# Bayesian Teaching Enables Probabilistic Reasoning in Large Language Models
**Authors**: Linlu Qiu, Fei Sha, Kelsey Allen, Yoon Kim, Tal Linzen, Sjoerd van Steenkiste
> Google DeepMindUniversity of British ColumbiaVector Institute
> Google ResearchNew York University
> Google Research
Corresponding author:
linluqiu@mit.edu, svansteenkiste@google.com, linzen@google.com
Abstract
Large language models (LLMs) are increasingly used as agents that interact with users and with the world. To do so successfully, LLMs must construct representations of the world and form probabilistic beliefs about them. To provide personalized recommendations, for example, the LLM needs to infer a user’s preferences from their behavior over multiple interactions. The Bayesian inference framework lays out the optimal way for an agent to update its beliefs as it receives new information. We first show that LLMs fall far short of the standard defined by the Bayesian framework. We then show that by teaching LLMs to mimic the predictions of the normative Bayesian model, we can dramatically improve their ability to update their beliefs; this ability generalizes to new tasks. We conclude that LLMs can effectively learn reasoning skills from examples and generalize those skills to new domains.
1 Introduction
Humans interact with the world based on our beliefs about it. To effectively support decision making, our beliefs need to correspond to the structure of the world as much as possible; in other words, our beliefs need to be supported by appropriate “world models” [Johnson-Laird, 1980, Ha and Schmidhuber, 2018, LeCun, 2022, Wong et al., 2023]. We typically do not have perfect knowledge about the outside world; to the extent that we are uncertain about our environment, our beliefs need to be probabilistic, reflecting this uncertainty. And for these beliefs to remain relevant as the world changes, or as new information about the world becomes available, we need to update our beliefs to reflect the new information. The framework of Bayesian inference describes the normative way in which new information should trigger a change in one’s beliefs so as to maximize the effectiveness of these beliefs as a foundation for acting in the world [Chater et al., 2006]. The Bayesian framework has informed a substantial body of work in cognitive science, which has identified both areas where humans act as the framework predicts, as well as deviations from it [Griffiths et al., 2024, Jern et al., 2017, Tenenbaum et al., 2011, Xu and Tenenbaum, 2007, Baker et al., 2011, Tenenbaum et al., 2006, Chater and Manning, 2006, Griffiths et al., 2007, Chaigneau et al., 2025, Rehder, 2018, Rottman and Hastie, 2016, Sloman and Lagnado, 2015].
In the last few years, artificial intelligence systems based on large language models (LLMs) have become dramatically more capable than in the past [Team, 2024a, Achiam et al., 2023, Anthropic, 2024, Team, 2024b, Touvron et al., 2023, Guo et al., 2025]. Far outgrowing their original motivation—as methods to estimate the probabilities of different word sequences—these systems are now being used for applications where they interact with users and with the outside world. As with humans, for the LLMs’ interactions with users to be effective, the LLMs’ beliefs need to reflect their experience with the user and to be continuously updated as more information becomes available. Here, we ask: do LLMs act as if they have probabilistic beliefs that are updated as expected from normative Bayesian inference? To the extent that the LLMs’ behavior deviates from the normative Bayesian strategy, how can we minimize these deviations?
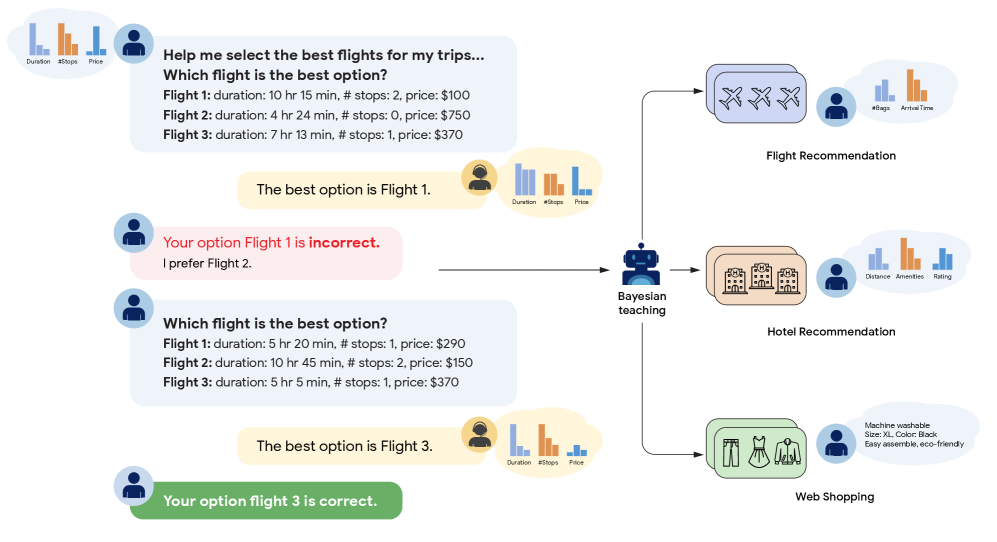
We begin to study these questions using a simple controlled setting: a flight recommendation task [Lin et al., 2022], illustrated in Fig. 1. This task involves multiple rounds of interactions between a simulated user and an LLM, where the LLM is acting as a flight booking assistant. In each round, the assistant is given a small number of flight options, and is expected to recommend one of them to the user, based on the user’s preferences. The user’s preferences are not directly communicated to the LLM: it only observes the choices the user makes among the flight options. To make optimal recommendations, then, the LLM must construct an implicit model of the factors that shape the user’s preferences, and must reason probabilistically about those factors as it learns about the user’s choices across multiple sets of flight options.
We compare the LLMs’ behavior to that of a model that follows the normative Bayesian strategy, which we refer to as the Bayesian Assistant. This model maintains a probability distribution that reflects its beliefs about the user’s preferences, and uses Bayes’ rule to update this distribution as new information about the user’s choices becomes available. Unlike many real-life scenarios, where it is difficult to specify and implement the Bayesian strategy computationally, in this controlled setting this strategy can be computed exactly, allowing us to precisely estimate the extent to which LLMs deviate from it.
We use this framework to evaluate a range of LLMs and find that they all perform significantly worse than the normative Bayesian Assistant (Fig. 2). Most importantly, in contrast to the Bayesian Assistant, which gradually improves its recommendations as it receives additional information about the user’s choices, LLMs’ performance often plateaus after a single interaction, pointing to a limited ability to adapt to new information.
We then introduce Bayesian teaching, a strategy to teach an LLM to approximate Bayesian reasoning. We provide the LLM with examples of interactions between the user and the Bayesian Assistant, and have the LLM mimic those interactions. We find that, by leading the LLMs to gradually adapt to the user over the course of the interactions, this method substantially improves the LLMs’ performance on the flight recommendation task. Crucially, teaching the LLMs to mimic the Bayesian Assistant in one task allows them to generalize to other tasks that similarly require making decisions under uncertainty; those include not only different variants of the flight recommendation task, but also a related hotel recommendation task, as well as a web shopping task with real-world products (Fig. 1), a much more complex task for which it is difficult to specify and implement a fully Bayesian model.
Notably, while the Bayesian Assistant often makes incorrect predictions as it reasons under uncertainty, especially in the early rounds of interaction, we find that it is a more effective teacher than a teacher that directly provides the LLMs with users’ choices (which we refer to as an oracle teacher); in other words, the Bayesian model’s educated guesses make for a stronger learning signal than the correct answers. Overall, we conclude that through observing the Bayesian Assistant perform a particular task, the LLMs are able to approximate transferable probabilistic reasoning skills.
To summarize our contributions: we first identify significant limitations of off-the-shelf LLMs in tasks that require forming and updating probabilistic beliefs. We then demonstrate that, by having the LLMs mimic an normative Bayesian model, we can teach them effectively to approximate probabilistic belief updates, and show that these skills can generalize to new environments. These findings suggest that LLMs can be used in interactive settings where information is provided gradually, including complex application domains where implementing an exact Bayesian model is difficult. More generally, our results highlight a unique strength of deep learning models such as LLMs: they can learn to mimic a symbolic model and generalize its strategy to domains that are too complex to specify in a classic symbolic model.
2 Evaluating Belief Updates via Flight Recommendations
<details>
<summary>x1.png Details</summary>
### Visual Description
## Flowchart: Bayesian Teaching in Recommendation Systems
### Overview
The diagram illustrates a conversational interaction between a user and a recommendation system, demonstrating how Bayesian teaching refines suggestions across three domains: Flight Recommendation, Hotel Recommendation, and Web Shopping. The system uses color-coded feedback (yellow: correct, pink: incorrect, green: correct) to iteratively improve its recommendations based on user preferences.
---
### Components/Axes
1. **Central Component**:
- **Bayesian Teaching**: A robotic figure labeled "Bayesian teaching" acts as the decision engine, connecting to all three recommendation domains via arrows.
- **User Interaction**: Speech bubbles represent user queries and system responses, with color-coded feedback.
2. **Recommendation Domains**:
- **Flight Recommendation**:
- Three flight options (Flight 1, 2, 3) with attributes:
- Duration (e.g., "10 hr 15 min"),
- Number of stops (e.g., "2 stops"),
- Price (e.g., "$100").
- Bar charts visualize duration, stops, and price for each flight.
- **Hotel Recommendation**:
- Attributes: Distance, amenities, rating.
- Bar charts compare these metrics.
- **Web Shopping**:
- Attributes: Machine-washable, size (XL), color (Black), ease of assembly, eco-friendliness.
- Product icons (clothing) represent these features.
3. **User Feedback**:
- Color-coded bubbles:
- **Yellow**: "Your option [X] is correct."
- **Pink**: "Your option [X] is incorrect. I prefer [Y]."
- **Green**: "Your option [X] is correct."
---
### Detailed Analysis
#### Flight Recommendation
- **First Query**:
- **Flight 1**: 10h15m, 2 stops, $100.
- **Flight 2**: 4h24m, 0 stops, $750.
- **Flight 3**: 7h13m, 1 stop, $370.
- User selects Flight 1 (yellow bubble). System corrects to Flight 2 (pink bubble).
- **Second Query**:
- **Flight 1**: 5h20m, 1 stop, $290.
- **Flight 2**: 10h45m, 2 stops, $150.
- **Flight 3**: 5h5m, 1 stop, $370.
- User selects Flight 3 (green bubble). System confirms correctness.
#### Hotel Recommendation
- Attributes visualized via bar charts:
- **Distance**: Shorter bars indicate closer proximity.
- **Amenities**: Number of amenities (e.g., pools, Wi-Fi).
- **Rating**: Star ratings (e.g., 4.5/5).
#### Web Shopping
- Product attributes:
- **Size**: XL (large).
- **Color**: Black.
- **Ease of Assembly**: "Easy" (simplified icon).
- **Eco-Friendliness**: "Eco-friendly" (leaf icon).
---
### Key Observations
1. **Iterative Learning**: The system adjusts recommendations based on user feedback (e.g., correcting Flight 1 to Flight 2).
2. **Attribute Prioritization**:
- Flights: Users prioritize shorter duration and fewer stops over price.
- Hotels: Proximity and amenities drive preferences.
- Web Shopping: Eco-friendliness and ease of use are critical.
3. **Color-Coded Feedback**: Yellow/green bubbles reinforce correct choices, while pink bubbles highlight suboptimal selections.
---
### Interpretation
The diagram demonstrates a **Bayesian teaching framework** where user feedback directly informs system adjustments. By analyzing preferences (e.g., favoring Flight 2 over Flight 1 despite higher cost), the system refines its model to align with user priorities. The flow from user input to system response and back creates a closed-loop learning process, emphasizing adaptability across domains.
Notably, the system’s ability to correct user choices (e.g., Flight 1 → Flight 2) suggests it incorporates cost-benefit analysis, balancing duration, convenience, and price. Similarly, the Web Shopping section highlights a shift toward sustainability (eco-friendly products) and practicality (easy assembly).
This structure underscores the importance of **context-aware recommendations** and the role of user feedback in optimizing decision-making systems.
</details>
Figure 1: Evaluating and improving LLMs’ probabilistic belief updates. The flight recommendation task (left) involves multi-round interactions between a user and a flight booking assistant. In each round, the assistant is asked to recommend to the user one of three available flight options. The assistant is then shown the flight that was in fact chosen by the user (based on the user’s reward function, which characterizes the user’s preferences). To make good recommendations, the assistant needs to infer the user’s preferences from the user’s choices. To teach the LLM to reason probabilistically, we fine-tune the LLM on interactions between users and a Bayesian Assistant, which represents the normative way to update beliefs about the user’s preferences. We then evaluate the fine-tuned model on the flight recommendation task as well as two new tasks (right).
We first describe the simplified flight recommendation task, derived that we use to evaluate the LLMs [Lin et al., 2022]. In this task, we have the LLMs interact with a simulated user for five rounds. In each round, three flight options are presented to both the user and the assistant. Each flight is defined by a departure time, a duration, a number of stops, and a cost (see Fig. 1). Each simulated user is characterized by a set of preferences: for each feature, they can have a strong or weak preference for high or low values of the feature (e.g., they may prefer longer or shorter flights), or no preference regarding this feature. We refer to this set of preferences as the user’s reward function. We have 624 possible users in total (see Appendix Section A). These preferences, which determine the flights that the user chooses, are not directly revealed to the assistant. The goal of the assistant is to recommend the flight that matches the user’s choice. At the end of each round, the user indicates to the assistant whether or not it chose correctly, and provides it with the correct answer.
After each round, we evaluate the accuracy of the assistant’s recommendations for 100 new sets of three flights that differ from the ones on which the assistant has received feedback. We do not provide any feedback to the assistant for these new flight option sets (see Appendix Fig. 7 for the evaluation workflow).
2.1 The Bayesian Assistant
Because the users’ preferences are only revealed gradually, through their choices among flight options, we cannot expect the LLMs to reach perfect accuracy immediately after a single round of interaction. As an upper bound on the LLMs’ performance, we define a Bayesian Assistant, which implements the strategy that optimally takes into account the evidence about the user’s preferences that accumulates over rounds of interaction. This entails maintaining uncertainty about those preferences when the evidence is partial: instead of committing to a single most likely reward function, which could turn out to be incorrect in future rounds, the assistant maintains a probability distribution over possible reward functions. After each round, the Bayesian Assistant updates its distribution over reward functions using Bayes’ rule: the probability of each reward function after the round (the posterior) is computed based on its probability before the round (the prior) and whether or not it was compatible with the user’s choice (the likelihood). This normative model represents the best performance that we can possibly expect from any system. Because the number of possible reward functions is small, we are able to perform exact Bayesian inference (see Appendix Section A).
This method requires us to define the Bayesian Assistant’s initial prior distribution, that is, its probabilistic assumptions about which user preferences are more likely, in advance of any interaction with the user. We use an uninformed prior, where all possible sets of user preferences are equally likely (for experiments with alternative priors, see Appendix Section D.4).
<details>
<summary>x2.png Details</summary>
### Visual Description
## Bar Chart: Model Accuracy Comparison Across Rounds
### Overview
The chart compares the accuracy percentages of various AI models (e.g., Gemma 2, Llama 3, Qwen 2.5, GPT-4.1, Gemini 1.5) and human/Bayesian Assistant performance across two evaluation rounds ("After 1st Round" and "Final Round"). A dashed line at 37% represents a "Random" baseline. Models are grouped by architecture size (e.g., 9B, 27B parameters) or name, with distinct colors for human and Bayesian Assistant.
### Components/Axes
- **X-axis**: Model names (e.g., "Gemma 2 9B," "Llama 3 70B," "Human," "Bayesian Assistant").
- **Y-axis**: Accuracy (%) from 0 to 100.
- **Legend**:
- Striped bars: "After 1st Round" (blue).
- Solid bars: "Final Round" (blue, green, beige).
- Dashed line: "Random" (37% baseline).
- **Colors**:
- Blue for AI models.
- Green for "Human."
- Beige for "Bayesian Assistant."
### Detailed Analysis
1. **Model Performance**:
- **Gemma 2 9B**: 37% (After 1st Round) → 37% (Final Round).
- **Gemma 2 27B**: 37% → 40%.
- **Llama 3 8B**: 36% → 38%.
- **Llama 3 70B**: 45% → 58% (highest improvement).
- **Qwen 2.5 7B**: 37% → 37%.
- **Qwen 2.5 32B**: 42% → 49%.
- **GPT-4.1 Mini**: 40% → 42%.
- **Gemini 1.5 Pro**: 45% → 51%.
- **Human**: 39% → 47%.
- **Bayesian Assistant**: 58% → 81% (highest final accuracy).
2. **Trends**:
- Most models improve from the first to the final round (e.g., Llama 3 70B +13%, Qwen 2.5 32B +7%).
- Human performance shows moderate improvement (+8%).
- Bayesian Assistant outperforms all models in both rounds, with a significant jump (+23%) in the final round.
3. **Random Baseline**:
- The dashed line at 37% indicates that most models (except Llama 3 8B and Qwen 2.5 7B) exceed random guessing even after the first round.
### Key Observations
- **Llama 3 70B** and **Bayesian Assistant** demonstrate the strongest performance, with Bayesian Assistant achieving the highest final accuracy (81%).
- **Human** performance (47%) is mid-range, trailing behind top models like Gemini 1.5 Pro (51%) and Bayesian Assistant.
- **Qwen 2.5 7B** and **Gemma 2 9B** show no improvement between rounds, suggesting potential limitations in scalability or training efficiency.
### Interpretation
The data highlights the impact of iterative refinement on model accuracy, with larger models (e.g., Llama 3 70B) and specialized architectures (Bayesian Assistant) achieving significant gains. The Bayesian Assistant’s 81% final accuracy suggests advanced reasoning capabilities, potentially surpassing human benchmarks. The lack of improvement in smaller models (e.g., Qwen 2.5 7B) may indicate challenges in scaling or task-specific optimization. The "Random" baseline underscores that even initial model performance exceeds chance, emphasizing the importance of iterative training in AI development.
</details>
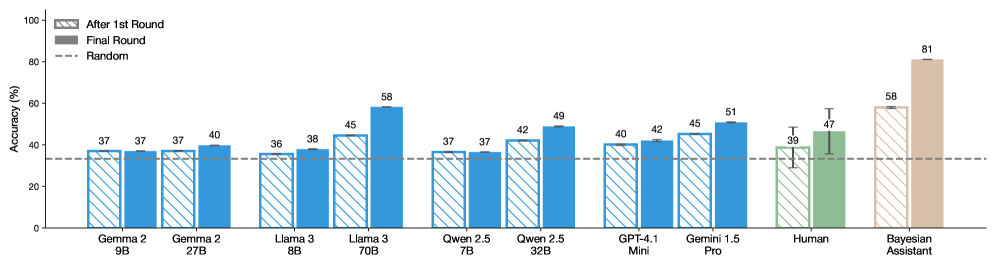
Figure 2: LLMs show limited or no improvement over multiple interactions with the user. We show accuracy after the first round and final (fifth) round. We compare off-the-shelf LLMs from different model families to human participants and the Bayesian Assistant. For human participants, we only evaluate on a subset of 48 out of our 624 simulated users. The LLMs perform considerably worse than the Bayesian Assistant. Human participants demonstrate a larger improvement than most LLMs as they receive more information, but they still fall short of the accuracy that characterizes the normative Bayesian strategy. For the human study, the error bars show the averaged standard error across participants; for models, they show the standard error across the three sets of interactions with each of the 624 users.
2.2 LLMs Show Limited Evidence of Belief Updating
The LLMs we evaluate, like most contemporary LLMs, are first trained to predict upcoming words in a large collection of texts (“pre-training”), and are then specialized to follow user instructions provided in natural language (“instruction-tuning”) [Sanh et al., 2022, Wei et al., 2022a]. Most commercially available models are closed-weights: we can query them but we cannot access their parameters. We evaluate two such closed-weights models, Gemini 1.5 Pro [Team, 2024a] and GPT-4.1 Mini [OpenAI, 2025], which were among the state-of-the-art LLMs at the time of writing [Chiang et al., 2024]. We also evaluate the following open-weights models: Gemma 2 (9B and 27B parameters) [Team, 2024b], Llama 3 (8B and 70B parameters) [Grattafiori et al., 2024], and Qwen 2.5 (7B and 32B parameters) [Yang et al., 2024a]. We chose those models because their performance was quite competitive, and their weights are openly available, which makes it possible to perform fine-tuning (see the next section). We provide these LLMs with English instructions explaining how to act as a flight booking assistant (see Fig. 1 for an example, and Appendix Table 3 for a detailed interaction).
We show results in Fig. 2. Overall, the accuracy of the LLMs after the five rounds of interaction is considerably lower than that of the Bayesian Assistant, and most of the models show little improvement after the first round of interaction (Fig. 2 shows results after the first and fifth round; for results after each of the five rounds, see Appendix Fig. 24). For an exploration of how the models’ performance varies across users’ possible reward functions, see Appendix Section D.2.
A range of follow-up experiments failed to produce meaningful improvement in the LLMs’ behavior (for details, see Appendix Section C.1). Those include experiments with “chain-of-thought prompting” [Wei et al., 2022b, Nye et al., 2021, Kojima et al., 2022], that is, instructions that are meant to encourage the LLM to reason more explicitly (Appendix Fig. 9); an experiment with alternative, purely numerical representations of the flight options that we hypothesized might be easier for the LLMs to parse than the verbal ones we used for our main experiments (Appendix Fig. 9); a setting where we have 30 instead of five rounds of interaction (Appendix Fig. 9); and experiments with models that are only pre-trained to predict upcoming words in texts, without subsequent training to follow user instructions (Appendix Fig. 9).
We also had human participants act as the assistant to a subset of 48 simulated users (see Appendix Section A and Appendix Section F.1 for details). The human participants made recommendations for five rounds and showed a significant improvement between round 1 and 5 (p = 0.002, logistic mixed-effects model). In terms of accuracy, they perform better than small LLMs and slightly worse than larger LLMs (see Appendix Fig. 24 for performance over rounds). That being said, like all LLMs, humans also fall substantially short of the accuracy expected from the normative Bayesian strategy.
3 Teaching LLMs to Approximate Bayesian Reasoning
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Chart: Accuracy (%) Across Model Variants and Rounds
### Overview
The chart compares the accuracy of different AI models (Gemma, Llama, Owen, Bayesian Assistant) across three conditions: "After 1st Round," "Final Round," and a "Random" baseline. Accuracy is measured in percentage, with values ranging from 0% to 100% on the y-axis. The x-axis categorizes models by name and variant (e.g., "Gemma Original," "Gemma Bayesian").
### Components/Axes
- **Y-Axis**: Accuracy (%) from 0 to 100, with increments of 20.
- **X-Axis**: Model variants grouped by name (Gemma, Llama, Owen, Bayesian Assistant), each with three subcategories:
- Original
- Oracle
- Bayesian
- **Legend**:
- **Blue (striped)**: "After 1st Round"
- **Orange (solid)**: "Final Round"
- **Dashed line**: "Random" baseline (37%)
### Detailed Analysis
1. **Gemma Models**:
- **Original**: 37% (After 1st Round), 37% (Final Round).
- **Oracle**: 50% (After 1st Round), 61% (Final Round).
- **Bayesian**: 57% (After 1st Round), 76% (Final Round).
2. **Llama Models**:
- **Original**: 36% (After 1st Round), 38% (Final Round).
- **Oracle**: 48% (After 1st Round), 62% (Final Round).
- **Bayesian**: 57% (After 1st Round), 75% (Final Round).
3. **Owen Models**:
- **Original**: 37% (After 1st Round), 37% (Final Round).
- **Oracle**: 43% (After 1st Round), 53% (Final Round).
- **Bayesian**: 55% (After 1st Round), 68% (Final Round).
4. **Bayesian Assistant**:
- **Bayesian**: 58% (After 1st Round), 81% (Final Round).
### Key Observations
- **Improvement Trends**: All models show increased accuracy from the "After 1st Round" to the "Final Round," except Gemma Original and Owen Original, which remain unchanged.
- **Bayesian Superiority**: Bayesian variants consistently outperform Original and Oracle versions in the Final Round (e.g., Bayesian Assistant reaches 81%, the highest value).
- **Random Baseline**: The dashed line at 37% aligns with the initial accuracies of Gemma Original, Owen Original, and Llama Original, suggesting these models perform near-random chance initially.
- **Oracle vs. Bayesian**: While Oracle models improve significantly (e.g., Llama Oracle: +14%), Bayesian models achieve higher final accuracies (e.g., Llama Bayesian: +18%).
### Interpretation
The data demonstrates that iterative refinement ("Final Round") enhances model performance across all variants. Bayesian approaches, which likely incorporate probabilistic reasoning, achieve the most substantial gains, suggesting they are more effective at leveraging iterative feedback. The "Random" baseline (37%) highlights that some models start with minimal utility, while others (e.g., Bayesian Assistant) surpass human-level performance in the Final Round. This underscores the importance of model architecture (e.g., Bayesian methods) in achieving high accuracy.
</details>
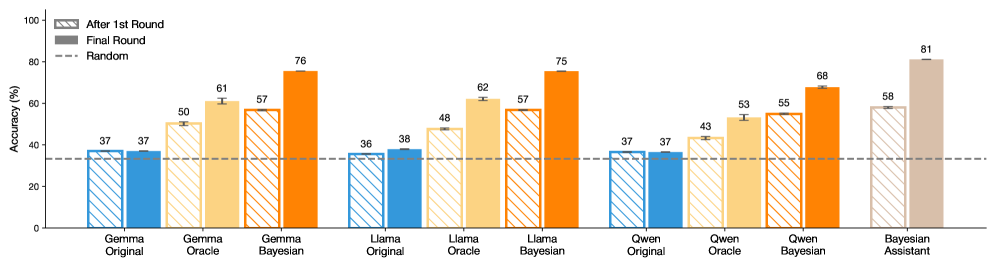
Figure 3: Supervised fine-tuning teaches LLMs to approximate probabilistic inference. We show accuracy after the first round and final (fifth) round across different assistants. We compare the original LLMs, LLMs fine-tuned on user interactions with the Bayesian Assistant, and LLMs fine-tuned on user interactions with an oracle, which always provides the correct answer. Both types of fine-tuning significantly improve LLMs’ performance, and Bayesian teaching is consistently more effectively than oracle teaching. Error bars show the standard error across three random seeds (and three training runs). All results are statistical significant, $p<0.001$ (see Appendix Section G).
We next describe the supervised fine-tuning technique we use to teach the LLM to mimic the normative Bayesian model; we show that this method substantially improves the LLM’s ability to update its beliefs correctly.
From a technical perspective, supervised fine-tuning is similar to the method used to train most LLMs in the first place. The model is provided with the first words of a text and is trained to predict the upcoming word. After each example, the LLM’s weights are adjusted to increase the likelihood of a correct prediction if the same example is observed again. The main difference is that while in the first phase of training the texts are typically drawn from the Internet or similar resources, in the supervised fine-tuning phase the texts are constructed in a targeted way (automatically or by human writers) so as to teach the LLM particular skills [Sanh et al., 2022, Wei et al., 2022a]; to improve arithmetic skills, for example, the model may be given the text “the output of $1+1=...$ is $2$ ”. We apply supervised fine-tuning to the three medium-sized open-weights models (Gemma 2 9B, Llama 3 8B, and Qwen 2.5 7B); we do not attempt to fine-tune the larger models from these families due to computational constraints. We update all of the models’ weights in fine-tuning (in Appendix Section C.2, we show that a different training objective, Direct Preference Optimization [Rafailov et al., 2023], produces similar results, as does a computationally cheaper fine-tuning method, LoRA [Hu et al., 2022], which only updates a subset of the model’s weights).
We explore two strategies to create supervised fine-tuning data. For both strategies, we construct 10 five-round interactions per user. These interactions follow the same format as described above (Appendix Table 3). In the first strategy, which we refer to as oracle teaching, we provide the LLM with interactions between simulated users and an “oracle” assistant that has perfect knowledge of the user’s preferences, and as such always recommends the option that is identical to the user’s choices.
The second strategy, which we call Bayesian teaching, provides the LLM with interactions between the user and the Bayesian Assistant. In this setting, the assistant will often choose flights that do not match the user’s preferred choice, especially in early rounds where it has considerable uncertainty about the user’s preferences. We hypothesize that despite this fact mimicking the Bayesian Assistant’s best guesses would teach the LLM to maintain uncertainty and update its beliefs more effectively than the first strategy where the LLM is trained on the correct choices. This approach can be seen as a form of distillation, where a model is trained by learning to mimic another system [Hinton et al., 2015, Kim and Rush, 2016, Deng et al., 2023, Wang et al., 2023b, Li et al., 2023b, Jung et al., 2024, Yu et al., 2024, Chen et al., 2024b]. We use a uniform prior for the Bayesian Assistant that produces the supervised fine-tuning data. Other priors perform similarly (see Appendix Fig. 16).
3.1 Fine-Tuning Teaches LLMs to Adapt to Users
Both supervised fine-tuning strategies, oracle teaching and Bayesian teaching, significantly improve the LLMs’ performance on the flight recommendation task (Fig. 3). Crucially, after fine-tuning, the LLMs’ performance gradually improves as more information becomes available; this contrasts with the original LLMs, which plateaued after the first round (see the substantial performance improvement between the first and last round in Fig. 3; for detailed results for each round, see Appendix Fig. 25). While there is still a performance gap between the fine-tuned LLMs and the normative Bayesian Assistant, this gap is much narrower than for the original LLMs. All three medium-sized LLMs, which before fine-tuning performed worse than either stronger models or our human participants, markedly outperform them after fine-tuning.
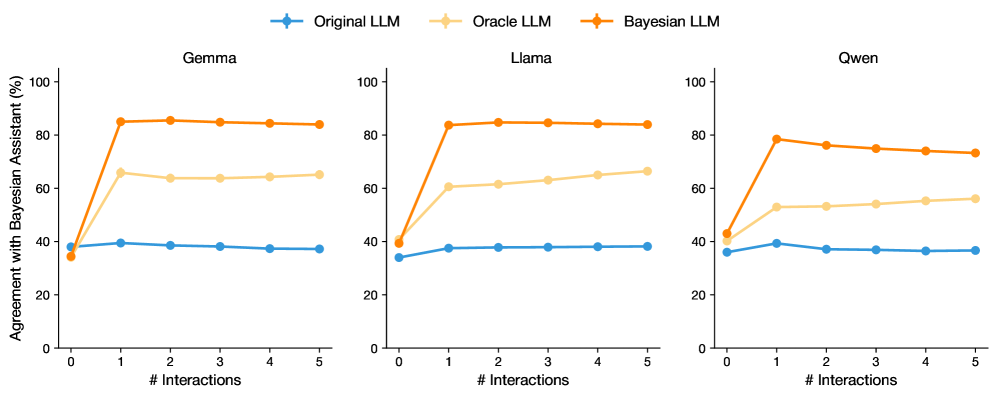
We find that Bayesian teaching leads to higher accuracy and less variability across repetitions of the experiment than oracle teaching (Fig. 3). Bayesian teaching also successfully makes the LLM more Bayesian: the Bayesian-tuned LLMs’ predictions agree with those of the Bayesian Assistant around 80% of the time, significantly more often than do the predictions of the original LLMs and oracle-tuned LLMs (Fig. 4). In Appendix Section D.4, we show that the effectiveness of Bayesian teaching cannot be explained by two potential confounds, and conclude that the effectiveness of this method is in fact due to the Bayesian signal it provides.
The amount of information that can be gained from the user’s choice for a particular option set varies from one set to another. For example, a choice between two flight options that differ in exactly one feature provides direct evidence for the user’s preference for that feature; such a choice could be more informative about the user’s preferences than the choice between options that differ along multiple dimensions. We expect a model with more sophisticated probabilistic skills to show greater sensitivity to this factor. Do our fine-tuned models show such sensitivity? Focusing on the Gemma models, we find that Gemma Original does not show sensitivity to option set informativity, but both fine-tuned versions of Gemma do, with Gemma Bayesian displaying considerably more sensitivity than Gemma Oracle (Appendix Section E).
Can the fine-tuned models accurately verbalize their beliefs? To address this question, we ask the LLMs explicitly for their beliefs about the user’s preferences—we have the simulated user ask them, for example, “on a scale of 1 to 5, what is my preference for price?”. We then test for the accuracy of these verbalized beliefs by deriving flight recommendations from those beliefs, using the same decision procedure we use with the Bayesian Assistant. We find that this approach generally performs better the approach we have used so far where we directly ask for the LLMs’ recommendations; that predictions based on the fine-tuned LLMs’ verbalized beliefs are substantially more accurate than those based on the original LLMs’ verbalized beliefs; and that the Bayesian-tuned LLMs produce more accurate beliefs than either the original LLMs or oracle-tuned ones (for additional details, see Appendix Section B).
