# Graph-Augmented Reasoning: Evolving Step-by-Step Knowledge Graph Retrieval for LLM Reasoning
**Authors**: Wenjie Wu, Yongcheng Jing, Yingjie Wang, Wenbin Hu, Dacheng Tao
> Wenjie Wu and Wenbin Hu are with Wuhan University (Email: Yongcheng Jing, Yingjie Wang, and Dacheng Tao are with Nanyang Technological University (Email:
## Abstract
Recent large language model (LLM) reasoning, despite its success, suffers from limited domain knowledge, susceptibility to hallucinations, and constrained reasoning depth, particularly in small-scale models deployed in resource-constrained environments. This paper presents the first investigation into integrating step-wise knowledge graph retrieval with step-wise reasoning to address these challenges, introducing a novel paradigm termed as graph-augmented reasoning. Our goal is to enable frozen, small-scale LLMs to retrieve and process relevant mathematical knowledge in a step-wise manner, enhancing their problem-solving abilities without additional training. To this end, we propose KG-RAR, a framework centered on process-oriented knowledge graph construction, a hierarchical retrieval strategy, and a universal post-retrieval processing and reward model (PRP-RM) that refines retrieved information and evaluates each reasoning step. Experiments on the Math500 and GSM8K benchmarks across six models demonstrate that KG-RAR yields encouraging results, achieving a 20.73% relative improvement with Llama-3B on Math500.
Index Terms: Large Language Model, Knowledge Graph, Reasoning
## 1 Introduction
Enhancing the reasoning capabilities of large language models (LLMs) continues to be a major challenge [1, 2, 3]. Conventional methods, such as chain-of-thought (CoT) prompting [4], improve inference by encouraging step-by-step articulation [5, 6, 7, 8, 9, 10], while external tool usage and domain-specific fine-tuning further refine specific task performance [11, 12, 13, 14, 15, 16]. Most recently, o1-like multi-step reasoning has emerged as a paradigm shift [17, 18, 19, 20, 21, 22], leveraging test-time compute strategies [5, 23, 24, 25, 26], exemplified by reasoning models like GPT-o1 [27] and DeepSeek-R1 [28]. These approaches, including Best-of-N [29] and Monte Carlo Tree Search [23] , allocate additional computational resources during inference to dynamically refine reasoning paths [30, 31, 29, 25].
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Comparison of Reasoning and Retrieval Methods
### Overview
This image presents a comparative diagram illustrating three different approaches to problem-solving and information retrieval: "Chain of Thought," "Traditional RAG," and "Step-by-Step KG-RAR." Each approach is depicted as a flowchart, outlining the sequence of steps from problem input to final answer. The diagram highlights the integration of different components like "Problem," "Docs," "KG" (Knowledge Graph), and specific processing steps.
### Components/Axes
The diagram is structured into three vertical flowcharts, each representing a distinct method.
**Common Elements Across Flowcharts:**
* **Input Boxes:** Represent initial inputs to the system.
* "?" with "Problem" (present in all three flowcharts).
* "Docs" (present in the "Traditional RAG" flowchart).
* "KG" (present in the "Step-by-Step KG-RAR" flowchart).
* **Processing Boxes:** Represent intermediate steps or operations.
* "CoT-prompting" (blue, in "Chain of Thought").
* "CoT + RAG" (green, in "Traditional RAG").
* "CoT + KG-RAR" (teal, in "Step-by-Step KG-RAR").
* "Step1" (white, present in all three flowcharts).
* "Step2" (white, present in all three flowcharts).
* "KG-RAR of Step1" (teal, in "Step-by-Step KG-RAR").
* **Sub-KG Boxes:** Represent sub-knowledge graphs used in "Step-by-Step KG-RAR."
* "Sub-KG" (white, associated with "Step1" and "Step2" in "Step-by-Step KG-RAR").
* **Output Box:**
* "Answer" (white, present in all three flowcharts).
* **Connectors:** Arrows indicate the flow of information or process.
* **Icons:**
* A lightning bolt icon (yellow, between "Step2" and "Answer" in "Chain of Thought" and "Traditional RAG").
* A question mark icon within a blue circle (in "Step-by-Step KG-RAR," near "Step1").
* A document icon with a magnifying glass (yellow, near "Docs" in "Traditional RAG").
* A knowledge graph icon (green, near "KG" in "Step-by-Step KG-RAR").
* A magnifying glass icon within a green circle (green, associated with feedback loops in "Step-by-Step KG-RAR").
* A plus sign within a green circle (green, associated with feedback loops in "Step-by-Step KG-RAR").
* An hourglass icon (blue, between "Step2" and "Answer" in "Step-by-Step KG-RAR").
**Labels Below Flowcharts:**
* "Chain of Thought" (blue text).
* "Traditional RAG" (green text).
* "Step-by-Step KG-RAR" (teal text).
### Detailed Analysis
**Flowchart 1: Chain of Thought**
1. **Input:** Starts with a "?" and "Problem."
2. **Processing:** Proceeds to "CoT-prompting" (blue box).
3. **Steps:** Continues sequentially through "Step1" and "Step2."
4. **Intermediate Indicator:** A yellow lightning bolt icon appears between "Step2" and "Answer," possibly indicating a computational or reasoning process.
5. **Output:** Concludes with "Answer."
6. **Label:** Titled "Chain of Thought" in blue.
**Flowchart 2: Traditional RAG**
1. **Inputs:** Starts with "?" and "Problem," and also takes "Docs" as input.
2. **Processing:** Proceeds to "CoT + RAG" (green box).
3. **Steps:** Continues sequentially through "Step1" and "Step2."
4. **Intermediate Indicator:** A yellow lightning bolt icon appears between "Step2" and "Answer," similar to the "Chain of Thought" method.
5. **Output:** Concludes with "Answer."
6. **Label:** Titled "Traditional RAG" in green.
**Flowchart 3: Step-by-Step KG-RAR**
1. **Inputs:** Starts with "?" and "Problem," and also takes "KG" (Knowledge Graph) as input.
2. **Initial Processing:** Proceeds to "CoT + KG-RAR" (teal box).
3. **Step 1 with Sub-KG:** From "Step1," it branches to "KG-RAR of Step1" (teal box). Simultaneously, "Step1" is associated with a "Sub-KG" (white box). A question mark icon is present near "Step1" and points towards "KG-RAR of Step1."
4. **Feedback Loop 1:** The output of "KG-RAR of Step1" is fed back into "Step1" via a blue arrow. A green magnifying glass icon and a green plus sign icon are associated with this feedback loop, suggesting refinement or augmentation.
5. **Step 2 with Sub-KG:** After "KG-RAR of Step1," the process moves to "Step2." Similar to Step 1, "Step2" is associated with a "Sub-KG" (white box).
6. **Intermediate Indicator:** A blue hourglass icon appears between "Step2" and "Answer," possibly indicating a time-dependent process or a final waiting period.
7. **Output:** Concludes with "Answer."
8. **Label:** Titled "Step-by-Step KG-RAR" in teal.
9. **Feedback Loop 2:** Another green magnifying glass and green plus sign icon are shown, connecting the "Sub-KG" associated with "Step2" to a point after "KG-RAR of Step1," implying a continuous or iterative refinement process involving the knowledge graph.
### Key Observations
* The "Chain of Thought" method appears to be the simplest, focusing solely on internal reasoning steps.
* "Traditional RAG" introduces external documents ("Docs") into the process, alongside Chain of Thought principles.
* "Step-by-Step KG-RAR" is the most complex, integrating a Knowledge Graph ("KG") and employing a recursive or iterative refinement process ("KG-RAR of Step1") with sub-knowledge graphs ("Sub-KG").
* The lightning bolt icon in the first two methods suggests a direct, perhaps less structured, computational step to reach the answer.
* The hourglass icon in the third method might imply a more deliberate or time-consuming finalization of the answer after extensive KG-based reasoning.
* The feedback loops with magnifying glass and plus icons in "Step-by-Step KG-RAR" strongly suggest an iterative refinement and augmentation mechanism, potentially for improving the accuracy or completeness of the reasoning at each step.
### Interpretation
This diagram visually contrasts three distinct methodologies for tackling problems that likely require both reasoning and information retrieval.
The **"Chain of Thought"** method represents a foundational approach where a problem is broken down into sequential steps, relying on internal thought processes to arrive at a solution. The lightning bolt icon suggests a direct, possibly rapid, generation of the answer after the steps are completed.
**"Traditional RAG"** builds upon this by incorporating external documents. This implies that the reasoning process is augmented by retrieving relevant information from a corpus of documents. The structure is similar to "Chain of Thought," suggesting that RAG is integrated into the existing step-by-step reasoning.
The **"Step-by-Step KG-RAR"** method presents a more sophisticated architecture. It not only integrates Chain of Thought principles but also leverages a Knowledge Graph (KG) and a "KG-RAR" (likely Knowledge Graph Retrieval, Augmentation, and Reasoning) component. The key innovation here appears to be the iterative refinement process. The "KG-RAR of Step1" suggests that for each step, the system not only reasons but also retrieves and reasons with information from the KG, potentially refining the current step's output. The presence of "Sub-KG" boxes associated with each step indicates that specific subsets of the KG are utilized at different stages. The feedback loops with the magnifying glass and plus icons are crucial, indicating that the system can revisit and improve its reasoning based on KG interactions, leading to a more robust and potentially accurate answer. The hourglass icon might signify that this iterative KG-based reasoning process, while powerful, could be more time-intensive than the simpler methods.
In essence, the diagram demonstrates an evolution from pure internal reasoning to document-augmented reasoning, and finally to knowledge graph-augmented, iteratively refined reasoning, suggesting a progression in complexity and likely in the depth and accuracy of problem-solving capabilities.
</details>
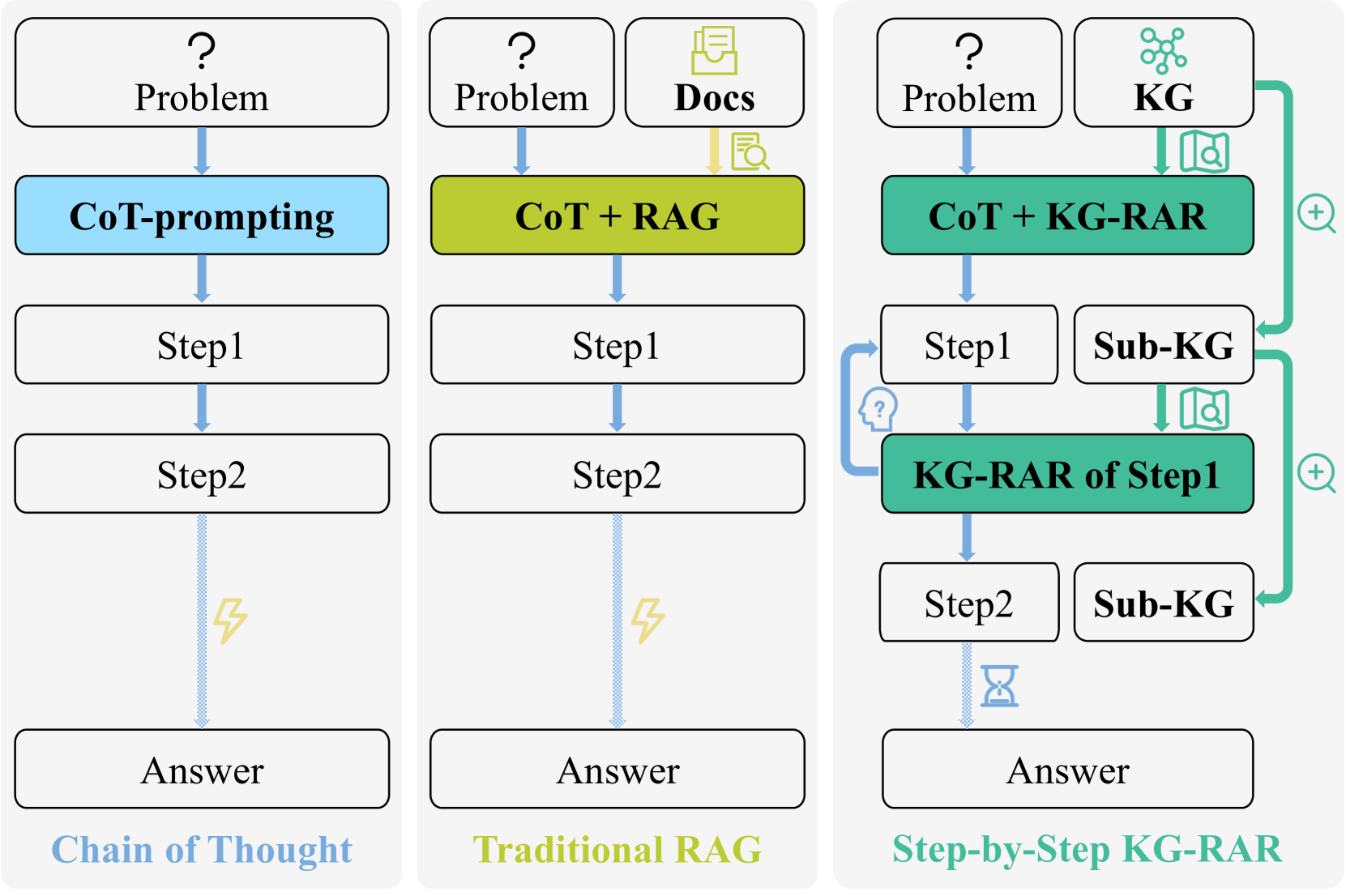
Figure 1: Illustration of the proposed step-by-step knowledge graph retrieval for o1-like reasoning, which dynamically retrieves and utilises structured sub-graphs (Sub-KGs) during reasoning. Our approach iteratively refines the reasoning process by retrieving relevant Sub-KGs at each step, enhancing accuracy, consistency, and reasoning depth for complex tasks, thereby offering a novel form of scaling test-time computation.
Despite encouraging advancements in o1-like reasoning, LLMs—particularly smaller and less powerful variants—continue to struggle with complex reasoning tasks in mathematics and science [2, 3, 32, 33]. These challenges arise from insufficient domain knowledge, susceptibility to hallucinations, and constrained reasoning depth [34, 35, 36]. Given the novelty of o1-like reasoning, effective solutions to these issues remain largely unexplored, with few studies addressing this gap in the literature [17, 18, 22]. One potential solution from the pre-o1 era is retrieval-augmented generation (RAG), which has been shown to mitigate hallucinations and factual inaccuracies by retrieving relevant information from external knowledge sources (Fig. 1, the 2 column) [37, 38, 39]. However, in the context of o1-like multi-step reasoning, traditional RAG faces two significant challenges:
- (1) Step-wise hallucinations: LLMs may hallucinate during intermediate steps —a problem not addressed by applying RAG solely to the initial prompt [40, 41];
- (2) Missing structured relationships: Traditional RAG may retrieve information that lacks the structured relationships necessary for complex reasoning tasks, leading to inadequate augmentation that fails to capture the depth required for accurate reasoning [39, 42].
In this paper, we strive to address both challenges by introducing a novel graph-augmented multi-step reasoning scheme to enhance LLMs’ o1-like reasoning capability, as depicted in Fig. 1. Our idea is motivated by the recent success of knowledge graphs (KGs) in knowledge-based question answering and fact-checking [43, 44, 45, 46, 47, 48, 49]. Recent advances have demonstrated the effectiveness of KGs in augmenting prompts with retrieved knowledge or enabling LLMs to query KGs for factual information [50, 51]. However, little attention has been given to improving step-by-step reasoning for complex tasks with KGs [52, 53], such as mathematical reasoning, which requires iterative logical inference rather than simple knowledge retrieval.
To fill this gap, the objective of the proposed graph-augmented reasoning paradigm is to integrate structured KG retrieval into the reasoning process in a step-by-step manner, providing contextually relevant information at each reasoning step to refine reasoning paths and mitigate step-wise inaccuracies and hallucinations, thereby addressing both aforementioned challenges simultaneously. This approach operates without additional training, making it particularly well-suited for small-scale LLMs in resource-constrained environments. Moreover, it extends test-time compute by incorporating external knowledge into the reasoning context, transitioning from direct CoT to step-wise guided retrieval and reasoning.
Nevertheless, implementing this graph-augmented reasoning paradigm is accompanied with several key issues: (1) Frozen LLMs struggle to query KGs effectively [50], necessitating a dynamic integration strategy for iterative incorporation of graph-based knowledge; (2) Existing KGs primarily encode static facts rather than the procedural knowledge required for multi-step reasoning [54, 55], highlighting the need for process-oriented KGs; (3) Reward models, which are essential for validating reasoning steps [30, 29], often require costly fine-tuning and suffer from poor generalization [56], underscoring the need for a universal, training-free scoring mechanism tailored to KG.
To address these issues, we propose KG-RAR, a step-by-step knowledge graph based retrieval-augmented reasoning framework that retrieves, refines, and reasons using structured knowledge graphs in a step-wise manner. Specifically, to enable effective KG querying, we design a hierarchical retrieval strategy in which questions and reasoning steps are progressively matched to relevant subgraphs, dynamically narrowing the search space. Also, we present a process-oriented math knowledge graph (MKG) construction method that encodes step-by-step procedural knowledge, ensuring that LLMs retrieve and apply structured reasoning sequences rather than static facts. Furthermore, we introduce the post-retrieval processing and reward model (PRP-RM)—a training-free scoring mechanism that refines retrieved knowledge before reasoning and evaluates step correctness in real time. By integrating structured retrieval with test-time computation, our approach mitigates reasoning inconsistencies, reduces hallucinations, and enhances stepwise verification—all without additional training.
In sum, our contribution is therefore the first attempt that dynamically integrates step-by-step KG retrieval into an o1-like multi-step reasoning process. This is achieved through our proposed hierarchical retrieval, process-oriented graph construction method, and PRP-RM—a training-free scoring mechanism that ensures retrieval relevance and step correctness. Experiments on Math500 and GSM8K validate the effectiveness of our approach across six smaller models from the Llama3 and Qwen2.5 series. The best-performing model, Llama-3B on Math500, achieves a 20.73% relative improvement over CoT prompting, followed by Llama-8B on Math500 with a 15.22% relative gain and Llama-8B on GSM8K with an 8.68% improvement.
## 2 Related Work
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Problem-Solving Flowchart for Remainder Calculation
### Overview
This diagram illustrates a problem-solving process for a mathematical question: "A factory produces items in batches of 35. If today is the 1234th batch, what is the remainder?" The diagram is structured into two main vertical sections: a detailed problem exploration on the left and a step-by-step solution on the right. The left side uses a mind-map-like structure with "Retrieving" and "Refining" stages, exploring various mathematical concepts and sub-questions. The right side presents a more linear "CoT" (Chain of Thought) approach, breaking down the solution into retrieval and reasoning steps.
### Components/Axes
The diagram is composed of interconnected text boxes of various colors, representing different stages and concepts in the problem-solving process. There are no traditional axes or legends as it is not a chart. The colors of the boxes appear to denote different categories of information:
* **Yellow:** High-level mathematical concepts or initial problem framing (e.g., Congruence, Modular Arithmetic, Number Theory).
* **Light Blue:** Questions or prompts for further investigation within a specific mathematical domain (e.g., "What is the remainder when...", "modular arithmetic: Is...", "division algorithm: Is...").
* **Green:** Actions, properties, or intermediate results within the problem-solving process (e.g., "observation of last digit property", "performing division to find the quotient and remainder", "Retrieval: The question can be solved using modular arithmetic...").
* **Orange:** A condition or outcome (e.g., "the solution does not satisfy the congruence condition").
* **White/Gray Background:** Overall structure and section titles (e.g., "Question:", "CoT:", "Refining", "Retrieval:", "Reasoning").
Arrows indicate the flow of thought and dependencies between different boxes.
### Detailed Analysis or Content Details
**Left Side (Problem Exploration):**
* **Question:** "A factory produces items in batches of 35. If today is the 1234th batch, what is the remainder?"
