# Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
**Authors**: DataCanvas Alaya NeW. BAAI.
Technical Report on Slow Thinking with LLMs: Evaluation Benchmark
Abstract
In recent years, the rapid development of large reasoning models has resulted in the saturation of existing benchmarks for evaluating mathematical reasoning, highlighting the urgent need for more challenging and rigorous evaluation frameworks. To address this gap, we introduce OlymMATH, a novel Olympiad-level mathematical benchmark, designed to rigorously test the complex reasoning capabilities of LLMs. OlymMATH features 200 meticulously curated problems, each manually verified and available in parallel English and Chinese versions. The problems are systematically organized into two distinct difficulty tiers: (1) AIME-level problems (easy) that establish a baseline for mathematical reasoning assessment, and (2) significantly more challenging problems (hard) designed to push the boundaries of current state-of-the-art models. In our benchmark, these problems span four core mathematical fields, each including a verifiable numerical solution to enable objective, rule-based evaluation. Empirical results underscore the significant challenge presented by OlymMATH, with state-of-the-art models including DeepSeek-R1, OpenAI’s o3-mini and Gemini 2.5 Pro Exp demonstrating notably limited accuracy on the hard subset. Furthermore, the benchmark facilitates comprehensive bilingual assessment of mathematical reasoning abilities—a critical dimension that remains largely unaddressed in mainstream mathematical reasoning benchmarks. We release the benchmark, evaluation code, detailed results and a data visualization tool at https://github.com/RUCAIBox/OlymMATH.
1 Introduction
The advent of large language models (LLMs) [1] has marked a significant leap forward in the capabilities of artificial intelligence, showcasing exceptional performance across a broad spectrum of tasks, and in some cases, even rivaling or exceeding human-level proficiency [2, 3]. Among the myriad of capabilities demonstrated by LLMs, mathematical reasoning has surfaced as a particularly pivotal and demanding area of research [4, 5, 6]. In recent years, the evaluation and enhancement of mathematical reasoning abilities have become a central focus in the development of LLMs [7].
Effective assessment of LLM reasoning necessitates reliable and verifiable evaluation benchmarks. Reliability ensures accurately designed problems and solutions, free from ambiguities or errors. Verifiability demands that the evaluation process be easily constructed, replicated, and validated, often relying on easily parsable answer formats. Many benchmarks adopt a single-answer format, like “ The answer is $3 3 3$ ”, to simplify parsing and enhance reproducibility.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Bar Chart: Accuracy Comparison of Different Models on Math Problems
### Overview
The image is a bar chart comparing the accuracy (in percentage) of seven different models on four different math problem sets: AIME 24, HMMT 202502, OlymMATH-EN-EASY, and OlymMATH-EN-HARD. Each problem set has a specified number of problems. The models being compared are Gemini 2.5 Pro Exp, OpenAI o3-mini (high), Qwen3-235B-A22B, Qwen3-30B-A3B, DeepSeek-R1, QwQ-32B, and GLM-Z1-AIR.
### Components/Axes
* **Y-axis:** Accuracy (%), ranging from 0 to 100. Increments of 10 are marked.
* **X-axis:** Four categories representing different math problem sets:
* AIME 24 (30 Problems)
* HMMT 202502 (30 Problems)
* OlymMATH-EN-EASY (100 Problems)
* OlymMATH-EN-HARD (100 Problems)
* **Legend:** Located on the top-right of the chart, mapping model names to bar colors:
* Gemini 2.5 Pro Exp (Pale Pink)
* OpenAI o3-mini (high) (Pale Green)
* Qwen3-235B-A22B (Yellow)
* Qwen3-30B-A3B (Light Blue)
* DeepSeek-R1 (Gray)
* QwQ-32B (Pale Beige)
* GLM-Z1-AIR (Light Orange)
### Detailed Analysis
**AIME 24 (30 Problems)**
* Gemini 2.5 Pro Exp (Pale Pink): 92.0%
* OpenAI o3-mini (high) (Pale Green): 87.3%
* Qwen3-235B-A22B (Yellow): 85.7%
* Qwen3-30B-A3B (Light Blue): 80.4%
* DeepSeek-R1 (Gray): 79.8%
* QwQ-32B (Pale Beige): 79.5%
* GLM-Z1-AIR (Light Orange): 80.8%
**HMMT 202502 (30 Problems)**
* Gemini 2.5 Pro Exp (Pale Pink): 82.5%
* OpenAI o3-mini (high) (Pale Green): 67.5%
* Qwen3-235B-A22B (Yellow): 62.5%
* Qwen3-30B-A3B (Light Blue): 50.8%
* DeepSeek-R1 (Gray): 41.7%
* QwQ-32B (Pale Beige): 47.5%
* GLM-Z1-AIR (Light Orange): Not specified, but visually estimated to be around 47.5%
**OlymMATH-EN-EASY (100 Problems)**
* Gemini 2.5 Pro Exp (Pale Pink): 92.2%
* OpenAI o3-mini (high) (Pale Green): 91.4%
* Qwen3-235B-A22B (Yellow): 90.5%
* Qwen3-30B-A3B (Light Blue): 87.2%
* DeepSeek-R1 (Gray): 79.6%
* QwQ-32B (Pale Beige): 84.0%
* GLM-Z1-AIR (Light Orange): 76.8%
**OlymMATH-EN-HARD (100 Problems)**
* Gemini 2.5 Pro Exp (Pale Pink): 58.4%
* OpenAI o3-mini (high) (Pale Green): 31.2%
* Qwen3-235B-A22B (Yellow): 36.5%
* Qwen3-30B-A3B (Light Blue): 26.3%
* DeepSeek-R1 (Gray): 19.5%
* QwQ-32B (Pale Beige): 23.1%
* GLM-Z1-AIR (Light Orange): 20.1%
### Key Observations
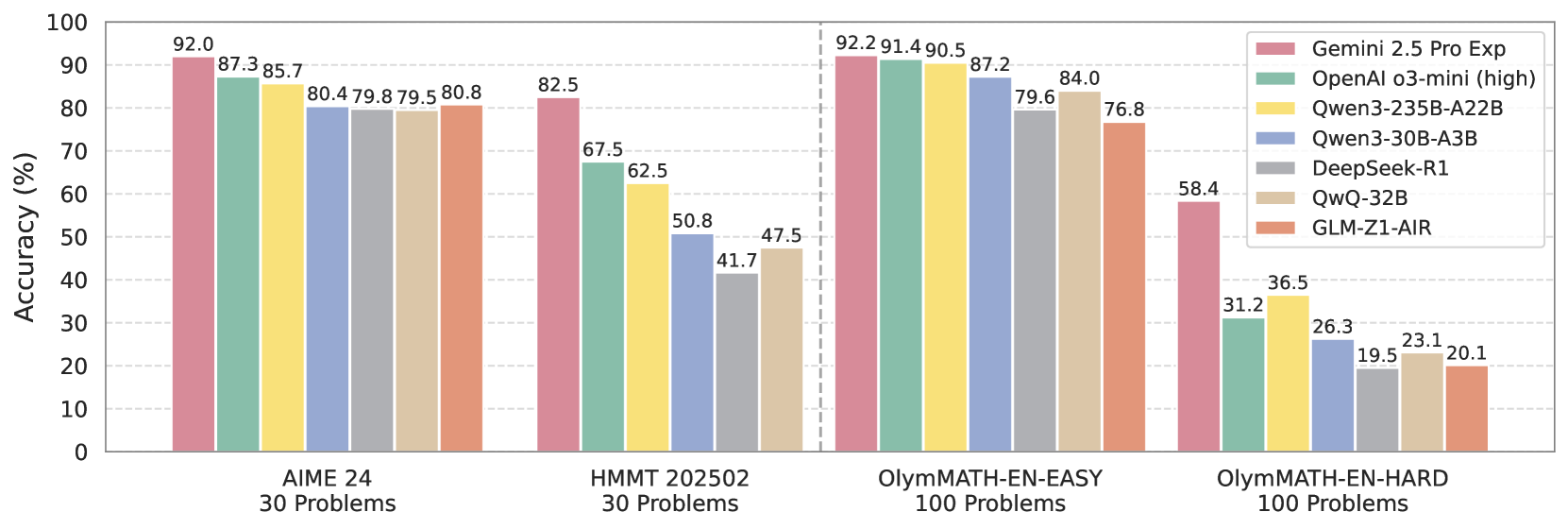
* Gemini 2.5 Pro Exp consistently performs well across all problem sets, achieving the highest accuracy in three out of the four categories.
* The accuracy of all models decreases significantly on the OlymMATH-EN-HARD problem set, indicating its higher difficulty level.
* OpenAI o3-mini (high) shows strong performance on OlymMATH-EN-EASY, closely following Gemini 2.5 Pro Exp.
* DeepSeek-R1 and GLM-Z1-AIR generally have lower accuracy compared to the other models, especially on the harder problem sets.
### Interpretation
The bar chart provides a comparative analysis of the accuracy of different language models on various math problem sets. The data suggests that Gemini 2.5 Pro Exp is a strong performer across different difficulty levels, while other models like OpenAI o3-mini (high) also exhibit competitive performance on specific problem sets. The significant drop in accuracy on the OlymMATH-EN-HARD problem set highlights the challenges associated with solving more complex mathematical problems. The chart is useful for understanding the relative strengths and weaknesses of each model in the context of mathematical reasoning and problem-solving.
</details>
Figure 1: Performance comparisons of mainstream reasoning models between our OlymMATH (English version) and other Olympiad-level mathematical benchmarks. Our OlymMATH dataset provides test results that align with those on existing benchmarks and features a significantly larger number of problems.
Evaluation benchmarks are primarily established to identify LLM limitations, and guiding future improvements. Over recent years, numerous high-quality mathematical benchmarks, such as GSM8K [8] and MATH [9], have been pivotal in advancing LLM reasoning capabilities [10, 11]. However, a significant trend is the saturation of many benchmarks, including those currently in use, due to rapid LLM advancements. For example, GSM8K [8], once a standard for earlier models like Llama 1 and 2, is now largely mastered by state-of-the-art models. Similarly, MATH [9], initially challenging for GPT-4-level models, has also become saturated by today’s leading models. This saturation is further compounded by slow-thinking models like DeepSeek-R1 [4], OpenAI’s o3-mini [12], and Gemini 2.5 Pro Experimental [13]. These models, which promote deliberate step-by-step reasoning, show that enhancing the reasoning process yields substantial performance gains, thereby diminishing the effectiveness of existing benchmarks in differentiating cutting-edge capabilities.
To better evaluate the performance of advanced reasoning models, more rigorous and challenging benchmarks are needed to assess their mathematical reasoning capabilities. The AIME dataset has emerged as a more demanding benchmark by incorporating problems from the American Invitational Mathematics Examination (AIME), which presents a higher level of difficulty. Due to their complexity and rigor, AIME problems continue to challenge state-of-the-art models under standard prompting. Nevertheless, the AIME dataset has three major limitations. First, the limited scale of the current dataset (containing merely 30 problems from AIME 2024) may compromise the statistical reliability and robustness of the evaluation results. Second, as reasoning models rapidly improve—through methods like fine-tuning with long chain-of-thought data [14] or reinforcement learning scaling [4] —the benchmark’s original performance ceiling is being surpassed. For example, models such as Gemini 2.5 Pro Exp now achieve 92% accuracy with single attempt, demonstrating that current top-performing models are approaching the limits of what AIME can effectively measure. Third, the dataset exclusively features English problems, leaving multilingual reasoning capabilities unassessed despite their importance for a comprehensive evaluation.
To overcome these limitations, we present OlymMATH: a rigorously curated, bilingual (English and Chinese) benchmark for Olympiad-level reasoning, comprising 200 problems split into easy (OlymMATH-EASY) and hard (OlymMATH-HARD) levels with parallel bilingual sets (EN & ZH). To prevent data leakage, problems were manually sourced from printed publications and expert-verified. OlymMATH requires precise numerical answers for reliable verification, covers four major mathematical fields, and adheres to the MATH dataset [9] format for compatibility (see Figure 2).
MATH Dataset
Problem: Compute:
$$
1-2+3-4+5-\dots+99-100.
$$
Answer: $-50$ .
Problem: Let $n$ be a positive integer. Simplify the expression
$$
\frac{(2^{4}+\frac{1}{4})(4^{4}+\frac{1}{4})\dotsm[(2n)^{4}+\frac{1}{4}]}{(1^{%
4}+\frac{1}{4})(3^{4}+\frac{1}{4})\dotsm[(2n-1)^{4}+\frac{1}{4}]}.
$$
Answer: $8n^{2}+4n+1$ .
v
OlymMATH-HARD (Ours) Problem-EN: {CJK} UTF8gbsn Find the remainder of $\sum_{k=0}^{1234}\binom{2016× 1234}{2016k}$ modulo $2017^{2}$ (provide the value in the range $[0,2017^{2})$ ). Answer: $1581330$ . Subject: Number Theory. OlymMATH-EASY (Ours) Problem-ZH: {CJK} UTF8gbsn 设 $O$ 为 $\triangle ABC$ 的内心, $AB=3$ , $AC=4$ , $BC=5$ , $\overrightarrow{OP}=x\overrightarrow{OA}+y\overrightarrow{OB}+z\overrightarrow%
{OC}$ , $0≤slant x,y,z≤slant 1$ . 求动点 $P$ 的轨迹所覆盖的平面区域的面积. Answer: $12$ . Subject: {CJK} UTF8gbsn几何.
