# TPU-Gen: LLM-Driven Custom Tensor Processing Unit Generator
**Authors**:
- Ramtin Zand, Shaahin Angizi (New Jersey Institute of Technology, Newark, NJ, USA,
University of South Carolina, Columbia, SC, USA)
- E-mails: {dv336,shaahin.angizi}@njit.edu
## Abstract
The increasing complexity and scale of Deep Neural Networks (DNNs) necessitate specialized tensor accelerators, such as Tensor Processing Units (TPUs), to meet various computational and energy efficiency requirements. Nevertheless, designing optimal TPU remains challenging due to the high domain expertise level, considerable manual design time, and lack of high-quality, domain-specific datasets. This paper introduces TPU-Gen, the first Large Language Model (LLM) based framework designed to automate the exact and approximate TPU generation process, focusing on systolic array architectures. TPU-Gen is supported with a meticulously curated, comprehensive, and open-source dataset that covers a wide range of spatial array designs and approximate multiply-and-accumulate units, enabling design reuse, adaptation, and customization for different DNN workloads. The proposed framework leverages Retrieval-Augmented Generation (RAG) as an effective solution for a data-scare hardware domain in building LLMs, addressing the most intriguing issue, hallucinations. TPU-Gen transforms high-level architectural specifications into optimized low-level implementations through an effective hardware generation pipeline. Our extensive experimental evaluations demonstrate superior performance, power, and area efficiency, with an average reduction in area and power of 92% and 96% from the manual optimization reference values. These results set new standards for driving advancements in next-generation design automation tools powered by LLMs.
## I Introduction
The rising computational demands of Deep Neural Networks (DNNs) have driven the adoption of specialized tensor processing accelerators, such as Tensor Processing Units (TPUs). These accelerators, characterized by low global data transfer, high clock frequencies, and deeply pipelined Processing Elements (PEs), excel in accelerating training and inference tasks by optimizing matrix multiplication [1]. Despite their effectiveness, the complexity and expertise required for their design remain significant barriers. Static accelerator design tools, such as Gemmini [2] and DNNWeaver [3], address some of these challenges by providing templates for systolic arrays, data flows, and software ecosystems [4, 5]. However, these tools still face limitations, including complex programming interfaces, high memory usage, and inefficiencies in handling diverse computational patterns [6, 7]. These constraints underscore the need for innovative solutions to streamline hardware design processes.
Large Language Models (LLMs) have emerged as a promising solution, offering the ability to generate hardware descriptions from high-level design intents. LLMs can potentially reduce the expertise and time required for DNN hardware development by encapsulating vast domain-specific knowledge. However, realizing this potential requires overcoming three critical challenges. First, existing datasets are often limited in size and detail, hindering the generation of reliable designs [8, 9]. Second, while fine-tuning is essential to minimize the human intervention, fine-tuning LLMs often results in hallucinations producing non-sensical or factually incorrect responses, compromising their applicability [10, 11]. Finally, an effective pipeline is needed to mitigate these hallucinations and ensure the generation of consistent, contextually accurate code [11]. Therefore, the core questions we seek to answer are the following– Can there be an effective way to rely on LLM to act as a critical mind and adapt implementations like Retrieval-Augmented Generation (RAG) to minimize hallucinations? Can we leverage domain-specific LLMs with RAG through an effective pipeline to automate the design process of TPU to meet various computational and energy efficiency requirements?
TABLE I: Comparison of the Selected LLM-based HDL/HLS generators.
| Property | Ours | [10] | [9] | [8] | [12] | [13] | [14] | [15] | [16] | [17] | [18] |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Function | TPU Gen. | Verilog Gen. | AI Accel. Gen. | Verilog Gen. | Verilog Gen. | Verilog Gen. | Hardware Verf. | Hardware Verf. | Verilog Gen. | $\dagger$ | AI Accel. Gen. |
| Chatbot ∗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ |
| Dataset | ✓ | ✓(Verilog) | ✗ | NA | NA | NA | ✗ | ✗ | ✓ | ✓ | ✓ |
| Output format | Verilog | Verilog | HLS | Verilog | Verilog | Verilog | Verilog | HDL | Verilog | Verilog | Chisel |
| Auto. Verif. | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ |
| Human in Loop | Low | Medium | Medium | Medium | High | Low | Low | Low | Low | Low | Low |
| Fine tuning | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ |
| RAG | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
∗ A user interface featuring Prompt template generation for the input of LLM. † Not applicable.
To answer this question, we develop the first-of-its-kind TPU-Gen as an automated exact and approximate TPU design generation framework with a comprehensive dataset specifically tailored for ever-growing DNN topologies. Our contributions in this paper are threefold: (1) Due to the limited availability of annotated data necessary for efficient fine-tuning of an open-source LLM, we introduce a meticulously curated dataset that encompasses various levels of detail and corresponding hardware descriptions, designed to enhance LLMs’ learning and generative capabilities in the context of TPU design; (2) We develop TPU-Gen as a potential solution to reduce hallucinations leveraging RAG and fine-tuning, to align best for the LLMs to streamline the approximate TPU design generation process considering budgetary constraints (e.g., power, latency, area), ensuring a seamless transition from high-level specifications to low-level implementations; and (3) We design extensive experiments to evaluate our approach’s performance and reliability, demonstrating its superiority over existing methods. We anticipate that TPU-Gen will provide a framework that will influence the future trajectory of DNN hardware acceleration research for generations to come The dataset and fine-tuned models are open-sourced. The link is omitted to maintain anonymity since the GitHub anonymous link should be under 2GB which is exceeded in this study..
## II background
LLM for Hardware Design. LLMs show promise in generating Hardware Description Language (HDL) and High-Level Synthesis (HLS) code. Table I compares notable methods in this field. VeriGen [10] and ChatEDA [19] refine hardware design workflows, automating the RTL to GDSII process with fine-tuned LLMs. ChipGPT [8] and Autochip [13] integrate LLMs to generate and optimize hardware designs, with Autochip producing precise Verilog code through simulation feedback. Chip-Chat [12] demonstrates interactive LLMs like ChatGPT-4 in accelerating design space exploration. MEV-LLM [20] proposes multi-expert LLM architecture for Verilog code generation. RTLLM [21] and GPT4AIGChip [9] enhance design efficiency, showcasing LLMs’ ability to manage complex design tasks and broaden access to AI accelerator design. To the best of our knowledge, GPT4AIGChip [9] and SA-DS [18] are a few initial works focus on an extensive framework specifically aimed at the generation of domain-specific AI accelerator designs where SA-DS focus on creating a dataset in HLS and employ fine-tuning free methods such as single-shot and multi-shot inputs to LLM. Other works for hardware also include creation of SPICE circuits [22, 23]. However, the absence of prompt optimization, tailored datasets, model fine-tuning, and LLM hallucination pose a barrier to fully harnessing the potential of LLMs in such frameworks [19, 18]. This limitation confines their application to standard LLMs without fine-tuning or In-Context Learning (ICL) [19], which are among the most promising methods for optimizing LLMs [24].
Retrieval-Augmented Generation. RAG is a promising paradigm that combines deep learning with traditional retrieval techniques to help mitigate hallucinations in LLMs [25]. RAG leverages external knowledge bases, such as databases, to retrieve relevant information, facilitating the generation of more accurate and reliable responses [26, 25]. The primary challenge in deploying LLMs for hardware generation or any application lies in their tendency to deviate from the data and hallucinate, making it challenging to capture the essence of circuits and architectural components. LLMs tend to prioritize creativity and finding innovative solutions, which often results in straying from the data [11]. As previous works show, the RAG model can be a cost-efficient solution by retrieving and augmenting data, avoiding heavy computational demands [27].
Approximate MAC Units. Approximate computing has been widely explored as a means to trade reduced accuracy for gains in design metrics, including area, power consumption, and performance [28, 29, 30, 31, 32, 33]. As the computation core in various PEs in TPUs, several approximate Multiply-and-Accumulate (MAC) units have been proposed as alternatives to precise multipliers and adders and extensively analyzed in accelerating deep learning [34, 35]. These MAC units are composed of two arithmetic stages—multiplication and accumulation with previous products—each of which can be independently approximated. Most approximate multipliers, such as logarithmic multipliers, are composed of two key components: low-precision arithmetic logic and a pre-processing unit that acts as steering logic to prepare the operands for low-precision computation [36]. These multipliers typically balance accuracy and power efficiency. For example, the logarithmic multiplier introduced in [29] emphasizes accuracy, while the multipliers in [37] are designed to reduce power and latency. On the other hand, most approximate adders, such as lower part OR adder (LOA) [38], exploit the fact that extended carry propagation is infrequent, allowing adders to be divided into independent sub-adders shortening the critical path. To preserve computational accuracy, the approximation is applied to the least significant bits of the operands, while the most significant bits remain accurate.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Block Diagram: Neural Network Processing Pipeline
### Overview
The diagram illustrates a multi-stage processing pipeline for neural network operations, featuring parallel computation paths, data routing, and memory management. Key components include demultiplexers (DEMUX), processing units (PAU/APE), memory blocks, and control logic.
### Components/Axes
1. **Input Memory**:
- **Weight/IFMAP Memory** (blue block on left)
- **DEMUX** (pink block) splits input into parallel paths
2. **Processing Units**:
- **PAU** (yellow blocks): Parallel Processing Units
- **APE** (green blocks): Arithmetic Processing Elements
3. **Control Logic**:
- **Controller** (white box) manages data flow
- **IFMAP/Weight Memory** (top blue block) stores input data
4. **Output Management**:
- **MUX** (pink block) merges processed data
- **Output Memory (OFMAP)** (bottom blue block) stores final results
### Detailed Analysis
1. **Data Flow Path**:
- Input from Weight/IFMAP Memory → DEMUX → 6 parallel paths
- Each path contains:
- FIFO buffer → PAU → APE
- Processed data from 6 APE units → MUX → Output Memory
2. **Component Connections**:
- DEMUX splits input into 3 paths (top) and 3 paths (bottom)
- Each path contains 2 PAUs and 2 APEs in sequence
- MUX combines all 6 APE outputs into single stream
3. **Memory Architecture**:
- Dual memory hierarchy:
- Top: IFMAP/Weight Memory (input data)
- Bottom: Output Memory (OFMAP) for results
### Key Observations
1. **Parallelism**:
- 6 parallel computation paths enable simultaneous processing
- Each path processes 1/6th of input data independently
2. **Pipelining**:
- Data flows through PAU → APE sequence in each path
- Suggests multi-stage processing (e.g., convolution → activation)
3. **Control Mechanism**:
- Controller coordinates DEMUX/MUX operations
- Implies synchronized data routing and timing
### Interpretation
This architecture appears designed for efficient neural network inference, particularly for convolutional networks. The DEMUX/MUX combination enables:
- **Bandwidth Optimization**: Parallel data streams reduce memory contention
- **Compute Efficiency**: PAU/APE specialization suggests hardware acceleration
- **Scalability**: Modular design allows adding more processing paths
The Controller's role in managing DEMUX/MUX operations indicates a need for precise timing control, likely to handle pipeline synchronization and data dependencies. The FIFO buffers suggest asynchronous operation between processing stages, allowing for variable latency between PAU and APE units.
