# Learning to Retrieve and Reason on Knowledge Graph through Active Self-Reflection
> Corresponding author.
## Abstract
Extensive research has investigated the integration of large language models (LLMs) with knowledge graphs to enhance the reasoning process. However, understanding how models perform reasoning utilizing structured graph knowledge remains underexplored. Most existing approaches rely on LLMs or retrievers to make binary judgments regarding the utilization of knowledge, which is too coarse. Meanwhile, there is still a lack of feedback mechanisms for reflection and correction throughout the entire reasoning path. This paper proposes an A ctive self- R eflection framework for knowledge G raph reasoning (ArG), introducing for the first time an end-to-end training approach to achieve iterative reasoning grounded on structured graphs. Within the framework, the model leverages special tokens to actively determine whether knowledge retrieval is necessary, performs reflective critique based on the retrieved knowledge, and iteratively reasons over the knowledge graph. The reasoning paths generated by the model exhibit high interpretability, enabling deeper exploration of the model’s understanding of structured knowledge. Ultimately, the proposed model achieves outstanding results compared to existing baselines in knowledge graph reasoning tasks.
Learning to Retrieve and Reason on Knowledge Graph through Active Self-Reflection
Han Zhang 12 , Langshi Zhou 2, Hanfang Yang 12 thanks: Corresponding author. 1 Center for Applied Statistics, Renmin University of China 2 School of Statistics, Renmin University of China {hanzhang0816,zhoulangshi,hyang}@ruc.edu.cn
## 1 Introduction
Knowledge graph (KG), offering structured, explicit, and interconnected knowledge representation, serves as a highly promising external knowledge source to augment large language models (LLMs). However, efficiently understanding structured graphs remains a significant challenge. Mainstream approaches can typically be categorized into two main types: Information Retrieval (IR)-based methods and Semantic Parsing (SP)-based methods. Specifically, IR-based methods enhance the generation process by retrieving related entities, relations, triplets or relation paths Luo et al. (2023) from KGs. SP-based methods generate structured logical forms (e.g., S-expression Gu et al. (2021), SPARQL Pérez et al. (2006)) and directly interact with KGs to obtain precise answers. Recently, LLM-based approaches have leveraged the reasoning capabilities of LLMs to derive answers in a step-wise and training-free manner Jiang et al. (2023a); Gu et al. (2023); Sun et al. (2023).
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: Comparison of Information Retrieval Methods for a Knowledge Graph Query
### Overview
The image is a technical diagram comparing three different methods for answering the factual question: **"[Q] Where do the Appalachian Mountains run?"**. It visually contrasts the processes and outcomes of a "Directly Retrieve" method, an "LLM Prune" method, and an "ARG" (likely Augmented Retrieval/Generation) method. The diagram is structured into three horizontal sections, each dedicated to one method, showing the flow from a topic entity through retrieved relations to a final result.
### Components/Axes
The diagram is organized into three main horizontal lanes, each with a consistent column structure defined by labels at the bottom:
1. **Topic Entity** (Leftmost column): The subject of the query, "Appalachian Mountains," presented in a light green rounded rectangle.
2. **Relation Retrieved** (Middle column): A list of potential knowledge graph relations connected to the topic entity, shown in light pink rectangles.
3. **Assessment** (Present only in the ARG section): A column evaluating the relevance of each retrieved relation.
4. **Result** (Rightmost column): The outcome of the process for each relation or the final answer, indicated by icons (red X, green checkmark, grey prohibition sign, or a dashed circle for pruned items).
**Legend/Key:** The column labels ("Topic Entity", "Relation Retrieved", "Assessment", "Result") are written in blue italic text at the bottom of the diagram, serving as a key for the columns above.
### Detailed Analysis
#### **Section 1: Directly Retrieve**
* **Process:** The topic entity "Appalachian Mountains" is used to directly retrieve relations from a knowledge base.
* **Retrieved Relations & Results:**
1. `mountain_range.mountains` -> Result: Red X (Incorrect/Irrelevant).
2. `river.origin` -> Result: Red X (Incorrect/Irrelevant).
3. `mountain.mountain type` -> Result: Red X (Incorrect/Irrelevant).
* **Outcome:** All three directly retrieved relations lead to incorrect or irrelevant results for answering the question.
#### **Section 2: LLM Prune**
* **Process:** The topic entity "Appalachian Mountains" is processed by an LLM (indicated by a brain-like icon) to prune retrieved relations.
* **Retrieved Relations, Actions, & Results:**
1. `mountain_range.mountains` -> Action: "Keep" -> Result: Red X (Incorrect/Irrelevant).
2. `mountain_range.passes` -> Action: "Keep" -> Result: Red X (Incorrect/Irrelevant).
3. `location.contained_by` -> Action: "Prune" -> Result: Dashed circle (Relation discarded).
* **Outcome:** The LLM-based pruning keeps two relations that are still incorrect and prunes a potentially relevant one (`location.contained_by`).
#### **Section 3: ARG (Augmented Retrieval/Generation)**
* **Process:** The topic entity "Appalachian Mountains" undergoes a more sophisticated retrieval and assessment process.
* **Retrieved Relations, Assessments, & Results:**
1. `mountain_range.mountains` -> Assessment: `[Unrelevant]` -> Action: "Prune" -> Result: Dashed circle.
2. `mountain.mountain_range` -> Assessment: `[Fully Relevant]` -> Result: **"North America"** in a green box with a green checkmark (Correct Answer).
3. `location.contained_by` -> Assessment: `[Partially Relevant]` -> Result: **"North America"** (Contributes to the correct answer).
4. `mountain_range.passes` -> Assessment: `[Partially Relevant]` -> Action: `[Unreasonable]` -> Result: Grey prohibition sign (Discarded as unreasonable).
* **Outcome:** The ARG method successfully identifies the correct answer, "North America," by assessing the relevance of different relations. It uses the `[Fully Relevant]` relation `mountain.mountain_range` and the `[Partially Relevant]` relation `location.contained_by` to arrive at the answer, while pruning irrelevant or unreasonable relations.
### Key Observations
1. **Methodological Progression:** The diagram shows a clear progression from a naive retrieval method (Direct) to a simple filtering method (LLM Prune) to a more advanced, assessment-based method (ARG).
2. **Critical Relation:** The relation `location.contained_by` is pivotal. It is incorrectly pruned by the LLM Prune method but is correctly identified as `[Partially Relevant]` by the ARG method, contributing to the correct answer.
3. **Assessment Labels:** The ARG method introduces explicit relevance assessments (`[Unrelevant]`, `[Fully Relevant]`, `[Partially Relevant]`) and a reasonableness check (`[Unreasonable]`), which are absent in the other methods.
4. **Visual Coding:** Results are consistently coded: Red X for failure, green checkmark for success, dashed circle for pruned items, and a grey prohibition sign for discarded unreasonable items.
### Interpretation
This diagram illustrates a core challenge in knowledge graph question answering: retrieving the correct relational path to answer a natural language query. It argues for the superiority of an ARG-style approach over simpler retrieval or LLM-based pruning.
* **What it demonstrates:** The "Directly Retrieve" method fails because it retrieves relations that are structurally connected but semantically irrelevant to the *question's intent* (e.g., knowing the mountains within a range doesn't tell you where the range runs). The "LLM Prune" method shows a limitation of using an LLM for filtering without deep semantic assessment—it keeps some irrelevant relations and, crucially, prunes a potentially useful one (`location.contained_by`).
* **Why ARG succeeds:** The ARG method's success hinges on its **assessment layer**. It doesn't just retrieve or prune; it evaluates the *relevance* of each relation to the specific question. The relation `mountain.mountain_range` (which likely links individual mountains to their parent range) is assessed as `[Fully Relevant]`, providing a direct path. The relation `location.contained_by` is `[Partially Relevant]`, offering supporting geographical context. By combining these assessed insights, ARG converges on the correct answer, "North America."
* **Underlying Message:** The diagram advocates for AI systems that can perform **semantic reasoning over structural knowledge**. It suggests that effective question answering requires not just accessing data (relations) but understanding their contextual relevance to the query, a task where structured assessment outperforms simple retrieval or generic LLM pruning.
</details>
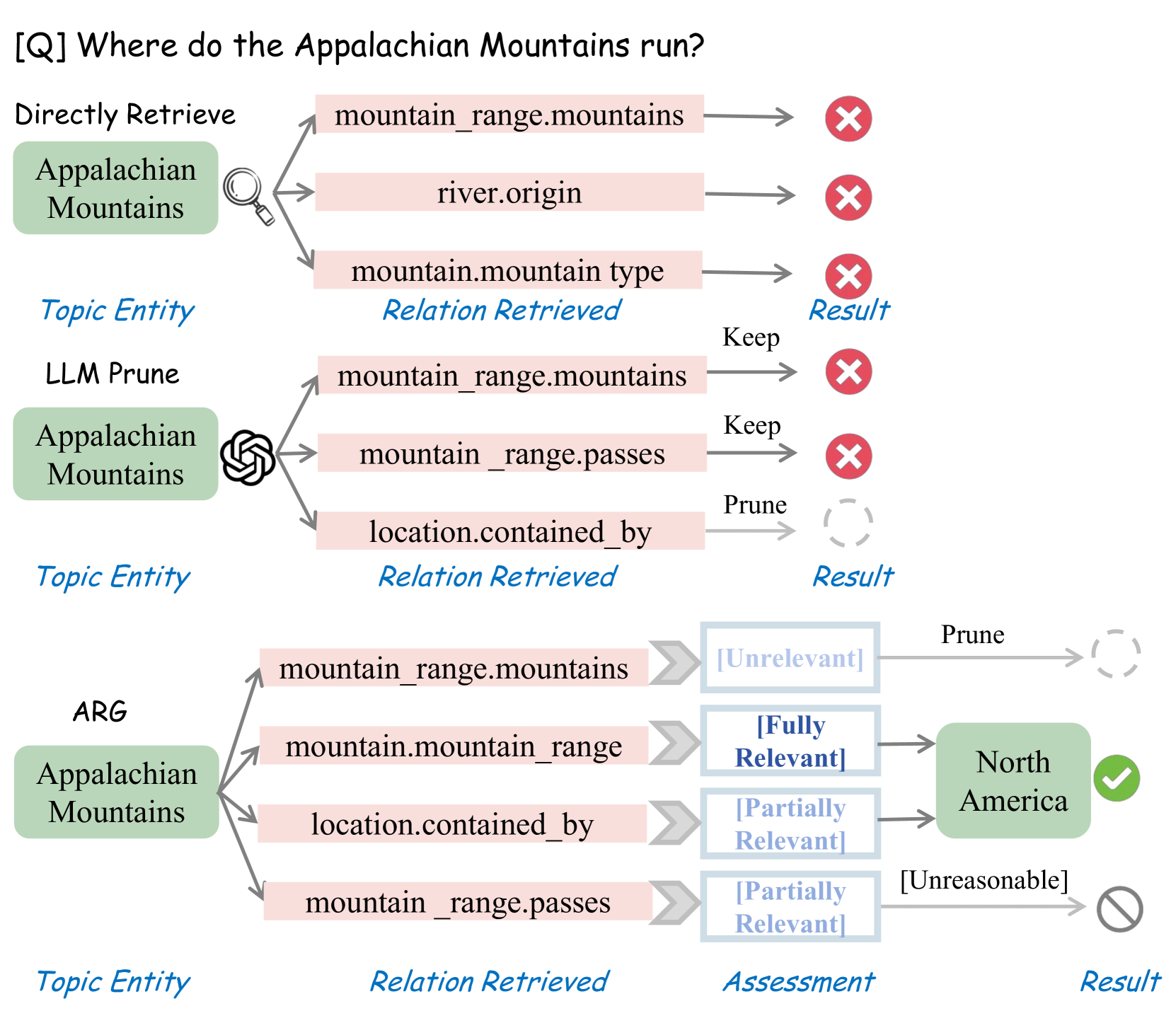
Figure 1: An example of ArG performs a more fine-grained assessment and actively retrieves knowledge (relations) compared to LLM pruning and direct retrieval.
