# Learning richness modulates equality reasoning in neural networks
**Authors**: Double blind review
## Abstract
Equality reasoning is ubiquitous and purely abstract: sameness or difference may be evaluated no matter the nature of the underlying objects. As a result, same-different (SD) tasks have been extensively studied as a starting point for understanding abstract reasoning in humans and across animal species. With the rise of neural networks that exhibit striking apparent proficiency for abstractions, equality reasoning in these models has also gained interest. Yet despite extensive study, conclusions about equality reasoning vary widely and with little consensus. To clarify the underlying principles in learning SD tasks, we develop a theory of equality reasoning in multi-layer perceptrons (MLP). Following observations in comparative psychology, we propose a spectrum of behavior that ranges from conceptual to perceptual outcomes. Conceptual behavior is characterized by task-specific representations, efficient learning, and insensitivity to spurious perceptual details. Perceptual behavior is characterized by strong sensitivity to spurious perceptual details, accompanied by the need for exhaustive training to learn the task. We develop a mathematical theory to show that an MLP’s behavior is driven by learning richness. Rich-regime MLPs exhibit conceptual behavior, whereas lazy-regime MLPs exhibit perceptual behavior. We validate our theoretical findings in vision SD experiments, showing that rich feature learning promotes success by encouraging hallmarks of conceptual behavior. Overall, our work identifies feature learning richness as a key parameter modulating equality reasoning, and suggests that equality reasoning in humans and animals may similarly depend on learning richness in neural circuits.
Keywords: equality reasoning; same-different; neural network; conceptual and perceptual behavior
## 1 Introduction
The ability to reason abstractly is a hallmark of human intelligence. Fluency with abstractions drives both our highest intellectual achievements and many of our daily necessities like telling time, navigating traffic, and planning leisure. At the same time, neural networks have grown tremendously in sophistication and scale. The latest examples exhibit increasingly impressive competency, and the potential to automate the reasoning process itself seems imminent (OpenAI, 2024, 2023; Bubeck ., 2023; Guo ., 2025). Nonetheless, it remains unclear to what extent these models are able to reason abstractly, and how consistently they behave (McCoy ., 2023; Mahowald ., 2024; Ullman, 2023). To begin answering these questions, we require a principled understanding of how neural networks can reason.
A particularly simple and salient form of abstract reasoning is equality reasoning: determining whether two objects are the same or different. The “sense of sameness is the very keel and backbone of our thinking,” (James, 1905) promoting its study as a tractable viewport into abstract reasoning across humans and animals (E A. Wasserman Young, 2010). Despite many decades of study, the history of equality reasoning abounds with widely varying conclusions. Success at same-different (SD) tasks have been documented in a large number of animals, including non-human primates (Vonk, 2003), honeybees (Giurfa ., 2001), pigeons (E A. Wasserman Young, 2010), crows (Smirnova ., 2015), and parrots (Obozova ., 2015). Others, however, have argued that animals employ perceptual shortcuts to solve these tasks like using stimulus variability, and lack a true conception of sameness or difference (Penn ., 2008). Competence at equality reasoning may require exposure to language or some form of symbolic training (Premack, 1983). Meanwhile, pre-lingual human infants have demonstrated sensitivity to same-different relations (G F. Marcus ., 1999; Saffran Thiessen, 2003; Rabagliati ., 2019).
Equality reasoning in neural networks is no less debated. G F. Marcus . (1999) discovered that seven-month-old infants succeed at an SD task where neural networks fail, launching a lively debate that continues to present day (Seidenberg ., 1999; Seidenberg Elman, 1999; Alhama Zuidema, 2019). Others have demonstrated severe shortcomings in neural networks directed to solve visual same-different reasoning and relational tasks (Kim ., 2018; Stabinger ., 2021; Vaishnav ., 2022; Webb ., 2023). Such failures motivate a growing literature in bespoke architectural advancements geared towards relational reasoning (Webb ., 2023, 2020; Santoro ., 2017; Battaglia ., 2018). At the same time, modern large language models routinely solve complex reasoning problems (Bubeck ., 2023). Their surprising success tempers earlier categorical claims against neural networks’ reasoning abilities. Even simple models like multi-layer perceptrons (MLPs) have recently been shown to solve equality and relational reasoning tasks with surprisingly efficacy (A. Geiger ., 2023; Tong Pehlevan, 2024).
The lack of consensus on equality reasoning in either organic or silicate brains speaks to the need for a stronger theoretical foundation. To this end, we present a theory of equality reasoning in MLPs that highlights the central role of a hitherto overlooked parameter: learning richness, a measure of how much internal representations change over the course of training (Chizat ., 2019). We find that MLPs in a rich learning regime exhibit conceptual behavior, where they develop salient, conceptual representations of sameness and difference, learn the task from few training examples, and remain largely insensitive to spurious perceptual details. In contrast, lazy regime MLPs exhibit perceptual behavior, where they solve the task only after exhaustive training and show strong sensitivity to perceptual variations. Our specific contributions are the following.
Contributions
- We hand-craft a solution to our same-different task that is expressible by an MLP, demonstrating the possibility for our model to solve this task. Our solution suggests what conceptual representations may look like, guiding subsequent analysis.
- We argue that an MLP trained in a rich feature learning regime attains the hand-crafted solution, and exhibits three hallmarks of conceptual behavior: conceptual representations, efficient learning, and insensitivity to spurious perceptual details.
- We prove that an MLP trained in a lazy learning regime can also solve an equality reasoning task, but exhibits perceptual behavior: it requires exhaustive training data and shows strong sensitivity to spurious perceptual details.
- We extend our results to same-different tasks with noise, calculating Bayes optimal performance under priors that either generalize to arbitrary inputs or memorize the training set. We demonstrate that rich MLPs attain Bayes optimal performance under the generalizing prior.
- We validate our results on complex visual SD tasks, showing that our theoretical predictions continue to hold.
Our theory clarifies the understudied role of learning richness in driving successful reasoning, with potential implications for both neural network design and animal cognition.
### 1.1 Related work
In studying same-different tasks comparatively across animal species, E. Wasserman . (2017) observe a continuum between perceptual and conceptual behavior. Some animals focus on spurious perceptual details in the task stimuli like image variability, and slowly gain competence through exhaustive repetition. Other animals and humans appear to develop a conceptual understanding of sameness, allowing them to learn the task quickly and ignore irrelevant percepts. Many others fall somewhere in between, exhibiting behavior with both perceptual and conceptual components. These observations lend themselves to a theory where representations and learning mechanisms operate over a continuous domain (Carstensen Frank, 2021).
Neural networks offer a natural instantiation of such a continuous theory. However, the extent to which neural networks can reason at all remains a hotly contested topic. Famously, Fodor Pylyshyn (1988) argue that connectionist models are poorly equipped to describe human reasoning. G F. Marcus (1998) further contends that neural networks are altogether incapable of solving many simple symbolic tasks (see also G F. Marcus . (1999); G F. Marcus (2003); G. Marcus (2020)). Boix-Adsera . (2023) have also argued that MLPs are unable to generalize on relational problems like our same-different task, though this finding has been contested (Tong Pehlevan, 2024; A. Geiger ., 2023).
Negative assertions about neural network reasoning appear to weaken when considering modern LLMs, which routinely solve complex math and logic problems (Bubeck ., 2023; OpenAI, 2024; Guo ., 2025). But even here, doubts remain about whether LLMs truly reason or merely reproduce superficial aspects of their enormous training set (McCoy ., 2023; Mahowald ., 2024). Nonetheless, A. Geiger . (2023) found that simple MLPs convincingly solve same-different tasks after moderate training. Tong Pehlevan (2024) further showed that MLPs solve a wide variety of relational reasoning tasks. We support these findings by arguing that MLPs solve a same-different task, but their performance is modulated by learning richness. In resonance with E. Wasserman . (2017), varying richness pushes an MLP along a spectrum between a perceptual and conceptual solutions to the task.
Learning richness itself refers to the degree of change in a neural network’s internal representations during training. A number of network parameters were recently discovered to control learning richness, including the readout scale, initialization scheme, and learning rate (Chizat ., 2019; Woodworth ., 2020; Yang Hu, 2021; Bordelon Pehlevan, 2022). In the brain, learning richness may correspond to forming adaptive representations that encode task-specific variables, in contrast to fixed representations that remain task agnostic (Farrell ., 2023). Studies have used learning richness to understand the neural representations underlying diverse phenomena like context-dependent decision making (Flesch ., 2022), multitask cognition (Ito Murray, 2023), generalizing knowledge to new tasks (Johnston Fusi, 2023), and even consciousness (Mastrovito ., 2024).
## 2 Setup
We consider the following same-different task, inspired by the setup in A. Geiger . (2023). The task consists of input pairs $\mathbf{z}_{1},\mathbf{z}_{2}\in\mathbb{R}^{d}$ , where $\mathbf{z}_{i}=\mathbf{s}_{i}+\mathbf{\eta}_{i}$ . The labeling function $y$ is given by
$$
y(\mathbf{z}_{1},\mathbf{z}_{2})=\begin{cases}1&\mathbf{s}_{1}=\mathbf{s}_{2}\\
0&\mathbf{s}_{1}\neq\mathbf{s}_{2}\end{cases}\,.
$$
Quantities $\mathbf{s}$ correspond to “symbols,” perturbed by a small amount of noise $\mathbf{\eta}$ . Noise is distributed as $\mathbf{\eta}\sim\mathcal{N}(\mathbf{0},\sigma^{2}\mathbf{I}/d)$ , for some choice of $\sigma^{2}$ . Initially we will take $\sigma^{2}=0$ so $\mathbf{z}=\mathbf{s}$ , but we will allow $\sigma^{2}$ to be nonzero when considering a noisy extension to the task. Our definition of equality implies exact identity, up to possible noise. Other commonly studied variants include equality up to transformation (Fleuret ., 2011), hierarchical equality (Premack, 1983), context-dependent equality (Raven, 2003), among many others. We pursue exact identity for its tractability and ubiquity in the literature, and investigate more general notions of equality later with experiments in the noisy case and in vision tasks.
The model consists of a two-layer MLP without bias parameters
$$
f(\mathbf{x})=\frac{1}{\gamma\sqrt{d}}\sum_{i=1}^{m}a_{i}\,\phi(\mathbf{w}_{i}\cdot\mathbf{x})\,, \tag{1}
$$
where $\phi$ is a ReLU activation applied point-wise to its inputs. We use the standard logit link function to produce predictions $\hat{y}=1/(1+e^{-f})$ . Inputs are concatenated as $\mathbf{x}=(\mathbf{z}_{1};\mathbf{z}_{2})\in\mathbb{R}^{2d}$ before being passed to $f$ . The model is trained using binary cross entropy loss with a learning rate $\alpha=\gamma^{2}d\,\alpha_{0}$ , for a fixed $\alpha_{0}$ . Hidden weight vectors are initialized as $\mathbf{w}_{i}\sim\mathcal{N}(\mathbf{0},\mathbf{I}/m)$ , and readouts as $a_{i}\sim\mathcal{N}(0,1/m)$ . To enable interpolation between rich and lazy learning regimes, the MLP is centered such that $f(\mathbf{x})=0$ at initialization, for all inputs $\mathbf{x}$ . We use a standard procedure for centering, described in Appendix F. Occasionally, we gather all readouts $a$ and hidden weights $\mathbf{w}$ into a single set $\mathbf{\theta}$ , and write $f(\mathbf{x};\mathbf{\theta})$ to mean an MLP $f$ parameterized by weights $\mathbf{\theta}$ . We avoid considering bias parameters to simplify the analysis. In practice, because the task is symmetric about the origin, we find that bias plays little role.
The parameter $\gamma$ controls learning richness, where higher values of $\gamma$ correspond to greater richness (Chizat ., 2019; M. Geiger ., 2020; Woodworth ., 2020; Bordelon Pehlevan, 2022). A neural network trained in a rich regime experiences significant changes to its hidden activations $\phi(\mathbf{w_{i}\cdot\mathbf{x}})$ , resulting in task-specific representations. In contrast, a neural network trained in a lazy regime retains task-agnostic representations determined by their initialization. The limit $\gamma\rightarrow 0$ induces lazy behavior. Increasing $\gamma$ increases learning richness. For our tasks, we find that $\gamma=1$ produces sufficiently rich learning $\gamma=1$ produces a scaling that is similar to $\mu$ P or mean-field parametrization common elsewhere in the rich learning literature (Yang Hu, 2021; Mei ., 2018; Rotskoff Vanden-Eijnden, 2022). However, these scalings technically consider an infinite width limit. Our setting considers an infinite input dimension limit (Biehl Schwarze, 1995; Saad Solla, 1995; Goldt ., 2019), resulting in an extra $1/\sqrt{d}$ prefactor that is not present in these other scalings., and increasing $\gamma$ beyond 1 does not qualitatively change our results (Figure C3). Appendix F elaborates on our scaling scheme.
Crucially, the training set consists of a finite number of symbols $\mathbf{s}_{1},\mathbf{s}_{2},\ldots,\mathbf{s}_{L}$ . These $L$ symbols are sampled before training begins as $\mathbf{s}\sim\mathcal{N}(\mathbf{0},\mathbf{I}/d)$ , then used exclusively to train the model. Training examples are balanced such that half consist of same examples and half consist of different examples. During testing, symbols $\mathbf{s}$ are sampled afresh for every input, measuring the model’s ability to generalize on unseen test examples. If a model has learned equality reasoning, then it should attain perfect test accuracy despite having never witnessed the particular inputs. When $\sigma^{2}=0$ , this procedure is precisely equivalent to using one-hot encoded symbol inputs with a fixed embedding matrix, where the model is trained on a subset of all possible symbols. Additional details on our model and setup are enumerated in Appendix G.
### 2.1 Conceptual and perceptual behavior
Central to our framework is the distinction between conceptual and perceptual behavior. Conceptual behavior refers to a facility with abstract concepts, enabling the reasoner to learn an abstract task quickly and generalize with limited dependency on spurious details. Perceptual behavior refers to the opposite, where the reasoner solves a task through sensory association. Such learning is typically characterized by exhaustive training and marked sensitivity to spurious perceptual details.
We posit that learning richness moves an MLP between conceptual and perceptual behavior. We identify three specific characteristics of a conceptual outcome:
1. Conceptual representations. We look for evidence of task-specific representations that denote sameness or difference. Such representations should be crucial to solving the task, and contribute towards the model’s efficiency and insensitivity to spurious perceptual details (below).
1. Efficiency. We measure learning efficiency using the number of different symbols $L$ observed during training. A conceptual reasoner should solve the task with a smaller $L$ than a perceptual reasoner.
1. Insensitivity to spurious perceptual details. Spurious perceptual details refer to aspects of the task that influence the input but not the correct output. A readily measurable example is the input dimension $d$ . Sameness or difference can be evaluated regardless of $d$ . A conceptual reasoner should perform equally well when training on tasks across a variety of $d$ , whereas a perceptual reasoner may find certain $d$ harder to learn with than others. We therefore evaluate this insensitivity by comparing the test accuracy of models trained across a large range of input dimensions.
A perceptual solution is characterized by the negation of each point: it does not develop task-specific representations, it requires a large $L$ to solve the task, and test accuracy changes substantially with $d$ . While potentially possible to have a mixed solution that exhibits a subset of these points, we do not observe them in practice, and the conceptual/perceptual distinction is sufficiently descriptive of our model.
<details>
<summary>x1.png Details</summary>
### Visual Description
## [Multi-Panel Scientific Figure]: Comparison of Rich (γ=1) vs. Lazy (γ≈0) Learning Regimes
### Overview
This image is a composite scientific figure containing six subplots (a-f) arranged in two rows and three columns. The top row (a, b, c) illustrates the "Rich regime (γ = 1)", while the bottom row (d, e, f) illustrates the "Lazy regime (γ ≈ 0)". The figure compares the learning dynamics, generalization performance, and internal representations of a machine learning model (likely a neural network) under these two distinct regimes. The plots include scatter plots, heatmaps, and line graphs.
### Components/Axes
**Global Structure:**
- **Top Row Title:** "Rich regime (γ = 1)"
- **Bottom Row Title:** "Lazy regime (γ ≈ 0)"
- **Panel Labels:** a, b, c (top row, left to right); d, e, f (bottom row, left to right).
**Panel a (Top-Left):**
- **Type:** Scatter plot.
- **X-axis Label:** `a_i`
- **Y-axis Label:** `(v_i^T · v_i^T) / l_i`
- **Y-axis Range:** Approximately -1 to 1.
- **X-axis Range:** Approximately -10 to 0.
- **Data:** A dense collection of blue points forming a sharp, step-like transition from y ≈ -1 to y ≈ 1 at x ≈ 0.
**Panel b (Top-Center):**
- **Type:** Heatmap.
- **X-axis Label:** `Input dimension (d)`
- **X-axis Ticks:** 2, 4, 7, 14, 27, 50, 93, 178, 382, 737.
- **Y-axis Label:** `# symbols (L)`
- **Y-axis Ticks:** 3, 5, 10, 20, 38, 74, 143, 275, 531, 1024.
- **Color Bar Label:** `Test acc.`
- **Color Bar Scale:** 0.5 (dark purple/black) to 1.0 (light peach/white).
- **Key Feature:** A horizontal dashed black line at approximately L = 5. The heatmap shows high test accuracy (light colors) across most of the space, particularly for larger d and L.
**Panel c (Top-Right):**
- **Type:** Line graph.
- **X-axis Label:** `# symbols (L)`
- **X-axis Scale:** Logarithmic, with ticks at 2³, 2⁶, 2⁹.
- **Y-axis Label:** `Test accuracy`
- **Y-axis Range:** 0.5 to 1.0.
- **Legend:** Located in the top-right corner. Contains:
- `Theory` (red dashed line)
- `γ = 1.00` (dark purple line with circle markers)
- `γ = 0.50` (purple line with circle markers)
- `γ = 0.25` (lighter purple line with circle markers)
- `γ = 0.10` (light purple line with circle markers)
- `γ = 0.05` (very light purple line with circle markers)
- `γ ≈ 0.00` (lightest purple/pink line with circle markers)
- **Horizontal Reference:** A dashed gray line labeled `chance` at y ≈ 0.5.
**Panel d (Bottom-Left):**
- **Type:** Scatter plot.
- **X-axis Label:** `a_i`
- **Y-axis Label:** `(v_i^T · v_i^T) / l_i` (same as panel a).
- **Y-axis Range:** Approximately -1 to 1.
- **X-axis Range:** Approximately -0.05 to 0.05.
- **Data:** A dense cloud of blue points centered around y = 0, with no sharp transition. The distribution is roughly symmetric and concentrated.
**Panel e (Bottom-Center):**
- **Type:** Heatmap.
- **X-axis Label:** `Input dimension (d)`
- **X-axis Ticks:** 128, 159, 198, 247, 307, 382, 476, 593, 737, 918.
- **Y-axis Label:** `# symbols (L)`
- **Y-axis Ticks:** 143, 178, 221, 275, 343, 427, 531, 661, 823, 1024.
- **Color Bar Label:** `Test acc.`
- **Color Bar Scale:** 0.6 (dark purple) to 1.0 (light peach/white).
- **Key Feature:** A diagonal dashed black line running from bottom-left to top-right. The heatmap shows a gradient where accuracy is highest (lightest) in the top-left (low d, high L) and lowest (darkest) in the bottom-right (high d, low L).
**Panel f (Bottom-Right):**
- **Type:** Line graph.
- **X-axis Label:** `Input dimension (d)`
- **X-axis Scale:** Logarithmic, with ticks at 2⁵, 2⁷, 2⁹.
- **Y-axis Label:** `Test accuracy`
- **Y-axis Range:** 0.5 to 1.0.
- **Legend:** Same as panel c (implied by color and marker consistency).
- **Horizontal Reference:** A dashed gray line labeled `chance` at y ≈ 0.5.
### Detailed Analysis
**Panel a (Rich Regime Scatter):** The plot shows a clear phase transition. For `a_i < 0`, the normalized inner product `(v_i^T · v_i^T) / l_i` is consistently -1. At `a_i ≈ 0`, there is a sharp, vertical jump to +1, which holds for `a_i > 0`. This indicates a binary, all-or-nothing change in the represented feature.
**Panel b (Rich Regime Heatmap):** Test accuracy is generally high (>0.8) across the explored space of input dimension `d` and number of symbols `L`. The horizontal dashed line at L≈5 may indicate a critical threshold for the number of symbols needed for good generalization in this regime. Accuracy appears to saturate near 1.0 for most combinations where L > 5.
**Panel c (Rich Regime Lines):** For the rich regime (γ=1.00, dark purple), test accuracy rapidly reaches ~1.0 as the number of symbols `L` increases beyond 2³ (8). As γ decreases (moving to lighter lines), the accuracy for a given `L` decreases, and more symbols are required to achieve high accuracy. The `γ ≈ 0.00` line shows the poorest performance, only slightly above chance for large `L`. The red dashed "Theory" line represents an upper bound or ideal performance.
**Panel d (Lazy Regime Scatter):** In contrast to panel a, the data points are scattered in a cloud centered at y=0, with a range of `a_i` values from -0.05 to 0.05. There is no sharp transition, suggesting a more gradual, distributed change in representations.
**Panel e (Lazy Regime Heatmap):** The accuracy pattern is fundamentally different from panel b. There is a strong diagonal trend: high accuracy is achieved only when the number of symbols `L` is large relative to the input dimension `d`. The diagonal dashed line likely represents a theoretical boundary (e.g., L ∝ d). Accuracy drops significantly in the region of high `d` and low `L` (bottom-right).
**Panel f (Lazy Regime Lines):** For the lazy regime, test accuracy is plotted against input dimension `d`. For all γ values, accuracy *decreases* as `d` increases. The rate of decrease is slower for higher γ values. Even for γ=1.00 (dark purple), accuracy falls from ~1.0 at d=2⁵ to ~0.8 at d=2⁹. For γ≈0.00, accuracy is near chance (0.5) for all `d`.
### Key Observations
1. **Regime Dichotomy:** The "Rich" and "Lazy" regimes exhibit qualitatively different behaviors in representation learning (a vs. d) and generalization scaling (b vs. e, c vs. f).
2. **Phase Transition vs. Gradual Change:** The rich regime shows a sharp, threshold-based transition in its internal metric (panel a), while the lazy regime shows a smooth, centered distribution (panel d).
3. **Scaling Laws:** In the rich regime, generalization improves with more symbols (`L`) and is robust to increasing input dimension (`d`). In the lazy regime, generalization degrades with increasing `d` and requires `L` to scale with `d` to maintain performance.
4. **Role of γ:** The parameter γ acts as a interpolation between regimes. As γ decreases from 1.00 towards 0.00, performance consistently degrades across all metrics, moving from the rich to the lazy regime's characteristics.
### Interpretation
This figure demonstrates a fundamental dichotomy in how neural networks can learn, governed by a hyperparameter γ (likely related to initialization scale or learning rate, akin to the "rich" vs. "lazy" or "feature" vs. "kernel" learning regimes in recent literature).
- **What the data suggests:** The "Rich regime" (γ=1) enables the model to learn discrete, symbolic representations (evidenced by the sharp transition in panel a) that generalize well and scale efficiently with problem complexity (panels b, c). The model actively shapes its internal features. The "Lazy regime" (γ≈0) results in a model that makes only small adjustments to its initial random features (panel d's cloud). Its generalization is akin to a kernel method, where performance is fundamentally limited by the ratio of symbols to input dimensions (panels e, f), leading to poor scaling with high-dimensional inputs.
- **How elements relate:** The scatter plots (a, d) explain the *mechanism* behind the performance curves (c, f) and heatmaps (b, e). The sharp transition in (a) allows for efficient coding and robust generalization, leading to the flat, high-accuracy curves in (c). The diffuse representation in (d) leads to the fragile, dimension-dependent performance in (f).
- **Notable anomalies/insights:** The most striking insight is the reversal of the scaling trend with input dimension `d`. In the rich regime, increasing `d` does not harm accuracy (panel b), while in the lazy regime, it is detrimental (panel e, f). This has critical implications for applying such models to high-dimensional real-world data. The diagonal boundary in panel e is a key quantitative finding, suggesting a precise scaling law (L ∝ d) for the lazy regime's capacity.
</details>
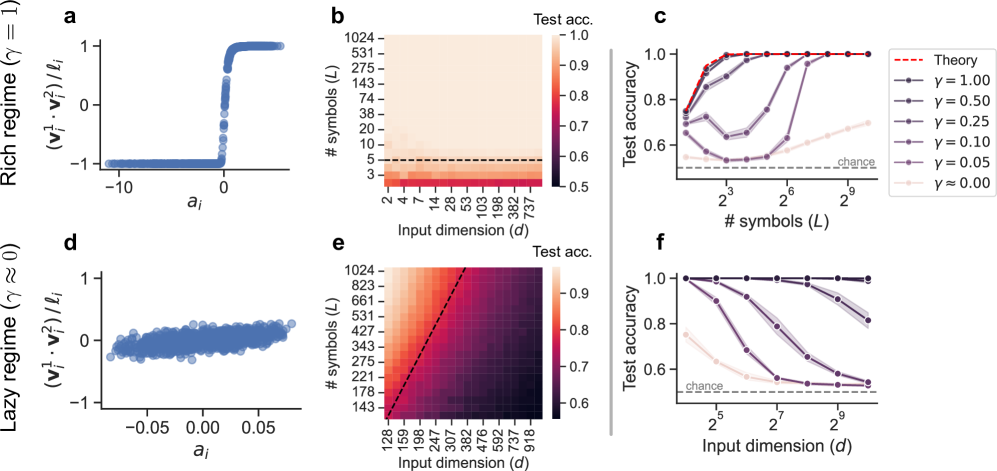
Figure 1: Rich and lazy regime simulations. We confirm our theoretical predictions with numeric simulations. (a). Hidden weight alignment plotted against readout weights for a rich model. Weights become parallel or antiparallel, with generally higher magnitudes among negative readouts. (b) Test accuracy across different input dimensions and training symbols for a rich model ( $m=4096$ ). Accuracy is not affected by input dimension. (c) Test accuracy across different numbers of training symbols, for varying learning richness ( $d=256$ , $m=1024$ ). Richer models attain high performance with substantially fewer training symbols. The theoretically predicted rich test accuracy shows excellent agreement with our richest model. Finer-grain validation is plotted in Figure C3. (d) Hidden weight alignment plotted against readout weights for a lazy model. There is some correlation between alignment and readout weight, but the weights are nowhere near as close to being parallel/antiparallel as in the rich regime. (e) Test accuracy across input dimensions and training symbols for a lazy model ( $m=4096$ ). Accuracy is substantially affected by input dimension. Theory predicts that the number of training symbols required to maintain high accuracy scales at worst as $L\propto d^{2}$ , plotted in black. (f) Test accuracy across different input dimensions, for varying learning richness ( $L=16,m=1024$ ). Richer models show less performance decay with increasing dimension. (all) Results are computed across six runs. Shading corresponds to empirical 95 percent confidence intervals.
## 3 Same-different task analysis
We present our analysis of the SD task. We first hand-craft a solution that is expressible by our MLP, and in the process suggest what conceptual representations of sameness and difference may look like (Section 3.1). We proceed to argue that a rich-regime MLP attains the hand-crafted solution through training. It leverages its conceptual representations to learn the task with few training symbols and insensitivity to the input dimension (Section 3.2), exhibiting conceptual behavior. In contrast, a lazy-regime MLP is unable to adapt its representations to the task, and consequently incurs a high training cost and substantial sensitivity to input dimension (Section 3.3), exhibiting perceptual behavior. In an extension to a noisy version of our task, we show that a rich MLP approaches Bayes optimal performance under a generalizing prior across different noise variance $\sigma^{2}$ (Section 3.3). We validate our results on more complex, image-based tasks in Section 4, and discuss broader implications in Section 5.
### 3.1 Hand-crafted solution
To establish whether an MLP can solve the same-different task at all, we first outline a hand-crafted solution using $m=4$ hidden units. Let $\mathbf{1}=(1,1,\ldots,1)\in\mathbb{R}^{d}$ . Define the weight vector $\mathbf{w}_{1}^{+}$ by concatenation: $\mathbf{w}_{1}^{+}=(\mathbf{1};\mathbf{1})\in\mathbb{R}^{2d}$ . Further define $\mathbf{w}_{2}^{+}=(-\mathbf{1};-\mathbf{1})$ , $\mathbf{w}_{1}^{-}=(\mathbf{1};-\mathbf{1})$ , and $\mathbf{w}_{2}^{-}=(-\mathbf{1};\mathbf{1})$ . Let $a^{+}=1$ and $a^{-}=\rho$ , for some value $\rho>0$ . Our MLP is given by
$$
\displaystyle f(\mathbf{x})=\,\, \displaystyle a^{+}\big{(}\phi(\mathbf{w}_{1}^{+}\cdot\mathbf{x})+\phi(\mathbf{w}_{2}^{+}\cdot\mathbf{x})\big{)} \displaystyle- \displaystyle a^{-}\big{(}\phi(\mathbf{w}_{1}^{-}\cdot\mathbf{x})+\phi(\mathbf{w}_{2}^{-}\cdot\mathbf{x})\big{)}\,. \tag{2}
$$
Note that the weight vectors $\mathbf{w}_{1}^{+},\mathbf{w}_{2}^{+}$ , which correspond to the positive readout $a^{+}$ , are parallel: their components point in the same direction with the same magnitude. Meanwhile, weight vectors $\mathbf{w}_{1}^{-},\mathbf{w}_{2}^{-}$ corresponding to the negative readout $a^{-}$ are antiparallel: their components point in exact opposite directions with the same magnitude. Only the sign of $f$ impacts the classification, so we assign $a^{+}=1$ and $a^{-}=\rho$ to represent the relative magnitude of $a^{-}$ against $a^{+}$ .
