# Multi-Agent Systems Powered by Large Language Models: Applications in Swarm Intelligence
**Authors**:
- Cristian Jimenez-Romero
- Cergy, France
- \And Alper Yegenoglu
- \And Christian Blum (Artificial Intelligence Research Institute (IIIA-CSIC))
- Campus of the UAB
- Bellaterra, Spain
Abstract
This work examines the integration of large language models (LLMs) into multi-agent simulations by replacing the hard-coded programs of agents with LLM-driven prompts. The proposed approach is showcased in the context of two examples of complex systems from the field of swarm intelligence: ant colony foraging and bird flocking. Central to this study is a toolchain that integrates LLMs with the NetLogo simulation platform, leveraging its Python extension to enable communication with GPT-4o via the OpenAI API. This toolchain facilitates prompt-driven behavior generation, allowing agents to respond adaptively to environmental data. For both example applications mentioned above, we employ both structured, rule-based prompts and autonomous, knowledge-driven prompts. Our work demonstrates how this toolchain enables LLMs to study self-organizing processes and induce emergent behaviors within multi-agent environments, paving the way for new approaches to exploring intelligent systems and modeling swarm intelligence inspired by natural phenomena. We provide the code, including simulation files and data at https://github.com/crjimene/swarm_gpt.
Keywords Agent-based modeling $·$ simulation $·$ LLM-guided agents
1 Introduction
1.1 From Rule-Based to LLM-Driven Agents: A New Paradigm in ABMS
In this study, we use the terms “agent” and “multi-agent” based on their foundational meanings in agent-based modeling and simulation (ABMS) [Macal and North, 2009], while extending them through the integration of large language models (LLMs) [Chang et al., 2024]. Traditionally, an agent in ABMS is an autonomous entity with localized decision-making abilities, interacting with its environment and other agents according to predefined rules or principles. A multi-agent system (MAS) [Wooldridge, 2009] refers to a collection of such agents operating within a shared environment, where global behaviors emerge from their local interactions. Examples of ABMS include simulations of ecosystem dynamics, urban development, and social interactions [Heckbert et al., 2010; Chen, 2012; Bianchi and Squazzoni, 2015].
Beyond rule-based agents, ABMS literature also explores agents controlled by neural networks, especially in applications that require adaptability or learning. Techniques like reinforcement learning and evolutionary strategies are commonly used to optimize agent behaviors in dynamic environments [Hecker and Moses, 2015; Ning and Xie, 2024; Liu et al., 2024a]. Other research investigates the application of biologically inspired architectures, particularly spiking neural networks, to develop solutions that are both energy-efficient and computationally effective Fang and Dickerson [2017]; Putra et al. [2024]. Within these systems, emergent behavior plays a pivotal role, facilitating the effective handling of complex tasks [Jimenez Romero et al., 2024].
Recently, these terms have been introduced in a different context within artificial intelligence. Here, AI agents often represent task-oriented entities designed to autonomously achieve specific goals, such as generating dialogues or managing workflows. These agents typically focus on individual task execution rather than the emergent dynamics central to ABMS ( [Talebirad and Nadiri, 2023; Kannan et al., 2024; Li et al., 2024]).
In our work, we employ the terms “agent” and “multi-agent” in the context of ABMS while integrating LLMs to guide agent behaviors. An agent in our simulations can be either LLM-steered or rule-based. We incorporate LLMs to guide agent behaviors in two ways: (1) simulations consisting entirely of LLM-steered agents, and (2) hybrid simulations where LLM-steered agents interact with traditional rule-based agents. This means our simulations can have populations of agents that are completely LLM-based or a mix of LLM-based and rule-based agents within the same environment.
We aim to explore the potential advantages of leveraging the decision-making and pattern-generation capabilities of LLMs to augment ABMS. Specifically, we are interested in investigating whether integrating LLMs can help us model emergent behavior using the language processing capabilities and the knowledge base of LLMs.
From this point forward, when we refer to “agents,” we mean agents within the ABMS framework that may incorporate LLM intelligence.
1.2 Motivation
The field of agent-based simulations has rapidly evolved, driven by advances in artificial intelligence (AI) and computational power. These simulations, which model the interactions of autonomous agents within a defined environment, are increasingly being enhanced by the integration of generative AI, particularly LLMs. In this context, LLMs—with their capacity to process and generate human-like text—offer a novel means of guiding and influencing agent behaviors in real-time. A critical aspect of this integration is prompt engineering, which is the careful design of prompts that serve as instructions for the agents, dictating how they should respond to their environment.
The motivation and contribution of this work are found in the presentation of a toolchain that integrates LLMs with agent-based simulations within the NetLogo environment [Tisue and Wilensky, 2004; Amblard et al., 2015], a platform widely recognized in the complexity science community for its robustness and versatility. NetLogo’s value as an educational tool spanning various academic levels further underscores its importance, making it an ideal choice for demonstrating the integration of advanced AI methods into multi-agent simulations.
Our study investigates two distinct approaches to utilizing LLMs within multi-agent environments, focusing on the role of prompt engineering in shaping agent behavior. The first approach employs detailed, structured prompts within an ant colony simulation. These prompts are designed to specify behaviors under clearly defined conditions, such as following pheromone trails or retrieving food. This method allows for precise control over agent actions, enabling a rule-based system where each agent’s behavior is explicitly dictated by the LLM-generated instructions.
In contrast, The second approach explores the use of less structured, principle-based prompts in a bird flocking simulation. Here, the prompts rely on the LLM’s inherent understanding of complex concepts such as flocking dynamics and self-organization. Instead of requiring explicit, rule-based instructions, these prompts allow the LLM to handle the intricate behavioral patterns that would otherwise need numerous rules to define. This approach leverages the LLM’s capacity to intuitively model these dynamics, enabling behaviors that emerge naturally from agents’ interactions with each other and their environment. As we will show, the LLM can produce adequate and adaptive agent behaviors that realistically reflect complex, emergent patterns within the simulation.
1.3 Research Objectives
The following are the main objectives of our research:
- To assess the efficacy of structured prompts in the context of the rule-based ant colony foraging simulation of NetLogo, which is a classic MAS model that demonstrates swarm intelligence principles based on how real ants find food and communicate via pheromones. It is widely used in artificial intelligence, complexity science, and optimization research.
- To assess the efficacy of structured prompts in NetLogo’s knowledge-driven bird flocking simulation, which is also a classic model demonstrating self-organizing behavior in MAS. It is inspired by Craig Reynolds’ “Boids” model [Reynolds, 1987], which simulates how birds, fish, or other animals move in cohesive groups without a central leader.
- To present a comprehensive toolchain that combines LLMs with multi-agent simulation environments, offering a new method for modeling and analyzing swarm behavior in complex systems.
This investigation aims to explore how LLMs, through effective prompt engineering, can be integrated into multi-agent systems to model and guide emergent, self-organizing behaviors in simulated environments.
1.4 Background and Related Work
The integration of generative AI into multi-agent systems represents a burgeoning field that seeks to enhance the autonomy, adaptability, and realism of agent behaviors in simulations. This approach leverages the vast knowledge embedded within LLMs to influence agent interactions in ways that were previously unfeasible with traditional rule-based systems. The use of generative AI in multi-agent simulations has opened new avenues for exploring complex behaviors, emergent dynamics, and adaptive systems.
In particular, the integration of LLMs with agent-based simulations represents a significant convergence of natural language processing (NLP) and complex systems modeling. LLMs, with their ability to generate human-like text and understand complex linguistic patterns, have transformed various fields within artificial intelligence, particularly in automating and interpreting language-based tasks. On the other hand, agent-based simulations are a robust framework for modeling complex systems where individual agents interact with each other and their environment, potentially leading to emergent behaviors. The use of LLMs in simulations may hereby vary widely, from highly structured, rule-based prompts that delineate specific actions to more generalized prompts that rely on the LLM’s broader knowledge base. This study highlights two distinct methodologies in applying LLM capabilities to simulate emergent, multi-agent behaviors with varying degrees of prompt specificity and autonomy.
Integrating LLMs with agent-based simulations presents transformative opportunities across various domains, enhancing the realism and complexity of simulations. This integration can significantly improve the modeling of social systems, industrial automation, and multi-agent interactions.
Park et al. [2023] introduce an LLM-driven agent that can engage and converse with both humans and other AI agents. The agent has the capability to generate text that can be comprehended and interpreted by other agents. This facilitates clear communication between them, fostering effective interactions and collaboration. The simulated environment functions as a sandbox composed of text, allowing the agent to perceive and interpret the surrounding context effectively. This setting enables the agent to navigate and interact with the provided information. Inspired by the work of Park et al. [2023], Junprung [2023] presents two LLM-driven experiments, two-agent negotiation, and a six-agent murder mystery game to simulate human behavior. The author describes the behavior of three categorical different LLM-driven simulations and discusses the limitations of large-scale language models.
Gao et al. [2023] create a framework for social network simulation called $S^{3}$ . They simulate motion, attitude, and interactive behaviors to emulate social behavior. Due to the changing environment, the agents have to adapt and retain a memory to utilize past experiences and adjust their behavior. They observe the emergence of collective behavior among the agents and conclude their environment holds potential for further exploration in the fields of social sciences and informed decision-making. This insight suggests that the dynamics observed could provide valuable perspectives on group interactions and collaborative processes.
The research of Dasgupta et al. [2023] investigates the use of LLMs to improve the decision-making abilities of AI agents that interact with their environment. The proposed system consists of three parts: a Planner that uses a pre-trained LLM to generate instructions, a reinforcement-learning agent, the Actor, that carries out these instructions, and a Reporter that provides environmental feedback to the Planner. The Planner reads a description of the task and breaks it down into simple instructions for the Actor, who was trained to understand simple instructions and operates upon them. The Reporter observes the effects of the Actor’s actions on the environment and communicates this information in a text-based form back to the Planner. The system is tested on complex tasks that require reasoning and gathering information, and the results show that it outperforms traditional reinforcement learning methods, especially when using larger language models. The researchers demonstrate that Large language models (70 billion parameters) consistently outperformed smaller language models (7 billion parameters) in the experiments, indicating that larger models have resilience against noisy or irrelevant information and greater capacity for the complex reasoning required to solve these tasks. Zhu et al. [2023] present Ghost in the Minecraft (GITM), a framework for developing general capable agents in the Minecraft world. In contrast to previous approaches, especially reinforcement learning algorithms, GITM uses large language models to achieve high success rates, e.g. in the "Obtain Diamond" task. Typical reinforcement learning-based agents often struggle with the complexity of Minecraft due to the long time horizon of the task, which can lead to difficulties in learning and adapting. In contrast, Zhu et al. [2023] leverages LLMs to enable a hierarchical decomposition of complex tasks into manageable sub-goals and structured actions. This approach yields significantly higher efficiency and robustness, allowing agents to better navigate and interact with the Minecraft environment. GITM integrates the logical reasoning and knowledge base of LLMs with text-based knowledge and memory, enabling effective interaction with the environment and the pursuit of intricate, long-term objectives. The article demonstrates the potential of LLMs for the development of generally capable agents in open, complex environments.
Recently, researchers incorporated LLM into swarm systems to leverage the reasoning and knowledge capabilities of these models [Gao et al., 2024; Qu, 2024]. Strobel et al. [2024] integrate LLMs into robot swarms to enhance their reasoning, planning, and collaboration abilities. They exchange the robot programming controller by proposing two changes: 1) An indirect integration uses LLMs to generate and validate the programming of the controller before or during the deployment. This approach improves efficiency and reduces human error by automating the design process. 2) A direct integration implements a separate LLM for each robot during deployment, enabling the robot to plan, reason, and collaborate using natural language. The LLM-driven robots can detect and respond to unexpected behaviors and are more resilient in dynamic environments without prior information.
Feng et al. [2024] present an algorithm aimed at adapting LLM experts using collaborative search techniques inspired by swarm intelligence. This method allows several LLMs to collaborate in exploring the weight space to optimize a specific utility function without the need for extensive fine-tuning data or strong assumptions about the models involved. In their work, each LLM can be treated as a particle within a swarm navigating within the weight space and adjusting its position based on its best or worst-found solutions. The algorithm demonstrates flexibility in different single or multi-task objectives. Due to their collaborative search approach the LLM experts can discover unseen capabilities, which enables the transition from weak to strong performance levels.
In their work, called Swarm-GPT, Jiao et al. [2023] integrate LLMs with motion-based planning to automate Unmanned Aerial Vehicle (UAVs) swarm choreography. Users are able to generate synchronized drone performance via language commands. Swarm-GPT is able to utilize LLMs to create UAVs formations and movements which are synchronized to music. The system includes a trajectory planner that utilizes waypoints generated by the LLM, guaranteeing that the drone movements are both collision-free and feasible. Swarm-GPT has been effectively demonstrated at live events, highlighting its practical application and ability to perform in real time.
Liu et al. [2024b] explore the application of multimodal LLMs to control the formation of UAVs using image and text inputs. The researchers first pre-trained an LLM on a single UAV, demonstrating the LLM’s potential to interpret and execute commands effectively. Then they expanded their approach to coordinate multiple UAVs in formation. The multimodal LLM recognizes environmental signals from the images captured by the primary drone (via a camera). Then, the pre-trained LLM analyzes the data and generates instructions for managing the UAV to attain a specified formation.
Another application in language-guided formation control is presented by Liu et al. [2024c]. The authors propose a framework called Language-Guided Pattern Formation (LGPF) for swarm robotics. Their system employs an LLM to translate a high-level pattern description into specific actions for a swarm of robots, integrating multi-agent reinforcement learning for detailed control. The LGPF framework allows for intuitive and flexible control of robot swarms, enabling them to achieve complex formations guided by natural language instructions.
2 Methods
In this study, we employed two distinct simulations of the behavior of social insects to explore the integration of LLMs in guiding agent behaviors within multi-agent systems. The experiments were designed to investigate the effectiveness of structured, rule-based prompts in one scenario and principle-based, knowledge-driven prompts in the other one. Both simulations utilize the LLM to process environmental inputs and generate agent actions, providing insights into how LLMs can be leveraged to model complex behaviors such as foraging and flocking.
Structured rule-based prompts are designed with explicit, predefined instructions that guide the LLM to generate deterministic agent actions. These prompts specify exact conditions and responses, ensuring consistent and predictable agent behaviors. For example, in a foraging scenario, structured prompts might include direct rules for following pheromone trails or picking up food when encountered.
Knowledge-driven prompts, on the other hand, rely on the LLM’s inherent understanding of broader behavioral concepts and principles. These prompts are less rigid and provide the LLM with general guidelines, enabling more adaptive and flexible agent behaviors. In the context of a bird flocking simulation, such prompts might encourage behaviors based on principles like alignment, cohesion, and separation without specifying exact actions, allowing the LLM to synthesize responses that foster emergent, self-organizing dynamics.