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Chart: Agreement with Bayesian Assistant Across LLM Variants
### Overview
The image displays three line charts comparing agreement percentages between different LLM variants (Original, Oracle, Bayesian) and a Bayesian Assistant across three scenarios: Gemma, Llama, and Owen. Each subplot tracks agreement over 0-5 interactions, with distinct trends for each LLM variant.
### Components/Axes
- **X-axis**: Number of Interactions (0-5, integer scale)
- **Y-axis**: Agreement with Bayesian Assistant (%) (0-100, linear scale)
- **Legend**:
- Blue: Original LLM
- Orange: Oracle LLM
- Red: Bayesian LLM
- **Subplots**:
- Left: Gemma
- Center: Llama
- Right: Owen
### Detailed Analysis
#### Gemma Subplot
- **Original LLM**: Starts at ~35%, remains flat (~35-38%) across all interactions.
- **Oracle LLM**: Begins at ~35%, rises to ~65% by interaction 1, then plateaus.
- **Bayesian LLM**: Starts at ~35%, spikes to ~85% by interaction 1, remains stable (~83-85%).
#### Llama Subplot
- **Original LLM**: Starts at ~35%, increases to ~40% by interaction 1, then stabilizes.
- **Oracle LLM**: Begins at ~40%, rises to ~65% by interaction 1, then plateaus.
- **Bayesian LLM**: Starts at ~40%, spikes to ~85% by interaction 1, remains stable (~83-85%).
#### Owen Subplot
- **Original LLM**: Starts at ~35%, increases to ~40% by interaction 1, then stabilizes.
- **Oracle LLM**: Begins at ~40%, rises to ~55% by interaction 1, then plateaus (~55-58%).
- **Bayesian LLM**: Starts at ~40%, spikes to ~75% by interaction 1, then declines slightly to ~70% by interaction 5.
### Key Observations
1. **Bayesian LLM Dominance**: Across all scenarios, Bayesian LLMs achieve the highest agreement, particularly after the first interaction.
2. **Oracle LLM Performance**: Oracle LLMs show moderate improvement over Original LLMs but lag behind Bayesian variants.
3. **Original LLM Stagnation**: Original LLMs exhibit minimal improvement across interactions, remaining near baseline levels.
4. **Owen Anomaly**: Bayesian LLM in Owen subplot shows a post-interaction-1 decline, unlike other scenarios.
### Interpretation
The data suggests Bayesian LLMs are most effective at aligning with the Bayesian Assistant, likely due to their probabilistic reasoning framework. Oracle LLMs demonstrate partial adaptation but lack the full Bayesian optimization. Original LLMs show no meaningful improvement, indicating limited capacity for dynamic adjustment. The Owen subplot's Bayesian decline may reflect scenario-specific constraints (e.g., data quality or task complexity) that reduce model confidence over time. These trends highlight the importance of Bayesian methods in high-stakes alignment tasks, though real-world performance may vary based on implementation details.
</details>
Figure 4: Fine-tuned LLMs agree more with the Bayesian Assistant. We show agreement between the LLMs and the Bayesian Assistant, measured by the proportion of trials where the LLMs makes the same predictions as the Bayesian Assistant. Fine-tuning on the Bayesian Assistant’s predictions makes the LLMs more Bayesian, with the Bayesian versions of each LLM achieving the highest agreement with the Bayesian Assistant. Error bars (too small to be visible in plot) show standard errors across three random seeds (and three training runs).
3.2 Fine-Tuned LLMs Generalize to New Tasks
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Graphs: Generalization to Different Numbers of Features
### Overview
Three line graphs compare the performance of machine learning models (Gemma, Llama, Owen) across tasks (Generalization, Hotel Recommendation, Web Shopping) as the number of features increases. Models include Original LLM, Oracle LLM, Bayesian LLM, Bayesian Assistant, and Random baseline.
### Components/Axes
- **X-axis**: Number of Features (2–8)
- **Y-axis**: Final-round Accuracy (%)
- **Legends**:
- Blue: Original LLM
- Yellow: Oracle LLM
- Orange: Bayesian LLM
- Pink: Bayesian Assistant
- Dashed Gray: Random
### Detailed Analysis
1. **Gemma (Top-Left Graph)**
- **Trend**: All models decline in accuracy as features increase. Bayesian LLM (orange) starts highest (~85%) and declines slowly, while Original LLM (blue) starts at ~40% and plateaus.
- **Data Points**:
- 2 features: Bayesian LLM 85%, Oracle LLM 70%, Original LLM 40%
- 8 features: Bayesian LLM 60%, Oracle LLM 50%, Original LLM 35%
2. **Llama (Top-Center Graph)**
- **Trend**: Similar decline, but Bayesian LLM maintains higher accuracy (~80% at 2 features vs. 60% for Original LLM).
- **Data Points**:
- 2 features: Bayesian LLM 80%, Oracle LLM 65%, Original LLM 38%
- 8 features: Bayesian LLM 65%, Oracle LLM 55%, Original LLM 37%
3. **Owen (Top-Right Graph)**
- **Trend**: Bayesian LLM starts at ~85% (2 features) and declines to ~60% (8 features). Original LLM starts at ~40% and drops to ~30%.
- **Data Points**:
- 2 features: Bayesian LLM 85%, Oracle LLM 70%, Original LLM 40%
- 8 features: Bayesian LLM 60%, Oracle LLM 50%, Original LLM 30%
### Key Observations
- Bayesian models consistently outperform others across all tasks and feature counts.
- Oracle LLM performs better than Original LLM but lags behind Bayesian models.
- Random baseline remains flat (~30–40%) across all tasks.
### Interpretation
Bayesian models demonstrate superior generalization, maintaining higher accuracy even with increased feature complexity. Oracle models approximate Bayesian performance but with a steeper decline, suggesting they may overfit or lack adaptability. The Random baseline’s flat performance indicates that all models outperform chance.
---
## Bar Charts: Generalization to Hotel Recommendation & Web Shopping
### Overview
Bar charts compare model performance (Gemma, Llama, Owen) in specific tasks (Hotel Recommendation, Web Shopping) using Original, Oracle, and Bayesian variants.
### Components/Axes
- **X-axis**: Model Variants (Original, Oracle, Bayesian)
- **Y-axis**: Final-round Accuracy (%)
- **Legends**:
- Blue: Original
- Yellow: Oracle
- Orange: Bayesian
### Detailed Analysis
1. **Hotel Recommendation (Bottom-Left Graph)**
- **Trend**: Bayesian models dominate:
- Gemma Bayesian: 66%
- Llama Bayesian: 65%
- Owen Bayesian: 59%
- **Original/Oracle**:
- Gemma Original: 37%, Oracle: 53%
- Llama Original: 41%, Oracle: 56%
- Owen Original: 36%, Oracle: 48%
2. **Web Shopping (Bottom-Center Graph)**
- **Trend**: Bayesian models again lead:
- Gemma Bayesian: 73%
- Llama Bayesian: 70%
- Owen Bayesian: 69%
- **Original/Oracle**:
- Gemma Original: 54%, Oracle: 61%
- Llama Original: 59%, Oracle: 63%
- Owen Original: 43%, Oracle: 66%
### Key Observations
- Bayesian models achieve **20–30% higher accuracy** than Oracle models in Web Shopping.
- In Hotel Recommendation, Bayesian models outperform Oracle by **10–15%**.
- Original models perform poorly compared to Oracle and Bayesian variants.
### Interpretation
Bayesian models excel in domain-specific tasks (Hotel Recommendation, Web Shopping), likely due to their probabilistic reasoning. Oracle models act as strong baselines but lack the adaptability of Bayesian approaches. The gap between Original and Oracle models highlights the importance of model architecture over raw data.
---
## General Trends Across All Charts
1. **Bayesian Superiority**: Bayesian models consistently outperform others, suggesting their probabilistic framework enhances generalization.
2. **Feature Complexity Trade-off**: Accuracy declines as features increase, but Bayesian models degrade slower, indicating robustness.
3. **Oracle as Midpoint**: Oracle models bridge the gap between Original and Bayesian but fail to match Bayesian adaptability.
4. **Random Baseline**: All models outperform chance (30–40%), validating their utility.
## Conclusion
Bayesian models demonstrate the best generalization across tasks and feature complexity, making them ideal for dynamic, real-world applications. Oracle models serve as strong benchmarks, while Original models require significant improvement for practical use. The data underscores the value of probabilistic reasoning in machine learning systems.
</details>
\phantomsubcaption \phantomsubcaption \phantomsubcaption
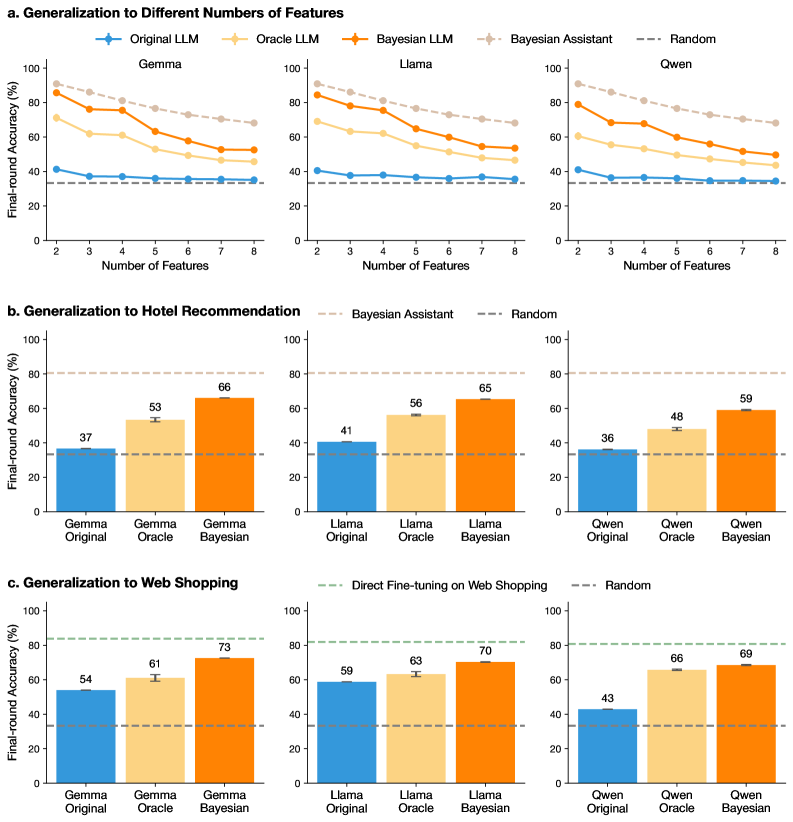
Figure 5: Bayesian teaching generalizes outside the task used for fine-tuning. (a) Final-round accuracy gain in fine-tuned models compared to the original LLM when varying task complexity (here the number of features is a proxy for task complexity). (b) Final-round accuracy for LLMs on the hotel recommendation task, which was not seen during fine-tuning. We show the normative Bayesian Assistant’s performance with brown dashed lines. (c) Final-round accuracy for LLMs on the web shopping domain, also unseen during fine-tuning. The green dashed line indicates the performance of the LLM when it is fine-tuned directly on web shopping data, such that no domain generalization is necessary. Error bars indicate the standard errors over three training runs (for web shopping) and additionally three random seeds (for flight recommendation and hotel recommendation).
As a result of Bayesian teaching, the LLMs demonstrate a greatly improved ability to approximate Bayesian probabilistic inference. Is this ability specific to the particular task the models were trained on, or do the LLMs’ probabilistic skills improve more broadly? To answer this question, we evaluate the fine-tuned LLMs on a set of tasks that diverge to different extents from our original flight recommendation task (see the right panel of Fig. 1 for an overview). All tasks require the LLMs to infer the user’s preferences from the user’s choices over multiple interactions. Overall, as we show in the rest of this section, we find that fine-tuned LLMs show considerable generalization to new settings, and that, as before, Bayesian teaching is more effective than oracle teaching.
We first test the LLMs on variants of the flight recommendation task with different numbers of features: whereas in the interactions provided during fine-tuning, flights were characterized by four features, in this evaluation setting flights are described by between two and eight features. This requires the LLM to generalize to features that were not included in fine-tuning (e.g., the number of checked bags). In this setting, we find that both types of fine-tuning lead to large improvement in accuracy compared to the original LLMs. We also find that Bayesian teaching is considerably more effective than oracle teaching, as before (Fig. 5). We note that as the number of features increases, the space of possible reward functions grows exponentially, and the task becomes inherently more difficult, even for the Bayesian Assistant. Despite this fact, for both fine-tuning methods, performance relative to the upper bound defined by the Bayesian Assistant drops off only moderately as the number of features increases.
The generalization experiments we have discussed so far focused on variants of the flight recommendation task. We next evaluate whether the LLMs can generalize the probabilistic skills they acquire through fine-tuning and apply them to other domains. We consider two such domains: hotel recommendations and web shopping. The hotel recommendation task is a synthetic task whose structure is similar to that of the flight recommendation task presented in fine-tuning. Here, each hotel is defined by four features: distance to downtown, price, rating, and amenities (for an example, see Appendix Table 11).
The web shopping task uses real-world products from a simulated environment [Yao et al., 2022], and differs much more substantially from the fine-tuning task than does the hotel recommendation task. It is difficult to construct a Bayesian Assistant for more natural scenarios like the web shopping task, where the space of user preferences is large and hard to specify formally. For this reason, successful transfer from synthetic settings like the flight recommendation task to more natural scenarios represents a particularly important application of Bayesian teaching. In the web shopping task, each user is defined by a set of randomly sampled goals that characterize the product they are interested in; for example, they might be looking for a shirt that is machine washable, or for a size XL shirt (see Appendix Table 1 for examples). As in the flight domain, the assistant interacts with the user for multiple rounds. In each round, a set of product options is randomly sampled from the product category (e.g., shirts), and the assistant is asked to recommend the best option. Each product is represented by a short title along with a detailed description (see Appendix Table 12 for an example). The user provides feedback at the end of each round, indicating whether or not the assistant’s recommendation was correct. The user’s preferred option is the one with the highest reward, as defined in Yao et al. [2022]. As mentioned above, it is difficult to construct a Bayesian Assistant for this task due to the large space of possible preferences. Instead, as an alternative upper bound on the transfer performance we can expect from the models fine-tuned on the flight recommendation task, we fine-tune LLMs directly on data from the shopping task.
We find that LLMs fine-tuned on the flight recommendation task generalize to both hotel recommendations and web shopping: they perform much better than the original LLMs on those tasks (Fig. 5 and Fig. 5). Bayesian teaching continues to outperform oracle teaching, though the gap is smaller for web shopping than hotel recommendations. There remains a gap between the generalization performance of the LLMs fine-tuned on flight recommendations and the upper bound obtained by fine-tuning the LLMs directly on the web shopping interactions (green dashed line in Fig. 5). Overall, we conclude that fine-tuning, and especially Bayesian teaching, imparts probabilistic skills that transfer substantially beyond the setting used for fine-tuning.
3.3 Generalization to Interactions with Human Users
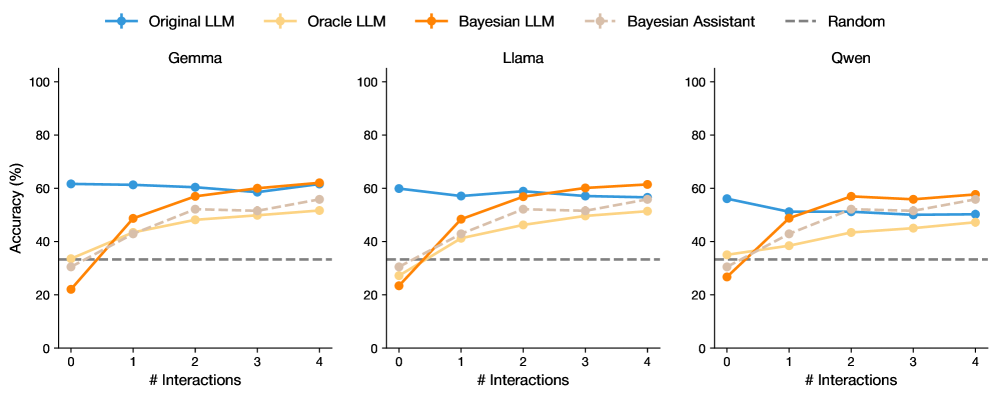
The synthetically generated data we have used so far makes two simplifying assumptions: the simulated users’ choices faithfully reflect the reward function that characterizes their preferences, and all reward functions are encountered equally often. In practice, these assumptions may not hold as humans’ behavior could occasionally be inconsistent with their preferences, due to inattention or other biases, and some preferences may be more common in the population than others (such as a preference for lower price). To evaluate the models in a more realistic setting, we recruit human participants to act as users. Each human participant is asked to first state their preferences for each of the flight features, and then select their preferred flight out of three options, for five different sets of options. We collect data from 10 human participants each for 50 lists of flight option sets, for a total of 500 participants (see Appendix Section A).
The performance of both fine-tuned models and the Bayesian Assistant for human users consistently improves over rounds (Fig. 6), and, as was the case for the simulated users, the Bayesian LLMs consistently outperform the Oracle LLMs; at least for some model families, the Bayesian LLMs also outperform the original LLMs. This indicates that the Bayesian LLMs generalize to human users from the simulated users on which they were fine-tuned.
All models, including the Bayesian Assistant, show substantially lower performance for humans than they did for simulated users, where accuracy after five rounds approached 80% (Fig. 3). In the Appendix Section F.2, we show that this is due to the fact that participants’ choices are not always consistent with their stated preferences, and as such are impossible to predict with high accuracy (Appendix Fig. 22). For the subset of human users whose choices are perfectly consistent with their preferences, the Bayesian LLM performs much better than the original LLM (Appendix Fig. 21; see also Appendix Section D.3, where we study inconsistent simulated users).
Unlike for the simulated users, for human users the original LLMs perform well even after a single interaction (although, crucially, the original LLMs do not improve over interactions). We attribute the original LLMs’ surprisingly strong performance to the fact that human users have generally predictable preferences (e.g., a preference for cheaper flights), such that guesses based on the LLM’s priors, without any adaptation to the individual user, can be quite effective (see Appendix Figs. 20 and 21 for evidence for this hypothesis).
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: Model Accuracy vs. Number of Interactions
### Overview
The image displays three subplots comparing the accuracy trends of five models (Original LLM, Oracle LLM, Bayesian LLM, Bayesian Assistant, and Random) across three datasets (Gemma, Llama, Owen). Accuracy (%) is plotted against the number of interactions (0–4), with distinct color-coded lines for each model.
---
### Components/Axes
- **X-axis**: Number of Interactions (0–4, integer steps)
- **Y-axis**: Accuracy (%) (0–100, linear scale)
- **Legend**: Located at the top, with color-coded labels:
- Blue: Original LLM
- Orange: Oracle LLM
- Brown: Bayesian LLM
- Gray: Bayesian Assistant
- Dashed Gray: Random
- **Subplots**: Three separate plots labeled "Gemma," "Llama," and "Owen" (left to right).
---
### Detailed Analysis
#### Gemma Subplot
- **Original LLM (Blue)**: Starts at ~60%, remains stable (~60–62%) across all interactions.
- **Oracle LLM (Orange)**: Begins at ~30%, rises steadily to ~60% by interaction 4.
- **Bayesian LLM (Brown)**: Starts at ~20%, increases sharply to ~60% by interaction 4.
- **Bayesian Assistant (Gray)**: Begins at ~30%, rises to ~55% by interaction 4.
- **Random (Dashed Gray)**: Flat at ~30% across all interactions.
#### Llama Subplot
- **Original LLM (Blue)**: Starts at ~60%, dips to ~55% at interaction 1, then stabilizes (~55–60%).
- **Oracle LLM (Orange)**: Begins at ~30%, rises to ~50% by interaction 4.
- **Bayesian LLM (Brown)**: Starts at ~20%, jumps to ~50% at interaction 2, remains stable.
- **Bayesian Assistant (Gray)**: Begins at ~30%, peaks at ~55% at interaction 3, then drops slightly.
- **Random (Dashed Gray)**: Flat at ~30%.
#### Owen Subplot
- **Original LLM (Blue)**: Starts at ~60%, drops to ~50% at interaction 1, then stabilizes (~50–55%).
- **Oracle LLM (Orange)**: Begins at ~30%, rises to ~45% by interaction 4.
- **Bayesian LLM (Brown)**: Starts at ~20%, jumps to ~55% at interaction 2, remains stable.
- **Bayesian Assistant (Gray)**: Begins at ~30%, peaks at ~55% at interaction 4.
- **Random (Dashed Gray)**: Flat at ~30%.
---
### Key Observations
1. **Bayesian Models Outperform**: Bayesian LLM and Bayesian Assistant consistently show the steepest improvement across all datasets, surpassing other models by interaction 2–4.
2. **Oracle LLM Improves Gradually**: Oracle LLM demonstrates steady gains but lags behind Bayesian models.
3. **Original LLM Stability**: Original LLM maintains relatively stable performance, with minor fluctuations.
4. **Random Baseline**: The Random model serves as a consistent lower bound (~30%) across all datasets.
5. **Dataset Variability**:
- Gemma shows the most pronounced improvement for Bayesian models.
- Owen exhibits the largest drop in Original LLM performance at interaction 1.
---
### Interpretation
The data suggests that **Bayesian methods (LLM and Assistant)** are highly effective at improving accuracy with increased interactions, outperforming non-Bayesian models. The Oracle LLM also benefits from interactions but to a lesser extent. The Original LLM’s performance is less sensitive to interaction count, while the Random model acts as a static baseline. Notably, the Bayesian Assistant’s peak at interaction 3 in Llama and interaction 4 in Owen indicates a delayed but significant improvement. These trends highlight the importance of interaction count in model refinement, particularly for Bayesian approaches.
</details>
Figure 6: Bayesian teaching generalizes to human users. We show accuracy over rounds when the user is a human participant. The original LLMs achieve strong performance but do not show any learning behavior. In contrast, fine-tuned LLMs (with both Bayesian and Oracle teachers) improve their performance over rounds, and the Bayesian LLMs consistently outperform the Oracle LLMs. Error bars show standard errors across four random seeds (and three training runs; the errors bars are not visible in the plot because they are very small).
4 Discussion
To interact with the world successfully, an agent needs to adapt its behavior as it obtains additional information about the statistics of this environment. To evaluate the ability of large language models (LLMs) to do so, we introduced a simple flight recommendation task where, in order to make accurate predictions, the model needs to adapt to a user’s preferences over multiple interactions with the user. We tested a range of LLMs and found that they struggle to form and update probabilistic beliefs. We further found that continuing the LLMs’ training through exposure to interactions between users and the Bayesian Assistant—a model that implements the normative probabilistic belief update strategy—dramatically improves the LLMs’ ability to approximate probabilistic reasoning. Crucially, this improvement did not only hold for the flight recommendation task the LLM was trained on, but also generalized to variants to the flight recommendation task that the LLM has not encountered before, as well as to other tasks. Across the board, this approach, which we refer to as Bayesian teaching, was more effective than a related approach where the LLM is fine-tuned directly on the correct answers, pointing to the effectiveness of the Bayesian training signal.
Our paradigm differs from those used in previous investigations of LLMs’ probabilistic reasoning abilities, where LLMs were expected to compute statistics explicitly [Nafar et al., 2025, Paruchuri et al., 2024] or provide probability judgments [Zhu and Griffiths, 2024, Belém et al., 2024]. In our paradigm, probabilistic reasoning is as essential as it is in explicit reasoning tasks, but, crucially, it is implicit in the task. Unlike in some recent studies, where the assistant is expected to ask questions to directly elicit the user’s preferences [Li et al., 2023a, Handa et al., 2024, Piriyakulkij et al., 2023, Andukuri et al., 2024, Peng et al., 2024, Aliannejadi et al., 2021, Chen et al., 2024a, Lin et al., 2022], our setup expects the assistant to gradually infer the user’s preferences by simply observing the user’s choices, and to provide recommendations that are increasingly in line with the user’s true preferences. Finally, our findings are consistent with those of concurrent work [Zhao et al., 2025], which also investigates LLMs’ ability to infer user preferences from different types of dialogues, including a condition where the user accepts or rejects one or more options provided by the assistant—a setup similar to ours—where the models performed poorly. Compared to this concurrent study, our work analyzes the LLMs’ behavior through the lens of Bayesian inference, and demonstrates the benefits of mimicking a Bayesian model in fine-tuning compared to a more standard fine-tuning strategy, where the model is always provided with the correct answer (oracle teaching, in the terminology we used in the current paper).
We observed robust generalization from the synthetic flight recommendation task on which the LLMs were fine-tuned to the more natural web shopping task. While performance was even stronger when we fine-tuned the LLM directly on interactions from this task (the green dashed line in Fig. 5), in practice it may be difficult or expensive to collect such data; our synthetic fine-tuning strategy provides an alternative that improves the LLM’s probabilistic reasoning abilities across tasks, without requiring collecting additional data and re-training the model on the new domain.
Our proposal is related to but distinct from approaches that embed an LLM inside a neuro-symbolic framework for probabilistic reasoning [Wong et al., 2023, Feng et al., 2024, Liu et al., 2024, Piriyakulkij et al., 2024, Grand et al., 2023, Ying et al., 2024, Ellis, 2023]. In those approaches, the LLM is used to translate between natural language inputs and formal representations, which in turn serve as input to a symbolic model that can update its beliefs according to the Bayesian framework [Wong et al., 2023]. Indeed, we provide further evidence that hybrid methods can outperform the LLM-only approach in Appendix Section B, where we describe a variation of our method where we first ask the LLM to verbalize its beliefs about the user’s preferences, and then we use an external, symbolic system to make predictions based on these verbalized beliefs. The experiments described in that Appendix section show that in simple tasks where preferences can be mapped to predictions, such hybrid methods indeed outperform a direct interaction with the LLM. Our preliminary explorations of this approach can be developed in greater detail in future work.
Besides their superior performance in certain cases, neuro-symbolic methods have the benefit of greater interpretability, and their probabilistic inferences could be more robust. Crucially, however, the utility of such methods is limited to problems whose structure can be made explicit in the symbolic component of the system. By contrast, the method we propose empowers the LLM to approximate probabilistic inference on its own, such that it can apply this skill to domains that are hard to codify explicitly in a symbolic system, domains such as the web shopping task we have examined. This approach leverages LLMs’ remarkable ability to generalize to new problems defined using natural language.
Notably, even in cases where the domain is simple enough for a purely symbolic model to be constructed, such models may not be consistently more accurate than LLMs. In our study, we found that while for “well-behaved” simulated users a moderate performance gap persisted between the fine-tuned models and the Bayesian Assistant, for human users, whose choices are not always consistent with their preferences, our Bayesian LLMs were in fact superior to the fully symbolic Bayesian Assistant, demonstrating LLMs’ greater robustness to noise compared to symbolic models.
We have argued that through mimicking the Bayesian Assistant the LLMs learn to perform probabilistic inference, albeit only approximately. This hypothesis may appear to be surprising in light of the fact that LLMs’ training objective does not explicitly provide supervision for this skill, and that the transformer architecture does not explicitly track probability distributions: it is trained only to predict the next word produced by the Bayesian Assistant. That being said, there is mounting evidence that in order to predict the next token successfully, LLMs can acquire sophisticated representations that match the structure of the process that generated those tokens. In the case of natural language syntax, for example, the internal representations of LLM trained solely to predict upcoming words have been shown to encode abstract features such as syntactic role and grammatical number [Lakretz et al., 2019, Hao and Linzen, 2023, Manning et al., 2020]. It would be a fruitful direction for future work to determine how probabilistic reasoning is implemented by the LLMs’ internal representations, for example by using techniques such as probes and causal interventions [Finlayson et al., 2021, Ravfogel et al., 2021, Vig et al., 2020] to find internal representations of the model’s probability distributions over users’ preferences, or using circuit analysis [Wang et al., 2023a] to explore the computations through which the model updates these distributions.
The success of Bayesian teaching in imparting approximate probabilistic reasoning skills to LLMs opens up a range of questions for future work. Would the benefits of Bayesian teaching extend to larger models than we were able to fine-tune in this work, or to the recent generation of models that are explicitly trained to reason in words [Guo et al., 2025]? Does the benefit of Bayesian teaching extend to continuous domains and real-world applications beyond the ones we evaluated (for example, interactions whose goal goes beyond shopping)? Could we provide the models with a stronger supervision signal—for example, by instructing them to consider explicit probability distributions, by providing them with explicit supervision on the optimal way to update these distributions (for example, by supervising beliefs as in Appendix Fig. 10), or by encouraging them to maintain explicit representations of users such that the probability distributions are consistent across interactions with the same user, through methods such as supervised fine-tuning or reinforcement learning?
The goal of this study was not to replicate human behavior in LLMs, but rather to identify methods that can bring LLMs’ probabilistic reasoning skills closer to the normative Bayesian strategy: for most applications we expect AI assistants to be follow normative reasoning standards rather than reproduce human deviations from that standard. That being said, our comparisons between LLMs and humans point to a number of directions for future work. Our participants showed substantial deviations from the normative reasoning strategy, in line with prior work on reasoning biases [Eisape et al., 2024, Rottman and Hastie, 2016, Chaigneau et al., 2025, Tversky and Kahneman, 1974]. To what extent can people be taught to follow the normative strategy more closely? Can participants’ apparent biases be explained as consequences of resource limitations [Simon, 1955]? How consistent are participants’ choices with their stated preferences? Do people’s deviations from the normative strategy align with those of LLMs [Eisape et al., 2024], and what properties of an LLM lead to closer alignment with humans?
While our findings from our first experiment point to the limitations of particular LLMs, the positive findings of our subsequent fine-tuning experiments can be viewed as a demonstration of the strength of the LLM “post-training” paradigm more generally: by training the LLMs on demonstrations of the normative strategy to perform the task, we were able to improve their performance considerably, suggesting that they learned to approximate the probabilistic reasoning strategy illustrated by the demonstrations. The LLMs were able to generalize this strategy to domains where it is difficult to encode it explicitly in a symbolic model, demonstrating the power of distilling a classic symbolic model into a neural network. We hypothesize that this generalization ability is, in part, responsible for LLMs’ remarkable empirical success.
Acknowledgments
We thank Stephanie Chan, Andrew Lampinen, Michael Mozer, Peter Shaw, and Zhaofeng Wu for helpful discussions.
Author Contributions
L.Q., F.S., T.L., and S.V.S. co-led the project. S.V.S. conceptualized the project direction. L.Q. conducted the experiments and analysis. L.Q., F.S., T.L., and S.V.S. framed, analyzed and designed experiments, with inputs from K.A. and Y.K. L.Q., T.L., and S.V.S. wrote the paper with help from F.S., K.A., and Y.K.
References
- Achiam et al. [2023] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. GPT-4 technical report. ArXiv preprint, abs/2303.08774, 2023.
- Aliannejadi et al. [2021] M. Aliannejadi, J. Kiseleva, A. Chuklin, J. Dalton, and M. Burtsev. Building and evaluating open-domain dialogue corpora with clarifying questions. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021.
- Andukuri et al. [2024] C. Andukuri, J.-P. Fränken, T. Gerstenberg, and N. Goodman. STaR-GATE: Teaching language models to ask clarifying questions. In First Conference on Language Modeling, 2024.
- Anthropic [2024] Anthropic. Claude 3, 2024.
- Baker et al. [2011] C. Baker, R. Saxe, and J. Tenenbaum. Bayesian theory of mind: Modeling joint belief-desire attribution. In Proceedings of the annual meeting of the cognitive science society, volume 33, 2011.
- Belém et al. [2024] C. G. Belém, M. Kelly, M. Steyvers, S. Singh, and P. Smyth. Perceptions of linguistic uncertainty by language models and humans. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024.
- Brown et al. [2020] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020.
- Chaigneau et al. [2025] S. Chaigneau, N. Marchant, and B. Rehder. Breaking the chains of independence: A bayesian uncertainty model of normative violations in human causal probabilistic reasoning. OSF, 2025.
- Chater and Manning [2006] N. Chater and C. D. Manning. Probabilistic models of language processing and acquisition. Trends in Cognitive Sciences, 10, 2006.
- Chater et al. [2006] N. Chater, J. B. Tenenbaum, and A. Yuille. Probabilistic models of cognition: Conceptual foundations. Trends in Cognitive Sciences, 10(7), 2006.