The existing methods still face notable limitations. SP-based methods are robust but require the annotation of high-quality, and often expensive, logical forms as supervision Zhang et al. (2022). Furthermore, these methods struggle to capture the procedural information underlying the comprehension of structured knowledge graphs, rendering the workflow overly "black-box". IR-based methods typically adopt a retrieve and generate framework. However, due to the disparity between natural language and structured graph knowledge, traditional approaches exhibit low retrieval efficiency Robertson and Zaragoza (2009); Izacard et al. (2022); Gao et al. (2021). LLM-enhanced methods are more computationally efficient but demand meticulous prompt design. Approaches like Sun et al. (2023); Jiang et al. (2023a) are inflexible by relying solely on LLMs to decide whether to adopt a certain instance of knowledge (e.g., triplets in KG).
In consideration of all existing methodologies, we raise three practical yet remain underexplored issues: (i) Lack of specific relevance score assessment. Most methods either directly retrieve or rely on LLMs for binary pruning, failing to assess to what extent the retrieved knowledge contributes to the query, as illustrated in Figure 1. (ii) Low retrieval efficiency. The representation of relations in KGs, such as Freebase Bollacker et al. (2008), differs from natural language questions. At the same time, numerous candidates with high lexical similarity exist. Conventional retrieval methods exhibit low efficiency and often overlook implicit relationships within the structured graph Liu et al. (2024). (iii) Lack of rational self-reflection. During iterative reasoning, it is crucial to terminate exploration of unreasonable paths in a timely manner. Evaluating the coherence of intermediate reasoning steps and the reliability of the final answer is essential for improving the model’s step-by-step reasoning over structured graphs.
Inspired by the rapid advancements in LLM for text embedding Wang et al. (2024) and Retrieval-Augmented Generation (RAG) Asai et al. (2023); Zhang et al. (2024b), this study introduces the ArG framework, which integrates specialized self-reflection tokens to enhance reasoning capabilities when interacting with structured graph data. By utilizing reasoning paths within the graph as weak supervision signals, the model is trained end-to-end to enable on-demand retrieval and reflective reasoning over knowledge graphs. At each step of the iterative reasoning process, the model determines whether retrieval is necessary. If so, it evaluates the relevance of the retrieved knowledge to the query (e.g., relations and entities) and assigns a rationality score based on the current reasoning path. Otherwise, it derives the final answer, accompanied by an evaluation of the answer’s utility. The reasoning process of ArG unfolds as a reasoning tree. Specifically, the candidates generated at each step form the nodes of the tree, enabling parallel expansion of downstream paths. Ultimately, the final score for each leaf node is computed based on backtracking the scores along its path.
In summary, our primary contributions include: (i) We propose an end-to-end training framework that enables the model to perform iterative reasoning over structured graph while actively deciding whether to retrieve knowledge. (ii) We innovatively introduce special tokens in graph reasoning tasks, equipping the model with the capability to evaluate and self-reflect on its reasoning process. (iii) We introduce a hypo-generator during the inference process to enhance retrieval efficiency.
## 2 Related Work
Knowledge Graph Question Answering. Traditional methods represent entities and relations within an embedding space, leveraging specifically designed model architectures such as Key-Value Memory Networks Miller et al. (2016); Das et al. (2017), as well as seq2seq frameworks like LSTM-based Sun et al. (2018) and T5-based Shu et al. (2022) networks. Recently, leveraging the powerful reasoning capabilities of LLMs, diverse methods have emerged for knowledge graph question answering. Prompt-based approaches, such as KB-BINDER Li et al. (2023), uses few-shot examples to guide the model in generating credible logical forms. Graph-CoT Jin et al. (2024) incorporates Chain-of-Thought (CoT) reasoning to encourage multi-step reasoning over KGs. ToG Sun et al. (2023) iteratively explores related entities and relations on KGs based on LLM-driven reasoning.
Other methods, such as Jiang et al. (2023a) and Xiong et al. (2024), enable iterative KG-based operations by integrating pre-defined functions as an interaction interface. Similarly, Jiang et al. (2024a) treat LLMs as intelligent agents, generating instruction data through KG reasoning programs for fine-tuning the base LLM. In contrast to these prompt-based approaches, we employ an end-to-end training framework, wherein distinct instruction tasks are explicitly defined during the data collection phase while simultaneously enabling procedural reasoning during the inference stage.
<details>
<summary>x2.png Details</summary>
### Visual Description
## [Diagram]: Multi-Step Reasoning Process for Question Answering
### Overview
The image is a detailed flowchart illustrating a multi-step reasoning and retrieval process used by an AI system to answer a factual question. The process begins with a question and a topic node, proceeds through iterative cycles of relation and entity retrieval, relevance evaluation, and critique, and concludes with a final answer and a utility score. The diagram is structured horizontally, with a primary flow from left to right across the top half, and a secondary, iterative loop in the bottom half. A "[Reasoning Paths]" section at the very bottom summarizes the successful path taken.
### Components/Axes
The diagram is composed of several distinct visual components and text labels:
**1. Header/Question:**
* **Text:** `[Q] What type of government is used in the country with Northern District?`
* **Position:** Top-left, in a light blue banner.
**2. Primary Flow (Top Half):**
This section depicts the initial reasoning steps to identify a relevant country.
* **Topic node:** A green box labeled `Northern District`.
* **Relation Candidates:** A list of potential database relations:
* `location.administrative_division.country (l.a.ct.)`
* `location.location.containedby (l.l.c)`
* `location.country.administrative_divisions (l.c.a.)`
* `location.administrative_division.capital (l.a.cp.)`
* **Relevance Token (for Relations):** A vertical list evaluating the above relations: `[Relevant]`, `[Partially]`, `[Partially]`, `[Unrelevant]`.
* **Entity Candidates:** A list of potential entities derived from the relevant relation:
* `(Northern District, l.a.ct., Israel)`
* `(Northern District, l.l.c., Nazareth)`
* `(Northern District, l.c.a., Israel)`
* **Relevance Token (for Entities):** A vertical list evaluating the above entities: `[Relevant]`, `[Unrelevant]`, `[Relevant]`.
* **Intermediate node:** A green box labeled `Israel`.
* **Rationality Token:** A blue box labeled `[Reasonable]`.
* **Process Blocks (Purple):** `Relation Retrieval` and `Entity Retrieval`.
* **Process Blocks (White):** `Query`, `Hypo-Generator`, `Retriever`, `Critique` (x2), `Reflection`.
* **Data Store:** An orange cylinder labeled `Relations cache`.
* **Numbered Steps (1-5):** Grey circles with numbers, each with a descriptive label:
1. `Retrieve relationship on demand`
2. `Evaluate relevance`
3. `Retrieve entity`
4. `Evaluate relevance`
5. `Critique reasoness` [sic - likely "reasoning"]
**3. Iterative Loop (Bottom Half):**
This section shows the process continuing from the intermediate node to find the final answer.
* **Intermediate node:** A green box labeled `Israel`.
* **Tail node:** A green box labeled `Parliamentary system`.
* **Output:** A green box labeled `Parliamentary system` with a green checkmark.
* **Retrieval Token:** A purple box labeled `Relation Retrieval` and a yellow box labeled `No Retrieval`.
* **Utility Token:** A blue box labeled `[Utility: 5]`.
* **Numbered Steps (6-7):**
6. `Iterate until retrieval is no longer needed`
7. `Provide the output and the utility score`
**4. Reasoning Paths (Bottom Section):**
A summary box titled `[Reasoning Paths]` visually maps the successful sequence:
* **Path 1:** `Northern Distric` [sic] -> `[Relation Retrieval]` -> `location.administrative_division.country` -> `[Relevant]` -> `[Entity Retrieval]` -> `[Relevant]` -> `Israel` -> `[Reasonable]`
* **Path 2:** `Israel` -> `[Relation Retrieval]` -> `location.country.form_of_government` -> `[Relevant]` -> `[Entity Retrieval]` -> `[Relevant]` -> `Parliamentary system` -> `[Reasonable]` -> `[No Retrieval]`
* **Final Output:** `Answer:Parliamentary system [Utility: 5]`
### Detailed Analysis
The diagram meticulously breaks down the question-answering process into discrete, numbered stages:
1. **Stage 1 (Retrieve relationship):** Starting with the topic "Northern District," the system generates a query and uses a "Hypo-Generator" to propose potential relations from a "Relations cache." The relation `location.administrative_division.country` is identified as `[Relevant]`.
2. **Stage 2 (Evaluate relevance):** The relevance of the proposed relations is critiqued.
3. **Stage 3 (Retrieve entity):** Using the relevant relation, the system retrieves entity candidates. The triple `(Northern District, l.a.ct., Israel)` is evaluated as `[Relevant]`.
4. **Stage 4 (Evaluate relevance):** The relevance of the entity candidates is critiqued.
5. **Stage 5 (Critique reasoness):** The intermediate node "Israel" is generated and its rationality is assessed as `[Reasonable]`.
6. **Stage 6 (Iterate):** The process repeats from the new intermediate node "Israel." A new relation, `location.country.form_of_government`, is retrieved and deemed `[Relevant]`. This leads to the tail node "Parliamentary system." The system then determines `[No Retrieval]` is needed further.
7. **Stage 7 (Provide output):** The final answer "Parliamentary system" is output with a `[Utility: 5]` score, indicating high confidence or usefulness.
### Key Observations
* **Color Coding:** Green boxes represent knowledge nodes (Topic, Intermediate, Tail, Output). Purple boxes denote active retrieval processes. Blue boxes are evaluation tokens (Relevance, Rationality, Utility). Orange represents a data store.
* **Flow Direction:** The primary flow is linear (Steps 1-5), followed by an iterative loop (Steps 6-7). Arrows clearly indicate the direction of data and control flow.
* **Textual Detail:** All candidate relations and entities are explicitly listed with their abbreviations (e.g., `l.a.ct.`). The relevance evaluations are shown for each candidate.
* **Error/Typo:** The word "reasoness" in Step 5 is likely a typo for "reasoning." The name "Northern Distric" in the Reasoning Paths section is missing a 't'.
* **Utility Scoring:** The process concludes with a quantified utility score (`5`), suggesting a metric for answer quality.
