# VisualPRM: An Effective Process Reward Model for Multimodal Reasoning
## Abstract
We introduce VisualPRM, an advanced multimodal Process Reward Model (PRM) with 8B parameters, which improves the reasoning abilities of existing Multimodal Large Language Models (MLLMs) across different model scales and families with Best-of-N (BoN) evaluation strategies. Specifically, our model improves the reasoning performance of three types of MLLMs and four different model scales. Even when applied to the highly capable InternVL2.5-78B, it achieves a 5.9-point improvement across seven multimodal reasoning benchmarks. Experimental results show that our model exhibits superior performance compared to Outcome Reward Models and Self-Consistency during BoN evaluation. To facilitate the training of multimodal PRMs, we construct a multimodal process supervision dataset VisualPRM400K using an automated data pipeline. For the evaluation of multimodal PRMs, we propose VisualProcessBench, a benchmark with human-annotated step-wise correctness labels, to measure the abilities of PRMs to detect erroneous steps in multimodal reasoning tasks. We hope that our work can inspire more future research and contribute to the development of MLLMs. Our model, data, and benchmark are released in this page.
🖂 Corresponding Author: wangwenhai@pjlab.org.cn
## 1 Introduction
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
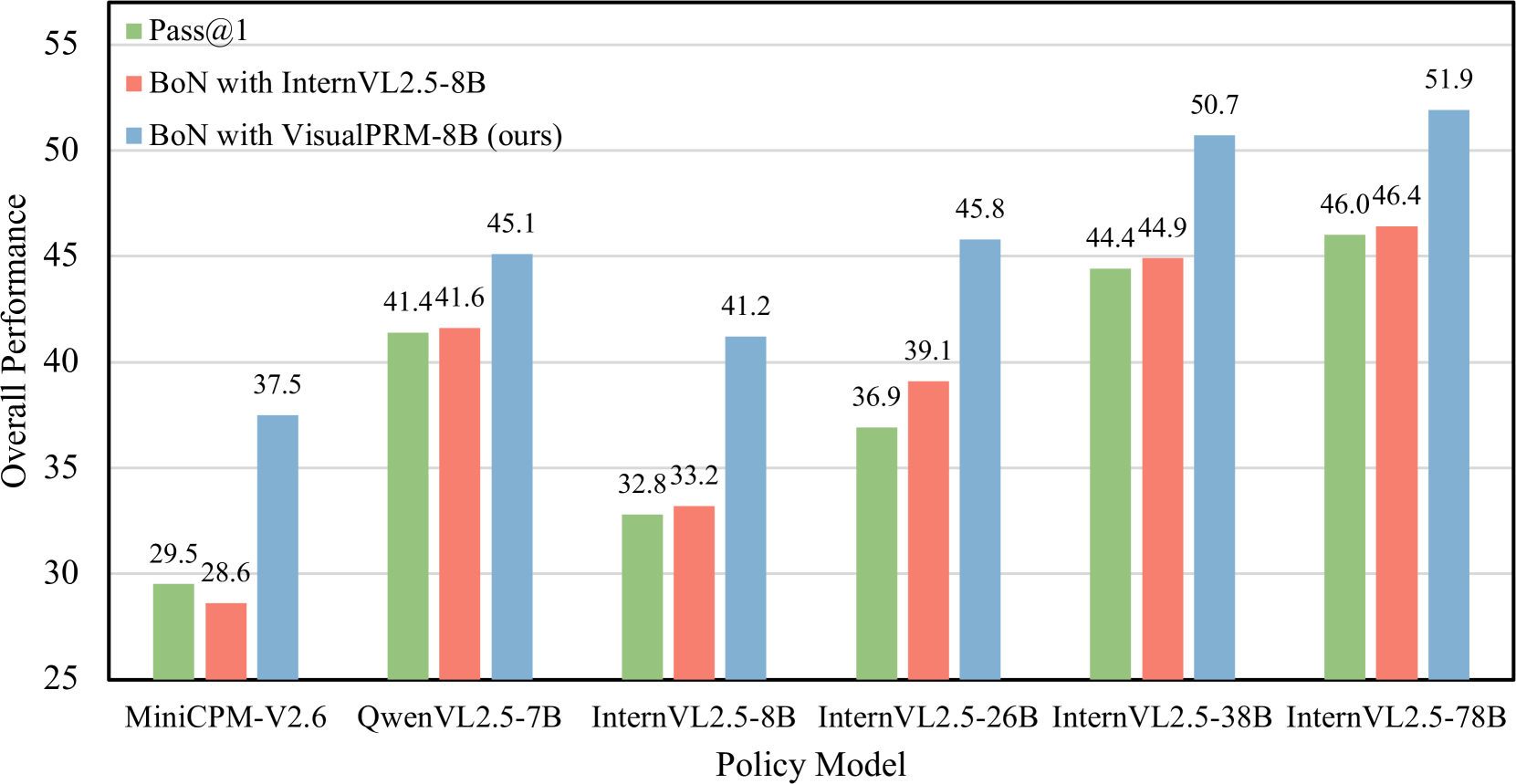
## Grouped Bar Chart: Overall Performance of Policy Models with Different Evaluation Methods
### Overview
This image is a grouped bar chart comparing the "Overall Performance" of six different vision-language policy models. Each model is evaluated using three distinct methods, represented by differently colored bars. The chart demonstrates the performance impact of using different reward models within a "Best-of-N" (BoN) sampling strategy compared to a baseline.
### Components/Axes
* **Y-Axis:** Labeled "Overall Performance". The scale ranges from 25 to 55, with major gridlines at intervals of 5 (25, 30, 35, 40, 45, 50, 55).
* **X-Axis:** Labeled "Policy Model". It lists six specific models:
1. MiniCPM-V2.6
2. QwenVL2.5-7B
3. InternVL2.5-8B
4. InternVL2.5-26B
5. InternVL2.5-38B
6. InternVL2.5-78B
* **Legend:** Positioned in the top-left corner of the chart area. It defines three data series:
* **Green Square:** `Pass@1`
* **Red Square:** `BoN with InternVL2.5-8B`
* **Blue Square:** `BoN with VisualPRM-8B (ours)`
* **Data Labels:** Each bar has its exact numerical value displayed directly above it.
### Detailed Analysis
The chart presents performance data for each policy model across the three evaluation methods. The values are as follows:
**1. MiniCPM-V2.6**
* Pass@1 (Green): 29.5
* BoN with InternVL2.5-8B (Red): 28.6
* BoN with VisualPRM-8B (Blue): 37.5
**2. QwenVL2.5-7B**
* Pass@1 (Green): 41.4
* BoN with InternVL2.5-8B (Red): 41.6
* BoN with VisualPRM-8B (Blue): 45.1
**3. InternVL2.5-8B**
* Pass@1 (Green): 32.8
* BoN with InternVL2.5-8B (Red): 33.2
* BoN with VisualPRM-8B (Blue): 41.2
**4. InternVL2.5-26B**
* Pass@1 (Green): 36.9
* BoN with InternVL2.5-8B (Red): 39.1
* BoN with VisualPRM-8B (Blue): 45.8
**5. InternVL2.5-38B**
* Pass@1 (Green): 44.4
* BoN with InternVL2.5-8B (Red): 44.9
* BoN with VisualPRM-8B (Blue): 50.7
**6. InternVL2.5-78B**
* Pass@1 (Green): 46.0
* BoN with InternVL2.5-8B (Red): 46.4
* BoN with VisualPRM-8B (Blue): 51.9
### Key Observations
1. **Consistent Superiority of VisualPRM-8B:** For every single policy model, the blue bar (`BoN with VisualPRM-8B (ours)`) is the tallest, indicating it yields the highest overall performance.
2. **Performance Hierarchy:** The general trend across all models is: `BoN with VisualPRM-8B` > `BoN with InternVL2.5-8B` ≈ `Pass@1`. The red and green bars are often very close in height.
3. **Scale of Improvement:** The performance gain from using VisualPRM-8B (blue) over the other methods is substantial, ranging from approximately +3.5 points (QwenVL2.5-7B) to +8.4 points (InternVL2.5-8B).
4. **Model Scaling Trend:** Within the InternVL2.5 model family, performance generally increases with model size (from 8B to 78B parameters) for all three evaluation methods.
5. **Outlier - MiniCPM-V2.6:** This model shows a unique pattern where `Pass@1` (29.5) slightly outperforms `BoN with InternVL2.5-8B` (28.6), which is the opposite of the trend seen in all other models.
### Interpretation
This chart is likely from a research paper introducing "VisualPRM-8B" as a new process reward model. The data serves as empirical evidence for its effectiveness.
* **What the data suggests:** The primary finding is that using VisualPRM-8B as a reward model within a Best-of-N sampling framework (`BoN with VisualPRM-8B`) consistently and significantly boosts the overall performance of various vision-language policy models compared to both a standard Pass@1 evaluation and using a different reward model (InternVL2.5-8B).
* **Relationship between elements:** The chart directly compares the proposed method (blue) against two baselines (green and red). The consistent gap between the blue bars and the others across diverse policy models (different architectures and sizes) strengthens the claim that the improvement is attributable to the reward model itself, not a specific policy model.
* **Notable implications:** The results imply that the quality of the reward model is a critical factor for improving vision-language model performance via sampling-based methods. The fact that VisualPRM-8B outperforms the larger InternVL2.5-8B when used as a reward model suggests it may have been specifically optimized or trained for this reward modeling task, making it a more effective "judge" for selecting good responses. The scaling trend within InternVL2.5 also hints that larger policy models benefit similarly from better reward models.
</details>
Figure 1: The overall Best-of-8 evaluation results across seven multimodal reasoning benchmarks with different critic models. Our VisualPRM greatly enhances the overall performance, while InternVL2.5-8B struggles to be an effective critic model.
With the remarkable success of Large Language Models (LLMs) [75, 76, 21, 5, 71, 10, 9, 1, 4] in natural language processing, Multimodal Large Language Models (MLLMs) [80, 36, 41, 42, 6, 84, 83, 14, 16, 15, 58, 61, 89] have also achieved significant advancements across various vision-language tasks. Despite their strong performance in perception and recognition, a large gap remains in reasoning capabilities between open-source and proprietary models. A series of studies have explored methods to enhance reasoning abilities, focusing on the perspectives of data collection and construction [57, 74, 38, 43], offline preference optimization [59, 82, 32], and online reinforcement learning [66, 24, 2, 26]. Additionally, another line of research [68, 20, 94, 79] investigates utilizing Test-Time Scaling (TTS) to enhance the reasoning abilities of LLMs. This approach requires the policy model to generate multiple response candidates and select the best one, based on the quality estimation of a critic model, thereby improving the response quality at the cost of higher inference time. However, TTS for MLLMs remains largely unexplored.
This work investigates the application of TTS for MLLMs, focusing on the Best-of-N (BoN) evaluation strategies. The challenges of adapting TTS for MLLMs involves: (1) Lack of effective critic models. In BoN evaluation, a critic model is required to estimate the quality of each response candidate. However, as shown in Figure 1, existing open-source MLLMs struggle to serve as critic models, leading to marginal improvements compared to models without TTS. This limitation stems from the lack of sufficient critic data in their training corpus. (2) Lack of evaluation benchmarks for multimodal critic models. The effectiveness of TTS heavily depends on the performance of the critic model. However, directly evaluating critics under BoN settings poses two key issues. First, the evaluation cost of BoN is expensive. Although the focus is on the performance of critic models, the policy model is required to generate $N$ reasoning processes, with the majority of computational costs arising from the policy model. Second, BoN performance is also affected by the policy model, making it difficult to compare different critic models when paired with varying policy models.
To solve these challenges, we first introduce VisualPRM400K, a dataset comprising approximately 400K multimodal process supervision data. Each sample includes an image, a question, a step-by-step solution, and correctness annotations for each step. Specifically, we collect question prompts from MMPR v1.1 [82] and then generate process correctness using an automatic data pipeline [79]. This pipeline samples multiple continuations starting from a certain step and computes the expected accuracy of that step as the average accuracy of its continuations.
To facilitate the evaluation of multimodal critic models, we introduce VisualProcessBench, a benchmark for evaluating PRMs and MLLMs in detecting erroneous steps in multimodal reasoning tasks. This benchmark includes 2,866 samples with 26,950 human-annotated step-wise correctness labels. Each sample includes a multimodal reasoning question, a step-by-step solution, and correctness labels for each step. To ensure annotation accuracy, we employ human experts with at least a university degree to manually assess the correctness of each step. Unlike prior benchmarks [96, 39], which require identifying only the first erroneous step, VisualProcessBench challenges models to detect all errors within a given solution. This adjustment aligns with recent advancements in model reflection abilities, helping to reduce false negatives in evaluations. Evaluation results reveal that existing open-source MLLMs struggle to accurately assess step-wise correctness, highlighting the need for improved multimodal critic models.
Building upon the dataset and benchmark, we develop VisualPRM, an advanced multimodal Process Reward Model (PRM) with 8B parameters, to serve as the critic model in BoN evaluation. Each training sample is formulated as a multi-turn chat. The first turn includes the image, the question, and the first solution step, while each subsequent turn presents a new step. The model is trained to predict the correctness of the given step at each turn. Experimental results demonstrate that VisualPRM enhances MLLM reasoning across different model families and scales. Specifically, VisualPRM improves the overall reasoning performance of MiniCPM-V2.6, QwenVL2.5-7B, InternVL2.5-8B, and InternVL2.5-78B by 8.0, 3.7, 8.4, and 5.9 points, respectively, across seven multimodal reasoning benchmarks [90, 50, 78, 93, 99, 60, 87]. Additionally, we compare PRMs with Outcome Reward Models and Self-Consistency in BoN evaluation, finding that PRMs consistently outperform both approaches.
In summary, our main contributions are as follows:
(1) We introduce VisualPRM400K, a dataset comprising approximately 400K multimodal process supervision data. Building upon this dataset, we develop VisualPRM, an advanced multimodal PRM to serve as the critic model in the BoN evaluation.
(2) We construct VisualProcessBench, a benchmark designed to measure the abilities of PRMs and MLLMs to identify erroneous steps in multimodal reasoning tasks. This benchmark comprises 2,866 samples with a total of 26,950 human-annotated step-wise correctness labels.
(3) Through extensive experiments, we demonstrate that PRMs can serve as effective critic models for test-time scaling of MLLMs. Specifically, VisualPRM enhances the overall multimodal reasoning performance of MiniCPM-V2.6, QwenVL2.5-7B, InternVL2.5-8B, and InternVL2.5-78B by 8.0, 3.7, 8.4, and 5.9 points, respectively, across seven multimodal reasoning benchmarks. Furthermore, our results show that PRMs consistently outperform both ORMs and SC in BoN evaluation. Additionally, experiments on VisualProcessBench reveal that existing open-source MLLMs struggle to accurately assess the correctness of each step.
<details>
<summary>x2.png Details</summary>

### Visual Description
\n
## Diagram: Geometry Problem Examples from AI Evaluation Datasets
### Overview
The image displays two distinct panels, each presenting a geometry problem with its diagram and a step-by-step solution. The panels are examples from two different datasets used for evaluating AI models on visual reasoning tasks. The top panel (blue border) is from "VisualPRM400K," and the bottom panel (brown border) is from "VisualProcessBench." Each includes a question, a geometric diagram, and a solution broken down into annotated steps.
### Components/Axes
The image is divided into two primary horizontal sections:
1. **Top Panel (Blue Border):**
* **Title:** "Data Example from VisualPRM400K"
* **Diagram:** A quadrilateral with vertices labeled Q, R, S, T. Interior angles are labeled: ∠R = x°, ∠Q = (2x + 5)°, ∠T = x°, ∠S = (2x + 7)°.
* **Question Text:** "Question: Find m \angle S."
* **Solution Text:** A multi-step solution with annotations in parentheses (e.g., `mc=0.75`).
2. **Bottom Panel (Brown Border):**
* **Title:** "Data Example from VisualProcessBench"
* **Diagram:** Two parallel horizontal lines (AB and CD) intersected by a transversal line (through E and F). A second line (EG) originates from point E on line AB. Angle 1 is marked as 50° at the intersection of the transversal and line CD. Angle 2 is marked between line EG and line CD.
* **Question Text:** "Question: As shown in the figure, AB parallel CD, EG bisects angle BEF, then angle 2 is equal to () Choices: A:50° B:60° C:65° D:90°"
* **Solution Text:** A multi-step reasoning process with annotations indicating correctness (e.g., `(Neural)`, `(Correct)`, `(Incorrect)`).
### Detailed Analysis
**Top Panel - VisualPRM400K Example:**
* **Problem:** Find the measure of angle S in a quadrilateral where angles are given as algebraic expressions in terms of `x`.
* **Solution Steps (Transcribed with Annotations):**
* `## Step-0 (mc=0.75)` To find \( m \angle S \) in the given quadrilateral, we'll use the property that the sum of the interior angles of any quadrilateral is \( 360^\circ \).
* `## Step-1 (mc=0.5)` Step 1: Write the equation for the sum of the angles: \( [ (2x + 5)^\circ + x^\circ + (2x + 7)^\circ + x^\circ = 360^\circ ] \)
* `## Step-2 (mc=0.5625)` Step 2: Simplify the equation: \( [ 2x + 5 + x + 2x + 7 + x = 360 ] \) \( [ 6x + 12 = 360 ] \)
* `## Step-3 (mc=0.5)` Step 3: Solve for \( x \): \( [ 6x + 12 = 360 ] \) \( [ 6x = 360 - 12 ] \) \( [ 6x = 348 ] \) \( [ x = 58 ] \)
* `## Step-4 (mc=0.0)` Step 4: Substitute \( x \) back into \( m \angle S \) which is given as \( x \): \( [ m \angle S = x = 58^\circ ] \)
* `## Step-5 (mc=0.0)` Final answer: 58
* **Key Data Points:** The solution correctly calculates `x = 58`, leading to the final answer `m∠S = 58°`.
**Bottom Panel - VisualProcessBench Example:**
* **Problem:** Given parallel lines AB and CD, with EG bisecting ∠BEF and ∠1 = 50°, find the measure of ∠2 from the given choices.
* **Solution Steps (Transcribed with Annotations):**
* `## Step-0 (Neural)` Reasoning:
* `## Step-1 (Correct)` Given Information: \( AB \parallel CD \) (AB is parallel to CD). \( EG \) bisects \( \angle BEF \). \( \angle 1 = 50^\circ \).
* `## Step-2 (Correct)` Understanding the Geometry: Since \( AB \parallel CD \), the transversal \( EG \) creates alternate interior angles and corresponding angles. \( EG \) bisects \( \angle BEF \), meaning \( \angle BEG = \angle GEF \).
* `## Step-3 (Correct)` Relationship Between Angles: \( \angle BEF = \angle BEG + \angle GEF \).
* `## Step-4 (Incorrect)` Since \( EG \) bisects \( \angle BEF \), \( \angle BEG = \angle GEF = 50^\circ \).
* `## Step-5 (Correct)` Finding \( \angle 2 \): \( \angle 2 \) and \( \angle GEF \) are congruent because \( AB \parallel CD \) and \( EG \) is a transversal.
* `## Step-6 (Incorrect)` Therefore, \( \angle 2 = \angle GEF = 50^\circ \).
* `## Step-7 (Incorrect)` Final Answer: The correct option is A.
* **Key Data Points:** The final answer is identified as option A (50°). The annotations indicate that steps 4, 6, and 7 are marked as "Incorrect," despite the final answer being correct.
### Key Observations
1. **Dataset Comparison:** The image contrasts two evaluation frameworks. VisualPRM400K uses numerical confidence scores (`mc`) for each step, while VisualProcessBench uses categorical correctness labels (`Correct`/`Incorrect`).
2. **Error Analysis:** The bottom example is particularly notable. The model's reasoning contains logical errors (Step 4 incorrectly assumes the bisected angles equal the given 50° angle, and Step 6 incorrectly concludes based on that), yet it arrives at the numerically correct final answer (50°). This highlights a potential disconnect between intermediate reasoning quality and final answer accuracy.
3. **Diagram Clarity:** Both diagrams are clear and standard for geometry problems. The top diagram uses algebraic expressions for angles, while the bottom uses numerical values and parallel line markings.
### Interpretation
These examples serve as diagnostic tools for assessing AI models' geometric reasoning capabilities. They reveal that:
* **Process vs. Outcome:** Evaluating only the final answer (as in many multiple-choice tests) can be misleading. The VisualProcessBench example shows a model can be "right for the wrong reasons," indicating a fragile understanding. The step-by-step annotation is crucial for identifying where reasoning breaks down.
* **Model Confidence:** The `mc` scores in the top example suggest a model's internal confidence can vary significantly across steps, even in a correct solution. Step-0 has high confidence (0.75), while the final substitution steps have zero confidence (0.0), which may indicate uncertainty in the final mapping back to the question.
* **Task Complexity:** The problems test different skills. The first requires algebraic manipulation within a geometric property. The second requires synthesizing multiple theorems (parallel lines, angle bisectors, transversal angles) and careful stepwise deduction. The errors in the second example stem from misapplying the given information (confusing which angle is 50°) rather than a lack of knowledge about the theorems themselves.
In essence, the image underscores the importance of **process-oriented evaluation** in AI, moving beyond simple answer matching to scrutinize the chain of reasoning, which is essential for building robust and trustworthy models.
</details>
Figure 2: Data examples in VisualPRM400K and VisualProcessBench. For VisualPRM400K, we generate the data using an automatic data pipeline. The key idea is to estimate the expected accuracy $mc_i$ of the given step $s_≤ i$ based on Monte Carlo sampling and consider the step correct if $mc_i>0$ . During the training process of VisualPRM, the data is formulated as multi-turn conversations and the model is required to predict the correctness of each step conditioned on the image, question, and previous steps. For VisualProcessBench, we collect questions from existing multimodal reasoning benchmarks [90, 78, 93, 99, 60] and generate the solutions using leading MLLMs [58, 4, 15, 82, 72]. Based on these questions and solutions, we employ a team of human experts with at least a university degree to manually annotate the correctness of each step in the solutions.
## 2 Related Work
Multimodal Large Language Models. A wide range of efforts has been made to advance the development of MLLMs, including improvements in model architecture, data construction, and training algorithms. From an architectural perspective, several studies [41, 42, 89, 15, 16, 84, 83, 45, 85, 7, 89] employ connectors to align visual embeddings from Vision Foundation Models (VFMs) [14, 91] with the latent space of LLMs [5, 75, 76, 71], achieving promising performance. Another series of works [3, 21, 73, 81] extends pre-trained LLMs with additional layers to fuse visual features, reducing the number of required visual tokens while introducing extra training cost. In terms of data construction, recent studies have made significant progress [63, 98, 34, 38, 43, 82, 95]. For example, OmniCorpus [38] offers a noisy but large-scale multimodal corpus for pre-training, while MMInstruct [43] provides an open-source, high-quality instruction-tuning dataset. Additionally, MMPR [82] constructs a preference dataset focusing on multimodal reasoning abilities. Regarding training algorithms, the InternVL2.5 series [15, 82] proposes square loss and Mix Preference Optimization to enhance MLLM capabilities. Despite these advancements, existing works primarily focus on the training process of MLLMs, leaving Test-Time Scaling (TTS) for MLLMs largely underexplored. In this work, we investigate TTS applications for MLLMs, specifically focusing on the Best-of-N evaluation to improve multimodal reasoning performance.
Process Reward Models. Reward models play a crucial role in Reinforcement Learning (RL) [64, 66, 2, 26] and TTS [68, 79, 20, 51]. Outcome Reward Models (ORMs) [55, 92, 77] directly assign an overall score to the given response. In contrast, Process Reward Models (PRMs) first estimate the quality of each step in the given response and then aggregate them into a final score. PRM800K [39] is the first open-source process supervision dataset, entirely annotated by human experts. To reduce annotation costs, MathShepherd [79] and OmegaPRM [51] introduce a Monte Carlo sampling-based data pipeline to automatically estimate the quality of each step. Despite these advancements in natural language processing, multimodal PRMs remain largely underexplored. In this work, we introduce VisualPRM400K, the first multimodal process supervision dataset, and develop VisualPRM, a multimodal PRM trained on this dataset.
Benchmarks for Reward Models. The evaluation of reward models (RMs) is a crucial research topic. A series of benchmarks [33, 37, 44] have been proposed to assess the effectiveness of RMs, typically formulated as a binary preference judgment task. Building on this, subsequent work [97] extends the evaluation settings and includes both pairwise and Best-of-N evaluations, providing a more comprehensive evaluation of RM performance. With the rapid advancement of PRMs, a series of benchmarks [96, 69] have been introduced to evaluate their step-wise judgment capabilities. Despite these developments, there remains a lack of a multimodal process benchmark. To bridge this gap and support the development of multimodal PRMs, we introduce VisualProcessBench, a benchmark designed to evaluate the ability of PRMs and MLLMs to detect erroneous steps in multimodal reasoning tasks.
## 3 Method
<details>
<summary>x3.png Details</summary>

