## Cognitive Bias Detection Using Advanced Prompt Engineering 1
Frederic Lemieux 2 , Aisha Behr 3 , Clara Kellermann-Bryant 4 , Zaki Mohammed 5
## Abstract
Cognitive biases, systematic deviations from rationality in judgment, pose significant challenges in generating objective content. This paper introduces a novel approach for real-time cognitive bias detection in user-generated text using large language models (LLMs) and advanced prompt engineering techniques. The proposed system analyzes textual data to identify common cognitive biases such as confirmation bias, circular reasoning, and hidden assumption. By designing tailored prompts, the system effectively leverages LLMs' capabilities to both recognize and mitigate these biases, improving the quality of human-generated content (e.g., news, media, reports). Experimental results demonstrate the high accuracy of our approach in identifying cognitive biases, offering a valuable tool for enhancing content objectivity and reducing the risks of biased decisionmaking.
## Introduction
Cognitive biases are systematic patterns of deviation from rational judgment, affecting decision-making processes across various domains, including media, policy-making, and legal reasoning. With the rapid expansion of artificial intelligence (AI) applications, large language models (LLMs) have demonstrated significant potential in processing and evaluating vast amounts of textual information. However, existing research has largely focused on mitigating biases within AI-generated outputs rather than leveraging AI to detect biases in human-generated content. This gap presents a critical challenge in ensuring transparency and fairness in AI-assisted decision-making. This study explores the application of structured prompt engineering as a novel approach to improving LLM accuracy in detecting cognitive biases. Prior research has identified key cognitive biases such as circular reasoning, false causality, and confirmation bias in various forms of communication. While existing bias detection models rely on conventional natural language processing (NLP) techniques, they often struggle with contextual accuracy and tend to produce high false-positive rates.
1 The authors want to thank the Initiative on Pedagogical Uses of AI (IPAI) at Georgetown University and CGI Federal for supporting this research.
2 Professor of the Practice and Faculty Director, Georgetown University.
3 Director Consulting Services, AI & Machine Learning, CGI Federal.
4 Graduate Student and Research Assistant, Georgetown University.
5 Graduate Student and Research Assistant, Georgetown University.
Our research introduces an optimized framework for designing structured prompts that enhance LLMs' ability to distinguish between biased and neutral statements more effectively. By conducting a comparative analysis against baseline models, this study evaluates the impact of structured prompt engineering in reducing misclassification and improving bias detection accuracy. The findings from this research contribute to the broader discourse on AI's role in cognitive bias detection by demonstrating that wellcrafted prompting strategies can significantly enhance model performance. This study also highlights the need for continued refinement in AI-driven bias detection methodologies, emphasizing the importance of human annotation, multilingual adaptation, and real-world application testing.
## Literature Review
Research on biases in artificial intelligence (AI) systems has focused on developing tools and strategies to detect and mitigate biases within automated systems, algorithms, and data. Early studies, such as those by Liang and Acuna (2020), introduced psychological frameworks to detect biases in AI, notably through the identification of gendered perceptions in sentiment analysis and word embeddings. These efforts highlighted how cognitive biases inherent in human behavior often propagate through AI outputs. Alelyani (2021) extended this by examining cognitive biases in machine learning datasets, revealing that human biases in data collection, such as those found in Amazon's hiring systems, lead to algorithmic discrimination. Her research called for greater transparency in datasets and model explainability to effectively mitigate these biases. The work of Raza et al. (2024) introduces Nbias, a framework designed to detect and mitigate biases in textual data across domains like social media, healthcare, and job hiring. By using a transformer-based token classification model, the framework identifies biased words/phrases, achieving accuracy improvements of 1% to 8% over baseline models while promoting the fair and ethical use of data. Rastogi et al. (2022) proposed a timebased de-biasing strategy for human-AI collaboration, enhancing decision-making by addressing biases like anchoring during interaction. These studies illustrate the complexity of bias in AI systems and the need for real-time intervention strategies.
This literature review primarily focuses on the detection of bias through natural language processing (NLP) techniques and the role of large language models (LLMs) in identifying cognitive biases in text. However, it is important to acknowledge that other approaches to bias detection and mitigation exist. Algorithmic auditing, as discussed by Raji et al. (2020), offers a framework for systematically evaluating biases embedded in AI models, particularly in high-stakes applications such as hiring and criminal justice. Fairness-aware machine learning models, such as those explored by Dwork et al. (2012), incorporate fairness constraints to mitigate biases in decision-making processes. Additionally, debiasing techniques in computer vision and facial recognition systems, studied by Buolamwini and Gebru (2018), have demonstrated the prevalence of racial and gender biases in automated image classification systems. These alternative approaches highlight the multifaceted nature of bias detection and mitigation, underscoring the need for interdisciplinary solutions to address cognitive biases across AI applications.
Incorporating foundational psychological research, the seminal work of Tversky et al. (1982) on heuristics and biases provides a strong theoretical underpinning for understanding how cognitive biases influence decision-making. Their studies on anchoring, availability, and representativeness heuristics laid the groundwork for contemporary discussions on bias detection in AI. Gigerenzer and Gaissmaier (2011) further examined the interplay between heuristics and rational decision-making, which has direct implications for how AI models detect and interpret cognitive biases in usergenerated text. By integrating these psychological insights, AI systems can be better designed to recognize and correct for cognitive distortions that arise in human communication.
From an ethical AI perspective, scholars such as Timnit Gebru and Joy Buolamwini (2018) have highlighted the risks of bias amplification in AI models, particularly in facial recognition and natural language processing applications. Their research underscores the need for algorithmic transparency and accountability, which aligns with this study's emphasis on real-time bias detection. Binns (2018) explored fairness in machine learning and how different philosophical approaches to fairness-such as distributive and procedural justice, impact bias mitigation strategies. These ethical considerations are crucial when developing AI systems designed to identify and address cognitive biases in human-generated content.
