## GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning
Jian Zhao 1,3 * , Runze Liu 1,2 *† , Kaiyan Zhang 1 , Zhimu Zhou 3 , Junqi Gao 4 , Dong Li 4 , Jiafei Lyu 1 , Zhouyi Qian 4 , Biqing Qi 2 ‡ , Xiu Li 1 ‡ and Bowen Zhou 1,2 ‡
1 Tsinghua University, 2 Shanghai AI Laboratory, 3 BUPT, 4 Harbin Institute of Technology
Recent advancements in Large Language Models (LLMs) have shown that it is promising to utilize Process Reward Models (PRMs) as verifiers to enhance the performance of LLMs. However, current PRMs face three key challenges: (1) limited process supervision and generalization capabilities, (2) dependence on scalar value prediction without leveraging the generative abilities of LLMs, and (3) inability to scale the test-time compute of PRMs. In this work, we introduce GenPRM, a generative process reward model that performs explicit Chain-of-Thought (CoT) reasoning with code verification before providing judgment for each reasoning step. To obtain high-quality process supervision labels and rationale data, we propose Relative Progress Estimation (RPE) and a rationale synthesis framework that incorporates code verification. Experimental results on ProcessBench and several mathematical reasoning tasks show that GenPRM significantly outperforms prior PRMs with only 23K training data from MATH dataset. Through test-time scaling, a 1.5B GenPRM outperforms GPT-4o , and a 7B GenPRM surpasses Qwen2.5-Math-PRM-72B on ProcessBench. Additionally, GenPRM demonstrates strong abilities to serve as a critic model for policy model refinement. This work establishes a new paradigm for process supervision that bridges the gap between PRMs and critic models in LLMs. Our code, model, and data are available in https://ryanliu112.github.io/GenPRM .
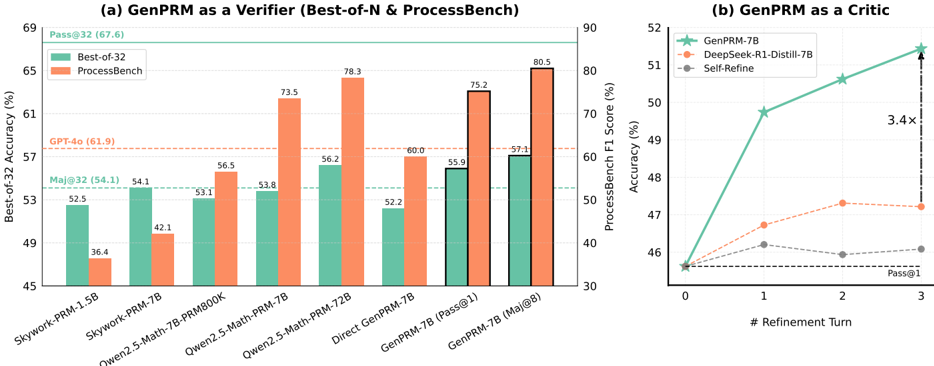
Figure 1: GenPRM achieves state-of-the-art performance across multiple benchmarks in two key roles: (a) As a verifier : GenPRM-7B outperforms all classification-based PRMs of comparable size and even surpasses Qwen2.5-Math-PRM-72B via test-time scaling. (b) As a critic : GenPRM-7B demonstrates superior critique capabilities, achieving 3.4× greater performance gains than DeepSeekR1-Distill-Qwen-7B after 3 refinement iterations.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Bar Chart: GenPRM as a Verifier (Best-of-N & ProcessBench)
### Overview
The chart compares the Best-of-32 accuracy (%) of various language models (LMs) across two evaluation frameworks: Best-of-32 and ProcessBench. Models include Skywork-PRM variants, Owen2.5-Math-PRM, Direct GenPRM, and GenPRM-7B. A horizontal dashed line at 61.9% represents GPT-4o's performance.
### Components/Axes
- **X-axis**: Models (Skywork-PRM-1.5B, Skywork-PRM-7B, Owen2.5-Math-7B-PRM800K, Owen2.5-Math-PRM-7B, Owen2.5-Math-PRM-72B, Direct GenPRM-7B, GenPRM-7B (Pass@1), GenPRM-7B (Maj@8)).
- **Y-axis**: Best-of-32 Accuracy (%) ranging from 45% to 69%.
- **Legend**:
- Green: Best-of-32
- Orange: ProcessBench
- **Additional Elements**:
- Horizontal dashed line at 61.9% (GPT-4o).
- Numerical annotations on bars (e.g., 52.5%, 36.4%).
### Detailed Analysis
- **Skywork-PRM-1.5B**:
- Best-of-32: 52.5% (green)
- ProcessBench: 36.4% (orange)
- **Skywork-PRM-7B**:
- Best-of-32: 54.1% (green)
- ProcessBench: 42.1% (orange)
- **Owen2.5-Math-7B-PRM800K**:
- Best-of-32: 53.1% (green)
- ProcessBench: 56.5% (orange)
- **Owen2.5-Math-PRM-7B**:
- Best-of-32: 53.8% (green)
- ProcessBench: 73.5% (orange)
- **Owen2.5-Math-PRM-72B**:
- Best-of-32: 56.2% (green)
- ProcessBench: 78.3% (orange)
- **Direct GenPRM-7B**:
- Best-of-32: 52.2% (green)
- ProcessBench: 60.0% (orange)
- **GenPRM-7B (Pass@1)**:
- Best-of-32: 55.9% (green)
- ProcessBench: 75.2% (orange)
- **GenPRM-7B (Maj@8)**:
- Best-of-32: 57.1% (green)
- ProcessBench: 80.5% (orange)
### Key Observations
1. **Performance Gaps**: ProcessBench scores are consistently lower than Best-of-32 for smaller models (e.g., Skywork-PRM-1.5B: 36.4% vs. 52.5%). Larger models (e.g., GenPRM-7B) narrow this gap.
2. **GenPRM-7B Dominance**: GenPRM-7B achieves the highest scores in both frameworks (80.5% in ProcessBench, 57.1% in Best-of-32).
3. **GPT-4o Benchmark**: The dashed line (61.9%) indicates GPT-4o outperforms most models except GenPRM-7B (Maj@8) in Best-of-32.
### Interpretation
GenPRM-7B demonstrates superior performance as a verifier, particularly in the ProcessBench framework, suggesting it excels at iterative refinement. The disparity between Best-of-32 and ProcessBench highlights the latter's sensitivity to model size and refinement strategies. GenPRM-7B's 3.4x improvement over Self-Refine (Chart b) underscores its efficiency in iterative tasks.
---
## Line Chart: GenPRM as a Critic
### Overview
The chart tracks accuracy improvements for three models (GenPRM-7B, DeepSeek-R1-Distill-7B, Self-Refine) across refinement turns (0–3). GenPRM-7B shows the steepest ascent, with a 3.4x improvement over Self-Refine at Pass@1.
### Components/Axes
- **X-axis**: # Refinement Turn (0, 1, 2, 3).
- **Y-axis**: Accuracy (%) ranging from 45% to 90%.
- **Legend**:
- Green: GenPRM-7B
- Orange: DeepSeek-R1-Distill-7B
- Gray: Self-Refine
- **Additional Elements**:
- Vertical dashed line at 3 refinement turns.
- Arrow indicating "3.4x" improvement.
### Detailed Analysis
- **GenPRM-7B**:
- Turn 0: 45.5%
- Turn 1: 68.0%
- Turn 2: 78.0%
- Turn 3: 85.5%
- **DeepSeek-R1-Distill-7B**:
- Turn 0: 45.5%
- Turn 1: 46.5%
- Turn 2: 49.5%
- Turn 3: 49.5%
- **Self-Refine**:
- Turn 0: 45.5%
- Turn 1: 45.5%
- Turn 2: 45.5%
- Turn 3: 45.5%
### Key Observations
1. **Rapid Improvement**: GenPRM-7B's accuracy jumps from 45.5% to 85.5% over 3 refinement turns.
2. **Stagnation in Baselines**: DeepSeek and Self-Refine show minimal improvement, plateauing near 45.5–49.5%.
3. **3.4x Efficiency**: GenPRM-7B outperforms Self-Refine by 3.4x at Pass@1, indicating superior refinement capability.
### Interpretation
GenPRM-7B's iterative refinement significantly enhances accuracy, making it highly effective as a critic. The stagnation of other models suggests they lack adaptive refinement mechanisms. This positions GenPRM-7B as a leader in dynamic, self-improving systems.
---
## Cross-Chart Insights
- **Consistency**: GenPRM-7B dominates both charts, excelling in static (Best-of-32) and dynamic (refinement) settings.
- **Framework Sensitivity**: ProcessBench amplifies performance differences between models compared to Best-of-32.
- **GPT-4o Context**: While GPT-4o (61.9%) outperforms most models, GenPRM-7B (Maj@8) surpasses it, highlighting its advanced capabilities.
</details>
* Equal contribution
‡ Corresponding authors: Biqing Qi (qibiqing@pjlab.org.cn), Xiu Li (li.xiu@sz.tsinghua.edu.cn), and Bowen Zhou (zhoubowen@tsinghua.edu.cn)
† Project lead & Work done during an internship at Shanghai AI Laboratory
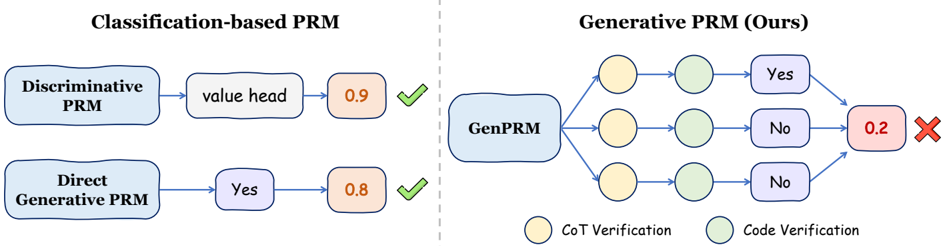
Figure 2: Comparison between GenPRM (right) and previous classification-based PRMs (left).
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: Comparison of Classification-based PRM vs. Generative PRM (Ours)
### Overview
The diagram contrasts two approaches to Program Repair Mechanism (PRM): a **Classification-based PRM** (left) and a **Generative PRM (Ours)** (right). It uses probabilistic outcomes (e.g., 0.9, 0.8, 0.2) and verification steps (CoT, Code) to illustrate decision flows and success rates.
---
### Components/Axes
1. **Left Section (Classification-based PRM)**:
- **Discriminative PRM** → **value head** (0.9, ✅).
- **Direct Generative PRM** → **Yes** (0.8, ✅).
- Arrows indicate sequential decision paths.
