# Human Cognition Inspired RAG with Knowledge Graph for Complex Problem Solving
**Authors**: Yao Cheng, Yibo Zhao, Jiapeng Zhu, Yao Liu, Xing Sun, Xiang Li
> Corresponding author.
## Abstract
Large Language Models (LLMs) have demonstrated significant potential across various domains. However, they often struggle with integrating external knowledge and performing complex reasoning, leading to hallucinations and unreliable outputs. Retrieval Augmented Generation (RAG) has emerged as a promising paradigm to mitigate these issues by incorporating external knowledge. Yet, conventional RAG approaches, especially those based on vector similarity, fail to effectively capture relational dependencies and support multi-step reasoning. In this work, we propose CogGRAG, a human cognition-inspired, graph-based RAG framework designed for Knowledge Graph Question Answering (KGQA). CogGRAG models the reasoning process as a tree-structured mind map that decomposes the original problem into interrelated subproblems and explicitly encodes their semantic relationships. This structure not only provides a global view to guide subsequent retrieval and reasoning but also enables self-consistent verification across reasoning paths. The framework operates in three stages: (1) top-down problem decomposition via mind map construction, (2) structured retrieval of both local and global knowledge from external Knowledge Graphs (KGs), and (3) bottom-up reasoning with dual-process self-verification. Unlike previous tree-based decomposition methods such as MindMap or Graph-CoT, CogGRAG unifies problem decomposition, knowledge retrieval, and reasoning under a single graph-structured cognitive framework, allowing early integration of relational knowledge and adaptive verification. Extensive experiments demonstrate that CogGRAG achieves superior accuracy and reliability compared to existing methods.
Code — https://github.com/cy623/RAG.git
## Introduction
As a foundational technology for artificial general intelligence (AGI), large language models (LLMs) have achieved remarkable success in practical applications, demonstrating transformative potential across a wide range of domains (llama2; llama3; qwen2). Their ability to process, generate, and reason with natural language has enabled significant advancements in areas such as machine translation (zhu2023multilingual), text summarization (basyal2023text), and question answering (pan2306unifying). Despite their impressive performance, LLMs still face significant limitations in knowledge integration beyond their pre-trained data boundaries. These limitations often lead to the generation of plausible but factually incorrect responses, a phenomenon commonly referred to as hallucinations, which undermines the reliability of LLMs in critical applications.
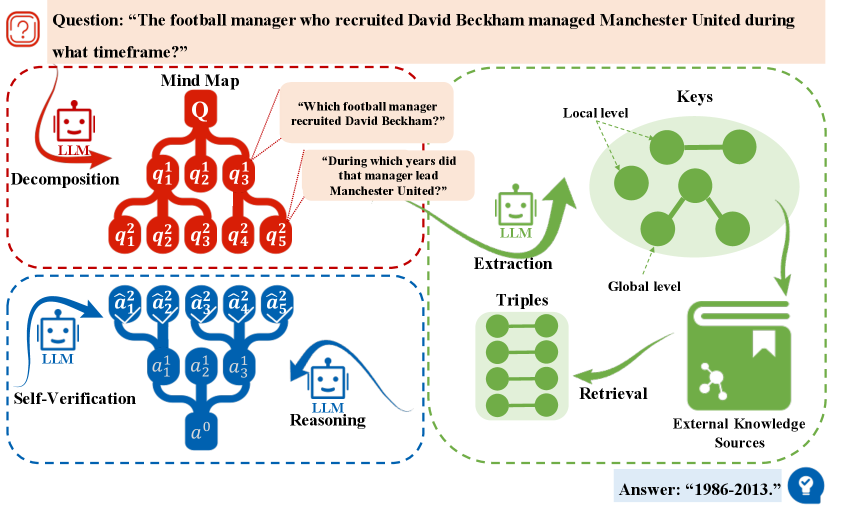
To mitigate hallucinations, Retrieval Augmented Generation (RAG) (niu2023ragtruth; gao2023retrieval; graphrag; xin2024atomr; chu2024beamaggr; cao2023probabilistic; wu2025pa; zhao20252graphrag) has emerged as a promising paradigm, significantly improving the accuracy and reliability of LLM-generated contents through the integration of external knowledge. However, while RAG successfully mitigates certain aspects of hallucination, it still exhibits inherent limitations in processing complex relational information. As shown in Figure 1 (a), the core limitation of standard RAG systems lies in their reliance on vector-based similarity matching, which processes knowledge segments as isolated units without capturing their contextual interdependencies or semantic relationships (graph_cot). Consequently, traditional RAG implementations are inadequate for supporting advanced reasoning capabilities in LLMs, particularly in scenarios requiring complex problem-solving, multi-step inference, or sophisticated knowledge integration.
<details>
<summary>x1.png Details</summary>

### Visual Description
## Diagram: Comparison of Retrieval-Augmented Generation (RAG) vs. Iterative RAG for LLMs
### Overview
The image is a technical diagram illustrating two methods for enhancing Large Language Models (LLMs) with external knowledge to answer complex questions. It uses a specific example question about football to demonstrate the processes and outcomes of standard Retrieval-Augmented Generation (RAG) versus Iterative RAG. The diagram is divided into two main panels, labeled (a) and (b), with a question at the top and the final correct answer at the bottom.
### Components/Axes
The diagram is structured as a flowchart with the following key components:
1. **Question Box (Top):** Contains the query: "The football manager who recruited David Beckham managed Manchester United during what timeframe?"
2. **Panel (a): Retrieval-Augmented Generation for Enhancing LLMs**
* **External Knowledge Sources:** Represented by a green book icon. It lists three retrieved text snippets with associated similarity scores.
* **LLM Icon:** A blue robot face representing the language model.
* **Output Box:** The model's generated response.
3. **Panel (b): Iterative Retrieval-Augmented Generation for Enhancing LLMs**
* **Iterative Retrieval Loop:** Shows multiple retrieval steps feeding into the LLM.
* **LLM Icon:** Same as in panel (a).
* **Intermediate Outputs:** Three generated statements, two marked with red "X" symbols.
* **Final Output Box:** The model's final answer after iteration.
4. **Answer Box (Bottom):** Displays the correct, verified answer: "1986-2013."
### Detailed Analysis
**Panel (a) - Standard RAG Process:**
* **Input:** The question is processed to retrieve relevant information from external sources.
* **Retrieved Data (from left to right):**
* "David Beckham ......" (Similarity Score: 0.8)
* "Manchester United......" (Similarity Score: 0.8)
* "Alex Ferguson......" (Similarity Score: 0.05)
* **Process:** The LLM receives these three snippets. The low score for "Alex Ferguson" is visually indicated by a green "X" over the arrow, suggesting it was not effectively utilized or was deemed irrelevant by the system.
* **Output:** The LLM states: "I cannot answer your question since I do not have enough information."
**Panel (b) - Iterative RAG Process:**
* **Step 1 Retrieval:** The process starts by retrieving "Manchester United......".
* **LLM Generation 1:** Produces the statement: "Jose Mourinho managed Manchester United from 2016 to 2018." This is marked with a red "X", indicating it is an incorrect or incomplete path for answering the original question.
* **Step 2 Retrieval:** Based on the first output, the system retrieves "Jose Mourinho......".
* **LLM Generation 2:** Produces: "Jose Mourinho managed Manchester United." Also marked with a red "X".
* **Step 3 Retrieval:** The system then retrieves "David Beckham......".
* **LLM Generation 3:** Produces: "David Beckham was recruited by Jose Mourinho." Marked with a red "X".
* **Final Output:** After these iterations, the system outputs: "From 2016 to 2018." This answer is derived from the first generated statement but is incorrect for the original question.
**Final Answer:**
* The correct answer, displayed separately at the bottom, is: "1986-2013."
### Key Observations
1. **Process Contrast:** Panel (a) shows a single retrieval step leading to failure. Panel (b) shows a multi-step, iterative process where each retrieval is informed by the previous LLM output.
2. **Error Propagation in Iteration:** The iterative process in (b) follows a logical but incorrect chain (Manchester United -> Jose Mourinho -> David Beckham), leading to a confident but wrong answer ("2016 to 2018").
3. **Similarity Score Discrepancy:** In panel (a), "Alex Ferguson" has a very low similarity score (0.05) compared to the other two terms (0.8). This is the critical missing piece of information needed to answer the question correctly (Alex Ferguson was the manager who recruited Beckham and had the 1986-2013 tenure).
4. **Visual Cues:** Red "X" marks are used to denote incorrect reasoning paths or outputs within the iterative process. Green arrows and icons denote the flow of information.
### Interpretation
This diagram serves as a pedagogical tool to explain the limitations of basic RAG and the potential pitfalls of iterative RAG.
* **What it demonstrates:** It shows that standard RAG can fail if the initial retrieval misses a key, low-similarity piece of information (Alex Ferguson). Iterative RAG attempts to refine answers by chaining retrievals, but this can lead the model down a plausible but incorrect reasoning path if the initial steps are misguided.
* **Relationship between elements:** The question is the driver. The external knowledge is the raw material. The LLM is the reasoning engine. The similarity scores guide the initial retrieval. The iterative loop shows how the model's own outputs can become inputs for the next retrieval step, creating a feedback loop.
* **Notable anomaly:** The core insight is the **similarity score paradox**. The most relevant fact for answering the question ("Alex Ferguson") has the lowest retrieval score. This highlights a fundamental challenge in RAG systems: semantic similarity search does not always equate to factual relevance for a complex, multi-hop question. The correct answer requires connecting three facts (Beckham, Manchester United, Ferguson) and a timeframe, which neither RAG approach in the diagram successfully achieves automatically. The correct answer is provided externally, underscoring the system's failure.
</details>
Figure 1: Representative workflow of two Retrieval-Augmented Generation paradigms for enhancing LLMs.
Recently, graph-based RAG (graphrag; tog2; graph_cot; gnnrag; xiong2024interactive) has been proposed to address the limitations of conventional RAG systems by incorporating deep structural information from external knowledge sources. These approaches typically utilize KGs to model complex relation patterns within external knowledge bases, employing structured triple representations (<entity, relation, entity>) to integrate fragmented information across multiple document segments. While graph-based RAG has shown promising results in mitigating hallucination and improving factual accuracy, several challenges remain unresolved:
$\bullet$ Lack of holistic reasoning structures. Complex problems cannot be resolved through simple queries; they typically require multi-step reasoning to derive the final answer. Existing methods often adopt iterative or sequential inference pipelines that are prone to cascading errors due to the absence of global reasoning plans (graph_cot; gnnrag). As shown in Figure 1 (b), each step in the iterative process relies on the result of the previous step, indicating that errors occurred at previous steps can propagate to subsequent steps.
