# From Language to Cognition: How LLMs Outgrow the Human Language Network
**Authors**:
- Antoine Bosselut Martin Schrimpf (EPFL MIT Georgia Institute of Technology)
## Abstract
Large language models (LLMs) exhibit remarkable similarity to neural activity in the human language network. However, the key properties of language underlying this alignment—and how brain-like representations emerge and change across training—remain unclear. We here benchmark 34 training checkpoints spanning 300B tokens across 8 different model sizes to analyze how brain alignment relates to linguistic competence. Specifically, we find that brain alignment tracks the development of formal linguistic competence—i.e., knowledge of linguistic rules—more closely than functional linguistic competence. While functional competence, which involves world knowledge and reasoning, continues to develop throughout training, its relationship with brain alignment is weaker, suggesting that the human language network primarily encodes formal linguistic structure rather than broader cognitive functions. Notably, we find that the correlation between next-word prediction, behavioral alignment, and brain alignment fades once models surpass human language proficiency. We further show that model size is not a reliable predictor of brain alignment when controlling for the number of features. Finally, using the largest set of rigorous neural language benchmarks to date, we show that language brain alignment benchmarks remain unsaturated, highlighting opportunities for improving future models. Taken together, our findings suggest that the human language network is best modeled by formal, rather than functional, aspects of language. Project Page: language-to-cognition.epfl.ch
From Language to Cognition: How LLMs Outgrow the Human Language Network
Badr AlKhamissi 1 Greta Tuckute 2 Yingtian Tang 1 Taha Binhuraib 3 Antoine Bosselut ∗,1 Martin Schrimpf ∗,1 1 EPFL 2 MIT 3 Georgia Institute of Technology
∗ Equal Supervision
## 1 Introduction
<details>
<summary>figures/brain-score-llms-main-final-final.drawio-4.png Details</summary>
### Visual Description
## Charts: Model Performance Metrics
### Overview
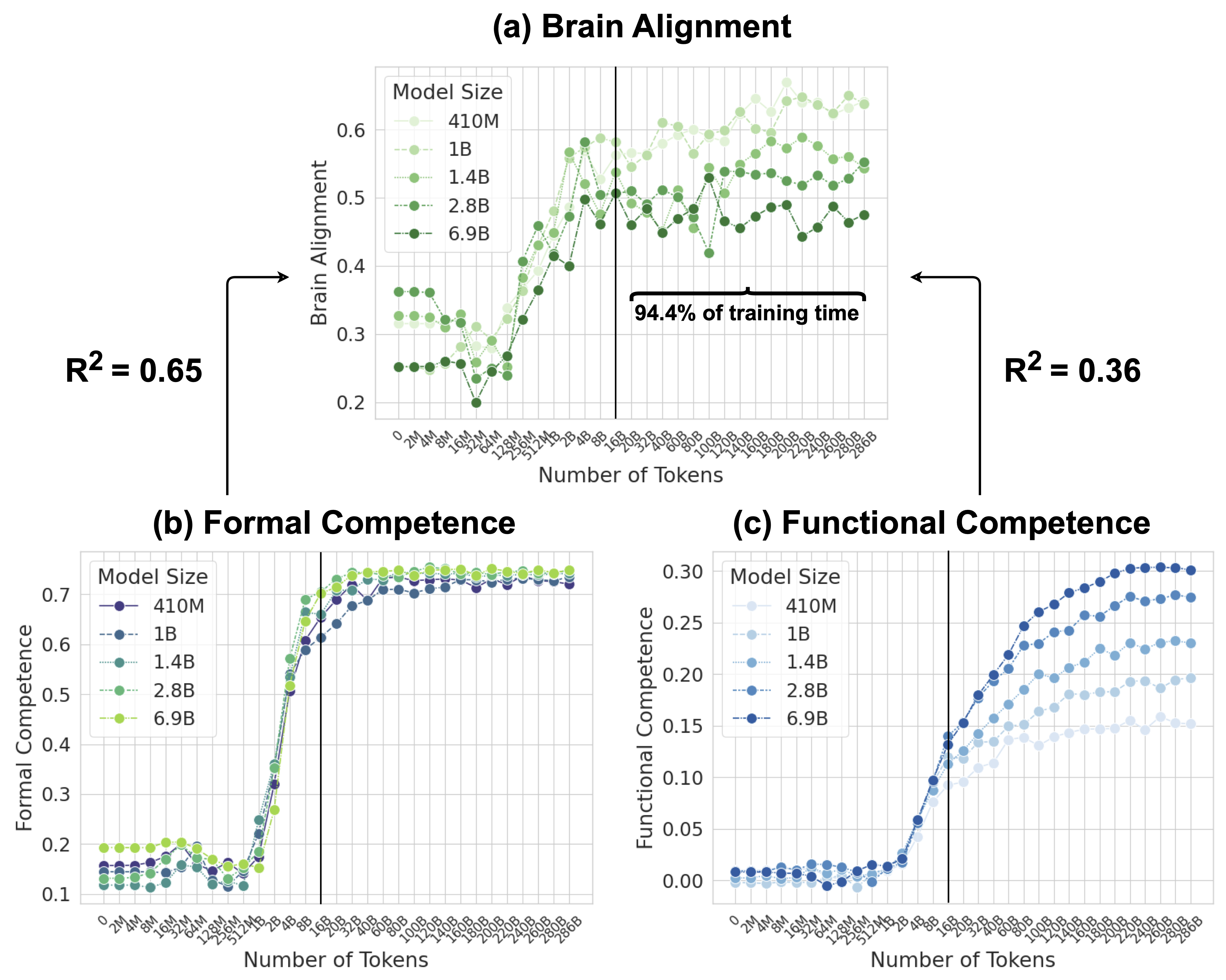
The image presents three scatter plots (a, b, and c) illustrating the performance of different language models (410M, 1B, 1.4B, 2.8B, and 6.9B parameters) across three metrics: Brain Alignment, Formal Competence, and Functional Competence. The x-axis of each plot represents the number of tokens processed during training, and the y-axis represents the corresponding metric value. Each plot includes an R-squared value and a vertical dashed line indicating 94.4% of the training time.
### Components/Axes
* **X-axis (all plots):** Number of Tokens. Scale: 2M to 300B, with markers at 2M, 10M, 50M, 100M, 200M, 500M, 1B, 2B, 5B, 10B, 20B, 50B, 100B, 200B, 300B.
* **Y-axis (a):** Brain Alignment. Scale: 0.2 to 0.6, with markers at 0.2, 0.3, 0.4, 0.5, 0.6.
* **Y-axis (b):** Formal Competence. Scale: 0.1 to 0.7, with markers at 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7.
* **Y-axis (c):** Functional Competence. Scale: 0.0 to 0.3, with markers at 0.0, 0.05, 0.1, 0.15, 0.2, 0.25, 0.3.
* **Legend (all plots):**
* 410M (Light Green)
* 1B (Dark Green)
* 1.4B (Teal)
* 2.8B (Blue)
* 6.9B (Purple)
* **R-squared values:** R² = 0.65 (left side of plot a), R² = 0.36 (right side of plot a).
* **Training Time Marker:** Vertical dashed line at approximately 20B tokens, labeled "94.4% of training time".
### Detailed Analysis or Content Details
**Plot (a): Brain Alignment**
* **410M:** Starts at approximately 0.22, remains relatively flat around 0.25 until approximately 50B tokens, then increases slightly to around 0.28.
* **1B:** Starts at approximately 0.23, increases rapidly to around 0.55 by 50B tokens, then plateaus around 0.58.
* **1.4B:** Starts at approximately 0.24, increases rapidly to around 0.60 by 50B tokens, then plateaus around 0.62.
* **2.8B:** Starts at approximately 0.25, increases rapidly to around 0.58 by 50B tokens, then plateaus around 0.60.
* **6.9B:** Starts at approximately 0.26, increases rapidly to around 0.55 by 50B tokens, then plateaus around 0.58.
* The R-squared value of 0.65 applies to the initial portion of the curves (before the plateau), while 0.36 applies to the plateau region.
**Plot (b): Formal Competence**
* **410M:** Remains consistently low around 0.10 across all token counts.
* **1B:** Remains consistently low around 0.10 across all token counts.
* **1.4B:** Remains consistently low around 0.10 across all token counts.
* **2.8B:** Increases rapidly from approximately 0.10 to around 0.70 by 50B tokens, then plateaus.
* **6.9B:** Increases rapidly from approximately 0.10 to around 0.70 by 50B tokens, then plateaus.
**Plot (c): Functional Competence**
* **410M:** Remains consistently low around 0.01 across all token counts.
* **1B:** Remains consistently low around 0.01 across all token counts.
* **1.4B:** Remains consistently low around 0.01 across all token counts.
* **2.8B:** Increases gradually from approximately 0.01 to around 0.15 by 200B tokens, then increases more rapidly to around 0.25 by 300B tokens.
* **6.9B:** Increases gradually from approximately 0.01 to around 0.10 by 200B tokens, then increases more rapidly to around 0.30 by 300B tokens.
### Key Observations
* Brain Alignment plateaus for all models after approximately 50B tokens.
* Formal Competence shows a clear divergence between smaller models (410M, 1B, 1.4B) and larger models (2.8B, 6.9B).
* Functional Competence exhibits a more gradual increase compared to Brain Alignment and Formal Competence, and continues to improve even after 200B tokens.
* The R-squared values suggest a stronger correlation between the number of tokens and Brain Alignment in the initial training phase.
* The 94.4% training time marker highlights the point at which the models have processed the majority of their training data.
### Interpretation
The data suggests that increasing model size significantly improves Brain Alignment and Formal Competence, but the gains diminish after a certain point (around 50B tokens). Functional Competence, however, continues to improve with more training data, even for the larger models. The plateau in Brain Alignment could indicate that the models are reaching a limit in their ability to align with human brain activity, or that the metric itself is not sensitive enough to capture further improvements. The divergence in Formal Competence highlights the importance of model size for achieving strong performance on formal tasks. The continued improvement in Functional Competence suggests that more training data is beneficial for developing practical skills. The R-squared values provide a quantitative measure of the strength of the relationship between training data and performance, and the difference between the two values in plot (a) suggests a change in the underlying dynamics of the training process. The vertical line at 94.4% of training time is a useful reference point for understanding the performance of the models at different stages of training.
</details>
Figure 1: Model Alignment with the Human Language Network is Primarily Driven by Formal than Functional Linguistic Competence. (a) Average brain alignment across five Pythia models and five brain recording datasets, normalized by cross-subject consistency, throughout training. (b) Average normalized accuracy of the same models on formal linguistic competence benchmarks (two benchmarks). (c) Average normalized accuracy on functional linguistic competence benchmarks (six benchmarks). The x-axis is logarithmically spaced up to 16B tokens, capturing early training dynamics, and then evenly spaced every 20B tokens from 20B to ~300B tokens.
Deciphering the brain’s algorithms underlying our ability to process language and communicate is a core goal in neuroscience. Human language processing is supported by the brain’s language network (LN), a set of left-lateralized fronto-temporal regions in the brain (Binder et al., 1997; Bates et al., 2003; Gorno‐Tempini et al., 2004; Price, 2010; Fedorenko, 2014; Hagoort, 2019) that respond robustly and selectively to linguistic input (Fedorenko et al., 2024a). Driven by recent advances in machine learning, large language models (LLMs) trained via next-word prediction on large corpora of text are now a particularly promising model family to capture the internal processes of the LN. In particular, when these models are exposed to the same linguistic stimuli (e.g., sentences or narratives) as human participants during neuroimaging and electrophysiology experiments, they account for a substantial portion of neural response variance (Schrimpf et al., 2021; Caucheteux and King, 2022; Goldstein et al., 2022; Pasquiou et al., 2022; Aw et al., 2023; Tuckute et al., 2024a; AlKhamissi et al., 2025; Rathi et al., 2025).
### 1.1 Key Questions and Contributions
This work investigates four key questions, all aimed at distilling why LLM aligns to brain responses. Specifically, we investigate the full model development cycle as a combination of model architecture (structural priors) and how linguistic competence emerges across training (developmental experience). We ask: (1) What drives brain alignment in untrained models? (2) Is brain alignment primarily linked to formal or functional linguistic competence (Mahowald et al., 2024)? (3) Do language models diverge from humans as they surpass human-level prediction? (4) Do current LLMs fully account for the explained variance in brain alignment benchmarks? To answer these questions, we introduce a rigorous brain-scoring framework to conduct a controlled and large-scale analysis of LLM brain alignment.
Our findings reveal that the initial brain alignment of models with untrained parameters is driven by context integration. During training, alignment primarily correlates with formal linguistic competence—tasks that probe mastery of grammar, syntax, and compositional rules, such as identifying subject–verb agreement, parsing nested syntactic structures, or completing well-formed sentences. This competence saturates relatively early in training ( $\sim 4$ B tokens), consistent with a plateauing of model-to-brain alignment. Functional linguistic competence, in contrast, concerns how language is used in context to convey meaning, intent, and social/pragmatic content—for example, tasks involving discourse coherence, reference resolution, inference about speaker meaning, or interpreting figurative language. Functional competence emerges later in training, tracks brain alignment less strongly, and continues to grow even after alignment with the language network has saturated.
This disconnect later in training is further exemplified by a fading of the correlation between models’ brain alignment and their next-word-prediction performance, as well as their behavioral alignment. Further, we show that model size is not a reliable predictor of brain alignment when controlling for the number of features, challenging the assumption that larger models necessarily resemble the brain more. Finally, we demonstrate that current brain alignment benchmarks remain unsaturated, indicating that LLMs can still be improved to model human language processing.
## 2 Preliminaries & Related Work
#### A Primer on Language in the Human Brain
The human language network (LN) is a set of left-lateralized frontal and temporal brain regions supporting language. These regions are functionally defined by contrasting responses to language inputs over perceptually matched controls (e.g., lists of non-words) (Fedorenko et al., 2010). The language network exhibits remarkable selectivity for language processing compared to various non-linguistic inputs and tasks, such as music perception (Fedorenko et al., 2012; Chen et al., 2023) or arithmetic computation (Fedorenko et al., 2011; Monti et al., 2012) (for review, see Fedorenko et al. (2024a)) and the language network only shows weak responses when participants comprehend or articulate meaningless non-words (Fedorenko et al., 2010; Hu et al., 2023). This selectivity profile is supported by extensive neuroimaging research and further corroborated by behavioral evidence from aphasia studies: when brain damage is confined to language areas, individuals lose their linguistic abilities while retaining other skills, such as mathematics (Benn et al., 2013; Varley et al., 2005), general reasoning (Varley and Siegal, 2000), and theory of mind (Siegal and Varley, 2006).
#### Model-to-Brain Alignment
Prior work has shown that the internal representations of certain artificial neural networks resemble those in the brain. This alignment was initially observed in the domain of vision (Yamins et al., 2014; Khaligh-Razavi and Kriegeskorte, 2014; Cichy et al., 2016; Schrimpf et al., 2018, 2020; Cadena et al., 2019; Kubilius et al., 2019; Zhuang et al., 2021) and has more recently been extended to auditory processing (Kell et al., 2018; Tuckute et al., 2023; Koumura et al., 2023) and language processing (Schrimpf et al., 2021; Caucheteux and King, 2022; Goldstein et al., 2022; Kauf et al., 2023; Hosseini et al., 2024; Aw et al., 2023; AlKhamissi et al., 2025; Tuckute et al., 2024b; Rathi et al., 2025).
#### Untrained Models
Recent work in vision neuroscience has shown that untrained convolutional networks can yield high brain alignment to recordings in the visual ventral stream without the need for training (Geiger et al., 2022; Kazemian et al., 2024). Other works have investigated the inductive biases in different architectures and initializations in models of visual processing (Cichy et al., 2016; Cadena et al., 2019; Geiger et al., 2022), speech perception (Millet and King, 2021; Tuckute et al., 2023), and language (Schrimpf et al., 2021; Pasquiou et al., 2022; Hosseini et al., 2024), highlighting that randomly initialized networks are not random functions (Teney et al., 2024).
## 3 Methods
### 3.1 Benchmarks for Brain Alignment
#### Neuroimaging & Behavioral Datasets
The neuroimaging datasets used in this work can be categorized along three dimensions: the imaging modality, the context length of the experimental materials, and the modality through which the language stimulus was presented to human participants (auditory or visual). Table 1 in Appendix A provides an overview of all datasets in this study. To focus specifically on language, we consider neural units (electrodes, voxels, or regions) associated with the brain’s language network, as localized by the original dataset authors using the method described in the Section 3.2 and implemented in Brain-Score Schrimpf et al. (2020, 2021) (however, see Appendix J for control brain regions). An exception is the Narratives dataset, which lacks functional localization. We here approximate the language regions using a probabilistic atlas of the human language network (Lipkin et al., 2022), extracting the top-10% language-selective voxels (from the probabilistic atlas) within anatomically defined language parcels, in line with the functional localization procedure used in the other datasets. In an additional analysis, we investigate model alignment with language behavior using the Futrell et al. (2018) dataset, which contains self-paced, per-word human reading times. See Appendix A for details of each dataset. To the best of our knowledge, this study examines the largest number of benchmarks compared to previous work, providing a more comprehensive and reliable foundation for identifying the properties that drive brain alignment in LLMs. The diversity of datasets ensures that our conclusions generalize beyond specific experimental stimuli and paradigms.
#### Brain-Alignment Metrics
Following standard practice in measuring brain alignment, we train a ridge regression model to predict brain activity from model representations, using the same linguistic stimuli presented to human participants in neuroimaging studies (Schrimpf et al., 2020, 2021). We then measure the Pearson correlation between the predicted brain activations and the actual brain activations of human participants on a held-out set that covers entirely different stories or topics (see Section 4). This process is repeated over $k$ cross-validation splits, and we report the average (mean) Pearson correlation as our final result. We refer to this metric as Linear Predictivity. In Section 5.1, we demonstrate why other metrics such as Centered Kernel Alignment (CKA; Kornblith et al., 2019) and Representational Similarity Analysis (RSA; Kriegeskorte et al., 2008) are not suitable measures for brain alignment on current language datasets.
#### Estimation of Cross-Subject Consistency
To assess the reliability of our datasets and account for the inherent noise in brain recordings, we compute a cross-subject consistency score (Feather et al., 2025), also referred to as the noise ceiling (Schrimpf et al., 2021). The consistency score is estimated by predicting the brain activity of a held-out subject using data from all other subjects, through 10-fold cross-validation of all subjects. To obtain a conservative ceiling estimate, we extrapolate subject pool sizes and report the final value based on extrapolation to infinitely many subjects. For Tuckute2024 we use the theoretical estimate provided by (Tuckute et al., 2024b). Consistency scores are provided in Appendix K. To aggregate scores across benchmarks, we normalize each model’s Pearson correlation ( $r$ ) score for Linear Predictivity by the cross-subject consistency estimate, using the formula: ( $\textnormal{normalized score}=\frac{\textnormal{raw score}}{\textnormal{consistency}}$ ). The final alignment score for each model is reported as the average across all benchmarks. Otherwise, when reporting raw alignment, we compute the mean Pearson correlation across datasets without normalization.
