {question} \n </question> <irrationality_analysis> \n {irrationality_analysis} \n </irrationality_analysis> <answer> \n {answer} \n </answer> ## Output Format: You must return a JSON object with keys: "rating" (int) and "explanation" (str), for example: {{\n "rating": [2], "explanation": "[Your justification for the rating]" \n}} Ensure that your response is **valid JSON** with the exact keys shown above without any additional text or formatting.
Figure 12: RuozhiBench-Gen evaluation prompt.
You are an expert evaluator tasked with assessing the quality of an answer to a given question. ## Question: \n {question} ## Answer: \n {answer} ## Evaluation Criteria: Rate the answer based on the following criteria: - 4: Excellent – The answer is complete, accurate, and well-explained. - 3: Good – The answer is mostly correct with minor inaccuracies or missing details. - 2: Fair – The answer has some correct elements but contains notable errors or omissions. - 1: Poor – The answer is mostly incorrect or incomplete. - 0: Very Poor – The answer is irrelevant or completely incorrect. ## Output Format: You must return a JSON object with keys: "rating" (int) and "explanation" (str), for example: {\n "rating": [0, 1, 2, 3, or 4], "explanation": "[Your justification for the rating]" \n} Ensure that your response is **valid JSON** with the exact keys shown above without any additional text or formatting.
Figure 13: RuozhiBench-MC evaluation prompt.
## Appendix B Option Distribution of RuozhiBench-MC
Figure 15 shows the option data source statistics of RuozhiBench-MC, and Figure 15 shows the gap distribution between “Good” and “Bad” options.
<details>
<summary>x10.png Details</summary>
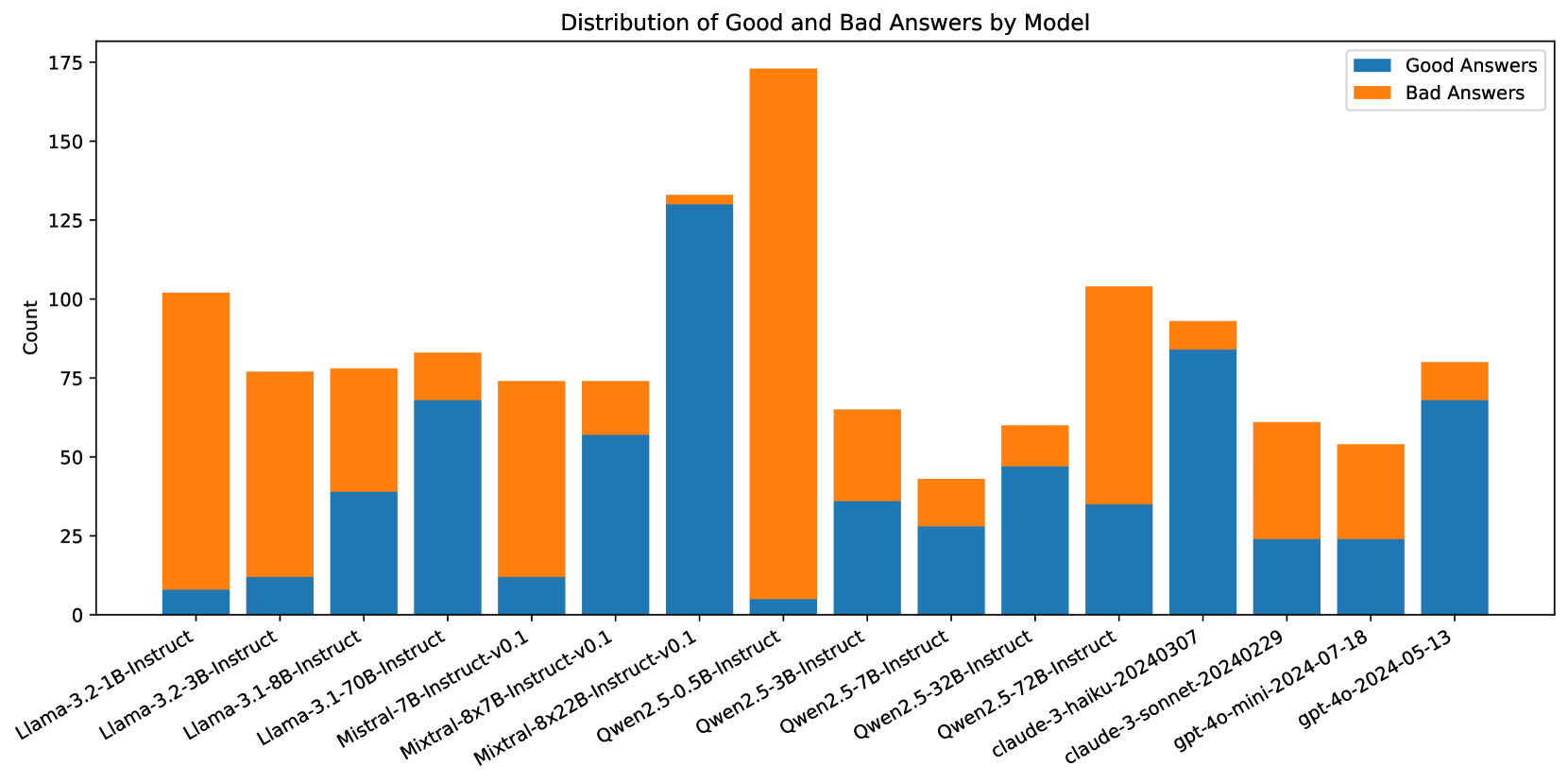
### Visual Description
## Stacked Bar Chart: Distribution of Good and Bad Answers by Model
### Overview
This stacked bar chart displays the distribution of "Good Answers" and "Bad Answers" across various language models. Each bar represents a specific model, and it is segmented into two parts: blue for good answers and orange for bad answers. The height of each segment indicates the count of answers for that category.
### Components/Axes
* **Title:** "Distribution of Good and Bad Answers by Model"
* **Y-axis Title:** "Count"
* **Y-axis Markers:** 0, 25, 50, 75, 100, 125, 150, 175
* **X-axis Labels:** The labels are rotated for readability and represent different language models:
* Llama-3.2-1B-Instruct
* Llama-3.2-3B-Instruct
* Llama-3.1-8B-Instruct
* Llama-3.1-70B-Instruct
* Mistral-7B-Instruct-v0.1
* Mixtral-8x7B-Instruct-v0.1
* Qwen2.5-0.5B-Instruct
* Qwen2.5-3B-Instruct
* Qwen2.5-7B-Instruct
* Qwen2.5-32B-Instruct
* claude-3-haiku-20240307
* claude-3-sonnet-20240229
* gpt-4o-mini-2024-07-18
* gpt-4o-2024-05-13
* **Legend:** Located in the top-right corner of the chart.
* Blue rectangle: "Good Answers"
* Orange rectangle: "Bad Answers"
### Detailed Analysis
The chart presents data for 14 different models. For each model, the count of good and bad answers is stacked.
1. **Llama-3.2-1B-Instruct:**
* Good Answers (Blue): Approximately 10.
* Bad Answers (Orange): Approximately 90.
* Total Count: Approximately 100.
2. **Llama-3.2-3B-Instruct:**
* Good Answers (Blue): Approximately 12.
* Bad Answers (Orange): Approximately 64.
* Total Count: Approximately 76.
3. **Llama-3.1-8B-Instruct:**
* Good Answers (Blue): Approximately 38.
* Bad Answers (Orange): Approximately 38.
* Total Count: Approximately 76.
4. **Llama-3.1-70B-Instruct:**
* Good Answers (Blue): Approximately 70.
* Bad Answers (Orange): Approximately 8.
* Total Count: Approximately 78.
5. **Mistral-7B-Instruct-v0.1:**
* Good Answers (Blue): Approximately 10.
* Bad Answers (Orange): Approximately 65.
* Total Count: Approximately 75.
6. **Mixtral-8x7B-Instruct-v0.1:**
* Good Answers (Blue): Approximately 58.
* Bad Answers (Orange): Approximately 17.
* Total Count: Approximately 75.
7. **Qwen2.5-0.5B-Instruct:**
* Good Answers (Blue): Approximately 32.
* Bad Answers (Orange): Approximately 1.
* Total Count: Approximately 33.
8. **Qwen2.5-3B-Instruct:**
* Good Answers (Blue): Approximately 40.
* Bad Answers (Orange): Approximately 30.
* Total Count: Approximately 70.
9. **Qwen2.5-7B-Instruct:**
* Good Answers (Blue): Approximately 30.
* Bad Answers (Orange): Approximately 15.
* Total Count: Approximately 45.
10. **Qwen2.5-32B-Instruct:**
* Good Answers (Blue): Approximately 48.
* Bad Answers (Orange): Approximately 20.
* Total Count: Approximately 68.
11. **claude-3-haiku-20240307:**
* Good Answers (Blue): Approximately 35.
* Bad Answers (Orange): Approximately 65.
* Total Count: Approximately 100.
12. **claude-3-sonnet-20240229:**
* Good Answers (Blue): Approximately 82.
* Bad Answers (Orange): Approximately 12.
* Total Count: Approximately 94.
13. **gpt-4o-mini-2024-07-18:**
* Good Answers (Blue): Approximately 54.
* Bad Answers (Orange): Approximately 3.
* Total Count: Approximately 57.
14. **gpt-4o-2024-05-13:**
* Good Answers (Blue): Approximately 68.
* Bad Answers (Orange): Approximately 10.
* Total Count: Approximately 78.
### Key Observations
* **Qwen2.5-0.5B-Instruct** has an overwhelmingly high proportion of good answers (approximately 32 good vs. 1 bad).
* **Llama-3.2-1B-Instruct** has an overwhelmingly high proportion of bad answers (approximately 10 good vs. 90 bad).
* **Qwen2.5-3B-Instruct** and **Qwen2.5-7B-Instruct** show a relatively balanced distribution of good and bad answers, with good answers slightly higher in count for Qwen2.5-3B-Instruct.
* **Llama-3.1-70B-Instruct**, **claude-3-sonnet-20240229**, and **gpt-4o-2024-05-13** have a significantly higher count of good answers compared to bad answers.
* **Mixtral-8x7B-Instruct-v0.1** has a substantial number of good answers (approximately 58) but also a notable number of bad answers (approximately 17).
* **claude-3-haiku-20240307** has a higher count of bad answers (approximately 65) than good answers (approximately 35).
* **gpt-4o-mini-2024-07-18** has a very high count of good answers (approximately 54) with a very low count of bad answers (approximately 3).
