# Statistical physics analysis of graph neural networks: Approaching optimality in the contextual stochastic block model
**Authors**: Duranthon, Lenka Zdeborová
> Statistical physics of computation laboratory, École polytechnique fédérale de Lausanne, Switzerland
(November 21, 2025)
## Abstract
Graph neural networks (GNNs) are designed to process data associated with graphs. They are finding an increasing range of applications; however, as with other modern machine learning techniques, their theoretical understanding is limited. GNNs can encounter difficulties in gathering information from nodes that are far apart by iterated aggregation steps. This situation is partly caused by so-called oversmoothing; and overcoming it is one of the practically motivated challenges. We consider the situation where information is aggregated by multiple steps of convolution, leading to graph convolutional networks (GCNs). We analyze the generalization performance of a basic GCN, trained for node classification on data generated by the contextual stochastic block model. We predict its asymptotic performance by deriving the free energy of the problem, using the replica method, in the high-dimensional limit. Calling depth the number of convolutional steps, we show the importance of going to large depth to approach the Bayes-optimality. We detail how the architecture of the GCN has to scale with the depth to avoid oversmoothing. The resulting large depth limit can be close to the Bayes-optimality and leads to a continuous GCN. Technically, we tackle this continuous limit via an approach that resembles dynamical mean-field theory (DMFT) with constraints at the initial and final times. An expansion around large regularization allows us to solve the corresponding equations for the performance of the deep GCN. This promising tool may contribute to the analysis of further deep neural networks.
## I Introduction
### I.1 Summary of the narrative
Graph neural networks (GNNs) emerged as the leading paradigm when learning from data that are associated with a graph or a network. Given the ubiquity of such data in sciences and technology, GNNs are gaining importance in their range of applications, including chemistry [1], biomedicine [2], neuroscience [3], simulating physical systems [4], particle physics [5] and solving combinatorial problems [6, 7]. As common in modern machine learning, the theoretical understanding of learning with GNNs is lagging behind their empirical success. In the context of GNNs, one pressing question concerns their ability to aggregate information from far away parts of the graph: the performance of GNNs often deteriorates as depth increases [8]. This issue is often attributed to oversmoothing [9, 10], a situation where a multi-layer GNN averages out the relevant information. Consequently, mostly relatively shallow GNNs are used in practice or other strategies are designed to avoid oversmoothing [11, 12].
Understanding the generalization properties of GNNs on unseen examples is a path towards yet more powerful models. Existing theoretical works addressed the generalization ability of GNNs mainly by deriving generalization bounds, with a minimal set of assumptions on the architecture and on the data, relying on VC dimension, Rademacher complexity or a PAC-Bayesian analysis; see for instance [13] and the references therein. Works along these lines that considered settings related to one of this work include [14], [15] or [16]. However, they only derive loose bounds for the test performance of the GNN and they do not provide insights on the effect of the structure of data. [14] provides sharper bounds; yet they do not take into account the data structure and depend on continuity constants that cannot be determined a priori. In order to provide more actionable outcomes, the interplay between the architecture of the GNN, the training algorithm and the data needs to be understood better, ideally including constant factors characterizing their dependencies on the variety of parameters.
Statistical physics traditionally plays a key role in understanding the behaviour of complex dynamical systems in the presence of disorder. In the context of neural networks, the dynamics refers to the training, and the disorder refers to the data used for learning. In the case of GNNs, the data is related to a graph. The statistical physics research strategy defines models that are simplified and allow analytical treatment. One models both the data generative process, and the learning procedure. A key ingredient is a properly defined thermodynamic limit in which quantities of interest self-average. One then aims to derive a closed set of equations for the quantities of interest, akin to obtaining exact expressions for free energies from which physical quantities can be derived. While numerous other research strategies are followed in other theoretical works on GNNs, see above, the statistical physics strategy is the main one accounting for constant factors in the generalization performance and as such provides invaluable insight about the properties of the studied systems. This line of research has been very fruitful in the context of fully connected feed-forward neural networks, see e.g. [17, 18, 19]. It is reasonable to expect that also in the context of GNNs this strategy will provide new actionable insights.
The analysis of generalization of GNNs in the framework of the statistical physics strategy was initiated recently in [20] where the authors studied the performance of a single-layer graph convolutional neural network (GCN) applied to data coming from the so-called contextual stochastic block model (CSBM). The CSBM, introduced in [21, 22], is particularly suited as a prototypical generative model for graph-structured data where each node belongs to one of several groups and is associated with a vector of attributes. The task is then the classification of the nodes into groups. Such data are used by practitioners as a benchmark for performance of GNNs [15, 23, 24, 25]. On the theoretical side, the follow-up work [26] generalized the analysis of [20] to a broader class of loss functions but also alerted to the relatively large gap between the performance of a single-layer GCN and the Bayes-optimal performance.
In this paper, we show that the close-formed analysis of training a GCN on data coming from the CSBM can be extended to networks performing multiple layers of convolutions. With a properly tuned regularization and strength of the residual connection this allows us to approach the Bayes-optimal performance very closely. Our analysis sheds light on the interplay between the different parameters –mainly the depth, the strength of the residual connection and the regularization– and on how to select the values of the parameters to mitigate oversmoothing. On a technical level the analysis relies on the replica method, with the limit of large depth leading to a continuous formulation similar to neural ordinary differential equations [27] that can be treated analytically via an approach that resembles dynamical mean-field theory with the position in the network playing the role of time. We anticipate that this type of infinite depth analysis can be generalized to studies of other deep networks with residual connections such a residual networks or multi-layer attention networks.
### I.2 Further motivations and related work
#### I.2.1 Graph neural networks:
In this work we focus on graph neural networks (GNNs). GNNs are neural networks designed to work on data that can be represented as graphs, such as molecules, knowledge graphs extracted from encyclopedias, interactions among proteins or social networks. GNNs can predict properties at the level of nodes, edges or the whole graph. Given a graph $\mathcal{G}$ over $N$ nodes, its adjacency matrix $A\in\mathbb{R}^{N\times N}$ and initial features $h_{i}^{(0)}\in\mathbb{R}^{M}$ on each node $i$ , a GNN can be expressed as the mapping
$$
\displaystyle h_{i}^{(k+1)}=f_{\theta^{(k)}}\left(h_{i}^{(k)},\mathrm{aggreg}(\{h_{j}^{(k)},j\sim i\})\right) \tag{1}
$$
for $k=0,\dots,K$ with $K$ being the depth of the network. where $f_{\theta^{(k)}}$ is a learnable function of parameters $\theta^{(k)}$ and $\mathrm{aggreg}()$ is a function that aggregates the features of the neighboring nodes in a permutation-invariant way. A common choice is the sum function, akin to a convolution on the graph
$$
\displaystyle\mathrm{aggreg}(\{h_{j},j\sim i\})=\sum_{j\sim i}h_{j}=(Ah)_{i}\ . \tag{2}
$$
Given this choice of aggregation the GNN is called graph convolutional network (GCN) [28]. For a GNN of depth $K$ the transformed features $h^{(K)}\in\mathbb{R}^{M^{\prime}}$ can be used to predict the properties of the nodes, the edges or the graph by a learnt projection.
In this work we will consider a GCN with the following architecture, that we will define more precisely in the detailed setting part II. We consider one trainable layer $w\in\mathbb{R}^{M}$ , since dealing with multiple layers of learnt weights is still a major issue [29], and since we want to focus on modeling the impact of numerous convolution steps on the generalization ability of the GCN.
$$
\displaystyle h^{(k+1)} \displaystyle=\left(\frac{1}{\sqrt{N}}\tilde{A}+c_{k}I_{N}\right)h^{(k)} \displaystyle\hat{y} \displaystyle=\operatorname{sign}\left(\frac{1}{\sqrt{N}}w^{T}h^{(K)}\right) \tag{3}
$$
where $\tilde{A}$ is a rescaling of the adjacency matrix, $I_{N}$ is the identity, $c_{k}\in\mathbb{R}$ for all $k$ are the residual connection strengths and $\hat{y}\in\mathbb{R}^{N}$ are the predicted labels of each node. We will call the number of layers $K$ the depth, but we reiterate that only the layer $w$ is learned.
#### I.2.2 Analyzable model of synthetic data:
Modeling the training data is a starting point to derive sharp predictions. A popular model of attributed graph, that we will consider in the present work and define in detail in sec. II.1, is the contextual stochastic block model (CSBM), introduced in [21, 22]. It consists in $N$ nodes with labels $y\in\{-1,+1\}^{N}$ , in a binary stochastic block model (SBM) to model the adjacency matrix $A\in\mathbb{R}^{N\times N}$ and in features (or attributes) $X\in\mathbb{R}^{N\times M}$ defined on the nodes and drawn according to a Gaussian mixture. $y$ has to be recovered given $A$ and $X$ . The inference is done in a semi-supervised way, in the sense that one also has access to a train subset of $y$ .
A key aspect in statistical physics is the thermodynamic limit, how should $N$ and $M$ scale together. In statistical physics we always aim at a scaling in which quantities of interest concentrate around deterministic values, and the performance of the system ranges between as bad as random guessing to as good as perfect learning. As we will see, these two requirements are satisfied in the high-dimensional limit $N\to\infty$ and $M\to\infty$ with $\alpha=N/M$ of order one. This scaling limit also aligns well with the common graph datasets that are of interest in practice, for instance Cora [30] ( $N=3.10^{3}$ and $M=3.10^{3}$ ), Coauthor CS [31] ( $N=2.10^{4}$ and $M=7.10^{3}$ ), CiteSeer [32] ( $N=4.10^{3}$ and $M=3.10^{3}$ ) and PubMed [33] ( $N=2.10^{4}$ and $M=5.10^{2}$ ).
A series of works that builds on the CSBM with lower dimensionality of features that is $M=o(N)$ exists. Authors of [34] consider a one-layer GNN trained on the CSBM by logistic regression and derive bounds for the test loss; however, they analyze its generalization ability on new graphs that are independent of the train graph and do not give exact predictions. In [35] they propose an architecture of GNN that is optimal on the CSBM with low-dimensional features, among classifiers that process local tree-like neighborhoods, and they derive its generalization error. In [36] the authors analyze the structure and the separability of the convolved data $\tilde{A}^{K}X$ , for different rescalings $\tilde{A}$ of the adjacency matrix, and provide a bound on the classification error. Compared to our work these articles consider a low-dimensional setting ([35]) where the dimension of the features $M$ is constant, or a setting where $M$ is negligible compared to $N$ ([34] and [36]).
#### I.2.3 Tight prediction on GNNs in the high-dimensional limit:
Little has been done as to tightly predicting the performance of GNNs in the high-dimensional limit where both the size of the graph and the dimensionality of the features diverge proportionally. The only pioneering references in this direction we are aware of are [20] and [26], where the authors consider a simple single-layer GCN that performs only one step of convolution, $K=1$ , trained on the CSBM in a semi-supervised setting. In these works the authors express the performance of the trained network as a function of a finite set of order parameters following a system of self-consistent equations.
There are two important motivations to extend these works and to consider GCNs with a higher depth $K$ . First, the GNNs that are used in practice almost always perform several steps of aggregation, and a more realistic model should take this in account. Second, [26] shows that the GCN it considers is far from the Bayes-optimal (BO) performance and the Bayes-optimal rate for all common losses. The BO performance is the best that any algorithm can achieve knowing the distribution of the data, and the BO rate is the rate of convergence toward perfect inference when the signal strength of the graph grows to infinity. Such a gap is intriguing in the sense that previous works [37, 38] show that a simple one-layer fully-connected neural network can reach or be very close to the Bayes-optimality on simple synthetic datasets, including Gaussian mixtures. A plausible explanation is that on the CSBM considering only one step of aggregation $K=1$ is not enough to retrieve all information, and one has to aggregate information from further nodes. Consequently, even on this simple dataset, introducing depth and considering a GCN with several convolution layers, $K>1$ , is crucial.
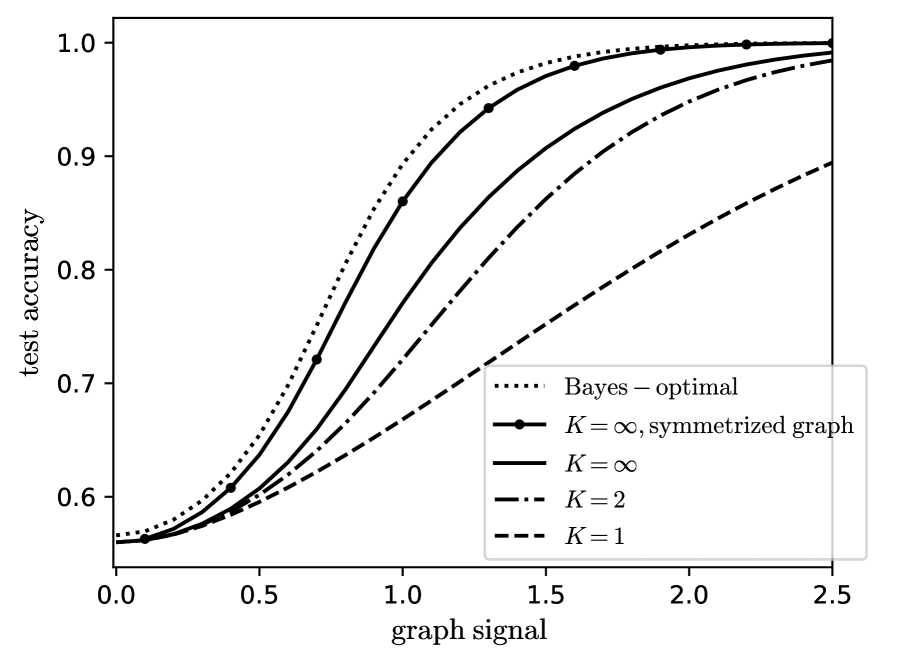
In the present work we study the effect of the depth $K$ of the convolution for the generalization ability of a simple GCN. A first part of our contribution consists in deriving the exact performance of a GCN performing several steps of convolution, trained on the CSBM, in the high-dimensional limit. We show that $K=2$ is the minimal number of steps to reach the BO learning rate. As to the performance at moderate signal strength, it appears that, if the architecture is well tuned, going to larger and larger $K$ increases the performance until it reaches a limit. This limit, if the adjacency matrix is symmetrized, can be close to the Bayes optimality. This is illustrated on fig. 1, which highlights the importance of numerous convolution layers.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Line Chart: Test Accuracy vs. Graph Signal
### Overview
The image presents a line chart illustrating the relationship between "graph signal" and "test accuracy" for different values of 'K' and a Bayes-optimal baseline. The chart compares the performance of several methods as the strength of the graph signal increases.
### Components/Axes
* **X-axis:** "graph signal", ranging from approximately 0.0 to 2.5.
* **Y-axis:** "test accuracy", ranging from approximately 0.55 to 1.05.
* **Legend:** Located in the top-right corner, listing the following data series:
* "Bayes – optimal" (dotted line, black)
* "K = ∞, symmetrized graph" (solid line, black)
* "K = ∞" (solid line, dark gray)
* "K = 2" (dashed line, gray)
* "K = 1" (dashed-dotted line, black)
### Detailed Analysis
The chart displays five distinct lines, each representing a different configuration.
* **Bayes – optimal (dotted black line):** This line starts at approximately (0.0, 0.6) and rapidly increases, reaching a plateau around (0.75, 0.98) and remaining near 1.0 for the rest of the range.
* **K = ∞, symmetrized graph (solid black line):** This line begins at approximately (0.0, 0.6) and increases more gradually than the Bayes-optimal line. It reaches approximately (0.75, 0.95) and continues to increase slowly, approaching 1.0 around (2.0, 0.99).
* **K = ∞ (solid dark gray line):** This line starts at approximately (0.0, 0.6) and increases at a rate between the Bayes-optimal and K = ∞, symmetrized graph lines. It reaches approximately (0.75, 0.93) and continues to increase, approaching 0.98 around (2.0, 0.98).
* **K = 2 (dashed gray line):** This line starts at approximately (0.0, 0.6) and increases at a slower rate than the previous lines. It reaches approximately (0.75, 0.85) and continues to increase, approaching 0.93 around (2.0, 0.93).
* **K = 1 (dashed-dotted black line):** This line starts at approximately (0.0, 0.6) and exhibits the slowest increase among all lines. It reaches approximately (0.75, 0.75) and continues to increase, approaching 0.88 around (2.0, 0.88).
All lines converge towards a test accuracy of approximately 1.0 as the graph signal increases.
### Key Observations
* The Bayes-optimal method consistently achieves the highest test accuracy across all graph signal values.
* Increasing the value of K generally improves test accuracy, with K = 1 performing the worst and K = ∞, symmetrized graph performing the best among the K values tested.
* The performance gap between the methods decreases as the graph signal increases.
* All methods start with a similar test accuracy at a graph signal of 0.0.
### Interpretation
The chart demonstrates the impact of graph signal strength and parameter 'K' on the test accuracy of different methods. The Bayes-optimal method represents an upper bound on achievable accuracy. The results suggest that as the graph signal becomes stronger (higher values on the x-axis), the performance of all methods improves and converges. The parameter 'K' appears to influence the rate of improvement, with larger values of K leading to faster convergence towards the optimal accuracy. The "symmetrized graph" modification for K = ∞ further enhances performance. This could indicate that incorporating symmetry into the graph structure improves the accuracy of the method. The chart highlights the trade-off between computational complexity (potentially higher for larger K) and accuracy. The data suggests that for weak graph signals, the choice of K is crucial, while for strong graph signals, the performance difference between different K values becomes less significant.
</details>
Figure 1: Test accuracy of the graph neural network on data generated by the contextual stochastic block model vs the signal strength. We define the model and the network in section II. The test accuracy is maximized over all the hyperparameters of the network. The Bayes-optimal performance is from [39]. The line $K=1$ has been studied by [20, 26]; we improve it to $K>1$ , $K=\infty$ and symmetrized graphs. All the curves are theoretical predictions we derive in this work.
#### I.2.4 Oversmoothing and residual connections:
Going to larger depth $K$ is essential to obtain better performance. Yet, GNNs used in practice can be quite shallow, because of the several difficulties encountered at increasing depth, such that vanishing gradient, which is not specific to graph neural networks, or oversmoothing [9, 10]. Oversmoothing refers to the fact that the GNN tends to act like a low-pass filter on the graph and to smooth the features $h_{i}$ , which after too many steps may converge to the same vector for every node. A few steps of aggregation are beneficial but too many degrade the performance, as [40] shows for a simple GNN, close to the one we study, on a particular model. In the present work we show that the model we consider can suffer from oversmoothing at increasing $K$ if its architecture is not well-tuned and we precisely quantify it.
A way to mitigate vanishing gradient and oversmoothing is to allow the nodes to remember their initial features $h_{i}^{(0)}$ . This is done by adding residual (or skip) connections to the neural network, so the update function becomes
$$
\displaystyle h_{i}^{(k+1)}=c_{k}h_{i}^{(k)}+f_{\theta^{(k)}}\left(h_{i}^{(k)},\mathrm{aggreg}(\{h_{j}^{(k)},j\sim i\})\right) \tag{5}
$$
where the $c_{k}$ modulate the strength of the residual connections. The resulting architecture is known as residual network or resnet [41] in the context of fully-connected and convolutional neural networks. As to GNNs, architectures with residual connections have been introduced in [42] and used in [11, 12] to reach large numbers of layers with competitive accuracy. [43] additionally shows that residual connections help gradient descent. In the setting we consider we prove that residual connections are necessary to circumvent oversmoothing, to go to larger $K$ and to improve the performance.
#### I.2.5 Continuous neural networks:
Continuous neural networks can be seen as the natural limit of residual networks, when the depth $K$ and the residual connection strengths $c_{k}$ go to infinity proportionally, if $f_{\theta^{(k)}}$ is smooth enough with respect to $k$ . In this limit, rescaling $h^{(k+1)}$ with $c_{k}$ and setting $x=k/K$ and $c_{k}=K/t$ , the rescaled $h$ satisfies the differential equation
$$
\displaystyle\frac{\mathrm{d}h_{i}}{\mathrm{d}x}(x)=tf_{\theta(x)}\left(h_{i}(x),\mathrm{aggreg}(\{h_{j}(x),j\sim i\})\right)\ . \tag{6}
$$
This equation is called a neural ordinary differential equation [27]. The convergence of a residual network to a continuous limit has been studied for instance in [44]. Continuous neural networks are commonly used to model and learn the dynamics of time-evolving systems, by usually taking the update function $f_{\theta}$ independent of the time $t$ . For an example [45] uses a continuous fully-connected neural network to model turbulence in a fluid. As such, they are a building block of scientific machine learning; see for instance [46] for several applications. As to the generalization ability of continuous neural networks, the only theoretical work we are aware of is [47], that derives loose bounds based on continuity arguments.
Continuous neural networks have been extended to continuous GNNs in [48, 49]. For the GCN that we consider the residual connections are implemented by adding self-loops $c_{k}I_{N}$ to the graph. The continuous dynamic of $h$ is then
$$
\displaystyle\frac{\mathrm{d}h}{\mathrm{d}x}(x)=t\tilde{A}h(x)\ , \tag{7}
$$
with $t\in\mathbb{R}$ ; which is a diffusion on the graph. Other types of dynamics have been considered, such as anisotropic diffusion, where the diffusion factors are learnt, or oscillatory dynamics, that should avoid oversmoothing too; see for instance the review [50] for more details. No prior works predict their generalization ability. In this work we fill this gap by deriving the performance of the continuous limit of the simple GCN we consider.
### I.3 Summary of the main results:
We first generalize the work of [20, 26] to predict the performance of a simple GCN with arbitrary number $K$ of convolution steps. The network is trained in a semi-supervised way on data generated by the CSBM for node classification. In the high-dimensional limit and in the limit of dense graphs, the main properties of the trained network concentrate onto deterministic values, that do not depend on the particular realization of the data. The network is described by a few order parameters (or summary statistics), that satisfy a set of self-consistent equations, that we solve analytically or numerically. We thus have access to the expected train and test errors and accuracies of the trained network.
From these predictions we draw several consequences. Our main guiding line is to search for the architecture and the hyperparameters of the GCN that maximize its performance, and check whether the optimal GCN can reach the Bayes-optimal performance on the CSBM. The main parameters we considers are the depth $K$ , the residual connection strengths $c_{k}$ , the regularization $r$ and the loss function.
We consider the convergence rates towards perfect inference at large graph signal. We show that $K=2$ is the minimal depth to reach the Bayes-optimal rate, after which increasing $K$ or fine-tuning $c_{k}$ only leads to sub-leading improvements. In case of asymmetric graphs the GCN is not able to deal the asymmetry, for all $K$ or $c_{k}$ , and one has to pre-process the graph by symmetrizing it.
At finite graph signal the behaviour of the GCN is more complex. We find that large regularization $r$ maximizes the test accuracy in the case we consider, while the loss has little effect. The residual connection strengths $c_{k}$ have to be tuned to a same optimal value $c$ that depends on the properties of the graph.
An important point is that going to larger $K$ seems to improve the test accuracy. Yet the residual connection $c$ has to vary accordingly. If $c$ stays constant with respect to $K$ then the GCN will perform PCA on the graph $A$ , oversmooth and discard the information from the features $X$ . Instead, if $c$ grows with $K$ , the residual connections alleviate oversmoothing and the performance of the GCN keeps increasing with $K$ , if the diffusion time $t=K/c$ is well tuned.
The limit $K\to\infty,c\propto K$ is thus of particular interest. It corresponds to a continuous GCN performing diffusion on the graph. Our analysis can be extended to this case by directly taking the limit in the self-consistent equations. One has to further jointly expand them around $r\to+\infty$ and we keep the first order. At the end we predict the performance of the continuous GCN in an explicit and closed form. To our knowledge this is the first tight prediction of the generalization ability of a continuous neural network, and in particular of a continuous graph neural network. The large regularization limit $r\to+\infty$ is important: on one hand it appears to lead to the optimal performance of the neural network; on another hand, it is instrumental to analyze the continuous limit $K\to\infty$ and it allows to analytically solve the self-consistent equations describing the neural network.
We show that the continuous GCN at optimal time $t$ performs better than any finite- $K$ GCN. The optimal $t$ depends on the properties of the graph, and can be negative for heterophilic graphs. This result is a step toward solving one of the major challenges identified by [8]; that is, creating benchmarks where depth is necessary and building efficient deep networks.
The continuous GCN as large $r$ is optimal. Moreover, if run on the symmetrized graph, it approaches the Bayes-optimality on a broad range of configurations of the CSBM, as exemplified on fig. 1. We identify when the GCN fails to approach the Bayes-optimality: this happens when most of the information is contained in the features and not in the graph, and has to be processed in an unsupervised manner.
We provide the code that allows to evaluate our predictions in the supplementary material.
## II Detailed setting
### II.1 Contextual Stochastic Block Model for attributed graphs
We consider the problem of semi-supervised node classification on an attributed graph, where the nodes have labels and carry additional attributes, or features, and where the structure of the graph correlates with the labels. We consider a graph $\mathcal{G}$ made of $N$ nodes; each node $i$ has a binary label $y_{i}=\pm 1$ that is a Rademacher random variable.
The structure of the graph should be correlated with $y$ . We model the graph with a binary stochastic block model (SBM): the adjacency matrix $A\in\mathbb{R}^{N\times N}$ is drawn according to
$$
A_{ij}\sim\mathcal{B}\left(\frac{d}{N}+\frac{\lambda}{\sqrt{N}}\sqrt{\frac{d}{N}\left(1-\frac{d}{N}\right)}y_{i}y_{j}\right) \tag{8}
$$
where $\lambda$ is the signal-to-noise ratio (snr) of the graph, $d$ is the average degree of the graph, $\mathcal{B}$ is a Bernoulli law and the elements $A_{ij}$ are independent for all $i$ and $j$ . It can be interpreted in the following manner: an edge between $i$ and $j$ appears with a higher probability if $\lambda y_{i}y_{j}>1$ i.e. for $\lambda>0$ if the two nodes are in the same group. The scaling with $d$ and $N$ is chosen so that this model does not have a trivial limit at $N\to\infty$ both for $d=\Theta(1)$ and $d=\Theta(N)$ . Notice that we take $A$ asymmetric.
Additionally to the graph, each node $i$ carries attributes $X_{i}\in\mathbb{R}^{M}$ , that we collect in the matrix $X\in\mathbb{R}^{N\times M}$ . We set $\alpha=N/M$ the aspect ratio between the number of nodes and the dimension of the features. We model them by a Gaussian mixture: we draw $M$ hidden Gaussian variables $u_{\nu}\sim\mathcal{N}(0,1)$ , the centroid $u\in\mathbb{R}^{M}$ , and we set
$$
X=\sqrt{\frac{\mu}{N}}yu^{T}+W \tag{9}
$$
where $\mu$ is the snr of the features and $W$ is noise whose components $W_{i\nu}$ are independent standard Gaussians. We use the notation $\mathcal{N}(m,V)$ for a Gaussian distribution or density of mean $m$ and variance $V$ . The whole model for $(y,A,X)$ is called the contextual stochastic block model (CSBM) and was introduced in [21, 22].
We consider the task of inferring the labels $y$ given a subset of them. We define the training set $R$ as the set of nodes whose labels are revealed; $\rho=|R|/N$ is the training ratio. The test set $R^{\prime}$ is selected from the complement of $R$ ; we define the testing ratio $\rho^{\prime}=|R^{\prime}|/N$ . We assume that $R$ and $R^{\prime}$ are independent from the other quantities. The inference problem is to find back $y$ and $u$ given $A$ , $X$ , $R$ and the parameters of the model.
[22, 51] prove that the effective snr of the CSBM is
$$
\mathrm{snr}_{\mathrm{CSBM}}=\lambda^{2}+\mu^{2}/\alpha\ , \tag{10}
$$
in the sense that in the unsupervised regime $\rho=0$ for $\mathrm{snr}_{\mathrm{CSBM}}<1$ no information on the labels can be recovered while for $\mathrm{snr}_{\mathrm{CSBM}}>1$ partial information can be recovered. The information given by the graph is $\lambda^{2}$ while the information given by the features is $\mu^{2}/\alpha$ . As soon as a finite fraction of nodes $\rho>0$ is revealed the phase transition between no recovery and weak recovery disappears.
We work in the high-dimensional limit $N\to\infty$ and $M\to\infty$ while the aspect ratio $\alpha=N/M$ is of order one. The average degree $d$ should be of order $N$ , but taking $d$ growing with $N$ should be sufficient for our results to hold, as shown by our experiments. The other parameters $\lambda$ , $\mu$ , $\rho$ and $\rho^{\prime}$ are of order one.
### II.2 Analyzed architecture
In this work, we focus on the role of applying several data aggregation steps. With the current theoretical tools, the tight analysis of the generic GNN described in eq. (1) is not possible: dealing with multiple layers of learnt weights is hard; and even for a fully-connected two-layer perceptron this is a current and major topic [29]. Instead, we consider a one-layer GNN with a learnt projection $w$ . We focus on graph convolutional networks (GCNs) [28], where the aggregation is a convolution done by applying powers of a rescaling $\tilde{A}$ of the adjacency matrix. Last we remove the non-linearities. As we will see, the fact that the GCN is linear does not prevent it to approach the optimality in some regimes. The resulting GCN is referred to as simple graph convolutional network; it has been shown to have good performance while being much easier to train [52, 53]. The network we consider transforms the graph and the features in the following manner:
$$
h(w)=\prod_{k=1}^{K}\left(\frac{1}{\sqrt{N}}\tilde{A}+c_{k}I_{N}\right)\frac{1}{\sqrt{N}}Xw \tag{11}
$$
where $w\in\mathbb{R}^{M}$ is the layer of trainable weights, $I_{N}$ is the identity, $c_{k}\in\mathbb{R}$ is the strength of the residual connections and $\tilde{A}\in\mathbb{R}^{N\times N}$ is a rescaling of the adjacency matrix defined by
$$
\tilde{A}_{ij}=\left(\frac{d}{N}\left(1-\frac{d}{N}\right)\right)^{-1/2}\left(A_{ij}-\frac{d}{N}\right),\;\mathrm{for\;all\;}i,\,j. \tag{12}
$$
The prediction $\hat{y}_{i}$ of the label of $i$ by the GNN is then $\hat{y}_{i}=\operatorname{sign}h(w)_{i}$ .
$\tilde{A}$ is a rescaling of $A$ that is centered and normalized. In the limit of dense graphs, where $d$ is large, this will allow us to rely on a Gaussian equivalence property to analyze this GCN. The equivalence [54, 22, 20] states that in the high-dimensional limit, for $d$ growing with $N$ , $\tilde{A}$ can be approximated by the following spiked matrix $A^{\mathrm{g}}$ without changing the macroscopic properties of the GCN:
$$
A^{\mathrm{g}}=\frac{\lambda}{\sqrt{N}}yy^{T}+\Xi\ , \tag{13}
$$
where the components of the $N\times N$ matrix $\Xi$ are independent standard Gaussian random variables. The main reason for considering dense graphs instead of sparse graphs $d=\Theta(1)$ is to ease the theoretical analysis. The dense model can be described by a few order parameters; while a sparse SBM would be harder to analyze because many quantities, such as the degrees of the nodes, do not self-average, and one would need to take in account all the nodes, by predicting the performance on one realization of the graph or by running population dynamics. We believe that it would lead to qualitatively similar results, as for instance [55] shows, for a related model.
The above architecture corresponds to applying $K$ times a graph convolution on the projected features $Xw$ . At each convolution step $k$ a node $i$ updates its features by summing those of its neighbors and adding $c_{k}$ times its own features. In [20, 26] the same architecture was considered for $K=1$ ; we generalize these works by deriving the performance of the GCN for arbitrary numbers $K$ of convolution steps. As we will show this is crucial to approach the Bayes-optimal performance.
Compared to [20, 26], another important improvement towards the Bayes-optimality is obtained by symmetrizing the graph, and we will also study the performance of the GCN when it acts by applying the symmetrized rescaled adjacency matrix $\tilde{A}^{\mathrm{s}}$ defined by:
$$
\tilde{A}^{\mathrm{s}}=\frac{1}{\sqrt{2}}(\tilde{A}+\tilde{A}^{T})\ ,\quad A^{\mathrm{g,s}}=\frac{\lambda^{\mathrm{s}}}{\sqrt{N}}yy^{T}+\Xi^{\mathrm{s}}\ . \tag{14}
$$
$A^{\mathrm{g,s}}$ is its Gaussian equivalent, with $\lambda^{\mathrm{s}}=\sqrt{2}\lambda$ , $\Xi^{\mathrm{s}}$ is symmetric and $\Xi^{\mathrm{s}}_{i\leq j}$ are independent standard Gaussian random variables. In this article we derive and show the performance of the GNN both acting with $\tilde{A}$ and $\tilde{A}^{\mathrm{s}}$ but in a first part we will mainly consider and state the expressions for $\tilde{A}$ because they are simpler. We will consider $\tilde{A}^{\mathrm{s}}$ in a second part while taking the continuous limit. To deal with both cases, asymmetric or symmetrized, we define $\tilde{A}^{\mathrm{e}}\in\{\tilde{A},\tilde{A}^{\mathrm{s}}\}$ and $\lambda^{\mathrm{e}}\in\{\lambda,\lambda^{\mathrm{s}}\}$ .
The continuous limit of the above network (11) is defined by
$$
h(w)=e^{\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}}\frac{1}{\sqrt{N}}Xw \tag{15}
$$
where $t$ is the diffusion time. It is obtained at large $K$ when the update between two convolutions becomes small, as follows:
$$
\left(\frac{t}{K\sqrt{N}}\tilde{A}^{\mathrm{e}}+I_{N}\right)^{K}\underset{K\to\infty}{\longrightarrow}e^{\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}}\ . \tag{16}
$$
$h$ is the solution at time $t$ of the time-continuous diffusion of the features on the graph $\mathcal{G}$ with Laplacian $\tilde{A}^{\mathrm{e}}$ , defined by $\partial_{x}X(x)=\frac{1}{\sqrt{N}}\tilde{A}^{\mathrm{e}}X(x)$ and $X(0)=X$ . The discrete GCN can be seen as the discretization of the differential equation in the forward Euler scheme. The mapping with eq. (11) is done by taking $c_{k}=K/t$ for all $k$ and by rescaling the features of the discrete GCN $h(w)$ as $h(w)\prod_{k}c_{k}^{-1}$ so they remain of order one when $K$ is large. For the discrete GCN we do not directly consider the update $h_{k+1}=(I_{N}+c_{k}^{-1}\tilde{A}/\sqrt{N})h_{k}$ because we want to study the effect of having no residual connections, i.e. $c_{k}=0$ . The case where the diffusion coefficient depends on the position in the network is equivalent to a constant diffusion coefficient. Indeed, because of commutativity, the solution at time $t$ of $\partial_{x}X(x)=\frac{1}{\sqrt{N}}\mathrm{a}(x)\tilde{A}^{\mathrm{e}}X(x)$ for $\mathrm{a}:\mathbb{R}\to\mathbb{R}$ is $\exp\left(\int_{0}^{t}\mathrm{d}x\,\mathrm{a}(x)\frac{1}{\sqrt{N}}\tilde{A}^{\mathrm{e}}\right)X(0)$ .
The discrete and the continuous GCNs are trained by empirical risk minimization. We define the regularized loss
$$
L_{A,X}(w)=\frac{1}{\rho N}\sum_{i\in R}\ell(y_{i}h_{i}(w))+\frac{r}{\rho N}\sum_{\nu}\gamma(w_{\nu}) \tag{17}
$$
where $\gamma$ is a strictly convex regularization function, $r$ is the regularization strength and $\ell$ is a convex loss function. The regularization ensures that the GCN does not overfit the train data and has good generalization properties on the test set. We will focus on $l_{2}$ -regularization $\gamma(x)=x^{2}/2$ and on the square loss $\ell(x)=(1-x)^{2}/2$ (ridge regression) or the logistic loss $\ell(x)=\log(1+e^{-x})$ (logistic regression). Since $L$ is strictly convex it admits a unique minimizer $w^{*}$ . The key quantities we want to estimate are the average train and test errors and accuracies of this model, which are
$$
\displaystyle E_{\mathrm{train/test}}=\mathbb{E}\ \frac{1}{|\hat{R}|}\sum_{i\in\hat{R}}\ell(y_{i}h(w^{*})_{i}) \displaystyle\mathrm{Acc}_{\mathrm{train/test}}=\mathbb{E}\ \frac{1}{|\hat{R}|}\sum_{i\in\hat{R}\ ,}\delta_{y_{i}=\operatorname{sign}{h(w^{*})_{i}}} \tag{18}
$$
where $\hat{R}$ stands either for the train set $R$ or the test set $R^{\prime}$ and the expectation is taken over $y$ , $u$ , $A$ , $X$ , $R$ and $R^{\prime}$ . $\mathrm{Acc}_{\mathrm{train/test}}$ is the proportion of train/test nodes that are correctly classified. A main part of the present work is dedicated to the derivation of exact expressions for the errors and the accuracies. We will then search for the architecture of the GCN that maximizes the test accuracy $\mathrm{Acc}_{\mathrm{test}}$ .
Notice that one could treat the residual connection strengths $c_{k}$ as supplementary parameters, jointly trained with $w$ to minimize the train loss. Our analysis can straightforwardly be extended to deal with this case. Yet, as we will show, to take trainable $c_{k}$ degrades the test performances; and it is better to consider them as hyperparameters optimizing the test accuracy.
Table 1: Summary of the parameters of the model.
| $N$ $M$ $\alpha=N/M$ | number of nodes dimension of the attributes aspect ratio |
| --- | --- |
| $d$ | average degree of the graph |
| $\lambda$ | signal strength of the graph |
| $\mu$ | signal strength of the features |
| $\rho=|R|/N$ | fraction of training nodes |
| $\ell$ , $\gamma$ | loss and regularization functions |
| $r$ | regularization strength |
| $K$ | number of aggregation steps |
| $c_{k}$ , $c$ , $t$ | residual connection strengths, diffusion time |
### II.3 Bayes-optimal performance:
An interesting consequence of modeling the data as we propose is that one has access to the Bayes-optimal (BO) performance on this task. The BO performance is defined as the upper-bound on the test accuracy that any algorithm can reach on this problem, knowing the model and its parameters $\alpha,\lambda,\mu$ and $\rho$ . It is of particular interest since it will allow us to check how far the GCNs are from the optimality and how much improvement can one hope for.
The BO performance on this problem has been derived in [22] and [39]. It is expressed as a function of the fixed-point of an algorithm based on approximate message-passing (AMP). In the limit of large degrees $d=\Theta(N)$ this algorithm can be tracked by a few scalar state-evolution (SE) equations that we reproduce in appendix C.
## III Asymptotic characterization of the GCN
In this section we provide an asymptotic characterization of the performance of the GCNs previously defined. It relies on a finite set of order parameters that satisfy a system of self-consistent, or fixed-point, equations, that we obtain thanks to the replica method in the high-dimensional limit at finite $K$ . In a second part, for the continuous GCN, we show how to take the limit $K\to\infty$ for the order parameters and for their self-consistent equations. The continuous GCN is still described by a finite set of order parameters, but these are now continuous functions and the self-consistent equations are integral equations.
Notice that for a quadratic loss function $\ell$ there is an analytical expression for the minimizer $w^{*}$ of the regularized loss $L_{A,X}$ eq. (17), given by the regularized least-squares formula. Based on that, a computation of the performance of the GCN with random matrix theory (RMT) is possible. It would not be straightforward in the sense that the convolved features, the weights $w^{*}$ and the labels $y$ are correlated, and such a computation would have to take in account these correlations. Instead, we prefer to use the replica method, which has already been successfully applied to analyze several architectures of one (learnable) layer neural networks in articles such that [17, 38]. Compared to RMT, the replica method allows us to seamlessly handle the regularized pseudo-inverse of the least-squares and to deal with logistic regression, where no explicit expression for $w^{*}$ exists.
We compute the average train and test errors and accuracies eqs. (18) and (19) in the high-dimensional limit $N$ and $M$ large. We define the Hamiltonian
$$
H(w)=s\sum_{i\in R}\ell(y_{i}h(w)_{i})+r\sum_{\nu}\gamma(w_{\nu})+s^{\prime}\sum_{i\in R^{\prime}}\ell(y_{i}h(w)_{i}) \tag{20}
$$
where $s$ and $s^{\prime}$ are external fields to probe the observables. The loss of the test samples is in $H$ for the purpose of the analysis; we will take $s^{\prime}=0$ later and the GCN is minimizing the training loss (17). The free energy $f$ is defined as
$$
Z=\int\mathrm{d}w\,e^{-\beta H(w)}\ ,\quad f=-\frac{1}{\beta N}\mathbb{E}\log Z\ . \tag{21}
$$
$\beta$ is an inverse temperature; we consider the limit $\beta\to\infty$ where the partition function $Z$ concentrates over $w^{*}$ at $s=1$ and $s^{\prime}=0$ . The train and test errors are then obtained according to
$$
E_{\mathrm{train}}=\frac{1}{\rho}\frac{\partial f}{\partial s}\ ,\quad E_{\mathrm{test}}=\frac{1}{\rho^{\prime}}\frac{\partial f}{\partial s^{\prime}} \tag{22}
$$
both evaluated at $(s,s^{\prime})=(1,0)$ . One can, in the same manner, compute the average accuracies by introducing the observables $\sum_{i\in\hat{R}}\delta_{y_{i}=\operatorname{sign}{h(w)_{i}}}$ in $H$ . To compute $f$ we introduce $n$ replica:
$$
\mathbb{E}\log Z=\mathbb{E}\frac{\partial Z^{n}}{\partial n}(n=0)=\left(\frac{\partial}{\partial n}\mathbb{E}Z^{n}\right)(n=0)\ . \tag{23}
$$
To pursue the computation we need to precise the architecture of the GCN.
### III.1 Discrete GCN
#### III.1.1 Asymptotic characterization
In this section, we work at finite $K$ . We consider only the asymmetric graph. We define the state of the GCN after the $k^{\mathrm{th}}$ convolution step as
$$
h_{k}=\left(\frac{1}{\sqrt{N}}\tilde{A}+c_{k}I_{N}\right)h_{k-1}\ ,\quad h_{0}=\frac{1}{\sqrt{N}}Xw\ . \tag{24}
$$
$h_{K}=h(w)\in\mathbb{R}^{N}$ is the output of the full GCN. We introduce $h_{k}$ in the replicated partition function $Z^{n}$ and we integrate over the fluctuations of $A$ and $X$ . This couples the variables across the different layers $k=0\ldots K$ and one has to take in account the correlations between the different $h_{k}$ , which will result into order parameters of dimension $K$ . One has to keep separate the indices $i\in R$ and $i\notin R$ , whether the loss $\ell$ is active or not; consequently the free entropy of the problem will be a linear combination of $\rho$ times a potential with $\ell$ and $(1-\rho)$ times without $\ell$ . The limit $N\to\infty$ is taken thanks to Laplace’s method. The extremization is done in the space of the replica-symmetric ansatz, which is justified by the convexity of $H$ . The detailed computation is given in appendix A.
