# Factored Agents: Decoupling In-Context Learning and Memorization for Robust Tool Use
**Authors**:
- Nicholas Roth (Google)
- &Christopher Hidey (Google)
- &Lucas Spangher (Google, MIT)
- \ANDWilliam F. Arnold (Google, KAIST)
- &Chang Ye (Google)
- &Nick Masiewicki (Google)
- \ANDJinoo Baek (Google)
- &Peter Grabowski (Google, UC Berkeley)
- &Eugene Ie (Google)
> Corresponding author: nicholasroth@google.com
Abstract
In this paper, we propose a novel factored agent architecture designed to overcome the limitations of traditional single-agent systems in agentic AI. Our approach decomposes the agent into two specialized components: (1) a large language model (LLM) that serves as a high level planner and in-context learner, which may use dynamically available information in user prompts, (2) a smaller language model which acts as a memorizer of tool format and output. This decoupling addresses prevalent issues in monolithic designs, including malformed, missing, and hallucinated API fields, as well as suboptimal planning in dynamic environments. Empirical evaluations demonstrate that our factored architecture significantly improves planning accuracy and error resilience, while elucidating the inherent trade-off between in-context learning and static memorization. These findings suggest that a factored approach is a promising pathway for developing more robust and adaptable agentic AI systems.
1 Introduction
Recent advances in Artificial Intelligence (AI) have brought forth the promise of “Agentic AI” systems endowed with a degree of autonomy and goal-directed behavior that could fundamentally transform computing and human–computer interactions. Agentic AI can be broadly defined as a class of models that can competently and reliably interact with external APIs, which they may use to interact with tools and systems. For our purposes, we note that they may synthesize both learned knowledge and contextual cues to achieve their objectives. Such systems hold the potential to not only perform complex computations but also to adapt dynamically to new tasks and environments (Acharya et al., 2025).
In its most common instantiation, agentic AI is generally proposed as a single-agent design. This baseline approach involves a monolithic Large Language Model (LLM) responsible for all aspects of planning, memory, and action execution. Such a system may be effective in a static environment when the format of the APIs that interact with external systems are included in its training or fine-tuning set.
However, in a large, dynamic, and real-world system, a single agent is ill-suited. Specifically, the single-agent framework is susceptible to several types of errors: those at the small scale of producing correct structured API output, and those at the larger scale of deciding what to do. In the small scale, we note that many of the following errors may come from parsing errors:
1. Malformed Fields: the LLM may misspell or misunderstand the input type required from it
1. Missing Fields: the LLM may not understand the complete set of arguments necessary for a given API call
1. Hallucinated Fields: the LLM may imagine additional fields that don’t exist – a long noted trait of LLMs (Goddard, 2023).
Such agents may also exhibit general planning errors, in which they suggest an incorrect order or set of actions to partake in, thereby limiting their effectiveness.
As we will argue further on, a critical tension arises between skills related to in-context learning (ICL) and memorization: we will argue that the parsing errors may be addressed through an agent skilled in memorizing, whereas the planning errors may be addressed with an agent skilled in in-context learning, and improvement in one area necessarily leads to decline in the other.
To address these challenges, we propose a novel factored agent architecture that decouples the roles of memory and context adaptation. Our design partitions the agent into two specialized components:
1. A larger in-context learner that dynamically assimilates new information from the prompt and plans an appropriate tool-use prompt.
1. A small language model which acts as a memorizer for tool APIs that retains and retrieves long-term knowledge.
Our factored agent thereby mitigates the drawbacks of the traditional single-agent approach while retaining its core benefits.
The contributions of this paper are as follows:
- We introduce a factored agent architecture that distinctly separates memorization and in-context learning.
- We provide a detailed critique of current single-agent frameworks, highlighting issues such as malformed, missing, and hallucinated fields, as well as general planning errors.
- We analyze the trade-offs between in-context learning and static memorization, offering insights into their respective advantages and limitations.
- We demonstrate through empirical evaluation that our proposed architecture significantly improves planning accuracy and error resilience in real-world tasks.
In the subsequent sections, we elaborate on the design and implementation of our factored agent, present comprehensive experimental results, and discuss the broader implications of our work for the future of agentic AI.
2 Background Literature
Agentic AI is a rapidly evolving field that seeks to create intelligent agents capable of performing tasks requiring both in-context learning (ICL) and memorization. A central challenge in this endeavor is that within modern single agents, there appears to be a trade off between these skills. Recent work, such as Li et al. (2023a), observes that as an agent becomes more of a memorizer, its ICL capabilities diminish, and vice versa; Biderman et al. (2024) report this finding as well in Low Rank Adaptor models. Regrettably for tool use models, memorization tends to increase in larger models (Satvaty et al., 2024; Kiyomaru et al., 2024) and seems to occur in current tool use agents (Li et al., 2023b). This suggests that a single agent may not be optimal for all tasks.
To address this, researchers have explored various approaches. TinyAgents (Erdogan et al., 2024) fine-tune small language models for specific tasks, but this approach may not scale well to a large number of tasks. ToolFormer (Schick et al., 2023) is a transformer specifically trained to generate API calls, but it may hallucinate in novel situations. Qin et al. (2024) trained ToolLLaMA on over 16,000 APIs (composing the ToolBench dataset) and evaluated on a subset. Gorilla (Patil et al., 2023) is a more general agent that can interact with APIs by including API documentation in a Retrieval Augmented Generation (RAG) approach, and maintains a continually expanding database of API calls. However, both approaches may fail when performing supervised fine-tuning (SFT) on the same model that may also need planning and ICL abilities.
A promising direction is to combine the strengths of memorization and ICL. ReAct (Yao et al., 2023) is an example of an agent that reasons and acts in the world. ReAct focuses on general orchestration of two agents, with the “reasoning” agent being a base reasoner, and the “acting” agent being the tool agent, but they often rely on external tools and knowledge bases. Other, older approaches have factored agent architectures: Wen et al. (2016) and Wu et al. (2019) are notable examples.