$\bullet$ Absence of verification mechanisms. Despite the integration of external knowledge sources, LLMs remain prone to generating inaccurate or fabricated responses when confronted with retrieval errors or insufficient knowledge coverage. Most approaches do not incorporate explicit self-verification, making them vulnerable to retrieval errors or spurious reasoning paths.
To address these challenges, we propose CogGRAG, a Cog nition inspired G raph RAG framework, designed to enhance the complex problem-solving capabilities of LLMs in Knowledge Graph Question Answering (KGQA) tasks. CogGRAG is motivated by dual-process theories in human cognition, where problem solving involves both structured decomposition and iterative reflection. Our key contributions are as follows:
$\bullet$ Human-inspired decomposition. CogGRAG introduces a top-down question decomposition strategy that constructs a tree-structured mind map, explicitly modeling semantic relationships among subproblems. This representation enables the system to capture dependencies, causal links, and reasoning order between subcomponents, providing a global structure that guides subsequent retrieval and reasoning.
$\bullet$ Hierarchical structured retrieval. CogGRAG performs both local-level (entity/triple-based) and global-level (subgraph) retrieval based on the mind map. This dual-level retrieval strategy ensures precise and context-rich knowledge grounding.
$\bullet$ Self-verifying reasoning. Inspired by cognitive self-reflection, CogGRAG employs a dual-LLM verification mechanism. The reasoning LLM generates answers, which are then reviewed by a separate verifier LLM to detect and revise erroneous outputs. This design reduces hallucinations and improves output faithfulness.
We validate CogGRAG across three general KGQA benchmarks (HotpotQA, CWQ, WebQSP) and one domain-specific KGQA dataset (GRBench). Empirical results demonstrate that CogGRAG consistently outperforms strong baselines in both accuracy and hallucination suppression, under multiple LLM backbones.
## Related Work
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Diagram: LLM-Based Complex Question Answering Process
### Overview
The image is a technical diagram illustrating a multi-step process for answering a complex, multi-hop question using a Large Language Model (LLM). The process involves decomposing the question, extracting relevant information from external knowledge sources, and performing self-verification of the answer. The example question used is: "The football manager who recruited David Beckham managed Manchester United during what timeframe?"
### Components/Axes
The diagram is organized into three main, color-coded sections connected by flow arrows:
1. **Decomposition (Red Dashed Box, Left Side):**
* **Input:** A complex question labeled "Q" at the top of a mind map.
* **Process:** An LLM (represented by a robot icon) decomposes the main question into a hierarchy of sub-questions.
* **Output:** A tree structure of sub-questions labeled `q¹₁`, `q¹₂`, `q¹₃` (first level) and `q²₁`, `q²₂`, `q²₃`, `q²₄`, `q²₅` (second level).
* **Example Sub-questions (in speech bubbles):**
* "Which football manager recruited David Beckham?"
* "During which years did that manager lead Manchester United?"
2. **Extraction & Retrieval (Green Dashed Box, Right Side):**
* **Process:** An LLM performs "Extraction" on the sub-questions.
* **Components:**
* **Keys:** A cluster of green nodes labeled "Local level" and "Global level," representing extracted key concepts or entities.
* **Triples:** A vertical stack of green nodes, representing structured knowledge triples (subject-predicate-object).
* **External Knowledge Sources:** Represented by a green book icon with a molecular symbol.
* **Flow:** Arrows show information flowing from the LLM to the Keys, then to the Triples, and finally interacting with the External Knowledge Sources via a "Retrieval" process.
3. **Self-Verification (Blue Dashed Box, Bottom Left):**
* **Process:** An LLM performs "Reasoning" and "Self-Verification."
* **Structure:** A tree structure of answers.
* Root node: `a⁰` (final answer).
* Intermediate nodes: `a¹₁`, `a¹₂`, `a¹₃`.
* Leaf nodes: `ã²₁`, `ã²₂`, `ã²₃`, `ã²₄`, `ã²₅` (verified sub-answers).
* **Flow:** Arrows indicate the LLM reasoning from sub-answers up to the final answer and a verification loop.
4. **Final Output (Bottom Right Corner):**
* A blue box contains the final answer to the example question: **"Answer: '1986-2013.'"**
### Detailed Analysis
The diagram visually maps the flow of information and processing steps:
1. A complex natural language question (**Q**) enters the system.
2. The **Decomposition** module breaks it into a structured set of simpler, answerable sub-questions (`q` nodes).
3. The **Extraction** module processes these sub-questions to identify key entities and relationships (**Keys**, **Triples**).
4. These keys and triples are used to **Retrieve** relevant facts from **External Knowledge Sources**.
5. The retrieved information feeds into the **Self-Verification** module, where an LLM reasons to construct intermediate answers (`a¹` nodes) and verifies sub-answers (`ã²` nodes) to build and confirm the final answer (`a⁰`).
6. The process culminates in a specific, factual answer: **"1986-2013."**
### Key Observations
* **Hierarchical Structure:** Both the question decomposition and answer construction are represented as tree structures, emphasizing a hierarchical, step-by-step reasoning process.
* **Modular Design:** The process is clearly segmented into distinct functional modules (Decomposition, Extraction, Verification), each with a specific role.
* **LLM Integration:** An LLM icon is present in all three main modules, indicating it is the core engine driving decomposition, extraction/retrieval, and reasoning/verification.
* **Example-Driven:** The diagram uses a concrete, multi-hop factual question about football history to ground the abstract process in a tangible example.
* **Color Coding:** Red is used for question processing, green for knowledge interaction, and blue for answer synthesis and verification, creating a clear visual distinction between phases.
### Interpretation
This diagram illustrates a sophisticated **neuro-symbolic or retrieval-augmented generation (RAG) pipeline** designed to overcome the limitations of a single LLM inference for complex queries. It demonstrates a **Peircean abductive-deductive reasoning cycle**:
1. **Abduction (Decomposition):** The system hypothesizes a structure of sub-problems (`q` nodes) that, if solved, would answer the main question.
2. **Deduction & Retrieval (Extraction):** It deduces what specific information (keys, triples) is needed to solve those sub-problems and retrieves it from an external knowledge base.
3. **Induction & Verification (Self-Verification):** It induces a final answer (`a⁰`) from the sub-answers and verifies its consistency and correctness.
The process highlights the importance of **structured reasoning** and **grounding** in external facts for accurate complex question answering. The final answer, "1986-2013," corresponds to the tenure of Sir Alex Ferguson, who is famously associated with signing David Beckham and managing Manchester United during that period. The diagram effectively argues that answering such questions reliably requires more than just pattern matching; it requires explicit decomposition, targeted knowledge retrieval, and systematic verification.
</details>
Figure 2: The overall process of CogGRAG. Given a target question $Q$ , CogGRAG first prompts the LLM to decompose it into a hierarchy of sub-problems in a top-down manner, constructing a structured mind map. Subsequently, CogGRAG prompts the LLM to extract both local level (entities and triples) and global level (subgraphs) key information from these questions. Finally, CogGRAG guides the LLM to perform bottom-up reasoning and verification based on the mind map and the retrieved knowledge, until the final answer is derived.
Reasoning with LLM Prompting. Recent advancements in prompt engineering have demonstrated that state-of-the-art prompting techniques can significantly enhance the reasoning capabilities of LLMs on complex problems (prompt_cot; prompt_tree; prompt_graph). Chain of Thought (CoT (prompt_cot) explores how generating a chain of thought—a series of intermediate reasoning steps—significantly improves the ability of large language models to perform complex reasoning. Tree of Thoughts (ToT) (prompt_tree) introduces a new framework for language model inference that generalizes the popular Chain of Thought approach to prompting language models, enabling exploration of coherent units of text (thoughts) as intermediate steps toward problem-solving. The Graph of Thoughts (GoT) (prompt_graph) models the information generated by a LLM as an arbitrary graph, enabling LLM reasoning to more closely resemble human thinking or brain mechanisms. However, these methods remain constrained by the limitations of the model’s pre-trained knowledge base and are unable to address hallucination issues stemming from the lack of access to external, up-to-date information.
Knowledge Graph Augmented LLM. KGs (wikidata) offer distinct advantages in enhancing LLMs with structured external knowledge. Early graph-based RAG methods (graphrag; G-retriever; GRAG; wu2023retrieve; jin2024survey) demonstrated this potential by retrieving and integrating structured, relevant information from external sources, enabling LLMs to achieve superior performance on knowledge-intensive tasks. However, these methods exhibit notable limitations when applied to complex problems. Recent advancements have introduced methods like chain-of-thought prompting to enhance LLMs’ reasoning on complex problems (Think_on_graph; tog2; graph_cot; chen2024plan; luo2025gfm; luo2024graph; li2024simple). Think-on-Graph (Think_on_graph) introduces a new approach that enables the LLM to iteratively execute beam search on the KGs, discover the most promising reasoning paths, and return the most likely reasoning results. ToG-2 (tog2) achieves deep and faithful reasoning in LLMs through an iterative knowledge retrieval process that involves collaboration between contexts and the KGs. GRAPH-COT (graph_cot) propose a simple and effective framework to augment LLMs with graphs by encouraging LLMs to reason on the graph iteratively. However, iterative reasoning processes are prone to error propagation, as errors cannot be corrected once introduced. This leads to error accumulation and makes it difficult to reason holistically or revise previous steps. In contrast, our CogGRAG framework constructs a complete reasoning plan in advance through top-down decomposition, forming a mind map that globally guides retrieval and reasoning. None of the aforementioned approaches incorporate a self-verification phase. Once an incorrect inference is made, it propagates without correction. CogGRAG addresses this by introducing a dual-LLM self-verification module inspired by dual-process cognitive theory, allowing the system to detect and revise incorrect outputs during the reasoning phase.
## Methodology
In this section, we introduce CogGRAG a human cognition-inspired graph-based retrieval-augmented generation framework designed to enhance complex reasoning in KGQA tasks. CogGRAG simulates human cognitive strategies by decomposing complex questions into structured sub-problems, retrieving relevant knowledge in a hierarchical manner, and verifying reasoning results through dual-process reflection. The overall framework consists of three stages: (1) Decomposition, (2) Structured Retrieval, and (3) Reasoning with Self-Verification. The workflow is illustrated in Figure 2.
