# Hallucination Detection in LLMs Using Spectral Features of Attention Maps
**Authors**:
- Bogdan Gabrys, Tomasz Kajdanowicz (Wroclaw University of Science and Technology,
University of Technology Sydney,)
- Correspondence: jakub.binkowski@pwr.edu.pl
## Abstract
Large Language Models (LLMs) have demonstrated remarkable performance across various tasks but remain prone to hallucinations. Detecting hallucinations is essential for safety-critical applications, and recent methods leverage attention map properties to this end, though their effectiveness remains limited. In this work, we investigate the spectral features of attention maps by interpreting them as adjacency matrices of graph structures. We propose the $\operatorname{LapEigvals}$ method, which utilizes the top- $k$ eigenvalues of the Laplacian matrix derived from the attention maps as an input to hallucination detection probes. Empirical evaluations demonstrate that our approach achieves state-of-the-art hallucination detection performance among attention-based methods. Extensive ablation studies further highlight the robustness and generalization of $\operatorname{LapEigvals}$ , paving the way for future advancements in the hallucination detection domain.
Hallucination Detection in LLMs Using Spectral Features of Attention Maps
Jakub Binkowski 1, Denis Janiak 1, Albert Sawczyn 1 Bogdan Gabrys 2, Tomasz Kajdanowicz 1 1 Wroclaw University of Science and Technology, 2 University of Technology Sydney, Correspondence: jakub.binkowski@pwr.edu.pl
## 1 Introduction
The recent surge of interest in Large Language Models (LLMs), driven by their impressive performance across various tasks, has led to significant advancements in their training, fine-tuning, and application to real-world problems. Despite progress, many challenges remain unresolved, particularly in safety-critical applications with a high cost of errors. A significant issue is that LLMs are prone to hallucinations, i.e. generating "content that is nonsensical or unfaithful to the provided source content" (Farquhar et al., 2024; Huang et al., 2023). Since eliminating hallucinations is impossible (Lee, 2023; Xu et al., 2024), there is a pressing need for methods to detect when a model produces hallucinations. In addition, examining the internal behavior of LLMs in the context of hallucinations may yield important insights into their characteristics and support further advancements in the field. Recent studies have shown that hallucinations can be detected using internal states of the model, e.g., hidden states (Chen et al., 2024) or attention maps (Chuang et al., 2024a), and that LLMs can internally "know when they do not know" (Azaria and Mitchell, 2023; Orgad et al., 2025). We show that spectral features of attention maps coincide with hallucinations and, building on this observation, propose a novel method for their detection.
As highlighted by (Barbero et al., 2024), attention maps can be viewed as weighted adjacency matrices of graphs. Building on this perspective, we performed statistical analysis and demonstrated that the eigenvalues of a Laplacian matrix derived from attention maps serve as good predictors of hallucinations. We propose the $\operatorname{LapEigvals}$ method, which utilizes the top- $k$ eigenvalues of the Laplacian as input features of a probing model to detect hallucinations. We share full implementation in a public repository: https://github.com/graphml-lab-pwr/lapeigvals.
We summarize our contributions as follows:
1. We perform statistical analysis of the Laplacian matrix derived from attention maps and show that it could serve as a better predictor of hallucinations compared to the previous method relying on the log-determinant of the maps.
1. Building on that analysis and advancements in the graph-processing domain, we propose leveraging the top- $k$ eigenvalues of the Laplacian matrix as features for hallucination detection probes and empirically show that it achieves state-of-the-art performance among attention-based approaches.
1. Through extensive ablation studies, we demonstrate properties, robustness and generalization of $\operatorname{LapEigvals}$ and suggest promising directions for further development.
## 2 Motivation
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Heatmaps: Attention Scores and Laplacian Eigenvalues
### Overview
The image presents two heatmaps displayed side-by-side. The left heatmap is titled "AttnScore" and the right is titled "Laplacian Eigenvalues". Both heatmaps share the same axes: "Head Index" on the x-axis and "Layer Index" on the y-axis. Both heatmaps use a color scale ranging from dark purple (approximately 0.0) to bright yellow (approximately 1.0), representing "p-value". The heatmaps visualize the relationship between layer and head indices, with color intensity indicating the corresponding p-value.
### Components/Axes
* **X-axis:** "Head Index", ranging from 0 to 28, with markers at integer values.
* **Y-axis:** "Layer Index", ranging from 0 to 28, with markers at integer values.
* **Color Scale:** A continuous scale from dark purple (0.0) to bright yellow (1.0), representing "p-value". The scale is positioned on the right side of the image.
* **Left Heatmap Title:** "AttnScore"
* **Right Heatmap Title:** "Laplacian Eigenvalues"
### Detailed Analysis or Content Details
**AttnScore Heatmap (Left)**
The AttnScore heatmap shows a sparse distribution of high p-values (bright yellow/orange). The heatmap appears to have several localized areas of higher intensity.
* Around Layer Index 0, there are several bright spots between Head Index 16 and 24.
* Around Layer Index 4, there are bright spots between Head Index 0 and 8.
* Around Layer Index 8, there are bright spots between Head Index 0 and 8.
* Around Layer Index 12, there are bright spots between Head Index 0 and 8.
* Around Layer Index 16, there are bright spots between Head Index 0 and 8.
* Around Layer Index 24, there are bright spots between Head Index 0 and 8.
* Around Layer Index 28, there are bright spots between Head Index 0 and 8.
The majority of the heatmap is dark purple, indicating low p-values (close to 0.0).
**Laplacian Eigenvalues Heatmap (Right)**
The Laplacian Eigenvalues heatmap also shows a sparse distribution of high p-values. The pattern is different from the AttnScore heatmap.
* Around Layer Index 0, there are bright spots between Head Index 20 and 24.
* Around Layer Index 4, there are bright spots between Head Index 16 and 20.
* Around Layer Index 8, there are bright spots between Head Index 16 and 20.
* Around Layer Index 12, there are bright spots between Head Index 16 and 20.
* Around Layer Index 16, there are bright spots between Head Index 16 and 20.
* Around Layer Index 24, there are bright spots between Head Index 16 and 20.
* Around Layer Index 28, there are bright spots between Head Index 16 and 20.
Similar to the AttnScore heatmap, most of the area is dark purple, indicating low p-values.
### Key Observations
* Both heatmaps exhibit sparse distributions of high p-values.
* The locations of high p-values differ between the two heatmaps, suggesting different relationships between layer and head indices for attention scores and Laplacian eigenvalues.
* The heatmaps suggest that certain combinations of layer and head indices are more significant (higher p-values) than others.
* The majority of the combinations have low p-values, indicating a generally weak relationship.
### Interpretation
The two heatmaps likely represent the results of an analysis of a neural network model, possibly a transformer. "AttnScore" likely represents the attention scores between different heads and layers, while "Laplacian Eigenvalues" might represent a spectral analysis of the network's connectivity. The p-values indicate the statistical significance of the relationships between the layer and head indices.
The differing patterns in the two heatmaps suggest that the attention mechanism and the network's spectral properties are governed by different underlying structures. The sparse distribution of high p-values suggests that the network is not fully connected or that only specific connections are crucial for its performance. The localized areas of high p-values could indicate important interactions between specific layers and heads.
Further investigation would be needed to understand the specific meaning of these patterns in the context of the model's task and architecture. The heatmaps provide a visual overview of the relationships between layers and heads, which can be used to guide further analysis and potentially improve the model's performance.
</details>
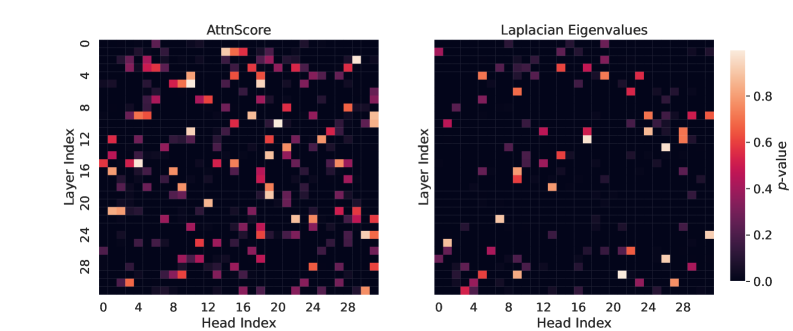
Figure 1: Visualization of $p$ -values from the two-sided Mann-Whitney U test for all layers and heads of Llama-3.1-8B across two feature types: $\operatorname{AttentionScore}$ and the $k{=}10$ Laplacian eigenvalues. These features were derived from attention maps collected when the LLM answered questions from the TriviaQA dataset. Higher $p$ -values indicate no significant difference in feature values between hallucinated and non-hallucinated examples. For $\operatorname{AttentionScore}$ , $80\$ of heads have $p<0.05$ , while for Laplacian eigenvalues, this percentage is $91\$ . Therefore, Laplacian eigenvalues may be better predictors of hallucinations, as feature values across more heads exhibit statistically significant differences between hallucinated and non-hallucinated examples.
Considering the attention matrix as an adjacency matrix representing a set of Markov chains, each corresponding to one layer of an LLM (Wu et al., 2024) (see Figure 2), we can leverage its spectral properties, as was done in many successful graph-based methods (Mohar, 1997; von Luxburg, 2007; Bruna et al., 2013; Topping et al., 2022). In particular, it was shown that the graph Laplacian might help to describe several graph properties, like the presence of bottlenecks (Topping et al., 2022; Black et al., 2023). We hypothesize that hallucinations may arise from disruptions in information flow, such as bottlenecks, which could be detected through the graph Laplacian.
To assess whether our hypothesis holds, we computed graph spectral features and verified if they provide a stronger coincidence with hallucinations than the previous attention-based method - $\operatorname{AttentionScore}$ (Sriramanan et al., 2024). We prompted an LLM with questions from the TriviaQA dataset (Joshi et al., 2017) and extracted attention maps, differentiating by layers and heads. We then computed the spectral features, i.e., the 10 largest eigenvalues of the Laplacian matrix from each head and layer. Further, we conducted a two-sided Mann-Whitney U test (Mann and Whitney, 1947) to compare whether Laplacian eigenvalues and the values of $\operatorname{AttentionScore}$ are different between hallucinated and non-hallucinated examples. Figure 1 shows $p$ -values for all layers and heads, indicating that $\operatorname{AttentionScore}$ often results in higher $p$ -values compared to Laplacian eigenvalues. Overall, we studied 7 datasets and 5 LLMs and found similar results (see Appendix A). Based on these findings, we propose leveraging top- $k$ Laplacian eigenvalues as features for a hallucination probe.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Diagram: Recurrent Neural Network Unfolding
### Overview
The image depicts an unfolded recurrent neural network (RNN) over three time steps. It illustrates the flow of information through the network, showing the connections between input, hidden states, and weights. The diagram highlights the recurrent connections that define the RNN's ability to process sequential data.
### Components/Axes
The diagram consists of the following components:
* **Input Nodes:** Represented by green rectangles labeled x₀, x₁, x₂, x̂₁, x̂₂, x̂₃.
* **Hidden State Nodes:** Represented by blue rounded rectangles labeled h₀⁽⁰⁾, h₁⁽⁰⁾, h₂⁽⁰⁾, h₀⁽¹⁾, h₁⁽¹⁾, h₂⁽¹⁾, h₀⁽²⁾, h₁⁽²⁾, h₂⁽²⁾. The superscript indicates the time step.
* **Weight Connections:** Represented by arrows with labels indicating the weight matrix and bias. The labels are in the format a⁽ᵗ⁾, where 't' represents the time step.
* **Recurrent Connections:** Represented by curved arrows connecting hidden states across time steps.
* **Feedforward Connections:** Represented by straight arrows connecting input nodes to hidden states and hidden states to subsequent hidden states.
### Detailed Analysis
The diagram shows three time steps (0, 1, and 2) of an RNN unfolded. Let's analyze the connections and labels:
**Time Step 0:**
* Input: x₀ connects to h₀⁽⁰⁾, h₁⁽⁰⁾, and h₂⁽⁰⁾.
* Weights: a⁽⁰⁾₁₀ connects x₀ to h₀⁽⁰⁾, a⁽⁰⁾₂₁ connects x₀ to h₁⁽⁰⁾, a⁽⁰⁾₂₀ connects x₀ to h₂⁽⁰⁾.
**Time Step 1:**
* Input: x̂₁ connects to h₀⁽¹⁾, h₁⁽¹⁾, and h₂⁽¹⁾.
* Recurrent Connection: h₀⁽⁰⁾ connects to h₀⁽¹⁾, h₁⁽⁰⁾ connects to h₁⁽¹⁾, and h₂⁽⁰⁾ connects to h₂⁽¹⁾.
* Weights: a⁽¹⁾₁₀ connects x̂₁ to h₀⁽¹⁾, a⁽¹⁾₂₁ connects x̂₁ to h₁⁽¹⁾, a⁽¹⁾₂₀ connects x̂₁ to h₂⁽¹⁾. a⁽¹⁾₂₀ connects h₀⁽⁰⁾ to h₀⁽¹⁾, a⁽¹⁾₂₁ connects h₁⁽⁰⁾ to h₁⁽¹⁾, a⁽¹⁾₂₀ connects h₂⁽⁰⁾ to h₂⁽¹⁾.
**Time Step 2:**
* Input: x̂₂ connects to h₀⁽²⁾, h₁⁽²⁾, and h₂⁽²⁾.
* Recurrent Connection: h₀⁽¹⁾ connects to h₀⁽²⁾, h₁⁽¹⁾ connects to h₁⁽²⁾, and h₂⁽¹⁾ connects to h₂⁽²⁾.
* Weights: a⁽²⁾₁₀ connects x̂₂ to h₀⁽²⁾, a⁽²⁾₂₁ connects x̂₂ to h₁⁽²⁾, a⁽²⁾₂₀ connects x̂₂ to h₂⁽²⁾. a⁽²⁾₂₀ connects h₀⁽¹⁾ to h₀⁽²⁾, a⁽²⁾₂₁ connects h₁⁽¹⁾ to h₁⁽²⁾, a⁽²⁾₂₀ connects h₂⁽¹⁾ to h₂⁽²⁾.
Finally, x̂₃ connects to h₀⁽²⁾, h₁⁽²⁾, and h₂⁽²⁾.
The weight labels are in the format a⁽ᵗ⁾ᵢⱼ, where:
* t is the time step.
* i is the index of the hidden unit at the current time step.
* j is the index of the hidden unit at the previous time step (for recurrent connections) or the input unit (for feedforward connections).
### Key Observations
* The diagram clearly illustrates the recurrent nature of the network, with hidden states at previous time steps influencing the hidden states at subsequent time steps.
* The weights (a) are shared across time steps, which is a key characteristic of RNNs.
* The diagram shows a fully connected RNN, where each hidden unit receives input from all hidden units at the previous time step and all input units at the current time step.
* The input sequence is x₀, x₁, x₂, and the intermediate outputs are x̂₁, x̂₂ and x̂₃.
### Interpretation
This diagram demonstrates the core mechanism of an RNN: the ability to maintain a hidden state that captures information about past inputs. The unfolding of the network over time allows us to visualize how the hidden state is updated at each time step based on the current input and the previous hidden state. The shared weights ensure that the network learns to process sequential data in a consistent manner. The diagram is a conceptual representation and doesn't specify the activation functions or the output layer of the RNN. It focuses solely on the flow of information through the recurrent connections and the associated weights. The diagram is a powerful tool for understanding the fundamental principles of RNNs and their ability to model sequential data.
</details>
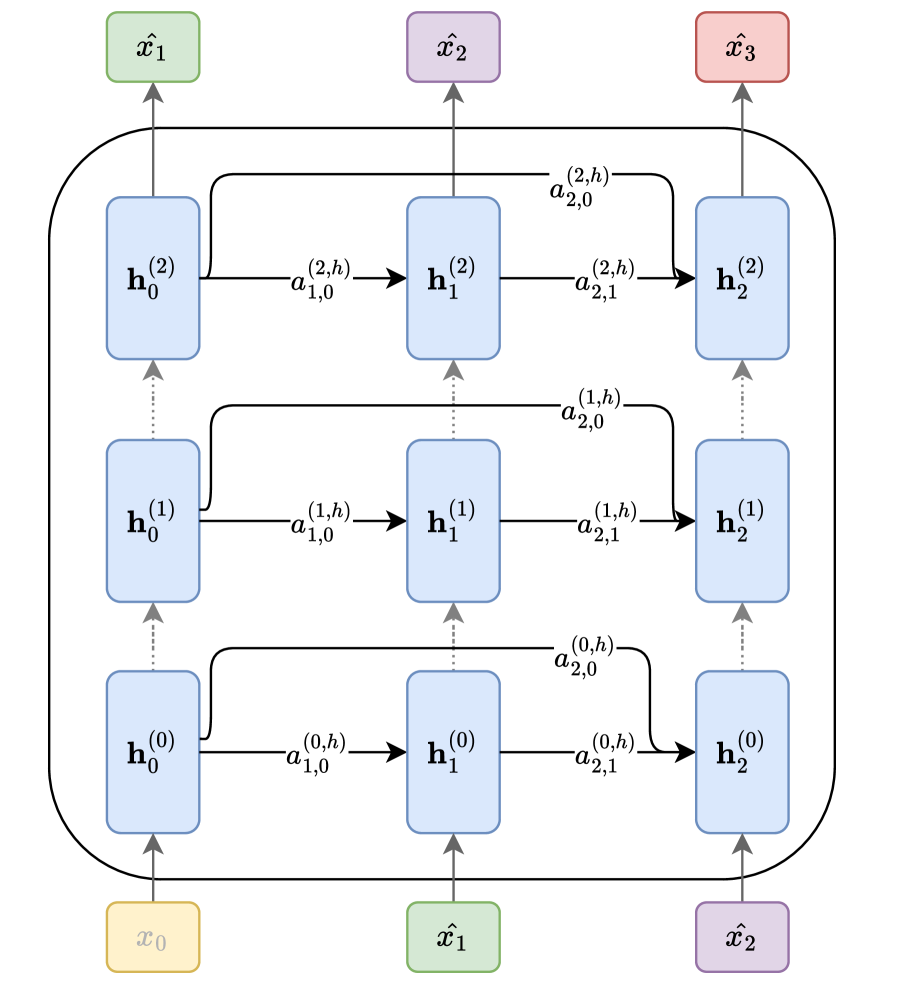
Figure 2: The autoregressive inference process in an LLM is depicted as a graph for a single attention head $h$ (as introduced by (Vaswani, 2017)) and three generated tokens ( $\hat{x}_{1},\hat{x}_{2},\hat{x}_{3}$ ). Here, $\mathbf{h}^{(l)}_{i}$ represents the hidden state at layer $l$ for the input token $i$ , while $a^{(l,h)}_{i,j}$ denotes the scalar attention score between tokens $i$ and $j$ at layer $l$ and attention head $h$ . Arrows direction refers to information flow during inference.
## 3 Method
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Diagram: LLM Hallucination Evaluation Pipeline
### Overview
The image depicts a diagram illustrating a pipeline for evaluating hallucinations in Large Language Models (LLMs). The pipeline takes a QA Dataset as input and processes it through several stages to identify and assess instances of hallucination. The diagram shows the flow of data and the components involved in this evaluation process.
### Components/Axes
The diagram consists of the following components, represented as rounded rectangles:
* **QA Dataset:** (Yellow) - The initial input to the pipeline.
* **LLM:** (Blue) - The Large Language Model being evaluated.
* **Attention Maps:** (Light Green) - Output from the LLM, representing attention weights.
* **Feature Extraction (LapEigvals):** (Blue) - A process for extracting features from the attention maps.
* **Hallucination Probe (logistic regression):** (Blue) - A model used to detect hallucinations based on extracted features.
* **Answers:** (Light Green) - Output from the LLM, representing the generated answers.
* **Judge LLM:** (Blue) - An LLM used to judge the correctness of the answers.
* **Hallucination Labels:** (Light Green) - Labels assigned by the Judge LLM indicating the presence or absence of hallucinations.
Arrows indicate the flow of data between these components. A dashed line connects the QA Dataset directly to the Judge LLM, indicating a separate input path.
### Detailed Analysis or Content Details
The pipeline operates as follows:
1. A **QA Dataset** is fed into the **LLM**.
2. The **LLM** generates **Answers** and produces **Attention Maps**.
3. The **Attention Maps** are processed by **Feature Extraction (LapEigvals)**.
4. The extracted features are used by the **Hallucination Probe (logistic regression)** to identify potential hallucinations.
5. The **Answers** are evaluated by a **Judge LLM**, which assigns **Hallucination Labels**.
6. The **Hallucination Labels** are then used to assess the performance of the LLM.
7. The **QA Dataset** is also directly input into the **Judge LLM** for comparison.
The diagram does not contain numerical data or specific values. It is a visual representation of a process.
### Key Observations
The diagram highlights a multi-faceted approach to hallucination detection, combining attention map analysis with a judgment process using another LLM. The use of a "Hallucination Probe" suggests a quantitative method for identifying hallucinations based on extracted features. The direct input of the QA Dataset to the Judge LLM implies a comparison between the LLM's answers and the ground truth.
### Interpretation
This diagram illustrates a sophisticated pipeline for evaluating the tendency of LLMs to "hallucinate" – generate outputs that are not grounded in the input data or factual knowledge. The pipeline attempts to address this issue by:
* **Analyzing Attention:** Examining where the LLM is focusing its attention during answer generation.
* **Quantitative Detection:** Using a machine learning model (logistic regression) to identify patterns in attention maps that correlate with hallucinations.
* **Human-in-the-Loop Evaluation:** Employing another LLM as a "judge" to assess the correctness of the generated answers.
The inclusion of both attention map analysis and a judge LLM suggests a desire to combine the strengths of both approaches – the ability to identify subtle patterns in the LLM's internal state (attention maps) with the ability to assess the overall quality and factual accuracy of the generated output (judge LLM). The dashed line from the QA Dataset to the Judge LLM indicates that the Judge LLM has access to the original question and answer pairs, allowing it to determine if the LLM's response is consistent with the provided information. This pipeline is designed to provide a comprehensive and reliable method for evaluating and mitigating hallucinations in LLMs.
</details>
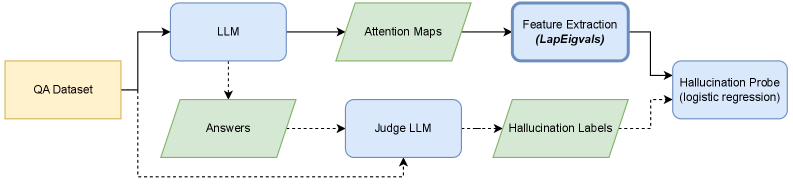
Figure 3: Overview of the methodology used in this work. Solid lines indicate the test-time pipeline, while dashed lines represent additional pipeline steps for generating labels for training the hallucination probe (logistic regression). The primary contribution of this work is leveraging the top- $k$ eigenvalues of the Laplacian as features for the hallucination probe, highlighted with a bold box on the diagram.
In our method, we train a hallucination probe using only attention maps, which we extracted during LLM inference, as illustrated in Figure 2. The attention map is a matrix containing attention scores for all tokens processed during inference, while the hallucination probe is a logistic regression model that uses features derived from attention maps as input. This work’s core contribution is using the top- $k$ eigenvalues of the Laplacian matrix as input features, which we detail below.
Denote $\mathbf{A}^{(l,h)}\in\mathbb{R}^{T\times T}$ as the attention map matrix for layer $l\in\{1\dotsc L\}$ and attention head $h\in\{1\dotsc H\}$ , where $T$ is the total number of tokens generated by an LLM (including input tokens), $L$ the number of layers (transformer blocks), and $H$ the number of attention heads. The attention matrix is row-stochastic, meaning each row sums to 1 ( $\sum_{j=0}^{T}\mathbf{A}^{(l,h)}_{:,j}=\mathbf{1}$ ). It is also lower triangular ( $a^{(l,h)}_{ij}=0$ for all $j>i$ ) and non-negative ( $a^{(l,h)}_{ij}\geq 0$ for all $i,j$ ). We can view $\mathbf{A}^{(l,h)}$ as a weighted adjacency matrix of a directed graph, where each node represents processed token, and each directed edge from token $i$ to token $j$ is weighted by the attention score, as depicted in Figure 2.
Then, we define the Laplacian of a layer $l$ and attention head $h$ as:
$$
\mathbf{L}^{(l,h)}=\mathbf{D}^{(l,h)}-\mathbf{A}^{(l,h)}, \tag{1}
$$
where $\mathbf{D}^{(l,h)}$ is a diagonal degree matrix. Since the attention map defines a directed graph, we distinguish between the in-degree and out-degree matrices. The in-degree is computed as the sum of attention scores from preceding tokens, and due to the softmax normalization, it is uniformly 1. Therefore, we define $\mathbf{D}^{(l,h)}$ as the out-degree matrix, which quantifies the total attention a token receives from tokens that follow it. To ensure these values remain independent of the sequence length, we normalize them by the number of subsequent tokens (i.e., the number of outgoing edges).
$$
d^{(l,h)}_{ii}=\frac{\sum_{u}{a^{(l,h)}_{ui}}}{T-i}, \tag{2}
$$
where $i,u\in\{0,\dots,(T-1)\}$ denote token indices. The Laplacian defined this way is bounded, i.e., $\mathbf{L}^{(l,h)}_{ij}\in\left[-1,1\right]$ (see Appendix B for proofs). Intuitively, the resulting Laplacian for each processed token represents the average attention score to previous tokens reduced by the attention score to itself. As eigenvalues of the Laplacian can summarize information flow in a graph (von Luxburg, 2007; Topping et al., 2022), we take eigenvalues of $\mathbf{L}^{(l,h)}$ , which are diagonal entries due to the lower triangularity of the Laplacian matrix, and sort them:
$$
\tilde{z}^{(l,h)}=\operatorname{sort\left(\operatorname{diag\left(\mathbf{L}^{(l,h)}\right)}\right)} \tag{3}
$$
Recently, (Zhu et al., 2024) found features from the entire token sequence, rather than a single token, improving hallucination detection. Similarly, (Kim et al., 2024) demonstrated that information from all layers, instead of a single one in isolation, yields better results on this task. Motivated by these findings, our method uses features from all tokens and all layers as input to the probe. Therefore, we take the top- $k$ largest values from each head and layer and concatenate them into a single feature vector $z$ , where $k$ is a hyperparameter of our method:
$$
z=\operatorname*{\mathchoice{\Big\|}{\big\|}{\|}{\|}}_{\forall l\in L,\forall h\in H}\left[\tilde{z}^{(l,h)}_{T},\tilde{z}^{(l,h)}_{T-1},\dotsc,\tilde{z}^{(l,h)}_{T-k}\right] \tag{4}
$$
Since LLMs contain dozens of layers and heads, the probe input vector $z\in\mathbb{R}^{L\cdot H\cdot k}$ can still be high-dimensional. Thus, we project it to a lower dimensionality using PCA (Jolliffe and Cadima, 2016). We call our approach $\operatorname{LapEigvals}$ .
## 4 Experimental setup
The overview of the methodology used in this work is presented in Figure 3. Next, we describe each step of the pipeline in detail.
### 4.1 Dataset construction
We use annotated QA datasets to construct the hallucination detection datasets and label incorrect LLM answers as hallucinations. To assess the correctness of generated answers, we followed prior work (Orgad et al., 2025) and adopted the llm-as-judge approach (Zheng et al., 2023), with the exception of one dataset where exact match evaluation against ground-truth answers was possible. For llm-as-judge, we prompted a large LLM to classify each response as either hallucination, non-hallucination, or rejected, where rejected indicates that it was unclear whether the answer was correct, e.g., the model refused to answer due to insufficient knowledge. Based on the manual qualitative inspection of several LLMs, we employed gpt-4o-mini (OpenAI et al., 2024) as the judge model since it provides the best trade-off between accuracy and cost. To confirm the reliability of the labels, we additionally verified agreement with the larger model, gpt-4.1, on Llama-3.1-8B and found that the agreement between models falls within the acceptable range widely adopted in the literature (see Appendix F).
For experiments, we selected 7 QA datasets previously utilized in the context of hallucination detection (Chen et al., 2024; Kossen et al., 2024; Chuang et al., 2024b; Mitra et al., 2024). Specifically, we used the validation set of NQ-Open (Kwiatkowski et al., 2019), comprising $3{,}610$ question-answer pairs, and the validation set of TriviaQA (Joshi et al., 2017), containing $7{,}983$ pairs. To evaluate our method on longer inputs, we employed the development set of CoQA (Reddy et al., 2019) and the rc.nocontext portion of the SQuADv2 (Rajpurkar et al., 2018) datasets, with $5{,}928$ and $9{,}960$ examples, respectively. Additionally, we incorporated the QA part of the HaluEvalQA (Li et al., 2023) dataset, containing $10{,}000$ examples, and the generation part of the TruthfulQA (Lin et al., 2022) benchmark with $817$ examples. Finally, we used test split of GSM8k dataset Cobbe et al. (2021) with $1{,}319$ grade school math problems, evaluated by exact match against labels. For TriviaQA, CoQA, and SQuADv2, we followed the same preprocessing procedure as (Chen et al., 2024).