* **Initial Retrieval/Concepts:**
* Congruence
* Modular Arithmetic
* Number Theory
* **Sub-questions/Explorations:**
* "Suppose that a 30-digit integer $N$ is composed of thirteen $7$s and seventeen $3$s. What is the remainder when $N$ is divided by $36$?" (This appears to be a related but distinct problem explored).
* "What is the remainder when 1,493,824 is divided by 4?" (Connected to Congruence).
* "What is the remainder when the product $1734 \times 5389 \times 80607$ is divided by 10?" (Connected to Number Theory and leads to further exploration).
* **Further Exploration from Product Remainder:**
* "observation of last digit property"
* "application of last digit property"
* "last digit property: Is ..."
* "multiplication of relevant units digits"
* "modular arithmetic: Is ..."
* **Second "Retrieving" Block:**
* "checking if the solution satisfies the congruence condition"
* "division algorithm: Is ..."
* "performing division to find the quotient and remainder"
* "expressing the number as a sum of powers of the base using the quotient and remainder"
* "quotient: Is ..."
* "finding the next multiple of the modulus"
* "zero remainder: Is ..."
* "remainder: Is ..."
* "the solution does not satisfy the congruence condition" (Orange box, indicating a potential negative outcome).
**Right Side (Step-by-Step Solution):**
* **CoT:** "Let's think step by step..."
* **Refining 1:**
* **Retrieval:** "The question can be solved using modular arithmetic..."
* **Reasoning 1:**
* **Step 1:** "Divide 1234 by 35: $1234 \div 35 = 35.2571$" (Note: This step calculates the decimal quotient, not the integer division for remainder).
* **Refining 2:**
* **Retrieval:** "The remainder is what remains after subtracting the largest multiple of 35 that fits into 1234..."
* **Reasoning 2:**
* **Step 2:** "Subtract this product from 1234 to find the remainder: $1234 - 35 \times 35 = 9$"
### Key Observations
* The diagram presents two distinct approaches to problem-solving: a broad exploration of related mathematical concepts on the left, and a focused, linear solution on the right.
* The left side explores several mathematical concepts like congruence, modular arithmetic, number theory, and properties of last digits, suggesting a deeper dive into the underlying principles before arriving at a solution.
* The right side directly addresses the original question with a clear "Chain of Thought" (CoT) approach, breaking it into retrieval and reasoning steps.
* Step 1 on the right side calculates a decimal quotient, which is not the standard way to find a remainder. This suggests it's an intermediate thought process rather than the final calculation for the remainder.
* Step 2 on the right side correctly calculates the remainder by finding the largest multiple of 35 less than or equal to 1234 ($35 \times 35 = 1225$) and subtracting it from 1234 ($1234 - 1225 = 9$).
### Interpretation
This diagram demonstrates a structured approach to solving a mathematical problem, particularly one involving remainders. The left side illustrates a more exploratory phase, where a problem solver might brainstorm related concepts and sub-problems to gain a deeper understanding or to identify potential solution pathways. This could be useful for complex problems or for educational purposes to show the breadth of relevant mathematical fields.
The right side, however, presents a more direct and efficient problem-solving strategy. It highlights the importance of identifying the correct mathematical tool (modular arithmetic) and then applying a clear reasoning process. The inclusion of "Refining" steps suggests an iterative process of understanding what information is needed and how to use it.
The calculation in Step 1 ($1234 \div 35 = 35.2571$) is a common initial step when thinking about division, but it's the subsequent reasoning in Step 2 that correctly isolates the remainder. This implies that the solver understands that the remainder is the difference between the dividend and the product of the integer quotient and the divisor. The calculation $35 \times 35 = 1225$ is the largest multiple of 35 that does not exceed 1234, and $1234 - 1225 = 9$ is the remainder.
The diagram effectively contrasts a broad, conceptual exploration with a focused, procedural solution, showcasing different facets of mathematical problem-solving. The question itself is a straightforward application of the modulo operation. The diagram suggests that while complex mathematical concepts might be relevant, the core of the problem can be solved with basic division and subtraction principles. The final answer to the question "A factory produces items in batches of 35. If today is the 1234th batch, what is the remainder?" is 9.
</details>
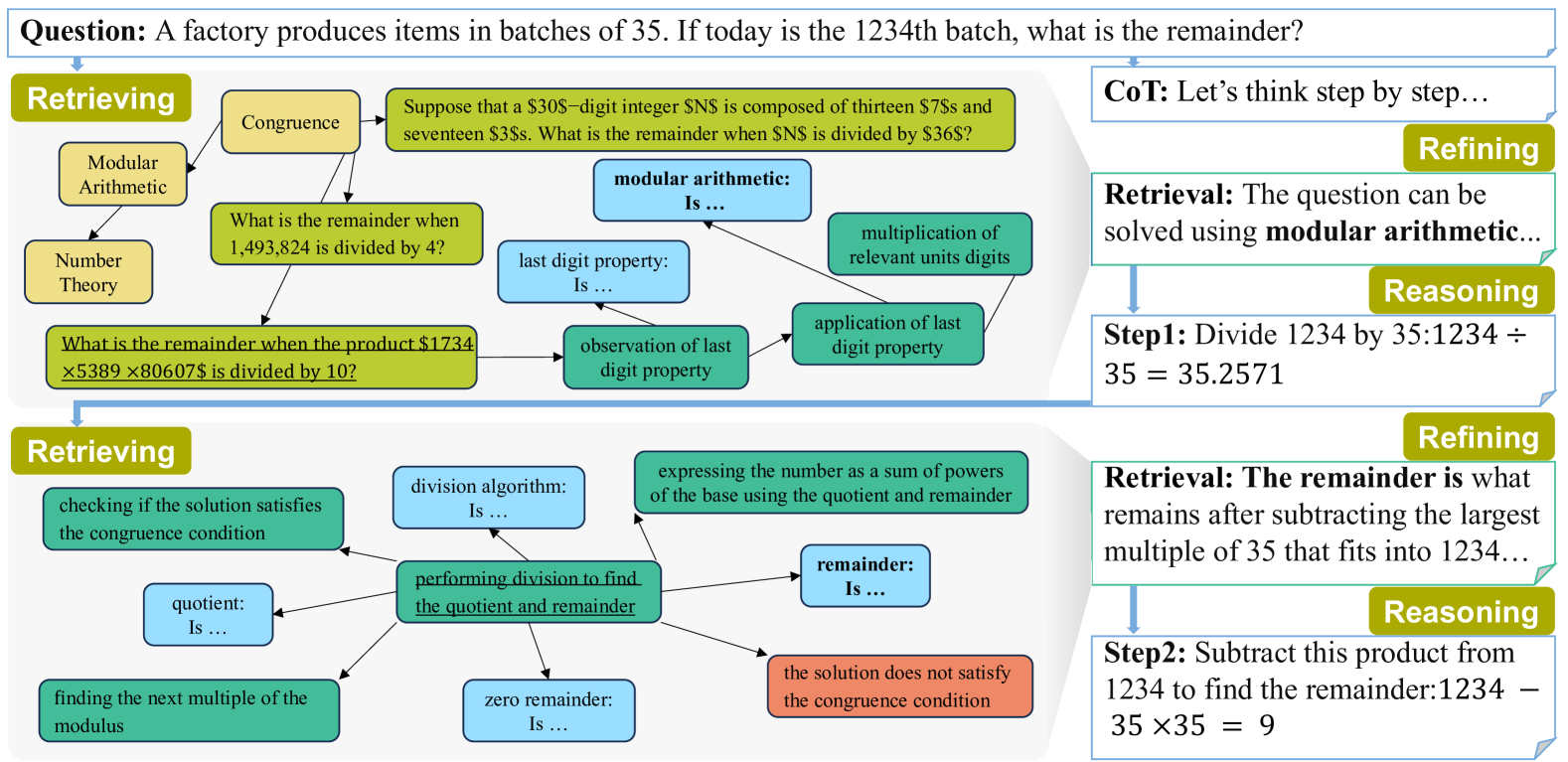
Figure 2: Example of Step-by-Step KG-RAR’s iterative process: 1) Retrieving: For a given question or intermediate reasoning step, the KG is retrieved to find the most similar problem or procedure (underlined in the figure) and extract its subgraph as the raw retrieval. 2) Refining: A frozen LLM processes the raw retrieval to generate a refined and targeted context for reasoning. 3) Reasoning: Using the refined retrieval, another LLM reflects on previous steps and generates next intermediate reasoning steps. This iterative workflow refines and guides the reasoning path to problem-solving.
### 2.1 LLM Reasoning
Large Language Models (LLMs) have advanced in structured reasoning through techniques like Chain-of-Thought (CoT) [4], Self-Consistency [5], and Tree-of-Thought [10], improving inference by generating intermediate steps rather than relying on greedy decoding [6, 7, 8, 57, 58, 9]. Recently, GPT-o1-like reasoning has emerged as a paradigm shift [17, 18, 25, 22], leveraging Test-Time Compute strategies such as Best-of-N [29], Beam Search [5], and Monte Carlo Tree Search [23], often integrated with reward models to refine reasoning paths dynamically [30, 31, 29, 59, 60, 61]. Reasoning models like DeepSeek-R1 exemplify this trend by iteratively searching, verifying, and refining solutions, significantly enhancing inference accuracy and robustness [27, 28]. However, these methods remain computationally expensive and challenging for small-scale LLMs, which struggle with hallucinations and inconsistencies due to limited reasoning capacity and lack of domain knowledge [32, 34, 3].
### 2.2 Knowledge Graphs Enhanced LLM Reasoning
Knowledge Graphs (KGs) are structured repositories of interconnected entities and relationships, offering efficient graph-based knowledge representation and retrieval [62, 63, 64, 65, 54]. Prior work integrating KGs with LLMs has primarily focused on knowledge-based reasoning tasks such as knowledge-based question answering [43, 44, 66, 67], fact-checking [45, 46, 68], and entity-centric reasoning [69, 47, 70, 48, 49]. However, in these tasks, ”reasoning” is predominantly limited to identifying and retrieving static knowledge rather than performing iterative, multi-step logical computations [71, 72, 73]. In contrast, our work is to integrate KGs with LLMs for o1-like reasoning in domains such as mathematics, where solving problems demands dynamic, step-by-step inference rather than static knowledge retrieval.
### 2.3 Reward Models
Reward models are essential across various domains such as computer vision [74, 75]. Notably, they play a crucial role in aligning LLM outputs with human preferences by evaluating accuracy, relevance, and logical consistency [76, 77, 78]. Fine-tuned reward models, including Outcome Reward Models (ORMs) [30] and Process Reward Models (PRMs) [31, 29, 60], improve validation accuracy but come at a high training cost and often lack generalization across diverse tasks [56]. Generative reward models [61] further enhance performance by integrating CoT reasoning into reward assessments, leveraging Test-Time Compute to refine evaluation. However, the reliance on fine-tuning makes these models resource-intensive and limits adaptability [56]. This underscores the need for universal, training-free scoring mechanisms that maintain robust performance while ensuring computational efficiency across various reasoning domains.
## 3 Pre-analysis
### 3.1 Motivation and Problem Definition
Motivation. LLMs have demonstrated remarkable capabilities across various domains [79, 4, 80, 81, 82], yet their proficiency in complex reasoning tasks remains limited [3, 83, 84]. Challenges such as hallucinations [34, 85], inaccuracies, and difficulties in handling complex, multi-step reasoning due to insufficient reasoning depth are particularly evident in smaller models or resource-constrained environments [86, 87, 88]. Moreover, traditional reward models, including ORMs [30] and PRMs [31, 29], require extensive fine-tuning, incurring significant computational costs for dataset collection, GPU usage, and prolonged training time [89, 90, 91]. Despite these efforts, fine-tuned reward models often suffer from poor generalization, restricting their effectiveness across diverse reasoning tasks [56].
To simultaneously overcome these challenges, this paper introduces a novel paradigm tailored for o1-like multi-step reasoning:
Remark 3.1 (Graph-Augmented Multi-Step Reasoning). The goal of graph-augmented reasoning is to enhance the step-by-step reasoning ability of frozen LLMs by integrating external knowledge graphs (KGs), eliminating the need for additional fine-tuning.
The proposed graph-augmented scheme aims to offer the following unique advantages:
- Improving Multi-Step Reasoning: Enhances reasoning capabilities, particularly for small-scale LLMs in resource-constrained environments;
- Scaling Test-Time Compute: Introduces a novel dimension of scaling test-time compute through dynamic integration of external knowledge;
- Transferability Across Reasoning Tasks: By leveraging domain-specific KGs, the framework can be easily adapted to various reasoning tasks, enabling transferability across different domains.
### 3.2 Challenge Analysis
However, implementing the proposed graph-augmented reasoning paradigm presents several critical challenges:
- Effective Integration: How can KGs be efficiently integrated with LLMs to support step-by-step reasoning without requiring model modifications? Frozen LLMs cannot directly query KGs effectively [50]. Additionally, since LLMs may suffer from hallucinations and inaccuracies during intermediate reasoning steps [34, 85, 41], it is crucial to dynamically integrate KGs at each step rather than relying solely on static knowledge retrieved at the initial stage;
- Knowledge Graph Construction: How can we design and construct process-oriented KGs tailored for LLM-driven multi-step reasoning? Existing KGs predominantly store static knowledge rather than the procedural and logical information required for reasoning [54, 55, 92]. A well-structured KG that represents reasoning steps, dependencies, and logical flows is necessary to support iterative reasoning;
- Universal Scoring Mechanism: How can we develop a training-free reward mechanism capable of universally evaluating reasoning paths across diverse tasks without domain-specific fine-tuning? Current approaches depend on fine-tuned reward models, which are computationally expensive and lack adaptability [56]. A universal, training-free scoring mechanism leveraging frozen LLMs is essential for scalable and efficient reasoning evaluation.
To address these challenges and unlock the full potential of graph-augmented reasoning, we propose a Step-by-Step Knowledge Graph based Retrieval-Augmented Reasoning (KG-RAR) framework, accompanied by a dedicated Post-Retrieval Processing and Reward Model (PRP-RM), which will be elaborated in the following section.
## 4 Proposed Approach
### 4.1 Overview
Our objective is to integrate KGs for o1-like reasoning with frozen, small-scale LLMs in a training-free and universal manner. This is achieved by integrating a step-by-step knowledge graph based retrieval-augmented reasoning (KG-RAR) module within a structured, iterative reasoning framework. As shown in Figure 2, the iterative process comprises three core phases: retrieving, refining, and reasoning.
### 4.2 Process-Oriented Math Knowledge Graph
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Math Knowledge Graph Representation
### Overview
This diagram illustrates a conceptual framework for representing mathematical knowledge, likely within the context of a Large Language Model (LLM) or a similar AI system. It depicts a flow from "Datasets" and "LLM" inputs into a structured "Math Knowledge Graph." The graph is composed of interconnected nodes representing different aspects of mathematical concepts, procedures, and outcomes.
### Components/Axes
The diagram is organized into three main vertical columns: "Datasets," "LLM," and "Math Knowledge Graph."
**Column 1: Datasets**
This column lists potential inputs or stages:
* **Problem**: Represented by text.
* **Step 1**: Accompanied by a "thumbs up" emoji (indicating success or a positive state).
* **Step 2**: Accompanied by a "thumbs up" emoji (indicating success or a positive state) and a snowflake icon.
* **Step 3**: Accompanied by a "sad face" emoji (indicating an error or a negative state).
**Column 2: LLM**
This column contains symbolic representations that likely indicate the LLM's processing or state at different stages:
* A llama icon is positioned next to "Problem."
* A snowflake icon is positioned next to "Step 2."
* Blue arrows connect the "Datasets" column to this "LLM" column and then to the "Math Knowledge Graph" column, indicating a flow of information or processing.
**Column 3: Math Knowledge Graph**
This column contains a series of interconnected rectangular nodes, color-coded and labeled, representing the structure of mathematical knowledge:
* **Yellow Nodes**:
* `Branch`: Positioned at the top-left.
* `SubField`: Positioned at the top-right, with an arrow pointing towards `Branch`.
* **Green Nodes**:
* `Problem`: Positioned below `Branch`, with an arrow pointing towards `Problem Type`.
* `Procedure1`: Positioned below `Problem`, with a downward arrow from `Problem`.
* `Procedure2`: Positioned below `Procedure1`, with a downward arrow from `Procedure1`.
* **Orange Node**:
* `Error3`: Positioned below `Procedure2`, with a downward arrow from `Procedure2`.
* **Blue Nodes**:
* `Knowledge1`: Positioned to the right of `Procedure1`, with an arrow pointing from `Procedure1`.
* `Knowledge2`: Positioned to the right of `Procedure2`, with an arrow pointing from `Procedure2`.
* `Knowledge3`: Positioned to the right of `Error3`, with an arrow pointing from `Error3`.
**Arrows:**
* Blue arrows indicate the primary flow of information from "Datasets" through "LLM" into the "Math Knowledge Graph."
* Black arrows within the "Math Knowledge Graph" indicate relationships and dependencies between nodes. Specifically:
* An arrow points from `SubField` to `Branch`.
* An arrow points from `Problem` to `Problem Type`.
* Downward arrows connect `Problem` to `Procedure1`, `Procedure1` to `Procedure2`, and `Procedure2` to `Error3`.
* Arrows point from `Procedure1` to `Knowledge1`, `Procedure2` to `Knowledge2`, and `Error3` to `Knowledge3`.
### Detailed Analysis or Content Details
The diagram outlines a hierarchical and procedural representation of mathematical knowledge.
* **Top Level**: `Branch` and `SubField` are related, with `SubField` potentially being a component or precursor to `Branch`.
* **Problem Representation**: A `Problem` is linked to its `Problem Type`. This suggests that problems are categorized.
* **Procedural Flow**: The diagram shows a sequence of procedures (`Procedure1`, `Procedure2`) that are likely executed to solve a problem.
* **Error Handling**: `Error3` is presented as a distinct outcome, possibly representing a failure or a specific type of error encountered during a procedure.
* **Knowledge Association**: Each procedure and the error state are associated with specific `Knowledge` components (`Knowledge1`, `Knowledge2`, `Knowledge3`). This implies that solving a procedure or encountering an error leads to or requires specific knowledge.
The "Datasets" column, with its emojis and icons, suggests a progression through different states or types of data being processed.
* "Problem" is the initial input, processed by the LLM (llama icon).
* "Step 1" (thumbs up) leads to a procedure and knowledge.
* "Step 2" (thumbs up, snowflake) leads to another procedure and knowledge. The snowflake might indicate a specific condition or type of problem/procedure.
* "Step 3" (sad face) leads to an error and associated knowledge.
### Key Observations
* The diagram emphasizes a structured approach to mathematical knowledge, moving from abstract concepts (`Branch`, `SubField`) to concrete problem-solving steps (`Procedure`) and outcomes (`Knowledge`, `Error`).
* The use of emojis in the "Datasets" column provides a qualitative indication of the success or failure of processing steps.
* The snowflake icon associated with "Step 2" and the LLM column suggests a potential specialization or condition related to that step.
* The explicit inclusion of "Error3" indicates that the system accounts for potential failures and links them to specific knowledge.
### Interpretation
This diagram likely represents a model for how an LLM might process and understand mathematical problems. The "Datasets" column could represent user input or intermediate states in a problem-solving process. The "LLM" column signifies the AI's engagement with these inputs. The "Math Knowledge Graph" is the core representation, where mathematical entities are organized and related.
The flow suggests that a problem is first understood in terms of its `Branch` and `SubField`, then its `Problem Type`. Subsequently, a series of `Procedures` are applied, each associated with specific `Knowledge`. The inclusion of `Error3` indicates that the model is designed to handle and potentially learn from errors. The emojis in the "Datasets" column could be interpreted as feedback mechanisms or indicators of the quality of the input or the success of a particular step. The snowflake icon might represent a specific type of mathematical problem (e.g., related to calculus, physics, or a specific algorithm) that the LLM is processing.
