2502.13247
Model: gemini-2.0-flash
# Grounding LLM Reasoning with Knowledge Graphs
**Authors**: Alfonso Amayuelas, UC Santa Barbara
> Work completed during an internship at JP Morgan AI Research
\workshoptitle
Foundations of Reasoning in Language Models
Abstract
Large Language Models (LLMs) excel at generating natural language answers, yet their outputs often remain unverifiable and difficult to trace. Knowledge Graphs (KGs) offer a complementary strength by representing entities and their relationships in structured form, providing a foundation for more reliable reasoning. We propose a novel framework that integrates LLM reasoning with KGs by linking each step of the reasoning process to graph-structured data. This grounding turns intermediate “thoughts” into interpretable traces that remain consistent with external knowledge. Our approach incorporates multiple reasoning strategies, Chain-of-Thought (CoT), Tree-of-Thought (ToT), and Graph-of-Thought (GoT), and is evaluated on GRBench, a benchmark for domain-specific graph reasoning. Our experiments show state-of-the-art (SOTA) performance, with at least 26.5% improvement over CoT baselines. Beyond accuracy, we analyze how step depth, branching structure, and model size influence reasoning quality, offering insights into the conditions that support effective reasoning. Together, these contributions highlight how grounding LLMs in structured knowledge enables both higher accuracy and greater interpretability in complex reasoning tasks.
1 Introduction
LLMs have shown remarkable versatility in answering questions posed in natural language. This is mainly due to their ability to generate text, their broad internal knowledge, and their capacity to access external information (toolqa; rag). However, a significant area for improvement is their tendency to produce information that, while plausible-sounding, is often unverifiable and lacks traceable origins and sources (hallucination_survey). This limitation highlights a deeper issue in how LLMs organize and apply reasoning, especially when reliable and accountable outputs are required.
The LLM generation process heavily relies on their internal parameters, making it difficult to link their outputs to external sources (llm_internal_knowledge; llm_kb). This limitation challenges their reliability in industrial applications (llm_explainability_survey). In applied settings, where LLMs handle critical operations, integrating them with domain-specific knowledge is essential. Fine-tuning LLMs for new domains is labor-intensive, especially for companies with proprietary data facing privacy and legal issues. As a result, there is a need for interventions that guide reasoning processes so that outputs remain accurate and transparent without requiring exhaustive re-training.
Methods such as Retrieval-Augmented Generation (RAG) (rag) and SQL-based querying (llm_eval_sql) address this gap partially. However, they often fail to capture the dynamic relationships between concepts that are necessary for comprehensive understanding. These approaches typically assume that knowledge is well-represented in discrete units, such as documents or tables, which can lead to incomplete insights when dealing with interconnected knowledge that spans multiple sources. This limits the ability to support reasoning over complex queries.
<details>
<summary>figures/general.png Details</summary>
### Visual Description
## Diagram: Agent vs. Automatic Exploration for Artwork Citation
### Overview
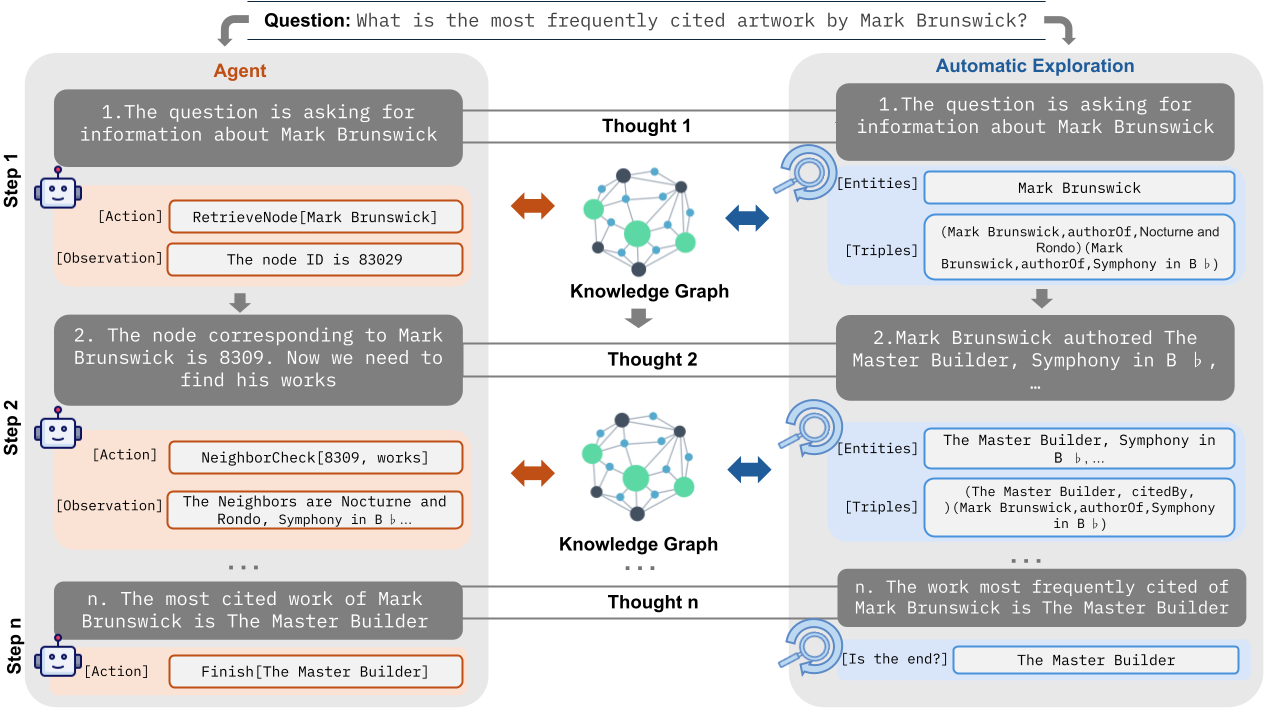
The image presents a diagram comparing two approaches, "Agent" and "Automatic Exploration," to answer the question: "What is the most frequently cited artwork by Mark Brunswick?" The diagram outlines the steps each approach takes, involving knowledge graphs, entity recognition, and triple extraction.
### Components/Axes
* **Title:** Question: What is the most frequently cited artwork by Mark Brunswick?
* **Approaches:**
* Agent (left side)
* Automatic Exploration (right side)
* **Steps:** The diagram shows steps labeled as "Step 1," "Step 2," and "Step n" for both approaches.
* **Knowledge Graph:** A visual representation of a knowledge graph is shown between the Agent and Automatic Exploration columns. It consists of interconnected nodes (green and blue) and edges.
* **Action/Observation (Agent):** Each step in the Agent approach includes an "[Action]" and an "[Observation]".
* **Entities/Triples (Automatic Exploration):** Each step in the Automatic Exploration approach includes "[Entities]" and "[Triples]".
### Detailed Analysis
**Agent Approach:**
* **Step 1:**
* Action: `RetrieveNode[Mark Brunswick]`
* Observation: `The node ID is 83029`
* **Step 2:**
* The node corresponding to Mark Brunswick is 8309. Now we need to find his works.
* Action: `NeighborCheck[8309, works]`
* Observation: `The Neighbors are Nocturne and Rondo, Symphony in Bb...`
* **Step n:**
* n. The most cited work of Mark Brunswick is The Master Builder
* Action: `Finish[The Master Builder]`
**Automatic Exploration Approach:**
* **Step 1:**
* The question is asking for information about Mark Brunswick
* Entities: `Mark Brunswick`
* Triples: `(Mark Brunswick, authorOf, Nocturne and Rondo) (Mark Brunswick, authorOf, Symphony in Bb)`
* **Step 2:**
* 2. Mark Brunswick authored The Master Builder, Symphony in Bb, ...
* Entities: `The Master Builder, Symphony in Bb...`
* Triples: `(The Master Builder, citedBy, ) (Mark Brunswick, authorOf, Symphony in Bb)`
* **Step n:**
* n. The work most frequently cited of Mark Brunswick is The Master Builder
* Is the end?: `The Master Builder`
### Key Observations
* Both approaches aim to answer the same question.
* The Agent approach uses actions and observations to navigate the knowledge graph.
* The Automatic Exploration approach focuses on extracting entities and triples from the knowledge graph.
* Both approaches ultimately arrive at the same answer: "The Master Builder" is the most frequently cited work of Mark Brunswick.
### Interpretation
The diagram illustrates two different methods for querying a knowledge graph to find information. The "Agent" approach simulates a step-by-step reasoning process, while the "Automatic Exploration" approach relies on extracting structured data (entities and triples) to infer the answer. The fact that both approaches converge on the same answer suggests the robustness of the knowledge graph and the validity of both querying methods. The diagram highlights the different strategies employed in AI for knowledge retrieval and reasoning.
</details>
Figure 1: Methods for Question-Answering in KGs (Section 4). Left: Agent. LLM decides to take one of the predefined actions to connect with the graph. Right: Automatic Graph Exploration. Entities are extracted in each reasoning step, triggering a search for each identified entity.
KGs capture such relationships by organizing entities and their connections in a structured representation. Recent work has begun to explore how KGs can guide reasoning in LLMs (rog). Building on this direction, we propose a framework that integrates reasoning strategies with domain-specific KGs from the GRBench dataset. Each reasoning step is explicitly connected to the graph, producing answers that are both accurate and traceable. We evaluate three strategies, CoT, ToT, and GoT, which provide different ways of organizing reasoning traces (Figure 2). Our framework achieves SOTA performance on GRBench, improving by at least 26.5% over CoT baselines. Beyond accuracy, we analyze how reasoning behaviors vary with step depth, branching, and model size (Section 7), offering insights into how reasoning evolves during inference and how it can be shaped by structured knowledge. Our contributions can be summarized as follows:
- We present a versatile framework that links reasoning steps with graph search, providing an intervention that can be applied across domains and knowledge settings.
- We show substantial gains over existing reasoning strategies, with state-of-the-art performance on GRBench and an improvement of at least 26.5% compared to CoT baselines.
- We conduct a detailed study of how reasoning quality is influenced by step depth, branching structure, and model size, offering insights into the conditions under which different interventions succeed (Section 7).
- By systematically grounding each step in a knowledge graph, we improve both the accuracy and the traceability of outputs, creating reasoning traces that are interpretable and verifiable.
2 Related Work
LLMs require substantial data and resources for training villalobos2024will. Retrieval-Augmented Generation (RAG) enable the models to incorporate external evidence at inference time (rag; demonstrate-search-predict). Recent work further combines RAG with structured knowledge, such as ontologies and KGs, to improve factuality and reasoning li2024structrag, underscoring the growing importance of structured data for robust and domain-adaptable LLMs.
Structured Knowledge
Structured knowledge, such as databases or KGs, provides organizations with reliable sources of information that can be systematically maintained and automatically updated. KGs in particular offer an adaptable knowledge model that captures complex relationships between interconnected concepts. Research has explored models that can interact with multiple types of structured knowledge, such as StructLM (structLM), and approaches that incorporate structured knowledge during pretraining to improve model performance (skill_llm_structured_knowledge_infusion).
Integrating KGs with LLMs
The integration of KGs with LLMs has emerged as a promising direction to strengthen reasoning capabilities and reliability (peng2024graph). In general, four primary methods can be distinguished: (1) learning graph representations (let_graph_do_thinking; graphllm), though latent representations often underperform compared to text-based methods on Knowledge Graph Question Answering (KGQA) tasks; (2) using Graph Neural Network (GNN) retrievers to extract relevant entities and feeding them as text-based input to the model (g-retriever; gnn-rag); (3) generating code, such as SPARQL queries, to directly retrieve information from graphs (kb-binder); and (4) step-by-step interaction methods that allow iterative reasoning over graphs (rog; decaf; chatkbqa), which currently achieve the strongest results on KGQA benchmarks.
LLM Reasoning with Graphs
Beyond retrieval, KGs have also been studied as a means to structure and analyze the reasoning processes of LLMs themselves wang2024understanding. This integration enables more coherent and contextually relevant outputs while also supporting the tracing and verification of reasoning steps. The most effective methods typically rely on interactive, step-by-step engagement between LLMs and graphs, as discussed above. Examples of this approach include systems such as think-on-graph; mindmap; rog; kg-gpt; li2025cot, which demonstrate improved reasoning performance through graph-based scaffolding. More recent work has further investigated the integration of traditional reasoning strategies, such as CoT and tree-structured reasoning, into KG-based interaction (graphCoT; tree-of-traversals).
Building on these advances, our framework integrates established reasoning strategies directly with domain-specific KGs. Unlike previous methods that treat KGs as retrieval tools or rely on latent representations, our approach systematically links each reasoning step to graph entities and relations.
3 Background
In this section, we formalize the prerequisite knowledge relevant to this paper. We use $p_{\theta}$ to denote a pre-trained language model with parameters $\theta$ , and letters $x,y,z$ to refer to a language sequence. $x=(x_{1},x_{2},...,x_{n})$ , where each generated token is $x_{i}$ is a such that $p_{\theta}(x)=\prod_{i=1}^{n}p_{\theta}(x_{i}|x_{1...i-1})$ .
Knowledge Graphs (KGs)
A KG is a heterogeneous directed graph that contains factual knowledge to model structured information. Nodes represent entities, events, or concepts, while edges represent the connection and types of relations between them. Formally, a KG is represented as $\mathcal{G}$ , defined by a set of triples $\mathcal{G}=\{(h,r,t)\mid h,t∈\mathcal{E},r∈\mathcal{R}\}$ , where $\mathcal{E}$ , $\mathcal{R}$ denote the set of entities and relations, respectively. KGs provide a structured framework that can guide reasoning processes by explicitly representing the relationships between concepts.
Knowledge Graph Question-Answering (KGQA)
It is a reasoning task that leverages KGs. Given a natural language question, $q$ , and an associated KG, $\mathcal{G}$ , the goal is to develop a method that retrieves the correct answer, $a$ , based on the knowledge extracted from the KG: $a=f(q,\mathcal{G})$ . Beyond retrieving facts, KGQA often requires integrating multiple reasoning steps that traverse the graph to connect related concepts.
Step-by-step Reasoning with LLMs
To improve the reasoning capabilities of LLMs at inference time, a common approach is to generate intermediate reasoning steps. The key idea is the introduction of intermediate steps, $Z_{p_{\theta}}=z_{1},...,z_{n}$ , to add inference sources to bridge the $q$ and $a$ . This decomposition allows models to tackle complex, multi-step problems incrementally, focusing computational effort on parts of reasoning chain that require deeper analysis. Stepwise reasoning over KGs offers a natural mechanism to track, guide, and interpret the reasoning process.
4 Method
This work demonstrates how progressively conditioning LLM reasoning at each step can enhance performance on domain-specific question answering over knowledge graphs. By structuring reasoning into incremental steps that interact with graph data, the model can manage complex dependencies and dynamically refine its conclusions. Our method combines reasoning strategies for LLMs: CoT, ToT, GoT with 2 graph interaction methods: (1) Agent, an agent to navigate the graph; and (2) Automatic Graph Exploration, an automatic graph traversal mechanism based on the generated text.