In industry-specific applications, biases in AI decision-making have been widely studied across various domains. In healthcare, Feehan et al. (2021) investigated how cognitive biases influence clinical decision-making, leading to diagnostic errors and disparities in patient treatment. AI tools capable of detecting these biases in medical records and decision-support systems can enhance objectivity and patient outcomes. In finance, Barocas et al. (2023) examined the role of algorithmic bias in credit scoring and loan approvals, where historical biases in financial data disproportionately affect marginalized groups. Similarly, in the legal field, Almasoud and Idowu (2024) explored the impact of bias in predictive policing and risk assessment algorithms, demonstrating how biased training data can perpetuate systemic inequalities. By applying bias detection techniques across these industries, AI can contribute to fairer decision-making processes and reduced disparities in automated decision systems.
Despite the progress in developing tools to mitigate biases, much of the research has focused on bias detection in AI-generated outputs, with limited exploration of the potential for AI to detect biases in human-generated content. Emerging literature highlights the promising role of AI in identifying cognitive biases in human communication. Atreides and Kelley (2024) demonstrated that LLMs could reliably detect 188 cognitive biases in text, such as confirmation bias and circular reasoning, outpacing human identification capabilities. Similarly, Parsapoor (2023) showed that AI could detect cognitive impairments like early Alzheimer's disease through speech and language analysis, illustrating AI's potential to identify subtle patterns in human communication that may indicate cognitive biases. Lee et al. (2024) further emphasized AI's ability to detect biases by incorporating human gaze patterns into explainable AI systems, improving both decision-making speed and accuracy.
While these studies have proven the feasibility of AI tools for bias detection, gaps remain in addressing the full spectrum of real-world applications. Few studies have systematically compared AI's performance across diverse textual contexts. Atreides and Kelley (2024) identified limitations in detecting biases related to memory and ambiguity, while Zhu et al. (2024) noted the need for improved evaluation of AI-generated outputs, as human cognitive biases influence how AI performance is perceived. This article addresses these gaps by proposing a systematic framework for training LLMs to recognize cognitive biases accurately, integrating prompt engineering and real-world applications to improve objectivity, transparency, and decision-making. By bridging theoretical research with practical use cases, the study offers a scalable solution for detecting cognitive biases in human communication.
The development of LLMs capable of detecting cognitive biases in textual content has profound implications across various fields. In healthcare, cognitive biases such as confirmation bias and anchoring bias can influence clinical judgments and treatment decisions (Lee et al., 2024). In the legal field, biases like framing effects and stereotyping impact judgments, legal drafting, and policymaking (Alelyani, 2021). Finally, biases in corporate decision-making, such as overconfidence and status quo bias, can result in flawed risk assessments and missed opportunities (Atreides & Kelley, 2024). The ability of LLMs to detect and mitigate these biases presents an opportunity to enhance decisionmaking, fairness, and transparency across diverse professional domains.
Previous studies have made significant strides in identifying and mitigating cognitive biases within AI systems and machine learning algorithms, but the majority of research has focused on detecting biases within AI-generated outputs or datasets. Fewer studies have explored the potential for AI, specifically large language models (LLMs), to detect cognitive biases in human-generated content. Existing work has largely been limited to identifying biases in controlled environments or through post-hoc analysis, without offering robust methodologies for improving detection accuracy through optimized AI interactions. This research contributes to the field by introducing a systematic framework for cognitive bias detection in user-generated text using advanced prompt engineering techniques. Unlike previous efforts that rely on standard NLP methodologies, this study emphasizes the rigor of prompt engineering as a fundamental approach to improving bias detection accuracy. By designing structured and contextually adaptive prompts, the research ensures that LLMs effectively identify a wide range of cognitive biases, such as confirmation bias, straw man fallacy, and circular reasoning, while minimizing hallucination and misclassification errors. Furthermore, this work goes beyond prior studies by demonstrating the scalability and adaptability of prompt engineering for cognitive bias detection across various domains. The framework is tested in practical contexts such as news reporting, social media, healthcare, legal professions, and corporate decision-making, illustrating how well-crafted prompts enhance bias recognition in diverse linguistic settings. In addressing these gaps, the research not only advances the methodological robustness of AI-driven bias detection but also lays the groundwork for future studies that refine LLM interactions for ethical AI applications. This contribution underscores the importance of structured AI prompting as a key factor in improving bias detection transparency and fairness in decision-making processes.
## Methodology
## Operationalization of concepts
The study examined the ability of a Large Language Model (LLM) and prompt engineering to detect common cognitive biases. For this study, we focused on six common cognitive biases and fallacies: Straw Man, False Causality, Circular Reasoning, Mirror Imaging, Confirmation Bias, and Hidden Assumptions. These biases were selected based on their prevalence in decision-making and discourse. Each of these biases follows a specific pattern of reasoning, which allows us to construct structured prompts that mirror their logical sequence, aiding in their detection Straw man refers to misrepresenting or oversimplifying an opponent's argument to make it easier to refute. This can lead to a misunderstanding of the actual position and a failure to address the real issues. False causality is a logical fallacy where a causal relationship is incorrectly assumed or established between two events or variables. This fallacy occurs when it is assumed that because one event follows another, the first event must be the cause of the second, without sufficient evidence to support this causal connection. Circular Reasoning refers to using a conclusion to support the assumption that was necessary to reach that conclusion. This creates a loop in reasoning where the evidence and conclusion are the same. Mirror imaging implies Assuming that other actors (states, organizations, individuals) will act or react in the same way as one's own country or group, based on one's own values, priorities, and decision-making processes. This can lead to misunderstandings of intentions and capabilities. Confirmation bias leads to selectively searching for, interpreting, and recalling information that confirms pre-existing beliefs, while ignoring or dismissing contradictory evidence. Finally, a hidden assumption, also known as an implicit assumption, is an unstated premise or belief that underlies an argument, decision, or belief system. It is not explicitly expressed or acknowledged but is necessary for the argument or decision to be coherent or valid (Watson et al., 2024; Pohl, 2004).