### Interpretation
This chart visually represents the performance of different language models in terms of generating good versus bad answers. The data suggests significant variability in model performance.
* **Model Specialization/Efficiency:** Models like **Qwen2.5-0.5B-Instruct** and **gpt-4o-mini-2024-07-18** appear to be highly efficient or specialized in producing correct responses, as indicated by their very low bad answer counts. Conversely, **Llama-3.2-1B-Instruct** seems to struggle significantly, with a vast majority of its answers being classified as bad.
* **Performance Tiers:** The models can be broadly categorized into tiers based on their good-to-bad answer ratio. Some models, like **Llama-3.1-70B-Instruct** and **claude-3-sonnet-20240229**, demonstrate a strong tendency towards good answers, suggesting higher overall quality. Others, like **Llama-3.2-1B-Instruct** and **claude-3-haiku-20240307**, exhibit a concerning number of bad answers.
* **Trade-offs:** The data might imply trade-offs between model size, architecture, and performance. For instance, larger models like **Llama-3.1-70B-Instruct** and **claude-3-sonnet-20240229** generally perform better, while smaller models like **Qwen2.5-0.5B-Instruct** can also be highly effective in specific contexts. However, **Llama-3.2-1B-Instruct** is a counterexample, showing poor performance despite its size.
* **Areas for Improvement:** The models with a high proportion of bad answers, such as **Llama-3.2-1B-Instruct** and **claude-3-haiku-20240307**, represent clear areas for further research and development to improve their accuracy and reliability. The models with a more balanced distribution, like **Qwen2.5-3B-Instruct**, might be suitable for applications where a mix of outcomes is acceptable or where further fine-tuning could enhance their good answer rate.
The chart effectively highlights the diverse capabilities and potential weaknesses of these language models, providing valuable insights for selection and development purposes.
</details>
Figure 14: Distribution of Good and Bad Answers by Model. The figure shows the total number of responses across various models, divided into good and bad answers. Most models exhibit a relatively balanced distribution, while models like Claude 3 Sonnet, Mixtral 8x22B, and GPT-4o produce a higher proportion of good answers. In contrast, models like Qwen 2.5 0.5B have a substantial number of responses but with a higher proportion of bad answers.
<details>
<summary>x11.png Details</summary>
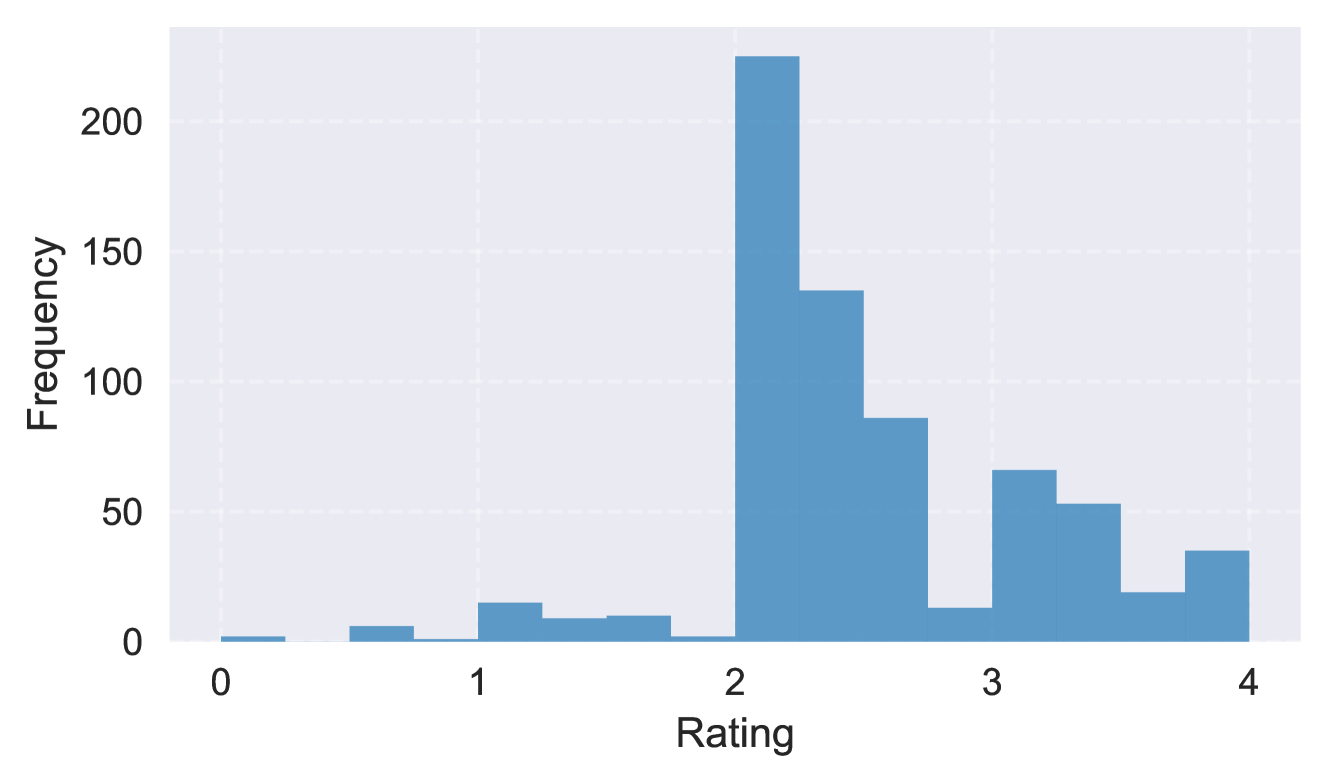
### Visual Description
## Histogram: Frequency Distribution of Ratings
### Overview
</details>
Figure 15: “Good” and “Bad” answer scores distribution. The majority of the data falls into categories with score differences greater than 2, indicating a clear gap between the options.
## Appendix C Recruitment and Payment
We hired 2 annotators with bachelor’s degrees or higher from China with an hourly rate of 50 Chinese Yuan. The annotators are native Chinese speakers and have studied English for more than 10 years. This rate is higher than the average hourly wage in China.
## Appendix D Full Evaluation Results on RuozhiBench-Gen
<details>
<summary>x12.png Details</summary>
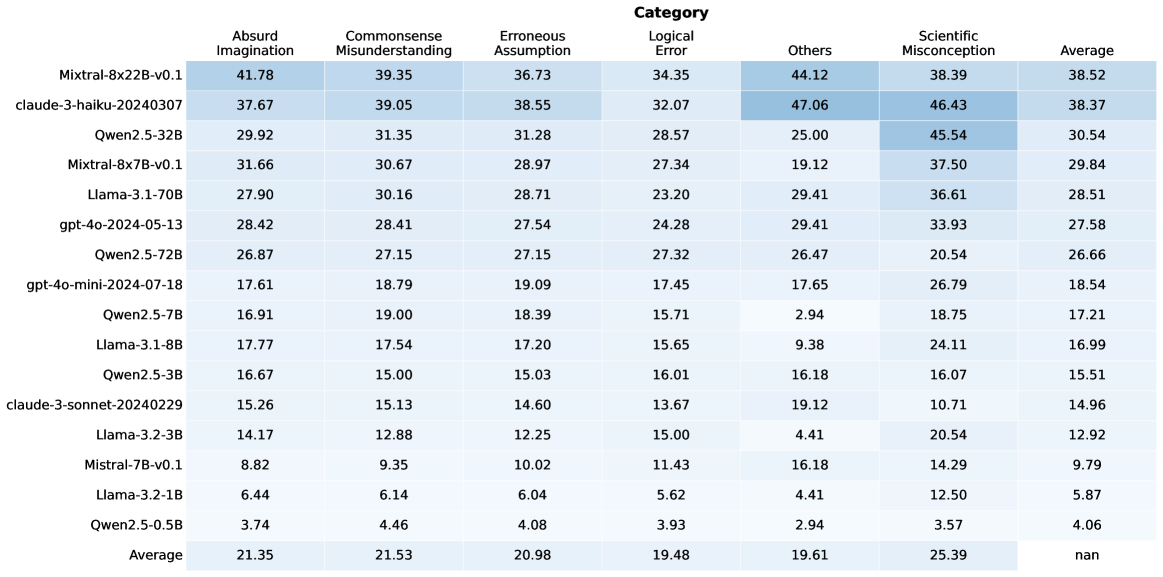
### Visual Description
## Data Table: Model Performance Metrics by Category
### Overview
The image displays a data table that presents performance metrics for various language models across different error categories. The table lists several model names in the first column and then provides numerical scores for "Absurd Imagination," "Commonsense Misunderstanding," "Erroneous Assumption," "Logical Error," "Others," "Scientific Misconception," and "Average." The data appears to represent some form of evaluation or scoring, with higher numbers potentially indicating worse performance in error categories and better performance in the "Average" category.
### Components/Axes
**Row Headers (Model Names):**
* Mixtral-8x22B-v0.1
* claude-3-haiku-20240307
* Qwen2.5-32B
* Mixtral-8x7B-v0.1
* Llama-3.1-70B
* gpt-4o-2024-05-13
* Qwen2.5-72B
* gpt-4o-mini-2024-07-18
* Qwen2.5-7B
* Llama-3.1-8B
* Qwen2.5-3B
* claude-3-sonnet-20240229
* Llama-3.2-3B
* Mistral-7B-v0.1
* Llama-3.2-1B
* Qwen2.5-0.5B
**Column Headers (Categories):**
* **Category** (This is a super-header for the following columns)
* Absurd Imagination
* Commonsense Misunderstanding
* Erroneous Assumption
* Logical Error
* Others
* Scientific Misconception
* Average
**Data Values:** Numerical scores are presented for each model under each category. The values are generally in the range of approximately 3 to 47. The "Average" column contains values generally in the range of approximately 4 to 38. The last entry in the "Average" column is "nan".
