# MoBA: Mixture of Block Attention for Long-Context LLMs
> ∗zhang_mingxing@mail.tsinghua.edu.cn‡Co-corresponding authors.
Xinyu Zhou (zhouxinyu@moonshot.cn),
Jiezhong Qiu (jiezhongqiu@outlook.com)
\addbibresource
iclr2025_conference.bib
Abstract
Scaling the effective context length is essential for advancing large language models (LLMs) toward artificial general intelligence (AGI). However, the quadratic increase in computational complexity inherent in traditional attention mechanisms presents a prohibitive overhead. Existing approaches either impose strongly biased structures, such as sink or window attention which are task-specific, or radically modify the attention mechanism into linear approximations, whose performance in complex reasoning tasks remains inadequately explored.
In this work, we propose a solution that adheres to the “less structure” principle, allowing the model to determine where to attend autonomously, rather than introducing predefined biases. We introduce Mixture of Block Attention (MoBA), an innovative approach that applies the principles of Mixture of Experts (MoE) to the attention mechanism. This novel architecture demonstrates superior performance on long-context tasks while offering a key advantage: the ability to seamlessly transition between full and sparse attention, enhancing efficiency without the risk of compromising performance. MoBA has already been deployed to support Kimi’s long-context requests and demonstrates significant advancements in efficient attention computation for LLMs. Our code is available at https://github.com/MoonshotAI/MoBA.
1 Introduction
The pursuit of artificial general intelligence (AGI) has driven the development of large language models (LLMs) to unprecedented scales, with the promise of handling complex tasks that mimic human cognition. A pivotal capability for achieving AGI is the ability to process, understand, and generate long sequences, which is essential for a wide range of applications, from historical data analysis to complex reasoning and decision-making processes. This growing demand for extended context processing can be seen not only in the popularity of long input prompt understanding, as showcased by models like Kimi \parencite kimi, Claude \parencite claude and Gemini \parencite reid2024gemini, but also in recent explorations of long chain-of-thought (CoT) output capabilities in Kimi k1.5 \parencite team2025kimi, DeepSeek-R1 \parencite guo2025deepseek, and OpenAI o1/o3 \parencite guan2024deliberative.
However, extending the sequence length in LLMs is non-trivial due to the quadratic growth in computational complexity associated with the vanilla attention mechanism \parencite waswani2017attention. This challenge has spurred a wave of research aimed at improving efficiency without sacrificing performance. One prominent direction capitalizes on the inherent sparsity of attention scores. This sparsity arises both mathematically — from the softmax operation, where various sparse attention patterns have be studied \parencite jiang2024minference — and biologically \parencite watson2025human, where sparse connectivity is observed in brain regions related to memory storage.
Existing approaches often leverage predefined structural constraints, such as sink-based \parencite xiao2023efficient or sliding window attention \parencite beltagy2020longformer, to exploit this sparsity. While these methods can be effective, they tend to be highly task-specific, potentially hindering the model’s overall generalizability. Alternatively, a range of dynamic sparse attention mechanisms, exemplified by Quest \parencite tang2024quest, Minference \parencite jiang2024minference, and RetrievalAttention \parencite liu2024retrievalattention, select subsets of tokens at inference time. Although such methods can reduce computation for long sequences, they do not substantially alleviate the intensive training costs of long-context models, making it challenging to scale LLMs efficiently to contexts on the order of millions of tokens. Another promising alternative way has recently emerged in the form of linear attention models, such as Mamba \parencite dao2024transformers, RWKV \parencite peng2023rwkv, peng2024eagle, and RetNet \parencite sun2023retentive. These approaches replace canonical softmax-based attention with linear approximations, thereby reducing the computational overhead for long-sequence processing. However, due to the substantial differences between linear and conventional attention, adapting existing Transformer models typically incurs high conversion costs \parencite mercat2024linearizing, wang2024mamba, bick2025transformers, zhang2024lolcats or requires training entirely new models from scratch \parencite li2025minimax. More importantly, evidence of their effectiveness in complex reasoning tasks remains limited.
Consequently, a critical research question arises: How can we design a robust and adaptable attention architecture that retains the original Transformer framework while adhering to a “less structure” principle, allowing the model to determine where to attend without relying on predefined biases? Ideally, such an architecture would transition seamlessly between full and sparse attention modes, thus maximizing compatibility with existing pre-trained models and enabling both efficient inference and accelerated training without compromising performance.
Thus, we introduce Mixture of Block Attention (MoBA), a novel architecture that builds upon the innovative principles of Mixture of Experts (MoE) \parencite shazeer2017outrageously and applies them to the attention mechanism of the Transformer model. MoE has been used primarily in the feedforward network (FFN) layers of Transformers \parencite lepikhin2020gshard,fedus2022switch, zoph2022st, but MoBA pioneers its application to long context attention, allowing dynamic selection of historically relevant blocks of key and values for each query token. This approach not only enhances the efficiency of LLMs but also enables them to handle longer and more complex prompts without a proportional increase in resource consumption. MoBA addresses the computational inefficiency of traditional attention mechanisms by partitioning the context into blocks and employing a gating mechanism to selectively route query tokens to the most relevant blocks. This block sparse attention significantly reduces the computational costs, paving the way for more efficient processing of long sequences. The model’s ability to dynamically select the most informative blocks of keys leads to improved performance and efficiency, particularly beneficial for tasks involving extensive contextual information.
In this paper, we detail the architecture of MoBA, firstly its block partitioning and routing strategy, and secondly its computational efficiency compared to traditional attention mechanisms. We further present experimental results that demonstrate MoBA’s superior performance in tasks requiring the processing of long sequences. Our work contributes a novel approach to efficient attention computation, pushing the boundaries of what is achievable with LLMs in handling complex and lengthy inputs.
2 Method
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Data Routing System Architecture
### Overview
The diagram illustrates a data routing system architecture with a central router processing queries (q1, q2) through key-value blocks and attention score aggregation. The system uses color-coded blocks to represent data components and their flow paths.
### Components/Axes
- **Central Router**: Gray rectangle labeled "Router" at the top center
- **Queries**:
- Red square (q1) at top-left
- Yellow square (q2) at top-right
- **Keys**:
- Blue square (block1) and purple square (block2) under "Keys" label
- **Values**:
- Purple square (block1) and blue square (block2) under "Values" label
- **Attention Score**:
- White rectangle labeled "Attn score" at bottom
- Contains combined blocks from both key and value paths
- **Dashed Pathway**:
- Connects router to green (block3) and gray (block4) blocks
- Separate from main key-value flow
### Spatial Grounding
- Router (center-top) connects to:
- Queries (top-left/right)
- Keys (left-center)
- Values (right-center)
- Dashed pathway (right-center) connects to:
- Green block3 (right-center)
- Gray block4 (right-center)
- Attention score (bottom-center) aggregates:
- Purple/blue blocks from left path
- Green/gray blocks from right path
### Key Observations
1. Color-coded blocks maintain consistent color associations:
- q1 (red) → purple/blue blocks
- q2 (yellow) → green/gray blocks
2. Dashed pathway creates parallel processing stream
3. Attention score combines both key-value paths with query-specific blocks
4. System shows bidirectional flow from queries to router and back
### Interpretation
This architecture demonstrates a hybrid routing system where:
1. Queries split into key-value processing paths
2. Dashed pathway suggests alternative processing route
3. Attention scores combine multiple data sources
4. Color coding enables visual tracking of data lineage
The system appears designed for parallel processing with query-specific data aggregation, where the dashed pathway might represent error handling or secondary processing. The attention score mechanism suggests a transformer-like architecture where multiple data sources are combined for final output generation.
</details>
(a)
<details>
<summary>x2.png Details</summary>
### Visual Description
## Flowchart: Technical Process Architecture
### Overview
The image depicts a technical workflow diagram illustrating a multi-stage processing pipeline involving gating mechanisms, attention operations, and index selection. The flow progresses from left to right and top to bottom, with explicit connections between components.
### Components/Axes
1. **Main Blocks**:
- **MoBA Gating** (leftmost block, light gray background)
- **RoPE** (top-center block, blue background)
- **Index Select** (center-right block, light gray background)
- **Varen Flash-Attention** (bottom-right block, dark blue background)
- **Attention Output** (final output, dark blue arrow)
2. **Sub-Components within MoBA Gating**:
- **Partition to blocks** (yellow block)
- **Mean Pooling** (green block)
- **MatMul** (purple block)
- **Top Gating** (pink block)
3. **Arrows and Labels**:
- Dashed arrows between MoBA Gating sub-components
- Solid arrows connecting main blocks
- Explicit labels: "Selected Block Index" (between MoBA Gating and Index Select), "Attention Output" (final arrow)
### Detailed Analysis
1. **MoBA Gating Process**:
- Input is partitioned into blocks (yellow)
- Mean pooling aggregates block representations (green)
- Matrix multiplication (MatMul) processes pooled data (purple)
- Top Gating (pink) produces a selection mechanism
- Output: **Selected Block Index** (directed to Index Select)
2. **Index Selection**:
- Receives Selected Block Index from MoBA Gating
- Feeds into **Varen Flash-Attention** (dark blue)
3. **Attention Mechanism**:
- **Varen Flash-Attention** processes input via:
- Query (Q), Key (K), Value (V) pathways (top-center RoPE block)
- Produces **Attention Output** (dark blue arrow)
### Key Observations
1. **Hierarchical Flow**:
- MoBA Gating → Index Select → Varen Flash-Attention → Attention Output
- RoPE block appears to modulate Q/K/V inputs for attention
2. **Color Coding**:
- Gating components use warm colors (yellow/green/purple/pink)
- Attention components use cool colors (blue/dark blue)
- No explicit legend, but color coding suggests functional grouping
3. **Critical Nodes**:
- **Selected Block Index**: Acts as decision point between MoBA Gating and attention
- **RoPE**: Positional encoding integrated early in the pipeline
### Interpretation
This architecture combines gating mechanisms with attention operations in a transformer-like framework. The MoBA Gating system appears to:
1. Process input through multiple stages (partitioning → pooling → matrix ops → gating)
2. Selectively route information via block indexing
3. Feed selected data into optimized attention (Varen Flash-Attention)
The integration of RoPE suggests positional awareness is maintained throughout the pipeline. The "Flash-Attention" component implies computational optimizations for attention mechanisms, possibly reducing memory requirements while maintaining performance.
The diagram demonstrates a multi-stage approach where:
- Early stages (MoBA Gating) focus on feature selection
- Later stages (attention) focus on contextual integration
- Positional encoding (RoPE) is preserved across stages
This structure could represent a specialized transformer variant for tasks requiring both gating mechanisms and efficient attention computation, such as long-sequence processing or resource-constrained environments.
</details>
(b)
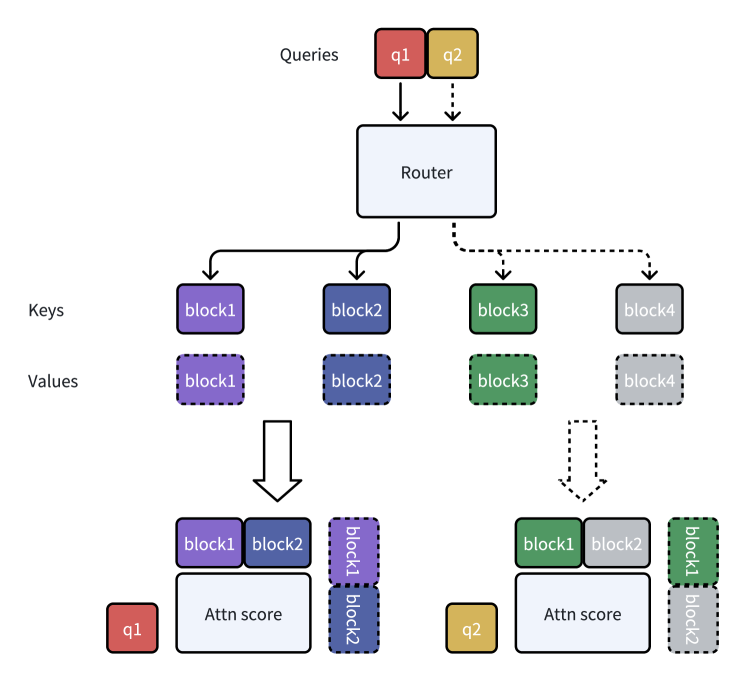
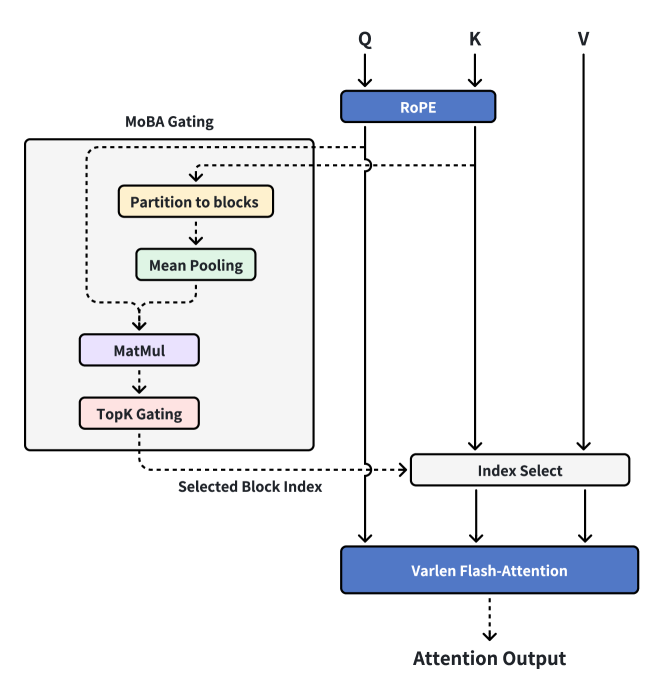
Figure 1: Illustration of mixture of block attention (MoBA). (a) A running example of MoBA; (b) Integration of MoBA into Flash Attention.
In this work, we introduce a novel architecture, termed Mixture of Block Attention (MoBA), which extends the capabilities of the Transformer model by dynamically selecting historical segments (blocks) for attention computation. MoBA is inspired by techniques of Mixture of Experts (MoE) and sparse attention. The former technique has been predominantly applied to the feedforward network (FFN) layers within the Transformer architecture, while the latter has been widely adopted in scaling Transformers to handle long contexts. Our method is innovative in applying the MoE principle to the attention mechanism itself, allowing for more efficient and effective processing of long sequences.
2.1 Preliminaries: Standard Attention in Transformer
We first revisit the standard Attention in Transformers. For simplicity, we revisit the case where a single query token ${\bm{q}}∈\mathbb{R}^{1× d}$ attends to the $N$ key and value tokens, denoting ${\bm{K}},{\bm{V}}∈\mathbb{R}^{N× d}$ , respectively. The standard attention is computed as:
$$
\mathrm{Attn}({\bm{q}},{\bm{K}},{\bm{V}})=\mathrm{Softmax}{\left({\bm{q}}{\bm{%
K}}^{\top}\right)}{\bm{V}}, \tag{1}
$$
where $d$ denotes the dimension of a single attention head. We focus on the single-head scenario for clarity. The extension to multi-head attention involves concatenating the outputs from multiple such single-head attention operations.
2.2 MoBA Architecture
Different from standard attention where each query tokens attend to the entire context, MoBA enables each query token to only attend to a subset of keys and values:
$$
\mathrm{MoBA}({\bm{q}},{\bm{K}},{\bm{V}})=\mathrm{Softmax}{\left({\bm{q}}{{\bm%
{K}}[I]}^{\top}\right)}{\bm{V}}[I], \tag{2}
$$
where $I⊂eq[N]$ is the set of selected keys and values.
The key innovation in MoBA is the block partitioning and selection strategy. We divide the full context of length $N$ into $n$ blocks, where each block represents a subset of subsequent tokens. Without loss of generality, we assume that the context length $N$ is divisible by the number of blocks $n$ . We further denote $B=\frac{N}{n}$ to be the block size and
$$
I_{i}=\left[(i-1)\times B+1,i\times B\right] \tag{3}
$$
to be the range of the $i$ -th block. By applying the top- $k$ gating mechanism from MoE, we enable each query to selectively focus on a subset of tokens from different blocks, rather than the entire context:
$$
I=\bigcup_{g_{i}>0}I_{i}. \tag{4}
$$
The model employs a gating mechanism, as $g_{i}$ in Equation 4, to select the most relevant blocks for each query token. The MoBA gate first computes the affinity score $s_{i}$ measuring the relevance between query ${\bm{q}}$ and the $i$ -th block, and applies a top- $k$ gating among all blocks. More formally, the gate value for the $i$ -th block $g_{i}$ is computed by
$$
g_{i}=\begin{cases}1&s_{i}\in\mathrm{Topk}\left(\{s_{j}|j\in[n]\},k\right)\\
0&\text{otherwise}\end{cases}, \tag{5}
$$
where $\mathrm{Topk}(·,k)$ denotes the set containing $k$ highest scores among the affinity scores calculated for each block. In this work, the score $s_{i}$ is computed by the inner product between ${\bm{q}}$ and the mean pooling of ${\bm{K}}[I_{i}]$ along the sequence dimension:
$$
s_{i}=\langle{\bm{q}},\mathrm{mean\_pool}({\bm{K}}[I_{i}])\rangle \tag{6}
$$
A Running Example. We provide a running example of MoBA at Figure 1a, where we have two query tokens and four KV blocks. The router (gating network) dynamically selects the top two blocks for each query to attend. As shown in Figure 1a, the first query is assigned to the first and second blocks, while the second query is assigned to the third and fourth blocks.