<details>
<summary>figures/cot.jpg Details</summary>
### Visual Description
## Diagram: Thought Process Flow
### Overview
The image is a flowchart illustrating a multi-stage thought process. It starts with an "Input," proceeds through iterative "Thought" stages, each associated with a network diagram, and culminates in an "Answer." The flow is sequential, indicated by downward-pointing arrows.
### Components/Axes
* **Nodes:**
* **Input:** An oval shape at the top, labeled "Input."
* **Thought:** Three rectangular boxes, each labeled "Thought."
* **Answer:** A rounded rectangle at the bottom, labeled "Answer."
* **Connectors:** Downward-pointing arrows connecting the nodes.
* **Network Diagrams:** Three network diagrams, each connected to a "Thought" box via a yellow plus sign. Each network diagram consists of nodes (large green, small blue, small dark blue) connected by lines.
### Detailed Analysis
1. **Input:** The process begins with an "Input" node, represented by a gray-bordered oval.
2. **Thought 1:** A gray arrow leads from "Input" to the first "Thought" box. A yellow plus sign connects the "Thought" box to a network diagram. This network diagram contains approximately 3 large green nodes, 6 small blue nodes, and 2 small dark blue nodes.
3. **Thought 2:** A gray arrow leads from the first "Thought" box to the second "Thought" box. A yellow plus sign connects the second "Thought" box to a network diagram. This network diagram contains approximately 3 large green nodes, 6 small blue nodes, and 2 small dark blue nodes.
4. **Thought 3:** A gray arrow leads from the second "Thought" box to the third "Thought" box. A yellow plus sign connects the third "Thought" box to a network diagram. This network diagram contains approximately 3 large green nodes, 6 small blue nodes, and 2 small dark blue nodes.
5. **Answer:** A gray arrow leads from the third "Thought" box to the "Answer" node, represented by a gray-bordered rounded rectangle.
The network diagrams attached to each "Thought" box appear visually similar, each containing a mix of large green, small blue, and small dark blue nodes connected by lines.
### Key Observations
* The diagram illustrates a sequential process.
* The "Thought" stage is repeated three times.
* Each "Thought" stage is associated with a network diagram.
* The network diagrams appear to be consistent across the three "Thought" stages.
### Interpretation
The diagram likely represents a simplified model of a cognitive process. The "Input" could be a stimulus or initial information. The iterative "Thought" stages suggest repeated processing or analysis of the input. The network diagrams might represent the interconnectedness of ideas or concepts within each stage of thought. The "Answer" represents the final outcome of the thought process. The consistency of the network diagrams across the "Thought" stages could indicate a stable underlying cognitive structure or a consistent approach to processing information. The plus sign may indicate an additive process, where each thought stage builds upon the previous one.
</details>
(a) Chain of Thought (CoT)
<details>
<summary>figures/tot.jpg Details</summary>
### Visual Description
## Diagram: Decision Tree with Graph-like Nodes
### Overview
The image depicts a decision tree-like diagram. The tree starts with an "Input" node at the top and branches down through multiple layers of nodes, each containing a "T" and connected to a graph-like structure. At each layer, a decision is made, indicated by either a green checkmark (✔) or a red "X", leading to different branches. The tree culminates in an "Answer" node at the bottom.
### Components/Axes
* **Nodes:** Each node is represented by a square containing the letter "T". Each node also has an associated graph-like structure consisting of interconnected green and blue circles.
* **Input:** An oval shape at the top, labeled "Input".
* **Answer:** A rounded rectangle at the bottom, labeled "Answer".
* **Decision Indicators:** Green checkmarks (✔) and red "X" symbols indicate the outcome of a decision at each node.
* **Arrows:** Gray arrows indicate the flow of the decision process. Green arrows indicate a positive decision path.
* **Horizontal Lines:** Gray horizontal lines visually separate the layers of the decision tree.
### Detailed Analysis
The diagram can be analyzed layer by layer:
* **Layer 1:**
* The "Input" node branches into three nodes, each containing "T".
* The leftmost node has a green checkmark (✔), and the path continues downward with a green arrow.
* The middle node has a red "X", indicating a negative decision.
* The rightmost node has a green checkmark (✔), and the path continues downward with a green arrow.
* The rightmost node also has a gray curved arrow looping back into itself.
* **Layer 2:**
* The leftmost node from Layer 1 branches into two nodes.
* The leftmost node has a green checkmark (✔), and the path continues downward with a green arrow.
* The rightmost node has a red "X", indicating a negative decision.
* The rightmost node from Layer 1 branches into three nodes.
* The leftmost node has a green checkmark (✔), and the path continues downward with a green arrow.
* The middle and rightmost nodes have a red "X", indicating a negative decision.
* **Layer 3:**
* The leftmost node from Layer 2 branches into two nodes.
* The leftmost node has a green checkmark (✔), and the path continues downward with a green arrow to the "Answer" node.
* The rightmost node has a red "X", indicating a negative decision.
* The leftmost node from the rightmost branch of Layer 2 branches into two nodes.
* Both nodes have a red "X", indicating a negative decision.
### Key Observations
* The diagram represents a hierarchical decision-making process.
* The green checkmarks (✔) indicate a positive decision, leading to further branching.
* The red "X" symbols indicate a negative decision, terminating that branch.
* The graph-like structures associated with each node might represent the state or features being evaluated at that decision point.
### Interpretation
The diagram illustrates a decision tree algorithm where each node evaluates a condition ("T") and branches based on the outcome. The graph-like structures associated with each node could represent the data or features being processed at that stage. The green checkmarks (✔) and red "X" symbols represent the results of these evaluations, guiding the flow of the algorithm towards a final "Answer". The looping arrow on the rightmost node of Layer 1 suggests a feedback mechanism or iterative process within that branch. The diagram demonstrates how a complex decision can be broken down into a series of simpler choices, ultimately leading to a final outcome.
</details>
(b) Tree of Thought (ToT)
<details>
<summary>figures/got.jpg Details</summary>
### Visual Description
## Decision Tree Diagram: Input to Answer
### Overview
The image is a diagram representing a decision tree or a flow chart. It starts with an "Input" node at the top and progresses through a series of nodes labeled "T", each representing a test or decision point. The flow is directed by green arrows, indicating a positive outcome or continuation, and red "X" marks, indicating a negative outcome or termination of a path. The diagram concludes with an "Answer" node at the bottom. Each "T" node is associated with a network of interconnected blue, green, and dark blue nodes.
### Components/Axes
* **Nodes:**
* **Input:** An oval node at the top, representing the starting point.
* **T Nodes:** Square nodes containing the letter "T", representing decision points. Each T node is surrounded by a network of interconnected nodes.
* **Answer:** A rounded rectangle node at the bottom, representing the final outcome.
* **Connectors:**
* **Green Arrows:** Indicate a positive outcome or continuation of the path.
* **Gray Arrows:** Indicate a continuation of the path.
* **Indicators:**
* **Green Checkmarks:** Indicate a successful or positive outcome at a "T" node.
* **Red "X" Marks:** Indicate a failure or negative outcome at a "T" node.
* **Network Nodes:**
* **Green Nodes:** Larger green circles surrounding each "T" node.
* **Blue Nodes:** Smaller blue circles surrounding each "T" node.
* **Dark Blue Nodes:** Dark blue circles surrounding each "T" node.
* **Horizontal Lines:** Gray horizontal lines separate the layers of the decision tree.
### Detailed Analysis
The diagram starts with the "Input" node, which branches into three "T" nodes in the first layer.
* **First Layer:**
* The first "T" node has a green checkmark.
* The second "T" node has a red "X" mark.
* The third "T" node has a green checkmark and a curved gray arrow looping back into itself.
* **Second Layer:**
* The first "T" node (connected to the first "T" node of the first layer) has a red "X" mark.
* The second "T" node (connected to the first "T" node of the first layer) has a green checkmark.
* The third "T" node (connected to the third "T" node of the first layer) has a green checkmark.
* The fourth "T" node (connected to the third "T" node of the first layer) has a green checkmark.
* The fifth "T" node (connected to the third "T" node of the first layer) has a green checkmark.
* **Third Layer:**
* The first "T" node (connected to the second "T" node of the second layer) has a red "X" mark.
* The second "T" node (connected to the third "T" node of the second layer) has a green checkmark.
* The third "T" node (connected to the fourth "T" node of the second layer) has a green checkmark.
* The fourth "T" node (connected to the fifth "T" node of the second layer) has a green checkmark and a curved gray arrow looping back into itself.
The green arrows from the "T" nodes in the third layer converge into the "Answer" node.
### Key Observations
* The diagram represents a multi-layered decision-making process.
* The "T" nodes represent tests or decision points.
* The green checkmarks and red "X" marks indicate the outcome of each test.
* The green arrows show the path of positive outcomes, while the red "X" marks indicate the termination of a path.
* The network of interconnected nodes surrounding each "T" node may represent the state or context at each decision point.
* The curved gray arrows looping back into the "T" nodes suggest a feedback mechanism or iterative process.
### Interpretation
The diagram illustrates a decision-making process where an "Input" is evaluated through a series of tests ("T" nodes). The outcome of each test determines the subsequent path. A green checkmark indicates a successful test, leading to further evaluation, while a red "X" mark indicates a failure, potentially terminating that particular path. The diagram suggests that multiple paths can lead to the final "Answer," and some paths may involve iterative loops. The interconnected nodes surrounding each "T" node likely represent the variables or factors considered at each decision point. The diagram could represent a machine learning algorithm, a problem-solving strategy, or any process that involves sequential decision-making.
</details>
(c) Graph of Thought (GoT)
Figure 2: Reasoning Strategies: This figure illustrates different LLM reasoning strategies to navigate the potential answer space: CoT, ToT, GoT. Each strategy consists of "thoughts" connected to the KG through search methods (Section 4.2) illustrating stepwise reasoning over structured knowledge.
4.1 Reasoning Strategies
Chain-of-Thought (CoT)
CoT is a well-known reasoning method that involves generating a sequence of logical steps, where each step builds upon previous ones, ultimately leading to a conclusion. Formally, it generates a sequence of reasoning steps $Z_{p_{\theta}}(q)=\{z_{1},z_{2},...,z_{n}\}$ , where each step $z_{i}$ is sampled sequentially given the input query $q$ , all previous steps and graph information from all steps , $\mathcal{G}^{\prime}$ , as $z_{i}\sim p_{\theta}^{\text{CoT}}(z_{i}|q,\mathcal{G}^{\prime},z_{1... i-1})$ . The final answer $a$ is derived from this reasoning process given all the generated thoughts $a\sim p_{\theta}^{\text{CoT}}(a|q,\mathcal{G}^{\prime},z_{1... n})$ . In practice, it is sampled as a continuous language sequence. Figure 2(a) represents this method, where each step is linked to the KG.
Tree-of-Thought (ToT)
ToT generalizes CoT by modeling the reasoning process as a tree, enabling simultaneous exploration of multiple reasoning paths. Starting from an initial state $s_{0}=[q]$ , where $q$ is the input, ToT incrementally expands each state by generating multiple candidate thoughts:
$$
z_{i+1}^{(j)}\sim p_{\theta}(z_{i+1}\mid s_{i}),\quad j=1,\dots,k \tag{1}
$$
Each candidate thought represents a node in the tree, forming new states. These states are evaluated by a heuristic scoring function $V(p_{\theta},s)$ , guiding the selection and pruning of branches. Search strategies, such as breadth-first search (BFS), systematically explore this tree:
$$
S_{t}=\text{argmax}_{S^{\prime}\subseteq\hat{S}_{t},|S^{\prime}|=b}\sum_{s\in S^{\prime}}V(p_{\theta},s) \tag{2}
$$
where $\hat{S}_{t}$ denotes candidate states at step $t$ , and $b$ limits the breadth. We implement two versions of heuristic functions $V$ to select the top $t$ states:
1. Selection: The LLM directly chooses the top $t$ states to proceed, discarding the others.
1. Score: The states are ranked by a heuristic voting mechanism: $V(p_{\theta},S)(s)=\mathbb{P}[s=s^{*}]$ where the LLM is prompted to estimate probability of the current state solving the given input question.
This structured search and pruning strategy allows the model to evaluate multiple candidate reasoning paths, enabling more deliberate and interpretable reasoning.
Graph-of-Thought (GoT)
GoT extends ToT by organizing reasoning into a directed graph structure $G=(V,E)$ , where each node represents a thought and edges reflect dependencies. Starting from initial thought, new thoughts are generated similarly to ToT and added to the graph. Each new thought is connected to its parent, and additional reasoning chains can be formed through merging operations:
$$
z_{i+1}=A(z_{i}^{(a)},z_{i}^{(b)}) \tag{3}
$$
where $A$ denotes a merge operation that integrates two thought chains into a single coherent reasoning step. The merged thought is added as a new node with edges from both parents. In our implementation, thoughts are evaluated using either Selection- or Score-based strategy as in ToT. Merged thoughts inherit information from both parents and can enhance robustness. At each depth, a fixed number of thoughts are retained using breadth-first traversal and evaluated for progression. The graph-based organization captures dependencies and merges information from multiple reasoning chains, supporting dynamic refinement and structured exploration of the reasoning space.
4.2 LLM + KG Interaction Methods
We implement methods to connect reasoning strategies with KGs. The LLM interacts with the KG at every step. This retrieves new information and conditions the model for subsequent steps. We present 2 methods to achieve this interaction, both illustrated in Appendix B.
4.2.1 Agent
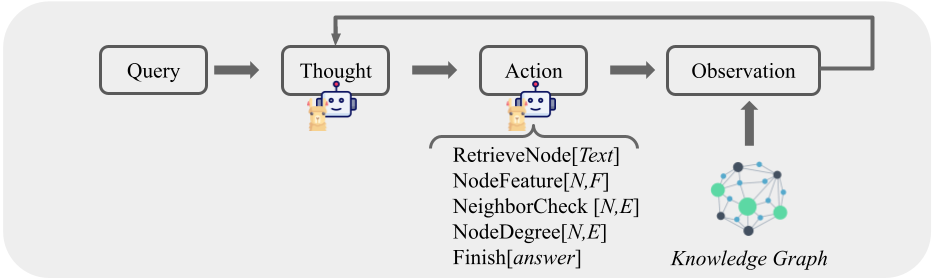
This approach creates an agent that interacts with the graph, following the methodology initially described in ReACT (react). After generating a thought, the LLM selects from a set of actions based on the given thought. Each step in the reasoning chain consists of an interleaved sequence: thought $→$ action $→$ retrieved data. This method implements four actions as described in GraphCoT (graphCoT): (a) RetrieveNode (Text): Identifies the related node in the graph using semantic search, (b) NodeFeature (NodeID, FeatureName): Retrieves textual information for a specific node from the graph, (c) NeighborCheck (NodeID, EdgeType): Retrieves neighbors’ information for a specific node, (d) NodeDegree (NodeID, EdgeType): Returns the degree (#neighbors) for a given node and edge type. These actions collectively enable the agent to navigate and extract meaningful information from the graph, enhancing the reasoning capabilities of the LLM by grounding its thoughts in structured, retrievable data.
