# GKG-LLM: A Unified Framework for Generalized Knowledge Graph Construction
> Corresponding author
## Abstract
The construction of Generalized Knowledge Graph (GKG), including knowledge graph, event knowledge graph and commonsense knowledge graph, is fundamental for various natural language processing tasks. Current studies typically construct these types of graph separately, overlooking holistic insights and potential unification that could be beneficial in computing resources and usage perspectives. However, a key challenge in developing a unified framework for GKG is obstacles arising from task-specific differences. In this study, we propose a unified framework for constructing generalized knowledge graphs to address this challenge. First, we collect data from 15 sub-tasks in 29 datasets across the three types of graphs, categorizing them into in-sample, counter-task, and out-of-distribution (OOD) data. Then, we propose a three-stage curriculum learning fine-tuning framework, by iteratively injecting knowledge from the three types of graphs into the Large Language Models. Extensive experiments show that our proposed model improves the construction of all three graph types across in-domain, OOD and counter-task data.
## 1 Introduction
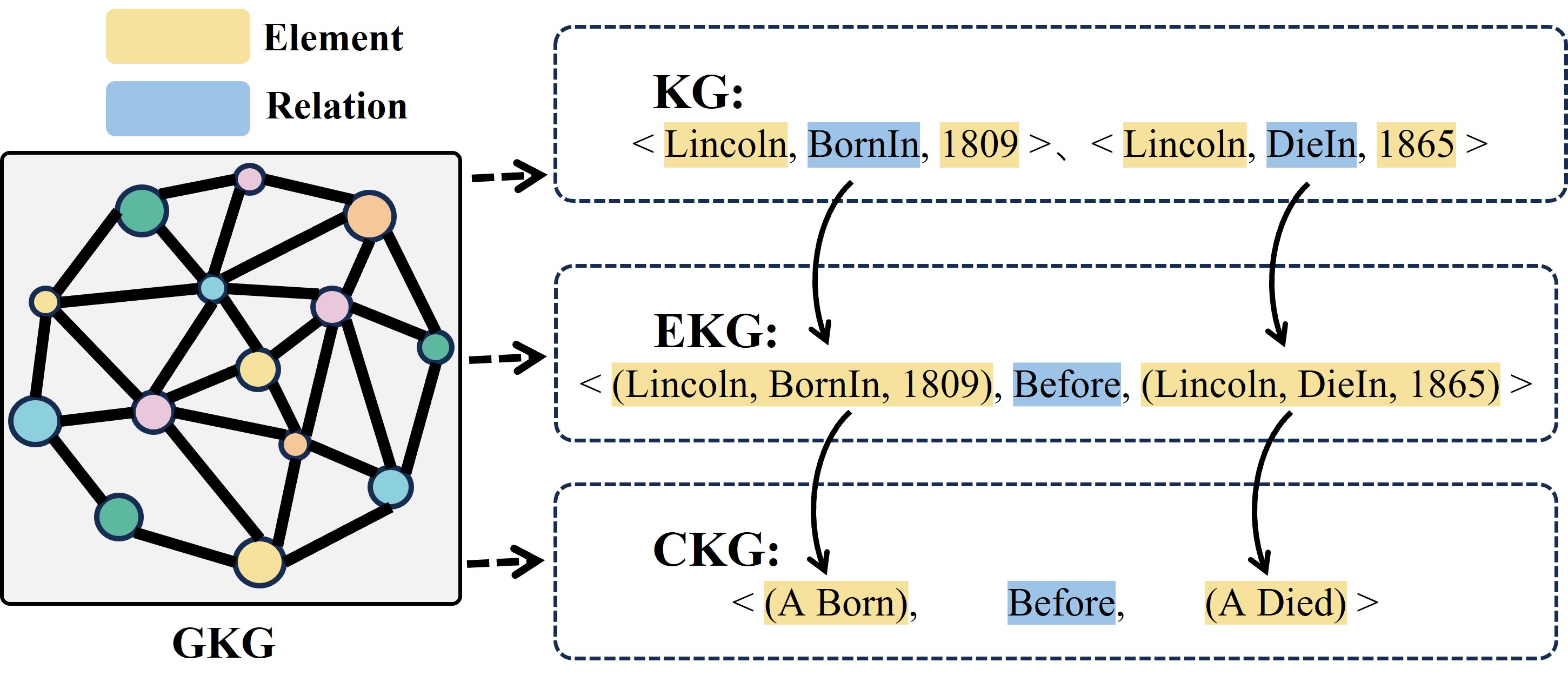
Generalized Knowledge Graph (GKG) Krause et al. (2022) includes Knowledge Graph (KG), Event Knowledge Graph (EKG) and Commonsense Knowledge Graph (CKG). The construction of GKG encompasses multiple essential tasks Peng et al. (2023), which are crucial for various applications in this field, including intelligence analysis Pimenov et al. (2023) and decision support Lai et al. (2023). As shown in Figure 1, KGs Lin et al. (2023, 2025a) are developed to more effectively describe concepts and relations in the physical world. The fundamental structure is <entity, relation, entity >, such as <Lincoln, BornIn, 1809>. With ongoing research, EKGs are introduced to study the dynamic progression of events. It is organized in the triplet format <event, relation, event >, as illustrated by <(Lincoln, BornIn, 1809), Before, (Lincoln, diedIn, 1865) >. The further generalization of event graphs has led to the development of CKG, which abstractly represent general relational patterns in the form of <commonsense, relation, commonsense>. For instance, <(A born), Before, (A died)>is also organized in a triplet format. In summary, KG, EKG, and CKG are all organized in the basic form of <element, relation, element >.
Overall, constructing the three types of graphs separately requires substantial resources, while using a unified framework for their construction improves parameter efficiency. Additionally, from a usage perspective, the knowledge contained in KGs facilitates the construction of both EKGs and CKGs. For example, a method leveraging hierarchical KGs to enhance the accuracy and effectiveness of biomedical event extraction is proposed by Huang et al. (2020). Similarly, for knowledge graphs aiding text classification in the construction of CKGs, KG-MTT-BERT He et al. (2022) is introduced to enhance BERT with KGs for multi-type medical text classification.
<details>
<summary>extracted/6285883/figures/example.jpg Details</summary>
### Visual Description
\n
## Diagram: Knowledge Graph Representation
### Overview
The image presents a diagram illustrating the transformation of a Knowledge Graph (KG) into an Event Knowledge Graph (EKG) and a Common Knowledge Graph (CKG). It visually represents how relationships between entities are structured and abstracted across these different graph types. The left side shows a complex graph structure labeled "GKG", while the right side shows three boxes representing KG, EKG, and CKG, with example relationships within each.
### Components/Axes
The diagram consists of the following components:
* **GKG (Graph Knowledge Graph):** A complex network of nodes (purple) and edges (gray) representing entities and their relationships.
* **KG (Knowledge Graph):** A box containing two example relationships: `<Lincoln, BornIn, 1809>` and `<Lincoln, DieIn, 1865>`.
* **EKG (Event Knowledge Graph):** A box containing a single example relationship: `<(Lincoln, BornIn, 1809), Before, (Lincoln, DieIn, 1865)>`.
* **CKG (Common Knowledge Graph):** A box containing a single example relationship: `<(A Born), Before, (A Died)>`.
* **Legend:** Located in the top-left corner, defining the color coding:
* Yellow: "Element"
* Blue: "Relation"
* **Arrows:** Arrows connect the GKG to each of the KG, EKG, and CKG boxes, indicating a transformation or projection process.
### Detailed Analysis or Content Details
Let's break down the content within each section:
* **GKG:** This is a complex graph with approximately 20 nodes (purple circles) interconnected by numerous edges (gray lines). The exact number of nodes and edges is difficult to determine precisely without a higher-resolution image. The graph appears to be fully connected or nearly so.
* **KG:** This section represents a simplified knowledge graph. It contains two triples:
* `<Lincoln, BornIn, 1809>`: Lincoln was born in 1809.
* `<Lincoln, DieIn, 1865>`: Lincoln died in 1865.
* **EKG:** This section represents an event knowledge graph. It contains one triple:
* `<(Lincoln, BornIn, 1809), Before, (Lincoln, DieIn, 1865)>`: The event "Lincoln was born in 1809" happened before the event "Lincoln died in 1865".
* **CKG:** This section represents a common knowledge graph. It contains one triple:
* `<(A Born), Before, (A Died)>`: The event "A was born" happened before the event "A died".
### Key Observations
* The diagram illustrates a progression from a detailed graph (GKG) to more abstract representations (KG, EKG, CKG).
* The EKG and CKG represent relationships *between* events, rather than relationships between entities and attributes as in the KG.
* The CKG generalizes the relationship found in the EKG, using "A" instead of "Lincoln".
* The legend clearly defines the visual representation of "Element" (yellow) and "Relation" (blue).
### Interpretation
The diagram demonstrates a method for representing knowledge at different levels of abstraction. The GKG represents a rich, detailed knowledge base. The KG extracts specific facts about entities. The EKG focuses on temporal relationships between events involving those entities. Finally, the CKG generalizes these relationships into common-sense knowledge applicable to any entity.
The transformation from GKG to KG involves selecting specific relationships. The transformation from KG to EKG involves creating new relationships *between* existing relationships, specifically focusing on temporal order. The transformation from EKG to CKG involves generalization, replacing specific entities with abstract placeholders.
This approach is useful for tasks such as reasoning about events, making inferences, and building more robust knowledge-based systems. The diagram highlights the importance of representing knowledge not only as facts about entities but also as relationships between events and common-sense knowledge. The use of triples (subject, predicate, object) is a standard way to represent knowledge in knowledge graphs.
</details>
Figure 1: An illustration of several triples and graphs. The left half shows a generalized knowledge graph. The right half includes specific examples of triples from KG, EKG, CKG and demonstrates their progressive relationship.
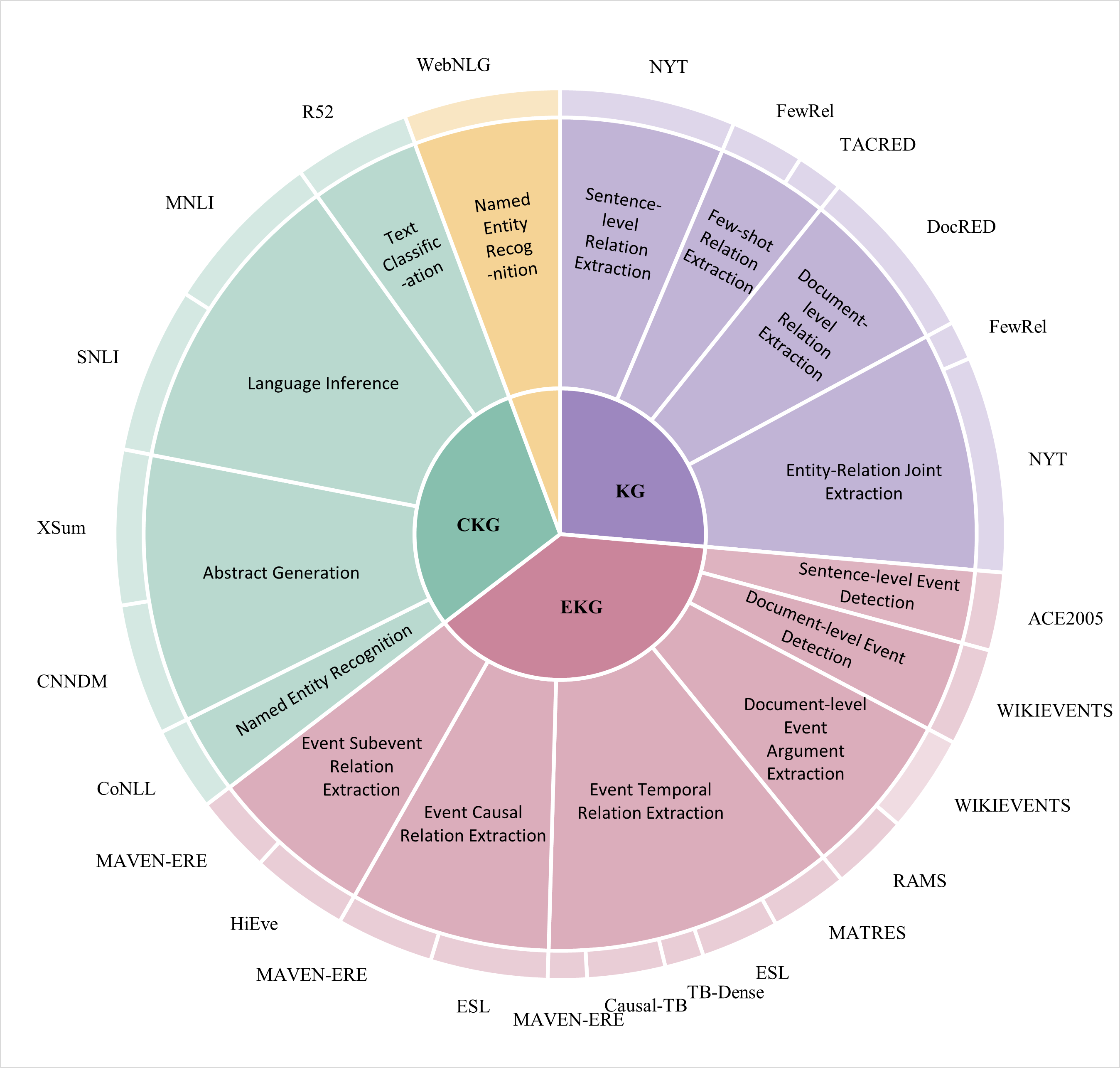
Naturally, we abstract a new task to build a unified framework for constructing GKG, in order to empower these foundational triples extraction tasks. However, a key challenge in this task is the obstacles arising from task-specific differences. The construction of different types of graph involves a wide variety of diverse sub-tasks. Specifically, as illustrated in Figure 2, the construction of KG includes sub-tasks such as sentence-level relation extraction Wadhwa et al. (2023), document-level relation extraction Ma et al. (2023) and joint entity and relation extraction Sui et al. (2023). The construction of EKG involves sub-tasks such as sentence-level event detection Hettiarachchi et al. (2023), document-level argument extraction Zhang et al. (2024), and event temporal relation extraction Chan et al. (2024). While the construction of CKG includes sub-tasks such as abstract generation Gao et al. (2023) and language inference Gubelmann et al. (2024). The abbreviations and introduction of the task can be found in Appendix F. These tasks differ in several ways, with the primary distinctions lying in their definitions and content. For instance, sentence-level relation extraction involves extracting the relationship between two entities from a single sentence, whereas abstract generation involves extracting an abstract from an entire article. Differences between these tasks have created obstacles to building a unified framework for constructing GKG.