### 3.2 Functional Localization
The human language network (LN) is defined functionally which means that units are chosen according to a ‘localizer’ experiment (Saxe et al., 2006). Specifically, the LN is the set of neural units (e.g., voxels/electrodes) that are more selective to sentences over a perceptually-matched control condition (Fedorenko et al., 2010). When selecting units from artificial models for comparison against LN units, previous work selected output units from an entire Transformer block based on brain alignment scores (Schrimpf et al., 2021). However, LLMs learn diverse concepts and behaviors during their considerable pretraining, not all of which are necessarily related to language processing, e.g., storage of knowledge (AlKhamissi et al., 2022) and the ability to perform complex reasoning (Huang and Chang, 2023). Therefore, we here follow the method proposed by AlKhamissi et al. (2025) that identifies language units in LLMs using functional localization as is already standard in neuroscience. This approach offers a key advantage: it enables direct comparisons across models by selecting a fixed set of units, identified through the independent localizer experiment. In this work, we localize $128$ units for all models unless otherwise specified, and we show in Appendix H that the results hold when selecting a different number of units.
<details>
<summary>figures/brain-score-llms-untrained-greens.drawio.png Details</summary>
### Visual Description
## Bar Charts & Diagram: Neural Network Alignment & Accuracy
### Overview
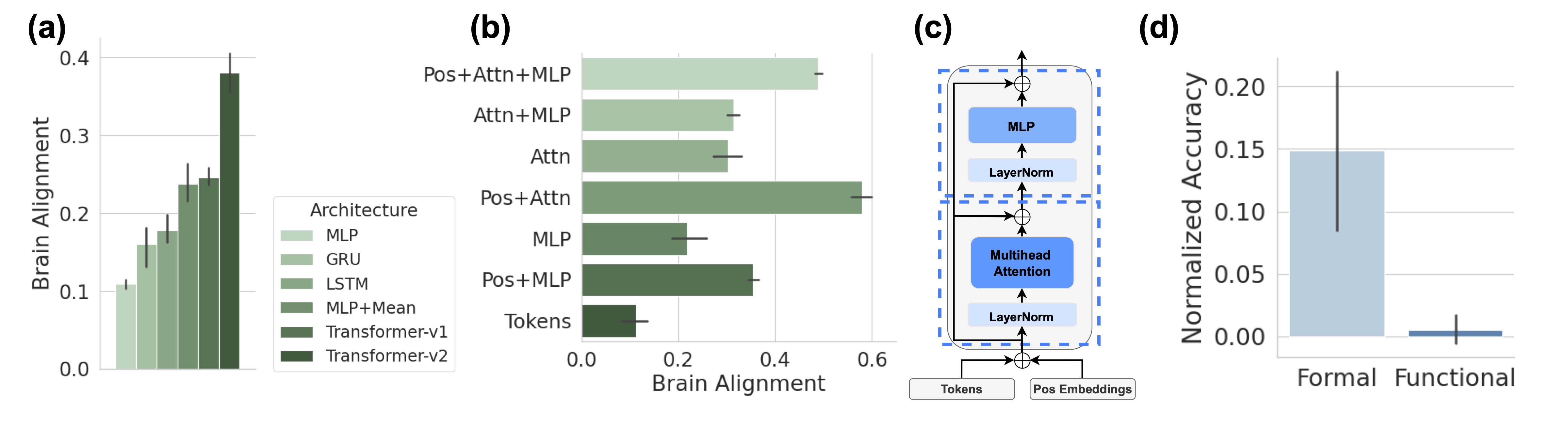
The image presents a series of four sub-figures (a, b, c, and d) illustrating the brain alignment scores of different neural network architectures and a diagram of a Transformer architecture, alongside a comparison of normalized accuracy between "Formal" and "Functional" approaches. Sub-figures (a) and (b) are bar charts with error bars, (c) is a diagram of a Transformer block, and (d) is a bar chart.
### Components/Axes
* **(a) Brain Alignment vs. Architecture:**
* X-axis: Architecture (MLP, GRU, LSTM, MLP+Mean, Transformer-v1, Transformer-v2)
* Y-axis: Brain Alignment (ranging from 0.0 to 0.4)
* **(b) Brain Alignment vs. Architecture:**
* X-axis: Architecture (MLP, Pos+MLP)
* Y-axis: Brain Alignment (ranging from 0.0 to 0.6)
* **(c) Transformer Block Diagram:**
* Components: Tokens, Pos Embeddings, Multihead Attention, LayerNorm, MLP. Arrows indicate data flow.
* **(d) Normalized Accuracy vs. Approach:**
* X-axis: Approach (Formal, Functional)
* Y-axis: Normalized Accuracy (ranging from 0.0 to 0.2)
* **Legend (a):**
* MLP: Light Green
* GRU: Medium Green
* LSTM: Dark Green
* MLP+Mean: Brown
* Transformer-v1: Dark Gray
* Transformer-v2: Black
* **Legend (b):**
* MLP: Light Green
* Pos+MLP: Dark Green
### Detailed Analysis or Content Details
**(a) Brain Alignment vs. Architecture:**
* **MLP:** Approximately 0.25 ± 0.05. The error bar extends from roughly 0.15 to 0.35.
* **GRU:** Approximately 0.18 ± 0.08. The error bar extends from roughly 0.10 to 0.26.
* **LSTM:** Approximately 0.22 ± 0.06. The error bar extends from roughly 0.16 to 0.28.
* **MLP+Mean:** Approximately 0.32 ± 0.07. The error bar extends from roughly 0.25 to 0.39.
* **Transformer-v1:** Approximately 0.35 ± 0.06. The error bar extends from roughly 0.29 to 0.41.
* **Transformer-v2:** Approximately 0.38 ± 0.04. The error bar extends from roughly 0.34 to 0.42.
**(b) Brain Alignment vs. Architecture:**
* **MLP:** Approximately 0.45 ± 0.05. The error bar extends from roughly 0.40 to 0.50.
* **Pos+MLP:** Approximately 0.52 ± 0.04. The error bar extends from roughly 0.48 to 0.56.
**(c) Transformer Block Diagram:**
* Tokens and Pos Embeddings are fed into a Multihead Attention layer.
* The output of Multihead Attention is passed through a LayerNorm.
* The output of LayerNorm is passed through an MLP (Multi-Layer Perceptron).
* The output of MLP is passed through another LayerNorm.
* Arrows indicate the flow of data from Tokens/Pos Embeddings -> Multihead Attention -> LayerNorm -> MLP -> LayerNorm.
**(d) Normalized Accuracy vs. Approach:**
* **Formal:** Approximately 0.16 ± 0.03. The error bar extends from roughly 0.13 to 0.19.
* **Functional:** Approximately 0.01 ± 0.01. The error bar extends from roughly 0.00 to 0.02.
### Key Observations
* Transformer-v2 consistently shows the highest brain alignment score in (a).
* Pos+MLP shows a higher brain alignment score than MLP in (b).
* The "Formal" approach exhibits significantly higher normalized accuracy than the "Functional" approach in (d).
* The error bars in (a) and (d) indicate some variability in the data.
### Interpretation
The data suggests that more complex architectures, specifically Transformer-v2, demonstrate a stronger alignment with brain activity as measured by the "Brain Alignment" metric. The addition of positional embeddings (Pos+MLP) also improves brain alignment compared to a standard MLP. The Transformer diagram (c) illustrates the core components of this architecture, highlighting the role of attention mechanisms and normalization layers.
The stark difference in normalized accuracy between the "Formal" and "Functional" approaches (d) indicates that the "Formal" approach is substantially more effective in this context. This could be due to the "Formal" approach being better suited to capture the underlying structure of the data or the task at hand.
The error bars suggest that there is some degree of uncertainty in the measurements, and further investigation may be needed to confirm these findings. The use of error bars is a good practice, as it acknowledges the inherent variability in experimental data. The combination of brain alignment scores and accuracy metrics provides a comprehensive evaluation of the different neural network architectures and approaches.
</details>
Figure 2: Context Integration drives Brain Alignment of Untrained Models. (a) Sequence-based models (GRU, LSTM, Transformers, and mean pooling) achieve higher brain alignment than models that rely solely on the last token representation (Linear, MLP), highlighting the importance of temporal integration. Error bars report five random initializations in all subplots. (b) Ablation study of architectural components in a single untrained Transformer-v2 block, demonstrating that attention mechanisms combined with positional encoding yield the highest brain alignment. (c) Diagram of the Transformer block architecture used in (b), with components grouped into attention (lower box) and MLP (upper box). (d) The average performance of five Pythia models with untrained parameters on formal and functional linguistic competence benchmarks, showing that formal competence exceeds chance level even in untrained parameter models.
### 3.3 Benchmarks for Linguistic Competence
There is substantial evidence in neuroscience research that formal and functional linguistic competence are governed by distinct neural mechanisms Mahowald et al. (2024); Fedorenko et al. (2024a, b). Formal linguistic competence pertains to the knowledge of linguistic rules and patterns, while functional linguistic competence involves using language to interpret and interact with the world. Therefore, to accurately track the evolution of each type of competence during training, we focus on benchmarks that specifically target these cognitive capacities in LLMs.
#### Formal Linguistic Competence
To assess formal linguistic competence, we use two benchmarks: BLiMP (Warstadt et al., 2019) and SyntaxGym (Gauthier et al., 2020). BLiMP evaluates key grammatical phenomena in English through 67 tasks, each containing 1,000 minimal pairs designed to test specific contrasts in syntax, morphology, and semantics. Complementing this, SyntaxGym consists of 31 tasks that systematically measure the syntactic knowledge of language models. Together, these benchmarks provide a robust framework for evaluating how well LLMs acquire and apply linguistic rules.
#### Functional Linguistic Competence
Functional competence extends beyond linguistic rules, engaging a broader set of cognitive mechanisms. To assess this, we use six benchmarks covering world knowledge (ARC-Easy, ARC-Challenge (Clark et al., 2018)), social reasoning (Social IQa (Sap et al., 2019)), physical reasoning (PIQA (Bisk et al., 2019)), and commonsense reasoning (WinoGrande (Sakaguchi et al., 2019), HellaSwag (Zellers et al., 2019)). Together, these benchmarks provide a comprehensive evaluation of an LLM’s ability to reason, infer implicit knowledge, and navigate real-world contexts.
#### Metrics
Inline with prior work, we evaluate all benchmarks in a zero-shot setting, using surprisal as the evaluation metric. where the model’s prediction is determined by selecting the most probable candidate, as packaged in the language model evaluation harness (Gao et al., 2024). We report accuracy normalized by chance performance, where 0% indicates performance at the random chance level.
#### Benchmark for Language Modeling
We use a subset of FineWebEdu Penedo et al. (2024) to evaluate the perplexity of the models on a held-out set. Specifically, use a maximum sequence length of 2048, and evaluate on the first 1000 documents of the Ay CC-MAIN-2024-10 subset.
### 3.4 Large Language Models (LLMs)
Throughout this work, we use eight models from the Pythia model suite (Biderman et al., 2023), spanning a range of sizes: {14M, 70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B}. Each model is evaluated across 34 training checkpoints, spanning approximately 300B tokens. These checkpoints include the untrained model, the final trained model, and 16 intermediate checkpoints that are logarithmically spaced up to 128B tokens. The remaining 14 checkpoints are evenly spaced every 20B tokens from 20B to 280B tokens, ensuring a comprehensive analysis of alignment trends throughout training. Since smaller models fail to surpass chance performance on many functional benchmarks, we exclude 14M, 70M, 160M from analyses that compare brain alignment with functional performance.
## 4 Rigorous Brain-Scoring
While substantial progress has been made in measuring alignment between LLM representations and neural activity, there’s no standard for comparing brain alignment across datasets and conditions. Therefore, to ensure we perform meaningful inferences, we propose two criteria: (1) alignment should reflect stimulus-driven responses, dropping for random token sequences; and (2) models should generalize to new linguistic contexts. We justify our metrics and cross-validation choices accordingly. For all benchmarks, we identify language-selective units to ensure fair model comparisons, consistent with neural site selection in neuroscience AlKhamissi et al. (2025).
### 4.1 Robust Metrics and Generalization Tests
#### Measuring Stimulus-Driven Responses
We first ask if the alignment procedure is meaningful, i.e., whether the encoding models capture meaningful linguistic information and generalize to new linguistic contexts. Figure 6 (a) in Appendix B shows average brain alignment across all brain datasets under three conditions: (1) a pretrained model processing original stimuli, (2) a pretrained model processing random token sequences, and (3) an untrained model processing original stimuli. To evaluate metric reliability, we expect random sequences to yield significantly lower alignment than real stimuli. However, CKA fails this criterion, assigning similar alignment scores to both, and even untrained models surpass pretrained ones. In contrast, linear predictivity differentiates between real and random stimuli, more so than RSA.
#### Generalization and Contextualization
The second criterion we propose is that LLMs with high brain alignment should be able to generalize to held-out stimuli, with a preference for generalizing far outside the stimuli used for mapping the model to brain activity. A key factor in designing a corresponding cross-validation scheme is contextualization—how the data is split into train and test sets Feghhi et al. (2024). The Pereira2018 dataset consists of 24 topics composed of multi-sentence passages, and sentences are presented in their original order to both humans and models. A random sentence split (contextualization) allows sentences from the same topic in both train and test sets, and is thus less demanding of generalization. A stronger generalization test ensures entire topics are held out, preventing models from leveraging shared context. Figure 6 (b) shows that contextualization makes it easier for the model to predict brain activity. In contrast, topic-based splits halve the raw alignment score for pretrained models. The score of untrained models is reduced even more strongly when enforcing generalization across topics, suggesting that much of their alignment is context-dependent. Nonetheless, untrained models retain significant alignment – about 50% of pretrained models – even with strong generalization requirements.
<details>
<summary>figures/brain-score-llms-brain-alignment-final.drawio.png Details</summary>
### Visual Description
\n
## Line Chart: Brain Alignment vs. Number of Tokens for Pythia Models
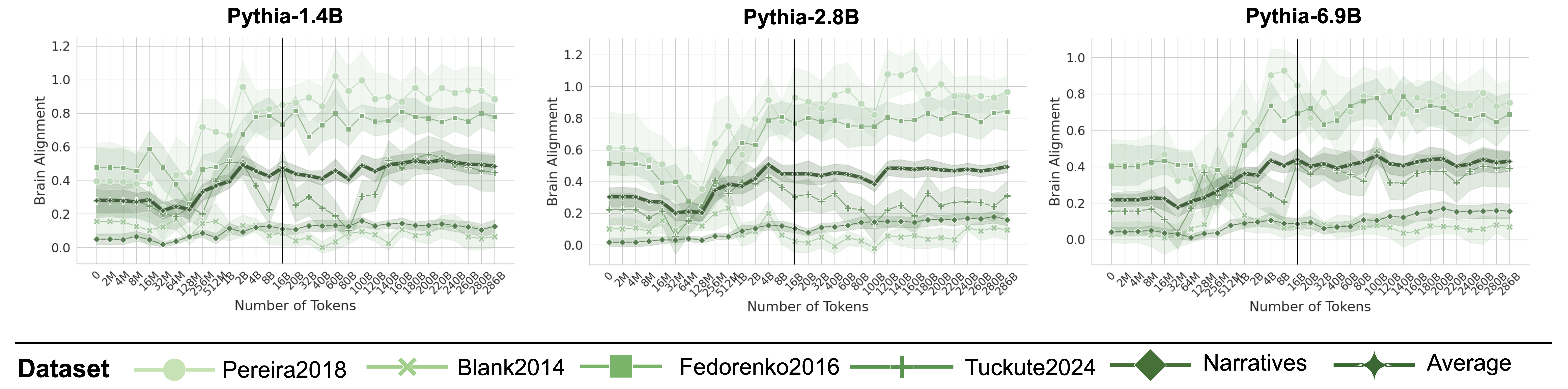
### Overview
The image presents three line charts, each displaying the relationship between "Brain Alignment" and "Number of Tokens" for different Pythia language models: Pythia-1.4B, Pythia-2.8B, and Pythia-6.9B. Each chart plots the brain alignment scores for several datasets as a function of the number of tokens. A legend at the bottom identifies the datasets and their corresponding line colors.
### Components/Axes
* **X-axis:** "Number of Tokens" - Ranges from approximately 0 to 1000 tokens. The scale is linear.
* **Y-axis:** "Brain Alignment" - Ranges from 0.0 to 1.2 (varying slightly between charts). The scale is linear.
* **Charts:** Three separate charts, one for each Pythia model:
* Pythia-1.4B
* Pythia-2.8B
* Pythia-6.9B
* **Legend:** Located at the bottom of the image. It identifies the datasets represented by each line color:
* Pereira2018 (Light Green)
* Blank2014 (Light Blue)
* Fedorenko2016 (Dark Green)
* Tuckute2024 (Light Grey)
* Narratives (Dark Grey)
* Average (Black)
### Detailed Analysis or Content Details
**Pythia-1.4B:**
* **Pereira2018 (Light Green):** Line starts at approximately 0.2, fluctuates between 0.2 and 0.4, with a slight upward trend towards the end, reaching around 0.45.
* **Blank2014 (Light Blue):** Line starts at approximately 0.05, remains relatively low, fluctuating between 0.0 and 0.15.
* **Fedorenko2016 (Dark Green):** Line starts at approximately 0.3, increases to a peak of around 0.5 at approximately 200 tokens, then declines to around 0.3.
* **Tuckute2024 (Light Grey):** Line starts at approximately 0.05, fluctuates between 0.0 and 0.2.
* **Narratives (Dark Grey):** Line starts at approximately 0.1, fluctuates between 0.05 and 0.25.
* **Average (Black):** Line starts at approximately 0.2, increases to a peak of around 0.35 at approximately 200 tokens, then declines to around 0.25.
**Pythia-2.8B:**
* **Pereira2018 (Light Green):** Line starts at approximately 0.3, increases to a peak of around 0.7 at approximately 400 tokens, then declines to around 0.5.
* **Blank2014 (Light Blue):** Line starts at approximately 0.05, remains relatively low, fluctuating between 0.0 and 0.2.
* **Fedorenko2016 (Dark Green):** Line starts at approximately 0.4, increases to a peak of around 0.8 at approximately 400 tokens, then declines to around 0.6.
* **Tuckute2024 (Light Grey):** Line starts at approximately 0.1, fluctuates between 0.05 and 0.3.
* **Narratives (Dark Grey):** Line starts at approximately 0.15, fluctuates between 0.05 and 0.3.
* **Average (Black):** Line starts at approximately 0.3, increases to a peak of around 0.5 at approximately 400 tokens, then declines to around 0.4.
**Pythia-6.9B:**
* **Pereira2018 (Light Green):** Line starts at approximately 0.4, increases to a peak of around 0.9 at approximately 400 tokens, then declines to around 0.7.
* **Blank2014 (Light Blue):** Line starts at approximately 0.05, remains relatively low, fluctuating between 0.0 and 0.2.
* **Fedorenko2016 (Dark Green):** Line starts at approximately 0.5, increases to a peak of around 0.9 at approximately 400 tokens, then declines to around 0.7.
* **Tuckute2024 (Light Grey):** Line starts at approximately 0.1, fluctuates between 0.05 and 0.3.
* **Narratives (Dark Grey):** Line starts at approximately 0.2, fluctuates between 0.1 and 0.4.
