# Generating Millions Of Lean Theorems With Proofs By Exploring State Transition Graphs
**Authors**: JingGao
[1] David S. Yin
[1] Lynbrook High School, 1280 Johnson Ave, San Jose, 95129, CA, USA
2] Purdue University, 465 Northwestern Ave, West Lafayette, 47907, IN, USA
## Abstract
Large Language Models (LLMs) have demonstrated significant potential in generating mathematical proofs. However, a persistent challenge is that LLMs occasionally make mistakes, while even a minor mistake can invalidate an entire proof. Proof assistants like Lean offer a great remedy. They are designed for verifying each step of a proof in a formal language, and in recent years researchers have created AI models to generate proofs in their languages. However, the scarcity of large-scale datasets of Lean proofs restrict the performance of such Automated Theorem Proving (ATP) models.
We developed LeanNavigator, a novel method for generating a large-scale dataset of Lean theorems and proofs by finding new ways to prove existing Lean theorems. By leveraging an interactive Lean client and an efficient method for proof step generation, LeanNavigator efficiently produces new theorems with corresponding proofs. Applying this approach to Mathlib4, we generated 4.7 million theorems totaling 1 billion tokens, surpassing previous datasets by more than an order of magnitude. Using this extensive dataset, we trained an AI model that outperforms the state-of-the-art ReProver model in theorem-proving tasks. These results confirm our hypothesis and demonstrate the critical role of large datasets in improving the performance of automated theorem provers.
keywords: Deep learning, Large language models, Theorem proving, Lean
## 1 Introduction
In recent years we have witnessed the incredible growth in the capabilities of LLMs in a large variety of tasks, ranging from writing songs to creating spreadsheets. There have been many studies on using LLMs to create mathematical proofs [1, 2, 3, 4, 5]. But one major challenge is that an LLM occasionally makes mistakes in the proofs, while even a small mistake can invalidate the whole proof. This severely impedes LLMs from providing complex math proofs. For example, GPT-4o only solved 12% of problems on the 2024 American Invitational Mathematics Examination (for high school students) [6].
This illustrates a key challenge in using generative models in solving mathematical problems, — the inability to verify each step of its proof. Proof assistants such as Lean [7], Coq [8], and HOL [9] can naturally help, because they are designed exactly for this purpose. If a mathematical proof is written in the language of a proof assistant, the assistant can verify the correctness of each step of the proof.
Among various proof assistants, Lean has emerged as a popular choice due to its intuitive design. It allows users to introduce hypotheses or subcases and offload much of the work to automated proof steps called tactics, simplifying the process of theorem proving. Lean has received great attention in recent years, with one prominent example being Terrence Tao, Timothy Gowers, Ben Green, and Freddie Manners proving the Polynomial Freiman-Ruzsa (PFR) conjecture using Lean in late 2023 [10]. In 2024 DeepMind introduced AlphaProof, a Lean-based system employing reinforcement learning, which nearly achieved a gold medal in the International Mathematical Olympiad (IMO) 2024, alongside AlphaGeometry [11].
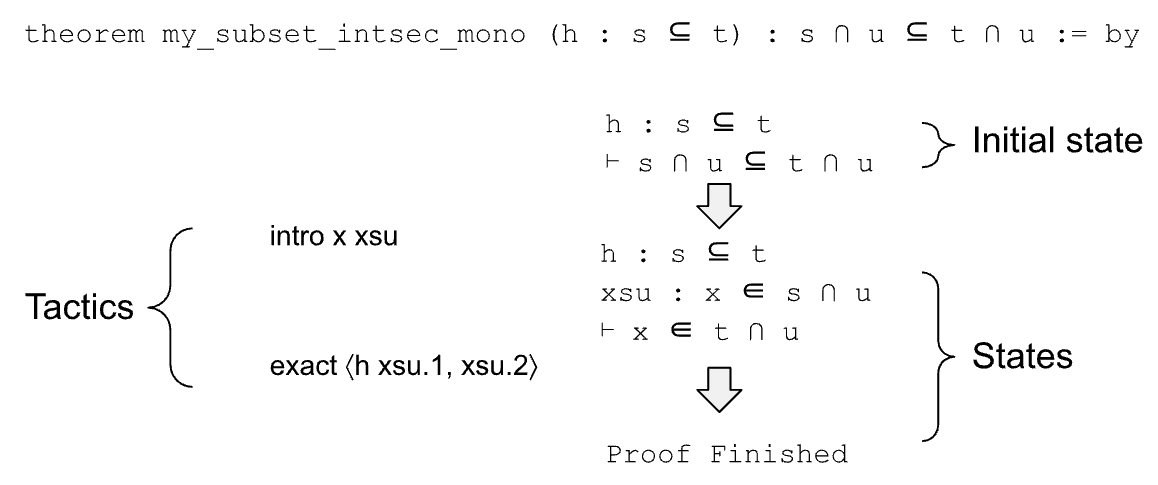
However, proof assistants are only designed to verify proofs, not for generating proofs. A proof assistant is analogous to the Python runtime, which can execute a sequence of Python commands and return the state after each command. There is a need to create an ML model that can automatically generate a proof for a theorem, just like Copilot generating python code for a programming task. Figure 1 shows an example theorem and its proof.
<details>
<summary>extracted/6207169/figure1.png Details</summary>
### Visual Description
## Diagram: Formal Proof Structure for a Set Theory Theorem
### Overview
The image is a diagram illustrating the step-by-step proof of a mathematical theorem using a formal proof assistant (likely Lean or a similar system). It visually breaks down the proof into its initial state, the tactics applied, the intermediate states, and the final conclusion. The diagram uses a flowchart style with text annotations and arrows to show the progression.
### Components/Axes
The diagram is organized into three main vertical sections:
1. **Left Column (Tactics):** Lists the proof tactics used.
2. **Center Column (Proof Flow):** Shows the logical state of the proof before and after each tactic application, connected by downward-pointing block arrows.
3. **Right Column (Annotations):** Provides descriptive labels for the states.
**Textual Elements & Spatial Grounding:**
* **Top (Center):** The theorem statement.
* **Left Side (Center-Left):** A curly brace labeled "Tactics" groups two lines of code.