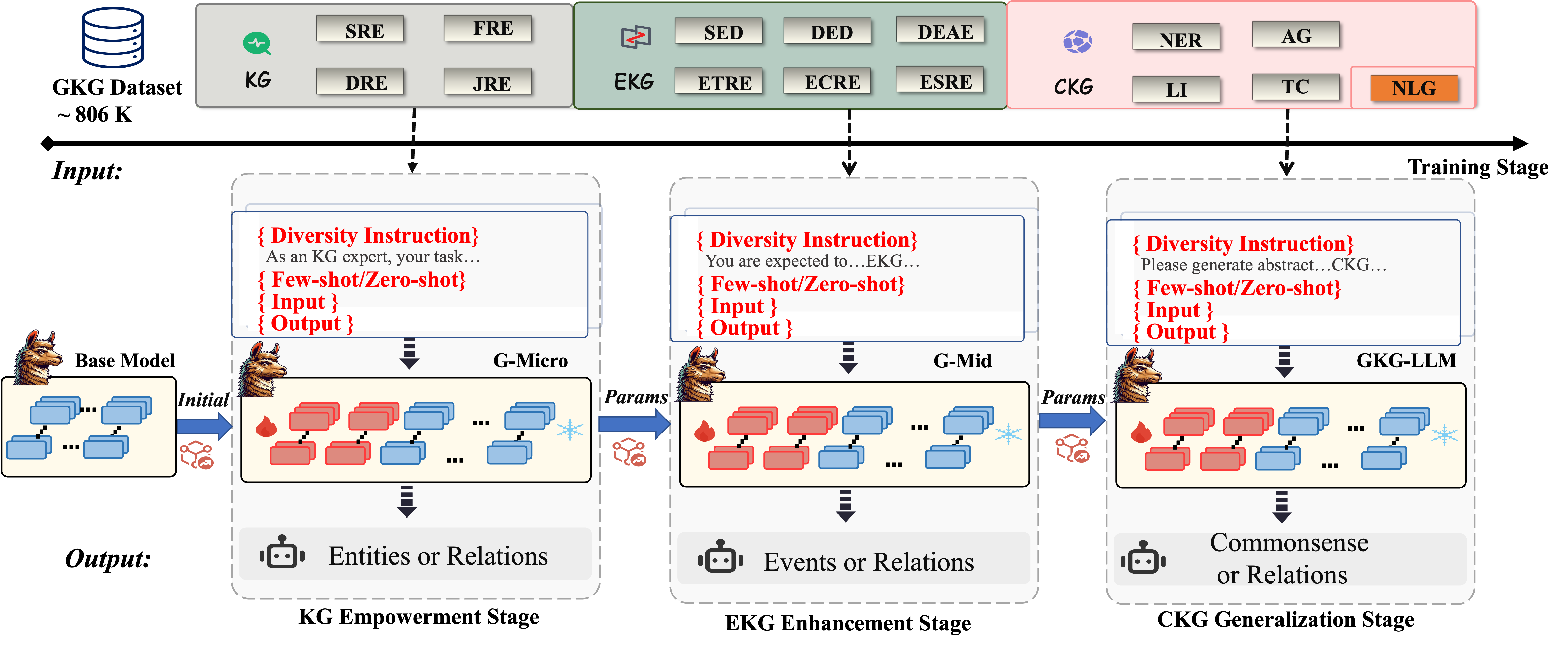
Thanks to the emergence of Large Language Models(LLMs), such as GPT4 Achiam et al. (2023) and LlaMA-3 Dubey et al. (2024), the realization of this new unified task has become possible. The standardized input-output format of LLMs unifies these sub-tasks from a structural perspective. To this end, we propose a three-stage curriculum learning tuning framework. Firstly, data collection and preparation involve extensively gathering data from three types of graphs, resulting in a total of 15 sub-tasks in 29 datasets. These datasets are categorized into three types: conventional datasets for training and testing, counter-task datasets also used for training and testing to prevent model overfitting and enhance generalization, and out-of-distribution (OOD) datasets used solely for testing. Secondly, the three-stage curriculum learning fine-tuning framework, built upon a base model, includes the KG Empowerment Stage, which leverages KG datasets, the EKG Enhancement Stage, utilizing EKG datasets, and the CKG Generalization Stage, which incorporates CKG datasets along with counter-task datasets. Through these three stages of training, we obtain the micro, mid, and macro versions of GKG-LLM, respectively. Finally, GKG-LLM has undergone extensive testing and analysis on all three graph types across in-domain, OOD, and counter-task data, demonstrating the effectiveness and advancement of diverse instruction design strategies and the three-stage fine-tuning framework.
<details>
<summary>extracted/6285883/figures/data_dis.png Details</summary>
### Visual Description
## Chart: Radial Visualization of NLP Tasks
### Overview
This image presents a radial chart, resembling a sunburst or rose diagram, visualizing relationships between various Natural Language Processing (NLP) tasks. The chart is organized concentrically, with tasks clustered around a central area. The tasks are color-coded, and the chart appears to illustrate the overlap or connections between different areas of NLP research.
### Components/Axes
The chart lacks traditional axes. Instead, it uses concentric rings and angular segments to represent tasks. The central area is labeled with "CKG" and "KG". The outer ring displays the names of specific NLP datasets/tasks. The color scheme is used to categorize tasks. The legend is implicitly defined by the color distribution within the chart.
### Detailed Analysis
The chart is divided into several segments, each representing a category of NLP tasks. Here's a breakdown, moving clockwise from the top:
* **Top-Right Quadrant (Light Blue/Green):**
* **NYT:** Appears twice, suggesting a significant role in multiple tasks.
* **FewRel:** Appears twice, also indicating importance.
* **TACRED:**
* **DocRED:**
* **Sentence-level Relation Extraction:**
* **Few-shot Relation Extraction:**
* **Document-level Relation Extraction:**
* **Entity-Relation Joint Extraction:**
* **Bottom-Right Quadrant (Yellow/Orange):**
* **WIKIEVENTS:** Appears twice.
* **ACE2005:**
* **RAMS:**
* **MATRES:**
* **ESL:**
* **Causal-TB-Dense MAVEN-ERE:**
* **Bottom-Left Quadrant (Green/Teal):**
* **MAVEN-ERE:** Appears twice.
* **HiEve:**
* **ESL:**
* **Event Temporal Relation Extraction:**
* **Event Causal Relation Extraction:**
* **Event Subevent Relation Extraction:**
* **Named Entity Recognition:**
* **Top-Left Quadrant (Purple/Pink):**
* **CNN/DM:**
* **CoNLL:**
* **XSum:**
* **SNLI:**
* **MNLI:**
* **R52:**
* **WebNLG:**
* **Text Classification:**
* **Named Entity Recognition:**
* **Language Inference:**
* **Abstract Generation:**
The central area is divided into two segments:
* **CKG:** (Color: Dark Green)
* **KG:** (Color: Light Green)
The chart shows a clear clustering of tasks. Relation extraction tasks are heavily concentrated in the top-right quadrant. Event-related tasks dominate the bottom-left. Text classification, language inference, and abstract generation are grouped in the top-left.
### Key Observations
* **Repetition of Tasks:** "NYT", "FewRel", "WIKIEVENTS", "MAVEN-ERE", and "ESL" appear multiple times, suggesting they are foundational datasets or tasks used across different areas of NLP.
* **Central Importance of CKG/KG:** The central positioning of "CKG" and "KG" suggests that Knowledge Graphs are a core component or underlying theme connecting these NLP tasks.
* **Task Overlap:** The overlapping segments indicate that many NLP tasks are interconnected and share common methodologies or data sources.
* **Uneven Distribution:** The distribution of tasks is not uniform, with some quadrants being more densely populated than others.
### Interpretation
This chart visually represents the landscape of NLP tasks and their interdependencies. The radial format emphasizes the relationships between tasks, rather than a hierarchical structure. The central placement of "CKG" and "KG" suggests that knowledge graphs play a crucial role in integrating and advancing various NLP applications. The repetition of certain datasets/tasks highlights their importance as benchmarks or foundational resources.
The chart suggests a trend towards increasingly complex NLP tasks that require reasoning about relationships between entities and events. The concentration of relation extraction and event detection tasks in the bottom half of the chart supports this observation. The chart is a high-level overview and doesn't provide specific performance metrics or quantitative data. It serves as a conceptual map of the NLP domain, illustrating the connections and overlaps between different research areas. The chart is a qualitative representation of the field, and does not provide any numerical data.
</details>
Figure 2: The illustration of the data distribution for all GKG sub-tasks.
<details>
<summary>extracted/6285883/figures/structure3.png Details</summary>
### Visual Description
## Diagram: Knowledge Graph Enhanced Large Language Model Training Pipeline
### Overview
This diagram illustrates a three-stage pipeline for training a large language model (LLM) enhanced with knowledge graphs (KG). The pipeline begins with a KG dataset, progresses through micro and mid-level training stages (G-Micro, G-Mid), and culminates in a KG-LLM stage. Each stage involves inputting data, processing it through a model, and generating an output. The diagram emphasizes the use of "Diversity Instruction" at each stage.
### Components/Axes
The diagram is structured into three main columns representing the three training stages: KG Empowerment, EKG Enhancement, and CKG Generalization. Each stage has an "Input" section, a processing block (G-Micro, G-Mid, GK-LLM), and an "Output" section. A "Base Model" is shown at the bottom, feeding into the first stage. A "GKG Dataset ~806K" cylinder is at the top-left, representing the initial data source.
**Input Stage Labels (Top Row):**
* **KG:** SRE, FRE, DRE, JRE
* **EKG:** SED, DED, DEAE, ETRE, ECRE, ESIE
* **CKG:** NER, AG, LI, TC, NLG
**Stage Titles:**
* KG Empowerment Stage
* EKG Enhancement Stage
* CKG Generalization Stage
**Diversity Instruction Boxes:**
* "As an KG expert, your task..." (KG Empowerment)
* "You are expected to...EKG..." (EKG Enhancement)
* "Please generate abstract...CKG..." (CKG Generalization)
**Model Blocks:**
* G-Micro
* G-Mid
* GK-LLM
**Output Icons:**
* Entities or Relations (KG Empowerment)
* Events or Relations (EKG Enhancement)
* Commonsense or Relations (CKG Generalization)
### Detailed Analysis or Content Details
The diagram shows a flow of information from the GKG Dataset (~806K) to the Base Model, then through the three stages.
**Stage 1: KG Empowerment**
* **Input:** The KG input consists of four categories: SRE, FRE, DRE, and JRE.
* **Processing:** The input is fed into the G-Micro model. The model is shown as a series of interconnected boxes, with arrows indicating data flow. "Params" are passed from the G-Micro model to the next stage.
* **Output:** The output is represented by an icon of entities or relations.
**Stage 2: EKG Enhancement**
* **Input:** The EKG input consists of six categories: SED, DED, DEAE, ETRE, ECRE, and ESIE.
* **Processing:** The input is fed into the G-Mid model, which is similarly structured as G-Micro. "Params" are passed from the G-Mid model to the next stage.
* **Output:** The output is represented by an icon of events or relations.
**Stage 3: CKG Generalization**
* **Input:** The CKG input consists of five categories: NER, AG, LI, TC, and NLG.