To see how this weight configuration solves the same-different task, suppose we receive a same example $\mathbf{x}=(\mathbf{z},\mathbf{z})$ . Plugging this into Eq (2) reveals that the negative terms vanish through our antiparallel weights, leaving $f(\mathbf{x})=2\,|\mathbf{1}\cdot\mathbf{z}|>0$ , correctly classifying this example.
Now suppose we receive a different example $\mathbf{x}^{\prime}=(\mathbf{z},\mathbf{z}^{\prime})$ . Recall that these quantities are sampled independently as $\mathbf{z},\mathbf{z}^{\prime}\sim\mathcal{N}(\mathbf{0},\mathbf{I}/d)$ . As a result, we can no longer rely on a convenient cancellation. The quantity $\phi(\mathbf{w}_{1}^{+}\cdot\mathbf{x}^{\prime})+\phi(\mathbf{w}_{2}^{+}\cdot\mathbf{x}^{\prime})$ is equal in distribution to the quantity $\phi(\mathbf{w}_{1}^{-}\cdot\mathbf{x}^{\prime})+\phi(\mathbf{w}_{2}^{-}\cdot\mathbf{x}^{\prime})$ , with respect to the randomness in $\mathbf{x}^{\prime}$ . Hence, to implement a consistent negative classification, we need to raise the relative magnitude $\rho$ of our negative readout weight. Indeed, we calculate $p(f(\mathbf{x}^{\prime})<0)=\frac{2}{\pi}\tan^{-1}(\rho)$ , which approaches $1$ for $\rho\gg 1$ . Full details are recorded in Appendix B. Hence, by maintaining a large negative readout, we classify negative examples correctly with high probability. An illustration of this solution is provided in Figure B1.
An MLP need not implement this precise weight configuration to solve the SD task. Rather, our hand-crafted solution suggests two general conditions:
1. Parallel/antiparallel weight vectors. Weights associated with positive readouts must be parallel, and weight associated with negative readouts must be antiparallel. This allows us to classify any same example by canceling the contribution from negative readouts.
1. Large negative readouts. The cumulative magnitude of the negative readouts must be larger than that of the positive readouts. This allows us to classify any different example by raising the contribution from negative readouts.
Observe also that parallel and antiparallel weights are suggestive of conceptual representations for sameness and difference. Parallel weights contribute to a same classification, and exemplify the structure of a same example: the two components point in the same direction. Antiparallel weights contribute to a different classification, and exemplify the structure of a different example: the two components point as far apart as possible. We look for parallel/antiparallel weight vectors as evidence for conceptual representations of our SD task.
### 3.2 Rich regime
The rich learning regime is characterized by substantial weight changes throughout the course of training. For the MLP given in Eq (1), larger values of $\gamma$ lead to rich learning behavior. We allow $\gamma$ to vary between 0 and 1. The range $\gamma>1$ is considered in Figure C3, where we see that no qualitative changes to our results occur for larger values of $\gamma$ .
To study the rich regime, we take two approaches. First, recent theoretical work (Morwani ., 2023; Wei ., 2019; Chizat Bach, 2020) suggest that MLPs trained in a rich learning regime on a classification task discover a max margin solution: the weights maximize the distance between training points of different classes. We derive the max margin weights for an MLP with quadratic activations in Theorem 1, finding that the max margin solution consists of parallel/antiparallel weight vectors, just as required from our hand-crafted solution. We defer the proof of this theorem to Appendix C.
**Theorem 1**
*Let $\mathcal{D}=\{\mathbf{x}_{n},y_{n}\}_{n=1}^{P}$ be a training set consisting of $P$ points sampled across $L$ training symbols, as specified in Section 2. Let $f$ be the MLP given by Eq 1, with two changes:
1. Fix the readouts $a_{i}=\pm 1$ , where exactly $m/2$ readouts are positive and the remaining are negative.
1. Use quadratic activations $\phi(\cdot)=(\cdot)^{2}$ .
For weights $\mathbf{\theta}=\left\{\mathbf{w}_{i}\right\}_{i=1}^{m}$ , define the max margin set $\Delta(\mathbf{\theta})$ to be
$$
\Delta(\mathbf{\theta})=\operatorname*{arg\,max}_{\mathbf{\theta}}\frac{1}{P}\sum_{n=1}^{P}\left[(2y_{n}-1)f(\mathbf{x}_{n};\mathbf{\theta})\right]\,,
$$
subject to the norm constraints $\left|\left|\mathbf{w}_{i}\right|\right|=1$ . If $P,L\rightarrow\infty$ , then for any $\mathbf{w}_{i}=(\mathbf{v}_{i}^{1};\mathbf{v}_{i}^{2})\in\Delta(\mathbf{\theta})$ and $\ell_{i}=\left|\left|\mathbf{v}_{i}^{1}\right|\right|\,\left|\left|\mathbf{v}_{i}^{2}\right|\right|$ , we have that $\mathbf{v}_{i}^{1}\cdot\mathbf{v}_{i}^{2}/\ell_{i}=1$ if $a_{i}=1$ and $\mathbf{v}_{i}^{1}\cdot\mathbf{v}_{i}^{2}/\ell_{i}=-1$ if $a_{i}=-1$ . Further, $\left|\left|\mathbf{v}_{i}^{1}\right|\right|=\left|\left|\mathbf{v}_{i}^{2}\right|\right|$ .*
However, the max margin result does not use ReLU MLPs, relies on fixed readouts $a_{i}$ , and says nothing about learning efficiency or insensitivity to spurious perceptual details, two additional properties we require from a conceptual solution. To address these shortcomings, we extend the analysis by proposing a heuristic construction that approximates a rich ReLU MLP as an ensemble of independent Markov processes (Section C.2). Doing so enables a deeper characterization of rich learning dynamics, resulting in the following approximation of the test accuracy. Given an unseen test point $\mathbf{x},y$ , and prediction $\hat{y}$ ,
$$
p(y=\hat{y}(\mathbf{x}))\approx\frac{1}{2}+\frac{1}{2}\Phi\left(\sqrt{\frac{2(L^{2}-L)}{13(\pi-2)}}\right)\,, \tag{3}
$$
where $L$ is the number of training symbols and $\Phi$ is the CDF of a standard normal distribution. This estimate is for $L\geq 3$ . For $L=2$ , $p(y=\hat{y})=3/4$ . See Section C.5 for details. This estimate suggests that the model attains over 95 percent test accuracy with as few as $L=5$ training symbols, and test accuracy does not change with different $d$ .
We confirm our theoretical predictions with simulations in Figure 1. At the end of training, the hidden weights indeed become parallel and antiparallel, with negative coefficients gaining larger magnitude (Figure 1 a). Figures 1 b and c show that the rich model learns the same-different task with substantially fewer training symbols than lazier models, and exhibits excellent agreement with our theoretical test accuracy prediction. As predicted, the rich model’s performance does not vary with input dimension (Figure 1 b).
Altogether, the rich model develops conceptual representations, learns the same-different task given only a small number of training symbols, and exhibits clear insensitivity to input dimension. In this way, it exhibits conceptual behavior on the same-different task.
<details>
<summary>x2.png Details</summary>

### Visual Description
## Multi-Panel Line Chart: Test Accuracy vs. Number of Symbols under Varying Noise Levels
### Overview
The image displays a series of four line charts arranged horizontally. Each chart plots "Test accuracy" on the y-axis against the "# symbols (L)" on the x-axis (logarithmic scale). The four panels represent experiments conducted under different noise levels, denoted by σ² (sigma squared), with values of 0, 1, 2, and 4 from left to right. Each panel contains multiple data series corresponding to different values of a regularization parameter γ (gamma), along with two baseline performance lines labeled "Bayes gen" and "Bayes mem".
### Components/Axes
* **Panels:** Four distinct plots, each titled with its noise level: `σ² = 0`, `σ² = 1`, `σ² = 2`, `σ² = 4`.
* **Y-Axis (All Panels):** Label: `Test accuracy`. Scale: Linear, ranging from 0.5 to 1.0. Major ticks are at 0.5 and 1.0.
* **X-Axis (All Panels):** Label: `# symbols (L)`. Scale: Logarithmic (base 2). Major ticks are labeled at `2^5` (32) and `2^10` (1024). The axis spans approximately from 2^0 (1) to 2^12 (4096).
* **Legend (Located to the right of the fourth panel):**
* **Data Series (Solid lines with circular markers):**
* `γ = 10^0` (Dark purple/black)
* `γ = 10^-1` (Dark purple)
* `γ = 10^-2` (Medium purple)
* `γ = 10^-3` (Light purple)
* `γ = 10^-4` (Lighter purple/pink)
* `γ = 0` (Light pink)
* **Baseline Series (Dashed lines):**
* `Bayes gen` (Red dashed line)
* `Bayes mem` (Magenta/pink dashed line)
### Detailed Analysis
**Panel 1: σ² = 0 (No Noise)**
* **Trend:** All models achieve high accuracy (>0.9) as the number of symbols (L) increases. The convergence speed depends heavily on γ.
* **Data Points (Approximate):**
* `γ = 10^0` and `γ = 10^-1`: Reach near-perfect accuracy (~1.0) very quickly, by L ≈ 2^3 (8).
* `γ = 10^-2`: Reaches ~1.0 by L ≈ 2^5 (32).
* `γ = 10^-3`: Reaches ~1.0 by L ≈ 2^7 (128).
* `γ = 10^-4`: Reaches ~0.98 by L ≈ 2^10 (1024).
* `γ = 0`: Shows a distinct dip in accuracy at low L (minimum ~0.6 at L≈2^2), then recovers to ~0.95 by L≈2^10.
* `Bayes gen` (Red dashed): Constant at 1.0.
* `Bayes mem` (Magenta dashed): Not visible/plotted in this panel, likely coincides with the top axis or is not applicable.
**Panel 2: σ² = 1 (Low Noise)**
* **Trend:** All models show reduced final accuracy compared to the noiseless case. Higher γ values lead to faster convergence but potentially lower asymptotic performance.
* **Data Points (Approximate):**
* `γ = 10^0`: Converges fastest, plateauing at ~0.95 by L≈2^7.
* `γ = 10^-1`: Plateaus at ~0.95 by L≈2^8.
* `γ = 10^-2`: Plateaus at ~0.93 by L≈2^9.
* `γ = 10^-3`: Plateaus at ~0.88 by L≈2^10.
* `γ = 10^-4`: Plateaus at ~0.82 by L≈2^11.
* `γ = 0`: Shows a shallow dip, then slowly rises to ~0.75 by L≈2^11.
* `Bayes gen` (Red dashed): Constant at ~0.98.
* `Bayes mem` (Magenta dashed): Constant at ~0.65.
**Panel 3: σ² = 2 (Medium Noise)**
* **Trend:** Performance degradation continues. The gap between high-γ and low-γ models widens. The `Bayes mem` baseline becomes more relevant.
* **Data Points (Approximate):**
* `γ = 10^0`: Plateaus at ~0.90 by L≈2^8.
* `γ = 10^-1`: Plateaus at ~0.88 by L≈2^9.
* `γ = 10^-2`: Plateaus at ~0.85 by L≈2^10.
* `γ = 10^-3`: Plateaus at ~0.78 by L≈2^11.
* `γ = 10^-4`: Plateaus at ~0.70 by L≈2^11.
* `γ = 0`: Rises slowly to ~0.65 by L≈2^11.
* `Bayes gen` (Red dashed): Constant at ~0.92.
* `Bayes mem` (Magenta dashed): Constant at ~0.60.
**Panel 4: σ² = 4 (High Noise)**
* **Trend:** All models struggle. Final accuracies are significantly lower. The benefit of increasing L diminishes for low-γ models.
* **Data Points (Approximate):**
* `γ = 10^0`: Plateaus at ~0.82 by L≈2^9.
* `γ = 10^-1`: Plateaus at ~0.80 by L≈2^10.
* `γ = 10^-2`: Plateaus at ~0.75 by L≈2^10.
* `γ = 10^-3`: Plateaus at ~0.68 by L≈2^11.
* `γ = 10^-4`: Plateaus at ~0.62 by L≈2^11.
* `γ = 0`: Rises very slowly to ~0.58 by L≈2^11.
* `Bayes gen` (Red dashed): Constant at ~0.80.
* `Bayes mem` (Magenta dashed): Constant at ~0.55.
### Key Observations
1. **Noise Impact:** Increasing noise (σ²) universally reduces the maximum achievable test accuracy for all models and baselines.
2. **Regularization (γ) Effect:** Higher γ values (stronger regularization) lead to faster learning (steeper initial slope) and better robustness to noise, as seen by their higher plateau in noisy conditions (σ²=2,4). However, in the noiseless case (σ²=0), very high γ (`10^0`) converges quickly but all high-γ models perform similarly at the top.
3. **Pathological Case (γ=0):** The model with no regularization (`γ=0`) performs worst in all scenarios. In the noiseless case, it exhibits a characteristic "U-shaped" learning curve, initially getting worse before improving.
4. **Baselines:** The `Bayes gen` (generalization) line represents an upper bound that decreases with noise. The `Bayes mem` (memorization) line represents a lower bound that also decreases with noise. The gap between these baselines narrows as noise increases.
5. **Data Efficiency:** For a fixed noise level, achieving a target accuracy requires exponentially more symbols (L) as γ decreases. For example, at σ²=1, reaching 0.9 accuracy requires L≈2^6 for γ=10^0 but L>2^10 for γ=10^-3.
### Interpretation
This chart demonstrates the **bias-variance tradeoff** in the context of learning from symbolic data under noise. The parameter γ controls model complexity/regularization.
* **High γ (High Bias, Low Variance):** These models learn simple patterns quickly and are robust to noise, as they are less likely to fit the noise. Their performance plateaus earlier but at a higher level in noisy environments.
* **Low γ (Low Bias, High Variance):** These models are more complex and can fit intricate patterns. In noiseless data, they eventually reach perfect accuracy but require more data (symbols). In noisy data, they are prone to overfitting the noise, leading to poorer generalization and lower final accuracy, as seen by their performance falling below the `Bayes gen` bound and sometimes approaching the `Bayes mem` bound.
* **The γ=0 case** is an extreme of low bias/high variance, where the model initially fits noise (causing the accuracy dip) before learning the true signal with enough data.
* The **Bayes baselines** provide theoretical benchmarks. The fact that models with appropriate regularization (e.g., γ=10^-1, 10^-2) can approach the `Bayes gen` line suggests they are achieving near-optimal generalization for the given noise level. The convergence of all models towards the `Bayes mem` line at very low L suggests that with insufficient data, all models are essentially memorizing.
**In summary, the visualization argues for the necessity of regularization (γ > 0) to achieve robust and data-efficient learning, especially in the presence of noise. The optimal γ is noise-dependent: stronger regularization is beneficial as noise increases.**
</details>
Figure 2: Bayesian simulations. Test accuracy across different numbers of training symbols, for varying richness and noise ( $d=64$ , $m=1024$ ). Bayes optimal accuracy for both generalizing and memorizing priors are plotted with dashed lines. In all cases, rich models attain the Bayes optimal test accuracy under a generalizing prior after sufficiently many training symbols. Shaded error regions are computed across six runs and correspond to empirical 95 percent confidence intervals.
### 3.3 Lazy regime
The lazy learning regime is characterized by vanishingly small change in the model’s hidden representations after training. Smaller values of $\gamma$ lead to lazy learning behavior. The limit $\gamma\rightarrow 0$ corresponds to the Neural Tangent Kernel (NTK) regime, where the network is well-described by a linearization around its initialization (Jacot ., 2018). In our numerics, we approximate this limit by using $\gamma=(1\times 10^{-5})/\sqrt{d}$ .
Because a lazy neural network cannot adapt its representations to an arbitrary pattern, it is impossible for a lazy MLP to learn parallel/antiparallel weights. However, because the statistics of a same example differ from that of a different example, it may still be possible for a lazy MLP to succeed at the task given enough training data For example, for a same input $\mathbf{x}=(\mathbf{z};\mathbf{z})$ and a different input $\mathbf{x}^{\prime}=(\mathbf{z}_{1},\mathbf{z}_{2})$ , the variance of $\mathbf{1}\cdot\mathbf{x}$ is twice that of $\mathbf{1}\cdot\mathbf{x}^{\prime}$ . Leveraging distinct statistics like this may still allow the lazy model to learn this task.. Using standard kernel arguments (Cho Saul, 2009; Jacot ., 2018), we bound the test error of a lazy MLP in Theorem 2. The proof is deferred to Appendix D.
**Theorem 2 (informal)**
*Let $f$ be an infinite-width ReLU MLP. If $f$ is trained on a dataset consisting of $P$ points constructed from $L$ symbols with input dimension $d$ , then the test error of $f$ is upper bounded by $\mathcal{O}\left(\exp\left\{-L/d^{2}\right\}\right)$ .*
This bound suggests that to maintain a consistently low test error (or equivalently, high test accuracy), the number of training symbols $L$ needs to scale quadratically (at worst) with the input dimension: $L\propto d^{2}$ .
We support our theoretical predictions with simulations in Figure 1. Because the model is in a lazy regime, the hidden weights do not move far from initialization, and no clear parallel/antiparallel structure emerges (Figure 1 d). Figure 1 c shows how models require increasingly more training data as richness decreases. Lazier models are also substantially more impacted by changes in input dimension (Figure 1 e and f), and the scaling of training symbols with input dimension is consistent with our theory (Figure 1 e).
Altogether, the lazy model is unable to learn conceptual representations, instead relying on statistical associations that require a large amount of training data to learn and exhibit strong sensitivity to input dimension. In this way, the lazy model exhibits perceptual behavior on the same-different task.
### 3.4 Same-different with noise
Up until now, we defined equality by exact identity: even a minuscule deviation in a single coordinate is enough to break equality and classify an example as different. Reality is far less clean, and real-world objects are rarely equal up to exact identity. As a first step towards this broader setting, we relax our dependence on exact identity and consider a noisy SD task. In the notation of our setup (Section 2), we allow $\sigma^{2}>0$ .
To understand optimal performance under noise, we apply the following Bayesian framework. As a baseline, we consider a prior corresponding to an idealized model which memorizes the training symbols. This memorizing prior assumes every input symbol is distributed uniformly among the training symbols. To contrast this baseline, we consider a gold-standard prior corresponding to a model which generalizes to novel symbols. This generalizing prior assumes every input symbol follows the true underlying distribution. By comparing the test accuracy of the trained models to the posteriors computed in these two settings, we identify which prior more closely reflects the models’ operation. The calculation of these posteriors are recorded in Appendix E.
Results are plotted in Figure 2. In all cases, we find that the rich model approaches Bayes optimal under the generalizing prior. Lazier models tend to plateau at lower test accuracies; they nonetheless tend to exceed the performance of the memorizing prior at higher noise, indicating some level of generalization. Overall, learning richness appears to support convincing generalization to novel training symbols in the noisy SD task.
<details>
<summary>x3.png Details</summary>
### Visual Description
## [Multi-Panel Figure]: Visual Recognition Task Analysis (PSVRT, Pentomino, CIFAR-100)
### Overview
The image is a composite of 8 panels (a–h) analyzing three visual recognition datasets: **PSVRT** (top row), **Pentomino** (middle row), and **CIFAR-100** (bottom row). Each dataset includes a visual example (a, d, g) and two test accuracy plots (b–c, e–f, h) with varying parameters (γ values) and task complexities (x-axes: number of bit-patterns, shapes, classes, or patches).
### Components/Axes
- **Datasets (Rows)**:
- Top: PSVRT (panels a, b, c)
- Middle: Pentomino (panels d, e, f)
- Bottom: CIFAR-100 (panels g, h)
- **Visual Examples (a, d, g)**:
- **a (PSVRT)**: Black/white pixel patterns (bit-patterns) on a gray background (two sets of patterns).
- **d (Pentomino)**: Black pentomino shapes (T, L, cross) on a gray background (two sets of shapes).
- **g (CIFAR-100)**: Color natural images (bee on flower, lamp, tree) on a gray background.
- **Accuracy Plots (b, c, e, f, h)**:
- **Y-axis**: Test accuracy (range: 0.6–1.0).
- **X-axes**:
- b: Number of bit-patterns (2⁶=64 to 2⁹=512).
- c: Number of patches (5–10).
- e: Number of shapes (5–15).
- f: Number of patches (2–10).
- h: Number of classes (2⁴=16 to 2⁶=64).
- **Legend (bottom-right)**: γ values (γ=10⁰, 10⁻¹, 10⁻², 10⁻³, 10⁻⁴, γ≈0) with line styles/colors (dark purple → light pink).
### Detailed Analysis
#### Panel a (PSVRT Visuals)
Two sets of black/white pixel patterns (bit-patterns) on a gray background. Left: Two blocky patterns; right: Two patterns (one checkerboard, one blocky).
#### Panel b (PSVRT: # bit-patterns vs Test Accuracy)
- **X**: Number of bit-patterns (2⁶=64, 2⁷=128, 2⁸=256, 2⁹=512).
- **Y**: Test accuracy (0.6–1.0).
- **Trend**: All lines *increase* with # bit-patterns.
- γ=10⁰ (dark purple): Highest accuracy (~1.0 at 2⁹).
- γ≈0 (lightest pink): Lowest accuracy (~0.75 at 2⁹).
#### Panel c (PSVRT: # patches vs Test Accuracy)
- **X**: Number of patches (5–10).
- **Y**: Test accuracy (0.6–1.0).
- **Trend**: All lines *decrease* with # patches.
- γ=10⁰ (dark purple): Highest accuracy (~1.0 at 5, ~0.95 at 10).
- γ≈0 (lightest pink): Lowest accuracy (~0.75 at 5, ~0.7 at 10).
#### Panel d (Pentomino Visuals)
Two sets of black pentomino shapes (T, L, cross) on a gray background. Left: T and L; right: L and cross.
#### Panel e (Pentomino: # shapes vs Test Accuracy)
- **X**: Number of shapes (5–15).
- **Y**: Test accuracy (0.6–1.0).
- **Trend**: All lines *increase* with # shapes.
- γ=10⁰ (dark purple): Highest accuracy (~0.95 at 15).
- γ≈0 (lightest pink): Lowest accuracy (~0.7 at 15).
#### Panel f (Pentomino: # patches vs Test Accuracy)
- **X**: Number of patches (2–10).
- **Y**: Test accuracy (0.6–1.0).
- **Trend**: All lines *decrease* with # patches.
- γ=10⁰ (dark purple): Highest accuracy (~0.9 at 2, ~0.85 at 10).
- γ≈0 (lightest pink): Lowest accuracy (~0.65 at 2, ~0.6 at 10).
#### Panel g (CIFAR-100 Visuals)
Four color natural images:
- Left: Bee on a yellow flower.
- Middle-left: Bee on a pink flower.
- Middle-right: Lamp on a table.
- Right: Tree in a landscape.
#### Panel h (CIFAR-100: # classes vs Test Accuracy)
- **X**: Number of classes (2⁴=16, 2⁵=32, 2⁶=64).
- **Y**: Test accuracy (0.6–1.0).
- **Trend**: All lines *increase* with # classes.
- γ=10⁰ (dark purple): Highest accuracy (~0.9 at 2⁶).
- γ≈0 (lightest pink): Lowest accuracy (~0.65 at 2⁶).
### Key Observations
1. **γ Impact**: Higher γ (e.g., γ=10⁰) consistently yields higher test accuracy across all datasets. Lower γ (e.g., γ≈0) reduces accuracy.
2. **Task Complexity**:
- For PSVRT (b) and Pentomino (e), increasing the number of bit-patterns/shapes *improves* accuracy.
- For PSVRT (c) and Pentomino (f), increasing the number of patches *decreases* accuracy.
- For CIFAR-100 (h), increasing the number of classes *improves* accuracy.
3. **Visual Diversity**: Each dataset uses distinct input types (pixel blocks, pentomino shapes, natural images), highlighting task-specific challenges.
### Interpretation
This figure explores how a parameter γ (likely a regularization/scaling factor) and task complexity (number of patterns, shapes, classes, or patches) influence test accuracy in visual recognition. Higher γ values improve performance, suggesting γ controls a trade-off (e.g., between model complexity and generalization). The x-axis variations reveal how task complexity (more patterns/shapes/classes) or data granularity (more patches) impacts recognition. The visual examples contextualize the tasks, showing input data diversity. This analysis informs model optimization for visual tasks by clarifying how parameters and task characteristics interact.
</details>
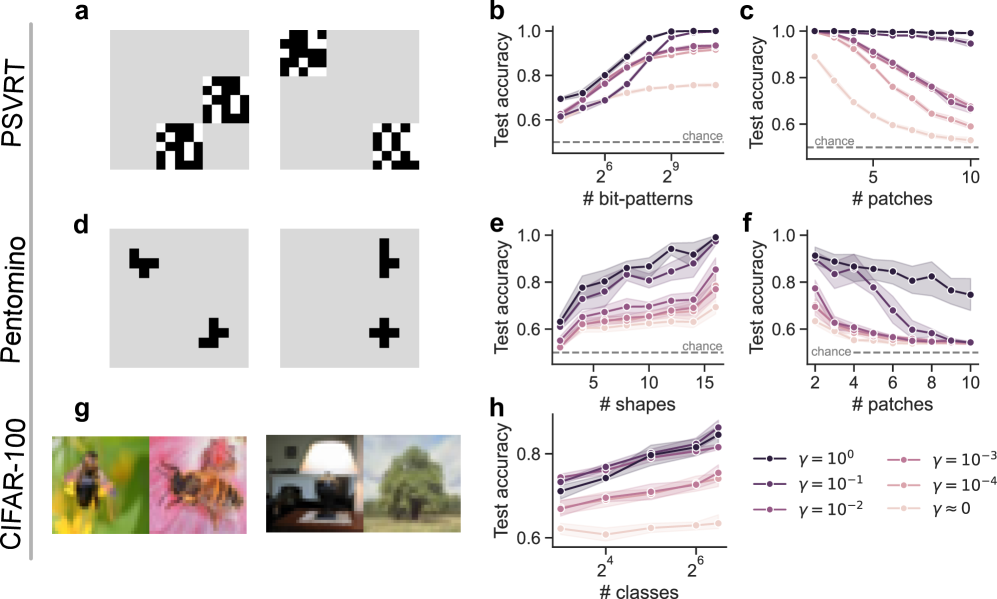
Figure 3: Visual same-different results. (a) PSVRT examples for same (left) and different (right). (b,c) Test accuracy on PSVRT across different numbers of training bit-patterns and image widths. Richer models learn the task with fewer patterns and exhibit less sensitivity to larger sizes. (d) Pentomino examples for same (left) and different (right). (e,f) Test accuracy on Pentomino across training shapes and image widths. As before, richer models learn the task with fewer training shapes and exhibit less sensitivity to larger sizes, though performance across models tends to diminish somewhat with increasing image size. (g) CIFAR-100 examples for same (left) and different (right). (h) Test accuracy on CIFAR-100 same-different across training classes. Richer models tend to perform better with fewer classes, though the richest model in this example performs worse. For this task, very rich models may overfit, necessitating an optimal richness level. (all) Shaded error regions are computed across six runs and correspond to empirical 95 percent confidence intervals.
## 4 Validation in vision tasks
To validate our theoretical findings in a more complex, naturalistic setting, we turn to visual same-different tasks. Specifically, we examine three datasets designed originally to study visual reasoning and computer vision: 1) PSVRT (Kim ., 2018), 2) Pentomino (Gülçehre Bengio, 2016), and 3) CIFAR-100 (Krizhevsky Hinton, 2009). These tasks offer significantly more challenge over the simple SD task we examine before. Rather than reason over symbol embeddings, a model must now reason over complex visual objects. Inputs are now images, and equality is no longer exact identity: inputs can be equal up to translation (in PSVRT), rotation (in Pentomino), or merely share a class label (CIFAR-100). All additional details on model and task configurations are enumerated in Appendix G.
We continue to use the same MLP model as before. Images are flattened before input to the model. Though better performance may be attained using CNNs or Vision Transformers, our ultimate goal is to study learning richness rather than maximize performance. Nonetheless, as we will soon see, an MLP performs astonishingly well on these tasks despite its simplicity — provided it remains in a rich learning regime. To validate our theoretical findings, we should continue to see the three hallmarks of a conceptual solution (conceptual representations, efficiency, and insensitivity to spurious perceptual details), but only in rich MLPs.