- Chen et al. [2024a] S. Chen, S. Wiseman, and B. Dhingra. Chatshop: Interactive information seeking with language agents. ArXiv preprint, abs/2404.09911, 2024a.
- Chen et al. [2024b] X. Chen, H. Huang, Y. Gao, Y. Wang, J. Zhao, and K. Ding. Learning to maximize mutual information for chain-of-thought distillation. In Findings of the Association for Computational Linguistics: ACL 2024, 2024b.
- Chiang et al. [2024] W. Chiang, L. Zheng, Y. Sheng, A. N. Angelopoulos, T. Li, D. Li, B. Zhu, H. Zhang, M. I. Jordan, J. E. Gonzalez, and I. Stoica. Chatbot arena: An open platform for evaluating llms by human preference. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, 2024.
- Christiano et al. [2017] P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, 2017.
- Deng et al. [2023] Y. Deng, K. Prasad, R. Fernandez, P. Smolensky, V. Chaudhary, and S. Shieber. Implicit chain of thought reasoning via knowledge distillation. ArXiv preprint, abs/2311.01460, 2023.
- Eisape et al. [2024] T. Eisape, M. Tessler, I. Dasgupta, F. Sha, S. Steenkiste, and T. Linzen. A systematic comparison of syllogistic reasoning in humans and language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024.
- Ellis [2023] K. Ellis. Human-like few-shot learning via bayesian reasoning over natural language. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023.
- Feng et al. [2024] Y. Feng, B. Zhou, W. Lin, and D. Roth. BIRD: A trustworthy bayesian inference framework for large language models. In The Thirteenth International Conference on Learning Representations, 2024.
- Finlayson et al. [2021] M. Finlayson, A. Mueller, S. Gehrmann, S. Shieber, T. Linzen, and Y. Belinkov. Causal analysis of syntactic agreement mechanisms in neural language models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021.
- Grand et al. [2023] G. Grand, V. Pepe, J. Andreas, and J. Tenenbaum. Loose lips sink ships: Asking questions in battleship with language-informed program sampling. In Proceedings of the Annual Meeting of the Cognitive Science Society, volume 46, 2023.
- Grattafiori et al. [2024] A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models, 2024.
- Griffiths et al. [2007] T. L. Griffiths, M. Steyvers, and J. B. Tenenbaum. Topics in semantic association. Psychological Review, 114, 2007.
- Griffiths et al. [2024] T. L. Griffiths, N. Chater, and J. B. Tenenbaum. Bayesian Models of Cognition: Reverse Engineering the Mind. The MIT Press, 2024. ISBN 9780262049412.
- Guo et al. [2025] D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in LLMs via reinforcement learning. Nature, 645, 2025.
- Ha and Schmidhuber [2018] D. Ha and J. Schmidhuber. Recurrent world models facilitate policy evolution. Advances in Neural Information Processing Systems, 31, 2018.
- Handa et al. [2024] K. Handa, Y. Gal, E. Pavlick, N. Goodman, J. Andreas, A. Tamkin, and B. Z. Li. Bayesian preference elicitation with language models. ArXiv preprint, abs/2403.05534, 2024.
- Hao and Linzen [2023] S. Hao and T. Linzen. Verb conjugation in transformers is determined by linear encodings of subject number. In Findings of the Association for Computational Linguistics: EMNLP 2023, 2023.
- Hinton et al. [2015] G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. stat, 1050:9, 2015.
- Hu et al. [2022] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022, 2022.
- Hu and Levy [2023] J. Hu and R. Levy. Prompting is not a substitute for probability measurements in large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023.
- J. Koehler and James [2010] D. J. Koehler and G. James. Probability matching and strategy availability. Memory & Cognition, 38(6), 2010.
- Jern et al. [2017] A. Jern, C. G. Lucas, and C. Kemp. People learn other people’s preferences through inverse decision-making. Cognition, 168, 2017. ISSN 0010-0277.
- Johnson-Laird [1980] P. N. Johnson-Laird. Mental models in cognitive science. Cognitive Science, 4(1), 1980.
- Jung et al. [2024] J. Jung, P. West, L. Jiang, F. Brahman, X. Lu, J. Fisher, T. Sorensen, and Y. Choi. Impossible distillation for paraphrasing and summarization: How to make high-quality lemonade out of small, low-quality model. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024.
- Kim and Rush [2016] Y. Kim and A. M. Rush. Sequence-level knowledge distillation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2016.
- Kojima et al. [2022] T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022.
- Kotha et al. [2024] S. Kotha, J. M. Springer, and A. Raghunathan. Understanding catastrophic forgetting in language models via implicit inference. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024.
- Lakretz et al. [2019] Y. Lakretz, G. Kruszewski, T. Desbordes, D. Hupkes, S. Dehaene, and M. Baroni. The emergence of number and syntax units in LSTM language models. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019.
- LeCun [2022] Y. LeCun. A path towards autonomous machine intelligence. Open Review, 62(1), 2022.
- Li et al. [2023a] B. Z. Li, A. Tamkin, N. Goodman, and J. Andreas. Eliciting human preferences with language models. In The Thirteenth International Conference on Learning Representations, 2023a.
- Li et al. [2023b] L. H. Li, J. Hessel, Y. Yu, X. Ren, K.-W. Chang, and Y. Choi. Symbolic chain-of-thought distillation: Small models can also “think” step-by-step. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023b.
- Lin et al. [2022] J. Lin, D. Fried, D. Klein, and A. Dragan. Inferring rewards from language in context. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022.
- Lin et al. [2024] Y. Lin, H. Lin, W. Xiong, S. Diao, J. Liu, J. Zhang, R. Pan, H. Wang, W. Hu, H. Zhang, H. Dong, R. Pi, H. Zhao, N. Jiang, H. Ji, Y. Yao, and T. Zhang. Mitigating the alignment tax of RLHF. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024.
- Liu et al. [2024] R. Liu, J. Geng, J. Peterson, I. Sucholutsky, and T. L. Griffiths. Large language models assume people are more rational than we really are. In The Thirteenth International Conference on Learning Representations, 2024.
- Manning et al. [2020] C. D. Manning, K. Clark, J. Hewitt, U. Khandelwal, and O. Levy. Emergent linguistic structure in artificial neural networks trained by self-supervision. Proceedings of the National Academy of Sciences, 117(48), 2020.
- Nafar et al. [2025] A. Nafar, K. B. Venable, and P. Kordjamshidi. Reasoning over uncertain text by generative large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, 2025.
- Nye et al. [2021] M. Nye, A. J. Andreassen, G. Gur-Ari, H. Michalewski, J. Austin, D. Bieber, D. Dohan, A. Lewkowycz, M. Bosma, D. Luan, et al. Show your work: Scratchpads for intermediate computation with language models. In Deep Learning for Code Workshop, 2021.
- OpenAI [2025] OpenAI. Introducing GPT-4.1 in the API, 2025.
- Ouyang et al. [2022] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022.
- Palan and Schitter [2018] S. Palan and C. Schitter. Prolific.ac—A subject pool for online experiments. Journal of Behavioral and Experimental Finance, 17, 2018.
- Paruchuri et al. [2024] A. Paruchuri, J. Garrison, S. Liao, J. B. Hernandez, J. Sunshine, T. Althoff, X. Liu, and D. McDuff. What are the odds? language models are capable of probabilistic reasoning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024.
- Peng et al. [2024] A. Peng, Y. Sun, T. Shu, and D. Abel. Pragmatic feature preferences: Learning reward-relevant preferences from human input. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, 2024.
- Piriyakulkij et al. [2023] T. Piriyakulkij, V. Kuleshov, and K. Ellis. Active preference inference using language models and probabilistic reasoning. In NeurIPS 2023 Foundation Models for Decision Making Workshop, 2023.
- Piriyakulkij et al. [2024] T. Piriyakulkij, C. Langenfeld, T. A. Le, and K. Ellis. Doing experiments and revising rules with natural language and probabilistic reasoning. In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024.
- Rafailov et al. [2023] R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023.
- Ravfogel et al. [2021] S. Ravfogel, G. Prasad, T. Linzen, and Y. Goldberg. Counterfactual interventions reveal the causal effect of relative clause representations on agreement prediction. In Proceedings of the 25th Conference on Computational Natural Language Learning, 2021.
- Rehder [2018] B. Rehder. Beyond Markov: Accounting for independence violations in causal reasoning. Cognitive Psychology, 103, 2018.
- Rottman and Hastie [2016] B. M. Rottman and R. Hastie. Do people reason rationally about causally related events? Markov violations, weak inferences, and failures of explaining away. Cognitive Psychology, 87, 2016.
- Sanh et al. [2022] V. Sanh, A. Webson, C. Raffel, S. H. Bach, L. Sutawika, Z. Alyafeai, A. Chaffin, A. Stiegler, A. Raja, M. Dey, M. S. Bari, C. Xu, U. Thakker, S. S. Sharma, E. Szczechla, T. Kim, G. Chhablani, N. V. Nayak, D. Datta, J. Chang, M. T. Jiang, H. Wang, M. Manica, S. Shen, Z. X. Yong, H. Pandey, R. Bawden, T. Wang, T. Neeraj, J. Rozen, A. Sharma, A. Santilli, T. Févry, J. A. Fries, R. Teehan, T. L. Scao, S. Biderman, L. Gao, T. Wolf, and A. M. Rush. Multitask prompted training enables zero-shot task generalization. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022, 2022.
- Simon [1955] H. A. Simon. A behavioral model of rational choice. The Quarterly Journal of Economics, 1955.
- Sloman and Lagnado [2015] S. A. Sloman and D. Lagnado. Causality in thought. Annual Review of Psychology, 66(1), 2015.
- Stiennon et al. [2020] N. Stiennon, L. Ouyang, J. Wu, D. M. Ziegler, R. Lowe, C. Voss, A. Radford, D. Amodei, and P. F. Christiano. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020.
- Team [2024a] Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024a.
- Team [2024b] G. Team. Gemma 2: Improving open language models at a practical size. ArXiv preprint, abs/2408.00118, 2024b.
- Tenenbaum et al. [2006] J. B. Tenenbaum, T. L. Griffiths, and C. Kemp. Theory-based bayesian models of inductive learning and reasoning. Trends in Cognitive Sciences, 10(7), 2006. ISSN 1364-6613. Special issue: Probabilistic models of cognition.
- Tenenbaum et al. [2011] J. B. Tenenbaum, C. Kemp, T. L. Griffiths, and N. D. Goodman. How to grow a mind: Statistics, structure, and abstraction. Science, 331(6022), 2011.
- Touvron et al. [2023] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. ArXiv preprint, abs/2307.09288, 2023.
- Tversky and Kahneman [1974] A. Tversky and D. Kahneman. Judgment under uncertainty: Heuristics and biases: Biases in judgments reveal some heuristics of thinking under uncertainty. Science, 185(4157), 1974.
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, 2017.
- Vig et al. [2020] J. Vig, S. Gehrmann, Y. Belinkov, S. Qian, D. Nevo, Y. Singer, and S. M. Shieber. Investigating gender bias in language models using causal mediation analysis. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020.
- Wang et al. [2023a] K. R. Wang, A. Variengien, A. Conmy, B. Shlegeris, and J. Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023, 2023a.
- Wang et al. [2023b] P. Wang, Z. Wang, Z. Li, Y. Gao, B. Yin, and X. Ren. SCOTT: Self-consistent chain-of-thought distillation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023b.
- Wang et al. [2024] Y. Wang, A. Bai, N. Peng, and C.-J. Hsieh. On the loss of context-awareness in general instruction fine-tuning. ArXiv preprint, abs/2411.02688, 2024.
- Wei et al. [2022a] J. Wei, M. Bosma, V. Y. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V. Le. Finetuned language models are zero-shot learners. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022, 2022a.
- Wei et al. [2022b] J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V. Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022b.
- Wong et al. [2023] L. Wong, G. Grand, A. K. Lew, N. D. Goodman, V. K. Mansinghka, J. Andreas, and J. B. Tenenbaum. From word models to world models: Translating from natural language to the probabilistic language of thought. ArXiv preprint, abs/2306.12672, 2023.
- Xu and Tenenbaum [2007] F. Xu and J. B. Tenenbaum. Word learning as Bayesian inference. Psychological Review, 114(2), 2007.
- Yang et al. [2024a] A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, et al. Qwen2. 5 technical report. arXiv e-prints, 2024a.
- Yang et al. [2024b] H. Yang, Y. Zhang, J. Xu, H. Lu, P.-A. Heng, and W. Lam. Unveiling the generalization power of fine-tuned large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024b.
- Yao et al. [2022] S. Yao, H. Chen, J. Yang, and K. Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022.
- Ying et al. [2024] L. Ying, T. Zhi-Xuan, L. Wong, V. Mansinghka, and J. Tenenbaum. Grounding language about belief in a bayesian theory-of-mind. In Proceedings of the Annual Meeting of the Cognitive Science Society, volume 46, 2024.
- Yu et al. [2024] P. Yu, J. Xu, J. E. Weston, and I. Kulikov. Distilling system 2 into system 1. In The First Workshop on System-2 Reasoning at Scale, NeurIPS’24, 2024.
- Zhao et al. [2025] S. Zhao, M. Hong, Y. Liu, D. Hazarika, and K. Lin. Do LLMs recognize your preferences? evaluating personalized preference following in LLMs. In The Thirteenth International Conference on Learning Representations, 2025.
- Zhu and Griffiths [2024] J.-Q. Zhu and T. Griffiths. Incoherent probability judgments in large language models. In Proceedings of the Annual Meeting of the Cognitive Science Society, volume 46, 2024.
Appendix A Experimental Details
A.1 Simulated Users in the Flight Recommendation Task
In each round, we presented a set of $k$ flight options $\mathcal{O}=\{o_{1},...,o_{k}\}$ to both the simulated user and the assistant (typically $k=3$ ). Each flight has a departure time, a duration, a number of stops, and a cost; these four features are encoded in a vector $\bm{\phi}(o)∈\mathbb{R}^{4}$ . For each flight option, each feature can take one of 11 values uniformly distributed between 0 and 1, except for the number of stops, which has 3 values. This defines $3× 11^{3}$ unique flight options. We converted these four numbers into a textual description illustrated in Fig. 1.
The user’s preferences are defined by a reward function $\bm{\theta}$ parameterized by four numbers, which indicate the user’s preferences for the aforementioned features. The space $\Theta$ of reward functions includes all four-dimensional vectors with the values $\{-1,-0.5,0,0.5,1\}$ , where $-1$ corresponds to a preference for low values of this feature (e.g., short flights) and $1$ to a preference for high values (e.g., long flights). Given a set of flight options $\mathcal{O}$ , the user computes the reward $r(o;\bm{\theta})=\bm{\theta^{T}}\bm{\phi}(o)$ of each flight $o$ , and chooses the flight with the highest reward:
$$
\displaystyle o^{*}(\mathcal{O},\bm{\theta})=\textrm{argmax}_{o\in\mathcal{O}}r(\mathcal{O};\bm{\theta}). \tag{1}
$$
When there was a tie between multiple options, we randomly selected one of the options that had the highest reward. We excluded the reward function $(0,0,0,0)$ , that is, the completely indifferent user. This results in a total of $5^{4}-1=624$ possible reward functions, corresponding to 624 simulated users. We note that these simulated users are highly simplified and are not meant to capture the full complexity of humans: humans do not always choose the option that maximizes their utility [J. Koehler and James, 2010], and their preferences may evolve over time.
A.2 The Bayesian Assistant
Since the space of reward functions is relatively small, we were able perform exact Bayesian updates. In each round, given options $\mathcal{O}$ and the user’s preferred option $o^{*}$ , the Bayesian Assistant updates its posterior as follows:
$$
\displaystyle q^{i+1}_{B}(\bm{\theta}|\mathcal{O}^{i+1},o^{*i+1})=\frac{p(o^{*i+1}|\bm{\theta},\mathcal{O}^{i+1})q^{i}_{B}(\bm{\theta})}{p(o^{*i+1}|\mathcal{O}^{i+1})}, \tag{2}
$$
where the likelihood function indicates whether the reward function is consistent with the user’s choice:
$$
\displaystyle p(o^{*}|\bm{\theta},\mathcal{O})=\mathbbm{1}\big[\max_{o\in\mathcal{O}}r(o;\bm{\theta})=o^{*}]. \tag{3}
$$
The Bayesian Assistant then makes flight recommendations based on its reward posterior mean, $\hat{\bm{\theta}}=\mathbb{E}_{q(\bm{\theta})}[\bm{\theta}]$ , following Equation 1. In most experiments, we used the uniform prior (for experiments with other priors, see Supplementary Fig. C10b).
A.3 LLMs
Our main experiments focus on the instruction-tuned versions of open-weights models, including models from the Gemma 2 [Team, 2024b], Llama 3 [Grattafiori et al., 2024], and Qwen 2.5 [Yang et al., 2024a] families. We used Gemma 2 models with 9B parameters (https://huggingface.co/google/gemma-2-9b-it) and 27B parameters (https://huggingface.co/google/gemma-2-27b-it), Llama 3 models with 8B parameters (https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct) and 70B parameters (https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct), and Qwen 2.5 models with 7B paramters (https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) and 32B parameters (https://huggingface.co/Qwen/Qwen2.5-32B-Instruct). We also evaluated Gemini 1.5 Pro [Team, 2024a] and GPT-4.1 Mini [OpenAI, 2025], which can only be accessed through an API, as representatives of stronger models whose weights are not accessible. All of the models we use are based on the Transformer neural network architecture [Vaswani et al., 2017]. We used greedy decoding (temperature of 0) for all experiments.
A.4 Generalization Tasks
For the variants of the flight recommendation task (see “Fine-tuned LLMs generalize to new tasks”), we varied the number of flight features, ranging from two to eight features. The full flight features include the following features, in addition to the above four: arrival time, layover duration, cancellation policy, and number of bags. As the number of possible reward functions grows exponentially with the number of features, we randomly sampled up to 1,000 reward functions (simulated users) for each number of features.
For the hotel recommendation task, the hotel features include distance to downtown, price, rating, and amenities. For each hotel option, the distance to downtown and price take one of 11 values uniformly distributed between 0 and 1, while rating and amenities take one of 5 values uniformly distributed between 0 and 1, resulting in $5× 5× 11^{2}$ unique hotel options. We evaluated $624$ different simulated users, as in the flight recommendation task.
For the web shopping task, we used real-world products that are publicly available at https://webshop-pnlp.github.io. We chose the 100 categories with the most products. Each product is described by a title and bullet point descriptions, whose length is limited to 800 characters. The reward of a user for a product was calculated based on text-matching heuristics on product attributes and options, following Yao et al. [2022]. For each category, we randomly sampled 10 users, each consisting of five-round interactions. Performance was evaluated on 100 held-out option sets within the same category.
To reduce the sensitivity of the results to the specific randomly selected option sets, we averaged all experiments over three random seeds for flight and hotel recommendations, and over all categories for web shopping. In each case, we report the mean and the standard error across runs and evaluation seeds.
A.5 LLM Fine-Tuning
We used the instruction-tuned version of Gemma 2 9B, Llama 3 8B, and Qwen 2.5 7B for all fine-tuning experiments. For each reward function, we generated 10 user–assistant interactions, resulting in $624× 10=6,240$ fine-tuning examples, each with five-round interactions. We experimented with fine-tuning on more examples but did not observe any significant improvement. The interactions were formatted as shown in Supplementary Table H3.
We used full fine-tuning (i.e. all parameters were updated) with a learning rate of 2e-6, a batch size of 128, and a maximum sequence length of 2048, for 1 epoch. The models were fine-tuned using the standard language modeling objective, i.e., the cross-entropy loss between the model’s predicted token probabilities and the ground-truth tokens in the training data. The loss was only computed on the model’s responses. For each setup, we trained three models with different random seeds. We conducted all fine-tuning experiments using 4 $×$ H100 GPUs based on the standard recipe (https://github.com/huggingface/alignment-handbook). Fine-tuning Gemma 2 9B, Llama 3 8B and Qwen 2.5 7B required about an hour for each model.
A.6 Human Annotations
We collected two sets of human annotations for the flight recommendation task: one where the annotators act as assistants and one where they act as users. The human annotators were recruited online and paid the market rate of $12 an hour, as suggested by the Prolific platform [Palan and Schitter, 2018] we used to recruit participants. See details in Supplementary Section E.
The annotation setup for the assistant role follows the evaluation setup we used for LLMs. In each round, the annotator was asked to make recommendations from three flight options, with each represented in the same format shown to the LLMs. After making their recommendation, the annotator received feedback indicating whether their choice was correct. They were then directed to a preference questionnaire, where they provided their estimates of the user’s preferences for each individual feature (see annotation interface in Supplementary Fig. G17). We sampled 48 reward functions by first grouping them based on the L2 distance between their four-dimensional parameter vector and the origin, then sampling from each group proportionally to its size. We had 15 separate participants provide annotations for each of the 48 simulated users (720 human participants in total).
When the annotator serves in the user role, we first asked them to rate their own preferences for different flight features; this serves as their reward function. Then, the annotator was asked to select their preferred option out of three flight options based on their preferences; this was repeated for five rounds. We constructed 50 such lists of five rounds of flights options, and had 10 annotators produce annotations for each of these 50 lists (500 human participants in total). We then produced three randomly shuffled variants of each of the interactions, for a total of 2000 interactions (500 original interactions and $3× 500$ shuffled interactions). This ensures that a particular option set is not consistently at a particular point in the interaction (for example, at the end of the interaction, where the participants may be paying less attention). To ensure quality, we required annotators to think for at least 30 seconds before making their selection.
Appendix B Can LLMs Accurately Verbalize Their Beliefs?
The results of the fine-tuning experiments described in the main text suggest that fine-tuned models are able to infer the user’s preferences, at least implicitly. Here, we test if the LLMs can verbalize their beliefs about the user’s preferences, based on the user’s previous booking history which is provided as context.
B.1 Eliciting Beliefs About User Preferences
We elicit beliefs in one of two ways. For the open-weights models (Gemma 2, Llama 3, and Qwen 2.5), for which we have access to the probability distribution over upcoming words, we employ continuation scoring, as follows. After interacting with the LLM for one or more rounds, the user asks the LLM for its beliefs about the user’s preferences, for example, “on a scale of 1 to 5, what is my preference for price?”, where $1$ indicates a strong preference for cheaper flights, $3$ indicates no strong preference, and $5$ indicates a strong preference for expensive flights. We score the numbers 1, 2, 3, 4, and 5 as possible continuations of the current text and re-normalize them to form a probability distribution over these five numbers (see Table 4 for a detailed example).
For closed-weights models (Gemini 1.5 Pro and GPT-4.1 Mini), where the LLM’s underlying probability distribution over upcoming words is not made accessible to researchers, we ask the LLM to explicitly provide a probability distribution over each of the five points on the scale (see Table 7; for a comparison between the scoring and explicit probability judgment method in Gemma 2, which finds that scoring yields more accurate estimates, see Section C.1). For our human participants, we use a similar survey to the one we use for closed-weights models.
We then approximate the distribution over reward functions as a factorization of these feature distributions:
$$
\displaystyle q_{LLM}^{i}(\bm{\theta}|\mathcal{O}^{i},o^{*i})\approx\prod_{j}q_{LLM}^{i}(\bm{\theta}_{j}|\mathcal{O}^{i},o^{*i},c_{j}^{i}). \tag{4}
$$
where $q_{LLM}^{i}(\bm{\theta}_{j}|\mathcal{O}^{i},o^{*i},c_{j}^{i})$ is the probability that the LLM assigns to each of the user’s preferences for feature $j$ given the current context in the prompt $c_{j}^{i}$ , using either scoring or explicit probability judgement. This makes an independence assumption, whereby the preference for one feature does not interact with the preference for another; because this assumption is quite strong, we cannot guarantee that it provides a complete picture of the LLM’s beliefs over all possible reward functions. We elicit the LLM’s beliefs by prompting it; it is possible that other techniques, such as probing, where a classifier is trained to decode the model’s internal activations, could yield different results. We leave a more systematic study of this question for future work.
B.2 Evaluating the LLM’s Verbalized Beliefs
To determine whether the LLM can accurately verbalize its beliefs about the user’s preferences, we derive flight recommendations from the LLM’s verbalized beliefs, using the same procedure that the Bayesian Assistant uses to make recommendations based on its explicit beliefs, and evaluate the accuracy of these recommendations. We follow the same evaluation setup as our main experiments, except at the end of each round, we query the LLM’s beliefs about the user’s preferences. Importantly, this process branches out from the main dialogue, ensuring the interaction remains unaffected (Fig. 7). We also examine whether the recommendations produced in this way are consistent with the recommendations made by the LLM directly. High consistency between these two measures would suggest that the LLM’s verbalized beliefs align with the implicit internal beliefs used by the LLM to make predictions in the original setup.
We also perform an analogous analysis for the experiment where human participants acted as the assistant to a simulated user. Recall that after each round we asked the participants what they thought the user’s preferences were. We use these verbalized beliefs about the user’s preferences as input to the same computation we used for the LLMs’ verbalized beliefs. As with the LLMs, we can compute the consistency between the flight choices derived in this way and the participants’ choices in the experiment. We only evaluated on the five-round interactions of the 48 simulated users for which we have human annotations.
<details>
<summary>x7.png Details</summary>
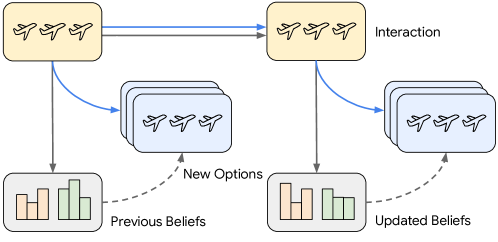
### Visual Description
## Diagram: Belief Update Process via Interaction
### Overview
The diagram illustrates a two-stage belief update mechanism where interactions between entities (represented by airplane icons) influence shifts in preferences. It contrasts "Previous Beliefs" with "Updated Beliefs" through bar charts, showing how interactions generate "New Options" and modify existing beliefs.
### Components/Axes
- **Key Elements**:
- **Interaction Boxes**: Two orange rectangles labeled "Interaction" (left and right), each containing three airplane icons.
- **Belief Charts**:
- **Previous Beliefs**: Left-side bar chart with three categories (Option A, B, C) in orange and green.
- **Updated Beliefs**: Right-side bar chart with the same categories, showing altered heights.
- **Arrows**:
- Solid blue arrows connect "Interaction" boxes to "New Options" and "Updated Beliefs."
- Dashed gray arrows link "Previous Beliefs" to "New Options" and "Updated Beliefs."
- **Legend**: No explicit legend, but color coding is used:
- **Orange**: Represents "Previous Beliefs" (left chart).
- **Green**: Represents "Updated Beliefs" (right chart).
### Detailed Analysis
- **Previous Beliefs**:
- **Option A**: Tallest orange bar (~60% height).
- **Option B**: Medium orange bar (~40% height).
- **Option C**: Shortest orange bar (~20% height).
- **Updated Beliefs**:
- **Option A**: Reduced height (~30%).
- **Option B**: Slightly reduced (~35%).
- **Option C**: Increased height (~50%).
- **Flow**:
1. **Left Interaction** → "New Options" → "Previous Beliefs" (dashed gray arrow).
2. **Left Interaction** → "Updated Beliefs" (solid blue arrow).
3. **Right Interaction** → "New Options" → "Updated Beliefs" (solid blue arrow).
### Key Observations
- **Trend Verification**:
- **Option A/B**: Decline in preference post-interaction (orange to green bars).
- **Option C**: Significant increase in preference (green bar surpasses orange).
- **Spatial Grounding**:
- "Previous Beliefs" (left) and "Updated Beliefs" (right) are spatially separated, emphasizing temporal progression.
- Color consistency confirms orange = prior data, green = updated data.
### Interpretation
The diagram suggests that interactions between entities (airplanes) act as catalysts for belief revision. The shift from "Previous Beliefs" to "Updated Beliefs" indicates a preference for Option C after interaction, possibly due to new information or social influence. The use of bar charts quantifies belief strength, while the directional arrows imply a causal relationship between interaction and belief change. The absence of explicit numerical values introduces uncertainty, but the relative heights of bars strongly support the trend toward Option C dominance. This could model decision-making processes in systems like recommendation algorithms or social dynamics.
</details>
Figure 7: Experimental design for LLM evaluation. At the end of each round, we evaluate the LLM using new option sets for which it has not received feedback. The evaluation branches out from the main interactions (that is, the evaluation performed after the first round is not included in the context of the second round). The LLM’s direct evaluation, where we ask the LLM directly to choose a flight, follows the blue lines; the belief-based evaluation, where we first assess the LLM’s beliefs about the user’s preferences and then use them to choose the flight, follows the gray lines. The dashed lines indicate the deterministic conversion of the LLM’s beliefs into flight recommendations.
<details>
<summary>x8.png Details</summary>
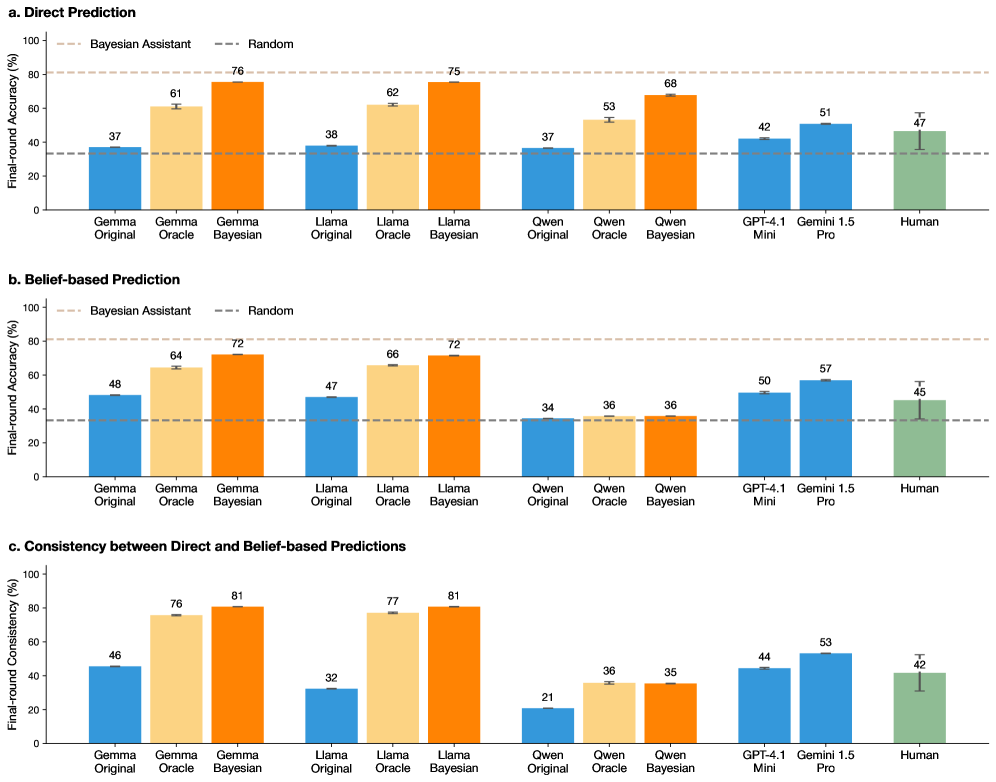
### Visual Description
## Bar Charts: Comparison of AI Models and Human Performance Across Prediction Metrics
### Overview
The image contains three grouped bar charts comparing the performance of various AI models (Gemini, Llama, Qwen, GPT-4.1 Mini, Gemini 1.5 Pro) and humans across three metrics:
1. **Direct Prediction** (Chart a)
2. **Belief-based Prediction** (Chart b)
3. **Consistency between Direct and Belief-based Predictions** (Chart c)
Each chart evaluates final-round accuracy (%) against a "Random" baseline (blue dashed line) and a "Bayesian Assistant" benchmark (orange bars).
### Components/Axes
- **X-axis**: Models/human (Gemini Original, Gemini Oracle, Gemini Bayesian, Llama Original, Llama Oracle, Llama Bayesian, Qwen Original, Qwen Oracle, Qwen Bayesian, GPT-4.1 Mini, Gemini 1.5 Pro, Human).
- **Y-axis**: Final-round accuracy (%) from 0 to 100.
- **Legends**:
- **Bayesian Assistant**: Orange bars (Bayesian-enhanced models).
- **Random**: Blue dashed line (baseline performance).
- **Spatial Grounding**:
- Legends are positioned on the right of each chart.
- X-axis labels are centered below each chart; y-axis labels are on the left.