**Summary Row:**
* Average (This row provides the average score across all models for each category)
* Absurd Imagination: 21.35
* Commonsense Misunderstanding: 21.53
* Erroneous Assumption: 20.98
* Logical Error: 19.48
* Others: 19.61
* Scientific Misconception: 25.39
* Average: nan
### Detailed Analysis or Content Details
The table contains the following data points:
| Model Name | Absurd Imagination | Commonsense Misunderstanding | Erroneous Assumption | Logical Error | Others | Scientific Misconception | Average |
| :----------------------------- | :----------------- | :--------------------------- | :------------------- | :------------ | :----- | :----------------------- | :------ |
| Mixtral-8x22B-v0.1 | 41.78 | 39.35 | 36.73 | 34.35 | 44.12 | 38.39 | 38.52 |
| claude-3-haiku-20240307 | 37.67 | 39.05 | 38.55 | 32.07 | 47.06 | 46.43 | 38.37 |
| Qwen2.5-32B | 29.92 | 31.35 | 31.28 | 28.57 | 25.00 | 45.54 | 30.54 |
| Mixtral-8x7B-v0.1 | 31.66 | 30.67 | 28.97 | 27.34 | 19.12 | 37.50 | 29.84 |
| Llama-3.1-70B | 27.90 | 30.16 | 28.71 | 23.20 | 29.41 | 36.61 | 28.51 |
| gpt-4o-2024-05-13 | 28.42 | 28.41 | 27.54 | 24.28 | 29.41 | 33.93 | 27.58 |
| Qwen2.5-72B | 26.87 | 27.15 | 27.15 | 27.32 | 26.47 | 20.54 | 26.66 |
| gpt-4o-mini-2024-07-18 | 17.61 | 18.79 | 19.09 | 17.45 | 17.65 | 26.79 | 18.54 |
| Qwen2.5-7B | 16.91 | 19.00 | 18.39 | 15.71 | 2.94 | 18.75 | 17.21 |
| Llama-3.1-8B | 17.77 | 17.54 | 17.20 | 15.65 | 9.38 | 24.11 | 16.99 |
| Qwen2.5-3B | 16.67 | 15.00 | 15.03 | 16.01 | 16.18 | 16.07 | 15.51 |
| claude-3-sonnet-20240229 | 15.26 | 15.13 | 14.60 | 13.67 | 19.12 | 10.71 | 14.96 |
| Llama-3.2-3B | 14.17 | 12.88 | 12.25 | 15.00 | 4.41 | 20.54 | 12.92 |
| Mistral-7B-v0.1 | 8.82 | 9.35 | 10.02 | 11.43 | 16.18 | 14.29 | 9.79 |
| Llama-3.2-1B | 6.44 | 6.14 | 6.04 | 5.62 | 4.41 | 12.50 | 5.87 |
| Qwen2.5-0.5B | 3.74 | 4.46 | 4.08 | 3.93 | 2.94 | 3.57 | 4.06 |
| **Average** | **21.35** | **21.53** | **20.98** | **19.48** | **19.61** | **25.39** | **nan** |
**Observations on Trends within Categories:**
* **Absurd Imagination:** Scores generally decrease from top to bottom, with Mixtral-8x22B-v0.1 (41.78) being the highest and Qwen2.5-0.5B (3.74) being the lowest.
* **Commonsense Misunderstanding:** Similar to "Absurd Imagination," scores generally decrease from top to bottom, with Mixtral-8x22B-v0.1 (39.35) and claude-3-haiku-20240307 (39.05) being the highest, and Qwen2.5-0.5B (4.46) being the lowest.
* **Erroneous Assumption:** The trend of decreasing scores from top to bottom is also visible, with Mixtral-8x22B-v0.1 (36.73) and claude-3-haiku-20240307 (38.55) at the higher end, and Qwen2.5-0.5B (4.08) at the lower end.
* **Logical Error:** This category also shows a general downward trend from top to bottom, with Mixtral-8x22B-v0.1 (34.35) being the highest and Qwen2.5-0.5B (3.93) being the lowest.
* **Others:** The trend is less consistent. Mixtral-8x22B-v0.1 (44.12) and claude-3-haiku-20240307 (47.06) have very high scores, while smaller models like Qwen2.5-7B (2.94), Llama-3.1-8B (9.38), Llama-3.2-3B (4.41), and Qwen2.5-0.5B (2.94) have very low scores.
* **Scientific Misconception:** This category shows a more varied pattern. While some top models have high scores (e.g., claude-3-haiku-20240307 at 46.43, Qwen2.5-32B at 45.54), some smaller models also have relatively high scores (e.g., gpt-4o-mini-2024-07-18 at 26.79). The lowest scores are generally found at the bottom of the list.
* **Average:** This column generally shows a decreasing trend from top to bottom, with Mixtral-8x22B-v0.1 (38.52) and claude-3-haiku-20240307 (38.37) having the highest average scores, and Qwen2.5-0.5B (4.06) having the lowest. The last entry is "nan".
### Key Observations
* **Top Performers (Higher Average Scores):** Mixtral-8x22B-v0.1 and claude-3-haiku-20240307 consistently score high across most categories, particularly in "Absurd Imagination," "Commonsense Misunderstanding," and "Erroneous Assumption," and also achieve the highest "Average" scores.
* **Lower Performers (Lower Average Scores):** Models like Qwen2.5-0.5B, Llama-3.2-1B, and Mistral-7B-v0.1 generally exhibit the lowest scores across most categories, including the "Average" score.
* **"Others" Category Anomaly:** The "Others" category shows significant variation. While some large models have high scores, several smaller models have exceptionally low scores (e.g., Qwen2.5-7B, Llama-3.2-3B, Qwen2.5-0.5B). This suggests that these smaller models might be particularly adept at avoiding whatever "Others" represents, or that the metric is not well-suited for them.
* **"Scientific Misconception" Variation:** This category shows less of a clear top-to-bottom trend compared to other error categories. Some mid-tier and even smaller models achieve relatively high scores in "Scientific Misconception" (e.g., Qwen2.5-32B, claude-3-haiku-20240307, gpt-4o-mini-2024-07-18).
* **"Average" Column:** The "Average" column appears to be a composite score. The presence of "nan" for the overall average is notable and suggests a potential issue with the calculation or data for that specific aggregate.
### Interpretation
This data table likely represents an evaluation of different language models based on their propensity to exhibit various types of errors or misconceptions. The categories "Absurd Imagination," "Commonsense Misunderstanding," "Erroneous Assumption," and "Logical Error" seem to represent different facets of flawed reasoning or knowledge. Higher scores in these categories likely indicate poorer performance or a greater tendency to make these types of errors.
The "Others" category is less defined but could represent a catch-all for other types of errors or a specific, less common type of failure. The "Scientific Misconception" category specifically targets errors related to scientific knowledge. The "Average" column likely represents an overall performance metric, where higher scores are better.
The observed trends suggest a general correlation between model size (implied by names like "70B," "32B," "0.5B") and performance, with larger models generally exhibiting fewer errors across most categories and achieving higher average scores. However, there are exceptions, particularly in the "Scientific Misconception" and "Others" categories, where smaller models can sometimes perform surprisingly well or poorly in specific ways.
The top-performing models (Mixtral-8x22B-v0.1 and claude-3-haiku-20240307) appear to be robust across a range of error types. The models at the bottom of the list (e.g., Qwen2.5-0.5B) are likely much smaller and less capable, struggling with most forms of error.
The "nan" in the overall average row for the "Average" column is a critical observation. It implies that the aggregate calculation for the final average could not be computed, possibly due to missing data, division by zero, or an incompatible data type in the source data for that specific calculation. This prevents a definitive overall performance ranking based on the provided aggregate.
In essence, the table demonstrates a comparative analysis of language model capabilities in avoiding specific types of errors, with implications for their reliability and accuracy in real-world applications. The data suggests that while larger models tend to be more reliable, the specific nature of the error being measured can lead to varied performance across different architectures and sizes.
</details>
Figure 16: Overall score on RuozhiBench-Gen using Claude-3-5-sonnet as an evaluator.
<details>
<summary>x13.png Details</summary>
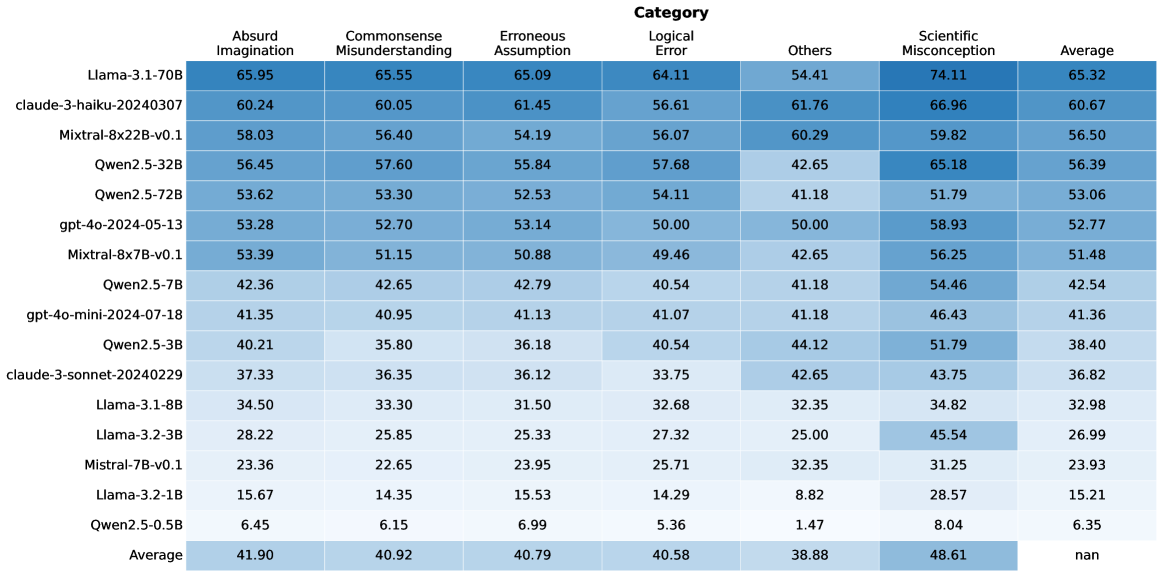
### Visual Description
## Data Table: Model Performance Across Categories
### Overview
The image displays a data table that presents performance scores for various language models across different categories of evaluation. The table lists specific model names on the left-hand side and evaluation categories as column headers. Numerical values, likely representing scores or percentages, are presented within the cells, with a color gradient indicating relative performance within each column. An "Average" row at the bottom summarizes the performance across all listed models for each category.
### Components/Axes
**Row Headers (Model Names):**
* Llama-3.1-70B
* claude-3-haiku-20240307
* Mistral-8x22B-v0.1
* Qwen2.5-32B
* Qwen2.5-72B
* gpt-4o-2024-05-13
* Mistral-8x7B-v0.1
* Qwen2.5-7B
* gpt-4o-mini-2024-07-18
* Qwen2.5-3B
* claude-3-sonnet-20240229
* Llama-3.1-8B
* Llama-3.2-3B
* Mistral-7B-v0.1
* Llama-3.2-1B
* Qwen2.5-0.5B
* Average
**Column Headers (Categories):**
* Absurd Imagination
* Commonsense Misunderstanding
* Erroneous Assumption
* Logical Error
* Others
* Scientific Misconception
* Average
**Data Cells:** Numerical values ranging from approximately 6.45 to 74.11. The "Average" column for the "Average" row contains "nan" (not a number), indicating no average could be computed for this specific cell.