2.1 Toolchain for LLM-Driven Multi-Agent Simulations with NetLogo
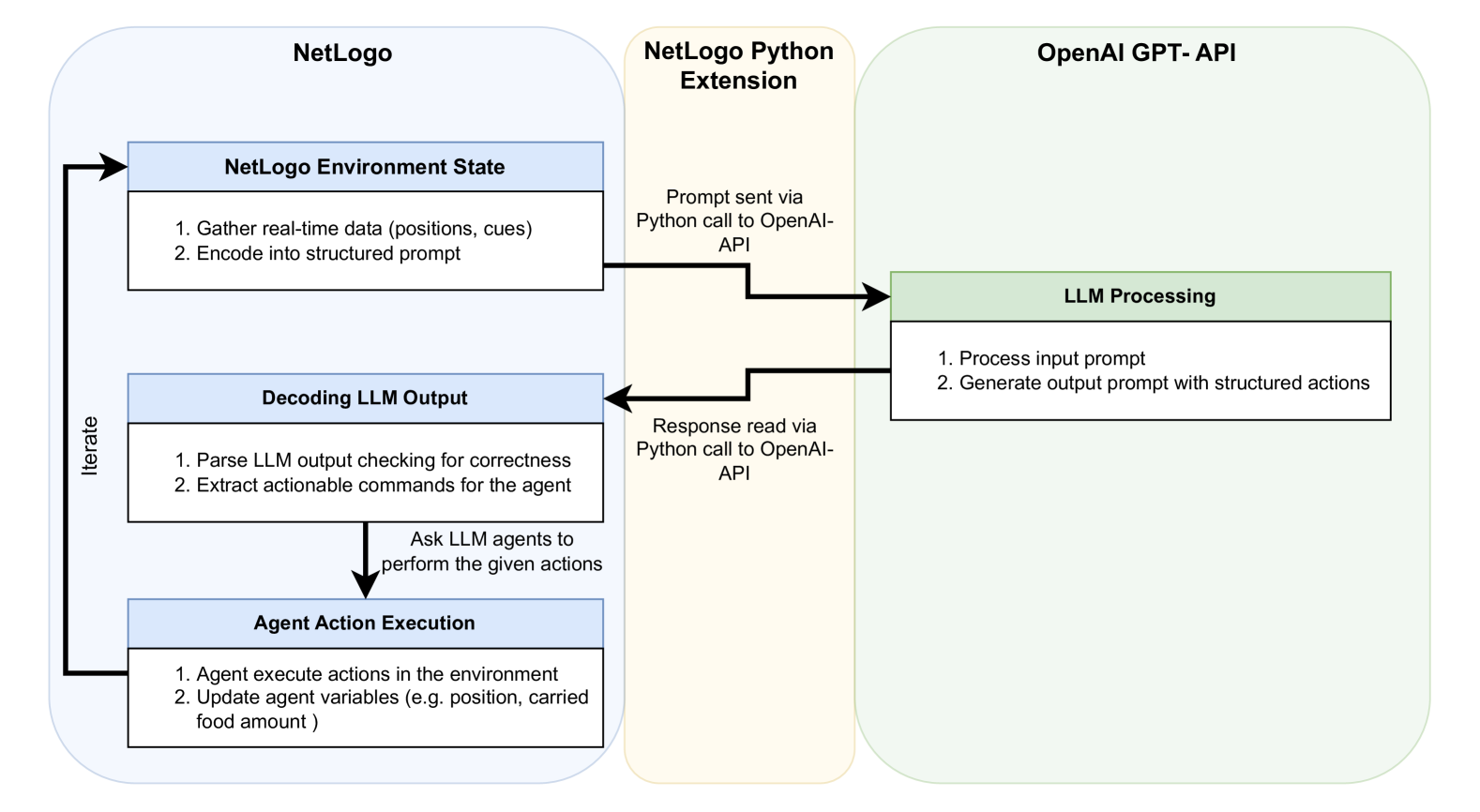
Figure 1 illustrates the toolchain for LLM-driven multi-agent simulations with NetLogo, showing the integration between NetLogo, GPT-4o, and the Python extension. The following describes each step of the workflow:
1. Environment Encoding: The simulation toolchain leverages NetLogo to capture real-time environmental states, including agent positions, inter-agent interactions, and other relevant environmental variables depending on the simulation (e.g. pheromone concentrations). These data are encoded into structured prompts that convey a comprehensive environmental context to the LLM. This encoding ensures that the LLM receives timely, accurate input representing dynamic changes in the environment.
1. Python Extension Integration: NetLogo uses its Python extension to facilitate communication with GPT-4o via the OpenAI API. This extension allows NetLogo to send encoded environmental data as prompts to the LLM and receive structured responses, enabling the interaction between the simulation platform and the LLM.
1. LLM Processing: The structured prompts are processed by GPT-4o, which interprets the input data and generates agent behavior suggestions based on encoded environmental information. The LLM’s ability to process complex, context-rich data allows it to infer and propose actions that adhere to predefined rules (for structured prompts) or leverage general behavioral principles (in principle-based prompts). This stage ensures that agent responses align with the overall objectives of the simulation, be it foraging success or cohesive flocking.
1. Decoding LLM Output: The LLM output, formatted as a structured JSON or Python dictionary, is translated into executable actions predefined within the NetLogo simulation. This step converts the structured actions generated by the LLM into precise instructions for agents, such as movement vectors, state transitions, or pheromone release behaviors. The Python extension facilitates this process by receiving the LLM responses from the OpenAI API and converting them into a NetLogo-compatible data structure. This translation mechanism ensures both syntactic and semantic alignment between the LLM’s output and the data format required by the simulation.
1. Agent Action Execution and Iterative Process: The decoded commands are executed by the agents in NetLogo, updating their states and behaviors in response to the LLM’s instructions. This action directly modifies the simulation environment, forming a closed-loop system where each action feeds back into the environmental context for the next iteration. The iterative process ensures that agent behaviors continuously respond to evolving environmental conditions and LLM feedback, fostering emergent behaviors and adaptive responses.
The following sections detail the setup, LLM integration, and procedures used in each experiment.
<details>
<summary>x4.png Details</summary>
### Visual Description
## System Diagram: NetLogo-OpenAI Integration
### Overview
The image is a system diagram illustrating the interaction between NetLogo, a NetLogo Python Extension, and the OpenAI GPT-API. It shows the flow of information and actions between these components, highlighting how NetLogo uses the OpenAI API for LLM processing to control agent behavior.
### Components/Axes
* **NetLogo (Left)**: Enclosed in a rounded rectangle. Contains three main blocks:
* NetLogo Environment State:
* "1. Gather real-time data (positions, cues)"
* "2. Encode into structured prompt"
* Decoding LLM Output:
* "1. Parse LLM output checking for correctness"
* "2. Extract actionable commands for the agent"
* Agent Action Execution:
* "1. Agent execute actions in the environment"
* "2. Update agent variables (e.g. position, carried food amount)"
* An "Iterate" arrow connects Agent Action Execution back to NetLogo Environment State.
* An arrow points from "Decoding LLM Output" to "Agent Action Execution" with the text "Ask LLM agents to perform the given actions"
* **NetLogo Python Extension (Center)**: Enclosed in a rounded rectangle.
* "Prompt sent via Python call to OpenAI-API" - connects to LLM Processing
* "Response read via Python call to OpenAI-API" - connects from LLM Processing
* **OpenAI GPT-API (Right)**: Enclosed in a rounded rectangle. Contains one main block:
* LLM Processing:
* "1. Process input prompt"
* "2. Generate output prompt with structured actions"
### Detailed Analysis
1. **NetLogo Environment State**:
* Gathers real-time data, including agent positions and environmental cues.
* Encodes this data into a structured prompt for the LLM.
2. **NetLogo Python Extension**:
* Facilitates communication between NetLogo and the OpenAI API.
* Sends the prompt to the OpenAI API using a Python call.
* Receives the response from the OpenAI API using a Python call.
3. **OpenAI GPT-API**:
* LLM Processing:
* Processes the input prompt received from NetLogo.
* Generates an output prompt with structured actions for the agents.
4. **Decoding LLM Output**:
* Parses the LLM output, checking for correctness.
* Extracts actionable commands for the agents.
5. **Agent Action Execution**:
* Agents execute the actions in the environment based on the LLM's commands.
* Agent variables, such as position and carried food amount, are updated.
6. **Iteration**:
* The process iterates, with the updated environment state being fed back into the NetLogo Environment State.
### Key Observations
* The diagram illustrates a closed-loop system where NetLogo uses the OpenAI API to control agent behavior based on real-time environmental data.
* The NetLogo Python Extension acts as a bridge between NetLogo and the OpenAI API.
* The "Iterate" loop indicates a continuous process of data gathering, prompt generation, LLM processing, action execution, and environment updating.
### Interpretation
The diagram demonstrates a system where NetLogo leverages the OpenAI GPT-API to create more intelligent and adaptive agents. By using real-time data and LLM processing, the agents can make more informed decisions and interact with the environment in a more sophisticated manner. The iterative nature of the system allows for continuous learning and adaptation. The system allows for the creation of complex simulations where agents can learn and adapt to their environment.
</details>
Figure 1: Diagram illustrating the toolchain for LLM-driven multi-agent simulations, integrating NetLogo and GPT-4o via the Python extension and OpenAI API. The workflow showcases a closed-loop process where environmental states are encoded into structured prompts, processed by GPT-4o to generate behavior suggestions, decoded into executable actions, and iteratively executed by agents within the NetLogo simulation environment.
3 Experiment 1: Ant Colony Foraging Simulation
As mentioned above, this experiment is based on the ant foraging model implemented in the NetLogo library (see https://ccl.northwestern.edu/netlogo/models/Ants). It takes place in a two-dimensional foraging area consisting of designated food sources scattered throughout the environment and a central nest where the ants must return to deposit the food they collect. The environment is designed to mimic natural foraging conditions, where agents (ants) must navigate to find food and return it to the nest while interacting with environmental cues such as pheromone trails and nest scents; see Figure 2.
<details>
<summary>extracted/6255105/llm_ants_netlogo_interface.png Details</summary>

### Visual Description
## Simulation: Ant Colony Optimization
### Overview
The image depicts a simulation environment, likely for demonstrating ant colony optimization. It shows a foraging area with ants moving between food sources, guided by pheromone trails. The simulation parameters are adjustable via controls on the left.
### Components/Axes
* **Simulation Area:** The main area shows a dark background with varying shades of green, representing pheromone concentrations. Brighter green indicates higher pheromone levels.
* **Food Sources:** There are four distinct food sources represented by colored circles: blue (top-left), purple (center), cyan (right), and blue (bottom-left).
* **Ants:** Several small ant icons are visible, primarily red, with one green ant. They appear to be moving along the pheromone trails.
* **Controls (Left Side):**
* `diffusion-rate`: Slider set to 50.
* `evaporation-rate`: Slider set to 2.
* `ant_speed`: Value set to 1.0.
* `Setup simulation`: Button to initialize the simulation.
* `Reload from log file`: Button to load simulation data from a log file.
* `Run Ilm-ants`: Button to start the ant colony optimization algorithm.
* `food_collected`: Display showing the value 8.
### Detailed Analysis
* **Pheromone Trails:** The ants are following a path of brighter green, indicating a pheromone trail. The trail connects the bottom-left blue food source to the purple and cyan food sources. A fainter trail extends towards the top-left blue food source.
* **Ant Movement:** The ants are clustered along the main pheromone trail, suggesting they are actively foraging and reinforcing the trail.
* **Food Collection:** The `food_collected` counter shows a value of 8, indicating that the ants have successfully collected 8 units of food.
* **Simulation Parameters:**
* `diffusion-rate` is set to 50, which controls how quickly pheromones spread.
* `evaporation-rate` is set to 2, which controls how quickly pheromones dissipate.
* `ant_speed` is set to 1.0, which controls the speed of the ants.
### Key Observations
* The ants are primarily following the strongest pheromone trail, which connects the bottom-left blue food source to the purple and cyan food sources.
* The `food_collected` counter is relatively low, suggesting the simulation is still in its early stages.
* The simulation parameters are set to specific values, which likely influence the behavior of the ants and the formation of pheromone trails.
### Interpretation
The image demonstrates a basic ant colony optimization simulation. The ants are exploring the environment, depositing pheromones, and following the trails laid down by other ants. The simulation parameters control the behavior of the ants and the dynamics of the pheromone trails. The goal of the simulation is likely to find the shortest or most efficient path between the food sources. The `food_collected` counter provides a measure of the simulation's performance. The presence of a "Reload from log file" button suggests the ability to analyze and replay previous simulation runs. The single green ant is an anomaly, and its purpose is unclear without further context.
</details>
Figure 2: Ant foraging simulation in NetLogo. The central circle depicts the nest area, while the three blue circles nearby indicate food sources.
- Agents: The simulation features stateless ants, each operating as an independent agent without memory of past actions. These ants rely entirely on real-time environmental inputs and LLM-generated prompts to determine their behaviors. The agents are designed to follow explicit, rule-based instructions derived from the LLM, ensuring that their actions are predictable and consistent with predefined conditions.
- LLM Integration: OpenAI GPT-4o is employed to process structured prompts that define the ants’ behaviors. The default API parameters are used, with the exception of the temperature, which is set to 0.0 to ensure deterministic results based on the provided inputs. The LLM receives real-time environmental information and generates actions according to a predefined set of rules. These structured prompts ensure that the ants’ responses are clearly defined and predictable, enabling systematic analysis of their behavior. Nevertheless, there is still a small chance that the LLM may occasionally generate responses that deviate from the specified rules.
3.1 Procedure
3.1.1 Prompt Design
The prompt is structured as a zero-shot prompt, requiring the LLM to generate accurate responses without relying on prior examples or contextual memory from previous interactions. This intentional design maintains stateless prompts to control the agents. We employed an API function that does not retain conversation context between prompts, making each interaction independent and requiring the LLM to interpret and respond solely based on the current input. The final prompt used in our experiments resulted from several iterations in a trial-and-error process to ensure the LLM could effectively understand the environment and rules and execute the expected tasks accordingly. For this experiment, precise behavioral rules were provided for the ants within the simulation, including instructions such as following pheromone trails when searching for food, picking up food when encountered, and releasing pheromones to mark food sources.
3.1.2 Tuning Process
Our initial approach utilized minimal instructions, providing a general description of the foraging task to assess how effectively ants could perform without specific guidance. This method aimed to determine the necessity of detailed instructions for reproducing pheromone-guided foraging behavior.
As the project progressed, it became clear that more explicit rules were essential for consistent and realistic ant behavior. Throughout this iterative process, the language model offered valuable feedback by highlighting misunderstandings or ambiguities in the prompts. This feedback was instrumental in refining the prompts to enhance the ants’ performance. Below, we present an analysis of how these prompts evolved, focusing on specific improvements and the reasoning behind each iteration.
Iteration 1
- Prompt Text
⬇
1 You are an ant in a 2 D simulation tasked with finding food, marking the path to food with trails of pheromones, and using nest scent to navigate back to the nest when carrying food.
2
3 Format your actions as a Python dictionary with these keys and options:
4 " move - forward ": True or False,
5 " rotate ": " left ", " right ", or " none ",
6 " pick - up - food ": True or False,
7 " drop - pheromone ": True or False,
8 " drop - food ": True or False.
9
10 You will be provided with environment information. Keep your response concise, under 3 5 tokens.
11
12 Current environment:
13 - Pheromone concentration (Left: 0, Front: 0, Right: 0),
14 - Nest presence: True,
15 - Nest scent (Left: 1 9 6. 8 4, Front: 1 9 6. 3 9, Right: 1 9 5. 7 6),
16 - Food concentration at your location: 0,
17 - Carrying food status: True
- Observed Behavior
In this first attempt, we provided general instructions to establish a baseline for ant behavior. The ants were tasked with finding food, marking paths with pheromones, and using nest scent to return home when carrying food. However, simulations revealed inconsistencies. Ants often failed to follow pheromone and nest scent gradients effectively, sometimes moving away from stronger cues. Some ants released pheromones unexpectedly, while others exhibited random movement patterns. This inconsistency prevented the colony from displaying an organized foraging behavior, indicating that clearer rules were needed for actions such as pheromone release and gradient follow-up.
- Analysis
While this prompt established the basic framework for the simulation, it lacked specific guidance on how ants should interpret and prioritize environmental cues or resolve conflicting signals. The absence of detailed instructions led to ambiguous behaviors, including inconsistencies in following pheromone and nest scent gradients. This highlighted the need for more explicit rules to ensure consistent and organized swarm behavior.