### Detailed Analysis
#### Chart a: Direct Prediction
- **Bayesian Models**:
- Gemini Bayesian: 76%
- Llama Bayesian: 75%
- Qwen Bayesian: 68%
- **Non-Bayesian Models**:
- Gemini Original: 37%
- Llama Original: 38%
- Qwen Original: 37%
- **Human**: 47%
#### Chart b: Belief-based Prediction
- **Bayesian Models**:
- Gemini Bayesian: 72%
- Llama Bayesian: 72%
- Qwen Bayesian: 36%
- **Non-Bayesian Models**:
- Gemini Original: 48%
- Llama Original: 47%
- Qwen Original: 34%
- **Human**: 45%
#### Chart c: Consistency between Direct and Belief-based Predictions
- **Bayesian Models**:
- Gemini Bayesian: 81%
- Llama Bayesian: 81%
- Qwen Bayesian: 35%
- **Non-Bayesian Models**:
- Gemini Original: 46%
- Llama Original: 32%
- Qwen Original: 21%
- **Human**: 42%
### Key Observations
1. **Bayesian Models Outperform Others**:
- Gemini and Llama Bayesian models consistently achieve the highest accuracy across all metrics (e.g., 76% in Direct Prediction, 81% in Consistency).
- Qwen Bayesian underperforms relative to its non-Bayesian counterpart in Belief-based Prediction (36% vs. 34%).
2. **Human Performance**:
- Humans score mid-range (42–47%) across metrics, outperforming non-Bayesian models but trailing Bayesian models.
3. **Qwen Anomalies**:
- Qwen Bayesian shows inconsistent results: 68% in Direct Prediction but only 35% in Consistency.
4. **Random Baseline**:
- All models and humans exceed the Random baseline (34–38%), indicating meaningful performance.
### Interpretation
- **Bayesian Advantage**: The use of Bayesian methods (e.g., Gemini Bayesian, Llama Bayesian) significantly improves accuracy and consistency, suggesting these models better integrate prior knowledge or uncertainty.
- **Qwen’s Limitations**: Qwen’s Bayesian implementation appears less effective, possibly due to architectural constraints or training data gaps.
- **Human vs. AI**: While humans outperform non-Bayesian models, they lag behind advanced Bayesian AI, highlighting the latter’s potential for complex reasoning tasks.
- **Consistency as a Proxy for Reliability**: High consistency scores (e.g., 81% for Gemini Bayesian) indicate stable performance across prediction types, a critical factor for real-world applications.
This analysis underscores the transformative impact of Bayesian approaches in AI systems, particularly for tasks requiring robust and reliable predictions.
</details>
\phantomsubcaption \phantomsubcaption \phantomsubcaption
Figure 8: Comparison of direct accuracy and belief-based accuracy. We show final-round accuracy based on (a) the LLM’s or human’s direct predictions and (b) predictions derived from their verbalized beliefs about the user’s preferences. The gray dashed line indicates random performance, while the brown dashed line indicates the performance of the Bayesian Assistant. For human participants, we only evaluate on a subset of our evaluation data, which includes 48 different simulated users. (c) Final-round consistency between two predictions: the prediction directly provided by the LLM or human participants and the prediction derived from their beliefs about the user’s preferences. Fine-tuned LLMs show better consistency than the original LLMs, with Bayesian LLMs achieving the highest consistency. Error bars show standard error across participants for humans and across three random seeds (and three training runs) for LLMs.
B.3 Results
For the original LLMs, we find that the approach described in this section—where we first estimate the LLMs’ beliefs about the user’s preferences by explicitly querying the LLMs, and then use a decision-making component that is external to the LLM—performs better than directly using the LLMs’ predictions (Fig. 8 vs. Fig. 8, original LLMs). We also find that the original LLMs’ direct predictions are often inconsistent with the belief-based predictions (those derived from the beliefs elicited from the LLMs), with less than 50% alignment between the two sets of predictions (Fig. 8). Human participants similarly show high inconsistency between the two types of predictions.
Predictions based on the fine-tuned LLMs’ verbalized beliefs are substantially more accurate than those based on the original LLM’s verbalized beliefs, except for Qwen 2.5 models (Fig. 8 and Fig. 8, Oracle LLMs and Bayesian LLMs). This suggests that both training methods teach the LLM to infer the user’s preferences and update them as more information becomes available, even though neither method provides the model with direct access to users’ preferences. For both Gemma 2 and Llama 3, the Bayesian variant of the LLMs produces more accurate estimates of the user’s beliefs than the Oracle one. Likewise, compared to the Oracle variants, the Bayesian variants achieve higher consistency between the predictions directly provided by the LLM and those derived from the LLM’s verbalized beliefs. The difference in overall accuracy between these models’ direct predictions and belief-based predictions is much smaller after fine-tuning. This trend, however, does not hold for Qwen 2.5 model: while direct prediction accuracy improves after fine-tuning, belief-based prediction accuracy remains unchanged from the original LLM. This suggests that for Gemma 2 and Llama 3, prompt-based prediction elicitation may tap into a representation that is shared with the computation used to make direct predictions, but that is not the case for Qwen 2.5.
Appendix C Additional Results
C.1 The Original LLMs’ Poor Performance is Robust to Evaluation Setup
<details>
<summary>x9.png Details</summary>
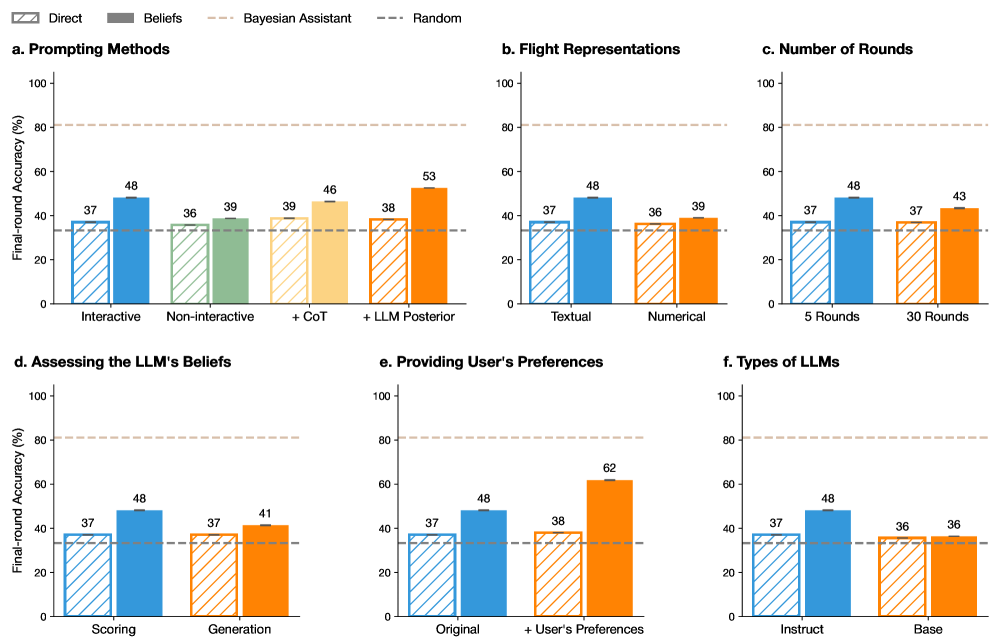
### Visual Description
## Bar Chart Analysis: Prompting Methods and LLM Performance
### Overview
The image contains six grouped bar charts (a-f) comparing final-round accuracy (%) across different prompting methods, flight representations, rounds, belief assessments, user preferences, and LLM types. All charts share a consistent y-axis (0-100% accuracy) and x-axis categories specific to each subplot. A dashed line at ~37% represents a "Random" baseline, while a dotted line at ~80% marks an upper threshold.
---
### Components/Axes
**Legend (Top-left):**
- **Direct** (blue with diagonal stripes)
- **Beliefs** (green with diagonal stripes)
- **Bayesian Assistant** (orange with diagonal stripes)
- **Random** (gray dashed line at ~37%)
**Subplot Labels:**
- **a. Prompting Methods**
- X-axis: Interactive, Non-interactive, + CoT, + LLM Posterior
- **b. Flight Representations**
- X-axis: Textual, Numerical
- **c. Number of Rounds**
- X-axis: 5 Rounds, 30 Rounds
- **d. Assessing the LLM's Beliefs**
- X-axis: Scoring, Generation
- **e. Providing User's Preferences**
- X-axis: Original, + User's Preferences
- **f. Types of LLMs**
- X-axis: Instruct, Base
---
### Detailed Analysis
#### a. Prompting Methods
- **Interactive**:
- Direct: 37%
- Beliefs: 48%
- **Non-interactive**:
- Direct: 36%
- Beliefs: 39%
- **+ CoT**:
- Direct: 39%
- Beliefs: 46%
- **+ LLM Posterior**:
- Direct: 38%
- Beliefs: 53%
#### b. Flight Representations
- **Textual**:
- Direct: 37%
- Beliefs: 48%
- **Numerical**:
- Direct: 36%
- Beliefs: 39%
#### c. Number of Rounds
- **5 Rounds**:
- Direct: 37%
- Beliefs: 48%
- **30 Rounds**:
- Direct: 37%
- Beliefs: 43%
#### d. Assessing the LLM's Beliefs
- **Scoring**:
- Direct: 37%
- Beliefs: 48%
- **Generation**:
- Direct: 37%
- Beliefs: 41%
#### e. Providing User's Preferences
- **Original**:
- Direct: 37%
- Beliefs: 48%
- **+ User's Preferences**:
- Direct: 38%
- Beliefs: 62%
#### f. Types of LLMs
- **Instruct**:
- Direct: 37%
- Beliefs: 48%
- **Base**:
- Direct: 36%
- Beliefs: 36%
---
### Key Observations
1. **Beliefs > Direct**: Across all subplots, "Beliefs" consistently outperforms "Direct" prompting, with the largest gap in **e. Providing User's Preferences** (+62% vs. 38%).
2. **User Preferences Impact**: Adding user preferences in subplot **e** causes the largest accuracy jump (62%), suggesting personalization significantly enhances performance.
3. **LLM Type Neutrality**: Subplot **f** shows no difference between "Instruct" and "Base" LLMs, indicating architectural differences may not affect outcomes under these methods.
4. **Diminishing Returns**: Increasing rounds from 5 to 30 in subplot **c** yields minimal improvement (48% → 43% for Beliefs), implying saturation.
5. **Random Baseline**: All "Direct" methods cluster near the 37% Random line, while "Beliefs" consistently exceeds it.
---
### Interpretation
- **Effective Strategies**:
- **Beliefs prompting** (e.g., incorporating LLM-generated beliefs) and **user preference integration** are the most impactful methods, outperforming direct instruction by 10-25%.
- **Flight representations** (Textual vs. Numerical) show mixed results, with Textual slightly better for Beliefs.
- **LLM Agnosticism**: The lack of difference between "Instruct" and "Base" LLMs suggests prompting method matters more than model architecture.
- **Diminishing Returns**: Extended rounds (30 vs. 5) show negligible gains, highlighting efficiency trade-offs.
- **Outlier**: The 62% accuracy in subplot **e** (+User Preferences) is an extreme outlier, warranting deeper investigation into why personalization drives such high performance.
This analysis underscores the importance of belief-aware prompting and user-centric customization in optimizing LLM performance, while cautioning against over-reliance on extended interaction rounds or architectural complexity.
</details>
\phantomsubcaption \phantomsubcaption \phantomsubcaption \phantomsubcaption \phantomsubcaption \phantomsubcaption
Figure 9: Final-round accuracy of Gemma Original under different variations of our experimental setup. We report both the model’s direct predictions (hatched bars) and the predictions derived from the model’s verbalized beliefs (solid bars; Supplementary Section B). (a) We compare the original interactive setting, where we directly ask the LLM to generate predictions and provide it with feedback, with other common techniques: non-interactive prompting, where we always provide correct examples; chain-of-thought (CoT) prompting, which encourages the LLM to think step-by-step; and methods that incorporate the LLM’s verbalized reward posterior distribution in the context. (b) The textual representation of the flight options, which uses natural language descriptions deterministically generated from the feature values, compared to the numerical representation, which directly uses the feature values. (c) 5-round interactions between the user and the LLM compared to 30-round interactions. (d) The scoring method, which assesses the LLM’s beliefs by scoring possible continuations, compared to the generation method, where we explicitly ask the LLM to generate probability judgments. (e) Performance without versus with the verbalized user’s preferences from the Bayesian model. (f) Instruction-tuned models versus their pre-trained base models. Error bars show standard errors across three random seeds.
In light of the poor performance of the original LLMs (before fine-tuning), we considered various modifications to our evaluation setting. These include prompting-based methods, that is, modifications to the instructions provided to the LLM; an alternative, numerical representation of the flight options; and a greater number of interactions. We also ablate methods that access the LLM’s verbalized beliefs, explore whether providing the user’s preferences improves performance, and compare the instructed version of the models with their corresponding pre-trained versions. These robustness analyses focus on Gemma 2 9B. Overall, we do not observe significant differences across these evaluations; the only methods that we find effectively improved model performance involved fine-tuning (see Section C.2).
Advanced prompting methods do not improve accuracy.
Our main experiments evaluate the LLM in an interactive setting, where the user provides it with feedback indicating whether the LLM’s choice is correct. In this case, the user’s feedback is always based on the LLM’s prediction. We first experiment with an alternative non-interactive setting, where the context for the assistant includes all previous rounds and the option chosen by the assistant in these context rounds is always correct, a setting that better approximates the standard few-shot or in-context learning setup for LLMs (Brown et al. [2020]; see Table 10 for an example). While performance on direct prediction remains similar, we observe a performance drop when evaluating with predictions derived from the LLM’s beliefs (Fig. 9, “Non-interactive’).
Chain-of-thought (CoT) prompting [Wei et al., 2022b, Nye et al., 2021, Kojima et al., 2022], which encourages the model to generate step-by-step reasoning chains, has been shown to be effective on many reasoning tasks. We evaluate the LLM using this strategy by explicitly including reasoning hints and the phrase “Let’s think step by step” in the instruction (see Table 8 for an example prompt). We find that LLMs prompted with CoT perform similarly to those prompted in the way described in the main text (Fig. 9, “ $+$ CoT”).
Since inferring user’s preferences based on current information before making recommendations is crucial in our task, we further evaluate another CoT-style two-stage prompting method, where we allow the LLM to explicitly reason over the posterior distribution over reward functions. Specifically, we verbalize the LLM’s reward posterior distribution using natural language and add it to the LLM’s context (see Table 9 for an example). Explicitly encouraging the LLM to reason over its own reward posterior distribution improves the predictions derived from its verbalized beliefs. However, direct prediction accuracy remains similar (Fig. 9, “ $+$ LLM Posterior”).
Though additional prompt engineering and advanced prompting techniques could potentially yield different results; in particular, some prompts may more effectively extract the model’s beliefs than the ones we used. For the moment, however, our preliminary findings suggest that it is challenging to significantly improve the LLM’s performance purely through prompting.
The LLMs’ poor performance is not due to inability to parse the flight representations.
Our main experiments use a representation that deterministically maps the feature value of each flight to a textual description (e.g., the departure time may be 02:00 PM and the duration 2 hr 30 min). While this textual representation is closer to realistic scenarios, and may therefore better align with the LLM’s training distribution, this setup introduces a potential confounder that complicates the interpretation of our results: the LLM’s poor performance in the flight recommendation task could be due to its inability to translate the text description into the feature space required for probabilistic reasoning. To control for this factor, we investigate an alternative numerical representation of the flight options, where we directly provide the LLM with numerical feature values in the same format we provide them to the Bayesian Assistant (e.g., the duration may be 0.9 instead of 16 hr 6 min; see Table 5 and Table 6 for examples). We find that, if anything, the textual representation outperforms its numerical counterpart in both accuracy metrics (Fig. 9). This suggests that the LLM’s poor performance cannot be attributed to an inability to parse the textual format to a numerical value.
Increasing the number of interactions does not improve performance.
Our previous experiments include only five rounds of interactions between the user and the LLM. To investigate the possibility that LLMs do in fact extract information from the interaction and update their beliefs, but do so more slowly than the Bayesian Assistant, we increase the number of interactions to 30. We find that Gemma Original still shows similar performance; if anything, its performance is slightly worse compared to our main experiments (Fig. 9). This indicates that simply increasing the number of interactions is unlikely to significantly improve the LLM’s performance.
Assessing the LLM’s beliefs: Scoring continuations vs. explicit probability judgments.
In the main experiment, for the open-weights LLMs where we have access to the probabilities the LLM assigns to upcoming words, we estimate the LLM’s distribution over reward functions by asking it to rate individual features and scoring the possible continuations; for flight duration, for example, we might ask it what the user’s preference is on a scale of 1 to 5. We refer to this method as “scoring”. Here, we compare this method to one where we instruct the LLM to assign a probability to each of the five ratings on each scale; we refer to this method as “generation” (see Table 7 for an example). The generation method is also used for experiments with the closed-weights models, as we do not have access to these LLM’s probabilities. As in the scoring method, we renormalize the probabilities to ensure that they sum to 1 (although we find that this step is typically not necessary as they already sum to 1). Overall, we find the scoring-based reward distribution, which we use in the main text for the open-weights models, is closer than the generation-based one to the ground truth distribution (Fig. 9; for related results, see Hu and Levy [2023]).
Can the LLM make recommendations given the user’s preferences?
The flight recommendation task requires two capabilities: inferring the user’s preferences and making predictions based on these preferences. We previously showed that the original LLM performs poorly at inferring the user’s preferences (Fig. 8). Here, we investigate its performance in the latter one. Specifically, we provide the LLM with the verbalized reward posterior distribution from the normative Bayesian model (see Table 9 for an example). In this case, the LLM only needs to make recommendations based on the provided preferences. We find that having access to the optimal reward posterior distribution improves belief-based accuracy; however, the direct prediction accuracy remains similar (Fig. 9). Although our method of presenting user’s preferences to the LLM may not be optimal, these results suggest that the LLM struggles to make correct recommendations even when the user’s preferences are explicitly provided.
Types of LLMs: Instructed model vs. pre-trained base model.
We use instruction-tuned LLMs for our main experiments. As these models are trained using an additional post-training alignment stage, their behavior is likely to differ from their pre-trained base model counterparts [Lin et al., 2024, Yang et al., 2024b, Wang et al., 2024, Kotha et al., 2024], though because we expect instruction-tuning to improve the models’ interactive capabilities, we hypothesize that the base version of Gemma would not perform better than the instruction-tuned one. As base models are not well-suited to interactive evaluation, we evaluate them using the non-interactive setting by providing them with in-context examples (see earlier in this section). We find that the base model performs comparably to the instruction-tuned one (Fig. 9); we omit the results for Llama 3 and Qwen 2.5, which were similar.
C.2 Modifications to Training Setup
This Supplementary describes variants on the methods we used to fine-tune the LLMs on interactions with users. We only explore these variants for Bayesian teaching, which was consistently more effective than oracle teaching). We use Gemma 2 9B for all of the follow-up experiments reported in this section.
<details>
<summary>x10.png Details</summary>
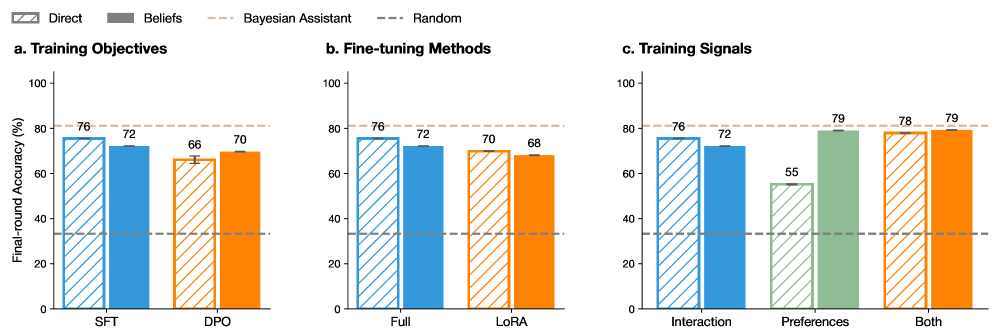
### Visual Description
## Bar Charts: Training Objectives, Fine-tuning Methods, and Training Signals
### Overview
The image contains three grouped bar charts labeled **a. Training Objectives**, **b. Fine-tuning Methods**, and **c. Training Signals**. Each chart compares performance metrics (Final-round Accuracy %) across different categories and methods, with a legend indicating four data series: **Direct**, **Beliefs**, **Bayesian Assistant**, and **Random**. The charts use distinct color patterns for each series to differentiate them.
---
### Components/Axes
- **Legend**: Located at the top-left corner.
- **Direct**: Blue with diagonal stripes.
- **Beliefs**: Gray.
- **Bayesian Assistant**: Orange with diagonal stripes.
- **Random**: Dashed line.
- **X-Axes**:
- **a. Training Objectives**: Categories **SFT** and **DPO**.
- **b. Fine-tuning Methods**: Categories **Full** and **LoRA**.
- **c. Training Signals**: Categories **Interaction**, **Preferences**, and **Both**.
- **Y-Axes**: All charts share the same scale: **Final-round Accuracy (%)**, ranging from 0 to 100.
---
### Detailed Analysis
#### a. Training Objectives
- **SFT**:
- Direct: 76% (blue striped).
- Beliefs: 72% (gray).
- Bayesian Assistant: 66% (orange striped).
- Random: 70% (dashed).
- **DPO**:
- Direct: 76% (blue striped).
- Beliefs: 72% (gray).
- Bayesian Assistant: 70% (orange striped).
- Random: 68% (dashed).
#### b. Fine-tuning Methods
- **Full**:
- Direct: 76% (blue striped).
- Beliefs: 72% (gray).
- Bayesian Assistant: 70% (orange striped).
- Random: 68% (dashed).
- **LoRA**:
- Direct: 76% (blue striped).
- Beliefs: 72% (gray).
- Bayesian Assistant: 70% (orange striped).
- Random: 68% (dashed).
#### c. Training Signals
- **Interaction**:
- Direct: 76% (blue striped).
- Beliefs: 72% (gray).
- Bayesian Assistant: 70% (orange striped).
- Random: 68% (dashed).
- **Preferences**:
- Direct: 55% (blue striped).
- Beliefs: 79% (gray).
- Bayesian Assistant: 78% (orange striped).
- Random: 79% (dashed).
- **Both**:
- Direct: 76% (blue striped).
- Beliefs: 78% (gray).
- Bayesian Assistant: 79% (orange striped).
- Random: 79% (dashed).
---
### Key Observations
1. **Consistency Across Methods**:
- In **a. Training Objectives** and **b. Fine-tuning Methods**, the **Direct** and **Beliefs** methods consistently outperform **Bayesian Assistant** and **Random**.
- **DPO** and **LoRA** show identical performance to **SFT** and **Full**, respectively, suggesting no significant difference between these subcategories.
2. **Training Signals Anomalies**:
- In **c. Training Signals**, the **Preferences** category shows a sharp drop in **Direct** (55%) compared to other methods, while **Beliefs** and **Random** achieve the highest accuracy (79%).
- The **Both** category combines the highest accuracy (79%) across all methods, indicating synergy between training signals.
3. **Random Baseline**:
- The **Random** series (dashed line) consistently underperforms, with values ranging from 68% to 79%, suggesting it serves as a weak baseline.
---
### Interpretation
- **Training Objectives**:
- **Direct** and **Beliefs** methods are more effective than **Bayesian Assistant** and **Random** in both **SFT** and **DPO** settings. This implies that explicit training objectives (e.g., direct feedback) yield better results than probabilistic or random approaches.
- **Fine-tuning Methods**:
- No significant difference is observed between **Full** and **LoRA** fine-tuning methods, indicating that the choice of fine-tuning strategy may not critically impact performance under the tested conditions.
- **Training Signals**:
- **Preferences** as a training signal significantly boosts **Beliefs** and **Random** accuracy, suggesting that user preferences or implicit signals can enhance model performance.
- The **Both** category (combining interaction and preferences) achieves the highest accuracy, highlighting the value of integrating multiple training signals.
- **Outliers**:
- The **Direct** method underperforms in the **Preferences** category (55%), possibly due to misalignment between direct feedback and user preferences.
---
### Conclusion
The data demonstrates that **Direct** and **Beliefs** methods are robust across training objectives and fine-tuning strategies, while **Preferences** as a training signal can significantly improve performance when combined with other signals. The **Random** baseline consistently underperforms, reinforcing the importance of structured training approaches. The consistency in **Full** and **LoRA** fine-tuning methods suggests that architectural choices may be less critical than the training objectives and signals themselves.
</details>
\phantomsubcaption \phantomsubcaption \phantomsubcaption
Figure 10: Final-round accuracy of LLMs fine-tuned with different training strategies on the flight recommendation task. We use Bayesian teaching (i.e. users’ interactions with the Bayesian Assistant) for all experiments. (a) Comparison of training objectives: supervised fine-tuning (SFT) vs. direct preference optimization (DPO). (b) Fine-tuning methods: full fine-tuning, which updates all model parameters, vs. LoRA fine-tuning, a parameter-efficient method that only updates partial parameters. (c) Training only on interactions between users and assistants, as in our other experiments, compared to training on the Bayesian Assistant’s estimate of the user’s preferences, as well as training on both interactions and the estimated preferences. Error bars show standard errors across three random seeds and three training runs.
Training objective: Supervised fine-tuning vs. Direct preference optimization.
In most of our experiments, we use supervised fine-tuning (SFT) to provide the oracle and Bayesian predictions. In this method, the LLM is trained to predict the upcoming token in the interaction, the same objective used during pre-trainining. Here, we examine the utility of reinforcement learning from human feedback (RLHF; Christiano et al. [2017], Ouyang et al. [2022], Stiennon et al. [2020]), another common practice for adapting LLMs’ behavior following pre-training, in which the LLM is instead provided with an explicit signal indicating whether an output is preferable. In particular, we use direct preference optimization (DPO; Rafailov et al. [2023]), where the model is trained to assign higher probability to the preferred response than to the less preferred one. We investigate the DPO training objective by treating the Bayesian Assistant’s prediction as the preferred one while using a different random recommendation as the less preferred one. We train the model with the DPO objective with a learning rate of 2e-6 and $\beta=0.1$ . We find that training on Bayesian predictions works comparably for both SFT (used in main experiments) and DPO objectives (Fig. 10), indicating that the approach is robust to the choice of training objective.
Full vs. parameter-efficient fine-tuning.
In our main experiments, we update all model parameters. As this approach becomes less feasible as the model size grows, a common strategy to improve training efficiency relies on parameter-efficient fine-tuning, where only a subset of parameters is updated. We evaluate this approach using Low-Rank Adaptation (LoRA; Hu et al. [2022]), a method that injects trainable rank decomposition matrices while keeping the original model weights frozen. We perform LoRA fine-tuning with a learning rate of 2e-5. While LoRA fine-tuning performs slightly worse than full fine-tuning (Fig. 10), it achieves comparable performance while significantly reducing training costs. This demonstrates that our fine-tuning strategy can be effectively applied in computationally efficient settings, which is particularly beneficial for larger LLMs.
Providing Bayesian preference estimates in fine-tuning.
We have shown in the main text that fine-tuning the LLMs to make better recommendations also significantly improves its ability to infer the user’s preferences, even though their supervision does not explicitly include the user’s preferences. Here, we investigate a complementary setup, where we explicitly train the model to match the Bayesian Assistant’s estimates of the user’s preferences, but not to make flight recommendations. The Bayesian Assistant produces a posterior probability distribution over all reward functions after each round; we select the reward function with the highest posterior probability and provide it to the LLM, formatted as in Table 4. We find that, like training on interactions, providing the user’s preferences as a fine-tuning signal improves both accuracy measures, compared to Gemma Original, but the gain in direct prediction accuracy on is smaller than when we fine-tune on interactions (Fig. 10). We also explore a setting where both the interactions and the preferences are provided during training; this setting leads to the best performance on both metrics, with accuracy approaching the accuracy of the Bayesian Assistant.
Appendix D Additional Analyses
D.1 LLM Priors
<details>
<summary>x11.png Details</summary>
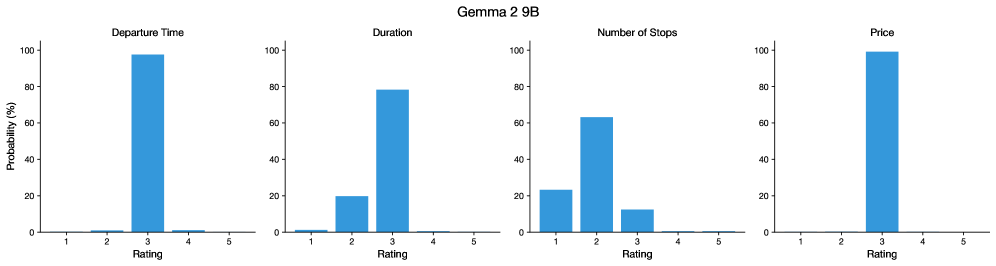
### Visual Description
## Bar Charts: Gamma 2 9B Ratings Distribution
### Overview
The image displays four side-by-side bar charts comparing user ratings (1-5) across four metrics: Departure Time, Duration, Number of Stops, and Price. All charts use a y-axis labeled "Probability (%)" (0-100) and x-axis labeled "Rating" (1-5). The charts show strong concentration of ratings at specific points, with minimal distribution across other values.
### Components/Axes
- **Main Title**: "Gamma 2 9B" (center top)
- **Y-Axes**: All charts share identical y-axis:
- Label: "Probability (%)"
- Scale: 0-100 in 20% increments
- **X-Axes**: All charts share identical x-axis:
- Label: "Rating"
- Categories: 1, 2, 3, 4, 5
- **Legend**: Not present
- **Bar Colors**: All bars use blue fill with white text labels
### Detailed Analysis
1. **Departure Time**
- Rating 3: ~98% probability (tallest bar)
- Ratings 2 & 4: ~1% each (tiny bars)
- Ratings 1 & 5: 0%
2. **Duration**
- Rating 3: ~78% probability
- Rating 2: ~20% probability
- Ratings 1, 4, 5: 0-1%
3. **Number of Stops**
- Rating 2: ~62% probability (tallest bar)
- Rating 3: ~12% probability
- Ratings 1, 4, 5: 0-1%
4. **Price**
- Rating 3: ~98% probability (tallest bar)
- Ratings 1-2, 4-5: 0%
### Key Observations
- **Dominance of Rating 3**: Three metrics (Departure Time, Duration, Price) show near-universal 3-star ratings
- **Bimodal Pattern**: Duration shows secondary peak at rating 2 (~20%)
- **Negative Correlation**: Number of Stops is the only metric with a dominant rating below 3 (rating 2)
- **Extreme Concentration**: All metrics show >90% of ratings clustered in single values
- **Missing Data**: No ratings recorded for 1, 4, or 5 in most metrics
### Interpretation
The data suggests users consistently rate these aspects of Gamma 2 9B at 3 stars, indicating moderate satisfaction. However, the Number of Stops metric deviates significantly, showing preference for fewer stops (rating 2). This could imply:
1. Users tolerate longer durations and higher prices if stops are minimized
2. The "3" rating may represent a neutral midpoint in their evaluation system
3. Potential data collection bias (e.g., only collecting ratings from specific user segments)
The extreme concentration of ratings suggests either:
- A highly standardized user experience
- Limited rating options available to users
- Possible data aggregation issues (e.g., rounding)
The absence of 1-2-4-5 ratings in most metrics raises questions about rating scale usage or data filtering criteria.
</details>
<details>
<summary>x12.png Details</summary>
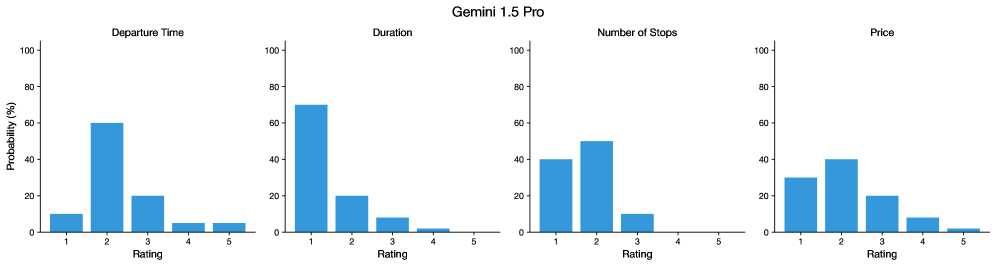
### Visual Description
## Bar Chart: Gemini 1.5 Pro
### Overview
The image displays four bar charts arranged in a 2x2 grid, each representing the probability distribution of different attributes (Departure Time, Duration, Number of Stops, Price) across a 5-point rating scale. All bars are blue, with a legend positioned at the top-right corner. The y-axis is labeled "Probability (%)" (0–100%), and the x-axis is labeled "Rating" (1–5). The main title "Gemini 1.5 Pro" is centered at the top.