### Visual Description
## Diagram: Multi-Step Problem Solving Process with Evaluation Metrics
### Overview
The image is a flowchart diagram illustrating a multi-step problem-solving process for a geometry question. It visually maps the progression from an initial question through several solution steps, with each step being evaluated by three distinct metrics: Expected Accuracy, Value-based PRM (Process Reward Model), and Advantage-based PRM. The diagram demonstrates how evaluation scores and correctness assessments can change across the solution trajectory.
### Components/Axes
The diagram is organized into a horizontal flow from left to right, with vertical stacking of evaluation metrics for each step.
**1. Problem & Solution Flow (Top Row - White Boxes):**
* **Question Box (Far Left):** Contains the text "Question: Find m∠S."
* **Step-0 Box:** "Step-0: To find \(m\angle S\) ..."
* **Step-1 Box:** "Step-1: Write the equation for ..."
* **Ellipsis (...):** Indicates omitted intermediate steps (Step-2, Step-3).
* **Step-4 Box:** "Step-4: Substitute \(x\) back ..."
* **Step-5 Box:** "Step-5: Final answer: 58"
* **Legend Box (Far Right):** "Question & Solution"
**2. Geometry Diagram (Below Question Box):**
A quadrilateral labeled with vertices Q (top), R (left), S (bottom), T (right). The interior angles are given as expressions:
* Angle at R: \(x^\circ\)
* Angle at Q: \((2x + 5)^\circ\)
* Angle at T: \(x^\circ\)
* Angle at S: \((2x + 7)^\circ\)
**3. Evaluation Metrics (Three Rows Below Solution Steps):**
Each step in the solution flow has a corresponding column of three colored boxes below it, representing different evaluation metrics.
* **Row 1 - Expected Accuracy (Light Blue Boxes):**
* Legend (Right): "Expected Accuracy"
* Values per step: `mc = 0.75` (Step-0), `mc = 0.5` (Step-1), `mc = 0.0` (Step-4), `mc = 0.0` (Step-5).
* **Row 2 - Value-based PRM (Light Green Boxes):**
* Legend (Right): "Value-based PRM"
* Assessments per step: `Correct (+)` (Step-0), `Correct (+)` (Step-1), `Incorrect (-)` (Step-4), `Incorrect (-)` (Step-5).
* **Row 3 - Advantage-based PRM (Light Orange Boxes):**
* Legend (Right): "Advantage-based PRM"
* Assessments per step: `Good (+)` (Step-0), `Bad (-)` (Step-1), `Bad (-)` (Step-4), `Tie (=)` (Step-5).
**Arrows:** Black arrows connect the boxes horizontally, indicating the flow from the Question to Step-0, Step-0 to Step-1, Step-1 to the ellipsis, the ellipsis to Step-4, and Step-4 to Step-5. Vertical alignment implies the evaluation boxes correspond to the step directly above them.
### Detailed Analysis
The diagram tracks the solution of a geometry problem where the goal is to find the measure of angle S (m∠S) in a quadrilateral with given angle expressions.
* **Problem Setup:** The quadrilateral QRST has angles defined in terms of a variable `x`. The sum of interior angles in a quadrilateral is 360°. The implied equation would be: \(x + (2x+5) + x + (2x+7) = 360\).
* **Solution Progression & Evaluation:**
* **Step-0 (Initial approach):** Evaluated with high Expected Accuracy (`mc=0.75`), marked as `Correct (+)` by Value-based PRM, and `Good (+)` by Advantage-based PRM.
* **Step-1 (Writing the equation):** Expected Accuracy drops to `mc=0.5`. It is still considered `Correct (+)` by Value-based PRM but is now rated `Bad (-)` by Advantage-based PRM, suggesting the step, while factually correct, may be suboptimal or inefficient.
* **Steps 2 & 3:** Are omitted (represented by `...`).
* **Step-4 (Substituting x back):** Expected Accuracy has fallen to `mc=0.0`. Both PRM metrics now judge the step as `Incorrect (-)` and `Bad (-)`.
* **Step-5 (Final answer):** The final answer is given as "58". Expected Accuracy remains `mc=0.0`. Value-based PRM still marks it `Incorrect (-)`, while Advantage-based PRM gives a `Tie (=)` assessment, possibly indicating the final answer is neither better nor worse than an alternative at this stage.
### Key Observations
1. **Diverging Metrics:** The three evaluation metrics do not always agree. For Step-1, Value-based PRM says "Correct" while Advantage-based PRM says "Bad." This highlights that a step can be technically right but poorly judged in terms of advantage or strategy.
2. **Accuracy Decay:** The "Expected Accuracy" (`mc`) metric shows a clear downward trend from 0.75 to 0.0, suggesting the model's confidence in the solution's correctness diminishes as the process continues, culminating in a final answer it deems incorrect.
3. **Error Propagation:** The diagram implies an error occurs somewhere in the omitted steps (2 or 3). This error propagates forward, causing Step-4 and Step-5 to be evaluated as incorrect by the Value-based PRM.
4. **Geometry Problem Context:** The specific geometry problem involves solving for `x` using the quadrilateral angle sum theorem. The final answer "58" likely refers to m∠S, which is \((2x+7)^\circ\). If the final answer is incorrect, the error likely occurred in solving the equation for `x`.
### Interpretation
This diagram serves as a meta-analysis of an AI or automated system's problem-solving process. It doesn't just show the solution steps; it visualizes the system's *self-evaluation* of those steps using different reward models.
* **What it demonstrates:** It illustrates how a process can start with high confidence and correct initial reasoning but still fail due to errors introduced later. The different PRM rows showcase alternative ways to judge the quality of each step—one based on the step's isolated correctness (Value-based) and another based on its strategic advantage within the whole process (Advantage-based).
* **Relationship between elements:** The horizontal flow represents the temporal sequence of solving the problem. The vertical stacks for each step provide a multi-faceted evaluation snapshot at that point in time. The geometry diagram is the concrete problem instance being processed.
* **Notable insight:** The most significant anomaly is the disconnect in Step-1 between the "Correct" and "Bad" labels. This suggests the evaluation framework can distinguish between factual accuracy and procedural quality. The final `Tie` assessment for an incorrect answer is also intriguing, possibly indicating the model's uncertainty or the presence of multiple plausible but wrong answer paths at the conclusion.
In essence, the image is a diagnostic tool for understanding not just *if* a solution fails, but *how* and *when* the failure occurs according to different evaluative lenses, using a concrete geometry problem as the test case.
</details>
Figure 3: Different modeling methods for PRMs. PRMs are developed to estimate the quality of each step in a given solution. For value-based PRMs, the quality of a certain step is determined by its expected accuracy $mc_i$ , where a step is considered correct if $mc_i>0$ . For advantage-based PRMs, the quality of a certain step is determined by the improvement of $mc_i$ over $mc_i-1$ , where a step is considered good if $mc_i-mc_i-1>0$ . During the training stage, the output space of PRMs is discretized into specific tokens, while during the inference stage, we compute the step score as the weighted sum of the generation probability for these discretized tokens.
During Best-of-N (BoN) evaluation, a critic model is required to estimate the quality of each response candidate. In this work, we formulate the critic model as a Process Reward Model (PRM). To develop a multimodal PRM, we first construct VisualPRM400K, a dataset comprising about 400K multimodal process supervision data, as detailed in Section 3.1. We then describe our PRM’s modeling approach in Section 3.2. Furthermore, to support the evaluation of critic models, we establish VisualProcessBench to measure the abilities of critic models to detect erroneous steps in multimodal reasoning, as introduced in Section 3.3.
### 3.1 VisualPRM400K
Definition. As shown in Figure 2, each data sample in our VisualPRM400K consists of an image $I∈I$ , a question $q∈Q$ , a step-by-step solution $s=\{s_0,s_1,⋯,s_n\}∈S$ , and the expected accuracy annotation $mc=\{mc_0,mc_1,⋯,mc_n\},mc_i∈ℝ_≥ 0$ for each step, where $n$ is the number of steps of a certain solution and $mc_i$ denotes the expected accuracy of step $s_i$ . The image sets $I$ and question sets $Q$ are collected from MMPR v1.1 [82], while the step-by-step solutions $S$ are sampled using InternVL2.5 series models [15, 82].
Process Supervision Generation. Given an image $I$ , a question $q$ , and a solution $s=\{s_0,s_1,⋯,s_n\}$ , we annotate the correctness of each step $s_i$ using an automatic data pipeline. The key idea is to estimate the expected accuracy of given steps $s_≤ i$ based on Monte Carlo sampling. Specifically, the model is required to complete the solution as follows:
$$
\tilde{s}_>i∼ M(\tilde{s}_>i\mid I,q,s_≤ i), \tag{1}
$$
where $\tilde{s}_>i$ is the completion of $s_≤ i$ . Besides, the expected accuracy of $s_i$ is defined as:
$$
mc_i=\frac{num(correct completions)}{num(sampled completions)}. \tag{2}
$$
Notably, to reduce the data construction costs, we set the max number of steps to 12 and evenly merge the steps if the number of current steps exceeds the threshold.
Statistics. During the construction process, we sample $4$ solutions for each image-question pair and split each of them into at most $12$ steps. For each step, we sample $16$ continuations and compute $m_i$ according to these continuations. The resulting dataset comprises approximately 400K samples and 2 million steps with process supervision. Each response averages 126.9 words and 5.6 steps, while each step averages 22.6 words. Among these steps, about 10% are incorrect steps. Despite the imbalanced distribution of correct and incorrect steps, our PRM demonstrates promising performance, as shown in Section 4.
### 3.2 VisualPRM
Overview. During the training process, we formulate the process supervision problem as a multi-turn chat task so that we can effectively leverage the generation ability of MLLMs. The image $I$ , question $q$ , and the first step $s_0$ of the solution to this question are included in the first turn and a new step is presented in each subsequent turn. The model is required to predict the quality of the given step in each turn as follows:
$$
y_i∼ M(y_i\mid I,q,s_≤ i), \tag{3}
$$
where $y_i$ denotes the quality of $i$ -th step.
For value-based PRMs, the quality of a certain step is determined by its expected accuracy $mc_i$ , which is similar to the definition of the value function in reinforcement learning. Following Math-Shepherd [79, 20], we require the model to predict the correctness $c_i∈\{+,-\}$ of the given step, rather than the exact score of $mc_i$ . The $i$ -th step is considered correct if $mc_i>0$ . We also try to set a threshold to reduce false positive steps, but find that such a threshold negatively impacts the PRM performance, as shown in Section 7. Notably, unlike previous works [79, 39, 20], which choose to supervise only up to the first incorrect step, we always supervise all steps.
For advantage-based PRMs, the quality of a certain step is determined by the improvement of $mc_i$ over $mc_i-1$ , which is analogous to the definition of the advantage function in reinforcement learning. Similar to value-based PRMs, the quality space is discretized into predefined values $\{+,=,-\}$ , meaning that the $i$ -th step $s_i$ results in a superior, comparable, or inferior situation.
During inference stage, we first compute the scores of each step and then merge them to obtain the response score. Specifically, the score for each step is defined as the weighted sum of the generation probability for the discretized scores. For value-based PRMs, the weights for $\{+,-\}$ are $\{1,0\}$ . For advantage-based PRMs, the weights for $\{+,=,-\}$ are $\{1,0,-1\}$ . Without further explanation, we average the scores of each step as the response score.
### 3.3 VisualProcessBench
| Total Samples - MMMU [90] - MathVision [78] | 2866 267 712 |
| --- | --- |
| - MathVerse [93] | 1026 |
| - DynaMath [99] | 570 |
| - WeMath [60] | 291 |
| Source Solutions | 2866 |
| - GPT-4o [58] | 870 |
| - Claude-3.5-Sonnet [4] | 865 |
| - QvQ-72B-Preview [72] | 825 |
| - InternVL2.5-78B [15] | 306 |
| Total Steps | 26950 |
| - Correct Steps | 16585 |
| - Incorrect Steps | 7691 |
| - Neural Steps | 2674 |
| Query Word Length Quartile | (22, 24, 50) |
| Response Word Length Quartile | (137, 193, 552) |
| Step Word Length Quartile | (13, 31, 67) |
| Number of Steps per Solution | 9.4 |
Table 1: Statistics of VisualProcessBench.
Definition. Each sample in our benchmark consists of a multimodal reasoning question, a step-by-step solution, and correctness annotations for each step. Considering that recent models begin to demonstrate reflection abilities to rectify their own reasoning process, the evaluation setting used in previous works [96, 39], which only requires the model to find the first erroneous step, may lead to a false negative estimation. Therefore, our benchmark requires the model to identify all erroneous steps in the given solution instead of only the first erroneous step.
Data Source. Our benchmark focuses on multimodal reasoning tasks, collecting images and questions from existing representative multimodal reasoning benchmarks, including MMMU [90], MathVision [78], MathVerse [93], DynaMath [99], and WeMath [60]. Given these questions, we generate step-by-step solutions using leading MLLMs, including GPT-4o [58], Claude-3.5-Sonnet [4], Gemini-2.0-Flash [70], QvQ-72B-Preview [72], and InternVL2.5-78B [15]. The solutions are sampled from different MLLMs to ensure their diversity.
Step Correctness Annotation. We employ a team of human experts with at least a university degree to manually annotate the correctness of each step in the solutions. Specifically, 13 people worked for 3 days, resulting in a workload of 39 person-days. The cost per person-day is approximately 37 dollars. During the annotation process, annotators are provided with the image, question, ground truth answer, and each step of the solution. Their task is to assign each step in the solution a label of positive, negative, or neutral, as illustrated in Figure 2. A positive label indicates that the step is correct, while a negative label signifies an incorrect step. The neural label is assigned to steps that do not involve any reasoning process or provide no additional information. To ensure the annotation quality, annotators are permitted to skip questions they do not understand. During the annotation process, our dataset is divided into 10 splits, each containing approximately 300 samples. For each split, the authors of this paper manually review about 10% of the samples. Splits with erroneous annotations are sent back for re-annotation. See Section 10 for more data examples.
Statistics. As shown in Table 1, our benchmark comprises 2866 samples. To enhance the diversity of our evaluation samples, we gather questions and solutions from a wide range of benchmarks and models while carefully regulating their distribution. The statistics of step distribution are presented in Section 8.
Metrics. In this work, we use macro F1 scores to compare model performance, aiming to mitigate the impact of the imbalanced distribution between correct and incorrect steps. Specifically, we first compute the F1 scores separately for correct and incorrect steps and then take their average to obtain the overall score.
## 4 Experiments
In this section, we first employ VisualPRM to evaluate various MLLMs using BoN evaluation strategies in Section 4.1, demonstrating that PRMs can significantly enhance the reasoning abilities of MLLMs. Next, we evaluate our VisualPRM and other leading MLLMs on VisualProcessBench in Section 4.2. Finally, the ablation studies are presented in Section 4.3 and Section 7.
| GPT-4o [58] Gemini-2.0-Flash [61] Claude-3.5-Sonnet [4] | 70.7 69.9 66.4 | 60.0 70.4 65.3 | 31.2 43.6 35.6 | 40.6 47.8 46.3 | 34.5 42.1 35.7 | 45.8 47.4 44.0 | 52.8 52.3 60.4 | 47.9 53.4 50.5 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Open-source Models | | | | | | | | |
| MiniCPM-V2.6-8B [89] | 49.8 | 60.8 | 23.4 | 18.9 | 9.8 | 16.4 | 27.5 | 29.5 |
| +VisualPRM | 56.8 | 65.7 | 24.7 | 35.8 | 11.2 | 31.0 | 37.4 | 37.5 |
| +7.0 | +4.9 | +1.3 | +16.9 | +1.4 | +14.6 | +9.8 | +8.0 | |
| Qwen2.5-VL-7B [7] | 55.0 | 67.8 | 25.4 | 41.1 | 21.0 | 35.2 | 44.1 | 41.4 |
| +VisualPRM | 58.6 | 70.3 | 31.3 | 44.3 | 23.0 | 39.8 | 48.3 | 45.1 |
| +3.6 | +2.5 | +5.9 | +3.2 | +2.0 | +4.6 | +4.2 | +3.7 | |
| InternVL2.5-8B [15] | 56.2 | 64.5 | 17.0 | 22.8 | 9.4 | 23.5 | 36.0 | 32.8 |
| +VisualPRM | 60.2 | 68.5 | 25.7 | 35.8 | 18.0 | 36.5 | 43.8 | 41.2 |
| +4.0 | +4.0 | +8.7 | +13.0 | +8.6 | +13.0 | +7.8 | +8.4 | |
| InternVL2.5-26B [15] | 60.7 | 68.2 | 23.4 | 24.0 | 11.4 | 30.9 | 39.6 | 36.9 |
| +VisualPRM | 63.9 | 73.1 | 29.6 | 39.1 | 23.2 | 40.8 | 51.0 | 45.8 |
| +3.2 | +4.9 | +6.2 | +15.1 | +11.8 | +9.9 | +11.4 | +8.9 | |
| InternVL2.5-38B [15] | 63.9 | 71.9 | 32.2 | 36.9 | 20.0 | 38.3 | 47.9 | 44.4 |
| +VisualPRM | 69.0 | 73.9 | 35.2 | 46.7 | 30.5 | 46.2 | 53.7 | 50.7 |
| +5.1 | +2.0 | +3.0 | +9.8 | +10.5 | +7.9 | +5.8 | +6.3 | |
| InternVL2.5-78B [15] | 70.0 | 72.3 | 32.2 | 39.2 | 19.2 | 39.8 | 49.0 | 46.0 |
| +VisualPRM | 70.7 | 75.1 | 35.9 | 47.1 | 31.3 | 49.1 | 53.9 | 51.9 |
| +0.7 | +2.8 | +3.7 | +7.9 | +12.1 | +9.3 | +4.9 | +5.9 | |
Table 2: Results on seven multimodal reasoning benchmarks. MMMU [90] is a multidisciplinary reasoning benchmark. MathVista [50], MathVision [78], MathVerse [93], DynaMath [99], and WeMath [60] are mathematics benchmarks. For MathVerse, we report the performance on Vision-Only (VO) split. LogicVista [87] is a logical reasoning benchmark. Part of the results are collected from the OpenCompass leaderboard [19]. The overall score is the average score of the above benchmarks. By using VisualPRM as the critic model, existing open-source MLLMs achieve significant improvements in reasoning ability under the Best-of-8 evaluation strategy.
### 4.1 Results with Best-of-N evaluation
Benchmarks. We evaluate the reasoning abilities of MLLMs across seven benchmarks, including MMMU [90], MathVista [50], MathVision [78], MathVerse [93], DynaMath [99], WeMath [60], and LogicVista [87]. The evaluation samples include subject-based, mathematical, and logical reasoning problems. We report the worst-case accuracy for DynaMath and the overall accuracy for the remaining benchmarks. For MathVerse, we report the performance on the Vision-Only split.
Settings. Without further explanation, we use VisualPRM as the critic model for BoN evaluation and set $N$ to $8$ by default. The policy model is required to generate $N$ distinct step-by-step Chain-of-Thought (CoT) reasoning processes with a temperature of 0.7. The response with the highest score is then selected to determine the correctness.
Results. As shown in Table 2, VisualPRM greatly enhances the reasoning abilities of MLLMs across different model scales and families. Specifically, for models with fewer than 10 billion parameters, the overall performance of InternVL2.5-8B, MiniCPM-V-8B, and Qwen2.5-VL-7B improves by 8.4, 8.0, and 3.7 points, respectively, demonstrating the effectiveness of test-time scaling across different model families. For larger models, InternVL2.5-26B, InternVL2.5-38B, and InternVL2.5-78B also achieve substantial performance gains over their counterparts without TTS, further validating the scalability and effectiveness of TTS across different model sizes.
### 4.2 Results on VisualProcessBench
Settings. For the evaluation of PRMs, a step is considered correct if the probability of outputting “ $+$ ” exceeds that of outputting “ $-$ ” by a certain threshold. For the evaluation of MLLMs, the model is prompted to analyze each step and determine its correctness, classifying it as either correct or incorrect. When computing the F1 score, we exclude steps labeled as neural by human annotators in Section 3.3.
Results. As shown in Table 3, most existing MLLMs struggle to accurately assess the correctness of each step. Specifically, the overall F1 score for random guessing is 50.0, while most open-source MLLMs achieve scores close to this baseline, highlighting their limitations as critic models. We manually check the judgments of these open-source MLLMs and observe that these models tend to provide positive analysis and label most steps as correct. For example, InternVL2.5-8B achieves an F1 score of 76.8 for positive steps, while its F1 score for negative steps is only 19.2, indicating that InternVL2.5-8B rarely identifies steps as incorrect. Furthermore, compared to proprietary models, our VisualPRM demonstrates competitive performance, achieving an overall F1 score of 62.0—outperforming GPT-4o and GPT-4o-Mini, and performing on par with Gemini-2.0-Flash. Notably, our model, with only 8 billion parameters, is more efficient than these proprietary counterparts.
| Model Random Guessing Proprietary Models | MMMU 50.0 | MathVision 50.0 | MathVerse-VO 50.0 | DynaMath 50.0 | WeMath 50.0 | Overall 50.0 |
| --- | --- | --- | --- | --- | --- | --- |
| GPT-4o-Mini [58] | 53.6 | 58.9 | 57.1 | 56.7 | 58.5 | 57.9 |
| GPT-4o [58] | 56.3 | 60.2 | 59.7 | 59.0 | 63.3 | 60.3 |
| Gemini-2.0-Flash [61] | 58.5 | 60.1 | 62.8 | 66.7 | 58.7 | 62.3 |
| Open-source Models | | | | | | |
| MiniCPM-V2.6-8B [89] | 44.9 | 50.9 | 58.9 | 46.7 | 57.4 | 50.4 |
| LLaVA-OV-7B [35] | 45.7 | 43.0 | 42.2 | 44.7 | 52.5 | 44.4 |
| LLaVA-OV-72B [35] | 46.1 | 48.4 | 53.0 | 57.0 | 57.3 | 52.3 |
| Qwen2.5-VL-7B [7] | 53.1 | 51.8 | 47.8 | 51.3 | 54.2 | 51.0 |
| Qwen2.5-VL-72B [7] | 59.2 | 59.0 | 59.7 | 62.9 | 62.3 | 60.5 |
| InternVL2.5-8B [15] | 47.1 | 45.5 | 47.8 | 50.3 | 50.8 | 48.0 |
| InternVL2.5-26B [15] | 48.8 | 47.4 | 49.2 | 50.4 | 51.4 | 49.2 |
| InternVL2.5-38B [15] | 51.5 | 48.4 | 50.9 | 51.8 | 52.5 | 50.8 |
| InternVL2.5-78B [15] | 52.0 | 51.7 | 53.7 | 50.8 | 52.5 | 52.6 |
| VisualPRM (ours) | 58.5 | 62.1 | 61.0 | 62.7 | 61.8 | 62.0 |
Table 3: Results on VisualProcessBench. We report the macro F1 of the correct and incorrect steps. The overall score is the micro average of the score from different data sources. Our VisualPRM exhibits state-of-the-art performance among open-source models.
### 4.3 Ablation Studies
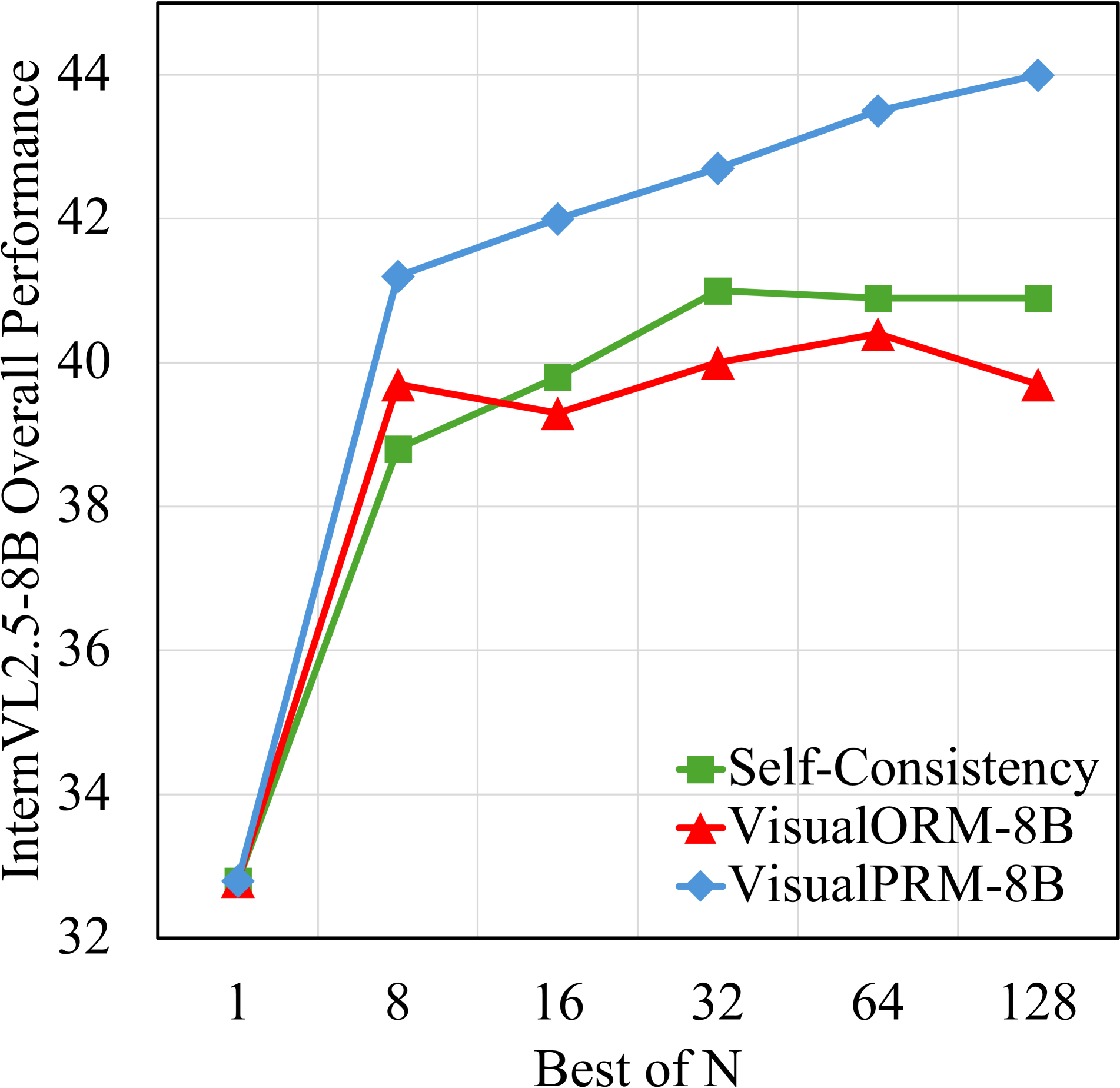
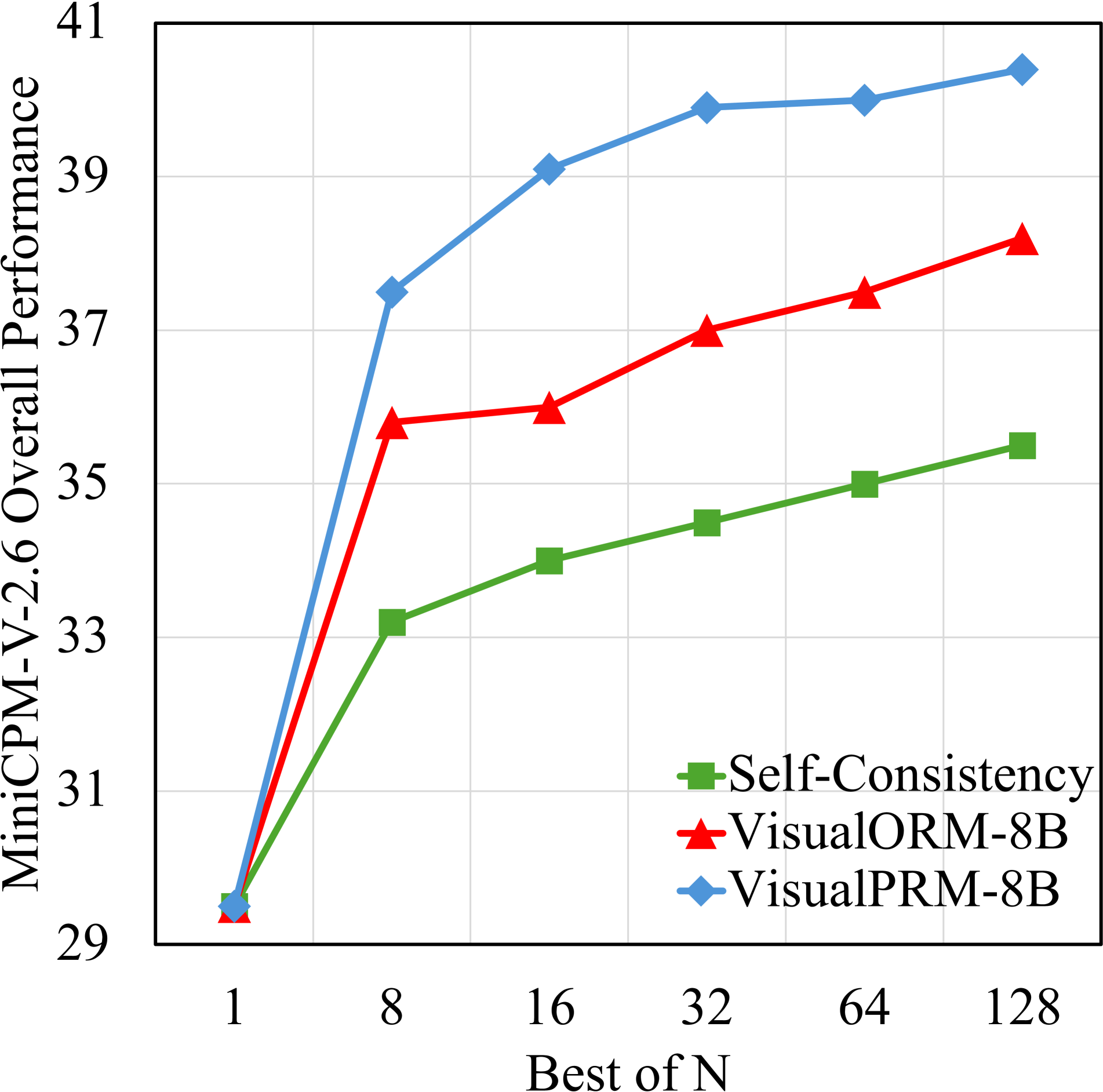
Effects of BoN. Here, we increase the number of response candidates sampled from InternVL2.5-8B and select the final response using Self-Consistency (SC) [86], Outcome Reward Model (ORM), and PRM. The training data for ORM are nearly identical to those used for PRM, except that all steps are concatenated into a single step and step-wise correctness annotations are converted into a single correctness label for the outcome. As shown in Figure 4, increasing the number of response candidates $N$ improves the reasoning performance of InternVL2.5-8B and MiniCPM-V2.6-8B when using SC, ORM, or PRM, with PRM yielding the most significant improvements. Specifically, when using InternVL2.5-8B as the policy model, PRM outperforms SC and ORM by 2.4 and 1.5 points, respectively, under the Best-of-8 evaluation setting. Moreover, this performance gap widens as $N$ increases, reaching 3.1 and 4.3 points when $N$ is set to $128$ . Notably, when using ORM as the critic model, although performance improves during Best-of-8 evaluation, further increasing $N$ does not lead to consistent gains for InternVL2.5-8B. For example, the Best-of-128 performance is inferior to the Best-of-64 performance. These results highlight the effectiveness of PRM in TTS.
Effects of PRM modeling methods. Here, we compare the value-based PRM and the advantage-based PRM introduced in Section 3.2, along with different methods for aggregating step scores into a final score, including averaging, as well as selecting the maximum or minimum value. The results are presented in Table 4. We find that value-based PRMs outperform advantage-based PRMs in both BoN evaluation settings and VL-ProcessBench. We attribute this to the inherent noise in our training data, which is generated through an automatic data pipeline, making it challenging to accurately determine whether a given step contributes to higher or lower expected accuracy. We also compare two training strategies: supervising all steps (i.e., w/o early stop) versus supervising only up to the first incorrect step (i.e., w. early stop) during training. Experimental results show that the former yields better performance. Regarding different score aggregation methods, we find that selecting the maximum value results in poorer performance compared to averaging or taking the minimum value. Analyzing the generated scores reveals that most responses contain a high-scored step, close to $1$ , at the beginning of the solution. This phenomenon likely arises because most erroneous steps appear in the middle of the solution. Our statistics of VisualProcessBench presented in Section 8 further demonstrate this conclusion. Furthermore, averaging performs better than selecting the maximum value, likely because the latter relies on a single step’s score, while averaging accounts for multiple steps and can be considered as an ensemble approach, which benefits the step quality estimation.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Performance Comparison Line Chart: Scaling Behavior of Three Methods on InternVL2.5-8B
### Overview
The image is a line chart comparing the performance of three different methods—Self-Consistency, VisualORM-8B, and VisualPRM-8B—on the "InternVL2.5-8B Overall Performance" benchmark. The performance is plotted against an increasing "Best of N" parameter, which likely represents the number of samples or attempts from which the best result is selected. The chart demonstrates how each method's performance scales as N increases.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **Y-Axis (Vertical):**
* **Label:** "InternVL2.5-8B Overall Performance" (text is rotated 90 degrees).
* **Scale:** Linear scale ranging from 32 to 44, with major gridlines at intervals of 2 (32, 34, 36, 38, 40, 42, 44).
* **X-Axis (Horizontal):**
* **Label:** "Best of N".
* **Scale:** Categorical scale with discrete, non-linearly spaced values: 1, 8, 16, 32, 64, 128.
* **Legend:**
* **Position:** Bottom-right corner of the plot area.
* **Items:**
1. **Green Square Marker:** "Self-Consistency"
2. **Red Triangle Marker:** "VisualORM-8B"
3. **Blue Diamond Marker:** "VisualPRM-8B"
* **Grid:** Light gray gridlines are present for both axes.
### Detailed Analysis
Data points are extracted by matching the marker color/shape to the legend and reading the approximate y-axis value for each x-axis category.
**1. VisualPRM-8B (Blue Diamond Line)**
* **Trend:** Shows a strong, consistent upward trend across all values of N. The slope is steepest between N=1 and N=8, then continues to rise steadily.
* **Data Points (Approximate):**
* N=1: ~32.8
* N=8: ~41.2
* N=16: ~42.0
* N=32: ~42.6
* N=64: ~43.5
* N=128: ~44.0
**2. Self-Consistency (Green Square Line)**
* **Trend:** Increases sharply from N=1 to N=8, continues to rise to N=32, then plateaus for N=64 and N=128.
* **Data Points (Approximate):**
* N=1: ~32.8 (overlaps with other points)
* N=8: ~38.8
* N=16: ~39.8
* N=32: ~41.0
* N=64: ~40.9
* N=128: ~40.9
**3. VisualORM-8B (Red Triangle Line)**
* **Trend:** Increases from N=1 to N=8, dips slightly at N=16, rises again to a peak at N=64, then decreases at N=128. It exhibits the most fluctuation.
* **Data Points (Approximate):**
* N=1: ~32.8 (overlaps with other points)
* N=8: ~39.6
* N=16: ~39.3
* N=32: ~40.0
* N=64: ~40.4
* N=128: ~39.7
### Key Observations
1. **Common Starting Point:** All three methods begin at approximately the same performance level (~32.8) when N=1.
2. **Divergence at N=8:** A significant performance gap opens at N=8, with VisualPRM-8B (~41.2) clearly outperforming VisualORM-8B (~39.6) and Self-Consistency (~38.8).
3. **VisualPRM-8B Dominance:** The blue line (VisualPRM-8B) remains the top-performing method for all N > 1, and its lead widens as N increases.
4. **Plateau vs. Fluctuation:** Self-Consistency performance stabilizes after N=32, while VisualORM-8B shows non-monotonic behavior, peaking at N=64 before declining.
5. **Scaling Efficiency:** VisualPRM-8B demonstrates the most efficient and consistent scaling with increased N, suggesting it benefits most from additional sampling/compute.
### Interpretation
This chart evaluates how different techniques improve the reliability or accuracy of the InternVL2.5-8B model when allowed multiple attempts ("Best of N"). The data suggests:
* **VisualPRM-8B is the most effective scaling method.** Its steady, near-linear improvement indicates a robust mechanism for leveraging additional samples to find better solutions. This could imply a superior reward model or verification process that consistently identifies higher-quality outputs.
* **Self-Consistency offers reliable but limited gains.** It provides a solid improvement over the single-sample baseline but hits a performance ceiling around N=32, indicating diminishing returns. This is typical of majority-voting or consensus-based approaches.
* **VisualORM-8B is less stable.** Its fluctuating performance, especially the drop at N=128, suggests its method for selecting the "best" output may be sensitive to noise or can become counterproductive with too many samples. It does not scale as reliably as the other methods.
**Overall Implication:** For tasks where computational cost (increasing N) is acceptable, **VisualPRM-8B is the clear choice** for maximizing model performance on this benchmark. The chart provides strong evidence that its underlying approach scales better than the alternatives tested.
</details>
(a)
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Performance Comparison of Three Methods Across "Best of N" Values
### Overview
The image displays a line chart comparing the performance of three different methods—Self-Consistency, VisualORM-8B, and VisualPRM-8B—on the "MiniCPM-V-2.6 Overall Performance" metric as a function of the "Best of N" parameter. The chart demonstrates how each method's performance scales as N increases from 1 to 128.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis:** Labeled **"Best of N"**. It has discrete, non-linearly spaced tick marks at values: **1, 8, 16, 32, 64, 128**.
* **Y-Axis:** Labeled **"MiniCPM-V-2.6 Overall Performance"**. The scale ranges from **29 to 41**, with major gridlines at intervals of 2 (29, 31, 33, 35, 37, 39, 41).
* **Legend:** Located in the **bottom-right quadrant** of the chart area. It contains three entries:
* **Green Square Marker:** Labeled **"Self-Consistency"**.
* **Red Triangle Marker:** Labeled **"VisualORM-8B"**.
* **Blue Diamond Marker:** Labeled **"VisualPRM-8B"**.
* **Grid:** A light gray grid is present in the background.
### Detailed Analysis
**Data Series and Trends:**
1. **VisualPRM-8B (Blue Diamond Line):**
* **Trend:** Shows the steepest initial increase and achieves the highest overall performance. The line slopes sharply upward from N=1 to N=8, continues to rise steadily until N=32, and then plateaus with very slight increases.
* **Approximate Data Points:**
* N=1: ~29.5
* N=8: ~37.5
* N=16: ~39.0
* N=32: ~40.0
* N=64: ~40.0
* N=128: ~40.5
2. **VisualORM-8B (Red Triangle Line):**
* **Trend:** Shows a strong, steady upward trend across all N values, consistently performing below VisualPRM-8B but above Self-Consistency. The growth rate is more linear compared to the blue line.
* **Approximate Data Points:**
* N=1: ~29.5
* N=8: ~35.5
* N=16: ~36.0
* N=32: ~37.0
* N=64: ~37.5
* N=128: ~38.0
3. **Self-Consistency (Green Square Line):**
* **Trend:** Shows the most gradual increase and the lowest performance among the three methods. The line has a consistent, moderate upward slope.
* **Approximate Data Points:**
* N=1: ~29.5
* N=8: ~33.0
* N=16: ~34.0
* N=32: ~34.5
* N=64: ~35.0
* N=128: ~35.5
### Key Observations
* **Common Starting Point:** All three methods begin at approximately the same performance level (~29.5) when N=1.
* **Divergence with N:** Performance diverges significantly as N increases. The gap between the best (VisualPRM-8B) and worst (Self-Consistency) performer widens substantially.
* **Diminishing Returns:** All curves show signs of diminishing returns. The performance gain from doubling N is largest in the early steps (e.g., N=1 to N=8) and becomes progressively smaller, especially for VisualPRM-8B after N=32.
* **Performance Hierarchy:** A clear and consistent hierarchy is established from N=8 onward: **VisualPRM-8B > VisualORM-8B > Self-Consistency**.
### Interpretation
The chart illustrates the effectiveness of different methods for improving the performance of the MiniCPM-V-2.6 model when leveraging multiple samples or attempts (the "Best of N" strategy).
* **Method Superiority:** VisualPRM-8B is the most effective method shown, providing the largest performance boost for any given N > 1. This suggests its underlying mechanism for selecting or aggregating the "best" result is superior to the other two approaches.
* **Value of Scaling N:** Increasing N universally improves performance for all methods, confirming the benefit of generating and evaluating more candidates. However, the cost-benefit ratio decreases as N grows large.
* **Practical Implication:** For resource-constrained scenarios, a moderate N (like 16 or 32) with VisualPRM-8B may offer the best trade-off between performance gain and computational cost. For maximum performance regardless of cost, VisualPRM-8B with N=128 is the optimal choice among the presented options.
* **Underlying Mechanism:** The significant gap between VisualPRM-8B/VisualORM-8B and Self-Consistency implies that the former two methods, likely involving more sophisticated reward modeling or process-based verification (as suggested by "ORM" and "PRM" in their names), are more capable of identifying high-quality outputs than a simple self-consistency (majority voting) approach.
</details>
(b)
Figure 4: Overall Best-of-N results across seven multimodal reasoning benchmarks with different policy and critic models. VisualPRM consistently enhances reasoning performance of both InternVL2.5-8B and MiniCPM-V as $N$ increases and outperforms the improvement introduced by Self-Consistency and ORM, highlighting the effectiveness of PRM in Test-Time Scaling.
| Critic Model Pass@1 Random Guessing | BoN 32.8 33.0 | VL-ProcessBench - 50.0 |
| --- | --- | --- |
| InternVL2.5-8B | 33.2 | 48.0 |
| InternVL2.5-78B | 34.2 | 52.6 |
| Advantage-based PRM | | |
| +Min | 36.8 | 55.0 |
| +Max | 36.9 | 55.0 |
| +Average | 37.4 | 55.0 |
| Value (w. early stop) | | |
| +Min | 40.3 | 61.6 |
| +Max | 37.0 | 61.6 |
| +Average | 40.6 | 61.6 |
| Value (w/o early stop) | | |
| +Min | 40.4 | 62.0 |
| +Max | 35.9 | 62.0 |
| +Average | 41.1 | 62.0 |
Table 4: Comparison of different critic models and score aggregation methods. Note that score aggregation methods do not affect performance on VisualProcessBench, which focuses on step correctness judgement. We find that supervising all steps (w/o early stop) during training perform slightly better than supervising only up to the first incorrect step (w. early steop).
MLLM-as-a-Judger. Existing MLLMs can be prompted to serve as a critic model. However, as shown in Table 4, the InternVL2.5 series struggle to improve BoN performance, resulting in only marginal improvements. Upon analyzing the generated scores, we find that these models assign similar scores to most solutions. Consistent with our observations in Section 4.2, the InternVL2.5 series tend to generate positive judgments for most steps, which hinders their ability to effectively distinguish and select the truly superior response. In addition to their effectiveness as critic models for MLLMs, their inference latency also limits efficiency. Specifically, MLLMs generate judgments for each step in an autoregressive manner, which is time-consuming. In contrast, our VisualPRM computes scores for all steps in a single forward pass by using a “+” as a placeholder for model responses and interpreting its generation probability as the step score.
Results on text-only performance. To assess the effectiveness of VisualPRM on text-only inputs, we evaluate the Qwen2.5 series [88] and InternVL2.5 series [15] on three text reasoning benchmarks under BoN evaluation settings: GSM8K [18], MATH-500 [25], and GPQA-Diamond [62]. We report accuracy as the evaluation metric for these benchmarks. As shown in Table 5, our model enhances the text reasoning abilities of both the Qwen2.5 series and the InternVL2.5 series. Specifically, Qwen2.5-7B achieves improvements of 6.1 and 5.0 points on MATH-500 and GPQA-Diamond, respectively. Similarly, Qwen2.5-72B demonstrates gains of 2.1 and 6.6 points on these benchmarks. For the InternVL2.5 series, InternVL2.5-8B, InternVL2.5-38B, and InternVL2.5-78B achieve improvements of 9.4 and 5.0, 4.6 and 8.1, and 7.4 and 3.5 points, respectively, on MATH-500 and GPQA-Diamond. These results demonstrate the effectiveness of our VisualPRM in text-only scenarios.
| Model Large Language Models Qwen2.5-7B [88] | GSM8K 91.6 | MATH-500 75.5 | GPQA 36.4 |
| --- | --- | --- | --- |
| +VisualPRM | 94.5 | 81.6 | 41.4 |
| +2.9 | +6.1 | +5.0 | |
| Qwen2.5-32B [88] | 95.9 | 83.1 | 49.5 |
| +VisualPRM | 96.1 | 85.4 | 53.5 |
| +0.2 | +2.3 | +4.0 | |
| Qwen2.5-72B [88] | 95.8 | 83.1 | 49.0 |
| +VisualPRM | 96.5 | 85.2 | 55.6 |
| +0.7 | +2.1 | +6.6 | |
| Multimodal Large Language Models | | | |
| InternVL2.5-8B [15] | 81.9 | 56.8 | 29.3 |
| +VisualPRM | 82.9 | 66.2 | 34.3 |
| +1.1 | +9.4 | +5.0 | |
| InternVL2.5-38B [15] | 94.6 | 75.4 | 44.4 |
| +VisualPRM | 95.6 | 80.0 | 52.5 |
| +1.0 | +4.6 | +8.1 | |
| InternVL2.5-78B [15] | 93.6 | 70.4 | 47.5 |
| +VisualPRM | 94.5 | 77.8 | 51.0 |
| +0.9 | +7.4 | +3.5 | |
Table 5: Results on text reasoning benchmarks. GSM8K and MATH500 are mathematics benchmarks, while GPQA is a multidisciplinary reasoning benchmark. For GPQA, we report the performance on the Diamond split. Our VisualPRM enhances the text reasoning abilities of both LLMs and MLLMs under the Best-of-8 evaluation settings.
## 5 Conclusion
In this work, we construct VisualPRM400K, a dataset comprising about 400K multimodal process supervision data. Building upon this dataset, we develop VisualPRM, an advanced multimodal Process Reward Model (PRM) capable of estimating the value score of each step during the reasoning process. With the Best-of-N (BoN) evaluation strategies, our model improves the reasoning abilities of existing Multimodal Large Language Models (MLLMs) across different model scales and families. Experimental results show that our model exhibits superior performance compared to Outcome Reward Models and Self-Consistency during BoN evaluation, highlighting the effectiveness of PRMs in Test-Time Scaling. To further facilitate the development of multimodal critic models, we construct VisualProcessBench, a benchmark designed to measure the abilities of PRMs and MLLMs to detect incorrect steps in multimodal reasoning tasks. Evaluation results show that existing open-source MLLMs struggle to effectively judge the correctness of each step. We hope that our work can inspire more future research and contribute to the development of MLLMs.
## References
- Achiam et al. [2023] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Ahmadian et al. [2024] Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms. arXiv preprint arXiv:2402.14740, 2024.
- Alayrac et al. [2022] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. NIPS, 35:23716–23736, 2022.
- Anthropic [2024] Anthropic. The claude 3 model family: Opus, sonnet, haiku. https://www.anthropic.com, 2024.
- Bai et al. [2023a] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023a.
- Bai et al. [2023b] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023b.
- Bai et al. [2025] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025.
- Biten et al. [2019] Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marçal Rusinol, Ernest Valveny, CV Jawahar, and Dimosthenis Karatzas. Scene text visual question answering. In ICCV, pages 4291–4301, 2019.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NIPS, 2020.
- Cai et al. [2024] Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, et al. Internlm2 technical report. arXiv preprint arXiv:2403.17297, 2024.
- Cao and Xiao [2022] Jie Cao and Jing Xiao. An augmented benchmark dataset for geometric question answering through dual parallel text encoding. In COLING, pages 1511–1520, 2022.
- Chang et al. [2022] Shuaichen Chang, David Palzer, Jialin Li, Eric Fosler-Lussier, and Ningchuan Xiao. Mapqa: A dataset for question answering on choropleth maps. arXiv preprint arXiv:2211.08545, 2022.
- Chen et al. [2024a] Qiguang Chen, Libo Qin, Jin Zhang, Zhi Chen, Xiao Xu, and Wanxiang Che. M3cot: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought. arXiv preprint arXiv:2405.16473, 2024a.
- Chen et al. [2023] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Zhong Muyan, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. arXiv preprint arXiv:2312.14238, 2023.
- Chen et al. [2024b] Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271, 2024b.
- Chen et al. [2024c] Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv preprint arXiv:2404.16821, 2024c.
- Clark and Gardner [2018] Christopher Clark and Matt Gardner. Simple and effective multi-paragraph reading comprehension. In ACL, pages 845–855, 2018.
- Cobbe et al. [2021] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Contributors [2023] OpenCompass Contributors. Opencompass: A universal evaluation platform for foundation models. https://github.com/open-compass/opencompass, 2023.
- Dong et al. [2024] Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, and Tong Zhang. Rlhf workflow: From reward modeling to online rlhf. arXiv preprint arXiv:2405.07863, 2024.
- Dubey et al. [2024] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Gao et al. [2023] Jiahui Gao, Renjie Pi, Jipeng Zhang, Jiacheng Ye, Wanjun Zhong, Yufei Wang, Lanqing Hong, Jianhua Han, Hang Xu, Zhenguo Li, et al. G-llava: Solving geometric problem with multi-modal large language model. arXiv preprint arXiv:2312.11370, 2023.
- Goyal et al. [2017] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In CVPR, pages 6904–6913, 2017.
- Guo et al. [2025] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
- Hendrycks et al. [2021] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
- Hu [2025] Jian Hu. Reinforce++: A simple and efficient approach for aligning large language models. arXiv preprint arXiv:2501.03262, 2025.
- Huang et al. [2019] Zheng Huang, Kai Chen, Jianhua He, Xiang Bai, Dimosthenis Karatzas, Shijian Lu, and CV Jawahar. Icdar2019 competition on scanned receipt ocr and information extraction. In 2019 International Conference on Document Analysis and Recognition (ICDAR), pages 1516–1520. IEEE, 2019.
- Hudson and Manning [2019] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In CVPR, pages 6700–6709, 2019.
- Kafle et al. [2018] Kushal Kafle, Brian Price, Scott Cohen, and Christopher Kanan. Dvqa: Understanding data visualizations via question answering. In CVPR, pages 5648–5656, 2018.
- Kazemi et al. [2023] Mehran Kazemi, Hamidreza Alvari, Ankit Anand, Jialin Wu, Xi Chen, and Radu Soricut. Geomverse: A systematic evaluation of large models for geometric reasoning. arXiv preprint arXiv:2312.12241, 2023.
- Kembhavi et al. [2016] Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. In ECCV, pages 235–251, 2016.
- Lai et al. [2024] Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, and Jiaya Jia. Step-dpo: Step-wise preference optimization for long-chain reasoning of llms. arXiv preprint arXiv:2406.18629, 2024.
- Lambert et al. [2024] Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, et al. Rewardbench: Evaluating reward models for language modeling. arXiv preprint arXiv:2403.13787, 2024.
- Laurençon et al. [2024] Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander Rush, Douwe Kiela, et al. Obelics: An open web-scale filtered dataset of interleaved image-text documents. NIPS, 36, 2024.
- Li et al. [2024a] Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024a.
- Li et al. [2023] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, pages 19730–19742. PMLR, 2023.
- Li et al. [2024b] Lei Li, Yuancheng Wei, Zhihui Xie, Xuqing Yang, Yifan Song, Peiyi Wang, Chenxin An, Tianyu Liu, Sujian Li, Bill Yuchen Lin, et al. Vlrewardbench: A challenging benchmark for vision-language generative reward models. arXiv preprint arXiv:2411.17451, 2024b.
- Li et al. [2024c] Qingyun Li, Zhe Chen, Weiyun Wang, Wenhai Wang, Shenglong Ye, Zhenjiang Jin, Guanzhou Chen, Yinan He, Zhangwei Gao, Erfei Cui, et al. Omnicorpus: An unified multimodal corpus of 10 billion-level images interleaved with text. arXiv preprint arXiv:2406.08418, 2024c.
- Lightman et al. [2023] Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In The Twelfth International Conference on Learning Representations, 2023.
- Lindström and Abraham [2022] Adam Dahlgren Lindström and Savitha Sam Abraham. Clevr-math: A dataset for compositional language, visual and mathematical reasoning. arXiv preprint arXiv:2208.05358, 2022.
- Liu et al. [2023a] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. NIPS, 36, 2023a.
- Liu et al. [2024a] Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, 2024a.
- Liu et al. [2024b] Yangzhou Liu, Yue Cao, Zhangwei Gao, Weiyun Wang, Zhe Chen, Wenhai Wang, Hao Tian, Lewei Lu, Xizhou Zhu, Tong Lu, et al. Mminstruct: A high-quality multi-modal instruction tuning dataset with extensive diversity. arXiv preprint arXiv:2407.15838, 2024b.
- Liu et al. [2024c] Yantao Liu, Zijun Yao, Rui Min, Yixin Cao, Lei Hou, and Juanzi Li. Rm-bench: Benchmarking reward models of language models with subtlety and style. arXiv preprint arXiv:2410.16184, 2024c.
- Liu et al. [2023b] Zhaoyang Liu, Yinan He, Wenhai Wang, Weiyun Wang, Yi Wang, Shoufa Chen, Qinglong Zhang, Zeqiang Lai, Yang Yang, Qingyun Li, Jiashuo Yu, et al. Interngpt: Solving vision-centric tasks by interacting with chatgpt beyond language. arXiv preprint arXiv:2305.05662, 2023b.
- Loshchilov and Hutter [2017] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Lu et al. [2021a] Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning. arXiv preprint arXiv:2105.04165, 2021a.
- Lu et al. [2021b] Pan Lu, Liang Qiu, Jiaqi Chen, Tony Xia, Yizhou Zhao, Wei Zhang, Zhou Yu, Xiaodan Liang, and Song-Chun Zhu. Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning. arXiv preprint arXiv:2110.13214, 2021b.
- Lu et al. [2022] Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. NIPS, 35:2507–2521, 2022.
- Lu et al. [2023] Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv preprint arXiv:2310.02255, 2023.
- Luo et al. [2024] Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, et al. Improve mathematical reasoning in language models by automated process supervision. arXiv preprint arXiv:2406.06592, 2, 2024.
- Marino et al. [2019] Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. In CVPR, pages 3195–3204, 2019.
- Masry et al. [2022] Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In ACL, pages 2263–2279, 2022.
- Mathew et al. [2022] Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar. Infographicvqa. In WACV, pages 1697–1706, 2022.
- McAleese et al. [2024] Nat McAleese, Rai Michael Pokorny, Juan Felipe Ceron Uribe, Evgenia Nitishinskaya, Maja Trebacz, and Jan Leike. Llm critics help catch llm bugs. arXiv preprint arXiv:2407.00215, 2024.
- Mishra et al. [2019] Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In ICDAR, pages 947–952, 2019.
- Muennighoff et al. [2025] Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling. arXiv preprint arXiv:2501.19393, 2025.
- OpenAI [2024] OpenAI. Gpt-4o system card. https://openai.com/index/gpt-4o-system-card/, 2024.
- Pang et al. [2024] Richard Yuanzhe Pang, Weizhe Yuan, Kyunghyun Cho, He He, Sainbayar Sukhbaatar, and Jason Weston. Iterative reasoning preference optimization. arXiv preprint arXiv:2404.19733, 2024.
- Qiao et al. [2024] Runqi Qiao, Qiuna Tan, Guanting Dong, Minhui Wu, Chong Sun, Xiaoshuai Song, Zhuoma GongQue, Shanglin Lei, Zhe Wei, Miaoxuan Zhang, et al. We-math: Does your large multimodal model achieve human-like mathematical reasoning? arXiv preprint arXiv:2407.01284, 2024.
- Reid et al. [2024] Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- Rein et al. [2024] David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling, 2024.
- Schuhmann et al. [2022] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. NIPS, 35:25278–25294, 2022.
- Schulman et al. [2017] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Seo et al. [2015] Minjoon Seo, Hannaneh Hajishirzi, Ali Farhadi, Oren Etzioni, and Clint Malcolm. Solving geometry problems: Combining text and diagram interpretation. In Proceedings of the 2015 conference on empirical methods in natural language processing, pages 1466–1476, 2015.
- Shao et al. [2024] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- Singh et al. [2019] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In CVPR, pages 8317–8326, 2019.
- Snell et al. [2024] Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314, 2024.
- Song et al. [2025] Mingyang Song, Zhaochen Su, Xiaoye Qu, Jiawei Zhou, and Yu Cheng. Prmbench: A fine-grained and challenging benchmark for process-level reward models. arXiv preprint arXiv:2501.03124, 2025.
- Team et al. [2023] Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Team [2023] InternLM Team. Internlm: A multilingual language model with progressively enhanced capabilities. https://github.com/InternLM/InternLM, 2023.
- Team [2024] Qwen Team. Qvq: To see the world with wisdom, 2024.
- Tian et al. [2024] Changyao Tian, Xizhou Zhu, Yuwen Xiong, Weiyun Wang, Zhe Chen, Wenhai Wang, Yuntao Chen, Lewei Lu, Tong Lu, Jie Zhou, et al. Mm-interleaved: Interleaved image-text generative modeling via multi-modal feature synchronizer. arXiv preprint arXiv:2401.10208, 2024.
- Toshniwal et al. [2025] Shubham Toshniwal, Ivan Moshkov, Sean Narenthiran, Daria Gitman, Fei Jia, and Igor Gitman. Openmathinstruct-1: A 1.8 million math instruction tuning dataset. Advances in Neural Information Processing Systems, 37:34737–34774, 2025.
- Touvron et al. [2023a] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
- Touvron et al. [2023b] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- Wang et al. [2024a] Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, and Tong Zhang. Interpretable preferences via multi-objective reward modeling and mixture-of-experts. In EMNLP, 2024a.
- Wang et al. [2024b] Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. arXiv preprint arXiv:2402.14804, 2024b.
- Wang et al. [2023a] Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. arXiv preprint arXiv:2312.08935, 2023a.
- Wang et al. [2023b] Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, et al. Visionllm: Large language model is also an open-ended decoder for vision-centric tasks. NIPS, 36, 2023b.
- Wang et al. [2023c] Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079, 2023c.
- Wang et al. [2024c] Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, et al. Enhancing the reasoning ability of multimodal large language models via mixed preference optimization. arXiv preprint arXiv:2411.10442, 2024c.
- Wang et al. [2024d] Weiyun Wang, Yiming Ren, Haowen Luo, Tiantong Li, Chenxiang Yan, Zhe Chen, Wenhai Wang, Qingyun Li, Lewei Lu, Xizhou Zhu, et al. The all-seeing project v2: Towards general relation comprehension of the open world. arXiv preprint arXiv:2402.19474, 2024d.
- Wang et al. [2024e] Weiyun Wang, Min Shi, Qingyun Li, Wenhai Wang, Zhenhang Huang, Linjie Xing, Zhe Chen, Hao Li, Xizhou Zhu, Zhiguo Cao, et al. The all-seeing project: Towards panoptic visual recognition and understanding of the open world. In ICLR, 2024e.
- Wang et al. [2024f] Weiyun Wang, Shuibo Zhang, Yiming Ren, Yuchen Duan, Tiantong Li, Shuo Liu, Mengkang Hu, Zhe Chen, Kaipeng Zhang, Lewei Lu, et al. Needle in a multimodal haystack. arXiv preprint arXiv:2406.07230, 2024f.
- Wang et al. [2022] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- Xiao et al. [2024] Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts. arXiv preprint arXiv:2407.04973, 2024.
- Yang et al. [2024] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115, 2024.
- Yao et al. [2024] Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800, 2024.
- Yue et al. [2024] Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In CVPR, 2024.
- Zhai et al. [2023] Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. In ICCV, pages 11975–11986, 2023.
- Zhang et al. [2024a] Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. Generative verifiers: Reward modeling as next-token prediction. arXiv preprint arXiv:2408.15240, 2024a.
- Zhang et al. [2024b] Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? arXiv preprint arXiv:2403.14624, 2024b.
- Zhang et al. [2025] Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. arXiv preprint arXiv:2501.07301, 2025.
- Zhao et al. [2025] Xiangyu Zhao, Shengyuan Ding, Zicheng Zhang, Haian Huang, Maosong Cao, Weiyun Wang, Jiaqi Wang, Xinyu Fang, Wenhai Wang, Guangtao Zhai, et al. Omnialign-v: Towards enhanced alignment of mllms with human preference. arXiv preprint arXiv:2502.18411, 2025.
- Zheng et al. [2024] Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process errors in mathematical reasoning. arXiv preprint arXiv:2412.06559, 2024.
- Zhou et al. [2024] Enyu Zhou, Guodong Zheng, Binghai Wang, Zhiheng Xi, Shihan Dou, Rong Bao, Wei Shen, Limao Xiong, Jessica Fan, Yurong Mou, et al. Rmb: Comprehensively benchmarking reward models in llm alignment. arXiv preprint arXiv:2410.09893, 2024.
- Zhu et al. [2024] Wanrong Zhu, Jack Hessel, Anas Awadalla, Samir Yitzhak Gadre, Jesse Dodge, Alex Fang, Youngjae Yu, Ludwig Schmidt, William Yang Wang, and Yejin Choi. Multimodal c4: An open, billion-scale corpus of images interleaved with text. NIPS, 36, 2024.
- Zou et al. [2024] Chengke Zou, Xingang Guo, Rui Yang, Junyu Zhang, Bin Hu, and Huan Zhang. Dynamath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models. arXiv preprint arXiv:2411.00836, 2024.
Supplementary Material
## 6 Training Hyper-parameters
During the training process of VisualPRM, the data-packing strategy [15] is enabled during training. We employ the AdamW optimizer [46] with the $β_1$ of $0.9$ , the $β_2$ of $0.999$ , and the weight decay of $0.05$ . The learning rate is initialized as $1e-5$ . The training phases include a linear warmup that lasts until the first 5% of training steps. The warmup is followed by a cosine decay strategy with a minimum learning rate of 0. We set the training epoch to 1.
## 7 More Ablation Studies
### 7.1 Effects of Training Hyper-parameters
When training our value-based Process Reward Model (PRM) using VisualPRM400K, we define a step as correct if its expected accuracy exceeds 0. In this section, we analyze the impact of varying expected accuracy thresholds for determining step correctness. As shown in Table 8, increasing the threshold results in a decline in both Best-of-8 evaluation performance and VisualProcessBench scores. These results are consistent with the observation in Qwen2.5-Math-PRM [94]. Therefore, we suggest setting the threshold to $0 0$ during training.
### 7.2 Effects of Generation Hyper-parameters
In this section, we analyze the impact of generation temperature on the Best-of-8 evaluation. As shown in Table 8, as the temperature increases from 0.3 to 1.3, the overall performance of InternVL2.5-8B first improves and then declines. We attribute this phenomenon to the trade-off between response diversity and accuracy. When the temperature is low (e.g., set to 0.3), the generated responses lack diversity, limiting the model’s performance upper bound. Conversely, when the temperature is high (e.g., set to 1.3), the responses become more random, reducing the accuracy of individual responses and lowering the model’s overall performance ceiling.
### 7.3 Effects of Best-of-N evaluation
In this section, we present the Best-of-N evaluation results as $N$ increases, as shown in Table 6 and Table 7. Our results indicate that as $N$ increases, VisualPRM consistently enhances the reasoning abilities of InternVL2.5-8B [15] and MiniCPM-V2.6 [89]. Specifically, as $N$ increases from $8$ to $128$ , the overall performance of InternVL2.5-8B improves from 41.2 to 44.0, while MiniCPM-V2.6 improves from 37.5 to 40.4, demonstrating the scalability of Test-Time Scaling for MLLMs.
| Self Consistency 8 16 | 1 58.0 58.6 | 56.2 65.9 65.8 | 64.5 23.4 26.3 | 17.0 30.5 32.1 | 22.8 18.4 19.4 | 9.4 32.7 33.0 | 23.5 43.0 43.4 | 36.0 38.8 39.8 | 32.8 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 32 | 60.4 | 66.7 | 28.0 | 32.6 | 20.8 | 34.1 | 44.7 | 41.0 | |
| 64 | 59.7 | 66.7 | 26.6 | 33.2 | 20.6 | 35.8 | 43.4 | 40.9 | |
| 128 | 60.6 | 67.4 | 25.7 | 32.0 | 22.6 | 34.7 | 43.2 | 40.9 | |
| VisualORM | 1 | 56.2 | 64.5 | 17.0 | 22.8 | 9.4 | 23.5 | 36.0 | 32.8 |
| 8 | 60.2 | 67.0 | 25.3 | 32.5 | 16.4 | 35.0 | 41.8 | 39.7 | |
| 16 | 58.3 | 67.7 | 27.0 | 33.6 | 16.6 | 33.1 | 39.1 | 39.3 | |
| 32 | 58.6 | 67.9 | 26.3 | 33.6 | 17.4 | 34.4 | 42.1 | 40.0 | |
| 64 | 59.4 | 66.8 | 28.6 | 33.9 | 17.8 | 34.1 | 42.3 | 40.4 | |
| 128 | 59.4 | 66.6 | 28.3 | 33.5 | 16.8 | 32.3 | 40.9 | 39.7 | |
| VisualPRM | 1 | 56.2 | 64.5 | 17.0 | 22.8 | 9.4 | 23.5 | 36.0 | 32.8 |
| 8 | 60.2 | 68.5 | 25.7 | 35.8 | 18.0 | 36.5 | 43.8 | 41.2 | |
| 16 | 60.2 | 69.9 | 27.3 | 36.4 | 19.0 | 38.8 | 42.5 | 42.0 | |
| 32 | 60.3 | 70.4 | 29.6 | 37.8 | 17.2 | 40.3 | 43.4 | 42.7 | |
| 64 | 61.4 | 69.6 | 30.6 | 38.2 | 18.8 | 40.2 | 45.4 | 43.5 | |
| 128 | 61.7 | 70.8 | 30.3 | 39.3 | 19.4 | 40.9 | 45.4 | 44.0 | |
Table 6: Overall Best-of-N results of InternVL2.5-8B across seven multimodal reasoning benchmarks with different critic models.
| Self Consistency 8 16 | 1 51.8 51.7 | 49.8 58.9 60.2 | 60.8 21.7 21.7 | 23.4 31.5 31.5 | 18.9 10.0 11.6 | 9.8 22.6 25.7 | 16.4 35.6 35.3 | 27.5 33.2 34.0 | 29.5 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 32 | 52.2 | 60.1 | 24.3 | 33.1 | 11.4 | 24.3 | 36.0 | 34.5 | |
| 64 | 51.7 | 61.0 | 23.4 | 34.8 | 12.8 | 25.8 | 35.3 | 35.0 | |
| 128 | 53.2 | 61.7 | 25.7 | 33.5 | 13.0 | 25.6 | 35.6 | 35.5 | |
| VisualORM | 1 | 49.8 | 60.8 | 23.4 | 18.9 | 9.8 | 16.4 | 27.5 | 29.5 |
| 8 | 55.7 | 66.0 | 22.0 | 33.5 | 10.2 | 24.1 | 38.9 | 35.8 | |
| 16 | 56.4 | 65.3 | 24.0 | 32.1 | 10.4 | 27.3 | 36.5 | 36.0 | |
| 32 | 58.8 | 64.8 | 19.7 | 35.7 | 12.0 | 29.4 | 38.5 | 37.0 | |
| 64 | 58.2 | 67.3 | 22.7 | 35.5 | 11.0 | 30.1 | 37.6 | 37.5 | |
| 128 | 58.2 | 66.5 | 25.3 | 35.4 | 11.6 | 30.0 | 40.7 | 38.2 | |
| VisualPRM | 1 | 49.8 | 60.8 | 23.4 | 18.9 | 9.8 | 16.4 | 27.5 | 29.5 |
| 8 | 56.8 | 65.7 | 24.7 | 35.8 | 11.2 | 31.0 | 37.4 | 37.5 | |
| 16 | 58.8 | 68.6 | 24.0 | 37.3 | 12.4 | 32.7 | 39.8 | 39.1 | |
| 32 | 57.8 | 68.4 | 26.6 | 38.5 | 13.4 | 35.3 | 39.1 | 39.9 | |
| 64 | 58.6 | 69.4 | 25.3 | 39.7 | 12.2 | 38.2 | 36.9 | 40.0 | |
| 128 | 59.3 | 69.4 | 25.3 | 39.1 | 14.4 | 37.0 | 38.3 | 40.4 | |
Table 7: Overall Best-of-N results of MiniCPM-V2.6 across seven multimodal reasoning benchmarks with different critic models.
| Threshold=0.00 Threshold=0.625 Threshold=0.125 | 59.3 59.7 58.0 | 68.5 66.8 67.9 | 25.7 24.7 27.6 | 35.8 36.7 35.4 | 18.0 18.4 17.4 | 36.5 35.0 35.3 | 43.8 41.8 41.6 | 41.1 40.4 40.5 | 62.0 61.0 60.7 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Threshold=0.25 | 58.6 | 67.6 | 25.7 | 33.6 | 16.8 | 36.0 | 41.4 | 40.0 | 60.2 |
| Temperature | | | | | | | | | |
| Temperature=0.3 | 59.7 | 69.4 | 26.0 | 32.6 | 17.6 | 35.5 | 42.7 | 40.5 | - |
| Temperature=0.7 | 59.3 | 68.5 | 25.7 | 35.8 | 18.0 | 36.5 | 43.8 | 41.1 | - |
| Temperature=1.0 | 61.7 | 67.2 | 27.3 | 35.8 | 16.6 | 34.2 | 43.2 | 40.9 | - |
| Temperature=1.3 | 57.9 | 66.1 | 25.0 | 32.1 | 16.8 | 31.9 | 40.5 | 38.6 | - |
Table 8: Ablation studies about the effects of expected accuracy threshold and generationo temperaure.
## 8 More Statistics for VisualProcessBench
<details>
<summary>x6.png Details</summary>
### Visual Description
\n
## Step Distribution Chart: Percentage of Steps by Index for Five Math Datasets
### Overview
This image is a step plot (or staircase line chart) displaying the distribution of "Steps (%)" across a "Step Index" for five distinct datasets. The chart visualizes how frequently problems or tasks of a certain step length (index) occur within each dataset, expressed as a percentage of the total. The data is heavily concentrated in the lower step indices (approximately 0-15), with a sharp decline thereafter.
### Components/Axes
* **Y-Axis:** Labeled **"Steps (%)"**. Scale ranges from 0 to 5, with major grid lines at intervals of 1. The axis represents the percentage of problems/steps in the dataset that correspond to a given step index.
* **X-Axis:** Labeled **"Step Index"**. Scale ranges from 0 to 30, with major ticks and labels at 5, 10, 15, 20, 25, and 30. The axis represents the sequential step number or problem length.
* **Legend:** Positioned in the **top-right corner** of the chart area. It contains five entries, each with a colored line and marker:
* **MathVision:** Dark gray line with circle markers.
* **MathVerse:** Red line with circle markers.
* **MMMU:** Blue line with circle markers.
* **DynaMath:** Green line with circle markers.
* **WeMath:** Purple line with circle markers.
* **Plot Area:** Features a light gray background with a dashed grid. Each dataset is represented by a colored step line and a semi-transparent shaded area of the same color beneath it.
### Detailed Analysis
The chart shows the percentage distribution of step counts for each dataset. The trend for all datasets is a concentration of data in the early step indices (roughly 4-15), followed by a long tail of very low percentages extending to index 30.
**Trend Verification & Data Points (Approximate Values):**
* **MathVerse (Red):** Exhibits the highest peaks. It rises sharply from index 4, reaching a major peak of **~5.3%** at index 7. It has another significant peak of **~4.8%** at index 14. The trend shows high variability in the early indices before dropping below 0.5% after index 15.
* **MathVision (Dark Gray):** Follows a similar pattern to MathVerse but with slightly lower peaks. Its highest point is **~5.0%** at index 14, closely matching MathVerse's second peak. It also shows a notable peak of **~2.9%** at index 8.
* **DynaMath (Green):** Shows moderate peaks. Its highest values are around **2.5-2.7%** in the index 4-8 range and again at index 14 (**~2.7%**).
* **MMMU (Blue):** Has the lowest overall percentages among the five. Its values generally stay below 1.5%, with a modest peak of **~1.2%** around index 7 and index 14.
* **WeMath (Purple):** Also has low percentages, similar to MMMU. It peaks at **~2.0%** at index 7 and shows a smaller peak of **~1.0%** at index 14.
**Spatial Grounding & Key Regions:**
1. **Primary Cluster (Indices 4-15):** This region contains all significant data mass. The lines for MathVerse and MathVision are consistently the highest, followed by DynaMath, then MMMU and WeMath.
2. **Secondary Cluster (Indices 15-30):** All datasets show a dramatic drop after index 15. Values in this region are uniformly low, mostly fluctuating between **0.0% and 0.4%**, forming a long tail.
3. **Notable Synchronization:** All five datasets show a pronounced local peak or step-up at **index 14**, suggesting a common characteristic or benchmark problem length across these collections.
### Key Observations
1. **Bimodal Distribution:** The data for the top datasets (MathVerse, MathVision) suggests a bimodal distribution with major concentrations around step indices 7-8 and 14-15.
2. **Sharp Cutoff:** There is a distinct and sharp decline in frequency for all datasets after step index 15. Problems requiring more than 15 steps are rare (<0.5%) in these collections.
3. **Dataset Hierarchy:** A clear hierarchy in step-count frequency is visible: MathVerse ≥ MathVision > DynaMath > MMMU ≈ WeMath. This implies MathVerse and MathVision contain a higher proportion of problems requiring a moderate number of steps (7-15).
4. **Common Anomaly at Index 14:** The synchronized peak at index 14 across all datasets is a significant anomaly, indicating this specific step length is disproportionately common.
### Interpretation
This chart likely analyzes the complexity or length of problems within different multimodal mathematical reasoning datasets. The "Step Index" probably corresponds to the number of reasoning steps required to solve a problem.
* **What the data suggests:** The datasets are not uniformly distributed across problem lengths. Instead, they are heavily skewed towards problems solvable in under 15 steps, with specific "sweet spots" around 7-8 and 14-15 steps. This could reflect dataset construction biases, the inherent nature of the mathematical problems included, or a focus on evaluating models on problems of a certain manageable complexity.
* **Relationship between elements:** The high correlation in the shape of the distributions (especially the peaks at 7 and 14) suggests these datasets may share similar sources, problem types, or design philosophies. The difference in magnitude (e.g., MathVerse being higher) indicates varying concentrations of these mid-length problems.
* **Notable implications:** The sharp cutoff after 15 steps implies these benchmarks may not effectively test a model's ability to handle very long, complex reasoning chains (20+ steps). The pronounced peak at 14 steps could be an artifact—perhaps a common template or a standard problem type that naturally requires 14 steps to solve. Researchers using these datasets should be aware that model performance might be heavily influenced by its ability to handle problems in the 7-15 step range.
</details>
(a)
<details>
<summary>x7.png Details</summary>
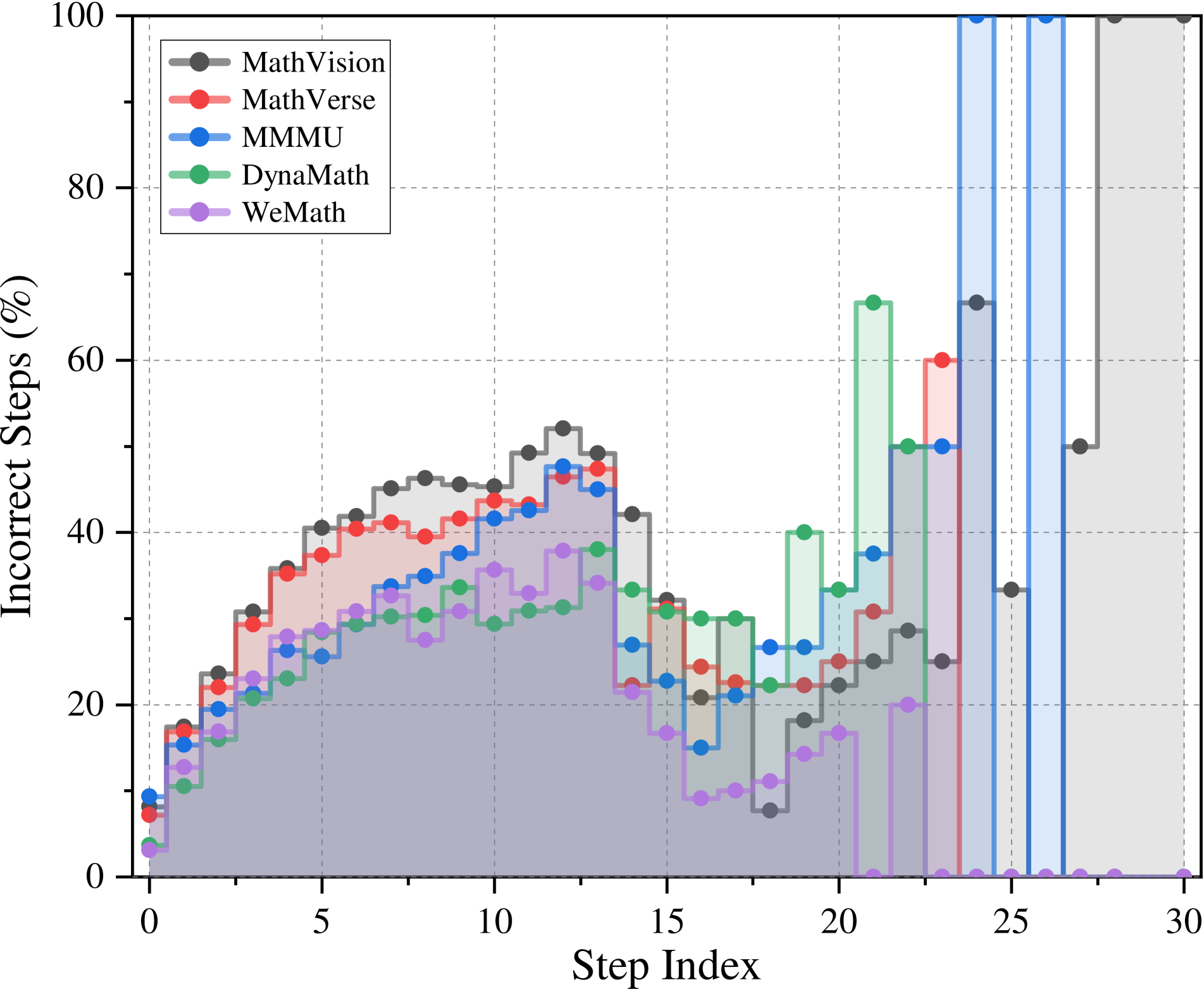
### Visual Description
\n
## Line Chart: Incorrect Steps (%) vs. Step Index for Five Datasets
### Overview
This is a line chart comparing the percentage of incorrect steps across a sequence of 30 steps for five different datasets or models. The chart illustrates how error rates evolve as the step index increases, showing distinct patterns of error accumulation and recovery for each series.
### Components/Axes
- **X-Axis**: Labeled "Step Index". It is a linear scale ranging from 0 to 30, with major tick marks every 5 units (0, 5, 10, 15, 20, 25, 30).
- **Y-Axis**: Labeled "Incorrect Steps (%)". It is a linear scale ranging from 0 to 100, with major tick marks every 20 units (0, 20, 40, 60, 80, 100).
- **Legend**: Positioned in the top-left corner of the chart area. It contains five entries, each with a colored line and circular marker:
- **MathVision**: Black line with black circular markers.
- **MathVerse**: Red line with red circular markers.
- **MMMU**: Blue line with blue circular markers.
- **DynaMath**: Green line with green circular markers.
- **WeMath**: Purple line with purple circular markers.
- **Data Series**: Each dataset is represented by a stepped line (showing discrete changes at each step index) with a semi-transparent shaded area beneath it, filling down to the x-axis.
### Detailed Analysis
**Trend Verification & Data Points (Approximate Values):**
1. **MathVision (Black Line):**
* **Trend**: Shows a steady, steep increase from step 0 to a peak around step 12-13, followed by a decline and high volatility with extreme spikes in the later steps.
* **Key Points**: Starts near 0%. Rises to ~52% at step 12. Declines to ~20% at step 18. Spikes dramatically to ~67% at step 23, then to ~100% at steps 24-26. Ends at ~50% at step 30.
2. **MathVerse (Red Line):**
* **Trend**: Follows a similar initial rise to MathVision but peaks slightly lower. It then declines and shows moderate volatility with one significant late spike.
* **Key Points**: Starts near 0%. Rises to ~48% at step 13. Declines to ~22% at step 18. Spikes to ~60% at step 23. Ends at ~50% at step 30.
3. **MMMU (Blue Line):**
* **Trend**: Rises steadily but remains below MathVision and MathVerse in the first half. It experiences a sharp drop, followed by volatility and the most extreme, sustained spike to 100%.
* **Key Points**: Starts near 10%. Rises to ~45% at step 13. Drops sharply to ~15% at step 16. Spikes to ~50% at step 22, then to 100% at steps 24-26. Ends at ~50% at step 30.
4. **DynaMath (Green Line):**
* **Trend**: Has the slowest initial rise. After a mid-chart decline, it exhibits a very sharp, isolated spike before returning to a moderate level.
* **Key Points**: Starts near 0%. Rises to ~38% at step 13. Declines to ~22% at step 18. Spikes sharply to ~66% at step 21. Ends at ~50% at step 30.
5. **WeMath (Purple Line):**
* **Trend**: Rises the least in the initial phase. After step 15, it shows a consistent and significant decline, ultimately achieving the lowest error rate.
* **Key Points**: Starts near 0%. Rises to ~35% at step 13. Declines steadily after step 15. Drops to near 0% from step 20 onward, remaining at ~0% through step 30.
**Spatial Grounding & Component Isolation:**
- The **legend** is anchored in the top-left quadrant, overlapping the grid lines but not the primary data trends in the early steps.
- The **shaded areas** under each line create a layered, overlapping visual in the first half of the chart (steps 0-15), making individual series harder to distinguish. The separation becomes clearer after step 15 as the lines diverge.
- The most dramatic visual elements are the **vertical spikes** in the MathVision (black), MMMU (blue), and DynaMath (green) series between steps 20-27, which dominate the right side of the chart.
### Key Observations
1. **Common Initial Phase**: All five series show a general trend of increasing incorrect steps from step 0 to approximately step 13, suggesting a common pattern of error accumulation in the early stages of the process being measured.
2. **Critical Divergence Point**: Around step 15, the behaviors of the series diverge significantly. This is a key inflection point in the data.
3. **Extreme Late-Stage Volatility**: MathVision, MMMU, and DynaMath exhibit extreme, sudden spikes in incorrect steps after step 20, with MathVision and MMMU reaching the maximum value of 100%. This indicates catastrophic failure modes at specific late steps for these models/datasets.
4. **WeMath's Anomalous Success**: WeMath is a clear outlier in the latter half. After step 15, its error rate plummets and stabilizes near 0%, indicating a fundamentally different and more robust performance profile in the later stages compared to the others.
5. **Convergence at the End**: Despite wildly different paths, MathVision, MathVerse, MMMU, and DynaMath all converge to a similar incorrect step percentage (~50%) at the final step (30).
### Interpretation
This chart likely visualizes the performance of different AI models or methods on a multi-step reasoning task (e.g., solving math problems). The "Step Index" represents sequential sub-problems or reasoning steps.
- **What the data suggests**: The initial rise in errors for all models indicates that early mistakes are common and may compound. The divergence after step 15 suggests that models handle mid-to-late stage complexity very differently. The extreme spikes imply that certain steps (around 21, 23, 24-26) are "killer steps" that cause total failure for some models. WeMath's performance suggests it either has a superior mechanism for error correction or is less susceptible to cascading failures in later stages.
- **Relationship between elements**: The shaded areas emphasize the cumulative burden of incorrect steps. The overlapping early phase shows shared difficulty, while the separated later phase highlights model-specific strengths and weaknesses. The final convergence at 50% is curious—it may indicate that for the very last step, models either succeed or fail in a balanced way, or it could be an artifact of the evaluation metric.
- **Notable anomalies**: The 100% incorrect steps for MathVision and MMMU are the most striking anomalies, representing complete breakdown. WeMath's drop to 0% is equally anomalous in the positive direction. The chart effectively tells a story of initial uniform struggle, followed by a crisis point where models either spectacularly fail, moderately persist, or brilliantly recover.
</details>
(b)
Figure 5: Step Distribution of VisualProcessBench. The X-axis represents the step index. (a) The Y-axis indicates the proportion of steps at each index relative to the total number of steps, reflecting the distribution of step positions in solutions. (b) The Y-axis represents the error rate of steps at each index, showing the likelihood of errors occurring at different step positions.
The statistics for step distribution of VisualProcessBench is presented in Figure 5. We observe that most solutions consist of fewer than 15 steps. Among these solutions with fewer than 15 steps, most solutions contain about 7 or 13 steps. For the correctness of each step, we observe that the error rate is lower in the first three steps and then increases as the step index grows. We attribute this to the fact that problems requiring more reasoning steps tend to be more challenging, leading to a gradual rise in step error rates. Notably, starting from step 15, the error rate drops sharply. This is because the number of steps in this range is relatively small, resulting in significant statistical fluctuations.
## 9 More Data Examples in VisualPRM400K
In this section, we provide more data examples of VisualPRM400K in Figure 6 from different domains, including general visual question answering (VQA) [23, 28, 52, 48], science [31, 13, 49], chart [53, 29, 12], mathematics [40, 65, 11, 47, 30, 22], OCR [54, 67, 8, 27, 56], and document [17].
## 10 More Data Examples in VisualProcessBench
In this section, we provide more data examples in VisualProcessBench from different data sources. Specifically, we randomly choose three examples from our benchmark and visualize them in Figure 7. Additionally, in Figure 8, we provide an example where the model initially generates an incorrect answer and then autonomously corrects it.
<details>
<summary>x8.png Details</summary>