### Detailed Analysis
The table contains numerical data for each model under each category. The values are presented with two decimal places.
**Row-wise Data (Selected Examples):**
* **Llama-3.1-70B:**
* Absurd Imagination: 65.95
* Commonsense Misunderstanding: 65.55
* Erroneous Assumption: 65.09
* Logical Error: 64.11
* Others: 54.41
* Scientific Misconception: 74.11
* Average: 65.32
* **claude-3-haiku-20240307:**
* Absurd Imagination: 60.24
* Commonsense Misunderstanding: 60.05
* Erroneous Assumption: 61.45
* Logical Error: 56.61
* Others: 61.76
* Scientific Misconception: 66.96
* Average: 60.67
* **Mistral-8x22B-v0.1:**
* Absurd Imagination: 58.03
* Commonsense Misunderstanding: 56.40
* Erroneous Assumption: 54.19
* Logical Error: 56.07
* Others: 60.29
* Scientific Misconception: 59.82
* Average: 56.50
* **Qwen2.5-0.5B:**
* Absurd Imagination: 6.45
* Commonsense Misunderstanding: 6.15
* Erroneous Assumption: 6.99
* Logical Error: 5.36
* Others: 1.47
* Scientific Misconception: 8.04
* Average: 6.35
**Column-wise Data (Averages):**
* **Absurd Imagination (Average):** 41.90
* **Commonsense Misunderstanding (Average):** 40.92
* **Erroneous Assumption (Average):** 40.79
* **Logical Error (Average):** 40.58
* **Others (Average):** 38.88
* **Scientific Misconception (Average):** 48.61
* **Average (Average):** nan
**Color Gradient Analysis:**
The table uses a blue color gradient. Lighter shades of blue generally correspond to lower numerical values, while darker shades correspond to higher numerical values within each column. This visually highlights the best and worst performing models for each specific category. For example, in the "Scientific Misconception" column, "Llama-3.1-70B" (74.11) is the darkest blue, indicating the highest score, while "Qwen2.5-0.5B" (8.04) is the lightest, indicating the lowest score.
### Key Observations
* **Top Performer:** "Llama-3.1-70B" consistently scores the highest across most categories, particularly in "Scientific Misconception" (74.11) and "Absurd Imagination" (65.95).
* **Lowest Performer:** "Qwen2.5-0.5B" consistently scores the lowest across all categories, with values generally below 10.
* **Category Performance:** "Scientific Misconception" appears to be a category where models generally score higher on average (48.61) compared to other categories like "Others" (38.88) or "Logical Error" (40.58).
* **Model Consistency:** Some models, like "Llama-3.1-70B" and "claude-3-haiku-20240307", show relatively high scores across multiple categories. Others, like "Qwen2.5-7B" and "gpt-4o-mini-2024-07-18", have scores in the low 40s for most categories.
* **Outlier in Averages:** The "Average" column for the "Average" row shows "nan", which is expected as it represents the average of averages, and the "Average" column itself is a summary metric.
### Interpretation
This data table likely represents an evaluation of different language models' capabilities in handling various types of prompts or questions. The categories suggest different cognitive or reasoning challenges:
* **"Absurd Imagination," "Commonsense Misunderstanding," "Erroneous Assumption," and "Logical Error"** likely assess a model's ability to understand and reason about non-factual or flawed information, or to identify and correct logical inconsistencies.
* **"Others"** is a more general category, possibly encompassing a range of tasks not specifically defined by the other categories.
* **"Scientific Misconception"** specifically tests the model's knowledge and ability to avoid or correct factual errors related to scientific concepts.
The consistently high scores of "Llama-3.1-70B" suggest it is a very capable model, particularly in areas requiring factual accuracy (Scientific Misconception) and potentially in understanding complex or unusual scenarios (Absurd Imagination). The low scores of "Qwen2.5-0.5B" indicate it is significantly less performant across the board.
The fact that "Scientific Misconception" has the highest average score across all models might imply that current language models are generally better at recalling and applying factual scientific knowledge than they are at navigating nuanced or flawed reasoning scenarios. Conversely, the "Others" category having the lowest average suggests it might be the most challenging or diverse set of tasks.
The presence of specific model versions (e.g., "Llama-3.1-70B", "claude-3-haiku-20240307") and dates (e.g., "gpt-4o-2024-05-13") indicates a comparative analysis of contemporary language models, likely to benchmark their strengths and weaknesses. The data allows for a granular understanding of which models excel in specific areas, which could inform their deployment for particular applications. For instance, a model performing well in "Logical Error" might be preferred for tasks requiring critical analysis, while one strong in "Scientific Misconception" would be better for knowledge-based queries.
</details>
Figure 17: Overall score on RuozhiBench-Gen using GPT-4o-2024-08-06 as an evaluator.
<details>
<summary>x14.png Details</summary>
### Visual Description
## Data Table: Model Performance Metrics by Category
### Overview
The image displays a data table that presents performance metrics for various language models across different categories of errors or assessments. The table lists model names on the left-hand side and categories of performance metrics as column headers. Numerical values, likely representing scores or percentages, are presented within the cells. The table also includes an "Average" row at the bottom, summarizing the performance across all listed models for each category.
### Components/Axes
**Row Headers (Model Names):**
* claude-3-haiku-20240307
* Qwen2.5-32B
* Qwen2.5-72B
* gpt-4o-2024-05-13
* Mixtral-8x22B-v0.1
* Llama-3.1-70B
* Qwen2.5-7B
* Mixtral-8x7B-v0.1
* Qwen2.5-3B
* gpt-4o-mini-2024-07-18
* Llama-3.1-8B
* claude-3-sonnet-20240229
* Llama-3.2-3B
* Mistral-7B-v0.1
* Llama-3.2-1B
* Qwen2.5-0.5B
* Average
**Column Headers (Categories):**
* Absurd Imagination
* Commonsense Misunderstanding
* Erroneous Assumption
* Category
* Logical Error
* Others
* Scientific Misconception
* Average
**Data Cells:** Numerical values ranging from approximately 26.92 to 88.07. The "Average" column for the "Average" row contains "nan" (Not a Number).
### Detailed Analysis
The table contains performance scores for 16 different language models, plus an overall average. The categories evaluated are: "Absurd Imagination", "Commonsense Misunderstanding", "Erroneous Assumption", "Logical Error", "Others", "Scientific Misconception", and a final "Average" score for each model.
**Model Performance Breakdown (Approximate Values):**
| Model Name | Absurd Imagination | Commonsense Misunderstanding | Erroneous Assumption | Logical Error | Others | Scientific Misconception | Average |
| :-------------------------- | :----------------- | :--------------------------- | :------------------- | :------------ | :----- | :----------------------- | :------ |
| claude-3-haiku-20240307 | 88.07 | 86.75 | 87.56 | 86.07 | 80.88 | 87.50 | 86.96 |
| Qwen2.5-32B | 86.31 | 87.00 | 86.23 | 87.68 | 72.06 | 87.50 | 86.26 |
| Qwen2.5-72B | 84.79 | 84.80 | 83.70 | 87.14 | 69.12 | 83.04 | 84.49 |
| gpt-4o-2024-05-13 | 83.09 | 83.60 | 83.81 | 81.79 | 83.82 | 77.68 | 82.94 |
| Mixtral-8x22B-v0.1 | 82.75 | 82.50 | 80.84 | 81.43 | 79.41 | 81.25 | 81.94 |
| Llama-3.1-70B | 79.24 | 79.90 | 79.07 | 78.75 | 73.53 | 80.36 | 79.51 |
| Qwen2.5-7B | 79.02 | 79.50 | 78.96 | 78.21 | 72.06 | 79.46 | 79.06 |
| Mixtral-8x7B-v0.1 | 80.32 | 79.40 | 77.81 | 77.32 | 72.06 | 81.25 | 78.73 |
| Qwen2.5-3B | 79.02 | 77.15 | 77.26 | 75.54 | 67.65 | 81.25 | 77.29 |
| gpt-4o-mini-2024-07-18 | 73.59 | 73.40 | 74.39 | 75.89 | 69.12 | 75.89 | 73.78 |
| Llama-3.1-8B | 70.19 | 69.80 | 69.22 | 69.46 | 61.76 | 69.64 | 69.68 |
| claude-3-sonnet-20240229 | 67.99 | 67.55 | 68.94 | 69.82 | 67.65 | 75.00 | 68.39 |
| Llama-3.2-3B | 65.61 | 64.70 | 62.83 | 67.68 | 61.76 | 75.89 | 65.03 |
| Mistral-7B-v0.1 | 52.26 | 50.75 | 51.87 | 52.50 | 57.35 | 55.36 | 52.03 |
| Llama-3.2-1B | 45.42 | 43.60 | 45.04 | 45.54 | 44.12 | 57.14 | 45.31 |
| Qwen2.5-0.5B | 26.92 | 26.85 | 27.81 | 32.32 | 17.65 | 29.46 | 27.70 |
**Average Row:**
| Category | Absurd Imagination | Commonsense Misunderstanding | Erroneous Assumption | Logical Error | Others | Scientific Misconception | Average |
| :----------------------- | :----------------- | :--------------------------- | :------------------- | :------------ | :----- | :----------------------- | :------ |
| Average | 71.54 | 71.08 | 70.96 | 71.70 | 65.62 | 73.60 | nan |
### Key Observations
* **Top Performers:** The models "claude-3-haiku-20240307" and "Qwen2.5-32B" consistently score the highest across most categories, with "claude-3-haiku-20240307" having the highest overall average score of 86.96.
* **Lowest Performers:** "Qwen2.5-0.5B" and "Llama-3.2-1B" exhibit the lowest scores across all categories, indicating significantly weaker performance.
* **Category Performance:** The "Others" category generally shows lower scores across most models compared to other categories like "Absurd Imagination" or "Commonsense Misunderstanding". The "Scientific Misconception" category has a wide range of scores, with some models performing very well and others poorly.
* **Inconsistent Performance:** Some models show significant variation in scores across categories. For example, "claude-3-sonnet-20240229" and "Llama-3.2-3B" perform relatively better in "Scientific Misconception" compared to other categories.