By carefully balancing memorization and ICL, we can create more versatile and intelligent agents.
3 System Design
<details>
<summary>extracted/6329000/images/model_flow.png Details</summary>
### Visual Description
## Diagram: LLM Agent Architecture with SLM Tool Calling
### Overview
This image is a technical flowchart illustrating a system architecture for an AI agent. It details the process flow from receiving a user query to generating a final response, highlighting the orchestration between Large Language Models (LLMs), Small Language Models (SLMs), retrieval systems, and external programmatic tools. The diagram uses color-coded rectangular nodes with rounded corners and directional arrows to indicate the sequence of operations.
*Note: As this is a structural flowchart, there are no numerical data points, axes, or charts present.*
### Components and Spatial Layout
The diagram is spatially organized into two main vertical columns: a primary execution flow on the left, and a secondary tool-calling loop on the right. Text labels are positioned to the left or right of the nodes to indicate the actor, technology, or system responsible for that specific step.
**Left Column (Primary Flow - Top to Bottom):**
1. **Actor Label:** *User* (Positioned top-left)
* **Node:** `Query` (Color: Light Green)
2. **Actor Label:** *Retrieval (possibly a model)* (Positioned mid-left)
* **Node:** `Prompt Generation` (Color: Light Blue)
3. **Actor Label:** *LLM* (Positioned mid-left)
* **Node:** `Planner` (Color: Light Blue)
4. **Actor Label:** *LLM* (Positioned bottom-left)
* **Node:** `Response` (Color: Light Blue)
**Right Column (Tool Loop - Top to Bottom, branching from Planner):**
1. **Actor Label:** *SLM* (Positioned mid-right)
* **Node:** `Tool Agent` (Color: Light Blue)
2. **Actor Label:** *API* (Positioned mid-right)
* **Node:** `Formatted Tool Call` (Color: Light Pink/Red)
3. **Actor Label:** *Program* (Positioned bottom-right)
* **Node:** `Run Tool or Punt` (Color: Light Yellow)
### Content Details (Process Flow)
The directional arrows dictate the logical progression of the system:
1. **Initial Input:** The flow begins at the top left with the `Query` node.
2. **Contextualization:** A downward arrow connects `Query` to `Prompt Generation`. The label indicates this step involves "Retrieval," suggesting a Retrieval-Augmented Generation (RAG) process to build the prompt.
3. **Orchestration:** A downward arrow connects `Prompt Generation` to the `Planner`. The `Planner` acts as the central routing hub of the architecture.
4. **Branching Logic:** From the `Planner`, the flow can take two distinct paths:
* **Path A (Completion):** A downward arrow leads directly from `Planner` to `Response`. This indicates the LLM has enough information to answer the user.
* **Path B (Tool Execution):** A rightward arrow leads from `Planner` to `Tool Agent`.
5. **Tool Execution Sequence:**
* A downward arrow connects `Tool Agent` to `Formatted Tool Call`.
* A downward arrow connects `Formatted Tool Call` to `Run Tool or Punt`.
6. **Feedback Loop:** A curved arrow originates from the left side of the `Run Tool or Punt` node and points upwards and leftwards, terminating back at the `Planner` node.
### Key Observations
* **Separation of Model Sizes:** The architecture explicitly separates the roles of an LLM (Large Language Model) and an SLM (Small Language Model). The LLM handles high-level tasks (`Planner`, `Response`), while the SLM is dedicated to a narrow task (`Tool Agent`).
* **The Orchestration Loop:** The curved arrow creates a distinct "While" loop. The `Planner` can continuously route to the `Tool Agent`, execute a tool, receive the result, and plan the next step until it decides to break the loop and move to `Response`.
* **Color Coding:** While not explicitly defined in a legend, colors appear to group functions: Green for input, Blue for neural model processing (Prompt Gen, Planner, Response, Tool Agent), Pink for structured data formatting (API call), and Yellow for external execution.
### Interpretation
This diagram outlines a highly optimized, agentic AI workflow—likely a variation of the ReAct (Reasoning and Acting) framework.
By reading between the lines, the explicit use of an **SLM** for the `Tool Agent` is the most critical architectural decision shown here. In traditional agentic frameworks, a massive, computationally expensive LLM is used to decide which tool to use and how to format the JSON/API request. By offloading the specific task of formatting tool calls to a smaller, faster, and cheaper SLM, the system designers are optimizing for lower latency and reduced inference costs.
The `Planner` (the LLM) acts as the "brain." It receives the augmented prompt, decides *if* a tool is needed, and passes the intent to the SLM. The SLM translates that intent into a `Formatted Tool Call` for an API. The external `Program` runs it, and the result is fed back to the LLM `Planner`. The inclusion of the word "Punt" in the execution node suggests a built-in error handling or fallback mechanism—if a tool fails or the request is invalid, the system "punts" the error back to the Planner to re-evaluate, rather than crashing the entire application. Ultimately, once the Planner has gathered sufficient data through this loop, it synthesizes the final `Response`.