4.2.2 Automatic Graph Exploration
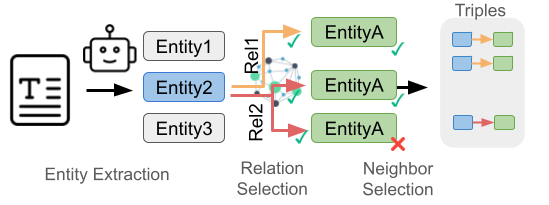
This method incrementally searches the graph by interleaving language generation with structured retrieval. At each step, the LLM generates a new "thought" based on previous thoughts and retrieved triples. Entities mentioned in the generated text are automatically extracted using LLM prompts and serve as anchors for further graph exploration.
<details>
<summary>figures/graph_search.png Details</summary>
### Visual Description
## Diagram: Entity and Relation Extraction Process
### Overview
The image illustrates a process for extracting entities and relations from text to form triples. It involves entity extraction, relation selection, and neighbor selection.
### Components/Axes
* **Header:** "Triples" is located at the top-right of the diagram.
* **Stages (Left to Right):**
* Entity Extraction
* Relation Selection
* Neighbor Selection
* **Entities:**
* Entity1 (top, light gray box)
* Entity2 (middle, light blue box)
* Entity3 (bottom, light gray box)
* **Relations:**
* Rel1 (orange arrow)
* Rel2 (red arrow)
* **Neighbor Entities:**
* EntityA (green box, top) - with a green checkmark
* EntityA (green box, middle) - with a green checkmark
* EntityA (green box, bottom) - with a red X mark
* **Input:** A document icon with a large "T" on it.
* **Process Indicators:** Arrows showing the flow of information.
* **Output:** Triples (blue box -> orange/red arrow -> green box)
### Detailed Analysis or Content Details
1. **Entity Extraction:**
* A document icon with a "T" is the input.
* An arrow points from the document to a robot icon, then to three entities: Entity1, Entity2, and Entity3. Entity2 is highlighted in blue.
2. **Relation Selection:**
* Arrows originate from Entity2 to a network graph.
* Rel1 (orange arrow) connects Entity2 to the network graph.
* Rel2 (red arrow) connects Entity2 to the network graph.
3. **Neighbor Selection:**
* The network graph connects to three instances of EntityA.
* The top two EntityA instances have green checkmarks, indicating successful selection.
* The bottom EntityA instance has a red X mark, indicating rejection.
4. **Triples:**
* The selected EntityA instances form triples with Entity2.
* Three triples are shown:
* Entity2 -> Rel1 -> EntityA (blue box -> orange arrow -> green box)
* Entity2 -> Rel1 -> EntityA (blue box -> orange arrow -> green box)
* Entity2 -> Rel2 -> EntityA (blue box -> red arrow -> green box)
### Key Observations
* Entity2 is the central entity for relation extraction.
* The network graph in "Relation Selection" likely represents a knowledge graph or relation database.
* Neighbor Selection filters the potential relations based on some criteria (indicated by the checkmarks and X mark).
### Interpretation
The diagram illustrates a knowledge extraction pipeline. It starts with identifying entities in a text document. Then, it selects relations between these entities using a knowledge graph. Finally, it selects appropriate neighbors (other entities) to form triples, which represent structured knowledge extracted from the text. The checkmarks and X mark suggest a validation or filtering step to ensure the quality of the extracted triples.
</details>
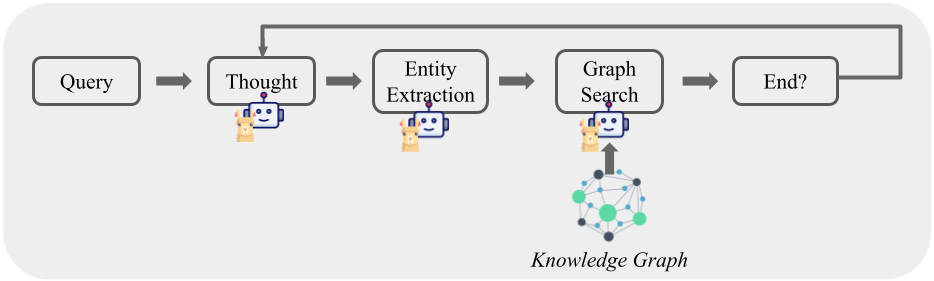
Figure 3: Automatic Graph Exploration. It extracts entities from text (query/thought), then select relevant relations and neighbors with the LLM. The resulting entity-relation-entity combinations form triples to expand the reasoning chain.
Graph exploration proceeds through a multi-step Search + Prune pipeline, inspired by the process described in think-on-graph. For each unvisited entity, the system first retrieves and prunes relation types using LLM guidance. Then, for each selected relation, neighboring entities are discovered and filtered using a second round of pruning. The model selects only the most relevant neighbors based on their contextual fit with the question and previous reasoning steps. This hierarchical pruning – first on relations, then on entities – ensures the method remains computationally tractable while preserving interpretability. The overall traversal follows a breadth-first search (BFS) pattern, with pruning decisions at each level directed by LLM. This process is shown in Figure 3. This iterative reasoning and retrieval process allows the model to condition future steps on progressively relevant subgraphs, shaping the reasoning trajectory. Unlike agentic methods that rely on predefined actions, the automatic approach operates in the graph space guided by the natural language, providing more freedom in the generation. The mechanism is designed to maximize information gain at each step while avoiding graph overgrowth. More details are provided in Algorithm 1.
5 Experiments
Benchmark
We use the GRBench dataset to evaluate our methods. This dataset is specifically designed to evaluate how effectively LLMs can perform stepwise reasoning over domain-specific graphs. It includes several graphs spanning various general domains. For our evaluation, we selected 7 graphs across multiple domains, excluding those with excessively high RAM requirements that exceed our available resources. Comprehensive graph statistics are provided in Appendix A.
Baselines
The proposed methods, Agent and Automatic Graph Exploration, applied to CoT, ToT, and GoT, are compared against the following baseline methods: (1) Zero-Shot: Directly querying the model to answer the question without additional context. (2) Text RAG rag_sruvey: Text-retrieval method that uses text representation of nodes as input for query, with retrieved data serving as context for the model. (3) Graph RAG: Includes node neighbors (1-hop) for additional context beyond Text RAG. (4) Graph CoT (Agent): Implements Graph CoT as an agent for CoT reasoning, utilizing the actions described in Section 4.2. These baselines allow us to measure impact of stepwise, knowledge-grounded reasoning versus simple retrieval-augmented or zero-shot approaches.
Experimental methods
We implement the methods described in Section 4, extending (1) Agent and (2) Automatic Graph Exploration with various reasoning strategies during inference: (1) CoT, (2) ToT, and (3) GoT. For ToT and GoT, we evaluate the impact of stepwise decision-making using State Evaluation methods: (1) Selection and (2) Score. In the results presented in Table 1, we set $n=10$ steps for all methods. ToT and GoT use a branching factor and Selection of $k=t=3$ . Our experiments focus on the effect of structured reasoning interventions on performance and stepwise refinement of answers. We use only open-access Llama 3.1 (Instruct) llama3models as the backend models, which enhances reproducibility and allows for unlimited free calls. Specifically, we employ the 8B, 70B, and 405B versions, using the FP8 variant for the 405B model.
Evaluation
We use rule-based and model-based metrics to evaluate the models, following GRBench paper graphCoT. For the rule-based metric, we use Rouge-L (R-L) (rouge_metric), which measures the longest sequence of words appearing in same order in both generated text and ground truth answer. For model-based metric, we prompt GPT-4o to assess if the model’s output matches ground truth answer. GPT4Score is percentage of answers that GPT-4o identifies as correct. These evaluation methods capture not only final answer accuracy but also the fidelity of reasoning steps, reflecting the effectiveness of our interventions in guiding LLM reasoning over structured knowledge.
Implementation Details
The experiments are run on NVIDIA TITAN RTX or NVIDIA A100 using Python 3.8. The models are deployed with vLLM vllm, a memory-efficient library for LLM inference and serving. For the baseline, Mpnet-v2 is used as the retriever, and FAISS faiss is employed for indexing.
6 Results
The main results from both the baselines and experimental methods, evaluated using R-L, are presented in Table 1. For brevity, additional results using GPT4Score can be found in Appendix D. Together, these findings allow us to compare different forms of reasoning interventions, agentic action selection, automatic graph exploration, and structured multi-path search, on their ability to guide LLMs toward accurate answers. We highlight three key insights from the findings: (1) The agentic method generally outperformed automatic graph exploration, indicating that targeted interventions on knowledge graph traversal enhance answer accuracy. (2) The ToT strategy demonstrated superior performance by effectively exploring multiple reasoning paths, showcasing the benefits of inference-time interventions that diversify reasoning trajectories. (3) Although GoT strategy showed potential, it did not significantly outperform ToT, suggesting that merging divergent reasoning paths remains a challenging intervention design problem. These results show the importance of reasoning strategies in enabling LLMs to navigate multiple paths in the graph, while also illustrating the limits of current intervention techniques.
| | Method | | Model | Healthcare | Goodreads | Biology | Chemistry | Materials Science | Medicine | Physics |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Baselines | | Llama 3.1 8B-Ins | 7.32 | 6.18 | 10.68 | 11.69 | 8.95 | 8.77 | 11.52 | |
| Base | Llama 3.1 70B-Ins | 9.74 | 9.79 | 11.49 | 12.58 | 10.40 | 12.21 | 12.61 | | |
| Llama 3.1 405B-Ins | 8.66 | 12.49 | 10.52 | 13.51 | 11.73 | 11.82 | 11.63 | | | |
| Llama 3.1 8B-Ins | 8.24 | 14.69 | 12.43 | 11.42 | 9.46 | 10.75 | 11.29 | | | |
| Text-RAG | Llama 3.1 70B-Ins | 10.32 | 18.81 | 11.87 | 16.35 | 12.25 | 12.77 | 12.54 | | |
| Llama 3.1 405B-Ins | 11.61 | 16.23 | 16.11 | 13.82 | 14.23 | 15.16 | 16.32 | | | |
| Llama 3.1 8B-Ins | 12.94 | 22.30 | 30.72 | 34.46 | 30.20 | 25.81 | 33.49 | | | |
| Graph-RAG | Llama 3.1 70B-Ins | 17.95 | 25.36 | 38.88 | 40.90 | 41.09 | 31.43 | 39.75 | | |
| Llama 3.1 405B-Ins | 16.12 | 23.13 | 37.57 | 42.58 | 37.74 | 33.34 | 40.98 | | | |
| Graph CoT | | Llama 3.1 8B-Ins | 16.83 | 30.91 | 20.15 | 18.43 | 26.29 | 14.95 | 21.41 | |
| Agent | Llama 3.1 70B-Ins | 33.48 | 40.98 | 50.00 | 51.53 | 49.6 | 48.27 | 44.35 | | |
| Llama 3.1 405B-Ins | 28.41 | 36.56 | 41.35 | 48.36 | 47.81 | 42.54 | 35.24 | | | |
| Graph Explore | Llama 3.1 8B-Ins | 25.58 | 32.34 | 36.65 | 35.33 | 31.06 | 31.05 | 35.96 | | |
| Llama 3.1 70B-Ins | 29.41 | 29.60 | 44.63 | 49.49 | 39.23 | 38.87 | 45.52 | | | |
| Llama 3.1 405B-Ins | 28.45 | 43.06 | 36.93 | 38.71 | 47.49 | 55.66 | 32.73 | | | |
| Graph ToT | Agent | Score | Llama 3.1 8B-Ins | 28.91 | 52.25 | 43.81 | 44.18 | 43.49 | 36.07 | 39.56 |
| Llama 3.1 70B-Ins | 38.51 | 51.58 | 64.44 | 61.13 | 55.19 | 63.00 | 55.33 | | | |
| Llama 3.1 405B-Ins | 47.51 | 50.73 | 70.34 | 64.9 | 49.02 | 65.40 | 44.63 | | | |
| Select | Llama 3.1 8B-Ins | 28.67 | 50.59 | 42.33 | 37.07 | 40.81 | 33.17 | 36.50 | | |
| Llama 3.1 70B-Ins | 40.26 | 52.59 | 64.53 | 66.84 | 61.42 | 61.21 | 55.89 | | | |
| Llama 3.1 405B-Ins | 46.90 | 51.68 | 70.27 | 67.95 | 63.74 | 64.23 | 59.56 | | | |
| Graph Explore | Score | Llama 3.1 8B-Ins | 24.49 | 36.80 | 35.81 | 36.41 | 34.28 | 34.49 | 37.69 | |
| Llama 3.1 70B-Ins | 32.79 | 38.19 | 53.83 | 58.25 | 48.55 | 52.18 | 48.07 | | | |
| Llama 3.1 405B-Ins | 33.90 | 42.68 | 46.87 | 57.43 | 50.46 | 55.56 | 48.73 | | | |
| Select | Llama 3.1 8B-Ins | 25.04 | 37.8 | 36.34 | 38.5 | 32.44 | 33.31 | 34.85 | | |
| Llama 3.1 70B-Ins | 33.40 | 39.13 | 54.78 | 58.53 | 47.19 | 51.13 | 47.51 | | | |
| Llama 3.1 405B-Ins | 33.82 | 43.63 | 44.47 | 59.06 | 48.52 | 55.62 | 46.07 | | | |
Table 1: Rouge-L (R-L) performance results on GRBench, comparing standard LLMs, Text-RAG, Graph-RAG, Graph-CoT, and Graph-ToT. Experiments are described in Section 5, using LLama 3.1 - Instruct backbone models with sizes 8B, 70B, and 405B-FP8.
Agent vs Graph Search
In our experimental results, the agentic method outperformed graph exploration approach across most datasets and reasoning strategies. The agent-based method, which involves LLM selecting specific actions to interact with KG, consistently improves performance as the number of reasoning steps increases, as shown in Section 7. This highlights that explicit, model-driven interventions are more effective than passive expansion strategies, as they promote iterative refinement and selective focus. While graph exploration can quickly provide broad coverage, the agentic method’s targeted, stepwise interactions yield more accurate and comprehensive answers over longer sequences of reasoning.