2. **Right Section (Generative PRM)**:
- **GenPRM** branches into three paths:
- **CoT Verification** (yellow) → **Yes** → 0.2 (❌).
- **Code Verification** (green) → **No** → 0.2 (❌).
- Mixed paths (CoT + Code) → **No** → 0.2 (❌).
- Legend at bottom-right distinguishes **CoT Verification** (yellow) and **Code Verification** (green).
---
### Detailed Analysis
- **Classification-based PRM**:
- **Discriminative PRM** achieves a high success rate (0.9) via a "value head" component.
- **Direct Generative PRM** has a slightly lower success rate (0.8) but still succeeds (✅).
- **Generative PRM (Ours)**:
- All paths from **GenPRM** lead to **No** outcomes, resulting in a low success rate (0.2, ❌).
- **CoT Verification** (yellow) and **Code Verification** (green) are used as intermediate steps but fail to improve outcomes.
---
### Key Observations
1. **Success Rates**:
- Classification-based PRM outperforms Generative PRM (0.9/0.8 vs. 0.2).
- Generative PRM’s success rate is significantly lower despite additional verification steps.
2. **Verification Steps**:
- CoT and Code Verification in Generative PRM do not mitigate failure (all paths end in ❌).
3. **Flow Direction**:
- Left section: Linear paths with clear success.
- Right section: Branching paths with uniform failure.
---
### Interpretation
- **Effectiveness of Approaches**:
- The Classification-based PRM demonstrates higher reliability, suggesting that discriminative methods (e.g., value head) are more robust for this task.
- The Generative PRM’s lower success rate (0.2) implies that generative models, even with verification steps, struggle to match the performance of classification-based systems in this context.
- **Verification Limitations**:
- The failure of CoT and Code Verification in Generative PRM highlights potential weaknesses in post-hoc validation steps when applied to generative models.
- **Design Implications**:
- The diagram suggests that hybrid approaches (combining discriminative and generative methods) might need architectural adjustments to improve outcomes. The stark contrast in success rates underscores the need for further optimization in generative PRM pipelines.
</details>
## 1. Introduction
Large Language Models (LLMs) have shown significant advances in recent years (OpenAI, 2023; Anthropic, 2023; OpenAI, 2024a,b; DeepSeek-AI et al., 2025). As OpenAI o1 demonstrates the great effectiveness of scaling test-time compute (OpenAI, 2024a), an increasing number of researches focus on Test-Time Scaling (TTS) methods to improve the reasoning performance of LLMs (Snell et al., 2025; Liu et al., 2025).
Effective TTS requires high-quality verifiers, such as Process Reward Models (PRMs) (Liu et al., 2025). However, existing PRMs face several limitations. They exhibit limited process supervision capabilities and struggle to generalize across different models and tasks (Zheng et al., 2024; Zhang et al., 2025c; Liu et al., 2025). Furthermore, most current approaches train PRMs as classifiers that output scalar values, neglecting the natural language generation abilities of LLMs, which are pre-trained on extensive corpora. This classifier-based modeling inherently prevents PRMs from leveraging test-time scaling methods to enhance process supervision capabilities. These limitations lead us to the following research question: How can generative modeling enhance the process supervision capabilities of PRMs while enabling test-time scaling?
In this work, we address these challenges through a generative process reward model, named GenPRM. Specifically, GenPRM differs from classification-based PRMs in that GenPRM redefines process supervision as a generative task rather than a discriminative scoring task by integrating Chain-of-Thought (CoT) (Wei et al., 2022) reasoning and code verification processes before providing final judgment. To improve conventional hard label estimation, we propose Relative Progress Estimation (RPE), which leverages a relative criterion for label estimation. Additionally, we introduce a rationale synthesis framework with code verification to obtain high-quality process supervision reasoning data. A comparison of our method with previous classification-based methods is presented in Figure 2.
Our contributions can be summarized as follows:
1. We propose a generative process reward model that performs explicit CoT reasoning with code verification and utilizes Relative Progress Estimation to obtain accurate PRM labels.
3. We provide a new perspective on PRMs in this work, fully leveraging their TTS capabilities, reshaping their applications, and opening new directions for future research in process supervision.
2. Empirical results on ProcessBench and common mathematical reasoning tasks demonstrate that GenPRM outperforms prior classification-based PRMs. Additionally, smaller GenPRM models can surpass larger PRMs via TTS.
## 2. Preliminaries
## 2.1. Markov Decision Process
Following Liu et al. (2025), we formulate the test-time scaling process with PRMs as a Markov Decision Process (MDP) defined by ( 𝒮 , 𝒜 , 𝑃, 𝑟, 𝛾 ) , where 𝒮 is the state space, 𝒜 is the action space, 𝑃 represents transition dynamics, 𝑟 : 𝒮 × 𝒜 → R is the reward function, and 𝛾 ∈ [0 , 1] is the discount factor. Starting with a prompt set 𝒳 and an initial state 𝑠 1 = 𝑥 ∼ 𝒳 , the policy model 𝜋 𝜃 generates an action 𝑎 1 ∼ 𝜋 𝜃 ( · | 𝑠 1 ) . 1 Unlike traditional RL methods with stochastic transitions (Liu et al., 2022, 2024), transitions in LLMs are deterministic, i.e., 𝑠 𝑡 +1 = 𝑃 ( · | 𝑠 𝑡 , 𝑎 𝑡 ) = [ 𝑠 𝑡 , 𝑎 𝑡 ] , where [ · , · ] denotes string concatenation. This process continues until the episode terminates (i.e., generating the [EOS] token), obtaining a trajectory of 𝑇 steps: 𝜏 = { 𝑎 1 , 𝑎 2 , · · · , 𝑎 𝑇 } . The goal is to optimize either the reward of each step (as in search-based methods) or the reward over the full response (as in Best-of-N sampling).
## 2.2. Supervised Fine-Tuning
Supervised Fine-Tuning (SFT) trains a model to predict the next token based on prior context. For a dataset 𝒟 SFT = { ( 𝑥 ( 𝑖 ) , 𝑦 ( 𝑖 ) ) } 𝑁 𝑖 =1 , the SFT loss is:
<!-- formula-not-decoded -->
where 𝜋 𝜃 represents a model with parameters 𝜃 .
## 2.3. Test-Time Scaling
In this work, we consider two test-time scaling methods, including majority voting and Best-of-N.
Majority Voting. Majority voting (Wang et al., 2023) selects the answer that appears the most frequently among all solutions.
Best-of-N. Best-of-N (BoN) (Brown et al., 2024; Snell et al., 2025) selects the best answer from 𝑁 candidate solutions.
## 3. Method
In this section, we first describe how to develop GenPRM and integrate the reasoning process with code verification. We then introduce how to scale test-time compute of policy models using GenPRM and apply TTS for GenPRM. Last, we present the improved label estimation method and data generation and filtering framework of GenPRM.
## 3.1. GenPRM and Test-Time Scaling
## 3.1.1. From Discriminative PRM to Generative PRM
Discriminative PRM. Assume we have a PRM dataset 𝒟 Disc = { ( 𝑠 𝑡 , 𝑎 𝑡 ) , 𝑟 𝑡 } , where 𝑟 𝑡 ∈ { 0 , 1 } for PRMlabels with hard estimation. The discriminative PRM 𝑟 𝜓 is trained via cross-entropy loss (Skywork
1 Following Snell et al. (2025); Liu et al. (2025), we refer to models that generate solutions as policy models.
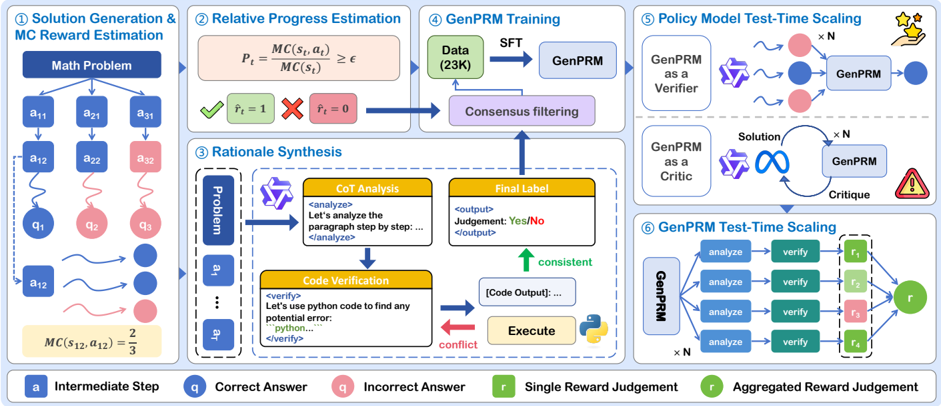
Figure 3: Overall framework of GenPRM. Our framework consists of six key parts: 1 /bigcircle The policy model generates solution steps, with MC scores estimated from rollout trajectories. 2 /bigcircle Our proposed RPE derives accurate PRM labels. 3 /bigcircle High-quality process supervision data is synthesized through CoT reasoning augmented with code verification. 4 /bigcircle We apply consensus filtering followed by SFT to train GenPRM. 5 /bigcircle The trained GenPRM functions as a verifier or critic, enabling enhanced test-time scaling for policy models. 6 /bigcircle The performance of GenPRM further improves through test-time scaling.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Flowchart: Multi-Stage Problem-Solving Workflow with GenPRM Integration
### Overview
The diagram illustrates a six-stage technical workflow for solving mathematical problems using a combination of reinforcement learning (MC reward estimation), natural language reasoning, and large language model (GenPRM) verification. The process emphasizes iterative refinement through consensus filtering and test-time scaling.
### Components/Axes
1. **Stage 1: Solution Generation & MC Reward Estimation**
- **Math Problem** → Branches to **Intermediate Steps** (a₁₁, a₂₁, a₃₁)
- **Actions** (a₁₂, a₂₂, a₃₂) with **Correctness Labels** (q₁, q₂, q₃)
- **MC Reward Calculation**: MC(s₁₂,a₁₂) = 2/3
- **Color Coding**: Blue (correct), Pink (incorrect)
2. **Stage 2: Relative Progress Estimation**
- **Formula**: Pₜ = MC(sₜ,aₜ)/MC(sₜ) ≥ ε
- **Reward Flags**: Green check (rₜ=1), Red X (rₜ=0)
3. **Stage 3: GenPRM Training**
- **Data Input**: 23K samples
- **Process**: SFT → GenPRM → Consensus Filtering
- **Output**: Filtered training data
4. **Stage 4: Rational Synthesis**
- **CoT Analysis**: "Let's analyze the paragraph step by step..."