### Interpretation
This diagram is a technical schematic of a **neuro-symbolic or retrieval-augmented generation (RAG) reasoning system**. It demonstrates how such a system can decompose a complex factual question ("What type of government...") into a series of simpler, verifiable sub-tasks.
* **What it demonstrates:** The system doesn't just know the answer; it *derives* it through a transparent, auditable process. It first grounds the ambiguous term "Northern District" by finding its containing country (Israel) using a knowledge base relation. It then queries the knowledge base again for that country's form of government.
* **Relationships between elements:** The "Relations cache" is the core knowledge source. The "Critique" and "Reflection" modules act as quality control gates, ensuring each step is logically sound before proceeding. The "Utility Token" provides a final confidence metric.
* **Notable patterns:** The process is **iterative and conditional**. Step 6 explicitly states "Iterate until retrieval is no longer needed," showing the system can chain multiple reasoning steps. The separation of "Relation Retrieval" and "Entity Retrieval" highlights a structured approach to querying knowledge graphs.
* **Underlying purpose:** The diagram argues for the robustness and interpretability of this AI architecture. By making each inference step explicit—from candidate generation to relevance scoring—it contrasts with "black box" models and provides a pathway for debugging and trust. The high utility score (5) for the correct answer ("Parliamentary system") validates the effectiveness of the depicted pipeline.
</details>
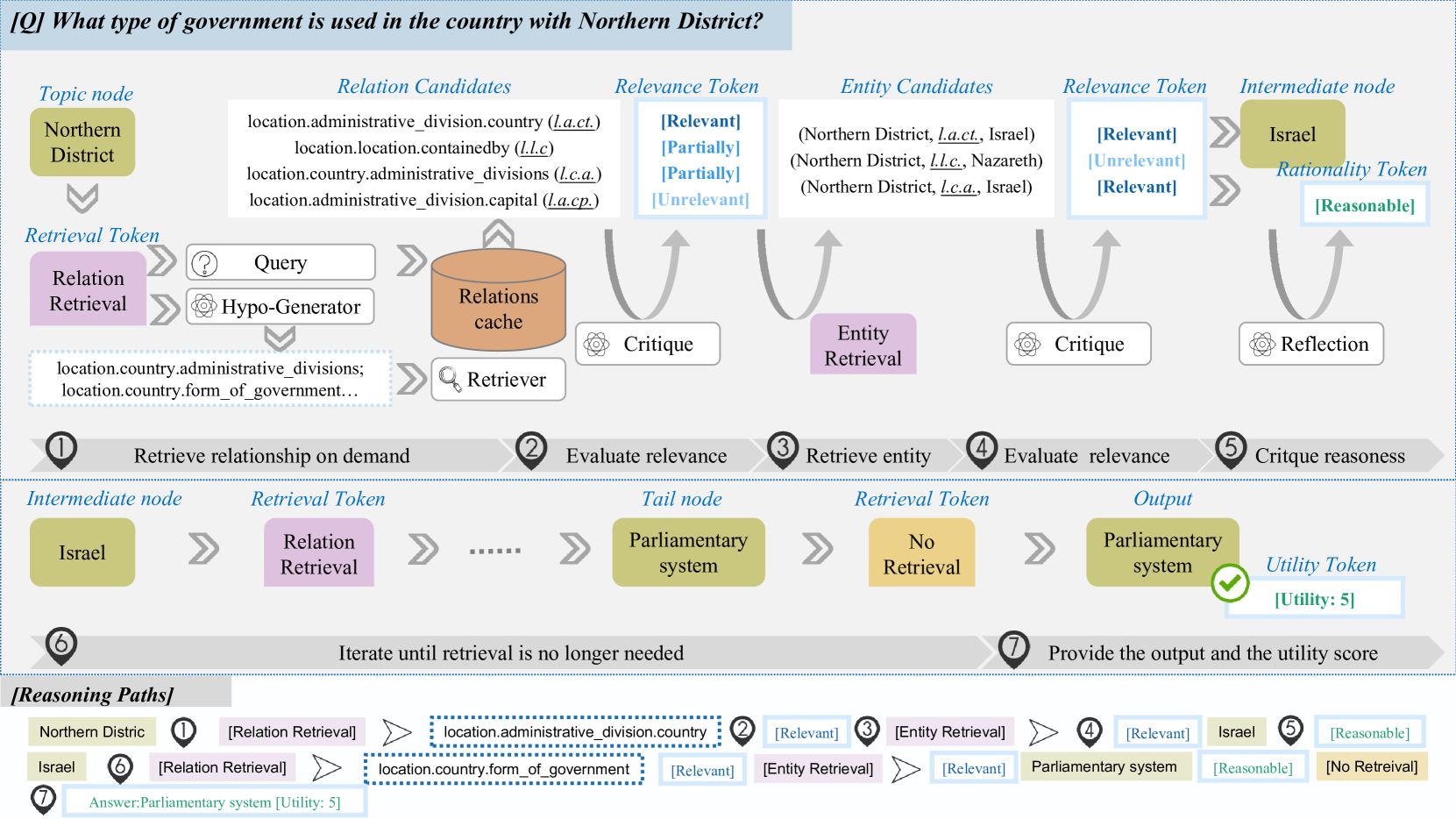
Figure 2: The overall framework of ArG. Given an input query, the trained generator model $M$ iteratively performs knowledge retrieval over the structual graph based on the retrieval token. Subsequently, the retrieved knowledge undergoes processes of critique and reflection, where implausible information is filtered. The iterative procedure culminates in the generation of an answer. ArG exhibits strong interpretability when applied to structured graph. As demonstrated in the example, the step-by-step reasoning path is organized in the lower half.
RAG with Knowledge Graph. Retrieval-Augmented Generation combines retrieved external knowledge with LLMs for improved task performance, incorporating domain-specific information to ensure factuality and credibility Guu et al. (2020). FLARE Jiang et al. (2023c) predicts upcoming sentences to adaptively retrieve relevant passages. Self-RAG Asai et al. (2023) learns to retrival on-demand guided by reflection tokens. OneGen further unifies retrieval and generation in one model. In the context of knowledge graphs, retrieval focuses primarily on graph databases rather than text corpora, necessitating additional consideration of relationships between texts and the structural information inside. GNN-RAG Mavromatis and Karypis (2024) integrate Graph Neural Networks (GNNs) with RAG to retrieve reasoning paths. TIARA Shu et al. (2022) and ChatKBQA Luo et al. (2024) enhance the generation of reliable logical forms by retrieving entities and relations from knowledge graphs. HyKGE Jiang et al. (2024b) leverages LLMs to explore feasible directions within medical knowledge graphs. Furthermore, Ji et al. (2024) advances the retrieval capabilities via CoT reasoning.
## 3 Preliminary
In this section, we introduce the fundamental concepts of the knowledge graph question answering (KGQA) task and the definition of reasoning paths.
KGQA. The task of KGQA requires predicting the correct answers based on reasoning over both free-form text $q$ and an inherently structured graph $G$ . The KG here consists of a set of triplets $(s,r,o)$ defined in the RDF format where $s$ is an entity, $r$ is the corresponding relation, and $o$ can be either an entity or a literal value. Each entity $e$ is uniquely identified by a MID and some have a friendly name, e.g., $e$ .id = "m.03_r3" with its friendly name "Jamaica". Relations in the Freebase KG are defined hierarchically, e.g., $r$ = "location.country.languages_spoken". We assume that the topic entities $\{e_q\}$ and the candidate answers $\{a\}$ are linked to the entities or values in $G$ .
Reasoning Path. We define a valid reasoning path $w$ of depth $D$ is a sequence of connected triplets connecting the topic entity $e_q$ and the answer $a$ , which can be also refereed to as a $D$ hop path:
$$
w_1:D=(e_q,r_1,e_1,⋯,r_D,a). \tag{1}
$$
Based on the iterative reasoning process, the objective of the KGQA task can be formulated as the optimization of the following function:
$$
P_θ(a|q,G)=E_w_{1:D∼ Q(w)}∏_i=1^DP_
θ(w_i|w_<i,q,G), \tag{2}
$$
where $Q(w)$ denotes the posterior distribution of the faithful reasoning path grounded in the KG.
## 4 Methodology
| Retrieval | {relation, entity, no} | trigger retrieval |
| --- | --- | --- |
| Relevance | {relevant, partially, unrelevant} | assess relevance with $q$ |
| Rationality | {reasonable, partially, unreasonable} | evaluate logical coherence |
| Utility | {5, 4, 3, 2, 1} | $a$ is a useful response to $q$ . |
Table 1: Four types of reflection tokens used in ArG. Each type uses several tokens to represent its output values. Details can be found in Appendix A
We propose A ctive Self- R eflection G raph Reasoning (ArG), as illustrated in Figure 2. ArG facilitates interpretable reasoning over knowledge graphs through the integration of four types of self-reflection tokens (see Table 1). The primary workflow during inference is detailed in Algorithm 1. The trained language model actively decides whether knowledge retrieval is necessary to answer the query, while continuously generating relevance assessments and rationality reflections throughout the graph reasoning process. The iterative process continues until the final answer and its associated utility score are produced. To further optimize retrieval efficiency during the retrieval stage, the trained model is additionally tasked with generating potential relation candidates to serve as supplementary inputs for the retriever. Ultimately, the final answer is derived from the reasoning tree constructed during the exploration process.
Require: Generator model $M$ , Retriever $R$ , KG $G$
Input: Topic entity $e_q$ and input query $q$
Output: predicted prediction tree $T$ .
Initialization: $T=[w_0],d=1,w_0=(e_q,)$
while $d$ $≤$ $D_max$ do
$M$ predicts Retrieval Token given $(q,w_<d)$ ;
if Retrieval Token == [Relation Retrieval] then
$\widehat{r_d}$ = $M(q,w_<d)$ ;
// Hypo-Generator
Retrieve relevant relationship $R$ using $R$ given $(q,e_d-1,\widehat{r_d})$ ;
foreach $r_d∈R$ do
$M$ predicts Relevance Token ;
if Relevance Token $\mathrel{\mathtt{!=}}$ [Unrelevant] then
Add $r_d$ to $w_d$ ;
else if Retrieval Token == [Entity Retrieval] then
Retrieve tail entities $E$ using $r_d$ ;
$M$ predicts Rationality Token ;
foreach $e∈E$ do
$M$ predicts Relevance Token ;
if Relevance Token $\mathrel{\mathtt{!=}}$ [Unrelevant] then
Add $e_d$ to $w_d$ ;
else if Retrieval Token == [No Retrieval] then
$M$ predicts Utility Token given $q,w_<d$ ;
Rank $w_d$ based on reflection score and append $w_d$ to $T$ ;
Algorithm 1 ArG Workflow
### 4.1 ArG Training
To emulate the inferential process within a graph structure, we construct the training dataset based on the reasoning paths. Reasoning paths Wang et al. (2021); Luo et al. (2023) are capable of capturing rich semantic information between entities. Each reasoning path can be regarded as a logically coherent walk over the knowledge graph.
