# RAG-Gym: Systematic Optimization of Language Agents for Retrieval-Augmented Generation
**Authors**: Guangzhi Xiong, Qiao Jin, Xiao Wang, Yin Fang, Haolin Liu, Yifan Yang, Fangyuan Chen, Zhixing Song, Dengyu Wang, Minjia Zhang, Zhiyong Lu, Aidong Zhang
> University of Virginia
> National Institutes of Health
> University of Illinois at Urbana Champaign
> Dana-Farber Cancer Institute
> University of Alabama at Birmingham
> Yale School of Medicine
Abstract
Retrieval-augmented generation (RAG) has shown great promise for knowledge-intensive tasks and recently advanced with agentic RAG, where language agents engage in multi-round interactions with external knowledge sources for adaptive information retrieval. However, existing agentic RAG methods often depend on ad-hoc prompt engineering and lack a unified optimization framework. We introduce RAG-Gym, a comprehensive platform that systematically explores three optimization dimensions: (1) prompt engineering, (2) actor tuning, and (3) critic training. For prompt engineering, we propose Re 2 Search, a novel agent incorporating reasoning reflection that significantly outperforms standard prompts. In actor tuning, we evaluate three popular post-training algorithms with fine-grained process supervision and identify direct preference optimization as the most effective. We further demonstrate that a trained critic can enhance inference by selecting higher-quality intermediate reasoning steps. Together, these findings lead to the optimized Re 2 Search++ agent, which surpasses most recent methods like Search-R1 by a relative increase of 3.2% to 11.6% in average F1. Finally, we examine the impact of different reward sources and analyze scaling properties in training and inference, offering practical insights for agentic RAG optimization. The project homepage is available at https://rag-gym.github.io/. footnotetext: Equal contribution. † Co-correspondence.
1 Introduction
Large language models (LLMs) often struggle with knowledge-intensive questions when lacking sufficient or up-to-date domain knowledge, leading to inaccurate responses or hallucinations [97, 59, 28]. Retrieval-augmented generation (RAG) addresses this by grounding outputs in relevant information from information retrieval (IR) systems, improving both accuracy and verifiability of answers [42, 18]. Agentic pipelines such as ReAct [91] enhances conventional RAG by allowing LLMs to actively generate search queries and interact with IR systems in multiple rounds, which has been shown to be more effective in solving complex tasks that need multi-hop reasoning [91, 4, 65]. However, most existing agentic RAG methods focus on prompt engineering [73, 4, 31, 54], which demands substantial manual effort and often fails to generalize across tasks [40, 70, 2].
Meanwhile, although various LLM post-training algorithms have been developed to enhance downstream performance, they are not directly suited for agentic RAG, where the model must dynamically adjust its token-generation strategy in response to newly retrieved context during the reasoning process. Recent works have adapted reinforcement learning with outcome-based rewards for agentic RAG [69, 33, 8]. However, by overlooking process-level supervision, these approaches risk generating suboptimal intermediate search actions and exhibit limited generalization on unseen data. Given that the retrieval steps fundamentally shape the reasoning trajectory and ultimately influence the final answer, providing fine-grained supervision over these intermediate steps is essential for optimizing agentic RAG. Nevertheless, systematic analyses on how to optimize the language agent and identify best practices for enhancing overall agentic RAG performance are still lacking.
In this work, we present RAG-Gym, a systematic framework that enhances agentic RAG along three dimensions: prompt engineering, actor tuning, and critic training. We review and compare the functional components of existing agentic RAG pipelines (see Table 1) and introduce a novel agent design Re 2 Search that leverages reasoning reflection to improve performance. Our comprehensive experiments across three widely used LLM post-training algorithms reveal that fine-grained, process-level supervision substantially boosts performance, particularly when both positive and negative feedback are integrated. Furthermore, we show that training a critic to evaluate intermediate steps yields additional gains across diverse LLMs. By integrating these insights, our optimized Re 2 Search++ agent achieves superior performance than existing methods on challenging knowledge-intensive tasks (+ 3.2% $\sim$ 11.6% in average F1), especially on unseen datasets (+ 8.5% $\sim$ 24.7%). We also discuss reward sources as well as the training and inference scaling properties of agentic RAG, providing practical guidelines for future optimization. Our key contributions are summarized as follows:
- We introduce RAG-Gym, a comprehensive framework that integrates advanced prompt engineering, actor tuning, and critic training to enhance agentic RAG.
- Our extensive experiments uncover best practices across these dimensions and lead to the development of the optimized agent Re 2 Search++, which consistently outperforms existing methods on challenging knowledge-intensive tasks.
- We provide a detailed analysis of reward sources as well as training and inference scaling properties, offering actionable insights for future advancements in agentic RAG.
2 RAG-Gym Framework
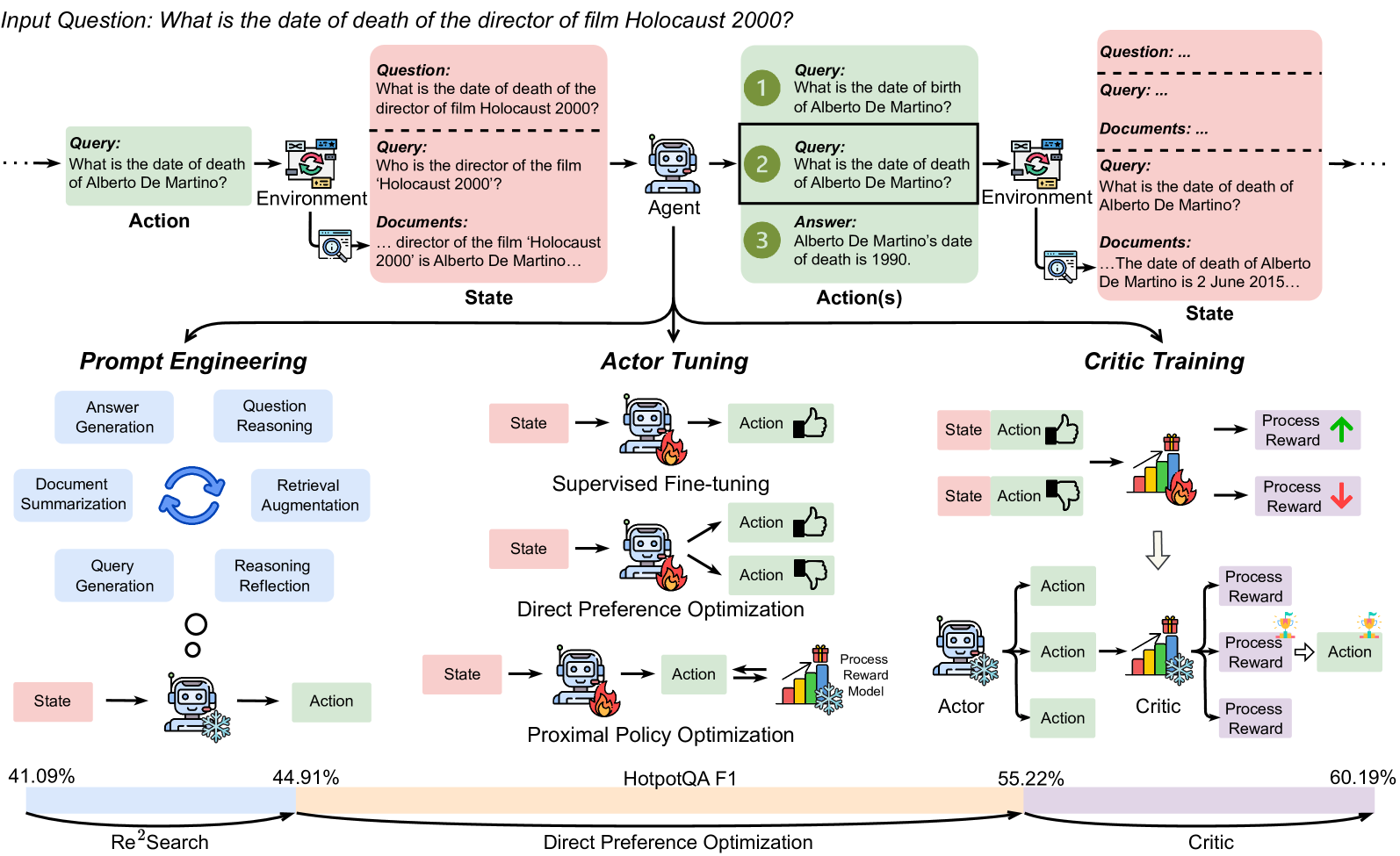
To facilitate fine-grained process-level supervision and systematic evaluation of optimization methods for agentic RAG, we introduce the RAG-Gym framework. RAG-Gym formulates knowledge-intensive question answering as a high-level MDP with well-defined intermediate actions, and provides a modular approach for optimizing language agents across three key components. An overview of RAG-Gym is presented in Figure 1.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Model Training Pipeline
### Overview
The image illustrates a model training pipeline, comparing three different approaches: Prompt Engineering, Actor Tuning, and Critic Training. The pipeline starts with an input question and progresses through different stages involving an environment, agent, and actions. The diagram highlights the flow of information and processes involved in each training approach, along with performance metrics at the bottom.
### Components/Axes
* **Title:** Input Question: What is the date of death of the director of film Holocaust 2000?
* **Sections:** The diagram is divided into three main sections: Prompt Engineering, Actor Tuning, and Critic Training.
* **Elements:** Each section contains elements such as "State" (pink boxes), "Action" (green boxes), "Environment" (light green boxes), "Agent" (robot icon), "Critic" (trophy icon), and "Process Reward" (arrows).
* **Metrics:** At the bottom, there is a horizontal bar representing "HotpotQA F1" with percentage values.
* **Flow:** Arrows indicate the flow of information and processes.
### Detailed Analysis
**1. Input Question and Initial Setup (Top)**
* The process begins with an "Input Question: What is the date of death of the director of film Holocaust 2000?".
* The question is processed through an "Environment" which involves a "Query: What is the date of death of Alberto De Martino?" and "Documents: ... director of the film 'Holocaust 2000' is Alberto De Martino...". This leads to a "State".
* An "Agent" receives the question and generates "Action(s)". The agent processes the "Query: What is the date of birth of Alberto De Martino?", "Query: What is the date of death of Alberto De Martino?", and provides an "Answer: Alberto De Martino's date of death is 1990."
* The right side shows a similar process with a slightly different "Environment" and "Documents: ... The date of death of Alberto De Martino is 2 June 2015...".
**2. Prompt Engineering (Left)**
* This section focuses on refining the input prompts.
* It includes processes like "Answer Generation", "Question Reasoning", "Document Summarization", "Retrieval Augmentation", "Query Generation", and "Reasoning Reflection".
* The flow involves a "State" leading to an "Action".
* The "HotpotQA F1" score for "Re²Search" is 41.09% to 44.91%.
**3. Actor Tuning (Middle)**
* This section focuses on tuning the "Actor" (the agent).
* It includes "Supervised Fine-tuning" and "Direct Preference Optimization" using "Proximal Policy Optimization".
* The flow involves a "State" leading to an "Action", with feedback mechanisms (thumbs up/down).
* The "HotpotQA F1" score for "Direct Preference Optimization" starts at 44.91% and extends to 55.22%.
**4. Critic Training (Right)**
* This section focuses on training a "Critic" to evaluate the "Actor's" actions.
* The flow involves a "State" leading to an "Action", which is evaluated by the "Critic". The "Critic" provides "Process Reward" feedback.
* The "HotpotQA F1" score for "Critic" starts at 55.22% and extends to 60.19%.
### Key Observations
* The diagram illustrates a comparative analysis of three different training approaches.
* The "Critic Training" approach appears to yield the highest "HotpotQA F1" score (60.19%).
* The diagram highlights the iterative nature of the training process, with feedback loops and refinement at each stage.
### Interpretation
The diagram demonstrates a model training pipeline where different strategies are employed to improve the model's performance in answering complex questions. The "Critic Training" approach, which involves training a separate model to evaluate the agent's actions, seems to be the most effective, as indicated by the highest "HotpotQA F1" score. This suggests that providing explicit feedback on the quality of the agent's responses can significantly enhance its performance. The diagram also underscores the importance of prompt engineering and actor tuning as crucial steps in optimizing the model's ability to understand and answer complex questions.
</details>
Figure 1: Overview of the RAG-Gym framework. RAG-Gym employs a modular design, comprising prompt engineering, actor tuning, and critic training, to systematically optimize agentic RAG performance. By leveraging all three components, RAG-Gym improves the F1 score of the ReAct agent on HotpotQA from 41.09% to 60.19%.
2.1 Knowledge-intensive Question Answering as Markov Decision Process
While sequential token generation in LLMs can be modeled as an MDP [43, 49, 93], the integration of interactions with the IR environment introduces complex and inconsistent state transitions across agent architectures. To address this, we propose a hierarchical MDP formulation in RAG-Gym that unifies diverse agentic RAG designs. At the high level, agentic RAG is represented as a sequence of reasoning steps that interact with an IR system, while at the low level, each action involves sequential token generation by LLMs. Below, we formally define the components of the high-level MDP.
States. For the agentic RAG process of a given question $\mathcal{Q}$ , we define the state $s_{t}$ at time step $t$ to be a set consisting of the original question $\mathcal{Q}$ and the information-seeking history $\mathcal{H}_{t}$ . The information-seeking history is a sequence of search queries $q_{1},·s,q_{t-1}$ and their corresponding sets of retrieved documents $D_{1},·s,D_{t-1}$ , and is used to augment the agent’s knowledge for answering the original question. The initial state is defined as $s_{1}=(\mathcal{Q},\mathcal{H}_{1})$ , where $\mathcal{H}_{1}$ is an empty set.
Actions. Although agents may employ various strategies to reason about the current state and generate different token sequences, RAG-Gym standardizes these outputs by defining a common macro-action space. At each time step $t$ , the action $a_{t}$ is either a search query or a predicted answer to the original question. While the detailed generated token sequences may differ among agent designs, they must always be semantically equivalent to a designated macro-action within the context of agentic RAG.
Environment. The high-level MDP environment in RAG-Gym is powered by an IR system, which is central to the agentic RAG approach. At each time step $t$ , if the agent’s action $a_{t}$ is a search query $q_{t}$ , the IR system returns a corresponding set of documents $D_{t}$ . The state is then updated from $s_{t}=(\mathcal{Q},\mathcal{H}_{t})$ to $s_{t+1}=(\mathcal{Q},\,\mathcal{H}_{t}\cup\{(q_{t},D_{t})\})$ . Conversely, if $a_{t}$ predicts an answer to $\mathcal{Q}$ , the episode terminates. To maintain stable and reproducible state transitions, the configuration of the IR system (e.g., the number of returned documents) remains constant throughout.