We generate answers using 5 open-source LLMs: Llama-3.1-8B hf.co/meta-llama/Llama-3.1-8B-Instruct and Llama-3.2-3B hf.co/meta-llama/Llama-3.2-3B-Instruct (Grattafiori et al., 2024), Phi-3.5 hf.co/microsoft/Phi-3.5-mini-instruct (Abdin et al., 2024), Mistral-Nemo hf.co/mistralai/Mistral-Nemo-Instruct-2407 (Mistral AI Team and NVIDIA, 2024), Mistral-Small-24B hf.co/mistralai/Mistral-Small-24B-Instruct-2501 (Mistral AI Team, 2025). We use two softmax temperatures for each LLM when decoding ( $temp\in\{0.1,1.0\}$ ) and one prompt (for all datasets we used a prompt in Listing 3, except for GSM8K in Listing 5). Overall, we evaluated hallucination detection probes on 10 LLM configurations and 7 QA datasets. We present the frequency of classes for answers from each configuration in Figure 9 (Appendix E).
### 4.2 Hallucination Probe
As a hallucination probe, we take a logistic regression model, using the implementation from scikit-learn (Pedregosa et al., 2011) with all parameters default, except for ${max\_iter{=}2000}$ and ${class\_weight{=}{{}^{\prime\prime}balanced^{\prime\prime}}}$ . For top- $k$ eigenvalues, we tested 5 values of $k\in\{5,10,20,50,100\}$ For datasets with examples having less than 100 tokens, we stop at $k{=}50$ and selected the result with the highest efficacy. All eigenvalues are projected with PCA onto 512 dimensions, except in per-layer experiments where there may be fewer than 512 features. In these cases, we apply PCA projection to match the input feature dimensionality, i.e., decorrelating them. As an evaluation metric, we use AUROC on the test split (additional results presenting Precision and Recall are reported in Appendix G.1).
### 4.3 Baselines
Our method is a supervised approach for detecting hallucinations using only attention maps. For a fair comparison, we adapt the unsupervised $\operatorname{AttentionScore}$ (Sriramanan et al., 2024) by using log-determinants of each head’s attention scores as features instead of summing them, and we also include the original $\operatorname{AttentionScore}$ , computed as the sum of log-determinants over heads, for reference. To evaluate the effectiveness of our proposed Laplacian eigenvalues, we compare them to the eigenvalues of raw attention maps, denoted as $\operatorname{AttnEigvals}$ . Extended results for each approach on a per-layer basis are provided in Appendix G.2, while Appendix G.4 presents a comparison with a method based on hidden states. Implementation and hardware details are provided in Appendix C.
## 5 Results
Table 1: Test AUROC for $\operatorname{LapEigvals}$ and several baseline methods. AUROC values were obtained in a single run of logistic regression training on features from a dataset generated with $temp{=}1.0$ . We mark results for $\operatorname{AttentionScore}$ in gray as it is an unsupervised approach, not directly comparable to the others. In bold, we highlight the best performance individually for each dataset and LLM. See Appendix G for extended results.
| Llama3.1-8B Llama3.1-8B Llama3.1-8B | $\operatorname{AttentionScore}$ $\operatorname{AttnLogDet}$ $\operatorname{AttnEigvals}$ | 0.493 0.769 0.782 | 0.720 0.826 0.838 | 0.589 0.827 0.819 | 0.556 0.793 0.790 | 0.538 0.748 0.768 | 0.532 0.842 0.843 | 0.541 0.814 0.833 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Llama3.1-8B | $\operatorname{LapEigvals}$ | 0.830 | 0.872 | 0.874 | 0.827 | 0.791 | 0.889 | 0.829 |
| Llama3.2-3B | $\operatorname{AttentionScore}$ | 0.509 | 0.717 | 0.588 | 0.546 | 0.530 | 0.515 | 0.581 |
| Llama3.2-3B | $\operatorname{AttnLogDet}$ | 0.700 | 0.851 | 0.801 | 0.690 | 0.734 | 0.789 | 0.795 |
| Llama3.2-3B | $\operatorname{AttnEigvals}$ | 0.724 | 0.768 | 0.819 | 0.694 | 0.749 | 0.804 | 0.723 |
| Llama3.2-3B | $\operatorname{LapEigvals}$ | 0.812 | 0.870 | 0.828 | 0.693 | 0.757 | 0.832 | 0.787 |
| Phi3.5 | $\operatorname{AttentionScore}$ | 0.520 | 0.666 | 0.541 | 0.594 | 0.504 | 0.540 | 0.554 |
| Phi3.5 | $\operatorname{AttnLogDet}$ | 0.745 | 0.842 | 0.818 | 0.815 | 0.769 | 0.848 | 0.755 |
| Phi3.5 | $\operatorname{AttnEigvals}$ | 0.771 | 0.794 | 0.829 | 0.798 | 0.782 | 0.850 | 0.802 |
| Phi3.5 | $\operatorname{LapEigvals}$ | 0.821 | 0.885 | 0.836 | 0.826 | 0.795 | 0.872 | 0.777 |
| Mistral-Nemo | $\operatorname{AttentionScore}$ | 0.493 | 0.630 | 0.531 | 0.529 | 0.510 | 0.532 | 0.494 |
| Mistral-Nemo | $\operatorname{AttnLogDet}$ | 0.728 | 0.856 | 0.798 | 0.769 | 0.772 | 0.812 | 0.852 |
| Mistral-Nemo | $\operatorname{AttnEigvals}$ | 0.778 | 0.842 | 0.781 | 0.761 | 0.758 | 0.821 | 0.802 |
| Mistral-Nemo | $\operatorname{LapEigvals}$ | 0.835 | 0.890 | 0.833 | 0.795 | 0.812 | 0.865 | 0.828 |
| Mistral-Small-24B | $\operatorname{AttentionScore}$ | 0.516 | 0.576 | 0.504 | 0.462 | 0.455 | 0.463 | 0.451 |
| Mistral-Small-24B | $\operatorname{AttnLogDet}$ | 0.766 | 0.853 | 0.842 | 0.747 | 0.753 | 0.833 | 0.735 |
| Mistral-Small-24B | $\operatorname{AttnEigvals}$ | 0.805 | 0.856 | 0.848 | 0.751 | 0.760 | 0.844 | 0.765 |
| Mistral-Small-24B | $\operatorname{LapEigvals}$ | 0.861 | 0.925 | 0.882 | 0.791 | 0.820 | 0.876 | 0.748 |
Table 1 presents the results of our method compared to the baselines. $\operatorname{LapEigvals}$ achieved the best performance among all tested methods on 6 out of 7 datasets. Moreover, our method consistently performs well across all 5 LLM architectures ranging from 3 up to 24 billion parameters. TruthfulQA was the only exception where $\operatorname{LapEigvals}$ was the second-best approach, yet it might stem from the small size of the dataset or severe class imbalance (depicted in Figure 9). In contrast, using eigenvalues of vanilla attention maps in $\operatorname{AttnEigvals}$ leads to worse performance, which suggests that transformation to Laplacian is the crucial step to uncover latent features of an LLM corresponding to hallucinations. In Appendix G, we show that $\operatorname{LapEigvals}$ consistently demonstrates a smaller generalization gap, i.e., the difference between training and test performance is smaller for our method. While the $\operatorname{AttentionScore}$ method performed poorly, it is fully unsupervised and should not be directly compared to other approaches. However, its supervised counterpart – $\operatorname{AttnLogDet}$ – remains inferior to methods based on spectral features, namely $\operatorname{AttnEigvals}$ and $\operatorname{LapEigvals}$ . In Table 6 in Appendix G.2, we present extended results, including per-layer and all-layers breakdowns, two temperatures used during answers generation, and a comparison between training and test AUROC. Moreover, compared to probes based on hidden states, our method performs best in most of the tested settings, as shown in Appendix G.4.
## 6 Ablation studies
To better understand the behavior of our method under different conditions, we conduct a comprehensive ablation study. This analysis provides valuable insights into the factors driving the $\operatorname{LapEigvals}$ performance and highlights the robustness of our approach across various scenarios. In order to ensure reliable results, we perform all studies on the TriviaQA dataset, which has a moderate input size and number of examples.
### 6.1 How does the number of eigenvalues influence performance?
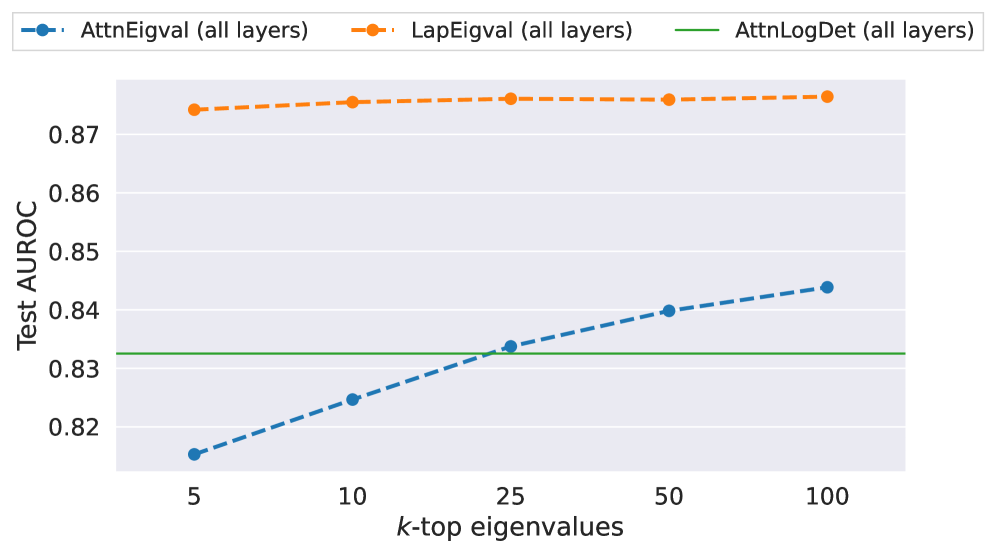
First, we verify how the number of eigenvalues influences the performance of the hallucination probe and present results for Mistral-Small-24B in Figure 4 (results for all models are showcased in Figure 10 in Appendix H). Generally, using more eigenvalues improves performance, but there is less variation in performance among different values of $k$ for $\operatorname{LapEigvals}$ compared to the baseline. Moreover, $\operatorname{LapEigvals}$ achieves significantly better performance with smaller input sizes, as $\operatorname{AttnEigvals}$ with the largest $k{=}100$ fails to surpass $\operatorname{LapEigvals}$ ’s performance at $k{=}5$ . These results confirm that spectral features derived from the Laplacian carry a robust signal indicating the presence of hallucinations and highlight the strength of our method.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Line Chart: Test AUROC vs. k-top eigenvalues
### Overview
This line chart displays the relationship between the number of k-top eigenvalues and the Test AUROC (Area Under the Receiver Operating Characteristic curve) for three different methods: AttnEigval, LapEigval, and AttnLogDet. All methods are evaluated across "all layers". The chart aims to demonstrate how performance (AUROC) changes as the number of eigenvalues considered increases.
### Components/Axes
* **X-axis:** "k-top eigenvalues" with markers at 5, 10, 25, 50, and 100.
* **Y-axis:** "Test AUROC" with a scale ranging from approximately 0.81 to 0.88.
* **Legend:** Located at the top-right of the chart, identifying the three data series:
* AttnEigval (all layers) - Blue dashed line with circle markers.
* LapEigval (all layers) - Orange dotted line with circle markers.
* AttnLogDet (all layers) - Green solid line.
### Detailed Analysis
* **AttnEigval (all layers) - Blue dashed line:**
* The line slopes upward, indicating increasing AUROC with increasing k-top eigenvalues.
* At k=5, AUROC ≈ 0.818.
* At k=10, AUROC ≈ 0.824.
* At k=25, AUROC ≈ 0.833.
* At k=50, AUROC ≈ 0.839.
* At k=100, AUROC ≈ 0.844.
* **LapEigval (all layers) - Orange dotted line:**
* The line is relatively flat, showing minimal change in AUROC as k increases.
* At k=5, AUROC ≈ 0.873.
* At k=10, AUROC ≈ 0.874.
* At k=25, AUROC ≈ 0.874.
* At k=50, AUROC ≈ 0.874.
* At k=100, AUROC ≈ 0.875.
* **AttnLogDet (all layers) - Green solid line:**
* The line is nearly horizontal, indicating a stable AUROC across all k values.
* AUROC remains consistently around 0.832 for all k values (5, 10, 25, 50, 100).
### Key Observations
* LapEigval consistently achieves the highest AUROC values across all k-top eigenvalues.
* AttnEigval shows a positive correlation between AUROC and the number of eigenvalues used, but starts from a lower AUROC value than LapEigval.
* AttnLogDet exhibits a stable AUROC, independent of the number of eigenvalues.
* The difference in AUROC between AttnEigval and the other two methods decreases as k increases.
### Interpretation
The data suggests that LapEigval is the most effective method for this task, regardless of the number of eigenvalues considered. AttnEigval's performance improves with more eigenvalues, indicating that incorporating more information from the eigenvalues is beneficial for this method. AttnLogDet's consistent performance suggests it is less sensitive to the number of eigenvalues used. The consistent high performance of LapEigval could be due to its inherent properties in capturing relevant information from the eigenvalue spectrum. The increasing performance of AttnEigval with more eigenvalues suggests that the method benefits from a more complete representation of the eigenvalue distribution. The stability of AttnLogDet might indicate that it is already capturing the most important information with a limited number of eigenvalues. The chart highlights a trade-off between computational cost (using more eigenvalues) and potential performance gains (for AttnEigval).
</details>
Figure 4: Probe performance across different top- $k$ eigenvalues: $k\in\{5,10,25,50,100\}$ for TriviaQA dataset with $temp{=}1.0$ and Mistral-Small-24B LLM.
### 6.2 Does using all layers at once improve performance?
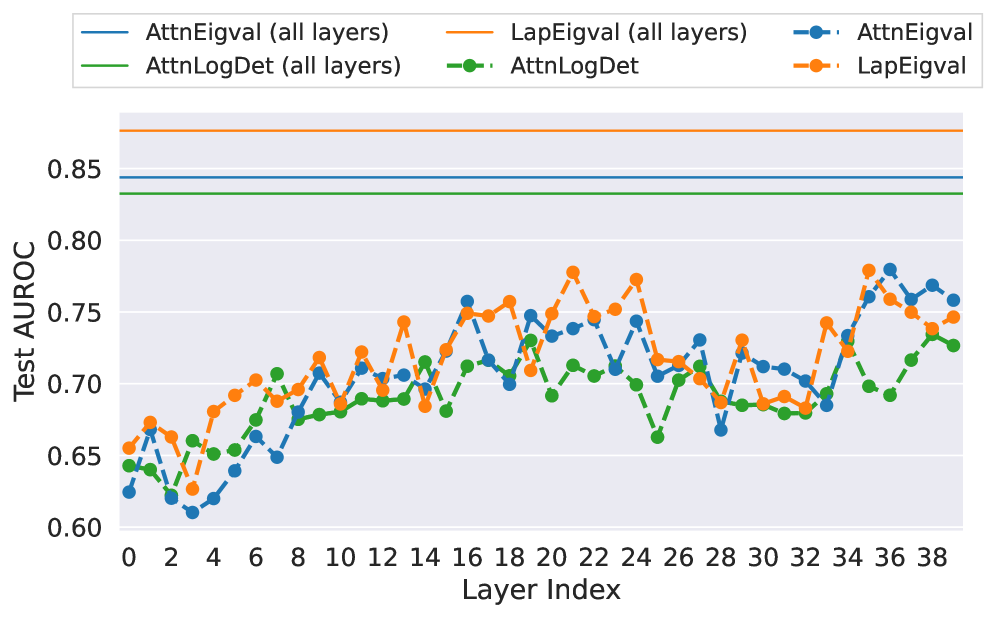
Second, we demonstrate that using all layers of an LLM instead of a single one improves performance. In Figure 5, we compare per-layer to all-layer efficacy for Mistral-Small-24B (results for all models are showcased in Figure 11 in Appendix H). For the per-layer approach, better performance is generally achieved with deeper LLM layers. Notably, peak performance varies across LLMs, requiring an additional search for each new LLM. In contrast, the all-layer probes consistently outperform the best per-layer probes across all LLMs. This finding suggests that information indicating hallucinations is spread across many layers of LLM, and considering them in isolation limits detection accuracy. Further, Table 6 in Appendix G summarises outcomes for the two variants on all datasets and LLM configurations examined in this work.
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Line Chart: Test AUROC vs. Layer Index
### Overview
This image presents a line chart comparing the Test Area Under the Receiver Operating Characteristic curve (AUROC) across different methods (AttnEigenval, AttnLogDet, LapEigenval, LapLogDet) as a function of Layer Index. The chart displays six distinct lines, each representing a different method, plotted against layer indices ranging from 0 to 38.
### Components/Axes
* **X-axis:** Layer Index (ranging from 0 to 38, with increments of 2)
* **Y-axis:** Test AUROC (ranging from 0.60 to 0.85, with increments of 0.05)
* **Legend:** Located at the top of the chart, identifying each line by color and method.
* AttnEigenval (all layers) - Dark Blue Solid Line
* AttnLogDet (all layers) - Dark Green Solid Line
* LapEigenval (all layers) - Orange Solid Line
* AttnEigenval - Blue Dashed Line
* AttnLogDet - Green Dashed Line
* LapEigenval - Orange Dotted Line
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points. Note that values are estimated from the visual representation.
* **AttnEigenval (all layers) - Dark Blue Solid Line:** This line generally slopes upward from Layer Index 0 to approximately 16, then fluctuates between 0.72 and 0.78.
* Layer 0: ~0.66
* Layer 4: ~0.68
* Layer 8: ~0.70
* Layer 12: ~0.72
* Layer 16: ~0.74
* Layer 20: ~0.75
* Layer 24: ~0.74
* Layer 28: ~0.73
* Layer 32: ~0.75
* Layer 36: ~0.76
* Layer 38: ~0.77
* **AttnLogDet (all layers) - Dark Green Solid Line:** This line shows an initial increase up to Layer Index 10, followed by fluctuations between 0.68 and 0.74.
* Layer 0: ~0.64
* Layer 4: ~0.66
* Layer 8: ~0.69
* Layer 12: ~0.71
* Layer 16: ~0.72
* Layer 20: ~0.72
* Layer 24: ~0.70
* Layer 28: ~0.71
* Layer 32: ~0.72
* Layer 36: ~0.71
* Layer 38: ~0.70
* **LapEigenval (all layers) - Orange Solid Line:** This line exhibits a steady increase from Layer Index 0 to approximately 20, then plateaus and fluctuates between 0.72 and 0.78.
* Layer 0: ~0.66
* Layer 4: ~0.69
* Layer 8: ~0.71
* Layer 12: ~0.73
* Layer 16: ~0.75
* Layer 20: ~0.76
* Layer 24: ~0.76
* Layer 28: ~0.75
* Layer 32: ~0.76
* Layer 36: ~0.77
* Layer 38: ~0.78
* **AttnEigenval - Blue Dashed Line:** This line fluctuates significantly, starting around 0.65 and reaching a peak around 0.77 at Layer Index 22, then decreasing to around 0.72.
* Layer 0: ~0.65
* Layer 4: ~0.66
* Layer 8: ~0.68
* Layer 12: ~0.70
* Layer 16: ~0.72
* Layer 20: ~0.75
* Layer 24: ~0.74
* Layer 28: ~0.72
* Layer 32: ~0.74
* Layer 36: ~0.75
* Layer 38: ~0.74
* **AttnLogDet - Green Dashed Line:** This line also fluctuates, starting around 0.64 and peaking around 0.75 at Layer Index 24, then decreasing to around 0.70.
* Layer 0: ~0.64
* Layer 4: ~0.65
* Layer 8: ~0.67
* Layer 12: ~0.69
* Layer 16: ~0.71
* Layer 20: ~0.73
* Layer 24: ~0.75
* Layer 28: ~0.73
* Layer 32: ~0.72
* Layer 36: ~0.71
* Layer 38: ~0.70
* **LapEigenval - Orange Dotted Line:** This line shows a gradual increase from 0.66 to approximately 0.76 at Layer Index 20, then fluctuates between 0.72 and 0.78.
* Layer 0: ~0.66
* Layer 4: ~0.68
* Layer 8: ~0.70
* Layer 12: ~0.72
* Layer 16: ~0.74
* Layer 20: ~0.76
* Layer 24: ~0.75
* Layer 28: ~0.74
* Layer 32: ~0.75
* Layer 36: ~0.76
* Layer 38: ~0.77
### Key Observations
* The "all layers" methods (solid lines) generally exhibit smoother trends compared to the individual layer methods (dashed and dotted lines).
* LapEigenval (all layers) consistently shows the highest AUROC values, particularly after Layer Index 16.
* The dashed and dotted lines show more variability, suggesting that the performance of individual layers fluctuates more than the aggregated "all layers" performance.
* There is a general trend of increasing AUROC with increasing Layer Index, up to a certain point, after which the performance plateaus or fluctuates.
### Interpretation
The chart demonstrates the performance of different methods for analyzing layers in a model, as measured by the Test AUROC. The consistent higher performance of LapEigenval (all layers) suggests that this method is more robust and effective at discriminating between classes across all layers. The fluctuations observed in the individual layer methods indicate that the effectiveness of these methods varies depending on the specific layer being analyzed. The initial increase in AUROC with Layer Index suggests that the model learns more discriminative features as it progresses through the layers. The plateauing or fluctuation in performance after a certain layer index could indicate that the model has reached its maximum discriminative capacity or that further layers introduce noise or redundancy. The difference between the "all layers" and individual layer methods highlights the benefits of aggregating information across layers to obtain a more stable and reliable performance metric.
</details>
Figure 5: Analysis of model performance across different layers for Mistral-Small-24B and TriviaQA dataset with $temp{=}1.0$ and $k{=}100$ top eigenvalues (results for models operating on all layers provided for reference).
### 6.3 Does sampling temperature influence results?
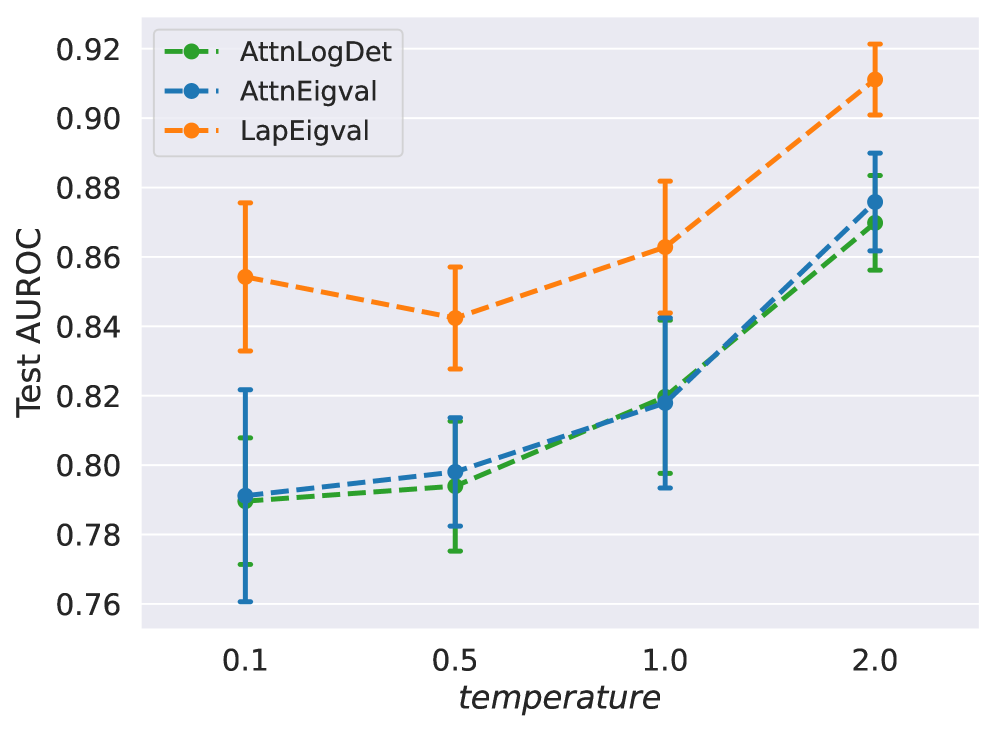
Here, we compare $\operatorname{LapEigvals}$ to the baselines on hallucination datasets, where each dataset contains answers generated at a specific decoding temperature. Higher temperatures typically produce more hallucinated examples (Lee, 2023; Renze, 2024), leading to dataset imbalance. Thus, to mitigate the effect of data imbalance, we sample a subset of $1{,}000$ hallucinated and $1{,}000$ non-hallucinated examples $10$ times for each temperature and train hallucination probes. Interestingly, in Figure 6, we observe that all models improve their performance at higher temperatures, but $\operatorname{LapEigvals}$ consistently achieves the best accuracy on all considered temperature values. The correlation of efficacy with temperature may be attributed to differences in the characteristics of hallucinations at higher temperatures compared to lower ones (Renze, 2024). Also, hallucination detection might be facilitated at higher temperatures due to underlying properties of softmax function (Veličković et al., 2024), and further exploration of this direction is left for future work.
<details>
<summary>x6.png Details</summary>
### Visual Description
\n
## Line Chart: Test AUROC vs. Temperature
### Overview
This line chart displays the relationship between "temperature" and "Test AUROC" for three different models: "AttnLogDet", "AttnEigval", and "LapEigval". Each data point represents the mean Test AUROC value at a given temperature, with error bars indicating the variability around that mean.
### Components/Axes
* **X-axis:** "temperature" with markers at 0.1, 0.5, 1.0, and 2.0.
* **Y-axis:** "Test AUROC" ranging from approximately 0.76 to 0.92.
* **Legend:** Located at the top-right corner of the chart.
* "AttnLogDet" - Green line with circular markers.
* "AttnEigval" - Blue line with circular markers.
* "LapEigval" - Orange dashed line with circular markers.
* **Error Bars:** Vertical lines extending above and below each data point, representing the standard deviation or confidence interval.
### Detailed Analysis
**AttnLogDet (Green Line):**
The green line shows an upward trend.
* At temperature 0.1, the Test AUROC is approximately 0.79 ± 0.03 (error bar extends from ~0.76 to ~0.82).
* At temperature 0.5, the Test AUROC is approximately 0.78 ± 0.02 (error bar extends from ~0.76 to ~0.80).
* At temperature 1.0, the Test AUROC is approximately 0.80 ± 0.02 (error bar extends from ~0.78 to ~0.82).
* At temperature 2.0, the Test AUROC is approximately 0.87 ± 0.02 (error bar extends from ~0.85 to ~0.89).
**AttnEigval (Blue Line):**
The blue line shows an upward trend.
* At temperature 0.1, the Test AUROC is approximately 0.81 ± 0.02 (error bar extends from ~0.79 to ~0.83).
* At temperature 0.5, the Test AUROC is approximately 0.80 ± 0.02 (error bar extends from ~0.78 to ~0.82).
* At temperature 1.0, the Test AUROC is approximately 0.82 ± 0.02 (error bar extends from ~0.80 to ~0.84).
* At temperature 2.0, the Test AUROC is approximately 0.88 ± 0.02 (error bar extends from ~0.86 to ~0.90).
**LapEigval (Orange Dashed Line):**
The orange dashed line shows a more complex trend, initially decreasing then increasing.
* At temperature 0.1, the Test AUROC is approximately 0.85 ± 0.03 (error bar extends from ~0.82 to ~0.88).
* At temperature 0.5, the Test AUROC is approximately 0.84 ± 0.03 (error bar extends from ~0.81 to ~0.87).
* At temperature 1.0, the Test AUROC is approximately 0.86 ± 0.03 (error bar extends from ~0.83 to ~0.89).
* At temperature 2.0, the Test AUROC is approximately 0.91 ± 0.03 (error bar extends from ~0.88 to ~0.94).
### Key Observations
* All three models show an increasing trend in Test AUROC as temperature increases.
* "LapEigval" starts with the highest Test AUROC at low temperatures (0.1 and 0.5) but is surpassed by "AttnEigval" and "AttnLogDet" at higher temperatures (2.0).
* The error bars suggest that the variability in Test AUROC is relatively consistent across temperatures for each model.
* "AttnLogDet" has the lowest Test AUROC values across all temperatures.
### Interpretation
The chart demonstrates the impact of "temperature" on the performance (measured by Test AUROC) of three different models. The increasing trend for all models suggests that higher temperatures generally lead to improved performance. However, the specific performance levels and the rate of improvement vary between models.
The "temperature" parameter likely controls a stochastic element within the models, such as the softmax function or a sampling process. Increasing the temperature introduces more randomness, which can help the models escape local optima and generalize better to unseen data, up to a certain point.
The initial higher performance of "LapEigval" at lower temperatures could indicate that it is less sensitive to the stochasticity introduced by temperature, or that it benefits from a more focused exploration of the solution space at lower temperatures. However, as the temperature increases, the benefits of the other models' increased exploration outweigh this advantage.
The error bars provide a measure of the robustness of each model's performance. The relatively small error bars suggest that the observed trends are statistically significant and not simply due to random fluctuations. Further investigation could explore the reasons for the differences in performance and variability between the models.
</details>
Figure 6: Test AUROC for different sampling $temp$ values during answer decoding on the TriviaQA dataset, using $k{=}100$ eigenvalues for $\operatorname{LapEigvals}$ and $\operatorname{AttnEigvals}$ with the Llama-3.1-8B LLM. Error bars indicate the standard deviation over 10 balanced samples containing $N=1000$ examples per class.