The outcome of the computation is that this problem is described by a set of twelve order parameters (or summary statistics). They are $\Theta=\{m_{w}\in\mathbb{R},Q_{w}\in\mathbb{R},V_{w}\in\mathbb{R},m\in\mathbb{R}^{K},Q\in\mathbb{R}^{K\times K},V\in\mathbb{R}^{K\times K}\}$ and their conjugates $\hat{\Theta}=\{\hat{m}_{w}\in\mathbb{R},\hat{Q}_{w}\in\mathbb{R},\hat{V}_{w}\in\mathbb{R},\hat{m}\in\mathbb{R},\hat{Q}\in\mathbb{R}^{K\times K},\hat{V}\in\mathbb{R}^{K\times K}\}$ , where
$$
\displaystyle m_{w}=\frac{1}{N}u^{T}w\ , \displaystyle m_{k}=\frac{1}{N}y^{T}h_{k}\ , \displaystyle Q_{w}=\frac{1}{N}w^{T}w\ , \displaystyle Q_{k,l}=\frac{1}{N}h^{T}_{k}h_{l}\ , \displaystyle V_{w}=\frac{\beta}{N}\operatorname{Tr}(\operatorname{Cov}_{\beta}(w,w))\ , \displaystyle V_{k,l}=\frac{\beta}{N}\operatorname{Tr}(\operatorname{Cov}_{\beta}(h_{k},h_{l}))\ . \tag{25}
$$
$m_{w}$ and $m_{k}$ are the magnetizations (or overlaps) between the weights and the hidden variables and between the $k^{\mathrm{th}}$ layer and the labels; the $Q$ s are the self-overlaps (or scalar products) between the different layers; and, writing $\operatorname{Cov}_{\beta}$ for the covariance under the density $e^{-\beta H}$ , the $V$ s are the covariances between different trainings on the same data, after rescaling by $\beta$ .
The order parameters $\Theta$ and $\hat{\Theta}$ satisfy the property that they extremize the following free entropy $\phi$ :
$$
\displaystyle\phi \displaystyle=\frac{1}{2}\left(\hat{V}_{w}V_{w}+\hat{V}_{w}Q_{w}-V_{w}\hat{Q}_{w}\right)-\hat{m}_{w}m_{w}+\frac{1}{2}\mathrm{tr}\left(\hat{V}V+\hat{V}Q-V\hat{Q}\right)-\hat{m}^{T}m \displaystyle\quad{}+\frac{1}{\alpha}\mathbb{E}_{u,\varsigma}\left(\log\int\mathrm{d}w\,e^{\psi_{w}(w)}\right)+\rho\mathbb{E}_{y,\xi,\zeta,\chi}\left(\log\int\prod_{k=0}^{K}\mathrm{d}h_{k}e^{\psi_{h}(h;s)}\right)+(1-\rho)\mathbb{E}_{y,\xi,\zeta,\chi}\left(\log\int\prod_{k=0}^{K}\mathrm{d}h_{k}e^{\psi_{h}(h;s^{\prime})}\right)\ , \tag{28}
$$
the potentials being
$$
\displaystyle\psi_{w}(w) \displaystyle=-r\gamma(w)-\frac{1}{2}\hat{V}_{w}w^{2}+\left(\sqrt{\hat{Q}_{w}}\varsigma+u\hat{m}_{w}\right)w \displaystyle\psi_{h}(h;\bar{s}) \displaystyle=-\bar{s}\ell(yh_{K})-\frac{1}{2}h_{<K}^{T}\hat{V}h_{<K}+\left(\xi^{T}\hat{Q}^{1/2}+y\hat{m}^{T}\right)h_{<K} \displaystyle\qquad{}+\log\mathcal{N}\left(h_{0}\left|\sqrt{\mu}ym_{w}+\sqrt{Q_{w}}\zeta;V_{w}\right.\right)+\log\mathcal{N}\left(h_{>0}\left|c\odot h_{<K}+\lambda ym+Q^{1/2}\chi;V\right.\right)\ , \tag{29}
$$
for $w\in\mathbb{R}$ and $h\in\mathbb{R}^{K+1}$ , where we introduced the Gaussian random variables $\varsigma\sim\mathcal{N}(0,1)$ , $\xi\sim\mathcal{N}(0,I_{K})$ , $\zeta\sim\mathcal{N}(0,1)$ and $\chi\sim\mathcal{N}(0,I_{K})$ , take $y$ Rademacher and $u\sim\mathcal{N}(0,1)$ , where we set $h_{>0}=(h_{1},\ldots,h_{K})^{T}$ , $h_{<K}=(h_{0},\ldots,h_{K-1})^{T}$ and $c\odot h_{<K}=(c_{1}h_{0},\ldots,c_{K}h_{K-1})^{T}$ and where $\bar{s}\in\{0,1\}$ controls whether the loss $\ell$ is active or not. We use the notation $\mathcal{N}(\cdot|m;V)$ for a Gaussian density of mean $m$ and variance $V$ . We emphasize that $\psi_{w}$ and $\psi_{h}$ are effective potentials taking in account the randomness of the model and that are defined over a finite number of variables, contrary to the initial loss function $H$ .
The extremality condition $\nabla_{\Theta,\hat{\Theta}}\,\phi=0$ can be stated in terms of a system of self-consistent equations that we give here. In the limit $\beta\to\infty$ one has to consider the extremizers of $\psi_{w}$ and $\psi_{h}$ defined as
$$
\displaystyle w^{*} \displaystyle=\operatorname*{argmax}_{w}\psi_{w}(w)\in\mathbb{R} \displaystyle h^{*} \displaystyle=\operatorname*{argmax}_{h}\psi_{h}(h;\bar{s}=1)\in\mathbb{R}^{K+1} \displaystyle h^{{}^{\prime}*} \displaystyle=\operatorname*{argmax}_{h}\psi_{h}(h;\bar{s}=0)\in\mathbb{R}^{K+1}\ . \tag{31}
$$
We also need to introduce $\operatorname{Cov}_{\psi_{h}}(h)$ and $\operatorname{Cov}_{\psi_{h}}(h^{\prime})$ the covariances of $h$ under the densities $e^{\psi_{h}(h,\bar{s}=1)}$ and $e^{\psi_{h}(h,\bar{s}=0)}$ . In the limit $\beta\to\infty$ they read
$$
\displaystyle\operatorname{Cov}_{\psi_{h}}(h) \displaystyle=\nabla\nabla\psi_{h}(h^{*};\bar{s}=1) \displaystyle\operatorname{Cov}_{\psi_{h}}(h^{\prime}) \displaystyle=\nabla\nabla\psi_{h}(h^{{}^{\prime}*};\bar{s}=0)\ , \tag{34}
$$
$\nabla\nabla$ being the Hessian with respect to $h$ . Last, for compactness we introduce the operator $\mathcal{P}$ that, for a function $g$ in $h$ , acts according to
$$
\mathcal{P}(g(h))=\rho g(h^{*})+(1-\rho)g(h^{{}^{\prime}*})\ . \tag{36}
$$
For instance $\mathcal{P}(hh^{T})=\rho h^{*}(h^{*})^{T}+(1-\rho)h^{{}^{\prime}*}(h^{{}^{\prime}*})^{T}$ and $\mathcal{P}(\operatorname{Cov}_{\psi_{h}}(h))=\rho\operatorname{Cov}_{\psi_{h}}(h)+(1-\rho)\operatorname{Cov}_{\psi_{h}}(h^{\prime})$ . Then the extremality condition gives the following self-consistent, or fixed-point, equations on the order parameters:
$$
\displaystyle m_{w}=\frac{1}{\alpha}\mathbb{E}_{u,\varsigma}\,uw^{*} \displaystyle Q_{w}=\frac{1}{\alpha}\mathbb{E}_{u,\varsigma}(w^{*})^{2} \displaystyle V_{w}=\frac{1}{\alpha}\frac{1}{\sqrt{\hat{Q}_{w}}}\mathbb{E}_{u,\varsigma}\,\varsigma w^{*} \displaystyle m=\mathbb{E}_{y,\xi,\zeta,\chi}\,y\mathcal{P}(h_{<K}) \displaystyle Q=\mathbb{E}_{y,\xi,\zeta,\chi}\mathcal{P}(h_{<K}h_{<K}^{T}) \displaystyle V=\mathbb{E}_{y,\xi,\zeta,\chi}\mathcal{P}(\operatorname{Cov}_{\psi_{h}}(h_{<K})) \displaystyle\hat{m}_{w}=\frac{\sqrt{\mu}}{V_{w}}\mathbb{E}_{y,\xi,\zeta,\chi}\,y\mathcal{P}(h_{0}-\sqrt{\mu}ym_{w}) \displaystyle\hat{Q}_{w}=\frac{1}{V_{w}^{2}}\mathbb{E}_{y,\xi,\zeta,\chi}\mathcal{P}\left((h_{0}-\sqrt{\mu}ym_{w}-\sqrt{Q}_{w}\zeta)^{2}\right) \displaystyle\hat{V}_{w}=\frac{1}{V_{w}}-\frac{1}{V_{w}^{2}}\mathbb{E}_{y,\xi,\zeta,\chi}\mathcal{P}(\operatorname{Cov}_{\psi_{h}}(h_{0})) \displaystyle\hat{m}=\lambda V^{-1}\mathbb{E}_{y,\xi,\zeta,\chi}\,y\mathcal{P}(h_{>0}-c\odot h_{<K}-\lambda ym) \displaystyle\hat{Q}=V^{-1}\mathbb{E}_{y,\xi,\zeta,\chi}\mathcal{P}\left((h_{>0}-c\odot h_{<K}-\lambda ym-Q^{1/2}\chi)^{\otimes 2}\right)V^{-1} \displaystyle\hat{V}=V^{-1}-V^{-1}\mathbb{E}_{y,\xi,\zeta,\chi}\mathcal{P}(\operatorname{Cov}_{\psi_{h}}(h_{>0}-c\odot h_{<K}))V^{-1} \tag{37}
$$
Once this system of equations is solved, the expected errors and accuracies can be expressed as
$$
\displaystyle E_{\mathrm{train}}=\mathbb{E}_{y,\xi,\zeta,\chi}\ell(yh_{K}^{*})\ , \displaystyle\mathrm{Acc}_{\mathrm{train}}=\mathbb{E}_{y,\xi,\zeta,\chi}\delta_{y=\operatorname{sign}(h_{K}^{*})} \displaystyle E_{\mathrm{test}}=\mathbb{E}_{y,\xi,\zeta,\chi}\ell(yh_{K}^{{}^{\prime}*})\ , \displaystyle\mathrm{Acc}_{\mathrm{test}}=\mathbb{E}_{y,\xi,\zeta,\chi}\delta_{y=\operatorname{sign}(h_{K}^{{}^{\prime}*})}\ . \tag{49}
$$
<details>
<summary>x2.png Details</summary>
### Visual Description
## Chart: Accuracy vs. Regularization Parameter
### Overview
The image presents a series of six line plots, arranged in a 2x3 grid, illustrating the relationship between accuracy and a regularization parameter 'c' for different values of 'K' (1, 2, and 3) and 'r' (10<sup>-2</sup>, 10<sup>0</sup>, 10<sup>2</sup>, 10<sup>4</sup>). The top row displays accuracy on the test set (Acc<sub>test</sub>), while the bottom row displays accuracy on the cost set (Acc<sub>cost</sub>). A contour plot is included in the center column, showing the relationship between c<sub>1</sub> and c<sub>2</sub>.
### Components/Axes
* **X-axis (all plots except contour):** 'c', ranging from approximately 0.0 to 3.0.
* **Y-axis (top row):** Acc<sub>test</sub>, ranging from approximately 0.7 to 1.0.
* **Y-axis (bottom row):** Acc<sub>cost</sub>, ranging from approximately 0.6 to 0.9.
* **Contour Plot X-axis:** c<sub>1</sub>, ranging from approximately 0.0 to 2.0.
* **Contour Plot Y-axis:** c<sub>2</sub>, ranging from approximately 0.0 to 3.0.
* **Legend (top-right):**
* `-- Bayes – optimal` (dashed black line)
* `r = 10^4` (solid dark grey line)
* `r = 10^2` (solid medium grey line)
* `r = 10^0` (solid light grey line)
* `r = 10^-2` (solid teal line)
* **Titles (top of each plot):** K = 1, K = 2, K = 3.
* **Vertical dashed lines:** Present in each plot, positioned at approximately c = 0.5, 1.5, and 2.5.
### Detailed Analysis or Content Details
**K = 1 (Left Column)**
* **Acc<sub>test</sub>:** The Bayes-optimal line (dashed black) is flat at approximately 0.96. The r = 10<sup>4</sup> line (dark grey) starts at approximately 0.80 and increases rapidly to approximately 0.95 by c = 1.5, then plateaus. The r = 10<sup>2</sup> line (medium grey) starts at approximately 0.78 and increases more gradually, reaching approximately 0.92 by c = 2.0. The r = 10<sup>0</sup> line (light grey) starts at approximately 0.75 and increases slowly, reaching approximately 0.88 by c = 2.0. The r = 10<sup>-2</sup> line (teal) starts at approximately 0.72 and increases steadily, reaching approximately 0.85 by c = 2.0.
* **Acc<sub>cost</sub>:** The Bayes-optimal line (dashed black) is flat at approximately 0.90. The r = 10<sup>4</sup> line (dark grey) starts at approximately 0.62 and increases rapidly to approximately 0.85 by c = 1.5, then plateaus. The r = 10<sup>2</sup> line (medium grey) starts at approximately 0.60 and increases more gradually, reaching approximately 0.80 by c = 2.0. The r = 10<sup>0</sup> line (light grey) starts at approximately 0.58 and increases slowly, reaching approximately 0.75 by c = 2.0. The r = 10<sup>-2</sup> line (teal) starts at approximately 0.56 and increases steadily, reaching approximately 0.70 by c = 2.0.
**K = 2 (Center Column)**
* **Acc<sub>test</sub>:** The Bayes-optimal line (dashed black) is flat at approximately 0.96. The r = 10<sup>4</sup> line (dark grey) starts at approximately 0.85 and increases rapidly to approximately 0.96 by c = 1.0, then plateaus. The r = 10<sup>2</sup> line (medium grey) starts at approximately 0.82 and increases more gradually, reaching approximately 0.94 by c = 2.0. The r = 10<sup>0</sup> line (light grey) starts at approximately 0.78 and increases slowly, reaching approximately 0.90 by c = 2.0. The r = 10<sup>-2</sup> line (teal) starts at approximately 0.75 and increases steadily, reaching approximately 0.87 by c = 2.0.
* **Acc<sub>cost</sub>:** The Bayes-optimal line (dashed black) is flat at approximately 0.90. The r = 10<sup>4</sup> line (dark grey) starts at approximately 0.68 and increases rapidly to approximately 0.88 by c = 1.0, then plateaus. The r = 10<sup>2</sup> line (medium grey) starts at approximately 0.65 and increases more gradually, reaching approximately 0.80 by c = 2.0. The r = 10<sup>0</sup> line (light grey) starts at approximately 0.62 and increases slowly, reaching approximately 0.75 by c = 2.0. The r = 10<sup>-2</sup> line (teal) starts at approximately 0.60 and increases steadily, reaching approximately 0.70 by c = 2.0.
* **Contour Plot:** The contour plot shows level curves representing different values. The yellow contour (approximately 0.9) is elongated and curves from the bottom-left to the top-right. The teal contour (approximately 0.7) is more circular and centered around c<sub>1</sub> = 0.5 and c<sub>2</sub> = 1.5.
**K = 3 (Right Column)**
* **Acc<sub>test</sub>:** The Bayes-optimal line (dashed black) is flat at approximately 0.96. The r = 10<sup>4</sup> line (dark grey) starts at approximately 0.90 and increases rapidly to approximately 0.98 by c = 1.0, then plateaus. The r = 10<sup>2</sup> line (medium grey) starts at approximately 0.87 and increases more gradually, reaching approximately 0.96 by c = 2.0. The r = 10<sup>0</sup> line (light grey) starts at approximately 0.83 and increases slowly, reaching approximately 0.92 by c = 2.0. The r = 10<sup>-2</sup> line (teal) starts at approximately 0.80 and increases steadily, reaching approximately 0.89 by c = 2.0.
* **Acc<sub>cost</sub>:** The Bayes-optimal line (dashed black) is flat at approximately 0.90. The r = 10<sup>4</sup> line (dark grey) starts at approximately 0.75 and increases rapidly to approximately 0.90 by c = 1.0, then plateaus. The r = 10<sup>2</sup> line (medium grey) starts at approximately 0.70 and increases more gradually, reaching approximately 0.85 by c = 2.0. The r = 10<sup>0</sup> line (light grey) starts at approximately 0.65 and increases slowly, reaching approximately 0.80 by c = 2.0. The r = 10<sup>-2</sup> line (teal) starts at approximately 0.60 and increases steadily, reaching approximately 0.75 by c = 2.0.
### Key Observations
* As 'K' increases, the accuracy generally increases for a given 'c' and 'r'.
* Larger values of 'r' (e.g., 10<sup>4</sup>) lead to faster convergence to higher accuracy, but may overfit.
* Smaller values of 'r' (e.g., 10<sup>-2</sup>) lead to slower convergence and lower accuracy, but may generalize better.
* The Bayes-optimal line represents an upper bound on achievable accuracy.
* The contour plot suggests an optimal region for c<sub>1</sub> and c<sub>2</sub> that maximizes accuracy.
### Interpretation
The plots demonstrate the trade-off between bias and variance in a model with a regularization parameter 'c'. Increasing 'c' reduces variance (overfitting) but may increase bias (underfitting). The optimal value of 'c' depends on the complexity of the model ('K') and the strength of the regularization ('r'). The contour plot provides a visual representation of this trade-off in a two-dimensional parameter space. The dashed black line representing the Bayes-optimal solution serves as a benchmark, indicating the maximum achievable accuracy given the data and model. The different lines representing different values of 'r' show how the regularization strength affects the model's performance. The vertical dashed lines may indicate points of interest for further analysis, potentially representing critical values of 'c' where the model's behavior changes significantly. The difference between Acc<sub>test</sub> and Acc<sub>cost</sub> suggests a potential discrepancy between the model's performance on the training and testing data, which could be indicative of overfitting or underfitting.
</details>
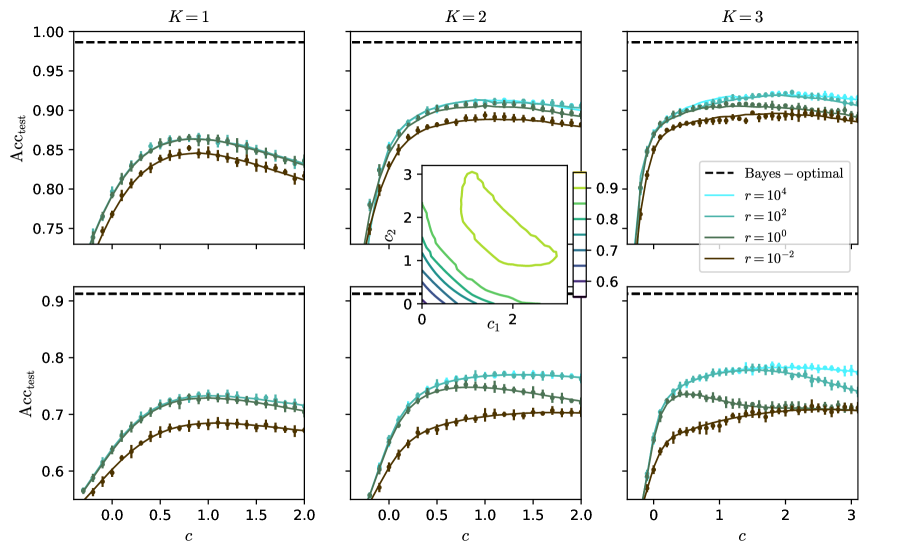
Figure 2: Predicted test accuracy $\mathrm{Acc}_{\mathrm{test}}$ for different values of $K$ . Top: for $\lambda=1.5$ , $\mu=3$ and logistic loss; bottom: for $\lambda=1$ , $\mu=2$ and quadratic loss; $\alpha=4$ and $\rho=0.1$ . We take $c_{k}=c$ for all $k$ . Inset: $\mathrm{Acc}_{\mathrm{test}}$ vs $c_{1}$ and $c_{2}$ at $K=2$ and at large $r$ . Dots: numerical simulation of the GCN for $N=10^{4}$ and $d=30$ , averaged over ten experiments.
#### III.1.2 Analytical solution
In general the system of self-consistent equations (37 - 48) has to be solved numerically. The equations are applied iteratively, starting from arbitrary $\Theta$ and $\hat{\Theta}$ , until convergence.
An analytical solution can be computed in some special cases. We consider ridge regression (i.e. quadratic $\ell$ ) and take $c=0$ no residual connections. Then $\operatorname{Cov}_{\psi_{h}}(h)$ , $\operatorname{Cov}_{\psi_{h}^{\prime}}(h)$ , $V$ and $\hat{V}$ are diagonal. We obtain that
$$
\mathrm{Acc}_{\mathrm{test}}=\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{\lambda q_{y,K-1}}{\sqrt{2}}\right)\right)\ ,\quad q_{y,k}=\frac{m_{k}}{\sqrt{Q_{k,k}}}\ . \tag{51}
$$
The test accuracy only depends on the angle (or overlap) $q_{y,k}$ between the labels $y$ and the last hidden state $h_{K-1}$ of the GCN. $q_{y,k}$ can easily be computed in the limit $r\to\infty$ . In appendix A.3 we explicit the equations (37 - 50) and give their solution in that limit. In particular we obtain for any $k$
$$
\displaystyle m_{k} \displaystyle=\frac{\rho}{\alpha r}\left(\mu\lambda^{K+k}+\sum_{l=0}^{k}\lambda^{K-k+2l}\right) \displaystyle Q_{k,k} \displaystyle=\frac{\rho}{\alpha^{2}r^{2}}\left(\alpha\left(1+\rho\mu\lambda^{2K}+\rho\sum_{l=1}^{K}\lambda^{2l}\right)\right. \displaystyle\hskip 18.49988pt\left.{}+\sum_{l=0}^{k}\left(1+\rho\sum_{l^{\prime}=1}^{K-1-l}\lambda^{2l^{\prime}}+\frac{\alpha^{2}r^{2}}{\rho}m_{l}^{2}\right)\right)\,. \tag{52}
$$
#### III.1.3 Consequences: going to large $K$ is necessary
We derive consequences from the previous theoretical predictions. We numerically solve eqs. (37 - 48) for some plausible values of the parameters of the data model. We keep balanced the signals from the graph, $\lambda^{2}$ , and from the features, $\mu^{2}/\alpha$ ; we take $\rho=0.1$ to stick to the common case where few train nodes are available. We focus on searching the architecture that maximizes the test accuracy by varying the loss $\ell$ , the regularization $r$ , the residual connections $c_{k}$ and $K$ . For simplicity we will mostly consider the case where $c_{k}=c$ for all $k$ and for a given $c$ . We compare our theoretical predictions to simulations of the GCN for $N=10^{4}$ in fig. 2; as expected, the predictions are within the statistical errors. Details on the numerics are provided in appendix D. We provide the code to run our predictions in the supplementary material.
[26] already studies in detail the effect of $\ell$ , $r$ and $c$ at $K=1$ . It reaches the conclusion that the optimal regularization is $r\to\infty$ , that the choice of the loss $\ell$ has little effect and that there is an optimal $c=c^{*}$ of order one. According to fig. 2, it seems that these results can be extrapolated to $K>1$ . We indeed observe that, for both the quadratic and the logistic loss, at $K\in\{1,2,3\}$ , $r\to\infty$ seems optimal. Then the choice of the loss has little effect, because at large $r$ the output $h(w)$ of the network is small and only the behaviour of $\ell$ around 0 matters. Notice that, though $h(w)$ is small and the error $E_{\mathrm{train/test}}$ is trivially equal to $\ell(0)$ , the sign of $h(w)$ is mostly correct and the accuracy $\mathrm{Acc}_{\mathrm{train/test}}$ is not trivial. Last, according to the inset of fig. 2 for $K=2$ , to take $c_{1}=c_{2}$ is optimal and our assumption $c_{k}=c$ for all $k$ is justified.
To take trainable $c_{k}$ would degrade the test performances. We show this in fig. 15 in appendix E, where optimizing the train error $E_{\mathrm{train}}$ over $c_{k}=c$ trivially leads to $c=+\infty$ . Indeed, in this case the graph is discarded and the convolved features are proportional to the features $X$ ; which, if $\alpha\rho$ is small enough, are separable, and lead to a null train error. Consequently $c_{k}$ should be treated as a hyperparameter, tuned to maximize $\mathrm{Acc}_{\mathrm{test}}$ , as we do in the rest of the article.
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Scatter Plot: Test Error vs. Lambda Squared
### Overview
This image presents a scatter plot comparing the test error (1 - Acc_test) against lambda squared (λ²). The plot displays data for different values of alpha (α) and mu (μ), along with theoretical bounds represented by dotted and dashed lines. The data points are color-coded based on the value of K.
### Components/Axes
* **X-axis:** λ² (Lambda Squared) - Scale ranges from approximately 10 to 26.
* **Y-axis:** 1 - Acc_test (1 minus Test Accuracy) - Logarithmic scale ranging from approximately 1e-6 to 0.02.
* **Legend (Top-Right):**
* Black Circles: α = 4, μ = 1
* Black Plus Signs: α = 2, μ = 2
* Black Dotted Line: 1/2 TBO (Theoretical Bound Optimization)
* Black Dashed Line: Bayes – optimal
* **Legend (Bottom-Center):**
* Dark Brown Circles: K = 1
* Brown Circles: K = 2
* Dark Yellow Circles: K = 3
* Yellow Circles: K = 2, symmetrized graph
* Light Yellow Circles: K = 3, symmetrized graph
### Detailed Analysis
The plot shows several data series. Let's analyze each:
* **α = 4, μ = 1 (Black Circles):** This series shows a generally decreasing trend as λ² increases, but with significant fluctuations.
* At λ² ≈ 10.5, 1 - Acc_test ≈ 0.015
* At λ² ≈ 14, 1 - Acc_test ≈ 0.005
* At λ² ≈ 18, 1 - Acc_test ≈ 0.02
* At λ² ≈ 24, 1 - Acc_test ≈ 0.003
* **α = 2, μ = 2 (Black Plus Signs):** This series also shows a decreasing trend, but the values are generally lower than the α = 4, μ = 1 series.
* At λ² ≈ 10.5, 1 - Acc_test ≈ 0.003
* At λ² ≈ 14, 1 - Acc_test ≈ 0.002
* At λ² ≈ 18, 1 - Acc_test ≈ 0.003
* At λ² ≈ 24, 1 - Acc_test ≈ 0.005
* **1/2 TBO (Black Dotted Line):** This line represents a theoretical bound. It shows a decreasing trend, starting at approximately 1 - Acc_test ≈ 0.001 at λ² ≈ 10 and decreasing to approximately 1 - Acc_test ≈ 0.0005 at λ² ≈ 26.
* **Bayes – optimal (Black Dashed Line):** This line represents the optimal Bayesian performance. It shows a steep decrease from approximately 1 - Acc_test ≈ 0.0002 at λ² ≈ 10 to approximately 1 - Acc_test ≈ 0.00005 at λ² ≈ 26.
* **K = 1 (Dark Brown Circles):** This series shows a decreasing trend, starting at approximately 1 - Acc_test ≈ 0.0002 at λ² ≈ 10 and decreasing to approximately 1 - Acc_test ≈ 0.00005 at λ² ≈ 26.
* **K = 2 (Brown Circles):** This series shows a decreasing trend, starting at approximately 1 - Acc_test ≈ 0.001 at λ² ≈ 10 and decreasing to approximately 1 - Acc_test ≈ 0.00005 at λ² ≈ 26.
* **K = 3 (Dark Yellow Circles):** This series shows a decreasing trend, starting at approximately 1 - Acc_test ≈ 0.002 at λ² ≈ 10 and decreasing to approximately 1 - Acc_test ≈ 0.00005 at λ² ≈ 26.
* **K = 2, symmetrized graph (Yellow Circles):** This series shows a decreasing trend, starting at approximately 1 - Acc_test ≈ 0.0005 at λ² ≈ 10 and decreasing to approximately 1 - Acc_test ≈ 0.00005 at λ² ≈ 26.
* **K = 3, symmetrized graph (Light Yellow Circles):** This series shows a decreasing trend, starting at approximately 1 - Acc_test ≈ 0.001 at λ² ≈ 10 and decreasing to approximately 1 - Acc_test ≈ 0.00005 at λ² ≈ 26.
### Key Observations
* The theoretical bounds (1/2 TBO and Bayes – optimal) provide a benchmark for the performance of the other data series.
* The α = 4, μ = 1 series consistently exhibits higher test error compared to the α = 2, μ = 2 series.
* The K values seem to influence the test error, with higher K values generally leading to lower test error.
* The "symmetrized graph" versions of K=2 and K=3 show lower test error than their non-symmetrized counterparts.
### Interpretation
The plot demonstrates the relationship between lambda squared (λ²) and test error (1 - Acc_test) under different parameter settings (α, μ, K). The decreasing trend in most series suggests that increasing λ² generally improves test accuracy. However, the fluctuations in the α = 4, μ = 1 series indicate that this relationship is not always straightforward and may be sensitive to the specific parameter values.
The theoretical bounds (1/2 TBO and Bayes – optimal) provide a reference point for evaluating the performance of the empirical data. The fact that the empirical data series generally fall above these bounds suggests that there is room for improvement in the model's performance.
The influence of K on test error suggests that the complexity of the model (as represented by K) plays a role in its ability to generalize to unseen data. The symmetrized graph versions of K=2 and K=3 performing better than their non-symmetrized counterparts suggests that the symmetrization process helps to reduce overfitting and improve generalization.
The logarithmic scale on the y-axis emphasizes the differences in test error, particularly at lower error rates. This is important for understanding the practical significance of the observed differences in performance.
</details>
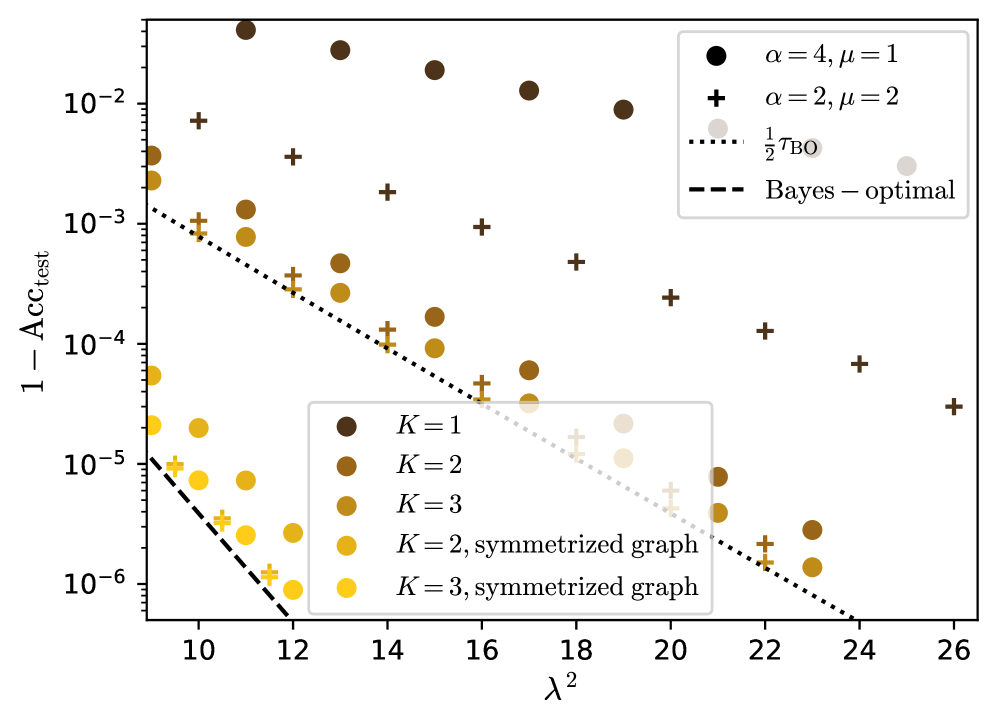
Figure 3: Predicted misclassification error $1-\mathrm{Acc}_{\mathrm{test}}$ at large $\lambda$ for two strengths of the feature signal. $r=\infty$ , $c=c^{*}$ is optimized by grid search and $\rho=0.1$ . The dots are theoretical predictions given by numerically solving the self-consistent equations (37 - 48) simplified in the limit $r\to\infty$ . For the symmetrized graph the self-consistent equations are eqs. (87 - 94) in the next part.
Finite $K$ :
We focus on the effect of varying the number $K$ of aggregation steps. [26] shows that at $K=1$ there is a large gap between the Bayes-optimal test accuracy and the best test accuracy of the GCN. We find that, according to fig. 2, for $K\in\{1,2,3\}$ , to increase $K$ reduces more and more the gap. Thus going to higher depth allows to approach the Bayes-optimality.
This also stands as to the learning rate when the signal $\lambda$ of the graph increases. At $\lambda\to\infty$ the GCN is consistent and correctly predicts the labels of all the test nodes, that is $\mathrm{Acc}_{\mathrm{test}}\underset{\lambda\to\infty}{\longrightarrow}1$ . The learning rate $\tau>0$ of the GCN is defined as
$$
\log(1-\mathrm{Acc}_{\mathrm{test}})\underset{\lambda\to\infty}{\sim}-\tau\lambda^{2}\ . \tag{54}
$$
As shown in [39], the rate $\tau_{\mathrm{BO}}$ of the Bayes-optimal test accuracy is
$$
\tau_{\mathrm{BO}}=1\ . \tag{55}
$$
For $K=1$ [26] proves that $\tau\leq\tau_{\mathrm{BO}}/2$ and that $\tau\to\tau_{\mathrm{BO}}/2$ when the signal from the features $\mu^{2}/\alpha$ diverges. We obtain that if $K>1$ then $\tau=\tau_{\mathrm{BO}}/2$ for any signal from the features. This is shown on fig. 3, where for $K=1$ the slope of the residual error varies with $\mu$ and $\alpha$ but does not reach half of the Bayes-optimal slope; while for $K>1$ it does, and the features only contribute with a sub-leading order.
Analytically, taking the limit in eqs. (52) and (53), at $c=0$ and $r\to\infty$ we have that
$$
\underset{\lambda\to\infty}{\mathrm{lim}}q_{y,K-1}\left\{\begin{array}[]{rr}=1&\mathrm{if}\,K>1\\
<1&\mathrm{if}\,K=1\end{array}\right. \tag{56}
$$
Since $\log(1-\operatorname{erf}(\lambda q_{y,K-1}/\sqrt{2}))\underset{\lambda\to\infty}{\sim}-\lambda^{2}q_{y,K-1}^{2}/2$ we recover the leading behaviour depicted on fig. 3. $c$ has little effect on the rate $\tau$ ; it only seems to vary the test accuracy by a sub-leading term.
Symmetrization:
We found that in order to reach the Bayes-optimal rate one has to further symmetrize the graph, according to eq. (14), and to perform the convolution steps by applying $\tilde{A}^{\mathrm{s}}$ instead of $\tilde{A}$ . Then, as shown on fig. 3, the GCN reaches the BO rate for any $K>1$ , at any signal from the features.
The reason of this improvement is the following. The GCN we consider is not able to deal with the asymmetry of the graph and the supplementary information it gives. This is shown on fig. 14 in appendix E for different values of $K$ at finite signal, in agreement with [20]. There is little difference in the performance of the simple GCN whether the graph is symmetric or not with same $\lambda$ . As to the rates, as shown by the computation in appendix C, a symmetric graph with signal $\lambda$ would lead to a BO rate $\tau_{\mathrm{BO}}^{\mathrm{s}}=1/2$ , which is the rate the GCN achieves on the asymmetric graph. It is thus better to let the GCN process the symmetrized the graph, which has a higher signal $\lambda^{\mathrm{s}}=\sqrt{2}\lambda$ , and which leads to $\tau=1=\tau_{\mathrm{BO}}$ .
Symmetrization is an important step toward the optimality and we will detail the analysis of the GCN on the symmetrized graph in part III.2.
Large $K$ and scaling of $c$ :
Going to larger $K$ is beneficial and allows the network to approach the Bayes optimality. Yet $K=3$ is not enough to reach it at finite $\lambda$ , and one can ask what happens at larger $K$ . An important point is that $c$ has to be well tuned. On fig. 2 we observe that $c^{*}$ , the optimal $c$ , is increasing with $K$ . To make this point more precise, on fig. 4 we show the predicted test accuracy for larger $K$ for different scalings of $c$ . We take $r=\infty$ since it appears to be the optimal regularization. We consider no residual connections, $c=0$ ; constant residual connections, $c=1$ ; or growing residual connections, $c\propto K$ .
<details>
<summary>x4.png Details</summary>
### Visual Description
## Chart: Test Accuracy vs. K
### Overview
The image presents two line charts displaying the relationship between 'K' (likely the number of clusters or components) and 'ACCtest' (test accuracy). The top chart shows accuracy values generally above 0.85, while the bottom chart shows values between 0.5 and 0.65. Each chart includes three data series, distinguished by color and marker shape, representing different values of 'c' (likely a parameter influencing the model). Horizontal dotted lines indicate 'continuous limit' and 'PCA on the graph' thresholds.
### Components/Axes
* **X-axis:** 'K', ranging from approximately 10⁰ to 10¹. The scale is logarithmic.
* **Y-axis:** 'ACCtest', ranging from approximately 0.5 to 0.95.
* **Legend (Top-Right of each chart):**
* Red circles: 'c = K'
* Blue stars: 'c = 1'
* Black plus signs: 'c = 0'
* Red dotted line: 'continuous limit'
* Black dotted line: 'PCA on the graph'
* **Horizontal Dotted Lines:**
* Top Chart: 'continuous limit' at approximately 0.92, 'PCA on the graph' at approximately 0.87.
* Bottom Chart: 'continuous limit' at approximately 0.65, 'PCA on the graph' at approximately 0.52.
### Detailed Analysis or Content Details
**Top Chart:**
* **c = K (Red Circles):** The line starts at approximately (10⁰, 0.87), rises to a peak of approximately (3, 0.92), then declines slightly to approximately (10¹, 0.90).
* **c = 1 (Blue Stars):** The line starts at approximately (10⁰, 0.85), rises to approximately (3, 0.91), then declines to approximately (10¹, 0.88).
* **c = 0 (Black Plus Signs):** The line remains relatively flat, starting at approximately (10⁰, 0.83) and ending at approximately (10¹, 0.85).
**Bottom Chart:**
* **c = K (Red Circles):** The line starts at approximately (10⁰, 0.62), rises to approximately (3, 0.65), then declines to approximately (10¹, 0.63).
* **c = 1 (Blue Stars):** The line starts at approximately (10⁰, 0.63), rises to approximately (3, 0.65), then declines to approximately (10¹, 0.57).
* **c = 0 (Black Plus Signs):** The line remains relatively flat, starting at approximately (10⁰, 0.54) and ending at approximately (10¹, 0.53).
### Key Observations
* In both charts, the 'c = 0' data series exhibits the lowest accuracy values and remains relatively stable across the range of 'K'.
* The 'c = K' and 'c = 1' data series show similar trends, with accuracy increasing initially and then decreasing as 'K' increases.
* The top chart consistently shows higher accuracy values than the bottom chart.
* The 'continuous limit' line appears to represent an upper bound on achievable accuracy.
* The 'PCA on the graph' line represents a lower bound on achievable accuracy.
### Interpretation
The charts likely represent the performance of a model (or multiple models with different parameter settings) as the number of components ('K') is varied. The parameter 'c' likely controls some aspect of the model's regularization or complexity.
The top chart suggests that for higher accuracy, the model performs best with a moderate value of 'K' (around 3) and either 'c = K' or 'c = 1'. The 'continuous limit' and 'PCA on the graph' lines indicate the theoretical maximum and minimum achievable accuracy, respectively.
The bottom chart shows significantly lower accuracy values, suggesting that the model configuration represented by this chart is less effective. The relatively flat 'c = 0' line indicates that this configuration is not sensitive to changes in 'K'.
The difference between the two charts could be due to different datasets, different model architectures, or different hyperparameter settings. The charts demonstrate a trade-off between model complexity ('K') and accuracy, and the optimal value of 'K' depends on the specific model configuration ('c'). The consistent performance of 'c=0' suggests it may be a baseline or a highly regularized configuration that prevents overfitting but also limits the model's ability to capture complex patterns in the data.
</details>
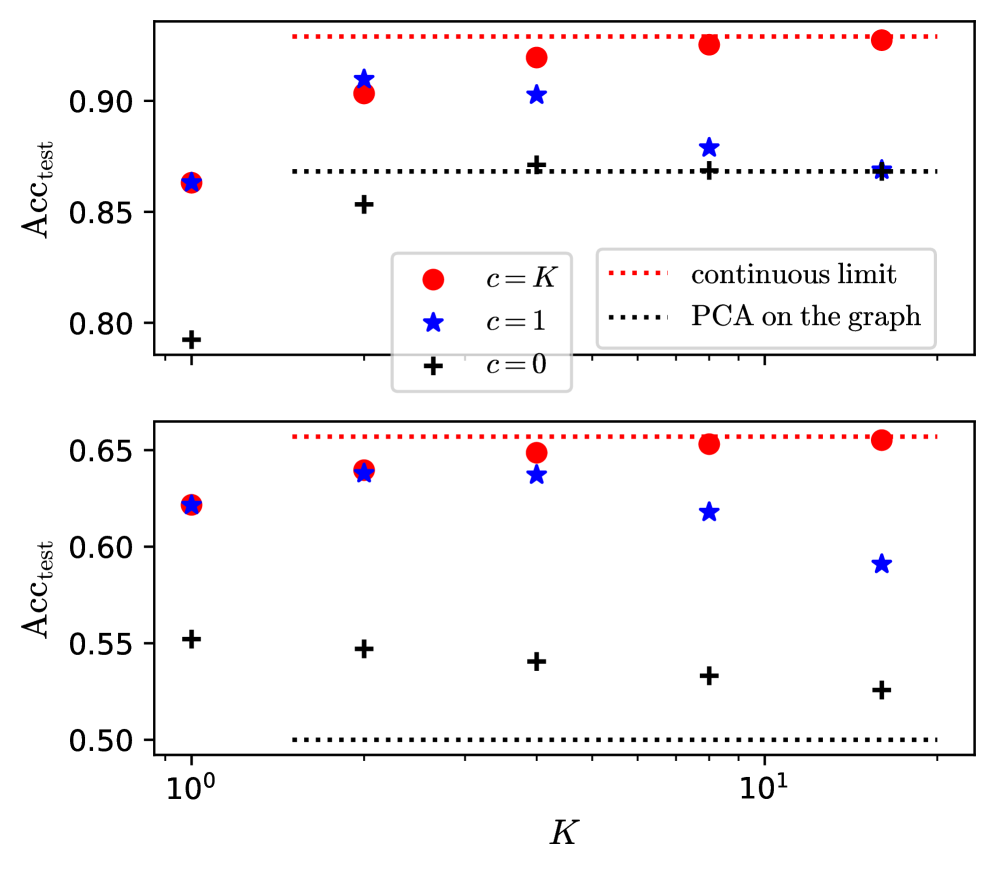
Figure 4: Predicted test accuracy $\mathrm{Acc}_{\mathrm{test}}$ vs $K$ for different scalings of $c$ , at $r=\infty$ . Top: for $\lambda=1.5$ , $\mu=3$ ; bottom: for $\lambda=0.7$ , $\mu=1$ ; $\alpha=4$ , $\rho=0.1$ . The predictions are given either by the explicit expression eqs. (51 - 53) for $c=0$ , either by solving the self-consistent equations (37 - 48) simplified in the limit $r\to\infty$ . The performance for the continuous limit are derived and given in the next section III.2, while the performance of PCA on the graph are given by eqs. (59 - 60).