Figure 2: Examples from the MATH dataset and our OlymMATH dataset.
By leveraging the OlymMATH benchmark, we conduct extensive experiments to evaluate the performance of several state-of-the-art models (see Figure 1). The results underscore our benchmark’s difficulty, with advanced models like DeepSeek-R1 [4], o3-mini [12], and Gemini 2.5 Pro Exp [13] achieving only 19.5%, 31.2%, and 58.4% accuracy, respectively, on OlymMATH-EN-HARD, indicating Olympiad-level math remains a significant challenge necessitating further research. Our multilingual comparison showed a consistent performance gap, with higher accuracy on English problems versus Chinese, highlighting the need for multilingual evaluation. Furthermore, case studies revealed models sometimes use heuristic “guessing” to reach answers without rigorous proofs. This underscores the importance of process-level inspection for accurate LLM capability assessment.
In summary, our contribution are as follows:
$\bullet$ We introduce OlymMATH, a manually curated, Olympiad-level mathematical benchmark. It features parallel English and Chinese versions for objective, bilingual evaluation of LLM mathematical reasoning, with answers efficiently verifiable using sympy -based tools.
$\bullet$ Experiments demonstrate OlymMATH’s reliability (aligned with AIME) and strong discriminative power; even state-of-the-art models achieve only moderate scores, highlighting OlymMATH’s potential to drive LLM reasoning advancements.
$\bullet$ Detailed analyses and case studies reveal key model limitations in complex problem-solving, including performance disparities between English and Chinese problems and instances of heuristic “guessing” rather than rigorous deduction.
$\bullet$ We open-source evaluation results and resources, including sampled long chain-of-thought reasoning trajectories (582,400 entries from 28 models on 400 problems), a data visualization tool, and standard solutions for problems where all LLMs struggled, to facilitate community research and analysis on diverse reasoning patterns and common reasoning issues.
2 Benchmark Construction
In this section, we describe the OlymMATH dataset in detail, including its construction methodology, problem composition, categorical distribution, and evaluation approach. Our dataset is specifically designed to provide a rigorous yet objectively verifiable benchmark for assessing the mathematical reasoning capabilities of LLMs. Additionally, we offer two parallel evaluation sets containing 200 problems each in English and Chinese as supplementary data to facilitate a comparative analysis of performance gaps between the two languages. Table 1 presents a basic comparison of our proposed OlymMATH benchmark and other mathematical reasoning benchmarks.
Table 1: Comparison of existing benchmarks. EN and ZH denote English and Chinese, respectively.
{tblr}
columneven = c, column3 = c, column5 = c, hline1,12 = -0.08em, hline2,10 = -0.05em, Name & # Problems # Field Language Evaluation Difficulty GSM8K [8] 1319 - EN Rule Grade School MATH [9] 5000 6 EN Rule Competition AIME 2024 [15] 30 - EN Rule Olympiad AIME 2025 [16] 30 - EN Rule Olympiad HMMT 202502 [17] 30 - EN Rule Olympiad USAMO 2025 [18] 6 - EN LLM Olympiad Olympiad Bench [19] 8476 3 ZH & EN Rule CEE & Olympiad Omni-MATH [20] 4428 33+ EN LLM Olympiad OlymMATH-EN 200 4 EN Rule Olympiad OlymMATH-ZH 200 4 ZH Rule Olympiad
2.1 Reliability: Contamination and Verification
Contamination
OlymMATH comprises 200 high-quality mathematical problems at the Olympiad level, meticulously curated from printed resources to ensure both quality and originality. These problems were manually gathered from a range of authoritative sources, including specialized magazines, textbooks, and official competition materials. To minimize the risk of data contamination, online repositories and forums were intentionally excluded from the sourcing process. This methodology ensures that the problems are intellectually challenging and representative of advanced mathematical reasoning, while also minimizing prior exposure on publicly accessible digital platforms. Consequently, OlymMATH serves as a reliable benchmark for evaluating the real capabilities of LLMs in solving complex mathematical tasks.
Verification
To enhance dataset reliability, we invited a China Mathematical Olympiad silver medalist and two provincial first-prize winners to verify and revise the problems and solutions. Since the answers to the problems were already provided, the verification difficulty was reduced, making the expertise of reviewers sufficient for this task. Each problem was reviewed by at least two reviewers. Additionally, official solutions for challenging problems are published for community oversight.
2.2 Problem Categories and Distribution
OlymMATH problems span four key high-school Olympiad mathematical fields—algebra, geometry, number theory, and combinatorics—classified by experts (not LLMs) for reliability. Problems are selected for their challenge, suitability for simple-answer verification, and topic diversity (e.g., inequalities, sequences, and more in algebra). Figure-based problems within this set are text-reformulated for LLM compatibility, with non-convertible ones excluded (e.g., Figure 6 in Appendix).
For refined evaluation, problems are categorized by difficulty: easy, designed to challenge standard prompting in mainstream models, and hard, tailored to test advanced reasoning (e.g., slow-thinking modes) in state-of-the-art models. The distribution details are described in Table 2.
Table 2: The distribution of contest problems by category.
{tblr}
cells = c, cell61 = c=2, hline1,7 = -0.08em, hline2,6 = -0.05em, Category & Topic # HARD # EASY # Total Algebra (Alg.) Inequality, Sequence, Trigonometry, etc. 25 25 50 Geometry (Geo.) Solid Geometry, Analytic Geometry, etc. 25 33 58 Number Theory (Num.) Divisibility, Diophantine Equation, etc. 25 13 38 Combinatorics (Com.) Graph Theory, Permutation, etc. 25 29 54 Total 100 100 200
2.3 Format and Verification Methodology
OlymMATH adopts the MATH dataset format (see Figure 2) for seamless integration with existing pipelines and enhancing clarity and processing efficiency. All problems are text-based, including geometry reformulated from diagrams to align with LLM evaluation, as mentioned previously. For consistent, objective assessment, answers are restricted to real numbers and intervals (see Table 3), avoiding ambiguous formats and enabling reliable sympy -based and numerical verification.
Table 3: The included and excluded formats of the final answer.
{tblr}
width = colspec = Q[c,m,wd=0.16] X[l,m] X[l,m], cell12 = halign=c, cell13 = halign=c, cell31 = r=2c, hline1,Z = 0.08em, solid, hline2 = 0.05em, solid, hline3 = 0.05em, solid & Type & Example Type & Example Included Real number: $16^{\circ}$ , $2^{2017}+\arctan 2$ Interval: $[\sqrt{33},+∞)$ , $(4,5\pi]$ Excluded Set Operations: $\{4,5\}\cup\{1,8\}$ Variable: $\sqrt[3]{5}a^{2}$ , $p^{2}-pq$ , $n!+2$ Complex number: $9+4\mathrm{i}$ , $\sqrt{-4}$ Text: East, Alice
To make the evaluation more challenging, OlymMATH includes problems with multiple numerical answers. These problems are modified to require a summary of all potential outcomes (e.g., sums, sums of squares; see Figure 7 in Appendix). This method effectively assesses whether models can consider all possible answers, thereby providing a robust evaluation of their reasoning capabilities.
2.4 Bilingual Extension
Originating from Chinese-language problems, the OlymMATH benchmark includes both original Chinese and translated English versions for comprehensive bilingual evaluation. Our LLM-based translation pipeline first uses Claude Sonnet 3.7 for initial English translations, which are then iteratively refined with GPT-4o. Finally, a crucial human verification stage by two expert annotators ensures mathematical accuracy, rigor, and linguistic fluency. These resulting parallel sets, OlymMATH-EN (English) and OlymMATH-ZH (Chinese) (see Figure 2), facilitate systematic comparison of cross-lingual reasoning, with their union denoted as OlymMATH (full set).
3 Experiments
In this section, we assess the performance of leading reasoning models using the OlymMATH benchmark and then provide a detailed analysis of their capabilities.
3.1 Experimental Setup
Models.
To conduct a thorough evaluation, we assess a range of representative LLMs. For open-source models, we investigated recent work on reasoning models, and evaluated DeepSeek-R1 series [4], STILL-3-Preview [21], DeepScaleR-Preview [22], QwQ [23], Light-R1 series [24], OpenThinker2 series [25], Skywork-OR1 series [26], GLM-Z1-Air [27], AceMath-RL [28], OpenMath-Nemotron series [29], and Qwen3 series [30]. For closed-source models, we include o3-mini (high) [12], Gemini 2.5 Pro Experimental 0325 [13] in our evaluation.
Table 4: Model performance on OlymMATH-EN. Models within each model size group are sorted by release time. The abbreviations “Alg.”, “Geo.”, “Num.”, and “Com.” represent the four categories in OlymMATH. Highest accuracy per model size is bolded. The second highest accuracy per model size is underlined. Models sampled only 8 times are marked in gray to indicate potential instability.