### 6.4 How does $\operatorname{LapEigvals}$ generalizes?
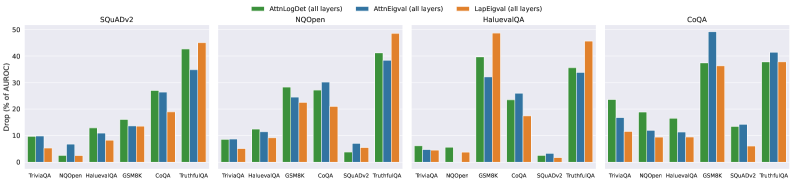
To check whether our method generalizes across datasets, we trained the hallucination probe on features from the training split of one QA dataset and evaluated it on the features from the test split of a different QA dataset. Due to space limitations, we present results for selected datasets and provide extended results and absolute efficacy values in Appendix I. Figure 7 showcases the percent drop in Test AUROC when using a different training dataset compared to training and testing on the same QA dataset. We can observe that $\operatorname{LapEigvals}$ provides a performance drop comparable to other baselines, and in several cases, it generalizes best. Interestingly, all methods exhibit poor generalization on TruthfulQA and GSM8K. We hypothesize that the weak performance on TruthfulQA arises from its limited size and class imbalance, whereas the difficulty on GSM8K likely reflects its distinct domain, which has been shown to hinder hallucination detection (Orgad et al., 2025). Additionally, in Appendix I, we show that $\operatorname{LapEigvals}$ achieves the highest test performance in all scenarios (except for TruthfulQA).
<details>
<summary>x7.png Details</summary>
### Visual Description
## Bar Chart: Drop (%) of AUROC for Different QA Datasets and Models
### Overview
The image presents a series of four bar charts, each representing a different Question Answering (QA) dataset: SQuADv2, NQOpen, HaluevalQA, and CoQA. Each chart compares the performance of three models – AttnLagDet (all layers), AttnEqual (all layers), and LapEqual (all layers) – based on the Drop (%) of Area Under the Receiver Operating Characteristic curve (AUROC). The charts visually compare the performance of these models across different QA datasets.
### Components/Axes
* **X-axis:** Represents different QA models: TriviaQA, Moopen, HaluevalQA, GSM8K, SQuAD, TruthQA, and PI/10.
* **Y-axis:** Represents "Drop (%) of AUROC", ranging from 0 to 50.
* **Legend:** Located at the top-center of the image, identifies the three models using color-coding:
* Green: AttnLagDet (all layers)
* Blue: AttnEqual (all layers)
* Orange: LapEqual (all layers)
* **Titles:** Each chart is labeled with the corresponding QA dataset name (SQuADv2, NQOpen, HaluevalQA, CoQA) positioned at the top-center.
### Detailed Analysis or Content Details
**SQuADv2 Chart:**
* TriviaQA: AttnLagDet ≈ 1.5%, AttnEqual ≈ 1.0%, LapEqual ≈ 1.0%
* Moopen: AttnLagDet ≈ 2.0%, AttnEqual ≈ 1.5%, LapEqual ≈ 1.5%
* HaluevalQA: AttnLagDet ≈ 10.0%, AttnEqual ≈ 6.0%, LapEqual ≈ 5.0%
* GSM8K: AttnLagDet ≈ 15.0%, AttnEqual ≈ 10.0%, LapEqual ≈ 8.0%
* SQuAD: AttnLagDet ≈ 42.0%, AttnEqual ≈ 30.0%, LapEqual ≈ 25.0%
* TruthQA: AttnLagDet ≈ 35.0%, AttnEqual ≈ 25.0%, LapEqual ≈ 20.0%
* PI/10: AttnLagDet ≈ 45.0%, AttnEqual ≈ 35.0%, LapEqual ≈ 30.0%
**NQOpen Chart:**
* TriviaQA: AttnLagDet ≈ 1.0%, AttnEqual ≈ 0.5%, LapEqual ≈ 0.5%
* Moopen: AttnLagDet ≈ 1.5%, AttnEqual ≈ 1.0%, LapEqual ≈ 1.0%
* HaluevalQA: AttnLagDet ≈ 5.0%, AttnEqual ≈ 3.0%, LapEqual ≈ 2.0%
* GSM8K: AttnLagDet ≈ 15.0%, AttnEqual ≈ 10.0%, LapEqual ≈ 8.0%
* SQuAD: AttnLagDet ≈ 30.0%, AttnEqual ≈ 20.0%, LapEqual ≈ 15.0%
* TruthQA: AttnLagDet ≈ 25.0%, AttnEqual ≈ 15.0%, LapEqual ≈ 10.0%
* PI/10: AttnLagDet ≈ 35.0%, AttnEqual ≈ 25.0%, LapEqual ≈ 20.0%
**HaluevalQA Chart:**
* TriviaQA: AttnLagDet ≈ 1.0%, AttnEqual ≈ 0.5%, LapEqual ≈ 0.5%
* Moopen: AttnLagDet ≈ 2.0%, AttnEqual ≈ 1.0%, LapEqual ≈ 1.0%
* HaluevalQA: AttnLagDet ≈ 45.0%, AttnEqual ≈ 30.0%, LapEqual ≈ 25.0%
* GSM8K: AttnLagDet ≈ 20.0%, AttnEqual ≈ 15.0%, LapEqual ≈ 10.0%
* SQuAD: AttnLagDet ≈ 40.0%, AttnEqual ≈ 30.0%, LapEqual ≈ 20.0%
* TruthQA: AttnLagDet ≈ 30.0%, AttnEqual ≈ 20.0%, LapEqual ≈ 15.0%
* PI/10: AttnLagDet ≈ 40.0%, AttnEqual ≈ 30.0%, LapEqual ≈ 25.0%
**CoQA Chart:**
* TriviaQA: AttnLagDet ≈ 1.0%, AttnEqual ≈ 0.5%, LapEqual ≈ 0.5%
* Moopen: AttnLagDet ≈ 2.0%, AttnEqual ≈ 1.0%, LapEqual ≈ 1.0%
* HaluevalQA: AttnLagDet ≈ 10.0%, AttnEqual ≈ 5.0%, LapEqual ≈ 5.0%
* GSM8K: AttnLagDet ≈ 15.0%, AttnEqual ≈ 10.0%, LapEqual ≈ 8.0%
* SQuAD: AttnLagDet ≈ 35.0%, AttnEqual ≈ 25.0%, LapEqual ≈ 20.0%
* TruthQA: AttnLagDet ≈ 30.0%, AttnEqual ≈ 20.0%, LapEqual ≈ 15.0%
* PI/10: AttnLagDet ≈ 40.0%, AttnEqual ≈ 30.0%, LapEqual ≈ 25.0%
### Key Observations
* Across all datasets, the AttnLagDet model generally exhibits the highest Drop (%) of AUROC, followed by AttnEqual and then LapEqual.
* The largest differences in performance between the models are observed on the SQuAD and HaluevalQA datasets.
* For TriviaQA, Moopen, and HaluevalQA, the Drop (%) of AUROC is consistently low across all models.
* The GSM8K dataset shows a moderate Drop (%) of AUROC for all models.
* The TruthQA and PI/10 datasets show a higher Drop (%) of AUROC compared to TriviaQA, Moopen, and HaluevalQA, but lower than SQuAD.
### Interpretation
The data suggests that the AttnLagDet model consistently outperforms AttnEqual and LapEqual across all tested QA datasets, as measured by the Drop (%) of AUROC. This indicates that the AttnLagDet model is more robust to changes in the input data or model parameters. The significant performance differences observed on the SQuAD and HaluevalQA datasets suggest that these datasets are more sensitive to the specific architectural choices made in the models. The consistently low Drop (%) of AUROC on TriviaQA, Moopen, and HaluevalQA may indicate that these datasets are relatively easy for the models to solve, or that the models are already performing well on these datasets. The differences in performance across datasets highlight the importance of evaluating models on a diverse set of QA tasks to ensure their generalizability. The consistent ranking of the models (AttnLagDet > AttnEqual > LapEqual) suggests a fundamental difference in their capabilities, rather than dataset-specific quirks.
</details>
Figure 7: Generalization across datasets measured as a percent performance drop in Test AUROC (less is better) when trained on one dataset and tested on the other. Training datasets are indicated in the plot titles, while test datasets are shown on the $x$ -axis. Results computed on Llama-3.1-8B with $k{=}100$ top eigenvalues and $temp{=}1.0$ . Results for all datasets are presented in Appendix I.
### 6.5 How does performance vary across prompts?
Lastly, to assess the stability of our method across different prompts used for answer generation, we compared the results of the hallucination probes trained on features regarding four distinct prompts, the content of which is included in Appendix M. As shown in Table 2, $\operatorname{LapEigvals}$ consistently outperforms all baselines across all four prompts. While we can observe variations in performance across prompts, $\operatorname{LapEigvals}$ demonstrates the lowest standard deviation ( $0.05$ ) compared to $\operatorname{AttnLogDet}$ ( $0.016$ ) and $\operatorname{AttnEigvals}$ ( $0.07$ ), indicating its greater robustness.
Table 2: Test AUROC across four different prompts for answers on the TriviaQA dataset using Llama-3.1-8B with $temp{=}1.0$ and $k{=}50$ (some prompts have led to fewer than 100 tokens). Prompt $\boldsymbol{p_{3}}$ was the main one used to compare our method to baselines, as presented in Tables 1.
| $\operatorname{AttnLogDet}$ $\operatorname{AttnEigvals}$ $\operatorname{LapEigvals}$ | 0.847 0.840 0.882 | 0.855 0.870 0.890 | 0.842 0.842 0.888 | 0.860 0.875 0.895 |
| --- | --- | --- | --- | --- |
## 7 Related Work
Hallucinations in LLMs were proved to be inevitable (Xu et al., 2024), and to detect them, one can leverage either black-box or white-box approaches. The former approach uses only the outputs from an LLM, while the latter uses hidden states, attention maps, or logits corresponding to generated tokens.
Black-box approaches focus on the text generated by LLMs. For instance, (Li et al., 2024) verified the truthfulness of factual statements using external knowledge sources, though this approach relies on the availability of additional resources. Alternatively, SelfCheckGPT (Manakul et al., 2023) generates multiple responses to the same prompt and evaluates their consistency, with low consistency indicating potential hallucination.
White-box methods have emerged as a promising approach for detecting hallucinations (Farquhar et al., 2024; Azaria and Mitchell, 2023; Arteaga et al., 2024; Orgad et al., 2025). These methods are universal across all LLMs and do not require additional domain adaptation compared to black-box ones (Farquhar et al., 2024). They draw inspiration from seminal works on analyzing the internal states of simple neural networks (Alain and Bengio, 2016), which introduced linear classifier probes – models operating on the internal states of neural networks. Linear probes have been widely applied to the internal states of LLMs, notably for detecting hallucinations.
One of the first such probes was SAPLMA (Azaria and Mitchell, 2023), which demonstrated that one could predict the correctness of generated text straight from LLM’s hidden states. Further, the INSIDE method (Chen et al., 2024) tackled hallucination detection by sampling multiple responses from an LLM and evaluating consistency between their hidden states using a normalized sum of the eigenvalues from their covariance matrix. Also, (Farquhar et al., 2024) proposed a complementary probabilistic approach, employing entropy to quantify the model’s intrinsic uncertainty. Their method involves generating multiple responses, clustering them by semantic similarity, and calculating Semantic Entropy using an appropriate estimator. To address concerns regarding the validity of LLM probes, (Marks and Tegmark, 2024) introduced a high-quality QA dataset with simple true / false answers and causally demonstrated that the truthfulness of such statements is linearly represented in LLMs, which supports the use of probes for short texts.
Self-consistency methods (Liang et al., 2024), like INSIDE or Semantic Entropy, require multiple runs of an LLM for each input example, which substantially lowers their applicability. Motivated by this limitation, (Kossen et al., 2024) proposed to use Semantic Entropy Probe, which is a small model trained to predict expensive Semantic Entropy (Farquhar et al., 2024) from LLM’s hidden states. Notably, (Orgad et al., 2025) explored how LLMs encode information about truthfulness and hallucinations. First, they revealed that truthfulness is concentrated in specific tokens. Second, they found that probing classifiers on LLM representations do not generalize well across datasets, especially across datasets requiring different skills, which we confirmed in Section 6.4. Lastly, they showed that the probes could select the correct answer from multiple generated answers with reasonable accuracy, meaning LLMs make mistakes at the decoding stage, besides knowing the correct answer.
Recent studies have started to explore hallucination detection exclusively from attention maps. (Chuang et al., 2024a) introduced the lookback ratio, which measures how much attention LLMs allocate to relevant input parts when answering questions based on the provided context. The work most closely related to ours is (Sriramanan et al., 2024), which introduces the $\operatorname{AttentionScore}$ method. Although the process is unsupervised and computationally efficient, the authors note that its performance can depend highly on the specific layer from which the score is extracted. Compared to $\operatorname{AttentionScore}$ , our method is fully supervised and grounded in graph theory, as we interpret inference in LLM as a graph. While $\operatorname{AttentionScore}$ aggregates only the attention diagonal to compute its log-determinant, we instead derive features from the graph Laplacian, which captures all attention scores (see Eq. (1) and (2)). Additionally, we utilize all layers for detecting hallucination rather than a single one, demonstrating effectiveness of this approach. We also demonstrate that it performs poorly on the datasets we evaluated. Nonetheless, we drew inspiration from their approach, particularly using the lower triangular structure of matrices when constructing features for the hallucination probe.
## 8 Conclusions
In this work, we demonstrated that the spectral features of LLMs’ attention maps, specifically the eigenvalues of the Laplacian matrix, carry a signal capable of detecting hallucinations. Specifically, we proposed the $\operatorname{LapEigvals}$ method, which employs the top- $k$ eigenvalues of the Laplacian as input to the hallucination detection probe. Through extensive evaluations, we empirically showed that our method consistently achieves state-of-the-art performance among all tested approaches. Furthermore, multiple ablation studies demonstrated that our method remains stable across varying numbers of eigenvalues, diverse prompts, and generation temperatures while offering reasonable generalization.
In addition, we hypothesize that self-supervised learning (Balestriero et al., 2023) could yield a more robust and generalizable approach while uncovering non-trivial intrinsic features of attention maps. Notably, results such as those in Section 6.3 suggest intriguing connections to recent advancements in LLM research (Veličković et al., 2024; Barbero et al., 2024), highlighting promising directions for future investigation.
## Limitations
Supervised method In our approach, one must provide labelled hallucinated and non-hallucinated examples to train the hallucination probe. While this can be handled by the llm-as-judge, it might introduce some noise or pose a risk of overfitting. Limited generalization across LLM architectures The method is incompatible with LLMs having different head and layer configurations. Developing architecture-agnostic hallucination probes is left for future work. Minimum length requirement Computing $\operatorname{top-k}$ Laplacian eigenvalues demands attention maps of at least $k$ tokens (e.g., $k{=}100$ require 100 tokens). Open LLMs Our method requires access to the internal states of LLM thus it cannot be applied to closed LLMs. Risks Please note that the proposed method was tested on selected LLMs and English data, so applying it to untested domains and tasks carries a considerable risk without additional validation.
## Acknowledgements
We sincerely thank Piotr Bielak for his valuable review and insightful feedback, which helped improve this work. This work was funded by the European Union under the Horizon Europe grant OMINO – Overcoming Multilevel INformation Overload (grant number 101086321, https://ominoproject.eu/). Views and opinions expressed are those of the authors alone and do not necessarily reflect those of the European Union or the European Research Executive Agency. Neither the European Union nor the European Research Executive Agency can be held responsible for them. It was also co-financed with funds from the Polish Ministry of Education and Science under the programme entitled International Co-Financed Projects, grant no. 573977. We gratefully acknowledge the Wroclaw Centre for Networking and Supercomputing for providing the computational resources used in this work. This work was co-funded by the National Science Centre, Poland under CHIST-ERA Open & Re-usable Research Data & Software (grant number 2022/04/Y/ST6/00183). The authors used ChatGPT to improve the clarity and readability of the manuscript.
## References
- Abdin et al. (2024) Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Qin Cai, Vishrav Chaudhary, Dong Chen, Dongdong Chen, Weizhu Chen, Yen-Chun Chen, Yi-Ling Chen, Hao Cheng, Parul Chopra, Xiyang Dai, Matthew Dixon, Ronen Eldan, Victor Fragoso, Jianfeng Gao, Mei Gao, Min Gao, Amit Garg, Allie Del Giorno, Abhishek Goswami, Suriya Gunasekar, Emman Haider, Junheng Hao, Russell J. Hewett, Wenxiang Hu, Jamie Huynh, Dan Iter, Sam Ade Jacobs, Mojan Javaheripi, Xin Jin, Nikos Karampatziakis, Piero Kauffmann, Mahoud Khademi, Dongwoo Kim, Young Jin Kim, Lev Kurilenko, James R. Lee, Yin Tat Lee, Yuanzhi Li, Yunsheng Li, Chen Liang, Lars Liden, Xihui Lin, Zeqi Lin, Ce Liu, Liyuan Liu, Mengchen Liu, Weishung Liu, Xiaodong Liu, Chong Luo, Piyush Madan, Ali Mahmoudzadeh, David Majercak, Matt Mazzola, Caio César Teodoro Mendes, Arindam Mitra, Hardik Modi, Anh Nguyen, Brandon Norick, Barun Patra, Daniel Perez-Becker, Thomas Portet, Reid Pryzant, Heyang Qin, Marko Radmilac, Liliang Ren, Gustavo de Rosa, Corby Rosset, Sambudha Roy, Olatunji Ruwase, Olli Saarikivi, Amin Saied, Adil Salim, Michael Santacroce, Shital Shah, Ning Shang, Hiteshi Sharma, Yelong Shen, Swadheen Shukla, Xia Song, Masahiro Tanaka, Andrea Tupini, Praneetha Vaddamanu, Chunyu Wang, Guanhua Wang, Lijuan Wang, Shuohang Wang, Xin Wang, Yu Wang, Rachel Ward, Wen Wen, Philipp Witte, Haiping Wu, Xiaoxia Wu, Michael Wyatt, Bin Xiao, Can Xu, Jiahang Xu, Weijian Xu, Jilong Xue, Sonali Yadav, Fan Yang, Jianwei Yang, Yifan Yang, Ziyi Yang, Donghan Yu, Lu Yuan, Chenruidong Zhang, Cyril Zhang, Jianwen Zhang, Li Lyna Zhang, Yi Zhang, Yue Zhang, Yunan Zhang, and Xiren Zhou. 2024. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv preprint. ArXiv:2404.14219 [cs].
- Alain and Bengio (2016) Guillaume Alain and Yoshua Bengio. 2016. Understanding intermediate layers using linear classifier probes.
- Ansel et al. (2024) Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michael Lazos, Mario Lezcano, Yanbo Liang, Jason Liang, Yinghai Lu, CK Luk, Bert Maher, Yunjie Pan, Christian Puhrsch, Matthias Reso, Mark Saroufim, Marcos Yukio Siraichi, Helen Suk, Michael Suo, Phil Tillet, Eikan Wang, Xiaodong Wang, William Wen, Shunting Zhang, Xu Zhao, Keren Zhou, Richard Zou, Ajit Mathews, Gregory Chanan, Peng Wu, and Soumith Chintala. 2024. PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation. In 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 (ASPLOS ’24). ACM.
- Arteaga et al. (2024) Gabriel Y. Arteaga, Thomas B. Schön, and Nicolas Pielawski. 2024. Hallucination Detection in LLMs: Fast and Memory-Efficient Finetuned Models. In Northern Lights Deep Learning Conference 2025.
- Azaria and Mitchell (2023) Amos Azaria and Tom Mitchell. 2023. The Internal State of an LLM Knows When It‘s Lying. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, Singapore. Association for Computational Linguistics.
- Balestriero et al. (2023) Randall Balestriero, Mark Ibrahim, Vlad Sobal, Ari Morcos, Shashank Shekhar, Tom Goldstein, Florian Bordes, Adrien Bardes, Gregoire Mialon, Yuandong Tian, Avi Schwarzschild, Andrew Gordon Wilson, Jonas Geiping, Quentin Garrido, Pierre Fernandez, Amir Bar, Hamed Pirsiavash, Yann LeCun, and Micah Goldblum. 2023. A Cookbook of Self-Supervised Learning. arXiv preprint. ArXiv:2304.12210 [cs].
- Barbero et al. (2024) Federico Barbero, Andrea Banino, Steven Kapturowski, Dharshan Kumaran, João G. M. Araújo, Alex Vitvitskyi, Razvan Pascanu, and Petar Veličković. 2024. Transformers need glasses! Information over-squashing in language tasks. arXiv preprint. ArXiv:2406.04267 [cs].
- Black et al. (2023) Mitchell Black, Zhengchao Wan, Amir Nayyeri, and Yusu Wang. 2023. Understanding Oversquashing in GNNs through the Lens of Effective Resistance. In International Conference on Machine Learning, pages 2528–2547. PMLR. ArXiv:2302.06835 [cs].
- Bruna et al. (2013) Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. 2013. Spectral Networks and Locally Connected Networks on Graphs. CoRR.
- Chen et al. (2024) Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. 2024. INSIDE: LLMs’ Internal States Retain the Power of Hallucination Detection. In The Twelfth International Conference on Learning Representations.
- Chuang et al. (2024a) Yung-Sung Chuang, Linlu Qiu, Cheng-Yu Hsieh, Ranjay Krishna, Yoon Kim, and James R. Glass. 2024a. Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1419–1436, Miami, Florida, USA. Association for Computational Linguistics.
- Chuang et al. (2024b) Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R. Glass, and Pengcheng He. 2024b. DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models. In The Twelfth International Conference on Learning Representations.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Dao et al. (2022) Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FLASHATTENTION: fast and memory-efficient exact attention with IO-awareness. In Proceedings of the 36th international conference on neural information processing systems, Nips ’22, New Orleans, LA, USA. Curran Associates Inc. Number of pages: 16 tex.address: Red Hook, NY, USA tex.articleno: 1189.
- Farquhar et al. (2024) Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. 2024. Detecting hallucinations in large language models using semantic entropy. Nature, 630(8017):625–630. Publisher: Nature Publishing Group.
- Grattafiori et al. (2024) Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Roziere, Bethany Biron, Binh Tang, Bobbie Chern, Charlotte Caucheteux, Chaya Nayak, Chloe Bi, Chris Marra, Chris McConnell, Christian Keller, Christophe Touret, Chunyang Wu, Corinne Wong, Cristian Canton Ferrer, Cyrus Nikolaidis, Damien Allonsius, Daniel Song, Danielle Pintz, Danny Livshits, Danny Wyatt, David Esiobu, Dhruv Choudhary, Dhruv Mahajan, Diego Garcia-Olano, Diego Perino, Dieuwke Hupkes, Egor Lakomkin, Ehab AlBadawy, Elina Lobanova, Emily Dinan, Eric Michael Smith, Filip Radenovic, Francisco Guzmán, Frank Zhang, Gabriel Synnaeve, Gabrielle Lee, Georgia Lewis Anderson, Govind Thattai, Graeme Nail, Gregoire Mialon, Guan Pang, Guillem Cucurell, Hailey Nguyen, Hannah Korevaar, Hu Xu, Hugo Touvron, Iliyan Zarov, Imanol Arrieta Ibarra, Isabel Kloumann, Ishan Misra, Ivan Evtimov, Jack Zhang, Jade Copet, Jaewon Lee, Jan Geffert, Jana Vranes, Jason Park, Jay Mahadeokar, Jeet Shah, Jelmer van der Linde, Jennifer Billock, Jenny Hong, Jenya Lee, Jeremy Fu, Jianfeng Chi, Jianyu Huang, Jiawen Liu, Jie Wang, Jiecao Yu, Joanna Bitton, Joe Spisak, Jongsoo Park, Joseph Rocca, Joshua Johnstun, Joshua Saxe, Junteng Jia, Kalyan Vasuden Alwala, Karthik Prasad, Kartikeya Upasani, Kate Plawiak, Ke Li, Kenneth Heafield, Kevin Stone, Khalid El-Arini, Krithika Iyer, Kshitiz Malik, Kuenley Chiu, Kunal Bhalla, Kushal Lakhotia, Lauren Rantala-Yeary, Laurens van der Maaten, Lawrence Chen, Liang Tan, Liz Jenkins, Louis Martin, Lovish Madaan, Lubo Malo, Lukas Blecher, Lukas Landzaat, Luke de Oliveira, Madeline Muzzi, Mahesh Pasupuleti, Mannat Singh, Manohar Paluri, Marcin Kardas, Maria Tsimpoukelli, Mathew Oldham, Mathieu Rita, Maya Pavlova, Melanie Kambadur, Mike Lewis, Min Si, Mitesh Kumar Singh, Mona Hassan, Naman Goyal, Narjes Torabi, Nikolay Bashlykov, Nikolay Bogoychev, Niladri Chatterji, Ning Zhang, Olivier Duchenne, Onur Çelebi, Patrick Alrassy, Pengchuan Zhang, Pengwei Li, Petar Vasic, Peter Weng, Prajjwal Bhargava, Pratik Dubal, Praveen Krishnan, Punit Singh Koura, Puxin Xu, Qing He, Qingxiao Dong, Ragavan Srinivasan, Raj Ganapathy, Ramon Calderer, Ricardo Silveira Cabral, Robert Stojnic, Roberta Raileanu, Rohan Maheswari, Rohit Girdhar, Rohit Patel, Romain Sauvestre, Ronnie Polidoro, Roshan Sumbaly, Ross Taylor, Ruan Silva, Rui Hou, Rui Wang, Saghar Hosseini, Sahana Chennabasappa, Sanjay Singh, Sean Bell, Seohyun Sonia Kim, Sergey Edunov, Shaoliang Nie, Sharan Narang, Sharath Raparthy, Sheng Shen, Shengye Wan, Shruti Bhosale, Shun Zhang, Simon Vandenhende, Soumya Batra, Spencer Whitman, Sten Sootla, Stephane Collot, Suchin Gururangan, Sydney Borodinsky, Tamar Herman, Tara Fowler, Tarek Sheasha, Thomas Georgiou, Thomas Scialom, Tobias Speckbacher, Todor Mihaylov, Tong Xiao, Ujjwal Karn, Vedanuj Goswami, Vibhor Gupta, Vignesh Ramanathan, Viktor Kerkez, Vincent Gonguet, Virginie Do, Vish Vogeti, Vítor Albiero, Vladan Petrovic, Weiwei Chu, Wenhan Xiong, Wenyin Fu, Whitney Meers, Xavier Martinet, Xiaodong Wang, Xiaofang Wang, Xiaoqing Ellen Tan, Xide Xia, Xinfeng Xie, Xuchao Jia, Xuewei Wang, Yaelle Goldschlag, Yashesh Gaur, Yasmine Babaei, Yi Wen, Yiwen Song, Yuchen Zhang, Yue Li, Yuning Mao, Zacharie Delpierre Coudert, Zheng Yan, Zhengxing Chen, Zoe Papakipos, Aaditya Singh, Aayushi Srivastava, Abha Jain, Adam Kelsey, Adam Shajnfeld, Adithya Gangidi, Adolfo Victoria, Ahuva Goldstand, Ajay Menon, Ajay Sharma, Alex Boesenberg, Alexei Baevski, Allie Feinstein, Amanda Kallet, Amit Sangani, Amos Teo, Anam Yunus, Andrei Lupu, Andres Alvarado, Andrew Caples, Andrew Gu, Andrew Ho, Andrew Poulton, Andrew Ryan, Ankit Ramchandani, Annie Dong, Annie Franco, Anuj Goyal, Aparajita Saraf, Arkabandhu Chowdhury, Ashley Gabriel, Ashwin Bharambe, Assaf Eisenman, Azadeh Yazdan, Beau James, Ben Maurer, Benjamin Leonhardi, Bernie Huang, Beth Loyd, Beto De Paola, Bhargavi Paranjape, Bing Liu, Bo Wu, Boyu Ni, Braden Hancock, Bram Wasti, Brandon Spence, Brani Stojkovic, Brian Gamido, Britt Montalvo, Carl Parker, Carly Burton, Catalina Mejia, Ce Liu, Changhan Wang, Changkyu Kim, Chao Zhou, Chester Hu, Ching-Hsiang Chu, Chris Cai, Chris Tindal, Christoph Feichtenhofer, Cynthia Gao, Damon Civin, Dana Beaty, Daniel Kreymer, Daniel Li, David Adkins, David Xu, Davide Testuggine, Delia David, Devi Parikh, Diana Liskovich, Didem Foss, Dingkang Wang, Duc Le, Dustin Holland, Edward Dowling, Eissa Jamil, Elaine Montgomery, Eleonora Presani, Emily Hahn, Emily Wood, Eric-Tuan Le, Erik Brinkman, Esteban Arcaute, Evan Dunbar, Evan Smothers, Fei Sun, Felix Kreuk, Feng Tian, Filippos Kokkinos, Firat Ozgenel, Francesco Caggioni, Frank Kanayet, Frank Seide, Gabriela Medina Florez, Gabriella Schwarz, Gada Badeer, Georgia Swee, Gil Halpern, Grant Herman, Grigory Sizov, Guangyi, Zhang, Guna Lakshminarayanan, Hakan Inan, Hamid Shojanazeri, Han Zou, Hannah Wang, Hanwen Zha, Haroun Habeeb, Harrison Rudolph, Helen Suk, Henry Aspegren, Hunter Goldman, Hongyuan Zhan, Ibrahim Damlaj, Igor Molybog, Igor Tufanov, Ilias Leontiadis, Irina-Elena Veliche, Itai Gat, Jake Weissman, James Geboski, James Kohli, Janice Lam, Japhet Asher, Jean-Baptiste Gaya, Jeff Marcus, Jeff Tang, Jennifer Chan, Jenny Zhen, Jeremy Reizenstein, Jeremy Teboul, Jessica Zhong, Jian Jin, Jingyi Yang, Joe Cummings, Jon Carvill, Jon Shepard, Jonathan McPhie, Jonathan Torres, Josh Ginsburg, Junjie Wang, Kai Wu, Kam Hou U, Karan Saxena, Kartikay Khandelwal, Katayoun Zand, Kathy Matosich, Kaushik Veeraraghavan, Kelly Michelena, Keqian Li, Kiran Jagadeesh, Kun Huang, Kunal Chawla, Kyle Huang, Lailin Chen, Lakshya Garg, Lavender A, Leandro Silva, Lee Bell, Lei Zhang, Liangpeng Guo, Licheng Yu, Liron Moshkovich, Luca Wehrstedt, Madian Khabsa, Manav Avalani, Manish Bhatt, Martynas Mankus, Matan Hasson, Matthew Lennie, Matthias Reso, Maxim Groshev, Maxim Naumov, Maya Lathi, Meghan Keneally, Miao Liu, Michael L. Seltzer, Michal Valko, Michelle Restrepo, Mihir Patel, Mik Vyatskov, Mikayel Samvelyan, Mike Clark, Mike Macey, Mike Wang, Miquel Jubert Hermoso, Mo Metanat, Mohammad Rastegari, Munish Bansal, Nandhini Santhanam, Natascha Parks, Natasha White, Navyata Bawa, Nayan Singhal, Nick Egebo, Nicolas Usunier, Nikhil Mehta, Nikolay Pavlovich Laptev, Ning Dong, Norman Cheng, Oleg Chernoguz, Olivia Hart, Omkar Salpekar, Ozlem Kalinli, Parkin Kent, Parth Parekh, Paul Saab, Pavan Balaji, Pedro Rittner, Philip Bontrager, Pierre Roux, Piotr Dollar, Polina Zvyagina, Prashant Ratanchandani, Pritish Yuvraj, Qian Liang, Rachad Alao, Rachel Rodriguez, Rafi Ayub, Raghotham Murthy, Raghu Nayani, Rahul Mitra, Rangaprabhu Parthasarathy, Raymond Li, Rebekkah Hogan, Robin Battey, Rocky Wang, Russ Howes, Ruty Rinott, Sachin Mehta, Sachin Siby, Sai Jayesh Bondu, Samyak Datta, Sara Chugh, Sara Hunt, Sargun Dhillon, Sasha Sidorov, Satadru Pan, Saurabh Mahajan, Saurabh Verma, Seiji Yamamoto, Sharadh Ramaswamy, Shaun Lindsay, Shaun Lindsay, Sheng Feng, Shenghao Lin, Shengxin Cindy Zha, Shishir Patil, Shiva Shankar, Shuqiang Zhang, Shuqiang Zhang, Sinong Wang, Sneha Agarwal, Soji Sajuyigbe, Soumith Chintala, Stephanie Max, Stephen Chen, Steve Kehoe, Steve Satterfield, Sudarshan Govindaprasad, Sumit Gupta, Summer Deng, Sungmin Cho, Sunny Virk, Suraj Subramanian, Sy Choudhury, Sydney Goldman, Tal Remez, Tamar Glaser, Tamara Best, Thilo Koehler, Thomas Robinson, Tianhe Li, Tianjun Zhang, Tim Matthews, Timothy Chou, Tzook Shaked, Varun Vontimitta, Victoria Ajayi, Victoria Montanez, Vijai Mohan, Vinay Satish Kumar, Vishal Mangla, Vlad Ionescu, Vlad Poenaru, Vlad Tiberiu Mihailescu, Vladimir Ivanov, Wei Li, Wenchen Wang, Wenwen Jiang, Wes Bouaziz, Will Constable, Xiaocheng Tang, Xiaojian Wu, Xiaolan Wang, Xilun Wu, Xinbo Gao, Yaniv Kleinman, Yanjun Chen, Ye Hu, Ye Jia, Ye Qi, Yenda Li, Yilin Zhang, Ying Zhang, Yossi Adi, Youngjin Nam, Yu, Wang, Yu Zhao, Yuchen Hao, Yundi Qian, Yunlu Li, Yuzi He, Zach Rait, Zachary DeVito, Zef Rosnbrick, Zhaoduo Wen, Zhenyu Yang, Zhiwei Zhao, and Zhiyu Ma. 2024. The Llama 3 Herd of Models. arXiv preprint. ArXiv:2407.21783 [cs].
