# Human Cognition Inspired RAG with Knowledge Graph for Complex Problem Solving
**Authors**: Yao Cheng, Yibo Zhao, Jiapeng Zhu, Yao Liu, Xing Sun, Xiang Li
> Corresponding author.
## Abstract
Large Language Models (LLMs) have demonstrated significant potential across various domains. However, they often struggle with integrating external knowledge and performing complex reasoning, leading to hallucinations and unreliable outputs. Retrieval Augmented Generation (RAG) has emerged as a promising paradigm to mitigate these issues by incorporating external knowledge. Yet, conventional RAG approaches, especially those based on vector similarity, fail to effectively capture relational dependencies and support multi-step reasoning. In this work, we propose CogGRAG, a human cognition-inspired, graph-based RAG framework designed for Knowledge Graph Question Answering (KGQA). CogGRAG models the reasoning process as a tree-structured mind map that decomposes the original problem into interrelated subproblems and explicitly encodes their semantic relationships. This structure not only provides a global view to guide subsequent retrieval and reasoning but also enables self-consistent verification across reasoning paths. The framework operates in three stages: (1) top-down problem decomposition via mind map construction, (2) structured retrieval of both local and global knowledge from external Knowledge Graphs (KGs), and (3) bottom-up reasoning with dual-process self-verification. Unlike previous tree-based decomposition methods such as MindMap or Graph-CoT, CogGRAG unifies problem decomposition, knowledge retrieval, and reasoning under a single graph-structured cognitive framework, allowing early integration of relational knowledge and adaptive verification. Extensive experiments demonstrate that CogGRAG achieves superior accuracy and reliability compared to existing methods.
Code — https://github.com/cy623/RAG.git
## Introduction
As a foundational technology for artificial general intelligence (AGI), large language models (LLMs) have achieved remarkable success in practical applications, demonstrating transformative potential across a wide range of domains (llama2; llama3; qwen2). Their ability to process, generate, and reason with natural language has enabled significant advancements in areas such as machine translation (zhu2023multilingual), text summarization (basyal2023text), and question answering (pan2306unifying). Despite their impressive performance, LLMs still face significant limitations in knowledge integration beyond their pre-trained data boundaries. These limitations often lead to the generation of plausible but factually incorrect responses, a phenomenon commonly referred to as hallucinations, which undermines the reliability of LLMs in critical applications.
To mitigate hallucinations, Retrieval Augmented Generation (RAG) (niu2023ragtruth; gao2023retrieval; graphrag; xin2024atomr; chu2024beamaggr; cao2023probabilistic; wu2025pa; zhao20252graphrag) has emerged as a promising paradigm, significantly improving the accuracy and reliability of LLM-generated contents through the integration of external knowledge. However, while RAG successfully mitigates certain aspects of hallucination, it still exhibits inherent limitations in processing complex relational information. As shown in Figure 1 (a), the core limitation of standard RAG systems lies in their reliance on vector-based similarity matching, which processes knowledge segments as isolated units without capturing their contextual interdependencies or semantic relationships (graph_cot). Consequently, traditional RAG implementations are inadequate for supporting advanced reasoning capabilities in LLMs, particularly in scenarios requiring complex problem-solving, multi-step inference, or sophisticated knowledge integration.
<details>
<summary>x1.png Details</summary>

### Visual Description
## Diagram: Retrieval-Augmented Generation for Enhancing LLMs
### Overview
The image compares two methods for enhancing Large Language Models (LLMs) using retrieval-augmented generation. It illustrates how iterative retrieval improves the LLM's ability to answer complex questions by refining external knowledge integration.
### Components/Axes
- **Question**: "The football manager who recruited David Beckham managed Manchester United during what timeframe?"
- **External Knowledge Sources**:
- David Beckham (Similarity Score: 0.8)
- Manchester United (Similarity Score: 0.8)
- Alex Ferguson (Similarity Score: 0.05)
- **LLM**: A blue robot icon with an "X" (indicating failure in (a)) and a "checkmark" (success in (b)).
- **Answer**:
- (a) "I cannot answer your question since I do not have enough information."
- (b) "From 2016 to 2018." (Incorrect, later corrected to "1986-2013.")
### Detailed Analysis
#### (a) Retrieval-Augmented Generation for Enhancing LLMs
- **Flow**:
1. External knowledge sources (David Beckham, Manchester United, Alex Ferguson) are retrieved.
2. The LLM processes these sources but fails to answer the question due to insufficient information.
- **Key Elements**:
- Similarity scores (0.8, 0.8, 0.05) indicate relevance of retrieved sources.
- The LLM’s inability to answer highlights limitations in single-step retrieval.
#### (b) Iterative Retrieval-Augmented Generation for Enhancing LLMs
- **Flow**:
1. The LLM retrieves "Manchester United" and "Jose Mourinho" (incorrectly linked to 2016–2018).
2. Iterative refinement connects "David Beckham" to "Jose Mourinho" (recruitment).
3. Final answer: "From 2016 to 2018." (Incorrect, but the correct answer is "1986-2013.").
- **Key Elements**:
- Cross-referencing of sources (e.g., "David Beckham was recruited by Jose Mourinho").
- Iterative process corrects initial errors, though the final answer remains inaccurate.
### Key Observations
- **Failure in (a)**: The LLM lacks sufficient context to link David Beckham’s recruitment to Manchester United’s timeframe.
- **Iterative Success in (b)**: The process identifies relevant connections (e.g., Jose Mourinho’s role) but fails to produce the correct answer.
- **Ambiguity in Answer**: The correct answer ("1986-2013") is provided separately, suggesting the diagram’s iterative method still has gaps.
### Interpretation
The diagram demonstrates that iterative retrieval-augmented generation improves the LLM’s ability to synthesize information from external sources. However, the final answer in (b) ("2016–2018") is incorrect, indicating that the method requires further refinement to handle temporal or contextual nuances. The use of similarity scores and cross-referencing highlights the importance of iterative feedback loops in enhancing LLM performance, even if the ultimate answer remains imperfect.
</details>
Figure 1: Representative workflow of two Retrieval-Augmented Generation paradigms for enhancing LLMs.
Recently, graph-based RAG (graphrag; tog2; graph_cot; gnnrag; xiong2024interactive) has been proposed to address the limitations of conventional RAG systems by incorporating deep structural information from external knowledge sources. These approaches typically utilize KGs to model complex relation patterns within external knowledge bases, employing structured triple representations (<entity, relation, entity>) to integrate fragmented information across multiple document segments. While graph-based RAG has shown promising results in mitigating hallucination and improving factual accuracy, several challenges remain unresolved:
$\bullet$ Lack of holistic reasoning structures. Complex problems cannot be resolved through simple queries; they typically require multi-step reasoning to derive the final answer. Existing methods often adopt iterative or sequential inference pipelines that are prone to cascading errors due to the absence of global reasoning plans (graph_cot; gnnrag). As shown in Figure 1 (b), each step in the iterative process relies on the result of the previous step, indicating that errors occurred at previous steps can propagate to subsequent steps.
$\bullet$ Absence of verification mechanisms. Despite the integration of external knowledge sources, LLMs remain prone to generating inaccurate or fabricated responses when confronted with retrieval errors or insufficient knowledge coverage. Most approaches do not incorporate explicit self-verification, making them vulnerable to retrieval errors or spurious reasoning paths.
To address these challenges, we propose CogGRAG, a Cog nition inspired G raph RAG framework, designed to enhance the complex problem-solving capabilities of LLMs in Knowledge Graph Question Answering (KGQA) tasks. CogGRAG is motivated by dual-process theories in human cognition, where problem solving involves both structured decomposition and iterative reflection. Our key contributions are as follows:
$\bullet$ Human-inspired decomposition. CogGRAG introduces a top-down question decomposition strategy that constructs a tree-structured mind map, explicitly modeling semantic relationships among subproblems. This representation enables the system to capture dependencies, causal links, and reasoning order between subcomponents, providing a global structure that guides subsequent retrieval and reasoning.
$\bullet$ Hierarchical structured retrieval. CogGRAG performs both local-level (entity/triple-based) and global-level (subgraph) retrieval based on the mind map. This dual-level retrieval strategy ensures precise and context-rich knowledge grounding.
$\bullet$ Self-verifying reasoning. Inspired by cognitive self-reflection, CogGRAG employs a dual-LLM verification mechanism. The reasoning LLM generates answers, which are then reviewed by a separate verifier LLM to detect and revise erroneous outputs. This design reduces hallucinations and improves output faithfulness.
We validate CogGRAG across three general KGQA benchmarks (HotpotQA, CWQ, WebQSP) and one domain-specific KGQA dataset (GRBench). Empirical results demonstrate that CogGRAG consistently outperforms strong baselines in both accuracy and hallucination suppression, under multiple LLM backbones.