| Model | OlymMATH-EN-HARD | OlymMATH-EN-EASY | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Alg. | Geo. | Num. | Com. | Avg. | Alg. | Geo. | Num. | Com. | Avg. | | | | | | | | | | | |
| P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | |
| Qwen3 (0.6B, Think) | 2.5 | 0.0 | 2.1 | 4.0 | 6.6 | 8.0 | 0.2 | 0.0 | 2.8 | 3.0 | 15.5 | 20.0 | 5.6 | 15.2 | 24.5 | 38.5 | 5.2 | 6.9 | 10.4 | 17.0 |
| DS-R1-Distill (1.5B) | 1.9 | 0.0 | 1.8 | 0.0 | 1.8 | 0.0 | 0.4 | 0.0 | 1.5 | 0.0 | 20.8 | 40.0 | 12.6 | 21.2 | 32.6 | 61.5 | 8.2 | 24.1 | 16.0 | 32.0 |
| STILL-3-Pre. (1.5B) | 3.7 | 0.0 | 4.9 | 4.0 | 5.8 | 8.0 | 0.8 | 0.0 | 3.8 | 3.0 | 22.7 | 36.0 | 14.8 | 30.3 | 37.6 | 69.2 | 10.3 | 17.2 | 18.4 | 33.0 |
| DeepScaleR-Pre. (1.5B) | 3.4 | 4.0 | 4.2 | 8.0 | 8.2 | 4.0 | 0.4 | 0.0 | 4.1 | 4.0 | 19.9 | 16.0 | 18.5 | 21.2 | 44.6 | 46.2 | 18.9 | 31.0 | 22.3 | 26.0 |
| OpenMath-Nemo. (1.5B) | 14.5 | 24.0 | 13.6 | 16.0 | 10.9 | 16.0 | 2.6 | 4.0 | 10.4 | 15.0 | 70.9 | 100.0 | 59.3 | 90.9 | 81.6 | 100.0 | 40.6 | 58.6 | 59.7 | 85.0 |
| Qwen3 (4B, Think) | 18.1 | 20.0 | 14.8 | 12.0 | 19.8 | 28.0 | 3.1 | 4.0 | 13.9 | 16.0 | 76.4 | 92.0 | 79.1 | 97.0 | 85.1 | 84.6 | 57.1 | 72.4 | 72.8 | 87.0 |
| DS-R1-Distill (7B) | 15.6 | 36.0 | 12.6 | 24.0 | 13.1 | 24.0 | 3.1 | 4.0 | 11.1 | 22.0 | 52.8 | 84.0 | 49.6 | 84.8 | 62.5 | 84.6 | 33.9 | 58.6 | 47.5 | 77.0 |
| Light-R1-DS (7B) | 17.1 | 28.0 | 15.2 | 16.0 | 12.8 | 24.0 | 3.6 | 4.0 | 12.2 | 18.0 | 57.1 | 84.0 | 53.6 | 93.9 | 73.7 | 84.6 | 39.5 | 51.7 | 53.0 | 78.0 |
| OpenThinker2 (7B) | 16.0 | 20.0 | 16.8 | 28.0 | 14.0 | 20.0 | 2.8 | 4.0 | 12.4 | 18.0 | 65.3 | 96.0 | 60.5 | 97.0 | 79.1 | 84.6 | 42.3 | 58.6 | 58.9 | 84.0 |
| Skywork-OR1-Pre. (7B) | 14.4 | 20.0 | 12.5 | 12.0 | 11.7 | 24.0 | 1.6 | 0.0 | 10.0 | 14.0 | 61.6 | 88.0 | 55.9 | 78.8 | 74.3 | 92.3 | 36.9 | 48.3 | 54.2 | 74.0 |
| Skywork-OR1-Math (7B) | 17.4 | 20.0 | 17.1 | 20.0 | 13.6 | 28.0 | 0.9 | 0.0 | 12.2 | 17.0 | 67.9 | 92.0 | 67.4 | 93.9 | 76.6 | 92.3 | 47.6 | 62.1 | 63.0 | 84.0 |
| AceMath-RL (7B) | 19.4 | 32.0 | 19.3 | 32.0 | 14.4 | 24.0 | 3.5 | 4.0 | 14.2 | 23.0 | 69.7 | 96.0 | 63.7 | 93.9 | 79.0 | 84.6 | 44.2 | 69.0 | 61.5 | 86.0 |
| OpenMath-Nemo. (7B) | 26.9 | 36.0 | 18.6 | 28.0 | 19.8 | 28.0 | 4.4 | 4.0 | 17.4 | 24.0 | 86.4 | 100.0 | 76.4 | 97.0 | 91.5 | 100.0 | 55.3 | 72.4 | 74.7 | 91.0 |
| DS-R1-Distill (14B) | 16.1 | 16.0 | 17.0 | 16.0 | 18.1 | 32.0 | 2.1 | 4.0 | 13.3 | 17.0 | 69.0 | 96.0 | 65.1 | 97.0 | 79.4 | 92.3 | 44.0 | 65.5 | 61.8 | 87.0 |
| Light-R1-DS (14B) | 21.8 | 24.0 | 22.2 | 28.0 | 17.8 | 36.0 | 2.6 | 4.0 | 16.1 | 23.0 | 72.3 | 88.0 | 73.0 | 100.0 | 84.3 | 92.3 | 47.6 | 65.5 | 66.9 | 86.0 |
| OpenMath-Nemo. (14B) | 28.7 | 40.0 | 22.1 | 32.0 | 21.0 | 32.0 | 3.4 | 4.0 | 18.8 | 27.0 | 87.9 | 100.0 | 78.5 | 93.9 | 95.8 | 100.0 | 59.9 | 86.2 | 77.7 | 94.0 |
| Qwen3 (30B-A3B, Think) | 38.8 | 44.0 | 33.8 | 44.0 | 26.7 | 36.0 | 5.9 | 4.0 | 26.3 | 32.0 | 91.4 | 100.0 | 92.9 | 100.0 | 90.9 | 92.3 | 75.6 | 93.1 | 87.2 | 97.0 |
| DS-R1-Distill (32B) | 22.4 | 32.0 | 21.4 | 24.0 | 20.3 | 40.0 | 3.4 | 4.0 | 16.9 | 25.0 | 73.6 | 100.0 | 71.8 | 97.0 | 84.5 | 92.3 | 49.0 | 69.0 | 67.3 | 89.0 |
| QwQ (32B) | 32.9 | 28.0 | 26.6 | 36.0 | 26.7 | 44.0 | 6.2 | 4.0 | 23.1 | 28.0 | 91.8 | 100.0 | 87.0 | 100.0 | 95.0 | 100.0 | 69.0 | 89.7 | 84.0 | 97.0 |
| Light-R1-DS (32B) | 28.9 | 44.0 | 31.1 | 52.0 | 24.1 | 36.0 | 5.2 | 8.0 | 22.3 | 35.0 | 84.2 | 100.0 | 83.3 | 100.0 | 92.5 | 100.0 | 62.1 | 82.8 | 78.6 | 95.0 |
| OpenThinker2 (32B) | 24.1 | 32.0 | 22.9 | 32.0 | 18.0 | 20.0 | 2.6 | 4.0 | 16.9 | 22.0 | 79.4 | 96.0 | 74.0 | 100.0 | 90.4 | 92.3 | 56.5 | 79.3 | 72.4 | 92.0 |
| Skywork-OR1-Pre. (32B) | 37.2 | 52.0 | 32.3 | 48.0 | 27.0 | 40.0 | 4.2 | 4.0 | 25.2 | 36.0 | 89.3 | 100.0 | 87.3 | 100.0 | 92.4 | 100.0 | 63.9 | 82.8 | 81.7 | 95.0 |
| GLM-Z1-Air (32B) | 35.0 | 44.0 | 21.5 | 32.0 | 19.5 | 24.0 | 4.5 | 4.0 | 20.1 | 26.0 | 86.5 | 100.0 | 79.5 | 90.9 | 90.4 | 100.0 | 59.1 | 75.9 | 76.8 | 90.0 |
| OpenMath-Nemo. (32B) | 22.0 | 36.0 | 21.0 | 28.0 | 20.0 | 24.0 | 3.5 | 4.0 | 16.6 | 23.0 | 75.5 | 100.0 | 60.6 | 90.9 | 89.4 | 100.0 | 42.2 | 69.0 | 62.7 | 88.0 |
| Qwen3 (235B-A22B, Think) | 48.0 | 52.0 | 49.5 | 60.0 | 38.0 | 36.0 | 10.5 | 16.0 | 36.5 | 41.0 | 93.5 | 100.0 | 92.4 | 100.0 | 99.0 | 100.0 | 81.9 | 93.1 | 90.5 | 98.0 |
| DeepSeek R1 | 30.0 | 40.0 | 25.5 | 32.0 | 18.5 | 24.0 | 4.0 | 4.0 | 19.5 | 25.0 | 90.5 | 100.0 | 82.2 | 97.0 | 94.2 | 100.0 | 60.8 | 72.4 | 79.6 | 91.0 |
| OpenAI o3-mini (high) | 29.5 | 32.0 | 29.0 | 44.0 | 49.5 | 60.0 | 17.0 | 20.0 | 31.2 | 39.0 | 93.0 | 92.0 | 89.8 | 100.0 | 97.1 | 100.0 | 89.2 | 96.6 | 91.4 | 97.0 |
| Gemini 2.5 Pro Exp 0325 | 71.5 | 76.0 | 75.5 | 84.0 | 59.0 | 72.0 | 27.5 | 36.0 | 58.4 | 67.0 | 92.0 | 100.0 | 97.0 | 100.0 | 98.1 | 100.0 | 84.5 | 89.7 | 92.2 | 97.0 |
Evaluation Details.
Our evaluation pipeline follows a systematic approach: for each problem, we generate 64 distinct responses from each comparison model, with the exception of certain models (i.e., OpenMath-Nemotron-32B, Qwen3-235B-A22B, GLM-Z1-Air, DeepSeek-R1, o3-mini (high) and Gemini 2.5 Pro Exp), for which, due to resource limitations and the relatively large scale of our dataset, we only conducted 8 samples. For the Pass@1 metric, we compute the mean accuracy across all sampled responses to derive the final accuracy score. For the Cons@64 and Cons@8 metric, we implement majority voting to determine a consensus answer for each problem, subsequently calculating the average accuracy across the entire dataset. For generation hyperparameters, we adhere to established practices from previous research [4, 23], configuring locally-evaluated models with temperature, top_p, min_p, and max_token set to $0.6$ , $0.95$ , $0 0$ , and $32768$ , respectively. For api-evaluated models (i.e., GLM-Z1-Air, DeepSeek-R1, o3-mini (high) and Gemini 2.5 Pro Exp), we expand their max_token limit to the maximum extent possible to unleash their reasoning capabilities better. We have open-sourced all the samples (a dataset of 582,400 math reasoning samples with long chain-of-thought, generated from the 400 problems in OlymMATH across 28 models), an online data visualization tool and standard solutions for problems where all LLMs struggled in our repository, aiming to help the community analyze the problem-solving patterns and characteristics of LLMs (see Section 4 for further information).
3.2 Evaluation Results
In this part, we assess the performance of reasoning models on our benchmark. We present the evaluation results of OlymMATH-EN and OlymMATH-ZH in Table 4 and Table 5, respectively.
Table 5: Model performance on OlymMATH-ZH. Models within each model size group are sorted by release time. The abbreviations “Alg.”, “Geo.”, “Num.”, and “Com.” represent the four categories in OlymMATH. Highest accuracy per model size is bolded. The second highest accuracy per model size is underlined. Models sampled only 8 times are marked in gray to indicate potential instability.
| Model | OlymMATH-ZH-HARD | OlymMATH-ZH-EASY | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Alg. | Geo. | Num. | Com. | Avg. | Alg. | Geo. | Num. | Com. | Avg. | | | | | | | | | | | |
| P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | P@1 | C@k | |
| Qwen3 (0.6B, Think) | 2.6 | 4.0 | 0.8 | 0.0 | 4.4 | 4.0 | 0.0 | 0.0 | 1.9 | 2.0 | 9.9 | 8.0 | 2.8 | 3.0 | 12.0 | 15.4 | 1.3 | 3.4 | 5.4 | 6.0 |
| DS-R1-Distill (1.5B) | 1.8 | 0.0 | 1.3 | 0.0 | 1.1 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 13.7 | 20.0 | 6.3 | 9.1 | 20.9 | 30.8 | 2.6 | 0.0 | 9.0 | 12.0 |
| STILL-3-Pre. (1.5B) | 2.9 | 0.0 | 2.2 | 0.0 | 4.5 | 4.0 | 0.2 | 0.0 | 2.5 | 1.0 | 15.9 | 32.0 | 7.4 | 18.2 | 27.6 | 46.2 | 4.3 | 6.9 | 11.3 | 22.0 |
| DeepScaleR-Pre. (1.5B) | 4.4 | 8.0 | 2.6 | 4.0 | 6.4 | 8.0 | 0.1 | 0.0 | 3.4 | 5.0 | 15.9 | 20.0 | 7.2 | 9.1 | 32.6 | 46.2 | 8.9 | 20.7 | 13.2 | 20.0 |
| OpenMath-Nemo. (1.5B) | 13.9 | 16.0 | 9.8 | 4.0 | 13.3 | 16.0 | 0.8 | 0.0 | 9.5 | 9.0 | 67.9 | 96.0 | 37.6 | 57.6 | 65.3 | 76.9 | 27.6 | 41.4 | 45.9 | 65.0 |
| Qwen3 (4B, Think) | 12.5 | 20.0 | 7.0 | 8.0 | 12.6 | 24.0 | 0.9 | 0.0 | 8.3 | 13.0 | 70.8 | 88.0 | 61.0 | 75.8 | 74.8 | 92.3 | 41.8 | 51.7 | 59.7 | 74.0 |