- Huang et al. (2023) Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2023. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. arXiv preprint. ArXiv:2311.05232 [cs].
- Jolliffe and Cadima (2016) Ian T. Jolliffe and Jorge Cadima. 2016. Principal component analysis: a review and recent developments. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 374(2065):20150202. Publisher: Royal Society.
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada. Association for Computational Linguistics.
- Kim et al. (2024) Hazel Kim, Adel Bibi, Philip Torr, and Yarin Gal. 2024. Detecting LLM Hallucination Through Layer-wise Information Deficiency: Analysis of Unanswerable Questions and Ambiguous Prompts. arXiv preprint. ArXiv:2412.10246 [cs].
- Kossen et al. (2024) Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. 2024. Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs. arXiv preprint. ArXiv:2406.15927 [cs].
- Kuprieiev et al. (2025) Ruslan Kuprieiev, skshetry, Peter Rowland, Dmitry Petrov, Pawel Redzynski, Casper da Costa-Luis, David de la Iglesia Castro, Alexander Schepanovski, Ivan Shcheklein, Gao, Batuhan Taskaya, Jorge Orpinel, Fábio Santos, Daniele, Ronan Lamy, Aman Sharma, Zhanibek Kaimuldenov, Dani Hodovic, Nikita Kodenko, Andrew Grigorev, Earl, Nabanita Dash, George Vyshnya, Dave Berenbaum, maykulkarni, Max Hora, Vera, and Sanidhya Mangal. 2025. DVC: Data Version Control - Git for Data & Models.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research. Transactions of the Association for Computational Linguistics, 7:452–466. Place: Cambridge, MA Publisher: MIT Press.
- Lee (2023) Minhyeok Lee. 2023. A Mathematical Investigation of Hallucination and Creativity in GPT Models. Mathematics, 11(10):2320.
- Li et al. (2024) Junyi Li, Jie Chen, Ruiyang Ren, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2024. The Dawn After the Dark: An Empirical Study on Factuality Hallucination in Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10879–10899, Bangkok, Thailand. Association for Computational Linguistics.
- Li et al. (2023) Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023. HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models. arXiv preprint. ArXiv:2305.11747 [cs].
- Liang et al. (2024) Xun Liang, Shichao Song, Zifan Zheng, Hanyu Wang, Qingchen Yu, Xunkai Li, Rong-Hua Li, Feiyu Xiong, and Zhiyu Li. 2024. Internal Consistency and Self-Feedback in Large Language Models: A Survey. CoRR, abs/2407.14507.
- Lin et al. (2022) Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. TruthfulQA: Measuring How Models Mimic Human Falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland. Association for Computational Linguistics.
- Manakul et al. (2023) Potsawee Manakul, Adian Liusie, and Mark Gales. 2023. SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004–9017, Singapore. Association for Computational Linguistics.
- Mann and Whitney (1947) Henry B Mann and Donald R Whitney. 1947. On a test of whether one of two random variables is stochastically larger than the other. The annals of mathematical statistics, pages 50–60. Publisher: JSTOR.
- Marks and Tegmark (2024) Samuel Marks and Max Tegmark. 2024. The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets. In First Conference on Language Modeling.
- Mistral AI Team (2025) Mistral AI Team. 2025. Mistral-small-24B-instruct-2501.
- Mistral AI Team and NVIDIA (2024) Mistral AI Team and NVIDIA. 2024. Mistral-nemo-instruct-2407.
- Mitra et al. (2024) Kushan Mitra, Dan Zhang, Sajjadur Rahman, and Estevam Hruschka. 2024. FactLens: Benchmarking Fine-Grained Fact Verification. arXiv preprint. ArXiv:2411.05980 [cs].
- Mohar (1997) Bojan Mohar. 1997. Some applications of Laplace eigenvalues of graphs. In Geňa Hahn and Gert Sabidussi, editors, Graph Symmetry, pages 225–275. Springer Netherlands, Dordrecht.
- OpenAI et al. (2024) OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Simón Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Rapha Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, Chris Hallacy, Jesse Han, Jeff Harris, Yuchen He, Mike Heaton, Johannes Heidecke, Chris Hesse, Alan Hickey, Wade Hickey, Peter Hoeschele, Brandon Houghton, Kenny Hsu, Shengli Hu, Xin Hu, Joost Huizinga, Shantanu Jain, Shawn Jain, Joanne Jang, Angela Jiang, Roger Jiang, Haozhun Jin, Denny Jin, Shino Jomoto, Billie Jonn, Heewoo Jun, Tomer Kaftan, Łukasz Kaiser, Ali Kamali, Ingmar Kanitscheider, Nitish Shirish Keskar, Tabarak Khan, Logan Kilpatrick, Jong Wook Kim, Christina Kim, Yongjik Kim, Jan Hendrik Kirchner, Jamie Kiros, Matt Knight, Daniel Kokotajlo, Łukasz Kondraciuk, Andrew Kondrich, Aris Konstantinidis, Kyle Kosic, Gretchen Krueger, Vishal Kuo, Michael Lampe, Ikai Lan, Teddy Lee, Jan Leike, Jade Leung, Daniel Levy, Chak Ming Li, Rachel Lim, Molly Lin, Stephanie Lin, Mateusz Litwin, Theresa Lopez, Ryan Lowe, Patricia Lue, Anna Makanju, Kim Malfacini, Sam Manning, Todor Markov, Yaniv Markovski, Bianca Martin, Katie Mayer, Andrew Mayne, Bob McGrew, Scott Mayer McKinney, Christine McLeavey, Paul McMillan, Jake McNeil, David Medina, Aalok Mehta, Jacob Menick, Luke Metz, Andrey Mishchenko, Pamela Mishkin, Vinnie Monaco, Evan Morikawa, Daniel Mossing, Tong Mu, Mira Murati, Oleg Murk, David Mély, Ashvin Nair, Reiichiro Nakano, Rajeev Nayak, Arvind Neelakantan, Richard Ngo, Hyeonwoo Noh, Long Ouyang, Cullen O’Keefe, Jakub Pachocki, Alex Paino, Joe Palermo, Ashley Pantuliano, Giambattista Parascandolo, Joel Parish, Emy Parparita, Alex Passos, Mikhail Pavlov, Andrew Peng, Adam Perelman, Filipe de Avila Belbute Peres, Michael Petrov, Henrique Ponde de Oliveira Pinto, Michael, Pokorny, Michelle Pokrass, Vitchyr H. Pong, Tolly Powell, Alethea Power, Boris Power, Elizabeth Proehl, Raul Puri, Alec Radford, Jack Rae, Aditya Ramesh, Cameron Raymond, Francis Real, Kendra Rimbach, Carl Ross, Bob Rotsted, Henri Roussez, Nick Ryder, Mario Saltarelli, Ted Sanders, Shibani Santurkar, Girish Sastry, Heather Schmidt, David Schnurr, John Schulman, Daniel Selsam, Kyla Sheppard, Toki Sherbakov, Jessica Shieh, Sarah Shoker, Pranav Shyam, Szymon Sidor, Eric Sigler, Maddie Simens, Jordan Sitkin, Katarina Slama, Ian Sohl, Benjamin Sokolowsky, Yang Song, Natalie Staudacher, Felipe Petroski Such, Natalie Summers, Ilya Sutskever, Jie Tang, Nikolas Tezak, Madeleine B. Thompson, Phil Tillet, Amin Tootoonchian, Elizabeth Tseng, Preston Tuggle, Nick Turley, Jerry Tworek, Juan Felipe Cerón Uribe, Andrea Vallone, Arun Vijayvergiya, Chelsea Voss, Carroll Wainwright, Justin Jay Wang, Alvin Wang, Ben Wang, Jonathan Ward, Jason Wei, C. J. Weinmann, Akila Welihinda, Peter Welinder, Jiayi Weng, Lilian Weng, Matt Wiethoff, Dave Willner, Clemens Winter, Samuel Wolrich, Hannah Wong, Lauren Workman, Sherwin Wu, Jeff Wu, Michael Wu, Kai Xiao, Tao Xu, Sarah Yoo, Kevin Yu, Qiming Yuan, Wojciech Zaremba, Rowan Zellers, Chong Zhang, Marvin Zhang, Shengjia Zhao, Tianhao Zheng, Juntang Zhuang, William Zhuk, and Barret Zoph. 2024. GPT-4 Technical Report. arXiv preprint. ArXiv:2303.08774 [cs].
- Orgad et al. (2025) Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. 2025. LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations. In The Thirteenth International Conference on Learning Representations.
- Pedregosa et al. (2011) F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12:2825–2830.
- Rajpurkar et al. (2018) Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. Know What You Don‘t Know: Unanswerable Questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 784–789, Melbourne, Australia. Association for Computational Linguistics.
- Reddy et al. (2019) Siva Reddy, Danqi Chen, and Christopher D. Manning. 2019. CoQA: A Conversational Question Answering Challenge. Transactions of the Association for Computational Linguistics, 7:249–266. Place: Cambridge, MA Publisher: MIT Press.
- Renze (2024) Matthew Renze. 2024. The Effect of Sampling Temperature on Problem Solving in Large Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7346–7356, Miami, Florida, USA. Association for Computational Linguistics.
- Sriramanan et al. (2024) Gaurang Sriramanan, Siddhant Bharti, Vinu Sankar Sadasivan, Shoumik Saha, Priyatham Kattakinda, and Soheil Feizi. 2024. LLM-Check: Investigating Detection of Hallucinations in Large Language Models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.
- team (2020) The pandas development team. 2020. pandas-dev/pandas: Pandas.
- Topping et al. (2022) Jake Topping, Francesco Di Giovanni, Benjamin Paul Chamberlain, Xiaowen Dong, and Michael M. Bronstein. 2022. Understanding over-squashing and bottlenecks on graphs via curvature. In International Conference on Learning Representations.
- Vaswani (2017) A Vaswani. 2017. Attention is all you need. Advances in Neural Information Processing Systems.
- Veličković et al. (2024) Petar Veličković, Christos Perivolaropoulos, Federico Barbero, and Razvan Pascanu. 2024. softmax is not enough (for sharp out-of-distribution). arXiv preprint. ArXiv:2410.01104 [cs].
- Virtanen et al. (2020) Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, İlhan Polat, Yu Feng, Eric W. Moore, Jake VanderPlas, Denis Laxalde, Josef Perktold, Robert Cimrman, Ian Henriksen, E. A. Quintero, Charles R. Harris, Anne M. Archibald, Antônio H. Ribeiro, Fabian Pedregosa, Paul van Mulbregt, and SciPy 1.0 Contributors. 2020. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17:261–272.
- von Luxburg (2007) Ulrike von Luxburg. 2007. A tutorial on spectral clustering. Statistics and Computing, 17(4):395–416.
- Waskom (2021) Michael L. Waskom. 2021. seaborn: statistical data visualization. Journal of Open Source Software, 6(60):3021. Publisher: The Open Journal.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Wu et al. (2024) Xinyi Wu, Amir Ajorlou, Yifei Wang, Stefanie Jegelka, and Ali Jadbabaie. 2024. On the role of attention masks and LayerNorm in transformers. In Advances in neural information processing systems, volume 37, pages 14774–14809. Curran Associates, Inc.
- Xu et al. (2024) Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. 2024. Hallucination is Inevitable: An Innate Limitation of Large Language Models. arXiv preprint. ArXiv:2401.11817.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-judge with MT-bench and Chatbot Arena. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA. Curran Associates Inc. Event-place: New Orleans, LA, USA.
- Zhu et al. (2024) Derui Zhu, Dingfan Chen, Qing Li, Zongxiong Chen, Lei Ma, Jens Grossklags, and Mario Fritz. 2024. PoLLMgraph: Unraveling Hallucinations in Large Language Models via State Transition Dynamics. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 4737–4751, Mexico City, Mexico. Association for Computational Linguistics.
## Appendix A Details of motivational study
We present a detailed description of the procedure used to obtain the results presented in Section 2, along with additional results for other datasets and LLMs.
Our goal was to test whether $\operatorname{AttentionScore}$ and eigenvalues of Laplacian matrix (used by our $\operatorname{LapEigvals}$ ) differ significantly when examples are split into hallucinated and non-hallucinated groups. To this end, we used 7 datasets (Section 4.1) and ran inference with 5 LLMs (Section 4.1) using $temp{=}0.1$ . From the extracted attention maps, we computed $\operatorname{AttentionScore}$ (Sriramanan et al., 2024), defined as the log-determinant of the attention matrices. Unlike the original work, we did not aggregate scores across heads, but instead analyzed them at the single-head level. For $\operatorname{LapEigvals}$ , we constructed the Laplacian as defined in Section 3, extracted the 10 largest eigenvalues per head, and applied the same single-head analysis as for $\operatorname{AttnEigvals}$ . Finally, we performed the Mann–Whitney U test (Mann and Whitney, 1947) using the SciPy implementation (Virtanen et al., 2020) and collected the resulting $p$ -values
Table 3 presents the percentage of heads having a statistically significant difference in feature values between hallucinated and non-hallucinated examples, as indicated by $p<0.05$ from the Mann-Whitney U test. These results show that the Laplacian eigenvalues better distinguish between the two classes for almost all considered LLMs and datasets.
Table 3: Percentage of heads having a statistically significant difference in feature values between hallucinated and non-hallucinated examples, as indicated by $p<0.05$ from the Mann-Whitney U test. Results were obtained for $\operatorname{AttentionScore}$ and the 10 largest Laplacian eigenvalues on 6 datasets and 5 LLMs.
| | | AttnScore | Laplacian eigvals |
| --- | --- | --- | --- |
| Llama3.1-8B | CoQA | 40 | 87 |
| Llama3.1-8B | GSM8K | 83 | 70 |
| Llama3.1-8B | HaluevalQA | 91 | 93 |
| Llama3.1-8B | NQOpen | 78 | 83 |
| Llama3.1-8B | SQuADv2 | 70 | 81 |
| Llama3.1-8B | TriviaQA | 80 | 91 |
| Llama3.1-8B | TruthfulQA | 40 | 60 |
| Llama3.2-3B | CoQA | 50 | 79 |
| Llama3.2-3B | GSM8K | 74 | 67 |
| Llama3.2-3B | HaluevalQA | 91 | 93 |
| Llama3.2-3B | NQOpen | 81 | 84 |
| Llama3.2-3B | SQuADv2 | 69 | 74 |
| Llama3.2-3B | TriviaQA | 81 | 87 |
| Llama3.2-3B | TruthfulQA | 40 | 62 |
| Phi3.5 | CoQA | 45 | 81 |
| Phi3.5 | GSM8K | 67 | 69 |
| Phi3.5 | HaluevalQA | 80 | 86 |
| Phi3.5 | NQOpen | 73 | 80 |
| Phi3.5 | SQuADv2 | 81 | 82 |
| Phi3.5 | TriviaQA | 86 | 92 |
| Phi3.5 | TruthfulQA | 41 | 53 |
| Mistral-Nemo | CoQA | 35 | 78 |
| Mistral-Nemo | GSM8K | 90 | 71 |
| Mistral-Nemo | HaluevalQA | 78 | 82 |
| Mistral-Nemo | NQOpen | 64 | 57 |
| Mistral-Nemo | SQuADv2 | 54 | 56 |
| Mistral-Nemo | TriviaQA | 71 | 74 |
| Mistral-Nemo | TruthfulQA | 40 | 50 |
| Mistral-Small-24B | CoQA | 28 | 78 |
| Mistral-Small-34B | GSM8K | 75 | 72 |
| Mistral-Small-24B | HaluevalQA | 68 | 70 |
| Mistral-Small-24B | NQOpen | 45 | 51 |
| Mistral-Small-24B | SQuADv2 | 75 | 82 |
| Mistral-Small-24B | TriviaQA | 65 | 70 |
| Mistral-Small-24B | TruthfulQA | 43 | 52 |
## Appendix B Bounds of the Laplacian
In the following section, we prove that the Laplacian defined in 3 is bounded and has at least one zero eigenvalue. We denote eigenvalues as $\lambda_{i}$ , and provide derivation for a single layer and head, which holds also after stacking them together into a single graph (set of per-layer graphs). For clarity, we omit the superscript ${(l,h)}$ indicating layer and head.
**Lemma 1**
*The Laplacian eigenvalues are bounded: $-1\leq\lambda_{i}\leq 1$ .*
* Proof*
Due to the lower-triangular structure of the Laplacian, its eigenvalues lie on the diagonal and are given by:
$$
\lambda_{i}=\mathbf{L}_{ii}=d_{ii}-a_{ii}
$$
The out-degree is defined as:
$$
d_{ii}=\frac{\sum_{u}{a_{ui}}}{T-i},
$$
Since $0\leq a_{ui}\leq 1$ , the sum in the numerator is upper bounded by $T-i$ , therefore $d_{ii}\leq 1$ , and consequently $\lambda_{i}=\mathbf{L}_{ii}\leq 1$ , which concludes upper-bound part of the proof. Recall that eigenvalues lie on the main diagonal of the Laplacian, hence $\lambda_{i}=\frac{\sum_{u}{a_{uj}}}{T-i}-a_{ii}$ . To find the lower bound of $\lambda_{i}$ , we need to minimize $X=\frac{\sum_{u}{a_{uj}}}{T-i}$ and maximize $Y=a_{ii}$ . First, we note that $X$ ’s denominator is always positive $T-i>0$ , since $i\in\{0\dots(T-1)\}$ (as defined by Eq. (2)). For the numerator, we recall that $0\leq a_{ui}\leq 1$ ; therefore, the sum has its minimum at 0, hence $X\geq 0$ . Second, to maximize $Y=a_{ii}$ , we can take maximum of $0\leq a_{ii}\leq 1$ which is $1$ . Finally, $X-Y=-1$ , consequently $\mathbf{L}_{ii}\geq-1$ , which concludes the lower-bound part of the proof. ∎
**Lemma 2**
*For every $\mathbf{L}_{ii}$ , there exists at least one zero-eigenvalue, and it corresponds to the last token $T$ , i.e., $\lambda_{T}=0$ .*
* Proof*
Recall that eigenvalues lie on the main diagonal of the Laplacian, hence $\lambda_{i}=\frac{\sum_{u}{a_{uj}}}{T-i}-a_{ii}$ . Consider last token, wherein the sum in the numerator reduces to $\sum_{u}{a_{uj}}=a_{TT}$ , denominator becomes $T-i=T-(T-1)=1$ , thus $\lambda_{T}=\frac{a_{TT}}{1}-a_{TT}=0$ . ∎
## Appendix C Implementation details
In our experiments, we used HuggingFace Transformers (Wolf et al., 2020), PyTorch (Ansel et al., 2024), and scikit-learn (Pedregosa et al., 2011). We utilized Pandas (team, 2020) and Seaborn (Waskom, 2021) for visualizations and analysis. To version data, we employed DVC (Kuprieiev et al., 2025). The Cursor IDE was employed to assist with code development. We performed LLM inference and acquired attention maps using a single Nvidia A40 with 40GB VRAM, except for Mistral-Small-24B for which we used Nvidia H100 with 96GB VRAM. Training the hallucination probe was done using the CPU only. To compute labels using the llm-as-judge approach, we leveraged gpt-4o-mini model available through OpenAI API. Detailed hyperparameter settings and code to reproduce the experiments are available in the public Github repository: https://github.com/graphml-lab-pwr/lapeigvals.
## Appendix D Details of QA datasets
We used 7 open and publicly available question answering datasets: NQ-Open (Kwiatkowski et al., 2019) (CC-BY-SA-3.0 license), SQuADv2 (Rajpurkar et al., 2018) (CC-BY-SA-4.0 license), TruthfulQA (Apache-2.0 license) (Lin et al., 2022), HaluEvalQA (MIT license) (Li et al., 2023), CoQA (Reddy et al., 2019) (domain-dependent licensing, detailed on https://stanfordnlp.github.io/coqa/), TriviaQA (Apache 2.0 license), GSM8K (Cobbe et al., 2021) (MIT license). Research purposes fall into the intended use of these datasets. To preprocess and filter TriviaQA, CoQA, and SQuADv2 we utilized open-source code of (Chen et al., 2024) https://github.com/alibaba/eigenscore (MIT license), which also borrows from (Farquhar et al., 2024) https://github.com/lorenzkuhn/semantic_uncertainty (MIT license). In Figure 8, we provide histogram plots of the number of tokens for $question$ and $answer$ of each dataset computed with meta-llama/Llama-3.1-8B-Instruct tokenizer.
<details>
<summary>x8.png Details</summary>
### Visual Description
\n
## Histograms: Token Distribution for Questions and Answers
### Overview
The image presents two histograms displayed side-by-side. The left histogram represents the distribution of token counts for "Question" data, and the right histogram represents the distribution of token counts for "Answer" data. Both histograms use a logarithmic scale on the y-axis (Frequency). The x-axis represents the number of tokens.
### Components/Axes
* **X-axis (Both Histograms):** "# Tokens" - Represents the number of tokens. The scale is logarithmic, ranging from approximately 10^2 (100) to 10^3 (1000) for the "Question" histogram and from approximately 10^0 (1) to 10^2 (100) for the "Answer" histogram.
* **Y-axis (Both Histograms):** "Frequency" - Represents the number of occurrences of a given token count. The scale is logarithmic, ranging from approximately 10^0 (1) to 10^3 (1000).
* **Title (Left Histogram):** "Question"
* **Title (Right Histogram):** "Answer"
* **No Legend:** No legend is present.
### Detailed Analysis or Content Details
**Question Histogram (Left):**
The histogram shows a roughly normal distribution, but skewed slightly to the right. The peak frequency occurs around 300-400 tokens.
* Frequency at approximately 200 tokens: ~10^1 (10)
* Frequency at approximately 300 tokens: ~10^2 (100)
* Frequency at approximately 400 tokens: ~80
* Frequency at approximately 500 tokens: ~10
* Frequency at approximately 600 tokens: ~2
* Frequency at approximately 800 tokens: ~1
* Frequency at approximately 1000 tokens: ~0.5
**Answer Histogram (Right):**
The histogram shows a distribution that is skewed to the right, with a peak at lower token counts. The peak frequency occurs around 10-20 tokens.
* Frequency at approximately 10 tokens: ~10^3 (1000)
* Frequency at approximately 20 tokens: ~500
* Frequency at approximately 30 tokens: ~300
* Frequency at approximately 40 tokens: ~200
* Frequency at approximately 50 tokens: ~100
* Frequency at approximately 60 tokens: ~50
* Frequency at approximately 80 tokens: ~20
* Frequency at approximately 100 tokens: ~5
### Key Observations
* The "Question" histogram has a higher average token count than the "Answer" histogram.
* The "Answer" histogram is more heavily concentrated at lower token counts.
* Both distributions are not perfectly symmetrical, indicating some skewness.
* The logarithmic scale on the y-axis emphasizes the differences in frequency at lower token counts.
### Interpretation
The data suggests that questions, on average, are significantly longer than answers in terms of token count. This is a common characteristic in question-answering datasets, where questions often require more context and detail than the corresponding answers. The right skewness in both distributions indicates that there are some questions and answers that are much longer than the typical length. The logarithmic scale highlights the prevalence of shorter answers, while still allowing us to see the distribution of longer questions. This information could be useful for optimizing models for question answering, such as setting appropriate maximum sequence lengths or using different architectures for processing questions and answers. The difference in distributions could also reflect the nature of the questions and answers themselves – perhaps questions are more open-ended and require more explanation, while answers are concise and direct.
</details>
(a) CoQA
<details>
<summary>x9.png Details</summary>
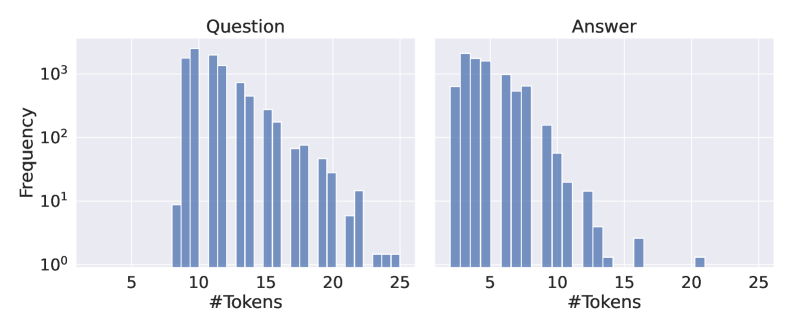
### Visual Description
\n
## Histograms: Token Frequency in Questions and Answers
### Overview
The image presents two histograms displayed side-by-side. Both histograms depict the frequency distribution of the number of tokens in a dataset. The left histogram represents the distribution for "Question" data, and the right histogram represents the distribution for "Answer" data. Both histograms use the same scale for the y-axis (Frequency) and x-axis (#Tokens).
### Components/Axes
* **X-axis Label:** "#Tokens" - Represents the number of tokens. The scale ranges from approximately 5 to 25.
* **Y-axis Label:** "Frequency" - Represents the number of occurrences. The scale is logarithmic, ranging from 1 to approximately 1000.
* **Title (Left):** "Question" - Indicates the histogram represents token counts in questions.
* **Title (Right):** "Answer" - Indicates the histogram represents token counts in answers.
* **Histogram Bars:** Blue bars representing the frequency of each token count.
### Detailed Analysis
**Question Histogram:**
The "Question" histogram shows a roughly normal distribution, peaking around 10-12 tokens. The frequency decreases as the number of tokens moves away from the peak in both directions.