* **Average (Black):** Line starts at approximately 0.4, increases to a peak of around 0.6 at approximately 400 tokens, then declines to around 0.5.
### Key Observations
* The "Average" line generally shows an initial increase in brain alignment with the number of tokens, followed by a decline.
* The "Pereira2018" and "Fedorenko2016" datasets consistently exhibit higher brain alignment scores compared to "Blank2014," "Tuckute2024," and "Narratives."
* As the model size increases (from 1.4B to 6.9B), the peak brain alignment scores generally increase.
* The "Blank2014" dataset consistently shows the lowest brain alignment scores across all models.
### Interpretation
The charts demonstrate how brain alignment, a measure of how well a language model's internal representations correlate with human brain activity, changes as the model processes more tokens. The initial increase in alignment suggests that the model is initially learning to represent information in a way that is more aligned with human understanding. The subsequent decline could indicate that the model is either overfitting to the training data or encountering limitations in its ability to maintain alignment as the context grows.
The differences in alignment scores between datasets suggest that some datasets are more conducive to learning human-like representations than others. The consistently high scores for "Pereira2018" and "Fedorenko2016" might indicate that these datasets contain more naturalistic or cognitively relevant language.
The increasing peak alignment scores with larger model sizes suggest that larger models have a greater capacity to learn and maintain human-aligned representations, at least up to a certain point. However, the decline in alignment after the peak suggests that simply increasing model size is not sufficient to achieve perfect alignment. Further research is needed to understand the factors that contribute to this decline and to develop techniques for improving brain alignment in large language models.
</details>
Figure 3: Brain Alignment Saturates Early on in Training. Plots indicate the brain alignment scores of three models from the Pythia model suite with varying sizes (log x-axis up to 16B tokens, uneven spacing after black line). Scores are normalized by their cross-subject consistency scores. Alignment quickly peaks around 2–8B tokens before saturating or declining, regardless of model size (see Appendix D and F for more models).
## 5 Results
The following sections progressively unpack the emergence and limits of brain alignment with the human language network in LLMs. Section 5.1 establishes the foundation by showing that untrained models already exhibit modest brain alignment, pointing to the role of architectural priors. Building on this, Section 5.2 tracks how alignment evolves with training and reveals that it strongly correlates with the early acquisition of formal linguistic competence, but less so with functional abilities. Section 5.3 then shows that as models exceed human-level performance in next-word prediction, their brain and behavioral alignment begins to diverge, suggesting that at this point, LLMs outgrow their initial alignment with human language processing.
### 5.1 Brain Alignment of Untrained Models
In Figure 6 we show that untrained models, despite achieving lower alignment scores than their pretrained counterparts ( $\sim 50\$ ), still achieve relatively decent alignment and surpass that of the models evaluated with a random sequence of tokens. Therefore, we here ask, what are the main drivers for this surprising alignment.
#### Inductive Biases of Untrained Models
We evaluate the brain alignment of various LLMs with untrained parameters to determine which architecture exhibits the strongest inductive bias toward the human language network. Figure 2 (a) presents the average alignment across five different random initializations for six different untrained models. Each model consists of a stack of two building blocks from its respective architecture, with a hidden state of $1024$ . To ensure a fair comparison, we apply the localizer to the output representations of the last token in the sequence from these two blocks, extracting 128 units to predict brain activity. Our findings reveal two key insights. First, sequence-based models—such as GRU, LSTM, Transformers, and even a simple mean operation over token representations—exhibit higher brain alignment than models that rely solely on the last token’s representation, such as Linear or MLP. In other words, context or temporal integration is a crucial factor in achieving high alignment. Second, we observe a notable difference between Transformer-v1 and Transformer-v2. While Transformer-v2 applies static positional embeddings by directly adding them to token embeddings, Transformer-v1 uses rotary position encoding. Our results suggest that static positional encoding enables models to capture intrinsic temporal dynamics in sentences—possibly tracking evolving word positions—providing further evidence that temporal integration is critical for brain-like language representations.
<details>
<summary>figures/brain-score-llms-lineplot-correlations.drawio.png Details</summary>
### Visual Description
\n
## Chart: Alignment and Competence vs. Number of Tokens for Pythia Models
### Overview
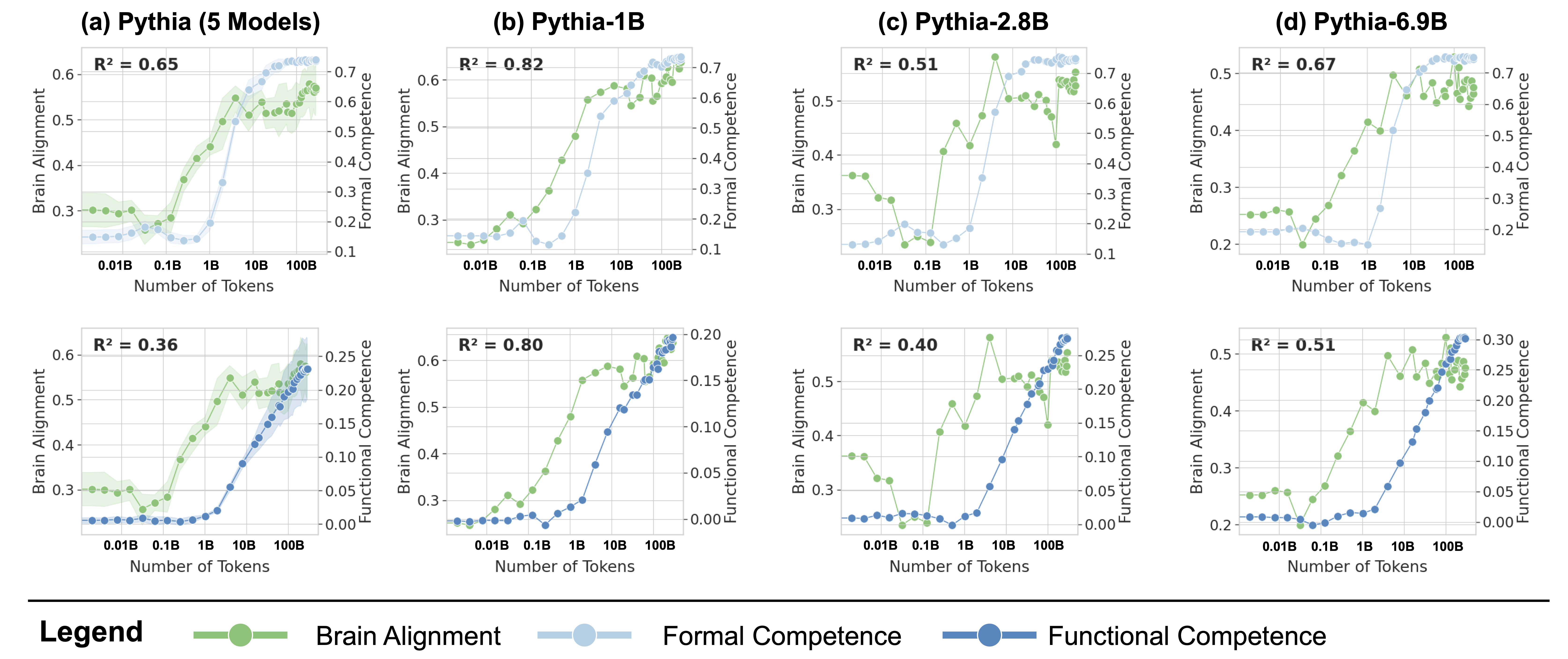
This image presents a series of six line charts comparing Brain Alignment, Formal Competence, and Functional Competence across different Pythia language models (Pythia-5 Models, Pythia-1B, Pythia-2.8B, and Pythia-6.9B) as a function of the number of tokens generated. Each chart displays two y-axes (left for Alignment, right for Competence) and an x-axis representing the number of tokens, ranging from 0.01B to 100B. R-squared values are provided for each chart.
### Components/Axes
* **X-axis (all charts):** Number of Tokens (scale: 0.01B, 1B, 10B, 100B).
* **Y-axis (left, all charts):** Brain Alignment (scale: 0.2 to 0.6).
* **Y-axis (right, all charts):** Formal Competence / Functional Competence (scales vary between charts, ranging from approximately 0.1 to 0.7 for Formal Competence and 0.0 to 0.25 for Functional Competence).
* **Charts:** Arranged in a 2x4 grid.
* (a) Pythia (5 Models)
* (b) Pythia-1B
* (c) Pythia-2.8B
* (d) Pythia-6.9B
* (e) Pythia (5 Models) - Functional Competence
* (f) Pythia-1B - Functional Competence
* (g) Pythia-2.8B - Functional Competence
* (h) Pythia-6.9B - Functional Competence
* **Legend (bottom-left):**
* Brain Alignment (Blue Line)
* Formal Competence (Green Line)
* Functional Competence (Orange Line)
* **R-squared values:** Displayed in the top-left corner of each chart.
### Detailed Analysis or Content Details
**Chart (a) Pythia (5 Models) - Brain Alignment & Formal Competence**
* R² = 0.65
* Brain Alignment (Blue): Starts at approximately 0.32, increases rapidly to a peak of around 0.58 at 10B tokens, then plateaus and slightly declines.
* Formal Competence (Green): Starts at approximately 0.35, increases steadily to around 0.65 at 100B tokens.
**Chart (b) Pythia-1B - Brain Alignment & Formal Competence**
* R² = 0.82
* Brain Alignment (Blue): Starts at approximately 0.30, increases rapidly to a peak of around 0.60 at 1B tokens, then declines to approximately 0.45 at 100B tokens.
* Formal Competence (Green): Starts at approximately 0.30, increases steadily to around 0.70 at 100B tokens.
**Chart (c) Pythia-2.8B - Brain Alignment & Formal Competence**
* R² = 0.51
* Brain Alignment (Blue): Starts at approximately 0.35, increases to a peak of around 0.55 at 1B tokens, then fluctuates around 0.50.
* Formal Competence (Green): Starts at approximately 0.40, increases steadily to around 0.65 at 100B tokens.
**Chart (d) Pythia-6.9B - Brain Alignment & Formal Competence**
* R² = 0.67
* Brain Alignment (Blue): Starts at approximately 0.35, increases to a peak of around 0.60 at 1B tokens, then fluctuates around 0.50.
* Formal Competence (Green): Starts at approximately 0.25, increases steadily to around 0.70 at 100B tokens.
**Chart (e) Pythia (5 Models) - Brain Alignment & Functional Competence**
* R² = 0.36
* Brain Alignment (Blue): Similar trend to (a), starting at approximately 0.32, peaking around 0.58 at 10B tokens, then plateauing.
* Functional Competence (Orange): Starts at approximately 0.05, increases steadily to around 0.20 at 100B tokens.
**Chart (f) Pythia-1B - Brain Alignment & Functional Competence**
* R² = 0.80
* Brain Alignment (Blue): Similar trend to (b), starting at approximately 0.30, peaking around 0.60 at 1B tokens, then declining.
* Functional Competence (Orange): Starts at approximately 0.05, increases steadily to around 0.25 at 100B tokens.
**Chart (g) Pythia-2.8B - Brain Alignment & Functional Competence**
* R² = 0.40
* Brain Alignment (Blue): Similar trend to (c), starting at approximately 0.35, peaking around 0.55 at 1B tokens, then fluctuating.
* Functional Competence (Orange): Starts at approximately 0.05, increases steadily to around 0.20 at 100B tokens.
**Chart (h) Pythia-6.9B - Brain Alignment & Functional Competence**
* R² = 0.51
* Brain Alignment (Blue): Similar trend to (d), starting at approximately 0.35, peaking around 0.60 at 1B tokens, then fluctuating.
* Functional Competence (Orange): Starts at approximately 0.05, increases steadily to around 0.25 at 100B tokens.
### Key Observations
* Brain Alignment generally peaks around 1B to 10B tokens for all models, then plateaus or slightly declines.
* Formal Competence consistently increases with the number of tokens for all models.
* Functional Competence also increases with the number of tokens, but at a slower rate and to a lower overall value than Formal Competence.
* Pythia-1B shows a strong correlation (R² = 0.82 and 0.80) between the number of tokens and both Brain Alignment and Formal Competence.
* The R-squared values for Functional Competence are generally lower than those for Brain Alignment and Formal Competence, indicating a weaker relationship.
### Interpretation
The charts demonstrate how different aspects of language model performance (Brain Alignment, Formal Competence, and Functional Competence) evolve as the model generates more tokens. The initial rapid increase in Brain Alignment suggests that the model quickly learns to align with human cognitive patterns. The consistent increase in Formal Competence indicates that the model's ability to follow grammatical rules and logical structures improves with more generated text. The slower growth of Functional Competence suggests that achieving practical, real-world usefulness is more challenging than simply mastering formal language skills.
The differences between the models (Pythia-5 Models, Pythia-1B, Pythia-2.8B, and Pythia-6.9B) highlight the impact of model size on these metrics. Larger models (e.g., Pythia-6.9B) generally exhibit higher levels of Formal Competence, but the relationship between model size and Brain Alignment/Functional Competence is less clear. The relatively high R-squared values for Pythia-1B suggest that this model may be particularly sensitive to the number of tokens generated, potentially indicating a more efficient learning process within its size constraints. The lower R-squared values for Functional Competence across all models suggest that this metric is influenced by factors beyond simply the number of tokens generated, such as the quality of the training data and the specific tasks the model is evaluated on.
</details>
Figure 4: Formal Competence Tracks Brain Alignment More Closely Than Functional Competence. Each column compares how the evolution of formal competence (top) and functional competence (bottom) tracks the evolution of brain alignment during training. The $R^{2}$ values quantify the strength of this relationship, with higher values in formal competence suggesting it as the key driver of the observed brain alignment. (a): The data averaged across models of five different sizes. (b-d): the same comparison as in (a), but with comparisons were made for models from the Pythia suite with three different sizes.
#### Key Components of Transformers
To further isolate the key elements responsible for brain alignment in untrained parameter models, we perform an ablation study on the architectural components of Transformer-v2 using a single block (Figure 2 (c)). By focusing on the untrained model, we isolate the effect of architecture alone, without confounding influences from training. The architectural components analyzed are labeled on the left of each bar in Figure 2 (b). Ay Attn refers to all components inside the lower box in Figure 2 (c), including the first layer norm, multi-head attention, and the residual connection that follows. Ay MLP corresponds to the components in the upper box, comprising the post-attention layer norm, MLP, and the subsequent residual layer. Ay Pos represents the addition of positional embeddings to token embeddings. Ay Tokens means the model directly returns the raw token embeddings without further processing. This systematic ablation helps pinpoint the components that contribute most to brain alignment. Once again, we observe that integration across tokens, via attention mechanisms and positional encoding, yields the highest brain alignment. Further, we found that untrained parameter models perform better than chance-level performance on formal competence benchmarks, mirroring their non-zero brain alignment. In contrast, functional competence benchmarks remain at chance level for untrained models. This further supports the finding that brain alignment is primarily driven by formal, rather than functional, linguistic competence. (see Figure 2 (d)).
<details>
<summary>figures/brain-score-llms-correlation-ppl-behavior.drawio.png Details</summary>
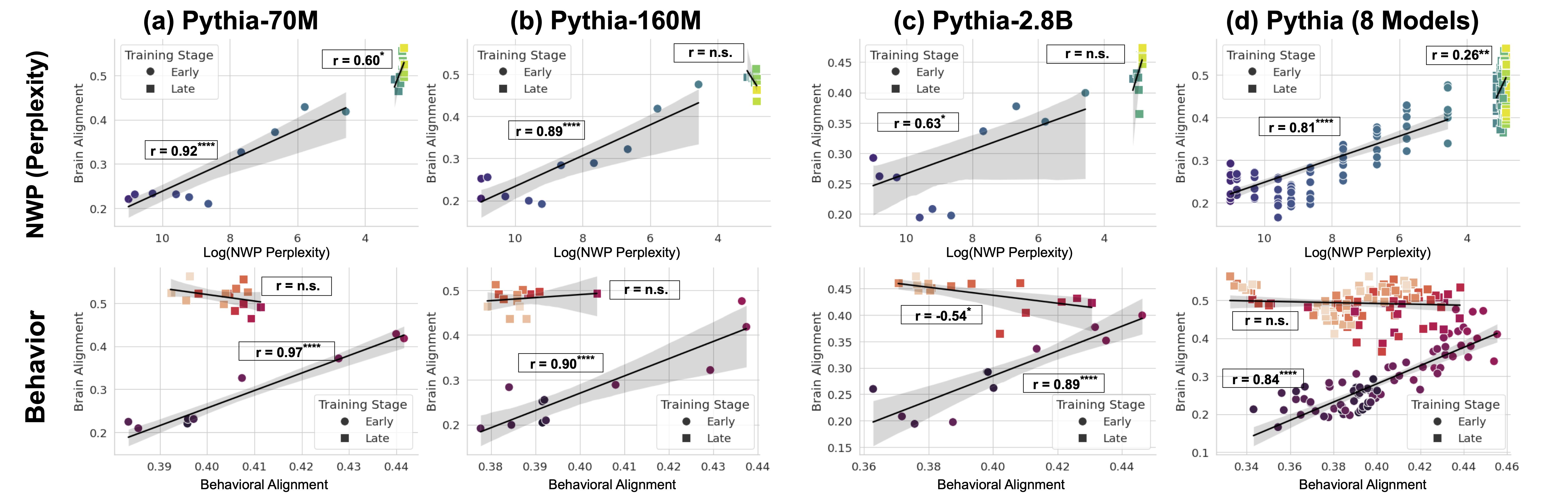
### Visual Description
## Scatter Plots: Alignment vs. Perplexity & Behavior
### Overview
The image presents four scatter plots, labeled (a) through (d), each representing a different model: Pythia-70M, Pythia-160M, Pythia-2.8B, and Pythia (8 Models). Each plot contains two scatter plots stacked vertically. The top plot shows the relationship between NWP (Perplexity) and Brain Alignment, while the bottom plot shows the relationship between Behavior and Behavioral Alignment. Each plot uses two colors to differentiate between "Early" and "Late" training stages, and includes correlation coefficients (r) with significance indicators.
### Components/Axes
Each plot shares the following components:
* **X-axis:** Log(NWP Perplexity) in plots (a) and (b), and Behavioral Alignment in plots (c) and (d). Scales range approximately from 3.8 to 10 in (a) and (b), and 0.38 to 0.46 in (c) and (d).
* **Y-axis:** Brain Alignment in the top plots (a-d), and Behavior in the bottom plots (a-d). Scales range approximately from 0.2 to 0.5 in all plots.
* **Legend:** Located in the top-left corner of each plot, distinguishing between "Early" (green) and "Late" (red) training stages.
* **Correlation Coefficient (r):** Displayed in each plot, indicating the strength and direction of the linear relationship between the variables. Significance is indicated by asterisks: * (p < 0.05), ** (p < 0.01), *** (p < 0.001), and n.s. (not significant).
* **Regression Line:** A black line representing the linear regression fit for each training stage (Early and Late).
* **Shaded Area:** A grey shaded area around each regression line, representing the 95% confidence interval.
### Detailed Analysis or Content Details
**Plot (a): Pythia-70M**
* **Top Plot (NWP Perplexity vs. Brain Alignment):**
* Early (Green): Line slopes downward. r = 0.80*, indicating a strong positive correlation. Approximately 15 data points.