- **Code Verification**: Python code execution with error detection
- **Consistency Check**: Green arrow (consistent), Red arrow (conflict)
5. **Stage 5: Policy Model Test-Time Scaling**
- **GenPRM Roles**:
- **Verifier**: Multiple pink/blue nodes → Single verification
- **Critic**: Feedback loop with solution refinement
- **Output**: Final solution with star rating
6. **Stage 6: GenPRM Test-Time Scaling**
- **Parallel Analysis**: 4 "analyze" nodes → Aggregated reward (r)
- **Verification Nodes**: 4 "verify" nodes with mixed green/pink outputs
### Detailed Analysis
- **Math Problem Structure**:
- Initial problem branches to 3 action paths (a₁₁→a₁₂, a₂₁→a₂₂, a₃₁→a₃₂)
- Each path has correctness indicators (q₁=correct, q₂=incorrect, q₃=incorrect)
- Reward calculation shows 2/3 success rate for action a₁₂
- **GenPRM Integration**:
- Trained on 23K samples with supervised fine-tuning (SFT)
- Functions as both verifier (multiple parallel checks) and critic (feedback loop)
- Consensus filtering removes conflicting outputs
- **Test-Time Scaling**:
- 4 parallel analysis paths (×N) for complex problems
- Aggregated reward (r) combines multiple verification results
- Final output includes star rating system (⭐⭐⭐)
### Key Observations
1. **Iterative Refinement**:
- Solutions progress through multiple verification stages
- Conflicting code outputs trigger re-execution
2. **Reward Engineering**:
- MC rewards quantify solution quality
- Aggregated rewards (r) combine multiple verification results
3. **GenPRM Dual Role**:
- Acts as both verifier (parallel checks) and critic (feedback)
- Creates closed-loop improvement system
4. **Color-Coded Logic**:
- Blue = Correct actions/answers
- Pink = Incorrect actions/answers
- Green = Positive rewards/consistent outputs
- Red = Negative rewards/conflicts
### Interpretation
This workflow demonstrates a sophisticated approach to mathematical problem-solving that combines:
1. **Reinforcement Learning**: MC rewards guide solution quality
2. **Natural Language Reasoning**: CoT analysis breaks down complex problems
3. **LLM Verification**: GenPRM provides multi-perspective validation
4. **Test-Time Optimization**: Parallel analysis paths handle complexity
The system's strength lies in its ability to:
- Quantify solution quality through MC rewards
- Detect and resolve conflicts through consensus filtering
- Scale verification efforts through parallel analysis
- Improve solutions iteratively through critic feedback
Notable patterns include the emphasis on verification at multiple stages (initial actions, code execution, final solution) and the use of both positive (green) and negative (red) feedback signals to drive improvement. The star rating system suggests a final quality assessment beyond binary correctness.
</details>
o1 Team, 2024; Zhang et al., 2025c):
<!-- formula-not-decoded -->
Direct Generative PRM. With a dataset 𝒟 Direct-Gen = { ( 𝑠 𝑡 , 𝑎 𝑡 ) , 𝑟 𝑡 } , where 𝑟 𝑡 is Yes for a correct step and No otherwise, the direct generative PRM (Xiong et al., 2024) is trained through SFT to predict Yes or No for each step. For step 𝑡 , we use the probability of the Yes token as the predicted process reward ˆ 𝑟 𝑡 :
<!-- formula-not-decoded -->
Generative PRM. By equipping the direct generative PRM with an explicit reasoning process like CoT (Wei et al., 2022), we obtain a generative PRM. Let 𝑣 1: 𝑡 -1 denote the rationale from step 1 to 𝑡 -1 and 𝑣 𝑡 denote the rationale for step 𝑡 . Assume we have a dataset 𝒟 Gen = { ( 𝑠 𝑡 , 𝑎 𝑡 , 𝑣 1: 𝑡 -1 ) , ( 𝑣 𝑡 , 𝑟 𝑡 ) } . GenPRM learns to reason and verify each step via SFT on this dataset. The generative process reward ˆ 𝑟 𝑡 can be obtained via the following equation:
<!-- formula-not-decoded -->
Generative PRM with Code Verification. If we only verify the reasoning step with CoT based on natural language, the process may lack robustness in certain complex scenarios (Zhu et al., 2024; Gou et al., 2024). The difference between the generative PRM and the generative PRM with code verification is that the latter generates code to verify the reasoning step by executing it and provides the judgment based on the execution results. At step 𝑡 , after generating the rationale 𝑣 𝑡 containing CoT and code, we execute the code and obtain feedback 𝑓 𝑡 . Given the current state 𝑠 𝑡 , action 𝑎 𝑡 , previous rationales 𝑣 1: 𝑡 -1 , and previous corresponding execution feedback 𝑓 1: 𝑡 -1 , the PRM first generates the
rationale 𝑣 𝑡 . After execution and obtaining the feedback 𝑓 𝑡 , we compute the final generative process reward as follows:
<!-- formula-not-decoded -->
In the following sections, we refer to GenPRM as this generative PRM type with code verification. The effectiveness of CoT and code verification can be found in Section 4.4.
## 3.1.2. Test-Time Scaling
Policy Model TTS: GenPRM as a Verifier. To scale the test-time compute of policy models, we can sampling multiple responses from policy models and then use GenPRM as a verifier to select the final answer (Snell et al., 2025) in the way of parallel TTS.
Policy Model TTS: GenPRM as a Critic. By equipping the PRM with generative process supervision abilities, GenPRM can be naturally used as a critic model to refine the outputs of policy models and we can scale the refinement process with multiple turns in a sequential TTS manner.
GenPRM TTS. When evaluating each solution step, we first sample 𝑁 reasoning verification paths and then use majority voting to obtain the final prediction by averaging the rewards. For GenPRM without code verification, the rewards are computed as follows:
<!-- formula-not-decoded -->
And we can further incorporate code verification and execution feedback into this reasoning process:
<!-- formula-not-decoded -->
Then the rewards can be used for ranking the responses of policy models or be converted into binary labels through a threshold 0 . 5 for judging the correctness of the step. The discussion of using code verification can be found at Table 5.
## 3.2. Synthesizing Data of GenPRM
In this section, we introduce our pipeline for synthesizing training data of GenPRM. The pipeline consists of three stages: (1) generating reasoning paths and obtaining PRM labels via Monte Carlo (MC) estimation; (2) evaluating the progress of each step via Relative Progress Estimation; and (3) synthesizing rationales with CoT and code verification, and inferring LLM-as-a-judge labels with consensus filtering.
## 3.2.1. Solution Generation and Monte Carlo Estimation
Solution Generation with Step Forcing. We utilize the 7.5K problems from the training set of the MATH dataset (Hendrycks et al., 2021) as the problem set. For each problem, we use Qwen2.5-7BInstruct (Yang et al., 2024a) as the generation model to collect multiple solutions. Since using ' \n\n ' for step division does not consider the semantics of each step and may result in overly fine-grained division, we apply a step forcing approach to generate solutions. Specifically, we add ' Step 1: ' as the prefix for the generation model to complete the response. For a response with 𝑇 reasoning steps, the format is as follows:
## The response format with step forcing
Step 1: {step content}
...
Step T:
{step content}
The proportion of correct paths versus incorrect paths varies significantly depending on the difficulty of the problems. To ensure a sufficient number of correct and incorrect paths, we sample up to 2048 paths for both hard and easy problems. If no correct or incorrect paths are found after sampling 2048 responses, we discard the corresponding problems.
Balancing the Precision and Efficiency of MC Estimation. Following Math-Shepherd (Wang et al., 2024b), we estimate the probability of correctness for each step using completion-based sampling. For each reasoning step 𝑠 𝑡 , we generate 𝐾 completion trajectories using a completion model, specifically Qwen2.5-Math-7B-Instruct (Yang et al., 2024b), and use MC estimation to calculate the probability that the current step 𝑎 𝑡 is correct (Wang et al., 2024b; Zhang et al., 2025c):
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
where 𝑞 𝑗 is the answer of the 𝑗 -th response, 𝑞 * is the ground-truth answer, and ✶ is the indicator function. However, it is difficult for the completion model to reach the correct answer for hard problems even when the original step is correct, leading to incorrect results for MC estimation. To address this and balance the computation cost, we use a dynamic 𝐾 based on the estimated Pass@1 𝑀𝐶 ( 𝑠 1 ) :
## 3.2.2. Relative Progress Estimation
Previous work has shown that hard label estimation is better than soft label estimation for PRMs (Zhang et al., 2025c). However, after MC estimation, we observe that although the MC score of many steps is greater than 0, the steps are incorrect, as also noted by Zhang et al. (2025c). On the other hand, we assume that a positive step should be both correct and beneficial. A reasoning step is considered as a beneficial one if it is easier to reach the correct answer by adding this step as the generation prefix. To address these issues, we propose Relative Progress Estimation (RPE), which shares a similar idea with relative advantage estimation in GRPO (Shao et al., 2024; DeepSeek-AI et al., 2025), to improve conventional hard label estimation.
Specifically , the MC score is an empirical estimation of the current state 𝑠 𝑡 . To evaluate the quality of the current action 𝑎 𝑡 , it is natural to compare the MC score of the next state 𝑠 𝑡 +1 with that of the current state 𝑠 𝑡 , since 𝑠 𝑡 +1 = [ 𝑠 𝑡 , 𝑎 𝑡 ] . For each response, if the first erroneous step is step 𝑡 ′ (i.e., 𝑀𝐶 ( 𝑠 𝑡 ′ ) = 0 ), we set the MC score of the following steps to 0. Our RPE 𝑃 𝑡 for step 𝑡 is defined as follows:
where 𝑀𝐶 ( 𝑠 1 ) is the estimated Pass@1 computed in the solution generation phase. However, we empirically find that using a strict criterion where progress is always greater than 1 leads to unsatisfactory performance, as shown in Table 3. To address this, we estimate the final reward label ˆ 𝑟 𝑡 by
<!-- formula-not-decoded -->
introducing a threshold 𝜖 :
<!-- formula-not-decoded -->
We also discuss another form of relative progress 𝑃 𝑡 = 𝑀𝐶 ( 𝑠 𝑡 , 𝑎 𝑡 ) -𝑀𝐶 ( 𝑠 𝑡 ) in Table 3 in Section 4.4.