* **Average Row Anomaly:** The "Average" column for the "Average" row is marked as "nan", which is expected if it represents a calculation that cannot be performed (e.g., averaging averages without proper weighting, or if the underlying data for that specific cell is missing). However, the other average values in the "Average" row are meaningful.
### Interpretation
This data table appears to be a benchmark or evaluation of different language models' capabilities in handling various types of problematic or nuanced inputs. The categories likely represent different challenges or failure modes for AI models.
* **Model Strengths and Weaknesses:** The table clearly delineates which models excel in specific areas. For instance, "claude-3-haiku-20240307" seems to be a robust model across the board, while others might have specialized strengths. The low scores in the "Others" category suggest that this might be a more challenging or less well-defined area for current models.
* **Evolution of Models:** The presence of different versions (e.g., Qwen2.5-32B vs. Qwen2.5-7B, Llama-3.1 vs. Llama-3.2) and different model sizes (e.g., Llama-3.2-3B vs. Llama-3.2-1B) allows for an assessment of performance improvements with model size or architectural changes.
* **"Scientific Misconception" as a Key Metric:** The relatively high scores in "Scientific Misconception" for some top models, and the wide variance, suggest this is a critical area for evaluating factual accuracy and understanding of scientific concepts.
* **"nan" in Average:** The "nan" in the final "Average" cell for the "Average" column is likely a placeholder or an indication that the average of the "Average" column itself is not a meaningful metric in this context, or that the calculation was not performed. The other average values in the "Average" row are the mean scores for each category across all models.
Overall, the table provides a quantitative assessment of language model performance, allowing for direct comparison and identification of leaders and laggards in specific areas of AI reasoning and knowledge. The data suggests that while models are improving, there are still distinct areas where performance varies significantly.
</details>
Figure 18: Overall score on RuozhiBench-Gen using Llama-3.3-70B-Instruction as an evaluator.
## Appendix E Rating Distribution of Evaluators on RuozhiBench-Gen
<details>
<summary>x15.png Details</summary>
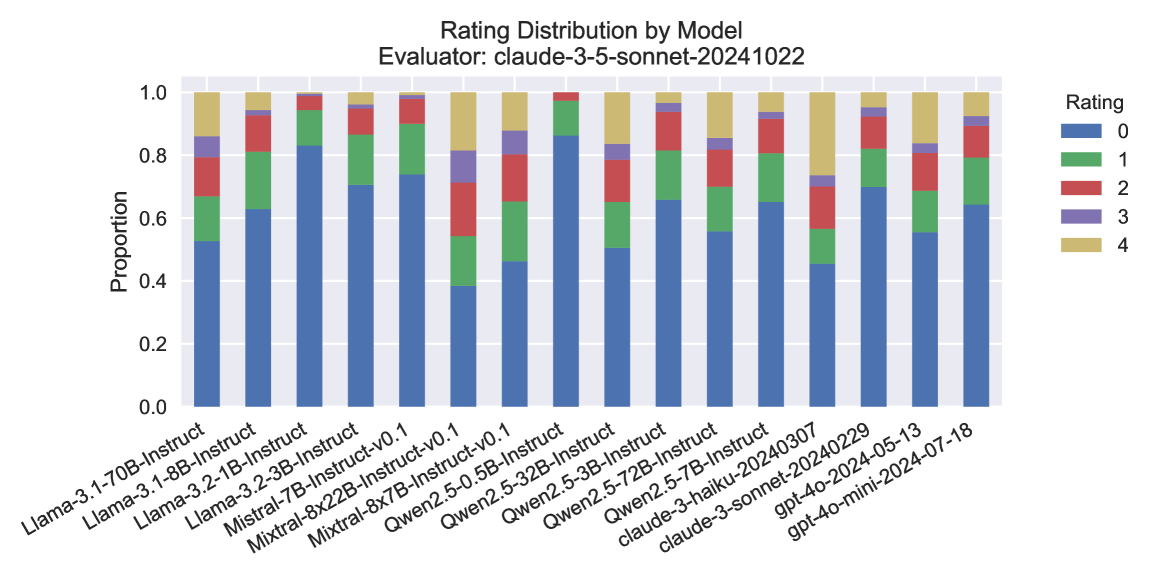
### Visual Description
## Stacked Bar Chart: Rating Distribution by Model
### Overview
This image displays a stacked bar chart showing the distribution of ratings (0 through 4) for various language models, as evaluated by "claude-3-5-sonnet-20241022". Each bar represents a specific model, and the segments within each bar indicate the proportion of responses that received each rating. The chart is designed to visually compare the rating profiles of different models.
### Components/Axes
* **Title:** "Rating Distribution by Model"
* **Subtitle:** "Evaluator: claude-3-5-sonnet-20241022"
* **Y-axis Title:** "Proportion"
* **Y-axis Scale:** Ranges from 0.0 to 1.0, with major ticks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-axis Labels:** These are the names of the different models being evaluated. They are rotated for readability and include:
* Llama-3.1-70B-Instruct
* Llama-3.1-8B-Instruct
* Llama-3.2-1B-Instruct
* Llama-3.2-3B-Instruct
* Mistral-7B-Instruct
* Mistral-8x22B-Instruct-v0.1
* Qwen2.5-0.5B-Instruct-v0.1
* Qwen2.5-2B-Instruct
* Qwen2.5-5.3B-Instruct
* Qwen2.5-72B-Instruct
* claude-3-haiku-20240307
* claude-3-sonnet-20240229
* gpt-4o-20240513
* gpt-4o-mini-2024-07-18
* **Legend:** Located in the top-right corner of the chart. It maps colors to rating values:
* Blue: Rating 0
* Green: Rating 1
* Red: Rating 2
* Purple: Rating 3
* Yellow: Rating 4
### Detailed Analysis
The chart displays 14 distinct models. For each model, the bar is segmented from bottom to top, representing the proportion of ratings from 0 to 4.
* **Llama-3.1-70B-Instruct:**
* Rating 0 (Blue): Approximately 0.55 (55%)
* Rating 1 (Green): Approximately 0.15 (15%), cumulative proportion ~0.70
* Rating 2 (Red): Approximately 0.10 (10%), cumulative proportion ~0.80
* Rating 3 (Purple): Approximately 0.05 (5%), cumulative proportion ~0.85
* Rating 4 (Yellow): Approximately 0.15 (15%), cumulative proportion ~1.00
* **Llama-3.1-8B-Instruct:**
* Rating 0 (Blue): Approximately 0.98 (98%)
* Rating 1 (Green): Approximately 0.01 (1%), cumulative proportion ~0.99
* Rating 2 (Red): Negligible, cumulative proportion ~0.99
* Rating 3 (Purple): Negligible, cumulative proportion ~0.99
* Rating 4 (Yellow): Approximately 0.01 (1%), cumulative proportion ~1.00
* **Llama-3.2-1B-Instruct:**
* Rating 0 (Blue): Approximately 0.98 (98%)
* Rating 1 (Green): Approximately 0.01 (1%), cumulative proportion ~0.99
* Rating 2 (Red): Negligible, cumulative proportion ~0.99
* Rating 3 (Purple): Negligible, cumulative proportion ~0.99
* Rating 4 (Yellow): Approximately 0.01 (1%), cumulative proportion ~1.00
* **Llama-3.2-3B-Instruct:**
* Rating 0 (Blue): Approximately 0.98 (98%)
* Rating 1 (Green): Approximately 0.01 (1%), cumulative proportion ~0.99
* Rating 2 (Red): Negligible, cumulative proportion ~0.99
* Rating 3 (Purple): Negligible, cumulative proportion ~0.99
* Rating 4 (Yellow): Approximately 0.01 (1%), cumulative proportion ~1.00
* **Mistral-7B-Instruct:**
* Rating 0 (Blue): Approximately 0.68 (68%)
* Rating 1 (Green): Approximately 0.15 (15%), cumulative proportion ~0.83
* Rating 2 (Red): Approximately 0.08 (8%), cumulative proportion ~0.91
* Rating 3 (Purple): Approximately 0.03 (3%), cumulative proportion ~0.94
* Rating 4 (Yellow): Approximately 0.06 (6%), cumulative proportion ~1.00
* **Mistral-8x22B-Instruct-v0.1:**
* Rating 0 (Blue): Approximately 0.42 (42%)
* Rating 1 (Green): Approximately 0.25 (25%), cumulative proportion ~0.67
* Rating 2 (Red): Approximately 0.15 (15%), cumulative proportion ~0.82
* Rating 3 (Purple): Approximately 0.08 (8%), cumulative proportion ~0.90
* Rating 4 (Yellow): Approximately 0.10 (10%), cumulative proportion ~1.00
* **Qwen2.5-0.5B-Instruct-v0.1:**
* Rating 0 (Blue): Approximately 0.40 (40%)
* Rating 1 (Green): Approximately 0.25 (25%), cumulative proportion ~0.65
* Rating 2 (Red): Approximately 0.15 (15%), cumulative proportion ~0.80
* Rating 3 (Purple): Approximately 0.08 (8%), cumulative proportion ~0.88
* Rating 4 (Yellow): Approximately 0.12 (12%), cumulative proportion ~1.00
* **Qwen2.5-2B-Instruct:**
* Rating 0 (Blue): Approximately 0.70 (70%)
* Rating 1 (Green): Approximately 0.15 (15%), cumulative proportion ~0.85
* Rating 2 (Red): Approximately 0.05 (5%), cumulative proportion ~0.90
* Rating 3 (Purple): Approximately 0.03 (3%), cumulative proportion ~0.93
* Rating 4 (Yellow): Approximately 0.07 (7%), cumulative proportion ~1.00
* **Qwen2.5-5.3B-Instruct:**
* Rating 0 (Blue): Approximately 0.65 (65%)
* Rating 1 (Green): Approximately 0.15 (15%), cumulative proportion ~0.80
* Rating 2 (Red): Approximately 0.08 (8%), cumulative proportion ~0.88
* Rating 3 (Purple): Approximately 0.05 (5%), cumulative proportion ~0.93
* Rating 4 (Yellow): Approximately 0.07 (7%), cumulative proportion ~1.00
* **Qwen2.5-72B-Instruct:**
* Rating 0 (Blue): Approximately 0.58 (58%)
* Rating 1 (Green): Approximately 0.18 (18%), cumulative proportion ~0.76
* Rating 2 (Red): Approximately 0.10 (10%), cumulative proportion ~0.86
* Rating 3 (Purple): Approximately 0.06 (6%), cumulative proportion ~0.92
* Rating 4 (Yellow): Approximately 0.08 (8%), cumulative proportion ~1.00
* **claude-3-haiku-20240307:**
* Rating 0 (Blue): Approximately 0.75 (75%)
* Rating 1 (Green): Approximately 0.10 (10%), cumulative proportion ~0.85
* Rating 2 (Red): Approximately 0.05 (5%), cumulative proportion ~0.90
* Rating 3 (Purple): Approximately 0.03 (3%), cumulative proportion ~0.93
* Rating 4 (Yellow): Approximately 0.07 (7%), cumulative proportion ~1.00
* **claude-3-sonnet-20240229:**
* Rating 0 (Blue): Approximately 0.60 (60%)
* Rating 1 (Green): Approximately 0.15 (15%), cumulative proportion ~0.75
* Rating 2 (Red): Approximately 0.10 (10%), cumulative proportion ~0.85
* Rating 3 (Purple): Approximately 0.05 (5%), cumulative proportion ~0.90
* Rating 4 (Yellow): Approximately 0.10 (10%), cumulative proportion ~1.00
* **gpt-4o-20240513:**
* Rating 0 (Blue): Approximately 0.58 (58%)
* Rating 1 (Green): Approximately 0.18 (18%), cumulative proportion ~0.76
* Rating 2 (Red): Approximately 0.10 (10%), cumulative proportion ~0.86
* Rating 3 (Purple): Approximately 0.05 (5%), cumulative proportion ~0.91
* Rating 4 (Yellow): Approximately 0.09 (9%), cumulative proportion ~1.00
* **gpt-4o-mini-2024-07-18:**
* Rating 0 (Blue): Approximately 0.55 (55%)
* Rating 1 (Green): Approximately 0.20 (20%), cumulative proportion ~0.75
* Rating 2 (Red): Approximately 0.10 (10%), cumulative proportion ~0.85
* Rating 3 (Purple): Approximately 0.05 (5%), cumulative proportion ~0.90
* Rating 4 (Yellow): Approximately 0.10 (10%), cumulative proportion ~1.00
### Key Observations
* **Dominance of Rating 0:** Most models show a significant proportion of Rating 0 responses, indicating that the lowest rating is the most frequent outcome for many of them.