## Related Work
<details>
<summary>x2.png Details</summary>
### Visual Description
## Flowchart: Process for Answering Complex Questions
### Overview
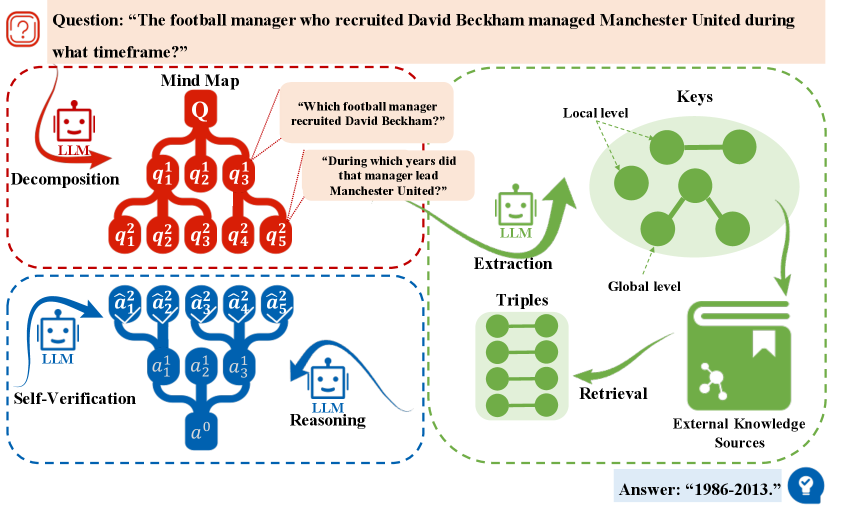
The image depicts a structured flowchart illustrating a multi-step process for answering complex questions using decomposition, self-verification, extraction, and retrieval. The flowchart uses color-coded sections (red, blue, green) to represent distinct stages and integrates external knowledge sources. The final answer provided is "1986-2013," linked to a historical query about David Beckham's recruitment timeline.
### Components/Axes
1. **Red Dashed Box (Mind Map - Decomposition)**
- **Labels**:
- "Q" (Main Question): "The football manager who recruited David Beckham managed Manchester United during what timeframe?"
- Sub-questions:
- `q1`, `q2`, `q3` (primary decomposition)
- `q1_1` to `q1_5`, `q2_1` to `q2_5`, `q3_1` to `q3_5` (further breakdown)
- **Flow**:
- Arrows from "Q" branch into sub-questions, indicating hierarchical decomposition.
2. **Blue Box (Self-Verification & Reasoning)**
- **Labels**:
- "Self-Verification": Arrows from `a1_1` to `a1_5` (hypotheses) to `a0` (final answer).
- "LLM Reasoning": Connects `a0` to the final answer.
- **Flow**:
- Blue arrows represent iterative verification and logical synthesis of answers.
3. **Green Dashed Box (Keys - Extraction & Retrieval)**
- **Labels**:
- "Local level" and "Global level" (knowledge hierarchies).
- "Triples": Structured data points (e.g., manager-recruitment-year relationships).
- "External Knowledge Sources": Icon of a book with a molecular structure.
- **Flow**:
- Green arrows link decomposition to extraction, retrieval, and synthesis of external data.
4. **Legend & Color Coding**
- **Red**: Decomposition of questions.
- **Blue**: Self-verification and reasoning.
- **Green**: Extraction, retrieval, and external knowledge integration.
### Detailed Analysis
- **Decomposition**:
The main question (`Q`) is split into three primary sub-questions (`q1`, `q2`, `q3`), each further divided into five granular components (e.g., `q1_1` to `q1_5`). This suggests a systematic breakdown of the query into verifiable components.
- **Self-Verification**:
Hypotheses (`a1_1` to `a1_5`) are tested against the original question, with verified answers (`a0`) synthesized through LLM reasoning. This step ensures accuracy by cross-checking intermediate results.
- **Extraction & Retrieval**:
The green section emphasizes leveraging both local (e.g., manager-specific data) and global (e.g., historical timelines) knowledge. "Triples" (e.g., "manager → recruited → Beckham → years") represent structured facts extracted from external sources.
- **Answer Synthesis**:
The final answer ("1986-2013") is derived by integrating verified sub-answers (`a0`) with retrieved knowledge, demonstrating a closed-loop process.
### Key Observations
1. **Hierarchical Question Breakdown**:
The decomposition into `q1_1` to `q3_5` ensures granularity, enabling targeted verification of each sub-question.
2. **Iterative Verification**:
The blue "Self-Verification" loop highlights the importance of cross-checking hypotheses before finalizing answers.
3. **Knowledge Integration**:
The green "Keys" section underscores the fusion of local (specific) and global (general) data, critical for contextual accuracy.
4. **Structured Output**:
The answer "1986-2013" is explicitly tied to the manager’s tenure, linking recruitment events to historical timelines.
### Interpretation
The flowchart represents a **knowledge graph-based reasoning framework** for answering complex queries. By decomposing questions into verifiable sub-components, iteratively testing hypotheses, and integrating structured data from external sources, the process ensures robust and accurate answers. The example answer ("1986-2013") demonstrates how this framework resolves historical queries by connecting managerial decisions (e.g., recruiting Beckham) to specific timeframes.
**Notable Patterns**:
- The use of color coding (red/blue/green) visually separates distinct cognitive stages, aiding in process clarity.
- The "Triples" structure suggests a knowledge graph approach, where relationships between entities (manager, player, years) are explicitly modeled.
**Underlying Logic**:
The diagram aligns with Peircean abductive reasoning: starting with an observation (Beckham’s recruitment), forming hypotheses (managerial timelines), testing them against data (extraction/retrieval), and refining the explanation (self-verification). This mirrors scientific inquiry, emphasizing iterative validation and knowledge integration.
</details>
Figure 2: The overall process of CogGRAG. Given a target question $Q$ , CogGRAG first prompts the LLM to decompose it into a hierarchy of sub-problems in a top-down manner, constructing a structured mind map. Subsequently, CogGRAG prompts the LLM to extract both local level (entities and triples) and global level (subgraphs) key information from these questions. Finally, CogGRAG guides the LLM to perform bottom-up reasoning and verification based on the mind map and the retrieved knowledge, until the final answer is derived.
Reasoning with LLM Prompting. Recent advancements in prompt engineering have demonstrated that state-of-the-art prompting techniques can significantly enhance the reasoning capabilities of LLMs on complex problems (prompt_cot; prompt_tree; prompt_graph). Chain of Thought (CoT (prompt_cot) explores how generating a chain of thought—a series of intermediate reasoning steps—significantly improves the ability of large language models to perform complex reasoning. Tree of Thoughts (ToT) (prompt_tree) introduces a new framework for language model inference that generalizes the popular Chain of Thought approach to prompting language models, enabling exploration of coherent units of text (thoughts) as intermediate steps toward problem-solving. The Graph of Thoughts (GoT) (prompt_graph) models the information generated by a LLM as an arbitrary graph, enabling LLM reasoning to more closely resemble human thinking or brain mechanisms. However, these methods remain constrained by the limitations of the model’s pre-trained knowledge base and are unable to address hallucination issues stemming from the lack of access to external, up-to-date information.
Knowledge Graph Augmented LLM. KGs (wikidata) offer distinct advantages in enhancing LLMs with structured external knowledge. Early graph-based RAG methods (graphrag; G-retriever; GRAG; wu2023retrieve; jin2024survey) demonstrated this potential by retrieving and integrating structured, relevant information from external sources, enabling LLMs to achieve superior performance on knowledge-intensive tasks. However, these methods exhibit notable limitations when applied to complex problems. Recent advancements have introduced methods like chain-of-thought prompting to enhance LLMs’ reasoning on complex problems (Think_on_graph; tog2; graph_cot; chen2024plan; luo2025gfm; luo2024graph; li2024simple). Think-on-Graph (Think_on_graph) introduces a new approach that enables the LLM to iteratively execute beam search on the KGs, discover the most promising reasoning paths, and return the most likely reasoning results. ToG-2 (tog2) achieves deep and faithful reasoning in LLMs through an iterative knowledge retrieval process that involves collaboration between contexts and the KGs. GRAPH-COT (graph_cot) propose a simple and effective framework to augment LLMs with graphs by encouraging LLMs to reason on the graph iteratively. However, iterative reasoning processes are prone to error propagation, as errors cannot be corrected once introduced. This leads to error accumulation and makes it difficult to reason holistically or revise previous steps. In contrast, our CogGRAG framework constructs a complete reasoning plan in advance through top-down decomposition, forming a mind map that globally guides retrieval and reasoning. None of the aforementioned approaches incorporate a self-verification phase. Once an incorrect inference is made, it propagates without correction. CogGRAG addresses this by introducing a dual-LLM self-verification module inspired by dual-process cognitive theory, allowing the system to detect and revise incorrect outputs during the reasoning phase.