## 3.2.3. Rationale Generation, Verification and Filtering
To obtain high-quality rationale data, we use QwQ-32B (Qwen Team, 2025) as the rationale generation model and introduce a three-step pipeline that automatically generates and verifies the rationale of each reasoning step. Given a problem 𝑥 with a ground-truth answer 𝑞 * and candidate steps { 𝑎 1 , · · · , 𝑎 𝑇 } , the generation and verification proceed as follows:
Step 1: Code-Based Rationale Generation. To evaluate the correctness of 𝑎 𝑡 , we synthesize step-by-step CoT analysis. It has been shown that program-based reasoning improves verification outcomes (Zhu et al., 2024). Based on CoT analysis, we continue to synthesize code-based rationales to verify 𝑎 𝑡 based on the problem and historical steps { 𝑎 1 , · · · , 𝑎 𝑡 -1 } . We prompt the rationale generation model to surround the CoT with <analyze> and </analyze> , and the code with <verify> and </verify> . The prompt for rationale generation is shown in Table A.2.
Step 2: Code Execution and Verification. With the generated code, we execute it and obtain the feedback 𝑓 𝑡 for step 𝑡 . The execution feedback is formatted as [Code output: {execution result}] and is concatenated to the generated CoT and code as the prefix for the subsequent generation. If the execution result is inconsistent with the generated CoT verification, we observe that QwQ-32B performs self-reflection behaviors until reaching a consensus.
Step 3: Label Judgment and Consensus Filtering. After generating and verifying the rationale data of all candidate steps, the rationale generation model finally outputs an number. If all steps are inferred to be correct, the number will be -1, otherwise will be the index of the first erroneous step. For each solution, if there is at least one process label with RPE is not consistent with the labels generated by LLM-as-a-judge (Zheng et al., 2023), we discard the entire solution and only retain the one with all labels consistent. After consensus filtering, we discard approximately 51% of the data and finally obtain a dataset containing 23K problems with reasoning steps and rationale data.
## 4. Experiments
In this section, we aim to answer the following questions:
- Q1: How does GenPRM perform compared with previous PRMs? (§4.2, §4.3)
- Q2: How does the performance of GenPRM scale with more test-time compute? (§4.2, §4.3)
- Q3: How does GenPRM benefit policy model test-time scaling? (§4.3)
- Q4: How do the components and hyperparameters influence GenPRM? (§4.4)
## 4.1. Setup
Benchmarks. We evaluate GenPRM and baseline methods on ProcessBench (Zheng et al., 2024), a benchmark designed to assess process supervision capabilities in mathematical reasoning tasks. 2
2 Our evaluation code is adapted from https://github.com/QwenLM/ProcessBench .
Additionally, we conduct BoN and critic refinement experiments using MATH (Hendrycks et al., 2021), AMC23 (AI-MO, 2024b), AIME24 (AI-MO, 2024a), and Minerva Math (Lewkowycz et al., 2022). For BoN response generation, we employ Qwen2.5-Math-7B-Instruct (Yang et al., 2024b) and Gemma-3-12b-it (Gemma Team and Google DeepMind, 2025) as policy models. For policy model TTS with GenPRM as the critic, we use Gemma-3-12b-it (Gemma Team and Google DeepMind, 2025) and Qwen2.5-7B-Instruct (Yang et al., 2024a) as generators.
Baselines. For ProcessBench and BoN experiments, we compare GenPRM with the following methods:
- Math-Shepherd-PRM-7B (Wang et al., 2024b): This method trains a PRM using hard labels computed based on MC estimation.
- Skywork-PRM series (Skywork o1 Team, 2024): Comprises Skywork-PRM-1.5B and SkyworkPRM-7B.
- RLHFlow series (Xiong et al., 2024): Includes RLHFlow-PRM-Mistral-8B and RLHFlow-PRMDeepseek-8B.
- EurusPRM (Cui et al., 2025): EurusPRM-Stage1 and EurusPRM-Stage2 are trained as implicit PRMs (Yuan et al., 2024).
- RetrievalPRM-7B (Zhu et al., 2025): The method enhances PRM with retrieved questions and corresponding steps.
- Qwen2.5-Math series (Zheng et al., 2024; Zhang et al., 2025c): Qwen2.5-Math-7B-MathShepherd and Qwen2.5-Math-7B-PRM800K are trained with Math-Shepherd (Wang et al., 2024b) and PRM800K (Lightman et al., 2024), respectively. For Qwen2.5-Math-PRM-7B and Qwen2.5-Math-PRM-72B, the training data is applied consensus filtering using LLM-as-ajudge (Zheng et al., 2023).
- Universal-PRM-7B (Tan et al., 2025): The method proposes an automated framework using ensemble prompting and reverse verification.
- Direct Generative PRM-7B : The method trains a direct generative PRM with the original language head via SFT using the same data as GenPRM, but without CoT and code verification.
- Dyve-14B (Zhong et al., 2025): This method dynamically applies fast or slow verification for each reasoning step.
For critic experiments, we use the following methods for comparison:
- Self-Refine (Madaan et al., 2023): This method uses the generator to self-critique and refine the solution.
- DeepSeek-R1-Distill-Qwen-7B (DeepSeek-AI et al., 2025): This model is fine-tuned based on Qwen2.5-Math-7B (Yang et al., 2024a) using high-quality reasoning data generated by DeepSeek-R1 (DeepSeek-AI et al., 2025).
Implementation Details. For RPE, we set 𝜖 = 0 . 8 across all experiments, with ablation studies presented in Section 4.4. Rationale data is generated using QwQ-32B (Qwen Team, 2025) and the prompt template is shown in Table A.2. Our base models are from the DeepSeek-R1-Distill series (DeepSeek-AI et al., 2025), specifically the 1.5B, 7B, and 32B parameter variants. The training configuration for our method uses a batch size of 64 and a learning rate of 2 . 0 × 10 -6 . During evaluation, we employ a temperature of 0.6. For critique refinement experiments, we extract content within the <analyze></analyze> tags, focusing exclusively on steps predicted as negative by the policy model. The baseline methods utilize standardized prompt templates (detailed in Table A.2) to ensure consistent critique generation formats.
Table 1: ProcessBench results reported with F1 scores. The results of GenPRM are shaded . For 1.5B PRMs, bold indicates the best Pass@1 or scores superior to GPT-4o. For 7-8B and 14-72B PRMs, bold denotes the best Pass@1 or scores superior to Qwen2.5-Math-PRM-72B.
| Model | # Samples | GSM8K | MATH | Olympiad Bench | Omni- MATH | Avg. |
|-------------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|
| Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) |
| GPT-4o-0806 o1-mini | unk unk | 79.2 93.2 | 63.6 88.9 | 51.4 87.2 | 53.5 82.4 | 61.9 87.9 |
| PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) |
| Skywork-PRM-1.5B | unk | 59.0 | 48.0 | 19.3 | 19.2 | 36.4 |
| GenPRM-1.5B (Pass@1) | 23K | 52.8 | 66.6 | 55.1 | 54.5 | 57.3 |
| GenPRM-1.5B (Maj@8) | 23K | 51.3 | 74.4 | 65.3 | 62.5 | 63.4 |
| PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) |
| Math-Shepherd-PRM-7B | 445K | 47.9 | 29.5 | 24.8 | 23.8 | 31.5 |
| RLHFlow-PRM-Mistral-8B | 273K | 50.4 | 33.4 | 13.8 | 15.8 | 28.4 |
| RLHFlow-PRM-Deepseek-8B | 253K | 38.8 | 33.8 | 16.9 | 16.9 | 26.6 |
| Skywork-PRM-7B | unk | 70.8 | 53.6 | 22.9 | 21.0 | 42.1 |
| EurusPRM-Stage1 | 463K | 44.3 | 35.6 | 21.7 | 23.1 | 31.2 |
| EurusPRM-Stage2 | 30K | 47.3 | 35.7 | 21.2 | 20.9 | 31.3 |
| Qwen2.5-Math-7B-Math-Shepherd | 445K | 62.5 | 31.6 | 13.7 | 7.7 | 28.9 |
| Qwen2.5-Math-7B-PRM800K | 264K | 68.2 | 62.6 | 50.7 | 44.3 | 56.5 |
| Qwen2.5-Math-PRM-7B | ∼ 344K | 82.4 | 77.6 | 67.5 | 66.3 | 73.5 |
| RetrievalPRM-7B | 404K | 74.6 | 71.1 | 60.2 | 57.3 | 65.8 |
| Universal-PRM-7B | unk | 85.8 | 77.7 | 67.6 | 66.4 | 74.3 |
| Direct Generative PRM-7B | 23K | 63.9 | 65.8 | 54.5 | 55.9 | 60.0 |
| GenPRM-7B (Pass@1) | 23K | 78.7 | 80.3 | 72.2 | 69.8 | 75.2 |
| GenPRM-7B (Maj@8) | 23K | 81.0 | 85.7 | 78.4 | 76.8 | 80.5 |
| PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) |
| Dyve-14B | 117K | 68.5 | 58.3 | 49.0 | 47.2 | 55.8 |
| Qwen2.5-Math-PRM-72B | ∼ 344K | 87.3 | 80.6 | 74.3 | 71.1 | 78.3 |
| GenPRM-32B (Pass@1) | 23K | 83.1 | 81.7 | 72.8 | 72.8 | 77.6 |
| GenPRM-32B (Maj@8) | 23K | 85.1 | 86.3 | 78.9 | 80.1 | 82.6 |
## 4.2. ProcessBench Results
GenPRM outperforms classification-based PRMs on ProcessBench. As shown in Table 1, GenPRM7B significantly outperforms direct generative PRM and surpasses all previous PRMs with parameters less than 72B on ProcessBench. Also, GenPRM-1.5B outperforms Skywork-PRM-1.5B by a large margin. It is noteworthy that GenPRM is trained with merely 23K data from MATH (Hendrycks et al., 2021) only. By comparing the detailed results in Table 6, we can find that the performance gain of GenPRM mainly comes from the stronger abilities of finding erroneous steps and we provide concrete cases in Appendix C. These results demonstrating the superiority of generative modeling of PRM.
GenPRM enables smaller PRMs surpass 10 × larger PRMs and GPT-4o via TTS. We also compare the TTS results of GenPRM in Table 1 and find that GenPRM-1.5B surpasses GPT-4 and GenPRM-7B exceeds Qwen2.5-Math-PRM-72B on ProcessBench via simply majority voting, showing that scaling test-time compute is highly effective for GenPRM. We also find that the performance improvement of scaling the test-time compute on harder problems is larger than that of easier questions.