Iteration 2
- Prompt Text
We add an instruction to the prompt to prioritize nest scent over pheromone trails when carrying food.
⬇
1 You are an ant in a 2 D simulation tasked with finding food, marking the path to food with pheromone trails, and using nest scent to navigate back to the nest when carrying food. Prioritize nest scent over pheromone trails when carrying food.
2 …
- Observed Behavior
To address the issues from the first prompt, we added a directive for ants to prioritize nest scent over pheromone trails when carrying food, aiming to better mimic foraging ant behavior. Despite this improvement, ants still exhibited inconsistencies in following pheromone and nest scent gradients. When nest scent and pheromone trails had similar strengths, ants demonstrated conflicting actions. Additionally, the prompt did not specify behaviors for ants not carrying food, leading to inefficient exploration. Ants tended to rotate aimlessly near the nest and were slow to venture outward, showing the need for clearer guidance to improve exploration efficiency.
- Analysis
Introducing prioritization helped align the ants’ actions when carrying food, but inconsistencies in following scent gradients persisted. Ants not carrying food and not sensing any pheromones tended to remain near the nest without effectively exploring the environment. This emphasized the necessity for comprehensive guidance covering all possible states and clearer instructions on responding to environmental cues to enhance exploration efficiency.
Iteration 3
- Prompt Text
As before, with added clarifications in the current environment:
⬇
1 …
2 - Nest presence: True (You are currently at the nest),
3 - Carrying food status: True (You are currently carrying food)
4 …
- Observed Behavior
We observed that ants sometimes failed to pick up food or drop it at the nest, possibly due to a lack of awareness of their current state. To rectify this, we explicitly stated their status in the prompt, such as whether they were at the nest or carrying food. This redundancy ensured that ants performed correct actions in these situations. However, inconsistencies in following pheromone and nest scent gradients remained. Ants continued to exhibit limited exploration when not carrying food, tending to stay near the nest rather than venturing into new areas or effectively following pheromone trails.
- Analysis
Explicitly stating the ants’ status improved decision-making by providing clear context, leading to better execution of actions like picking up and dropping food. Yet, the lack of specific instructions on following scent gradients meant ants still showed inconsistencies in navigating toward pheromone trails or nest scent. Their inefficient exploration highlighted the need for clearer guidance to enhance movement away from the nest.
Iteration 4
- Prompt Text
We add an instruction to the prompt to use the highest pheromone scent to navigate to food when not carrying any.
⬇
1 You are an ant in a 2 D simulation. Your task is to pick up food and release it at the nest. Use nest scent to navigate back to the nest when carrying food, prioritizing nest scent over pheromones. Use highest pheromone scent to navigate to food when not carrying any.
2 …
- Observed Behavior
To guide ants not carrying food, we specified that they should navigate toward food using the highest pheromone concentration. Their ability to find food sources when pheromone trails were present was clearly improved in this way. However, inconsistencies in following pheromone gradients persisted. In the absence of pheromones or nest scents, ants tended to remain near the nest, exhibiting inefficient exploration behaviors.
- Analysis
By distinguishing between the states of carrying and not carrying food, we enhanced the ants’ foraging efficiency when environmental cues were available. Nonetheless, inconsistencies in following pheromone gradients indicated that ants needed clearer instructions on interpreting and acting upon varying scent intensities. The lack of an effective exploration strategy, when cues were absent, remained a challenge.
Iteration 5
- Prompt Text
Environmental information about pheromone concentration and nest scent presented with directional cues instead of quantities:
⬇
1 …
2 Current environment:
3 - Higher Pheromone Concentration: Front,
4 - Nest Presence: False (You are not currently at the nest),
5 - Stronger Nest Scent: Left,
6 - Food Concentration at your location: 0,
7 - Carrying Food Status: True (You are currently carrying food)}
- Observed Behavior
Recognizing the need for better interpretation of environmental cues, we modified how information was presented by using directional descriptions instead of numerical values—–e.g., “Higher Pheromone Concentration: Front” and “Stronger Nest Scent: Left.” This adjustment significantly improved the ants’ ability to follow pheromone and nest scent gradients. Ants became more consistent in moving toward stronger cues, enhancing their navigation and foraging efficiency.
However, when no scents were detected, ants still showed limited exploration, often remaining near the nest rather than actively searching new areas. This indicated that while gradient following had improved, the exploration strategy was still inefficient in the absence of sensory cues.
- Analysis
Using directional cues provided clearer guidance on responding to environmental gradients, resolving many inconsistencies observed in previous prompts. From Prompt 5 onward, ants became more adept at following pheromone and nest scent gradients, leading to a more organized foraging behavior. Despite these improvements, ants’ exploration remained inefficient when no sensory cues were present, indicating a need for further instructions to promote effective exploration.
Iteration 6
- Prompt Text
We add an instruction to the prompt to release pheromones on food sources and while carrying food.
⬇
1 You are an ant in a 2 D simulation. Your task is to pick up food and release it at the nest. Release pheromone on food source and while you are carrying food. Use nest scent to navigate back to the nest when carrying food, prioritizing nest scent over pheromones. Use highest pheromone scent to navigate to food when not carrying any.
2 …
- Observed Behavior
To encourage trail formation back to the nest, we instructed ants to release pheromones while carrying food. This led to stronger trails and improved the efficiency of other ants in locating food sources. With the improved gradient-following ability from Prompt 5, ants were more consistent in navigation.
Nevertheless, in the absence of pheromones and nest scents, ants still exhibited limited exploration behaviors, tending to stay near the nest. This indicated that their exploration strategy was still inefficient and required refinement.
- Analysis
By enhancing pheromone deposition during food transport and improving gradient following, we boosted colony cooperation and foraging success. However, the persistent issue of limited exploration in scent-free areas indicated that additional instructions were necessary to promote outward movement and enhance exploration efficiency.
Iteration 7
- Prompt Text
We added the word “only” in the prompt as follows:
⬇
1 You are an ant in a 2 D simulation. Your task is to pick up food and release it at the nest. Release pheromone on food source and while you are carrying food. Use nest scent to navigate back to the nest only when carrying food, prioritizing nest scent over pheromones. Use highest pheromone scent to navigate to food when not carrying any.
2 …
- Observed Behavior
In earlier iterations, ants sometimes prioritized nest scent over pheromones even when not carrying food, leading them to return to the nest unnecessarily. With this clarification, the ants began to prioritize the nest scent appropriately, using it only when they were carrying food. However, ants still exhibited limited exploration when no sensory cues were present, tending to remain near the nest rather than actively searching new areas.
- Analysis
Adding “only” to the instruction text was crucial to ensure that the ants did not prioritize the scent of the nest when they were looking for food. This eliminated unnecessary returns and improved foraging efficiency.
Iteration 8
- Prompt Text
We added an instruction to the prompt to move away from the nest and rotate randomly if not carrying any food and not sensing any pheromone.
⬇
1 You are an ant in a 2 D simulation. Your task is to pick up food and release it at the nest. Release pheromone on food source and while you are carrying food. Use nest scent to navigate back to the nest only when carrying food, prioritizing nest scent over pheromones. Use highest pheromone scent to navigate to food when not carrying any. Move away from nest and rotate randomly if you are not carrying any food and you are not sensing any pheromone.
2 …
- Observed Behavior
In previous iterations, we observed limited exploratory behavior of the ants in areas without scents. To address this, we introduced a directive for proactive exploration. This approach improved exploration, with ants venturing further from the nest and discovering food sources in fewer simulation steps. However, a noticeable bias concerning the rotation remained, particularly around the nest, indicating that the randomness was not functioning as efficiently as intended.
- Analysis
By instructing ants to move away from the nest and rotate randomly when not carrying food and not sensing pheromones, we encouraged them to explore new areas more effectively. This change increased the likelihood of ants finding food, as they ventured further from the nest rather than lingering nearby.
Iteration 9
- Prompt Text
We expanded the rotation options to include “random”:
⬇
1 …
2 " rotate ": " left ", " right ", " none ", or "random"
3 …
- Observed Behavior
With this adjustment, ants demonstrated more varied and unpredictable movement patterns during exploration. They effectively moved away from the nest and searched a wider area, increasing their chances of encountering food sources more quickly and efficiently.
- Analysis
To enhance the randomness of the ants’ exploration, we expanded their rotation options to include “random.” This meant that when the LLM selected “random” as the rotation action, it was making a high-level decision to delegate the choice of direction to chance. In the simulation, this “random’ ’ option was implemented at a programming level in NetLogo to randomly choose the direction of rotation either left or right.
Through iterative tuning, we significantly enhanced the simulated ants’ behavior, making it more consistent with the ant foraging dynamics observed in the rule-based NetLogo model. Each prompt iteration addressed specific issues identified in simulations, with language model feedback guiding some of the adjustments.
3.1.3 Prompt Deployment
The prompts are presented in a format that the LLM can process and output as a series of actionable commands. Communication with the LLM is facilitated through the OpenAI API, specifically using the chat.completions mechanism, which allows context-free messages to be passed at each step. This setup involves sending a system prompt that outlines the overall task and rules, followed by user prompts that provide real-time environmental information.
At each simulation step, NetLogo translates the agent’s perception of its environment into the input variables described in the prompt. This ensures that the LLM has an accurate and up-to-date representation of the environment on which its decisions can be based. The LLM then generates a response formatted as a Python dictionary, containing specific actions the agent should take. The following example prompt illustrates the process:
- System Prompt
⬇
1 You are an ant in a 2 D simulation. Your task is to pick up food and release it at the nest. Release pheromone on food source and while you are carrying food. Use nest scent to navigate back to the nest only when carrying food, prioritizing nest scent over pheromones. Use highest pheromone scent to navigate to food when not carrying any. Move away from nest and rotate randomly if you are not carrying any food and you are not sensing any pheromone. Format your actions as a Python dictionary with these keys and options:
2
3 " move - forward " (options: True, False)
4 " rotate " (options: " left ", " right ", " none ", " random " )
5 " pick - up - food " (options: True, False)
6 " drop - pheromone " (options: True, False)
7 " drop - food " (options: True, False).
8
9 You will be provided with environment information. Keep your response concise, under 4 5 tokens.
- Possible User Prompt
⬇
1 This is your current environment:
2 - Highest Pheromone Concentration: None,
3 - Nest Presence: True (You are currently at the nest),
4 - Stronger Nest Scent: Front,
5 - Food Concentration at your location: 0,
6 - Carrying Food Status: False (You are not currently carrying food).
- Possible response from the LLM
⬇
1 {
2 " move - forward ": True,
3 " rotate ": " none ",
4 " pick - up - food ": False,
5 " drop - pheromone ": False,
6 " drop - food ": False
7}
3.2 System Monitoring
The simulation monitors the ants’ efficiency in navigating the environment, specifically their ability to locate food, follow pheromone trails, and return food to the nest. Key metrics include the time taken to find and return food, the consistency of pheromone trail usage, and the accuracy of following the nest scent when carrying food. The observed behaviours and performance analysis are documented in the result section.
4 Experiment 2: Bird Flocking Simulation
As mentioned before, the bird flocking model of NetLogo (see https://ccl.northwestern.edu/netlogo/models/Flocking) is an implementation of the famous Boids model from [Reynolds, 1987]. The simulation takes place in two-dimensional airspace. Although this environment is relatively simple, it effectively replicates key flocking behaviors like group cohesion, allowing for the observation of flocking dynamics under varying conditions. By adjusting specific parameters, the simulation provides insights into how changes in the environment influence flocking behavior.
- Agents: The agents in this simulation are modeled as birds, each operating under principle-based prompts. Unlike rule-based systems, these birds are guided by general principles of flocking dynamics, that is, by alignment, separation, and cohesion [Reynolds, 1987]. These principles help the birds navigate their environment by adjusting their headings in response to the positions and headings of neighboring birds.
- LLM Integration: The prompts provided to the LLM leverage its inherent knowledge of flocking dynamics, requiring it to apply these general principles to guide the behavior of each bird. The LLM is responsible for interpreting environmental data and generating responses that ensure the birds align with their flockmates, maintain an appropriate distance to avoid collisions, and stay cohesive as a group.
4.1 Procedure
4.1.1 Prompt Design
Similar to the setup in the case of ant foraging, prompts for the flocking task are structured as zero-shot prompts, meaning they operate without prior examples or contextual memory from previous interactions. The final prompt was tuned through several iterations (see below) in a trial-and-error process to ensure the LLM could effectively interpret the environment and calculate heading directions according to flocking principles. Each prompt guiding a bird is designed to determine its heading based on the three core principles of flocking dynamics as implemented in the NetLogo library: Separation (steering to avoid crowding neighbors), Alignment (steering towards the average heading of nearby birds), and Cohesion (steering towards the average position of nearby flockmates).
4.1.2 Tuning Process
As will be shown below, it was crucial to explicitly state in the prompt that the compass convention is used in the simulation. This alignment with NetLogo’s world representation, where headings are measured in degrees—0 degrees pointing north, 90 degrees east, 180 degrees south, and 270 degrees west—was essential. Clearly defining this convention ensured that the LLM could accurately compute and adjust the birds’ headings according to flocking dynamics, maintaining consistency in the agents’ behavior within NetLogo’s simulation environment.
Iteration 1
- Prompt Text
⬇
1
2 You are an agent in a 2 D simulation. Your task is to determine your new heading based on the flocking principles of separation turn, alignment turn (average heading of neighbors), and coherence turn (average heading towards flockmates). The parameters for these principles are: maximum - separate - turn, maximum - align - turn, maximum - cohere - turn, minimum - separation - distance. The simulation provides the following information: Current heading, Neighbors in vision radius.
3
4 Provide your final new heading after applying these rules, expressed as an angle in degrees. The result should be in JSON format, with the key and value: " new - heading " (value: heading in degrees). Summarize your answer in no more than 1 2 0 words.
5
6 These are the flocking parameters:
7
8 Maximum separate turn: 1. 5
9 Maximum align turn: 5
10 Maximum cohere turn: 3
11 Minimum separation: 1
12
13 This is your current environment:
14
15 Current heading: 1 3 8 deg
16 Neighbors in vision radius: neighbor_1: x: 0. 5 3, y: - 3. 6 9, heading: 2 4 8 deg
- Observed Behavior
In this initial attempt, we provided general instructions to establish a baseline for flocking behavior. The agents were instructed to determine their heading based on the principles of separation, alignment, and coherence. However, most of the LLM-generated responses were not interpretable by the simulation, as they did not adhere to the expected format. Additionally, even when successfully parsed, inconsistencies in the agents’ behavior were observed, preventing the emergence of flocking.
- Analysis
While this prompt defined the basic framework for the simulation, it lacked constraints to enforce a structured response. In many cases, the LLM’s output included extended textual and mathematical explanations before or alongside the JSON object, which interfered with proper parsing.
Iteration 2
- Prompt Text
An explicit instruction was added to limit the response to the JSON object only.
⬇
1 …
2 Provide your final new heading after applying these rules, expressed as an angle in degrees. The result should be in JSON format only, with the key and value: " new - heading " (value: heading in degrees). Summarize your answer in no more than 1 2 0 words.
3 …
- Observed Behavior To address the issues from the first iteration, we added a directive restricting the response format to a JSON object only. This modification successfully constrained the output, making it more reliable and compatible with the simulation. However, while some flocking behavior emerged, it was inconsistent. Small clusters formed briefly, but overall alignment and coherence were weaker than expected.
- Analysis We compared the resulting headings with those produced by a rule-based model. While some calculated headings were numerically similar, they often pointed in opposite directions. This suggested ambiguity in the LLM’s coordinate system. Since NetLogo employs a compass convention for heading calculations, we decided to explicitly specify this convention in the next iteration.
Iteration 3
- Prompt Text
An instruction was added to specify that the compass convention should be used.