* **Processing:** The input is fed into the GK-LLM model, which is similarly structured as G-Micro and G-Mid.
* **Output:** The output is represented by an icon of commonsense or relations.
The "Training Stage" label is positioned at the top-right, indicating the overall context of the diagram. The "Input" label is positioned at the top-left, and the "Output" label is positioned at the bottom-center. The "Diversity Instruction" boxes are placed above each model block, indicating their role in guiding the training process.
### Key Observations
The diagram highlights a sequential training process, where each stage builds upon the previous one. The use of "Diversity Instruction" suggests a focus on generating varied and robust outputs. The increasing complexity of the input categories (4 in KG, 6 in EKG, 5 in CKG) might indicate a growing need for more nuanced data as the model progresses. The outputs shift from basic entities/relations to more complex events/relations and finally to commonsense/relations, suggesting a progression in the model's understanding capabilities.
### Interpretation
This diagram depicts a pipeline for enhancing a large language model with knowledge graphs. The three stages – KG Empowerment, EKG Enhancement, and CKG Generalization – represent a phased approach to integrating knowledge into the model. The initial stage focuses on establishing a foundation of entities and relations, the second stage refines this with event-based knowledge, and the final stage aims to instill commonsense reasoning. The "Diversity Instruction" component suggests a deliberate effort to avoid biases and promote generalization. The diagram implies that the model starts with a "Base Model" and iteratively improves its performance through the three stages, leveraging the knowledge graphs and the specified training instructions. The use of "Params" passing between stages suggests a form of transfer learning or fine-tuning. The diagram is a high-level overview and doesn't provide specific details about the model architectures or training algorithms used.
</details>
Figure 3: Three-stage curriculum learning tuning framework of GKG-LLM. The upper part represents the GKG dataset $\mathcal{D}_{G}$ , consisting of the unified datasets. The lower part shows the three stages of GKG training: the KG empowerment stage using the KG datasets to build foundational skills, the EKG enhancement stage using the EKG datasets to enhance specific capabilities, and the CKG generalization stage using the CKG datasets and the counter task dataset to achieve generalization of the GKG-LLM capabilities. The thick arrows between the stages represent the delivery of model parameters from base model to each version of GKG-LLM.
The contributions of this research are listed as follows:
- We propose an approach for building GKG using a three-stage curriculum learning fine-tuning framework, resulting in a GKG-LLM https://anonymous.4open.science/r/GKG-sample-64DB. This part is the core weight of the code. Once finalized, the manuscript will be shared with the open-source community. that addresses task-specific differences and enables the unified construction of GKG.
- From a data perspective, this study is the first to collect and process sub-task datasets from three types of graphs in a comprehensive view, exploring their intrinsic connections in constructing GKG, as far as we know.
- Extensive experiments report that GKG-LLM achieves the effectiveness and advancement on three types of data and further analysis validates the superiority of our architecture.
## 2 Methodology
In this section, we first present the three-stage curriculum learning tuning framework in Section 2.1, then describe data collection and preparation in Section 2.2 and introduce our training strategy in Section 2.3.
The formal definition of GKG construction involves reformulating the various sub-tasks of KG, EKG, and CKG using a unified seq2seq format and structure. Then we solve it through three-stage fine-tuning LLMs, as shown in Figure 3. Specifically, the unified input is a task document or sentence, and the unified output consists of the elements or relations that form the GKG triples.
### 2.1 GKG-LLM
The overview of GKG-LLM is shown in Figure 3. It consists of three stages of tuning curriculum learning. Curriculum learning Wang et al. (2021) breaks down complex tasks into simpler ones and trains models in an increasing order of difficulty. This approach mimics the way humans learn by first mastering basic concepts before progressing to more complex knowledge.
From the previous theoretical analysis, we find that the three types of graphs have a progressive relationship. In a KG, entities and relations are represented as triples, which can be understood as event nodes in an EKG to some extent. EKG further explores the relationships between event nodes, while a CKG can be seen as a generalization of EKG, based on more universal commonsense knowledge.
Therefore, the tuning framework is divided into three stages following a curriculum learning approach: the KG empowerment stage, the EKG enhancement stage, and the CKG generalization stage. After the KG empowerment stage, we obtain the G-Micro model, which is expected to handle basic sub-tasks related to KG, such as handling various entity and relation extraction tasks. However, GKG nodes and relationships may include dynamic knowledge. Next, in the EKG enhancement stage, we utilize EKG-related sub-tasks datasets to further empower GKG-LLM on the basis of G-Micro, resulting in the G-Mid model, capable of handling sub-tasks involving dynamic knowledge. Furthermore, in the CKG generalization stage, we inject CKG-related sub-tasks and counter task data into the G-Mid model, generalizing the task handling capability of KG to broader scenarios, ultimately resulting in the GKG-LLM model.
#### KG empowerment stage
At this stage, we only inject the KG sub-task dataset into LLMs, and the training loss function is defined as cross-entropy loss:
$$
\mathcal{L}_{\text{CE}}=-\sum\limits_{i}p\left(y_{i}\right)\log p_{\theta}
\left(\hat{y_{i}}\mid s_{i};x_{i}\right), \tag{1}
$$
where $p_{\theta}$ represents the tunable LLM with parameters $\theta$ , initialized from the base model. The instruction $s_{i}$ is concatenated with the input $x_{i}$ denotes the prompt format to LLMs. $\hat{y_{i}}$ is the predicted output, while $y_{i}$ represents the ground truth.
#### EKG Enhancement Stage
At this stage, we inject knowledge about dynamic nodes and relationships to enhance the model’s capability. Specifically, we train the G-Micro model from the first stage using the EKG sub-task dataset. This process expands the model’s understanding of complex graphs, enabling it to handle dynamic nodes and relationships with temporal dependencies and causal features, improving its adaptability to changing data and laying a foundation for the subsequent stages. The loss function is the same as in the first stage.
#### CKG Generalization Stage
Real-world scenarios go beyond static knowledge and specific events, encompassing commonsense knowledge for a broader understanding. Therefore, at this stage, we train the G-Mid model from the second stage using the CKG sub-task dataset to enhance its generalization and applicability. This expands the model’s commonsense knowledge, enabling it to excel in open-ended and complex reasoning tasks Xu et al. (2025). The model becomes more practical and effective in real-world scenarios, ultimately resulting in the GKG-LLM.
This study conducts extensive testing and analysis on three types of data: In-domain, OOD and counter task data. Detailed implementation specifics is discussed in the following sections.
### 2.2 Data Collection and Preparation
As a comprehensive dataset encompassing the GKG construction tasks, it requires extensive datasets for each sub-task across the three types of graphs. Additionally, it is necessary to perform reasonable partitioning of the various datasets and format them to prepare for the unified GKG construction framework.
The overview of data distribution of all of GKG sub-tasks is shown as Figure 2. The GKG dataset is $\mathcal{D}_{G}=\mathcal{D}_{KG}\bigcup\mathcal{D}_{EKG}\bigcup\mathcal{D}_{ CKG}\bigcup\mathcal{D}_{ct}$ . Here, $\mathcal{D}_{KG}$ includes the sub-tasks of KG such as relation extraction and entity-relation joint extraction; For $\mathcal{D}_{EKG}$ , sub-tasks include sentence-level event detection, document-level event argument extraction, and event temporal relation extraction; And for $\mathcal{D}_{CKG}$ , sub-tasks include summary generation and text inference. $\mathcal{D}_{ct}$ refers to a structure-to-text dataset, specifically the WebNLG task and dataset used for natural language generation, designed to serve as a counter-task for all GKG sub-tasks to prevent overfitting and enhance generalization without compromising the primary performance. Finally, we obtain $\mathcal{D}_{G}$ of $\sim$ 806K pieces for training and $\sim$ 140K pieces for testing. Details of each dataset are attached in Appendix A. The details of each sub-task are provided in Appendix F.
After data collection, we format each piece $i$ of the GKG dataset into a unified format, which includes $ID$ , instruction $s_{i}$ , few-shot $fs$ / zero-shot $zs$ , input $x_{i}$ , and output $y_{i}$ . Details of the data format and few-shot organization can be found in Appendix B.
### 2.3 Training Strategy
To effectively fine-tune our model on the unified dataset, we employ the LoRA+ Hayou et al. (2024) technique, an advanced version of Low-Rank Adaptation (LoRA), which has shown great promise in parameter-efficient fine-tuning (PEFT). LoRA+ adapts only a small subset of model parameters, reducing computational costs while maintaining high performance. By leveraging low-rank matrix approximations, LoRA+ allows us to efficiently update the model parameters without the need for extensive computational resources. Formally, LoRA+ modifies the weight matrix $W$ in the neural network as follows:
| Graphs | Tasks | Datasets | GPT- | Claude- | Gemini- | LlaMA- | Single- | Integrated- | GKG- | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 4 | 3 | 1.5 | 2-GKG | 3-Instruct | SFT | SFT | LLM | | | |
| KG | SRE | NYT | 64.94 | 66.76 | 68.59 | 78.18 | 55.12 | 74.39 | 79.32 | 80.63 |
| FRE | FewRel | 26.28 | 27.45 | 30.20 | 89.45 | 22.64 | 78.65 | 86.74 | 90.48 | |
| TACRED | 18.85 | 20.23 | 22.43 | 86.71 | 12.74 | 70.66 | 84.66 | 88.96 | | |
| DRE | DOCRED | 38.84 | 36.28 | 42.63 | 83.18 | 34.63 | 74.53 | 83.61 | 85.71 | |
| JE&RE | FewRel | 6.32 | 5.44 | 7.52 | 42.05 | 3.20 | 26.76 | 30.56 | 34.32 | |
| NYT | 6.22 | 5.85 | 8.36 | 53.33 | 0.0 | 40.16 | 48.66 | 52.27 | | |
| EKG | SED | ACE2005 | 17.50 | 8.57 | 22.40 | 32.47 | 0.0 | 22.74 | 34.32 | 80.63 |
| DED | WIKIEVENTS | 16.54 | 9.14 | 14.87 | 24.87 | 18.62 | 29.59 | 23.84 | 39.86 | |
| DEAE | WIKIEVENTS | 42.58 | 53.41 | 47.69 | 70.46 | 41.76 | 63.38 | 69.30 | 75.22 | |
| RAMS | 13.84 | 5.70 | 38.49 | 48.33 | 30.74 | 53.43 | 52.09 | 63.62 | | |
| ETRE | MATRES | 39.97 | 36.62 | 38.51 | 62.94 | 22.79 | 37.91 | 44.26 | 71.51 | |
| ESL | 64.24 | 47.65 | 42.18 | 68.96 | 21.67 | 74.06 | 67.63 | 75.33 | | |
| TB-Dense | 43.73 | 36.58 | 42.43 | 52.89 | 36.55 | 49.30 | 51.23 | 53.54 | | |
| Causal-TB | 6.67 | 8.01 | 8.74 | 42.79 | 16.43 | 37.35 | 49.83 | 45.26 | | |
| MAVEN-ERE | 43.80 | 21.73 | 42.10 | 71.55 | 40.29 | 37.35 | 75.44 | 81.95 | | |
| TCR ∗ | 15.43 | 18.74 | 25.34 | 24.88 | 24.71 | 20.68 | 22.09 | 26.45 | | |
| ECRE | ESL | 28.57 | 19.26 | 55.21 | 75.33 | 26.33 | 62.92 | 78.74 | 84.89 | |
| MAVEN-ERE | 51.98 | 11.36 | 43.38 | 76.48 | 13.37 | 78.91 | 88.59 | 90.18 | | |
| Causal-TB ∗ | 39.67 | 41.23 | 43.44 | 33.94 | 30.02 | 48.41 | 48.80 | 55.79 | | |
| ESRE | HiEve | 38.81 | 30.92 | 48.83 | 55.60 | 48.61 | 57.64 | 58.01 | 58.61 | |
| MAVEN-ERE | 40.09 | 13.12 | 38.09 | 44.37 | 33.49 | 39.11 | 37.30 | 48.49 | | |
| CKG | NER | CoNLL | 15.94 | 14.46 | 18.27 | 77.50 | 15.60 | 64.74 | 70.53 | 82.30 |
| AG $\dagger$ | CNNDM | 30 | 28 | 22 | 36 | 18 | 35 | 35 | 45 | |
| XSum | 33 | 26 | 29 | 28 | 9 | 24 | 30 | 38 | | |
| LI | SNLI | 51.26 | 47.56 | 60.38 | 69.51 | 44.50 | 87.09 | 89.35 | 89.03 | |
| MNLI | 81.80 | 39.33 | 48.80 | 58.97 | 53.70 | 86.78 | 84.62 | 86.35 | | |
| TC | R8 ∗ | 72.26 | 36.43 | 66.58 | 65.27 | 58.89 | 28.83 | 58.64 | 69.33 | |
| R52 | 82.18 | 83.75 | 80.63 | 94.16 | 29.68 | 89.02 | 88.81 | 90.34 | | |
| Counter | NLG $\dagger$ | WebNLG | 78 | 65 | 76 | 83 | 15 | 80 | 80 | 85 |
| Average Performance | 38.25 | 29.81 | 39.07 | 59.70 | 26.83 | 52.97 | 60.41 | 67.90 | | |
Table 1: Performance comparison across various datasets and tasks. The best result for each sub-task is highlighted in bold, while the second-best result is underlined. The OOD datasets are starred by *. $\dagger$ means the task is evaluated by metric Rough-L of percentage. The results for GPT-4, Claude-3, and Gemini-1.5 are obtained via their respective APIs. LlaMA-2-GKG, LlaMA-3-Instruct, Single-SFT, and Integrated-SFT are implemented by us. The GKG-LLM column represents the final model obtained after three-stage tuning.
$$
W^{\prime}=W+\Delta W, \tag{2}
$$
where $\Delta W=AB$ , with $A\in\mathbb{R}^{d\times r}$ and $B\in\mathbb{R}^{r\times k}$ . Here, $d$ is the dimension of the input, $k$ is the dimension of the output, and $r$ is the rank of the adaptation matrices, which is much smaller than both $d$ and $k$ , making the adaptation parameter-efficient. To make better use of limited resources for training the model, the advancement of LoRA+ is reflected, as shown in Equation 3, in the use of different update hyperparameters $\eta_{A}$ and $\eta_{B}$ for the two low-rank matrices $A$ and $B$ :
$$
\left\{\begin{aligned} &A=A-\eta_{A}G_{A}\\
&B=B-\eta_{B}G_{B}.\end{aligned}\right. \tag{3}
$$
This approach accelerates convergence and effectively demonstrates the efficient and adaptive capabilities of GKG-LLM in handling GKG construction sub-tasks.