Directly obtaining labeled inferential paths $W^*$ from the knowledge graph often proves to be challenging. Instead, we can typically leverage graph search algorithms to identify the shortest paths connecting the topic entity and the target candidates. While these paths may not always correspond to the optimal reasoning paths, they are grounded in the knowledge graph and offer valuable insights toward deriving the answer, as shown in the following Example.
Example. Given the question "Which countries border the US", one of the labeled reasoning paths is: $w$ = US $\xrightarrow{\texttt{adjoin}}$ Canada. At the same time, another valid reasoning path exists: $w^\prime$ = US $\xrightarrow{\texttt{contains}}$ Columbia River $\xrightarrow{\texttt{flow\_through}}$ Canada.
Although the latter path $w^\prime$ does not directly provide the adjacency information between the two countries, it uses the fact that the Columbia River flows through Canada and arrives at the correct entity. Consequently, we leverage the reasoning paths grounded within the graph and design curated self-reflection tasks to insert reflection tokens, ultimately training the generator model.
#### Weakly Supervised Data Collecter.
We summarize the process of data collection in Algorithm 2. We first extract the shortest paths connecting the questions and answers as supervisory reasoning paths, following RoG Luo et al. (2023). For each reasoning path, we augment it with candidate sets for both the relations and entities involved, which will be utilized for downstream relevance assessment. The retriever $R$ is employed to retrieve $K$ semantically relevant relations as candidate relations $C_r$ . Similarly, all tail nodes corresponding to the same relation at the current hop are retrieved as candidate entities $C_e$ .
For special token incorporation, we modularize each task with different instruction prompts and leverage critic model $C$ like GPT models https://platform.openai.com/docs/models for assessment, facilitating the efficient insertion of reflection tokens. We prompt the critic model with type-specific instructions, wherein relevant knowledge from the reasoning path is extracted and provided as input. Through few-shot demonstrations, the model produces the corresponding evaluation and reflection. For each reasoning path, we divide it into segments based on the number of hops. At each hop, we assess the relevance of both candidate entities and relations, while simultaneously evaluating the logical coherence of the current path. Retrieval tokens are inserted accordingly until the answer entity is reached. The utility of the final answer is evaluated at last. Ultimately, each reasoning path is assembled sequentially with self-reflection tokens. Notably, when the model predicts the reasoning as [Unreasonable], the retrieval process is immediately terminated, and the answer is added directly. This ensures that the training data avoids propagation through unreasonable paths. Moreover, the model can learn to provide responses based on its own knowledge when encountering unreasonable paths. We provide an example data from the training data in Figure 4. More details are provided in the Appendix D.
#### Generator Learning.
We train the generator model $M$ by training on the curated reasoning paths augmented with self-reflection tokens from $D_gen$ . We approximate the expectation with $K$ sampled valid paths $W_k^*⊆W^*$ , using the standard next token objective:
$$
\displaystyleL=\max_θE_(w,q,r)\log≤ft(P_θ
≤ft(r|w,q\right)P_θ≤ft(w|q,G\right)\right) \displaystyle∝∑_w∈W_k^*∑_i=1^D\log≤ft(P_
θ≤ft(r_i|w_≤ i\right)P_θ≤ft(w_i|w_<i,q,G
\right)\right), \tag{3}
$$
where $(w,q,r)$ is sampled from the distribution of $D_gen$ . The generator model $M$ learns to predict the next-hop path accompanied by the corresponding reflection tokens. During training, the loss is computed jointly for the retrieved knowledge (surrounded by <paragraph> and </paragraph> in Figure 4), enabling the model to concurrently learn the implicit mapping between queries and structural knowledge. The original vocabulary $V$ is expanded with all reflection tokens.
### 4.2 ArG Inference
Fine-grained reflection tokens provide a quantitative evaluation of the reasoning path. During the inference process, we employ a tree-based reasoning framework and assign a score derived from generation probability to each node. The scoring mechanism enables the effective pruning of redundant nodes. Additionally, by incorporating a hypothesis-enhancement method, we improve retrieval accuracy by actively generating candidates one future step forward during the relation retrieval process.
#### Hypo-Generator.
Direct retrieval based solely on coarse-grained retrievers or LLMs often suffers from low precision due to the inherent gap between the query and the underlying knowledge Ma et al. (2023); Zhang et al. (2024a). Moreover, the representation of relations (hierarchical in Freebase) in graphs does not always align with natural language. The issue is even more severe in automatically-constructed knowledge graphs Bi et al. (2024); Li et al. (2022). During the training phase, ArG learns the implicit associations between queries and structural knowledge by actively predicting retrieved relations from the graph. In the relation retrieval process during inference, the trained model predicts one more step for hypothetical relations. The predictions are transformed as additional input to the retriever. The output from the hypo-generator is aligned with the representation of relations in the graph, effectively bridging the gap between query representations and structured knowledge.
#### Tree-based inference.
During each retrieval step, the generator model is capable of processing multiple candidates (both relations and entities) in parallel, leading to the generation of diverse downstream reasoning paths. The parallel candidate sets collectively form a reasoning tree for the given query. Tree-based reasoning methods Yao et al. (2024); Feng et al. (2023); Wu et al. (2024) have recently been widely adopted to enhance the reasoning process. Unlike other approaches that train a separate reward model, our model leverages the evaluation of special tokens as a process reward model, enabling effective assessment of tree nodes within the graph. During inference time, we integrate both hard and soft constraints and adopt a hop-level beam search strategy, retaining the top- $B$ candidates with the highest relevance and logical coherence scores. Specifically, for any candidate with undesirable tokens generated (e.g., Unrelevant), we simply prune it. Otherwise, we proceed to explore based on the current candidate and compute scores derived from the generation probability of special tokens. For the leaf nodes of the tree, we traverse back through the entire tree to aggregate final scores. The detailed score mechanism can be found in Appendix E.
## 5 Experiments
### 5.1 Datasets and Evaluation Metrics.
We evaluate our proposed method and compare it with other methods on two widely-used KGQA benchmark datasets: WebQSP (Yih et al., 2016) and CWQ (Talmor and Berant, 2018). Specifically, WebQSP contains 4,737 natural language questions with SPARQL queries, with 3,098 in the training set and 1,639 in the testing set. CWQ contains 34,689 natural language questions with SPARQL queries, with 27,639 in the training set 3,519 in the validation set and 3,531 in the testing set. Both datasets are based on Freebase (Bollacker et al., 2008) KB. More details of datasets are in Appendix B.
### 5.2 Baselines.
We compare ArG with 13 baseline methods grouped into 3 categories: 1) Semantic Parsing(SP)-based methods, 2) Information Retrieval(IR)-based methods, and 3) LLM-based methods. More details of baselines are in Appendix C.
### 5.3 Experimental Settings.
#### Training details.
In total, we collect 29,117 training samples based on the training splits of WebQSP and CWQ. For the modular evaluation task of different self-reflection tokens, we employ GPT-4-mini considering computational costs and efficiency. During the training process, we use 4 NVIDIA A100 GPUs with 40GB memory to train the generator model. All models are trained for 3 epochs, with a batch size of 16 and a maximum learning rate of 1e-5. We use Deepspeed stage 3 Rajbhandari et al. (2020) for multi-GPU distributed training. For the efficient training framework, we utilize LlamaFactory Zheng et al. (2024). We employ LLama3-8b Dubey et al. (2024) as our base LLM backbone.
#### Inference settings.
For each hop-level segment, we employ a beam width of 3 by default. For the WebQSP dataset, the default search depth is set to 2, while for CWQ, the default search depth is 4. During the inference process, we utilize VLLM to accelerate reasoning. For the default retriever $R$ , we adopt bge-large-en-v1.5 Xiao et al. (2023). During the construction of training data and the retrieval process, the default number of retrieved items is set to $K=5$ .
Table 2: Results of different methods on WebQSP and CWQ. (We use underline to denote the second-best performance, bold to denote the best performance. $B$ stands for beam-width and Exhuasted means exhausted search.)
$$
\clubsuit \heartsuit \spadesuit B=1 B=3 \tag{2023}
$$
### 5.4 Main Results
We present in Table 2 the comparative results of ArG employing beam-width of $1$ and $3$ , as well as exhaustive search, with the baselines on the WebQSP and CWQ datasets. From the table, it is evident that our method achieves significant improvements on both datasets. Notably, ArG achieves state-of-the-art results on WebQSP. On CWQ, the model’s performance surpasses all IR-based and LLM-based models. Specifically, when compared to ToG, the latest graph-based iterative reasoning approach leveraging GPT-4, ArG ( $B=3$ ) achieves improvements of $7.6\$ and $4.8\$ , respectively. As the beam width increases, the performance of our model also improves. The outstanding performance of ArG underscores its capability to effectively explore knowledge within the graph and accurately identify plausible answers.
### 5.5 Ablation Study
We carry out an ablation study to assess the impact of various components and hyperparameters on the performance of ArG, as well as to explore the contribution of each type of self-reflection token.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Charts: Performance Metrics (Hit@1 and F1) vs. Depth and Width on WebQSP and CWQ Datasets
### Overview
The image contains four line charts arranged in a 2x2 grid. The charts display the performance of a system (likely a question-answering or retrieval model) on two datasets, **WebQSP** (top row) and **CWQ** (bottom row). Performance is measured by two metrics: **Hit@1** (blue line with circle markers) and **F1** (red line with square markers). The charts explore how these metrics change with two different parameters: **Depth** (left column) and **Width** (right column).
### Components/Axes
* **Titles:** Each chart has a title indicating the dataset: "WebQSP" (top-left, top-right) and "CWQ" (bottom-left, bottom-right).
* **Y-Axes (Dual Axis):**
* **Left Y-Axis:** Labeled "Hit@1". Scale ranges vary slightly per chart (e.g., 45-95 for WebQSP, 40-90 for CWQ).
* **Right Y-Axis:** Labeled "F1". Scale ranges are identical to the left axis for each respective chart.
* **X-Axes:**
* **Left Column Charts:** Labeled "Depth". Categories are discrete integers: 1, 2, 3, 4.
* **Right Column Charts:** Labeled "Width". Categories are: 1, 3, 5, and "Exhausted".
* **Legend:** Present in all charts. Contains two entries:
* Blue line with circle marker: "Hits@1" (Note: Label uses "Hits@1" while axis uses "Hit@1").
* Red line with square marker: "F1".
* **Legend Placement:** In the top-left and bottom-left charts, the legend is placed inside the plot area, roughly in the center-right region. In the top-right and bottom-right charts, the legend is placed in the top-left corner of the plot area.
### Detailed Analysis
#### **Chart 1: WebQSP vs. Depth (Top-Left)**
* **Trend Verification:**
* **Hit@1 (Blue):** Shows a sharp increase from Depth=1 to Depth=2, then plateaus.
* **F1 (Red):** Shows a moderate increase from Depth=1 to Depth=2, then plateaus with a slight upward trend.
* **Data Points (Approximate):**
* Depth=1: Hit@1 ≈ 69, F1 ≈ 52
* Depth=2: Hit@1 ≈ 90, F1 ≈ 65
* Depth=3: Hit@1 ≈ 90, F1 ≈ 65
* Depth=4: Hit@1 ≈ 91, F1 ≈ 67
#### **Chart 2: WebQSP vs. Width (Top-Right)**
* **Trend Verification:**
* **Hit@1 (Blue):** Shows a steady, gradual increase as Width increases.