Overall, the diagram illustrates a structured, knowledge-driven approach to mathematical problem-solving, where different components of mathematical understanding are interconnected and processed sequentially. It suggests a system that can not only solve problems but also potentially diagnose errors and associate knowledge with different stages of the process.
</details>
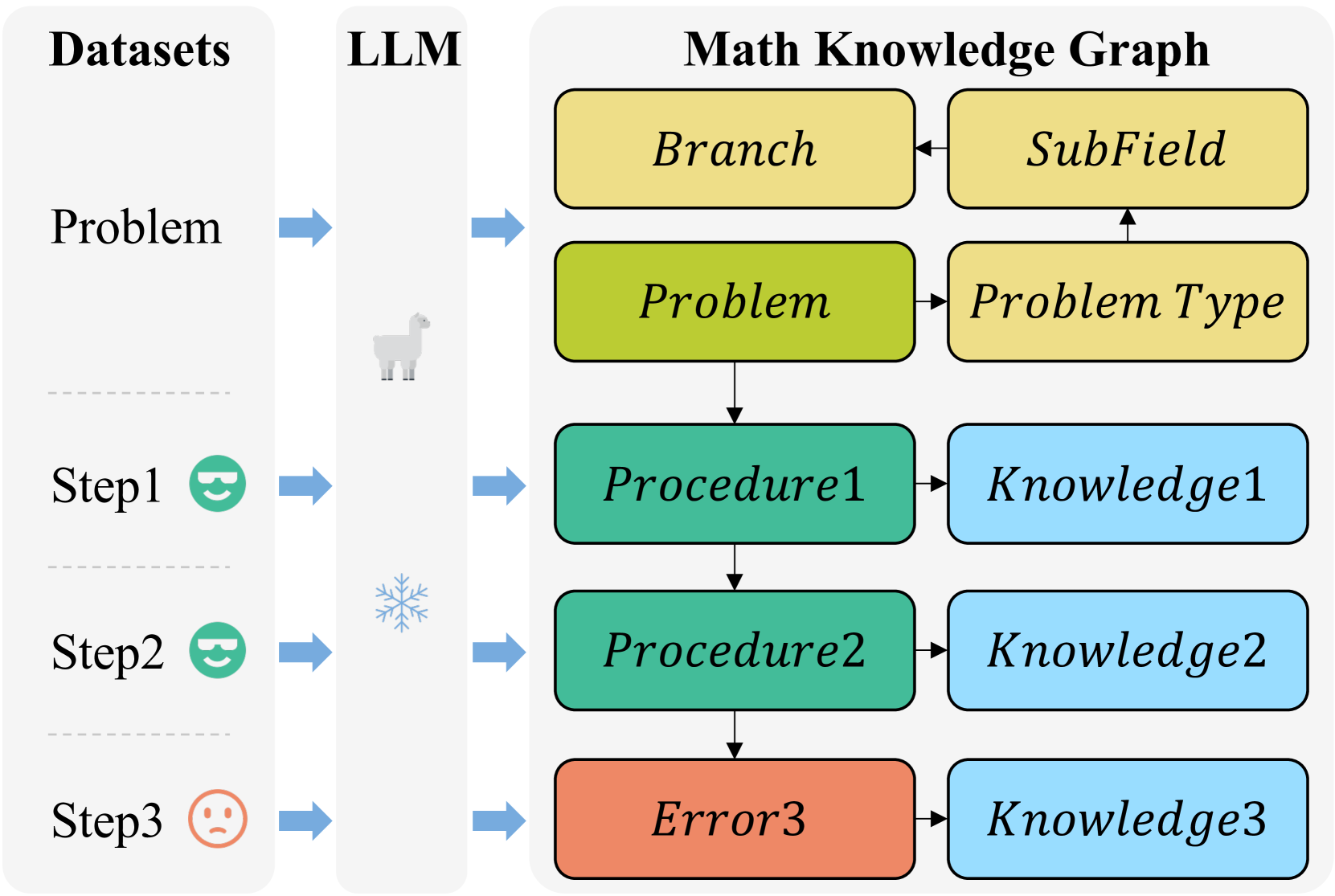
Figure 3: Pipeline for constructing the process-oriented math knowledge graph from process supervision datasets.
To support o1-like multi-step reasoning, we construct a Mathematical Knowledge Graph tailored for multi-step logical inference. Public process supervision datasets, such as PRM800K [29], provide structured problem-solving steps annotated with artificial ratings. Each sample will be decomposed into the following structured components: branch, subfield, problem type, problem, procedures, errors, and related knowledge.
The Knowledge Graph is formally defined as: $G=(V,E)$ , where $V$ represents nodes—including problems, procedures, errors, and mathematical knowledge—and $E$ represents edges encoding their relationships (e.g., ”derived from,” ”related to”).
As shown in Figure 3, for a given problem $P$ with solutions $S_1,S_2,\dots,S_n$ and human ratings, the structured representation is:
$$
P↦\{B_p,F_p,T_p,r\},
$$
| | $\displaystyle S_i^good$ | $\displaystyle↦\{S_i,K_i,r_i^good\}, S_i^ bad↦\{E_i,K_i,r_i^bad\},$ | |
| --- | --- | --- | --- |
where $B_p,F_p,T_p$ represent the branch, subfield, and type of $P$ , respectively. The symbols $S_i$ and $E_i$ denote the procedures derived from correct steps and the errors from incorrect steps, respectively. Additionally, $K_i$ contains relevant mathematical knowledge. The relationships between problems, steps, and knowledge are encoded through $r,r_i^good,r_i^bad$ , which capture the edge relationships linking these elements.
To ensure a balance between computational efficiency and quality of KG, we employ a Llama-3.1-8B-Instruct model to process about 10,000 unduplicated samples from PRM800K. The LLM is prompted to output structured JSON data, which is subsequently transformed into a Neo4j-based MKG. This process yields a graph with approximately $80,000$ nodes and $200,000$ edges, optimized for efficient retrieval.
### 4.3 Step-by-Step Knowledge Graph Retrieval
KG-RAR for Problem Retrieval. For a given test problem $Q$ , the most relevant problem $P^*∈ V_p$ and its subgraph are retrieved to assist reasoning. The retrieval pipeline comprises the following steps:
1. Initial Filtering: Classify $Q$ by $B_q,F_q,T_q$ (branch, subfield, and problem type). The candidate set $V_Q⊂ V_p$ is filtered hierarchically, starting from $T_q$ , expanding to $F_q$ , and then to $B_q$ if no exact match is found.
2. Semantic Similarity Scoring:
$$
P^*=\arg\max_P∈ V_{Q}\cos(e_Q,e_P),
$$
where:
$$
\cos(e_Q,e_P)=\frac{⟨e_Q,e_P
⟩}{\|e_Q\|\|e_P\|}
$$
and $e_Q,e_P∈ℝ^d$ are embeddings of $Q$ and $P$ , respectively.
3. Context Retrieval: Perform Depth-First Search (DFS) on $G$ to retrieve procedures ( $S_p$ ), errors ( $E_p$ ), and knowledge ( $K_p$ ) connected to $P^*$ .
Input: Test problem $Q$ and MKG $G$
Output: Most relevant problem $P^*$ and its context $(S_p,E_p,K_p)$
1 Filter $G$ using $B_q$ , $F_q$ , and $T_q$ to obtain $V_Q$ ;
2 foreach $P∈ V_Q$ do
3 Compute $Sim_semantic(Q,P)$ ;
4
5 $P^*←\arg\max_P∈ V_{Q}Sim_semantic(Q,P)$ ;
6 Retrieve $S_p$ , $E_p$ , and $K_p$ from $P^*$ using DFS;
7 return $P^*$ , $S_p$ , $E_p$ , and $K_p$ ;
Algorithm 1 KG-RAR for Problem Retrieval
KG-RAR for Step Retrieval. Given an intermediate reasoning step $S$ , the most relevant step $S^*∈ G$ and its subgraph is retrieved dynamically:
1. Contextual Filtering: Restrict the search space $V_S$ to the subgraph induced by previously retrieved top-k similar problems $\{P_1,P_2,\dots,P_k\}∈ V_Q$ .
2. Step Similarity Scoring:
$$
S^*=\arg\max_S_{i∈ V_S}\cos(e_S,e_S_{i}).
$$
3. Context Retrieval: Perform Breadth-First Search (BFS) on $G$ to extract subgraph of $S^*$ , including potential next steps, related knowledge, and error patterns.
### 4.4 Post-Retrieval Processing and Reward Model
Step Verification and End-of-Reasoning Detection. Inspired by previous works [93, 56, 94, 61], we use a frozen LLM to evaluate both step correctness and whether reasoning should terminate. The model is queried with an instruction, producing a binary classification decision:
$$
\textit{Is this step correct (Yes/No)? }\begin{cases}Yes\xrightarrow[
Probability]{Token}p(Yes)\\
No\xrightarrow[Probability]{Token}p(No)\\
Other Tokens.\end{cases}
$$
The corresponding confidence score for step verification or reasoning termination is computed as:
$$
Score(S,I)=\frac{\exp(p(Yes|S,I))}{\exp(p(Yes|S,I))+\exp(p(\text
{No}|S,I))}.
$$
For step correctness, the instruction $I$ is ”Is this step correct (Yes/No)?”, while for reasoning termination, the instruction $I_E$ is ”Has a final answer been reached (Yes/No)?”.
Post-Retrieval Processing. Post-retrieval processing is a crucial component of the retrieval-augmented generation (RAG) framework, ensuring that retrieved information is improved to maximize relevance while minimizing noise [37, 95, 96].
For a problem $P$ or a reasoning step $S$ :
$$
R^\prime=_refine(P+R or
S+R),
$$
where $R$ is the raw retrieved context, and $R^\prime$ represents its rewritten, targeted form.
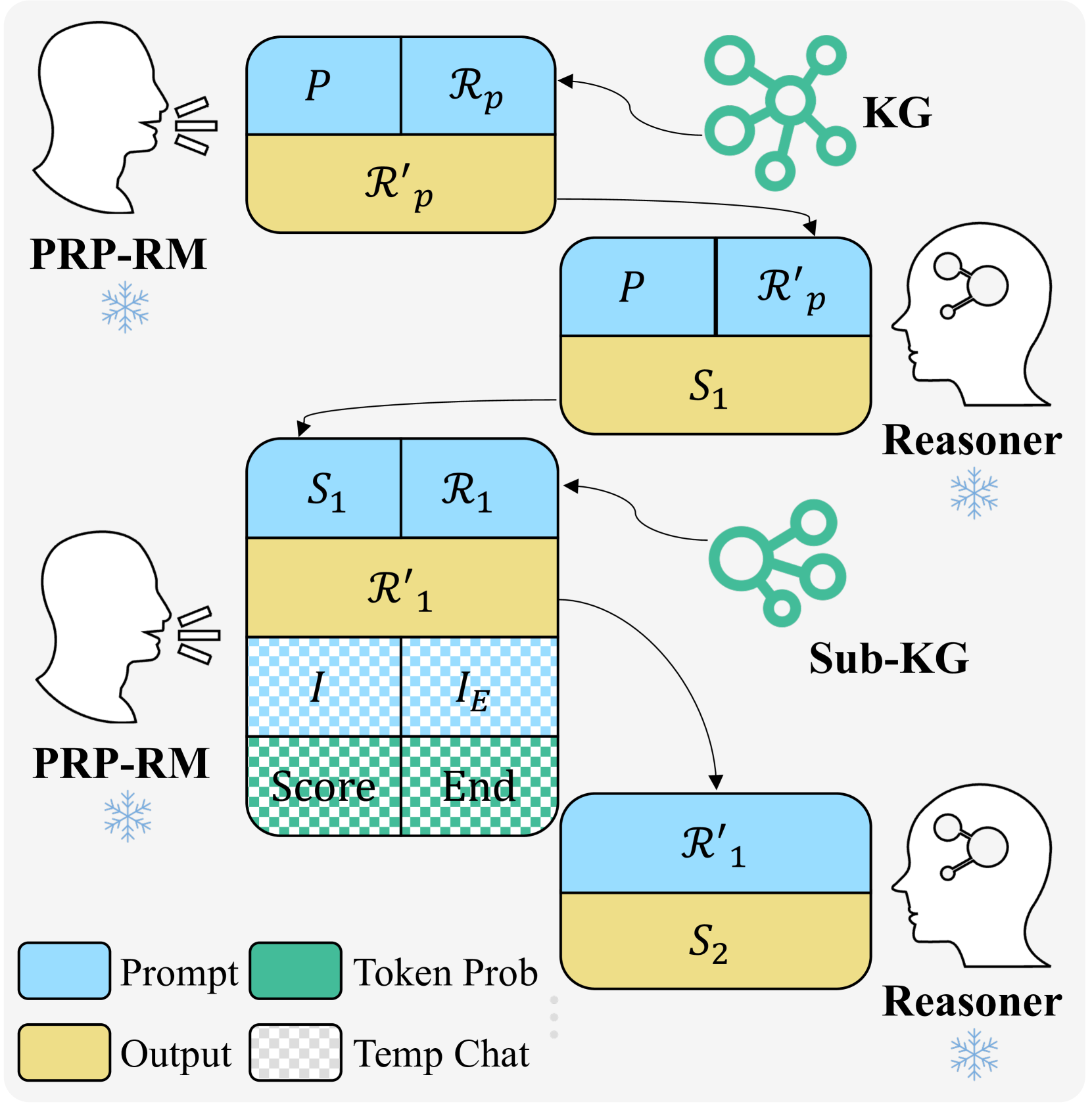
Iterative Refinement and Verification. Inspired by generative reward models [61, 97], we integrate retrieval refinement as a form of CoT reasoning before scoring each step. To ensure consistency in multi-step reasoning, we employ an iterative retrieval refinement and scoring mechanism, as illustrated in Figure 4.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: Process Flow of a Reasoning System
### Overview
This diagram illustrates a multi-stage reasoning process, likely within a natural language processing or artificial intelligence context. It depicts interactions between a "PRP-RM" (likely a prompt-response module or similar entity) and a "Reasoner" component, utilizing knowledge graphs (KG and Sub-KG) and various internal states represented by labeled blocks. The process appears iterative, with outputs from one stage feeding into the next.
### Components/Axes
The diagram does not contain traditional axes or charts. Instead, it features several distinct components:
* **PRP-RM (Prompt-Response Module):** Represented by a silhouette of a head with speech bubbles, indicating input or generation of text. Two instances of PRP-RM are shown, each associated with a snowflake icon, suggesting a potential "cold start" or initial state.
* **Reasoner:** Represented by a silhouette of a head with interconnected circles inside, symbolizing thought or reasoning. Two instances of Reasoner are shown, also associated with snowflake icons.
* **Knowledge Graphs (KG and Sub-KG):** Depicted as green, interconnected node-like structures. "KG" is positioned above and to the right of the first stage, while "Sub-KG" is positioned between the first and second stages.
* **Data Blocks:** Rectangular blocks with rounded corners, divided into sections, representing internal states or data structures. These blocks are color-coded and labeled with letters and symbols.
* **Blue Sections:** Labeled with "P", "Rp", "S1", "R1", "R'1". According to the legend, blue represents "Prompt".
* **Yellow Sections:** Labeled with "R'p", "S1", "S2". According to the legend, yellow represents "Output".
* **Green Sections:** Labeled with "Score", "End". According to the legend, green represents "Token Prob".
* **Checkered Sections:** Labeled with "I", "IE". According to the legend, checkered represents "Temp Chat".
* **Arrows:** Indicate the flow of information or control between components.
* **Legend:** Located at the bottom-left of the image, it defines the color coding for different types of data:
* **Blue Rectangle:** Prompt
* **Yellow Rectangle:** Output
* **Green Rectangle:** Token Prob
* **Checkered Rectangle:** Temp Chat
### Detailed Analysis or Content Details
The diagram illustrates a sequential process:
**Stage 1:**
1. A **PRP-RM** is shown, associated with a block divided into two sections:
* Top-left (blue): Labeled "P" (Prompt).
* Top-right (blue): Labeled "Rp" (Prompt Response).
* Bottom (yellow): Labeled "R'p" (Output).
2. An arrow originates from the "Rp" section of this block and points towards the **KG**.
3. An arrow originates from the **KG** and points to the "P" section of a subsequent block.
4. This subsequent block is associated with a **Reasoner** and is divided into:
* Top-left (blue): Labeled "P" (Prompt).
* Top-right (blue): Labeled "Rp" (Prompt Response).
* Bottom (yellow): Labeled "S1" (State 1 or similar).
**Stage 2:**
1. A second **PRP-RM** is shown, associated with a block divided into multiple sections:
* Top (blue): Labeled "S1" (State 1).
* Second row (blue): Labeled "R1" (Response 1).
* Third row (yellow): Labeled "R'1" (Output 1).
* Fourth row, left (checkered): Labeled "I" (Intermediate or Input).
* Fourth row, right (checkered): Labeled "IE" (Intermediate or Input Extended).
* Fifth row, left (green): Labeled "Score".
* Fifth row, right (green): Labeled "End".
2. An arrow originates from the "R1" section of this block and points towards the **Sub-KG**.
3. An arrow originates from the **Sub-KG** and points to the "R'1" section of a subsequent block.
4. This subsequent block is associated with a **Reasoner** and is divided into:
* Top (blue): Labeled "R'1" (Output 1).
* Bottom (yellow): Labeled "S2" (State 2 or similar).
5. A dotted line extends from this block, suggesting further stages or iterations.
### Key Observations
* The diagram depicts a cyclical or iterative process where information is processed, potentially refined, and fed back into the system.
* Knowledge graphs (KG and Sub-KG) play a role in augmenting or guiding the reasoning process.
* The "PRP-RM" component seems to be responsible for initial prompt handling and response generation, while the "Reasoner" component processes these outputs and potentially interacts with knowledge bases.
* The internal states of the blocks (e.g., P, Rp, R'p, S1, R1, R'1, I, IE, Score, End) represent different types of information or stages within the reasoning pipeline.
* The snowflake icons associated with the initial PRP-RM and Reasoner components might indicate a "cold start" scenario where no prior context or learned parameters are available, or it could represent a specific mode of operation.
### Interpretation
This diagram outlines a sophisticated reasoning architecture. The "PRP-RM" likely acts as an interface for external input (prompts) and generates initial outputs. The "Reasoner" then takes these outputs, potentially consults knowledge graphs (KG and Sub-KG) for contextual information or factual grounding, and produces further refined outputs or internal states. The iterative nature, suggested by the dotted line and the progression from S1 to S2, implies that the system can perform multi-hop reasoning or refine its understanding over several steps. The inclusion of "Score" and "End" in the final PRP-RM block suggests that the process might involve evaluating the quality of generated content or determining when a task is complete. The "Temp Chat" sections (I, IE) could represent temporary conversational states or intermediate reasoning steps that are not directly part of the final output but are crucial for the process. The use of knowledge graphs indicates a system that aims for factual accuracy and contextual relevance in its reasoning.
</details>
Figure 4: Illustration of the Post-Retrieval Processing and Reward Model (PRP-RM). Given a problem $P$ and its retrieved context $R_p$ from the Knowledge Graph (KG), PRP-RM refines it into $R^\prime_p$ . The Reasoner LLM generates step $S_1$ based on $R^\prime_p$ , followed by iterative retrieval and refinement ( $R_t→R^\prime_t$ ) for each step $S_t$ . Correctness is assessed using $I=$ ”Is this step correct?” to compute $(S_t)$ , while completion is checked via $I_E=$ ”Has a final answer been reached?” to compute $(S_t)$ . The process continues until $(S_t)$ surpasses a threshold or a predefined inference depth is reached.