### Visual Description
## Document Analysis: Receipt and Solution Breakdown
### Overview
The image is a composite technical document displaying two primary components side-by-side. On the left is a scanned copy of a commercial receipt. On the right is a structured, step-by-step solution to a question derived from the receipt, complete with confidence scores for each step. The document appears to be an example from an OCR (Optical Character Recognition) or automated reasoning system, as indicated by the "OCR" header at the top.
### Components/Axes
The image is divided into two main vertical panels.
**Left Panel (Receipt):**
* **Header Information:** Contains business details, invoice metadata, and table number.
* **Itemized List:** A table with columns for ITEM, QTY (Quantity), U/P (Unit Price), DISC (Discount), Amt+GST (Amount including Goods and Services Tax).
* **Totals Section:** Lists subtotals, service charge, total sales, rounding adjustment, final TOTAL, CASH tendered, and CHANGE given.
* **Footer:** Contains item count, discount total, and a GST Summary table.
**Right Panel (Solution):**
* **Question:** A single-line query about the receipt.
* **Solution:** A numbered list of steps (Step-0 to Step-9). Each step is prefixed with a confidence score in the format `(mc=0.XXXX)`, where `mc` likely stands for "model confidence." The steps logically break down the process of extracting the answer from the receipt.
### Detailed Analysis
#### **Receipt Content (Left Panel)**
* **Business Header:**
* `Geoventure`
* `Taste Of The World Sdn Bhd`
* `965857-A`
* `Lot 38, 39 1st Boulevard,`
* `Jalan Kenari 5, Bandar Puchong Jaya,`
* `47170 Puchong, Selangor`
* `TEL: 03 - 8079 0255`
* `GST REG NO: 000136577024`
* `RESERVATION NO: 010 - 7745055`
* `SIMPLIFIED TAX INVOICE`
* **Invoice Details:**
* `Invoice: 581355`
* `Cashier: NINI`
* `POS No: 1`
* `Pax: 0`
* `Date: 5/3/2018 22:52:33`
* `Table No: C38` (This appears to be stamped or handwritten).
* **Itemized Table:**
* **Item 1:** `S Tiger Bucket`, `GTG02`, Qty: `1`, U/P: `55.00`, DISC: `0+0`, Amt+GST: `55.00`.
* **Item 2:** `S Service Chrg(Incl GST 6%)`, Amount: `RM 5.83`.
* **Subtotal Line:** `Total Sales (Incl GST 6%)`, Amount: `RM 64.13`.
* **Adjustment:** `Rounding Adjustment`, Amount: `RM 0.02`.
* **Payment Summary:**
* `TOTAL`: `RM 64.15`
* `CASH`: `RM 100.00`
* `CHANGE`: `RM 35.85`
* **Footer Details:**
* `Main Item Count`: `1`
* `Total Discount`: `RM 0.00`
* **GST Summary Table:**
* Header: `GST Summary`, `Amount (RM)`, `Tax (RM)`
* Row 1: `S`, `6%`, `60.50`, `3.63`
* Row 2: `Z`, `0%`, `0.00`, `0.00`
#### **Solution Content (Right Panel)**
* **Question:** `What is the total amount of this receipt?`
* **Solution Steps:**
* `## Step-0 (mc=0.5625)`: To determine the total amount on this receipt, follow these steps:
* `## Step-1 (mc=0.8125)`: 1. Identify the items and their prices on the receipt: "S Tiger Bucket" costs RM 55.00.
* `## Step-2 (mc=0.5625)`: 2. Add up the total cost of the items: Total cost of the items: RM 55.00.
* `## Step-3 (mc=0.4375)`: 3. Look for any additional charges (if any): There is a service charge (S.Chrg) including GST of RM 5.83.
* `## Step-4 (mc=0.5625)`: 4. Include the service charge in the total cost: Total with service charge: RM 55.00 + RM 5.83 = RM 60.83.
* `## Step-5 (mc=0.8125)`: 5. Total Sales (including GST): RM 64.15 is listed under "Total Sales (Incl GST 6%)". This includes the GST (which is calculated based on the service charge).
* `## Step-6 (mc=0.5)`: 6. Calculate the amount paid by the customer: Cash paid: RM 100.00.
* `## Step-7 (mc=0.625)`: 7. Subtract the total sales from the amount paid: Change received: RM 100.00 - RM 64.15 = RM 35.85.
* `## Step-8 (mc=0.0625)`: So, the total amount on this receipt is the customer's cash payment:
* `## Step-9 (mc=0.0)`: Final answer: 100.00
### Key Observations
1. **Data Consistency:** The numerical data in the solution steps (RM 55.00, RM 5.83, RM 64.15, RM 100.00, RM 35.85) is perfectly consistent with the corresponding values on the receipt.
2. **Confidence Score Trend:** The model's confidence (`mc`) fluctuates significantly. It is highest (0.8125) for steps involving direct data extraction (Step-1, Step-5) and lowest (0.0) for the final answer step, suggesting uncertainty in the interpretation of the question.
3. **Logical Discrepancy in Solution:** The solution's final conclusion (Step-8 & Step-9) states the "total amount" is the cash payment of RM 100.00. However, the receipt's explicit `TOTAL` is RM 64.15. The solution interprets "total amount" as the amount tendered by the customer, not the invoice total. This is a critical semantic ambiguity.
4. **Receipt Anomaly:** The `Total Sales (Incl GST 6%)` is listed as `RM 64.13`, but the final `TOTAL` is `RM 64.15`. The difference of `RM 0.02` is accounted for by the `Rounding Adjustment` line, which is a common practice for cash transactions.
### Interpretation
This document serves as a case study for an automated system processing a financial document. The receipt itself is a standard Malaysian tax invoice, detailing a single item purchase with a service charge and GST. The solution panel demonstrates a reasoning chain attempting to answer a natural language question about the receipt.
The core investigative finding is the **interpretation gap**. The question "What is the total amount of this receipt?" is ambiguous. A human would almost certainly answer RM 64.15 (the invoice total). The automated system, however, follows a logical path that culminates in identifying the cash payment (RM 100.00) as the answer. This highlights a key challenge in AI: moving from accurate data extraction (which the system does well) to correct contextual interpretation of human language. The plummeting confidence score in the final steps (`mc=0.0625` then `mc=0.0`) may indicate the model's internal uncertainty about this interpretive leap. The document thus illustrates not just OCR capability, but the complexities of automated reasoning and the importance of precise question formulation.
</details>
(a)
<details>
<summary>x9.png Details</summary>