### 4.1 PSVRT
The parameterized-SVRT (PSVRT) dataset is a version of the Synthetic Visual Reasoning Test (SVRT), a collection of challenging visual reasoning tasks based on abstract shapes (Kim ., 2018). PSVRT replaces the original shapes with random bit-patterns in order to better control image variability. The task input consists of an image that has two blocks of bit-patterns, placed randomly on a blank background. The model must determine whether the blocks contain the same bit pattern, or different patterns. The training set consists of a fixed number of predetermined bit patterns. The test set consists of novel bit-patterns never encountered during training.
Bit-patterns are patch-aligned: they occur in non-overlapping locations that tile the image. The width of an image may be specified by the number of patches. Figure 3 a illustrates examples from PSVRT that are three patches wide.
Results. Figure 3 b plots a model’s test accuracy on PSVRT as a function of the number of training patterns. As our theory suggests, richer models learn the task more easily and generalize after substantially fewer training patterns. To test our models under perceptual variation, we consider larger image sizes. We keep the same size of bit-patterns, but increase the number of patches to make a bigger input. Figure 3 c indicates that a rich model continues to perform perfectly irrespective of image size, whereas lazier models exhibit a performance decay with larger inputs.
Finally, we identify parallel/antiparallel analogs for PSVRT in the weights of a rich model (Figure A1 a). The presence of these conceptual representations suggests that our theory remains a reasonable description for how a rich MLP may learn a conceptual solution to the PSVRT same-different task.
### 4.2 Pentomino
The Pentomino task uses inputs that are pentomino polygons: shapes consisting of five squares glued by edge (Gülçehre Bengio, 2016). The input consists of an image with two pentominoes, placed arbitrarily on a blank background. The pentominoes may either be the same shape, or different. In contrast with the PSVRT task, sameness in this task implies equality up to rotation. After training on a fixed set of pentomino shapes, the model must generalize to entirely novel shapes. Like with PSVRT, shapes are patch-aligned. Figure 3 d illustrates example inputs from this task that are three patches wide.
Results. Figure 3 e plots a model’s test accuracy on Pentomino as a function of the number of training shapes. Consistent with our theory, richer models learn the task more easily and generalize after substantially fewer training shapes. To test our models under perceptual variation, we consider larger image sizes. Like with PSVRT, we add additional patches to enlarge the input. Figure 3 f indicates that a rich model continues to perform well on larger image sizes, though its performance does start to decay somewhat. Performance decays substantially faster for lazier models.
We again identify parallel/antiparallel analogs for Pentomino in the weights of a rich model (Figure A1 c). The presence of these conceptual representations continues to support our theoretical perspective. Notably, Gülçehre Bengio (2016) introduced this task to motivate curriculum learning, finding that their MLP fails to perform above chance. We found that curriculum learning is unnecessary in the presence of sufficient richness.
### 4.3 CIFAR-100
The CIFAR-100 dataset consists of 60 thousand real-world images, each 32 by 32 pixels (Krizhevsky Hinton, 2009). Images belong to one of 100 different classes. In this task, the input consists of two different unlabeled images that belong either to the same or different classes. After training on images from a fixed set of labels, the model must generalize to entirely novel labels. The sets of train and test labels are disjoint, making this an extremely challenging task. The labels themselves are not provided in any form during training. Example inputs are illustrated in Figure 3 g. We also experiment with providing features from VGG-16 pretrained on ImageNet (Simonyan Zisserman, 2014). We pass CIFAR-100 images to VGG-16, then use intermediate features as inputs to our MLP. The weights of VGG-16 are fixed throughout the whole process. Note also that ImageNet is disjoint from CIFAR-100, so there is limited possibility of contamination in the test images.
Results. Figure 3 h plots a model’s test accuracy on CIFAR-100 images as a function of the number of training classes. We use outputs from VGG-16 block 4, layer 3, which performed the best with our model. As before, richer models tend to perform better with fewer training classes, but with a curious exception: in contrast to the previous two tasks, the richest model does not always perform decisively the best. This is particularly evident using the activations from other intermediate VGG layers, plotted in Figure G 1. For certain layers and number of training classes, the optimal $\gamma$ appears to be somewhat less than 1. This outcome may be in part an artifact of overfitting. Given the complexity of the task and the limited data, richer models are plausibly more susceptible to idiosyncratic features of the training set that generalize poorly, analogous to overfitting effects in classical statistics that degrade the performance of powerful models. In this case, slightly less learning richness may be the optimal setting. Since CIFAR-100 images are fixed to 32 by 32 pixels, we skipped testing variable image size for this task.
As before, we identify parallel/antiparallel analogs for this task in the weights of a rich model (Figure A1 e). The general benefit of richness together with the presence of conceptual representations continues to align with our theoretical perspective. Across our three visual same-different tasks, we identified generally consistent relationships between learning richness, conceptual solutions, and good performance, supporting our theoretical findings.
## 5 Discussion
We studied equality reasoning using a simple same-different task. We showed that learning richness drives the development of either conceptual or perceptual behavior. Rich MLPs develop conceptual representations, learn from few training examples, and remain largely insensitive to perceptual variation. Meanwhile, lazy MLPs require exhaustive training examples and deteriorate substantially with spurious perceptual changes.
Varying learning richness recapitulates E. Wasserman . (2017) ’s continuum between perceptual and conceptual behavior on same-different tasks. Perhaps a pigeon’s competency at equality reasoning may be broadly comparable to a lazy MLP’s, requiring a great deal of training and exhibiting persistent sensitivity to spurious details. Perhaps equality reasoning in human or even language-trained great apes may be comparable to a rich MLP, where learning is faster, less sensitive to spurious details, and presumably involves conceptual abstractions. We suggest that a key parameter underlying these behavioral differences may be learning richness.
Learning richness is a concept imported from machine learning theory, and it is not altogether clear how to measure richness in a living brain. Since richness specifies the degree of change in a neural network’s hidden representations, the most direct analogy in the brain is to look for adaptive representations that seem to encode task-specific variables. Such approaches have implicated richness as an essential property for context-dependent decision making, multitask cognition, generalizing knowledge, among many other phenomena (Flesch ., 2022; Ito Murray, 2023; Johnston Fusi, 2023; Farrell ., 2023). Our theory predicts that greater learning richness relates to faster generalization in equality reasoning, and look forward to possible experimental validation of this principle.
Our work also contributes to the longstanding debate on a neural network’s facility with abstract reasoning. Rich MLPs demonstrate successful generalization to unseen symbols irrespective of input dimension or even high noise variance. Further, the rich MLP’s development of parallel/antiparallel components suggests the formation of abstractions, supporting the account that neural networks may indeed learn to develop and manipulate symbolic representations.
Practically, we demonstrate that learning richness is a vital hyperparameter. Increasing richness generally increases test performance substantially, improves data efficiency, and reduces sensitivity to spurious details. For complex tasks tuned with a large range of $\gamma$ , there may be an optimal level of richness. Indeed, for CIFAR-100, we observed that more richness is not always better, and an optimal level exists. We encourage more widespread application of richness parametrizations like $\mu$ P, and advocate for adding $\gamma$ to the list of tunable hyperparameters that every practitioner must consider when developing neural networks (Atanasov ., 2024).
Acknowledgments.
Special thanks to Alex Atanasov for a serendipitous conversation that inspired much of this project. We also thank Hamza Chaudhry, Ben Ruben, Sab Sainathan, Jacob Zavatone-Veth, and members of the Pehlevan Group for many helpful comments and discussions on our manuscript. WLT is supported by a Kempner Graduate Fellowship. CP is supported by NSF grant DMS-2134157, NSF CAREER Award IIS-2239780, DARPA grant DIAL-FP-038, a Sloan Research Fellowship, and The William F. Milton Fund from Harvard University. This work has been made possible in part by a gift from the Chan Zuckerberg Initiative Foundation to establish the Kempner Institute for the Study of Natural and Artificial Intelligence. The computations in this paper were run on the FASRC cluster supported by the FAS Division of Science Research Computing Group at Harvard University.
## References
- Alhama Zuidema (2019) Alhama2019-review Alhama, R G. Zuidema, W. 20191 08. A review of computational models of basic rule learning: The neural-symbolic debate and beyond A review of computational models of basic rule learning: The neural-symbolic debate and beyond. Psychon Bull Rev2641174–1194.
- Atanasov . (2024) atanasov2024ultrarich Atanasov, A., Meterez, A., Simon, J B. Pehlevan, C. 2024. The Optimization Landscape of SGD Across the Feature Learning Strength The optimization landscape of sgd across the feature learning strength. arXiv preprint arXiv:2410.04642.
- Battaglia . (2018) Battaglia2018-graph Battaglia, P W., Hamrick, J B., Bapst, V., Sanchez-Gonzalez, A., Zambaldi, V., Malinowski, M. Pascanu, R. 201817 10. Relational inductive biases, deep learning, and graph networks Relational inductive biases, deep learning, and graph networks. arXiv.
- Bernstein . (2018) signSGD Bernstein, J., Wang, Y X., Azizzadenesheli, K. Anandkumar, A. 2018. signSGD: Compressed optimisation for non-convex problems signsgd: Compressed optimisation for non-convex problems. International Conference on Machine Learning International conference on machine learning ( 560–569).
- Biehl Schwarze (1995) biehl1995learning_online_gd Biehl, M. Schwarze, H. 1995. Learning by on-line gradient descent Learning by on-line gradient descent. Journal of Physics A: Mathematical and general283643.
- Boix-Adsera . (2023) boix_abbe Boix-Adsera, E., Saremi, O., Abbe, E., Bengio, S., Littwin, E. Susskind, J. 2023. When can transformers reason with abstract symbols? When can transformers reason with abstract symbols? arXiv preprint arXiv:2310.09753.
- Bordelon Pehlevan (2022) bordelon_self_consistent Bordelon, B. Pehlevan, C. 2022. Self-consistent dynamical field theory of kernel evolution in wide neural networks Self-consistent dynamical field theory of kernel evolution in wide neural networks. Advances in Neural Information Processing Systems3532240–32256.
- Bubeck . (2023) Bubeck2023_sparks_of_agi Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E. Zhang, Y. 202313 04. Sparks of Artificial General Intelligence: Early experiments with GPT-4 Sparks of artificial general intelligence: Early experiments with GPT-4. arXiv.
- Carstensen Frank (2021) carstensen_graded_abs Carstensen, A. Frank, M C. 2021. Do graded representations support abstract thought? Do graded representations support abstract thought? Current Opinion in Behavioral Sciences3790–97.
- Chizat Bach (2020) chizat_bach_max_margin Chizat, L. Bach, F. 2020. Implicit bias of gradient descent for wide two-layer neural networks trained with the logistic loss Implicit bias of gradient descent for wide two-layer neural networks trained with the logistic loss. Conference on learning theory Conference on learning theory ( 1305–1338).
- Chizat . (2019) chizat2019lazy_rich Chizat, L., Oyallon, E. Bach, F. 2019. On lazy training in differentiable programming On lazy training in differentiable programming. Advances in neural information processing systems32.
- Cho Saul (2009) cho_saul_kernel Cho, Y. Saul, L. 2009. Kernel methods for deep learning Kernel methods for deep learning. Advances in neural information processing systems22.
- Farrell . (2023) Farrell2023-lazy_rich Farrell, M., Recanatesi, S. Shea-Brown, E. 20231 12. From lazy to rich to exclusive task representations in neural networks and neural codes From lazy to rich to exclusive task representations in neural networks and neural codes. Curr. Opin. Neurobiol.83102780102780.
- Flesch . (2022) Flesch2022-orthogonal Flesch, T., Juechems, K., Dumbalska, T., Saxe, A. Summerfield, C. 20226 04. Orthogonal representations for robust context-dependent task performance in brains and neural networks Orthogonal representations for robust context-dependent task performance in brains and neural networks. Neuron11071258–1270.e11.
- Fleuret . (2011) fleuret2011svrt Fleuret, F., Li, T., Dubout, C., Wampler, E K., Yantis, S. Geman, D. 2011. Comparing machines and humans on a visual categorization test Comparing machines and humans on a visual categorization test. Proceedings of the National Academy of Sciences1084317621–17625.
- Fodor Pylyshyn (1988) fodor_and_pylyshyn Fodor, J A. Pylyshyn, Z W. 1988. Connectionism and cognitive architecture: A critical analysis Connectionism and cognitive architecture: A critical analysis. Cognition281-23–71.
- A. Geiger . (2023) geiger_nonsym Geiger, A., Carstensen, A., Frank, M C. Potts, C. 2023. Relational reasoning and generalization using nonsymbolic neural networks. Relational reasoning and generalization using nonsymbolic neural networks. Psychological Review1302308.
- M. Geiger . (2020) geiger2020disentangling_feature_and_lazy Geiger, M., Spigler, S., Jacot, A. Wyart, M. 2020. Disentangling feature and lazy training in deep neural networks Disentangling feature and lazy training in deep neural networks. Journal of Statistical Mechanics: Theory and Experiment202011113301.
- Giurfa . (2001) Giurfa2001-bee Giurfa, M., Zhang, S., Jenett, A., Menzel, R. Srinivasan, M V. 200119 04. The concepts of ’sameness’ and ’difference’ in an insect The concepts of ’sameness’ and ’difference’ in an insect. Nature4106831930–933.
- Goldt . (2019) goldt2019dynamics Goldt, S., Advani, M., Saxe, A M., Krzakala, F. Zdeborová, L. 2019. Dynamics of stochastic gradient descent for two-layer neural networks in the teacher-student setup Dynamics of stochastic gradient descent for two-layer neural networks in the teacher-student setup. Advances in neural information processing systems32.
- Gülçehre Bengio (2016) gulccehre2016pentomino Gülçehre, Ç. Bengio, Y. 2016. Knowledge matters: Importance of prior information for optimization Knowledge matters: Importance of prior information for optimization. The Journal of Machine Learning Research171226–257.
- Guo . (2025) guo2025deepseek_r1 Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R. others 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
- Ito Murray (2023) Ito2023-multitask Ito, T. Murray, J D. 2023 02. Multitask representations in the human cortex transform along a sensory-to-motor hierarchy Multitask representations in the human cortex transform along a sensory-to-motor hierarchy. Nat. Neurosci.262306–315.
- Jacot . (2018) jacot_ntk Jacot, A., Gabriel, F. Hongler, C. 2018. Neural tangent kernel: Convergence and generalization in neural networks Neural tangent kernel: Convergence and generalization in neural networks. Advances in neural information processing systems31.
- James (1905) james1905principles_of_psych James, W. 1905. The Principles of Psychology The principles of psychology. New York,: H. Holt.
- Johnston Fusi (2023) johnston2023abstract_rep Johnston, W J. Fusi, S. 2023. Abstract representations emerge naturally in neural networks trained to perform multiple tasks Abstract representations emerge naturally in neural networks trained to perform multiple tasks. Nature Communications1411040.
- Kim . (2018) Kim2018-not_so_clevr Kim, J., Ricci, M. Serre, T. 201815 06. Not-So-CLEVR: learning same–different relations strains feedforward neural networks Not-so-CLEVR: learning same–different relations strains feedforward neural networks. Interface Focus8420180011.
- Kingma (2014) kingma2014adam Kingma, D P. 2014. Adam: A method for stochastic optimization Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Krizhevsky Hinton (2009) krizhevsky2009cifar100 Krizhevsky, A. Hinton, G. 2009. Learning multiple layers of features from tiny images Learning multiple layers of features from tiny images. Technical report.
- Mahowald . (2024) Mahowald2024-dissociate Mahowald, K., Ivanova, A A., Blank, I A., Kanwisher, N., Tenenbaum, J B. Fedorenko, E. 20241 06. Dissociating language and thought in large language models Dissociating language and thought in large language models. Trends Cogn. Sci.286517–540.
- G. Marcus (2020) Marcus2020-next_decade Marcus, G. 202019 02. The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence The next decade in AI: Four steps towards robust artificial intelligence. arXiv.
- G F. Marcus (1998) marcus1998rethinking Marcus, G F. 1998. Rethinking eliminative connectionism Rethinking eliminative connectionism. Cognitive psychology373243–282.
- G F. Marcus (2003) Marcus2003-algebraic Marcus, G F. 2003. The algebraic mind: Integrating connectionism and cognitive science The algebraic mind: Integrating connectionism and cognitive science. Cambridge, MABradford Books.
- G F. Marcus . (1999) Marcus1999-rule_learning Marcus, G F., Vijayan, S., Bandi Rao, S. Vishton, P M. 19991 01. Rule learning by seven-month-old infants Rule learning by seven-month-old infants. Science283539877–80.
- Mastrovito . (2024) Mastrovito2024-consciousness Mastrovito, D., Liu, Y H., Kusmierz, L., Shea-Brown, E., Koch, C. Mihalas, S. 202415 05. Transition to chaos separates learning regimes and relates to measure of consciousness in recurrent neural networks Transition to chaos separates learning regimes and relates to measure of consciousness in recurrent neural networks. bioRxivorg2024.05.15.594236.
- McCoy . (2023) McCoy2023-embers McCoy, R T., Yao, S., Friedman, D., Hardy, M. Griffiths, T L. 202324 09. Embers of Autoregression: Understanding Large Language Models Through the Problem They are Trained to Solve Embers of autoregression: Understanding large language models through the problem they are trained to solve. arXiv.
- Mei . (2018) mei2018mean_field Mei, S., Montanari, A. Nguyen, P M. 2018. A mean field view of the landscape of two-layer neural networks A mean field view of the landscape of two-layer neural networks. Proceedings of the National Academy of Sciences11533E7665–E7671.
- Morwani . (2023) morwani_max_margin Morwani, D., Edelman, B L., Oncescu, C A., Zhao, R. Kakade, S. 2023. Feature emergence via margin maximization: case studies in algebraic tasks Feature emergence via margin maximization: case studies in algebraic tasks. arXiv preprint arXiv:2311.07568.
- Obozova . (2015) Obozova2015-parrot Obozova, T., Smirnova, A., Zorina, Z. Wasserman, E. 201518 11. Analogical reasoning in amazons Analogical reasoning in amazons. Anim. Cogn.1861363–1371.
- OpenAI (2023) gpt4 OpenAI. 202315 03. GPT-4 Technical Report GPT-4 technical report. arXiv.
- OpenAI (2024) o1 OpenAI. 2024. Learning to Reason with LLMs. Learning to reason with LLMs. https://openai.com/index/learning-to-reason-with-llms/.
- Penn . (2008) Penn2008-darwin_mistake Penn, D C., Holyoak, K J. Povinelli, D J. 2008 04. Darwin’s mistake: Explaining the discontinuity between human and nonhuman minds Darwin’s mistake: Explaining the discontinuity between human and nonhuman minds. Behav. Brain Sci.312109–130.
- Premack (1983) Premack1983-codes Premack, D. 1983 03. The codes of man and beasts The codes of man and beasts. Behav. Brain Sci.61125–136.
- Rabagliati . (2019) Rabagliati2019-infant_abstract_rule_learning Rabagliati, H., Ferguson, B. Lew-Williams, C. 20191 01. The profile of abstract rule learning in infancy: Meta-analytic and experimental evidence The profile of abstract rule learning in infancy: Meta-analytic and experimental evidence. Dev. Sci.221e12704.
- Raven (2003) raven2003raven_prog_mats Raven, J. 2003. Raven progressive matrices Raven progressive matrices. Handbook of nonverbal assessment Handbook of nonverbal assessment ( 223–237). Springer.
- Rotskoff Vanden-Eijnden (2022) rotskoff2022trainability Rotskoff, G. Vanden-Eijnden, E. 2022. Trainability and accuracy of artificial neural networks: An interacting particle system approach Trainability and accuracy of artificial neural networks: An interacting particle system approach. Communications on Pure and Applied Mathematics7591889–1935.
- Saad Solla (1995) saad_learning_soft_comm Saad, D. Solla, S A. 1995. On-line learning in soft committee machines On-line learning in soft committee machines. Physical Review E5244225.
- Saffran Thiessen (2003) Saffran2003-infant Saffran, J R. Thiessen, E D. 2003 05. Pattern induction by infant language learners Pattern induction by infant language learners. Dev. Psychol.393484–494.
- Santoro . (2017) Santoro2017-relational_module Santoro, A., Raposo, D., Barrett, D G T., Malinowski, M., Pascanu, R., Battaglia, P. Lillicrap, T. 20175 06. A simple neural network module for relational reasoning A simple neural network module for relational reasoning. arXiv.
- Seidenberg . (1999) Seidenberg1999-infants_grammar Seidenberg, M S., Elman, J., Eimas, P D., M, N. Marcus, G F. 199916 04. Do infants learn grammar with algebra or statistics? Do infants learn grammar with algebra or statistics? Science2845413434–5; author reply 436–7.
- Seidenberg Elman (1999) Seidenberg1999-rules Seidenberg, M S. Elman, J L. 19991 08. Networks are not ’hidden rules’ Networks are not ’hidden rules’. Trends Cogn. Sci.38288–289.
- Simonyan Zisserman (2014) simonyan2014vgg Simonyan, K. Zisserman, A. 2014. Very deep convolutional networks for large-scale image recognition Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- Smirnova . (2015) Smirnova2015-crow Smirnova, A., Zorina, Z., Obozova, T. Wasserman, E. 201519 01. Crows spontaneously exhibit analogical reasoning Crows spontaneously exhibit analogical reasoning. Curr. Biol.252256–260.
- Stabinger . (2021) Stabinger2021-evaluating Stabinger, S., Peer, D., Piater, J. Rodríguez-Sánchez, A. 20215 10. Evaluating the progress of deep learning for visual relational concepts Evaluating the progress of deep learning for visual relational concepts. J. Vis.21118.
- Tong Pehlevan (2024) Tong2024-mlps Tong, W L. Pehlevan, C. 202424 05. MLPs learn in-context on regression and classification tasks MLPs learn in-context on regression and classification tasks. arXiv.
- Ullman (2023) Ullman2023-fail Ullman, T. 202316 02. Large language models fail on trivial alterations to Theory-of-Mind tasks Large language models fail on trivial alterations to theory-of-mind tasks. arXiv.
- Vaishnav . (2022) Vaishnav2022-computational_demands Vaishnav, M., Cadene, R., Alamia, A., Linsley, D., VanRullen, R. Serre, T. 202215 04. Understanding the computational demands underlying visual reasoning Understanding the computational demands underlying visual reasoning. Neural Comput.3451075–1099.
- Vonk (2003) Vonk2003-primate Vonk, J. 20031 06. Gorilla ( Gorilla gorilla gorilla) and orangutan ( Pongo abelii) understanding of first- and second-order relations Gorilla ( gorilla gorilla gorilla) and orangutan ( pongo abelii) understanding of first- and second-order relations. Anim. Cogn.6277–86.
- E. Wasserman . (2017) Wasserman2017-perceptual_to_conceptual Wasserman, E., Castro, L. Fagot, J. 2017. Relational thinking in animals and humans: From percepts to concepts Relational thinking in animals and humans: From percepts to concepts. APA handbook of comparative psychology: Perception, learning, and cognition Apa handbook of comparative psychology: Perception, learning, and cognition ( 359–384). WashingtonAmerican Psychological Association.
- E A. Wasserman Young (2010) Wasserman2010_same_diff Wasserman, E A. Young, M E. 2010 01. Same-different discrimination: the keel and backbone of thought and reasoning Same-different discrimination: the keel and backbone of thought and reasoning. J. Exp. Psychol. Anim. Behav. Process.3613–22.
- Webb . (2023) Webb2023-relational_bottleneck Webb, T W., Frankland, S M., Altabaa, A., Krishnamurthy, K., Campbell, D., Russin, J. Cohen, J D. 202312 09. The Relational Bottleneck as an Inductive Bias for Efficient Abstraction The relational bottleneck as an inductive bias for efficient abstraction. arXiv.
- Webb . (2020) Webb2020-emergent Webb, T W., Sinha, I. Cohen, J D. 202028 12. Emergent symbols through binding in external memory Emergent symbols through binding in external memory. arXiv.
- Wei . (2019) wei_ma_max_margin Wei, C., Lee, J D., Liu, Q. Ma, T. 2019. Regularization matters: Generalization and optimization of neural nets vs their induced kernel Regularization matters: Generalization and optimization of neural nets vs their induced kernel. Advances in Neural Information Processing Systems32.
- Woodworth . (2020) woodworth2020kernel Woodworth, B., Gunasekar, S., Lee, J D., Moroshko, E., Savarese, P., Golan, I. Srebro, N. 2020. Kernel and rich regimes in overparametrized models Kernel and rich regimes in overparametrized models. Conference on Learning Theory Conference on learning theory ( 3635–3673).
- Yang Hu (2021) yang2021feature_learning Yang, G. Hu, E J. 2021. Tensor programs iv: Feature learning in infinite-width neural networks Tensor programs iv: Feature learning in infinite-width neural networks. International Conference on Machine Learning International conference on machine learning ( 11727–11737).
- Yang . (2022) Yang2022-mup_transfer Yang, G., Hu, E J., Babuschkin, I., Sidor, S., Liu, X., Farhi, D. Gao, J. 20227 03. Tensor programs V: Tuning large neural networks via zero-shot hyperparameter transfer Tensor programs V: Tuning large neural networks via zero-shot hyperparameter transfer. arXiv.
## Appendix
## Appendix A Conceptual representations in visual same-different
<details>
<summary>x4.png Details</summary>
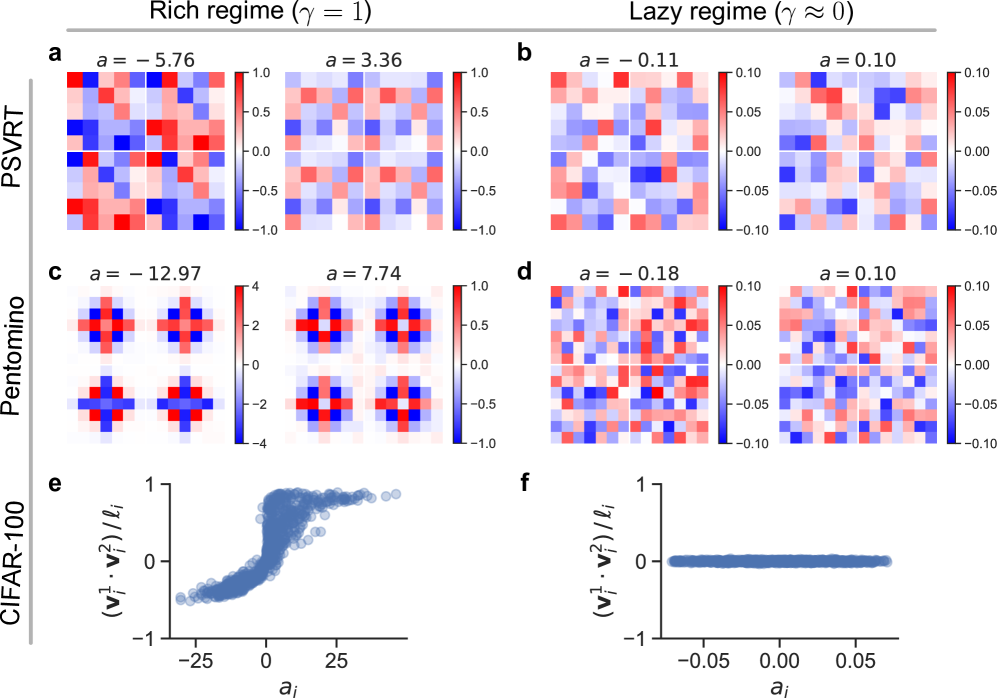
### Visual Description
## [Composite Scientific Figure]: Regime Comparison (Rich vs Lazy) Across Tasks
### Overview
The image is a multi-panel scientific figure comparing two regimes—**Rich regime (γ = 1)** (left column) and **Lazy regime (γ ≈ 0)** (right column)—across three tasks/datasets: *PSVRT*, *Pentomino*, and *CIFAR-100*. It includes heatmaps (subplots a–d) and scatter plots (subplots e–f) to visualize data distributions, patterns, and relationships.
### Components/Axes
- **Regimes**: Two columns labeled *“Rich regime (γ = 1)”* (left) and *“Lazy regime (γ ≈ 0)”* (right).
- **Rows**: Three rows labeled *“PSVRT”*, *“Pentomino”*, and *“CIFAR-100”* (vertical labels on the left).
- **Subplots**:
- **a (PSVRT, Rich)**: Two 10×10 (approx) heatmaps with color bars (range: −1.0 to 1.0). Titles: *“a = −5.76”* (left) and *“a = 3.36”* (right).
- **b (PSVRT, Lazy)**: Two 10×10 (approx) heatmaps with color bars (range: −0.10 to 0.10). Titles: *“a = −0.11”* (left) and *“a = 0.10”* (right).