Input: Current step $S$ and retrieved problems $\{P_1,…,P_k\}$
Output: Relevant step $S^*$ and its context subgraph
1 Initialize step collection $V_S←\bigcup_i=1^kSteps(P_i)$ ;
2 foreach $S_i∈ V_S$ do
3 Compute semantic similarity $Sim_semantic(S,S_i)$ ;
4
5 $S^*←\arg\max_S_{i∈ V_S}Sim_semantic(S,S_i)$ ;
6 Construct context subgraph via $BFS(S^*)$ ;
7 return $S^*$ , $subgraph(S^*)$ ;
Algorithm 2 KG-RAR for Step Retrieval
For a reasoning step $S_t$ , the iterative refinement history is:
$$
H_t=\{P+R_p,R^\prime_p,S_1+R_1,
R^\prime_1,\dots,S_t+R_t,R^\prime_t\}.
$$
The refined retrieval context is generated recursively:
$$
R^\prime_t=_refine(H_t-1,S_t+
R_t).
$$
The correctness and end-of-reasoning probabilities are:
$$
(S_t)=\frac{\exp(p(Yes|H_t,I))}{\exp(p(
Yes|H_t,I))+\exp(p(No|H_t,I))},
$$
$$
(S_t)=\frac{\exp(p(Yes|H_t,I_E))}{\exp(p(
Yes|H_t,I_E))+\exp(p(No|H_t,I_E))}.
$$
This process iterates until $(S_t)>θ$ , signaling completion.
TABLE I: Performance evaluation across different levels of the Math500 dataset using various models and methods.
| Dataset: Math500 | Level 1 (+9.09%) | Level 2 (+5.38%) | Level 3 (+8.90%) | Level 4 (+7.61%) | Level 5 (+16.43%) | Overall (+8.95%) | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Model | Method | Maj | Last | Maj | Last | Maj | Last | Maj | Last | Maj | Last | Maj | Last |
| Llama-3.1-8B (+15.22%) | CoT-prompting | 80.6 | 80.6 | 74.1 | 74.1 | 59.4 | 59.4 | 46.4 | 46.4 | 27.4 | 27.1 | 51.9 | 51.9 |
| Step-by-Step KG-RAR | 88.4 | 81.4 | 83.3 | 82.2 | 70.5 | 69.5 | 53.9 | 53.9 | 32.1 | 25.4 | 59.8 | 57.0 | |
| Llama-3.2-3B (+20.73%) | CoT-prompting | 63.6 | 65.1 | 61.9 | 61.9 | 51.1 | 51.1 | 43.2 | 43.2 | 20.4 | 20.4 | 43.9 | 44.0 |
| Step-by-Step KG-RAR | 83.7 | 79.1 | 68.9 | 68.9 | 61.0 | 52.4 | 49.2 | 47.7 | 29.9 | 28.4 | 53.0 | 50.0 | |
| Llama-3.2-1B (-4.02%) | CoT-prompting | 64.3 | 64.3 | 52.6 | 52.2 | 41.6 | 41.6 | 25.3 | 25.3 | 8.0 | 8.2 | 32.3 | 32.3 |
| Step-by-Step KG-RAR | 72.1 | 72.1 | 50.0 | 50.0 | 40.0 | 40.0 | 18.0 | 19.5 | 10.4 | 13.4 | 31.0 | 32.2 | |
| Qwen2.5-7B (+2.91%) | CoT-prompting | 95.3 | 95.3 | 88.9 | 88.9 | 86.7 | 86.3 | 77.3 | 77.1 | 50.0 | 49.8 | 75.6 | 75.4 |
| Step-by-Step KG-RAR | 95.3 | 93.0 | 90.0 | 90.0 | 87.6 | 88.6 | 79.7 | 79.7 | 54.5 | 56.7 | 77.8 | 78.4 | |
| Qwen2.5-3B (+3.13%) | CoT-prompting | 93.0 | 93.0 | 85.2 | 85.2 | 81.0 | 80.6 | 62.5 | 62.5 | 40.1 | 39.3 | 67.1 | 66.8 |
| Step-by-Step KG-RAR | 95.3 | 95.3 | 84.4 | 85.6 | 83.8 | 77.1 | 64.1 | 64.1 | 44.0 | 38.1 | 69.2 | 66.4 | |
| Qwen2.5-1.5B (-5.12%) | CoT-prompting | 88.4 | 88.4 | 78.5 | 77.4 | 71.4 | 68.9 | 49.2 | 49.5 | 34.6 | 34.3 | 58.6 | 57.9 |
| Step-by-Step KG-RAR | 97.7 | 93.0 | 78.9 | 75.6 | 66.7 | 67.6 | 48.4 | 44.5 | 24.6 | 23.1 | 55.6 | 53.4 | |
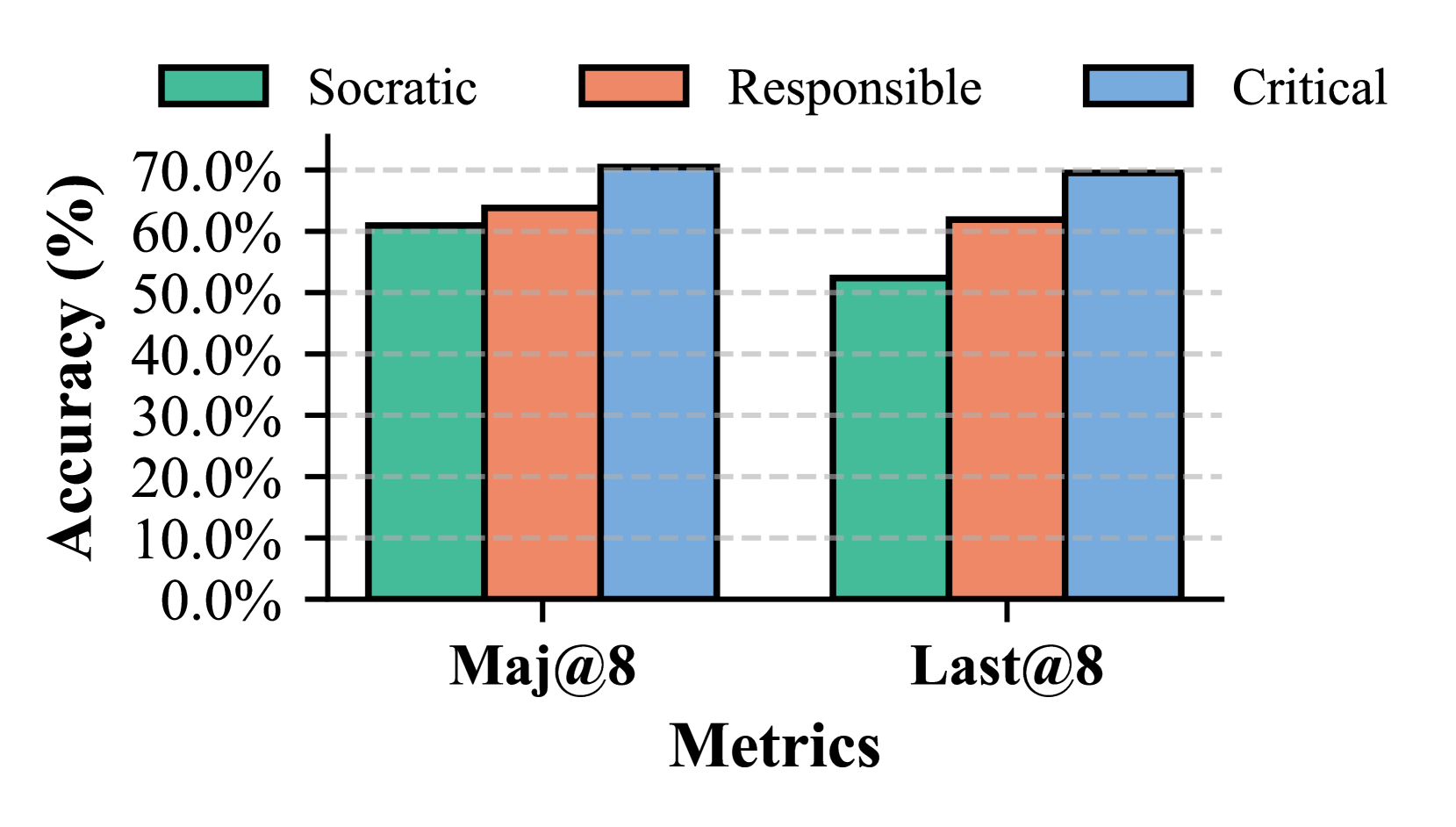
Role-Based System Prompting. Inspired by agent-based reasoning frameworks [98, 99, 100], we introduce role-based system prompting to further optimize our PRP-RM. In this approach, we define three distinct personas to enhance the reasoning process. The Responsible Teacher [101] processes retrieved knowledge into structured guidance and evaluates the correctness of each step. The Socratic Teacher [102], rather than pr oviding direct guidance, reformulates the retrieved content into heuristic questions, encouraging self-reflection. Finally, the Critical Teacher [103] acts as a critical evaluator, diagnosing reasoning errors before assigning a score. Each role focuses on different aspects of post-retrieval processing, improving robustness and interpretability.
## 5 Experiments
In this section, we evaluate the effectiveness of our proposed Step-by-Step KG-RAR and PRP-RM methods by comparing them with Chain-of-Thought (CoT) prompting [4] and finetuned reward models [30, 29]. Additionally, we perform ablation studies to examine the impact of individual components.
### 5.1 Experimental Setup
Following prior works [5, 29, 21], we evaluate on Math500 [104] and GSM8K [30], using Accuracy (%) as the primary metric. Experiments focus on instruction-tuned Llama3 [105] and Qwen2.5 [106], with Best-of-N [107, 30, 29] search ( $n=8$ for Math500, $n=4$ for GSM8K). We employ Majority Vote [5] for self-consistency and Last Vote [25] for benchmarking reward models. To evaluate PRP-RM, we compare against fine-tuned reward models: Math-Shepherd-PRM-7B [108], RLHFlow-ORM-Deepseek-8B and RLHFlow-PRM-Deepseek-8B [109]. For Step-by-Step KG-RAR, we set step depth to $8$ and padding to $4$ . The Socratic Teacher role is used in PRP-RM to minimize direct solving. Both the Reasoner LLM and PRP-RM remain consistent for fair comparison.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Difficulty Level for Different Models
### Overview
This image displays a line chart illustrating the accuracy of four different models across five difficulty levels. The chart shows a general downward trend in accuracy as the difficulty level increases for all models.
### Components/Axes
* **Title**: Implicitly, the chart title is "Accuracy vs. Difficulty Level for Different Models".
* **Y-axis**:
* **Label**: "Accuracy (%)"
* **Scale**: Ranges from 0% to 80%, with major tick marks at 0%, 20%, 40%, 60%, and 80%. Minor dashed grid lines are present at 10% intervals.
* **X-axis**:
* **Label**: "Difficulty Level"
* **Scale**: Ranges from 1 to 5, with major tick marks at 1, 2, 3, 4, and 5.
* **Legend**: Located in the top-center of the chart, it defines the four data series and their corresponding markers and colors:
* **Math-Shepherd-PRM-7B**: Teal line with circular markers.
* **RLHFlow-ORM-Deepseek-8B**: Orange line with square markers.
* **RLHFlow-PRM-Deepseek-8B**: Blue line with triangular markers.
* **PRP-RM(frozen Llama-3.2-3B)**: Red line with diamond markers.
### Detailed Analysis
The chart presents data points for each model at Difficulty Levels 1 through 5.
**1. Math-Shepherd-PRM-7B (Teal, Circle Markers)**
* **Trend**: The accuracy generally decreases as the difficulty level increases.
* **Data Points (approximate values with uncertainty +/- 2%)**:
* Difficulty Level 1: 68%
* Difficulty Level 2: 55%
* Difficulty Level 3: 50%
* Difficulty Level 4: 45%
* Difficulty Level 5: 20%
**2. RLHFlow-ORM-Deepseek-8B (Orange, Square Markers)**
* **Trend**: The accuracy generally decreases as the difficulty level increases.
* **Data Points (approximate values with uncertainty +/- 2%)**:
* Difficulty Level 1: 63%
* Difficulty Level 2: 62%
* Difficulty Level 3: 52%
* Difficulty Level 4: 41%
* Difficulty Level 5: 19%
**3. RLHFlow-PRM-Deepseek-8B (Blue, Triangle Markers)**
* **Trend**: The accuracy generally decreases as the difficulty level increases.
* **Data Points (approximate values with uncertainty +/- 2%)**:
* Difficulty Level 1: 70%
* Difficulty Level 2: 60%
* Difficulty Level 3: 50%
* Difficulty Level 4: 45%
* Difficulty Level 5: 21%
**4. PRP-RM(frozen Llama-3.2-3B) (Red, Diamond Markers)**
* **Trend**: The accuracy generally decreases as the difficulty level increases.
* **Data Points (approximate values with uncertainty +/- 2%)**:
* Difficulty Level 1: 79%
* Difficulty Level 2: 65%
* Difficulty Level 3: 54%
* Difficulty Level 4: 42%
* Difficulty Level 5: 29%
### Key Observations
* **Overall Trend**: All four models exhibit a consistent decline in accuracy as the difficulty level increases from 1 to 5.
* **Highest Accuracy at Difficulty 1**: The PRP-RM(frozen Llama-3.2-3B) model shows the highest accuracy (approximately 79%) at the easiest difficulty level (1).
* **Lowest Accuracy at Difficulty 5**: At the highest difficulty level (5), all models perform poorly, with accuracies ranging from approximately 19% to 29%.
* **Model Performance Comparison**:
* At Difficulty Level 1, PRP-RM(frozen Llama-3.2-3B) is the best performer, followed closely by RLHFlow-PRM-Deepseek-8B.
* At Difficulty Level 2, RLHFlow-ORM-Deepseek-8B shows a slight dip but remains relatively high, while Math-Shepherd-PRM-7B and RLHFlow-PRM-Deepseek-8B are similar. PRP-RM(frozen Llama-3.2-3B) is still leading.
* From Difficulty Level 3 onwards, the performance of Math-Shepherd-PRM-7B and RLHFlow-PRM-Deepseek-8B becomes very similar, often overlapping.
* RLHFlow-ORM-Deepseek-8B consistently shows slightly lower accuracy than Math-Shepherd-PRM-7B and RLHFlow-PRM-Deepseek-8B from Difficulty Level 3 onwards.
* PRP-RM(frozen Llama-3.2-3B) maintains a lead over the other models until Difficulty Level 4, after which it shows a significant drop in accuracy at Difficulty Level 5, becoming the second-best performer at that level, just above RLHFlow-ORM-Deepseek-8B.
### Interpretation
This chart demonstrates the impact of increasing difficulty on the performance of different language models. The general downward trend suggests that as tasks become more complex, the models' ability to accurately solve them diminishes.
The variation in performance across models at different difficulty levels is notable. PRP-RM(frozen Llama-3.2-3B) appears to be the most robust at lower difficulty levels, indicating a strong initial capability. However, its performance degrades significantly at higher difficulties, suggesting it might be less adaptable to complex challenges compared to some other models.
Conversely, models like Math-Shepherd-PRM-7B and RLHFlow-PRM-Deepseek-8B show a more gradual decline, indicating a potentially more consistent performance across a wider range of difficulties, although their peak performance is lower than PRP-RM. RLHFlow-ORM-Deepseek-8B consistently lags slightly behind the others, particularly at higher difficulty levels, suggesting it might be the least effective of the four models presented in this context.
The data implies that model selection for tasks involving varying difficulty levels should consider not only peak performance but also performance degradation under stress. For tasks with a high likelihood of encountering complex problems, models with a more stable performance curve (like Math-Shepherd-PRM-7B or RLHFlow-PRM-Deepseek-8B) might be preferable over those that excel at easy tasks but falter significantly at hard ones (like PRP-RM). The sharp drop in accuracy for all models at Difficulty Level 5 highlights a common limitation in current AI models when faced with extremely challenging problems.
</details>
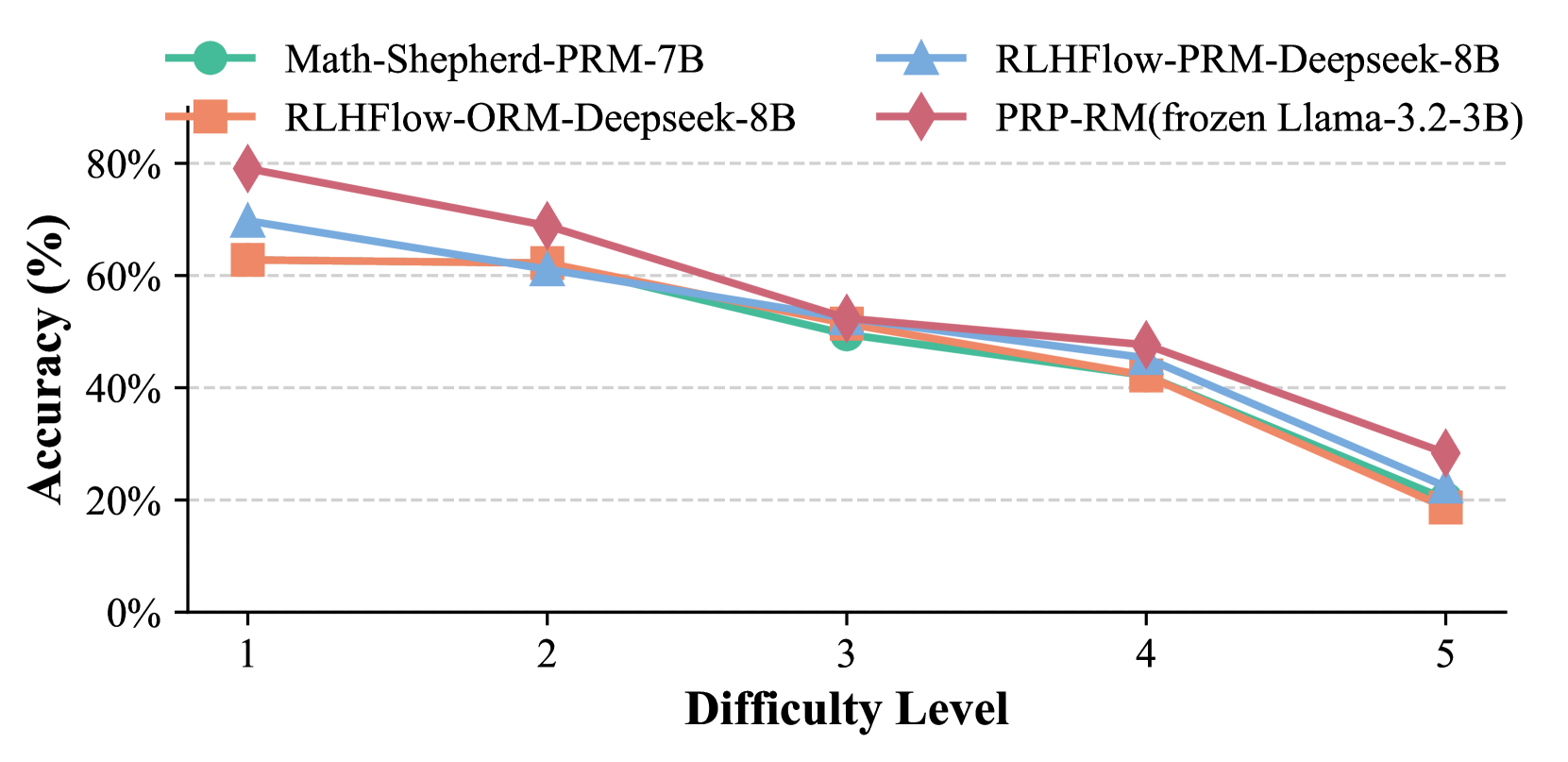
Figure 5: Comparison of reward models under Last@8.