Rewards. For the high-level MDP, the immediate reward for a state-action pair $(s_{t},a_{t})$ is defined as zero when $a_{t}$ is a search query, and as the correctness of the predicted answer when $a_{t}$ is an answer. Moreover, by formulating knowledge-intensive QA as a high-level MDP, we can directly assess the quality of intermediate actions, with process-level rewards derived from various sources (e.g., human annotations, LLM evaluations, or rollouts). This enables both the evaluation of intermediate actions and the fine-grained supervision of language agents through process-level feedback.
2.2 Systematic Optimization of Agentic Retrieval-augmented Generation
With the high-level MDP formulation, RAG-Gym optimizes the agentic RAG system through three key components: (1) prompt engineering, which refines the language agent’s structure and operational design; (2) actor tuning, which adjusts the LLM parameters to improve decision-making; and (3) critic training, which develops an external verifier to assess the quality of generated macro-actions.
2.2.1 Prompt Engineering
The first aspect of optimizing agentic RAG is crafting effective prompts that guide the language model in generating the appropriate actions. The system prompt defines the agent’s functional capabilities when processing a given state. RAG-Gym summarizes the essential functions into six distinct categories:
- Answer generation: The agent produces a final answer to the question.
- Question reasoning: The agent outlines reasoning steps before providing the answer.
- Retrieval augmentation: The agent incorporates retrieved content to enhance its answer.
- Query generation: The agent formulates queries to search for relevant documents.
- Document summarization: The agent condenses retrieved content to extract key information.
- Reasoning reflection: The agent reviews its reasoning to identify any unverified claims.
While the first five components have already been employed in existing agent architectures, the final component reasoning reflection is a novel addition by RAG-Gym. Inspired by recent advancements in reasoning models in which the models can reflect on their own reasoning process for self-correction [19], the newly introduced reasoning reflection directs the agent to scrutinize its reasoning process and identify claims that are unsupported by the information seeking history, thereby linking search query generation to answer reasoning to produce more precise and relevant queries.
Combining reasoning reflection with other existing components, we propose a new agent architecture called Re 2 Search, which stands for Re asoning, Re flection, and Search. A Re 2 Search agent first reasons about all available information to construct an answer to the original question. It then reflects on its reasoning process to identify unverified claims that lack sufficient justification based on available evidence. These unverified claims form the basis for generating the next search query that is designed to retrieve the missing information required for constructing the answer. Table 1 summarizes the presence or absence of these components in several existing agent architectures, including Direct, CoT [81], RAG [42], ReAct [91], Search-o1 [44], and our proposed Re 2 Search, each enabling different LLM capabilities through prompting.
Table 1: A comparative overview of agent architectures based on their functional components.
| Component | Direct | CoT [81] | RAG [42] | ReAct [91] | Search-o1 [44] | Re 2 Search |
| --- | --- | --- | --- | --- | --- | --- |
| Answer Generation | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Question Reasoning | ✗ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Retrieval Augmentation | ✗ | ✗ | ✔ | ✔ | ✔ | ✔ |
| Query Generation | ✗ | ✗ | ✗ | ✔ | ✔ | ✔ |
| Document Summarization | ✗ | ✗ | ✗ | ✗ | ✔ | ✔ |
| Reasoning Reflection | ✗ | ✗ | ✗ | ✗ | ✗ | ✔ |
2.2.2 Actor Tuning
The second aspect of optimizing agentic RAG is tuning LLM parameters to directly enhance reasoning capability. Decomposing knowledge-intensive QA into intermediate steps, the high-level MDP in RAG-Gym enables the targeted optimization of language agents by focusing on the generated action at each step, reducing the task to standard text generation. This streamlines the training process and facilitates the application of various LLM post-training algorithms to enhance agent performance.
Process Reward Data Collection. As discussed in our high-level MDP definition, the process reward for intermediate actions can be derived from multiple sources, including human annotations, LLM evaluations, or rollouts. In our implementation, we focus on collecting process reward data using advanced LLMs such as GPT-4o [1]. Specifically, we sample trajectories from an untuned agent and obtain process reward annotations from GPT-4o, while filtering out trajectories that do not result in a correct final answer using the outcome reward. This strategy enables us to efficiently gather high-quality process reward data, which is subsequently used to optimize the LLMs for agentic RAG. Further details on alternative process reward sources can be found in Section 4.1, with additional information about the data collection pipeline provided in Appendix E.
Process-based Training Algorithms.
Let $\mathfrak{D}$ denote the process reward dataset, which consists of tuples $(s,a^{+},a^{-})$ , where $s$ is a state, $a^{+}$ is a preferred (high-quality) action, and $a^{-}$ is a less-preferred (lower-quality) action. Each action is annotated based on the quality of the generated query or predicted answer. We assign the preference label to the entire token sequence produced when reasoning about the state, thereby reducing process-based actor tuning to a standard text generation problem. RAG-Gym implements and compares three widely used LLM post-training algorithms:
- Supervised fine-tuning (SFT) [52]: This method uses high-quality intermediate actions to train language agents by maximizing the log-likelihood of preferred actions ( $a^{+}$ ) conditioned on their respective states $s$ .
- Direct preference optimization (DPO) [56]: This approach employs a contrastive learning framework that utilizes both preferred ( $a^{+}$ ) and unpreferred ( $a^{-}$ ) actions. The DPO objective encourages the agent to increase the likelihood of preferred actions while decreasing that of unpreferred actions.
- Proximal policy optimization (PPO) [60]: This is an online reinforcement learning algorithm for policy optimization. The collected data $\mathfrak{D}$ is first used to train a process reward model $r_{\phi}(s,a)$ . PPO then optimizes the agent to maximize the process reward of newly generated actions, while constraining policy updates to ensure stability.
2.2.3 Critic Training
The third aspect of optimizing agentic RAG involves training a critic, denoted as $r_{\phi}$ , to act as an external evaluator of generated actions. The critic is designed to predict process rewards for a given state-action pair $(s,a)$ . Its training objective employs a contrastive loss that distinguishes preferred actions from less-preferred ones, following the preference modeling approach widely used in LLM alignment and reward modeling [47, 52]:
$$
\mathcal{L}_{\text{critic}}(\phi)=-\mathbb{E}_{(s,a^{+},a^{-})\sim%
\mathfrak{D}}\Big{[}\log\sigma\big{(}r_{\phi}(s,a^{+})-r_{\phi}(s,a^{-})\big{)%
}\Big{]}, \tag{1}
$$
where $\sigma$ is the sigmoid function and $\mathfrak{D}$ denotes the process reward dataset containing both preferred ( $a^{+}$ ) and less-preferred ( $a^{-}$ ) actions.
While process reward modeling has been studied in the context of math reasoning [62, 46], its application to agentic RAG for knowledge-intensive question answering remains largely underexplored. In RAG-Gym, our process-level critic is tailored to evaluate intermediate actions such as search queries, rather than only final answers. This approach enables more fine-grained and actionable feedback, facilitating the optimization of agentic RAG systems through process-level supervision. Once trained, the critic provides targeted feedback on generated actions, guiding the language agent to make decisions that are more likely to lead to successful outcomes.
3 Main Results
3.1 Experimental Settings
To assess the performance of various agents on knowledge-intensive QA tasks and evaluate the benefits of different optimization methods in RAG-Gym, we consider four datasets that are both knowledge- and reasoning-intensive, spanning general and medical domains. Specifically, we use HotpotQA [90], 2WikiMultihopQA [21], and Bamboogle [54], which are popular multi-hop QA datasets constructed from Wikipedia, as well as the MedQA dataset [34], which consists of medical exam questions that require specialized domain knowledge and complex reasoning. Following prior work [61], HotpotQA, 2WikiMultihopQA, and Bamboogle are evaluated using Exact Match (EM) and F1 scores, while the multi-choice MedQA dataset is assessed with accuracy (Acc). We also compute the average EM and F1 scores across different tasks, treating accuracy as equivalent to both metrics in the multi-choice evaluation setting. For actor and critic training in RAG-Gym, 1k questions were sampled from the HotpotQA and MedQA training sets for process reward data collection. To test the generalizability of the tuned agents, 2WikiMultihopQA and Bamboogle were evaluated using LLMs trained on HotpotQA. More implementation details can be found in Appendices C, E, H.
3.2 Performance Improvements by Prompt Engineering and Actor Tuning
Table 2 presents a performance comparison of various agents and their tuned versions using different actor tuning algorithms in RAG-Gym. The results indicate that the Re 2 Search agent consistently outperforms other agents in both zero-shot and actor-tuned settings. Furthermore, when comparing Table 2 with Table 1, which details the functional components of each agent, it can be observed that more components generally leads to improved performance. This observation validates the effectiveness of the summarized functions in RAG-Gym, as well as the design of the Re 2 Search agent, which incorporates all identified components, including our newly proposed reasoning reflection. Additional case studies of our proposed Re 2 Search agent are provided in Appendices G.1 and G.2.
Table 2: Agent performance with Llama-3.1-8B backbone. Highest scores are bolded.
| Method | Agent | HotpotQA | 2Wiki | Bamboogle | MedQA | Average | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| EM | F1 | EM | F1 | EM | F1 | Acc | EM | F1 | | |
| Zero-shot Learning | Direct | 21.10 | 27.93 | 24.10 | 27.68 | 9.60 | 14.89 | 61.82 | 29.16 | 33.08 |
| CoT | 27.10 | 35.17 | 25.70 | 30.08 | 37.60 | 49.50 | 69.60 | 40.00 | 46.09 | |
| RAG | 38.30 | 48.57 | 32.00 | 36.91 | 22.40 | 33.73 | 66.85 | 39.89 | 46.51 | |
| ReAct | 30.70 | 41.09 | 28.90 | 35.03 | 32.00 | 41.35 | 62.37 | 38.49 | 44.96 | |
| Search-o1 | 35.30 | 47.33 | 34.00 | 41.29 | 44.80 | 52.50 | 66.14 | 45.06 | 51.82 | |
| Re 2 Search | 34.00 | 44.91 | 41.50 | 49.06 | 44.80 | 55.33 | 70.31 | 47.65 | 54.90 | |
| RAG-Gym Supervised Fine-tuning | Direct | 22.80 | 31.67 | 28.00 | 33.17 | 20.00 | 27.21 | 63.63 | 33.61 | 38.92 |
| CoT | 26.50 | 35.60 | 27.30 | 32.10 | 42.40 | 53.89 | 69.68 | 41.47 | 47.82 | |
| RAG | 41.50 | 52.26 | 38.00 | 42.74 | 28.80 | 40.76 | 67.79 | 44.02 | 50.89 | |
| ReAct | 35.50 | 46.06 | 31.00 | 36.79 | 34.40 | 44.17 | 66.69 | 41.90 | 48.43 | |
| Search-o1 | 38.20 | 50.02 | 39.00 | 45.91 | 46.40 | 57.18 | 67.64 | 47.81 | 55.19 | |
| Re 2 Search | 37.60 | 49.16 | 44.00 | 50.54 | 44.80 | 56.78 | 69.52 | 48.98 | 56.50 | |
| RAG-Gym Direct Preference Optimization | Direct | 20.80 | 28.79 | 25.20 | 29.45 | 12.00 | 20.67 | 62.37 | 30.09 | 35.32 |
| CoT | 26.30 | 35.06 | 28.20 | 32.84 | 40.80 | 51.67 | 71.33 | 41.66 | 47.73 | |
| RAG | 38.00 | 49.38 | 37.60 | 42.88 | 28.80 | 39.57 | 67.79 | 43.05 | 49.91 | |
| ReAct | 33.00 | 43.96 | 32.20 | 39.24 | 44.80 | 54.35 | 68.89 | 44.72 | 51.61 | |
| Search-o1 | 42.20 | 54.34 | 44.10 | 52.66 | 42.40 | 55.59 | 70.23 | 49.73 | 58.21 | |
| Re 2 Search | 42.20 | 55.22 | 44.30 | 51.36 | 48.00 | 56.57 | 72.11 | 51.65 | 58.82 | |
| RAG-Gym Proximal Policy Optimization | Direct | 19.20 | 26.17 | 25.60 | 28.84 | 7.20 | 12.17 | 61.12 | 28.28 | 32.08 |
| CoT | 25.50 | 33.68 | 24.20 | 29.02 | 43.20 | 52.54 | 68.50 | 40.35 | 45.94 | |
| RAG | 37.70 | 47.60 | 32.00 | 36.29 | 28.80 | 40.24 | 68.03 | 41.63 | 41.44 | |
| ReAct | 35.80 | 47.56 | 33.20 | 40.06 | 36.80 | 46.79 | 67.32 | 43.28 | 50.43 | |
| Search-o1 | 38.30 | 50.24 | 32.60 | 39.34 | 50.40 | 59.92 | 70.15 | 47.86 | 54.91 | |
| Re 2 Search | 38.40 | 50.30 | 41.40 | 48.06 | 49.60 | 62.06 | 71.72 | 50.28 | 58.04 | |
By comparing different process supervision approaches for actor tuning, we observe that process supervision consistently enhances agent performance relative to the zero-shot learning (ZSL) baseline. This improvement underscores the critical role of process supervision in refining agentic RAG. Notably, for Direct, CoT, and RAG agents, where tuning focuses solely on answer generation, SFT slightly outperforms both DPO and PPO. In contrast, for ReAct, Search-o1, and Re 2 Search agents, where the tuning process also involves generating high-quality queries, DPO and PPO surpass SFT, with DPO demonstrating a slight edge over PPO on most tasks. These findings highlight the importance of utilizing both positive and negative samples during training, especially for agents that require complex, multi-step reasoning with environmental feedback. Furthermore, the tuned agents tend to generate more search queries during inference, as elaborated in Appendix F.