A main observation is that, on fig. 4 for $K\to\infty$ , $c=0$ or $c=1$ converge to the same limit while $c\propto K$ converge to a different limit, that has higher accuracy.
In the case where $c=0$ or $c=1$ the GCN oversmooths at large $K$ . The limit it converges to corresponds to the accuracy of principal component analysis (PCA) on the sole graph; that is, it corresponds to the accuracy of the estimator $\hat{y}_{\mathrm{PCA}}=\operatorname{sign}\left(\mathrm{Re}(y_{1})\right)$ where $y_{1}$ is the leading eigenvector of $\tilde{A}$ . The overlap $q_{\mathrm{PCA}}$ between $y$ and $\hat{y}_{\mathrm{PCA}}$ and the accuracy are
$$
\displaystyle q_{\mathrm{PCA}}=\left\{\begin{array}[]{cr}\sqrt{1-\lambda^{-2}}&\mathrm{if}\,\lambda\geq 1\\
0&\mathrm{if}\,\lambda\leq 1\end{array}\right.\ , \displaystyle\mathrm{Acc}_{\mathrm{test,PCA}}=\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{\lambda q_{\mathrm{PCA}}}{\sqrt{2}}\right)\right)\ . \tag{59}
$$
Consequently, if $c$ does not grow, the GCN will oversmooth at large $K$ , in the sense that all the information from the features $X$ vanishes. Only the information from the graph remains, that can still be informative if $\lambda>1$ . The formula (59 – 60) is obtained by taking the limit $K\to\infty$ in eqs. (51 – 53), for $c=0$ . For any constant $c$ it can also be recovered by considering the leading eigenvector $y_{1}$ of $\tilde{A}$ . At large $K$ , $(\tilde{A}/\sqrt{N}+cI)^{K}$ is dominated by $y_{1}$ and the output of the GCN is $h(w)\propto y_{1}$ for any $w$ . Consequently the GCN exactly acts like thresholded PCA on $\tilde{A}$ . The sharp transition at $\lambda=1$ corresponds to the BBP phase transition in the spectrum of $A^{g}$ and $\tilde{A}$ [56]. According to eqs. (51 – 53) the convergence of $q_{y,K-1}$ toward $q_{\mathrm{PCA}}$ is exponentially fast in $K$ if $\lambda>1$ ; it is like $1/\sqrt{K}$ , much slower, if $\lambda<1$ .
The fact that the oversmoothed features can be informative differs from several previous works where they are fully non-informative, such as [9, 10, 40]. This is mainly due to the normalization $\tilde{A}$ of $A$ we use and that these works do not use. It allows to remove the uniform eigenvector $(1,\ldots,1)^{T}$ , that otherwise dominates $A$ and leads to non-informative features. [36] emphasizes on this point and compares different ways of normalizing and correcting $A$ . This work concludes, as we do, that for a correct rescaling $\tilde{A}$ of $A$ , similar to ours, going to higher $K$ is always beneficial if $\lambda$ is high enough, and that the convergence to the limit is exponentially fast. Yet, at large $K$ it obtains bounds on the test accuracy that do not depend on the features: the network they consider still oversmooths in the precise sense we defined. This can be expected since it does not have residual connections, i.e. $c=0$ , that appear to be decisive.
In the case where $c\propto K$ the GCN does not oversmooth and it converges to a continuous limit, obtained as $(cI+\tilde{A}/\sqrt{N})^{K}\propto(I+t\tilde{A}/K\sqrt{N})^{K}\to e^{\frac{t\tilde{A}}{\sqrt{N}}}$ . We study this limit in detail in the next part where we predict the resulting accuracy for all constant ratios $t=c/K$ . In general the continuous limit has a better performance than the limit at constant $c$ that relies only on the graph, performing PCA, because it can take in account the features, which bring additional information.
Fig. 4 suggests that $\mathrm{Acc}_{\mathrm{test}}$ is monotonically increasing with $K$ if $c\propto K$ and that the continuous limit is the upper-bound on the performance at any $K$ . We will make this point more precise in the next part. Yet we can already see that, for this to be true, one has to correctly tune the ratio $c/K$ : for instance if $\lambda$ is small $\tilde{A}$ mostly contains noise and applying it to $X$ will mostly lower the accuracy. Shortly, if $c/K$ is optimized then $K\to\infty$ is better than any fixed $K$ . Consequently the continuous limit is the correct limit to maximize the test accuracy and it is of particular relevance.
### III.2 Continuous GCN
In this section we present the asymptotic characterization of the continuous GCN, both for the asymmetric graph and for its symmetrization. The continuous GCN is the limit of the discrete GCN when the number of convolution steps $K$ diverges while the residual connections $c$ become large. The order parameters that describe it, as well as the self-consistent equations they follow, can be obtained as the limit of those of the discrete GCN. We give a detailed derivation of how the limit is taken, since it is of independent interest.
The outcome is that the state $h$ of the GCN across the convolutions is described by a set of equations resembling the dynamical mean-field theory. The order parameters of the problem are continuous functions and the self-consistent equations can be expressed by expansion around large regularization $r\to\infty$ as integral equations, that specialize to differential equations in the asymmetric case. The resulting equations can be solved analytically; for asymmetric graphs, the covariance and its conjugate are propagators (or resolvant) of the two-dimensional Klein-Gordon equation. We show numerically that our approach is justified and agrees with simulations. Last we show that going to the continuous limit while symmetrizing the graph corresponds to the optimum of the architecture and allows to approach the Bayes-optimality.
#### III.2.1 Asymptotic characterization
To deal with both cases, asymmetric or symmetrized, we define $(\delta_{\mathrm{e}},\tilde{A}^{\mathrm{e}},\lambda^{\mathrm{e}})\in\{(0,\tilde{A},\lambda),(1,\tilde{A}^{\mathrm{s}},\lambda^{\mathrm{s}})\}$ , where we remind that $\tilde{A}^{\mathrm{s}}$ is the symmetrized $\tilde{A}$ with effective signal $\lambda^{\mathrm{s}}=\sqrt{2}\lambda$ . In particular $\delta_{\mathrm{e}}=0$ for the asymmetric and $\delta_{\mathrm{e}}=1$ for the symmetrized.
The continuous GCN is defined by the output function
$$
h(w)=e^{\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}}\frac{1}{\sqrt{N}}Xw\ . \tag{61}
$$
We first derive the free entropy of the discretization of the GCN and then take the continuous limit. The discretization at finite $K$ is
$$
\displaystyle h(w)=h_{K}\ , \displaystyle h_{k+1}=\left(I_{N}+\frac{t}{K\sqrt{N}}\tilde{A}^{\mathrm{e}}\right)h_{k}\ , \displaystyle h_{0}=\frac{1}{\sqrt{N}}Xw\ . \tag{62}
$$
In the case of the asymmetric graph this discretization can be mapped to the discrete GCN of the previous section A as detailed in eq. (16) and the following paragraph; the free entropy and the order parameters of the two models are the same, up to a rescaling by $c$ .
The order parameters of the discretization of the GCN are $m_{w}\in\mathbb{R},Q_{w}\in\mathbb{R},V_{w}\in\mathbb{R},m\in\mathbb{R}^{K},Q_{h}\in\mathbb{R}^{K\times K},V_{h}\in\mathbb{R}^{K\times K}$ , their conjugates $\hat{m}_{w}\in\mathbb{R},\hat{Q}_{w}\in\mathbb{R},\hat{V}_{w}\in\mathbb{R},\hat{m}\in\mathbb{R},\hat{Q}_{h}\in\mathbb{R}^{K\times K},\hat{V}_{h}\in\mathbb{R}^{K\times K}$ and the two additional order parameters $Q_{qh}\in\mathbb{R}^{K\times K}$ and $V_{qh}\in\mathbb{R}^{K\times K}$ that account for the supplementary correlations the symmetry of the graph induces; $Q_{qh}=V_{qh}=0$ for the asymmetric case.
The free entropy and its derivation are given in appendix B. The outcome is that $h$ is described by the effective low-dimensional potential $\psi_{h}$ over $\mathbb{R}^{K+1}$ that is
$$
\displaystyle\psi_{h}(h;\bar{s}) \displaystyle=-\frac{1}{2}h^{T}Gh+h^{T}\left(B_{h}+D_{qh}^{T}G_{0}^{-1}B\right)\ ; \tag{65}
$$
where
$$
\displaystyle G \displaystyle=G_{h}+D_{qh}^{T}G_{0}^{-1}D_{qh}\ , \displaystyle G_{h} \displaystyle=\left(\begin{smallmatrix}\hat{V}_{h}&0\\
0&\bar{s}\end{smallmatrix}\right)\ , \displaystyle G_{0} \displaystyle=\left(\begin{smallmatrix}K^{2}V_{w}&0\\
0&t^{2}V_{h}\end{smallmatrix}\right)\ , \displaystyle D_{qh} \displaystyle=D-t\left(\begin{smallmatrix}0&0\\
-\mathrm{i}\delta_{\mathrm{e}}V_{qh}^{T}&0\end{smallmatrix}\right) \tag{66}
$$
are $(K+1)\times(K+1)$ block matrices;
$$
\displaystyle D \displaystyle=K\left(\begin{smallmatrix}1&&&0\\
-1&\ddots&&\\
&\ddots&\ddots&\\
0&&-1&1\end{smallmatrix}\right) \tag{70}
$$
is the $(K+1)\times(K+1)$ discrete derivative;
$$
\displaystyle B \displaystyle=\left(\begin{smallmatrix}K\sqrt{Q_{w}}\chi\\
\mathrm{i}t\left(\hat{Q}^{1/2}\zeta\right)_{q}\end{smallmatrix}\right)+y\left(\begin{smallmatrix}K\sqrt{\mu}m_{w}\\
\lambda^{\mathrm{e}}tm\end{smallmatrix}\right)\ , \displaystyle B_{h} \displaystyle=\left(\begin{smallmatrix}\left(\hat{Q}^{1/2}\zeta\right)_{h}\\
0\end{smallmatrix}\right)+y\left(\begin{smallmatrix}\hat{m}\\
\bar{s}\end{smallmatrix}\right)\ , \displaystyle\left(\begin{smallmatrix}(\hat{Q}^{1/2}\zeta)_{q}\\
(\hat{Q}^{1/2}\zeta)_{h}\end{smallmatrix}\right) \displaystyle=\left(\begin{smallmatrix}-Q_{h}&-\delta_{\mathrm{e}}Q_{qh}^{T}\\
-\delta_{\mathrm{e}}Q_{qh}&\hat{Q}_{h}\end{smallmatrix}\right)^{1/2}\left(\begin{smallmatrix}\zeta_{q}\\
\zeta_{h}\end{smallmatrix}\right) \tag{71}
$$
are vectors of size $K+1$ , where $y=\pm 1$ is Rademacher and $\zeta_{q}\sim\mathcal{N}(0,I_{K+1})$ , $\zeta_{h}\sim\mathcal{N}(0,I_{K+1})$ and $\chi\sim\mathcal{N}(0,1)$ are standard Gaussians. $\bar{s}$ determines whether the loss is active $\bar{s}=1$ or not $\bar{s}=0$ . We assumed that $\ell$ is quadratic. Later we will take the limit $r\to\infty$ where $h$ is small and where $\ell$ can effectively be expanded around $0$ as a quadratic potential. Notice that in the case $\delta_{\mathrm{e}}=0$ we recover the potential $\psi_{h}$ eq. (30) of the previous part.
This potential eq. (65) corresponds to a one dimensional interacting chain, involving the positions $h$ and their effective derivative $D_{qh}h$ , and with constraints at the two ends, for the loss on $h_{K}$ and the regularized weights on $h_{0}$ . Its extremizer $h^{*}$ is
$$
h^{*}=G^{-1}\left(B_{h}+D_{qh}^{T}G_{0}^{-1}B\right)\ . \tag{74}
$$
The order parameters are determined by the following fixed-point equations, obtained by extremizing the free entropy. As before $\mathcal{P}$ acts by linearly combining quantities evaluated at $h^{*}$ , taken with $\bar{s}=1$ and $\bar{s}=0$ with weights $\rho$ and $1-\rho$ .
$$
\displaystyle m_{w}=\frac{1}{\alpha}\frac{\hat{m}_{w}}{r+\hat{V}_{w}} \displaystyle Q_{w}=\frac{1}{\alpha}\frac{\hat{Q}_{w}+\hat{m}_{w}^{2}}{(r+\hat{V}_{w})^{2}} \displaystyle V_{w}=\frac{1}{\alpha}\frac{1}{r+\hat{V}_{w}} \displaystyle\left(\begin{smallmatrix}\hat{m}_{w}\\
\hat{m}\\
m\\
\cdot\end{smallmatrix}\right)=\left(\begin{smallmatrix}K\sqrt{\mu}&&0\\
&\lambda^{\mathrm{e}}tI_{K}&\\
0&&I_{K+1}\end{smallmatrix}\right)\mathbb{E}_{y,\xi,\zeta}\,y\mathcal{P}\left(\begin{smallmatrix}G_{0}^{-1}(D_{qh}h-B)\\
h\end{smallmatrix}\right) \displaystyle\begin{multlined}\left(\begin{smallmatrix}\hat{Q}_{w}&&&\cdot\\
&\hat{Q}_{h}&Q_{qh}&\\
&Q_{qh}^{T}&Q_{h}&\\
\cdot&&&\cdot\end{smallmatrix}\right)=\left(\begin{smallmatrix}K&&0\\
&tI_{K}&\\
0&&I_{K+1}\end{smallmatrix}\right)\\
\hskip 18.49988pt\mathbb{E}_{y,\xi,\zeta}\mathcal{P}\left(\left(\begin{smallmatrix}G_{0}^{-1}(D_{qh}h-B)\\
h\end{smallmatrix}\right)^{\otimes 2}\right)\left(\begin{smallmatrix}K&&0\\
&tI_{K}&\\
0&&I_{K+1}\end{smallmatrix}\right)\end{multlined}\left(\begin{smallmatrix}\hat{Q}_{w}&&&\cdot\\
&\hat{Q}_{h}&Q_{qh}&\\
&Q_{qh}^{T}&Q_{h}&\\
\cdot&&&\cdot\end{smallmatrix}\right)=\left(\begin{smallmatrix}K&&0\\
&tI_{K}&\\
0&&I_{K+1}\end{smallmatrix}\right)\\
\hskip 18.49988pt\mathbb{E}_{y,\xi,\zeta}\mathcal{P}\left(\left(\begin{smallmatrix}G_{0}^{-1}(D_{qh}h-B)\\
h\end{smallmatrix}\right)^{\otimes 2}\right)\left(\begin{smallmatrix}K&&0\\
&tI_{K}&\\
0&&I_{K+1}\end{smallmatrix}\right) \displaystyle\left(\begin{smallmatrix}\cdot&\cdot\\
-\mathrm{i}V_{qh}&\cdot\end{smallmatrix}\right)=t\mathcal{P}\left(G_{0}^{-1}D_{qh}G^{-1}\right) \displaystyle\left(\begin{smallmatrix}V_{h}&\cdot\\
\cdot&\cdot\end{smallmatrix}\right)=\mathcal{P}\left(G^{-1}\right) \displaystyle\left(\begin{smallmatrix}\hat{V}_{w}&\cdot\\
\cdot&\hat{V}_{h}\end{smallmatrix}\right)=\left(\begin{smallmatrix}K^{2}&0\\
0&t^{2}I_{K}\end{smallmatrix}\right)\mathcal{P}\left(G_{0}^{-1}-G_{0}^{-1}D_{qh}G^{-1}D_{qh}^{T}G_{0}^{-1}\right) \tag{75}
$$
where $\cdot$ are unspecified elements that pad the vector to the size $2(K+1)$ and the matrices to the size $2(K+1)\times 2(K+1)$ and $(K+1)\times(K+1)$ . On $w$ we assumed $l_{2}$ regularization and obtained the same equations as in part III.1.
Once a solution to this system is found the train and test accuracies are expressed as
$$
\displaystyle\mathrm{Acc}_{\mathrm{train/test}}=\mathbb{E}_{y,\zeta,\chi}\delta_{y=\operatorname{sign}(h_{K}^{*})}\ , \tag{85}
$$
taking $\bar{s}=1$ or $\bar{s}=0$ .
#### III.2.2 Expansion around large regularization $r$ and continuous limit
Solving the above self-consistent equations (75 - 84) is difficult as such. One can solve them numerically by repeated updates; but this does not allow to go to large $K$ because of numerical instability. One has to invert $G$ eq. (66) and to make sense of the continuous limit of matrix inverts. This is an issue in the sense that, for a generic $K\times K$ matrix $(M)_{ij}$ whose elements vary smoothly with $i$ and $j$ in the limit of large $K$ , the elements of its inverse $M^{-1}$ are not necessarly continuous with respect to their indices and can vary with a large magnitude.
Our analysis from the previous part III.1 gives an insight on how to achieve this. It appears that the limit of large regularization $r\to\infty$ is of particular relevance. In this limit the above system can be solved analytically thanks to an expansion around large $r$ . This expansion is natural in the sense that it leads to several simplifications and corresponds to expanding the matrix inverts in Neumann series. Keeping the first terms of the expansion the limit $K\to\infty$ is then well defined. In this section we detail this expansion; we take the continuous limit and, keeping the first constant order, we solve (75 - 84).
In the limit of large regularization $h$ and $w$ are of order $1/r$ ; the parameters $m_{w}$ , $m$ , $V_{w}$ and $V$ are of order $1/r$ and $Q_{w}$ and $Q$ are of order $1/r^{2}$ , while all their conjugates, $Q_{qh}$ and $V_{qh}$ are of order one. Consequently we have $G_{0}^{-1}\sim r\gg G_{h}\sim 1$ and we expand $G^{-1}$ around $G_{0}$ :
$$
\displaystyle G^{-1} \displaystyle=D_{qh}^{-1}G_{0}D_{qh}^{-1,T}\sum_{a\geq 0}\left(-G_{h}D_{qh}^{-1}G_{0}D_{qh}^{-1,T}\right)^{a}\ . \tag{86}
$$
Constant order:
We detail how to solve the self-consistent equations (75 - 84) taking the continuous limit $K\to\infty$ at the constant order in $1/r$ . As we will show later, truncating $G^{-1}$ to the constant order gives predictions that are close to the simulations at finite $r$ , even for $r\approx 1$ if $t$ is not too large. Considering higher orders is feasible but more challenging and we will only provide insights on how to pursue the computation.
The truncated expansion gives, starting from the variances:
$$
\displaystyle\left(\begin{smallmatrix}\cdot&\cdot\\
-\mathrm{i}V_{qh}&\cdot\end{smallmatrix}\right) \displaystyle=tD_{qh}^{-1,T}\ , \displaystyle\left(\begin{smallmatrix}V_{h}&\cdot\\
\cdot&\cdot\end{smallmatrix}\right) \displaystyle=D_{qh}^{-1}\left(\begin{smallmatrix}K^{2}V_{w}&0\\
0&t^{2}V_{h}\end{smallmatrix}\right)D_{qh}^{-1,T}, \displaystyle\left(\begin{smallmatrix}\hat{V}_{w}&\cdot\\
\cdot&\hat{V}_{h}\end{smallmatrix}\right) \displaystyle=\left(\begin{smallmatrix}K^{2}&0\\
0&t^{2}I_{K}\end{smallmatrix}\right)D_{qh}^{-1,T}\left(\begin{smallmatrix}\hat{V}_{h}&0\\
0&\rho\end{smallmatrix}\right)D_{qh}^{-1}\ . \tag{87}
$$
We kept the order $a=0$ for $V_{qh}$ and $V_{h}$ , and the orders $a\leq 1$ for $\hat{V}_{w}$ and $\hat{V}_{h}$ . We expand $h^{*}\approx D_{qh}^{-1}G_{0}D_{qh}^{-1,T}B_{h}+D_{qh}^{-1}B$ keeping the order $a=0$ and obtain the remaining self-consistent equations
$$
\displaystyle\left(\begin{smallmatrix}\hat{m}_{w}\\
\hat{m}\end{smallmatrix}\right) \displaystyle=\left(\begin{smallmatrix}K\sqrt{\mu}&0\\
0&\lambda^{\mathrm{e}}tI_{K}\cdot\end{smallmatrix}\right)D_{qh}^{-1,T}\left(\begin{smallmatrix}\hat{m}\\
\rho\end{smallmatrix}\right) \displaystyle\left(\begin{smallmatrix}m\\
\cdot\end{smallmatrix}\right) \displaystyle=D_{qh}^{-1}G_{0}D_{qh}^{-1,T}\left(\begin{smallmatrix}\hat{m}\\
\rho\end{smallmatrix}\right)+D_{qh}^{-1}\left(\begin{smallmatrix}K\sqrt{\mu}m_{w}\\
\lambda^{\mathrm{e}}tm\end{smallmatrix}\right) \tag{90}
$$
$$
\displaystyle\left(\begin{smallmatrix}\hat{Q}_{w}&\cdot\\
\cdot&\hat{Q}_{h}\end{smallmatrix}\right) \displaystyle=\left(\begin{smallmatrix}K&0\\
0&tI_{K}\end{smallmatrix}\right)D_{qh}^{-1,T}\left(\left(\begin{smallmatrix}\hat{Q}_{h}&0\\
0&0\end{smallmatrix}\right)+\rho\left(\begin{smallmatrix}\hat{m}\\
1\end{smallmatrix}\right)^{\otimes 2}+(1-\rho)\left(\begin{smallmatrix}\hat{m}\\
0\end{smallmatrix}\right)^{\otimes 2}\right)D_{qh}^{-1}\left(\begin{smallmatrix}K&0\\
0&tI_{K}\end{smallmatrix}\right) \displaystyle\left(\begin{smallmatrix}\cdot&\cdot\\
-\mathrm{i}Q_{qh}&\cdot\end{smallmatrix}\right) \displaystyle=tD_{qh}^{-1,T}\left[\left(t\delta_{\mathrm{e}}\left(\begin{smallmatrix}0&-\mathrm{i}Q_{qh}\\
0&0\end{smallmatrix}\right)+\left(\begin{smallmatrix}\hat{m}\\
\rho\end{smallmatrix}\right)\left(\begin{smallmatrix}K\sqrt{\mu}m_{w}\\
\lambda^{\mathrm{e}}tm\end{smallmatrix}\right)^{T}\right)D_{qh}^{-1,T}+\left(\left(\begin{smallmatrix}\hat{Q}_{h}&0\\
0&0\end{smallmatrix}\right)+\rho\left(\begin{smallmatrix}\hat{m}\\
1\end{smallmatrix}\right)^{\otimes 2}+(1-\rho)\left(\begin{smallmatrix}\hat{m}\\
0\end{smallmatrix}\right)^{\otimes 2}\right)D_{qh}^{-1}G_{0}D_{qh}^{-1,T}\right] \displaystyle\left(\begin{smallmatrix}Q_{h}&\cdot\\
\cdot&\cdot\end{smallmatrix}\right) \displaystyle=D_{qh}^{-1}G_{0}D_{qh}^{-1,T}\left(\left(\begin{smallmatrix}\hat{Q}_{h}&0\\
0&0\end{smallmatrix}\right)+\rho\left(\begin{smallmatrix}\hat{m}\\
1\end{smallmatrix}\right)^{\otimes 2}+(1-\rho)\left(\begin{smallmatrix}\hat{m}\\
0\end{smallmatrix}\right)^{\otimes 2}\right)D_{qh}^{-1}G_{0}D_{qh}^{-1,T}+D_{qh}^{-1}\left(\left(\begin{smallmatrix}K^{2}Q_{w}&0\\
0&t^{2}Q_{h}\end{smallmatrix}\right)+\left(\begin{smallmatrix}K\sqrt{\mu}m_{w}\\
\lambda^{\mathrm{e}}tm\end{smallmatrix}\right)^{\otimes 2}\right)D_{qh}^{-1,T} \displaystyle{}+D_{qh}^{-1}G_{0}D_{qh}^{-1,T}\left(t\delta_{\mathrm{e}}\left(\begin{smallmatrix}0&-\mathrm{i}Q_{qh}\\
0&0\end{smallmatrix}\right)+\left(\begin{smallmatrix}\hat{m}\\
\rho\end{smallmatrix}\right)\left(\begin{smallmatrix}K\sqrt{\mu}m_{w}\\
\lambda^{\mathrm{e}}tm\end{smallmatrix}\right)^{T}\right)D_{qh}^{-1,T}+D_{qh}^{-1}\left(t\delta_{\mathrm{e}}\left(\begin{smallmatrix}0&0\\
-\mathrm{i}Q_{qh}^{T}&0\end{smallmatrix}\right)+\left(\begin{smallmatrix}K\sqrt{\mu}m_{w}\\
\lambda^{\mathrm{e}}tm\end{smallmatrix}\right)\left(\begin{smallmatrix}\hat{m}\\
\rho\end{smallmatrix}\right)^{T}\right)D_{qh}^{-1}G_{0}D_{qh}^{-1,T} \tag{92}
$$
We see that all these self-consistent equations (88 - 94) are vectorial or matricial equations of the form $x=\lambda^{\mathrm{e}}tD_{qh}^{-1}x$ or $X=t^{2}D_{qh}^{-1}XD_{qh}^{-1,T}$ , over $x$ or $X$ , plus inhomogenuous terms and boundary conditions at 0 or $(0,0)$ . The equations are recursive in the sense that each equation only depends on the previous ones and they can be solved one by one. It is thus enough to compute the resolvants of these two equations. Last eq. (87) shows how to invert $D_{qh}$ and express $D_{qh}^{-1}$ . These different properties make the system of self-consistent equations easily solvable, provided one can compute $D_{qh}$ and the two resolvants. This furthermore highlights the relevance of the $r\to\infty$ limit.
We take the continuous limit $K\to\infty$ . We translate the above self-consistent equations into functional equations. Thanks to the expansion around large $r$ we have a well defined limit, that does not involve any matrix inverse. We set $x=k/K$ and $z=l/K$ continuous indices ranging from 0 to 1. We extend the vectors and the matrices by continuity to match the correct dimensions. We apply the following rescaling to obtain quantities that are independent of $K$ in that limit:
$$
\displaystyle\hat{m}\to K\hat{m}\ , \displaystyle\hat{Q}_{h}\to K^{2}\hat{Q}_{h}\ , \displaystyle\hat{V}_{h}\to K^{2}\hat{V}_{h}\ , \displaystyle Q_{qh}\to KQ_{qh}\ , \displaystyle V_{qh}\to KV_{qh}\ . \tag{95}
$$
We first compute the effective derivative $D_{qh}=D-t\left(\begin{smallmatrix}0&0\\ -\mathrm{i}\delta_{\mathrm{e}}V_{qh}^{T}&0\end{smallmatrix}\right)$ and its inverse. In the asymmetric case we have $D_{qh}=D$ , the usual derivative. In the symmetric case we have $D_{qh}=D-tV_{qh}^{T}$ where $V_{qh}$ satisfies eq. (87) which reads
$$
\displaystyle\partial_{z}V_{qh}(x,z)+\delta(z)V_{qh}(x,z)= \displaystyle\qquad\qquad t\delta(z-x)+t\int_{0}^{1}\mathrm{d}x^{\prime}\,V_{qh}(x,x^{\prime})V_{qh}(x^{\prime},z)\ , \tag{97}
$$
where we multiplied both sides by $D_{qh}^{T}$ and took $V_{qh}(x,z)$ for $-\mathrm{i}V_{qh}$ . The solution to this integro-differential equation is
$$
\displaystyle V_{qh}(x,z) \displaystyle=\theta(z-x)\frac{I_{1}(2t(z-x))}{z-x} \tag{98}
$$
with $\theta$ the step function and $I_{\nu}$ the modified Bessel function of the second kind of order $\nu$ . Consequently we obtain the effective inverse derivative
$$
\displaystyle D_{qh}^{-1}(x,z) \displaystyle=D_{qh}^{-1,T}(z,x)=\left\{\begin{array}[]{cc}\theta(x-z)&\mathrm{if}\,\delta_{\mathrm{e}}=0\\
\frac{1}{t}V_{qh}(z,x)&\mathrm{if}\,\delta_{\mathrm{e}}=1\end{array}\right.\ . \tag{101}
$$
We then define the resolvants (or propagators) $\varphi$ and $\Phi$ of the integral equations as
$$
\displaystyle D_{qh}\varphi(x) \displaystyle=\lambda^{\mathrm{e}}t\varphi(x)+\delta(x)\ , \displaystyle D_{qh}\Phi(x,z)D_{qh}^{T} \displaystyle=t^{2}\Phi(x,z)+\delta(x,z)\ . \tag{102}
$$
Notice that in the asymmetric case, $D_{qh}=\partial_{x}$ , $D_{qh}^{T}=\partial_{z}$ and $\Phi$ is the propagator of the two-dimensional Klein-Gordon equation up to a change of variables. The resolvants can be expressed as
$$
\displaystyle\varphi(x) \displaystyle=\left\{\begin{array}[]{cc}e^{\lambda^{\mathrm{e}}tx}&\mathrm{if}\,\delta_{\mathrm{e}}=0\\
\sum_{\nu>0}^{\infty}\nu(\lambda^{\mathrm{e}})^{\nu-1}\frac{I_{\nu}(2tx)}{tx}&\mathrm{if}\,\delta_{\mathrm{e}}=1\end{array}\right.\ , \displaystyle\Phi(x,z) \displaystyle=\left\{\begin{array}[]{cc}I_{0}(2t\sqrt{xz})&\mathrm{if}\,\delta_{\mathrm{e}}=0\\
\frac{I_{1}(2t(x+z))}{t(x+z)}&\mathrm{if}\,\delta_{\mathrm{e}}=1\end{array}\right.\ . \tag{106}
$$
We obtain the solution of the self-consistent equations by convolving $\varphi$ or $\Phi$ with the non-homogenuous terms. We flip $\hat{m}$ along it axis to match the vectorial equation with boundary condition at $x=0$ ; we do the same for $\hat{V}_{h}$ and $\hat{Q}_{h}$ along there two axes, and for $Q_{qh}$ along its first axis. This gives the following expressions for the order parameters:
$$
\displaystyle V_{w}=\frac{1}{r\alpha} \displaystyle V_{h}(x,z)=V_{w}\Phi(x,z) \displaystyle\hat{V}_{h}(1-x,1-z)=t^{2}\rho\Phi(x,z) \displaystyle\hat{V}_{w}=t^{-2}\hat{V}_{h}(0,0) \displaystyle\hat{m}(1-x)=\rho\lambda^{\mathrm{e}}t\varphi(x) \displaystyle\hat{m}_{w}=\sqrt{\mu}\frac{1}{\lambda^{\mathrm{e}}t}\hat{m}(0) \displaystyle m_{w}=\frac{\hat{m}_{w}}{r\alpha} \displaystyle m(x)=(1+\mu)\frac{m_{w}}{\sqrt{\mu}}\varphi(x) \displaystyle\qquad{}+\frac{t}{\lambda^{\mathrm{e}}}\int_{0}^{x}\mathrm{d}x^{\prime}\int_{0}^{1}\mathrm{d}x^{\prime\prime}\,\varphi(x-x^{\prime})V_{h}(x^{\prime},x^{\prime\prime})\hat{m}(x^{\prime\prime}) \displaystyle\hat{Q}_{w}=t^{-2}\hat{Q}_{h}(0,0) \displaystyle Q_{w}=\frac{\hat{Q}_{w}+\hat{m}_{w}^{2}}{r^{2}\alpha} \tag{110}
$$
$$
\displaystyle\hat{Q}_{h}(1-x,1-z)=t^{2}\int_{0^{-},0^{-}}^{x,z}\mathrm{d}x^{\prime}\mathrm{d}z^{\prime}\ \Phi(x-x^{\prime},z-z^{\prime})\left[\mathcal{P}(\hat{m}^{\otimes 2})(1-x^{\prime},1-z^{\prime})\right] \displaystyle Q_{qh}(1-x,z)=t\int_{0^{-},0^{-}}^{x,z}\mathrm{d}x^{\prime}\mathrm{d}z^{\prime}\ \Phi(x-x^{\prime},z-z^{\prime})\Bigg[\mathcal{P}(\hat{m})(1-x^{\prime})(\lambda^{\mathrm{e}}tm(z^{\prime})+\sqrt{\mu}m_{w}\delta(z^{\prime})) \displaystyle\hskip 18.49988pt\left.{}+\int_{0,0^{-}}^{1^{+},1}\mathrm{d}x^{\prime\prime}\mathrm{d}z^{\prime\prime}\,\left(\hat{Q}_{h}(1-x^{\prime},x^{\prime\prime})+\mathcal{P}(\hat{m}^{\otimes 2})(1-x^{\prime},x^{\prime\prime})\right)D_{qh}^{-1}(x^{\prime\prime},z^{\prime\prime})G_{0}(z^{\prime\prime},z^{\prime})\right] \tag{120}
$$
$$
\displaystyle Q_{h}(x,z)=\int_{0^{-},0^{-}}^{x,z}\mathrm{d}x^{\prime}\mathrm{d}z^{\prime}\ \Phi(x-x^{\prime},z-z^{\prime})\Bigg[\hat{Q}_{w}\delta(x^{\prime},z^{\prime})+(\lambda^{\mathrm{e}}tm(x^{\prime})+\sqrt{\mu}m_{w}\delta(x^{\prime}))(\lambda^{\mathrm{e}}tm(z^{\prime})+\sqrt{\mu}m_{w}\delta(z^{\prime})) \displaystyle\hskip 18.49988pt{}+\int_{0^{-},0}^{1,1^{+}}\mathrm{d}x^{\prime\prime}\mathrm{d}x^{\prime\prime\prime}\,G_{0}(x^{\prime},x^{\prime\prime})D_{qh}^{-1,T}(x^{\prime\prime},x^{\prime\prime\prime})\left(t\delta_{\mathrm{e}}Q_{qh}(x^{\prime\prime\prime},z^{\prime})+\mathcal{P}(\hat{m})(x^{\prime\prime\prime})(\lambda^{\mathrm{e}}tm(z^{\prime})+\sqrt{\mu}m_{w}\delta(z^{\prime}))\right) \displaystyle\hskip 18.49988pt{}+\int_{0,0^{-}}^{1^{+},1}\mathrm{d}z^{\prime\prime\prime}\mathrm{d}z^{\prime\prime}\,\left(t\delta_{\mathrm{e}}Q_{qh}(z^{\prime\prime\prime},x^{\prime})+(\lambda^{\mathrm{e}}tm(x^{\prime})+\sqrt{\mu}m_{w}\delta(x^{\prime}))\mathcal{P}(\hat{m})(z^{\prime\prime\prime})\right)D_{qh}^{-1}(z^{\prime\prime\prime},z^{\prime\prime})G_{0}(z^{\prime\prime},z^{\prime}) \displaystyle\qquad\left.{}+\int_{0^{-},0,0,0^{-}}^{1,1^{+},1^{+},1}\mathrm{d}x^{\prime\prime}\mathrm{d}x^{\prime\prime\prime}\mathrm{d}z^{\prime\prime\prime}\mathrm{d}z^{\prime\prime}\,G_{0}(x^{\prime},x^{\prime\prime})D_{qh}^{-1,T}(x^{\prime\prime},x^{\prime\prime\prime})\left(\hat{Q}_{h}(x^{\prime\prime\prime},z^{\prime\prime\prime})+\mathcal{P}(\hat{m}^{\otimes 2})(x^{\prime\prime\prime},z^{\prime\prime\prime})\right)D_{qh}^{-1}(z^{\prime\prime\prime},z^{\prime\prime})G_{0}(z^{\prime\prime},z^{\prime})\right]\ ; \tag{122}
$$
where we set
$$
\displaystyle\mathcal{P}(\hat{m})(x) \displaystyle=\hat{m}(x)+\rho\delta(1-x)\ , \displaystyle\mathcal{P}(\hat{m}^{\otimes 2})(x,z) \displaystyle=\rho\left(\hat{m}(x)+\delta(1-x)\right)\left(\hat{m}(z)+\delta(1-z)\right) \displaystyle\quad{}+(1-\rho)\hat{m}(x)\hat{m}(z)\ , \displaystyle G_{0}(x,z) \displaystyle=t^{2}V_{h}(x,z)+V_{w}\delta(x,z) \tag{123}
$$
and take $Q_{qh}(x,z)$ for $-\mathrm{i}Q_{qh}$ . The accuracies are, with $\bar{s}=1$ for train and $\bar{s}=0$ for test:
$$
\displaystyle\mathrm{Acc}_{\mathrm{train/test}}= \displaystyle\qquad\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{m(1)+(\bar{s}-\rho)V_{h}(1,1)}{\sqrt{2}\sqrt{Q_{h}(1,1)-m(1)^{2}-\rho(1-\rho)V_{h}(1,1)^{2}}}\right)\right)\ . \tag{126}
$$
Notice that we fully solved the model, in a certain limit, by giving an explicit expression of the performance of the GCN. This is an uncommon result in the sense that, in several works analyzing the performance of neural networks in a high-dimensional limit, the performance are only expressed as the function of the self-consistent of a system of equations similar to ours (75 - 84). These systems have to be solved numerically, which may be unsatisfactory for the understanding of the studied models.
So far, we dealt with infinite regularization $r$ keeping only the first constant order. The predicted accuracy (126) does not depend on $r$ . We briefly show how to pursue the computation at any order in appendix B.4, by a perturbative approach with expansion in powers of $1/r$ .
Interpretation in terms of dynamical mean-field theory:
The order parameters $V_{h}$ , $V_{qh}$ and $\hat{V}_{h}$ come from the replica computation and were introduced as the covariances between $h$ and its conjugate $q$ . Their values are determined by extremizing the free entropy of the problem. In the above lines we derived that $V_{h}(x,z)\propto\Phi(x,z)$ is the forward propagator, from the weights to the loss, while $\hat{V}_{h}(x,z)\propto\Phi(1-x,1-z)$ is the backward propagator, from the loss to the weights.
In this section we state an equivalence between these order parameters and the correlation and response functions of the dynamical process followed by $h$ .
We introduce the tilting field $\eta(x)\in\mathbb{R}^{N}$ and the tilted Hamiltonian as
$$
\displaystyle\frac{\mathrm{d}h}{\mathrm{d}x}(x)=\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}h(x)+\eta(x)+\delta(x)\frac{1}{\sqrt{N}}Xw\ , \displaystyle h(x)=\int_{0^{-}}^{x}\mathrm{d}x^{\prime}e^{(x-x^{\prime})\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}}\left(\eta(x^{\prime})+\delta(x^{\prime})\frac{1}{\sqrt{N}}Xw\right)\ , \displaystyle H(\eta)=\frac{1}{2}(y-h(1))^{T}R(y-h(1))+\frac{r}{2}w^{T}w\ , \tag{127}
$$
where $R\in\mathbb{R}^{N\times N}$ diagonal accounts for the train and test nodes. We write $\langle\cdot\rangle_{\beta}$ the expectation under the density $e^{-\beta H(\eta)}/Z$ (normalized only at $\eta=0$ ).
Then we have
$$
\displaystyle V_{h}(x,z) \displaystyle=\frac{\beta}{N}\operatorname{Tr}\left[\langle h(x)h(z)^{T}\rangle_{\beta}-\langle h(x)\rangle_{\beta}\langle h(z)^{T}\rangle_{\beta}\right]|_{\eta=0}\ , \displaystyle V_{qh}(x,z) \displaystyle=\frac{t}{N}\operatorname{Tr}\frac{\partial}{\partial\eta(z)}\langle h(x)\rangle_{\beta}|_{\eta=0}\ , \displaystyle\hat{V}_{h}(x,z) \displaystyle=\frac{t^{2}}{\beta^{2}N}\operatorname{Tr}\frac{\partial^{2}}{\partial\eta(x)\partial\eta(z)}\langle 1\rangle_{\beta}|_{\eta=0}\ ; \tag{130}
$$
that is to say $V_{h}$ is the correlation function, $V_{qh}\approx tD_{qh}^{-1,T}$ is the response function and $\hat{V}_{h}$ is the correlation function of the responses of $h$ . We prove these equalities at the constant order in $r$ using random matrix theory in the appendix B.5.
#### III.2.3 Consequences
Convergences:
We compare our predictions to numerical simulations of the continuous GCN for $N=10^{4}$ and $N=7\times 10^{3}$ in fig. 5 and figs. 8, 10 and 11 in appendix E. The predicted test accuracies are well within the statistical errors. On these figures we can observe the convergence of $\mathrm{Acc}_{\mathrm{test}}$ with respect to $r$ . The interversion of the two limits $r\to\infty$ and $K\to\infty$ we did to obtain (126) seems valid. Indeed on the figures we simulate the continuous GCN with $e^{\frac{t\tilde{A}}{\sqrt{N}}}$ or $e^{\frac{t\tilde{A}^{\mathrm{s}}}{\sqrt{N}}}$ and take $r\to\infty$ after the continuous limit $K\to\infty$ ; and we observe that the simulated accuracies converge well toward the predicted ones. To keep only the constant order in $1/r$ gives a good approximation of the continuous GCN. Indeed, the convergence with respect to $1/r$ can be fast: at $t\lessapprox 1$ not too large, $r\gtrapprox 1$ is enough to reach the continuous limit.
<details>
<summary>x5.png Details</summary>
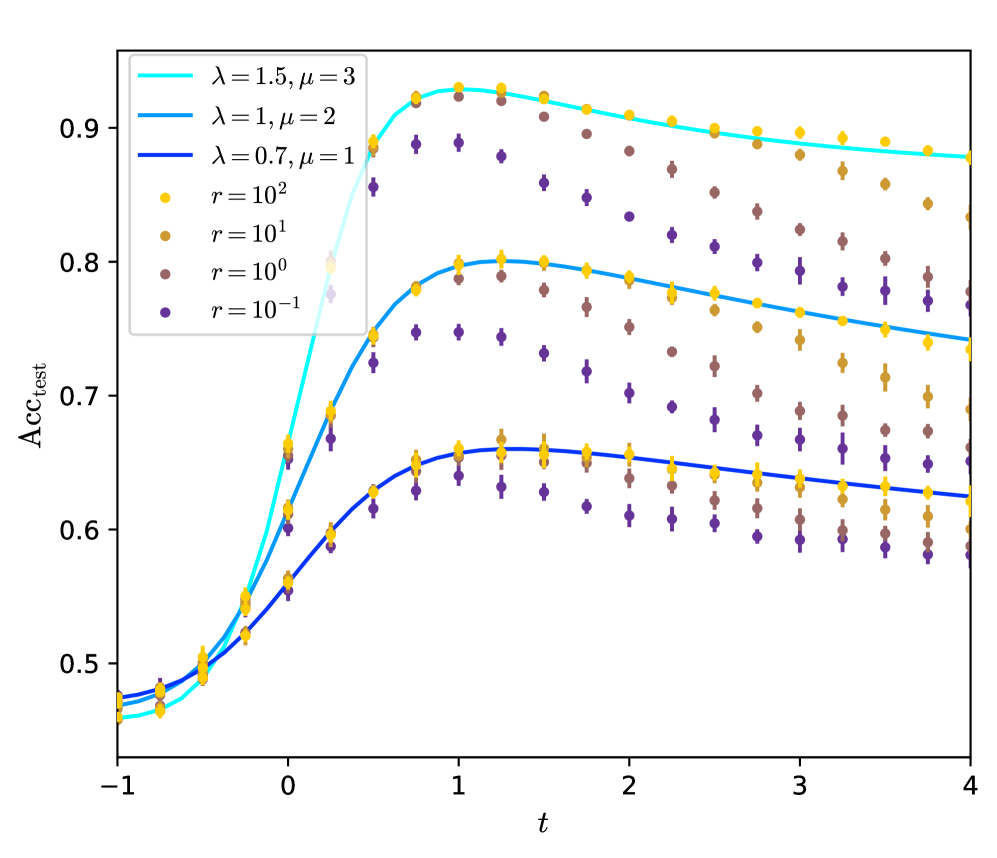
### Visual Description
## Line Chart: Acc_test vs. t with Parameter Variations
### Overview
The image presents a line chart illustrating the relationship between `Acc_test` (Accuracy on a test set) and `t` (likely representing time or training steps). The chart compares the performance of different parameter settings, denoted by λ (lambda) and μ (mu), as well as different values of 'r'. The data is presented as multiple lines and scattered points.