### 5.2 Comparative Experimental Results
TABLE II: Evaluation results on the GSM8K dataset.
| Model | Method | Maj@4 | Last@4 |
| --- | --- | --- | --- |
| Llama-3.1-8B (+8.68%) | CoT-prompting | 81.8 | 82.0 |
| Step-by-Step KG-RAR | 88.9 | 88.0 | |
| Qwen-2.5-7B (+1.09%) | CoT-prompting | 91.6 | 91.1 |
| Step-by-Step KG-RAR | 92.6 | 93.1 | |
Table I shows that Step-by-Step KG-RAR consistently outperforms CoT-prompting across all difficulty levels on Math500, with more pronounced improvements in the Llama3 series compared to Qwen2.5, likely due to Qwen2.5’s higher baseline accuracy leaving less room for improvement. Performance declines for smaller models like Qwen-1.5B and Llama-1B on harder problems due to increased reasoning inconsistencies. Among models showing improvements, Step-by-Step KG-RAR achieves an average relative accuracy gain of 8.95% on Math500 under Maj@8, while Llama-3.2-8B attains a 8.68% improvement on GSM8K under Maj@4 (Table II). Additionally, PRP-RM achieves comparable performance to ORM and PRM. Figure 5 confirms its effectiveness with Llama-3B on Math500, highlighting its viability as a training-free alternative.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Bar Chart: Accuracy Comparison of Raw vs. Processed Metrics
### Overview
This image is a bar chart comparing the accuracy of "Raw" and "Processed" metrics across two different categories: "Maj@8" and "Last@8". The chart displays accuracy percentages on the y-axis and the metrics categories on the x-axis.
### Components/Axes
* **Title:** Implicitly, the chart compares accuracy.
* **Y-axis Label:** "Accuracy (%)"
* **Scale:** Ranges from 0% to 50%, with major tick marks at 0%, 10%, 20%, 30%, 40%, and 50%.
* **Grid Lines:** Dashed horizontal lines are present at each major tick mark, aiding in reading values.
* **X-axis Label:** "Metrics"
* **Categories:** "Maj@8" and "Last@8".
* **Legend:** Located at the top-center of the chart.
* **"Raw"**: Represented by an orange rectangle.
* **"Processed"**: Represented by a teal rectangle.
### Detailed Analysis
The chart presents two sets of paired bars, one for each metric category.
**1. Maj@8 Category:**
* **Raw (Orange Bar):** This bar's top aligns with the 30% mark on the y-axis.
* **Value:** Approximately 31% (with an uncertainty of +/- 1%).
* **Processed (Teal Bar):** This bar's top aligns with the 40% mark on the y-axis.
* **Value:** Approximately 40% (with an uncertainty of +/- 1%).
**2. Last@8 Category:**
* **Raw (Orange Bar):** This bar's top aligns slightly above the 30% mark, approximately at the 35% mark.
* **Value:** Approximately 35% (with an uncertainty of +/- 1%).
* **Processed (Teal Bar):** This bar's top aligns with the 40% mark on the y-axis.
* **Value:** Approximately 40% (with an uncertainty of +/- 1%).
### Key Observations
* For both "Maj@8" and "Last@8" metrics, the "Processed" accuracy is higher than the "Raw" accuracy.
* The "Processed" accuracy for "Maj@8" is approximately 40%.
* The "Processed" accuracy for "Last@8" is also approximately 40%.
* The "Raw" accuracy for "Maj@8" is approximately 31%.
* The "Raw" accuracy for "Last@8" is approximately 35%.
* The difference in accuracy between "Processed" and "Raw" is more pronounced for the "Maj@8" metric (approximately 9%) compared to the "Last@8" metric (approximately 5%).
### Interpretation
This bar chart demonstrates the impact of processing on the accuracy of two different metrics, "Maj@8" and "Last@8". The data strongly suggests that processing the metrics leads to a significant improvement in accuracy across both categories.
Specifically, the "Processed" bars consistently reach a higher accuracy level than their "Raw" counterparts. The "Processed" accuracy appears to plateau around 40% for both "Maj@8" and "Last@8", indicating a potential ceiling or consistent performance after processing.
The "Raw" accuracy, however, shows some variation between the two metrics, with "Last@8" performing better than "Maj@8". The improvement gained by processing is more substantial for "Maj@8", suggesting that this metric might benefit more from the applied processing techniques. This could imply that the "Raw" "Maj@8" data contains more noise or irrelevant information that the processing effectively filters out, leading to a greater relative gain in accuracy. Conversely, "Raw" "Last@8" might already be closer to optimal performance, thus showing a smaller, though still positive, improvement after processing.
In essence, the chart visually supports the hypothesis that data processing is a beneficial step for improving the performance of these metrics.
</details>
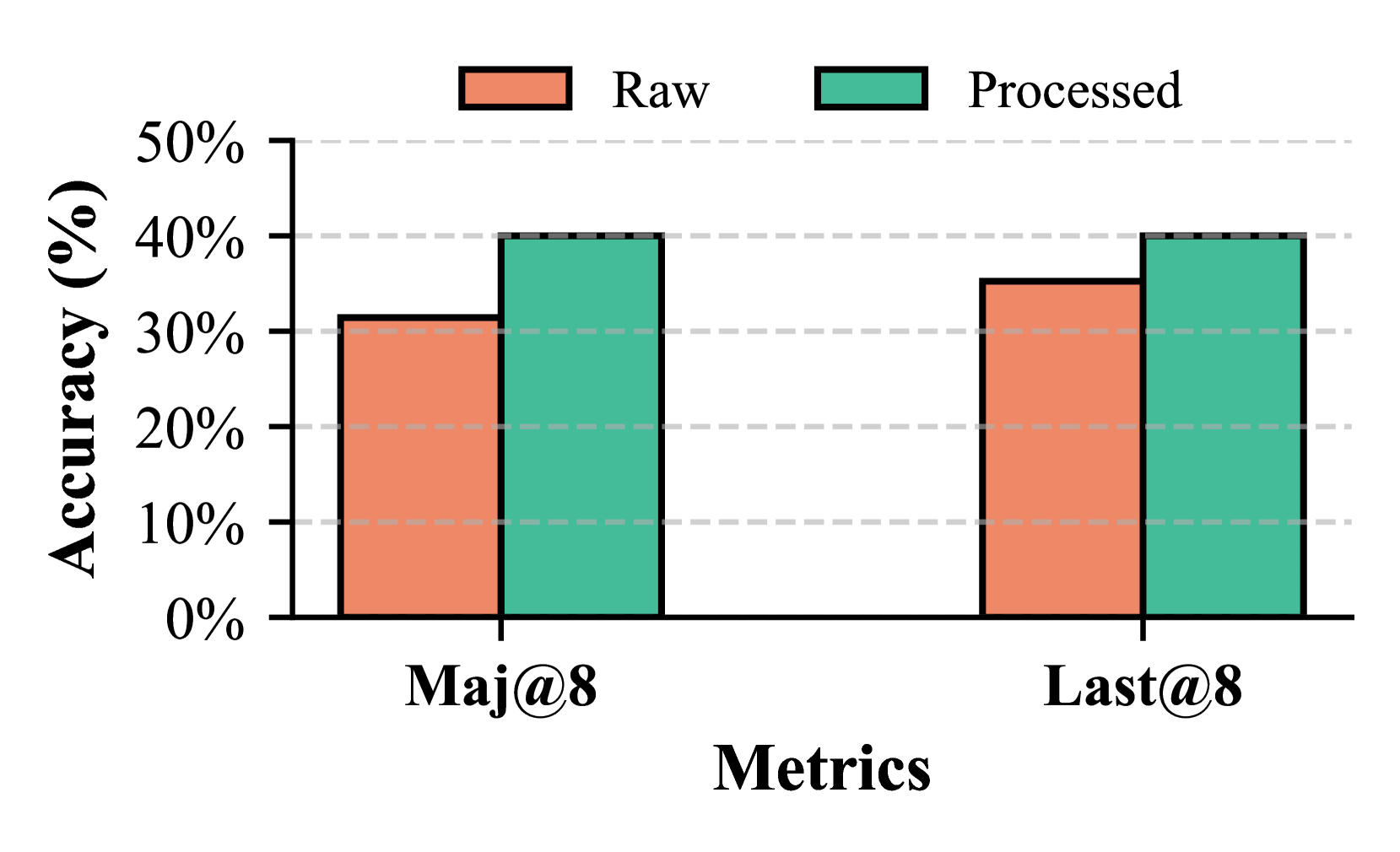
Figure 6: Comparison of raw and processed retrieval.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Bar Chart: Accuracy Comparison Across Metrics and Methods
### Overview
This image displays a bar chart comparing the accuracy of three different methods ("None", "RAG", and "KG-RAG") across two metrics ("Maj@8" and "Last@8"). The y-axis represents accuracy in percentage, ranging from 0% to 60%.
### Components/Axes
* **Title:** Implicitly, the chart title is a comparison of accuracy.
* **Y-axis Label:** "Accuracy (%)"
* **Scale:** 0%, 10%, 20%, 30%, 40%, 50%, 60%
* **X-axis Label:** "Metrics"
* **Categories:** "Maj@8", "Last@8"
* **Legend:** Located at the top-center of the chart.
* **"None"**: Represented by a blue square.
* **"RAG"**: Represented by an orange/coral square.
* **"KG-RAG"**: Represented by a teal/green square.
### Detailed Analysis
The chart is divided into two main sections on the x-axis, corresponding to the metrics "Maj@8" and "Last@8". Within each section, there are three bars representing the accuracy for "None", "RAG", and "KG-RAG" methods.
**For "Maj@8" metric:**
* **"None" (Blue bar):** The bar reaches approximately 51% accuracy.
* **"RAG" (Orange bar):** The bar reaches approximately 52% accuracy.
* **"KG-RAG" (Teal bar):** The bar reaches approximately 53% accuracy.
**For "Last@8" metric:**
* **"None" (Blue bar):** The bar reaches approximately 44% accuracy.
* **"RAG" (Orange bar):** The bar reaches approximately 44% accuracy.
* **"KG-RAG" (Teal bar):** The bar reaches approximately 51% accuracy.
### Key Observations
* **"Maj@8" Metric:** All three methods show very similar accuracy, with "KG-RAG" being slightly higher (approximately 53%) than "RAG" (approximately 52%) and "None" (approximately 51%). The difference between the highest and lowest is about 2 percentage points.
* **"Last@8" Metric:** There is a more noticeable difference in accuracy. "KG-RAG" achieves the highest accuracy (approximately 51%), while "None" and "RAG" have significantly lower and nearly identical accuracy (approximately 44%). The difference between the highest and lowest is about 7 percentage points.
* **Method Comparison:** "KG-RAG" consistently performs at or above the other methods across both metrics. It shows a substantial improvement over "None" and "RAG" for the "Last@8" metric.
* **Metric Comparison:** Accuracy generally decreases from "Maj@8" to "Last@8" for the "None" and "RAG" methods. However, "KG-RAG" maintains a high accuracy for "Maj@8" and shows a slight decrease but still remains the highest for "Last@8".
### Interpretation
The data suggests that the "KG-RAG" method is the most effective across both metrics, particularly for the "Last@8" metric where it demonstrates a significant advantage. The "RAG" method shows a marginal improvement over "None" for "Maj@8" but performs similarly to "None" for "Last@8". The "None" method, representing a baseline without any specific augmentation, shows the lowest or tied-lowest accuracy in both cases.
The performance difference between "Maj@8" and "Last@8" for "None" and "RAG" indicates that these methods might be more sensitive to the specific characteristics of the "Last@8" metric, leading to a drop in accuracy. In contrast, "KG-RAG" appears to be more robust, maintaining a high level of accuracy even for the "Last@8" metric. This implies that the knowledge graph integration in "KG-RAG" provides a benefit that helps in achieving better performance, especially when dealing with the challenges presented by the "Last@8" metric.
</details>
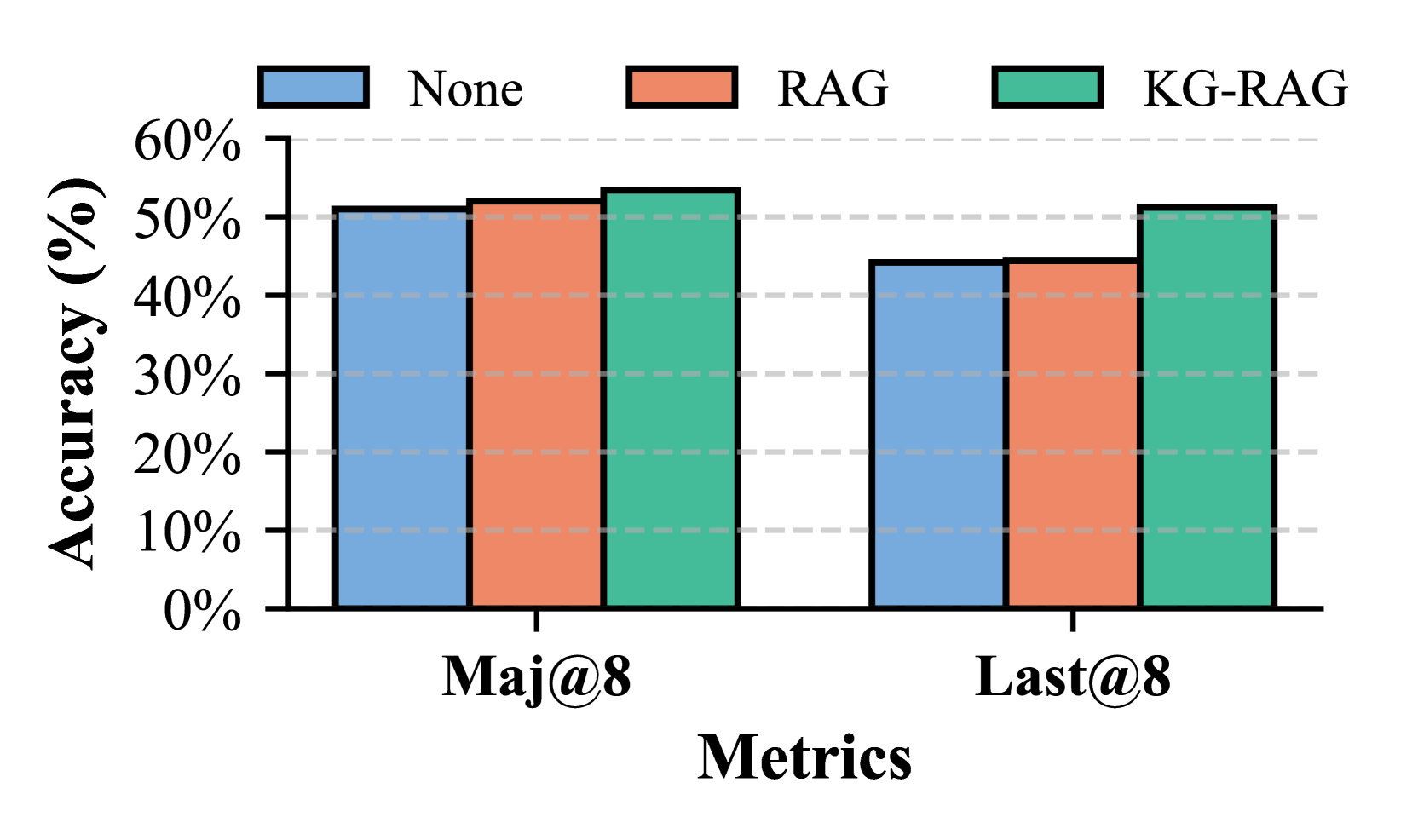
Figure 7: Comparison of various RAG types.
### 5.3 Ablation Studies
Effectiveness of Post-Retrieval Processing (PRP). We compare reasoning with refined retrieval from PRP-RM against raw retrieval directly from Knowledge Graphs. Figure 7 shows that refining the retrieval context significantly improves performance, with experiments using Llama-3B on Math500 Level 3.
Effectiveness of Knowledge Graphs (KGs). KG-RAR outperforms both no RAG and unstructured RAG (PRM800K) baselines, demonstrating the advantage of structured retrieval (Figure 7, Qwen-0.5B Reasoner, Qwen-3B PRP-RM, Math500).
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Step Padding with Computation Levels
### Overview
This image displays a line chart illustrating the relationship between "Step Padding" on the x-axis and "Accuracy (%)" on the y-axis. Two data series are plotted: "Maj@8" (represented by a teal line with circular markers) and "Compute" (represented by a dashed black line with cross markers). A secondary y-axis on the right indicates levels of "Computation" (More, Medium, Less).
### Components/Axes
* **Primary Y-axis (Left):**
* **Title:** "Accuracy (%)"
* **Scale:** Ranges from 20% to 50%, with major tick marks at 20%, 30%, 40%, and 50%.
* **Tick Markers:** Labeled at 20%, 30%, 40%, 50%.
* **X-axis:**
* **Title:** "Step Padding"
* **Scale:** Logarithmic scale, with labeled tick marks at 1, 4, and "+∞". There are also minor tick marks between these labels.
* **Secondary Y-axis (Right):**
* **Title:** "Computation" (rotated vertically)
* **Scale:** Categorical, with labels "More", "Medium", and "Less" positioned at different vertical levels.
* "More" is aligned with the top of the chart area.
* "Medium" is aligned approximately with the 40% mark on the primary y-axis.
* "Less" is aligned approximately with the 20% mark on the primary y-axis.
* **Legend:**
* Located in the top-center area of the chart.
* **"Maj@8":** Teal line with a circular marker.
* **"Compute":** Dashed black line with a cross marker.
### Detailed Analysis
**Data Series: Maj@8 (Teal line with circular markers)**
* **Trend:** The "Maj@8" line generally slopes downward as "Step Padding" increases.
* **Data Points:**
* At Step Padding = 1: Accuracy is approximately 35% (±1%).
* At Step Padding = 4: Accuracy is approximately 40% (±1%).
* At Step Padding = +∞: Accuracy is approximately 35% (±1%).
**Data Series: Compute (Dashed black line with cross markers)**
* **Trend:** The "Compute" line slopes downward sharply as "Step Padding" increases.
* **Data Points:**
* At Step Padding = 1: Accuracy is approximately 46% (±1%).
* At Step Padding = 4: Accuracy is approximately 39% (±1%).
* At Step Padding = +∞: Accuracy is approximately 23% (±1%).
### Key Observations
* Both data series show a decrease in accuracy as "Step Padding" increases, although the "Compute" series exhibits a more pronounced decline.
* The "Maj@8" series shows an initial increase in accuracy from Step Padding 1 to 4, followed by a decrease.
* The "Compute" series starts with the highest accuracy at Step Padding 1 but drops significantly by Step Padding +∞.
* At Step Padding 4, the accuracy for both "Maj@8" and "Compute" is very close, around 40% and 39% respectively.
* The "Computation" axis suggests that higher "Step Padding" values correspond to "Less" computation.
### Interpretation
The chart demonstrates the trade-off between "Step Padding" and "Accuracy" for two different methods, "Maj@8" and "Compute". The x-axis, "Step Padding", is presented on a logarithmic scale, with "+∞" representing the highest level of padding (and thus, presumably, the least computation).
The data suggests that increasing "Step Padding" generally leads to a decrease in accuracy, particularly for the "Compute" method, which experiences a substantial drop. The "Maj@8" method shows a more nuanced behavior, with an initial improvement in accuracy at a moderate level of padding (Step Padding = 4) before declining.
The secondary axis, "Computation", implies that as "Step Padding" increases towards infinity, the computational cost decreases. Therefore, the chart illustrates that while reducing computation (by increasing padding) can be beneficial for efficiency, it comes at the cost of accuracy, with the "Compute" method being more sensitive to this trade-off than "Maj@8". The point at Step Padding = 4 appears to be a sweet spot where both methods achieve relatively high accuracy with potentially moderate computational requirements. The "Maj@8" method seems to be more robust to higher levels of padding compared to the "Compute" method.