## Methodology
In this section, we introduce CogGRAG a human cognition-inspired graph-based retrieval-augmented generation framework designed to enhance complex reasoning in KGQA tasks. CogGRAG simulates human cognitive strategies by decomposing complex questions into structured sub-problems, retrieving relevant knowledge in a hierarchical manner, and verifying reasoning results through dual-process reflection. The overall framework consists of three stages: (1) Decomposition, (2) Structured Retrieval, and (3) Reasoning with Self-Verification. The workflow is illustrated in Figure 2.
### Problem Formulation
Given a natural language question $Q$ , the goal is to generate a correct answer $A$ using an LLM $p_{\theta}$ augmented with a KG $\mathcal{G}$ . CogGRAG aim to design a graph-based RAG framework with an LLM backbone $p_{\theta}$ to enhance the complex problem-solving capabilities and generate the answer $A$ .
### Top-Down Decomposition
Inspired by human cognition in problem-solving, we simulate a top-down analytical process by decomposing the original question into a hierarchy of semantically coherent sub-questions. This decomposition process produces a reasoning mind map, which serves as an explicit structure to guide subsequent retrieval and reasoning steps. In this mind map, each node represents a sub-question, and edges capture the logical dependencies among them. Specifically, CogGRAG decomposes the original question $Q$ into a hierarchical structure forming a mind map $\mathcal{M}$ . Each node in $\mathcal{M}$ is defined as a tuple $m=(q,t,s)$ , where $q$ denotes the sub-question, $t$ indicates its depth level in the tree, and $s\in\{\texttt{Continue},\texttt{End}\}$ specifies whether further decomposition is required.
The decomposition proceeds recursively using the LLM:
$$
\{(q^{t+1}_{j},s^{t+1}_{j})\}_{j=1}^{N}=\texttt{Decompose}(q^{t},p_{\theta},\texttt{prompt}_{dec}), \tag{1}
$$
where $N$ is determined adaptively by LLM. This process continues until all leaves in $\mathcal{M}$ are labeled with End, representing atomic questions.
This hierarchical planning mechanism allows CogGRAG to surface latent semantic dependencies that may be overlooked by traditional matching-based RAG methods. For instance, consider the query: “ The football manager who recruited David Beckham managed Manchester United during what timeframe? ” A conventional retrieval pipeline may fail to resolve the intermediate entity “Alex Ferguson,” as it is not directly mentioned in the input question. In contrast, CogGRAG first decomposes the query into “Who recruited David Beckham?” and “When did that manager coach Manchester United?”, thereby enabling the system to recover critical missing entities and construct a more accurate reasoning path.
By performing top-down question decomposition before any retrieval or reasoning, CogGRAG explicitly separates planning from execution. This design enables holistic reasoning over the entire problem space, mitigates error propagation, and sets the foundation for effective downstream processing.
### Structured Knowledge Retrieval
Once the mind map $\mathcal{M}$ has been constructed through top-down decomposition, CogGRAG enters retrieval stage. This phase is responsible for identifying the external knowledge required to support reasoning across all sub-questions. In contrast to prior iterative methods (graph_cot) that retrieve relevant content at each reasoning step, CogGRAG performs a one-pass, globally informed retrieval guided by the full structure of $\mathcal{M}$ . This design not only enhances retrieval completeness and contextual coherence, but also avoids error accumulation caused by sequential retrieval failures.
To retrieve relevant information from the KG $\mathcal{G}$ , CogGRAG extracts two levels of key information from $\mathcal{M}$ . Local-level information captures entities and fine-grained relational facts associated with individual sub-questions. These include entity mentions, entity-relation pairs, and triples. Global-level information reflects semantic dependencies across multiple sub-questions and is expressed as interconnected subgraphs. These subgraphs encode logical chains or joint constraints necessary to resolve the overall problem. For example, given the decomposed question “ Which football manager recruited David Beckham? ”, we can extract local-level information such as the entity (David Beckham) and the triple (manager, recruited, David Beckham). By additionally considering another decomposed question—such as “ During which years did that manager lead Manchester United? ”—we can derive global level information, which is represented in the form of a subgraph [(manager, recruited, David Beckham), (manager, manage, Manchester United)]. The extraction process is performed using the LLM:
$$
\mathcal{K}=\texttt{Extract}(\mathcal{M},p_{\theta},\texttt{prompt}_{ext}), \tag{2}
$$
where $\mathcal{K}$ denotes the set of all extracted keys, including entity nodes, triples, and subgraph segments. This design ensures that both isolated facts and relational contexts are captured prior to KGs querying. These keys guide graph-based retrieval. For each entity $e$ in the extracted key set $\mathcal{K}$ , we expand to its neighborhood in $\mathcal{G}$ , yielding a candidate triple set $\tilde{\mathcal{T}}$ . A semantic similarity filter is applied to retain only relevant triples:
$$
\mathcal{T}=\{\tau\in\tilde{\mathcal{T}},k\in\mathcal{K}\mid\texttt{sim}(\tau,k)>\varepsilon\}, \tag{3}
$$
where $\texttt{sim}(\cdot)$ is cosine similarity, $\varepsilon$ is a threshold, $\tau$ is the triple in candidate triple set $\tilde{\mathcal{T}}$ and $k$ is the triple in the extracted key set $\mathcal{K}$ . The final retrieved triple set $\mathcal{T}$ serves as the input evidence pool for the reasoning module. By leveraging both local and global context from $\mathcal{M}$ , CogGRAG ensures that $\mathcal{T}$ is semantically rich, structurally connected, and targeted toward the entire reasoning path.
### Reasoning with Self-Verification
The final stage of CogGRAG emulates human problem-solving behavior, where conclusions are not only derived through reasoning but also reviewed through self-reflection (frederick2005cognitive). To this end, CogGRAG employs a dual-process reasoning architecture, composed of two distinct LLMs:
- LLM res: responsible for answer generation via bottom-up reasoning over the mind map $\mathcal{M}$ ;
- LLM ver: responsible for evaluating the validity of generated answers based on context and prior reasoning history.
This dual-agent setup is inspired by dual-process theories in cognitive psychology (vaisey2009motivation), where System 1 performs intuitive reasoning and System 2 monitors and corrects errors.
#### Bottom-Up Reasoning.
Given the final retrieved triple set $\mathcal{T}$ and the structured mind map $\mathcal{M}$ , CogGRAG performs reasoning in a bottom-up fashion: sub-questions at the lowest level are answered first, and their verified results are recursively used to resolve higher-level nodes.
Let $\mathcal{M}$ denote the full mind map. We define $\hat{\mathcal{M}}\subset\mathcal{M}$ as the subset of sub-questions that have been answered and verified. Each element in $\hat{\mathcal{M}}$ is a tuple $(q,\hat{a})$ , where $q$ is a sub-question and $\hat{a}$ is its verified answer. Then the reasoning LLM generates a candidate answer:
$$
a^{t}=\texttt{LLM}_{\text{res}}(\mathcal{T},q^{t},\hat{\mathcal{M}},\texttt{prompt}_{res}). \tag{4}
$$
#### Self-Verification and Re-thinking.
The candidate answer $a^{t}$ is passed to the verifier LLM along with the current reasoning path. The verifier assesses consistency, factual grounding, and logical coherence. If the answer fails validation, a re-thinked response $\hat{a}^{t}$ is regenerated:
$$
\hat{a}^{t}=\begin{cases}\texttt{LLM}_{\text{res}}(\mathcal{T},q^{t},\hat{\mathcal{M}},\texttt{prompt}_{rethink})&\text{if }\delta^{t}=\texttt{False},\\
a^{t}&\text{otherwise.}\end{cases} \tag{5}
$$
Here, $\delta^{t}$ is a boolean indicator defined as:
$$
\delta^{t}=\texttt{LLM}_{\text{ver}}(q^{t},a^{t},\hat{\mathcal{M}},\texttt{prompt}_{ver}), \tag{6}
$$
which returns True if the verification module accepts $a^{t}$ , and False otherwise. In addition to verification, CogGRAG incorporates a selective abstention mechanism. When the reasoning LLM cannot confidently produce a grounded answer based on $\mathcal{T}$ , it is explicitly prompted to respond with “ I don’t know ” rather than hallucinating. The final answer $A$ to the original question $Q$ is obtained by recursively aggregating verified answers $\hat{a}^{t}$ from the leaf nodes up to the root node $q^{0}$ , such that $A=\hat{a}^{0}$ .