Tree of Thought (ToT)
The ToT reasoning strategy showed superior performance across its various interaction methods and state evaluators, as summarized in Table 1. ToT achieved performance improvements of 54.74% in agent performance and 11.74% in exploration mode compared to the CoT baseline. However, this improvement comes with the trade-off of increased inference time, highlighting the cost of inference-time reasoning interventions. The success of ToT illustrates how branching interventions that explore multiple candidate paths can substantially enhance reasoning accuracy, especially when coupled with evaluators that prune unpromising trajectories. We also compared the two State Evaluation methods (Selection and Score), finding complementary benefits depending on dataset and scale.
| Method | Model | Healthcare | Biology | |
| --- | --- | --- | --- | --- |
| Agent | Score | Llama 3.1 8B-Ins | 29.11 | 33.25 |
| Llama 3.1 70B-Ins | 30.88 | 56.64 | | |
| Llama 3.1 405B-Ins | 43.53 | 48.1 | | |
| Select | Llama 3.1 8B-Ins | 29.05 | 40.37 | |
| Llama 3.1 70B-Ins | 40.74 | 65.59 | | |
| Llama 3.1 405B-Ins | 47.63 | 71.49 | | |
| Graph Explore | Score | Llama 3.1 8B-Ins | 24.96 | 21.72 |
| Llama 3.1 70B-Ins | 31.24 | 50.70 | | |
| Llama 3.1 405B-Ins | 35.00 | 39.10 | | |
| Select | Llama 3.1 8B-Ins | 25.06 | 21.84 | |
| Llama 3.1 70B-Ins | 36.95 | 52.32 | | |
| Llama 3.1 405B-Ins | 33.74 | 54.64 | | |
Table 2: Graph-GoT results on GRBench using Rouge-L
Graph of Thought (GoT)
The results for GoT strategy are summarized in Table 2. Due to the additional computational cost, we report results for two datasets only. GoT did not outperform ToT. Our initial hypothesis was that LLMs could integrate divergent results from multiple branches, but in practice the models struggled to merge these effectively. Specifically, in the graph exploration setting, models often failed to combine different triples found in separate branches. This reveals a current limitation of reasoning interventions based on aggregation: while branching helps discover diverse facts, robust mechanisms for synthesis and reconciliation are still underdeveloped. This finding opens a direction for future research into more advanced intervention strategies for merging partial reasoning outcomes.
7 Analysis & Ablation studies
In this section, we want to better understand the nuances of our methods for LLM and KG grounding. We conduct an analysis on the Academic datasets from the benchmark, as they all contain the same number of samples and feature questions generated from similar templates to ensure a controlled comparison.
<details>
<summary>figures/analysis_steps_academic_rl.png Details</summary>
### Visual Description
## Line Chart: Rouge-L vs. Steps for Agent and Explore
### Overview
The image is a line chart comparing the Rouge-L score of two methods, "Agent" and "Explore," over 10 steps. The chart displays the trend of each method's performance, with shaded areas indicating the uncertainty or variance around the mean values.
### Components/Axes
* **X-axis:** "Steps," labeled from 1 to 10.
* **Y-axis:** "Rouge-L," ranging from 0 to 60, with increments of 10.
* **Legend:** Located in the bottom-right corner.
* Blue line with circle markers: "Agent"
* Orange line with square markers: "Explore"
### Detailed Analysis
* **Agent (Blue Line):**
* Trend: The Agent line shows a steep upward trend from step 1 to step 5, then plateaus and slightly increases until step 10.
* Data Points:
* Step 1: Approximately 0
* Step 3: Approximately 15
* Step 5: Approximately 45
* Step 10: Approximately 57
* **Explore (Orange Line):**
* Trend: The Explore line starts higher than the Agent line and shows a slight upward trend, plateauing after step 3.
* Data Points:
* Step 1: Approximately 42
* Step 3: Approximately 49
* Step 5: Approximately 50
* Step 10: Approximately 50
### Key Observations
* The Agent method starts with a significantly lower Rouge-L score but rapidly improves, surpassing the Explore method by step 5.
* The Explore method maintains a relatively stable Rouge-L score throughout the steps.
* The shaded areas around the lines indicate the variability in the Rouge-L scores for each method at each step.
### Interpretation
The chart suggests that the "Agent" method is more effective at improving its Rouge-L score over time compared to the "Explore" method. While "Explore" starts with a higher initial score, "Agent" demonstrates a greater learning capacity, eventually outperforming "Explore." The shaded areas provide insight into the consistency of each method's performance, with wider areas indicating greater variability. The rapid initial improvement of the "Agent" method suggests it benefits significantly from the initial steps of training or exploration.
</details>
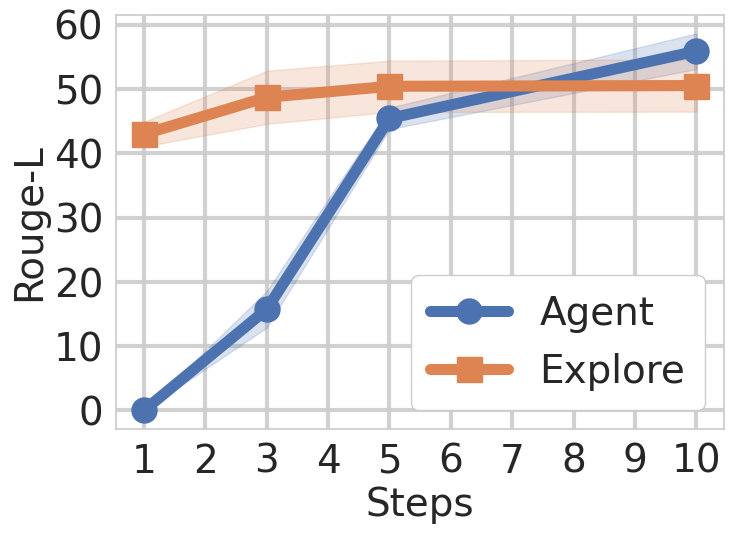
Figure 4: Effect of the number of steps in the LLM-KG Interaction Methods. The Agent requires more steps to obtain the performance of the Graph Exploration, while the Graph Exploration only needs the anchor entities to perform the search within the graph.
<details>
<summary>figures/search_depth_academic_rl.png Details</summary>
### Visual Description
## Line Chart: Rouge-L vs. Search Depth
### Overview
The image is a line chart showing the relationship between "Search Depth" (on the x-axis) and "Rouge-L" (on the y-axis). The chart displays a single data series labeled "Explore" along with a shaded region representing the standard deviation (SD).
### Components/Axes
* **X-axis:** "Search Depth" with values ranging from 1 to 5.
* **Y-axis:** "Rouge-L" with values ranging from 30 to 70, in increments of 5.
* **Legend:** Located in the top-left corner, it identifies the blue line as "Explore" and the light blue shaded area as "SD (σ)".
### Detailed Analysis
* **Explore (Blue Line):** The "Explore" line shows an upward trend initially, then plateaus.
* Search Depth 1: Rouge-L ≈ 36
* Search Depth 2: Rouge-L ≈ 42
* Search Depth 3: Rouge-L ≈ 43
* Search Depth 4: Rouge-L ≈ 43.5
* Search Depth 5: Rouge-L ≈ 43
* **SD (σ) (Light Blue Shaded Area):** The shaded area represents the standard deviation around the "Explore" line. The width of the shaded area indicates the variability in the Rouge-L score for each search depth.
* Search Depth 1: SD ranges from approximately 33 to 39.
* Search Depth 2: SD ranges from approximately 39 to 45.
* Search Depth 3: SD ranges from approximately 40 to 46.
* Search Depth 4: SD ranges from approximately 39 to 48.
* Search Depth 5: SD ranges from approximately 38 to 48.
### Key Observations
* The Rouge-L score increases significantly from a search depth of 1 to 2.
* Beyond a search depth of 2, the Rouge-L score plateaus, with only marginal improvements.
* The standard deviation is relatively consistent across different search depths.
### Interpretation
The chart suggests that increasing the search depth initially improves the Rouge-L score, a measure of text summarization quality. However, after a certain point (around a search depth of 2), further increases in search depth yield diminishing returns. The standard deviation indicates the variability in the Rouge-L scores, providing a measure of the robustness of the results. The plateauing effect suggests that there may be a point of diminishing returns in increasing search depth, and other factors may become more important in improving summarization quality beyond this point.
</details>
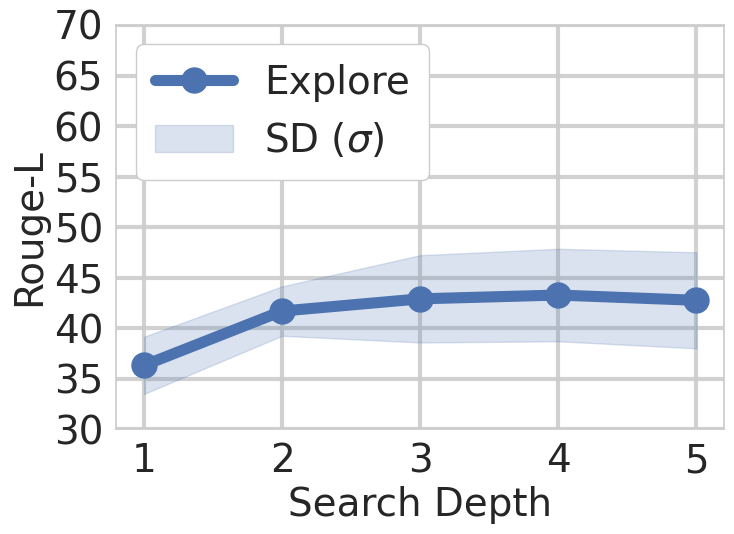
Figure 5: Effect of the Search depth in Graph Exploration interaction method for a fixed steps number. The method can achieve relatively good performance with the anchor entities extracted from the question.
How does the number of steps affect the results?
We observe in Figure 5 the effect of varying the number of steps in the KG interaction methods (Agent, Explore) across all academic datasets. The plots indicate that graph exploration performs better with fewer steps, as it automatically traverses the graph for the identified anchor entities. Conversely, the agentic methods improve as the number of steps increases, eventually achieving better performance. This validates our framework’s design choice to support both exploration and agentic strategies, each excels in complementary regimes.
<details>
<summary>figures/tree_width_academic_rl.png Details</summary>
### Visual Description
## Line Chart: Rouge-L vs. Tree Width
### Overview
The image is a line chart comparing the performance of two methods, "ToT-Explore" and "CoT," based on their Rouge-L scores across different tree widths. The chart also displays the standard deviation (SD) for the "ToT-Explore" method.
### Components/Axes
* **X-axis (Horizontal):** "Tree Width" with values 1, 2, 3, 4, and 5.
* **Y-axis (Vertical):** "Rouge-L" ranging from 30 to 70, with increments of 5.
* **Legend (Right Side):**
* **ToT-Explore:** Solid orange line with circular markers.
* **SD (σ):** Shaded orange area around the "ToT-Explore" line, representing the standard deviation.
* **CoT:** Orange "x" markers.
### Detailed Analysis
* **ToT-Explore (Orange Line):**
* At Tree Width 1, Rouge-L is approximately 43.
* At Tree Width 2, Rouge-L is approximately 58.
* At Tree Width 3, Rouge-L is approximately 61.
* At Tree Width 4, Rouge-L is approximately 62.
* At Tree Width 5, Rouge-L is approximately 61.
* Trend: The Rouge-L score increases sharply from Tree Width 1 to 2, then increases more gradually from 2 to 4, and slightly decreases from 4 to 5.
* **SD (σ) - Shaded Orange Area:** The shaded area around the "ToT-Explore" line indicates the standard deviation. The width of the shaded area varies, suggesting different levels of variability at different tree widths. The standard deviation appears to be largest around Tree Width 2 and decreases as the Tree Width increases.
* **CoT (Orange "x" Markers):**
* At Tree Width 1, Rouge-L is approximately 43.
* Trend: Only one data point is provided for CoT.
### Key Observations
* The "ToT-Explore" method generally outperforms "CoT" (at Tree Width 1).
* The "ToT-Explore" method shows diminishing returns as the tree width increases beyond 2.
* The standard deviation for "ToT-Explore" is relatively high, especially at lower tree widths.
### Interpretation
The chart suggests that increasing the tree width for the "ToT-Explore" method initially leads to a significant improvement in the Rouge-L score. However, the gains diminish as the tree width increases further, and there is a slight decrease at a tree width of 5. The standard deviation indicates that the performance of "ToT-Explore" can vary, particularly at lower tree widths. The single data point for "CoT" shows that at a tree width of 1, it performs similarly to "ToT-Explore". The data implies that "ToT-Explore" is more effective than "CoT" at higher tree widths, but more data points for "CoT" would be needed to confirm this.
</details>
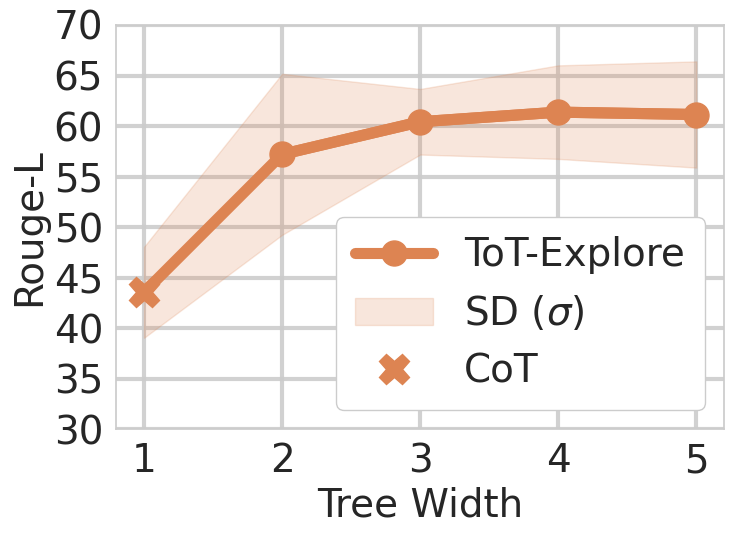
Figure 6: Impact of tree width on Agentic ToT performance. It shows a general trend of performance improvement with increasing tree width.
<details>
<summary>figures/state_evaluators.png Details</summary>
### Visual Description
## Bar Chart: Rouge-L Scores for Agent and Explore
### Overview
The image presents a bar chart comparing Rouge-L scores for two categories: "Agent" and "Explore." Each category is further divided into three sub-categories: "8B," "70B," and "405B." Within each sub-category, there are two bars representing "Score" and "Select." The chart includes error bars indicating the variability in the scores.
### Components/Axes
* **Title:** The chart is divided into two sections, titled "Agent" (left) and "Explore" (right).
* **Y-axis:** Labeled "Rouge-L," with a numerical scale ranging from 30 to 70 in increments of 10.
* **X-axis:** Categorical, with labels "8B," "70B," and "405B" for both "Agent" and "Explore."
* **Legend:** Located at the bottom of the chart.
* "Score" is represented by solid color bars: blue for 8B, orange for 70B, and green for 405B.
* "Select" is represented by hatched bars: light blue for 8B, light orange for 70B, and light green for 405B.
### Detailed Analysis
**Agent Category:**
* **8B:**
* Score (blue): Approximately 41 with error bars extending from ~37 to ~45.
* Select (light blue, hatched): Approximately 38 with error bars extending from ~34 to ~42.