### Visual Description
## Document Screenshot: Question and Solution Analysis
### Overview
The image is a horizontal screenshot displaying a two-part layout. On the left is a scanned, grayscale image of a typed document (a letter or note). On the right is a structured, digital text block presenting a question about the document and a step-by-step solution to answer it. The overall context appears to be an example of a document-based question-answering task, possibly from an educational or technical dataset.
### Components/Axes
The image is divided into two primary regions:
1. **Left Region (Document Scan):** A rectangular area containing a scanned paper document. The paper has visible texture and some minor smudges or marks. The text is typewritten in a monospaced font.
2. **Right Region (Question & Solution):** A clean, digital text area with a white background. It contains a bold header "Question:", a question in plain text, a bold header "Solution:", and a series of steps formatted with markdown-like syntax (`## Step-X`) and associated confidence scores (`mc=...`).
### Detailed Analysis / Content Details
#### Left Region: Scanned Document Transcription
The scanned document contains the following text, transcribed line by line. The language is English.
```
Mr. Plock:
Dudley's sister gave me his new address. It is
POW
Company B -- USNTS
Ward Island, Corpus Christie, Texas.
I wrote to him today, (11/20) and repeated my that you were busy in
NYC today, Washington Monday. This Island is a training base and supple-
ments his book learning.
Charles.
```
* **Spatial Grounding:** The text is left-aligned on the page. The date "(11/20)" is located in the third line of the main paragraph, enclosed in parentheses. The signature "Charles." is at the bottom right of the text block.
* **Source Annotation:** At the very bottom of the scanned image, in a smaller font, is the text: `Source: https://www.industrydocuments.ucsf.edu/docs/ffhl0226`
#### Right Region: Question and Solution Transcription
The digital text on the right is as follows:
**Question:**
What is the date mentioned in the document?
**Solution:**
```
## Step-0 (mc=0.0625) To determine the date mentioned in the document, let's follow these steps:
## Step-1 (mc=0.1875) 1.Look for any reference to a date in the text.
2.Identify the date by its numerical form or any text that explicitly mentions a date.
## Step-2 (mc=0.125) Steps broken down:
## Step-3 (mc=0.5625) 1.In the document, the date "11/20" is mentioned in the text.
2.This is likely an abbreviation of November 20, indicating a date.
## Step-4 (mc=0.0) Final answer: 11/20
```
* **Component Isolation:** The solution is segmented into five distinct steps (Step-0 to Step-4). Each step is prefixed with a confidence score (`mc=`) in green text, except for Step-4 which has `mc=0.0` in red. The steps logically progress from stating the goal, to outlining the method, to executing the method, to stating the final answer.
### Key Observations
1. **Data Extraction Accuracy:** The solution correctly identifies the date "11/20" from the document text. The transcription in Step-3 matches the text in the scanned document exactly.
2. **Confidence Score Pattern:** The confidence scores (`mc` values) fluctuate through the steps (0.0625, 0.1875, 0.125, 0.5625, 0.0). The highest confidence (0.5625) is assigned to the step that directly extracts the date from the text. The final answer step has a confidence of 0.0, which may indicate a system-specific notation for a concluded answer rather than low confidence.
3. **Document Context:** The scanned document is a personal letter providing an update about a third party ("Dudley") and mentioning the sender's ("Charles") recent correspondence. The date "11/20" is embedded within a narrative sentence.
### Interpretation
This image demonstrates a closed-loop example of information extraction from an unstructured source (a scanned letter) to answer a specific factual question. The process is explicitly broken down, showing the reasoning steps an automated system or a human might follow.
* **What the data suggests:** The document contains a clear, unambiguous date reference ("11/20"). The solution process validates that this is the only date mentioned and correctly interprets it as a month/day format.
* **How elements relate:** The left side provides the raw data source. The right side models the cognitive process of querying that source. The connection is direct and successful, as the solution's final answer is verifiable against the source document.
* **Notable patterns:** The structure highlights a methodical approach to document QA: 1) Define the task, 2) Establish a search strategy, 3) Locate and extract the specific data point, 4) Interpret the data format, 5) Provide the answer. The inclusion of confidence scores suggests this may be output from a model or a system designed to quantify certainty at each reasoning step.
* **Underlying information:** The document itself, while serving as an example here, originates from the UCSF Industry Documents Library, indicating it is part of a historical archive, likely related to tobacco or other industry litigation. The content of the letter (mentioning a training base, "USNTS" possibly meaning U.S. Naval Training Station) provides a small glimpse into personal correspondence from a specific historical context.
</details>
(b)
<details>
<summary>x10.png Details</summary>