## 4.3. Policy Model Test-Time Scaling Results
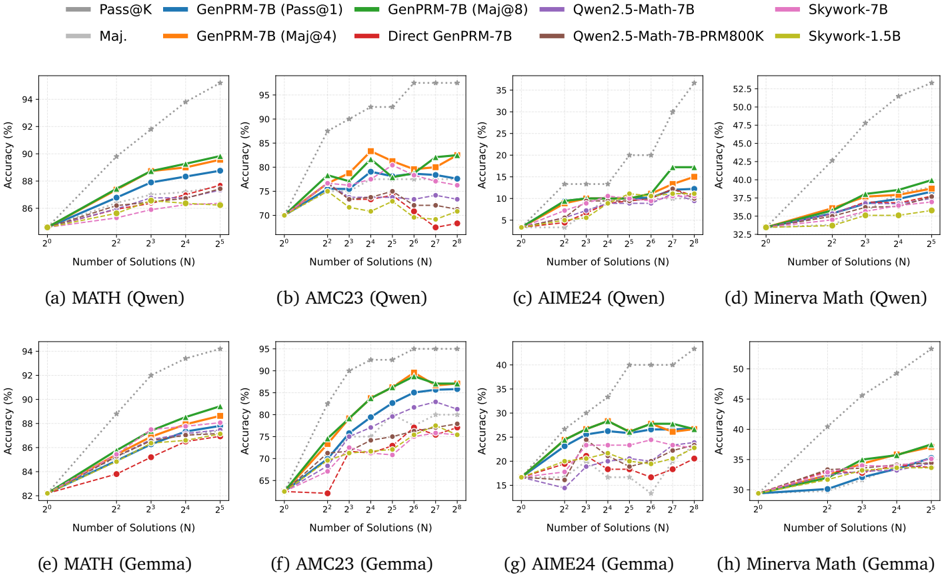
GenPRM as a Verifier. The results in Figure 4 (a)-(d) show that GenPRM outperforms the baselines on MATH, AMC23, AIME24, and Minerva Math with Qwen2.5-Math-7B-Instruct (Yang et al., 2024b) as the generation model. The advantage of GenPRM becomes larger by scaling the test-time compute of GenPRM and the generation model. Figure 4 (e)-(h) demonstrates that GenPRM generalizes well to responses with Gemma-3-12b-it (Gemma Team and Google DeepMind, 2025) as the generation model.
Figure 4: BoN results with different generation models on multiple mathematical benchmarks.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Line Graphs: Model Accuracy vs. Number of Solutions Across Datasets
### Overview
The image contains eight line graphs comparing the accuracy of various AI models across four datasets (MATH, AMC23, AIME24, Minerva Math) as the number of solutions (N) increases. Each graph tests two problem sets (Qwen and Gemma) and evaluates models like Pass@K, GenPRM-7B variants, Direct GenPRM-7B, Qwen2.5-Math-7B, and Skywork models. Accuracy (%) is plotted against N (logarithmic scale: 2⁰ to 2⁸).
---
### Components/Axes
- **X-axis**: Number of Solutions (N) – Logarithmic scale (2⁰, 2¹, ..., 2⁸).
- **Y-axis**: Accuracy (%) – Ranges from ~30% to 95% depending on the dataset.
- **Legends**:
- **Colors**:
- Gray (dotted): Pass@K (baseline).
- Blue: GenPRM-7B (Pass@1).
- Green: GenPRM-7B (Maj@8).
- Orange: GenPRM-7B (Maj@4).
- Red: Direct GenPRM-7B.
- Purple: Qwen2.5-Math-7B.
- Pink: Skywork-7B.
- Brown: Qwen2.5-Math-7B-PRM800K.
- Yellow: Skywork-1.5B.
- **Placement**: Top-right corner of each graph.
---
### Detailed Analysis
#### (a) MATH (Qwen)
- **Trend**: Pass@K (gray dotted) slopes steeply upward (~85% at 2⁰ → ~94% at 2⁸).
- **Models**:
- GenPRM-7B (Pass@1, blue) starts at ~85% (2⁰) and reaches ~90% (2⁸).
- GenPRM-7B (Maj@8, green) peaks at ~91% (2⁸).
- Direct GenPRM-7B (red dashed) lags behind, peaking at ~88% (2⁸).
- **Key**: Pass@K dominates; GenPRM-7B variants improve with N.
#### (b) AMC23 (Qwen)
- **Trend**: Pass@K rises from ~70% (2⁰) to ~95% (2⁸).
- **Models**:
- GenPRM-7B (Maj@4, orange) peaks at ~88% (2⁶) then declines slightly.
- Qwen2.5-Math-7B (purple) stabilizes at ~85% (2⁸).
- **Key**: Maj@4 configuration underperforms at higher N.
#### (c) AIME24 (Qwen)
- **Trend**: Pass@K increases from ~35% (2⁰) to ~52% (2⁸).
- **Models**:
- GenPRM-7B (Pass@1, blue) reaches ~42% (2⁸).
- Skywork-7B (pink) peaks at ~38% (2⁸).
- **Key**: All models lag Pass@K; Skywork-7B performs better than GenPRM-7B.
#### (d) Minerva Math (Qwen)
- **Trend**: Pass@K rises from ~32% (2⁰) to ~53% (2⁸).
- **Models**:
- GenPRM-7B (Maj@8, green) peaks at ~42% (2⁸).
- Qwen2.5-Math-7B-PRM800K (brown) stabilizes at ~38% (2⁸).
- **Key**: Maj@8 configuration outperforms others.
#### (e) MATH (Gemma)
- **Trend**: Pass@K rises from ~82% (2⁰) to ~94% (2⁸).
- **Models**:
- GenPRM-7B (Pass@1, blue) reaches ~89% (2⁸).
- Skywork-1.5B (yellow) peaks at ~87% (2⁸).
- **Key**: Skywork-1.5B closely matches GenPRM-7B.
#### (f) AMC23 (Gemma)
- **Trend**: Pass@K increases from ~65% (2⁰) to ~95% (2⁸).
- **Models**:
- GenPRM-7B (Maj@4, orange) peaks at ~85% (2⁶) then drops.
- Qwen2.5-Math-7B (purple) stabilizes at ~80% (2⁸).
- **Key**: Maj@4 configuration shows overfitting.
#### (g) AIME24 (Gemma)
- **Trend**: Pass@K rises from ~15% (2⁰) to ~40% (2⁸).
- **Models**:
- GenPRM-7B (Pass@1, blue) reaches ~35% (2⁸).
- Skywork-7B (pink) peaks at ~32% (2⁸).
- **Key**: Skywork-7B slightly outperforms GenPRM-7B.
#### (h) Minerva Math (Gemma)
- **Trend**: Pass@K increases from ~30% (2⁰) to ~50% (2⁸).
- **Models**:
- GenPRM-7B (Maj@8, green) peaks at ~40% (2⁸).
- Skywork-1.5B (yellow) stabilizes at ~37% (2⁸).
- **Key**: Maj@8 configuration leads.
---
### Key Observations
1. **Pass@K Baseline**: Consistently outperforms all models across datasets.
2. **Model Variants**:
- GenPRM-7B (Maj@8) generally performs better than Pass@1 or Maj@4.
- Direct GenPRM-7B (red dashed) underperforms variants.
3. **Diminishing Returns**: Some models (e.g., GenPRM-7B Maj@4 in AMC23) plateau or decline at higher N.
4. **Skywork Models**: Competitive with GenPRM-7B in MATH and AIME24 but lag in AMC23.
---
### Interpretation
- **Scalability**: Increasing N improves accuracy, but gains diminish as N grows (e.g., AMC23 Qwen).
- **Model Efficiency**: GenPRM-7B variants with majority voting (Maj@8) often outperform simpler configurations.
- **Dataset-Specific Behavior**:
- AIME24 (high-difficulty math) shows the largest gap between models and Pass@K.
- Minerva Math (reasoning-focused) benefits more from majority voting.
- **Anomalies**:
- Direct GenPRM-7B (red dashed) consistently underperforms, suggesting architectural limitations.
- Skywork-1.5B matches GenPRM-7B in MATH but struggles in AMC23, indicating dataset-specific weaknesses.
This analysis highlights the trade-offs between model complexity, voting strategies, and dataset characteristics in solving math problems.
</details>
GenPRM as a Critic. We also conduct experiments by using GenPRM as a critic to refine the outputs of the policy model. The results in Table 2 and Figure 1 (right) show that GenPRM exhibits strong critique abilities than the baselines, significantly improving the performance of the policy model and the performance continues to increase with more refinement based on the critic feedback.
## 4.4. Analysis
Label Estimation Method and Criterion. To explore how different label estimation influences GenPRM, we conduct experiments with the following methods: (1) hard label (Wang et al., 2024b; Zhang et al., 2025c); (2) RPE in (10); and (3) a RPE variant ( 𝑃 𝑡 = 𝑀𝐶 ( 𝑠 𝑡 , 𝑎 𝑡 ) -𝑀𝐶 ( 𝑠 𝑡 ) ). For the RPE and its variant, we use different thresholds 𝜖 for evaluation and set the labels as correct by checking whether 𝑃 𝑡 ≥ 𝜖 . The results in Table 3 show that RPE and its variant outperforms hard label estimation and RPE with 𝜖 = 0 . 8 achieves the best result. By scaling test-time compute with majority voting, the results in Table 4 demonstrate that RPE with 𝜖 = 0 . 8 still reaches the best.
Table 2: Results of critique refinement experiments. The results of GenPRM are shaded . For each refinement turn, the highest values are bolded .