### Problem Formulation
Given a natural language question $Q$ , the goal is to generate a correct answer $A$ using an LLM $p_{\theta}$ augmented with a KG $\mathcal{G}$ . CogGRAG aim to design a graph-based RAG framework with an LLM backbone $p_{\theta}$ to enhance the complex problem-solving capabilities and generate the answer $A$ .
### Top-Down Decomposition
Inspired by human cognition in problem-solving, we simulate a top-down analytical process by decomposing the original question into a hierarchy of semantically coherent sub-questions. This decomposition process produces a reasoning mind map, which serves as an explicit structure to guide subsequent retrieval and reasoning steps. In this mind map, each node represents a sub-question, and edges capture the logical dependencies among them. Specifically, CogGRAG decomposes the original question $Q$ into a hierarchical structure forming a mind map $\mathcal{M}$ . Each node in $\mathcal{M}$ is defined as a tuple $m=(q,t,s)$ , where $q$ denotes the sub-question, $t$ indicates its depth level in the tree, and $s\in\{\texttt{Continue},\texttt{End}\}$ specifies whether further decomposition is required.
The decomposition proceeds recursively using the LLM:
$$
\{(q^{t+1}_{j},s^{t+1}_{j})\}_{j=1}^{N}=\texttt{Decompose}(q^{t},p_{\theta},\texttt{prompt}_{dec}), \tag{1}
$$
where $N$ is determined adaptively by LLM. This process continues until all leaves in $\mathcal{M}$ are labeled with End, representing atomic questions.
This hierarchical planning mechanism allows CogGRAG to surface latent semantic dependencies that may be overlooked by traditional matching-based RAG methods. For instance, consider the query: “ The football manager who recruited David Beckham managed Manchester United during what timeframe? ” A conventional retrieval pipeline may fail to resolve the intermediate entity “Alex Ferguson,” as it is not directly mentioned in the input question. In contrast, CogGRAG first decomposes the query into “Who recruited David Beckham?” and “When did that manager coach Manchester United?”, thereby enabling the system to recover critical missing entities and construct a more accurate reasoning path.
By performing top-down question decomposition before any retrieval or reasoning, CogGRAG explicitly separates planning from execution. This design enables holistic reasoning over the entire problem space, mitigates error propagation, and sets the foundation for effective downstream processing.
### Structured Knowledge Retrieval
Once the mind map $\mathcal{M}$ has been constructed through top-down decomposition, CogGRAG enters retrieval stage. This phase is responsible for identifying the external knowledge required to support reasoning across all sub-questions. In contrast to prior iterative methods (graph_cot) that retrieve relevant content at each reasoning step, CogGRAG performs a one-pass, globally informed retrieval guided by the full structure of $\mathcal{M}$ . This design not only enhances retrieval completeness and contextual coherence, but also avoids error accumulation caused by sequential retrieval failures.
To retrieve relevant information from the KG $\mathcal{G}$ , CogGRAG extracts two levels of key information from $\mathcal{M}$ . Local-level information captures entities and fine-grained relational facts associated with individual sub-questions. These include entity mentions, entity-relation pairs, and triples. Global-level information reflects semantic dependencies across multiple sub-questions and is expressed as interconnected subgraphs. These subgraphs encode logical chains or joint constraints necessary to resolve the overall problem. For example, given the decomposed question “ Which football manager recruited David Beckham? ”, we can extract local-level information such as the entity (David Beckham) and the triple (manager, recruited, David Beckham). By additionally considering another decomposed question—such as “ During which years did that manager lead Manchester United? ”—we can derive global level information, which is represented in the form of a subgraph [(manager, recruited, David Beckham), (manager, manage, Manchester United)]. The extraction process is performed using the LLM:
$$
\mathcal{K}=\texttt{Extract}(\mathcal{M},p_{\theta},\texttt{prompt}_{ext}), \tag{2}
$$
where $\mathcal{K}$ denotes the set of all extracted keys, including entity nodes, triples, and subgraph segments. This design ensures that both isolated facts and relational contexts are captured prior to KGs querying. These keys guide graph-based retrieval. For each entity $e$ in the extracted key set $\mathcal{K}$ , we expand to its neighborhood in $\mathcal{G}$ , yielding a candidate triple set $\tilde{\mathcal{T}}$ . A semantic similarity filter is applied to retain only relevant triples:
$$
\mathcal{T}=\{\tau\in\tilde{\mathcal{T}},k\in\mathcal{K}\mid\texttt{sim}(\tau,k)>\varepsilon\}, \tag{3}
$$
where $\texttt{sim}(\cdot)$ is cosine similarity, $\varepsilon$ is a threshold, $\tau$ is the triple in candidate triple set $\tilde{\mathcal{T}}$ and $k$ is the triple in the extracted key set $\mathcal{K}$ . The final retrieved triple set $\mathcal{T}$ serves as the input evidence pool for the reasoning module. By leveraging both local and global context from $\mathcal{M}$ , CogGRAG ensures that $\mathcal{T}$ is semantically rich, structurally connected, and targeted toward the entire reasoning path.
### Reasoning with Self-Verification
The final stage of CogGRAG emulates human problem-solving behavior, where conclusions are not only derived through reasoning but also reviewed through self-reflection (frederick2005cognitive). To this end, CogGRAG employs a dual-process reasoning architecture, composed of two distinct LLMs:
- LLM res: responsible for answer generation via bottom-up reasoning over the mind map $\mathcal{M}$ ;
- LLM ver: responsible for evaluating the validity of generated answers based on context and prior reasoning history.
This dual-agent setup is inspired by dual-process theories in cognitive psychology (vaisey2009motivation), where System 1 performs intuitive reasoning and System 2 monitors and corrects errors.
#### Bottom-Up Reasoning.
Given the final retrieved triple set $\mathcal{T}$ and the structured mind map $\mathcal{M}$ , CogGRAG performs reasoning in a bottom-up fashion: sub-questions at the lowest level are answered first, and their verified results are recursively used to resolve higher-level nodes.
Let $\mathcal{M}$ denote the full mind map. We define $\hat{\mathcal{M}}\subset\mathcal{M}$ as the subset of sub-questions that have been answered and verified. Each element in $\hat{\mathcal{M}}$ is a tuple $(q,\hat{a})$ , where $q$ is a sub-question and $\hat{a}$ is its verified answer. Then the reasoning LLM generates a candidate answer:
$$
a^{t}=\texttt{LLM}_{\text{res}}(\mathcal{T},q^{t},\hat{\mathcal{M}},\texttt{prompt}_{res}). \tag{4}
$$
#### Self-Verification and Re-thinking.
The candidate answer $a^{t}$ is passed to the verifier LLM along with the current reasoning path. The verifier assesses consistency, factual grounding, and logical coherence. If the answer fails validation, a re-thinked response $\hat{a}^{t}$ is regenerated:
$$
\hat{a}^{t}=\begin{cases}\texttt{LLM}_{\text{res}}(\mathcal{T},q^{t},\hat{\mathcal{M}},\texttt{prompt}_{rethink})&\text{if }\delta^{t}=\texttt{False},\\
a^{t}&\text{otherwise.}\end{cases} \tag{5}
$$
Here, $\delta^{t}$ is a boolean indicator defined as:
$$
\delta^{t}=\texttt{LLM}_{\text{ver}}(q^{t},a^{t},\hat{\mathcal{M}},\texttt{prompt}_{ver}), \tag{6}
$$
which returns True if the verification module accepts $a^{t}$ , and False otherwise. In addition to verification, CogGRAG incorporates a selective abstention mechanism. When the reasoning LLM cannot confidently produce a grounded answer based on $\mathcal{T}$ , it is explicitly prompted to respond with “ I don’t know ” rather than hallucinating. The final answer $A$ to the original question $Q$ is obtained by recursively aggregating verified answers $\hat{a}^{t}$ from the leaf nodes up to the root node $q^{0}$ , such that $A=\hat{a}^{0}$ .
This bottom-up reasoning pipeline, governed by a globally constructed mind map and protected by verification layers, enables CogGRAG to perform accurate and reliable complex reasoning over structured knowledge. All prompt templates used in CogGRAG can be found in the Appendix.
| Type | Method | HotpotQA | CWQ | WebQSP | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| RL | EM | F1 | RL | EM | F1 | RL | EM | F1 | | |
| LLM-only | Direct | 19.1% | 17.3% | 18.7% | 31.4% | 28.8% | 31.7% | 51.4% | 47.9% | 53.5% |
| CoT | 23.3% | 20.8% | 22.1% | 35.1% | 32.7% | 33.5% | 55.2% | 51.6% | 55.3% | |
| LLM+KG | Direct+KG | 27.5% | 23.7% | 27.6% | 39.7% | 35.1% | 38.3% | 52.5% | 49.3% | 52.1% |
| CoT+KG | 28.7% | 25.4% | 26.9% | 42.2% | 37.6% | 40.8% | 52.8% | 48.1% | 50.5% | |
| Graph-based RAG | ToG | 29.3% | 26.4% | 29.6% | 49.1% | 46.1% | 47.7% | 54.6% | 57.4% | 56.1% |
| MindMap | 27.9% | 25.6% | 27.8% | 46.7% | 43.7% | 44.1% | 56.6% | 53.1% | 58.3% | |
| RoG | 30.7% | 28.1% | 30.4% | 55.3% | 51.8% | 54.7% | 65.2% | 62.8% | 67.2% | |
| GoG | 31.5% | 30.1% | 31.1% | 55.7% | 52.4% | 54.8% | 65.5% | 59.1% | 63.6% | |
| Ours | CogGRAG | 34.4% | 30.7% | 35.5% | 56.3% | 53.4% | 55.8% | 59.8% | 56.1% | 58.9% |
Table 1: Overall results of our CogGRAG on three KBQA datasets. The best score on each dataset is highlighted.