- **c (Pentomino, Rich)**: Two 5×5 (approx) heatmaps. Left: Color bar (range: −4 to 4), title *“a = −12.97”*; Right: Color bar (range: −1.0 to 1.0), title *“a = 7.74”*.
- **d (Pentomino, Lazy)**: Two 10×10 (approx) heatmaps with color bars (range: −0.10 to 0.10). Titles: *“a = −0.18”* (left) and *“a = 0.10”* (right).
- **e (CIFAR-100, Rich)**: Scatter plot with x-axis *“a_i”* (range: ~−25 to 25) and y-axis *“(v_i^1 · v_i^2)/ℓ_i”* (range: −1 to 1).
- **f (CIFAR-100, Lazy)**: Scatter plot with x-axis *“a_i”* (range: ~−0.05 to 0.05) and y-axis *“(v_i^1 · v_i^2)/ℓ_i”* (range: −1 to 1).
### Detailed Analysis
#### Heatmaps (a–d)
- **PSVRT (a, b)**:
- **a (Rich)**: Left heatmap (*a = −5.76*) has more blue (negative) and red (positive) regions; right heatmap (*a = 3.36*) has more white (near 0) with sparse red/blue. Color bar: −1.0 (blue) to 1.0 (red).
- **b (Lazy)**: Left heatmap (*a = −0.11*) has blue/red regions; right heatmap (*a = 0.10*) is mostly white with sparse blue/red. Color bar: −0.10 (blue) to 0.10 (red).
- **Pentomino (c, d)**:
- **c (Rich)**: Left heatmap (*a = −12.97*) has strong blue/red (high magnitude, color bar: −4 to 4); right heatmap (*a = 7.74*) has more white with sparse red/blue (color bar: −1.0 to 1.0).
- **d (Lazy)**: Left heatmap (*a = −0.18*) has blue/red regions; right heatmap (*a = 0.10*) is mostly white with sparse blue/red. Color bar: −0.10 (blue) to 0.10 (red).
#### Scatter Plots (e, f)
- **e (CIFAR-100, Rich)**: X-axis *“a_i”* (range: ~−25 to 25), Y-axis *“(v_i^1 · v_i^2)/ℓ_i”* (range: −1 to 1). Data points cluster densely around *a_i ≈ 0* and spread outward, showing a **positive correlation** (as *a_i* increases, y-values increase).
- **f (CIFAR-100, Lazy)**: X-axis *“a_i”* (range: ~−0.05 to 0.05), Y-axis same as e. Data points form a dense cluster around *y ≈ 0* with minimal spread, showing **no strong correlation** (flat trend).
### Key Observations
1. **Regime Magnitude**: Rich regime (γ=1) has larger data magnitudes (wider color bars, larger *a_i* range) than Lazy regime (γ≈0) (narrower color bars, smaller *a_i* range).
2. **Pattern Structure**: Rich regime heatmaps (a, c) show more structured patterns (e.g., distinct blue/red regions in Pentomino), while Lazy regime heatmaps (b, d) are more uniform/white (less structure).
3. **CIFAR-100 Trend**: Rich regime (e) has a clear positive correlation between *a_i* and the dot product term; Lazy regime (f) is flat (no correlation).
### Interpretation
The figure illustrates how a parameter γ (defining “Rich” vs “Lazy” regimes) impacts model behavior or data representation across tasks:
- **Rich regime (γ=1)**: Likely corresponds to a more expressive model or data with larger variance, showing structured patterns (heatmaps) and strong correlations (CIFAR-100 scatter plot).
- **Lazy regime (γ≈0)**: Corresponds to a more constrained model (e.g., regularized) or data with smaller variance, showing less structure (heatmaps) and weak correlations (CIFAR-100 scatter plot).
This comparison suggests γ controls model expressivity or data complexity: Rich regimes enable richer representations (useful for complex tasks), while Lazy regimes enforce simplicity (useful for regularization or low-variance data). The heatmaps and scatter plots collectively demonstrate how regime choice shapes data distributions and relationships, with implications for model generalization and task performance.
(Note: All text is in English; no non-English text is present.)
</details>
Figure A1: Conceptual representations in visual same-different tasks. (a) Visualization of representative hidden weights associated with maximal positive and negative readout weights, for a rich model training on PSVRT. Parallel/antiparallel structures are visible in how regions are either the same or precisely the opposite of their neighbors. (b) Visualization of representative hidden weights associated with maximal positive and negative readouts, for a lazy model training on PSVRT. There is no discernible structure, and the magnitudes of both readouts and hidden weights are small. (c) The same as (a), but for a rich model on the Pentomino task. Parallel/antiparallel structures are likewise visible. (d) The same as (b), but for a lazy model on the Pentomino task. There is no discernible structure, and the magnitudes of both readouts and hidden weights are small. (e) For a rich model trained on the CIFAR-100 task, we plot the alignment between weight components corresponding to the two images. There is a distinct parallel/antiparallel-like structure visible in the weight alignment, as we saw for MLPs trained on our simple SD task. (f) For a lazy model trained on the CIFAR-100 task, we plot the alignment between weight components corresponding to the two images. There are no discernible parallel/antiparallel structures at all.
In Section 4, we experimented with three different visual same-different tasks to validate our theoretical predictions in more complex settings. We found that richer models tend to learn the task with fewer training examples, and display some insensitivity to spurious details. The final signature of a conceptual solution is the presence of conceptual representations. In this appendix, we examine the hidden weights learned by rich and lazy models on these tasks, and present evidence for conceptual representations.
PSVRT
Recall our MLP given in Eq (1). To interrogate the hidden weights $\mathbf{w}_{i}$ for conceptual representations, we reshape the weights to match the input shape and visualize them directly. The results are plotted in Figure A1 a and b. For ease of visualization, this task consists of images that are two patches wide.
The rich model learns an interesting analog of parallel/antiparallel weights. Recall for our MLPs trained on the simple same-different task, weight vectors associated with negative readouts tend to develop antiparalllel components. Weight vectors associated with positive readouts tend to develop parallel components.
We witness a similar development for PSVRT. For the example weights with a negative readout, adjacent patches are exactly the opposite, learning a negative weight where the neighboring patch has a positive weight. This structure mirrors the antiparallel weights learned in the simple same-different task. One difference is that for PSVRT, while two pairs of regions are precisely the opposite, the other two pairs are the same. While it is impossible to have every region become antiparallel to every other region, it is not obvious why two pairs should become parallel despite the negative readout weight.
Meanwhile, the example weights with a positive readout feature identical patches, matching weights exactly across the four regions of the input. These parallel regions are exactly what we would expect from our consideration of the simple same-different task.
In the lazy regime, the model learns no discernible structure. The magnitudes of both the readout and hidden weights are also significantly smaller. Altogether, the existence of parallel/antiparallel analogs for PSVRT strongly suggests that only the rich model has learned conceptual representations.
Pentomino
We perform the same analysis of the hidden weights $\mathbf{w}_{i}$ for the Pentomino task. The results are visualized in Figure A1 c and d. For ease of visualization, this task consists of images that are two patches wide.
As we saw for PSVRT, the rich model learns analogs of parallel/antiparallel weights. For the example weights corresponding to a negative readout, the top regions are precisely the opposite of the bottom regions, suggestive of the antiparallel weight components we characterized in the simple same-different task. For example weights corresponding to a positive readout, all four regions are the same, suggestive of parallel weight components.
These structure emerge only in the rich regime. For the lazy regime model, no discernible structure is learned. The overall magnitudes of the readouts and hidden weights are also much smaller. Altogether, the existence of parallel/antiparallel analogs for Penotmino strongly suggests only the rich model has learned conceptual representations.
### A.1 CIFAR-100
For the CIFAR-100 task, we visualize the hidden weights in the same way as we did for the simple same-different task in Figure 1. We separate the weight vector $\mathbf{w}_{i}$ into two components, corresponding to the two flattened input images, and measure their alignment. The results are plotted in Figure A1 e and f.
For the rich case, alignment associated with negative readouts tends to be negative, and alignment associated with positive readouts tends to be positive, suggestive of the right parallel/antiparallel structure. The alignment is quite similar to what we saw for the rich model on the simple same-different task, though the antiparallel alignment is not as strong. The lazy model shows no apparent correlation at all between readouts and alignment. Altogether, the relationship between readouts and alignment witnessed only in the rich model strongly suggests only the rich model has learned conceptual representations.
## Appendix B Hand-crafted solution details
We outline in full detail how our hand-crafted solution solves the same-different task. Recall that the hand-crafted solution is given by the following weight configuration:
| | $\displaystyle\mathbf{w}_{1}^{+}$ | $\displaystyle=(\mathbf{1};\mathbf{1})\,,$ | |
| --- | --- | --- | --- |
for $\mathbf{1}=(1,1,\ldots,1)\in\mathbb{R}^{d}$ and some $\rho>0$ . The MLP is given by
| | $\displaystyle f(\mathbf{x})=\,\,$ | $\displaystyle a^{+}\big{(}\phi(\mathbf{w}_{1}^{+}\cdot\mathbf{x})+\phi(\mathbf{w}_{2}^{+}\cdot\mathbf{x})\big{)}$ | |
| --- | --- | --- | --- |
Upon receiving a same example $\mathbf{x}^{+}=(\mathbf{z},\mathbf{z})$ , our model returns
| | $\displaystyle f(\mathbf{x}^{+})$ | $\displaystyle=\phi(\mathbf{1}\cdot\mathbf{z}+\mathbf{1}\cdot\mathbf{z})+\phi(-\mathbf{1}\cdot\mathbf{z}-\mathbf{1}\cdot\mathbf{z})$ | |
| --- | --- | --- | --- |
which is certainly a positive quantity. Hence, the model classifies all positive examples correctly.
Upon receiving a different example $\mathbf{x}^{-}=(\mathbf{z},\mathbf{z}^{\prime})$ , our model returns
| | $\displaystyle f(\mathbf{x}^{-})$ | $\displaystyle=\phi(\mathbf{1}\cdot\mathbf{z}+\mathbf{1}\cdot\mathbf{z}^{\prime})+\phi(-\mathbf{1}\cdot\mathbf{z}-\mathbf{1}\cdot\mathbf{z}^{\prime})$ | |
| --- | --- | --- | --- |
Since training symbols are sampled as $\mathbf{z}\sim\mathcal{N}(0,\mathbf{I}/d)$ , we have that $\mathbf{z}\overset{d}{=}-\mathbf{z}$ . Furthermore, a sum of independent Gaussians remains Gaussian, so $\mathbf{1}\cdot\mathbf{z}\pm 1\cdot\mathbf{z}^{\prime}\sim\mathcal{N}(0,2)$ . Hence, $f(\mathbf{x}^{-})\overset{d}{=}u-\rho v$ , where $u,v\sim\text{HalfNormal}(0,2)$ . Note, the ReLU nonlinearity ensures these quantities are distributed along a Half-Normal distribution, rather than a Gaussian. Further, $u$ and $v$ are independent since $\mathbf{1}\cdot\mathbf{z}+\mathbf{1}\cdot\mathbf{z}^{\prime}$ is independent from $\mathbf{1}\cdot\mathbf{z}-\mathbf{1}\cdot\mathbf{z}^{\prime}$ (the two sums are jointly Gaussian with zero covariance).
The test accuracy of the model on $\mathbf{x}^{-}$ is given by $p(f(\mathbf{x}^{-})<0)$ , which can be expressed as an integral over the joint PDF of $u,v$ :
| | $\displaystyle p(f(\mathbf{x}^{-})<0)$ | $\displaystyle=p(u-\rho v<0)$ | |
| --- | --- | --- | --- |
To compute this quantity, we convert to polar coordinates. Let $u=r\cos(\theta)$ and $v=r\sin(\theta)$ . Under this change of variables, we have
| | $\displaystyle p(f(\mathbf{x}^{-})<0)$ | $\displaystyle=\frac{1}{2\pi}\int_{\tan^{-1}(1/\rho)}^{\pi/2}\int_{0}^{\infty}r\exp e^{-r^{2}/8}\,dr\,d\theta$ | |
| --- | --- | --- | --- |
For $\rho\rightarrow\infty$ , this quantity approaches $1$ . Since $\rho$ cancels in the result for the same input, $\rho$ can be arbitrarily large without impacting the classification accuracy on same inputs. Hence, the hand-crafted solution overall solves the same-different task provided the relative magnitude of the negative readouts is large.
A technical detail required for both successful positive and negative classifications is that the test example is not precisely orthogonal to the parallel/antiparallel vectors, in which case the relevant dot products would be zero. However, a test example is exactly orthogonal to the weight vectors with probability zero, so this eventuality does not impact the solution’s overall test accuracy.
Figure B1 illustrates how parallel/antiparallel weight vectors may correctly classify a same or different example.
<details>
<summary>x5.png Details</summary>
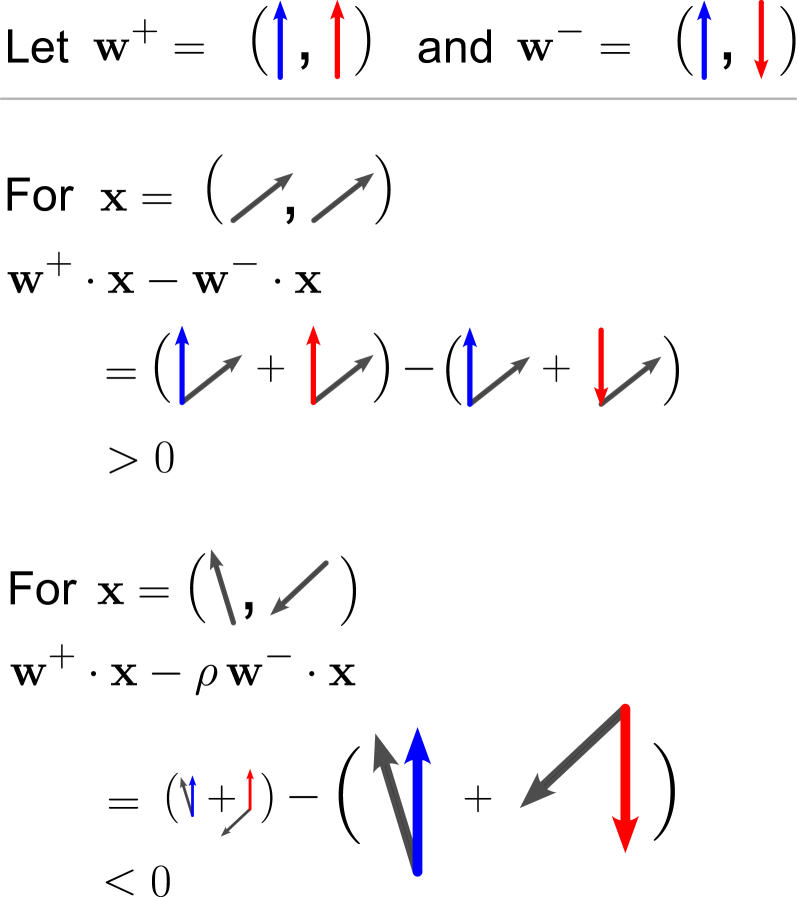
### Visual Description
## [Mathematical Diagram]: Vector Dot Product Illustration for Weighted Classification
### Overview
The image is a mathematical illustration demonstrating vector dot product calculations for two input vectors \( \boldsymbol{\mathbf{x}} \), using two weight vectors \( \boldsymbol{\mathbf{w}}^+ \) and \( \boldsymbol{\mathbf{w}}^- \). It includes text, vector symbols (arrows), and algebraic expressions to show how different input patterns interact with the weight vectors.
### Components/Elements
- **Text Elements**:
- Top: *"Let \( \boldsymbol{\mathbf{w}}^+ = (\uparrow, \uparrow) \) and \( \boldsymbol{\mathbf{w}}^- = (\uparrow, \downarrow) \)"* (defines two weight vectors).
- First case: *"For \( \boldsymbol{\mathbf{x}} = (\nearrow, \nearrow) \)"* (input vector with two right-up arrows), followed by the expression \( \boldsymbol{\mathbf{w}}^+ \cdot \boldsymbol{\mathbf{x}} - \boldsymbol{\mathbf{w}}^- \cdot \boldsymbol{\mathbf{x}} \), expanded form, and result \( > 0 \).
- Second case: *"For \( \boldsymbol{\mathbf{x}} = (\nwarrow, \searrow) \)"* (input vector with left-up and right-down arrows), followed by the expression \( \boldsymbol{\mathbf{w}}^+ \cdot \boldsymbol{\mathbf{x}} - \rho \boldsymbol{\mathbf{w}}^- \cdot \boldsymbol{\mathbf{x}} \) (with scalar \( \rho \)), expanded form, and result \( < 0 \).
- **Vector Symbols**:
- \( \boldsymbol{\mathbf{w}}^+ \): Two upward arrows (blue and red, representing components).
- \( \boldsymbol{\mathbf{w}}^- \): One upward (blue) and one downward (red) arrow.
- \( \boldsymbol{\mathbf{x}} \) (first case): Two right-up arrows (gray).
- \( \boldsymbol{\mathbf{x}} \) (second case): One left-up (gray) and one right-down (gray) arrow.
- Dot product illustrations: Arrows showing the dot product (e.g., \( \uparrow \cdot \nearrow \) as a blue arrow with a gray arrow).
### Detailed Analysis
#### Case 1: \( \boldsymbol{\mathbf{x}} = (\nearrow, \nearrow) \)
- **Expression**: \( \boldsymbol{\mathbf{w}}^+ \cdot \boldsymbol{\mathbf{x}} - \boldsymbol{\mathbf{w}}^- \cdot \boldsymbol{\mathbf{x}} \)
- **Expanded Form**: \( (\uparrow \cdot \nearrow + \uparrow \cdot \nearrow) - (\uparrow \cdot \nearrow + \downarrow \cdot \nearrow) \)
- **Simplification**: \( (\uparrow \cdot \nearrow - \downarrow \cdot \nearrow) + (\uparrow \cdot \nearrow - \uparrow \cdot \nearrow) = (\uparrow - \downarrow) \cdot \nearrow \)
- **Result**: \( > 0 \) (since \( \uparrow \) and \( \downarrow \) are opposite, their dot product with \( \nearrow \) yields a positive difference).
#### Case 2: \( \boldsymbol{\mathbf{x}} = (\nwarrow, \searrow) \)
- **Expression**: \( \boldsymbol{\mathbf{w}}^+ \cdot \boldsymbol{\mathbf{x}} - \rho \boldsymbol{\mathbf{w}}^- \cdot \boldsymbol{\mathbf{x}} \) ( \( \rho \) = scalar weight parameter)
- **Expanded Form**: \( (\uparrow \cdot \nwarrow + \uparrow \cdot \searrow) - \rho (\uparrow \cdot \nwarrow + \downarrow \cdot \searrow) \)
- **Simplification** (using vector components: \( \uparrow = (0,1) \), \( \downarrow = (0,-1) \), \( \nwarrow = (-1,1) \), \( \searrow = (1,-1) \)):
- \( \uparrow \cdot \nwarrow = 0(-1) + 1(1) = 1 \)
- \( \uparrow \cdot \searrow = 0(1) + 1(-1) = -1 \)
- \( \downarrow \cdot \searrow = 0(1) + (-1)(-1) = 1 \)
- \( \boldsymbol{\mathbf{w}}^+ \cdot \boldsymbol{\mathbf{x}} = 1 + (-1) = 0 \)
- \( \boldsymbol{\mathbf{w}}^- \cdot \boldsymbol{\mathbf{x}} = 1 + 1 = 2 \)
- Expression: \( 0 - \rho(2) = -2\rho \)
- **Result**: \( < 0 \) (assuming \( \rho > 0 \), typical for weight parameters).
### Key Observations
- The diagram uses vector dot products to show how input vectors \( \boldsymbol{\mathbf{x}} \) interact with weight vectors \( \boldsymbol{\mathbf{w}}^+ \) and \( \boldsymbol{\mathbf{w}}^- \).
- The first case ( \( \boldsymbol{\mathbf{x}} \) with two right-up arrows) produces a positive value, while the second case ( \( \boldsymbol{\mathbf{x}} \) with left-up/right-down arrows) produces a negative value (with scalar \( \rho \)).
- Vector symbols (arrows) visually represent components, and dot product illustrations clarify mathematical operations.
### Interpretation
This diagram likely illustrates a **linear classification** concept (e.g., perceptron or linear classifier) in machine learning:
- \( \boldsymbol{\mathbf{w}}^+ \) and \( \boldsymbol{\mathbf{w}}^- \) are weight vectors for positive/negative classes.
- \( \boldsymbol{\mathbf{x}} \) is an input vector; the dot product difference (or weighted difference) determines the classification sign (positive/negative).
- The first case shows a *positive classification* (e.g., “class 1”), and the second shows a *negative classification* (e.g., “class 0”), demonstrating how input patterns interact with weights.
- The scalar \( \rho \) may act as a regularization parameter or weight for the negative class, adjusting \( \boldsymbol{\mathbf{w}}^- \)’s influence.
(No non-English text is present; all content is in English with mathematical notation.)
</details>
Figure B1: Illustration of hand-crafted solution. Parallel/antiparallel weight vectors $\mathbf{w}^{+},\mathbf{w}^{-}$ are represented pictorially as sets of two vectors. The dot product operation is represented by conjoining the corresponding vectors: the dot product equals the cosine angle scaled by the magnitudes of the component vectors. For a same test example, the $\mathbf{w}^{+}\cdot\mathbf{x}$ remains positive while $\mathbf{w}^{-}\cdot\mathbf{x}$ cancels to zero. For a different test example, the relative magnitude $\rho$ enables a successful negative classification.
## Appendix C Rich regime details
We conduct our analysis of the rich regime in two parts. We begin with a derivation of the max margin solution to our same-different task in Section C.1. Doing so requires us to replace our model’s ReLU activations with quadratic activations. The max margin solution also does not demonstrate the rich model’s learning efficiency or insensitivity to perceptual details. To address these shortcomings, we extend our analysis by considering a heuristic construction in which we approximate a rich MLP using an ensemble of independent Markov processes (Section C.2). Using this construction, we derive a finer-grain characterization of the MLP’s weight structure, and apply it to estimate the model’s test accuracy for varying $L$ and $d$ .
### C.1 Max margin solution
An MLP trained on a classification objective often learns a max margin solution over the dataset (Morwani ., 2023; Chizat Bach, 2020; Wei ., 2019). While this outcome is not guaranteed in our setting, studying the structure of the max margin solution nonetheless reveals critical details about how our MLP may be solving the same-different task. Following Morwani . (2023), we adopt two conditions to expedite our analysis:
1. We replace a strict max margin objective with a max average margin objective over a dataset $\mathcal{D}=\left\{\mathbf{x}_{n},y_{n}\right\}_{n=1}^{P}$
$$
\max_{\mathbf{\theta}}\,\frac{1}{P}\sum_{n=1}^{P}\left[(2y_{n}-1)f(\mathbf{x}_{n};\mathbf{\theta})\right]\,,
$$
where $\mathbf{x}_{n},y_{n}$ are sampled over a training distribution with $L$ symbols and the objective is subject to some norm constraint on $\mathbf{\theta}$ . Given the symmetry of the task, a max average margin objective forms a reasonable proxy to the strict max margin.
1. We consider quadratic activations $\phi(\cdot)=(\cdot)^{2}$ rather than ReLU. Doing so alters our model from Eq (1), but we later use a heuristic construction to argue that the resulting solution is recovered under ReLU activations in a rich learning regime.
We further allow $P,L\rightarrow\infty$ . Following these simplifications, we derive the max average margin solution.
**Theorem 1**
*Let $\mathcal{D}=\{\mathbf{x}_{n},y_{n}\}_{n=1}^{P}$ be a training set consisting of $P$ points sampled across $L$ training symbols, as specified in Section 2. Let $f$ be the MLP given by Eq 1, with two changes:
1. Fix the readouts $a_{i}=\pm 1$ , where exactly $m/2$ readouts are positive and the remaining are negative.
1. Use quadratic activations $\phi(\cdot)=(\cdot)^{2}$ .
For weights $\mathbf{\theta}=\left\{\mathbf{w}_{i}\right\}_{i=1}^{m}$ , define the max margin set $\Delta(\mathbf{\theta})$ to be
$$
\Delta(\mathbf{\theta})=\operatorname*{arg\,max}_{\mathbf{\theta}}\frac{1}{P}\sum_{n=1}^{P}\left[(2y_{n}-1)f(\mathbf{x}_{n};\mathbf{\theta})\right]\,,
$$
subject to the norm constraints $\left|\left|\mathbf{w}_{i}\right|\right|=1$ . If $P,L\rightarrow\infty$ , then for any $\mathbf{w}_{i}=(\mathbf{v}_{i}^{1};\mathbf{v}_{i}^{2})\in\Delta(\mathbf{\theta})$ and $\ell_{i}=\left|\left|\mathbf{v}_{i}^{1}\right|\right|\,\left|\left|\mathbf{v}_{i}^{2}\right|\right|$ , we have that $\mathbf{v}_{i}^{1}\cdot\mathbf{v}_{i}^{2}/\ell_{i}=1$ if $a_{i}=1$ and $\mathbf{v}_{i}^{1}\cdot\mathbf{v}_{i}^{2}/\ell_{i}=-1$ if $a_{i}=-1$ . Further, $\left|\left|\mathbf{v}_{i}^{1}\right|\right|=\left|\left|\mathbf{v}_{i}^{2}\right|\right|$ .*
* Proof*
Let $\mathcal{D}^{+}$ be the subset of $\mathcal{D}$ consisting of same examples and $\mathcal{D}^{-}$ be the subset of different examples. Let $\mathcal{I}^{+}$ be the set of indices $i$ such that the readout weight $a_{i}>0$ . Let $\mathcal{I}^{-}$ be the set of indices $j$ such that $a_{j}<0$ . Then our max average margin solution becomes | | $\displaystyle\max_{\mathbf{\theta}}\,\frac{1}{P}\sum_{n=1}^{P}\left[(2y_{n}-1)f(\mathbf{x}_{n};\mathbf{\theta})\right]$ | $\displaystyle=\max_{\mathbf{\theta}}\,\frac{1}{P}\left[\sum_{\mathbf{x}^{+}\in\mathcal{D}^{+}}\left[f(\mathbf{x}^{+};\mathbf{\theta})\right]-\sum_{\mathbf{x}^{-}\in\mathcal{D}^{-}}\left[f(\mathbf{x}^{-};\mathbf{\theta})\right]\right]$ | |
| --- | --- | --- | --- | Suppose we stack all same training examples $\mathbf{x}^{+}$ into a large matrix $\mathbf{X}^{+}\in\mathbb{R}^{|\mathcal{D}^{+}|\times 2d}$ and stack all different training examples $\mathbf{x}^{-}$ into a large matrix $\mathbf{X}^{-}\in\mathbb{R}^{|\mathcal{D}^{-}|\times 2d}$ . Applying the norm constraints $\left|\left|\mathbf{w}_{i}\right|\right|=1$ , our max margin solution is resolved by the following objectives
| | $\displaystyle\mathbf{w}_{*}^{+}=$ | $\displaystyle\operatorname*{arg\,max}_{\mathbf{w}}\,\frac{1}{P}\left[\left|\left|\mathbf{X}^{+}\mathbf{w}\right|\right|^{2}-\left|\left|\mathbf{X}^{-}\mathbf{w}\right|\right|^{2}\right]\quad\text{such that}\,\left|\left|\mathbf{w}\right|\right|=1\,,$ | |
| --- | --- | --- | --- |
where $\mathbf{w}_{*}^{+}$ and $\mathbf{w}_{*}^{-}$ represent the hidden weights of the max average margin solution. Maximizing (or minimizing) this objective is equivalent to finding the largest (or smallest) eigenvector of the matrix $\mathbf{X}=\frac{1}{P}\left[\left(\mathbf{X}^{+}\right)^{\intercal}\mathbf{X}^{+}-\left(\mathbf{X}^{-}\right)^{\intercal}\mathbf{X}^{-}\right]$ . In the limit $P,L\rightarrow\infty$ , this matrix becomes circulant. Let us see how. Note that $\mathbf{X}\in\mathbb{R}^{2d\times 2d}$ . Suppose there are exactly $P/2$ same examples and $P/2$ different examples. Along the diagonal of $\mathbf{X}$ are terms
$$
X_{ii}=\frac{1}{P}\sum_{j=1}^{P/2}\left[(x_{ij}^{+})^{2}-(x_{ij}^{-})^{2}\right]\,,
$$
where $x_{ij}^{+}$ corresponds to the $i$ th index of the $j$ th same example, and $x_{ij}^{-}$ is the same for the $j$ th different example. Because $L\rightarrow\infty$ , we have that $x_{i,j}^{+}\sim\mathcal{N}(0,1/d)$ and $x_{i,j}^{-}\sim\mathcal{N}(0,1/d)$ , where $x_{i,j}^{+}$ is independent of $x_{i,j}^{-}$ . Hence, $X_{ii}\rightarrow 0$ as $P\rightarrow\infty$ . Now let us consider the diagonal of the first quadrant
$$
X_{i,2i}=\frac{1}{P}\sum_{j=1}^{P/2}\left[x_{ij}^{+}\,x_{2i,j}^{+}-x_{ij}^{-}\,x_{2i,j}^{-}\right]\,.
$$
For same examples, $x_{ij}^{+}=x_{2i,j}^{+}$ , so
$$
\frac{1}{P}\sum_{j=1}^{P/2}x_{ij}^{+}x_{2i,j}^{+}=\frac{1}{P}\sum_{j=1}^{P/2}\left(x_{ij}^{+}\right)^{2}\rightarrow\frac{1}{2}\mathbb{E}\left[\left(x_{ij}^{+}\right)^{2}\right]=\frac{1}{2d}
$$
For different examples, $x_{ij}^{-}$ remains independent of $x_{2i,j}^{-}$ , so
$$
\frac{1}{P}\sum_{j=1}^{P/2}x_{ij}^{+}x_{2i,j}^{+}\rightarrow 0\,.
$$
We therefore have overall that $X_{i,2i}\rightarrow 1/2d$ . The same argument applies for the diagonal of the third quadrant, revealing that $X_{2i,i}\rightarrow 1/2d$ . For all other terms $X_{ik}$ where $i\neq k$ , $i\neq k/2$ , and $i/2\neq k$ , we must have that $x_{ij}$ is independent of $x_{kj}$ for both same and different examples, so $X_{ik}\rightarrow 0$ . Hence, $\mathbf{X}$ is circulant with nonzero values $1/2d$ only on the diagonals of the first and third quadrant. Figure C1 plots an example $\mathbf{X}$ . In the remainder of this section, we multiply $\mathbf{X}$ by a normalization factor $2d$ . Doing so does not impact the max margin weights, but changes the value along the quadrant diagonals to 1.