3.3 Performance Improvements by Critic Training
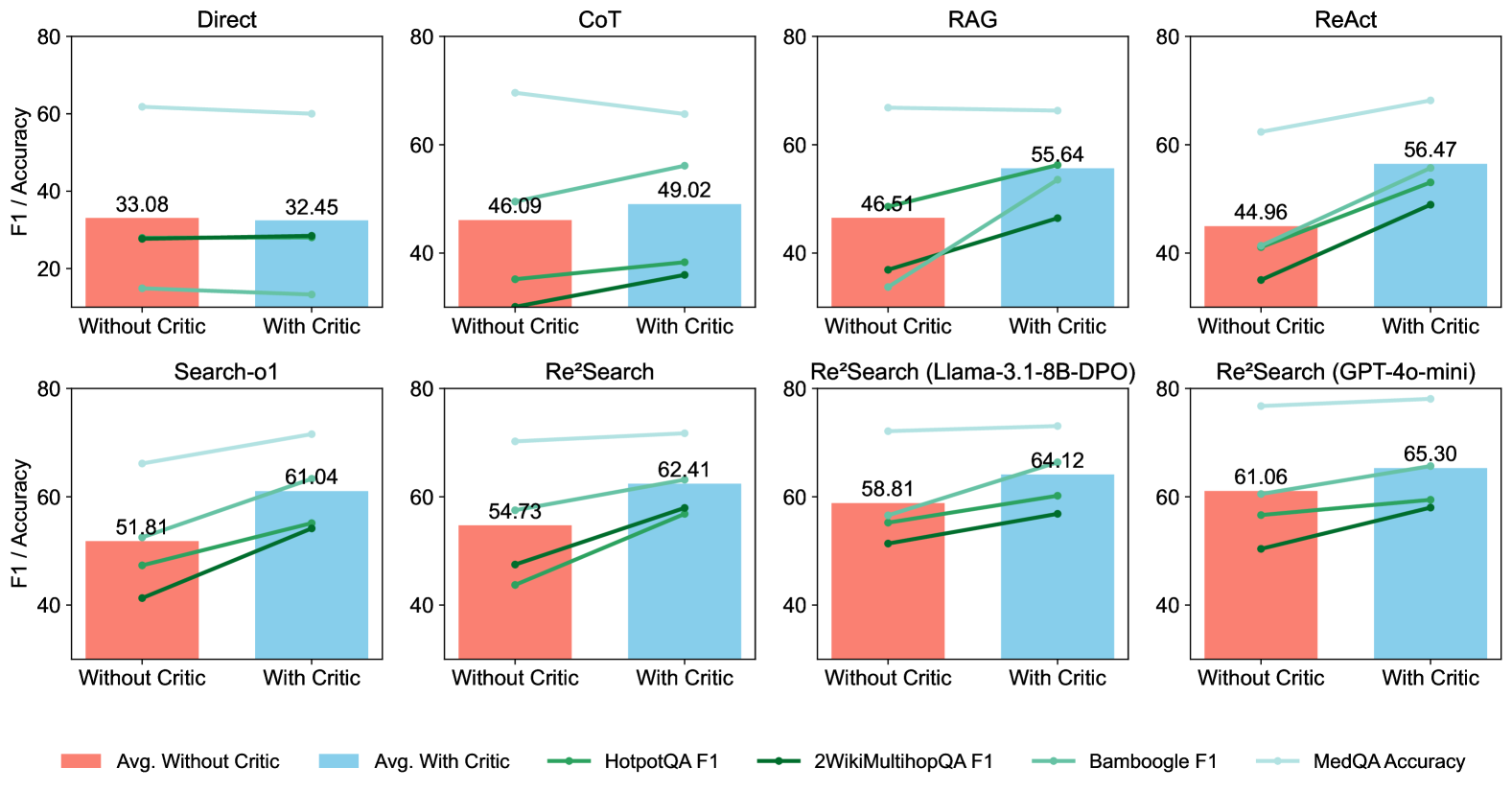
Figure 2 illustrates the performance improvements achieved through critic training. The label “With Critic” indicates that an external critic evaluates 10 sampled actions at each step to select the best one. In our experiments, all agents except for “Direct” consistently benefit from critic training. Moreover, these performance gains transfer to actors using different LLMs. As shown in the figure, not only does the original Llama-3.1-8B benefit from the trained critic, but both the DPO-tuned Llama-3.1-8B and GPT-4o-mini also experience significant improvements across all datasets using the same critic. This highlights the potential of employing trained critics as a plug-and-play module to enhance agentic RAG performance, particularly for proprietary LLMs where direct fine-tuning is not feasible. A case study of using trained critics during inference is provided in Appendix G.3.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Bar and Line Chart: Performance Comparison with and without Critic
### Overview
The image presents a series of bar and line charts comparing the performance of different models or methods ("Direct", "CoT", "RAG", "ReAct", "Search-o1", "Re²Search", "Re²Search (Llama-3.1-8B-DPO)", "Re²Search (GPT-4o-mini)") with and without a "Critic" component. The charts display F1 scores and accuracy metrics for various datasets (HotpotQA, 2WikiMultihopQA, Bamboogle, MedQA). The x-axis indicates "Without Critic" and "With Critic", while the y-axis represents "F1 / Accuracy".
### Components/Axes
* **Titles:** Each chart has a title indicating the model or method being evaluated (e.g., "Direct", "CoT", "RAG", "ReAct", "Search-o1", "Re²Search", "Re²Search (Llama-3.1-8B-DPO)", "Re²Search (GPT-4o-mini)").
* **X-axis:** Categorical axis with two categories: "Without Critic" and "With Critic".
* **Y-axis:** Numerical axis labeled "F1 / Accuracy", ranging from 0 to 80.
* **Bars:** Represent the average F1/Accuracy "Without Critic" (coral color) and "With Critic" (light blue color).
* **Lines:** Represent F1/Accuracy scores for different datasets:
* HotpotQA F1 (green)
* 2WikiMultihopQA F1 (dark green)
* Bamboogle F1 (light green)
* MedQA Accuracy (light blue)
* **Legend:** Located at the bottom of the image, associating colors with data series:
* Coral: Avg. Without Critic
* Light Blue: Avg. With Critic
* Green: HotpotQA F1
* Dark Green: 2WikiMultihopQA F1
* Light Green: Bamboogle F1
* Light Blue: MedQA Accuracy
### Detailed Analysis
**Chart 1: Direct**
* Avg. Without Critic: 33.08
* Avg. With Critic: 32.45
* HotpotQA F1: 27.5 to 27.5 (approximately equal)
* Bamboogle F1: 61.5 to 59.5 (approximately equal)
**Chart 2: CoT**
* Avg. Without Critic: 46.09
* Avg. With Critic: 49.02
* HotpotQA F1: 35 to 37
* 2WikiMultihopQA F1: 30 to 32
* Bamboogle F1: 69 to 66
**Chart 3: RAG**
* Avg. Without Critic: 46.51
* Avg. With Critic: 55.64
* HotpotQA F1: 40 to 48
* 2WikiMultihopQA F1: 27 to 50
* Bamboogle F1: 67 to 67 (approximately equal)
**Chart 4: ReAct**
* Avg. Without Critic: 44.96
* Avg. With Critic: 56.47
* HotpotQA F1: 39 to 50
* 2WikiMultihopQA F1: 42 to 52
* Bamboogle F1: 63 to 65
**Chart 5: Search-o1**
* Avg. Without Critic: 51.81
* Avg. With Critic: 61.04
* HotpotQA F1: 41 to 54
* 2WikiMultihopQA F1: 47 to 55
* Bamboogle F1: 67 to 70
**Chart 6: Re²Search**
* Avg. Without Critic: 54.73
* Avg. With Critic: 62.41
* HotpotQA F1: 46 to 58
* 2WikiMultihopQA F1: 48 to 59
* Bamboogle F1: 70 to 72
**Chart 7: Re²Search (Llama-3.1-8B-DPO)**
* Avg. Without Critic: 58.81
* Avg. With Critic: 64.12
* HotpotQA F1: 52 to 59
* 2WikiMultihopQA F1: 54 to 60
* Bamboogle F1: 72 to 74
**Chart 8: Re²Search (GPT-4o-mini)**
* Avg. Without Critic: 61.06
* Avg. With Critic: 65.30
* HotpotQA F1: 56 to 59
* 2WikiMultihopQA F1: 57 to 60
* Bamboogle F1: 74 to 76
### Key Observations
* In most cases, the "With Critic" configuration results in a higher average F1/Accuracy compared to "Without Critic". The "Direct" method is an exception, where the "With Critic" performance is slightly lower.
* The Bamboogle F1 score is consistently higher than the HotpotQA and 2WikiMultihopQA F1 scores across all models/methods.
* The Re²Search methods (especially with Llama-3.1-8B-DPO and GPT-4o-mini) generally achieve higher average F1/Accuracy scores compared to the other methods.
### Interpretation
The data suggests that incorporating a "Critic" component generally improves the performance of the models/methods evaluated, as indicated by the higher average F1/Accuracy scores in most cases. The "Direct" method is a notable exception, suggesting that the "Critic" component may not be beneficial or may even hinder performance in certain architectures. The consistently high Bamboogle F1 scores indicate that these models/methods perform well on the Bamboogle dataset. The Re²Search methods, particularly those using Llama-3.1-8B-DPO and GPT-4o-mini, appear to be the most effective overall, suggesting that the Re²Search approach combined with these language models yields superior results.
</details>
Figure 2: Performance improvements across various agents with critics.
3.4 Comparisons with Outcome Supervision Methods
Combining the findings from previous sections, we introduce Re 2 Search++, an optimized agent that integrates the best choices from each optimization direction. Built on Re 2 Search and tuned with DPO while utilizing a trained critic for action selection, Re 2 Search++ is evaluated against recent methods such as Search-R1 [33] and R1-Searcher [69], which rely on outcome supervision via reinforcement learning (RL) with over 8k training questions. As these methods primarily focus on general-domain questions, we exclude MedQA from this evaluation for a fair comparison. Table 3 shows that Re 2 Search++ achieves performance comparable to that of the RL-tuned agents on the datasets used for their training (HotpotQA for Search-R1; HotpotQA and 2WikiMultihopQA for R1-Searcher), while significantly outperforming them on unseen datasets and achieving the best performance on average. This result underscores the overfitting issues of RL-based outcome supervision methods and highlights the robustness and generalizability of Re 2 Search++ through its fine-grained process supervision on intermediate steps.
Table 3: Comparison of Re 2 Search++ and other methods. Shading indicates in-domain model performance. CEM represents the “Cover Exact Match” used in [69].
| LLM | Method | HotpotQA | 2WikiMultihopQA | Bamboogle | Average | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| EM | CEM | F1 | EM | CEM | F1 | EM | CEM | F1 | EM | CEM | F1 | | |
| Llama -3.1-8B | ReAct | 30.70 | 38.40 | 41.09 | 28.90 | 38.00 | 35.03 | 32.00 | 36.80 | 41.35 | 30.57 | 37.73 | 39.16 |
| Search-o1 | 35.30 | 43.80 | 47.33 | 34.00 | 45.80 | 41.29 | 44.80 | 48.80 | 52.50 | 38.03 | 46.13 | 47.04 | |
| R1-Searcher | 44.90 | 50.40 | 56.88 | 48.70 | 51.30 | 54.24 | 38.40 | 40.80 | 53.21 | 44.00 | 47.50 | 54.78 | |
| Re 2 Search++ | 46.50 | 57.80 | 60.19 | 48.90 | 60.50 | 56.85 | 55.20 | 63.20 | 66.37 | 50.20 | 60.50 | 61.14 | |
| Qwen -2.5-7B | ReAct | 36.00 | 40.10 | 45.84 | 38.60 | 44.50 | 45.02 | 35.20 | 38.40 | 44.94 | 36.60 | 41.00 | 45.27 |
| Search-o1 | 40.70 | 46.60 | 52.15 | 38.90 | 46.20 | 45.79 | 40.80 | 44.80 | 52.91 | 40.17 | 45.87 | 50.28 | |
| Search-R1 | 44.90 | 49.40 | 57.30 | 43.90 | 47.80 | 50.07 | 40.80 | 41.60 | 51.69 | 43.20 | 46.27 | 53.02 | |
| R1-Searcher | 46.80 | 53.70 | 59.61 | 48.80 | 55.00 | 55.36 | 44.80 | 48.00 | 54.01 | 46.80 | 52.23 | 56.33 | |
| Re 2 Search++ | 44.40 | 50.30 | 56.47 | 47.00 | 56.50 | 54.35 | 52.94 | 56.30 | 63.51 | 48.11 | 54.37 | 58.11 | |
4 Analysis and Discussion
4.1 Comparison of Different Reward Sources
As discussed in Section 2, the process reward can be collected from different sources. This section focuses on the evaluation of the effectiveness of these sources in guiding the agent’s action selection toward correct answers, as well as their alignment with human preferences, which are often considered to have the highest quality for process annotation [98]. Specifically, we compare the GPT-4o annotations with Llama-3.1-8B, as well as the rollout-based annotations using Math-Shepherd [77]. We collect process annotations from human experts on MedQA to examine the alignment between the trained reward models and human preferences.
Table 4: Comparison of various reward sources. ORM/PRM denotes the outcome/process reward model. Outcome sources are labeled for PRMs due to the trajectory filtering in RAG-Gym.
| Type | Outcome Source | Process Source | HotpotQA (EM / F1) | 2Wiki (EM / F1) | Bamboogle (EM / F1) | MedQA (Acc / Agree) |
| --- | --- | --- | --- | --- | --- | --- |
| ORM | Truth | – | 41.10 / 53.35 | 47.70 / 55.59 | 43.20 / 57.46 | 66.77 / – |
| PRM (Random) | – | – | 32.20 / 42.83 | 35.70 / 42.00 | 38.40 / 47.86 | 68.26 / 50.00 |
| PRM (Rollout) | Truth | Rollout | 39.60 / 51.85 | 42.94 / 49.57 | 48.80 / 56.05 | 68.34 / 71.03 |
| PRM (Llama) | Truth | Llama-3.1-8B | 40.30 / 51.74 | 40.70 / 48.22 | 44.80 / 54.36 | 68.50 / 65.99 |
| PRM (GPT) | Truth | GPT-4o | 44.10 / 56.84 | 50.20 / 57.94 | 51.20 / 63.15 | 71.96 / 85.85 |
The results are shown in Table 4. The reward model trained with GPT-4o annotations delivers the highest performance across all datasets, effectively providing accurate, fine-grained process rewards for agent optimization. Moreover, it exhibits the best alignment with human preferences, achieving an agreement rate of 85.85% with human annotators. In contrast, although rollouts and Llama-3.1-8B annotations improve action selection relative to a process reward model with random selections, they are generally less effective than GPT-4o annotations and sometimes even bring inferior outcomes on general-domain questions. This result underscores the limitations of current rollout-based methods, originally designed for math reasoning, in the context of complex reasoning and search tasks, and highlights the need for tailored approaches in agentic RAG.