* **F1 (Red):** Shows a steady, gradual decrease as Width increases.
* **Data Points (Approximate):**
* Width=1: Hit@1 ≈ 84, F1 ≈ 70
* Width=3: Hit@1 ≈ 90, F1 ≈ 65
* Width=5: Hit@1 ≈ 92, F1 ≈ 60
* Width=Exhausted: Hit@1 ≈ 94, F1 ≈ 53
#### **Chart 3: CWQ vs. Depth (Bottom-Left)**
* **Trend Verification:**
* **Hit@1 (Blue):** Shows a sharp increase from Depth=1 to Depth=2, then a slower, steady increase.
* **F1 (Red):** Shows a sharp increase from Depth=1 to Depth=2, then a slower, steady increase.
* **Data Points (Approximate):**
* Depth=1: Hit@1 ≈ 46, F1 ≈ 41
* Depth=2: Hit@1 ≈ 69, F1 ≈ 54
* Depth=3: Hit@1 ≈ 71, F1 ≈ 57
* Depth=4: Hit@1 ≈ 72, F1 ≈ 57
#### **Chart 4: CWQ vs. Width (Bottom-Right)**
* **Trend Verification:**
* **Hit@1 (Blue):** Shows a steady, gradual increase as Width increases.
* **F1 (Red):** Shows a slight initial plateau/increase from Width=1 to Width=3, followed by a steady decrease.
* **Data Points (Approximate):**
* Width=1: Hit@1 ≈ 62, F1 ≈ 54
* Width=3: Hit@1 ≈ 72, F1 ≈ 55
* Width=5: Hit@1 ≈ 76, F1 ≈ 52
* Width=Exhausted: Hit@1 ≈ 80, F1 ≈ 45
### Key Observations
1. **Depth vs. Width Trade-off:** Increasing **Depth** improves both Hit@1 and F1 metrics on both datasets, with the most significant gain occurring between depth 1 and 2. Increasing **Width** consistently improves Hit@1 but leads to a decline in F1, especially at higher widths.
2. **Dataset Comparison:** The system achieves higher absolute performance scores on the **WebQSP** dataset compared to the **CWQ** dataset across all conditions. The general trends, however, are consistent between the two datasets.
3. **"Exhausted" Width:** The "Exhausted" width condition yields the highest Hit@1 score in both WebQSP (~94) and CWQ (~80), but also the lowest or near-lowest F1 score for each respective dataset (WebQSP: ~53, CWQ: ~45).
4. **Metric Divergence with Width:** The gap between the Hit@1 and F1 lines widens as Width increases, indicating the two metrics are responding oppositely to this parameter.
### Interpretation
The data suggests a fundamental trade-off in the system's behavior when expanding search **width** versus **depth**.
* **Depth appears to enhance quality and precision.** Increasing the depth of search (perhaps the number of reasoning steps or hops in a knowledge graph) allows the system to find more correct top answers (higher Hit@1) while also improving the overall precision/recall balance (higher F1). The plateau after depth 2 suggests diminishing returns.
* **Width appears to enhance recall at the cost of precision.** Increasing the width (perhaps the number of parallel paths or candidates considered) makes it more likely the correct answer is found somewhere in the results (higher Hit@1). However, it also introduces more noise or incorrect candidates, which degrades the F1 score, which balances precision and recall. The "Exhausted" state represents the extreme of this strategy: maximizing the chance of finding the answer but with significant collateral noise.
Therefore, the choice between increasing depth or width depends on the application's priority. If finding the single best answer (Hit@1) is paramount and some noise is acceptable, a wider search is beneficial. If the overall quality and correctness of the answer set (F1) are critical, a deeper, more focused search is preferable. The consistent trends across two different datasets (WebQSP and CWQ) indicate this is a robust characteristic of the evaluated system.
</details>
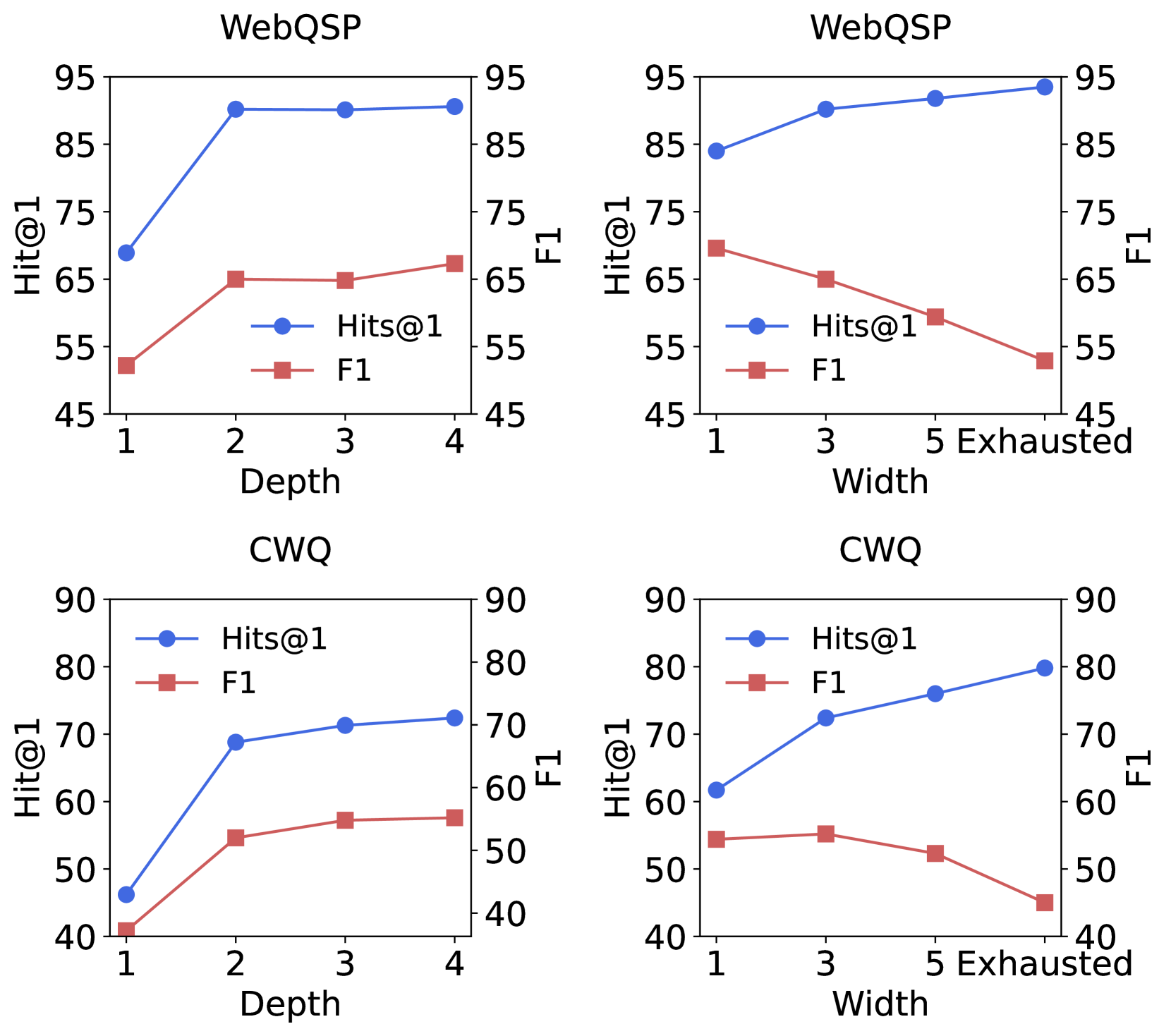
Figure 3: Ablation results of different reasoning depth and search depth on the WebQSP and CWQ.
Analysis of Search Depth & Width. To investigate the impact of reasoning depth and beam width on the performance of ArG, we conduct ablation experiments on the CWQ and WebQSP datasets. We vary the depth from $1$ to $4$ and the beam-width from $1$ to $5$ . Additionally, we adopt an exhaustive search during the retrieval process, retaining all valid nodes for expansion (excluding undesirable tokens). The results are presented in Figure 3. From the results, it can be observed that increasing the width and depth during reasoning significantly enhances the performance, demonstrating that ArG is capable of capturing deeper and broader effective information by improving the exploration range. For the WebQSP dataset, the decline in performance improvement when the hops exceed $2$ is attributed to the dataset’s focus on questions primarily within 2 hops. Meanwhile, broader reasoning, particularly with a wider retrieval width, may introduce noise, leading to increased uncertainty, as reflected in the changes in F1 scores. Therefore, selecting appropriate parameters is indeed necessary in practice.
Analysis of Self-Reflection Tokens. We further investigate the role of self-reflection tokens in ArG by conducting an ablation study on the WebQSP dataset. Specifically, during the reasoning process, we selectively removed the contributions of four types of scores, including Relevance, Rationality, Utility, and Sequence. The experimental results are illustrated in Figure 3. From the experimental results, we observe that removing either the Relevance or Rationality score individually leads to a slight decline in model performance. However, when both Relevance and Rationality scores are omitted, the model’s performance deteriorates significantly. This demonstrates the importance of both Relevance and Rationality and the complementary relationship of the two aspects. The most significant performance decline occurs when only the utility token is utilized. In this scenario, the model solely evaluates the quality of generations, which compromises the factuality of the reasoning process. With all scores integrated together, ArG achieves optimal performance.
Table 3: Ablation results for investigating the impact of special tokens, the check mark indicates the retention of the contribution of that particular token type to the final score.
| 1F5F8 | 1F5F8 | 1F5F8 | 1F5F8 | 83.9 |
| --- | --- | --- | --- | --- |
| 1F5F8 | 1F5F8 | 1F5F8 | 82.4 (-1.5) | |
| 1F5F8 | | 1F5F8 | 1F5F8 | 83.6 (-0.3) |
| 1F5F8 | 1F5F8 | 80.9 (-3.0) | | |
| 1F5F8 | | 78.9 (-5.0) | | |
| 1F5F8 | 79.7 (-4.2) | | | |
Table 4: Ablation results of different retrieval settings, where w/o. hypo-generator represents using the query directly as the retrieval input.
| Methods | Hit@1 | |
| --- | --- | --- |
| WebQSP | CWQ | |
| Ours ( $K=5$ ) | 90.2 | 72.4 |
| w/o. hyper generator | 85.1 | 69.3 |
| w/o. naive retriever | 87.2 | 70.3 |
| ArG ( $K=3$ ) | 89.5 | 71.1 |
Analysis of Hypo-Generator. We conducted an investigation into the impact of the hypo-generator module on the retrieval efficiency of ArG. The experimental results are presented in the Table 4. We compared the performance of direct retrieval based solely on the query and retrieval enhanced exclusively by the hypo-generator. From the results, it can be observed that both approaches exhibit some performance degradation. However, it is noteworthy that ArG with $K=3$ significantly outperforms the individual use of either method. This indicates that the hypo-generator is effectively integrated into the ArG framework and serves to enhance the retrieval process.