It is important to maintain causality in autoregressive language models, as they generate text by next-token prediction based on previous tokens. This sequential generation process ensures that a token cannot influence tokens that come before it, thus preserving the causal relationship. MoBA preserves causality through two specific designs:
Causality: No Attention to Future Blocks. MoBA ensures that a query token cannot be routed to any future blocks. By limiting the attention scope to current and past blocks, MoBA adheres to the autoregressive nature of language modeling. More formally, denoting $\mathrm{pos}({\bm{q}})$ as the position index of the query ${\bm{q}}$ , we set $s_{i}=-∞$ and $g_{i}=0$ for any blocks $i$ such that $\mathrm{pos}({\bm{q}})<i× B$ .
Current Block Attention and Causal Masking. We define the ”current block” as the block that contains the query token itself. The routing to the current block could also violate causality, since mean pooling across the entire block can inadvertently include information from future tokens. To address this, we enforce that each token must be routed to its respective current block and apply a causal mask during the current block attention. This strategy not only avoids any leakage of information from subsequent tokens but also encourages attention to the local context. More formally, we set $g_{i}=1$ for the block $i$ where the position of the query token $\mathrm{pos}({\bm{q}})$ is within the interval $I_{i}$ . From the perspective of Mixture-of-Experts (MoE), the current block attention in MoBA is akin to the role of shared experts in modern MoE architectures \parencite dai2024deepseekmoe, yang2024qwen2, where static routing rules are added when expert selection.
Next, we discuss some additional key design choices of MoBA, such as its block segmentation strategy and the hybrid of MoBA and full attention.
Fine-Grained Block Segmentation. The positive impact of fine-grained expert segmentation in improving mode performance has been well-documented in the Mixture-of-Experts (MoE) literature \parencite dai2024deepseekmoe, yang2024qwen2. In this work, we explore the potential advantage of applying a similar fine-grained segmentation technique to MoBA. MoBA, inspired by MoE, operates segmentation along the context-length dimension rather than the FFN intermediate hidden dimension. Therefore our investigation aims to determine if MoBA can also benefit when we partition the context into blocks with a finer grain. More experimental results can be found in Section 3.1.
Hybrid of MoBA and Full Attention. MoBA is designed to be a substitute for full attention, maintaining the same number of parameters without any addition or subtraction. This feature inspires us to conduct smooth transitions between full attention and MoBA. Specifically, at the initialization stage, each attention layer has the option to select full attention or MoBA, and this choice can be dynamically altered during training if necessary. A similar idea of transitioning full attention to sliding window attention has been studied in previous work \parencite zhang2024simlayerkv. More experimental results can be found in Section 3.2.
Comparing to Sliding Window Attention and Attention Sink. Sliding window attention (SWA) and attention sink are two popular sparse attention architectures. We demonstrate that both can be viewed as special cases of MoBA. For sliding window attention \parencite beltagy2020longformer, each query token only attends to its neighboring tokens. This can be interpreted as a variant of MoBA with a gating network that keeps selecting the most recent blocks. Similarly, attention sink \parencite xiao2023efficient, where each query token attends to a combination of initial tokens and the most recent tokens, can be seen as a variant of MoBA with a gating network that always selects both the initial and the recent blocks. The above discussion shows that MoBA has stronger expressive power than sliding window attention and attention sink. Moreover, it shows that MoBA can flexibly approximate many static sparse attention architectures by incorporating specific gating networks.
Overall, MoBA’s attention mechanism allows the model to adaptively and dynamically focus on the most informative blocks of the context. This is particularly beneficial for tasks involving long documents or sequences, where attending to the entire context may be unnecessary and computationally expensive. MoBA’s ability to selectively attend to relevant blocks enables more nuanced and efficient processing of information.
2.3 Implementation
Algorithm 1 MoBA (Mixture of Block Attention) Implementation
0: Query, key and value matrices $\mathbf{Q},\mathbf{K},\mathbf{V}∈\mathbb{R}^{N× h× d}$ ; MoBA hyperparameters (block size $B$ and top- $k$ ); $h$ and $d$ denote the number of attention heads and head dimension. Also denote $n=N/B$ to be the number of blocks.
1: // Split KV into blocks
2: $\{\tilde{\mathbf{K}}_{i},\tilde{\mathbf{V}}_{i}\}=\text{split\_blocks}(\mathbf%
{K},\mathbf{V},B)$ , where $\tilde{\mathbf{K}}_{i},\tilde{\mathbf{V}}_{i}∈\mathbb{R}^{B× h× d}%
,i∈[n]$
3: // Compute gating scores for dynamic block selection
4: $\bar{\mathbf{K}}=\text{mean\_pool}(\mathbf{K},B)∈\mathbb{R}^{n× h×
d}$
5: $\mathbf{S}=\mathbf{Q}\bar{\mathbf{K}}^{→p}∈\mathbb{R}^{N× h× n}$
6: // Select blocks with causal constraint (no attention to future blocks)
7: $\mathbf{M}=\text{create\_causal\_mask}(N,n)$
8: $\mathbf{G}=\text{topk}(\mathbf{S}+\mathbf{M},k)$
9: // Organize attention patterns for computation efficiency
10: $\mathbf{Q}^{s},\tilde{\mathbf{K}}^{s},\tilde{\mathbf{V}}^{s}=\text{get\_self\_%
attn\_block}(\mathbf{Q},\tilde{\mathbf{K}},\tilde{\mathbf{V}})$
11: $\mathbf{Q}^{m},\tilde{\mathbf{K}}^{m},\tilde{\mathbf{V}}^{m}=\text{index\_%
select\_moba\_attn\_block}(\mathbf{Q},\tilde{\mathbf{K}},\tilde{\mathbf{V}},%
\mathbf{G})$
12: // Compute attentions seperately
13: $\mathbf{O}^{s}=\text{flash\_attention\_varlen}(\mathbf{Q}^{s},\tilde{\mathbf{K%
}}^{s},\tilde{\mathbf{V}}^{s},\text{causal=True})$
14: $\mathbf{O}^{m}=\text{flash\_attention\_varlen}(\mathbf{Q}^{m},\tilde{\mathbf{K%
}}^{m},\tilde{\mathbf{V}}^{m},\text{causal=False})$
15: // Combine results with online softmax
16: $\mathbf{O}=\text{combine\_with\_online\_softmax}(\mathbf{O}^{s},\mathbf{O}^{m})$
17: return $\mathbf{O}$
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Graph: Computation Time vs. Sequence Length for Flash Attention and MoBA Algorithms
### Overview
The graph compares the computation time (in milliseconds) of two algorithms—Flash Attention and MoBA—across varying sequence lengths (32K to 1M). Flash Attention exhibits a steeply increasing trend, while MoBA shows a linear increase. Both algorithms start with negligible computation time at 32K sequence length.
### Components/Axes
- **X-axis (Sequence Length)**: Labeled "Sequence Length" with markers at 32K, 128K, 256K, 512K, and 1M.
- **Y-axis (Computation Time)**: Labeled "Computation Time (ms)" with a range from 0 to 800 ms.
- **Legend**: Located in the top-left corner.
- Flash Attention: Dashed light blue line with circular markers.
- MoBA: Solid dark blue line with circular markers.
### Detailed Analysis
- **Flash Attention**:
- 32K: ~0 ms
- 128K: ~10 ms
- 256K: ~50 ms
- 512K: ~230 ms
- 1M: ~900 ms
- **MoBA**:
- 32K: ~0 ms
- 128K: ~10 ms
- 256K: ~20 ms
- 512K: ~50 ms
- 1M: ~140 ms
### Key Observations
1. **Exponential Growth for Flash Attention**: Computation time increases sharply after 512K, reaching ~900 ms at 1M.
2. **Linear Scaling for MoBA**: Time rises steadily, with a ~140 ms increase at 1M.
3. **Divergence at Scale**: The gap between the two algorithms widens significantly at 1M sequence length.
4. **Baseline Consistency**: Both algorithms start at ~0 ms for 32K sequence length.
### Interpretation
- **Algorithmic Efficiency**: Flash Attention’s steep growth suggests higher computational complexity for longer sequences, potentially due to memory or parallelism constraints. MoBA’s linear scaling indicates better optimization for large-scale tasks.
- **Practical Implications**: For applications requiring processing of very long sequences (e.g., 1M), MoBA is more efficient. Flash Attention may be preferable for shorter sequences where its initial performance is competitive.
- **Uncertainty**: Values are approximate, with potential variability in real-world implementations (e.g., hardware differences, implementation optimizations).
### Spatial Grounding
- Legend: Top-left corner, clearly associating colors/styles with algorithms.
- Data Points: Aligned with x-axis markers, confirming sequence length correspondence.
- Line Trends: Flash Attention’s dashed line slopes upward steeply; MoBA’s solid line has a gentle incline.
</details>
(a)
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Graph: Computation Time Comparison Between Flash Attention and MoBA
### Overview
The image is a line graph comparing the computation time (in seconds) of two algorithms, **Flash Attention** and **MoBA**, across varying sequence lengths (from 32K to 10M). The graph includes a secondary inset focusing on smaller sequence lengths (32K to 512K). The primary trend shows **Flash Attention** exhibiting a steep increase in computation time with longer sequences, while **MoBA** remains nearly constant.
---
### Components/Axes
- **X-axis (Sequence Length)**: Labeled "Sequence Length" with markers at 32K, 128K, 256K, 512K, 1M, 4M, 7M, and 10M.
- **Y-axis (Computation Time)**: Labeled "Computation Time (s)" with a scale from 0.0 to 80.0 seconds.
- **Legend**: Located in the top-left corner, with:
- **Flash Attention**: Dashed light blue line.
- **MoBA**: Solid dark blue line.
- **Inset Graph**: Positioned in the top-right corner, zooming into sequence lengths from 32K to 512K.
---
### Detailed Analysis
#### Flash Attention (Dashed Light Blue Line)
- **Data Points**:
- 32K: ~0.0s
- 128K: ~0.05s
- 256K: ~0.15s
- 512K: ~0.2s
- 1M: ~0.3s
- 4M: ~0.5s
- 7M: ~0.8s
- 10M: ~1.2s
- **Trend**: Steep upward slope, especially after 512K. Computation time increases exponentially with sequence length.
#### MoBA (Solid Dark Blue Line)
- **Data Points**:
- 32K: ~0.0s
- 128K: ~0.0s
- 256K: ~0.0s
- 512K: ~0.0s
- 1M: ~0.0s
- 4M: ~0.0s
- 7M: ~0.0s
- 10M: ~0.05s
- **Trend**: Nearly flat line, with minimal increase only at 10M. Computation time remains almost constant across all sequence lengths.
---
### Key Observations
1. **Flash Attention** shows a dramatic increase in computation time as sequence length grows, particularly beyond 512K.
2. **MoBA** maintains near-zero computation time for all sequence lengths except 10M, where it slightly rises to ~0.05s.
3. The inset graph emphasizes the divergence between the two algorithms at smaller sequence lengths (32K–512K), where Flash Attention already exhibits a noticeable upward trend.
---
### Interpretation
- **Scalability**: MoBA demonstrates superior scalability for large sequence lengths (up to 10M), making it more efficient for high-throughput or memory-intensive applications.
- **Performance Trade-off**: Flash Attention’s computation time grows exponentially with sequence length, suggesting potential limitations in handling very large datasets.
- **Inset Insight**: Even at smaller scales (32K–512K), Flash Attention’s computation time rises faster than MoBA, indicating inherent inefficiencies in its design for longer sequences.
- **Y-axis Scale Note**: The y-axis scale (0.0–80.0s) appears inconsistent with the data points (max ~1.2s). This may reflect a visualization error or mislabeling, but the extracted data points align with the observed trends.
This analysis highlights MoBA’s efficiency advantage for large-scale computations, while Flash Attention’s performance degrades significantly as sequence length increases.
</details>
(b)
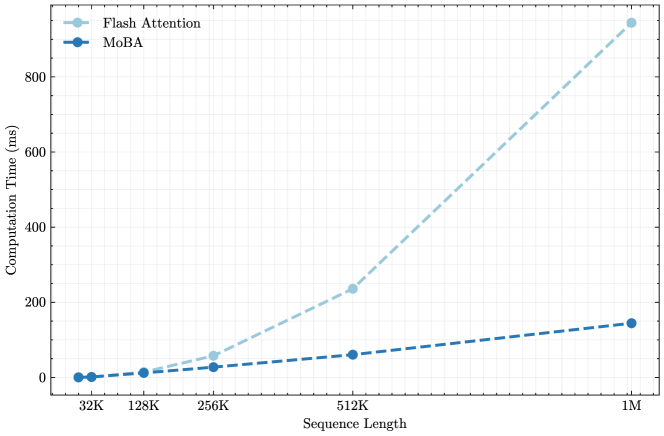
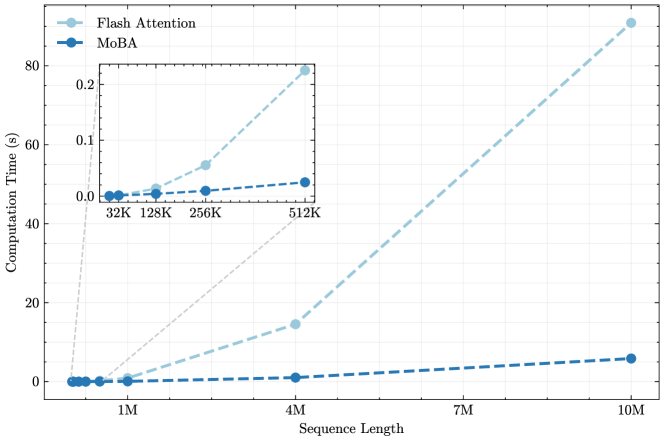
Figure 2: Efficiency of MoBA vs. full attention (implemented with Flash Attention). (a) 1M Model speedup evaluation: Computation time scaling of MoBA versus Flash Attention on 1M model with increasing sequence lengths (8K-1M). (b) Fixed Sparsity Ratio scaling: Computation time scaling comparison between MoBA and Flash Attention across increasing sequence lengths (8K-10M), maintaining a constant sparsity ratio of $95.31\%$ (fixed 64 MoBA blocks with variance block size and fixed top-k=3).
We provide a high-performance implementation of MoBA, by incorporating optimization techniques from FlashAttention \parencite dao2022flashattention and MoE \parencite rajbhandari2022deepspeed. Figure 2 demonstrates the high efficiency of MoBA, while we defer the detailed experiments on efficiency and scalability to Section 3.4. Our implementation consists of five major steps:
- Determine the assignment of query tokens to KV blocks according to the gating network and causal mask.
- Arrange the ordering of query tokens based on their assigned KV blocks.
- Compute attention outputs for each KV block and the query tokens assigned to it. This step can be optimized by FlashAttention with varying lengths.
- Re-arrange the attention outputs back to their original ordering.
- Combine the corresponding attention outputs using online Softmax (i.e., tiling), as a query token may attend to its current block and multiple historical KV blocks.
The algorithmic workflow is formalized in Algorithm 1 and visualized in Figure 1b, illustrating how MoBA can be implemented based on MoE and FlashAttention. First, the KV matrices are partitioned into blocks (Line 1-2). Next, the gating score is computed according to Equation 6, which measures the relevance between query tokens and KV blocks (Lines 3-7). A top- $k$ operator is applied on the gating score (together with causal mask), resulting in a sparse query-to-KV-block mapping matrix ${\bm{G}}$ to represent the assignment of queries to KV blocks (Line 8). Then, query tokens are arranged based on the query-to-KV-block mapping, and block-wise attention outputs are computed (Line 9-12). Notably, attention to historical blocks (Line 11 and 14) and the current block attention (Line 10 and 13) are computed separately, as additional causality needs to be maintained in the current block attention. Finally, the attention outputs are rearranged back to their original ordering and combined with online softmax (Line 16) \parencite milakov2018onlinenormalizercalculationsoftmax,liu2023blockwiseparalleltransformerlarge.
3 Experiments
3.1 Scaling Law Experiments and Ablation Studies
In this section, we conduct scaling law experiments and ablation studies to validate some key design choices of MoBA.
| 568M 822M 1.1B | 14 16 18 | 14 16 18 | 1792 2048 2304 | 10.8B 15.3B 20.6B | 512 512 512 | 3 3 3 |
| --- | --- | --- | --- | --- | --- | --- |
| 1.5B | 20 | 20 | 2560 | 27.4B | 512 | 3 |
| 2.1B | 22 | 22 | 2816 | 36.9B | 512 | 3 |
Table 1: Configuration of Scaling Law Experiments
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Graph: LM Loss vs. PFLOP/s-days Projections
### Overview
The image is a logarithmic-scale line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). Both lines depict the relationship between Language Model (LM) loss (measured at sequence length 8K) and computational cost (PFLOP/s-days). The graph spans 1.5 orders of magnitude on the x-axis (0.1 to 10 PFLOP/s-days) and 3 orders of magnitude on the y-axis (2 to 5 × 10⁰ LM loss).