⬇
1 You are an agent in a 2 D simulation. Following the compass convention, your task is to determine your new heading based on the flocking principles of separation turn, alignment turn (average heading of neighbors), and coherence turn (average heading towards flockmates)
2 …
- Observed Behavior By explicitly specifying the compass convention for heading calculations, flocking behavior improved. Larger clusters formed compared to previous iterations. However, flocking remained inconsistent, as some agents moved in seemingly random directions.
- Analysis Examining the erratic headings, we requested the LLM to explain its calculations. When generating a reasoning process before outputting the final heading, the LLM produced correct answers. However, errors occurred when providing only the numerical result. This highlighted the need for a structured reasoning process, or “chain of thought,” to ensure accurate heading calculations.
Iteration 4
- Prompt Text
A new key, “rationale”, was added to the JSON output to encourage reasoning before determining the final heading.
⬇
1 …
2 Provide your final new heading after applying these rules, expressed as an angle in degrees. The result should be in JSON format only, with the keys and values: " rationale " (value: your explanation) and " new - heading " (value: heading in degrees).
3 …
- Observed Behavior Introducing the “rationale” key significantly improved flocking behavior. The agents demonstrated more consistent heading adjustments, enhancing the emergence of flocking dynamics. However, occasional errors persisted, particularly when agents needed to turn counterclockwise to reach a nearby target heading.
- Analysis The “rationale” key enabled the LLM to engage in a structured thought process, substantially improving flocking behavior. However, some agents still moved in the opposite direction when making small adjustments, particularly for counterclockwise turns. This suggested that additional guidance was necessary to ensure agents always chose the shortest rotation path.
Iteration 5
- Prompt Text
An explicit instruction was added to ensure the shortest rotational path (clockwise or counterclockwise) was always chosen when adjusting the heading.
⬇
1 You are an agent in a 2 D simulation. Following the compass convention, your task is to determine your new heading based on the flocking principles of separation turn, alignment turn (average heading of neighbors), and coherence turn (average heading towards flockmates). The parameters for these principles are: maximum - separate - turn, maximum - align - turn, maximum - cohere - turn, minimum - separation - distance. The simulation provides the following information: Current heading, Neighbors in vision radius. When calculating the alignment turn, always choose the shortest path (clockwise or counterclockwise) to align with the average heading of neighbors.
2 …
- Observed Behavior By explicitly instructing the model to select the shortest path to the target heading, flocking behavior improved significantly. The LLM-driven agents formed larger, more stable flocking clusters, achieving performance comparable to the original, rule-based NetLogo model.
- Analysis Including the shortest-path directive ensured that LLM-based agents correctly aligned their heading adjustments with both LLM-based and rule-based agents. This modification resolved the previously observed issues, leading to a more coherent and emergent flocking behavior.
4.1.3 Prompt Deployment
This task uses the same prompt deployment mechanism as Experiment 1. Communication with the LLM is handled via the OpenAI API using the chat.completions mechanism, which supports context-free messaging. A system prompt defines the task and rules, followed by a user prompt providing real-time environmental data.
At each simulation step, NetLogo translates the agent’s perception into the input variables in the prompt, including the heading and position of other agents within its vision radius, into the input variables used in the prompt. This ensures the LLM has an accurate, up-to-date view of the environment. The LLM then generates a response formatted in JSON, specifying the agent’s actions. The following example prompt illustrates this process:
- System Prompt
⬇
1 You are an agent in a 2 D simulation. Following the compass convention, your task is to determine your new heading based on the flocking principles of separation turn, alignment turn (average heading of neighbors), and coherence turn (average heading towards flockmates). The parameters for these principles are: maximum - separate - turn, maximum - align - turn, maximum - cohere - turn, minimum - separation - distance. The simulation provides the following information: Current heading, Neighbors in vision radius. When calculating the alignment turn, always choose the shortest path (clockwise or counterclockwise) to align with the average heading of neighbors.
2
3 Provide your final new heading after applying these rules, expressed as an angle in degrees. The result should be in JSON format only, with the keys and values: ’ rationale ’ (value: your explanation) and ’ new - heading ’ (value: heading in degrees).
- Possible User Prompt
⬇
1 These are the flocking parameters:
2 - Maximum separate turn: 1. 5,
3 - Maximum align turn: 5,
4 - Maximum cohere turn: 3,
5 - Minimum separation: 1. 5;
6
7 This is your current environment:
8 - Current heading: 1 3 8 deg,
9 - Neighbors in vision radius: neighbor_1: x: 0. 5 3, y: - 3. 6 9, heading: 2 4 8 deg;
- Possible Response of the LLM
⬇
1 {
2 " rationale ": Given the current heading of 1 3 8 degrees and one neighbor at (0. 5 3, - 3. 6 9) with a heading of 2 4 8 degrees, we first calculate the separation turn. The distance to the neighbor is sqrt (0. 5 3 ^ 2 + (- 3. 6 9)^ 2) = 3. 7 3, which is greater than the minimum separation distance of 1. 5, so no separation turn is needed. For alignment, the average heading of the neighbor is 2 4 8 degrees. The shortest path to align with 2 4 8 degrees from 1 3 8 degrees is clockwise, which is a turn of 1 1 0 degrees. However, the maximum align turn is 5 degrees, so we turn 5 degrees clockwise to 1 4 3 degrees. For coherence, since there is only one neighbor, the average heading towards the neighbor is the same as the neighbor ’ s heading, 2 4 8 degrees. The shortest path to align with 2 4 8 degrees from 1 4 3 degrees is clockwise, which is a turn of 1 0 5 degrees. However, the maximum cohere turn is 3 degrees, so we turn 3 degrees clockwise to 1 4 6 degrees. The final new heading is 1 4 6 degrees.,
3 " new - heading ": 1 4 6
4}
4.2 Monitoring Behavior
Key metrics include the degree of separation maintained between agents, the consistency of alignment with the average heading of nearby birds, and the effectiveness of cohesion in moving toward the flock’s center of mass. The observed behaviors and performance analyses are documented in the results section.
5 Results
5.1 Experiment 1: Ant Foraging with Structured Rule-Based Prompting
The following three variants of the ants foraging simulation were applied:
1. The original NetLogo model (henceforth simply called “NetLogo”).
1. The model in which the rule-governed ants of the original model are replaced by LLM-governed ants (henceforth called “LLM”).
1. A hybrid model in which half of the ants are rule-governed and the other half are LLM-governed (henceforth called “Hybrid”).
In all simulations, we used a colony of 10 ants, three food patches to be exploited, and a stopping criterion of 1000 simulation steps. Moreover, each experiment was repeated five times (with different seeds). The efficacy of each model was assessed by quantifying the total amount of food gathered within these 1000 simulation steps.
5.1.1 Food collection behavior
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Food Amount vs. Step Number for Different Model Variants
### Overview
The image is a line chart comparing the "Food Amount" over "Step Number" for three different "Model Variants": LLM, NetLogo, and Hybrid. The chart includes a zoomed-in inset of the initial steps. Each line is accompanied by a shaded region, presumably representing the standard deviation or confidence interval.
### Components/Axes
* **Title:** There is no explicit title on the chart.
* **X-axis:** "Step Number" ranging from 0 to 1000. Axis markers are present at intervals of 200 (0, 200, 400, 600, 800, 1000).
* **Y-axis:** "Food Amount" ranging from 0 to 100. Axis markers are present at intervals of 20 (0, 20, 40, 60, 80, 100).
* **Legend:** Located in the top-left corner.
* LLM (Sea Green)
* NetLogo (Salmon)
* Hybrid (Steel Blue)
* **Inset:** A zoomed-in view of the main chart for Step Number 0-100 and Food Amount 0-40.
### Detailed Analysis
* **LLM (Sea Green):** The line generally slopes upward.
* At Step Number 0, Food Amount is approximately 0.
* At Step Number 200, Food Amount is approximately 10.
* At Step Number 500, Food Amount is approximately 40.
* At Step Number 1000, Food Amount is approximately 80.
* **NetLogo (Salmon):** The line generally slopes upward.
* At Step Number 0, Food Amount is approximately 0.
* At Step Number 200, Food Amount is approximately 10.
* At Step Number 500, Food Amount is approximately 40.
* At Step Number 1000, Food Amount is approximately 75.
* **Hybrid (Steel Blue):** The line generally slopes upward.
* At Step Number 0, Food Amount is approximately 2.
* At Step Number 200, Food Amount is approximately 15.
* At Step Number 500, Food Amount is approximately 50.
* At Step Number 1000, Food Amount is approximately 90.
### Key Observations
* All three model variants show an increase in "Food Amount" as "Step Number" increases.
* The "Hybrid" model variant consistently has a higher "Food Amount" than the "LLM" and "NetLogo" variants.
* The "LLM" and "NetLogo" variants have similar "Food Amount" values throughout the range of "Step Number".
* The shaded regions around each line indicate variability in the "Food Amount" for each model variant. The "Hybrid" model appears to have the largest variability.
* The inset shows that the "Hybrid" model starts with a non-zero "Food Amount," while the other two start at zero.
### Interpretation
The chart compares the performance of three different model variants (LLM, NetLogo, and Hybrid) in terms of "Food Amount" over a series of "Step Number". The "Hybrid" model appears to perform better than the "LLM" and "NetLogo" models, consistently achieving a higher "Food Amount". The variability in "Food Amount," as indicated by the shaded regions, suggests that the performance of each model variant may fluctuate. The inset highlights the initial differences in "Food Amount" between the models, with the "Hybrid" model starting with a non-zero value. This could indicate an initial advantage or a different starting condition for the "Hybrid" model. The data suggests that the "Hybrid" model is more effective at accumulating "Food Amount" over time compared to the other two models.
</details>
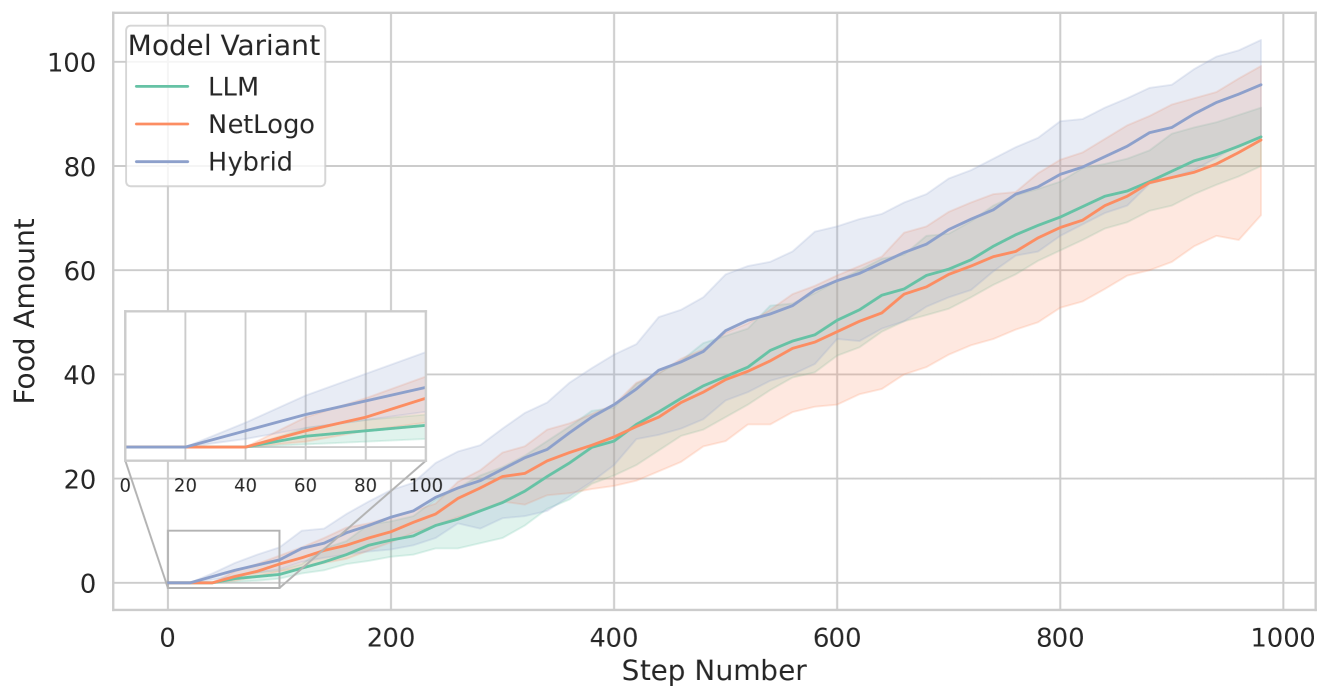
Figure 3: Comparison of the total food collected across the three tested models: NetLogo (represented by the orange line), LLM (green line), and Hybrid (blue line). This visualization highlights the food collection performance differences among the different models over five runs with different seeds. The lines represent the means, while the shaded areas indicate the standard deviations.
Figure 3 shows the total amount of food collected over 1000 simulation steps for the three different model variants. NetLogo and LLM perform similarly in terms of the ants’ success in bringing food back to the nest, with both models accumulating approximately 85 units of food by the end of the simulation. However, the standard deviation for NetLogo is around 20, whereas LLM displays a much lower standard deviation of about 7.
In contrast, the Hybrid model outperforms the other two variants, collecting an average of approximately $95$ units of food with a standard deviation of about $12$ . This superior performance is due to the combination of the behavioural differences between LLM-guided ants and rule-based ants. The zoomed inset in Figure 3, for example, shows that Hybrid starts returning food to the nest at around 20 simulation steps, whereas LLM and NetLogo begin this process at about 40 steps. This means that, for some reason, the Hybrid variant is more efficient in quickly finding food sources.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Box Plot: Steps vs. Food Patch by Model Variant
### Overview
The image is a box plot comparing the number of steps taken by three different model variants (LLM, NetLogo, and Hybrid) across three different food patch scenarios (1, 2, and 3). The y-axis represents the number of steps, and the x-axis represents the food patch. The box plot visually summarizes the distribution of steps for each model variant at each food patch, showing the median, quartiles, and outliers.
### Components/Axes
* **Title:** Implicit, but the chart compares "Steps" vs "Food Patch" by "Model Variant"
* **X-axis:** "Food Patch" with categories 1, 2, and 3.
* **Y-axis:** "Steps" with a numerical scale ranging from 15 to 50, with tick marks at intervals of 5.
* **Legend:** Located in the bottom-right corner, indicating the model variants:
* LLM (light green)
* NetLogo (light orange)
* Hybrid (light blue/grey)
### Detailed Analysis
**Food Patch 1:**
* **LLM (light green):** The box extends from approximately 21 to 25 steps, with a median around 23 steps. The lower whisker extends down to approximately 16 steps, and the upper whisker extends to approximately 30 steps. There are two outliers at approximately 45 and 48 steps.
* **NetLogo (light orange):** The box extends from approximately 18 to 24 steps, with a median around 20 steps. The lower whisker extends down to approximately 13 steps, and the upper whisker extends to approximately 33 steps. There are two outliers at approximately 43 and 45 steps.
* **Hybrid (light blue/grey):** The box extends from approximately 19 to 25 steps, with a median around 22 steps. The lower whisker extends down to approximately 13 steps, and the upper whisker extends to approximately 30 steps. There is one outlier at approximately 49 steps.
**Food Patch 2:**
* **LLM (light green):** The box extends from approximately 31 to 34 steps, with a median around 33 steps. The lower whisker extends down to approximately 26 steps, and the upper whisker extends to approximately 39 steps. There are two outliers at approximately 26 and 49 steps.
* **NetLogo (light orange):** The box extends from approximately 28 to 32 steps, with a median around 30 steps. The lower whisker extends down to approximately 23 steps, and the upper whisker extends to approximately 37 steps. There are two outliers at approximately 41 and 45 steps.