4.2 Training Time Scaling
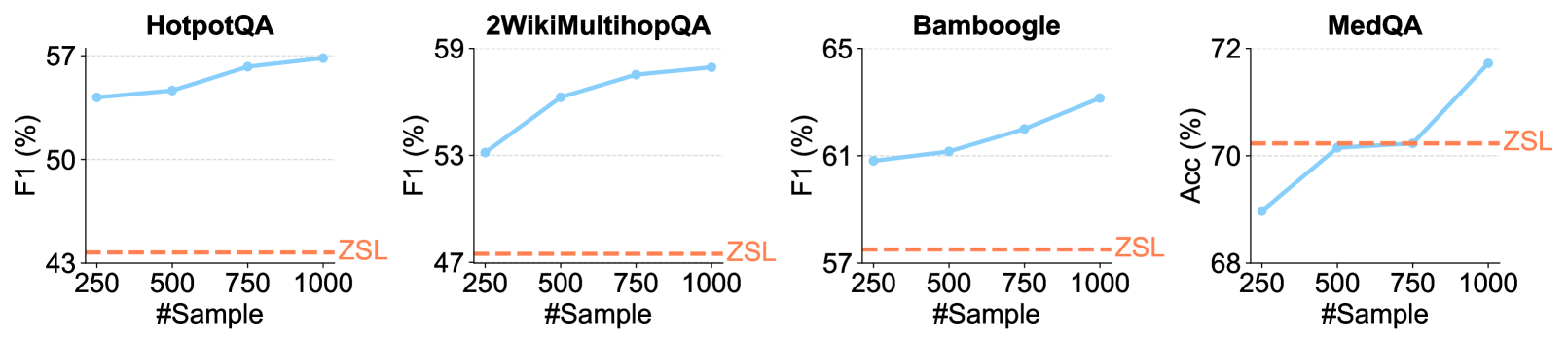
For the evaluation of training sample size and its impacts on the performance of Re 2 Search agents, we conducted experiments using critics trained on varying numbers of instances, ranging from 250 to 1000 questions. The results, presented in Figure 3, show how the agent’s performance scales with the availability of more training data across four datasets. In general, the performance of Re 2 Search improves with an increasing number of training samples, but the gains tend to converge as the sample size grows. Notably, there is a sharp improvement in F1 scores on HotpotQA, 2WikiMultihopQA, and Bamboogle when comparing the ZSL baseline to process reward models trained on 250 samples, showing that even a small amount of process reward data can yield significant performance gains. However, the improvements become less pronounced on HotpotQA and 2WikiMultihopQA when increasing the training samples from 500 to 1000, indicating diminishing returns as the model approaches a saturation point in its learning from additional data.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Charts: Performance Comparison on Different Datasets
### Overview
The image contains four line charts, each displaying the performance of a model on a different question-answering dataset. The x-axis represents the number of samples used for training, and the y-axis represents the performance metric (F1 score or Accuracy). A horizontal dashed line indicates the Zero-Shot Learning (ZSL) performance for each dataset.
### Components/Axes
* **Titles (Top of each chart):**
* HotpotQA
* 2WikiMultihopQA
* Bamboogle
* MedQA
* **X-axis (Shared for all charts):**
* Label: "#Sample"
* Values: 250, 500, 750, 1000
* **Y-axis:**
* **HotpotQA:**
* Label: "F1 (%)"
* Values: 43, 50, 57
* **2WikiMultihopQA:**
* Label: "F1 (%)"
* Values: 47, 53, 59
* **Bamboogle:**
* Label: "F1 (%)"
* Values: 57, 61, 65
* **MedQA:**
* Label: "Acc (%)"
* Values: 68, 70, 72
* **Data Series:**
* Blue Line: Performance with increasing number of samples.
* Orange Dashed Line: ZSL (Zero-Shot Learning) performance.
### Detailed Analysis
**1. HotpotQA**
* Y-axis: F1 (%)
* Trend: The blue line shows an upward trend, indicating improved performance with more samples.
* Data Points:
* 250 Samples: F1 ≈ 55%
* 500 Samples: F1 ≈ 56%
* 750 Samples: F1 ≈ 57%
* 1000 Samples: F1 ≈ 57%
* ZSL: The orange dashed line is at F1 ≈ 43%.
**2. 2WikiMultihopQA**
* Y-axis: F1 (%)
* Trend: The blue line shows an upward trend, indicating improved performance with more samples.
* Data Points:
* 250 Samples: F1 ≈ 53%
* 500 Samples: F1 ≈ 56%
* 750 Samples: F1 ≈ 58%
* 1000 Samples: F1 ≈ 58.5%
* ZSL: The orange dashed line is at F1 ≈ 47%.
**3. Bamboogle**
* Y-axis: F1 (%)
* Trend: The blue line shows an upward trend, indicating improved performance with more samples.
* Data Points:
* 250 Samples: F1 ≈ 61%
* 500 Samples: F1 ≈ 62%
* 750 Samples: F1 ≈ 63%
* 1000 Samples: F1 ≈ 64%
* ZSL: The orange dashed line is at F1 ≈ 57%.
**4. MedQA**
* Y-axis: Acc (%)
* Trend: The blue line shows a significant upward trend, indicating improved performance with more samples.
* Data Points:
* 250 Samples: Acc ≈ 69%
* 500 Samples: Acc ≈ 70.5%
* 750 Samples: Acc ≈ 71%
* 1000 Samples: Acc ≈ 72%
* ZSL: The orange dashed line is at Acc ≈ 70.5%.
### Key Observations
* For all datasets, increasing the number of samples generally improves performance (F1 score or Accuracy).
* The MedQA dataset shows the most significant performance increase with more samples.
* The ZSL performance varies across datasets.
* For MedQA, the performance with 500 samples is already at the ZSL level.
### Interpretation
The charts demonstrate the impact of increasing training data size on the performance of a model across different question-answering datasets. The upward trends in the blue lines suggest that the model benefits from more data. The ZSL performance provides a baseline for comparison, showing how well the model performs without any training on the specific dataset. The MedQA dataset's rapid performance increase suggests that the model can quickly adapt to this dataset with relatively few samples. The fact that the performance on MedQA surpasses the ZSL baseline with only 500 samples indicates that even a small amount of training data can significantly improve performance compared to a zero-shot approach.
</details>
Figure 3: Performance of Re 2 Search agents with critics trained on different numbers of samples.
For MedQA, which involves complex reasoning and information-seeking tasks requiring domain-specific knowledge, a different trend is observed. With only 250 training samples, the performance slightly drops below the ZSL baseline, highlighting the challenges of capturing intricate domain-specific processes with limited training data. As the sample size increases, however, the performance gradually recovers and eventually surpasses the ZSL baseline, achieving the highest accuracy of 71.72% with 1000 samples. This underscores the importance of sufficient training data in capturing the nuanced reasoning and query-generation processes required for specialized tasks.
4.3 Inference Time Scaling
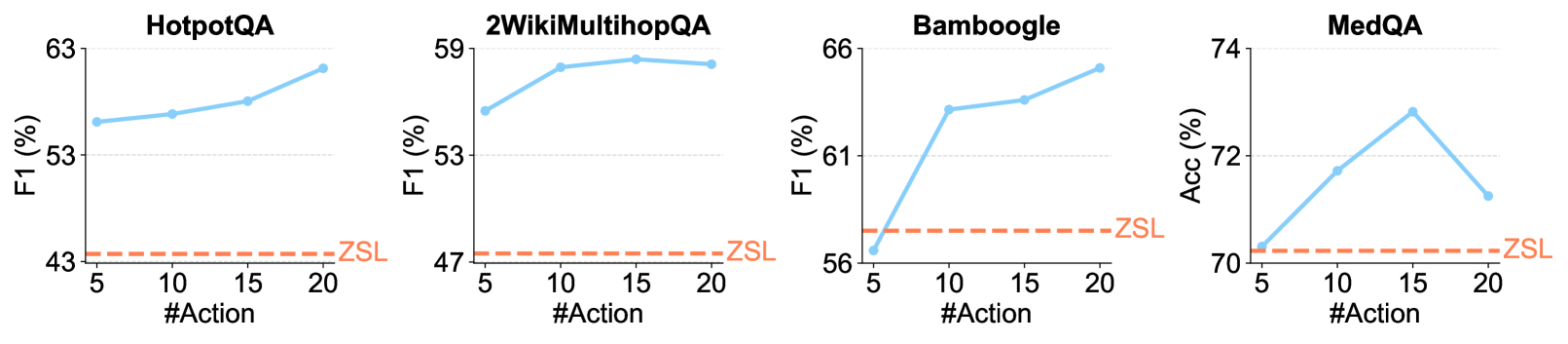
Since trained critics optimize action-taking by identifying high-quality actions from the generated candidates during inference, we explored how the agent performance changes with the increasing number of sampled actions at each time step. Figure 4 displays the results of our inference time scaling study, with Re 2 Search as the tested agent. We observe a consistent trend across multiple benchmarks, where increasing the number of sampled actions generally improves performance. Specifically, for HotpotQA and Bamboogle, the F1 score continues to rise as more actions are sampled, demonstrating the benefits of expanding the candidate set to enable better action selection at each step. However, performance gains gradually diminish, indicating that the agent reaches a point where additional sampled actions contribute less to improvement. This suggests that while action sampling is beneficial, there is a limit to how much additional sampling enhances decision-making.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Charts: Performance Comparison Across Datasets
### Overview
The image contains four line charts, each displaying the performance of a model on a different question-answering dataset. The x-axis represents the number of actions, and the y-axis represents the F1 score (for HotpotQA, 2WikiMultihopQA, and Bamboogle) or Accuracy (for MedQA). A horizontal dashed line indicates the Zero-Shot Learning (ZSL) baseline performance for each dataset.
### Components/Axes
* **Titles (Top of each chart):**
* HotpotQA
* 2WikiMultihopQA
* Bamboogle
* MedQA
* **X-Axis:**
* Label: "#Action"
* Values: 5, 10, 15, 20
* **Y-Axis:**
* Label (Charts 1-3): "F1 (%)"
* Scale: Varies for each chart.
* HotpotQA: 43 to 63
* 2WikiMultihopQA: 47 to 59
* Bamboogle: 56 to 66
* Label (Chart 4): "Acc (%)"
* Scale: 70 to 74
* **Data Series:**
* Blue Line: Model Performance
* Orange Dashed Line: ZSL (Zero-Shot Learning) Baseline
* **Legend:** The label "ZSL" is placed near the right end of each orange dashed line.
### Detailed Analysis
**1. HotpotQA**
* Y-Axis Range: 53 to 63
* Blue Line Trend: Upward sloping
* (#Action = 5): F1 ≈ 57%
* (#Action = 10): F1 ≈ 58%
* (#Action = 15): F1 ≈ 60%
* (#Action = 20): F1 ≈ 62.5%
* ZSL Baseline: F1 ≈ 43% (horizontal dashed orange line)
**2. 2WikiMultihopQA**
* Y-Axis Range: 53 to 59
* Blue Line Trend: Increases then plateaus
* (#Action = 5): F1 ≈ 55%
* (#Action = 10): F1 ≈ 58%
* (#Action = 15): F1 ≈ 58.8%
* (#Action = 20): F1 ≈ 58.5%
* ZSL Baseline: F1 ≈ 47% (horizontal dashed orange line)
**3. Bamboogle**
* Y-Axis Range: 61 to 66
* Blue Line Trend: Upward sloping
* (#Action = 5): F1 ≈ 56.2%
* (#Action = 10): F1 ≈ 63%
* (#Action = 15): F1 ≈ 64%
* (#Action = 20): F1 ≈ 65%
* ZSL Baseline: F1 ≈ 56.5% (horizontal dashed orange line)
**4. MedQA**
* Y-Axis Range: 70 to 74
* Blue Line Trend: Increases then decreases (peak at #Action = 10)
* (#Action = 5): Accuracy ≈ 71%
* (#Action = 10): Accuracy ≈ 73%
* (#Action = 15): Accuracy ≈ 72%
* (#Action = 20): Accuracy ≈ 71%
* ZSL Baseline: Accuracy ≈ 70.2% (horizontal dashed orange line)
### Key Observations
* The model's performance (blue line) generally improves with an increasing number of actions for HotpotQA and Bamboogle.
* For 2WikiMultihopQA, the performance plateaus after 10 actions.
* For MedQA, the performance peaks at 10 actions and then declines.
* In all datasets, the model's performance is better than the ZSL baseline.
### Interpretation
The charts demonstrate the impact of the number of actions on the model's performance across different question-answering datasets. The upward trends in HotpotQA and Bamboogle suggest that increasing the number of actions can lead to better performance on these datasets. However, the plateau in 2WikiMultihopQA and the peak-and-decline pattern in MedQA indicate that there may be a point of diminishing returns or even a negative impact from increasing the number of actions beyond a certain threshold for these datasets. The fact that the model consistently outperforms the ZSL baseline suggests that the model is learning and generalizing effectively. The MedQA dataset shows a unique trend, suggesting that too many actions may lead to overfitting or confusion.
</details>
Figure 4: Performance of Re 2 Search agents with different numbers of actions sampled per step.
5 Related Work
5.1 Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm for enhancing large language models (LLMs) on knowledge-intensive tasks. A typical RAG framework comprises two core components: a retriever, which selects relevant documents from a large corpus, and a generator, which synthesizes information from these documents to produce coherent and contextually appropriate responses [42, 18, 9]. RAG has demonstrated strong performance across diverse domains, including open-domain question answering [37, 25, 7, 88, 63], fact-checking [78, 66], and summarization [3]. Subsequent research has focused on improving both the retriever’s ability to select relevant documents [95, 51, 89, 30, 32] and the generator’s capacity to effectively utilize retrieved information [15, 82, 80], thereby boosting overall system performance [26, 96, 36, 94]. Nevertheless, most RAG pipelines still rely on a single retrieval step, which can be inadequate for complex queries that require synthesizing information from multiple sources.
5.2 Multi-hop Question Answering
Multi-hop question answering (QA) tasks require systems to synthesize information from multiple, diverse sources to produce accurate answers [90, 21]. These tasks highlight the limitations of conventional RAG architectures, where a single retrieval step often fails to capture the comprehensive context needed for complex queries. To address this, language agents such as ReAct [91, 73, 4, 31, 54] have been proposed, interleaving reasoning and retrieval to dynamically accumulate relevant evidence [57, 79, 38, 61], which has shown promise in improving LLM performance [76, 64, 92, 27, 29]. However, most of these methods still rely heavily on prompt engineering, which can be fragile and may not effectively optimize language agents for knowledge-intensive tasks [40, 70, 2]. Recent studies have explored reinforcement learning (RL) to optimize language agents for multi-hop QA [69, 33, 8, 17, 55], but these approaches risk generating suboptimal intermediate search actions and show limited generalization to unseen data, as demonstrated in our experiments. Other concurrent work investigates process-level supervision [22, 12, 45, 71], but typically focuses on specific agent architectures and a narrow set of supervision methods, offering limited insight into the systematic optimization of language agents.
5.3 Post-training of Large Language Models
Beyond the foundational knowledge acquired during pre-training, post-training methods are essential for refining Large Language Models (LLMs) and aligning them with specific downstream tasks and desired behaviors. Supervised Fine-Tuning (SFT) adapts models using curated instruction-response pairs to promote task-specific capabilities [52, 10]. While SFT enhances instruction-following, further alignment with nuanced human preferences is often achieved through Reinforcement Learning from Human Feedback (RLHF) [52, 6, 5], typically implemented via Proximal Policy Optimization (PPO) [60]. More recently, critic-free approaches such as Direct Preference Optimization (DPO) have emerged as streamlined alternatives [56, 50, 14, 87], directly optimizing the LLM policy based on reward annotations and bypassing the need for a separately trained reward model. Although these techniques bring strong gains on text generation benchmarks, their integration into agentic RAG pipelines, where models must dynamically interact with retrieval systems and adapt reasoning strategies to evolving contexts, remains underexplored.
6 Conclusion
This work presents RAG-Gym as a unified and extensible framework for systematically optimizing agentic RAG along the axes of prompt engineering, actor tuning, and critic training. Through extensive empirical analysis, we demonstrate that integrating reasoning reflection, process-level direct preference optimization, and critic-guided inference yields substantial improvements over existing approaches. We hope RAG-Gym will serve as a foundation for further advances in robust, adaptive, and interpretable retrieval-augmented language agents.