### Components/Axes
* **X-axis:** Labeled as `t`, ranging from approximately -1 to 4.
* **Y-axis:** Labeled as `Acc_test`, ranging from approximately 0.48 to 0.92.
* **Lines:** Three lines representing different (λ, μ) parameter combinations:
* λ = 1.5, μ = 3 (Light Blue)
* λ = 1, μ = 2 (Medium Blue)
* λ = 0.7, μ = 1 (Dark Blue)
* **Scatter Points:** Three sets of scatter points representing different 'r' values:
* r = 10<sup>2</sup> (Yellow)
* r = 10<sup>1</sup> (Orange)
* r = 10<sup>-1</sup> (Purple)
* **Legend:** Located in the top-left corner, clearly labeling each line and scatter point series.
### Detailed Analysis
Let's analyze each data series individually:
**Line Series:**
* **λ = 1.5, μ = 3 (Light Blue):** This line starts at approximately ( -1, 0.50) and rapidly increases, reaching a plateau around (1.5, 0.88). It remains relatively stable between approximately 0.86 and 0.90 for t > 1.5.
* **λ = 1, μ = 2 (Medium Blue):** This line begins at approximately (-1, 0.50) and increases more gradually than the light blue line, reaching a plateau around (2, 0.82). It fluctuates between approximately 0.78 and 0.84 for t > 2.
* **λ = 0.7, μ = 1 (Dark Blue):** This line starts at approximately (-1, 0.50) and exhibits the slowest increase, reaching a plateau around (3, 0.68). It remains relatively stable between approximately 0.64 and 0.72 for t > 3.
**Scatter Point Series:**
* **r = 10<sup>2</sup> (Yellow):** These points are scattered, generally trending upwards. Starting around (-1, 0.55), they reach a peak around (3.5, 0.88) and then fluctuate.
* **r = 10<sup>1</sup> (Orange):** These points are also scattered, with a similar upward trend but generally lower values than the yellow points. Starting around (-1, 0.60), they reach a peak around (3.5, 0.80) and then fluctuate.
* **r = 10<sup>-1</sup> (Purple):** These points are scattered, exhibiting a more erratic pattern. They start around (-1, 0.65), reach a peak around (1, 0.85), and then decline, fluctuating between approximately 0.65 and 0.85.
### Key Observations
* The lines representing different (λ, μ) combinations demonstrate that higher values of λ and μ generally lead to faster convergence and higher `Acc_test` values.
* The scatter points for different 'r' values show a general trend of increasing accuracy with increasing 'r', but with significant variability.
* The purple scatter points (r = 10<sup>-1</sup>) exhibit a more unstable behavior, suggesting that very small values of 'r' may lead to less reliable performance.
* All lines start at the same `Acc_test` value at t = -1.
### Interpretation
This chart likely represents the performance of a learning algorithm (or a model) over time (or training iterations). The parameters λ and μ likely control the learning rate or regularization strength of the algorithm. The parameter 'r' could represent the amount of data or the complexity of the model.
The data suggests that:
* Increasing λ and μ can accelerate learning, but may also lead to overfitting or instability if the values are too high.
* Increasing 'r' generally improves performance, but the relationship is not strictly linear and is subject to noise.
* The scatter points represent individual runs or trials, and the variability suggests that the algorithm's performance is sensitive to initial conditions or random factors.
The plateauing of the lines indicates that the algorithm is converging to a stable state. The differences in the plateau levels suggest that different parameter settings lead to different levels of performance. The purple scatter points' erratic behavior could indicate that the model is struggling to learn with a very small 'r' value, potentially due to insufficient data or model capacity. The chart provides valuable insights into the sensitivity of the algorithm's performance to different parameter settings and the importance of choosing appropriate values for λ, μ, and 'r'.
</details>
Figure 5: Predicted test accuracy $\mathrm{Acc}_{\mathrm{test}}$ of the continuous GCN on the asymmetric graph, at $r=\infty$ . $\alpha=4$ and $\rho=0.1$ . The performance of the continuous GCN are given by eq. (126). Dots: numerical simulation of the continuous GCN for $N=10^{4}$ and $d=30$ , trained with quadratic loss, averaged over ten experiments.
The convergence with respect to $K\to\infty$ , taken after $r\to\infty$ , is depicted in fig. 6 and fig. 9 in appendix E. Again the continuous limit enjoyes good convergence properties since $K\gtrapprox 16$ is enough if $t$ is not too large.
<details>
<summary>x6.png Details</summary>
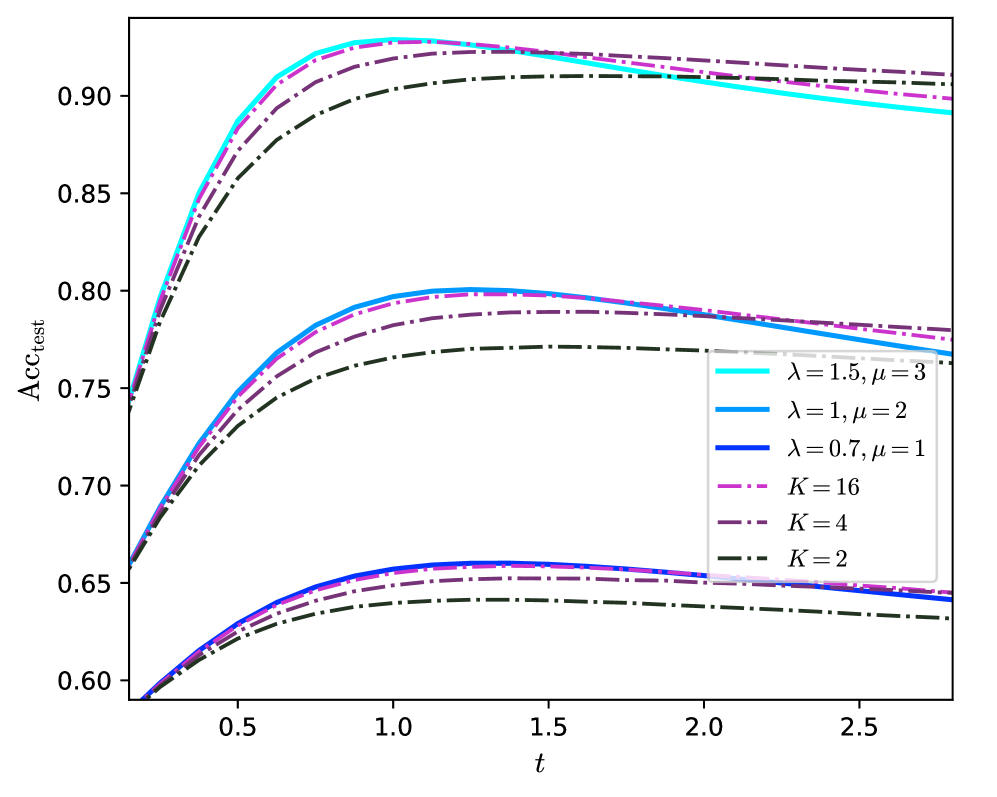
### Visual Description
## Line Chart: Test Accuracy vs. Time
### Overview
This image presents a line chart illustrating the relationship between test accuracy (Acc<sub>test</sub>) and time (t) for different parameter settings. Several lines are plotted, representing different combinations of lambda (λ) and mu (μ) values, as well as different values of K. The chart appears to demonstrate how test accuracy evolves over time under varying conditions.
### Components/Axes
* **X-axis:** Labeled "t", representing time. The scale ranges from approximately 0.3 to 2.7.
* **Y-axis:** Labeled "Acc<sub>test</sub>", representing test accuracy. The scale ranges from approximately 0.60 to 0.92.
* **Legend:** Located in the top-right corner of the chart. It contains the following entries:
* λ = 1.5, μ = 3 (Light Blue Solid Line)
* λ = 1, μ = 2 (Blue Solid Line)
* λ = 0.7, μ = 1 (Dark Blue Solid Line)
* K = 16 (Purple Dashed Line)
* K = 4 (Purple Dashed-Dotted Line)
* K = 2 (Black Dashed-Dotted Line)
### Detailed Analysis
The chart displays six distinct lines, each representing a different set of parameters.
* **λ = 1.5, μ = 3 (Light Blue):** This line starts at approximately Acc<sub>test</sub> = 0.62 at t = 0.3, rises rapidly, and plateaus around Acc<sub>test</sub> = 0.91 at t = 1.0, remaining relatively stable thereafter.
* **λ = 1, μ = 2 (Blue):** This line begins at approximately Acc<sub>test</sub> = 0.63 at t = 0.3, increases steadily, and reaches a plateau around Acc<sub>test</sub> = 0.88 at t = 1.5, with minimal change after that.
* **λ = 0.7, μ = 1 (Dark Blue):** This line starts at approximately Acc<sub>test</sub> = 0.64 at t = 0.3, exhibits a slower increase compared to the other two, and plateaus around Acc<sub>test</sub> = 0.77 at t = 2.0.
* **K = 16 (Purple Dashed):** This line starts at approximately Acc<sub>test</sub> = 0.61 at t = 0.3, increases rapidly, and reaches a plateau around Acc<sub>test</sub> = 0.89 at t = 1.0, remaining relatively stable.
* **K = 4 (Purple Dashed-Dotted):** This line begins at approximately Acc<sub>test</sub> = 0.62 at t = 0.3, increases steadily, and plateaus around Acc<sub>test</sub> = 0.78 at t = 1.5.
* **K = 2 (Black Dashed-Dotted):** This line starts at approximately Acc<sub>test</sub> = 0.60 at t = 0.3, increases slowly, and plateaus around Acc<sub>test</sub> = 0.67 at t = 2.0.
All lines exhibit an initial increase in Acc<sub>test</sub> as t increases, but the rate of increase and the final plateau value vary significantly.
### Key Observations
* The lines representing different values of λ and μ (light blue, blue, and dark blue) generally achieve higher test accuracy than those representing different values of K (purple and black).
* Higher values of λ and μ appear to lead to faster convergence to a higher test accuracy.
* Increasing K from 2 to 4 to 16 results in a noticeable increase in test accuracy, but the accuracy remains lower than that achieved with higher λ and μ values.
* The line for K=2 shows the lowest overall test accuracy.
### Interpretation
The chart suggests that the parameters λ and μ have a more significant impact on test accuracy than the parameter K. The values of λ and μ likely control the learning rate or the strength of the model's ability to capture patterns in the data, while K might represent the complexity or capacity of the model. The rapid initial increase in accuracy followed by a plateau indicates that the model quickly learns the initial patterns but then reaches a point of diminishing returns. The differences in the plateau values suggest that different parameter settings lead to different levels of model performance. The relatively low accuracy achieved with K=2 suggests that a model with insufficient capacity may not be able to fully capture the underlying patterns in the data, even with optimal values of λ and μ. The chart demonstrates a trade-off between model complexity (K) and learning parameters (λ, μ) in achieving optimal test accuracy.
</details>
Figure 6: Predicted test accuracy $\mathrm{Acc}_{\mathrm{test}}$ of the continuous GCN and of its discrete counterpart with depth $K$ on the asymmetric graph, at $r=\infty$ . $\alpha=1$ and $\rho=0.1$ . The performance of the continuous GCN are given by eq. (126) while for the discrete GCN they are given by numerically solving the fixed-point equations (88 - 94).
To summarize, figs. 5, 6 and appendix E validate our method that consists in deriving the self-consistent equations at finite $K$ with replica, expanding them with respect to $1/r$ , taking the continuous limit $K\to\infty$ and then solving the integral equations.
Optimal diffusion time $t^{*}$ :
We observe on the previous figures that there is an optimal diffusion time $t^{*}$ that maximizes $\mathrm{Acc}_{\mathrm{test}}$ . Though we are able to solve the self-consistent equations and to obtain an explicit and analytical expression (126), it is hard to analyze it in order to evaluate $t^{*}$ . We have to consider further limiting cases or to compute $t^{*}$ numerically. The derivation of the following equations is detailed in appendix B.6.
We first consider the case $t\to 0$ . Expanding (126) to the first order in $t$ we obtain
$$
\mathrm{Acc}_{\mathrm{test}}\underset{t\to 0}{=}\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{1}{\sqrt{2}}\sqrt{\frac{\rho}{\alpha}}\frac{\mu+\lambda^{\mathrm{e}}t(2+\mu)}{\sqrt{1+\rho\mu}}\right)\right)+o(t)\ . \tag{133}
$$
This expression shows in particular that $t^{*}>0$ , i.e. some diffusion on the graph is always beneficial compared to no diffusion, as long as $\lambda t>0$ i.e. the diffusion is done forward if the graph is homophilic $\lambda>0$ and backward if it is heterophilic $\lambda<0$ . We recover the result of [40] for the discrete case in a slightly different setting. This holds even if the features of the graph are not informative $\mu=0$ . Notice the explicit invariance by the change $(\lambda,t)\to(-\lambda,-t)$ in the potential (65) and in (133), which allows us to focus on $\lambda\geq 0$ . The case $t=0$ no diffusion corresponds to performing ridge regression on the Gaussian mixture $X$ alone. Such a model has been studied in [37]; we checked we obtain the same expression as theirs at large regularization.
We now consider the case $t\to+\infty$ and $\lambda\geq 0$ . Taking the limit in (126) we obtain
$$
\mathrm{Acc}_{\mathrm{test}}\underset{t\to\infty}{\longrightarrow}\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{\lambda^{\mathrm{e}}q_{\mathrm{PCA}}}{\sqrt{2}}\right)\right)\ , \tag{134}
$$
where $q_{\mathrm{PCA}}$ is the same as for the discrete GCN, defined in eq. (59). This shows that the continuous GCN will oversmooth at large diffusion times. Thus, if the features are informative, if $\mu^{2}/\alpha>0$ , the optimal diffusion time should be finite, $t^{*}<+\infty$ . The continuous GCN does exactly as does the discrete GCN at $K\to\infty$ if $c$ is fixed. This is not surprising because of the mapping $c=K/t$ : taking $t$ large is equivalent to take $c$ small with respect to $K$ . $e^{\frac{t}{\sqrt{N}}\tilde{A}}$ is dominated by the same leading eigenvector $y_{1}$ .
These two limits show that at finite time $t$ the GCN avoids oversmoothing and interpolates between an estimator that is only function of the features at $t=0$ and an estimator only function of the graph at $t=\infty$ . $t$ has to be fine-tuned to reach the best trade-off $t^{*}$ and the optimal performance.
In the insets of fig. 7 and fig. 12 in appendix E we show how $t^{*}$ depends on $\lambda$ . In particular, $t^{*}$ is finite for any $\lambda$ : some diffusion is always beneficial but too much diffusion leads to oversmoothing. We have $t^{*}\underset{\lambda\to 0}{\longrightarrow}0$ . This is expected since if $\lambda=0$ then $A$ is not informative and any diffusion $t>0$ would degrade the performance. The non-monotonicity of $t^{*}$ with respect to $\lambda$ is less expected and we do not have a clear interpretation for it. Last $t^{*}$ decreases when the feature signal $\mu^{2}/\alpha$ increases: the more informative $X$ the less needed diffusion is.
<details>
<summary>x7.png Details</summary>
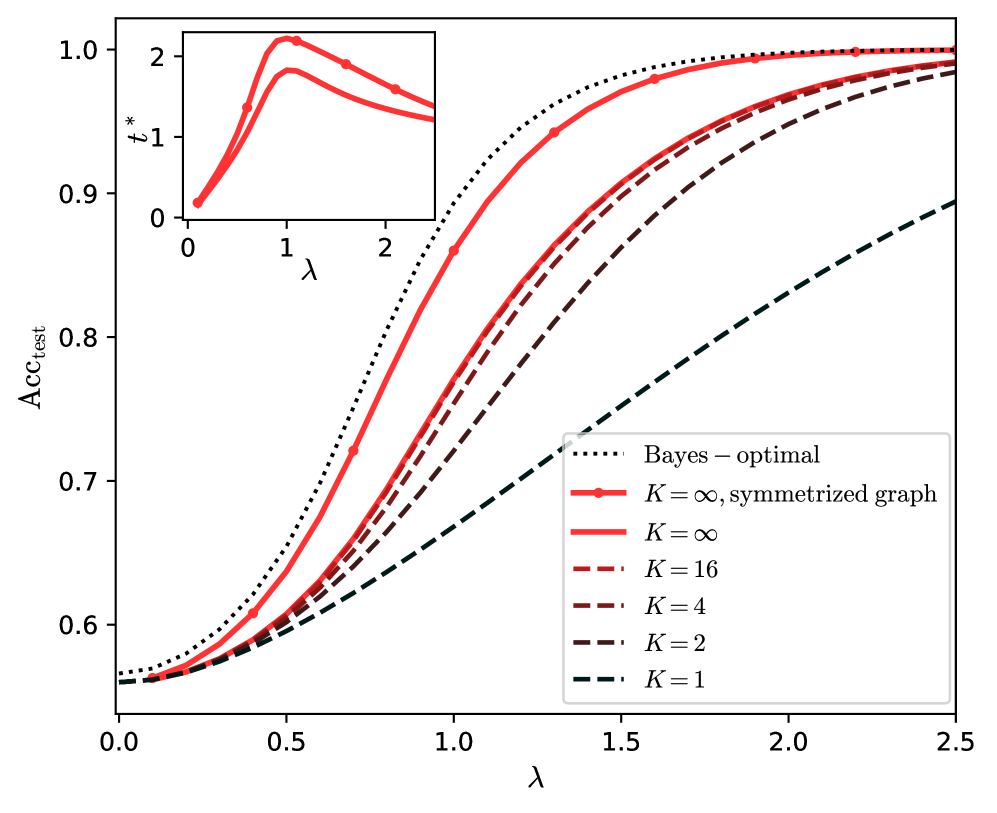
### Visual Description
\n
## Chart: Test Accuracy vs. Lambda
### Overview
The image presents a line chart illustrating the relationship between a parameter lambda (λ) and the test accuracy (Acc<sub>test</sub>) for different values of K. A smaller inset chart shows the relationship between lambda and t*. The chart appears to be evaluating the performance of a model or algorithm under varying conditions.
### Components/Axes
* **X-axis:** Lambda (λ), ranging from 0.0 to 2.5.
* **Y-axis:** Test Accuracy (Acc<sub>test</sub>), ranging from 0.55 to 1.05.
* **Inset Chart X-axis:** Lambda (λ), ranging from 0.0 to 2.5.
* **Inset Chart Y-axis:** t*, ranging from 0.0 to 2.5.
* **Legend:** Located in the top-right corner, listing the different lines:
* Bayes – optimal (solid blue line)
* K = ∞, symmetrized graph (dotted red line)
* K = ∞ (solid red line)
* K = 16 (dashed brown line)
* K = 4 (dashed dark red line)
* K = 2 (dashed black line)
* K = 1 (dashed very dark black line)
### Detailed Analysis
The main chart displays several lines representing different values of K.
* **Bayes – optimal (solid blue line):** This line starts at approximately 0.62 at λ = 0.0, rises rapidly to approximately 0.95 at λ = 0.7, and then plateaus, remaining around 0.98-1.0 for λ > 1.0.
* **K = ∞, symmetrized graph (dotted red line):** This line begins at approximately 0.62 at λ = 0.0, increases steadily to approximately 0.95 at λ = 1.0, and then plateaus around 0.98-1.0 for λ > 1.0.
* **K = ∞ (solid red line):** This line starts at approximately 0.62 at λ = 0.0, rises steadily to approximately 0.95 at λ = 1.0, and then plateaus around 0.98-1.0 for λ > 1.0.
* **K = 16 (dashed brown line):** This line starts at approximately 0.62 at λ = 0.0, increases more slowly than the previous lines, reaching approximately 0.85 at λ = 1.0, and then continues to rise, approaching 0.95 at λ = 2.5.
* **K = 4 (dashed dark red line):** This line starts at approximately 0.62 at λ = 0.0, increases slowly, reaching approximately 0.75 at λ = 1.0, and then continues to rise, approaching 0.90 at λ = 2.5.
* **K = 2 (dashed black line):** This line starts at approximately 0.62 at λ = 0.0, increases very slowly, reaching approximately 0.68 at λ = 1.0, and then continues to rise, approaching 0.80 at λ = 2.5.
* **K = 1 (dashed very dark black line):** This line starts at approximately 0.62 at λ = 0.0, increases extremely slowly, reaching approximately 0.65 at λ = 1.0, and then continues to rise, approaching 0.75 at λ = 2.5.
The inset chart shows a curve for t* vs. λ. The curve peaks at approximately t* = 2.1 at λ = 0.8, and then decreases to approximately t* = 1.0 at λ = 2.5.
### Key Observations
* The "Bayes – optimal" and "K = ∞" lines achieve the highest test accuracy, plateauing around 0.98-1.0 for λ > 1.0.
* As K decreases, the test accuracy decreases, and the rate of increase with respect to λ slows down.
* The inset chart shows a non-monotonic relationship between t* and λ, with a peak around λ = 0.8.
* All lines start at the same accuracy level (approximately 0.62) when λ = 0.
### Interpretation
The chart demonstrates the impact of the parameter K on the test accuracy of a model as a function of lambda (λ). The "Bayes – optimal" line represents the theoretical upper bound on performance. The lines corresponding to higher values of K (K = ∞ and K = 16) approach this optimal performance more closely than those with lower values of K (K = 4, K = 2, and K = 1). This suggests that increasing K improves the model's ability to generalize to unseen data, up to a certain point.
The inset chart provides additional information about a parameter t* that is related to λ. The peak in the curve suggests that there is an optimal value of λ (around 0.8) that maximizes t*. The relationship between t* and λ may be indicative of the model's sensitivity to changes in λ.
The data suggests that for achieving high test accuracy, a larger value of K is preferable, and that there is a specific value of lambda that optimizes another parameter, t*. The choice of K and λ should be made based on the desired trade-off between accuracy and other factors, such as computational cost or model complexity.
</details>
Figure 7: Predicted test accuracy $\mathrm{Acc}_{\mathrm{test}}$ of the continuous GCN and of its discrete counterpart with depth $K$ , at optimal times $t^{*}$ and $r=\infty$ . $\alpha=4$ , $\mu=1$ and $\rho=0.1$ . The performance of the continuous GCN $K=\infty$ are given by eq. (126) while for its discretization at finite $K$ they are given by numerically solving eqs. (87 - 94). Inset: $t^{*}$ the maximizer at $K=\infty$ .
Optimality of the continuous limit:
A major result is that, at $t=t^{*}$ , the continuous GCN is better than any fixed- $K$ GCN. Taking the continuous limit of the simple GCN is the way to reach its optimal performance. This was suggested by fig. 4 in the previous part; we show this more precisely in fig. 7 and fig. 12 in appendix E. We compare the continuous GCN to its discretization at different depths $K$ for several configurations $\alpha,\lambda,\mu$ and $\rho$ of the data model. The result is that at $t^{*}$ the test accuracy appears to be always an increasing function of $K$ , and that its value at $K\to\infty$ and $t^{*}$ is a upper-bound for all $K$ and $t$ .
Additionally, if the GCN is run on the symmetrized graph it can approach the Bayes-optimality and almost close the gap that [26] describes, as shown by figs. 7, 12 and 13 right. For all the considered $\lambda$ and $\mu$ the GCN is less than a few percents of accuracy far from the optimality.
However we shall precise this statement: the GCN approaches the Bayes-optimality only for a certain range of the parameters of the CSBM, as exemplified by figs. 12 and 13 left. In these figures, the GCN is far from the Bayes-optimality when $\lambda$ is small but $\mu$ is large. In this regime we have $\mathrm{snr}_{\mathrm{CSBM}}>1$ ; even at $\rho=0$ information can be retrieved on the labels and the problem is closer to an unsupervised classification of the sole features $X$ . On $X$ the GCN acts as a supervised classifier, and as long as $\rho\neq 1$ it cannot catch all information. As previously highlighted by [39] the comparison with the Bayes-optimality is more relevant at $\mathrm{snr}_{\mathrm{CSBM}}<1$ where supervision is necessary. Then, as shown by figs. 7, 12 and 13 the symmetrized continuous GCN is close to the Bayes-optimality. The GCN is also able to close the gap in the region where $\lambda$ is large because, as we saw, it can perform unsupervised PCA on $A$ .
## IV Conclusion
In this article we derived the performance of a simple GCN trained for node classification in a semi-supervised way on data generated by the CSBM in the high-dimensional limit. We first studied a discrete network with a finite number $K$ of convolution steps. We showed the importance of going to large $K$ to approach the Bayes-optimality, while scaling accordingly the residual connections $c$ of the network to avoid oversmoothing. The resulting limit is a continuous GCN.
In a second part we were able to explicitly derive the performance of the continuous GCN. We highlighted the importance of the double limit $r,K\to\infty$ , which allows to reach the optimal architecture and which can be analyzed thanks to an expansion in powers of $1/r$ . In is an interesting question for future work whether this approach could allow the study of fully-connected large-depth neural networks.
Though the continuous GCN can be close to the Bayes-optimality, it has to better handle the features, especially when they are the main source of information.
## Acknowledgments
We acknowledge useful discussions with J. Zavatone-Veth, F. Zamponi and V. Erba. This work is supported by the Swiss National Science Foundation under grant SNSF SMArtNet (grant number 212049).
## Appendix A Asymptotic characterisation of the discrete GCN
In this part we compute the free energy of the discrete finite- $K$ GCN using replica. We derive the fixed-point equations for the order parameters of the problem and the asymptotic characterization of the errors and accuracies in function of the order parameters. We consider only the asymmetric graph $\tilde{A}$ ; the symmetrized case $\tilde{A}^{\mathrm{s}}$ is analyzed in the following section B together with the continuous GCN.
The free energy of the problem is $-\beta Nf=\partial_{n}\mathbb{E}_{u,\Xi,W,y}Z^{n}(n=0)$ where the partition function is
$$
\displaystyle Z \displaystyle=\int\prod_{\nu}^{M}\mathrm{d}w_{\nu}e^{-\beta r\gamma(w_{\nu})}e^{-\beta s\sum_{i\in R}\ell(y_{i}h(w)_{i})-\beta s^{\prime}\sum_{i\in R^{\prime}}\ell(y_{i}h(w)_{i})}\ . \tag{135}
$$
To lighten the notations we take $\rho^{\prime}=1-\rho$ i.e. the test set is the whole complementary of the train set. This does not change the result since the performances do not depend on the size of the test set.
We recall that $\tilde{A}$ admits the following Gaussian equivalent:
$$
\tilde{A}\approx A^{\mathrm{g}}=\frac{\lambda}{\sqrt{N}}yy^{T}+\Xi\ ,\quad\Xi_{ij}\sim\mathcal{N}(0,1)\ . \tag{136}
$$
$\tilde{A}$ can be approximated by $A^{\mathrm{g}}$ with a vanishing change in the free energy $f$ .
### A.1 Derivation of the free energy
We define the intermediate states of the GCN as
$$
h_{k}=\left(\frac{1}{\sqrt{N}}\tilde{A}+c_{k}I_{N}\right)h_{k-1}\ ,\quad h_{0}=\frac{1}{\sqrt{N}}Xw\ . \tag{137}
$$
We introduce them in $Z$ thanks to Dirac deltas. The expectation of the replicated partition function is
$$
\displaystyle\mathbb{E}Z^{n}\propto \displaystyle\,\mathbb{E}_{u,\Xi,W,y}\int\prod_{a}^{n}\prod_{\nu}^{M}\mathrm{d}w_{\nu}^{a}e^{-\beta r\gamma(w_{\nu}^{a})}\prod_{a}^{n}\prod_{i}^{N}\prod_{k=0}^{K}\mathrm{d}h_{i,k}^{a}\mathrm{d}q_{i,k}^{a}e^{-\beta s\sum_{a,i\in R}\ell(y_{i}h_{i,K}^{a})-\beta s^{\prime}\sum_{a,i\in R^{\prime}}\ell(y_{i}h_{i,K}^{a})} \displaystyle\quad\quad e^{\sum_{a,i}\sum_{k=1}^{K}\mathrm{i}q_{i,k}^{a}\left(h_{i,k}^{a}-\frac{1}{\sqrt{N}}\sum_{j}(\frac{\lambda}{\sqrt{N}}y_{i}y_{j}+\Xi_{ij})h_{j,k-1}^{a}-c_{k}h_{i,k-1}^{a}\right)+\sum_{a,i}\mathrm{i}q_{i,0}^{a}\left(h_{i,0}^{a}-\frac{1}{\sqrt{N}}\sum_{\nu}\left(\sqrt{\frac{\mu}{N}}y_{i}u_{\nu}+W_{i\nu}\right)w_{\nu}^{a}\right)} \displaystyle= \displaystyle\,\mathbb{E}_{u,y}\int\prod_{a,\nu}\mathrm{d}w_{\nu}^{a}e^{-\beta r\gamma(w_{\nu}^{a})}\prod_{a,i,k}\mathrm{d}h_{i,k}^{a}e^{-\beta s\sum_{a,i\in R}\ell(y_{i}h_{i,K}^{a})-\beta s^{\prime}\sum_{a,i\in R^{\prime}}\ell(y_{i}h_{i,K}^{a})} \displaystyle\quad\quad\prod_{i}\mathcal{N}\left(h_{i,>0}\left|c\odot h_{i,<K}+y_{i}\frac{\lambda}{N}\sum_{j}y_{j}h_{j,<K};\tilde{Q}\right.\right)\prod_{i}\mathcal{N}\left(h_{i,0}\left|y_{i}\frac{\sqrt{\mu}}{N}\sum_{\nu}u_{\nu}w_{\nu};\frac{1}{N}\sum_{\nu}w_{\nu}w_{\nu}^{T}\right.\right)\ . \tag{138}
$$
$\mathcal{N}(\cdot|m;V)$ is the Gaussian density of mean $m$ and covariance $V$ . We integrated over the random fluctuations $\Xi$ and $W$ and then over the $q$ s. We collected the replica in vectors of size $n$ and assembled them as
$$
\displaystyle h_{i,>0}=\left(\begin{smallmatrix}h_{i,1}\\
\vdots\\
h_{i,K}\end{smallmatrix}\right)\in\mathbb{R}^{nK},\quad h_{i,<K}=\left(\begin{smallmatrix}h_{i,0}\\
\vdots\\
h_{i,K-1}\end{smallmatrix}\right)\in\mathbb{R}^{nK},\quad c\odot h_{i,<K}=\left(\begin{smallmatrix}c_{1}h_{i,0}\\
\vdots\\
c_{K}h_{i,K-1}\end{smallmatrix}\right), \displaystyle\tilde{Q}_{k,l}=\frac{1}{N}\sum_{j}h_{j,k}h_{j,l}^{T}\ ,\quad\tilde{Q}=\left(\begin{smallmatrix}\tilde{Q}_{0,0}&\ldots&\tilde{Q}_{0,K-1}\\
\vdots&&\vdots\\
\tilde{Q}_{K-1,0}&\ldots&\tilde{Q}_{K-1,K-1}\end{smallmatrix}\right)\in\mathbb{R}^{nK\times nK}\ . \tag{139}
$$
We introduce the order parameters
$$
\displaystyle m_{w}^{a}=\frac{1}{N}\sum_{\nu}u_{\nu}w_{\nu}^{a}\ ,\quad Q_{w}^{ab}=\frac{1}{N}\sum_{\nu}w_{\nu}^{a}w_{\nu}^{b}\ , \displaystyle m_{k}^{a}=\frac{1}{N}\sum_{j}y_{j}k_{j,k}^{a}\ ,\quad Q_{k}^{ab}=(\tilde{Q}_{k,k})_{a,b}=\frac{1}{N}\sum_{j}h_{j,k}^{a}h_{j,k}^{b}\ ,\quad Q_{k,l}^{ab}=(\tilde{Q}_{k,l})_{a,b}=\frac{1}{N}\sum_{j}h_{j,k}^{a}h_{j,l}^{b}\ . \tag{141}
$$
$m_{k}$ is the magnetization (or overlap) between the $k^{\mathrm{th}}$ layer and the labels; $m_{w}$ is the magnetization between the weights and the hidden variables and the $Q$ s are the self-overlaps across the different layers. In the following we write $\tilde{Q}$ for the matrix with elements $(\tilde{Q})_{ak,bl}=Q_{k,l}^{ab}$ . We introduce these quantities thanks to new Dirac deltas. This allows us to factorize the spacial $i$ and $\nu$ indices.
$$
\displaystyle\mathbb{E}Z^{n}\propto \displaystyle\,\int\prod_{a}\prod_{k=0}^{K-1}\mathrm{d}\hat{m}_{k}^{a}\mathrm{d}m_{k}^{a}e^{N\hat{m}_{k}^{a}m_{k}^{a}}\prod_{a}\mathrm{d}\hat{m}_{w}^{a}\mathrm{d}m_{w}^{a}e^{N\hat{m}_{w}^{a}m_{w}^{a}}\prod_{a\leq b}\prod_{k=0}^{K-1}\mathrm{d}\hat{Q}_{k}^{ab}\mathrm{d}Q_{k}^{ab}e^{N\hat{Q}_{k}^{ab}Q_{k}^{ab}}\prod_{a,b}\prod_{k<l}^{K-1}\mathrm{d}\hat{Q}_{k,l}^{ab}\mathrm{d}Q_{k,l}^{ab}e^{N\hat{Q}_{k,l}^{ab}Q_{k,l}^{ab}} \displaystyle\prod_{a\leq b}d\hat{Q}_{w}^{ab}\mathrm{d}Q_{w}^{ab}e^{N\hat{Q}_{w}^{ab}Q_{w}^{ab}}\left[\mathbb{E}_{u}\int\prod_{a}\mathrm{d}w^{a}e^{\psi_{w}^{(n)}(w)}\right]^{\frac{N}{\alpha}}\left[\mathbb{E}_{y}\int\prod_{a,k}\mathrm{d}h_{k}^{a}e^{\psi_{h}^{(n)}(h;s)}\right]^{\rho N}\left[\mathbb{E}_{y}\int\prod_{a,k}\mathrm{d}h_{k}^{a}e^{\psi_{h}^{(n)}(h;s^{\prime})}\right]^{(1-\rho)N} \tag{143}
$$
where we defined the two potentials
$$
\displaystyle\psi_{w}^{(n)}(w)=-\beta r\sum_{a}\gamma(w^{a})-\sum_{a\leq b}\hat{Q}_{w}^{ab}w^{a}w^{b}-\sum_{a}\hat{m}_{w}^{a}uw^{a} \displaystyle\psi_{h}^{(n)}(h;\bar{s})=-\beta\bar{s}\sum_{a}\ell(yh_{K}^{a})-\sum_{a\leq b}\sum_{k=0}^{K-1}\hat{Q}_{k}^{ab}h_{k}^{a}h_{k}^{b}-\sum_{a,b}\sum_{k<l}^{K-1}\hat{Q}_{k,l}^{ab}h_{k}^{a}h_{l}^{b}-\sum_{a}\sum_{k=0}^{K-1}\hat{m}_{k}^{a}yh_{k}^{a} \displaystyle\qquad\qquad{}+\log\mathcal{N}\left(h_{>0}\left|c\odot h_{<K}+\lambda ym_{<K};\tilde{Q}\right.\right)+\log\mathcal{N}\left(h_{0}\left|\sqrt{\mu}ym_{w};Q_{w}\right.\right)\ . \tag{144}
$$
We leverage the replica-symmetric ansatz. It is justified by the convexity of the Hamiltonian $H$ . We assume that for all $a$ and $b$
$$
\displaystyle m_{k}^{a}=m_{k}\ , \displaystyle\hat{m}_{k}^{a}=-\hat{m}_{k}\ , \displaystyle m_{w}^{a}=m_{w}\ , \displaystyle\hat{m}_{w}^{a}=-\hat{m}_{w}\ , \displaystyle Q_{k}^{ab}=Q_{k}J+V_{k}I\ , \displaystyle\hat{Q}_{k}^{ab}=-\hat{Q}_{k}J+\frac{1}{2}(\hat{V}_{k}+\hat{Q}_{k})I\ , \displaystyle Q_{w}^{ab}=Q_{w}J+V_{w}I\ , \displaystyle\hat{Q}_{w}^{ab}=-\hat{Q}_{w}J+\frac{1}{2}(\hat{V}_{w}+\hat{Q}_{w})I\ , \displaystyle Q_{k,l}^{ab}=Q_{k,l}J+V_{k,l}I\ , \displaystyle\hat{Q}_{k,l}^{ab}=-\hat{Q}_{k,l}J+\hat{V}_{k,l}I\ . \tag{146}
$$
$I$ is the $n\times n$ identity and $J$ is the $n\times n$ matrix filled with ones. We introduce the $K\times K$ symmetric matrices $Q$ and $V$ , filled with $(Q_{k})_{0\leq k\leq K-1}$ and $(V_{k})_{0\leq k\leq K-1}$ on the diagonal, and $(Q_{k,l})_{0\leq k<l\leq K-1}$ and $(V_{k,l})_{0\leq k<l\leq K-1}$ off the diagonal, such that $\tilde{Q}$ can be written in terms of Kronecker products as
$$
\displaystyle\tilde{Q}=Q\otimes J+V\otimes I\ . \tag{149}
$$
The entropic terms of $\psi_{w}^{(n)}$ and $\psi_{h}^{(n)}$ can be computed. Since we will take $n=0$ we discard subleading terms in $n$ . We obtain
$$
\displaystyle\sum_{a}\hat{m}_{w}^{a}m_{w}^{a}=n\hat{m}_{w}m_{w}\ ,\quad\sum_{a\leq b}\hat{Q}_{w}^{ab}Q_{w}^{ab}=\frac{n}{2}(\hat{V}_{w}V_{w}+\hat{V}_{w}Q_{w}-V_{w}\hat{Q}_{w})\ , \displaystyle\sum_{a}\hat{m}_{k}^{a}m_{k}^{a}=n\hat{m}_{k}m_{k}\ ,\quad\sum_{a\leq b}\hat{Q}_{k}^{ab}Q_{k}^{ab}=\frac{n}{2}(\hat{V}_{k}V_{k}+\hat{V}_{k}Q_{k}-V_{k}\hat{Q}_{k})\ ,\quad\sum_{a,b}\hat{Q}_{k,l}^{ab}Q_{k,l}^{ab}=n(\hat{V}_{k,l}V_{k,l}+\hat{V}_{k,l}Q_{k,l}-V_{k,l}\hat{Q}_{k,l})\ . \tag{150}
$$
The Gaussian densities can be explicited, keeping again the main order in $n$ and using the formula for a rank-1 update to a matrix (Sherman-Morrison formula):
$$
\displaystyle Q_{w}^{-1}=\frac{1}{V_{w}}I-\frac{Q_{w}}{V_{w}^{2}}J\ ,\quad\log\det Q_{w}=n\frac{Q_{w}}{V_{w}}+n\log V_{w}\ , \displaystyle\tilde{Q}^{-1}=V^{-1}\otimes I-(V^{-1}QV^{-1})\otimes J\ ,\quad\log\det\tilde{Q}=n\operatorname{Tr}(V^{-1}Q)+n\log V\ . \tag{152}
$$
Then we can factorize the replica by introducing random Gaussian variables:
$$
\displaystyle\int\prod_{a}\mathrm{d}w^{a}e^{\psi_{w}^{(n)}(w)} \displaystyle=\int\prod_{a}\mathrm{d}w^{a}e^{\sum_{a}\log P_{W}(w^{a})+\frac{1}{2}\hat{Q}_{w}w^{T}Jw-\frac{1}{2}\hat{V}_{w}w^{T}w+u\hat{m}_{w}^{T}w}=\mathbb{E}_{\varsigma}\left(\int\mathrm{d}we^{\psi_{w}(w)}\right)^{n} \tag{154}
$$
where $\varsigma\sim\mathcal{N}(0,1)$ and the potential is
$$
\displaystyle\psi_{w}(w)=\log P_{W}(w)-\frac{1}{2}\hat{V}_{w}w^{2}+\left(\sqrt{\hat{Q}_{w}}\varsigma+u\hat{m}_{w}\right)w\ ; \tag{155}
$$
and samely
$$
\displaystyle\int\prod_{a,k}\mathrm{d}h_{k}^{a}e^{\psi_{h}^{(n)}(h;\bar{s})} \displaystyle=\int\prod_{a,k}\mathrm{d}h_{k}^{a}e^{-\beta\bar{s}\sum_{a}\ell(yk_{K}^{a})+\sum_{k=0}^{K-1}\left(\frac{1}{2}\hat{Q}_{k}h_{k}^{T}Jh_{k}-\frac{1}{2}\hat{V}_{k}h_{k}^{T}h_{k}+y\hat{m}_{k}^{T}h_{k}\right)+\sum_{k<l}^{K-1}(\hat{Q}_{k,l}h_{k}^{T}Jh_{l}-\hat{V}_{k,l}h_{k}^{T}h_{l})} \displaystyle e^{-\frac{1}{2}(h_{0}-\sqrt{\mu}ym_{w})^{T}\left(\frac{1}{V_{w}}I-\frac{Q_{w}}{V_{w}^{2}}J\right)(h_{0}-\sqrt{\mu}ym_{w})-\frac{1}{2}n\frac{Q_{w}}{V_{w}}-\frac{1}{2}n\log V_{w}} \displaystyle e^{-\frac{1}{2}\sum_{k,l}^{K}(h_{k}-c_{k}h_{k-1}-\lambda ym_{k-1})^{T}\left({(V^{-1})_{k-1,l-1}}I-(V^{-1}QV^{-1})_{k-1,l-1}J\right)(h_{l}-c_{l}h_{l-1}-\lambda ym_{l-1})-\frac{n}{2}\operatorname{Tr}(V^{-1}Q)-\frac{n}{2}\log\det V} \displaystyle=\mathbb{E}_{\xi,\chi,\zeta}\left(\int\prod_{k=0}^{K}\mathrm{d}h_{k}e^{\psi_{h}(h;\bar{s})}\right)^{n} \tag{156}
$$
where $\xi\sim\mathcal{N}(0,I_{K})$ , $\chi\sim\mathcal{N}(0,I_{K})$ , $\zeta\sim\mathcal{N}(0,1)$ and the potential is
$$
\displaystyle\psi_{h}(h;\bar{s}) \displaystyle=-\beta\bar{s}\ell(yh_{K})-\frac{1}{2}h_{<K}^{T}\hat{V}h_{<K}+\left(\xi^{T}\hat{Q}^{1/2}+y\hat{m}^{T}\right)h_{<K} \displaystyle\quad\quad{}+\log\mathcal{N}\left(h_{0}\left|\sqrt{\mu}ym_{w}+\sqrt{Q_{w}}\zeta;V_{w}\right.\right)+\log\mathcal{N}\left(h_{>0}\left|c\odot h_{<K}+\lambda ym+Q^{1/2}\chi;V\right.\right)\ ; \tag{158}
$$
where $h_{>0}=(h_{1},\ldots,h_{K})\in\mathbb{R}^{K}$ , $h_{<K}=(h_{0},\ldots,h_{K-1})\in\mathbb{R}^{K}$ , $c\odot h_{<K}=(c_{1}h_{0},\ldots,c_{K}h_{K-1})$ , $\hat{m}=(\hat{m}_{0},\ldots,\hat{m}_{K-1})\in\mathbb{R}^{K}$ , $m=(m_{0},\ldots,m_{K-1})\in\mathbb{R}^{K}$ , $\hat{Q}$ and $\hat{V}$ are the $K\times K$ symmetric matrix filled with $(\hat{Q}_{k})_{0\leq k\leq K-1}$ and $(\hat{V}_{k})_{0\leq k\leq K-1}$ on the diagonal, and $(\hat{Q}_{k,l})_{0\leq k<l\leq K-1}$ and $(\hat{V}_{k,l})_{0\leq k<l\leq K-1}$ off the diagonal. We used that $\mathbb{E}_{\zeta}e^{-\frac{n}{2}\frac{Q_{w}}{V_{w}}\zeta^{2}}=e^{-\frac{n}{2}\frac{Q_{w}}{V_{w}}}$ in the limit $n\to 0$ to factorize $\sqrt{Q_{w}}\zeta$ and the same for $Q^{1/2}\chi$ .