### 5.6 Transferring to Other KGs
To further validate the transferability of our approach to other KGs, we conduct additional experiments on the Wiki-Movies KG, whose relational representations differ from those of Freebase. We use the MetaQA-3hop Zhang et al. (2018) dataset for the construction of training data and evaluation purposes. From the training split, we sample 1,000 examples and construct the training set following the same data construction methodology in Section 4.1. Subsequently, we fine-tune ArG using two distinct training strategies, as utilized by RoG Luo et al. (2023): 1) training from scratch, where the model is trained directly from the base LLM; and 2) transfer from Freebase, where the model pre-trained on Freebase is further fine-tuned on the new dataset. We select several representative works that demonstrate transferability across multiple knowledge graphs for comparison. The comparative results are presented in Table 5. From the results, it can be observed that our model demonstrates adaptability to different KGs. Moreover, the model fine-tuned from Freebase exhibits superior performance, demonstrating that by learning structural knowledge representation internally, the model can rapidly transfer to other new graphs.
### 5.7 Case Study
Table 5: Results of transferability of ArG on MetaQA-3hop dataset based on Wiki-Movies KG.
We conduct a detailed case study to compare our method with the ToG approach, which also performs iterative reasoning, thereby highlighting the advantages of our proposed framework. Specific paths are provided in Table 6 - 8. In Table 6 the user queries the wife of "Niall Ferguson". ToG employs a 3-hop-deep reasoning path, retrieving a large number of relationships and entities at depth-1. It subsequently continues reasoning based on erroneous entities, resulting in additional computational overhead. In contrast, ArG successfully retrieved the correct answer, "Ayaan Hirsi Ali," after just 2 inference steps. The reasoning process starting from "Marriage" was identified as Unreasonable within a single step and was promptly terminated. This demonstrates that ArG is capable of halting unreasonable retrieval processes during inference, thereby reducing unnecessary overhead.
In Table 7, the user queries about the type of art "Marc Chagall" do. ToG fails to retrieve the correct relationship, ultimately producing a vague response, "Painting." In contrast, ArG identifies subtle relationships within the knowledge graph and, utilizing the hypothesis generator, retrieves the proper answers through the correct relational pathway. This demonstrates the effectiveness of the hypo-generator in enhancing retrieval process.
In Table 8, the user queries "where do Florida Panthers play?". ToG provides "Sunrise", which is the incorrect answer. Notably, ToG does retrieve the correct answer, "Miami Arena," at depth-2; however, it fails to identify the entity and doesn’t output the correct result. In contrast, ArG finds two correct answers "Miami Arena" and "BB&T Center" through a concise reasoning path. This indicates that ArG also has advantages in the ability to retrieve and identify correct entities.
## 6 Conclusion
This work introduces ArG, a novel framework designed for reliable reasoning over structured graph data through on-demand retrieval and self-reflection mechanisms. By leveraging reasoning paths as weakly supervised training data, the model is trained to perform iterative retrieval, reflection, and generation. Furthermore, the retrieval performance is significantly enhanced through the hypo-generator, enabling the capture of latent information within the graph. The generated reasoning paths exhibit high interpretability. We posit that our approach offers valuable insights into how models comprehend structured information, contributing to the broader exploration of interpretable reasoning in machine learning.
## 7 Limitations
ArG achieves iterative reflective reasoning over structured graphs in an end-to-end manner, where the final answer is derived through a reasoning tree during the inference process. Recently, tree-based reasoning methods are frequently employed in complex reasoning tasks; however, conventional tree-based approaches often introduce uncertainty, which is reflected in suboptimal precision. In the future, integrating advanced tree reasoning techniques, such as those utilized in Reinforcement Learning from Human Feedback (RLHF) and deep reasoning models Feng et al. (2023); Xie et al. (2023); Guan et al. (2025), could further enhance the precision of tree-structured reasoning. We will leave these explorations for future work.
## References
- Asai et al. (2023) Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-RAG: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511.
- Bi et al. (2024) Zhen Bi, Jing Chen, Yinuo Jiang, Feiyu Xiong, Wei Guo, Huajun Chen, and Ningyu Zhang. 2024. Codekgc: Code language model for generative knowledge graph construction. ACM Trans. Asian Low-Resour. Lang. Inf. Process., 23(3).
- Bollacker et al. (2008) Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, SIGMOD ’08, page 1247–1250, New York, NY, USA. Association for Computing Machinery.
- Das et al. (2017) Rajarshi Das, Manzil Zaheer, Siva Reddy, and Andrew McCallum. 2017. Question answering on knowledge bases and text using universal schema and memory networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 358–365, Vancouver, Canada. Association for Computational Linguistics.
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783.
- Feng et al. (2023) Xidong Feng, Ziyu Wan, Muning Wen, Stephen Marcus McAleer, Ying Wen, Weinan Zhang, and Jun Wang. 2023. Alphazero-like tree-search can guide large language model decoding and training. arXiv preprint arXiv:2309.17179.
- Gao et al. (2021) Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. SimCSE: Simple contrastive learning of sentence embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6894–6910, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Gu et al. (2023) Yu Gu, Xiang Deng, and Yu Su. 2023. Don‘t generate, discriminate: A proposal for grounding language models to real-world environments. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4928–4949, Toronto, Canada. Association for Computational Linguistics.
- Gu et al. (2021) Yu Gu, Sue Kase, Michelle Vanni, Brian Sadler, Percy Liang, Xifeng Yan, and Yu Su. 2021. Beyond i.i.d.: Three levels of generalization for question answering on knowledge bases. In Proceedings of the Web Conference 2021, WWW ’21, page 3477–3488, New York, NY, USA. Association for Computing Machinery.
- Gu and Su (2022) Yu Gu and Yu Su. 2022. ArcaneQA: Dynamic program induction and contextualized encoding for knowledge base question answering. In Proceedings of the 29th International Conference on Computational Linguistics, pages 1718–1731, Gyeongju, Republic of Korea. International Committee on Computational Linguistics.
- Guan et al. (2025) Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. 2025. rstar-math: Small llms can master math reasoning with self-evolved deep thinking. arXiv preprint arXiv:2501.04519.
- Guu et al. (2020) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. 2020. Retrieval augmented language model pre-training. In International Conference on Machine Learning.
- Izacard et al. (2022) Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised dense information retrieval with contrastive learning. Transactions on Machine Learning Research.
- Ji et al. (2024) Yixin Ji, Kaixin Wu, Juntao Li, Wei Chen, Mingjie Zhong, Xu Jia, and Min Zhang. 2024. Retrieval and reasoning on KGs: Integrate knowledge graphs into large language models for complex question answering. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7598–7610, Miami, Florida, USA. Association for Computational Linguistics.
- Jiang et al. (2023a) Jinhao Jiang, Kun Zhou, Zican Dong, Keming Ye, Xin Zhao, and Ji-Rong Wen. 2023a. StructGPT: A general framework for large language model to reason over structured data. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9237–9251, Singapore. Association for Computational Linguistics.
- Jiang et al. (2024a) Jinhao Jiang, Kun Zhou, Wayne Xin Zhao, Yang Song, Chen Zhu, Hengshu Zhu, and Ji-Rong Wen. 2024a. Kg-agent: An efficient autonomous agent framework for complex reasoning over knowledge graph. arXiv preprint arXiv:2402.11163.
- Jiang et al. (2023b) Jinhao Jiang, Kun Zhou, Xin Zhao, and Ji-Rong Wen. 2023b. UniKGQA: Unified retrieval and reasoning for solving multi-hop question answering over knowledge graph. In The Eleventh International Conference on Learning Representations.
- Jiang et al. (2024b) Xinke Jiang, Ruizhe Zhang, Yongxin Xu, Rihong Qiu, Yue Fang, Zhiyuan Wang, Jinyi Tang, Hongxin Ding, Xu Chu, Junfeng Zhao, et al. 2024b. Hykge: A hypothesis knowledge graph enhanced framework for accurate and reliable medical llms responses. arXiv preprint arXiv:2312.15883.
- Jiang et al. (2023c) Zhengbao Jiang, Frank Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023c. Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969–7992, Singapore. Association for Computational Linguistics.
- Jin et al. (2024) Bowen Jin, Chulin Xie, Jiawei Zhang, Kashob Kumar Roy, Yu Zhang, Zheng Li, Ruirui Li, Xianfeng Tang, Suhang Wang, Yu Meng, and Jiawei Han. 2024. Graph chain-of-thought: Augmenting large language models by reasoning on graphs. In Findings of the Association for Computational Linguistics: ACL 2024, pages 163–184, Bangkok, Thailand. Association for Computational Linguistics.
- Li et al. (2022) Dawei Li, Yanran Li, Jiayi Zhang, Ke Li, Chen Wei, Jianwei Cui, and Bin Wang. 2022. C 3 KG: A Chinese commonsense conversation knowledge graph. In Findings of the Association for Computational Linguistics: ACL 2022, pages 1369–1383, Dublin, Ireland. Association for Computational Linguistics.
- Li et al. (2023) Tianle Li, Xueguang Ma, Alex Zhuang, Yu Gu, Yu Su, and Wenhu Chen. 2023. Few-shot in-context learning on knowledge base question answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6966–6980, Toronto, Canada. Association for Computational Linguistics.
- Liu et al. (2024) Haochen Liu, Song Wang, Yaochen Zhu, Yushun Dong, and Jundong Li. 2024. Knowledge graph-enhanced large language models via path selection. In Findings of the Association for Computational Linguistics: ACL 2024, pages 6311–6321, Bangkok, Thailand. Association for Computational Linguistics.
- Luo et al. (2024) Haoran Luo, Haihong E, Zichen Tang, Shiyao Peng, Yikai Guo, Wentai Zhang, Chenghao Ma, Guanting Dong, Meina Song, Wei Lin, Yifan Zhu, and Anh Tuan Luu. 2024. ChatKBQA: A generate-then-retrieve framework for knowledge base question answering with fine-tuned large language models. In Findings of the Association for Computational Linguistics: ACL 2024, pages 2039–2056, Bangkok, Thailand. Association for Computational Linguistics.
- Luo et al. (2023) Linhao Luo, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. 2023. Reasoning on graphs: Faithful and interpretable large language model reasoning. arXiv preprint arXiv:2310.01061.
- Ma et al. (2023) Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. 2023. Query rewriting in retrieval-augmented large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5303–5315, Singapore. Association for Computational Linguistics.
- Mavromatis and Karypis (2024) Costas Mavromatis and George Karypis. 2024. Gnn-rag: Graph neural retrieval for large language model reasoning. arXiv preprint arXiv:2405.20139.
- Miller et al. (2016) Alexander Miller, Adam Fisch, Jesse Dodge, Amir-Hossein Karimi, Antoine Bordes, and Jason Weston. 2016. Key-value memory networks for directly reading documents. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1400–1409, Austin, Texas. Association for Computational Linguistics.
- Pérez et al. (2006) Jorge Pérez, Marcelo Arenas, and Claudio Gutierrez. 2006. Semantics and complexity of sparql. In The Semantic Web - ISWC 2006, pages 30–43, Berlin, Heidelberg. Springer Berlin Heidelberg.