In summary, our training process harnesses the strengths of LoRA+ for efficient fine-tuning while experimenting with diverse data utilization strategies to optimize model performance for comprehensive GKG construction. This approach ensures that our model not only learns effectively from the data but also adapts seamlessly to various NLP tasks within GKG.
## 3 Experiments
In this section, we thoroughly evaluate the performance of GKG-LLM across three data settings, including in-sample data, counter-task data, and out-of-distribution data. The baseline methods and evaluation metrics are presented in Section 3.1, while the main experimental results are presented in Sections 3.2. The stage generalization results are presented in Appendix C. Hyper-parameter settings are provided in Appendix E.
### 3.1 Baselines and Metrics
To perform a comprehensive evaluation, the final version of GKG-LLM is compared with two main categories of existing baselines: close-source baselines and open-source baselines.
For closed-source baselines, we access the model through the OpenAI API, specifically using the gpt-4-turbo-preview version https://openai.com/api/, and the Anthropic API to access the Claude-3-Opus version https://www.anthropic.com/api for evaluation. We also use the Google API to access the Gemini-1.5-Pro version https://deepmind.google/technologies/gemini/pro/ for evaluation.
For open-source baselines, we conduct experiments on two foundations: LlaMA-2-Chat https://huggingface.co/meta-llama/Llama-2-7b-chat-hf and LlaMA-3-Instruct https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct. The LlaMA-2-GKG is fine-tuned from Llama-2-Chat, while LlaMA-3-Instruct serves as the foundation for GKG-LLM and also acts as a baseline. This model is fine-tuned to fit a specific graph, serving as a strong baseline. Our integrated SFT method trains all datasets from the three types of graphs simultaneously.
Referencing the general evaluation metrics for each sub-task, for abstraction generation and structure-to-text tasks, the Rough-L metric is used, while all other tasks employ the F1 score as the evaluation metric.
### 3.2 Main Results
In this section, we thoroughly evaluate the performance of GKG-LLM on in-domain, OOD, and counter tasks. Specifically, as detailed in Table 1, we assess its performance across various sub-tasks in the three types of graphs. Compared to the baseline, the results demonstrate the effectiveness and practicality of GKG-LLM on the construction of all three graph types across in-domain, OOD, and counter-task data.
#### KG Sub-task Datasets
KG sub-task datasets focus on various types of relation extraction, including sentence-level relation extraction, few-shot relation extraction, and entity relation extraction, etc. Compared to the three closed-source LLMs, GKG-LLM achieves the best performance, with a minimum performance improvement of 12.04%. Additionally, when compared to a model tuned solely with KG sub-task datasets, GKG-LLM demonstrates a minimum performance gain of 7.6%. Across all baselines, GKG-LLM consistently achieves either the best or the second-best performance.
#### EKG Sub-task Datasets
EKG sub-task datasets primarily include event detection, event argument extraction, and event relation extraction. Compared to the three closed-source LLMs, GKG-LLM achieves the best performance, with a minimum improvement of 9.88%. An interesting observation is that the Integrated SFT model achieves the second-best performance in half of the tasks; however, GKG-LLM still consistently performs either the best or the second-best overall. Another interesting point is that in the OOD datasets, specifically the TCR dataset for the ETRE sub-task and the Causal-TB dataset for the ECRE sub-task, GKG-LLM outperforms the second-best baseline by 1.11% and 6.99%, respectively, demonstrating its strong generalization capability on OOD data.
#### CKG Sub-task Datasets
For the CKG sub-task dataset, the focus is closer to common-sense nodes and relations reasoning, involving tasks such as abstract generation and language inference. For the R8 dataset in the Text Classification sub-task, which serves as an OOD dataset, GPT-4 achieves the best performance, attributed to its exceptional capabilities in language understanding. Even so, GKG-LLM still achieves the second-best performance. Since CKG closely resembles real-world commonsense scenarios, both LlaMA-2-GKG and Single-SFT also demonstrates strong results. However, overall, GKG-LLM consistently maintains either the best or the second-best performance.
GKG-LLM achieves the best performance on the WebNLG dataset for the Natural Language Generation (NLG) task, surpassing the strongest baseline by 2%, further highlighting its strong structure-to-text capabilities. It consistently performs at the best or second-best level across all GKG sub-tasks, with an average improvement of 7.49% over the strongest baseline. Additionally, its strong performance on OOD data demonstrates its ability to generalize effectively to unseen data distributions, with ablation studies and OOD analysis detailed in Section 4.
### 3.3 Exploration of Three Stages
As discussed in Section 1, a triple in a KG can, to some extent, be considered as a node in an EKG, while the triples in EKG and CKG are linked through the relationship between the concrete and the abstract. Theoretically, there exists a progressive relationship among these three types of graphs, which serves as the theoretical basis for our three-stage fine-tuning framework. Therefore, this subsection will explore the performance of the three types of graphs under different fine-tuning sequences, as well as the performance of the intermediate versions of our three-stage fine-tuning framework on the sub-tasks of the three types of graphs.
<details>
<summary>extracted/6285883/figures/2.png Details</summary>
### Visual Description
\n
## Bar Chart: Performance of Different Fine-Tuning Orders
### Overview
This bar chart compares the performance results of six different fine-tuning orders, labeled as K-E-C, K-C-E, E-K-C, E-C-K, C-K-E, and C-E-K. The performance is measured on a scale from 0 to 70.
### Components/Axes
* **Title:** "Performance of Different Fine-Tuning Orders" - positioned at the top-center of the chart.
* **X-axis:** "Fine-Tuning Order" - lists the six fine-tuning orders: K-E-C, K-C-E, E-K-C, E-C-K, C-K-E, and C-E-K. The labels are rotated approximately 45 degrees for readability.
* **Y-axis:** "Results" - represents the performance score, ranging from 0 to 70.
* **Bars:** Six vertical bars, each representing a different fine-tuning order. The bars are colored as follows:
* K-E-C: Blue
* K-C-E: Light Blue
* E-K-C: Light Green
* E-C-K: Orange
* C-K-E: Purple
* C-E-K: Dark Orange
### Detailed Analysis
* **K-E-C (Blue):** The bar reaches approximately 69 on the Y-axis.
* **K-C-E (Light Blue):** The bar reaches approximately 66 on the Y-axis.
* **E-K-C (Light Green):** The bar reaches approximately 64 on the Y-axis.
* **E-C-K (Orange):** The bar reaches approximately 62 on the Y-axis.
* **C-K-E (Purple):** The bar reaches approximately 57 on the Y-axis.
* **C-E-K (Dark Orange):** The bar reaches approximately 53 on the Y-axis.
### Key Observations
The highest performance is achieved with the fine-tuning order K-E-C, followed closely by K-C-E and E-K-C. The lowest performance is observed with the C-E-K order. There is a general trend of decreasing performance as the order shifts towards C-E-K.
### Interpretation
The chart demonstrates the significant impact of the fine-tuning order on the performance of a model. The order K-E-C appears to be the most effective, suggesting that fine-tuning in this sequence leads to optimal results. The differences in performance between the orders highlight the importance of carefully considering the order in which different components or layers are fine-tuned. The consistent decline in performance as the order changes to C-E-K suggests that this sequence is suboptimal. This data could be used to inform the design of future fine-tuning strategies, prioritizing the K-E-C order or exploring variations thereof. The specific meaning of K, E, and C is not provided in the chart, but they likely represent different components, layers, or stages of the model.
</details>
Figure 4: Results of different fine-tuning orders. “K-E-C” means the fine-tuning order is KG, EKG and CKG. The following sets of experiments are similar to this one.
As shown in Figure 4, the three types of graphs show varying performance in terms of average performance across all tasks under different fine-tuning sequences. The “K-E-C” sequence adopted in this study demonstrates the best performance, further confirming the theoretical correctness and experimental effectiveness of our three-stage fine-tuning sequence.
<details>
<summary>extracted/6285883/figures/1.png Details</summary>
### Visual Description
## Bar Chart: Comparison on Different Settings
### Overview
This bar chart compares the "Results" achieved by four different settings: Single-SFT, G-Micro, G-Mid, and GKG-LLM, across three different "Settings" categories: KG, EKG, and CKG. The results are presented as bar heights, with the y-axis representing the results (ranging from 0 to 100) and the x-axis representing the settings.
### Components/Axes
* **Title:** "Comparison on Different Settings" (centered at the top)
* **X-axis Label:** "Settings" (centered at the bottom)
* **X-axis Markers:** KG, EKG, CKG (equally spaced)
* **Y-axis Label:** "Results" (left side, vertical)
* **Y-axis Scale:** 0 to 100 (incrementing by 20)
* **Legend:** Located in the top-left corner.
* **Single-SFT:** Light Blue (hatched)
* **G-Micro:** Light Green (dotted)
* **G-Mid:** Light Teal (hatched)
* **GKG-LLM:** Light Orange (solid)
### Detailed Analysis
The chart consists of three groups of four bars, one for each setting (KG, EKG, CKG) and one bar per model (Single-SFT, G-Micro, G-Mid, GKG-LLM).
**KG Settings:**
* **Single-SFT:** Approximately 62. The bar extends to roughly the 62 mark on the y-axis.
* **G-Micro:** Approximately 58. The bar extends to roughly the 58 mark on the y-axis.
* **G-Mid:** Approximately 68. The bar extends to roughly the 68 mark on the y-axis.
* **GKG-LLM:** Approximately 73. The bar extends to roughly the 73 mark on the y-axis.
**EKG Settings:**
* **Single-SFT:** Approximately 54. The bar extends to roughly the 54 mark on the y-axis.
* **G-Micro:** Approximately 60. The bar extends to roughly the 60 mark on the y-axis.
* **G-Mid:** Approximately 62. The bar extends to roughly the 62 mark on the y-axis.
* **GKG-LLM:** Approximately 68. The bar extends to roughly the 68 mark on the y-axis.
**CKG Settings:**
* **Single-SFT:** Approximately 63. The bar extends to roughly the 63 mark on the y-axis.
* **G-Micro:** Approximately 56. The bar extends to roughly the 56 mark on the y-axis.
* **G-Mid:** Approximately 64. The bar extends to roughly the 64 mark on the y-axis.
* **GKG-LLM:** Approximately 74. The bar extends to roughly the 74 mark on the y-axis.
### Key Observations
* **GKG-LLM consistently outperforms other models:** Across all three settings (KG, EKG, CKG), GKG-LLM achieves the highest results.
* **Single-SFT generally performs better than G-Micro:** In two out of three settings (KG and CKG), Single-SFT has higher results than G-Micro.
* **G-Mid consistently performs better than G-Micro:** In all three settings, G-Mid has higher results than G-Micro.
* **EKG settings yield the lowest results overall:** The results for all models are generally lower in the EKG setting compared to KG and CKG.
### Interpretation
The data suggests that the GKG-LLM setting is the most effective across all tested configurations. The consistent outperformance of GKG-LLM indicates that incorporating knowledge graphs and large language models (as the name suggests) leads to improved results. The lower performance in the EKG setting might indicate that this particular setting presents unique challenges or is less suited for the models being tested. The relative performance of Single-SFT, G-Micro, and G-Mid suggests a hierarchy of effectiveness, with G-Mid generally outperforming G-Micro and Single-SFT showing a slight edge over G-Micro in some cases. This could be due to the increased complexity and knowledge integration in the G-Mid model. The chart provides a clear visual comparison of the different settings, allowing for a quick assessment of their relative strengths and weaknesses.
</details>
Figure 5: Fine-tuning with a single type of graph and performance of different intermediate version in the GKG-LLM.
Figure 5 presents the performance of the single SFT model and the three-stage models across the KG, EKG, and CKG sub-tasks. In each sub-task, the results improve as the fine-tuning progresses through the three stages. Compared to single-SFT, our GKG-LLM framework demonstrates better performance, validating the practicality of the three-stage fine-tuning approach.
## 4 Analysis
In this section, we introduce the ablation study in Section 4.1 and provide a comprehensive analysis and explanation of the OOD data in Section 4.2. An analysis of data scaling in training is introduced in Section 4.3. The evaluation of the optimal model under various hyper-parameter settings is presented in Appendix D.
| $\mathcal{P}_{\text{si}}$ $\Delta$ $\mathcal{P}_{\text{zs}}$ | 68.46 (-3.60) 65.17 | 59.34 (-4.08) 55.09 | 69.10 (-2.38) 66.05 | 64.33 (-3.57) 60.06 |
| --- | --- | --- | --- | --- |
| $\Delta$ | (-6.89) | (-8.33) | (-5.43) | (-7.84) |
| $\mathcal{P}_{\text{si+zs}}$ | 62.44 | 52.26 | 64.66 | 58.15 |
| $\Delta$ | (-9.62) | (-11.16) | (-6.82) | (-9.75) |
Table 2: Performance comparison of different prompt strategies on the evaluation metrics. $\mathcal{P}$ denotes full prompts, $\mathcal{P}_{\text{si}}$ refers to a single instruction regardless of diversity, $\mathcal{P}_{\text{zs}}$ represents zero-shot only, and $\mathcal{P}_{\text{si+zs}}$ combines single instruction with zero-shot prompting.
### 4.1 Ablation Studies
In this section, we present the ablation study for three different prompt strategies: (1) using only a single instruction to construct the prompt format, (2) using only zero-shot prompts without employing any few-shot examples, and (3) removing both strategies simultaneously. We compare the performance across three types of graphs and the overall dataset, with the comparison results shown in Table 2. Examples of different types of prompts can be found in the respective sections of Appendix B.
The results show that removing the diversity of instructions causes a noticeable performance drop, as diverse instructions better reflect real-world scenarios where different questioners have unique styles, requiring the model to adapt to various instruction formats. Removing the few-shot learning strategy lead to an even greater performance degradation, as LLMs lost their ability to perform in-context learning and relies only on inherent capabilities, affecting their ability to generate the corresponding elements or relationships. The most performance drop occurs when both strategies are removed, highlighting that the advantages of these strategies are cumulative, further validating the superiority and effectiveness of our data construction strategy.
### 4.2 OOD Analysis
This section specifically discusses the performance of GKG-LLM on OOD datasets. As introduced in Section 2.1, our data is divided into three parts, with the OOD portion deliberately excluded during the initial training design, meaning that GKG-LLM has never encountered these types of data before. Therefore, the performance on this part serves as an indicator of our model’s generalization ability from the perspective of OOD data.
As shown in Figure 7, overall, our method achieves the best performance, reaching 50.52%, which is 5.40% higher than the second-best model, Gemini-1.5-pro. Despite the fact that these data points were entirely unfamiliar to both closed-source LLMs and our tuned open-source LLMs, our model still demonstrates strong robustness and effectiveness.
### 4.3 Analysis on Different Data Scaling
This section explores the impact of different data scales on model performance. The model is trained using 10%, 20%, 40%, 60%, 80%, and 100% of the data, sampled from the three types of graph sub-tasks separately. The results show that as the data proportion increases, model performance improves progressively, with performance being limited at 10%, improving at 20% and 40%, and continuing to enhance at 60% and 80%, reaching near-optimal performance at 100%.
<details>
<summary>extracted/6285883/figures/datascaling1.png Details</summary>
### Visual Description
## Line Chart: Results of Different Data Scaling
### Overview
This image presents a line chart comparing the results of four different data scaling methods (KG, EKG, CKG, and GKG) across varying data percentages, ranging from 10% to 100%. The chart visually demonstrates how the performance of each scaling method changes as the amount of data used increases.
### Components/Axes
* **Title:** "Results of different data scaling" - positioned at the top-center of the chart.
* **X-axis:** "Data Percentages" - ranging from 10% to 100%, with markers at 10%, 20%, 40%, 60%, 80%, and 100%.
* **Y-axis:** "Results" - ranging from approximately 30 to 75, with markers at 30, 40, 50, 60, and 70.
* **Legend:** Located in the top-left corner of the chart. It identifies the four data scaling methods with corresponding colors and line styles:
* KG (Blue, solid line with circle markers)
* EKG (Red, dashed line with square markers)
* CKG (Green, dash-dot line with triangle markers)
* GKG (Yellow, dotted line with diamond markers)
### Detailed Analysis
Here's a breakdown of each data series and their approximate values, verified against the legend colors:
* **KG (Blue):** The line slopes steadily upward.
* 10%: ~32
* 20%: ~42
* 40%: ~52
* 60%: ~64
* 80%: ~70
* 100%: ~73
* **EKG (Red):** The line shows a slower initial increase, then accelerates.
* 10%: ~30
* 20%: ~37
* 40%: ~46
* 60%: ~56
* 80%: ~60
* 100%: ~63
* **CKG (Green):** The line starts with the highest values and has a moderate upward slope.
* 10%: ~38
* 20%: ~47
* 40%: ~54
* 60%: ~62
* 80%: ~67
* 100%: ~70
* **GKG (Yellow):** The line shows a consistent, moderate upward slope.
* 10%: ~34
* 20%: ~43
* 40%: ~51
* 60%: ~58
* 80%: ~65
* 100%: ~69
### Key Observations
* CKG consistently yields the highest results across all data percentages.
* EKG starts with the lowest results and exhibits the slowest initial growth.
* KG and GKG show similar performance, with KG slightly outperforming GKG at higher data percentages.
* All methods demonstrate increasing results as the data percentage increases, indicating that more data generally leads to better performance.
### Interpretation
The chart suggests that the CKG data scaling method is the most effective across the tested data percentages. The consistent superiority of CKG implies it is less sensitive to the amount of data available compared to the other methods. EKG, while showing improvement with more data, consistently underperforms the other methods, suggesting it may be more suitable for scenarios with very large datasets where initial processing speed is critical. The similar performance of KG and GKG indicates they are comparable options, with KG potentially being slightly more advantageous when a larger dataset is available. The overall trend of increasing results with data percentage highlights the importance of data quantity in achieving optimal performance for all scaling methods. The differences between the methods are relatively small, suggesting that the choice of scaling method may not be the most critical factor, and other aspects of the data processing pipeline may have a more significant impact.
</details>
Figure 6: Results of training with different proportions of complete data.
Figure 6 shows that as the data volume increases, the model’s average scores across all tasks gradually improve. Notably, the average scores for the three types of graph sub-tasks follow similar trends, with diminishing performance gains beyond 80% data usage, indicating a saturation point where the additional data brings marginal benefits.
<details>
<summary>extracted/6285883/figures/OOD.png Details</summary>
### Visual Description
\n
## Bar Chart: OOD datasets for Different Models
### Overview
This bar chart compares the average F1 scores of several large language models (LLMs) on out-of-distribution (OOD) datasets. The chart displays the performance of each model as a vertical bar, with the height of the bar representing the average F1 score.
### Components/Axes
* **Title:** "OOD datasets for Different Models" - positioned at the top-center of the chart.
* **X-axis:** "Models" - lists the names of the LLMs being compared: GPT-4, Claude 3, Gemini-1.5-pro, LLaMA-2-7BKG, LLaMA 3-8B, Single-SFT, Integrated-SFT, and GKG-LLM.
* **Y-axis:** "Average Scores (F1)" - represents the average F1 score, ranging from approximately 0 to 50.
* **Bars:** Each bar represents a different model, with the color varying for each model.
### Detailed Analysis
The chart contains 8 bars, each representing a different model. The bars are arranged horizontally along the x-axis.
* **GPT-4:** The bar for GPT-4 is a light orange color and reaches approximately 47 on the y-axis.
* **Claude 3:** The bar for Claude 3 is a slightly darker orange color and reaches approximately 44 on the y-axis.
* **Gemini-1.5-pro:** The bar for Gemini-1.5-pro is a light blue color and reaches approximately 32 on the y-axis.
* **LLaMA-2-7BKG:** The bar for LLaMA-2-7BKG is a light green color and reaches approximately 45 on the y-axis.
* **LLaMA 3-8B:** The bar for LLaMA 3-8B is a medium green color and reaches approximately 39 on the y-axis.
* **Single-SFT:** The bar for Single-SFT is a light purple color and reaches approximately 34 on the y-axis.
* **Integrated-SFT:** The bar for Integrated-SFT is a medium purple color and reaches approximately 43 on the y-axis.
* **GKG-LLM:** The bar for GKG-LLM is a light teal color and reaches approximately 51 on the y-axis.
### Key Observations
* GKG-LLM exhibits the highest average F1 score (approximately 51).
* GPT-4 and LLaMA-2-7BKG have relatively high scores, around 47 and 45 respectively.
* Gemini-1.5-pro and Single-SFT have the lowest scores, around 32 and 34 respectively.
* There is a noticeable variation in performance across the different models.
### Interpretation
The chart demonstrates the performance differences between various LLMs when evaluated on OOD datasets using the F1 score metric. GKG-LLM appears to be the most robust model in this comparison, achieving the highest average F1 score. GPT-4 and LLaMA-2-7BKG also perform well, suggesting they generalize reasonably well to unseen data. Gemini-1.5-pro and Single-SFT show lower performance, indicating potential challenges in handling OOD data.
The use of OOD datasets is crucial for evaluating the generalization capabilities of LLMs. Models that perform well on OOD datasets are more likely to be reliable in real-world applications where they encounter data that differs from their training distribution. The observed differences in performance highlight the importance of model selection and the need for further research into improving the robustness of LLMs to OOD data. The chart suggests that incorporating knowledge graphs (as potentially done in GKG-LLM) may be a promising approach for enhancing OOD performance.
</details>
Figure 7: The average performance on OOD datasets, consisting TCR, Causal-TB and R8 datasets.
## 5 Related Works
This section introduces two types of related work. Section 5.1 covers three typical tasks within GKG sub-tasks, while Section 5.2 discusses research related to LLMs.
### 5.1 GKG Sub-tasks
In this section, we introduce a representative task for each of the three types of graphs: the entity-relation joint extraction task in the KGs, the document-level event argument extraction task in the EKGs, and the abstract generation task in the CKGs.
Entity-relation joint extraction task has been a focus in the domain of knowledge graph construction, as it aims to simultaneously extract entities and their relationships from unstructured text. Current state-of-the-art methods leverage transformer architecture to model interactions between entities within sentences or documents, which provides further performance gains Sui et al. (2023). Document-level event argument extraction aims to extract the arguments of events from long texts to better understand complex event relations and event chains. Pre-trained models such as BERT have been widely employed in event extraction tasks. By combining pre-trained knowledge with task-specific fine-tuning, these models have proven effective in understanding complex contexts Zhang et al. (2024). Abstract generation particularly with the rise of pre-trained transformer-based models. A recent state-of-the-art approach by Gao et al. (2023) utilizes a combination of pre-trained language models and reinforcement learning to enhance the quality of generated abstracts.
### 5.2 Large Language Models
With the emergence of closed-source and open-source LLMs represented by GPT4 Achiam et al. (2023) and LlaMA-3 Dubey et al. (2024), respectively, a large amount of research has focused on these models. This section introduces some of the work based on close-source and open-source LLMs.
Research based on closed-source LLMs typically involves evaluating these large models Gandhi et al. (2024) and integrating them with traditional tasks. For example, such studies may focus on enhancing certain aspects of conventional natural language tasks Zheng et al. (2023) or providing new perspectives for text analysis Savelka et al. (2023). The study by Xu et al. (2024) using LlaMA-2 as the foundation, explores the possibility of a unified approach to symbol-centric tasks through full fine-tuning and extend this approach to generalize to natural language-centric tasks. A survey by Zhang et al. (2023) introduce various paradigms of instruction fine-tuning for LLMs, providing a comprehensive overview of its advantages, limitations, and implementation methods.
However, up to now, no study has integrated the broad task of GKG construction. This research unifies such tasks from both the task and data perspectives by fine-tuning open-source LLMs.
## 6 Conclusion
This study proposes a new task for building GKG. It represents the first collection approached from the unified perspective in terms of data, and the first unified construction of three types of graphs from the task perspective. This task addresses two issues: obstacles arising from differences between tasks, and the neglect of intrinsic connections among different types of graphs. To address these challenges, we propose a three-stage curriculum learning framework that iteratively injects sub-task knowledge from KG, EKG, and CKG into GKG-LLM, aiming for broad and outstanding performance in GKG construction. Extensive experiments demonstrate the effectiveness and robustness of the GKG-LLM approach. The models and data from this study will be fully released upon acceptance of the paper. In the future, we will expand the application of GKG-LLM into a broader range of scenarios, such as intelligent healthcare He et al. (2025); Lin et al. (2025b), to enhance its utility and impact.
## References
- Achiam et al. [2023] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Alt et al. [2020] Christoph Alt, Aleksandra Gabryszak, and Leonhard Hennig. Tacred revisited: A thorough evaluation of the tacred relation extraction task. arXiv preprint arXiv:2004.14855, 2020.
- Camburu et al. [2018] Oana-Maria Camburu, Tim Rocktäschel, Thomas Lukasiewicz, and Phil Blunsom. e-snli: Natural language inference with natural language explanations. Advances in Neural Information Processing Systems, 31, 2018.
- Chan et al. [2024] Chunkit Chan, Cheng Jiayang, Weiqi Wang, Yuxin Jiang, Tianqing Fang, Xin Liu, and Yangqiu Song. Exploring the potential of chatgpt on sentence level relations: A focus on temporal, causal, and discourse relations. In Findings of the Association for Computational Linguistics: EACL 2024, pages 684–721, 2024.
- Chen et al. [2021] Yulong Chen, Yang Liu, Liang Chen, and Yue Zhang. Dialogsum: A real-life scenario dialogue summarization dataset. arXiv preprint arXiv:2105.06762, 2021.
- Dubey et al. [2024] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Ebner et al. [2020] Seth Ebner, Patrick Xia, Ryan Culkin, Kyle Rawlins, and Benjamin Van Durme. Multi-sentence argument linking. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8057–8077, 2020.
- Gandhi et al. [2024] Kanishk Gandhi, Jan-Philipp Fränken, Tobias Gerstenberg, and Noah Goodman. Understanding social reasoning in language models with language models. Advances in Neural Information Processing Systems, 36, 2024.
- Gao et al. [2023] Catherine A Gao, Frederick M Howard, Nikolay S Markov, Emma C Dyer, Siddhi Ramesh, Yuan Luo, and Alexander T Pearson. Comparing scientific abstracts generated by chatgpt to real abstracts with detectors and blinded human reviewers. NPJ Digital Medicine, 6(1):75, 2023.
- Gardent et al. [2017] Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. The webnlg challenge: Generating text from rdf data. In 10th International Conference on Natural Language Generation, pages 124–133. ACL Anthology, 2017.
- Ge and Moh [2017] Lihao Ge and Teng-Sheng Moh. Improving text classification with word embedding. In 2017 IEEE International Conference on Big Data (Big Data), pages 1796–1805. IEEE, 2017.
- Glavaš et al. [2014] Goran Glavaš, Jan Šnajder, Parisa Kordjamshidi, and Marie-Francine Moens. Hieve: A corpus for extracting event hierarchies from news stories. 2014.
- Grishman et al. [2005] Ralph Grishman, David Westbrook, and Adam Meyers. Nyu’s english ace 2005 system description. Ace, 5(2), 2005.
- Gubelmann et al. [2024] Reto Gubelmann, Ioannis Katis, Christina Niklaus, and Siegfried Handschuh. Capturing the varieties of natural language inference: A systematic survey of existing datasets and two novel benchmarks. Journal of Logic, Language and Information, 33(1):21–48, 2024.
- Han et al. [2018] Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, and Maosong Sun. Fewrel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. arXiv preprint arXiv:1810.10147, 2018.
- Han et al. [2019] Rujun Han, I Hsu, Mu Yang, Aram Galstyan, Ralph Weischedel, Nanyun Peng, et al. Deep structured neural network for event temporal relation extraction. arXiv preprint arXiv:1909.10094, 2019.
- Hasan et al. [2021] Tahmid Hasan, Abhik Bhattacharjee, Md Saiful Islam, Kazi Samin, Yuan-Fang Li, Yong-Bin Kang, M Sohel Rahman, and Rifat Shahriyar. Xl-sum: Large-scale multilingual abstractive summarization for 44 languages. arXiv preprint arXiv:2106.13822, 2021.
- Hayou et al. [2024] Soufiane Hayou, Nikhil Ghosh, and Bin Yu. Lora+: Efficient low rank adaptation of large models. arXiv preprint arXiv:2402.12354, 2024.
- He et al. [2022] Yong He, Cheng Wang, Shun Zhang, Nan Li, Zhaorong Li, and Zhenyu Zeng. Kg-mtt-bert: Knowledge graph enhanced bert for multi-type medical text classification. arXiv preprint arXiv:2210.03970, 2022.
- He et al. [2025] Kai He, Rui Mao, Qika Lin, Yucheng Ruan, Xiang Lan, Mengling Feng, and Erik Cambria. A survey of large language models for healthcare: from data, technology, and applications to accountability and ethics. Information Fusion, 118:102963, 2025.
- Hettiarachchi et al. [2023] Hansi Hettiarachchi, Mariam Adedoyin-Olowe, Jagdev Bhogal, and Mohamed Medhat Gaber. Ttl: transformer-based two-phase transfer learning for cross-lingual news event detection. International Journal of Machine Learning and Cybernetics, 2023.
- Hu et al. [2020] Hai Hu, Kyle Richardson, Liang Xu, Lu Li, Sandra Kübler, and Lawrence S Moss. Ocnli: Original chinese natural language inference. arXiv preprint arXiv:2010.05444, 2020.
- Huang et al. [2020] Kung-Hsiang Huang, Mu Yang, and Nanyun Peng. Biomedical event extraction with hierarchical knowledge graphs. arXiv preprint arXiv:2009.09335, 2020.
- Krause et al. [2022] Franz Krause, Tobias Weller, and Heiko Paulheim. On a generalized framework for time-aware knowledge graphs. In Towards a Knowledge-Aware AI, pages 69–74. IOS Press, 2022.
- Lai et al. [2023] Vivian Lai, Chacha Chen, Alison Smith-Renner, Q Vera Liao, and Chenhao Tan. Towards a science of human-ai decision making: An overview of design space in empirical human-subject studies. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pages 1369–1385, 2023.
- Li et al. [2021] Sha Li, Heng Ji, and Jiawei Han. Document-level event argument extraction by conditional generation. arXiv preprint arXiv:2104.05919, 2021.
- Lin et al. [2023] Qika Lin, Jun Liu, Rui Mao, Fangzhi Xu, and Erik Cambria. TECHS: temporal logical graph networks for explainable extrapolation reasoning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), pages 1281–1293, 2023.
- Lin et al. [2025a] Qika Lin, Tianzhe Zhao, Kai He, Zhen Peng, Fangzhi Xu, Ling Huang, Jingying Ma, and Mengling Feng. Self-supervised quantized representation for seamlessly integrating knowledge graphs with large language models. CoRR, abs/2501.18119, 2025.
- Lin et al. [2025b] Qika Lin, Yifan Zhu, Xin Mei, Ling Huang, Jingying Ma, Kai He, Zhen Peng, Erik Cambria, and Mengling Feng. Has multimodal learning delivered universal intelligence in healthcare? A comprehensive survey. Information Fusion, 116:102795, 2025.
- Ma et al. [2023] Youmi Ma, An Wang, and Naoaki Okazaki. Dreeam: Guiding attention with evidence for improving document-level relation extraction. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 1971–1983, 2023.
- Mirza and Tonelli [2016] Paramita Mirza and Sara Tonelli. Catena: Causal and temporal relation extraction from natural language texts. In The 26th international conference on computational linguistics, pages 64–75. ACL, 2016.
- Ning et al. [2019] Qiang Ning, Sanjay Subramanian, and Dan Roth. An improved neural baseline for temporal relation extraction. arXiv preprint arXiv:1909.00429, 2019.
- Paulus [2017] R Paulus. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304, 2017.
- Peng et al. [2023] Ciyuan Peng, Feng Xia, Mehdi Naseriparsa, and Francesco Osborne. Knowledge graphs: Opportunities and challenges. Artificial Intelligence Review, 56(11):13071–13102, 2023.
- Pimenov et al. [2023] Danil Yu Pimenov, Andres Bustillo, Szymon Wojciechowski, Vishal S Sharma, Munish K Gupta, and Mustafa Kuntoğlu. Artificial intelligence systems for tool condition monitoring in machining: Analysis and critical review. Journal of Intelligent Manufacturing, 34(5):2079–2121, 2023.
- Sang and De Meulder [2003] Erik F Sang and Fien De Meulder. Introduction to the conll-2003 shared task: Language-independent named entity recognition. arXiv preprint cs/0306050, 2003.
- Savelka et al. [2023] Jaromir Savelka, Kevin D Ashley, Morgan A Gray, Hannes Westermann, and Huihui Xu. Can gpt-4 support analysis of textual data in tasks requiring highly specialized domain expertise? arXiv preprint arXiv:2306.13906, 2023.
- Sui et al. [2023] Dianbo Sui, Xiangrong Zeng, Yubo Chen, Kang Liu, and Jun Zhao. Joint entity and relation extraction with set prediction networks. IEEE Transactions on Neural Networks and Learning Systems, 2023.
- Wadhwa et al. [2023] Somin Wadhwa, Silvio Amir, and Byron C Wallace. Revisiting relation extraction in the era of large language models. In Proceedings of the conference. Association for Computational Linguistics. Meeting, volume 2023, page 15566. NIH Public Access, 2023.
- Wang et al. [2021] Xin Wang, Yudong Chen, and Wenwu Zhu. A survey on curriculum learning. IEEE transactions on pattern analysis and machine intelligence, 44(9):4555–4576, 2021.
- Wang et al. [2022] Xiaozhi Wang, Yulin Chen, Ning Ding, Hao Peng, Zimu Wang, Yankai Lin, Xu Han, Lei Hou, Juanzi Li, Zhiyuan Liu, et al. Maven-ere: A unified large-scale dataset for event coreference, temporal, causal, and subevent relation extraction. arXiv preprint arXiv:2211.07342, 2022.
- Xu et al. [2024] Fangzhi Xu, Zhiyong Wu, Qiushi Sun, Siyu Ren, Fei Yuan, Shuai Yuan, Qika Lin, Yu Qiao, and Jun Liu. Symbol-llm: Towards foundational symbol-centric interface for large language models. In ACL, 2024.
- Xu et al. [2025] Fangzhi Xu, Qika Lin, Jiawei Han, Tianzhe Zhao, Jun Liu, and Erik Cambria. Are large language models really good logical reasoners? a comprehensive evaluation and beyond. IEEE Transactions on Knowledge and Data Engineering, 2025.
- Yamada and Shindo [2019] Ikuya Yamada and Hiroyuki Shindo. Neural attentive bag-of-entities model for text classification. arXiv preprint arXiv:1909.01259, 2019.
- Yao et al. [2019] Yuan Yao, Deming Ye, Peng Li, Xu Han, Yankai Lin, Zhenghao Liu, Zhiyuan Liu, Lixin Huang, Jie Zhou, and Maosong Sun. Docred: A large-scale document-level relation extraction dataset. arXiv preprint arXiv:1906.06127, 2019.
- Zhang et al. [2023] Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, et al. Instruction tuning for large language models: A survey. arXiv preprint arXiv:2308.10792, 2023.
- Zhang et al. [2024] Jian Zhang, Changlin Yang, Haiping Zhu, Qika Lin, Fangzhi Xu, and Jun Liu. A semantic mention graph augmented model for document-level event argument extraction. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 1577–1587, 2024.
- Zheng et al. [2023] Mingkai Zheng, Xiu Su, Shan You, Fei Wang, Chen Qian, Chang Xu, and Samuel Albanie. Can gpt-4 perform neural architecture search? arXiv preprint arXiv:2304.10970, 2023.
## Appendix A Details of Data Collection
This section provides detailed information on all datasets of $\sim$ 806K pieces for training and $\sim$ 140K pieces for testing, including an overall introduction in Section A.1, and the categorization of datasets into three types in Section A.2.
### A.1 General Introduction
As shown in Table 3, we have collected, to the best of our ability, three types of different graph construction sub-task datasets for the GKG Dataset, along with an additional counter task (NLG task) dataset, resulting in a total of 15 sub-tasks and 29 datasets. To ensure data balance and reasonable distribution, we sample and partition some of the datasets. These sampling and partitioning processes are clearly indicated in Table 3 under the ”Sampled?” field, allowing readers to better understand the data handling approach.
In the KG sub-task dataset, the focus is primarily on various types of relation extraction, including sentence-level relation extraction, few-shot relation extraction, and entity relation extraction, etc. This is because nodes in the KG sub-task are entities, and an important sub-task is to extract relationships between these entities. Furthermore, the EKG sub-task dataset primarily includes event detection, event argument extraction, and event relation extraction, as the event nodes are more complex, containing trigger words and various arguments. For the CKG sub-task dataset, the focus is closer to common-sense nodes and relations reasoning, involving tasks such as abstract generation and language inference.
### A.2 Three Categorizations
The GKG Dataset is divided into three types: in-domain data, counter task data, and OOD data. The OOD data is separately indicated in Table 3 and is used only during the testing phase, not during training, to evaluate the model’s performance on OOD data. The counter task is included to prevent overfitting and to enhance the generalizability of GKG-LLM.
Specifically, in-domain data consists of various GKG sub-tasks, combined with the counter task dataset (WebNLG) to form the training set. Using a curriculum learning fine-tuning framework, we obtained the final version of GKG-LLM. After testing on all in-domain datasets and the counter task dataset, we proceeded to test on three OOD datasets—TCR, Causal-TB, and R8—to validate the model’s superior performance.
| Graphs | Tasks | Datasets | # Train | # Test | sampled? | held-out? | Original Source |
| --- | --- | --- | --- | --- | --- | --- | --- |
| KG | SRE | NYT | 96,229 | 8,110 | | | Paulus [2017] |
| FRE | FewRel | 56,576 | 11,775 | | | Han et al. [2018] | |
| TACRED | 18,448 | 3,325 | | | Alt et al. [2020] | | |
| DRE | DOCRED | 61,380 | 6,137 | ✓ | | Yao et al. [2019] | |
| JE&RE | FewRel | 28,288 | 11,775 | ✓ | | | |
| NYT | 48,114 | 8,110 | ✓ | | | | |
| EKG | SED | ACE2005 | 3,681 | 409 | | | Grishman et al. [2005] |
| DED | WIKIEVENTS | 3,586 | 365 | | | Li et al. [2021] | |
| DEAE | WIKIEVENTS | 3,586 | 365 | | | | |
| RAMS | 7,339 | 761 | | | Ebner et al. [2020] | | |
| ETRE | MATRES | 12,216 | 1,361 | | | Ning et al. [2019] | |
| ESL | 7,652 | 852 | | | | | |
| TB-Dense | 9,257 | 2,639 | | | Han et al. [2019] | | |
| Causal-TB | 5,427 | 603 | | | Mirza and Tonelli [2016] | | |
| MAVEN-ERE | 80,000 | 5,000 | ✓ | | Wang et al. [2022] | | |
| TCR | | 3,515 | | ✓ | Han et al. [2019] | | |
| ECRE | ESL | 3,196 | 356 | | | | |
| MAVEN-ERE | 63,980 | 7,330 | ✓ | | | | |
| Causal-TB | | 318 | | ✓ | | | |
| ESRE | HiEve | 12,107 | 1,348 | | | Glavaš et al. [2014] | |
| MAVEN-ERE | 31,365 | 4,244 | | | | | |
| CKG | NER | CoNLL | 17,293 | 3,454 | | | Sang and De Meulder [2003] |
| AG | CNNDM | 51,684 | 11,490 | ✓ | | Chen et al. [2021] | |
| XSum | 50,666 | 11,334 | ✓ | | Hasan et al. [2021] | | |
| LI | SNLI | 50,000 | 10,000 | ✓ | | Camburu et al. [2018] | |
| MNLI | 50,000 | 10,000 | ✓ | | Hu et al. [2020] | | |
| TC | R8 | | 7,674 | | ✓ | Yamada and Shindo [2019] | |
| R52 | 7,816 | 1,284 | ✓ | | Ge and Moh [2017] | | |
| Counter | NLG | WebNLG | 26,302 | 6,513 | | | Gardent et al. [2017] |
Table 3: Detailed illustrations of 15 sub-task types across 29 datasets, categorized within three types of graphs, along with a counter dataset—WebNLG. # Train and # Test represent the number of training and testing samples, respectively. Sampled? indicates whether the dataset is sampled from the original to achieve data balancing. Held-out? specifies whether the dataset is used during the training phase. Original Source refers to the citation of the original paper.
## Appendix B Data Format
<details>
<summary>extracted/6285883/figures/dataFormat2.jpg Details</summary>
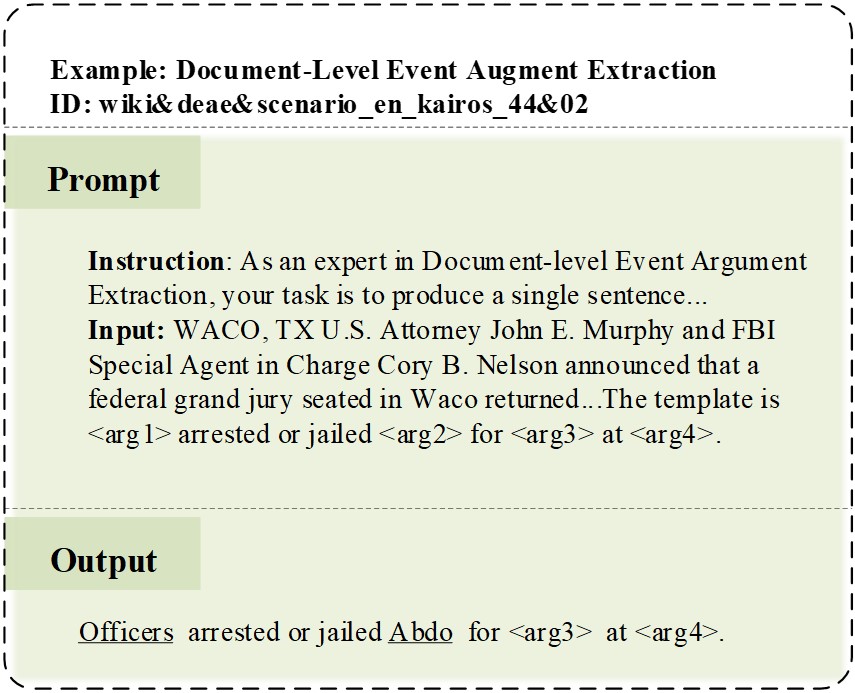
### Visual Description
\n
## Screenshot: Document-Level Event Argument Extraction Example
### Overview
The image is a screenshot of a document demonstrating an example of Document-Level Event Argument Extraction. It shows a "Prompt" section with instructions and input text, and an "Output" section displaying the extracted result. The screenshot is framed by a dashed border.
### Components/Axes
The screenshot is divided into three main sections:
1. **Header:** Contains the text "Example: Document-Level Event Augment Extraction" and "ID: wiki&deae&scenario_en_kairos_44&02". This is positioned at the top-center of the image.
2. **Prompt Section:** Labeled "Prompt", this section contains the instructions and input text. It is positioned in the upper-left portion of the image.
3. **Output Section:** Labeled "Output", this section displays the extracted output. It is positioned in the bottom-left portion of the image.
### Content Details
**Header Text:**
"Example: Document-Level Event Augment Extraction"
"ID: wiki&deae&scenario_en_kairos_44&02"
**Prompt Text:**
"Instruction: As an expert in Document-level Event Argument Extraction, your task is to produce a single sentence..."
"Input: WACO, TX U.S. Attorney John E. Murphy and FBI Special Agent in Charge Cory B. Nelson announced that a federal grand jury seated in Waco returned...The template is <arg1> arrested or jailed <arg2> for <arg3> at <arg4>."
**Output Text:**
"Officers arrested or jailed Abdo for <arg3> at <arg4>."
### Key Observations
The example demonstrates how a template with argument placeholders (<arg1>, <arg2>, <arg3>, <arg4>) is populated with extracted information from the input text. The output sentence fills in "Officers" for <arg1> and "Abdo" for <arg2>, while leaving <arg3> and <arg4> as placeholders.
### Interpretation
This screenshot illustrates a natural language processing (NLP) task focused on event argument extraction. The goal is to identify key elements within a text (the arguments) and map them to predefined roles within a template. The example shows a simplified scenario where the system successfully identifies the agents involved in an arrest or jailing event. The remaining placeholders suggest that further processing or information is needed to complete the sentence. The "ID" suggests this is part of a larger dataset or experiment ("wiki&deae&scenario_en_kairos_44&02"). The use of "kairos" in the ID might indicate a focus on timeliness or opportune moments in event extraction.
</details>
Figure 8: An example from the WIKEVENTS dataset. It consists of five fields $ID$ , instruction $s_{i}$ , few-shot $fs$ / zero-shot $zs$ , input $x_{i}$ , and output $y_{i}$ .
To bridge the gap between the dataset’s data format and the instruction-tuning format, we formatted all the data. Specifically, each data entry consists of five fields– $ID$ , instruction $s_{i}$ , few-shot $fs$ / zero-shot $zs$ , input $x_{i}$ , and output $y_{i}$ . as shown in Figure 8, this example is from the WIKIEVENTS dataset. $ID$ represents the unique identifier of each data entry, which includes the task name, dataset name, and specific data entry. The instruction $s_{i}$ provides a formal definition of each sub-task and is passed to the base model to help it understand the task’s intent. few-shot $fs$ / zero-shot $zs$ field indicates whether a few-shot example is included in the prompt; in particular, for zero-shot, this field can be omitted. The input $x_{i}$ represents the specific input data, while the output $y_{i}$ represents the corresponding output.
To more comprehensively simulate real-world scenarios, we utilize GPT-4 to generate ten diverse instructions, which are then randomly assigned to the instruction field of each data entry. This approach aims to enhance the model’s ability to understand and handle a variety of task instructions, thereby increasing its flexibility and adaptability for real-world multitasking needs. By diversifying the instructions, we aim to train the model to better respond to different directives, similar to a practical deployment setting. Additionally, for 10% of the data pieces, we randomly added a few-shot example to help the base model understand the task structure more effectively. The majority of the data entries, however, remained in a zero-shot setting, ensuring that the model could learn general patterns of GKG construction tasks without extensive direct guidance. By balancing few-shot and zero-shot learning, we aim to improve the model’s generalization capabilities across a range of GKG-related tasks.
## Appendix C Stage Generalization
In this section, we examine the effect of the three-stage training strategy on subsequent data exploration stages. Specifically, we test G-Micro, trained only on KG-related sub-task datasets, on EKG and CKG sub-task datasets, and G-Mid on the CKG sub-task dataset. The results are shown in Figure 9.
<details>
<summary>extracted/6285883/figures/stageGeneralization2.png Details</summary>
### Visual Description
\n
## Bar Chart: Comparison with Different Settings and GKG-LLM
### Overview
This bar chart compares the "Results" achieved using different settings alongside a GKG-LLM approach. The chart displays three settings: "KG->EKG", "KG->CKG", and "KG+EKG->CKG". For each setting, two bars are presented: one representing "Different Settings" (darker blue) and another representing "GKG-LLM" (lighter blue with a cross-hatch pattern). Error bars are included on top of each bar, indicating the variability or uncertainty in the results.
### Components/Axes
* **Title:** "Comparison with Different Settings and GKG-LLM" (centered at the top)
* **X-axis:** "Settings" with three categories: "KG->EKG", "KG->CKG", "KG+EKG->CKG"
* **Y-axis:** "Results" with a scale ranging from 0 to 70 (approximately).
* **Legend:** Located in the top-left corner.
* "Different Settings" - represented by a solid, darker blue color.
* "GKG-LLM" - represented by a lighter blue color with a cross-hatch pattern.
### Detailed Analysis
The chart presents the following data points (approximate values based on visual inspection):
* **KG->EKG:**
* Different Settings: Approximately 48 ± 4 (based on the error bar).
* GKG-LLM: Approximately 64 ± 5.
* **KG->CKG:**
* Different Settings: Approximately 52 ± 4.
* GKG-LLM: Approximately 72 ± 5.
* **KG+EKG->CKG:**
* Different Settings: Approximately 66 ± 4.
* GKG-LLM: Approximately 72 ± 5.
The "GKG-LLM" bars are consistently higher than the "Different Settings" bars across all three settings. The error bars indicate some variability in the results, but the GKG-LLM approach generally yields better results.
### Key Observations
* The GKG-LLM approach consistently outperforms the "Different Settings" approach across all tested settings.
* The largest difference in performance between the two approaches is observed for the "KG->CKG" setting.
* The "KG+EKG->CKG" setting yields the highest overall results for both approaches.
* The error bars suggest that the results for "GKG-LLM" are slightly more variable than those for "Different Settings".
### Interpretation
The data suggests that incorporating the GKG-LLM approach leads to improved results compared to using different settings alone. The consistent outperformance of GKG-LLM indicates its effectiveness in enhancing the performance of the system being evaluated. The largest improvement observed with the "KG->CKG" setting might suggest that this setting benefits most from the GKG-LLM integration. The relatively small error bars suggest a reasonable degree of confidence in the results, although some variability exists. The chart demonstrates a clear positive correlation between the use of GKG-LLM and the achieved results, highlighting its potential as a valuable component in the system. The settings themselves likely represent different configurations or parameters used within the system, and the chart provides a comparative analysis of their performance with and without the GKG-LLM enhancement.
</details>
Figure 9: Comparison of Results by different settings and GKG-LLM.
The experimental results show that, despite some trade-offs in the exploratory experiments, the three-stage curriculum learning approach achieves superior performance. This demonstrates: 1). earlier GKG-LLM versions influence subsequent tasks, indicating task correlation; 2). the unified approach to the three types of graphs in GKG is valuable and meaningful, reflecting their progressive relationship within a unified framework.
## Appendix D Exploration of LoRA+ Hyperparameter Values
As described in Section 2.3, we adopt the LoRA+ training strategy, where the low-rank matrices $A$ and $B$ have different rates of change, meaning they each have distinct hyperparameters $\eta_{A}$ and $\eta_{B}$ .
In this section, we explore the effects of different combinations of the hyperparameters $\eta_{A}$ and $\eta_{B}$ on the model’s performance. The experimental results are illustrated in Figure 10, the vertical axis represents $B$ , which is expressed as a multiple of $\eta_{A}$ . The model’s performance is highly sensitive to changes in $\eta_{A}$ and $\eta_{B}$ . The highest performance score of 67.90% was achieved with $\eta_{A}=4\times 10^{-4}$ and $\eta_{B}=4\times 10^{-3}$ . This suggests that higher learning rates for $\eta_{A}$ combined with moderate values of $\eta_{B}$ are beneficial for fine-tuning. Conversely, the lowest performance scores were observed with the smallest value of $\eta_{A}=5\times 10^{-5}$ , regardless of the value of $\eta_{B}$ . This indicates that too low a learning rate for the adaptation matrices may not be sufficient for effective fine-tuning. Increasing $\eta_{B}$ tends to enhance performance up to a certain point, after which the performance gains stabilize or diminish. For example, $\eta_{A}=2\times 10^{-4}$ with $\eta_{B}=8\times 10^{-3}$ shows a obvious score, but further increasing $\eta_{B}$ does not yield substantial improvements.
<details>
<summary>extracted/6285883/figures/hyperparameters1.png Details</summary>
### Visual Description
## Heatmap: Heatmap of Scores for Different ηΔ and Plus Values
### Overview
This image presents a heatmap visualizing the relationship between ηΔ (eta delta) values and Plus Multipliers, with the corresponding Score represented by color intensity. The heatmap displays scores ranging from approximately 29 to 80, with darker blue shades indicating higher scores.
### Components/Axes
* **Title:** "Heatmap of Scores for Different ηΔ and Plus Values" (top-center)
* **X-axis:** ηΔ Values, with markers at 5.00E-05, 2.00E-04, 4.00E-04, and 6.00E-04.
* **Y-axis:** Plus Multipliers, with markers at 5, 10, 20, and 40.
* **Color Scale/Legend:** Located in the top-right corner, representing Score values. The scale ranges from approximately 30 (lightest blue) to 80 (darkest blue).
* **Data Points:** Each cell in the heatmap represents a specific combination of ηΔ and Plus Multiplier, with the score indicated by the cell's color.
### Detailed Analysis
The heatmap is a 4x4 grid. I will analyze row by row, noting the score for each ηΔ value.
* **Plus Multipliers = 5:**
* ηΔ = 5.00E-05: Score = 29.49
* ηΔ = 2.00E-04: Score = 42.90
* ηΔ = 4.00E-04: Score = 46.39
* ηΔ = 6.00E-04: Score = 45.71
* **Plus Multipliers = 10:**
* ηΔ = 5.00E-05: Score = 40.93
* ηΔ = 2.00E-04: Score = 48.50
* ηΔ = 4.00E-04: Score = 67.90
* ηΔ = 6.00E-04: Score = 52.69
* **Plus Multipliers = 20:**
* ηΔ = 5.00E-05: Score = 29.36
* ηΔ = 2.00E-04: Score = 56.40
* ηΔ = 4.00E-04: Score = 64.86
* ηΔ = 6.00E-04: Score = 62.63
* **Plus Multipliers = 40:**
* ηΔ = 5.00E-05: Score = 29.67
* ηΔ = 2.00E-04: Score = 62.03
* ηΔ = 4.00E-04: Score = 51.84
* ηΔ = 6.00E-04: Score = 50.43
The highest score (approximately 68) is observed when Plus Multiplier is 10 and ηΔ is 4.00E-04. The lowest scores (around 29) are observed when Plus Multiplier is 5 or 40 and ηΔ is 5.00E-05.
### Key Observations
* **Trend:** Generally, increasing ηΔ values lead to higher scores for Plus Multipliers of 10 and 20. However, this trend is not consistent across all Plus Multiplier values.
* **Peak:** The maximum score is concentrated around Plus Multiplier = 10 and ηΔ = 4.00E-04.
* **Minimums:** The minimum scores are clustered around low ηΔ values (5.00E-05) and Plus Multipliers of 5 and 40.
* **Non-linearity:** The relationship between ηΔ and Plus Multipliers is not strictly linear, as evidenced by the varying score changes across different combinations.
### Interpretation
The heatmap suggests that the optimal combination of ηΔ and Plus Multiplier for achieving the highest score is around ηΔ = 4.00E-04 and Plus Multiplier = 10. The data indicates a complex interaction between these two parameters. The score is sensitive to changes in both parameters, and the optimal values are not simply the highest values for each parameter independently.
The lower scores observed at low ηΔ values (5.00E-05) suggest that a minimum threshold of ηΔ is required to achieve reasonable scores, regardless of the Plus Multiplier. The variation in scores for Plus Multiplier = 40 compared to Plus Multiplier = 20 suggests that the effect of Plus Multiplier may diminish at higher values.
This data could be used to optimize a system or process where ηΔ and Plus Multiplier are adjustable parameters, aiming to maximize the resulting score. Further investigation might involve exploring the underlying mechanisms driving these relationships and identifying the reasons for the observed non-linearity.
</details>
Figure 10: Heatmap of Scores for Different $\eta_{A}$ and $\eta_{B}$ Values for our training strategy.
These findings highlight the importance of carefully tuning the hyperparameters $\eta_{A}$ and $\eta_{B}$ in the LoRA+ framework to achieve optimal model performance. The insights gained from this exploration can guide future experiments and the development of more effective fine-tuning strategies for LLMs. In summary, the exploration of LoRA+ hyperparameters reveals that selecting the appropriate values for $\eta_{A}$ and $\eta_{B}$ is crucial for maximizing model performance. This study provides a foundational understanding that can be leveraged to further enhance the efficiency and effectiveness of fine-tuning LLMs using low-rank adaptation techniques.
## Appendix E Hyper-parameters
In the implementation, we leverage the LoRA+ technique to fine-tune models using four A800 (80GB) GPUs, with a maximum sequence length of 4,096. The fine-tuning process is optimized with FlashAttention2, while the AdamW optimizer is employed with a learning rate of 5e-5 across three curriculum learning stages, each controlled by a linear learning rate scheduler. We use one epoch per stage to complete the tuning process.
During the KG empowerment stage, model weights are initialized from LLaMA-3-Instruct, resulting in the tuned model named G-Micro. In the EKG enhancement stage, G-Micro serves as the starting point, producing G-Mid. Similarly, in the CKG generalization stage, we initialize from G-Mid and ultimately obtain GKG-LLM. Inference process is conduct on a single A800 (80GB) GPU using greedy search.
## Appendix F Sub-tasks Introduction
The GKG dataset is composed of three types of sub-task datasets: KG , EKG and CKG. The data is categorized into three types: In-domain data, OOD data, and counter-task data. The specific descriptions of these tasks are as follows.
### F.1 KG
#### SRE (Sentence-level Relation Extraction)
For the SRE task, we utilize the NYT dataset. This task focuses on identifying the entities mentioned in a complex news sentence and, based on entity recognition, detecting and labeling the relationships between the entities. This task plays a critical role in the process of transforming unstructured textual data into structured knowledge.
#### FRE (Few-shot Relation Extraction)
Due to the issue of insufficient labeled corpora in many domains and the high cost of manual annotation, the FRE task aims to train a model using a small amount of labeled sample data, enabling the model to learn the characteristic information of entities that form relationships. During the testing phase, the model is asked to identify previously unseen relationship types from new datasets. In our work, we utilize the FewRel and TACRED datasets for both training and testing.
#### DRE (Document-level Relation Extraction)
Compared to SRE, the DRE task is more challenging, as it requires the model not only to identify relations within a single sentence but also to understand the context and possess the ability to recognize relations across sentences and even across paragraphs. In this paper, we conduct experiments using the DocRED dataset. The input is a long text document containing multiple sentences and entities, while the output consists of all entity pairs in the document and their corresponding relation types.
#### JE&RE (Entity-Relation Joint Extraction)
The previously mentioned relation extraction approaches follow a pipeline where entity recognition is performed first, followed by relation classification based on the identified entities. In contrast, JE&RE task differs by requiring the model to extract both entities and relations simultaneously, without dividing the process into two separate tasks. In this work, we conduct experiments using the FewRel and NYT datasets.
### F.2 EKG
#### SED (Sentence-level Event Detection)
Event detection (ED) aims to identify the events mentioned in a given text and recognize their characteristics, such as event type, participants, time, and other relevant attributes. SED is a specific form of ED, where the task requires the model to detect events within individual sentences. In this work, we utilize the ACE2005 dataset for training and testing the model.
#### DED (Document-level Event Detection)
DED aims to identify multiple events within a document and extract relevant information, such as participants, triggers, and other attributes. Since these events may be distributed across different sentences, DED requires the model to have cross-sentence contextual understanding, making it more complex and enriched compared to sentence-level tasks. In this work, we use the WIKIEVENTS dataset, leveraging Wikipedia entries as events to train and test the model.
#### DEAE(Document-level Event Argument Extraction)
DEAE is a task designed to extract argumentative material from a full document, requiring the identification of arguments in a relationship and the extraction of the relations between arguments and events. In our work, we train and test the model using the WIKIEVENTS and RAMS datasets, where the RAMS dataset includes a rich set of argument types and deals with the relations of argument elements between different sentences.
#### ETRE (Event Temporal Relation Extraction)
ETRE aims to extract events mentioned in a text and determine the temporal order in which these events occur. In our experiments, we use the MATRES, ESL, TB-Dense, Causal-TB, MAVEN-ERE, and TCR datasets for training and testing the model. Notably, the TCR dataset, as an OOD dataset, is only used for testing and not for training.
#### ECRE (Event Causal Relation Extraction)
ECRE aims to identify and extract causal relationships between different events in a text. In our work, we use the ESL and MAVEN-ERE datasets for training and testing the model. The ESL dataset is further annotated with various types of causal relationships between events, including direct causality, indirect causality, and opposition relationships. Additionally, during testing, we employ the Causal-TB dataset as an OOD dataset, which is only used for testing and not for training.
#### ESRE (Event Subevent Relation Extraction)
In complex texts, events often do not exist independently but can exhibit hierarchical structures, where one event may be the cause, effect, or sub-event of another. ESRE aims to identify these hierarchical relationships between events to achieve a more comprehensive understanding of the event timeline and causal chains. The input to this task is typically a text containing multiple events, and the output is pairs of events along with their hierarchical relationship labels, such as parent event and child event, causal relation, and parallel relation. In this work, we use the HiEve and MAVEN-ERE datasets for model training and testing.
### F.3 CKG
#### NER (Named Entity Recognition)
NER aims to identify entities with specific semantic meanings from a text and classify them into predefined categories, such as person names, locations, organizations, dates, times, and numerical values. Given a natural language text as input, the output consists of the extracted named entities and their corresponding categories. NER plays a critical role in the construction of knowledge graphs by recognizing entities in the text and linking them to existing entity nodes in the knowledge graph, facilitating the automated development and expansion of the graph. In this work, we use the CoNLL dataset for training and testing the NER task.
#### AG (Abstract Generation)
AG aims to compress a lengthy input text into a concise and accurate abstract while retaining key information and themes. Since CKG can provide rich background and relational information, we employ a CKG-based abstraction task. For this purpose, we train and test the model using the CNNDM and XSum datasets, with the ROUGE-L percentage metric used as the evaluation criterion.
#### LI (Language Inference)
The task of LI aims to establish an understanding of relationships between sentences. The core objective of this task is to determine whether a given pair of sentences exhibits entailment, contradiction, or neutrality. Typically, the input consists of a pair of texts, and the output indicates whether the relationship between the two sentences is entailment, contradiction, or neutral. In this work, we use two specialized datasets in the field of natural language inference, the SNLI and MNLI datasets, for training and testing the model.
#### TC (Text Classification)
TC task aims to automatically assign textual data to one or more predefined categories. Given a text as input, the output is typically the predicted category or categories corresponding to the input text. In this work, we use the R8 and R52 datasets for model training and testing, with R8 serving as an OOD dataset that is used only for training and not for testing.
### F.4 Counter
#### NLG (Natural Language Generation)
NLG aims to generate natural language text in a predefined format or structure based on specific input information or structure. Unlike traditional free-text generation, the structured text generation task emphasizes the structure and accuracy of the information in the output. The input can take various forms of structured data, such as knowledge graphs, tables, or tuples, and the output is typically a coherent piece of text that adheres to the predetermined structure. In this work, we use the WebNLG dataset, a typical dataset in this domain, for model training and testing. Specifically, we employ the ROUGE-L percentage metric as the evaluation criterion.