| Critic Model | Gemma-3-12b-it as Generator | Gemma-3-12b-it as Generator | Gemma-3-12b-it as Generator | Gemma-3-12b-it as Generator | Gemma-3-12b-it as Generator | Qwen2.5-7B-Instruct as Generator | Qwen2.5-7B-Instruct as Generator | Qwen2.5-7B-Instruct as Generator | Qwen2.5-7B-Instruct as Generator | Qwen2.5-7B-Instruct as Generator | Avg. |
|------------------------|-------------------------------|-------------------------------|-------------------------------|-------------------------------|-------------------------------|------------------------------------|------------------------------------|------------------------------------|------------------------------------|------------------------------------|--------|
| Critic Model | AMC23 | AIME24 | MATH | Minerva Math | Avg. | AMC23 | AIME24 | MATH | Minerva Math | Avg. | Avg. |
| Zero-shot | 64.1 | 15.8 | 83.8 | 31.9 | 48.9 | 51.6 | 7.1 | 76.2 | 34.5 | 42.4 | 45.7 |
| Turn 1 | Turn 1 | Turn 1 | Turn 1 | Turn 1 | Turn 1 | Turn 1 | Turn 1 | Turn 1 | Turn 1 | Turn 1 | Turn 1 |
| Generator | 66.6 | 15.8 | 84.7 | 33.3 | 50.1 | 50.6 | 8.0 | 76.8 | 34.0 | 42.4 | 46.3 |
| DeepSeek-R1-Distill-7B | 69.1 | 17.9 | 84.6 | 33.0 | 51.2 | 50.6 | 6.3 | 77.7 | 34.7 | 42.3 | 46.8 |
| GenPRM-7B | 74.1 | 19.6 | 86.0 | 35.3 | 53.8 | 57.5 | 8.3 | 80.6 | 36.5 | 45.7 | 49.8 |
| Turn 2 | Turn 2 | Turn 2 | Turn 2 | Turn 2 | Turn 2 | Turn 2 | Turn 2 | Turn 2 | Turn 2 | Turn 2 | Turn 2 |
| Generator | 66.6 | 18.0 | 84.8 | 31.6 | 50.3 | 49.8 | 8.0 | 76.9 | 31.8 | 41.6 | 46.0 |
| DeepSeek-R1-Distill-7B | 70.9 | 18.3 | 85.0 | 33.5 | 51.9 | 51.9 | 7.9 | 78.1 | 32.8 | 42.7 | 47.3 |
| GenPRM-7B | 75.0 | 21.3 | 86.9 | 35.6 | 54.7 | 59.4 | 9.6 | 82.2 | 35.0 | 46.6 | 50.7 |
| Turn 3 | Turn 3 | Turn 3 | Turn 3 | Turn 3 | Turn 3 | Turn 3 | Turn 3 | Turn 3 | Turn 3 | Turn 3 | Turn 3 |
| Generator | 67.8 | 18.1 | 85.0 | 32.1 | 50.8 | 49.7 | 8.1 | 77.1 | 30.8 | 41.4 | 46.1 |
| DeepSeek-R1-Distill-7B | 69.6 | 18.8 | 85.0 | 33.4 | 51.7 | 51.9 | 8.3 | 78.2 | 32.7 | 42.7 | 47.2 |
| GenPRM-7B | 76.2 | 22.8 | 86.7 | 36.0 | 55.4 | 62.7 | 9.3 | 82.9 | 34.9 | 47.5 | 51.5 |
Table 3: Results of GenPRM with different label estimation method and threshold on ProcessBench, reported with Pass@1. The best results are shown in bold .
| Estimation Method | Positive Label Criterion | GSM8K | MATH | Olympiad Bench | Omni- MATH | Avg. |
|------------------------------------|----------------------------|---------|--------|------------------|--------------|--------|
| 𝑃 𝑡 = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) (hard label) | 𝑃 𝑡 > 0 | 72.9 | 78.9 | 73.2 | 68 | 73.2 |
| 𝑃 𝑡 = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) - 𝑀𝐶 ( 𝑠 𝑡 ) | 𝑃 𝑡 ≥ - 0 . 1 | 77.3 | 79.9 | 70.8 | 68.5 | 74.1 |
| 𝑃 𝑡 = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) - 𝑀𝐶 ( 𝑠 𝑡 ) | 𝑃 𝑡 ≥ - 0 . 3 | 76.8 | 79.6 | 71.1 | 69 | 74.1 |
| 𝑃 𝑡 = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) - 𝑀𝐶 ( 𝑠 𝑡 ) | 𝑃 𝑡 ≥ - 0 . 5 | 75.8 | 80.2 | 72.8 | 68.6 | 74.3 |
| = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) 𝑀𝐶 ( 𝑠 𝑡 ) | 𝑃 𝑡 ≥ 0 . 1 | 74.8 | 78.7 | 71.6 | 68.7 | 73.5 |
| = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) 𝑀𝐶 ( 𝑠 𝑡 ) | 𝑃 𝑡 ≥ 0 . 5 | 75.7 | 79.2 | 70.4 | 68.5 | 73.5 |
| 𝑃 𝑡 | 𝑃 𝑡 ≥ 0 . 8 | 78.7 | 80.3 | 72.2 | 69.8 | 75.2 |
| | 𝑃 𝑡 ≥ 1 . 0 | 76.4 | 77.4 | 68.1 | 67.2 | 72.3 |
Table 4: Results of GenPRM with different label estimation method and threshold on ProcessBench, reported with Maj@8. The best results are shown in bold .
| Estimation Method | Positive Label Criterion | GSM8K | MATH | Olympiad Bench | Omni- MATH | Avg. |
|------------------------------------|----------------------------|---------|--------|------------------|--------------|--------|
| 𝑃 𝑡 = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) (hard label) | 𝑃 𝑡 > 0 | 75.1 | 83.8 | 80.6 | 74.4 | 78.5 |
| 𝑃 𝑡 = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) - 𝑀𝐶 ( 𝑠 𝑡 ) | 𝑃 𝑡 ≥ - 0 . 1 | 79.8 | 85.1 | 78 | 74.5 | 79.4 |
| 𝑃 𝑡 = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) - 𝑀𝐶 ( 𝑠 𝑡 ) | 𝑃 𝑡 ≥ - 0 . 3 | 80.9 | 86.5 | 78.1 | 75 | 80.2 |
| 𝑃 𝑡 = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) - 𝑀𝐶 ( 𝑠 𝑡 ) | 𝑃 𝑡 ≥ - 0 . 5 | 78.1 | 85.6 | 79.1 | 73.4 | 79.1 |
| = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) 𝑀𝐶 ( 𝑠 𝑡 ) | 𝑃 𝑡 ≥ 0 . 1 | 77 | 84.6 | 78.1 | 75.3 | 78.7 |
| = 𝑀𝐶 ( 𝑠 𝑡 ,𝑎 𝑡 ) 𝑀𝐶 ( 𝑠 𝑡 ) | 𝑃 𝑡 ≥ 0 . 5 | 78 | 85.2 | 78.2 | 74.3 | 78.9 |
| 𝑃 𝑡 | 𝑃 𝑡 ≥ 0 . 8 | 81 | 85.7 | 78.4 | 76.8 | 80.5 |
| | 𝑃 𝑡 ≥ 1 . 0 | 81.1 | 84.1 | 76 | 74.7 | 79 |
Reasoning Components. To understand how each reasoning component influence GenPRM, we conduct experiments by training GenPRM with: (1) CoT data only, (2) code verification data only, and (3) full data. During inference phase, we also compare several variants. For example, GenPRM trained with full data can be used to only verify each step with CoT only by stopping generation at </analyze> token. The results in Table 5 show that: (1) the improvement of GenPRM mainly comes
from CoT reasoning; (2) generating code and reasoning with code execution result improves the process verification performance as well.
Table 5: Results on ProcessBench of GenPRM with different reasoning components, reported with Maj@8. The best results are shown in bold .
| Training | Training | Inference | Inference | Inference | GSM8K | MATH | Olympiad Bench | Omni- MATH | Avg. |
|------------|------------|-------------|-------------|-------------|---------|--------|------------------|--------------|--------|
| CoT | Code | CoT | Code | Code Exec. | GSM8K | MATH | Olympiad Bench | Omni- MATH | Avg. |
| ✗ | ✗ | ✗ | ✗ | ✗ | 63.9 | 65.8 | 54.5 | 55.9 | 60.0 |
| ✗ | ✓ | ✗ | ✓ | ✗ | 67.0 | 70.8 | 61.6 | 57.4 | 64.2 |
| ✗ | ✓ | ✗ | ✓ | ✓ | 70.6 | 76.6 | 67.3 | 63.9 | 69.6 |
| ✓ | ✗ | ✓ | ✗ | ✗ | 76.4 | 83.0 | 80.5 | 75.4 | 78.8 |
| | | ✗ | ✓ | ✗ | 60.1 | 66.7 | 59.9 | 59.2 | 61.5 |
| | | ✗ | ✓ | ✓ | 61.3 | 74.7 | 68.1 | 62.0 | 66.5 |
| ✓ | ✓ | ✓ | ✗ | ✗ | 78.8 | 85.1 | 78.7 | 74.9 | 79.3 |
| | | ✓ | ✓ | ✗ | 81.0 | 85.1 | 78.1 | 75.5 | 79.9 |
| | | ✓ | ✓ | ✓ | 81.0 | 85.7 | 78.4 | 76.8 | 80.5 |
## 5. Related Work
Process Reward Models. Process reward models have been proved to be effective for providing step-wise scores and are superior to outcome reward models in mathematical reasoning tasks (Uesato et al., 2022; Lightman et al., 2024). However, annotating a process supervision dataset such as PRM800K (Lightman et al., 2024) requires significant human costs. To mitigate this cost, prior works utilize Monte Carlo estimation (Wang et al., 2024b) and binary search (Luo et al., 2024) for automated label generation. Subsequent research improves PRMs through methods such as advantage modeling (Setlur et al., 2025), 𝑄 -value rankings (Li and Li, 2025), implicit entropy regularization (Zhang et al., 2024a), retrieval-augmented generation (Zhu et al., 2025), and fast-slow verification (Zhong et al., 2025). Furthermore, the community has developed high-quality opensource PRMs, including the RLHFlow series (Xiong et al., 2024), Math-psa (Wang et al., 2024a), Skywork series (Skywork o1 Team, 2024), and Qwen2.5-Math series (Zheng et al., 2024; Zhang et al., 2025c). Recently, a line of works focus on extending PRMs to other tasks, including coding (Zhang et al., 2024b), medical tasks (Jiang et al., 2025), agentic tasks (Choudhury, 2025), general domain tasks (Zhang et al., 2025a; Zeng et al., 2025), and multimodal tasks (Wang et al., 2025). Current studies also focus on benchmarking PRMs (Zheng et al., 2024; Song et al., 2025) to systematically evaluate their performance.
Large Language Model Test-Time Scaling. Scaling test-time computation is an effective method for improving performance during the inference phase (OpenAI, 2024a,b; DeepSeek-AI et al., 2025). TTS is commonly implemented with external verifiers (e.g., ORMs and PRMs) or strategies (e.g., beam search and MCTS) (Wu et al., 2025; Snell et al., 2025; Beeching et al., 2024; Liu et al., 2025). In this work, we scale the test-time computation of a generative PRM with an explicit reasoning process and GenPRM can also serve as a verifier or a critic model in external TTS.
Enhancing the Generative Abilities of Reward Models. Previous research has investigated methods to enhance the generative capabilities of reward models using CoT reasoning (Ankner et al., 2024; Zhang et al., 2025b; Mahan et al., 2024). For instance, CLoud reward models (Ankner et al., 2024) are trained to generate critiques for responses and predict rewards using an additional reward
head. GenRM-CoT (Zhang et al., 2025b) and GenRM (Mahan et al., 2024) train generative reward models that perform CoT reasoning before making final predictions via SFT and preference learning, respectively. CTRL (Xie et al., 2025) demonstrates that critic models exhibit strong discriminative abilities when utilized as generative reward models. Prior to these works, GRM (Yang et al., 2024c) regularizes the hidden states of reward models with a text generation loss.