### Components/Axes
- **Legend**: Located at the top-right corner, indicating the color blue corresponds to all data series (no explicit labels for categories).
- **Axes**:
- **X-axis**: "Rating" (1–5), evenly spaced.
- **Y-axis**: "Probability (%)" (0–100%), with increments of 20%.
- **Charts**:
1. **Departure Time**: Highest probability at Rating 2 (~60%), followed by Rating 3 (~20%), and lower values for Ratings 1, 4, and 5.
2. **Duration**: Highest probability at Rating 1 (~70%), followed by Rating 2 (~20%), with negligible values for Ratings 3–5.
3. **Number of Stops**: Highest probability at Rating 2 (~50%), followed by Rating 1 (~40%), and Rating 3 (~10%), with no values for Ratings 4–5.
4. **Price**: Highest probability at Rating 2 (~40%), followed by Rating 1 (~30%), Rating 3 (~20%), Rating 4 (~10%), and Rating 5 (~2%).
### Detailed Analysis
- **Departure Time**:
- Rating 2 dominates (~60%), suggesting a strong preference for this rating.
- Ratings 1, 4, and 5 have low probabilities (<10%).
- **Duration**:
- Rating 1 is most probable (~70%), indicating a preference for shorter durations.
- Ratings 3–5 have minimal probabilities (<5%).
- **Number of Stops**:
- Rating 2 is the most probable (~50%), followed by Rating 1 (~40%).
- Rating 3 has a smaller share (~10%), while Ratings 4–5 are absent.
- **Price**:
- Rating 2 is the most probable (~40%), with Rating 1 (~30%) and Rating 3 (~20%) also significant.
- Ratings 4 and 5 have low probabilities (~10% and ~2%, respectively).
### Key Observations
1. **Dominance of Lower Ratings**: Departure Time, Duration, and Number of Stops show strong probabilities for lower ratings (1–3), suggesting a preference for shorter, simpler, or less frequent options.
2. **Price Anomaly**: While Rating 2 is the most probable for Price, Rating 1 also has a notable share (~30%), unlike other categories where Rating 1 is less dominant.
3. **High Ratings (4–5)**: Rarely appear in all categories, with only Rating 5 in Price having a minimal presence (~2%).
### Interpretation
The data suggests that users or systems prioritize lower ratings for attributes like Departure Time, Duration, and Number of Stops, likely due to efficiency or cost concerns. For Price, Rating 2 is the most probable, but Rating 1’s significant share (~30%) may indicate a bifurcation in pricing strategies (e.g., budget vs. mid-range options). The near-absence of high ratings (4–5) across most categories implies that extreme values (e.g., very long durations or high prices) are uncommon or undesirable. The anomaly in Price’s Rating 5 (~2%) could reflect a niche market or outliers in pricing data. Overall, the trends highlight a preference for balanced, mid-range options over extremes.
</details>
Figure 11: Priors of Gemma 2 9B Original and Gemini 1.5 Pro for each flight feature. We obtain these priors via the prompting-based elicitation method (Supplementary B). A rating of 1 indicates a strongest preference for the earliest departure time, the shortest duration, the fewest number of stops, and the lowest price, while a rating of 5 indicates the opposite. A rating of 3 indicates no preference.
In the section Generalization to interactions with human users, we find that the original LLMs, before fine-tuning, were able to provide recommendations with an accuracy substantially higher than chance even before their first interaction with the user, suggesting that the LLMs’ priors are aligned with human preferences. In this section, we test this hypothesis by asking two models, Gemma 2 and Gemini 1.5, for their verbalized beliefs in advance of any interaction with a particular user. Fig. 11 shows the results. For Gemma 2 9B, the hypothesis is only partly supported: the prior derived from this model assigns a high probability to “no preference” for most of the features, with the exception of the number of stops, where it reflects a moderate preference for fewer stops. By contrast, Gemini 1.5 Pro has a more diffuse prior over these features, which favors cheaper and shorter flights, as well as flights that leave earlier in the day, plausibly reflecting the preferences of most flyers. We note that the interpretation of this pattern of results is complicated by the fact that Gemma’s verbalized prior beliefs may not faithfully reflect the underlying prior it uses to make recommendations before having interacted with a user.
<details>
<summary>x13.png Details</summary>
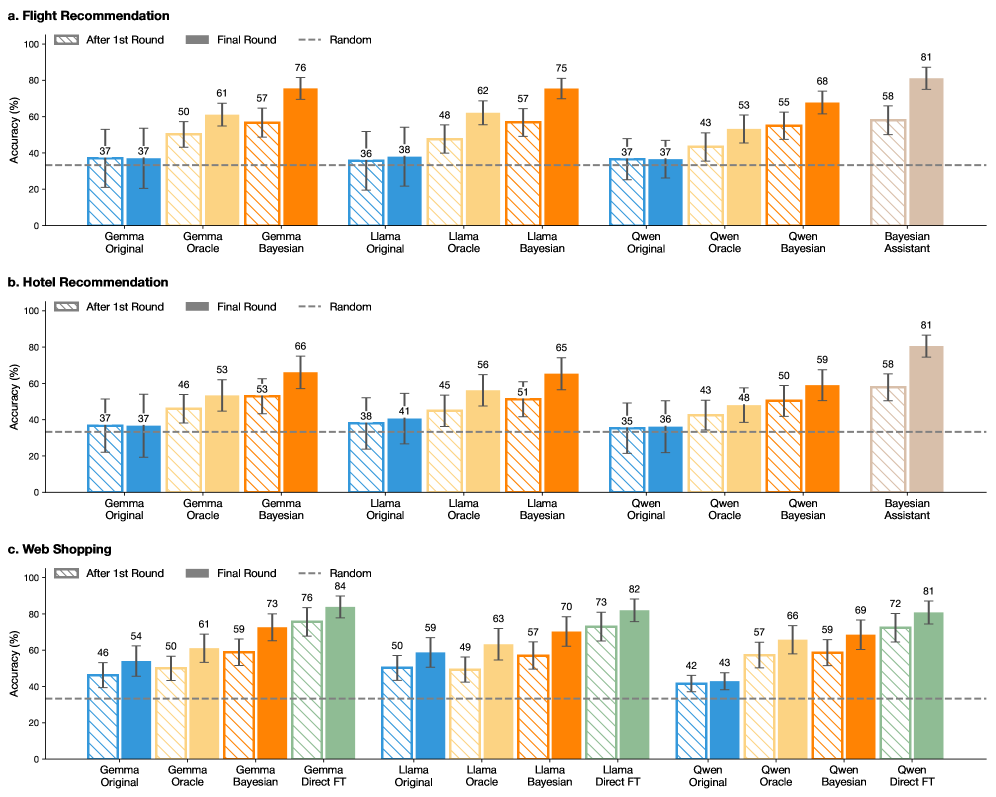
### Visual Description
## Grouped Bar Chart: Accuracy Comparison Across Recommendation Systems
### Overview
The image presents three grouped bar charts comparing the accuracy of different recommendation systems across three domains: **Flight**, **Hotel**, and **Web Shopping**. Each chart evaluates models like **Gemma**, **Llama**, **Qwen**, and their variants (e.g., Oracle, Bayesian, Direct FT) across three stages: **After 1st Round**, **Final Round**, and **Random**. Accuracy is measured on a 0–100% scale, with error bars indicating variability.
---
### Components/Axes
- **X-Axis**: Models (e.g., Gemma Original, Llama Bayesian, Qwen Direct FT).
- **Y-Axis**: Accuracy (%) with error bars.
- **Legend**:
- **After 1st Round**: Blue (solid) with diagonal white stripes.
- **Final Round**: Orange (solid).
- **Random**: Green (solid) with diagonal white stripes.
- **Color Patterns**:
- Blue: Gemma Original/Oracle.
- Orange: Bayesian variants.
- Green: Direct FT variants.
---
### Detailed Analysis
#### Flight Recommendation
- **Gemma Original**: 37% (After 1st Round), 37% (Final Round).
- **Gemma Oracle**: 50% (After 1st Round), 61% (Final Round).
- **Gemma Bayesian**: 57% (After 1st Round), 76% (Final Round).
- **Llama Original**: 36% (After 1st Round), 38% (Final Round).
- **Llama Oracle**: 48% (After 1st Round), 62% (Final Round).
- **Llama Bayesian**: 57% (After 1st Round), 75% (Final Round).
- **Qwen Original**: 37% (After 1st Round), 37% (Final Round).
- **Qwen Oracle**: 43% (After 1st Round), 53% (Final Round).
- **Qwen Bayesian**: 55% (After 1st Round), 68% (Final Round).
- **Bayesian Assistant**: 58% (After 1st Round), 81% (Final Round).
#### Hotel Recommendation
- **Gemma Original**: 37% (After 1st Round), 37% (Final Round).
- **Gemma Oracle**: 46% (After 1st Round), 53% (Final Round).
- **Gemma Bayesian**: 53% (After 1st Round), 66% (Final Round).
- **Llama Original**: 38% (After 1st Round), 41% (Final Round).
- **Llama Oracle**: 45% (After 1st Round), 56% (Final Round).
- **Llama Bayesian**: 51% (After 1st Round), 65% (Final Round).
- **Qwen Original**: 35% (After 1st Round), 36% (Final Round).
- **Qwen Oracle**: 43% (After 1st Round), 48% (Final Round).
- **Qwen Bayesian**: 50% (After 1st Round), 59% (Final Round).
- **Bayesian Assistant**: 58% (After 1st Round), 81% (Final Round).
#### Web Shopping
- **Gemma Original**: 46% (After 1st Round), 54% (Final Round).
- **Gemma Oracle**: 50% (After 1st Round), 61% (Final Round).
- **Gemma Bayesian**: 59% (After 1st Round), 73% (Final Round).
- **Gemma Direct FT**: 76% (After 1st Round), 84% (Final Round).
- **Llama Original**: 50% (After 1st Round), 59% (Final Round).
- **Llama Oracle**: 49% (After 1st Round), 63% (Final Round).
- **Llama Bayesian**: 57% (After 1st Round), 70% (Final Round).
- **Llama Direct FT**: 73% (After 1st Round), 82% (Final Round).
- **Qwen Original**: 42% (After 1st Round), 43% (Final Round).
- **Qwen Oracle**: 57% (After 1st Round), 66% (Final Round).
- **Qwen Bayesian**: 59% (After 1st Round), 69% (Final Round).
- **Qwen Direct FT**: 72% (After 1st Round), 81% (Final Round).
---
### Key Observations
1. **Final Round Improvements**: All models show significant accuracy gains from the first round to the final round (e.g., Gemma Bayesian: +19% in Flight).
2. **Bayesian Models Dominance**: Bayesian variants (e.g., Llama Bayesian, Qwen Bayesian) consistently outperform others in the Final Round across domains.
3. **Direct FT Superiority**: In Web Shopping, Direct FT models (e.g., Gemma Direct FT: 84%) achieve the highest accuracy.
4. **Random Baseline**: The green "Random" bars (e.g., 37–43%) serve as a control, showing models outperform chance.
---
### Interpretation
- **Model Effectiveness**: Bayesian and Direct FT models leverage advanced algorithms (e.g., probabilistic reasoning, fine-tuning) to achieve higher accuracy, suggesting they are better suited for dynamic recommendation tasks.
- **Iterative Refinement**: The "Final Round" likely incorporates feedback loops or optimization steps, as seen in the 15–20% average accuracy boost across domains.
- **Domain-Specific Trends**: Web Shopping benefits most from Direct FT (e.g., 84% accuracy), possibly due to complex user behavior patterns requiring tailored adjustments.
- **Outliers**: The Bayesian Assistant in Flight (81%) and Gemma Direct FT in Web Shopping (84%) stand out as top performers, indicating specialized architectures for niche domains.
This data underscores the importance of model architecture and iterative refinement in recommendation systems, with Bayesian and Direct FT approaches offering the most robust performance.
</details>
Figure 12: Variability across simulated users. We show accuracy after the first and final (fifth) rounds. (a) We compare the original LLMs, fine-tuned LLMs, and the upper bound (the Bayesian Assistant) on flight recommendation. (b) Comparison of LLMs and the upper bound (the Bayesian Assistant) on hotel recommendation. (c) Comparison of LLMs and the upper bound (LLMs fine-tuned directly on the task) for web shopping. Error bars indicate the standard deviation across reward functions (for flight and hotel recommendations) or product categories (for web shopping).
D.2 Variability in LLM Accuracy Across Simulated Users
In our main experiments, we show results averaged over all simulated users. Here, we explore how the LLM’s accuracy varies by user. As before, for flight and hotel recommendations, the user is characterized as a reward function. For web shopping, we have 10 users with different goals (i.e. preferred attributes) for each category; we average their performance and compute the standard deviation across 100 product categories (see Table 1 for examples). All methods exhibit high variance as shown in Fig. 12.
Table 1: Example product categories and their corresponding goals of different users.
| Product Category | User’s Goals (Preferred Attributes) |
| --- | --- |
| Beds | eco friendly, twin with drawers |
| wood frame, easy assemble, twin | |
| memory foam, solid wood | |
| Men’s athletic shoes | running shoes, lace up |
| non slip, mesh | |
| daily wear, color back, size 14 | |
| Food & beverage | simple ingredients |
| gluten free | |
| low sodium | |
<details>
<summary>x14.png Details</summary>
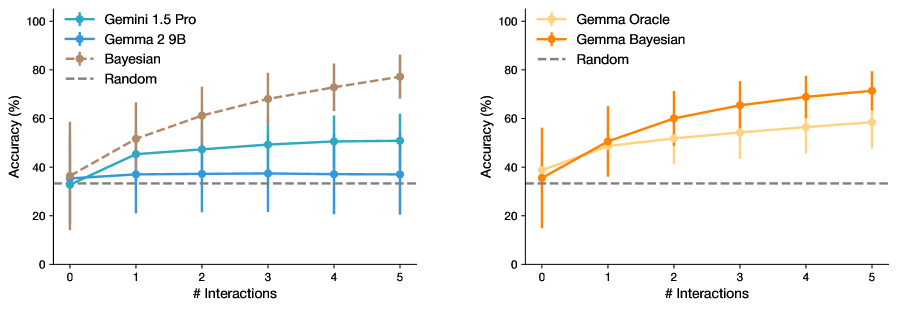
### Visual Description
## Line Charts: Model Accuracy vs. Number of Interactions
### Overview
The image contains two side-by-side line charts comparing the accuracy of different machine learning models as a function of interaction count. Both charts use percentage accuracy on the y-axis (0-100%) and interaction count (0-5) on the x-axis. The left chart compares Gemini 1.5 Pro, Gemma 2 9B, Bayesian, and Random models. The right chart compares Gamma Oracle, Gamma Bayesian, and Random models.
### Components/Axes
**Left Chart:**
- **X-axis**: "# Interactions" (0-5, integer scale)
- **Y-axis**: "Accuracy (%)" (0-100%, linear scale)
- **Legend**: Top-left corner with four entries:
- Green: Gemini 1.5 Pro
- Blue: Gemma 2 9B
- Brown: Bayesian
- Gray: Random
- **Lines**: Four distinct colored lines with error bars
**Right Chart:**
- **X-axis**: "# Interactions" (0-5, integer scale)
- **Y-axis**: "Accuracy (%)" (0-100%, linear scale)
- **Legend**: Top-left corner with three entries:
- Orange: Gamma Oracle
- Red: Gamma Bayesian
- Gray: Random
- **Lines**: Three distinct colored lines with error bars
### Detailed Analysis
**Left Chart Trends:**
1. **Gemini 1.5 Pro** (Green): Starts at ~30% accuracy at 0 interactions, increases steadily to ~50% by 5 interactions (error bars ±5-10%)
2. **Gemma 2 9B** (Blue): Remains flat at ~35% accuracy across all interactions (error bars ±5%)
3. **Bayesian** (Brown): Starts at ~35%, rises sharply to ~75% by 5 interactions (error bars ±5-15%)
4. **Random** (Gray): Flat line at ~30% accuracy (error bars ±3%)
**Right Chart Trends:**
1. **Gamma Oracle** (Orange): Starts at ~35%, increases to ~55% by 5 interactions (error bars ±5-10%)
2. **Gamma Bayesian** (Red): Starts at ~30%, rises to ~70% by 5 interactions (error bars ±5-15%)
3. **Random** (Gray): Flat line at ~30% accuracy (error bars ±3%)
### Key Observations
1. **Interaction-Dependent Performance**: Both Bayesian models (Bayesian and Gamma Bayesian) show significant accuracy improvements with more interactions, while non-Bayesian models plateau early.
2. **Error Bar Patterns**: Bayesian models exhibit larger error bars, suggesting greater variability in performance across trials.
3. **Random Baseline**: The Random model maintains consistent performance across both charts, serving as a performance floor.
4. **Model Divergence**: The Gamma Bayesian model outperforms Gamma Oracle by ~15% at 5 interactions despite similar starting points.
### Interpretation
The data suggests that Bayesian modeling frameworks (Bayesian and Gamma Bayesian) demonstrate superior adaptability to increased interaction data, achieving ~40-50% higher accuracy than non-Bayesian models at maximum interactions. This implies that Bayesian methods may be particularly effective for incremental learning scenarios where models receive sequential data inputs. The consistent performance of Random models across both charts indicates that the observed improvements are not due to baseline model architecture differences but rather to the interaction data volume and model architecture choices. The larger error bars for Bayesian models warrant further investigation into their stability under varying conditions.
</details>
Figure 13: Variability across reward functions over rounds. Error bars indicate standard deviation across reward functions.
We additionally show results over rounds in Fig. 13. We find that both original LLMs and the Bayesian Assistant display high variance across reward function. While the variance of the Bayesian Assistant decreases as the number of interactions increases, as does that of the fine-tuned LLMs, the variance of the original LLM remains largely constant across interactions. Notably, Gemma Bayesian has lower variance while maintaining similar performance to the Bayesian Assistant.
In particular, we hypothesize that reward functions that more strongly deviate from the LLM’s prior (Supplementary Section D.1) may be harder to infer. For example, the LLM may assume most people prefer shorter flights over long ones, making it more difficult to infer the preferences of an “abnormal” user who prefers longer flights. To test the hypothesis that the variability across reward functions is due in part to the prior, we fit linear regression models predicting a reward function’s final-round accuracy from its L2 distance to the mean of the prior reward distribution, focusing on Gemma in this experiment. We elicit the priors separately for Gemma Original, Gemma Bayesian and Gemma Oracle. The prior of the Bayesian Assistant is uniform, as before. Before computing distances we normalize the reward functions (divide them by their sum) to account for the fact that some functions are equivalent; for example, the reward function $[-1,-1,-1,-1]$ is equivalent to the function $[-0.5,-0.5,-0.5,-0.5]$ as both will always lead the user to prefer the same flights.
In line with this hypothesis, we find negative regression coefficients for Gemma Original, indicating it performs worse when the reward function deviates from its priors (Fig. 14). The absolute coefficients for the Bayesian Assistant and Gemma Bayesian are similar, and much smaller than that of Gemma Original. For these three models, the impact of L2 distance from prior on the final-round accuracy is all significant (p $<$ 0.001). The Gemma Oracle does not show sensitivity to this distance (p = 0.24).
<details>
<summary>x15.png Details</summary>
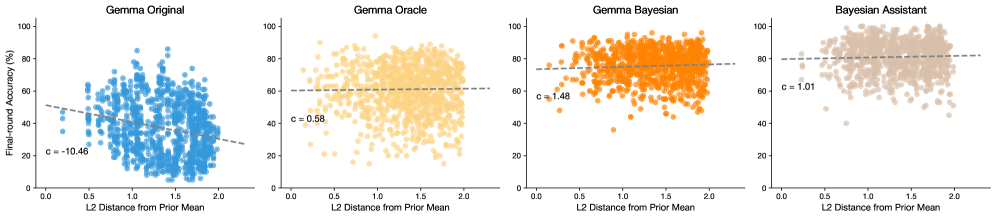
### Visual Description
## Scatter Plots: Final-round Accuracy vs L2 Distance from Prior Mean
### Overview
The image contains four scatter plots comparing final-round accuracy (y-axis) to L2 distance from prior mean (x-axis) for different models or conditions. Each plot uses a distinct color scheme and includes a dashed reference line labeled with a "c" value. The plots are arranged horizontally, with legends positioned to the right of each plot.
### Components/Axes
- **X-axis**: "L2 Distance from Prior Mean" (range: 0.0 to 2.0)
- **Y-axis**: "Final-round Accuracy (%)" (range: 0 to 100)
- **Legends**: Positioned right-aligned, matching the color of data points in each plot
- **Dashed Lines**: Labeled with "c = [value]" (e.g., "c = -10.46"), positioned diagonally across plots
### Detailed Analysis
1. **Gamma Original** (blue points):
- **c = -10.46**: Strong negative slope
- Data points: Widely scattered, with higher accuracy at lower L2 distances
- Trend: Negative correlation between L2 distance and accuracy
2. **Gamma Oracle** (orange points):
- **c = 0.58**: Weak positive slope
- Data points: Clustered around the dashed line, moderate spread
- Trend: Slight positive correlation, but low variability
3. **Gamma Bayesian** (orange points):
- **c = 1.48**: Strong positive slope
- Data points: Dense cluster near the dashed line, minimal spread
- Trend: Strong positive correlation, consistent performance
4. **Bayesian Assistant** (beige points):
- **c = 1.01**: Moderate positive slope
- Data points: Moderate spread, some outliers above the dashed line
- Trend: Positive correlation with slight variability
### Key Observations
- **Negative Correlation**: Gamma Original shows a strong inverse relationship (c = -10.46), suggesting accuracy decreases as L2 distance increases.
- **Positive Correlations**: All other plots exhibit positive relationships, with Gamma Bayesian having the strongest (c = 1.48).
- **Data Density**: Gamma Bayesian has the tightest clustering, indicating consistent model behavior. Gamma Original has the most dispersed data.
- **Outliers**: Bayesian Assistant shows a few points above the dashed line, suggesting occasional overperformance.
### Interpretation
The "c" values likely represent regression coefficients or model-specific parameters. Gamma Original's negative c implies a detrimental effect of prior mean distance on accuracy, while positive c values in other plots suggest beneficial relationships. The Bayesian models (Oracle and Bayesian) demonstrate higher c values, indicating better alignment between prior mean distance and accuracy. The Gamma Bayesian plot's tight clustering suggests optimal model calibration, whereas Gamma Original's dispersion may indicate overfitting or poor prior selection. The Bayesian Assistant's moderate c and spread reflect a balance between prior influence and adaptability.
</details>
Figure 14: The relationship between the final-round accuracy and the normalized L2 distance to the mean of the prior reward distribution (1000 randomly sampled points for readability). $c$ refers to the coefficient in a linear regression predicting accuracy from L2 distance. The impact of L2 distance on final-round accuracy is significant (p $<$ 0.001) for Gemma Original, Gemma Bayesian, and Bayesian Assistant, but not for Gemma Oracle (p = 0.24).
D.3 Interacting with Non-deterministic Users
Our main experiments assume the simulated user always makes decisions that are consistent with its reward function. By contrast, as we show in the section Generalization to interactions with human users, humans may behave inconsistently with their stated preferences. To simulate this real-world stochasticity, we evaluate a setting where the LLM interacts with a non-deterministic user. We add noise to the user’s behavior, such that with a certain probability they select a non-optimal choice, that is a choice that does not maximize their reward. The relationship between the percentage of noise and final-round accuracy is shown in Fig. 15. We experiment with the three variants of Gemma, and with the Bayesian Assistant. As expected, performance decreases across the board as the amount of noise increases. For realistic noise values in the 10–60% range, we find that Gemma Bayesian is more robust to noise compared not only to Gemma Original and Gemma Oracle, but also to the Bayesian Assistant, which is the best model in the noiseless setting. This robustness to noise illustrates an advantage of an LLM fine-tuned to mimic a symbolic model compared to the original symbolic model (see Discussion).
<details>
<summary>x16.png Details</summary>
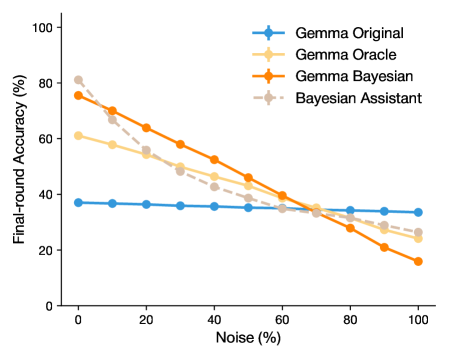
### Visual Description
## Line Graph: Final-round Accuracy vs. Noise (%)
### Overview
The graph illustrates the relationship between noise percentage (0-100%) and final-round accuracy (%) for four distinct models: Gemma Original, Gemma Oracle, Gemma Bayesian, and Bayesian Assistant. All models exhibit declining accuracy as noise increases, with varying rates of degradation.
### Components/Axes
- **X-axis**: Noise (%) ranging from 0 to 100 in 20% increments.
- **Y-axis**: Final-round Accuracy (%) ranging from 0 to 100 in 20% increments.
- **Legend**: Located in the top-right corner, associating colors with models:
- **Blue**: Gemma Original
- **Orange**: Gemma Oracle
- **Gray**: Gemma Bayesian
- **Dashed Gray**: Bayesian Assistant
### Detailed Analysis
1. **Gemma Original (Blue)**:
- Maintains a flat line at ~35-40% accuracy across all noise levels.
- No significant deviation observed.
2. **Gemma Oracle (Orange)**:
- Starts at ~75% accuracy at 0% noise.
- Declines steadily to ~20% at 100% noise.
- Steepest slope among all models.
3. **Gemma Bayesian (Gray)**:
- Begins at ~80% accuracy at 0% noise.
- Decreases to ~30% at 100% noise.
- Slightly less steep decline than Gemma Oracle.
4. **Bayesian Assistant (Dashed Gray)**:
- Starts at ~80% accuracy at 0% noise.
- Drops to ~25% at 100% noise.
- Similar trajectory to Gemma Bayesian but ends marginally higher.
### Key Observations
- **Initial Performance**: Gemma Oracle and Bayesian models (Gemma Bayesian/Bayesian Assistant) outperform Gemma Original at 0% noise.
- **Noise Sensitivity**: All models degrade with noise, but Gemma Oracle shows the most pronounced decline.
- **Robustness**: Bayesian approaches (Gemma Bayesian/Bayesian Assistant) retain higher accuracy than Gemma Original under noise.
- **Dashed Line Distinction**: Bayesian Assistant’s dashed line suggests a variant of Bayesian methods, possibly with adaptive mechanisms.
### Interpretation
The data highlights trade-offs between model complexity and noise resilience. Gemma Oracle’s high initial accuracy likely stems from oracle-guided training but lacks generalization under noise. Bayesian methods (Gemma Bayesian/Bayesian Assistant) balance initial performance with moderate noise tolerance, suggesting inherent robustness. Gemma Original’s stability at lower accuracy implies simplicity but limited adaptability. The Bayesian Assistant’s dashed line may indicate a hybrid approach, optimizing for noise resistance without sacrificing initial performance. These trends underscore the importance of model design choices in real-world noisy environments.
</details>
Figure 15: Final-round accuracy when interacting with a noisy simulated user. We add noise to the simulated user’s choice such that with some probability the user chooses an option that is different from the one that maximizes its reward. We plot fine-round accuracy with respect to the amount of noise. While all models show a decrease in performance as noise increases, Gemma Bayesian demonstrates greater robustness for noise levels between 10% and 60%. Error bars (too small to be visible in the plot) show standard errors across three random seeds (and three training runs).
D.4 What Makes Bayesian Teaching Effective?
We have shown that it is more effective to fine-tune our LLMs on the Bayesian Assistant’s predictions than on the user’s true choices. In this section, we explore and rule out two deflationary hypotheses that might explain the effectiveness of this method, and tentatively conclude that the advantage of Bayesian teaching is in fact due the probabilistically optimal predictions made by the Bayesian Assistant. In all of the experiments described in this section, we focus on Gemma 2 9B. We use the same list of flight option sets for all models, and vary only the supervision we provide during fine-tuning (i.e. the assistant’s recommendations).
<details>
<summary>x17.png Details</summary>
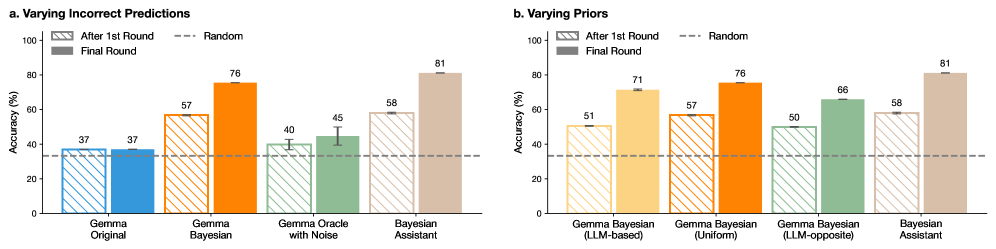
### Visual Description
## Bar Chart: Model Accuracy Comparison Across Scenarios
### Overview
The image presents two grouped bar charts comparing model accuracy across different configurations and scenarios. The charts are divided into two sections:
- **a. Varying Incorrect Predictions**
- **b. Varying Priors**
Each section evaluates four models (Gemma Original, Gemma Bayesian, Gemma Oracle with Noise, Bayesian Assistant in part a; Gemma Bayesian variants and Bayesian Assistant in part b) across three evaluation stages: After 1st Round, Random baseline, and Final Round. Accuracy is measured in percentage.
---
### Components/Axes
#### **Part a: Varying Incorrect Predictions**
- **X-axis (Categories)**:
- Gemma Original
- Gemma Bayesian
- Gemma Oracle with Noise
- Bayesian Assistant
- **Y-axis (Scale)**: Accuracy (%) from 0 to 100.
- **Legend**:
- **After 1st Round**: Striped bars (light gray with diagonal lines).
- **Random**: Dashed horizontal line at 37%.
- **Final Round**: Solid bars (dark gray).
#### **Part b: Varying Priors**
- **X-axis (Categories)**:
- Gemma Bayesian (LLM-based)
- Gemma Bayesian (Uniform)
- Gemma Bayesian (LLM-opposite)
- Bayesian Assistant
- **Y-axis (Scale)**: Accuracy (%) from 0 to 100.
- **Legend**: Same as part a (striped, dashed, solid).
---
### Detailed Analysis
#### **Part a: Varying Incorrect Predictions**
- **Gemma Original**:
- After 1st Round: 37% (striped, matches Random baseline).
- Final Round: 37% (solid, no improvement).
- **Gemma Bayesian**:
- After 1st Round: 57% (striped).
- Final Round: 76% (solid, +19% improvement).
- **Gemma Oracle with Noise**:
- After 1st Round: 40% (striped).
- Final Round: 45% (solid, +5% improvement).
- **Bayesian Assistant**:
- After 1st Round: 58% (striped).
- Final Round: 81% (solid, +23% improvement).
#### **Part b: Varying Priors**
- **Gemma Bayesian (LLM-based)**:
- After 1st Round: 51% (striped).
- Final Round: 71% (solid, +20% improvement).
- **Gemma Bayesian (Uniform)**:
- After 1st Round: 57% (striped).
- Final Round: 76% (solid, +19% improvement).
- **Gemma Bayesian (LLM-opposite)**:
- After 1st Round: 50% (striped).
- Final Round: 66% (solid, +16% improvement).
- **Bayesian Assistant**:
- After 1st Round: 58% (striped).
- Final Round: 81% (solid, +23% improvement).
---
### Key Observations
1. **Bayesian Assistant Dominance**:
- Achieves the highest Final Round accuracy (81%) in both scenarios, outperforming all other models by a significant margin.
2. **Model Improvement Trends**:
- All models except **Gemma Original** show improvement from the first to the final round.
- **Gemma Bayesian (LLM-based)** and **Gemma Bayesian (Uniform)** demonstrate the largest gains (+20% and +19%, respectively).
3. **Noise Sensitivity**:
- **Gemma Oracle with Noise** (part a) has the lowest Final Round accuracy (45%), highlighting vulnerability to input quality.