- Rajbhandari et al. (2020) Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. Zero: Memory optimizations toward training trillion parameter models. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis.
- Robertson and Zaragoza (2009) Stephen Robertson and Hugo Zaragoza. 2009. The probabilistic relevance framework: Bm25 and beyond. Found. Trends Inf. Retr., 3(4):333–389.
- Shu et al. (2022) Yiheng Shu, Zhiwei Yu, Yuhan Li, Börje Karlsson, Tingting Ma, Yuzhong Qu, and Chin-Yew Lin. 2022. TIARA: Multi-grained retrieval for robust question answering over large knowledge base. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8108–8121, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Sun et al. (2019) Haitian Sun, Tania Bedrax-Weiss, and William Cohen. 2019. Pullnet: Open domain question answering with iterative retrieval on knowledge bases and text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2380–2390.
- Sun et al. (2018) Haitian Sun, Bhuwan Dhingra, Manzil Zaheer, Kathryn Mazaitis, Ruslan Salakhutdinov, and William Cohen. 2018. Open domain question answering using early fusion of knowledge bases and text. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4231–4242, Brussels, Belgium. Association for Computational Linguistics.
- Sun et al. (2023) Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Heung-Yeung Shum, and Jian Guo. 2023. Think-on-graph: Deep and responsible reasoning of large language model with knowledge graph. arXiv preprint arXiv:2307.07697.
- Talmor and Berant (2018) Alon Talmor and Jonathan Berant. 2018. The web as a knowledge-base for answering complex questions. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 641–651, New Orleans, Louisiana. Association for Computational Linguistics.
- Wang et al. (2021) Hongwei Wang, Hongyu Ren, and Jure Leskovec. 2021. Relational message passing for knowledge graph completion. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 1697–1707.
- Wang et al. (2024) Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Improving text embeddings with large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11897–11916, Bangkok, Thailand. Association for Computational Linguistics.
- Wu et al. (2024) Siwei Wu, Zhongyuan Peng, Xinrun Du, Tuney Zheng, Minghao Liu, Jialong Wu, Jiachen Ma, Yizhi Li, Jian Yang, Wangchunshu Zhou, et al. 2024. A comparative study on reasoning patterns of openai’s o1 model. arXiv preprint arXiv:2410.13639.
- Xiao et al. (2023) Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. 2023. C-pack: Packaged resources to advance general chinese embedding. Preprint, arXiv:2309.07597.
- Xie et al. (2023) Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, James Xu Zhao, Min-Yen Kan, Junxian He, and Michael Xie. 2023. Self-evaluation guided beam search for reasoning. Advances in Neural Information Processing Systems, 36:41618–41650.
- Xiong et al. (2024) Guanming Xiong, Junwei Bao, and Wen Zhao. 2024. Interactive-KBQA: Multi-turn interactions for knowledge base question answering with large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10561–10582, Bangkok, Thailand. Association for Computational Linguistics.
- Yao et al. (2024) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2024. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36.
- Yih et al. (2016) Wen-tau Yih, Matthew Richardson, Chris Meek, Ming-Wei Chang, and Jina Suh. 2016. The value of semantic parse labeling for knowledge base question answering. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 201–206, Berlin, Germany. Association for Computational Linguistics.
- Yu et al. (2023) Donghan Yu, Sheng Zhang, Patrick Ng, Henghui Zhu, Alexander Hanbo Li, Jun Wang, Yiqun Hu, William Yang Wang, Zhiguo Wang, and Bing Xiang. 2023. DecAF: Joint decoding of answers and logical forms for question answering over knowledge bases. In The Eleventh International Conference on Learning Representations.
- Zhang et al. (2024a) Han Zhang, Yuheng Ma, and Hanfang Yang. 2024a. Alter: Augmentation for large-table-based reasoning. arXiv preprint arXiv:2407.03061.
- Zhang et al. (2022) Jing Zhang, Xiaokang Zhang, Jifan Yu, Jian Tang, Jie Tang, Cuiping Li, and Hong Chen. 2022. Subgraph retrieval enhanced model for multi-hop knowledge base question answering. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5773–5784, Dublin, Ireland. Association for Computational Linguistics.
- Zhang et al. (2024b) Jintian Zhang, Cheng Peng, Mengshu Sun, Xiang Chen, Lei Liang, Zhiqiang Zhang, Jun Zhou, Huajun Chen, and Ningyu Zhang. 2024b. OneGen: Efficient one-pass unified generation and retrieval for LLMs. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 4088–4119, Miami, Florida, USA. Association for Computational Linguistics.
- Zhang et al. (2018) Yuyu Zhang, Hanjun Dai, Zornitsa Kozareva, Alexander Smola, and Le Song. 2018. Variational reasoning for question answering with knowledge graph. In Proceedings of the AAAI conference on artificial intelligence, volume 32.
- Zheng et al. (2024) Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. 2024. LlamaFactory: Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 400–410, Bangkok, Thailand. Association for Computational Linguistics.
## Appendix A Reflection Tokens
#### Definitions of Reflection Tokens.
This section provides detailed definitions of the four types of reflection tokens used in ArG.
#### Retrieval Token ( Retrieval Token )
indicates whether the output can be fully verified by the provided evidence and historical information, or if it requires additional external retrieval. There are three possible scenarios: - If the output can be verified using the evidence and history, the Retrieval Token should be [No Retrieval]. - If additional information based on relations is required, the Retrieval Token should be [Relation Retrieval]. - If additional information based on entities is needed, the Retrieval Token should be [Entity Retrieval].
#### Relevance Token ( Relevance Token )
indicates whether the knowledge retrieved is relevant to the query or contributes to answering it. This is evaluated on a scale from [Fully Relevant] to [Partially Relevant] and [Irrelevant]. Here, "knowledge" refers to relations or entities.
#### Rationality Token ( Rationality Token )
indicates whether the reasoning process (from the topic entity to the answer) is logical and coherent. This is evaluated on a scale from [Fully Reasonable] to [Partially Reasonable] and [Unreasonable].
#### Utility Token ( Utility Token )
indicates whether the answer is a useful response to the query, using a five-point scale from [Utility:1] (the least useful) to [Utility:5] (the most useful).
## Appendix B Details of Datasets
This section provides information about the two benchmark datasets used in our experiment.
#### WebQSP
(WebQuestionsSP) (Yih et al., 2016) is a widely-used KGQA dataset. It is developed to evaluate the importance of gathering semantic parses compared to answers alone for a set of questions. WebQSP consists of 4,737 KBQA questions, with 34 logical form skeletons and 2,461 entities involved. There are 628 relations specified within the dataset, which is divided into a training set of 3,098 questions and a testing set of 1,639 questions. This dataset utilizes Freebase as its knowledge base and is tailored for developing systems that can process and answer natural language questions using structured data.
#### CWQ
(ComplexWebQuestions) (Talmor and Berant, 2018) is another commonly used KGQA dataset. It is designed to answer complex questions requiring reasoning over multiple web snippets, which contains a large set of complex questions in natural language and is versatile in its applications. CWQ is considerably larger with 34,689 questions, underpinned by 174 logical form skeletons. It encompasses a more extensive set of entities amounting to 11,422 and includes 845 relations. The training set comprises 27,639 questions, supplemented by a validation set of 3,519 questions and a test set of 3,531 questions. CWQ also leverages Freebase as its knowledge base and is designed for complex question-answering tasks that require the interpretation and synthesis of information from various sources.
## Appendix C Baselines
We compare ARG with 13 baseline methods, which can be grouped into 3 categories: 1) Semantic Parsing(SP)-based methods, 2) Information Retrieval(IR)-based methods, and 3) LLM-based methods. In this section, details of baselines are described as follows.
#### SP-based methods.
DECAF Yu et al. (2023) is a framework that jointly generates both logical forms and direct answers, and then combines the merits of them to get the final answers. Moreover, it is based on simple free-text retrieval without relying on any entity linking tools, which eases its adaptation to different datasets.
TIARA Shu et al. (2022) is a KBQA model which addresses the issues of coverage and generalization settings by applying multi-grained retrieval to help the PLM focus on the most relevant KB context, viz., entities, exemplary logical forms, and schema items.
ArcaneQA Gu and Su (2022) is a generation-based model that addresses both the large search space and the schema linking challenges in a unified framework with two mutually boosting ingredients: dynamic program induction for tackling the large search space and dynamic contextualized encoding for schema linking.
ChatKBQA Luo et al. (2024) is a generate-then-retrieve KBQA framework, which proposes first generating the logical form with fine-tuned LLMs, then retrieving and replacing entities and relations with an unsupervised retrieval method, to improve both generation and retrieval more directly.
#### IR-based methods.
GrafNet Sun et al. (2018) is a model for extracting answers from a question-specific subgraph containing text and KB entities and relations, which is competitive with the state-of-the-art when tested using either KBs or text alone, and vastly outperforms existing methods in the combined setting.
PullNet Sun et al. (2019) is an integrated framework for learning what to retrieve (from the KB and/or corpus) and reasoning with this heterogeneous information to find the best answer. It uses an iterative process to construct a question-specific subgraph that contains information relevant to the question.
Subgraph Retrieval Zhang et al. (2022) is a trainable model, decoupled from the subsequent reasoning process, which enables a plug-and-play framework to enhance any subgraph-oriented KBQA model. Extensive experiments demonstrate that it achieves significantly better retrieval and QA performance than existing retrieval methods.
UniKGQA Jiang et al. (2023b) is an approach for multi-hop KGQA task, by unifying retrieval and reasoning in both model architecture and parameter learning. Extensive experiments on three benchmark datasets have demonstrated the effectiveness of UniKGQA on the multi-hop KGQA task.
#### LLM-based methods
StructGPT Jiang et al. (2023a) is an Iterative Reading-then-Reasoning (IRR) framework to solve question answering tasks based on structured data. In this framework, the specialized interfaces collect relevant evidence from structured data (i.e., reading), and LLMs concentrate on the reasoning task based on the collected information (i.e., reasoning).
KG-Agent Jiang et al. (2024a) is an autonomous LLM-based agent framework, which enables a small LLM to actively make decisions until finishing the reasoning process over knowledge graphs (KGs). It has improved the reasoning ability of LLMs over KGs to answer complex questions.
RoG Luo et al. (2023) (Reasoning on Graphs) is a method that synergizes LLMs with KGs to enable faithful and interpretable reasoning. It not only distills knowledge from KGs to improve the reasoning ability of LLMs through training but also allows seamless integration with any arbitrary LLMs during inference.
## Appendix D Prompt
In this section, we present the instructions used to prompt GPT models for collecting self-reflection tokens, including Relevance, Rationality, and Utility. Notably, data for retrieval on demand is not required, as the reasoning path itself provides directional guidance to the model for conducting retrieval. Figure 5 and Figure 6 present the instructions for the Relevance token, while Figure 7 and Figure 8 provide the instructions for the Rationality token and Utility token, respectively.