</details>
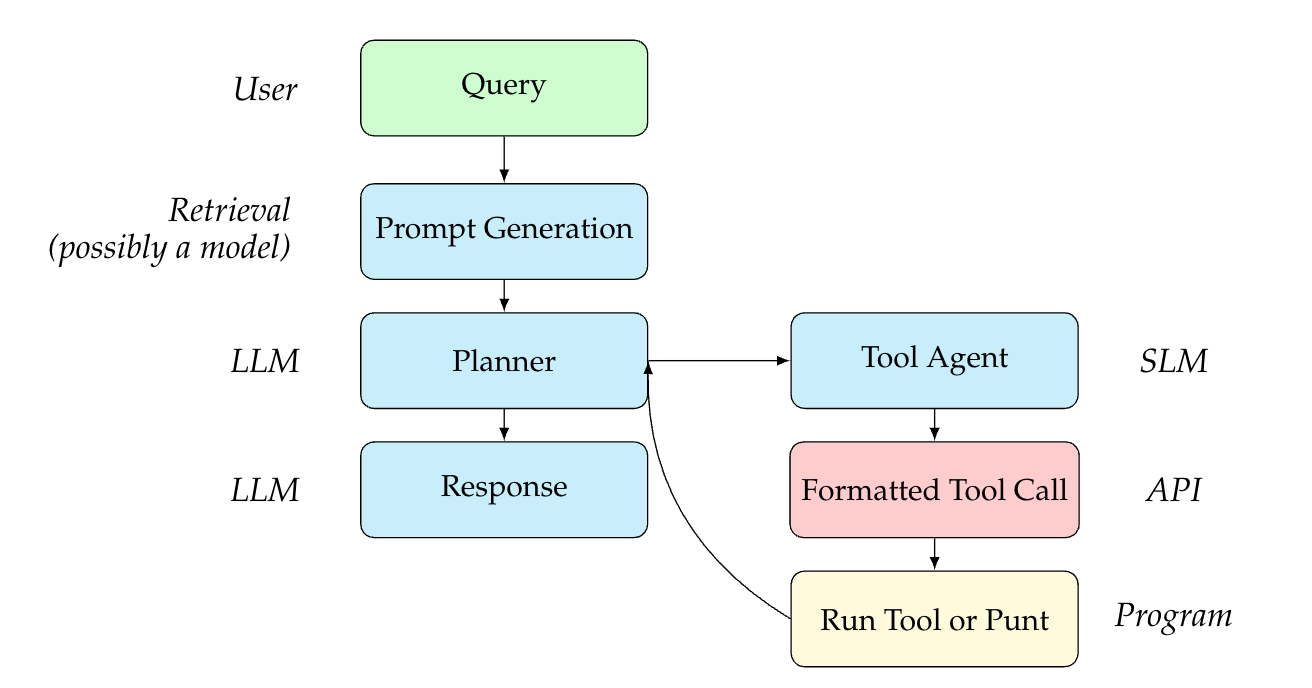
Figure 1: Representation of the factored agents model with a flow of information between users, with hand-offs between various models.
Please see Figure 1 for a diagram of the model setup and a flow of intermediate hand-offs between agents in our factored approach.
In an abstracted example, let’s assume that the user may desire to adopt a cat in San Francisco. They would initiate an interaction with the system, i.e. inputting a query like “Book the first available interview with Paws Cat Shelter in San Francisco.” Such an interaction would make an API call to the calendar of Paws Cat Shelter.
In our setup, the query is first handled by the prompt generator, which may be an LLM or may be as simple as an automatic prompt augmenter, concatenating information about the person or setting to the query (i.e. demographic information that Paws Cat Shelter may need to know). This is passed to a planning agent, an LLM, that chooses which API to engage with and includes the appropriate information given the type of API (date, time, etc.). This LLM then passes a query to the Tool Agent, a Small Language Model (SLM) whose job it is to format the tool call. The query is a natural language representation of the tool call, akin to a chain of thought or a summary, e.g. “Use the paws_shelter tool to book an interview on November 2, 2025.”, whereas the formatted tool call returned by the SLM will have the proper syntax (e.g. “ {"api": "paws_shelter", "operation_id": "book_interview", "date": "2025-11-02"} ”). After the tool call is used on the API, the API response is returned to the Planner, which then invokes its underlying program that generates a detailed prompt capturing the necessary details (e.g., name, date, type of appointment, adoption context, etc.).
Our planner is a much larger agent, which is necessary to devise an efficient and possibly creative plan. The tool agent, meanwhile, is small and fine-tuned to adjust to specific classes of APIs. We will show ablations around this in the discussion.
4 Experimental Setup
4.1 Model Configurations
For each benchmark, we train a tool-agent on a synthetic dataset created from the tools exposed in the training corpus. Thus, we have different tool-agents for each benchmark. We use an off-the-shelf LLM (GPT-4o) as a planner agent to coordinate the tool-use by dispatching natural language calls to the tool-agent. The output of the tool-agent is dispatched to the test tool/API.
We use Gemini Pro 1.5 (Georgiev et al., 2024) to create a synthetic dataset given only the tool schemas in the training data (effectively a zero-shot approach). As a pre-processing step, we convert the schemas to OpenAPI format. First, because previous work indicated that diverse personas also result in better synthetic data (Ge et al., 2024), we uniformly sample a persona from a predefined list of names and locations. https://github.com/dominictarr/random-name Given the tool schema, persona, and a Python environment with the $numpy$ library, we instruct the model to write Python code to create a world state, which may include random dates, for example. Then, we instruct the model to generate conversations conditioned on the world state and a uniformly-sampled number of user/assistant turns. At the next stage, we generate a “natural language tool call” given the output of the previous stages. Finally, we generate a structured tool call (as JSON) and only accept candidates where the model judges that the JSON tool call is faithful to the context (conversation and natural language tool call). At each stage, we accept the first response from the LLM that satisfies all criteria. If we reject all candidates at a given stage, we exit early and return no synthetic example.
4.2 Benchmarks
4.2.1 Tool-Use Benchmarks
We tested our models on TauBench (Yao et al., 2024). TauBench is a benchmark designed to evaluate the performance and reliability of tool-use agents. TauBench tests agents on multi-turn dialogues where an AI agent must dynamically interact with a simulated human user and various domain-specific tools, specifically focusing on those used in retail and airline scenarios. It simulates realistic databases, APIs, and policy guidelines. Additionally, TauBench defines and uses a multi-trial metric, “Pass^ k ”, which tests an agent multiple times on the same task. All models, including our own, struggle to output the same function calls on multiple passes, and so pass ^ k metrics for baselines reported by TauBench steadily decrease as k increases.