* **Hybrid (light blue/grey):** The box extends from approximately 27 to 31 steps, with a median around 29 steps. The lower whisker extends down to approximately 24 steps, and the upper whisker extends to approximately 37 steps. There is one outlier at approximately 40 steps.
**Food Patch 3:**
* **LLM (light green):** The box extends from approximately 38 to 41 steps, with a median around 40 steps. The lower whisker extends down to approximately 37 steps, and the upper whisker extends to approximately 42 steps.
* **NetLogo (light orange):** The box extends from approximately 37 to 39 steps, with a median around 38 steps. The lower whisker extends down to approximately 35 steps, and the upper whisker extends to approximately 42 steps.
* **Hybrid (light blue/grey):** The box extends from approximately 38 to 40 steps, with a median around 39 steps. The lower whisker extends down to approximately 37 steps, and the upper whisker extends to approximately 42 steps.
### Key Observations
* Across all food patches, the number of steps generally increases from Food Patch 1 to Food Patch 3.
* For Food Patch 1, the LLM model has a slightly higher median number of steps compared to NetLogo and Hybrid.
* For Food Patch 2, the LLM model has a slightly higher median number of steps compared to NetLogo and Hybrid.
* For Food Patch 3, the LLM, NetLogo, and Hybrid models have similar median number of steps.
* The number of outliers decreases as the food patch number increases.
### Interpretation
The box plot suggests that as the food patch number increases, the number of steps required by all three model variants generally increases. This could indicate that the complexity or distance to the food source increases with the food patch number. The LLM model tends to have a slightly higher median number of steps compared to NetLogo and Hybrid for Food Patches 1 and 2, but the models converge for Food Patch 3. The presence of outliers in Food Patch 1 and 2 suggests that there are instances where the models take significantly more steps than usual, possibly due to getting stuck or taking a less efficient path. The decrease in outliers for Food Patch 3 could indicate that the models are more consistent in their performance as the food patch number increases.
</details>
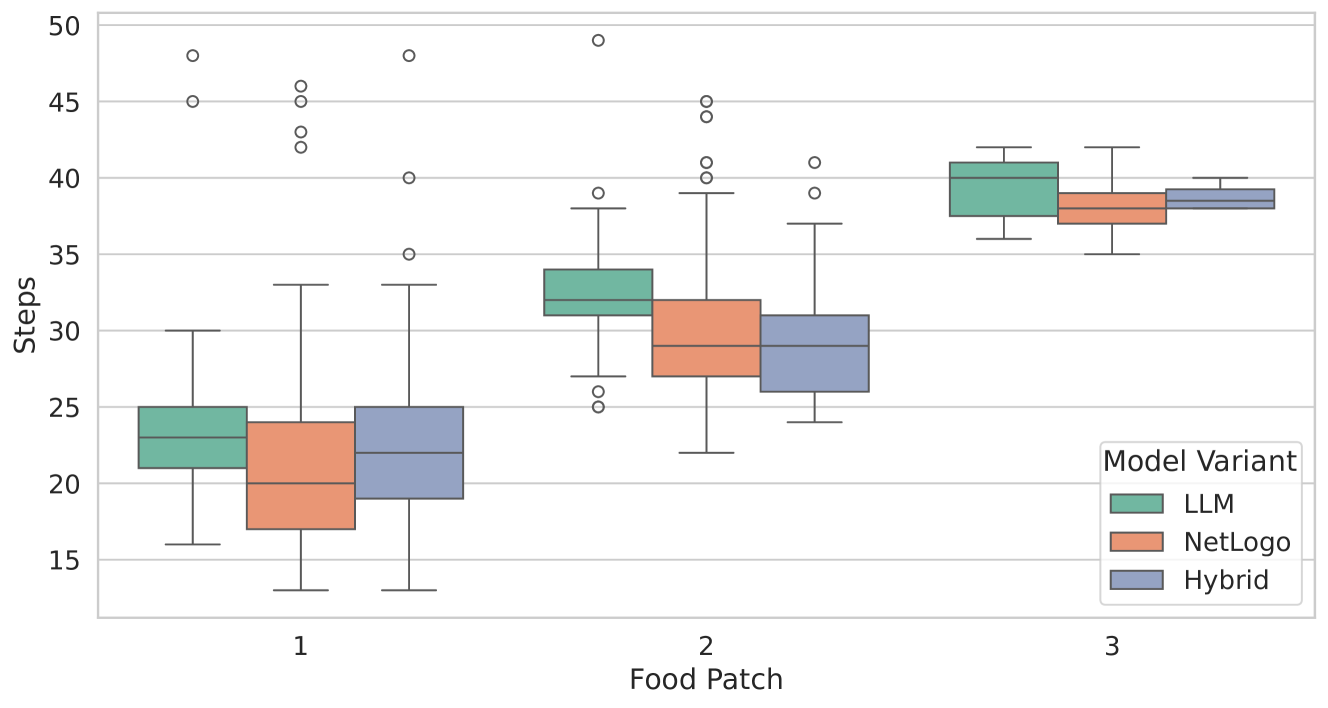
Figure 4: The average number of steps taken by an ant to return to its nest after picking up food (for food patches 1–3). The green boxplots represent the simulations of LLM, the orange boxplots those of NetLogo, while the blue boxplots show the results of Hybrid. Each boxplot spans from the first to the third quartile, with the vertical line within the box indicating the median. The whiskers extend to represent the minimum and maximum number of steps taken, while the circles denote outliers.
Table 1: Statistics concerning the average amount of steps taken by an ant to return food to the nest.
| 1 | LLM NetLogo Hybrid | 23.04 21.0 21.98 | 3.34 5.3 4.32 | 16.0 13.0 13.0 | 21.0 17.0 19.0 | 23.0 20.0 22.0 | 25.0 24.0 25.00 | 48.0 46.0 48.0 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| LLM | 32.3 | 3.41 | 25.0 | 31.0 | 32.0 | 34.0 | 49.0 | |
| 2 | NetLogo | 30.16 | 4.93 | 22.0 | 27.0 | 29.0 | 32.0 | 45.0 |
| Hybrid | 29.46 | 3.90 | 24.0 | 26.0 | 29.0 | 31.00 | 41.0 | |
| LLM | 39.29 | 2.36 | 36.0 | 37.5 | 40.0 | 41.0 | 42.0 | |
| 3 | NetLogo | 38.11 | 2.02 | 35.0 | 37.0 | 38.0 | 39.0 | 42.0 |
| Hybrid | 38.75 | 0.96 | 38.0 | 38.0 | 38.5 | 39.25 | 40.0 | |
The average number of simulation steps taken by an ant to return to its nest after picking up food is depicted as boxplots in Figure 4. This plot illustrates the effectiveness of the three model variants concerning individual ants. Generally, ants in NetLogo (rule-governed ants) require fewer steps than those controlled by the LLM. The LLM-guided ants demonstrate consistent foraging behavior across the different experiments, particularly for food patches 1 and 2. Notably, food patch 1 is the closest to the nest, while food patch 3 is the farthest away. Detailed statistics, including the three quartiles, mean, standard deviation, and minimum and maximum amounts of food collected, are provided in Table 1.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Box Plot: Steps vs. Food Patch by Model Variant
### Overview
The image is a box plot comparing the number of steps taken by three different model variants (LLM, NetLogo, and Hybrid) across three different food patch scenarios (1, 2, and 3). The y-axis represents the number of steps, and the x-axis represents the food patch number. The plot shows the distribution of steps for each model variant at each food patch, including median, quartiles, and outliers.
### Components/Axes
* **Title:** There is no explicit title on the chart.
* **X-axis:** "Food Patch" with categories 1, 2, and 3.
* **Y-axis:** "Steps" with a numerical scale from 0 to 700, incrementing by 100.
* **Legend:** Located in the top-right corner, labeled "Model Variant".
* LLM (light green)
* NetLogo (light orange)
* Hybrid (light blue/grey)
### Detailed Analysis
The box plot displays the distribution of "Steps" for each "Model Variant" across different "Food Patch" values.
**Food Patch 1:**
* **LLM (light green):** The box extends from approximately 30 to 90 steps. The median is around 60 steps. There are numerous outliers ranging from approximately 150 to 470 steps.
* **NetLogo (light orange):** The box extends from approximately 20 to 100 steps. The median is around 50 steps. There are numerous outliers ranging from approximately 150 to 400 steps.
* **Hybrid (light blue/grey):** The box extends from approximately 20 to 80 steps. The median is around 50 steps. There are numerous outliers ranging from approximately 160 to 400 steps.
**Food Patch 2:**
* **LLM (light green):** The box extends from approximately 30 to 80 steps. The median is around 50 steps. There are numerous outliers ranging from approximately 120 to 720 steps.
* **NetLogo (light orange):** The box extends from approximately 20 to 120 steps. The median is around 60 steps. There are numerous outliers ranging from approximately 150 to 520 steps.
* **Hybrid (light blue/grey):** The box extends from approximately 20 to 80 steps. The median is around 50 steps. There are numerous outliers ranging from approximately 120 to 370 steps.
**Food Patch 3:**
* **LLM (light green):** The box extends from approximately 40 to 110 steps. The median is around 80 steps. There is one outlier at approximately 300 steps and another at approximately 430 steps.
* **NetLogo (light orange):** The box extends from approximately 30 to 80 steps. The median is around 50 steps. There are no visible outliers.
* **Hybrid (light blue/grey):** The box extends from approximately 40 to 70 steps. The median is around 60 steps. There are no visible outliers.
### Key Observations
* The number of steps generally decreases from Food Patch 1 to Food Patch 3 for all model variants.
* Food Patch 2 has the most outliers, particularly for the LLM and NetLogo variants.
* The Hybrid model variant consistently has a lower median and fewer outliers compared to LLM and NetLogo, especially in Food Patch 1 and 2.
* The LLM variant has the highest outlier values in Food Patch 2.
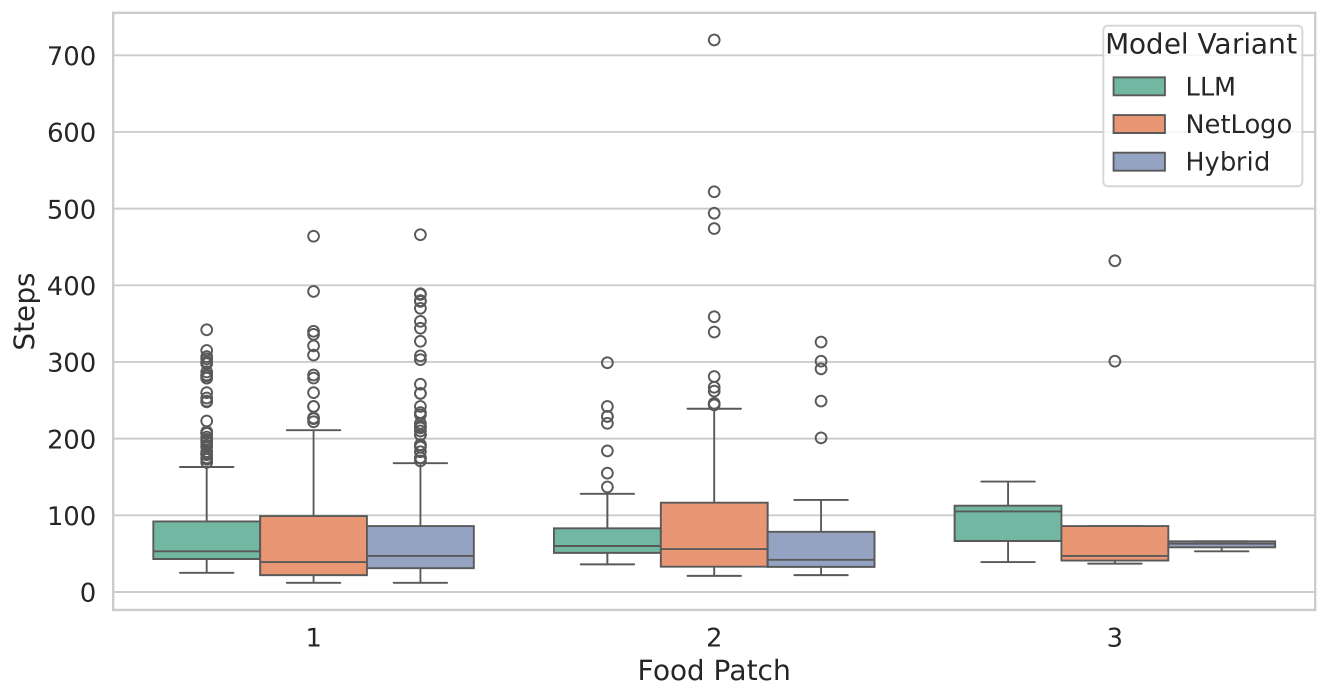
### Interpretation
The box plot suggests that the "Hybrid" model variant is more efficient (takes fewer steps) compared to the "LLM" and "NetLogo" variants, especially in scenarios represented by Food Patch 1 and 2. The high number of outliers in Food Patch 1 and 2 for LLM and NetLogo indicates that these models are more prone to taking a significantly larger number of steps in certain instances. The decrease in steps from Food Patch 1 to Food Patch 3 could indicate that the environment or task becomes easier or more streamlined as the food patch number increases. The outliers may represent instances where the models got "stuck" or took a less direct path to the goal.
</details>
Figure 5: Average number of steps taken by an ant from leaving the nest to finding a food source. Each boxplot spans from the first to the third quartile, with the vertical line within the box indicating the median. The whiskers extend to represent the minimum and maximum number of steps taken, while the circles denote outliers.
The average number of steps taken by an ant from leaving the nest until finding a food source is represented in Figure 5. We specifically track and count ants that are not carrying food and are exploring their environment until they start to carry the food. Hybrid demonstrates consistent performance in finding food patches 1 and 2. In contrast, LLM and NetLogo display a more variable behavior during food searches. Notably, concerning food patch 1, the models exhibit a higher number of outliers, which can be attributed to the ants’ initial exploration of the environment before encountering the food. A notable outlier is observed in the context of NetLogo and food patch 2, where an ant required $720$ steps to find food. Detailed statistics are listed in Table 2.
Table 2: Statistics for the average amount of steps taken by an ant to find and collect food.
| 1 | LLM NetLogo Hybrid | 79.65 71.48 71.42 | 63.25 72.77 68.88 | 25.0 12.0 12.0 | 43.0 22.0 31.0 | 53.0 39.0 47.0 | 92.0 99.0 86.0 | 342.0 464.0 466.0 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| LLM | 79.44 | 50.04 | 36.0 | 51.0 | 60.0 | 83.0 | 299.0 | |
| 2 | NetLogo | 93.74 | 102.09 | 21.0 | 33.0 | 56.0 | 116.50 | 720.0 |
| Hybrid | 73.81 | 74.81 | 22.00 | 32.75 | 42.00 | 78.50 | 326.0 | |
| LLM | 92.29 | 36.53 | 39.0 | 66.50 | 105.0 | 112.50 | 144.0 | |
| 3 | NetLogo | 123.33 | 142.92 | 37.0 | 41.0 | 47.0 | 86.0 | 432.0 |
| Hybrid | 61.25 | 6.18 | 53.0 | 58.25 | 63.0 | 66.0 | 66.0 | |
5.2 Experiment 2: Bird Flocking Simulation with Knowledge-driven Prompts
The following two model variants were experimentally tested and evaluated:
1. The original NetLogo model (henceforth simply called “NetLogo”, just like in the ant foraging case).
1. The model in which some of the rule-governed birds of the original model are replaced by LLM-governed birds (henceforth called “Hybrid”).