## Data Collection & Preprocessing
For the purpose of this study, open-source data was collected from diverse sources, including X, Reddit, Medium, ResearchGate, the University of Michigan Library, the Library of Congress, The Economic History of India-Oxford Academic, Marines.com, Whitehouse.gov, the Israel US Embassy, Europol, and DHS. Sample texts derived from these sources provided a wide range of text types for evaluating the model's performance. The use of open-source data from various sources ensured a broad representation of text types and potential biases. In addition, the team selected varying lengths of text to ensure our model was able to handle this kind of variation.
To ensure a diverse and balanced dataset, we categorized data sources into three levels of rigor: low, medium, and high. Low-rigor sources, such as politicians' speeches, social media posts, and personal blogs, undergo little to no review and often reflect personal opinions. Medium-rigor sources, including newspaper articles and podcast transcripts, may have some editorial oversight but still contain biases. High-rigor sources, such as think tank reports, academic papers, and policy briefs, are subjected to thorough peer or institutional reviews, ensuring greater credibility and trustworthiness. Additionally, human annotators deliberately sought out biases from opposing perspectives on controversial issues, such as gun control, abortion, and climate change. By incorporating biases from both sides of debates, we ensured a balanced representation of different viewpoints, making the dataset more comprehensive.
Next, we processed the collected data by converting each text file into a LangChain Document object. To facilitate efficient processing by the LLM, we employed the Recursive Character Text Splitter technique to segment each document into smaller, more manageable chunks. This chunking process ensured that the input sequences were compatible with the LLM's context window while preserving the semantic integrity of the text. To evaluate the effectiveness of our approach, we designed a robust annotation pipeline. First, the processed text was incorporated into a carefully crafted prompt template and input to the LLM. The resulting LLM-generated output, along with the original text sample, was then passed to our human annotation system, powered by Argilla. Argilla, a user-friendly platform for data annotation and analysis in NLP, facilitated the efficient review and labeling of our data. This human-in-the-loop approach allowed annotators of varying expertise to readily interact with the text and LLM outputs, providing valuable feedback for evaluating our approach and ensuring the accurate identification of cognitive biases.
To enhance objectivity in content evaluation and annotation, this study employed a rigorous evaluation process. Human annotators were trained to identify the selected cognitive biases using the logical pattern followed by each cognitive bias and fallacy, providing a necessary framework to assess the LLM's performance. Their task involved reviewing the LLM-generated responses and evaluating their accuracy in detecting or dismissing the presence of bias. This human evaluation served as a crucial validation step, ensuring the reliability and effectiveness of the LLM responses. The human annotators' expertise in identifying nuanced instances of cognitive biases provided valuable feedback for refining the system and enhancing its overall performance. Following the human evaluation and annotation of the dataset, we proceeded to the analysis phase. This phase aimed to rigorously assess the performance of our model in accurately detecting the presence or absence of various cognitive biases within the text. Specifically, we evaluated the model's ability to identify each predefined cognitive bias component, such as confirmation bias, straw man fallacy, and circular reasoning. This analysis allowed us to determine the accuracy of our model in recognizing these biases and provided crucial insights into its overall effectiveness in detecting and flagging potentially biased language.
## Prompt Engineering Methodology
The core contribution of this research is the rigor of prompt engineering for cognitive bias detection. Unlike traditional NLP-based classification models, our approach employs structured and optimized prompts designed to mimic cognitive bias reasoning patterns. Cognitive biases often follow systematic sequences of thought, making them detectable through engineered prompts that guide the LLM in identifying logical inconsistencies. Our methodology leveraged prompt engineering to effectively steer the LLM towards accurate bias detection. Contextual cues were embedded to help the LLM recognize subtle forms of bias while mitigating hallucinations. By structuring prompts to align with cognitive bias patterns, we enhanced detection accuracy beyond conventional classification models. A structured prompt template was constructed, consisting of two key components: 1) A set of explicit directives outlining the specific type of bias to be identified and 2) the text input to be analyzed. This structured approach allowed us to systematically control the LLM output space, effectively constraining the LLM's generation process, shifting the probability distribution towards the desired outcome and increasing the likelihood of accurate and relevant bias detection.
## Experimental Design
For this study, we selected the Mixtral 7x8B instruct model as our foundation and leveraged the Langchain framework to design and implement our prompt templates. This choice was motivated by several key strengths of Mixtral 7x8b. Firstly, its instruction variant is specifically fine-tuned to follow instructions and perform tasks as defined in the prompt, making it ideal for complex prompt engineering. Secondly, despite its relatively smaller size compared to some larger LLMs, Mixtral 7x8b demonstrates impressive performance across various benchmarks, including those related to reasoning and understanding natural language. This balance of size and performance makes it a suitable choice for real-time applications where computational efficiency is crucial. Finally, its open-weight nature allows for greater transparency and customization, enabling us to further refine the model for our specific bias detection task. Utilizing Langchain for prompt construction streamlined the process of managing and optimizing complex prompt structures, facilitating experimentation with different prompting strategies.
To evaluate the effectiveness of our prompt engineering approach, we benchmarked our model against two baseline models. Our first baseline utilized the Mixtral 7x8B instruct model, but forewent our specialized prompt template. Instead, we used a simple prompt instructing the model to detect the specific cognitive bias under consideration without the set of explicit directives given in our prompt engineering strategy. This allowed us to isolate the impact of our prompt engineering. Our second baseline utilized the Llama 3 70B instruct model, also with a basic prompt. We included Llama 3 70B, a significantly larger language model, to assess the influence of model scale on bias detection performance. Comparing our approach with both a mid-sized model like Mixtral and a large-scale model like Llama 3 provides valuable insights into the interplay between model size, prompt engineering, and bias detection accuracy.