4.2.2 In-context learning benchmarks
We use two datasets to test in-context learning for a discussion on mechanistic interpretability: BigBenchHard (BBH) and Grade School Math 8k (questions) (GSM8k). BigBenchHard (BBH) is a curated subset of the larger BIG-bench benchmark, which was originally developed by Google along with contributions from the research community. BBH specifically comprises a set of challenging tasks, including boolean expressions, logical deduction with varying numbers of objects, temporal sequences, and more abstract challenges like hyperbaton and disambiguation QA. Prior work has leaned on BBH as harder problems requiring multi-step in context learning (Agarwal et al., 2024) as many questions are designed specifically to be unsearchable (Cobbe et al., 2021).
GSM8k is a collection of grade school math problems, including addition, subtraction, multiplication, and division, as well as more complex tasks like multi-step reasoning, unit conversion, and basic probability. Many of the problems are framed as word problems that require careful reading, extraction of relevant information, and sequential problem solving. We claim, as others have (Wei et al., 2022), that GSM8K requires inductive skills due to math problems being extrapolations from other forms given prior insight. This is closer to the type of in-context learning from papers we hypothesis on. These are questions that clearly aren’t searchable and unlikely memorizable because they are like solutions to math questions. There are too many variations to enumerate and store.
We chose these benchmarks motivated by mechanistic interpretability research from Anthropic (Li et al., 2023a) and Google Deepmind (Chan et al., 2022). Both groups demonstrate the presence of induction circuits (i.e. conditional copying of data between semantic locations for ICL) in small neural networks and their function in simple in-context learning tasks. The latter work also explores how in-context learning ability diminishes overall as a model memorizes out-of-distribution (OOD) information, despite this causing the model to perform better within the previously-OOD data specifically.
4.3 Training Setup
For tool-agent model training, we use Hugging Face TRL (von Werra et al., 2020) and transformers (Wolf et al., 2020) libraries for supervised fine-tuning, leveraging DeepSpeed (Rajbhandari et al., 2020) through accelerate (Gugger et al., 2022).
The synthetic assistant-style conversational data are used to condition the tool-agent before generating the structured tool-call request.
For TauBench, we use 11,241 synthetic examples to train on 30 tools – 14 airline tools and 16 retail tools.
4.4 Baseline
We choose to compare our method to a base model with a specific prompt suffix that encourages the model to output JSON. The suffix is listed in Appendix A.2.
Comparing our model to the state of the art GPT-4o Function Calling (FC) agent would not be an altogether fair baseline: GPT-4o FC has many other optimizations that are orthogonal to and may be implemented alongside our factored agents approach. Thus, although we considered using GPT-4o FC as a baseline, we ultimately decided to use a more apples-to-apples comparison instead.
4.5 Computational Setup
Tool-agent training was conducted using 2x to 8x A100 NVIDIA GPUs per experiment.
4.6 Ablations and details
To compare the tool-agent’s ability to generate well-formed requests with correct tool and parameters, we utilize GPT-4o as a planner to convert the high level request into individual natural language tool-requests. We ablate on the LLM architecture used, cycling between Gemma 3 (Kamath et al., 2025) (1.5B, 4B, 12B) and DeepSeek R1 distilled Qwen (DeepSeek-AI, 2025) (1.5B and 7B) to compare impact of base model and size. These models were carefully chosen to have been less likely to include TauBench training data in their pretraining corpus.
4.7 In Context Learning
In order to understand the impact of training structured tool-call generation on natural language models, we run BIG-Bench Hard (BBH) (Srivastava et al., 2023) on the tool-agents to measure the impact of structured tool-use on general in-context-learning ability. BBH has frequently been used in the literature for testing ICL (Agarwal et al., 2024).
5 Results
Table 1 presents the pass-hat-k accuracy (P^1 through P^4) for the Retail and Airline test series. In the Retail domain, the baseline model (GPT-4o + FAEP) achieves lower performance than each of the Gemma3 configurations, with the 4 billion-parameter variant obtaining the highest values overall (0.45 at P^1 and 0.23 at P^4). The DeepSeek Qwen Distill models also outperform the baseline on Retail, though their scores (e.g., 0.44 at P^1 for the 7B version) remain slightly below Gemma 4b at the higher passes. This pattern suggests that funneling additional parameters or using more advanced tool-use approaches can yield consistent gains for Retail tasks.
Conversely, on the Airline tests, only the Gemma3 12b and the DeepSeek1.5B models exceed baseline performance at P^1, with Gemma3 12b producing the top scores across all passes (e.g., 0.31 at P^1, 0.16 at P^4). Interestingly, Gemma3 1b and 4b drop below the baseline’s accuracy, indicating that merely adding parameters may not guarantee improvements in this domain. Overall, the results highlight variation in how different tool-use or parameter expansions translate into accuracy gains, depending on the task domain and pass depth.