* **70B:**
* Score (orange): Approximately 60 with error bars extending from ~56 to ~64.
* Select (light orange, hatched): Approximately 62 with error bars extending from ~58 to ~66.
* **405B:**
* Score (green): Approximately 59 with error bars extending from ~46 to ~72.
* Select (light green, hatched): Approximately 65 with error bars extending from ~52 to ~78.
**Explore Category:**
* **8B:**
* Score (blue): Approximately 36 with error bars extending from ~32 to ~40.
* Select (light blue, hatched): Approximately 35 with error bars extending from ~31 to ~39.
* **70B:**
* Score (orange): Approximately 52 with error bars extending from ~48 to ~56.
* Select (light orange, hatched): Approximately 52 with error bars extending from ~48 to ~56.
* **405B:**
* Score (green): Approximately 52 with error bars extending from ~48 to ~56.
* Select (light green, hatched): Approximately 51 with error bars extending from ~47 to ~55.
### Key Observations
* In the "Agent" category, both "Score" and "Select" generally increase as the model size increases from 8B to 70B, but the 405B "Score" decreases slightly.
* In the "Explore" category, the "Score" and "Select" values are relatively similar across all model sizes (8B, 70B, and 405B).
* The error bars are generally larger for the "Agent" category, especially for the 405B model, indicating greater variability in the Rouge-L scores.
### Interpretation
The chart compares the Rouge-L scores of "Agent" and "Explore" methods across different model sizes (8B, 70B, 405B) using "Score" and "Select" metrics. The "Agent" category shows a more pronounced increase in performance with larger model sizes, while the "Explore" category remains relatively stable. The larger error bars for the "Agent" category, particularly with the 405B model, suggest that the performance of the "Agent" method may be more sensitive to variations in the data or experimental setup. The "Select" method generally performs slightly better than the "Score" method, especially for the "Agent" category with larger models.
</details>
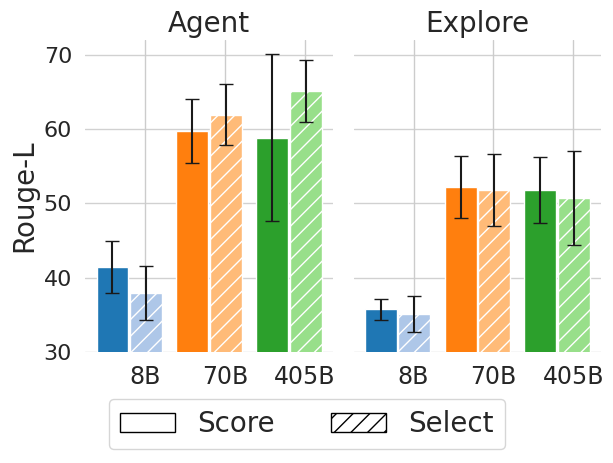
Figure 7: Influence of the State Evaluators in ToT. The Select method obtains better results over Score method.
What is the effect of Search Depth in Automatic Graph Exploration?
We observe the effect of search depth in Figure 5, which presents performance results across various depths, with fixed step size of one. The results demonstrate that the performance of depth-first search plateaus at depth of 3, highlighting the relevance of search exploration with respect to the given query. Beyond this point, deeper traversal yields no significant gains, likely due to diminishing relevance of distant nodes. This shows why shallow, targeted exploration is sufficient in our framework, keeping search efficient without sacrificing accuracy.
What is the effect of tree width in the reasoning strategy (ToT)?
Based on experimental results across all academic datasets, we observe performance variations among different methods. To gain further insight, we observe in Figure 7 the effect of tree width on results. We notice a slight upward trend in performance as the tree width increases, although the difference is more pronounced between CoT and ToT itself, going from one branch to two. The added computational time and resources likely contribute to this performance enhancement.
What is the influence of the state evaluator?
We observe in Figure 7 the impact of state evaluators, specifically Score and Select, within the ToT framework. The analysis indicates that, while there is no significant difference between the two methods, the Select evaluator generally yields slightly better results. This trend is especially evident in the context of the Agent’s performance, though the advantage is less pronounced in automatic graph exploration.
How are errors different for each strategy?
<details>
<summary>figures/pie_cot.png Details</summary>
### Visual Description
## Chart Type: Pie Chart
### Overview
The image is a pie chart displaying three categories with their respective percentages. The categories are represented by different colors: blue, green, and orange. The green category occupies the largest portion of the pie, followed by blue, and then orange.
### Components/Axes
* **Categories:** The pie chart represents three distinct categories, each identified by a unique color.
* **Percentages:** Each category is labeled with a percentage value, indicating its proportion of the whole.
### Detailed Analysis
* **Blue Category:** The blue section occupies approximately 34.1% of the pie chart. It is located in the top-right quadrant.
* **Green Category:** The green section occupies approximately 60.4% of the pie chart. It is located in the bottom-left quadrant.
* **Orange Category:** The orange section occupies approximately 5.5% of the pie chart. It is located in the top-left quadrant.
### Key Observations
* The green category represents the majority (60.4%) of the data.
* The orange category represents a small fraction (5.5%) of the data.
* The blue category represents a significant portion (34.1%) of the data, but less than the green category.
### Interpretation
The pie chart visually represents the distribution of data across three categories. The green category dominates, suggesting it is the most prevalent or significant component. The orange category is the least prevalent. The chart provides a clear and concise overview of the relative proportions of each category within the whole. Without further context, it's difficult to determine the specific meaning of these categories, but the chart effectively communicates their relative sizes.
</details>
(a) CoT
<details>
<summary>figures/pie_tot.png Details</summary>
### Visual Description
## Chart Type: Pie Chart
### Overview
The image is a pie chart displaying three categories with their respective percentages. The categories are represented by different colors: blue, orange, and green. The percentages are displayed directly on the chart.
### Components/Axes
* **Categories:** The pie chart is divided into three sections, each representing a different category.
* **Percentages:** Each section is labeled with a percentage value, indicating its proportion of the whole.
* **Colors:** The sections are colored blue, orange, and green.
### Detailed Analysis
* **Blue Section:** Located in the top-right quadrant, representing 10.9% of the total.
* **Orange Section:** Located in the top-left quadrant, representing 21.3% of the total.
* **Green Section:** Occupies the majority of the pie chart, located in the bottom half, representing 67.8% of the total.
### Key Observations
* The green category makes up the largest portion of the pie chart, accounting for over two-thirds of the total.
* The blue category is the smallest, representing approximately 10.9%.
* The orange category represents approximately 21.3%.
### Interpretation
The pie chart visually represents the distribution of a whole into three distinct parts. The green category is the dominant component, while the blue category is the smallest. The chart provides a clear and concise comparison of the relative sizes of the three categories. The data suggests that the element represented by the green section is significantly more prevalent than the other two.
</details>
(b) ToT
<details>
<summary>figures/pie_got.png Details</summary>
### Visual Description
## Chart Type: Pie Chart
### Overview
The image is a pie chart displaying three categories with their respective percentages. The categories are represented by different colors: blue, orange, and green. The green category occupies the largest portion of the pie, followed by blue, and then orange.
### Components/Axes
* **Categories:** The pie chart is divided into three categories, each represented by a different color.
* **Percentages:** Each category is labeled with a percentage value indicating its proportion of the whole.
* **Colors:** The colors used are blue, orange, and green.
### Detailed Analysis
* **Blue Category:** Located in the top-right quadrant, representing 20.0% of the pie.
* **Orange Category:** Located in the top-left quadrant, representing 12.2% of the pie.
* **Green Category:** Occupies the majority of the pie chart, located in the bottom half, representing 67.8% of the pie.
### Key Observations
* The green category is the largest, accounting for over two-thirds of the pie chart.
* The orange category is the smallest, representing only 12.2% of the pie chart.
* The blue category represents a fifth of the pie chart.
### Interpretation
The pie chart visually represents the distribution of a whole into three parts. The green category dominates, suggesting it represents the largest portion of whatever is being measured. The orange category is the smallest, indicating it represents the smallest portion. The blue category falls in between. Without further context, it's impossible to determine what these categories represent, but the chart clearly shows their relative proportions.
</details>
(c) GoT
<details>
<summary>figures/pie_legend.png Details</summary>
### Visual Description
## Legend: Error Analysis
### Overview
The image presents a legend used for error analysis, categorizing different types of errors encountered. It uses colored squares to represent each error type, followed by a textual description.
### Components/Axes
The legend consists of three categories, each represented by a distinct color:
- Blue: "Reached limit"
- Green: "Found answer but not returned"
- Orange: "Wrong reasoning"
### Detailed Analysis or ### Content Details
The legend is structured horizontally, with each category comprising a colored square followed by its corresponding text label.
### Key Observations
The legend provides a clear and concise way to differentiate between three specific error types.
### Interpretation
This legend is likely used in conjunction with a chart, graph, or table to visually represent the frequency or distribution of each error type. The categories suggest potential issues in a system or process where limits are reached, correct answers are found but not utilized, or incorrect reasoning leads to errors.
</details>
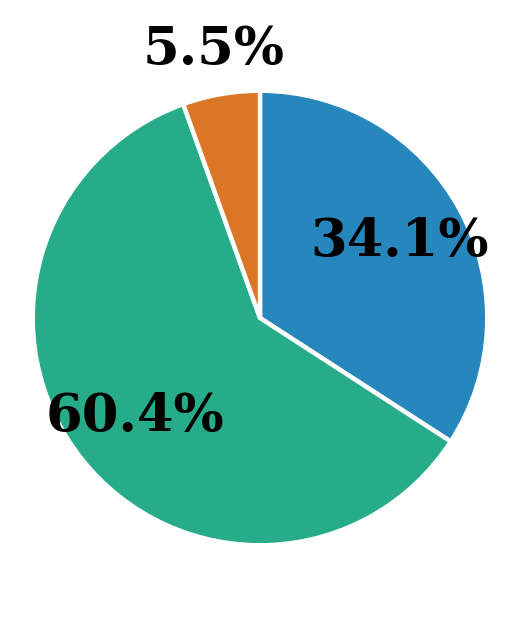
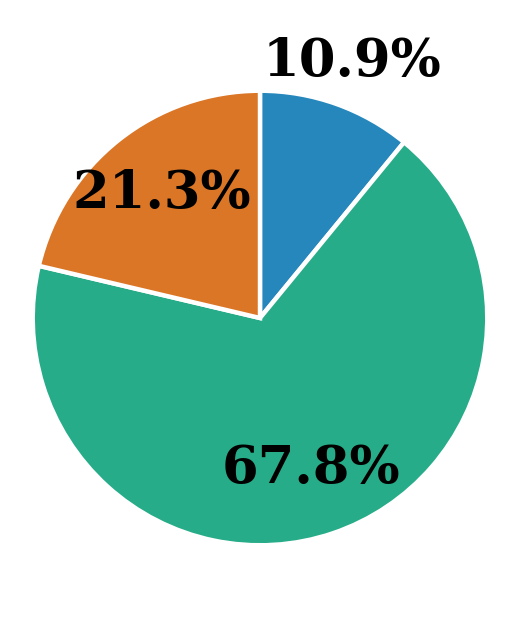
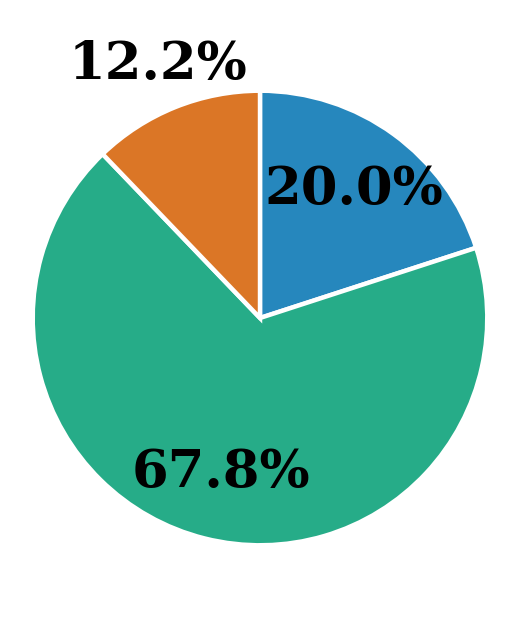
Figure 8: Error distribution across strategies. ToT and GoT reduce unanswered cases but increase logical errors due to more complex reasoning.
To understand failure patterns, we define three error types: (1) Reached limit — the reasoning hit the step limit; (2) Answer found but not returned — the correct answer appeared but was not output; (3) Wrong reasoning step — the model followed an illogical step. Using GPT-4o, we labeled a larger set of answers and traces. We observe in Figure 8 that ToT and GoT show more “answer found but not returned” cases than CoT, suggesting better retrieval but occasional failures in synthesis. This comes with a slight rise in logical errors, likely due to the complexity of multiple reasoning paths.
8 Limitations
In this work, we demonstrate how LLMs can be used to explore a graph while conditioning the next steps based on the graph’s results. We show that the two approaches presented achieve superior results in graph exploration. Integrating KGs with LLMs can provide complex relational knowledge for LLMs to leverage. However, the overall effectiveness depends heavily on both the coverage and quality of the underlying graph, as well as the capabilities of the language model.
Extending inference-time reasoning methods for LLMs is significantly constrained by computational resources and the time available to the user. We analyze the computational complexity of the methods in Appendix E, where we show the exponential growth of ToT and GoT due to its branching structure. GoT further compounds this by allowing merges between reasoning paths, which increases the total number of evaluations. Additionally, loading large graphs into memory introduces substantial RAM overhead, limiting applicability to resource-rich environments.
While LLMs conditioned on external knowledge can generate outputs based on accessed content, their generated output is not strictly limited to that information. Thus, they may still hallucinate. Our framework helps mitigate this risk by grounding reasoning in explicit graph structure, but does not eliminate it.
9 Conclusion
We present a framework for grounding LLM reasoning in KGs by integrating each step with structured graph retrieval. By combining strategies like CoT, ToT, and GoT with adaptive graph search, our method achieves state-of-the-art performance on GRBench. Beyond performance, we find that explicitly linking reasoning steps to graph structure offers a more interpretable view of how LLMs navigate knowledge. The approach enables inference-time reasoning, offering flexibility across domains, and suggests a path toward reasoning interventions that are both systematic and transparent. Future work includes extending this framework to larger and more heterogeneous graphs, and exploring how structured retrieval can guide reasoning in domains where accuracy and verifiability are critical.
Disclaimers
This [paper/presentation] was prepared for informational purposes [“in part” if the work is collaborative with external partners] by the Artificial Intelligence Research group of JPMorganChase and its affiliates ("JP Morgan”) and is not a product of the Research Department of JP Morgan. JP Morgan makes no representation and warranty whatsoever and disclaims all liability, for the completeness, accuracy or reliability of the information contained herein. This document is not intended as investment research or investment advice, or a recommendation, offer or solicitation for the purchase or sale of any security, financial instrument, financial product or service, or to be used in any way for evaluating the merits of participating in any transaction, and shall not constitute a solicitation under any jurisdiction or to any person, if such solicitation under such jurisdiction or to such person would be unlawful.