## Evaluation Metrics & Human Annotation
The human annotation phase was crucial for evaluating the performance of our cognitive bias detection system and was divided into two distinct phases.
Phase 1: This phase focused solely on assessing the accuracy of the LLM's responses when employing our novel prompt engineering technique. We meticulously examined whether the LLM, guided by our prompts, could effectively identify instances of cognitive biases in the text data. This initial evaluation allowed us to ensure the LLM was properly equipped to analyze the text for biases.
Phase 2: In this phase, we broadened our evaluation to compare the accuracy of our model against two established baseline models. Human annotators independently reviewed the responses from all three models and compared them against their own expert judgment. This comparative analysis provided valuable insights into the relative strengths and weaknesses of each approach, further validating the effectiveness of our proposed system. To ensure a comprehensive evaluation, we employed a multi-faceted approach to determining the accuracy of the LLM responses generated using our prompt engineering technique. Accuracy was established under the following conditions:
Agreement on Bias Detection : Both the LLM and the human annotator identified the presence of the same cognitive bias in the text.
Agreement on No Bias : Both the LLM and the human annotator agreed that no cognitive bias was present in the text.
Agreement on Ambiguity : Both the LLM and the human annotator concluded that it was unclear whether a cognitive bias existed in the text.
Any deviation from these conditions, where the human annotator disagreed with the LLM's assessment, resulted in the LLM response being classified as incorrect. This rigorous evaluation process ensured a robust and reliable assessment of our system's performance in detecting cognitive biases. During the first phase of human annotation, labelers assessed multiple factors, including whether the sample text exhibited any bias, the accuracy of the model's responses in detecting the presence or absence of bias, and, in cases of incorrect model outputs, they supplied a correct response based on the logical framework established by the university, as illustrated in Figure 1: Phase 1 Human Annotation System . This phase was essential in aligning the model with the intended system objectives, ensuring a strong foundation for precise and unbiased results.
Figure 1: Phase 1 Human Annotation System
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Screenshot: LLM Response Evaluation Interface
### Overview
The image depicts a web-based interface for evaluating LLM-generated responses. It includes a sample text, an LLM-generated response, annotation guidelines, and UI controls for saving or submitting evaluations.
### Components/Axes
#### Left Panel (Sample Text & LLM Response)
- **Sample Text**:
- "One month of Steve's political imprisonment down. Three to go. Those who love this country the most are treated the worst by the regime."
- **Source File**: `all/All_2_20240821.csv`
- **LLM Generated Response**:
- Analyzes the sample text for false causality, concluding that the text assumes political imprisonment is directly caused by love for the country without sufficient evidence.
#### Right Panel (Annotation Guidelines)
- **Question 1**: "Is bias present in the sample text?"
- Options: `Yes` (1), `No` (2), `Unclear` (3)
- **Question 2**: "Is the LLM Generated Response accurate for the given prompt?"
- Options: `Yes` (1), `No` (2)
- **Evaluator Response**: A text box for free-form input (empty in the screenshot).
#### UI Elements
- **Top Bar**:
- Tabs: `Pending` (highlighted), `Filters`, `Sort`
- Pagination: `1 of 369` with navigation arrows
- **Bottom Bar**:
- Actions: `Discard`, `Ctrl+S` (Save as draft), `Submit`
- **Icons**:
- Moon icon (dark mode toggle), refresh icon (right panel)
### Content Details
- **Sample Text**: A politically charged statement about imprisonment and patriotism.
- **LLM Response**: A critical analysis identifying potential logical fallacies in the sample text.
- **Annotation Guidelines**: Structured as binary/multi-choice questions to assess bias and response accuracy.
### Key Observations
1. The interface is designed for human evaluators to audit LLM outputs.
2. The LLM’s response explicitly flags "False Causality" in the sample text.
3. The UI emphasizes efficiency with keyboard shortcuts (`Ctrl+S`) and bulk actions (`Discard`, `Submit`).
### Interpretation
This interface likely belongs to a quality assurance pipeline for LLM outputs. Evaluators assess both the original text’s bias and the model’s analytical accuracy. The "Pending" status suggests this is part of a larger dataset (369 items total), indicating scalability for large-scale human-AI collaboration. The focus on false causality highlights concerns about the model’s ability to detect logical fallacies in politically sensitive content.
## No charts, diagrams, or numerical data present.
</details>
During the second phase, the human laborers evaluated our model's responses against two baseline models as shown in Figure 2: Phase 2 Human Annotation System . This comparison enabled us to assess our model not just in terms of intent alignment, but also in relation to the responses generated by other models that did not incorporate our design approach. This comprehensive assessment provided valuable insights into the strengths of our model, highlighting its unique capabilities and the impact of our design choices on its performance.
Figure 2: Phase 2 Human Annotation System
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Screenshot: Text Annotation Interface for Disaster Response Communication
### Overview
The image shows a text annotation interface used to evaluate the accuracy, appropriateness, and potential bias in a government statement about Hurricane Helene's aftermath. The interface includes a sample text, multiple-choice annotation questions, and an evaluator response section.
### Components/Axes
1. **Left Panel (Sample Text)**:
- Header: "Sample Text"
- Body: 3-paragraph statement about Hurricane Helene's impact
- Footer: Source file identifier "all/All_phase_2_20241002.csv"
2. **Right Panel (Annotation Interface)**:
- Header: "Annotation guidelines"
- Three evaluation questions with radio buttons:
- "Is bias present in the Sample Text?"
- "Is Response 1 accurate or appropriate?"
- "Is Response 2 accurate or appropriate?"
- "Is Response 3 accurate or appropriate?"