<details>
<summary>x6.png Details</summary>
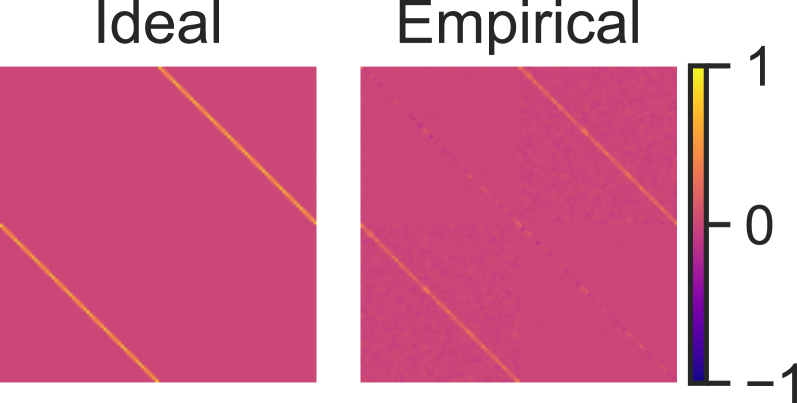
### Visual Description
## [Heatmap Pair]: Comparison of Ideal vs. Empirical Correlation Matrices
### Overview
The image displays two square heatmaps positioned side-by-side, labeled "Ideal" and "Empirical," respectively. They are accompanied by a shared vertical color scale bar on the far right. The heatmaps visually represent numerical data, likely correlation matrices, where color intensity corresponds to a value between -1 and 1. The "Ideal" map shows a perfect, noise-free pattern, while the "Empirical" map shows a similar pattern with visible noise or variance.
### Components/Axes
* **Titles:** The text "Ideal" is centered above the left heatmap. The text "Empirical" is centered above the right heatmap.
* **Color Scale Bar:** Located on the far right of the image, oriented vertically.
* **Axis Markers/Labels:** The scale is labeled with three numerical values: `1` at the top, `0` in the middle, and `-1` at the bottom.
* **Color Gradient:** The bar shows a continuous color gradient. The top (value `1`) is bright yellow. The middle (value `0`) is a pink/magenta hue. The bottom (value `-1`) is dark purple/black.
* **Heatmap Content:** Both heatmaps are square matrices. The axes of the matrices themselves are not labeled with text, implying they represent indices (e.g., variable 1, variable 2, etc.).
### Detailed Analysis
**1. "Ideal" Heatmap (Left):**
* **Background:** The entire background is a uniform pink/magenta color, corresponding to the value `0` on the color scale.
* **Data Series/Trends:**
* **Main Diagonal:** A sharp, continuous, bright yellow line runs from the top-left corner to the bottom-right corner. This indicates a value of `1` for all elements where the row index equals the column index.
* **Anti-Diagonal:** A second sharp, continuous, bright yellow line runs from the bottom-left corner to the top-right corner. This indicates a value of `1` for elements where the row index and column index sum to a constant (e.g., in a 4x4 matrix, positions (4,1), (3,2), (2,3), (1,4)).
* **Pattern:** The pattern is perfectly clean and geometric, with no noise or deviation from the two diagonal lines.
**2. "Empirical" Heatmap (Right):**
* **Background:** The background is predominantly pink/magenta (value ~`0`), but it is not perfectly uniform. There is visible granular noise or speckling throughout, with slight variations in the pink hue.
* **Data Series/Trends:**
* **Main Diagonal:** A bright yellow line is clearly visible from the top-left to the bottom-right. It is slightly less sharp than in the "Ideal" case, with some minor pixelation or variation in intensity along its length.
* **Anti-Diagonal:** A bright yellow line is also visible from the bottom-left to the top-right. Similar to the main diagonal, it shows slight imperfections and noise.
* **Noise:** Scattered yellowish pixels (values > `0`) and slightly darker pink pixels (values < `0`) are present across the entire matrix, not confined to the diagonals. This indicates deviations from the ideal `0` value in the off-diagonal elements.
* **Pattern:** The core two-diagonal structure is preserved but is overlaid with a layer of random noise, typical of real-world or simulated empirical data.
### Key Observations
1. **Structural Similarity:** The "Empirical" heatmap successfully replicates the fundamental two-diagonal structure of the "Ideal" case.
2. **Noise Introduction:** The primary difference is the presence of broadband noise in the "Empirical" data, affecting both the background (off-diagonal elements) and the signal lines (diagonal elements).
3. **Value Range:** Both heatmaps appear to utilize only the upper half of the color scale (from `0` to `1`). There are no visually distinct dark purple regions that would indicate strong negative correlations (values near `-1`).
4. **Spatial Layout:** The color bar is positioned to the right of both heatmaps, serving as a common legend. The heatmaps are of equal size and are aligned horizontally.
### Interpretation
This image is a classic visualization comparing a theoretical model to observed data, most likely in the context of **correlation or similarity matrices**.
* **What the Data Suggests:** The "Ideal" matrix represents a perfect, deterministic relationship. The two diagonals suggest a system where each element is perfectly correlated with itself (main diagonal) and with one specific other element (anti-diagonal). This could model a system with paired relationships or a specific symmetric structure.
* **Relationship Between Elements:** The "Empirical" matrix demonstrates that real-world measurements or simulations approximate this ideal structure but are subject to noise. The noise could stem from measurement error, sampling variance, or unmodeled interactions in the system.
* **Notable Anomalies/Trends:** The absence of strong negative values (dark purple) is notable. It suggests the underlying phenomenon being measured does not produce strong anti-correlations, or the scale is normalized in a way that centers on zero. The noise appears relatively uniform, indicating it may be random (e.g., Gaussian) rather than systematic.
* **Why it Matters:** This type of comparison is fundamental in scientific and engineering fields. It allows researchers to validate models against data, quantify the signal-to-noise ratio, and assess whether the core theoretical structure is supported by empirical evidence. The visual immediately communicates that the model captures the essential pattern but that real-world data is inherently "messier."
</details>
Figure C1: Example ideal and empirical $\mathbf{X}$ . The matrix does indeed become circulant with nonzero values on the diagonal of the first and third quadrants. The empirical $\mathbf{X}$ is computed from a batch of 3000 examples sampled from a training set consisting of 64 symbols. The eigendecomposition of a circulant matrix is well studied, and can be given in terms of Fourier modes. In particular, the $\ell$ th eigenvector $\mathbf{u}_{\ell}$ is given by
$$
\mathbf{u}_{\ell}=\frac{1}{\sqrt{2d}}(1,r^{\ell},r^{2\ell},\ldots,r^{(2d-1)\ell})\,,
$$
where
$$
r=e^{\frac{\pi i}{d}}\,
$$
and $\ell$ ranges from $0$ to $2d-1$ . The corresponding eigenvalues $\lambda_{\ell}$ are
$$
\lambda_{\ell}=r^{d\ell}=e^{\ell\pi i}\,.
$$
This expression implies that $\lambda_{\ell}=1$ for even $\ell$ and $\lambda_{\ell}=-1$ for odd $\ell$ . Hence, $\mathbf{w}_{*}^{+}$ lies in the subspace spanned by $\mathbf{u}_{\ell}$ for even $\ell$ , and $\mathbf{w}_{*}^{-}$ lies in the subspace spanned by eigenvectors with odd $\ell$ . To characterize this solution further, suppose we partition a weight vector $\mathbf{w}\in\mathbb{R}^{2d}$ into equal halves $\mathbf{w}=(\mathbf{v}^{1};\mathbf{v}^{2})$ , where $\mathbf{v}^{1}\in\mathbb{R}^{d}$ . Considering the even case first, suppose $\mathbf{w}\in\mathbf{U}_{2}$ where $\mathbf{U}_{2}=\text{span}\left\{\mathbf{u}_{0},\mathbf{u}_{2},\ldots,\mathbf{u}_{2(d-1)}\right\}$ . Then there exist coefficients $c_{0},c_{2},\ldots c_{2(d-1)}$ such that
$$
\mathbf{w}=\sum_{n=0}^{d-1}c_{2n}\mathbf{u}_{2n}\,.
$$
Note that
$$
r^{k\ell_{1}}\cdot\overline{r}^{k\ell_{2}+d}=e^{\frac{k\pi i}{d}(\ell_{1}-\ell_{2})}\cdot e^{-\pi i\ell_{2}}\,.
$$
If we partition our set of eigenvectors as $\mathbf{u}_{\ell}=(\mathbf{s}_{\ell}^{1},\mathbf{s}_{\ell}^{2})$ , then
$$
\mathbf{s}_{\ell_{1}}^{1}\cdot\mathbf{s}_{\ell_{2}}^{2}=e^{-\pi i\ell_{2}}\sum_{k=0}^{d-1}e^{\frac{k\pi i}{d}(\ell_{1}-\ell_{2})}\,.
$$
This quantity is 0 when $\ell_{1}\neq\ell_{2}$ . Otherwise, it is $1$ if $\ell_{1}=\ell_{2}$ are even and $-1$ if they are odd. Hence, for $(\mathbf{v}^{1};\mathbf{v}^{2})\in\mathbf{U}_{2}$ , we have that
$$
\mathbf{v}^{1}\cdot\mathbf{v}^{2}=\frac{1}{2d}\left(c_{0}^{2}+c_{2}^{2}+\ldots+c_{2(d-1)}^{2}\right)\,.
$$
Observe also that
$$
\left|\left|\mathbf{v}^{1}\right|\right|=\left|\left|\mathbf{v}^{2}\right|\right|=\frac{1}{\sqrt{2d}}\sqrt{c_{0}^{2}+c_{2}^{2}+\ldots+c_{2(d-1)}^{2}}\,,
$$
so we must have
$$
\frac{\mathbf{v}^{1}\cdot\mathbf{v}^{2}}{\left|\left|\mathbf{v}^{1}\right|\right|\,\left|\left|\mathbf{v}^{2}\right|\right|}=1\,.
$$
In this way, we see that the components of $\mathbf{w}^{+}_{*}$ must be parallel and share the same mangitude. We may repeat the same calculation for $\mathbf{w}\in\mathbf{U}_{1}$ , where $\mathbf{U}_{1}=\text{span}\left\{\mathbf{u}_{1},\mathbf{u}_{3},\ldots,\mathbf{u}_{2d-1}\right\}$ . Doing so reveals that
$$
\frac{\mathbf{v}^{1}\cdot\mathbf{v}^{2}}{\left|\left|\mathbf{v}^{1}\right|\right|\,\left|\left|\mathbf{v}^{2}\right|\right|}=-1\,,
$$
so the components of $\mathbf{w}^{-}_{*}$ must be antiparallel. ∎
### C.2 Heuristic construction
By examining the max average margin solution, we witness the emergence of parallel/antiparallel weight vectors. In Section 3.1, we discussed how parallel/antiparallel weights allow an MLP to solve the SD task. However, it remains unclear how to characterize the learning efficiency and insensitivity to spurious perceptual details in the resulting model, and whether these results apply at all to a ReLU MLP trained on a finite dataset. To begin answering these questions, we develop a heuristic construction that summarizes the learning dynamics of a ReLU MLP over the subsequent sections. We will demonstrate that
1. The hidden weights $\mathbf{w}$ become parallel (or antiparallel) for correspondingly positive (or negative) readout weights $a$
1. The magnitude of the readout weights are such that $|\overline{a^{-}}|>|\overline{a^{+}}|$ , where $\overline{a^{-}}$ denotes the average across negative readout weights and $\overline{a^{+}}$ denotes the average across positive readout weights
We then leverage our understanding of the weight structure to estimate a rich model’s test accuracy on our SD task. The remainder of this appendix is dedicated to developing this heuristic approach.
We proceed using a Markov process approximation to the full learning dynamics in the noiseless setting ( $\sigma^{2}=0$ ). Observe that the gradient updates to the readout and hidden weights take the following form. For a batch containing $N$ training examples,
| | $\displaystyle\Delta a_{i}$ | $\displaystyle=-\frac{c}{N}\sum_{j=1}^{N}\frac{\partial\mathcal{L}_{j}}{\partial f}\,\phi(\mathbf{w}_{i}\cdot\mathbf{x}_{j})\,,$ | |
| --- | --- | --- | --- |
where $c=\frac{\alpha}{\gamma\sqrt{d}}$ , $\alpha$ is the learning rate, and
$$
\displaystyle-\frac{\partial\mathcal{L}_{j}}{\partial f} \displaystyle=-\frac{\partial\mathcal{L}(y,f(\mathbf{x}))}{\partial f}\Bigg{|}_{y_{j},f(\mathbf{x}_{j})} \displaystyle=\frac{y_{j}}{1+e^{f(\mathbf{x}_{j})}}-\frac{1-y_{j}}{1+e^{-f(\mathbf{x}_{j})}}\,.
$$
Focusing on $\Delta\mathbf{w}_{i}$ , we rewrite its gradient update as
$$
\Delta\mathbf{w}_{i}=\sum_{j=1}^{N}\xi_{ij}\mathbf{x}_{j}\,,
$$
where
$$
\xi_{ij}=-\frac{c}{N}\frac{\partial\mathcal{L}_{j}}{\partial f}\,a_{i}\,\phi^{\prime}(\mathbf{w}_{i}\cdot\mathbf{x}_{i})\,.
$$
When written in this form, it becomes clear that the hidden weight gradient updates lie in the basis of the training examples $\mathbf{x}_{j}$ . If the initialization of the hidden weights $\mathbf{w}_{i}$ is small, then $\mathbf{w}_{i}$ lies approximately in the basis of training examples also. Specifically, we require that
$$
\mathbf{w}_{i}(0)\neq\mathbf{0}\;\;\text{and}\;\;\frac{1}{\xi_{ij}}\,\mathbf{w}_{i}(0)\cdot\mathbf{x}_{j}\rightarrow 0\quad\text{as}\;\;d\rightarrow\infty\,, \tag{0}
$$
where $\mathbf{w}_{i}(0)$ refers to $\mathbf{w}_{i}$ at initialization (generally, $\mathbf{w}_{i}(t)$ is the value of $\mathbf{w}_{i}$ after $t$ gradient steps). The requirement that $\mathbf{w}_{i}(0)\neq\mathbf{0}$ ensures that the initial gradient update is nonzero.
Suppose our training set consists of $L$ symbols $\mathbf{z}_{1};\mathbf{z}_{2},\ldots,\mathbf{z}_{L}$ . If we partition $\mathbf{w}_{i}=(\mathbf{v}_{i}^{1};\mathbf{v}_{i}^{2})$ , then after $t$ gradient steps and in the infinite limit $d\rightarrow\infty$
$$
\displaystyle\mathbf{v}_{i}^{1}(t) \displaystyle=\omega_{i,1}^{1}(t)\,\mathbf{z}_{1}+\omega_{i,2}^{1}(t)\,\mathbf{z}_{2}+\ldots+\omega_{i,L}^{1}(t)\,\mathbf{z}_{L}\,, \displaystyle\mathbf{v}_{i}^{2}(t) \displaystyle=\omega_{i,1}^{2}(t)\,\mathbf{z}_{1}+\omega_{i,2}^{2}(t)\,\mathbf{z}_{2}+\ldots+\omega_{i,L}^{2}(t)\,\mathbf{z}_{L}\,,
$$
where $\omega_{i,k}^{p}(t)$ corresponds to the overlap $\mathbf{w}_{i}^{p}(t)\cdot\mathbf{z}_{k}$ . The large number of indices on $\omega$ is unwieldy, so we will omit some or all of them where context allows. Note, for these relations to hold, we require that $\mathbf{z}_{i}\cdot\mathbf{z}_{j}=\delta_{ij}$ as $d\rightarrow\infty$ . In this way, we may consider the $\omega$ ’s to be the coordinates of $\mathbf{w}$ in the basis of the training symbols $\mathbf{z}$ .
Note that $\omega$ is a function of the update coefficients $\xi_{ij}$ . If $\mathbf{w}_{i}\cdot\mathbf{x}_{j}<0$ , then $\xi_{ij}=0$ . Otherwise, $\xi_{ij}$ depends on $\frac{\partial\mathcal{L}_{j}}{\partial f}$ and $a_{i}$ , introducing many additional and complex couplings to other parameters in the model. Our ultimate goal is to understand the general structure of the hidden weights $\mathbf{w}_{i}$ , rather than to obtain exact formulas, so we apply the following coarse approximation
$$
\xi_{ij}=\begin{cases}\text{sign}\left(-\frac{\partial\mathcal{L}_{j}}{\partial f}\,a_{i}\right)&\mathbf{w}_{i}\cdot\mathbf{x}_{j}>0\,,\\
0&\mathbf{w}_{i}\cdot\mathbf{x}_{j}\leq 0\,.\end{cases}
$$
Such an approximation resembles sign-based gradient methods like signSGD (Bernstein ., 2018) and Adam (Kingma, 2014). We also verify empirically that this approximation describes rich regime learning dynamics well.
From Eq (C.1), observe that $\text{sign}\left(-\frac{\partial\mathcal{L}_{j}}{\partial f}\right)=1$ given a label $y_{j}=1$ , and $\text{sign}\left(-\frac{\partial\mathcal{L}_{j}}{\partial f}\right)=-1$ for the label $y_{j}=0$ . Recall from our hand-crafted solution that $a_{i}>0$ implies that $\mathbf{w}_{i}$ should align with same examples, and $a_{i}<0$ implies that $\mathbf{w}_{i}$ should align with different examples. Hence, if $\mathbf{w}_{i}\cdot\mathbf{x}_{j}>0$ , we conclude that $\xi_{ij}=1$ if the example $\mathbf{x}_{j}$ matches the corresponding readout weight $a_{i}$ — that is, $\mathbf{x}_{j}$ is same and $a_{i}>0$ , or $\mathbf{x}_{j}$ is different and $a_{i}<0$ . Otherwise, if there is a mismatch, $\xi_{ij}=-1$ . In this way, we may interpret $\mathbf{w}_{i}$ as a “state vector” to which we add or subtract examples $\mathbf{x}_{j}$ based on a simple set of update rules. We proceed to study the limiting form of $\mathbf{w}_{i}$ by treating it as a Markov process. Our approximation in Eq (C.4) decouples the dependency between hidden weight vectors. The set of hidden weights can be treated as an ensemble of independent Markov processes evolving in parallel, allowing us to understand the overall structure of the hidden weights.
### C.3 Markov process approximation
Altogether, we summarize the learning dynamics on $\mathbf{w}$ through the following Markov process. In the remainder of this section, we drop the index $i$ from $\mathbf{w}_{i}$ and $a_{i}$ , and $\mathbf{w}$ and $a$ should be understood as a representative sets of weights. Similarly, we write $\omega_{k}^{p}(t)$ to represent the coefficient of $\mathbf{v}^{p}$ (the $p$ th partition of $\mathbf{w}$ , $p\in\{1,2\}$ ) for the $k$ th training symbol after $t$ steps. The set of coefficients $\omega$ represent the state of the Markov process, which proceeds as follows.
Step 1.
Initialize $\omega_{k}^{p}(0)=0$ for all $k$ , $p$ . Initialize the time step $t=0$ . Initialize batch updates $b_{k}^{p}=0$ and batch counter $n=0$ . Set the batch size $N$ .
Step 2.
Sample an integer $u$ uniformly at random from the set $[L]=\{1,2,\ldots,L\}$ .
With probability 1/2, set $v=u$ .
Otherwise, sample $v$ uniformly from $[L]\setminus\{u\}$ .
Step 3.
Compute $\rho=\omega_{u}^{1}(t)+\omega_{v}^{2}(t)$ .
If $\rho>0$ , proceed to step 4.
If $\rho=0$ , with probability $1/2$ proceed to step 4. Otherwise, proceed to step 5.
If $\rho<0$ , proceed to step 5.
Step 4.
If $a>0$ , $u=v$ , or $a<0$ , $u\neq v$ , update
| | $\displaystyle b_{u}^{1}$ | $\displaystyle\leftarrow b^{1}_{u}+1\,,$ | |
| --- | --- | --- | --- |
Otherwise, update
| | $\displaystyle b_{u}^{1}$ | $\displaystyle\leftarrow b^{1}_{u}-1\,,$ | |
| --- | --- | --- | --- |
Step 5.
Increment the batch counter $n\leftarrow n+1$ .
If $n=N$ , Set $\omega_{k}^{p}(t+1)\leftarrow\omega_{k}^{p}(t)+b_{k}^{p}$ and increment the time step $t\leftarrow t+1$ . Reset $n\leftarrow 0,b_{k}^{p}\leftarrow 0$ .
Proceed to step 2.
Remarks.
This Markov process approximates the learning dynamics of an MLP given the simplification in Eq (C.4). We elaborate on the link below.
In step 1, we initialize the weight vector to zero. In practice, weight vectors are initialized as $\mathbf{w}\sim\mathcal{N}(\mathbf{0},\mathbf{I}/d)$ . For large $d$ , the condition required in Eq (C.2) allows us to approximate this as zero, with some caveats described below.
In step 2, we sample a training example. Because we operate in the basis spanned by training examples, we discard the vector content of a training symbol and consider only its index. With half the training examples being same and half being different, we sample indices accordingly.
In step 3, we consider the overlap $\mathbf{w}\cdot\mathbf{x}$ , where $\mathbf{x}=(\mathbf{z}_{u},\mathbf{z}_{v})$ . Given the assumptions in Eq (C.2), we have that
| | $\displaystyle\rho$ | $\displaystyle=\mathbf{w}\cdot\mathbf{x}$ | |
| --- | --- | --- | --- |
If the overlap $\rho$ is positive, then the update coefficient $\xi\neq 0$ , so we branch to the step where the state is updated. If $\rho$ is negative, we must have that $\xi=0$ , so we skip the update. If $\omega_{u}^{1}+\omega_{v}^{2}=0$ , the overlap still picks up the initialization, $\mathbf{w}\cdot\mathbf{x}=\mathbf{w}(0)\cdot\mathbf{x}$ . In the limit $d\rightarrow\infty$ , we have that $\mathbf{w}(0)\cdot\mathbf{x}\rightarrow 0$ . However, $\mathbf{w}(0)\cdot\mathbf{x}\neq 0$ almost surely for any finite $d$ . Because $\mathbf{w}(0)$ and $\mathbf{x}$ are radially symmetric about the origin, their overlap is positive with probability 1/2. Thus, when $\rho=0$ , we branch to the corresponding positive or negative overlap steps each with probability 1/2.
In step 4, we apply the updates from $\xi=\pm 1$ , based on whether the training example $\mathbf{z}_{u},\mathbf{z}_{v}$ matches the readout weight $a$ . We conclude the training loop in step 5, and restart with a fresh example.
### C.4 Limiting weight structure
With the setup now complete, we analyze the Markov process proposed above to understand the limiting structure of $\mathbf{w}$ and $a$ . Specifically, we will show that for large $L$ and as $t\rightarrow\infty$ ,
1. If $a>0$ , then $\left|\left|\mathbf{v}_{1}\right|\right|=\left|\left|\mathbf{v}_{2}\right|\right|$ and $\mathbf{v}^{1}\cdot\mathbf{v}^{2}/(\left|\left|\mathbf{v}^{1}\right|\right|\,\left|\left|\mathbf{v}^{2}\right|\right|)=1$
1. If $a<0$ , then $\left|\left|\mathbf{v}_{1}\right|\right|=\left|\left|\mathbf{v}_{2}\right|\right|$ and $\mathbf{v}^{1}\cdot\mathbf{v}^{2}/(\left|\left|\mathbf{v}^{1}\right|\right|\,\left|\left|\mathbf{v}^{2}\right|\right|)=-1$
1. Suppose $\overline{a^{+}}$ is the average over all weights $a>0$ , and $\overline{a^{-}}$ is the average over all weights $a<0$ . Then $|\overline{a^{-}}|>|\overline{a^{+}}|$ .
Our general approach will involve factorizing the Markov process into an ensemble of random walkers with simple dependencies, then reason about the long time-scale behavior of these walkers. For simplicity, we will focus on the single batch case $N=1$ . Generalizing to $N>1$ is straightforward but notationally cluttered, and does not change the final result.
#### C.4.1 Same case
We begin by examining weights $\mathbf{w}$ such that the corresponding readout $a>0$ . Recall that these weights favor same examples. Consider a random walker on $\mathbb{R}$ whose position at time $t$ is given by $s_{u}(t)=\omega_{u}^{1}(t)+\omega_{u}^{2}(t)$ . Then the following rules govern the walker’s dynamics:
1. If $s_{u}(t)>0$ and the model receives a same training example $(\mathbf{z}_{u},\mathbf{z}_{u})$ , then $s_{u}(t+1)=s_{u}(t)+2$ .
1. If the model receives a different training example $(\mathbf{z}_{u},\mathbf{z}_{v})$ , where $u\neq v$ then $s_{u}(t+1)\geq s(t)-1$ .
1. If $s_{u}(T)<0$ , then $s_{u}(t)<0$ for all $t>T$ .
Rules 1 and 2 reflect the update dynamics of the Markov process. Since $s_{u}(t)>0$ , upon receiving a same example $(\mathbf{z}_{u},\mathbf{z}_{u})$ , we witness updates $\omega_{u}^{1}(t+1)=\omega_{u}^{1}(t)+1$ and $\omega_{u}^{2}(t+1)=\omega_{u}^{2}(t)+1$ , so $s_{u}(t+1)=s_{u}(t)+2$ . Similarly, upon receiving a different example $(\mathbf{z}_{u},\mathbf{z}_{v})$ , we have that $\omega_{u}^{1}(t+1)=\omega_{u}^{1}(t)-1$ if $\omega_{u}(t)+\omega_{v}(t)>0$ , so $s_{u}$ decreases at most by 1. Finally, for rule 3, if $s_{u}$ ever falls below 0, then it will never increment. Hence, $s_{u}$ will remain negative for all subsequent steps.
Together, these rules partition our ensemble of walkers $s_{u}$ into two sets: walkers with positive position $\mathcal{S}^{+}(t)=\left\{s_{u}:s_{u}(t)>0\right\}$ and walkers with negative position $\mathcal{S}^{-}(t)=\left\{s_{v}:s_{v}(t)<0\right\}$ . We will show that under typical conditions, members of $\mathcal{S}^{+}$ grow continually more positive, while members of $\mathcal{S}^{-}$ grow continually more negative. We denote $n^{+}(t)=|\mathcal{S}^{+}(t)|$ and $n^{-}(t)=|\mathcal{S}^{-}(t)|$ . Where the meaning is unambiguous, we drop the indices $t$ .
We first make the following counterintuitive observation about the relative occurrence of same and different examples. Although training examples are sampled from each class with equal probability, the probabilities of observing a same or different pair when conditioned on observing a particular training symbol are not equal. Suppose we would like to count all training pairs that contain at least one occurrence of $\mathbf{z}_{u}$ . Out of all same examples, we would expect roughly $\frac{1}{L}$ of such examples to contain $\mathbf{z}_{u}$ . Out of all different examples, we would expect roughly $\frac{2}{L(L-1)}$ occurrences of the pair $(\mathbf{z}_{u},\mathbf{z}_{v})$ , for a specific $v\neq u$ . Across all $L-1$ possible $v$ , this proportion rises to $\frac{2}{L(L-1)}\cdot(L-1)=\frac{2}{L}$ . Hence, the probability of observing a same example conditioned on containing $\mathbf{z}_{u}$ is actually $\frac{1/L}{1/L+2/L}=\frac{1}{3}$ , while the probability of observing different is $\frac{2}{3}$ .