* **Right Side (Top-Right):** A curly brace labeled "Initial state" points to the first state block.
* **Right Side (Center-Right):** A curly brace labeled "States" points to the second state block.
* **Bottom (Center):** The text "Proof Finished".
### Detailed Analysis
**1. Theorem Statement (Top Center):**
```
theorem my_subset_intsec_mono (h : s ⊆ t) : s ∩ u ⊆ t ∩ u := by
```
* **Language:** The text is in a formal proof language syntax. The primary language is English with embedded mathematical notation.
* **Transcription:** The theorem is named `my_subset_intsec_mono`. It takes a hypothesis `h` which states that set `s` is a subset of set `t` (`s ⊆ t`). The goal to prove is that the intersection of `s` and `u` (`s ∩ u`) is a subset of the intersection of `t` and `u` (`t ∩ u`). The `:= by` indicates the start of the proof script.
**2. Proof Flow & States (Center Column):**
The proof progresses through two main states, separated by a downward arrow.
* **Initial State (Top Block):**
```
h : s ⊆ t
⊢ s ∩ u ⊆ t ∩ u
```
* **Components:** This block lists the given hypothesis (`h`) and the goal to be proven (indicated by the turnstile symbol `⊢`).
* **Annotation:** This block is labeled "Initial state" by the brace on the right.
* **First Tactic Application (Arrow & Left Column):**
A downward arrow points from the Initial State to the next state. To the left of this arrow is the first tactic:
```
intro x xsu
```
* **Tactic:** `intro` is used to introduce variables and hypotheses into the context. Here, it introduces a variable `x` and a hypothesis `xsu`.
* **Intermediate State (Middle Block):**
```
h : s ⊆ t
xsu : x ∈ s ∩ u
⊢ x ∈ t ∩ u
```
* **Components:** The context now includes the original hypothesis `h` and the new hypothesis `xsu`, which states that `x` is an element of `s ∩ u`. The goal has been transformed into proving that `x` is an element of `t ∩ u`.
* **Annotation:** This block is labeled "States" by the brace on the right.
* **Second Tactic Application (Arrow & Left Column):**
A second downward arrow points from the Intermediate State to the final text. To the left of this arrow is the second tactic:
```
exact ⟨h xsu.1, xsu.2⟩
```
* **Tactic:** `exact` is used to provide a precise term that proves the current goal. The term `⟨h xsu.1, xsu.2⟩` constructs a proof of the conjunction `x ∈ t ∩ u` by proving `x ∈ t` (using `h` on the first part of `xsu`) and `x ∈ u` (using the second part of `xsu`).
* **Final State (Bottom Text):**
```
Proof Finished
```
* This text indicates the successful completion of the proof.
### Key Observations
* **Proof Structure:** The diagram clearly shows a "proof by introduction and exact proof term" pattern, common in formal verification.
* **State Transformation:** The core logical move is transforming a subset goal (`⊆`) into an element membership goal (`∈`) for an arbitrary element `x`, which is a standard technique.
* **Notation:** The proof uses standard set theory notation (`⊆`, `∩`, `∈`) and logical notation (`⊢`). The pair notation `⟨...⟩` is used for constructing a proof of a conjunction (AND).
* **Clarity:** The annotations ("Initial state", "Tactics", "States") effectively segment the diagram for educational purposes.
### Interpretation
This diagram is an educational tool that deconstructs a concise formal proof into its logical steps. It demonstrates how high-level mathematical reasoning (proving a property about set intersections) is translated into a sequence of primitive, verifiable tactics in a proof assistant.
* **What it demonstrates:** The proof shows that if `s` is contained in `t`, then anything common to `s` and another set `u` must also be common to `t` and `u`. The tactics reveal the underlying mechanism: take an arbitrary element from the left-hand intersection, use the subset hypothesis to show it's in `t`, and note it's already in `u` by definition.
* **Relationship between elements:** The "Tactics" column contains the *instructions* or *actions*. The "States" column contains the *current knowledge* or *proof state*. The arrows show how each action transforms the state. The annotations provide a meta-commentary on the structure.
* **Notable pattern:** The proof is minimal and efficient. It uses the `intro` tactic to set up the context perfectly for the `exact` tactic to finish in one step. There are no redundant steps or branching, indicating a straightforward, well-structured proof. The diagram itself is a clear example of how to visualize formal proof development for teaching or documentation.
</details>
Figure 1: Lean proof of a very simple theorem “ (h: s $\subseteq$ t) : s $\cap$ u $\subseteq$ t $\cap$ u ”. There is a hypothesis h which says “ s $\subseteq$ t ”, and the target is to prove “ s $\cap$ u $\subseteq$ t $\cap$ u ”. The proof contains two tactics. The first tactic “ intro x xsu ” introduces a new variable x and new hypothesis “ xsu : x $\in$ s $\cap$ u ”, i.e., x belongs to the left-hand side of the target. It transforms the initial state into “ h: s $\subseteq$ t, xsu : x $\in$ s $\cap$ u $\vdash$ x $\in$ t $\cap$ u ”. The second tactic “ exact $\langle$ h xsu.1, xsu.2 $\rangle$ ” first applies h and xsu.1 (i.e., “ s $\subseteq$ t ” and “ x $\in$ s ”) on the target, and then applies xsu.2 (i.e., “ x $\in$ u ”) on the target, which finishes the proof.
In recent years the explosive growth of LLMs has encouraged researchers to explore their potential in training Automated Theorem Prover (ATP) models [12, 13, 3, 5], which aim at generating proofs for Lean theorems. A major challenge, however, is the limited availability of large datasets for training these models. For example, ReProver [5], a Lean-based automated prover published very recently, was trained on 112K theorems from Mathlib4. Although Mathlib4 is the official library of mathematical proofs of Lean and includes almost all major areas of mathematics, it still falls short of the scale required for optimal LLM training.
In contrast, LLMs like Llama-2 have been trained on datasets containing trillions of tokens. It is impractical to expect an LLM to have good performances after being trained on such a small dataset. On the other hand, the existing corpus of math problems and solutions are not useful for training Lean proof models, because the proof for Lean (or other proof assistants such as Coq and Agda) is very different from a typical math proof. For example, a proof for a simple theorem such as “ a * 1 = a ” requires four special tactics in Lean (more details in Section 2.3). In fact LLMs such as GPT-4o understand Lean and can explain Lean theorems very well. But they have disappointing performances on generating proofs in Lean [3, 5].