- Evaluator Response section with text box
- Footer controls: "Discard", "Save as draft", "Submit"
### Detailed Analysis
**Sample Text Content**:
- Expresses condolences for Hurricane Helene victims
- Mentions Doug and the speaker's personal loss
- States commitment to federal support for affected communities
- Lists states with emergency declarations: Alabama, Florida, Georgia, North Carolina, South Carolina, Tennessee
- Mentions FEMA Administrator Deanne Criswell briefings
**Annotation Questions**:
1. Bias presence:
- Options: Yes (selected), No, Unclear
2. Response 1 accuracy:
- Options: Yes (selected), No
3. Response 2 accuracy:
- Options: Yes, No (selected)
4. Response 3 accuracy:
- Options: Yes, No (selected)
**Evaluator Response**:
- Empty text box for qualitative feedback
### Key Observations
1. The evaluator marked bias as present in the text
2. Only the first response was rated as accurate/appropriate
3. All subsequent responses were marked as inaccurate/inappropriate
4. No qualitative feedback provided in the evaluator response section
### Interpretation
The annotation pattern suggests the evaluator perceived bias in the original text but found the first response (likely addressing the personal loss mention) appropriate. The subsequent responses (possibly about federal actions) were deemed inappropriate, potentially indicating:
1. Disagreement with the administration's stated commitments
2. Perceived inconsistency between the text's tone and factual claims
3. Possible concerns about resource allocation or political messaging
The lack of qualitative feedback in the evaluator response section limits understanding of the specific concerns behind these ratings. The interface design appears to force binary judgments on complex communication elements, which may oversimplify nuanced evaluations of government disaster response messaging.
</details>
## Results
This study was conducted in two phases. Phase 1 focused on testing and refining our prompt-engineered model for detecting cognitive biases, while Phase 2 compared our optimized model against two baseline models: Mixtral 7x8B (without our prompt strategy) and Llama 3 70B (without our prompt strategy). The results of both phases demonstrate the effectiveness of structured prompt engineering in improving bias detection accuracy.
## Phase 1
In the first phase, a dataset of 4,321 texts containing various cognitive biases was selected and analyzed by our model. These texts were curated to ensure equal representation across all six cognitive biases. The results indicate that our model was able to determine whether bias was present with an accuracy of at least 96% ( Table 1 ). The model achieved perfect accuracy in detecting circular reasoning and performed exceptionally well in identifying confirmation bias, false causality, hidden assumptions, mirror imaging, and straw man fallacy. Circular reasoning had the highest accuracy, suggesting that the model effectively recognizes the logical loop inherent in this bias. False causality, however, had a slightly lower accuracy, which could be attributed to the challenge of distinguishing causation from correlation in textual data. Overall, the results from Phase 1 demonstrate that our model can reliably detect cognitive biases in usergenerated content with a high degree of accuracy.
Table 1: Accuracy of Our model with Phase 1 dataset
| Bias | Correct | Incorrect | Accuracy |
|--------------------|-----------|-------------|------------|
| Circular Reasoning | 442 | 0 | 100 |
| Confirmation Bias | 721 | 12 | 98.36 |
| False Causality | 610 | 25 | 96.06 |
| Hidden Assumption | 725 | 1 | 99.86 |
| Mirror Imaging | 1144 | 7 | 99.39 |
| Straw Man Fallacy | 619 | 15 | 97.63 |
## Phase 2
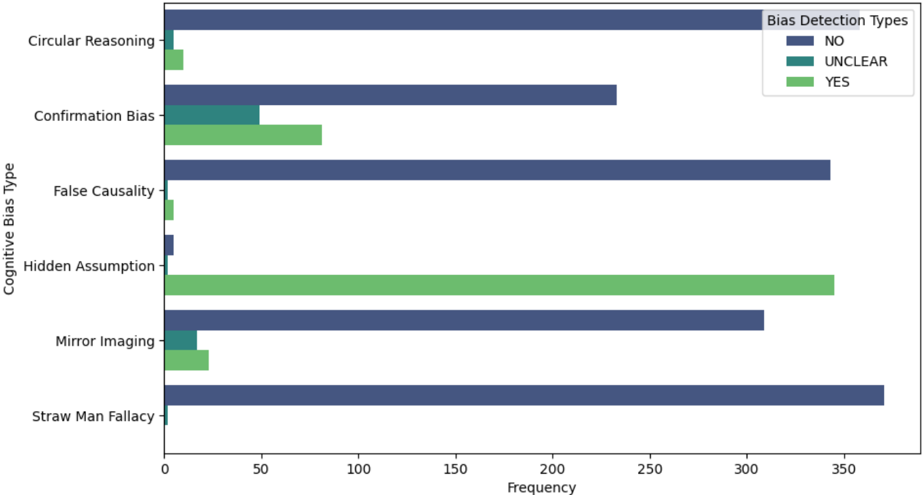
The second phase sought to compare our optimized model against two baseline models to assess the impact of structured prompt engineering on bias detection. An additional dataset of 2,160 texts was evaluated using our model that incorporated our prompt strategy, the Mixtral 7x8B baseline model, and the Llama 3 70B baseline model. Each model was tested on 305 distinct sample texts per cognitive bias to ensure a fair comparison. Our model outperformed both baseline models in all categories, achieving nearly perfect accuracy across all six biases. The results revealed that structured prompt engineering plays a crucial role in enhancing model performance. While our model consistently identified biases with high accuracy, the baseline models struggled, particularly with more nuanced biases such as false causality and hidden assumptions. Figure 3 presents the distribution of the Bias Detection Types vs the Cognitive Bias Types. It is important to note that while the majority of the collected samples are a 'no' as the Bias Detection Type for each Cognitive Bias Type, if the model evaluated the response as 'no', then that is still considered an accurate response.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Bar Chart: Cognitive Bias Detection Frequency by Type
### Overview
The chart visualizes the frequency of cognitive bias detection across six bias types (Circular Reasoning, Confirmation Bias, False Causality, Hidden Assumption, Mirror Imaging, Straw Man Fallacy) using three detection categories: NO (dark blue), UNCLEAR (teal), and YES (green). The x-axis represents frequency (0–350), and the y-axis lists bias types.