We pursue the computation:
$$
\displaystyle\mathbb{E}Z^{n}\propto \displaystyle\,\int\mathrm{d}\hat{m}_{w}\mathrm{d}m_{w}e^{Nn\hat{m}_{w}m_{w}}\mathrm{d}\hat{Q}_{w}\mathrm{d}Q_{w}\mathrm{d}\hat{V}_{w}\mathrm{d}V_{w}e^{N\frac{n}{2}(\hat{V}_{w}V_{w}+\hat{V}_{w}Q_{w}-V_{w}\hat{Q}_{w})}\prod_{k=0}^{K-1}\mathrm{d}\hat{m}_{k}\mathrm{d}m_{k}e^{Nn\hat{m}^{T}m} \displaystyle\quad\prod_{k=0}^{K-1}\mathrm{d}\hat{Q}_{k}\mathrm{d}Q_{k}\mathrm{d}\hat{V}_{k}\mathrm{d}V_{k}\prod_{k<l}^{K-1}\mathrm{d}\hat{Q}_{k,l}\mathrm{d}Q_{k,l}\mathrm{d}\hat{V}_{k,l}\mathrm{d}V_{k,l}e^{N\frac{n}{2}\mathrm{tr}\left(\hat{V}V+\hat{V}Q-V\hat{Q}\right)} \displaystyle\quad\left[\mathbb{E}_{u,\varsigma}\left(\int\mathrm{d}we^{\psi_{w}(w)}\right)^{n}\right]^{N/\alpha}\left[\mathbb{E}_{y,\xi,\chi,\zeta}\left(\int\prod_{k=0}^{K}\mathrm{d}h_{k}e^{\psi_{h}(h;s)}\right)^{n}\right]^{\rho N}\left[\mathbb{E}_{y,\xi,\chi,\zeta}\left(\int\prod_{k=0}^{K}\mathrm{d}h_{k}e^{\psi_{h}(h;s^{\prime})}\right)^{n}\right]^{(1-\rho)N} \displaystyle:= \displaystyle\ \int\mathrm{d}\Theta\mathrm{d}\hat{\Theta}e^{N\phi^{(n)}(\Theta,\hat{\Theta})}\ . \tag{159}
$$
where $\Theta=\{m_{w},Q_{w},V_{w},m,Q,V\}$ and $\hat{\Theta}=\{\hat{m}_{w},\hat{Q}_{w},\hat{V}_{w},\hat{m},\hat{Q},\hat{V}\}$ are the sets of the order parameters. We can now take the limit $N\to\infty$ thanks to Laplace’s method.
$$
\displaystyle-\beta f\propto \displaystyle\frac{1}{N}\frac{\partial}{\partial n}(n=0)\int\mathrm{d}\Theta\mathrm{d}\hat{\Theta}\,e^{N\phi^{(n)}(\Theta,\hat{\Theta})} \displaystyle= \displaystyle\operatorname*{extr}_{\Theta,\hat{\Theta}}\frac{\partial}{\partial n}(n=0)\phi^{(n)}(\Theta,\hat{\Theta}) \displaystyle:= \displaystyle\operatorname*{extr}_{\Theta,\hat{\Theta}}\phi(\Theta,\hat{\Theta})\ , \tag{161}
$$
where we extremize the following free entropy $\phi$ :
$$
\displaystyle\phi \displaystyle=\frac{1}{2}\left(\hat{V}_{w}V_{w}+\hat{V}_{w}Q_{w}-V_{w}\hat{Q}_{w}\right)-\hat{m}_{w}m_{w}+\frac{1}{2}\mathrm{tr}\left(\hat{V}V+\hat{V}Q-V\hat{Q}\right)-\hat{m}^{T}m \displaystyle\quad{}+\frac{1}{\alpha}\mathbb{E}_{u,\xi}\left(\log\int\mathrm{d}w\,e^{\psi_{w}(w)}\right)+\rho\mathbb{E}_{y,\xi,\zeta,\chi}\left(\log\int\prod_{k=0}^{K}\mathrm{d}h_{k}e^{\psi_{h}(h;s)}\right)+(1-\rho)\mathbb{E}_{y,\xi,\zeta,\chi}\left(\log\int\prod_{k=0}^{K}\mathrm{d}h_{k}e^{\psi_{h}(h;s^{\prime})}\right)\ . \tag{164}
$$
We take the limit $\beta\to\infty$ . Later we will differentiate $\phi$ with respect to the order parameters or to $\bar{s}$ and these derivatives will simplify in that limit. We introduce the measures
$$
\displaystyle\mathrm{d}P_{w}=\frac{\mathrm{d}w\,e^{\psi_{w}(w)}}{\int\mathrm{d}w\,e^{\psi_{w}(w)}}\quad,\quad\mathrm{d}P_{h}=\frac{\prod_{k=0}^{K}\mathrm{d}h_{k}\,e^{\psi_{h}(h;\bar{s}=1)}}{\int\prod_{k=0}^{K}\mathrm{d}h_{k}\,e^{\psi_{h}(h;\bar{s}=1)}}\quad,\quad\mathrm{d}P_{h}^{\prime}=\frac{\prod_{k=0}^{K}\mathrm{d}h_{k}\,e^{\psi_{h}(h;\bar{s}=0)}}{\int\prod_{k=0}^{K}\mathrm{d}h_{k}\,e^{\psi_{h}(h;\bar{s}=0)}}\ . \tag{165}
$$
We have to rescale the order parameters not to obtain a degenerated solution when $\beta\to\infty$ (we recall that, in $\psi_{w}$ , $\log P_{W}(w)\propto\beta$ ). We take
$$
\displaystyle\hat{m}_{w}\to\beta\hat{m}_{w}\ , \displaystyle\hat{Q}_{w}\to\beta^{2}\hat{Q}_{w}\ , \displaystyle\hat{V}_{w}\to\beta\hat{V}_{w}\ , \displaystyle V_{w}\to\beta^{-1}V_{w} \displaystyle\hat{m}\to\beta\hat{m}\ , \displaystyle\hat{Q}\to\beta^{2}\hat{Q}\ , \displaystyle\hat{V}\to\beta\hat{V}\ , \displaystyle V\to\beta^{-1}V \tag{166}
$$
So we obtain that $f=-\phi$ . Then $\mathrm{d}P_{w}$ , $\mathrm{d}P_{h}$ and $\mathrm{d}P_{h}^{\prime}$ are picked around their maximum and can be approximated by Gaussian measures. We define
$$
\displaystyle w^{*}=\operatorname*{argmax}_{w}\psi_{w}(w)\ ,\quad h^{*}=\operatorname*{argmax}_{h}\psi_{h}(h;\bar{s}=1)\ ,\quad h^{{}^{\prime}*}=\operatorname*{argmax}_{h}\psi_{h}(h;\bar{s}=0)\ . \tag{168}
$$
Then we have the expected value of a function $g$ in $h$ $\mathbb{E}_{P_{h}}g(h)=g(h^{*})$ and the covariance $\operatorname{Cov}_{P_{h}}(h)=-\frac{1}{2}(\nabla\nabla\psi_{h}(h^{*}))^{-1}$ with $\nabla\nabla$ the Hessian; and similarly for $\mathrm{d}P_{w}$ and $\mathrm{d}P_{h}^{\prime}$ .
Last we compute the expected errors and accuracies. We differentiate the free energy $f$ with respect to $s$ and $s^{\prime}$ to obtain that
$$
\displaystyle E_{\mathrm{train}}=\mathbb{E}_{y,\xi,\zeta,\chi}\ell(yh_{K}^{*})\ ,\quad E_{\mathrm{test}}=\mathbb{E}_{y,\xi,\zeta,\chi}\ell(yh_{K}^{{}^{\prime}*})\ . \tag{169}
$$
Augmenting $H$ with the observable $\frac{1}{|\hat{R}|}\sum_{i\in\hat{R}}\delta_{y_{i}=\operatorname{sign}h(w)_{i}}$ and following the same steps gives the expected accuracies
$$
\displaystyle\mathrm{Acc}_{\mathrm{train}}=\mathbb{E}_{y,\xi,\zeta,\chi}\delta_{y=\operatorname{sign}(h_{K}^{*})}\ ,\quad\mathrm{Acc}_{\mathrm{test}}=\mathbb{E}_{y,\xi,\zeta,\chi}\delta_{y=\operatorname{sign}(h_{K}^{{}^{\prime}*})}\ . \tag{170}
$$
### A.2 Self-consistent equations
The two above formula (169) and (170) are valid only at the values of the order parameters that extremize the free entropy. We seek the extremizer of $\phi$ . The extremality condition $\nabla_{\Theta,\hat{\Theta}}\phi=0$ gives the following self-consistent equations:
$$
\displaystyle m_{w}=\frac{1}{\alpha}\mathbb{E}_{u,\varsigma}\,uw^{*}\quad\quad m=\mathbb{E}_{y,\xi,\zeta,\chi}\,y\left(\rho h_{<K}^{*}+(1-\rho)h_{<K}^{{}^{\prime}*}\right) \displaystyle Q_{w}=\frac{1}{\alpha}\mathbb{E}_{u,\varsigma}(w^{*})^{2}\quad\quad Q=\mathbb{E}_{y,\xi,\zeta,\chi}\left(\rho(h_{<K}^{*})^{\otimes 2}+(1-\rho)(h_{<K}^{{}^{\prime}*})^{\otimes 2}\right) \displaystyle V_{w}=\frac{1}{\alpha}\frac{1}{\sqrt{\hat{Q}_{w}}}\mathbb{E}_{u,\varsigma}\,\varsigma w^{*}\quad\quad V=\mathbb{E}_{y,\xi,\zeta,\chi}\left(\rho\operatorname{Cov}_{P_{h}}(h_{<K})+(1-\rho)\operatorname{Cov}_{P_{h}^{\prime}}(h_{<K})\right) \displaystyle\hat{m}_{w}=\frac{\sqrt{\mu}}{V_{w}}\mathbb{E}_{y,\xi,\zeta,\chi}\,y\left(\rho(h^{*}_{0}-\sqrt{\mu}ym_{w})+(1-\rho)(h_{0}^{{}^{\prime}*}-\sqrt{\mu}ym_{w})\right) \displaystyle\hat{Q}_{w}=\frac{1}{V_{w}^{2}}\mathbb{E}_{y,\xi,\zeta,\chi}\left(\rho(h_{0}^{*}-\sqrt{\mu}ym_{w}-\sqrt{Q}_{w}\zeta)^{2}+(1-\rho)(h_{0}^{{}^{\prime}*}-\sqrt{\mu}ym_{w}-\sqrt{Q}_{w}\zeta)^{2}\right) \displaystyle\hat{V}_{w}=\frac{1}{V_{w}}-\frac{1}{V_{w}^{2}}\mathbb{E}_{y,\xi,\zeta,\chi}\left(\rho\operatorname{Cov}_{P_{h}}(h_{0})+(1-\rho)\operatorname{Cov}_{P_{h}}(h_{0})\right) \displaystyle\hat{m}=\lambda V^{-1}\mathbb{E}_{y,\xi,\zeta,\chi}\,y\left(\rho(h_{>0}^{*}-c\odot h_{<K}^{*}-\lambda ym)+(1-\rho)(h_{>0}^{{}^{\prime}*}-c\odot h_{<K}^{{}^{\prime}*}-\lambda ym)\right) \displaystyle\hat{Q}=V^{-1}\mathbb{E}_{y,\xi,\zeta,\chi}\left(\rho(h_{>0}^{*}-c\odot h_{<K}^{*}-\lambda ym-Q^{1/2}\chi)^{\otimes 2}+(1-\rho)(h_{>0}^{{}^{\prime}*}-c\odot h_{<K}^{{}^{\prime}*}-\lambda ym-Q^{1/2}\chi)^{\otimes 2}\right)V^{-1} \displaystyle\hat{V}=V^{-1}-V^{-1}\mathbb{E}_{y,\xi,\zeta,\chi}\left(\rho\operatorname{Cov}_{P_{h}}(h_{>0}-c\odot h_{<K})+(1-\rho)\operatorname{Cov}_{P_{h}^{\prime}}(h_{>0}-c\odot h_{<K})\right)V^{-1} \tag{171}
$$
We introduced the covariance $\operatorname{Cov}_{P}(x)=\mathbb{E}_{P}(xx^{T})-\mathbb{E}_{P}(x)\mathbb{E}_{P}(x^{T})$ and the tensorial product $x^{\otimes 2}=xx^{T}$ . We used Stein’s lemma to simplify the differentials of $Q^{1/2}$ and $\hat{Q}^{1/2}$ and to transform the expression of $\hat{V}_{w}$ into a more accurate expression for numerical computation in terms of covariance. We used the identities $2x^{T}Q^{1/2}\frac{\partial Q^{1/2}}{\partial E_{k,l}}x=x^{T}E_{k,l}x$ and $-x^{T}V\frac{\partial V^{-1}}{\partial E_{k,l}}Vx=x^{T}E_{k,l}x$ for any element matrix $E_{k,l}$ and for any vector $x$ . We have also that $\nabla_{V}\log\det V=V^{-1}$ , considering its comatrix. Last we kept the first order in $\beta$ with the approximations $Q+V\approx Q$ and $\hat{Q}-\hat{V}\approx\hat{Q}$ .
These self-consistent equations are reproduced in the main part III.1.1.
### A.3 Solution for ridge regression
We take quadratic $\ell$ and $\gamma$ . Moreover we assume there is no residual connections $c=0$ ; this simplifies largely the analysis in the sense that the covariances of $h$ under $P_{h}$ or $P_{h}^{\prime}$ become diagonal. We have
$$
\displaystyle\operatorname{Cov}_{P_{h}}(h)=\mathrm{diag}\left(\frac{V_{w}}{1+V_{w}\hat{V}_{0}},\frac{V_{0}}{1+V_{0}\hat{V}_{1}},\ldots,\frac{V_{K-2}}{1+V_{K-2}\hat{V}_{K-1}},\frac{V_{K-1}}{1+V_{K-1}}\right) \displaystyle\operatorname{Cov}_{P_{h}^{\prime}}(h)=\mathrm{diag}\left(\frac{V_{w}}{1+V_{w}\hat{V}_{0}},\frac{V_{0}}{1+V_{0}\hat{V}_{1}},\ldots,\frac{V_{K-2}}{1+V_{K-2}\hat{V}_{K-1}},V_{K-1}\right) \displaystyle h^{*}=\operatorname{Cov}_{P_{h}}(h)\left(\begin{pmatrix}\hat{Q}^{1/2}\xi+y\hat{m}\\
y\end{pmatrix}+\begin{pmatrix}\frac{1}{V_{w}}(\sqrt{\mu}ym_{w}+\sqrt{Q_{w}}\zeta)\\
V^{-1}\left(\lambda ym+Q^{1/2}\chi\right)\end{pmatrix}\right) \displaystyle h^{{}^{\prime}*}=\operatorname{Cov}_{P_{h}^{\prime}}(h)\left(\begin{pmatrix}\hat{Q}^{1/2}\xi+y\hat{m}\\
0\end{pmatrix}+\begin{pmatrix}\frac{1}{V_{w}}(\sqrt{\mu}ym_{w}+\sqrt{Q_{w}}\zeta)\\
V^{-1}\left(\lambda ym+Q^{1/2}\chi\right)\end{pmatrix}\right) \tag{180}
$$
where diag means the diagonal matrix with the given diagonal. We packed elements into block vectors of size $K+1$ . The self-consistent equations can be explicited:
$$
\displaystyle m_{w}=\frac{1}{\alpha}\frac{\hat{m}_{w}}{r+\hat{V}_{w}} \displaystyle\quad V_{w}=\frac{1}{\alpha}\frac{1}{r+\hat{V}_{w}} \displaystyle\quad Q_{w}=\frac{1}{\alpha}\frac{\hat{Q}_{w}+\hat{m}_{w}^{2}}{(r+\hat{V}_{w})^{2}} \displaystyle m=V\left(\hat{m}+\left(\begin{smallmatrix}\sqrt{\mu}\frac{m_{w}}{V_{w}}\\
\lambda V_{<K-1}^{-1}m_{<K-1}\end{smallmatrix}\right)\right) \displaystyle\quad V=\mathrm{diag}\left(\begin{smallmatrix}\frac{V_{w}}{1+V_{w}\hat{V}_{0}},\frac{V_{0}}{1+V_{0}\hat{V}_{1}},\ldots,\frac{V_{K-2}}{1+V_{K-2}\hat{V}_{K-1}}\end{smallmatrix}\right) \displaystyle\hat{m}_{w}=\frac{\sqrt{\mu}}{V_{w}}(m_{0}-\sqrt{\mu}m_{w}) \displaystyle\quad\hat{V}_{w}=\frac{\hat{V}_{0}}{1+V_{w}\hat{V}_{0}} \displaystyle\hat{m}=\lambda\hat{V}\left(\left(\begin{smallmatrix}\hat{V}_{>0}^{-1}\hat{m}_{>0}\\
1\end{smallmatrix}\right)-\lambda m\right) \displaystyle\quad\hat{V}=\mathrm{diag}\left(\begin{smallmatrix}\frac{\hat{V}_{1}}{1+V_{0}\hat{V}_{1}},\ldots,\frac{\hat{V}_{K-1}}{1+V_{K-2}\hat{V}_{K-1}},\frac{\rho}{1+V_{K-1}}\end{smallmatrix}\right) \tag{184}
$$
and
$$
\displaystyle\hat{Q}_{w}=\frac{V_{0}^{2}}{V_{w}^{2}}\hat{Q}_{0,0}+\left(\frac{V_{0}}{V_{w}}-1\right)^{2}\frac{Q_{w}}{V_{w}^{2}}+\frac{\hat{m}_{w}^{2}}{\mu} \displaystyle Q=V\left(\hat{Q}+\left(\begin{smallmatrix}\frac{Q_{w}}{V_{w}^{2}}&0\\
0&V_{<K-1}^{-1}Q_{<K-1}V_{<K-1}^{-1}\end{smallmatrix}\right)\right)V+m^{\otimes 2} \displaystyle\hat{Q}=\hat{V}\left(\left(\begin{smallmatrix}\hat{V}_{>0}^{-1}\hat{Q}_{>0}\hat{V}_{>0}^{-1}&0\\
0&0\end{smallmatrix}\right)+\rho\left(\begin{smallmatrix}I_{K-1}&0\\
0&\rho^{-1}\end{smallmatrix}\right)Q\left(\begin{smallmatrix}I_{K-1}&0\\
0&\rho^{-1}\end{smallmatrix}\right)+(1-\rho)\left(\begin{smallmatrix}I_{K-1}&0\\
0&0\end{smallmatrix}\right)Q\left(\begin{smallmatrix}I_{K-1}&0\\
0&0\end{smallmatrix}\right)\right)\hat{V} \displaystyle\qquad{}+\rho\left(\begin{smallmatrix}\frac{1}{\lambda}\hat{m}_{<K-1}\\
\frac{1}{\lambda\rho}\hat{m}_{K-1}\end{smallmatrix}\right)^{\otimes 2}+(1-\rho)\left(\begin{smallmatrix}\frac{1}{\lambda}\hat{m}_{<K-1}\\
0\end{smallmatrix}\right)^{\otimes 2} \tag{188}
$$
We used the notations $m_{<K-1}=(m_{k})_{0\leq k<K-1}$ , $\hat{m}_{<K-1}=(\hat{m}_{k})_{0\leq k<K-1}$ , $\hat{m}_{>0}=(\hat{m}_{k})_{0<k\leq K-1}$ , $Q_{<K-1}=(Q_{k,l})_{0\leq k,l<K-1}$ , $Q_{>0}=(Q_{k,l})_{0<k,l\leq K-1}$ , $V_{<K-1}=(V_{k,l})_{0\leq k,l<K-1}$ and $V_{>0}=(V_{k,l})_{0<k,l\leq K-1}$ . We simplified the equations by combining the expressions of $V$ , $\hat{V}$ , $m$ and $\hat{m}$ : the above system of equations is equivalent to the generic equations only at the fixed-point. The expected losses and accuracies are
$$
\displaystyle E_{\mathrm{train}}=\frac{1}{2\rho}\hat{Q}_{K-1,K-1} \displaystyle E_{\mathrm{test}}=\frac{1}{2\rho}(1+V_{K-1,K-1})^{2}\hat{Q}_{K-1,K-1} \displaystyle\mathrm{Acc}_{\mathrm{train}}=\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{V_{K-1,K-1}+\lambda m_{K-1}}{\sqrt{2Q_{K-1,K-1}}}\right)\right) \displaystyle\mathrm{Acc}_{\mathrm{test}}=\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{\lambda m_{K-1}}{\sqrt{2Q_{K-1,K-1}}}\right)\right)\ . \tag{191}
$$
To obtain a simple solution we take the limit $r\to\infty$ . The solution of this system is then
$$
\displaystyle m_{w}=\frac{\rho\sqrt{\mu}}{\alpha r}\lambda^{K} \displaystyle\quad V_{w}=\frac{1}{\alpha r} \displaystyle\quad Q_{w}=\frac{1}{\alpha r^{2}}\left(\rho+\rho^{2}\mu\lambda^{2K}+\rho^{2}\sum_{l=1}^{K}\lambda^{2l}\right) \displaystyle m_{k}=\frac{\rho}{\alpha r}\left(\mu\lambda^{K+k}+\sum_{l=0}^{k}\lambda^{K-k+2l}\right) \displaystyle\quad V_{k,k}=\frac{1}{\alpha r} \displaystyle\hat{m}_{w}=\rho\sqrt{\mu}\lambda^{K} \displaystyle\quad\hat{V}_{w}=\rho \displaystyle\quad\hat{Q}_{w}=\rho+\rho^{2}\sum_{l=1}^{K}\lambda^{2l} \displaystyle\hat{m}_{k}=\rho\lambda^{K-k} \displaystyle\quad\hat{V}_{k,k}=\rho \displaystyle\quad\hat{Q}_{k,k}=\rho+\rho^{2}\sum_{l=1}^{K-1-k}\lambda^{2l} \tag{193}
$$
and
$$
\displaystyle Q_{k,k}=\frac{\rho}{\alpha^{2}r^{2}}\left(\alpha\left(1+\rho\mu\lambda^{2K}+\rho\sum_{l=1}^{K}\lambda^{2l}\right)+\sum_{m=0}^{k}\left(1+\rho\sum_{l=1}^{K-1-m}\lambda^{2l}+\rho\left(\mu\lambda^{K+m}+\sum_{l=0}^{m}\lambda^{K-m+2l}\right)^{2}\right)\right) \tag{197}
$$
We did not precise the off-diagonal parts of $Q$ and $\hat{Q}$ since they do not enter in the computation of the losses and accuracies. The expressions for $m$ and $Q$ are reproduced in the main part III.1.2.
## Appendix B Asymptotic characterization of the continuous GCN, for asymmetric and symmetrized graphs
In this part we derive the asymptotic characterization of the continuous GCN for both the asymmetric and symmetrized graphs $\tilde{A}$ and $\tilde{A}^{\mathrm{s}}$ . As shown in the main section III.2 this architecture is particularly relevant since it can be close to the Bayes-optimality.
We start by discretizing the GCN and deriving its free energy and the self-consistent equations on its order parameters. Then we take the continuous limit $K\to\infty$ , jointly with an expansion around large regularization $r$ . The derivation of the free energy and of the self-consistent equations follows the same steps as in the previous section A; in particular for the asymmetric case the expressions are identical up to the point where the continuous limit is taken.
To deal with both cases, asymmetric or symmetrized, we define $(\delta_{\mathrm{e}},\tilde{A}^{\mathrm{e}},A^{\mathrm{g,e}},\lambda^{\mathrm{e}},\Xi^{\mathrm{e}})\in\{(0,\tilde{A},A^{\mathrm{g}},\lambda,\Xi),(1,\tilde{A}^{\mathrm{s}},A^{\mathrm{g,s}},\lambda^{\mathrm{s}},\Xi^{\mathrm{s}})\}$ . In particular $\delta_{\mathrm{e}}=0$ for the asymmetric and $\delta_{\mathrm{e}}=1$ for the symmetrized. We remind that $\tilde{A}^{\mathrm{s}}$ is the symmetrized $\tilde{A}$ with effective signal $\lambda^{\mathrm{s}}=\sqrt{2}\lambda$ . $\tilde{A}^{\mathrm{e}}$ admits the following Gaussian equivalent [54, 22, 20]:
$$
\tilde{A}^{\mathrm{e}}\approx A^{\mathrm{g,e}}=\frac{\lambda^{\mathrm{e}}}{\sqrt{N}}yy^{T}+\Xi^{\mathrm{e}}\ , \tag{198}
$$
with $(\Xi)_{ij}$ i.i.d. for all $i$ and $j$ while $\Xi^{\mathrm{s}}$ is taken from the Gaussian orthogonal ensemble.
### B.1 Derivation of the free energy
The continuous GCN is defined by the output function
$$
h(w)=e^{\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}}\frac{1}{\sqrt{N}}Xw\ . \tag{199}
$$
Its discretization at finite $K$ is
$$
h(w)=h_{K}\ ,\qquad h_{k}=\left(I_{N}+\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}\right)h_{k-1}\ ,\qquad h_{0}=\frac{1}{\sqrt{N}}Xw\ . \tag{200}
$$
It can be mapped to the discrete GCN of the previous section A by taking $c=t/K$ .
The free energy is $-\beta Nf=\partial_{n}\mathbb{E}_{u,\Xi^{\mathrm{e}},W,y}Z^{n}(n=0)$ where the partition function is
$$
\displaystyle Z \displaystyle=\int\prod_{\nu}^{M}\mathrm{d}w_{\nu}e^{-\beta r\gamma(w_{\nu})}e^{-\beta s\sum_{i\in R}\ell(y_{i}h(w)_{i})-\beta s^{\prime}\sum_{i\in R^{\prime}}\ell(y_{i}h(w)_{i})}\ . \tag{201}
$$
The expectation of the replicated partition function is
$$
\displaystyle\mathbb{E}Z^{n}\propto\,\mathbb{E}_{u,\Xi^{\mathrm{e}},W,y}\int\prod_{a}^{n}\prod_{\nu}^{M}\mathrm{d}w_{\nu}^{a}e^{-\beta r\gamma(w_{\nu}^{a})}\prod_{a}^{n}\prod_{i}^{N}\prod_{k=0}^{K}\mathrm{d}h_{i,k}^{a}\mathrm{d}q_{i,k}^{a}e^{-\beta s\sum_{a,i\in R}\ell(y_{i}h_{i,K}^{a})-\beta s^{\prime}\sum_{a,i\in R^{\prime}}\ell(y_{i}h_{i,K}^{a})} \displaystyle\qquad\qquad e^{\sum_{a,i}\sum_{k=1}^{K}\mathrm{i}q_{i,k}^{a}\left(\frac{K}{t}h_{i,k}^{a}-\frac{1}{\sqrt{N}}\sum_{j}\left(\sqrt{N}\frac{K}{t}\delta_{i,j}+\frac{\lambda^{\mathrm{e}}}{\sqrt{N}}y_{i}y_{j}+\Xi^{\mathrm{e}}_{ij}\right)h_{j,k-1}^{a}\right)+\sum_{a,i}\mathrm{i}q_{i,0}^{a}\left(h_{i,0}^{a}-\frac{1}{\sqrt{N}}\sum_{\nu}\left(\sqrt{\frac{\mu}{N}}y_{j}u_{\nu}+W_{j\nu}\right)w_{\nu}^{a}\right)} \displaystyle=\mathbb{E}_{u,y}\int\prod_{a,\nu}\mathrm{d}w_{\nu}^{a}e^{-\beta r\gamma(w_{\nu}^{a})}\prod_{a,i,k}\mathrm{d}h_{i,k}^{a}\mathrm{d}q_{i,k}^{a}e^{-\beta s\sum_{a,i\in R}\ell(y_{i}h_{i,K}^{a})-\beta s^{\prime}\sum_{a,i\in R^{\prime}}\ell(y_{i}h_{i,K}^{a})+\mathrm{i}\sum_{a,i,k>0}q_{i,k}^{a}\left(\frac{K}{t}(h_{i,k}^{a}-h_{i,k-1}^{a})-\frac{\lambda^{\mathrm{e}}}{\sqrt{N}}y_{i}\sum_{j}y_{j}h_{j,k-1}^{a}\right)} \displaystyle\qquad e^{-\frac{1}{2N}\sum_{i,j}\sum_{a,b}\sum_{k>0,l>0}(q_{i,k}^{a}h_{j,k-1}^{a}q_{i,l}^{b}h_{j,l-1}^{b}+\delta_{\mathrm{e}}q_{i,k}^{a}h_{j,k-1}^{a}q_{j,l}^{b}h_{i,l-1}^{b})-\mathrm{i}\sum_{a,i}\frac{\sqrt{\mu}}{N}y_{i}q_{i,0}^{a}\sum_{\nu}u_{\nu}w_{\nu}^{a}-\frac{1}{2N}\sum_{i,\nu,a,b}q_{i,0}^{a}q_{i,0}^{b}w_{\nu}^{a}w_{\nu}^{b}}\ . \tag{202}
$$
Compared to part A, because of the symmetry the expectation over $\Xi^{\mathrm{s}}$ gives an additional cross-term. We symmetrized $\sum_{i<j}$ by neglecting the diagonal terms. We introduce new order parameters between $h$ and its conjugate $q$ . We set for all $a$ and $b$ and for $0<k\leq K$ and $0<l\leq K$
$$
\displaystyle m_{w}^{a}=\frac{1}{N}\sum_{\nu}u_{\nu}w_{\nu}^{a}\ ,\quad Q_{w}^{ab}=\frac{1}{N}\sum_{\nu}w_{\nu}^{a}w_{\nu}^{b}\ , \displaystyle m_{k}^{a}=\frac{1}{N}\sum_{j}y_{j}h_{j,k-1}^{a}\ ,\quad Q_{h,kl}^{ab}=\frac{1}{N}\sum_{j}h_{j,k-1}^{a}h_{j,l-1}^{b}\ , \displaystyle Q_{q,kl}^{ab}=\frac{1}{N}\sum_{j}q_{j,k}^{a}q_{j,l}^{b}\ ,\quad Q_{qh,kl}^{ab}=\frac{1}{N}\sum_{j}q_{j,k}^{a}h_{j,l-1}^{b}\ . \tag{204}
$$
We introduce these quantities via $\delta$ -Dirac functions. Their conjugates are $\hat{m}_{w}^{a}$ , $\hat{Q}_{w}^{ab}$ , $\hat{V}_{w}^{ab}$ , $\hat{m}^{a}$ , $\hat{Q}^{ab}$ and $\hat{V}^{ab}$ . We factorize the $\nu$ and $i$ indices. We leverage the replica-symmetric ansatz. We assume that for all $a$ and $b$
$$
m_{w}^{a}=m_{w}\ ,\qquad\hat{m}_{w}^{a}=-\hat{m}_{w}\ ,\qquad m_{k}^{a}=m_{k}\ ,\qquad\hat{m}_{k}^{a}=-\hat{m}_{k} \tag{207}
$$
and
$$
\displaystyle Q_{w}^{ab}=Q_{w}+V_{w}\delta_{a,b}\ , \displaystyle\hat{Q}_{w}^{ab}=-\hat{Q}_{w}+\frac{1}{2}(\hat{V}_{w}+\hat{Q}_{w})\delta_{a,b}\ , \displaystyle Q_{h,kl}^{ab}=Q_{h,kl}+V_{h,kl}\delta_{a,b}\ , \displaystyle\hat{Q}_{h,kk}^{ab}=-\hat{Q}_{h,kk}+\frac{1}{2}(\hat{V}_{h,kk}+\hat{Q}_{h,kk})\delta_{a,b}\ , \displaystyle\hat{Q}_{h,kl}^{ab}=-\hat{Q}_{h,kl}+\hat{V}_{h,kl}\delta_{a,b}\ , \displaystyle Q_{q,kl}^{ab}=Q_{q,kl}+V_{q,kl}\delta_{a,b}\ , \displaystyle\hat{Q}_{q,kk}^{ab}=-\hat{Q}_{q,kk}+\frac{1}{2}(\hat{V}_{q,kk}+\hat{Q}_{q,kk})\delta_{a,b}\ , \displaystyle\hat{Q}_{q,kl}^{ab}=-\hat{Q}_{q,kl}+\hat{V}_{q,kl}\delta_{a,b}\ , \displaystyle Q_{qh,kl}^{ab}=Q_{qh,kl}+V_{qh,kl}\delta_{a,b}\ , \displaystyle\hat{Q}_{qh,kk}^{ab}=-\hat{Q}_{qh,kk}+\hat{V}_{qh,kk}\delta_{a,b}\ , \displaystyle\hat{Q}_{qh,kl}^{ab}=-\hat{Q}_{qh,kl}+\hat{V}_{qh,kl}\delta_{a,b}\ . \tag{208}
$$
$\delta_{a,b}$ is a Kronecker delta between $a$ and $b$ . $Q_{h}$ , $Q_{q}$ , $Q_{qh}$ , $V_{h}$ , $V_{q}$ , $V_{qh}$ , and their conjugates, written with a hat, are $K\times K$ matrices that we pack into the following $2K\times 2K$ symmetric block matrices:
$$
\displaystyle Q=\left(\begin{smallmatrix}Q_{q}&Q_{qh}\\
Q_{qh}^{T}&Q_{h}\end{smallmatrix}\right)\ , \displaystyle V=\left(\begin{smallmatrix}V_{q}&V_{qh}\\
V_{qh}^{T}&V_{h}\end{smallmatrix}\right)\ , \displaystyle\hat{Q}=\left(\begin{smallmatrix}\hat{Q}_{q}&\hat{Q}_{qh}\\
\hat{Q}_{qh}^{T}&\hat{Q}_{h}\end{smallmatrix}\right)\ , \displaystyle\hat{V}=\left(\begin{smallmatrix}\hat{V}_{q}&\hat{V}_{qh}\\
\hat{V}_{qh}^{T}&\hat{V}_{h}\end{smallmatrix}\right)\ . \tag{212}
$$
We obtain that
$$
\displaystyle\mathbb{E}Z^{n}\propto \displaystyle\,\int\mathrm{d}\hat{Q}_{w}\mathrm{d}\hat{V}_{w}\mathrm{d}Q_{w}\mathrm{d}V_{w}\mathrm{d}\hat{Q}\mathrm{d}\hat{V}\mathrm{d}Q\mathrm{d}Ve^{\frac{nN}{2}(\hat{V}_{w}V_{w}+\hat{V}_{w}Q_{w}-V_{w}\hat{Q}_{w}+\mathrm{tr}(\hat{V}V+\hat{V}Q-V\hat{Q})-\mathrm{tr}(V_{q}V_{h}+V_{q}Q_{h}+V_{h}Q_{q}+\delta_{\mathrm{e}}V_{qh}^{2}+2\delta_{\mathrm{e}}V_{qh}Q_{qh}))} \displaystyle\quad\quad\mathrm{d}\hat{m}_{w}\mathrm{d}m_{w}\mathrm{d}\hat{m}_{\sigma}\mathrm{d}m_{\sigma}e^{-nN(\hat{m}_{w}m_{w}+\hat{m}_{\sigma}m_{\sigma})}\left[\mathbb{E}_{u}\int\prod_{a}\mathrm{d}w^{a}\,e^{\psi_{w}^{(n)}(w)}\right]^{N/\alpha} \displaystyle\quad\quad\left[\mathbb{E}_{y}\int\prod_{a,k}\mathrm{d}h_{k}^{a}\mathrm{d}q_{k}^{a}e^{\psi_{h}^{(n)}(h,q;s)}\right]^{\rho N}\left[\mathbb{E}_{y}\int\prod_{a,k}\mathrm{d}h_{k}^{a}\mathrm{d}q_{k}^{a}e^{\psi_{h}^{(n)}(h,q;s^{\prime})}\right]^{(1-\rho)N} \displaystyle:= \displaystyle\ \int\mathrm{d}\Theta\mathrm{d}\hat{\Theta}e^{N\phi^{(n)}(\Theta,\hat{\Theta})}\ , \tag{214}
$$
with $\Theta=\{m_{w},Q_{w},V_{w},m,Q,V\}$ and $\hat{\Theta}=\{\hat{m}_{w},\hat{Q}_{w},\hat{V}_{w},\hat{m},\hat{Q},\hat{V}\}$ the sets of order parameters and
$$
\displaystyle\psi_{w}^{(n)}(w) \displaystyle=-\beta r\sum_{a}\gamma(w^{a})-\frac{1}{2}\hat{V}_{w}\sum_{a}(w^{a})^{2}+\hat{Q}_{w}\sum_{a,b}w^{a}w^{b}+u\hat{m}_{w}\sum_{a}w^{a} \displaystyle\psi_{h}^{(n)}(h,q;\bar{s}) \displaystyle=-\beta\bar{s}\sum_{a}\ell(yh_{K}^{a})-\frac{1}{2}V_{w}\sum_{a}(q_{0}^{a})^{2}+Q_{w}\sum_{a,b}q_{0}^{a}q_{0}^{b}-\frac{1}{2}\sum_{a}\left(\begin{smallmatrix}q_{>0}^{a}\\
h_{<K}^{a}\end{smallmatrix}\right)^{T}\hat{V}\left(\begin{smallmatrix}q_{>0}^{a}\\
h_{<K}^{a}\end{smallmatrix}\right)+\sum_{a,b}\left(\begin{smallmatrix}q_{>0}^{a}\\
h_{<K}^{a}\end{smallmatrix}\right)^{T}\hat{Q}\left(\begin{smallmatrix}q_{>0}^{b}\\
h_{<K}^{b}\end{smallmatrix}\right) \displaystyle\qquad{}+y\hat{m}^{T}\sum_{a}h_{<K}^{a}+\mathrm{i}\sum_{a}(q_{>0}^{a})^{T}\left(\frac{K}{t}(h_{>0}^{a}-h_{<K}^{a})-\lambda^{\mathrm{e}}ym^{a}\right)-\mathrm{i}\sqrt{\mu}ym_{w}\sum_{a}q_{0}^{a} \tag{216}
$$
$u$ is a scalar standard Gaussian and $y$ is a scalar Rademacher variable. We use the notation $q_{>0}^{a}\in\mathbb{R}^{K}$ for $(q_{k}^{a})_{k>0}$ and similarly as to $h_{>0}^{a}$ and $h_{<K}^{a}=(h_{k}^{a})_{k<K}$ . We packed them into vectors of size $2K$ .
We take the limit $N\to\infty$ thanks to Laplace’s method.
$$
\displaystyle-\beta f\propto \displaystyle\frac{1}{N}\frac{\partial}{\partial n}(n=0)\int\mathrm{d}\Theta\mathrm{d}\hat{\Theta}\,e^{N\phi^{(n)}(\Theta,\hat{\Theta})} \displaystyle= \displaystyle\operatorname*{extr}_{\Theta,\hat{\Theta}}\frac{\partial}{\partial n}(n=0)\phi^{(n)}(\Theta,\hat{\Theta}) \displaystyle:= \displaystyle\operatorname*{extr}_{\Theta,\hat{\Theta}}\phi(\Theta,\hat{\Theta})\ , \tag{218}
$$
where we extremize the following free entropy $\phi$ :
$$
\displaystyle\phi= \displaystyle\frac{1}{2}(V_{w}\hat{V}_{w}+\hat{V}_{w}Q_{w}-V_{w}\hat{Q}_{w})+\frac{1}{2}\operatorname{Tr}(V_{q}\hat{V}_{q}+\hat{V}_{q}Q_{q}-V_{q}\hat{Q}_{q})+\frac{1}{2}\operatorname{Tr}(V_{h}\hat{V}_{h}+\hat{V}_{h}Q_{h}-V_{h}\hat{Q}_{h}) \displaystyle{}+\operatorname{Tr}(V_{qh}\hat{V}_{qh}^{T}+\hat{V}_{qh}Q_{qh}^{T}-V_{qh}\hat{Q}_{qh}^{T})-\frac{1}{2}\operatorname{Tr}(V_{q}V_{h}+V_{q}Q_{h}+Q_{q}V_{h}+\delta_{\mathrm{e}}V_{qh}^{2}+2\delta_{\mathrm{e}}V_{qh}Q_{qh})-m_{w}\hat{m}_{w}-m^{T}\hat{m} \displaystyle{}+\mathbb{E}_{u,\varsigma}\int\mathrm{d}w\,e^{\psi_{w}(w)}+\rho\mathbb{E}_{y,\zeta,\chi}\int\mathrm{d}q\mathrm{d}h\,e^{\psi_{qh}(q,h;s)}+(1-\rho)\mathbb{E}_{y,\zeta,\chi}\int\mathrm{d}q\mathrm{d}h\,e^{\psi_{qh}(q,h;s^{\prime})}\ . \tag{221}
$$
We factorized the replica and took the derivative with respect to $n$ by introducing independent standard Gaussian random variables $\varsigma\in\mathbb{R}$ , $\zeta=\left(\begin{smallmatrix}\zeta_{q}\\ \zeta_{h}\end{smallmatrix}\right)\in\mathbb{R}^{2K}$ and $\chi\in\mathbb{R}$ . The potentials are
$$
\displaystyle\psi_{w}(w)= \displaystyle-\beta r\gamma(w)-\frac{1}{2}\hat{V}_{w}w^{2}+\left(\sqrt{\hat{Q}_{w}}\varsigma+u\hat{m}_{w}\right)w \displaystyle\psi_{qh}(q,h;\bar{s})= \displaystyle-\beta\bar{s}\ell(yh_{K})-\frac{1}{2}V_{w}q_{0}^{2}-\frac{1}{2}\left(\begin{smallmatrix}q_{>0}\\
h_{<K}\end{smallmatrix}\right)^{T}\hat{V}\left(\begin{smallmatrix}q_{>0}\\
h_{<K}\end{smallmatrix}\right)+\left(\begin{smallmatrix}q_{>0}\\
h_{<K}\end{smallmatrix}\right)^{T}\hat{Q}^{1/2}\left(\begin{smallmatrix}\zeta_{q}\\
\zeta_{h}\end{smallmatrix}\right) \displaystyle{}+yh_{<K}^{T}\hat{m}+\mathrm{i}q^{T}\left(\left(\begin{smallmatrix}1/K&\\
&I/t\end{smallmatrix}\right)Dh-\left(\begin{smallmatrix}y\sqrt{\mu}m_{w}+\sqrt{Q_{w}}\chi\\
y\lambda^{\mathrm{e}}m\end{smallmatrix}\right)\right) \tag{222}
$$
We already extremize $\phi$ with respect to $Q$ and $V$ to obtain the following equalities:
$$
\displaystyle\hat{V}_{q}=V_{h}\ , \displaystyle V_{q}=\hat{V}_{h}\ , \displaystyle\hat{V}_{qh}=\delta_{\mathrm{e}}V_{qh}^{T}\ , \displaystyle\hat{Q}_{q}=-Q_{h}\ , \displaystyle Q_{q}=-\hat{Q}_{h}\ , \displaystyle\hat{Q}_{qh}=-\delta_{\mathrm{e}}Q_{qh}^{T}\ . \tag{224}
$$
In particular this shows that in the asymmetric case where $\delta_{\mathrm{e}}=0$ one has $\hat{V}_{qh}=\hat{Q}_{qh}=0$ and as a consequence $V_{qh}=Q_{qh}=0$ ; and we recover the potential $\psi_{h}$ previously derived in part A.