This bottom-up reasoning pipeline, governed by a globally constructed mind map and protected by verification layers, enables CogGRAG to perform accurate and reliable complex reasoning over structured knowledge. All prompt templates used in CogGRAG can be found in the Appendix.
| Type | Method | HotpotQA | CWQ | WebQSP | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| RL | EM | F1 | RL | EM | F1 | RL | EM | F1 | | |
| LLM-only | Direct | 19.1% | 17.3% | 18.7% | 31.4% | 28.8% | 31.7% | 51.4% | 47.9% | 53.5% |
| CoT | 23.3% | 20.8% | 22.1% | 35.1% | 32.7% | 33.5% | 55.2% | 51.6% | 55.3% | |
| LLM+KG | Direct+KG | 27.5% | 23.7% | 27.6% | 39.7% | 35.1% | 38.3% | 52.5% | 49.3% | 52.1% |
| CoT+KG | 28.7% | 25.4% | 26.9% | 42.2% | 37.6% | 40.8% | 52.8% | 48.1% | 50.5% | |
| Graph-based RAG | ToG | 29.3% | 26.4% | 29.6% | 49.1% | 46.1% | 47.7% | 54.6% | 57.4% | 56.1% |
| MindMap | 27.9% | 25.6% | 27.8% | 46.7% | 43.7% | 44.1% | 56.6% | 53.1% | 58.3% | |
| RoG | 30.7% | 28.1% | 30.4% | 55.3% | 51.8% | 54.7% | 65.2% | 62.8% | 67.2% | |
| GoG | 31.5% | 30.1% | 31.1% | 55.7% | 52.4% | 54.8% | 65.5% | 59.1% | 63.6% | |
| Ours | CogGRAG | 34.4% | 30.7% | 35.5% | 56.3% | 53.4% | 55.8% | 59.8% | 56.1% | 58.9% |
Table 1: Overall results of our CogGRAG on three KBQA datasets. The best score on each dataset is highlighted.
## Experiments
### Experimental Settings
Datasets and evaluation metrics. In order to test CogGRAG’s complex problem-solving capabilities on KGQA tasks, we evaluate CogGRAG on three widely used complex KGQA benchmarks: (1) HotpotQA (yang2018hotpotqa), (2) WebQSP (yih2016value), (3) CWQ (talmor2018web). Following previous work (cok), full Wikidata (wikidata) is used as structured knowledge sources for all of these datasets. Considering that Wikidata is commonly used for training LLMs, there is a need for a domain-specific QA dataset that is not exposed during the pretraining process of LLMs in order to better evaluate the performance. Thus, we also test CogGRAG on a recently released domain-specific dataset GRBENCH (graph_cot). All methods need to interact with domain-specific graphs containing rich knowledge to solve the problem in this dataset. The statistics and details of these datasets can be found in Appendix. For all datasets, we use three evaluation metrics: (1) Exact match (EM): measures whether the predicted answer or result matches the target answer exactly. (2) Rouge-L (RL): measures the longest common subsequence of words between the responses and the ground truth answers. (3) F1 Score (F1): computes the harmonic mean of precision and recall between the predicted and gold answers, capturing both completeness and exactness of overlapping tokens.
Baselines. In our main results, we compare CogGRAG with three types state-of-the-art methods: (1) LLM-only methods without external knowledge, including direct reasoning and CoT (prompt_cot) by LLM. (2) LLM+KG methods integrate relevant knowledge retrieved from the KG into the LLM to assist in reasoning, including direct reasoning and CoT by LLM. (3) Graph-based RAG methods allow KGs and LLMs to work in tandem, complementing each other’s capabilities at each step of graph reasoning, including Mindmap (mindmap), Think-on-graph (Think_on_graph), Graph-CoT (graph_cot), RoG (luo2024rog), GoG (xu2024gog). Due to the space limitation, we move details on datasets, baselines and experimental setup to Appendix.
Experimental Setup. We conduct experiments with four LLM backbones: LLaMA2-13B (llama2), LLaMA3-8B (llama3), Qwen2.5-7B (qwen2) and Qwen2.5-32B (hui2024qwen2). For all LLMs, we load the checkpoints from huggingface https://huggingface.co and use the models directly without fine-tuning. We implemented CogGRAG and conducted the experiments with one A800 GPU. Consistent with the Think-on-graph settings, we set the temperature parameter to 0.4 during exploration and 0 during reasoning. The threshold $\epsilon$ in the retrieval step is set to $0.7$ .
| LLM-only LLaMA3-8B LLaMA2-13B | Qwen2.5-7B 17.5% 19.1% | 15.3% 14.9% 17.3% | 15.0% 16.2% 18.7% | 15.8% 30.3% 31.4% | 25.4% 27.5% 28.8% | 24.1% 29.0% 31.7% | 24.5% 50.4% 51.4% | 46.7% 45.1% 47.9% | 45.3% 48.3% 53.5% | 45.5% |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Qwen2.5-32B | 28.7% | 27.4% | 28.5% | 55.1% | 50.3% | 54.2% | 68.4% | 60.5% | 65.1% | |
| LLM+KG | Qwen2.5-7B+KG | 24.2% | 15.6% | 21.4% | 33.8% | 32.1% | 34.9% | 46.7% | 45.3% | 46.1% |
| LLaMA3-8B+KG | 25.9% | 21.4% | 23.6% | 40.6% | 35.3% | 39.1% | 53.6% | 49.1% | 52.3% | |
| LLaMA2-13B+KG | 27.5% | 23.7% | 27.6% | 39.7% | 35.1% | 38.3% | 52.5% | 49.3% | 52.1% | |
| Qwen2.5-32B+KG | 35.6% | 32.8% | 34.9% | 58.3% | 54.7% | 57.6% | 70.2% | 65.1% | 68.4% | |
| Graph-Based RAG | CogGRAG w/ Qwen2.5-7B | 28.4% | 27.1% | 28.2% | 50.5% | 45.7% | 48.9% | 53.2% | 51.6% | 55.0% |
| CogGRAG w/ LLaMA3-8B | 32.1% | 27.2% | 31.0% | 53.5% | 48.4% | 52.6% | 57.2% | 55.3% | 55.4% | |
| CogGRAG w/ LLaMA2-13B | 34.4% | 30.7% | 35.5% | 56.3% | 53.4% | 55.8% | 59.8% | 56.1% | 58.9% | |
| CogGRAG w/ Qwen2.5-32B | 40.5% | 37.1% | 40.2% | 66.5% | 62.7% | 65.4% | 74.1% | 68.3% | 73.0% | |
Table 2: Overall results of our CogGRAG with different backbone models on three KBQA datasets.
### Main Results
We perform experiments to verify the effectiveness of our framework CogGRAG, and report the results in Table 1. We use Rouge-L (RL), Exact match (EM) and F1 Score (F1) as metric for all three datasets. The backbone model for all the methods is LLaMA2-13B. From the table, the following observations can be derived: (1) CogGRAG achieves the best results in most cases except on WebSQP. Since the dataset is widely used, we attribute the reason to be data leakage. (2) Compared to methods that incorporate external knowledge, the LLM-only approach demonstrates significantly inferior performance. This performance gap arises from the lack of necessary knowledge in LLMs for reasoning tasks, highlighting the critical role of external knowledge integration in enhancing the reasoning capabilities of LLMs. (3) Graph-based RAG methods demonstrate superior performance compared to LLM+KG approaches. This performance advantage is particularly evident in complex problems, where not only external knowledge integration but also involving “thinking procedure” is essential. These methods synergize LLMs with KGs to enhance performance by retrieving and reasoning over the KGs, thereby generating the most probable inference outcomes through “thinking” on the KGs.
We attribute CogGRAG ’s outstanding effectiveness in most cases primarily to its ability to decompose complex problems and construct a structured mind map prior to retrieval. This approach enables the construction of a comprehensive reasoning pathway, facilitating more precise and targeted retrieval of relevant information. Furthermore, CogGRAG incorporates a self-verification mechanism during the reasoning phase, further enhancing the accuracy and reliability of the final results. Together, these designs collectively enhance LLMs’ ability to tackle complex problems.