4. **Random Baseline**:
- The dashed line at 37% serves as a reference, showing that even the weakest models (e.g., Gemma Original) slightly outperform random guessing.
---
### Interpretation
- **Bayesian Assistant's Superiority**:
The consistent top performance of the Bayesian Assistant suggests it is robust to both incorrect predictions and prior variations, making it the most reliable model in these scenarios.
- **Gemma Bayesian Variants**:
The LLM-based and Uniform configurations outperform the LLM-opposite variant, indicating that alignment with the model's training framework (LLM) enhances accuracy.
- **Noise Impact**:
The Gemma Oracle with Noise model’s poor performance underscores the importance of clean, high-quality data for accurate predictions.
- **Iterative Refinement**:
The improvement from the first to the final round across most models implies that iterative adjustments or additional training phases enhance performance.
This analysis highlights the critical role of model architecture (e.g., Bayesian methods) and data quality in achieving high accuracy, with the Bayesian Assistant emerging as the optimal choice for these tasks.
</details>
\phantomsubcaption \phantomsubcaption
Figure 16: Final-round accuracy of LLMs fine-tuned with different data variants. (a) Accuracy of the model using Bayesian teaching and the model using oracle teaching with random noise. (b) Accuracy of models fine-tuned on predictions from variants of the Bayesian Assistant, initialized with different priors. Error bars show standard errors across three random seeds (and three training runs).
Hypothesis: Incorrect predictions regularize training.
The Bayesian Assistant can make incorrect predictions, especially in the first few rounds, due to the fact that it only has limited information about the user (see the Bayesian Assistant’s accuracy over rounds in Fig. 24). Could these incorrect predictions regularize training and prevent overfitting, accounting for the effectiveness of Bayesian teaching? To test this hypothesis, we fine-tune the LLM using oracle teaching injected with random noise: 40% of the time, instead of predicting the user’s choice, the assistant recommends one of the incorrect options at random. The proportion of incorrect predictions in this control roughly matches that of the Bayesian predictions averaged across all five interactions. Contrary to the regularization hypothesis, we find that incorrect predictions do not necessarily improve performance: the model fine-tuned on noisy user’s choices (Gemma Oracle with Noise) barely outperforms the original LLM and has high standard error (Fig. 16). This suggests that random noise alone cannot explain why Bayesian predictions are more effective; rather, the Bayesian’s educated mistakes are more valuable than random errors.
Hypothesis: The LLM benefits from the correct prior.
We initialize the Bayesian Assistant using the uniform prior, which assigns equal probability to all reward functions, and therefore aligns with the data generation process of our evaluation. One hypothesis is that the LLM benefits from this correct prior (in the sense that it is calibrated to the distribution of simulated users in our experiment), which makes the predictions of the Bayesian Assistant more effective for supervised fine-tuning.
To test this hypothesis, we fine-tune Gemma three times, using the predictions of three variants of the Bayesian Assistant, initialized with three different priors: the uniform prior, the LLM-based prior obtained from Gemma Original (see Fig. 11), and the prior that is contrary to the LLM-based one (e.g., if Gemma’s prior favors cheaper flights, this prior would instead prefer more expensive flights). The results are shown in Fig. 16. LLMs fine-tuned on predictions from all three Bayesian models perform very well and dramatically better than the original LLM. The choice of prior does influence the performance of the fine-tuned LLMs. The model fine-tuned on Bayesian predictions using the uniform prior, which matches the distribution of users in our sample, achieves the best accuracy. The LLM-based prior, despite being biased and spiky, leads to accuracy that is only slightly worse. The LLM-opposite prior, which is both biased and mismatches the LLM’s beliefs, leads to a more significant performance drop. That being said, the vast gap between all three LLMs fine-tuned on Bayesian predictions and Gemma Original suggests that the correct prior alone does not fully explain the effectiveness of Bayesian teaching.
D.5 Qualitative Example
In Fig. 17, we show a qualitative example of the evolution of the reward distributions of Gemma Original and the Bayesian Assistant over interactions. In this case, since the user’s true reward function differs significantly from the LLM’s prior, both Gemma Original and the Bayesian Assistant perform poorly at the start of the interactions. However, while the Bayesian Assistant gradually converges toward the ground-truth reward function after a few rounds, Gemma Original continues to assign high probability to reward functions that are inconsistent with its observations.
<details>
<summary>x18.png Details</summary>
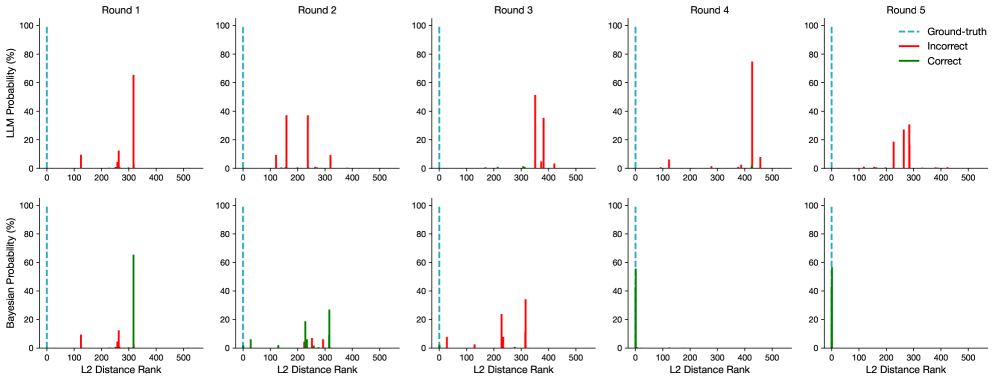
### Visual Description
## Bar Charts: LLM and Bayesian Probability by Round and L2 Distance Rank
### Overview
The image contains 10 bar charts (2 per round across 5 rounds) comparing **LLM Probability** and **Bayesian Probability** distributions across L2 Distance Ranks. Each chart includes a **Ground-truth** (blue dashed line at x=0), **Incorrect** (red bars), and **Correct** (green bars) categories. The x-axis represents L2 Distance Rank (0–500), and the y-axis represents probability percentage (0–100%).
---
### Components/Axes
- **X-axis**: L2 Distance Rank (0–500, linear scale).
- **Y-axis**: Probability (%) (0–100%, linear scale).
- **Legends**:
- **Ground-truth**: Blue dashed vertical line at x=0 (100% probability).
- **Incorrect**: Red bars.
- **Correct**: Green bars.
- **Chart Titles**: "Round X" (X = 1–5) for each pair of charts.
---
### Detailed Analysis
#### Round 1
- **LLM Probability**:
- Ground-truth: 100% at x=0.
- Incorrect: ~65% at x≈650.
- Correct: ~50% at x≈500.
- **Bayesian Probability**:
- Ground-truth: 100% at x=0.
- Incorrect: ~10% at x≈100.
- Correct: ~30% at x≈300.
#### Round 2
- **LLM Probability**:
- Ground-truth: 100% at x=0.
- Incorrect: ~40% at x≈200, ~30% at x≈300.
- Correct: ~20% at x≈400.
- **Bayesian Probability**:
- Ground-truth: 100% at x=0.
- Incorrect: ~5% at x≈100, ~10% at x≈200.
- Correct: ~20% at x≈300, ~15% at x≈400.
#### Round 3
- **LLM Probability**:
- Ground-truth: 100% at x=0.
- Incorrect: ~50% at x≈400.
- Correct: ~30% at x≈300.
- **Bayesian Probability**:
- Ground-truth: 100% at x=0.
- Incorrect: ~20% at x≈200.
- Correct: ~40% at x≈300.
#### Round 4
- **LLM Probability**:
- Ground-truth: 100% at x=0.
- Incorrect: ~75% at x≈450.
- Correct: ~10% at x≈400.
- **Bayesian Probability**:
- Ground-truth: 100% at x=0.
- Incorrect: ~30% at x≈300.
- Correct: ~50% at x≈400.
#### Round 5
- **LLM Probability**:
- Ground-truth: 100% at x=0.
- Incorrect: ~30% at x≈200, ~25% at x≈300.
- Correct: ~15% at x≈400.
- **Bayesian Probability**:
- Ground-truth: 100% at x=0.
- Incorrect: ~20% at x≈200.
- Correct: ~60% at x≈400.
---
### Key Observations
1. **Ground-truth Consistency**: The blue dashed line at x=0 (100%) appears in all charts, indicating the true answer’s position.
2. **LLM vs. Bayesian Performance**:
- **LLM Probability**: Incorrect answers often dominate (e.g., Round 1: 65% vs. 50% Correct).
- **Bayesian Probability**: Correct answers sometimes outperform Incorrect (e.g., Round 5: 60% vs. 20%).
3. **L2 Distance Trends**:
- Higher L2 ranks (x-axis) correlate with lower probabilities for both models.
- Bayesian models show sharper peaks for Correct answers (e.g., Round 5: 60% at x=400).
---
### Interpretation
- **LLM Limitations**: The models struggle to distinguish Correct answers from Incorrect ones in many rounds, with Incorrect probabilities frequently exceeding Correct (e.g., Round 1, 4).
- **Bayesian Advantage**: Bayesian models better isolate Correct answers in later rounds (e.g., Round 5: 60% Correct vs. 20% Incorrect), suggesting improved calibration or confidence estimation.
- **Ground-truth Anchoring**: The consistent placement of the Ground-truth at x=0 implies the true answer is always the closest in L2 distance, but models fail to prioritize it reliably.
---
### Spatial Grounding & Verification
- **Legend Placement**: Top-right corner of all charts, ensuring clear association with bar colors.
- **Color Consistency**: Red (Incorrect) and green (Correct) bars match legend labels across all rounds.
- **Trend Verification**: For example, in Round 4 LLM Probability, the red bar at x=450 (75%) is visually taller than the green bar at x=400 (10%), confirming the data.
---
### Conclusion
The data highlights a critical gap in LLM performance: Incorrect answers often receive higher probabilities than Correct ones, even when the Ground-truth is unambiguous. Bayesian models show promise in later rounds but still lag in early stages. This suggests opportunities to refine model calibration or incorporate Bayesian uncertainty estimation for better reliability.
</details>
Figure 17: The reward distributions of Gemma Original (top) and the Bayesian Assistant (bottom) over multiple rounds. The reward functions are sorted by their normalized L2 distance from the ground-truth (GT) reward function, indicated by the blue dashed line at $x=0$ . Red indicates that the reward function’s prediction on the given options is incorrect, while green indicates that its prediction is correct.
Appendix E Sensitivity to the Informativeness of Option Sets
In each round of the flight recommendation task, we present the model with a set of three flight options, and the user’s choice among those options. The amount of information that can be gained through this process varies from round to round. For example, a choice between two flight options that differ in exactly one feature could be more informative than the choice between options that differ along multiple dimensions: the minimal pair of options provides direct evidence for the user’s preference for the particular feature. We expect a strong probabilistic reasoner to be sensitive to this factor: when the user’s choice between a particular set of options provides more information about their preferences, we expect the system to update its beliefs more substantially.
In this section we test whether LLMs display this behavior. In contrast with the main experiments, where we sample the option sets randomly, here we sample them based on their informativeness. To measure the amount of information contained in a set of options $\mathcal{O}$ , we define the ground truth information gain as
$$
\displaystyle g(\mathcal{O},o^{*},p(\bm{\theta}),q(\bm{\theta})) \displaystyle=\mathrm{KL}(p(\bm{\theta})||q(\bm{\theta}))-\mathrm{KL}(p(\bm{\theta})||q(\bm{\theta}|\mathcal{O},o^{*})) \displaystyle=\log q(\bm{\theta}^{*}|\mathcal{O},o^{*})-\log q(\bm{\theta}^{*}), \tag{5}
$$
where $p(\bm{\theta})=\delta(\bm{\theta}^{*})$ and $q(\bm{\theta})$ is either $q_{B}(\bm{\theta})$ or $q_{LLM}(\bm{\theta})$ . This metric captures the increase in the posterior probability of the ground-truth reward function (that is, the user’s true reward function) after this set of options has been observed. Note that $g$ is relative to the model that is used to update the probability distribution; we use $g_{\textit{B}}$ and $g_{\textit{LLM}}$ to refer to the gain derived from the Bayesian Assistant and the LLM, respectively.
E.1 Experimental Setup
We randomly sample 5,000 candidate option sets, compute the ground truth information gain of each one based on the Bayesian Assistant, and select the option set that leads to the desired value of $g_{\textit{B}}$ . The performance is evaluated at the end of a five-round interaction, and the ground truth information gain is averaged over these five rounds. We evaluate the Bayesian Assistant as well as Gemma Original, Gemma Oracle, and Gemma Bayesian; as in our main experiments, the Bayesian Assistant is initialized with the uniform prior.
<details>
<summary>x19.png Details</summary>
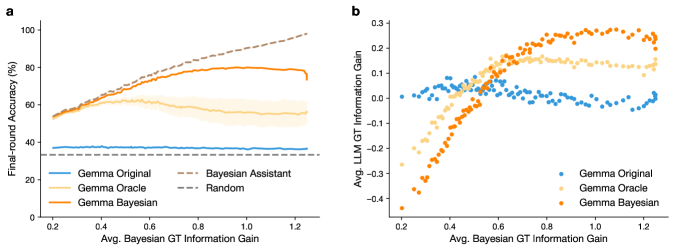
### Visual Description
## Line Graph and Scatter Plot: Performance Analysis of Gemma Models with Bayesian GT Information Gain
### Overview
The image contains two charts (a and b) analyzing the performance of different Gemma models (Original, Oracle, Bayesian) and comparison methods (Bayesian Assistant, Random) across two metrics: final-round accuracy and information gain correlation. Chart a shows accuracy trends against Bayesian GT information gain, while Chart b examines the relationship between Bayesian and LLM GT information gains.
### Components/Axes
#### Chart a (Line Graph)
- **X-axis**: "Avg. Bayesian GT Information Gain" (range: 0.2–1.2)
- **Y-axis**: "Final-round Accuracy (%)" (range: 0–100)
- **Legend**: Located on the left, with five entries:
- **Blue**: Gemma Original
- **Yellow**: Gemma Oracle
- **Orange**: Gemma Bayesian
- **Gray dashed**: Bayesian Assistant
- **Dark gray dashed**: Random
- **Lines**:
- **Gemma Original**: Flat line near 35–40% (blue)
- **Gemma Oracle**: Flat line near 55–60% (yellow)
- **Gemma Bayesian**: Rising line from ~50% to ~80% (orange)
- **Bayesian Assistant**: Rising line from ~50% to ~95% (gray dashed)
- **Random**: Flat line near 35% (dark gray dashed)
#### Chart b (Scatter Plot)
- **X-axis**: "Avg. Bayesian GT Information Gain" (range: 0.2–1.2)
- **Y-axis**: "Avg. LLM GT Information Gain" (range: -0.4–0.3)
- **Legend**: Located on the right, with three entries:
- **Blue**: Gemma Original
- **Yellow**: Gemma Oracle
- **Orange**: Gemma Bayesian
- **Data Points**:
- **Gemma Original**: Scattered around x=0.4–0.8, y=-0.1–0.1
- **Gemma Oracle**: Clustered around x=0.6–1.0, y=0.0–0.2
- **Gemma Bayesian**: Clustered around x=0.8–1.2, y=0.1–0.3
### Detailed Analysis
#### Chart a Trends
1. **Gemma Bayesian (Orange)**: Steady upward trend, starting at ~50% accuracy at x=0.2 and reaching ~80% at x=1.2.
2. **Bayesian Assistant (Gray Dashed)**: Sharp rise from ~50% to ~95%, surpassing Gemma Bayesian at higher x-values.
3. **Gemma Oracle (Yellow)**: Flat line at ~55–60%, indicating no improvement with Bayesian GT gain.
4. **Gemma Original (Blue)**: Minimal variation (~35–40%), lowest performance.
5. **Random (Dark Gray Dashed)**: Flat line at ~35%, baseline performance.
#### Chart b Trends
1. **Positive Correlation**: Higher Bayesian GT gain (x-axis) aligns with higher LLM GT gain (y-axis).
2. **Gemma Bayesian (Orange)**: Data points form a tight cluster in the upper-right quadrant (x=0.8–1.2, y=0.1–0.3), showing strong performance.
3. **Gemma Oracle (Yellow)**: Moderate cluster (x=0.6–1.0, y=0.0–0.2), less consistent than Gemma Bayesian.
4. **Gemma Original (Blue)**: Scattered points with weak correlation (x=0.4–0.8, y=-0.1–0.1), indicating poor alignment between metrics.
### Key Observations
1. **Bayesian Methods Outperform**: Both Gemma Bayesian and Bayesian Assistant show significant accuracy gains in Chart a, with Bayesian Assistant achieving near-perfect performance at high Bayesian GT gains.
2. **Information Gain Alignment**: Chart b reveals that Gemma Bayesian’s LLM GT gains closely mirror its Bayesian GT gains, suggesting effective utilization of Bayesian insights.
3. **Oracle Limitations**: Gemma Oracle’s flat accuracy curve (Chart a) and moderate scatter (Chart b) indicate it does not benefit from Bayesian GT improvements.
4. **Original Model Weakness**: Gemma Original underperforms across both metrics, with minimal correlation between GT gains.
### Interpretation
The data demonstrates that **Bayesian GT information gain is a critical driver of model performance**. Gemma Bayesian and Bayesian Assistant leverage this gain effectively, achieving higher accuracy and stronger alignment between Bayesian and LLM GT metrics. In contrast, Gemma Original and Oracle show limited responsiveness to Bayesian GT improvements, suggesting suboptimal integration of Bayesian insights. The Bayesian Assistant’s near-perfect performance at high Bayesian GT gains implies it may serve as a superior benchmark for future model development. These findings highlight the importance of Bayesian GT in optimizing LLM performance, particularly for models like Gemma Bayesian designed to exploit such information.
</details>
\phantomsubcaption \phantomsubcaption
Figure 18: Analysis of sensitivity of LLMs to the informativeness of option sets. (a) Effect of option set informativity on model performance. Option set informativity is defined by ground-truth information gain, i.e., the increase in the log probability assigned by the Bayesian Assistant to the ground truth reward function after observing the provided options. We plot accuracy after five interactions as a function of option set informativity averaged over the five interactions. (b) The relationship between ground-truth information gain computed from the Bayesian Assistant and from LLMs.
E.2 Results
The Bayesian Assistant’s performance consistently improves as option sets become more informative: after observing highly informative options, its performance is almost perfect (Fig. 18). Gemma Original does not show sensitivity to option set informativity, but the fine-tuned models are much more sensitive to this factor: their performance positively correlates with the Bayesian ground-truth information gain up to a certain point. Gemma Bayesian saturates later than Gemma Oracle, and achieves higher final accuracy, especially in the highly informative regime.
E.3 Comparing LLM-derived and Bayesian Information Gain
Recall that information gain is relative to the model that is used to update the probability distributions: $g_{\textit{LLM}}$ quantifies the amount of information the LLM can absorb from a particular set of options, whereas $g_{\textit{B}}$ quantifies the amount that the ideal Bayesian reasoner can absorb. How does $g_{\textit{LLM}}$ related to $g_{\textit{B}}$ for each of the variants of Gemma? We find that the correlation between the two measures is weak for Gemma Original (Fig. 18). For Gemma Oracle and Gemma Bayesian, we observe a more complex pattern. When $g_{\textit{B}}$ is small, there is a positive relationship between the two metrics, indicating that options that are informative from the Bayesian perspective are beneficial for the fine-tuned LLMs. In this part of the range, the information gain derived from Gemma Bayesian shows a stronger correlation with $g_{\textit{B}}$ compared with Gemma Oracle. When $g_{\textit{B}}$ is large, however, the relationship levels off and we no longer see a correlation between $g_{\textit{B}}$ and $g_{\textit{LLM}}$ for either of the fine-tuned models. This suggests that even Gemma Bayesian only approximates and does not fully implement the normative Bayesian reasoning strategy.
Appendix F Human Experiments
F.1 Humans As Assistants
Participants.
For the experiment where human participants acted as the assistant to a simulated user, we recruited 720 participants through the Prolific platform [Palan and Schitter, 2018]. Each human participant interacted with one simulated user from a subset of 48 simulated users (out of the total 624 users), which we sampled based on the L2 distance of their reward function from the origin. The average age of human participants was 37.2 (SD=12.5). Of those, 54.9% identified as male (395), 44.6% as female (321), and 0.6% preferred not to say (4). The major nationalities of human participants were the United States at 32.5% (234), United Kingdom at 23.2% (167), South Africa at 10.3% (74), Canada at 7.6% (55), and Poland at 4.4% (32). By ethnicity, 62.5% (450) were White, 17.4% (125) were Black, 11.9% (86) were Asian, and 5.6% (40) were Mixed. All participants reported using English as their primary language.
Procedure.
At the beginning of the experiment, each participant was asked to complete a preference questionnaire to indicate their initial guess of the user’s preferences for each individual feature. The participant subsequently proceeded to the annotation round, where they made recommendations from three flight options. After the selection, the human annotator received feedback indicating whether their choice was correct. They were then redirected to the preference questionnaire to report their updated beliefs about the user’s preferences. This completed one round. The annotator repeated the same procedure for five rounds. Following these five rounds, we also implemented a quality control annotation round where the annotator interacted with a typical user with a highly informative option list (differing only in one feature dimension). We expected this quality control round to be very easy for participants who were paying close attention to task. We filtered out participants who failed the quality control annotation. The mean and median completion time (including the quality control annotation) was 9.35 minutes and 7.90 minutes, respectively, with a standard deviation of 5.08 minutes.
Additional Results.
Our main results show the accuracy of human assistants using their direct predictions of the user’s preferred choices. Since we also ask the annotator to rate their beliefs about the user’s preferences after each round, we can also use these estimated preferences to make recommendations—the same procedure we use in Section B. This allows us to evaluate on the larger held-out set and reduce the noise. As shown in Fig. 19, we find that while the accuracy of the human annotators’ direct prediction may not monotonically improve from one round to the next, their beliefs about the user’s preferences become consistently more accurate over rounds.
<details>
<summary>x20.png Details</summary>
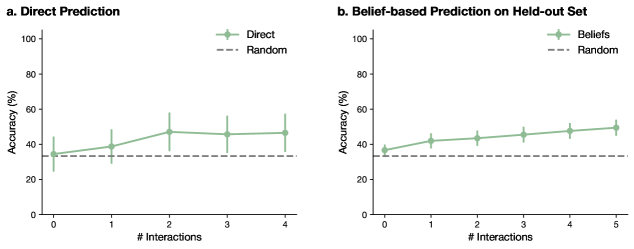
### Visual Description
## Line Graphs: Direct vs. Belief-based Prediction Accuracy
### Overview
The image contains two line graphs comparing the accuracy of two prediction methods ("Direct Prediction" and "Belief-based Prediction") against a random baseline. Both graphs plot accuracy (%) on the y-axis against the number of interactions (# Interactions) on the x-axis. The graphs are labeled **a. Direct Prediction** (left) and **b. Belief-based Prediction on Held-out Set** (right). Error bars indicate variability in measurements.
---
### Components/Axes
- **X-axis (Horizontal):**
- **Graph a:** # Interactions (0 to 4, integer steps).
- **Graph b:** # Interactions (0 to 5, integer steps).
- Label: "# Interactions" in bold black text.
- **Y-axis (Vertical):**
- Accuracy (%) ranging from 0 to 100 in 20% increments.
- Label: "Accuracy (%)" in bold black text.
- **Legends:**
- **Top-right corner** of both graphs.
- **Direct Prediction:** Green line with circular markers (solid line).
- **Random:** Dashed gray line.
- **Error Bars:**
- Vertical lines extending from data points in both graphs, indicating measurement variability.
---
### Detailed Analysis
#### Graph a: Direct Prediction
- **Trend:**
- The green line (Direct) starts at ~35% accuracy at 0 interactions, rises to ~45% at 1 interaction, peaks at ~50% at 2 interactions, then slightly declines to ~48% at 3 and 4 interactions.
- The dashed gray line (Random) remains flat at ~30% across all interactions.
- **Data Points:**
- 0 interactions: ~35% (Direct), ~30% (Random).
- 1 interaction: ~45% (Direct), ~30% (Random).
- 2 interactions: ~50% (Direct), ~30% (Random).
- 3 interactions: ~48% (Direct), ~30% (Random).
- 4 interactions: ~48% (Direct), ~30% (Random).
#### Graph b: Belief-based Prediction on Held-out Set
- **Trend:**
- The green line (Beliefs) starts at ~40% accuracy at 0 interactions and increases steadily to ~50% at 5 interactions.
- The dashed gray line (Random) remains flat at ~30% across all interactions.
- **Data Points:**
- 0 interactions: ~40% (Beliefs), ~30% (Random).
- 1 interaction: ~42% (Beliefs), ~30% (Random).
- 2 interactions: ~44% (Beliefs), ~30% (Random).
- 3 interactions: ~46% (Beliefs), ~30% (Random).
- 4 interactions: ~48% (Beliefs), ~30% (Random).
- 5 interactions: ~50% (Beliefs), ~30% (Random).
---
### Key Observations
1. **Performance vs. Random Baseline:**
- Both methods consistently outperform the random baseline (~30%) across all interaction counts.
2. **Direct Prediction (Graph a):**
- Shows an initial improvement with interactions but plateaus and slightly declines after 2 interactions.
- Higher variability (larger error bars) compared to Belief-based Prediction.
3. **Belief-based Prediction (Graph b):**
- Demonstrates a steady, linear improvement with increasing interactions.
- Lower variability (smaller error bars) than Direct Prediction.
---
### Interpretation
- **Belief-based Prediction** appears more robust and reliable, as its accuracy improves monotonically with interactions and exhibits less variability. This suggests that incorporating belief-based reasoning enhances generalization over time.
- **Direct Prediction** shows diminishing returns after 2 interactions, with a slight decline at higher interaction counts. This could indicate overfitting or sensitivity to noise in the data.
- The **Random baseline** serves as a control, confirming that both methods provide meaningful improvements beyond chance performance.
- Error bars highlight that Direct Prediction’s results are less consistent, possibly due to higher sensitivity to input variations or model instability.
The data underscores the advantages of belief-based approaches in dynamic prediction tasks, particularly when interactions increase.
</details>
Figure 19: Accuracy of the human assistant over rounds. (a) Based on the human’s direct predictions on provided option sets. (b) Based on the human’s beliefs about the user’s preferences on held-out option sets. Error bars show the averaged standard error across human participants.
Qualitative Analysis.
One pattern we observe in human assistants is that they tend to favor simpler heuristics when there is limited evidence. For example, in Table 2, we show that when there are multiple valid user preferences, human assistants may rely on simpler heuristics, e.g. in this example, always choosing the cheapest flight. In contrast, the fine-tuned Gemma Bayesian model does not seem to exhibit this behavior.
Table 2: Qualitative examples of LLM and human predictions. Here, the user strongly prefers an early departure time, weakly prefers a short flight duration, and has no preference for the number of stops and the price. Most human participants tend to favor a simpler heuristic, i.e., always choosing the cheapest flight, while Gemma Bayesian does not seem to exhibit this behavior.
| Flight 1 | 05:12 PM | 30 min | 1 | $190 | Flight 1 | Flight 1 | Flight 1: 66.7% |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Flight 2 | 03:36 PM | 12 hr 12 min | 2 | $460 | Flight 2: 26.7% | | |
| Flight 3 | 10:00 PM | 10 hr 15 min | 2 | $640 | Flight 3: 6.7% | | |
| Flight 1 | 06:48 PM | 4 hr 24 min | 1 | $370 | Flight 2 | Flight 2 | Flight 1: 40.0% |
| Flight 2 | 07:36 AM | 16 hr 6 min | 1 | $100 | Flight 2: 33.3% | | |
| Flight 3 | 10:00 PM | 20 hr | 0 | $550 | Flight 3: 26.7% | | |
| Flight 1 | 10:00 PM | 30 min | 1 | $280 | Flight 3 | Flight 3 | Flight 1: 60% |
| Flight 2 | 08:24 PM | 30 min | 0 | $910 | Flight 2: 0.0% | | |
| Flight 3 | 06:00 AM | 8 hr 18 min | 0 | $370 | Flight 3: 40% | | |
F.2 Humans As Users
Participants.
For the experiment where human participants acted as the users, we recruited 500 participants through the Prolific platform. The average age of the participants was 38.7 (SD=13.6); 51.0% identified as male (255), 48.4% as female (242), and 0.6% preferred not to say (3). The major nationalities of human participants were the United States at 40.0% (200), United Kingdom at 16.0% (80), South Africa at 9.0% (45), Canada at 7.8% (39), and Australia at 5.6% (28), with smaller representations from other countries. In terms of ethnicity, 65.2% (326) identified as White, 15.0% (75) as Black, 8.4% (42) as Asian, 7.2% (36) as Mixed, and 4.0% (20) as Other. All participants reported that English is their primary language.
Procedure.
Each participant in this experiment was first asked to complete a preference questionnaire to indicate their own preferences for different flight features. They then proceeded to the annotation rounds, where they needed to select their preferred option out of three flight options. To ensure quality, we required annotators to think for at least 30 seconds before making their selection. The procedure continued for five rounds. Participants were told to make choices consistent with their initially stated preferences throughout all five rounds. The mean and median completion times were 6.43 minutes and 5.18 minutes, respectively, with a standard deviation of 3.51 minutes.
Additional Results.
<details>
<summary>x21.png Details</summary>
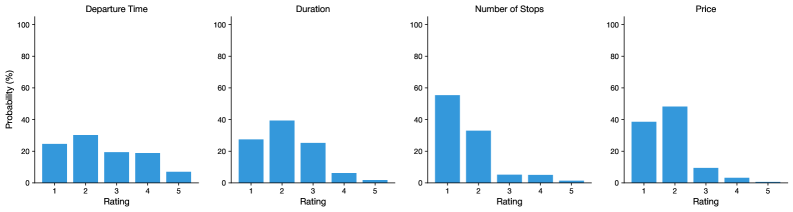
### Visual Description
## Bar Charts: Probability Distribution by Rating
### Overview
The image contains four bar charts arranged in a 2x2 grid, each depicting the probability distribution of different metrics (Departure Time, Duration, Number of Stops, Price) across a 5-point rating scale (1 to 5). All charts share identical axis labels and use blue bars to represent data.
### Components/Axes
- **X-axis**: "Rating" (categories: 1, 2, 3, 4, 5)
- **Y-axis**: "Probability (%)" (scale: 0 to 100, increments of 20)
- **Chart Titles**:
- Top-left: "Departure Time"
- Top-right: "Duration"
- Bottom-left: "Number of Stops"
- Bottom-right: "Price"
- **Legend**: None present.
### Detailed Analysis
1. **Departure Time**
- Rating 1: ~25%
- Rating 2: ~30%
- Rating 3: ~20%
- Rating 4: ~18%
- Rating 5: ~5%
- **Trend**: Probability decreases steadily from 1 to 5.
2. **Duration**
- Rating 1: ~25%
- Rating 2: ~40%
- Rating 3: ~25%
- Rating 4: ~5%
- Rating 5: ~1%
- **Trend**: Peaks at Rating 2, then declines sharply.
3. **Number of Stops**
- Rating 1: ~55%
- Rating 2: ~35%
- Rating 3: ~5%
- Rating 4: ~5%
- Rating 5: ~1%
- **Trend**: Dominated by Rating 1, with steep declines afterward.
4. **Price**
- Rating 1: ~40%
- Rating 2: ~50%
- Rating 3: ~10%
- Rating 4: ~2%
- Rating 5: ~0.5%
- **Trend**: Peaks at Rating 2, then drops sharply.
### Key Observations
- **Consistent Decline**: Departure Time, Duration, and Price show decreasing probabilities for higher ratings (4–5).
- **Outliers**:
- Number of Stops has the highest probability at Rating 1 (~55%).
- Duration and Price peak at Rating 2 (~40% and ~50%, respectively).
- **Low Probability for High Ratings**: All metrics assign <5% probability to Rating 5.
### Interpretation
The data suggests that higher ratings (4–5) are associated with lower probabilities across all metrics, indicating potential dissatisfaction or avoidance of extreme values. For example:
- **Departure Time**: Customers may prefer moderate departure times (Rating 2) over very early or late ones.
- **Duration**: Longer durations (Rating 2) are most common, possibly reflecting unavoidable travel constraints.
- **Number of Stops**: A high probability at Rating 1 implies that frequent stops are strongly disliked.
- **Price**: Mid-range prices (Rating 2) dominate, suggesting price sensitivity or market positioning.