We assume that $\ell$ is quadratic so $\psi_{qh}$ can be written as the following quadratic potential. Later we will take the limit $r\to\infty$ where $h$ is small and where $\ell$ can effectively be expanded around $0$ as a quadratic potential.
$$
\displaystyle\psi_{qh}(q,h;\bar{s}) \displaystyle=-\frac{1}{2}\left(\begin{smallmatrix}q\\
h\end{smallmatrix}\right)^{T}\left(\begin{smallmatrix}G_{q}&-\mathrm{i}G_{qh}\\
-\mathrm{i}G_{qh}^{T}&G_{h}\end{smallmatrix}\right)\left(\begin{smallmatrix}q\\
h\end{smallmatrix}\right)+\left(\begin{smallmatrix}q\\
h\end{smallmatrix}\right)^{T}\left(\begin{smallmatrix}-\mathrm{i}B_{q}\\
B_{h}\end{smallmatrix}\right) \tag{226}
$$
with
$$
\displaystyle G_{q}=\left(\begin{smallmatrix}V_{w}&0\\
0&\hat{V}_{q}\end{smallmatrix}\right)\ ,\qquad G_{h}=\left(\begin{smallmatrix}\hat{V}_{h}&0\\
0&\beta\bar{s}\end{smallmatrix}\right)\ ,\qquad G_{qh}=\left(\begin{smallmatrix}1/K&0\\
0&I_{K}/t\end{smallmatrix}\right)D+\left(\begin{smallmatrix}0&0\\
\mathrm{i}\hat{V}_{qh}&0\end{smallmatrix}\right)\ ,\qquad D=K\left(\begin{smallmatrix}1&&&0\\
-1&\ddots&&\\
&\ddots&\ddots&\\
0&&-1&1\end{smallmatrix}\right)\ , \displaystyle B_{q}=\left(\begin{smallmatrix}\sqrt{Q_{w}}\chi\\
\mathrm{i}\left(\hat{Q}^{1/2}\zeta\right)_{q}\end{smallmatrix}\right)+y\left(\begin{smallmatrix}\sqrt{\mu}m_{w}\\
\lambda^{\mathrm{e}}m\end{smallmatrix}\right)\ ,\qquad B_{h}=\left(\begin{smallmatrix}\left(\hat{Q}^{1/2}\zeta\right)_{h}\\
0\end{smallmatrix}\right)+y\left(\begin{smallmatrix}\hat{m}\\
\beta\bar{s}\end{smallmatrix}\right)\ ,\qquad\left(\begin{smallmatrix}(\hat{Q}^{1/2}\zeta)_{q}\\
(\hat{Q}^{1/2}\zeta)_{h}\end{smallmatrix}\right)=\left(\begin{smallmatrix}\hat{Q}_{q}&\hat{Q}_{qh}\\
\hat{Q}_{qh}^{T}&\hat{Q}_{h}\end{smallmatrix}\right)^{1/2}\left(\begin{smallmatrix}\zeta_{q}\\
\zeta_{h}\end{smallmatrix}\right)\ . \tag{227}
$$
$G_{q}$ , $G_{h}$ , $G_{qh}$ and $D$ are in $\mathbb{R}^{(K+1)\times(K+1)}$ . $D$ is the discrete derivative. $B_{q}$ , $B_{h}$ and $\left(\begin{smallmatrix}q\\ h\end{smallmatrix}\right)$ are in $\mathbb{R}^{2(K+1)}$ . We can marginalize $e^{\psi_{qh}}$ over $q$ :
$$
\displaystyle\int\mathrm{d}q\mathrm{d}h\,e^{\psi_{qh}(q,h;\bar{s})}=\int\mathrm{d}h\,e^{\psi_{h}(h;\bar{s})} \displaystyle\psi_{h}(h;\bar{s})=-\frac{1}{2}h^{T}G_{h}h+h^{T}B_{h}-\frac{1}{2}\log\det G_{q}-\frac{1}{2}(G_{qh}h-B_{q})^{T}G_{q}^{-1}(G_{qh}h-B_{q}) \displaystyle\quad=-\frac{1}{2}h^{T}Gh+h^{T}\left(B_{h}+D_{qh}^{T}G_{0}^{-1}B\right)-\frac{1}{2}\log\det G_{q}\ , \tag{229}
$$
where we set
$$
\displaystyle G \displaystyle=G_{h}+D_{qh}^{T}G_{0}^{-1}D_{qh}\ , \displaystyle G_{0} \displaystyle=\left(\begin{smallmatrix}K^{2}V_{w}&0\\
0&t^{2}V_{h}\end{smallmatrix}\right)\ , \displaystyle D_{qh} \displaystyle=D-t\left(\begin{smallmatrix}0&0\\
-\mathrm{i}\delta_{\mathrm{e}}V_{qh}^{T}&0\end{smallmatrix}\right)\ , \displaystyle B \displaystyle=\left(\begin{smallmatrix}K\sqrt{Q_{w}}\chi\\
\mathrm{i}t\left(\hat{Q}^{1/2}\zeta\right)_{q}\end{smallmatrix}\right)+y\left(\begin{smallmatrix}K\sqrt{\mu}m_{w}\\
\lambda^{\mathrm{e}}tm\end{smallmatrix}\right)\ . \tag{232}
$$
Eq. (231) is the potential eq. (65) given in the main part, up to a term independent of $h$ .
We take the limit $\beta\to\infty$ . As before we introduce the measures $\mathrm{d}P_{w}$ , $\mathrm{d}P_{qh}$ and $\mathrm{d}P_{qh}^{\prime}$ , $\mathrm{d}P_{h}$ and $\mathrm{d}P_{h}^{\prime}$ whose unnormalized densities are $e^{\psi_{\mathrm{w}}(w)}$ , $e^{\psi_{qh}(h,q;s)}$ , $e^{\psi_{qh}(h,q;s^{\prime})}$ , $e^{\psi_{h}(h;s)}$ and $e^{\psi_{h}(h;s^{\prime})}$ . We use Laplace’s method to evaluate them. We have to rescale the order parameters not to obtain a degenerated solution. We take
$$
\displaystyle m_{w}\to m_{w}\ , \displaystyle Q_{w}\to Q_{w}\ , \displaystyle V_{w}\to V_{w}/\beta\ , \displaystyle\hat{m}_{w}\to\beta\hat{m}_{w}\ , \displaystyle\hat{Q}_{w}\to\beta^{2}\hat{Q}_{w}\ , \displaystyle\hat{V}_{w}\to\beta\hat{V}_{w}\ , \displaystyle m\to m\ , \displaystyle Q_{h}\to Q_{h}\ , \displaystyle V_{h}\to V_{h}/\beta\ , \displaystyle\hat{m}\to\beta\hat{m}\ , \displaystyle\hat{Q}_{h}\to\beta^{2}\hat{Q}_{h}\ , \displaystyle\hat{V}_{h}\to\beta\hat{V}_{h}\ , \displaystyle Q_{qh}\to\beta Q_{qh}\ , \displaystyle V_{qh}\to V_{qh}\ . \tag{236}
$$
We take this scaling for $Q_{qh}$ and $V_{qh}$ because we want $D_{qh}$ and $B$ to be of order one while $G$ , $B_{h}$ and $G_{0}^{-1}$ to be of order $\beta$ . Taking the matrix square root we obtain the block-wise scaling
$$
\hat{Q}^{1/2}\to\left(\begin{smallmatrix}1&1\\
1&\beta\end{smallmatrix}\right)\odot\hat{Q}^{1/2}\ , \tag{241}
$$
which does give $(\hat{Q}^{1/2}\zeta)_{q}$ of order one and $(\hat{Q}^{1/2}\zeta)_{h}$ of order $\beta$ . As a consequence we obtain that $f=-\phi$ and that $P_{w}$ , $P_{h}$ and $P_{h}^{\prime}$ are peaked around their respective maximum $w^{*}$ , $h^{*}$ and $h^{{}^{\prime}*}$ , and that they can be approximated by Gaussian measures. Notice that $P_{qh}$ is not peaked as to its $q$ variable, which has to be integrated over all its range, which leads to the marginale $P_{h}$ and the potential $\psi_{h}$ eq. (231).
Last, differentiating the free energy $f$ with respect to $s$ and $s^{\prime}$ we obtain the expected errors and accuracies:
$$
\displaystyle E_{\mathrm{train}}=\mathbb{E}_{y,\zeta,\xi}\ell(yh_{K}^{*})\ , \displaystyle\mathrm{Acc}_{\mathrm{train}}=\mathbb{E}_{y,\zeta,\xi}\delta_{y=\operatorname{sign}(h_{K}^{*})}\ , \displaystyle E_{\mathrm{test}}=\mathbb{E}_{y,\zeta,\xi}\ell(yh_{K}^{{}^{\prime}*})\ , \displaystyle\mathrm{Acc}_{\mathrm{test}}=\mathbb{E}_{y,\zeta,\xi}\delta_{y=\operatorname{sign}(h_{K}^{{}^{\prime}*})}\ . \tag{242}
$$
### B.2 Self-consistent equations
The extremality condition $\nabla_{\Theta,\hat{\Theta}}\phi$ gives the following self-consistent equations on the order parameters. $\mathcal{P}$ is the operator that acts by linearly combining quantities evaluated at $h^{*}$ , taken with $\bar{s}=1$ and $\bar{s}=0$ with weights $\rho$ and $1-\rho$ , according to $\mathcal{P}(g(h))=\rho g(h^{*})+(1-\rho)g(h^{{}^{\prime}*})$ . We assume $l_{2}$ regularization, i.e. $\gamma(w)=w^{2}/2$ .
$$
\displaystyle m_{w}=\frac{1}{\alpha}\frac{\hat{m}_{w}}{r+\hat{V}_{w}} \displaystyle Q_{w}=\frac{1}{\alpha}\frac{\hat{Q}_{w}+\hat{m}_{w}^{2}}{(r+\hat{V}_{w})^{2}} \displaystyle V_{w}=\frac{1}{\alpha}\frac{1}{r+\hat{V}_{w}} \displaystyle\left(\begin{smallmatrix}\hat{m}_{w}\\
\hat{m}\\
m\\
\cdot\end{smallmatrix}\right)=\left(\begin{smallmatrix}K\sqrt{\mu}&&0\\
&\lambda^{\mathrm{e}}tI_{K}&\\
0&&I_{K+1}\end{smallmatrix}\right)\mathbb{E}_{y,\xi,\zeta}\,y\mathcal{P}\left(\begin{smallmatrix}G_{0}^{-1}(D_{qh}h-B)\\
h\end{smallmatrix}\right) \displaystyle\left(\begin{smallmatrix}\hat{Q}_{w}&&&\cdot\\
&\hat{Q}_{h}&Q_{qh}&\\
&Q_{qh}^{T}&Q_{h}&\\
\cdot&&&\cdot\end{smallmatrix}\right)=\left(\begin{smallmatrix}K&&0\\
&tI_{K}&\\
0&&I_{K+1}\end{smallmatrix}\right)\mathbb{E}_{y,\xi,\zeta}\mathcal{P}\left(\left(\begin{smallmatrix}G_{0}^{-1}(D_{qh}h-B)\\
h\end{smallmatrix}\right)^{\otimes 2}\right)\left(\begin{smallmatrix}K&&0\\
&tI_{K}&\\
0&&I_{K+1}\end{smallmatrix}\right) \displaystyle\left(\begin{smallmatrix}\hat{V}_{w}&&&\cdot\\
&\hat{V}_{h}&V_{qh}&\\
&V_{qh}^{T}&V_{h}&\\
\cdot&&&\cdot\end{smallmatrix}\right)=\mathcal{P}\left(\operatorname{Cov}_{\psi_{qh}}\left(\begin{smallmatrix}q\\
h\end{smallmatrix}\right)\right) \tag{244}
$$
We use the notation $\cdot$ for unspecified padding to reach vectors of size $2(K+1)$ and matrices of size $2(K+1)\times 2(K+1)$ .
The extremizer $h^{*}$ of $\psi_{h}$ is
$$
\displaystyle h^{*}=G^{-1}\left(B_{h}+D_{qh}^{T}G_{0}^{-1}B\right)\ . \tag{250}
$$
It has to be plugged in to the fixed-point equations (247 - 248) and the expectation over the disorder has to be taken.
As to the variances eq. (249), we have $\operatorname{Cov}_{\psi_{qh}}\left(\begin{smallmatrix}q\\ h\end{smallmatrix}\right)=\left(\begin{smallmatrix}G_{q}&-\mathrm{i}G_{qh}\\ -\mathrm{i}G_{qh}^{T}&G_{h}\end{smallmatrix}\right)^{-1}$ and using Schur’s complement on $G_{q}$ invertible, one obtains
$$
\displaystyle\left(\begin{smallmatrix}\cdot&\cdot\\
-\mathrm{i}V_{qh}&\cdot\end{smallmatrix}\right)=t\mathcal{P}\left(G_{0}^{-1}D_{qh}G^{-1}\right) \displaystyle\left(\begin{smallmatrix}V_{h}&\cdot\\
\cdot&\cdot\end{smallmatrix}\right)=\mathcal{P}\left(G^{-1}\right) \displaystyle\left(\begin{smallmatrix}\hat{V}_{w}&\cdot\\
\cdot&\hat{V}_{h}\end{smallmatrix}\right)=\left(\begin{smallmatrix}K^{2}&0\\
0&t^{2}I_{K}\end{smallmatrix}\right)\mathcal{P}\left(G_{0}^{-1}-G_{0}^{-1}D_{qh}G^{-1}D_{qh}^{T}G_{0}^{-1}\right) \tag{251}
$$
The continuation of the computation and how to solve these equations is detailed in the main part III.2.2.
### B.3 Solution in the continuous limit at large $r$
We report the final values of the order parameters, given in the main part III.2.1. We set $x=k/K$ and $z=l/K$ continuous indices ranging from 0 to 1. We define the resolvants
$$
\displaystyle\varphi(x) \displaystyle=\left\{\begin{array}[]{cc}e^{\lambda^{\mathrm{e}}tx}&\mathrm{if}\,\delta_{\mathrm{e}}=0\\
\sum_{\nu>0}^{\infty}\nu(\lambda^{\mathrm{e}})^{\nu-1}\frac{I_{\nu}(2tx)}{tx}&\mathrm{if}\,\delta_{\mathrm{e}}=1\end{array}\right.\ , \displaystyle\Phi(x,z) \displaystyle=\left\{\begin{array}[]{cc}I_{0}(2t\sqrt{xz})&\mathrm{if}\,\delta_{\mathrm{e}}=0\\
\frac{I_{1}(2t(x+z))}{t(x+z)}&\mathrm{if}\,\delta_{\mathrm{e}}=1\end{array}\right.\ , \tag{256}
$$
with $I_{\nu}$ the modified Bessel function of the second kind of order $\nu$ . The effective inverse derivative is
$$
\displaystyle V_{qh}(x,z) \displaystyle=\theta(z-x)(z-x)^{-1}I_{1}(2t(z-x))\ , \displaystyle D_{qh}^{-1}(x,z) \displaystyle=D_{qh}^{-1,T}(z,x)=\left\{\begin{array}[]{cc}\theta(x-z)&\mathrm{if}\,\delta_{\mathrm{e}}=0\\
\frac{1}{t}V_{qh}(z,x)&\mathrm{if}\,\delta_{\mathrm{e}}=1\end{array}\right.\ , \tag{260}
$$
with $\theta$ the step function.
The solution to the fixed-point equations, in the continuous limit $K\to\infty$ , at first constant order in $1/r$ , is
$$
\displaystyle V_{w}=\frac{1}{r\alpha} \displaystyle V_{h}(x,z)=V_{w}\Phi(x,z) \displaystyle\hat{V}_{h}(1-x,1-z)=t^{2}\rho\Phi(x,z) \displaystyle\hat{V}_{w}=t^{-2}\hat{V}_{h}(0,0) \displaystyle\hat{m}(1-x)=\rho\lambda^{\mathrm{e}}t\varphi(x) \displaystyle\hat{m}_{w}=\sqrt{\mu}\frac{1}{\lambda^{\mathrm{e}}t}\hat{m}(0) \displaystyle m_{w}=\frac{\hat{m}_{w}}{r\alpha} \displaystyle m(x)=(1+\mu)\frac{m_{w}}{\sqrt{\mu}}\varphi(x)+\frac{t}{\lambda^{\mathrm{e}}}\int_{0}^{x}\mathrm{d}x^{\prime}\int_{0}^{1}\mathrm{d}x^{\prime\prime}\,\varphi(x-x^{\prime})V_{h}(x^{\prime},x^{\prime\prime})\hat{m}(x^{\prime\prime}) \displaystyle\hat{Q}_{w}=t^{-2}\hat{Q}_{h}(0,0) \displaystyle Q_{w}=\frac{\hat{Q}_{w}+\hat{m}_{w}^{2}}{r^{2}\alpha} \displaystyle\hat{Q}_{h}(1-x,1-z)=t^{2}\int_{0^{-},0^{-}}^{x,z}\mathrm{d}x^{\prime}\mathrm{d}z^{\prime}\ \Phi(x-x^{\prime},z-z^{\prime})\left[\mathcal{P}(\hat{m}^{\otimes 2})(1-x^{\prime},1-z^{\prime})\right] \displaystyle Q_{qh}(1-x,z)=t\int_{0^{-},0^{-}}^{x,z}\mathrm{d}x^{\prime}\mathrm{d}z^{\prime}\ \Phi(x-x^{\prime},z-z^{\prime})\Bigg[\mathcal{P}(\hat{m})(1-x^{\prime})(\lambda^{\mathrm{e}}tm(z^{\prime})+\sqrt{\mu}m_{w}\delta(z^{\prime})) \displaystyle\hskip 18.49988pt\left.{}+\int_{0,0^{-}}^{1^{+},1}\mathrm{d}x^{\prime\prime}\mathrm{d}z^{\prime\prime}\,\left(\hat{Q}_{h}(1-x^{\prime},x^{\prime\prime})+\mathcal{P}(\hat{m}^{\otimes 2})(1-x^{\prime},x^{\prime\prime})\right)D_{qh}^{-1}(x^{\prime\prime},z^{\prime\prime})G_{0}(z^{\prime\prime},z^{\prime})\right] \displaystyle Q_{h}(x,z)=\int_{0^{-},0^{-}}^{x,z}\mathrm{d}x^{\prime}\mathrm{d}z^{\prime}\ \Phi(x-x^{\prime},z-z^{\prime})\Bigg[\hat{Q}_{w}\delta(x^{\prime},z^{\prime})+(\lambda^{\mathrm{e}}tm(x^{\prime})+\sqrt{\mu}m_{w}\delta(x^{\prime}))(\lambda^{\mathrm{e}}tm(z^{\prime})+\sqrt{\mu}m_{w}\delta(z^{\prime})) \displaystyle\hskip 18.49988pt{}+\int_{0^{-},0}^{1,1^{+}}\mathrm{d}x^{\prime\prime}\mathrm{d}x^{\prime\prime\prime}\,G_{0}(x^{\prime},x^{\prime\prime})D_{qh}^{-1,T}(x^{\prime\prime},x^{\prime\prime\prime})\left(t\delta_{\mathrm{e}}Q_{qh}(x^{\prime\prime\prime},z^{\prime})+\mathcal{P}(\hat{m})(x^{\prime\prime\prime})(\lambda^{\mathrm{e}}tm(z^{\prime})+\sqrt{\mu}m_{w}\delta(z^{\prime}))\right) \displaystyle\hskip 18.49988pt{}+\int_{0,0^{-}}^{1^{+},1}\mathrm{d}z^{\prime\prime\prime}\mathrm{d}z^{\prime\prime}\,\left(t\delta_{\mathrm{e}}Q_{qh}(z^{\prime\prime\prime},x^{\prime})+(\lambda^{\mathrm{e}}tm(x^{\prime})+\sqrt{\mu}m_{w}\delta(x^{\prime}))\mathcal{P}(\hat{m})(z^{\prime\prime\prime})\right)D_{qh}^{-1}(z^{\prime\prime\prime},z^{\prime\prime})G_{0}(z^{\prime\prime},z^{\prime}) \displaystyle\qquad\left.{}+\int_{0^{-},0,0,0^{-}}^{1,1^{+},1^{+},1}\mathrm{d}x^{\prime\prime}\mathrm{d}x^{\prime\prime\prime}\mathrm{d}z^{\prime\prime\prime}\mathrm{d}z^{\prime\prime}\,G_{0}(x^{\prime},x^{\prime\prime})D_{qh}^{-1,T}(x^{\prime\prime},x^{\prime\prime\prime})\left(\hat{Q}_{h}(x^{\prime\prime\prime},z^{\prime\prime\prime})+\mathcal{P}(\hat{m}^{\otimes 2})(x^{\prime\prime\prime},z^{\prime\prime\prime})\right)D_{qh}^{-1}(z^{\prime\prime\prime},z^{\prime\prime})G_{0}(z^{\prime\prime},z^{\prime})\right]\ ; \tag{264}
$$
where we set
$$
\displaystyle\mathcal{P}(\hat{m})(x) \displaystyle=\hat{m}(x)+\rho\delta(1-x)\ , \displaystyle\mathcal{P}(\hat{m}^{\otimes 2})(x,z) \displaystyle=\rho\left(\hat{m}(x)+\delta(1-x)\right)\left(\hat{m}(z)+\delta(1-z)\right)+(1-\rho)\hat{m}(x)\hat{m}(z)\ , \displaystyle G_{0}(x,z) \displaystyle=t^{2}V_{h}(x,z)+V_{w}\delta(x,z)\ . \tag{277}
$$
The test and train accuracies are
$$
\displaystyle\mathrm{Acc}_{\mathrm{test}} \displaystyle=\mathbb{E}_{y,\xi,\zeta,\chi}\delta_{y=\operatorname{sign}(h^{{}^{\prime}*}(1))} \displaystyle=\mathbb{E}_{\xi,\zeta,\chi}\delta_{0<\sqrt{\mu}m_{w}+K\int_{0}^{1}\mathrm{d}x\,V(1,x)\hat{m}(x)+\lambda t\int_{0}^{1}\mathrm{d}x\,m(x)+\sqrt{Q_{w}}\zeta+K\int_{0}^{1}\mathrm{d}x\mathrm{d}z\,V(1,x)\hat{Q}^{1/2}(x,z)\xi(z)+t\int_{0}^{1}\mathrm{d}x\mathrm{d}z\,Q^{1/2}(x,z)\chi(z)} \displaystyle=\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{\sqrt{\mu}m_{w}+K\int_{0}^{1}\mathrm{d}x\,V(1,x)\hat{m}(x)+\lambda t\int_{0}^{1}\mathrm{d}x\,m(x)}{\sqrt{2}\sqrt{Q_{w}+K^{2}\int_{0}^{1}\mathrm{d}x\mathrm{d}z\,V(1,x)\hat{Q}(x,z)V(z,1)+t^{2}\int_{0}^{1}\mathrm{d}x\mathrm{d}z\,Q(x,z)}}\right)\right) \displaystyle=\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{m(1)-\rho V(1,1)}{\sqrt{2}\sqrt{Q(1,1)-m(1)^{2}-\rho(1-\rho)V(1,1)^{2}}}\right)\right) \tag{1}
$$
and
$$
\displaystyle\mathrm{Acc}_{\mathrm{train}} \displaystyle=\mathbb{E}_{y,\xi,\zeta,\chi}\delta_{y=\operatorname{sign}(h^{*}(1))} \displaystyle=\mathbb{E}_{y,\xi,\zeta,\chi}\delta_{y=\operatorname{sign}(h^{{}^{\prime}*}(1)+V(1,1)y)} \displaystyle=\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{m(1)+(1-\rho)V(1,1)}{\sqrt{2}\sqrt{Q(1,1)-m(1)^{2}-\rho(1-\rho)V(1,1)^{2}}}\right)\right) \tag{1}
$$
To obtain the last expressions we integrated $m$ and $Q$ by parts thanks to the self-consistent conditions they satisfy.
### B.4 Higher orders in $1/r$ : how to pursue the computation
The solution given in the main part III.2.1 and reproduced above are for infinite regularization $r$ , keeping only the first constant order. We briefly show how to pursue the computation at any order.
The self-consistent equations for $V_{qh}$ , $V_{h}$ and $\hat{V}_{h}$ at any order can be phrased as, rewritting eqs. (251 - 253) and extending the matrices by continuity:
$$
\displaystyle\frac{1}{t}V_{qh}=\mathcal{P}\left(D_{qh}^{-1,T}\sum_{a\geq 0}\left(-G_{h}D_{qh}^{-1}G_{0}D_{qh}^{-1,T}\right)^{a}\right)\ , \displaystyle V_{h}=D_{qh}^{-1}\mathcal{P}\left(G_{0}\sum_{a\geq 0}\left(-D_{qh}^{-1,T}G_{h}D_{qh}^{-1}G_{0}\right)^{a}\right)D_{qh}^{-1,T}\ , \displaystyle\hat{V}_{h}=t^{2}D_{qh}^{-1,T}\mathcal{P}\left(G_{h}\sum_{a\geq 0}\left(-D_{qh}^{-1}G_{0}D_{qh}^{-1,T}G_{h}\right)^{a}\right)D_{qh}^{-1} \tag{287}
$$
where we remind that $G_{0}=t^{2}V_{h}+V_{w}\delta(x,z)=\mathcal{O}(1/r)$ , $G_{h}=\hat{V}_{h}+\bar{s}\delta(1-x,1-z)$ and $D_{qh}=D-t\delta_{\mathrm{e}}V_{qh}^{T}$ . These equations form a system of non-linear integral equations. A perturbative approach with expansion in powers of $1/r$ should allow to solve it. At each order one has to solve linear integral equations whose resolvant is $\Phi$ for $V_{h}$ and $\hat{V}_{h}$ , the previously determined resolvant to the constant order. The perturbations have to summed and the resulting $V_{qh}$ , $V_{h}$ and $\hat{V}_{h}$ can be used to express $h^{*}$ , $h^{{}^{\prime}*}$ and the other order parameters.
### B.5 Interpretation of terms of DMFT: computation
We prove the relations given in the main part III.2.2, that state an equivalence between the order parameters $V_{h}$ , $V_{qh}$ and $\hat{V}_{h}$ stemming from the replica computation and the correlation and response functions of the dynamical process that $h$ follows. We assume that the regularization $r$ is large and we derive the equalities to the constant order.
We introduce the tilting field $\eta(x)\in\mathbb{R}^{N}$ and the tilted Hamiltonian as
$$
\displaystyle\frac{\mathrm{d}h}{\mathrm{d}x}(x)=\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}h(x)+\eta(x)\ , \displaystyle h(x)=\int_{0}^{x}\mathrm{d}x^{\prime}e^{(x-x^{\prime})\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}}\left(\eta(x^{\prime})+\delta(x^{\prime})\frac{1}{\sqrt{N}}Xw\right)\ , \displaystyle H(\eta)=\frac{1}{2}(y-h(1))^{T}R(y-h(1))+\frac{r}{2}w^{T}w\ , \tag{290}
$$
where $R\in\mathbb{R}^{N\times N}$ diagonal accounts for the train and test nodes. We write $\langle\cdot\rangle_{\beta}$ the expectation under the density $e^{-\beta H(\eta)}/Z$ (normalized only at $\eta=0$ , $Z$ is not a function of $\eta$ ).
For $V_{h}$ we have:
$$
\displaystyle\frac{\beta}{N}\operatorname{Tr}\left[\langle h(x)h(z)^{T}\rangle_{\beta}-\langle h(x)\rangle_{\beta}\langle h(z)^{T}\rangle_{\beta}\right]|_{\eta=0} \displaystyle\quad=\frac{1}{N}\operatorname{Tr}\left(e^{\frac{tx}{\sqrt{N}}\tilde{A}^{\mathrm{e}}}\frac{1}{N}X(\langle ww^{T}\rangle_{\beta}-\langle w\rangle_{\beta}\langle w^{T}\rangle_{\beta})X^{T}e^{\frac{tz}{\sqrt{N}}\tilde{A}^{\mathrm{e}}}\right) \displaystyle\quad=\frac{V_{w}}{N}\left\{\begin{array}[]{lc}\operatorname{Tr}\left(e^{\frac{tx}{\sqrt{N}}\tilde{A}}e^{\frac{tz}{\sqrt{N}}\tilde{A}^{T}}\right)&\mathrm{if}\,\delta_{\mathrm{e}}=0\\
\operatorname{Tr}\left(e^{\frac{tx+tz}{\sqrt{N}}\tilde{A}^{\mathrm{s}}}\right)&\mathrm{if}\,\delta_{\mathrm{e}}=1\end{array}\right.\ . \tag{293}
$$
We used that in the large regularization limit the covariance of $w$ is $I_{M}/r$ and $V_{w}=r\alpha$ . We distinguish the two cases symmetrized or not. For the symmetrized case we have
$$
\displaystyle\frac{V_{w}}{N}\operatorname{Tr}\left(e^{\frac{tx+tz}{\sqrt{N}}\tilde{A}^{\mathrm{s}}}\right) \displaystyle=\int_{-2}^{+2}\frac{\mathrm{d}\hat{\lambda}}{2\pi}\sqrt{4-\hat{\lambda}^{2}}e^{\hat{\lambda}t(x+z)} \displaystyle=V_{w}\frac{I_{1}(2t(x+z))}{t(x+z)}\ , \tag{298}
$$
where we used that the spectrum of $\tilde{A}^{\mathrm{s}}/\sqrt{N}$ follows the semi-circle law up to negligible corrections. For the asymmetric case we expand the two exponentials. $\tilde{A}\approx\Xi$ has independent Gaussian entries.
$$
\displaystyle\frac{V_{w}}{N}\operatorname{Tr}\left(e^{\frac{tx}{\sqrt{N}}\tilde{A}}e^{\frac{tz}{\sqrt{N}}\tilde{A}^{T}}\right) \displaystyle\quad=\sum_{n,m\geq 0}\frac{V_{w}}{N^{1+\frac{n+m}{2}}}\frac{(tx)^{n}(tz)^{m}}{n!m!} \displaystyle\qquad\sum_{i_{1},\ldots,i_{n}}\sum_{j_{1},\ldots,j_{m}}\Xi_{i_{1}i_{2}}\ldots\Xi_{i_{n-1}i_{n}}\Xi_{i_{n}j_{1}}\Xi_{j_{2}j_{1}}\Xi_{j_{3}j_{2}}\ldots\Xi_{i_{1}j_{m}} \displaystyle\quad=V_{w}\sum_{n}\frac{(t^{2}xz)^{n}}{(n!)^{2}}=V_{w}I_{0}(2t\sqrt{xz})\ . \tag{300}
$$
In the sum only contribute the terms where $j_{2}=i_{n},\ldots,j_{m}=i_{2}$ for $m=n$ . Consequently in both cases we obtain that
$$
\displaystyle V_{h}(x,z)=\frac{\beta}{N}\operatorname{Tr}\left[\langle h(x)h(z)^{T}\rangle_{\beta}-\langle h(x)\rangle_{\beta}\langle h(z)^{T}\rangle_{\beta}\right]|_{\eta=0} \tag{303}
$$
$V_{h}$ is the correlation function between the states $h(x)\in\mathbb{R}^{N}$ of the network, under the dynamic defined by the Hamiltonian (20).
This derivation can be used to compute the resolvant $\Phi=V_{h}/V_{w}$ in the symmetrized case, instead of solving the integral equation that defines it eq. (103), that is $\Phi(x,z)=D_{qh}^{-1}(t^{2}\Phi(x,z)+\delta(x,z))D_{qh}^{-1,T}$ . As a consequence of the two equivalent definitions we obtain the following mathematical identity, for all $x$ and $z$ :
$$
\displaystyle\int_{0,0}^{x,z}\mathrm{d}x^{\prime}\mathrm{d}z^{\prime}\,\frac{I_{1}(2(x-x^{\prime}))}{x-x^{\prime}}\frac{I_{1}(2(x^{\prime}+z^{\prime}))}{x^{\prime}+z^{\prime}}\frac{I_{1}(2(z-z^{\prime}))}{z-z^{\prime}} \displaystyle\quad=\frac{I_{1}(2(x+z))}{x+z}-\frac{I_{1}(2x)I_{1}(2z)}{xz}\ . \tag{304}
$$
For $V_{qh}$ we have:
$$
\displaystyle\frac{t}{N}\operatorname{Tr}\frac{\partial}{\partial\eta(z)}\langle h(x)\rangle_{\beta}|_{\eta=0} \displaystyle\quad=\frac{t}{N}\operatorname{Tr}e^{(x-z)\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}}\theta(x-z) \displaystyle\quad=\left\{\begin{array}[]{lc}\theta(x-z)&\mathrm{if}\,\delta_{\mathrm{e}}=0\\
\theta(x-z)(x-z)^{-1}I_{1}(2t(x-z))&\mathrm{if}\,\delta_{\mathrm{e}}=1\end{array}\right. \displaystyle\quad=V_{qh}(x,z)\ . \tag{305}
$$
We neglected the terms of order $1/r$ stemming from $w$ . We integrated over the spectrum of $\tilde{A}^{\mathrm{e}}$ , which follows the semi-circle law (symmetric case) or the circular law (asymmetric) up to negligeable corrections. We obtain that $V_{qh}$ is the response function oh $h$ .
Last for $\hat{V}_{h}$ we have:
$$
\displaystyle\frac{t^{2}}{\beta^{2}N}\operatorname{Tr}\frac{\partial^{2}}{\partial\eta(x)\partial\eta(z)}\langle 1\rangle_{\beta}|_{\eta=0} \displaystyle\quad=\frac{t^{2}}{N}\operatorname{Tr}\left[R\langle(y-h(1))^{\otimes 2}\rangle_{\beta}|_{\eta=0}\right. \displaystyle\qquad\qquad\left.Re^{(1-z)\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}}e^{(1-x)\frac{t}{\sqrt{N}}(\tilde{A}^{\mathrm{e}})^{T}}\right] \displaystyle\quad=\frac{\rho t^{2}}{N}\operatorname{Tr}e^{(1-z)\frac{t}{\sqrt{N}}\tilde{A}^{\mathrm{e}}}e^{(1-x)\frac{t}{\sqrt{N}}(\tilde{A}^{\mathrm{e}})^{T}} \displaystyle\quad=\hat{V}_{h}(x,z)\ . \tag{311}
$$
We neglected the terms of order $1/\beta$ obtained by differenciating only once $e^{-\beta H}$ and these of order $1/r$ , i.e. $y-h(1)\approx y$ . We obtain that $\hat{V}_{h}$ is the correlation function between the responses.
### B.6 Limiting cases
To obtain insights on the behaviour of the test accuracy and to make connections with already studied models we expand (283) around the limiting cases $t\to 0$ and $t\to\infty$ .
At $t\to 0$ we use that $\varphi(x)=1+\lambda^{\mathrm{e}}tx+O(t^{2})$ and $\Phi(x,z)=1+O(t^{2})$ ; this simplifies several terms. We obtain the following expansions at the first order in $t$ :
$$
\displaystyle V_{w}=\frac{1}{r\alpha}\ ,\quad V(x,z)=\frac{1}{r\alpha}\ , \displaystyle\hat{m}_{w}=\rho\sqrt{\mu}\ ,\quad\hat{m}(x)=\rho\lambda^{\mathrm{e}}t\ , \displaystyle m_{w}=\frac{\rho}{r\alpha}\sqrt{\mu}\ ,\quad m(x)=\frac{\rho}{r\alpha}(1+\mu)(1+\lambda^{\mathrm{e}}t(x+1))\ , \displaystyle\hat{Q}_{w}=\rho\ ,\quad\hat{Q}_{h}(x,z)=0\ , \displaystyle Q_{w}=\frac{\rho+\rho^{2}\mu}{r\alpha}\ ,\quad Q_{qh}=O(t)\ , \displaystyle Q_{h}(1,1)=Q_{w}+m(0)^{2}+\rho(1-\rho)V_{w}^{2}+2\frac{\rho^{2}}{r^{2}\alpha^{2}}(1+\mu)^{2}\lambda^{\mathrm{e}}t\ . \tag{315}
$$
Pluging them in eq. (283) we obtain the expression given in the main part III.2.3:
$$
\mathrm{Acc}_{\mathrm{test}}=\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{1}{\sqrt{2}}\sqrt{\frac{\rho}{\alpha}}\frac{\mu+\lambda^{\mathrm{e}}t(2+\mu)}{\sqrt{1+\rho\mu}}\right)\right)\ . \tag{321}
$$
At $t\to\infty$ we assume that $\lambda^{\mathrm{e}}>1$ . We distinguish the two cases asymmetric or symmetrized. For asymmetric we have $\varphi(x)=\exp(\lambda^{\mathrm{e}}tx)$ and $\log\Phi(x,z)=\Theta(2t\sqrt{xz})$ . For the symmetrized we have
$$
\displaystyle\varphi(x) \displaystyle=\frac{1}{tx}\frac{\partial}{\partial\lambda^{\mathrm{e}}}\sum_{\nu\geq 0}^{\infty}(\lambda^{\mathrm{e}})^{\nu}I_{\nu}(2tx) \displaystyle\approx\frac{1}{tx}\frac{\partial}{\partial\lambda^{\mathrm{e}}}\sum_{\nu=-\infty}^{+\infty}(\lambda^{\mathrm{e}})^{\nu}I_{\nu}(2tx) \displaystyle=\frac{1}{tx}\frac{\partial}{\partial\lambda^{\mathrm{e}}}e^{tx(\lambda^{\mathrm{e}}+1/\lambda^{\mathrm{e}})} \displaystyle=(1-(\lambda^{\mathrm{e}})^{-2})e^{tx(\lambda^{\mathrm{e}}+1/\lambda^{\mathrm{e}})} \tag{322}
$$
and $\log\Phi(x,z)=\Theta(2t(x+z))$ . In the two cases, only the few dominant terms scaling like $e^{2\lambda^{\mathrm{e}}t}$ or $e^{2(\lambda^{\mathrm{e}}+1/\lambda^{\mathrm{e}})t}$ dominate in (283). We obtain
$$
\displaystyle\mathrm{Acc}_{\mathrm{test}}\approx\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{m(1)}{\sqrt{2}\sqrt{Q(1,1)-m(1)^{2}}}\right)\right) \displaystyle m(x)=\frac{\rho}{r\alpha}\varphi(1)\varphi(x)(1+\mu+C(\lambda^{\mathrm{e}})) \displaystyle C(\lambda^{\mathrm{e}})\mkern-5.0mu=\mkern-5.0mu\int_{0}^{\infty}\mkern-9.0mu\mathrm{d}x^{\prime}\mathrm{d}z^{\prime}\left\{\begin{array}[]{lc}I_{0}(2\sqrt{x^{\prime}z^{\prime}})e^{-(x^{\prime}+z^{\prime})\lambda^{\mathrm{e}}}&\mathrm{if}\,\delta_{\mathrm{e}}=0\\
\mkern-5.0mu\frac{I_{1}(2(x^{\prime}+z^{\prime}))}{x^{\prime}+z^{\prime}}e^{-(x^{\prime}+z^{\prime})(\lambda^{\mathrm{e}}+1/\lambda^{\mathrm{e}})}&\mathrm{if}\,\delta_{\mathrm{e}}=1\end{array}\right. \displaystyle Q(1,1)\approx\int_{0}^{1}\mathrm{d}x^{\prime}\mathrm{d}z^{\prime}\Phi(1-x^{\prime},1-z^{\prime})(\lambda^{\mathrm{e}})^{2}t^{2}m(x^{\prime})m(z^{\prime}) \tag{1}
$$
where in $m$ we performed the changes of variables $x^{\prime}\to x^{\prime}/t$ and $z^{\prime}\to z^{\prime}/t$ and took the limit $t\to\infty$ in the integration bounds to remove the dependency in $t$ and $x$ . Performing a change of variables $1-x^{\prime}\to x^{\prime}/t$ and $1-z^{\prime}\to z^{\prime}/t$ in $Q(1,1)$ we can express $\mathrm{Acc}_{\mathrm{test}}$ solely in terms of $C(\lambda^{\mathrm{e}})$ . Last we use the identity
$$
C(\lambda^{\mathrm{e}})=\frac{1}{(\lambda^{\mathrm{e}})^{2}-1}\ , \tag{332}
$$
valid in the two cases asymmetric or not, to obtain the expression given in the main part III.2.3:
$$
\displaystyle\mathrm{Acc}_{\mathrm{test}} \displaystyle\underset{t\to\infty}{\longrightarrow}\frac{1}{2}\left(1+\mathrm{erf}\left(\frac{\lambda^{\mathrm{e}}q_{\mathrm{PCA}}}{\sqrt{2}}\right)\right)\ , \displaystyle q_{\mathrm{PCA}} \displaystyle=\sqrt{1-(\lambda^{\mathrm{e}})^{-2}} \tag{333}
$$
## Appendix C State-evolution equations for the Bayes-optimal performance
The Bayes-optimal (BO) performance for semi-supervised classification on the binary CSBM can be computed thanks to the following iterative state-evolution equations, that have been derived in [22, 39].
The equations have been derived for a symmetric graph. We map the asymmetric $\tilde{A}$ to a symmetric matrix by the symmetrization $(\tilde{A}+\tilde{A}^{T})/\sqrt{2}$ . Thus the BO performance on $A$ asymmetric are the BO performance on $A$ symmetrized and effective signal $\lambda^{\mathrm{s}}=\sqrt{2}\lambda$ .