## Experiments
### Experimental Settings
Datasets and evaluation metrics. In order to test CogGRAG’s complex problem-solving capabilities on KGQA tasks, we evaluate CogGRAG on three widely used complex KGQA benchmarks: (1) HotpotQA (yang2018hotpotqa), (2) WebQSP (yih2016value), (3) CWQ (talmor2018web). Following previous work (cok), full Wikidata (wikidata) is used as structured knowledge sources for all of these datasets. Considering that Wikidata is commonly used for training LLMs, there is a need for a domain-specific QA dataset that is not exposed during the pretraining process of LLMs in order to better evaluate the performance. Thus, we also test CogGRAG on a recently released domain-specific dataset GRBENCH (graph_cot). All methods need to interact with domain-specific graphs containing rich knowledge to solve the problem in this dataset. The statistics and details of these datasets can be found in Appendix. For all datasets, we use three evaluation metrics: (1) Exact match (EM): measures whether the predicted answer or result matches the target answer exactly. (2) Rouge-L (RL): measures the longest common subsequence of words between the responses and the ground truth answers. (3) F1 Score (F1): computes the harmonic mean of precision and recall between the predicted and gold answers, capturing both completeness and exactness of overlapping tokens.
Baselines. In our main results, we compare CogGRAG with three types state-of-the-art methods: (1) LLM-only methods without external knowledge, including direct reasoning and CoT (prompt_cot) by LLM. (2) LLM+KG methods integrate relevant knowledge retrieved from the KG into the LLM to assist in reasoning, including direct reasoning and CoT by LLM. (3) Graph-based RAG methods allow KGs and LLMs to work in tandem, complementing each other’s capabilities at each step of graph reasoning, including Mindmap (mindmap), Think-on-graph (Think_on_graph), Graph-CoT (graph_cot), RoG (luo2024rog), GoG (xu2024gog). Due to the space limitation, we move details on datasets, baselines and experimental setup to Appendix.
Experimental Setup. We conduct experiments with four LLM backbones: LLaMA2-13B (llama2), LLaMA3-8B (llama3), Qwen2.5-7B (qwen2) and Qwen2.5-32B (hui2024qwen2). For all LLMs, we load the checkpoints from huggingface https://huggingface.co and use the models directly without fine-tuning. We implemented CogGRAG and conducted the experiments with one A800 GPU. Consistent with the Think-on-graph settings, we set the temperature parameter to 0.4 during exploration and 0 during reasoning. The threshold $\epsilon$ in the retrieval step is set to $0.7$ .
| LLM-only LLaMA3-8B LLaMA2-13B | Qwen2.5-7B 17.5% 19.1% | 15.3% 14.9% 17.3% | 15.0% 16.2% 18.7% | 15.8% 30.3% 31.4% | 25.4% 27.5% 28.8% | 24.1% 29.0% 31.7% | 24.5% 50.4% 51.4% | 46.7% 45.1% 47.9% | 45.3% 48.3% 53.5% | 45.5% |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Qwen2.5-32B | 28.7% | 27.4% | 28.5% | 55.1% | 50.3% | 54.2% | 68.4% | 60.5% | 65.1% | |
| LLM+KG | Qwen2.5-7B+KG | 24.2% | 15.6% | 21.4% | 33.8% | 32.1% | 34.9% | 46.7% | 45.3% | 46.1% |
| LLaMA3-8B+KG | 25.9% | 21.4% | 23.6% | 40.6% | 35.3% | 39.1% | 53.6% | 49.1% | 52.3% | |
| LLaMA2-13B+KG | 27.5% | 23.7% | 27.6% | 39.7% | 35.1% | 38.3% | 52.5% | 49.3% | 52.1% | |
| Qwen2.5-32B+KG | 35.6% | 32.8% | 34.9% | 58.3% | 54.7% | 57.6% | 70.2% | 65.1% | 68.4% | |
| Graph-Based RAG | CogGRAG w/ Qwen2.5-7B | 28.4% | 27.1% | 28.2% | 50.5% | 45.7% | 48.9% | 53.2% | 51.6% | 55.0% |
| CogGRAG w/ LLaMA3-8B | 32.1% | 27.2% | 31.0% | 53.5% | 48.4% | 52.6% | 57.2% | 55.3% | 55.4% | |
| CogGRAG w/ LLaMA2-13B | 34.4% | 30.7% | 35.5% | 56.3% | 53.4% | 55.8% | 59.8% | 56.1% | 58.9% | |
| CogGRAG w/ Qwen2.5-32B | 40.5% | 37.1% | 40.2% | 66.5% | 62.7% | 65.4% | 74.1% | 68.3% | 73.0% | |
Table 2: Overall results of our CogGRAG with different backbone models on three KBQA datasets.
### Main Results
We perform experiments to verify the effectiveness of our framework CogGRAG, and report the results in Table 1. We use Rouge-L (RL), Exact match (EM) and F1 Score (F1) as metric for all three datasets. The backbone model for all the methods is LLaMA2-13B. From the table, the following observations can be derived: (1) CogGRAG achieves the best results in most cases except on WebSQP. Since the dataset is widely used, we attribute the reason to be data leakage. (2) Compared to methods that incorporate external knowledge, the LLM-only approach demonstrates significantly inferior performance. This performance gap arises from the lack of necessary knowledge in LLMs for reasoning tasks, highlighting the critical role of external knowledge integration in enhancing the reasoning capabilities of LLMs. (3) Graph-based RAG methods demonstrate superior performance compared to LLM+KG approaches. This performance advantage is particularly evident in complex problems, where not only external knowledge integration but also involving “thinking procedure” is essential. These methods synergize LLMs with KGs to enhance performance by retrieving and reasoning over the KGs, thereby generating the most probable inference outcomes through “thinking” on the KGs.
We attribute CogGRAG ’s outstanding effectiveness in most cases primarily to its ability to decompose complex problems and construct a structured mind map prior to retrieval. This approach enables the construction of a comprehensive reasoning pathway, facilitating more precise and targeted retrieval of relevant information. Furthermore, CogGRAG incorporates a self-verification mechanism during the reasoning phase, further enhancing the accuracy and reliability of the final results. Together, these designs collectively enhance LLMs’ ability to tackle complex problems.
### Performance with different backbone models
We evaluate how different backbone models affect its performance on three datasets HotpotQA, CWQ and WebQSP, and report the results in Table 2. We conduct experiments with three LLM backbones LLaMA2-13B, LLaMA3-8B, Qwen2.5-7B and Qwen2.5-32B. For all LLMs, we load the checkpoints from huggingface and use the models directly without fine-tuning. From the table, we can observe the following key findings: (1) CogGRAG achieves the best results across all backbone models compared to the baseline approaches, demonstrating the robustness and stability of our method. (2) The performance of our method improves consistently as the model scale increases, reflecting enhanced reasoning capabilities. This trend suggests that our approach has significant potential for further exploration with larger-scale models, indicating promising scalability and adaptability.
| LLaMA2-13B Graph-CoT CogGRAG | 7.1% 26.4% 30.2% | 6.8% 24.0% 28.7% | 6.9% 25.3% 29.5% | 5.4% 26.7% 32.4% | 5.1% 23.3% 30.1% | 5.3% 24.9% 31.3% | 5.4% 19.3% 23.6% | 4.7% 14.8% 21.5% | 5.1% 16.9% 22.7% | 4.3% 28.1% 27.4% | 3.1% 25.2% 25.6% | 3.6% 26.7% 26.2% |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
Table 3: Overall results of our CogGRAG on GRBENCH dataset. We highlight the best score on each dataset in bold.
### Performance on domain-specific KG
Given the risk of data leakage due to Wikidata being used as pretraining corpora for LLMs, we further evaluate the performance of CogGRAG on a recently released domain-specific dataset GRBENCH (graph_cot) and report the results in Table 3. This dataset requires all questions to interact with a domain-specific KG. We use Rouge-L (RL), Exact match (EM) and F1 Score (F1) as metrics for this dataset. The backbone model for all the methods is LLaMA2-13B (llama2). The table reveals the following observations: (1) CogGRAG continues to outperform in most cases. This demonstrates that our method consistently achieves stable and reliable results even on domain-specific KGs. (2) Both CogGRAG and Graph-CoT outperform LLaMA2-13B by more than 20%, which can be ascribed to the fact that LLMs are typically not trained on domain-specific data. In contrast, graph-based RAG methods can effectively supplement LLMs with external knowledge, thereby enhancing their reasoning capabilities. This result underscores the effectiveness of the RAG approach in bridging knowledge gaps and improving performance in specialized domains.
### Ablation Study
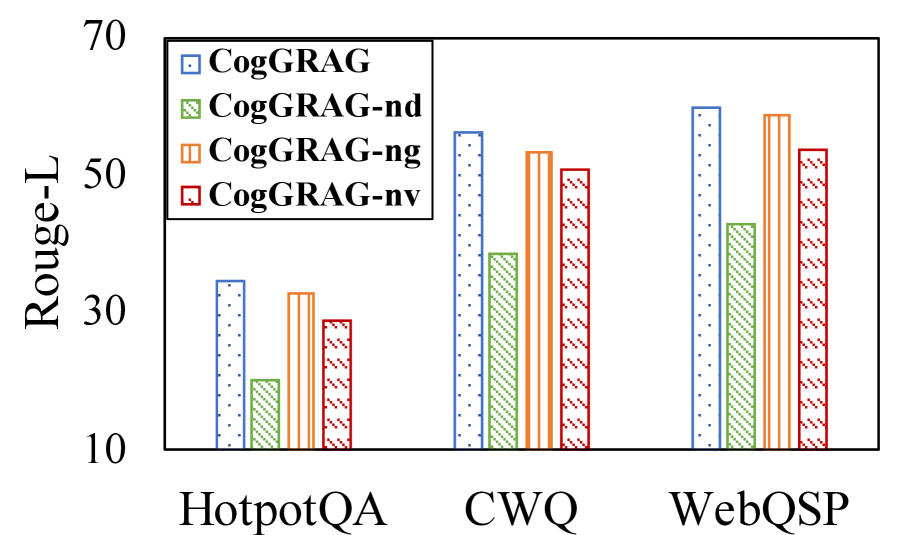
The ablation study is conducted to understand the importance of main components of CogGRAG. We select HotpotQA, CWQ and WebQSP as three representative datasets. First, we remove the problem decomposition module, directly extracting information for the target question, and referred to this variant as CogGRAG-nd (n o d ecomposition). Next, we eliminate the global-level retrieval phase, naming this variant CogGRAG-ng (n o g lobal level). Finally, we remove the self-verification mechanism during the reasoning stage, designating this variant as CogGRAG-nv (n o v erification). These experiments aim to systematically assess the impact of each component on the overall performance of the framework. We compare CogGRAG with these three variants, and the results are presented in Figure 3. Our findings show that CogGRAG outperforms all the variants on the three datasets. Furthermore, the performance gap between CogGRAG and CogGRAG-nd highlights the importance of decomposition for complex problem reasoning in KGQA tasks.