## Appendix E Details of Score Calculations
We obtain the value of each tree node by computing a confidence score. For each special reflection token $\hat{t}$ generated along the reasoning path at depth- $d$ , the confidence score is derived by applying the softmax function to its log probability.
$$
s_d(\hat{t})=\frac{exp≤ft(p_d(\hat{t})\right)}{∑_i=1^Gexp≤ft(p_
{d}(t_i)\right)}. \tag{4}
$$
Here $s_d(\hat{t})$ represents the score of the special token at depth $d$ , where $G$ denotes the number of categories for tokens of the same type. The aggregate score for each node is computed using the following equation:
$$
S(d)=S_seq(d)+k_1S_rel(d)*S_rat(d)+k_2*S_uti, \tag{5}
$$
where $S_seq$ denotes the cumulative probability. For a valid reasoning path $w$ , the final score is computed by backtracking the score along the pathway. In the experiments, we set $k_1=1$ and $k_2=0.5$ . For $S_rel$ , $S_rat$ and $S_uti$ , we compute the score as follows:
$$
\displaystyle S_rel(d) \displaystyle=s_d({\color[rgb]{0.765625,0.21484375,0.3515625
\definecolor[named]{pgfstrokecolor}{rgb}{0.765625,0.21484375,0.3515625}{[Fully
Relevant]}}}) \displaystyle+0.5× s_d({\color[rgb]{0.765625,0.21484375,0.3515625}
\definecolor[named]{pgfstrokecolor}{rgb}{0.765625,0.21484375,0.3515625}{
\texttt{[Partially Relevant]}}}), \displaystyle S_rat(d) \displaystyle=s_d({\color[rgb]{0.765625,0.21484375,0.3515625
\definecolor[named]{pgfstrokecolor}{rgb}{0.765625,0.21484375,0.3515625}{[Fully
Reasonable]}}}) \displaystyle+0.5× s_d({\color[rgb]{0.765625,0.21484375,0.3515625}
\definecolor[named]{pgfstrokecolor}{rgb}{0.765625,0.21484375,0.3515625}{
\texttt{[Partially Reasonable]}}}), \displaystyle S_uti \displaystyle=∑_i=1^5s_D({\color[rgb]{0.765625,0.21484375,0.3515625}
\definecolor[named]{pgfstrokecolor}{rgb}{0.765625,0.21484375,0.3515625}\texttt
{[Utility]}}=i). \tag{6}
$$
⬇ Q uery: what organization did martin luther king lead O utput: [Retrieve Relation] <paragraph>organization.organization_founder.organizations_founded;religion.religious_organization.leaders;organization.organization.founders;organization.organization.leadership;organization.leadership.organization</paragraph> organization. organization_founder. organizations_founded [Fully Relevant] religion. religious_organization. leaders [Partially Relevant] organization. organization. founders [Unrelevant] organization. organization. leadership [Partially Relevant] organization. leadership. organization [Partially Relevant] [Retrieve Entity] <paragraph>(Martin Luther King, Jr., organization.organization_founder.organizations_founded, Montgomery Improvement Association);(Martin Luther King, Jr., organization.organization_founder.organizations_founded, Southern Christian Leadership Conference)</paragraph> Montgomery Improvement Association [Fully Relevant] Southern Christian Leadership Conference [Fully Relevant] [Partially Reasonable] [No Retrieval] Answer: Southern Christian Leadership Conference; Montgomery Improvement Association [Utility:5]
Figure 4: An example of ArG training data.
⬇ You will receive a query, topic entity, evidence and optional preceding sentences containing history information. The evidence contains graph relationships possibly useful to answering the query. Your task is evaluate each relationship ’ s contribution to answering the query and provide a relevance score for each relation, output your explanations for the score. The score of relevance range from [Fully Relevant], [Partially Relevant] to [Unrelevant]: - If the relationship directly contains information directly about the query or can answer the query with information in preceding sentences, return [Fully Relevant]. - If the relationship do not directly answer the query, but includes information possibly point to the answer, return [Partially Relevant]. - If the relationship contains irrelevant information about the query, return [Unrelevant].
Figure 5: Instructions for Relevance Token (for relations).
⬇ You will receive a query, evidence and optional preceding historical information for the task. The evidence and preceding information include associated retrieved knowledge graph triplets presented as (head entity, relation, tail entity). Your task is to assign a relevance score to the query for each tail entity in the evidence. Additionally, you are required to provide explanations for the scores assigned. The relevance scores should fall into one of the following categories: [Fully Relevant], [Partially Relevant], or [Unrelevant].
Figure 6: Instructions for Relevance Token (for entities).
⬇ You will receive a query, output and a reasoning path. The reasoning path contains the current reasoning process starting from the topic entitiy to the answer. Your task is to rate rationality score for the path and output your explanations for the score. The score of rationality range from [Fully Reasonable], [Partially Reasonable] to [Unreasonable].
Figure 7: Instructions for Rationality Token .
⬇ You will be given a query and the answers, where the answers may consist of one or more individual answers, separated by commas (,). Your task is to generate a ** rating ** to evaluate whether the answer is a useful response to the query. Use the following entailment scale to give the utility score: [Utility:5]: Generally, the output provides a complete, highly detailed, and informative response to the query, fully satisfying the information needs. [Utility:4]: Generally, the output mostly fulfills the need in the query and provides helpful answers, while there can be some minor improvements, such as discussing more detailed information or providing additional correct answers beyond the current output. [Utility:3]: Generally, the output is correct and acceptable, but there are obvious problems, such as being too vague or not specific enough, limiting its helpfulness in addressing the query. [Utility:2]: Generally, the output still discusses the topic of the query, but it is incorrect or does not actually meet the requirements of the query. [Utility:1]: Generally, the output is completely irrelevant to the query or does not give an answer in the end.
Figure 8: Instructions for Utility Token .
| Input: Who is Niall Ferguson’s wife? (from WebQSP) |
| --- |
| ToG: |
| Depth-1: Niall Ferguson $→$ people.person.children $→$ Thomas Ferguson, Niall Ferguson $→$ people.person.gender $→$ Erkek, Niall Ferguson $→$ people.person.nationality $→$ Scotland, Niall Ferguson $→$ people.person.nationality $→$ United Kingdom, |
| Depth-2: Scotland $→$ base.aareas.schema.administrative_area.administrative_parent $→$ United Kingdom, Thomas Ferguson $→$ people.person.gender $→$ Erkek, Thomas Ferguson $→$ people.person.parents $→$ Ayaan Hirsi Ali, Thomas Ferguson $→$ people.person.parents $→$ Niall Ferguson, Erkek $→$ base.gender.gender_identity.people $→$ UnName Entity, |
| Depth-3: UnName Entity $→$ base.gender.personal_gender_identity.person $→$ Renée Richards, Ayaan Hirsi Ali $→$ people.person.children $→$ Thomas Ferguson, Niall Ferguson $→$ people.person.children $→$ Thomas Ferguson, UnName Entity $→$ base.gender.personal_gender_identity.gender_identity $→$ Erkek, Niall Ferguson $→$ people.person.gender $→$ Erkek. |
| Answer: Niall Ferguson’s wife is Ayaan Hirsi Ali. |
| ArG: |
| Niall Ferguson $→$ people.person.spouse_s $→$ m.0j4jq57 [Partially Reasonable], m.0j4jq57 $→$ Ayaan Hirsi Ali. [Fully Reasonable] |
| Marriage $→$ people.marriage.type_of_union $→$ m.0j4jt43. [Unreasonable] |
| Answer: Ayaan Hirsi Ali [Utility:5] |
Table 6: Case Study 1 between ToG and ArG.
| Input: What type of art does Marc Chagall do? (from WebQSP) |
| --- |
| ToG: |
| Depth-1: Marc Chagall $→$ visual_art.visual_artist.art_forms $→$ Glezniecība, Marc Chagall $→$ visual_art.visual_artist.artworks $→$ America Windows, Marc Chagall $→$ visual_art.visual_artist.artworks $→$ Autoritratto con sette dita, Marc Chagall $→$ visual_art.visual_artist.artworks $→$ Birth, Marc Chagall $→$ visual_art.visual_artist.artworks $→$ Calvary. |
| Answer: Painting |
| ArG: |
| Marc Chagall $→$ visual_art.visual_artist.associated_periods_or_movements $→$ Modern art [Fully Relevant], Marc Chagall $→$ visual_art.visual_artist.associated_periods_or_movements $→$ Cubism [Partially Relevant], Marc Chagall $→$ visual_art.visual_artist.associated_periods_or_movements $→$ Surrealism [Partially Relevant], Marc Chagall $→$ visual_art.visual_artist.associated_periods_or_movements $→$ Expressionism [Partially Relevant], Marc Chagall $→$ visual_art.visual_artist.associated_periods_or_movements $→$ Fauvism [Partially Relevant]. |
| Answer: Expressionism; Modern art; Cubism; Surrealism; Fauvism [Utility:3] |
Table 7: Case Study 2 between ToG and ArG.
| Input: Where do Florida Panthers play? (from WebQSP) |
| --- |
| ToG: |
| Depth-1: Florida Panthers $→$ sports.sports_team.location $→$ Sunrise, Florida Panthers $→$ sports.sports_team.venue $→$ UnName_Entity, Florida Panthers $→$ sports.sports_team.venue $→$ UnName_Entity, Florida Panthers $→$ ice_hockey.hockey_team.conference $→$ Eastern Conference, Florida Panthers $→$ ice_hockey.hockey_team.division $→$ Atlantic Division, |
| Depth-2: Sunrise $→$ sports.sports_team_location.teams $→$ Florida Panthers, UnName_Entity $→$ sports.team_venue_relationship.venue $→$ Miami Arena, UnName_Entity $→$ sports.team_venue_relationship.team $→$ Florida Panthers, Eastern Conference $→$ ice_hockey.hockey_conference.league $→$ National Hockey League, Atlantic Division $→$ ice_hockey.hockey_division.conference $→$ Eastern Conference. |
| Answer: Sunrise |
| ArG: |
| Florida Panthers $→$ sports.sports_team.arena_stadium $→$ Miami Arena [Partially Relevant], Florida Panthers $→$ sports.sports_team.arena_stadium $→$ BB&T Center [Fully Relevant]. |
| Answer: Miami Arena; BB&T Center [Utility:4] |
Table 8: Case Study 3 between ToG and ArG.
Input: Query $q$ , Valid reasoning path $w=w_1:D$ , Retriever $R$ , Critic Model $C$
Output: Augmented reasoning path and self-reflection tokens
while $d≤ D$ do
$(r_d,e_d)=w_d$ ;
Add [Relation Retrieval] == True ;
$C_r$ = Retrieve $(q,r^d,e^d)$ using $R$ ;
/* Get candidate relationships */
$C$ predicts Relevance Token for each $c_r∈C_r$ ;
Add [Entity Retrieval] == True;
$C_e$ = SearchTailNode $(e^d,r^d)$ ;
/* Get candidate brother nodes */
$C$ predicts Relevance Token for each $c_e∈C_e$ ;
$C$ predicts Rationality Token based on current reasoning path $w_<=d$
/* Evaluate reasoness based on current path */
if Rationality Token == [UnReasonable] then
break ;
/* Early stop for unreasonable path */
Add [Relation Retrieval] == False;
$C$ predicts Utility Token for each $a$ in $A$ ;
Algorithm 2 $M_gen$ Data Creation