Therefore, it is highly desirable to have a large dataset of Lean proofs, in order to train an LLM to generate math proofs in Lean automatically. In this paper we propose an approach that can generate millions of theorems in Lean, by exploring the state graphs of Lean theorems. As shown in Figure 1, we can use a tactic to transfer a state into another one. We define a State Graph to be a directed graph of states, with a tactic on each edge (as shown in Figure 2). If we can identify many relevant tactics for each state, we can generate many new states from a given theorem. If there is a path from a new state to a “Proof Finished” node in the state graph, this new state can be considered as a new theorem, with a proof corresponding to the sequence of tactics on the path.
We introduce LeanNavigator, a method for generating a large number of theorems in Lean, by leveraging an interactive Lean client to traverse the state graphs of theorems. In order to efficiently generate relevant tactics and traverse the state graph, we use an embedding-based-retrieval method for tactic generation, which is more efficient than the generative model used by [5]. By applying LeanNavigator on Mathlib4, we generated 4.7M theorems in Lean, with 1B tokens in total. In contrast, the dataset used to train ReProver [5], the previous state-of-the-art automated prover in Lean, contains only 57M tokens.
The larger dataset enables us to train a better model for automated proof generation, which outperforms ReProver [5] in two testing datasets.
Here are the list of main contributions made in this paper:
- We proposed LeanNavigator, a system that explores the state graphs of existing lean theorems, in order to generate many new theorems with proofs.
- We generated 4.7M theorems with proofs by applying LeanNavigator on Mathlib, the official math library of Lean.
- We trained a large language model using our dataset, which outperforms existing state-of-the-art models in proving theorems. This shows how a large dataset can help in training LLMs in generating mathematical proofs for Automated Theorem Proving.
The remainder of this paper is organized as follows. First, we will discuss the history of automated theorem proving and related datasets. Then, we will describe the format of our dataset and how to generate it. Finally, we will share our experimental results.
## 2 Related Work
### 2.1 Proof assistants
Over time, many softwares have been created to algorithmically check the correctness of mathematical proofs written in formalized mathematics, or a machine-readable language. Most proof assistants are based on type theory, which groups mathematical objects into types like integers and functions.
In most proof assistants, proving a theorem means transforming a beginning state to an end state using tactics, or preexisting theorems. Each state could also be considered a theorem of its own. For example, the state “ (a b c : $\mathbb{R}$ ) (a * b) * c = a * (b * c) ” is the associative property of multiplication.
An early example of a proof assistant is HOL, which allows theorems to be proven in higher-order logic. However, it is fairly difficult to learn. Currently, the most popular proof assistants are Lean [7], Agda [14], Coq [8], and Isabelle [15]. Among them, Lean has gained the most popularity in recent years. Lean allows the user to introduce hypotheses or subcases, and a large amount of work can be offloaded to these tactics, making automated theorem proving much easier. In late 2023 Terrence Tao, Timothy Gowers, Ben Green, and Freddie Manners proved the polynomial Freiman-Ruzsa (PFR) conjecture using Lean [10]. In 2024 DeepMind unveiled the Lean-based AlphaProof [11], which was close to getting a gold medal in IMO 2024, together with AlphaGeometry.
### 2.2 Automated Theorem Provers
Currently, there are many models that attempt to perform automated theorem proving using methods like premise selection, which selects several potential tactics, and chooses one to apply. Recently, language models like GPT-f [3] leveraging the power of generative models have also become viable for ATP.
The HOList [12] environment represents a significant step in applying machine learning to automated theorem proving in the primitive HOL formal logic language, as it was one of the earliest neural network based approaches. HOList integrates neural networks and reinforcement learning to guide the proof search process. Bansal et al. [12] have also created a comprehensive dataset derived from formal proofs in the HOL Light system, capturing proof states, tactics, and other relevant information.
Paliwal et al. (2019) [14] investigates the use of graph neural networks (GNNs) to improve HOL theorem proving. The authors propose several graphical representations of higher order logic, including abstract syntax trees (ASTs), which are a tree representation of formal logic expressions. Each logical expression, including function applications, variable bindings, and operators, is encoded as a subtree within a larger AST. Nodes in an AST are variables, variable operators like functions, function definitions, and constant values. The study demonstrates that GNNs can effectively guide the proof search process by learning from these graph representations, leading to significant performance improvements in theorem proving tasks.
A very recent study employing large language models and Lean is ReProver [5], which performs premise generation by first embedding the theorem state, and then choosing the premises with embeddings closest to the theorem’s. ReProver’s training data is obtained via LeanDojo [5], a program that enables interaction with and extracts specific theorem data from the Lean formal logic environment. Other methods like PACT [16] put more emphasis on the training format, trying methods like predicting masked parts of a proof.
### 2.3 LLMs As Automated Theorem Provers
In recent years we have witnessed the improvements of LLMs in solving generic math problems. However, the generic purpose LLMs have disappointing performances on generating proofs in formal languages such as Lean. This is because generating mathematical proofs in a formal language is a distinct challenge, differing significantly from proving theorems in natural language. Consider the example from Lean’s official tutorial (Mathematics in Lean), which proves “ a * 1 = a ”, where a belongs to a group G.
In a typical mathematical book, one can probably prove the above theorem directly using the group’s property. For example, here is a proof given by GPT-4o:
“To prove the statement $a\cdot 1=a$ where a belongs to a group, we rely on the group axiom of Identity element: There exists an element $1\in G$ such that for every $a\in G$ , $a\cdot 1=1\cdot a=a$ .
By this axiom of the group, the identity element 1 satisfies $a\cdot 1=a$ for all $a\in G$ . Therefore, this equality holds directly from the definition of the identity element in a group.”