In all simulations, we used a flock of 30 birds and a simulation length of 800 steps. In the case of Hybrid, five of 30 rule-based birds are replaced by LLM-guided birds. Moreover, each experiment was repeated five times (with different seeds). The effectiveness of the flocking behavior is evaluated by measuring the distances and angular disparities between birds across the entire simulation. Figure 6 depicts the flocking simulation executed in the NetLogo environment, featuring a heterogeneous population of 25 rule-based and five LLM-guided birds.
<details>
<summary>extracted/6255105/llm_flocking_netlogo_interface.png Details</summary>
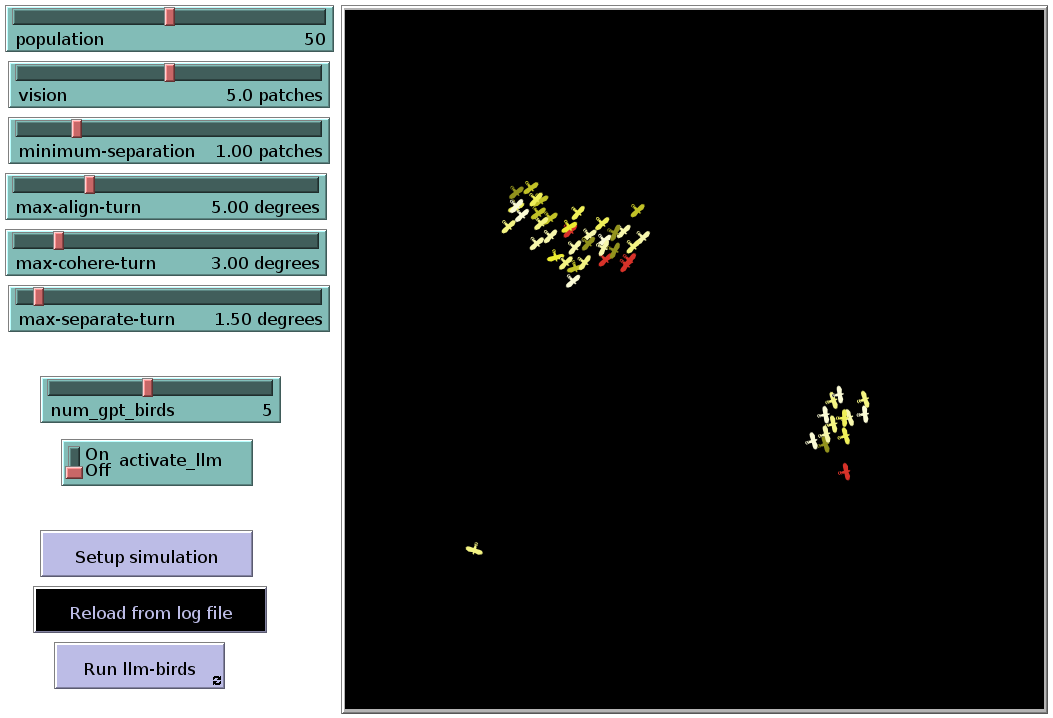
### Visual Description
## Agent-Based Model: Bird Flocking Simulation
### Overview
The image depicts a snapshot of an agent-based model simulating bird flocking behavior. The left side of the image shows the control panel with adjustable parameters, while the right side displays the simulation environment with agents (birds) represented as small airplane-like icons. The simulation appears to be running, with birds clustered in two distinct flocks.
### Components/Axes
**Left Panel (Control Panel):**
* **population:** Slider control with a current value of 50.
* **vision:** Slider control with a current value of 5.0 patches.
* **minimum-separation:** Slider control with a current value of 1.00 patches.
* **max-align-turn:** Slider control with a current value of 5.00 degrees.
* **max-cohere-turn:** Slider control with a current value of 3.00 degrees.
* **max-separate-turn:** Slider control with a current value of 1.50 degrees.
* **num_gpt_birds:** Slider control with a current value of 5.
* **activate_llm:** On/Off toggle switch, currently set to "On".
* **Buttons:**
* "Setup simulation"
* "Reload from log file"
* "Run llm-birds"
**Right Panel (Simulation Environment):**
* **Background:** Black.
* **Agents (Birds):** Represented as small airplane-like icons. The agents have varying colors, primarily yellow and red.
* **Flocks:** Two distinct flocks are visible. One larger flock is located in the upper-center of the environment, and a smaller flock is in the lower-right. A single agent is located in the bottom-left.
### Detailed Analysis
* **Agent Distribution:** The agents are not uniformly distributed. They are clustered into two flocks, suggesting that the flocking behavior is active.
* **Agent Color:** The agents have varying colors, primarily yellow and red. The color variation might represent different states or properties of the agents within the simulation.
* **Parameter Settings:** The control panel shows the current settings for various parameters that influence the flocking behavior, such as vision, minimum separation, and turning angles.
### Key Observations
* The simulation is running with specific parameter settings.
* The agents are exhibiting flocking behavior, forming two distinct groups.
* The agents have varying colors, which may indicate different states or properties.
### Interpretation
The image provides a snapshot of an agent-based model simulating bird flocking behavior. The control panel allows users to adjust parameters that influence the flocking behavior, such as vision, minimum separation, and turning angles. The simulation environment displays the agents (birds) and their interactions. The formation of flocks demonstrates the emergent behavior resulting from the interaction of individual agents based on the defined rules. The varying colors of the agents suggest that there may be additional factors or states influencing their behavior within the simulation. The single agent in the bottom-left is an outlier, and may be in the process of joining a flock, or may be too far away from other agents to be influenced by the flocking rules.
</details>
Figure 6: Bird flocking simulation in the NetLogo environment: yellow birds follow rule-based behavior, while red birds are guided by the LLM.
5.2.1 Flocking behavior
<details>
<summary>x8.png Details</summary>
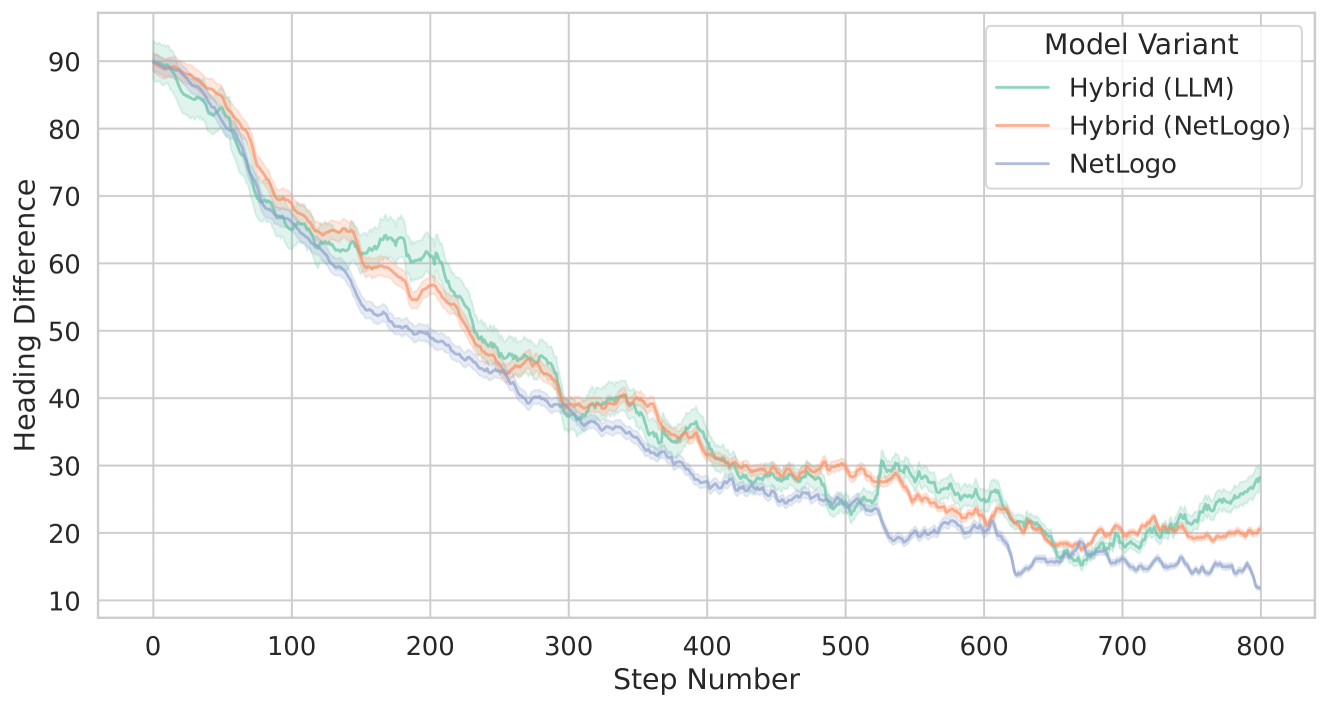
### Visual Description
## Line Chart: Heading Difference vs. Step Number for Different Model Variants
### Overview
The image is a line chart comparing the "Heading Difference" over "Step Number" for three different model variants: "Hybrid (LLM)", "Hybrid (NetLogo)", and "NetLogo". The chart displays how the heading difference changes over 800 steps for each model. The lines are surrounded by shaded regions, indicating uncertainty or variance in the data.
### Components/Axes
* **Title:** There is no explicit title on the chart.
* **X-axis:** "Step Number", ranging from 0 to 800 in increments of 100.
* **Y-axis:** "Heading Difference", ranging from 10 to 90 in increments of 10.
* **Legend:** Located in the top-right corner, labeled "Model Variant".
* **Hybrid (LLM):** Represented by a light green line with a light green shaded region.
* **Hybrid (NetLogo):** Represented by a light orange line with a light orange shaded region.
* **NetLogo:** Represented by a light blue line with a light blue shaded region.
### Detailed Analysis
* **Hybrid (LLM) - Light Green:**
* Trend: Initially decreases sharply from approximately 90 at step 0 to around 60 at step 100. It continues to decrease, but at a slower rate, reaching approximately 45 at step 300. From step 300 to 600, it fluctuates between 30 and 40. After step 600, it shows a slight increase, ending around 25 at step 800.
* Data Points:
* Step 0: ~90
* Step 100: ~60
* Step 300: ~45
* Step 600: ~30
* Step 800: ~25
* **Hybrid (NetLogo) - Light Orange:**
* Trend: Similar to "Hybrid (LLM)", it starts at approximately 90 at step 0 and decreases sharply to around 65 at step 100. It continues to decrease, reaching approximately 45 at step 300. From step 300 to 600, it fluctuates between 25 and 35. After step 600, it shows a slight increase, ending around 20 at step 800.
* Data Points:
* Step 0: ~90
* Step 100: ~65
* Step 300: ~45
* Step 600: ~25
* Step 800: ~20
* **NetLogo - Light Blue:**
* Trend: Starts at approximately 90 at step 0 and decreases sharply to around 65 at step 100. It continues to decrease, reaching approximately 45 at step 300. From step 300 to 600, it fluctuates between 20 and 30. After step 600, it shows a slight increase, ending around 15 at step 800.
* Data Points:
* Step 0: ~90
* Step 100: ~65
* Step 300: ~45
* Step 600: ~20
* Step 800: ~15
### Key Observations
* All three model variants show a decreasing trend in "Heading Difference" as "Step Number" increases.
* The most significant decrease occurs within the first 300 steps for all models.
* After 600 steps, all models show a slight increase in "Heading Difference".
* The "NetLogo" model generally has a lower "Heading Difference" compared to the "Hybrid (LLM)" and "Hybrid (NetLogo)" models, especially after step 300.
* The shaded regions around each line indicate the variability or uncertainty associated with each model's performance.
### Interpretation
The data suggests that as the number of steps increases, the "Heading Difference" tends to decrease for all model variants. This could indicate that the models are converging or becoming more aligned in their heading as they run for a longer duration. The "NetLogo" model appears to perform slightly better in terms of achieving a lower "Heading Difference" compared to the hybrid models, particularly in the later steps. The shaded regions highlight the variability in the models' performance, which could be due to various factors such as randomness in the environment or differences in the models' internal mechanisms. The slight increase in "Heading Difference" after 600 steps could indicate a potential instability or exploration phase in the models' behavior.
</details>
Figure 7: Comparison of bird flocking heading differences across two simulation approaches: original NetLogo (blue line) and Hybrid (orange and green lines). In fact, the orange line shows the behavior of the 25 rule-based birds of Hybrid, while the green line presents the behavior of the 5 LLM-guided birds of Hybrid. The lines represent the means, while the shaded areas indicate the standard deviations.
<details>
<summary>x9.png Details</summary>
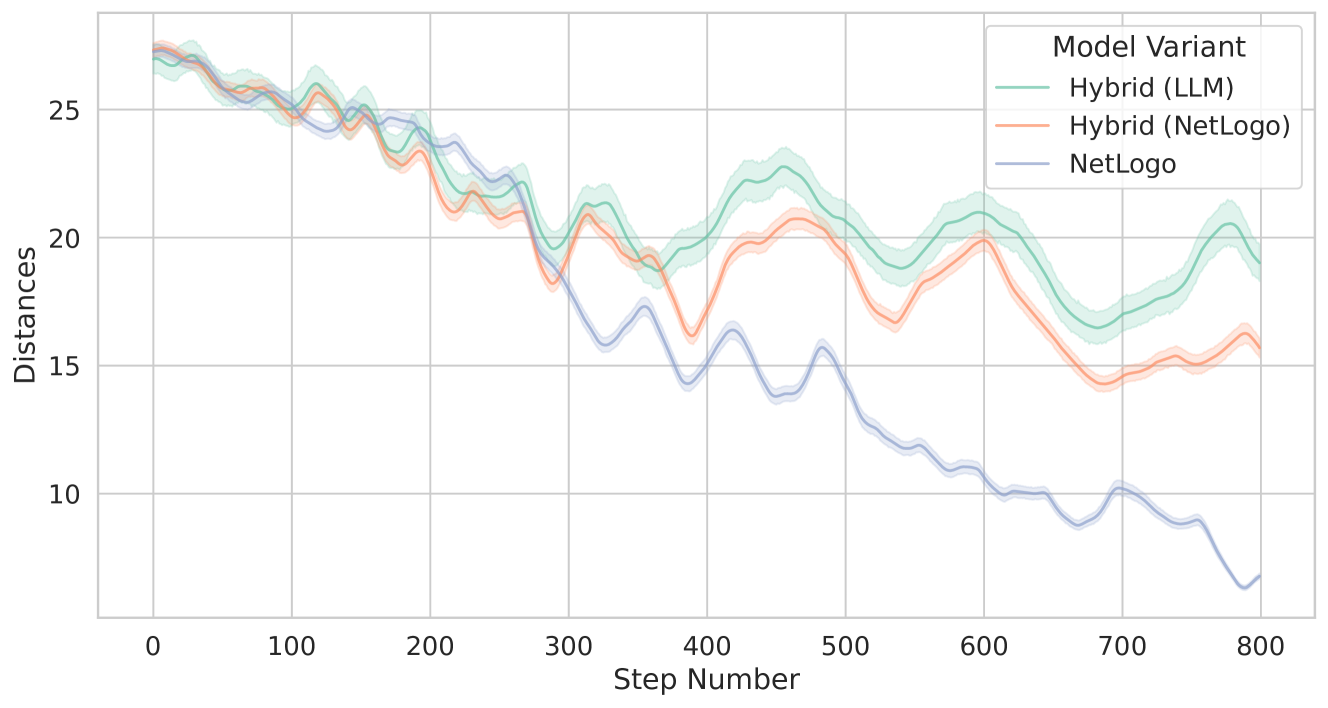
### Visual Description
## Line Chart: Distances vs. Step Number for Different Model Variants
### Overview
The image is a line chart comparing the "Distances" metric over "Step Number" for three different model variants: "Hybrid (LLM)", "Hybrid (NetLogo)", and "NetLogo". The chart displays the trend of each model's performance with shaded regions indicating variability or uncertainty.