References
- Achiam et al. [2023] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Akinwande et al. [2023] Victor Akinwande, Yiding Jiang, Dylan Sam, and J Zico Kolter. Understanding prompt engineering may not require rethinking generalization. arXiv preprint arXiv:2310.03957, 2023.
- An et al. [2021] Chenxin An, Ming Zhong, Zhichao Geng, Jianqiang Yang, and Xipeng Qiu. Retrievalsum: A retrieval enhanced framework for abstractive summarization. arXiv preprint arXiv:2109.07943, 2021.
- Asai et al. [2024] Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=hSyW5go0v8.
- Askell et al. [2021] Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861, 2021.
- Bai et al. [2022] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- Borgeaud et al. [2022] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pages 2206–2240. PMLR, 2022.
- Chen et al. [2025] Mingyang Chen, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Jeff Z Pan, Wen Zhang, Huajun Chen, Fan Yang, et al. Research: Learning to reason with search for llms via reinforcement learning. arXiv preprint arXiv:2503.19470, 2025.
- Cheng et al. [2025] Mingyue Cheng, Yucong Luo, Jie Ouyang, Qi Liu, Huijie Liu, Li Li, Shuo Yu, Bohou Zhang, Jiawei Cao, Jie Ma, et al. A survey on knowledge-oriented retrieval-augmented generation. arXiv preprint arXiv:2503.10677, 2025.
- Chung et al. [2024] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53, 2024.
- Cormack et al. [2009] Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval, pages 758–759, 2009.
- Dong et al. [2024] Guanting Dong, Chenghao Zhang, Mengjie Deng, Yutao Zhu, Zhicheng Dou, and Ji-Rong Wen. Progressive multimodal reasoning via active retrieval. arXiv preprint arXiv:2412.14835, 2024.
- Dubey et al. [2024] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Ethayarajh et al. [2024] Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306, 2024.
- Fang et al. [2024] Feiteng Fang, Yuelin Bai, Shiwen Ni, Min Yang, Xiaojun Chen, and Ruifeng Xu. Enhancing noise robustness of retrieval-augmented language models with adaptive adversarial training. arXiv preprint arXiv:2405.20978, 2024.
- Fu et al. [2025] Jiayi Fu, Xuandong Zhao, Chengyuan Yao, Heng Wang, Qi Han, and Yanghua Xiao. Reward shaping to mitigate reward hacking in rlhf. arXiv preprint arXiv:2502.18770, 2025.
- Gao et al. [2024] Jingsheng Gao, Linxu Li, Weiyuan Li, Yuzhuo Fu, and Bin Dai. Smartrag: Jointly learn rag-related tasks from the environment feedback. arXiv preprint arXiv:2410.18141, 2024.
- Gao et al. [2023] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023.
- Guo et al. [2025] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
- Han et al. [2024] Binglan Han, Teo Susnjak, and Anuradha Mathrani. Automating systematic literature reviews with retrieval-augmented generation: A comprehensive overview. Applied Sciences, 14(19):9103, 2024.
- Ho et al. [2020] Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. In Proceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020.
- Hsu et al. [2024] Sheryl Hsu, Omar Khattab, Chelsea Finn, and Archit Sharma. Grounding by trying: Llms with reinforcement learning-enhanced retrieval. arXiv preprint arXiv:2410.23214, 2024.
- Hu et al. [2021] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Hu et al. [2024] Jian Hu, Xibin Wu, Zilin Zhu, Weixun Wang, Dehao Zhang, Yu Cao, et al. Openrlhf: An easy-to-use, scalable and high-performance rlhf framework. arXiv preprint arXiv:2405.11143, 2024.
- Izacard and Grave [2021] Gautier Izacard and Édouard Grave. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874–880, 2021.
- Izacard et al. [2023] Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Atlas: Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research, 24(251):1–43, 2023.
- Jeong et al. [2024] Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong-Cheol Park. Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity. In 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 7036–7050. Association for Computational Linguistics, 2024.
- Ji et al. [2023] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023.
- Jiang et al. [2025a] Pengcheng Jiang, Lang Cao, Ruike Zhu, Minhao Jiang, Yunyi Zhang, Jimeng Sun, and Jiawei Han. Ras: Retrieval-and-structuring for knowledge-intensive llm generation. arXiv preprint arXiv:2502.10996, 2025a.
- Jiang et al. [2025b] Pengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, and Jiawei Han. Deepretrieval: Hacking real search engines and retrievers with large language models via reinforcement learning. arXiv preprint arXiv:2503.00223, 2025b.
- Jiang et al. [2023] Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969–7992, 2023.
- Jiang et al. [2024] Ziyan Jiang, Xueguang Ma, and Wenhu Chen. Longrag: Enhancing retrieval-augmented generation with long-context llms. arXiv preprint arXiv:2406.15319, 2024.
- Jin et al. [2025] Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516, 2025.
- Jin et al. [2021] Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14):6421, 2021.
- Jin et al. [2023] Qiao Jin, Won Kim, Qingyu Chen, Donald C Comeau, Lana Yeganova, W John Wilbur, and Zhiyong Lu. Medcpt: Contrastive pre-trained transformers with large-scale pubmed search logs for zero-shot biomedical information retrieval. Bioinformatics, 39(11):btad651, 2023.
- Jin et al. [2024] Zhuoran Jin, Hongbang Yuan, Tianyi Men, Pengfei Cao, Yubo Chen, Kang Liu, and Jun Zhao. Rag-rewardbench: Benchmarking reward models in retrieval augmented generation for preference alignment. arXiv preprint arXiv:2412.13746, 2024.
- Karpukhin et al. [2020] Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, 2020.
- Khot et al. [2023] Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. Decomposed prompting: A modular approach for solving complex tasks. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/forum?id=_nGgzQjzaRy.
- Lála et al. [2023] Jakub Lála, Odhran O’Donoghue, Aleksandar Shtedritski, Sam Cox, Samuel G Rodriques, and Andrew D White. Paperqa: Retrieval-augmented generative agent for scientific research. arXiv preprint arXiv:2312.07559, 2023.
- Lamba [2024] Divya Lamba. The role of prompt engineering in improving language understanding and generation. International Journal For Multidisciplinary Research, 2024. URL https://api.semanticscholar.org/CorpusID:274939741.
- Lang and Gürpinar [2025] Guido Lang and Tan Gürpinar. Ai-powered learning support: A study of retrieval-augmented generation (rag) chatbot effectiveness in an online course. Information Systems Education Journal, 23(2), 2025.
- Lewis et al. [2020] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- Li et al. [2024a] Dongheng Li, Yongchang Hao, and Lili Mou. Llmr: Knowledge distillation with a large language model-induced reward. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 10657–10664, 2024a.
- Li et al. [2025] Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. arXiv preprint arXiv:2501.05366, 2025.
- Li et al. [2024b] Xingxuan Li, Weiwen Xu, Ruochen Zhao, Fangkai Jiao, Shafiq Joty, and Lidong Bing. Can we further elicit reasoning in llms? critic-guided planning with retrieval-augmentation for solving challenging tasks. arXiv preprint arXiv:2410.01428, 2024b.
- Lightman et al. [2024] Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=v8L0pN6EOi.
- Liu et al. [2020] Fei Liu et al. Learning to summarize from human feedback. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 583–592, 2020.
- Liu et al. [2025] Siru Liu, Allison B McCoy, and Adam Wright. Improving large language model applications in biomedicine with retrieval-augmented generation: a systematic review, meta-analysis, and clinical development guidelines. Journal of the American Medical Informatics Association, page ocaf008, 2025.
- Ma et al. [2024] Hao Ma, Tianyi Hu, Zhiqiang Pu, Liu Boyin, Xiaolin Ai, Yanyan Liang, and Min Chen. Coevolving with the other you: Fine-tuning llm with sequential cooperative multi-agent reinforcement learning. Advances in Neural Information Processing Systems, 37:15497–15525, 2024.
- Meng et al. [2024] Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward. Advances in Neural Information Processing Systems, 37:124198–124235, 2024.
- Nguyen et al. [2024] Thang Nguyen, Peter Chin, and Yu-Wing Tai. Reward-rag: Enhancing rag with reward driven supervision. arXiv preprint arXiv:2410.03780, 2024.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- Pipitone and Alami [2024] Nicholas Pipitone and Ghita Houir Alami. Legalbench-rag: A benchmark for retrieval-augmented generation in the legal domain. arXiv preprint arXiv:2408.10343, 2024.
- Press et al. [2023] Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, 2023.
- Qian et al. [2025] Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. Toolrl: Reward is all tool learning needs. arXiv preprint arXiv:2504.13958, 2025.
- Rafailov et al. [2023] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36:53728–53741, 2023.
- Ram et al. [2023] Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. In-context retrieval-augmented language models. Transactions of the Association for Computational Linguistics, 11:1316–1331, 2023.
- Robertson et al. [2009] Stephen Robertson, Hugo Zaragoza, et al. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval, 3(4):333–389, 2009.
- Sahoo et al. [2024] Satya S Sahoo, Joseph M Plasek, Hua Xu, Özlem Uzuner, Trevor Cohen, Meliha Yetisgen, Hongfang Liu, Stéphane Meystre, and Yanshan Wang. Large language models for biomedicine: foundations, opportunities, challenges, and best practices. Journal of the American Medical Informatics Association, page ocae074, 2024.
- Schulman et al. [2017] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Shao et al. [2023] Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9248–9274, 2023.
- Shao et al. [2024] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- Shi et al. [2025] Yucheng Shi, Tianze Yang, Canyu Chen, Quanzheng Li, Tianming Liu, Xiang Li, and Ninghao Liu. Searchrag: Can search engines be helpful for llm-based medical question answering? arXiv preprint arXiv:2502.13233, 2025.
- Shi et al. [2024] Zhengliang Shi, Shuo Zhang, Weiwei Sun, Shen Gao, Pengjie Ren, Zhumin Chen, and Zhaochun Ren. Generate-then-ground in retrieval-augmented generation for multi-hop question answering. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7339–7353, 2024.
- Shinn et al. [2024] Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024.
- Shuster et al. [2021] Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. Retrieval augmentation reduces hallucination in conversation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 3784–3803, 2021.
- Skalse et al. [2022] Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward gaming. Advances in Neural Information Processing Systems, 35:9460–9471, 2022.
- Skarlinski et al. [2024] Michael D Skarlinski, Sam Cox, Jon M Laurent, James D Braza, Michaela Hinks, Michael J Hammerling, Manvitha Ponnapati, Samuel G Rodriques, and Andrew D White. Language agents achieve superhuman synthesis of scientific knowledge. arXiv preprint arXiv:2409.13740, 2024.
- Song et al. [2025] Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning. arXiv preprint arXiv:2503.05592, 2025.
- Subramonyam et al. [2025] Hari Subramonyam, Divy Thakkar, Andrew Ku, Juergen Dieber, and Anoop K Sinha. Prototyping with prompts: Emerging approaches and challenges in generative ai design for collaborative software teams. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–22, 2025.
- Sun et al. [2025] Zhongxiang Sun, Qipeng Wang, Weijie Yu, Xiaoxue Zang, Kai Zheng, Jun Xu, Xiao Zhang, Song Yang, and Han Li. Rearter: Retrieval-augmented reasoning with trustworthy process rewarding. arXiv preprint arXiv:2501.07861, 2025.
- Swacha and Gracel [2025] Jakub Swacha and Michał Gracel. Retrieval-augmented generation (rag) chatbots for education: A survey of applications. Applied Sciences, 15(8):4234, 2025.
- Trivedi et al. [2023] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10014–10037, 2023.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- von Werra et al. [2020] Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020.
- Wang et al. [2023] Keheng Wang, Feiyu Duan, Sirui Wang, Peiguang Li, Yunsen Xian, Chuantao Yin, Wenge Rong, and Zhang Xiong. Knowledge-driven cot: Exploring faithful reasoning in llms for knowledge-intensive question answering. arXiv preprint arXiv:2308.13259, 2023.
- Wang et al. [2024a] Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024a.
- Wang et al. [2024b] Yuxia Wang, Minghan Wang, Muhammad Arslan Manzoor, Fei Liu, Georgi Georgiev, Rocktim Das, and Preslav Nakov. Factuality of large language models: A survey. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 19519–19529, 2024b.
- Wang et al. [2024c] Zihao Wang, Anji Liu, Haowei Lin, Jiaqi Li, Xiaojian Ma, and Yitao Liang. Rat: Retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation. arXiv preprint arXiv:2403.05313, 2024c.
- Wang et al. [2024d] Zilong Wang, Zifeng Wang, Long Le, Huaixiu Steven Zheng, Swaroop Mishra, Vincent Perot, Yuwei Zhang, Anush Mattapalli, Ankur Taly, Jingbo Shang, et al. Speculative rag: Enhancing retrieval augmented generation through drafting. arXiv preprint arXiv:2407.08223, 2024d.
- Wei et al. [2022] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- Wei et al. [2025] Zhepei Wei, Wei-Lin Chen, and Yu Meng. InstructRAG: Instructing retrieval-augmented generation via self-synthesized rationales. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=P1qhkp8gQT.
- Wiratunga et al. [2024] Nirmalie Wiratunga, Ramitha Abeyratne, Lasal Jayawardena, Kyle Martin, Stewart Massie, Ikechukwu Nkisi-Orji, Ruvan Weerasinghe, Anne Liret, and Bruno Fleisch. Cbr-rag: case-based reasoning for retrieval augmented generation in llms for legal question answering. In International Conference on Case-Based Reasoning, pages 445–460. Springer, 2024.
- Xiao et al. [2023] Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general chinese embedding, 2023.
- Xiong et al. [2024a] Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang. Benchmarking retrieval-augmented generation for medicine. In Findings of the Association for Computational Linguistics ACL 2024, pages 6233–6251, 2024a.
- Xiong et al. [2024b] Guangzhi Xiong, Qiao Jin, Xiao Wang, Minjia Zhang, Zhiyong Lu, and Aidong Zhang. Improving retrieval-augmented generation in medicine with iterative follow-up questions. In Biocomputing 2025: Proceedings of the Pacific Symposium, pages 199–214. World Scientific, 2024b.
- Xu et al. [2024a] Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation. In International Conference on Machine Learning, pages 55204–55224. PMLR, 2024a.
- Xu et al. [2024b] Ran Xu, Hui Liu, Sreyashi Nag, Zhenwei Dai, Yaochen Xie, Xianfeng Tang, Chen Luo, Yang Li, Joyce C Ho, Carl Yang, et al. Simrag: Self-improving retrieval-augmented generation for adapting large language models to specialized domains. arXiv preprint arXiv:2410.17952, 2024b.
- Xu et al. [2024c] Ran Xu, Wenqi Shi, Yue Yu, Yuchen Zhuang, Yanqiao Zhu, May Dongmei Wang, Joyce C. Ho, Chao Zhang, and Carl Yang. BMRetriever: Tuning large language models as better biomedical text retrievers. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22234–22254, Miami, Florida, USA, November 2024c. Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.1241. URL https://aclanthology.org/2024.emnlp-main.1241/.