| DS-R1-Distill (7B) | 6.1 | 8.0 | 7.9 | 12.0 | 6.6 | 8.0 | 0.6 | 0.0 | 5.3 | 7.0 | 38.0 | 64.0 | 30.8 | 51.5 | 49.2 | 61.5 | 18.7 | 27.6 | 31.5 | 49.0 |
| Light-R1-DS (7B) | 7.1 | 4.0 | 9.4 | 12.0 | 7.8 | 12.0 | 1.1 | 0.0 | 6.3 | 7.0 | 42.9 | 76.0 | 42.7 | 72.7 | 56.9 | 61.5 | 22.7 | 31.0 | 38.8 | 60.0 |
| OpenThinker2 (7B) | 7.0 | 0.0 | 7.3 | 8.0 | 7.4 | 8.0 | 1.0 | 0.0 | 5.7 | 4.0 | 48.2 | 80.0 | 44.7 | 72.7 | 57.8 | 76.9 | 22.4 | 37.9 | 40.8 | 65.0 |
| Skywork-OR1-Pre. (7B) | 4.7 | 4.0 | 7.8 | 8.0 | 7.4 | 8.0 | 0.4 | 0.0 | 5.1 | 5.0 | 41.1 | 60.0 | 36.6 | 54.5 | 58.1 | 69.2 | 23.6 | 34.5 | 36.8 | 52.0 |
| Skywork-OR1-Math (7B) | 6.4 | 8.0 | 8.3 | 8.0 | 9.8 | 12.0 | 0.8 | 0.0 | 6.3 | 7.0 | 45.2 | 72.0 | 40.0 | 63.6 | 62.3 | 69.2 | 30.2 | 37.9 | 41.3 | 59.0 |
| AceMath-RL (7B) | 6.4 | 8.0 | 10.7 | 12.0 | 7.8 | 8.0 | 1.4 | 0.0 | 6.6 | 7.0 | 55.1 | 88.0 | 46.6 | 75.8 | 66.9 | 76.9 | 31.0 | 44.8 | 46.9 | 70.0 |
| OpenMath-Nemo. (7B) | 25.0 | 32.0 | 20.8 | 28.0 | 22.3 | 36.0 | 4.8 | 4.0 | 18.2 | 25.0 | 86.8 | 100.0 | 72.7 | 90.9 | 91.8 | 100.0 | 57.9 | 79.3 | 74.4 | 91.0 |
| DS-R1-Distill (14B) | 5.2 | 0.0 | 5.3 | 4.0 | 8.7 | 16.0 | 0.2 | 0.0 | 4.9 | 5.0 | 43.1 | 56.0 | 38.9 | 66.7 | 58.2 | 69.2 | 24.8 | 31.0 | 38.4 | 54.0 |
| Light-R1-DS (14B) | 6.2 | 4.0 | 7.5 | 8.0 | 10.9 | 12.0 | 0.2 | 0.0 | 6.2 | 6.0 | 56.6 | 84.0 | 45.5 | 75.8 | 66.5 | 76.9 | 28.7 | 37.9 | 46.1 | 67.0 |
| OpenMath-Nemo. (14B) | 28.7 | 32.0 | 26.1 | 40.0 | 26.8 | 40.0 | 4.2 | 4.0 | 21.4 | 29.0 | 88.3 | 100.0 | 75.2 | 100.0 | 94.5 | 100.0 | 60.2 | 86.2 | 76.6 | 96.0 |
| Qwen3 (30B-A3B, Think) | 35.6 | 40.0 | 24.1 | 28.0 | 18.1 | 24.0 | 2.7 | 4.0 | 20.1 | 24.0 | 87.8 | 92.0 | 84.7 | 97.0 | 91.3 | 100.0 | 61.9 | 65.5 | 79.7 | 87.0 |
| DS-R1-Distill (32B) | 6.5 | 0.0 | 5.4 | 4.0 | 10.6 | 12.0 | 0.7 | 0.0 | 5.8 | 4.0 | 45.2 | 52.0 | 41.8 | 63.6 | 60.2 | 69.2 | 26.0 | 37.9 | 40.4 | 54.0 |
| QwQ (32B) | 20.9 | 24.0 | 15.9 | 16.0 | 17.6 | 24.0 | 2.0 | 0.0 | 14.1 | 16.0 | 85.4 | 96.0 | 76.6 | 97.0 | 92.9 | 100.0 | 53.8 | 69.0 | 74.3 | 89.0 |
| Light-R1-DS (32B) | 16.8 | 28.0 | 12.0 | 12.0 | 13.4 | 16.0 | 4.4 | 16.0 | 11.6 | 18.0 | 70.1 | 96.0 | 64.1 | 93.9 | 80.4 | 92.3 | 39.8 | 51.7 | 60.7 | 82.0 |
| OpenThinker2 (32B) | 13.6 | 16.0 | 11.1 | 16.0 | 12.7 | 20.0 | 0.9 | 0.0 | 9.6 | 13.0 | 68.0 | 92.0 | 64.3 | 93.9 | 84.6 | 92.3 | 44.8 | 65.5 | 62.2 | 85.0 |
| Skywork-OR1-Pre. (32B) | 19.6 | 20.0 | 16.8 | 20.0 | 18.9 | 24.0 | 3.5 | 4.0 | 14.7 | 17.0 | 79.5 | 96.0 | 72.1 | 93.9 | 88.0 | 100.0 | 45.4 | 58.6 | 68.3 | 85.0 |
| GLM-Z1-Air (32B) | 18.0 | 16.0 | 12.0 | 8.0 | 16.0 | 16.0 | 2.5 | 4.0 | 12.1 | 11.0 | 76.0 | 96.0 | 69.3 | 78.8 | 89.4 | 92.3 | 41.8 | 48.3 | 65.6 | 76.0 |
| OpenMath-Nemo. (32B) | 22.5 | 36.0 | 22.5 | 32.0 | 22.5 | 28.0 | 3.5 | 4.0 | 17.8 | 25.0 | 68.0 | 96.0 | 62.5 | 90.9 | 90.4 | 100.0 | 48.7 | 72.4 | 63.5 | 88.0 |
| Qwen3 (235B-A22B, Think) | 36.5 | 48.0 | 43.5 | 48.0 | 28.5 | 32.0 | 4.0 | 8.0 | 28.1 | 34.0 | 91.0 | 100.0 | 90.2 | 97.0 | 94.2 | 100.0 | 78.4 | 89.7 | 87.5 | 96.0 |
| DeepSeek R1 | 20.0 | 24.0 | 25.0 | 28.0 | 17.0 | 16.0 | 1.5 | 0.0 | 15.9 | 17.0 | 79.5 | 96.0 | 74.6 | 84.8 | 88.5 | 92.3 | 49.6 | 55.2 | 70.4 | 80.0 |
| OpenAI o3-mini (high) | 31.5 | 40.0 | 32.5 | 44.0 | 48.5 | 56.0 | 19.0 | 28.0 | 32.9 | 42.0 | 93.0 | 96.0 | 89.4 | 100.0 | 99.0 | 100.0 | 85.8 | 93.1 | 90.5 | 97.0 |
| Gemini 2.5 Pro Exp 0325 | 65.0 | 76.0 | 78.0 | 80.0 | 53.5 | 56.0 | 25.0 | 40.0 | 55.4 | 63.0 | 90.5 | 96.0 | 93.2 | 93.9 | 100.0 | 100.0 | 84.1 | 86.2 | 90.8 | 93.0 |
First, we observe that all tested models exhibit relatively poor performance, with even OpenAI o3-mini (high) and Gemini 2.5 Pro Exp achieving only 31.2% and 58.4% on OlymMATH-EN-HARD. This underscores the high overall difficulty of our benchmark, which demands stronger reasoning abilities and a deeper understanding of mathematical knowledge to solve the problems effectively. In contrast, the performance of these advanced reasoning models on OlymMATH-EN-EASY is more modest and comparable to that on AIME 2024 and AIME 2025, suggesting that OlymMATH-EN-EASY is well-suited for evaluating the capabilities of less advanced reasoning models.
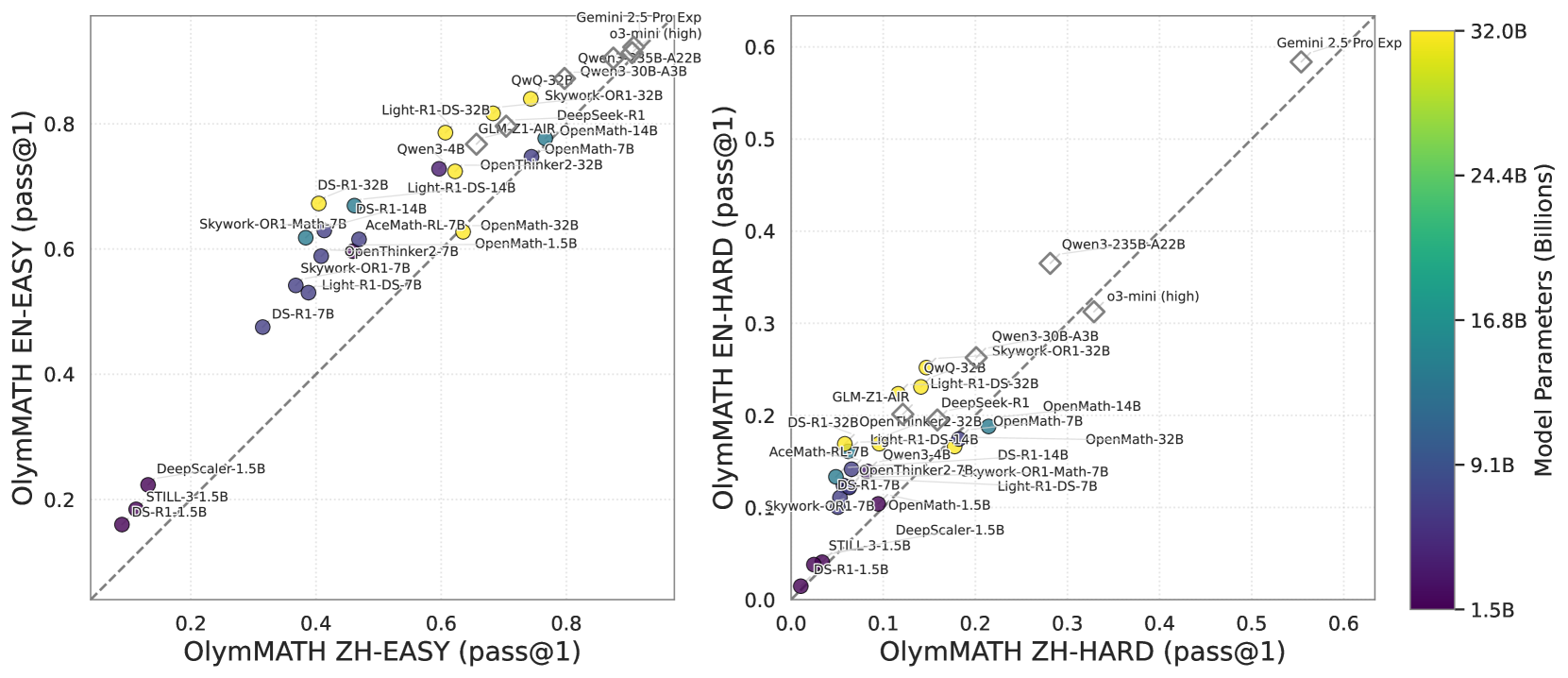
Second, by comparing the performance of LLMs on OlymMATH-EN and OlymMATH-ZH, we find that language can influence the reasoning performance of LLMs to some extent (see Figure 3). Overall, all models tend to achieve higher performance on the English benchmarks. A potential reason for this is that English corpora still dominate existing pre-training datasets, making the English-based task-solving capabilities of LLMs generally more superior compared to other languages. This finding highlights the importance of considering performance across different languages when conducting a comprehensive evaluation of LLMs.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Scatter Plot: OlymMATH Performance vs. Model Size
### Overview
The image consists of two scatter plots, each comparing the performance of various language models on the OlymMATH dataset. The left plot shows performance on the "EASY" subset, while the right plot shows performance on the "HARD" subset. The x-axis represents performance on the Chinese version (ZH) of the dataset, and the y-axis represents performance on the English version (EN). Data points are colored according to the model size, with a color gradient ranging from purple (small) to yellow (large). A dashed diagonal line is present in both plots, representing equal performance on both ZH and EN versions.
### Components/Axes
**Left Plot (EASY)**
* **Title:** OlymMATH EN-EASY (pass@1) vs. OlymMATH ZH-EASY (pass@1)
* **X-axis:** OlymMATH ZH-EASY (pass@1)
* Scale: 0.0 to 0.8, incrementing by 0.2
* **Y-axis:** OlymMATH EN-EASY (pass@1)
* Scale: 0.2 to 0.8, incrementing by 0.2
* **Data Points:** Represent different language models, colored by model size.
* Shapes: Circles and Diamonds
* **Diagonal Line:** Dashed line indicating equal performance on ZH and EN.
**Right Plot (HARD)**
* **Title:** OlymMATH EN-HARD (pass@1) vs. OlymMATH ZH-HARD (pass@1)
* **X-axis:** OlymMATH ZH-HARD (pass@1)
* Scale: 0.0 to 0.6, incrementing by 0.1
* **Y-axis:** OlymMATH EN-HARD (pass@1)
* Scale: 0.0 to 0.6, incrementing by 0.1
* **Data Points:** Represent different language models, colored by model size.
* Shapes: Circles and Diamonds
* **Diagonal Line:** Dashed line indicating equal performance on ZH and EN.
**Color Legend (Right Side)**
* **Title:** Model Parameters (Billions)
* **Scale:** 1.5B to 32.0B
* 1.5B (Purple)
* 9.1B (Blue)
* 16.8B (Green)
* 24.4B (Yellow-Green)
* 32.0B (Yellow)
### Detailed Analysis
**Left Plot (EASY)**
* **DS-R1-1.5B:** Located at approximately (0.1, 0.15), purple.
* **STILL-3-1.5B:** Located at approximately (0.15, 0.2), purple.
* **DeepScaler-1.5B:** Located at approximately (0.2, 0.2), purple.
* **Light-R1-DS-7B:** Located at approximately (0.4, 0.5), blue.
* **DS-R1-7B:** Located at approximately (0.35, 0.45), blue.
* **Skywork-OR1-7B:** Located at approximately (0.35, 0.5), blue.
* **OpenThinker2-7B:** Located at approximately (0.5, 0.6), blue.
* **AceMath-RL-7B:** Located at approximately (0.5, 0.65), blue.
* **Skywork-OR1-Math-7B:** Located at approximately (0.4, 0.6), blue.
* **DS-R1-14B:** Located at approximately (0.55, 0.7), light blue.
* **Light-R1-DS-14B:** Located at approximately (0.5, 0.7), light blue.
* **DS-R1-32B:** Located at approximately (0.6, 0.7), yellow-green.
* **Qwen3-4B:** Located at approximately (0.65, 0.8), yellow-green.
* **Light-R1-DS-32B:** Located at approximately (0.6, 0.8), yellow-green.
* **OpenMath-1.5B:** Located at approximately (0.65, 0.4), purple.
* **OpenMath-7B:** Located at approximately (0.7, 0.6), blue.
* **OpenMath-14B:** Located at approximately (0.75, 0.75), light blue.
* **OpenMath-32B:** Located at approximately (0.55, 0.65), yellow-green.
* **Skywork-OR1-32B:** Located at approximately (0.75, 0.85), yellow-green.
* **QWQ-32B:** Located at approximately (0.75, 0.85), yellow-green.
* **Qwen3-30B-A3B:** Located at approximately (0.75, 0.85), yellow-green.