### Performance with different backbone models
We evaluate how different backbone models affect its performance on three datasets HotpotQA, CWQ and WebQSP, and report the results in Table 2. We conduct experiments with three LLM backbones LLaMA2-13B, LLaMA3-8B, Qwen2.5-7B and Qwen2.5-32B. For all LLMs, we load the checkpoints from huggingface and use the models directly without fine-tuning. From the table, we can observe the following key findings: (1) CogGRAG achieves the best results across all backbone models compared to the baseline approaches, demonstrating the robustness and stability of our method. (2) The performance of our method improves consistently as the model scale increases, reflecting enhanced reasoning capabilities. This trend suggests that our approach has significant potential for further exploration with larger-scale models, indicating promising scalability and adaptability.
| LLaMA2-13B Graph-CoT CogGRAG | 7.1% 26.4% 30.2% | 6.8% 24.0% 28.7% | 6.9% 25.3% 29.5% | 5.4% 26.7% 32.4% | 5.1% 23.3% 30.1% | 5.3% 24.9% 31.3% | 5.4% 19.3% 23.6% | 4.7% 14.8% 21.5% | 5.1% 16.9% 22.7% | 4.3% 28.1% 27.4% | 3.1% 25.2% 25.6% | 3.6% 26.7% 26.2% |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
Table 3: Overall results of our CogGRAG on GRBENCH dataset. We highlight the best score on each dataset in bold.
### Performance on domain-specific KG
Given the risk of data leakage due to Wikidata being used as pretraining corpora for LLMs, we further evaluate the performance of CogGRAG on a recently released domain-specific dataset GRBENCH (graph_cot) and report the results in Table 3. This dataset requires all questions to interact with a domain-specific KG. We use Rouge-L (RL), Exact match (EM) and F1 Score (F1) as metrics for this dataset. The backbone model for all the methods is LLaMA2-13B (llama2). The table reveals the following observations: (1) CogGRAG continues to outperform in most cases. This demonstrates that our method consistently achieves stable and reliable results even on domain-specific KGs. (2) Both CogGRAG and Graph-CoT outperform LLaMA2-13B by more than 20%, which can be ascribed to the fact that LLMs are typically not trained on domain-specific data. In contrast, graph-based RAG methods can effectively supplement LLMs with external knowledge, thereby enhancing their reasoning capabilities. This result underscores the effectiveness of the RAG approach in bridging knowledge gaps and improving performance in specialized domains.
### Ablation Study
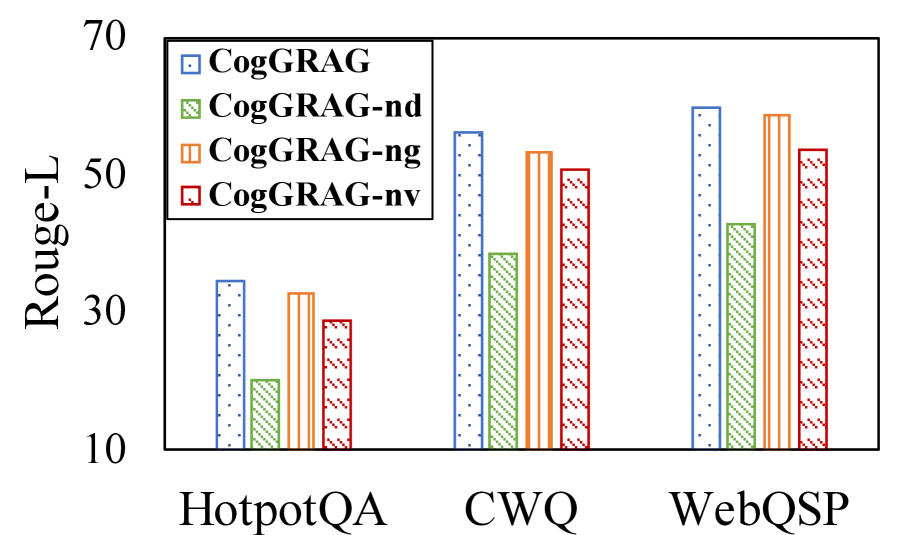
The ablation study is conducted to understand the importance of main components of CogGRAG. We select HotpotQA, CWQ and WebQSP as three representative datasets. First, we remove the problem decomposition module, directly extracting information for the target question, and referred to this variant as CogGRAG-nd (n o d ecomposition). Next, we eliminate the global-level retrieval phase, naming this variant CogGRAG-ng (n o g lobal level). Finally, we remove the self-verification mechanism during the reasoning stage, designating this variant as CogGRAG-nv (n o v erification). These experiments aim to systematically assess the impact of each component on the overall performance of the framework. We compare CogGRAG with these three variants, and the results are presented in Figure 3. Our findings show that CogGRAG outperforms all the variants on the three datasets. Furthermore, the performance gap between CogGRAG and CogGRAG-nd highlights the importance of decomposition for complex problem reasoning in KGQA tasks.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Chart: Rouge-L Scores Across Datasets for CogGRAG Variants
### Overview
The chart compares Rouge-L scores of four CogGRAG model variants (CogGRAG, CogGRAG-nd, CogGRAG-ng, CogGRAG-nv) across three question-answering datasets: HotpotQA, CWQ, and WebQSP. The y-axis represents Rouge-L scores (10–70), while the x-axis categorizes datasets. Each variant is visually distinct via color and pattern.
### Components/Axes
- **X-axis (Datasets)**:
- HotpotQA (leftmost)
- CWQ (middle)
- WebQSP (rightmost)
- **Y-axis (Rouge-L Scores)**:
- Scale: 10, 30, 50, 70 (linear)
- **Legend (Top-left)**:
- **CogGRAG**: Blue dotted bars
- **CogGRAG-nd**: Green striped bars
- **CogGRAG-ng**: Orange striped bars
- **CogGRAG-nv**: Red striped bars
### Detailed Analysis
1. **HotpotQA**:
- CogGRAG: ~32 (blue dotted)
- CogGRAG-nd: ~22 (green striped)
- CogGRAG-ng: ~31 (orange striped)
- CogGRAG-nv: ~29 (red striped)
2. **CWQ**:
- CogGRAG: ~55 (blue dotted)
- CogGRAG-nd: ~40 (green striped)
- CogGRAG-ng: ~52 (orange striped)
- CogGRAG-nv: ~50 (red striped)
3. **WebQSP**:
- CogGRAG: ~60 (blue dotted)
- CogGRAG-nd: ~45 (green striped)
- CogGRAG-ng: ~58 (orange striped)
- CogGRAG-nv: ~53 (red striped)
### Key Observations
- **Consistent Performance**: CogGRAG (blue dotted) outperforms all variants in every dataset.
- **Dataset Variance**: WebQSP shows the highest scores overall, while HotpotQA has the lowest.
- **Component Impact**: Removing components (nd, ng, nv) reduces scores, with CogGRAG-nd (green striped) consistently lowest.
- **Trend**: Scores increase from HotpotQA to WebQSP for CogGRAG, suggesting dataset complexity correlates with performance.
### Interpretation
The data demonstrates that the base CogGRAG model achieves the highest Rouge-L scores, indicating its effectiveness in question-answering tasks. The removal of specific components (e.g., "nd," "ng," "nv") degrades performance, suggesting these elements are critical to the model's success. WebQSP's higher scores may reflect its alignment with the model's training data or task complexity. The consistent underperformance of CogGRAG-nd highlights the importance of the "nd" component in maintaining model accuracy. This analysis underscores the need for careful component selection in model design to optimize performance across diverse datasets.
</details>
Figure 3: Ablation study on the main components of CogGRAG.
| LLaMA2-13B ToG MindMap | 19.1% 29.3% 27.9% | 25.7% 20.2% 22.4% | 55.2% 50.5% 49.7% |
| --- | --- | --- | --- |
| CogGRAG | 34.4% | 40.6% | 25.0% |
Table 4: Overall results of our CogGRAG on GRBENCH dataset. We highlight the best score on each dataset in bold.
### Hallucination and Missing Evaluation
In the reasoning and self-verification phase of CogGRAG, we prompt the LLM to respond with “I don’t know” when encountering questions with insufficient or incomplete relevant information during the reasoning process. This approach is designed to mitigate the hallucination issue commonly observed in LLMs. To evaluate the effectiveness of this strategy, we test the model on the HotpotQA dataset, with results reported in Table 4. We categorize the responses into three types: “Correct” for accurate answers, “Missing” for cases where the model responds with “I don’t know,” and “Hallucination” for incorrect answers. As shown in the table results, our model demonstrates the ability to refrain from answering questions with insufficient information, significantly reducing the occurrence of hallucinations.
| Graph-CoT GoG CogGRAG | 22.39 21.50 18.24 | 29.04 32.20 31.57 | 15.79 18.80 16.32 | 32.97 37.50 35.64 |
| --- | --- | --- | --- | --- |
Table 5: Average inference time per question (s).
### Performance in Inference Times
We conduct the verification on four datasets GRBENCH-Academic, GRBENCH-Amazon, GRBENCH-Goodreads, and GRBENCH-Disease. Table 5 presents the average runtime of CogGRAG, Graph-CoT and GoG. From the table, we can see that CogGRAG is on par with Graph-CoT and GoG. Although our reasoning process introduces self-verification, which increases the time cost, CogGRAG does not require iterative repeated reasoning and retrieval. Instead, it retrieves all relevant information in one step based on the mind map, avoiding redundant retrieval, which provides an advantage in large-scale KGs. Moreover, while self-verification adds additional time costs, it also improves the accuracy of reasoning results, as confirmed in the ablation experiments.