- Yang et al. [2018] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors, Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium, October-November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-1259. URL https://aclanthology.org/D18-1259.
- Yao et al. [2023] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023.
- Yu et al. [2024] Tian Yu, Shaolei Zhang, and Yang Feng. Auto-rag: Autonomous retrieval-augmented generation for large language models. 2024. URL https://arxiv.org/abs/2411.19443.
- Zekri et al. [2024] Oussama Zekri, Ambroise Odonnat, Abdelhakim Benechehab, Linus Bleistein, Nicolas Boullé, and Ievgen Redko. Large language models as markov chains. arXiv preprint arXiv:2410.02724, 2024.
- Zhang et al. [2025a] Hanning Zhang, Juntong Song, Juno Zhu, Yuanhao Wu, Tong Zhang, and Cheng Niu. Rag-reward: Optimizing rag with reward modeling and rlhf. arXiv preprint arXiv:2501.13264, 2025a.
- Zhang et al. [2023a] Peitian Zhang, Shitao Xiao, Zheng Liu, Zhicheng Dou, and Jian-Yun Nie. Retrieve anything to augment large language models. arXiv preprint arXiv:2310.07554, 2023a.
- Zhang et al. [2024] Tianjun Zhang, Shishir G Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, and Joseph E Gonzalez. Raft: Adapting language model to domain specific rag. arXiv preprint arXiv:2403.10131, 2024.
- Zhang et al. [2023b] Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. Siren’s song in the ai ocean: a survey on hallucination in large language models. arXiv preprint arXiv:2309.01219, 2023b.
- Zhang et al. [2025b] Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. arXiv preprint arXiv:2501.07301, 2025b.
Appendix A Limitations and Future Work
Despite the strengths of RAG-Gym, several limitations remain. First, our framework relies on high-quality process reward judgments to supervise intermediate agent actions. Obtaining such fine-grained annotations for complex reasoning or domain-specific scenarios can be challenging. Second, as with other reward modeling approaches, there is an inherent risk of reward hacking: agents may learn to exploit imperfections or biases in the reward model, optimizing for the reward signal rather than genuine task performance [67, 16]. Third, while our experiments focus on knowledge-intensive question answering, the generalizability of RAG-Gym to other task types (e.g., dialogue, summarization, or planning) remains to be systematically evaluated.
While RAG-Gym serves as a pilot study of when and how process supervision works for agentic RAG, several promising directions remain for future work. First, developing more scalable and cost-effective annotation strategies for process reward modeling is essential, especially for complex or specialized domains. Since existing rollout-based methods such as Math-Shepherd [77] did not yield significant gains in our experiments (Table 4), new approaches are needed to facilitate efficient and high-quality process reward collection. Second, the design and training of process reward judges can be further refined to improve robustness and reduce susceptibility to reward hacking. Third, extending RAG-Gym to a broader range of agentic tasks beyond knowledge-intensive question answering such as dialogue will help assess its generalizability and reveal new challenges, particularly in settings where outcome rewards are ambiguous and process supervision is even more critical.
Appendix B Broader Impacts
RAG-Gym systematically evalutes different optimization approaches for retrieval-augmented language agents, which has the potential for wide-ranging societal benefits and risks. By enabling high-quality intermediate steps with process-level supervsion, our framework can improve the reliability of AI assistants in knowledge-intensive domains such as education [72, 41], healthcare [48, 86], scientific research [20, 39, 68], and legal analysis [83, 53]. Also, process-level actor tuning and critic-guided inference may help reduce hallucinations and increase transparency, supporting more trustworthy AI deployments.
However, these advances also raise important considerations. The reliance on high-quality process reward annotations may introduce biases if the annotation sources are not representative or contain systematic errors. Reward hacking remains a risk, as agents may learn to exploit weaknesses in the reward model, potentially leading to unintended behaviors or misinformation.
Appendix C Dataset Descriptions
In this section, we provide detailed descriptions of the datasets used in our experiments, including HotpotQA [90], 2WikiMultihopQA [21], Bamboogle [54], and MedQA [34].
HotpotQA.
HotpotQA is a large-scale, multi-hop question-answering dataset that requires reasoning across multiple documents. It consists of questions that explicitly demand retrieving and synthesizing information from different sources. The dataset provides both distractor and supporting documents, allowing evaluation of models’ ability to filter relevant information effectively. As the answers to the test questions in HotpotQA are not publicly available we took a subsample from its validation set (7,405 instances) as previous research did [91, 44]. The last 1,000 validation questions were selected for the agent evaluation on HotpotQA. The first 1,000 questions were used as the training data for process supervision.
2WikiMultihopQA.
2WikiMultihopQA is another multi-hop question-answering dataset constructed from Wikipedia. 2WikiMultihopQA focuses on high-quality reasoning paths by selecting supporting documents more systematically. The dataset contains questions that require reasoning across different Wikipedia pages, ensuring a diverse range of factual and inferential challenges. The last 1000 questions in the development set (12,576 question in total) were used for agent evaluation.
Bamboogle.
Bamboogle is a manually constructed dataset designed to evaluate compositional reasoning and adversarial robustness. It consists of 2-hop questions written by researchers, where both supporting facts exist in Wikipedia but are structured to be challenging for retrieval-based systems. Unlike automatically generated datasets like 2WikiMultihopQA and Musique, Bamboogle questions do not follow fixed templates, increasing their variability. We used the whole test set with 125 questions for the evaluation of agents on Bamboogle.
MedQA.
MedQA is a medical question-answering dataset sourced from professional medical exams such as the USMLE (United States Medical Licensing Examination). It requires domain-specific knowledge and reasoning to answer multiple-choice medical questions. We focused on the English split of MedQA with 1,273 USMLE-style test questions. A subset of 1,000 questions was sampled from the training set (10,178 questions) for the optimization of various agents.
Appendix D Baseline Descriptions
Here are the detailed descriptions of various baseline agents that we implemented in the experiments.
Direct.
The Direct agent represents the simplest baseline, where the language model is prompted to output the predicted answer immediately, without any explicit intermediate reasoning or search steps. This approach tests the model’s ability to answer questions in a single step, relying solely on its internal knowledge and without leveraging external retrieval or multi-step reasoning.
CoT [81].
The Chain-of-Thought (CoT) agent encourages the model to generate a step-by-step reasoning process before producing the final answer, but still does so in a single iteration. The agent is prompted to articulate its reasoning explicitly, which can help with complex questions by making the model’s thought process transparent and potentially improving answer accuracy. However, CoT does not incorporate external retrieval or iterative search.
RAG [42].
The Retrieval-Augmented Generation (RAG) agent augments the language model with a retrieval step. At the first iteration, the agent issues the original question as a search query to retrieve relevant documents. In the subsequent step, it reasons about the updated state, which includes the retrieved information, and generates a predicted answer. This approach leverages external knowledge but does not perform multi-hop or iterative search.
ReAct [91].
The ReAct agent combines reasoning and acting by allowing the model to interleave natural language reasoning with actions, such as issuing search queries or providing answers. At each step, the agent reasons about the current state and decides whether to search for more information or to answer the question. This enables multi-step, interactive information-seeking and supports more complex reasoning chains.
Search-o1 [44].
The Search-o1 agent extends the ReAct framework by introducing a knowledge summarization step before reasoning. For each search query, the agent reasons about the retrieved documents and briefly summarize the useful information as the direct answer to the search query, forming query-answer pairs that are used as input for subsequent reasoning steps. This approach replaces the use of raw documents with structured summaries, potentially improving reasoning efficiency. Search-o1 can be viewed as a special case of ReAct where retrieval is performed via RAG and the agent operates on summarized knowledge rather than full documents.
Appendix E Implementation Details
In our experiments, we selected Llama-3.1-8B-Instruct [13] as the base LLM for the implementations of various language agents, due to its context length of 128k tokens and its availability of open-source parameters. The critic is also trained based on the same Llama-3.1-8B-Instruct, same as the actor. We involved GPT-4o-mini and Qwen-2.5-7B-Instruct to show the transferability of the trained critic (Figure 2) and the generalizability of RAG-Gym (Table 3) to other LLMs.
E.1 Details of Process Data Collection
To evaluate intermediate reasoning and search steps in RAG-Gym, we design a process reward function that assesses queries based on three key criteria:
- If the retrieval history already contains sufficient information, answering should be the preferred action instead of searching further.
- Queries should also be precise, actionable, and foundational to solving the question while avoiding unnecessary details.
- Queries should introduce new, useful information rather than repeating past searches.
These criteria ensure that queries are efficient, targeted, and contribute meaningfully to constructing the final answer.
The data collection pipeline begins with trajectory sampling, where the language agent generates a sequence of actions based on its current policy. At each step in the trajectory, multiple candidate actions are proposed, and the best action is selected according to predefined evaluation criteria. To streamline the annotation process and ensure consistency, we employ a ranking-based evaluation framework rather than assigning numerical scores. The selected action is then executed, and the trajectory transitions to the next state. This process is repeated iteratively until the trajectory terminates.
To ensure quality, only sampled trajectories that result in a correct final answer are retained, as determined by the outcome reward. This filtering guarantees that the selected actions not only align with the process reward criteria but also contribute to successful task completion. To address the challenges of slow and costly human annotation, we leverage LLMs such as GPT-4o to annotate the sampled trajectories. As demonstrated in our experiments (Table 4), annotations generated by GPT-4o exhibit high reliability, closely aligning with domain expert judgments. This approach enables scalable and efficient data collection, making it feasible to gather high-quality process reward data at scale.
<details>
<summary>x5.png Details</summary>
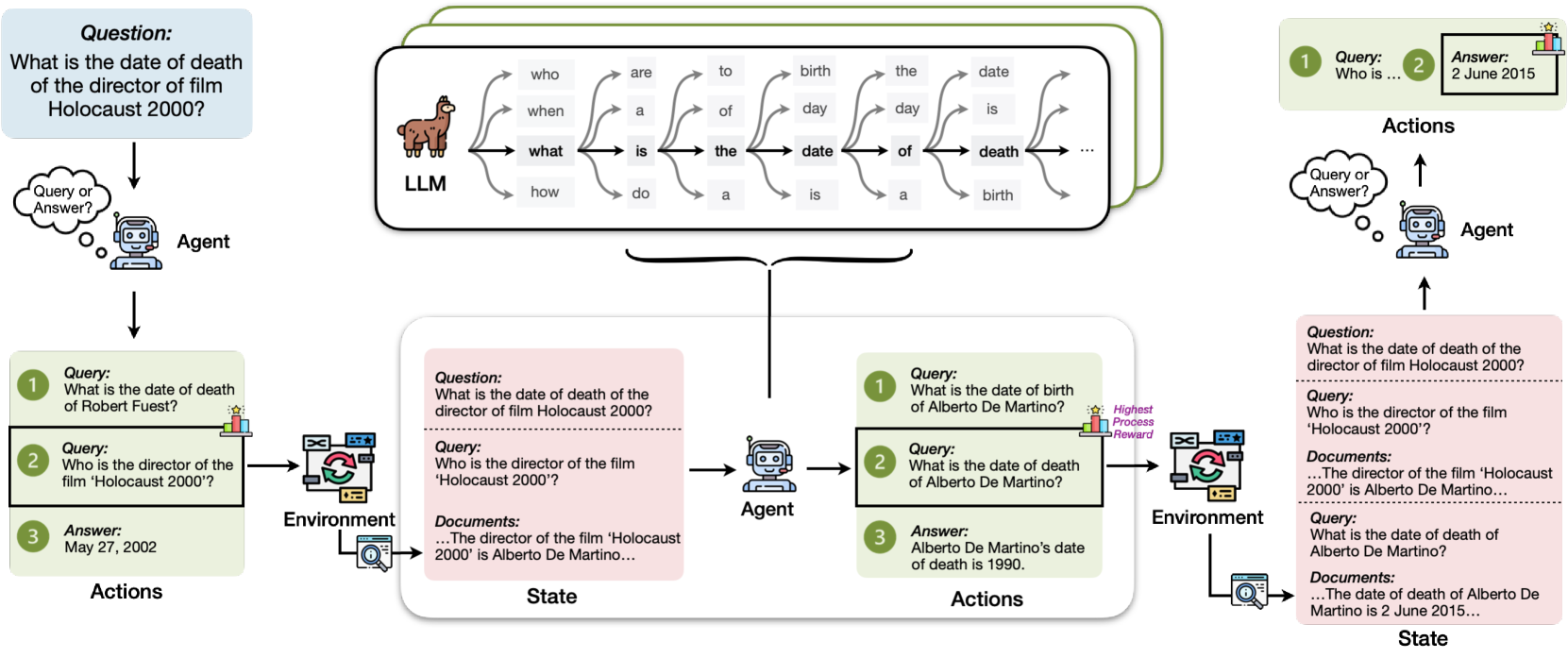
### Visual Description
## Diagram: Agent Interaction with LLM and Environment
### Overview
The image illustrates a diagram depicting the interaction of an agent with a Large Language Model (LLM) and an environment to answer questions. The diagram shows the flow of information and actions between the agent, the LLM, and the environment in two different scenarios.
### Components/Axes
* **Agent:** A robotic figure representing the intelligent agent.
* **LLM:** A llama icon representing the Large Language Model.
* **Environment:** A representation of the external world or knowledge base.
* **State:** The current information available to the agent.
* **Actions:** The steps taken by the agent.
* **Query:** The question posed to the system.
* **Answer:** The response provided by the system.
* **Highest Process Reward:** A visual indicator of successful processing.
### Detailed Analysis or ### Content Details
**Top Section:**
* **Question (Top-Left):** "What is the date of death of the director of film Holocaust 2000?"
* **Agent (Top-Left):** Receives the question.
* **LLM (Top-Center):** Processes the question using various linguistic paths:
* "who are to birth the date"
* "when a of day day is"
* "what is the date of death"
* "how do a is a birth"
* **Agent (Top-Right):** Performs actions based on the LLM's processing:
* Query 1: "Who is..."
* Answer 2: "2 June 2015"
**Bottom-Left Section:**
* **Question:** "What is the date of death of the director of film Holocaust 2000?"
* **Agent:** Receives the question.
* **Actions:**
* Query 1: "What is the date of death of Robert Fuest?"
* Query 2: "Who is the director of the film 'Holocaust 2000'?"
* Answer 3: "May 27, 2002"
* **Environment:** Processes the queries.
* **State:**
* Question: "What is the date of death of the director of film Holocaust 2000?"
* Query: "Who is the director of the film 'Holocaust 2000'?"
* Documents: "...The director of the film 'Holocaust 2000' is Alberto De Martino..."
**Bottom-Right Section:**
* **Question:** "What is the date of death of the director of film Holocaust 2000?"
* **Agent:** Receives the question.
* **Actions:**
* Query 1: "What is the date of birth of Alberto De Martino?"