Let $m_{y}^{0}$ and $m_{u}^{0}$ be the initial condition. The state-evolution equations are
$$
\displaystyle m_{u}^{t+1}=\frac{\mu m_{y}^{t}}{1+\mu m_{y}^{t}} \displaystyle m^{t}=\frac{\mu}{\alpha}m_{u}^{t}+(\lambda^{\mathrm{s}})^{2}m_{y}^{t-1} \displaystyle m_{y}^{t}=\rho+(1-\rho)\mathbb{E}_{W}\left[\tanh\left(m^{t}+\sqrt{m^{t}}W\right)\right] \tag{335}
$$
where $W$ is a standard scalar Gaussian. These equations are iterated until convergence to a fixed-point $(m,m_{y},m_{u})$ . Then the BO test accuracy is
$$
\mathrm{Acc}_{\mathrm{test}}=\frac{1}{2}(1+\mathrm{erf}\sqrt{m/2})\ . \tag{338}
$$
In the large $\lambda$ limit we have $m_{y}\to 1$ and
$$
\log(1-\mathrm{Acc}_{\mathrm{test}})\underset{\lambda\to\infty}{\sim}-\lambda^{2}\ . \tag{339}
$$
## Appendix D Details on the numerics
For the discrete GCN, the system of fixed-point equations (37 – 48) is solved by iterating it until convergence. The iterations are stable up to $K\approx 4$ and no damping is necessary. The integration over $(\xi,\zeta,\chi)$ is done by Hermite quadrature (quadratic loss) or Monte-Carlo sampling (logistic loss) over about $10^{6}$ samples. For the quadratic loss $h^{*}$ has to be computed by Newton’s method. Then the whole computation takes around one minute on a single CPU.
For the continuous GCN the equation (126) is evaluated by a trapezoidal integration scheme with a hundred of discretization points. In the nested integrals of $Q(1,1)$ , $\hat{Q}$ can be evaluated only once at each discretization point. The whole computation takes a few seconds.
We provide the code to evaluate our predictions in the supplementary material.
## Appendix E Supplementary figures
In this section we provide the supplementary figures of part III.2.3. They show the convergence to the continuous limit with respect to $K$ and $r$ , and that the continuous limit can be close to the optimality. We also provide the supplementary figures of part III.1.3, that compare the GCN on symmetric and asymmetric graphs, and that show the train error versus the residual connection strength.
### Asymmetric graph
The following figures support the discussion of part III.2.3 for the asymmetric graph. They compare the theoretical predictions for the continuous GCN to numerical simulations of the trained network. They show the convergence towards the limit $r\to\infty$ and the optimality of the continuous GCN over its discretization at finite $K$ .
<details>
<summary>x8.png Details</summary>
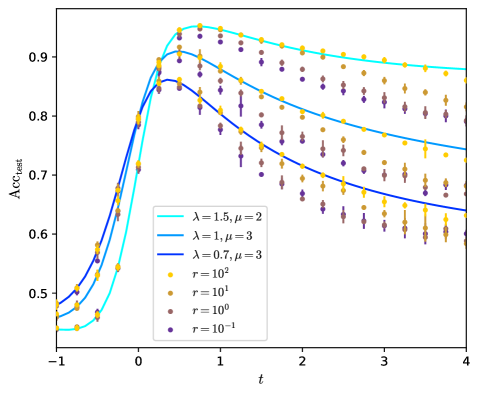
### Visual Description
## Line Chart: Accuracy vs. Time
### Overview
The image presents a line chart illustrating the relationship between accuracy (Acc<sub>test</sub>) and time (t) under varying parameters λ, μ, and r. The chart displays multiple lines, each representing a different combination of these parameters. Data points are scattered along each line, indicating individual measurements or observations.
### Components/Axes
* **X-axis:** Labeled as "t", ranging approximately from -1 to 4.
* **Y-axis:** Labeled as "Acc<sub>test</sub>", ranging approximately from 0.5 to 0.95.
* **Legend:** Located in the top-left corner, listing the following parameter combinations:
* λ = 1.5, μ = 2 (Light Blue)
* λ = 1, μ = 3 (Blue)
* λ = 0.7, μ = 3 (Dark Blue)
* r = 10<sup>2</sup> (Yellow)
* r = 10<sup>1</sup> (Orange)
* r = 10<sup>0</sup> (Brown/Reddish)
* r = 10<sup>-1</sup> (Purple)
### Detailed Analysis
The chart contains seven distinct lines, each representing a different set of parameters.
* **λ = 1.5, μ = 2 (Light Blue):** This line starts at approximately (-1, 0.52) and rises sharply, reaching a peak around (0.5, 0.93). It then plateaus, remaining relatively stable around 0.91-0.92 for t > 1.
* **λ = 1, μ = 3 (Blue):** This line begins at approximately (-1, 0.53) and increases rapidly, reaching a maximum around (0.7, 0.92). It then gradually declines, falling to approximately 0.82 at t = 2 and 0.74 at t = 4.
* **λ = 0.7, μ = 3 (Dark Blue):** Starting at approximately (-1, 0.53), this line exhibits a similar upward trend to the others, peaking around (0.6, 0.91). It then decreases more steeply than the previous line, reaching approximately 0.68 at t = 2 and 0.62 at t = 4.
* **r = 10<sup>2</sup> (Yellow):** This line starts at approximately (-1, 0.55) and rises to a peak around (0.5, 0.88). It then declines slowly, remaining around 0.78 at t = 2 and 0.72 at t = 4.
* **r = 10<sup>1</sup> (Orange):** Beginning at approximately (-1, 0.54), this line increases to a peak around (0.6, 0.86). It then decreases, reaching approximately 0.74 at t = 2 and 0.68 at t = 4.
* **r = 10<sup>0</sup> (Brown/Reddish):** Starting at approximately (-1, 0.52), this line rises to a peak around (0.7, 0.84). It then declines, reaching approximately 0.70 at t = 2 and 0.64 at t = 4.
* **r = 10<sup>-1</sup> (Purple):** This line starts at approximately (-1, 0.51) and rises to a peak around (0.6, 0.82). It then declines, reaching approximately 0.66 at t = 2 and 0.60 at t = 4.
### Key Observations
* All lines initially exhibit an increasing trend, indicating improving accuracy with increasing time.
* The lines corresponding to different values of λ and μ reach their peaks at different times, with higher λ values generally leading to earlier peaks.
* The lines corresponding to different values of r all decline after reaching their peaks, suggesting a diminishing return in accuracy as r increases.
* The lines with higher values of λ and μ generally maintain higher accuracy levels for longer periods.
* The lines with lower values of r exhibit lower peak accuracy and faster decline rates.
### Interpretation
The chart demonstrates the impact of parameters λ, μ, and r on the accuracy of a model or system over time. The parameters likely represent learning rates, regularization strengths, or other factors influencing the system's performance.
The initial increase in accuracy suggests a learning or adaptation phase, where the system improves its performance as it processes more data or experiences more iterations. The subsequent decline in accuracy for some lines may indicate overfitting, where the system becomes too specialized to the training data and loses its ability to generalize to new data.
The differences in peak accuracy and decline rates across the lines suggest that the optimal values of λ, μ, and r depend on the specific characteristics of the data and the desired trade-off between accuracy and generalization. The chart highlights the importance of carefully tuning these parameters to achieve optimal performance. The parameter 'r' appears to be a regularization parameter, as lower values of 'r' lead to higher initial accuracy but faster decline, suggesting a greater risk of overfitting. The parameters λ and μ likely control the rate and stability of the learning process, with higher values leading to faster initial learning but potentially less stable long-term performance.
</details>
<details>
<summary>x9.png Details</summary>
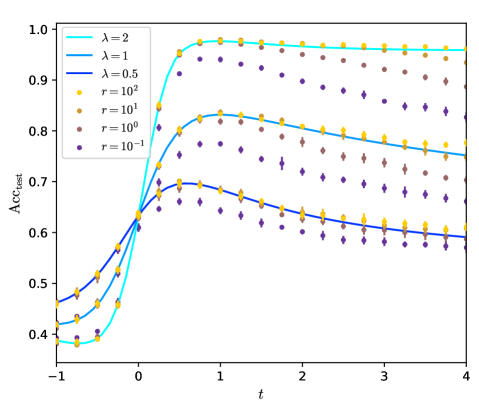
### Visual Description
\n
## Line Chart: Test Accuracy vs. Time
### Overview
The image presents a line chart illustrating the relationship between test accuracy (Acc_test) and time (t) for different values of lambda (λ) and r. The chart displays multiple lines, each representing a unique combination of λ and r, showing how test accuracy changes over time.
### Components/Axes
* **X-axis:** Labeled as 't', representing time. The scale ranges from approximately -1 to 4.
* **Y-axis:** Labeled as 'Acc_test', representing test accuracy. The scale ranges from approximately 0.4 to 1.0.
* **Legend:** Located in the top-left corner, providing labels for each line:
* λ = 2 (Cyan)
* λ = 1 (Blue)
* λ = 0.5 (Dark Blue)
* r = 10<sup>2</sup> (Yellow)
* r = 10<sup>1</sup> (Orange)
* r = 10<sup>0</sup> (Purple)
### Detailed Analysis
The chart contains six distinct lines, each representing a different parameter setting.
* **λ = 2 (Cyan):** This line exhibits a rapid increase in Acc_test from approximately 0.4 at t = -1 to nearly 1.0 at t = 1. It plateaus around 0.98-1.0 for t > 1.
* **λ = 1 (Blue):** This line shows a slower increase in Acc_test compared to λ = 2, starting at approximately 0.4 at t = -1 and reaching around 0.8 at t = 1. It then plateaus around 0.82-0.85 for t > 1.
* **λ = 0.5 (Dark Blue):** This line demonstrates the slowest increase in Acc_test among the λ series, starting at approximately 0.4 at t = -1 and reaching around 0.65 at t = 1. It plateaus around 0.58-0.62 for t > 1.
* **r = 10<sup>2</sup> (Yellow):** This line starts at approximately 0.4 at t = -1, increases to around 0.85 at t = 1, and then gradually decreases to approximately 0.78 at t = 4.
* **r = 10<sup>1</sup> (Orange):** This line begins at approximately 0.4 at t = -1, increases to around 0.8 at t = 1, and then gradually decreases to approximately 0.72 at t = 4.
* **r = 10<sup>0</sup> (Purple):** This line starts at approximately 0.4 at t = -1, increases to around 0.7 at t = 1, and then gradually decreases to approximately 0.58 at t = 4.
### Key Observations
* Higher values of λ (2 and 1) lead to faster convergence to higher test accuracy.
* The lines for different values of r exhibit an initial increase in accuracy followed by a decrease, suggesting a potential overfitting or instability issue.
* The λ series lines plateau at higher accuracy levels than the r series lines.
* The r = 10<sup>2</sup> line maintains the highest accuracy among the r series throughout the observed time range.
### Interpretation
The chart likely represents the performance of a learning algorithm or model over time, with λ and r being hyperparameters controlling the learning process. The λ parameter appears to influence the learning rate or regularization strength, with higher values leading to faster learning and potentially better generalization (as indicated by the higher plateau accuracy). The r parameter might relate to a different aspect of the model or learning process, such as the complexity or capacity of the model. The decreasing accuracy for the r series suggests that increasing r beyond a certain point can lead to overfitting or instability, causing the model to perform worse on unseen data. The data suggests that a balance between λ and r is crucial for achieving optimal performance. The initial increase in accuracy for all lines indicates that the model is initially learning from the data, but the subsequent behavior depends on the specific parameter settings.
</details>
Figure 8: Predicted test accuracy $\mathrm{Acc}_{\mathrm{test}}$ of the continuous GCN, at $r=\infty$ . Left: for $\alpha=1$ and $\rho=0.1$ ; right: for $\alpha=2$ , $\mu=1$ and $\rho=0.3$ . The performance of the continuous GCN are given by eq. (126). Dots: numerical simulation of the continuous GCN for $N=7\times 10^{3}$ and $d=30$ , trained with quadratic loss, averaged over ten experiments.
<details>
<summary>x10.png Details</summary>
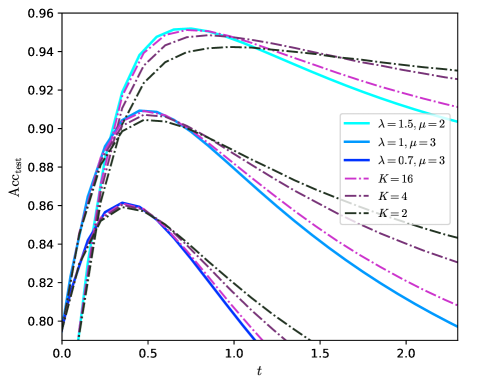
### Visual Description
## Line Chart: Accuracy vs. Time
### Overview
The image presents a line chart illustrating the relationship between accuracy (Acc_test) and time (t) for different parameter settings. Several lines represent different combinations of λ, μ, and K values. The chart appears to model a learning or convergence process, where accuracy increases initially and then plateaus or declines.
### Components/Axes
* **X-axis:** Labeled as "t", ranging from approximately 0.0 to 2.2.
* **Y-axis:** Labeled as "Acc_test", ranging from approximately 0.80 to 0.96.
* **Legend:** Located in the top-right corner, containing the following lines and their corresponding parameters:
* λ = 1.5, μ = 2 (Light Blue, Solid)
* λ = 1, μ = 3 (Blue, Solid)
* λ = 0.7, μ = 3 (Dark Blue, Solid)
* K = 16 (Pink, Dashed)
* K = 4 (Purple, Dashed)
* K = 2 (Black, Dashed)
### Detailed Analysis
Let's analyze each line's trend and approximate data points:
* **λ = 1.5, μ = 2 (Light Blue, Solid):** This line starts at approximately Acc_test = 0.81 at t = 0.0. It increases rapidly, reaching a peak of approximately Acc_test = 0.95 at t ≈ 0.6. After the peak, it gradually declines to approximately Acc_test = 0.94 at t = 2.0.
* **λ = 1, μ = 3 (Blue, Solid):** This line begins at approximately Acc_test = 0.81 at t = 0.0. It rises quickly, peaking at approximately Acc_test = 0.95 at t ≈ 0.5. It then decreases slowly, reaching approximately Acc_test = 0.94 at t = 2.0.
* **λ = 0.7, μ = 3 (Dark Blue, Solid):** Starting at approximately Acc_test = 0.81 at t = 0.0, this line increases to a peak of approximately Acc_test = 0.92 at t ≈ 0.4. It then declines more rapidly than the other two lines, reaching approximately Acc_test = 0.90 at t = 2.0.
* **K = 16 (Pink, Dashed):** This line starts at approximately Acc_test = 0.86 at t = 0.0. It increases to a peak of approximately Acc_test = 0.94 at t ≈ 0.7. It then declines slowly, reaching approximately Acc_test = 0.93 at t = 2.0.
* **K = 4 (Purple, Dashed):** Beginning at approximately Acc_test = 0.85 at t = 0.0, this line rises to a peak of approximately Acc_test = 0.92 at t ≈ 0.6. It then declines more noticeably, reaching approximately Acc_test = 0.90 at t = 2.0.
* **K = 2 (Black, Dashed):** This line starts at approximately Acc_test = 0.84 at t = 0.0. It increases to a peak of approximately Acc_test = 0.89 at t ≈ 0.5. It then declines, reaching approximately Acc_test = 0.86 at t = 2.0.
### Key Observations
* The lines representing different values of λ and μ generally exhibit a similar trend: initial increase followed by a plateau or decline.
* Higher values of λ and μ (e.g., λ = 1.5, μ = 2 and λ = 1, μ = 3) tend to achieve higher peak accuracies.
* The lines representing different values of K show a similar trend, but generally achieve lower peak accuracies compared to the λ and μ lines.
* The line for K = 2 consistently shows the lowest accuracy throughout the entire time range.
* The lines for K = 16 and K = 4 have similar trajectories, peaking around the same accuracy level.
### Interpretation
The chart likely represents the performance of a model or algorithm over time, where λ, μ, and K are hyperparameters controlling its behavior. The Acc_test metric indicates the accuracy of the model on a test dataset.
The data suggests that:
* Increasing λ and μ generally improves the model's accuracy, at least initially.
* The value of K has a significant impact on accuracy, with higher values of K leading to better performance (up to a certain point).
* The decline in accuracy after the peak could indicate overfitting, where the model starts to perform worse on unseen data as it becomes too specialized to the training data.
* The different lines represent different configurations of the model, and the chart allows for a comparison of their performance under different conditions.
The chart provides valuable insights into the sensitivity of the model's performance to different hyperparameters, which can be used to optimize its configuration for better accuracy and generalization ability. The fact that all lines eventually decline suggests a need for regularization or other techniques to prevent overfitting.
</details>
<details>
<summary>x11.png Details</summary>
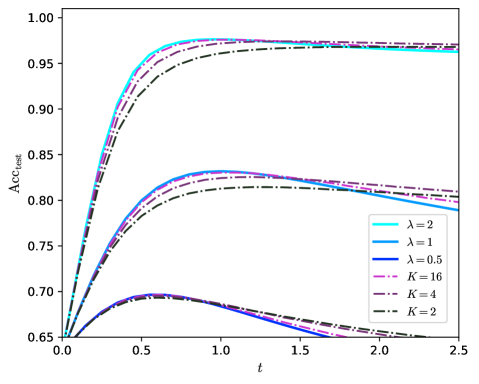
### Visual Description
\n
## Line Chart: Test Accuracy vs. Time
### Overview
The image presents a line chart illustrating the relationship between test accuracy (Acc<sub>test</sub>) and time (t) for different parameter settings. Several lines represent different values of lambda (λ) and K, showing how test accuracy evolves over time.
### Components/Axes
* **X-axis:** Labeled "t", representing time. The scale ranges from approximately 0.0 to 2.5.
* **Y-axis:** Labeled "Acc<sub>test</sub>", representing test accuracy. The scale ranges from approximately 0.65 to 1.00.
* **Legend:** Located in the top-right corner, containing the following lines and their corresponding parameters:
* λ = 2 (Cyan) - Solid Line
* λ = 1 (Blue) - Solid Line
* λ = 0.5 (Dark Blue) - Solid Line
* K = 16 (Magenta) - Dashed Line
* K = 4 (Purple) - Dashed Line
* K = 2 (Dark Grey) - Dashed Line
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points:
* **λ = 2 (Cyan):** The line slopes sharply upward initially, reaching approximately 0.95 at t = 0.5, and then plateaus, remaining around 0.96-0.97 for t > 1.0.
* **λ = 1 (Blue):** This line also slopes upward, but less steeply than λ = 2. It reaches approximately 0.92 at t = 0.5, and plateaus around 0.94-0.95 for t > 1.0.
* **λ = 0.5 (Dark Blue):** This line exhibits a slower initial increase compared to λ = 1 and λ = 2. It reaches approximately 0.85 at t = 0.5, and plateaus around 0.88-0.90 for t > 1.0.
* **K = 16 (Magenta):** The line starts at approximately 0.67 at t = 0.0, increases moderately, reaching around 0.85 at t = 0.5, and then plateaus around 0.87-0.88 for t > 1.0.
* **K = 4 (Purple):** This line begins at approximately 0.68 at t = 0.0, increases more slowly than K = 16, reaching around 0.78 at t = 0.5, and plateaus around 0.80-0.82 for t > 1.0.
* **K = 2 (Dark Grey):** This line has the slowest initial increase, starting at approximately 0.66 at t = 0.0, reaching around 0.72 at t = 0.5, and plateaus around 0.74-0.76 for t > 1.0.
### Key Observations
* Higher values of λ (2 and 1) lead to faster convergence to higher test accuracy.
* Higher values of K (16 and 4) result in higher test accuracy compared to lower values (2), but the convergence is slower.
* The lines representing different parameter settings all appear to converge to a stable accuracy level as time increases.
* The lines for K = 2 and K = 4 are very close together, suggesting that the impact of K diminishes beyond a certain point.
### Interpretation
The chart demonstrates the impact of parameters λ and K on the test accuracy of a model over time. The parameter λ appears to control the speed of learning, with higher values leading to faster convergence. The parameter K seems to influence the ultimate achievable accuracy, with higher values resulting in better performance. The plateauing of the lines suggests that the model reaches a point of diminishing returns, where further training does not significantly improve accuracy. This could indicate that the model has converged or that other factors are limiting performance. The differences in the curves suggest that the optimal values of λ and K depend on the specific application and desired trade-off between learning speed and final accuracy.
</details>
Figure 9: Predicted test accuracy $\mathrm{Acc}_{\mathrm{test}}$ of the continuous GCN, at $r=\infty$ . Left: for $\alpha=1$ and $\rho=0.1$ ; right: for $\alpha=2$ , $\mu=1$ and $\rho=0.3$ . The performance of the continuous GCN are given by eq. (126) while for its discretization at finite $K$ they are given by numerically solving the fixed-point equations (87 - 94).
### Symmetrized graph
The following figures support the discussion of part III.2.3 for the symmetrized graph. They compare the theoretical predictions for the continuous GCN to numerical simulations of the trained network. They show the convergence towards the limit $r\to\infty$ .
<details>
<summary>x12.png Details</summary>
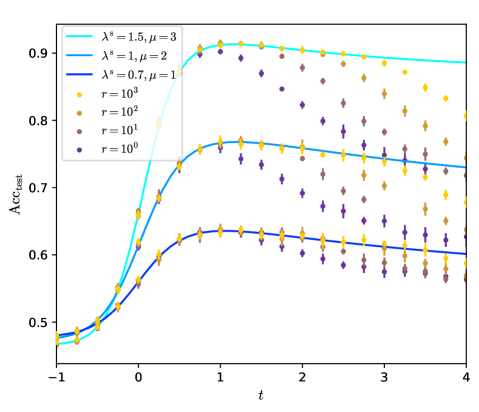
### Visual Description
\n
## Line Chart: Accuracy vs. Time
### Overview
The image presents a line chart illustrating the relationship between accuracy (A<sub>Acctest</sub>) and time (t) for different parameter settings. Several lines represent different combinations of λ<sup>σ</sup> and μ values, while scatter points represent data for varying values of 'r'. The chart appears to demonstrate how accuracy evolves over time under different conditions.
### Components/Axes
* **X-axis:** Labeled "t", representing time. The scale ranges from approximately -1 to 4.
* **Y-axis:** Labeled "A<sub>Acctest</sub>", representing accuracy. The scale ranges from approximately 0.5 to 0.95.
* **Lines:**
* Light Cyan: λ<sup>σ</sup> = 1.5, μ = 3
* Blue: λ<sup>σ</sup> = 1, μ = 2
* Dark Cyan: λ<sup>σ</sup> = 0.7, μ = 1
* **Scatter Points:**
* Yellow: r = 10<sup>3</sup>
* Orange: r = 10<sup>2</sup>
* Purple: r = 10<sup>1</sup>
* Dark Purple: r = 10<sup>0</sup>
* **Legend:** Located in the top-left corner of the chart, clearly associating colors with parameter values.
### Detailed Analysis
The chart displays several distinct trends.
* **Light Cyan Line (λ<sup>σ</sup> = 1.5, μ = 3):** This line exhibits a rapid initial increase in accuracy, reaching approximately 0.85 at t = 0.5. It then plateaus, maintaining an accuracy of around 0.87-0.88 from t = 1 onwards.
* **Blue Line (λ<sup>σ</sup> = 1, μ = 2):** This line also shows an initial increase in accuracy, but at a slower rate than the light cyan line. It reaches approximately 0.75 at t = 0.5 and plateaus around 0.82-0.83 from t = 1 onwards.
* **Dark Cyan Line (λ<sup>σ</sup> = 0.7, μ = 1):** This line demonstrates the slowest initial increase in accuracy, reaching approximately 0.65 at t = 0.5. It plateaus around 0.67-0.68 from t = 1 onwards.
* **Yellow Scatter Points (r = 10<sup>3</sup>):** These points show a relatively stable accuracy around 0.88-0.9, with some fluctuations. The accuracy appears to be highest among all the data series.
* **Orange Scatter Points (r = 10<sup>2</sup>):** These points exhibit a fluctuating accuracy, starting around 0.7 at t = -1 and reaching a peak of approximately 0.82 at t = 1. It then declines to around 0.75 at t = 4.
* **Purple Scatter Points (r = 10<sup>1</sup>):** These points show a fluctuating accuracy, starting around 0.6 at t = -1 and reaching a peak of approximately 0.73 at t = 1. It then declines to around 0.68 at t = 4.
* **Dark Purple Scatter Points (r = 10<sup>0</sup>):** These points exhibit a fluctuating accuracy, starting around 0.55 at t = -1 and reaching a peak of approximately 0.65 at t = 1. It then declines to around 0.6 at t = 4.
### Key Observations
* Higher values of λ<sup>σ</sup> and μ generally lead to faster increases in accuracy and higher overall accuracy levels.
* The scatter points representing different 'r' values show more variability in accuracy compared to the smooth lines representing the λ<sup>σ</sup> and μ combinations.
* The accuracy for all series appears to stabilize after t = 1.
* The 'r' values of 10<sup>3</sup> consistently demonstrate the highest accuracy.
### Interpretation
The chart suggests that the parameters λ<sup>σ</sup> and μ significantly influence the rate and level of accuracy achieved over time. The lines demonstrate a clear trend: increasing λ<sup>σ</sup> and μ leads to faster convergence and higher accuracy. The scatter points, representing different 'r' values, indicate that the initial conditions or some other factor represented by 'r' also play a role in the accuracy, but with more variability.
The stabilization of accuracy after t = 1 suggests that the system reaches a steady state or equilibrium point. The differences in accuracy between the lines and scatter points could be due to the underlying mechanisms governing the system's behavior. The higher accuracy observed for r = 10<sup>3</sup> might indicate that larger initial values of 'r' promote more stable and accurate outcomes.
The chart could be representing the learning curve of a model or the convergence of an algorithm under different parameter settings. The λ<sup>σ</sup> and μ parameters might represent learning rates or regularization strengths, while 'r' could represent the size of the training dataset or the complexity of the problem. The data suggests that careful tuning of these parameters is crucial for achieving optimal performance.
</details>
Figure 10: Predicted test accuracy $\mathrm{Acc}_{\mathrm{test}}$ of the continuous GCN, at $r=\infty$ for a symmetrized graph. $\alpha=4$ , $\rho=0.1$ . We remind that $\lambda^{\mathrm{s}}=\sqrt{2}\lambda$ . The performance of the continuous GCN are given by eq. (126). Dots: numerical simulation of the continuous GCN for $N=10^{4}$ and $d=30$ , trained with quadratic loss, averaged over ten experiments.
<details>
<summary>x13.png Details</summary>
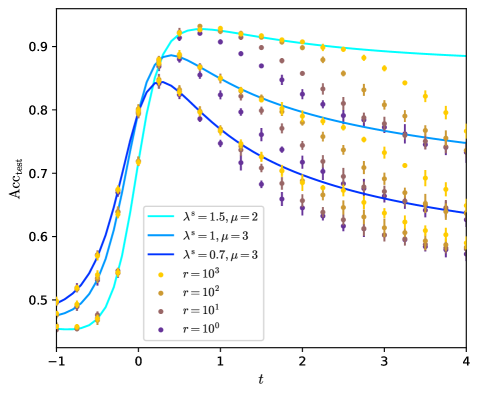
### Visual Description
## Line Chart: Accuracy vs. Time
### Overview
The image presents a line chart illustrating the relationship between accuracy (Acc<sub>test</sub>) and time (t) under different parameter settings. The chart displays four distinct lines, each representing a unique combination of λ<sup>*</sup> and μ, or a specific value of r. Error bars are present for each data point, indicating variability.
### Components/Axes
* **X-axis:** Labeled "t", ranging from approximately -1 to 4.
* **Y-axis:** Labeled "Acc<sub>test</sub>", ranging from approximately 0.5 to 0.95.
* **Legend:** Located in the bottom-left corner, containing the following entries:
* λ<sup>*</sup> = 1.5, μ = 2 (Light Blue)
* λ<sup>*</sup> = 1, μ = 3 (Blue)
* λ<sup>*</sup> = 0.7, μ = 3 (Dark Blue)
* r = 10<sup>3</sup> (Yellow)
* r = 10<sup>2</sup> (Orange)
* r = 10<sup>1</sup> (Brown)
* r = 10<sup>0</sup> (Purple)
### Detailed Analysis
* **λ<sup>*</sup> = 1.5, μ = 2 (Light Blue):** This line starts at approximately 0.52 at t = -1, rapidly increases to a peak of around 0.93 at t = 0, and then gradually plateaus around 0.91 between t = 1 and t = 4. Error bars are small.
* **λ<sup>*</sup> = 1, μ = 3 (Blue):** This line begins at approximately 0.53 at t = -1, increases quickly to a peak of around 0.92 at t = 0, and then slowly declines to approximately 0.86 at t = 4. Error bars are small.
* **λ<sup>*</sup> = 0.7, μ = 3 (Dark Blue):** This line starts at approximately 0.51 at t = -1, rises to a peak of around 0.88 at t = 0, and then steadily decreases to approximately 0.74 at t = 4. Error bars are moderate.
* **r = 10<sup>3</sup> (Yellow):** This line starts at approximately 0.53 at t = -1, increases to a peak of around 0.92 at t = 0, and then gradually declines to approximately 0.88 at t = 4. Error bars are large.
* **r = 10<sup>2</sup> (Orange):** This line starts at approximately 0.52 at t = -1, increases to a peak of around 0.91 at t = 0, and then gradually declines to approximately 0.83 at t = 4. Error bars are large.
* **r = 10<sup>1</sup> (Brown):** This line starts at approximately 0.51 at t = -1, increases to a peak of around 0.87 at t = 0, and then gradually declines to approximately 0.78 at t = 4. Error bars are large.
* **r = 10<sup>0</sup> (Purple):** This line starts at approximately 0.50 at t = -1, increases to a peak of around 0.84 at t = 0, and then gradually declines to approximately 0.70 at t = 4. Error bars are large.
### Key Observations
* The lines representing different λ<sup>*</sup> and μ combinations exhibit a rapid initial increase in accuracy, followed by a plateau or gradual decline.
* The lines representing different 'r' values show a similar initial increase, but a more consistent decline over time.
* The error bars are significantly larger for the 'r' values compared to the λ<sup>*</sup> and μ combinations, indicating greater variability in accuracy for different 'r' values.
* The highest accuracy is consistently achieved by the lines representing λ<sup>*</sup> = 1.5, μ = 2 and λ<sup>*</sup> = 1, μ = 3, particularly in the initial stages.
### Interpretation
The chart likely represents the performance of a model or algorithm over time, with λ<sup>*</sup> and μ representing parameters influencing learning or adaptation, and 'r' representing a different parameter set. The initial rapid increase in accuracy suggests a period of fast learning or adaptation. The subsequent plateau or decline could indicate convergence, overfitting, or the influence of other factors. The larger error bars for the 'r' values suggest that the accuracy is more sensitive to variations in 'r' than in λ<sup>*</sup> and μ. The consistent decline in accuracy for the 'r' values might indicate a form of decay or instability. The data suggests that the parameter combinations λ<sup>*</sup> = 1.5, μ = 2 and λ<sup>*</sup> = 1, μ = 3 lead to better and more stable performance than the tested 'r' values. The chart provides insights into the sensitivity of the model's performance to different parameter settings and highlights the importance of choosing appropriate parameter values for optimal results.
</details>
<details>
<summary>x14.png Details</summary>
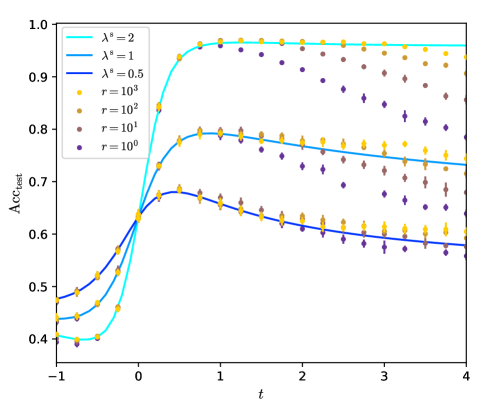
### Visual Description
\n
## Line Chart: Acc_test vs. t for Different Lambda and r Values
### Overview
This image presents a line chart illustrating the relationship between `Acc_test` (test accuracy) and `t` (time) for various values of lambda (λ⁰) and r. The chart displays multiple lines representing different parameter settings, allowing for a comparison of their performance over time.
### Components/Axes
* **X-axis:** `t` (Time), ranging from approximately -1 to 4.
* **Y-axis:** `Acc_test` (Test Accuracy), ranging from approximately 0.4 to 1.0.
* **Legend:** Located in the top-left corner, identifying each line with its corresponding parameter values.
* λ⁰ = 2 (Light Blue)
* λ⁰ = 1 (Blue)
* λ⁰ = 0.5 (Dark Blue)
* r = 10³ (Yellow)
* r = 10² (Orange)
* r = 10⁰ (Purple)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points, cross-referencing with the legend colors:
* **λ⁰ = 2 (Light Blue):** This line exhibits a steep upward slope initially, rapidly increasing from approximately 0.4 at t = -1 to nearly 1.0 by t = 1. It then plateaus, remaining relatively stable around 0.98-1.0 for the rest of the observed time.
* t = -1, Acc_test ≈ 0.4
* t = 0, Acc_test ≈ 0.65
* t = 1, Acc_test ≈ 0.98
* t = 2, Acc_test ≈ 0.99
* t = 3, Acc_test ≈ 0.99
* t = 4, Acc_test ≈ 0.99
* **λ⁰ = 1 (Blue):** This line also shows an upward trend, but it's less steep than the λ⁰ = 2 line. It starts around 0.45 at t = -1 and reaches approximately 0.9 by t = 1. It then levels off, fluctuating around 0.9.
* t = -1, Acc_test ≈ 0.45
* t = 0, Acc_test ≈ 0.6
* t = 1, Acc_test ≈ 0.9
* t = 2, Acc_test ≈ 0.91
* t = 3, Acc_test ≈ 0.9
* t = 4, Acc_test ≈ 0.9
* **λ⁰ = 0.5 (Dark Blue):** This line has the slowest initial increase. It begins around 0.48 at t = -1 and reaches approximately 0.7 by t = 1. It then plateaus around 0.7.
* t = -1, Acc_test ≈ 0.48
* t = 0, Acc_test ≈ 0.55
* t = 1, Acc_test ≈ 0.7
* t = 2, Acc_test ≈ 0.7
* t = 3, Acc_test ≈ 0.7
* t = 4, Acc_test ≈ 0.7
* **r = 10³ (Yellow):** This line initially increases from approximately 0.45 at t = -1 to around 0.8 by t = 1. It then fluctuates around 0.8, showing some variability.
* t = -1, Acc_test ≈ 0.45
* t = 0, Acc_test ≈ 0.6
* t = 1, Acc_test ≈ 0.8
* t = 2, Acc_test ≈ 0.78
* t = 3, Acc_test ≈ 0.78
* t = 4, Acc_test ≈ 0.78
* **r = 10² (Orange):** This line starts around 0.5 at t = -1 and increases to approximately 0.78 by t = 1. It then fluctuates around 0.75-0.8.
* t = -1, Acc_test ≈ 0.5
* t = 0, Acc_test ≈ 0.6
* t = 1, Acc_test ≈ 0.78
* t = 2, Acc_test ≈ 0.76
* t = 3, Acc_test ≈ 0.76
* t = 4, Acc_test ≈ 0.76
* **r = 10⁰ (Purple):** This line exhibits a more erratic pattern. It starts around 0.48 at t = -1, increases to approximately 0.7 by t = 1, and then fluctuates significantly, decreasing to around 0.6 at t = 3 and then increasing again.
* t = -1, Acc_test ≈ 0.48
* t = 0, Acc_test ≈ 0.6
* t = 1, Acc_test ≈ 0.7
* t = 2, Acc_test ≈ 0.75
* t = 3, Acc_test ≈ 0.6
* t = 4, Acc_test ≈ 0.7
### Key Observations
* Higher values of λ⁰ (2 and 1) lead to faster convergence to high accuracy.
* The line for r = 10³ shows a relatively stable accuracy after the initial increase.
* The line for r = 10⁰ exhibits the most variability in accuracy over time.
* The lines for r = 10² and r = 10³ are relatively close to each other.
### Interpretation
The chart demonstrates the impact of different parameter settings (λ⁰ and r) on the test accuracy (`Acc_test`) of a model over time (`t`). The results suggest that a larger λ⁰ value leads to faster learning and higher accuracy. The parameter 'r' appears to have a less pronounced effect, with values of 10³ and 10² resulting in similar performance. The erratic behavior of the r = 10⁰ line suggests that this parameter setting may be unstable or sensitive to initial conditions.
The rapid increase in accuracy for higher λ⁰ values could indicate a faster learning rate, while the fluctuations in the r = 10⁰ line might be due to overfitting or underfitting. The plateauing of the lines after a certain time suggests that the models have converged to a stable state. This data could be used to optimize the parameter settings for the model to achieve the best possible performance.
</details>
Figure 11: Predicted test accuracy $\mathrm{Acc}_{\mathrm{test}}$ of the continuous GCN, at $r=\infty$ for a symmetrized graph. Left: for $\alpha=1$ and $\rho=0.1$ ; right: for $\alpha=2$ , $\mu=1$ and $\rho=0.3$ . We remind that $\lambda^{\mathrm{s}}=\sqrt{2}\lambda$ . The performance of the continuous GCN are given by eq. (126). Dots: numerical simulation of the continuous GCN for $N=7\times 10^{3}$ and $d=30$ , trained with quadratic loss, averaged over ten experiments.
### Comparison with optimality
The following figures support the discussion of parts III.2.3 and III.2.3. They show how the optimal diffusion time $t^{*}$ varies with respect to the parameters of the model and they compare the performance of the optimal continuous GCN and its discrete counterpart to the Bayes-optimality.
<details>
<summary>x15.png Details</summary>
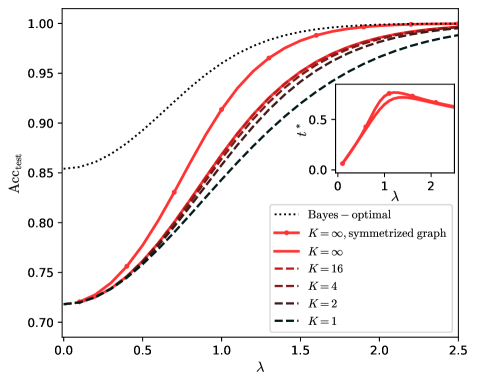
### Visual Description
## Line Chart: Test Accuracy vs. Lambda
### Overview
This image presents a line chart illustrating the relationship between test accuracy (Acc<sub>test</sub>) and a parameter lambda (λ) for different values of K. A smaller inset chart shows the relationship between t<sub>r</sub> and lambda. The chart compares the performance of several models, including a Bayes-optimal model and models with varying values of K.
### Components/Axes
* **X-axis:** Lambda (λ), ranging from approximately 0.0 to 2.5.
* **Y-axis:** Test Accuracy (Acc<sub>test</sub>), ranging from approximately 0.70 to 1.00.
* **Legend:** Located in the top-right corner, listing the different models:
* Bayes – optimal (dotted black line)
* K = ∞, symmetrized graph (dark grey solid line)
* K = ∞ (red solid line)
* K = 16 (red dashed line)
* K = 4 (black dashed line)
* K = 2 (black dash-dot line)
* K = 1 (black dotted line)
* **Inset Chart:** Located in the top-right corner.
* **X-axis:** Lambda (λ), ranging from approximately 0.0 to 2.0.
* **Y-axis:** t<sub>r</sub>, ranging from approximately 0.0 to 0.6.
### Detailed Analysis or Content Details
**Main Chart:**
* **Bayes – optimal (dotted black line):** Starts at approximately Acc<sub>test</sub> = 0.82 when λ = 0.0, increases steadily, and reaches approximately Acc<sub>test</sub> = 0.98 when λ = 2.0.
* **K = ∞, symmetrized graph (dark grey solid line):** Starts at approximately Acc<sub>test</sub> = 0.72 when λ = 0.0, increases gradually, and reaches approximately Acc<sub>test</sub> = 0.99 when λ = 2.0.
* **K = ∞ (red solid line):** Starts at approximately Acc<sub>test</sub> = 0.73 when λ = 0.0, increases rapidly between λ = 0.5 and λ = 1.0, and reaches approximately Acc<sub>test</sub> = 0.99 when λ = 2.0.
* **K = 16 (red dashed line):** Starts at approximately Acc<sub>test</sub> = 0.74 when λ = 0.0, increases gradually, and reaches approximately Acc<sub>test</sub> = 0.96 when λ = 2.0.
* **K = 4 (black dashed line):** Starts at approximately Acc<sub>test</sub> = 0.75 when λ = 0.0, increases gradually, and reaches approximately Acc<sub>test</sub> = 0.93 when λ = 2.0.
* **K = 2 (black dash-dot line):** Starts at approximately Acc<sub>test</sub> = 0.76 when λ = 0.0, increases gradually, and reaches approximately Acc<sub>test</sub> = 0.89 when λ = 2.0.
* **K = 1 (black dotted line):** Starts at approximately Acc<sub>test</sub> = 0.77 when λ = 0.0, increases gradually, and reaches approximately Acc<sub>test</sub> = 0.85 when λ = 2.0.
**Inset Chart:**
* The red solid line shows a curve that initially increases rapidly from approximately t<sub>r</sub> = 0.0 when λ = 0.0, reaching a peak of approximately t<sub>r</sub> = 0.55 when λ = 1.0, and then decreases gradually to approximately t<sub>r</sub> = 0.52 when λ = 2.0.
### Key Observations
* The Bayes-optimal model consistently achieves the highest test accuracy across all values of λ.
* The model with K = ∞ exhibits a performance close to the Bayes-optimal model, especially at higher values of λ.
* As K decreases, the test accuracy generally decreases, indicating that a larger value of K leads to better performance.
* The inset chart shows that t<sub>r</sub> peaks around λ = 1.0.
### Interpretation
The chart demonstrates the impact of the parameter K on the test accuracy of a model as a function of lambda. The results suggest that increasing K improves the model's performance, approaching the performance of the Bayes-optimal model as K approaches infinity. The inset chart indicates a relationship between lambda and t<sub>r</sub>, potentially representing a trade-off or characteristic of the model's behavior. The rapid increase in accuracy for K=∞ between λ=0.5 and λ=1.0 suggests a critical threshold or optimal range for lambda when K is large. The decreasing performance with smaller K values highlights the importance of model complexity or the number of parameters in achieving high accuracy. The Bayes-optimal curve serves as an upper bound on achievable accuracy, and the other curves show how different model configurations approach this limit.
</details>
<details>
<summary>x16.png Details</summary>
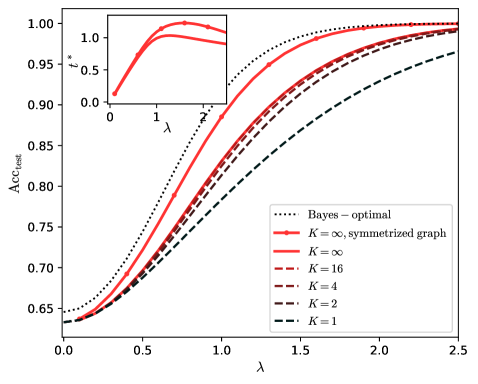
### Visual Description
## Chart: Test Accuracy vs. Lambda
### Overview
The image presents a line chart illustrating the relationship between test accuracy (Acc<sub>test</sub>) and a parameter lambda (λ) for different values of K. An inset chart shows a separate relationship between a value 'x*' and lambda. The chart compares the performance of different models or configurations, likely in a machine learning context.