</details>
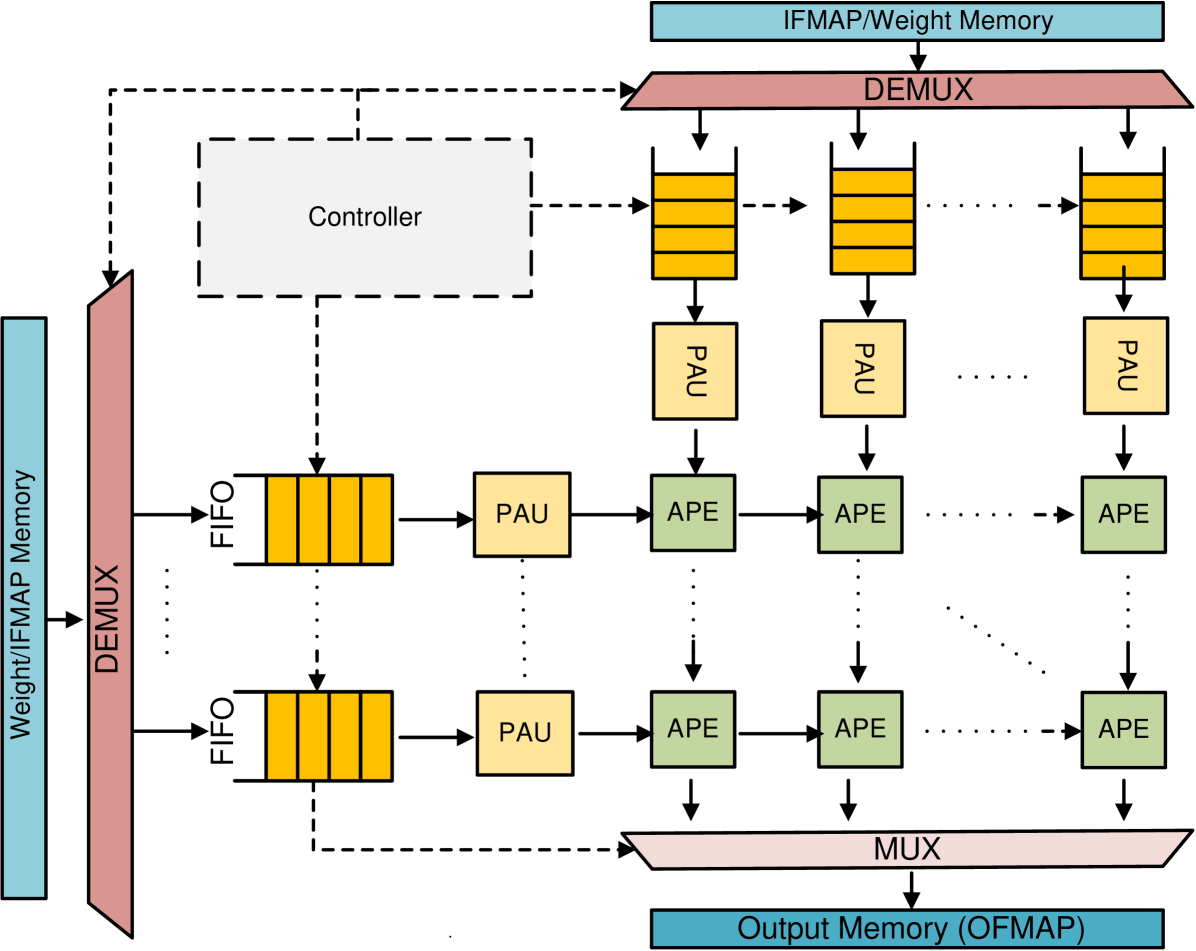
Figure 1: The overall template for TPU design.
## III TPU-Gen Framework
### III-A Architectural Template
Developing a Generic Template. The TPU architecture utilizes a systolic array of PEs with MAC units for efficient matrix and vector computations. This design enhances performance and reduces energy consumption by reusing data, minimizing buffer operations [1]. Input data propagates diagonally through the array in parallel. The TPU template, illustrated in Fig. 1, extends the TPU’s systolic array with Output Stationary (OS) dataflow to enable concurrent approximation of input feature maps (IFMaps) and weights. It comprises five components: weight/IFMap memory, FIFOs, a controller, Pre-Approximate Units (PAUs), and Approximate Processing Elements (APEs). The weights and IFMaps are stored in their respective memories, with the controller managing memory access and data transfer to FIFOs per the OS dataflow. PAUs, positioned between FIFOs and APEs, dynamically truncate high-precision operands to lower precision before sending them to APEs, which perform MAC operations using approximate multipliers and adders. Sharing PAUs across rows and columns reduces hardware overhead, introducing minimal latency but significantly improving overall performance [39].
Highly-Parameterized RTL Code. We design highly flexible and parameterized RTL codes for 13 different approximate adders and 12 different approximate multipliers as representative approximate circuits. For the approximate adders, we have two tunable parameters: the bit-width and the imprecise part. The bit-width specifies the number of bits for each operand and the imprecise part specifies the number of inexact bits in the adder output. For the approximate multipliers, we have one common parameter, i.e., Width (W), which specifies the bit-width of the multiplication operands. We also have more tunable parameters based on specific multipliers, some of which are listed in Table II.
TABLE II: Approximate multiplier hyper-parameters
| Design | Parameter | Description | Default |
| --- | --- | --- | --- |
| BAM [40] | VBL | No. of zero bits during partial product generation | W/2 |
| ALM_LOA [41] | M | Inaccurate part of LOA adder | W/2 |
| ALM_MAA3 [41] | M | Inaccurate part of MAA3 adder | W/2 |
| ALM_SOA [41] | M | Inaccurate part of SOA adder | W/2 |
| ASM [42] | Nibble_Width | number of precomputed alphabets | 4 |
| DRALM [37] | MULT_DW | Truncated bits of each operand | W/2 |
| RoBA [43] | ROUND_WIDTH | Scales the widths of the shifter | 1 |
We leveraged the parametrized RTL library of approximate arithmetic circuits to build a TPU library that enables automatic selection of the systolic array size $S$ , bit precision $n$ , and one of the approximate multipliers and approximate adders. The internal parameters that are used to tune the approximate arithmetic libraries are also included in the TPU parameterized RTL library, thus, allowing the user to have complete flexibility to adjust their designs to meet specific hardware specifications and application accuracy requirements. Moreover, we developed a design automation methodology, enabling the automatic implementation and simulation of many TPU circuits in various simulation platforms such as Design Compiler and Vivado. In addition to the highly parameterized RTL codes, we developed TCL and Python scripts to autonomously measure their error, area, performance, and power dissipation under various constraints.
### III-B Framework Overview
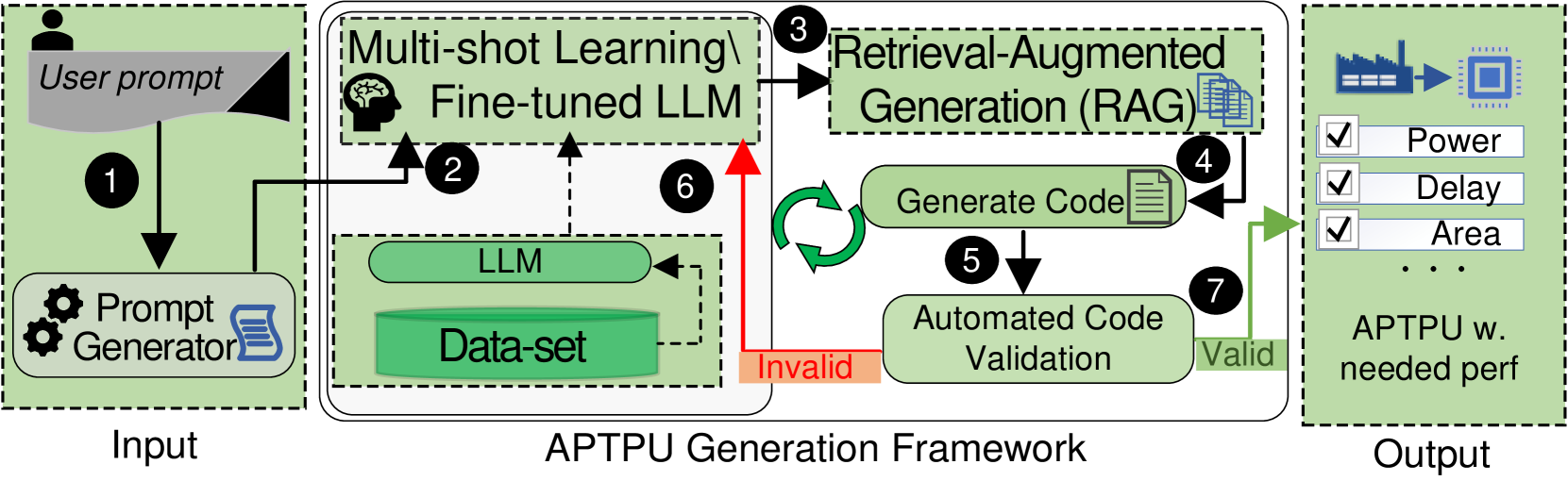
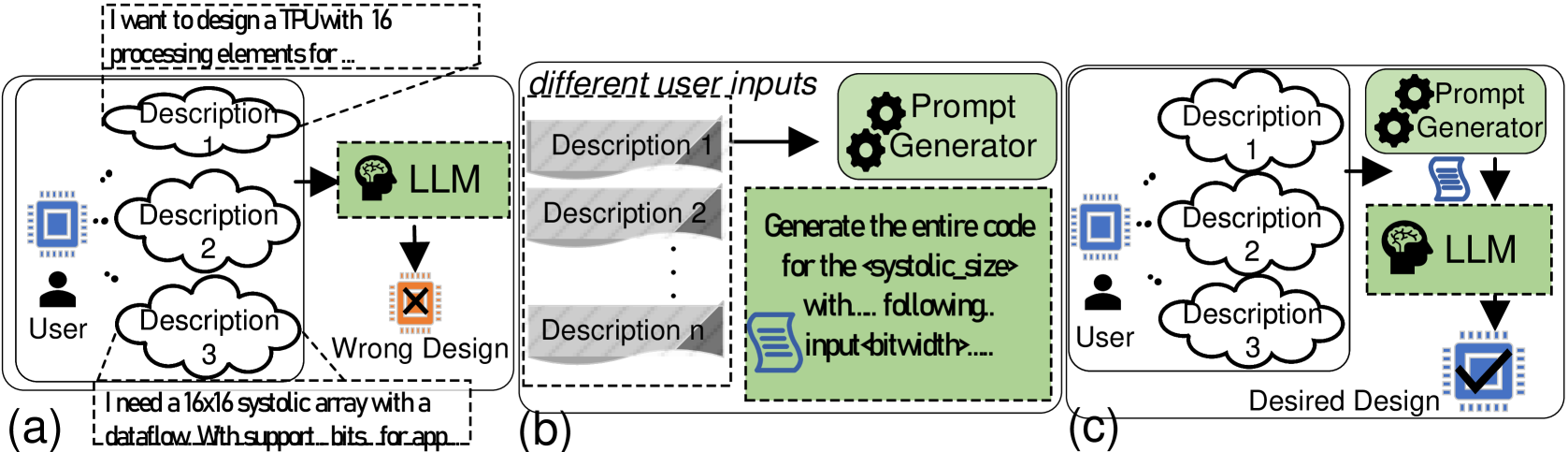
TPU-Gen framework depicted in Fig. 2 targets the development of domain-specific LLMs, emphasizing the interplay between the model’s responses and two key factors: the input prompt and the model’s learned parameters. The framework optimizes both elements to enhance LLM’s performance. An initial prompt conveying the user’s intent and key software and hardware specifications of the intended TPU design and application is enabled through the Prompt Generator in Step 1. A verbal description of a tensor processing accelerator design can often result in a many-to-one mapping as shown in Fig. 3 (a), especially when such descriptions do not align with the format of the training dataset. This misalignment increases the likelihood of hallucinations in the LLM’s output, potentially leading to faulty designs [44]. To minimize hallucinations and incorrect outputs in LLM-generated designs, studies have shown that inputs adhering closely to patterns observed in the training data produce more accurate and desirable results [17, 18]. However, this critical aspect has often been overlooked in previous state-of-the-art research [9], with some researchers opting instead to address the issue through prompt optimization techniques [18]. In this framework, we tackle the problem by employing a script that extracts key features, such as systolic size and relevant metrics, from any given verbal input by the user. These features are then embedded into a template, which serves as the prompt for the LLM input. As a domain-specific LLM, TPU-Gen focuses on generating the most valuable RTL top file detailing the circuit, and blocks involved in the presented architectural template in Section III.A.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Flowchart: APTPU Generation Framework
### Overview
The diagram illustrates a multi-stage workflow for generating an APTPU (Application-Specific Technology Processing Unit) design. It begins with a user prompt, progresses through iterative code generation and validation, and concludes with an optimized APTPU output meeting performance criteria (Power, Delay, Area).