* Query 2: "What is the date of death of Alberto De Martino?"
* Answer 3: "Alberto De Martino's date of death is 1990."
* **Environment:** Processes the queries.
* **State:**
* Question: "What is the date of death of the director of film Holocaust 2000?"
* Query: "Who is the director of the film 'Holocaust 2000'?"
* Documents: "...The director of the film 'Holocaust 2000' is Alberto De Martino..."
* Query: "What is the date of death of Alberto De Martino?"
* Documents: "...The date of death of Alberto De Martino is 2 June 2015..."
### Key Observations
* The LLM is used to generate initial queries.
* The agent interacts with the environment to gather information.
* The state represents the current knowledge of the agent.
* The actions represent the queries and answers exchanged between the agent and the environment.
* The "Highest Process Reward" is associated with the correct answer.
### Interpretation
The diagram illustrates how an agent uses an LLM and interacts with an environment to answer a complex question. The agent breaks down the initial question into simpler queries, gathers information from the environment, and uses the LLM to generate answers. The two scenarios presented show different paths the agent can take to arrive at an answer, highlighting the iterative and exploratory nature of the process. The diagram demonstrates the importance of both the LLM for generating queries and the environment for providing information in answering complex questions.
</details>
Figure 5: Pipeline of the process data collection in RAG-Gym. Process reward data is collected by randomly sampling action candidates at each time step and using an external annotator (e.g., GPT-4o) to select the best one. The episode is terminated when the agent generates a final answer.
For the implementation of the IR environment, we select Wikipedia as the supporting corpus for the retrieval of relevant information for questions from HotpotQA, 2WikiMultihopQA, and Bamboogle. For the environment of solving MedQA questions, we use a combination of medical textbooks and StatPearls which were pre-processed in MedRAG [85]. For all tasks, we used both lexical and semantic retrievers whose results were merged with Reciprocal Rank Fusion [11]. BM25 [58] and BGE-Base [84] were used for HotpotQA, 2WikiMultihopQA, and Bamboogle, while in MedQA, we selected BM25 and MedCPT [35]. A set of 32 documents will be retrieved for each search query.
E.2 Details of LLM Post-training
For the actor tuning, we employed Low-Rank Adaptation (LoRA) [23] in the implementaion of supervised fine-tuning (SFT) [52] and direct preference optimization (DPO) [56] [60] with $r=256$ and $alpha=512$ on all attention components in the transformers architecture [74]. SFT and DPO were implemented using the TRL package [75]. For proximal policy optimization (PPO), we used the OpenRLHF package [24] with full-parameter tuning. Detailed hyperparameter settings for SFT, DPO, and PPO can be found in our source code. For the tuning of Search-o1 and Re 2 Search agents, only the LLM for action reasoning is trained while the one for history knowledge summarization remains untuned.
E.3 Details of LLM Inference
All results of zero-shot learning (ZSL), supervised fine-tuning (SFT), direct preference optimization (DPO), and proximal policy optimization (PPO) are generated with a temperature of 0.0. For the evaluation of agents with a critic, we employed a temperature of 1.0 with 10 different actions sampled for each step in the information-seeking trajectory. Algorithm 1 presents our algorithm of using the trained process reward model to guide the action selection during inference. All experiments were conducted on NVIDIA A100 and A6000 GPUs.
Algorithm 1 PRM-Guided Inference with Best-of-N Selection
1. Input: Original question $Q$ , actor $\pi_{\theta}$ , critic $r_{\phi}$ , number of candidate actions $N$ , maximum steps $T$ , information retrieval function IR.
1. Initialize state $S←(Q,H_{1}=\emptyset)$ .
1. For $t=1$ to $T$ :
1. Generate $N$ candidate actions: $a_{q},·s,a_{N}\sim\pi_{f(\theta)}(·|S)$ .
1. Compute process rewards and select the best action: $a^{*}←\arg\max_{a∈\{a_{1},·s,a_{N}\}}r_{\phi}(S,a)$ .
1. If $a^{*}$ is a search query:
1. Retrieve documents: $D←\text{IR}(a^{*})$ .
1. Update state: $S←(Q,H_{t+1}=H_{t}\cup\{(a^{*},D)\})$ .
1. If $a^{*}$ is a final answer:
1. Return $a^{*}$ and terminate the process.
1. End For
Appendix F Study on the Number of Search Queries
In addition to the results presented in Table 2, we further analyzed the number of search queries generated by Re 2 Search agents across different datasets. Table 5 reports the minimum, maximum, and mean number of search queries issued. The maximum value is capped at 10, reflecting the upper limit of iterations allowed per question in our experiments. The results show that tuned agents (SFT, DPO, and PPO) consistently generate more search queries than the zero-shot agent (ZSL), indicating that fine-tuning encourages more extensive information-seeking behavior, which aligns with their improved performance.
Table 5: Minimum, maximum, and mean number of search queries generated by Re 2 Search agents for each dataset.
| | HotpotQA | 2Wiki | Bamboogle | MedQA | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Min | Max | Mean | Min | Max | Mean | Min | Max | Mean | Min | Max | Mean | |
| ZSL | 0.0 | 9.0 | 1.5 | 0.0 | 9.0 | 3.4 | 0.0 | 9.0 | 1.0 | 0.0 | 9.0 | 0.4 |
| SFT | 0.0 | 9.0 | 2.1 | 0.0 | 9.0 | 3.8 | 0.0 | 9.0 | 1.9 | 0.0 | 9.0 | 0.6 |
| DPO | 0.0 | 9.0 | 3.2 | 0.0 | 9.0 | 4.5 | 0.0 | 9.0 | 3.4 | 0.0 | 9.0 | 2.2 |
| PPO | 0.0 | 9.0 | 4.6 | 0.0 | 9.0 | 5.6 | 0.0 | 9.0 | 2.7 | 0.0 | 9.0 | 5.6 |
Appendix G Case Studies
G.1 Comparison of Agent Designs on Bamboogle
We analyze the reasoning and search behaviors of RAG, ReAct, Search-o1, and Re 2 Search using an example from the Bamboogle dataset. As shown in Figure 7, given the question “What was the father of the last surviving Canadian father of Confederation?", the three agents show distinct behaviors when generating the first action.
The RAG agent directly passes the question as a search query without decomposition, relying entirely on retrieval to infer the answer. This often leads to ineffective searches that fail to retrieve necessary intermediate facts. ReAct and Search-o1 improve upon this by engaging in stepwise query reasoning, first identifying the need to determine the last surviving Canadian father of Confederation before issuing a search query. However, the generated query, “List of Canadian fathers of Confederation”, retrieves broad information rather than directly resolving the missing knowledge.
In contrast, Re 2 Search explicitly integrates answer reasoning with search. It first constructs a potential answer, identifying an unverified claim that William Lyon Mackenzie King is among the last surviving Canadian fathers of Confederation. Recognizing the missing evidence, it formulates a targeted query, “Who is the last surviving Canadian father of Confederation?”, to resolve the uncertainty. This approach ensures that retrieval is aligned with answer construction, minimizing unnecessary queries and improving information efficiency. The case study illustrates how Re 2 Search effectively refines the search process by linking query generation to specific knowledge gaps.
<details>
<summary>x6.png Details</summary>
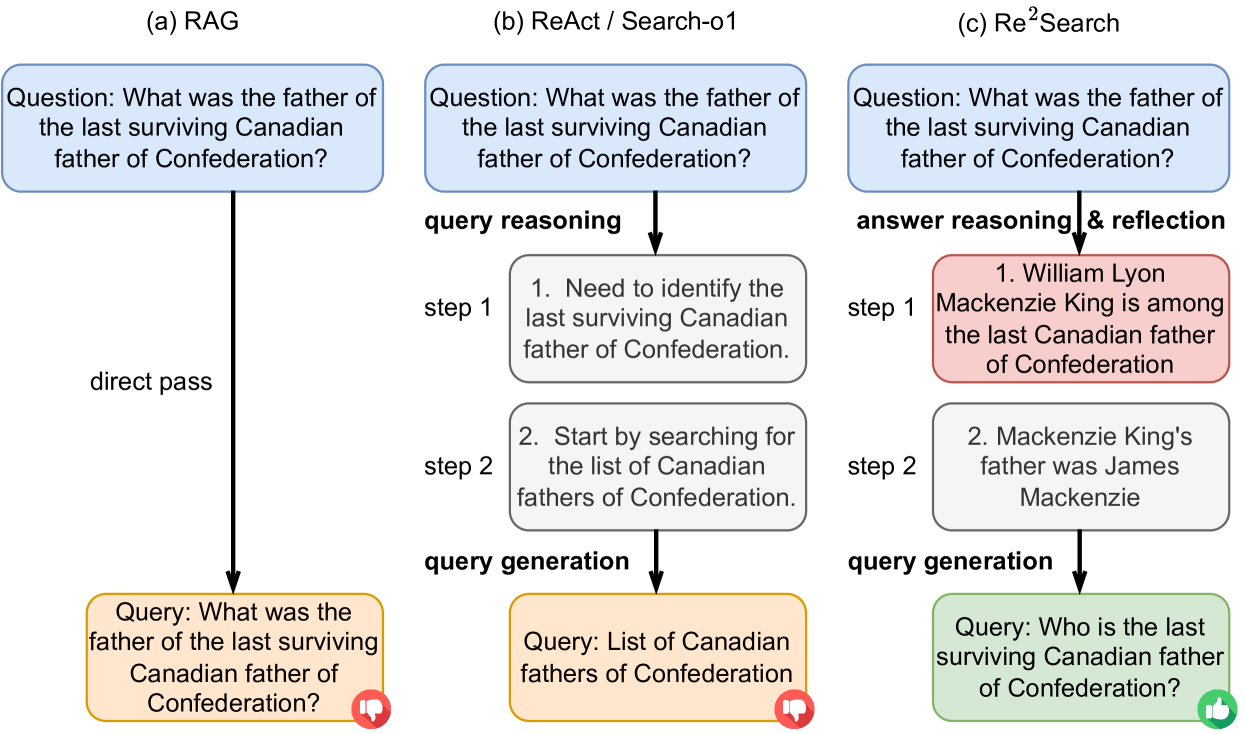
### Visual Description
## Diagram: Comparison of Question Answering Approaches
### Overview
The image presents a comparative diagram illustrating three different approaches to answering a complex question: RAG (Retrieval-Augmented Generation), ReAct/Search-o1, and Re²Search. Each approach is depicted as a flowchart, showing the steps involved in processing the question and generating a query. The diagram highlights the differences in reasoning and query generation strategies among the three methods.
### Components/Axes
* **Titles:** The diagram is divided into three sections, each labeled with a title: (a) RAG, (b) ReAct / Search-o1, and (c) Re²Search.
* **Question:** Each section starts with the same initial question, presented in a light blue rounded box: "What was the father of the last surviving Canadian father of Confederation?"
* **Flow Arrows:** Black arrows indicate the flow of information and processing steps within each approach.
* **Process Steps:** Rectangular boxes represent individual steps in the reasoning and query generation process. These boxes are colored differently depending on the approach:
* RAG: Orange box for the final query.
* ReAct/Search-o1: Gray boxes for reasoning steps, orange box for the final query.
* Re²Search: Red box for answer reasoning, gray box for a subsequent step, and green box for the final query.
* **Step Labels:** Each reasoning step is labeled with "step 1", "step 2", etc.
* **Query Generation Labels:** The sections for ReAct/Search-o1 and Re²Search have labels indicating "query reasoning" and "query generation". The Re²Search section also has a label for "answer reasoning & reflection".
* **Feedback Icons:** Each final query box has a small icon in the bottom-right corner: a thumbs-down icon (red) for RAG and ReAct/Search-o1, and a thumbs-up icon (green) for Re²Search.
### Detailed Analysis
**RAG (Retrieval-Augmented Generation):**
* The initial question (light blue box) is "What was the father of the last surviving Canadian father of Confederation?".
* A "direct pass" arrow leads directly to the query generation stage.
* The generated query (orange box) is the same as the initial question: "What was the father of the last surviving Canadian father of Confederation?".
* A red thumbs-down icon is present.
**ReAct / Search-o1:**
* The initial question (light blue box) is "What was the father of the last surviving Canadian father of Confederation?".
* The process involves "query reasoning" in two steps (gray boxes):
* Step 1: "Need to identify the last surviving Canadian father of Confederation."
* Step 2: "Start by searching for the list of Canadian fathers of Confederation."
* The "query generation" stage (orange box) produces the query: "List of Canadian fathers of Confederation".
* A red thumbs-down icon is present.
**Re²Search:**
* The initial question (light blue box) is "What was the father of the last surviving Canadian father of Confederation?".
* The process involves "answer reasoning & reflection" in two steps:
* Step 1 (red box): "William Lyon Mackenzie King is among the last Canadian father of Confederation".
* Step 2 (gray box): "Mackenzie King's father was James Mackenzie".
* The "query generation" stage (green box) produces the query: "Who is the last surviving Canadian father of Confederation?".
* A green thumbs-up icon is present.
### Key Observations
* RAG directly uses the initial question as the query, without any intermediate reasoning steps.
* ReAct/Search-o1 performs query reasoning to generate a more specific query aimed at retrieving a list of relevant individuals.
* Re²Search incorporates answer reasoning and reflection, leading to a refined query that directly asks for the last surviving Canadian father of Confederation.
* The thumbs-up/thumbs-down icons suggest a qualitative assessment of the effectiveness of each approach, with Re²Search being the most successful.
### Interpretation
The diagram illustrates how different question-answering approaches handle a complex question. RAG's direct pass approach may be less effective for questions requiring reasoning or specific information retrieval strategies. ReAct/Search-o1 attempts to improve upon this by incorporating query reasoning, but still generates a query that requires further processing. Re²Search, with its answer reasoning and reflection, appears to be the most effective, generating a query that directly addresses the question and leads to a more accurate answer. The thumbs-up/thumbs-down icons visually reinforce this assessment. The diagram highlights the importance of reasoning and reflection in question answering systems, particularly for complex or nuanced queries.
</details>
Figure 6: Comparison of different agent architectures in handling a multi-hop question from Bamboogle.
G.2 Comparison of Agent Designs on MedQA
Similarly, when presented with a complex medical question from MedQA, the distinct approaches of the agents are evident. The RAG agent, as before, directly uses a truncated version of the lengthy input as its search query, which is unlikely to yield specific, actionable information. ReAct and Search-o1 engage in query reasoning, first hypothesizing that these symptoms suggest a possible diagnosis of serotonin syndrome and then deciding to search for information on the treatment of serotonin syndrome. While this is more targeted than RAG, Re 2 Search demonstrates a more refined process by engaging in answer reasoning and reasoning reflection. It posits that the symptoms are suggestive of a cholinergic syndrome. Recognizing the need to confirm the relationship between the patient’s existing conditions and the suspected syndrome, it generates a highly specific query about the relationship between constipation, fibromyalgia, and cholinergic syndrome. This demonstrates Re 2 Search’s ability to align its search strategy with the nuances of constructing a well-supported answer, thereby improving the precision of its information retrieval in a complex diagnostic scenario.