</details>
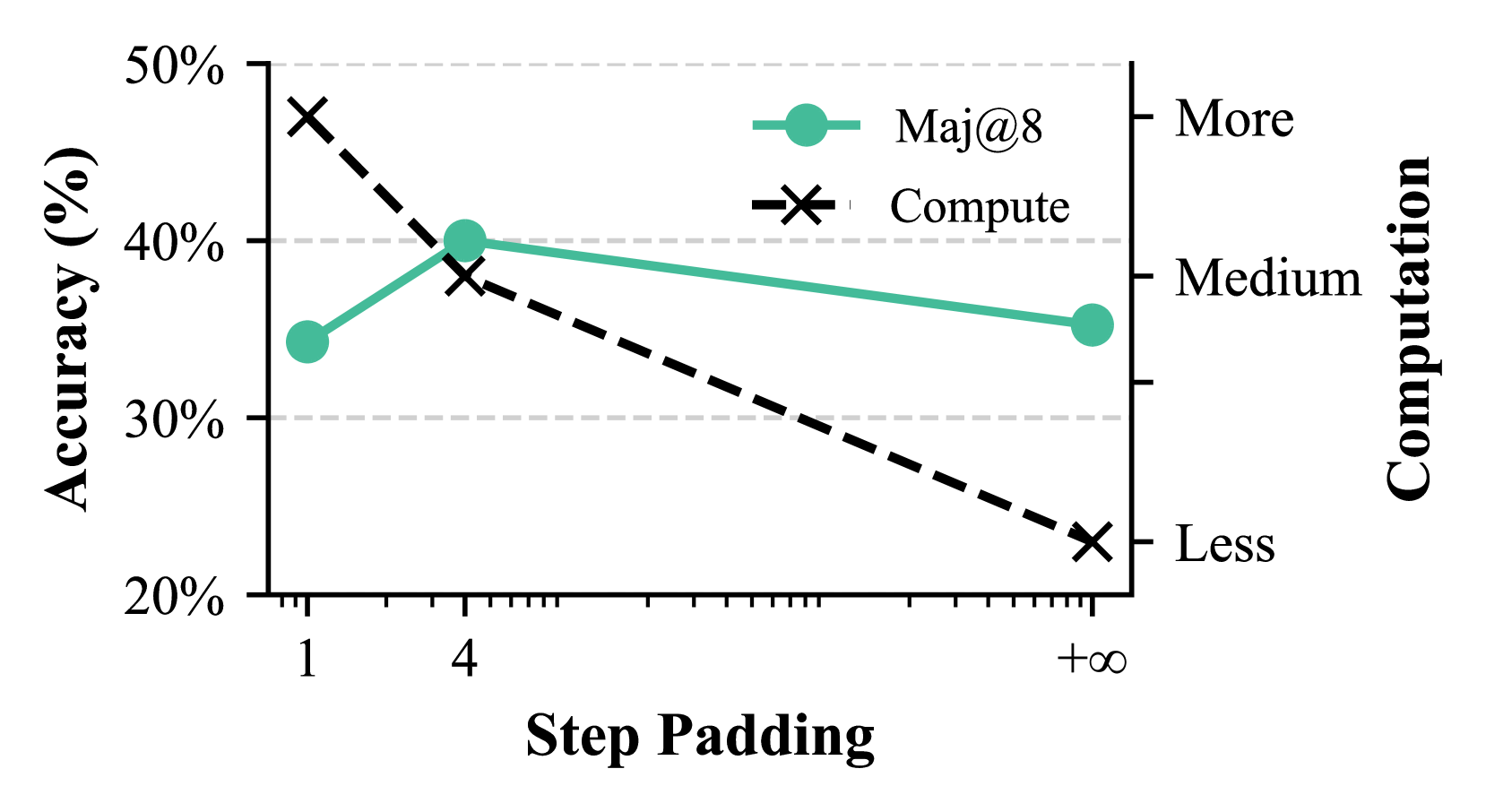
Figure 8: Comparison of step padding settings.
<details>
<summary>x9.png Details</summary>
### Visual Description
## Bar Chart: Accuracy by Metrics and Strategy
### Overview
This image is a bar chart displaying the accuracy (%) for three different strategies (Socratic, Responsible, Critical) across two metrics (Maj@8 and Last@8). The chart uses vertical bars to represent the accuracy values for each combination.
### Components/Axes
* **Title:** The chart does not have an explicit overall title, but the content is described by the axis labels and legend.
* **Y-axis:**
* **Label:** "Accuracy (%)"
* **Scale:** Ranges from 0.0% to 70.0%, with major tick marks at 10.0% intervals (0.0%, 10.0%, 20.0%, 30.0%, 40.0%, 50.0%, 60.0%, 70.0%).
* **Tick Markers:** Horizontal dashed lines are present at each 10.0% increment.
* **X-axis:**
* **Label:** "Metrics"
* **Categories:** Two main categories are displayed: "Maj@8" and "Last@8".
* **Legend:** Located at the top of the chart, it associates colors with strategies:
* Teal square: "Socratic"
* Coral square: "Responsible"
* Light blue square: "Critical"
### Detailed Analysis
The chart presents data for two metrics, "Maj@8" and "Last@8". For each metric, there are three bars representing the accuracy of the "Socratic", "Responsible", and "Critical" strategies.
**Metric: Maj@8**
* **Socratic (Teal bar):** The bar reaches approximately 61.0% accuracy.
* **Responsible (Coral bar):** The bar reaches approximately 64.0% accuracy.
* **Critical (Light blue bar):** The bar reaches approximately 71.0% accuracy.
**Metric: Last@8**
* **Socratic (Teal bar):** The bar reaches approximately 52.0% accuracy.
* **Responsible (Coral bar):** The bar reaches approximately 62.0% accuracy.
* **Critical (Light blue bar):** The bar reaches approximately 70.0% accuracy.
### Key Observations
* **"Critical" strategy consistently shows the highest accuracy** across both metrics.
* **"Socratic" strategy shows the lowest accuracy** across both metrics.
* There is a **general decrease in accuracy for the "Socratic" strategy** from "Maj@8" to "Last@8" (from ~61% to ~52%).
* The **"Responsible" and "Critical" strategies maintain relatively high accuracy** from "Maj@8" to "Last@8", with a slight decrease for "Critical" (~71% to ~70%) and a slight decrease for "Responsible" (~64% to ~62%).
### Interpretation
This bar chart demonstrates the comparative performance of three different strategies ("Socratic", "Responsible", "Critical") based on accuracy for two distinct metrics ("Maj@8" and "Last@8").
The data suggests that the "Critical" strategy is the most effective in terms of accuracy, consistently outperforming the other two strategies. Conversely, the "Socratic" strategy appears to be the least effective. The "Responsible" strategy falls in between.
The trend observed for the "Socratic" strategy, showing a notable drop in accuracy from "Maj@8" to "Last@8", might indicate that this strategy is less robust or adaptable to changes represented by the "Last@8" metric. The relative stability of the "Responsible" and "Critical" strategies suggests they are more consistent performers.
The "Maj@8" metric seems to yield higher accuracies overall for the "Responsible" and "Critical" strategies compared to "Last@8", although the difference is more pronounced for "Socratic". This could imply that the "Maj@8" metric is a more favorable or easier condition for achieving high accuracy with these strategies, or that "Last@8" introduces a more challenging aspect.
In essence, the chart provides a clear visual comparison of strategy effectiveness, highlighting "Critical" as the top performer and "Socratic" as the lowest, with "Responsible" in the middle, across the evaluated metrics.
</details>
Figure 9: Comparison of PRP-RM roles.
Effectiveness of Step-by-Step RAG. We evaluate step padding at 1, 4, and 1000. Small padding causes inconsistencies, while large padding hinders refinement. Figure 9 illustrates this trade-off (Llama-1B, Math500 Level 3).
<details>
<summary>x10.png Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Model Size
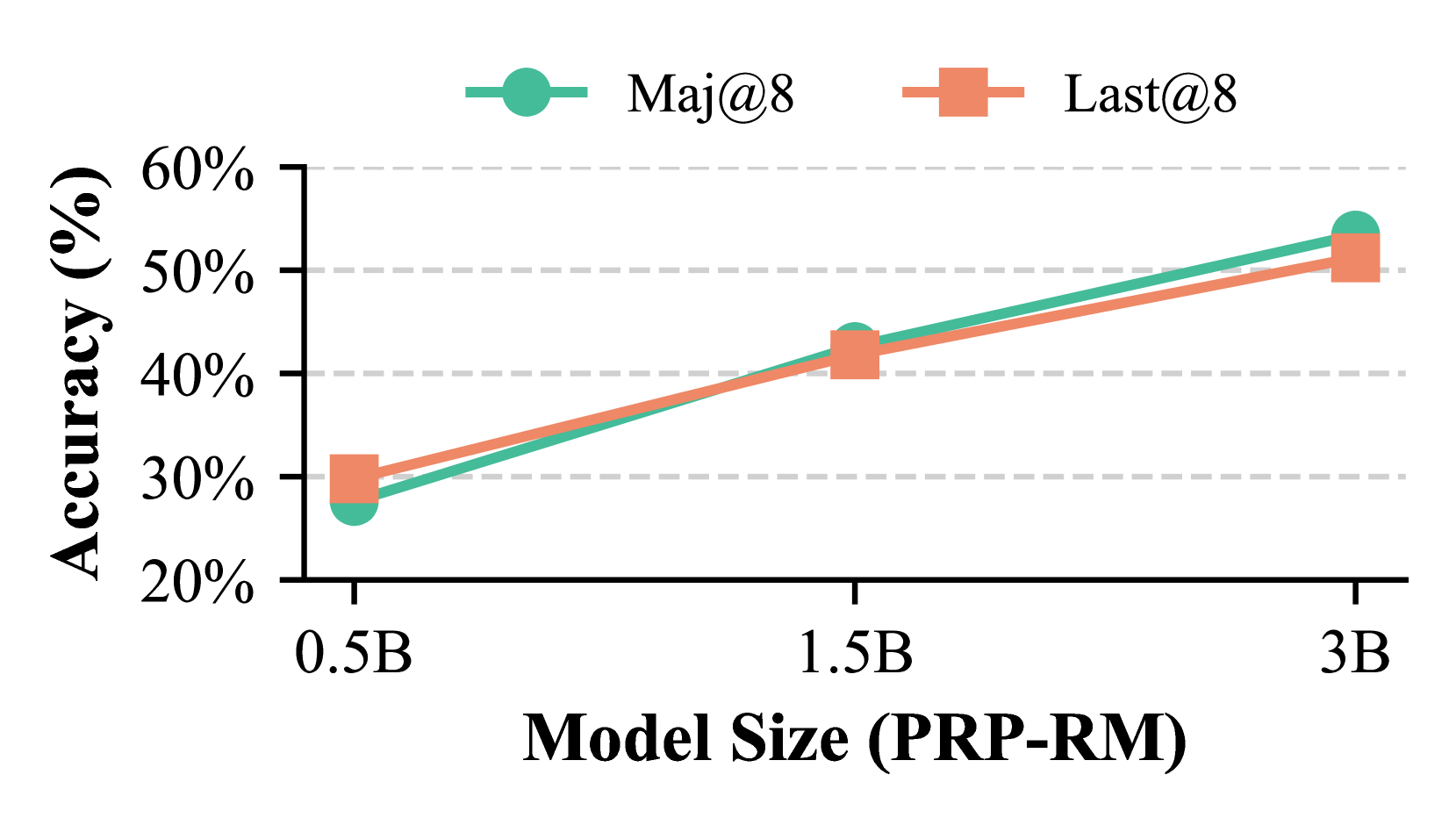
### Overview
This image displays a line chart illustrating the relationship between "Model Size (PRP-RM)" on the x-axis and "Accuracy (%)" on the y-axis. Two data series, "Maj@8" and "Last@8", are plotted, showing how their accuracy changes with increasing model size.
### Components/Axes
* **X-axis Title:** Model Size (PRP-RM)
* **X-axis Markers:** 0.5B, 1.5B, 3B
* **Y-axis Title:** Accuracy (%)
* **Y-axis Markers:** 20%, 30%, 40%, 50%, 60%
* **Legend:** Located in the top-center of the chart.
* **Maj@8:** Represented by a teal circle marker and a teal line.
* **Last@8:** Represented by an orange square marker and an orange line.
### Detailed Analysis
**Data Series: Maj@8 (Teal Line with Circle Markers)**
* **Trend:** The "Maj@8" data series shows a consistent upward trend in accuracy as the model size increases.
* **Data Points:**
* At 0.5B model size, the accuracy is approximately 27%.
* At 1.5B model size, the accuracy is approximately 42%.
* At 3B model size, the accuracy is approximately 54%.
**Data Series: Last@8 (Orange Line with Square Markers)**
* **Trend:** The "Last@8" data series also exhibits a consistent upward trend in accuracy with increasing model size, closely mirroring the "Maj@8" series.
* **Data Points:**
* At 0.5B model size, the accuracy is approximately 30%.
* At 1.5B model size, the accuracy is approximately 41%.
* At 3B model size, the accuracy is approximately 51%.
### Key Observations
* Both "Maj@8" and "Last@8" demonstrate a positive correlation between model size and accuracy. As the model size increases from 0.5B to 3B, the accuracy for both metrics improves.
* The "Last@8" metric starts with a slightly higher accuracy at 0.5B model size (approximately 30%) compared to "Maj@8" (approximately 27%).
* As the model size increases to 1.5B, the accuracies become very close, with "Maj@8" at approximately 42% and "Last@8" at approximately 41%.
* At the largest model size of 3B, "Maj@8" achieves a slightly higher accuracy (approximately 54%) than "Last@8" (approximately 51%).
* The gap between "Maj@8" and "Last@8" narrows between 0.5B and 1.5B and then widens slightly in favor of "Maj@8" at 3B.
### Interpretation
The chart suggests that for the evaluated metrics ("Maj@8" and "Last@8"), increasing the model size (PRP-RM) generally leads to improved accuracy. This is a common observation in machine learning, where larger models often have a greater capacity to learn complex patterns.
The initial observation that "Last@8" performs slightly better at the smallest model size (0.5B) might indicate that this metric is more sensitive to initial learning or that the smaller model is better suited for the "Last@8" evaluation criteria at this scale. However, as the model size grows, "Maj@8" appears to gain an advantage, particularly at the 3B scale, suggesting it scales more effectively or benefits more from larger model capacities. The close performance between the two metrics at 1.5B indicates a point where their performance is nearly equivalent.
The data demonstrates a trade-off or differing scaling properties between the "Maj@8" and "Last@8" metrics as model size increases. Further investigation could explore why "Maj@8" shows superior performance at larger scales and what specific aspects of the model architecture or training process contribute to this difference. The consistent upward trend for both metrics validates the general principle of model scaling for performance improvement within the tested range.
</details>
Figure 10: Scaling PRP-RM sizes
<details>
<summary>x11.png Details</summary>
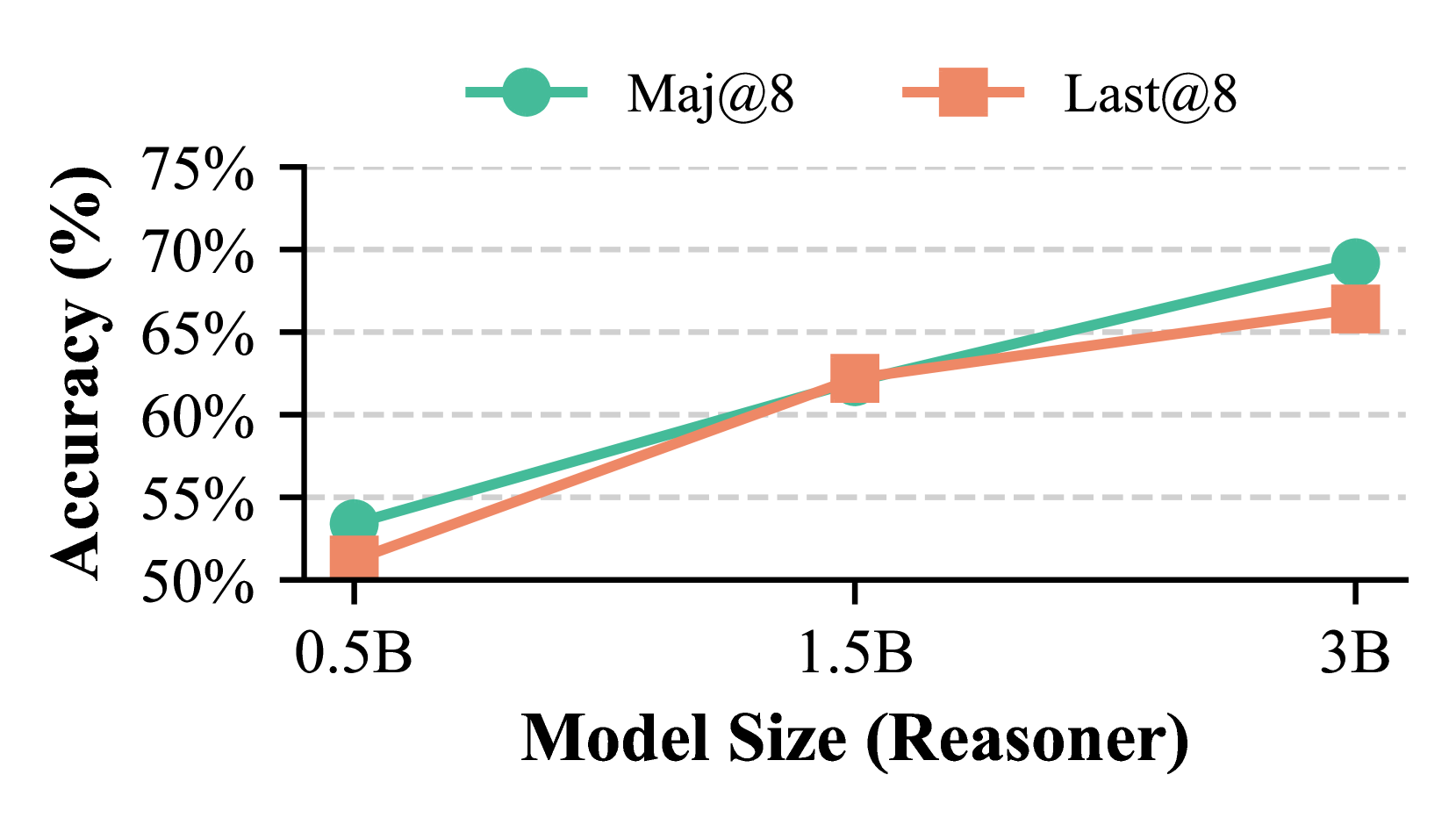
### Visual Description
## Line Chart: Accuracy vs. Model Size
### Overview
This image displays a line chart illustrating the relationship between "Model Size (Reasoner)" on the x-axis and "Accuracy (%)" on the y-axis. Two data series, "Maj@8" and "Last@8", are plotted, showing how their accuracy changes with increasing model size.
### Components/Axes
* **X-axis Title:** "Model Size (Reasoner)"
* **X-axis Markers:** "0.5B", "1.5B", "3B"
* **Y-axis Title:** "Accuracy (%)"
* **Y-axis Markers:** "50%", "55%", "60%", "65%", "70%", "75%"
* **Legend:** Located in the top-center of the chart.
* **"Maj@8"**: Represented by a teal-colored line with circular markers.
* **"Last@8"**: Represented by an orange-colored line with square markers.
### Detailed Analysis
The chart shows two lines, "Maj@8" (teal, circles) and "Last@8" (orange, squares), both exhibiting an upward trend in accuracy as the model size increases from 0.5B to 3B.
**Data Series: Maj@8 (Teal, Circles)**
* **Trend:** The "Maj@8" line slopes upward consistently across the observed model sizes.
* **Data Points (approximate):**
* At 0.5B model size: Approximately 54% accuracy.
* At 1.5B model size: Approximately 63% accuracy.
* At 3B model size: Approximately 70% accuracy.
**Data Series: Last@8 (Orange, Squares)**
* **Trend:** The "Last@8" line also slopes upward, mirroring the general trend of "Maj@8".
* **Data Points (approximate):**
* At 0.5B model size: Approximately 51% accuracy.
* At 1.5B model size: Approximately 62% accuracy.
* At 3B model size: Approximately 66% accuracy.
### Key Observations
* Both "Maj@8" and "Last@8" show a positive correlation between model size and accuracy.