Table 1: Side-by-side results for Retail and Airline test series. Please note that the baseline, FAEP, is the Factored Agents Equivalent Prompt. All $P\textasciicircum k$ are abbreviations of Pass $\textasciicircum k$ . All rows are defined by a GPT4o base model with an additional tool-use model $i$ (defined in "+ $i$ ").
| + FAEP (baseline) + Gemma3 1b + Gemma3 4b | 0.37 0.41 0.45 | 0.23 0.26 0.33 | 0.17 0.19 0.27 | 0.14 0.16 0.23 | 0.29 0.22 0.25 | 0.19 0.15 0.17 | 0.15 0.11 0.14 | 0.12 0.08 0.12 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| + Gemma3 12b | 0.42 | 0.30 | 0.24 | 0.21 | 0.31 | 0.23 | 0.19 | 0.16 |
| + DeepSeek Qwen Distill 1.5B | 0.39 | 0.28 | 0.23 | 0.21 | 0.31 | 0.20 | 0.16 | 0.12 |
| + DeepSeek Qwen Distill 7B | 0.44 | 0.31 | 0.24 | 0.20 | 0.26 | 0.18 | 0.13 | 0.10 |
6 Discussion
<details>
<summary>extracted/6329000/images/subplots.png Details</summary>
### Visual Description
## Line Charts: Performance Comparison of Qwen Models (Base vs. Tool SFT)
### Overview
The image consists of a 2x2 grid of line charts comparing the performance of two language model variants ("Base Model" and "Tool SFT") across two different model sizes (Qwen-1.5B and Qwen-7B) and two different evaluation benchmarks (BBH and GSM8K). The performance is measured across varying numbers of "Few-Shot" examples.
### Components/Axes
The image is divided into four distinct subplots.
**Shared Elements:**
* **X-Axis (Horizontal):** Labeled "Few-Shot". The bottom row explicitly shows tick marks for `1`, `2`, and `3`. The top row shares this axis alignment, though the numbers are omitted to save space.
* **Y-Axis (Vertical):** Labeled "Metric". The left column explicitly shows tick marks ranging from `0.2` to `0.7` in increments of `0.1`. The right column shares this vertical scale, though the labels are omitted.
* **Legend:** Each subplot contains a legend.
* **Blue line with circular markers:** `Base Model`
* **Orange line with circular markers:** `Tool SFT`
* *Spatial Grounding:* In the BBH charts (left column), the legend is positioned in the top-right corner. In the GSM8K charts (right column), the legend is positioned in the top-left corner to avoid overlapping the data lines.
---
### Detailed Analysis by Component
#### 1. Top-Left Quadrant: Qwen-1.5B - BBH
* **Header/Title:** `Qwen-1.5B - BBH`
* **Trend Verification:** Both the Base Model (blue) and Tool SFT (orange) lines slope gently upward from 1-shot to 2-shot, and continue a very slight upward slope to 3-shot. The lines are nearly identical, with the Base Model starting slightly higher at 1-shot before they converge.
* **Data Points (Approximate):**
* **Base Model (Blue):** 1-shot: ~0.31 | 2-shot: ~0.38 | 3-shot: ~0.40
* **Tool SFT (Orange):** 1-shot: ~0.30 | 2-shot: ~0.38 | 3-shot: ~0.40
#### 2. Top-Right Quadrant: Qwen-1.5B - GSM8K
* **Header/Title:** `Qwen-1.5B - GSM8K`
* **Trend Verification:** Both lines exhibit a steep upward slope from 1-shot to 2-shot, followed by a shallower upward slope to 3-shot. The Tool SFT (orange) line remains consistently above the Base Model (blue) line across all points, though the gap narrows slightly at 3-shot.
* **Data Points (Approximate):**
* **Base Model (Blue):** 1-shot: ~0.37 | 2-shot: ~0.64 | 3-shot: ~0.68
* **Tool SFT (Orange):** 1-shot: ~0.42 | 2-shot: ~0.66 | 3-shot: ~0.69
#### 3. Bottom-Left Quadrant: Qwen-7B - BBH
* **Header/Title:** `Qwen-7B - BBH`
* **Trend Verification:** Both lines slope steadily upward from 1-shot to 3-shot. The Base Model (blue) line remains consistently, though slightly, above the Tool SFT (orange) line across all data points.
* **Data Points (Approximate):**
* **Base Model (Blue):** 1-shot: ~0.43 | 2-shot: ~0.51 | 3-shot: ~0.55
* **Tool SFT (Orange):** 1-shot: ~0.42 | 2-shot: ~0.48 | 3-shot: ~0.54
#### 4. Bottom-Right Quadrant: Qwen-7B - GSM8K
* **Header/Title:** `Qwen-7B - GSM8K`
* **Trend Verification:** This chart shows the most significant divergence. The Base Model (blue) slopes steeply upward from 1 to 2, then slightly *downward* from 2 to 3. The Tool SFT (orange) line slopes upward from 1 to 2, and continues upward to 3. Crucially, the Base Model is drastically higher than the Tool SFT model at every point.
* **Data Points (Approximate):**
* **Base Model (Blue):** 1-shot: ~0.57 | 2-shot: ~0.73 | 3-shot: ~0.72
* **Tool SFT (Orange):** 1-shot: ~0.22 | 2-shot: ~0.43 | 3-shot: ~0.47
---
### Key Observations
1. **Few-Shot Efficacy:** Across almost all models and benchmarks, increasing the number of few-shot examples from 1 to 2 yields a significant performance increase. The gain from 2 to 3 is generally marginal (and slightly negative for Qwen-7B Base on GSM8K).
2. **The GSM8K Anomaly (7B Model):** The most striking visual outlier is in the bottom-right chart. Applying "Tool SFT" to the Qwen-7B model causes a massive degradation in performance on the GSM8K benchmark compared to its Base Model counterpart (a drop of roughly 0.30 to 0.35 points across all few-shot settings).
3. **Varying Impact of Tool SFT:**
* On the 1.5B model, Tool SFT slightly *improves* GSM8K performance and has negligible impact on BBH.
* On the 7B model, Tool SFT slightly *degrades* BBH performance and severely *degrades* GSM8K performance.
### Interpretation
The data presented in these charts illustrates a classic problem in Large Language Model (LLM) fine-tuning: **alignment tax or catastrophic forgetting**.
"Tool SFT" likely refers to Supervised Fine-Tuning designed to teach the model how to use external tools (like calculators or APIs).
* For the smaller **1.5B model**, this fine-tuning appears beneficial or neutral. It actually helps the model on GSM8K (a math word problem benchmark), perhaps because the tool training helped structure its reasoning.