<details>
<summary>x7.png Details</summary>
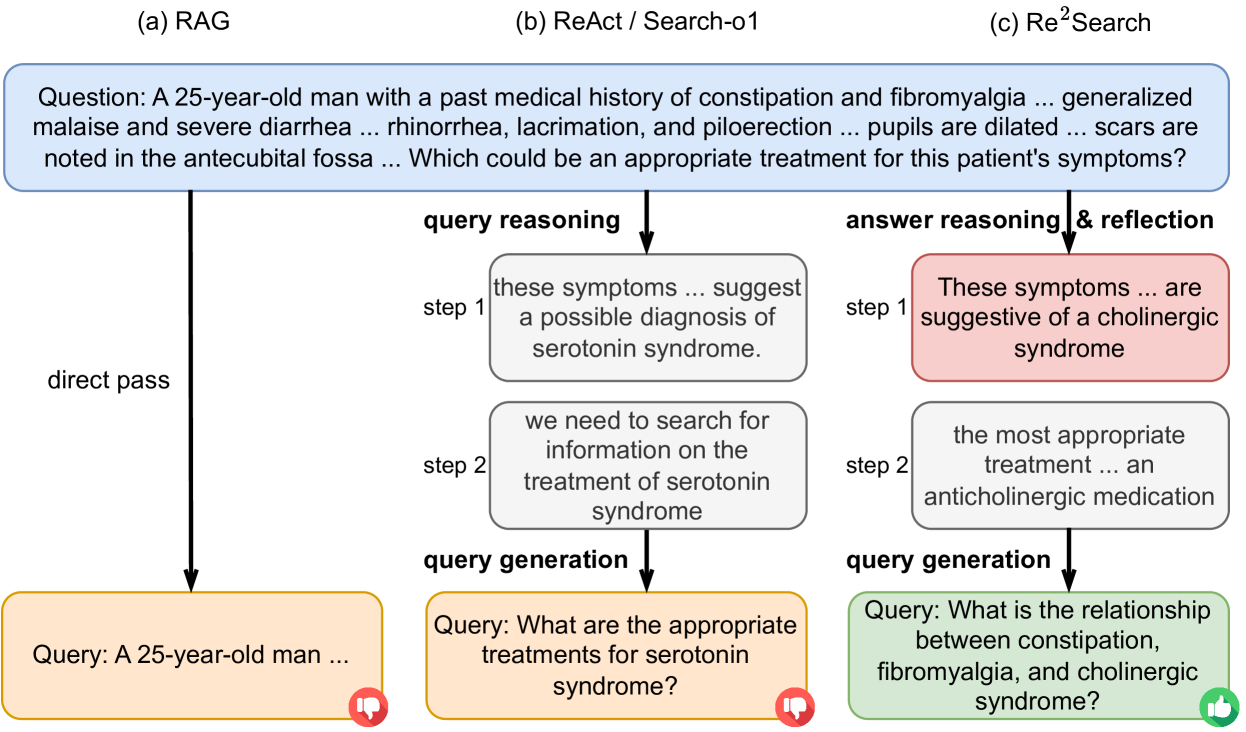
### Visual Description
## Flowchart: Comparison of Question Answering Systems
### Overview
The image presents a flowchart comparing three different question-answering systems: RAG, ReAct/Search-01, and Re²Search. Each system processes a medical question about a patient's symptoms, illustrating their respective approaches to query reasoning, answer reasoning/reflection, and query generation. The flowchart highlights the steps involved in each system and the final query generated.
### Components/Axes
* **Titles:**
* (a) RAG (top-left)
* (b) ReAct / Search-01 (top-center)
* (c) Re²Search (top-right)
* **Initial Question (Top):** "Question: A 25-year-old man with a past medical history of constipation and fibromyalgia ... generalized malaise and severe diarrhea ... rhinorrhea, lacrimation, and piloerection ... pupils are dilated ... scars are noted in the antecubital fossa ... Which could be an appropriate treatment for this patient's symptoms?" (Presented in a blue rounded rectangle, common to all three systems)
* **Flow Direction:** Top to bottom, indicated by arrows.
* **Nodes:** Representing steps in the reasoning and query generation process.
* **Feedback Icons:** Thumbs up and thumbs down icons at the bottom of each system's flow.
### Detailed Analysis or Content Details
**System (a): RAG**
* **Process:** Direct pass from the initial question to query generation.
* **Query Generation (Orange):** "Query: A 25-year-old man ..."
* **Feedback:** Thumbs down (red).
**System (b): ReAct / Search-01**
* **Query Reasoning:**
* **Step 1 (Gray):** "these symptoms ... suggest a possible diagnosis of serotonin syndrome."
* **Step 2 (Gray):** "we need to search for information on the treatment of serotonin syndrome."
* **Query Generation (Orange):** "Query: What are the appropriate treatments for serotonin syndrome?"
* **Feedback:** Thumbs down (red).
**System (c): Re²Search**
* **Answer Reasoning & Reflection:**
* **Step 1 (Red):** "These symptoms ... are suggestive of a cholinergic syndrome."
* **Step 2 (Gray):** "the most appropriate treatment ... an anticholinergic medication"
* **Query Generation (Green):** "Query: What is the relationship between constipation, fibromyalgia, and cholinergic syndrome?"
* **Feedback:** Thumbs up (green).
### Key Observations
* RAG directly uses the initial question for query generation.
* ReAct/Search-01 performs query reasoning in two steps before generating a query focused on serotonin syndrome treatment.
* Re²Search performs answer reasoning and reflection, suggesting a cholinergic syndrome, before generating a query about the relationship between multiple conditions.
* The feedback icons indicate that Re²Search is considered the most appropriate approach, while RAG and ReAct/Search-01 are not.
### Interpretation
The flowchart illustrates different strategies for question answering in a medical context. RAG represents a basic approach, directly using the question to form a query. ReAct/Search-01 attempts to refine the query by reasoning about the symptoms and potential diagnoses. Re²Search goes further by reflecting on potential answers and generating a query that explores the relationships between different medical conditions. The positive feedback for Re²Search suggests that a more nuanced and reflective approach to query generation can lead to better results in complex medical question answering. The negative feedback for RAG and ReAct/Search-01 suggests that these approaches may be too simplistic for the given question.
</details>
Figure 7: Comparison of different agent architectures in handling a multi-hop question from MedQA.
G.3 Critic-Guided Action Selection in MedQA
Table 6: An example of how PRM helps identify high-quality actions that lead to correct answers. The unverified claims in the presented example are highlighted.
| MedQA Question |
| --- |
| Question: A 60-year-old woman presents to a physician for worsening shortness of breath and increasing abdominal distention over the last 3 months. She says that the shortness of breath is worse on exertion and improves with rest. While she could previously walk to the nearby store for her groceries, she now has to drive because she gets ”winded” on the way. The patient was diagnosed with diabetes 5 years ago and is compliant with her medications. The medical history is otherwise unremarkable. The physical examination reveals gross ascites and visibly engorged periumbilical veins. Bilateral pitting edema is noted around the ankles. The finger-prick blood glucose level is 100 mg/dL. What is the mechanism of action of the anti-diabetic medication this patient is most likely taking? A. Binding to the alpha subunit of the insulin receptor, B. Closure of ATP-sensitive K-channels in the pancreatic beta-cell, C. Increased gene expression of GLUT-4, D. Glucagon-like peptide-1 receptor agonist |
| Answer (invisible): C |
| Action 1 |
| [Candidate 1 – Reasoning] … |
| [Candidate 1 – Action] |
| Query: What is the primary concern with the patient’s condition, specifically whether heart failure is confirmed based on symptoms and physical examination findings? \faThumbsDown |
| [Candidate 2 – Reasoning] |
| 1. The patient presents with worsening shortness of breath, increasing abdominal distention, and gross ascites. These symptoms, along with visibly engorged periumbilical veins and bilateral pitting edema, are indicative of fluid overload and congestive heart failure. |
| 2. The patient’s history of diabetes, which is compliant with medication, suggests that her anti-diabetic medication is likely a type of oral hypoglycemic agent rather than insulin. |
| 3. Considering the patient’s age (60 years) and symptoms, it is unlikely that she is taking a glucagon-like peptide-1 (GLP-1) receptor agonist, which is typically used in younger patients with type 2 diabetes and has a different side-effect profile. |
| 4. With the remaining options, ’Binding to the alpha subunit of the insulin receptor’ and ’Closure of ATP-sensitive K-channels in the pancreatic beta-cell’, we can narrow down the possibilities. ’Binding to the alpha subunit of the insulin receptor’ is more characteristic of insulin receptor agonists or insulin itself, which is unlikely given the patient’s age and the oral nature of her medication. Therefore, ’Closure of ATP-sensitive K-channels in the pancreatic beta-cell’ is the most plausible mechanism of action. |
| 5. This mechanism is consistent with the sulfonylureas class of medications, which are commonly used in patients with type 2 diabetes. |
| [Candidate 2 – Action] |
| Query: What are common classes of oral anti-diabetic medications? \faThumbsUp |
| Environment Feedback 1 |
| [+ Documents] |
| Common classes of oral anti-diabetic medications include: 1. Sulfonylureas, 2. Dipeptidyl Peptidase IV (DPP IV) inhibitors (gliptins), 3. Thiazolidinediones, 4. Meglitinides, 5. Sodium-glucose co-transporter 2 (SGLT 2) inhibitors, 6. Alpha-glucosidase inhibitors, 7. Biguanides (metformin). |
| Action 2 |
| [Candidate 1 – Reasoning] … |
| [Candidate 1 – Action] |
| Query: Is metformin commonly prescribed for type 2 diabetes and known to cause lactic acidosis as a side effect? \faThumbsDown |
| [Candidate 2 – Reasoning] … |
| [Candidate 2 – Action] |
| Query: What is the mechanism of action of Biguanides (metformin)? \faThumbsUp |
| Environment Feedback 2 |
| [+ Documents] |
| The mechanism of action of Biguanides (metformin) is to activate the enzyme AMP-activated protein kinase (AMPK) and reduce hepatic glucose production. |
| Action 3 |
| [Candidate 1 – Reasoning] … [Candidate 1 – Action] Answer: B \faThumbsDown |
| [Candidate 2 – Reasoning] … [Candidate 2 – Action] Answer: C \faThumbsUp |
To illustrate how the trained critic improves decision-making, we examine a case from the MedQA dataset (Table 6). The model is tasked with identifying the mechanism of action of the most likely anti-diabetic medication for a 60-year-old patient presenting with symptoms indicative of fluid overload.
For the generation of the first action, the agent initially generates a broad and less actionable query about heart failure, which, while relevant, does not directly contribute to identifying the correct medication. Meanwhile, it also provides another candidate action with the query “What are common classes of oral anti-diabetic medications?", which leads to retrieving a structured list of relevant drug categories. The process reward model estimates the quality of these two candidates and identifies the second candidate as the better action.
As the reasoning progresses, the process reward model continues to refine action selection, identifying the best queries to resolve missing information efficiently. The rewarded queries ultimately guide the agent toward correctly inferring that the medication is most likely to be Biguanides (metformin), which acts by increasing gene expression of GLUT-4. This case demonstrates how process reward models enhance decision quality by selecting queries that effectively bridge knowledge gaps, leading to more precise reasoning and higher answer accuracy.
Appendix H Prompt Templates
We provide structured prompt templates for history knowledge summarization and action generation in our proposed Re 2 Search agent. The template in Figure 8 ensures that retrieved documents are summarized concisely and factually for follow-up queries. Figure 9 shows the prompt template used by Re 2 Search to align the answer construction with query formulation. The prompt of using GPT-4o for process reward data annotation is presented in Figure 10. Prompt template for history knowledge summarization in Search-o1 and Re 2 Search
You are a helpful assistant tasked with answering a follow-up query using the relevant documents provided. ### Relevant Documents {{documents}} ### Context Original question: {{question}} ### Follow-up Query {{query}} Answer the follow-up query succinctly, using only the information from the documents. When the documents do not provide sufficient information, explicitly point this out instead of making up facts. Do not include unrelated or excessive details in the response.
Figure 8: Template used for history knowledge summarization in Search-o1 and Re 2 Search. Prompt template for generating actions using the Re 2 Search agent
You are a helpful assistant. Your task is to answer a given question following user instructions.’ ### Information-seeking History {{history}} ### Original Question {{question}} Your output must include three sections: 1. **### Step-by-step Reasoning**: - Think step-by-step and then answer the question. 2. **### Unverified Claim Identification**: - Identify if there are claims in the step-by-step reasoning section that are not grounded in the information-seeking history section. - If yes, summarize the first piece of missing information as an atomic query to search in an external knowledge base. - If no, clearly state that no further query is needed. 3. **### Structured Output**: - Present your predicted answer and generated query (if applicable) in the following JSON format: “‘json { “predicted_answer": “Provide a single letter (for multiple-choice questions), digit, word, or short phrase here.", “generated_query": “Provide an entity, question, or statement to be searched in an external knowledge base. Output \“None\" if no query is generated.", } “‘
Figure 9: Template used to generate actions for the Re 2 Search agent. Prompt template for ranking candidate actions with GPT-4o
You are a decision-evaluation assistant. Your task is to rank the proposed actions from the most appropriate to the least appropriate as the next step in a sequential decision-making process aimed at solving a given question. ### Original Question: {{question}} ### Information-Seeking History: {{curr_history}} ### Proposed Next Actions: {{actions_text}} ### Important Assumption The agent has no prior knowledge about the subject matter. It must rely solely on the information-seeking history provided to evaluate and answer the original question. Assumptions not explicitly supported by the history must not influence the ranking of proposed actions. ### Evaluation Criteria for Appropriateness 1. **Sufficiency Check**: - Determine whether the available information is sufficient to directly answer the original question. If not, the proposed action to “Answer” is inappropriate. - Prioritize queries that gather specific, missing information essential to solving the question. - If the history already contains all necessary information, then “Answer” is the most appropriate action, and the correct answer should be ranked highest. 2. **Utility Check**: - Queries must be precise, actionable, and directly relevant to solving the question. - Prioritize foundational queries that establish critical context or general knowledge necessary for more specific follow-ups. - Rank overly narrow or prematurely specific queries lower if they presume knowledge not yet available. - Avoid irrelevant queries that do not contribute to solving the original question. 3. **Redundancy Check**: - Queries that duplicate information already covered in the history or repeat previous queries should be ranked lower. - Proposed actions must add new value to the decision-making process by seeking new or clarifying missing information. ### Expected Output Format - Output the indices of the ranked actions in JSON format: “‘json{“ranked_indices”: [list of indices]}”’. - Rank actions from most appropriate to least appropriate based on the evaluation criteria above. - Do not provide additional explanations or reasoning.”’
Figure 10: Template used by GPT-4o to rank action candidates given the state.