* **Llama 3.1 Small Models:** The Llama 3.1 8B, 3.2-1B, and 3.2-3B Instruct models exhibit an extremely high proportion of Rating 0 (around 98%) with very little distribution across other ratings. This suggests a consistent, low-quality output or a specific failure mode for these models in this evaluation.
* **Qwen2.5 Models:** The Qwen2.5 models (0.5B, 2B, 5.3B, 72B) show a relatively consistent distribution pattern, with Rating 0 being the largest segment, followed by Rating 1, and then smaller proportions for Ratings 2, 3, and 4. The 72B model has a slightly higher proportion of higher ratings (1-4) compared to its smaller counterparts.
* **Claude Models:** Both Claude models (Haiku and Sonnet) show a substantial proportion of Rating 0, but also a more distributed pattern for higher ratings compared to the Llama small models. Claude-3-haiku-20240307 has a higher proportion of Rating 0 than Claude-3-sonnet-20240229.
* **GPT-4o Models:** The two GPT-4o models (gpt-4o-20240513 and gpt-4o-mini-2024-07-18) have similar rating distributions, with Rating 0 being the largest segment, followed by Rating 1, and then a noticeable presence of Ratings 2 and 4.
* **Mistral Models:** Mistral-7B-Instruct has a higher proportion of Rating 0 than Mistral-8x22B-Instruct-v0.1. The 8x22B model shows a more even distribution across ratings 0, 1, and 2, with a smaller but present proportion of 3 and 4.
### Interpretation
This stacked bar chart provides a comparative view of how different language models perform when evaluated by a specific instance of Claude 3.5 Sonnet. The prevalence of Rating 0 across most models suggests that the evaluation criteria or the nature of the tasks might be challenging, leading to frequent low scores.
The extreme concentration of Rating 0 for the smaller Llama 3.1 models is a significant finding. It implies that these specific versions might be highly prone to errors or not well-suited for the evaluated tasks. In contrast, models like the Qwen2.5 series and the GPT-4o variants show a more nuanced distribution, indicating a broader range of performance rather than a consistent failure.
The presence of higher ratings (1-4) in varying degrees across models suggests that some models are more capable of producing satisfactory or even excellent outputs. The evaluator's specific version ("claude-3-5-sonnet-20241022") is crucial context, as different evaluators or even different versions of the same model could yield different results. The chart allows for a direct comparison of these models' "rating profiles" under identical evaluation conditions. The data suggests that while many models struggle with consistently high ratings, there are clear differences in their ability to avoid the lowest rating and achieve better scores.
</details>
Figure 19: Rating distribution on RuozhiBench-Gen using Claude-3-5-sonnet as an evaluator.
<details>
<summary>x16.png Details</summary>
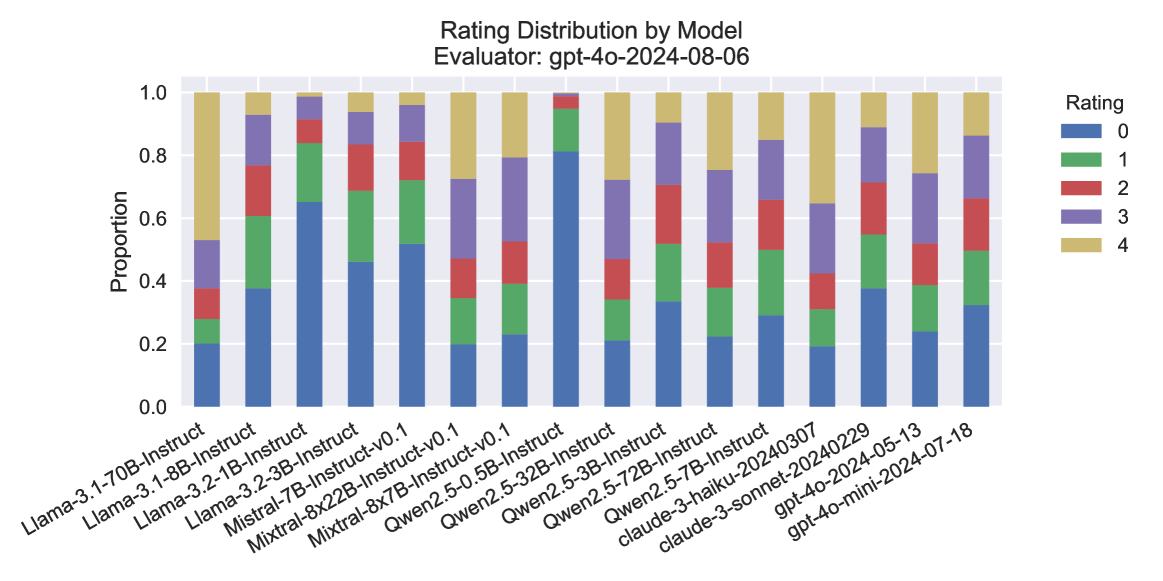
### Visual Description
## Stacked Bar Chart: Rating Distribution by Model
### Overview
This stacked bar chart displays the distribution of ratings (0 through 4) for various language models, as evaluated by "gpt-4o-2024-08-06". Each bar represents a specific model, and the segments within the bar indicate the proportion of responses that received each rating. The chart allows for a visual comparison of how different models perform across the rating scale.
### Components/Axes
* **Title:** "Rating Distribution by Model"
* **Subtitle:** "Evaluator: gpt-4o-2024-08-06"
* **Y-axis Title:** "Proportion"
* **Y-axis Scale:** Ranges from 0.0 to 1.0, representing proportions from 0% to 100%. Major tick marks are at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-axis Labels:** These are the names of the different language models being evaluated. They are rotated for readability. The models are:
* Llama-3.1-70B-Instruct
* Llama-3.1-8B-Instruct
* Llama-3.2-1B-Instruct
* Llama-3.2-3B-Instruct
* Mistral-7B-Instruct
* Mistral-8x22B-Instruct-v0.1
* Qwen2.5-0.5B-Instruct-v0.1
* Qwen2.5-32B-Instruct
* Qwen2.5-72B-Instruct
* claude-3-haiku-20240307
* claude-3-sonnet-20240229
* gpt-4o-2024-05-13
* gpt-4o-mini-2024-07-18
* **Legend:** Located in the top-right corner of the chart. It maps colors to rating values:
* Blue: Rating 0
* Green: Rating 1
* Red: Rating 2
* Purple: Rating 3
* Yellow: Rating 4
### Detailed Analysis
The chart displays 13 different models. For each model, the bar is segmented by color, representing the proportion of ratings from 0 (bottom, blue) to 4 (top, yellow).