In contrast, below is the proof from Mathematics In Lean, the official tutorial of Lean’s Mathlib.
theorem mul_one (a : G) : a * 1 = a := by rw [ $\leftarrow$ mul_left_inv a] rw [ $\leftarrow$ mul_assoc] rw [mul_inv_cancel] rw [one_mul]
We can see the proof in Lean is much more complex. Mathlib contains a theorem saying “ 1 * a = a ”, we must convert the above theorem into that. However, four steps are needed because group multiplication is noncommutative. The first step rewrites the “ 1 ” into “ (a -1 * a) ” using the definition of a multiplicative inverse. The second step removes the parentheses using the associative property of multiplication. The third step uses the multiplicative inverse definition again, turning the state into “ 1 * a = a ”. The final step proves the theorem using the fact that multiplication between the identity element of a group and any other element of it keeps it the same.
From the above example we can see that, although LLMs have been trained on huge datasets and could finish some relatively easy proofs in natural languages, such training is not very helpful for generating proofs in Lean.
## 3 Methodology
### 3.1 State Graph of Lean
In this section we will describe the format of our dataset and the generation process. Before describing our method, we would first show an example of a lean theorem and its proof. Below is a very simple theorem stating that a * b * c = b * (a * c), where a, b and c are real numbers.
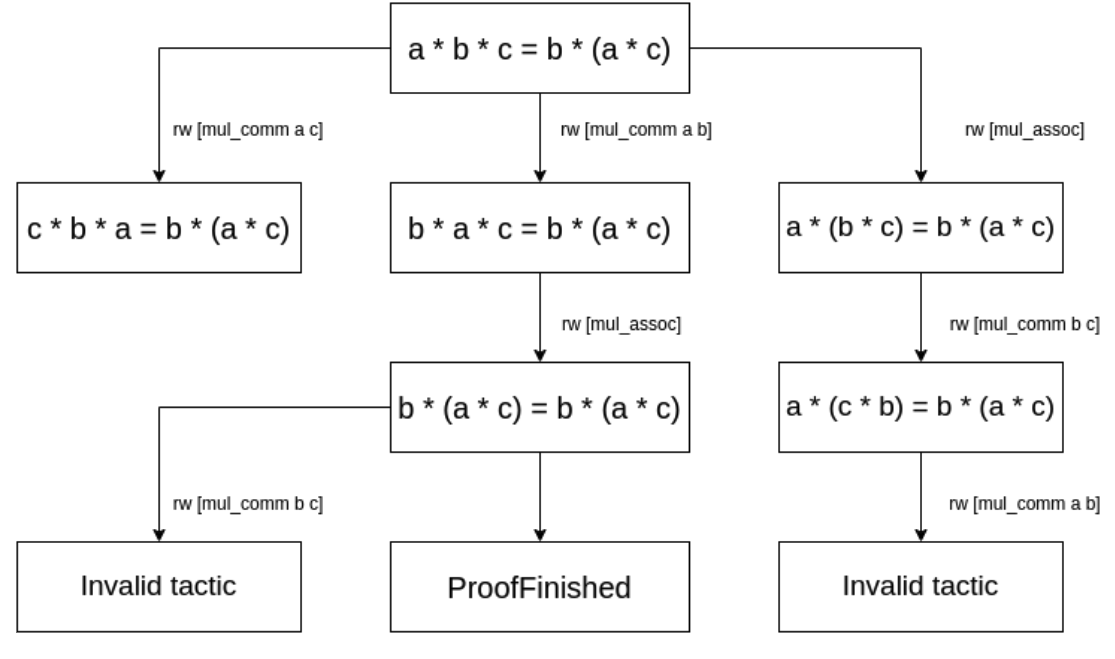
theorem my_mul_comm_assoc (a b c : $\mathbb{R}$ ) a * b * c = b * (a * c) := by rw [mul_comm a b] // Note: current state=“ b * a * c = b * (a * c) ” rw [mul_assoc] // Note: current state=“ b * (a * c) = b * (a * c) ”, ProofFinished
At the beginning of the proof, we have the initial state of the theorem, which is:
a b c : $\mathbb{R}$ $\vdash$ a * b * c = b * (a * c)
At any step of a Lean proof, there is always a current state. The initial state is simply the theorem itself: “ a * b * c = b * (a * c) ”. A proof consists of a list of tactics, each transits the current state into another state, which becomes the new current state. For example, the first tactic “ rw [mul_comm a b] ” applies the commutative property of multiplication on “ a ” and “ b ”, which transfers the initial state into a new state “ b * a * c = b * (a * c) ”. The second tactic “ rw [mul_assoc] ” applies the associative property, which transfers the state into “ b * (a * c) = b * (a * c) ”, which is tautology and finishes the proof.
We can draw an analogy between a Lean proof and a Python program. A theorem is like a programming task, with variables defined in the Python environment. Each tactic is like a Python command, which modifies or creates some variables, leading to a new “state” in Python. The task is finished when the current state satisfies certain requirements (e.g., tautology).
Figure 2 shows how the initial state of theorem my_mul_comm_assoc is transited with each tactic applied, and finally reaching the ProofFinished state. This can be considered as a directed graph of states, with a tactic on each edge.
<details>
<summary>extracted/6207169/figure2.png Details</summary>
### Visual Description
\n
## Diagram: Proof Tree for Algebraic Identity
### Overview
The image displays a hierarchical proof tree diagram illustrating different derivation paths for proving the algebraic identity `a * b * c = b * (a * c)`. The diagram shows how applying different rewrite rules (commutativity and associativity of multiplication) to the initial equation leads to various intermediate states, with only one path successfully concluding with "ProofFinished."
### Components/Axes
The diagram is structured as a tree with a root node at the top and leaf nodes at the bottom. It consists of rectangular boxes containing mathematical equations or status messages, connected by directional arrows. Each arrow is labeled with a rewrite rule (`rw`) that specifies the transformation applied to reach the next state.