Suppose we allow our Markov process to run for $t$ time steps, after which there are $n^{+}$ walkers in a positive position and $n^{-}$ walkers in a negative position, among $L=n^{+}+n^{-}\equiv n$ total walkers. Upon receiving the next training example $(\mathbf{z}_{u},\mathbf{z}_{v})$ , there are four possible outcomes.
Case 1.
The walker $s_{u}(t)>0$ and we receive a same example (so $u=v$ ). In this case, $s_{u}(t+1)=s_{u}(t)+2$ . The probability of observing a same pair containing $\mathbf{z}_{u}$ is $\frac{1}{3}$ , so we summarize this case as
$$
p(s_{u}\leftarrow s_{u}+2\,|\,s_{u}>0)=\frac{1}{3}\,.
$$
Case 2.
The walker $s_{u}(t)>0$ and we receive a different example (so $u\neq v$ ). Whether $s_{u}$ decrements in this case is complex to determine, and depends on the precise coordinates $\omega_{u}$ and $\omega_{v}$ . We treat this issue coarsely by modeling the probability of decrement through an average case approximation: if $s_{v}>0$ , we assume that $s_{u}$ will always decrement; if $s_{v}<0$ , we assume that $s_{u}$ will decrement with some mean probability $\mu$ . Since $p(s_{v}>0)=\frac{n^{+}-1}{n-1}$ and $p(s_{v}<0)=\frac{n^{-}}{n-1}$ , and the probability of selecting a different example overall remains $2/3$ , we summarize this case as
$$
p(s_{u}\leftarrow s_{u}-1\,|\,s_{u}>0)=\frac{2}{3}\left(\frac{n^{+}-1}{n-1}+\frac{n^{-}}{n-1}\mu\right)\,.
$$
This average case approximation is similar in flavor to the mean field ansatz common in physics, and we employ it for similar reasons: it simplifies a complex many-bodied interaction into a simple interaction between a single body and an average field. We validate the accuracy of this approximation later below.
Case 3.
The walker $s_{u}(t)<0$ and we receive a same example. No updates occur in this case. For completeness, we summarize it as
$$
p(s_{u}\leftarrow s_{u}+2\,|\,s_{u}<0)=0\,.
$$
Case 4.
The walker $s_{u}(t)<0$ and we receive a different example. We again apply a coarse, average case approximation to model the probability of decrementing. If $s_{v}<0$ , we assume that $s_{u}$ will never decrement. If $s_{v}>0$ , the probability of decrementing again depends on our mean quantity $\mu$ . The probability of selecting a different example overall remain $2/3$ , so we summarize this case as
$$
p(s_{u}\leftarrow s_{u}-1\,|\,s_{u}<0)=\frac{2}{3}\left(\frac{n^{+}}{n-1}\mu\right)\,.
$$
To gain greater insight into $\mu$ , we consider how much a walker’s position may drift as it encounters different training examples. Define a walker’s expected drift to be the quantity $\Delta s(t)=\mathbb{E}[s(t+1)-s(t)]$ , averaged over possible walker states $s$ . Then under Eq (C.5) and Eq (C.6), considering a positive walker $s^{+}>0$
$$
\displaystyle\Delta s^{+}(t) \displaystyle=2\,p(s^{+}>0)\,p(s^{+}\leftarrow s^{+}+2\,|\,s^{+}>0) \displaystyle\quad-p(s^{+}>0)p(s^{+}\leftarrow s^{+}-1\,|\,s^{+}>0) \displaystyle=\frac{2n^{+}}{3n}\left(1-\frac{n^{+}+n^{-}\mu-1}{n-1}\right) \displaystyle=\frac{2n^{+}n^{-}(1-\mu)}{3n(n-1)}\,.
$$
Similarly, under Eq (C.7) and Eq (C.8), a negative walker $s^{-}$ has expected drift
$$
\displaystyle\Delta s^{-}(t) \displaystyle=-\,p(s^{-}<0)\,p(s^{-}\leftarrow s^{-}-1\,|\,s^{-}<0) \displaystyle=-\frac{2n^{-}n^{+}\mu}{3n(n-1)}\,.
$$
Suppose $\mu=1$ . In this case, if we encounter a different example $(\mathbf{z}_{u},\mathbf{z}_{v})$ such that $s_{u}>0$ and $s_{v}<0$ , then $s_{u}$ will always decrement. On average, $\Delta s_{u}=0$ while $\Delta s_{v}$ is a negative quantity, indicating that $s_{u}$ will on average remain around the same position while $s_{v}$ decreases. However, if $s_{v}$ decreases without bound, there comes a point where $\omega_{u}+\omega_{v}<0$ , preventing further decrements. This situation implies that $\mu=0$ , resulting in $\Delta s_{u}>0$ and $\Delta s_{v}=0$ . However, if $s_{u}$ now increases without bound, there comes a point where $\omega_{u}+\omega_{v}>0$ , allowing again further decrements, raising our mean update probability back to $\mu=1$ .
In general, if $|\Delta s_{u}|<|\Delta s_{v}|$ , we experience further increments until $|\Delta s_{u}|>|\Delta s_{v}|$ , at which point we experience further decrements, returning us back to $|\Delta s_{u}|<|\Delta s_{v}|$ . Over a long time period, we might therefore expect our dynamics to settle around an average point $|\Delta s_{u}|=|\Delta s_{v}|$ . If this is true, then we employ the relation $|\Delta s^{+}|=|\Delta s^{-}|$ as a self-consistency condition to solve for $\mu$ . Equating (C.9) and (C.10) reveals that $\mu=\frac{1}{2}$ .
Altogether, we arrive at the following picture of the walkers’ dynamics. Walkers $s_{u}$ at a positive position drift with an average rate
$$
\Delta s_{u}=\frac{n^{+}n^{-}}{3n(n-1)}\,.
$$
Meanwhile, walkers $s_{v}$ at a negative position drift with an average rate $\Delta s_{v}=-\Delta s_{u}$ . Over long time periods, $s_{u}\rightarrow\infty$ while $s_{v}\rightarrow-\infty$ . Because positive updates increment both coordinates $\omega_{u}^{1}$ and $\omega_{u}^{2}$ equally, we have that $\omega_{u}^{1}\approx\omega_{u}^{2}>0$ . Meanwhile, because negative updates have a higher chance of decrementing a more positive coordinate, we also have that $\omega_{v}^{1}\approx\omega_{v}^{2}<0$ . In this way, we must have overall that $\left|\left|\mathbf{v}_{1}\right|\right|=\left|\left|\mathbf{v}_{2}\right|\right|$ and $\mathbf{v}^{1}\cdot\mathbf{v}^{2}/(\left|\left|\mathbf{v}^{1}\right|\right|\,\left|\left|\mathbf{v}^{2}\right|\right|)=1$ at long time scales, confirming that a weight vector aligned with same examples adopts parallel components.
To validate our key assumption on $\mu$ , we simulate the Markov process $100$ times with $L=16$ and a batch size of $512$ . We empirically find that $\mu=0.508\pm 0.056$ (given by two standard deviations), matching closely our conjecture that $\mu=\frac{1}{2}$ .
One caveat we have not addressed is the case where $n^{-}=n$ . In this case, no further updates occur and the weights are frozen in their current position. However, as we suggest later in Section C.4.3, the corresponding readout of these weights will be relatively small, reducing its impact. In practice, “dead” weights like these that are negatively aligned with all training symbols appear to be rare in trained models.
#### C.4.2 Different case
For weights $\mathbf{w}$ corresponding to a readout $a<0$ , similar rules hold but now with flipped signs. Considering again a random walker with position $s_{u}(t)=\omega_{u}^{1}(t)+\omega_{u}^{2}(t)$ , the following rules govern the walker’s dynamics:
1. If $s_{u}(t)>0$ and the model receives a training example $(\mathbf{z}_{u},\mathbf{z}_{u})$ , then $s_{u}(t+1)=s_{u}(t)-2$ .
1. If the model receives a training example $(\mathbf{z}_{u},\mathbf{z}_{v})$ or its reverse $(\mathbf{z}_{v},\mathbf{z}_{u})$ , where $u\neq v$ then $s_{u}(t+1)\leq s(t)+1$ .
The rules follow from the update dynamics of the Markov process precisely as before, now for weights sensitive to different examples. Note, there is no equivalence to Rule 3 in this case, since a walker may (in most cases) continue to receive either positive or negative updates regardless of the sign of its position. Indeed, this added symmetry to the different case simplifies the analysis somewhat compared to the same case, where it was necessary to study the interactions between two ensembles of random walkers that evolve in different ways. Here, we may treat all walkers uniformly.
Our general approach for analyzing this case is the same. Conditioned on training examples containing the $u$ th training symbol, recall that observing a same pair $(\mathbf{z}_{u},\mathbf{z}_{u})$ has probability 1/3, and observing a different pair $(\mathbf{z}_{u},\mathbf{z}_{v})$ has probability 2/3. Then we have the following cases:
Case 1.
The walker $s_{u}(t)>0$ and receives a same example. In this case, $s_{u}(t+1)=s_{u}(t)-2$ . The probability of observing a same pair containing $\mathbf{z}_{u}$ is 1/3, so we summarize this case as
$$
p(s_{u}\leftarrow s_{u}-2\,|\,s_{u}>0)=\frac{1}{3}\,.
$$
Case 2.
The walker $s_{u}(t)>0$ and we receive a different example. Whether $s_{u}$ increments is complex to determine, and depends on the precise coordinates $\omega_{u}$ and $\omega_{v}$ . As before, we treat this issue coarsely by approximating the probability of incrementing through an average case parameter $\mu$ . The probability of selecting a different example overall remains $2/3$ , so we summarize this case as
$$
p(s_{u}\leftarrow s_{u}+1\,|\,s_{u}>0)=\frac{2}{3}\mu\,.
$$
Case 3.
The walker $s_{u}(t)<0$ and we receive a same example. No updates occur in this case. For completeness, we summarize it as
$$
p(s_{u}\leftarrow s_{u}-2\,|\,s_{u}<0)=0\,.
$$
Case 4.
The walker $s_{u}(t)<0$ and we receive a different example. We again use our average case parameter to describe the probability of incrementing. The probability of selecting a different example overall remains $2/3$ , so we summarize this case as
$$
p(s_{u}\leftarrow s_{u}+1\,|\,s_{u}<0)=\frac{2}{3}\mu\,.
$$
To obtain a self-consistent condition for $\mu$ , we consider again the expected drift of walkers at positive or negative positions. After $t$ timesteps have elapsed, suppose the number of walkers with position $s^{+}>0$ is $n^{+}$ , and the number of walkers with position $s^{-}<0$ is $n^{-}$ , where $L=n^{+}+n^{-}\equiv n$ . Then combining Eq (C.12) and (C.13), the expected drift for positive walkers is
$$
\Delta s^{+}=\frac{2n^{+}}{3n}(\mu-1)\,.
$$
Combining Eq (C.14) and (C.15), the expected drift of the negative walkers is
$$
\Delta s^{-}=\frac{2n^{-}}{3n}\mu
$$
Note, unlike the same case, the expected drift for positive walkers is negative, and the expected drift for negative walkers is positive. Hence, for $\mu\in(0,1)$ , if $|\Delta s^{+}|>|\Delta s^{-}|$ , the number of positive walkers decreases faster than it increases, so we eventually reach a point where $|\Delta s^{+}|\leq|\Delta s^{+}|$ . However, when $|\Delta s^{+}|<|\Delta s^{-}|$ , the number of negative walkers decreases faster than it increases, so we oscillate back to $|\Delta s^{+}|\geq|\Delta s^{-}|$ . Over a long time period, we assume our walkers settle around an average point $|\Delta s^{+}|=|\Delta s^{-}|$ . If this is true, then as before, we employ the relation $|\Delta s^{+}|=|\Delta s^{-}|$ as a self-consistency condition to solve for $\mu$ . Equating (C.16) and (C.17) indicates that $\mu=\frac{n^{+}}{n}$ .
There are three potential settings for $n^{+}$ to consider: $0<n^{+}<n$ , $n^{+}=n$ , or $n^{+}=0$ . Let us begin with $0<n^{+}<n$ . Because $n^{+}<n$ , the average position of positive walkers experiences a net negative drift, gradually bringing them closer to zero. Because $n^{+}>0$ , the average position of negative walkers experiences a net positive drift, gradually bringing them closer to zero also. Over a long period of time, we would therefore expect $n^{+}\approx n^{-}$ (and $\mu\approx\frac{1}{2}$ ).
If $n^{+}=n$ , then all walkers are in a positive position and $\Delta s^{+}=0$ . Over a long period of time, as the variance in walker position grows, through random chance at least one walker will eventually drift to a negative position, returning us to the case where $0<n^{+}<n$ . If $n^{+}=0$ , then all walkers are in a negative position, and $\Delta s^{-}>0$ . Over time, the walkers’ average position grows more positive, until at least one becomes positive and we again re-enter the case $0<n^{+}<n$ .
Altogether, we arrive at the following picture of the walker’s dynamics. Walkers at a positive position drift with a negative rate down to zero, and walkers at a negative position drift with a positive rate up to zero. After sufficient time has elapsed, we would therefore expect the position of all walkers to be close to zero. However, for a walker $s_{u}$ , positive updates increment the underlying coordinates $\omega_{u}^{1}$ and $\omega_{u}^{2}$ asymmetrically. Furthermore, a more positive coordinate receives a positive update with greater probability. Hence, we must have that $\omega_{u}^{1}\gg\omega_{u}^{2}$ or $\omega_{u}^{1}\ll\omega_{u}^{2}$ . Because their sum must remain close to zero, it must be true that $\omega_{u}^{1}\approx-\omega_{u}^{2}$ . Thus, we have overall that $\left|\left|\mathbf{v}_{1}\right|\right|=\left|\left|\mathbf{v}_{2}\right|\right|$ and $\mathbf{v}^{1}\cdot\mathbf{v}^{2}/(\left|\left|\mathbf{v}^{1}\right|\right|\,\left|\left|\mathbf{v}^{2}\right|\right|)=-1$ , confirming that a weight vector aligned with different examples adopts antiparallel components.
To validate our key assumption on $\mu$ , we simulate the Markov process $100$ times with $L=16$ and a batch size of $512$ . We empirically find that $\mu=0.499\pm 0.009$ (given by two standard deviations), matching closely our conjecture that $\mu=\frac{1}{2}$ .
#### C.4.3 Magnitude of readouts
The final piece to demonstrate in our study of the rich regime is that $|\overline{a^{+}}|<|\overline{a^{-}}|$ , where $\overline{a^{+}}$ corresponds to the average across all positive readout weights and $\overline{a^{-}}$ corresponds to the average across all negative readout weights. Exactly characterizing these magnitudes is difficult, so we apply a heuristic argument based what we learned about the structure of parallel and antiparallel weights above and support it with numeric evidence.
Recall that the update rule for a readout weight $a_{i}$ is given by
$$
\Delta a=-\frac{c}{N}\sum_{j=1}^{N}\frac{\partial\mathcal{L}_{j}}{\partial f}\phi(\mathbf{w}\cdot\mathbf{x}_{j}),
$$
where $c=\frac{\alpha}{\gamma\sqrt{d}}$ and $\alpha$ is the learning rate. Suppose $\mathbf{x}_{j}=(\mathbf{z}_{u},\mathbf{z}_{v})$ . Then the update rule becomes
$$
\Delta a=-\frac{c}{N}\sum_{u,v}\frac{\partial\mathcal{L}_{u,v}}{\partial f}\phi(\omega_{u}^{1}+\omega_{v}^{2})\,.
$$
If $\frac{\partial\mathcal{L}}{\partial f}$ is about the same in magnitude across all training examples, then our readout updates are proportional to
$$
\Delta a\propto\sum_{u,v}S(u,v)\,\phi(\omega_{u}^{1}+\omega_{v}^{2})\,.
$$
where
$$
S(u,v)=\begin{cases}1&u=v\\
-1&u\neq v\,.\end{cases}
$$
Let us first consider the case where $\mathbf{w}$ corresponds to a negative readout weight $a^{-}$ . From above, we know that $\mathbf{w}$ is antiparallel. Hence, when encountering a same example, $\omega_{u}+\omega_{u}\approx 0$ . If the magnitude of all coordinates are roughly equal, when encountering a different example, $\omega_{u}+\omega_{v}>0$ about $1/4$ of the time. Comparing Eq (C.11) to Eq (C.16), we see that the expected drift for antiparallel weight vectors is roughly twice that of parallel weight vectors over long timescales. Altogether, since the number of same and different examples is balanced, we have overall that $|\Delta a^{-}|\propto 2\cdot\frac{1}{4}=\frac{1}{2}$ for $a^{-}<0$ .
Now consider the case where $\mathbf{w}$ corresponds to a positive readout weight $a^{+}$ . From above, we know that $\mathbf{w}$ is parallel. For large batch sizes $N$ , the expected drift of a walker at initialization is 0 There is a 1/3 chance of observing a same example, which increments by 2. There is a 2/3 chance of observing a different example, which decrements by 1. Hence, the expected drift at initialization must be zero overall., so we expect $n^{+}\approx n^{-}$ . If the magnitude of all coordinates are roughly equal and $L$ is large, when encountering a same example, $\omega_{u}+\omega_{v}>0$ about $1/2$ of the time. When encountering a different example, $\omega_{u}+\omega_{v}>0$ about $1/4$ of the time. Altogether, we would therefore expected $|\Delta a^{+}|\propto\frac{1}{2}-\frac{1}{4}=\frac{1}{4}$ .
From this rough estimate, we find that $\frac{|\Delta a^{-}|}{|\Delta a^{+}|}\approx 2$ for average negative and positive readouts. Since the rate of increase for negative readouts tends to be larger than that of positive readouts, we would expect the magnitude of negative readouts to be similarly larger. In fact, if readouts start with small initialization, we may conjecture that $\frac{|\overline{a^{-}}|}{|\overline{a^{+}}|}\approx 2$ . In practice, this quantity turns out to be about $1.56\pm 0.09$ (with 2 standard deviations), computed from 10 runs The MLP has width $m=1024$ , and inputs have dimension $d=512$ . There are $L=32$ training symbols.
Note in the case that $L$ is small (for instance, $L=2$ ), our estimate $|\Delta a^{+}|\propto\frac{1}{4}$ breaks down since there may be only a single set of positive coordinates and no penalty is incurred on negative examples. In this case, we would have $|\Delta a^{+}|\propto\frac{1}{2}$ , so $\frac{|\Delta a^{-}|}{|\Delta a^{+}|}=1$ . Indeed, this is exactly what we observe in the case where $L=2$ . Computing this quantity empirically yields $0.99\pm 0.07$ (with 2 standard deviations), computed from 10 runs As before, the MLP has width $m=1024$ , and inputs have dimension $d=512$ . There are $L=2$ training symbols. This outcome seems to be part of the reason why the model does not generalize well on the SD task with only $2$ symbols, despite developing parallel/antiparallel weights (Figure C2). For $L\geq 3$ , there seems to be sufficient pairs of positive coordinates in parallel weight vectors to restore the situation where $|\Delta a^{-}|>|\Delta a^{+}|$ .
<details>
<summary>x7.png Details</summary>
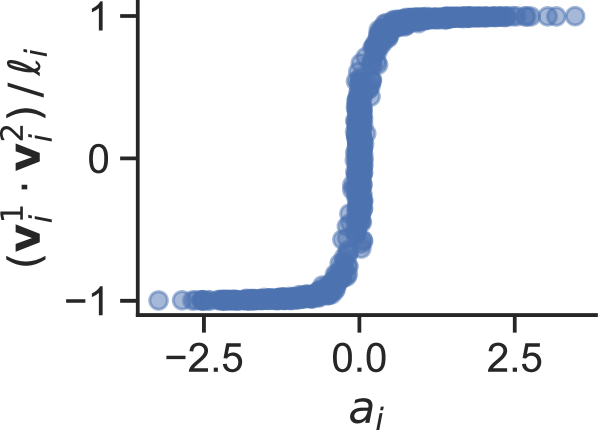
### Visual Description
## Scatter Plot: Sigmoidal Relationship between \(a_i\) and \((v_i^1 \cdot v_i^2) / \ell_i\)
### Overview
The image is a scatter plot displaying a dense collection of data points that form a clear, smooth sigmoidal (S-shaped) curve. The plot illustrates a strong, non-linear relationship between the variable on the horizontal axis (\(a_i\)) and the computed quantity on the vertical axis. The data points are represented as semi-transparent blue circles, which overlap heavily in the central transition region, indicating a high density of observations there.
### Components/Axes
* **X-Axis (Horizontal):**
* **Label:** \(a_i\)
* **Scale:** Linear.
* **Visible Tick Marks:** -2.5, 0.0, 2.5.
* **Range:** Approximately -3.0 to +3.0.
* **Y-Axis (Vertical):**
* **Label:** \((v_i^1 \cdot v_i^2) / \ell_i\)
* **Scale:** Linear.
* **Visible Tick Marks:** -1, 0, 1.
* **Range:** Approximately -1.0 to +1.0.
* **Data Series:**
* A single series of blue circular markers.
* No legend is present, as there is only one data series.
* **Spatial Layout:** The plot area is centered. The y-axis label is rotated 90 degrees and positioned to the left of the axis. The x-axis label is centered below the axis.
### Detailed Analysis
* **Trend Verification:** The data series exhibits a classic sigmoidal trend. For negative values of \(a_i\) (left side), the y-values are clustered near -1. As \(a_i\) approaches 0 from the negative side, the y-values begin to rise. There is an extremely sharp, near-vertical transition centered at \(a_i \approx 0\). For positive values of \(a_i\) (right side), the y-values plateau and cluster near +1.
* **Data Point Distribution & Approximate Values:**
* **Left Plateau (\(a_i < -1.0\)):** Data points are tightly clustered around \(y \approx -1.0\). The curve is essentially flat in this region.
* **Transition Region (\(-1.0 < a_i < 1.0\)):** This is the most densely populated area. The relationship is very steep. For example:
* At \(a_i \approx -0.5\), \(y\) is approximately -0.8 to -0.6.
* At \(a_i \approx 0.0\), \(y\) is approximately 0.0 (the inflection point).
* At \(a_i \approx 0.5\), \(y\) is approximately 0.6 to 0.8.
* **Right Plateau (\(a_i > 1.0\)):** Data points are tightly clustered around \(y \approx +1.0\). The curve is essentially flat in this region.
* **Uncertainty:** The values are approximate based on visual inspection. The tight clustering of points suggests low variance in the relationship for a given \(a_i\), except within the steep transition zone where small changes in \(a_i\) lead to large changes in \(y\).
### Key Observations
1. **Perfect Sigmoidal Shape:** The data follows an idealized sigmoid function (like a hyperbolic tangent, tanh) with remarkable precision, suggesting a deterministic or very low-noise underlying process.
2. **Sharp Threshold:** The transition from the lower to upper plateau is extremely abrupt, occurring over a narrow range of \(a_i\) (roughly between -0.5 and 0.5). This indicates a strong threshold or switching behavior.
3. **Symmetry:** The curve appears symmetric about the origin (0,0). The shape and density of points on the left (negative) side mirror those on the right (positive) side.
4. **Saturation:** The output variable \((v_i^1 \cdot v_i^2) / \ell_i\) is clearly bounded between -1 and +1, saturating at these limits for sufficiently large magnitude inputs \(|a_i|\).
### Interpretation
This plot demonstrates a **hard, symmetric thresholding function**. The variable \(a_i\) acts as a control parameter that determines the output \((v_i^1 \cdot v_i^2) / \ell_i\).
* **What it suggests:** The relationship is characteristic of systems with a bistable or switch-like response. When the input \(a_i\) is negative, the system is in one stable state (output ≈ -1). When \(a_i\) is positive, it switches to the opposite stable state (output ≈ +1). The near-vertical transition at \(a_i = 0\) implies that the system is highly sensitive to the sign of \(a_i\) around zero.
* **How elements relate:** The x-axis variable \(a_i\) is the independent driver. The y-axis quantity is a dependent, normalized measure (given the division by \(\ell_i\)) that likely represents a correlation, projection, or alignment metric between two vectors \(v_i^1\) and \(v_i^2\). The sigmoidal shape indicates this metric is forced to its maximum (+1) or minimum (-1) values except in a narrow "uncertainty" band around \(a_i = 0\).
* **Potential Context:** In machine learning or physics, such a curve often represents the activation function of a neuron (like tanh), the result of a normalized dot product (cosine similarity) under a constraint, or the order parameter in a phase transition. The tight fit suggests the data may be generated from a formula rather than collected from a noisy experiment. The key takeaway is the **binary, sign-dependent outcome** with a very sharp decision boundary.
</details>
Figure C2: Rich-regime weight structure when $L=2$ . The model continues to develop parallel/antiparallel weights, though the magnitude of negative readouts is now about the same as the magnitude of positive readouts.
### C.5 Test accuracy prediction
We apply our knowledge on the structure of $\mathbf{w}$ and $a$ to estimate the test accuracy of the rich regime model. Our derivation is heuristic, but seeks to capture broad phenomena rather than achieve exact precision. We validate our predicted test accuracy in Figure C3, demonstrating excellent agreement.
Recall from Section 3.1 that a model achieving the hand-crafted solution exhibits perfect classification of same examples. Any errors are therefore accumulated from misclassifying different examples. The crux of our estimate stems from approximating the classification accuracy of different examples.
Define $\mathcal{I}^{+}$ to be the set of weight indices $i$ such that $a_{i}>0$ , and define $\mathcal{I}^{-}$ to be the set of weight indices $j$ where $a_{j}<0$ . Let $\mathbf{x}$ be a different example. Dropping constants that do not affect the outcome of a classification, our model becomes
$$
f(\mathbf{x})=\sum_{i\in I^{+}}|a_{i}|\,\phi(\mathbf{w}_{i}\cdot\mathbf{x})-\sum_{j\in I^{-}}|a_{j}|\,\phi(\mathbf{w}_{j}\cdot\mathbf{x})\,.
$$
Define the weighted sums
| | $\displaystyle\overline{a^{+}}_{*}$ | $\displaystyle=\frac{\sum_{i\in I^{+}}|a_{i}|\,\phi(\mathbf{w}_{i}\cdot\mathbf{x})}{\sum_{i\in I^{+}}\phi(\mathbf{w}_{i}\cdot\mathbf{x})}\,,$ | |
| --- | --- | --- | --- |
Then
$$
f(\mathbf{x})=\overline{a}^{+}_{*}\sum_{i\in I^{+}}\phi(\mathbf{w}_{i}\cdot\mathbf{x})-\overline{a}^{-}_{*}\sum_{j\in I^{-}}\phi(\mathbf{w}_{j}\cdot\mathbf{x})\,.
$$
If the magnitudes of $\phi(\mathbf{w}_{i}\cdot\mathbf{x})$ are the same for all $i$ and all $\mathbf{x}$ , then $\overline{a^{+}}_{*}=\overline{a^{+}}=\frac{1}{|I^{+}|}\sum_{i\in I^{+}}a_{i}$ . Since $\mathbf{x}$ is an unseen different example, by symmetry we conclude that $\overline{a^{+}}_{*}=\overline{a^{+}}$ is a reasonable approximation. The same applies for $\overline{a^{-}}_{*}=\overline{a^{-}}$ .
Since the magnitude of $f(\mathbf{x})$ does not affect its classification, we divide through by $\overline{a^{+}}$ to redefine our model as
$$
f(\mathbf{x})=\sum_{i\in I^{+}}\phi(\mathbf{w}_{i}\cdot\mathbf{x})-\rho\sum_{j\in I^{-}}\phi(\mathbf{w}_{j}\cdot\mathbf{x})\,,
$$
where $\rho=\frac{|\overline{a^{-}}|}{|\overline{a^{+}}|}$ . To calculate the probability of classifying an unseen different example, we would like to estimate $p(f(\mathbf{x})<0)$ , for $\mathbf{x}=(\mathbf{z},\mathbf{z}^{\prime})$ and $\mathbf{z},\mathbf{z}^{\prime}\sim\mathcal{N}(\mathbf{0},\mathbf{I}/d)$ .