* Approximately 5 tokens: Frequency ~ 10
* Approximately 8 tokens: Frequency ~ 50
* Approximately 10 tokens: Frequency ~ 900
* Approximately 12 tokens: Frequency ~ 700
* Approximately 14 tokens: Frequency ~ 400
* Approximately 16 tokens: Frequency ~ 200
* Approximately 18 tokens: Frequency ~ 80
* Approximately 20 tokens: Frequency ~ 30
* Approximately 22 tokens: Frequency ~ 10
* Approximately 24 tokens: Frequency ~ 2
**Answer Histogram:**
The "Answer" histogram also shows a distribution peaking around 8-10 tokens, but it decays more rapidly than the "Question" histogram.
* Approximately 5 tokens: Frequency ~ 10
* Approximately 7 tokens: Frequency ~ 100
* Approximately 9 tokens: Frequency ~ 800
* Approximately 11 tokens: Frequency ~ 500
* Approximately 13 tokens: Frequency ~ 200
* Approximately 15 tokens: Frequency ~ 50
* Approximately 17 tokens: Frequency ~ 10
* Approximately 19 tokens: Frequency ~ 3
* Approximately 21 tokens: Frequency ~ 1
* Approximately 23 tokens: Frequency ~ 1
### Key Observations
* Both distributions are right-skewed, meaning there are more shorter sequences than longer sequences.
* The peak of the "Question" histogram is slightly shifted to the right compared to the "Answer" histogram, suggesting questions tend to have slightly more tokens than answers.
* The "Question" histogram has a longer tail, indicating a greater number of questions with a higher token count compared to answers.
* The logarithmic scale on the y-axis emphasizes the differences in frequency at lower token counts.
### Interpretation
The data suggests that both questions and answers in this dataset tend to be relatively short, with most falling within the range of 5 to 20 tokens. However, questions exhibit a wider range of token counts, with a non-negligible number of questions exceeding 20 tokens, while answers are more concentrated in the lower token count range. This could indicate that questions are more open-ended and require more context, while answers are typically concise and direct. The logarithmic scale highlights the prevalence of shorter sequences, suggesting that the dataset is dominated by short questions and answers. The difference in the distributions could be a characteristic of the dataset itself, or it could reflect the nature of the task or domain from which the data was collected. Further investigation into the dataset's source and characteristics would be needed to draw more definitive conclusions.
</details>
(b) NQ-Open
<details>
<summary>x10.png Details</summary>
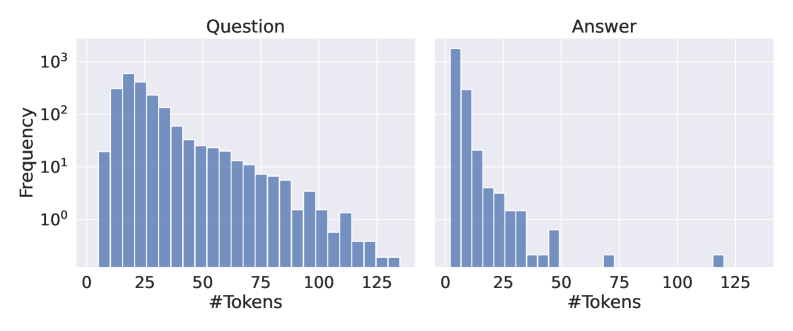
### Visual Description
\n
## Chart: Token Frequency Distribution - Question vs. Answer
### Overview
The image presents two histograms displayed side-by-side. The left histogram represents the frequency distribution of the number of tokens in "Question" data, while the right histogram represents the frequency distribution of the number of tokens in "Answer" data. Both histograms use a logarithmic scale on the y-axis (Frequency).
### Components/Axes
* **X-axis (both charts):** "#Tokens" - representing the number of tokens. The scale ranges from 0 to 125, with markings at 0, 25, 50, 75, 100, and 125.
* **Y-axis (both charts):** "Frequency" - representing the number of occurrences. The scale is logarithmic, ranging from 10⁰ (1) to 10³ (1000).
* **Title (left chart):** "Question"
* **Title (right chart):** "Answer"
* **Bar Color (both charts):** Blue.
### Detailed Analysis
**Left Chart (Question):**
The histogram shows a decreasing frequency as the number of tokens increases. The highest frequency occurs between 0 and 25 tokens. The distribution appears to be right-skewed.
* Approximately 800-900 occurrences between 0-25 tokens.
* Approximately 200-300 occurrences between 25-50 tokens.
* Approximately 80-120 occurrences between 50-75 tokens.
* Approximately 30-50 occurrences between 75-100 tokens.
* Approximately 10-20 occurrences between 100-125 tokens.
**Right Chart (Answer):**
The histogram also shows a decreasing frequency as the number of tokens increases, but the decrease is much more rapid than in the "Question" chart. The highest frequency occurs between 0 and 25 tokens. The distribution is strongly right-skewed.
* Approximately 1000-1200 occurrences between 0-25 tokens.
* Approximately 50-80 occurrences between 25-50 tokens.
* Approximately 5-10 occurrences between 50-75 tokens.
* Approximately 1-2 occurrences between 75-100 tokens.
* Approximately less than 1 occurrence between 100-125 tokens.
### Key Observations
* The "Answer" data has a much higher concentration of short token sequences (0-25 tokens) compared to the "Question" data.
* The "Question" data has a longer tail, indicating a greater number of questions with a higher number of tokens.
* Both distributions are right-skewed, meaning that most questions and answers are relatively short, but there are some longer ones.
* The y-axis is logarithmic, which emphasizes the differences in frequency for lower token counts.
### Interpretation
The data suggests that answers tend to be significantly shorter than questions. This is a common characteristic of question-answering systems, where questions often require more context and detail than the corresponding answers. The logarithmic scale highlights the dramatic difference in frequency between the most common token counts and the less common ones. The right skewness in both distributions indicates that while most questions and answers are concise, there's a non-negligible portion that are more elaborate. This could be due to complex questions requiring detailed answers, or questions that are themselves lengthy and require extensive context. The difference in the distributions between questions and answers suggests a compression of information during the answering process.
</details>
(c) HaluEvalQA
<details>
<summary>x11.png Details</summary>
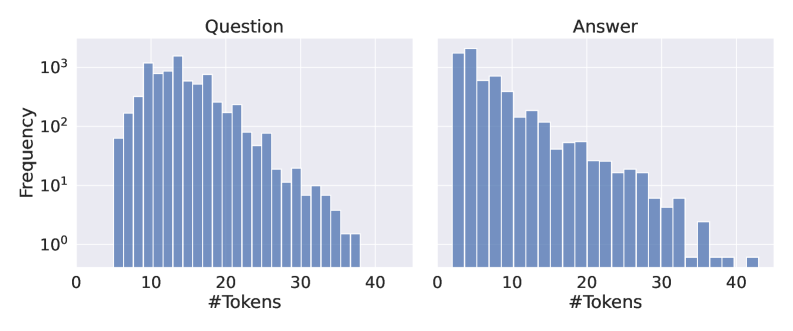
### Visual Description
\n
## Histograms: Token Frequency Distribution for Question and Answer
### Overview
The image presents two histograms displayed side-by-side. The left histogram represents the distribution of token counts for "Question" data, and the right histogram represents the distribution of token counts for "Answer" data. Both histograms share the same x-axis scale representing the number of tokens, and a y-axis scale representing frequency, displayed on a logarithmic scale.
### Components/Axes
* **X-axis Label:** "#Tokens" (Number of Tokens) - ranging from 0 to 40.
* **Y-axis Label:** "Frequency" - ranging from approximately 1 (10⁰) to 1000 (10³). The y-axis is logarithmic.
* **Left Histogram Title:** "Question"
* **Right Histogram Title:** "Answer"
* **Bar Color:** A consistent shade of blue is used for all bars in both histograms.
### Detailed Analysis
**Question Histogram:**
The "Question" histogram shows a roughly normal distribution, but skewed slightly to the right. The peak frequency occurs between approximately 10 and 16 tokens. The distribution decreases as the number of tokens increases beyond 16.
* Frequency at ~5 tokens: ~50
* Frequency at ~10 tokens: ~200
* Frequency at ~15 tokens: ~350
* Frequency at ~20 tokens: ~250
* Frequency at ~25 tokens: ~120
* Frequency at ~30 tokens: ~60
* Frequency at ~35 tokens: ~20
* Frequency at ~40 tokens: ~5
**Answer Histogram:**
The "Answer" histogram also exhibits a distribution skewed to the right, but is more heavily skewed than the "Question" histogram. The peak frequency occurs between approximately 6 and 12 tokens. The distribution decreases more rapidly as the number of tokens increases beyond 12.
* Frequency at ~5 tokens: ~100
* Frequency at ~10 tokens: ~400
* Frequency at ~15 tokens: ~250
* Frequency at ~20 tokens: ~120
* Frequency at ~25 tokens: ~50
* Frequency at ~30 tokens: ~20
* Frequency at ~35 tokens: ~5
* Frequency at ~40 tokens: ~1
### Key Observations
* The "Answer" histogram has a higher peak frequency than the "Question" histogram, indicating that answers tend to be shorter than questions.
* Both distributions are right-skewed, meaning that there are more shorter questions and answers than longer ones.
* The logarithmic scale on the y-axis emphasizes the differences in frequency at lower token counts.
* The "Answer" histogram has a more rapid decline in frequency as the number of tokens increases, suggesting a stronger preference for shorter answers.
### Interpretation
The data suggests that questions, on average, are longer than answers. This is a reasonable expectation, as questions often require more context and detail than answers. The right skewness of both distributions indicates that while most questions and answers are relatively short, there are some longer examples. The logarithmic scale highlights the prevalence of shorter questions and answers. The difference in the rate of decline between the two histograms suggests that answers are more constrained in length than questions. This could be due to factors such as the need for conciseness or the limitations of the response format. The data could be used to inform the design of question-answering systems, for example, by setting appropriate length limits for questions and answers.
</details>
(d) SQuADv2
<details>
<summary>x12.png Details</summary>
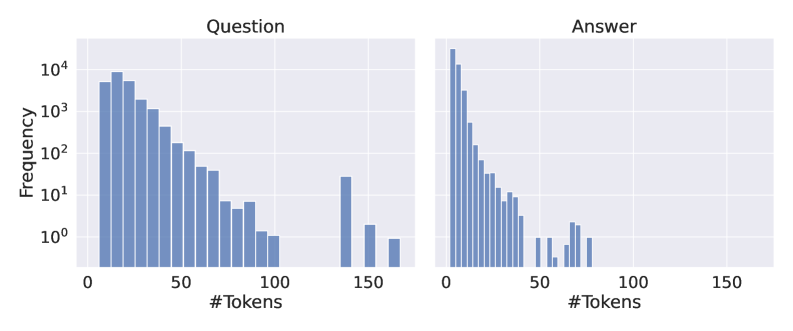
### Visual Description
\n
## Histograms: Token Frequency Distribution for Question and Answer
### Overview
The image presents two histograms displayed side-by-side. Both histograms depict the frequency distribution of the number of tokens. The left histogram represents the distribution for "Question" data, and the right histogram represents the distribution for "Answer" data. Both histograms use a logarithmic scale on the y-axis (Frequency).
### Components/Axes
* **X-axis Label (Both Histograms):** "#Tokens" - Represents the number of tokens. The scale ranges from 0 to 150, with markings at increments of 25.
* **Y-axis Label (Both Histograms):** "Frequency" - Represents the number of occurrences of a given number of tokens. The scale is logarithmic, ranging from 10⁰ (1) to 10⁴ (10,000).
* **Title (Left Histogram):** "Question"
* **Title (Right Histogram):** "Answer"
* **Histogram Type:** Bar chart representing frequency distribution.
* **Color:** All bars are a shade of blue.
### Detailed Analysis
**Question Histogram:**
The Question histogram shows a decreasing frequency as the number of tokens increases. The highest frequency occurs between 0 and 25 tokens, approximately at a frequency of 5000. The frequency decreases steadily until around 75 tokens, where it drops more rapidly. There are smaller peaks around 125 and 150 tokens, indicating some questions have a significantly higher token count.
Approximate Data Points (reading from the graph):
* 0-25 Tokens: Frequency ≈ 5000
* 25-50 Tokens: Frequency ≈ 1500
* 50-75 Tokens: Frequency ≈ 500
* 75-100 Tokens: Frequency ≈ 150
* 100-125 Tokens: Frequency ≈ 50
* 125-150 Tokens: Frequency ≈ 20
**Answer Histogram:**
The Answer histogram also shows a decreasing frequency with increasing tokens, but the distribution is more concentrated towards lower token counts. The peak frequency is between 0 and 25 tokens, approximately at a frequency of 8000. The frequency drops off more quickly than in the Question histogram. There are smaller peaks around 50 and 75 tokens, but they are much less pronounced than those in the Question histogram.
Approximate Data Points (reading from the graph):
* 0-25 Tokens: Frequency ≈ 8000
* 25-50 Tokens: Frequency ≈ 2000
* 50-75 Tokens: Frequency ≈ 500
* 75-100 Tokens: Frequency ≈ 100
* 100-125 Tokens: Frequency ≈ 20
* 125-150 Tokens: Frequency ≈ 5
### Key Observations
* Answers generally have fewer tokens than questions. This is evident from the more concentrated distribution of the Answer histogram towards lower token counts.
* Both distributions are right-skewed, meaning they have a long tail extending towards higher token counts.
* The logarithmic scale on the y-axis emphasizes the differences in frequency at lower token counts.
* The Question histogram has more variability in token counts, as indicated by the broader distribution and the presence of peaks at higher token counts.
### Interpretation
The data suggests that questions tend to be longer and more variable in length than answers. This is likely because questions require more context and detail to be fully formed, while answers can be more concise and direct. The right-skewed distributions indicate that while most questions and answers are relatively short, there are some outliers with a significantly higher number of tokens. This could be due to complex questions or detailed answers. The use of a logarithmic scale highlights the prevalence of shorter questions and answers, while still allowing us to observe the distribution of longer ones. The difference in distributions between questions and answers could be used to inform the design of natural language processing models, such as those used for question answering systems. For example, models could be optimized to handle the longer and more variable lengths of questions.
</details>
(e) TriviaQA
<details>
<summary>x13.png Details</summary>
### Visual Description
\n
## Chart: Token Frequency Distribution for Questions and Answers
### Overview
The image presents two histograms displayed side-by-side. Both histograms depict the frequency distribution of the number of tokens in a dataset. The left histogram represents the distribution for "Question" data, and the right histogram represents the distribution for "Answer" data. Both histograms use a logarithmic scale on the y-axis (Frequency).
### Components/Axes
* **X-axis Label (Both Charts):** "#Tokens" - Represents the number of tokens. The scale ranges from 0 to 60.
* **Y-axis Label (Both Charts):** "Frequency" - Represents the number of occurrences of a given number of tokens. The scale is logarithmic, ranging from 10⁰ (1) to 10² (100).
* **Title (Left Chart):** "Question"
* **Title (Right Chart):** "Answer"
* **Data Series (Both Charts):** A single series of bar heights representing the frequency of each token count.
### Detailed Analysis
**Question Histogram:**
The distribution is approximately normal, but skewed to the right. The peak frequency occurs around 10-12 tokens. The frequency decreases as the number of tokens increases, with a long tail extending to 60 tokens.
* Approximately 100 occurrences between 8 and 14 tokens.
* Approximately 50 occurrences between 15 and 20 tokens.
* Approximately 20 occurrences between 20 and 25 tokens.
* Approximately 10 occurrences between 25 and 30 tokens.
* Approximately 5 occurrences between 30 and 40 tokens.
* Approximately 2 occurrences between 40 and 50 tokens.
* Approximately 1 occurrence between 50 and 60 tokens.
**Answer Histogram:**
The distribution is also approximately normal, but slightly more concentrated around the lower token counts compared to the Question histogram. The peak frequency occurs around 10-14 tokens. The frequency decreases as the number of tokens increases, with a tail extending to 60 tokens.
* Approximately 120 occurrences between 8 and 14 tokens.
* Approximately 60 occurrences between 15 and 20 tokens.
* Approximately 30 occurrences between 20 and 25 tokens.
* Approximately 15 occurrences between 25 and 30 tokens.
* Approximately 7 occurrences between 30 and 35 tokens.
* Approximately 3 occurrences between 35 and 40 tokens.
* Approximately 1 occurrence between 40 and 50 tokens.
* Approximately 1 occurrence between 50 and 60 tokens.
### Key Observations
* The "Answer" histogram has a higher peak frequency than the "Question" histogram, suggesting that answers tend to be shorter than questions.
* Both distributions are right-skewed, indicating that there are some questions and answers with a significantly higher number of tokens than the average.
* The logarithmic scale on the y-axis emphasizes the differences in frequency at lower token counts.
### Interpretation
The data suggests that the length of questions and answers in the dataset varies, but answers are generally shorter than questions. The distributions provide insights into the typical length of text used in this question-answering context. The right skewness indicates that while most questions and answers are relatively short, there are some outliers with a large number of tokens, potentially representing complex or detailed queries and responses. The difference in peak frequency between the two histograms suggests a systematic difference in the length of questions and answers, which could be due to the nature of the task or the way the data was collected. The use of a logarithmic scale is appropriate for visualizing frequency distributions where there is a wide range of values, as it allows for better visualization of the lower frequency events.
</details>
(f) TruthfulQA
<details>
<summary>x14.png Details</summary>
### Visual Description
\n
## Chart: Token Frequency Distribution - Question vs. Answer
### Overview
The image presents two histograms displayed side-by-side. Both histograms represent the frequency distribution of the number of tokens in a dataset. The left histogram represents the distribution for "Question" data, and the right histogram represents the distribution for "Answer" data. Both y-axes are on a logarithmic scale.
### Components/Axes
* **X-axis Label (Both Charts):** "#Tokens" - Represents the number of tokens. Scale ranges from approximately 0 to 300.
* **Y-axis Label (Both Charts):** "Frequency" - Represents the number of occurrences of a given number of tokens. The scale is logarithmic, ranging from approximately 10<sup>-1</sup> to 10<sup>1</sup>.
* **Chart Titles:**
* Left Chart: "Question"
* Right Chart: "Answer"
* **Histogram Bars:** Each bar represents the frequency of a specific number of tokens.
### Detailed Analysis
**Question Histogram:**
The "Question" histogram shows a distribution that is heavily skewed to the left. The highest frequency occurs around 80-100 tokens. The frequency decreases as the number of tokens increases.
* Approximately 15 tokens have a frequency of around 8.
* Approximately 100 tokens have a frequency of around 4.
* Approximately 150 tokens have a frequency of around 1.
* Approximately 200 tokens have a frequency of around 0.3.
* Approximately 250 tokens have a frequency of around 0.1.
* Approximately 300 tokens have a frequency of around 0.03.
**Answer Histogram:**
The "Answer" histogram also shows a distribution skewed to the left, but it appears to be slightly more spread out than the "Question" histogram. The peak frequency occurs around 120-140 tokens.
* Approximately 100 tokens have a frequency of around 7.
* Approximately 150 tokens have a frequency of around 5.
* Approximately 200 tokens have a frequency of around 2.
* Approximately 250 tokens have a frequency of around 0.5.
* Approximately 300 tokens have a frequency of around 0.1.
### Key Observations
* Both distributions are right-skewed, indicating that most questions and answers have a relatively small number of tokens, with fewer instances of longer questions or answers.
* The peak of the "Question" distribution is slightly to the left of the peak of the "Answer" distribution, suggesting that questions tend to be shorter than answers on average.
* The logarithmic scale on the y-axis emphasizes the differences in frequency for lower token counts.
### Interpretation
The data suggests that the length of questions and answers in the dataset varies, but there's a tendency for questions to be shorter than answers. The skewed distributions indicate that a small number of very long questions or answers exist, but they are relatively rare compared to shorter ones. This information could be useful for tasks such as optimizing language model input lengths or understanding the complexity of the question-answering task. The logarithmic scale is used to better visualize the frequency of the more common, shorter token lengths, as the frequency drops off rapidly for longer token counts. The distributions provide insight into the characteristics of the text data used for question answering.
</details>
(g) GSM8K
Figure 8: Token count histograms for the datasets used in our experiments. Token counts were computed separately for each example’s $question$ (left) and gold $answer$ (right) using the meta-llama/Llama-3.1-8B-Instruct tokenizer. In cases with multiple answers, they were flattened into one.
## Appendix E Hallucination dataset sizes
Figure 9 shows the number of examples per label, determined using exact match for GSM8K and the llm-as-judge heuristic for the other datasets. It is worth noting that different generation configurations result in different splits, as LLMs might produce different answers. All examples classified as $Rejected$ were discarded from the hallucination probe training and evaluation. We observe that most datasets are imbalanced, typically underrepresenting non-hallucinated examples, with the exception of TriviaQA and GSM8K. We split each dataset into 80% training examples and 20% test examples. Splits were stratified according to hallucination labels.
<details>
<summary>x15.png Details</summary>
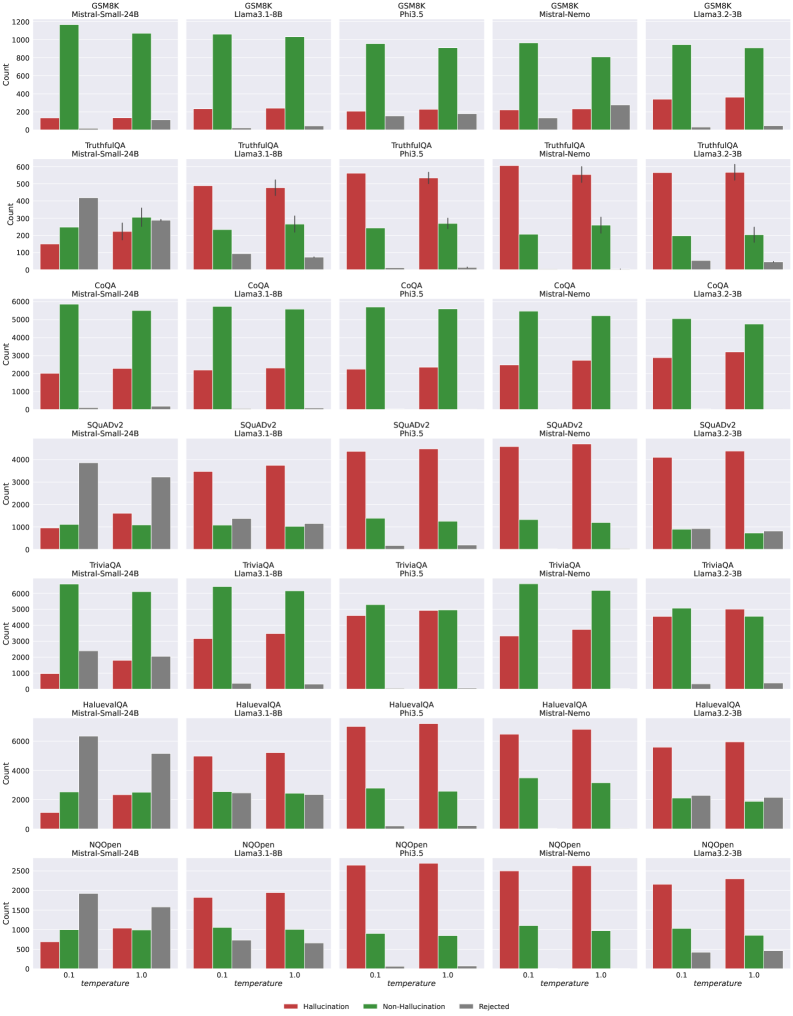
### Visual Description
## Bar Chart: Model Performance on Various QA Datasets
### Overview
The image presents a series of bar charts comparing the performance of different language models (Mistral-Small-24B, Llama3-1-8B, Phi3.5, Mistral-Nemo, and Llama3-2-3B) across seven Question Answering (QA) datasets: GSM8K, TruthfulQA, CoQA, SQuADv2, TriviaQA, HaluevalQA, and NQOpen. The performance metric is "Count," likely representing the number of correctly answered questions or a similar measure of accuracy. Each chart displays the performance for each model on a specific dataset, categorized by "temperature" (0.1, 0.5, 1.0).
### Components/Axes
* **X-axis:** Temperature (0.1, 0.5, 1.0). Labeled as "temperature"
* **Y-axis:** Count. Labeled as "Count". The scale varies for each chart, ranging from 0 to approximately 1200 for GSM8K, 0 to 600 for TruthfulQA, 0 to 6000 for CoQA, 0 to 4000 for SQuADv2, 0 to 6000 for TriviaQA, 0 to 6000 for HaluevalQA, and 0 to 2500 for NQOpen.
* **Models:** Mistral-Small-24B (dark red), Llama3-1-8B (green), Phi3.5 (light green), Mistral-Nemo (blue), Llama3-2-3B (grey).
* **Datasets:** GSM8K, TruthfulQA, CoQA, SQuADv2, TriviaQA, HaluevalQA, NQOpen.
* **Legend:** Located in the bottom-left corner, associating colors with each model. The legend labels are: "Mistral-Small-24B", "Llama3-1-8B", "Phi3.5", "Mistral-Nemo", "Llama3-2-3B".
### Detailed Analysis or Content Details
Each dataset has its own bar chart. I will analyze each one individually, noting trends and approximate values.
**1. GSM8K:**
* Mistral-Small-24B: At temperature 0.1: ~1100, 0.5: ~900, 1.0: ~700. Decreasing trend.
* Llama3-1-8B: At temperature 0.1: ~800, 0.5: ~1000, 1.0: ~800. Increasing then decreasing trend.
* Phi3.5: At temperature 0.1: ~1000, 0.5: ~1100, 1.0: ~900. Increasing then decreasing trend.
* Mistral-Nemo: At temperature 0.1: ~800, 0.5: ~1000, 1.0: ~800. Increasing then decreasing trend.
* Llama3-2-3B: At temperature 0.1: ~1000, 0.5: ~1100, 1.0: ~900. Increasing then decreasing trend.
**2. TruthfulQA:**
* Mistral-Small-24B: At temperature 0.1: ~500, 0.5: ~400, 1.0: ~300. Decreasing trend.
* Llama3-1-8B: At temperature 0.1: ~500, 0.5: ~500, 1.0: ~400. Relatively flat, slight decrease.
* Phi3.5: At temperature 0.1: ~500, 0.5: ~500, 1.0: ~400. Relatively flat, slight decrease.
* Mistral-Nemo: At temperature 0.1: ~500, 0.5: ~500, 1.0: ~400. Relatively flat, slight decrease.
* Llama3-2-3B: At temperature 0.1: ~500, 0.5: ~500, 1.0: ~400. Relatively flat, slight decrease.
**3. CoQA:**
* Mistral-Small-24B: At temperature 0.1: ~5000, 0.5: ~4000, 1.0: ~3000. Decreasing trend.
* Llama3-1-8B: At temperature 0.1: ~4000, 0.5: ~5000, 1.0: ~4000. Increasing then decreasing trend.
* Phi3.5: At temperature 0.1: ~5000, 0.5: ~5500, 1.0: ~4500. Increasing then decreasing trend.
* Mistral-Nemo: At temperature 0.1: ~4000, 0.5: ~5000, 1.0: ~4000. Increasing then decreasing trend.
* Llama3-2-3B: At temperature 0.1: ~5000, 0.5: ~5500, 1.0: ~4500. Increasing then decreasing trend.
**4. SQuADv2:**
* Mistral-Small-24B: At temperature 0.1: ~3000, 0.5: ~3500, 1.0: ~3000. Increasing then decreasing trend.
* Llama3-1-8B: At temperature 0.1: ~3500, 0.5: ~4000, 1.0: ~3500. Increasing then decreasing trend.
* Phi3.5: At temperature 0.1: ~4000, 0.5: ~4500, 1.0: ~4000. Increasing then decreasing trend.
* Mistral-Nemo: At temperature 0.1: ~3500, 0.5: ~4000, 1.0: ~3500. Increasing then decreasing trend.
* Llama3-2-3B: At temperature 0.1: ~4000, 0.5: ~4500, 1.0: ~4000. Increasing then decreasing trend.
**5. TriviaQA:**
* Mistral-Small-24B: At temperature 0.1: ~5000, 0.5: ~4000, 1.0: ~3000. Decreasing trend.
* Llama3-1-8B: At temperature 0.1: ~4000, 0.5: ~5000, 1.0: ~4000. Increasing then decreasing trend.
* Phi3.5: At temperature 0.1: ~5000, 0.5: ~5500, 1.0: ~4500. Increasing then decreasing trend.
* Mistral-Nemo: At temperature 0.1: ~4000, 0.5: ~5000, 1.0: ~4000. Increasing then decreasing trend.
* Llama3-2-3B: At temperature 0.1: ~5000, 0.5: ~5500, 1.0: ~4500. Increasing then decreasing trend.
**6. HaluevalQA:**
* Mistral-Small-24B: At temperature 0.1: ~5000, 0.5: ~4000, 1.0: ~3000. Decreasing trend.
* Llama3-1-8B: At temperature 0.1: ~4000, 0.5: ~5000, 1.0: ~4000. Increasing then decreasing trend.
* Phi3.5: At temperature 0.1: ~5000, 0.5: ~5500, 1.0: ~4500. Increasing then decreasing trend.
* Mistral-Nemo: At temperature 0.1: ~4000, 0.5: ~5000, 1.0: ~4000. Increasing then decreasing trend.
* Llama3-2-3B: At temperature 0.1: ~5000, 0.5: ~5500, 1.0: ~4500. Increasing then decreasing trend.