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Grouped Bar Chart: CogGRAG Model Performance Comparison
### Overview
The image is a grouped bar chart comparing the performance of four model variants across three different question-answering datasets. The performance metric is "Rouge-L," a common evaluation metric for text generation tasks that measures the overlap of longest common subsequences between generated and reference text. The chart visually demonstrates the impact of removing specific components (dense retrieval, graph, verification) from the base CogGRAG model.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:**
* **Label:** "Rouge-L" (written vertically).
* **Scale:** Linear scale from 10 to 70.
* **Major Tick Marks:** 10, 30, 50, 70.
* **X-Axis:**
* **Label:** None explicit. The categories are the dataset names.
* **Categories (from left to right):** "HotpotQA", "CWQ", "WebQSP".
* **Legend:**
* **Position:** Top-left corner of the chart area.
* **Items (with visual pattern/color):**
1. **CogGRAG:** Blue bar with a dotted pattern.
2. **CogGRAG-nd:** Green bar with a cross-hatch (X) pattern.
3. **CogGRAG-ng:** Orange bar with a vertical line pattern.
4. **CogGRAG-nv:** Red bar with a diagonal line pattern (top-left to bottom-right).
### Detailed Analysis
The chart presents the Rouge-L score for each model variant on each dataset. Values are approximate based on visual estimation against the y-axis.
**1. HotpotQA Dataset (Leftmost Group):**
* **CogGRAG (Blue, dotted):** ~34
* **CogGRAG-nd (Green, cross-hatch):** ~20
* **CogGRAG-ng (Orange, vertical lines):** ~32
* **CogGRAG-nv (Red, diagonal lines):** ~28
* **Trend within group:** CogGRAG performs best, followed closely by CogGRAG-ng. CogGRAG-nv is slightly lower, and CogGRAG-nd shows a significant drop.
**2. CWQ Dataset (Middle Group):**
* **CogGRAG (Blue, dotted):** ~56
* **CogGRAG-nd (Green, cross-hatch):** ~38
* **CogGRAG-ng (Orange, vertical lines):** ~53
* **CogGRAG-nv (Red, diagonal lines):** ~50
* **Trend within group:** The same performance order is maintained: CogGRAG > CogGRAG-ng > CogGRAG-nv > CogGRAG-nd. All scores are higher than on HotpotQA.
**3. WebQSP Dataset (Rightmost Group):**
* **CogGRAG (Blue, dotted):** ~60
* **CogGRAG-nd (Green, cross-hatch):** ~43
* **CogGRAG-ng (Orange, vertical lines):** ~58
* **CogGRAG-nv (Red, diagonal lines):** ~53
* **Trend within group:** Consistent pattern again. CogGRAG and CogGRAG-ng are very close at the top, with CogGRAG-nv and CogGRAG-nd following. This dataset yields the highest overall scores.
**Overall Trend Across Datasets:**
* Performance (Rouge-L score) increases for all models when moving from HotpotQA to CWQ to WebQSP.
* The relative ranking of the four models is consistent across all three datasets: **CogGRAG (full model) > CogGRAG-ng > CogGRAG-nv > CogGRAG-nd**.
### Key Observations
1. **Consistent Model Hierarchy:** The full CogGRAG model consistently outperforms all its ablated variants. The variant without dense retrieval (`-nd`) consistently performs the worst.
2. **Impact of Components:** Removing the graph component (`-ng`) causes a small but consistent performance drop compared to the full model. Removing the verification component (`-nv`) causes a slightly larger drop than removing the graph.
3. **Dataset Difficulty:** The models achieve the lowest scores on HotpotQA and the highest on WebQSP, suggesting HotpotQA may be the most challenging task for these models, or WebQSP the most aligned with their training.
4. **Visual Encoding:** The chart uses both distinct colors (blue, green, orange, red) and distinct fill patterns (dots, cross-hatch, vertical lines, diagonal lines) to differentiate the four model series, ensuring clarity.
### Interpretation
This chart presents an **ablation study** for the CogGRAG model. The data strongly suggests that all three core components—dense retrieval (`nd`), graph integration (`ng`), and verification (`nv`)—contribute positively to the model's performance on complex question-answering tasks.
* **The most critical component appears to be dense retrieval (`-nd`),** as its removal leads to the most substantial performance degradation across all datasets. This implies that the ability to retrieve relevant passages is foundational to the model's success.
* **Graph integration (`-ng`) and verification (`-nv`) provide secondary but meaningful improvements.** The graph component likely helps in reasoning over structured knowledge, while verification refines the generated answers. The fact that `-ng` performs slightly better than `-nv` might suggest that structured knowledge is marginally more beneficial than the verification step for these specific benchmarks, or that the verification module's design could be further optimized.
* The consistent performance increase across datasets (HotpotQA < CWQ < WebQSP) could indicate varying levels of complexity or different types of reasoning required, with WebQSP being the most amenable to the CogGRAG architecture.
In summary, the chart provides clear empirical evidence that the full CogGRAG system, combining dense retrieval, graph-based reasoning, and verification, is more effective than any simplified version of itself for the evaluated tasks. The ablation study validates the design choice of incorporating these three modules.
</details>
Figure 3: Ablation study on the main components of CogGRAG.
| LLaMA2-13B ToG MindMap | 19.1% 29.3% 27.9% | 25.7% 20.2% 22.4% | 55.2% 50.5% 49.7% |
| --- | --- | --- | --- |
| CogGRAG | 34.4% | 40.6% | 25.0% |
Table 4: Overall results of our CogGRAG on GRBENCH dataset. We highlight the best score on each dataset in bold.
### Hallucination and Missing Evaluation
In the reasoning and self-verification phase of CogGRAG, we prompt the LLM to respond with “I don’t know” when encountering questions with insufficient or incomplete relevant information during the reasoning process. This approach is designed to mitigate the hallucination issue commonly observed in LLMs. To evaluate the effectiveness of this strategy, we test the model on the HotpotQA dataset, with results reported in Table 4. We categorize the responses into three types: “Correct” for accurate answers, “Missing” for cases where the model responds with “I don’t know,” and “Hallucination” for incorrect answers. As shown in the table results, our model demonstrates the ability to refrain from answering questions with insufficient information, significantly reducing the occurrence of hallucinations.
| Graph-CoT GoG CogGRAG | 22.39 21.50 18.24 | 29.04 32.20 31.57 | 15.79 18.80 16.32 | 32.97 37.50 35.64 |
| --- | --- | --- | --- | --- |
Table 5: Average inference time per question (s).
### Performance in Inference Times
We conduct the verification on four datasets GRBENCH-Academic, GRBENCH-Amazon, GRBENCH-Goodreads, and GRBENCH-Disease. Table 5 presents the average runtime of CogGRAG, Graph-CoT and GoG. From the table, we can see that CogGRAG is on par with Graph-CoT and GoG. Although our reasoning process introduces self-verification, which increases the time cost, CogGRAG does not require iterative repeated reasoning and retrieval. Instead, it retrieves all relevant information in one step based on the mind map, avoiding redundant retrieval, which provides an advantage in large-scale KGs. Moreover, while self-verification adds additional time costs, it also improves the accuracy of reasoning results, as confirmed in the ablation experiments.
## Conclusion
In this paper, we proposed CogGRAG, a graph-based RAG framework to enhance LLMs’ complex reasoning for KGQA tasks. CogGRAG generates tree-structured mind maps, explicitly encoding semantic relationships among subproblems, which guide both local and global knowledge retrieval. A self-verification module further detects and revises potential errors, forming a dual-phase reasoning paradigm that reduces hallucinations and improves factual consistency. Extensive experiments show that CogGRAG substantially outperforms existing RAG baselines on complex multi-hop QA benchmarks.
## Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant 42375146 and National Natural Science Foundation of China No. 62202172.
## Appendix A Datastes
Here, we introduce the four datasets used in our experiments in detail. For HotpotQA and CWQ datasets, we evaluated the performance of all methods on the dev set. For WebQSP dataset, we evaluated the performance of all methods on the train set. The statistics and details of these datasets can be found in Table 6, and we describe each dataset in detail below:
HotpotQA is a large-scale question answering dataset aimed at facilitating the development of QA systems capable of performing explainable, multi-hop reasoning over diverse natural language. It contains 113k question-answer pairs that were collected through crowdsourcing based on Wikipedia articles.
WebQSP is a dataset designed specifically for question answering and information retrieval tasks, aiming to promote research on multi-hop reasoning and web-based question answering techniques. It contains 4,737 natural language questions that are answerable using a subset Freebase KG (bollacker2008freebase).
CWQ is a dataset specially designed to evaluate the performance of models in complex question answering tasks. It is generated from WebQSP by extending the question entities or adding constraints to answers, in order to construct more complex multi-hop questions.
GRBENCH is a dataset to evaluate how effectively LLMs can interact with domain-specific graphs containing rich knowledge to solve the desired problem. GRBENCH contains 10 graphs from 5 general domains (academia, e-commerce, literature, healthcare, and legal). Each data sample in GRBENCH is a question-answer pair.
| Wikipedia WebQSP CWQ | HotpotQA 3098 27,734 | 90564 0 3480 | 7405 1639 3475 | 7405 |
| --- | --- | --- | --- | --- |
| Academic | GRBENCH-Academic | 850 | | |
| E-commerce | GRBENCH-Amazon | 200 | | |
| Literature | GRBENCH-Goodreads | 240 | | |
| Healthcare | GRBENCH-Disease | 270 | | |
Table 6: Datasets statistics.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: Question Answering Process Flowchart
### Overview
The image is a technical flowchart diagram illustrating a multi-step natural language question answering (QA) process. It visually decomposes a complex question about a football team's league cup name into sub-questions, retrieves relevant information from a knowledge base, performs reasoning and self-verification, and arrives at a final answer. The diagram uses color-coded sections and directional arrows to show the flow of information and logic.
### Components/Axes
The diagram is structured into four main sections, each with a distinct border color and label:
1. **Main Question (Top, Beige Box):** Contains the initial query.