The absence of high probabilities for Rating 5 across all metrics highlights a possible bias toward moderate or negative perceptions, which could inform service optimization or customer satisfaction strategies.
</details>
Figure 20: The distributions of human participants’ initial preferences for different flight features. A rating of 1 indicates the strongest preference for the earliest departure time, the shortest duration, the fewest number of stops, and the lowest price, while a rating of 5 indicates the opposite. A rating of 3 indicates no preference.
<details>
<summary>x22.png Details</summary>
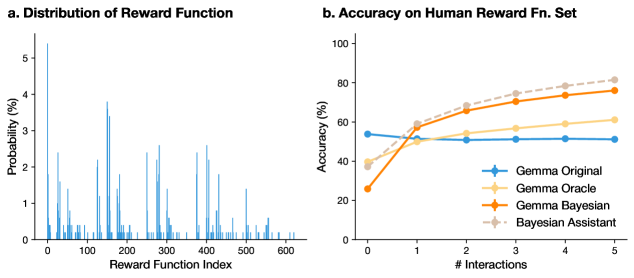
### Visual Description
## Line Graph and Bar Chart: Reward Function Distribution and Accuracy Trends
### Overview
The image contains two side-by-side visualizations:
1. **Left (Bar Chart)**: "a. Distribution of Reward Function" showing probability (%) across Reward Function Index (0–600).
2. **Right (Line Graph)**: "b. Accuracy on Human Reward Fn. Set" comparing four methods (Gamma Original, Gamma Oracle, Gamma Bayesian, Bayesian Assistant) across 0–5 interactions.
---
### Components/Axes
#### Left Chart (Bar Chart):
- **Title**: "a. Distribution of Reward Function"
- **Y-Axis**: "Probability (%)" (scale: 0–5%)
- **X-Axis**: "Reward Function Index" (0–600, integer steps)
- **Legend**: Not explicitly labeled (bars are blue).
#### Right Chart (Line Graph):
- **Title**: "b. Accuracy on Human Reward Fn. Set"
- **Y-Axis**: "Accuracy (%)" (scale: 0–100%)
- **X-Axis**: "# Interactions" (0–5, integer steps)
- **Legend**:
- **Blue (+)**: Gamma Original
- **Yellow (+)**: Gamma Oracle
- **Orange (+)**: Gamma Bayesian
- **Gray (dashed)**: Bayesian Assistant
---
### Detailed Analysis
#### Left Chart (Bar Chart):
- **Distribution**:
- Multimodal with sharp peaks at indices ~0, 100, 200, 300, 400, 500.
- Peaks vary in height (e.g., ~5% at index 0, ~4% at index 200, ~3% at index 400).
- Most indices have low probability (<1%), with sparse data beyond index 500.
#### Right Chart (Line Graph):
- **Trends**:
1. **Gamma Original (Blue)**: Flat line at ~50% accuracy across all interactions.
2. **Gamma Oracle (Yellow)**: Starts at ~40% (0 interactions), rises to ~60% by 5 interactions.
3. **Gamma Bayesian (Orange)**: Starts at ~20% (0 interactions), steeply increases to ~80% by 5 interactions.
4. **Bayesian Assistant (Gray, dashed)**: Starts at ~30% (0 interactions), rises to ~85% by 5 interactions.
- **Notable**:
- Gamma Bayesian and Bayesian Assistant show the steepest improvement.
- Bayesian Assistant’s dashed line suggests a projected or smoothed trend.
---
### Key Observations
1. **Left Chart**:
- Reward functions are unevenly distributed, with a few dominant indices.
- No clear pattern in peak positions or magnitudes.
2. **Right Chart**:
- All methods improve with more interactions, but Gamma Bayesian and Bayesian Assistant outperform others.
- Gamma Original’s stagnation suggests poor adaptability.
---
### Interpretation
- **Reward Function Distribution**: The left chart implies that certain reward functions are more prevalent or effective, but the sparse data limits conclusions.
- **Accuracy Trends**:
- **Gamma Bayesian** and **Bayesian Assistant** demonstrate superior performance, likely due to adaptive learning or probabilistic modeling.
- **Gamma Original**’s flat line indicates it fails to leverage interactions, possibly due to rigid parameterization.
- The **Bayesian Assistant**’s dashed line may represent a confidence interval or ensemble average, suggesting robustness.
- **Implications**: Bayesian methods (especially Bayesian Assistant) are more effective for dynamic reward function optimization, aligning with principles of probabilistic reasoning and iterative improvement.
---
**Note**: Exact numerical values for bar heights and line points are approximated due to lack of gridlines or numerical annotations. Trends are inferred from visual slopes and relative positioning.
</details>
\phantomsubcaption \phantomsubcaption
Figure 21: Analysis of human reward functions. (a) Distribution of human reward functions. (b) Accuracy over rounds on the subset of the original data where the simulated user’s reward function is set of reward functions stated by the human participants. Error bars show standard errors across three random seeds (and three training runs).
<details>
<summary>x23.png Details</summary>
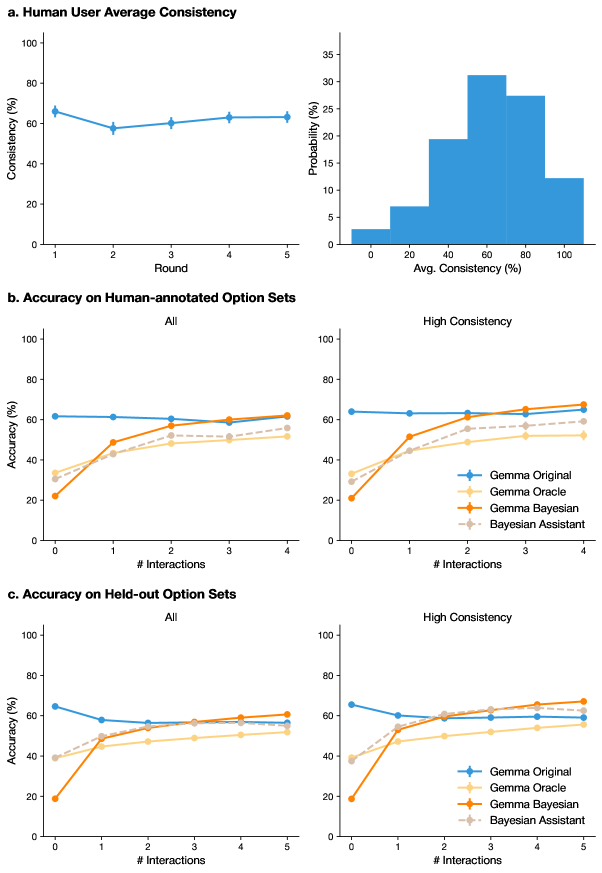
### Visual Description
## Line Graphs and Histograms: Human Consistency and Accuracy Analysis
### Overview
The image contains six visualizations analyzing human consistency and accuracy across different interaction scenarios. Key elements include line graphs tracking performance over rounds/interactions and a histogram showing consistency distribution. Four data series are compared: Gemma Original, Gemma Oracle, Gemma Bayesian, and Bayesian Assistant.
### Components/Axes
1. **Top Left (a. Human User Average Consistency)**
- X-axis: "Round" (1–5)
- Y-axis: "Consistency (%)" (0–100)
- Data: Blue line with markers showing slight dip in Round 2, stabilizing at ~60–65% thereafter.
2. **Top Right (b. Accuracy on Human-annotated Option Sets)**
- X-axis: "Avg. Consistency (%)" (0–100)
- Y-axis: "Probability (%)" (0–35)
- Data: Blue histogram bars peaking at 60–80% consistency.
3. **Middle Left (c. Accuracy on Held-out Option Sets - All)**
- X-axis: "# Interactions" (0–5)
- Y-axis: "Accuracy (%)" (0–100)
- Data: Four lines (blue, yellow, orange, gray) representing different models.
4. **Middle Right (High Consistency Subset)**
- Same axes as Middle Left but filtered for high-consistency users.
5. **Bottom Left (c. Accuracy on Held-out Option Sets - All)**
- Same as Middle Left but extended to 5 rounds.
6. **Bottom Right (High Consistency Subset)**
- Same as Middle Right but extended to 5 rounds.
### Detailed Analysis
#### a. Human User Average Consistency
- **Trend**: Consistency starts at ~65% (Round 1), drops to ~58% (Round 2), then rises to ~62% (Round 3) and stabilizes (~63–64%) in Rounds 4–5.
- **Uncertainty**: Approximate values due to lack of gridlines; error bars not visible.
#### b. Accuracy on Human-annotated Option Sets
- **Distribution**: 70% of users fall within 60–80% consistency. Lower tails (0–40%) have negligible probability.
#### c. Accuracy on Held-out Option Sets (All)
- **Gemma Original (Blue)**: Starts at ~62% (0 interactions), dips to ~58% (Round 5).
- **Gemma Oracle (Yellow)**: Starts at ~30% (0 interactions), rises to ~50% (Round 5).
- **Gemma Bayesian (Orange)**: Starts at ~20% (0 interactions), surges to ~60% (Round 5).
- **Bayesian Assistant (Gray)**: Starts at ~35% (0 interactions), reaches ~55% (Round 5).
#### High Consistency Subset
- **Trends**: All models show steeper improvement. Gemma Bayesian jumps from ~25% (0 interactions) to ~65% (Round 5).
### Key Observations
1. **Consistency Stability**: Human users maintain ~60–65% consistency across rounds, with minor fluctuations.
2. **Model Performance**:
- Gemma Bayesian outperforms others in held-out sets, especially with high consistency users.
- Bayesian Assistant shows moderate improvement but lags behind Gemma Bayesian.
3. **Interaction Impact**: Accuracy improves significantly with more interactions for all models.
### Interpretation
- **Human Behavior**: Stable consistency suggests reliable user performance, though slight dips may indicate task fatigue or learning curves.
- **Model Efficacy**:
- Gemma Bayesian’s rapid improvement implies strong adaptability to user feedback.
- Oracle and Assistant models perform better with high-consistency users, highlighting the importance of data quality.
- **Practical Implications**: Bayesian models (Gemma Bayesian, Bayesian Assistant) are more effective in dynamic environments requiring iterative learning. High-consistency users may represent a subset where models achieve near-human performance.
*Note: All values are approximate due to the absence of gridlines or exact numerical labels in the image.*
</details>
\phantomsubcaption \phantomsubcaption \phantomsubcaption
Figure 22: Results on interactions with real human users. (a) Consistency between the human users’ choices and the predictions derived from their initially stated preferences. We show user consistency over rounds and the distribution of the average user consistency. Error bars show standard errors across five-round option sets list. (b) Accuracy over rounds on human-annotated option sets. We show the results of all human users and users with high consistency, i.e., their choices matched their initially stated preferences in 4 or 5 of the rounds (40.4% of the data). (c) Accuracy over rounds on the held-out set, where the preferred choices are deterministically computed based on the human user’s preferences. Error bars show standard errors across three random seeds (and three training runs).
In the main paper we report results for this more realistic setting where the model interacts with real human users on the flight recommendation task. Surprisingly, we also find that the original LLMs achieved good performance, unlike what was observed in earlier experiments.
We hypothesize that two factors may contribute to its improved performance. First, unlike our simulated users whose preferences are uniformly sampled from the space of possible reward functions, human preferences are biased towards particular types of functions, and in Fig. 21 we show that some reward functions are considerably more common than others in our sample of human participants. For example, most participants report preferring cheaper flights (see Fig. 20). As such, a viable strategy for the original LLM could be to rely on its prior knowledge about user preferences to make relatively good recommendations. To investigate this further, we filter results for simulated users based on reward functions stated by the human participants in Fig. 21. We observe that also in this case, Gemma Original achieves a higher accuracy of around 60% (as opposed to 37% in Fig. 2, matching the high accuracy it obtained in Fig. 6. This makes it clear that the bias among the human preferences in this experiment contributes to the stronger performance of original LLMs.
Secondly, human users may not necessarily behave consistently with their preferences, i.e., their choices may differ from those that would reflect their initially stated preferences. Indeed, note how in Fig. 21 the gap between the original LLM and the Bayesian LLM increases significantly when evaluating on consistent simulated users. To quantify this potential discrepancy, we compute the consistency between the human user’s choices and the predictions derived from their preferences. The latter are obtained by mapping their stated preferences to corresponding reward functions and selecting the option with the highest reward accordingly. In line with our hypothesis, the average consistency is relatively low at 60%, with chance performance being 33.3% (Fig. 22).
We further break down the performance by user consistency over rounds and show results for high-consistency users; that is, users whose choices were consistent with their stated preferences in 4 or 5 of the rounds (Fig. 22). We find that all models perform better for the high-consistency users. Specifically, when user consistency is high, the improvement of Gemma Bayesian over Gemma Original increases.
Finally, to limit the effect of such inconsistencies, while still retaining the real interactions between human users and the model, we also evaluate the LLMs on a held-out set of 100 randomly sampled options that simulate perfectly consistent users; to do so we use the preferred options derived from the participants’ initially stated preferences rather than the participants’ actual choices. As shown in Fig. 22, when removing inconsistency from the evaluation data, Gemma Bayesian achieves the best performance. Gemma Original performs best initially, likely due to its correct prior about human users, but its performance decreases over rounds, indicating its limited ability to incorporate the simulated user’s feedback.
F.3 Human Annotation Interface
We show the human annotation interface where humans act as the assistant in Fig. 23. The interface allows the human annotator to select the best option from three flight options, rate their estimation of the user’s preferences, and check the flight booking history from previous rounds. The annotation interface where humans act as the user is similar.
Appendix G Statistical Analyses
This Supplementary reports analyses that test whether Bayesian teaching leads to statistically significant improvement over the baselines. We fit linear mixed-effects models treating each method (Bayesian teaching, oracle teaching, and the original) and model family (Gemma, Llama, and Qwen) as fixed effects while controlling for various sources of randomness. For flight and hotel recommendation, we include training run, evaluation random seed, and reward function as random effects. For web shopping, we treat training run ad product category as random effects. Overall, the models demonstrate statistically significant differences between methods across all domains and all three model families (Gemma, Llama, and Qwen).
In flight recommendation, the original LLM achieves a baseline accuracy of 37.0% (95% CI: 30.6–43.5%). The Oracle LLM performs significantly better with a 24.0% increase (95% CI: 16.6–31.4%, p $<$ 0.001), while the Bayesian LLM shows an even more substantial 38.5% increase (95% CI: 31.1–45.9%, p $<$ 0.001). Model family shows no significant effect on performance, with differences between model families all non-significant. The interaction between method and model family was not statistically significant (minimum p = 0.19). Within each model family, improvements between all methods are significant (p $<$ 0.001), with the exception of Qwen Oracle versus Qwen Original which shows slightly weaker but still significant improvement (p = 0.002).
In hotel recommendation, the original LLM achieves a baseline accuracy of 36.7% (95% CI: 32.1–41.3%). The Oracle LLM performs significantly better with a 16.7% increase (95% CI: 11.4–22.0%, p $<$ 0.001), while the Bayesian LLM shows a 29.4% increase (95% CI: 24.1–34.7%, p $<$ 0.001). Model family shows no significant main effect on performance. The interaction between method and model family is not statistically significant (all interaction p-values $>$ 0.11). Within each model family, most pairwise comparisons show p-values $<$ 0.001, with two exceptions: Llama Bayesian versus Llama Oracle shows weak significance (p = 0.001), and Qwen Oracle versus Qwen Original shows weaker significance (p = 0.002).
In web shopping, the original LLM achieves a baseline accuracy of 54.0% (95% CI: 49.6–58.4%). The Oracle LLM performs significantly better with a 7.1% increase (95% CI: 2.3–11.8%, p = 0.013), while the Bayesian LLM shows a more substantial 18.6% increase (95% CI: 13.8–23.4%, p $<$ 0.001). Unlike the other domains, model family shows a significant effect, with Qwen showing a significant decrease of -11.1% (95% CI: -17.0–5.3%, p = 0.003) compared to the baseline. There is also a significant interaction between Oracle method and Qwen (15.8%, 95% CI: 9.0–22.6%, p = 0.001). Within-family pairwise comparisons show different patterns: for Gemma, all method comparisons are significant (Original-Oracle: p = 0.033; others p $<$ 0.001); for Llama, Original-Oracle is non-significant (p = 0.199) while Original-Bayesian (p = 0.001) and Oracle-Bayesian (p = 0.004) are significant; for Qwen, Original-Oracle and Original-Bayesian are highly significant (p $<$ 0.001), but Oracle-Bayesian is non-significant (p = 0.282).
Appendix H Results Details
We show results over rounds for different models and methods in Fig. 24 – 27. For each, we show the accuracy based on the LLM’s or human direct prediction (“direct”) and accuracy based on predictions derived from their beliefs about the user’s preferences (“beliefs”) if available.
<details>
<summary>x24.png Details</summary>
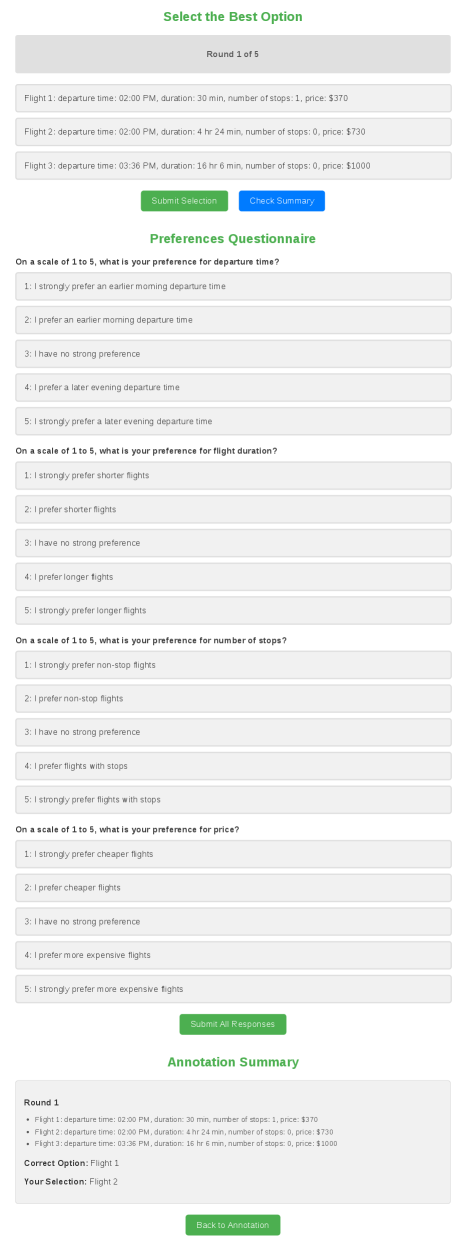
### Visual Description
## Screenshot: Flight Selection Interface with Preferences Questionnaire
### Overview
The image depicts a flight selection interface with a multi-step questionnaire. The interface includes flight options, preference questions, and an annotation summary. The design uses a clean layout with green and blue buttons for actions.
### Components/Axes
1. **Header Section**:
- Title: "Select the Best Option" (green text)
- Progress Indicator: "Round 1 of 5" (gray banner)
2. **Flight Options**:
- Three flight options listed in gray banners:
- **Flight 1**: Departure 02:00 PM, Duration 30 min, 1 stop, $370
- **Flight 2**: Departure 02:00 PM, Duration 4h24m, 0 stops, $730
- **Flight 3**: Departure 03:36 PM, Duration 16h6m, 0 stops, $1000
- Buttons: "Submit Selection" (green) and "Check Summary" (blue)
3. **Preferences Questionnaire**:
- Four questions with 1-5 Likert scales:
1. **Departure Time Preference**:
- 1: Strongly prefer earlier morning
- 2: Prefer earlier morning
- 3: No strong preference
- 4: Prefer later evening
- 5: Strongly prefer later evening
2. **Flight Duration Preference**:
- 1: Strongly prefer shorter flights
- 2: Prefer shorter flights
- 3: No strong preference
- 4: Prefer longer flights
- 5: Strongly prefer longer flights
3. **Number of Stops Preference**:
- 1: Strongly prefer non-stop flights
- 2: Prefer non-stop flights
- 3: No strong preference
- 4: Prefer flights with stops
- 5: Strongly prefer flights with stops
4. **Price Preference**:
- 1: Strongly prefer cheaper flights
- 2: Prefer cheaper flights
- 3: No strong preference
- 4: Prefer more expensive flights
- 5: Strongly prefer more expensive flights
4. **Annotation Summary**:
- Header: "Annotation Summary" (green text)
- Content:
- **Round 1**:
- Flight 1: 02:00 PM, 30 min, 1 stop, $370
- Flight 2: 02:00 PM, 4h24m, 0 stops, $730
- Flight 3: 03:36 PM, 16h6m, 0 stops, $1000
- **Correct Option**: Flight 1
- **Your Selection**: Flight 2
- Button: "Back to Annotation" (green)
### Detailed Analysis
- **Flight Options**:
- Flight 1 is the cheapest ($370) but has 1 stop and shortest duration.
- Flight 2 is mid-priced ($730) with no stops but longer duration.
- Flight 3 is the most expensive ($1000) with no stops and longest duration.
- **Questionnaire Structure**:
- All questions use a 1-5 scale with clear preference gradients.
- Questions cover time, duration, stops, and price preferences.
- **Annotation Summary**:
- Highlights the discrepancy between the "correct" option (Flight 1) and the user's selection (Flight 2).
### Key Observations
1. **Price vs. Convenience Tradeoff**:
- Flight 1 is the most economical but least convenient (1 stop).
- Flight 2 balances cost and convenience (no stops, mid-duration).
- Flight 3 prioritizes convenience (no stops) at the highest cost.
2. **User Preference Conflict**:
- The user selected Flight 2 despite Flight 1 being cheaper and shorter.
- This suggests the user may prioritize non-stop flights over cost.
3. **Questionnaire Design**:
- Clear Likert scales allow granular preference capture.
- Questions are logically ordered (time → duration → stops → price).
### Interpretation
The interface appears designed to optimize flight selection based on user preferences. However, the user's choice of Flight 2 over the cheaper Flight 1 indicates a potential misalignment between the "correct" option (cost-effective) and the user's actual priorities (non-stop flights). This could reflect:
- A design flaw if the "correct" option is algorithmically determined without considering user preferences.
- A need for better user education about tradeoffs between cost, time, and convenience.
- An opportunity to refine the questionnaire to better align selections with user values.
The interface effectively structures data but may benefit from dynamic recommendations that adapt to user preferences rather than a static "correct" option.
</details>
Figure 23: Example of annotation interface where humans act as the flight recommendation assistant. The human annotator was asked to select the best option and rate their estimation of the user’s preferences. We also allow the annotator to check a summary of previous flight booking history. The annotation interface where humans act as the user is similar.
<details>
<summary>x25.png Details</summary>
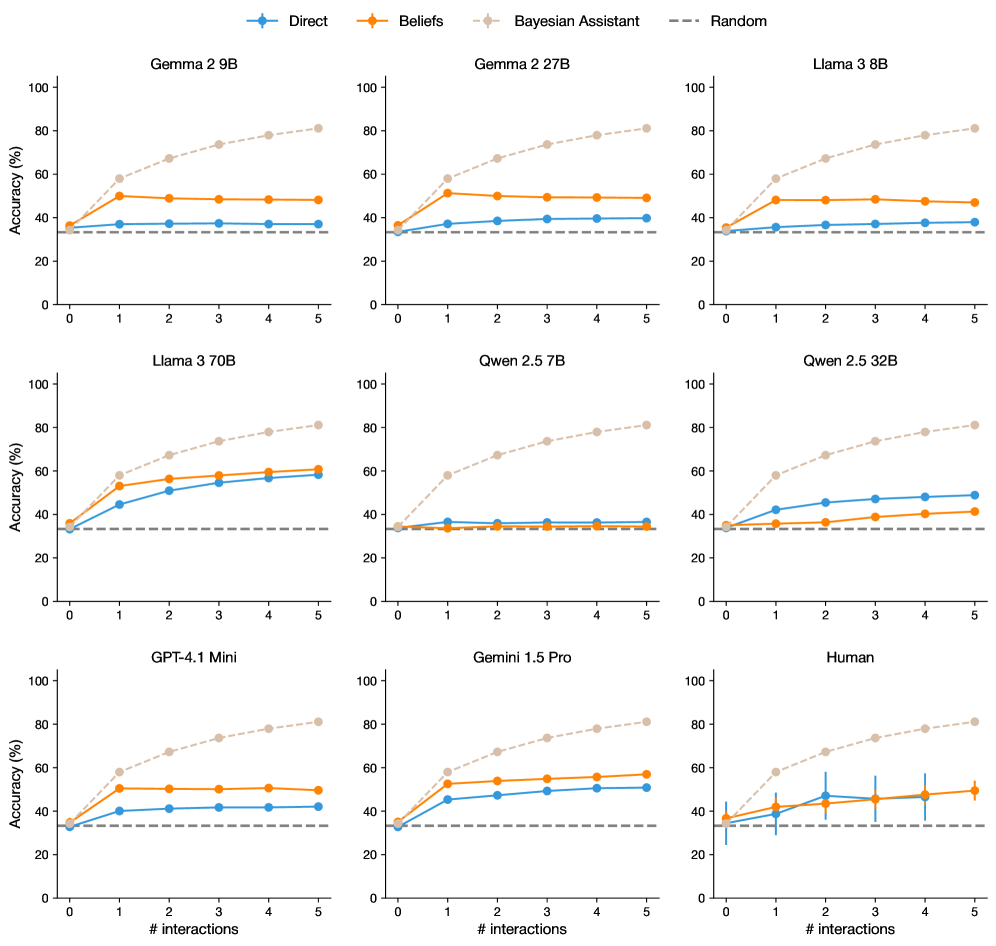
### Visual Description
## Line Chart Grid: Model Performance Across Interaction Counts
### Overview
The image displays a 3x3 grid of line charts comparing the accuracy performance of different AI models (Gemma 2 9B, Gemma 2 27B, Llama 3 8B, Llama 3 70B, Quen 2.5 7B, Quen 2.5 32B, GPT-4.1 Mini, Gemini 1.5 Pro, and Human) across 5 interaction counts (0-5). Each chart tracks three performance metrics: Direct, Beliefs, and Bayesian Assistant, against a Random baseline. All charts share identical axes and legend conventions.
### Components/Axes
- **X-axis**: "# interactions" (0-5, integer scale)
- **Y-axis**: "Accuracy (%)" (0-100, linear scale)
- **Legend**:
- Blue circles: Direct
- Orange squares: Beliefs
- Gray diamonds: Bayesian Assistant
- Dashed gray line: Random baseline
- **Chart Titles**: Model names (e.g., "Gemma 2 9B", "Human") positioned at top of each subplot
### Detailed Analysis
1. **Gemma 2 9B**
- Direct: 35% → 55% (steady increase)
- Beliefs: 40% → 50% (moderate growth)
- Bayesian Assistant: 35% → 80% (sharp improvement)
- Random: 30% (flat)
2. **Gemma 2 27B**
- Direct: 30% → 45% (consistent rise)
- Beliefs: 40% → 50% (flat after interaction 3)
- Bayesian Assistant: 35% → 80% (linear growth)
- Random: 30% (flat)
3. **Llama 3 8B**
- Direct: 35% → 45% (slow climb)
- Beliefs: 40% → 45% (minimal improvement)
- Bayesian Assistant: 35% → 80% (rapid ascent)
- Random: 30% (flat)
4. **Llama 3 70B**
- Direct: 30% → 55% (steep increase)
- Beliefs: 40% → 60% (moderate growth)
- Bayesian Assistant: 35% → 85% (linear trajectory)
- Random: 30% (flat)
5. **Quen 2.5 7B**
- Direct: 35% → 45% (gradual rise)
- Beliefs: 40% → 50% (flat after interaction 2)
- Bayesian Assistant: 35% → 80% (steady climb)
- Random: 30% (flat)
6. **Quen 2.5 32B**
- Direct: 30% → 45% (consistent growth)
- Beliefs: 40% → 45% (minimal improvement)
- Bayesian Assistant: 35% → 80% (linear trajectory)
- Random: 30% (flat)
7. **GPT-4.1 Mini**
- Direct: 35% → 50% (moderate increase)
- Beliefs: 40% → 55% (steady climb)
- Bayesian Assistant: 35% → 85% (sharp rise)
- Random: 30% (flat)
8. **Gemini 1.5 Pro**
- Direct: 30% → 50% (consistent growth)
- Beliefs: 40% → 55% (moderate improvement)
- Bayesian Assistant: 35% → 85% (linear trajectory)
- Random: 30% (flat)
9. **Human**
- Direct: 35% → 45% → 40% → 50% → 45% (volatility)
- Beliefs: 40% → 45% → 50% → 48% → 52% (noise)
- Bayesian Assistant: 35% → 80% → 85% → 88% → 90% (steady climb)
- Random: 30% (flat)
- Error bars: ±5% variability in human performance
### Key Observations
1. **Bayesian Assistant Dominance**: All models show Bayesian Assistant outperforming others by 20-50% at 5 interactions, with linear growth patterns.
2. **Direct vs Beliefs**: Direct consistently outperforms Beliefs except in GPT-4.1 Mini (interaction 5: 50% vs 55%).
3. **Human Variability**: Human performance shows significant fluctuation (±5% error bars), unlike model stability.
4. **Diminishing Returns**: Most models plateau after 3-4 interactions, except Bayesian Assistant which maintains linear growth.
5. **Random Baseline**: All charts maintain 30% accuracy for Random, suggesting a performance floor.
### Interpretation
The data demonstrates that Bayesian Assistant integration significantly enhances model performance across all architectures, suggesting it provides critical contextual grounding. The consistent linear growth of Bayesian Assistant contrasts with plateauing trends in other methods, indicating its scalability with interaction count. Human performance volatility highlights the challenge of replicating model consistency in human-AI collaboration. The Direct method's superiority over Beliefs (except in GPT-4.1 Mini) suggests that belief-based reasoning may introduce unnecessary complexity without proportional accuracy gains. The Random baseline's flat 30% performance establishes a minimum threshold for meaningful interaction design.
</details>
Figure 24: Accuracy over rounds for different original LLMs. We show accuracy based on direct predictions and accuracy based on predictions derived from their beliefs about users’ preferences. Error bars show standard errors across three random seeds (and three training runs).
<details>
<summary>x26.png Details</summary>
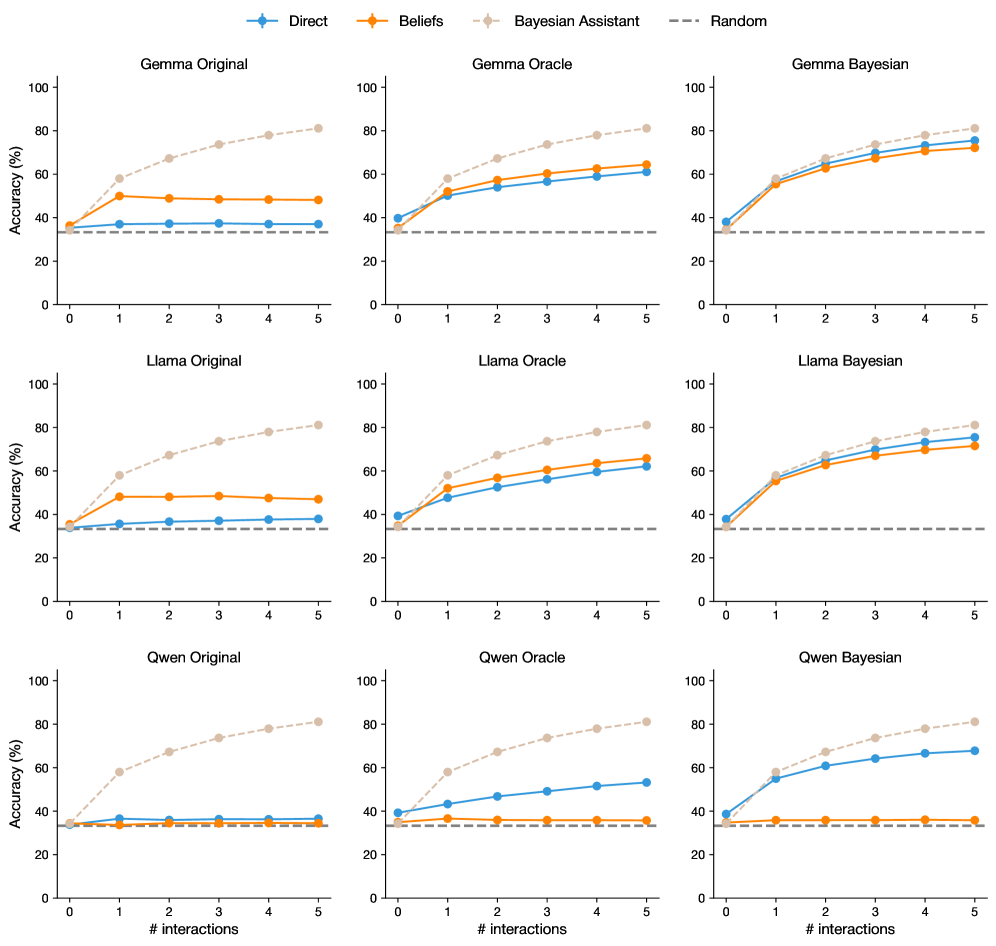
### Visual Description
## Line Graphs: Model Performance Across Interaction Counts
### Overview
The image contains nine line graphs arranged in a 3x3 grid, comparing the accuracy of three AI models (Gemma, Llama, Gwen) under three configurations (Original, Oracle, Bayesian) across 0-5 interaction counts. Each graph tracks four data series: Direct (blue), Beliefs (orange), Bayesian Assistant (light brown), and Random (gray dashed). All graphs share identical axes and legend placement.