### Visual Description
## Mathematics Problem: Sphere Subtraction
### Overview
The image displays a mathematics problem presented in a structured format. It consists of a header, a 3D rendered visual aid on the left, and a textual question with a step-by-step solution on the right. The problem involves counting and subtracting specific objects from a visual scene.
### Components
1. **Header:** The word "Mathematics" is displayed in the top-left corner, underlined by a horizontal blue line that spans the width of the content area.
2. **Visual Aid (Left Side):** A 3D rendered image showing several geometric objects on a plain, light-gray surface. The objects are:
* A small, matte blue sphere (left).
* A small, matte gray cylinder (front-left).
* A small, matte yellow cube (center-back).
* A small, matte purple cube (center).
* A large, shiny red sphere (center-right, behind the blue sphere).
* A large, shiny blue sphere (center-right, in front of the red sphere).
* A large, shiny blue cylinder (right).
3. **Textual Content (Right Side):**
* **Question:** "Subtract all red shiny spheres. How many spheres are left?"
* **Solution:** A numbered list of steps, each prefixed with a step label and a confidence score (`mc` value) in parentheses.
* `## Step-0 (mc=0.6875)` To determine how many spheres are left after subtracting the red shiny sphere, let's break down the objects in the image step by step:
* `## Step-1 (mc=0.0)` 1.There are two spheres visible in the image.
* `## Step-2 (mc=0.0625)` 2.One of these spheres is red and shiny.
* `## Step-3 (mc=0.0)` 3.The other sphere is blue and shiny.
* `## Step-4 (mc=0.0)` Since the question asks for the spheres after removing the red one, we need to subtract the red sphere from the total count of spheres.
* `## Step-5 (mc=0.0)` Final answer: 1
### Detailed Analysis
* **Object Inventory from Visual Aid:**
* **Spheres:** 2 total. One is large, shiny, and red. One is large, shiny, and blue.
* **Cylinders:** 2 total. One is small and matte gray. One is large and shiny blue.
* **Cubes:** 2 total. One is small and matte yellow. One is small and matte purple.
* **Solution Logic:**
1. The solution correctly identifies the total number of spheres in the image as two.
2. It correctly identifies the properties of each sphere: one is red and shiny, the other is blue and shiny.
3. The operation is defined as subtracting (removing) all red shiny spheres from the total set of spheres.
4. Calculation: 2 (total spheres) - 1 (red shiny sphere) = 1 sphere remaining.
* **Confidence Scores (`mc` values):** The solution steps are annotated with numerical confidence scores. The initial step (Step-0) has a moderate confidence of 0.6875. The subsequent factual statements (Steps 1, 2, 3) and the final answer step have very low confidence scores (0.0 or 0.0625), which is an unusual annotation for a straightforward logical deduction.
### Key Observations
* The visual scene contains objects of varying colors (blue, gray, yellow, purple, red), materials (matte, shiny), and shapes (sphere, cylinder, cube).
* The problem and solution focus exclusively on the subset of objects that are both "spheres" and "shiny," and further filters by color.
* The confidence scores (`mc` values) attached to the solution steps are inconsistent with the clarity of the problem. The factual observations (e.g., "there are two spheres") are given near-zero confidence, while the introductory meta-commentary has the highest confidence.
### Interpretation
This image presents a basic visual arithmetic problem designed to test object recognition and attribute filtering (shape, material, color) followed by simple subtraction. The 3D render provides the necessary data, and the text outlines the logical process to arrive at the answer.
The notable anomaly is the inclusion of `mc` (likely "model confidence") scores. Their values do not correlate with the objective truth of the statements. For instance, the statement "One of these spheres is red and shiny" is visually verifiable and should have high confidence, yet it is assigned `mc=0.0625`. This suggests the `mc` values may be artifacts of an automated generation or evaluation process, rather than a meaningful measure of the solution's correctness. The core informational content—the problem, the visual data, and the logical solution—remains clear and unambiguous despite these confusing annotations. The final answer, "1", is correct based on the provided visual evidence.
</details>
(c)
<details>
<summary>x11.png Details</summary>

### Visual Description
## Diagram: Footprint Analysis for Foot Type Identification
### Overview
The image is a technical educational diagram from a "Science" section, presenting a multiple-choice question about identifying foot types from footprint impressions. It includes three footprint silhouettes labeled B, A, and D, a question, multiple-choice options, and a detailed step-by-step solution with confidence scores.
### Components/Axes
* **Header:** The word "Science" is positioned in the top-left corner.
* **Diagram Area (Left Side):** Contains three black footprint silhouettes arranged horizontally.
* **Footprint B (Left):** Shows a footprint with a moderate arch impression. Labeled with a blue rectangle containing the white letter "B" directly below it.
* **Footprint A (Center):** Shows a footprint with almost no arch, appearing as a full, solid impression. Labeled with a blue rectangle containing the white letter "A" directly below it. A blue rectangle containing the white letter "C" is positioned above this footprint.
* **Footprint D (Right):** Shows a footprint with a very pronounced, narrow arch, leaving a distinct gap in the midfoot area. Labeled with a blue rectangle containing the white letter "D" directly below it.
* **Text Area (Right Side):** Contains the question and solution.
* **Question:** "Diagram D corresponds with what foot type? Normal Flat Rigid Big. Please answer the question based on the options mentioned before."
* **Solution:** A multi-step analysis with associated confidence scores (`mc` values). Each step is prefixed with "## Step-X" and contains a confidence score in parentheses (e.g., `(mc=0.75)`).
### Detailed Analysis / Content Details
**Transcribed Text from Solution:**
* **Step-0 (mc=0.75):** "To determine the foot type corresponding to Diagram D, let us analyze the footprint:"
* **Step-1 (mc=0.9375):** "1.Normal Foot: This type of footprint generally shows evenly distributed pressure across the sole, with well-defined arches."
* **Step-2 (mc=1.0):** "2.Flat Foot: The footprint of a flat foot typically shows the entire foot pressing against the ground, with little to no arch (or almost no arch) visible."
* **Step-3 (mc=1.0):** "3.Rigid Foot: This type of footprint is harder to identify but generally tends to show little flexibility or bouncing when walking."
* **Step-4 (mc=0.9375):** "4.Big Foot: This option seems to refer to the general size of the foot rather than its type based on pressure distribution."
* **Step-5 (mc=0.0):** "Upon examining Diagram D, the footprint shows that the heel and the front of the foot are touching the ground while the arch is distinctly visible. This is characteristic of a normal foot, where there is a clear arch leaving an impression on the ground."
* **Step-6 (mc=0.0):** "Final answer: Normal"
**Visual Analysis of Footprints:**
* **Footprint B:** Displays a moderate, curved arch. The impression connects the heel and forefoot with a band of moderate width.
* **Footprint A:** Displays a full, solid impression from heel to toe with no visible arch gap. This matches the textual description of a "Flat Foot."
* **Footprint D:** Displays a very narrow connection between the heel and forefoot, indicating a high, pronounced arch. The solution text explicitly identifies this as characteristic of a "Normal Foot."
### Key Observations
1. **Direct Labeling:** Each footprint is unambiguously labeled with a letter (B, A, D) in a blue box below it. An additional label "C" is placed above the central footprint (A).
2. **Solution Logic:** The solution systematically defines each foot type option (Normal, Flat, Rigid, Big) before applying the definitions to Diagram D.
3. **Confidence Scores:** The solution includes numerical confidence scores (`mc` values) for each analytical step, ranging from 0.0 to 1.0. The final two steps (Step-5 and Step-6) have a confidence score of 0.0, which may indicate a system artifact or a different scoring metric for conclusion steps.
4. **Visual-Textual Correlation:** The visual characteristic of Footprint D (distinct arch) is directly correlated with the textual definition of a "Normal Foot" in Step-1 and Step-5.
5. **Elimination of "Big Foot":** The solution explicitly dismisses the "Big Foot" option as pertaining to size, not the pressure-distribution-based type being analyzed.
### Interpretation
This diagram serves as an educational tool for teaching biomechanical or anatomical classification based on static footprint analysis. The core principle demonstrated is that the shape of a wet footprint or pressure impression can indicate arch height and, by extension, foot type.
* **What the Data Suggests:** The primary data point is the visual form of Footprint D. Its pronounced arch is presented as the definitive evidence for classifying it as a "Normal" foot type within this specific diagnostic framework. The accompanying text provides the necessary criteria to make this classification.
* **Relationship Between Elements:** The diagram (visual evidence) and the solution text (diagnostic criteria) are interdependent. The text defines the categories, and the diagram provides the case study (D) to which those categories are applied. The labels (A, B, D) are crucial for linking the visual examples to the analytical process.
* **Notable Anomalies:** The inclusion of confidence scores (`mc` values) is unusual for a standard educational diagram and suggests this image may be output from an AI tutoring system or a diagnostic algorithm that quantifies certainty at each reasoning step. The 0.0 scores on the concluding steps are particularly noteworthy and may indicate a specific technical reporting style rather than a lack of confidence in the answer. The label "C" above footprint A is not referenced in the question or solution, making its purpose ambiguous—it may be a remnant from a larger diagram or a label for the central example.
</details>
(d)
<details>
<summary>x12.png Details</summary>

### Visual Description
## General VQA: Symmetry Assessment Problem
### Overview
The image is a structured example of a Visual Question Answering (VQA) task. It presents a visual diagram alongside a multiple-choice question and a step-by-step solution with confidence scores. The content is educational or technical, demonstrating how an AI or a person might analyze an image to answer a question about symmetry.
### Components/Axes
The image is divided into two main regions:
1. **Left Region (Diagram):** Contains a graphical element.
* **Object:** A stylized, blue, 3D-rendered object resembling a flying object, shell, or abstract form. It has a darker blue underside and lighter blue top surfaces.
* **Line:** A black, dashed diagonal line runs from the top-left corner to the bottom-right corner of the diagram's bounding box, passing through the object.
* **Bounding Box:** The diagram is enclosed within a thin black rectangular border.
2. **Right Region (Text):** Contains the textual problem and solution.
* **Header:** "General VQA" in bold, located at the top-left of the entire image, followed by a horizontal line.
* **Question Section:**
* Label: "Question:" in bold.
* Text: "Does this picture have symmetry?"
* Options: "A. yes" and "B. no" listed vertically.
* **Solution Section:**
* Label: "Solution:" in bold.
* Steps: Four steps labeled "## Step-0" through "## Step-3", each followed by a confidence score in parentheses (e.g., `(mc=0.625)`). The text for Steps 1, 2, and 3 is in a lighter gray color.
* Step Content: A numbered list (1, 2, 3) explaining the reasoning process.
* Conclusion: The text "Final answer: A".
### Detailed Analysis
**Text Transcription:**
All text in the image is in English.
```
General VQA
Question:
Does this picture have symmetry?
A. yes
B. no
Solution:
## Step-0 (mc=0.625) To determine if the picture has symmetry, follow these steps:
## Step-1 (mc=0.0) 1.Identify the object in the picture. In this case, it is a stylized representation of a flying object.
## Step-1 (mc=0.0) 2.Look at the object's shape. The object appears to be bilaterally symmetrical, meaning it is symmetrical around a line that runs down the middle of the object.
## Step-2 (mc=0.0) 3.This symmetry can be demonstrated by the object appearing to be a mirror image of itself along the central vertical line.
## Step-3 (mc=0.0) Since the object appears to meet the criteria for symmetry, the answer is:
Final answer: A
```
*Note: The step labels "## Step-1" appear twice consecutively in the original text.*
**Diagram Analysis:**
* The blue object is oriented horizontally. Its left side features a rounded, bulbous shape, while the right side tapers into a series of ridged or segmented sections.
* The dashed diagonal line does **not** align with the object's apparent axis of symmetry. The object's natural axis of symmetry appears to be a horizontal line running through its center from left to right, not a vertical or diagonal one.
### Key Observations
1. **Text-Image Discrepancy:** The solution text (Step 2) describes the symmetry axis as a "central vertical line." However, the accompanying diagram shows a **diagonal** dashed line. This is a significant inconsistency between the visual evidence and the written reasoning.
2. **Confidence Score Pattern:** The initial step (`Step-0`) has a moderate confidence score (`mc=0.625`), while all subsequent reasoning steps and the final answer have a confidence score of `0.0`. This suggests the system is confident in initiating the process but has zero confidence in the specific logical steps it generated.
3. **Object Symmetry:** Visually, the blue object itself appears to have **bilateral symmetry along a horizontal axis** (if rotated 90 degrees). The top half mirrors the bottom half. It does not exhibit symmetry along the diagonal line drawn.
### Interpretation
This image serves as a meta-example of AI reasoning, likely used for training or evaluation. It demonstrates a process where a model attempts to answer a visual question but contains internal contradictions.
* **What the data suggests:** The model correctly identifies the need to look for symmetry and concludes "yes." However, its reasoning is flawed. It incorrectly identifies the axis of symmetry as vertical, which contradicts both the visual diagram (which shows a diagonal line) and the object's actual horizontal symmetry. The zero confidence scores for the reasoning steps may indicate the model's internal uncertainty or a failure in its self-evaluation mechanism.
* **How elements relate:** The diagram is meant to illustrate the problem, but the dashed line seems to be a generic placeholder or an error, as it doesn't correspond to the symmetry axis described in the text. The text provides a logical flow that arrives at an answer, but the logic is based on a misinterpretation of the visual data.
* **Notable anomalies:** The primary anomaly is the disconnect between the described "central vertical line" and the depicted diagonal line. This highlights a potential failure mode in multimodal AI where textual reasoning and visual perception are not properly aligned. The object's true symmetry (horizontal) is never mentioned in the solution.
</details>
(e)
<details>
<summary>x13.png Details</summary>