2. **Decomposition (Left, Red Dashed Border):** Breaks the main question into simpler sub-questions.
3. **Retrieval (Right, Green Dashed Border):** Shows the extraction and pruning of relevant knowledge graph information.
4. **Reasoning and Self-Verification (Bottom Left, Blue Dashed Border):** Demonstrates the logical steps to answer the sub-questions and verify the main answer.
5. **Answer (Bottom Right, Beige Box):** Presents the final output.
### Detailed Analysis / Content Details
**1. Main Question (Top Center):**
* **Text:** `Question: "The 2017–18 Wigan Athletic F.C. season will be a year in which the team competes in the league cup known as what for sponsorship reasons?"`
**2. Decomposition Section (Left):**
* **Central Red Box:** Contains the original question.
* **Two Sub-question Red Boxes (below central box):**
* Left Sub-question: `{"Sub-question": "What league cup is the Wigan Athletic F.C. competing in during the 2017-18 season?", "State": "End."}`
* Right Sub-question: `{"Sub-question": "What is the name of the league cup from the 2017-18 Wigan Athletic F.C. season?", "State": "End."}`
**3. Retrieval Section (Right):**
* **Extraction Sub-section (Top Green Box):**
* **Entity:** `["Wigan Athletic F.C.", "2017–18 season", "league cup", "sponsorship reasons"]`
* **Triples:** `( "Wigan Athletic F.C.", "competes in", "league cup" ), ( "league cup", "sponsorship name", "unknown" ), ( "2017–18 season", "associated with", "Wigan Athletic F.C." ), ( "league cup", "associated with", "2017–18 season" )`
* **Subgraph:** `[ ("Wigan Athletic F.C.", "competes in", "league cup"), ("Wigan Athletic F.C.", "competes in", "2017-18 season"), ("Wigan Athletic F.C.", "has", "league cup name") ]`
* **Retrieval and Prune Sub-section (Bottom Green Box):**
* **Triples:** `( "Wigan Athletic F.C.", "is a", "football club" ), ( "Wigan Athletic F.C.", "based in", "Wigan, England" ), ( "Wigan Athletic F.C.", "founded in", "1932" ), ( "Wigan Athletic F.C.", "competes in", "EFL Championship" ), ( "2017–18 season", "start date", "August 2017" ), ( "2017–18 season", "end date", "May 2018" ), ( "league cup", "official name", "EFL Cup" ), ( "league cup", "sponsored by", "Carabao" ), ( "league cup", "involves", "Wigan Athletic F.C." ), ( "league cup", "associated with", "EFL Championship" ), ( "league cup", "sponsorship name", "Carabao Cup" )......]`
**4. Reasoning and Self-Verification Section (Bottom Left):**
* **Top Blue Box (Main Reasoning):**
* `({"Question": "The 2017–18 Wigan Athletic F.C. season will be a year in which the team competes in the league cup known as what for sponsorship reasons?", "Answer": "Carabao Cup."})`
* **Two Supporting Blue Boxes (below, connected by lines labeled "[right]"):**
* Left Box: `{ "Question": "In which league cup did Wigan Athletic F.C. compete during the 2017-18 season?", "Answer": "Wigan Athletic F.C. competed in the EFL Cup during the 2017-18 season." }`
* Right Box: `{ "Question": "What was the sponsored name of the league cup identified in sub-question #1 during the 2017-18 season?", "Answer": "The sponsored name of the league cup during the 2017-18 season was the Carabao Cup." }`
**5. Final Answer (Bottom Right):**
* **Text:** `Answer: "Carabao Cup."`
### Key Observations
* **Process Flow:** The diagram clearly shows a sequential pipeline: Question → Decomposition → Retrieval → Reasoning → Answer.
* **Knowledge Representation:** The "Retrieval" section explicitly uses a knowledge graph format with entities and (subject, predicate, object) triples.
* **Self-Verification:** The reasoning step includes verifying the answer against the decomposed sub-questions, as indicated by the "[right]" labels on the connecting lines.
* **Information Hierarchy:** The initial retrieval ("Extraction") yields incomplete information (e.g., `"sponsorship name", "unknown"`), while the pruned retrieval contains the definitive fact (`"sponsorship name", "Carabao Cup"`).
### Interpretation
This diagram is a schematic representation of a neuro-symbolic or hybrid AI question-answering system. It demonstrates how a complex, multi-fact question is handled not as a single black-box operation, but through a structured, interpretable process.
* **What it demonstrates:** The system first parses the question into atomic, answerable parts (Decomposition). It then queries a structured knowledge base (like a knowledge graph) to gather relevant facts (Retrieval). The "Retrieval and Prune" step suggests a filtering or ranking mechanism to select the most pertinent information. Finally, it uses logical reasoning over the retrieved facts to answer the sub-questions and synthesize the final answer, with a built-in verification step.
* **Relationships:** The Decomposition guides the Retrieval. The outputs of Retrieval (the triples) are the raw materials for the Reasoning module. The Reasoning module's success is validated by its ability to correctly answer the sub-questions derived from the original Decomposition.
* **Notable Pattern:** The process explicitly handles uncertainty. The initial extraction identifies "sponsorship name" as "unknown," but the subsequent retrieval and pruning step resolves this to "Carabao Cup," showing how the system iteratively refines its information gathering.
* **Underlying Mechanism:** The use of triples and subgraphs points to a symbolic AI component (knowledge graphs, logical inference) working in tandem with a natural language understanding component (for parsing and question decomposition). This is a classic architecture for achieving high accuracy and explainability in factual QA tasks.
</details>
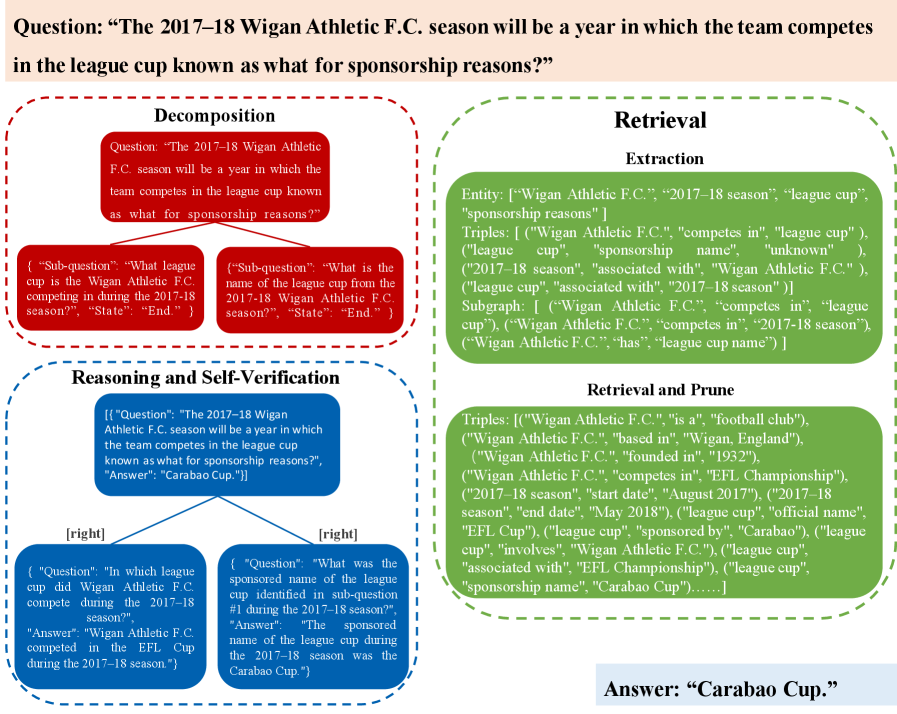
Figure 4: Case of CogGRAG.
## Appendix B Baselines
In this subsection, we introduce the baselines used in our experiments, including LLaMA2-13B, LLaMA3-8B, Qwen2.5-7B, Qwen2.5-32B, Chain-of-Thought (CoT) prompting, Think-on-graph (ToG), MindMap, Graph-CoT, Reasoning on Graphs (RoG), Generate-on-Graph (GoG).
LLaMA2-13B (llama2) is a member of the LLM series developed by Meta and is the second generation version of the LLaMA (Large Language Model Meta AI) model. LLaMA2-13B contains 13 billion parameters and is a medium-sized large language model.
LLaMA3-8B (llama3) is an efficient and lightweight LLM with 8 billion parameters, designed to provide high-performance natural language processing capabilities while reducing computing resource requirements.
Qwen2.5-7B (qwen2) is an efficient and lightweight LLM launched by Alibaba with 7 billion parameters. It aims at making it more efficient, specialized, and optimized for particular applications.
Qwen2.5-32B (hui2024qwen2) is an efficient LLM launched by Alibaba with 32 billion parameters. It is a more comprehensive foundation for real-world applications such as Code Agents. Not only enhancing coding capabilities but also maintaining its strengths in mathematics and general competencies.
Chain-of-Thought (prompt_cot) is a method designed to enhance a model’s reasoning ability, particularly for complex tasks that require multiple reasoning steps. It works by prompting the model to generate intermediate reasoning steps rather than just providing the final answer, thereby improving the model’s ability to reason through complex problems.
Think-on-graph (Think_on_graph) proposed a new LLM-KG integration paradigm, “LLM $\otimes$ KG”, which treats the LLM as an agent to interactively explore relevant entities and relationships on the KG and perform reasoning based on the retrieved knowledge. It further implements this paradigm by introducing a novel approach called “Graph-based Thinking”, in which the LLM agent iteratively performs beam search on the KG, discovers the most promising reasoning paths, and returns the most likely reasoning result.
MindMap (mindmap) propose a novel prompting pipeline, that leverages KGs to enhance LLMs’ inference and transparency. It enables LLMs to comprehend KG inputs and infer with a combination of implicit and external knowledge. Moreover, it elicits the mind map of LLMs, which reveals their reasoning pathways based on the ontology of knowledge.
Graph-CoT (graph_cot) propose a simple and effective framework called Graph Chain-of-thought to augment LLMs with graphs by encouraging LLMs to reason on the graph iteratively. Moreover, it manually construct a Graph Reasoning Benchmark dataset called GRBENCH, containing 1,740 questions that can be answered with the knowledge from 10 domain graphs.