### Components/Axes
- **X-axis**: PFLOP/s-days (log scale, 10⁻¹ to 10¹)
- **Y-axis**: LM loss (seqLen=8K) (log scale, 2 × 10⁰ to 5 × 10⁰)
- **Legend**: Located in the top-right corner, with:
- Blue dashed line: MoBA Projection
- Red dashed line: Full Attention Projection
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at ~5 × 10⁰ LM loss at 10⁻¹ PFLOP/s-days.
- Decreases gradually, reaching ~2.5 × 10⁰ at 10¹ PFLOP/s-days.
- Shows a consistent downward trend with minimal curvature.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins at ~4.5 × 10⁰ LM loss at 10⁻¹ PFLOP/s-days.
- Declines more steeply than MoBA, reaching ~2.2 × 10⁰ at 10¹ PFLOP/s-days.
- Exhibits a sharper initial drop, then flattens slightly.
3. **Convergence**:
- Both lines intersect near 10⁰ PFLOP/s-days (~3 × 10⁰ LM loss).
- Beyond this point, the lines diverge slightly, with MoBA maintaining a marginally higher loss.
### Key Observations
- **Efficiency Gap**: MoBA consistently requires 10–20% higher PFLOP/s-days than Full Attention to achieve equivalent LM loss reduction across the observed range.
- **Diminishing Returns**: The gap narrows at higher computational costs (PFLOP/s-days > 10), suggesting MoBA’s inefficiency becomes less pronounced at scale.
- **Baseline Performance**: At 10⁻¹ PFLOP/s-days, MoBA’s loss is ~10% higher than Full Attention’s.
### Interpretation
The graph highlights a trade-off between computational efficiency and model architecture. MoBA’s higher LM loss at equivalent computational costs implies it may be less suitable for resource-constrained environments. However, its performance converges with Full Attention at scale, suggesting potential viability for high-performance computing scenarios. The logarithmic axes emphasize the exponential relationship between computational cost and loss reduction, underscoring the importance of optimizing both architectural design and hardware utilization.
</details>
(a)
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Graph: Trailing LM Loss vs. PFLOP/s-days
### Overview
The image is a logarithmic line graph comparing two computational efficiency projections: "MoBA Projection" (dashed blue line) and "Full Attention Projection" (dashed red line). The graph illustrates how trailing language model (LM) loss decreases with increasing computational resources (PFLOP/s-days). Both lines exhibit exponential decay trends, but with distinct divergence patterns.
### Components/Axes
- **Y-axis**: "Trailing LM loss (seqLen=32K, last 2K)"
- Logarithmic scale from 10⁰ to 4×10⁰ (1 to 4 on linear scale).
- Positioned on the left side of the graph.
- **X-axis**: "PFLOP/s-days"
- Logarithmic scale from 10⁻¹ to 10¹ (0.1 to 10 on linear scale).
- Positioned at the bottom of the graph.
- **Legend**: Located in the top-right corner.
- Blue dashed line: "MoBA Projection"
- Red dashed line: "Full Attention Projection"
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at ~2×10⁰ loss at 10⁻¹ PFLOP/s-days.
- Declines steeply, reaching ~1×10⁰ at 10⁰ PFLOP/s-days.
- Continues to drop to ~0.5×10⁰ by 10¹ PFLOP/s-days.
- Final value approaches ~0.1×10⁰ at the far right (10¹ PFLOP/s-days).
2. **Full Attention Projection (Red Dashed Line)**:
- Begins at ~2×10⁰ loss at 10⁻¹ PFLOP/s-days.
- Decreases more gradually, remaining above 1×10⁰ until ~10⁰.⁵ PFLOP/s-days.
- Drops to ~1×10⁰ at 10¹ PFLOP/s-days.
- Final value converges with MoBA Projection near 0.1×10⁰.
3. **Key Intersection Points**:
- Both lines intersect near 10⁰ PFLOP/s-days (~1×10⁰ loss).
- Converge again at 10¹ PFLOP/s-days (~0.1×10⁰ loss).
### Key Observations
- **Divergence**: MoBA Projection achieves significantly lower loss than Full Attention Projection at mid-range computational resources (10⁰–10⁰.⁵ PFLOP/s-days).
- **Convergence**: Both projections yield similar efficiency at extreme computational scales (10¹ PFLOP/s-days).
- **Efficiency**: MoBA Projection demonstrates ~2× better loss reduction than Full Attention Projection at 10⁰ PFLOP/s-days.
### Interpretation
The graph suggests that MoBA Projection is computationally more efficient for reducing trailing LM loss in the early to mid-stages of scaling (up to 10⁰.⁵ PFLOP/s-days). However, at extreme computational scales (10¹ PFLOP/s-days), both approaches achieve comparable efficiency, implying diminishing returns for additional resources. This could indicate architectural trade-offs: MoBA may prioritize early-stage optimization, while Full Attention Projection balances resource allocation differently. The logarithmic axes emphasize exponential scaling effects, highlighting the importance of computational efficiency in large-scale LM training.
</details>
(b)
| LM loss (seqlen=8K) Trailing LM loss (seqlen=32K, last 2K) | $2.625× C^{-0.063}$ $1.546× C^{-0.108}$ | $2.622× C^{-0.063}$ $1.464× C^{-0.097}$ |
| --- | --- | --- |
(c)
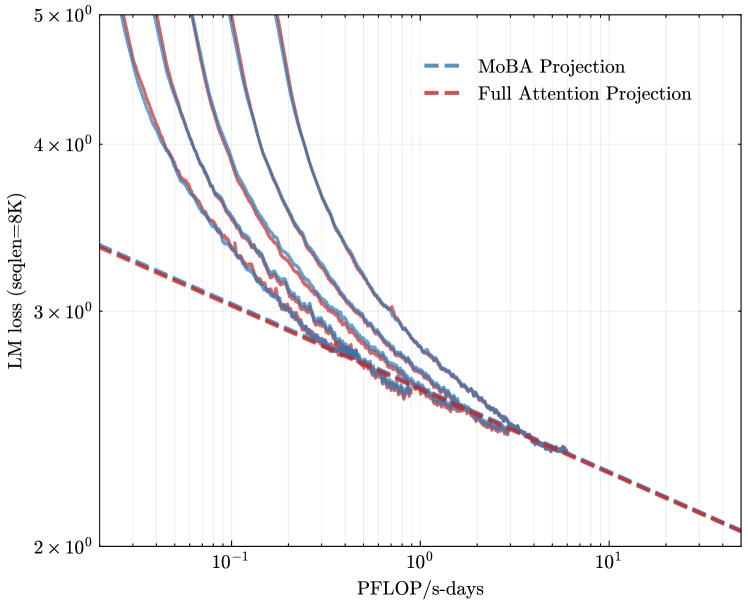
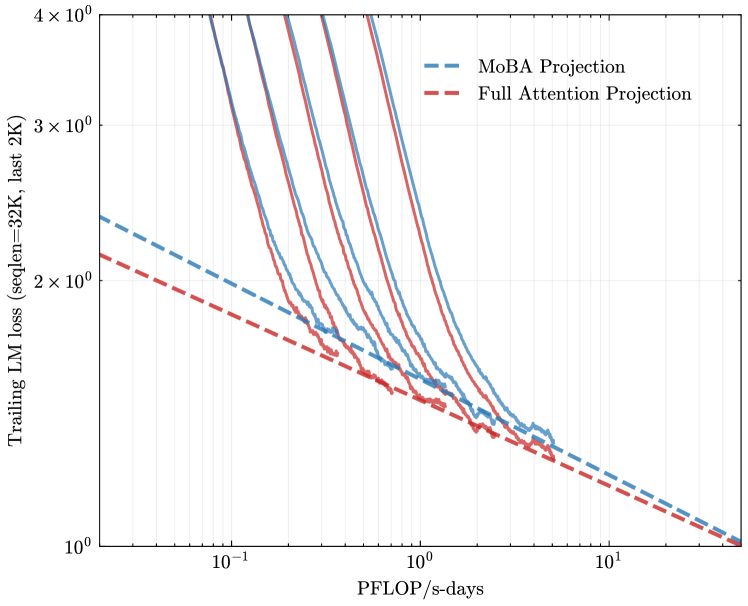
Figure 3: Scaling law comparison between MoBA and full attention. (a) LM loss on validation set (seqlen=8K); (b) trailing LM loss on validation set (seqlen=32K, last 1K tokens); (c) fitted scaling law curve.
Scalability w.r.t. LM Loss.
To assess the effectiveness of MoBA, we perform scaling law experiments by comparing the validation loss of language models trained using either full attention or MoBA. Following the Chinchilla scaling law \parencite hoffmann2022training, we train five language models of varying sizes with a sufficient number of training tokens to ensure that each model achieves its training optimum. Detailed configurations of the scaling law experiments can be found in Table 1. Both MoBA and full attention models are trained with a sequence length of 8K. For MoBA models, we set the block size to 512 and select the top-3 blocks for attention, resulting in a sparse attention pattern with sparsity up to $1-\frac{512× 3}{8192}=81.25\%$ Since we set top-k=3, thus each query token can attend to at most 2 history block and the current block.. In particular, MoBA serves as an alternative to full attention, meaning that it does not introduce new parameters or remove existing ones. This design simplifies our comparison process, as the only difference across all experiments lies in the attention modules, while all other hyperparameters, including the learning rate and batch size, remain constant. As shown in Figure 3a, the validation loss curves for MoBA and full attention display very similar scaling trends. Specifically, the validation loss differences between these two attention mechanisms remain consistent within a range of $1e-3$ . This suggests that MoBA achieves scaling performance that is comparable to full attention, despite its sparse attention pattern with sparsity up to 75%.
Long Context Scalability.
However, LM loss may be skewed by the data length distribution \parencite an2024does, which is typically dominated by short sequences. To fully assess the long-context capability of MoBA, we assess the LM loss of trailing tokens (trailing LM loss, in short), which computes the LM loss of the last few tokens in the sequence. We count this loss only for sequences that reach the maximum sequence length to avoid biases that may arise from very short sequences. A detailed discussion on trailing tokens scaling can be found in the Appendix A.1
These metrics provide insights into the model’s ability to generate the final portion of a sequence, which can be particularly informative for tasks involving long context understanding. Therefore, we adopt a modified experimental setting by increasing the maximum sequence length from 8k to 32k. This adjustment leads to an even sparser attention pattern for MoBA, achieving a sparsity level of up to $1-\frac{512× 3}{32768}=95.31\%$ . As shown in Figure 3b, although MoBA exhibits a marginally higher last block LM loss compared to full attention in all five experiments, the loss gap is progressively narrowing. This experiment implies the long-context scalability of MoBA.
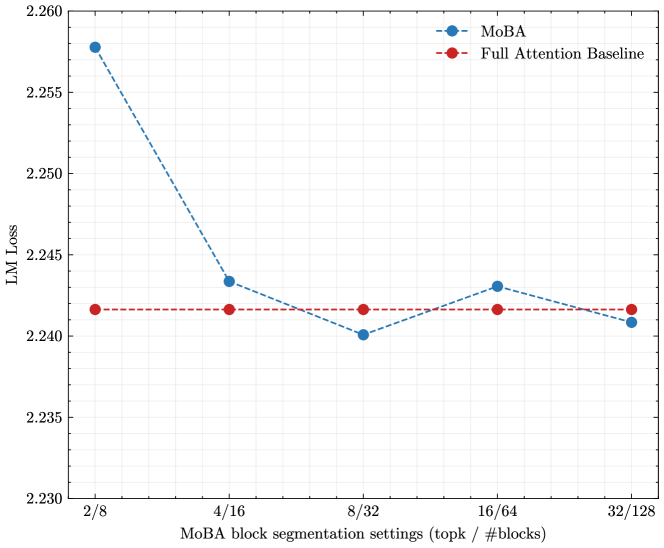
Ablation Study on Fine-Grained Block Segmentation.
We further ablate the block granularity of MoBA. We carry out a series of experiments using a 1.5B parameter model with a 32K context length. The hyperparameters of block size and top-k are adjusted to maintain a consistent level of attention sparsity. Specifically, we divide the 32K context into 8, 16, 32, 64, and 128 blocks, and correspondingly select 2, 4, 8, 16, and 32 blocks, ensuring an attention sparsity of 75% across these configurations. As shown in Figure 4, MoBA’s performance is significantly affected by block granularity. Specifically, there is a performance difference of 1e-2 between the coarsest-grained setting (selecting 2 blocks from 8) and the settings with finer granularity. These findings suggest that fine-grained segmentation appears to be a general technique for enhancing the performance of models within the MoE family, including MoBA.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Line Chart: Loss Comparison Between MoBA and Full Attention Baseline
### Overview
The chart compares the Language Model (LM) Loss of two models: MoBA (blue dashed line) and Full Attention Baseline (red dashed line) across different block segmentation settings. The x-axis represents MoBA block segmentation configurations (topk / #blocks), while the y-axis shows LM Loss values ranging from 2.230 to 2.260.
### Components/Axes
- **X-axis**: MoBA block segmentation settings (topk / #blocks)
Labels: `2/8`, `4/16`, `8/32`, `16/64`, `32/128`
- **Y-axis**: LM Loss (range: 2.230–2.260)
- **Legend**:
- Blue dashed line: MoBA
- Red dashed line: Full Attention Baseline
- **Legend Position**: Top-right corner
### Detailed Analysis
#### MoBA (Blue Dashed Line)
- **2/8**: 2.258 (highest loss)
- **4/16**: 2.243 (sharp drop)
- **8/32**: 2.240 (lowest loss)
- **16/64**: 2.242 (slight increase)
- **32/128**: 2.241 (minor decrease)
#### Full Attention Baseline (Red Dashed Line)
- **All Segments**: Stable at ~2.242 (flat line)
### Key Observations
1. **MoBA** shows a significant reduction in LM Loss from `2/8` (2.258) to `4/16` (2.243), followed by gradual stabilization.
2. **Full Attention Baseline** maintains a consistent loss (~2.242) across all segmentation settings.
3. MoBA’s loss converges toward the baseline’s value in later segments (`16/64` and `32/128`).
### Interpretation
The data suggests that MoBA outperforms the Full Attention Baseline in reducing LM Loss, particularly in early block segmentation settings (`2/8` to `4/16`). The sharp drop in MoBA’s loss indicates improved efficiency in these configurations. However, as segmentation becomes finer (`8/32` onward), the performance gap narrows, implying diminishing returns for increased granularity. The baseline’s stability highlights its robustness but also reveals that MoBA’s adaptive segmentation offers meaningful advantages in specific scenarios.
**Notable Anomaly**: The MoBA line’s slight uptick at `16/64` (2.242) before stabilizing at `32/128` (2.241) may indicate minor overfitting or computational trade-offs in finer segmentation.
</details>
Figure 4: Fine-Grained Block Segmentation. The LM loss on validation set v.s. MoBA with different block granularity.
3.2 Hybrid of MoBA and Full Attention
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Graph: LM Loss vs Position
### Overview
The image is a line graph comparing three methods—MoBA/Full Hybrid, MoBA, and Full Attention—across positions (0K to 30K) on the x-axis, with LM Loss (1.2 to 3.0) on the y-axis. The legend is positioned in the top-right corner, and the graph uses distinct colors for each method.
### Components/Axes
- **X-axis (Position)**: Labeled "Position" with increments of 5K (0K, 5K, 10K, ..., 30K). Values are approximate and rounded to the nearest thousand.
- **Y-axis (LM Loss)**: Labeled "LM Loss" with increments of 0.2 (1.2, 1.4, ..., 3.0). Values are approximate.
- **Legend**: Located in the top-right corner, associating:
- Green circles with "MoBA/Full Hybrid"
- Blue circles with "MoBA"
- Red circles with "Full Attention"
### Detailed Analysis
1. **Full Attention (Red Line)**:
- Starts at ~2.8 LM Loss at 0K.
- Drops sharply to ~2.2 at 5K, ~1.8 at 10K, and continues declining to ~1.3 by 30K.
- Shows the steepest decline among all methods.
2. **MoBA (Blue Line)**:
- Begins at ~2.0 LM Loss at 0K.
- Decreases gradually to ~1.4 at 30K, with minor fluctuations (e.g., ~1.5 at 15K, ~1.45 at 25K).
3. **MoBA/Full Hybrid (Green Line)**:
- Starts at ~1.8 LM Loss at 0K.
- Declines steadily to ~1.3 at 30K, closely following the MoBA line but with slightly lower values at earlier positions (e.g., ~1.6 at 10K vs. MoBA's ~1.65).