Then from Eq C.3
$$
\phi(\mathbf{w}_{i}\cdot\mathbf{x})=\phi\left(\sum_{k=1}^{L}\left[\omega_{i,k}^{1}\,\mathbf{z}_{k}\cdot\mathbf{z}\pm\omega_{i,k}^{2}\,\mathbf{z}_{k}\cdot\mathbf{z}^{\prime}\right]\right)\,.
$$
Over the distribution of an unseen symbol $\mathbf{z}$
$$
\mathbf{z}_{k}\cdot\mathbf{z}\overset{d}{=}-\mathbf{z}_{k}\cdot\mathbf{z}\,,
$$
so we replace $\pm$ with simply $+$ in the summation. Summing across all weight vectors corresponding to the same class yields
| | $\displaystyle\sum_{i\in I^{+}}\phi(\mathbf{w}_{i}\cdot\mathbf{x})$ | $\displaystyle=\sum_{i\in I^{+}}\phi\left(\sum_{k=1}^{L}\left[\omega_{i,k}^{1}\,\mathbf{z}_{k}\cdot\mathbf{z}+\omega_{i,k}^{2}\,\mathbf{z}_{k}\cdot\mathbf{z}^{\prime}\right]\right)$ | |
| --- | --- | --- | --- |
Since $\mathbf{w}_{i}\cdot\mathbf{x}>0$ , it is likely that $\mathbf{\omega}_{i,k}^{1}\,\mathbf{z}_{k}\cdot\mathbf{z}>0$ . Since $\mathbf{z}_{k}\cdot\mathbf{z}$ is approximately Normal at high $d$ , we approximate the term $c_{i,k}^{1}\equiv\omega_{i,k}^{1}\mathbf{z}_{k}\cdot\mathbf{z}$ as a Half-Normal random variable. We therefore focus on characterizing the distribution of a sum over Half-Normal random variables, which we denote by $\overline{c^{+}}$ :
$$
\sum_{i\in\mathcal{I^{+}}}\phi(\mathbf{w}_{i}\cdot\mathbf{x})\overset{d}{=}\overline{c^{+}}\equiv\sum_{i=1}^{|\mathcal{I}^{+}|}\sum_{k=1}^{L}\left[c_{i,k}^{1}+c_{i,k}^{2}\right]\,.
$$
The individual $c_{i,k}^{1}$ and $c_{i,k}^{2}$ are learned from a finite set of training symbols, so they cannot be independently distributed. However, since training symbols are sampled independently, we would expect for any particular weight index $i=i_{0}$ , the corresponding $c_{i_{0},k}^{1}$ and $c_{i_{0},k}^{2}$ are indeed independent. Hence, we have at least $2L$ independent terms for a particular index $i=i_{0}$ .
The dependency structure across weight indices $i$ is more subtle, but we make a reasonable guess at their structure and later validate this heuristic with numerics. While our analysis in Appendix C assumed each weight vector evolves independently, in a training model they evolve based on the same set of inputs. As a result, significant correlations emerge across weight vectors. To understand these correlations, let us fix our training symbol index to $k=k_{0}$ and consider all terms $c_{i,k_{0}}^{1}=\omega_{i,k_{0}}^{1}\mathbf{z}_{k_{0}}\cdot\mathbf{z}$ . Since they all share $\mathbf{z}_{k_{0}}\cdot\mathbf{z}$ , these quantities are not strictly independent. However, after $T$ training steps, we have that $\omega_{i,k_{0}}^{1}=\mathcal{O}(T)$ and $c_{i,k_{0}}^{1}=\mathcal{O}(T)$ while $\mathbf{z}_{k_{0}}\cdot\mathbf{z}=\mathcal{O}(1)$ , so for our approximation we will consider the dependency incurred from $\mathbf{z}_{k_{0}}\cdot\mathbf{z}$ as negligible.
Let us therefore turn our attention to the coordinates $\omega_{i,k_{0}}^{1}$ . If the model only ever received same inputs $(\mathbf{z}_{k_{0}},\mathbf{z}_{k_{0}})$ , all $\omega_{i,k_{0}}^{1}$ would be identical or zero across indices $i$ . However, if we allow the model to witness different inputs $(\mathbf{z}_{k_{0}},\mathbf{z}_{\ell})$ for some $\ell\neq k_{0}$ , we would expect a distribution of $\omega_{i,k_{0}}^{1}$ driven by the underlying initialization of $\mathbf{w}_{i}$ and the number of symbols $L$ . Coordinates where $\omega_{i,k_{0}}^{1}(0)+\omega_{i,1}^{1}(0)>0$ and $\omega_{i,k_{0}}^{1}(0)+\omega_{i,2}^{1}(0)<0$ would evolve differently from coordinates where $\omega_{i,k_{0}}^{1}(0)+\omega_{i,1}^{1}(0)<0$ and $\omega_{i,k_{0}}^{1}(0)+\omega_{i,1}^{2}(0)>0$ . If the number of training symbols increases, we would expect the number of independent coordinates $\omega_{i,k_{0}}^{1}$ to also increase. Given $L$ training symbols, we might therefore guess that the number of independent coordinates to be proportional to $L-1$ , for $L-1$ symbols where $\ell\neq k_{0}$ . However, we also need to account for the sign of $\mathbf{z}_{\ell}\cdot\mathbf{z}^{\prime}$ . If this quantity is positive and the corresponding readout is positive, then correlations resulting from the symbol $\mathbf{z}_{\ell}$ would be unimportant since they lower the probability that $\mathbf{w}_{i}\cdot\mathbf{x}>0$ , filtering them from the sum. (The reverse is true for weights corresponding to negative readouts.) Hence, roughly half the $L-1$ symbols contribute to unique coordinates. The total number of unique coordinates $\omega_{i,k_{0}}^{1}$ is therefore approximately $\frac{1}{2}(L-1)$ .
If each of our $\frac{1}{2}(L-1)$ independent coordinates carries $2L$ independent dot-product terms, we have
$$
\overline{c^{+}}\overset{d}{=}\,\sum_{\ell=1}^{L\left(L-1\right)}c_{\ell}\,,
$$
where $c_{\ell}$ is distributed Half-Normal with mean $0$ and some variance $\sigma^{2}$ , which will cancel in the final calculation.
Applying the central limit theorem together with the first and second moments of a Half-Normal distribution reveals that
$$
\overline{c^{+}}\sim\mathcal{N}\left((L^{2}-L)\sigma\sqrt{\frac{2}{\pi}}\,,\,(L^{2}-L)\left(1-\frac{2}{\pi}\right)\right)\,.
$$
As we noted before, $\mathbf{z}_{k}\cdot\mathbf{z}\overset{d}{=}\mathbf{z}_{k}\mathbf{z}^{\prime}$ for large $d$ , so the distribution of $\sum\phi(\mathbf{w}\cdot\mathbf{x})$ is the same regardless if the weight vectors $\mathbf{w}$ are parallel or antiparallel. Hence, $\overline{c^{+}}\overset{d}{=}\overline{c^{-}}$ . The distribution of our output is therefore
$$
f(\mathbf{x})\overset{d}{=}\overline{c^{+}}-\rho\,\overline{c^{-}}\,.
$$
Our final probability of classifying an unseen different example correctly is
$$
p(f(\mathbf{x})<0)=\Phi\left(\sqrt{\frac{(2L^{2}-2L)(\rho-1)^{2}}{(\pi-2)(\rho^{2}+1)}}\right)\,,
$$
where $\Phi$ is the CDF of a standard Normal.
From Section C.4.3, we found that $\rho\approx 1.5$ for $L\geq 3$ and $\rho=1$ for $L=2$ . Plugging this value into Eq (C.18) allows us to compute the probability of classifying an unseen different example. If the model classifies all unseen same examples correctly, the total test accuracy of the rich regime model is given by $\frac{1}{2}+\frac{1}{2}p(f(\mathbf{x})<0)$ , yielding the expression we report in Eq (3). We validate this prediction in Figure C3, showing excellent agreement with the measured test accuracy of a rich model.
<details>
<summary>x8.png Details</summary>
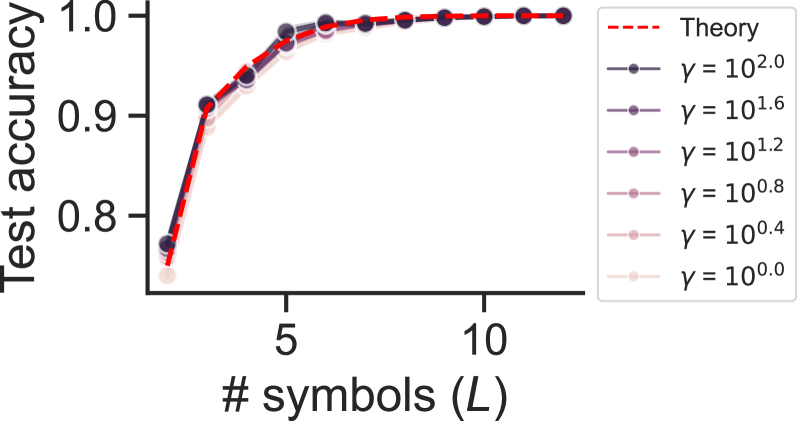
### Visual Description
## Line Chart: Test Accuracy vs. Number of Symbols (L)
### Overview
The image is a line chart plotting "Test accuracy" against the "# symbols (L)". It compares the performance of a model under different values of a parameter, gamma (γ), against a theoretical prediction. All data series show a rapid increase in accuracy as the number of symbols increases from 1 to approximately 5, after which accuracy plateaus near 1.0.
### Components/Axes
* **Y-Axis (Vertical):**
* **Label:** "Test accuracy"
* **Scale:** Linear, ranging from approximately 0.75 to 1.0.
* **Major Ticks:** 0.8, 0.9, 1.0.
* **X-Axis (Horizontal):**
* **Label:** "# symbols (L)"
* **Scale:** Linear, ranging from 1 to approximately 12.
* **Major Ticks:** 5, 10.
* **Legend (Positioned to the right of the plot area):**
* **"Theory"**: Represented by a red dashed line (`---`).
* **"γ = 10².⁰"**: Dark purple solid line with circular markers.
* **"γ = 10¹.⁶"**: Medium purple solid line with circular markers.
* **"γ = 10¹.²"**: Light purple solid line with circular markers.
* **"γ = 10⁰.⁸"**: Pinkish-purple solid line with circular markers.
* **"γ = 10⁰.⁴"**: Light pink solid line with circular markers.
* **"γ = 10⁰.⁰"**: Very light pink (almost white) solid line with circular markers.
### Detailed Analysis
**Trend Verification:** All seven data series (six γ values and the Theory line) exhibit the same fundamental trend: a steep, concave-down increase in test accuracy from L=1 to L≈5, followed by a flat plateau where accuracy remains near 1.0 for L > 5.
**Data Point Extraction (Approximate Values):**
* **At L = 1:**
* Theory: ~0.76
* γ = 10².⁰ (Dark Purple): ~0.77
* γ = 10⁰.⁰ (Lightest Pink): ~0.74
* *Observation: There is a small spread in starting accuracy, with higher γ values starting slightly higher.*
* **At L = 3:**
* Theory: ~0.94
* All γ lines are tightly clustered between ~0.92 and ~0.95.
* **At L = 5:**
* Theory: ~0.99
* All γ lines are extremely close to the theory line, between ~0.98 and ~1.0.
* **At L = 10:**
* Theory: 1.0
* All γ lines: 1.0 (visually indistinguishable from the theory line and each other).
**Component Isolation - Plot Region:**
* **Header:** Contains the y-axis label "Test accuracy".
* **Main Chart:** Contains the plotted lines. The red dashed "Theory" line serves as the upper bound or target. The solid lines for different γ values are layered, with the darkest (γ=10².⁰) generally on top and the lightest (γ=10⁰.⁰) at the bottom in the initial rising phase (L=1 to L=3). They converge completely by L=5.
* **Footer:** Contains the x-axis label "# symbols (L)" and its tick marks.
### Key Observations
1. **Convergence:** All empirical data series (for different γ) converge to the theoretical prediction line as the number of symbols (L) increases.
2. **Diminishing Returns:** The most significant gains in test accuracy occur when increasing L from 1 to about 5. Beyond L=5, additional symbols yield negligible improvement, as accuracy is already at or near 100%.
3. **Parameter (γ) Sensitivity:** The parameter γ has a noticeable but small effect on accuracy only when the number of symbols (L) is very low (L=1, 2, 3). Higher γ values (e.g., 10².⁰) result in marginally higher accuracy in this region. For L ≥ 5, the model's performance is insensitive to the value of γ within the tested range.
4. **Tight Clustering:** The data points for all γ values are tightly clustered around the theory line, indicating strong agreement between the theoretical model and the empirical results across the parameter space.
### Interpretation
This chart demonstrates the relationship between model complexity (represented by the number of symbols, L) and performance (test accuracy), under varying regularization or noise conditions (parameter γ).
* **What the data suggests:** The system or model being tested achieves near-perfect accuracy once it has access to a sufficient number of symbols (L ≥ 5). The theoretical model accurately predicts this performance ceiling.
* **How elements relate:** The γ parameter likely controls a factor like learning rate, noise level, or regularization strength. Its impact is only relevant in the data-starved regime (low L), where a higher γ (which could mean lower noise or stronger learning) provides a slight advantage. Once sufficient data (symbols) is available, this advantage disappears, and the system performs optimally regardless of γ.
* **Notable Anomaly/Insight:** The most striking feature is not an outlier, but the *lack* of them. The perfect convergence of all lines to the theory line for L > 5 is a powerful result. It indicates a highly predictable system where theoretical bounds are tight and achievable in practice. The plateau at 1.0 accuracy suggests the task becomes trivial for the model once a critical threshold of information (L≈5) is provided. This could imply the task has an inherent complexity that is fully captured by about 5 symbols.
</details>
Figure C3: Rich-regime test accuracy. We demonstrate close agreement between the theoretically predicted and empirically measured rich-regime test accuracy. The rich-regime parametrization explored in the main text corresponds to $\gamma=1$ . To confirm that our results hold for arbitrarily rich models, we also plot accuracies attained in the ultra-rich regime $\gamma\gg 1$ (Atanasov ., 2024). In all cases, our predictions continue to hold.
Two important details to note:
- The test accuracy of the rich model rises rapidly with $L$ . By $L=3$ , the model already attains over 90 percent test accuracy.
- The test error does not depend on the input dimension $d$ . The impact of $d$ is captured in the variance of $\sigma^{2}$ of our Half-Normal random variables $c$ , which cancels in the final calculation.
In this way, we see how the conceptual parallel/antiparallel representations of the same-different model lead to highly efficient learning and insensitivity to input dimension, completing our analysis of the rich regime.
## Appendix D Lazy regime details
In the lazy regime, we will demonstrate that the model requires 1) far more training symbols than in the rich regime to learn the SD task, and 2) the model’s test accuracy depends explicitly on the input dimension $d$ .
A lazy MLP’s learning dynamics can be described using kernel methods. In particular, the case where $\gamma\rightarrow 0$ corresponds to using the Neural Tangent Kernel (NTK) (Jacot ., 2018), in which weights evolve linearly around their initialization. We demonstrate that the number of training symbols required to generalize using the NTK grows quadratically with the input dimension.
Recall that our model has form
$$
f(\mathbf{x})=\sum_{i=1}^{m}a_{i}\,\phi(\mathbf{w}_{i}\cdot\mathbf{x})\,.
$$
If there are $P$ unique training examples in our dataset, we may rewrite our model in its dual form
$$
f(\mathbf{x})=\sum_{j=1}^{P}b_{j}\,K(\mathbf{x},\mathbf{x}_{j})\,,
$$
for the kernel
$$
K(\mathbf{x},\mathbf{x}_{j})=\frac{1}{m}\sum_{i=1}^{m}\phi(\mathbf{w}_{i}\cdot\mathbf{x})\,\phi(\mathbf{w}_{i}\cdot\mathbf{x}_{j})\,.
$$
For ease of exposition, we assume that inputs $\mathbf{x}$ lie on the unit sphere $\mathbf{x}\in\mathbb{S}^{2d-1}$ . This is exactly true (up to a constant radius) as $d\rightarrow\infty$ . For width $m\rightarrow\infty$ and ReLU activations $\phi$ , the analytic form of the NTK kernel $K$ is known to be
$$
K(u)=u\left(1-\frac{1}{\pi}\cos^{-1}(u)\right)+\frac{1}{2\pi}\sqrt{1-u^{2}}\,.
$$
where $u=\mathbf{x}\cdot\mathbf{x}^{\prime}$ (Cho Saul, 2009).
With the setup complete, we present our central result.
**Theorem 2**
*Let $f$ be an infinite-width ReLU MLP as given in Eq D.1, with an NTK kernel. Suppose inputs $\mathbf{x}$ are restricted to lie on the unit sphere $\mathbf{x}\in\mathbb{S}^{2d-1}$ . If $f$ is trained on a dataset consisting of $P$ points constructed from $L$ symbols with input dimension $d$ , then the test error of $f$ is upper bounded by $\mathcal{O}\left(\exp\left\{-\frac{L}{d^{2}}\right\}\right)$ .*
* Proof*
Our proof strategy proceeds as follows. We restrict the space over which our dual coefficients $b$ can vary to a convenient subset, and upper bound the achievable test error of $f$ over this restricted parameter space. Because the restricted parameter space is a subset of the full parameter space, our derived upper bound applies to the unrestricted model as well. We restrict the dual coefficients $b$ as follows. Let $I^{+}$ be the set of all indices $i$ such that $\mathbf{x}_{i}$ is a same example, and $I^{-}$ be the set of all indices $j$ such that $\mathbf{x}_{j}$ is different. Then for all $i\in I^{+}$ , we fix $b_{i}=b^{+}>0$ . For all $j\in I^{-}$ , we fix $b_{j}=b^{-}<0$ . Hence, we effectively tune just two parameters: $b^{+}$ and $b^{-}$ . We also set a number of coefficients $b$ to zero. Given a dataset with symbols $\mathbf{z}_{1},\mathbf{z}_{2},\ldots,\mathbf{z}_{L}$ , partition the symbols such that set $\mathcal{S}_{1}=\left\{\mathbf{z}_{1},\mathbf{z}_{2},\ldots\mathbf{z}_{L/3}\right\}$ and $\mathcal{S}_{2}=\left\{\mathbf{z}_{L/3+1},\mathbf{z}_{L/3+2},\ldots\mathbf{z}_{L}\right\}$ . Consider the kernel coefficient $b_{k}$ , which corresponds to a training example $\mathbf{x}_{k}=(\mathbf{z}_{\ell_{1}};\mathbf{z}_{\ell_{2}})$ . If $\mathbf{z}_{\ell_{1}}=\mathbf{z}_{\ell_{2}}$ and $\mathbf{z}_{\ell_{1}}\notin\mathcal{S}_{1}$ , then we fix $b_{k}=0$ . If $\mathbf{z}_{\ell_{1}}\neq\mathbf{z}_{\ell_{2}}$ , then we check three conditions: (1) $\mathbf{z}_{\ell_{1}}\in\mathcal{S}_{2}$ , (2) $\ell_{2}-\ell_{1}=1$ , and $\ell_{1}$ is odd. If any one of these conditions is violated, we set $b_{k}=0$ . This procedure for deciding whether $b_{k}=0$ ensures that the remaining nonzero terms in Eq (D.1) are independent, and that there are an equal number of same and different examples remaining. The set $\mathcal{S}_{1}$ determines the symbols that contribute to same examples. The disjoint set $\mathcal{S}_{2}$ determines the symbols that contribute to different examples. We further stipulate that different examples do not contain overlapping symbols, leading to the three conditions enumerated above. Note, to construct a dataset such that there are $P$ nonzero terms in our kernel sum, we require $L\propto P$ symbols. First, suppose $\mathbf{x}$ is a same test example. Since we restricted the summands to be independent in our kernel function, the probability of mis-classifying $\mathbf{x}$ can bounded through a straightforward application of Hoeffding’s inequality
$$
p(f(\mathbf{x})<0)\leq\exp\left\{-\frac{2\mathbb{E}[f(\mathbf{x})]^{2}}{Pc^{2}}\right\}\,
$$
where $P$ is the size of the training set and $c$ is a constant related to the range of individual summands $b_{j}K(\mathbf{x},\mathbf{x}_{j})$ . Note, $b_{j}$ can be arbitrarily small without changing the classification and $0\leq K(u)<3$ , so $c$ is finite. Distributing the expectation, we have
$$
\mathbb{E}[f(\mathbf{x})]=\sum_{i\in I^{+}}b^{+}\,\mathbb{E}[K(\mathbf{x},\mathbf{x}_{i})]+\sum_{j\in I^{-}}b^{-}\,\mathbb{E}[K(\mathbf{x},\mathbf{x}_{j})]\,.
$$
Taylor expanding $K$ to second order in $u$ reveals that
$$
\mathbb{E}[K(u)]=\frac{1}{2\pi}+\frac{\mathbb{E}[u]}{2}+\frac{3\mathbb{E}[u^{2}]}{4\pi}+o(\mathbb{E}[u^{2}])
$$
Since input symbols are normally distributed with mean zero, we know that $\mathbb{E}[u]=0$ and $\mathbb{E}[u^{2}]\propto 1/d$ . Furthermore, if $\mathbf{x}_{j}$ is a same training example and $\mathbf{x}_{k}$ is a different training example, inspecting second moments reveals that $\mathbb{E}[(\mathbf{x}\cdot\mathbf{x}_{j})^{2}]=2\mathbb{E}[(\mathbf{x}\cdot\mathbf{x}_{k})^{2}]$ , for an unseen same example $\mathbf{x}$ . Thus, provided that $|b^{-}/b^{+}|<2$ , substituting (D.4) into (D.3) yields
$$
\mathbb{E}[f(\mathbf{x})]=\mathcal{O}\left(\frac{P}{d}\right)\,,
$$
which implies that
$$
p(f(\mathbf{x})<0)\leq\mathcal{O}\left(\exp\left\{-\frac{P}{d^{2}}\right\}\right)\,.
$$ Now suppose $\mathbf{x}$ is a different test example. If $x^{+}$ is a same training example and $x^{-}$ is a different training example, then the first and second moments of $\mathbf{x}\cdot\mathbf{x}^{+}$ are equal to that of $\mathbf{x}\cdot\mathbf{x}^{-}$ . Hence, (D.4) and (D.3) suggest that if $|b^{-}|-|b^{+}|=\mathcal{O}(1)$ , then $\mathbb{E}[f(\mathbf{x})]=-\mathcal{O}(P)$ . Applying Hoeffding’s a second time suggests that
$$
p(f(\mathbf{x})>0)=\mathcal{O}\left(\exp\left\{-P\right\}\right)\,.
$$
Note, it is possible to satisfy both $|b^{-}|-|b^{+}|$ and $|b^{-}/b^{+}|<2$ , for example with $b^{+}=1$ and $b^{-}=1.1$ . The test error overall is dominated by the contribution from mis-classifying same examples $p(f(\mathbf{x})<0)=\mathcal{O}(\exp\left\{-P/d^{2}\right\})$ . Because of our independence restriction on the dual coefficients $b$ , in order to produce $P$ training examples, we require $L\propto P$ training symbols. The test error of the model overall is therefore upper bounded by $\mathcal{O}\left(\exp\left\{-\frac{L}{d^{2}}\right\}\right)$ . ∎
Hence, in order to maintain a constant error rate, our bound suggests that the number of training symbols $L$ should scale as $L\propto d^{2}$ . While this scaling is an upper bound on the true error rate of a lazy model, Figure 1 f suggests that this quadratic relationship remains descriptive of the full model. There are two important consequences of this result:
1. For a large $d$ , the lazy model requires substantially more training symbols to learn the SD task than the rich model. In Appendix D, we found that the rich model can generalize with as few as $L=3$ symbols. In contrast, Figure 1 f suggests the lazy model will often require hundreds or thousands of training symbols to generalize.
1. For a fixed number of training symbols, a lazy model’s performance decays as $d$ increases. Unlike in the rich case, there is an explicit dependency on $d$ in the test error for the lazy model, hurting its performance as $d$ grows larger.
In this way, we see how a lazy model can leverage the differing statistics of same and different examples to accomplish the SD task, but at the cost of exhaustive training data and strong sensitivity to input dimension.
## Appendix E Bayesian posterior calculations
In Section 3.4, we compute with the posteriors corresponding to two different idealized models: one that generalizes to novel symbols based on the true underlying symbol distribution, and one that memorizes the training symbols. Below, we present the Bayes optimal classifier for our noisy same different, and derive the posteriors associated with these two settings.
### E.1 Generalizing prior
We define the following data generating process that constitutes a prior which generalizes to arbitrary, unseen symbols.
| | $\displaystyle r$ | $\displaystyle\sim\text{Bernoulli}\left(p=\frac{1}{2}\right)$ | |
| --- | --- | --- | --- |
The quantity $r$ represents either a same or different relation. Variables $\mathbf{s}_{1},\mathbf{s}_{2}$ are symbols matching their description in Section 2. The notation $\delta(\mathbf{s}_{1})$ denotes a Delta distribution centered at $\mathbf{s}_{1}$ . Hence, $\mathbf{s}_{1}=\mathbf{s}_{2}$ if $r=1$ , and differ otherwise. Typically, we consider the noiseless case $\sigma^{2}=0$ , but to develop a Bayesian treatment, we allow $\sigma^{2}>0$ . We approximate the noiseless case by considering $\sigma^{2}\rightarrow 0$ .
The Bayes optimal classifier is
$$
\hat{y}_{bayes}=\begin{cases}1&p(r=1\,|\,\mathbf{z}_{1},\mathbf{z}_{2})\geq\frac{1}{2}\\
0&\text{otherwise}\end{cases}
$$
From Bayes rule, we know that
$$
p(r\,|\,\mathbf{z}_{1},\mathbf{z}_{2})\propto p(\mathbf{z}_{1},\mathbf{z}_{2}\,|\,r)\,p(r)\,.
$$
Since $r$ is sampled with equal probability $1$ or $0$ , we have simply
$$
p(r\,|\,\mathbf{z}_{1},\mathbf{z}_{2})\propto p(\mathbf{z}_{1},\mathbf{z}_{2}\,|\,r)\,.
$$
We use the notation $\mathcal{N}(\mathbf{x};\mathbf{\mu},\sigma^{2})$ to mean the PDF of a Normal distribution evaluated at $\mathbf{x}$ , with mean $\mathbf{\mu}$ and covariance $\sigma^{2}\mathbf{I}$ . We then compute
$$
\displaystyle p(\mathbf{z}_{1},\mathbf{z}_{2}\,|\,r=1) \displaystyle=\int\mathcal{N}\left(\mathbf{z}_{1};\mathbf{s},\frac{\sigma^{2}}{d}\right)\,\mathcal{N}\left(\mathbf{z}_{2};\mathbf{s},\frac{\sigma^{2}}{d}\right)\,\mathcal{N}\left(\mathbf{s};\mathbf{0},\frac{\sigma^{2}}{d}\right)\,d\mathbf{s} \displaystyle=\left(\frac{d}{2\pi\sqrt{\sigma^{2}(2+\sigma^{2})}}\right)^{d}\exp\left\{-\frac{d}{2\sigma^{2}}\left(\frac{1+\sigma^{2}}{2+\sigma^{2}}\left(\left|\left|\mathbf{z}_{1}\right|\right|^{2}+\left|\left|\mathbf{z}_{2}\right|\right|^{2}\right)-\frac{2}{2+\sigma^{2}}\left(\mathbf{z}_{1}\cdot\mathbf{z}_{2}\right)\right)\right\}\,, \displaystyle p(\mathbf{z}_{1},\mathbf{z}_{2}\,|\,r=0) \displaystyle=\int\int\mathcal{N}\left(\mathbf{z}_{1};\mathbf{s}_{1},\frac{\sigma^{2}}{d}\right)\,\mathcal{N}\left(\mathbf{z}_{2};\mathbf{s}_{2},\frac{\sigma^{2}}{d}\right)\,\mathcal{N}\left(\mathbf{s}_{1};\mathbf{0},\frac{\sigma^{2}}{d}\right)\,\mathcal{N}\left(\mathbf{s}_{2};\mathbf{0},\frac{\sigma^{2}}{d}\right)\,d\mathbf{s}_{1}\,d\mathbf{s}_{2} \displaystyle=\left(\frac{d}{2\pi(1+\sigma^{2})}\right)^{d}\exp\left\{-\frac{d}{2}\left(\frac{1}{1+\sigma^{2}}\right)\left(\left|\left|\mathbf{z}_{1}\right|\right|^{2}+\left|\left|\mathbf{z}_{2}\right|\right|^{2}\right)\right\}\,.
$$
Using Eq (C.2) and (C.3), we compute
$$
p(r=1\,|\,\mathbf{z}_{1},\mathbf{z}_{2})=\frac{p(\mathbf{z}_{1},\mathbf{z}_{2}\,|\,r=1)}{p(\mathbf{z}_{1},\mathbf{z}_{2}\,|\,r=1)+p(\mathbf{z}_{1},\mathbf{z}_{2}\,|r=0)}\,,
$$
which we plug back into Eq (E.1) to obtain our Bayes classifier under a generalizing prior.
### E.2 Memorizing prior
The data generating process for a model that memorizes the training data is similar to the generalizing model, but the crucial difference is that the symbols $\mathbf{s}$ are now distributed uniformly across the training symbols rather than sampled from their population distribution.