Reasoning on Graphs (luo2024rog) propose a novel method called reasoning on graphs (RoG) that synergizes LLMs with KGs to enable faithful and interpretable reasoning. Specifically, they present a planning retrieval-reasoning framework, where RoG first generates relation paths grounded by KGs as faithful plans. These plans are then used to retrieve valid reasoning paths from the KGs for LLMs to conduct faithful reasoning.
Generate-on-Graph (xu2024gog) propose leveraging LLMs for QA under Incomplete Knowledge Graph (IKGQA), where the provided KG lacks some of the factual triples for each question, and construct corresponding datasets. To handle IKGQA, they propose a training-free method called Generate-on-Graph (GoG), which can generate new factual triples while exploring KGs.
## Appendix C Case Studies
In this section, we present a case analysis of the HotpotQA dataset to evaluate the performance of CogGRAG. As illustrated in Figure 4, CogGRAG decomposes the input question into two logically related sub-questions. Specifically, the complex question is broken down into “In which league cup” and “What was the sponsored name”, allowing the system to first identify the league cup and then determine its sponsored name based on the identified league. These sub-questions form a mind map, capturing the relationships between different levels of the problem. Next, CogGRAG extracts key information from all sub-questions, including both local level information within individual sub-questions and global level information across different sub-questions. A subgraph is constructed to represent the interconnected triples within the subgraph, enabling a global perspective to model the relationships between different questions. The retrieved triples are pruned based on similarity metrics. All information retrieved from the KG is represented in the form of triples. Using this knowledge, CogGRAG prompts the LLM to perform bottom-up reasoning and self-verification based on the constructed mind map. Through this process, the system ultimately derives the answer to the target question: “Carabao Cup.” This case demonstrates the effectiveness of CogGRAG in handling complex, multi-step reasoning tasks by leveraging hierarchical decomposition, structured knowledge retrieval, and self-verification mechanisms.
Additionally, Figure 5, Figure 7 and Figure 6 illustrate the process of prompting the large language model (LLM) to perform reasoning and self-verification, which provides a detailed breakdown of how the model generates and validates intermediate reasoning steps, ensuring the accuracy and reliability of the final output.
## Appendix D Prompts in CogGRAG
In this section, we show all the prompts that need to be used in the main experiments as shown in Table 7, Table 8, Table 9, Table 10, Table 11 and Table 12.
| Prompt head: “Your task is to decompose the given question Q into sub-questions. You should based on the specific logic of the question to determine the number of sub-questions and output them sequentially.” |
| --- |
| Instruction: “Please only output the decomposed sub-questions as a string in list format, where each element represents the text of a sub-question, in the form of {[“subq1”, “subq2”, “subq3”]}. For each sub-question, if you consider the sub-question to be sufficiently simple and no further decomposition is needed, then output “End.”, otherwise, output “Continue.” Please strictly follow the format of the example below when answering the question. |
| Here are some examples:” |
| “Input: “What year did Guns N Roses perform a promo for a movie starring Arnold Schwarzenegger as a former New York Police detective?” |
| Output: [ { “Sub-question”: “What movie starring Arnold Schwarzenegger as a former New York Police detective is being referred to?”, “State”: “Continue.” }, { “Sub-question”: “In what year did Guns N Roses perform a promo for the movie mentioned in sub-question #1?”, “State”: “End.” } ]” |
| “Input: “What is the name of the fight song of the university whose main campus is in Lawrence, Kansas and whose branch campuses are in the Kansas City metropolitan area?” |
| Output: [ { “Sub-question”: “Which university has its main campus in Lawrence, Kansas and branch campuses in the Kansas City metropolitan area?”, “State”: “End.” }, { “Sub-question”: “What is the name of the fight song of the university identified in sub-question #1?”, “State”: “End.” } ]” |
| “Input: “Are the Laleli Mosque and Esma Sultan Mansion located in the same neighborhood?” |
| Output: [ { “Sub-question”: “Where is the Laleli Mosque located?”, “State”: “End.” }, { “Sub-question”: “Where is the Esma Sultan Mansion located?”, “State”: “End.” }, { “Sub-question”: “Are the locations of the Laleli Mosque and the Esma Sultan Mansion in the same neighborhood?”, “State”: “End.” } ]” |
| “ Input: Question $Q$ ” |
| “ Output: ” |
Table 7: The prompt template for decomposition.
| Prompt head: “Your task is to extract the entities (such as people, places, organizations, etc.) and relations (representing behaviors or properties between entities, such as verbs, attributes, or categories, etc.) involved in the input questions. These entities and relations can help answer the input questions.” |
| --- |
| Instruction: “Please extract entities and relations in one of the following forms: entity, tuples, or triples from the given input List. Entity means that only an entity, i.e. <entity>. Tuples means that an entity and a relation, i.e. <entity-relation>. Triples means that complete triples, i.e. <entity-relation-entity>. Please strictly follow the format of the example below when answering the question.” |
| “ Input: [The mind map $\mathcal{M}$ ] ” |
| “ Output: ” |
Table 8: The prompt template for extraction on local level.
| Prompt head: “Your task is to extract the subgraphs involved in a set of input questions.” |
| --- |
| Instruction: “Please extract and organize information from a set of input questions into structured subgraphs. Each subgraph represents a group of triples (subject, relation, object) that share common entities and capture the logical relationships between the questions. Here are some examples:” |
| “Input: [“What is the capital of France?”, “Who is the president of France?”, “What is the population of Paris?”] |
| Output: [(“France”, “capital”, “Paris”), (“France”, “president”, “Current President”), (“Paris”, “population”, “Population Number”)]” |
| “ Input: [The mind map $\mathcal{M}$ ] ” |
| “ Output: ” |
Table 9: The prompt template for extraction on global level.
| Prompt head: “Your task is to answer the questions with the provided completed reasoning and input knowledge.” |
| --- |
| Instruction: “Please note that the response must be included in square brackets [xxx].” |
| “ The completed reasoning: [The set of verified answers $\hat{\mathcal{M}}$ ] ” |
| “ The knowledge graph: [The final retrieved triple set $\mathcal{T}$ ] ” |
| “ Input: [Subquestion $q^{t}$ ] ” |
| “ Output: ” |
Table 10: The prompt template for reasoning.
| Prompt head: “You are a logical verification assistant. Your task is to check whether the answer to a given question is logically consistent with the provided completed reasoning and input knowledge. If the answer is consistent, respond with “right”. If the answer is inconsistent, respond with “wrong”.” |
| --- |
| Instruction: “Please note that the response must be included in square brackets [xxx].” |
| “ The completed reasoning: [The set of verified answers $\hat{\mathcal{M}}$ ] ” |
| “ The knowledge graph: [The final retrieved triple set $\mathcal{T}$ ] ” |
| “ Answer: [The candidate answer $a^{t}$ ] ” |
| “ Input: [Subquestion $q^{t}$ ] ” |
| “ Output: ” |
Table 11: The prompt template for self-verification.
| Prompt head: “You are a reasoning and knowledge integration assistant. Your task is to re-think a question that was previously answered incorrectly by the self-verification model. Use the provided completed reasoning and input knowledge to generate a new answer.” |
| --- |
| Instruction: “Please note, if the knowledge is insufficient to answer the question, respond with “Insufficient information, I don’t know”. The response must be included in square brackets [xxx].” |
| “ The completed reasoning: [The set of verified answers $\hat{\mathcal{M}}$ ] ” |
| “ The knowledge graph: [The final retrieved triple set $\mathcal{T}$ ] ” |
| “ Input: [Subquestion $q^{t}$ ] ” |
| “ Output: ” |
Table 12: The prompt template for re-thinking.
<details>
<summary>x5.png Details</summary>

### Visual Description
\n
## Technical Document: Structured Q&A Task Specification
### Overview
The image displays a technical specification for a question-answering task. It defines an input format containing a task description, reasoning, knowledge data, and questions, followed by a required output format. The content is entirely textual and structured, resembling a prompt template or a test case for an information extraction system.
### Content Details
#### **Input Section**
The section is titled **"Input:"** in bold. The text below it provides instructions:
- **Task Description:** "Your task is to answer the questions with the provided completed reasoning and input knowledge. Please note that the response must be included in square brackets [xxx]."
- **Completed Reasoning:** "The completed reasoning: [ ]" (The brackets are empty).
- **Knowledge Triples:** A list of structured data in the format `(subject, predicate, object)`. The triples are:
1. `("Wigan Athletic F.C.", "is a", "football club")`
2. `("Wigan Athletic F.C.", "based in", "Wigan, England")`
3. `("Wigan Athletic F.C.", "founded in", "1932")`
4. `("Wigan Athletic F.C.", "competes in", "EFL Championship")`
5. `("2017–18 season", "start date", "August 2017")`
6. `("2017–18 season", "end date", "May 2018")`
7. `("league cup", "official name", "EFL Cup")`
8. `("league cup", "sponsored by", "Carabao")`
9. `("league cup", "involves", "Wigan Athletic F.C.")`
10. `("league cup", "associated with", "EFL Championship")`
11. `("league cup", "sponsorship name", "Carabao Cup")`
- **Input Questions:** A list containing two questions:
1. `"In which league cup did Wigan Athletic F.C. compete during the 2017–18 season?"`
2. `"What was the sponsored name of the league cup identified in sub-question #1 during the 2017–18 season?"`
#### **Response Section**
The section is titled **"Response:"** in bold. It shows the expected output format, which is a JSON-like array of objects enclosed in square brackets `[ ]`. Each object contains a `"Question"` and an `"Answer"` key.
- **First Q&A Pair:**
- **Question:** "In which league cup did Wigan Athletic F.C. compete during the 2017–18 season?"
- **Answer:** "Wigan Athletic F.C. competed in the EFL Cup during the 2017–18 season."
- **Second Q&A Pair:**
- **Question:** "What was the sponsored name of the league cup identified in sub-question #1 during the 2017–18 season?"
- **Answer:** "The sponsored name of the league cup during the 2017–18 season was the Carabao Cup."
### Key Observations
1. **Data Source:** All answers are directly derivable from the provided knowledge triples. The first answer uses triples #4, #7, and #9. The second answer uses triples #8 and #11.
2. **Logical Flow:** The second question explicitly references "sub-question #1," creating a dependency. The system must first identify the cup as the "EFL Cup" before retrieving its sponsored name.
3. **Formatting Requirement:** The instruction mandates that the final response be enclosed in square brackets `[xxx]`, which is demonstrated in the example output.
4. **Language:** The entire document is in English. No other languages are present.