### Components/Axes
1. **Input Section**
- **User Prompt**: Initial input from a user (represented by a human icon).
- **Prompt Generator**: Converts the user prompt into structured input for the LLM.
2. **APTPU Generation Framework**
- **Multi-shot Learning / Fine-tuned LLM**: Processes the prompt using a large language model (LLM) trained on a dataset.
- **Retrieval-Augmented Generation (RAG)**: Generates code iteratively, with feedback loops for refinement.
- **Automated Code Validation**: Validates generated code (marked "Valid" or "Invalid").
- **Data-set**: A repository of training data for the LLM.
3. **Output Section**
- **APTPU w. needed perf**: Final output specifying an APTPU design optimized for Power, Delay, and Area.
### Detailed Analysis
- **Step 1**: User prompt → Prompt Generator → LLM input.
- **Step 2**: Multi-shot learning fine-tunes the LLM using the dataset.
- **Step 3**: RAG generates code (Step 4: "Generate Code").
- **Step 5**: Automated Code Validation checks validity.
- If **Invalid** (red arrow), the process loops back to RAG (Step 3).
- If **Valid** (green arrow), the workflow proceeds to output.
- **Step 6**: Data-set is referenced during LLM fine-tuning.
- **Step 7**: Final output includes APTPU specifications with performance metrics.
### Key Observations
- **Cyclical Refinement**: Code generation (Step 4) and validation (Step 5) form a feedback loop, ensuring iterative improvement.
- **Performance Optimization**: The output explicitly prioritizes Power, Delay, and Area, suggesting hardware-aware design constraints.
- **Validation Gatekeeper**: Invalid code is discarded, emphasizing quality control in the generation process.
### Interpretation
The framework demonstrates a closed-loop system where user intent is translated into optimized hardware design through iterative AI-driven code generation and validation. The integration of RAG and automated validation ensures robustness, while the focus on performance metrics aligns with hardware-software co-design principles. The absence of explicit numerical values suggests the diagram emphasizes process flow over quantitative results.
</details>
Figure 2: The proposed TPU-Gen framework.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Technical Workflow for Systolic Array Design with LLM Integration
### Overview
The diagram illustrates a three-stage technical workflow for designing a systolic array using a Large Language Model (LLM) and prompt engineering. It contrasts incorrect and correct design outcomes based on user input processing. Three labeled sections (a, b, c) depict progressive stages of the process.
### Components/Axes
1. **User Input Section**
- Three cloud-shaped nodes labeled "Description 1," "Description 2," and "Description 3" represent user requirements.
- Arrows indicate flow from user to LLM (brain icon) and prompt generator (gear icon).
2. **Processing Components**
- **LLM (Large Language Model)**: Green box with brain icon, positioned centrally in all sections.
- **Prompt Generator**: Gear icon, responsible for code generation.
- **Output Nodes**:
- "Wrong Design" (red X) in section (a).
- "Desired Design" (blue checkmark) in section (c).
3. **Textual Descriptions**
- **Section (a)**: User input specifies "16x16 systolic array with dataflow with support bits for app..."
- **Section (b)**: Prompt generator task: "Generate the entire code for the systolic_size with... input_bitwidth..."
- **Section (c)**: Final output labeled "Desired Design" with checkmark.
### Detailed Analysis
- **Section (a)**:
User provides three descriptions to the LLM, which outputs a "Wrong Design" (red X). The LLM lacks explicit guidance on systolic array parameters.
- **Section (b)**:
User inputs are processed by a **Prompt Generator**, which refines requirements into structured code specifications (e.g., systolic array dimensions, bitwidth).
- **Section (c)**:
The prompt generator feeds refined specifications to the LLM, resulting in a "Desired Design" (blue checkmark).
### Key Observations
1. **Flow Direction**:
- Left-to-right progression from raw user input to final design.
- Sections (a) and (c) share identical user inputs but differ in LLM interaction.
2. **Critical Path**:
- The prompt generator acts as a bridge between ambiguous user requirements and precise LLM output.
3. **Symbol Consistency**:
- Brain icon (LLM) and gear icon (prompt generator) are spatially anchored near their respective processing stages.
### Interpretation
The diagram emphasizes the necessity of **prompt engineering** to transform vague user requirements into actionable technical specifications. Without the prompt generator (section a), the LLM produces an incorrect design. With it (sections b and c), the LLM generates the desired systolic array code. This highlights the LLM's dependency on structured input for accurate technical output, aligning with principles of human-AI collaboration in engineering workflows.
</details>
Figure 3: (a) Multiple descriptions for a single TPU design demonstrate that a design can be verbally defined in numerous ways, potentially misleading LLMs in generating the intended design, (b) Proposed prompt generator extracts the required features from the given verbal descriptions, (c) Using a script to generate a verbal description aligned with the training data.
An immediate usage of the proposed dataset explained in Section III.C in TPU-Gen is to help fine-tune a generic LLM for the task of TPU design, where the input with a prompt will be fed to the LLM (Step 2 in Fig. 2). Equivalently, one may employ ICL, or multi-shot learning as a more computationally efficient compromise to fine-tuning [24]. The multi-shot prompting techniques can be used where the proposed dataset will function as the source for multi-shot examples. Given that the TPU-Gen dataset integrates verbal descriptions with corresponding TPU systolic array design pairs, the LLM generates a TPU’s top-level file as the output in Verilog. This top-level file includes all necessary architectural module dependencies to ensure a fully functional design (step 3). Further, we propose to leverage the RAG module to generate the other dependency files into the project, completing the design (step 4). Next, a third-party quality evaluation tool can be employed to provide a quantitative evaluation of the design, verify functional correctness, and integrate the design with the full stack (step 5). Here, for quality and functional evaluation, the generated designs, initially described in Verilog, are synthesized using YOSYS [45]. This synthesis process incorporates an automated RTL-to-GDSII validation stage, where the generated designs are evaluated and classified as either Valid or Invalid based on the completeness of their code sequences and the correctness of their input-output relationships. Valid designs proceed to resource validation, where they are optimized with respect to Power, Performance, and Area (PPA) metrics. In contrast, designs flagged as Invalid initiate a feedback loop for error analysis and subsequent LLM retraining, enabling iterative refinement (steps 2 to 6) to achieve predefined performance criteria. Ultimately, designs that successfully pass these stages in step 7 are ready for submission to the foundry.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Flowchart: APTPU Process Workflow
### Overview
The image depicts a multi-stage iterative process for generating and refining APTPU (Automated Process for Tuning and Parameterization of Uncertainty) configurations. The workflow involves tuning variables, verification, OpenRoad PPA reports, corpus creation, and final database generation. Feedback loops indicate iterative refinement.
### Components/Axes
1. **Stages**:
- **Blue Rectangles**:
- "APTPU CONFIG FILES" (Step 1)
- "Verification" (Step 2)
- "OpenRoad" (Step 3)
- **Orange Rectangle**: "APTPU + Metrics corpus" (Step 4)
- **Green Rectangles**: "APTPU + Metrics + Descriptions" (Step 5)
- **Database**: "APTPU-Gen" (Final output)
2. **Arrows**:
- **Black Arrows**: Sequential flow (Steps 1→2→3→4→5).
- **Light Blue Arrow**: Feedback loop labeled "Iterative process" connecting Step 4 to Step 1.
3. **Icons**:
- **Gears**: Represent "Tune variables, features" in Step 1.
- **Document Icon**: Appears in verification (Step 2) and OpenRoad (Step 3).
- **Database Icon**: Final output "APTPU-Gen."
### Detailed Analysis
1. **Step 1 (Blue)**:
- **Input**: "APTPU CONFIG FILES."
- **Action**: "Tune variables, features" (gears icon).
- **Output**: Feeds into Step 2.
2. **Step 2 (Blue)**:
- **Action**: "Verification" with sub-actions "Verify, Synthesize."
- **Output**: Connects to Step 3 via black arrow.
3. **Step 3 (Blue)**:
- **Input**: "OpenRoad PPA reports."
- **Output**: Connects to Step 4 via black arrow.
4. **Step 4 (Orange)**:
- **Input**: "APTPU + Metrics corpus."
- **Action**: "granulated prompt" (document icon).
- **Output**: Connects to Step 5 and feedback loop to Step 1.
5. **Step 5 (Green)**:
- **Input**: "APTPU + Metrics + Descriptions."
- **Output**: Final database "APTPU-Gen."
### Key Observations
- **Iterative Refinement**: The feedback loop from Step 4 to Step 1 ensures continuous tuning and improvement.