Here's a breakdown of approximate proportions for each model, reading from bottom to top (Rating 0 to Rating 4):
1. **Llama-3.1-70B-Instruct:**
* Rating 0 (Blue): ~0.20
* Rating 1 (Green): ~0.10 (cumulative ~0.30)
* Rating 2 (Red): ~0.10 (cumulative ~0.40)
* Rating 3 (Purple): ~0.25 (cumulative ~0.65)
* Rating 4 (Yellow): ~0.35 (cumulative ~1.00)
2. **Llama-3.1-8B-Instruct:**
* Rating 0 (Blue): ~0.38
* Rating 1 (Green): ~0.15 (cumulative ~0.53)
* Rating 2 (Red): ~0.12 (cumulative ~0.65)
* Rating 3 (Purple): ~0.20 (cumulative ~0.85)
* Rating 4 (Yellow): ~0.15 (cumulative ~1.00)
3. **Llama-3.2-1B-Instruct:**
* Rating 0 (Blue): ~0.45
* Rating 1 (Green): ~0.15 (cumulative ~0.60)
* Rating 2 (Red): ~0.10 (cumulative ~0.70)
* Rating 3 (Purple): ~0.15 (cumulative ~0.85)
* Rating 4 (Yellow): ~0.15 (cumulative ~1.00)
4. **Llama-3.2-3B-Instruct:**
* Rating 0 (Blue): ~0.40
* Rating 1 (Green): ~0.15 (cumulative ~0.55)
* Rating 2 (Red): ~0.10 (cumulative ~0.65)
* Rating 3 (Purple): ~0.20 (cumulative ~0.85)
* Rating 4 (Yellow): ~0.15 (cumulative ~1.00)
5. **Mistral-7B-Instruct:**
* Rating 0 (Blue): ~0.20
* Rating 1 (Green): ~0.15 (cumulative ~0.35)
* Rating 2 (Red): ~0.15 (cumulative ~0.50)
* Rating 3 (Purple): ~0.30 (cumulative ~0.80)
* Rating 4 (Yellow): ~0.20 (cumulative ~1.00)
6. **Mistral-8x22B-Instruct-v0.1:**
* Rating 0 (Blue): ~0.20
* Rating 1 (Green): ~0.15 (cumulative ~0.35)
* Rating 2 (Red): ~0.15 (cumulative ~0.50)
* Rating 3 (Purple): ~0.30 (cumulative ~0.80)
* Rating 4 (Yellow): ~0.20 (cumulative ~1.00)
*(Note: Mistral-7B-Instruct and Mistral-8x22B-Instruct-v0.1 appear to have very similar distributions.)*
7. **Qwen2.5-0.5B-Instruct-v0.1:**
* Rating 0 (Blue): ~0.20
* Rating 1 (Green): ~0.15 (cumulative ~0.35)
* Rating 2 (Red): ~0.15 (cumulative ~0.50)
* Rating 3 (Purple): ~0.30 (cumulative ~0.80)
* Rating 4 (Yellow): ~0.20 (cumulative ~1.00)
*(Note: Qwen2.5-0.5B-Instruct-v0.1 also shows a very similar distribution to the Mistral models.)*
8. **Qwen2.5-32B-Instruct:**
* Rating 0 (Blue): ~0.20
* Rating 1 (Green): ~0.15 (cumulative ~0.35)
* Rating 2 (Red): ~0.15 (cumulative ~0.50)
* Rating 3 (Purple): ~0.30 (cumulative ~0.80)
* Rating 4 (Yellow): ~0.20 (cumulative ~1.00)
*(Note: Qwen2.5-32B-Instruct also exhibits a very similar distribution.)*
9. **Qwen2.5-72B-Instruct:**
* Rating 0 (Blue): ~0.20
* Rating 1 (Green): ~0.15 (cumulative ~0.35)
* Rating 2 (Red): ~0.15 (cumulative ~0.50)
* Rating 3 (Purple): ~0.30 (cumulative ~0.80)
* Rating 4 (Yellow): ~0.20 (cumulative ~1.00)
*(Note: Qwen2.5-72B-Instruct also shows a very similar distribution.)*
10. **claude-3-haiku-20240307:**
* Rating 0 (Blue): ~0.10
* Rating 1 (Green): ~0.10 (cumulative ~0.20)
* Rating 2 (Red): ~0.10 (cumulative ~0.30)
* Rating 3 (Purple): ~0.30 (cumulative ~0.60)
* Rating 4 (Yellow): ~0.40 (cumulative ~1.00)
11. **claude-3-sonnet-20240229:**
* Rating 0 (Blue): ~0.10
* Rating 1 (Green): ~0.10 (cumulative ~0.20)
* Rating 2 (Red): ~0.10 (cumulative ~0.30)
* Rating 3 (Purple): ~0.30 (cumulative ~0.60)
* Rating 4 (Yellow): ~0.40 (cumulative ~1.00)
*(Note: claude-3-haiku-20240307 and claude-3-sonnet-20240229 appear to have identical distributions.)*
12. **gpt-4o-2024-05-13:**
* Rating 0 (Blue): ~0.10
* Rating 1 (Green): ~0.10 (cumulative ~0.20)
* Rating 2 (Red): ~0.10 (cumulative ~0.30)
* Rating 3 (Purple): ~0.30 (cumulative ~0.60)
* Rating 4 (Yellow): ~0.40 (cumulative ~1.00)
*(Note: gpt-4o-2024-05-13 also shows an identical distribution to the Claude models.)*
13. **gpt-4o-mini-2024-07-18:**
* Rating 0 (Blue): ~0.38
* Rating 1 (Green): ~0.15 (cumulative ~0.53)
* Rating 2 (Red): ~0.12 (cumulative ~0.65)
* Rating 3 (Purple): ~0.20 (cumulative ~0.85)
* Rating 4 (Yellow): ~0.15 (cumulative ~1.00)
*(Note: gpt-4o-mini-2024-07-18 has a distribution very similar to Llama-3.1-8B-Instruct.)*
### Key Observations
* **Clustering of Distributions:** Several models exhibit remarkably similar rating distributions.
* The Mistral models (Mistral-7B-Instruct, Mistral-8x22B-Instruct-v0.1) and the Qwen2.5 models (Qwen2.5-0.5B-Instruct-v0.1, Qwen2.5-32B-Instruct, Qwen2.5-72B-Instruct) all share a nearly identical distribution: approximately 20% Rating 0, 15% Rating 1, 15% Rating 2, 30% Rating 3, and 20% Rating 4. This suggests a common performance profile among these groups.
* The Claude models (claude-3-haiku-20240307, claude-3-sonnet-20240229) and one of the GPT-4o variants (gpt-4o-2024-05-13) also share an identical distribution: approximately 10% Rating 0, 10% Rating 1, 10% Rating 2, 30% Rating 3, and 40% Rating 4. This indicates a high proportion of top ratings (3 and 4) for these models.
* **Outliers/Distinct Distributions:**
* Llama-3.1-70B-Instruct stands out with a significantly higher proportion of Rating 4 (approximately 35%) and a lower proportion of Rating 0 (approximately 20%) compared to some other Llama models.
* Llama-3.1-8B-Instruct and gpt-4o-mini-2024-07-18 have very similar distributions, characterized by a higher proportion of Rating 0 (around 38%) and lower proportions of higher ratings compared to the Claude/gpt-4o-2024-05-13 group.
* **Dominance of Lower Ratings:** For many models (e.g., Llama-3.1-8B-Instruct, Llama-3.2-1B-Instruct, Llama-3.2-3B-Instruct, gpt-4o-mini-2024-07-18), Rating 0 constitutes the largest single proportion, suggesting that a substantial portion of responses did not meet a high standard.
* **Dominance of Higher Ratings:** Conversely, the Claude models and gpt-4o-2024-05-13 show a strong preference for Ratings 3 and 4, indicating superior performance according to this evaluator.
### Interpretation
This chart provides a comparative analysis of the performance of various language models as judged by a specific evaluator ("gpt-4o-2024-08-06"). The data suggests that different models have distinct performance characteristics.
The clustering of distributions for the Mistral and Qwen2.5 models implies that these models, despite their different parameter counts or versions, are being evaluated similarly by this specific system. This could indicate a consistent evaluation criterion being applied, or that these models are inherently performing at a similar level of quality.
The Claude models and gpt-4o-2024-05-13 appear to be the top performers in this evaluation, consistently receiving higher ratings (3 and 4). This suggests they are more adept at generating responses that satisfy the evaluator's criteria.
The Llama models show more varied performance. Llama-3.1-70B-Instruct seems to perform better than some of its smaller Llama counterparts, particularly in achieving higher ratings. Llama-3.1-8B-Instruct and gpt-4o-mini-2024-07-18, on the other hand, show a tendency towards lower ratings, indicating potential areas for improvement.
The presence of a significant proportion of Rating 0 for several models suggests that the evaluation criteria are stringent, or that these models struggle with certain types of prompts or tasks. Conversely, the high proportion of Ratings 3 and 4 for the top-performing models highlights their strengths.
In essence, the chart allows for a quick assessment of which models are generally perceived as better by the evaluator, and which might require further development or fine-tuning. The consistency in some distributions is a notable finding, potentially pointing to shared architectural similarities or training data influences.
</details>
Figure 20: Rating distribution on RuozhiBench-Gen using GPT-4o-2024-08-06 as an evaluator.
<details>
<summary>x17.png Details</summary>
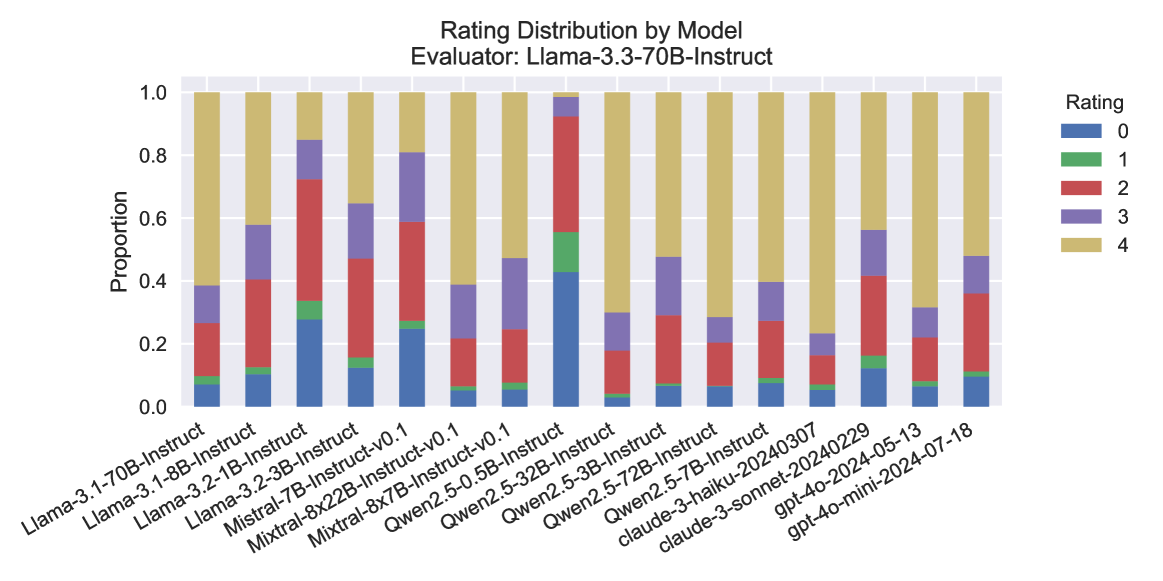
### Visual Description
## Stacked Bar Chart: Rating Distribution by Model
### Overview
This stacked bar chart displays the distribution of ratings (0 through 4) for various language models, as evaluated by "Llama-3.3-70B-Instruct". Each bar represents a specific model, and the segments within the bar indicate the proportion of responses that received each rating. The chart allows for a visual comparison of how different models perform according to the evaluator.