©2025 JPMorganChase. All rights reserved
Appendix A GRBench Statistics
Detailed statistics of the graphs in GRBench graphCoT are shown in Table 3. Academic Graphs contain 3 types of nodes: paper, author, venue. Literature Graphs contain 4 types of nodes: book, author, publisher and series. Healthcare Graph contains 11 types of nodes: anatomy, biological process, cellular component, compound, disease, gene, molecular function, pathway, pharmacologic class, side effect, and symptom. Questions are created according to multiple templates labeled as easy, medium, and hard, depending on the number of nodes required to give the answer.
| Domain | Topic | Graph Statistics | Data | | |
| --- | --- | --- | --- | --- | --- |
| # Nodes | # Edges | # Templates | # Questions | | |
| Academic | Biology | $\sim$ 4M | $\sim$ 39M | 14 | 140 |
| Chemistry | $\sim$ 4M | $\sim$ 30M | 14 | 140 | |
| Material Science | $\sim$ 3M | $\sim$ 22M | 14 | 140 | |
| Medicine | $\sim$ 6M | $\sim$ 30M | 14 | 140 | |
| Physics | $\sim$ 2M | $\sim$ 33M | 14 | 140 | |
| Literature | Goodreads | $\sim$ 3M | $\sim$ 22M | 24 | 240 |
| Healthcare | Disease | $\sim$ 47K | $\sim$ 4M | 27 | 270 |
| SUM | - | - | - | 121 | 1210 |
Table 3: Detailed statistics of the GRBench graphCoT.
Appendix B LLM <–> KG Interaction Pipelines
Description of the two LLM + KG Interaction Pipelines in their CoT form:
1. Agent – Figure 9 A pipeline where the LLM alternates between generating a reasoning step, selecting an explicit action (e.g., retrieving a node, checking neighbors), and observing results from the KG until termination.
1. Automatic Graph Exploration – Figure 10. A pipeline where entities are automatically extracted from the LLM’s generated text and used to guide iterative graph traversal with pruning, progressively expanding the reasoning chain.
<details>
<summary>figures/agent_pipeline.png Details</summary>
### Visual Description
## Diagram: Query-Thought-Action-Observation Cycle with Knowledge Graph
### Overview
The image is a diagram illustrating a cyclical process involving a query, thought, action, and observation, with a knowledge graph providing input to the observation stage. The cycle is represented by rounded rectangles connected by arrows, indicating the flow of information.
### Components/Axes
* **Nodes:**
* Query: A rounded rectangle labeled "Query" at the beginning of the cycle.
* Thought: A rounded rectangle labeled "Thought" following the "Query" node. A small image of a llama and a robot is below the "Thought" node.
* Action: A rounded rectangle labeled "Action" following the "Thought" node. A small image of a llama and a robot is below the "Action" node.
* Observation: A rounded rectangle labeled "Observation" following the "Action" node.
* **Flow:**
* Arrows: Arrows connect the nodes in the sequence Query -> Thought -> Action -> Observation.
* Feedback Loop: An arrow connects the "Observation" node back to the "Thought" node, creating a cycle.
* Knowledge Graph Input: An arrow points from the "Knowledge Graph" up to the "Observation" node.
* **Knowledge Graph:**
* Representation: A network of interconnected nodes and edges, with some nodes colored green and others dark gray.
* Label: "Knowledge Graph" is written below the graph.
* **Action Details:**
* RetrieveNode[Text]
* NodeFeature[N,F]
* NeighborCheck[N,E]
* NodeDegree[N,E]
* Finish[answer]
### Detailed Analysis
The diagram depicts a closed-loop system where a "Query" initiates a "Thought" process, leading to an "Action." The "Action" results in an "Observation," which is informed by a "Knowledge Graph." The "Observation" then feeds back into the "Thought" process, creating a continuous cycle.
The "Action" node is further detailed with a list of specific actions:
* RetrieveNode[Text]: Retrieves a node based on text.
* NodeFeature[N,F]: Extracts features from a node, denoted by N and F.
* NeighborCheck[N,E]: Checks the neighbors of a node, denoted by N and E.
* NodeDegree[N,E]: Determines the degree of a node, denoted by N and E.
* Finish[answer]: Completes the process with an answer.
The Knowledge Graph is represented visually as a network of nodes and edges. Some nodes are colored green, while others are dark gray.
### Key Observations
* The diagram emphasizes the iterative nature of the process, with the "Observation" influencing subsequent "Thought" processes.
* The "Knowledge Graph" plays a crucial role in informing the "Observation" stage.
* The "Action" node is broken down into specific actions, providing more detail about this stage.
### Interpretation
The diagram illustrates a system where a query is processed through a series of steps, leveraging a knowledge graph to inform the observation and subsequent decision-making. The cyclical nature of the process suggests continuous learning and refinement based on observations. The inclusion of specific actions within the "Action" node provides insight into the types of operations performed during this stage. The presence of the Knowledge Graph highlights the importance of structured knowledge in the overall process. The llama and robot images below the "Thought" and "Action" nodes may represent different types of agents or models involved in these stages.
</details>
Figure 9: Agent Pipeline: (1) Input Query, (2) Thought Generation (3) Action Selection, (4) Environment Observation from the Knowledge Graph. The process is repeated until termination action is generated or limit reached.
<details>
<summary>figures/graph_explore_pipeline.png Details</summary>
### Visual Description
## Diagram: Knowledge Graph Search Process
### Overview
The image is a diagram illustrating a process flow for knowledge graph search. It depicts a sequence of steps, starting with a query and ending with a decision point, with a loop back to an earlier stage. Each step is represented by a rounded rectangle containing a label, and arrows indicate the direction of the process flow.
### Components/Axes
* **Nodes:**
* Query
* Thought (with a robot and llama icon)
* Entity Extraction (with a robot and llama icon)
* Graph Search (with a robot and llama icon)
* End?
* **Knowledge Graph:** A network of interconnected nodes, some colored light green and others dark blue.
* **Arrows:** Indicate the flow of the process.
* **Icons:** Each of the "Thought", "Entity Extraction", and "Graph Search" nodes has a small icon of a robot head and a llama.
### Detailed Analysis or ### Content Details
The process flow is as follows:
1. **Query:** The process begins with a query.
2. **Thought:** The query is processed, represented by the "Thought" node. A robot and llama icon are present.
3. **Entity Extraction:** Entities are extracted from the thought. A robot and llama icon are present.
4. **Graph Search:** A graph search is performed using the extracted entities. A robot and llama icon are present. The search interacts with a "Knowledge Graph," which is depicted as a network of interconnected nodes. Some nodes are light green, and others are dark blue.
5. **End?:** A decision point is reached. If the process is not complete, it loops back to the "Thought" node.
### Key Observations
* The diagram illustrates an iterative process, as indicated by the loop from "End?" back to "Thought."
* The robot and llama icons appear consistently in the "Thought," "Entity Extraction," and "Graph Search" nodes, suggesting a common agent or system performing these tasks.
* The Knowledge Graph is a key component of the process, providing the data for the graph search.
### Interpretation
The diagram describes a system that takes a query, extracts relevant entities, searches a knowledge graph, and then iteratively refines the process until a desired outcome is achieved. The presence of the robot and llama icons suggests that this system may involve a combination of automated and human-assisted processes, or perhaps a specific AI model or framework. The loop indicates that the system can refine its search based on the results of previous iterations.
</details>
Figure 10: Automatic Graph Exploration Pipeline: (1) Input Query, (2) Thought Generation, (3) Entity Extraction (from query or thought with LLM), (4) Automatic Graph Search as described in Algorithm 1 (5) Query LLM for answer or continue
Algorithm 1 presents the pseudocode for the Automatic Graph Exploration described in Section 4.2.2.
Algorithm 1 Graph Exploration Algorithm
1: procedure GraphExplore ( $LLM,seen\_entities,search\_depth$ )
2: $relevant\_attributes$ , $found\_triples← 0$
3: for $depth$ in $search\_depth$ do
4: for $entity$ in $seen\_entities$ do
5: if $seen\_entities[entity\_id].visited$ == True then
6: Continue
7: else
8: $seen\_entities[entity]←$ Visited
9: end if
10: $head\_entity\_name$ , $entity\_attributes$ , $neighbors←$ Graph[ $entity$ ]
11: $pruned\_neighbors←$ prune_relations( $LLM,neighbors$ )
12: $pruned\_neighbors←$ prune_entities( $LLM,pruned\_neighbors$ )
13: $found\_triples←$ generate_triples( $entity,pruned\_neighbros$ )
14: end for
15: $seen\_entities←$ Update( $seen\_entities$ , neighbors)
16: if End?( $LLM,found\_triples,relevant\_attributes$ ) == True then
17: break
18: end if
19: end for
20: return $found\_triples,relevant\_attributes,seen\_entities$
21: end procedure
Appendix C Performance results in plots
Figures 11 and 12 illustrate the performance results using the Rouge-L and GPT4score metrics, respectively, for the healthcare graph for all methods. The results were run on the LLama 3.1 Instruct models (8B, 70B, and 405B-FP8) and demonstrate the improved performance achieved through more complex reasoning and search strategies during inference.
<details>
<summary>figures/healthcare_rl_all.png Details</summary>
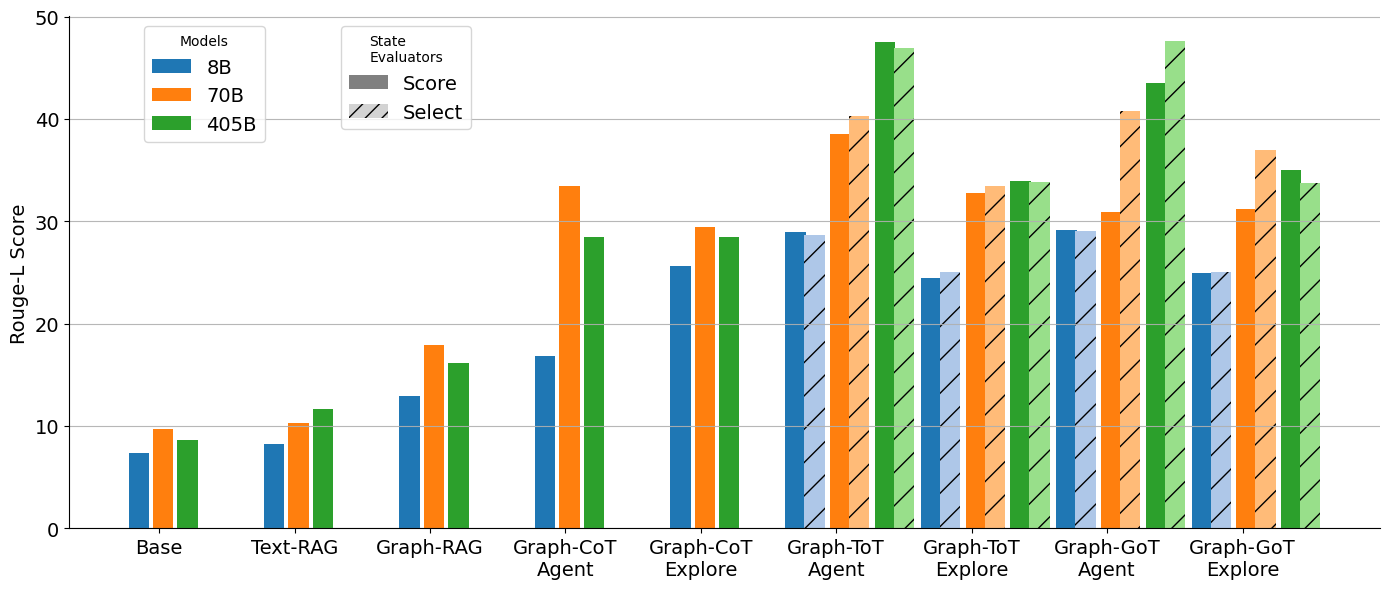
### Visual Description
## Bar Chart: Rouge-L Score by Model and State Evaluator
### Overview
The image is a bar chart comparing the Rouge-L scores of different models (8B, 70B, 405B) across various tasks and state evaluators (Score, Select). The x-axis represents the tasks, and the y-axis represents the Rouge-L score. The chart uses different colored bars to represent the models and patterned bars to represent the state evaluators.
### Components/Axes
* **Y-axis:** "Rouge-L Score", ranging from 0 to 50, with gridlines at intervals of 10.
* **X-axis:** Categorical axis representing different tasks: "Base", "Text-RAG", "Graph-RAG", "Graph-CoT Agent", "Graph-CoT Explore", "Graph-ToT Agent", "Graph-ToT Explore", "Graph-GoT Agent", "Graph-GoT Explore".
* **Legend (Top-Left):**
* "Models":
* Blue: "8B"
* Orange: "70B"
* Green: "405B"
* "State Evaluators" (Top-Right):
* Gray: "Score" (Solid fill)
* Diagonal Lines: "Select" (Hatched fill)
### Detailed Analysis
Here's a breakdown of the Rouge-L scores for each task and model, considering both "Score" and "Select" state evaluators:
* **Base:**
* 8B (Score): ~7.5
* 70B (Score): ~10
* 405B (Score): ~9
* **Text-RAG:**
* 8B (Score): ~8.5
* 70B (Score): ~10.5
* 405B (Score): ~12
* **Graph-RAG:**
* 8B (Score): ~13
* 70B (Score): ~18
* 405B (Score): ~16.5
* **Graph-CoT Agent:**
* 8B (Score): ~17
* 70B (Score): ~33.5
* 405B (Score): ~28.5
* **Graph-CoT Explore:**
* 8B (Score): ~25.5
* 70B (Score): ~29
* 405B (Score): ~29
* **Graph-ToT Agent:**
* 8B (Score): ~29
* 70B (Score): ~39
* 405B (Score): ~48
* **Graph-ToT Explore:**
* 8B (Score): ~24.5 (Select)
* 70B (Score): ~33.5 (Select)
* 405B (Score): ~34 (Select)
* **Graph-GoT Agent:**
* 8B (Score): ~29
* 70B (Score): ~31
* 405B (Score): ~44
* **Graph-GoT Explore:**
* 8B (Score): ~24.5 (Select)
* 70B (Score): ~36 (Select)
* 405B (Score): ~34 (Select)
**Trends:**
* Generally, the Rouge-L score increases as the model size increases (8B < 70B < 405B).
* The "Graph-ToT Agent" task shows the highest Rouge-L scores for all models.
* The "Base" and "Text-RAG" tasks have the lowest Rouge-L scores.
* The "Select" state evaluator generally results in lower scores compared to the "Score" evaluator, especially for "Graph-ToT Explore" and "Graph-GoT Explore".
### Key Observations
* The 405B model consistently outperforms the 70B and 8B models across all tasks.