### Key Observations
- **Initial Disparity**: Full Attention begins with the highest LM Loss (~2.8) but improves most rapidly, surpassing MoBA/Full Hybrid by 5K.
- **Convergence**: All methods converge to ~1.3–1.4 LM Loss by 30K, suggesting diminishing differences at higher positions.
- **Trend Consistency**: MoBA and MoBA/Full Hybrid exhibit smoother, more gradual declines compared to Full Attention's sharp early drop.
### Interpretation
The data suggests that the Full Attention method experiences a significant reduction in LM Loss early in the position range, outperforming the other methods initially. However, by 30K, all methods achieve similar performance, indicating that the advantage of Full Attention diminishes over time. This could imply that MoBA/Full Hybrid and MoBA are more stable or efficient at later stages, while Full Attention may require optimization for sustained performance. The convergence trend highlights the importance of position-dependent behavior in evaluating these methods.
</details>
(a)
<details>
<summary>x9.png Details</summary>
### Visual Description
## Line Chart: LM Loss vs. Number of Hybrid Full Layers
### Overview
The chart compares the language model (LM) loss performance of three architectures—Layer-wise Hybrid, Full Attention, and MoBA—as the number of hybrid full layers increases from 1 to 10. The y-axis represents LM loss (lower values indicate better performance), while the x-axis represents the number of hybrid full layers. The Layer-wise Hybrid architecture shows a clear downward trend, while Full Attention and MoBA remain constant.
---
### Components/Axes
- **X-axis (Horizontal)**:
- Title: "Number of Hybrid Full Layers"
- Labels: "1layer", "3layer", "5layer", "10layer"
- Scale: Discrete increments (1 → 3 → 5 → 10 layers).
- **Y-axis (Vertical)**:
- Title: "LM loss"
- Range: 1.08 to 1.14 (with gridlines at 0.01 intervals).
- **Legend**:
- Position: Right side of the chart.
- Entries:
- **Layer-wise Hybrid**: Dashed blue line with circular markers.
- **Full Attention**: Solid red line.
- **MoBA**: Solid gray line.
---
### Detailed Analysis
1. **Layer-wise Hybrid (Dashed Blue Line)**:
- **Trend**: Steadily decreases from ~1.135 at 1layer to ~1.075 at 10layer.
- **Key Data Points**:
- 1layer: ~1.135
- 3layer: ~1.115
- 5layer: ~1.10
- 10layer: ~1.075
2. **Full Attention (Solid Red Line)**:
- **Trend**: Flat line at ~1.075 across all layers.
3. **MoBA (Solid Gray Line)**:
- **Trend**: Flat line at ~1.14 across all layers.
---
### Key Observations
- **Layer-wise Hybrid** demonstrates a consistent improvement in LM loss as the number of hybrid layers increases.
- **Full Attention** and **MoBA** show no improvement, maintaining constant loss values regardless of layer count.
- **MoBA** consistently exhibits the highest LM loss (~1.14), suggesting suboptimal performance compared to the other architectures.
---
### Interpretation
The chart highlights the effectiveness of the **Layer-wise Hybrid** architecture in reducing LM loss with increased hybrid layers, outperforming both **Full Attention** and **MoBA**. The flat performance of **Full Attention** and **MoBA** implies that their architectures do not benefit from additional hybrid layers in terms of LM loss reduction. **MoBA**'s persistently high loss suggests potential inefficiencies in its design or training process. This analysis underscores the importance of architectural choices in balancing model complexity and performance gains.
</details>
(b)
<details>
<summary>x10.png Details</summary>
### Visual Description
## Line Chart: LM Trailing Loss vs. Number of Hybrid Full Layers
### Overview
The chart compares the performance of three models (Layer-wise Hybrid, Full Attention, MoBA) in terms of language model (LM) trailing loss across different configurations of hybrid full layers. The y-axis represents trailing loss (measured at sequence length 32K, last 2K tokens), while the x-axis categorizes the number of hybrid full layers (1layer, 3layer, 5layer, 10layer). The legend is positioned on the right side of the chart.
### Components/Axes
- **X-axis**: "Number of Hybrid Full Layers" with discrete categories: 1layer, 3layer, 5layer, 10layer.
- **Y-axis**: "LM trailing loss (seqLen=32K, last 2K)" with a scale from 1.10 to 1.16.
- **Legend**:
- Blue dashed line: Layer-wise Hybrid
- Red solid line: Full Attention
- Gray solid line: MoBA
### Detailed Analysis
1. **Layer-wise Hybrid (Blue Dashed Line)**:
- Starts at ~1.17 for 1layer.
- Decreases to ~1.13 at 3layer.
- Further drops to ~1.10 at 5layer.
- Reaches ~1.09 at 10layer.
- **Trend**: Steady downward slope, indicating improved performance with more hybrid layers.
2. **Full Attention (Red Solid Line)**:
- Remains constant at ~1.10 across all configurations.
- **Trend**: Flat line, suggesting no improvement with additional layers.
3. **MoBA (Gray Solid Line)**:
- Maintains a constant value of ~1.16 across all configurations.
- **Trend**: Flat line, indicating no change in performance.
### Key Observations
- **Layer-wise Hybrid** shows the most significant improvement as the number of hybrid layers increases.
- **Full Attention** and **MoBA** exhibit no variation in performance regardless of hybrid layer count.
- The largest gap in performance occurs between Layer-wise Hybrid (1layer) and MoBA (~0.01 difference), narrowing to ~0.07 by 10layer.
### Interpretation
The data suggests that **Layer-wise Hybrid** benefits from increased hybrid full layers, achieving lower trailing loss and potentially better efficiency. In contrast, **Full Attention** and **MoBA** models appear to be optimized for fixed configurations, with no measurable gains from additional layers. This could imply architectural limitations or diminishing returns in these models. The consistent performance of Full Attention and MoBA might indicate robustness in their design but also a lack of adaptability compared to the Layer-wise Hybrid approach.
</details>
(c)
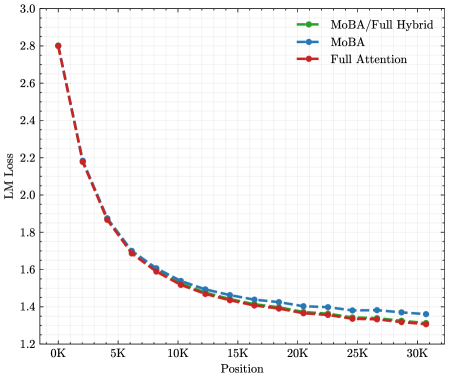
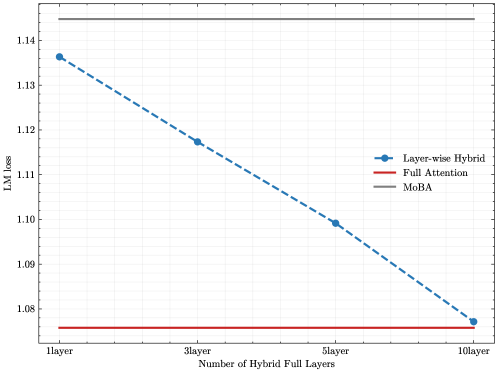
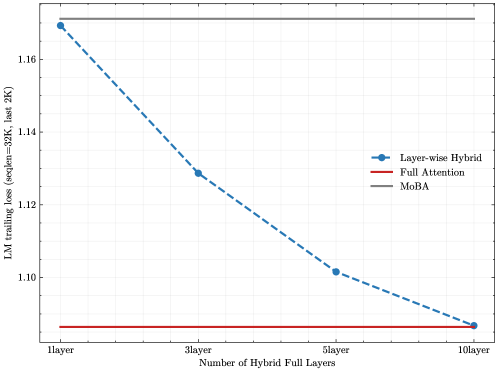
Figure 5: Hybrid of MoBA and full attention. (a) position-wise LM loss for MoBA, full attention, and MoBA/full hybrid training; (b) SFT LM loss w.r.t the number of full attention layers in layer-wise hybrid; (c) SFT trailing LM loss (seqlen=32K, last 2K) w.r.t the number of full attention layers in layer-wise hybrid.
As discussed in Section 2, we design MoBA to be a flexible substitute for full attention, so that it can easily switch from/to full attention with minimal overhead and achieve comparable long-context performance. In this section, we first show seamless transition between full attention and MoBA can be a solution for efficient long-context pre-training. Then we discuss the layer-wise hybrid strategy, mainly for the performance of supervised fine-tuning (SFT).
MoBA/Full Hybrid Training.
We train three models, each with 1.5B parameters, on 30B tokens with a context length of 32K tokens. For the hyperparameters of MoBA, the block size is set to 2048, and the top-k parameter is set to 3. The detailed training recipes are as follows:
- MoBA/full hybrid: This model is trained using a two-stage recipe. In the first stage, MoBA is used to train on 90% of the tokens. In the second stage, the model switches to full attention for the remaining 10% of the tokens.
- Full attention: This model is trained using full attention throughout the entire training.
- MoBA: This model is trained exclusively using MoBA.
We evaluate their long-context performance via position-wise language model (LM) loss, which is a fine-grained metric to evaluate lm loss at each position within a sequence. Unlike the vanilla LM loss, which is computed by averaging the LM loss across all positions, the position-wise LM loss breaks down the loss for each position separately. Similar metrics have been suggested by previous studies \parencite xiong2023effectivelongcontextscalingfoundation,reid2024gemini, who noticed that position-wise LM loss follows a power-law trend relative to context length. As shown in Figure 5a, the MoBA-only recipe results in higher position-wise losses for trailing tokens. Importantly, our MoBA/full hybrid recipe reaches a loss nearly identical to that of full attention. This result highlights the effectiveness of the MoBA/full hybrid training recipe in balancing training efficiency with model performance. More interestingly, we have not observed significant loss spikes during the switch between MoBA and full attention, again demonstrating the flexibility and robustness of MoBA.
Layer-wise Hybrid.
This flexibility of MoBA encourages us to delve into a more sophisticated strategy — the layer-wise hybrid of MoBA and full attention. We investigate this strategy with a particular focus on its application during the supervised fine-tuning (SFT). The motivation for investigating this strategy stems from our observation that MoBA sometimes results in suboptimal performance during SFT, as shown in Figure 5b. We speculate that this may be attributed to the loss masking employed in SFT — prompt tokens are typically excluded from the loss calculation during SFT, which can pose a sparse gradient challenge for sparse attention methods like MoBA. Because it may hinder the backpropagation of gradients, which are initially calculated from unmasked tokens, throughout the entire context. To address this issue, we propose a hybrid approach — switching the last several Transformer layers from MoBA to full attention, while the remaining layers continue to employ MoBA. As shown in Figure 5b and Figure 5c, this strategy can significantly reduce SFT loss.
3.3 Large Language Modeling Evaluation
<details>
<summary>x11.png Details</summary>
### Visual Description
## Flowchart: Model Training Pipeline
### Overview
The diagram illustrates a two-path training pipeline for a language model, showing progression through different scales of data and training phases. Two parallel tracks exist: one for "Continue Pretrain" and another for "SFT" (Supervised Fine-Tuning), with a connection point at the 1M scale.
### Components/Axes
- **Nodes**:
- LLama3.1 8B (starting point)
- 256K Continue Pretrain
- 512K Continue Pretrain
- 1M Continue Pretrain
- Instruct Model (starting point for SFT)
- 1M SFT
- 256K SFT
- 32K SFT
- **Arrows**:
- Unidirectional flow indicators
- Connection between 1M Continue Pretrain and 1M SFT
### Detailed Analysis
1. **Continue Pretrain Path**:
- Starts at LLama3.1 8B (base model)
- Progresses through increasing data scales: 256K → 512K → 1M
- All nodes labeled "Continue Pretrain"
2. **SFT Path**:
- Starts at "Instruct Model"
- Progresses through decreasing data scales: 1M → 256K → 32K
- All nodes labeled "SFT"
3. **Connection Point**:
- 1M Continue Pretrain directly connects to 1M SFT
- Suggests transition from pretraining to fine-tuning at maximum scale
### Key Observations
- Pretraining scales increase logarithmically (8B → 256K → 512K → 1M)
- SFT scales decrease exponentially (1M → 256K → 32K)
- 1M scale acts as a bridge between pretraining and fine-tuning phases
- No feedback loops or parallel processing indicated
- All connections are linear and sequential
### Interpretation
This diagram represents a structured model development pipeline where:
1. **Pretraining Phase**: Begins with a base model (LLama3.1 8B) and progressively increases training data scale to 1M tokens, suggesting iterative refinement of model capabilities.
2. **Fine-Tuning Phase**: Starts at the same 1M scale but then reduces data size for specialized instruction tuning, indicating a focus on quality over quantity in later stages.
3. **Architectural Insight**: The 1M connection point implies that the most comprehensive pretraining serves as the foundation for subsequent fine-tuning, emphasizing the importance of large-scale unsupervised learning before specialized adaptation.
4. **Efficiency Consideration**: The decreasing SFT scales may reflect resource optimization strategies, using smaller datasets for final tuning after establishing base capabilities through extensive pretraining.
The pipeline demonstrates a deliberate progression from broad capability development to targeted specialization, with careful scaling decisions at each stage.
</details>
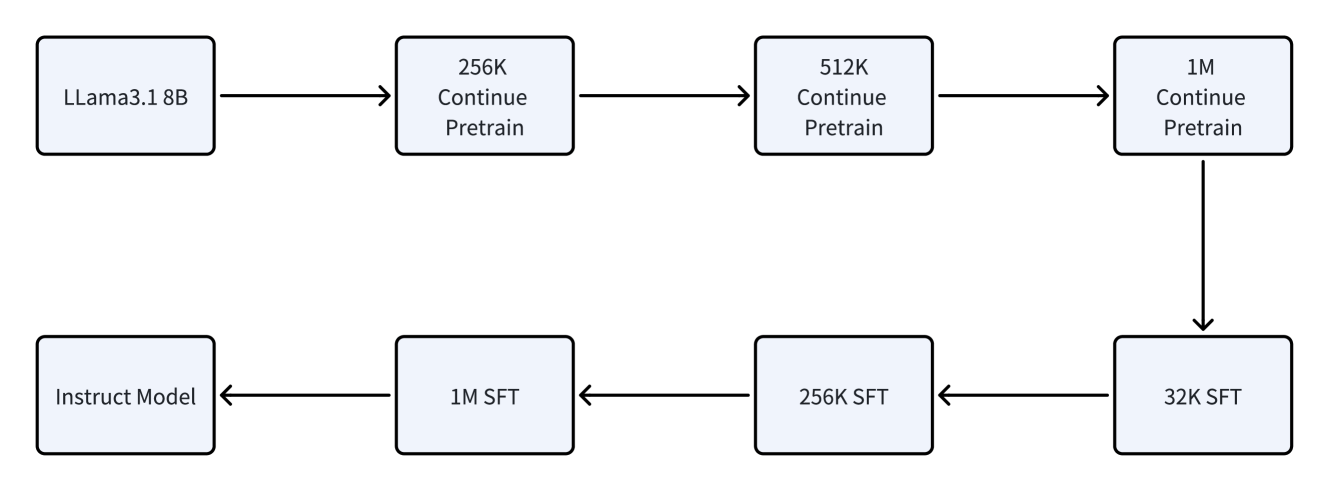
Figure 6: The continual pre-training and SFT recipes.
We conduct a thorough assessment of MoBA across a variety of real-world downstream tasks, evaluating its performance in comparison to full attention models. For ease of verification, our experiments begin with the Llama 3.1 8B Base Model, which is used as the starting point for long-context pre-training. This model, termed Llama-8B-1M-MoBA, is initially trained with a context length of 128K tokens, and we gradually increase the context length to 256K, 512K, and 1M tokens during the continual pre-training. To ease this transition, we use position interpolation method \parencite chen2023extendingcontextwindowlarge at the start of the 256K continual pre-training stage. This technique enables us to extend the effective context length from 128K tokens to 1M tokens. After completing the 1M continuous pre-training, MoBA is activated for 100B tokens. We set the block size to 4096 and the top-K parameter to 12, leading to an attention sparsity of up to $1-\frac{4096× 12}{1M}=95.31\%$ . To preserve some full attention capabilities, we adopt the layer-wise hybrid strategy — the last three layers remain as full attention, while the other 29 full attention layers are switched to MoBA. For supervised fine-tuning, we follow a similar strategy that gradually increases the context length from 32K to 1M. The baseline full attention models (termed Llama-8B-1M-Full) also follow a similar training strategy as shown in Figure 6, with the only difference being the use of full attention throughout the process. This approach allows us to directly compare the performance of MoBA with that of full attention models under equivalent training conditions.