### Components/Axes
- **X-axis**: Frequency (0–350, increments of 50)
- **Y-axis**: Cognitive Bias Type (Circular Reasoning to Straw Man Fallacy)
- **Legend**:
- NO (dark blue)
- UNCLEAR (teal)
- YES (green)
- **Legend Position**: Top-right corner
### Detailed Analysis
1. **Circular Reasoning**
- NO (dark blue): ~360
- UNCLEAR (teal): ~5
- YES (green): ~10
2. **Confirmation Bias**
- NO (dark blue): ~230
- UNCLEAR (teal): ~50
- YES (green): ~80
3. **False Causality**
- NO (dark blue): ~340
- UNCLEAR (teal): ~2
- YES (green): ~5
4. **Hidden Assumption**
- NO (dark blue): ~5
- UNCLEAR (teal): ~2
- YES (green): ~340
5. **Mirror Imaging**
- NO (dark blue): ~310
- UNCLEAR (teal): ~20
- YES (green): ~25
6. **Straw Man Fallacy**
- NO (dark blue): ~370
- UNCLEAR (teal): ~2
- YES (green): ~3
### Key Observations
- **Dominance of NO**: Most biases (Circular Reasoning, False Causality, Mirror Imaging, Straw Man Fallacy) show the highest frequency in the NO category, suggesting they are often undetected.
- **Hidden Assumption Outlier**: The YES category dominates for Hidden Assumption (~340), indicating it is frequently identified correctly.
- **Confirmation Bias Ambiguity**: Confirmation Bias has a notable UNCLEAR frequency (~50), higher than YES (~80) and NO (~230), suggesting detection uncertainty.
- **Straw Man Fallacy Extremes**: Straw Man Fallacy has the highest NO (~370) and lowest YES (~3), implying it is rarely detected accurately.
### Interpretation
The data suggests cognitive biases are generally under-detected (NO), with Hidden Assumption being a notable exception where detection is robust (YES). Confirmation Bias stands out for its UNCLEAR frequency, highlighting ambiguity in its identification. Straw Man Fallacy’s extreme NO frequency (~370) may indicate systemic challenges in recognizing this bias, while its minimal YES (~3) suggests rare accurate detections. The UNCLEAR category’s sparsity (except for Confirmation Bias) implies most biases are either clearly present or absent, with limited intermediate uncertainty. This could reflect detection thresholds or training data biases favoring binary classifications.
</details>
Frequency
Figure 3: Distribution of Bias Detection Types by Cognitive Bias
For Circular reasoning, our model correctly identified if a sample text had bias, did not have bias, or was deemed unclear for 373/373 samples, as shown in Table 2 . For Confirmation bias, 360/363 samples were correctly identified with our model. For False causality, 350/350 samples were correctly identified. For Hidden assumption, 352/352 samples were correctly identified. For Mirror imaging, 349/349 samples were correctly identified. For Straw man fallacy, 373/373 samples were correctly identified.
| Bias | Correct | Incorrect | Accuracy |
|--------------------|-----------|-------------|------------|
| Circular Reasoning | 373 | 0 | 100 |
| Confirmation Bias | 360 | 3 | 99.17 |
| False Causality | 350 | 0 | 100 |
| Hidden Assumption | 353 | 0 | 100 |
| Mirror Imaging | 349 | 0 | 100 |
Table 2: Accuracy of Our model in Phase 2
| Straw Man Fallacy | 373 | 0 | 100.00 |
|---------------------|-------|-----|----------|
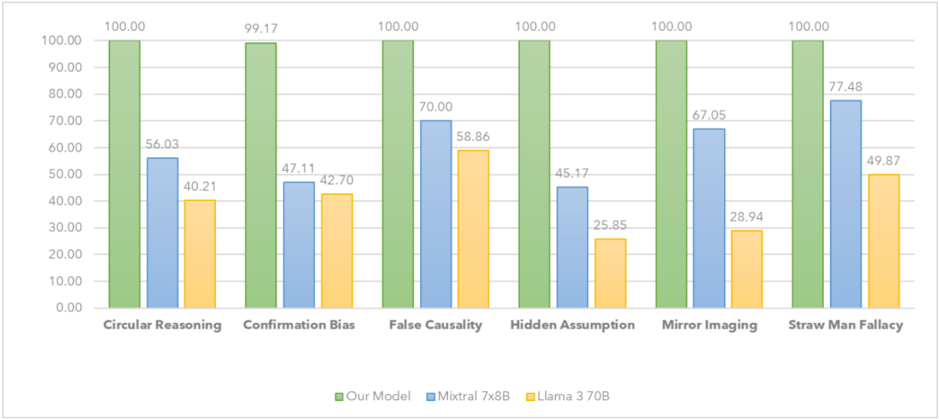
The comparative analysis highlights the significant performance gap between models with and without a set of well crafted directives in the structured prompt (see Figure 2 ). For example, in detecting circular reasoning, our model correctly identified bias in all 373 samples, whereas the Mixtral 7x8B baseline model identified only 209 samples correctly, and the Llama 3 70B baseline model correctly identified just 150 samples. A similar trend was observed across other biases, with the accuracy of the baseline models dropping sharply compared to our structured approach. The Llama 3 70B model, despite its larger size, underperformed in comparison to our optimized Mixtral 7x8B model. This suggests that model size alone does not compensate for the lack of structured prompting and that effective prompt engineering is a more significant determinant of bias detection performance than sheer model scale.
Figure 2: Our Model vs. Baseline Models
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Bar Chart: Cognitive Bias Performance Comparison
### Overview
The chart compares the performance of three AI models ("Our Model," "Mixtural 7x8B," and "Llama 3 70B") across six cognitive biases. Performance is measured as a percentage, with "Our Model" consistently achieving 100% across all categories except "Confirmation Bias" (99.17%). "Mixtural 7x8B" and "Llama 3 70B" show variable performance, with "Mixtural" generally outperforming "Llama" in most categories.