**7. NQOpen:**
* Mistral-Small-24B: At temperature 0.1: ~2000, 0.5: ~1500, 1.0: ~1000. Decreasing trend.
* Llama3-1-8B: At temperature 0.1: ~1500, 0.5: ~2000, 1.0: ~1500. Increasing then decreasing trend.
* Phi3.5: At temperature 0.1: ~2000, 0.5: ~2200, 1.0: ~1800. Increasing then decreasing trend.
* Mistral-Nemo: At temperature 0.1: ~1500, 0.5: ~2000, 1.0: ~1500. Increasing then decreasing trend.
* Llama3-2-3B: At temperature 0.1: ~2000, 0.5: ~2200, 1.0: ~1800. Increasing then decreasing trend.
### Key Observations
* Generally, performance decreases as temperature increases for Mistral-Small-24B across all datasets.
* Llama3-1-8B, Phi3.5, Mistral-Nemo, and Llama3-2-3B often show an initial increase in performance at temperature 0.5 before decreasing at temperature 1.0.
* CoQA, TriviaQA, and HaluevalQA have significantly higher "Count" values compared to GSM8K and TruthfulQA, indicating potentially easier or different types of questions.
* Phi3.5 consistently performs well, often achieving the highest "Count" values, particularly at a temperature of 0.5.
### Interpretation
The charts demonstrate the impact of temperature settings on the performance of different language models across various QA datasets. Lower temperatures (0.1) generally lead to more deterministic and potentially conservative responses, while higher temperatures (1.0) introduce more randomness and creativity, which can sometimes improve performance but often leads to decreased accuracy. The varying performance across datasets suggests that the models' strengths and weaknesses are dataset-specific. The consistent strong performance of Phi3.5 suggests it is a robust model capable of handling a wide range of QA tasks effectively. The trend of decreasing performance with increasing temperature for Mistral-Small-24B suggests it may be more sensitive to temperature adjustments than the other models. The differences in scale between datasets suggest varying difficulty or different scoring mechanisms. The data suggests that a temperature of 0.5 often represents a good balance between accuracy and exploration for the Llama3 and Mistral-Nemo models.
</details>
Figure 9: Number of examples per each label in generated datasets ( $Hallucination$ - number of hallucinated examples, $Non{-}Hallucination$ - number of truthful examples, $Rejected$ - number of examples unable to evaluate).
## Appendix F LLM-as-Judge agreement
To ensure the high quality of labels generated using the llm-as-judge approach, we complemented manual evaluation of random examples with a second judge LLM and measured agreement between the models. We assume that higher agreement among LLMs indicates better label quality. The reduced performance of $\operatorname{LapEigvals}$ on TriviaQA may be attributed to the lower agreement, as well as the dataset’s size and class imbalance discussed earlier.
Table 4: Agreement between LLM judges labeling hallucinations (gpt-4o-mini, gpt-4.1), measured with Cohen’s Kappa.
| CoQA HaluevalQA NQOpen | 0.876 0.946 0.883 |
| --- | --- |
| SquadV2 | 0.854 |
| TriviaQA | 0.939 |
| TruthfulQA | 0.714 |
## Appendix G Extended results
### G.1 Precision and Recall analysis
To provide insights relevant for potential practical usage, we analyze the Precision and Recall of our method. While it has not yet been fully evaluated in production settings, this analysis illustrates the trade-offs between these metrics and informs how the method might behave in real-world applications. Metrics were computed using the default threshold of 0.5, as reported in Table 5. Although trade-off patterns vary across datasets, they are consistent across all evaluated LLMs. Specifically, we observe higher recall on CoQA, GSM8K, and TriviaQA, whereas HaluEvalQA, NQ-Open, SQuADv2, and TruthfulQA exhibit higher precision. These insights can guide threshold adjustments to balance precision and recall for different production scenarios.
Table 5: Precision and Recall values for the $\operatorname{LapEigvals}$ method, complementary to AUROC presented in Table 1. Values are presented as Precision / Recall for each dataset and model combination.
| Llama3.1-8B Llama3.2-3B Phi3.5 | 0.583 / 0.710 0.679 / 0.728 0.560 / 0.703 | 0.644 / 0.729 0.718 / 0.699 0.600 / 0.739 | 0.895 / 0.785 0.912 / 0.788 0.899 / 0.768 | 0.859 / 0.740 0.894 / 0.662 0.910 / 0.785 | 0.896 / 0.720 0.924 / 0.720 0.906 / 0.731 | 0.719 / 0.812 0.787 / 0.729 0.787 / 0.785 | 0.872 / 0.781 0.910 / 0.746 0.829 / 0.798 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Mistral-Nemo | 0.646 / 0.714 | 0.594 / 0.809 | 0.873 / 0.760 | 0.875 / 0.751 | 0.920 / 0.756 | 0.707 / 0.769 | 0.892 / 0.825 |
| Mistral-Small-24B | 0.610 / 0.779 | 0.561 / 0.852 | 0.811 / 0.801 | 0.700 / 0.750 | 0.784 / 0.789 | 0.575 / 0.787 | 0.679 / 0.655 |
### G.2 Extended method comparison
In Tables 6 and 7, we present the extended results corresponding to those summarized in Table 1 in the main part of this paper. The extended results cover probes trained with both all-layers and per-layer variants across all models, as well as lower temperature ( $temp\in\{0.1,1.0\}$ ). In almost all cases, the all-layers variant outperforms the per-layer variant, suggesting that hallucination-related information is distributed across multiple layers. Additionally, we observe a smaller generalization gap (measured as the difference between test and training performance) for the $\operatorname{LapEigvals}$ method, indicating more robust features present in the Laplacian eigenvalues. Finally, as demonstrated in Section 6, increasing the temperature during answer generation improves probe performance, which is also evident in Table 6, where probes trained on answers generated with $temp{=}1.0$ consistently outperform those trained on data generated with $temp{=}0.1$ .
Table 6: (Part I) Performance comparison of methods on an extended set of configurations. We mark results for $\operatorname{AttentionScore}$ in gray as it is an unsupervised approach, not directly comparable to the others. In bold, we highlight the best performance on the test split of data, individually for each dataset, LLM, and temperature.
| Llama3.1-8B | 0.1 | $\operatorname{AttentionScore}$ | | ✓ | 0.509 | 0.683 | 0.667 | 0.607 | 0.556 | 0.567 | 0.563 | 0.541 | 0.764 | 0.653 | 0.631 | 0.575 | 0.571 | 0.650 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Llama3.1-8B | 0.1 | $\operatorname{AttentionScore}$ | ✓ | | 0.494 | 0.677 | 0.614 | 0.568 | 0.522 | 0.522 | 0.489 | 0.504 | 0.708 | 0.587 | 0.558 | 0.521 | 0.511 | 0.537 |
| Llama3.1-8B | 0.1 | $\operatorname{AttnLogDet}$ | | ✓ | 0.574 | 0.810 | 0.776 | 0.702 | 0.688 | 0.739 | 0.709 | 0.606 | 0.840 | 0.770 | 0.713 | 0.708 | 0.741 | 0.777 |
| Llama3.1-8B | 0.1 | $\operatorname{AttnLogDet}$ | ✓ | | 0.843 | 0.977 | 0.884 | 0.851 | 0.839 | 0.861 | 0.913 | 0.770 | 0.833 | 0.837 | 0.768 | 0.758 | 0.827 | 0.820 |
| Llama3.1-8B | 0.1 | $\operatorname{AttnEigvals}$ | | ✓ | 0.764 | 0.879 | 0.828 | 0.713 | 0.742 | 0.793 | 0.680 | 0.729 | 0.798 | 0.799 | 0.728 | 0.749 | 0.773 | 0.790 |
| Llama3.1-8B | 0.1 | $\operatorname{AttnEigvals}$ | ✓ | | 0.861 | 0.992 | 0.895 | 0.878 | 0.858 | 0.867 | 0.979 | 0.776 | 0.841 | 0.838 | 0.755 | 0.781 | 0.822 | 0.819 |
| Llama3.1-8B | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 0.758 | 0.777 | 0.817 | 0.698 | 0.707 | 0.781 | 0.708 | 0.757 | 0.844 | 0.793 | 0.711 | 0.733 | 0.780 | 0.764 |
| Llama3.1-8B | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 0.869 | 0.928 | 0.901 | 0.864 | 0.855 | 0.896 | 0.903 | 0.836 | 0.887 | 0.867 | 0.793 | 0.782 | 0.872 | 0.822 |
| Llama3.1-8B | 1.0 | $\operatorname{AttentionScore}$ | | ✓ | 0.514 | 0.705 | 0.640 | 0.607 | 0.558 | 0.578 | 0.533 | 0.525 | 0.731 | 0.642 | 0.607 | 0.572 | 0.602 | 0.629 |
| Llama3.1-8B | 1.0 | $\operatorname{AttentionScore}$ | ✓ | | 0.507 | 0.710 | 0.602 | 0.580 | 0.534 | 0.535 | 0.546 | 0.493 | 0.720 | 0.589 | 0.556 | 0.538 | 0.532 | 0.541 |
| Llama3.1-8B | 1.0 | $\operatorname{AttnLogDet}$ | | ✓ | 0.596 | 0.791 | 0.755 | 0.704 | 0.697 | 0.750 | 0.757 | 0.597 | 0.828 | 0.763 | 0.757 | 0.686 | 0.754 | 0.771 |
| Llama3.1-8B | 1.0 | $\operatorname{AttnLogDet}$ | ✓ | | 0.848 | 0.973 | 0.882 | 0.856 | 0.846 | 0.867 | 0.930 | 0.769 | 0.826 | 0.827 | 0.793 | 0.748 | 0.842 | 0.814 |
| Llama3.1-8B | 1.0 | $\operatorname{AttnEigvals}$ | | ✓ | 0.762 | 0.864 | 0.820 | 0.758 | 0.754 | 0.800 | 0.796 | 0.723 | 0.812 | 0.784 | 0.732 | 0.728 | 0.796 | 0.770 |
| Llama3.1-8B | 1.0 | $\operatorname{AttnEigvals}$ | ✓ | | 0.867 | 0.995 | 0.889 | 0.873 | 0.867 | 0.876 | 0.972 | 0.782 | 0.838 | 0.819 | 0.790 | 0.768 | 0.843 | 0.833 |
| Llama3.1-8B | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 0.760 | 0.873 | 0.803 | 0.732 | 0.722 | 0.795 | 0.751 | 0.743 | 0.833 | 0.789 | 0.725 | 0.724 | 0.794 | 0.764 |
| Llama3.1-8B | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 0.879 | 0.936 | 0.896 | 0.866 | 0.857 | 0.901 | 0.918 | 0.830 | 0.872 | 0.874 | 0.827 | 0.791 | 0.889 | 0.829 |
| Llama3.2-3B | 0.1 | $\operatorname{AttentionScore}$ | | ✓ | 0.526 | 0.662 | 0.697 | 0.592 | 0.570 | 0.570 | 0.569 | 0.547 | 0.640 | 0.714 | 0.643 | 0.582 | 0.551 | 0.564 |
| Llama3.2-3B | 0.1 | $\operatorname{AttentionScore}$ | ✓ | | 0.506 | 0.638 | 0.635 | 0.523 | 0.515 | 0.534 | 0.473 | 0.519 | 0.609 | 0.644 | 0.573 | 0.561 | 0.510 | 0.489 |
| Llama3.2-3B | 0.1 | $\operatorname{AttnLogDet}$ | | ✓ | 0.573 | 0.774 | 0.762 | 0.692 | 0.682 | 0.719 | 0.725 | 0.579 | 0.794 | 0.774 | 0.735 | 0.698 | 0.711 | 0.674 |
| Llama3.2-3B | 0.1 | $\operatorname{AttnLogDet}$ | ✓ | | 0.782 | 0.946 | 0.868 | 0.845 | 0.827 | 0.824 | 0.918 | 0.695 | 0.841 | 0.843 | 0.763 | 0.749 | 0.796 | 0.678 |
| Llama3.2-3B | 0.1 | $\operatorname{AttnEigvals}$ | | ✓ | 0.675 | 0.784 | 0.782 | 0.750 | 0.725 | 0.755 | 0.727 | 0.626 | 0.761 | 0.792 | 0.734 | 0.695 | 0.724 | 0.720 |
| Llama3.2-3B | 0.1 | $\operatorname{AttnEigvals}$ | ✓ | | 0.814 | 0.977 | 0.873 | 0.872 | 0.852 | 0.842 | 0.963 | 0.723 | 0.808 | 0.844 | 0.772 | 0.744 | 0.788 | 0.688 |
| Llama3.2-3B | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 0.681 | 0.763 | 0.774 | 0.733 | 0.708 | 0.733 | 0.722 | 0.676 | 0.835 | 0.781 | 0.736 | 0.697 | 0.732 | 0.690 |
| Llama3.2-3B | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 0.831 | 0.889 | 0.875 | 0.837 | 0.832 | 0.852 | 0.895 | 0.801 | 0.852 | 0.857 | 0.779 | 0.736 | 0.826 | 0.743 |
| Llama3.2-3B | 1.0 | $\operatorname{AttentionScore}$ | | ✓ | 0.532 | 0.674 | 0.668 | 0.588 | 0.578 | 0.553 | 0.555 | 0.557 | 0.753 | 0.637 | 0.592 | 0.593 | 0.558 | 0.675 |
| Llama3.2-3B | 1.0 | $\operatorname{AttentionScore}$ | ✓ | | 0.512 | 0.648 | 0.606 | 0.554 | 0.529 | 0.517 | 0.484 | 0.509 | 0.717 | 0.588 | 0.546 | 0.530 | 0.515 | 0.581 |
| Llama3.2-3B | 1.0 | $\operatorname{AttnLogDet}$ | | ✓ | 0.578 | 0.807 | 0.738 | 0.677 | 0.720 | 0.716 | 0.739 | 0.597 | 0.816 | 0.724 | 0.678 | 0.707 | 0.711 | 0.742 |
| Llama3.2-3B | 1.0 | $\operatorname{AttnLogDet}$ | ✓ | | 0.784 | 0.951 | 0.869 | 0.816 | 0.839 | 0.831 | 0.924 | 0.700 | 0.851 | 0.801 | 0.690 | 0.734 | 0.789 | 0.795 |
| Llama3.2-3B | 1.0 | $\operatorname{AttnEigvals}$ | | ✓ | 0.642 | 0.807 | 0.777 | 0.716 | 0.747 | 0.763 | 0.735 | 0.641 | 0.817 | 0.756 | 0.696 | 0.703 | 0.746 | 0.748 |
| Llama3.2-3B | 1.0 | $\operatorname{AttnEigvals}$ | ✓ | | 0.819 | 0.973 | 0.878 | 0.847 | 0.876 | 0.847 | 0.978 | 0.724 | 0.768 | 0.819 | 0.694 | 0.749 | 0.804 | 0.723 |
| Llama3.2-3B | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 0.695 | 0.781 | 0.764 | 0.683 | 0.719 | 0.727 | 0.682 | 0.715 | 0.815 | 0.754 | 0.671 | 0.711 | 0.738 | 0.767 |
| Llama3.2-3B | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 0.842 | 0.894 | 0.885 | 0.803 | 0.850 | 0.863 | 0.911 | 0.812 | 0.870 | 0.828 | 0.693 | 0.757 | 0.832 | 0.787 |
| Phi3.5 | 0.1 | $\operatorname{AttentionScore}$ | | ✓ | 0.517 | 0.723 | 0.559 | 0.565 | 0.606 | 0.625 | 0.601 | 0.528 | 0.682 | 0.551 | 0.637 | 0.621 | 0.628 | 0.637 |
| Phi3.5 | 0.1 | $\operatorname{AttentionScore}$ | ✓ | | 0.499 | 0.632 | 0.538 | 0.532 | 0.473 | 0.539 | 0.522 | 0.505 | 0.605 | 0.511 | 0.578 | 0.458 | 0.534 | 0.554 |
| Phi3.5 | 0.1 | $\operatorname{AttnLogDet}$ | | ✓ | 0.583 | 0.805 | 0.732 | 0.741 | 0.711 | 0.757 | 0.720 | 0.585 | 0.749 | 0.726 | 0.785 | 0.726 | 0.772 | 0.765 |
| Phi3.5 | 0.1 | $\operatorname{AttnLogDet}$ | ✓ | | 0.845 | 0.995 | 0.863 | 0.905 | 0.852 | 0.875 | 0.981 | 0.723 | 0.752 | 0.802 | 0.802 | 0.759 | 0.842 | 0.716 |
| Phi3.5 | 0.1 | $\operatorname{AttnEigvals}$ | | ✓ | 0.760 | 0.882 | 0.781 | 0.793 | 0.745 | 0.802 | 0.854 | 0.678 | 0.764 | 0.764 | 0.790 | 0.747 | 0.791 | 0.774 |
| Phi3.5 | 0.1 | $\operatorname{AttnEigvals}$ | ✓ | | 0.862 | 1.000 | 0.867 | 0.904 | 0.861 | 0.881 | 0.999 | 0.728 | 0.732 | 0.802 | 0.787 | 0.740 | 0.838 | 0.761 |
| Phi3.5 | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 0.734 | 0.713 | 0.758 | 0.737 | 0.704 | 0.775 | 0.759 | 0.716 | 0.753 | 0.757 | 0.761 | 0.732 | 0.768 | 0.741 |
| Phi3.5 | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 0.856 | 0.946 | 0.860 | 0.897 | 0.841 | 0.884 | 0.965 | 0.810 | 0.785 | 0.819 | 0.815 | 0.791 | 0.858 | 0.717 |
| Phi3.5 | 1.0 | $\operatorname{AttentionScore}$ | | ✓ | 0.499 | 0.699 | 0.567 | 0.615 | 0.626 | 0.637 | 0.618 | 0.533 | 0.722 | 0.581 | 0.630 | 0.645 | 0.642 | 0.626 |
| Phi3.5 | 1.0 | $\operatorname{AttentionScore}$ | ✓ | | 0.489 | 0.640 | 0.540 | 0.566 | 0.469 | 0.553 | 0.541 | 0.520 | 0.666 | 0.541 | 0.594 | 0.504 | 0.540 | 0.554 |
| Phi3.5 | 1.0 | $\operatorname{AttnLogDet}$ | | ✓ | 0.587 | 0.831 | 0.733 | 0.773 | 0.722 | 0.766 | 0.753 | 0.557 | 0.842 | 0.762 | 0.784 | 0.736 | 0.772 | 0.763 |
| Phi3.5 | 1.0 | $\operatorname{AttnLogDet}$ | ✓ | | 0.842 | 0.993 | 0.868 | 0.921 | 0.859 | 0.879 | 0.971 | 0.745 | 0.842 | 0.818 | 0.815 | 0.769 | 0.848 | 0.755 |
| Phi3.5 | 1.0 | $\operatorname{AttnEigvals}$ | | ✓ | 0.755 | 0.852 | 0.794 | 0.820 | 0.790 | 0.809 | 0.864 | 0.710 | 0.809 | 0.795 | 0.787 | 0.752 | 0.799 | 0.747 |
| Phi3.5 | 1.0 | $\operatorname{AttnEigvals}$ | ✓ | | 0.858 | 1.000 | 0.871 | 0.924 | 0.876 | 0.887 | 0.998 | 0.771 | 0.794 | 0.829 | 0.798 | 0.782 | 0.850 | 0.802 |
| Phi3.5 | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 0.733 | 0.771 | 0.755 | 0.755 | 0.718 | 0.779 | 0.713 | 0.723 | 0.816 | 0.769 | 0.755 | 0.732 | 0.792 | 0.732 |
| Phi3.5 | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 0.856 | 0.937 | 0.863 | 0.911 | 0.849 | 0.889 | 0.961 | 0.821 | 0.885 | 0.836 | 0.826 | 0.795 | 0.872 | 0.777 |
Table 7: (Part II) Performance comparison of methods on an extended set of configurations. We mark results for $\operatorname{AttentionScore}$ in gray as it is an unsupervised approach, not directly comparable to the others. In bold, we highlight the best performance on the test split of data, individually for each dataset, LLM, and temperature.
| Mistral-Nemo | 0.1 | $\operatorname{AttentionScore}$ | | ✓ | 0.504 | 0.727 | 0.574 | 0.591 | 0.509 | 0.550 | 0.546 | 0.515 | 0.697 | 0.559 | 0.587 | 0.527 | 0.545 | 0.681 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Mistral-Nemo | 0.1 | $\operatorname{AttentionScore}$ | ✓ | | 0.508 | 0.707 | 0.536 | 0.537 | 0.507 | 0.520 | 0.535 | 0.484 | 0.667 | 0.523 | 0.533 | 0.495 | 0.505 | 0.631 |
| Mistral-Nemo | 0.1 | $\operatorname{AttnLogDet}$ | | ✓ | 0.584 | 0.801 | 0.716 | 0.702 | 0.675 | 0.689 | 0.744 | 0.583 | 0.807 | 0.723 | 0.688 | 0.668 | 0.722 | 0.731 |
| Mistral-Nemo | 0.1 | $\operatorname{AttnLogDet}$ | ✓ | | 0.828 | 0.993 | 0.842 | 0.861 | 0.858 | 0.854 | 0.963 | 0.734 | 0.820 | 0.786 | 0.752 | 0.709 | 0.822 | 0.776 |
| Mistral-Nemo | 0.1 | $\operatorname{AttnEigvals}$ | | ✓ | 0.708 | 0.865 | 0.751 | 0.749 | 0.749 | 0.747 | 0.797 | 0.672 | 0.795 | 0.740 | 0.701 | 0.704 | 0.738 | 0.717 |
| Mistral-Nemo | 0.1 | $\operatorname{AttnEigvals}$ | ✓ | | 0.845 | 1.000 | 0.842 | 0.878 | 0.864 | 0.859 | 0.996 | 0.768 | 0.771 | 0.789 | 0.743 | 0.716 | 0.809 | 0.752 |
| Mistral-Nemo | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 0.763 | 0.777 | 0.772 | 0.732 | 0.723 | 0.781 | 0.725 | 0.759 | 0.751 | 0.760 | 0.697 | 0.696 | 0.769 | 0.710 |
| Mistral-Nemo | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 0.868 | 0.969 | 0.862 | 0.875 | 0.869 | 0.886 | 0.977 | 0.823 | 0.805 | 0.821 | 0.755 | 0.767 | 0.858 | 0.737 |
| Mistral-Nemo | 1.0 | $\operatorname{AttentionScore}$ | | ✓ | 0.502 | 0.656 | 0.586 | 0.606 | 0.546 | 0.553 | 0.570 | 0.525 | 0.670 | 0.587 | 0.588 | 0.564 | 0.570 | 0.632 |
| Mistral-Nemo | 1.0 | $\operatorname{AttentionScore}$ | ✓ | | 0.493 | 0.675 | 0.541 | 0.552 | 0.503 | 0.521 | 0.531 | 0.493 | 0.630 | 0.531 | 0.529 | 0.510 | 0.532 | 0.494 |
| Mistral-Nemo | 1.0 | $\operatorname{AttnLogDet}$ | | ✓ | 0.591 | 0.790 | 0.723 | 0.716 | 0.717 | 0.717 | 0.741 | 0.581 | 0.782 | 0.730 | 0.703 | 0.711 | 0.707 | 0.801 |
| Mistral-Nemo | 1.0 | $\operatorname{AttnLogDet}$ | ✓ | | 0.829 | 0.994 | 0.851 | 0.870 | 0.860 | 0.857 | 0.963 | 0.728 | 0.856 | 0.798 | 0.769 | 0.772 | 0.812 | 0.852 |
| Mistral-Nemo | 1.0 | $\operatorname{AttnEigvals}$ | | ✓ | 0.704 | 0.845 | 0.762 | 0.742 | 0.757 | 0.752 | 0.806 | 0.670 | 0.781 | 0.749 | 0.742 | 0.719 | 0.737 | 0.804 |
| Mistral-Nemo | 1.0 | $\operatorname{AttnEigvals}$ | ✓ | | 0.844 | 1.000 | 0.851 | 0.893 | 0.864 | 0.862 | 0.996 | 0.778 | 0.842 | 0.781 | 0.761 | 0.758 | 0.821 | 0.802 |
| Mistral-Nemo | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 0.765 | 0.820 | 0.790 | 0.749 | 0.740 | 0.804 | 0.779 | 0.738 | 0.808 | 0.763 | 0.708 | 0.723 | 0.785 | 0.818 |
| Mistral-Nemo | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 0.876 | 0.965 | 0.877 | 0.884 | 0.881 | 0.901 | 0.978 | 0.835 | 0.890 | 0.833 | 0.795 | 0.812 | 0.865 | 0.828 |
| Mistral-Small-24B | 0.1 | $\operatorname{AttentionScore}$ | | ✓ | 0.520 | 0.759 | 0.538 | 0.517 | 0.577 | 0.535 | 0.571 | 0.525 | 0.685 | 0.552 | 0.592 | 0.625 | 0.533 | 0.724 |
| Mistral-Small-24B | 0.1 | $\operatorname{AttentionScore}$ | ✓ | | 0.520 | 0.668 | 0.472 | 0.449 | 0.510 | 0.449 | 0.491 | 0.493 | 0.578 | 0.493 | 0.467 | 0.556 | 0.461 | 0.645 |
| Mistral-Small-24B | 0.1 | $\operatorname{AttnLogDet}$ | | ✓ | 0.585 | 0.834 | 0.674 | 0.659 | 0.724 | 0.685 | 0.698 | 0.586 | 0.809 | 0.684 | 0.695 | 0.752 | 0.682 | 0.721 |
| Mistral-Small-24B | 0.1 | $\operatorname{AttnLogDet}$ | ✓ | | 0.851 | 0.990 | 0.817 | 0.799 | 0.820 | 0.861 | 0.898 | 0.762 | 0.896 | 0.760 | 0.725 | 0.763 | 0.778 | 0.767 |
| Mistral-Small-24B | 0.1 | $\operatorname{AttnEigvals}$ | | ✓ | 0.734 | 0.863 | 0.722 | 0.667 | 0.745 | 0.757 | 0.732 | 0.720 | 0.837 | 0.707 | 0.697 | 0.773 | 0.758 | 0.765 |
| Mistral-Small-24B | 0.1 | $\operatorname{AttnEigvals}$ | ✓ | | 0.872 | 0.999 | 0.873 | 0.923 | 0.903 | 0.899 | 0.993 | 0.793 | 0.896 | 0.771 | 0.731 | 0.803 | 0.809 | 0.796 |
| Mistral-Small-24B | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 0.802 | 0.781 | 0.720 | 0.646 | 0.714 | 0.742 | 0.694 | 0.800 | 0.850 | 0.719 | 0.674 | 0.784 | 0.757 | 0.827 |
| Mistral-Small-24B | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 0.887 | 0.985 | 0.870 | 0.901 | 0.887 | 0.905 | 0.979 | 0.852 | 0.881 | 0.808 | 0.722 | 0.821 | 0.831 | 0.757 |
| Mistral-Small-24B | 1.0 | $\operatorname{AttentionScore}$ | | ✓ | 0.511 | 0.706 | 0.555 | 0.582 | 0.561 | 0.562 | 0.542 | 0.535 | 0.713 | 0.566 | 0.576 | 0.567 | 0.574 | 0.606 |
| Mistral-Small-24B | 1.0 | $\operatorname{AttentionScore}$ | ✓ | | 0.497 | 0.595 | 0.503 | 0.463 | 0.519 | 0.451 | 0.493 | 0.516 | 0.576 | 0.504 | 0.462 | 0.455 | 0.463 | 0.451 |
| Mistral-Small-24B | 1.0 | $\operatorname{AttnLogDet}$ | | ✓ | 0.591 | 0.824 | 0.727 | 0.710 | 0.732 | 0.720 | 0.677 | 0.600 | 0.869 | 0.771 | 0.714 | 0.726 | 0.734 | 0.687 |
| Mistral-Small-24B | 1.0 | $\operatorname{AttnLogDet}$ | ✓ | | 0.850 | 0.989 | 0.847 | 0.827 | 0.856 | 0.853 | 0.877 | 0.766 | 0.853 | 0.842 | 0.747 | 0.753 | 0.833 | 0.735 |
| Mistral-Small-24B | 1.0 | $\operatorname{AttnEigvals}$ | | ✓ | 0.757 | 0.920 | 0.743 | 0.728 | 0.764 | 0.779 | 0.741 | 0.723 | 0.868 | 0.780 | 0.733 | 0.734 | 0.780 | 0.718 |
| Mistral-Small-24B | 1.0 | $\operatorname{AttnEigvals}$ | ✓ | | 0.877 | 1.000 | 0.878 | 0.923 | 0.911 | 0.895 | 0.997 | 0.805 | 0.846 | 0.848 | 0.751 | 0.760 | 0.844 | 0.765 |
| Mistral-Small-24B | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 0.814 | 0.860 | 0.762 | 0.733 | 0.790 | 0.766 | 0.703 | 0.805 | 0.897 | 0.790 | 0.712 | 0.781 | 0.779 | 0.725 |
| Mistral-Small-24B | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 0.895 | 0.980 | 0.890 | 0.898 | 0.910 | 0.907 | 0.965 | 0.861 | 0.925 | 0.882 | 0.791 | 0.820 | 0.876 | 0.748 |
### G.3 Best found hyperparameters
We present the hyperparameter values corresponding to the results in Table 1 and Table 6. Table 8 shows the optimal hyperparameter $k$ for selecting the top- $k$ eigenvalues from either the attention maps in $\operatorname{AttnEigvals}$ or the Laplacian matrix in $\operatorname{LapEigvals}$ . While fewer eigenvalues were sufficient for optimal performance in some cases, the best results were generally achieved with the highest tested value, $k{=}100$ .