* **Qwen3-235B-A22B:** Located at approximately (0.75, 0.85), yellow-green.
* **o3-mini (high):** Located at approximately (0.75, 0.85), yellow-green.
* **Gemini 2.5 Pro Exp:** Located at approximately (0.75, 0.85), yellow-green.
* **DeepSeek-R1:** Located at approximately (0.75, 0.8), yellow-green.
* **GLM-Z1-AIR:** Located at approximately (0.75, 0.8), yellow-green.
* **OpenThinker2-32B:** Located at approximately (0.7, 0.7), yellow-green.
**Right Plot (HARD)**
* **DS-R1-1.5B:** Located at approximately (0.02, 0.01), purple.
* **STILL-3-1.5B:** Located at approximately (0.05, 0.02), purple.
* **DeepScaler-1.5B:** Located at approximately (0.1, 0.05), purple.
* **Light-R1-DS-7B:** Located at approximately (0.25, 0.05), blue.
* **DS-R1-7B:** Located at approximately (0.05, 0.05), blue.
* **Skywork-OR1-7B:** Located at approximately (0.05, 0.05), blue.
* **OpenThinker2-7B:** Located at approximately (0.15, 0.1), blue.
* **AceMath-RL-7B:** Located at approximately (0.1, 0.1), blue.
* **Skywork-OR1-Math-7B:** Located at approximately (0.25, 0.1), blue.
* **DS-R1-14B:** Located at approximately (0.25, 0.15), light blue.
* **Light-R1-DS-14B:** Located at approximately (0.15, 0.15), light blue.
* **DS-R1-32B:** Located at approximately (0.1, 0.2), yellow-green.
* **Qwen3-4B:** Located at approximately (0.15, 0.15), yellow-green.
* **Light-R1-DS-32B:** Located at approximately (0.15, 0.25), yellow-green.
* **OpenMath-1.5B:** Located at approximately (0.25, 0.05), purple.
* **OpenMath-7B:** Located at approximately (0.35, 0.2), blue.
* **OpenMath-14B:** Located at approximately (0.3, 0.25), light blue.
* **OpenMath-32B:** Located at approximately (0.4, 0.2), yellow-green.
* **Skywork-OR1-32B:** Located at approximately (0.25, 0.3), yellow-green.
* **QWQ-32B:** Located at approximately (0.15, 0.25), yellow-green.
* **Qwen3-30B-A3B:** Located at approximately (0.25, 0.3), yellow-green.
* **Qwen3-235B-A22B:** Located at approximately (0.3, 0.4), yellow-green.
* **o3-mini (high):** Located at approximately (0.35, 0.35), yellow-green.
* **Gemini 2.5 Pro Exp:** Located at approximately (0.6, 0.6), yellow-green.
* **DeepSeek-R1:** Located at approximately (0.2, 0.25), yellow-green.
* **GLM-Z1-AIR:** Located at approximately (0.15, 0.25), yellow-green.
* **OpenThinker2-32B:** Located at approximately (0.2, 0.2), yellow-green.
### Key Observations
* **Model Size and Performance:** Generally, larger models (yellow) tend to perform better on both EASY and HARD subsets, as indicated by their position towards the top-right of the plots.
* **Difficulty Impact:** The performance range is compressed in the HARD subset compared to the EASY subset, suggesting that the HARD subset is more challenging for all models.
* **ZH vs. EN Performance:** Most models cluster around the diagonal line, indicating similar performance on both Chinese and English versions of the dataset. However, some models deviate, suggesting a bias towards one language.
* **Outliers:** Gemini 2.5 Pro Exp stands out in the HARD subset, showing significantly better performance compared to other models.
* **Model Grouping:** Models with similar architectures or training methodologies tend to cluster together, indicating shared strengths and weaknesses.
### Interpretation
The scatter plots provide a comparative analysis of language model performance on the OlymMATH dataset, considering both problem difficulty (EASY vs. HARD) and language (ZH vs. EN). The data suggests that model size is a significant factor in performance, with larger models generally achieving higher accuracy. However, the plots also reveal that architectural choices and training methodologies play a crucial role, as models with similar characteristics tend to cluster together.
The HARD subset highlights the limitations of current models, as the performance range is compressed, indicating that even the largest models struggle with the more challenging problems. The presence of outliers, such as Gemini 2.5 Pro Exp, suggests that certain models may have specific advantages in handling complex mathematical reasoning.
The comparison between ZH and EN performance reveals potential language biases in some models, which could be attributed to differences in training data or architectural design. Further investigation into these biases could lead to improvements in model generalization and cross-lingual transfer learning.
In summary, the scatter plots provide valuable insights into the strengths and weaknesses of various language models on the OlymMATH dataset, highlighting the importance of model size, architecture, and training methodology in achieving high accuracy and robustness.
</details>
Figure 3: Pass@1 accuracy on OlymMATH EN (y) vs. ZH (x), the dashed line shows parity. Points above favor English, below favor Chinese. Solid circles (local dense models, colored by size) indicate larger models trend towards higher accuracy. Hollow diamonds are MoE or API evaluated models.
3.3 Benchmark Comparison
<details>
<summary>x3.png Details</summary>
### Visual Description
## Scatter Plot: OlymMATH EN Accuracy vs. AIME24 Accuracy
### Overview
The image is a scatter plot comparing the performance of various language models on two different benchmarks: OlymMATH EN (English) and AIME24. The plot shows the accuracy of each model on these benchmarks, with data points colored according to their release date (from January 2025 to April 2025). The plot includes trend lines for both "EN-EASY" and "EN-HARD" datasets.
### Components/Axes
* **X-axis:** AIME24 Accuracy, ranging from 0.1 to 1.0 in increments of 0.1.
* **Y-axis:** OlymMATH EN Accuracy (pass@1), ranging from 0.0 to 1.0 in increments of 0.2.
* **Legend (Top-Left):**
* EN-EASY (Blue Circle)
* EN-EASY Trend (Blue Dashed Line)
* EN-HARD (Green Triangle)
* EN-HARD Trend (Red Dashed Line)
* **Color Bar (Right):** Represents the release date, ranging from Jan 2025 (dark purple) to Apr 2025 (yellow). The color bar is labeled "Release Date (Later -> Brighter)".
* **Data Points:** Each data point represents a language model, labeled with its name (e.g., "Qwen3-235B-A22B", "OpenMath-7B"). The size of the data point is not explained.
### Detailed Analysis or Content Details
**EN-EASY Dataset (Blue Circles and Dashed Line):**
* Trend: The EN-EASY trend line slopes upward, indicating a positive correlation between AIME24 accuracy and OlymMATH EN accuracy.
* Data Points:
* At AIME24 Accuracy ~0.3, OlymMATH EN Accuracy is ~0.2
* At AIME24 Accuracy ~0.6, OlymMATH EN Accuracy is ~0.6
* At AIME24 Accuracy ~0.8, OlymMATH EN Accuracy is ~0.8
* At AIME24 Accuracy ~0.9, OlymMATH EN Accuracy is ~0.9
**EN-HARD Dataset (Green Triangles and Red Dashed Line):**
* Trend: The EN-HARD trend line also slopes upward, but at a shallower angle than the EN-EASY trend line.
* Data Points:
* At AIME24 Accuracy ~0.3, OlymMATH EN Accuracy is ~0.0
* At AIME24 Accuracy ~0.6, OlymMATH EN Accuracy is ~0.1
* At AIME24 Accuracy ~0.8, OlymMATH EN Accuracy is ~0.2
**Specific Data Points (Examples):**
* "Gemini 2.5 Pro Exp" (Green Star) has an AIME24 accuracy of approximately 0.92 and an OlymMATH EN accuracy of approximately 0.73. The color is yellow, indicating a release date of approximately April 2025.
* "OpenMATH-1.5B" (Blue Circle) has an AIME24 accuracy of approximately 0.55 and an OlymMATH EN accuracy of approximately 0.6. The color is green, indicating a release date of approximately March 2025.
* "Qwen3-4B" (Purple Triangle) has an AIME24 accuracy of approximately 0.7 and an OlymMATH EN accuracy of approximately 0.05. The color is dark purple, indicating a release date of approximately January 2025.
**Other Models:**
* Qwen3-235B-A22B
* Qwen3-30B-A3B
* QwQ-32B
* OpenMath-7B
* OpenMath-14B
* Skywork-OR1-32B
* 03-mini (high)
### Key Observations
* There is a positive correlation between AIME24 accuracy and OlymMATH EN accuracy for both EN-EASY and EN-HARD datasets.
* The EN-EASY dataset generally shows higher OlymMATH EN accuracy for a given AIME24 accuracy compared to the EN-HARD dataset.
* Models released later (closer to April 2025) tend to have higher accuracy on both benchmarks.
* The "Gemini 2.5 Pro Exp" model appears to be an outlier, with high accuracy on both benchmarks.
### Interpretation
The scatter plot suggests that language models are generally improving in their ability to solve both AIME24 and OlymMATH EN problems over time. The difference in performance between the EN-EASY and EN-HARD datasets indicates that the difficulty of the benchmark significantly impacts the accuracy of the models. The color gradient reveals a trend: newer models (released later) tend to perform better, suggesting ongoing progress in language model development. The outlier "Gemini 2.5 Pro Exp" demonstrates that some models significantly outperform others, potentially due to architectural innovations or training methodologies. The size of the data points is not explained, and could represent another variable.
</details>
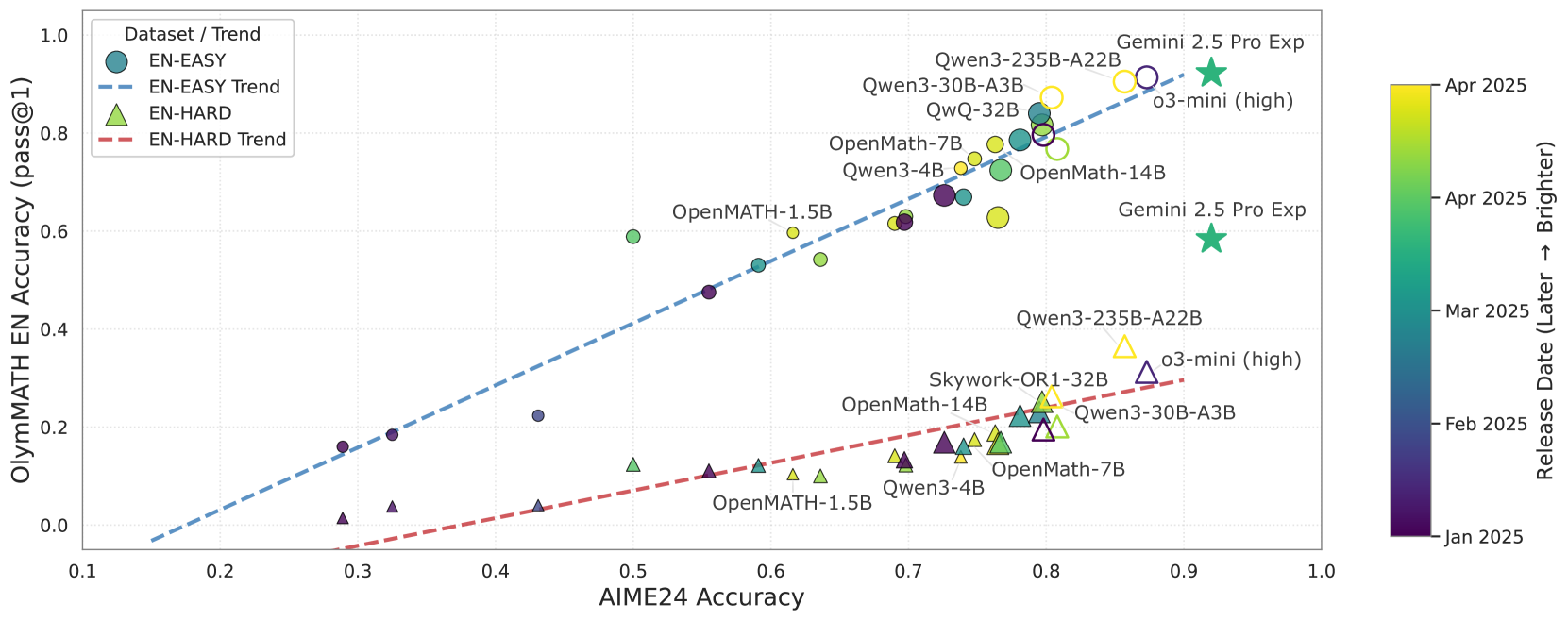
Figure 4: Correlation of Pass@1 performance: OlymMATH-EN vs. AIME24. Dashed lines indicate linear trends per dataset. Solid shapes are local dense models (size = model size, color = release date). Hollow shapes denote MoE or API evaluated models. Stars mark the best overall model.
To comprehensively evaluate OlymMATH against existing benchmarks, we compare state-of-the-art model performance across widely used mathematical benchmarks (see Figure 1). Results are sourced from research reports or the MathArena platform https://matharena.ai/ .