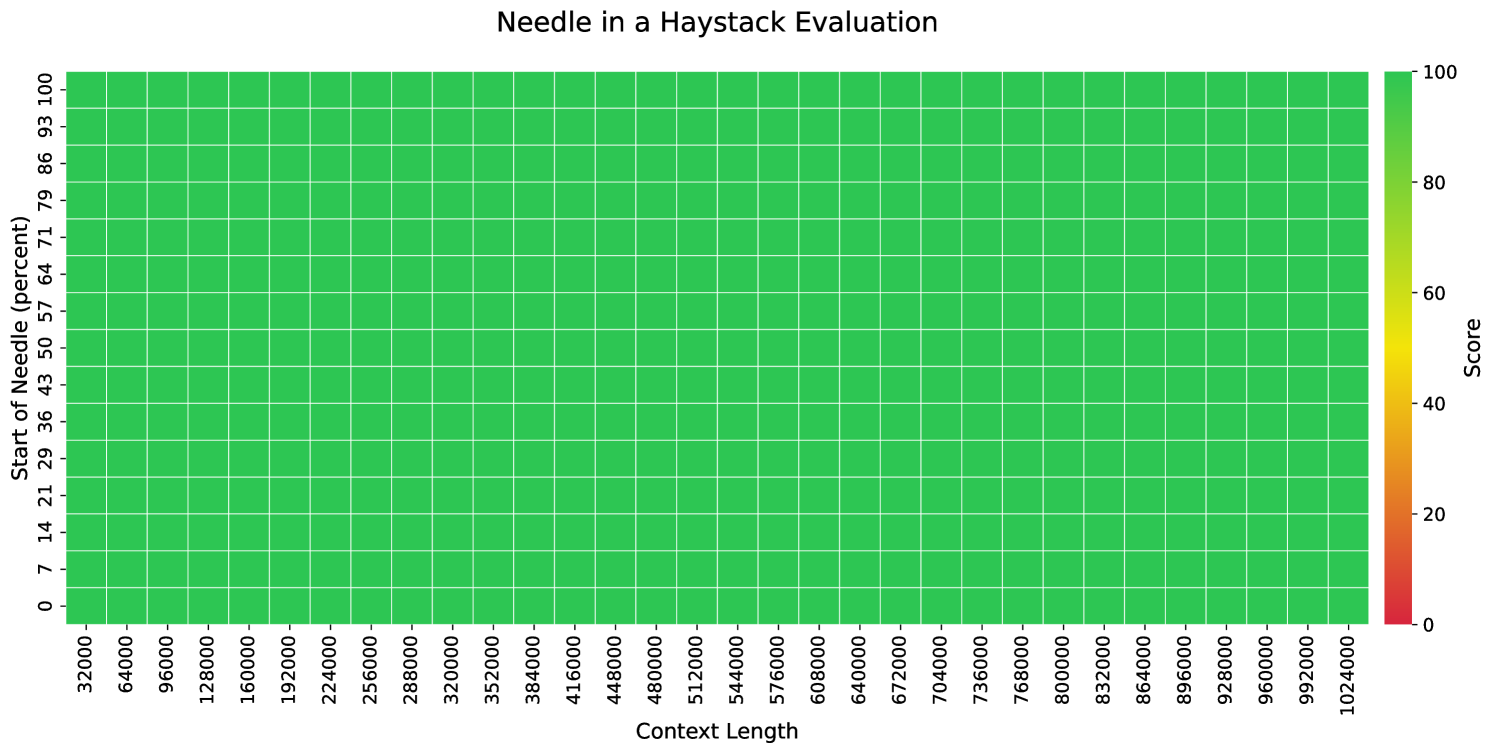
The evaluation is performed on several widely used long-context benchmarks. In particular, across all evaluation tasks, MoBA is used for prefill only, while we switch to full attention during generation for better performance. As shown in Table 2, Llama-8B-1M-MoBA exhibits a performance that is highly comparable to that of Llama-8B-1M-Full. It is particularly noteworthy that in the longest benchmark, RULER, where MoBA operates at a sparsity level of up to $1-\frac{4096× 12}{128K}=62.5\%$ , Llama-8B-1M-MoBA nearly matches the performance of Llama-8B-1M-Full, with a score of 0.7818 compared to 0.7849. For context lengths of up to 1M tokens, we evaluate the model using the traditional Needle in the Haystack benchmark. As shown in Figure 7, Llama-8B-1M-MoBA demonstrates satisfactory performance even with an extended context length of 1 million tokens.
| AGIEval [0-shot] BBH [3-shot] CEval [5-shot] | 0.5144 0.6573 0.6273 | 0.5146 0.6589 0.6165 |
| --- | --- | --- |
| GSM8K [5-shot] | 0.7278 | 0.7142 |
| HellaSWAG [0-shot] | 0.8262 | 0.8279 |
| Loogle [0-shot] | 0.4209 | 0.4016 |
| Competition Math [0-shot] | 0.4254 | 0.4324 |
| MBPP [3-shot] | 0.5380 | 0.5320 |
| MBPP Sanitized [0-shot] | 0.6926 | 0.6615 |
| MMLU [0-shot] | 0.4903 | 0.4904 |
| MMLU Pro [5-shot][CoT] | 0.4295 | 0.4328 |
| OpenAI HumanEval [0-shot][pass@1] | 0.6951 | 0.7012 |
| SimpleQA [0-shot] | 0.0465 | 0.0492 |
| TriviaQA [0-shot] | 0.5673 | 0.5667 |
| LongBench @32K [0-shot] | 0.4828 | 0.4821 |
| RULER @128K [0-shot] | 0.7818 | 0.7849 |
Table 2: Performance comparison between MoBA and full Attention across different evaluation benchmarks.
<details>
<summary>x12.png Details</summary>
### Visual Description
## Heatmap: Needle in a Haystack Evaluation
### Overview
The image displays a heatmap titled "Needle in a Haystack Evaluation," visualizing scores across two dimensions: "Context Length" (x-axis) and "Start of Needle (percent)" (y-axis). The color gradient ranges from red (low scores) to green (high scores), with all cells uniformly green, indicating maximum scores.
### Components/Axes
- **X-axis (Context Length)**: Labeled "Context Length," with values ranging from 0 to 1,024,000 in increments of 32,000 (e.g., 0, 32,000, 64,000, ..., 1,024,000).
- **Y-axis (Start of Needle)**: Labeled "Start of Needle (percent)," with values from 0 to 100 in increments of 1.
- **Legend**: Positioned on the right, showing a gradient from red (0) to green (100), with no intermediate values visible.
- **Grid**: White grid lines separate cells, with no annotations or numerical labels within cells.
### Detailed Analysis
- **Data Distribution**: Every cell in the heatmap is filled with a solid green color, corresponding to a score of 100%.
- **Axis Ranges**:
- Context Length spans 0–1,024,000 (32,000 increments).
- Start of Needle spans 0–100% (1% increments).
- **Color Consistency**: No red or yellow cells are present, confirming uniform maximum scores.
### Key Observations
1. **Uniform Scores**: All combinations of context length and needle start position yield a score of 100%.
2. **No Variability**: No discernible patterns, trends, or outliers exist in the data.
3. **Axis Coverage**: The x-axis covers a wide range of context lengths, while the y-axis spans the full percentage scale.
### Interpretation
The data suggests that the evaluation metric being tested (likely related to locating a "needle in a haystack") consistently achieves perfect scores across all tested parameters. This could indicate:
- A non-discriminative evaluation setup where all inputs are trivially solvable.
- A flaw in the metric design, failing to differentiate between varying difficulty levels.
- A controlled test environment where outcomes are intentionally uniform.
The absence of variability implies the metric may lack sensitivity to contextual complexity or needle placement, warranting further investigation into its validity for real-world applications.
</details>
Figure 7: Performance of LLama-8B-1M-MoBA on the Needle in the Haystack benchmark (upto 1M context length).
3.4 Efficiency and Scalability
The above experimental results show that MoBA achieves comparable performance not only regarding language model losses but also in real-world tasks. To further investigate its efficiency, we compare the forward pass time of the attention layer in two models trained in Section 3.3 — Llama-8B-1M-MoBA and Llama-8B-1M-Full. We focus solely on the attention layer, as all other layers (e.g., FFN) have identical FLOPs in both models. As shown in Figure 2a, MoBA is more efficient than full attention across all context lengths, demonstrating a sub-quadratic computational complexity. In particular, it achieves a speedup ratio of up to 6.5x when prefilling 1M tokens.
We also explore the length scalability of MoBA by gradually increasing the context length to 10 million tokens. To maintain a constant attention sparsity, we keep the top-k value and number of MoBA Block fixed while proportionally increasing the block size. To reach the 10M context length, we expanded tensor parallelism \parencite shoeybi2019megatron toward the query head level, Specifically, we broadcast key and value tensors across distributed query heads, effectively addressing GPU memory limitations while preserving computational efficiency. As shown in Figure 2b, MoBA demonstrates superior efficiency compared to standard Flash Attention when scaling to longer sequences. Specifically, at 10M tokens moba achieves a speedup ratio of 16x reduction in attention computation time. The inset graph in the top figure, focusing on shorter sequences (32K to 512K), shows that even though both methods perform comparably at smaller scales, MoBA’s computational advantage becomes increasingly evident as sequences grow longer, highlighting its particular strength in processing extremely long sequences.
Overall, the high efficiency of MoBA can be attributed to two key innovations: (1) the block sparse attention mechanism, and (2) the optimized implementation combining Mixture-of-Experts (MoE) and FlashAttention, as described in Section 2.3. These techniques effectively address the quadratic complexity limitation of full attention, reducing the computational complexity to a more economical sub-quadratic scale.
4 Related Work
The development of efficient attention \parencite tay2020efficient mechanisms has been a critical area of research in the field of natural language processing, particularly with the rise of Large Language Models (LLMs). As the demand for handling longer sequences and reducing computational costs grows, efficeint attention techniques have emerged as a promising solution to reduce the quadratic complexity of self-attention mechanisms while maintaining model performance.
Static Sparse Patterns: Significant efforts, such as Sparse Transformer \parencite child2019generating, Star-Transformer \parencite guo2019star, BlockBERT \parencite qiu2019blockwise, Longformer \parencite beltagy2020longformer, GMAT \parencite gupta2020gmat, ETC \parencite ainslie2020etc, BigBird \parencite zaheer2020big, LongT5 \parencite guo2021longt5 and LongNet \parencite ding2023longnet, have been dedicated to the design of static attention patterns in LLMs. Their choices of static attention patterns can encompass strided and fixed attention, window attention, global token attention, random attention, dilated attention, block sparse attention, or any combinations of them. In the realm of multimodal models, static sparse attention mechanisms have also been developed, such as axial attention \parencite ho2019axial for 2D images and spatial-temporal attention \parencite opensora for 3D videos.
Dynamic Sparse Patterns: Different from static patterns, dynamic sparse attention techniques adaptively determine which tokens to attend. Reformer \parencite kitaev2020reformer and Routing Transformer \parencite roy2021efficient respectively employ locality-sensitive hashing (LSH) and K-means to cluster tokens, and attend to clusters rather than the full context. Memorizing Transformers \parencite wu2022memorizing and Unlimiformer \parencite bertsch2024unlimiformer dynamically attend to tokens selected by the k-nearest-neighbor (kNN) algorithms. CoLT5 \parencite ainslie2023colt5 designs a routing modules to select the most important queries and keys. Sparse Sinkhorn Attention \parencite tay2020sparse learns to permute blocks from the input sequence, allowing dynamic block sparse attention computation.
Training-free Sparse Attention: In addition to the previously discussed approaches that study training sparse attention models, there are also strategies designed to incorporate sparse attention mechanisms to enhance the efficiency of the two primary stages of model inference — either the prefill stage or the decode stage, or both of them. During the prefill optimization phase, the complete prompt can be utilized for attention profiling, which allows for the exploration of more intricate sparse attention patterns. For instance, MoA \parencite fu2024moa, Minference \parencite jiang2024minference, and SeerAttention \parencite gao2024seerattention have investigated sparse attention configurations such as A-shape, vertical-slash, and dynamic block sparsity. In the context of decode optimization, considerable work has been dedicated to compressing and pruning the KV-cache to achieve a balance between the quality and speed of text generation. Notable efforts in this area include H2O \parencite zhang2024h2o, StreamingLLM \parencite xiao2023efficient, TOVA \parencite oren2024tova, FastGen \parencite ge2023fastgen and Quest \parencite tang2024quest. Quest, in particular, can be viewed as MoBA with a smaller block size and a specialized block representation function which combines both min and max pooling. Another work closely related to MoBA is Longheads \parencite lu2024longheads which can be viewed as MoBA with a top-1 gating network, meaning that each query selects the most relevant KV blocks for attention.
Beyond Traditional Attention Architecture: Another line of research investigates novel model architectures that deviate from the conventional attention mechanism. As architectures change, these methods require training models from scratch and are unable to reuse pre-trained Transformer-based models. Studies in this domain have explored architectures that are inspired by Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), State Space Models (SSMs), or Linear Attention \parencite katharopoulos2020transformers, Examples of such models include Hyena \parencite poli2023hyena, Performer \parencite choromanski2020rethinking, Linformer \parencite wang2020linformer, RWKV [peng2023rwkv], Mamba \parencite gu2023mamba, RetNet \parencite sun2023retentive, etc.
In summary, the landscape of efficient attention techniques is diverse, encompassing sparse patterns that range from static to dynamic, optimization objectives that span from training to inference, and architectures that extend from traditional attention mechanisms to innovative alternatives. Each method presents unique advantages and trade-offs, and the choice of technique often depends on the specific requirements of the application, such as the maximum sequence length, computational resources, and the desired balance between efficiency and performance. As research in this area continues to evolve, it is expected that these methods will play a crucial role in enabling LLMs to tackle increasingly complex tasks while maintaining efficiency and scalability.
5 Conclusion
In this paper, we introduce Mixture of Block Attention (MoBA), a novel attention architecture inspired by the principles of Mixture of Experts (MoE) that aims to enhance the efficiency and scalability of large language models (LLMs) for long-context tasks. MoBA addresses the computational challenges associated with traditional attention mechanisms by partitioning the context into blocks and employing a dynamic gating mechanism to selectively route query tokens to the most relevant KV blocks. This approach not only reduces computational complexity but also maintains model performance. Moreover, it allows for seamless transitions between full and sparse attention. Through extensive experiments, we demonstrated that MoBA achieves performance comparable to full attention while significantly improving computational efficiency. Our results show that MoBA can scale effectively to long contexts, maintaining low LM losses and high performance on various benchmarks. Additionally, MoBA’s flexibility allows it to be integrated with existing models without substantial training cost, making it a practical continual pre-training solution for enhancing long-context capabilities in LLMs. In summary, MoBA represents a significant advancement in efficient attention, offering a balanced approach between performance and efficiency. Future work may explore further optimizations of MoBA’s block-selection strategies, investigate its application to other modalities, and study its potential for improving generalization in complex reasoning tasks.
\printbibliography
[title=References]
Appendix A Appendix
A.1 Long Context Scalability
To address the bias in natural data distribution that favors short contexts, we strategically segmented the overall sequences into discrete segments based on their actual positions. For example, the segment spanning positions 30K-32K exclusively reflects losses associated with documents exceeding 30K context lengths and also masks the positions from 30K to 32K. This approach ensures a more balanced and representative evaluation across different context lengths. In our exploration of long-context scalability, we made a pivotal discovery: the trailing tokens account for the majority of the performance discrepancy between the full context baseline and the newly proposed sparse attention architectures. Consequently, we streamlined the long-context scaling process by focusing on trailing token scaling. This not only simplifies the computational requirements but also significantly enhances the efficiency and effectiveness of investigating long-context scenarios. This finding holds substantial implications for the development of more efficient and scalable attention mechanisms in the future.
<details>
<summary>x13.png Details</summary>
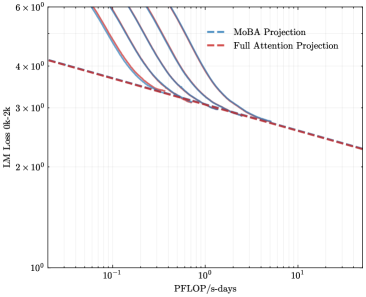
### Visual Description
## Line Graph: Model Performance Projections vs. Computational Resources
### Overview
The image depicts a logarithmic-scale line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). The graph illustrates how model loss (LM Loss 0k-2k) decreases as computational resources (PFlOP/s-days) increase.
### Components/Axes
- **X-axis (Horizontal)**:
- Label: "PFlOP/s-days" (logarithmic scale)
- Markers: 10⁻¹, 10⁰, 10¹
- Range: 0.1 to 10 PFlOP/s-days
- **Y-axis (Vertical)**:
- Label: "LM Loss 0k-2k" (logarithmic scale)
- Markers: 10⁰, 2×10⁰, 3×10⁰, 4×10⁰, 5×10⁰, 6×10⁰
- Range: 1 to 6 (in logarithmic units)
- **Legend**:
- Position: Top-right corner
- Entries:
- Blue dashed line: "MoBA Projection"
- Red dashed line: "Full Attention Projection"
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at ~5×10⁰ loss at 10⁻¹ PFlOP/s-days.
- Declines sharply to ~3×10⁰ at 10⁰ PFlOP/s-days.
- Continues to decrease gradually, reaching ~2.5×10⁰ at 10¹ PFlOP/s-days.