* The "Graph-ToT Agent" task appears to be the most effective, yielding the highest scores.
* The "Select" state evaluator seems to be more conservative or selective, resulting in lower scores.
### Interpretation
The data suggests that larger models (405B) generally achieve higher Rouge-L scores, indicating better performance in these tasks. The "Graph-ToT Agent" task seems to be particularly well-suited for these models, potentially due to its ability to leverage graph-based reasoning and agent-based exploration. The difference between "Score" and "Select" state evaluators highlights the impact of evaluation criteria on the reported performance. The "Select" evaluator might be prioritizing precision over recall, leading to lower overall scores but potentially higher-quality results. The performance increase from "Base" to "Text-RAG" to "Graph-RAG" suggests that incorporating graph-based information retrieval enhances the models' capabilities.
</details>
Figure 11: Performance results using the Rouge-L metric on the healthcare graph of GRBench graphCoT, comparing all methods with LLama 3.1 Instruct models of various sizes (8B, 70B, 405B-FP8). Experimental details are included in Section 5.
<details>
<summary>figures/healthcare_gpt4score_all.png Details</summary>
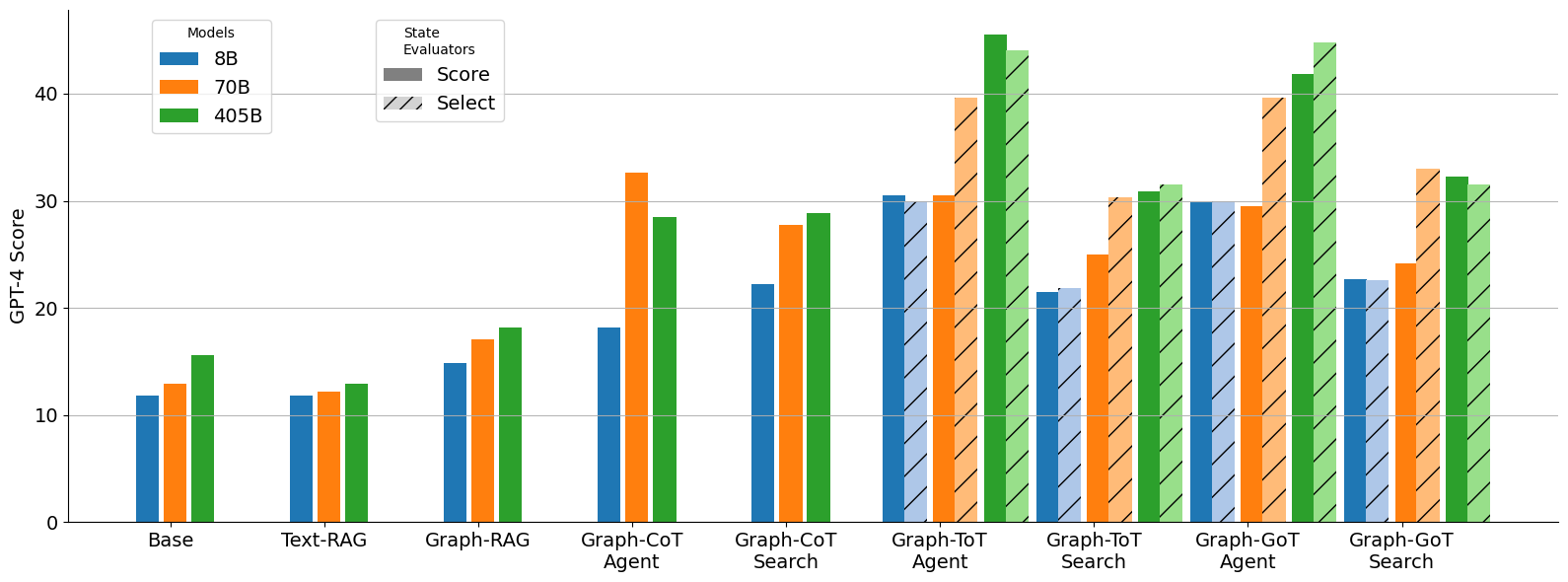
### Visual Description
## Bar Chart: GPT-4 Score Comparison of Different Models and State Evaluators
### Overview
The image is a bar chart comparing the GPT-4 scores of different models (8B, 70B, 405B) across various state evaluators (Base, Text-RAG, Graph-RAG, Graph-CoT Agent, Graph-CoT Search, Graph-ToT Agent, Graph-ToT Search, Graph-GoT Agent, Graph-GoT Search). The chart also distinguishes between "Score" and "Select" state evaluators, with "Select" bars having a diagonal striped pattern.
### Components/Axes
* **Y-axis:** "GPT-4 Score", with a numerical scale from 0 to 40 in increments of 10.
* **X-axis:** Categorical axis representing different state evaluators: Base, Text-RAG, Graph-RAG, Graph-CoT Agent, Graph-CoT Search, Graph-ToT Agent, Graph-ToT Search, Graph-GoT Agent, Graph-GoT Search.
* **Legend (Models):** Located at the top-left of the chart.
* Blue: 8B model
* Orange: 70B model
* Green: 405B model
* **Legend (State Evaluators):** Located at the top-right of the chart.
* Gray: Score
* Diagonal Stripes: Select
### Detailed Analysis
Here's a breakdown of the GPT-4 scores for each model and state evaluator:
* **Base:**
* 8B: ~12
* 70B: ~13
* 405B: ~15
* **Text-RAG:**
* 8B: ~12
* 70B: ~13
* 405B: ~13
* **Graph-RAG:**
* 8B: ~15
* 70B: ~17
* 405B: ~18
* **Graph-CoT Agent:**
* 8B: ~18
* 70B: ~33
* 405B: ~29
* **Graph-CoT Search:**
* 8B: ~28
* 70B: ~29
* 405B: ~29
* **Graph-ToT Agent:**
* 8B (Select): ~31
* 70B (Select): ~31
* 405B (Select): ~45
* **Graph-ToT Search:**
* 8B: ~22
* 70B: ~30
* 405B: ~31
* **Graph-GoT Agent:**
* 8B: ~30
* 70B: ~30
* 405B: ~42
* **Graph-GoT Search:**
* 8B: ~24
* 70B: ~33
* 405B: ~32
### Key Observations
* The 405B model generally outperforms the 70B and 8B models across all state evaluators.
* The "Graph-ToT Agent" state evaluator with "Select" shows the highest score for the 405B model.
* The "Base" and "Text-RAG" state evaluators have the lowest scores across all models.
* The "Graph-CoT Search" state evaluator shows similar scores across all models.
* The "Graph-GoT Agent" and "Graph-GoT Search" state evaluators show high scores for the 405B model.
### Interpretation
The chart suggests that the choice of state evaluator significantly impacts the GPT-4 score, and that larger models (405B) tend to perform better. The "Graph-ToT Agent" state evaluator, particularly with the "Select" setting, appears to be the most effective for the 405B model. The relatively low scores for "Base" and "Text-RAG" indicate that these approaches may not be as effective as the graph-based methods. The similar scores for "Graph-CoT Search" across all models suggest that this approach may be less sensitive to model size.
</details>
Figure 12: Performance results using the GPT4Score metric on the healthcare graph of GRBench graphCoT, comparing all methods with LLama 3.1 Instruct models of various sizes (8B, 70B, 405B-FP8). Experimental details are included in Section 5.
Appendix D Results on GPT4Score
In this section, we present the results of the experiments described in Section 5 for all methods, using the GPT4Score metric. This metric calculates the percentage of "correct" answers as judged by GPT-4 when presented with both the correct and the generated answer. The tables in this section present the same data as in Tables 1 and 2, but evaluated using GPT4Score.
| | Method | | Model | Healthcare | Goodreads | Biology | Chemistry | Materials Science | Medicine | Physics |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Baselines | | Llama 3.1 8B-Ins | 11.85 | 13.33 | 10.71 | 11.43 | 7.86 | 7.87 | 9.29 | |
| Base | Llama 3.1 70B-Ins | 12.96 | 19.17 | 10.00 | 12.14 | 11.43 | 11.43 | 12.86 | | |
| Llama 3.1 405B-Ins | 15.55 | 26.67 | 12.86 | 12.14 | 12.14 | 13.57 | 12.14 | | | |
| Llama 3.1 8B-Ins | 11.85 | 21.67 | 12.86 | 10.00 | 10.00 | 8.57 | 7.86 | | | |
| Text-RAG | Llama 3.1 70B-Ins | 12.22 | 27.5 | 12.14 | 13.57 | 13.57 | 13.57 | 12.86 | | |
| Llama 3.1 405B-Ins | 12.96 | 26.67 | 15.00 | 13.57 | 12.86 | 14.29 | 13.57 | | | |
| Llama 3.1 8B-Ins | 14.81 | 32.50 | 29.29 | 29.28 | 27.86 | 25.71 | 29.29 | | | |
| Graph-RAG | Llama 3.1 70B-Ins | 17.04 | 32.92 | 39.29 | 40.71 | 43.57 | 34.29 | 40.00 | | |
| Llama 3.1 405B-Ins | 18.15 | 31.67 | 37.14 | 42.86 | 40.00 | 36.43 | 41.43 | | | |
| Graph CoT | | Llama 3.1 8B-Ins | 18.15 | 32.5 | 20.71 | 19.28 | 25.00 | 14.29 | 21.43 | |
| Agent | Llama 3.1 70B-Ins | 32.59 | 43.75 | 50.00 | 51.43 | 50.00 | 48.57 | 46.43 | | |
| Llama 3.1 405B-Ins | 28.89 | 48.33 | 38.57 | 38.57 | 47.86 | 56.43 | 34.29 | | | |
| Graph Explore | Llama 3.1 8B-Ins | 22.22 | 36.67 | 35.00 | 30.71 | 29.29 | 29.29 | 32.86 | | |
| Llama 3.1 70B-Ins | 27.78 | 32.92 | 45.71 | 49.29 | 40.00 | 40.00 | 44.29 | | | |
| Llama 3.1 405B-Ins | 28.89 | 48.33 | 38.57 | 38.57 | 47.86 | 56.43 | 34.29 | | | |
| Graph ToT | Agent | Score | Llama 3.1 8B-Ins | 30.49 | 55.14 | 43.33 | 41.67 | 44.05 | 36.43 | 39.52 |
| Llama 3.1 70B-Ins | 30.49 | 54.48 | 65.48 | 62.14 | 55.95 | 63.57 | 56.19 | | | |
| Llama 3.1 405B-Ins | 45.55 | 56.53 | 71.67 | 65.71 | 52.62 | 68.81 | 44.76 | | | |
| Select | Llama 3.1 8B-Ins | 30.00 | 54.17 | 40.71 | 37.14 | 40.00 | 32.86 | 36.43 | | |
| Llama 3.1 70B-Ins | 39.63 | 56.67 | 65.00 | 67.14 | 62.86 | 60.71 | 55.55 | | | |
| Llama 3.1 405B-Ins | 44.07 | 58.75 | 71.43 | 69.29 | 65.00 | 68.81 | 60.00 | | | |
| Graph Explore | Score | Llama 3.1 8B-Ins | 21.48 | 41.10 | 32.86 | 31.67 | 31.43 | 32.14 | 35.24 | |
| Llama 3.1 70B-Ins | 24.94 | 40.97 | 52.38 | 57.86 | 49.29 | 54.29 | 47.86 | | | |
| Llama 3.1 405B-Ins | 30.86 | 48.33 | 47.86 | 57.14 | 50.71 | 56.67 | 47.14 | | | |
| Select | Llama 3.1 8B-Ins | 21.85 | 41.67 | 32.86 | 31.67 | 31.43 | 32.14 | 35.24 | | |
| Llama 3.1 70B-Ins | 30.37 | 42.08 | 54.29 | 57.14 | 47.86 | 52.14 | 46.43 | | | |
| Llama 3.1 405B-Ins | 31.48 | 48.75 | 45.00 | 57.86 | 48.86 | 57.14 | 45.71 | | | |
Table 4: GPT4Score performance results on GRBench graphCoT, comparing standard LLMs, Text-RAG, Graph-RAG, Graph-CoT, and Graph-ToT. Experiments are described in Section 5, using LLama 3.1 - Instruct backbone models with sizes 8B, 70B, and 405B.
| Method | Model | Healthcare | Biology | |
| --- | --- | --- | --- | --- |
| Agent | Score | Llama 3.1 8B-Ins | 29.88 | 32.86 |
| Llama 3.1 70B-Ins | 29.51 | 61.69 | | |
| Llama 3.1 405B-Ins | 41.81 | 48.33 | | |
| Select | Llama 3.1 8B-Ins | 30.00 | 40.71 | |
| Llama 3.1 70B-Ins | 39.63 | 69.83 | | |
| Llama 3.1 405B-Ins | 44.81 | 72.86 | | |
| Graph Explore | Score | Llama 3.1 8B-Ins | 22.72 | 21.19 |
| Llama 3.1 70B-Ins | 24.20 | 48.57 | | |
| Llama 3.1 405B-Ins | 32.22 | 41.67 | | |
| Select | Llama 3.1 8B-Ins | 22.59 | 19.28 | |
| Llama 3.1 70B-Ins | 32.96 | 52.86 | | |
| Llama 3.1 405B-Ins | 31.48 | 57.86 | | |
Figure 13: Graph-GoT results (GPT4Score) on GRBench with Llama 3.1 Instruct sizes 8B, 70B, and 405B.
<details>
<summary>figures/radar_levels.png Details</summary>
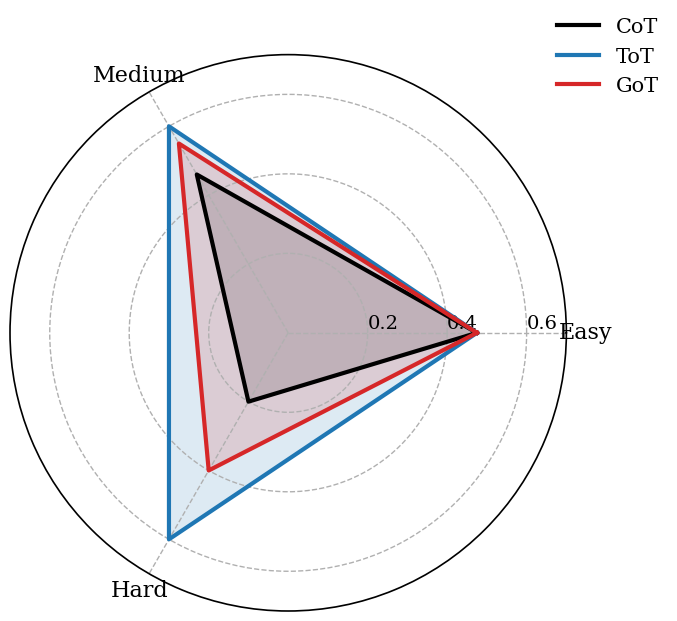
### Visual Description
## Radar Chart: Performance Comparison of CoT, ToT, and GoT
### Overview
The image is a radar chart comparing the performance of three methods: CoT (Chain of Thought), ToT (Tree of Thoughts), and GoT (Graph of Thoughts) across three difficulty levels: Easy, Medium, and Hard. The chart visualizes the relative performance of each method on each difficulty level, with higher values indicating better performance.