- **Data Progression**: Each stage adds complexity (config files → verification → metrics → descriptions).
- **Final Output**: "APTPU-Gen" database aggregates all prior stages.
### Interpretation
This flowchart represents an engineering or computational workflow for optimizing APTPU configurations. The iterative process suggests that metrics and descriptions generated in later stages (Steps 4–5) are critical for refining initial variables and features (Step 1). The inclusion of "granulated prompt" in Step 4 implies a focus on detailed, structured input for subsequent stages. The final "APTPU-Gen" database likely serves as a centralized repository for validated configurations, metrics, and descriptions, enabling scalable deployment or further analysis. The use of distinct colors (blue for initial stages, orange/green for advanced stages) visually emphasizes the progression from raw configuration to refined, data-driven outputs.
</details>
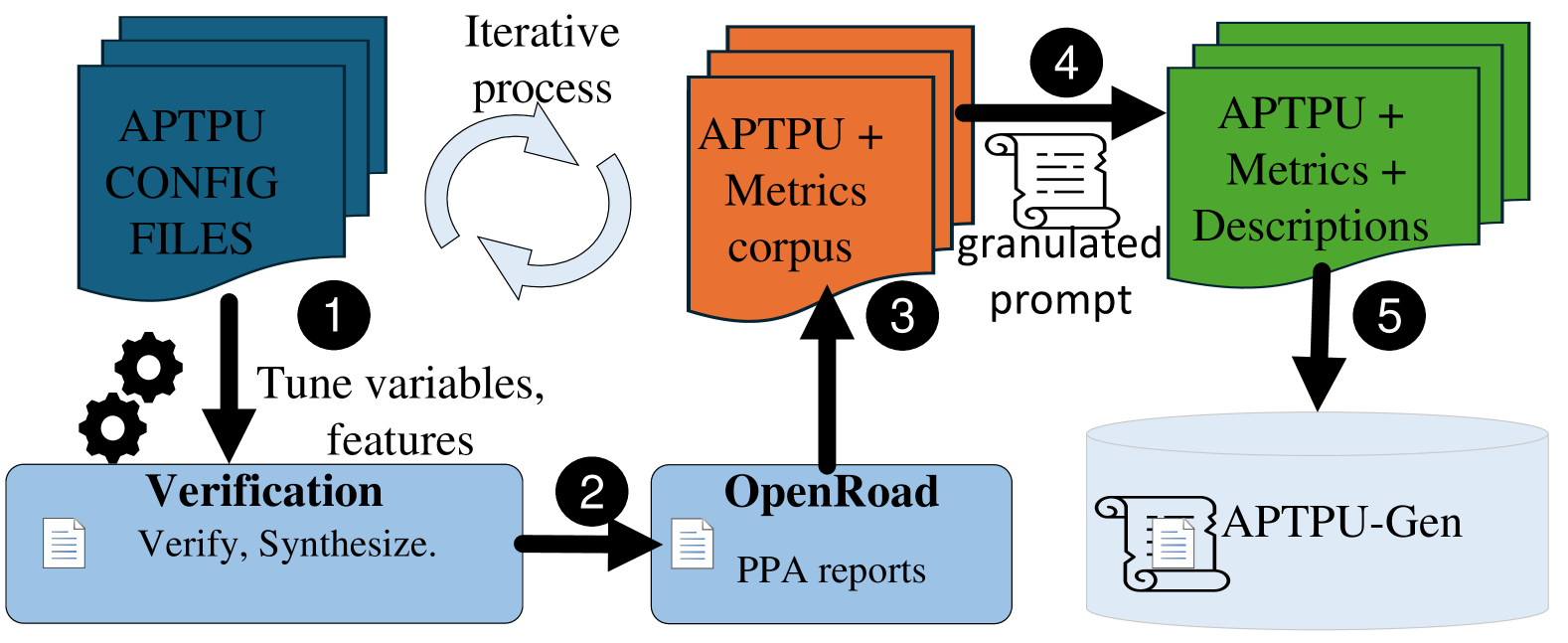
Figure 4: TPU-Gen dataset curation.
### III-C Dataset Curation
Leveraging the parameterized RTL code of the TPU, we develop a script to systematically explore various architectural configurations and generate a wide range of designs within the proposed framework (step 1 in Fig. 4). The generated designs undergo synthesis and functional verification (step 2). Subsequently, the OpenROAD suite [46] is employed to produce PPA metrics (step 3). The PPA data is parsed using Pyverilog (step 4), resulting in the creation of a detailed, multi-level dataset that captures the reported PPA metrics (step 5). Steps 1 to 3 are iterated until all architectural variations are generated. The time required for each data point generation varies depending on the specific configuration. To efficiently populate the TPU-Gen dataset, we utilize multiple scripts that automate the generation of data points across different systolic array sizes, ensuring comprehensive coverage of design space exploration. Fig. 4 shows the detailed methodology underpinning our dataset creation. The validation when compared to prior works [10, 47] understanding we work in a different design space abstraction makes it tough to have a fair comparison. However, looking by the scale of operation and the framework’s efficiency we require minimal efforts comparatively.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Block Diagram: Processing Array Unit (PAU) Architecture
### Overview
The diagram illustrates a computational architecture for a Processing Array Unit (PAU) with data flow between Input Feature Maps (IFMaps), Processing Elements (APEs), and an Approximate Processing Tensor Unit (APTU). The system emphasizes approximate arithmetic operations for efficiency, with specialized components for adders and multipliers.
### Components/Axes
**Legend (Right Side):**
- **Weight Types:**
- DW: [8,16,32] (Dotted black line)
- WW: [3,4,5,6,7,8,16,32] (Dashed black line)
- Mult_DW: [2,3,4,...,12] (Solid red line)
- **Approximate Adders:** SETA, HERLOA, MHEAA (10 more examples)
- **Approximate Multipliers:** BAM, UDM, ALM_LOA (10 more examples)
**Main Diagram Elements:**
1. **IFMaps (Input Feature Maps):**
- Two input blocks (dashed yellow arrows) feeding into PAU
- Positioned left of PAU
2. **PAU (Processing Array Unit):**
- Central blue box containing:
- Four APE blocks (green squares)
- Internal operations:
- `X <<` (bit-shift operation)
- `+` (addition)
- Connected to APTU via `APTU (MxN)` arrow
3. **APTU (Approximate Processing Tensor Unit):**
- Bottom of PAU block
- Receives aggregated output from APEs
**Data Flow:**
- IFMaps → PAU → APEs → APTU
- Weight inputs feed into PAU from top
### Detailed Analysis
**Weight Configuration:**
- DW (8/16/32-bit weights) likely represent standard precision
- WW (3-8/16/32-bit weights) suggest variable-width quantization
- Mult_DW (2-12-bit weights) indicate specialized multiplication units
**Approximate Arithmetic Units:**
- Adders: 12+ specialized units (SETA, HERLOA, MHEAA)
- Multipliers: 12+ specialized units (BAM, UDM, ALM_LOA)
- Positioned in separate boxes, suggesting hardware acceleration
**Processing Flow:**
1. IFMaps provide input data to PAU
2. PAU processes data through four parallel APEs
3. Each APE performs:
- Bit-shift operation (`X <<`)
- Addition (`+`)
4. Results aggregate in APTU (MxN matrix operations)
### Key Observations
1. **Modular Design:**
- Clear separation between input (IFMaps), processing (PAU/APEs), and output (APTU)
- Parallel APE architecture enables concurrent operations
2. **Approximation Focus:**
- 22+ specialized approximate units (adders/multipliers)
- Suggests power/energy efficiency optimization
3. **Weight Flexibility:**
- Multiple weight formats (DW/WW/Mult_DW) indicate support for:
- Quantized neural network models
- Mixed-precision computations
4. **Matrix Operations:**
- APTU's MxN configuration implies tensor/matrix multiplication capabilities
- Critical for deep learning operations
### Interpretation
This architecture appears designed for:
1. **Edge AI Acceleration:**
- Approximate arithmetic reduces power consumption
- Specialized units optimize for neural network operations
2. **Quantized Model Support:**
- Multiple weight formats (DW/WW/Mult_DW) enable:
- 8-bit/16-bit/32-bit fixed-point operations
- Variable-width quantization for different layers
3. **Efficient Data Flow:**
- Direct IFMap → PAU → APTU pathway minimizes latency
- APE parallelism enables high throughput
4. **Hardware-Software Co-Design:**
- Approximate adders/multipliers suggest custom silicon
- Balances accuracy (standard operations) with efficiency (approximate units)
The diagram reveals a sophisticated computational engine optimized for:
- Low-power neural network inference
- Mixed-precision computations
- High-throughput matrix operations
- Customizable weight handling through multiple formats
</details>
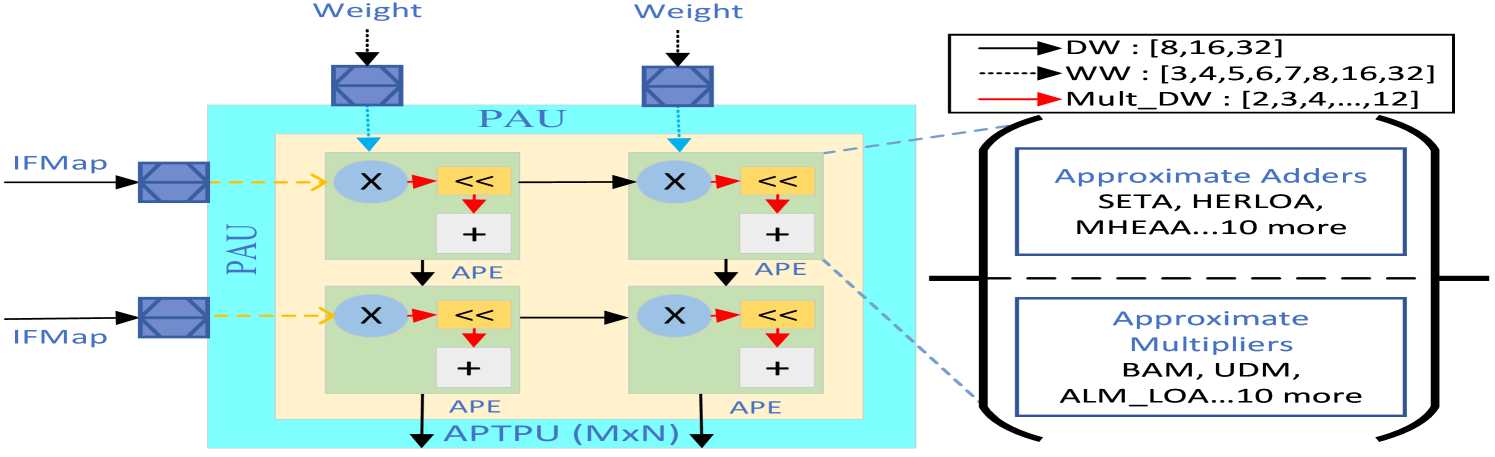
Figure 5: An example of one category and its design space parameters.