Figure 1 illustrates that OlymMATH is more challenging, yielding lower accuracy compared to saturated benchmarks like MATH-500 (where even DeepSeek-R1-Distill-Qwen-7B exceeds 92% accuracy [4]) or AIME24 (where top LLMs reach 92% with single attempt). Unlike these benchmarks whose high performance limits discriminative power, OlymMATH elicits more varied scores, offering superior differentiation of reasoning capabilities. For example, while Gemini 2.5 Pro Exp and o3-mini (high) achieve similar AIME24 accuracy (92.0% vs. 87.3%), their OlymMATH-EN-HARD performance diverges significantly (58.4% vs. 31.2%).
Figure 4 further demonstrates OlymMATH’s reliability by comparing OlymMATH-EN performance against AIME24. The close clustering of data points around linear trend lines indicates consistent relative model performance across both benchmarks. This strong correlation suggests OlymMATH measures similar underlying mathematical reasoning abilities as the respected AIME24 dataset, validating its use for LLM evaluation (see Figure 8 in Appendix for more information). Despite this alignment, OlymMATH, particularly the HARD subset, remains significantly more challenging than AIME24 for most models, reinforcing its superior ability to differentiate state-of-the-art capabilities.
3.4 Case Study
During our data collection and preliminary experiments, we empirically observed that LLMs sometimes resort to empirical guesses —such as heuristics, symmetry assumptions, or even fabrication—rather than rigorous reasoning. For instance, o3-mini-high merely “guessed” $b=c$ due to symmetry in a geometric optimization problem (see Figure 9 in Appendix). While such intuitive approaches might yield correct answers, they lack logical rigor and this case becomes problematic when employing rule-based or LLM-as-judge methods, as neither can effectively assess the quality of rigorous reasoning, thus potentially leading to an illusory improvement in accuracy via “shortcuts”.
Similar issues were observed in the AIME 2025 and Omni-MATH benchmarks (see Figure 10 and 11 in Appendix), indicating that despite performance gains, LLMs still exhibit deficiencies in deliberative thinking. This underscores the importance of process-level supervision, though its scalability remains a challenge. Currently, we do not accurately measure the proportion of “guesses” in these benchmarks, leaving this as an important direction for future work.
Notably, these guessing strategies often fail on our OlymMATH dataset. For example, a model incorrectly assumed symmetry for a complex optimization problem in OlymMATH, yielding $3081$ instead of the correct $2625$ (see Figure 12 in Appendix). OlymMATH problems, particularly in the HARD subset, are selected and designed so that their reasoning steps are difficult to “hack” through empirical guessing, thus providing a more robust evaluation of genuine reasoning capabilities.
4 Usability and Accessibility
To support research into LLM reasoning, we have open-sourced the OlymMATH-eval dataset at https://hf.co/datasets/RUC-AIBOX/OlymMATH-eval, with 582,400 entries from 28 models, to help compare reasoning capabilities across different models and mathematical domains.
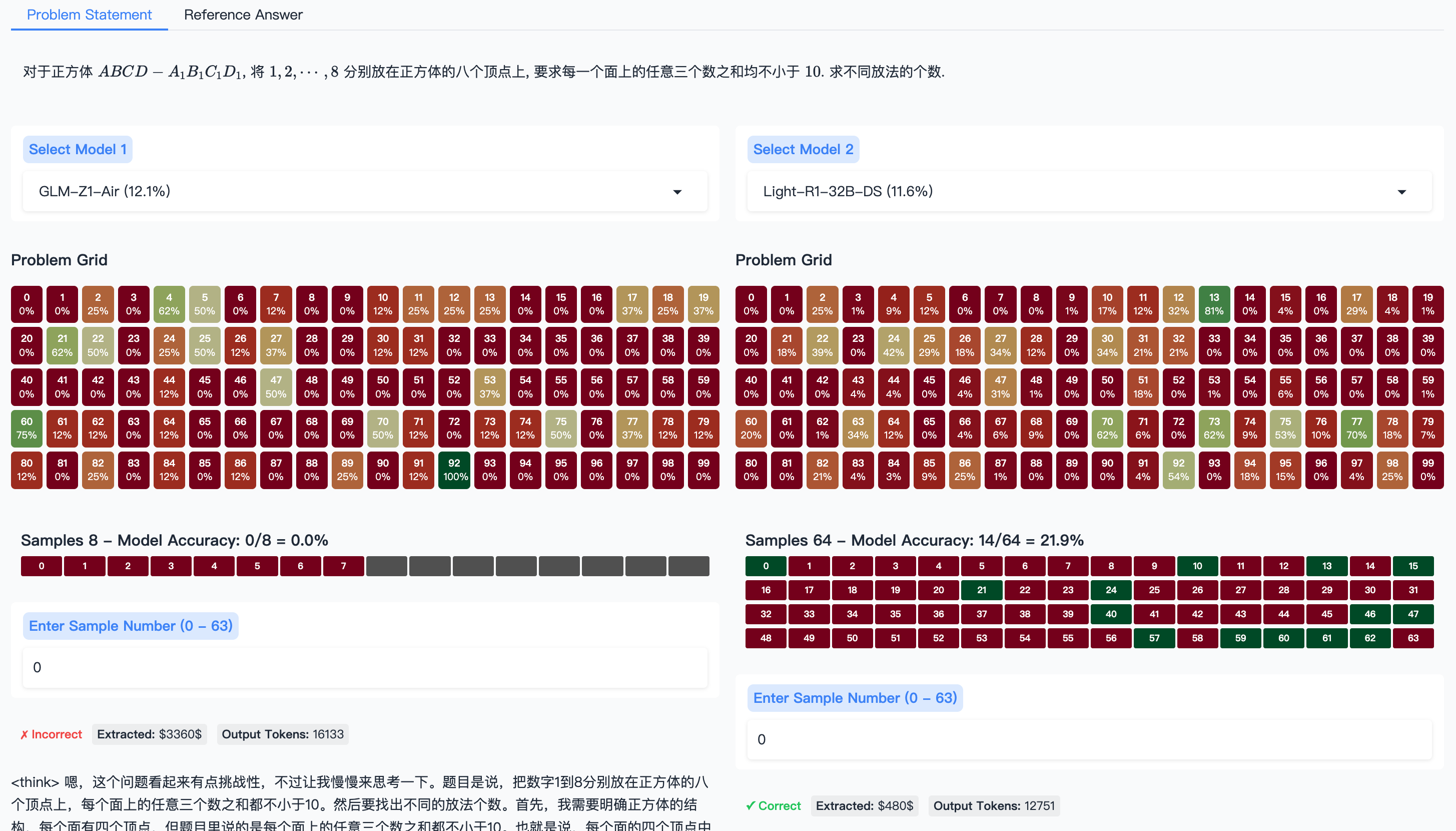
Furthermore, we provide the OlymMATH-demo visualization tool (https://hf.co/spaces/RUC-AIBOX/OlymMATH-demo; see Figure 5) to facilitate in-depth analysis of LLM reasoning. This interactive interface enables: (1) Side-by-side comparison of two selected LLMs on the same L a T e X -rendered problem, with access to reference answers. (2) Color-coded “Problem Grids” for each model, displaying per-problem accuracy for quick identification of challenging areas. (3) Examination of individual model-generated reasoning samples, including correctness, extracted answers, and token counts, crucial for understanding solution processes and identifying flaws. The tool also includes standard solutions for difficult problems and supports local deployment. OlymMATH-demo is thus a valuable asset for dissecting reasoning patterns, diagnosing errors, and guiding LLM development.
<details>
<summary>extracted/6453487/figs/demo.png Details</summary>
### Visual Description
## Problem Solving with Model Comparison
### Overview
The image presents a problem-solving scenario where two different models (GLM-Z1-Air and Light-R1-32B-DS) are used to solve a mathematical problem related to placing numbers on the vertices of a cube. The image shows the problem statement, the model selection dropdowns, a grid representing the problem space, and the model accuracy. It also includes input fields for sample numbers and indicates whether the model's answer was correct or incorrect, along with extracted values and output tokens.
### Components/Axes
* **Header:**
* "Problem Statement"
* "Reference Answer"
* **Problem Statement (Chinese):**
* 对于正方体 ABCD - A1B1C1D1,将1,2,…,8分别放在正方体的八个顶点上,要求每一个面上的任意三个数之和均不小于10. 求不同放法的个数.
* Translation: "For a cube ABCD - A1B1C1D1, place the numbers 1, 2, ..., 8 on the eight vertices of the cube, such that the sum of any three numbers on each face is not less than 10. Find the number of different placement methods."
* **Model Selection:**
* "Select Model 1"
* Dropdown showing "GLM-Z1-Air (12.1%)"
* "Select Model 2"
* Dropdown showing "Light-R1-32B-DS (11.6%)"
* **Problem Grid (Model 1):**
* A 10x10 grid of cells numbered 0-99. Each cell contains a number and a percentage.
* **Problem Grid (Model 2):**
* A 10x10 grid of cells numbered 0-99. Each cell contains a number and a percentage.
* **Model Accuracy:**
* "Samples 8 - Model Accuracy: 0/8 = 0.0%"
* "Samples 64 - Model Accuracy: 14/64 = 21.9%"
* **Sample Selection:**
* "Enter Sample Number (0 - 63)" - Input field
* **Model Output:**
* Model 1: "X Incorrect Extracted: $3360$ Output Tokens: 16133"
* Model 2: "✓ Correct Extracted: $480$ Output Tokens: 12751"
* **Footer (Chinese):**
* <think>嗯,这个问题看起来有点挑战性,不过让我慢慢来思考一下。题目是说,把数字1到8分别放在正方体的八个顶点上,每个面上的任意三个数之和都不小于10。然后要找出不同的放法个数。首先,我需要明确正方体的结构,每个面有四个顶点,但题目里说的是每个面上的任意一个数之和都不小于10,也就是说,每个面的四个顶点中
* Translation: "<think> Hmm, this problem seems a bit challenging, but let me think about it slowly. The problem states that the numbers 1 to 8 are placed on the eight vertices of a cube, such that the sum of any three numbers on each face is not less than 10. Then, we need to find the number of different placement methods. First, I need to clarify the structure of the cube. Each face has four vertices, but the problem states that the sum of any three numbers on each face is not less than 10, which means that among the four vertices on each face..."
### Detailed Analysis or Content Details
**Problem Grid (Model 1 - GLM-Z1-Air (12.1%)):**
The grid consists of 100 cells, numbered 0 to 99. Each cell displays a percentage value, presumably representing the model's confidence or probability associated with that particular state or configuration.
* Cell 0: 0%
* Cell 1: 0%
* Cell 2: 25%
* Cell 3: 0%
* Cell 4: 62%
* Cell 5: 50%
* Cell 6: 0%
* Cell 7: 12%
* Cell 8: 0%
* Cell 9: 0%
* Cell 10: 12%
* Cell 11: 25%
* Cell 12: 25%
* Cell 13: 25%
* Cell 14: 0%
* Cell 15: 0%
* Cell 16: 0%
* Cell 17: 37%
* Cell 18: 25%
* Cell 19: 37%
* Cell 20: 0%
* Cell 21: 62%
* Cell 22: 50%
* Cell 23: 0%
* Cell 24: 25%
* Cell 25: 50%
* Cell 26: 12%
* Cell 27: 37%
* Cell 28: 0%
* Cell 29: 0%
* Cell 30: 12%
* Cell 31: 12%
* Cell 32: 0%
* Cell 33: 0%
* Cell 34: 0%
* Cell 35: 0%
* Cell 36: 0%
* Cell 37: 0%
* Cell 38: 0%
* Cell 39: 0%
* Cell 40: 0%
* Cell 41: 12%
* Cell 42: 0%
* Cell 43: 0%
* Cell 44: 0%
* Cell 45: 50%
* Cell 46: 0%
* Cell 47: 0%
* Cell 48: 0%
* Cell 49: 0%
* Cell 50: 0%
* Cell 51: 0%
* Cell 52: 0%
* Cell 53: 50%
* Cell 54: 0%
* Cell 55: 0%
* Cell 56: 0%
* Cell 57: 0%
* Cell 58: 0%
* Cell 59: 0%
* Cell 60: 75%
* Cell 61: 12%
* Cell 62: 12%
* Cell 63: 0%
* Cell 64: 12%
* Cell 65: 0%
* Cell 66: 0%
* Cell 67: 0%
* Cell 68: 0%
* Cell 69: 0%
* Cell 70: 50%
* Cell 71: 12%
* Cell 72: 0%
* Cell 73: 12%
* Cell 74: 12%
* Cell 75: 50%
* Cell 76: 0%
* Cell 77: 37%
* Cell 78: 12%
* Cell 79: 12%
* Cell 80: 12%
* Cell 81: 0%
* Cell 82: 25%
* Cell 83: 0%
* Cell 84: 12%
* Cell 85: 0%
* Cell 86: 12%
* Cell 87: 0%
* Cell 88: 0%
* Cell 89: 25%
* Cell 90: 0%
* Cell 91: 12%
* Cell 92: 100%
* Cell 93: 0%
* Cell 94: 0%
* Cell 95: 0%
* Cell 96: 0%
* Cell 97: 0%
* Cell 98: 0%
* Cell 99: 0%
**Problem Grid (Model 2 - Light-R1-32B-DS (11.6%)):**
The grid consists of 100 cells, numbered 0 to 99. Each cell displays a percentage value, presumably representing the model's confidence or probability associated with that particular state or configuration.