### Components/Axes
- **X-axis (Categories)**: Six cognitive biases:
1. Circular Reasoning
2. Confirmation Bias
3. False Causality
4. Hidden Assumption
5. Mirror Imaging
6. Straw Man Fallacy
- **Y-axis (Values)**: Percentage scale (0.00–100.00).
- **Legend**:
- Green: "Our Model"
- Blue: "Mixtural 7x8B"
- Orange: "Llama 3 70B"
- **Bar Colors**:
- Green bars (Our Model) are tallest in all categories.
- Blue bars (Mixtural) are intermediate.
- Orange bars (Llama) are shortest in most categories.
### Detailed Analysis
1. **Circular Reasoning**:
- Our Model: 100.00%
- Mixtural 7x8B: 56.03%
- Llama 3 70B: 40.21%
2. **Confirmation Bias**:
- Our Model: 99.17%
- Mixtural 7x8B: 47.11%
- Llama 3 70B: 42.70%
3. **False Causality**:
- Our Model: 100.00%
- Mixtural 7x8B: 70.00%
- Llama 3 70B: 58.86%
4. **Hidden Assumption**:
- Our Model: 100.00%
- Mixtural 7x8B: 45.17%
- Llama 3 70B: 25.85%
5. **Mirror Imaging**:
- Our Model: 100.00%
- Mixtural 7x8B: 67.05%
- Llama 3 70B: 28.94%
6. **Straw Man Fallacy**:
- Our Model: 100.00%
- Mixtural 7x8B: 77.48%
- Llama 3 70B: 49.87%
### Key Observations
- **Our Model Dominance**: Achieves 100% in 5/6 categories, with only a minor dip in "Confirmation Bias" (99.17%).
- **Mixtural vs. Llama**:
- Mixtural outperforms Llama in all categories except "False Causality" (70.00% vs. 58.86%).
- Llama’s lowest performance is in "Hidden Assumption" (25.85%).
- **Straw Man Fallacy**: Mixtural achieves the highest non-100% score (77.48%), while Llama scores 49.87%.
### Interpretation
The data suggests "Our Model" is optimized to avoid cognitive biases, performing flawlessly in most cases. "Mixtural 7x8B" demonstrates moderate capability, with strengths in "Straw Man Fallacy" and "False Causality." "Llama 3 70B" struggles significantly, particularly with "Hidden Assumption" (25.85%) and "Mirror Imaging" (28.94%). The stark contrast between "Our Model" and the other two models highlights potential architectural or training differences. The consistent 100% scores for "Our Model" may indicate specialized bias mitigation strategies, while Llama’s lower scores suggest limitations in handling abstract reasoning tasks.
</details>
## Analysis and Discussion
The results of this study confirm that well crafted directives within the structured prompt engineering strategy substantially improves the accuracy of LLM-based cognitive bias detection. By guiding the model through structured reasoning patterns, our approach enabled more precise differentiation between biased and neutral statements. One of the key advantages of our methodology was its ability to reduce false positives by refining the detection process through human annotators and ensuring that biases were identified with contextual accuracy. The comparison with baseline models further reinforces the effectiveness of structured prompting, demonstrating that even a mid-sized model with optimized prompts can outperform a much larger model with basic prompting techniques.
Another key finding is that different biases vary in their ease of detection. Circular reasoning and hidden assumptions were consistently identified with high accuracy, likely because their logical structures are more explicit and easily recognized. In contrast, biases such as false causality presented a greater challenge, suggesting that distinguishing causation from correlation in text remains an area for future research. The strong performance of our model indicates that structured prompt engineering not only enhances bias detection but also contributes to improving transparency in AI-driven content evaluation. The ability to systematically surface and explain biases within usergenerated text has profound implications for media analysis, policy research, and automated decision-support systems.
These findings align with prior research discussed in the literature review, particularly the work of Atreides and Kelley (2024), which demonstrated that automated systems can detect a broad range of cognitive biases. Similarly, Xie et al. (2024) emphasized the potential of multi-agent systems to detect subtle biases that might evade traditional NLP methods. However, unlike previous studies that focused primarily on detecting biases within AI-generated outputs, our approach is uniquely designed to analyze and detect biases within human-generated content, bridging a crucial gap in existing research. Furthermore, while prior research, such as that of Zhu et al. (2024), highlighted the cognitive biases that humans exhibit toward AI-generated content, our findings suggest that AI, when properly structured through engineered prompts, can effectively serve as a tool for enhancing objectivity in bias detection. Also, our results are particularly strong when compared to prior studies in the field, such as the work by Raza et al. (2024), who reported F1-scores of 88.4%, 90.6%, and 91.8% for their model in detecting Social Media Bias, Health-related Bias, and Job Hiring Bias, respectively. While Raza's model demonstrated solid performance, our approach with structured prompt engineering showed superior results in cognitive bias detection across all biases tested, surpassing the F1-scores achieved by Raza's Nbias model. This suggests that, while Raza's framework works well in certain applications, our model benefits from optimized prompting strategies that enhance both the precision and recall of bias detection.
Despite the strengths of our approach, there are several limitations to consider. First, while our model demonstrated high accuracy in detecting explicit biases, more nuanced and context-dependent biases may still pose challenges. Biases that rely heavily on domain-specific knowledge or require deep contextual understanding may require further prompt refinement or hybrid approaches that incorporate additional linguistic or factual verification mechanisms. Additionally, our evaluation focused primarily on English- language text, meaning that the generalizability of our findings to other languages and cultural contexts remains an open question. Future research should explore multilingual bias detection and assess whether structured prompting techniques can be effectively adapted to different linguistic structures.