* Late (Red): Line slopes downward. r = 0.92***, indicating a very strong positive correlation. Approximately 15 data points.
* **Bottom Plot (Behavior vs. Behavioral Alignment):**
* Early (Green): Line slopes upward. r = n.s., indicating no significant correlation. Approximately 15 data points.
* Late (Red): Line slopes upward. r = 0.97***, indicating a very strong positive correlation. Approximately 15 data points.
**Plot (b): Pythia-160M**
* **Top Plot (NWP Perplexity vs. Brain Alignment):**
* Early (Green): Line is approximately horizontal. r = n.s., indicating no significant correlation. Approximately 15 data points.
* Late (Red): Line slopes downward. r = 0.89***, indicating a very strong positive correlation. Approximately 15 data points.
* **Bottom Plot (Behavior vs. Behavioral Alignment):**
* Early (Green): Line slopes upward. r = n.s., indicating no significant correlation. Approximately 15 data points.
* Late (Red): Line slopes upward. r = 0.90***, indicating a very strong positive correlation. Approximately 15 data points.
**Plot (c): Pythia-2.8B**
* **Top Plot (NWP Perplexity vs. Brain Alignment):**
* Early (Green): Line is approximately horizontal. r = n.s., indicating no significant correlation. Approximately 15 data points.
* Late (Red): Line slopes downward. r = 0.83***, indicating a very strong positive correlation. Approximately 15 data points.
* **Bottom Plot (Behavior vs. Behavioral Alignment):**
* Early (Green): Line slopes upward. r = 0.45*, indicating a weak positive correlation. Approximately 15 data points.
* Late (Red): Line slopes upward. r = 0.89***, indicating a very strong positive correlation. Approximately 15 data points.
**Plot (d): Pythia (8 Models)**
* **Top Plot (NWP Perplexity vs. Brain Alignment):**
* Early (Green): Line slopes downward. r = 0.28*, indicating a weak positive correlation. Approximately 15 data points.
* Late (Red): Line slopes downward. r = 0.81***, indicating a very strong positive correlation. Approximately 15 data points.
* **Bottom Plot (Behavior vs. Behavioral Alignment):**
* Early (Green): Line slopes upward. r = n.s., indicating no significant correlation. Approximately 15 data points.
* Late (Red): Line slopes upward. r = 0.84***, indicating a very strong positive correlation. Approximately 15 data points.
### Key Observations
* The "Late" training stage consistently shows a strong negative correlation between NWP Perplexity and Brain Alignment across all models.
* The "Late" training stage consistently shows a strong positive correlation between Behavior and Behavioral Alignment across all models.
* The "Early" training stage often shows no significant correlation or a weak correlation in both the top and bottom plots.
* The strength of the correlation generally increases with model size (from 70M to 2.8B).
* The Pythia (8 Models) plot shows a weaker correlation in the top plot for the "Early" stage compared to the other models.
### Interpretation
The data suggests that as models are trained ("Late" stage), they exhibit a stronger alignment between their internal representations (Brain Alignment) and their performance on language tasks (NWP Perplexity). Lower perplexity (better performance) is associated with higher brain alignment. Similarly, the "Late" stage shows a strong alignment between the model's behavior and its behavioral alignment, indicating that the model is learning to behave in a more consistent and predictable manner.
The lack of significant correlation in the "Early" stage suggests that the models are still in a phase of exploration and haven't yet converged on stable representations or behaviors. The increasing correlation with model size indicates that larger models are better able to learn and maintain these alignments.
The outlier in plot (d) for the "Early" stage in the top plot suggests that there might be some variability in the initial stages of training, or that the relationship between NWP Perplexity and Brain Alignment is more complex for larger models. The consistent strong correlations in the "Late" stage across all models suggest a fundamental principle of language model training: as models learn, they develop more coherent internal representations and behaviors.
</details>
Figure 5: NWP and Behavioral Alignment Correlate with Brain Alignment Only in Early Training. (Top Row): Correlation between brain alignment and language modeling loss shows a strong, significant relationship during early training (up to 2B tokens). While this correlation weakens in later stages (up to ~300B tokens). Results are shown for three models and the average of all 8 models (last column). (Bottom Row): The same analysis, but for the correlation between brain alignment and behavioral alignment, revealing a similar trend—strong correlation early in training, but no significant relationship as models surpass human proficiency.
### 5.2 Brain Alignment Over Training
Having established the architectural components that make an untrained model brain-aligned in the previous section, we now investigate how brain alignment evolves during training. To do so, we use the Pythia model suite Biderman et al. (2023), which consists of models of various sizes, all trained on the same $\sim$ 300B tokens, with publicly available intermediate checkpoints. We report results for a model from a different family, SmolLM2-360M (Allal et al., 2025), which provides checkpoints at 250B-token intervals, in Appendix F.
Figure 3 illustrates the brain alignment of six Pythia models across five brain recording datasets at 34 training checkpoints, spanning approximately 300B tokens. Each panel presents checkpoints that are logarithmically spaced up to the vertical line, emphasizing the early-stage increase in brain alignment, which occurs within the first 5.6% of training time. Beyond this point, the panels display the remaining training period, where brain alignment stabilizes. More specifically, we observe the following trend: (1) Brain alignment is similar to the untrained model until approximately 128M tokens. (2) A sharp increase follows, peaking around 8B tokens. (3) Brain alignment then saturates for the remainder of training. Despite the vast difference in model sizes shown in Figure 3, the trajectory of brain alignment is remarkably similar.
#### Alignment Tracks Formal Competence
Following the observation that brain alignment plateaus early in training, we next investigate how this relates to the emergence of formal and functional linguistic competence in LLMs. Figure 4 displays the average brain alignment alongside the average performance on formal competence benchmarks (top row) and functional competence benchmarks (bottom row). This is shown for three Pythia models (1B, 2.8B, and 6.9B parameters) and the average of five Pythia models (first column) across the training process. To quantify this relationship, we train a ridge regression model (with a single scalar weight) to predict brain alignment scores from benchmark scores using 10-fold cross-validation. The average R-squared value across these folds serves as our metric for comparing the relationship between formal/functional linguistic competence and brain alignment. These R-squared values are shown in each panel of Figure 4. Finally, we perform a Wilcoxon signed-rank test on the distributions of R-squared values. This test reveals that formal linguistic competence is significantly more strongly correlated with brain alignment than functional competence (W = 0.0, p $<$ 0.002). One possible explanation for why brain alignment emerges before formal linguistic competence is that existing LLM benchmarks assess performance using discrete accuracy thresholds (hard metrics), rather than capturing the gradual progression of competence through more nuanced, continuous measures (soft metrics) (Schaeffer et al., 2023). We show the individual benchmark scores across all checkpoints in Figure 8 in Appendix E.
### 5.3 LLMs Lose Behavioral Alignment
Do language models that improve in next-word prediction remain aligned with human behavioral and neural responses, or do they diverge as they surpass human proficiency? To answer this question we use the Futrell2018 benchmark, which has been widely used in previous research to measure linguistic behavior (Futrell et al., 2018; Schrimpf et al., 2021; Aw et al., 2023). This dataset consists of self-paced reading times for naturalistic story materials from 180 participants. Per-word reading times provide a measure of incremental comprehension difficulty, a cornerstone of psycholinguistic research for testing theories of sentence comprehension (Gibson, 1998; Smith and Levy, 2013; Brothers and Kuperberg, 2021; Shain et al., 2024). We measure alignment by calculating the Pearson correlation between a model’s cross-entropy loss for a specific token in the sequence and the average human per-word reading time. The loss for words that comprise multiple tokens is added together before computing the correlation.
Early in training, LLMs align with this pattern, but as they surpass human proficiency (Shlegeris et al., 2022), their perplexity drops and they begin encoding statistical regularities that diverge from human intuition (Oh and Schuler, 2023; Steuer et al., 2023). This shift correlates with a decline in behavioral alignment, suggesting that superhuman models rely on different mechanisms than those underlying human language comprehension. Figure 5 shows that brain alignment initially correlates with perplexity and behavioral alignment, but only during the early stages of training (up to ~2B tokens). Beyond this point, these correlations diminish. In larger models, we observe a negative correlation between brain alignment and behavioral alignment in the later stages of training. This trend reinforces that early training aligns LLMs with human-like processing as also observed in earlier stages, while in later stages their language mechanisms diverge from humans.
## 6 Conclusion
In this work, we investigate how brain alignment in LLMs evolves throughout training, revealing different learning processes at play. We demonstrate that alignment with the human language network (LN) primarily correlates with formal linguistic competence Mahowald et al. (2024), peaking and saturating early in training. In contrast, functional linguistic competence, which involves world knowledge and reasoning, continues to grow beyond this stage. These findings suggest that the LN primarily encodes syntactic and compositional structure, in line with the literature of language neuroscience Fedorenko et al. (2024a), while broader linguistic functions may rely on other cognitive systems beyond the LN. This developmental approach reveals when brain-like representations emerge, offering a dynamic perspective compared to prior work focused on fully trained models. For example, Oota et al. (2023) demonstrated that syntactic structure contributes to alignment by selectively removing specific properties from already trained models. In contrast, we show that formal linguistic competence actively drives brain alignment during the early phases of training. Similarly, Hosseini et al. (2024) reported that models achieve strong alignment with limited data; we identify why: the brain-like representations emerge as soon as core formal linguistic knowledge is acquired. Further, their study evaluated only four training checkpoints and 2 models on a single dataset (Pereira2018). Our study evaluated eight models (14M–6.7B parameters) across 34 checkpoints spanning 300B tokens, and used five neural benchmarks within a rigorous brain‑scoring framework. This extensive design enabled fine‑grained correlations with both formal and functional linguistic benchmarks and ensured our results are robust and generalizable.
We also show that model size is not a reliable predictor of brain alignment when controlling for the number of features (see Appendix I). Instead, alignment is shaped by architectural inductive biases, token integration mechanisms, and training dynamics. Our standardized brain-scoring framework eliminates contextualization biases from previous work, ensuring more rigorous evaluations. Finally, we demonstrate that current brain alignment benchmarks are not saturated, indicating that LLMs can still be improved in modeling human language processing. Together, these findings challenge prior assumptions about how alignment emerges in LLMs and provide new insights into the relationship between artificial and biological language processing.
## Limitations
While this study offers a comprehensive analysis of brain alignment in LLMs, several open questions remain. If functional competence extends beyond the language network, future work should explore which additional brain regions LLMs align with as they develop reasoning and world knowledge, particularly in other cognitive networks like the multiple demand (Duncan and Owen, 2000) or theory of mind network (Saxe and Kanwisher, 2003; Saxe and Powell, 2006). Our findings suggest that LLM brain alignment studies should be broadened from the LN to downstream representations underlying other parts of cognition. This raises the question of whether specific transformer units specialize in formal vs. functional linguistic competence (AlKhamissi et al., 2025).
One other limitation of our study is that we rely exclusively on brain data collected from experiments conducted with English stimuli. As such, we do not explore whether our findings generalize across languages. This remains an open question and warrants further investigation. That said, evidence from cross-linguistic neuroscience research studying 45 languages from 12 language families (Malik-Moraleda et al., 2022) suggests the existence of a universal language network in the brain that is robust across languages and language families, both in topography and core functional properties.
Finally, a key question remains: Does LLM alignment evolution mirror human language acquisition? Comparing LLM representations to developmental data could reveal insights into learning trajectories and help differentiate formal from functional language learning. Expanding brain-scoring benchmarks and incorporating multimodal models will help address these questions, further bridging the gap between artificial and biological intelligence and deepening our understanding of how both systems process and represent language.
## Ethical Statement
This research relies on previously published neuroimaging (fMRI, ECoG) and behavioral datasets, collected by the original research groups under their institutional ethical guidelines with informed consent and IRB/ethics approval. Our work involved only secondary analysis of de-identified data, with no new data collection or direct participant interaction, and we remain committed to using such data responsibly and respectfully.
## Acknowledgments
We thank the members of the EPFL NeuroAI and NLP labs for their valuable feedback and insightful suggestions. We also gratefully acknowledge the support of the Swiss National Science Foundation (No. 215390), Innosuisse (PFFS-21-29), the EPFL Center for Imaging, Sony Group Corporation, and a Meta LLM Evaluation Research Grant.
## References
- AlKhamissi et al. (2022) Badr AlKhamissi, Millicent Li, Asli Celikyilmaz, Mona T. Diab, and Marjan Ghazvininejad. 2022. A review on language models as knowledge bases. ArXiv, abs/2204.06031.
- AlKhamissi et al. (2025) Badr AlKhamissi, Greta Tuckute, Antoine Bosselut, and Martin Schrimpf. 2025. The LLM language network: A neuroscientific approach for identifying causally task-relevant units. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 10887–10911, Albuquerque, New Mexico. Association for Computational Linguistics.
- Allal et al. (2025) Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Andrés Marafioti, Hynek Kydlíček, Agustín Piqueres Lajarín, Vaibhav Srivastav, and 1 others. 2025. Smollm2: When smol goes big–data-centric training of a small language model. arXiv preprint arXiv:2502.02737.
- Aw et al. (2023) Khai Loong Aw, Syrielle Montariol, Badr AlKhamissi, Martin Schrimpf, and Antoine Bosselut. 2023. Instruction-tuning aligns llms to the human brain.
- Bates et al. (2003) Elizabeth Bates, Stephen M. Wilson, Ayse Pinar Saygin, Frederic Dick, Martin I. Sereno, Robert T. Knight, and Nina F. Dronkers. 2003. Voxel-based lesion–symptom mapping. Nature Neuroscience, 6(5):448–450.
- Benn et al. (2013) Yael Benn, Iain D. Wilkinson, Ying Zheng, Kathrin Cohen Kadosh, Charles A.J. Romanowski, Michael Siegal, and Rosemary Varley. 2013. Differentiating core and co-opted mechanisms in calculation: The neuroimaging of calculation in aphasia. Brain and Cognition, 82(3):254–264.
- Biderman et al. (2023) Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar Van Der Wal. 2023. Pythia: a suite for analyzing large language models across training and scaling. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org.
- Binder et al. (1997) Jeffrey R. Binder, Julie A. Frost, Thomas A. Hammeke, Robert W. Cox, Stephen M. Rao, and Thomas Prieto. 1997. Human brain language areas identified by functional magnetic resonance imaging. The Journal of Neuroscience, 17(1):353–362.
- Bisk et al. (2019) Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2019. Piqa: Reasoning about physical commonsense in natural language. In AAAI Conference on Artificial Intelligence.
- Blank et al. (2014) Idan Blank, Nancy Kanwisher, and Evelina Fedorenko. 2014. A functional dissociation between language and multiple-demand systems revealed in patterns of BOLD signal fluctuations. Journal of Neurophysiology, 112(5):1105–1118.
- Brothers and Kuperberg (2021) Trevor Brothers and Gina R Kuperberg. 2021. Word predictability effects are linear, not logarithmic: Implications for probabilistic models of sentence comprehension. Journal of Memory and Language, 116:104174.
- Cadena et al. (2019) Santiago A Cadena, George H Denfield, Edgar Y Walker, Leon A Gatys, Andreas S Tolias, Matthias Bethge, and Alexander S Ecker. 2019. Deep convolutional models improve predictions of macaque v1 responses to natural images. PLoS computational biology, 15(4):e1006897.
- Caucheteux and King (2022) Charlotte Caucheteux and Jean-Rémi King. 2022. Brains and algorithms partially converge in natural language processing. Communications biology, 5(1):134.
- Chen et al. (2023) Xuanyi Chen, Josef Affourtit, Rachel Ryskin, Tamar I Regev, Samuel Norman-Haignere, Olessia Jouravlev, Saima Malik-Moraleda, Hope Kean, Rosemary Varley, and Evelina Fedorenko. 2023. The human language system, including its inferior frontal component in “broca’s area,” does not support music perception. Cerebral Cortex, 33(12):7904–7929.
- Cichy et al. (2016) Radoslaw Martin Cichy, Aditya Khosla, Dimitrios Pantazis, Antonio Torralba, and Aude Oliva. 2016. Comparison of deep neural networks to spatio-temporal cortical dynamics of human visual object recognition reveals hierarchical correspondence. Scientific reports, 6(1):27755.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv, abs/1803.05457.
- Duncan and Owen (2000) John Duncan and Adrian M Owen. 2000. Common regions of the human frontal lobe recruited by diverse cognitive demands. Trends in Neurosciences, 23(10):475–483.
- Feather et al. (2025) Jenelle Feather, Meenakshi Khosla, N. Apurva, Ratan Murty, and Aran Nayebi. 2025. Brain-model evaluations need the neuroai turing test.
- Fedorenko (2014) Evelina Fedorenko. 2014. The role of domain-general cognitive control in language comprehension. Frontiers in Psychology, 5.
- Fedorenko et al. (2011) Evelina Fedorenko, Michael K Behr, and Nancy Kanwisher. 2011. Functional specificity for high-level linguistic processing in the human brain. Proceedings of the National Academy of Sciences, 108(39):16428–16433.
- Fedorenko et al. (2010) Evelina Fedorenko, Po-Jang Hsieh, Alfonso Nieto-Castanon, Susan L. Whitfield-Gabrieli, and Nancy G. Kanwisher. 2010. New method for fmri investigations of language: defining rois functionally in individual subjects. Journal of neurophysiology, 104 2:1177–94.
- Fedorenko et al. (2024a) Evelina Fedorenko, Anna A. Ivanova, and Tamar I. Regev. 2024a. The language network as a natural kind within the broader landscape of the human brain. Nature Reviews Neuroscience, 25(5):289–312.
- Fedorenko et al. (2012) Evelina Fedorenko, Josh H. McDermott, Sam Norman-Haignere, and Nancy Kanwisher. 2012. Sensitivity to musical structure in the human brain. Journal of Neurophysiology, 108(12):3289–3300.
- Fedorenko et al. (2024b) Evelina Fedorenko, Steven T. Piantadosi, and Edward A. F. Gibson. 2024b. Language is primarily a tool for communication rather than thought. Nature, 630(8017):575–586.
- Fedorenko et al. (2016) Evelina Fedorenko, Terri L. Scott, Peter Brunner, William G. Coon, Brianna Pritchett, Gerwin Schalk, and Nancy Kanwisher. 2016. Neural correlate of the construction of sentence meaning. Proceedings of the National Academy of Sciences, 113(41):E6256–E6262.
- Feghhi et al. (2024) Ebrahim Feghhi, Nima Hadidi, Bryan Song, Idan A. Blank, and Jonathan C. Kao. 2024. What are large language models mapping to in the brain? a case against over-reliance on brain scores.
- Futrell et al. (2018) Richard Futrell, Edward Gibson, Harry J. Tily, Idan Blank, Anastasia Vishnevetsky, Steven Piantadosi, and Evelina Fedorenko. 2018. The natural stories corpus. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan. European Language Resources Association (ELRA).
- Gao et al. (2024) Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, and 5 others. 2024. A framework for few-shot language model evaluation.
- Gauthier et al. (2020) Jon Gauthier, Jennifer Hu, Ethan Wilcox, Peng Qian, and Roger Levy. 2020. SyntaxGym: An online platform for targeted evaluation of language models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 70–76, Online. Association for Computational Linguistics.