* Cell 0: 0%
* Cell 1: 0%
* Cell 2: 25%
* Cell 3: 1%
* Cell 4: 9%
* Cell 5: 12%
* Cell 6: 0%
* Cell 7: 0%
* Cell 8: 0%
* Cell 9: 1%
* Cell 10: 17%
* Cell 11: 12%
* Cell 12: 32%
* Cell 13: 81%
* Cell 14: 0%
* Cell 15: 4%
* Cell 16: 0%
* Cell 17: 29%
* Cell 18: 4%
* Cell 19: 1%
* Cell 20: 0%
* Cell 21: 18%
* Cell 22: 39%
* Cell 23: 0%
* Cell 24: 42%
* Cell 25: 29%
* Cell 26: 18%
* Cell 27: 34%
* Cell 28: 12%
* Cell 29: 0%
* Cell 30: 34%
* Cell 31: 21%
* Cell 32: 21%
* Cell 33: 0%
* Cell 34: 0%
* Cell 35: 0%
* Cell 36: 6%
* Cell 37: 0%
* Cell 38: 0%
* Cell 39: 0%
* Cell 40: 4%
* Cell 41: 4%
* Cell 42: 0%
* Cell 43: 4%
* Cell 44: 0%
* Cell 45: 31%
* Cell 46: 1%
* Cell 47: 0%
* Cell 48: 0%
* Cell 49: 18%
* Cell 50: 0%
* Cell 51: 1%
* Cell 52: 0%
* Cell 53: 6%
* Cell 54: 0%
* Cell 55: 0%
* Cell 56: 0%
* Cell 57: 1%
* Cell 58: 20%
* Cell 59: 0%
* Cell 60: 20%
* Cell 61: 0%
* Cell 62: 1%
* Cell 63: 34%
* Cell 64: 12%
* Cell 65: 0%
* Cell 66: 4%
* Cell 67: 6%
* Cell 68: 9%
* Cell 69: 0%
* Cell 70: 62%
* Cell 71: 6%
* Cell 72: 0%
* Cell 73: 62%
* Cell 74: 9%
* Cell 75: 53%
* Cell 76: 10%
* Cell 77: 70%
* Cell 78: 18%
* Cell 79: 7%
* Cell 80: 0%
* Cell 81: 0%
* Cell 82: 21%
* Cell 83: 4%
* Cell 84: 3%
* Cell 85: 9%
* Cell 86: 25%
* Cell 87: 1%
* Cell 88: 0%
* Cell 89: 0%
* Cell 90: 4%
* Cell 91: 54%
* Cell 92: 0%
* Cell 93: 18%
* Cell 94: 15%
* Cell 95: 0%
* Cell 96: 4%
* Cell 97: 25%
* Cell 98: 0%
* Cell 99: 0%
**Model Accuracy:**
* Model 1 (GLM-Z1-Air): 0 correct out of 8 samples (0.0% accuracy)
* Model 2 (Light-R1-32B-DS): 14 correct out of 64 samples (21.9% accuracy)
**Model Output Details:**
* Model 1: Incorrect, Extracted: $3360, Output Tokens: 16133
* Model 2: Correct, Extracted: $480, Output Tokens: 12751
### Key Observations
* The problem involves placing numbers 1-8 on the vertices of a cube with a constraint on the sum of numbers on each face.
* Two different models are being compared for their ability to solve this problem.
* Model 2 (Light-R1-32B-DS) has a significantly higher accuracy (21.9%) compared to Model 1 (GLM-Z1-Air) (0.0%).
* The "Problem Grid" likely represents the model's internal state or probability distribution over possible solutions.
* The "Extracted" value likely represents the model's final answer or a related metric.
* The "Output Tokens" value likely represents the complexity or length of the model's reasoning process.
### Interpretation
The image demonstrates a comparison of two AI models in solving a combinatorial problem. The significant difference in accuracy suggests that Model 2 (Light-R1-32B-DS) is better suited for this type of problem than Model 1 (GLM-Z1-Air). The "Problem Grid" provides insight into how each model explores the solution space, with the percentages indicating the model's confidence in different configurations. The "Extracted" and "Output Tokens" values provide additional information about the model's performance and computational effort. The Chinese text in the footer indicates the user's thought process and understanding of the problem. The fact that Model 2's answer was correct, and Model 1's was incorrect, despite Model 1 using more tokens and a higher extracted value, suggests that Model 2 is more efficient and accurate in its reasoning.
</details>
Figure 5: The OlymMATH-demo interface. It is currently being maintained on HuggingFace Spaces.
5 Conclusion
We introduced OlymMATH, a challenging math benchmark for LLMs, uniquely curated from printed materials. It includes 200 problems across four fields, with easy (AIME-level) and hard (more challenging) subsets, in parallel English and Chinese versions. Our experiments with state-of-the-art LLMs, especially in slow-thinking modes, show significant struggles. Analysis highlights language-specific strengths and universal limitations like empirical guessing, identifying weaknesses in LLMs’ multi-step reasoning and logical consistency. Meanwhile, to facilitate community research, we have open-sourced over 580k reasoning data, a visualization tool, and solutions for challenging problems.
As part of our STILL project, OlymMATH affirms our belief in benchmarks’ pivotal role in advancing LLMs’ reasoning capabilities. We advocate for benchmarks to evolve faster than methodologies, guiding the field’s progress. Our planned expansion of OlymMATH embodies this commitment, aiming to further cultivate the development of more robust reasoning models and continue pushing the boundaries of language intelligence.
References
- [1] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models, 2025.
- [2] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024.
- [3] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurélien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Rozière, Bethany Biron, Binh Tang, Bobbie Chern, Charlotte Caucheteux, Chaya Nayak, Chloe Bi, Chris Marra, Chris McConnell, Christian Keller, Christophe Touret, Chunyang Wu, Corinne Wong, Cristian Canton Ferrer, Cyrus Nikolaidis, Damien Allonsius, Daniel Song, Danielle Pintz, Danny Livshits, David Esiobu, Dhruv Choudhary, Dhruv Mahajan, Diego Garcia-Olano, Diego Perino, Dieuwke Hupkes, Egor Lakomkin, Ehab AlBadawy, Elina Lobanova, Emily Dinan, Eric Michael Smith, Filip Radenovic, Frank Zhang, Gabriel Synnaeve, Gabrielle Lee, Georgia Lewis Anderson, Graeme Nail, Grégoire Mialon, Guan Pang, Guillem Cucurell, Hailey Nguyen, Hannah Korevaar, Hu Xu, Hugo Touvron, Iliyan Zarov, Imanol Arrieta Ibarra, Isabel M. Kloumann, Ishan Misra, Ivan Evtimov, Jade Copet, Jaewon Lee, Jan Geffert, Jana Vranes, Jason Park, Jay Mahadeokar, Jeet Shah, Jelmer van der Linde, Jennifer Billock, Jenny Hong, Jenya Lee, Jeremy Fu, Jianfeng Chi, Jianyu Huang, Jiawen Liu, Jie Wang, Jiecao Yu, Joanna Bitton, Joe Spisak, Jongsoo Park, Joseph Rocca, Joshua Johnstun, Joshua Saxe, Junteng Jia, Kalyan Vasuden Alwala, Kartikeya Upasani, Kate Plawiak, Ke Li, Kenneth Heafield, Kevin Stone, and et al. The llama 3 herd of models. CoRR, abs/2407.21783, 2024.
- [4] DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Qu, Hui Li, Jianzhong Guo, Jiashi Li, Jiawei Wang, Jingchang Chen, Jingyang Yuan, Junjie Qiu, Junlong Li, J. L. Cai, Jiaqi Ni, Jian Liang, Jin Chen, Kai Dong, Kai Hu, Kaige Gao, Kang Guan, Kexin Huang, Kuai Yu, Lean Wang, Lecong Zhang, Liang Zhao, Litong Wang, Liyue Zhang, Lei Xu, Leyi Xia, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Meng Li, Miaojun Wang, Mingming Li, Ning Tian, Panpan Huang, Peng Zhang, Qiancheng Wang, Qinyu Chen, Qiushi Du, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, R. J. Chen, R. L. Jin, Ruyi Chen, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shengfeng Ye, Shiyu Wang, Shuiping Yu, Shunfeng Zhou, Shuting Pan, and S. S. Li. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. CoRR, abs/2501.12948, 2025.
- [5] OpenAI. Openai o1 system card, 2024.
- [6] Zhipeng Chen, Yingqian Min, Beichen Zhang, Jie Chen, Jinhao Jiang, Daixuan Cheng, Wayne Xin Zhao, Zheng Liu, Xu Miao, Yang Lu, Lei Fang, Zhongyuan Wang, and Ji-Rong Wen. An empirical study on eliciting and improving r1-like reasoning models, 2025.
- [7] An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, 2024.
- [8] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [9] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual, 2021.
- [10] Meng Fang, Xiangpeng Wan, Fei Lu, Fei Xing, and Kai Zou. Mathodyssey: Benchmarking mathematical problem-solving skills in large language models using odyssey math data, 2024.
- [11] Daman Arora, Himanshu Gaurav Singh, and Mausam. Have llms advanced enough? a challenging problem solving benchmark for large language models, 2023.
- [12] OpenAI. Openai o3-mini: Pushing the frontier of cost-effective reasoning, 1 2025.
- [13] Google Deepmind. Gemini 2.5: Our most intelligent ai model, 3 2025.
- [14] Yingqian Min, Zhipeng Chen, Jinhao Jiang, Jie Chen, Jia Deng, Yiwen Hu, Yiru Tang, Jiapeng Wang, Xiaoxue Cheng, Huatong Song, Wayne Xin Zhao, Zheng Liu, Zhongyuan Wang, and Ji-Rong Wen. Imitate, explore, and self-improve: A reproduction report on slow-thinking reasoning systems, 2024.
- [15] Mathematical Association of America. Aime 2024, 2024.
- [16] Mathematical Association of America. Aime 2025, 2025.
- [17] HMMT. Hmmt 202502, 2025.
- [18] Mathematical Association of America. Usamo 2025, 2025.
- [19] Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 3828–3850, 2024.
- [20] Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, et al. Omni-math: A universal olympiad level mathematic benchmark for large language models. arXiv preprint arXiv:2410.07985, 2024.
- [21] RUCAIBox STILL Team. Still-3-1.5b-preview: Enhancing slow thinking abilities of small models through reinforcement learning. 2025.
- [22] Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y. Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, and Ion Stoica. Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl, 2025. Notion Blog.
- [23] Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, March 2025.
- [24] Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, Haosheng Zou, Yongchao Deng, Shousheng Jia, and Xiangzheng Zhang. Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond, 2025.
- [25] OpenThoughts Team. Open Thoughts. https://open-thoughts.ai, January 2025.
- [26] Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui Yan, Chaojie Wang, Peng Cheng, Xiaoyu Zhang, Fuxiang Zhang, Jiacheng Xu, Wei Shen, Siyuan Li, Liang Zeng, Tianwen Wei, Cheng Cheng, Yang Liu, and Yahui Zhou. Skywork open reasoner series, 2025. Notion Blog.
- [27] Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, Shuxun Yang, Weng Lam Tam, Wenyi Zhao, Xiao Liu, Xiao Xia, Xiaohan Zhang, Xiaotao Gu, Xin Lv, Xinghan Liu, Xinyi Liu, Xinyue Yang, Xixuan Song, Xunkai Zhang, Yifan An, Yifan Xu, Yilin Niu, Yuantao Yang, Yueyan Li, Yushi Bai, Yuxiao Dong, Zehan Qi, Zhaoyu Wang, Zhen Yang, Zhengxiao Du, Zhenyu Hou, and Zihan Wang. Chatglm: A family of large language models from glm-130b to glm-4 all tools, 2024.
- [28] Zihan Liu, Yang Chen, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Acemath: Advancing frontier math reasoning with post-training and reward modeling. arXiv preprint, 2024.
- [29] Ivan Moshkov, Darragh Hanley, Ivan Sorokin, Shubham Toshniwal, Christof Henkel, Benedikt Schifferer, Wei Du, and Igor Gitman. Aimo-2 winning solution: Building state-of-the-art mathematical reasoning models with openmathreasoning dataset, 2025.
- [30] Qwen Team. Qwen3, April 2025.