## Conclusion
In this paper, we proposed CogGRAG, a graph-based RAG framework to enhance LLMs’ complex reasoning for KGQA tasks. CogGRAG generates tree-structured mind maps, explicitly encoding semantic relationships among subproblems, which guide both local and global knowledge retrieval. A self-verification module further detects and revises potential errors, forming a dual-phase reasoning paradigm that reduces hallucinations and improves factual consistency. Extensive experiments show that CogGRAG substantially outperforms existing RAG baselines on complex multi-hop QA benchmarks.
## Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant 42375146 and National Natural Science Foundation of China No. 62202172.
## Appendix A Datastes
Here, we introduce the four datasets used in our experiments in detail. For HotpotQA and CWQ datasets, we evaluated the performance of all methods on the dev set. For WebQSP dataset, we evaluated the performance of all methods on the train set. The statistics and details of these datasets can be found in Table 6, and we describe each dataset in detail below:
HotpotQA is a large-scale question answering dataset aimed at facilitating the development of QA systems capable of performing explainable, multi-hop reasoning over diverse natural language. It contains 113k question-answer pairs that were collected through crowdsourcing based on Wikipedia articles.
WebQSP is a dataset designed specifically for question answering and information retrieval tasks, aiming to promote research on multi-hop reasoning and web-based question answering techniques. It contains 4,737 natural language questions that are answerable using a subset Freebase KG (bollacker2008freebase).
CWQ is a dataset specially designed to evaluate the performance of models in complex question answering tasks. It is generated from WebQSP by extending the question entities or adding constraints to answers, in order to construct more complex multi-hop questions.
GRBENCH is a dataset to evaluate how effectively LLMs can interact with domain-specific graphs containing rich knowledge to solve the desired problem. GRBENCH contains 10 graphs from 5 general domains (academia, e-commerce, literature, healthcare, and legal). Each data sample in GRBENCH is a question-answer pair.
| Wikipedia WebQSP CWQ | HotpotQA 3098 27,734 | 90564 0 3480 | 7405 1639 3475 | 7405 |
| --- | --- | --- | --- | --- |
| Academic | GRBENCH-Academic | 850 | | |
| E-commerce | GRBENCH-Amazon | 200 | | |
| Literature | GRBENCH-Goodreads | 240 | | |
| Healthcare | GRBENCH-Disease | 270 | | |
Table 6: Datasets statistics.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Flowchart: Question Answering Process for Sponsorship Identification
### Overview
The flowchart illustrates a structured process to answer the question: *"The 2017–18 Wigan Athletic F.C. season will be a year in which the team competes in the league cup known as what for sponsorship reasons?"* It breaks the problem into decomposition, retrieval, and reasoning/self-verification steps, using color-coded blocks (red, green, blue) to represent each phase.
### Components/Axes
- **Decomposition (Red Block)**:
- **Sub-question 1**: *"What league cup is the Wigan Athletic F.C. competing in during the 2017-18 season?"*
- **Sub-question 2**: *"What is the name of the league cup from the 2017-18 Wigan Athletic F.C. season?"*
- **State**: *"End."*
- **Retrieval (Green Block)**:
- **Entity Extraction**:
- `"Wigan Athletic F.C."`, `"2017–18 season"`, `"league cup"`, `"sponsorship reasons"`.
- **Triple Extraction**:
- Triples like `("Wigan Athletic F.C.", "competes in", "league cup")`, `("2017–18 season", "associated with", "Wigan Athletic F.C.")`, and `("league cup", "sponsorship name", "unknown")`.
- **Subgraph**:
- Relationships such as `("Wigan Athletic F.C.", "competes in", "league cup")` and `("league cup", "sponsorship name", "Carabao Cup")`.
- **Reasoning and Self-Verification (Blue Block)**:
- **Verification Steps**:
1. *"In which league cup did Wigan Athletic F.C. compete during the 2017–18 season?"* → Answer: `"EFL Cup"`.
2. *"What was the sponsored name of the league cup identified in sub-question #1 during the 2017–18 season?"* → Answer: `"Carabao Cup"`.
### Content Details
- **Decomposition**:
- The question is split into two sub-questions to isolate the league cup name and its sponsorship name.
- **Retrieval**:
- Entities and triples are extracted from a knowledge graph, linking the team, season, league cup, and sponsorship.
- The subgraph confirms the league cup as the `"EFL Cup"` (official name: `"Carabao Cup"`).
- **Reasoning**:
- Self-verification cross-checks answers using retrieved data, ensuring consistency.
### Key Observations
- The flowchart emphasizes **modular problem-solving**, breaking the question into smaller, verifiable components.
- The answer `"Carabao Cup"` is derived through iterative validation of retrieved triples.
- The `"sponsorship name"` triple initially marked as `"unknown"` is resolved to `"Carabao Cup"` in the final step.
### Interpretation
The flowchart demonstrates a **knowledge graph-based QA system** where:
1. **Decomposition** reduces ambiguity by isolating sub-problems.
2. **Retrieval** leverages structured data (entities/triples) to populate knowledge gaps.
3. **Self-verification** ensures answers align with retrieved facts, avoiding hallucinations.
The process highlights how sponsorship names (e.g., `"Carabao Cup"`) are dynamically linked to league cups via temporal and contextual relationships in the knowledge graph. The use of color coding aids in tracing the flow of logic from question decomposition to final answer validation.
</details>
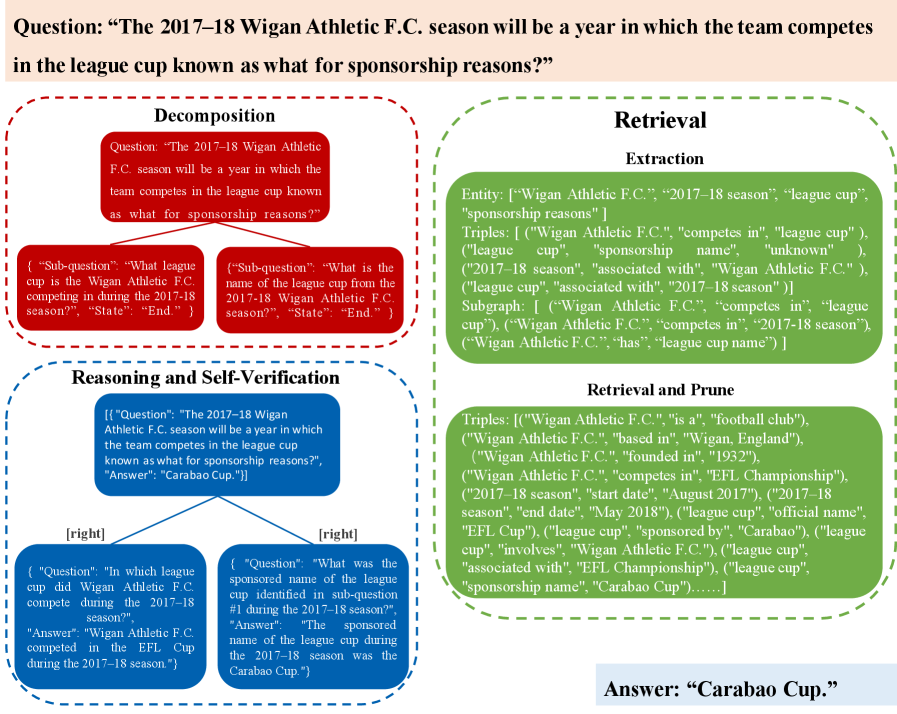
Figure 4: Case of CogGRAG.
## Appendix B Baselines
In this subsection, we introduce the baselines used in our experiments, including LLaMA2-13B, LLaMA3-8B, Qwen2.5-7B, Qwen2.5-32B, Chain-of-Thought (CoT) prompting, Think-on-graph (ToG), MindMap, Graph-CoT, Reasoning on Graphs (RoG), Generate-on-Graph (GoG).
LLaMA2-13B (llama2) is a member of the LLM series developed by Meta and is the second generation version of the LLaMA (Large Language Model Meta AI) model. LLaMA2-13B contains 13 billion parameters and is a medium-sized large language model.
LLaMA3-8B (llama3) is an efficient and lightweight LLM with 8 billion parameters, designed to provide high-performance natural language processing capabilities while reducing computing resource requirements.
Qwen2.5-7B (qwen2) is an efficient and lightweight LLM launched by Alibaba with 7 billion parameters. It aims at making it more efficient, specialized, and optimized for particular applications.