* However, for the larger **7B model**, the Tool SFT process severely damaged its inherent ability to solve GSM8K problems. This suggests that the fine-tuning data distribution for tool use conflicted with the model's pre-existing mathematical reasoning capabilities, causing it to "forget" or overwrite those skills.
* The BBH (BigBench Hard) benchmark, which tests a broader variety of reasoning tasks, was relatively unaffected by the Tool SFT process across both model sizes, indicating that the degradation is highly specific to the skills required for GSM8K.
Ultimately, this document serves as a cautionary visualization for AI researchers: fine-tuning a model for a specific new capability (tool use) can result in severe, unexpected regressions in core capabilities (math reasoning), particularly as model scale increases.
</details>
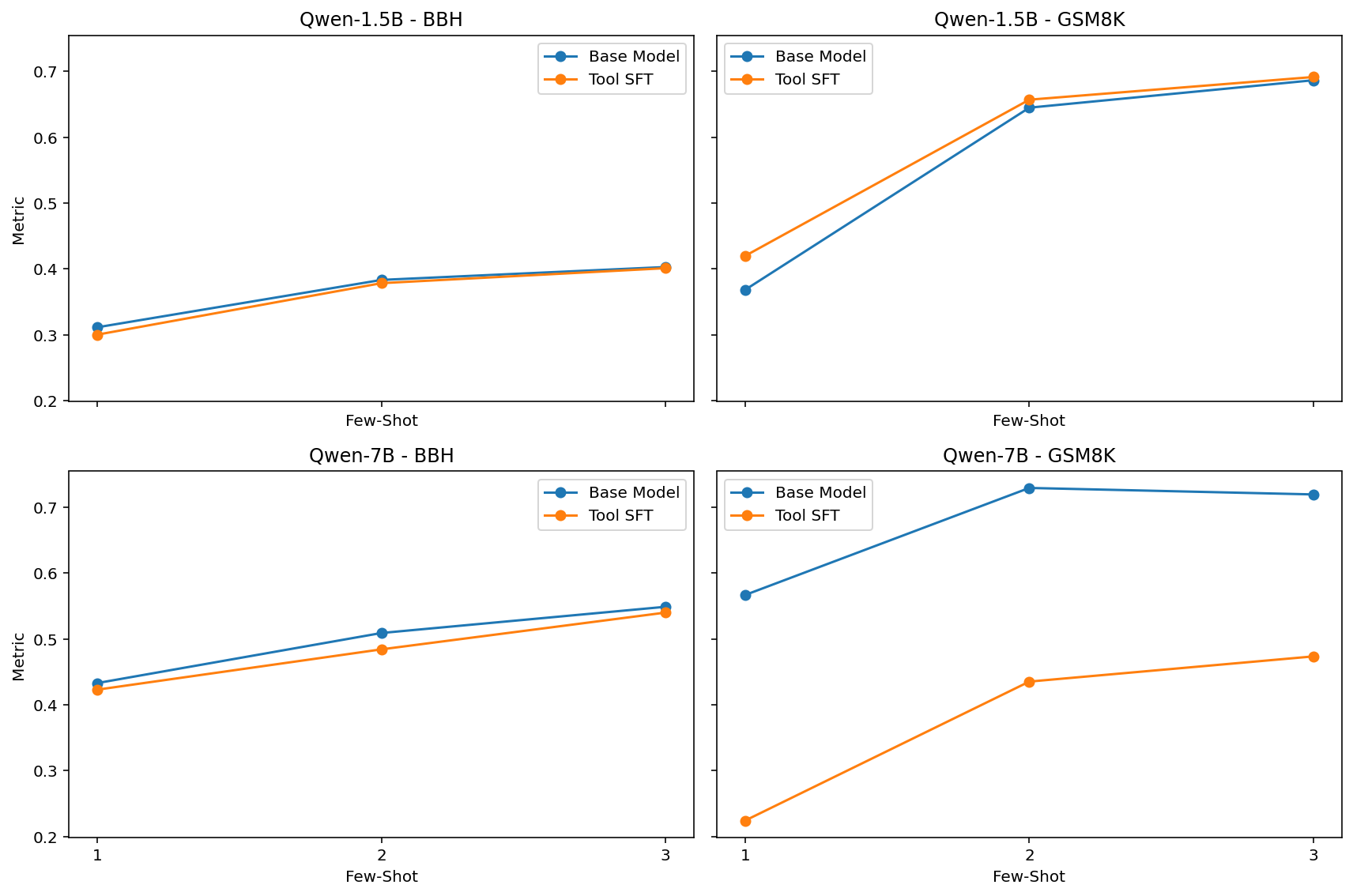
Figure 2: In this plot, we compare the DeepSeek-R1-Distill-Qwen base model to the tool-use model across two benchmarks, BigBenchHard and GSM8k. The x-axis increases the number of shots present in few-shot test time, and the y axis measures proportion of scored answers that are an exact match.
The two main hypotheses we seek to evaluate are:
1. That in-context learning trades off with memorization of tool semantics, and
1. That using separate models for in-context learning tasks from memorizing tools can improve performance on tool-use tasks
We wanted to explore this work with simple experiments geared towards a practical tool-use context. It is common practice to memorize tools (i.e. ToolLlama, Toolformer, Gorilla) in-weights, which seems at odds with the basic findings of this body of prior work. If we see a degradation in in-context learning and an improvement in performance from memorizing specific tools with a separate model, it will support the existence of this tradeoff in a highly-relevant, practical setting while also demonstrating that the tradeoff can be avoided, at least in part, by separating these fundamental responsibilities into separate models. Future work may further extend these experiments, examining how the performance improvements from Factored Agents stack with techniques like tool RAG, chain-of-thought prompting, ReAct, Act, constrained decoding, reinforcement learning (i.e. RL on natural_language_tool_call and tool environments more generally), and other commonly-applied planning and tool-use methods.