### Visual Description
## Horizontal Bar Chart: Public Perception of Party Competence on Key Issues
### Overview
The image displays a horizontal bar chart titled "Democrats Hold Advantages on Environment, Abortion, Education; Neither Party Has Edge on the Economy." It presents survey data on the percentage of respondents who believe the Democratic or Republican Party is better able to handle a series of specific issues. To the right of the chart, a question and a step-by-step solution are provided, calculating a ratio based on one of the data points.
### Components/Axes
* **Chart Title:** "Democrats Hold Advantages on Environment, Abortion, Education; Neither Party Has Edge on the Economy"
* **Subtitle:** "% who say each party is better able to handle..."
* **Columns (Left to Right):**
1. **Issue Category:** A list of 11 policy issues.
2. **Democratic Party:** A blue bar and percentage value.
3. **Republican Party:** A red bar and percentage value.
4. **Diff:** The difference between the two percentages, labeled with "D+" (Democratic advantage) or "R+" (Republican advantage).
* **Legend:** Implicitly defined by column headers and bar colors: Blue = Democratic Party, Red = Republican Party.
* **Footer Text:** "Survey conducted July 14-20, 2015. PEW RESEARCH CENTER"
### Detailed Analysis
**Chart Data (Issue, Democratic %, Republican %, Difference):**
1. **Gun control:** 36% (D), 48% (R), R+12
2. **Terrorist threat:** 34% (D), 44% (R), R+10
3. **Budget deficit:** 37% (D), 41% (R), R+4
4. **Taxes:** 41% (D), 42% (R), R+1
5. **Immigration:** 42% (D), 40% (R), D+2
6. **Economy:** 44% (D), 41% (R), D+3
7. **Foreign policy:** 41% (D), 38% (R), D+3
8. **Health care:** 46% (D), 36% (R), D+10
9. **Education:** 46% (D), 34% (R), D+12
10. **Abortion & contraception:** 50% (D), 31% (R), D+19
11. **Environment:** 53% (D), 27% (R), D+26
**Question & Solution Text (Right Side):**
* **Question:** "What is the ratio between Democratic and Republican Party in Foreign policy?"
* **Solution Steps (Transcribed from visible text):**
* **Step-0 (mc=0.5625):** "To determine the ratio between the percentage of Democrats and Republicans who believe that their party is better able to handle foreign policy, we need to look at the corresponding values in the table."
* **Step-1 (mc=0.3125):** "1. Identify the percentage of Democrats who think the Democratic Party is better at handling foreign policy. In the "Foreign policy" row, the percentage is 41%."
* **Step-2 (mc=0.375):** "2. Identify the percentage of Republicans who think the Republican Party is better at handling foreign policy. In the "Foreign policy" row, the percentage is 38%."
* **Step-3 (mc=0.6875):** "3. The ratio between the percentage of Democrats and Republicans is calculated by dividing the percentage of Democrats by the percentage of Republicans."
* **Step-4 (mc=0.5):** "\[ \text{Ratio} = \frac{\text{Percentage of Democrats}}{\text{Percentage of Republicans}} \]"
* **Step-5 (mc=0.75):** "\[ \text{Ratio} = \frac{41}{38} \]"
* **Step-6 (mc=0.0):** "Final answer: \( \frac{41}{38} \)" (Note: The final answer text is partially faded/obscured but the fraction is legible).
### Key Observations
1. **Clear Issue-Based Divide:** The chart shows a stark partisan divide on issues. Democrats hold significant advantages on social and domestic policy issues (Environment +26, Abortion +19, Education +12, Health care +10). Republicans hold advantages on security and fiscal issues (Gun control +12, Terrorist threat +10, Budget deficit +4).
2. **Economy as a Toss-Up:** The "Economy" issue shows the smallest Democratic advantage (D+3), aligning with the chart's title stating neither party has a clear edge.
3. **Data Consistency:** The solution on the right correctly extracts the values for "Foreign policy" (D:41%, R:38%) from the chart and performs the stated calculation.
4. **Visual Layout:** The chart is positioned on the left third of the image. The question and solution occupy the right two-thirds. The legend (column headers) is at the top of the chart area.
### Interpretation
This data, from a 2015 Pew Research Center survey, illustrates the perceived comparative advantages of the two major U.S. political parties on key national issues. The pattern suggests that voter trust is highly segmented by policy domain.
* **Democratic Strengths:** The Democratic Party's largest leads are on issues often framed around social welfare, individual rights, and regulation (environment, healthcare, education, reproductive rights). This reflects a brand associated with government-led solutions in these areas.
* **Republican Strengths:** The Republican Party's largest leads are on issues framed around security, defense, and fiscal restraint (terrorism, gun rights, deficits). This aligns with a brand emphasizing national security and limited government spending.
* **The "Foreign Policy" Ratio:** The specific calculation requested (41/38 ≈ 1.08) shows a very slight Democratic advantage in perceived competence on foreign policy at the time of the survey. This is a relatively small margin (D+3), placing it closer to the "Economy" as a competitive issue rather than a clear partisan strength.
* **Strategic Implications:** For political strategists, this map highlights which issues each party can use to mobilize its base and which issues are potential battlegrounds for persuading swing voters. The large gaps on issues like the environment and gun control suggest these are powerful tools for partisan differentiation and turnout.
</details>
(f)
Figure 6: More data examples from VisualPRM400K.
<details>
<summary>x14.png Details</summary>

### Visual Description
\n
## Screenshot: Educational Data Example from MMMU
### Overview
The image is a screenshot of an educational slide or document titled "Data Example from MMMU." It presents a multiple-choice question based on a visual diagram illustrating the "Elements of Art." The layout is divided into a header, a left-side diagram, and a right-side text block containing a question and a step-by-step solution.
### Components
1. **Header**: A title bar at the top with the text "**Data Example from MMMU**" in bold, underlined with a brown line.
2. **Left Diagram ("Elements of Art")**: A beige rectangular panel containing seven labeled cards arranged in two rows.
* **Top Row (Left to Right)**:
* Card 1: Illustration of various lines (wavy, straight, circles). Label below: **Line**.
* Card 2: Illustration of geometric shapes (square, circle, triangle). Label below: **Shape**.
* Card 3: Illustration of 3D objects (cube, cone, cylinder). Label below: **Form**.
* Card 4: Illustration suggesting positive and negative space with abstract shapes. Label below: **Space**.
* **Bottom Row (Left to Right)**:
* Card 5: Illustration of different brushstroke textures. Label below: **Texture**.
* Card 6: Illustration of a gradient from dark to light. Label below: **Value**.
* Card 7: Illustration of a color spectrum/gradient. Label below: **Color**.
3. **Right Text Block**: Contains a question and a multi-step solution.
* **Question Section**:
* Label: **Question:**
* Text: "Based on <image 1>. When lines meet to form an enclosed area, this is formed."
* Options: "A. Space B. Shape C. Form D. Line"
* **Solution Section**:
* Label: **Solution:**
* A series of steps, each prefixed with a step number and a status label in parentheses. The status labels are color-coded: "Neural" in yellow, "Correct" in green.
* The steps provide definitions for each term (Space, Shape, Form, Line) and conclude with the final answer.
### Detailed Analysis / Content Details
**Transcription of All Text:**
* **Header**: `Data Example from MMMU`
* **Diagram Title**: `Elements of Art`
* **Diagram Card Labels**: `Line`, `Shape`, `Form`, `Space`, `Texture`, `Value`, `Color`
* **Question Block**:
```
Question:
Based on <image 1>. When lines meet to form an enclosed area, this is formed.
A. Space B. Shape C. Form D. Line
```
* **Solution Block**:
```
Solution:
## Step-0 (Neural) To determine the correct answer, let's analyze the terms and their definitions:
## Step-1 (Correct) 1. **Space**: This refers to the area between or around elements of art. It can be positive (occupied by objects) or negative (empty).
## Step-2 (Correct) 2. **Shape**: This is an enclosed area created by lines or other elements. It can be geometric or organic.
## Step-3 (Correct) 3. **Form**: This refers to the three-dimensional aspect of an object, giving it volume and depth.
## Step-4 (Correct) 4. **Line**: This is a mark made by a moving point.
## Step-5 (Correct) When lines meet to form an enclosed area, this is called a "Shape." Therefore, the correct answer is:
## Step-6 (Correct) Final answer: B
```
### Key Observations
1. **Pedagogical Structure**: The image is designed as a teaching or assessment tool. It pairs a visual reference (the Elements of Art diagram) with a conceptual question.
2. **Solution Methodology**: The solution uses a clear, step-by-step deductive process. It first defines all relevant terms from the multiple-choice options before applying the definition to the question's premise.
3. **Visual-Textual Link**: The question explicitly references "<image 1>", which corresponds to the "Elements of Art" diagram on the left. The correct answer, "Shape," is directly supported by the visual and label on the second card in the diagram.
4. **Formatting Cues**: The use of bold text for key terms (**Space**, **Shape**, etc.) and color-coded status labels (Neural/Correct) helps guide the reader's attention and indicates the reasoning process's validation.
### Interpretation
This image is a self-contained educational module. Its primary purpose is to test and reinforce the understanding of fundamental art vocabulary. The data it presents is not numerical but definitional and relational.
* **What it demonstrates**: It demonstrates the application of visual knowledge (identifying elements in a diagram) to answer a theoretical question. The correct answer, **Shape**, is defined both visually (as an enclosed area on the "Shape" card) and textually ("an enclosed area created by lines").
* **Relationship between elements**: The diagram serves as the primary source material. The question queries a specific property of one of those materials. The solution acts as a bridge, explicitly connecting the question's phrasing ("lines meet to form an enclosed area") to the formal definition of "Shape," thereby validating the answer.
* **Notable aspects**: The inclusion of the "Neural" step (Step-0) is interesting. It frames the initial analysis as a neutral, procedural starting point before the "Correct" steps provide the authoritative definitions. This structure mirrors a logical or algorithmic approach to problem-solving, breaking it down into discrete, verifiable parts. The entire example likely serves as a model for how to approach similar conceptual questions in art or design education.
</details>
(a)
<details>
<summary>x15.png Details</summary>

### Visual Description
## Musical Notation Problem: Key Determination
### Overview
The image displays an educational example, likely from a test or textbook, titled "Data Example from MMMU." It presents a short musical melody in standard notation and asks the viewer to determine its key from four multiple-choice options. A detailed, step-by-step solution is provided alongside the notation.
### Components/Axes
1. **Header:** The text "Data Example from MMMU" is centered at the top, underlined by a brown horizontal rule.
2. **Musical Notation (Left Side):**
* Labeled "(a)".
* A single staff with a treble clef.
* **Key Signature:** One sharp (F♯), placed immediately after the clef.
* **Time Signature:** Common time (C), indicating 4/4.
* **Notes:** A sequence of eighth notes and quarter notes across two measures. Notable accidentals include a D♯ in the first measure and a C♯ in the second measure.
3. **Question & Solution (Right Side):**
* **Question:** "Choose the correct key of each of the melody. <image 1>"
* **Options:** A. B major, B. E major, C. A minor, D. E minor.
* **Solution:** A structured, three-step analysis with annotations.
* `## Step-0 (Neural)` (in yellow/orange text)
* `## Step-1 (Correct)` (in green text)
* `## Step-2 (Correct)` (in green text)
* `## Step-3 (Correct)` (in green text)
### Detailed Analysis
**Musical Notation Transcription:**
The melody is written in the treble clef with a key signature of one sharp (F♯). The time signature is common time (C). The note sequence (approximated from visual inspection) is:
* Measure 1: E (eighth), G (eighth), B (quarter), D♯ (eighth), E (eighth).
* Measure 2: G (eighth), B (eighth), A (quarter), C♯ (eighth), B (eighth).
**Textual Content Transcription:**
**Question:**
Choose the correct key of each of the melody. <image 1>
A. B major B. E major C. A minor D. E minor
**Solution:**
To determine the key of the melody, we analyze the key signature, accidentals, and the tonal center. Here's the breakdown:
1. **Key Signature**: The melody has a key signature with one sharp (F♯), which corresponds to either **G major** or **E minor**.
2. **Accidentals**: The melody contains a D♯ accidental, which is the leading tone in the key of E minor. This suggests the melody is in **E minor**.
3. **Tonal Center**: The melody revolves around E as the tonic, further confirming **E minor** as the key.
### Correct Answer: **D. E minor**
### Key Observations
1. **Pedagogical Structure:** The image is designed as a teaching tool. It presents a problem and then deconstructs the reasoning process into clear, numbered steps.
2. **Color-Coded Annotations:** The solution steps are annotated with colored labels: "(Neural)" in yellow/orange and "(Correct)" in green, likely indicating the source or validation of each step.
3. **Music Theory Logic:** The solution correctly applies standard music theory: a one-sharp key signature indicates G major or E minor. The presence of D♯ (the raised 7th degree or leading tone of E minor) is a strong indicator of the minor key, as it creates the necessary pull to the tonic (E).
4. **Spatial Layout:** The musical notation is positioned on the left, with the corresponding question and explanatory text aligned to its right, creating a clear two-column format for study.
### Interpretation
This image is a self-contained music theory lesson. It demonstrates the practical process of key identification by analyzing three core elements: the key signature, the use of accidentals, and the perceived tonal center (the "home" note of the melody).
The data suggests that the melody is firmly in **E minor**. The key signature sets the initial framework, but the critical piece of evidence is the D♯ accidental. In the key of E natural minor, the seventh degree is D. Raising it to D♯ creates the harmonic minor scale, which is essential for establishing a strong dominant-to-tonic harmonic progression. The melody's emphasis on the note E (as both the starting note and a recurring pitch) solidifies it as the tonic.
The example effectively teaches that while a key signature narrows the possibilities, the specific notes used within the melody—particularly chromatic alterations like leading tones—are decisive for distinguishing between a major key and its relative minor. The structured solution models a logical, step-by-step approach for students to follow.
</details>
(b)
<details>
<summary>x16.png Details</summary>

### Visual Description
## Diagram: Phillips Curve with Economic Question and Solution
### Overview
The image is an educational example, likely from a learning platform or test (labeled "Data Example from MMMU"). It consists of two main sections: a **Phillips Curve chart** on the left and a **text-based question with a multi-step solution** on the right. The content tests understanding of macroeconomic theory regarding the long-run effects of monetary policy on inflation and unemployment.
### Components/Axes
**Chart (Left Side):**
* **Chart Type:** Line graph with labeled points, representing a Phillips Curve model.
* **Vertical Axis (Y-axis):** Labeled "Inflation Rate (%)". Scale runs from 0 to 10 in increments of 1.
* **Horizontal Axis (X-axis):** Labeled "Unemployment Rate (%)". Scale runs from 0 to 10 in increments of 1.
* **Curves:**
* **Curve 1:** A vertical red line positioned at an Unemployment Rate of 6%. This represents the Long-Run Phillips Curve (LRPC) or the Non-Accelerating Inflation Rate of Unemployment (NAIRU).
* **Curve 2:** A downward-sloping black line. This represents the Short-Run Phillips Curve (SRPC), showing an inverse relationship between inflation and unemployment.
* **Data Points:** Five points are plotted and labeled:
* **A:** Located at approximately (Unemployment: 4%, Inflation: 5%).
* **B:** Located at approximately (Unemployment: 6%, Inflation: 3%). This is the stated starting point.
* **C:** Located at approximately (Unemployment: 8%, Inflation: 1%).
* **D:** Located at approximately (Unemployment: 6%, Inflation: 6%). This point is on Curve 1 (the vertical line) directly above point B.
* **E:** Located at approximately (Unemployment: 6%, Inflation: 2%). This point is on Curve 1 directly below point B.
**Text (Right Side):**
* **Header:** "Data Example from MMMU"
* **Question Section:**
* **Label:** "Question:"
* **Text:** "<image 1> If the economy starts at B and the money supply growth rate increases, in the long run the economy"
* **Options:**
* A. moves to C.
* B. moves to D.
* C. stays at B.
* **Solution Section:**
* **Label:** "Solution:"
* **Step-0 (Correct):** "To understand the movement of the economy, we need to consider the Phillips Curve, which typically represents the inverse relationship between inflation and unemployment in the short run. In the long run, when the money supply growth rate increases, leading to higher inflation, the economy usually moves along the Phillips Curve to a new point where unemployment returns to its natural rate (also known as the Non-Accelerating Inflation Rate of Unemployment or NAIRU)."
* **Step-1 (Correct):** "1. **Identify the initial point (B)**: The economy starts at point B on the curve, where the unemployment rate is approximately 6% and the inflation rate is approximately 3%."
* **Step-2 (Correct):** "2. **Impact of increased money supply growth rate**: An increase in the money supply growth rate typically leads to higher inflation in the short run. This moves the economy along the Phillips Curve to a point with higher inflation but does not change the natural rate of unemployment."
* **Step-3 (Correct):** "3. **Phillips Curve movement**: In the long run, the higher inflation does not affect the natural rate of unemployment, which remains at the same level. So, the economy moves along the curve to maintain the same unemployment rate but with higher inflation."
* **Step-4 (Incorrect):** "4. **Identify the new point**: The new point where the economy settles in the long run will have the same unemployment rate as the initial point (6%) but a higher inflation rate. This is indicated by point C on the curve."
* **Step-5 (Neural):** "Given these steps:"
* **Step-6 (Incorrect):** "- The economy moves from B to C in the long run due to the increased money supply growth rate."
* **Step-7 (Incorrect):** "Final answer: A"
### Detailed Analysis
**Question Analysis:**
The question poses a standard macroeconomic scenario: starting from an initial equilibrium (Point B: 6% unemployment, 3% inflation), an expansionary monetary policy (increased money supply growth) is implemented. The task is to identify the long-run outcome from the given options.
**Solution Step Analysis:**
The provided solution walks through the logic using the Phillips Curve framework.
* **Steps 0-3 (Marked Correct):** These steps correctly outline the theory. They state that in the short run, higher money supply growth increases inflation, moving the economy along the Short-Run Phillips Curve (Curve 2). In the long run, expectations adjust, and unemployment returns to its natural rate (NAIRU), which is represented by the vertical Long-Run Phillips Curve (Curve 1) at 6% unemployment.
* **Step 4 (Marked Incorrect):** This step contains a critical error. It correctly states the long-run outcome should have the same unemployment rate (6%) but higher inflation. However, it incorrectly identifies this point as **Point C**. Point C is at (8%, 1%), which has a *higher* unemployment rate and *lower* inflation rate, contradicting the described outcome.
* **Steps 5-7 (Marked Incorrect/Neural):** These steps conclude based on the flawed Step 4. They state the economy moves from B to C and select final answer "A" (which corresponds to "moves to C"). This conclusion is logically inconsistent with the correct theory outlined in the earlier steps.
**Chart Data Point Verification:**
* **Point B (Start):** (Unemployment ~6%, Inflation ~3%). Lies on both Curve 1 (vertical) and Curve 2 (downward-sloping).
* **Theoretical Long-Run Point:** According to the correct theory in Steps 0-3, the new long-run point should be on the vertical Curve 1 (at 6% unemployment) but at a higher inflation level than 3%. Looking at the chart, **Point D** at (6%, 6%) fits this description perfectly.
* **Point C (Incorrectly Identified):** (Unemployment ~8%, Inflation ~1%). This point is on Curve 2 but represents a movement to *higher* unemployment and *lower* inflation, which is not the predicted outcome of an increase in money supply growth.
### Key Observations
1. **Contradiction in Solution:** There is a direct contradiction between the correct theoretical explanation (Steps 0-3) and the final identification of the point and answer (Steps 4, 6, 7). The solution's own logic points to a movement to a point like D, but it concludes C.
2. **Visual Misalignment:** The solution text in Step 4 claims Point C indicates "the same unemployment rate as the initial point (6%)". Visually, Point C is clearly at an unemployment rate of approximately 8%, not 6%. This is a factual error in reading the graph.
3. **Correct Answer Implication:** Based on the correct theory described, the economy, starting at B (6%, 3%), would in the long run move vertically up along the 6% unemployment line (Curve 1) to a point with higher inflation. **Point D (6%, 6%)** is the only labeled point that matches this outcome. Therefore, the correct answer to the question should be "B. moves to D.", not "A. moves to C." as the solution concludes.
### Interpretation
This image serves as a case study in both economic theory and the process of logical reasoning. The data and diagram illustrate the core concept of the **expectations-augmented Phillips Curve** and the **vertical Long-Run Phillips Curve**. It demonstrates that while monetary policy can temporarily trade higher inflation for lower unemployment (moving along SRPC), in the long run, it only results in higher inflation with no permanent change in the unemployment rate, which returns to the NAIRU.
The provided solution, however, contains a significant analytical failure. It correctly recalls and explains the theory but fails in its application by misreading the graph and drawing a conclusion that contradicts its own premises. This highlights the importance of careful data verification and consistency between theoretical reasoning and empirical (or graphical) evidence. The "Incorrect" and "Neural" markers suggest this may be an example used to train or test an AI's ability to spot such inconsistencies, making the image a meta-example of error analysis in technical problem-solving.
</details>
(c)
<details>
<summary>x17.png Details</summary>

### Visual Description
## Screenshot: Math Problem and Solution
### Overview
The image is a screenshot of a mathematical problem and its solution, presented as a "Data Example from MathVision." It contains a visual representation of an addition problem using empty squares, a question prompt, and a step-by-step solution with annotations indicating the correctness of each step.
### Components/Axes
* **Header:** "Data Example from MathVision" (top-left, bold, serif font).
* **Visual Element:** A diagram showing four empty squares arranged as `[ ][ ] + [ ][ ]`. This represents the addition of two two-digit numbers.
* **Text Sections:**
* **Question:** A block of text posing the problem.
* **Solution:** A numbered list of steps, each prefixed with a step label (e.g., `## Step-0`) and a correctness annotation in parentheses (e.g., `(Correct)` in green, `(Incorrect)` in red).
### Detailed Analysis / Content Details
**Question Text:**
"Hint: Please answer the question and provide the final answer at the end. Question: Each of the digits 2, 3, 4 and 5 will be placed in a square. Then there will be two numbers, which will be added together. What is the biggest number that they could make?"
**Solution Text (Transcribed with original formatting and annotations):**
```
## Step-0 (Correct) To maximize the sum of the two numbers, we should form the largest possible numbers by arranging the digits in descending order. Here's how:
## Step-1 (Incorrect) 1. Arrange the digits \\( 2, 3, 4, 5 \\) in descending order: \\( 5, 4, 3, 2 \\).
2. Split them into two numbers such that the largest digits are in the tens place. This ensures the largest sum.
## Step-2 (Incorrect) - First number: \\( 54 \\) - Second number: \\( 32 \\)
## Step-3 (Correct) 3. Add the two numbers: \n \\[\n 54 + 32 = 86\n \\]
## Step-4 (Incorrect) ### Final Answer: **86**
```
* **Note on Annotations:** The steps are inconsistently marked. The initial reasoning (Step-0) and the final addition (Step-3) are marked `(Correct)`. The specific digit arrangement (Step-1), the number formation (Step-2), and the final answer line (Step-4) are marked `(Incorrect)`. This suggests the provided solution contains errors or is part of an exercise to identify mistakes.
### Key Observations
1. **Contradictory Annotations:** The core logic of arranging digits descending (5,4,3,2) and placing the largest digits in the tens places (5 and 4) is marked as incorrect in Step-1 and Step-2, while the overarching strategy and the arithmetic are marked correct. This is the most notable feature.
2. **Mathematical Content:** The problem is a classic digit arrangement puzzle. The solution attempts to apply the principle that to maximize a sum, the largest digits should occupy the highest place values (tens places).
3. **Final Answer:** The computed sum presented is 86, derived from adding 54 and 32.
### Interpretation
The image presents a pedagogical example, likely from an educational platform or dataset. Its primary purpose is not to present clean data but to illustrate a problem-solving process, potentially including common errors.
* **What the data suggests:** The conflicting correctness labels imply this is a "find the error" exercise. The solver correctly identifies the high-level strategy (descending order, largest digits in tens place) but may have made a mistake in the specific execution or the platform's answer key is flawed. The most logical arrangement for the digits 2,3,4,5 to maximize the sum of two 2-digit numbers is indeed 54 + 32 = 86, or alternatively 53 + 42 = 95, which is larger. The solution's Step-1 lists the digits in descending order (5,4,3,2) but then forms 54 and 32, which uses 5 and 4 as tens digits correctly. The marking of this as "Incorrect" is therefore puzzling and is the central anomaly.
* **How elements relate:** The visual diagram (`[ ][ ] + [ ][ ]`) directly corresponds to the problem statement. The solution text attempts to walk through the logical steps to fill those squares.
* **Notable Anomaly:** The key anomaly is the `(Incorrect)` label on Step-1 and Step-2. A plausible interpretation is that the solution contains a subtle error: while the digits are listed descending, the split into 54 and 32 does not strictly follow "descending order" for the *sequence of digits used* (5,4,3,2). A stricter descending order split might be 53 and 42. However, 54+32=86 and 53+42=95 are both valid arrangements; 95 is larger. The solution's final answer of 86 is therefore not the *biggest* possible number, which explains why the steps leading to it might be marked incorrect. The problem asks for the "biggest number," and the solution provided does not achieve that maximum.
</details>
(d)
<details>
<summary>x18.png Details</summary>