* The "Maj@8" series consistently achieves higher accuracy than the "Last@8" series across all model sizes presented.
* The gap in accuracy between "Maj@8" and "Last@8" appears to widen slightly as the model size increases from 1.5B to 3B. At 0.5B, the difference is about 3%, at 1.5B it's about 1%, and at 3B it's about 4%.
### Interpretation
The data presented in this chart suggests that for both "Maj@8" and "Last@8" methods, increasing the model size (Reasoner) leads to improved accuracy. The "Maj@8" method appears to be more effective or robust, consistently outperforming "Last@8" across the tested model sizes. The widening gap at larger model sizes might indicate that "Maj@8" scales more favorably with increased model complexity compared to "Last@8". This implies that if computational resources allow, employing larger models with the "Maj@8" approach could yield significantly better results. The "Reasoner" in the x-axis title likely refers to a component or aspect of the model that is being scaled, and its size directly impacts the overall model's performance as measured by accuracy.
</details>
Figure 11: Scaling reasoner LLM sizes
Comparison of PRP-RM Roles. Socratic Teacher minimizes direct problem-solving but sometimes introduces extraneous questions. Figure 9 shows Critical Teacher performs best among three roles (Llama-3B, Math500).
Scaling Model Size. Scaling trends in Section 5.2 are validated on Math500. Figures 11 and 11 confirm performance gains as both the Reasoner LLM and PRP-RM scale independently.
Scaling of Number of Solutions. We vary the number of generated solutions using Llama-3B on Math500 Level 3. Figure 13 shows accuracy improves incrementally with more solutions, underscoring the benefits of multiple candidates.
<details>
<summary>x12.png Details</summary>
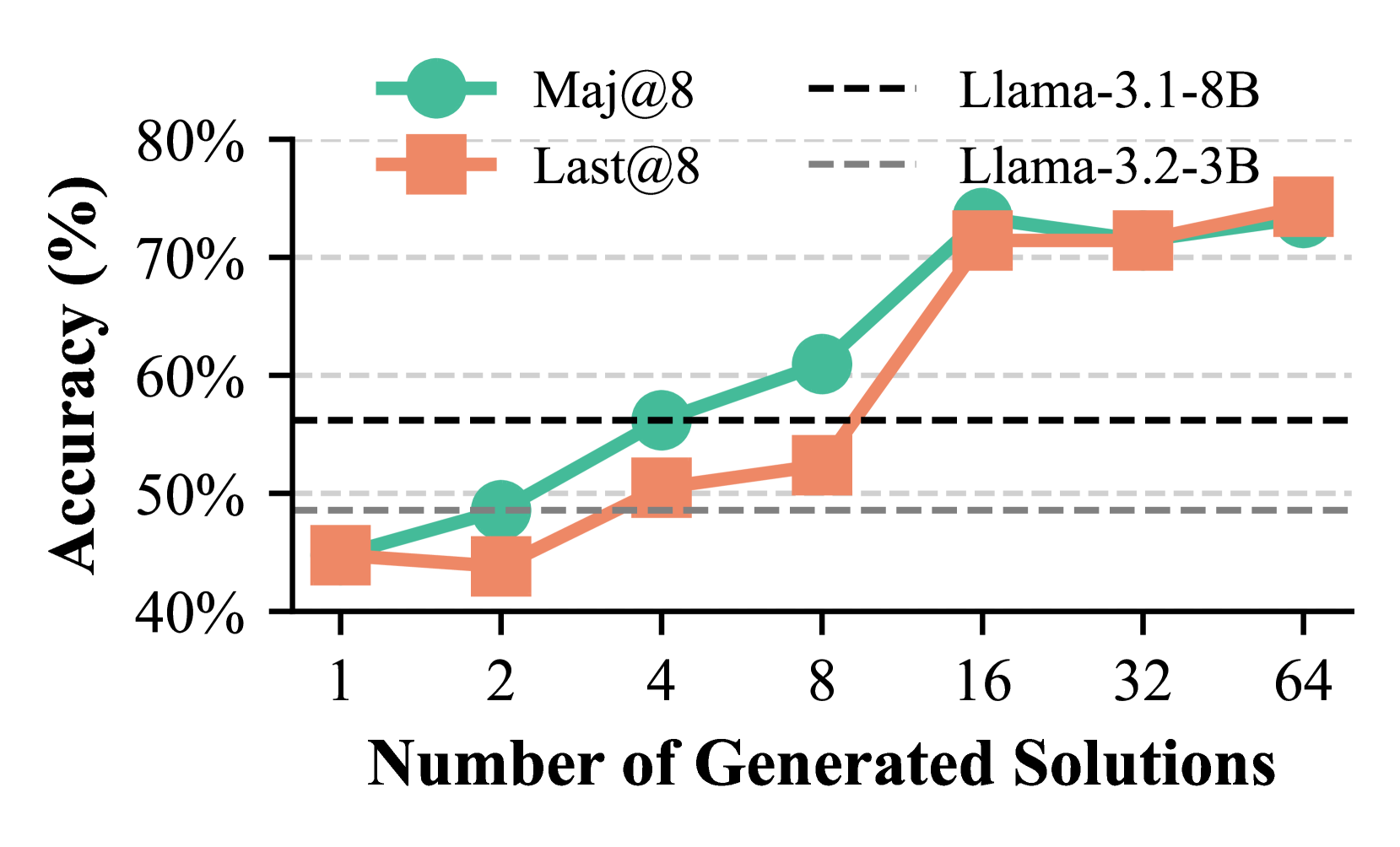
### Visual Description
## Line Chart: Accuracy vs. Number of Generated Solutions
### Overview
This image displays a line chart illustrating the accuracy of two different methods, "Maj@8" and "Last@8", as a function of the "Number of Generated Solutions". The chart also includes two horizontal dashed lines representing baseline accuracies for "Llama-3.1-8B" and "Llama-3.2-3B". The primary trend shows that accuracy generally increases with the number of generated solutions for both "Maj@8" and "Last@8".
### Components/Axes
* **Chart Type**: Line Chart
* **Title**: Implicitly, "Accuracy of Methods with Varying Number of Generated Solutions"
* **Y-axis Label**: "Accuracy (%)"
* **Scale**: Linear, ranging from approximately 40% to 80%.
* **Markers**: 40%, 50%, 60%, 70%, 80%.
* **X-axis Label**: "Number of Generated Solutions"
* **Scale**: Logarithmic (implied by the spacing of markers), with markers at 1, 2, 4, 8, 16, 32, 64.
* **Legend**: Located in the top-center of the chart.
* **"Maj@8"**: Represented by a teal line with circular markers.
* **"Last@8"**: Represented by an orange line with square markers.
* **"Llama-3.1-8B"**: Represented by a dashed black line.
* **"Llama-3.2-3B"**: Represented by a dashed grey line.
### Detailed Analysis
**Data Series: "Maj@8" (Teal Line with Circles)**
* **Trend**: The "Maj@8" line shows a consistent upward trend, indicating that accuracy improves as more solutions are generated. The slope appears to steepen between 4 and 16 generated solutions, then flattens out.
* **Data Points (approximate values with uncertainty +/- 1%)**:
* At 1 solution: ~45%
* At 2 solutions: ~50%
* At 4 solutions: ~57%
* At 8 solutions: ~61%
* At 16 solutions: ~72%
* At 32 solutions: ~72%
* At 64 solutions: ~74%
**Data Series: "Last@8" (Orange Line with Squares)**
* **Trend**: The "Last@8" line also shows an upward trend, but generally at a lower accuracy than "Maj@8" for most of the plotted range. The trend is less steep than "Maj@8" initially, but catches up and surpasses "Maj@8" between 8 and 16 solutions before falling slightly behind again.
* **Data Points (approximate values with uncertainty +/- 1%)**:
* At 1 solution: ~43%
* At 2 solutions: ~42%
* At 4 solutions: ~50%
* At 8 solutions: ~51%
* At 16 solutions: ~71%
* At 32 solutions: ~71%
* At 64 solutions: ~73%
**Baseline Data Series:**
* **"Llama-3.1-8B" (Dashed Black Line)**: This line is positioned at approximately 57% accuracy.
* **"Llama-3.2-3B" (Dashed Grey Line)**: This line is positioned at approximately 49% accuracy.
### Key Observations
* Both "Maj@8" and "Last@8" methods demonstrate a positive correlation between the number of generated solutions and accuracy.
* The "Maj@8" method generally achieves higher accuracy than the "Last@8" method, especially at lower numbers of generated solutions (1-4).
* The "Last@8" method shows a significant jump in accuracy between 4 and 16 generated solutions, briefly matching the performance of "Maj@8" at 16 and 32 solutions.
* Both methods surpass the "Llama-3.2-3B" baseline at 4 generated solutions and the "Llama-3.1-8B" baseline at 16 generated solutions.
* The accuracy gains for both methods appear to plateau or diminish at higher numbers of generated solutions (beyond 16).
### Interpretation
The data suggests that for the tasks represented by "Maj@8" and "Last@8", increasing the number of generated solutions is a viable strategy to improve accuracy. The "Maj@8" method appears to be more robust and consistently performs better, particularly when fewer solutions are available. The "Last@8" method, while initially lagging, shows a strong improvement curve, indicating it might be more sensitive to a larger pool of generated solutions.
The horizontal lines for "Llama-3.1-8B" and "Llama-3.2-3B" serve as benchmarks. The fact that both "Maj@8" and "Last@8" eventually exceed these benchmarks implies that these methods are effective for the problem domain. The plateauing of accuracy at higher numbers of generated solutions suggests diminishing returns, meaning that generating significantly more solutions beyond a certain point might not yield substantial improvements in accuracy and could incur higher computational costs. This could indicate that the models are converging or that the diversity of generated solutions is no longer significantly contributing to finding more correct answers.
</details>
Figure 12: Scaling of the number of solutions.
<details>
<summary>x13.png Details</summary>
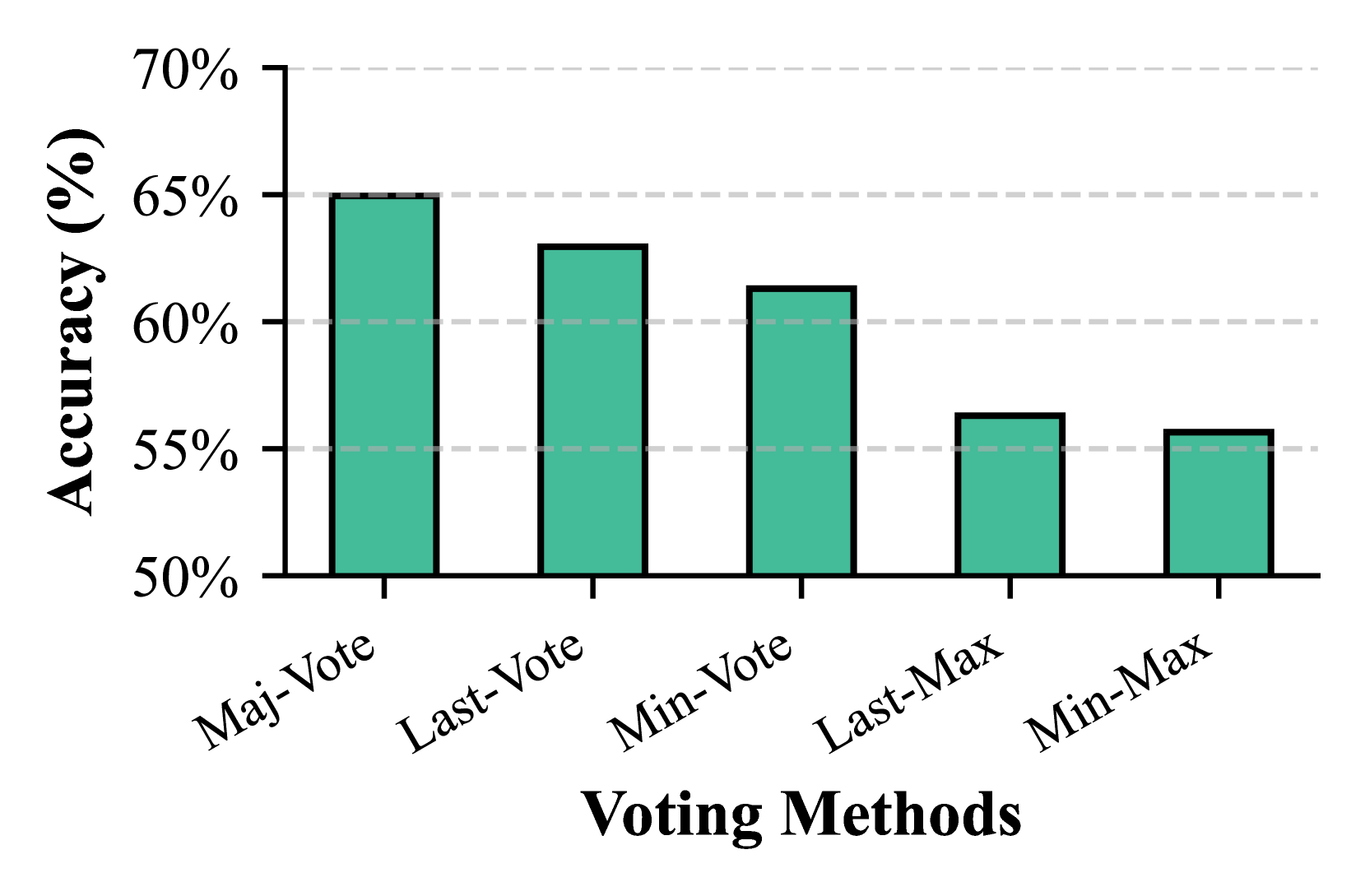
### Visual Description
## Bar Chart: Accuracy by Voting Method
### Overview
This image displays a bar chart comparing the accuracy of different voting methods. The chart shows five distinct voting methods on the x-axis and their corresponding accuracy percentages on the y-axis.
### Components/Axes
* **Y-axis Title**: "Accuracy (%)"
* **Scale**: Ranges from 50% to 70%, with major tick marks at 50%, 55%, 60%, 65%, and 70%.
* **Grid Lines**: Horizontal dashed lines are present at each major tick mark (50%, 55%, 60%, 65%, 70%) for easier reading.
* **X-axis Title**: "Voting Methods"
* **Categories**: The x-axis displays five categories representing different voting methods: "Maj-Vote", "Last-Vote", "Min-Vote", "Last-Max", and "Min-Max".
* **Bars**: Five vertical bars, all colored in a teal/cyan hue, represent the accuracy for each voting method.
### Detailed Analysis or Content Details
The chart presents the following data points for each voting method:
* **Maj-Vote**: The bar reaches approximately 65.2% accuracy.
* **Last-Vote**: The bar reaches approximately 63.2% accuracy.
* **Min-Vote**: The bar reaches approximately 61.8% accuracy.
* **Last-Max**: The bar reaches approximately 56.2% accuracy.
* **Min-Max**: The bar reaches approximately 55.8% accuracy.
### Key Observations
* The "Maj-Vote" method exhibits the highest accuracy among all tested methods.
* There is a general downward trend in accuracy as we move from "Maj-Vote" to "Min-Max", with a notable drop between "Min-Vote" and "Last-Max".
* "Last-Max" and "Min-Max" have very similar and the lowest accuracy scores.
### Interpretation
The data presented in this bar chart suggests that the "Maj-Vote" method is the most effective in terms of accuracy for the task or dataset represented. Conversely, "Last-Max" and "Min-Max" voting methods appear to be the least accurate. The observed trend indicates that simpler voting strategies like majority vote might yield better results compared to more complex or specific methods like "Last-Max" or "Min-Max" in this context. The significant drop in accuracy between "Min-Vote" and "Last-Max" could indicate a point where the voting strategy becomes less robust or suitable for the underlying data distribution. This visualization is crucial for selecting the optimal voting method for a given application, prioritizing accuracy.
</details>
Figure 13: Comparison of various voting methods.
Comparison of Voting Methods. We widely evaluate five PRP-RM voting strategies: Majority Vote, Last Vote, Min Vote, Min-Max, and Last-Max [23, 21]. Majority Vote and Last Vote outperform others, as extreme-based methods are prone to PRP-RM overconfidence in incorrect solutions (Figure 13).
## 6 Conclusions and Limitations
In this paper, we introduce a novel graph-augmented reasoning paradigm that aims to enhance o1-like multi-step reasoning capabilities of frozen LLMs by integrating external KGs. Towards this end, we present step-by-step knowledge graph based retrieval-augmented reasoning (KG-RAR), a novel iterative retrieve-refine-reason framework that strengthens o1-like reasoning, facilitated by an innovative post-retrieval processing and reward model (PRP-RM) that refines raw retrievals and assigns step-wise scores to guide reasoning more effectively. Experimental results demonstrate an 8.95% relative improvement on average over CoT-prompting on Math500, with PRP-RM achieving competitive performance against fine-tuned reward models, yet without the heavy training or fine-tuning costs.
Despite these merits, the proposed approach indeed has some limitations, such as higher computational overhead and potential cases where KG-RAR may introduce unnecessary noise or fail to enhance reasoning. Our future work will focus on optimising the framework by incorporating active learning to dynamically update KGs, improving retrieval efficiency, and exploring broader applications in complex reasoning domains such as scientific discovery and real-world decision-making.
## References
- [1] J. Huang and K. C.-C. Chang, “Towards reasoning in large language models: A survey,” arXiv preprint arXiv:2212.10403, 2022.
- [2] J. Sun, C. Zheng, E. Xie, Z. Liu, R. Chu, J. Qiu, J. Xu, M. Ding, H. Li, M. Geng et al., “A survey of reasoning with foundation models,” arXiv preprint arXiv:2312.11562, 2023.
- [3] A. Plaat, A. Wong, S. Verberne, J. Broekens, N. van Stein, and T. Back, “Reasoning with large language models, a survey,” arXiv preprint arXiv:2407.11511, 2024.
- [4] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou et al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022.
- [5] X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” arXiv preprint arXiv:2203.11171, 2022.
- [6] S. Zhou, U. Alon, F. F. Xu, Z. Jiang, and G. Neubig, “Docprompting: Generating code by retrieving the docs,” in The Eleventh International Conference on Learning Representations, 2022.
- [7] T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa, “Large language models are zero-shot reasoners,” Advances in neural information processing systems, vol. 35, pp. 22 199–22 213, 2022.
- [8] A. Creswell, M. Shanahan, and I. Higgins, “Selection-inference: Exploiting large language models for interpretable logical reasoning,” arXiv preprint arXiv:2205.09712, 2022.
- [9] N. Shinn, B. Labash, and A. Gopinath, “Reflexion: an autonomous agent with dynamic memory and self-reflection,” arXiv preprint arXiv:2303.11366, 2023.
- [10] S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y. Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [11] W. Chen, X. Ma, X. Wang, and W. W. Cohen, “Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks,” arXiv preprint arXiv:2211.12588, 2022.
- [12] R. Yamauchi, S. Sonoda, A. Sannai, and W. Kumagai, “Lpml: Llm-prompting markup language for mathematical reasoning,” arXiv preprint arXiv:2309.13078, 2023.
- [13] Y. Zhuang, Y. Yu, K. Wang, H. Sun, and C. Zhang, “Toolqa: A dataset for llm question answering with external tools,” Advances in Neural Information Processing Systems, vol. 36, pp. 50 117–50 143, 2023.
- [14] B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y. Adi, J. Liu, R. Sauvestre, T. Remez et al., “Code llama: Open foundation models for code,” arXiv preprint arXiv:2308.12950, 2023.
- [15] L. Yu, W. Jiang, H. Shi, J. Yu, Z. Liu, Y. Zhang, J. T. Kwok, Z. Li, A. Weller, and W. Liu, “Metamath: Bootstrap your own mathematical questions for large language models,” arXiv preprint arXiv:2309.12284, 2023.