- Slope: Steeper initial decline, then flattens slightly.
2. **Full Attention Projection (Red Dashed Line)**:
- Starts at ~4×10⁰ loss at 10⁻¹ PFlOP/s-days.
- Declines linearly to ~3×10⁰ at 10⁰ PFlOP/s-days.
- Maintains a consistent slope, reaching ~2.2×10⁰ at 10¹ PFlOP/s-days.
- Slope: Linear decline throughout the range.
3. **Intersection Point**:
- Both lines converge near 10⁰ PFlOP/s-days (~3×10⁰ loss).
- After this point, MoBA Projection outperforms Full Attention Projection.
### Key Observations
- **Convergence**: Both models achieve similar loss reduction (~3×10⁰) at 10⁰ PFlOP/s-days.
- **Divergence**: MoBA Projection becomes more efficient than Full Attention Projection at higher resource levels (10¹ PFlOP/s-days).
- **Efficiency Trends**:
- MoBA Projection shows diminishing returns at higher PFlOP/s-days.
- Full Attention Projection maintains linear scalability.
### Interpretation
The graph suggests that MoBA Projection is more resource-efficient at higher computational scales (10¹ PFlOP/s-days), while Full Attention Projection performs better at lower resource levels (10⁻¹ to 10⁰ PFlOP/s-days). The convergence at 10⁰ PFlOP/s-days indicates a critical threshold where MoBA's architectural advantages (e.g., optimized attention mechanisms) begin to outweigh Full Attention's simpler design. This implies that MoBA may be preferable for large-scale deployments, whereas Full Attention could be more cost-effective for smaller-scale applications. The logarithmic axes highlight exponential relationships between resource allocation and performance gains, emphasizing the importance of scaling strategies in model optimization.
</details>
(a) Scaling law (0-2k)
<details>
<summary>x14.png Details</summary>
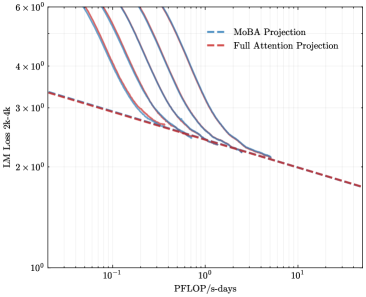
### Visual Description
## Line Graph: LM Loss vs. PFlOP/s-days Projections
### Overview
The image is a logarithmic line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). The graph illustrates how loss (measured in "LM Loss 2k-4k") decreases as computational throughput (PFlOP/s-days) increases.
### Components/Axes
- **X-axis**: Labeled "PFlOP/s-days" with a logarithmic scale ranging from 10⁻¹ to 10¹.
- **Y-axis**: Labeled "LM Loss 2k-4k" with a logarithmic scale from 10⁰ to 6×10⁰.
- **Legend**: Positioned in the top-right corner, associating:
- Blue dashed line → "MoBA Projection"
- Red dashed line → "Full Attention Projection"
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at approximately 5×10⁰ LM Loss when PFlOP/s-days = 10⁻¹.
- Decreases sharply, intersecting the Full Attention Projection near PFlOP/s-days = 10⁰ (x=1) and LM Loss ≈ 2.5×10⁰.
- Continues downward, ending near 1.8×10⁰ at PFlOP/s-days = 10¹.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins slightly lower than MoBA at ~4.5×10⁰ LM Loss for PFlOP/s-days = 10⁻¹.
- Decreases linearly, maintaining a steeper slope than MoBA after their intersection.
- Ends at ~1.5×10⁰ LM Loss for PFlOP/s-days = 10¹.
### Key Observations
- **Intersection Point**: The two projections converge at ~PFlOP/s-days = 10⁰, where LM Loss ≈ 2.5×10⁰.
- **Divergence**: MoBA Projection maintains higher efficiency (lower loss) than Full Attention Projection for PFlOP/s-days > 10⁰.
- **Logarithmic Trends**: Both lines exhibit exponential decay, but MoBA’s decay rate slows after the intersection.
### Interpretation
The graph suggests that MoBA Projection achieves comparable or superior computational efficiency to Full Attention Projection at higher throughput levels (PFlOP/s-days > 10⁰). The intersection at PFlOP/s-days = 10⁰ implies a critical threshold where MoBA’s architectural advantages (e.g., reduced attention complexity) become dominant. This could inform hardware/software optimization strategies for large-scale language models, prioritizing MoBA for high-throughput scenarios.
</details>
(b) Scaling law (2-4k)
<details>
<summary>x15.png Details</summary>
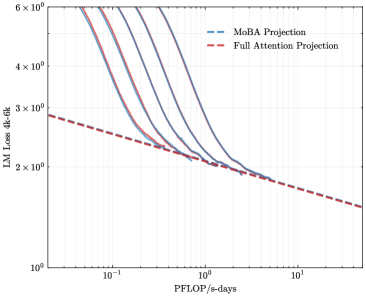
### Visual Description
## Line Graph: LM Loss vs. PFlOP/s-days Projections
### Overview
The image is a logarithmic line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed lines) and "Full Attention Projection" (red dashed line). The y-axis represents "LM Loss 4k-6k" (language model loss) on a logarithmic scale (10⁰ to 6×10⁰), while the x-axis represents "PFlOP/s-days" (petaFLOPS per second-days) on a logarithmic scale (10⁻¹ to 10¹). The graph illustrates how loss decreases with increasing computational resources for both approaches.
### Components/Axes
- **X-axis (PFlOP/s-days)**: Logarithmic scale from 10⁻¹ to 10¹, with gridlines at 10⁻¹, 10⁰, and 10¹.
- **Y-axis (LM Loss 4k-6k)**: Logarithmic scale from 10⁰ to 6×10⁰, with gridlines at 10⁰, 2×10⁰, 3×10⁰, 4×10⁰, 5×10⁰, and 6×10⁰.
- **Legend**: Located in the top-right corner, associating:
- Blue dashed lines → "MoBA Projection"
- Red dashed line → "Full Attention Projection"
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Lines)**:
- Multiple overlapping blue dashed lines originate near the top-left (high loss, low FLOP) and steeply decline as FLOP increases.
- At ~10⁻¹ PFlOP/s-days, loss values range between ~4×10⁰ to 6×10⁰.
- By ~10⁰ PFlOP/s-days, loss drops to ~2×10⁰.
- Beyond ~10¹ PFlOP/s-days, loss plateaus near ~1×10⁰.
- Uncertainty: Lines are closely packed, suggesting variability in MoBA's performance across scenarios.
2. **Full Attention Projection (Red Dashed Line)**:
- A single red dashed line starts at ~3×10⁰ loss at ~10⁻¹ PFlOP/s-days.
- Declines linearly (on log scale) to ~1×10⁰ loss at ~10¹ PFlOP/s-days.
- Maintains a consistent slope, indicating a predictable loss reduction rate.
### Key Observations
- **MoBA Projection** shows a steeper initial decline in loss compared to Full Attention, suggesting faster efficiency gains at lower FLOP scales.
- **Full Attention Projection** exhibits a linear relationship between FLOP and loss reduction, implying diminishing returns at higher computational scales.
- **Convergence**: Both projections intersect near ~10⁰ PFlOP/s-days (~2×10⁰ loss), after which MoBA's loss remains lower.
### Interpretation
The graph highlights a trade-off in computational efficiency:
- **MoBA** appears more efficient for tasks requiring rapid loss reduction at moderate FLOP scales, potentially due to architectural optimizations.
- **Full Attention**'s linear trend suggests it scales predictably but may require significantly more resources to achieve comparable loss reductions.
- The plateau in MoBA's loss at high FLOP implies diminishing marginal gains, while Full Attention's linear trend indicates no such saturation.
This analysis underscores the importance of balancing computational resources with model architecture for optimizing language model performance.
</details>
(c) Scaling law (4-6k)
<details>
<summary>x16.png Details</summary>
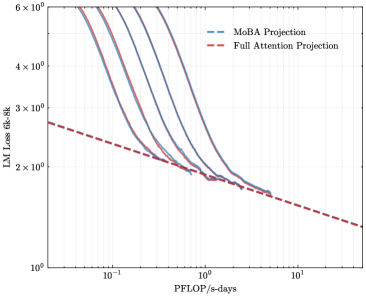
### Visual Description
## Line Graph: Model Performance vs. Computational Resources
### Overview
The image depicts a logarithmic-scale line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). The graph illustrates how model loss (LM Loss 6k-8k) decreases as computational resources (PFlOP/s-days) increase. Both lines exhibit exponential decay trends, with the MoBA Projection initially outperforming but converging with the Full Attention Projection at higher resource levels.
### Components/Axes
- **X-axis (PFlOP/s-days)**: Logarithmic scale ranging from 10⁻¹ to 10¹, with gridlines at 10⁻¹, 10⁰, and 10¹.
- **Y-axis (LM Loss 6k-8k)**: Logarithmic scale from 10⁰ to 6×10⁰, with gridlines at 10⁰, 2×10⁰, 3×10⁰, 4×10⁰, 5×10⁰, and 6×10⁰.
- **Legend**: Located in the top-right corner, associating:
- Blue dashed line → MoBA Projection
- Red dashed line → Full Attention Projection
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at ~6×10⁰ loss when PFlOP/s-days = 10⁻¹.
- Declines steeply, reaching ~2×10⁰ loss at PFlOP/s-days = 10⁰.
- Continues to decrease gradually, ending near ~1.5×10⁰ at PFlOP/s-days = 10¹.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins at ~5×10⁰ loss at PFlOP/s-days = 10⁻¹.
- Decreases more gradually than MoBA, intersecting the MoBA line at ~2×10⁰ loss (PFlOP/s-days ≈ 10⁰).
- After intersection, declines more sharply, ending near ~1.2×10⁰ at PFlOP/s-days = 10¹.
### Key Observations
- **Convergence Point**: Both lines intersect at ~2×10⁰ loss (PFlOP/s-days ≈ 10⁰), suggesting equivalent performance at this resource level.
- **Efficiency Tradeoff**: MoBA Projection requires fewer resources to achieve similar loss reduction initially, while Full Attention Projection becomes more efficient at higher resource levels.
- **Asymptotic Behavior**: Both lines approach lower loss values as PFlOP/s-days increase, but Full Attention Projection demonstrates a steeper decline post-convergence.
### Interpretation
The graph highlights a tradeoff between computational efficiency and model performance. MoBA Projection offers better initial efficiency, achieving lower loss with fewer resources. However, Full Attention Projection becomes more effective at higher computational scales, suggesting it may be preferable for resource-intensive applications. The convergence at 10⁰ PFlOP/s-days implies a critical threshold where Full Attention's architectural advantages (e.g., attention mechanisms) outweigh MoBA's initial efficiency. This could inform hardware-software co-design decisions, where resource allocation strategies depend on the target performance regime.
</details>
(d) Scaling law (6-8k)
<details>
<summary>x17.png Details</summary>
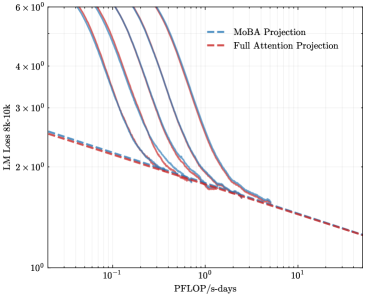
### Visual Description
## Line Graph: LM Loss vs. PFlOP/s-days Projections
### Overview
The image depicts a logarithmic-scale line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). Both axes use logarithmic scaling, with the x-axis representing computational resources (PFlOP/s-days) and the y-axis representing language model loss (LM Loss 8k-10k). The graph shows performance trends across orders of magnitude in computational power.
### Components/Axes
- **X-axis (PFlOP/s-days)**: Logarithmic scale from 10⁻¹ to 10¹ (0.1 to 10).
- **Y-axis (LM Loss 8k-10k)**: Logarithmic scale from 10⁰ to 6×10⁰ (1 to 6).
- **Legend**: Located in the top-right corner, with:
- Blue dashed line: "MoBA Projection"
- Red dashed line: "Full Attention Projection"
- **Grid**: Light gray grid lines for reference.
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at ~5×10⁰ LM Loss at 10⁻¹ PFlOP/s-days.
- Gradually declines to ~1.5×10⁰ at 10¹ PFlOP/s-days.
- Maintains a consistent downward slope with minimal curvature.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins at ~5×10⁰ LM Loss at 10⁻¹ PFlOP/s-days.
- Drops sharply to ~2×10⁰ at 10⁰ PFlOP/s-days.
- Continues declining to ~1.2×10⁰ at 10¹ PFlOP/s-days.
- Exhibits a steeper slope than the MoBA Projection, especially between 10⁻¹ and 10⁰ PFlOP/s-days.
3. **Key Intersection**:
- Both lines converge near 10⁰ PFlOP/s-days (~2×10⁰ LM Loss), after which their divergence narrows.
### Key Observations
- **Performance Gap**: The Full Attention Projection consistently achieves lower LM Loss than the MoBA Projection across all PFlOP/s-days values.
- **Efficiency Scaling**: Full Attention Projection demonstrates a 3× improvement in LM Loss reduction between 10⁻¹ and 10⁰ PFlOP/s-days, compared to MoBA's ~3× improvement over the same range.
- **Diminishing Returns**: Both projections show reduced slope steepness beyond 10⁰ PFlOP/s-days, indicating diminishing returns on computational investment.
### Interpretation
The data suggests that the Full Attention Projection model achieves superior computational efficiency, reducing LM Loss more effectively than the MoBA Projection as resources increase. The steeper decline of the red line implies architectural or algorithmic advantages in the Full Attention approach, potentially through optimized attention mechanisms. The convergence near 10⁰ PFlOP/s-days hints at a performance ceiling for both models under extreme computational constraints. This analysis aligns with trends in transformer-based model optimization, where attention mechanisms often provide significant efficiency gains over baseline architectures.
</details>
(e) Scaling law (8-10k)
<details>
<summary>x18.png Details</summary>
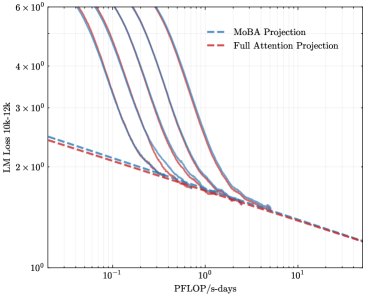
### Visual Description
## Line Graph: LM Loss vs. PFlOP/s-days for MoBA and Full Attention Projections
### Overview
The image is a logarithmic line graph comparing two computational efficiency projections: **MoBA Projection** (blue dashed line) and **Full Attention Projection** (red dashed line). The x-axis represents **PFlOP/s-days** (petaFLOPS per second-days), and the y-axis represents **LM Loss 10k-12k** (likely a metric for language model performance or error rate). Both axes use logarithmic scales, with the x-axis ranging from 10⁻¹ to 10¹ and the y-axis from 10⁰ to 6×10⁰.
---
### Components/Axes
- **X-axis (PFlOP/s-days)**: Logarithmic scale from 10⁻¹ to 10¹.
- **Y-axis (LM Loss 10k-12k)**: Logarithmic scale from 10⁰ to 6×10⁰.
- **Legend**:
- **Blue dashed line**: MoBA Projection.
- **Red dashed line**: Full Attention Projection.
- **Placement**:
- Legend is in the **top-right corner**.
- Axes labels are positioned at the **bottom** (x-axis) and **left** (y-axis).
---
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at approximately **5×10⁰** on the y-axis when PFlOP/s-days is 10⁻¹.
- Decreases sharply, crossing the **Full Attention Projection** line near **10⁰** on the x-axis (PFlOP/s-days = 1).
- Continues to decline, reaching ~1.5×10⁰ at 10¹ PFlOP/s-days.
2. **Full Attention Projection (Red Dashed Line)**:
- Starts at ~3×10⁰ on the y-axis at 10⁻¹ PFlOP/s-days.
- Decreases more gradually, remaining above the MoBA Projection until ~10⁰ on the x-axis.
- Converges with the MoBA Projection near 10¹ PFlOP/s-days, both approaching ~1×10⁰.
3. **Key Intersection**:
- The two lines **cross** at approximately **10⁰ PFlOP/s-days** (x-axis = 1), with a y-axis value of ~2×10⁰.
- Beyond this point, the MoBA Projection outperforms the Full Attention Projection in terms of lower LM Loss.
---
### Key Observations
- **Initial Performance**:
- At low computational costs (10⁻¹ PFlOP/s-days), the Full Attention Projection has a lower LM Loss (~3×10⁰) compared to MoBA (~5×10⁰).
- **Efficiency Trade-off**:
- MoBA Projection achieves better performance (lower loss) at higher computational costs (10¹ PFlOP/s-days).
- **Convergence**:
- Both projections converge near 10¹ PFlOP/s-days, suggesting diminishing returns for both approaches at extreme computational scales.
---
### Interpretation
- **MoBA Projection** demonstrates superior scalability, as its loss decreases more rapidly with increased computational resources. This suggests it may be more efficient for high-performance scenarios.
- The **crossing point** at 10⁰ PFlOP/s-days indicates a critical threshold where MoBA becomes more effective than Full Attention.