Another limitation is the reliance on human annotation as a benchmark for evaluating bias detection performance. While human annotators were trained using a standardized framework, cognitive biases are inherently subjective, and interpretations of bias may vary among individuals. This introduces a level of subjectivity that, while mitigated through inter-annotator agreement measures, may still impact overall evaluations. Future studies could explore ways to refine human annotation methods, such as incorporating expert review panels or using adversarial testing to assess model robustness. Finally, while our model significantly outperformed baseline approaches, ongoing improvements in LLMs suggest that larger-scale models with enhanced reasoning capabilities could further refine bias detection. Future work should investigate whether fine-tuning specialized models for cognitive bias detection, rather than relying solely on prompt engineering, could yield additional improvements in accuracy and reliability.
## Conclusion
This study establishes that prompt engineering significantly enhances the accuracy of LLM-based cognitive bias detection. The results from both phases demonstrate that structured prompting leads to a substantial performance increase compared to baseline models that lack this optimization. The findings also indicate that model size alone is not the primary determinant of bias detection accuracy; rather, well-crafted prompting strategies play a more critical role. Despite the strengths of our approach, there are several limitations that warrant further exploration. The reliance on English-language data constrains the generalizability of the model across linguistic and cultural contexts, emphasizing the need for multilingual adaptations in future studies. Additionally, while our model effectively detected explicit biases, more complex biases requiring deeper contextual analysis may necessitate alternative approaches, such as fine-tuning specialized models for domain-specific bias detection. Moreover, the subjective nature of human annotation introduces an inherent challenge in validating bias detection accuracy, necessitating ongoing refinements in human-in-the-loop AI evaluation methods. Future research should focus on expanding the dataset to include more complex and domainspecific biases, refining prompts to further reduce false positives, and exploring real-world deployment scenarios. Additionally, investigating the applicability of structured prompting techniques in multilingual settings and domain-specific fields would further enhance the robustness and generalizability of AI-driven bias detection systems. The insights gained from this study can serve as a foundation for improving AI-driven content moderation, misinformation detection, and automated bias identification across multiple sectors.
## References
Alelyani, S. (2021). Detection and Evaluation of Machine Learning Bias. Applied Sciences , 11 (14), 6271. https://doi.org/10.3390/app11146271
Almasoud, A. S., & Idowu, J. A. (2024). Algorithmic fairness in predictive policing. AI and Ethics , 1-15.
Atreides, K., & Kelley, D. J. (2024). Cognitive biases in natural language: Automatically detecting, differentiating, and measuring bias in text. Cognitive Systems Research , 88 , 101304.
Barocas, S., Hardt, M., & Narayanan, A. (2023). Fairness and machine learning: Limitations and opportunities . MIT press.
Binns, R. (2018, January). Fairness in machine learning: Lessons from political philosophy. In Conference on fairness, accountability and transparency : PMLR, 149-159.
Buolamwini, J., & Gebru, T. (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. Conference on Fairness, Accountability, and Transparency, PMLR, 77-91
Dwork, C., Hardt, M., Pitassi, T., Reingold, O., & Zemel, R. (2012, January). Fairness through awareness. In Proceedings of the 3rd innovations in theoretical computer science conference . 214-226.
Feehan, M., Owen, L. A., McKinnon, I. M., & DeAngelis, M. M. (2021). Artificial Intelligence, Heuristic Biases, and the Optimization of Health Outcomes: Cautionary Optimism. Journal of Clinical Medicine , 10 (22), 5284. https://doi.org/10.3390/jcm10225284
Gigerenzer, G., & Gaissmaier, W. (2011). Heuristic decision making. Annual review of psychology , 62 (1), 451-482.
Kahneman, D. (2011). Thinking, fast and slow. Farrar, Straus and Giroux.
Lee, C., Kwon, H. Y., & Cha, K. J. (2024). Human Cognition for Mitigating the Paradox of AI Explainability: A Pilot Study on Human Gaze-based Text Highlighting. The International FLAIRS Conference Proceedings , 37 (1). https://doi.org/10.32473/flairs.37.1.135331
Liang, L., & Acuna, D. E. (2020). Artificial mental phenomena: Psychophysics as a framework to detect perception biases in AI models. In Proceedings of the 2020 conference on fairness, accountability, and transparency , 403-412.
Parsapoor, M. (2023). AI -based assessments of speech and language impairments in dementia. Alzheimer's & Dementia , 19 (10), 4675-4687.
Pohl, R. (Ed.). (2004). Cognitive illusions: A handbook on fallacies and biases in thinking, judgement and memory . Psychology press.
Raji, I. D., Smart, A., White, R. N., Mitchell, M., Gebru, T., Hutchinson, B., ... & Barnes, P. (2020, January). Closing the AI accountability gap: Defining an end-to-end framework for internal algorithmic auditing. In Proceedings of the 2020 conference on fairness, accountability, and transparency , 33-44.
Rastogi, C., Zhang, Y., Wei, D., Varshney, K. R., Dhurandhar, A., & Tomsett, R. (2022). Deciding fast and slow: The role of cognitive biases in ai-assisted decision-making. Proceedings of the ACM on Human-Computer Interaction , 6 , 1-22.
Raza, S., Garg, M., Reji, D. J., Bashir, S. R., & Ding, C. (2024). Nbias: A natural language processing framework for BIAS identification in text. Expert Systems with Applications , 237 , 121542.
Ruggiero, V. R. (2014). Beyond feelings: A guide to critical thinking (9th ed.). McGrawHill.
Tversky, A., Kahneman, D., & Slovic, P. (1982). Judgment under uncertainty: Heuristics and biases . Taylor & Francis, 3-20.
Watson, J. C., Arp, R., & King, S. (2024). Critical thinking: An introduction to reasoning well . Bloomsbury Publishing.
Xie, Z., Zhao, J., Wang, Y., Shi, J., Bai, Y., Wu, X., & He, L. (2024). MindScope: Exploring cognitive biases in large language models through Multi-Agent Systems. arXiv preprint arXiv:2410.04452 .
Zhu, T., Weissburg, I., Zhang, K., & Wang, W. Y. (2024). Human Bias in the Face of AI: The Role of Human Judgement in AI Generated Text Evaluation. arXiv preprint arXiv:2410.03723 .