Appendix A Appendix
This part presents the detailed content of the dataset and the case study examples mentioned before.
| Problem: Given that two vertices of an equilateral triangle are on the parabola $y^{2}=4x$ , and the third vertex is on the directrix of the parabola, and the distance from the center of the triangle to the directrix equals $\frac{1}{9}$ of the perimeter. Find the area of the triangle. Subject: Geometry |
| --- |
Figure 6: A geometry problem described precisely in text from OlymMATH.
| Original problem: If the distances from the eight vertices of a cube to a certain plane are $0 0$ , $1$ , $2$ , $3$ , $4$ , $5$ , $6$ , $7$ respectively, what is the possible edge length of this cube? After transformation: If the distances from the eight vertices of a cube to a certain plane are $0 0$ , $1$ , $2$ , $3$ , $4$ , $5$ , $6$ , $7$ respectively, consider all possible edge lengths of this cube. Assuming the possible edge lengths form a set $S$ , find the sum of squares of all elements in $S$ . |
| --- |
Figure 7: An OlymMATH-HARD example testing model’s identification of all possible answers.
<details>
<summary>x4.png Details</summary>
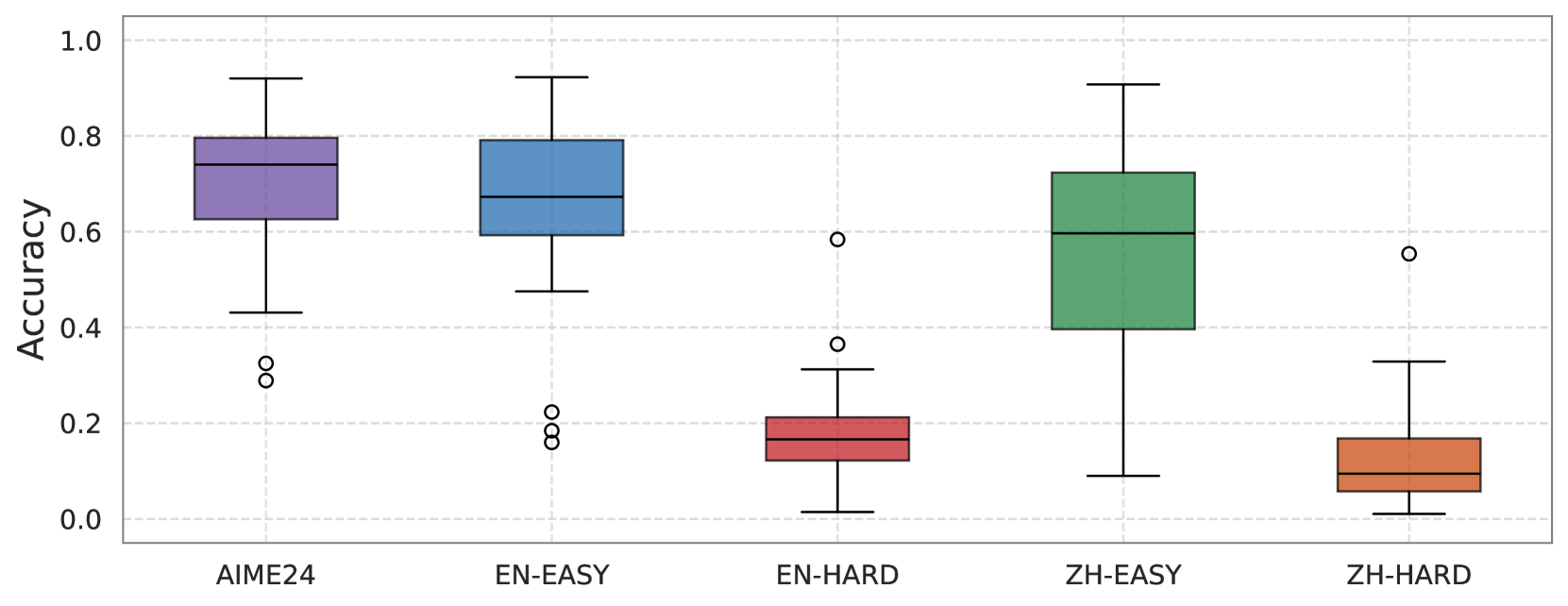
### Visual Description
## Box Plot: Accuracy Comparison Across Datasets
### Overview
The image is a box plot comparing the accuracy of a model across five different datasets: AIME24, EN-EASY, EN-HARD, ZH-EASY, and ZH-HARD. The y-axis represents accuracy, ranging from 0.0 to 1.0. The box plot visually represents the distribution of accuracy for each dataset, showing the median, quartiles, and outliers.
### Components/Axes
* **X-axis:** Datasets (AIME24, EN-EASY, EN-HARD, ZH-EASY, ZH-HARD)
* **Y-axis:** Accuracy, ranging from 0.0 to 1.0 with increments of 0.2.
* 0.0
* 0.2
* 0.4
* 0.6
* 0.8
* 1.0
* **Box Plot Components:** Each box plot shows the median (horizontal line within the box), the first and third quartiles (edges of the box), and the whiskers extending to the furthest data point within 1.5 times the interquartile range. Outliers are plotted as individual points.
* **Colors:**
* AIME24: Purple
* EN-EASY: Blue
* EN-HARD: Red
* ZH-EASY: Green
* ZH-HARD: Orange
### Detailed Analysis
* **AIME24 (Purple):**
* Median accuracy: ~0.75
* Box extends from ~0.65 to ~0.80
* Whiskers extend from ~0.43 to ~0.92
* Outliers present below the lower whisker, around ~0.30
* Trend: Relatively high and consistent accuracy with some low outliers.
* **EN-EASY (Blue):**
* Median accuracy: ~0.68
* Box extends from ~0.60 to ~0.77
* Whiskers extend from ~0.48 to ~0.92
* Outliers present below the lower whisker, around ~0.18 and ~0.22
* Trend: High accuracy with some low outliers.
* **EN-HARD (Red):**
* Median accuracy: ~0.18
* Box extends from ~0.15 to ~0.22
* Whiskers extend from ~0.02 to ~0.32
* Outlier present above the upper whisker, around ~0.58
* Trend: Low accuracy with one high outlier.
* **ZH-EASY (Green):**
* Median accuracy: ~0.62
* Box extends from ~0.40 to ~0.72
* Whiskers extend from ~0.08 to ~0.90
* Outliers present above the upper whisker, around ~0.90
* Trend: Wide range of accuracy, with a median around 0.62.
* **ZH-HARD (Orange):**
* Median accuracy: ~0.10
* Box extends from ~0.06 to ~0.17
* Whiskers extend from ~0.0 to ~0.33
* Outlier present above the upper whisker, around ~0.55
* Trend: Low accuracy with one high outlier.
### Key Observations
* AIME24 and EN-EASY datasets show the highest median accuracy.
* EN-HARD and ZH-HARD datasets show the lowest median accuracy.
* ZH-EASY has a wider interquartile range compared to other datasets, indicating more variability in accuracy.
* Outliers are present in all datasets, indicating instances where the model performed significantly better or worse than usual.
### Interpretation
The box plot provides a comparative view of the model's performance across different datasets. The "EASY" datasets (EN-EASY and ZH-EASY) generally show higher accuracy than the "HARD" datasets (EN-HARD and ZH-HARD), which is expected. AIME24 shows the highest overall accuracy. The presence of outliers suggests that the model's performance is not always consistent and can be influenced by specific instances within each dataset. The wider interquartile range for ZH-EASY indicates that the model's performance on this dataset is more variable compared to the others.
</details>
Figure 8: This boxplot shows that our EASY dataset has AIME-level difficulty with a wider distribution, while the HARD dataset is significantly more challenging, demonstrating the discriminative power of our benchmark.
| Problem: In the triangle $\triangle ABC$ , the lengths of the three sides are $a,b,c$ , satisfying the condition $2a^{2}+b^{2}+c^{2}=4$ . Find the maximum value of the area of $\triangle ABC$ . Answer: $\frac{\sqrt{5}}{5}$ . (When $a=\frac{2}{\sqrt{5}}$ , $b=c=\sqrt{\frac{6}{5}}$ ) |
| --- |
| Model Output: We wish to maximize the area of $\triangle ABC$ , subject to $2a^{2}+b^{2}+c^{2}=4.$ Because the condition is symmetric in $b$ and $c$ (but not in $a$ ), it is reasonable to look for an optimum among triangles having $b=c$ . (Later one can check that assuming $b=c$ indeed gives the maximum.) The problem involves maximizing the area of an isosceles triangle with sides $a,b,b$ under the constraint $2a^{2}+b^{2}+c^{2}=4$ . By assuming $b=c$ , we derive a formula for the area in terms of $b$ and find the maximum area by expressing it as a function of $u=b^{2}$ . We then determine the critical points of this quadratic function, identify the maximum area, and finally recover the side lengths to verify that they satisfy the original constraints. The maximum area achieved is $\frac{\sqrt{5}}{5}$ . |
Figure 9: An example during our data collection. o3-mini (high) found the correct answer without rigorously solving the problem. Due to length constraints, we provide only a summary of its original solution steps.
| Col1 |
| --- |
| Problem: Let the sequence of rationals $x_{1},x_{2},...$ be defined such that $x_{1}=\frac{25}{11}$ and $x_{k+1}=\frac{1}{3}\left(x_{k}+\frac{1}{x_{k}}-1\right).$ $x_{2025}$ can be expressed as $\frac{m}{n}$ for relatively prime positive integers $m$ and $n$ . Find the remainder when $m+n$ is divided by $1000$ . Answer: $248$ . |
| Model Output: We will show that if $x_{1}=\frac{25}{11}$ and $x_{k+1}=\frac{1}{3}\Bigl{(}x_{k}+\frac{1}{x_{k}}-1\Bigr{)},$ then after “many” iterations the answer to $x_{2025}=\frac{m}{n}$ (in lowest terms) satisfies $m+n\equiv 248±od{1000}.$ In what follows we briefly describe one way (via a “miraculous” change-of–variables) to “solve” the recurrence; the details need not be reproduced fully here. A good hint is that the recurrence $x_{k+1}=\frac{1}{3}\Bigl{(}x_{k}+\frac{1}{x_{k}}-1\Bigr{)}$ has the curious symmetry $T(x)=\frac{1}{3}\Bigl{(}x+\frac{1}{x}-1\Bigr{)}=T\Bigl{(}\frac{1}{x}\Bigr{)},$ so the expression $x+\frac{1}{x}$ (which is “symmetric” in $x$ and its reciprocal) naturally appears. In fact, one may rewrite the recurrence in the form $3x_{k+1}+1=x_{k}+\frac{1}{x_{k}}.$ A useful idea is then to “complete the square” by writing $\left(\sqrt{x_{k}}-\frac{1}{\sqrt{x_{k}}}\right)^{2}=x_{k}+\frac{1}{x_{k}}-2$ , so that $3x_{k+1}+1=\left(\sqrt{x_{k}}-\frac{1}{\sqrt{x_{k}}}\right)^{2}+2.$ Defining $u_{k}=\sqrt{x_{k}}-\frac{1}{\sqrt{x_{k}}}$ , one obtains the “linear-looking” relation $u_{k}^{2}=3x_{k+1}-1.$ With some additional work it turns out that if we write $x_{k}=\frac{m_{k}}{n_{k}}$ (in lowest terms), then one may prove by induction that $m_{k}+n_{k}=36· 12^{(2^{\,k-1}-1)}.$ (In our case one checks that $m_{1}+n_{1}=25+11=36$ , $m_{2}+n_{2}=432$ , $m_{3}+n_{3}=62208,$ and indeed $36,432,62208$ equal $36· 12^{0},\,36· 12^{1},\,36· 12^{3}$ respectively.) Thus, for $k=2025$ we have $m+n=36· 12^{\left(2^{2024}-1\right)}.$ Even though this number is astronomically large, we are only asked to compute $m+n±od{1000}.$ Using modular reductions, we compute $m+n$ modulo 1000. First, modulo 8, we find $36· 12^{(2^{2024}-1)}\equiv 0±od{8}$ . Modulo 125, Euler’s theorem helps reduce $12^{N}$ to $12^{15}\equiv 118±od{125}$ , giving $36· 12^{N}\equiv 123±od{125}$ . Using the Chinese Remainder Theorem, solving $125k+123\equiv 0±od{8}$ gives $k\equiv 1±od{8}$ , leading to the final answer: $\boxed{248}$ . |
Figure 10: An example from AIME 2025. o3-mini (high) forgot to prove that $(m_{k},n_{k})=1$ and it claimed that $m_{k}+n_{k}=36· 12^{\left(2^{k-1}-1\right)}$ without providing the complete proof (highlighted in red). Instead, the model “guessed” this expression by calculating the first several terms in the sequence one by one. Due to length constraints, we provide only a summary of its unimportant steps.
Figure 11: An example from Omni-MATH. The solution provided by Omni-MATH itself is flawed and problematic. Both the reference solution and o3-mini (high) failed to prove that there are no other possible function $f$ that satisfies the condition (highlighted in red). Due to length constraints, we have omitted its unimportant steps.
Figure 12: An example from OlymMATH-EN-HARD subset. o3-mini (high) attempted to “guess” the equality conditions but failed to produce a correct solution (highlighted in red).