- Geiger et al. (2022) Franziska Geiger, Martin Schrimpf, Tiago Marques, and James J DiCarlo. 2022. Wiring up vision: Minimizing supervised synaptic updates needed to produce a primate ventral stream. In International Conference on Learning Representations 2022 Spotlight.
- Gibson (1998) Edward Gibson. 1998. Linguistic complexity: locality of syntactic dependencies. Cognition, 68(1):1–76.
- Goldstein et al. (2022) Ariel Goldstein, Zaid Zada, Eliav Buchnik, Mariano Schain, Amy Price, Bobbi Aubrey, Samuel A. Nastase, Amir Feder, Dotan Emanuel, Alon Cohen, Aren Jansen, Harshvardhan Gazula, Gina Choe, Aditi Rao, Catherine Kim, Colton Casto, Lora Fanda, Werner Doyle, Daniel Friedman, and 13 others. 2022. Shared computational principles for language processing in humans and deep language models. Nature Neuroscience, 25(3):369–380.
- Gorno‐Tempini et al. (2004) Maria Luisa Gorno‐Tempini, Nina F. Dronkers, Katherine P. Rankin, Jennifer M. Ogar, La Phengrasamy, Howard J. Rosen, Julene K. Johnson, Michael W. Weiner, and Bruce L. Miller. 2004. Cognition and anatomy in three variants of primary progressive aphasia. Annals of Neurology, 55(3):335–346.
- Hagoort (2019) Peter Hagoort. 2019. The neurobiology of language beyond single-word processing. Science, 366(6461):55–58.
- Harvey et al. (2023) Sarah E Harvey, Brett W. Larsen, and Alex H Williams. 2023. Duality of bures and shape distances with implications for comparing neural representations. In UniReps: the First Workshop on Unifying Representations in Neural Models.
- Hosseini et al. (2024) Eghbal A Hosseini, Martin Schrimpf, Yian Zhang, Samuel Bowman, Noga Zaslavsky, and Evelina Fedorenko. 2024. Artificial neural network language models predict human brain responses to language even after a developmentally realistic amount of training. Neurobiology of Language, pages 1–21.
- Hu et al. (2023) Jennifer Hu, Hannah Small, Hope Kean, Atsushi Takahashi, Leo Zekelman, Daniel Kleinman, Elizabeth Ryan, Alfonso Nieto-Castañón, Victor Ferreira, and Evelina Fedorenko. 2023. Precision fmri reveals that the language-selective network supports both phrase-structure building and lexical access during language production. Cerebral Cortex, 33(8):4384–4404.
- Huang and Chang (2023) Jie Huang and Kevin Chen-Chuan Chang. 2023. Towards reasoning in large language models: A survey. In Findings of the Association for Computational Linguistics: ACL 2023, pages 1049–1065, Toronto, Canada. Association for Computational Linguistics.
- Kauf et al. (2023) Carina Kauf, Greta Tuckute, Roger Levy, Jacob Andreas, and Evelina Fedorenko. 2023. Lexical-Semantic Content, Not Syntactic Structure, Is the Main Contributor to ANN-Brain Similarity of fMRI Responses in the Language Network. Neurobiology of Language, pages 1–36.
- Kazemian et al. (2024) Atlas Kazemian, Eric Elmoznino, and Michael F. Bonner. 2024. Convolutional architectures are cortex-aligned de novo. bioRxiv.
- Kell et al. (2018) Alexander JE Kell, Daniel LK Yamins, Erica N Shook, Sam V Norman-Haignere, and Josh H McDermott. 2018. A task-optimized neural network replicates human auditory behavior, predicts brain responses, and reveals a cortical processing hierarchy. Neuron, 98(3):630–644.
- Khaligh-Razavi and Kriegeskorte (2014) Seyed Mahdi Khaligh-Razavi and Nikolaus Kriegeskorte. 2014. Deep Supervised, but Not Unsupervised, Models May Explain IT Cortical Representation. PLoS Computational Biology, 10(11). Publisher: Public Library of Science ISBN: 1553-7358 (Electronic)\r1553-734X (Linking).
- Kornblith et al. (2019) Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. 2019. Similarity of neural network representations revisited. In International conference on machine learning, pages 3519–3529. PMLR.
- Koumura et al. (2023) Takuya Koumura, Hiroki Terashima, and Shigeto Furukawa. 2023. Human-like modulation sensitivity emerging through optimization to natural sound recognition. Journal of Neuroscience, 43(21):3876–3894.
- Kriegeskorte et al. (2008) Nikolaus Kriegeskorte, Marieke Mur, and Peter Bandettini. 2008. Representational similarity analysis - connecting the branches of systems neuroscience. Frontiers in Systems Neuroscience, 2.
- Kubilius et al. (2019) Jonas Kubilius, Martin Schrimpf, Kohitij Kar, Rishi Rajalingham, Ha Hong, Najib Majaj, Elias Issa, Pouya Bashivan, Jonathan Prescott-Roy, Kailyn Schmidt, Aran Nayebi, Daniel Bear, Daniel L Yamins, and James J DiCarlo. 2019. Brain-like object recognition with high-performing shallow recurrent anns. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
- Lipkin et al. (2022) Benjamin Lipkin, Greta Tuckute, Josef Affourtit, Hannah Small, Zachary Mineroff, Hope Kean, Olessia Jouravlev, Lara Rakocevic, Brianna Pritchett, Matthew Siegelman, Caitlyn Hoeflin, Alvincé Pongos, Idan A. Blank, Melissa Kline Struhl, Anna Ivanova, Steven Shannon, Aalok Sathe, Malte Hoffmann, Alfonso Nieto-Castañón, and Evelina Fedorenko. 2022. Probabilistic atlas for the language network based on precision fmri data from>800 individuals. Scientific Data, 9(1).
- Mahowald et al. (2024) Kyle Mahowald, Anna A Ivanova, Idan A Blank, Nancy Kanwisher, Joshua B Tenenbaum, and Evelina Fedorenko. 2024. Dissociating language and thought in large language models. Trends in Cognitive Sciences.
- Malik-Moraleda et al. (2022) Saima Malik-Moraleda, Dima Ayyash, Jeanne Gallée, Josef Affourtit, Malte Hoffmann, Zachary Mineroff, Olessia Jouravlev, and Evelina Fedorenko. 2022. An investigation across 45 languages and 12 language families reveals a universal language network. Nature Neuroscience, 25(8):1014–1019.
- Millet and King (2021) Juliette Millet and Jean-Rémi King. 2021. Inductive biases, pretraining and fine-tuning jointly account for brain responses to speech. ArXiv, abs/2103.01032.
- Monti et al. (2012) Martin M Monti, Lawrence M Parsons, and Daniel N Osherson. 2012. Thought beyond language: neural dissociation of algebra and natural language. Psychological science, 23(8):914–922.
- Nastase et al. (2021) Samuel A. Nastase, Yun-Fei Liu, Hanna Hillman, Asieh Zadbood, Liat Hasenfratz, Neggin Keshavarzian, Janice Chen, Christopher J. Honey, Yaara Yeshurun, Mor Regev, and et al. 2021. The “narratives” fmri dataset for evaluating models of naturalistic language comprehension. Scientific Data, 8(1).
- Oh and Schuler (2023) Byung-Doh Oh and William Schuler. 2023. Why does surprisal from larger transformer-based language models provide a poorer fit to human reading times? Transactions of the Association for Computational Linguistics, 11:336–350.
- Oota et al. (2023) Subba Reddy Oota, Manish Gupta, and Mariya Toneva. 2023. Joint processing of linguistic properties in brains and language models. Preprint, arXiv:2212.08094.
- Pasquiou et al. (2022) Alexandre Pasquiou, Yair Lakretz, John Hale, Bertrand Thirion, and Christophe Pallier. 2022. Neural language models are not born equal to fit brain data, but training helps. Preprint, arXiv:2207.03380.
- Penedo et al. (2024) Guilherme Penedo, Hynek Kydlíček, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. 2024. The fineweb datasets: Decanting the web for the finest text data at scale. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Pereira et al. (2018) Francisco Pereira, Bin Lou, Brianna Pritchett, Samuel Ritter, Samuel J. Gershman, Nancy Kanwisher, Matthew Botvinick, and Evelina Fedorenko. 2018. Toward a universal decoder of linguistic meaning from brain activation. Nature Communications, 9(1):963.
- Price (2010) Cathy J. Price. 2010. The anatomy of language: a review of 100 fmri studies published in 2009. Annals of the New York Academy of Sciences, 1191(1):62–88.
- Rathi et al. (2025) Neil Rathi, Johannes Mehrer, Badr AlKhamissi, Taha Binhuraib, Nicholas M. Blauch, and Martin Schrimpf. 2025. TopoLM: Brain-like spatio-functional organization in a topographic language model. In International Conference on Learning Representations (ICLR).
- Sakaguchi et al. (2019) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2019. Winogrande. Communications of the ACM, 64:99 – 106.
- Sap et al. (2019) Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. 2019. Social IQa: Commonsense reasoning about social interactions. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4463–4473, Hong Kong, China. Association for Computational Linguistics.
- Saxe and Kanwisher (2003) R Saxe and N Kanwisher. 2003. People thinking about thinking peoplethe role of the temporo-parietal junction in “theory of mind”. NeuroImage, 19(4):1835–1842.
- Saxe et al. (2006) Rebecca Saxe, Matthew Brett, and Nancy Kanwisher. 2006. Divide and conquer: a defense of functional localizers. Neuroimage, 30(4):1088–1096.
- Saxe and Powell (2006) Rebecca Saxe and Lindsey J. Powell. 2006. It’s the thought that counts: Specific brain regions for one component of theory of mind. Psychological Science, 17(8):692–699.
- Schaeffer et al. (2023) Rylan Schaeffer, Brando Miranda, and Oluwasanmi Koyejo. 2023. Are emergent abilities of large language models a mirage? ArXiv, abs/2304.15004.
- Schrimpf et al. (2021) Martin Schrimpf, Idan Asher Blank, Greta Tuckute, Carina Kauf, Eghbal A. Hosseini, Nancy Kanwisher, Joshua B. Tenenbaum, and Evelina Fedorenko. 2021. The neural architecture of language: Integrative modeling converges on predictive processing. Proceedings of the National Academy of Sciences, 118(45):e2105646118.
- Schrimpf et al. (2018) Martin Schrimpf, Jonas Kubilius, Ha Hong, Najib J. Majaj, Rishi Rajalingham, Elias B. Issa, Kohitij Kar, Pouya Bashivan, Jonathan Prescott-Roy, Franziska Geiger, Kailyn Schmidt, Daniel L. K. Yamins, and James J. DiCarlo. 2018. Brain-Score: Which Artificial Neural Network for Object Recognition is most Brain-Like? preprint, Neuroscience.
- Schrimpf et al. (2020) Martin Schrimpf, Jonas Kubilius, Michael J. Lee, N. Apurva Ratan Murty, Robert Ajemian, and James J. DiCarlo. 2020. Integrative benchmarking to advance neurally mechanistic models of human intelligence. Neuron, 108(3):413–423.
- Shain et al. (2024) Cory Shain, Clara Meister, Tiago Pimentel, Ryan Cotterell, and Roger Levy. 2024. Large-scale evidence for logarithmic effects of word predictability on reading time. Proceedings of the National Academy of Sciences, 121(10):e2307876121.
- Shlegeris et al. (2022) Buck Shlegeris, Fabien Roger, Lawrence Chan, and Euan McLean. 2022. Language models are better than humans at next-token prediction. ArXiv, abs/2212.11281.
- Siegal and Varley (2006) Michael Siegal and Rosemary Varley. 2006. Aphasia, language, and theory of mind. Social Neuroscience, 1(3–4):167–174.
- Smith and Levy (2013) Nathaniel J. Smith and Roger Levy. 2013. The effect of word predictability on reading time is logarithmic. Cognition, 128(3):302–319.
- Steuer et al. (2023) Julius Steuer, Marius Mosbach, and Dietrich Klakow. 2023. Large gpt-like models are bad babies: A closer look at the relationship between linguistic competence and psycholinguistic measures. arXiv preprint arXiv:2311.04547.
- Teney et al. (2024) Damien Teney, Armand Nicolicioiu, Valentin Hartmann, and Ehsan Abbasnejad. 2024. Neural redshift: Random networks are not random functions. Preprint, arXiv:2403.02241.
- Tuckute et al. (2023) Greta Tuckute, Jenelle Feather, Dana Boebinger, and Josh H. McDermott. 2023. Many but not all deep neural network audio models capture brain responses and exhibit correspondence between model stages and brain regions. PLOS Biology, 21(12):1–70.
- Tuckute et al. (2024a) Greta Tuckute, Nancy Kanwisher, and Evelina Fedorenko. 2024a. Language in brains, minds, and machines. Annual Review of Neuroscience, 47.
- Tuckute et al. (2024b) Greta Tuckute, Aalok Sathe, Shashank Srikant, Maya Taliaferro, Mingye Wang, Martin Schrimpf, Kendrick Kay, and Evelina Fedorenko. 2024b. Driving and suppressing the human language network using large language models. Nature Human Behaviour, pages 1–18.
- Varley and Siegal (2000) Rosemary Varley and Michael Siegal. 2000. Evidence for cognition without grammar from causal reasoning and ‘theory of mind’ in an agrammatic aphasic patient. Current Biology, 10(12):723–726.
- Varley et al. (2005) Rosemary A. Varley, Nicolai J. C. Klessinger, Charles A. J. Romanowski, and Michael Siegal. 2005. Agrammatic but numerate. Proceedings of the National Academy of Sciences, 102(9):3519–3524.
- Warstadt et al. (2019) Alex Warstadt, Alicia Parrish, Haokun Liu, Anhad Mohananey, Wei Peng, Sheng-Fu Wang, and Samuel R. Bowman. 2019. Blimp: The benchmark of linguistic minimal pairs for english. Transactions of the Association for Computational Linguistics, 8:377–392.
- Wolf et al. (2019) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, and Jamie Brew. 2019. Huggingface’s transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771.
- Yamins et al. (2014) Daniel LK Yamins, Ha Hong, Charles F Cadieu, Ethan A Solomon, Darren Seibert, and James J DiCarlo. 2014. Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proceedings of the national academy of sciences, 111(23):8619–8624.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Annual Meeting of the Association for Computational Linguistics.
- Zhuang et al. (2021) Chengxu Zhuang, Siming Yan, Aran Nayebi, Martin Schrimpf, Michael C. Frank, James J. DiCarlo, and Daniel L.K. Yamins. 2021. Unsupervised neural network models of the ventral visual stream. Proceedings of the National Academy of Sciences (PNAS), 118(3). Publisher: Cold Spring Harbor Laboratory.
| Pereira2018 | fMRI | Reading | Accordions produce sound with bellows … |
| --- | --- | --- | --- |
| Blank2014 | fMRI | Listening | A clear and joyous day it was and out on the wide … |
| Fedorenko2016 | ECoG | Reading | ‘ALEX’, ‘WAS’, ‘TIRED’, ‘SO’, ‘HE’, ‘TOOK’, … |
| Tuckute2024 | fMRI | Reading | The judge spoke, breaking the silence. |
| Narratives | fMRI | Listening | Okay so getting back to our story about uh Lucy … |
| Futrell2018 | Reading Times | Reading | A clear and joyous day it was and out on the wide … |
Table 1: Datasets Used for Evaluating Model Alignment. Neuroimaging datasets were collected via either functional magnetic resonance imaging (fMRI) or electrocorticography (ECoG). Stimuli range from short sentences (Fedorenko2016, Tuckute2024) to paragraphs (Pereira2018) and entire stories (Blank2014, Narratives, Futrell2018) and were presented either visually or auditorily. Futrell2018 is a behavioral dataset.
<details>
<summary>figures/brain-score-llms-metrics.drawio.png Details</summary>
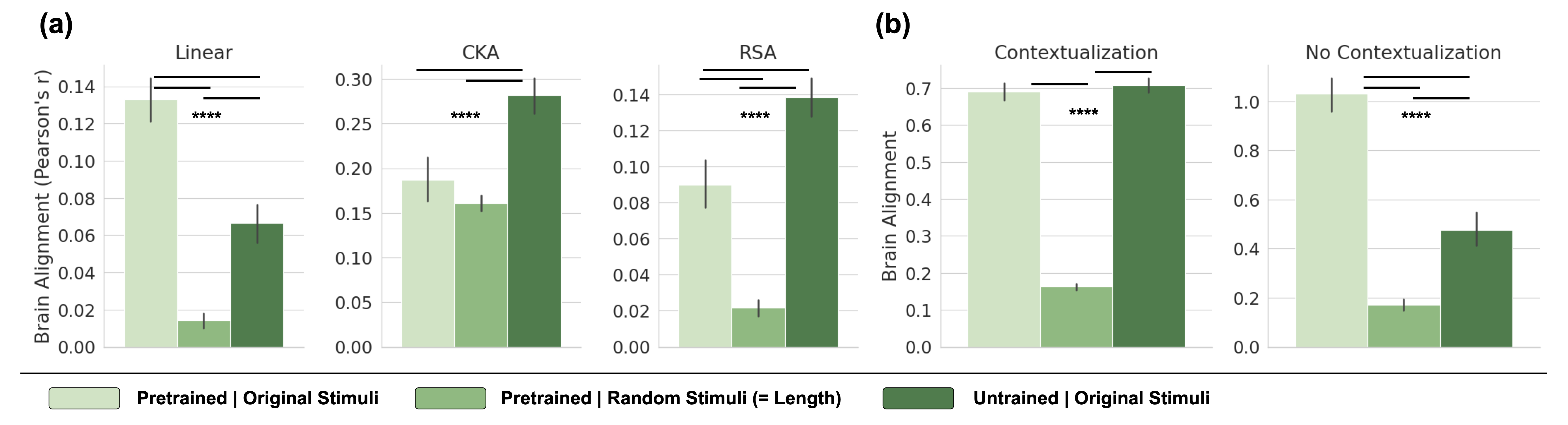
### Visual Description
\n
## Bar Charts: Brain Alignment Comparison
### Overview
The image presents two sets of bar charts (labeled (a) and (b)) comparing brain alignment scores under different conditions and using different alignment metrics. Chart (a) compares alignment for "Pretrained | Original Stimuli" vs. "Pretrained | Random Stimuli (= Length)" using Linear, CKA, and RSA metrics. Chart (b) compares "Untrained | Original Stimuli" with a baseline. Error bars are present on all bars, and significance is indicated with asterisks.
### Components/Axes
**Chart (a):**
* **X-axis:** Categorical - "Pretrained | Original Stimuli" and "Pretrained | Random Stimuli (= Length)".
* **Y-axis:** "Brain Alignment (Pearson's r)", ranging from 0.00 to 0.30.
* **Metrics (Sub-charts):** Linear, CKA, RSA.
* **Bar Colors:** Light green and dark green.
* **Significance Markers:** Four asterisks (****) above each bar.
**Chart (b):**
* **X-axis:** Categorical - "Untrained | Original Stimuli".
* **Y-axis:** "Brain Alignment", ranging from 0.0 to 1.0.
* **Conditions (Sub-charts):** Contextualization and No Contextualization.
* **Bar Colors:** Light green and dark green.
* **Significance Markers:** Three asterisks (***) above each bar.