Our performance on TauBench of a baseline Factored Agents implementation with a naive prompt-only implementation shows what the prior work leads us to expect – that is, not only from a larger model do abilities like in-context learning emerge, but 7B is a reasonable inflection point of such properties, especially given more modern training techniques (see Figure 4 in Wei et al. (2022).) We see a performance benefit by sampling from a model that has been fine-tuned to memorize the tools we use rather than sampling from GPT-4o, which attempts to model a much wider distribution of knowledge. In both cases, the output is conditioned on a very similar, simple prompt.
Our investigation into the degradation of in-context learning abilities under out-of-distribution (OOD) fine-tuning yielded unexpected findings. Consistent with the observations reported in the Google DeepMind study, our results indicate that in-context learning performance deteriorates following OOD fine-tuning, as evidenced by a significant decline on the GSM8K benchmark. In contrast, the performance on BigBenchHard does not exhibit a similarly pronounced degradation, suggesting a differential sensitivity to OOD fine-tuning across these benchmarks.
We claim, as others have, that GSM8K requires inductive skills due to math problems being extrapolations from other forms given prior insight. This is closer to the type of in-context learning from the papers that prompted our work. These are questions that clearly are not searchable and are unlikely memorizable because, as solutions to math questions, they populate a space too large to enumerate and store.
In contrast to GSM8K, BigBenchHard contains tasks like: (1) logical deduction between three objects, (2) five objects, and (3) seven objects, (4) sports understanding, (5) ruin names, (6) object counting, (7) disambiguation qa, and (8) snarks that rely heavily on process that are more difficult to frame as the simple logical induction tasks that these papers study. It is possible that many different learning mechanisms beyond in-context learning are required for these tasks, complicating their interpretation.
The plots for the small 1.5B-parameter model all show no change between the finetuned model and the base model on our selected in-context learning benchmarks. This is also expected given the prior work (Wei et al., 2022) shows how in-context learning performance increases dramatically as models increase in size. Such a small model is likely to resort to memorization-oriented mechanisms disproportionately, and thus we can expect such models to be less-effected in this way by memorization-oriented training, though we might expect to see a small performance decrease due to catastrophic forgetting, which makes these results still slightly surprising.
7 Conclusion
Our study demonstrates that decoupling the roles of memorization and context adaptation within an agentic AI framework leads to marked improvements in standard tool-use benchmarks, implying an improvement of planning and reduction of errors. The proposed factored agent architecture outperforms traditional single-agent designs by specifically addressing issues such as incorrect API output and flawed planning sequences. Through ablations on model size and standard ICL benchmarks, we have shown that separating the memory and in-context learning functionalities not only enhances overall system robustness but also provides a flexible platform for integrating advanced tool-use strategies. These results underscore the potential of factored agents to serve as a foundational paradigm for next-generation agentic AI, while also highlighting avenues for future research on scalability and the integration of additional specialized modules.
8 Limitations and Future Work
Our work has a number of limitations. We include a limited number of benchmarks relative to the breadth of those included in other work (Wei et al., 2022; Agarwal et al., 2024). Our setup only entails a unidirectional pathway between planner and tool user – if the planner could call the tool agent multiple times or engage in a dialogue, the output may lead to more general tool calling.
In the future, we hope to expand our analysis to improve the error resilience of our models. First, testing with additional methods on the planner model, like Low-Rank Adaptation (LoRA) and reinforcement learning, that could elicit stronger planning performance with natural-language tool-calls. We hope to experiment with Classifier Free Guidance (CFG) as a method to direct the planner model to focus on relevant parts of the prompt, perhaps improving the relevance of the information observed. As prior work has shown that this can reduce the prevalence of hallucinations (Sanchez et al., 2023), we believe that this may force the LLM to focus on the natural language tool call. We would also like to benchmark factored agents as part of a more sophisticated tool-use system, incorporating advanced prompting techniques and inference-time optimizations like constrained decoding.
Finally, we would like to focus model’s effort on the rest of the conversation, tending to errors by using their specialized understanding of the tool’s semantics. Techniques like dropout and noising natural-language tool-calls when training tool agents could lead them to catch additional errors and hallucinations made by the planner.
9 Ethical Considerations
Here, we consider possible ethical ramifictions of our work. Memorization of tool-related data may, if trained improperly, may result in recitation of unwanted details. We do not provide this training ourselves, and we would advise that those specifically worried about this outcome may consider using the smallest tool-use models possible at the expense of degradation of services.
Better tool-use models may be used to automate the use of unethical tools or may be used in unethical tool-use system. Our work does not directly provide this access.
References
- Acharya et al. (2025) Deepak Bhaskar Acharya, Karthigeyan Kuppan, and B Divya. Agentic ai: Autonomous intelligence for complex goals–a comprehensive survey. IEEE Access, 2025.
- Agarwal et al. (2024) Rishabh Agarwal, Avi Singh, Lei Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, et al. Many-shot in-context learning. Advances in Neural Information Processing Systems, 37:76930–76966, 2024.
- Biderman et al. (2024) Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, and John P. Cunningham. Lora learns less and forgets less, 2024. URL https://arxiv.org/abs/2405.09673.
- Chan et al. (2022) Stephanie Chan, Adam Santoro, Andrew Lampinen, Jane Wang, Aaditya Singh, Pierre Richemond, James McClelland, and Felix Hill. Data distributional properties drive emergent in-context learning in transformers. Advances in neural information processing systems, 35:18878–18891, 2022.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/abs/2110.14168.
- DeepSeek-AI (2025) DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948.
- Erdogan et al. (2024) Lutfi Eren Erdogan, Nicholas Lee, Siddharth Jha, Sehoon Kim, Ryan Tabrizi, Suhong Moon, Coleman Hooper, Gopala Anumanchipalli, Kurt Keutzer, and Amir Gholami. Tinyagent: Function calling at the edge, 2024. URL https://arxiv.org/abs/2409.00608.