Qwen2.5-32B (hui2024qwen2) is an efficient LLM launched by Alibaba with 32 billion parameters. It is a more comprehensive foundation for real-world applications such as Code Agents. Not only enhancing coding capabilities but also maintaining its strengths in mathematics and general competencies.
Chain-of-Thought (prompt_cot) is a method designed to enhance a model’s reasoning ability, particularly for complex tasks that require multiple reasoning steps. It works by prompting the model to generate intermediate reasoning steps rather than just providing the final answer, thereby improving the model’s ability to reason through complex problems.
Think-on-graph (Think_on_graph) proposed a new LLM-KG integration paradigm, “LLM $\otimes$ KG”, which treats the LLM as an agent to interactively explore relevant entities and relationships on the KG and perform reasoning based on the retrieved knowledge. It further implements this paradigm by introducing a novel approach called “Graph-based Thinking”, in which the LLM agent iteratively performs beam search on the KG, discovers the most promising reasoning paths, and returns the most likely reasoning result.
MindMap (mindmap) propose a novel prompting pipeline, that leverages KGs to enhance LLMs’ inference and transparency. It enables LLMs to comprehend KG inputs and infer with a combination of implicit and external knowledge. Moreover, it elicits the mind map of LLMs, which reveals their reasoning pathways based on the ontology of knowledge.
Graph-CoT (graph_cot) propose a simple and effective framework called Graph Chain-of-thought to augment LLMs with graphs by encouraging LLMs to reason on the graph iteratively. Moreover, it manually construct a Graph Reasoning Benchmark dataset called GRBENCH, containing 1,740 questions that can be answered with the knowledge from 10 domain graphs.
Reasoning on Graphs (luo2024rog) propose a novel method called reasoning on graphs (RoG) that synergizes LLMs with KGs to enable faithful and interpretable reasoning. Specifically, they present a planning retrieval-reasoning framework, where RoG first generates relation paths grounded by KGs as faithful plans. These plans are then used to retrieve valid reasoning paths from the KGs for LLMs to conduct faithful reasoning.
Generate-on-Graph (xu2024gog) propose leveraging LLMs for QA under Incomplete Knowledge Graph (IKGQA), where the provided KG lacks some of the factual triples for each question, and construct corresponding datasets. To handle IKGQA, they propose a training-free method called Generate-on-Graph (GoG), which can generate new factual triples while exploring KGs.
## Appendix C Case Studies
In this section, we present a case analysis of the HotpotQA dataset to evaluate the performance of CogGRAG. As illustrated in Figure 4, CogGRAG decomposes the input question into two logically related sub-questions. Specifically, the complex question is broken down into “In which league cup” and “What was the sponsored name”, allowing the system to first identify the league cup and then determine its sponsored name based on the identified league. These sub-questions form a mind map, capturing the relationships between different levels of the problem. Next, CogGRAG extracts key information from all sub-questions, including both local level information within individual sub-questions and global level information across different sub-questions. A subgraph is constructed to represent the interconnected triples within the subgraph, enabling a global perspective to model the relationships between different questions. The retrieved triples are pruned based on similarity metrics. All information retrieved from the KG is represented in the form of triples. Using this knowledge, CogGRAG prompts the LLM to perform bottom-up reasoning and self-verification based on the constructed mind map. Through this process, the system ultimately derives the answer to the target question: “Carabao Cup.” This case demonstrates the effectiveness of CogGRAG in handling complex, multi-step reasoning tasks by leveraging hierarchical decomposition, structured knowledge retrieval, and self-verification mechanisms.
Additionally, Figure 5, Figure 7 and Figure 6 illustrate the process of prompting the large language model (LLM) to perform reasoning and self-verification, which provides a detailed breakdown of how the model generates and validates intermediate reasoning steps, ensuring the accuracy and reliability of the final output.
## Appendix D Prompts in CogGRAG
In this section, we show all the prompts that need to be used in the main experiments as shown in Table 7, Table 8, Table 9, Table 10, Table 11 and Table 12.
| Prompt head: “Your task is to decompose the given question Q into sub-questions. You should based on the specific logic of the question to determine the number of sub-questions and output them sequentially.” |
| --- |
| Instruction: “Please only output the decomposed sub-questions as a string in list format, where each element represents the text of a sub-question, in the form of {[“subq1”, “subq2”, “subq3”]}. For each sub-question, if you consider the sub-question to be sufficiently simple and no further decomposition is needed, then output “End.”, otherwise, output “Continue.” Please strictly follow the format of the example below when answering the question. |
| Here are some examples:” |
| “Input: “What year did Guns N Roses perform a promo for a movie starring Arnold Schwarzenegger as a former New York Police detective?” |
| Output: [ { “Sub-question”: “What movie starring Arnold Schwarzenegger as a former New York Police detective is being referred to?”, “State”: “Continue.” }, { “Sub-question”: “In what year did Guns N Roses perform a promo for the movie mentioned in sub-question #1?”, “State”: “End.” } ]” |
| “Input: “What is the name of the fight song of the university whose main campus is in Lawrence, Kansas and whose branch campuses are in the Kansas City metropolitan area?” |
| Output: [ { “Sub-question”: “Which university has its main campus in Lawrence, Kansas and branch campuses in the Kansas City metropolitan area?”, “State”: “End.” }, { “Sub-question”: “What is the name of the fight song of the university identified in sub-question #1?”, “State”: “End.” } ]” |
| “Input: “Are the Laleli Mosque and Esma Sultan Mansion located in the same neighborhood?” |
| Output: [ { “Sub-question”: “Where is the Laleli Mosque located?”, “State”: “End.” }, { “Sub-question”: “Where is the Esma Sultan Mansion located?”, “State”: “End.” }, { “Sub-question”: “Are the locations of the Laleli Mosque and the Esma Sultan Mansion in the same neighborhood?”, “State”: “End.” } ]” |
| “ Input: Question $Q$ ” |
| “ Output: ” |
Table 7: The prompt template for decomposition.
| Prompt head: “Your task is to extract the entities (such as people, places, organizations, etc.) and relations (representing behaviors or properties between entities, such as verbs, attributes, or categories, etc.) involved in the input questions. These entities and relations can help answer the input questions.” |
| --- |
| Instruction: “Please extract entities and relations in one of the following forms: entity, tuples, or triples from the given input List. Entity means that only an entity, i.e. <entity>. Tuples means that an entity and a relation, i.e. <entity-relation>. Triples means that complete triples, i.e. <entity-relation-entity>. Please strictly follow the format of the example below when answering the question.” |
| “ Input: [The mind map $\mathcal{M}$ ] ” |
| “ Output: ” |
Table 8: The prompt template for extraction on local level.
| Prompt head: “Your task is to extract the subgraphs involved in a set of input questions.” |
| --- |
| Instruction: “Please extract and organize information from a set of input questions into structured subgraphs. Each subgraph represents a group of triples (subject, relation, object) that share common entities and capture the logical relationships between the questions. Here are some examples:” |
| “Input: [“What is the capital of France?”, “Who is the president of France?”, “What is the population of Paris?”] |
| Output: [(“France”, “capital”, “Paris”), (“France”, “president”, “Current President”), (“Paris”, “population”, “Population Number”)]” |
| “ Input: [The mind map $\mathcal{M}$ ] ” |
| “ Output: ” |
Table 9: The prompt template for extraction on global level.
| Prompt head: “Your task is to answer the questions with the provided completed reasoning and input knowledge.” |
| --- |
| Instruction: “Please note that the response must be included in square brackets [xxx].” |
| “ The completed reasoning: [The set of verified answers $\hat{\mathcal{M}}$ ] ” |
| “ The knowledge graph: [The final retrieved triple set $\mathcal{T}$ ] ” |
| “ Input: [Subquestion $q^{t}$ ] ” |
| “ Output: ” |
Table 10: The prompt template for reasoning.
| Prompt head: “You are a logical verification assistant. Your task is to check whether the answer to a given question is logically consistent with the provided completed reasoning and input knowledge. If the answer is consistent, respond with “right”. If the answer is inconsistent, respond with “wrong”.” |
| --- |
| Instruction: “Please note that the response must be included in square brackets [xxx].” |
| “ The completed reasoning: [The set of verified answers $\hat{\mathcal{M}}$ ] ” |
| “ The knowledge graph: [The final retrieved triple set $\mathcal{T}$ ] ” |
| “ Answer: [The candidate answer $a^{t}$ ] ” |
| “ Input: [Subquestion $q^{t}$ ] ” |
| “ Output: ” |
Table 11: The prompt template for self-verification.
| Prompt head: “You are a reasoning and knowledge integration assistant. Your task is to re-think a question that was previously answered incorrectly by the self-verification model. Use the provided completed reasoning and input knowledge to generate a new answer.” |
| --- |
| Instruction: “Please note, if the knowledge is insufficient to answer the question, respond with “Insufficient information, I don’t know”. The response must be included in square brackets [xxx].” |
| “ The completed reasoning: [The set of verified answers $\hat{\mathcal{M}}$ ] ” |
| “ The knowledge graph: [The final retrieved triple set $\mathcal{T}$ ] ” |
| “ Input: [Subquestion $q^{t}$ ] ” |
| “ Output: ” |
Table 12: The prompt template for re-thinking.