Fig. 5 visualizes the selection of different circuits to make PAUs and APEs accommodating different input Data Widths (DW) (8, 16, 32 bits) and Weight Widths (WW) (ranging from 3 to 32 bits) to generate approximate MAC units. These feature units highlight the flexible template of the TPU and enhance its adaptability and performance across various DNN workloads. Including lower bit-width weights is particularly advantageous for highly quantified models, enabling efficient processing with reduced computational resources.
<details>
<summary>x6.png Details</summary>

### Visual Description
## Screenshot: Verilog Code with Design Summaries
### Overview
The image shows a Verilog code snippet with embedded comments and three global summaries. The left side contains metrics, design parameters, and conditional macros, while the right side provides block-level and high-level design explanations.
### Components/Axes
- **Left Panel (Code/Metrics):**
- **Metrics:**
- `"Area": "29162"`
- `"WNS": "-12.268"`
- `"Total Power": "4.21e-03"`
- **Design Parameters:**
- `\`define DW 8` (IFMAP bitwidth)
- `\`define M 4` (Systolic array M-dimension)
- `\`define N 4` (Systolic array N-dimension)
- `\`define HERLOA //APADDER` (Multiplier type)
- Conditional macros:
- `\`ifdef MITCHELL`
- `\`define SHARED_PRE_APPROX`
- `\`elseif ALM_SOA`
- `\`define SHARED_PRE_APPROX`
- `\`elseif ALM_LOA`
- `\`define SHARED_PRE_APPROX`
- `\`elseif ROBA`
- **Right Panel (Summaries):**
1. **Block Summary:**
- Describes preprocessor macros for design parameters (e.g., `NIBBLE_WIDTH`, systolic array dimensions `M`/`N`, approximate multipliers `MULT_DW`).
- Mentions the `ALM` macro for approximate multipliers.
2. **Detailed Global Summary:**
- Explains the 4x4 systolic array implementation, including multiplier type (`HERLOA`), adder, and pre-approximation (`SHARED_PRE_APPROX`).
- Notes that macros are controlled by selections (e.g., `MITCHELL`, `ALM_SOA`).
3. **High-Level Global Summary:**
- Highlights the configurable 4x4 systolic array design with adjustable features (adder, HERLOA, bitwidths).
- Emphasizes trade-offs between area, power, and timing for machine learning efficiency.
### Detailed Analysis
- **Metrics:**
- Area: 29,162 (exact value, no uncertainty).
- WNS: -12.268 (likely timing slack, negative indicates violation).
- Total Power: 0.00421 (scientific notation, ~4.21 mW).
- **Code Structure:**
- Conditional compilation (`\`ifdef`, `\`elseif`) allows selecting design variants (e.g., `MITCHELL`, `ALM_SOA`).
- `SHARED_PRE_APPROX` is defined across all branches, suggesting a shared approximation strategy.
- **Design Choices:**
- Systolic array dimensions: 4x4 (fixed via `\`define M 4` and `\`define N 4`).
- Multiplier type: `HERLOA` (APADDER) with optional pre-approximation.
### Key Observations
1. **Configurable Design:** The code prioritizes flexibility via preprocessor macros, enabling trade-offs between area, power, and performance.
2. **Approximation Focus:** `SHARED_PRE_APPROX` is consistently defined, indicating its importance in optimizing resource usage.
3. **Timing Constraints:** Negative WNS (-12.268) suggests timing violations, requiring optimization.
### Interpretation
The Verilog code represents a highly configurable systolic array design for machine learning acceleration. By adjusting parameters like multiplier type (`HERLOA`), bitwidths (`DW`), and pre-approximation strategies (`SHARED_PRE_APPROX`), the design balances area, power, and timing. The negative WNS highlights a critical timing issue that must be resolved to meet performance targets. The 4x4 systolic array structure and conditional macros suggest a focus on scalability and adaptability for different computational workloads.
</details>
Figure 6: An example of a data point by adapting MG-V format.
TPU-Gen dataset offers 29,952 possible variations for a systolic array size with 8 different systolic array implementations to facilitate various workloads spanning from 4 $\times$ 4 for smaller loads to 256 $\times$ 256 to crunch bigger DNN workloads. Accounting for the systolic size variations in the TPU-Gen dataset promises a total of 29,952 $\times$ 8 = 2,39,616 data points with PPA metrics reported. While TPU-Gen is constantly growing with newer data points, we checkpoint our dataset creation currently reported as having 25,000 individual TPU designs. We provide two variations: $(i)$ A top module file consisting of details of the entire circuit implementation, which can be used in cases such as RAG implementation to save the computation resources, and $(ii)$ A detailed, multi-level granulated dataset, as depicted in Fig. 6, is curated by adapting MG-Verilog [17] to assist LLM in generating Verilog code to support the development of a highly sophisticated, fine-tuned model. This model facilitates the automated generation of individual hardware modules, intelligent integration, deployment, and reuse across various designs and architectures. Please note that due to the domain-specific nature of the dataset, some data redundancy is inevitable, as similar modules are reused and reconfigured to construct new TPUs with varying architectural configurations. This structured dataset enables efficient exploration and customization of TPU designs while ensuring that the generated modules can be systematically adapted for different design requirements, leading to enhanced flexibility and scalability in hardware design automation. Additionally, we provide detailed metrics for each design iteration, which aid the LLM in generating budget-constrained designs or in creating an efficient design space exploration strategy to accelerate the result optimization process.
TABLE III: Prompts to successfully generate exact TPU modules via TPU-Gen.
| LLM Model Mistral-7B (Q3) | Module Generation Pass@1 17% | Module Integration Pass@3 83% | Pass@5 100% | Pass@10 100% | Pass@1 0% | Pass@3 25% | Pass@5 75% | Pass@10 100% |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| CodeLlama-7B (Q4) | 0% | 50% | 83% | 100% | 0% | 50% | 75% | 100% |
| CodeLlama-13B (Q4) | 66% | 83% | 100% | 100% | 25% | 75% | 100% | 100% |
| Claude 3.5 Sonnet | 83% | 100% | 100% | 100% | 75% | 100% | 100% | 100% |
| ChatGPT-4o | 83% | 100% | 100% | 100% | 50% | 100% | 100% | 100% |
| Gemmini Advanced | 50% | 50% | 74% | 91% | 25% | 75% | 74% | 91% |
## IV Experiment Results
### IV-A Objectives
We designed four distinct experiments employing various approaches, each tailored to the unique capabilities of LLMs such as GPT [48], Gemini [49], and Claude [50], as well as the best open-source models from the leader board [51]. Each model is deployed in experiments aligning with the study’s objectives and anticipated outcomes. Experiments 1 focus on observing the prompting mechanism that assists LLM in generating the desired output by implementing ICL; with this knowledge, we develop the prompt template discussed in Sections III-B. Experiment 2 focuses on adapting the proposed TPU-Gen framework by fine-tuning LLM models. For fine-tuning, we used 4 $\times$ A100 GPU with 80GB VRAM. Experiment 3 is to demonstrate the effectiveness of RAG in TPU-Gen and it’s applicability for hardware design. Experiment 4 tests the TPU-Gen framework’s ability to generate designs efficiently with an industry-standard 45nm technology library. Throughout the process, we also consider hardware under the given PPA budget to ensure the feasibility of achieving the objectives outlined in the initial phases.
### IV-B Experiments and Results
<details>
<summary>x7.png Details</summary>
### Visual Description
## Bar Charts: Average Prompts for LLMs and Model-Specific Prompt Counts
### Overview
The image contains two bar charts comparing Large Language Model (LLM) performance metrics. Chart (a) shows average prompts required for Commercial vs. Open-Sourced LLMs across APTPU modules, while Chart (b) displays prompt counts for specific LLM models. Both charts use color-coded bars with trend lines and legends for interpretation.
### Components/Axes
**Chart (a):**
- **X-axis**: APTPU Modules (0–25, integer increments)
- **Y-axis**: Average Prompts for LLMs (0–25, integer increments)
- **Legend**:
- Top-left position
- Black = Commercial LLMs
- Gray = Open-Sourced LLMs
- Blue dashed = Trendline Commercial
- Red dashed = Trendline Open-Sourced
**Chart (b):**
- **X-axis**: LLM Models (1–6, integer labels)
- **Y-axis**: Number of Prompts (0–8, integer increments)
- **Legend**:
- Right-aligned
- Color-coded models:
- Black = ChatGPT 4o
- Dark gray = Gemini Advanced
- Medium gray = Claude
- Light gray = Codellama 13B
- Very light gray = Codellama 7B
- White = Mistral 7B
### Detailed Analysis
**Chart (a):**
- **Commercial LLMs (black bars)**:
- Average prompts range from ~2 (module 0) to ~8 (module 25)
- Blue dashed trendline shows steady upward slope (R² ~0.95)
- **Open-Sourced LLMs (gray bars)**:
- Average prompts range from ~7 (module 0) to ~20 (module 25)
- Red dashed trendline shows nonlinear growth with plateauing (R² ~0.88)
- **Key data points**:
- Module 10: Commercial = 4.2, Open-Sourced = 12.8
- Module 20: Commercial = 6.5, Open-Sourced = 18.3
**Chart (b):**
- **Prompt counts by model**:
- ChatGPT 4o (black): ~3.2 prompts
- Gemini Advanced (dark gray): ~2.1 prompts
- Claude (medium gray): ~3.8 prompts
- Codellama 13B (light gray): ~7.0 prompts
- Codellama 7B (very light gray): ~6.2 prompts
- Mistral 7B (white): ~4.0 prompts
- **Notable outlier**: Codellama 13B requires 2.2x more prompts than Mistral 7B
### Key Observations
1. Open-Sourced LLMs consistently require 2.5–3x more prompts than Commercial LLMs across all modules
2. Codellama 13B demonstrates the highest prompt intensity (7.0), exceeding all other models
3. Commercial LLMs show linear scalability (blue trendline), while Open-Sourced LLMs exhibit diminishing returns after module 15
### Interpretation
The data suggests Open-Sourced LLMs face greater computational inefficiency, requiring significantly more prompts for equivalent tasks. The Codellama 13B model's outlier performance indicates potential architectural limitations compared to Mistral 7B. Commercial LLMs demonstrate predictable scaling behavior, making them more suitable for applications requiring consistent prompt efficiency. The trendline divergence after module 15 implies Open-Sourced LLMs may benefit from architectural optimizations to reduce prompt requirements in high-complexity scenarios.