**Nodes (Boxes) and their Content:**
1. **Root Node (Top Center):** `a * b * c = b * (a * c)`
2. **Second Level (Left to Right):**
* Left: `c * b * a = b * (a * c)`
* Center: `b * a * c = b * (a * c)`
* Right: `a * (b * c) = b * (a * c)`
3. **Third Level (Left to Right):**
* Left: `Invalid tactic` (connected from the left node of Level 2)
* Center: `b * (a * c) = b * (a * c)` (connected from the center node of Level 2)
* Right: `a * (c * b) = b * (a * c)` (connected from the right node of Level 2)
4. **Leaf Nodes (Bottom, Left to Right):**
* Left: `Invalid tactic`
* Center: `ProofFinished`
* Right: `Invalid tactic`
**Arrows (Transitions) and their Labels:**
* From Root to Level 2 Left: `rw [mul_comm a c]`
* From Root to Level 2 Center: `rw [mul_comm a b]`
* From Root to Level 2 Right: `rw [mul_assoc]`
* From Level 2 Center to Level 3 Center: `rw [mul_assoc]`
* From Level 2 Right to Level 3 Right: `rw [mul_comm b c]`
* From Level 3 Center to Leaf Center: (Unlabeled arrow, direct progression)
* From Level 3 Center to Leaf Left: `rw [mul_comm b c]`
* From Level 3 Right to Leaf Right: `rw [mul_comm a b]`
### Detailed Analysis
The diagram maps out three distinct proof strategies starting from the same goal.
1. **Left Branch Strategy:**
* **Step 1:** Applies commutativity to swap `a` and `c` (`mul_comm a c`), transforming the left side from `a * b * c` to `c * b * a`. The right side remains unchanged.
* **Step 2:** Attempts to apply commutativity to `b` and `c` (`mul_comm b c`). This leads to an "Invalid tactic" state, indicating this sequence of rewrites does not successfully prove the goal.
2. **Center Branch Strategy (Successful):**
* **Step 1:** Applies commutativity to swap `a` and `b` (`mul_comm a b`), transforming the left side to `b * a * c`.
* **Step 2:** Applies associativity (`mul_assoc`) to the left side, regrouping `b * a * c` into `b * (a * c)`. This results in the equation `b * (a * c) = b * (a * c)`, which is a tautology (both sides are identical).
* **Conclusion:** The proof is complete, as indicated by the "ProofFinished" node. An alternative path from this tautology state attempts to apply `mul_comm b c`, which is deemed an "Invalid tactic."
3. **Right Branch Strategy:**
* **Step 1:** Applies associativity (`mul_assoc`) to the left side, regrouping `a * b * c` into `a * (b * c)`.
* **Step 2:** Applies commutativity to swap `b` and `c` (`mul_comm b c`) inside the parentheses, resulting in `a * (c * b)`.
* **Step 3:** Attempts to apply commutativity to `a` and `b` (`mul_comm a b`). This leads to an "Invalid tactic" state.
### Key Observations
* **Single Successful Path:** Only the center branch, which uses commutativity followed by associativity, results in a successful proof.
* **Tautology as Goal:** The successful path reaches a state where both sides of the equation are syntactically identical (`b * (a * c) = b * (a * c)`), which is the logical endpoint of the proof.
* **Invalid Tactics:** Three separate paths terminate in "Invalid tactic," showing that not all sequences of valid algebraic manipulations necessarily lead to the desired proof state within this formal system.
* **Symmetry in Failure:** The left and right branches both fail after two rewrite steps, while the center branch succeeds. The failure in the left branch occurs after attempting a commutativity rewrite on the already-transformed expression.
### Interpretation
This diagram is a visual representation of a **formal proof search** in automated theorem proving or interactive theorem assistants. It demonstrates the concept of a **proof state space**, where each node is an equation (or goal) and each edge is a transformation rule.
* **What it demonstrates:** The tree illustrates that proving a seemingly simple algebraic identity requires choosing the correct sequence of rewrite rules. It highlights the difference between *applying valid rules* and *finding a valid proof*. Commutativity and associativity are fundamental properties, but their application order matters.
* **Relationship between elements:** The root is the initial goal. Each level represents a step in the proof search. The leaf nodes represent terminal states: either success ("ProofFinished") or failure ("Invalid tactic"), where no further applicable rules lead toward the goal.
* **Underlying Logic:** The successful path reveals the core logical strategy: first, use commutativity to position the term `b` at the front of the left-hand side, then use associativity to group the remaining terms `(a * c)` together, matching the right-hand side exactly. The failed paths show alternative, but ultimately unproductive, rearrangements of the terms.
* **Context:** This type of visualization is crucial for understanding how automated provers work, debugging proof strategies, and teaching the mechanics of formal logic. It makes the abstract process of symbolic manipulation concrete and traceable.
</details>
Figure 2: An example Lean state graph of theorem “ theorem my_mul_comm_assoc (a b c : $\mathbb{R}$ ) a * b * c = b * (a * c) ”. Please note a randomly chosen tactic is seldom applicable to a state, and therefore we need to train models to predict useful tactics.
Please note that the above theorem does not contain any hypotheses. In many theorems a state can contain one or more hypotheses. For example, the following state contains a hypothesis h, which says “ a = b + c ”.
a b c : $\mathbb{R}$ h : a = b + c $\vdash$ a * a = b * b + 2 * b * c + c * c
### 3.2 Dataset Description
Each element in our dataset contains a theorem, which is created from a Lean state. It also contains a proof, which is a list of tactics that would transfer this theorem’s initial state to “ ProofFinished ”. This allows us to train a LLM to output a valid proof given a state. During the process of generating a proof, we can use Lean’s interactive client to verify if each tactic generated is applicable to the current state. Therefore, to prove a theorem, we will use the LLM to repeatedly generate a new tactic, test each tactic using Lean’s client, and stop when we reach a state of “ ProofFinished ”.