<details>
<summary>x5.png Details</summary>

### Visual Description
## Text-Based Document: QA System with Knowledge Graph
### Overview
The image depicts a structured technical document outlining a question-answering system that uses a knowledge graph. It includes input instructions, a knowledge base represented as triples, and a response to specific questions.
### Components/Axes
#### Input Section
- **Task Description**:
- "Your task is to answer the questions with the provided completed reasoning and input knowledge. Please note that the response must be included in square brackets [xxx]."
- **Completed Reasoning**: Empty placeholder `[]`.
#### Knowledge Section
- **Triples (Knowledge Graph)**:
1. `("Wigan Athletic F.C.", "is a", "football club")`
2. `("Wigan Athletic F.C.", "based in", "Wigan, England")`
3. `("Wigan Athletic F.C.", "founded in", "1932")`
4. `("Wigan Athletic F.C.", "competes in", "EFL Championship")`
5. `("2017–18 season", "start date", "August 2017")`
6. `("2017–18 season", "end date", "May 2018")`
7. `("league cup", "official name", "EFL Cup")`
8. `("league cup", "sponsored by", "Carabao")`
9. `("league cup", "involves", "Wigan Athletic F.C.")`
10. `("league cup", "associated with", "EFL Championship")`
11. `("league cup", "sponsorship name", "Carabao Cup")`
#### Response Section
- **Question 1**:
- `"In which league cup did Wigan Athletic F.C. compete during the 2017–18 season?"`
- **Answer**: `"Wigan Athletic F.C. competed in the EFL Cup during the 2017–18 season."`
- **Question 2**:
- `"What was the sponsored name of the league cup identified in sub-question #1 during the 2017–18 season?"`
- **Answer**: `"The sponsored name of the league cup during the 2017–18 season was the Carabao Cup."`
### Key Observations
1. The knowledge graph explicitly links Wigan Athletic F.C. to the EFL Cup (league cup) via the triple `("league cup", "involves", "Wigan Athletic F.C.")`.
2. The sponsored name of the EFL Cup is clarified as the "Carabao Cup" through the triple `("league cup", "sponsorship name", "Carabao Cup")`.
3. The 2017–18 season dates (August 2017–May 2018) are provided but not directly used in the answers.
### Interpretation
- The system uses a knowledge graph to answer domain-specific questions. The triples act as facts, enabling the extraction of structured answers.
- The EFL Cup is identified as the league cup Wigan Athletic F.C. competed in during 2017–18, with its sponsored name being the Carabao Cup. This demonstrates how sponsorship renames official competitions.
- The absence of numerical data or visualizations suggests the focus is on semantic relationships rather than quantitative analysis.
### Notes
- No charts, diagrams, or numerical trends are present.
- All text is in English; no other languages are detected.
- The response directly maps to the knowledge graph triples, confirming the system’s reliance on structured facts.
</details>
Figure 5: The prompt case of reasoning.
<details>
<summary>x6.png Details</summary>

### Visual Description
## Textual Structure Analysis: QA System with Knowledge Triples
### Overview
The image contains a structured textual representation of a question-answering system utilizing knowledge triples. It includes input prompts, reasoning chains, knowledge graphs, and response generation examples. The content focuses on Wigan Athletic Football Club's participation in league competitions during the 2017-18 season.
### Components/Axes
1. **Input Section**
- Task description: Answer questions using provided reasoning and knowledge
- Format: Square brackets for responses
- Example input: "The 2017-18 Wigan Athletic F.C. season will be a year in which the team competes in the league cup known as what for sponsorship reasons?"
2. **Completed Reasoning**
- Nested question-answer pairs
- Example:
- Q: "In which league cup did Wigan Athletic F.C. compete during the 2017-18 season?"
- A: "Wigan Athletic F.C. competed in the EFL Cup during the 2017-18 season."
3. **Knowledge Triples**
- Structured as (subject, predicate, object)
- Key entities:
- ("Wigan Athletic F.C.", "is a", "football club")
- ("Wigan Athletic F.C.", "based in", "Wigan, England")
- ("Wigan Athletic F.C.", "founded in", "1932")
- ("Wigan Athletic F.C.", "competes in", "EFL Championship")
- ("2017-18 season", "start date", "August 2017")
- ("2017-18 season", "end date", "May 2018")
- ("league cup", "official name", "EFL Cup")
- ("league cup", "sponsored by", "Carabao")
- ("league cup", "involves", "Wigan Athletic F.C.")
- ("league cup", "associated with", "EFL Championship")
- ("league cup", "sponsorship name", "Carabao Cup")
4. **Input/Output Example**
- Input: "The 2017-18 Wigan Athletic F.C. season will be a year in which the team competes in the league cup known as what for sponsorship reasons?"
- Output: "Carabao Cup"
5. **Response Section**
- Final QA pair:
- Q: "The 2017-18 Wigan Athletic F.C. season will be a year in which the team competes in the league cup known as what for sponsorship reasons?"
- A: "During the 2017-18 season, Wigan Athletic F.C. competed in the league cup known as the Carabao Cup for sponsorship reasons."
### Detailed Analysis
- **Temporal Context**:
- Season duration: August 2017 - May 2018
- Club history: Founded in 1932
- **Competition Structure**:
- Primary league: EFL Championship
- Cup competition: EFL Cup (officially named, sponsored by Carabao)
- Sponsorship naming: League cup becomes "Carabao Cup" for branding
- **Geospatial Context**:
- Club location: Wigan, England
- **Temporal Relationships**:
- Season dates directly correlate with competition participation
### Key Observations
1. Sponsorship naming rights transform the competition's official name (EFL Cup) to Carabao Cup
2. Wigan Athletic F.C. participates in both league (EFL Championship) and cup (EFL Cup) competitions
3. Temporal alignment: Cup participation occurs within the 2017-18 season timeframe
4. Geospatial consistency: Club's location in Wigan, England remains constant across triples
### Interpretation
The knowledge triples demonstrate a semantic network connecting Wigan Athletic F.C. to its competitive activities, temporal context, and sponsorship relationships. The QA system effectively uses this structured knowledge to answer domain-specific questions about the club's 2017-18 season activities. The response generation shows how the system combines multiple triples (competition participation + sponsorship naming) to produce accurate answers about branded competition names. This structure enables precise extraction of factual information while maintaining contextual relationships between entities, events, and temporal markers.
</details>
Figure 6: The prompt case of reasoning with the completed reasoning.
<details>
<summary>x7.png Details</summary>

### Visual Description
## Logical Verification Task
### Overview
The task involves verifying whether an answer to a question is logically consistent with provided knowledge and reasoning. The knowledge is structured as triples, and the answer must align with these facts.
### Components/Axes
- **Knowledge**: Triples describing Wigan Athletic F.C. (e.g., "is a football club," "based in Wigan, England," "competes in EFL Championship").
- **Question**: "In which league cup did Wigan Athletic F.C. compete during the 2017–18 season?"
- **Answer**: "Wigan Athletic F.C. competed in the EFL Cup during the 2017–18 season."
### Detailed Analysis
1. **Triple Verification**:
- The triple `("league cup", "official name", "EFL Cup")` confirms the league cup's official name is the EFL Cup.
- The triple `("league cup", "involves", "Wigan Athletic F.C.")` confirms Wigan Athletic F.C. participates in the league cup.
- The triple `("league cup", "associated with", "EFL Championship")` links the league cup to the EFL Championship, which aligns with the season dates (August 2017–May 2018) provided in the knowledge.
2. **Answer Consistency**:
- The answer explicitly states Wigan Athletic F.C. competed in the **EFL Cup** (matching the triple `("league cup", "official name", "EFL Cup")`).
- The timeframe "2017–18 season" matches the `("2017–18 season", "start date", "August 2017")` and `("2017–18 season", "end date", "May 2018")` triples.
### Key Observations
- The answer directly uses the **official name** of the league cup from the knowledge.
- No contradictions exist between the answer and the triples.
### Interpretation
The answer is logically consistent with the provided knowledge. The triples confirm Wigan Athletic F.C. competed in the EFL Cup (league cup) during the 2017–18 season. The sponsorship by Carabao and association with the EFL Championship are additional details but do not affect the answer's validity.
## Output
[right]
</details>
Figure 7: The prompt case of self-verification.