Let $\mathbf{\hat{s}}_{1},\mathbf{\hat{s}}_{2},\ldots,\mathbf{\hat{s}}_{L}$ be the set of $L$ training symbols. Then the data generating process is given by
| | $\displaystyle r$ | $\displaystyle\sim\text{Bernoulli}\left(p=\frac{1}{2}\right)$ | |
| --- | --- | --- | --- |
As before, we compute the probabilities $p(\mathbf{z}_{1},\mathbf{z}_{2}\,|\,r=1)$ and $p(\mathbf{z}_{1},\mathbf{z}_{2},\,|\,r=0)$ , which are given by
$$
\displaystyle p(\mathbf{z}_{1},\mathbf{z}_{2}\,|\,r=1) \displaystyle=\frac{1}{L}\sum_{i=1}^{L}p(\mathbf{z}_{1},\mathbf{z}_{2}\,|\,\mathbf{\hat{s}}_{i}) \displaystyle=\frac{1}{L}\sum_{i=1}^{L}\mathcal{N}\left(\mathbf{z}_{1};\mathbf{\hat{s}}_{i},\frac{\sigma^{2}}{d}\right)\,\mathcal{N}\left(\mathbf{z}_{2};\mathbf{\hat{s}}_{i},\frac{\sigma^{2}}{d}\right) \displaystyle=\left(\frac{d}{2\pi\sigma^{2}}\right)^{d}\exp\left\{-\frac{d}{2\sigma^{2}}\left(\frac{1}{2}\left(\left|\left|\mathbf{z}_{1}\right|\right|^{2}+\left|\left|\mathbf{z}_{2}\right|\right|\right)^{2}-\mathbf{z}_{1}\cdot\mathbf{z}_{2}\right)\right\}\left(\frac{1}{L}\sum_{i=1}^{L}\exp\left\{-\frac{d}{\sigma^{2}}\left|\left|\mathbf{\hat{s}}_{i}-\frac{\mathbf{z}_{1}+\mathbf{z}_{2}}{2}\right|\right|^{2}\right\}\right)\,, \displaystyle p(\mathbf{z}_{1},\mathbf{z}_{2}\,|\,r=0) \displaystyle=\frac{1}{L(L-1)}\sum_{i\neq j}p(\mathbf{z}_{1}\,|\,\mathbf{\hat{s}}_{i})\,p(\mathbf{z}_{2}\,|\,\mathbf{\hat{s}}_{j}) \displaystyle=\frac{1}{L(L-1)}\sum_{i\neq j}^{L}\mathcal{N}\left(\mathbf{z}_{1};\mathbf{\hat{s}}_{i},\frac{\sigma^{2}}{d}\right)\,\mathcal{N}\left(\mathbf{z}_{2};\mathbf{\hat{s}}_{j},\frac{\sigma^{2}}{d}\right) \displaystyle=\frac{1}{L(L-1)}\sum_{i\neq j}\left(\frac{d}{2\pi\sigma^{2}}\right)^{d}\exp\left\{-\frac{d}{2\sigma^{2}}\left|\left|\mathbf{z}_{1}-\mathbf{\hat{s}}_{i}\right|\right|^{2}\right\}\exp\left\{-\frac{d}{2\sigma^{2}}\left|\left|\mathbf{z}_{2}-\mathbf{\hat{s}}_{j}\right|\right|^{2}\right\}\,.
$$
Using Eq (C.4) and (C.5), we compute Eq (E.1) to obtain our Bayes classifier under a memorizing prior.
## Appendix F Rich and lazy scaling
We review rich and lazy regime scaling in our setting. In particular, we consider learning dynamics as we increase the input dimension $d$ (Saad Solla, 1995; Biehl Schwarze, 1995; Goldt ., 2019). This setting differs from other rich-regime studies, where scaling is considered with respect to increasing width $m$ . In particular, maximal update ( $\mu$ P) and the related mean-field parameterizations consider an infinite-width limit (Yang Hu, 2021; Mei ., 2018; Rotskoff Vanden-Eijnden, 2022). Our analysis holds $m$ fixed.
Recall that our model is given by
$$
f(\mathbf{x};\mathbf{\theta})=\frac{1}{\gamma\sqrt{d}}\sum_{i=1}^{m}a_{i}\,\phi(\mathbf{w}_{i}\cdot\mathbf{x})\,.
$$
Let $\mathbf{\theta}(t)$ be the value of the parameters $\mathbf{\theta}$ at time-step $t$ . Crucially, to permit a valid interpolation between rich and lazy learning regimes, our MLP is centered: $f(\mathbf{x};\mathbf{\theta}(0))=0$ . Following Chizat . (2019), we enforce centering by subtracting the initial logit from every prediction. Hence, our classifier takes the form
$$
\displaystyle\tilde{f}(\mathbf{x};\mathbf{\theta}) \displaystyle=f(\mathbf{x};\mathbf{\theta})-f(\mathbf{x};\mathbf{\theta}(0))\,. \tag{0}
$$
We use $\tilde{f}$ as our centered MLP in all experiments.
To see how changing $\gamma$ interpolates between rich and lazy learning regimes, recall that learning richness is a description of activation change over the course of training. One way to operationalize this description is to define rich learning as the case in which parameters $\mathbf{\theta}$ change substantially in comparison with changes in the model output $\tilde{f}$ , and lazy learning as the case in which $\mathbf{\theta}$ change very little with respect to the model output.
<details>
<summary>x9.png Details</summary>
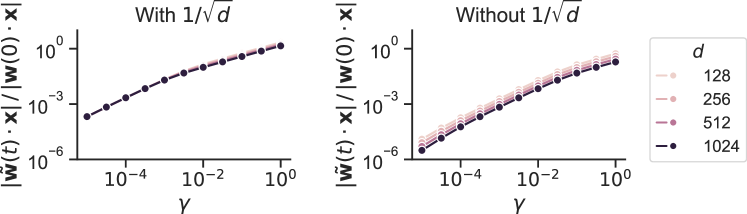
### Visual Description
## [Line Charts with Logarithmic Axes]: Comparison of Normalized Weight Update Magnitude With and Without Scaling by 1/√d
### Overview
The image displays two side-by-side line charts on a logarithmic scale. The charts compare the evolution of a normalized quantity, likely related to neural network training dynamics, under two different scaling conditions. The left chart is titled "With 1/√d" and the right chart is titled "Without 1/√d". A shared legend on the far right defines four data series corresponding to different values of a parameter `d`.
### Components/Axes
* **Titles:**
* Left Chart: "With 1/√d"
* Right Chart: "Without 1/√d"
* **Y-Axis (Both Charts):**
* Label: `|w̃(t)·x| / |w(0)·x|`
* Scale: Logarithmic, ranging from approximately 10⁻⁶ to 10⁰ (1).
* Major Ticks: 10⁻⁶, 10⁻³, 10⁰.
* **X-Axis (Both Charts):**
* Label: `γ` (Greek letter gamma).
* Scale: Logarithmic, ranging from approximately 10⁻⁵ to 10⁰ (1).
* Major Ticks: 10⁻⁴, 10⁻², 10⁰.
* **Legend (Positioned to the right of both charts):**
* Header: `d`
* Series (from top to bottom in legend, corresponding to line color/shade):
* `128` (Lightest pink/peach color)
* `256` (Medium-light pink)
* `512` (Medium-dark pink/mauve)
* `1024` (Darkest purple/black)
### Detailed Analysis
**Left Chart ("With 1/√d"):**
* **Trend Verification:** All four data series (for d=128, 256, 512, 1024) follow an almost identical, monotonically increasing trend. The lines are tightly clustered, appearing as a single, slightly thickened line.
* **Data Points (Approximate):**
* At γ ≈ 10⁻⁵, the normalized value is ≈ 10⁻⁴.
* At γ ≈ 10⁻⁴, the value is ≈ 10⁻³.
* At γ ≈ 10⁻², the value is ≈ 10⁻¹.
* At γ ≈ 10⁰ (1), the value approaches 10⁰ (1).
* **Spatial Grounding:** The lines originate from the bottom-left and progress to the top-right of the plot area. The legend order (128 to 1024) does not correspond to a visible vertical separation of lines in this chart.
**Right Chart ("Without 1/√d"):**
* **Trend Verification:** All four data series show a monotonically increasing trend. However, there is clear vertical separation between the lines, with the separation increasing as γ increases.
* **Data Points & Series Relationship (Approximate):**
* The series are ordered vertically. For any given γ > 10⁻⁴, the line for `d=128` is the highest, followed by `d=256`, then `d=512`, and the line for `d=1024` is the lowest.
* At γ ≈ 10⁻⁴: Values range from ≈ 10⁻⁵ (for d=1024) to ≈ 10⁻⁴ (for d=128).
* At γ ≈ 10⁰ (1): Values range from ≈ 10⁻¹ (for d=1024) to ≈ 10⁰ (1) (for d=128).
* **Spatial Grounding:** The lines fan out from the bottom-left. The legend's color/shade gradient (light to dark) maps directly to the vertical order of the lines from top to bottom (lightest/highest to darkest/lowest).
### Key Observations
1. **Effect of Scaling:** The primary observation is the dramatic difference between the two charts. The scaling factor `1/√d` in the left chart collapses the behavior of all four `d` values onto a single curve. Without this scaling (right chart), the curves separate significantly based on `d`.
2. **Monotonic Increase:** In both scenarios, the normalized quantity `|w̃(t)·x| / |w(0)·x|` increases with `γ`.
3. **Inverse Relationship with d (Without Scaling):** In the right chart, for a fixed `γ`, a larger dimension `d` results in a smaller normalized value. The relationship appears consistent across the plotted range.
### Interpretation
This figure likely illustrates a concept from the theory of neural network initialization or training dynamics, specifically concerning the scaling of weights or gradients with the network width or dimension `d`.
* **What the data suggests:** The quantity `|w̃(t)·x| / |w(0)·x|` represents the magnitude of a weight update or a feature activation at time `t`, normalized by its initial magnitude. `γ` is likely a parameter controlling the step size or learning rate.
* **How elements relate:** The comparison demonstrates that without proper scaling (right chart), the training dynamics (as measured by this normalized update) are dependent on the network dimension `d`. Larger networks (higher `d`) experience smaller relative updates. Applying the scaling factor `1/√d` (left chart) removes this dependency, making the dynamics invariant to `d`. This is a crucial principle for ensuring consistent behavior across networks of different sizes.
* **Notable Implication:** The "With 1/√d" condition promotes scale invariance, a desirable property for theoretical analysis and for ensuring that hyperparameters (like learning rate) generalize across models of different widths. The "Without" condition shows that failing to scale appropriately leads to dimension-dependent behavior, which could complicate training and hyperparameter tuning.
</details>
Figure F 1: Activation scales with $\gamma$ and $d$ . We plot the average absolute activation change across 6000 test examples as a function of $\gamma$ (for $m=4096$ ), normalized by the initial activation size $|\mathbf{w}(0)\cdot\mathbf{x}|$ . Higher $\gamma$ leads to more activation change. In the absence of a $1/\sqrt{d}$ prefactor, the activation change scales inversely with $d$ . Including the $1/\sqrt{d}$ prefactor suppresses this change.
Consider the change in $\tilde{f}$ after one step of gradient descent. For a learning rate $\alpha$ and training set size $P$ , we update our parameters as
$$
\displaystyle\mathbf{\theta}(1) \displaystyle=\mathbf{\theta}(0)-\alpha\nabla_{\mathbf{\theta}}\left(\frac{1}{P}\sum_{p=1}^{P}\mathcal{L}(y_{p},\tilde{f}(\mathbf{x}_{p};\mathbf{\theta}))\right) \displaystyle=\mathbf{\theta}(0)-\frac{\alpha}{P}\sum_{p=1}^{P}(y_{p}-\sigma(\tilde{f}(\mathbf{x}_{p};\mathbf{\theta}))\nabla_{\mathbf{\theta}}\tilde{f}(\mathbf{x}_{p};\mathbf{\theta})\,. \tag{1}
$$
Note that for an input $\mathbf{x}$ ,
| | $\displaystyle\frac{\partial\tilde{f}}{\partial a_{i}}$ | $\displaystyle=\frac{1}{\gamma\sqrt{d}}\phi(\mathbf{w}_{i}\cdot\mathbf{x})\,,$ | |
| --- | --- | --- | --- |
Define
| | $\displaystyle\Delta a_{i}\equiv\frac{1}{P}\sum_{p=1}^{P}(y_{p}-\sigma(\tilde{f}(\mathbf{x}_{p};\mathbf{\theta})))\frac{\partial\tilde{f}}{\partial a_{i}}\,,$ | |
| --- | --- | --- |
Substituting our weight updates into our model reveals that
$$
\displaystyle\tilde{f}(\mathbf{x};\mathbf{\theta}(1))=\frac{\alpha}{\gamma^{2}d} \displaystyle\sum_{i=1}^{m}\Big{[}\Delta a_{i}\,\phi(\Delta w_{i}\cdot\mathbf{x})/(\gamma\sqrt{d}) \displaystyle+\Delta a_{i}\,\phi(\mathbf{w}(0)\cdot\mathbf{x}) \displaystyle+a_{i}(0)\,\phi(\Delta\mathbf{w}_{i}\cdot\mathbf{x})\Big{]}\,. \tag{1}
$$
Observe that $|\Delta a_{i}\,\phi(\mathbf{w}(0)\cdot\mathbf{x})|=\mathcal{O}_{d}(1)$ and $|a_{i}(0)\,\phi(\Delta\mathbf{w}_{i}\cdot\mathbf{x})|=\mathcal{O}_{d}(1/\sqrt{d})$ for a test point $\mathbf{x}$ . If we adopt a learning rate $\alpha=\gamma^{2}d$ , then we have overall
$$
|\tilde{f}(\mathbf{x};\mathbf{\theta}(1))|=\mathcal{O}_{d}(1)\,. \tag{1}
$$
In this way, we find that the model output changes by a constant amount relative to the input dimension $d$ . Meanwhile, the parameters change by a total magnitude
$$
||\mathbf{\theta}(1)-\mathbf{\theta}(0)||=\mathcal{O}_{d}(\alpha\left(|\Delta a_{i}|+||\Delta\mathbf{w}_{i}||\right)=\mathcal{O}_{d}(\gamma\sqrt{d})\,. \tag{1}
$$
At initialization, we have that
$$
||\mathbf{\theta}(0)||=\mathcal{O}_{d}(|a_{i}(0)|+||\mathbf{w}_{i}(0)||)=\mathcal{O}_{d}(\sqrt{d})\,, \tag{0}
$$
so the change in weights relative to the scale of their initialization is simply
$$
||\mathbf{\theta}(1)-\mathbf{\theta}(0)||/||\mathbf{\theta}(0)||=\mathcal{O}_{d}(\gamma)\,. \tag{1}
$$
All together, after one gradient step, while the model output changes by a constant amount with respect to $d$ , the model parameters change by $\gamma$ relative to their initialization. For $\gamma\rightarrow 0$ , the initialization dominates (even as the model output changes), resulting in lazy learning. For increasing $\gamma$ , the parameters move proportionally further from their initialization, resulting in progressively rich learning.
Peculiar to our setting is the additional $1/\sqrt{d}$ factor in the output scale of the MLP, not found in other rich-regime studies that consider width scaling (Yang Hu, 2021; Mei ., 2018; Rotskoff Vanden-Eijnden, 2022). In the absence of the $1/\sqrt{d}$ factor, Eqs (F.1) and (F.2) suggest that we should adjust our learning rate to be $\alpha=\gamma^{2}$ in order to maintain a stable $\mathcal{O}_{d}(1)$ output change with increasing $d$ . However, the relative weight change in Eq (F.3) now becomes $\mathcal{O}_{d}(\gamma/\sqrt{d})$ . For fixed $\gamma$ , a model becomes lazier as $d$ increases. Hence, to maintain consistent richness, we require an additional $1/\sqrt{d}$ prefactor on the MLP (along with the corresponding $\alpha=\gamma^{2}d$ learning rate).
Figure F 1 illustrates these conclusions. Increasing $\gamma$ increases the change in activations $|\mathbf{\tilde{w}}(t)\cdot\mathbf{x}|$ for a test example $\mathbf{x}$ . In the absence of the $1/\sqrt{d}$ prefactor, increasing $d$ also decreases the change in activations.
## Appendix G Model and task details
We enumerate all model and task configurations in this Appendix. Exact details are available in our code, https://github.com/wtong98/equality-reasoning, which can be run to reproduce all plots in this manuscript.
### G.1 Model
In all experiments, we use a two-layer MLP without biases that takes inputs $\mathbf{x}\in\mathbb{R}^{d}$ and outputs
$$
f(\mathbf{x})=\frac{1}{\gamma\sqrt{d}}\sum_{i=1}^{m}a_{i}\,\phi(\mathbf{w}_{i}\cdot\mathbf{x})\,,
$$
where $\phi$ is a point-wise ReLU nonlinearity and $\gamma$ is a hyperparamter that governs learning richness. Our MLP is centered using the procedure described in Appendix F. To produce a classification, $f$ is passed through a standard logit link function
$$
\hat{y}=\frac{1}{1+e^{-f}}\,.
$$
Parameters are initialized based on $\mu$ P (Yang ., 2022). Specifically, we initialize our weights as
| | $\displaystyle a_{i}$ | $\displaystyle\sim\mathcal{N}\left(0,1/m\right)\,,$ | |
| --- | --- | --- | --- |
We train the model using stochastic gradient descent on binary cross entropy loss. Following Atanasov . (2024), we set the learning rate $\alpha$ as $\alpha=\gamma^{2}d\,\alpha_{0}$ for $\gamma\leq 1$ and $\alpha=\gamma\sqrt{d}\,\alpha_{0}$ for $\gamma>1$ . The base learning rate $\alpha_{0}$ is task-specific, and varies from $0.01$ to $0.5$ . To measure a model’s performance, we train for a large, fixed number of iterations past convergence in training accuracy, and select the best test accuracy from the model’s history.
### G.2 Same-Different
The same-different task consists of input pairs $\mathbf{z}_{1},\mathbf{z}_{2}\in\mathbb{R}^{d}$ , where $\mathbf{z}_{i}=\mathbf{s}_{i}+\mathbf{\eta}_{i}$ . The labeling function $y$ is given by
$$
y(\mathbf{z}_{1},\mathbf{z}_{2})=\begin{cases}1&\mathbf{s}_{1}=\mathbf{s}_{2}\\
0&\mathbf{s}_{1}\neq\mathbf{s}_{2}\end{cases}\,.
$$
We sample these quantities as
| | $\displaystyle\mathbf{s}$ | $\displaystyle\sim\mathcal{N}\left(\mathbf{0},\mathbf{I}/d\right)\,,$ | |
| --- | --- | --- | --- |
A training set is sampled such that half the training examples belong to class $1$ , and half belong to class $0$ . Crucially, the training set consists of $L$ fixed symbols $\mathbf{s}_{1},\mathbf{s}_{2},\ldots,\mathbf{s}_{L}$ sampled prior to the experiment. All training examples are constructed from these $L$ symbols. During testing, symbols are sampled afresh, forcing the model to generalize. If the noise variance $\sigma$ is not explicitly stated, then we take it to be $\sigma=0$ . We use a base learning rate $\alpha_{0}=0.1$ with batches of size 128.
### G.3 PSVRT
The PSVRT task consists of a single-channel square image with two blocks of bit-patterns. If the bit-patterns match exactly, then the image belongs to the same class. If the bit-patterns differ, then the image belongs to the different class. Images are flattened before being passed to the MLP.
Images are patch-aligned to prevent overlapping bit-patterns. An image is tiled by non-overlapping square regions which may be filled by bit-patterns. No two bit-patterns may share a single patch. Unless otherwise stated, we use patches that are 5 pixels to a side, and images that are 5 patches to a side, for a total of 25 by 25 pixels.
One important feature of PSVRT is that the inputs do not grow in norm as their dimension increases. Because there are only ever two patches in an image, regardless of its size, the total norm of the input remains constant regardless of the image dimensions. As a result, the $1/\sqrt{d}$ scaling on the MLP output is extraneous for PSVRT, and we remove it in these experiments.
A subset of all possible bit-patterns are used for training. The remaining unseen bit-patterns are used for testing. We use a base learning rate $\alpha_{0}=0.5$ with batches of size 128.
### G.4 Pentomino
The Pentomino task consists of a single-channel square image with two pentomino shapes. If the shapes are the same (up to rotation, but not reflection), then the image belongs to the same class. If the bit-patterns differ, then the image belongs to the different class. Images are flattened before being passed to the MLP.
Like before, images are patch-aligned. To provide a border around each pentomino, patches are 7 pixels to a side. Unless otherwise stated, images are 2 patches to a side, for a total of 14 by 14 pixels.
As with PSVRT, the inputs for Pentomino do not grow in norm as their dimension icnreases. There are only ever two pentomino shapes in an image, regardless of its dimension, so the total norm of the input remains constant. Like with PSVRT, we remove the $1/\sqrt{d}$ output scaling on the MLP for these experiments.
There are a total of 18 possible pentomino shapes. A subset of these 18 is held out for testing, and the model trains on the remainder. To improve training stability, mild Gaussian blurs are randomly applied to training images, but not testing images. We use a base learning rate $\alpha_{0}=0.5$ with batches of size 128.
### G.5 CIFAR-100
The CIFAR-100 same-different task consists of full-color images taken from the CIFAR-100 dataset. Images are 32 by 32 pixels, and depict 1 of among 100 different classes. To form an input example, we place two images side-by-side, forming a larger 64 by 32 pixel image. If the images come from the same class (but are not necessarily the same exact image), the example belongs to the same class. If the images come from different classes, the example belong to the different class.
To separate an MLP’s ability to reason about equality from its ability to extract meaningful visual features, we first pass the image through a VGG-16 backbone pretrained on ImageNet. Activations are then taken from an intermediate layer, flattened, and passed to the MLP. Because VGG-16 activations are coordinate-wise $O(1)$ in magnitude, we normalize them by $1/\sqrt{d}$ before input to the model. The resulting performance of the MLP from activations of each layer are plotted in Figure G 1.
Of the 100 total classes, a subset is held out for testing, and the model trains on the remainder. We use a base learning rate $\alpha_{0}=0.01$ with batches of size 128.
<details>
<summary>x10.png Details</summary>
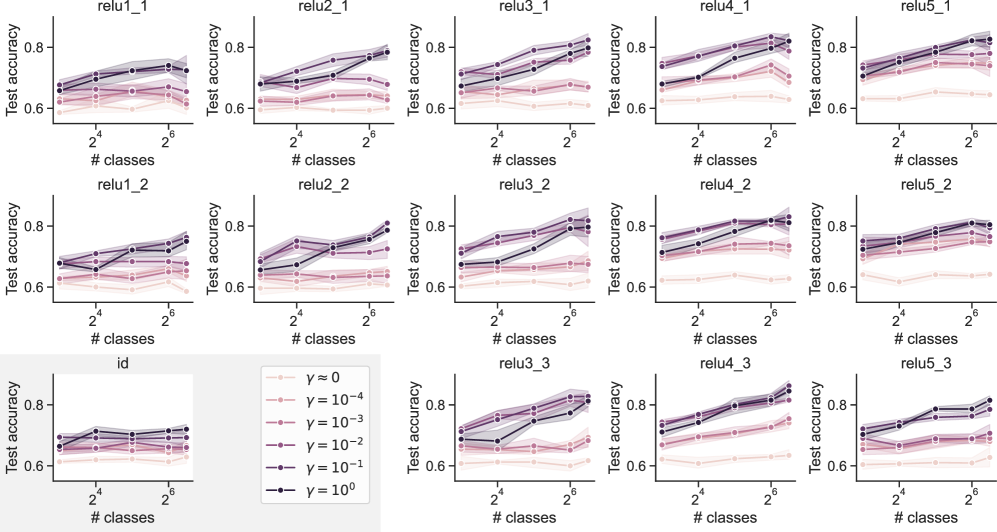
### Visual Description
## [Grid of Line Charts]: Test Accuracy vs. Number of Classes for Different γ Values
### Overview
The image displays a 3×5 grid of line charts (15 subplots total) illustrating **test accuracy** (y-axis) as a function of the **number of classes** (x-axis, log₂ scale: \(2^4 = 16\) to \(2^6 = 64\)) for six different values of a parameter \(\boldsymbol{\gamma}\) (legend: \(\gamma = 0, 10^{-4}, 10^{-3}, 10^{-2}, 10^{-1}, 10^0\)). Each subplot has a title (e.g., `relu1_1`, `relu2_1`, `id`, etc.), and the legend is positioned at the bottom-left (below the `id` subplot).
### Components/Axes
- **X-axis**: Labeled `# classes`, with major ticks at \(2^4 = 16\) and \(2^6 = 64\) (logarithmic scale).
- **Y-axis**: Labeled `Test accuracy`, ranging from ~0.6 to 0.8 (linear scale).
- **Legend**: Six entries (bottom-left):
- \(\gamma = 0\): Light pink, open circles (lowest accuracy).
- \(\gamma = 10^{-4}\): Light pink, filled circles.
- \(\gamma = 10^{-3}\): Pink, filled circles.
- \(\gamma = 10^{-2}\): Darker pink, filled circles.
- \(\gamma = 10^{-1}\): Purple, filled circles.
- \(\gamma = 10^0\): Dark purple/black, filled circles (highest accuracy).
- **Subplot Titles**:
- Row 1: `relu1_1`, `relu2_1`, `relu3_1`, `relu4_1`, `relu5_1`
- Row 2: `relu1_2`, `relu2_2`, `relu3_2`, `relu4_2`, `relu5_2`
- Row 3: `id`, `relu3_3`, `relu4_3`, `relu5_3` (and a fifth subplot, likely `relu5_3` or similar).
### Detailed Analysis
Each subplot shows test accuracy trends for \(\gamma\) values:
#### Trend for \(\boldsymbol{\gamma = 0}\) (light pink, open circles):
- Lowest test accuracy across all subplots.
- Slight increase or flat trend as `# classes` increases (e.g., in `relu1_1`, starts ~0.62, rises to ~0.65 at 64 classes).
#### Trend for \(\boldsymbol{\gamma = 10^{-4}}\) (light pink, filled circles):
- Slightly higher than \(\gamma = 0\), with a similar (slight increase/flat) trend.
#### Trend for \(\boldsymbol{\gamma = 10^{-3}}\) (pink, filled circles):
- Higher than \(\gamma = 10^{-4}\), with a more noticeable increase as `# classes` rises.
#### Trend for \(\boldsymbol{\gamma = 10^{-2}}\) (darker pink, filled circles):
- Higher than \(\gamma = 10^{-3}\), with a steeper increase.
#### Trend for \(\boldsymbol{\gamma = 10^{-1}}\) (purple, filled circles):
- Higher than \(\gamma = 10^{-2}\), with a steeper increase.
#### Trend for \(\boldsymbol{\gamma = 10^0}\) (dark purple/black, filled circles):
- Highest test accuracy across all subplots.
- Steepest increase as `# classes` rises (e.g., in `relu1_1`, starts ~0.72, rises to ~0.78 at 64 classes).
#### Subplot `id` (Row 3, Col 1):
- Anomaly: Lower overall accuracy (~0.6–0.7) and less variation between \(\gamma\) values.
- Trend: \(\gamma = 10^0\) still highest, but increase with `# classes` is less steep.
### Key Observations
1. **\(\boldsymbol{\gamma}\) Impact**: Higher \(\gamma\) values (closer to \(10^0\)) consistently yield higher test accuracy.
2. **Class Number Impact**: Test accuracy increases with `# classes` (16→64) for all \(\gamma\), with steeper increases for higher \(\gamma\).
3. **`id` Subplot Anomaly**: The `id` subplot shows lower accuracy and less \(\gamma\)-sensitivity, suggesting a different model/configuration.
4. **Consistency in `relu` Subplots**: All `relu`-titled subplots follow the same \(\gamma\)/class number pattern, indicating a systematic relationship.
### Interpretation
The data suggests:
- Increasing the number of classes (16→64) improves test accuracy, especially for higher \(\gamma\).
- Higher \(\gamma\) values (e.g., \(10^0\)) likely represent a stronger regularization or model parameter that enhances performance.
- The `id` subplot’s distinct behavior implies a different model architecture or training setup, where \(\gamma\) and class number have less impact.
This pattern indicates that \(\gamma\) and class number are critical hyperparameters for optimizing test accuracy in the `relu`-based models, while the `id` model is more robust (or less sensitive) to these parameters.
(Note: All text is in English; no non-English text is present.)
</details>
Figure G 1: CIFAR-100 same-different accuracy across different VGG-16 activations. Activations are named by relu[block]_[layer] The plot with name id corresponds to using the raw images directly without first preprocessing in VGG-16. Earlier and later layers demonstrate an interesting collapse where learning richness does not seem to impact classification accuracy very strongly. Intermediate layers suggest that greater learning richness tends to perform better, though the richest model tends to do poorly. Shaded error regions correspond to 95 percent confidence intervals estimated from 6 runs.