### Detailed Analysis or Content Details
**Chart (a):**
* **Linear:**
* "Pretrained | Original Stimuli": Approximately 0.06 ± 0.01 (visually estimated from error bar).
* "Pretrained | Random Stimuli (= Length)": Approximately 0.24 ± 0.02.
* **CKA:**
* "Pretrained | Original Stimuli": Approximately 0.14 ± 0.02.
* "Pretrained | Random Stimuli (= Length)": Approximately 0.26 ± 0.02.
* **RSA:**
* "Pretrained | Original Stimuli": Approximately 0.04 ± 0.01.
* "Pretrained | Random Stimuli (= Length)": Approximately 0.13 ± 0.02.
**Chart (b):**
* **Contextualization:**
* "Untrained | Original Stimuli": Approximately 0.65 ± 0.05.
* **No Contextualization:**
* "Untrained | Original Stimuli": Approximately 0.22 ± 0.04.
### Key Observations
* In Chart (a), for all three metrics (Linear, CKA, RSA), the "Pretrained | Random Stimuli (= Length)" condition consistently shows significantly higher brain alignment scores than the "Pretrained | Original Stimuli" condition.
* In Chart (b), the "Contextualization" condition exhibits a substantially higher brain alignment score compared to the "No Contextualization" condition.
* The error bars suggest relatively low variance within each condition.
* The significance markers (asterisks) indicate that the differences observed in all conditions are statistically significant.
### Interpretation
The data suggests that pretraining on random stimuli (matched in length to original stimuli) leads to higher brain alignment compared to pretraining on original stimuli, as measured by Linear, CKA, and RSA metrics. This could indicate that the model learns representations that are more aligned with brain activity when exposed to random data of similar dimensionality.
Chart (b) demonstrates that contextualization significantly enhances brain alignment. The substantial difference between the "Contextualization" and "No Contextualization" conditions suggests that incorporating contextual information is crucial for aligning model representations with brain activity.
The consistent pattern of higher alignment scores for random stimuli in Chart (a) and the strong effect of contextualization in Chart (b) highlight the importance of both data characteristics and contextual information in building models that better reflect brain processing. The asterisks indicate that these differences are not due to chance. The use of different alignment metrics (Linear, CKA, RSA) in Chart (a) provides robustness to the findings, as the same trend is observed across all metrics.
</details>
Figure 6: Evaluating Brain Alignment with Linear Predictivity and No Contextualization is Most Stringent. (a) Average brain alignment across 8 Pythia models under three conditions: (1) a pretrained model processing the original stimuli, (2) a pretrained model processing random sequences of the same length (averaged over five random seeds) as a control condition, and (3) the model with untrained parameters processing the original stimuli. The linear predictivity metric differentiates between meaningful and random stimuli most strongly, while RSA and CKA overestimate alignment. (b) Brain alignment on the Pereira2018 dataset under two cross-validation schemes: with contextualization (random sentence split) and without contextualization (story-based split).
## Appendix
## Appendix A Neuroimaging & Behavioral Datasets
Table 1 shows the different neuroimaging and behavioral datasets used in this work, along with the dataset modality, presentation mode, and a stimulus example.
### A.1 Neuroimaging Datasets
#### Pereira et al. (2018)
This dataset consists of fMRI activations (blood-oxygen-level-dependent; BOLD responses) recorded as participants read short passages presented one sentence at a time for 4 s. The dataset is composed of two distinct experiments: one with 9 subjects presented with 384 sentences, and another with 6 subjects presented with 243 sentences each. The passages in each experiment spanned 24 different topics. The results reported for this dataset are the average alignment across both experiments after normalizing with their respective cross-subject consistency estimates.
#### Blank et al. (2014)
This dataset also involves fMRI signals but recorded from only 12 functional regions of interest (fROI) instead of the higher resolution signal used by Pereira et al. (2018). The data was collected from 5 participants as they listened to 8 long naturalistic stories that were adapted from existing fairy tales and short stories (Futrell et al., 2018). Each story was approximately 5 minutes long, averaging up to 165 sentences, providing a much longer context length than the other neuroimaging datasets. When measuring brain alignment, we use the input stimuli of the last 32 TRs as the model’s context.
#### Fedorenko et al. (2016)
This dataset captures ECoG signals from 5 participants as they read 8-word-long sentences presented one word at a time for 450 or 700 ms. Following Schrimpf et al. (2021) we select the 52/80 sentences that were presented to all participants.
#### Tuckute et al. (2024b)
In this dataset, 5 participants read 1000 6-word sentences presented one sentence at a time for 2 s. BOLD responses from voxels in the language network were averaged within each participant and then across participants to yield an overall average language network response to each sentence. The stimuli used span a large part of the linguistic space, enabling model-brain comparisons across a wide range of single sentences. Sentence presentation order was randomized across participants. In combination with the diversity in linguistic materials, this dataset presents a particularly challenging dataset for model evaluation.
#### Narratives Dataset (Nastase et al., 2021)
This dataset consists of fMRI data collected while human subjects listened to 27 diverse spoken story stimuli. The collection includes 345 subjects, 891 functional scans, and approximately 4.6 hours of unique audio stimuli. For our story-based analysis, we focused on 5 participants who each listened to both the Lucy and Tunnel stories. Since functional localization was not performed in the Narratives dataset, we approximated language regions by extracting the top-10% voxels from each anatomically defined language region according to a probabilistic atlas for the human language system (Lipkin et al., 2022). Due to the limited corpus of two stories, traditional 10-fold cross-validation was not feasible. To implement topic-based splitting while maintaining methodological rigor, we partitioned each story into $n$ distinct segments, with each segment functioning as an independent narrative unit. This segmentation approach effectively prevented cross-contamination of contextual information between splits, thereby preserving the integrity of our evaluation framework.
### A.2 Behavioral Dataset
#### (Futrell et al., 2018)
This dataset consists of self-paced reading times for each word from 180 participants. The stimuli include 10 stories from the Natural Stories Corpus (Futrell et al., 2018), similar to Blank2014. Each participant read between 5 and all 10 stories.
## Appendix B Rigorous Brain-Scoring
Despite progress in linking LLMs to neural activity, there’s no standard for comparing brain alignment across datasets and conditions. Here, we aim to establish a set of desiderata for evaluating brain alignment. For a model to be considered truly brain-aligned, two key criteria must be met. First, high alignment scores should indicate that the model captures stimulus-driven responses—meaning that when presented with a random sequence of tokens, alignment should drop significantly compared to original linguistic stimuli. Second, a brain-aligned model should generalize effectively to new linguistic contexts rather than overfitting to specific examples. We address these two points in Section 4 to justify our choice of metric and cross-validation scheme for each dataset (see Figure 6). For all benchmarks, we localize language-selective units, which is consistent with neural site selection in neuroscience experiments and allows for fair comparisons across models irrespective of model size AlKhamissi et al. (2025). A key limitation of previous methods is their reliance on the raw hidden state dimensions, which inherently favors larger models by providing a greater feature space and artificially inflating alignment scores.
| 250B 500B 750B | 1.00 0.97 0.99 | 0.19 0.08 0.08 | 0.47 0.51 0.52 | 0.78 0.87 0.78 | 0.04 0.04 0.04 | 0.50 0.49 0.48 |
| --- | --- | --- | --- | --- | --- | --- |
| 1T | 1.07 | 0.12 | 0.55 | 0.84 | 0.04 | 0.52 |
| 1.25T | 1.00 | 0.12 | 0.50 | 0.82 | 0.03 | 0.49 |
| 1.5T | 1.00 | 0.12 | 0.52 | 0.79 | 0.03 | 0.49 |
| 1.75T | 0.96 | 0.13 | 0.48 | 0.79 | 0.04 | 0.48 |
| 2T | 1.05 | 0.15 | 0.56 | 0.84 | 0.04 | 0.53 |
| 2.25T | 1.08 | 0.16 | 0.55 | 0.75 | 0.04 | 0.51 |
| 2.5T | 1.12 | 0.17 | 0.52 | 0.72 | 0.01 | 0.51 |
| 2.75T | 1.13 | 0.12 | 0.49 | 0.75 | 0.04 | 0.49 |
| 3T | 1.03 | 0.26 | 0.51 | 0.55 | 0.01 | 0.47 |
| 3.25T | 1.02 | 0.13 | 0.52 | 0.68 | 0.02 | 0.47 |
| 3.5T | 1.04 | 0.14 | 0.52 | 0.72 | 0.04 | 0.49 |
| 3.75T | 1.14 | 0.06 | 0.57 | 0.84 | 0.03 | 0.53 |
| 4T | 1.05 | 0.13 | 0.63 | 0.82 | 0.05 | 0.54 |
Table 2: Brain Alignment Performance of SmolLM2-360M Across Training Checkpoints. Reported scores correspond to normalized correlations with neural responses from five benchmark datasets (Pereira2018, Blank2014, Tuckute2024, Fedorenko2016, Narratives), along with their average (Avg). These results assess the extent to which the model’s internal representations align with activity in the human language network.
## Appendix C Brain-Score Using Additional Metrics
#### Centered Kernel Alignment (CKA)
Kornblith et al. (2019) introduced CKA as a substitute for Canonical Correlation Analysis (CCA) to assess the similarity between neural network representations. Unlike linear predictivity, it is a non-parameteric metric and therefore does not require any additional training. CKA is particularly effective with high-dimensional representations, and its reliability in identifying correspondences between representations in networks trained from different initializations (Kornblith et al., 2019).
#### Representational Similarity Analysis (RSA)
Kriegeskorte et al. (2008) introduced RDMs as a solution to the challenge of integrating brain-activity measurements, behavioral observations, and computational models in systems neuroscience. RDMs are part of a broader analytical framework referred to as representational similarity analysis (RSA). In practical terms, to compute the dissimilarity matrix for an $N$ -dimensional network’s responses to $M$ different stimuli, an $M$ × $M$ matrix of distances between all pairs of evoked responses is generated for both brain activity and the language model’s activations Harvey et al. (2023). The correlation between these two matrices is then used as a measure of brain alignment.
| 250B 500B 750B | 0.81 0.80 0.80 | 0.80 0.78 0.82 | 0.81 0.79 0.81 | 0.33 0.78 0.69 | 0.66 0.66 0.69 | 0.35 0.35 0.34 | 0.70 0.70 0.71 | 0.55 0.56 0.57 | 0.47 0.49 0.50 | 0.52 0.53 0.53 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 1T | 0.81 | 0.78 | 0.80 | 0.69 | 0.69 | 0.35 | 0.71 | 0.57 | 0.50 | 0.54 |
| 1.25T | 0.81 | 0.78 | 0.79 | 0.68 | 0.68 | 0.35 | 0.71 | 0.57 | 0.51 | 0.54 |
| 1.5T | 0.81 | 0.80 | 0.80 | 0.69 | 0.68 | 0.35 | 0.72 | 0.56 | 0.51 | 0.54 |
| 1.75T | 0.80 | 0.79 | 0.79 | 0.68 | 0.68 | 0.36 | 0.72 | 0.59 | 0.51 | 0.54 |
| 2T | 0.81 | 0.81 | 0.81 | 0.69 | 0.69 | 0.35 | 0.72 | 0.59 | 0.52 | 0.54 |
| 2.25T | 0.81 | 0.82 | 0.81 | 0.68 | 0.68 | 0.35 | 0.71 | 0.59 | 0.51 | 0.54 |
| 2.5T | 0.81 | 0.82 | 0.82 | 0.68 | 0.68 | 0.36 | 0.70 | 0.56 | 0.52 | 0.54 |
| 2.75T | 0.81 | 0.82 | 0.81 | 0.25 | 0.23 | 0.35 | 0.50 | 0.57 | 0.50 | 0.50 |
| 3T | 0.81 | 0.81 | 0.81 | 0.25 | 0.23 | 0.35 | 0.50 | 0.57 | 0.50 | 0.50 |
| 3.25T | 0.81 | 0.77 | 0.79 | 0.67 | 0.67 | 0.34 | 0.67 | 0.57 | 0.51 | 0.52 |
| 3.5T | 0.81 | 0.79 | 0.80 | 0.71 | 0.71 | 0.38 | 0.72 | 0.58 | 0.53 | 0.55 |
| 3.75T | 0.80 | 0.78 | 0.79 | 0.72 | 0.72 | 0.58 | 0.58 | 0.54 | 0.56 | 0.56 |
| 4T | 0.81 | 0.79 | 0.80 | 0.73 | 0.73 | 0.39 | 0.74 | 0.61 | 0.56 | 0.57 |
Table 3: Performance of SmolLM2-360M on Formal and Functional Linguistic Benchmarks Across Training Checkpoints. Formal competence is measured using BLiMP and SyntaxGym (with averages reported as Avg Formal). Functional competence is measured using ARC-Easy, ARC-Challenge, Social-IQA, PIQA, WinoGrande, and HellaSwag (with averages reported as Avg Functional). Together, these results characterize the relationship between training progression and the development of different aspects of linguistic ability.
## Appendix D Brain Alignment Over Training
<details>
<summary>figures/brain-score-llms-brain-alignment-final.drawio-3.png Details</summary>
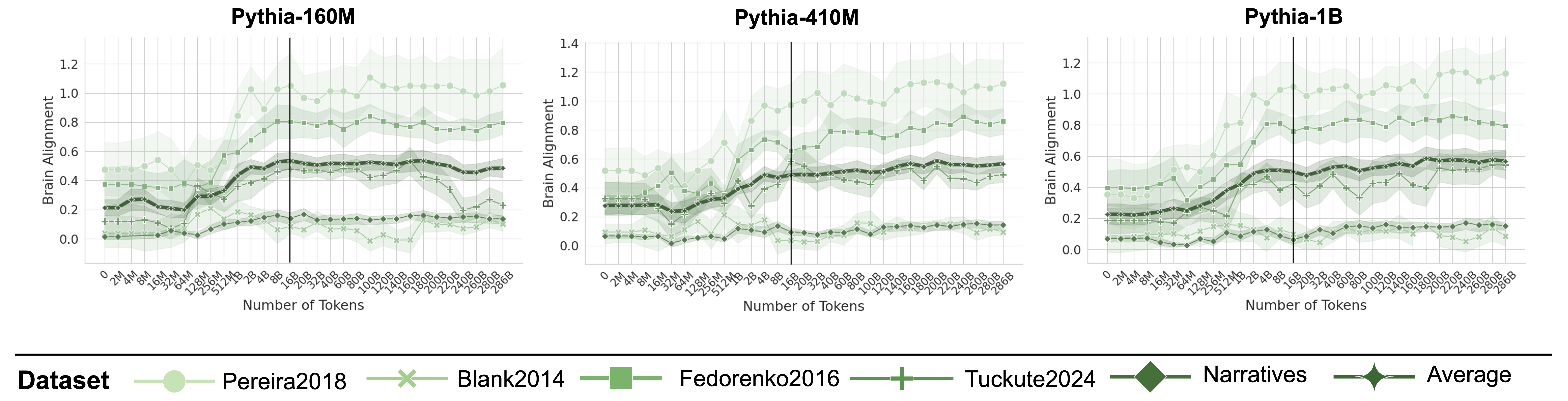
### Visual Description
\n
## Line Chart: Brain Alignment vs. Number of Tokens for Pythia Models
### Overview
This image presents three line charts, each displaying the relationship between "Brain Alignment" (y-axis) and "Number of Tokens" (x-axis) for different datasets. The charts compare the performance of three Pythia language models: Pythia-160M, Pythia-410M, and Pythia-1B. Each chart includes data for five datasets: Pereira2018, Blank2014, Fedorenko2016, Tuckute2024, and Narratives, as well as an "Average" line.
### Components/Axes
* **X-axis:** "Number of Tokens" - Ranges from approximately 0 to 1000.
* **Y-axis:** "Brain Alignment" - Ranges from 0.0 to 1.2.
* **Charts:** Three separate charts, each representing a different Pythia model:
* Pythia-160M
* Pythia-410M
* Pythia-1B
* **Legend:** Located at the bottom-center of the image. It identifies the datasets and the average alignment using both color and marker style.
* Pereira2018 (Light Green Circle)
* Blank2014 (Light Grey X)
* Fedorenko2016 (Dark Green Square)
* Tuckute2024 (Black Diamond)
* Narratives (Dark Green Hexagon)
* Average (Black Circle)
### Detailed Analysis
**Pythia-160M:**
* **Pereira2018 (Light Green Circle):** The line starts at approximately 0.2, rises to a peak of around 1.1 at approximately 400 tokens, and then declines to around 0.6 at 1000 tokens.
* **Blank2014 (Light Grey X):** The line remains relatively low, fluctuating between 0.1 and 0.3 throughout the entire range of tokens.
* **Fedorenko2016 (Dark Green Square):** The line starts at approximately 0.3, increases to around 0.7 at 400 tokens, and then plateaus around 0.6-0.7.
* **Tuckute2024 (Black Diamond):** The line starts at approximately 0.1, rises to a peak of around 0.6 at 400 tokens, and then declines to around 0.3 at 1000 tokens.
* **Narratives (Dark Green Hexagon):** The line starts at approximately 0.2, increases to around 0.7 at 400 tokens, and then declines to around 0.4 at 1000 tokens.
* **Average (Black Circle):** The line starts at approximately 0.2, rises to a peak of around 0.7 at 400 tokens, and then declines to around 0.4 at 1000 tokens.
**Pythia-410M:**
* **Pereira2018 (Light Green Circle):** The line starts at approximately 0.3, rises to a peak of around 1.2 at approximately 400 tokens, and then declines to around 0.7 at 1000 tokens.
* **Blank2014 (Light Grey X):** The line remains relatively low, fluctuating between 0.1 and 0.3 throughout the entire range of tokens.
* **Fedorenko2016 (Dark Green Square):** The line starts at approximately 0.4, increases to around 0.8 at 400 tokens, and then plateaus around 0.7-0.8.
* **Tuckute2024 (Black Diamond):** The line starts at approximately 0.2, rises to a peak of around 0.7 at 400 tokens, and then declines to around 0.4 at 1000 tokens.
* **Narratives (Dark Green Hexagon):** The line starts at approximately 0.3, increases to around 0.8 at 400 tokens, and then declines to around 0.5 at 1000 tokens.
* **Average (Black Circle):** The line starts at approximately 0.3, rises to a peak of around 0.8 at 400 tokens, and then declines to around 0.5 at 1000 tokens.
**Pythia-1B:**
* **Pereira2018 (Light Green Circle):** The line starts at approximately 0.3, rises to a peak of around 1.1 at approximately 400 tokens, and then declines to around 0.7 at 1000 tokens.
* **Blank2014 (Light Grey X):** The line remains relatively low, fluctuating between 0.1 and 0.3 throughout the entire range of tokens.
* **Fedorenko2016 (Dark Green Square):** The line starts at approximately 0.4, increases to around 0.8 at 400 tokens, and then plateaus around 0.7-0.8.
* **Tuckute2024 (Black Diamond):** The line starts at approximately 0.2, rises to a peak of around 0.7 at 400 tokens, and then declines to around 0.4 at 1000 tokens.
* **Narratives (Dark Green Hexagon):** The line starts at approximately 0.3, increases to around 0.8 at 400 tokens, and then declines to around 0.5 at 1000 tokens.