### Visual Description
\n
## Diagram: Quadratic Function Graph Identification Problem
### Overview
The image is a screenshot of a mathematical problem from "MathVision." It presents a multiple-choice question asking to identify which of five given graph segments does not belong, as four represent pieces of the same quadratic function. The image includes the question, five labeled graph options (A-E), and a detailed step-by-step solution.
### Components/Axes
**Layout:**
- **Header:** "Data Example from MathVision" in the top-left corner.
- **Left Section:** Contains the question and five small coordinate plane graphs labeled (A) through (E).
- **Right Section:** Contains the "Question" text, "Choices," and a detailed "Solution" broken into steps.
**Graph Components (Left Section):**
Each graph is a small Cartesian coordinate system with:
- **x-axis:** Horizontal axis with tick marks and numerical labels.
- **y-axis:** Vertical axis with tick marks and numerical labels.
- **Curve/Line:** A black line or curve plotted on the axes.
- **Label:** A letter (A, B, C, D, E) below each graph.
**Text Components (Right Section):**
- **Question Text:** "Hint: Please answer the question and provide the correct option letter, e.g., A, B, C, D, at the end. Question: Four of the following five pictures show pieces of the graph of the same quadratic function. Which piece does not belong? Choices:(A) A (B) B (C) C (D) D (E) E"
- **Solution Text:** Structured with step headers (e.g., "## Step-0 (Neural)", "## Step-1 (Correct)") and analysis in bullet points and paragraphs.
### Detailed Analysis
**Graph Descriptions (Spatially from left to right):**
1. **Graph (A):**
* **Axes:** x-axis labeled with ticks at 1 and 2. y-axis has no numerical labels.
* **Curve:** An upward-sloping curve (increasing from left to right), appearing to be the right half of a parabola opening upwards.
* **Label:** "(A)" below the graph.
2. **Graph (B):**
* **Axes:** x-axis has no numerical labels. y-axis labeled with ticks at -1 and -2.
* **Curve:** A downward-sloping curve (decreasing from left to right), appearing to be the left half of a parabola opening downwards.
* **Label:** "(B)" below the graph.
3. **Graph (C):**
* **Axes:** x-axis labeled with ticks at 3 and 4. y-axis has no numerical labels.
* **Line:** A straight, downward-sloping line. **This is not a curve.**
* **Label:** "(C)" below the graph.
4. **Graph (D):**
* **Axes:** x-axis has no numerical labels. y-axis labeled with ticks at -1 and -2.
* **Curve:** An upward-sloping curve (increasing from left to right), appearing to be the right half of a parabola opening upwards.
* **Label:** "(D)" below the graph.
5. **Graph (E):**
* **Axes:** x-axis labeled with ticks at -4 and -3. y-axis has no numerical labels.
* **Curve:** A downward-sloping curve (decreasing from left to right), appearing to be the left half of a parabola opening downwards.
* **Label:** "(E)" below the graph.
**Solution Text Transcription:**
```
Solution:
## Step-0 (Neural) To solve this, we analyze the graphs:
## Step-1 (Correct) - A quadratic function has a parabolic shape, either opening upwards or downwards.
- The correct graphs must align with this property.
### Analysis:
- **Option A**: A curve increasing from left to right, consistent with a quadratic function opening upwards.
- **Option B**: A curve decreasing from left to right, consistent with a quadratic function opening downwards.
- **Option C**: A line, not a curve, inconsistent with a quadratic function.
- **Option D**: A curve increasing from left to right, consistent with a quadratic function opening upwards.
- **Option E**: A curve decreasing from left to right, consistent with a quadratic function opening downwards.
## Step-3 (Correct) ### Conclusion:
The graph in **C** does not belong because it is not a parabola.
## Step-4 (Correct) **Correct Answer: C**
```
### Key Observations
1. **The Outlier:** Graph (C) is the only one displaying a straight line, while all others (A, B, D, E) display curves.
2. **Pattern in Correct Options:** The four graphs that belong together (A, B, D, E) are all consistent with being segments of a parabola. Two (A, D) show an increasing trend (right side of an upward-opening parabola), and two (B, E) show a decreasing trend (left side of a downward-opening parabola).
3. **Axis Labeling:** The numerical labels on the axes are sparse and appear to be illustrative rather than defining a specific function. They provide context for the slope/direction of the curve/line.
4. **Solution Structure:** The solution uses a clear, pedagogical format with step labels and bold text to highlight the final answer and key reasoning points.
### Interpretation
This image presents a classic visual logic problem designed to test understanding of the fundamental geometric property of quadratic functions: their graphs are parabolas. The exercise is not about calculating a specific function but about pattern recognition and applying a definitional rule.
The data (the five graphs) demonstrates that the defining characteristic for inclusion in the set "pieces of the same quadratic function" is the **curvature** of a parabola. The linear graph (C) is the clear anomaly because it lacks this curvature, violating the core property stated in the solution. The problem effectively isolates this single variable (curve vs. line) while varying other aspects (direction of slope, axis labels) to ensure the solver focuses on the essential feature.
The step-by-step solution reinforces a methodical approach: first state the general rule (quadratic = parabola), then evaluate each option against that rule. This structure is typical of educational materials aimed at building conceptual understanding rather than rote computation.
</details>
(e)
<details>
<summary>x19.png Details</summary>

### Visual Description
\n
## Diagram and Text: MathVision Data Example
### Overview
The image is a composite educational or test example titled "Data Example from MathVision." It consists of two main parts: a diagram on the left showing a tangled line with attached fish and a ring, and a text block on the right presenting a question, hint, and a step-by-step solution with evaluative annotations. The overall purpose is to present a spatial reasoning puzzle.
### Components
1. **Header:** A brown horizontal bar at the top containing the title text "Data Example from MathVision" in a bold, serif font.
2. **Left Diagram:**
* A single, continuous, dark grey line forms a complex, overlapping tangle.
* At the far left end of the line is a simple, unfilled black circle (the "ring").
* Attached along the length of the line are 10 stylized fish figures. Each fish is oriented with its head pointing along the line in one direction.
* The fish are colored. From the ring moving along the line, the approximate sequence and colors are: green, yellow, blue, green, pink, blue, green, pink, blue, pink. (Note: The exact order is difficult to trace due to the tangle).
3. **Right Text Block:** Contains the following transcribed text:
**Question:**
Hint: Please answer the question and provide the final answer at the end.
Question: How many fish will have their heads pointing towards the ring when we straighten the line?
**Solution:**
## Step-0 *(Neural)* To determine how many fish will have their heads pointing towards the ring when we straighten the line, follow these steps:
## Step-1 *(Correct)* 1. Identify the fish with their heads pointing towards the ring in the current configuration.
2. Visualize straightening the line and see which fish's heads will align with the ring.
## Step-2 *(Neural)* Step-by-step reasoning:
## Step-3 *(Incorrect)* 1. In the current configuration, the fish with their heads pointing towards the ring are:
- The green fish on the left side.
## Step-4 *(Incorrect)* 2. When the line is straightened, the fish with their heads pointing towards the ring will be those whose heads are aligned with the ring's position in the straightened line.
## Step-5 *(Incorrect)* From the image, it appears that only the green fish at the far left is aligned with the ring's position in the straightened line.
## Step-6 *(Incorrect)* Final answer: 3
### Detailed Analysis
* **Diagram Logic:** The puzzle requires mentally "straightening" the tangled line into a straight line with the ring at one end. The key is to determine the final orientation of each fish's head relative to the ring after this transformation. A fish's head will point *towards* the ring if, on the original tangled line, its head is oriented along the path that leads *back* to the ring.
* **Text Analysis:** The provided solution steps are annotated with evaluations: `(Neural)`, `(Correct)`, and `(Incorrect)`.
* Steps 0 and 2 are marked as neutral process descriptions.
* Step 1 is marked as correct in its general approach.
* Steps 3, 4, 5, and 6 are all marked as **Incorrect**. This indicates the reasoning and final answer ("3") provided in the text are flawed according to the evaluator.
* The incorrect reasoning in Step 3 claims only "the green fish on the left side" points to the ring currently. Step 5 then incorrectly concludes only that same fish would align after straightening.
### Key Observations
1. **Contradiction:** The most significant observation is the direct contradiction between the solution's final answer ("3") and the evaluator's marking of every substantive reasoning step (3-6) as "Incorrect." This suggests the provided solution is an example of a failed or erroneous attempt.
2. **Diagram Complexity:** The tangled line is intentionally complex, making it challenging to trace the path and determine each fish's orientation relative to the ring without careful analysis.
3. **Annotation System:** The text uses a specific annotation system (`## Step-N *(Evaluation)*`) to label and judge each part of the reasoning process, which is central to the document's purpose as a "data example."
### Interpretation
This image is not a straightforward puzzle with a provided answer. Instead, it is a **meta-example** likely used for training or evaluating AI systems (hinted at by the "MathVision" source and "(Neural)" tags). Its primary informational content is the *structure of a flawed solution process*.
* **What it Demonstrates:** It shows how a reasoning chain can be structured (steps, sub-steps) and how each component can be evaluated for correctness. The errors are not just in the final answer but in the foundational observations (Step 3) and the subsequent logical deductions (Steps 4 & 5).
* **Relationship Between Elements:** The diagram is the problem source. The text is an attempted solution to that problem. The annotations are a meta-layer evaluating the solution's quality. The core task for a viewer (or an AI) is to ignore the incorrect solution and solve the diagram's puzzle independently.
* **Underlying Puzzle (Inferred):** To solve the actual puzzle, one must trace the line from the ring. A fish's head points *toward* the ring if, on the tangled line, its head is oriented in the direction that follows the line *back to the ring*. A fish's head points *away* if its head follows the line *away from the ring*. The correct answer is likely not 3, given the annotations. A careful visual trace suggests the answer may be 4 or 5, but the image's purpose is to highlight the flawed reasoning process, not to provide the correct answer.
</details>
(f)
<details>
<summary>x20.png Details</summary>

### Visual Description
## Mathematical Problem and Solution: Linear Inequality from a Graph
### Overview
The image is a screenshot from a platform called "MathVerse," presenting a mathematics problem. It consists of a header, a graph on the left, and a detailed step-by-step solution on the right. The problem asks the viewer to determine the inequality that represents a shaded region on a coordinate plane.
### Components/Axes
**Header:**
- Text: "Data Example from MathVerse" (top-left, bold, with a brown underline).
**Graph (Left Side):**
- **Type:** 2D Cartesian coordinate plane.
- **Axes:**
- **X-axis:** Horizontal, labeled with numbers at intervals of 5: -10, -5, 0, 5, 10. The axis is labeled with a small "x" at the far right.
- **Y-axis:** Vertical, labeled with numbers at intervals of 5: -10, -5, 0, 5, 10. The axis is labeled with a small "y" at the top.
- **Plotted Elements:**
- A **solid black line** passes through two clearly marked points: (-5, -5) and (0, 5).
- The region **above this line** is shaded in a uniform light gray.
- **Graph Title/Instruction:** Above the graph, text reads: "State the inequality that describes the region drawn in the number plane."
**Solution Text (Right Side):**
- **Question Prompt:** "Question: According to the question shown in the image, please directly answer the question and provide the final value, e.g., 1, 2.5, 300."
- **Solution Steps:** The solution is broken into numbered steps, each preceded by a status label (e.g., "## Step-0 (Neutral)"). The word "Incorrect" appears in red for Steps 1 through 4.
- **Step Content:**
- **Step-0 (Neutral):** "### Reasoning:"
- **Step-1 (Incorrect):** "1. **Understand the Problem:**"
- Bullet points explaining the boundary line is solid (included, using ≤ or ≥) and the shaded region is above the line.
- **Step-2 (Incorrect):** "2. **Find the Equation of the Line:**"
- Identifies two points: Point 1: (-5, -5), Point 2: (0, 5).
- Calculates slope (m) using formula: `m = (y_2 - y_1)/(x_2 - x_1) = (5 - (-5))/(0 - (-5)) = 10/5 = 2`.
- Uses slope-intercept form `y = mx + b`, substitutes (0,5) to find `b = 5`.
- States the line equation: `y = 2x + 5`.
- **Step-3 (Incorrect):** "3. **Determine the Inequality:**"
- States: "Since the shaded region is above the line, the inequality is `y ≥ 2x + 5`."
- **Step-4 (Incorrect):** "### Final Answer:"
- Presents the final answer in a formatted block: `y ≥ 2x + 5`.
### Detailed Analysis
**Graph Data Points & Trend:**
- The boundary line has a **positive slope**, rising from left to right.
- It passes precisely through the points (-5, -5) and (0, 5).
- The y-intercept is at (0, 5).
- The shaded region is entirely above this line, indicating all points (x, y) where the y-value is greater than or equal to the y-value on the line for the same x.
**Solution Logic Flow:**
1. **Problem Interpretation:** Correctly identifies the need for an inequality including the boundary (solid line) and the region above it.
2. **Equation Derivation:** Correctly calculates the slope (m=2) and y-intercept (b=5) from the two given points, resulting in the line equation `y = 2x + 5`.
3. **Inequality Formulation:** Correctly concludes that "above the line" corresponds to `y ≥ 2x + 5`.
4. **Final Answer:** The derived inequality is presented as the solution.
### Key Observations
- The solution steps are all marked as "Incorrect" in red text, despite the mathematical reasoning and final answer appearing logically sound and correct based on the graph.
- The only step not marked incorrect is "Step-0," labeled "Neutral."
- The graph is clear, with the line and shaded region unambiguously defined.
- The mathematical notation in the solution uses a mix of plain text and LaTeX-style formatting (e.g., `\\(y \\geq 2x + 5\\)`).
### Interpretation
The image demonstrates a standard algebra problem: translating a graphical representation of a linear inequality into its symbolic form. The data (the graph) shows a linear boundary and a half-plane. The solution correctly interprets this visual data through a deductive process: identifying key features (points, line type, shading direction), performing calculations (slope, intercept), and applying algebraic rules to form the inequality.
The notable anomaly is the labeling of all solution steps as "Incorrect." This suggests the image might be from an educational or testing platform where the *process* is being evaluated against a specific rubric, or it could be an example of a system flagging steps for pedagogical reasons, even if the final answer is right. The core mathematical information—the graph and the derived inequality `y ≥ 2x + 5`—is consistent and correct. The image serves as a complete example of a math problem, its visual representation, and a detailed, albeit flagged, solution pathway.
</details>
(g)
<details>
<summary>x21.png Details</summary>

### Visual Description
## Diagram: Geometry Problem with Solution Steps
### Overview
The image is a screenshot of a mathematics problem from a dataset labeled "Data Example from MathVerse." It presents a geometry question involving a circle, a tangent line, and an inscribed angle, along with a multiple-choice answer set and a detailed, step-by-step solution. The solution includes both correct and incorrect reasoning steps, culminating in the final answer.
### Components/Axes
The image is divided into two main sections:
1. **Left Section (Problem Statement & Diagram):**
* **Header Text:** "Data Example from MathVerse"
* **Question Text:** "Question: According to the question shown in the image, please directly answer the question and provide the correct option letter, e.g., A, B, C, D."
* **Problem Statement Text:** "As shown in the figure, passing point C to draw the tangent of circle O, then the degree of angle A is ( )"
* **Multiple-Choice Options:** "Choices: A:20° B:25° C:40° D:50°"
* **Diagram:** A circle with center labeled **O**. Points **A**, **B**, and **C** are on the circumference. A line segment **CD** is drawn from point **C** to an external point **D**, and is indicated as a tangent to the circle at **C**. A chord connects **A** to **B**. A line connects **B** to **C**. An angle at point **D**, formed by the tangent **CD** and the line **BD**, is labeled **50°**.
2. **Right Section (Solution):**
* **Header Text:** "Solution:"
* **Step-0 (Correct):** "To find the degree of angle A, we can use the property that the angle subtended by an arc at the center of the circle is twice the angle subtended at any point on the circle."
* **Step-1 (Correct):** "1. **Identify the key points:** - The arcs are AC and BC. - Angle A is subtended by these arcs at point O (the center of the circle)."
* **Step-2 (Correct):** "2. **Understand the given information:** - CD is a tangent at point C. - The angle between the tangent and the chord is equal to the angle subtended by the chord at the circumference. Therefore, angle CDB = 50°." *(Note: \u00b0 is the Unicode for the degree symbol °)*
* **Step-3 (Incorrect):** "3. **Angle properties:** - The angle A is subtended by arc BC at the center. - Since CD is a tangent, angle A = 50° (as the inscribed angle is half the central angle)."
* **Step-4 (Correct):** "Thus, the degree of angle A is 20°."
* **Step-5 (Correct):** "Final answer: A"
### Detailed Analysis
The problem asks for the measure of angle **A** (∠CAB) in the given circle diagram.
* **Given:** Tangent **CD** at point **C**. The angle between tangent **CD** and chord **CB** (angle **CDB**) is **50°**.
* **Geometric Principle Applied (Step-2):** The angle between a tangent and a chord through the point of contact is equal to the angle in the alternate segment. Therefore, the inscribed angle subtended by chord **CB** at point **A** on the circumference (∠CAB, which is angle **A**) is equal to angle **CDB**. This would directly imply ∠A = 50°.
* **Contradiction in Solution:** Step-2 correctly states the tangent-chord theorem and concludes angle CDB = 50°. However, Step-3 incorrectly applies a different property, stating "angle A = 50° (as the inscribed angle is half the central angle)." This is a misapplication; the "inscribed angle half the central angle" theorem relates an inscribed angle to the central angle subtending the *same arc*, not to a tangent-chord angle.
* **Resolution (Step-4):** Despite the error in Step-3's reasoning, Step-4 arrives at the correct numerical answer of **20°**. This suggests the solver may have intended to use a different chain of reasoning: If angle CDB (50°) is the angle between tangent and chord, then the inscribed angle in the alternate segment (∠CAB) should be 50°. However, the final answer is 20°, indicating a possible mislabeling in the diagram or a different interpretation. The most consistent interpretation with the final answer is that the **50°** label refers to the **central angle** ∠COB, not the tangent-chord angle ∠CDB. If ∠COB = 50°, then the inscribed angle ∠CAB (angle A) subtended by the same arc CB is half of that, which is **25°**. Yet the answer given is **20°**. This discrepancy points to an error in the problem's diagram or the provided solution's logic.
### Key Observations
1. **Solution Inconsistency:** The solution contains a clear logical error in Step-3, marked as "(Incorrect)". The reasoning jumps from correct theorems to an incorrect conclusion.
2. **Ambiguous Diagram Label:** The placement of the **50°** label is critical. It is positioned near point **D**, suggesting it is ∠CDB. However, the final answer of **20°** is not derivable from that fact using standard theorems without additional information.
3. **Final Answer Discrepancy:** The stated final answer is **A (20°)**. Based on the diagram as labeled (50° = ∠CDB), the correct answer should be **D (50°)** using the tangent-chord theorem. If the 50° were the central angle ∠COB, the answer would be **B (25°)**. The answer **20°** does not logically follow from the given visual information.
### Interpretation
This image serves as a **pedagogical example of error analysis** in mathematical problem-solving. It demonstrates:
* **The Importance of Diagram Clarity:** Ambiguous labeling (whether 50° is a tangent-chord angle or a central angle) leads to multiple possible interpretations and incorrect solutions.
* **The Value of Step-by-Step Verification:** The inclusion of an "(Incorrect)" step highlights the process of debugging one's own reasoning. It shows that even with correct initial theorems (Steps 0, 1, 2), a misapplication in an intermediate step (Step 3) can derail the solution.
* **A Potential Dataset Flaw:** As a "Data Example," this may be intentionally included to train models or students to identify inconsistencies. The disconnect between the diagram, the reasoning steps, and the final answer makes it a rich case study for critical thinking. The core geometric concepts involved are the **Tangent-Chord Theorem** and the **Inscribed Angle Theorem**. The problem, as presented, is unsolvable with a unique answer without clarifying the intended meaning of the 50° angle.
</details>
(h)
<details>
<summary>x22.png Details</summary>

### Visual Description
## Mathematical Problem and Solution: Common Roots of Two Functions
### Overview
The image displays a mathematical problem from a source titled "Data Example from MathVerse." It presents a question about finding the number of common roots between two functions, `f(x)` and `g(x)`, accompanied by a graph of `g(x)` and a multi-step solution. The content is structured as a problem statement, a graph, and a detailed solution with reasoning.
### Components/Axes
1. **Header:** "Data Example from MathVerse" (top-left, brown text).
2. **Problem Statement (Left Column):**
* **Function Definition:** `f(x)=x²+x-6.`
* **Question:** "How many roots do the functions have in common, f(x) and g(x)?"
* **Choices:**
* A: `f` and `g` share the same root(s).
* B: `f` and `g` share one root in common but each have another root that is not shared.
* C: `f` and `g` share no roots in common.
3. **Graph (Left Column, below problem):**
* **Type:** Cartesian coordinate plot.
* **Title/Label:** `y = g(x)` (positioned to the right of the parabola).
* **X-axis:** Labeled `x`. Range from -7 to 7, with major grid lines at integer intervals.
* **Y-axis:** Labeled `y`. Range from -7 to 7, with major grid lines at integer intervals.
* **Data Series:** A single blue parabola opening upwards. It intersects the x-axis at two points.
4. **Solution Section (Right Column):**
* **Question Prompt:** "According to the question shown in the image, please directly answer the question and provide the correct option letter, e.g., A, B, C, D."
* **Solution Header:** "Solution:"
* **Step Labels (Left-aligned, colored):**
* `## Step-0 (Neutral)`
* `## Step-1 (Correct)`
* `## Step-2 (Incorrect)`
* `## Step-3 (Incorrect)`
* `## Step-4 (Incorrect)`
* **Reasoning and Answer (Right-aligned):**
* **### Reasoning:**
1. **Roots of `f(x)`:** States `f(x) = x^2 + x - 6` is quadratic. Factorizes it as `(x + 3)(x - 2)`. Concludes roots are `x = -3` and `x = 2`.
2. **Roots of `g(x)`:** States that by observing the graph, the parabola intersects the x-axis at `x = -3` and `x = 4`. Concludes roots are `x = -3` and `x = 4`.
3. **Comparison of the roots:** Lists roots for `f(x)` and `g(x)`. States they share one root (`x = -3`) but each has another unshared root (`x = 2` for `f(x)`, `x = 4` for `g(x)`).
* **### Answer:** "The correct option is **B**. `f` and `g` share one root in common but each have another root that is not shared."
### Detailed Analysis
* **Graph Data Points:** The blue parabola `y = g(x)` visually confirms the roots stated in the solution. It crosses the x-axis at approximately `(-3, 0)` and `(4, 0)`. Its vertex appears to be near `(0.5, -6.25)`.
* **Solution Logic:**
* **Step 1 (Correct):** Algebraically finds the roots of `f(x)` by factoring.
* **Step 2 (Incorrect):** Correctly identifies the roots of `g(x)` from the graph (`x = -3`, `x = 4`), but the step is labeled "Incorrect." This may indicate the step itself is correct, but its placement or labeling within a larger sequence is flawed, or it's part of a pedagogical demonstration of common errors.
* **Step 3 (Incorrect):** Correctly compares the roots and arrives at the right conclusion (one shared root), yet is also labeled "Incorrect." This reinforces that the labels may be part of an instructional framework highlighting potential missteps in reasoning order or presentation.
* **Step 4 (Incorrect):** This label appears without associated reasoning text, suggesting it might be a placeholder or an error in the source material.
* **Final Answer:** The reasoning correctly concludes that the functions share exactly one root (`x = -3`), leading to option **B**.
### Key Observations
1. **Discrepancy in Step Labels:** The most notable observation is that Steps 2 and 3 contain correct mathematical reasoning but are labeled "(Incorrect)." This strongly suggests the image is from an educational tool or dataset designed to analyze or teach problem-solving processes, where steps are tagged not just by correctness but by their role in a potential solution path (e.g., identifying common pitfalls in sequencing).
2. **Graph-Text Consistency:** The graphical representation of `g(x)` is perfectly consistent with the textual description of its roots in the solution.
3. **Clear Multiple-Choice Structure:** The problem is presented in a standard multiple-choice format with three distinct options.
### Interpretation
This image is a pedagogical artifact, likely from a dataset like MathVerse used for training or evaluating AI models on mathematical reasoning. It demonstrates a complete problem-solving workflow: interpreting a question, extracting data from a graph, performing algebraic manipulation, and comparing results to select a multiple-choice answer.
The "Incorrect" labels on logically sound steps are the key investigative element. They imply the source material is not just presenting a solution, but is annotated to reflect a more nuanced analysis of the solution process. This could be for:
* **Error Analysis:** Showing where a student might go wrong in their *explanation* even if the math is right.
* **Process Evaluation:** Grading the sequence or completeness of steps, not just the final answer.
* **Training Data:** Providing rich annotations for AI models to learn not just *what* is correct, but *how* to structure a correct explanation and avoid procedural missteps.
The core mathematical fact demonstrated is that two functions can share a subset of their roots. Here, `f(x)` and `g(x)` share the root `x = -3` but differ at `x = 2` and `x = 4`, respectively. This is a fundamental concept in algebra concerning the relationship between equations and their graphical representations.
</details>
(i)
<details>
<summary>x23.png Details</summary>

### Visual Description
## Diagram: DynaMath Protractor Angle Measurement Problem
### Overview
The image displays a mathematical problem from a source titled "Data Example from DynaMath." It consists of a diagram of a protractor measuring a blue angle, accompanied by a question and a multi-step solution. The solution steps are annotated with labels indicating their correctness.
### Components/Axes
1. **Header:** "Data Example from DynaMath" (top-left, bold, serif font).
2. **Diagram (Left Side):** A standard semicircular protractor.
* **Scale:** Marked from 0° to 180° in both clockwise and counterclockwise directions. Major tick marks are labeled every 10 degrees (0, 10, 20... 180). Smaller tick marks indicate individual degrees.
* **Angle:** A blue angle is drawn. One ray lies along the protractor's baseline (pointing to 0° on the inner scale and 180° on the outer scale). The other ray points upwards and to the left.
* **Measurement:** The second ray of the blue angle aligns precisely with the 40° mark on the protractor's inner scale (which corresponds to 140° on the outer scale).
3. **Text Block (Right Side):**
* **Question Label:** "Question:" (bold).
* **Question Text:** "Based on the measurement results shown in the diagram, this blue angle is ( )°."
* **Solution Label:** "Solution:" (bold).
* **Solution Steps:** A numbered list with annotations.
- Step-0 (Neural): "To determine the measure of the blue angle in the diagram, follow these steps:"
- Step-1 (Incorrect): "1. Observe the protractor: The protractor measures angles from 0° to 180°."
- Step-1 (Incorrect): "2. Identify the measurement: The blue angle is indicated by a line pointing to a specific degree on the protractor."
- Step-1 (Incorrect): "3. Locate the angle: The blue line points to the number 40° on the protractor."
- Step-2 (Incorrect): "Thus, the measure of the blue angle is 40°."
- Step-3 (Incorrect): "Final answer: 40"
### Detailed Analysis
* **Diagram Analysis:** The protractor is oriented with its baseline horizontal. The vertex of the angle is at the protractor's center point. The initial side (ray) is aligned with the 0° mark on the inner scale. The terminal side (ray) passes directly through the 40° mark on the same inner scale. Visually, this represents an acute angle of 40 degrees.
* **Text Transcription:**
* **Header:** Data Example from DynaMath
* **Question:** Based on the measurement results shown in the diagram, this blue angle is ( )°.
* **Solution Steps:**
- Step-0 (Neural): To determine the measure of the blue angle in the diagram, follow these steps:
- Step-1 (Incorrect): 1. Observe the protractor: The protractor measures angles from 0° to 180°.
- Step-1 (Incorrect): 2. Identify the measurement: The blue angle is indicated by a line pointing to a specific degree on the protractor.
- Step-1 (Incorrect): 3. Locate the angle: The blue line points to the number 40° on the protractor.
- Step-2 (Incorrect): Thus, the measure of the blue angle is 40°.
- Step-3 (Incorrect): Final answer: 40
### Key Observations
1. **Contradictory Annotations:** The solution steps are logically sound and correctly describe the process of reading the protractor to find a 40° angle. However, each step from 1 to 3 is explicitly labeled as **(Incorrect)** in red, italicized text. Step-0 is labeled **(Neural)** in yellow, italicized text.
2. **Spatial Layout:** The diagram is positioned to the left of the textual question and solution, creating a clear reference between the visual data and the problem statement.
3. **Precision:** The blue angle's terminal ray aligns exactly with the 40° tick mark, leaving no ambiguity in the measurement from the diagram.
### Interpretation
This image appears to be a critique or analysis of an AI-generated (or "Neural") solution to a simple geometry problem. The core factual content is the measurement of the angle, which is unambiguously 40 degrees based on the protractor diagram.
The key informational payload is not the angle measurement itself, but the **meta-commentary** provided by the annotations. The labels suggest that while the neural network's reasoning process (Step-0) and its final answer (40) are factually correct, the entire solution pathway is being classified as "Incorrect." This implies the image is likely from a dataset or research paper evaluating AI reasoning, where the "correctness" may be judged on criteria beyond factual accuracy—perhaps on the formality of the proof, the use of specific terminology, or adherence to a prescribed solution template. The repetition of "Step-1" for three sub-points also indicates a potential formatting or parsing error in the source material being analyzed. The image thus serves as a data point for examining the gap between correct factual output and formally validated reasoning in AI systems.
</details>
(j)
<details>
<summary>x24.png Details</summary>