</details>
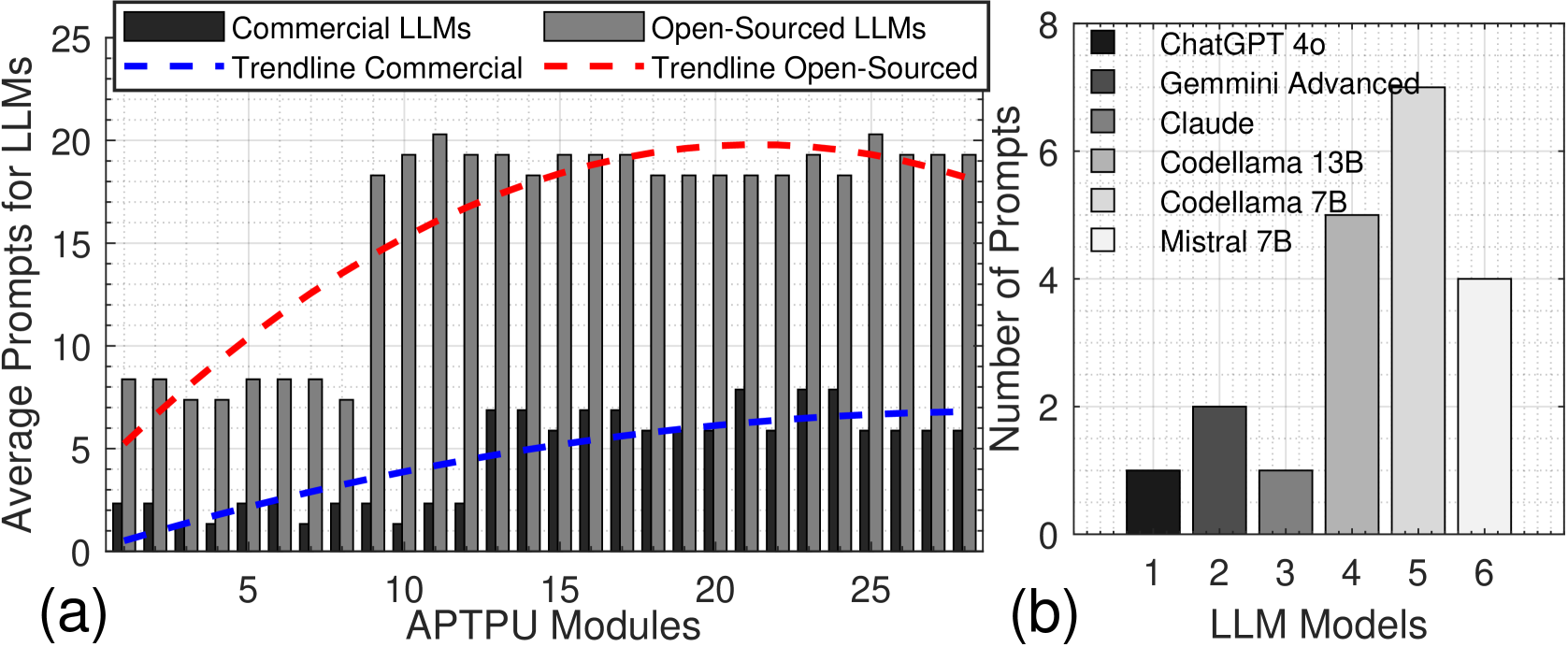
Figure 7: Average TPU-Gen prompts for (a) Module Generation, and (b) Module Integration via LLMs.
#### IV-B 1 Experiment 1: ICL-Driven TPU Generation and Approximate Design Adaptation.
We evaluate the capability of LLMs to generate and synthesize a novel TPU architecture and its approximate version using TPU-Gen. Utilizing the prompt template from [18], we refined it to harness LLM capabilities better. LLM performance is assessed on two metrics: $(i)$ Module Generation —the ability to generate required modules, and $(ii)$ Module Integration —the capability to construct the top module by integrating components. We tested commercial models like [48, 49] via chat interfaces and open-source models listed in Table III, using LM Studio [52]. For the TPU, we successfully developed the design and obtained the GDSII layout (Fig. 8 (a)). Commercial models performed well with a single prompt at pass@1, averaging 72% in module generation and 50% in integration. Open-source models performed better with the increase of pass@k, averaging 72% for pass@1 in module generation to 100% and 50% to 100% upscale from pass@3 to pass@10 in integration. For the approximate TPU, involving approximate circuit algorithms, we provided example circuits and used ICL and Chain of Thought (CoT) to guide the LLMs. Open-source models struggled due to a lack of specialized knowledge, as shown in Fig. 7. The design layout from this experiment is in Fig. 8 (b). All outputs were manually verified using test benches. This is the first work to generate both exact and approximate TPU architectures using prompting to LLM. However, significant human expertise and intervention are required, especially for complex architectures like approximate circuits. To minimize the human involvement, we implement fine-tuning.
Takeaway 1. LLMs with efficient prompting are capable of generating exact and approximate TPU modules and integrate them to create complete designs. However, human involvement is extensively required, especially for novel architectures. Fine-tuning LLMs is necessary to reduce human intervention and facilitate the exploration of new designs.
#### IV-B 2 Experiment 2: Full TPU-Gen Implementation
This experiment investigates cost-efficient approaches for adapting domain-specific language models to hardware design. In previous experiments, we observed that limited spatial and hierarchical hardware knowledge hindered LLM performance in integrating circuits. The TPU-Gen template (Fig. 2) addresses this by delegating creative tasks to the LLM and retrieving dependent modules via RAG, optimizing AI accelerator design while reducing computational overhead and minimizing LLM hallucinations. ICL experiments show that fine-tuning enhances LLM reliability. The TPU-Gen proposes a way to develop domain-specific LLMs with minimal data. The experiment used a TPU-Gen dataset version 1 of 5,000 Verilog headers DW and WW inputs. This dataset comprises systolic array implementations with biased approximate circuit variations. We split data statically in 80:20 for training and testing open-source LLMs [51], with two primary goals of $1.$ Analyzing the impact of the prompt template generator on the fine-tuned LLM’s performance (Table IV). $2.$ Investigating the RAG model for hardware development.
<details>
<summary>extracted/6256789/Figures/GDSII.jpg Details</summary>
### Visual Description
## Heatmap/Grid Diagram: Colored Line Distribution Analysis
### Overview
The image presents three side-by-side grid-based visualizations (a, b, c) depicting colored line distributions across a structured matrix. Each panel uses a dark blue background with white grid lines, overlaid with green, red, and blue lines of varying density and orientation. The visualizations appear to represent spatial or network data with color-coded categories.
### Components/Axes
- **Grid Structure**:
- All panels feature a 2D grid with white lines on a dark blue background.
- Grid density varies slightly between panels but maintains consistent alignment.
- **Color Legend**:
- Located in the top-left corner of each panel (spatial grounding: top-left).
- Colors correspond to categories:
- **Green**: Primary data points (highest density in panel a).
- **Red**: Secondary data points (dominant in panels b and c).
- **Blue**: Tertiary data points (sparse across all panels).
- **Line Orientation**:
- Panel (a): Predominantly horizontal/vertical lines with clustered groupings.
- Panel (b): Horizontal red lines dominate, with green lines forming irregular clusters.
- Panel (c): Vertical red lines dominate, with green lines forming fragmented patterns.
### Detailed Analysis
- **Panel (a)**:
- Green lines form dense, irregular clusters (≈60% of grid area).
- Red lines appear as sparse, isolated segments (≈20%).
- Blue lines are minimal (≈5%).
- **Panel (b)**:
- Horizontal red lines span ≈70% of the grid, creating uniform bands.
- Green lines form smaller clusters (≈25%) between red bands.
- Blue lines remain sparse (≈5%).
- **Panel (c)**:
- Vertical red lines dominate (≈80% of grid height).
- Green lines form fragmented, non-continuous segments (≈15%).
- Blue lines are nearly absent (≈0.5%).
### Key Observations
1. **Color Consistency**: Red lines shift from sparse (panel a) to dominant (panels b/c), suggesting a progression or variable emphasis.
2. **Line Density**: Green line density decreases from panel (a) to (c), while red line orientation shifts from horizontal to vertical.
3. **Grid Segmentation**: Panel (c) shows increased fragmentation, with red lines creating isolated vertical zones.
### Interpretation
The visualizations likely represent sequential data layers or comparative analyses:
- **Panel (a)**: Baseline state with clustered primary (green) data.
- **Panel (b)**: Introduction of a secondary metric (red) that dominates horizontally, potentially indicating a new constraint or variable.
- **Panel (c)**: Further evolution where red lines become vertical, suggesting a structural shift (e.g., time-based progression or axis inversion).
The absence of explicit labels necessitates inference: green may represent "active nodes," red "constraints," and blue "outliers." The progression from clustered to segmented patterns could model network evolution, resource allocation changes, or spatial-temporal dynamics. Outliers (blue lines) remain consistently rare, implying stable secondary metrics across iterations.
</details>
Figure 8: A GDSII layout of (a) TPU, (b) TPU by prompting LLM, (c) approximate TPU by TPU-Gen framework.
All models used Low-Rank Adaptation (LoRA) fine-tuning with the Adam optimizer at a learning rate of $1e^{-5}$ . The fine-tuned models were evaluated to generate the desired results efficiently with a random prompt at pass@ $1$ to generate the TPU. From Table IV, we can observe that the outputs without the prompt generator are labeled as failures as they were unsuitable for further development and RAG integration. We can observe the same prompt when parsed to the prompt-template generator with a single try; we score an accuracy of 86.6%. Further, we used RAG and then processed the generated Verilog headers for module retrieval. According to [11], LLMs tend to prioritize creativity and finding innovative solutions, which often results in straying from the data. To address this, we employed a compute and cost-efficient method. This shows that the fine-tuning along with RAG can greatly enhance the performance. Fig. 8 (c) shows the GDSII layout of the design generated by the TPU-Gen framework.
TABLE IV: Prompt Generator vs Human inputs to Fine-tuned models.
| CodeLlama-7B-hf CodeQwen1.5 -7B Mistral -7B | 27 25 28 | 03 05 02 | 01 0 02 | 29 30 28 |
| --- | --- | --- | --- | --- |
| Starcoder2-7B | 24 | 06 | 0 | 30 |
Takeaway 2. Prompting techniques such as prompt template steer LLM to generate desired results after fine-tuning, as observed 86% success in generation. RAG, a cost-efficient method to generate the hardware modules reliably, completing the entire Verilog design for an application with minimal computational overhead.