### Components/Axes
- **X-axis**: "# interactions" (0-5, integer increments)
- **Y-axis**: "Accuracy (%)" (0-100, 20% increments)
- **Legend**: Top-left corner, color-coded:
- Blue: Direct
- Orange: Beliefs
- Light brown: Bayesian Assistant
- Gray dashed: Random
- **Graph Titles**: Model + Configuration (e.g., "Gemma Original", "Llama Bayesian")
### Detailed Analysis
#### Gemma Original
- **Bayesian Assistant**: Starts at ~30%, rises steadily to ~85% by interaction 5
- **Beliefs**: Flat at ~45% throughout
- **Direct**: Flat at ~35% throughout
- **Random**: Constant at ~30%
#### Gemma Oracle
- **Bayesian Assistant**: Starts at ~35%, rises to ~75% by interaction 5
- **Beliefs**: Flat at ~50% throughout
- **Direct**: Flat at ~45% throughout
- **Random**: Constant at ~30%
#### Gemma Bayesian
- **Bayesian Assistant**: Starts at ~30%, rises to ~80% by interaction 5
- **Beliefs**: Flat at ~55% throughout
- **Direct**: Flat at ~50% throughout
- **Random**: Constant at ~30%
#### Llama Original
- **Bayesian Assistant**: Starts at ~35%, rises to ~80% by interaction 5
- **Beliefs**: Flat at ~40% throughout
- **Direct**: Flat at ~35% throughout
- **Random**: Constant at ~30%
#### Llama Oracle
- **Bayesian Assistant**: Starts at ~40%, rises to ~70% by interaction 5
- **Beliefs**: Flat at ~50% throughout
- **Direct**: Flat at ~40% throughout
- **Random**: Constant at ~30%
#### Llama Bayesian
- **Bayesian Assistant**: Starts at ~35%, rises to ~75% by interaction 5
- **Beliefs**: Flat at ~55% throughout
- **Direct**: Flat at ~50% throughout
- **Random**: Constant at ~30%
#### Gwen Original
- **Bayesian Assistant**: Starts at ~30%, rises to ~85% by interaction 5
- **Beliefs**: Flat at ~40% throughout
- **Direct**: Flat at ~35% throughout
- **Random**: Constant at ~30%
#### Gwen Oracle
- **Bayesian Assistant**: Starts at ~35%, rises to ~75% by interaction 5
- **Beliefs**: Flat at ~45% throughout
- **Direct**: Flat at ~40% throughout
- **Random**: Constant at ~30%
#### Gwen Bayesian
- **Bayesian Assistant**: Starts at ~30%, rises to ~80% by interaction 5
- **Beliefs**: Flat at ~45% throughout
- **Direct**: Flat at ~40% throughout
- **Random**: Constant at ~30%
### Key Observations
1. **Bayesian Assistant Dominance**: Consistently outperforms all other methods across all models and configurations, with accuracy gains accelerating with more interactions
2. **Oracle vs Original**: Oracle configurations show ~5-10% higher baseline accuracy than Original versions, but Bayesian versions close this gap through interaction
3. **Beliefs vs Direct**: Beliefs consistently outperform Direct by ~5-10% across all models, though both remain flat regardless of interactions
4. **Random Baseline**: All models perform significantly better than the 30% random chance line
5. **Interaction Impact**: Accuracy improvements for Bayesian Assistant are most pronounced between interactions 2-5
### Interpretation
The data demonstrates that Bayesian methods significantly enhance model performance through iterative interactions, with the Bayesian Assistant configuration showing the most substantial gains. The Oracle configurations suggest that pre-optimized models provide a performance floor, while Bayesian approaches enable continuous improvement. The consistent gap between Beliefs and Direct indicates that belief-based reasoning provides a measurable advantage over direct inference. The Gwen model's lower performance across all configurations suggests architectural or training data differences compared to Gemma/Llama models. Notably, all models show diminishing returns after interaction 3, implying diminishing marginal utility of additional interactions.
</details>
Figure 25: Accuracy over rounds for different original LLMs and fine-tuned LLMs on the flight recommendation task. We show accuracy based on direct predictions and accuracy based on predictions derived from their beliefs about users’ preferences. Error bars show standard errors across three random seeds (and three training runs).
<details>
<summary>x27.png Details</summary>
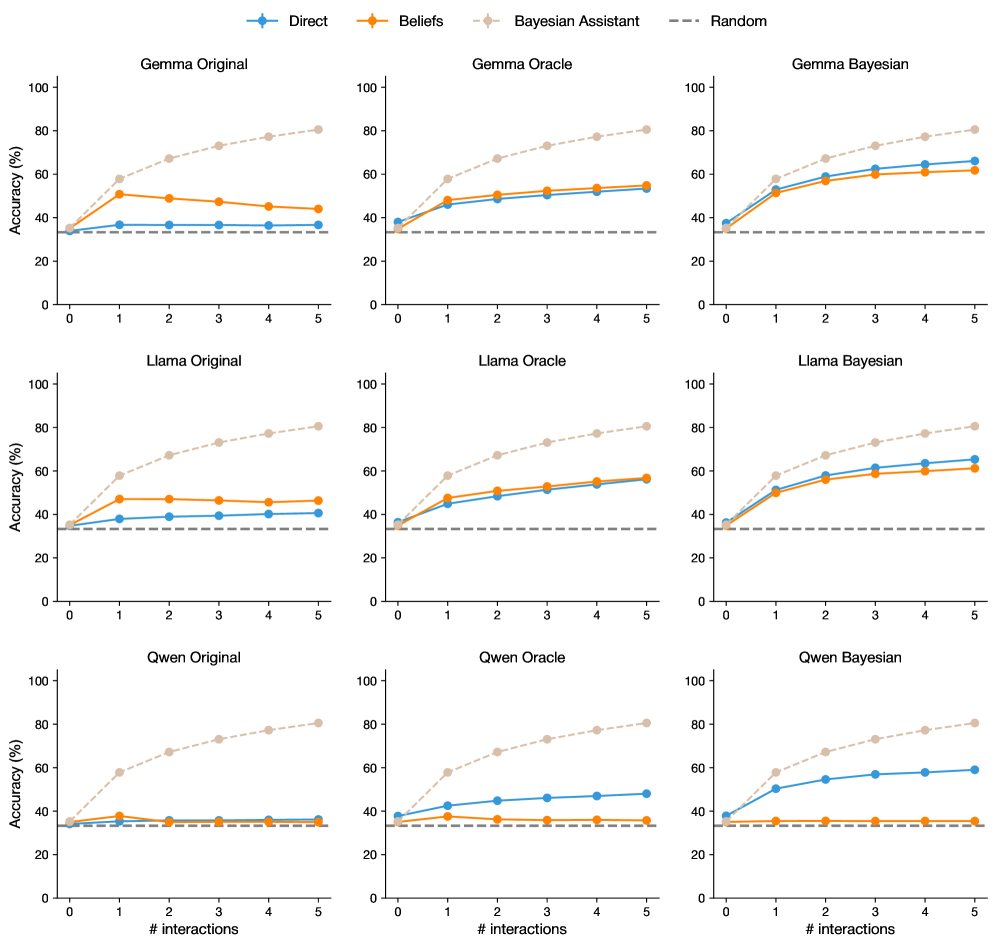
### Visual Description
## Line Graphs: Model Performance Across Interaction Counts
### Overview
The image contains a 3x3 grid of line graphs comparing the accuracy of three AI models (Gemma, Llama, Qwen) across three configurations (Original, Oracle, Bayesian) over 5 interaction steps. Four performance metrics are tracked: Direct, Beliefs, Bayesian Assistant, and Random. Each graph shows distinct trends in accuracy improvement with increasing interactions.
### Components/Axes
- **X-axis**: "# interactions" (0–5, integer steps)
- **Y-axis**: "Accuracy (%)" (0–100, linear scale)
- **Legends**: Positioned at the top of each graph with four categories:
- **Direct** (blue circles)
- **Beliefs** (orange squares)
- **Bayesian Assistant** (beige diamonds)
- **Random** (gray dashed line)
- **Graph Titles**: Format = "[Model] [Configuration]" (e.g., "Gemma Original")
### Detailed Analysis
#### Gemma Original
- **Direct**: Starts at ~30%, rises to ~60% by interaction 5
- **Beliefs**: Peaks at ~50% (interaction 2), drops to ~45% by interaction 5
- **Bayesian Assistant**: Steady climb from ~30% to ~80%
- **Random**: Flat at ~30%
#### Gemma Oracle
- **Direct**: ~30% → ~50%
- **Beliefs**: Peaks at ~55% (interaction 3), drops to ~50%
- **Bayesian Assistant**: ~30% → ~75%
- **Random**: Flat at ~30%
#### Gemma Bayesian
- **Direct**: ~30% → ~65%
- **Beliefs**: Peaks at ~60% (interaction 3), drops to ~55%
- **Bayesian Assistant**: ~30% → ~85%
- **Random**: Flat at ~30%
#### Llama Original
- **Direct**: ~30% → ~50%
- **Beliefs**: Peaks at ~50% (interaction 2), drops to ~45%
- **Bayesian Assistant**: ~30% → ~80%
- **Random**: Flat at ~30%
#### Llama Oracle
- **Direct**: ~30% → ~55%
- **Beliefs**: Peaks at ~55% (interaction 3), drops to ~50%
- **Bayesian Assistant**: ~30% → ~75%
- **Random**: Flat at ~30%
#### Llama Bayesian
- **Direct**: ~30% → ~60%
- **Beliefs**: Peaks at ~60% (interaction 3), drops to ~55%
- **Bayesian Assistant**: ~30% → ~85%
- **Random**: Flat at ~30%
#### Qwen Original
- **Direct**: ~30% → ~50%
- **Beliefs**: Peaks at ~40% (interaction 1), drops to ~35%
- **Bayesian Assistant**: ~30% → ~80%
- **Random**: Flat at ~30%
#### Qwen Oracle
- **Direct**: ~30% → ~50%
- **Beliefs**: Peaks at ~40% (interaction 1), drops to ~35%
- **Bayesian Assistant**: ~30% → ~75%
- **Random**: Flat at ~30%
#### Qwen Bayesian
- **Direct**: ~30% → ~60%
- **Beliefs**: Peaks at ~50% (interaction 3), drops to ~45%
- **Bayesian Assistant**: ~30% → ~85%
- **Random**: Flat at ~30%
### Key Observations
1. **Bayesian Assistant Dominance**: Consistently achieves highest accuracy across all models and configurations, suggesting Bayesian methods significantly enhance performance.
2. **Direct vs. Beliefs**: Both metrics show initial improvement with interactions but plateau or decline after 3–4 steps, indicating diminishing returns.
3. **Random Baseline**: All models outperform the random baseline (30%) by interaction 1, demonstrating baseline effectiveness.
4. **Model-Specific Trends**:
- Qwen shows the most pronounced drop in Beliefs accuracy after peak
- Llama and Gemma maintain more stable Beliefs performance
- Bayesian configurations show 20–30% absolute improvement over Original/Oracle
### Interpretation
The data suggests Bayesian approaches (Bayesian Assistant) provide the most reliable accuracy gains, likely through probabilistic reasoning and uncertainty quantification. Direct and Beliefs metrics indicate that while interaction depth improves performance initially, excessive interactions may introduce noise or overfitting. The consistent Random baseline (30%) across all graphs implies these models outperform chance-level guessing by at least 30 percentage points. Notably, the Bayesian Assistant's performance improvement correlates with interaction count, suggesting it effectively leverages additional context. The Beliefs metric's volatility across models may reflect differences in how each architecture handles uncertainty representation.
</details>
Figure 26: Accuracy over rounds for different original LLMs and fine-tuned LLMs on the hotel recommendation task. We show accuracy based on direct predictions and accuracy based on predictions derived from their beliefs about users’ preferences. Error bars show standard errors across three random seeds (and three training runs).
<details>
<summary>x28.png Details</summary>
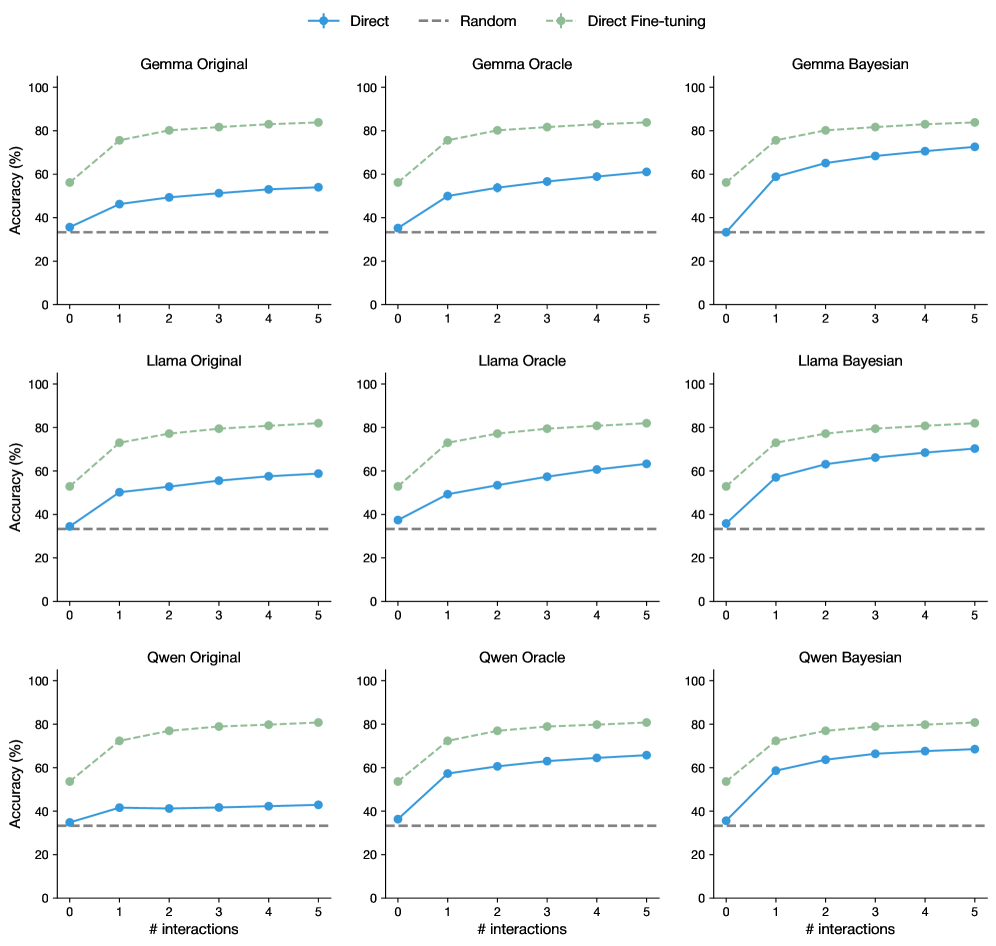
### Visual Description
## Line Graph Grid: Model Performance Across Interaction Counts
### Overview
The image contains a 3x3 grid of line graphs comparing model accuracy across three datasets (Gamma, Llama, Qwen) under three conditions: Original, Oracle, and Bayesian. Each subplot tracks accuracy (%) against interaction count (0-5), with three data series: Direct (blue), Random (gray dashed), and Direct Fine-tuning (green). All graphs share identical axes and legend placement.
### Components/Axes
- **X-axis**: "# interactions" (0-5, integer ticks)
- **Y-axis**: "Accuracy (%)" (0-100, 20% increments)
- **Legend**: Top-right of each subplot, with:
- Blue circles: Direct
- Gray dashed line: Random
- Green diamonds: Direct Fine-tuning
- **Subplot Titles**: Top-left corner (e.g., "Gamma Original", "Llama Bayesian")
### Detailed Analysis
1. **Gamma Original**
- Direct: Starts at ~35% (0 interactions), rises to ~50% (5 interactions)
- Random: Flat at ~30%
- Direct Fine-tuning: Starts at ~55%, rises to ~85%
2. **Gamma Oracle**
- Direct: ~40% → ~55%
- Random: ~30%
- Direct Fine-tuning: ~60% → ~88%
3. **Gamma Bayesian**
- Direct: ~45% → ~70%
- Random: ~30%
- Direct Fine-tuning: ~65% → ~89%
4. **Llama Original**
- Direct: ~40% → ~55%
- Random: ~30%
- Direct Fine-tuning: ~60% → ~88%
5. **Llama Oracle**
- Direct: ~45% → ~60%
- Random: ~30%
- Direct Fine-tuning: ~70% → ~90%
6. **Llama Bayesian**
- Direct: ~50% → ~75%
- Random: ~30%
- Direct Fine-tuning: ~75% → 92%
7. **Qwen Original**
- Direct: ~40% → ~45%
- Random: ~30%
- Direct Fine-tuning: ~60% → ~85%
8. **Qwen Oracle**
- Direct: ~50% → ~65%
- Random: ~30%
- Direct Fine-tuning: ~70% → ~90%
9. **Qwen Bayesian**
- Direct: ~55% → ~70%
- Random: ~30%
- Direct Fine-tuning: ~75% → 93%
### Key Observations
1. **Direct Fine-tuning Dominance**: Consistently highest accuracy across all datasets and conditions, with ~20-30% absolute improvement over Direct and ~50-60% over Random.
2. **Bayesian Advantage**: In Gamma and Llama datasets, Bayesian conditions outperform Oracle in Direct Fine-tuning accuracy.
3. **Interaction Dependency**: Direct methods show gradual improvement with more interactions (r² ~0.9 for linear fits), while Fine-tuning plateaus near 90%.
4. **Random Baseline**: All Random lines remain flat at ~30%, serving as a performance floor.
### Interpretation
The data demonstrates that fine-tuning significantly enhances model performance, particularly when combined with Bayesian approaches. The Direct method's linear improvement suggests incremental gains from additional interactions, but fine-tuning achieves near-ceiling performance faster. The Oracle condition's intermediate performance implies it captures some but not all benefits of Bayesian methods. The consistent Random baseline confirms models outperform chance-level guessing. These results highlight fine-tuning as the most effective strategy for maximizing accuracy, with Bayesian frameworks offering additional gains in certain contexts.
</details>
Figure 27: Accuracy over rounds for different original LLMs and fine-tuned LLMs on the web shopping task. We show accuracy based on direct predictions and accuracy based on predictions derived from their beliefs about users’ preferences. Error bars show standard errors across three training runs if any.
Appendix I Example Interactions
We show example interactions in Tables 3 – 12.
Table 3: Example of a two-round interaction between the user and the LLM.
| Col1 |
| --- |
| User: Help me select the best flights for my trips. I have specific preferences for what I like and dislike in a flight, and these preferences remain the same. You need to figure out my preferences and select the best flights for me. Use your best judgment if you are unsure. Do not say you need more information. Which flight is the best option? Flight 1: departure time: 02:00 PM, duration: 2 hr 30 min, number of stops: 1, price: $370 Flight 2: departure time: 10:00 PM, duration: 4 hr 24 min, number of stops: 0, price: $730 Flight 3: departure time: 03:36 PM, duration: 16 hr 6 min, number of stops: 0, price: $900 Model: The best option is Flight 1. User: Your option Flight 1 is incorrect. I prefer Flight 2. Which flight is the best option? Flight 1: departure time: 04:00 PM, duration: 18 hr 3 min, number of stops: 2, price: $280 Flight 2: departure time: 10:48 AM, duration: 6 hr 21 min, number of stops: 1, price: $370 Flight 3: departure time: 06:48 PM, duration: 10 hr 5 min, number of stops: 1, price: $810 Model: The best option is Flight 2. User: Your option Flight 2 is correct. |
Table 4: Example of prompting the LLM for the user’s preference on a single feature.
| Col1 |
| --- |
| User: Help me select the best flights for my trips. I have specific preferences for what I like and dislike in a flight, and these preferences remain the same. You need to figure out my preferences and select the best flights for me. Use your best judgment if you are unsure. Do not say you need more information. Which flight is the best option? Flight 1: departure time: 02:00 PM, duration: 2 hr 30 min, number of stops: 1, price: $370 Flight 2: departure time: 10:00 PM, duration: 4 hr 24 min, number of stops: 0, price: $730 Flight 3: departure time: 03:36 PM, duration: 16 hr 6 min, number of stops: 0, price: $900 Model: The best option is Flight 1. User: Your option Flight 1 is incorrect. I prefer Flight 2. On a scale of 1 to 5, what is my preference for price? - 1: I strongly prefer a cheaper flight - 2: I prefer a cheaper flight - 3: I have no strong preference - 4: I prefer a more expensive flight - 5: I strongly prefer a more expensive flight Model: Your preference for price is: 1. |
Table 5: Example of a two-round interaction between the user and the LLM using the numerical representation of flights.
| Col1 |
| --- |
| User: Help me select the best flights for my trips. I have specific preferences for what I like and dislike in a flight, and these preferences remain the same. You need to figure out my preferences and select the best flights for me. Use your best judgment if you are unsure. Do not say you need more information. Which flight is the best option? Flight 1: departure time: 0.7, duration: 0.5, number of stops: 1.0, price: 0.9 Flight 2: departure time: 0.9, duration: 0.6, number of stops: 0.0, price: 0.7 Flight 3: departure time: 0.5, duration: 0.9, number of stops: 0.5, price: 0.1 Model: The best option is Flight 1. User: Your option Flight 1 is incorrect. I prefer Flight 2. Which flight is the best option? Flight 1: departure time: 0.5, duration: 0.9, number of stops: 0.5, price: 0.1 Flight 2: departure time: 0.2, duration: 0.3, number of stops: 0.5, price: 0.2 Flight 3: departure time: 0.8, duration: 0.8, number of stops: 1.0, price: 0.9 Model: The best option is Flight 2. User: Your option Flight 2 is correct. |
Table 6: Example of prompting the LLM for the user’s preference on a single feature using the numerical representation of flights.
| Col1 |
| --- |
| User: Help me select the best flights for my trips. I have specific preferences for what I like and dislike in a flight, and these preferences remain the same. You need to figure out my preferences and select the best flights for me. Use your best judgment if you are unsure. Do not say you need more information. Which flight is the best option? Flight 1: departure time: 0.7, duration: 0.5, number of stops: 1.0, price: 0.9 Flight 2: departure time: 0.9, duration: 0.6, number of stops: 0.0, price: 0.7 Flight 3: departure time: 0.5, duration: 0.9, number of stops: 0.5, price: 0.1 Model: The best option is Flight 1. User: Your option Flight 1 is incorrect. I prefer Flight 2. On a scale of 1 to 5, what is my preference for duration? - 1: I strongly prefer the minimum value - 2: I prefer the minimum value - 3: I have no strong preference - 4: I prefer the maximum value - 5: I strongly prefer the maximum value |
Table 7: Example of prompting the LLM for the user’s preference on a single feature using the model’s directly generated probability judgements.
| Col1 |
| --- |
| User: Help me select the best flights for my trips. I have specific preferences for what I like and dislike in a flight, and these preferences remain the same. You need to figure out my preferences and select the best flights for me. Use your best judgment if you are unsure. Do not say you need more information. Which flight is the best option? Flight 1: departure time: 02:00 PM, duration: 2 hr 30 min, number of stops: 1, price: $370 Flight 2: departure time: 10:00 PM, duration: 4 hr 24 min, number of stops: 0, price: $730 Flight 3: departure time: 03:36 PM, duration: 16 hr 6 min, number of stops: 0, price: $900 Model: The best option is Flight 1. User: Your option Flight 1 is incorrect. I prefer Flight 2. On a scale of 1 to 5, what is my preference for price? - 1: I strongly prefer a cheaper flight - 2: I prefer a cheaper flight - 3: I have no strong preference - 4: I prefer a more expensive flight - 5: I strongly prefer a more expensive flight Provide an integer between 0 and 100 (%) that reflects the probability of each scale. Format your response exactly as follows: - 1: ??% ... Model: The probabilities of each scale are: - 1: 70% - 2: 10% - 3: 15% - 4: 5% - 5: 0% |
Table 8: Example of a first-round interaction between the user and the LLM using chain-of-thought prompting.
| Col1 |
| --- |
| User: Help me select the best flights for my trips. I have specific preferences for what I like and dislike in a flight, and these preferences remain the same. You need to figure out my preferences and select the best flights for me. First, infer my preferences by reasoning about each feature. For each feature, estimate the probability distribution of my preference across a 1-to-5 scale. For example, you might estimate a 30% probability that I strongly prefer an earlier morning flight (scale 1), a 10% probability that I prefer an earlier morning flight (scale 2), a 20% probability that I have no strong preference (scale 3), and so on. Then, use these probabilities to determine the best flights for me. Use your best judgment if you are unsure. Do not say you need more information. Which flight is the best option? Flight 1: departure time: 02:00 PM, duration: 2 hr 30 min, number of stops: 1, price: $370 Flight 2: departure time: 10:00 PM, duration: 4 hr 24 min, number of stops: 0, price: $730 Flight 3: departure time: 03:36 PM, duration: 16 hr 6 min, number of stops: 0, price: $900 Let’s think step by step. End your response with ‘The best option is Flight <your choice>.’. Model: Let’s analyze each flight feature and estimate your preferences: ... <Model’s reasoning chain> ... The best option is Flight 2. User: Your option Flight 2 is correct. |
Table 9: Example of a first-round interaction between the user and the LLM with verbalized reward posterior distribution.
| Col1 |
| --- |
| User: Help me select the best flights for my trips. I have specific preferences for what I like and dislike in a flight, and these preferences remain the same. You need to figure out my preferences and select the best flights for me. Use your best judgment if you are unsure. Do not say you need more information. Model: Based on the current information, the probabilities for each preference scale across all features are: The probabilities for each scale of your preference for departure time are: - 1: I strongly prefer an earlier morning departure time, 0.3% - 2: I prefer an earlier morning departure time, 1.0% - 3: I have no strong preference, 97.6% - 4: I prefer a later evening departure time, 1.1% - 5: I strongly prefer a later evening departure time, 0.1% The probabilities for each scale of your preference for duration are: ... User: Which flight is the best option? Flight 1: departure time: 02:00 PM, duration: 2 hr 30 min, number of stops: 1, price: $370 Flight 2: departure time: 10:00 PM, duration: 4 hr 24 min, number of stops: 0, price: $730 Flight 3: departure time: 03:36 PM, duration: 16 hr 6 min, number of stops: 0, price: $900 Model: The best option is Flight 2. User: Your option Flight 2 is incorrect. I prefer Flight 1. Model: Based on the current information, the probabilities for each preference scale across all features are: The probabilities for each scale of your preference for departure time are: - 1: I strongly prefer an earlier morning departure time, 0.1% - 2: I prefer an earlier morning departure time, 4.1% - 3: I have no strong preference, 2.5% - 4: I prefer a later evening departure time, 93.2% - 5: I strongly prefer a later evening departure time, 0.1% |
Table 10: Example of a two-round interaction between the user and the LLM using the non-interactive setting. The blue part highlights the difference compared to the interactive setting in Table 3.
| Col1 |
| --- |
| User: Help me select the best flights for my trips. I have specific preferences for what I like and dislike in a flight, and these preferences remain the same. You need to figure out my preferences and select the best flights for me. Use your best judgment if you are unsure. Do not say you need more information. Which flight is the best option? Flight 1: departure time: 02:00 PM, duration: 2 hr 30 min, number of stops: 1, price: $370 Flight 2: departure time: 10:00 PM, duration: 4 hr 24 min, number of stops: 0, price: $730 Flight 3: departure time: 03:36 PM, duration: 16 hr 6 min, number of stops: 0, price: $900 Model: The best option is Flight 2. User: Your option Flight 2 is correct. Which flight is the best option? Flight 1: departure time: 04:00 PM, duration: 18 hr 3 min, number of stops: 2, price: $280 Flight 2: departure time: 10:48 AM, duration: 6 hr 21 min, number of stops: 1, price: $370 Flight 3: departure time: 06:48 PM, duration: 10 hr 5 min, number of stops: 1, price: $810 Model: The best option is Flight 2. User: Your option Flight 2 is correct. |
Table 11: Example of a first-round interaction between the user and the LLM on the hotel recommendation task.
| Col1 |
| --- |
| User: Help me select the best hotels for my trips. I have specific preferences for what I like and dislike in a hotel, and these preferences remain the same. You need to figure out my preferences and select the best hotels for me. Use your best judgment if you are unsure. Do not say you need more information. Which hotel is the best option? Hotel 1: distance to downtown: 4 miles, price: $550, rating: 3 stars, amenities: free parking and free breakfast Hotel 2: distance to downtown: 3 miles, price: $820, rating: 2 stars, amenities: free parking, free breakfast, and pool Hotel 3: distance to downtown: 2.3 miles, price: $370, rating: 1 stars, amenities: free parking Model: The best option is Hotel 3. User: Your option Hotel 3 is incorrect. I prefer Hotel 2. |
Table 12: Example of a first-round interaction between the user and the LLM on the web shopping task.
| Col1 |
| --- |
| User: Help me select the best product. I have specific preferences for what I like and dislike in a product, and these preferences remain the same. You need to figure out my preferences and select the best products for me. Use your best judgment if you are unsure. Do not say you need more information. Which product is the best option? Product 1: Title: Chic D Independence Day Table Runner 72 Inches Long, Gnome Cotton Linen Spring Table Cloth Runners for Wedding Party Dinning Coffee Holiday, Farmhouse Style, USA Flag Description: - 14x72inch Dining Table Runner Size: 36x183cm, fits round, square or rectangular tables that seat 4 to 8 people. - High Quality Cotton Linen Table Runner: 30%cotton, 70%burlap. triangle hem, wrinkle-free, no fade. easy to maintain and reusable. - Our elegant table runner is perfect for holidays, catering, birthday party, dinning, brunches, potlucks, BBQ’s, buffets, garden, bridal party etc - Decorative Table Runner can be used as decor on kitchen tables; dining tables; entry tables; desks & more - Custom table runner, u also can personalized your tabletop decoration Color: black white Size: 13x108inch Product 2: Title: Ambesonne Orange Mandala Coffee Table, Pastel Colored Flourishes and Dark Toned Details Spring Bloom, Acrylic Glass Center Table with Wooden Frame for Offices Dorms, Small, Peach Dark Brown Cream Description: - Measurements - 24" Long x 18" Wide x 15" High coffee table with patterns that will add vitality to your living room. - Made from - High Quality Beech Wooden Frame and Acrylic Glass Table Top. Durable and Elegant! - Features- Light weight and easy to move around. You can place anywhere and enjoy its beauty! - Easy To Use- It is easy to assembly with numbered parts and clear instructions. - Versatile- Small coffee table, to keep your necessities within reach. Practical item for your living room! Color: blue purple Size: large Product 3: Title: White Round Dining Table and 4 Chairs,Mid-Century Modern Coffee Table Round Kitchen Table Small Office Table for Office Kitchen Dining Room (Round Table+4 Pale Grey Chairs) Description: - Dining Table and Chair Size:The dining table size is 35.4*35.4*29.5 inch, dining chairs is 36*17.5 inch.Our table and chairs suitable for 4-6 people. This glass table can also be used as a conference table, coffee table - Glass Dining Table and Chair Material:The table top is made of clear glass and equipped with solid wood metal legs, with a modern design style and elegant appearance.The Chair is made of velvet and solid wood metal cushions, the dining table and chair is an essential furniture Size: round table with wood legs Model: The best option is Product 3. User: Your option Product 3 is incorrect. I prefer Product 2. |