### Visual Description
\n
## Data Table with Problem-Solving Example: House Sales Range Calculation
### Overview
The image displays a data example from "DynaMath," presenting a table of house sales numbers for various cities alongside a mathematical question and a step-by-step solution. The solution provided contains multiple errors, which are explicitly labeled.
### Components/Axes
The image is divided into two main sections within a brown-bordered frame:
1. **Left Section (Data Table):** A two-column table.
* **Column 1 Header:** `city`
* **Column 2 Header:** `Sales number`
* The table lists 8 cities and their corresponding sales figures.
2. **Right Section (Problem & Solution):**
* **Question:** "A real estate agent looked into how many houses were sold in different cities. What is the range of the numbers?"
* **Solution:** A 5-step process (Step-0 to Step-4). Each step is prefixed with a label in gray text (e.g., "## Step-0") followed by a status in parentheses. The status is either "(Neural)" in yellow or "(Incorrect)" in red.
### Detailed Analysis
**Data Table Content:**
| city | Sales number |
| :--- | :--- |
| Briggs Corner | 83 |
| New Humburg | 83 |
| Melville | 86 |
| Fremont | 81 |
| liberty City | 92 |
| Charles Falls | 84 |
| Pleasent Town | 93 |
| Penny Town | 97 |
**Solution Steps Transcription:**
* **Step-0 (Neural):** Let me help you find the range of the sales numbers.
* **Step-1 (Incorrect):** The range is calculated by subtracting the minimum value from the maximum value.
* **Step-2 (Incorrect):** Minimum sales number: 81 (Fremont)
Maximum sales number: 97 (Penny Town)
* **Step-3 (Incorrect):** Range = Maximum - Minimum
Range = 97 - 81 = 16
* **Step-4 (Incorrect):** Therefore, the range of house sales numbers across these cities is 16.
### Key Observations
1. **Data Discrepancy:** The solution in Step-2 incorrectly identifies the maximum sales number as 97 (Penny Town). According to the provided table, the correct maximum value is 93 (Pleasant Town). Penny Town's value of 97 is not present in the table.
2. **Cascading Error:** This initial misidentification of the maximum value leads to an incorrect calculation of the range (16) in Steps 3 and 4. The correct range, using the table's data, would be 93 (max) - 81 (min) = 12.
3. **Error Labeling:** The solution's steps are explicitly marked as "(Incorrect)" in red text, indicating the provided solution is intentionally flawed, likely as a teaching example.
4. **Spelling:** The city name "Pleasent Town" appears to be a misspelling of "Pleasant Town."
### Interpretation
This image serves as a pedagogical tool demonstrating a common error in data analysis: misreading or misrepresenting source data. The core factual data is contained in the table on the left. The narrative on the right shows a logical process (calculating range) that is correctly structured but fails at the data extraction step (Step-2), using a value (97) not supported by the provided dataset.
The "Neural" label on Step-0 suggests an AI or automated system initiated the problem-solving process. The subsequent "Incorrect" labels highlight where the reasoning diverged from the facts. This setup is likely designed to teach students to:
1. Carefully verify source data against any derived conclusions.
2. Understand that a correct method (range = max - min) can still produce a wrong answer if the input data is wrong.
3. Critically evaluate step-by-step solutions, even those generated by automated systems.
The notable anomaly is the introduction of the number 97 for "Penny Town" in the solution, which directly contradicts the table. This is the root cause of the error and the central teaching point of the example.
</details>
(k)
<details>
<summary>x25.png Details</summary>

### Visual Description
## Radar Chart: DynaMath Data Example
### Overview
The image displays a technical document or problem card from a dataset or system named "DynaMath." It consists of two primary sections: a radar chart on the left and a textual question-and-solution block on the right. The entire content is enclosed within a thin brown border.
### Components/Axes
**1. Radar Chart (Left Side):**
* **Title:** "Radar Chart" (centered above the chart).
* **Axes/Categories:** Five categories are plotted radially, labeled with single letters:
* **A** (positioned at approximately 3 o'clock)
* **B** (positioned at approximately 12 o'clock)
* **C** (positioned at approximately 10 o'clock)
* **D** (positioned at approximately 8 o'clock)
* **E** (positioned at approximately 6 o'clock)
* **Scale:** Concentric circles represent the scale, with markers at **20, 40, 60, 80, and 100**. The center represents 0.
* **Data Series:** A single data series is plotted as a blue, semi-transparent polygon connecting points on each category axis.
**2. Text Block (Right Side):**
* **Main Title:** "Data Example from DynaMath" (top, bold, left-aligned).
* **Question Section:**
* **Label:** "Question:" (bold).
* **Text:** "The radar chart below represents different categories. Which category is second highest?"
* **Choices:** "Choices: (A) A (B) B (C) C (D) D (E) E"
* **Solution Section:**
* **Label:** "Solution:" (bold).
* **Step-0:** Labeled "(Neural)" in yellow text. Text: "Looking at the radar chart, I can see that there are 5 categories (A, B, C, D, and E) plotted on a scale from 0 to 100. After analyzing the values:"
* **Step-1:** Labeled "(Incorrect)" in red text. Text: "- Category C appears to be the highest\n- Category D shows the second highest value\n- Categories A, B, and E have lower values"
* **Step-2:** Labeled "(Incorrect)" in red text. Text: "Therefore, category D (choice D) is the second highest in the radar chart."
* **Step-3:** Labeled "(Incorrect)" in red text. Text: "The answer is (D)."
### Detailed Analysis
**Chart Data Extraction (Estimated Values):**
Based on visual inspection of the blue polygon's vertices against the concentric scale:
* **Category C:** The vertex extends to the outermost ring, indicating a value of **~100**.
* **Category D:** The vertex is between the 80 and 100 rings, closer to 100. Estimated value: **~90**.
* **Category B:** The vertex is between the 60 and 80 rings. Estimated value: **~70**.
* **Category A:** The vertex is between the 40 and 60 rings. Estimated value: **~50**.
* **Category E:** The vertex is between the 20 and 40 rings. Estimated value: **~30**.
**Text Transcription:**
All text is in English. The transcription is provided above in the Components section. Notable formatting includes the use of bold for labels ("Question:", "Solution:"), colored text for step annotations (yellow for "Neural", red for "Incorrect"), and a line break (`\n`) in the Step-1 text.
### Key Observations
1. **Data Ranking:** Visually, the order from highest to lowest value is: **C (~100) > D (~90) > B (~70) > A (~50) > E (~30)**.
2. **Solution Discrepancy:** The provided "Solution" text correctly identifies C as highest and D as second highest in Step-1. However, every step of this solution (Step-0 through Step-3) is annotated as either "(Neural)" or, more prominently, **"(Incorrect)"**.
3. **Final Answer:** The solution concludes with "The answer is (D)." Given the visual data, this conclusion (that D is second highest) appears factually correct based on the chart, yet the system labels the entire reasoning chain as incorrect.
### Interpretation
This image is not a presentation of raw data but a **meta-example of an AI or automated reasoning system's output**. The core informational content is twofold:
1. **The Radar Chart Data:** It presents a simple, clear dataset where category C has the maximum value (100) and category D has the second-highest value (~90). The chart is designed for straightforward visual comparison.
2. **The Reasoning Process Artifact:** The more significant information lies in the structure and annotations of the "Solution." The labels "(Neural)" and "(Incorrect)" suggest this is a logged output from a model (possibly a neural network) being evaluated. The fact that a logically sound conclusion (D is second highest) is marked "Incorrect" implies one of two scenarios:
* **The evaluation is about the *process*, not the answer:** The system may be flagging the reasoning steps as flawed (e.g., lacking precision, using informal language like "appears to be") even though the final answer is correct.
* **There is an external ground truth mismatch:** The dataset ("DynaMath") may have a different correct answer for this specific chart, making the model's conclusion wrong despite its visual plausibility. This would indicate a potential error in the chart's rendering or the dataset's answer key.
The image serves as a diagnostic or training example, highlighting the challenge of aligning visual data interpretation with formal reasoning validation. It demonstrates that in technical AI evaluation, correctness is not solely about the final output but also about the trace and quality of the steps taken to reach it.
</details>
(l)
<details>
<summary>x26.png Details</summary>

### Visual Description
\n
## Screenshot: Math Problem and Solution
### Overview
The image is a digital document snippet titled "Data Example from WeMath." It presents a geometry problem involving a conical container, provides multiple-choice answers, and includes a detailed, step-by-step solution. A diagram of the cone is shown to the left of the text.
### Components/Axes
* **Header:** "Data Example from WeMath" at the top left.
* **Diagram (Left Side):** A line drawing of a right circular cone. A vertical double-headed arrow to its left is labeled "20cm," indicating the cone's height. The base is depicted as an ellipse with a dashed line showing its radius.
* **Question Block (Right Side, Top):** Contains the problem statement and answer choices.
* **Solution Block (Right Side, Below Question):** A numbered, step-by-step mathematical derivation. Each step is prefixed with a label like "## Step-0 (Correct)" in light gray text.
### Detailed Analysis / Content Details
**1. Question Text:**
> Given that the circumference of the upper edge of a conical water container is 62.8 cm, what is the radius of its base circle in cm?
> A. 8 B. 9 C. 10 D. Cannot be determined E. No correct answer
**2. Solution Steps (Transcribed with original formatting):**
The solution uses a mix of plain text and LaTeX-like notation (e.g., `\\( ... \\)`, `\\[ ... \\]`).
* **## Step-0 (Correct):** To determine the **radius** of the base of the cone:
* **## Step-1 (Correct):** 1. The formula for the circumference of a circle is:
`\\[ C = 2\\pi r \\]`
where `\\(C\\)` is the circumference and `\\(r\\)` is the radius.
* **## Step-2 (Correct):** 2. We are given `\\(C = 62.8 \\, \\text{cm}\\)`. Substitute this value into the formula:
`\\[ 62.8 = 2\\pi r \\]`
* **## Step-3 (Correct):** 3. Solve for `\\(r\\)`:
`\\[ r = \\frac{62.8}{2\\pi} \\]`
* **## Step-4 (Correct):** 4. Use the approximation `\\(\\pi \\approx 3.14\\)`:
`\\[ r = \\frac{62.8}{2 \\times 3.14} = \\frac{62.8}{6.28} = 10 \\, \\text{cm} \\]`
* **## Step-5 (Correct):** Thus, the radius of the base circle is **10 cm**.
* **## Step-6 (Correct):** ### Final Answer: **C. 10**
### Key Observations
* The problem provides the circumference of the cone's base (referred to as the "upper edge") and asks for its radius.
* The diagram includes a height measurement (20cm), but this information is **not used** in the solution. The solution relies solely on the circumference formula.
* The solution correctly identifies that the circumference of the base circle is given, making the height irrelevant for finding the radius.
* The calculation uses the approximation π ≈ 3.14, leading to a clean, integer result of 10 cm.
* The final answer corresponds to option **C**.
### Interpretation
This image serves as an educational example demonstrating the direct application of the circle circumference formula (`C = 2πr`). The core investigative reading is the identification of relevant versus irrelevant information: the problem includes a distractor (the cone's height of 20cm) which is not needed to solve for the radius when the circumference is known. The step-by-step solution reinforces proper algebraic manipulation and the use of a standard π approximation. The "WeMath" header suggests this is from a platform or resource focused on mathematical problem-solving, likely intended for students learning geometry. The structure, with labeled "Correct" steps, is designed to build confidence by validating each part of the logical process.
</details>
(m)
<details>
<summary>x27.png Details</summary>

### Visual Description
## Diagram: Geometry Problem with Solution Steps
### Overview
The image displays a geometry problem from a source titled "Data Example from WeMath." It consists of a labeled diagram of a quadrilateral on the left and a corresponding question with a multi-step solution on the right. The problem involves using symmetry to find the perimeter of a parallelogram.
### Components/Axes
**Diagram (Left Side):**
* A quadrilateral labeled with vertices **A**, **B**, **C**, and **D**.
* A dashed vertical line labeled **EF** runs through the center, identified as the axis of symmetry. Point **E** is on side AD, and point **F** is on side BC.
* A measurement label **"3cm"** is placed along the segment from **A** to **E**.
* A measurement label **"5cm"** is placed along side **CD**.
* The diagram visually suggests that ABCD is an isosceles trapezoid with EF as its line of symmetry.
**Text (Right Side):**
* **Header:** "Data Example from WeMath"
* **Question Section:**
* **Question Text:** "As shown in the diagram, EF is the axis of symmetry for quadrilateral ABCD. Given that CD = 5 cm and AD = 3 cm, what is the perimeter of parallelogram ABFD in cm?"
* **Multiple Choice Options:** A. 12, B. 10, C. 14, D. 16, E. No correct answer
* **Solution Section:** A step-by-step solution is provided, with each step prefixed by "## Step-X" and a correctness label in parentheses (Correct/Incorrect).
### Detailed Analysis
**Transcription of Solution Steps:**
* **## Step-0 (Correct):** To find the perimeter of parallelogram ABFD, we need to use the given information about the quadrilateral ABCD and its symmetry with respect to EF.
* **## Step-1 (Correct):** 1. EF is the axis of symmetry for the quadrilateral ABCD. This means that EF divides ABCD into two congruent halves.
* **## Step-2 (Incorrect):** 2. Since EF is the axis of symmetry and AD = 3 cm, AD = DF.
* **## Step-3 (Incorrect):** 3. CD is given as 5 cm. Since EF is the axis of symmetry, CD = BF.
* **## Step-4 (Correct):** Now, let's calculate the perimeter of the parallelogram ABFD:
* - AD + DF + BF + AB
* **## Step-5 (Incorrect):** Since AD = DF and CD = BF, we can substitute the measurements:
* - AD = 3 cm
* - BF = CD = 5 cm
* **## Step-6 (Incorrect):** Therefore, the perimeter is:
* - AD + DF + BF + AB
* - 3 cm + 3 cm + 5 cm + 5 cm = 16 cm
* **## Step-7 (Correct):** Final answer: D
### Key Observations
1. **Solution Logic Error:** The solution contains a critical logical error in Steps 2 and 3. The axis of symmetry EF implies that corresponding segments on either side are equal (e.g., AE = ED, BF = FC). However, it does **not** imply that a segment on one side (AD) is equal to a segment that crosses the axis (DF), nor that a side (CD) is equal to a segment on the opposite side (BF). The correct equalities from symmetry are: AE = ED, BF = FC, AB = DC, and ∠A = ∠D.
2. **Correct Final Answer Despite Errors:** The final numerical answer (16 cm) and the choice (D) are marked as correct. This suggests the problem's intended answer is 16 cm, but the provided solution path to reach it is flawed.
3. **Diagram vs. Text:** The diagram labels AD as 3cm, but the text of the question also states AD = 3 cm. The diagram labels CD as 5cm, which matches the question text.
### Interpretation
This image presents a pedagogical example, likely from an educational platform, demonstrating a common student mistake in applying symmetry properties. The core task is to find the perimeter of parallelogram ABFD.
* **What the Data Suggests:** The problem tests the understanding that symmetry about a line (EF) creates mirror-image congruence. The incorrect steps reveal a misapplication of this property, confusing which segments are congruent.
* **Relationship Between Elements:** The diagram is essential for visualizing the shape and the axis of symmetry. The solution text attempts to derive the answer from the diagram's properties but fails in its reasoning. The correctness labels (Correct/Incorrect) serve as a meta-commentary, highlighting where the reasoning breaks down.
* **Notable Anomaly:** The most significant anomaly is the disconnect between the incorrect reasoning (Steps 2, 3, 5, 6) and the correct final answer (Step 7). This implies that while the final answer (D. 16) is correct for the given problem, the explanatory solution provided is invalid. A correct solution would need to establish that ABFD is a parallelogram (likely by showing AB ∥ DF and AD ∥ BF) and then correctly deduce the lengths of its sides using the given measurements and symmetry (e.g., AB = CD = 5 cm, and AD = 3 cm is given; finding DF and BF would require additional correct geometric reasoning not present in the flawed steps).
</details>
(n)
<details>
<summary>x28.png Details</summary>

### Visual Description
\n
## Diagram: WeMath Data Example - Book Stacking Logic Problem
### Overview
The image is an educational slide or document excerpt titled "Data Example from WeMath". It presents a visual logic puzzle involving the arrangement of colored books on two desks. The layout is divided into two main sections: a diagram on the left and a textual question with a step-by-step solution on the right.
### Components/Axes
**1. Header:**
* **Title:** "Data Example from WeMath" (located at the top-left, underlined with a brown horizontal rule).
**2. Diagram Section (Left Side):**
* **Visual Elements:** Two identical school desks, labeled with circled numbers, and a cartoon girl walking between them.
* **Desk ① (Left):** A stack of three books. From top to bottom: a green book, a red book, and a blue book.
* **Desk ② (Right):** A stack of three books. From top to bottom: a red book, a green book, and a yellow book.
* **Labels:** The desks are labeled with circled numbers: "①" below the left desk and "②" below the right desk.
* **Character:** A girl with brown hair in a ponytail, wearing an orange shirt and yellow shorts, is depicted walking from left to right between the two desks.
**3. Text Section (Right Side):**
* **Question Block:**
* **Label:** "Question:"
* **Text:** "As shown in the diagram, what is the color of the bottommost book placed on Desk \u2460?"
* *Note: "\u2460" is the Unicode character for the circled number 1, corresponding to Desk ① in the diagram.*
* **Multiple Choice Options:**
* A. Red
* B. Green
* C. Blue
* D. Yellow
* E. No correct answer
* **Solution Block:**
* **Label:** "Solution:"
* **Step-0 (Neural):** "To solve this question, we need to visually analyze the stack of books on Desk \u2460 depicted in the diagram. Starting from the top and moving downward, the books are arranged in the following order:"
* **Step-1 (Correct):** A numbered list:
1. "**Green** (topmost book)"
2. "**Red** (second book)"
3. "**Blue** (third book, bottommost book)"
* **Step-2 (Correct):** "Thus, the color of the bottommost book on Desk \u2460 is **Blue**."
* **Step-3 (Correct):** "### Final Answer: **C. Blue**"
### Detailed Analysis
The core task is to identify the color of the bottom book on the desk labeled "①".
* **Visual Data from Diagram for Desk ①:** The stack is clearly depicted with three distinct colored books. The top book is green, the middle book is red, and the bottom book is blue.
* **Textual Solution Logic:** The solution text explicitly walks through the visual analysis, listing the book colors from top to bottom for Desk ①, confirming the bottommost book is blue.
* **Cross-Reference:** The solution's final answer (C. Blue) matches the visual evidence from the diagram for Desk ①. The diagram for Desk ② (with a yellow bottom book) is a distractor and is not referenced in the question or solution.
### Key Observations
1. **Spatial Reasoning:** The problem tests the ability to correctly associate the label "Desk \u2460" (or ①) with the correct visual element in the diagram.
2. **Color Identification:** Requires accurate perception of the colors in the specified stack.
3. **Sequential Order:** The solution methodically lists the order from top to bottom, which is a reliable way to avoid confusion.
4. **Distractor Element:** The presence of a second desk (Desk ②) with a different book order serves as a visual distractor, testing if the solver focuses on the correct labeled item.
### Interpretation
This image is a pedagogical tool designed to teach or assess basic visual analysis and logical deduction skills, likely for a young audience. It demonstrates a clear problem-solving framework:
1. **Identify the Target:** The question specifies "Desk \u2460".
2. **Locate the Target:** Find the corresponding element in the diagram (the left desk labeled ①).
3. **Analyze the Target:** Observe the specific property requested (color of the bottommost book).
4. **Formulate the Answer:** Based on observation, select the matching option.
The inclusion of a "Neural" step and "Correct" steps suggests this might be an example from a dataset or a demonstration of an AI's reasoning process, showing how it breaks down a visual question into logical steps. The structure emphasizes methodical, verifiable reasoning over a simple guess. The clear separation between the visual data and the textual reasoning process makes it an effective example for explaining how to solve such puzzles.
</details>
(o)
Figure 7: More data examples from VisualProcessBench.
<details>
<summary>x29.png Details</summary>

### Visual Description
## Diagram: Geometry Problem and Solution Process
### Overview
The image displays a technical example from "VisualProcessBench," presenting a geometry problem involving an isosceles triangle and a detailed, annotated step-by-step solution process. The layout is divided into two main sections: a geometric diagram on the left and a textual problem statement with a multi-step solution on the right.
### Components/Axes
**1. Diagram (Left Side):**
* **Type:** A geometric line drawing of a triangle with an extended line.
* **Labels & Points:**
* Triangle vertices are labeled **A**, **B**, and **C**.
* Point **B** is at the bottom-left vertex.
* Point **A** is at the top vertex.
* Point **C** is at the bottom-right vertex.
* **Angles & Values:**
* Angle at vertex **B** is labeled **25°**.
* Angle at vertex **A** is labeled **130°**.
* Angle at vertex **C** (inside the triangle) is labeled **25°**.
* An exterior angle at point **C**, formed by extending side BC, is labeled **1**.
* An angle adjacent to angle **1** on the straight line is labeled **35°**.
* **Spatial Grounding:** The diagram is positioned on the left half of the image. The triangle is oriented with its base (BC) horizontal. The 35° angle is to the right of angle 1, on the same straight line extending from point C.
**2. Textual Content (Right Side):**
* **Header:** "Data Example from VisualProcessBench" (top-left corner of the entire frame).
* **Question Section:**
* **Label:** "Question:"
* **Text:** "As shown in the figure, triangle ABC is an isosceles triangle, ∠B = 25°, then the angle of ∠1 is ( )"
* **Options:** "A. 95° B. 145° C. 120° D. No correct answer"
* **Solution Section:**
* **Label:** "Solution:"
* **Structure:** A series of numbered steps (## Step-0, ## Step-1, etc.) with annotations in parentheses indicating the reasoning quality.
* **Annotations (Color-Coded in Original):**
* `(Neural)` - Appears in yellow/gold.
* `(Correct)` - Appears in green.
* `(Incorrect)` - Appears in red.
* **Ellipses:** Vertical colons (`:`) are used between steps to indicate omitted intermediate steps.
### Detailed Analysis / Content Details
**Step-by-Step Solution Transcription:**
#### Step-0 (Neural)
"Let's see. I have this problem here about an isosceles triangle. It says that in triangle ABC, angle B is 25 degrees, and it's an isosceles triangle. I need to find the measure of angle 1. The options are A. 95°, B. 145°, C. 120°, and D. no correct answer."
#### Step-1 (Correct)
"First, I should recall that in an isosceles triangle, two sides are equal in length, and the angles opposite those sides are also equal. So, in triangle ABC, if angle B is 25 degrees, then either angle A or angle C is also 25 degrees. But wait, looking at the figure, it seems like angle C is also 25 degrees because there's a mark indicating that angle C is 25 degrees."
**[Omitted Steps]**
#### Step-4 (Incorrect)
"So, if angle 1 is an exterior angle at point C, then its measure should be equal to the sum of the measures of the angles at points A and B. Given that angle A is 130 degrees and angle B is 25 degrees, *then angle 1 should be 130° + 25° = 155°*."
#### Step-5 (Correct)
"But that's not one of the options. Option D says 'no correct answer,' *but maybe I'm missing something. Wait, perhaps the figure is not exactly as I described. Let me look again.*"
**[Omitted Steps]**
#### Step-12 (Correct)
"Looking back at the figure, if angle 1 is the exterior angle at C, which is 155 degrees, and there's a 35-degree angle adjacent to it on the straight line, then the angle between them would be 155° - 35° = 120°. *Therefore, angle 1 is 120 degrees.* Yes, that makes sense. So, the answer should be option C. 120°. Final Answer \[ \boxed{C} \]"
### Key Observations
1. **Reasoning Trajectory:** The solution demonstrates a common error (Step-4) where the exterior angle theorem is misapplied by summing the two remote interior angles (A and B) without accounting for the adjacent 35° angle shown in the diagram.
2. **Self-Correction:** The process includes a critical self-correction phase (Step-5) where the solver notices the discrepancy between their calculated answer (155°) and the given options, prompting a re-examination of the figure.
3. **Final Resolution:** The correct solution (Step-12) integrates all visual data: the exterior angle (155°) and the adjacent 35° angle on a straight line, leading to the calculation 155° - 35° = 120°.
4. **Annotated Process:** The use of `(Neural)`, `(Correct)`, and `(Incorrect)` tags suggests this is a trace of a problem-solving agent (possibly an AI), highlighting its initial interpretation, errors, and eventual correct reasoning.
### Interpretation
This image serves as a **worked example of geometric problem-solving with metacognitive annotation**. It doesn't just present a problem and answer; it exposes the *process* of reasoning, including a plausible mistake and its correction.
* **What it demonstrates:** The core task is to find the measure of an exterior angle (∠1) in a specific geometric configuration. The solution hinges on correctly interpreting the diagram—specifically, recognizing that ∠1 and the 35° angle are supplementary angles on a straight line, not that ∠1 is a simple exterior angle of the triangle.
* **Relationship between elements:** The diagram is the primary source of truth. The textual solution must align with it. The error in Step-4 arises from a temporary misalignment between the solver's mental model and the diagram's details. The correction occurs when the solver re-consults the visual data.
* **Broader significance:** This format is valuable for educational or AI training purposes. It illustrates the importance of:
1. **Careful diagram reading:** Not assuming standard configurations.
2. **Verification against options:** Using multiple-choice answers as a sanity check.
3. **Iterative reasoning:** The ability to backtrack and revise a hypothesis based on new evidence (the diagram and the answer choices).
The final answer, **C. 120°**, is derived by synthesizing the triangle's properties (isosceles, angles 25°-130°-25°) with the linear pair relationship at point C (155° + 35° = 180°).
</details>
Figure 8: Data example with model reflection from VisualProcessBench. Red highlights the incorrect answer, orange highlights the reflection words, and green highlights the correct answer.