Table 9 reports the layer indices that yielded the highest performance for the per-layer models. Performance typically peaked in layers above the 10th, especially for Llama-3.1-8B, where attention maps from the final layers more often led to better hallucination detection. Interestingly, the first layer’s attention maps also produced strong performance in a few cases. Overall, no clear pattern emerges regarding the optimal layer, and as noted in prior work, selecting the best layer in the per-layer setup often requires a search.
Table 8: Values of $k$ hyperparameter, denoting how many highest eigenvalues are taken from the Laplacian matrix, corresponding to the best results in Table 1 and Table 6.
| | | | | | CoQA | GSM8K | HaluevalQA | NQOpen | SQuADv2 | TriviaQA | TruthfulQA |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Llama3.1-8B | 0.1 | $\operatorname{AttnEigvals}$ | | ✓ | 50 | 100 | 100 | 25 | 100 | 100 | 10 |
| Llama3.1-8B | 0.1 | $\operatorname{AttnEigvals}$ | ✓ | | 100 | 100 | 100 | 100 | 100 | 50 | 100 |
| Llama3.1-8B | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 50 | 50 | 100 | 10 | 100 | 100 | 100 |
| Llama3.1-8B | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 10 | 100 | 100 | 100 | 100 | 100 | 100 |
| Llama3.1-8B | 1.0 | $\operatorname{AttnEigvals}$ | | ✓ | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Llama3.1-8B | 1.0 | $\operatorname{AttnEigvals}$ | ✓ | | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Llama3.1-8B | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 100 | 50 | 100 | 100 | 100 | 100 | 100 |
| Llama3.1-8B | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 100 | 100 | 25 | 100 | 100 | 100 | 100 |
| Llama3.2-3B | 0.1 | $\operatorname{AttnEigvals}$ | | ✓ | 100 | 100 | 100 | 100 | 100 | 100 | 10 |
| Llama3.2-3B | 0.1 | $\operatorname{AttnEigvals}$ | ✓ | | 100 | 100 | 25 | 100 | 100 | 100 | 100 |
| Llama3.2-3B | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 100 | 25 | 100 | 100 | 100 | 50 | 5 |
| Llama3.2-3B | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 25 | 100 | 100 | 100 | 100 | 100 | 100 |
| Llama3.2-3B | 1.0 | $\operatorname{AttnEigvals}$ | | ✓ | 100 | 100 | 100 | 100 | 100 | 100 | 50 |
| Llama3.2-3B | 1.0 | $\operatorname{AttnEigvals}$ | ✓ | | 100 | 50 | 100 | 100 | 100 | 100 | 100 |
| Llama3.2-3B | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 100 | 50 | 100 | 10 | 100 | 100 | 25 |
| Llama3.2-3B | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 25 | 100 | 100 | 100 | 100 | 100 | 100 |
| Phi3.5 | 0.1 | $\operatorname{AttnEigvals}$ | | ✓ | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Phi3.5 | 0.1 | $\operatorname{AttnEigvals}$ | ✓ | | 100 | 25 | 10 | 10 | 25 | 100 | 50 |
| Phi3.5 | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 100 | 10 | 100 | 100 | 100 | 100 | 100 |
| Phi3.5 | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 10 | 100 | 50 | 100 | 100 | 100 | 100 |
| Phi3.5 | 1.0 | $\operatorname{AttnEigvals}$ | | ✓ | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Phi3.5 | 1.0 | $\operatorname{AttnEigvals}$ | ✓ | | 100 | 100 | 100 | 10 | 100 | 100 | 50 |
| Phi3.5 | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 100 | 25 | 100 | 100 | 100 | 100 | 50 |
| Phi3.5 | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 10 | 25 | 100 | 100 | 100 | 100 | 100 |
| Mistral-Nemo | 0.1 | $\operatorname{AttnEigvals}$ | | ✓ | 100 | 50 | 100 | 100 | 100 | 100 | 100 |
| Mistral-Nemo | 0.1 | $\operatorname{AttnEigvals}$ | ✓ | | 100 | 50 | 100 | 100 | 100 | 100 | 100 |
| Mistral-Nemo | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 100 | 25 | 100 | 100 | 100 | 100 | 10 |
| Mistral-Nemo | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 10 | 100 | 25 | 100 | 50 | 100 | 100 |
| Mistral-Nemo | 1.0 | $\operatorname{AttnEigvals}$ | | ✓ | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Mistral-Nemo | 1.0 | $\operatorname{AttnEigvals}$ | ✓ | | 100 | 100 | 100 | 100 | 100 | 50 | 100 |
| Mistral-Nemo | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 100 | 100 | 100 | 50 | 100 | 100 | 100 |
| Mistral-Nemo | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 10 | 100 | 50 | 100 | 100 | 100 | 100 |
| Mistral-Small-24B | 0.1 | $\operatorname{AttnEigvals}$ | | ✓ | 100 | 100 | 100 | 10 | 100 | 50 | 25 |
| Mistral-Small-24B | 0.1 | $\operatorname{AttnEigvals}$ | ✓ | | 100 | 100 | 100 | 100 | 100 | 100 | 25 |
| Mistral-Small-24B | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 100 | 50 | 100 | 50 | 100 | 100 | 10 |
| Mistral-Small-24B | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 25 | 100 | 100 | 100 | 100 | 10 | 100 |
| Mistral-Small-24B | 1.0 | $\operatorname{AttnEigvals}$ | | ✓ | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Mistral-Small-24B | 1.0 | $\operatorname{AttnEigvals}$ | ✓ | | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Mistral-Small-24B | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 100 | 100 | 100 | 100 | 50 | 100 | 50 |
| Mistral-Small-24B | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 10 | 100 | 50 | 10 | 10 | 100 | 50 |
Table 9: Values of a layer index (numbered from 0) corresponding to the best results for per-layer models in Table 6.
| | | | CoQA | GSM8K | HaluevalQA | NQOpen | SQuADv2 | TriviaQA | TruthfulQA |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Llama3.1-8B | 0.1 | $\operatorname{AttentionScore}$ | 13 | 28 | 10 | 0 | 0 | 0 | 28 |
| Llama3.1-8B | 0.1 | $\operatorname{AttnLogDet}$ | 7 | 31 | 13 | 16 | 11 | 29 | 21 |
| Llama3.1-8B | 0.1 | $\operatorname{AttnEigvals}$ | 22 | 31 | 31 | 26 | 31 | 31 | 7 |
| Llama3.1-8B | 0.1 | $\operatorname{LapEigvals}$ | 15 | 25 | 14 | 20 | 29 | 31 | 20 |
| Llama3.1-8B | 1.0 | $\operatorname{AttentionScore}$ | 29 | 3 | 10 | 0 | 0 | 0 | 23 |
| Llama3.1-8B | 1.0 | $\operatorname{AttnLogDet}$ | 17 | 16 | 11 | 13 | 29 | 29 | 30 |
| Llama3.1-8B | 1.0 | $\operatorname{AttnEigvals}$ | 22 | 28 | 31 | 31 | 31 | 31 | 31 |
| Llama3.1-8B | 1.0 | $\operatorname{LapEigvals}$ | 15 | 11 | 14 | 31 | 29 | 29 | 29 |
| Llama3.2-3B | 0.1 | $\operatorname{AttentionScore}$ | 15 | 17 | 12 | 12 | 12 | 21 | 14 |
| Llama3.2-3B | 0.1 | $\operatorname{AttnLogDet}$ | 12 | 18 | 13 | 24 | 10 | 25 | 14 |
| Llama3.2-3B | 0.1 | $\operatorname{AttnEigvals}$ | 27 | 14 | 14 | 14 | 25 | 27 | 17 |
| Llama3.2-3B | 0.1 | $\operatorname{LapEigvals}$ | 11 | 24 | 8 | 12 | 25 | 12 | 14 |
| Llama3.2-3B | 1.0 | $\operatorname{AttentionScore}$ | 24 | 25 | 12 | 0 | 24 | 21 | 14 |
| Llama3.2-3B | 1.0 | $\operatorname{AttnLogDet}$ | 12 | 18 | 26 | 23 | 25 | 25 | 12 |
| Llama3.2-3B | 1.0 | $\operatorname{AttnEigvals}$ | 11 | 14 | 27 | 25 | 25 | 27 | 10 |
| Llama3.2-3B | 1.0 | $\operatorname{LapEigvals}$ | 11 | 10 | 18 | 12 | 25 | 25 | 11 |
| Phi3.5 | 0.1 | $\operatorname{AttentionScore}$ | 7 | 1 | 15 | 0 | 0 | 0 | 19 |
| Phi3.5 | 0.1 | $\operatorname{AttnLogDet}$ | 20 | 19 | 18 | 16 | 17 | 13 | 23 |
| Phi3.5 | 0.1 | $\operatorname{AttnEigvals}$ | 18 | 18 | 19 | 15 | 19 | 18 | 28 |
| Phi3.5 | 0.1 | $\operatorname{LapEigvals}$ | 18 | 23 | 28 | 28 | 19 | 31 | 28 |
| Phi3.5 | 1.0 | $\operatorname{AttentionScore}$ | 19 | 1 | 0 | 1 | 0 | 0 | 19 |
| Phi3.5 | 1.0 | $\operatorname{AttnLogDet}$ | 12 | 19 | 29 | 14 | 19 | 13 | 14 |
| Phi3.5 | 1.0 | $\operatorname{AttnEigvals}$ | 18 | 1 | 30 | 17 | 31 | 31 | 31 |
| Phi3.5 | 1.0 | $\operatorname{LapEigvals}$ | 18 | 16 | 28 | 15 | 19 | 31 | 31 |
| Mistral-Nemo | 0.1 | $\operatorname{AttentionScore}$ | 2 | 27 | 18 | 35 | 0 | 30 | 35 |
| Mistral-Nemo | 0.1 | $\operatorname{AttnLogDet}$ | 37 | 20 | 17 | 15 | 38 | 38 | 33 |
| Mistral-Nemo | 0.1 | $\operatorname{AttnEigvals}$ | 38 | 37 | 38 | 18 | 18 | 15 | 31 |
| Mistral-Nemo | 0.1 | $\operatorname{LapEigvals}$ | 16 | 38 | 37 | 37 | 18 | 37 | 8 |
| Mistral-Nemo | 1.0 | $\operatorname{AttentionScore}$ | 10 | 2 | 16 | 28 | 14 | 30 | 21 |
| Mistral-Nemo | 1.0 | $\operatorname{AttnLogDet}$ | 18 | 17 | 20 | 18 | 18 | 15 | 18 |
| Mistral-Nemo | 1.0 | $\operatorname{AttnEigvals}$ | 38 | 30 | 39 | 39 | 18 | 15 | 18 |
| Mistral-Nemo | 1.0 | $\operatorname{LapEigvals}$ | 16 | 39 | 37 | 37 | 18 | 37 | 18 |
| Mistral-Small-24B | 0.1 | $\operatorname{AttentionScore}$ | 14 | 1 | 39 | 33 | 35 | 0 | 30 |
| Mistral-Small-24B | 0.1 | $\operatorname{AttnLogDet}$ | 16 | 29 | 38 | 18 | 16 | 38 | 11 |
| Mistral-Small-24B | 0.1 | $\operatorname{AttnEigvals}$ | 36 | 27 | 36 | 19 | 16 | 38 | 20 |
| Mistral-Small-24B | 0.1 | $\operatorname{LapEigvals}$ | 21 | 3 | 35 | 24 | 36 | 35 | 34 |
| Mistral-Small-24B | 1.0 | $\operatorname{AttentionScore}$ | 15 | 1 | 1 | 0 | 1 | 0 | 30 |
| Mistral-Small-24B | 1.0 | $\operatorname{AttnLogDet}$ | 14 | 24 | 27 | 17 | 24 | 38 | 34 |
| Mistral-Small-24B | 1.0 | $\operatorname{AttnEigvals}$ | 36 | 39 | 27 | 21 | 24 | 36 | 23 |
| Mistral-Small-24B | 1.0 | $\operatorname{LapEigvals}$ | 21 | 39 | 36 | 16 | 21 | 35 | 34 |
### G.4 Comparison with hidden-states-based baselines
We take an approach considered in the previous works Azaria and Mitchell (2023); Orgad et al. (2025) and aligned to our evaluation protocol. Specifically, we trained a logistic regression classifier on PCA-projected hidden states to predict whether the model is hallucinating or not. To this end, we select the last token of the answer. While we also tested the last token of the prompt, we observed significantly lower performance, which aligns with results presented by (Orgad et al., 2025). We considered hidden states either from all layers or a single layer corresponding to the selected token. In the all-layer scenario, we use the concatenation of hidden states of all layers, and in the per-layer scenario, we use the hidden states of each layer separately and select the best-performing layer.
In Table 10, we show the obtained results. The all-layer version is consistently worse than our $\operatorname{LapEigvals}$ , which further confirms the strength of the proposed method. Our work is one of the first to detect hallucinations solely using attention maps, providing an important insight into the behavior of LLMs, and it motivates further theoretical research on information flow patterns inside these models.
Table 10: Results of the probe trained on the hidden state features from the last generated token.
| | CoQA | GSM8K | HaluevalQA | NQOpen | SQuADv2 | TriviaQA | TruthfulQA | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Llama3.1-8B | 0.1 | $\operatorname{HiddenStates}$ | ✓ | | 0.835 | 0.799 | 0.840 | 0.766 | 0.736 | 0.820 | 0.834 |
| Llama3.1-8B | 0.1 | $\operatorname{HiddenStates}$ | | ✓ | 0.821 | 0.765 | 0.825 | 0.728 | 0.723 | 0.791 | 0.785 |
| Llama3.1-8B | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 0.757 | 0.844 | 0.793 | 0.711 | 0.733 | 0.780 | 0.764 |
| Llama3.1-8B | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 0.836 | 0.887 | 0.867 | 0.793 | 0.782 | 0.872 | 0.822 |
| Llama3.1-8B | 1.0 | $\operatorname{HiddenStates}$ | ✓ | | 0.836 | 0.816 | 0.850 | 0.786 | 0.754 | 0.850 | 0.823 |
| Llama3.1-8B | 1.0 | $\operatorname{HiddenStates}$ | | ✓ | 0.835 | 0.759 | 0.847 | 0.757 | 0.749 | 0.838 | 0.808 |
| Llama3.1-8B | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 0.743 | 0.833 | 0.789 | 0.725 | 0.724 | 0.794 | 0.764 |
| Llama3.1-8B | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 0.830 | 0.872 | 0.874 | 0.827 | 0.791 | 0.889 | 0.829 |
| Llama3.2-3B | 0.1 | $\operatorname{HiddenStates}$ | ✓ | | 0.800 | 0.826 | 0.808 | 0.732 | 0.750 | 0.782 | 0.760 |
| Llama3.2-3B | 0.1 | $\operatorname{HiddenStates}$ | | ✓ | 0.790 | 0.802 | 0.784 | 0.709 | 0.721 | 0.760 | 0.770 |
| Llama3.2-3B | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 0.676 | 0.835 | 0.774 | 0.730 | 0.727 | 0.712 | 0.690 |
| Llama3.2-3B | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 0.801 | 0.852 | 0.844 | 0.771 | 0.778 | 0.821 | 0.743 |
| Llama3.2-3B | 1.0 | $\operatorname{HiddenStates}$ | ✓ | | 0.778 | 0.727 | 0.758 | 0.679 | 0.719 | 0.773 | 0.716 |
| Llama3.2-3B | 1.0 | $\operatorname{HiddenStates}$ | | ✓ | 0.773 | 0.652 | 0.753 | 0.657 | 0.681 | 0.761 | 0.618 |
| Llama3.2-3B | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 0.715 | 0.815 | 0.765 | 0.696 | 0.696 | 0.738 | 0.767 |
| Llama3.2-3B | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 0.812 | 0.870 | 0.857 | 0.798 | 0.751 | 0.836 | 0.787 |
| Phi3.5 | 0.1 | $\operatorname{HiddenStates}$ | ✓ | | 0.841 | 0.773 | 0.845 | 0.813 | 0.781 | 0.886 | 0.737 |
| Phi3.5 | 0.1 | $\operatorname{HiddenStates}$ | | ✓ | 0.833 | 0.696 | 0.840 | 0.806 | 0.774 | 0.878 | 0.689 |
| Phi3.5 | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 0.716 | 0.753 | 0.757 | 0.761 | 0.732 | 0.768 | 0.741 |
| Phi3.5 | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 0.810 | 0.785 | 0.819 | 0.815 | 0.791 | 0.858 | 0.717 |
| Phi3.5 | 1.0 | $\operatorname{HiddenStates}$ | ✓ | | 0.872 | 0.784 | 0.850 | 0.821 | 0.806 | 0.891 | 0.822 |
| Phi3.5 | 1.0 | $\operatorname{HiddenStates}$ | | ✓ | 0.853 | 0.686 | 0.844 | 0.804 | 0.790 | 0.887 | 0.752 |
| Phi3.5 | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 0.723 | 0.816 | 0.769 | 0.755 | 0.732 | 0.792 | 0.732 |
| Phi3.5 | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 0.821 | 0.885 | 0.836 | 0.826 | 0.795 | 0.872 | 0.777 |
| Mistral-Nemo | 0.1 | $\operatorname{HiddenStates}$ | ✓ | | 0.818 | 0.757 | 0.814 | 0.734 | 0.731 | 0.821 | 0.792 |
| Mistral-Nemo | 0.1 | $\operatorname{HiddenStates}$ | | ✓ | 0.805 | 0.741 | 0.784 | 0.722 | 0.730 | 0.793 | 0.699 |
| Mistral-Nemo | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 0.759 | 0.751 | 0.760 | 0.697 | 0.696 | 0.769 | 0.710 |
| Mistral-Nemo | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 0.823 | 0.805 | 0.821 | 0.755 | 0.767 | 0.858 | 0.737 |
| Mistral-Nemo | 1.0 | $\operatorname{HiddenStates}$ | ✓ | | 0.793 | 0.832 | 0.777 | 0.738 | 0.719 | 0.783 | 0.722 |
| Mistral-Nemo | 1.0 | $\operatorname{HiddenStates}$ | | ✓ | 0.771 | 0.834 | 0.771 | 0.706 | 0.685 | 0.779 | 0.644 |
| Mistral-Nemo | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 0.738 | 0.808 | 0.763 | 0.708 | 0.723 | 0.785 | 0.818 |
| Mistral-Nemo | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 0.835 | 0.890 | 0.833 | 0.795 | 0.812 | 0.865 | 0.828 |
| Mistral-Small-24B | 0.1 | $\operatorname{HiddenStates}$ | ✓ | | 0.838 | 0.872 | 0.744 | 0.680 | 0.700 | 0.749 | 0.735 |
| Mistral-Small-24B | 0.1 | $\operatorname{HiddenStates}$ | | ✓ | 0.815 | 0.812 | 0.703 | 0.632 | 0.629 | 0.726 | 0.589 |
| Mistral-Small-24B | 0.1 | $\operatorname{LapEigvals}$ | ✓ | | 0.800 | 0.850 | 0.719 | 0.674 | 0.784 | 0.757 | 0.827 |
| Mistral-Small-24B | 0.1 | $\operatorname{LapEigvals}$ | | ✓ | 0.852 | 0.881 | 0.808 | 0.722 | 0.821 | 0.831 | 0.757 |
| Mistral-Small-24B | 1.0 | $\operatorname{HiddenStates}$ | ✓ | | 0.801 | 0.879 | 0.720 | 0.665 | 0.603 | 0.684 | 0.581 |
| Mistral-Small-24B | 1.0 | $\operatorname{HiddenStates}$ | | ✓ | 0.770 | 0.760 | 0.703 | 0.617 | 0.575 | 0.659 | 0.485 |
| Mistral-Small-24B | 1.0 | $\operatorname{LapEigvals}$ | ✓ | | 0.805 | 0.897 | 0.790 | 0.712 | 0.781 | 0.779 | 0.725 |
| Mistral-Small-24B | 1.0 | $\operatorname{LapEigvals}$ | | ✓ | 0.861 | 0.925 | 0.882 | 0.791 | 0.820 | 0.876 | 0.748 |
## Appendix H Extended results of ablations
In the following section, we extend the ablation results presented in Section 6.1 and Section 6.2. Figure 10 compares the top $k$ eigenvalues across all five LLMs. In Figure 11 we present a layer-wise performance comparison for each model.
<details>
<summary>x16.png Details</summary>
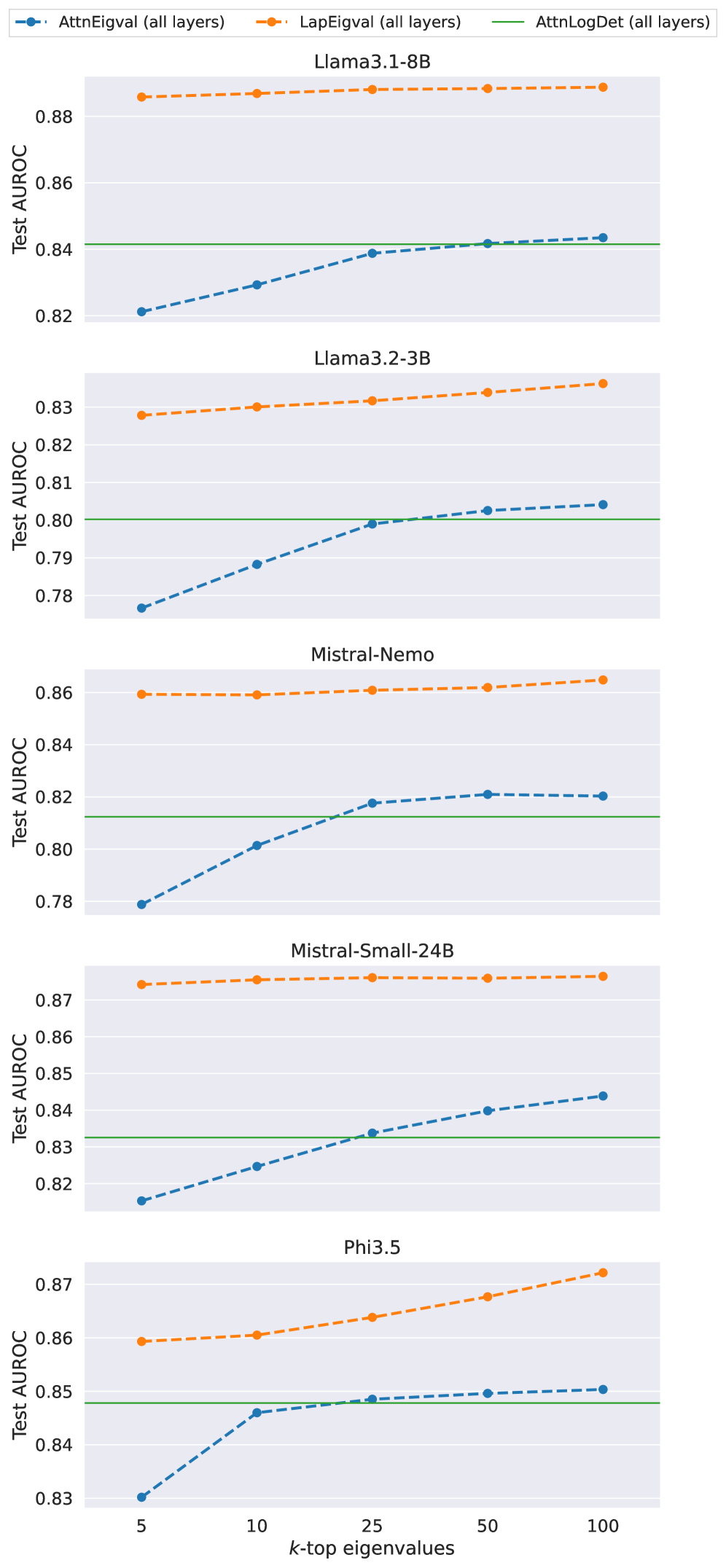
### Visual Description
\n
## Line Chart: Test AUROC vs. k-top eigenvalues
### Overview
This image presents a line chart comparing the Test AUROC (Area Under the Receiver Operating Characteristic curve) scores for five different language models (Llama3.1-8B, Llama3.2-3B, Mistral-Nemo, Mistral-Small-24B, and Phi3.5) across varying numbers of k-top eigenvalues (5, 10, 25, 50, and 100). Three different metrics – AttnEigval, LapEigval, and AttnLogDet – are used to calculate the AUROC scores for each model.
### Components/Axes
* **X-axis:** k-top eigenvalues (Scale: 5, 10, 25, 50, 100)
* **Y-axis:** Test AUROC (Scale: 0.78 to 0.88)
* **Legend:** Located at the top-right corner of the chart.
* AttnEigval (all layers) - Blue dashed line with circle markers
* LapEigval (all layers) - Orange dashed line with circle markers
* AttnLogDet (all layers) - Green dashed line with circle markers
* **Models:** Llama3.1-8B, Llama3.2-3B, Mistral-Nemo, Mistral-Small-24B, Phi3.5. Each model is represented by a separate row of data.
### Detailed Analysis
The chart consists of five sub-charts, one for each model. Each sub-chart displays the Test AUROC scores for the three metrics as a function of the number of k-top eigenvalues.
**Llama3.1-8B:**
* AttnEigval: Starts at approximately 0.835 at k=5, remains relatively stable around 0.84-0.85, and slightly increases to approximately 0.85 at k=100.
* LapEigval: Starts at approximately 0.86 at k=5, remains relatively stable around 0.85-0.86, and slightly decreases to approximately 0.85 at k=100.
* AttnLogDet: Remains relatively constant at approximately 0.84 across all k-top eigenvalue values.
**Llama3.2-3B:**
* AttnEigval: Starts at approximately 0.795 at k=5, increases to approximately 0.81 at k=25, and then slightly decreases to approximately 0.805 at k=100.
* LapEigval: Starts at approximately 0.825 at k=5, remains relatively stable around 0.82-0.83, and slightly decreases to approximately 0.82 at k=100.
* AttnLogDet: Remains relatively constant at approximately 0.81 across all k-top eigenvalue values.
**Mistral-Nemo:**
* AttnEigval: Starts at approximately 0.79 at k=5, increases to approximately 0.82 at k=50, and then slightly decreases to approximately 0.81 at k=100.
* LapEigval: Starts at approximately 0.85 at k=5, remains relatively stable around 0.84-0.85, and slightly decreases to approximately 0.84 at k=100.
* AttnLogDet: Remains relatively constant at approximately 0.83 across all k-top eigenvalue values.
**Mistral-Small-24B:**
* AttnEigval: Starts at approximately 0.83 at k=5, increases to approximately 0.85 at k=50, and then slightly decreases to approximately 0.84 at k=100.
* LapEigval: Starts at approximately 0.86 at k=5, remains relatively stable around 0.86-0.87, and slightly decreases to approximately 0.86 at k=100.
* AttnLogDet: Remains relatively constant at approximately 0.84 across all k-top eigenvalue values.
**Phi3.5:**
* AttnEigval: Starts at approximately 0.845 at k=5, increases to approximately 0.855 at k=25, and then remains relatively stable around 0.85 at k=50 and k=100.
* LapEigval: Starts at approximately 0.865 at k=5, remains relatively stable around 0.86-0.87, and slightly decreases to approximately 0.86 at k=100.
* AttnLogDet: Remains relatively constant at approximately 0.85 across all k-top eigenvalue values.
### Key Observations
* LapEigval generally yields the highest AUROC scores across all models and k-top eigenvalue values.
* AttnLogDet consistently shows the most stable AUROC scores, with minimal variation across different k-top eigenvalue values.
* AttnEigval shows the most variation in AUROC scores, particularly for Llama3.2-3B and Mistral-Nemo, where the scores increase significantly between k=5 and k=25.
* The impact of increasing k-top eigenvalues on AUROC scores appears to diminish as k increases beyond 25 for most models and metrics.
### Interpretation
The chart demonstrates the performance of different language models using three different eigenvalue-based metrics. The consistent high performance of LapEigval suggests that Laplacian eigenvalues are a robust indicator of model quality. The stability of AttnLogDet indicates that the logarithm of the attention determinant is less sensitive to the number of eigenvalues considered. The varying performance of AttnEigval suggests that attention eigenvalues may be more sensitive to specific model architectures or training data.
The diminishing returns of increasing k-top eigenvalues beyond 25 suggest that a limited number of eigenvalues capture most of the relevant information for evaluating model performance. This could be useful for reducing computational costs and simplifying the evaluation process.
The differences in performance between the models highlight the varying strengths and weaknesses of different language model architectures. Llama3.1-8B and Mistral-Small-24B consistently show higher AUROC scores than Llama3.2-3B and Mistral-Nemo, suggesting that larger models or different architectures may be more effective at capturing relevant information. Phi3.5 shows a moderate performance, generally falling between the two groups.
</details>
Figure 10: Probe performance across different top- $k$ eigenvalues: $k\in\{5,10,25,50,100\}$ for TriviaQA dataset with $temp{=}1.0$ and five considered LLMs.