### Interpretation
This document serves as a clear specification for a **knowledge-grounded question-answering system**. It demonstrates how to:
- **Structure Input:** Provide a self-contained context with explicit knowledge (triples) and clear questions.
- **Derive Answers:** Use the provided knowledge graph to find precise, factual answers without external information.
- **Format Output:** Return answers in a structured, machine-readable format (JSON array within brackets) that pairs each question with its corresponding answer.
The example highlights the importance of **entity linking** (connecting "league cup" in the question to the specific entity in the knowledge base) and **relationship traversal** (moving from "league cup" to its "official name" and then to its "sponsorship name"). The empty "completed reasoning" field suggests this might be a template where a reasoning trace could be inserted, but for this task, only the final answer derived from the knowledge is required.
</details>
Figure 5: The prompt case of reasoning.
<details>
<summary>x6.png Details</summary>

### Visual Description
## Technical Document Screenshot: Structured Q&A and Knowledge Extraction
### Overview
The image is a screenshot of a technical document or interface displaying a structured question-answering task. It presents a completed reasoning process, a set of knowledge triples, a specific input question, and the corresponding formatted output. The document is divided into two primary sections labeled "Input" and "Response," separated by a horizontal rule.
### Components/Axes
The document contains the following textual components and structural elements:
1. **Section Header: "Input:"** (Bold, top-left)
2. **Instructional Text:** A paragraph explaining the task requirements, including the need to enclose responses in square brackets `[xxx]`.
3. **"The completed reasoning:"** A block of text containing a JSON-like array of two question-answer pairs.
4. **"The knowledge: Triples:"** A block of text containing a list of knowledge triples in the format `(subject, predicate, object)`.
5. **"The Input:"** A block of text containing the specific question to be answered.
6. **"Output:"** A label indicating where the result should be placed.
7. **Horizontal Rule:** A solid black line separating the Input and Response sections.
8. **Section Header: "Response:"** (Bold, below the horizontal rule)
9. **Formatted Output:** The final answer, structured as a JSON-like array containing the original question and a generated answer, all enclosed within square brackets `[]`.
### Detailed Analysis / Content Details
**1. Instructional Text:**
* Text: "Your task is to answer the questions with the provided completed reasoning and input the,,,, the,...: the the,,,, the the. the. and input knowledge. Please note that the response must be included in square brackets [xxx]."
**2. Completed Reasoning Block:**
* Format: A JSON-style array `[ { ... }, { ... } ]`.
* **First Q&A Pair:**
* Question: "In which league cup did Wigan Athletic F.C. compete during the 2017–18 season?"
* Answer: "Wigan Athletic F.C. competed in the EFL Cup during the 2017–18 season."
* **Second Q&A Pair:**
* Question: "What was the sponsored name of the league cup identified in sub-question #1 during the 2017–18 season?"
* Answer: "The sponsored name of the league cup during the 2017–18 season was the Carabao Cup."
**3. Knowledge Triples Block:**
* Format: A list of tuples `(subject, predicate, object)`.
* Extracted Triples (transcribed verbatim):
* ("Wigan Athletic F.C.", "is a", "football club")
* ("Wigan Athletic F.C.", "based in", "Wigan, England")
* ("Wigan Athletic F.C.", "founded in", "1932")
* ("Wigan Athletic F.C.", "competes in", "EFL Championship")
* ("2017–18 season", "start date", "August 2017")
* ("2017–18 season", "end date", "May 2018")
* ("league cup", "official name", "EFL Cup")
* ("league cup", "sponsored by", "Carabao")
* ("league cup", "involves", "Wigan Athletic F.C.")
* ("league cup", "associated with", "EFL Championship")
* ("league cup", "sponsorship name", "Carabao Cup")
**4. The Input Question:**
* Text: "The 2017–18 Wigan Athletic F.C. season will be a year in which the team competes in the league cup known as what for sponsorship reasons?"
**5. The Response Output:**
* Format: A JSON-style array `[ { ... } ]` enclosed in square brackets.
* Content:
* Question: "The 2017–18 Wigan Athletic F.C. season will be a year in which the team competes in the league cup known as what for sponsorship reasons?"
* Answer: "During the 2017–18 season, Wigan Athletic F.C. competed in the league cup known as the Carabao Cup for sponsorship reasons."
### Key Observations
1. **Structured Data Flow:** The document demonstrates a clear pipeline: a task instruction is given, followed by supporting data (reasoning examples and knowledge base), a target input, and finally the generated output.
2. **Knowledge Representation:** The "knowledge" is represented as a set of semantic triples, forming a small knowledge graph about Wigan Athletic F.C., the 2017-18 season, and the league cup.
3. **Question Decomposition:** The "completed reasoning" shows a multi-step QA process where the first question identifies the cup's official name (EFL Cup), and the second derives its sponsored name (Carabao Cup).
4. **Output Formatting:** The final response strictly adheres to the initial instruction, wrapping the JSON object in square brackets.
5. **Consistency:** The answer in the "Response" section correctly synthesizes information from the knowledge triples (specifically, the triple `("league cup", "sponsorship name", "Carabao Cup")`) to answer the input question.
### Interpretation
This image illustrates a **few-shot learning or retrieval-augmented generation (RAG) setup for a question-answering system**. The "Input" section provides the system with:
* **A task definition:** Answer questions using provided context.
* **Demonstrations (Few-shot examples):** The "completed reasoning" shows the expected format and logic for breaking down a complex query.
* **A Knowledge Base:** The triples act as a structured fact repository the system can query.
* **A Target Query:** The final input question.
The "Response" section shows the system's successful execution. It correctly:
1. Identifies the core entity (Wigan Athletic F.C.) and time frame (2017-18 season) from the input.
2. Retrieves the relevant fact from the knowledge triples: the league cup associated with that team and season has the sponsorship name "Carabao Cup."
3. Formulates a natural language answer that directly addresses the "sponsorship reasons" aspect of the question.
4. Formats the output as specified.
The document serves as a technical specification or log for a knowledge-grounded QA task, emphasizing structured data, precise formatting, and traceable reasoning from provided facts to the final answer. The absence of charts or diagrams indicates the primary information is **propositional and relational knowledge**, not quantitative data.
</details>
Figure 6: The prompt case of reasoning with the completed reasoning.
<details>
<summary>x7.png Details</summary>

### Visual Description
## Screenshot: Logical Verification Task Interface
### Overview
The image is a screenshot of a structured text document, likely from an AI system or a testing interface. It presents a logical verification task where an assistant must determine if a given answer is consistent with provided reasoning and knowledge. The document is divided into three main sections: **Input**, **Output**, and **Response**.
### Components/Axes
The document is organized into clearly labeled sections with horizontal dividers:
1. **Input Section**: Contains the task description, completed reasoning, knowledge base (as triples), the original question, and the answer to be verified.
2. **Output Section**: A placeholder for the verification result.
3. **Response Section**: Contains the final verification result and a brief explanation.
### Detailed Analysis / Content Details
**1. Input Section Text:**
* **Task Description:** "You are a logical verification assistant. Your task is to check whether the answer to a given question is logically consistent with the provided completed reasoning and input knowledge. If the answer is consistent, respond with “right”. If the answer is inconsistent, respond with “wrong”. Please note that the response must be included in square brackets [xxx]."
* **Completed Reasoning:** `[ ]` (Empty brackets, indicating no prior reasoning was provided).
* **Knowledge (Triples):**
* `("Wigan Athletic F.C.", "is a", "football club")`
* `("Wigan Athletic F.C.", "based in", "Wigan, England")`
* `("Wigan Athletic F.C.", "founded in", "1932")`
* `("Wigan Athletic F.C.", "competes in", "EFL Championship")`
* `("2017–18 season", "start date", "August 2017")`
* `("2017–18 season", "end date", "May 2018")`
* `("league cup", "official name", "EFL Cup")`
* `("league cup", "sponsored by", "Carabao")`
* `("league cup", "involves", "Wigan Athletic F.C.")`
* `("league cup", "associated with", "EFL Championship")`
* `("league cup", "sponsorship name", "Carabao Cup")`
* **The Input (Question):** `["In which league cup did Wigan Athletic F.C. compete during the 2017–18 season?"]`
* **The Answer:** `[ { "Question": "In which league cup did Wigan Athletic F.C. compete during the 2017–18 season?", "Answer": "Wigan Athletic F.C. competed in the EFL Cup during the 2017–18 season."} ]`
**2. Output Section Text:**
* `Output:` (This is a label; the actual output field is empty in the screenshot).
**3. Response Section Text:**
* `[right]`
* "The answers are logically consistent with the provided knowledge. The triples confirm that Wigan Athletic F.C. competed in the EFL Cup (league cup) during the 2017–18 season, and the sponsored name of the league cup was the Carabao Cup. Therefore, the answers are correct."
### Key Observations
* The "Completed Reasoning" field is empty (`[ ]`), meaning the verification was performed solely against the provided knowledge triples.
* The knowledge base uses a structured triple format `(subject, predicate, object)` to encode facts.
* The answer being verified is presented in a JSON-like structure within a list.
* The final response (`[right]`) and its explanation are located in the bottom "Response" section of the document.
### Interpretation
This document illustrates a **fact-checking or consistency verification process**. The system is not generating new information but is performing a logical cross-reference.
1. **Task Logic:** The core task is to see if the statement "Wigan Athletic F.C. competed in the EFL Cup during the 2017–18 season" can be derived from the given knowledge.
2. **Evidence Chain:** The knowledge triples provide the necessary links:
* The "league cup" has the "official name" "EFL Cup".
* The "league cup" "involves" "Wigan Athletic F.C.".
* The "2017–18 season" is defined by its start and end dates.
* While not explicitly stating "Wigan competed in the 2017-18 EFL Cup," the combination of the team's involvement in the league cup and the definition of the season allows for a reasonable inference, which the verifier accepts.
3. **Notable Detail:** The knowledge also includes the sponsored name ("Carabao Cup"), which the response explanation mentions but correctly identifies as separate from the official name used in the answer.
4. **Purpose:** This setup is typical for evaluating the reasoning capabilities of AI models, testing their ability to perform deductive logic over a structured knowledge base without hallucinating information. The empty "Completed Reasoning" suggests this might be a test of pure knowledge-grounded verification rather than reasoning-chain validation.
</details>
Figure 7: The prompt case of self-verification.