### Components/Axes
* **X-axis:** Lambda (λ), ranging from approximately 0.0 to 2.5.
* **Y-axis:** Test Accuracy (Acc<sub>test</sub>), ranging from approximately 0.65 to 1.00.
* **Legend:** Located in the top-right corner, identifies the different lines:
* Bayes – optimal (dotted black line)
* K = ∞, symmetrized graph (solid red line)
* K = ∞ (solid red line)
* K = 16 (dashed red line)
* K = 4 (dashed brown line)
* K = 2 (dashed gray line)
* K = 1 (dashed black line)
* **Inset Chart:** Located in the top-left corner, shows a plot of 'x*' versus lambda (λ), ranging from approximately 0.0 to 2.0 for lambda and 0.0 to 1.0 for x*.
### Detailed Analysis
The main chart displays several curves representing different values of K.
* **Bayes – optimal (dotted black line):** This line starts at approximately 0.66 at λ = 0.0, increases rapidly, and reaches approximately 0.98 at λ = 1.0, then plateaus.
* **K = ∞, symmetrized graph (solid red line):** This line starts at approximately 0.66 at λ = 0.0, increases more slowly than the Bayes line, reaches approximately 0.99 at λ = 1.5, and plateaus.
* **K = ∞ (solid red line):** This line is nearly identical to the "K = ∞, symmetrized graph" line, starting at approximately 0.66 at λ = 0.0, increasing slowly, and reaching approximately 0.99 at λ = 1.5, then plateaus.
* **K = 16 (dashed red line):** This line starts at approximately 0.66 at λ = 0.0, increases at a moderate rate, reaches approximately 0.95 at λ = 1.5, and plateaus.
* **K = 4 (dashed brown line):** This line starts at approximately 0.66 at λ = 0.0, increases at a slower rate than K=16, reaches approximately 0.85 at λ = 1.5, and plateaus.
* **K = 2 (dashed gray line):** This line starts at approximately 0.66 at λ = 0.0, increases slowly, reaches approximately 0.75 at λ = 1.5, and plateaus.
* **K = 1 (dashed black line):** This line starts at approximately 0.66 at λ = 0.0, increases slowly, reaches approximately 0.70 at λ = 1.5, and plateaus.
The inset chart shows a single curve.
* **Inset Chart:** The curve starts at approximately 0.4 at λ = 0.0, increases to a peak of approximately 1.0 at λ = 1.0, and then decreases to approximately 0.7 at λ = 2.0.
### Key Observations
* The Bayes – optimal line consistently outperforms all other configurations across the range of λ.
* As K increases, the test accuracy generally increases, with K = ∞ providing the best performance among the K-based models.
* The inset chart shows a non-monotonic relationship between 'x*' and λ, peaking at λ = 1.0.
* All lines start at the same accuracy level (approximately 0.66) when λ = 0.0.
### Interpretation
The chart demonstrates the impact of the parameter K on the test accuracy of a model as a function of lambda. The "Bayes – optimal" line represents a theoretical upper bound on performance. The results suggest that increasing K generally improves performance, approaching the optimal Bayes solution as K approaches infinity. The inset chart likely represents a related parameter or metric that influences the overall model behavior, exhibiting a peak performance at a specific value of lambda. The fact that all lines start at the same accuracy suggests that the initial performance is independent of K, but the subsequent improvement is heavily influenced by it. The plateauing of the lines at higher lambda values indicates that the model reaches a saturation point where further increases in lambda do not lead to significant improvements in accuracy. This could be due to overfitting or other limitations of the model.
</details>
Figure 12: Predicted test accuracy $\mathrm{Acc}_{\mathrm{test}}$ of the continuous GCN and of its discrete counterpart with depth $K$ , at optimal times $t^{*}$ and $r=\infty$ . Left: for $\alpha=1$ , $\mu=2$ and $\rho=0.1$ ; right: for $\alpha=2$ , $\mu=1$ and $\rho=0.3$ . The performance of the continuous GCN $K=\infty$ are given by eq. (126) while for its discretization at finite $K$ they are given by numerically solving the fixed-point equations (87 - 94). Inset: $t^{*}$ the maximizer at $K=\infty$ .
<details>
<summary>x17.png Details</summary>
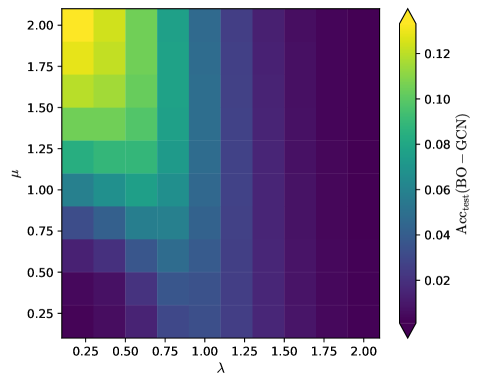
### Visual Description
\n
## Heatmap: BO - GCN Accuracy
### Overview
The image presents a heatmap visualizing the relationship between two parameters, λ (lambda) and μ (mu), and their impact on the test accuracy (Acc_test) of a Bayesian Optimization - Graph Convolutional Network (BO-GCN) model. The heatmap displays a color gradient representing the accuracy values, ranging from approximately 0.02 (dark purple) to 0.12 (bright yellow).
### Components/Axes
* **X-axis:** λ (lambda) - ranges from 0.25 to 2.00, with increments of approximately 0.25.
* **Y-axis:** μ (mu) - ranges from 0.25 to 2.00, with increments of approximately 0.25.
* **Color Scale (Legend):** Located on the right side of the heatmap, the color scale represents the Acc_test (BO - GCN) values.
* Yellow: ~0.12
* Light Green: ~0.10
* Green: ~0.08
* Light Blue: ~0.06
* Blue: ~0.04
* Dark Purple: ~0.02
### Detailed Analysis
The heatmap is a 9x9 grid, representing combinations of λ and μ values. The color intensity at each grid point corresponds to the Acc_test value for that specific combination.
Here's a breakdown of approximate Acc_test values based on the color gradient:
* **λ = 0.25:**
* μ = 0.25: ~0.02
* μ = 0.50: ~0.04
* μ = 0.75: ~0.06
* μ = 1.00: ~0.08
* μ = 1.25: ~0.08
* μ = 1.50: ~0.06
* μ = 1.75: ~0.04
* μ = 2.00: ~0.02
* **λ = 0.50:**
* μ = 0.25: ~0.04
* μ = 0.50: ~0.06
* μ = 0.75: ~0.08
* μ = 1.00: ~0.10
* μ = 1.25: ~0.10
* μ = 1.50: ~0.08
* μ = 1.75: ~0.06
* μ = 2.00: ~0.04
* **λ = 0.75:**
* μ = 0.25: ~0.06
* μ = 0.50: ~0.08
* μ = 0.75: ~0.10
* μ = 1.00: ~0.12
* μ = 1.25: ~0.10
* μ = 1.50: ~0.08
* μ = 1.75: ~0.06
* μ = 2.00: ~0.04
* **λ = 1.00:**
* μ = 0.25: ~0.08
* μ = 0.50: ~0.10
* μ = 0.75: ~0.12
* μ = 1.00: ~0.12
* μ = 1.25: ~0.10
* μ = 1.50: ~0.08
* μ = 1.75: ~0.06
* μ = 2.00: ~0.04
* **λ = 1.25:**
* μ = 0.25: ~0.08
* μ = 0.50: ~0.10
* μ = 0.75: ~0.10
* μ = 1.00: ~0.08
* μ = 1.25: ~0.06
* μ = 1.50: ~0.04
* μ = 1.75: ~0.02
* μ = 2.00: ~0.02
* **λ = 1.50:**
* μ = 0.25: ~0.06
* μ = 0.50: ~0.08
* μ = 0.75: ~0.10
* μ = 1.00: ~0.08
* μ = 1.25: ~0.06
* μ = 1.50: ~0.04
* μ = 1.75: ~0.02
* μ = 2.00: ~0.02
* **λ = 1.75:**
* μ = 0.25: ~0.04
* μ = 0.50: ~0.06
* μ = 0.75: ~0.08
* μ = 1.00: ~0.06
* μ = 1.25: ~0.04
* μ = 1.50: ~0.02
* μ = 1.75: ~0.02
* μ = 2.00: ~0.02
* **λ = 2.00:**
* μ = 0.25: ~0.02
* μ = 0.50: ~0.04
* μ = 0.75: ~0.06
* μ = 1.00: ~0.04
* μ = 1.25: ~0.02
* μ = 1.50: ~0.02
* μ = 1.75: ~0.02
* μ = 2.00: ~0.02
### Key Observations
* The highest accuracy values (around 0.12) are concentrated in the region where both λ and μ are around 0.75 to 1.00.
* Accuracy generally decreases as λ and μ move away from this optimal region, towards lower or higher values.
* There's a noticeable diagonal pattern, suggesting a correlation between λ and μ in influencing the accuracy.
* The bottom-left and top-right corners of the heatmap consistently show the lowest accuracy values (around 0.02).
### Interpretation
The heatmap demonstrates the impact of the hyperparameters λ and μ on the performance of the BO-GCN model. The optimal combination of these parameters appears to be around λ = 0.75-1.00 and μ = 0.75-1.00, where the model achieves the highest test accuracy. The decrease in accuracy as these parameters deviate from the optimal range suggests that these values are crucial for the model's ability to effectively learn and generalize. The diagonal pattern indicates that the interplay between λ and μ is important; increasing one parameter may require adjusting the other to maintain optimal performance. The heatmap provides valuable insights for hyperparameter tuning, guiding the selection of λ and μ values to maximize the model's accuracy. The data suggests a non-linear relationship between the parameters and the accuracy, as the highest accuracy is not achieved at the maximum values of either parameter.
</details>
<details>
<summary>x18.png Details</summary>
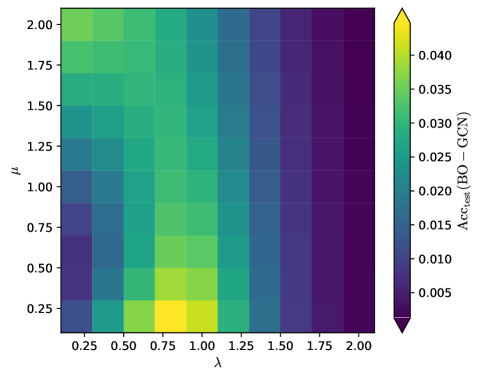
### Visual Description
\n
## Heatmap: Acc_test (BO - GCN) vs. λ and μ
### Overview
The image presents a heatmap visualizing the relationship between two parameters, λ (lambda) and μ (mu), and their impact on the `Acc_test (BO - GCN)` metric. The heatmap displays a color gradient representing the values of `Acc_test`, with warmer colors (yellow/green) indicating higher values and cooler colors (blue/purple) indicating lower values.
### Components/Axes
* **X-axis:** λ (lambda), ranging from approximately 0.20 to 2.00, with increments of approximately 0.25.
* **Y-axis:** μ (mu), ranging from approximately 0.20 to 2.00, with increments of approximately 0.25.
* **Colorbar:** Located on the right side of the heatmap, representing the `Acc_test (BO - GCN)` values. The scale ranges from approximately 0.005 (dark purple) to 0.040 (bright yellow).
* **Title:** Implicitly, the title is related to the metric being visualized: `Acc_test (BO - GCN)`.
### Detailed Analysis
The heatmap is a 9x9 grid, with each cell representing a unique combination of λ and μ values. The color of each cell corresponds to the `Acc_test` value for that combination.
Here's a breakdown of approximate `Acc_test` values based on color and grid position:
* **λ = 0.25, μ = 0.25:** Approximately 0.007 (dark purple)
* **λ = 0.25, μ = 0.50:** Approximately 0.010 (purple)
* **λ = 0.25, μ = 0.75:** Approximately 0.015 (purple)
* **λ = 0.25, μ = 1.00:** Approximately 0.020 (purple)
* **λ = 0.25, μ = 1.25:** Approximately 0.025 (blue)
* **λ = 0.25, μ = 1.50:** Approximately 0.025 (blue)
* **λ = 0.25, μ = 1.75:** Approximately 0.030 (blue)
* **λ = 0.25, μ = 2.00:** Approximately 0.030 (blue)
* **λ = 0.50, μ = 0.25:** Approximately 0.010 (purple)
* **λ = 0.50, μ = 0.50:** Approximately 0.015 (blue)
* **λ = 0.50, μ = 0.75:** Approximately 0.020 (blue)
* **λ = 0.50, μ = 1.00:** Approximately 0.025 (blue)
* **λ = 0.50, μ = 1.25:** Approximately 0.030 (blue)
* **λ = 0.50, μ = 1.50:** Approximately 0.030 (blue)
* **λ = 0.50, μ = 1.75:** Approximately 0.035 (green)
* **λ = 0.50, μ = 2.00:** Approximately 0.035 (green)
* **λ = 0.75, μ = 0.25:** Approximately 0.015 (blue)
* **λ = 0.75, μ = 0.50:** Approximately 0.020 (blue)
* **λ = 0.75, μ = 0.75:** Approximately 0.025 (blue)
* **λ = 0.75, μ = 1.00:** Approximately 0.030 (blue)
* **λ = 0.75, μ = 1.25:** Approximately 0.035 (green)
* **λ = 0.75, μ = 1.50:** Approximately 0.035 (green)
* **λ = 0.75, μ = 1.75:** Approximately 0.040 (yellow)
* **λ = 0.75, μ = 2.00:** Approximately 0.040 (yellow)
* **λ = 1.00, μ = 0.25:** Approximately 0.020 (blue)
* **λ = 1.00, μ = 0.50:** Approximately 0.025 (blue)
* **λ = 1.00, μ = 0.75:** Approximately 0.030 (blue)
* **λ = 1.00, μ = 1.00:** Approximately 0.035 (green)
* **λ = 1.00, μ = 1.25:** Approximately 0.035 (green)
* **λ = 1.00, μ = 1.50:** Approximately 0.040 (yellow)
* **λ = 1.00, μ = 1.75:** Approximately 0.040 (yellow)
* **λ = 1.00, μ = 2.00:** Approximately 0.040 (yellow)
* **λ = 1.25, μ = 0.25:** Approximately 0.025 (blue)
* **λ = 1.25, μ = 0.50:** Approximately 0.030 (blue)
* **λ = 1.25, μ = 0.75:** Approximately 0.035 (green)
* **λ = 1.25, μ = 1.00:** Approximately 0.035 (green)
* **λ = 1.25, μ = 1.25:** Approximately 0.040 (yellow)
* **λ = 1.25, μ = 1.50:** Approximately 0.040 (yellow)
* **λ = 1.25, μ = 1.75:** Approximately 0.040 (yellow)
* **λ = 1.25, μ = 2.00:** Approximately 0.040 (yellow)
The trend shows that as both λ and μ increase, the `Acc_test` value generally increases, reaching its maximum around λ = 0.75 and μ = 1.75, and remaining high for larger values of λ and μ.
### Key Observations
* The lowest `Acc_test` values are concentrated in the bottom-left corner of the heatmap (low λ and low μ).
* The highest `Acc_test` values are concentrated in the top-right corner (high λ and high μ).
* There appears to be a relatively flat region of high `Acc_test` values when both λ and μ are greater than approximately 1.0.
### Interpretation
The heatmap suggests that the `Acc_test (BO - GCN)` metric is positively correlated with both λ and μ. This implies that increasing the values of these parameters generally improves the test accuracy of the BO-GCN model. The plateau in the top-right corner indicates that there may be a point of diminishing returns, where further increases in λ and μ do not significantly improve accuracy. The model performs poorly when both parameters are low. This visualization is useful for hyperparameter tuning, as it provides a clear indication of the optimal range for λ and μ to maximize test accuracy. The BO-GCN model is sensitive to the values of λ and μ, and careful selection of these parameters is crucial for achieving good performance.
</details>
Figure 13: Gap to the Bayes-optimality. Predicted difference between the Bayes-optimal test accuracy and the test accuracy of the continuous GCN at optimal time $t^{*}$ and $r=\infty$ , vs the two signals $\lambda$ and $\mu$ . Left: for $\alpha=1$ and $\rho=0.1$ ; right: for $\alpha=2$ and $\rho=0.3$ . The performance of the continuous GCN are given by eq. (126).
### Comparison between symmetric and asymmetric graphs
The following figure supports the claim of part III.1.3, that the performance of the GCN depends little whether the graph is symmetric or not at same $\lambda$ , and that it is not able to deal with the supplementary information the asymmetry gives.
<details>
<summary>x19.png Details</summary>
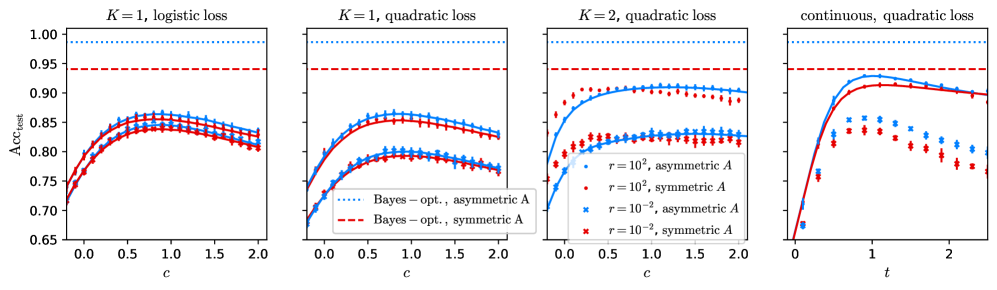
### Visual Description
## Charts: Performance Comparison under Different Loss Functions and Parameters
### Overview
The image presents four separate charts comparing the performance (Acc_test) of different models under varying conditions. Each chart explores a different loss function and parameter setting. The x-axis represents a parameter 'c' in the first three charts and 't' in the last chart. The y-axis, labeled "Acc_test", represents the accuracy score. Two model types are compared: "asymmetric A" and "symmetric A", with different values of 'r' (10^2 and 10^-2). Each chart also includes a "Bayes – opt." baseline, represented by dotted lines, for both asymmetric and symmetric cases.
### Components/Axes
* **Y-axis (all charts):** Acc_test (Accuracy Score), ranging from approximately 0.65 to 1.00.
* **Chart 1:** K = 1, logistic loss; X-axis: c, ranging from 0.0 to 2.0.
* **Chart 2:** K = 1, quadratic loss; X-axis: c, ranging from 0.0 to 2.0.
* **Chart 3:** K = 2, quadratic loss; X-axis: c, ranging from 0.0 to 2.0.
* **Chart 4:** continuous, quadratic loss; X-axis: t, ranging from 0.0 to 2.0.
* **Legend (all charts):**
* `r = 10^2, asymmetric A` (Blue, marked with 'x')
* `r = 10^2, symmetric A` (Red, marked with '+')
* `r = 10^-2, asymmetric A` (Blue, dotted, marked with '.')
* `r = 10^-2, symmetric A` (Red, dotted, marked with '.')
* `Bayes – opt., asymmetric A` (Blue, dashed)
* `Bayes – opt., symmetric A` (Red, dashed)
### Detailed Analysis or Content Details
**Chart 1: K = 1, logistic loss**
* The blue 'x' line (r = 10^2, asymmetric A) starts at approximately 0.72 and increases to around 0.87 at c = 2.0.
* The red '+' line (r = 10^2, symmetric A) starts at approximately 0.70 and increases to around 0.85 at c = 2.0.
* The blue dotted line (r = 10^-2, asymmetric A) starts at approximately 0.73 and increases to around 0.86 at c = 2.0.
* The red dotted line (r = 10^-2, symmetric A) starts at approximately 0.71 and increases to around 0.84 at c = 2.0.
* The blue dashed line (Bayes – opt., asymmetric A) starts at approximately 0.75 and increases to around 0.90 at c = 2.0.
* The red dashed line (Bayes – opt., symmetric A) starts at approximately 0.74 and increases to around 0.89 at c = 2.0.
**Chart 2: K = 1, quadratic loss**
* The blue 'x' line (r = 10^2, asymmetric A) starts at approximately 0.70 and increases rapidly to around 0.92 at c = 1.5, then plateaus at around 0.93 at c = 2.0.
* The red '+' line (r = 10^2, symmetric A) starts at approximately 0.68 and increases rapidly to around 0.90 at c = 1.5, then plateaus at around 0.91 at c = 2.0.
* The blue dotted line (r = 10^-2, asymmetric A) starts at approximately 0.71 and increases to around 0.88 at c = 2.0.
* The red dotted line (r = 10^-2, symmetric A) starts at approximately 0.69 and increases to around 0.87 at c = 2.0.
* The blue dashed line (Bayes – opt., asymmetric A) starts at approximately 0.73 and increases to around 0.94 at c = 2.0.
* The red dashed line (Bayes – opt., symmetric A) starts at approximately 0.72 and increases to around 0.93 at c = 2.0.
**Chart 3: K = 2, quadratic loss**
* The blue 'x' line (r = 10^2, asymmetric A) starts at approximately 0.70 and increases to around 0.94 at c = 2.0.
* The red '+' line (r = 10^2, symmetric A) starts at approximately 0.68 and increases to around 0.92 at c = 2.0.
* The blue dotted line (r = 10^-2, asymmetric A) starts at approximately 0.72 and increases to around 0.88 at c = 2.0.
* The red dotted line (r = 10^-2, symmetric A) starts at approximately 0.70 and increases to around 0.86 at c = 2.0.
* The blue dashed line (Bayes – opt., asymmetric A) starts at approximately 0.74 and increases to around 0.96 at c = 2.0.
* The red dashed line (Bayes – opt., symmetric A) starts at approximately 0.73 and increases to around 0.95 at c = 2.0.
**Chart 4: continuous, quadratic loss**
* The blue 'x' line (r = 10^2, asymmetric A) starts at approximately 0.75 and increases to around 0.98 at t = 1.0, then decreases slightly to around 0.96 at t = 2.0.
* The red '+' line (r = 10^2, symmetric A) starts at approximately 0.73 and increases to around 0.97 at t = 1.0, then decreases slightly to around 0.95 at t = 2.0.
* The blue dotted line (r = 10^-2, asymmetric A) starts at approximately 0.76 and increases to around 0.90 at t = 2.0.
* The red dotted line (r = 10^-2, symmetric A) starts at approximately 0.74 and increases to around 0.88 at t = 2.0.
* The blue dashed line (Bayes – opt., asymmetric A) starts at approximately 0.78 and increases to around 0.99 at t = 1.0, then decreases slightly to around 0.97 at t = 2.0.
* The red dashed line (Bayes – opt., symmetric A) starts at approximately 0.77 and increases to around 0.98 at t = 1.0, then decreases slightly to around 0.96 at t = 2.0.
### Key Observations
* The "Bayes – opt." lines consistently outperform the other models across all charts.
* In the first three charts, the performance of models with r = 10^2 is generally better than those with r = 10^-2.
* The difference between asymmetric and symmetric models is relatively small, especially for the "Bayes – opt." lines.
* Chart 4 shows a peak in performance around t = 1.0 for all models, followed by a slight decrease.
### Interpretation
The charts demonstrate the performance of different models under various loss functions (logistic and quadratic) and parameter settings (K and r). The consistent outperformance of the "Bayes – opt." models suggests they provide a strong baseline for comparison. The choice of 'r' value significantly impacts performance, with larger values (10^2) generally leading to better accuracy, particularly in the first three charts. The slight performance decrease observed in Chart 4 after t = 1.0 could indicate overfitting or a saturation point in the learning process. The relatively small difference between asymmetric and symmetric models suggests that the asymmetry of the model does not have a substantial impact on performance in these scenarios. These results could inform the selection of appropriate model parameters and loss functions for similar tasks.
</details>
Figure 14: Test accuracy of the GCN, on asymmetric $A$ and its symmetric counterpart, obtained by equaling $A_{ij}$ with $A_{ji}$ for all $i<j$ . $\alpha=4$ , $\lambda=1.5$ , $\mu=3$ and $\rho=0.1$ . Lines: predictions. Dots: numerical simulation of the GCN for $N=10^{4}$ and $d=30$ , averaged over ten experiments.
### Train error
The following figure displays the train error $E_{\mathrm{train}}$ eq. 18 vs the self-loop intensity $c$ , in the same settings as fig. 2 of part III.1. It shows in particular that to treat $c$ as a parameter trained to minimize the train error would degrade the performance, since it would lead to $c\to\infty$ . As a consequence, $c$ should be treated as a hyperparameter, tuned to maximize the test accuracy, as done in the main part of the article.
<details>
<summary>x20.png Details</summary>
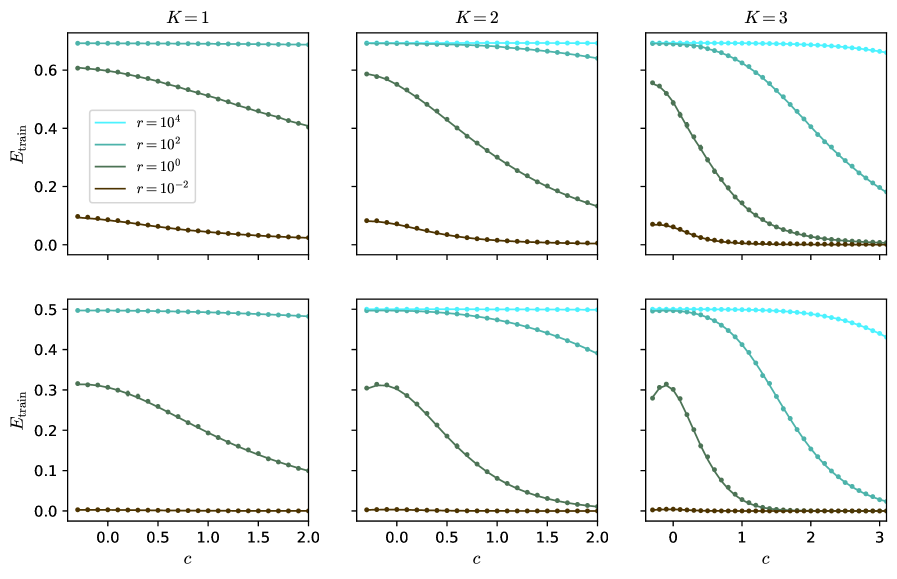
### Visual Description
## Chart: Training Error vs. Regularization Parameter
### Overview
The image presents a 2x3 grid of line charts, each depicting the relationship between training error (E_train) and a regularization parameter 'c' for different values of 'K' (1, 2, and 3) and 'r' (10^4, 10^2, 10^0, and 10^-2). Each chart shows multiple lines representing different values of 'r' for a fixed 'K'. The top row shows charts with a c-axis ranging from 0 to 2, while the bottom row extends to c=3 for K=3.
### Components/Axes
* **X-axis:** 'c' (Regularization Parameter) - Scale varies between charts, ranging from 0 to 2 (top row) and 0 to 3 (bottom row).
* **Y-axis:** 'E_train' (Training Error) - Scale ranges from 0 to 0.65.
* **Legend:** Located in the top-left corner of each chart, identifying the lines by 'r' values:
* r = 10^4 (Light Blue)
* r = 10^2 (Gray)
* r = 10^0 (Dark Green)
* r = 10^-2 (Dark Brown)
* **Titles:** Each chart is labeled with 'K = 1', 'K = 2', or 'K = 3' at the top center.
### Detailed Analysis or Content Details
**Chart 1: K = 1**
* **r = 10^4 (Light Blue):** Line is nearly flat, starting at approximately 0.63 and decreasing very slightly to around 0.61 as 'c' increases from 0 to 2.
* **r = 10^2 (Gray):** Line slopes downward, starting at approximately 0.22 and decreasing to around 0.05 as 'c' increases from 0 to 2.
* **r = 10^0 (Dark Green):** Line slopes downward, starting at approximately 0.10 and decreasing to around 0.02 as 'c' increases from 0 to 2.
* **r = 10^-2 (Dark Brown):** Line is relatively flat, starting at approximately 0.03 and remaining around 0.02 as 'c' increases from 0 to 2.
**Chart 2: K = 2**
* **r = 10^4 (Light Blue):** Line slopes downward, starting at approximately 0.65 and decreasing to around 0.15 as 'c' increases from 0 to 2.
* **r = 10^2 (Gray):** Line slopes downward, starting at approximately 0.25 and decreasing to around 0.05 as 'c' increases from 0 to 2.
* **r = 10^0 (Dark Green):** Line slopes downward, starting at approximately 0.20 and decreasing to around 0.05 as 'c' increases from 0 to 2.
* **r = 10^-2 (Dark Brown):** Line is relatively flat, starting at approximately 0.05 and remaining around 0.03 as 'c' increases from 0 to 2.
**Chart 3: K = 3**
* **r = 10^4 (Light Blue):** Line initially decreases, reaching a minimum around c=1.5 (approximately 0.25), then increases to around 0.35 at c=3.
* **r = 10^2 (Gray):** Line slopes downward, starting at approximately 0.35 and decreasing to around 0.10 as 'c' increases from 0 to 2. It then increases slightly to around 0.12 at c=3.
* **r = 10^0 (Dark Green):** Line initially decreases, reaching a minimum around c=1.5 (approximately 0.10), then increases to around 0.15 at c=3.
* **r = 10^-2 (Dark Brown):** Line initially decreases, reaching a minimum around c=2 (approximately 0.05), then increases to around 0.08 at c=3.
### Key Observations
* For K=1 and K=2, increasing 'c' generally decreases the training error for all values of 'r'.
* For K=3, the training error initially decreases with 'c', but then increases beyond a certain point (around c=1.5-2). This suggests overfitting for larger values of 'c' when K=3.
* Higher values of 'r' (10^4) consistently result in higher training errors compared to lower values of 'r' (10^-2), especially for K=1 and K=2.
* The effect of 'r' on training error is less pronounced for K=3, particularly at higher values of 'c'.
### Interpretation
The charts illustrate the impact of regularization (parameter 'c') on training error for different values of 'K' and 'r'. The parameter 'K' likely represents the number of components or clusters in a model, while 'r' could be a regularization strength parameter.
The decreasing trend of training error with increasing 'c' for K=1 and K=2 indicates that regularization helps prevent overfitting. However, the increase in training error for K=3 at higher 'c' values suggests that excessive regularization can lead to underfitting.
The influence of 'r' on training error suggests that a larger 'r' (stronger regularization) can lead to higher training error, potentially due to a more constrained model. The optimal value of 'c' and 'r' likely depends on the specific value of 'K' and the complexity of the underlying data. The charts demonstrate a trade-off between bias and variance, where increasing 'c' reduces variance but can increase bias, and vice versa. The charts suggest that the optimal regularization strength is dependent on the complexity of the model (K).
</details>
Figure 15: Predicted train error $E_{\mathrm{test}}$ for different values of $K$ . Top: for $\lambda=1.5$ , $\mu=3$ and logistic loss; bottom: for $\lambda=1$ , $\mu=2$ and quadratic loss; $\alpha=4$ and $\rho=0.1$ . We take $c_{k}=c$ for all $k$ . Dots: numerical simulation of the GCN for $N=10^{4}$ and $d=30$ , averaged over ten experiments.
## References
- Wang et al. [2023] Y. Wang, Z. Li, and A. Barati Farimani, Graph neural networks for molecules, in Machine Learning in Molecular Sciences (Springer International Publishing, 2023) p. 21–66, arXiv:2209.05582.
- Li et al. [2022] M. M. Li, K. Huang, and M. Zitnik, Graph representation learning in biomedicine and healthcare, Nature Biomedical Engineering 6, 1353–1369 (2022), arXiv:2104.04883.
- Bessadok et al. [2021] A. Bessadok, M. A. Mahjoub, and I. Rekik, Graph neural networks in network neuroscience (2021), arXiv:2106.03535.
- Sanchez-Gonzalez et al. [2020] A. Sanchez-Gonzalez, J. Godwin, T. Pfaff, R. Ying, J. Leskovec, and P. W. Battaglia, Learning to simulate complex physics with graph networks, in Proceedings of the 37th International Conference on Machine Learning (2020) arXiv:2002.09405.
- Shlomi et al. [2020] J. Shlomi, P. Battaglia, and J.-R. Vlimant, Graph neural networks in particle physics, Machine Learning: Science and Technology 2 (2020), arXiv:2007.13681.
- Peng et al. [2021] Y. Peng, B. Choi, and J. Xu, Graph learning for combinatorial optimization: A survey of state-of-the-art, Data Science and Engineering 6, 119 (2021), arXiv:2008.12646.
- Cappart et al. [2023] Q. Cappart, D. Chételat, E. Khalil, A. Lodi, C. Morris, and P. Veličković, Combinatorial optimization and reasoning with graph neural networks, Journal of Machine Learning Research 24, 1 (2023), arXiv:2102.09544.
- Morris et al. [2024] C. Morris, F. Frasca, N. Dym, H. Maron, I. I. Ceylan, R. Levie, D. Lim, M. Bronstein, M. Grohe, and S. Jegelka, Position: Future directions in the theory of graph machine learning, in Proceedings of the 41st International Conference on Machine Learning (2024).
- Li et al. [2018] Q. Li, Z. Han, and X.-M. Wu, Deeper insights into graph convolutional networks for semi-supervised learning, in Thirty-Second AAAI conference on artificial intelligence (2018) arXiv:1801.07606.
- Oono and Suzuki [2020] K. Oono and T. Suzuki, Graph neural networks exponentially lose expressive power for node classification, in International conference on learning representations (2020) arXiv:1905.10947.
- Li et al. [2019] G. Li, M. Müller, A. Thabet, and B. Ghanem, DeepGCNs: Can GCNs go as deep as CNNs?, in ICCV (2019) arXiv:1904.03751.
- Chen et al. [2020] M. Chen, Z. Wei, Z. Huang, B. Ding, and Y. Li, Simple and deep graph convolutional networks, in Proceedings of the 37th International Conference on Machine Learning (2020) arXiv:2007.02133.
- Ju et al. [2023] H. Ju, D. Li, A. Sharma, and H. R. Zhang, Generalization in graph neural networks: Improved PAC-Bayesian bounds on graph diffusion, in AISTATS (2023) arXiv:2302.04451.
- Tang and Liu [2023] H. Tang and Y. Liu, Towards understanding the generalization of graph neural networks (2023), arXiv:2305.08048.
- Cong et al. [2021] W. Cong, M. Ramezani, and M. Mahdavi, On provable benefits of depth in training graph convolutional networks, in 35th Conference on Neural Information Processing Systems (2021) arxiv:2110.15174.
- Esser et al. [2021] P. M. Esser, L. C. Vankadara, and D. Ghoshdastidar, Learning theory can (sometimes) explain generalisation in graph neural networks, in 35th Conference on Neural Information Processing Systems (2021) arXiv:2112.03968.
- Seung et al. [1992] H. S. Seung, H. Sompolinsky, and N. Tishby, Statistical mechanics of learning from examples, Physical review A 45, 6056 (1992).
- Loureiro et al. [2021] B. Loureiro, C. Gerbelot, H. Cui, S. Goldt, F. Krzakala, M. Mezard, and L. Zdeborová, Learning curves of generic features maps for realistic datasets with a teacher-student model, Advances in Neural Information Processing Systems 34, 18137 (2021).
- Mei and Montanari [2022] S. Mei and A. Montanari, The generalization error of random features regression: Precise asymptotics and the double descent curve, Communications on Pure and Applied Mathematics 75, 667 (2022).
- Shi et al. [2023] C. Shi, L. Pan, H. Hu, and I. Dokmanić, Homophily modulates double descent generalization in graph convolution networks, PNAS 121 (2023), arXiv:2212.13069.
- Yan and Sarkar [2021] B. Yan and P. Sarkar, Covariate regularized community detection in sparse graphs, Journal of the American Statistical Association 116, 734 (2021), arxiv:1607.02675.
- Deshpande et al. [2018] Y. Deshpande, S. Sen, A. Montanari, and E. Mossel, Contextual stochastic block models, in Advances in Neural Information Processing Systems, Vol. 31, edited by S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (2018) arxiv:1807.09596.
- Chien et al. [2021] E. Chien, J. Peng, P. Li, and O. Milenkovic, Adaptative universal generalized pagerank graph neural network, in Proceedings of the 39th International Conference on Learning Representations (2021) arxiv:2006.07988.
- Fu et al. [2021] G. Fu, P. Zhao, and Y. Bian, p-Laplacian based graph neural networks, in Proceedings of the 39th International Conference on Machine Learning (2021) arxiv:2111.07337.
- Lei et al. [2022] R. Lei, Z. Wang, Y. Li, B. Ding, and Z. Wei, EvenNet: Ignoring odd-hop neighbors improves robustness of graph neural networks, in 36th Conference on Neural Information Processing Systems (2022) arxiv:2205.13892.
- Duranthon and Zdeborová [2024a] O. Duranthon and L. Zdeborová, Asymptotic generalization error of a single-layer graph convolutional network, in The Learning on Graphs Conference (2024) arxiv:2402.03818.
- Chen et al. [2018] R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. Duvenaud, Neural ordinary differential equations, in 32nd Conference on Neural Information Processing Systems (2018) arXiv:1806.07366.
- Kipf and Welling [2017] T. N. Kipf and M. Welling, Semi-supervised classification with graph convolutional networks, in International Conference on Learning Representations (2017) arxiv:1609.02907.
- Cui et al. [2023] H. Cui, F. Krzakala, and L. Zdeborová, Bayes-optimal learning of deep random networks of extensive-width, in Proceedings of the 40th International Conference on Machine Learning (2023) arxiv:2302.00375.
- McCallum et al. [2000] A. K. McCallum, K. Nigam, J. Rennie, and K. Seymore, Automating the construction of internet portals with machine learning, Information Retrieval 3, 127–163 (2000).
- Shchur et al. [2018] O. Shchur, M. Mumme, A. Bojchevski, and S. Günnemann, Pitfalls of graph neural network evaluation, (2018), arXiv:1811.05868.
- Giles et al. [1998] C. L. Giles, K. D. Bollacker, and S. Lawrenc, Citeseer: An automatic citation indexing system, in Proceedings of the third ACM conference on Digital libraries (1998) p. 89–98.
- Sen et al. [2008] P. Sen, G. Namata, M. Bilgic, L. Getoor, B. Galligher, and T. Eliassi-Rad, Collective classification in network data, AI magazine 29 (2008).
- Baranwal et al. [2021] A. Baranwal, K. Fountoulakis, and A. Jagannath, Graph convolution for semi-supervised classification: Improved linear separability and out-of-distribution generalization, in Proceedings of the 38th International Conference on Machine Learning (2021) arxiv:2102.06966.
- Baranwal et al. [2023] A. Baranwal, K. Fountoulakis, and A. Jagannath, Optimality of message-passing architectures for sparse graphs, in 37th Conference on Neural Information Processing Systems (2023) arxiv:2305.10391.
- Wang et al. [2024] R. Wang, A. Baranwal, and K. Fountoulakis, Analysis of corrected graph convolutions (2024), arXiv:2405.13987.
- Mignacco et al. [2020] F. Mignacco, F. Krzakala, Y. M. Lu, and L. Zdeborová, The role of regularization in classification of high-dimensional noisy Gaussian mixture, in International conference on learning representations (2020) arxiv:2002.11544.
- Aubin et al. [2020] B. Aubin, F. Krzakala, Y. M. Lu, and L. Zdeborová, Generalization error in high-dimensional perceptrons: Approaching Bayes error with convex optimization, in Advances in Neural Information Processing Systems (2020) arxiv:2006.06560.
- Duranthon and Zdeborová [2024b] O. Duranthon and L. Zdeborová, Optimal inference in contextual stochastic block models, Transactions on Machine Learning Research (2024b), arxiv:2306.07948.
- Keriven [2022] N. Keriven, Not too little, not too much: a theoretical analysis of graph (over)smoothing, in 36th Conference on Neural Information Processing Systems (2022) arXiv:2205.12156.
- He et al. [2016] K. He, X. Zhang, S. Ren, and J. Sun, Deep residual learning for image recognition, in IEEE Conference on Computer Vision and Pattern Recognition (2016) arXiv:1512.03385.
- Pham et al. [2017] T. Pham, T. Tran, D. Phung, and S. Venkatesh, Column networks for collective classification, in AAAI (2017) arXiv:1609.04508.
- Xu et al. [2021] K. Xu, M. Zhang, S. Jegelka, and K. Kawaguchi, Optimization of graph neural networks: Implicit acceleration by skip connections and more depth, in Proceedings of the 38th International Conference on Machine Learning (2021) arXiv:2105.04550.
- Sander et al. [2022] M. E. Sander, P. Ablin, and G. Peyré, Do residual neural networks discretize neural ordinary differential equations?, in 36th Conference on Neural Information Processing Systems (2022) arXiv:2205.14612.
- Ling et al. [2016] J. Ling, A. Kurzawski, and J. Templeton, Reynolds averaged turbulence modelling using deep neural networks with embedded invariance, Journal of Fluid Mechanics 807, 155–166 (2016).
- Rackauckas et al. [2020] C. Rackauckas, Y. Ma, J. Martensen, C. Warner, K. Zubov, R. Supekar, D. Skinner, A. Ramadhan, and A. Edelman, Universal differential equations for scientific machine learning (2020), arXiv:2001.04385.
- Marion [2023] P. Marion, Generalization bounds for neural ordinary differential equations and deep residual networks (2023), arXiv:2305.06648.
- Poli et al. [2019] M. Poli, S. Massaroli, J. Park, A. Yamashita, H. Asama, and J. Park, Graph neural ordinary differential equations (2019), arXiv:1911.07532.
- Xhonneux et al. [2020] L.-P. A. C. Xhonneux, M. Qu, and J. Tang, Continuous graph neural networks, in Proceedings of the 37th International Conference on Machine Learning (2020) arXiv:1912.00967.
- Han et al. [2023] A. Han, D. Shi, L. Lin, and J. Gao, From continuous dynamics to graph neural networks: Neural diffusion and beyond (2023), arXiv:2310.10121.
- Lu and Sen [2020] C. Lu and S. Sen, Contextual stochastic block model: Sharp thresholds and contiguity (2020), arXiv:2011.09841.
- Wu et al. [2019] F. Wu, T. Zhang, A. H. de Souza Jr., C. Fifty, T. Yu, and K. Q. Weinberger, Simplifying graph convolutional networks, in Proceedings of the 36th International Conference on Machine Learning (2019) arxiv:1902.07153.
- Zhu and Koniusz [2021] H. Zhu and P. Koniusz, Simple spectral graph convolution, in International Conference on Learning Representations (2021).
- Lesieur et al. [2017] T. Lesieur, F. Krzakala, and L. Zdeborová, Constrained low-rank matrix estimation: Phase transitions, approximate message passing and applications, Journal of Statistical Mechanics: Theory and Experiment 2017, 073403 (2017), arxiv:1701.00858.
- Duranthon and Zdeborová [2023] O. Duranthon and L. Zdeborová, Neural-prior stochastic block model, Mach. Learn.: Sci. Technol. (2023), arxiv:2303.09995.
- Baik et al. [2005] J. Baik, G. B. Arous, and S. Péché, Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices, Annals of Probability , 1643 (2005).