#### IV-B 3 Experiment 3: Significance of RAG
To assess the effectiveness of RAG in the TPU-Gen framework, we evaluated 1,000 Verilog header codes generated by fine-tuned LLMs under two conditions: with and without RAG integration. Table V presents results over 30 designs tested by our framework to generate complete project files. Without RAG, failures occurred due to output token limitations and hallucinated variables. RAG is essential as the design is not a standalone file to compile. Validated header codes were provided in the RAG-enabled pipeline, and required modules were dynamically retrieved from the RAG database, ensuring fully functional and accurate designs. Conversely, models without RAG relied solely on internal knowledge, leading to hallucinations, token constraints, and incomplete designs. Models using RAG consistently achieved pass rates exceeding 95%, with Mistral-7B and CodeLlama-7B-hf attaining 100% success. In contrast, all models failed entirely without RAG, underscoring its pivotal role in ensuring design accuracy and addressing LLM limitations. RAG provides a robust solution to key challenges in fine-tuned LLMs for TPU hardware design by retrieving external information from the RAG database, ensuring contextual accuracy, and significantly reducing hallucinations. Additionally, RAG dynamically fetches dependencies in a modular manner, enabling the generation of complete and accurate designs without exceeding token limits. RAG is a promising solution in this context since our models were fine-tuned with only Verilog header data detailing design features. However, fine-tuning models with the entire design data would expose LLMs to severe hallucinations and token limitations, making generating detailed and functional designs challenging.
TABLE V: significance of RAG in TPU-Gen.
| CodeLama-7B-hf Mistral-7B CodeQwen1.5-7B | 100 100 95 | 0 0 5 | 0 0 0 | 100 100 100 |
| --- | --- | --- | --- | --- |
| StarCoder2-7B | 98 | 2 | 0 | 100 |
Takeaway 3. The experiment highlights the significance of the RAG usage with a fine-tuned model to avoid hallucinations and let LLM be creative consistently.
#### IV-B 4 Experiment 4: Design Generation Efficiency
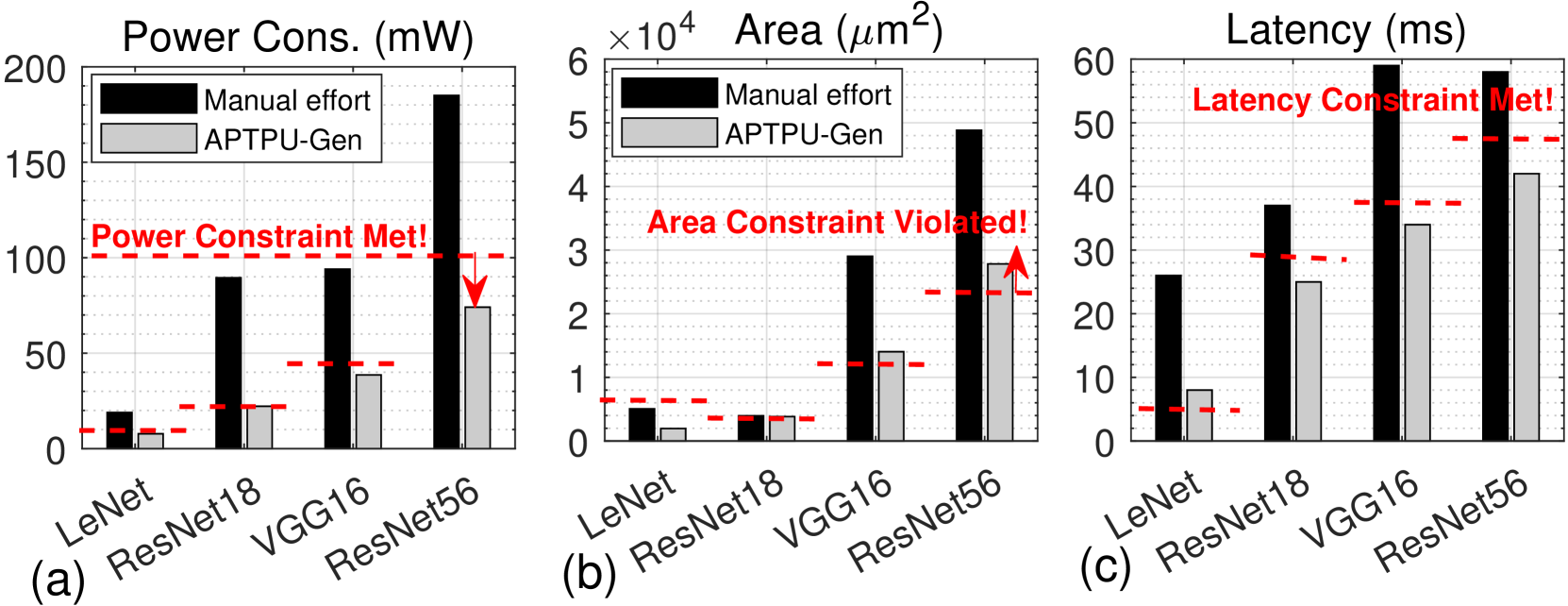
Building on the successful generation of approximate TPU in experiment 2, here we evaluate and benchmark the architectures produced by the TPU-Gen framework as the work performed in this paper is the first of it’s kind we are comparing against manual optimization created by expert human designers, focusing on power, area, and latency as shown in Fig. 9 (a)-(c). We utilize four DNN architectures for this evaluation: LeNet, ResNet18, VGG16, and ResNet56, performing inference tasks on the MNIST, CIFAR-10, SVHN, and CIFAR-100 datasets. In the manually optimized designs, a skilled hardware engineer fine-tunes parameters within the TPU template. This iterative optimization process is repeated until no further performance gains can be achieved within a reasonable timeframe of approximately one day [9], or the expert determines, based on empirical results, that additional refinements would yield minimal benefits. Using the PPA metrics as reference values (e.g., 100mW, 0.25mm 2, 48ms for ResNet56), both TPU-Gen and the manual user are tasked with generating the TPU architecture. Fig. 9 illustrates that across a range of network architectures, TPU-Gen consistently yields results with minimal deviation from the reference benchmarks. In contrast, the manual designs exhibit significant violations in terms of PPA.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Three-Panel Bar Chart: Performance Comparison of Neural Network Models
### Overview
The image presents a comparative analysis of four neural network architectures (LeNet, ResNet18, VGG16, ResNet56) across three performance metrics: power consumption, computational area, and latency. Each metric is visualized in a separate panel with dual-bar comparisons between "Manual effort" (black bars) and "APTPU-Gen" (gray bars). Red dashed lines indicate constraint thresholds, with annotations highlighting compliance or violations.
---
### Components/Axes
1. **Panel (a): Power Consumption (mW)**
- **X-axis**: Neural network models (LeNet, ResNet18, VGG16, ResNet56)
- **Y-axis**: Power consumption in milliwatts (0–200 mW)
- **Legend**:
- Black = Manual effort
- Gray = APTPU-Gen
- **Annotations**:
- Red dashed line at 100 mW labeled "Power Constraint Met!"
- Red arrows pointing to ResNet56 (APTPU-Gen) and VGG16 (Manual effort)
2. **Panel (b): Area (μm² × 10⁴)**
- **X-axis**: Same neural network models
- **Y-axis**: Area in square micrometers (0–6×10⁴ μm²)
- **Legend**: Same as Panel (a)
- **Annotations**:
- Red dashed line at 3×10⁴ μm² labeled "Area Constraint Violated!"
- Red arrow pointing to ResNet56 (Manual effort)
3. **Panel (c): Latency (ms)**
- **X-axis**: Same neural network models
- **Y-axis**: Latency in milliseconds (0–60 ms)
- **Legend**: Same as Panel (a)
- **Annotations**:
- Red dashed line at 50 ms labeled "Latency Constraint Met!"
- Red arrows pointing to ResNet56 (Manual effort) and VGG16 (APTPU-Gen)
---
### Detailed Analysis
#### Panel (a): Power Consumption
- **LeNet**:
- Manual effort: ~15 mW
- APTPU-Gen: ~5 mW
- **ResNet18**:
- Manual effort: ~90 mW
- APTPU-Gen: ~30 mW
- **VGG16**:
- Manual effort: ~100 mW
- APTPU-Gen: ~50 mW
- **ResNet56**:
- Manual effort: ~180 mW
- APTPU-Gen: ~70 mW
- **Trend**: APTPU-Gen consistently reduces power consumption by 50–70% across all models.
#### Panel (b): Area
- **LeNet**:
- Manual effort: ~0.5×10⁴ μm²
- APTPU-Gen: ~0.2×10⁴ μm²
- **ResNet18**:
- Manual effort: ~0.3×10⁴ μm²
- APTPU-Gen: ~0.1×10⁴ μm²
- **VGG16**:
- Manual effort: ~3×10⁴ μm² (violates constraint)
- APTPU-Gen: ~1.5×10⁴ μm²
- **ResNet56**:
- Manual effort: ~5×10⁴ μm² (violates constraint)
- APTPU-Gen: ~2.5×10⁴ μm²
- **Trend**: APTPU-Gen reduces area by 50–70%, but ResNet56 and VGG16 still exceed the 3×10⁴ μm² threshold under manual effort.
#### Panel (c): Latency
- **LeNet**:
- Manual effort: ~25 ms
- APTPU-Gen: ~10 ms
- **ResNet18**:
- Manual effort: ~35 ms
- APTPU-Gen: ~20 ms
- **VGG16**:
- Manual effort: ~50 ms
- APTPU-Gen: ~30 ms
- **ResNet56**:
- Manual effort: ~55 ms
- APTPU-Gen: ~40 ms
- **Trend**: APTPU-Gen reduces latency by 40–55% across all models, with all APTPU-Gen values meeting the 50 ms constraint.
---
### Key Observations
1. **APTPU-Gen Advantages**:
- Achieves 50–70% reductions in power, area, and latency compared to manual effort.
- Meets power and latency constraints for all models.
- Reduces area violations for ResNet56 and VGG16 under manual effort.
2. **Outliers**:
- **ResNet56**: Highest values in all metrics (power: 180 mW, area: 5×10⁴ μm², latency: 55 ms).
- **VGG16**: Exceeds area constraint under manual effort (3×10⁴ μm²).
3. **Constraint Compliance**:
- Power and latency constraints are universally met by APTPU-Gen.
- Area constraint is violated for ResNet56 and VGG16 under manual effort but resolved with APTPU-Gen.
---
### Interpretation
The data demonstrates that APTPU-Gen significantly improves efficiency across all metrics compared to manual effort. While ResNet56 and VGG16 exceed area constraints in manual configurations, APTPU-Gen mitigates these violations, suggesting its potential for optimizing resource-constrained deployments. The consistent latency improvements (all APTPU-Gen values ≤40 ms) highlight its suitability for real-time applications. ResNet56’s high resource demands underscore the need for hardware-aware optimizations in large-scale models.
</details>
Figure 9: PPA metrics comparison for TPU architectures generated by TPU-Gen and the manual user: (a) Power consumption, (b) Area, (c) Latency.
Takeaway 4. TPU-Gen consistently yields results with minimal deviation from the PPA reference, whereas the manual designs exhibit significant violations.
## V Conclusions
This paper introduces TPU-Gen, a novel dataset and a novel framework for TPU generation, addressing the complexities of generating AI accelerators amidst rapid AI model evolution. A key challenge, hallucinated variables, is mitigated using an RAG approach, dynamically adapting hardware modules. RAG enables cost-effective, full-scale RTL code generation, achieving budget-constrained outputs via fine-tuned models. Our extensive experimental evaluations demonstrate superior performance, power, and area efficiency, with an average reduction in area and power of 92% and 96% from the manual optimization reference values. These results set new standards for driving advancements in next-generation design automation tools powered by LLMs. We are committed to releasing the dataset and fine-tuned models publicly if accepted.