<details>
<summary>x17.png Details</summary>
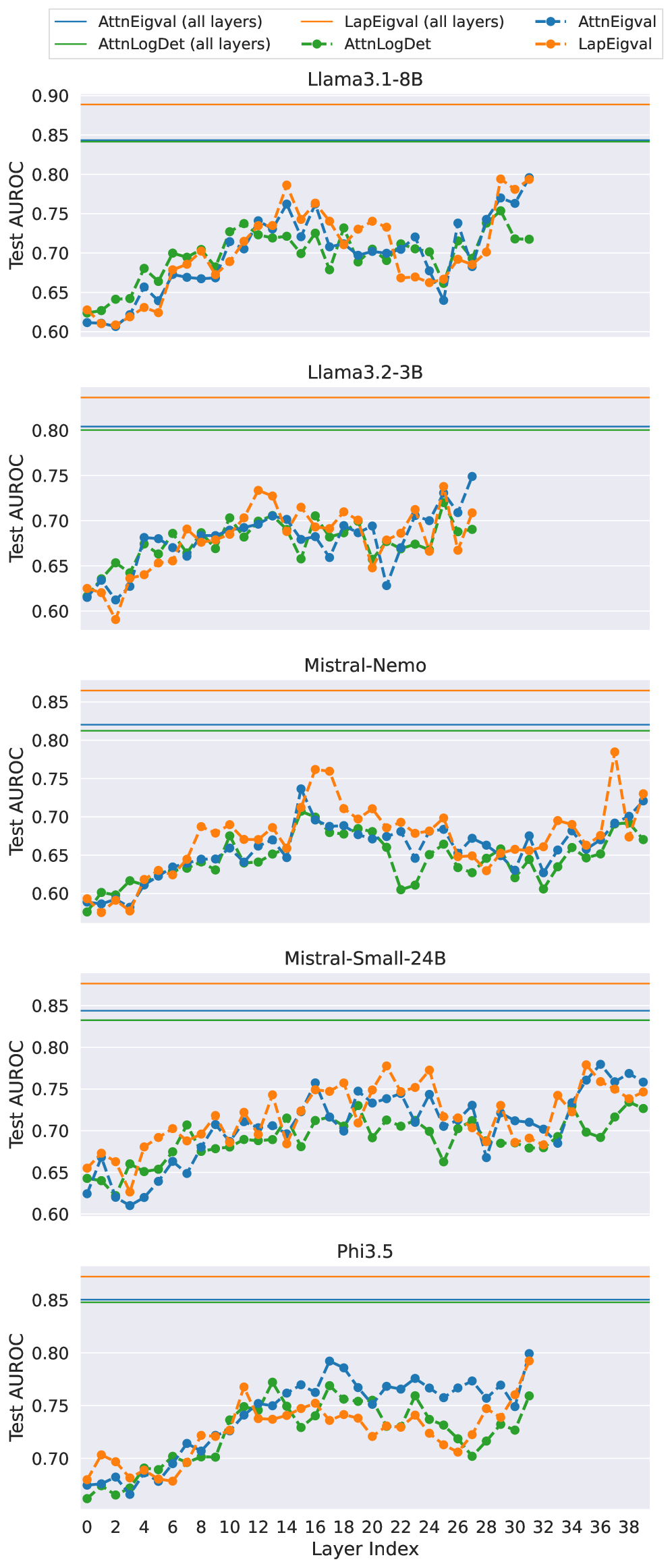
### Visual Description
\n
## Line Chart: Test AUROC vs. Layer Index for Different Models
### Overview
The image presents a line chart comparing the Test Area Under the Receiver Operating Characteristic curve (AUROC) across different layers for five different language models: Llama3.1-8B, Llama3.2-3B, Mistral-Nemo, Mistral-Small-24B, and Phi3.5. The x-axis represents the Layer Index, ranging from 0 to 36. The y-axis represents the Test AUROC, ranging from 0.60 to 0.90. Four different attention mechanisms are evaluated: AttnEigval (all layers), LapEigval (all layers), AttnLogDet (all layers), and LapLogDet (all layers). Each model has its own subplot, displaying the AUROC values for each attention mechanism as a function of the layer index.
### Components/Axes
* **X-axis:** Layer Index (0 to 36)
* **Y-axis:** Test AUROC (approximately 0.60 to 0.90)
* **Models (Subplots):**
* Llama3.1-8B
* Llama3.2-3B
* Mistral-Nemo
* Mistral-Small-24B
* Phi3.5
* **Attention Mechanisms (Lines/Colors):**
* AttnEigval (all layers) - Blue
* LapEigval (all layers) - Green
* AttnLogDet (all layers) - Yellow
* LapLogDet (all layers) - Red
* **Legend:** Located at the top-right of the image, mapping colors to attention mechanisms.
### Detailed Analysis or Content Details
**Llama3.1-8B:**
* AttnEigval: Starts at approximately 0.78, dips to around 0.73 at layer 8, then rises to approximately 0.82 at layer 16, and fluctuates between 0.78 and 0.82 for the remaining layers.
* LapEigval: Starts at approximately 0.75, remains relatively stable around 0.75-0.78 until layer 24, then decreases to approximately 0.72 at layer 36.
* AttnLogDet: Starts at approximately 0.68, increases to around 0.74 at layer 8, then decreases to approximately 0.69 at layer 24, and ends around 0.70.
* LapLogDet: Starts at approximately 0.69, increases to around 0.75 at layer 8, then decreases to approximately 0.70 at layer 24, and ends around 0.71.
**Llama3.2-3B:**
* AttnEigval: Starts at approximately 0.76, fluctuates between 0.74 and 0.78, with a slight dip to 0.73 around layer 24.
* LapEigval: Starts at approximately 0.72, remains relatively stable around 0.72-0.75, with a slight increase to 0.76 around layer 32.
* AttnLogDet: Starts at approximately 0.66, increases to around 0.70 at layer 8, then decreases to approximately 0.67 at layer 24, and ends around 0.68.
* LapLogDet: Starts at approximately 0.67, increases to around 0.71 at layer 8, then decreases to approximately 0.68 at layer 24, and ends around 0.69.
**Mistral-Nemo:**
* AttnEigval: Starts at approximately 0.76, fluctuates between 0.74 and 0.78, with a slight dip to 0.73 around layer 24.
* LapEigval: Starts at approximately 0.72, remains relatively stable around 0.72-0.75, with a slight increase to 0.76 around layer 32.
* AttnLogDet: Starts at approximately 0.66, increases to around 0.70 at layer 8, then decreases to approximately 0.67 at layer 24, and ends around 0.68.
* LapLogDet: Starts at approximately 0.67, increases to around 0.71 at layer 8, then decreases to approximately 0.68 at layer 24, and ends around 0.69.
**Mistral-Small-24B:**
* AttnEigval: Starts at approximately 0.78, fluctuates between 0.76 and 0.80, with a slight dip to 0.75 around layer 24.
* LapEigval: Starts at approximately 0.74, remains relatively stable around 0.73-0.76, with a slight increase to 0.77 around layer 32.
* AttnLogDet: Starts at approximately 0.68, increases to around 0.72 at layer 8, then decreases to approximately 0.69 at layer 24, and ends around 0.70.
* LapLogDet: Starts at approximately 0.69, increases to around 0.73 at layer 8, then decreases to approximately 0.70 at layer 24, and ends around 0.71.
**Phi3.5:**
* AttnEigval: Starts at approximately 0.78, fluctuates between 0.76 and 0.80, with a slight dip to 0.75 around layer 24.
* LapEigval: Starts at approximately 0.74, remains relatively stable around 0.73-0.76, with a slight increase to 0.77 around layer 32.
* AttnLogDet: Starts at approximately 0.68, increases to around 0.72 at layer 8, then decreases to approximately 0.69 at layer 24, and ends around 0.70.
* LapLogDet: Starts at approximately 0.69, increases to around 0.73 at layer 8, then decreases to approximately 0.70 at layer 24, and ends around 0.71.
### Key Observations
* AttnEigval consistently shows higher AUROC values compared to the other attention mechanisms across all models.
* LapLogDet and AttnLogDet generally have the lowest AUROC values.
* The AUROC values tend to fluctuate across layers, indicating that the performance of each attention mechanism varies depending on the layer.
* There isn't a clear monotonic trend (increasing or decreasing) for any of the attention mechanisms across all models.
### Interpretation
The chart demonstrates the performance of different attention mechanisms within various language models, as measured by the Test AUROC. The consistent superiority of AttnEigval suggests that this attention mechanism is more effective at capturing relevant information across layers in these models. The lower performance of LapLogDet and AttnLogDet might indicate that these mechanisms are less efficient or struggle with the specific characteristics of the data or model architecture. The fluctuations in AUROC values across layers suggest that the optimal attention mechanism might vary depending on the depth of the network. The differences in performance between models highlight the importance of model-specific optimization of attention mechanisms. The data suggests that the choice of attention mechanism can significantly impact the performance of a language model, and further research is needed to understand the underlying reasons for these differences.
</details>
Figure 11: Analysis of model performance across different layers for and 5 considered LLMs and TriviaQA dataset with $temp{=}1.0$ and $k{=}100$ top eigenvalues (results for models operating on all layers provided for reference).
## Appendix I Extended results of generalization study
We present the complete results of the generalization ablation discussed in Section 6.4 of the main paper. Table 11 reports the absolute Test AUROC values for each method and test dataset. Except for TruthfulQA, $\operatorname{LapEigvals}$ achieves the highest performance across all configurations. Notably, some methods perform close to random, whereas $\operatorname{LapEigvals}$ consistently outperforms this baseline. Regarding relative performance drop (Figure 12), $\operatorname{LapEigvals}$ remains competitive, exhibiting the lowest drop in nearly half of the scenarios. These results indicate that our method is robust but warrants further investigation across more datasets, particularly with a deeper analysis of TruthfulQA.
Table 11: Full results of the generalization study. By gray color we denote results obtained on test split from the same QA dataset as training split, otherwise results are from test split of different QA dataset. We highlight the best performance in bold.
| $\operatorname{AttnLogDet}$ $\operatorname{AttnEigvals}$ $\operatorname{LapEigvals}$ | CoQA CoQA CoQA | 0.758 0.782 0.830 | 0.518 0.426 0.555 | 0.687 0.726 0.790 | 0.644 0.696 0.748 | 0.646 0.659 0.743 | 0.640 0.702 0.786 | 0.587 0.560 0.629 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $\operatorname{AttnLogDet}$ | GSM8K | 0.515 | 0.828 | 0.513 | 0.502 | 0.555 | 0.503 | 0.586 |
| $\operatorname{AttnEigvals}$ | GSM8K | 0.510 | 0.838 | 0.563 | 0.545 | 0.549 | 0.579 | 0.557 |
| $\operatorname{LapEigvals}$ | GSM8K | 0.568 | 0.872 | 0.648 | 0.596 | 0.611 | 0.610 | 0.538 |
| $\operatorname{AttnLogDet}$ | HaluevalQA | 0.580 | 0.500 | 0.823 | 0.750 | 0.727 | 0.787 | 0.668 |
| $\operatorname{AttnEigvals}$ | HaluevalQA | 0.579 | 0.569 | 0.819 | 0.792 | 0.743 | 0.803 | 0.688 |
| $\operatorname{LapEigvals}$ | HaluevalQA | 0.685 | 0.448 | 0.873 | 0.796 | 0.778 | 0.848 | 0.595 |
| $\operatorname{AttnLogDet}$ | NQOpen | 0.552 | 0.594 | 0.720 | 0.794 | 0.717 | 0.766 | 0.597 |
| $\operatorname{AttnEigvals}$ | NQOpen | 0.546 | 0.633 | 0.725 | 0.790 | 0.714 | 0.770 | 0.618 |
| $\operatorname{LapEigvals}$ | NQOpen | 0.656 | 0.676 | 0.792 | 0.827 | 0.748 | 0.843 | 0.564 |
| $\operatorname{AttnLogDet}$ | SQuADv2 | 0.553 | 0.695 | 0.716 | 0.774 | 0.746 | 0.757 | 0.658 |
| $\operatorname{AttnEigvals}$ | SQuADv2 | 0.576 | 0.723 | 0.730 | 0.737 | 0.768 | 0.760 | 0.711 |
| $\operatorname{LapEigvals}$ | SQuADv2 | 0.673 | 0.754 | 0.801 | 0.806 | 0.791 | 0.841 | 0.625 |
| $\operatorname{AttnLogDet}$ | TriviaQA | 0.565 | 0.618 | 0.761 | 0.793 | 0.736 | 0.838 | 0.572 |
| $\operatorname{AttnEigvals}$ | TriviaQA | 0.577 | 0.667 | 0.770 | 0.786 | 0.742 | 0.843 | 0.616 |
| $\operatorname{LapEigvals}$ | TriviaQA | 0.702 | 0.612 | 0.813 | 0.818 | 0.773 | 0.889 | 0.522 |
| $\operatorname{AttnLogDet}$ | TruthfulQA | 0.550 | 0.706 | 0.597 | 0.603 | 0.604 | 0.662 | 0.811 |
| $\operatorname{AttnEigvals}$ | TruthfulQA | 0.538 | 0.579 | 0.600 | 0.595 | 0.646 | 0.685 | 0.833 |
| $\operatorname{LapEigvals}$ | TruthfulQA | 0.590 | 0.722 | 0.552 | 0.529 | 0.569 | 0.631 | 0.829 |
<details>
<summary>x18.png Details</summary>
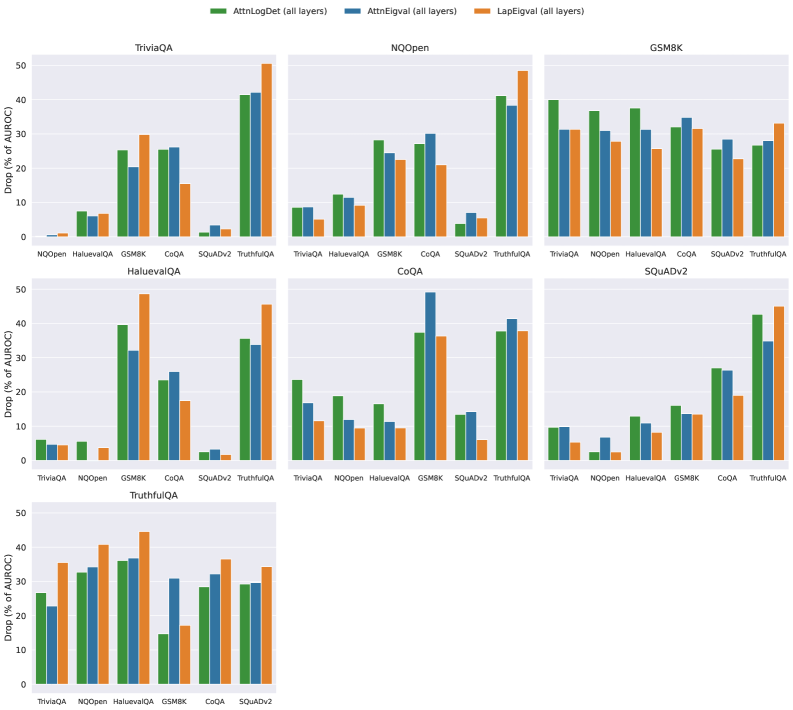
### Visual Description
## Bar Chart: Performance Comparison of Different Methods on Question Answering Datasets
### Overview
The image presents a series of bar charts comparing the performance of three methods – AttnLogDet (all layers), AttnEigval (all layers), and LapEigval (all layers) – across seven different question answering datasets: TriviaQA, NQOpen, GSM8K, HaluevalQA, CoQA, SQuADv2, and TruthfulQA. The performance metric is "Drop (%) of AUROC", representing the percentage drop in Area Under the Receiver Operating Characteristic curve. The charts are arranged in a 3x3 grid, with the datasets displayed on the x-axis and the Drop (%) of AUROC on the y-axis.
### Components/Axes
* **X-axis:** Datasets - TriviaQA, NQOpen, GSM8K, HaluevalQA, CoQA, SQuADv2, TruthfulQA.
* **Y-axis:** Drop (%) of AUROC, ranging from 0 to 50, with increments of 10.
* **Legend:**
* Green: AttnLogDet (all layers)
* Orange: AttnEigval (all layers)
* Brown: LapEigval (all layers)
* **Grid:** The charts are arranged in a 3x3 grid. The top row contains TriviaQA, NQOpen, and GSM8K. The middle row contains HaluevalQA, CoQA, and SQuADv2. The bottom row contains TruthfulQA.
* **Horizontal Gridlines:** Light gray horizontal lines are present at y-axis intervals of 10.
### Detailed Analysis or Content Details
**Top Row:**
* **TriviaQA:** AttnLogDet ~42%, AttnEigval ~22%, LapEigval ~25%.
* **NQOpen:** AttnLogDet ~38%, AttnEigval ~18%, LapEigval ~20%.
* **GSM8K:** AttnLogDet ~25%, AttnEigval ~22%, LapEigval ~24%.
**Middle Row:**
* **HaluevalQA:** AttnLogDet ~40%, AttnEigval ~28%, LapEigval ~25%.
* **CoQA:** AttnLogDet ~12%, AttnEigval ~8%, LapEigval ~10%.
* **SQuADv2:** AttnLogDet ~8%, AttnEigval ~5%, LapEigval ~6%.
**Bottom Row:**
* **TruthfulQA:** AttnLogDet ~32%, AttnEigval ~30%, LapEigval ~34%.
**Trend Verification & Specific Values:**
* **TriviaQA:** AttnLogDet shows the highest drop, significantly outperforming the other two methods.
* **NQOpen:** AttnLogDet again exhibits the largest drop, followed by AttnEigval and LapEigval.
* **GSM8K:** The drop values are relatively close for all three methods, with AttnLogDet slightly higher.
* **HaluevalQA:** AttnLogDet shows the highest drop, followed by AttnEigval and LapEigval.
* **CoQA:** AttnLogDet shows the highest drop, followed by LapEigval and AttnEigval.
* **SQuADv2:** AttnLogDet shows the highest drop, followed by LapEigval and AttnEigval.
* **TruthfulQA:** LapEigval shows the highest drop, followed by AttnLogDet and AttnEigval.
### Key Observations
* AttnLogDet consistently outperforms AttnEigval and LapEigval on most datasets (TriviaQA, NQOpen, GSM8K, HaluevalQA, CoQA, SQuADv2).
* LapEigval and AttnEigval show similar performance on several datasets (GSM8K, HaluevalQA).
* TruthfulQA is the only dataset where LapEigval shows the highest drop, indicating a potential advantage of this method on this specific task.
* The drop values are generally higher for TriviaQA, NQOpen, and HaluevalQA, suggesting these datasets are more sensitive to the differences between the methods.
* The drop values are relatively low for CoQA and SQuADv2, indicating that the methods perform similarly on these datasets.
### Interpretation
The data suggests that AttnLogDet is generally the most effective method across a range of question answering datasets, as evidenced by its consistently higher drop in AUROC compared to AttnEigval and LapEigval. However, the performance of the methods varies depending on the dataset. The superior performance of LapEigval on TruthfulQA suggests that this method may be particularly well-suited for tasks requiring truthful reasoning or knowledge.
The differences in performance across datasets could be attributed to the specific characteristics of each dataset, such as the type of questions asked, the complexity of the reasoning required, and the presence of biases or noise. The relatively low drop values for CoQA and SQuADv2 may indicate that these datasets are less challenging or that the methods have already achieved a high level of performance on these tasks.
The consistent outperformance of AttnLogDet suggests that the features or mechanisms it employs are generally beneficial for question answering. Further investigation into the specific differences between these methods could provide insights into the factors that contribute to their performance and guide the development of more effective question answering systems. The fact that LapEigval performs best on TruthfulQA is interesting and suggests that the eigval approach may be more robust to generating truthful answers.
</details>
Figure 12: Generalization across datasets measured as a percent performance drop in Test AUROC (less is better) when trained on one dataset and tested on the other. Training datasets are indicated in the plot titles, while test datasets are shown on the $x$ -axis. Results computed on Llama-3.1-8B with $k{=}100$ top eigenvalues and $temp{=}1.0$ .
## Appendix J Influence of dataset size
One of the limitations of $\operatorname{LapEigvals}$ is that it is a supervised method and thus requires labelled hallucination data. To check whether it requires a large volume of data, we conducted an additional study in which we trained $\operatorname{LapEigvals}$ on only a stratified fraction of the available examples for each hallucination dataset (using a dataset created from Llama-3.1-8B outputs) and evaluated on the full test split. The AUROC scores are presented in Table 12. As shown, LapEigvals maintains reasonable performance even when trained on as few as a few hundred examples. Additionally, we emphasise that labelling can be efficiently automated and scaled using the llm-as-judge paradigm.
Table 12: Impact of training dataset size on performance. Test AUROC scores are reported for different fractions of the training data. The study uses a dataset derived from Llama-3.1-8B answers with $temp{=}1.0$ and $k{=}100$ top eigenvalues, with absolute dataset sizes shown in parentheses.
## Appendix K Reliability of spectral features
Our method relies on ordered spectral features, which may exhibit sensitivity to perturbations and limited robustness. In our setup, both attention weights and extracted features were stored as bfloat16 type, which has lower precision than float32. The reduced precision acts as a form of regularization–minor fluctuations are often rounded off, making the method more robust to small perturbations that might otherwise affect the eigenvalue ordering.
To further investigate perturbation-sensitivity, we conducted a controlled analysis on one model by adding Gaussian noise to randomly selected input feature dimensions before the eigenvalue sorting step. We varied both the noise standard deviation and the fraction of perturbed dimensions (ranging from 0.5 to 1.0). Perturbations were applied consistently to both the training and test sets. In Table 13 we report the mean and standard deviation of performance across 5 runs on hallucination data generated by Llama-3.1-8B on the TriviaQA dataset with $temp{=}1.0$ , along with percentage change relative to the unperturbed baseline (0.0 indicates no perturbation applied). We observe that small perturbations have a negligible impact on performance and further confirm the robustness of our method.
Table 13: Impact of Gaussian noise perturbations on input features for different top- $k$ eigenvalues and noise standard deviations $\sigma$ . Results are averaged over five perturbations, with mean and standard deviation reported; relative percentage drops are shown in parentheses. Results were obtained for Llama-3.1-8B with $temp{=}1.0$ on TriviaQA dataset.
| 5 10 20 | 0.867 ± 0.0 (0.0%) 0.867 ± 0.0 (0.0%) 0.869 ± 0.0 (0.0%) | 0.867 ± 0.0 (0.0%) 0.867 ± 0.0 (0.0%) 0.869 ± 0.0 (0.0%) | 0.867 ± 0.0 (0.0%) 0.867 ± 0.0 (0.0%) 0.869 ± 0.0 (0.0%) | 0.867 ± 0.0 (-0.01%) 0.867 ± 0.0 (0.03%) 0.869 ± 0.0 (0.0%) | 0.859 ± 0.003 (0.86%) 0.861 ± 0.002 (0.78%) 0.862 ± 0.002 (0.84%) | 0.573 ± 0.017 (33.84%) 0.579 ± 0.01 (33.3%) 0.584 ± 0.018 (32.76%) |
| --- | --- | --- | --- | --- | --- | --- |
| 50 | 0.870 ± 0.0 (0.0%) | 0.870 ± 0.0 (0.0%) | 0.870 ± 0.0 (0.0%) | 0.869 ± 0.0 (0.02%) | 0.864 ± 0.002 (0.66%) | 0.606 ± 0.014 (30.31%) |
| 100 | 0.872 ± 0.0 (0.0%) | 0.872 ± 0.0 (0.0%) | 0.872 ± 0.0 (0.01%) | 0.872 ± 0.0 (-0.0%) | 0.866 ± 0.001 (0.66%) | 0.640 ± 0.007 (26.64%) |
## Appendix L Cost and time analysis
Providing precise cost and time measurements is nontrivial due to the multi-stage nature of our method, as it involves external services (e.g., OpenAI API for labelling), and the runtime and cost can vary depending on the hardware and platform used. Nonetheless, we present an overview of the costs and complexity as follows.
1. Inference with LLM (preparing hallucination dataset) - does not introduce additional cost beyond regular LLM inference; however, it may limit certain optimizations (e.g. FlashAttention (Dao et al., 2022)) since the full attention matrix needs to be materialized in memory.
1. Automated labeling with llm-as-judge using OpenAI API - we estimate labeling costs using the tiktoken library and OpenAI API pricing ($0.60 per 1M output tokens). However, these estimates exclude caching effects and could be reduced using the Batch API; Table 14 reports total and per-item hallucination labelling costs across all datasets (including 5 LLMs and 2 temperature settings). Estimation for GSM8K dataset is not present as the outputs for this dataset are evaluated by exact-match.
1. Computing spectral features - since we exploit the fact that eigenvalues of the Laplacian lie on the diagonal, the complexity is dominated by the computation of the out-degree matrix, which in turn is dominated by the computation of the mean over rows of the attention matrix. Thus, it is $O(n^{2})$ time, where $n$ is the number of tokens. Then, we have to sort eigenvalues, which takes $O(n\log n)$ time. The overall complexity multiplies by the number of layers and heads of a particular LLM. Practically, in our implementation, we fused feature computation with LLM inference, since we observed a memory bottleneck compared to using raw attention matrices stored on disk.
Table 14: Estimation of costs regarding llm-as-judge labelling with OpenAI API.
| CoQA NQOpen HaluEvalQA | 52,194,357 11,853,621 33,511,346 | 320,613 150,782 421,572 | 653.82 328.36 335.11 | 4.02 4.18 4.22 | 7.83 1.78 5.03 | 0.19 0.09 0.25 | 8.02 1.87 5.28 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| SQuADv2 | 19,601,322 | 251,264 | 330.66 | 4.24 | 2.94 | 0.15 | 3.09 |
| TriviaQA | 41,114,137 | 408,067 | 412.79 | 4.10 | 6.17 | 0.24 | 6.41 |
| TruthfulQA | 2,908,183 | 33,836 | 355.96 | 4.14 | 0.44 | 0.02 | 0.46 |
| Total | 158,242,166 | 1,575,134 | 402.62 | 4.15 | 24.19 | 0.94 | 25.13 |
## Appendix M QA prompts
Following, we describe all prompts for QA used to obtain the results presented in this work:
- prompt $p_{1}$ – medium-length one-shot prompt with single example of QA task (Listing 1),
- prompt $p_{2}$ – medium-length zero-shot prompt without examples (Listing 2),
- prompt $p_{3}$ – long few-shot prompt; the main prompt used in this work; modification of prompt used by (Kossen et al., 2024) (Listing 3),
- prompt $p_{4}$ – short-length zero-shot prompt without examples (Listing 4),
- prompt $gsm8k$ – short prompt used for GSM8K dataset with output-format instruction.
Listing 1: One-shot QA (prompt $p_{1}$ )
⬇
Deliver a succinct and straightforward answer to the question below. Focus on being brief while maintaining essential information. Keep extra details to a minimum.
Here is an example:
Question: What is the Riemann hypothesis?
Answer: All non - trivial zeros of the Riemann zeta function have real part 1/2
Question: {question}
Answer:
Listing 2: Zero-shot QA (prompt $p_{2}$ ).
⬇
Please provide a concise and direct response to the following question, keeping your answer as brief and to - the - point as possible while ensuring clarity. Avoid any unnecessary elaboration or additional details.
Question: {question}
Answer:
Listing 3: Few-shot QA prompt (prompt $p_{3}$ ), modified version of prompt used by (Kossen et al., 2024).
⬇
Answer the following question as briefly as possible.
Here are several examples:
Question: What is the capital of France?
Answer: Paris
Question: Who wrote * Romeo and Juliet *?
Answer: William Shakespeare
Question: What is the boiling point of water in Celsius?
Answer: 100 ∘ C
Question: How many continents are there on Earth?
Answer: Seven
Question: What is the fastest land animal?
Answer: Cheetah
Question: {question}
Answer:
Listing 4: Zero-shot short QA prompt (prompt $p_{4}$ ).
⬇
Answer the following question as briefly as possible.
Question: {question}
Answer:
Listing 5: Zero-shot QA prompt for GSM8K dataset.
⬇
Given the following problem, reason and give a final answer to the problem.
Problem: {question}
Your response should end with " The final answer is [answer]" where [answer] is the response to the problem.
## Appendix N LLM-as-Judge prompt
During hallucinations dataset construction we leveraged llm-as-judge approach to label answers generated by the LLMs. To this end, we utilized gpt-4o-mini with prompt in Listing 6, which is an adapted version of the prompt used by (Orgad et al., 2025).
Listing 6: Prompt used in llm-as-judge approach for determining hallucination labels. Prompt is a modified version of the one used by (Orgad et al., 2025).
⬇
You will evaluate answers to questions. For each question, I will provide a model ’ s answer and one or more correct reference answers.
You would have to determine if the model answer is correct, incorrect, or model refused to answer. The model answer to be correct has to match from one to all of the possible correct answers.
If the model answer is correct, write ’ correct ’ and if it is not correct, write ’ incorrect ’. If the Model Answer is a refusal, stating that they don ’ t have enough information, write ’ refuse ’.
For example:
Question: who is the young guitarist who played with buddy guy?
Ground Truth: [Quinn Sullivan, Eric Gales]
Model Answer: Ronnie Earl
Correctness: incorrect
Question: What is the name of the actor who plays Iron Man in the Marvel movies?
Ground Truth: [Robert Downey Jr.]
Model Answer: Robert Downey Jr. played the role of Tony Stark / Iron Man in the Marvel Cinematic Universe films.
Correctness: correct
Question: what is the capital of France?
Ground Truth: [Paris]
Model Answer: I don ’ t have enough information to answer this question.
Correctness: refuse
Question: who was the first person to walk on the moon?
Ground Truth: [Neil Armstrong]
Model Answer: I apologize, but I cannot provide an answer without verifying the historical facts.
Correctness: refuse
Question: {{question}}
Ground Truth: {{gold_answer}}
Model Answer: {{predicted_answer}}
Correctness: