# SACTOR: LLM-Driven Correct and Idiomatic C to Rust Translation with Static Analysis and FFI-Based Verification
**Authors**: Tianyang Zhou, Ziyi Zhang, Haowen Lin, Somesh Jha, Mihai Christodorescu, Kirill Levchenko, Varun Chandrasekaran
> University of Illinois Urbana-Champaign
> University of Wisconsin–Madison
> Google
## Abstract
Translating software written in C to Rust has significant benefits in improving memory safety. However, manual translation is cumbersome, error-prone, and often produces unidiomatic code. Large language models (LLMs) have demonstrated promise in producing idiomatic translations, but offer no correctness guarantees. We propose SACTOR, an LLM-driven C-to-Rust translation tool that employs a two-step process: an initial “unidiomatic” translation to preserve interface, followed by an “idiomatic” refinement to align with Rust standards. To validate correctness of our function-wise incremental translation that mixes C and Rust, we use end-to-end testing via the foreign function interface. We evaluate SACTOR on $200$ programs from two public datasets and on two more complex scenarios (a 50-sample subset of CRust-Bench and the libogg library), comparing multiple LLMs. Across datasets, SACTOR delivers high end-to-end correctness and produces safe, idiomatic Rust with up to 7 $\times$ fewer Clippy warnings; On CRust-Bench, SACTOR achieves an average (across samples) of 85% unidiomatic and 52% idiomatic success, and on libogg it attains full unidiomatic and up to 78% idiomatic coverage on GPT-5.
Keywords Software Engineering $\cdot$ Static Analysis $\cdot$ C $\cdot$ Rust $\cdot$ Large Language Models $\cdot$ Machine Learning
## 1 Introduction
C is widely used due to its ability to directly manipulate memory and hardware (love2013linux). However, manual memory management leads to vulnerabilities such as buffer overflows, dangling pointers, and memory leaks (bigvul). Rust addresses these issues by enforcing memory safety through a strict ownership model without garbage collection (matsakis2014rust), and has been adopted in projects like the Linux kernel https://github.com/Rust-for-Linux/linux and Mozilla Firefox. Translating legacy C code into idiomatic Rust improves safety and maintainability, but manual translation is error-prone, slow, and requires expertise in both languages.
Automatic tools such as C2Rust (c2rust) generate Rust by analyzing C ASTs, but rule-based or static approaches (crown; c2rust; emre2021translating; hong2024don; ling2022rust) typically yield unidiomatic code with heavy use of unsafe. Given semantic differences between C and Rust, idiomatic translations are crucial for compiler-enforced safety, readability, and maintainability.
Large language models (LLMs) show potential for capturing syntax and semantics (pan2023understanding), but they hallucinate and often generate incorrect or unsafe code (perry2023users). In C-to-Rust translation, naive prompting produces unsafe or semantically misaligned outputs. Prior work has explored prompting strategies (syzygy; c2saferrust; shiraishi2024context) and verification methods such as fuzzing and symbolic execution (vert; flourine). While these improve correctness, they struggle with complex programs and rarely yield idiomatic Rust. For example, Vert (vert) fails on programs with complex data structures, and C2SaferRust (c2saferrust) still produces Rust with numerous unsafe blocks.
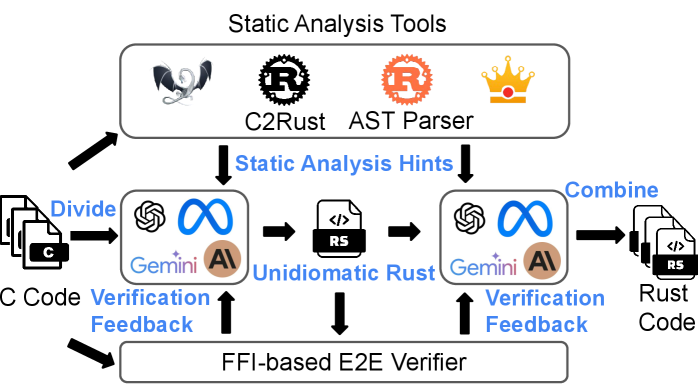
In this paper, we introduce SACTOR, a structure-aware, LLM-driven C-to-Rust translator (Figure 1). SACTOR follows a two-stage pipeline:
- C $\to$ Unidiomatic Rust: Interface-preserving translation that may use unsafe for low-level operations.
- Unidiomatic $\to$ Idiomatic Rust: Behaviorally-equivalent translation that refines to Rust idioms, eliminating unsafe and migrating C API patterns to Rust equivalents.
Static analysis of C code (pointer semantics, dependencies) guides both stages. To verify correctness, we embed the translated Rust with the original C via the Foreign Function Interface (FFI), enabling end-to-end testing on both stages and accept a stage when all end-to-end tests can pass. This decomposition separates syntax from semantics, simplifies the LLM task, and ensures more idiomatic, memory-safe Rust SACTOR code is available at https://github.com/qsdrqs/sactor and datasets are available at https://github.com/qsdrqs/sactor-datasets. An example of SACTOR translation process is in Appendix E.
LLM orchestration. SACTOR places the LLM inside a neuro-symbolic feedback loop. Static analysis and a machine-readable interface specification guide prompting; compiler diagnostics and end-to-end tests provide structured feedback. In the idiomatic verification phase, a rule-based harness generator with an LLM fallback completes the feedback loop. This design first ensures semantic correctness in unidiomatic Rust, then refines it into idiomatic Rust, with both stages verifiable in a unified two-step process.
Our contributions are as follows:
- Method: An LLM-orchestrated, structure-aware two-phase pipeline that separates semantic preservation from idiomatic refinement, guided by static analysis (§ 4)
- Verification: SACTOR verifies both unidiomatic and idiomatic translations via FFI-based testing. During idiomatic verification, it uses a co-produced interface specification to synthesize C/Rust harnesses with an LLM fallback for missing patterns; compiler and test feedback are structured into targeted prompt repairs (§ 4.3).
- Evaluation: Across two datasets (200 programs) and five LLMs, SACTOR reaches 93% / 84% end-to-end correctness (DeepSeek-R1) and improves idiomaticity (§ 6.2). On CRust-Bench (50 samples), unidiomatic translation averages 85% function-level success rate across all samples (82% aggregated across functions), with 32/50 samples fully translated; idiomatic success is computed on those 32 samples and averages 52% (43% aggregated; 8/32 fully idiomatic). On libogg (77 functions), the function-level success rate is 100% for unidiomatic and 53% and 78% for idiomatic across GPT-4o and GPT-5, respectively (§ 6.3).
- Diagnostics: We analyze efficiency, feedback, temperature sensitivity, and failure cases: GPT-4o is the most token-efficient, compilation/testing feedback boosts weaker models by 17%, temperature has little effect, and reasoning models like DeepSeek-R1 excel on complex bugs such as format-string and array errors (Appendix H).
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: C to Rust Code Conversion Process
### Overview
This diagram illustrates a process for converting C code to Rust code, utilizing static analysis tools, an AST parser, and a feedback loop for verification. The process involves dividing C code, converting it to idiomatic Rust, and then verifying the conversion using an FFI-based end-to-end (E2E) verifier. Gemini AI is used to provide verification feedback.
### Components/Axes
The diagram can be divided into three main sections:
1. **Header:** "Static Analysis Tools" containing icons representing different tools.
2. **Main Flow:** The core conversion process with arrows indicating the flow of code and feedback.
3. **Footer:** "FFI-based E2E Verifier"
The key components are:
* C Code
* C2Rust AST Parser
* Unidiomatic Rust
* Rust Code
* Gemini AI (Verification Feedback)
* FFI-based E2E Verifier
The diagram uses arrows to indicate the direction of the process flow.
### Detailed Analysis or Content Details
The process begins with "C Code" (represented by a file icon with a "C" inside) which is "Divided" and sent to the "C2Rust AST Parser". The parser is represented by a rectangular box containing four icons:
* A penguin-like icon (likely representing a specific tool)
* An "R" icon with a curly brace
* An "R" icon with a crown
* A crown icon
The output of the parser is "Static Analysis Hints" which are sent to "Unidiomatic Rust" (represented by a code block icon with "</> RS"). Gemini AI provides "Verification Feedback" to both the C Code and the Unidiomatic Rust. The Unidiomatic Rust is then converted to "Rust Code" (represented by a code block icon with "</> RS"). Gemini AI also provides "Verification Feedback" to the Rust Code. Finally, the Rust Code is "Combined" with the initial C Code through a feedback loop. The entire process is verified by the "FFI-based E2E Verifier" (represented by a rectangular box).
The arrows indicate the following flow:
* C Code -> C2Rust AST Parser
* C2Rust AST Parser -> Static Analysis Hints -> Unidiomatic Rust
* Unidiomatic Rust -> Rust Code
* C Code <- Verification Feedback (from Gemini AI)
* Unidiomatic Rust <- Verification Feedback (from Gemini AI)
* Rust Code <- Verification Feedback (from Gemini AI)
* Rust Code -> Combined with C Code
### Key Observations
The diagram highlights a cyclical process with feedback loops, suggesting an iterative refinement approach to code conversion. The use of Gemini AI for verification feedback indicates an attempt to automate and improve the quality of the conversion. The FFI-based E2E verifier suggests a focus on ensuring functional equivalence between the original C code and the converted Rust code.
### Interpretation
The diagram demonstrates a sophisticated approach to converting C code to Rust, going beyond a simple translation. The inclusion of static analysis, an AST parser, and a verification loop suggests a focus on producing high-quality, idiomatic Rust code. The use of Gemini AI for feedback indicates an attempt to leverage machine learning to improve the conversion process. The FFI-based E2E verifier is crucial for ensuring that the converted Rust code behaves identically to the original C code, which is essential for maintaining functionality and avoiding regressions. The diagram suggests a complex system designed to minimize errors and maximize the quality of the converted code. The cyclical nature of the process implies that the conversion is not a one-time event but rather an iterative process of refinement and verification.
</details>
Figure 1: Overview of the SACTOR methodology.
## 2 Background
Primer on C and Rust: C is a low-level language that provides direct access to memory and hardware through pointers and abstracts machine-level instructions (tiobe). While this makes it efficient, it suffers from memory vulnerabilities (sbufferoverflow; hbufferoverflow; uaf; memoryleak). Rust, in contrast, provides memory safety without additional performance penalty, and has the same ability to access low-level hardware as C; it enforces strict compile-time memory safety through ownership, borrowing, and lifetimes to eliminate memory vulnerabilities (matsakis2014rust; jung2017rustbelt).
Challenges in Code Translation: Despite its advantages, and since Rust is relatively new, many widely used system-level programs remain in C. It is desirable to translate such programs to Rust, but the process is challenging due to fundamental language differences. Figure 3 in Appendix A shows an example of a simple C program and its Rust equivalent to illustrate the differences between two languages in terms of memory management and error handling. While Rust permits unsafe blocks for C-like pointer operations, their use is discouraged due to the absence of compiler guarantees and their non-idiomatic nature for further maintenance Other differences include string representation, pointer usage, array handling, reference lifetimes, and error propagation. A non-exhaustive summary appears in Appendix A..
## 3 Related Work
LLMs for C-to-Rust Translation: Vert (vert) combines LLM-generated candidates with fuzz testing and symbolic execution to ensure equivalence, but this strict verification struggles with scalability and complex C features. Flourine (flourine) incorporates error feedback and fuzzing, using data type serialization to mitigate mismatches, yet serialization issues still account for nearly half of errors. shiraishi2024context decompose C programs into sub-tasks (e.g., macros) and translate them with predefined Rust idioms, but evaluate only compilation success without functional correctness. syzygy employ dynamic analysis to capture runtime behavior as translation guidance, but coverage limits hinder generalization across execution paths. c2saferrust refine C2Rust outputs with LLMs to reduce unidiomatic constructs (unsafe, libc), but remain constrained by C2Rust’s preprocessing, which strips comments and directives (§ 4.2) and reduces context for idiomatic translation.
Non-LLM Approaches for C-to-Rust Translation: C2Rust (c2rust) translates by converting C ASTs into Rust ASTs and applying rule-based transformations. While syntactically correct, the results are structural translations that rely heavily on unsafe blocks and explicit type conversions, yielding low readability. Crown (crown) introduces static ownership tracking to reduce pointer usage in generated Rust code. hong2024don focus on handling return values in translation, while ling2022rust rely on rules and heuristics. Although these methods reduce some unsafe usage compared to C2Rust, the resulting code remains largely unidiomatic.
## 4 SACTOR Methodology
We propose SACTOR, an LLM-driven C-to-Rust translation tool using a two-step translation methodology. As Rust and C differ substantially in semantics (§ 2), SACTOR augments the LLM with static-analysis-derived “hints” that capture semantic information in the C code. The four main stages of SACTOR are outlined below.
### 4.1 Task Division
We begin by dividing the program into smaller parts that can be processed by the LLM independently. This enables the LLM to focus on a narrower scope for each translation task and ensures the program fits within its context window. This strategy is supported by studies showing that LLM performance degrades on long-context understanding and generation tasks (liu2024longgenbench; li2024long). By breaking the program into smaller pieces, we can mitigate these limitations and improve performance on each individual task. To facilitate task division and extract relevant language information – such as definitions, declarations, and dependencies – from C code, we developed a static analysis tool called C Parser based on libclang (a library that provides a C compiler interface, allowing access to semantic information of the code).
Our C Parser analyzes the input program and splits the program into fragments consisting of a single type, global variable, or function definition. This step also extracts semantic dependencies between each part (e.g., a function definition depending on a prior type definition). We then process each program fragment in dependency order: all dependencies of a code fragment are processed before the fragment. Concretely, C Parser constructs a directed dependency graph whose nodes are types, global variables, and functions, and whose edges point from each item to the items it directly depends on. We compute a translation order by repeatedly selecting items whose dependencies have already been processed. If the dependency graph contains a cycle, SACTOR currently treats this as an unsupported case and terminates with an explicit error. In addition, to support real-world C projects, SACTOR makes use of the C project compile commands generated by the make tool and performs preprocessing on the C source files. In Appendix B, we provide more details on how we preprocess source files and divide programs.
### 4.2 Translation
To ensure that each program fragment is translated only after its dependencies have been processed, we begin by translating data types, as they form the foundational elements for functions. This is followed by global variables and functions. We divide the translation process into two steps.
Step 1. Unidiomatic Rust Translation: We aim to produce interface equivalent Rust code from the original C code, which allows the use of unsafe blocks to do pointer manipulations and C standard library functions while keeping the same interface as original C code. For data type translation, we leverage information from C2Rust (c2rust) to help the conversion. While C2Rust provides reliable data type translation, it struggles with function translation due to its compiler-based approach, which omits source-level details like comments, macros, and other elements. These omissions significantly reduce the readability and usability of the generated Rust code. Thus, we use C2Rust only for data type translation, and use an LLM to translate global variables and functions. For functions, we rely on our C Parser to automatically extract dependencies (e.g., function signatures, data types, and global variables) and reference the corresponding Rust code. This approach guides the LLM to accurately translate functions by leveraging the previously translated components and directly reusing or invoking them as needed.
Step 2. Idiomatic Rust Translation: The goal of this step is to refine unidiomatic Rust into idiomatic Rust by removing unsafe blocks and following Rust idioms. This stage focuses on rewriting behavioral-equivalent but low-level constructs into type-safe abstractions while preserving behavior verified in the previous step. Handling pointers from C code is a key challenge, as they are considered unsafe in Rust. Unsafe pointers should be replaced with Rust types such as references, arrays, or owned types. To address this, we use Crown (crown) to facilitate the translation by analyzing pointer mutability, fatness (e.g., arrays), and ownership. This information provided by Crown helps the LLM assign appropriate Rust types to pointers. Owned pointers are translated to Box, while borrowed pointers use references or smart pointers. Crown assists in translating data types like struct and union, which are processed first as they are often dependencies for functions. For function translations, Crown analyzes parameters and return pointers, while local variable pointers are inferred by the LLM. Dependencies are extracted using our C Parser to guide accurate function translation. The idiomatic code is produced together with an interface transformation specification, forms the input to the verification step in § 4.3.
### 4.3 Verification
To verify the equivalence between source and target languages, prior work has relied on symbolic execution and fuzz testing, are impractical for real-world C-to-Rust translation (details in Appendix C). We instead validate correctness through soft equivalence: ensuring functional equivalence of the entire program via end-to-end (E2E) tests. This avoids the complexity of generating specific inputs or constraints for individual functions and is well-suited for real-world programs where such E2E tests are often available and reusable. Correctness confidence in this framework depends on the code coverage of the E2E tests: the broader the coverage, stronger the assurance of equivalence.
Verifying Unidiomatic Rust Code. This is straightforward, as it is semantically equivalent to the original C code and maintains compatible function signatures and data types, which ensures a consistent Application Binary Interface (ABI) between the two languages and enabling direct use of the FFI for cross-language linking. The verification process involves two main steps: First, the unidiomatic Rust code is compiled using the Rust compiler to check for successful compilation. Then, the original C code is recompiled with the Rust translation linked as a shared library. This setup ensures that when the C code calls the target function, it invokes the Rust translation instead. To verify correctness, E2E tests are run on the entire program, comparing the outputs of the original C code and the unidiomatic Rust translation. If all tests pass, the target function is considered verified.
Verifying Idiomatic Rust Code. Idiomatic Rust diverges from the original C program in both types and function signatures, producing an ABI mismatch that prevents direct linking into the C build. We therefore verify it via a synthesized, C-compatible test harness together with E2E tests.
During idiomatic translation, SACTOR co-produces a small, machine-readable specification (SPEC) for each function/struct. The SPEC captures, in a compact form, how C-facing values map to idiomatic Rust, including the expected pointer shape (slice / cstring / ref), where lengths come from (a sibling field or a constant), and basic nullability and return conventions; it also allows marking fields that should be compared in self-checks. A rule-based generator consumes the SPEC to synthesize a C-compatible harness that bridges from the C ABI to idiomatic code and backwards. Figure 9 shows the schematic, and Table 12 summarizes current supported patterns; Appendix L presents a detailed exposition of the SPEC-driven harness generation technique (rules and design choices), and Appendix D provides a concrete example of the generated harness. For structs, the SPEC defines bidirectional converters between the C-facing and idiomatic layouts, validated by a lightweight roundtrip test that checks the fields marked as comparable for consistency after conversion. When the SPEC includes a pattern the generator does not yet implement (e.g., aliasing/offset views or unsupported pointer kinds or types), we emit a localized TODO and use an LLM guided by the SPEC to fill only the missing conversions. Finally, we compile the idiomatic crate and the generated harness, link them into the original C build via FFI, and run the program’s existing E2E tests; passing tests validate the idiomatic translation under the coverage of those tests, while failures trigger the feedback procedure in § 4.3.
Feedback Mechanism. For failures, we feed structured signals back to translation: compiler errors guide fixes for build breaks; for E2E failures we use the Rust procedural macro to automatically instrument the target to log salient inputs/outputs, re-run tests, and return the traces to the translator for refinement.
### 4.4 Code Combination
By translating and verifying all functions and data types, we integrate them into a unified Rust codebase. We first collect the translated Rust code from each subtask and remove duplicate definitions and other redundancies required only for standalone compilation. The cleaned code is then organized into a well-structured Rust implementation of the original C program. Finally, we run end-to-end tests on the combined program to verify the correctness of the final Rust output. If all tests pass, the translation is considered successful.
## 5 Experimental Setup
### 5.1 Datasets Used
For the selection of datasets for evaluation, we consider the following criteria:
- Sufficient Number: The dataset should contain a substantial number of C programs to ensure a robust evaluation of the approach’s performance across a diverse set of examples.
- Presence of Non-Trivial C Features: The dataset should include C programs with advanced features such as multiple functions, struct s, and other non-trivial constructs as it enables the evaluation to assess the approach’s ability to handle complex features of C.
- Availability of E2E Tests: The dataset should either include E2E tests or make it easy to generate them as this is essential for accurately evaluating the correctness of the translated code.
Based on the above criteria, we evaluate on two widely used program suites in the translation literature: TransCoder-IR (transcoderir) and Project CodeNet (codenet). Complete details for these datasets are in Appendix F. For TransCoder-IR and CodeNet, we randomly sample 100 C programs from each (for CodeNet, among programs with external inputs) to ensure computational feasibility while maintaining statistical significance.
To better reflect the language features of real-world C codebases and allow test reuse (§ 6.3), we also evaluate on two targets: (i) a 50-sample subset of CRust-Bench (khatry2025crust) and (ii) the libogg multimedia container library (libogg). In CRust-Bench, we exclude entries outside our pipeline’s scope (e.g., circular dependencies or compiler-specific intrinsics). libogg is a real-world C project of about 2,000 lines of code with 77 functions involving non-trivial struct s, buffer s, and pointer manipulation. Both benchmarks reuse their upstream end-to-end tests to verify the translated code.
### 5.2 Evaluation Metrics
Success Rate: This is defined as the ratio of the number of programs that can (a) successfully be translated to Rust, and (b) successfully pass the E2E tests for both unidiomatic and idiomatic translation phases to the total number of programs. To enable the LLMs to utilize feedback from previous failed attempts, we allow the LLM to make up to 6 attempts for each translation process.
Idiomaticity: To evaluate the idiomaticity of the translated code, we use three metrics:
- Lint Alert Count is measured by running Rust-Clippy (clippy), a tool that provides lints on unidiomatic Rust (including improper use of unsafe code and other common style issues). By collecting the warnings and errors generated by Rust-Clippy for the translated code, we can assess its idiomaticity: fewer alerts indicate more idiomaticity. Previous translation works (vert; flourine) have also used Rust-Clippy.
- Unsafe Code Fraction, inspired by shiraishi2024context, is defined as the ratio of tokens inside unsafe code blocks or functions to total tokens for a single program. High usage of unsafe is considered unidiomatic, as it bypasses compiler safety checks, introduces potential memory safety issues and reduces code readability.
- Unsafe Free Fraction indicates the percentage of translated programs in a dataset that do not contain any unsafe code. Since unsafe code represents potential points where the compiler cannot guarantee safety, this metric helps determine the fraction of results that can be achieved without relying on unsafe code.
### 5.3 LLMs Used
We evaluate 6 models across different experiments. On the two datasets (TransCoder-IR and CodeNet) we use four non-reasoning models—GPT-4o (OpenAI), Claude 3.5 Sonnet (Anthropic), Gemini 2.0 Flash (Google), and Llama 3.3 70B Instruct (Meta), and one reasoning model DeepSeek-R1 (DeepSeek). For real-world codebases, we run GPT-4o on CRust-Bench and run both GPT-4o and GPT-5 on libogg. Model configurations appear in Appendix G.
## 6 Evaluation
Through our evaluation, we answer: (1) How successful is SACTOR in generating idiomatic Rust code using different LLM models?; (2) How idiomatic is the Rust code produced by SACTOR compared to existing approaches?; and (3) How well does SACTOR generalize to real-world C codebases?
Our results show that: (1) DeepSeek-R1 achieves the highest success rates (93%) with SACTOR on TransCoder-IR and also reaches the highest success rates (84%) on Project CodeNet (§ 6.1), while failure reasons vary between datasets and models (Appendix H); (2) SACTOR ’s idiomatic translation results outperforms all previous baselines, producing Rust code with fewer Clippy warnings and 100% unsafe-free translations (§ 6.2); and (3) For real-world codebases (§ 6.3), SACTOR attains strong unidiomatic success and moderate idiomatic success: on CRust-Bench, unidiomatic averages 85% across 50 samples (82% aggregated across 966 functions; 32/50 fully translated) and idiomatic averages 52% across 32 samples that fully translated into unidiomatic Rust (43% aggregated across 580 functions; 8/32 fully translated); on libogg unidiomatic reaches 100% and idiomatic spans 53% and 78% for GPT-4o and GPT-5, respectively. Failures concentrate at ABI/type boundaries and harness synthesis (pointer/slice shape, length sources, lifetime or mutability), with additional cases from unsupported features and borrow/ownership pitfalls. Overall, improving the model itself alleviates a subset of failure modes; for a fixed model, strengthening the framework and interface rules also improves outcomes but remains limited when confronted with previously unseen patterns.
We also evaluate the computational cost of SACTOR (Appendix I), the impact of the feedback mechanism (Appendix J), and temperature settings (Appendix K) . GPT-4o and Gemini 2.0 achieve the best cost-performance balance, while Llama 3.3 consumes the most tokens among non-reasoning models. DeepSeek-R1 uses 3-7 $\times$ more tokens than others. The feedback mechanism boosts Llama 3.3’s success rate by 17%, but has little effect on GPT-4o, suggesting it benefits lower-performing models more. Temperature has minimal impact.
### 6.1 Success Rate Evaluation
<details>
<summary>x2.png Details</summary>

### Visual Description
\n
## Legend: Color Key for Data Series
### Overview
The image presents a legend defining color-coded labels for twelve distinct data series. The series are categorized into "Unid." and "Idiom." prefixes, each with six sub-series labeled "SR1" through "SR6". This suggests the legend is associated with a chart or diagram where these series are visually represented using these colors.
### Components/Axes
The image consists solely of a legend. There are no axes, scales, or other chart elements present. The legend is organized into two columns. The left column contains the "Unid." series, and the right column contains the "Idiom." series. Each entry consists of a colored block and a corresponding text label.
### Detailed Analysis or Content Details
Here's a breakdown of each data series and its associated color:
* **Unid. SR1:** Dark Blue (approximately RGB 30, 70, 140)
* **Unid. SR2:** Medium Blue (approximately RGB 70, 120, 190)
* **Unid. SR3:** Light Blue with Cross-Hatching (approximately RGB 120, 170, 230)
* **Unid. SR4:** Dark Grey with Cross-Hatching (approximately RGB 80, 80, 80)
* **Unid. SR5:** Medium Grey with Cross-Hatching (approximately RGB 130, 130, 130)
* **Unid. SR6:** Light Grey with Cross-Hatching (approximately RGB 180, 180, 180)
* **Idiom. SR1:** Orange (approximately RGB 230, 120, 30)
* **Idiom. SR2:** Medium Orange (approximately RGB 200, 150, 50)
* **Idiom. SR3:** Light Orange with Cross-Hatching (approximately RGB 250, 180, 80)
* **Idiom. SR4:** Dark Brown with Cross-Hatching (approximately RGB 100, 60, 20)
* **Idiom. SR5:** Medium Brown with Cross-Hatching (approximately RGB 150, 90, 30)
* **Idiom. SR6:** Light Brown with Cross-Hatching (approximately RGB 200, 140, 70)
The cross-hatching pattern is consistently applied to the "Unid. SR4", "Unid. SR5", "Unid. SR6", "Idiom. SR3", "Idiom. SR4", and "Idiom. SR5" series.
### Key Observations
The legend categorizes data series into two groups: "Unid." and "Idiom.". The "Unid." series uses solid colors, while the "Idiom." series uses colors with a cross-hatching pattern. This suggests a distinction in the nature or origin of the data represented by these series. The consistent numbering (SR1-SR6) within each category implies a sequential or ordered relationship between the sub-series.
### Interpretation
The legend likely accompanies a visualization comparing two types of data: "Unid." and "Idiom.". The use of different visual encodings (solid color vs. cross-hatching) suggests that these categories represent fundamentally different data types or sources. The "SR" labels likely denote specific sub-categories or measurements within each main category. Without the accompanying chart or diagram, it's difficult to determine the precise meaning of these series, but the legend provides a clear mapping between color and data identity, enabling interpretation of the visualization. The cross-hatching could indicate a different level of confidence, a different method of calculation, or a different source of data. The consistent use of SR1-SR6 suggests a systematic comparison across these two data types.
</details>
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Bar Chart: LLM Success Rates
### Overview
This is a grouped bar chart comparing the success rates of five different Large Language Models (LLMs) – Claude 3.5, Gemini 2.0, Llama 3.3, GPT-4.0, and DeepSeek-R1. Each LLM has three bars representing different conditions or categories, indicated by different patterns within the bars. The y-axis represents the success rate in percentage, ranging from 0 to 100, while the x-axis lists the LLM models.
### Components/Axes
* **X-axis Label:** "LLM Models"
* **Y-axis Label:** "Success Rate (%)"
* **LLM Models (Categories):** Claude 3.5, Gemini 2.0, Llama 3.3, GPT-4.0, DeepSeek-R1
* **Bar Patterns (Sub-categories):** Three distinct patterns are used to differentiate the conditions. Let's label them as Pattern A (solid blue), Pattern B (diagonal stripes), and Pattern C (cross-hatch).
* **Legend:** There is no explicit legend, but the patterns within the bars represent different conditions.
### Detailed Analysis
Let's analyze each LLM's success rates for each pattern:
* **Claude 3.5:**
* Pattern A (solid blue): Approximately 50%
* Pattern B (diagonal stripes): Approximately 55%
* Pattern C (cross-hatch): Approximately 58%
* **Gemini 2.0:**
* Pattern A (solid blue): Approximately 65%
* Pattern B (diagonal stripes): Approximately 72%
* Pattern C (cross-hatch): Approximately 75%
* **Llama 3.3:**
* Pattern A (solid blue): Approximately 60%
* Pattern B (diagonal stripes): Approximately 68%
* Pattern C (cross-hatch): Approximately 70%
* **GPT-4.0:**
* Pattern A (solid blue): Approximately 75%
* Pattern B (diagonal stripes): Approximately 80%
* Pattern C (cross-hatch): Approximately 82%
* **DeepSeek-R1:**
* Pattern A (solid blue): Approximately 70%
* Pattern B (diagonal stripes): Approximately 85%
* Pattern C (cross-hatch): Approximately 90%
**Trends:**
* For all LLMs, the success rate generally increases from Pattern A to Pattern C.
* GPT-4.0 and DeepSeek-R1 consistently demonstrate higher success rates across all patterns compared to Claude 3.5, Gemini 2.0, and Llama 3.3.
* DeepSeek-R1 shows the most significant improvement from Pattern A to Pattern C.
### Key Observations
* DeepSeek-R1 consistently outperforms other models, especially in Pattern C, achieving a success rate close to 90%.
* Claude 3.5 has the lowest success rates across all patterns.
* The difference in success rates between Pattern A and Pattern C is more pronounced for GPT-4.0 and DeepSeek-R1.
### Interpretation
The chart demonstrates the performance of different LLMs under varying conditions (represented by the three patterns). The increasing success rate from Pattern A to Pattern C suggests that the conditions represented by Pattern C are more favorable for these models. GPT-4.0 and DeepSeek-R1 are the most robust models, consistently achieving high success rates regardless of the condition. Claude 3.5 appears to be the least capable model in this comparison.
The lack of a legend makes it difficult to determine what the different patterns represent. However, the consistent trend of increasing success rates with Pattern C suggests that this condition might involve simpler tasks, more training data, or a more suitable input format. The chart highlights the varying capabilities of different LLMs and the importance of considering the specific conditions when evaluating their performance. Further investigation is needed to understand the meaning of the patterns and the factors contributing to the observed differences in success rates.
</details>
(a) TransCoder-IR SR
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Bar Chart: LLM Performance Comparison
### Overview
This is a grouped bar chart comparing the performance of five Large Language Models (LLMs) – Claude 3.5, Gemini 2.0, Llama 3.3, GPT-4.0, and DeepSeek-R1 – across three different metrics. The chart uses stacked bars to represent the contribution of each metric to the overall performance score.
### Components/Axes
* **X-axis:** LLM Models (Claude 3.5, Gemini 2.0, Llama 3.3, GPT-4.0, DeepSeek-R1)
* **Y-axis:** Scale ranging from 0 to 100 (representing performance score, units not specified).
* **Bar Groups:** Each LLM has a group of three bars, representing different metrics.
* **Legend:** (Inferred from bar colors)
* Blue: Metric 1 (unspecified)
* Orange: Metric 2 (unspecified)
* Hatched Pattern: Metric 3 (unspecified)
### Detailed Analysis
The chart presents performance data for each LLM, broken down into three components.
**Claude 3.5:**
* Metric 1 (Blue): Approximately 62.
* Metric 2 (Orange): Approximately 15.
* Metric 3 (Hatched): Approximately 23.
* Total: Approximately 100.
**Gemini 2.0:**
* Metric 1 (Blue): Approximately 72.
* Metric 2 (Orange): Approximately 15.
* Metric 3 (Hatched): Approximately 13.
* Total: Approximately 100.
**Llama 3.3:**
* Metric 1 (Blue): Approximately 65.
* Metric 2 (Orange): Approximately 15.
* Metric 3 (Hatched): Approximately 20.
* Total: Approximately 100.
**GPT-4.0:**
* Metric 1 (Blue): Approximately 82.
* Metric 2 (Orange): Approximately 15.
* Metric 3 (Hatched): Approximately 3.
* Total: Approximately 100.
**DeepSeek-R1:**
* Metric 1 (Blue): Approximately 75.
* Metric 2 (Orange): Approximately 15.
* Metric 3 (Hatched): Approximately 10.
* Total: Approximately 100.
### Key Observations
* GPT-4.0 consistently demonstrates the highest performance in Metric 1 (Blue), significantly outperforming other models.
* All models have a similar score for Metric 2 (Orange), around 15.
* The contribution of Metric 3 (Hatched) varies considerably between models.
* The total score for each model is approximately 100, suggesting the metrics are weighted to sum to this value.
### Interpretation
The chart suggests that GPT-4.0 excels in a particular performance aspect represented by Metric 1. The consistent performance of all models on Metric 2 indicates that this metric might represent a baseline capability or a common feature across these LLMs. The variation in Metric 3 suggests that this aspect is where the models differentiate themselves the most.
Without knowing what the metrics represent, it's difficult to draw definitive conclusions. However, the data implies that GPT-4.0 is the strongest performer overall, while the other models exhibit varying strengths and weaknesses in the third metric. The chart is useful for a comparative analysis of LLM performance, but requires further context to understand the specific capabilities being measured. The consistent value of Metric 2 across all models suggests it may be a fundamental capability or a standardized test component.
</details>
(b) CodeNet SR
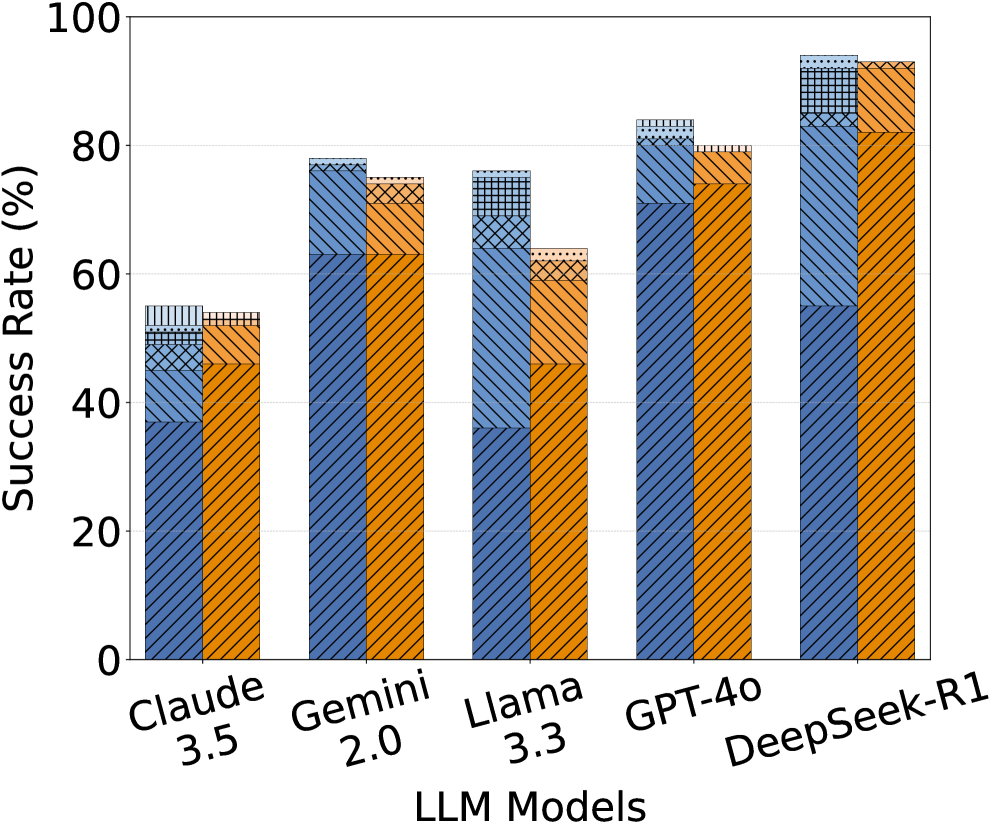
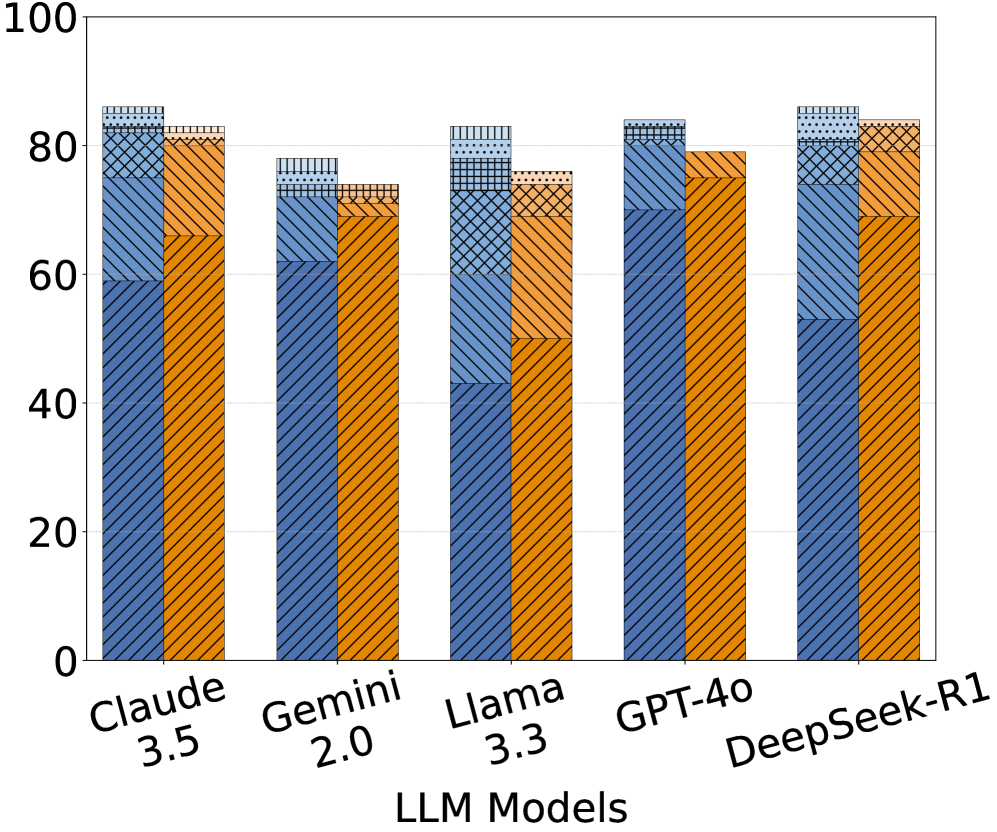
Figure 2: Success rates (SR) across different LLM models for the TransCoder-IR and CodeNet datasets. SR 1-6 represent the number of attempts made to achieve a successful translation. Unid. and Idiom. denote unidiomatic and idiomatic translation steps, respectively.
We evaluate the success rate (as defined in § 5.2) for the two datasets on different models. For idiomatic translation, we also plot how many attempts are needed.
(1) TransCoder-IR (Figure 2(a)): DeepSeek-R1 achieves the highest success rate (SR) in both unidiomatic (94%) and idiomatic (93%) steps, only 1% drops in the idiomatic translation step, demonstrating strong consistency in code translation. GPT-4o follows with 84% in the unidiomatic step and 80% in the idiomatic step. Gemini 2.0 comes next with 78% and 75%, respectively. Claude 3.5 struggles in the unidiomatic step (55%) but does not show substantial degradation when converting unidiomatic Rust to idiomatic Rust (54%, only a 1% drop), but it is still the worst model compared to the others. Llama 3.3 performs well in the unidiomatic step (76%) but drops significantly in the idiomatic step (64%), and requiring more attempts for correctness.
(2) Project CodeNet (Figure 2(b)): DeepSeek-R1 again leads with 86% in the unidiomatic step and 84% in the idiomatic step, showing only a 2% drop in the idiomatic translation step. Claude 3.5 follows closely with 86% success rate in the unidiomatic step and 83% in the idiomatic step. GPT-4o performs consistently well in the unidiomatic step (84%) but drops to 79% in the idiomatic step, indicating a 5% drop between the two steps. Gemini 2.0 follows with 78% in the unidiomatic step and 74% in the idiomatic step, showing consistent performance between two datasets. Llama 3.3 still exhibits significant drops (83% to 76%) in both steps and finishes last in the idiomatic step.
The results demonstrates that DeepSeek-R1’s SRs remain high and consistent–94%/93% (unidiomatic/idiomatic) on TransCoder-IR versus 86%/84% on CodeNet–while other models exhibit notable performance drops when moving to TransCoder-IR. This suggests that models with reasoning capabilities may be better for handling complex code logic and data manipulation.
### 6.2 Measuring Idiomaticity
We compare our approach with four baselines: C2Rust (c2rust), Crown (crown), C2SaferRust (c2saferrust) and Vert (vert). Of these baselines, C2Rust is the most versatile Versatility refers to an approach’s applicability to diverse C programs., supporting most C programs, while Crown is also broad but lacks support for some language features. C2SaferRust focuses on refining the unsafe code produced by C2Rust, allowing it to handle a wide range of C programs. In contrast, Vert targets a specific subset of simpler C programs. We assess the idiomaticity of Rust code generated by C2Rust, Crown, and C2SaferRust on both datasets. Since Vert produced Rust code only for TransCoder-IR, we evaluate it solely on this dataset. All the experiments are conducted using GPT-4o as the LLM for baselines and our approach, with max 6 attempts per translation.
Results: Figure LABEL:fig:idiomaticity presents the lint alert count (sum up of Clippy warnings and errors count for a single program) across all approaches. C2Rust consistently exhibits high Clippy issues, and Crown shows little improvement over C2Rust, indicating both struggle to generate idiomatic Rust. C2SaferRust reduces Clippy issues, but it still retains a significant number of warnings and errors. Notably, even the unidiomatic output of SACTOR surpasses all of these 3. This underscores the advantage of LLMs over rule-based methods. While Vert improves idiomaticity, SACTOR ’s idiomatic phase yields fewer Clippy issues, outperforming some existing LLM-based approaches.
Table LABEL:tab:unsafe_stats summarizes unsafe code statistics. Unsafe-Free indicates the percentage of programs without unsafe code, while Avg. Unsafe represents the average proportion of unsafe code across all translations. C2Rust and Crown generate unsafe code in all programs with a high average unsafe percentage. C2SaferRust has the ability to reduce unsafe code and able to generate unsafe-free programs in some cases (45.6% in TransCoder-IR), but cannot sufficiently reduce the unsafe uses in the CodeNet dataset. Vert has a higher success rate than SACTOR but occasionally introduces unsafe code. SACTOR ’s unidiomatic phase retains C semantics, leading to a high unsafe percentage. However, its idiomatic phase eliminates all unsafe code, achieving a 100% Unsafe-Free rate.
### 6.3 Real-world Code-bases
To evaluate SACTOR ’s performance on two real-world code-bases, we run the translation process up to three times per sample, with SACTOR attempts to translate each function, struct and global variable at most six attempts in each run. For libogg, we also experiment with both GPT-4o and GPT-5 to compare their performance.
CRust-Bench.
Measured at the function level, the mean per-sample translation success rate is 85.15%. Aggregated across the 50 samples, SACTOR translates 788 of 966 functions (81.57% combined). 32 samples achieve 100% function-level translation, i.e., the entire C codebase for the sample is translated to unidiomatic Rust. For idiomatic translation, we evaluate only on the 32 samples whose unidiomatic stage reached 100% function-level translation. On these samples, the mean per-sample function translation rate is 51.85%. Aggregated across them, SACTOR translates 249 of 580 functions (42.93% combined); 8 samples achieve 100% function-level idiomatic translation, which the entire C codebases are translated to idiomatic Rust.
| Unidi. Idiom. | 50 32 $\dagger$ | 85.15% 51.85% | 788 / 966 (81.57%) 249 / 580 (42.93%) | 32 / 50 (64.00%) 8 / 32 (25.00%) | 2.96 0.28 |
| --- | --- | --- | --- | --- | --- |
Table 1: CRust-Bench function-level translation results. Success rate (SR) is averaged per-sample; $\dagger$ idiomatic stage is evaluated only on samples whose unidiomatic pass fully translated all functions.
Table 1 summarizes stage-level outcomes.
Observations and failure modes. We organize failures into five main categories. (1) Interface/name drift: Symbol casing or exact-name mismatches (e.g., CamelCase vs. snake_case). (2) Semantic mapping errors: Mistakes in translating C constructs to idiomatic Rust (e.g., pointer-of-pointer vs. Vec, shape drift, lifetime or mutability issues). (3) C-specific features: Incomplete handling some features like function pointers and C variadics. (4) Borrowing and resource-model violations: Compile-time borrow-checker errors in idiomatic Rust bodies (e.g., overlapping borrows in updates). (5) Harness/runtime faults: Faulty test harnesses translation (e.g. buffer mis-sizing, out-of-bounds access). Other minor cases include unsupported intrinsics (SIMD) and global-state divergence (shadowed globals). Table LABEL:tab:crust_failures (in Appendix M.1) summarizes each sample’s outcome and its primary cause.
Idiomaticity. Unidiomatic outputs exhibit many lint alerts and heavy reliance on unsafe: the mean Clippy alert sum is 50.14 per sample (2.96 per function); the mean unsafe fraction is 97.86% with an unsafe-free rate of 0%. Idiomatic outputs reverse this profile: the mean Clippy alert sum drops to only 2.27 per sample (0.28 per function); the mean unsafe fraction is 0% with a 100% unsafe-free rate.
Libogg.
Step (model) SR (%) Avg. lint / Function Avg. attempt Unid. (GPT-4o) 100 1.45 1.52 Idiom. (GPT-4o) 53 0.28 2.00 Unid. (GPT-5) 100 1.45 1.04 Idiom. (GPT-5) 78 0.23 1.25
Table 2: Evaluation of SACTOR ’s function translation on libogg. “Unid.”/“Idiom.” denotes unidiomatic/idiomatic translation. “SR” is the success rate of translating functions. “Avg. lint”/“Avg. attempt” is the average lint alert count/average number of attempts, for functions that both LLM models succeed in translating.
The unidiomatic and idiomatic translations of all structs and global variables are successful with each LLM model. For functions, the result is summarized in Table 2. SACTOR succeeds in all functions’ unidiomatic translations. For idiomatic translations, SACTOR ’s success rate is 53% and SACTOR takes 2.00 attempts on average to produce a correct translation with GPT-4o. For GPT-5, the performance is significantly better with a success rate of 78% and average number of attempts of 1.25.
Observations and failure modes. The most significant reasons for failed idiomatic translations include: (1) failure to pass tests due to mistakes in translating pointer manipulation and heap memory management; (2) compile errors in translated functions, especially arising from violation of Rust safety rules on lifetimes, borrowing and mutability; (3) failure to generate compilable test harnesses for data types with pointers and arrays. GPT-5 performs significantly better than GPT-4o. For example, GPT-5 only have one failure caused by a compile error in the translated function, in contrast to six compile error failures with GPT-4o, which shows the progress of GPT-5 in understanding Rust grammar and fixing compile errors. More details can be found in Appendix M.2.
Idiomaticity. SACTOR ’s unidiomatic translations cause lint alerts largely due to the use of unsafe code while idiomatic translations lead to very few lint alerts, i.e., fewer than 0.3 alerts per function on average (Table 2). With each model, the unidiomatic translations are all in unsafe code but the idiomatic translations are all in safe code. As a result, the idiomatic translations have an avg. unsafe fraction of 0% and unsafe-free fraction of 100%. The unidiomatic translations are the opposite.
## 7 Conclusions
Translating C to Rust enhances memory safety but remains error-prone and often unidiomatic. While LLMs improve translation, they still lack correctness guarantees and struggle with semantic gaps. SACTOR addresses these through a two-stage pipeline: preserving ABI interface first, then refining to idiomatic Rust. Guided by static analysis and validated via FFI-based testing, SACTOR achieves high correctness and idiomaticity across multiple benchmarks, surpassing prior tools. Remaining challenges include stronger correctness assurance, richer C-feature coverage, and improved scalability and efficiency (see § 8). Example prompts appear in Appendix N.
## 8 Limitations
While SACTOR is effective in producing correct, idiomatic Rust, several limitations remain:
- Test coverage dependence. Our soft-equivalence checks rely on existing end-to-end tests; shallow or incomplete coverage can miss subtle semantic errors. Integrating fuzzing or test generation could raise coverage and catch corner cases.
- Model variance. Translation quality depends on the underlying LLM. Although GPT-4o and DeepSeek-R1 perform well in our study, other models show lower accuracy and stability.
- Unsupported C features. Complex macros, pervasive function pointers, global state, C variadics and inline assembly are only partially handled, limiting applicability to such codebases (see § 6.3).
- Static analysis precision. Current analysis may under-specify aliasing, ownership, and pointer shapes in challenging code, leading to adapter/spec errors. Stronger analyses could improve mapping and reduce retries.
- Harness generation stability. The rule-based generator with LLM fallback can still emit incomplete or brittle adapters on complex patterns (e.g., unusual pointer shapes or length expressions), causing otherwise-correct translations to fail verification. Hardening rules and reducing reliance on the fallback should improve robustness and reproducibility.
- Cost and latency. Multi-stage prompting, compilation, and test loops incur non-trivial token and time costs, which matter for large-scale migrations.
## Appendix A Differences Between C and Rust
### A.1 Code Snippets
Here is a code example to demonstrate the differences between C and Rust. The example shows a simple C program and its equivalent Rust program. The create_sequence function takes an integer n as input and returns an array with a sequence of integers. In C, the function needs to allocate memory for the array using malloc and will return the pointer to the allocated memory as an array. If the size is invalid, or the allocation fails, the function will return NULL. The caller of the function is responsible for freeing the memory using free when it is done with the array to prevent memory leaks.
C Code:
<details>
<summary>x5.png Details</summary>

### Visual Description
\n
## Code Snippet: C Function for Sequence Creation and Memory Management
### Overview
The image presents a C code snippet defining a function `create_sequence` that dynamically allocates an integer array of size `n` and initializes it with values from 0 to `n-1`. It also demonstrates how to call this function and the importance of freeing the allocated memory.
### Content Details
The code consists of two main parts: the function definition and an example of its usage.
**1. Function Definition:**
```c
int* create_sequence(int n) {
if (n <= 0) {
return NULL;
}
int* arr = malloc(n * sizeof(int));
if (!arr) {
return NULL;
}
for (int i = 0; i < n; i++) {
arr[i] = i;
}
return arr;
}
```
* **Function Signature:** `int* create_sequence(int n)` - The function takes an integer `n` as input and returns a pointer to an integer array.
* **Error Handling:** If `n` is less than or equal to 0, the function returns `NULL`.
* **Memory Allocation:** `int* arr = malloc(n * sizeof(int));` - Dynamically allocates memory for an integer array of size `n`.
* **Allocation Failure Check:** `if (!arr) { return NULL; }` - Checks if the memory allocation was successful. If not, it returns `NULL`.
* **Initialization Loop:** `for (int i = 0; i < n; i++) { arr[i] = i; }` - Initializes the array elements with values from 0 to `n-1`.
* **Return Value:** `return arr;` - Returns a pointer to the newly created and initialized array.
**2. Function Usage Example:**
```c
int* sequence = create_sequence(5);
if (sequence == NULL) {
...
}
free(sequence); // Need to free the memory when done
```
* **Function Call:** `int* sequence = create_sequence(5);` - Calls the `create_sequence` function with `n = 5`, allocating an array of 5 integers.
* **Null Check:** `if (sequence == NULL) { ... }` - Checks if the function returned `NULL`, indicating a memory allocation failure. The `...` suggests further error handling would be implemented here.
* **Memory Deallocation:** `free(sequence);` - Deallocates the memory pointed to by `sequence` using the `free` function. A comment explicitly states the importance of this step to prevent memory leaks.
### Key Observations
* The code demonstrates a common pattern for dynamically allocating and initializing arrays in C.
* The inclusion of error handling (checking for `n <= 0` and `malloc` failure) is good practice.
* The comment `// Need to free the memory when done` highlights the crucial aspect of memory management in C. Failure to `free` allocated memory leads to memory leaks.
* The `...` in the error handling block suggests incomplete code.
### Interpretation
This code snippet illustrates a fundamental concept in C programming: dynamic memory allocation. The `create_sequence` function provides a way to create an array of a size determined at runtime. The use of `malloc` allows the program to request memory from the heap, which is essential when the array size is not known at compile time. However, dynamic memory allocation comes with the responsibility of explicitly deallocating the memory when it is no longer needed, using `free`. The example demonstrates this best practice, emphasizing the importance of preventing memory leaks. The code is a simple but effective illustration of how to manage memory in C, a skill critical for writing robust and efficient programs.
</details>
Rust Code:
<details>
<summary>x6.png Details</summary>

### Visual Description
\n
## Code Snippet: Rust Function Definition
### Overview
The image presents a Rust code snippet defining a function `create_sequence` and demonstrating its usage with a `match` statement. The code aims to create a vector of i32 integers from 0 up to (and including) a given input `n`. It handles the case where `n` is zero or negative by returning `None`.
### Components/Axes
There are no axes or traditional chart components. The image consists entirely of code. The key elements are:
* **Function Definition:** `fn create_sequence(n: i32) -> Option<Vec<i32>> { ... }`
* **Conditional Statement:** `if n <= 0 { return None; }`
* **Vector Initialization:** `let mut arr = Vec::with_capacity(n as usize);`
* **Loop:** `for i in 0..n { arr.push(i); }`
* **Return Statement:** `Some(arr)`
* **Match Statement:** `match create_sequence(5) { ... }`
* **Match Cases:** `Some(sequence) => { ... }` and `None => { ... }`
* **Comments:** `// Does not need to free the memory`
### Detailed Analysis or Content Details
The code defines a function `create_sequence` that takes an integer `n` as input and returns an `Option<Vec<i32>>`.
1. **Function Signature:**
* `fn create_sequence(n: i32) -> Option<Vec<i32>>`
* The function is named `create_sequence`.
* It accepts a single argument `n` of type `i32` (32-bit signed integer).
* It returns an `Option<Vec<i32>>`. `Option` is an enum that can be either `Some(value)` or `None`. `Vec<i32>` represents a dynamically sized vector of `i32` integers.
2. **Conditional Logic:**
* `if n <= 0 { return None; }`
* If `n` is less than or equal to 0, the function immediately returns `None`, indicating that no sequence can be created.
3. **Vector Creation and Population:**
* `let mut arr = Vec::with_capacity(n as usize);`
* A mutable vector named `arr` is created using `Vec::with_capacity(n as usize)`. `with_capacity` pre-allocates memory for `n` elements, improving performance. The `n` is cast to `usize` which is an unsigned integer type used for indexing.
* `for i in 0..n { arr.push(i); }`
* A `for` loop iterates from `i = 0` up to (but not including) `n`.
* Inside the loop, `arr.push(i)` adds the current value of `i` to the end of the vector `arr`.
4. **Return Value:**
* `Some(arr)`
* If `n` is greater than 0, the function returns `Some(arr)`, wrapping the created vector `arr` inside the `Some` variant of the `Option` enum.
5. **Match Statement Usage:**
* `match create_sequence(5) { ... }`
* The `match` statement calls `create_sequence` with the argument `5`.
* The `match` statement then handles the possible return values of `create_sequence(5)`.
6. **Match Cases:**
* `Some(sequence) => { ... }`
* If `create_sequence(5)` returns `Some(sequence)`, this case is executed. The vector is bound to the variable `sequence`. The code within this block is represented by `...`.
* `None => { ... }`
* If `create_sequence(5)` returns `None`, this case is executed. The code within this block is represented by `...`.
7. **Comment:**
* `// Does not need to free the memory`
* This comment indicates that Rust's ownership and borrowing system automatically manages memory, so explicit memory deallocation is not required.
### Key Observations
* The code demonstrates a common pattern in Rust: using `Option` to handle cases where a function might not be able to produce a valid result.
* The use of `Vec::with_capacity` is a performance optimization.
* The `match` statement provides a concise way to handle different possible return values.
* The comment highlights Rust's memory safety features.
### Interpretation
The code snippet illustrates a safe and efficient way to create a sequence of integers in Rust. The use of `Option` and `Vec::with_capacity` demonstrates Rust's focus on error handling and performance. The `match` statement provides a clear and structured way to handle the different possible outcomes of the function call. The comment about memory management underscores Rust's automatic memory management system, which eliminates the need for manual memory allocation and deallocation, reducing the risk of memory leaks and other memory-related errors. The code is well-structured and easy to understand, showcasing the readability of the Rust language.
</details>
Figure 3: Example of a simple C program and its equivalent Rust program, both hand-written for illustration.
### A.2 Tabular Summary
Here, we present a non-exhaustive list of differences between C and Rust in Table 3, highlighting the key features that make translating code from C to Rust challenging. While the list is not comprehensive, it provides insights into the fundamental distinctions between the two languages, which can help developers understand the challenges of migrating C code to Rust.
| Memory Management Pointers Lifetime Management | Manual (through malloc/free) Raw pointers like *p Manual freeing of memory | Automatic (through ownership and borrowing) Safe references like &p/&mut p, Box and Rc Lifetime annotations and borrow checker |
| --- | --- | --- |
| Error Handling | Error codes and manual checks | Explicit handling with Result and Option types |
| Null Safety | Null pointers allowed (e.g., NULL) | No null pointers; uses Option for nullable values |
| Concurrency | No built-in protections for data races | Enforces safe concurrency with ownership rules |
| Type Conversion | Implicit conversions allowed and common | Strongly typed; no implicit conversions |
| Standard Library | C stand library with direct system calls | Rust standard library with utilities for strings, collections, and I/O |
| Language Features | Procedure-oriented with minimal abstractions | Modern features like pattern matching, generics, and traits |
Table 3: Key Differences Between C and Rust
## Appendix B Preprocessing and Task Division
### B.1 Preprocessing of C Files
To support real-world C projects, SACTOR parses the compile commands generated by the make tool, extracting relevant flags for preprocessing, parsing, compilation, linking, and third-party tools’ use.
C source files usually contain preprocessing directives, such as #include, #define, #ifdef, #endif, etc., which we need to resolve before parsing C files. For #include, we copy and expand non-system headers recursively while keeping #include of system headers intact, because included non-system headers contain project-specific definitions such as structs and enums that the LLM has not known while system headers’ contents are known to the LLM and expanding them would unnecessarily introduce too much noise. For other directives, we pass relevant C project compile flags to the C preprocessor from GCC to resolve them.
### B.2 Algorithm for Task Division
The task division algorithm is used to determine the order in which the items should be translated. The algorithm is shown in Algorithm 1.
Algorithm 1 Translation Task Order Determination
1: $L_{i}$ : List of items to be translated
2: $dep(a)$ : Function to get dependencies of item $a$
3: $L_{sorted}$ : List of groups resolving dependencies
4: $L_{sorted}\leftarrow\emptyset$ $\triangleright$ Empty list
5: while $|L_{sorted}|<|L_{i}|$ do
6: $L_{processed}\leftarrow\emptyset$
7: for $a\in L_{i}$ do
8: if $a\notin L_{processed}$ and $dep(a)\subseteq L_{processed}$ then
9: $L_{sorted}\leftarrow L_{sorted}+a$ $\triangleright$ Add to sorted list
10: $L_{processed}\leftarrow L_{processed}\cup a$
11: end if
12: end for
13: if $L_{processed}=\emptyset$ then
14: $L_{circular}\leftarrow DFS(L_{i},dep)$ $\triangleright$ Circular dependencies
15: $L_{sorted}\leftarrow L_{sorted}+L_{circular}$ $\triangleright$ Add a group to sorted list
16: end if
17: end while
18: return $L_{sorted}$
In the algorithm, $L_{i}$ is the list of items to be translated, and $dep(a)$ is a function that returns the dependencies of item $a$ . The algorithm returns a list $L_{sorted}$ that contains the items in the order in which they should be translated. $DFS(L_{i},dep)$ is a depth-first search function that returns a list of items involved in a circular dependency. It begins by collecting all items (e.g., functions, structs) to be translated and their respective dependencies (in both functions and data types). Items with no unresolved dependencies are pushed into the translation order list first, and other items will remove them from their dependencies list. This process continues until all items are pushed into the list, or circular dependencies are detected. If circular dependencies are detected, we resolve them through a depth-first search strategy, ensuring that all items involved in a circular dependency are grouped together and handled as a single unit.
## Appendix C Equivalence Testing Details in Prior Literature
### C.1 Symbolic Execution-Based Equivalence
Symbolic execution explores all potential execution paths of a program by using symbolic inputs to generate constraints [king1976symbolic, baldoni2018survey, coward1988symbolic]. While theoretically powerful, this method is impractical for verifying C-to-Rust equivalence due to differences in language features. For instance, Rust’s RAII (Resource Acquisition Is Initialization) pattern automatically inserts destructors for memory management, while C relies on explicit malloc and free calls. These differences cause mismatches in compiled code, making it difficult for symbolic execution engines to prove equivalence. Additionally, Rust’s compiler adds safety checks (e.g., array boundary checks), which further complicate equivalence verification.
### C.2 Fuzz Testing-Based Equivalence
Fuzz testing generates random or mutated inputs to test whether program outputs match expected results [zhu2022fuzzing, miller1990empirical, liang2018fuzzing]. While more practical than symbolic execution, fuzz testing faces challenges in constructing meaningful inputs for real-world programs. For example, testing a URL parsing function requires generating valid URLs with specific formats, which is non-trivial. For large C programs, this difficulty scales, making it infeasible to produce high-quality test cases for every translated Rust function.
## Appendix D An Example of the Test Harness
Here, we provide an example of the test harness used to verify the correctness of the translated code in Figure 4, which is used to verify the idiomatic Rust code. In this example, the concat_str_idiomatic function is the idiomatic translation we are testing, while the concat_str_c function is the test harness function that can be linked back to the original C code. where a string and an integer are passed as input, and an owned string is returned. Input strings are converted from C’s char* to Rust’s &str, and output strings are converted from Rust’s String back to C’s char*.
<details>
<summary>x7.png Details</summary>

### Visual Description
\n
## Code Snippet: Rust Function Definitions
### Overview
The image presents a code snippet written in the Rust programming language. It defines two functions: `concat_str_idiomatic` and `concat_str`. The code demonstrates string concatenation and handling of C-style strings.
### Components/Axes
There are no axes or traditional chart components. The content is purely textual code. The code is formatted with indentation to indicate block structure. Comments are included to explain the purpose of certain code sections.
### Detailed Analysis or Content Details
**Function 1: `concat_str_idiomatic`**
```rust
fn concat_str_idiomatic(orig: &str, num: i32) -> String {
format!("{}{}", orig, num)
}
```
* **Function Signature:** `fn concat_str_idiomatic(orig: &str, num: i32) -> String`
* `fn`: Keyword indicating a function definition.
* `concat_str_idiomatic`: Function name.
* `orig: &str`: Input parameter named `orig` of type `&str` (string slice).
* `num: i32`: Input parameter named `num` of type `i32` (32-bit integer).
* `-> String`: Return type is `String` (owned string).
* **Function Body:** `format!("{}{}", orig, num)`
* `format!()`: Macro for string formatting.
* `"{}{}"`: Format string with two placeholders.
* `orig`: First argument to be inserted into the format string.
* `num`: Second argument to be inserted into the format string.
**Function 2: `concat_str`**
```rust
fn concat_str(orig: *const c_char, num: c_int) -> *const c_char {
// convert input
let orig_str = CStr::from_ptr(orig)
.to_str()
.expect("Invalid UTF-8 string");
// call target function
let out = concat_str_idiomatic(orig_str, num as i32);
// convert output
let out_str = CString::new(out).unwrap();
// `into_raw` transfers ownership to the caller
out_str.into_raw()
}
```
* **Function Signature:** `fn concat_str(orig: *const c_char, num: c_int) -> *const c_char`
* `orig: *const c_char`: Input parameter named `orig` of type `*const c_char` (raw pointer to a C-style string).
* `num: c_int`: Input parameter named `num` of type `c_int` (C integer).
* `-> *const c_char`: Return type is `*const c_char` (raw pointer to a C-style string).
* **Function Body:**
* `let orig_str = CStr::from_ptr(orig).to_str().expect("Invalid UTF-8 string");`: Converts the C-style string pointer `orig` to a Rust string slice `orig_str`. It uses `CStr::from_ptr` to create a `CStr` from the raw pointer, then `to_str()` to convert it to a `&str`. The `expect` method handles potential errors if the C-style string is not valid UTF-8.
* `let out = concat_str_idiomatic(orig_str, num as i32);`: Calls the `concat_str_idiomatic` function with the Rust string slice `orig_str` and the integer `num` (cast to `i32`). The result is stored in the `out` variable.
* `let out_str = CString::new(out).unwrap();`: Creates a `CString` from the Rust `String` `out`. The `unwrap` method handles potential errors if the string cannot be converted to a C-style string.
* `out_str.into_raw()`: Consumes the `CString` and returns a raw pointer to its underlying data. This transfers ownership of the memory to the caller.
### Key Observations
* The `concat_str` function acts as a bridge between C-style strings and Rust strings.
* Error handling is present in the `concat_str` function to ensure the input C-style string is valid UTF-8.
* The `into_raw()` method is used to transfer ownership of the allocated memory to the caller, which is a common pattern when interacting with C code.
* The `concat_str_idiomatic` function provides a simple string concatenation using the `format!` macro.
### Interpretation
The code snippet demonstrates how to concatenate strings in Rust, specifically handling the conversion between Rust strings and C-style strings. This is often necessary when interfacing with C libraries or APIs. The `concat_str` function provides a safe and convenient way to perform this conversion, including error handling for invalid UTF-8 strings. The use of `into_raw()` is crucial for managing memory ownership correctly when passing the resulting C-style string back to the caller. The code highlights Rust's emphasis on memory safety and error handling, even when dealing with potentially unsafe operations like raw pointers. The two functions provide a clear separation of concerns: `concat_str_idiomatic` handles the core string concatenation logic, while `concat_str` handles the conversion between different string representations.
</details>
Figure 4: Test harness used for verifying concat_str translation
## Appendix E An Example of SACTOR Translation Process
To demonstrate the translation process of SACTOR, we present a straightforward example of translating a C function to Rust. The C program includes an atoi function that converts a string to an integer, and a main function that parses command-line arguments and calls the atoi function. The C code is shown in Figure 5(a).
<details>
<summary>x8.png Details</summary>

### Visual Description
\n
## Code Snippet: C atoi Implementation
### Overview
The image contains a C code snippet implementing the `atoi` function, which converts a string to an integer. It also includes a `main` function demonstrating its usage. The code handles whitespace, optional signs (+/-), and performs the conversion digit by digit.
### Components/Axes
There are no axes or charts in this image. It is a block of code. The code is structured into two functions: `atoi` and `main`.
### Detailed Analysis or Content Details
Here's a transcription of the C code:
```c
#include <stdio.h>
int atoi(char *str) {
int result = 0;
int sign = 1;
while (*str == ' ' || *str == '\t' || *str == '\n' ||
*str == '\r' || *str == '\v' || *str == '\f') {
str++;
}
if (*str == '+' || *str == '-') {
if (*str == '-') {
sign = -1;
}
str++;
}
while (*str >= '0' && *str <= '9') {
result = result * 10 + (*str - '0');
str++;
}
return sign * result;
}
int main(int argc, char *argv[]) {
if (argc != 2) {
printf("Usage: %s <number>\n", argv[0]);
return 1;
}
int value = atoi(argv[1]);
printf("Parsed integer: %d\n", value);
return 0;
}
```
**Function `atoi(char *str)`:**
* **Initialization:** `result` is initialized to 0, and `sign` to 1 (positive).
* **Whitespace Handling:** The `while` loop skips leading whitespace characters (space, tab, newline, carriage return, vertical tab, form feed).
* **Sign Handling:** The `if` statement checks for an optional '+' or '-' sign. If '-' is found, `sign` is set to -1.
* **Digit Conversion:** The second `while` loop iterates through the digits of the string. Inside the loop:
* `result` is multiplied by 10.
* The current digit (converted from its ASCII value to an integer by subtracting '0') is added to `result`.
* **Return Value:** The function returns the final `result` multiplied by the `sign`.
**Function `main(int argc, char *argv[])`:**
* **Argument Check:** Checks if exactly one command-line argument is provided (besides the program name). If not, it prints a usage message and returns 1 (error).
* **`atoi` Call:** Calls the `atoi` function to convert the first command-line argument (`argv[1]`) to an integer.
* **Output:** Prints the parsed integer to the console.
* **Return Value:** Returns 0 (success).
### Key Observations
* The code handles basic error checking in the `main` function to ensure the correct number of arguments is provided.
* The `atoi` function does not perform extensive error checking (e.g., it doesn't handle overflow or invalid characters after the digits).
* The code uses pointer arithmetic to iterate through the string.
* The code is relatively simple and straightforward, implementing a basic string-to-integer conversion.
### Interpretation
The code demonstrates a fundamental algorithm for converting a string representation of a number into its integer equivalent. The `atoi` function is a common utility function in C programming. The `main` function provides a simple example of how to use the `atoi` function from the command line. The code's simplicity highlights the core logic of the conversion process, but also reveals its limitations in terms of error handling and robustness. The code is a good example of a low-level implementation of a common task, illustrating the importance of understanding how data is represented and manipulated at the character level.
</details>
(a) C implementation of atoi
<details>
<summary>x9.png Details</summary>

### Visual Description
\n
## Code Snippet: Rust Function Definitions
### Overview
The image contains a Rust code snippet defining two functions: `atoi` and `main`. The `atoi` function appears to convert a C-style string to an i32 integer, handling potential signs and validating input. The `main` function parses command-line arguments, attempts to convert the first argument to an integer using `atoi`, and prints the parsed value.
### Components/Axes
There are no axes or charts in this image. It is a block of code. The code is structured into function definitions, control flow statements (while loops, if statements), and variable declarations.
### Detailed Analysis or Content Details
**Function `atoi`:**
```rust
use libc::c_char;
use std::env;
use std::ffi::CString;
use std::process;
pub unsafe fn atoi(str: *const c_char) -> i32 {
let mut result: i32 = 0;
let mut sign: i32 = 1;
let mut ptr = str;
while *ptr == '\t' as c_char || *ptr == '\n' as c_char || *ptr == '\r' as c_char || *ptr == '\x0B' as c_char || *ptr == '\x0C' as c_char {
ptr = ptr.add(1);
}
if *ptr == '+' as c_char || *ptr == '-' as c_char {
if *ptr == '-' as c_char {
sign = -1;
}
ptr = ptr.add(1);
}
while *ptr >= '0' as c_char && *ptr <= '9' as c_char {
let digit = (*ptr - '0' as c_char) as i32;
if let Some(new_result) = result.checked_mul(10).and_then(|r| r.checked_add(digit)) {
result = new_result;
} else {
return if sign == 1 { i32::MAX } else { i32::MIN };
}
ptr = ptr.add(1);
}
sign * result
}
```
* The function takes a `*const c_char` (a C-style string pointer) as input.
* It initializes `result` to 0 and `sign` to 1.
* It skips leading whitespace characters (tab, newline, carriage return, vertical tab, form feed).
* It checks for an optional sign (+ or -) and updates the `sign` variable accordingly.
* It iterates through the remaining characters, converting digits to integers and building the `result`.
* It uses `checked_mul` and `checked_add` to prevent integer overflow. If overflow occurs, it returns `i32::MAX` or `i32::MIN` depending on the sign.
* Finally, it returns the signed `result`.
**Function `main`:**
```rust
pub fn main() {
let args: Vec<CString> = env::args().collect();
if args.len() != 2 {
println!("Usage: {} <number>", args[0]);
process::exit(1);
}
let c_str = match CString::new(args[1].as_str()) {
Ok(cstring) => cstring,
Err(_) => {
eprintln!("Failed to create CString from input");
process::exit(1);
}
};
let value = unsafe { atoi(c_str.as_ptr() as *const c_char) };
println!("Parsed integer: {{}}, value)", value);
}
```
* The function retrieves command-line arguments as a vector of `CString` objects.
* It checks if exactly one argument is provided (besides the program name). If not, it prints a usage message and exits.
* It attempts to create a `CString` from the first argument. If this fails (e.g., due to invalid UTF-8), it prints an error message and exits.
* It calls the `atoi` function to convert the `CString` to an i32 integer. The `unsafe` block is necessary because `atoi` is declared as `unsafe`.
* It prints the parsed integer value.
### Key Observations
* The `atoi` function is marked as `unsafe`, indicating that it relies on potentially unsafe operations (e.g., raw pointer dereferencing).
* The `main` function performs basic argument parsing and error handling.
* The code uses `checked_mul` and `checked_add` to handle potential integer overflows, which is good practice for robust code.
* The code uses `CString` to interface with C-style strings, which is common in Rust when interacting with C libraries.
### Interpretation
The code provides a basic implementation of an integer parsing function (`atoi`) and a main function that demonstrates its usage. The `atoi` function is designed to be relatively robust by handling whitespace, signs, and potential integer overflows. The `main` function provides a simple command-line interface for parsing integers. The use of `unsafe` in the `atoi` function suggests that it relies on low-level operations that require careful attention to memory safety. The code demonstrates a common pattern in Rust for interacting with C-style strings and handling potential errors. The error handling in `main` is basic, but sufficient for a simple example. The overall structure is clear and well-organized, making it easy to understand the purpose and functionality of the code.
</details>
(b) Unidiomatic Rust translation from C
<details>
<summary>x10.png Details</summary>

### Visual Description
\n
## Code Block: Rust Function `atoi` and `main`
### Overview
The image contains a block of Rust code defining a function `atoi` which parses a string into a signed 132-bit integer, and a `main` function that demonstrates its usage. The code handles optional leading plus or minus signs and performs error checking for integer overflow.
### Components/Axes
There are no axes or charts in this image. It is a code snippet. The code is structured into two main functions: `atoi` and `main`. The `atoi` function is the core logic for string-to-integer conversion. The `main` function handles command-line arguments and calls `atoi`.
### Detailed Analysis or Content Details
Here's a transcription of the Rust code:
```rust
use std::env;
use std::process;
pub fn atoi(input: &str) -> i32 {
let mut result: i32 = 0;
let mut sign: i32 = 1;
let mut chars = input.chars().peekable();
while let Some(&c) = chars.peek() {
if c.is_whitespace() {
chars.next();
} else {
break;
}
}
if let Some(&c) = chars.peek() {
if c == '+' || c == '-' {
if c == '-' {
sign = -1;
}
chars.next();
}
}
for c in chars {
if let Some(digit) = c.to_digit(10) {
if let Some(new_result) = result
.checked_mul(10)
.and_then(|r| r.checked_add(digit as i32)) {
result = new_result;
} else {
return if sign == 1 { i32::MAX } else { i32::MIN };
}
} else {
break;
}
}
sign * result
}
pub fn main() {
let args: Vec<String> = env::args().collect();
if args.len() != 2 {
println!("Usage: {} <number>", args[0]);
process::exit(1);
}
let input = &args[1];
let value = atoi(input);
println!("Parsed integer: {}", value);
}
```
**Breakdown of `atoi` function:**
1. **Initialization:**
* `result`: Initialized to 0 (i32).
* `sign`: Initialized to 1 (positive).
* `chars`: A peekable iterator over the characters of the input string.
2. **Whitespace Handling:**
* The `while` loop skips leading whitespace characters.
3. **Sign Handling:**
* Checks for an optional leading '+' or '-' sign.
* If '-' is found, `sign` is set to -1.
4. **Digit Conversion and Accumulation:**
* The `for` loop iterates through the remaining characters.
* `c.to_digit(10)` attempts to convert the character to a digit (base 10).
* `checked_mul(10)` multiplies the current `result` by 10, returning `None` if overflow occurs.
* `checked_add(digit as i32)` adds the digit to the multiplied result, returning `None` if overflow occurs.
* If both operations succeed, `result` is updated.
* If either operation fails (overflow), the function returns `i32::MAX` if the sign is positive, or `i32::MIN` if the sign is negative.
5. **Final Result:**
* The function returns the final `result` multiplied by the `sign`.
**Breakdown of `main` function:**
1. **Argument Handling:**
* `env::args().collect()` collects command-line arguments into a `Vec<String>`.
* Checks if exactly one argument (the number to parse) is provided.
* If not, prints a usage message and exits with an error code (1).
2. **Parsing and Output:**
* `input` is assigned the value of the first command-line argument.
* `atoi(input)` calls the `atoi` function to parse the input string.
* `println!("Parsed integer: {}", value)` prints the parsed integer to the console.
### Key Observations
The code demonstrates a robust approach to string-to-integer conversion, including handling whitespace, signs, and potential integer overflows. The use of `checked_mul` and `checked_add` is crucial for preventing unexpected behavior due to overflow. The `peekable()` iterator allows for looking ahead at the next character without consuming it, which is useful for handling the sign.
### Interpretation
This code snippet provides a practical example of how to implement a string-to-integer conversion function in Rust, with a focus on safety and error handling. The `atoi` function is designed to be resilient to invalid input and to prevent integer overflows, which are common sources of bugs in software. The `main` function demonstrates how to use the `atoi` function in a simple command-line application. The code is well-structured and easy to understand, making it a good example of Rust programming style. The use of `i32` limits the range of numbers that can be parsed, but this is a common trade-off for performance and memory usage.
</details>
(c) Idiomatic Rust translation from unidiomatic Rust
Figure 5: SACTOR translation process for atoi program
We assume that there are numerous end-to-end tests for the C code, allowing SACTOR to use them for verifying the correctness of the translated Rust code.
First, the divider will divide the C code into two parts: the atoi function and the main function, and determine the translation order is first atoi and then main, as atoi is the dependency of main and the atoi function is a pure function.
Next, SACTOR proceeds with the unidiomatic translation, converting both functions into unidiomatic Rust code. This generated code will keep the semantics of the original C code while using Rust syntax. Once the translation is complete, the unidiomatic verifier executes the end-to-end tests to ensure the correctness of the translated function. If the verifier passes all tests, SACTOR considers the unidiomatic translation accurate and progresses to the next function. If any test fails, SACTOR will retry the translation process using the feedback information collected from the verifier, as described in § 4.3. After translating all sections of the C code, SACTOR will combine the unidiomatic Rust code segments to form the final unidiomatic Rust code. The unidiomatic Rust code is shown in Figure 5(b).
Then, the SACTOR will start the idiomatic translation process and translate the unidiomatic Rust code into idiomatic Rust code. The idiomatic translator requests the LLM to adapt the C semantics into idiomatic Rust, eliminating any unsafe and non-idiomatic constructs, as detailed in § 4.2. Based on the same order, the SACTOR will translate two functions accordingly, and using the idiomatic verifier to verify and provide the feedback to the LLM if the verification fails. After all parts of the Rust code are translated into idiomatic Rust, verified, and combined, the SACTOR will produces the final idiomatic Rust code. The idiomatic Rust code is shown in Figure 5(c), representing the final output of SACTOR.
## Appendix F Dataset Details
| TransCoder-IR [transcoderir] | 100 | Removed buggy programs (compilation/memory errors) and entries with existing Rust | Present | 97.97% / 99.5% |
| --- | --- | --- | --- | --- |
| Project CodeNet [codenet] | 100 | Filtered for external-input programs (argc / argv); auto-generated tests | Generated | 94.37% / 100% |
| CRust-Bench [khatry2025crust] | 50 | Excluded unsupported patterns; combine code of each sample to a single lib.c | Present | 76.18% / 80.98% |
| libogg [libogg] | 1 | None. Each component of the library is contained within a single C file. | Present | 83.3% / 75.3% |
Table 4: Summary of datasets and real-world code-bases used for evaluation; coverage audited with gcov on the tests exercised in our pipeline.
### F.1 TransCoder-IR Dataset [transcoderir]
The TransCoder-IR dataset is used to evaluate the TransCoder-IR model and consists of solutions to coding challenges in various programming languages. For evaluation, we focus on the 698 C programs available in this dataset. First, we filter out programs that already have corresponding Rust code. Several C programs in the dataset contain bugs, which are removed by checking their ability to compile. We then use valgrind to identify and discard programs with memory errors during the end-to-end tests. Finally, we select 100 programs with the most lines of code for our experiments.
### F.2 Project CodeNet [codenet]
Project CodeNet is a large-scale dataset for code understanding and translation, containing 14 million code samples in over 50 programming languages collected from online judge websites. From this dataset, which includes more than 750,000 C programs, we target only those that accept external input. Specifically, we filter programs using argc and argv, which process input from the command line. As the end-to-end tests are not available for this dataset, we develop the SACTOR test generator to automatically generate end-to-end tests for these programs based on the source code. For evaluation, we select 200 programs and refine the dataset to include 100 programs that successfully generate end-to-end tests.
### F.3 CRust-Bench [khatry2025crust]
CRust-Bench is a repository-level benchmark for C-to-safe-Rust transpilation. It collects 100 real-world C repositories (the CBench suite) and pairs each with a manually written, safe Rust interface and a set of tests that assert functional correctness. By evaluating full repositories rather than isolated functions, CRust-Bench surfaces challenges common in practice, such as complex, pointer-rich APIs. In our evaluation, we use a 50-sample subset in CRust-Bench, which exclude entries that are out of scope for our pipeline (e.g., circular type or function dependencies and compiler-specific intrinsics that do not map cleanly). For each selected sample, we reuse the upstream end-to-end tests and relink them so that calls exercise our translated code; build environments and link flags follow the sample’s configuration.
### F.4 libogg [libogg]
libogg is the reference implementation of the Ogg multimedia container. Ogg is a stream-oriented format that frames, timestamps, and multiplexes compressed media bitstreams (e.g., audio/video) into a robust, seekable stream. The libogg distribution contains only the Ogg container library (codecs such as Vorbis or Theora are hosted separately). In our case study, the codebase comprises roughly 2,041 lines of code (excluding tests), six struct definitions, three global variables, and 77 exported functions. We use the project’s upstream tests and build scripts. This single-project evaluation complements the CRust-Bench subset by focusing on non-trivial structs, buffers, and pointer manipulation in a real-world C library.
## Appendix G LLM Configurations
Table 5 shows our configurations for different LLMs in evaluation. All other hyperparameters (e.g., Top-P, Top-K) use provider defaults. As GPT-5 does not support temperature setting, we use its default temperature.
| GPT-4o | gpt-4o-2024-08-06 | 0 |
| --- | --- | --- |
| Claude 3.5 Sonnet | claude-3-5-sonnet-20241022 | 0 |
| Gemini 2.0 Flash | gemini-2.0-flash-exp | 0 |
| Llama 3.3 Instruct 70B | Llama 3.3 Instruct 70B 1 | 0 |
| DeepSeek-R1 | DeepSeek-R1 671B 2 | 0 |
| GPT-5 | gpt-5-2025-08-07 | default |
- https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct
- https://huggingface.co/deepseek-ai/DeepSeek-R1
Table 5: Configurations of Different LLMs in Evaluation
## Appendix H Failure Analysis in Evaluating SACTOR
(a) TransCoder-IR
| R1 | Memory safety violations in array operations due to improper bounds checking |
| --- | --- |
| R2 | Mismatched data type translations |
| R3 | Incorrect array sizing and memory layout translations |
| R4 | Incorrect string representation conversion between C and Rust |
| R5 | Failure to handle C’s undefined behavior with Rust’s safety mechanisms |
| R6 | Use of C-specific functions in Rust without proper Rust wrappers |
(b) Project CodeNet
| S1 | Improper translation of command-line argument handling or attempt to fix wrong handling |
| --- | --- |
| S2 | Function naming mismatches between C and Rust |
| S3 | Format string directive mistranslation causing output inconsistencies |
| S4 | Original code contains random number generation |
| S5 | SACTOR unable to translate mutable global state variables |
| S6 | Mismatched data type translations |
| S7 | Incorrect control flow or loop boundary condition translations |
Table 6: Failure reason categories for translating TransCoder-IR and Project CodeNet datasets.
<details>
<summary>x11.png Details</summary>

### Visual Description
Icon/Small Image (797x38)
</details>
<details>
<summary>x12.png Details</summary>
### Visual Description
## Bar Chart: Number of Files per Category
### Overview
The image presents a bar chart illustrating the number of files associated with different categories, labeled R1 through R6. The chart uses multiple colored bars for each category, suggesting multiple data series are being compared. The y-axis represents the "Number of Files," while the x-axis represents "Categories."
### Components/Axes
* **X-axis:** "Categories" with markers R1, R2, R3, R4, R5, and R6.
* **Y-axis:** "Number of Files" ranging from 0 to 25, with increments of 5.
* **Data Series:** Six distinct colored bar series are present:
* Blue
* Orange
* Green
* Red
* Purple
* Teal
* **Legend:** There is no explicit legend, but the colors are consistently used for each series across all categories.
### Detailed Analysis
Let's analyze each category and the values for each data series. I will describe the trend of each series within a category before providing approximate values.
* **R1:**
* Blue: Flat, approximately 3.5 files.
* Orange: Flat, approximately 1.5 files.
* Green: Flat, approximately 2.5 files.
* Red: Flat, approximately 2 files.
* Purple: Flat, approximately 1 file.
* Teal: Flat, approximately 3 files.
* **R2:**
* Blue: Flat, approximately 4.5 files.
* Orange: Flat, approximately 4 files.
* Green: Flat, approximately 3.5 files.
* Red: Flat, approximately 2.5 files.
* Purple: Flat, approximately 1.5 files.
* Teal: Flat, approximately 4 files.
* **R3:**
* Blue: Flat, approximately 4 files.
* Orange: Flat, approximately 1 file.
* Green: Increasing, approximately 9 files.
* Red: Flat, approximately 5 files.
* Purple: Flat, approximately 2 files.
* Teal: Flat, approximately 4 files.
* **R4:**
* Blue: Flat, approximately 2 files.
* Orange: Spiking upwards, approximately 25 files.
* Green: Flat, approximately 1 file.
* Red: Flat, approximately 6 files.
* Purple: Flat, approximately 3 files.
* Teal: Flat, approximately 2 files.
* **R5:**
* Blue: Flat, approximately 3.5 files.
* Orange: Flat, approximately 2 files.
* Green: Flat, approximately 4 files.
* Red: Flat, approximately 2.5 files.
* Purple: Flat, approximately 3 files.
* Teal: Flat, approximately 4 files.
* **R6:**
* Blue: Flat, approximately 3 files.
* Orange: Flat, approximately 1 file.
* Green: Increasing, approximately 5 files.
* Red: Flat, approximately 3 files.
* Purple: Flat, approximately 1 file.
* Teal: Flat, approximately 4 files.
### Key Observations
* Category R4 exhibits a significantly higher number of files for the orange data series compared to all other categories and data series. This is a clear outlier.
* The green data series shows a noticeable increase in R3 and R6 compared to other categories.
* The purple data series consistently has the lowest number of files across all categories.
* The blue, teal, and red data series generally remain within a similar range of file counts across all categories.
### Interpretation
The chart demonstrates the distribution of files across six categories (R1-R6), broken down by six different data series (represented by color). The stark difference in the orange series for category R4 suggests a unique characteristic or event associated with that category. It could indicate a specific type of file, a particular process, or an anomaly within that category. The increasing trend of the green series in R3 and R6 might indicate a growing trend or a specific activity related to those categories. The consistently low values for the purple series suggest it represents a less frequent or less significant type of file. Without knowing what the categories and data series *represent*, it's difficult to draw definitive conclusions, but the chart clearly highlights areas of concentration and potential investigation. The chart is a comparative analysis of file distribution, and the significant outlier in R4 warrants further examination.
</details>
(a) TransCoder-IR
<details>
<summary>x13.png Details</summary>
### Visual Description
\n
## Bar Chart: Number of Files per Category
### Overview
The image presents a bar chart illustrating the number of files associated with different categories, labeled S1 through S7. Each category has multiple data series represented by different colored bars. The y-axis represents the "Number of Files," ranging from 0 to 7, while the x-axis represents the "Categories" (S1 to S7).
### Components/Axes
* **X-axis:** "Categories" with markers S1, S2, S3, S4, S5, S6, S7.
* **Y-axis:** "Number of Files" with a scale from 0 to 7, incrementing by 1.
* **Data Series:** Represented by the following colors:
* Red
* Green
* Purple
* Orange
* Blue
### Detailed Analysis
Let's analyze each category and its corresponding data series:
* **S1:**
* Red: Approximately 5.0
* Green: Approximately 4.2
* Purple: Approximately 3.0
* Orange: Approximately 2.0
* Blue: Approximately 1.0
* **S2:**
* Red: Approximately 1.2
* Green: Approximately 1.0
* Purple: Approximately 1.2
* Orange: Approximately 1.0
* Blue: Approximately 1.0
* **S3:**
* Red: Approximately 5.0
* Green: Approximately 4.2
* Purple: Approximately 3.0
* Orange: Approximately 2.0
* Blue: Approximately 2.0
* **S4:**
* Red: Approximately 1.0
* Green: Approximately 1.0
* Purple: Approximately 1.2
* Orange: Approximately 1.0
* Blue: Approximately 1.0
* **S5:**
* Red: Approximately 2.0
* Green: Approximately 2.2
* Purple: Approximately 2.0
* Orange: Approximately 2.0
* Blue: Approximately 2.0
* **S6:**
* Red: Approximately 7.0
* Green: Approximately 4.0
* Purple: Approximately 2.0
* Orange: Approximately 2.0
* Blue: Approximately 2.0
* **S7:**
* Red: Approximately 4.0
* Green: Approximately 4.2
* Purple: Approximately 2.0
* Orange: Approximately 2.0
* Blue: Approximately 2.0
### Key Observations
* Category S6 exhibits the highest number of files for the red data series, reaching approximately 7.0.
* Categories S2 and S4 have the lowest number of files across all data series, generally around 1.0.
* The red and green data series generally show higher values compared to the purple, orange, and blue series.
* S1 and S3 have similar profiles across all data series.
### Interpretation
The chart suggests a varying distribution of files across the seven categories. Category S6 is significantly more populated with files (specifically, of the 'red' type) than other categories. The consistent low values in S2 and S4 might indicate these categories contain fewer files overall, or that the files are categorized differently. The similarity between S1 and S3 suggests a potential relationship or commonality between these two categories in terms of file distribution. The differences in the height of the bars within each category indicate that different data series (represented by colors) contribute differently to the total number of files in each category. This could represent different file types, sources, or attributes. Further investigation would be needed to understand the meaning of each color and the underlying reasons for these observed patterns.
</details>
(b) Project CodeNet
Figure 6: Failure reasons across different LLM models for both datasets.
Here, we analyze the failure cases of SACTOR in translating C code to Rust that we conducted in Section 6.1. as cases where SACTOR fails offer valuable insights into areas that require refinement. For each failure case in the two datasets, we conduct an analysis to determine the primary cause of translation failure. This process involves leveraging DeepSeek-R1 to identify potential reasons (prompts available in Appendix N.5), followed by manual verification to ensure correctness. We only focus on the translation process from C to unidiomatic Rust because: (1) it is the most challenging step, and (2) it can better reflect the model’s ability to fit the syntactic and semantic differences between the two languages. Table 6 summarize the categories of failure reasons, and Figure 6(a) and 6(b) illustrate failure reasons (FRs) across models.
(1) TransCoder-IR (Table 6(a), Figure 6(a)): Based on the analysis, we observe that different models exhibit varying failure reasons. Claude 3.5 shows a particularly high incidence of string representation conversion errors (R4), with 25 out of 45 total failures in the unidiomatic translation step. In contrast, GPT-4o has only 1 out of 17 failures in this category. Llama 3.3 demonstrates consistent challenges with both R3 (incorrect array sizing and memory layout translations) and R6 (using C-specific functions without proper Rust wrappers), with 10 files for each category. GPT-4o shows a more balanced distribution of errors, with its highest count in R3. All models except GPT-4o struggle with string handling (R4) to varying degrees, suggesting this is one of the most challenging aspects of the translation process. For R6 (use of C-specific functions in Rust), which primarily is a compilation failure, only Llama 3.3 and Gemini 2.0 consistently fail to resolve the issue in some cases, while all other models can successfully handle the compilation errors through feedback and avoid failure in this category. DeepSeek-R1 has the fewest overall errors across categories, with failures only in R1 (1 file), R3 (2 files), and R4 (3 files), while completely avoiding errors in R2, R5, and R6.
(2) Project CodeNet (Table 6(b), Figure 6(b)): Similar to the TransCoder-IR dataset, we also observe that different models in Project CodeNet demonstrate varying failure reasons. C-to-Rust code translation challenges in the CodeNet dataset. Most notably, S6 (mismatched data type translations) presents a significant barrier for Llama 3.3 and Gemini 2.0 (7 files each), while GPT-4o and Claude 3.5 completely avoid this issue. Input argument handling (S1) and format string mistranslations (S3) emerge as common challenges across all models in CodeNet, suggesting fundamental difficulties in translating these language features regardless of model architecture. Only Llama 3.3 and DeepSeek-R1 encounter control flow translation failures (S7), with 2 files each. S4 (random number generation) and S5 (mutable global state variables) are unable to be translated by SACTOR because the current SACTOR implementation does not support these features.
Compared to the results in TransCoder-IR, string representation conversion (R4 in TransCoder-IR, S3 in CodeNet) remains a consistent challenge across both datasets for all models, though the issue is significantly more severe in TransCoder-IR, particularly for Claude 3.5 (24 files). This also suggests that reasoning models like DeepSeek-R1 are better at handling complex code logic and string/array manipulation, as they exhibit fewer failures in these areas, demonstrating the potential of reasoning models to address complex translation tasks.
## Appendix I SACTOR Cost Analysis
| Claude 3.5 Gemini 2.0 | TransCoder-IR CodeNet TransCoder-IR | 4595.33 3080.28 3343.12 | 5.15 3.15 4.24 |
| --- | --- | --- | --- |
| CodeNet | 2209.38 | 2.39 | |
| Llama 3.3 | TransCoder-IR | 4622.80 | 5.39 |
| CodeNet | 4456.84 | 3.80 | |
| GPT-4o | TransCoder-IR | 2651.21 | 4.24 |
| CodeNet | 2565.36 | 2.95 | |
| DeepSeek-R1 | TransCoder-IR | 17895.52 | 4.77 |
| CodeNet | 13592.61 | 3.11 | |
Table 7: Average Cost Comparison of Different LLMs Across Two Datasets. The color intensity represents the relative cost of each metric for each dataset.
Here, we conduct a cost analysis of SACTOR for experiments in § 6.1 to evaluate the efficiency of different LLMs in generating idiomatic Rust code. To evaluate the cost of our approach, we measure (1) Total LLM Queries as the number of total LLM queries made during translation and verification for a single test case in each dataset, and (2) Total Token Count as the total number of tokens processed by the LLM for a single test case in each dataset. To ensure a fair comparison across models, we use the same tokenizer (tiktoken) and encoding (o200k_base).
In order to better understand costs, we only analyze programs that successfully generate idiomatic Rust code, excluding failed attempts (as they always reach the maximum retry limit and do not contribute meaningfully to the cost analysis). We evaluate the combined cost of both translation phases to assess overall efficiency. Table 7 compares the average cost of different LLMs across two datasets, measured in token usage and query count per successful idiomatic Rust translation as mentioned in § 5.2.
Results: Gemini 2.0 and GPT-4o are the most efficient models, requiring the fewest tokens and queries. GPT-4o maintains a low token cost (2651.21 on TransCoder-IR, 2565.36 on CodeNet) with 4.24 and 2.95 average queries, respectively. Gemini 2.0 is similarly efficient, especially on CodeNet, with the lowest token usage (2209.38) and requiring only 2.39 queries on average. Claude 3.5, despite its strong performance on CodeNet, incurs higher costs on TransCoder-IR (4595.33 tokens, 5.15 queries), likely due to additional translation steps. Llama 3.3 is the least efficient in non-thinking model (GPT-4o, Claude 3.5, Gemini 2.0), consuming the most tokens (4622.80 and 4456.84, respectively) and requiring the highest number of queries (5.39 and 3.80, respectively), indicating significant resource demands.
As a reasoning model, DeepSeek-R1 consumes significantly more tokens (17,895.52 vs. 13,592.61) than non-reasoning models–5-7 times higher than GPT-4o–despite having a similar average query count (4.77 vs. 3.11) for generating idiomatic Rust code. This high token usage comes from the “reasoning process” required before code generation.
## Appendix J Ablation Study on SACTOR Designs
This appendix reports additional ablations that evaluate key design choices in SACTOR. All experiments in this section use GPT-4o with the same configuration as Table 5.
### J.1 Feedback Mechanism
To evaluate the effectiveness of the feedback mechanism proposed in § 4.3, we conduct an ablation study by removing the mechanism and comparing the model’s performance with and without it. We consider two experimental groups: (1) with the feedback mechanism enabled, and (2) without the feedback mechanism. In the latter setting, if any part of the translation fails, the system simply restarts the translation attempt using the original prompt, without providing any feedback from the failure.
We use the same dataset and evaluation metrics described in § 5, and focus our evaluation on only two models: GPT-4o and Llama 3.3 70B. We choose these models because GPT-4o demonstrated one of the highest performance and Llama 3.3 70B the lowest in our earlier experiments. By comparing the success rates between the two groups, we assess whether the feedback mechanism improves translation performance across models of different capabilities.
The results are shown in Figure 7.
<details>
<summary>x14.png Details</summary>

### Visual Description
\n
## Legend: Pattern and Color Key
### Overview
The image presents a legend defining a set of patterns and associated colors. These patterns are labeled with identifiers indicating "Unidiomatic" or "Idiomatic" followed by a "SR" number (1 through 6) or the abbreviation "(-FBK)". The legend appears to be designed for use with a chart or diagram where these patterns represent different data categories.
### Components/Axes
The legend consists of 12 entries, each comprising a visual pattern and a text label. The patterns are variations of lines, cross-hatching, and fills. The labels are arranged horizontally in three rows.
### Detailed Analysis or Content Details
Here's a breakdown of each entry in the legend:
* **Unidiomatic SR 1:** Represented by a solid, dark blue pattern with horizontal lines.
* **Unidiomatic SR 2:** Represented by a pattern of diagonal lines, dark blue.
* **Unidiomatic SR 3:** Represented by a pattern of intersecting diagonal lines, dark blue.
* **Unidiomatic SR 4:** Represented by a pattern of closely spaced, dark blue horizontal lines.
* **Unidiomatic SR 5:** Represented by a pattern of closely spaced, dark blue vertical lines.
* **Unidiomatic SR 6:** Represented by a pattern of closely spaced, dark blue diagonal lines.
* **Unidiomatic (-FBK):** Represented by a solid, green fill.
* **Idiomatic SR 1:** Represented by a pattern of diagonal lines, orange.
* **Idiomatic SR 2:** Represented by a pattern of closely spaced, orange horizontal lines.
* **Idiomatic SR 3:** Represented by a pattern of intersecting diagonal lines, orange.
* **Idiomatic SR 4:** Represented by a pattern of closely spaced, orange vertical lines.
* **Idiomatic SR 5:** Represented by a pattern of closely spaced, orange diagonal lines.
* **Idiomatic SR 6:** Represented by a pattern of closely spaced, orange horizontal lines.
* **Idiomatic (-FBK):** Represented by a solid, red fill.
### Key Observations
The legend clearly distinguishes between "Unidiomatic" and "Idiomatic" categories, each further subdivided by "SR" numbers 1 through 6 and a separate category denoted by "(-FBK)". The patterns within each category are visually distinct, likely to facilitate easy identification on a chart or diagram. The color scheme is consistent, with blue representing "Unidiomatic" and orange/red representing "Idiomatic".
### Interpretation
This legend suggests a comparative analysis between "Unidiomatic" and "Idiomatic" instances across six different "SR" levels, plus a separate category labeled "(-FBK)". The use of patterns and colors indicates that the data will likely be visualized in a way that highlights these distinctions. The "SR" numbers could represent stages, levels, or types within each category. The "(-FBK)" category might represent a special case or outlier. Without the accompanying chart or diagram, the specific meaning of these categories remains unclear, but the legend provides a clear framework for understanding the data representation. The data is descriptive, not quantitative.
</details>
<details>
<summary>x15.png Details</summary>
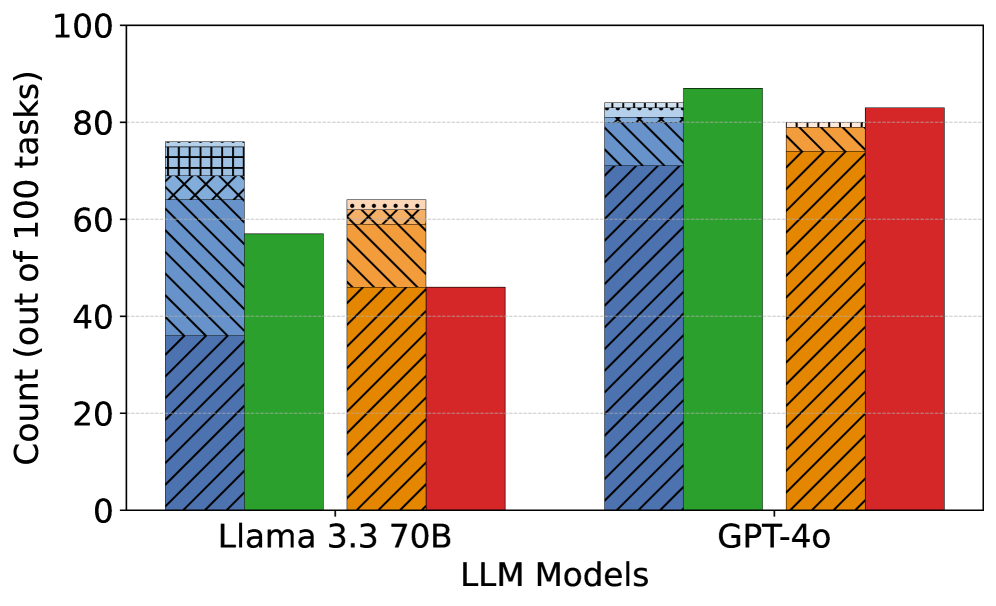
### Visual Description
\n
## Bar Chart: LLM Performance Comparison
### Overview
This bar chart compares the performance of three Large Language Models (LLMs) – Llama 3.3 70B and GPT-40 – across a set of tasks. The performance is measured by the count of tasks successfully completed out of 100. Each LLM has four bars representing different performance levels, visually distinguished by color and pattern.
### Components/Axes
* **X-axis:** "LLM Models" with categories: "Llama 3.3 70B", and "GPT-40".
* **Y-axis:** "Count (out of 100 tasks)" ranging from 0 to 100, with increments of 10.
* **Bars:** Each LLM has four bars representing different performance levels.
* **Colors/Patterns:**
* Dark Blue: Hatch pattern
* Green: Solid color
* Orange: Solid color
* Red: Solid color
### Detailed Analysis
The chart presents performance data for each LLM, broken down into four categories represented by the different colored bars.
**Llama 3.3 70B:**
* Dark Blue Bar: The line slopes upward, starting at approximately 72 and reaching a maximum of approximately 78.
* Green Bar: The line slopes downward, starting at approximately 56 and reaching a minimum of approximately 52.
* Orange Bar: The line slopes upward, starting at approximately 54 and reaching a maximum of approximately 60.
* Red Bar: The line slopes downward, starting at approximately 48 and reaching a minimum of approximately 44.
**GPT-40:**
* Dark Blue Bar: The line slopes upward, starting at approximately 82 and reaching a maximum of approximately 86.
* Green Bar: The line slopes upward, starting at approximately 84 and reaching a maximum of approximately 90.
* Orange Bar: The line slopes downward, starting at approximately 78 and reaching a minimum of approximately 74.
* Red Bar: The line slopes downward, starting at approximately 76 and reaching a minimum of approximately 72.
### Key Observations
* GPT-40 consistently outperforms Llama 3.3 70B across all performance categories.
* For both models, the dark blue and green bars show the highest and lowest performance, respectively.
* The difference in performance between GPT-40 and Llama 3.3 70B is most pronounced in the dark blue category.
### Interpretation
The data suggests that GPT-40 is a more capable LLM than Llama 3.3 70B, achieving higher counts of successful tasks across all measured categories. The consistent pattern of dark blue being the highest and green being the lowest suggests that these categories represent the easiest and most difficult tasks, respectively. The larger gap in the dark blue category indicates that GPT-40 excels at the simpler tasks, while the smaller gap in the red category suggests a more comparable performance on the most challenging tasks. This chart provides a quantitative comparison of the two models, highlighting the strengths of GPT-40. The use of stacked bars allows for a clear visual comparison of performance across different categories for each model.
</details>
(a) TransCoder-IR With/Without Feedback
<details>
<summary>x16.png Details</summary>
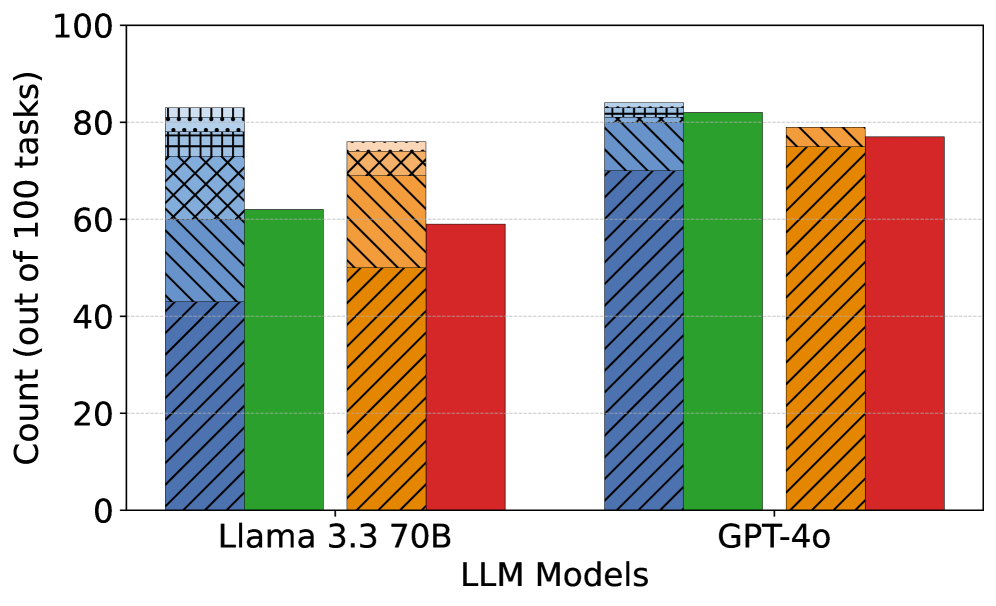
### Visual Description
\n
## Bar Chart: LLM Performance Comparison
### Overview
This bar chart compares the performance of three Large Language Models (LLMs) – Llama 3.3 70B, and GPT-40 – across a set of tasks. The performance is measured as the count of tasks successfully completed out of 100. Each LLM has four bars representing different performance levels, visually distinguished by color and pattern.
### Components/Axes
* **X-axis:** "LLM Models" with categories: "Llama 3.3 70B", and "GPT-40".
* **Y-axis:** "Count (out of 100 tasks)" ranging from 0 to 100, with increments of 10.
* **Bars:** Four bars per LLM, each representing a different performance level.
* **Colors/Patterns:**
* Dark Blue: Hatched with forward slashes.
* Green: Solid color.
* Orange: Hatched with backward slashes.
* Red: Solid color.
### Detailed Analysis
**Llama 3.3 70B:**
* **Dark Blue:** The bar slopes downward slightly, starting at approximately 84 and ending at approximately 78.
* **Green:** The bar is relatively flat, starting at approximately 62 and ending at approximately 60.
* **Orange:** The bar is relatively flat, starting at approximately 76 and ending at approximately 74.
* **Red:** The bar is relatively flat, starting at approximately 58 and ending at approximately 56.
**GPT-40:**
* **Dark Blue:** The bar slopes downward slightly, starting at approximately 82 and ending at approximately 79.
* **Green:** The bar is relatively flat, starting at approximately 84 and ending at approximately 82.
* **Orange:** The bar is relatively flat, starting at approximately 78 and ending at approximately 76.
* **Red:** The bar is relatively flat, starting at approximately 76 and ending at approximately 74.
### Key Observations
* GPT-40 consistently outperforms Llama 3.3 70B across all performance levels.
* The dark blue performance level is the highest for both models.
* The red performance level is the lowest for both models.
* The differences in performance between the different levels within each model are relatively small.
### Interpretation
The chart suggests that GPT-40 is a more capable LLM than Llama 3.3 70B, achieving higher counts of successful tasks across all measured performance levels. The relatively small differences between the performance levels within each model indicate that the models exhibit consistent performance across the evaluated tasks, without significant variations in success rates. The downward slope in the dark blue bars for both models could indicate a slight decrease in performance as the task complexity increases within that level. The chart provides a comparative snapshot of the LLMs' capabilities, but does not offer insights into the specific tasks or the nature of the performance differences. Further investigation would be needed to understand the underlying reasons for the observed performance variations.
</details>
(b) CodeNet With/Without Feedback
Figure 7: Ablation study on the feedback mechanism. The success rates of the models with and without the feedback (marked as -FBK) mechanism are shown for both TransCoder-IR and CodeNet datasets.
(1) TransCoder-IR (Figure 7(a)): Incorporating the feedback mechanism increased the number of successful translations for Llama 3.3 70B from 57 to 76 in the unidiomatic setting and from 46 to 64 in the idiomatic setting. In contrast, GPT-4o performed slightly worse with feedback, decreasing from 87 to 84 (unidiomatic) and from 83 to 80 (idiomatic).
(2) Project CodeNet (Figure 7(b)): A similar trend is observed where Llama 3.3 70B improved from 62 to 83 (unidiomatic) and from 59 to 76 (idiomatic), corresponding to gains of 21 and 17 percentage points, respectively. GPT-4o, however, showed only marginal improvements: from 82 to 84 in the unidiomatic setting and from 77 to 79 in the idiomatic setting.
These results suggest that the feedback mechanism is particularly effective for lower-capability models like Llama 3.3, substantially improving their translation success rates. In contrast, higher-capability models such as GPT-4o already perform near optimal with simple random sampling, leaving little space for improvement. This indicates that the feedback mechanism is more beneficial for models with lower capabilities, as they can leverage the feedback to enhance their overall performance.
### J.2 Plain LLM Translation vs. SACTOR
We compare SACTOR against a trivial baseline where GPT-4o directly translates each CRust-Bench sample from C to Rust in a single step. We reuse the same end-to-end (E2E) test harness as SACTOR, and give the trivial baseline more budget: up to 10 repair attempts with compiler/test feedback (vs. 6 attempts in SACTOR). We study two prompts: (i) a minimal one (“translate the following C code to Rust”); and (ii) an interface-preserving one that explicitly asks the model to preserve pointer arithmetic, memory layout, and integer type semantics (thereby encouraging unsafe). We report function success as the fraction of functions whose Rust translation passes all tests, and sample success as the fraction of samples where all translated functions pass.
| SACTOR unidiomatic SACTOR idiomatic † Trivial (1-step) | 6 6 10 | 788/966 (81.57%) 249/580 (42.93%) 77/966 (7.97%) | 32/50 (64.00%) 8/32 (25.00%) 12/50 (24.00%) | 2.96 0.28 1.60 |
| --- | --- | --- | --- | --- |
| Trivial (1-step, encourage unsafe) | 10 | 207/966 (21.43%) | 20/50 (40.00%) | 1.90 |
Table 8: Plain LLM translation vs. SACTOR on CRust-Bench (GPT-4o). The trivial baselines directly translate each sample in one step with up to 10 repair attempts. $\dagger$ The idiomatic stage is evaluated only on samples whose unidiomatic stage fully translated all functions.
Results on CRust-Bench. Even with 10 attempts and an “encourage unsafe ” prompt, the trivial baseline reaches only 21.43% function success and 40.00% sample success. Its sample-level performance exceeds SACTOR ’s idiomatic stage (40.00% vs. 25.00%) because preserving C-style pointer logic in unsafe Rust is substantially easier than performing an idiomatic rewrite. However, SACTOR achieves much higher function-level correctness and produces significantly more idiomatic code (e.g., 0.28 vs. 1.90 average Clippy alerts per function).
Results on libogg. Under the same E2E tests and attempt budget as SACTOR, both trivial prompts fail to produce any test-passing translations, whereas SACTOR achieves 100% unidiomatic and 53% idiomatic success with GPT-4o (Table 2). This indicates that plain one-shot translation collapses on pointer-heavy libraries, while SACTOR remains effective.
### J.3 Effect of Crown in the Idiomatic Stage
We ablate Crown’s contribution to idiomatic translation (§ 4.2) on libogg, using the same setup as § 6.3 and keeping all other components unchanged. Table 9 reports idiomatic function success with and without Crown.
| SACTOR SACTOR w/o Crown | 41 34 | 53% 44% | – 17% |
| --- | --- | --- | --- |
Table 9: Ablating Crown on libogg (GPT-4o).
Results and Representative failure patterns. Turning off Crown reduces idiomatic success from 41 to 34 functions. The failures are structured. Two representative patterns are:
⬇
// Without Crown (shape lost):
pub struct OggPackBuffer { pub ptr: usize }
// With Crown (shape preserved):
pub struct OggPackBuffer { pub ptr: Vec < u8 > }
// Without Crown (ownership misclassified as owned):
pub struct OggIovec { pub iov_base: Vec < u8 > }
// With Crown (ownership made explicit):
pub struct OggIovec <’ a > { pub iov_base: &’ a [u8] }
Once a buffer pointer is collapsed into a scalar index, the harness cannot reconstruct a valid C-facing view of the struct, so pointer arithmetic and buffer access fail together. Similarly, if a non-owning pointer (e.g., unsigned char *iov_base) is misclassified as owned storage (Vec<u8>), Rust ends up “owning” memory that C actually controls, making safe round-tripping infeasible without inventing allocation/free rules that do not exist.
Interpretation. These failures do not indicate model weakness but an information-theoretic limitation: local C syntax does not encode pointer fatness or ownership. For a declaration such as char *iov_base, both Vec<u8> and &mut u8 are locally plausible. Even an idealized oracle model cannot uniquely infer the correct Rust type without global information about ownership and fatness. Crown supplies these semantics via whole-program static analysis; removing it makes idiomatic translation of pointer-heavy code underdetermined and explains the observed drop.
### J.4 Prompting about unsafe in Stage 1
We ablate the stage-1 (unidiomatic translation) prompt line that says “the model may use unsafe if needed.” All experiments in this subsection are conducted on libogg, using exactly the same setup as in § 6.3.
#### J.4.1 Removing “may use unsafe if needed”
We compare the original stage-1 prompt with a variant that deletes this line, keeping everything else unchanged.
| Baseline stage 1 (may use unsafe) | 100% | 108 | 76 | 1 | 8704/8705 (99.99%) |
| --- | --- | --- | --- | --- | --- |
| Remove “may use unsafe ” | 100% | 224 | 37 | 146 | 8100/8219 (98.55%) |
Table 10: Removing explicit permission to use unsafe in stage 1 on libogg (GPT-4o).
Two observations follow. (1) Overall unsafety hardly changes: the unsafe fraction drops only from 99.99% to 98.55%. (2) The safety profile becomes worse: clippy::not_unsafe_ptr_arg_deref jumps from 1 to 146. That is, the model keeps APIs safe-looking but dereferences raw pointer arguments inside function bodies, pushing unsafety from explicit unsafe fn signatures into hidden dereferences inside safe-looking public functions.
#### J.4.2 Replacing With “AVOID using unsafe ”
We replace “may use unsafe if needed” with a stronger directive: “AVOID using unsafe whenever possible”.
| Baseline stage 1 Replace with “AVOID unsafe ” | 77/77 66/77 | 100% 85% | – 15% |
| --- | --- | --- | --- |
Table 11: Discouraging unsafe in stage 1 harms unidiomatic success on libogg (GPT-4o).
Under “AVOID unsafe ”, the model often attempts premature “safe Rust” rewrites of pointer-heavy C code (changing buffer layouts, index arithmetic, and integer types), which increases logic and type errors and breaks translations. Together, these two prompt variants show that discouraging unsafe in stage 1 harms correctness and produces a worse safety profile, supporting our design choice: allow necessary unsafe in the syntactic first stage, then systematically remove it in the idiomatic refinement stage.
## Appendix K SACTOR Performance with Different Temperatures
In § 6, all the experiments are conducted with the temperature set to default values, as explained on Appendix G. To investigate how temperature affects the performance of SACTOR, we conduct additional experiments with different temperature settings (0.0, 0.5, 1.0) for GPT-4o on both TransCoder-IR and Project CodeNet datasets, as shown in Figure 8. Through some preliminary experiments and discussions on OpenAI’s community forum https://community.openai.com/t/cheat-sheet-mastering-temperature-and-top-p-in-chatgpt-api/172683, we find that setting the temperature more than 1 will likely to generate more random and less relevant outputs, which is not suitable for our task.
<details>
<summary>x17.png Details</summary>

### Visual Description
\n
## Legend: Pattern Key
### Overview
The image presents a legend defining a set of patterned fills. It appears to be a key for a chart or diagram where different series are represented by distinct patterns. There are two sets of patterns, labeled "Unidiomatic" and "Idiomatic", each containing six series (SR 1 through SR 6).
### Components/Axes
The legend consists of two main sections: "Unidiomatic" and "Idiomatic". Each section contains six patterned boxes, each labeled with a series identifier (SR 1, SR 2, SR 3, SR 4, SR 5, SR 6). The patterns vary in line style and density.
### Detailed Analysis or Content Details
Here's a breakdown of the patterns and their corresponding labels:
**Unidiomatic Series:**
* **Unidiomatic SR 1:** Solid blue fill with horizontal lines.
* **Unidiomatic SR 2:** Diagonal lines, blue fill.
* **Unidiomatic SR 3:** Cross-hatch pattern, blue fill.
* **Unidiomatic SR 4:** Small, closely spaced horizontal lines, light blue fill.
* **Unidiomatic SR 5:** Dotted pattern, light blue fill.
* **Unidiomatic SR 6:** Small, closely spaced vertical lines, light blue fill.
**Idiomatic Series:**
* **Idiomatic SR 1:** Solid orange fill with horizontal lines.
* **Idiomatic SR 2:** Diagonal lines, orange fill.
* **Idiomatic SR 3:** Cross-hatch pattern, orange fill.
* **Idiomatic SR 4:** Small, closely spaced horizontal lines, light orange fill.
* **Idiomatic SR 5:** Dotted pattern, light orange fill.
* **Idiomatic SR 6:** Small, closely spaced vertical lines, light orange fill.
### Key Observations
The legend presents two sets of patterned fills, "Unidiomatic" and "Idiomatic", which appear to be visually similar but differentiated by color (blue vs. orange). Each set contains the same six series (SR 1 to SR 6) represented by the same pattern types. This suggests a comparison between two different categories or conditions, potentially representing two different datasets or experimental groups.
### Interpretation
This legend likely accompanies a chart or diagram where the different series are visually distinguished by these patterns. The "Unidiomatic" and "Idiomatic" labels suggest a distinction based on some linguistic or conceptual characteristic. The patterns themselves are designed to be visually distinct, allowing for easy identification of each series within the larger chart. The parallel structure of the two sets (same series numbers, same patterns, different colors) implies a direct comparison between the "Unidiomatic" and "Idiomatic" groups. Without the accompanying chart, it's difficult to determine the specific meaning of the data represented by these series. However, the legend provides the necessary key to interpret the visual information presented in the chart.
</details>
<details>
<summary>x18.png Details</summary>
### Visual Description
\n
## Bar Chart: TransCoder-IR Dataset - Success Rate vs. Temperature
### Overview
This bar chart visualizes the success rate of the GPT-4o model on the TransCoder-IR dataset, comparing performance across three different temperature settings (t=0, t=0.5, and t=1). Two data series are presented for each temperature: one representing a baseline or primary metric, and another representing a secondary metric. The chart uses paired bars to show the comparison.
### Components/Axes
* **Title:** "TransCoder-IR dataset" - positioned at the top-center of the chart.
* **X-axis:** "GPT-4o Model (Temperature)" - labeled with three temperature values: "t=0", "t=0.5", and "t=1". These are evenly spaced along the x-axis.
* **Y-axis:** "Success Rate (%)" - ranging from 0 to 100, with tick marks at intervals of 20.
* **Legend:** Implicitly defined by the bar colors. The blue bars represent one metric, and the orange bars represent another. The legend is not explicitly labeled, but the color association is consistent throughout the chart.
### Detailed Analysis
The chart consists of three groups of paired bars, one for each temperature setting.
* **t=0:**
* Blue Bar: The blue bar at t=0 reaches approximately 88% success rate.
* Orange Bar: The orange bar at t=0 reaches approximately 82% success rate.
* **t=0.5:**
* Blue Bar: The blue bar at t=0.5 reaches approximately 84% success rate.
* Orange Bar: The orange bar at t=0.5 reaches approximately 79% success rate.
* **t=1:**
* Blue Bar: The blue bar at t=1 reaches approximately 82% success rate.
* Orange Bar: The orange bar at t=1 reaches approximately 77% success rate.
The blue bars generally show a slight decreasing trend as the temperature increases, while the orange bars also show a similar decreasing trend.
### Key Observations
* The blue metric consistently outperforms the orange metric across all temperature settings.
* The highest success rate for both metrics is achieved at t=0.
* As the temperature increases, the success rate for both metrics decreases, although the decrease is relatively small.
* The difference in success rate between the blue and orange metrics remains relatively constant across all temperature settings, around 6-8%.
### Interpretation
The data suggests that the GPT-4o model performs best on the TransCoder-IR dataset at a temperature of 0. Increasing the temperature (introducing more randomness) leads to a slight decrease in performance for both the primary and secondary metrics being evaluated. The consistent outperformance of the blue metric indicates that it is a more robust or reliable measure of success for this task. The relatively small difference in performance across temperature settings suggests that the model is not highly sensitive to temperature variations within the tested range. This could be due to the nature of the TransCoder-IR dataset or the specific configuration of the GPT-4o model. Further investigation would be needed to understand the underlying reasons for these trends and to determine the optimal temperature setting for maximizing performance on this dataset.
</details>
(a) Success Rate on TransCoder-IR
<details>
<summary>x19.png Details</summary>
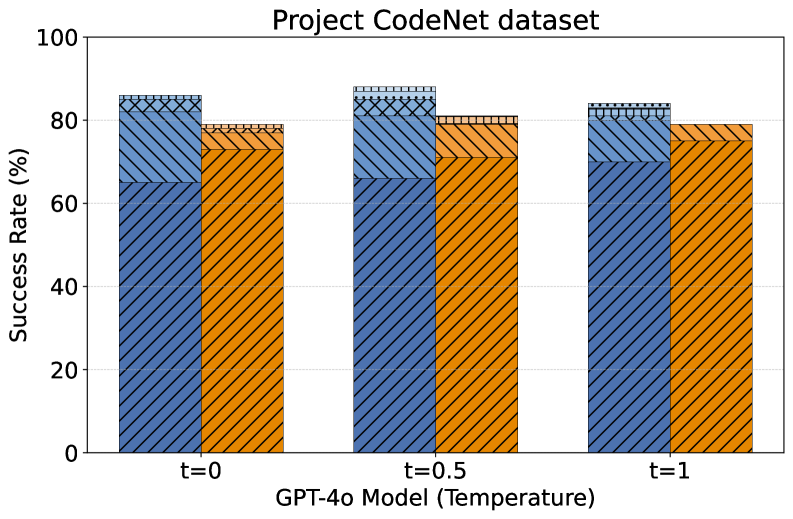
### Visual Description
\n
## Bar Chart: Project CodeNet Dataset - Success Rate vs. Temperature
### Overview
This bar chart visualizes the success rate of the GPT-4o model on the Project CodeNet dataset at three different temperature settings (t=0, t=0.5, and t=1). The success rate is represented as a percentage, with each bar divided into two components, likely representing different aspects of success.
### Components/Axes
* **Title:** Project CodeNet dataset
* **X-axis:** GPT-4o Model (Temperature) - with markers t=0, t=0.5, and t=1.
* **Y-axis:** Success Rate (%) - ranging from 0 to 100.
* **Data Series:** Two stacked bar series are present for each temperature setting.
* Series 1: Dark Blue, with a hatched pattern.
* Series 2: Orange, with a cross-hatched pattern.
* **No explicit legend is provided**, but the color coding is consistent across all bars.
### Detailed Analysis
The chart consists of three groups of stacked bars, one for each temperature setting.
* **t=0:**
* Dark Blue component: Approximately 72%
* Orange component: Approximately 8%
* Total Success Rate: Approximately 80%
* **t=0.5:**
* Dark Blue component: Approximately 75%
* Orange component: Approximately 8%
* Total Success Rate: Approximately 83%
* **t=1:**
* Dark Blue component: Approximately 70%
* Orange component: Approximately 8%
* Total Success Rate: Approximately 78%
The dark blue component dominates the success rate across all temperature settings. The orange component remains relatively constant at around 8% for all temperatures.
### Key Observations
* The highest overall success rate is observed at t=0.5 (approximately 83%).
* The success rate decreases slightly as the temperature increases from 0.5 to 1.
* The orange component contributes a small but consistent portion to the overall success rate.
* The dark blue component shows a slight decrease in success rate as temperature increases.
### Interpretation
The data suggests that the GPT-4o model performs best on the Project CodeNet dataset at a temperature of 0.5. Increasing the temperature to 1 results in a slight decrease in overall success rate. The consistent contribution of the orange component indicates that there's a specific aspect of the task where the model consistently achieves a success rate of around 8%, regardless of the temperature setting.
The temperature parameter in language models controls the randomness of the output. A temperature of 0 makes the output deterministic (always the same for a given input), while higher temperatures introduce more randomness. The observed trend suggests that a moderate level of randomness (t=0.5) is optimal for this particular dataset and task. The slight decrease in performance at t=1 could be due to the increased randomness leading to more incorrect or irrelevant outputs.
The two components of the stacked bars likely represent different facets of success. The dark blue component could represent the primary success metric, while the orange component might represent a secondary or more nuanced aspect of success. Further context about the Project CodeNet dataset and the specific task would be needed to fully interpret the meaning of these components.
</details>
(b) Success Rate on Project CodeNet
Figure 8: Success Rate of SACTOR with different temperature settings for GPT-4o on TransCoder-IR and Project CodeNet datasets.
(1) TransCoder-IR (Figure 8(a)): Setting the decoder to a deterministic temperature of $t=0$ resulted in 83 successful translations (83%), while both $t=0.5$ and $t=1.0$ yielded 80 successes (80%) each. This represents a slightly improvement with 3 additional correct predictions under the deterministic setting.
(2) Project CodeNet (Figure 8(b)): Temperature does not have a significant impact: the model produced 79, 81, and 79 successful outputs at $t=0$ , $t=0.5$ , and $t=1.0$ respectively (79–81%), which does not indicate any outstanding trend in performance across the temperature settings.
The results on both datasets suggests that lowering temperature to zero can offer a slight boost in reliability some of the cases, but it does not significantly affect the overall performance of SACTOR.
## Appendix L Spec-driven Harness Rules
<details>
<summary>x20.png Details</summary>
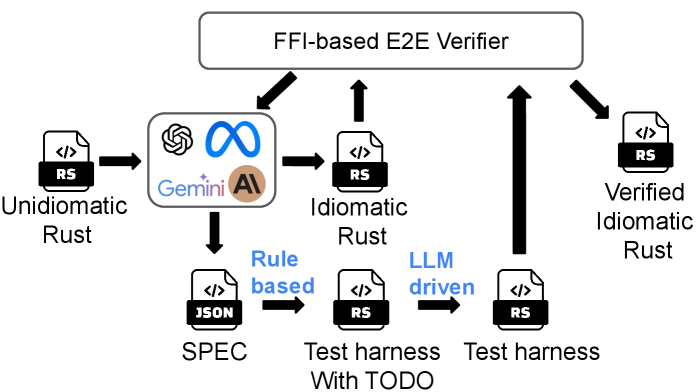
### Visual Description
\n
## Diagram: Gemini AI-Powered Rust Verification Flow
### Overview
This diagram illustrates a workflow for verifying Rust code using Gemini AI and a Foreign Function Interface (FFI)-based End-to-End (E2E) verifier. The process begins with unidiomatic Rust code, transforms it through Gemini AI, and ultimately produces verified idiomatic Rust code. The diagram highlights the role of rule-based and LLM-driven test harnesses in the verification process.
### Components/Axes
The diagram consists of several key components connected by arrows indicating the flow of data/code:
* **Input:** "Unidiomatic Rust" (represented by a code block icon with "RS" inside)
* **Gemini AI:** A circular icon with the text "Gemini AI" and an infinity symbol.
* **Intermediate Code 1:** "Idiomatic Rust" (represented by a code block icon with "RS" inside)
* **Intermediate Code 2:** "SPEC" (represented by a code block icon with "JSON" inside)
* **Intermediate Code 3:** "Test harness With TODO" (represented by a code block icon with "RS" inside)
* **Intermediate Code 4:** "Test harness" (represented by a code block icon with "RS" inside)
* **Output:** "Verified Idiomatic Rust" (represented by a code block icon with "RS" inside)
* **FFI-based E2E Verifier:** A rectangular box at the top labeled "FFI-based E2E Verifier".
* **Arrows:** Black arrows indicate the primary flow.
* **Colored Arrows:** A purple arrow labeled "Rule based" connects "SPEC" to "Test harness With TODO". A cyan arrow labeled "LLM driven" connects "Test harness With TODO" to "Test harness".
### Detailed Analysis or Content Details
The diagram depicts a cyclical process:
1. **Unidiomatic Rust to Idiomatic Rust:** Unidiomatic Rust code is fed into Gemini AI, which transforms it into Idiomatic Rust code. This is indicated by a black arrow.
2. **Idiomatic Rust to SPEC & Test Harness:** The Idiomatic Rust code is then used to generate a "SPEC" (JSON format) and a "Test harness With TODO". This is indicated by a black arrow splitting into two.
3. **SPEC to Test Harness With TODO:** The "SPEC" is processed using a "Rule based" approach to create a "Test harness With TODO". This is indicated by a purple arrow.
4. **Test Harness With TODO to Test Harness:** The "Test harness With TODO" is processed using an "LLM driven" approach to create a "Test harness". This is indicated by a cyan arrow.
5. **Test Harness to Verified Idiomatic Rust:** The "Test harness" is used by the "FFI-based E2E Verifier" to produce "Verified Idiomatic Rust". This is indicated by a black arrow.
6. **Verification Loop:** The "Verified Idiomatic Rust" is then fed back into the "FFI-based E2E Verifier" to continue the verification process.
### Key Observations
* The diagram emphasizes the iterative nature of the verification process.
* Gemini AI plays a central role in transforming unidiomatic code into idiomatic code.
* The use of both rule-based and LLM-driven approaches for test harness generation suggests a hybrid verification strategy.
* The "TODO" in "Test harness With TODO" indicates that the test harness is not yet complete.
### Interpretation
The diagram illustrates a modern approach to Rust code verification leveraging the power of AI. Gemini AI acts as a translator, converting potentially complex or non-standard Rust code into a more standardized and verifiable form. The subsequent use of rule-based and LLM-driven test harness generation demonstrates a layered approach to ensuring code quality. The "FFI-based E2E Verifier" suggests that the verification process involves interacting with external systems or libraries. The cyclical nature of the diagram highlights the importance of continuous verification and refinement. The presence of "TODO" in the test harness indicates that this is an ongoing development process. The diagram suggests a system designed to automate and improve the reliability of Rust code, potentially reducing errors and vulnerabilities.
</details>
Figure 9: Spec-driven harness generation and verification loop. The idiomatic translator co-produces idiomatic Rust and a machine-readable SPEC. A rule-based generator synthesizes a C-compatible harness from the SPEC; unsupported mappings trigger a localized LLM fallback. Harness and idiomatic code are linked via FFI for end-to-end tests.
Figure 9 illustrates the co-production timing and dataflow among artifacts (idiomatic code, SPEC, harness) and the verifier. Table 12 summarizes the SPEC patterns our rule-based generator currently supports.
| Scalars | shape: "scalar" | scalar $\rightarrow$ scalar | Common libc types are cast with as when needed; default compare is by value in roundtrip selftest. |
| --- | --- | --- | --- |
| C string | ptr.kind: "cstring", ptr.null | *const/*mut c_char $\rightarrow$ String / &str / Option<String> | NULL handling via ptr.null or Option< >; uses CStr / CString with lossless fallback. Return strings are converted back to *mut c_char. |
| Slices | ptr.kind: "slice", len_from | len_const | *const/*mut T + length $\rightarrow$ Vec<T>, &[T], or Option<...> | Requires a length source; empty or NULL produces None or empty according to spec; writes back length on I $\rightarrow$ U when a paired length field exists. |
| Single-element ref | ptr.kind: "ref" | *const/*mut T $\rightarrow$ Box<T> / Option<Box<T>> | For struct T, generator calls auto struct converters C T_to_T_mut / T_to_C T_mut. |
| Derived length path | idiomatic path ending with .len | len field $\leftrightarrow$ vec.len | Recognizes idiomatic data.len and reuses the same U-side length field on roundtrip. |
| Nullability | ptr.null: nullable|forbidden | C pointers $\rightarrow$ field with/without Option | nullable maps to Option< > or tolerant empty handling. |
| &mut struct params | ownership: transient | *mut CStruct $\rightarrow$ &mut Struct or Option<&mut Struct> | Copies back mutated values after the call using generated struct converters. |
| Return mapping | Field with i_field.name = "ret" | idiomatic return $\rightarrow$ U output(s) | Scalars: direct or via *mut T. Strings: to *mut c_char. Slices: pointer + length writeback. Structs: via struct converters. |
| Comparison hints | compare: by_value|by_slice|skip | selftest behavior | Optional per-field checks after U $\rightarrow$ I1 $\rightarrow$ U $\rightarrow$ I2 roundtrip, and compare with I1 and I2 |
| Unsupported paths | All SPEC key pairs other than supported paths | fallback | Generator emits localized TODOs for LLM completion; schema validation rejects malformed SPECs. |
Table 12: SPEC-driven harness coverage. U denotes the unidiomatic C-facing representation; I denotes the idiomatic Rust side.
Harness construction details.
The generator consumes a per-item SPEC (JSON) produced alongside idiomatic code and synthesizes: (i) a C-compatible shim that matches the original ABI, and (ii) idiomatic adapters that convert to/from Rust types. Pointer shapes (scalar, cstring, slice, ref) determine how memory is borrowed or owned; length sources come from sibling fields or constants; nullability and ownership hints select Option< > or strict checks. Return values are mapped back to U form, writing lengths when needed. This bridging resolves the ABI mismatch introduced by idiomatic function signatures.
Struct mappings and self-check.
For structs, the SPEC defines bidirectional converters between unidiomatic and idiomatic layouts. We validate adapter consistency with a minimal roundtrip: Unidiomatic $\rightarrow$ Idiomatic(1) $\rightarrow$ Unidiomatic $\rightarrow$ Idiomatic(2). The self-check compares Idiomatic(1) and Idiomatic(2) field-by-field according to compare hints: by_value requires exact equality on scalar fields; by_slice compares slice contents using the SPEC-recorded length source; skip omits fields that are aliasing views or externally owned to avoid false positives. Seed unidiomatic values are synthesized by an LLM guided by the SPEC so that nullability, ownership, and length sources are populated consistently.
Fallback and verification loop.
When a SPEC uses patterns not yet implemented (e.g., pointer kinds outside cstring / slice / ref; non-trivial len_from expressions; string args whose spec.kind $\neq$ cstring), the generator emits a localized TODO that is completed by an LLM using the same SPEC as guidance; the resulting harness is then validated as usual. End-to-end tests run against the linked harness and idiomatic crate; passing tests provide confidence under their coverage, while failures trigger the paper’s feedback procedure for regeneration and refinement.
### SPEC rule reference
This section explains the rule families the SPEC uses to describe how unidiomatic, C-facing values become idiomatic Rust and back. The schema has two top-level forms: a struct description and a function description. Both are expressed as small collections of field mappings from the unidiomatic side to idiomatic paths; a function return is just another mapping whose idiomatic path is the special name ret. This uniform treatment keeps the generator simple and makes the SPEC readable by humans and machines alike.
Pointer handling is captured by a compact notion of shape. A field is either a scalar or one of three pointer shapes: a byte string that follows C conventions, a slice that pairs a pointer with a length, or a single-object reference. Slices record where their length comes from (either a sibling field or a constant). Each pointer also carries a null policy that distinguishes admissible NULL from forbidden NULL, which in turn selects idiomatic options versus strict checks in the generated adapters.
Two lightweight hints influence how the harness allocates and how the roundtrip self-check behaves. An ownership hint (owning vs transient) signals whether the idiomatic side should materialize owned data or borrow it for the duration of the call. A comparison hint (by value, by slice, or skip) declares how roundtrip checks should assert equality, so that aliasing views or externally owned buffers can be skipped without producing spurious failures.
Finally, the schema enforces well-formedness and defines a safe escape hatch. Invalid combinations are rejected early by validation. Patterns that are valid but not yet implemented by the generator, such as complex dotted paths or unusual pointer views, are localized and handed to the LLM fallback described earlier; the SPEC itself remains the single source of truth for the intended mapping.
## Appendix M Real-world Codebase Evaluation Details
### M.1 CRust-Bench Per-sample Outcomes
Table LABEL:tab:crust_failures lists, for each of the 50 samples, the function-level translation status and a concise failure analysis. Status is reported as per-sample function-level percentages in separate columns for the unidiomatic (Unid.) and idiomatic (Id.) stages.
### M.2 libogg Outcomes
(1) Using GPT-4o. 36 functions cannot be translated idiomatically. nine of the translation failures are caused by translated functions not passing the test cases of libogg. Six failures are due to compile errors in the translations, five of which result from the LLM violating Rust’s safety rules on lifetime, borrow, and mutability. For example, the translation of function _os_lacing_expand fails because the translation sets the value of a function parameter to a reference to the function’s local variable vec, leading to an error “`vec` does not live long enough." Two failures are due to SACTOR being unable to generate compilable test harnesses. If a function calls another function that SACTOR cannot translate, then the caller function cannot be translated either. This is the reason why the remaining 13 translations fail.