## 6. Conclusion
In this work, we propose GenPRM, a generative process reward model that performs explicit reasoning and code verification for process supervision and enables scaling the test-time compute of PRMs. Experimental results on ProcessBench and several mathematical datasets show GenPRM outperforms prior PRMs. We also demonstrate that the performance of GenPRM increases via test-time scaling and GenPRM is effective as a critic model. We believe that this work provides perspectives on PRMs by demonstrating the strong TTS abilities of PRMs and extending the applications of PRMs.
Limitations. First, GenPRM provides process supervision by generative reasoning, which introduces additional computation during inference phase. Future work will investigate how to prune the reasoning process dynamically (Zhong et al., 2025). Although GenPRM focuses mainly on mathematical reasoning tasks, it is worth to explore how to apply generative reasoning on coding and general reasoning tasks in the future (Zhang et al., 2025a). Additionally, it would be interesting to leverage RL to incentivize the generative reasoning abilities of GenPRM.
## References
- AI-MO. AIME 2024, 2024a. URL https://huggingface.co/datasets/AI-MO/ aimo-validation-aime .
- AI-MO. AMC 2023, 2024b. URL https://huggingface.co/datasets/AI-MO/ aimo-validation-amc .
- Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D Chang, and Prithviraj Ammanabrolu. Critique-out-Loud Reward Models. arXiv preprint arXiv:2408.11791 , 2024.
- Anthropic. Introducing Claude, 2023. URL https://www.anthropic.com/index/ introducing-claude/ .
- Edward Beeching, Lewis Tunstall, and Sasha Rush. Scaling Test-Time Compute with Open Models, 2024. URL https://huggingface.co/spaces/HuggingFaceH4/ blogpost-scaling-test-time-compute .
- Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large Language Monkeys: Scaling Inference Compute with Repeated Sampling. arXiv preprint arXiv:2407.21787 , 2024.
- Sanjiban Choudhury. Process Reward Models for LLM Agents: Practical Framework and Directions. arXiv preprint arXiv:2502.10325 , 2025.
- Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. Process Reinforcement through Implicit Rewards. arXiv preprint arXiv:2502.01456 , 2025.
- DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Qu, Hui Li, Jianzhong Guo, Jiashi Li, Jiawei Wang, Jingchang Chen, Jingyang Yuan, Junjie Qiu, Junlong Li, J. L. Cai, Jiaqi Ni, Jian Liang, Jin Chen, Kai Dong, Kai Hu, Kaige Gao, Kang Guan, Kexin Huang, Kuai Yu, Lean Wang, Lecong Zhang, Liang Zhao, Litong Wang, Liyue Zhang, Lei Xu, Leyi Xia, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Meng Li, Miaojun Wang, Mingming Li, Ning Tian, Panpan Huang, Peng Zhang, Qiancheng Wang, Qinyu Chen, Qiushi Du, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, R. J. Chen, R. L. Jin, Ruyi Chen, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shengfeng Ye, Shiyu Wang, Shuiping Yu, Shunfeng Zhou, Shuting Pan, S. S. Li, Shuang Zhou, Shaoqing Wu, Shengfeng Ye, Tao Yun, Tian Pei, Tianyu Sun, T. Wang, Wangding Zeng, Wanjia Zhao, Wen Liu, Wenfeng Liang, Wenjun Gao, Wenqin Yu, Wentao Zhang, W. L. Xiao, Wei An, Xiaodong Liu, Xiaohan Wang, Xiaokang Chen, Xiaotao Nie, Xin Cheng, Xin Liu, Xin Xie, Xingchao Liu, Xinyu Yang, Xinyuan Li, Xuecheng Su, Xuheng Lin, X. Q. Li, Xiangyue Jin, Xiaojin Shen, Xiaosha Chen, Xiaowen Sun, Xiaoxiang Wang, Xinnan Song, Xinyi Zhou, Xianzu Wang, Xinxia Shan, Y. K. Li, Y. Q. Wang, Y. X. Wei, Yang Zhang, Yanhong Xu, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Wang, Yi Yu, Yichao Zhang, Yifan Shi, Yiliang Xiong, Ying He, Yishi Piao, Yisong Wang, Yixuan Tan, Yiyang Ma, Yiyuan Liu, Yongqiang Guo, Yuan Ou, Yuduan Wang, Yue Gong, Yuheng Zou, Yujia He, Yunfan Xiong, Yuxiang Luo, Yuxiang You, Yuxuan Liu, Yuyang Zhou, Y. X. Zhu, Yanhong Xu, Yanping Huang, Yaohui Li, Yi Zheng, Yuchen Zhu, Yunxian Ma, Ying Tang, Yukun Zha, Yuting Yan, Z. Z. Ren, Zehui Ren, Zhangli Sha, Zhe Fu, Zhean Xu, Zhenda Xie, Zhengyan Zhang, Zhewen Hao, Zhicheng Ma, Zhigang Yan, Zhiyu Wu, Zihui Gu, Zijia Zhu, Zijun Liu, Zilin Li, Ziwei Xie, Ziyang Song, Zizheng Pan, Zhen Huang, Zhipeng Xu, Zhongyu Zhang, and Zhen Zhang. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948 , 2025.
- Gemma Team and Google DeepMind. Introducing Gemma 3: The most capable model you can run on a single GPU or TPU, March 2025. URL https://blog.google/technology/developers/ gemma-3 .
- Zhibin Gou, Zhihong Shao, Yeyun Gong, yelong shen, Yujiu Yang, Nan Duan, and Weizhu Chen. CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing. In International Conference on Learning Representations (ICLR) , 2024. URL https://openreview.net/forum? id=Sx038qxjek .
- Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring Mathematical Problem Solving With the MATH Dataset. In Advances in Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , 2021. URL https://openreview.net/forum?id=7Bywt2mQsCe .
- Shuyang Jiang, Yusheng Liao, Zhe Chen, Ya Zhang, Yanfeng Wang, and Yu Wang. MedS 3 : Towards Medical Small Language Models with Self-Evolved Slow Thinking. arXiv preprint arXiv:2501.12051 , 2025.
- Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving Quantitative Reasoning Problems with Language Models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,
- Advances in Neural Information Processing Systems (NeurIPS) , volume 35, pages 3843-3857. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper\_files/paper/ 2022/file/18abbeef8cfe9203fdf9053c9c4fe191-Paper-Conference.pdf .
- Wendi Li and Yixuan Li. Process Reward Model with Q-value Rankings. In International Conference on Learning Representations (ICLR) , 2025. URL https://openreview.net/forum?id= wQEdh2cgEk .
- Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's Verify Step by Step. In International Conference on Learning Representations (ICLR) , 2024. URL https://openreview.net/forum? id=v8L0pN6EOi .
- Runze Liu, Fengshuo Bai, Yali Du, and Yaodong Yang. Meta-Reward-Net: Implicitly Differentiable Reward Learning for Preference-based Reinforcement Learning. In Advances in Neural Information Processing Systems (NeurIPS) , volume 35, pages 22270-22284, 2022.
- Runze Liu, Yali Du, Fengshuo Bai, Jiafei Lyu, and Xiu Li. PEARL: Zero-shot Cross-task Preference Alignment and Robust Reward Learning for Robotic Manipulation. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, International Conference on Machine Learning (ICML) , volume 235 of Proceedings of Machine Learning Research , pages 30946-30964. PMLR, 21-27 Jul 2024. URL https://proceedings. mlr.press/v235/liu24o.html .
- Runze Liu, Junqi Gao, Jian Zhao, Kaiyan Zhang, Xiu Li, Biqing Qi, Wanli Ouyang, and Bowen Zhou. Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling. arXiv preprint arXiv:2502.06703 , 2025.
- Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, et al. Improve Mathematical Reasoning in Language Models by Automated Process Supervision. arXiv preprint arXiv:2406.06592 , 2024.
- Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-Refine: Iterative Refinement with Self-Feedback. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems (NeurIPS) , volume 36, pages 46534-46594. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper\_files/paper/2023/file/ 91edff07232fb1b55a505a9e9f6c0ff3-Paper-Conference.pdf .
- Dakota Mahan, Duy Van Phung, Rafael Rafailov, Chase Blagden, Nathan Lile, Louis Castricato, JanPhilipp Fränken, Chelsea Finn, and Alon Albalak. Generative Reward Models. arXiv preprint arXiv:2410.12832 , 2024.
OpenAI. GPT-4 Technical Report. arXiv preprint arXiv:2303.08774 , 2023.
- OpenAI. Learning to reason with LLMs, 2024a. URL https://openai.com/index/ learning-to-reason-with-llms .
- OpenAI. OpenAI o3-mini, 2024b. URL https://openai.com/index/openai-o3-mini .
- Qwen Team. QwQ-32B: Embracing the Power of Reinforcement Learning, March 2025. URL https://qwenlm.github.io/blog/qwq-32b .
- Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning. In International Conference on Learning Representations (ICLR) , 2025. URL https://openreview.net/forum?id=A6Y7AqlzLW .
- Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv preprint arXiv:2402.03300 , 2024.
- Skywork o1 Team. Skywork-o1 Open Series. https://huggingface.co/Skywork , November 2024. URL https://huggingface.co/Skywork .
- Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM Test-Time Compute Optimally Can be More Effective than Scaling Parameters for Reasoning. In International Conference on Learning Representations (ICLR) , 2025. URL https://openreview.net/forum?id= 4FWAwZtd2n .
- Mingyang Song, Zhaochen Su, Xiaoye Qu, Jiawei Zhou, and Yu Cheng. PRMBench: A Fine-grained and Challenging Benchmark for Process-Level Reward Models. arXiv preprint arXiv:2501.03124 , 2025.
- Xiaoyu Tan, Tianchu Yao, Chao Qu, Bin Li, Minghao Yang, Dakuan Lu, Haozhe Wang, Xihe Qiu, Wei Chu, Yinghui Xu, et al. AURORA: Automated Training Framework of Universal Process Reward Models via Ensemble Prompting and Reverse Verification. arXiv preprint arXiv:2502.11520 , 2025.
- Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275 , 2022.
- Jun Wang, Meng Fang, Ziyu Wan, Muning Wen, Jiachen Zhu, Anjie Liu, Ziqin Gong, Yan Song, Lei Chen, Lionel M Ni, et al. OpenR: An open source framework for advanced reasoning with large language models. arXiv preprint arXiv:2410.09671 , 2024a.
- Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 9426-9439, 2024b.
- Weiyun Wang, Zhangwei Gao, Lianjie Chen, Chen Zhe, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, Lewei Lu, Haodong Duan, Yu Qiao, Jifeng Dai, and Wenhai Wang. VisualPRM: An Effective Process Reward Model for Multimodal Reasoning. arXiv preprint arXiv:2503.10291 , 2025.
- Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In International Conference on Learning Representations (ICLR) , 2023. URL https: //openreview.net/forum?id=1PL1NIMMrw .