- Ge et al. (2024) Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. Scaling synthetic data creation with 1,000,000,000 personas, 2024. URL https://arxiv.org/abs/2406.20094.
- Georgiev et al. (2024) Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, Soroosh Mariooryad, Yifan Ding, Xinyang Geng, Fred Alcober, Roy Frostig, Mark Omernick, Lexi Walker, Cosmin Paduraru, Christina Sorokin, Andrea Tacchetti, …, and Oriol Vinyals. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024. URL https://arxiv.org/abs/2403.05530.
- Goddard (2023) Jerome Goddard. Hallucinations in chatgpt: A cautionary study. Journal of Biomedical Informatics, 45:123–130, 2023.
- Gugger et al. (2022) Sylvain Gugger, Lysandre Debut, Thomas Wolf, Philipp Schmid, Zachary Mueller, Sourab Mangrulkar, Marc Sun, and Benjamin Bossan. Accelerate: Training and inference at scale made simple, efficient and adaptable., 2022. URL https://github.com/huggingface/accelerate.
- Kamath et al. (2025) Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, …, and Léonard Hussenot. Gemma 3. 2025. URL https://goo.gle/Gemma3Report.
- Kiyomaru et al. (2024) Hirokazu Kiyomaru, Issa Sugiura, Daisuke Kawahara, and Sadao Kurohashi. A comprehensive analysis of memorization in large language models. In Saad Mahamood, Nguyen Le Minh, and Daphne Ippolito (eds.), Proceedings of the 17th International Natural Language Generation Conference, pp. 584–596, Tokyo, Japan, September 2024. Association for Computational Linguistics. URL https://aclanthology.org/2024.inlg-main.45/.
- Li et al. (2023a) Yiding Li, Haotian Li, Jianwei Li, and Tong Zhang. Icl heads and data distributional heads drive in context learning. arXiv preprint arXiv:2305.16880, 2023a.
- Li et al. (2023b) Yuchen Li, Haotian Li, Jianwei Li, and Tong Zhang. Toolformer: Interactive learning of tool use from human feedback. In NeurIPS, 2023b.
- Patil et al. (2023) Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive apis, 2023. URL https://arxiv.org/abs/2305.15334.
- Qin et al. (2024) Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, dahai li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=dHng2O0Jjr.
- Rajbhandari et al. (2020) Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models, 2020. URL https://arxiv.org/abs/1910.02054.
- Sanchez et al. (2023) Guillaume Sanchez, Honglu Fan, Alexander Spangher, Elad Levi, Pawan Sasanka Ammanamanchi, and Stella Biderman. Stay on topic with classifier-free guidance, 2023. URL https://arxiv.org/abs/2306.17806.
- Satvaty et al. (2024) Ali Satvaty, Suzan Verberne, and Fatih Turkmen. Undesirable memorization in large language models: A survey, 2024. URL https://arxiv.org/abs/2410.02650.
- Schick et al. (2023) Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36:68539–68551, 2023.
- Srivastava et al. (2023) Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, Agnieszka Kluska, Aitor Lewkowycz, Akshat Agarwal, Alethea Power, Alex Ray, Alex Warstadt, Alexander W. Kocurek, Ali Safaya, Ali Tazarv, …, and Ziyi Wu. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=uyTL5Bvosj.
- von Werra et al. (2020) Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. Trl: Transformer reinforcement learning, 2020. URL https://github.com/huggingface/trl.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022.
- Wen et al. (2016) Tsung-Hsien Wen, David Vandyke, Nikola Mrksic, Milica Gasic, Lina M Rojas-Barahona, Pei-Hao Su, Stefan Ultes, and Steve Young. A network-based end-to-end trainable task-oriented dialogue system. arXiv preprint arXiv:1604.04562, 2016.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38–45, Online, October 2020. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/2020.emnlp-demos.6.
- Wu et al. (2019) Chien-Sheng Wu, Richard Socher, and Caiming Xiong. Global-to-local memory pointer networks for task-oriented dialogue, 2019. URL https://arxiv.org/abs/1901.04713.
- Yao et al. (2023) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URL https://arxiv.org/abs/2210.03629.
- Yao et al. (2024) Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. $\tau$ -bench: A benchmark for tool-agent-user interaction in real-world domains. arXiv preprint arXiv:2406.12045, 2024.
Appendix A Appendix
A.1 Factored Agents Prompt (TauBench)
Remember, to invoke a tool, output a single English paragraph, a natural language request starting with "natural_language_tool_call". Only use one tool at a time.
The paragraph should include all of the tool name, parameters, and their values and nothing else. Specify the exact tool name, but the rest of the paragraph must be in English. Do not write code. Do not use JSON. Specify the exact function tool name. Return the single natural_language_tool_call paragraph and nothing else. For example, to call the example_1 function, the request might be phrased as: "natural_language_tool_call I will use the example_1 function with the text argument "Hello World" to say hello." It’s very important to invoke a tool with "natural_language_tool_call" in English if you say that you are going to do something, look something up, or take any action!
A.2 Factored Agents Equivalent Prompt (TauBench)
Remember, to invoke a tool, output JSON starting with "json_tool_call". Only use one tool at a time.
The program should include a function call with all of the tool name, parameters, and their values and nothing else. Write "json_tool_call", but the rest of the output must be in JSON. Do not write English. Do not use Python. Do NOT use parameters – these are arguments. Do NOT use functions.example_1 – use only example_1 – never use functions.*! Return the single json_tool_call and nothing else. For example, to call the example_1 function, the request might be phrased as: "json_tool_call {"name": "example_1", "arguments": {"salutation": "Hello World"}}".
It’s very important to invoke a tool with "json_tool_call" if you say that you are going to do something, look something up, or take any action!