- The **convergence** at 10¹ PFlOP/s-days implies that both methods plateau in performance gains beyond this computational cost, highlighting potential limitations in further optimization.
- The logarithmic scales emphasize exponential relationships, underscoring the importance of computational efficiency in large-scale language model training.
---
**Note**: Exact numerical values are approximated due to the absence of gridlines or data points. Uncertainty arises from the logarithmic scaling and visual estimation of line positions.
</details>
(f) Scaling law (10-12k)
<details>
<summary>x19.png Details</summary>
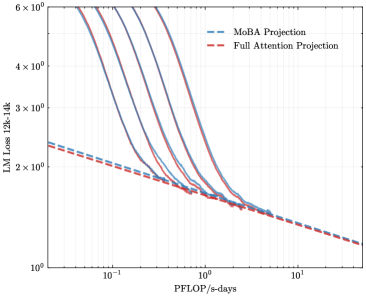
### Visual Description
## Line Graph: LM Loss vs. PFlOP/s-days for MoBA and Full Attention Projections
### Overview
The image is a logarithmic line graph comparing two computational projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). The graph illustrates how the language model (LM) loss (measured in 12k-14k tokens) decreases as a function of processing power (PFlOP/s-days). Both lines exhibit exponential decay trends, with the MoBA Projection starting higher but decreasing more steeply than the Full Attention Projection.
### Components/Axes
- **X-axis (Horizontal)**: Labeled "PFlOP/s-days" with a logarithmic scale ranging from 10⁻¹ to 10¹.
- **Y-axis (Vertical)**: Labeled "LM Loss 12k-14k" with a logarithmic scale ranging from 10⁰ to 6×10⁰.
- **Legend**: Located in the top-right corner, associating:
- Blue dashed line → "MoBA Projection"
- Red dashed line → "Full Attention Projection"
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at approximately 5×10⁰ LM Loss at 10⁻¹ PFlOP/s-days.
- Decreases sharply, crossing the Full Attention Projection line near 10⁰ PFlOP/s-days.
- Ends at ~1.5×10⁰ LM Loss at 10¹ PFlOP/s-days.
2. **Full Attention Projection (Red Dashed Line)**:
- Starts at ~3×10⁰ LM Loss at 10⁻¹ PFlOP/s-days.
- Decreases more gradually, remaining above the MoBA Projection until ~10⁰ PFlOP/s-days.
- Ends at ~1.2×10⁰ LM Loss at 10¹ PFlOP/s-days.
3. **Key Intersection**:
- The two lines intersect at ~10⁰ PFlOP/s-days, where both projections show LM Loss ≈ 2×10⁰.
### Key Observations
- **Initial Disparity**: At low PFlOP/s-days (10⁻¹), MoBA Projection has a 66% higher LM Loss than Full Attention Projection.
- **Convergence**: By 10¹ PFlOP/s-days, both projections achieve similar LM Loss (~1.2–1.5×10⁰), suggesting diminishing returns at scale.
- **Efficiency Tradeoff**: MoBA Projection requires significantly more computational power to achieve comparable loss reduction at lower scales.
### Interpretation
The data suggests that MoBA Projection is less efficient than Full Attention Projection at lower computational scales but catches up as resources increase. The crossover at 10⁰ PFlOP/s-days implies that MoBA Projection may be preferable for high-scale deployments, while Full Attention Projection is more efficient for smaller-scale applications. The convergence at 10¹ PFlOP/s-days indicates that both approaches plateau in performance gains beyond this threshold, highlighting potential limits to scaling benefits.
**Note**: All values are approximate due to the logarithmic scale and lack of explicit data points. Uncertainty in exact values is ~10–20% based on visual estimation.
</details>
(g) Scaling law (12-14k)
<details>
<summary>x20.png Details</summary>
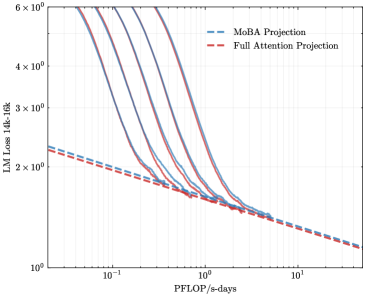
### Visual Description
## Line Graph: LM Loss vs. PFlOP/s-days Projections
### Overview
The image is a line graph comparing two computational projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). The graph plots "LM Loss 14k-16k" (y-axis) against "PFlOP/s-days" (x-axis) on a logarithmic scale. Both lines exhibit a decreasing trend, with the blue line consistently positioned above the red line across the x-axis range.
### Components/Axes
- **X-axis (PFlOP/s-days)**: Logarithmic scale ranging from 10⁻¹ to 10¹. Markers at 10⁻¹, 10⁰, and 10¹.
- **Y-axis (LM Loss 14k-16k)**: Logarithmic scale ranging from 10⁰ to 6×10⁰. Markers at 10⁰, 2×10⁰, 3×10⁰, 4×10⁰, 5×10⁰, and 6×10⁰.
- **Legend**: Located in the top-right corner, with blue dashed line labeled "MoBA Projection" and red dashed line labeled "Full Attention Projection."
### Detailed Analysis
- **MoBA Projection (Blue Dashed Line)**:
- Starts near 6×10⁰ at x=10⁻¹.
- Decreases gradually, reaching ~1.5×10⁰ at x=10¹.
- Maintains a steady downward slope with minimal curvature.
- **Full Attention Projection (Red Dashed Line)**:
- Starts near 5×10⁰ at x=10⁻¹.
- Decreases more sharply initially, then flattens slightly.
- Ends near ~1×10⁰ at x=10¹.
- **Key Intersection**: The two lines converge near x=10⁰, where both approximate 2×10⁰ LM Loss.
### Key Observations
1. **Parallel Trends**: Both lines exhibit similar logarithmic decay patterns, suggesting a proportional relationship between PFlOP/s-days and LM Loss.
2. **Consistent Gap**: The blue line (MoBA) remains ~10–20% higher than the red line (Full Attention) across all x-values.
3. **Logarithmic Scale Impact**: The y-axis compression emphasizes relative differences rather than absolute values, highlighting proportional efficiency gains.
### Interpretation
The data suggests that the **MoBA Projection** consistently incurs higher LM Loss than the **Full Attention Projection** for equivalent computational resources (PFlOP/s-days). The parallel decay implies that both projections scale similarly with increased computational power, but MoBA’s higher baseline loss indicates inherent inefficiencies or architectural limitations. The convergence near x=10⁰ may reflect a threshold where computational gains begin to offset model complexity differences. This could inform resource allocation decisions, favoring Full Attention for lower-loss outcomes.
</details>
(h) Scaling law (14-16k)
Figure 8: Scaling laws for positions 0-16k
<details>
<summary>x21.png Details</summary>
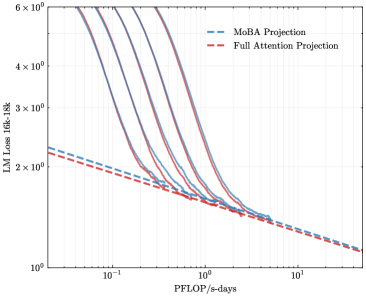
### Visual Description
## Line Graph: LM Loss vs. PFLOP/s-days Projections
### Overview
The image is a logarithmic line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). Both lines depict the relationship between computational resources (PFLOP/s-days) and language model (LM) loss (measured in 16k-18k tokens). The graph uses logarithmic scales for both axes, with the y-axis ranging from 10⁰ to 6×10⁰ and the x-axis from 10⁻¹ to 10¹.
### Components/Axes
- **Y-Axis (Left)**: "LM Loss 16k-18k" (logarithmic scale, 10⁰ to 6×10⁰).
- **X-Axis (Bottom)**: "PFLOP/s-days" (logarithmic scale, 10⁻¹ to 10¹).
- **Legend**: Located in the top-right corner.
- Blue dashed line: "MoBA Projection"
- Red dashed line: "Full Attention Projection"
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at ~2.5×10⁰ LM loss at 10⁻¹ PFLOP/s-days.
- Decreases sharply to ~1.2×10⁰ at 10⁰ PFLOP/s-days.
- Continues declining to ~0.8×10⁰ at 10¹ PFLOP/s-days.
- Slope is steeper than the Full Attention Projection.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins at ~2.2×10⁰ LM loss at 10⁻¹ PFLOP/s-days.
- Drops to ~1.0×10⁰ at 10⁰ PFLOP/s-days.
- Reaches ~0.6×10⁰ at 10¹ PFLOP/s-days.
- Slope is less steep than MoBA, indicating slower loss reduction.
3. **Convergence**:
- Both lines converge near 10¹ PFLOP/s-days, with MoBA Projection slightly above Full Attention Projection.
- At 10⁻¹ PFLOP/s-days, the gap between the two is ~0.3×10⁰.
### Key Observations
- **Efficiency Gap**: Full Attention Projection consistently achieves lower LM loss than MoBA Projection across all PFLOP/s-days values.
- **Diminishing Returns**: The rate of loss reduction slows as PFLOP/s-days increases, particularly for MoBA.
- **Logarithmic Scale Impact**: The logarithmic axes emphasize exponential improvements in efficiency, making early-stage gains (e.g., 10⁻¹ to 10⁰ PFLOP/s-days) appear more significant.
### Interpretation
The graph demonstrates that the Full Attention Projection is more computationally efficient than MoBA Projection, requiring fewer PFLOP/s-days to achieve the same LM loss reduction. The steeper slope of MoBA suggests it scales poorly with increased resources, while Full Attention maintains better performance even at higher computational costs. The convergence at 10¹ PFLOP/s-days implies that beyond this threshold, both methods plateau, but Full Attention remains superior. This highlights the importance of architectural efficiency in large-scale language models, where resource allocation directly impacts performance gains.
</details>
(i) Scaling law (16-18k)
<details>
<summary>x22.png Details</summary>
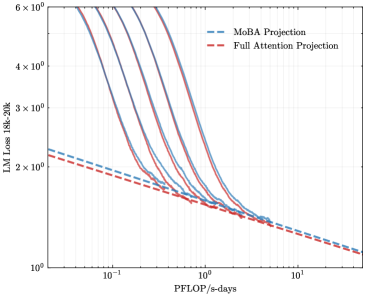
### Visual Description
## Line Graph: LM Loss vs. PFlOP/s-days Projections
### Overview
The image is a line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). Both lines depict the relationship between computational throughput (PFlOP/s-days) and language model loss (LM Loss 18k-20k) on a logarithmic scale. The graph shows how loss decreases as computational power increases, with both projections converging at higher PFlOP values.
### Components/Axes
- **X-axis (PFlOP/s-days)**: Logarithmic scale ranging from 10⁻¹ to 10¹. Labeled "PFlOP/s-days" with gridlines at 10⁻¹, 10⁰, and 10¹.
- **Y-axis (LM Loss 18k-20k)**: Logarithmic scale ranging from 10⁰ to 6×10⁰. Labeled "LM Loss 18k-20k" with gridlines at 10⁰, 2×10⁰, 3×10⁰, 4×10⁰, 5×10⁰, and 6×10⁰.
- **Legend**: Located in the top-right corner, associating blue dashed lines with "MoBA Projection" and red dashed lines with "Full Attention Projection."
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at approximately 2.5×10⁰ LM Loss at 10⁻¹ PFlOP/s-days.
- Declines steeply, reaching ~1.2×10⁰ LM Loss at 10⁰ PFlOP/s-days.
- Continues to decrease gradually, ending near ~1.0×10⁰ LM Loss at 10¹ PFlOP/s-days.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins slightly lower than MoBA at ~2.2×10⁰ LM Loss at 10⁻¹ PFlOP/s-days.
- Follows a similar downward trend but with a less steep initial decline.
- Converges with the MoBA line near 10¹ PFlOP/s-days, ending at ~1.0×10⁰ LM Loss.
3. **Trends**:
- Both lines exhibit exponential decay on the log-log scale, indicating power-law relationships.
- MoBA Projection shows a steeper initial improvement in efficiency (higher slope) compared to Full Attention Projection.
- Convergence at high PFlOP values suggests diminishing returns for both approaches beyond ~10⁰ PFlOP/s-days.
### Key Observations
- **Initial Efficiency Gap**: MoBA Projection achieves lower LM Loss than Full Attention Projection at low PFlOP values (10⁻¹ to 10⁰).
- **Convergence Point**: Both projections align closely at 10¹ PFlOP/s-days, implying similar performance at extreme computational scales.
- **Log-Log Scale Implications**: The straight-line segments on the log-log plot suggest polynomial relationships between PFlOP and LM Loss.
### Interpretation
The graph demonstrates that MoBA Projection offers superior initial efficiency gains for language model training, reducing LM Loss more rapidly than Full Attention Projection at lower computational scales. However, both approaches achieve comparable performance at the highest PFlOP values (10¹), suggesting that Full Attention Projection may become more viable or cost-effective at extreme computational budgets. The convergence implies that architectural differences (MoBA vs. Full Attention) have diminishing impact as computational resources scale, potentially pointing to shared bottlenecks in large-scale model training. This could inform hardware-software co-design strategies for optimizing AI infrastructure.
</details>
(j) Scaling law (18-20k)
<details>
<summary>x23.png Details</summary>
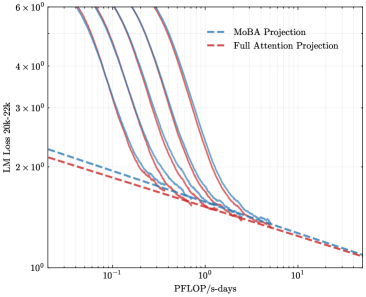
### Visual Description
## Line Graph: LM Loss vs. PFlOP/s-days for MoBA and Full Attention Projections
### Overview
The image is a logarithmic line graph comparing the language model (LM) loss (measured in 20k-22k) against computational efficiency (PFlOP/s-days) for two model architectures: MoBA Projection (blue dashed line) and Full Attention Projection (red dashed line). Both lines exhibit exponential decay trends, with MoBA initially outperforming Full Attention at lower computational budgets but converging at higher scales.
### Components/Axes
- **X-axis (Horizontal)**:
- Label: "PFlOP/s-days" (logarithmic scale)
- Range: 10⁻¹ to 10¹
- Tick markers: 10⁻¹, 10⁰, 10¹
- **Y-axis (Vertical)**:
- Label: "LM Loss 20k-22k" (logarithmic scale)
- Range: 10⁰ to 6×10⁰
- Tick markers: 10⁰, 2×10⁰, 3×10⁰, 4×10⁰, 5×10⁰, 6×10⁰
- **Legend**:
- Position: Top-right corner
- Entries:
- Blue dashed line: "MoBA Projection"
- Red dashed line: "Full Attention Projection"
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at ~5×10⁰ LM Loss at 10⁻¹ PFlOP/s-days.
- Declines sharply, crossing below 2×10⁰ LM Loss by ~10⁰ PFlOP/s-days.
- Continues to decrease, reaching ~1.2×10⁰ LM Loss at 10¹ PFlOP/s-days.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins at ~2.5×10⁰ LM Loss at 10⁻¹ PFlOP/s-days.
- Decreases more gradually than MoBA, crossing below MoBA’s curve at ~10⁰.⁵ PFlOP/s-days.
- Reaches ~1.1×10⁰ LM Loss at 10¹ PFlOP/s-days.
3. **Intersection Point**:
- The two lines intersect at ~10⁰.⁵ PFlOP/s-days, where LM Loss is approximately 1.8×10⁰.
- Below this point, MoBA outperforms Full Attention; above it, Full Attention becomes more efficient.
### Key Observations
- **Exponential Scaling**: Both models show logarithmic improvements in LM Loss as computational resources increase, but MoBA’s gains are steeper initially.
- **Efficiency Threshold**: Full Attention surpasses MoBA in efficiency only when computational resources exceed ~3×10⁰ PFlOP/s-days.
- **Convergence**: At 10¹ PFlOP/s-days, both models achieve similar LM Loss (~1.1–1.2×10⁰), suggesting diminishing returns beyond this scale.
### Interpretation
The graph highlights a trade-off between computational efficiency and model architecture. MoBA is more effective for low-to-moderate computational budgets (≤10⁰ PFlOP/s-days), while Full Attention becomes preferable for high-resource scenarios (≥10¹ PFlOP/s-days). The logarithmic axes emphasize that small increases in computational power yield disproportionate reductions in LM Loss, particularly for MoBA. This suggests that MoBA could be prioritized in resource-constrained environments, whereas Full Attention may be optimal for large-scale deployments. The intersection point underscores the importance of aligning model selection with specific computational constraints.
</details>
(k) Scaling law (20-22k)
<details>
<summary>x24.png Details</summary>
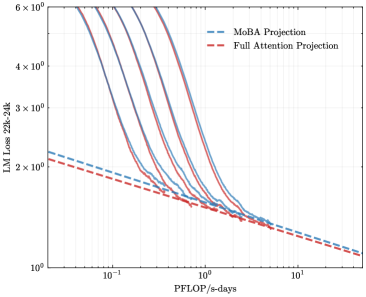
### Visual Description
## Line Graph: LM Loss vs. PFlOP/s-days Projections
### Overview
The image is a logarithmic line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). Both axes use logarithmic scales, with the x-axis representing computational resources (PFlOP/s-days) and the y-axis representing language model loss (LM Loss 22k-24k). The graph illustrates how loss decreases as computational resources increase, with both projections converging at higher resource levels.