(2) Using GPT-5. 17 functions cannot be translated idiomatically. Among them, three are because the generated functions cannot pass the test cases and three are due to failure to generate compilable test harnesses. Only one is caused by a compile error in the translated function, which shows the progress of GPT-5 in understanding Rust grammar and fixing compile errors. The remaining failures result from the callee functions of those functions being untranslatable.
Table 13: CRust-Bench per-sample outcomes (function-level). Translation Status columns report per-sample function-level success rates for unidiomatic (Unid.) and idiomatic (Id.) stages.
| 2DPartInt | 100.0% | 100.0% | – | – |
| --- | --- | --- | --- | --- |
| 42-Kocaeli-Printf | 75.0% | – | C variadics require unstable c_variadic; unresolved va_list import blocks build. | Unidiomatic compile (C varargs/unstable feature) |
| CircularBuffer | 100.0% | 54.6% | CamelCase-to-snake_case renaming breaks signature lookup; later run panics under no-unwind context. | Idiomatic compile (symbol/name mapping) |
| FastHamming | 100.0% | 60.0% | Output buffer sized to input length in harness; bounds-check panic at runtime. | Harness runtime (buffer/length) |
| Holdem-Odds | 100.0% | 6.9% | Off-by-one rank yields out-of-bounds bucket index; SIGSEGV under tests. | Runtime fault (boundary/indexing) |
| Linear-Algebra-C | 100.0% | 44.8% | Pointer vs reference semantics mismatch (nullable C pointers vs Rust references); harness compile errors. | Harness compile (pointer/ref semantics) |
| NandC | 100.0% | 100.0% | – | – |
| Phills_DHT | 75.0% | – | Shadowed global hash_table keeps dht_is_initialised() false; assertion in tests. | Runtime fault (global state divergence) |
| Simple-Sparsehash | 100.0% | 40.0% | CamelCase-to-snake_case renaming causes signature/type mismatches; harness does not compile. | Idiomatic compile (symbol/name mapping) |
| SimpleXML | 83.3% | – | Missing ParseState and CamelCase-to-snake_case renaming breaks signatures; unidiomatic stalls. | Idiomatic compile (symbol/name mapping) |
| aes128-SIMD | 85.7% | – | Array-shape mismatch (expects 4x4 refs; passes row pointer); plus intrinsics/typedef noise. | Unidiomatic compile (array shape; intrinsics/types) |
| amp | 80.0% | – | Returned C string from amp_decode_arg is not NULL-terminated; strcmp reads past allocation and trips invalid read under tests. | Runtime fault (C string NULL termination) |
| approxidate | 85.7% | – | match_alpha references anonymous enum C2RustUnnamed that is never defined, causing cascaded missing-type errors across retries. | Unidiomatic compile (types/aliases) |
| avalanche | 100.0% | 75.0% | Capturing closure passed where fn pointer required; FILE*/Rust File bridging mis-modeled; compile fails. | Harness runtime (I/O/resource model mismatch) |
| bhshell | 88.2% | – | Many parser errors (enum lacks PartialEq, missing consts, u64 to usize drift, duplicates). | Unidiomatic compile (types/aliases) |
| bitset | 100.0% | 50.0% | Treats bit count as byte count in converter; overreads and panics under tests. | Harness runtime (buffer/length) |
| bostree | 52.4% | – | Function-pointer typedefs and pointer-shape drift break callback bridging. | Unidiomatic compile (function-pointer types/deps) |
| btree-map | 100.0% | 26.3% | Trace/instrumentation proc macro requires Debug on opaque C type node; harness compilation fails for get_node_count. | Harness compile (instrumentation bound) |
| c-aces | 100.0% | 3.9% | Struct converter mismatch (Vec<CMatrix2D> vs Vec<Matrix2D>) in generated harness; compile fails after retries. | Harness compile (struct converter/shape) |
| c-string | 100.0% | 29.4% | Size vs capacity mismatch in StringT constructor; empty buffer returned, C asserts. | Runtime fault (size/capacity mismatch) |
| carrays | 100.0% | 68.5% | Trace macro imposes Debug on generic T and callback; harness fails to compile (e.g., gca_lsearch). | Harness compile (instrumentation bound) |
| cfsm | 50.0% | – | Missing typedefs for C function-pointer callbacks; harness lacks nullable extern signatures, compile fails. | Unidiomatic compile (function-pointer types/deps) |
| chtrie | 100.0% | 0.0% | Pointer-of-pointers vs Vec adapter mismatch for struct chtrie | Harness compile (struct converter/shape) |
| cissy | 100.0% | 19.1% | Anonymous C types that c2rust renamed cannot be fetched correctly as a dependency | Unidiomatic compile (types/aliases) |
| clog | 31.6% | – | Variadic logging APIs and duplicate globals; unresolved vfprintf / c_variadic; compile fails. | Unidiomatic compile (C varargs/unstable feature) |
| cset | 100.0% | 25.0% | Translator renames XXH_readLE64 to xxh_read_le64; SPEC/harness require exact C name; exhausts six attempts. | Idiomatic compile (symbol/name mapping) |
| csyncmers | 66.7% | – | Unsigned underflow in compute_closed_syncmers (i - S + 1 without guard) triggers overflow panic; prior __uint128_t typedef issues. | Runtime fault (arithmetic underflow) |
| dict | 17.7% | – | Fn-pointer fields modeled non-optional (need Option<extern "C" fn>); plus va_list requires nightly c_variadic; compile fails. | Unidiomatic compile (function-pointer types/deps) |
| emlang | 16.3% | – | Anonymous-union alias (C2RustUnnamed) misuse; duplicate program_new; assertion bridging (__assert_fail) mis-modeled. | Unidiomatic compile (types/aliases) |
| expr | 33.3% | – | Missing C2RustUnnamed alias; C varargs in trace_eval; strncmp len type mismatch. | Unidiomatic compile (types/aliases) |
| file2str | 100.0% | 100.0% | – | – |
| fs_c | 100.0% | 60.0% | Idiomatic I/O wrappers mismatch C expectations (closed fd/OwnedFd abort; Err(NotFound) leads to C-side segfault). | Harness runtime (I/O/resource model mismatch) |
| geofence | 100.0% | 100.0% | – | – |
| gfc | 100.0% | 54.6% | Converter overread + ownership misuse; later compile errors. | Harness runtime (converter/ownership) |
| gorilla-paper-encode | 100.0% | 9.1% | Missing adapters + lifetimes (Cbitwriter_s / Cbitreader_s vs BitWriter / BitReader<’a>). | Harness compile (lifetimes/struct adapters) |
| hydra | 100.0% | 50.0% | Borrow overlap in list update; name mapping for FindCommand. | Idiomatic compile (borrow/lifetime; symbol mapping) |
| inversion_list | 17.0% | – | C allows NULL comparator/function pointers; wrapper unwraps and panics. | Runtime fault (function-pointer nullability) |
| jccc | 88.7% | – | Missing C2RustUnnamed alias and duplicate Expression / Lexer types; compile fails. | Unidiomatic compile (types/aliases) |
| leftpad | 100.0% | 100.0% | – | – |
| lib2bit | 100.0% | 13.6% | Non-clonable std::fs::File in harness (C FILE* vs Rust File I/O handle mismatch) | Harness runtime (I/O/resource model mismatch) |
| libbase122 | 100.0% | 37.5% | Reader cursor/buffer not preserved across calls; writer shape mismatch; tests fail. | Harness runtime (converter/ownership) |
| libbeaufort | 100.0% | 66.7% | Returns reference to temporary tableau; matrix parameter shape drift (char** vs Vec<Option<String>>); compile fails. | Idiomatic compile (borrow/lifetime) |
| libwecan | 100.0% | 100.0% | – | – |
| morton | 100.0% | 100.0% | – | – |
| murmurhash_c | 100.0% | 100.0% | – | – |
| razz_simulation | 33.3% | – | Type-name drift; node shape; ptr/ref API mismatch. | Harness compile (type/name drift; API mismatch) |
| rhbloom | 100.0% | 33.3% | Pointer/ref misuse; bit-length as bytes; overreads/panics. | Harness runtime (pointer/ref; length units) |
| totp | 77.8% | – | Anonymous C types that c2rust renamed cannot be fetched correctly as a dependency; plus duplicate helpers (pack32 / unpack64 / hmac_sha1); compile fails. | Unidiomatic compile (types/aliases) |
| utf8 | 100.0% | 30.8% | NULL deref + unchecked indices; SIGSEGV in tests. | Runtime fault (NULL deref/out-of-bounds) |
| vec | 100.0% | 0.0% | Idiomatic rewrite uses a bounds-checked copy; out-of-range panic under tests. | Runtime fault (boundary/indexing) |
## Appendix N Examples of Prompts Used in SACTOR
The following prompts are used to guide the LLM in C-to-Rust translation and verification tasks. The prompts may slightly vary to accommodate different translation task, as SACTOR leverages static analysis to fetch the necessary information for the LLM.
### N.1 Unidiomatic Translation
Figure 10 shows the prompt for translating unidiomatic C code to Rust.
⬇
Translate the following C function to Rust. Try to keep the ** equivalence ** as much as possible.
‘ libc ‘ will be included as the ** only ** dependency you can use. To keep the equivalence, you can use ‘ unsafe ‘ if you want.
The function is:
‘‘‘ c
{C_FUNCTION}
‘‘‘
// Specific for main function
The function is the ‘ main ‘ function, which is the entry point of the program. The function signature should be: ‘ pub fn main () -> ()‘.
For ‘ return 0;‘, you can directly ‘ return;‘ in Rust or ignore it if it ’ s the last statement.
For other return values, you can use ‘ std:: process:: exit ()‘ to return the value.
For ‘ argc ‘ and ‘ argv ‘, you can use ‘ std:: env:: args ()‘ to get the arguments.
The function uses some of the following stdio file descriptors: stdin. Which will be included as
‘‘‘ rust
extern " C " {
static mut stdin: * mut libc:: FILE;
}
‘‘‘
You should ** NOT ** include them in your translation, as the system will automatically include them.
The function uses the following functions, which are already translated as (you should ** NOT ** include them in your translation, as the system will automatically include them):
‘‘‘ rust
{DEPENDENCIES}
‘‘‘
Output the translated function into this format (wrap with the following tags):
---- FUNCTION ----
‘‘‘ rust
// Your translated function here
‘‘‘
---- END FUNCTION ----
Figure 10: Unidiomatic Translation Prompt
### N.2 Unidiomatic Translation with Feedback
Figure 11 shows the prompt for translating unidiomatic C code to Rust with feedback from the previous incorrect translation and error message.
⬇
Translate the following C function to Rust. Try to keep the ** equivalence ** as much as possible.
‘ libc ‘ will be included as the ** only ** dependency you can use. To keep the equivalence, you can use ‘ unsafe ‘ if you want.
The function is:
‘‘‘ c
{C_FUNCTION}
‘‘‘
// Specific for main function
The function is the ‘ main ‘ function, which is the entry point of the program. The function signature should be: ‘ pub fn main () -> ()‘.
For ‘ return 0;‘, you can directly ‘ return;‘ in Rust or ignore it if it ’ s the last statement.
For other return values, you can use ‘ std:: process:: exit ()‘ to return the value.
For ‘ argc ‘ and ‘ argv ‘, you can use ‘ std:: env:: args ()‘ to get the arguments.
The function uses some of the following stdio file descriptors: stdin. Which will be included as
‘‘‘ rust
extern " C " {
static mut stdin: * mut libc:: FILE;
}
‘‘‘
You should ** NOT ** include them in your translation, as the system will automatically include them.
The function uses the following functions, which are already translated as (you should ** NOT ** include them in your translation, as the system will automatically include them):
‘‘‘ rust
fn atoi (str : * const c_char) -> c_int;
‘‘‘
Output the translated function into this format (wrap with the following tags):
---- FUNCTION ----
‘‘‘ rust
// Your translated function here
‘‘‘
---- END FUNCTION ----
Lastly, the function is translated as:
‘‘‘ rust
{COUNTER_EXAMPLE}
‘‘‘
It failed to compile with the following error message:
‘‘‘
{ERROR_MESSAGE}
‘‘‘
Analyzing the error messages, think about the possible reasons, and try to avoid this error.
Figure 11: Unidiomatic Translation with Feedback Prompt
### N.3 Idiomatic Translation
Figure 12 shows the prompt for translating unidiomatic Rust code to idiomatic Rust. Crown is used to hint the LLM about the ownership, mutability, and fatness of pointers.
⬇
Translate the following unidiomatic Rust function into idiomatic Rust. Try to remove all the ‘ unsafe ‘ blocks and only use the safe Rust code or use the ‘ unsafe ‘ blocks only when necessary.
Before translating, analyze the unsafe blocks one by one and how to convert them into safe Rust code.
** libc may not be provided in the idiomatic code, so try to avoid using libc functions and types, and avoid using ‘ std:: ffi ‘ module.**
‘‘‘ rust
{RUST_FUNCTION}
‘‘‘
" Crown " is a pointer analysis tool that can help to identify the ownership, mutability and fatness of pointers. Following are the possible annotations for pointers:
‘‘‘
fatness:
- ‘ Ptr ‘: Single pointer
- ‘ Arr ‘: Pointer is an array
mutability:
- ‘ Mut ‘: Mutable pointer
- ‘ Imm ‘: Immutable pointer
ownership:
- ‘ Owning ‘: Owns the pointer
- ‘ Transient ‘: Not owns the pointer
‘‘‘‘
The following is the output of Crown for this function:
‘‘‘
{CROWN_RESULT}
‘‘‘
Analyze the Crown output firstly, then translate the pointers in function arguments and return values with the help of the Crown output.
Try to avoid using pointers in the function arguments and return values if possible.
Output the translated function into this format (wrap with the following tags):
---- FUNCTION ----
‘‘‘ rust
// Your translated function here
‘‘‘
---- END FUNCTION ----
Also output a minimal JSON spec that maps the unidiomatic Rust layout to the idiomatic Rust for the function arguments and return value.
Full JSON Schema for the SPEC (do not output the schema; output only an instance that conforms to it):
‘‘‘ json
{_schema_text}
‘‘‘
---- SPEC ----
‘‘‘ json
{{
" function_name ": "{function. name}",
" fields ": [
{{
" u_field ": {{
" name ": "...",
" type ": "...",
" shape ": " scalar " | {{" ptr ": {{" kind ": " slice | cstring | ref ", " len_from ": "?", " len_const ": 1}}}}
}},
" i_field ": {{
" name ": "...",
" type ": "..."
}}
}}
]
}}
‘‘‘
---- END SPEC ----
Few - shot examples (each with unidiomatic Rust signature, idiomatic Rust signature, and the SPEC):
Example F1 (slice arg):
Unidiomatic Rust:
‘‘‘ rust
pub unsafe extern " C " fn sum (xs: * const i32, n: usize) -> i32;
‘‘‘
Idiomatic Rust:
‘‘‘ rust
pub fn sum (xs: &[i32]) -> i32;
‘‘‘
---- SPEC ----
‘‘‘ json
{{
" function_name ": " sum ",
" fields ": [
{{ " u_field ": {{" name ": " xs ", " type ": "* const i32 ", " shape ": {{ " ptr ": {{ " kind ": " slice ", " len_from ": " n " }} }} }},
" i_field ": {{" name ": " xs ", " type ": "&[i32]" }} }},
{{ " u_field ": {{" name ": " n ", " type ": " usize ", " shape ": " scalar " }},
" i_field ": {{" name ": " xs. len ", " type ": " usize " }} }}
]
}}
‘‘‘
---- END SPEC ----
Example F2 (ref out):
Unidiomatic Rust:
‘‘‘ rust
pub unsafe extern " C " fn get_value (out_value: * mut i32);
‘‘‘
Idiomatic Rust:
‘‘‘ rust
pub fn get_value () -> i32;
‘‘‘
---- SPEC ----
‘‘‘ json
{{
" function_name ": " get_value ",
" fields ": [
{{ " u_field ": {{" name ": " out_value ", " type ": "* mut i32 ", " shape ": {{ " ptr ": {{ " kind ": " ref " }} }} }},
" i_field ": {{" name ": " ret ", " type ": " i32 " }} }}
]
}}
‘‘‘
---- END SPEC ----
Example F3 (nullable cstring maps to Option):
Unidiomatic Rust:
‘‘‘ rust
pub unsafe extern " C " fn set_name (name: * const libc:: c_char);
‘‘‘
Idiomatic Rust:
‘‘‘ rust
pub fn set_name (name: Option <& str >);
‘‘‘
---- SPEC ----
‘‘‘ json
{{
" function_name ": " set_name ",
" fields ": [
{{ " u_field ": {{" name ": " name ", " type ": "* const c_char ", " shape ": {{ " ptr ": {{ " kind ": " cstring ", " null ": " nullable " }} }} }},
" i_field ": {{" name ": " name ", " type ": " Option <& str >" }} }}
]
}}
‘‘‘
---- END SPEC ----
Figure 12: Idiomatic Translation Prompt
### N.4 Idiomatic Verification
Idiomatic verification is the process of verifying the correctness of the translated idiomatic Rust code by generating a test harness. The prompt for idiomatic verification is shown in Figure 13.
⬇
We have an initial spec - driven harness with TODOs. Finish all TODOs and ensure it compiles.
Idiomatic signature:
‘‘‘ rust
pub fn compute_idiomatic (
x: i32,
name: & str,
data: &[u8],
meta: HashMap < String, String >,
) -> i32;;
‘‘‘
Unidiomatic signature:
‘‘‘ rust
pub unsafe extern " C " fn compute (x: i32, name: * const libc:: c_char, data: * const u8, len: usize, meta: * const libc:: c_char) -> i32;;
‘‘‘
Current harness:
‘‘‘ rust
pub unsafe extern " C " fn compute (x: i32, name: * const libc:: c_char, data: * const u8, len: usize, meta: * const libc:: c_char) -> i32
{
// Arg ’ name ’: borrowed C string at name
let name_str = if ! name. is_null () {
unsafe { std:: ffi:: CStr:: from_ptr (name) }. to_string_lossy (). into_owned ()
} else {
String:: new ()
};
// Arg ’ data ’: slice from data with len len as usize
let data_len = len as usize;
let data_len_non_null = if data. is_null () { 0 } else { data_len };
let data: &[u8] = if data_len_non_null == 0 {
&[]
} else {
unsafe { std:: slice:: from_raw_parts (data as * const u8, data_len_non_null) }
};
// TODO: param meta of type HashMap < String , String >: unsupported mapping
let __ret = compute_idiomatic (x, & name_str, data, /* TODO param meta */);
return __ret;
}
‘‘‘
Output only the final function in this format:
---- FUNCTION ----
‘‘‘ rust
// Your translated function here
‘‘‘
---- END FUNCTION ----
Figure 13: Idiomatic Verification Prompt
### N.5 Failure Reason Analysis
Figure 14 shows the prompt for analyzing the reasons for the failure of the translation.
⬇
Given the following C code:
‘‘‘ c
{original_code}
‘‘‘
The following code is generated by a tool that translates C code to Rust code. The tool has a bug that causes it to generate incorrect Rust code. The bug is related to the following error message:
‘‘‘ json
{json_data}
‘‘‘
Please analyze the error message and provide a reason why the tool generated incorrect Rust code.
1. Append a new reason to the list of reasons.
2. Select a reason from the list of reasons that best describes the error message.
Please provide a reason why the tool generated incorrect Rust code ** FUNDAMENTALLY **.
List of reasons:
{all_current_reasons}
Please provide the analysis output in the following format:
‘‘‘ json
{
" action ": " append ", // or " select " to select a reason from the list of reasons
" reason ": " Format string differences between C and Rust ", // the reason for the error message, if action is " append "
" selection ": 1 // the index of the reason from the list of reasons, if action is " select "
// " reason " and " selection " are mutually exclusive, you should only provide one of them
}
‘‘‘
Please ** make sure ** to provide a general reason that can be applied to multiple cases, not a specific reason that only applies to the current case.
Please provide a reason why the tool generated incorrect Rust code ** FUNDAMENTALLY ** (NOTE that the reason of first failure is always NOT the fundamental reason).
Figure 14: Failure Reason Analysis Prompt