### Components/Axes
* **X-axis:** "Step Number", ranging from 0 to 800 in increments of 100.
* **Y-axis:** "Distances", ranging from 10 to 25 in increments of 5.
* **Legend (Top-Right):**
* "Hybrid (LLM)" - Light Green line with light green shaded region.
* "Hybrid (NetLogo)" - Light Orange line with light orange shaded region.
* "NetLogo" - Light Blue line with light blue shaded region.
### Detailed Analysis
* **Hybrid (LLM) - Light Green:**
* The line starts at approximately 27 at step 0.
* The line decreases to approximately 20 at step 300.
* The line then increases to approximately 22 at step 600.
* The line then decreases to approximately 20 at step 800.
* **Hybrid (NetLogo) - Light Orange:**
* The line starts at approximately 26 at step 0.
* The line decreases to approximately 19 at step 300.
* The line then increases to approximately 21 at step 500.
* The line then decreases to approximately 16 at step 800.
* **NetLogo - Light Blue:**
* The line starts at approximately 26 at step 0.
* The line decreases to approximately 16 at step 300.
* The line then decreases to approximately 7 at step 800.
### Key Observations
* All three models start with similar "Distances" values around 26-27 at step 0.
* The "NetLogo" model shows a more significant and consistent decrease in "Distances" compared to the other two models.
* The "Hybrid (LLM)" and "Hybrid (NetLogo)" models exhibit more fluctuation, with periods of increase and decrease in "Distances".
* The shaded regions around each line indicate the variability or uncertainty in the "Distances" values for each model at each step number.
### Interpretation
The chart suggests that the "NetLogo" model performs differently compared to the hybrid models. The consistent decrease in "Distances" for the "NetLogo" model could indicate a more stable or efficient learning process, or a different behavior pattern compared to the hybrid models. The fluctuations in the "Hybrid (LLM)" and "Hybrid (NetLogo)" models could be due to the integration of different components (LLM and NetLogo), leading to more complex dynamics. The shaded regions provide insight into the reliability of the data, with wider regions indicating more variability in the results. Further analysis would be needed to understand the specific context of "Distances" and "Step Number" to draw more concrete conclusions about the models' performance.
</details>
Figure 8: Comparison of average bird distances across the two tested model variants
Figure 7 compares the differences in the birds’ heading directions between two model variants, as outlined above. However, note that the heading differences between the rule-based birds and all other birds in model variant Hybrid (orange line) are separated from the heading differences between the LLM-guided birds and all other birds of Hybrid (green line).
The results shown in Figure 7 allow to make the following observations. While the two bird types of Hybrid show a similar evolution of the heading differences, the rule-based birds of the original NetLogo model show somewhat lower heading differences. We anticipate that with longer simulation runs, the heading differences of the two model variants would converge to similar values. We also observed that the LLM-guided birds tend to congregate at the outer peripheries of the flocks, positioning themselves further away from the flocks’ center. An example of this behavior is visualized in Figure 6 (see the flock on the right) and also illustrated in Figure 8 which indicates the average distances between birds. We hypothesize that this rather “conservative” behavior of the LLM-guided birds contributes to greater heading differences among the rule-based birds of Hybrid, as this behavior introduces slight perturbations in the flocking dynamics. Another possible interpretation involves the internal representation of distance within the LLM. Although we define distance in Euclidean space and provide these distances as float values to the language model, it may interpret and represent distances in a different manner.
<details>
<summary>x10.png Details</summary>
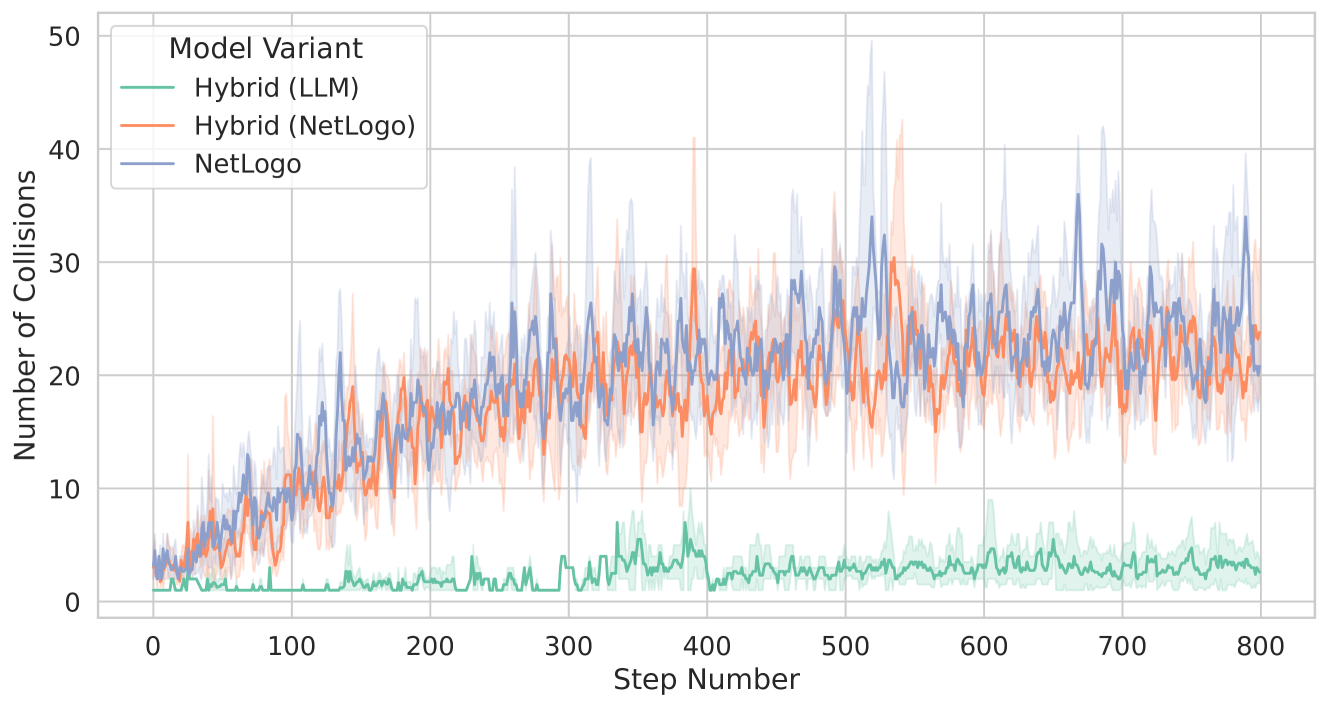
### Visual Description
## Line Chart: Number of Collisions vs. Step Number for Different Model Variants
### Overview
The image is a line chart comparing the number of collisions over time (step number) for three different model variants: Hybrid (LLM), Hybrid (NetLogo), and NetLogo. The chart displays the average number of collisions for each model, along with a shaded region indicating the variability or uncertainty around the average.
### Components/Axes
* **X-axis:** Step Number, ranging from 0 to 800 in increments of 100.
* **Y-axis:** Number of Collisions, ranging from 0 to 50 in increments of 10.
* **Legend (Top-Left):**
* Hybrid (LLM) - Green line
* Hybrid (NetLogo) - Orange line
* NetLogo - Blue line
### Detailed Analysis
* **Hybrid (LLM) - Green Line:**
* Trend: The number of collisions remains relatively low and stable throughout the simulation, generally staying below 10.
* Data Points: Starts around 1-2 collisions. Fluctuates between 1 and 7 collisions for most of the steps.
* **Hybrid (NetLogo) - Orange Line:**
* Trend: The number of collisions increases initially, then fluctuates around an average of approximately 20-25 collisions after step 200.
* Data Points: Starts around 3-4 collisions. Increases to approximately 20 collisions by step 200. Fluctuates between 15 and 30 collisions for the remaining steps.
* **NetLogo - Blue Line:**
* Trend: Similar to Hybrid (NetLogo), the number of collisions increases initially, then fluctuates around an average of approximately 20-25 collisions after step 200. The variability (shaded region) appears slightly larger than that of Hybrid (NetLogo).
* Data Points: Starts around 3-4 collisions. Increases to approximately 20 collisions by step 200. Fluctuates between 15 and 35 collisions for the remaining steps.
### Key Observations
* The Hybrid (LLM) model consistently exhibits significantly fewer collisions compared to the other two models.
* The Hybrid (NetLogo) and NetLogo models show similar trends in the number of collisions, with both increasing initially and then fluctuating around a similar average.
* The shaded regions around the lines indicate the variability in the number of collisions for each model. The NetLogo model appears to have slightly higher variability than the Hybrid (NetLogo) model.
### Interpretation
The data suggests that integrating a Large Language Model (LLM) into the hybrid model significantly reduces the number of collisions compared to using only NetLogo or a hybrid NetLogo approach. This could indicate that the LLM is better at guiding agents to avoid collisions or that it introduces a mechanism that inherently reduces collisions. The similar performance of the Hybrid (NetLogo) and NetLogo models suggests that simply combining NetLogo with itself does not significantly impact the number of collisions. The variability in the number of collisions for the NetLogo model may indicate that its behavior is less predictable or more sensitive to initial conditions compared to the Hybrid (NetLogo) model.
</details>
Figure 9: Collisions between birds. A collision occurs when the distance $d$ between birds is at most one (that is, $d≤ 1$ ).
We further investigated the behavior of rather staying at the border of flocks by examining collisions between birds, which are defined as occasions in which the Euclidean distance between two birds is smaller than one. In fact, it turns out that, throughout a simulation, the LLM-guided birds try to avoid collisions; see Figure 9. In contrast, the rule-based birds from Hybrid and those from NetLogo, exhibit a much higher number of collisions.
<details>
<summary>x11.png Details</summary>
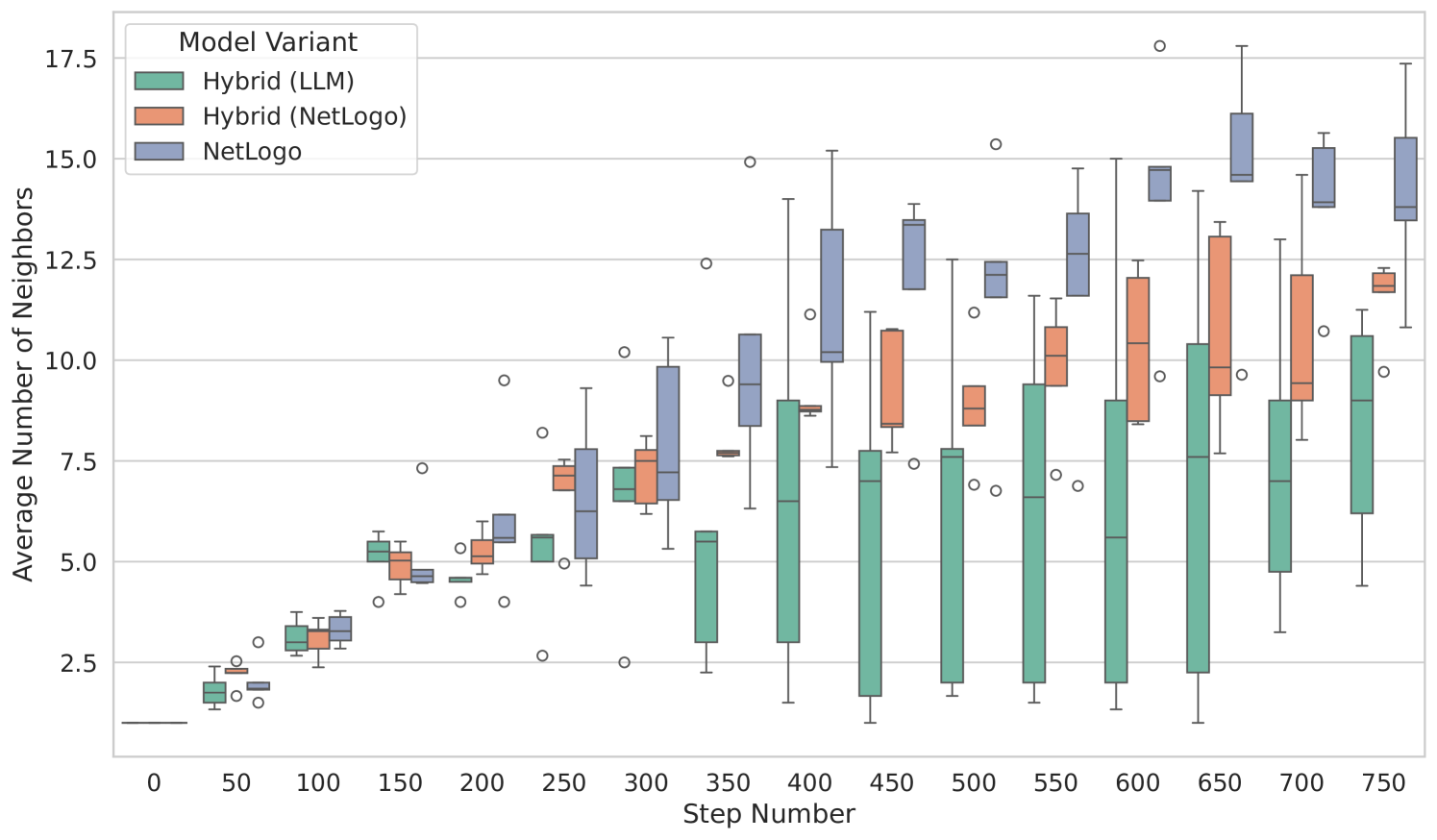
### Visual Description
## Box Plot: Average Number of Neighbors vs. Step Number for Different Model Variants
### Overview
The image is a box plot comparing the average number of neighbors for three different model variants (Hybrid (LLM), Hybrid (NetLogo), and NetLogo) across various step numbers. The x-axis represents the step number, and the y-axis represents the average number of neighbors. The plot displays the distribution of the average number of neighbors for each model variant at each step number using box plots.
### Components/Axes
* **Title:** None explicitly given in the image.
* **X-axis:**
* Label: "Step Number"
* Scale: 0 to 750, with markers at 0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550, 600, 650, 700, and 750.
* **Y-axis:**
* Label: "Average Number of Neighbors"
* Scale: 2.5 to 17.5, with markers at 2.5, 5.0, 7.5, 10.0, 12.5, 15.0, and 17.5.
* **Legend:** Located in the top-left corner.
* Hybrid (LLM): Teal color
* Hybrid (NetLogo): Salmon color
* NetLogo: Slate Blue color
### Detailed Analysis
The data is presented as box plots, where each box represents the interquartile range (IQR), the line inside the box represents the median, the whiskers extend to 1.5 times the IQR, and the circles represent outliers.
**Hybrid (LLM) - Teal:**
* Trend: Generally increasing from step 0 to step 350, then appears to plateau with some fluctuations.
* Step 0: Median around 1
* Step 50: Median around 2
* Step 100: Median around 3
* Step 150: Median around 4.5
* Step 200: Median around 5
* Step 250: Median around 6
* Step 300: Median around 7
* Step 350: Median around 5.5
* Step 400: Median around 2.5
* Step 450: Median around 7
* Step 500: Median around 7
* Step 550: Median around 9
* Step 600: Median around 9
* Step 650: Median around 9
* Step 700: Median around 9
* Step 750: Median around 9
**Hybrid (NetLogo) - Salmon:**
* Trend: Generally increasing from step 50 to step 750.