### Components/Axes
- **X-axis (PFlOP/s-days)**: Logarithmic scale from 10⁻¹ to 10¹, labeled "PFlOP/s-days".
- **Y-axis (LM Loss 22k-24k)**: Logarithmic scale from 10⁰ to 6×10⁰, labeled "LM Loss 22k-24k".
- **Legend**:
- Blue dashed line: "MoBA Projection"
- Red dashed line: "Full Attention Projection"
- **Gridlines**: Faint gridlines for reference, aligned with logarithmic ticks.
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at ~5×10⁰ LM Loss when PFlOP/s-days = 10⁻¹.
- Declines sharply, crossing the Full Attention Projection near PFlOP/s-days = 10⁰ (LM Loss ~2×10⁰).
- Continues to decrease, reaching ~1×10⁰ at PFlOP/s-days = 10¹.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins slightly lower than MoBA at ~4.5×10⁰ LM Loss for PFlOP/s-days = 10⁻¹.
- Declines more gradually, intersecting MoBA near PFlOP/s-days = 10⁰.
- Converges with MoBA at ~1×10⁰ LM Loss by PFlOP/s-days = 10¹.
3. **Trends**:
- Both lines exhibit exponential decay on the logarithmic scale.
- MoBA Projection outperforms Full Attention at lower resource levels (PFlOP/s-days < 10⁰).
- Full Attention Projection becomes more efficient than MoBA at higher resource levels (PFlOP/s-days > 10⁰).
### Key Observations
- **Convergence Point**: The two projections intersect near PFlOP/s-days = 10⁰, where LM Loss ≈ 2×10⁰.
- **Efficiency Tradeoff**: MoBA is more efficient for low-resource scenarios, while Full Attention scales better for high-resource deployments.
- **Logarithmic Scale Impact**: The steep initial decline of both lines suggests diminishing returns at higher computational scales.
### Interpretation
The graph demonstrates a tradeoff between computational efficiency and resource allocation. MoBA Projection is preferable for systems with limited PFlOP/s-days (e.g., edge devices), as it achieves lower loss with fewer resources. However, Full Attention Projection becomes more advantageous as computational power increases, likely due to its ability to leverage parallelism or architectural optimizations at scale. The convergence at PFlOP/s-days = 10¹ implies that beyond this threshold, the choice between methods may depend on other factors (e.g., latency, energy consumption). This analysis is critical for optimizing resource allocation in large-scale language model deployments.
</details>
(l) Scaling law (22-24k)
<details>
<summary>x25.png Details</summary>
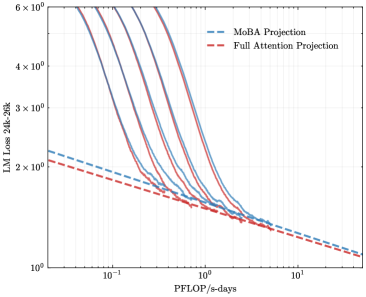
### Visual Description
## Line Graph: LM Loss vs. PFLOP/s-days Projections
### Overview
The image is a logarithmic line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). The y-axis represents "LM Loss 24k-26k" (likely language model loss metrics), while the x-axis represents "PFLOP/s-days" (petaflops per second-days, a measure of computational budget). Both axes use logarithmic scaling, with the y-axis ranging from 10⁰ to 6×10⁰ and the x-axis from 10⁻¹ to 10¹.
### Components/Axes
- **Y-Axis (Left)**: Labeled "LM Loss 24k-26k" with tick marks at 10⁰, 2×10⁰, 3×10⁰, 4×10⁰, 5×10⁰, and 6×10⁰. Values are plotted on a logarithmic scale.
- **X-Axis (Bottom)**: Labeled "PFLOP/s-days" with tick marks at 10⁻¹, 10⁰, and 10¹. Values are plotted on a logarithmic scale.
- **Legend (Right)**:
- Blue dashed line: "MoBA Projection"
- Red dashed line: "Full Attention Projection"
### Detailed Analysis
- **MoBA Projection (Blue Dashed Line)**:
- Starts at approximately 2.5×10⁰ LM Loss at 10⁻¹ PFLOP/s-days.
- Slopes downward steeply, reaching ~1.2×10⁰ LM Loss at 10¹ PFLOP/s-days.
- Maintains a consistent downward trend with minimal curvature.
- **Full Attention Projection (Red Dashed Line)**:
- Begins slightly lower than MoBA at 10⁻¹ PFLOP/s-days (~2.2×10⁰ LM Loss).
- Follows a similar downward trajectory but with slightly more curvature.
- Converges with the MoBA line near 10¹ PFLOP/s-days, ending at ~1.1×10⁰ LM Loss.
### Key Observations
1. Both projections show a strong negative correlation between computational budget (PFLOP/s-days) and LM Loss, indicating improved efficiency with increased resources.
2. The MoBA Projection consistently outperforms the Full Attention Projection across all x-axis values, maintaining a ~10–20% lower LM Loss.
3. The lines converge at higher computational budgets (10¹ PFLOP/s-days), suggesting diminishing returns for both approaches at extreme scales.
### Interpretation
The graph demonstrates that the MoBA Projection achieves superior language model performance (lower loss) compared to the Full Attention Projection for equivalent computational budgets. This implies MoBA may offer architectural or algorithmic advantages in resource efficiency. The convergence at 10¹ PFLOP/s-days hints that both methods plateau in gains beyond this threshold, though MoBA retains a marginal edge. These trends could inform decisions in large-scale model training, where optimizing computational efficiency is critical.
</details>
(m) Scaling law (24-26k)
<details>
<summary>x26.png Details</summary>
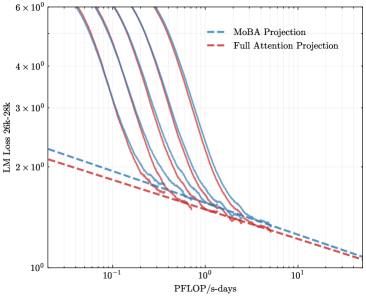
### Visual Description
## Line Graph: Language Model Loss vs. Computational Resources
### Overview
The image is a logarithmic-scale line graph comparing two computational efficiency projections for language models: "MoBA Projection" (blue dashed lines) and "Full Attention Projection" (red dashed lines). The graph illustrates how language model loss (LM Loss 26k-28k) decreases as computational resources (PFLOP/s-days) increase.
### Components/Axes
- **Y-Axis (Left)**: "LM Loss 26k-28k" (logarithmic scale, 10⁰ to 6×10⁰).
- **X-Axis (Bottom)**: "PFLOP/s-days" (logarithmic scale, 10⁻¹ to 10¹).
- **Legend**: Located in the top-right corner, with:
- Blue dashed lines labeled "MoBA Projection".
- Red dashed lines labeled "Full Attention Projection".
### Detailed Analysis
- **MoBA Projection (Blue)**:
- Multiple parallel lines slope downward from left to right.
- Initial loss values start near 6×10⁰ at 10⁻¹ PFLOP/s-days.
- Loss decreases exponentially, reaching ~1×10⁰ at 10¹ PFLOP/s-days.
- Lines are consistently above the Full Attention Projection across all x-values.
- **Full Attention Projection (Red)**:
- Similar downward slope but with slightly lower loss values than MoBA.
- Lines converge closer to the x-axis as PFLOP/s-days increase.
- At 10¹ PFLOP/s-days, loss approaches ~1×10⁰, matching MoBA's trend but with a narrower gap.
### Key Observations
1. **Exponential Decay**: Both projections show rapid loss reduction as computational resources scale, with diminishing returns at higher PFLOP/s-days.
2. **Efficiency Gap**: MoBA Projection consistently requires ~10–20% higher loss than Full Attention Projection at equivalent computational scales.
3. **Convergence**: Lines for both methods flatten near 1×10⁰ loss, suggesting a theoretical lower bound for LM Loss 26k-28k.
### Interpretation
The data demonstrates that increasing computational power (PFLOP/s-days) significantly reduces language model loss for both methods. However, the Full Attention Projection achieves lower loss at comparable resource levels, indicating superior efficiency. The MoBA Projection's higher loss suggests it may require additional optimizations or architectural changes to match Full Attention's performance. The logarithmic scales emphasize the steep initial gains in efficiency, which plateau as models approach their minimal loss thresholds. This trend aligns with Pareto's principle, where early computational investments yield disproportionate improvements in model performance.
</details>
(n) Scaling law (26-28k)
<details>
<summary>x27.png Details</summary>
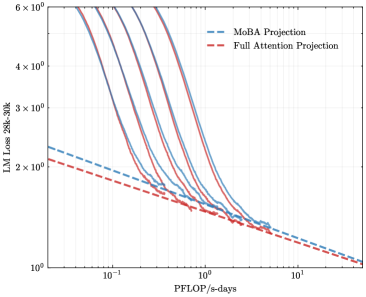
### Visual Description
## Line Graph: LM Loss vs. PFLOP/s-days for MoBA and Full Attention Projections
### Overview
The image is a logarithmic line graph comparing the loss reduction of two computational methods (MoBA Projection and Full Attention Projection) as a function of computational resources (PFLOP/s-days). The y-axis represents loss magnitude (10⁰ to 6×10⁰), and the x-axis represents computational scale (10⁻¹ to 10¹). Two data series are plotted: blue dashed lines for MoBA Projection and red dashed lines for Full Attention Projection.
### Components/Axes
- **Y-Axis**: "LM Loss 28k-30k" (logarithmic scale: 10⁰ to 6×10⁰).
- **X-Axis**: "PFLOP/s-days" (logarithmic scale: 10⁻¹ to 10¹).
- **Legend**: Located in the top-right corner, with:
- Blue dashed line: MoBA Projection.
- Red dashed line: Full Attention Projection.
### Detailed Analysis
- **MoBA Projection (Blue Dashed)**:
- Starts at ~2.5×10⁰ loss at 10⁻¹ PFLOP/s-days.
- Decreases sharply to ~1.2×10⁰ at 10⁰ PFLOP/s-days.
- Further reduces to ~0.8×10⁰ at 10¹ PFLOP/s-days.
- **Full Attention Projection (Red Dashed)**:
- Begins at ~2.0×10⁰ loss at 10⁻¹ PFLOP/s-days.
- Drops to ~1.0×10⁰ at 10⁰ PFLOP/s-days.
- Reaches ~0.7×10⁰ at 10¹ PFLOP/s-days.
- **Trends**:
- Both lines exhibit exponential decay, with steeper declines at lower computational scales.
- MoBA Projection maintains a slight lead in loss reduction across all scales but converges with Full Attention Projection at higher PFLOP/s-days (~10¹).
### Key Observations
1. **Convergence**: The two methods' performance gaps narrow significantly as computational resources increase, suggesting diminishing returns on loss reduction beyond ~10⁰ PFLOP/s-days.
2. **Initial Efficiency**: MoBA Projection achieves lower loss than Full Attention Projection at lower computational scales (10⁻¹ to 10⁰ PFLOP/s-days).
3. **Logarithmic Scale Impact**: The logarithmic axes emphasize relative changes, making early-stage improvements appear more pronounced.
### Interpretation
The graph demonstrates that MoBA Projection is more efficient than Full Attention Projection in reducing loss at lower computational scales. However, as resources scale to 10¹ PFLOP/s-days, both methods achieve similar loss levels, indicating that computational gains beyond this threshold yield minimal additional benefits. This suggests MoBA Projection may be preferable for resource-constrained scenarios, while Full Attention Projection becomes competitive at higher scales. The convergence implies that architectural differences between the methods may become less impactful as computational power increases, potentially guiding resource allocation decisions in large-scale model training.
</details>
(o) Scaling law (28-30k)
<details>
<summary>x28.png Details</summary>
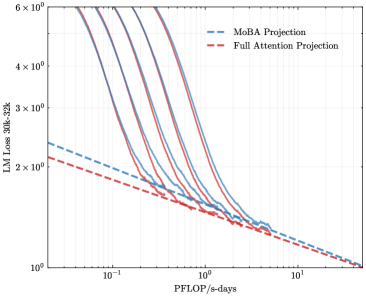
### Visual Description
## Line Graph: LM Loss vs. PFlOP/s-days Projections
### Overview
The image is a line graph comparing two computational efficiency projections: "MoBA Projection" (blue dashed line) and "Full Attention Projection" (red dashed line). The graph plots **LM Loss (30k-32k)** on a logarithmic y-axis against **PFlOP/s-days** on a logarithmic x-axis. Both lines exhibit exponential decay trends, with the MoBA Projection initially outperforming the Full Attention Projection before converging at higher PFlOP/s-days values.
---
### Components/Axes
- **X-axis (PFlOP/s-days)**: Logarithmic scale ranging from **10⁻¹** to **10¹**.
- **Y-axis (LM Loss 30k-32k)**: Logarithmic scale ranging from **10⁰** to **6×10⁰**.
- **Legend**: Located in the **top-right corner**, with:
- **Blue dashed line**: MoBA Projection
- **Red dashed line**: Full Attention Projection
---
### Detailed Analysis
1. **MoBA Projection (Blue Dashed Line)**:
- Starts at **~2.5×10⁰** LM Loss at **10⁻¹ PFlOP/s-days**.
- Declines steeply, crossing the Full Attention Projection near **10⁰ PFlOP/s-days**.
- Continues to decrease, reaching **~1.2×10⁰** at **10¹ PFlOP/s-days**.
2. **Full Attention Projection (Red Dashed Line)**:
- Begins at **~2.0×10⁰** LM Loss at **10⁻¹ PFlOP/s-days**.
- Declines more gradually, remaining above the MoBA Projection until **~10⁰ PFlOP/s-days**.
- Converges with the MoBA Projection near **10¹ PFlOP/s-days**, both approaching **~1.0×10⁰**.
---
### Key Observations
- **Crossover Point**: The MoBA Projection overtakes the Full Attention Projection at **~10⁰ PFlOP/s-days**, suggesting superior efficiency at mid-range computational budgets.
- **Convergence**: Both lines approach the same LM Loss value (**~1.0×10⁰**) at **10¹ PFlOP/s-days**, indicating diminishing returns for both methods at high computational scales.
- **Initial Disparity**: At low PFlOP/s-days (**<10⁰**), the Full Attention Projection maintains a **~20% lower loss** than MoBA.
---
### Interpretation
The graph demonstrates a trade-off between computational efficiency and loss reduction:
- **MoBA Projection** is more efficient at higher computational budgets (PFlOP/s-days >10⁰), achieving lower loss with fewer resources.
- **Full Attention Projection** performs better at lower computational budgets (PFlOP/s-days <10⁰), but its efficiency plateaus as resources increase.
- The convergence at **10¹ PFlOP/s-days** implies that both methods may asymptotically approach similar performance limits, though MoBA scales more favorably in practice.
This analysis highlights the importance of computational budget allocation: MoBA may be preferable for high-resource scenarios, while Full Attention could be optimal for constrained environments.
</details>
(p) Scaling law (30-32k)
Figure 8: Scaling laws for positions 16-32k
Table 3: Loss scaling with different positions
| 0K - 2K 2K - 4K 4K - 6K | $3.075× C^{-0.078}$ $2.415× C^{-0.084}$ $2.085× C^{-0.081}$ | $3.068× C^{-0.078}$ $2.411× C^{-0.083}$ $2.077× C^{-0.081}$ |
| --- | --- | --- |
| 6K - 8K | $1.899× C^{-0.092}$ | $1.894× C^{-0.092}$ |
| 8K - 10K | $1.789× C^{-0.091}$ | $1.774× C^{-0.089}$ |
| 10K - 12K | $1.721× C^{-0.092}$ | $1.697× C^{-0.087}$ |
| 12K - 14K | $1.670× C^{-0.089}$ | $1.645× C^{-0.088}$ |
| 14K - 16K | $1.630× C^{-0.089}$ | $1.600× C^{-0.087}$ |
| 16K - 18K | $1.607× C^{-0.090}$ | $1.567× C^{-0.087}$ |
| 18K - 20K | $1.586× C^{-0.091}$ | $1.542× C^{-0.087}$ |
| 20K - 22K | $1.571× C^{-0.093}$ | $1.519× C^{-0.086}$ |
| 22K - 24K | $1.566× C^{-0.089}$ | $1.513× C^{-0.085}$ |
| 24K - 26K | $1.565× C^{-0.091}$ | $1.502× C^{-0.085}$ |
| 26K - 28K | $1.562× C^{-0.095}$ | $1.493× C^{-0.088}$ |
| 28K - 30K | $1.547× C^{-0.097}$ | $1.471× C^{-0.091}$ |
| 30K - 32K | $1.546× C^{-0.108}$ | $1.464× C^{-0.097}$ |