- [16] Y. Wu, F. Jia, S. Zhang, H. Li, E. Zhu, Y. Wang, Y. T. Lee, R. Peng, Q. Wu, and C. Wang, “Mathchat: Converse to tackle challenging math problems with llm agents,” in ICLR 2024 Workshop on Large Language Model (LLM) Agents, 2024.
- [17] S. Wu, Z. Peng, X. Du, T. Zheng, M. Liu, J. Wu, J. Ma, Y. Li, J. Yang, W. Zhou et al., “A comparative study on reasoning patterns of openai’s o1 model,” arXiv preprint arXiv:2410.13639, 2024.
- [18] D. Zhang, J. Wu, J. Lei, T. Che, J. Li, T. Xie, X. Huang, S. Zhang, M. Pavone, Y. Li et al., “Llama-berry: Pairwise optimization for o1-like olympiad-level mathematical reasoning,” arXiv preprint arXiv:2410.02884, 2024.
- [19] Y. Zhang, S. Wu, Y. Yang, J. Shu, J. Xiao, C. Kong, and J. Sang, “o1-coder: an o1 replication for coding,” arXiv preprint arXiv:2412.00154, 2024.
- [20] J. Wang, F. Meng, Y. Liang, and J. Zhou, “Drt-o1: Optimized deep reasoning translation via long chain-of-thought,” arXiv preprint arXiv:2412.17498, 2024.
- [21] J. Wang, M. Fang, Z. Wan, M. Wen, J. Zhu, A. Liu, Z. Gong, Y. Song, L. Chen, L. M. Ni et al., “Openr: An open source framework for advanced reasoning with large language models,” arXiv preprint arXiv:2410.09671, 2024.
- [22] H. Luo, L. Shen, H. He, Y. Wang, S. Liu, W. Li, N. Tan, X. Cao, and D. Tao, “O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning,” arXiv preprint arXiv:2501.12570, 2025.
- [23] X. Feng, Z. Wan, M. Wen, Y. Wen, W. Zhang, and J. Wang, “Alphazero-like tree-search can guide large language model decoding and training,” in ICML 2024, 2024.
- [24] S. Hao, Y. Gu, H. Ma, J. J. Hong, Z. Wang, D. Z. Wang, and Z. Hu, “Reasoning with language model is planning with world model,” arXiv preprint arXiv:2305.14992, 2023.
- [25] C. Snell, J. Lee, K. Xu, and A. Kumar, “Scaling llm test-time compute optimally can be more effective than scaling model parameters,” arXiv preprint arXiv:2408.03314, 2024.
- [26] Y. Chen, X. Pan, Y. Li, B. Ding, and J. Zhou, “A simple and provable scaling law for the test-time compute of large language models,” arXiv preprint arXiv:2411.19477, 2024.
- [27] OpenAI, “Learning to reason with llms,” https://openai.com/index/learning-to-reason-with-llms/, 2024.
- [28] DeepSeek-AI, D. Guo, D. Yang, and et al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,” 2025. [Online]. Available: https://arxiv.org/abs/2501.12948
- [29] H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe, “Let’s verify step by step,” arXiv preprint arXiv:2305.20050, 2023.
- [30] K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano et al., “Training verifiers to solve math word problems,” arXiv preprint arXiv:2110.14168, 2021.
- [31] J. Uesato, N. Kushman, R. Kumar, F. Song, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins, “Solving math word problems with process-and outcome-based feedback,” arXiv preprint arXiv:2211.14275, 2022.
- [32] A. Satpute, N. Gießing, A. Greiner-Petter, M. Schubotz, O. Teschke, A. Aizawa, and B. Gipp, “Can llms master math? investigating large language models on math stack exchange,” in Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, 2024, pp. 2316–2320.
- [33] I. Mirzadeh, K. Alizadeh, H. Shahrokhi, O. Tuzel, S. Bengio, and M. Farajtabar, “Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models,” arXiv preprint arXiv:2410.05229, 2024.
- [34] L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin et al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” arXiv preprint arXiv:2311.05232, 2023.
- [35] S. Banerjee, A. Agarwal, and S. Singla, “Llms will always hallucinate, and we need to live with this,” arXiv preprint arXiv:2409.05746, 2024.
- [36] Z. Xu, S. Jain, and M. Kankanhalli, “Hallucination is inevitable: An innate limitation of large language models,” arXiv preprint arXiv:2401.11817, 2024.
- [37] Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, and H. Wang, “Retrieval-augmented generation for large language models: A survey,” arXiv preprint arXiv:2312.10997, 2023.
- [38] W. Fan, Y. Ding, L. Ning, S. Wang, H. Li, D. Yin, T.-S. Chua, and Q. Li, “A survey on rag meeting llms: Towards retrieval-augmented large language models,” in Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 6491–6501.
- [39] B. Peng, Y. Zhu, Y. Liu, X. Bo, H. Shi, C. Hong, Y. Zhang, and S. Tang, “Graph retrieval-augmented generation: A survey,” arXiv preprint arXiv:2408.08921, 2024.
- [40] S. Barnett, S. Kurniawan, S. Thudumu, Z. Brannelly, and M. Abdelrazek, “Seven failure points when engineering a retrieval augmented generation system,” in Proceedings of the IEEE/ACM 3rd International Conference on AI Engineering-Software Engineering for AI, 2024, pp. 194–199.
- [41] Z. Wang, A. Liu, H. Lin, J. Li, X. Ma, and Y. Liang, “Rat: Retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation,” arXiv preprint arXiv:2403.05313, 2024.
- [42] Y. Hu, Z. Lei, Z. Zhang, B. Pan, C. Ling, and L. Zhao, “Grag: Graph retrieval-augmented generation,” arXiv preprint arXiv:2405.16506, 2024.
- [43] X. Li, R. Zhao, Y. K. Chia, B. Ding, S. Joty, S. Poria, and L. Bing, “Chain-of-knowledge: Grounding large language models via dynamic knowledge adapting over heterogeneous sources,” arXiv preprint arXiv:2305.13269, 2023.
- [44] X. He, Y. Tian, Y. Sun, N. V. Chawla, T. Laurent, Y. LeCun, X. Bresson, and B. Hooi, “G-retriever: Retrieval-augmented generation for textual graph understanding and question answering,” arXiv preprint arXiv:2402.07630, 2024.
- [45] R.-C. Chang and J. Zhang, “Communitykg-rag: Leveraging community structures in knowledge graphs for advanced retrieval-augmented generation in fact-checking,” arXiv preprint arXiv:2408.08535, 2024.
- [46] Y. Mu, P. Niu, K. Bontcheva, and N. Aletras, “Predicting and analyzing the popularity of false rumors in weibo,” Expert Systems with Applications, vol. 243, p. 122791, 2024.
- [47] L. Luo, Y.-F. Li, G. Haffari, and S. Pan, “Reasoning on graphs: Faithful and interpretable large language model reasoning,” arXiv preprint arXiv:2310.01061, 2023.
- [48] J. Sun, C. Xu, L. Tang, S. Wang, C. Lin, Y. Gong, H.-Y. Shum, and J. Guo, “Think-on-graph: Deep and responsible reasoning of large language model with knowledge graph,” arXiv preprint arXiv:2307.07697, 2023.
- [49] H. Liu, S. Wang, Y. Zhu, Y. Dong, and J. Li, “Knowledge graph-enhanced large language models via path selection,” arXiv preprint arXiv:2406.13862, 2024.
- [50] L. Luo, Z. Zhao, C. Gong, G. Haffari, and S. Pan, “Graph-constrained reasoning: Faithful reasoning on knowledge graphs with large language models,” arXiv preprint arXiv:2410.13080, 2024.
- [51] Q. Zhang, J. Dong, H. Chen, D. Zha, Z. Yu, and X. Huang, “Knowgpt: Knowledge graph based prompting for large language models,” in The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024.
- [52] N. Choudhary and C. K. Reddy, “Complex logical reasoning over knowledge graphs using large language models,” arXiv preprint arXiv:2305.01157, 2023.
- [53] Z. Zhao, Y. Rong, D. Guo, E. Gözlüklü, E. Gülboy, and E. Kasneci, “Stepwise self-consistent mathematical reasoning with large language models,” arXiv preprint arXiv:2402.17786, 2024.
- [54] S. Ji, S. Pan, E. Cambria, P. Marttinen, and S. Y. Philip, “A survey on knowledge graphs: Representation, acquisition, and applications,” IEEE transactions on neural networks and learning systems, vol. 33, no. 2, pp. 494–514, 2021.
- [55] J. Wang, “Math-kg: Construction and applications of mathematical knowledge graph,” arXiv preprint arXiv:2205.03772, 2022.
- [56] C. Zheng, Z. Zhang, B. Zhang, R. Lin, K. Lu, B. Yu, D. Liu, J. Zhou, and J. Lin, “Processbench: Identifying process errors in mathematical reasoning,” arXiv preprint arXiv:2412.06559, 2024.
- [57] M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, L. Gianinazzi, J. Gajda, T. Lehmann, M. Podstawski, H. Niewiadomski, P. Nyczyk et al., “Graph of thoughts: Solving elaborate problems with large language models,” arXiv preprint arXiv:2308.09687, 2023.
- [58] E. Zelikman, Y. Wu, J. Mu, and N. Goodman, “Star: Bootstrapping reasoning with reasoning,” Advances in Neural Information Processing Systems, vol. 35, pp. 15 476–15 488, 2022.
- [59] Y. Li, Z. Lin, S. Zhang, Q. Fu, B. Chen, J.-G. Lou, and W. Chen, “Making large language models better reasoners with step-aware verifier,” arXiv preprint arXiv:2206.02336, 2022.
- [60] F. Yu, A. Gao, and B. Wang, “Ovm, outcome-supervised value models for planning in mathematical reasoning,” in Findings of the Association for Computational Linguistics: NAACL 2024, 2024, pp. 858–875.
- [61] L. Zhang, A. Hosseini, H. Bansal, M. Kazemi, A. Kumar, and R. Agarwal, “Generative verifiers: Reward modeling as next-token prediction,” arXiv preprint arXiv:2408.15240, 2024.
- [62] H. Paulheim, “Knowledge graph refinement: A survey of approaches and evaluation methods,” Semantic web, vol. 8, no. 3, pp. 489–508, 2016.
- [63] Q. Wang, Z. Mao, B. Wang, and L. Guo, “Knowledge graph embedding: A survey of approaches and applications,” IEEE transactions on knowledge and data engineering, vol. 29, no. 12, pp. 2724–2743, 2017.
- [64] Y. Jing, Y. Yang, X. Wang, M. Song, and D. Tao, “Meta-aggregator: Learning to aggregate for 1-bit graph neural networks,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 5301–5310.
- [65] Y. Jing, C. Yuan, L. Ju, Y. Yang, X. Wang, and D. Tao, “Deep graph reprogramming,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 24 345–24 354.
- [66] D. Sanmartin, “Kg-rag: Bridging the gap between knowledge and creativity,” arXiv preprint arXiv:2405.12035, 2024.
- [67] Y. Wang, N. Lipka, R. A. Rossi, A. Siu, R. Zhang, and T. Derr, “Knowledge graph prompting for multi-document question answering,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 19 206–19 214.
- [68] A. Kau, X. He, A. Nambissan, A. Astudillo, H. Yin, and A. Aryani, “Combining knowledge graphs and large language models,” arXiv preprint arXiv:2407.06564, 2024.
- [69] J. Jiang, K. Zhou, Z. Dong, K. Ye, W. X. Zhao, and J.-R. Wen, “Structgpt: A general framework for large language model to reason over structured data,” arXiv preprint arXiv:2305.09645, 2023.
- [70] Z. Chai, T. Zhang, L. Wu, K. Han, X. Hu, X. Huang, and Y. Yang, “Graphllm: Boosting graph reasoning ability of large language model,” arXiv preprint arXiv:2310.05845, 2023.
- [71] Y. Zhu, X. Wang, J. Chen, S. Qiao, Y. Ou, Y. Yao, S. Deng, H. Chen, and N. Zhang, “Llms for knowledge graph construction and reasoning: Recent capabilities and future opportunities,” World Wide Web, vol. 27, no. 5, p. 58, 2024.
- [72] S. Pan, L. Luo, Y. Wang, C. Chen, J. Wang, and X. Wu, “Unifying large language models and knowledge graphs: A roadmap,” IEEE Transactions on Knowledge and Data Engineering, 2024.
- [73] G. Agrawal, T. Kumarage, Z. Alghamdi, and H. Liu, “Can knowledge graphs reduce hallucinations in llms?: A survey,” arXiv preprint arXiv:2311.07914, 2023.
- [74] A. S. Pinto, A. Kolesnikov, Y. Shi, L. Beyer, and X. Zhai, “Tuning computer vision models with task rewards,” in International Conference on Machine Learning. PMLR, 2023, pp. 33 229–33 239.
- [75] Y. Jing, Y. Yang, X. Wang, M. Song, and D. Tao, “Turning frequency to resolution: Video super-resolution via event cameras,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7772–7781.
- [76] M. Kwon, S. M. Xie, K. Bullard, and D. Sadigh, “Reward design with language models,” arXiv preprint arXiv:2303.00001, 2023.
- [77] Y. Cao, H. Zhao, Y. Cheng, T. Shu, Y. Chen, G. Liu, G. Liang, J. Zhao, J. Yan, and Y. Li, “Survey on large language model-enhanced reinforcement learning: Concept, taxonomy, and methods,” IEEE Transactions on Neural Networks and Learning Systems, 2024.
- [78] Z. Wang, B. Bi, S. K. Pentyala, K. Ramnath, S. Chaudhuri, S. Mehrotra, X.-B. Mao, S. Asur et al., “A comprehensive survey of llm alignment techniques: Rlhf, rlaif, ppo, dpo and more,” arXiv preprint arXiv:2407.16216, 2024.
- [79] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020.
- [80] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” arXiv preprint arXiv:2210.03629, 2022.
- [81] D. Zhou, N. Schärli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. V. Le, and E. H. Chi, “Least-to-most prompting enables complex reasoning in large language models,” in The Eleventh International Conference on Learning Representations, ICLR 2023, 2023.
- [82] X. Wang and D. Zhou, “Chain-of-thought reasoning without prompting,” arXiv preprint arXiv:2402.10200, 2024.
- [83] Y. Zhang, S. Mao, T. Ge, X. Wang, A. de Wynter, Y. Xia, W. Wu, T. Song, M. Lan, and F. Wei, “Llm as a mastermind: A survey of strategic reasoning with large language models,” arXiv preprint arXiv:2404.01230, 2024.
- [84] F. Yu, H. Zhang, P. Tiwari, and B. Wang, “Natural language reasoning, a survey,” ACM Computing Surveys, vol. 56, no. 12, pp. 1–39, 2024.
- [85] L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin et al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” ACM Transactions on Information Systems, 2024.
- [86] Z. Chu, J. Chen, Q. Chen, W. Yu, T. He, H. Wang, W. Peng, M. Liu, B. Qin, and T. Liu, “A survey of chain of thought reasoning: Advances, frontiers and future,” arXiv preprint arXiv:2309.15402, 2023.
- [87] J. Ahn, R. Verma, R. Lou, D. Liu, R. Zhang, and W. Yin, “Large language models for mathematical reasoning: Progresses and challenges,” arXiv preprint arXiv:2402.00157, 2024.
- [88] Z. Li, Y. Cao, X. Xu, J. Jiang, X. Liu, Y. S. Teo, S.-W. Lin, and Y. Liu, “Llms for relational reasoning: How far are we?” in Proceedings of the 1st International Workshop on Large Language Models for Code, 2024, pp. 119–126.
- [89] Y. Wang, W. Zhong, L. Li, F. Mi, X. Zeng, W. Huang, L. Shang, X. Jiang, and Q. Liu, “Aligning large language models with human: A survey,” arXiv preprint arXiv:2307.12966, 2023.
- [90] T. Shen, R. Jin, Y. Huang, C. Liu, W. Dong, Z. Guo, X. Wu, Y. Liu, and D. Xiong, “Large language model alignment: A survey,” arXiv preprint arXiv:2309.15025, 2023.
- [91] S. R. Balseiro, O. Besbes, and D. Pizarro, “Survey of dynamic resource-constrained reward collection problems: Unified model and analysis,” Operations Research, vol. 72, no. 5, pp. 2168–2189, 2024.
- [92] D. Tomaszuk, Ł. Szeremeta, and A. Korniłowicz, “Mmlkg: Knowledge graph for mathematical definitions, statements and proofs,” Scientific Data, vol. 10, no. 1, p. 791, 2023.
- [93] L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing et al., “Judging llm-as-a-judge with mt-bench and chatbot arena,” Advances in Neural Information Processing Systems, vol. 36, pp. 46 595–46 623, 2023.
- [94] D. Li, B. Jiang, L. Huang, A. Beigi, C. Zhao, Z. Tan, A. Bhattacharjee, Y. Jiang, C. Chen, T. Wu et al., “From generation to judgment: Opportunities and challenges of llm-as-a-judge,” arXiv preprint arXiv:2411.16594, 2024.
- [95] Y. Shi, X. Zi, Z. Shi, H. Zhang, Q. Wu, and M. Xu, “Enhancing retrieval and managing retrieval: A four-module synergy for improved quality and efficiency in rag systems,” arXiv preprint arXiv:2407.10670, 2024.
- [96] Y. Cao, Z. Gao, Z. Li, X. Xie, and S. K. Zhou, “Lego-graphrag: Modularizing graph-based retrieval-augmented generation for design space exploration,” arXiv preprint arXiv:2411.05844, 2024.
- [97] D. Mahan, D. Van Phung, R. Rafailov, C. Blagden, N. Lile, L. Castricato, J.-P. Fränken, C. Finn, and A. Albalak, “Generative reward models,” arXiv preprint arXiv:2410.12832, 2024.
- [98] C.-M. Chan, W. Chen, Y. Su, J. Yu, W. Xue, S. Zhang, J. Fu, and Z. Liu, “Chateval: Towards better llm-based evaluators through multi-agent debate,” arXiv preprint arXiv:2308.07201, 2023.
- [99] Y. Talebirad and A. Nadiri, “Multi-agent collaboration: Harnessing the power of intelligent llm agents,” arXiv preprint arXiv:2306.03314, 2023.
- [100] A. Zhao, D. Huang, Q. Xu, M. Lin, Y.-J. Liu, and G. Huang, “Expel: Llm agents are experiential learners,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 19 632–19 642.
- [101] X. Ning, Z. Wang, S. Li, Z. Lin, P. Yao, T. Fu, M. B. Blaschko, G. Dai, H. Yang, and Y. Wang, “Can llms learn by teaching for better reasoning? a preliminary study,” arXiv preprint arXiv:2406.14629, 2024.
- [102] E. Y. Chang, “Prompting large language models with the socratic method,” in 2023 IEEE 13th Annual Computing and Communication Workshop and Conference (CCWC). IEEE, 2023, pp. 0351–0360.
- [103] P. Ke, B. Wen, Z. Feng, X. Liu, X. Lei, J. Cheng, S. Wang, A. Zeng, Y. Dong, H. Wang et al., “Critiquellm: Scaling llm-as-critic for effective and explainable evaluation of large language model generation,” arXiv preprint arXiv:2311.18702, 2023.
- [104] D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the math dataset,” NeurIPS, 2021.
- [105] A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan et al., “The llama 3 herd of models,” arXiv preprint arXiv:2407.21783, 2024.
- [106] A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei et al., “Qwen2. 5 technical report,” arXiv preprint arXiv:2412.15115, 2024.
- [107] E. Charniak and M. Johnson, “Coarse-to-fine n-best parsing and maxent discriminative reranking,” in Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), 2005, pp. 173–180.
- [108] P. Wang, L. Li, Z. Shao, R. Xu, D. Dai, Y. Li, D. Chen, Y. Wu, and Z. Sui, “Math-shepherd: Verify and reinforce llms step-by-step without human annotations,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 9426–9439.
- [109] W. Xiong, H. Zhang, N. Jiang, and T. Zhang, “An implementation of generative prm,” https://github.com/RLHFlow/RLHF-Reward-Modeling, 2024.