### Components/Axes
* **Chart Type:** Radar Chart (also known as a spider chart or star chart)
* **Axes:** Three axes radiating from the center, representing the difficulty levels: Easy, Medium, and Hard.
* **Scale:** The radial scale ranges from 0 to 0.6, with concentric dashed circles indicating values of 0.2, 0.4, and 0.6.
* **Legend:** Located in the top-right corner:
* Black line: CoT
* Blue line: ToT
* Red line: GoT
### Detailed Analysis
* **CoT (Chain of Thought):** (Black Line)
* Easy: Approximately 0.4
* Medium: Approximately 0.45
* Hard: Approximately 0.3
* **ToT (Tree of Thoughts):** (Blue Line)
* Easy: Approximately 0.4
* Medium: Approximately 0.5
* Hard: Approximately 0.5
* **GoT (Graph of Thoughts):** (Red Line)
* Easy: Approximately 0.4
* Medium: Approximately 0.4
* Hard: Approximately 0.35
### Key Observations
* ToT (Tree of Thoughts) consistently outperforms CoT (Chain of Thought) and GoT (Graph of Thoughts) on Medium and Hard difficulty levels.
* All three methods have similar performance on Easy difficulty.
* The performance of CoT and GoT decreases as the difficulty increases, while ToT maintains a relatively high performance even on Hard difficulty.
### Interpretation
The radar chart suggests that Tree of Thoughts (ToT) is a more robust method for handling complex problems compared to Chain of Thought (CoT) and Graph of Thoughts (GoT). While all three methods perform similarly on easy tasks, ToT's performance remains high even as the difficulty increases, indicating its ability to explore and evaluate multiple solution paths effectively. The decline in performance of CoT and GoT on harder tasks suggests that these methods may struggle with the increased complexity and branching possibilities of more challenging problems. The chart highlights the potential benefits of using a tree-based approach for problem-solving, especially in scenarios where the solution space is large and complex.
</details>
Figure 14: Results decomposed into easy/medium/hard questions according to GPT4Score.
Appendix E Computational Analysis
<details>
<summary>figures/computational_analysis.png Details</summary>
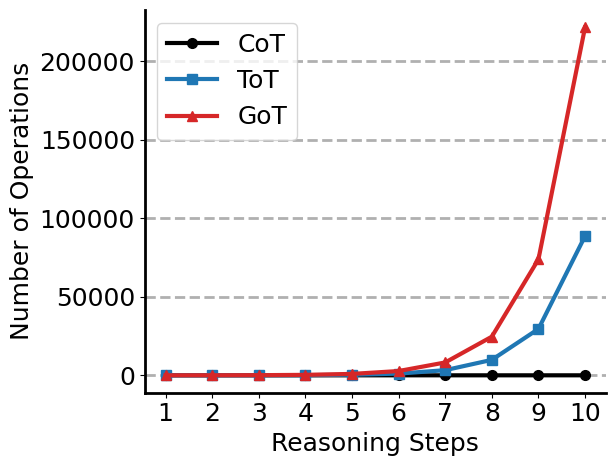
### Visual Description
## Line Chart: Number of Operations vs. Reasoning Steps for CoT, ToT, and GoT
### Overview
The image is a line chart comparing the number of operations required by three different methods (CoT, ToT, and GoT) across 10 reasoning steps. The x-axis represents the number of reasoning steps, and the y-axis represents the number of operations. The chart shows how the number of operations changes with an increasing number of reasoning steps for each method.
### Components/Axes
* **X-axis:** Reasoning Steps, labeled from 1 to 10 in increments of 1.
* **Y-axis:** Number of Operations, ranging from 0 to 200000, with gridlines at intervals of 50000.
* **Legend (Top-Left):**
* Black line with circle marker: CoT
* Blue line with square marker: ToT
* Red line with triangle marker: GoT
### Detailed Analysis
* **CoT (Black Line):** The number of operations remains relatively constant at approximately 1000, with minor fluctuations, across all 10 reasoning steps.
* Step 1: ~1000
* Step 10: ~1000
* **ToT (Blue Line):** The number of operations remains low for the first 7 reasoning steps, then increases significantly from step 8 to step 10.
* Step 1: ~1000
* Step 7: ~1000
* Step 8: ~5000
* Step 9: ~30000
* Step 10: ~90000
* **GoT (Red Line):** The number of operations remains low for the first 7 reasoning steps, then increases exponentially from step 8 to step 10.
* Step 1: ~1000
* Step 7: ~2000
* Step 8: ~10000
* Step 9: ~50000
* Step 10: ~220000
### Key Observations
* CoT maintains a consistent number of operations regardless of the number of reasoning steps.
* ToT and GoT exhibit a similar trend, with a sharp increase in the number of operations after step 7.
* GoT requires significantly more operations than ToT as the number of reasoning steps increases beyond 7.
### Interpretation
The chart suggests that CoT is more efficient in terms of the number of operations required, as it remains constant regardless of the number of reasoning steps. ToT and GoT, on the other hand, become increasingly computationally expensive as the number of reasoning steps increases, with GoT showing a much steeper increase than ToT. This implies that for tasks requiring a large number of reasoning steps, CoT might be a more suitable choice due to its lower computational cost. The sharp increase in operations for ToT and GoT after step 7 could indicate a threshold where the complexity of these methods starts to significantly impact their performance.
</details>
Figure 15: Comparison of computational costs across different reasoning strategies — CoT, ToT, GoT — as a function of reasoning steps. GoT exhibits the highest cost due to merge operations and graph traversal.
| | Method | Key Parameters | Approx. # LLM Calls | Approx. # KG Operations | Primary Growth Driver(s) |
| --- | --- | --- | --- | --- | --- |
| CoT | Agent | $n$ | $\mathcal{O}(n)$ | $\mathcal{O}(n)$ | $n$ (linear) |
| Graph Explore | $n$ , $d$ | $\mathcal{O}(n)$ | $\mathcal{O}(n·\text{Cost}_{\text{Explore}}(d))$ | $n$ , $d$ | |
| ToT | Agent | $D_{\text{max}}$ , $k$ , $t$ | $\mathcal{O}\left(k·\frac{t^{D_{\text{max}}}-1}{t-1}\right)$ | Same as LLM Calls | $D_{\text{max}}$ , $k$ , $t$ (exponential in $D_{\text{max}}$ ) |
| Graph Explore | $D_{\text{max}}$ , $k$ , $t$ , $d$ | $\mathcal{O}\left(k·\frac{t^{D_{\text{max}}}-1}{t-1}\right)$ | $\mathcal{O}\left(k·\frac{t^{D_{\text{max}}}-1}{t-1}·\text{Cost}_{\text{Explore}}(d)\right)$ | $D_{\text{max}}$ , $k$ , $t$ , $d$ | |
| GoT | Agent | $D_{\text{max}}$ , $k$ , $t$ | . $\mathcal{O}\left(k·\frac{t^{D_{\text{max}}}-1}{t-1}+\sum_{i=1}^{D_{\text{max}}}\left\lfloor\frac{k· t^{i}}{2}\right\rfloor\right)$ | Same as LLM Calls | $D_{\text{max}}$ , $k$ , $t$ (aggregation adds extra cost) |
| Graph Explore | $D_{\text{max}}$ , $k$ , $t$ , $d$ | Same as Agent | $\mathcal{O}\left(\text{LLM Calls}·\text{Cost}_{\text{Explore}}(d)\right)$ | $D_{\text{max}}$ , $k$ , $t$ , $d$ | |
Table 5: Theoretical computational complexity comparison of reasoning methods. Parameters: $n$ (reasoning steps), $D_{\text{max}}$ (tree depth), $k$ (branching factor), $t$ (paths retained), $d$ (KG search depth), and $\text{Cost}_{\text{Explore}}(d)$ (cost per KG search). GoT includes pairwise aggregation of thoughts at each depth.
The computational analysis summarized in Table 5 highlights the trade-offs between reasoning power and computational cost when grounding LLMs with Knowledge Graphs (KGs). The Agent -based methods scale linearly with the number of reasoning steps or tree nodes, with CoT representing the lowest cost baseline. In contrast, Automatic Graph Exploration methods introduce additional overhead via entity extraction, multi-hop traversal up to a fixed max_depth, and LLM-based pruning at each step.
Among reasoning strategies, ToT introduces exponential growth in cost with respect to depth due to its exploration of $k$ branches and selection of $t$ continuations per level. GoT further amplifies this by incorporating aggregation transformations that attempt to merge every pair of thoughts at each depth, leading to an additional cost proportional to $\sum_{i=1}^{D_{\text{max}}}\left\lfloor\frac{k· t^{i}}{2}\right\rfloor$ .
Importantly, our experiments reveal that the higher complexity of GoT does not consistently translate to improved accuracy compared to ToT, suggesting diminishing returns. While the model size (e.g., 8B, 70B, 405B) influences the latency and memory footprint of each LLM call, it does not affect the algorithmic complexity classes shown. Hence, selecting a strategy requires balancing reasoning depth with feasible compute budgets.
Appendix F Prompts Archive
In this section, we gather the necessary prompts essential for implementing the proposed methodologies.
Agent
Agent Step: Solve a question answering task with interleaving Thought, Interaction with Graph, Feedback from Graph steps. In Thought step, you can think about what further information is needed, and In Interaction step, you can get feedback from graphs with four functions: (1) RetrieveNode[keyword], which retrieves the related node from the graph according to the corresponding query. (2) NodeFeature[Node, feature], which returns the detailed attribute information of Node regarding the given "feature" key. (3) NodeDegree[Node, neighbor_type], which calculates the number of "neighbor_type" neighbors of the node Node in the graph. (4) NeighbourCheck[Node, neighbor_type], which lists the "neighbor_type" neighbours of the node Node in the graph and returns them. You may take as many steps as necessary. Here are some examples: {examples} Please answer by providing node main feature (e.g., names) rather than node IDs. Generate the next step. Definition of the graph: {graph_definition} Question: {question} {scratchpad}
Automatic Graph Exploration
Search Thought: Given the previous thoughts, generate the next thought to answer the provided question. Your end goal is to answer the question step by step. For context, you are also provided with some knowledge triples from a knowledge base. Follow the format of the examples to generate the next thought. {examples} Graph Definition: {graph_definition} Question: {question} Knowledge Triples: {triples} Previous thoughts: {thoughts} Related Entity Attributes: {attributes} Next Thought: Search End?: Your are provided with the an original question, the associated subquestion thoughts and their corresponding knowledge graph triples (head_entity -> relation -> tail_entity). Your task is to answer whether it’s sufficient for you to answer the original question (Yes or No). You are provided with examples. You should follow the same format as in the examples, writing ’Yes’ or ’No’ within brackets at the beginning of the answer. (Examples) Task: Question: {question} Thoughts: {thoughts} Knowledge Triples: {triples} Entity Attributes: {attributes} Answer: Entity Extraction: Given the provided text, extract the relevant entities that may appear in a knowledge base. Return the answer at the end with brackets relevant entities as shown in the following examples. If there are several entities, separate them with commas. (Examples) Task: Text: {text} Relevant Entities: Prune Relations: From the given entity and relations, select only the relevant relations to answer the question. Provide the answer at the end with bracketsanswer , as shown in the following example. (Examples) Question: {question} Head Entity: {entity} Relations: {relations} Answer: Prune entities: You are provided with a question, a head entity, a relation and tail entity or entities from a knowledge base. Select the tail entity or entities to answer the question. Return the tail entity or entities at the end with brackets relevant entity or entities, as shown in the following examples. (Examples) Question: {question} Head Entity: {head_entity} Relation: {relation} Tail Entities: {tail_entities} Relevant Entities: Search Attributes: Is any of the attributes relevant to answer the question? Return the answer at the end with brackets answer , as shown in the following examples. (Examples) Question: {question} Entity: {entity} Attributes: {attributes} Relevant Attributes:
State Evaluators
Selection Vote: Given a question, you need to select the possible chain of thought that may lead to the correct answer with higher probablity. You are provided with several choices with thouhgts and related triples from a knowledge base. Decide which choice is most promising to complete the task. Analyze each choice in detail, then conclude in the last line: "The best choice is s" , where s the integer id of the choice. (Examples) Question: {question} Choices: {choices} (+ attributes/triples) Answer: Score Vote: Generate a score for the given reasoning chain. The score represents the probability that the chain will lead to the correct answer. The chains contain interleaved thoughts and related triples from a knowledge base. Some chains may not be complete, but you need to judge the steps that are provided. The score can be any floating number between 0 and 1. (Examples) Question: {question} Thought Chain: {thoughts} (+ attributes/triples) Score:
Graph of Thoughts
Graph of Thought Merge: Generate the next thought for the merged chain of thoughts. You are provided with the question, two chains of thoughts, and the corresponding merged chain of thought. Identify inconsistencies or errors from the previous chains and provide the next thought for the merged chain. You should follow the same format as in the examples. (Examples) Question: {question} Chain 1: {chain_1} (+triples/attributes) Chain 2: {chain_2} (+triples/attributes) Merged Chain: {merged_chain} Next Thought:
Appendix G Examples
| Example 1: Multi-step Reasoning over Graph | Example 2: Direct Triple Lookup |
| --- | --- |
| Question: What anatomy can be expressed by gene KRT39? Ground Truth Answer: head, skin of body Model Answer: head, skin of body
Thought 1: The question is related to a gene node (KRT39). We need to find this node in the graph. Action 1: RetrieveNode[KRT39] Observation 1: The ID of the node is 390792. Thought 2: We need to check the ’Anatomy-expresses-Gene’ neighbors of this gene node. Action 2: NeighbourCheck[390792, Anatomy-expresses-Gene] Observation 2: The neighbors are [’UBERON:0000033’, ’UBERON:0002097’]. Thought 3: Retrieve names of the anatomy nodes. Action 3: NodeFeature[UBERON:0000033, name], NodeFeature[UBERON:0002097, name] Observation 3: UBERON:0000033 $→$ head, UBERON:0002097 $→$ skin of body. Thought 4: These are the anatomy terms expressed by the gene. Action 4: Finish[head, skin of body] | Question: What anatomy can be expressed by gene KRT39? Ground Truth Answer: head, skin of body Model Answer: head, skin of body
Thought 1: KRT39 is a gene that is known to be expressed in two anatomical regions. Found Triples: •
"KRT39" --> Anatomy-expresses-Gene --> head •
"KRT39" --> Anatomy-expresses-Gene --> skin of body Action: Finish[head, skin of body] |
Table 6: Comparison of two LLM-generated reasoning traces for the same question using different strategies: multi-step graph traversal (Example 1) vs. direct triple lookup (Example 2).