* **Average (Black Circle):** The line starts at approximately 0.3, rises to a peak of around 0.8 at 400 tokens, and then declines to around 0.5 at 1000 tokens.
### Key Observations
* All datasets exhibit a general trend of increasing brain alignment up to approximately 400 tokens, followed by a decline.
* The "Pereira2018" dataset consistently shows the highest brain alignment across all three models.
* The "Blank2014" dataset consistently shows the lowest brain alignment across all three models.
* The "Average" line generally follows the trend of the "Narratives" dataset.
* As the model size increases (160M -> 410M -> 1B), the peak brain alignment tends to increase slightly.
### Interpretation
The charts demonstrate how well the Pythia language models align with brain activity patterns as the number of processed tokens increases. The initial increase in brain alignment suggests that the models are initially capturing relevant information from the input text. The subsequent decline may indicate that the models are losing focus or encountering diminishing returns as they process more tokens.
The consistent high performance of the "Pereira2018" dataset suggests that this dataset is particularly well-suited for evaluating brain alignment. Conversely, the low performance of the "Blank2014" dataset may indicate that it is less representative of natural language processing tasks.
The slight increase in peak brain alignment with larger model sizes suggests that larger models are capable of capturing more complex relationships between language and brain activity, but this effect is not dramatic. The overall trends are consistent across all three models, indicating a general pattern in how these models process language. The fact that all lines decline after a peak suggests a potential limitation in the models' ability to maintain alignment over extended sequences.
</details>
Figure 7: Brain Alignment Saturates Early on in Training. Plots complementing Figure 3 showing the brain alignment scores of three other models from the Pythia model suite with varying sizes (log x-axis up to 16B tokens, uneven spacing after black line). Scores are normalized by their cross-subject consistency scores. Alignment quickly peaks around 2–8B tokens before saturating or declining, regardless of model size.
Figure 7 complements Figure 3 in the main paper, illustrating that brain alignment saturates early on in training for all models analyzed in this work.
## Appendix E Formal & Functional Scores
<details>
<summary>figures/brain-score-llms-formal-competence.drawio.png Details</summary>
### Visual Description
\n
## Chart: Model Performance vs. Number of Tokens
### Overview
The image presents a series of four charts comparing the performance of different Pythia models (1B, 2.8B, 6.9B, and an ensemble of 5 models) on two types of competence tests: Formal and Functional. Performance is measured as Normalized Accuracy against the Number of Tokens processed. Each chart displays multiple data series representing different benchmark datasets.
### Components/Axes
* **X-axis:** Number of Tokens (Scale: 0 to approximately 2000, with no specific markings)
* **Y-axis (Top Charts - Formal Competence):** Normalized Accuracy (Scale: 0 to 0.8, with markings at 0, 0.2, 0.4, 0.6, and 0.8)
* **Y-axis (Bottom Charts - Functional Competence):** Normalized Accuracy (Scale: -0.1 to 0.4, with markings at -0.1, 0, 0.1, 0.2, 0.3, and 0.4)
* **Legend:** Located at the bottom-center of the image.
* **Formal Competence:** BLIMP (Light Blue), SyntaxGym (Light Green)
* **Functional Competence:** ARC-Easy (Dark Green), PIQA (Orange), Social-IQA (Dark Blue), ARC Challenge (Purple), HellaSwag (Teal), and Winogrande (Red)
* **Sub-Titles:** Each chart is labeled (a) Pythia-1B, (b) Pythia-2.8B, (c) Pythia-6.9B, (d) Pythia (5 Models)
* **Annotation:** Chart (d) includes the annotation "5.6% of training time"
### Detailed Analysis or Content Details
**Chart (a) Pythia-1B:**
* **Formal Competence:**
* BLIMP: Line slopes upward, starting around 0.05 and reaching approximately 0.25.
* SyntaxGym: Line is relatively flat, fluctuating around 0.1.
* **Functional Competence:**
* ARC-Easy: Line starts near 0 and increases to approximately 0.15.
* PIQA: Line starts near 0 and increases to approximately 0.2.
* Social-IQA: Line starts near 0 and increases to approximately 0.1.
* ARC Challenge: Line is relatively flat, fluctuating around 0.
* HellaSwag: Line starts near 0 and increases to approximately 0.1.
* Winogrande: Line is relatively flat, fluctuating around 0.
**Chart (b) Pythia-2.8B:**
* **Formal Competence:**
* BLIMP: Line slopes upward, starting around 0.1 and reaching approximately 0.4.
* SyntaxGym: Line is relatively flat, fluctuating around 0.15.
* **Functional Competence:**
* ARC-Easy: Line starts near 0 and increases to approximately 0.3.
* PIQA: Line starts near 0 and increases to approximately 0.35.
* Social-IQA: Line starts near 0 and increases to approximately 0.2.
* ARC Challenge: Line is relatively flat, fluctuating around 0.
* HellaSwag: Line starts near 0 and increases to approximately 0.2.
* Winogrande: Line is relatively flat, fluctuating around 0.
**Chart (c) Pythia-6.9B:**
* **Formal Competence:**
* BLIMP: Line slopes upward, starting around 0.15 and reaching approximately 0.6.
* SyntaxGym: Line is relatively flat, fluctuating around 0.2.
* **Functional Competence:**
* ARC-Easy: Line starts near 0 and increases to approximately 0.4.
* PIQA: Line starts near 0 and increases to approximately 0.45.
* Social-IQA: Line starts near 0 and increases to approximately 0.3.
* ARC Challenge: Line is relatively flat, fluctuating around 0.
* HellaSwag: Line starts near 0 and increases to approximately 0.3.
* Winogrande: Line is relatively flat, fluctuating around 0.
**Chart (d) Pythia (5 Models):**
* **Formal Competence:**
* BLIMP: Line slopes upward, starting around 0.2 and reaching approximately 0.7.
* SyntaxGym: Line is relatively flat, fluctuating around 0.25.
* **Functional Competence:**
* ARC-Easy: Line starts near 0 and increases to approximately 0.3.
* PIQA: Line starts near 0 and increases to approximately 0.35.
* Social-IQA: Line starts near 0 and increases to approximately 0.25.
* ARC Challenge: Line is relatively flat, fluctuating around 0.
* HellaSwag: Line starts near 0 and increases to approximately 0.25.
* Winogrande: Line is relatively flat, fluctuating around 0.
### Key Observations
* Generally, performance on both Formal and Functional Competence tasks increases with model size (1B to 6.9B to 5 Models).
* BLIMP consistently shows the highest performance among the Formal Competence benchmarks.
* PIQA consistently shows the highest performance among the Functional Competence benchmarks.
* ARC Challenge and Winogrande consistently show the lowest performance across all models.
* The 5-model ensemble shows the highest overall performance, particularly on Formal Competence.
* The shaded areas around the lines represent the variance in performance.
### Interpretation
The charts demonstrate a clear positive correlation between model size and performance on both Formal and Functional competence benchmarks. Larger models (Pythia-6.9B and the 5-model ensemble) consistently outperform smaller models (Pythia-1B and Pythia-2.8B). This suggests that increasing model capacity leads to improved ability to process and understand language.
The divergence in performance between Formal and Functional Competence tasks indicates that the models may be better at tasks requiring strict grammatical understanding (Formal) than those requiring real-world reasoning and common sense (Functional). The consistently low performance on ARC Challenge and Winogrande suggests these tasks are particularly challenging for the models, potentially due to their reliance on complex reasoning or nuanced understanding of context.
The annotation "5.6% of training time" on chart (d) suggests that the 5-model ensemble achieves its superior performance at a computational cost, requiring significantly more training time than the individual models. This highlights the trade-off between performance and efficiency in model development. The shaded areas around the lines indicate the variability in performance, which could be due to factors such as data sampling or model initialization.
</details>
Figure 8: Individual Benchmark Scores for Formal and Functional Competence. (a-c): each column shows the evolution of individual benchmark scores for formal competence (top) and functional competence (bottom) during training. Data is presented for Pythia models of three different sizes. (d): the same as (a–c), with data averaged across models of five different sizes.
Figure 8 presents the individual benchmark scores for both formal and functional linguistic competence across training. Formal benchmarks peak early, mirroring the trajectory of brain alignment, and remain saturated throughout training. In contrast, functional benchmarks continue to improve, reflecting the models’ increasing ability to acquire factual knowledge and reasoning skills as they are trained on significantly more tokens using next-word prediction.
## Appendix F Results on SmolLM2-360M
To assess the generalizability of our findings, we replicated our experiments using a model from a different language family. Specifically, we evaluated multiple training checkpoints of SmolLM2-360M on the brain alignment, formal, and functional linguistic competence benchmarks. Since SmolLM2 only provides checkpoints at intervals of 250B tokens, we cannot capture the gradual emergence of brain alignment and formal competence, both of which typically saturate around 4B–8B tokens. Given this limitation, our hypothesis was that brain alignment and formal competence would remain largely stable across these checkpoints, while functional competence would continue to improve. The results are consistent with this hypothesis as shown in Tables 2 and 3.
## Appendix G Role of Weight Initialization
<details>
<summary>figures/untrained_init_range_comparison_nunits=128.png Details</summary>
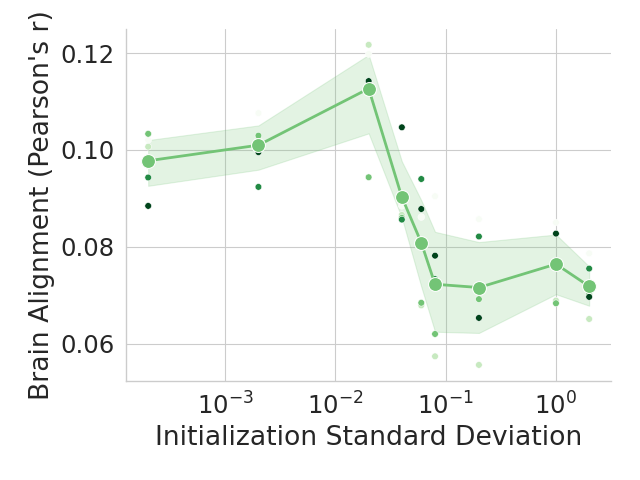
### Visual Description
\n
## Line Chart: Brain Alignment vs. Initialization Standard Deviation
### Overview
The image presents a line chart illustrating the relationship between "Initialization Standard Deviation" and "Brain Alignment (Pearson's r)". The chart displays a central line representing the trend, surrounded by a shaded region indicating variability or confidence intervals. Individual data points are scattered around the line. The x-axis uses a logarithmic scale.
### Components/Axes
* **X-axis:** "Initialization Standard Deviation" with a logarithmic scale ranging from 10<sup>-3</sup> to 10<sup>0</sup> (1). Markers are at 10<sup>-3</sup>, 10<sup>-2</sup>, 10<sup>-1</sup>, and 10<sup>0</sup>.
* **Y-axis:** "Brain Alignment (Pearson's r)" ranging from approximately 0.06 to 0.12.
* **Line:** A single green line representing the central tendency of the data.
* **Shaded Region:** A light green shaded area surrounding the line, representing the variability or confidence interval.
* **Data Points:** Numerous dark green dots scattered around the line, representing individual data observations.
### Detailed Analysis
The line chart shows a complex relationship.
* **Initial Trend (10<sup>-3</sup> to 10<sup>-2</sup>):** The line initially shows a slight increase in Brain Alignment as Initialization Standard Deviation increases from 10<sup>-3</sup> to 10<sup>-2</sup>.
* At 10<sup>-3</sup>, Brain Alignment is approximately 0.095.
* At 10<sup>-2</sup>, Brain Alignment reaches a local maximum of approximately 0.11.
* **Peak and Decline (10<sup>-2</sup> to 10<sup>-1</sup>):** From 10<sup>-2</sup> to 10<sup>-1</sup>, the line exhibits a sharp decline in Brain Alignment.
* At 10<sup>-1</sup>, Brain Alignment drops to approximately 0.075.
* **Stabilization (10<sup>-1</sup> to 10<sup>0</sup>):** Between 10<sup>-1</sup> and 10<sup>0</sup>, the line stabilizes, showing a slight fluctuation around 0.08.
* At 10<sup>0</sup>, Brain Alignment is approximately 0.078.
The data points are generally clustered around the line, but there is noticeable scatter, particularly at the higher Initialization Standard Deviation values (around 10<sup>-1</sup> and 10<sup>0</sup>).
### Key Observations
* The relationship between Initialization Standard Deviation and Brain Alignment is not monotonic. It initially increases, then decreases, and finally stabilizes.
* The most significant change in Brain Alignment occurs between Initialization Standard Deviation values of 10<sup>-2</sup> and 10<sup>-1</sup>.
* The shaded region indicates a relatively wide range of variability, especially at higher Initialization Standard Deviation values.
* There are no obvious outliers, but the scatter of data points suggests that other factors may influence Brain Alignment.
### Interpretation
The chart suggests that there is an optimal range for the Initialization Standard Deviation to maximize Brain Alignment. Increasing the Initialization Standard Deviation beyond a certain point (around 10<sup>-2</sup>) leads to a decrease in Brain Alignment. The stabilization at higher values suggests that further increases in Initialization Standard Deviation do not significantly impact Brain Alignment, but also do not improve it.
The variability indicated by the shaded region suggests that the relationship is not deterministic and that other variables likely play a role in determining Brain Alignment. The logarithmic scale on the x-axis implies that small changes in Initialization Standard Deviation at lower values have a greater impact than similar changes at higher values.
This data could be used to inform the selection of an appropriate Initialization Standard Deviation value for a system or model where Brain Alignment is a desired outcome. The optimal value appears to be around 10<sup>-2</sup>, but further investigation may be needed to account for the observed variability.
</details>
Figure 9: Role of Weight Initialization on Brain Alignment in Untrained Models The default initialization standard deviation in the HuggingFace library (sd = 0.02) yields the highest brain alignment for untrained models, suggesting that initialization choices play a crucial role in shaping alignment even before training begins.
Figure 9 examines the effect of weight initialization variance on brain alignment in untrained models. We systematically vary the initialization standard deviation (sd) and find that the default HuggingFace Wolf et al. (2019) initialization (sd = 0.02) achieves the highest alignment across datasets. This suggests that even before training begins, the choice of initialization can significantly influence how well a model’s representations align with neural activity. This finding raises an intriguing hypothesis: could brain alignment, a computationally inexpensive metric, serve as a useful heuristic for selecting optimal initialization parameters? If so, it could help models learn tasks more efficiently and converge faster, reducing the need for extensive trial-and-error in training from scratch. The results highlight the importance of architectural inductive biases and suggest that brain alignment may serve as a useful heuristic for optimizing model initialization.
## Appendix H Effect of Number of Units on Brain Alignment
<details>
<summary>figures/pretrained_num_units_model_size.png Details</summary>
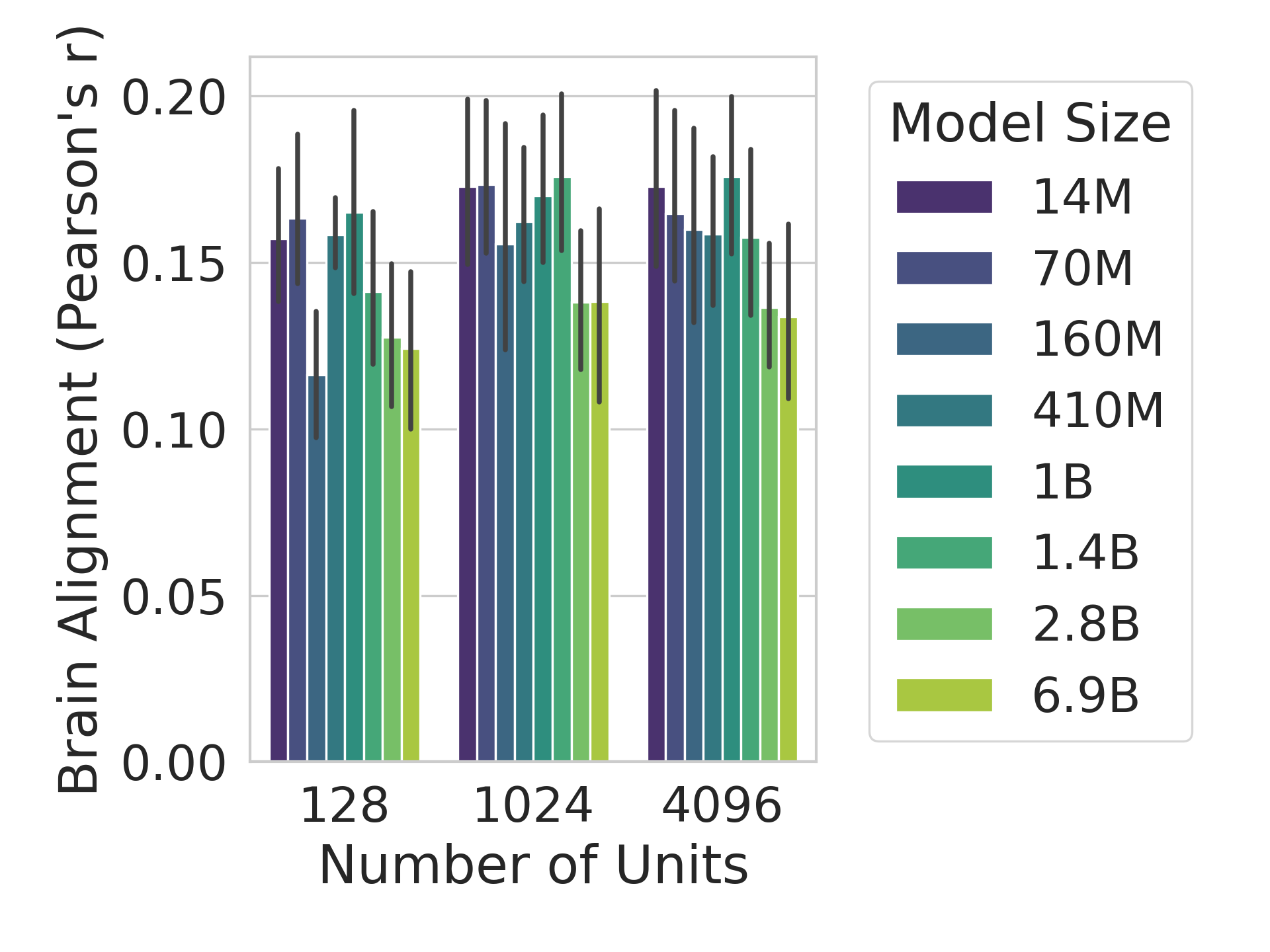
### Visual Description
\n
## Bar Chart: Brain Alignment vs. Model Size & Number of Units
### Overview
This image presents a bar chart illustrating the relationship between brain alignment (measured by Pearson's r) and two categorical variables: model size and number of units. The chart displays the average brain alignment for different model sizes at three different unit counts (128, 1024, and 4096). Error bars indicate the variability around each mean.
### Components/Axes
* **X-axis:** Number of Units, with markers at 128, 1024, and 4096.
* **Y-axis:** Brain Alignment (Pearson's r), ranging from approximately 0.00 to 0.20.