### Components/Axes
* **Title:** "Rating Distribution by Model"
* **Subtitle:** "Evaluator: Llama-3.3-70B-Instruct"
* **Y-axis Title:** "Proportion"
* **Y-axis Scale:** Ranges from 0.0 to 1.0, representing proportions from 0% to 100%. Major ticks are at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-axis Labels:** These are the names of the evaluated models. They are rotated for readability and include:
* Llama-3.1-70B-Instruct
* Llama-3.1-8B-Instruct
* Llama-3.2-1B-Instruct
* Llama-3.2-3B-Instruct
* Mistral-7B-Instruct
* Mistral-8x22B-Instruct-v0.1
* Qwen2.5-0.5B-Instruct-v0.1
* Qwen2.5-32B-Instruct
* Qwen2.5-72B-Instruct
* claude-3-haiku-20240307
* claude-3-sonnet-20240229
* gpt-4o-mini-20240513
* gpt-4o-2024-07-18
* **Legend:** Located in the top-right corner of the chart. It maps colors to rating values:
* Blue: Rating 0
* Green: Rating 1
* Red: Rating 2
* Purple: Rating 3
* Yellow: Rating 4
### Detailed Analysis
The chart displays 13 different models. For each model, the bar is segmented from bottom to top, representing the cumulative proportion of ratings from 0 to 4.
* **Llama-3.1-70B-Instruct:**
* Rating 0 (Blue): ~0.08
* Rating 1 (Green): ~0.02 (cumulative ~0.10)
* Rating 2 (Red): ~0.15 (cumulative ~0.25)
* Rating 3 (Purple): ~0.15 (cumulative ~0.40)
* Rating 4 (Yellow): ~0.60 (cumulative ~1.00)
* Trend: Starts with a moderate proportion of low ratings, then a significant portion of high ratings.
* **Llama-3.1-8B-Instruct:**
* Rating 0 (Blue): ~0.05
* Rating 1 (Green): ~0.01 (cumulative ~0.06)
* Rating 2 (Red): ~0.20 (cumulative ~0.26)
* Rating 3 (Purple): ~0.34 (cumulative ~0.60)
* Rating 4 (Yellow): ~0.40 (cumulative ~1.00)
* Trend: Similar to the previous model, but with a higher proportion of ratings 2 and 3, and a lower proportion of rating 4.
* **Llama-3.2-1B-Instruct:**
* Rating 0 (Blue): ~0.18
* Rating 1 (Green): ~0.01 (cumulative ~0.19)
* Rating 2 (Red): ~0.15 (cumulative ~0.34)
* Rating 3 (Purple): ~0.26 (cumulative ~0.60)
* Rating 4 (Yellow): ~0.40 (cumulative ~1.00)
* Trend: Higher proportion of rating 0 compared to the previous two Llama models.
* **Llama-3.2-3B-Instruct:**
* Rating 0 (Blue): ~0.10
* Rating 1 (Green): ~0.01 (cumulative ~0.11)
* Rating 2 (Red): ~0.12 (cumulative ~0.23)
* Rating 3 (Purple): ~0.17 (cumulative ~0.40)
* Rating 4 (Yellow): ~0.60 (cumulative ~1.00)
* Trend: A relatively balanced distribution across ratings 0-3, with a strong majority in rating 4.
* **Mistral-7B-Instruct:**
* Rating 0 (Blue): ~0.23
* Rating 1 (Green): ~0.01 (cumulative ~0.24)
* Rating 2 (Red): ~0.17 (cumulative ~0.41)
* Rating 3 (Purple): ~0.19 (cumulative ~0.60)
* Rating 4 (Yellow): ~0.40 (cumulative ~1.00)
* Trend: Higher proportion of rating 0 than previous Llama models.
* **Mistral-8x22B-Instruct-v0.1:**
* Rating 0 (Blue): ~0.15
* Rating 1 (Green): ~0.01 (cumulative ~0.16)
* Rating 2 (Red): ~0.10 (cumulative ~0.26)
* Rating 3 (Purple): ~0.57 (cumulative ~0.83)
* Rating 4 (Yellow): ~0.17 (cumulative ~1.00)
* Trend: This model shows a significantly higher proportion of rating 3 and a much lower proportion of rating 4 compared to most other models.
* **Qwen2.5-0.5B-Instruct-v0.1:**
* Rating 0 (Blue): ~0.10
* Rating 1 (Green): ~0.01 (cumulative ~0.11)
* Rating 2 (Red): ~0.12 (cumulative ~0.23)
* Rating 3 (Purple): ~0.17 (cumulative ~0.40)
* Rating 4 (Yellow): ~0.60 (cumulative ~1.00)
* Trend: Similar distribution to Llama-3.2-3B-Instruct, with a strong majority in rating 4.
* **Qwen2.5-32B-Instruct:**
* Rating 0 (Blue): ~0.08
* Rating 1 (Green): ~0.01 (cumulative ~0.09)
* Rating 2 (Red): ~0.10 (cumulative ~0.19)
* Rating 3 (Purple): ~0.12 (cumulative ~0.31)
* Rating 4 (Yellow): ~0.69 (cumulative ~1.00)
* Trend: This model has the highest proportion of rating 4 among all displayed models.
* **Qwen2.5-72B-Instruct:**
* Rating 0 (Blue): ~0.07
* Rating 1 (Green): ~0.01 (cumulative ~0.08)
* Rating 2 (Red): ~0.10 (cumulative ~0.18)
* Rating 3 (Purple): ~0.15 (cumulative ~0.33)
* Rating 4 (Yellow): ~0.67 (cumulative ~1.00)
* Trend: Very similar to Qwen2.5-32B-Instruct, with a very high proportion of rating 4.
* **claude-3-haiku-20240307:**
* Rating 0 (Blue): ~0.10
* Rating 1 (Green): ~0.01 (cumulative ~0.11)
* Rating 2 (Red): ~0.15 (cumulative ~0.26)
* Rating 3 (Purple): ~0.20 (cumulative ~0.46)
* Rating 4 (Yellow): ~0.54 (cumulative ~1.00)
* Trend: A moderate distribution, with a good proportion of rating 4.
* **claude-3-sonnet-20240229:**
* Rating 0 (Blue): ~0.07
* Rating 1 (Green): ~0.01 (cumulative ~0.08)
* Rating 2 (Red): ~0.10 (cumulative ~0.18)
* Rating 3 (Purple): ~0.15 (cumulative ~0.33)
* Rating 4 (Yellow): ~0.67 (cumulative ~1.00)
* Trend: Similar to Qwen2.5-72B-Instruct, with a high proportion of rating 4.
* **gpt-4o-mini-20240513:**
* Rating 0 (Blue): ~0.12
* Rating 1 (Green): ~0.01 (cumulative ~0.13)
* Rating 2 (Red): ~0.10 (cumulative ~0.23)
* Rating 3 (Purple): ~0.10 (cumulative ~0.33)
* Rating 4 (Yellow): ~0.67 (cumulative ~1.00)
* Trend: A relatively even distribution across ratings 0-3, with a strong majority in rating 4.
* **gpt-4o-2024-07-18:**
* Rating 0 (Blue): ~0.10
* Rating 1 (Green): ~0.01 (cumulative ~0.11)
* Rating 2 (Red): ~0.25 (cumulative ~0.36)
* Rating 3 (Purple): ~0.15 (cumulative ~0.51)
* Rating 4 (Yellow): ~0.49 (cumulative ~1.00)
* Trend: This model has a notably higher proportion of rating 2 compared to many others, and a slightly lower proportion of rating 4.
### Key Observations
* **Dominance of Rating 4:** The majority of models show a substantial proportion of responses receiving a rating of 4 (yellow segment), indicating generally high performance as judged by the evaluator.
* **Qwen2.5 Models Excel:** The Qwen2.5 models (0.5B, 32B, and 72B) and the claude-3-sonnet model appear to achieve the highest proportions of rating 4, with Qwen2.5-32B-Instruct and Qwen2.5-72B-Instruct showing the largest yellow segments (approximately 69% and 67% respectively).
* **Mistral-8x22B-Instruct Anomaly:** Mistral-8x22B-Instruct-v0.1 stands out with a significantly higher proportion of rating 3 (purple segment, ~57%) and a considerably lower proportion of rating 4 (~17%) compared to most other models.
* **gpt-4o-2024-07-18 Variation:** This model shows a higher proportion of rating 2 (red segment, ~25%) than many other models, and a slightly lower proportion of rating 4.
* **Llama Models:** The Llama models generally show a good distribution, with a significant portion of rating 4, though some variations exist in the proportions of lower ratings. Llama-3.1-70B-Instruct and Llama-3.2-3B-Instruct have a higher proportion of rating 4 compared to Llama-3.1-8B-Instruct and Llama-3.2-1B-Instruct.
* **Rating 0 Proportions:** Most models have a rating 0 proportion between 5% and 15%. Mistral-7B-Instruct and Mistral-8x22B-Instruct-v0.1 have slightly higher proportions of rating 0 (around 23% and 15% respectively).
### Interpretation
This chart provides a comparative performance analysis of various language models when evaluated by "Llama-3.3-70B-Instruct". The data suggests that while many models perform well, achieving high ratings, there are distinct differences in their rating distributions.
The prevalence of rating 4 across most models indicates that the evaluator, "Llama-3.3-70B-Instruct", tends to assign high scores, suggesting a generally positive assessment of the evaluated models' outputs. However, the variations in the proportions of ratings 0, 1, 2, and 3 highlight subtle but important differences in how each model's responses are perceived.
The Qwen2.5 family of models, particularly the larger versions (32B and 72B), and claude-3-sonnet appear to be the strongest performers according to this specific evaluator, consistently receiving the highest proportion of top ratings. This suggests that these models might be more aligned with the evaluation criteria or possess capabilities that the evaluator prioritizes.
The outlier, Mistral-8x22B-Instruct-v0.1, with its high proportion of rating 3 and low rating 4, suggests a different performance profile. It might be that its responses are consistently good but not exceptional, or that it struggles with certain aspects that lead to a rating of 4. Similarly, gpt-4o-2024-07-18's higher proportion of rating 2 might indicate a tendency for its responses to be moderately good rather than excellent or poor.
The Llama models show a generally good performance, but the differences between them might reflect variations in their architecture or training data, leading to slightly different response qualities.
In essence, the chart demonstrates that while a high rating is common, the nuances in the distribution of lower ratings can reveal specific strengths and weaknesses of each model as perceived by the "Llama-3.3-70B-Instruct" evaluator. This data is crucial for understanding model capabilities in a comparative context and for identifying models that excel in specific areas or align best with particular evaluation standards.
</details>
Figure 21: Rating distribution on RuozhiBench-Gen using Llama-3.3-70B-Instruction as an evaluator.