## References
- [1] N. Jouppi, C. Young, N. Patil, and D. Patterson, “Motivation for and evaluation of the first tensor processing unit,” IEEE Micro, vol. 38, no. 3, pp. 10–19, 2018.
- [2] H. Genc et al., “Gemmini: Enabling systematic deep-learning architecture evaluation via full-stack integration,” in 2021 58th ACM/IEEE Design Automation Conference (DAC). IEEE, 2021, pp. 769–774.
- [3] H. Sharma, J. Park, D. Mahajan, E. Amaro, J. K. Kim, C. Shao, A. Mishra, and H. Esmaeilzadeh, “From high-level deep neural models to fpgas,” in 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2016, pp. 1–12.
- [4] W.-Q. Ren et al., “A survey on collaborative dnn inference for edge intelligence,” Machine Intelligence Research, vol. 20, no. 3, pp. 370–395, 2023.
- [5] D. Vungarala, M. Morsali, S. Tabrizchi, A. Roohi, and S. Angizi, “Comparative study of low bit-width dnn accelerators: Opportunities and challenges,” in 2023 IEEE 66th International Midwest Symposium on Circuits and Systems (MWSCAS). IEEE, 2023, pp. 797–800.
- [6] P. Xu and Y. Liang, “Automatic code generation for rocket chip rocc accelerators,” 2020.
- [7] S. Angizi, Z. He, A. Awad, and D. Fan, “Mrima: An mram-based in-memory accelerator,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 39, no. 5, pp. 1123–1136, 2019.
- [8] K. Chang, Y. Wang, H. Ren, M. Wang, S. Liang, Y. Han, H. Li, and X. Li, “Chipgpt: How far are we from natural language hardware design,” arXiv preprint arXiv:2305.14019, 2023.
- [9] Y. Fu, Y. Zhang, Z. Yu, S. Li, Z. Ye, C. Li, C. Wan, and Y. C. Lin, “Gpt4aigchip: Towards next-generation ai accelerator design automation via large language models,” in 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 2023, pp. 1–9.
- [10] S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “Verigen: A large language model for verilog code generation,” ACM Transactions on Design Automation of Electronic Systems, vol. 29, no. 3, pp. 1–31, 2024.
- [11] X. Jiang, Y. Tian, F. Hua, C. Xu, Y. Wang, and J. Guo, “A survey on large language model hallucination via a creativity perspective,” arXiv preprint arXiv:2402.06647, 2024.
- [12] J. Blocklove, S. Garg, R. Karri, and H. Pearce, “Chip-chat: Challenges and opportunities in conversational hardware design,” in 2023 ACM/IEEE 5th Workshop on Machine Learning for CAD (MLCAD). IEEE, 2023, pp. 1–6.
- [13] S. Thakur, J. Blocklove, H. Pearce, B. Tan, S. Garg, and R. Karri, “Autochip: Automating hdl generation using llm feedback,” arXiv preprint arXiv:2311.04887, 2023.
- [14] R. Ma, Y. Yang, Z. Liu, J. Zhang, M. Li, J. Huang, and G. Luo, “Verilogreader: Llm-aided hardware test generation,” arXiv:2406.04373v1, 2024.
- [15] W. Fang et al., “Assertllm: Generating and evaluating hardware verification assertions from design specifications via multi-llms,” arXiv:2402.00386v1, 2024.
- [16] M. Liu, N. Pinckney, B. Khailany, and H. Ren, “Verilogeval: Evaluating large language models for verilog code generation,” arXiv:2309.07544v2, 2024.
- [17] Y. Zhang, Z. Yu, Y. Fu, C. Wan, and Y. C. Lin, “Mg-verilog: Multi-grained dataset towards enhanced llm-assisted verilog generation,” arXiv preprint arXiv:2407.01910, 2024.
- [18] D. Vungarala, M. Nazzal, M. Morsali, C. Zhang, A. Ghosh, A. Khreishah, and S. Angizi, “Sa-ds: A dataset for large language model-driven ai accelerator design generation,” arXiv e-prints, pp. arXiv–2404, 2024.
- [19] H. Wu et al., “Chateda: A large language model powered autonomous agent for eda,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024.
- [20] B. Nadimi and H. Zheng, “A multi-expert large language model architecture for verilog code generation,” arXiv preprint arXiv:2404.08029, 2024.
- [21] Y. Lu, S. Liu, Q. Zhang, and Z. Xie, “Rtllm: An open-source benchmark for design rtl generation with large language model,” in 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 2024, pp. 722–727.
- [22] D. Vungarala, S. Alam, A. Ghosh, and S. Angizi, “Spicepilot: Navigating spice code generation and simulation with ai guidance,” arXiv preprint arXiv:2410.20553, 2024.
- [23] Y. Lai, S. Lee, G. Chen, S. Poddar, M. Hu, D. Z. Pan, and P. Luo, “Analogcoder: Analog circuit design via training-free code generation,” arXiv preprint arXiv:2405.14918, 2024.
- [24] D. Dai, Y. Sun, L. Dong, Y. Hao, S. Ma, Z. Sui, and F. Wei, “Why can gpt learn in-context? language models implicitly perform gradient descent as meta-optimizers,” arXiv preprint arXiv:2212.10559, 2022.
- [25] G. Izacard et al., “Atlas: Few-shot learning with retrieval augmented language models,” Journal of Machine Learning Research, vol. 24, no. 251, pp. 1–43, 2023.
- [26] J. Chen, H. Lin, X. Han, and L. Sun, “Benchmarking large language models in retrieval-augmented generation,” arXiv preprint arXiv:2309.01431, 2023.
- [27] R. Qin et al., “Robust implementation of retrieval-augmented generation on edge-based computing-in-memory architectures,” arXiv:2405.04700v1, 2024.
- [28] A. Roohi, S. Sheikhfaal, S. Angizi, D. Fan, and R. F. DeMara, “Apgan: Approximate gan for robust low energy learning from imprecise components,” IEEE Transactions on Computers, vol. 69, no. 3, pp. 349–360, 2019.
- [29] M. S. Ansari, B. Cockburn, and J. Han, “An improved logarithmic multiplier for energy-efficient neural computing,” IEEE Trans. on Comput., vol. 70, pp. 614–625, 2021.
- [30] S. Angizi, M. Morsali, S. Tabrizchi, and A. Roohi, “A near-sensor processing accelerator for approximate local binary pattern networks,” IEEE Transactions on Emerging Topics in Computing, vol. 12, no. 1, pp. 73–83, 2023.
- [31] H. Jiang, S. Angizi, D. Fan, J. Han, and L. Liu, “Non-volatile approximate arithmetic circuits using scalable hybrid spin-cmos majority gates,” IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 68, no. 3, pp. 1217–1230, 2021.
- [32] S. Angizi, Z. He, A. S. Rakin, and D. Fan, “Cmp-pim: an energy-efficient comparator-based processing-in-memory neural network accelerator,” in Proceedings of the 55th Annual Design Automation Conference, 2018, pp. 1–6.
- [33] S. Angizi, H. Jiang, R. F. DeMara, J. Han, and D. Fan, “Majority-based spin-cmos primitives for approximate computing,” IEEE Transactions on Nanotechnology, vol. 17, no. 4, pp. 795–806, 2018.
- [34] M. E. Elbtity, H.-W. Son, D.-Y. Lee, and H. Kim, “High speed, approximate arithmetic based convolutional neural network accelerator,” 2020 International SoC Design Conference (ISOCC), pp. 71–72, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:231826033
- [35] H. Younes, A. Ibrahim, M. Rizk, and M. Valle, “Algorithmic level approximate computing for machine learning classifiers,” 2019 26th IEEE Int. Conf. on Electron., Circuits and Syst. (ICECS), pp. 113–114, 2019.
- [36] S. Hashemi, R. I. Bahar, and S. Reda, “DRUM: A dynamic range unbiased multiplier for approximate applications,” 2015 IEEE/ACM Int. Conf. on Comput.-Aided Design (ICCAD), pp. 418–425, 2015.
- [37] P. Yin, C. Wang, H. Waris, W. Liu, Y. Han, and F. Lombardi, “Design and analysis of energy-efficient dynamic range approximate logarithmic multipliers for machine learning,” IEEE Transactions on Sustainable Computing, vol. 6, no. 4, pp. 612–625, 2021.
- [38] A. Dalloo, A. Najafi, and A. Garcia-Ortiz, “Systematic design of an approximate adder: The optimized lower part constant-or adder,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 26, no. 8, pp. 1595–1599, 2018.
- [39] M. E. Elbtity, P. S. Chandarana, B. Reidy, J. K. Eshraghian, and R. Zand, “Aptpu: Approximate computing based tensor processing unit,” IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 69, no. 12, pp. 5135–5146, 2022.
- [40] F. Farshchi et al., “New approximate multiplier for low power digital signal processing,” The 17th CSI International Symposium on Computer Architecture & Digital Systems (CADS 2013), pp. 25–30, 2013.
- [41] W. Liu et al., “Design and evaluation of approximate logarithmic multipliers for low power error-tolerant applications,” IEEE Trans. on Circuits and Syst. I: Reg. Papers, vol. 65, pp. 2856–2868, 2018.
- [42] S. S. Sarwar et al., “Energy-efficient neural computing with approximate multipliers,” ACM Journal on Emerging Technologies in Computing Systems (JETC), vol. 14, pp. 1 – 23, 2018.
- [43] R. Zendegani et al., “Roba multiplier: A rounding-based approximate multiplier for high-speed yet energy-efficient digital signal processing,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 25, pp. 393–401, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:206810935
- [44] M. Niu, H. Li, J. Shi, H. Haddadi, and F. Mo, “Mitigating hallucinations in large language models via self-refinement-enhanced knowledge retrieval,” arXiv preprint arXiv:2405.06545, 2024.
- [45] (2024) Yosys. [Online]. Available: https://github.com/YosysHQ/yosys
- [46] (2018) Openroad. [Online]. Available: https://github.com/The-OpenROAD-Project/OpenROAD
- [47] H. Pearce et al., “Dave: Deriving automatically verilog from english,” in MLCAD, 2020, pp. 27–32.
- [48] (2024) Openai gpt-4. [Online]. Available: https://openai.com/index/hello-gpt-4o/
- [49] (2024) Gemini. [Online]. Available: https://deepmind.google
- [50] (2023) Anthropic. [Online]. Available: https://www.anthropic.com
- [51] Evalplus leaderboard. https://evalplus.github.io/leaderboard.html. Accessed: 2024-09-21.
- [52] “Lm studio - discover, download, and run local llms,” https://lmstudio.ai/, accessed: 2024-09-21.