Below is an example of how a new theorem can be generated using tactics.
theorem mul_inv_rev (a b : G) : (a * b) -1 = b -1 * a -1 := by rw[ $\leftarrow$ one_mul (b -1 * a -1)] // Note: Current state: (a * b) -1 = 1 * (b -1 * a -1) rw[ $\leftarrow$ mul_left_inv (a * b)] // Note: Current state: (a * b) -1 = (a * b) -1 * (a * b) * (b -1 * a -1)
Example 1: A more complex Lean theorem showing the utility of tactics
theorem mul_inv_rev_proof (a b : G) : (a * b) -1 = (a * b) -1 * (a * b) * (b -1 * a -1) := by rw[mul_left_inv (a * b)] rw[one_mul (b -1 * a -1)] rw[ $\leftarrow$ one_mul (b -1 * a -1)] rw[mul_assoc] rw[mul_assoc] rw[ $\leftarrow$ mul_assoc b b -1] rw[mul_right_inv] rw[one_mul] rw[mul_right_inv] rw[mul_one]
Example 2: The proof for the theorem generated by state navigation in Example 1
In Example 1, the initial state says that for group elements a and b, the inverse of (a * b) is equal to the inverse of b multiplied by the inverse of a. is used to prove another more complex state. The first tactic uses the fact that for any group element a, the identity element multiplied by a does not change it. The second tactic uses the fact that a group element’s inverse multiplied by the element results in the identity element. These two tactics can transform a state into a very different one, showing that traversing the state graph can lead to meaningful new states, which can be used as new theorems.
Example 2 provides a proof for the theorem derived in Example 1. It first applies the inverse tactics in Example 1, and then expands the right side of the equation using the associative theorem of multiplication and the fact that a group element multiplied by its inverse is the identity element. Finally, it simplifies the equation by canceling out group elements with their inverses.
### 3.3 Tactic Generation
Some readers may think that to prove a theorem in Lean, it would be feasible to try every single tactic in Mathlib. However, that is incredibly costly. Mathlib has more than 200 built-in tactics like simp and rw. Since most theorems in Mathlib like one_mul and mul_assoc can also be used as tactics, the total number of tactics can reach into the hundreds of thousands. As the number of possible states grows exponentially with the number of tactics, applying every tactic for every state is obviously infeasible. Therefore, a more efficient method is needed.
Let us first review how previous methods like ReProver [5] generate tactics. It contains two versions: Direct generation and RAG. The direct-generation version generates the next tactic based on the current state of the theorem, which is treated as a string. The RAG version first embeds the current theorem state by treating it as a string. Then it embeds a list of tactics whose embeddings are nearest to the theorem state’s embedding to a list of potential tactics. These tactics are then fed with the theorem state into a language model to create a more accurate prediction.
However, finding the right tactic can be very difficult, as Lean tactics can be passed different variables and hypotheses can be given arbitrary names. For example, “ rw [mul_comm a b] ” and “ rw [mul_comm x y] ” are considered two different tactics. In different types of proofs, the variable names are likely to be different even in two uses of the same tactic in the same proof, meaning that the tactics have different embeddings. This might not be a problem if there are billions of complex theorems to train on, but currently Lean’s Mathlib library only contains around 100,000 theorems, with only 3.8 tactics each on average.
To solve this problem, we convert tactics into tactic templates. Tactic templates have all variables replaced with placeholders. In the example in Figure 1, the first intermediate tactic would be changed to “ rw [mul_comm {var0} {var1}] ”, where {var0} and {var1} represent two different variables. We will also replace hypotheses like “ a = b ” or “ k > 1 ” with {hypothesis} and unrecognized parts of our tactics with {unknown}. Then, we will embed the tactic template using a GPTNeo-350M model [17] trained to embed tactic templates and relevant theorem states to similar vectors. The model is trained using contrastive learning [18], where each example contains a theorem state, a correct tactic, and a randomly selected incorrect one. The model then aims to embed the state as close to the correct tactic’s embedding as possible.
This approach has two advantages. The first is that it will make identical embeddings for different usages of the same tactic, as variable and hypothesis names are standardized. The second advantage is that it requires less training data to understand the semantics of a tactic, as each tactic template appears more often than the raw tactics.
We place the embeddings of all tactic templates into a FAISS index [19], which enables nearest neighbor search based on embedding similarity. To generate tactics for a theorem state, we will first turn the state into an embedding using the previously mentioned model. We then find the 100 nearest tactic template embeddings from the FAISS index. Finally, we will generate all possible combinations of variables and hypotheses that the tactic could use. As the number of possible combinations grows exponentially with the number of templates, we will limit the number of generated tactics to 200.
### 3.4 Dataset Generation
One attractive property of Lean is that it allows efficient transitions among its states. In our experiments, the average time spent on applying a tactic was only 0.12 seconds per tactic. Given a theorem which has an initial state, we can keep applying tactics one by one, to transit among many different states. Each new state consists of a new set of hypotheses and/or a new goal, and this new state can be considered as a new theorem.
When generating our dataset, we will store information like the current state, the states leading to the current state, and the tactics required to prove the state from previous states. This allows us to construct a collection of graphs where nodes are states, edges are tactics, and the tactics in a path from one node to the other is a proof. We will call this graph the state transition graph. Therefore, to generate a proof, we have to traverse the state transition graph to find a path between the initial state and the proven state.
If a theorem is proven in a node, we will refer to it as a ProofFinished node. All ProofFinished nodes in the state graph of a theorem can be considered as a single node. If the ProofFinished node is reachable from a certain node $n$ in the graph, we call $n$ a provable node, and the corresponding state $s$ is a provable state. We can construct a theorem for each provable state, by collecting the tactics along the path from its node to the ProofFinished node, which is a proof for this theorem. Please note there can be multiple paths from a state to the ProofFinished node, each corresponding to a different proof. We pick the proof with the least number of tactics as our proof (and break ties by total string length of the tactics).
In this study we built an efficient approach to explore this huge state graph, in order to generate millions of theorems, each of which being a distinct state.
In the algorithm, we will run a breadth-first search from the initial state specified by the theorem to construct the state graph mentioned in Section 3.1.
Algorithm 1: ExploreStates(theorem) initial_state $\leftarrow$ dojo.enter(theorem) state_dict $\leftarrow$ {initial_state: [None, [], []]} # state graph in our dataset push the initial_state into the priority queue with priority 0 state_idx $\leftarrow$ 1 while queue is not empty: curr_state $\leftarrow$ the state with lowest priority pop the state with lowest priority convert curr_state into embedding with state-embedder find tactic templates that are closest to above embedding from the faiss index for each template: substitute placeholders with variables and hypotheses to generate tactics for tactic in tactics: try applying tactic to curr_state to get next_state if next_state is error: continue else: state_data $\leftarrow$ (curr_state,tactic,state_dict[curr_state].prefix + tactic) add state_data to state_dict[next_state] if next_state is not ProofFinished: push next_state into the priority queue with priority state_idx state_idx += 1
To run a tactic, we will use the LeanDojo [5] tool, which allows us to automatically apply tactics to a Lean state.