* **Legend:** Located in the top-right corner, detailing the Model Size categories:
* 14M (Dark Purple)
* 70M (Blue)
* 160M (Grayish Blue)
* 410M (Teal)
* 1B (Green)
* 1.4B (Light Green)
* 2.8B (Pale Green)
* 6.9B (Yellow)
### Detailed Analysis
The chart consists of grouped bar plots. Each group represents a specific number of units (128, 1024, or 4096). Within each group, there are eight bars, each corresponding to a different model size. Each bar is accompanied by an error bar indicating the standard error or confidence interval.
**Data Points (Approximate):**
**Number of Units = 128:**
* 14M: Brain Alignment ≈ 0.16, Error Bar ≈ ±0.02
* 70M: Brain Alignment ≈ 0.14, Error Bar ≈ ±0.02
* 160M: Brain Alignment ≈ 0.13, Error Bar ≈ ±0.02
* 410M: Brain Alignment ≈ 0.14, Error Bar ≈ ±0.02
* 1B: Brain Alignment ≈ 0.15, Error Bar ≈ ±0.02
* 1.4B: Brain Alignment ≈ 0.14, Error Bar ≈ ±0.02
* 2.8B: Brain Alignment ≈ 0.13, Error Bar ≈ ±0.02
* 6.9B: Brain Alignment ≈ 0.12, Error Bar ≈ ±0.02
**Number of Units = 1024:**
* 14M: Brain Alignment ≈ 0.17, Error Bar ≈ ±0.02
* 70M: Brain Alignment ≈ 0.16, Error Bar ≈ ±0.02
* 160M: Brain Alignment ≈ 0.15, Error Bar ≈ ±0.02
* 410M: Brain Alignment ≈ 0.16, Error Bar ≈ ±0.02
* 1B: Brain Alignment ≈ 0.17, Error Bar ≈ ±0.02
* 1.4B: Brain Alignment ≈ 0.16, Error Bar ≈ ±0.02
* 2.8B: Brain Alignment ≈ 0.15, Error Bar ≈ ±0.02
* 6.9B: Brain Alignment ≈ 0.14, Error Bar ≈ ±0.02
**Number of Units = 4096:**
* 14M: Brain Alignment ≈ 0.17, Error Bar ≈ ±0.02
* 70M: Brain Alignment ≈ 0.16, Error Bar ≈ ±0.02
* 160M: Brain Alignment ≈ 0.15, Error Bar ≈ ±0.02
* 410M: Brain Alignment ≈ 0.16, Error Bar ≈ ±0.02
* 1B: Brain Alignment ≈ 0.17, Error Bar ≈ ±0.02
* 1.4B: Brain Alignment ≈ 0.16, Error Bar ≈ ±0.02
* 2.8B: Brain Alignment ≈ 0.15, Error Bar ≈ ±0.02
* 6.9B: Brain Alignment ≈ 0.14, Error Bar ≈ ±0.02
**Trends:**
* For each number of units, the brain alignment values are relatively similar across different model sizes.
* There is a slight tendency for brain alignment to increase as the number of units increases, particularly for smaller model sizes.
* The error bars suggest that the differences in brain alignment between model sizes are not statistically significant.
### Key Observations
* The brain alignment values generally fall between 0.12 and 0.17, indicating a moderate level of alignment.
* The error bars are relatively consistent across all model sizes and unit counts, suggesting that the variability in brain alignment is similar for all conditions.
* The largest model size (6.9B) consistently shows slightly lower brain alignment compared to smaller models, but the difference is not substantial.
### Interpretation
The chart suggests that brain alignment is not strongly dependent on model size, at least within the range tested. The number of units appears to have a more noticeable, though still modest, effect on brain alignment. The relatively small error bars indicate that the observed alignment is reasonably consistent across different runs or samples.
The data implies that increasing model size alone may not be sufficient to improve brain alignment. Other factors, such as the architecture of the model or the training data, may play a more significant role. The slight increase in alignment with more units suggests that increasing model capacity can contribute to better alignment, but the effect is limited.
The consistent error bars across all conditions suggest that the variability in brain alignment is inherent to the system being studied, rather than being driven by differences in model size or unit count. This could be due to noise in the data, limitations in the measurement technique, or fundamental properties of the brain itself.
</details>
Figure 10: The Effect of the Number of Localized Units on Final Brain Alignment Brain alignment is evaluated after localizing 128, 1024, and 4096 units. While increasing the number of units slightly affects overall alignment, the relative ranking of models remains largely unchanged, indicating that model comparisons are robust to the choice of unit count.
Figure 10 illustrates the impact of localizing more units on final brain alignment across the eight Pythia models used in this study. We find that increasing the number of units has minimal impact on the relative ranking of models, with only a slight increase in average alignment. Additionally, model size does not influence brain alignment once the number of units is controlled, reinforcing the idea that alignment is driven by feature selection rather than scale.
<details>
<summary>figures/brain-score-llms-brain-alignment-v1.drawio.png Details</summary>

### Visual Description
## Line Chart: Brain Alignment vs. Number of Tokens for Different Model Sizes
### Overview
This image presents three line charts displaying the relationship between the number of tokens processed and brain alignment (measured by Pearson's r) for three different model sizes: 14M, 70M, and 160M parameters. Two brain regions are compared: "Language Network" and "V1". The charts share the same x and y axes, but are presented as separate panels.
### Components/Axes
* **X-axis:** "Number of Tokens". The scale appears to be linear, ranging from approximately 0 to 90, with tick marks at intervals of 10. The labels are rotated approximately 45 degrees.
* **Y-axis:** "Brain Alignment (Pearson's r)". The scale ranges from approximately -0.025 to 0.155. Tick marks are present at intervals of 0.025.
* **Legend:** Located at the bottom-center of the image. It identifies two data series:
* "Language Network" - represented by a green line with circular markers.
* "V1" - represented by a purple line with cross markers.
* **Titles:** Each chart panel is labeled with the model size: "14M", "70M", and "160M", positioned at the top-center of each respective chart.
* **Shaded Area:** A light purple shaded area surrounds each line, representing the standard error or confidence interval.
### Detailed Analysis
Each chart shows the brain alignment for both the Language Network and V1 regions as the number of tokens increases.
**14M Model:**
* **Language Network (Green):** The line starts at approximately 0.045 and generally slopes upward, reaching a peak of around 0.135 at approximately 70 tokens. After the peak, the line fluctuates but remains relatively stable, ending at approximately 0.11 at 90 tokens.
* **V1 (Purple):** The line starts at approximately 0.01 and remains relatively flat throughout, fluctuating around 0.015. It ends at approximately 0.01 at 90 tokens.
**70M Model:**
* **Language Network (Green):** The line starts at approximately 0.06 and increases more rapidly than in the 14M model, reaching a peak of around 0.145 at approximately 60 tokens. It then declines slightly, ending at approximately 0.125 at 90 tokens.
* **V1 (Purple):** Similar to the 14M model, the line remains relatively flat, fluctuating around 0.02. It ends at approximately 0.015 at 90 tokens.
**160M Model:**
* **Language Network (Green):** The line starts at approximately 0.07 and exhibits a similar trend to the 70M model, reaching a peak of around 0.14 at approximately 60 tokens. It then declines slightly, ending at approximately 0.12 at 90 tokens.
* **V1 (Purple):** Again, the line remains relatively flat, fluctuating around 0.02. It ends at approximately 0.015 at 90 tokens.
### Key Observations
* The Language Network consistently shows a higher brain alignment score than V1 across all model sizes.
* Brain alignment generally increases with the number of tokens processed, up to a certain point, after which it plateaus or slightly declines.
* Larger models (70M and 160M) exhibit higher peak brain alignment scores compared to the smaller model (14M).
* The V1 region shows minimal change in brain alignment regardless of model size or number of tokens.
* The shaded areas indicate the variability in brain alignment, which appears relatively consistent across all conditions.
### Interpretation
The data suggests that as language models process more tokens, their activity becomes more aligned with brain regions associated with language processing (Language Network). This alignment appears to be stronger in larger models, indicating that increased model capacity allows for a more nuanced representation of language that resonates with human brain activity. The consistently low alignment in the V1 region suggests that this visual cortex area is not strongly engaged during language processing in these models. The plateauing or slight decline in alignment after a certain number of tokens could indicate a saturation point, where further processing does not lead to increased alignment, or potentially introduces noise. The standard error bands suggest that the observed trends are relatively robust. This data could be used to evaluate the effectiveness of different model architectures and training strategies in creating models that better reflect human cognitive processes.
</details>
Figure 11: Brain Alignment with the Language Network vs. V1 Across Training. Raw brain alignment scores (Pearson’s r) of three Pythia models of varying sizes are shown on the Pereira2018 dataset. The x-axis (log-scaled up to 16B tokens; then evenly spaced after the black line every 20B tokens) represents training progress. Alignment with V1, an early visual region, remains stable throughout training, while alignment with the language network (LN) increases around 4B tokens before plateauing.
## Appendix I Model Size Does Not Predict Alignment
<details>
<summary>figures/brain-score-llms-model-size-greens.drawio.png Details</summary>
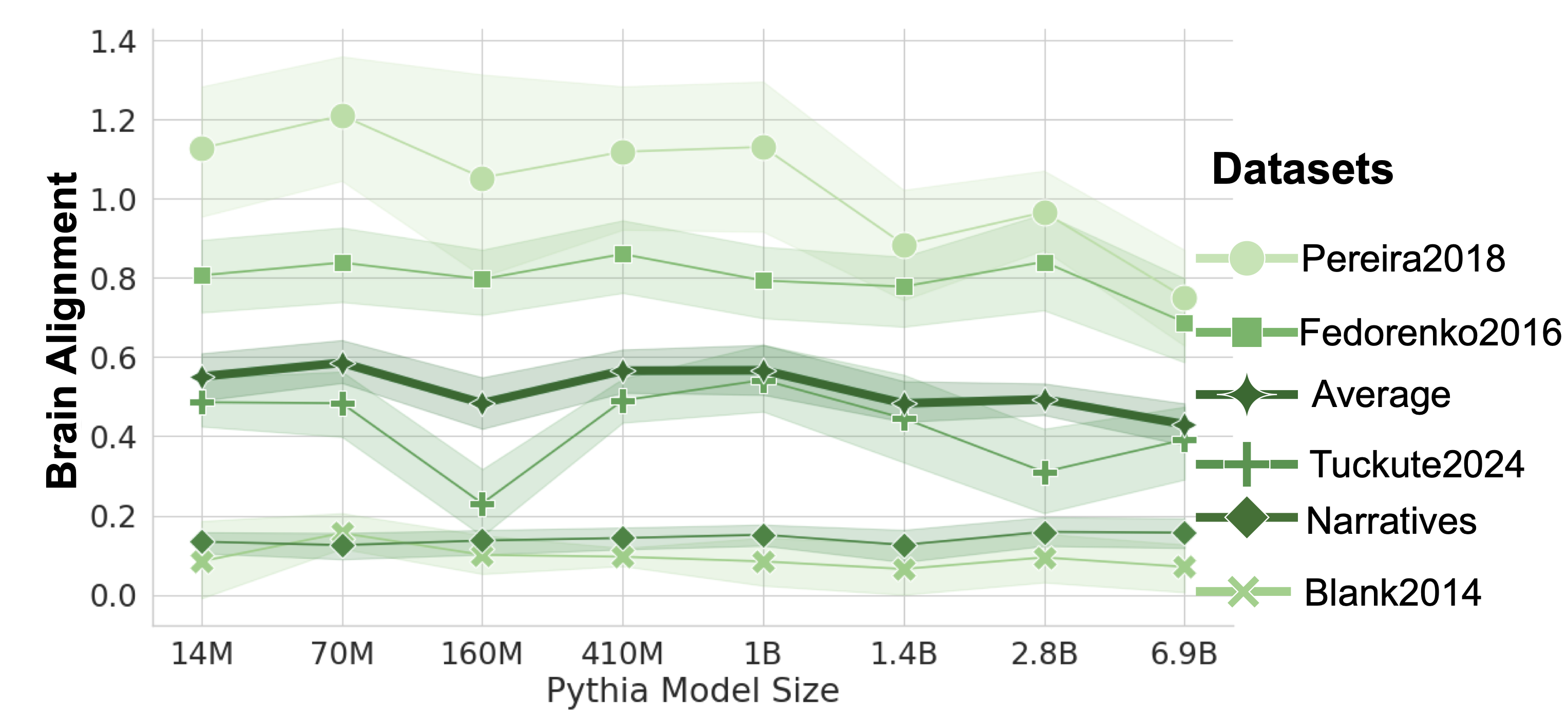
### Visual Description
## Line Chart: Brain Alignment vs. Pythia Model Size
### Overview
This line chart depicts the relationship between Brain Alignment scores and Pythia Model Size across several datasets. The chart displays six different datasets as lines, showing how Brain Alignment changes as the Pythia Model Size increases. A shaded region encompasses the lines, representing the average Brain Alignment.
### Components/Axes
* **X-axis:** Pythia Model Size, with markers at 14M, 70M, 160M, 410M, 1B, 1.4B, 2.8B, and 6.9B.
* **Y-axis:** Brain Alignment, ranging from 0.0 to 1.4.
* **Legend (top-right):** Lists the datasets and their corresponding line colors:
* Pereira2018 (light green)
* Fedorenko2016 (dark green)
* Average (dark grey)
* Tuckute2024 (light grey)
* Narratives (dark brown)
* Blank2014 (light purple)
### Detailed Analysis
Let's analyze each line's trend and extract approximate data points.
* **Pereira2018 (light green):** The line starts at approximately 1.25 at 14M, decreases to around 0.95 at 70M, rises to approximately 1.1 at 160M, remains relatively stable around 1.1-1.05 until 2.8B, and then decreases to approximately 0.9 at 6.9B.
* **Fedorenko2016 (dark green):** The line begins at approximately 0.85 at 14M, decreases to around 0.75 at 70M, remains relatively stable around 0.75-0.8 until 1.4B, then decreases to approximately 0.6 at 6.9B.
* **Average (dark grey):** The line starts at approximately 0.5 at 14M, increases to around 0.6 at 70M, remains relatively stable around 0.6-0.7 until 1.4B, then decreases to approximately 0.5 at 6.9B.
* **Tuckute2024 (light grey):** The line begins at approximately 0.55 at 14M, decreases to around 0.5 at 70M, remains relatively stable around 0.5-0.6 until 1.4B, then decreases to approximately 0.3 at 6.9B.
* **Narratives (dark brown):** The line starts at approximately 0.2 at 14M, increases to around 0.3 at 70M, remains relatively stable around 0.3-0.4 until 1.4B, then decreases to approximately 0.1 at 6.9B.
* **Blank2014 (light purple):** The line begins at approximately 0.1 at 14M, increases to around 0.2 at 70M, remains relatively stable around 0.2-0.3 until 1.4B, then decreases to approximately 0.05 at 6.9B.
### Key Observations
* The Pereira2018 dataset consistently exhibits the highest Brain Alignment scores across all model sizes.
* The Blank2014 and Narratives datasets consistently exhibit the lowest Brain Alignment scores.
* Generally, Brain Alignment tends to decrease as the Pythia Model Size increases beyond 1.4B for most datasets.
* The average Brain Alignment remains relatively stable between 14M and 1.4B, then decreases at 6.9B.
### Interpretation
The chart suggests that increasing the Pythia Model Size does not necessarily lead to higher Brain Alignment, and may even decrease it for some datasets. The varying responses across datasets indicate that the relationship between model size and Brain Alignment is dataset-dependent. The consistently high alignment of Pereira2018 suggests this dataset is particularly well-suited to the Pythia model architecture, or that the model captures its features effectively. Conversely, the low alignment of Blank2014 and Narratives suggests these datasets are less aligned with the model's learned representations. The decrease in alignment at larger model sizes (6.9B) could indicate overfitting or a diminishing return on investment in model capacity. The average line provides a general trend, but the individual dataset lines reveal more nuanced behavior. This data could be used to inform model selection and training strategies, potentially suggesting that smaller models may be preferable for certain datasets, or that regularization techniques are needed to prevent overfitting in larger models.
</details>
Figure 12: Model Size Does Not Predict Brain Alignment when localizing a fixed set of language units. Brain alignment across model sizes in the Pythia suite, measured at their final training checkpoints. Brain alignment is shown for each dataset, along with the average score across datasets, for eight models of varying sizes.
Figure 12 presents the brain alignment for each dataset, along with the average alignment across datasets, for eight models of varying sizes from the Pythia model suite (final checkpoint). Contrary to the assumption that larger models exhibit higher brain alignment Aw et al. (2023), we observe a decline in average alignment starting from 1B parameters up to 6.9B parameters, when controlling for feature size. This analysis is made possible by functional localization, which allows us to extract a fixed number of units from each model, rather than relying on hidden state dimensions, as done in previous studies. This approach ensures a fairer comparison among models. We show in Appendix H that increasing the number of localized units has minimal impact on the relative ranking of the models. Additionally, these findings align with expectations in the neuroscience language community, where it is widely believed that human language processing does not require superhuman-scale models to capture neural activity in the brain’s language network.
## Appendix J Alignment with Other Brain Regions
As a control, we also examine alignment with non-language brain regions. Specifically, Figure 11 shows the brain alignment of three Pythia models with both the language network (LN) and V1—an early visual cortex region—on the Pereira2018 dataset. While alignment with the LN increases early in training (around 4B tokens) and then saturates, alignment with V1 remains largely unchanged throughout training. This divergence highlights a key aspect of LLM representations: they do not appear to encode low-level perceptual features, such as those processed in early visual areas. If models were learning perceptual structure from the stimuli, we would expect alignment with V1 to increase alongside LN alignment. Instead, the stability of V1 alignment across training suggests that language models selectively develop internal representations that align with higher-order linguistic processing rather than general sensory processing.
One reason for not measuring alignment against other higher-level cognitive brain regions such as the default mode network (DMN), the multiple demand network (MD) or the theory of mind network (ToM) is due to a major limitation in current neuroimaging datasets: the linguistic stimuli used in studies with publicly available datasets (e.g., Pereira2018) do not reliably engage these higher-level cognitive regions, leading to substantial variability across individuals and thus much lower cross-subject consistency scores. Simply “looking” for alignment in the DMN or MD is therefore insufficient. Instead, we need new datasets that deliberately activate non‑language networks and record item‑level neural responses. For example, most MD studies rely on blocked fMRI designs (e.g., hard vs. easy math), yielding one activation estimate per condition rather than per stimulus. Such coarse measurements limit their utility to evaluate model‑to‑brain correspondence at the granularity of individual items. We expect alignment with the MD network, a brain region involved in logical reasoning, to track functional linguistic competence more than formal competence as models improve on relevant benchmarks. We leave this investigation for future work, pending the availability of suitable datasets.
## Appendix K Cross-Subject Consistency Scores
| Pereira2018 (Exp 2) ∗ Pereira2018 (Exp 3) Blank2014 | 0.086 0.144 0.178 |
| --- | --- |
| Fedorenko2016 | 0.222 |
| Tucktue2024 | 0.559 |
| Narratives | 0.181 |
| Futrell2018 | 0.858 |
Table 4: Cross-Subject Consistency Scores The values used to normalize the raw Pearson correlation. ∗ Pereira2018 (Exp 2) was computed without extrapolation.
Table 4 shows the cross-subject consistency scores computed with extrapolation for the different benchmarks used in this work.