* Step 50: Median around 2.5
* Step 100: Median around 3.5
* Step 150: Median around 5
* Step 200: Median around 5.5
* Step 250: Median around 7
* Step 300: Median around 7
* Step 350: Median around 8
* Step 400: Median around 10
* Step 450: Median around 9
* Step 500: Median around 8
* Step 550: Median around 10
* Step 600: Median around 12
* Step 650: Median around 12
* Step 700: Median around 11
* Step 750: Median around 12
**NetLogo - Slate Blue:**
* Trend: Generally increasing from step 50 to step 750.
* Step 50: Median around 2
* Step 100: Median around 2
* Step 150: Median around 3.5
* Step 200: Median around 5
* Step 250: Median around 7
* Step 300: Median around 8
* Step 350: Median around 9
* Step 400: Median around 12
* Step 450: Median around 12
* Step 500: Median around 11
* Step 550: Median around 12
* Step 600: Median around 14
* Step 650: Median around 15
* Step 700: Median around 15
* Step 750: Median around 15
### Key Observations
* The Hybrid (LLM) model shows an initial increase in the average number of neighbors, but plateaus after step 350.
* The Hybrid (NetLogo) and NetLogo models show a consistent increase in the average number of neighbors as the step number increases.
* The NetLogo model generally has a higher average number of neighbors compared to the other two models, especially at later steps.
* There are several outliers in all three models, indicating some variability in the average number of neighbors.
### Interpretation
The box plot suggests that the NetLogo model and the Hybrid (NetLogo) model tend to form more connections (neighbors) as the simulation progresses, while the Hybrid (LLM) model's connectivity plateaus. This could indicate that the NetLogo and Hybrid (NetLogo) models are more effective at establishing and maintaining connections within the simulation environment as the number of steps increases. The Hybrid (LLM) model might have a different mechanism that limits the number of neighbors it forms after a certain point. The outliers suggest that there are instances where the average number of neighbors deviates significantly from the typical range for each model at each step. This could be due to random variations in the simulation or specific conditions that cause some agents to have significantly more or fewer neighbors than usual.
</details>
Figure 10: Average number of neighbors: A neighbor is defined as any entity within a distance $d$ such that $1≤ d≤ 5$ , thereby excluding collisions. Furthermore, we establish a heading difference criterion of $h≤ 15$ .
Table 3: Statistics for the average number of flocking neighbors. The values are aggregated over all steps and experiments.
| Hybrid (LLM) Hybrid (NetLogo) NetLogo | 6.27 9.23 11.42 | 5.40 9.44 11.24 | 4.23 4.30 6.27 | 1.00 1.04 1.04 | 2.75 6.44 6.02 | 5.40 9.44 11.24 | 8.63 12.25 16.87 | 17.80 16.76 22.56 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
Furthermore, triggered by our earlier observations, we examined the average number of neighbors of a bird, as shown in Figure 10. Hereby, we define two birds as neighbors if they are at a distance greater than one (no collision) and within a distance $d$ of at most five (that is, $1<d≤ 5$ ). Moreover, we require a heading difference of $h≤ 15$ . As expected, rule-based birds exhibit the highest number of neighbors, while the LLM-guided birds display the lowest number, a result of their conservative behavior. Statistics on the average number of flocking neighbors can be found in Table 3.
6 Discussion
We explored two complementary strategies for integrating Large Language Models (LLMs) into multi-agent simulations: (i) a structured, rule-based approach in an ant foraging context, and (ii) a principle-based, knowledge-driven approach in a bird flocking scenario. In both cases, our experiments demonstrated how LLMs can support swarm-like behaviors: guiding ants to locate and retrieve food by following pheromone trails, and prompting “birds” to coordinate alignment according to core flocking principles. Overall, the LLM-driven agents performed comparably to their fully rule-based counterparts, but they sometimes displayed notable differences in how they interpreted and prioritized local cues when relying on text-based decision-making.
A key theme across both simulations was the importance of iterative prompt-tuning, which proved essential for producing consistent and context-appropriate responses. In the ant foraging simulations, early prompts did not specify what ants should do if no pheromone or nest scent was present, leading to confusion or inaction. Through multiple rounds of tuning, we added directives, such as “move away from the nest when no pheromone signals are detected” that encouraged exploration. Similarly, clarifying that nest scent should take precedence over pheromone while carrying food helped ants more reliably locate and deposit resources. Following these refinements, the foraging performance of the LLM-driven ants nearly matched that of the standard NetLogo model.
A new insight arose from the hybrid simulations, in which a portion of the ant colony was rule-based while the rest was LLM-driven. These mixed colonies often outperformed both purely rule-based and purely LLM-based groups. One possible explanation is that deterministic if-then logic efficiently manages well-understood aspects of foraging, while LLM-driven exploration provides adaptability in more uncertain situations. Thus, combining traditional rules with text-based reasoning can yield more robust foraging strategies. However, this seemingly better performance of the hybrid populations warrants further investigation. We recommend running the simulations for longer durations so that the colony has enough time to collect any remaining pieces of food, which may help clarify the mechanisms driving this performance advantage.
In the bird flocking simulations, using longer prompts that highlighted alignment, separation, and cohesion improved stability. Early prompts did not define heading conventions (e.g., $0^{\circ}$ = north, $90^{\circ}$ = east), causing erratic turns and reversals. After establishing the conventions and clarifying the short-turn logic (which favored minimal angular adjustments), the flocks became more cohesive. However, LLM-driven birds generally stayed slightly farther from the flock center and experienced fewer collisions than their rule-based counterparts, indicating that LLMs can interpret spatial cues in subtly different ways while still maintaining coherent swarm behavior.
In both scenarios, we observed that LLM decision-making can function effectively in a “stateless” manner, relying on complete contextual details at every step. This guarantees that the model consistently acts on relevant information but also necessitates highly detailed prompts. Failing to include key details—like pheromone intensity or heading conventions—can result in ambiguous or incorrect actions. Expanding this approach to incorporate short-term memory or more sophisticated environmental representations could enable LLM-driven agents to maintain internal states that more closely resemble those in traditional agent-based models.
Together, these results confirm that LLMs can serve as flexible engines for agent behaviors that align with swarm principles, offering adaptive, context-driven responses. They also highlight how prompt design and iterative refinement are central to achieving the desired outcomes. Even small changes in the prompts, such as specifying the angle to rotate or how to handle conflicting signals, can significantly influence emergent group-level patterns. This underscores both the potential and the complexity of integrating LLMs into agent-based simulations, where subtle details of agent logic can greatly affect collective behavior.
Finally, regarding potential drawbacks of our approach, two key issues must be noted: computation time and cost. First, the interaction between an agent (such as an ant or bird) and the remote LLM at each iteration of a simulation requires significantly more computation time compared to executing simple rules within NetLogo. Second, utilizing GPT-4o through an API incurs token-based costs associated with the use of an API key. However, this rise in computation time and cost could be reduced by deploying a smaller, locally hosted model after training and fine-tuning.
7 Conclusion
By applying LLMs to two classic multiagent models, ant foraging and bird flocking, this study shows that LLMs can serve as a viable alternative or complement to traditional rule-based logic in achieving effective swarm-like dynamics.
In ant foraging simulations, LLM-guided ants gathered food at rates comparable to ants of the standard NetLogo model, as long as their instructions were meticulously designed. Moreover, hybrid colonies that integrated LLM-driven and rule-based ants outperformed uniform groups, indicating that the combination of deterministic efficiency and text-based reasoning can be mutually beneficial.
In bird flocking, LLM-driven agents adhered to the separation, alignment, and cohesion principles to form cohesive flocks. While heading convergence sometimes lagged behind purely rule-based simulations, the resulting formations remained visually coherent. Notably, LLM-based birds adopted slightly more peripheral positions, indicating that nuanced differences in textual instructions such as how distance and turning are interpreted, can shape global flock patterns.
These experiments emphasize the crucial role of iterative prompt tuning in aligning LLMs with specific multi-agent objectives. Meticulous attention to prompt length, structure, and content is necessary to ensure reliable, context-aware behavior at each time step. At the same time, this reliance on well-tuned prompts opens up exciting avenues for further research: more complex simulations might benefit from greater LLM-driven adaptability, especially if additional mechanisms like partial memory or reinforcement signals are introduced to move beyond purely stateless approaches. Ultimately, this work underscores the potential for advanced language models, guided by carefully designed prompts, to enrich or even extend the capabilities of traditional agent-based models, offering new perspectives on swarm intelligence, self-organization, and emergent behaviors.
Acknowledgements
This research was supported by the EUTOPIA Science and Innovation Fellowship Programme and funded by the European Union Horizon 2020 programme under the Marie Sklodowska-Curie grant agreement No 945380.
Christian Blum was supported by grant PID2022-136787NB-I00 funded by MCIN/AEI/10.13039/501100011033.
Disclaimer
This article reflects only the author’s view and the EU Research Executive Agency is not responsible for any use that may be made of the information it contains.
References
- Macal and North [2009] Charles M. Macal and Michael J. North. Agent-based modeling and simulation. In Proceedings of the 2009 Winter Simulation Conference (WSC), pages 86–98, 2009. doi: 10.1109/WSC.2009.5429318.
- Chang et al. [2024] Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. A survey on evaluation of large language models. 15(3), 2024. URL https://doi.org/10.1145/3641289.
- Wooldridge [2009] Michael Wooldridge. An introduction to multiagent systems. John wiley & sons, 2009.
- Heckbert et al. [2010] Scott Heckbert, Tim Baynes, and Andrew Reeson. Agent-based modeling in ecological economics. Annals of the new York Academy of Sciences, 1185(1):39–53, 2010.
- Chen [2012] Liang Chen. Agent-based modeling in urban and architectural research: A brief literature review. Frontiers of Architectural Research, 1(2):166–177, 2012.
- Bianchi and Squazzoni [2015] Federico Bianchi and Flaminio Squazzoni. Agent-based models in sociology. Wiley Interdisciplinary Reviews: Computational Statistics, 7(4):284–306, 2015.
- Hecker and Moses [2015] Joshua P Hecker and Melanie E Moses. Beyond pheromones: evolving error-tolerant, flexible, and scalable ant-inspired robot swarms. Swarm Intelligence, 9:43–70, 2015.
- Ning and Xie [2024] Zepeng Ning and Lihua Xie. A survey on multi-agent reinforcement learning and its application. Journal of Automation and Intelligence, 2024.
- Liu et al. [2024a] Haiying Liu, ZhiHao Li, Kuihua Huang, Rui Wang, Guangquan Cheng, and Tiexiang Li. Evolutionary reinforcement learning algorithm for large-scale multi-agent cooperation and confrontation applications. The Journal of Supercomputing, 80(2):2319–2346, 2024a.
- Fang and Dickerson [2017] Yan Fang and Samuel J Dickerson. Achieving swarm intelligence with spiking neural oscillators. In 2017 IEEE International Conference on Rebooting Computing (ICRC), pages 1–4. IEEE, 2017.
- Putra et al. [2024] Rachmad Vidya Wicaksana Putra, Alberto Marchisio, and Muhammad Shafique. Snn4agents: A framework for developing energy-efficient embodied spiking neural networks for autonomous agents. arXiv preprint arXiv:2404.09331, 2024.
- Jimenez Romero et al. [2024] Cristian Jimenez Romero, Alper Yegenoglu, Aarón Pérez Martín, Sandra Diaz-Pier, and Abigail Morrison. Emergent communication enhances foraging behavior in evolved swarms controlled by spiking neural networks. Swarm Intelligence, 18(1):1–29, 2024.
- Talebirad and Nadiri [2023] Yashar Talebirad and Amirhossein Nadiri. Multi-agent collaboration: Harnessing the power of intelligent llm agents. arXiv preprint arXiv:2306.03314, 2023.
- Kannan et al. [2024] Shyam Sundar Kannan, Vishnunandan LN Venkatesh, and Byung-Cheol Min. Smart-llm: Smart multi-agent robot task planning using large language models. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12140–12147. IEEE, 2024.
- Li et al. [2024] Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges. Vicinagearth, 1(1):9, 2024.
- Tisue and Wilensky [2004] Seth Tisue and Uri Wilensky. Netlogo: A simple environment for modeling complexity. In International Conference on Complex Systems, volume 21, pages 16–21, 2004.
- Amblard et al. [2015] Frédéric Amblard, Eric Daudé, Benoît Gaudou, Arnaud Grignard, Guillaume Hutzler, Christophe Lang, Nicolas Marilleau, Jean-Marc Nicod, David Sheeren, and Patrick Taillandier. Introduction to NetLogo. In Agent-based spatial simulation with Netlogo, pages 75–123. Elsevier, 2015.
- Reynolds [1987] Craig W. Reynolds. Flocks, herds and schools: A distributed behavioral model. In Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques, pages 25–34, 1987.
- Park et al. [2023] Joon Sung Park, Joseph C. O’Brien, Carrie Cai, Meredith Ringel Morris, Percy Liang, and Michael Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, 2023.
- Junprung [2023] Edward Junprung. Exploring the intersection of large language models and agent-based modeling via prompt engineering. arXiv preprint arXiv:2308.07411, 2023.
- Gao et al. [2023] Chen Gao, Xiaochong Lan, Zhihong Lu, Jinzhu Mao, Jinghua Piao, Huandong Wang, Depeng Jin, and Yong Li. $s^{3}$ : Social-network simulation system with large language model-empowered agents. arXiv preprint arXiv:2307.14984, 2023.
- Dasgupta et al. [2023] Ishita Dasgupta, Christine Kaeser-Chen, Kenneth Marino, Arun Ahuja, Sheila Babayan, Felix Hill, and Rob Fergus. Collaborating with language models for embodied reasoning. arXiv preprint arXiv:2302.00763, 2023.
- Zhu et al. [2023] Xizhou Zhu, Yuntao Chen, Hao Tian, Chenxin Tao, Weijie Su, Chenyu Yang, Gao Huang, Bin Li, Lewei Lu, Xiaogang Wang, et al. Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory. arXiv preprint arXiv:2305.17144, 2023.
- Gao et al. [2024] Chen Gao, Xiaochong Lan, Nian Li, Yuan Yuan, Jingtao Ding, Zhilun Zhou, Fengli Xu, and Yong Li. Large language models empowered agent-based modeling and simulation: A survey and perspectives. Humanities and Social Sciences Communications, 11(1):1–24, 2024.
- Qu [2024] Youyang Qu. Federated learning driven large language models for swarm intelligence: A survey. arXiv preprint arXiv:2406.09831, 2024.
- Strobel et al. [2024] Volker Strobel, Marco Dorigo, and Mario Fritz. Llm2swarm: robot swarms that responsively reason, plan, and collaborate through llms. arXiv preprint arXiv:2410.11387, 2024.
- Feng et al. [2024] Shangbin Feng, Zifeng Wang, Yike Wang, Sayna Ebrahimi, Hamid Palangi, Lesly Miculicich, Achin Kulshrestha, Nathalie Rauschmayr, Yejin Choi, Yulia Tsvetkov, et al. Model swarms: Collaborative search to adapt llm experts via swarm intelligence. arXiv preprint arXiv:2410.11163, 2024.
- Jiao et al. [2023] Aoran Jiao, Tanmay P Patel, Sanjmi Khurana, Anna-Mariya Korol, Lukas Brunke, Vivek K Adajania, Utku Culha, Siqi Zhou, and Angela P Schoellig. Swarm-gpt: Combining large language models with safe motion planning for robot choreography design. arXiv preprint arXiv:2312.01059, 2023.
- Liu et al. [2024b] Yitong Liu, Zihao Zhou, Jiawen Liu, Liangming Chen, and Jiankun Wang. Multi-agent formation control using large language models. Authorea Preprints, 2024b.
- Liu et al. [2024c] Hsu-Shen Liu, So Kuroki, Tadashi Kozuno, Wei-Fang Sun, and Chun-Yi Lee. Language-guided pattern formation for swarm robotics with multi-agent reinforcement learning. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8998–9005. IEEE, 2024c.