Since the state graph of a theorem can be very huge or even infinite, we limit the amount of computation done with each theorem. We will terminate it after 30 minutes, or 200,000 state transitions. We will then add all states that have a distance of 8 tactics or less from a ProofFinished state into our dataset, each of which being a theorem with a proof consisting of at most 8 tactics.
## 4 Experimental Results
In this section, we will describe our evaluation process and share its results. All evaluation is performed on an NVIDIA A6000 with 48GB of memory, and an Intel i7-12700K. Evaluation is done using two benchmarks, the mathematics-in-lean(MIL) [20] and the MiniF2F benchmark [21]. MIL is the official tutorial of Mathlib (Lean’s math library), consisting of many theorems covering advanced fields such as group theory, topology, and number theory. The following is an example theorem in the dataset, which involves profound knowledge of different tactics and mathematical experience.
theorem natAbs_norm_mod_lt (x y : gaussInt) (hy : $y\neq 0$ ) : (x $\mod$ y).norm.natAbs < y.norm.natAbs := by apply Int.ofNat_lt.1 simp only [Int.coe_natAbs, abs_of_nonneg, norm_nonneg] apply norm_mod_lt x hy
The second dataset, MiniF2F, contains many competition math problems from sources like the AMC, AIME, and IMO. It includes problems like:
Which of the following is equivalent to
$(2+3)*(2^{2}+3^{2})*(2^{4}*3^{4})*(2^{8}+3^{8})*(2^{16}+3^{16})*(2^{32}+3^{32} )(2^{64}+3^{64})?$
Solving these problems requires creativity and intuition. For example, the above problem can be solved by multiplying $(3-2)=1$ , and applying the difference of squares.
### 4.1 State Generation
In order to generate a very large dataset, the speed of data generation is a key factor. Therefore, we first evaluate the efficiency of our method’s state generation, by running the dataset generation process in Section 3.3. For comparison, we will also use ReProver to generate states on the same dataset. We randomly select 121 theorems from the MIL dataset, let each approach navigate in the state graph, and count how many states each approach can reach within 2 minutes. The results are shown in Table 2, which shows the average number of states reached by each approach.
| LeanNavigator | 2035.45 |
| --- | --- |
| ReProver | 21.69 |
Table 1: A comparison between the state generation abilities of LeanNavigator and ReProver, with each method given two minutes per theorem.
As shown in Table 1, LeanNavigator generates states far more efficiently than ReProver for the following two reasons:
(1) we use an embedding-based-retrieval based on FAISS(Douze et al. 2024) which is highly optimized, and
(2) ReProver uses a generative model which generates one byte at a time, while we retrieve the most relevant tactic-templates and fill the template with variable names.
### 4.2 Dataset
Having a large dataset can massively improve model performance, as shown by [22]. For example, Llama [23] was trained on 2T tokens of data. However, models like ReProver only have a small amount of data to work with (57M tokens).
We use RAY with 24 processes, which work on up to 24 theorems simultaneously. It took 28 days to finish processing all the theorems in Mathlib4. Our dataset contains almost 20 times more tokens compared with ReProver’s dataset, as shown in Table 2, which enables us to train models with more prediction power without overfitting.
| LeanNavigator | 4.7M | 1B |
| --- | --- | --- |
| ReProver | 112K | 57M |
Table 2: A comparison between LeanNavigator and ReProver’s dataset sizes
### 4.3 Effectiveness In Training Predictive Models
To measure the effectiveness of our dataset, we will also use it to train the flan-t5 base and flan-t5 small [24] generative models, with 350M and 80M parameters respectively. We then compare our model with ReProver, [5], which is the state-of-the-art method for generating lean proofs.
ReProver uses the byt5-small model [25], a model with 300M parameters which treats each byte as a token in training and inference. This explodes the token length and is much slower than most LLMs using a tokenizer. It is probably OK for training on a small dataset, but is very expensive on a large dataset. Our model uses a BPE [26] tokenizer just like most language models today [24]. For example, the tactic apply Int.ofNat_lt.1 is tokenized into [ $<$ s $>$ , apply, Int, ., of, N, at, _, lt, ., 1] by our tokenizer, while in ReProver each character is treated as a token.
We compare our model and ReProver [5] by using each of them to generate proofs on the MIL and MiniF2F benchmarks, in order to gauge their effectiveness across a wide range of fields. Please note that all our training data are created from the Mathlib4 dataset, and therefore our model has never seen any contents in MIL and MiniF2F. This is more rigorous than randomly sampling a part of the Mathlib4 dataset as the testing set (which was used in ReProver), because it contains many theorems that are similar to each other and have similar proofs. We only compare the performance of generative language models (instead of RAG models), since most popular LLMs today are generative models (such as Llama, Phi and Mistral).
Each model is given two minutes per theorem for evaluation, as otherwise the model may get into an infinite loop or continuously make meaningless transitions among the states. For each state, the model has ten tries to find a valid tactic that results in a new, unseen state. The evaluation will then continue from the first of those states.
| MIL Results | 39/117 | 25/117 | 30/117 |
| --- | --- | --- | --- |
| MiniF2F Results | 104/493 | 52/493 | 99/493 |
Table 3: LeanNavigator and ReProver’s results on the MIL and MiniF2F benchmarks.
As you can see in Table 3, the flan-t5 base model we trained on LeanNavigator significantly outperforms the ReProver model on MIL, and also outperforms it on MiniF2F. Our model has a similar number of parameters as byt5-small, which shows the effectiveness of our dataset and the importance of a large dataset when training LLMs for automated theorem proving.
## 5 Conclusion
In this paper, we presented LeanNavigator, a novel approach to Lean dataset generation by exploring state transition graphs. Our method uses Lean’s tactic system to traverse the state graph, significantly expanding the dataset available for training automated theorem provers. We also introduce tactic templates in order to improve the efficiency in data generation. Through our approach, we generated 4.7 million theorems, — more than an order of magnitude larger than previous datasets like that used by ReProver [5].
Our experiments demonstrate that LeanNavigator leads to notable improvements in automated theorem proving. The larger dataset allowed us to train a language model that outperforms existing state-of-the-art models in theorem proving benchmarks like the MIL [20] and MiniF2F [21] datasets.
These results underscore the importance of large-scale datasets in advancing the capabilities of automated theorem provers. LeanNavigator’s ability to generate millions of diverse theorems provides the foundation for training new automated theorem proving models. We believe that our approach paves the way for even larger and more sophisticated models, enhancing the accuracy and reliability of proofs generated by automated systems. Future work could further optimize the tactic generation process and explore applications in other proof assistants, aiming to build a unified framework for formal theorem proving in mathematics.
## Data availability
The LeanNavigator dataset is hosted using Zenodo(a data repository by CERN) at https://zenodo.org/records/13989482. The code for dataset generation and testing are released at https://github.com/davidsyin/leannavigator.
## Declarations
### Conflict of Interest
The authors declare that they have no competing interests.
### Ethical Approval
There are no ethical conflicts.
### Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
### Author’s Contributions
Both authors contributed to ideation and writing. David Yin contributed to implementation and experimentation.
## References
- Schulz [2002] Schulz, S.: E–a brainiac theorem prover. AI Communications 15 (2-3), 111–126 (2002)
- Kovacs and Voronkov [2013] Kovacs, L., Voronkov, A.: First-order theorem proving and vampire. International Conference on Computer Aided Verification 25 (1), 1–35 (2013)
- Polu [2020] Polu, S.: Generative Language Modeling for Automated Theorem Proving. arXiv preprint arXiv:2009.03393 (2020)
- Lample [2022] Lample, G.: Hypertree proof search for neural theorem proving. Advances in Neural Information Processing Systems 35, 26337–26349 (2022)
- Yang et al. [2023] Yang, K., Swope, A., Gu, A., Chalamala, R., Song, P., Yu, S., Godil, S., Prenger, R.J., Anandkumar, A.: Leandojo: Theorem proving with retrieval-augmented language models. Advances in Neural Information Processing Systems 36 (2023)
- OpenAI [2024] OpenAI: Learning to Reason with LLMs. https://openai.com/index/learning-to-reason-with-llms/. Accessed 13 October 2024 (2024)
- Moura and Ullrich [2021] Moura, L.D., Ullrich, S.: The Lean 4 Theorem Prover and Programming Language. Paper presented at the 28th International Conference on Automated Deduction, Virtual Event, July 12–15, 2021 (2021)
- Huet et al. [1997] Huet, G., Kahn, G., Paulin-Mohring, C.: The Coq Proof Assistant: A Tutorial. Rapport Technique 178 (1997)
- Gordon and Melham [1993] Gordon, M., Melham, F.: Introduction to HOL: A Theorem Proving Environment for Higher Order Logic. Cambridge University Press, New York (1993)
- Gowers et al. [2023] Gowers, W.T., Green, B., Manners, F., Tao, T.: On a conjecture of Marton. arXiv preprint arXiv:2311.05762 (2023)
- DeepMind [2024] DeepMind, G.: AI achieves silver-medal standard solving International Mathematical Olympiad problem. https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/. Accessed 13 October 2024 (2024)
- Bansal et al. [2019] Bansal, K., Loos, S., Rabe, M., Szegedy, C., Wilcox, S.: Holist: An environment for machine learning of higher order logic theorem proving. In: International Conference on Machine Learning, pp. 454–463 (2019)
- Paliwal et al. [2020] Paliwal, A., Loos, S., Rabe, M., Bansal, K., Szegedy, C.: Graph representations for higher-order logic and theorem proving. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 2967–2974 (2020)
- Bove et al. [2009] Bove, A., Dybjer, P., Norell, U.: A brief overview of agda – a functional language with dependent types. In: Theorem Proving in Higher Order Logics: 22nd International Conference, TPHOLs 2009, pp. 73–78 (2009)
- Paulson [1994] Paulson, L.C.: Isabelle: a Generic Theorem Prover. Springer, Heidelberg (1994)
- Han et al. [2021] Han, J.M., Rute, J., Wu, Y., Ayers, E.W., Polu, S.: Proof artifact co-training for theorem proving with language models. arXiv preprint arXiv:2102.06203 (2021)
- Black et al. [2021] Black, S., Gao, L., Wang, P., Leahy, C., Biderman, S.: Gpt-neo: Large scale autoregressive language modeling with mesh-tensorflow. 58(2) (2021)
- Chen et al. [2020] Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: International Conference on Machine Learning, pp. 1597–1607 (2020)
- Douze et al. [2024] Douze, M., Guzhva, A., Deng, C., Johnson, J., Szilvasy, G., Mazaré, P.E., Lomeli, M., Hosseini, L., Jégou, H.: The faiss library. arXiv preprint arXiv:2401.08281 (2024)
- Avigad et al. [2020] Avigad, J., Buzzard, K., Lewis, R.Y., Massot, P.: Mathematics in Lean. https://leanprover-community.github.io/mathematics_in_lean/mathematics_in_lean.pdf. (2020)
- Zheng et al. [2021] Zheng, K., Han, J.M., Polu, S.: Minif2f: a cross-system benchmark for formal olympiad-level mathematics. arXiv preprint arXiv:2109.00110 (2021)
- Kaplan et al. [2020] Kaplan, J., McCandlish, S., Henighan, T., Brown, T.B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., Amodei, D.: Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 (2020)
- Touvron et al. [2023] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
- Chung et al. [2024] Chung, H.W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., Webson, A.: Scaling instruction-finetuned language models. Journal of Machine Learning Research 25 (70), 1–35 (2024)
- Xue et al. [2020] Xue, L., Barua, A., Constant, N., Al-Rfou, R., Narang, S., Kale, M., Roberts, A., Raffel, C.: Byt5: Towards a token-free future with pre-trained byte-to-byte models. In: International Conference on Machine Learning, pp. 1597–1607 (2020)
- Shibata et al. [1999] Shibata, Y., Kida, T., Fukamachi, S., Takeda, M., Shinohara, A., Shinohara, T., Arikawa, S.: Byte pair encoding: a text compression scheme that accelerates pattern matching (1999)