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. In Advances in neural information processing systems (NeurIPS) , volume 35, pages 24824-24837, 2022.
- Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for LLM Problem-Solving. In International Conference on Learning Representations (ICLR) , 2025. URL https://openreview.net/forum? id=VNckp7JEHn .
- Zhihui Xie, Liyu Chen, Weichao Mao, Jingjing Xu, Lingpeng Kong, et al. Teaching Language Models to Critique via Reinforcement Learning. arXiv preprint arXiv:2502.03492 , 2025.
- Wei Xiong, Hanning Zhang, Nan Jiang, and Tong Zhang. An Implementation of Generative PRM. https://github.com/RLHFlow/RLHF-Reward-Modeling , 2024.
- An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. Qwen2.5 Technical Report. arXiv preprint arXiv:2412.15115 , 2024a.
- An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement. arXiv preprint arXiv:2409.12122 , 2024b.
- Rui Yang, Ruomeng Ding, Yong Lin, Huan Zhang, and Tong Zhang. Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs. In Advances in Neural Information Processing Systems (NeurIPS) , 2024c. URL https://openreview.net/forum?id=jwh9MHEfmY .
- Lifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. Free Process Rewards without Process Labels. arXiv preprint arXiv:2412.01981 , 2024.
- Thomas Zeng, Shuibai Zhang, Shutong Wu, Christian Classen, Daewon Chae, Ethan Ewer, Minjae Lee, Heeju Kim, Wonjun Kang, Jackson Kunde, et al. VersaPRM: Multi-Domain Process Reward Model via Synthetic Reasoning Data. arXiv preprint arXiv:2502.06737 , 2025.
- Hanning Zhang, Pengcheng Wang, Shizhe Diao, Yong Lin, Rui Pan, Hanze Dong, Dylan Zhang, Pavlo Molchanov, and Tong Zhang. Entropy-Regularized Process Reward Model. arXiv preprint arXiv:2412.11006 , 2024a.
- Kaiyan Zhang, Jiayuan Zhang, Haoxin Li, Xuekai Zhu, Ermo Hua, Xingtai Lv, Ning Ding, Biqing Qi, and Bowen Zhou. OpenPRM: Building Open-domain Process-based Reward Models with Preference Trees. In International Conference on Learning Representations (ICLR) , 2025a. URL https://openreview.net/forum?id=fGIqGfmgkW .
- Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. Generative Verifiers: Reward Modeling as Next-Token Prediction. In International Conference on Learning Representations (ICLR) , 2025b. URL https://openreview.net/forum?id=Ccwp4tFEtE .
- Yuxiang Zhang, Shangxi Wu, Yuqi Yang, Jiangming Shu, Jinlin Xiao, Chao Kong, and Jitao Sang. o1-Coder: an o1 Replication for Coding. arXiv preprint arXiv:2412.00154 , 2024b.
- Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The Lessons of Developing Process Reward Models in Mathematical Reasoning. arXiv preprint arXiv:2501.07301 , 2025c.
- Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. ProcessBench: Identifying Process Errors in Mathematical Reasoning. arXiv preprint arXiv:2412.06559 , 2024.
- Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems (NeurIPS) , volume 36, pages 46595-46623. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper\_files/paper/2023/file/ 91f18a1287b398d378ef22505bf41832-Paper-Datasets\_and\_Benchmarks.pdf .
- Jianyuan Zhong, Zeju Li, Zhijian Xu, Xiangyu Wen, and Qiang Xu. Dyve: Thinking Fast and Slow for Dynamic Process Verification. arXiv preprint arXiv:2502.11157 , 2025.
- Jiachen Zhu, Congmin Zheng, Jianghao Lin, Kounianhua Du, Ying Wen, Yong Yu, Jun Wang, and Weinan Zhang. Retrieval-Augmented Process Reward Model for Generalizable Mathematical Reasoning. arXiv preprint arXiv:2502.14361 , 2025.
- Xuekai Zhu, Biqing Qi, Kaiyan Zhang, Xinwei Long, Zhouhan Lin, and Bowen Zhou. PaD: Programaided Distillation Can Teach Small Models Reasoning Better than Chain-of-thought Fine-tuning. In Kevin Duh, Helena Gomez, and Steven Bethard, editors, Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages 2571-2597, Mexico City, Mexico, June 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-long.142. URL https://aclanthology.org/2024.naacl-long.142/ .
## A. Experimental Details
## A.1. Scoring and Voting Methods
PRM-Last. PRM-Last considers the process reward of the last step of the entire LLM response as the final score, i.e., score = 𝑟 𝑇 .
PRM-Avg. PRM-Avg computes the mean process reward across all steps as the final score, i.e., score = 1 𝑇 ∑︀ 𝑇 𝑡 =1 𝑟 𝑡 .
PRM-Min. PRM-Min uses the minimum process reward across all steps as the final score, i.e., score = min 𝑟 { 𝑟 𝑡 } 𝑇 𝑡 =1 .
## A.2. Implementation Details
Prompt for CoT and code rationale generation is shown in Table A.2.
## Prompt for CoT and code rationale generation
## [System]:
You are a math teacher. Your task is to review and critique the paragraphs in solution step by step with python code.
## [User]:
The following is the math problem and a solution (split into paragraphs, enclosed with tags and indexed from 1):
[Math Problem] {problem} [ Solution] <paragraph\_1> {solution\_section\_1} </paragraph\_1> ... <paragraph\_n> {solution\_section\_n} </paragraph\_n> Your task is to verify the correctness of paragraph in the solution. Split your verification by '### Paragraph {{ID}}' .
Your verification for each paragraph should be constructed by 2 parts, wrapped by '<analyze></analyze>' and '<verify></verify>' separately.
1. In '<analyze></analyze>' part, you need to analyze the reasoning process and explain why the paragraph is correct or incorrect in detail.
2. In '<verify></verify>' part, you must write **Python code** in the form of '''python\n{{CODE}}\n''' to verify every details that can be verified by code. You can import PyPI (i.e., 'sympy', 'scipy' and so on) to implement complicated calculation. Make sure to print the critic results in the code. Every code will be executed automatically by system. You need to analyze the '[Code Output]' after code executing.
3. >Pay attention that you must follow the format of '''python\n{{CODE}}\n''' when you write the code, otherwise the code will not be executed.
After all verifications, if you identify an error in a paragraph, return the **index of the paragraph where the earliest error occurs**. Otherwise, return the **index of -1 (which typically denotes "not found")**. Please put your final answer (i.e., the index) within box in the form of '$\\boxed{{INDEX}}$' .
Following Zheng et al. (2024); Zhang et al. (2025c), we use the prompt in Table A.2 to evaluate LLM-as-a-judge methods on ProcessBench (Zheng et al., 2024).
## Evaluation prompt for LLM-as-a-judge methods on ProcessBench
I will provide a math problem along with a solution. They will be formatted as follows:
[Math Problem]
```
```
Your task is to review each paragraph of the solution in sequence, analyzing, verifying, and critiquing the reasoning in detail. You need to provide the analyses and the conclusion in the following format:
```
```
... <analysis\_n> ...(analysis of paragraph n)... </analysis\_n> <conclusion> Correct/Incorrect </conclusion> * When you analyze each paragraph, you should use proper verification, recalculation, or reflection to indicate whether it is logically and mathematically valid. Please elaborate on the analysis process carefully. * If an error is detected in any paragraph, you should describe the nature and cause of the error in detail, and suggest how to correct the error or the correct approach. Once a paragraph is found to contain any error, stop further analysis of subsequent paragraphs (as they may depend on the identified error) and directly provide the conclusion of "Incorrect." For instance, given a solution of five paragraphs, if an error is found in the third paragraph, you should reply in the following format: <analysis\_1> ...(analysis of paragraph 1)... </analysis\_1> <analysis\_2> ...(analysis of paragraph 2)... </analysis\_2> <analysis\_3> ...(analysis of paragraph 3; since an error is found here, also provide detailed critique and correction guideline)... </analysis\_3> <conclusion> Incorrect </conclusion> Note that the analyses of paragraphs 4 and 5 should be skipped as the paragraph 3 has been found to contain an error. * Respond with your analyses and conclusion directly. -----------------The following is the math problem and the solution for you task:
[Math Problem]
{tagged\_problem}
[ Solution]
{tagged\_response}
## Prompt for critique generation
## [User]:
The following is a math problem and my solution. Your task is to review and critique the paragraphs in solution step by step. Pay attention that you should not solve the problem and give the final answer. All of your task is to critique. Output your judgement of whether the paragraph is correct in the form of '\\boxed{{Yes|No}}' at the end of each paragraph verification:
```
```
## B. Additional Results
We provide full results of ProcessBench in Table 6.
Model Size. We investigate the impact of model size on GenPRM by evaluating variants with 1.5B, 7B, and 32B parameters. As shown in Table 7, scaling the model from 1.5B to 7B parameters yields substantial performance gains (57.3 → 75.2 and 63.4 → 80.5). However, further increasing the model size to 32B provides only marginal improvements, suggesting that the 7B variant offers the best balance between efficiency and effectiveness.
Data Size. To assess the influence of training data volume, we train GenPRM on progressively larger subsets of ProcessBench (25%, 50%, and 100% of the full dataset). Table 8 demonstrates that Pass@1 F1 scores improve rapidly with initial data increases, but the growth rate slows substantially with additional data.
Inference Tokens. We provide statistics of the reasoning tokens per step and per response in Table 9.
Table 6: Full results of critic models and PRMs on ProcessBench.
| Model | GSM8K | GSM8K | GSM8K | MATH | MATH | MATH | OlympiadBench | OlympiadBench | OlympiadBench | Omni-MATH | Omni-MATH | Omni-MATH | Avg. |
|-------------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|----------------------------|
| Model | Err. | Corr. | F1 | Err. | Corr. | F1 | Err. | Corr. | F1 | Err. | Corr. | F1 | F1 |
| Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) | Proprietary LLMs ( Critic) |
| GPT-4-0806 | 70.0 | 91.2 | 79.2 | 54.4 | 76.6 | 63.6 | 45.8 | 58.4 | 51.4 | 45.2 | 65.6 | 53.5 | 61.9 |
| o1-mini | 88.9 | 97.9 | 93.2 | 83.5 | 95.1 | 88.9 | 80.2 | 95.6 | 87.2 | 74.8 | 91.7 | 82.4 | 87.9 |
| Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) | Open-Source LLMs ( Critic) |
| Llama-3-8B-Instruct | 42.5 | 7.8 | 13.1 | 28.6 | 9.1 | 13.8 | 27.1 | 2.7 | 4.8 | 26.1 | 8.3 | 12.6 | 11.1 |
| Llama-3-70B-Instruct | 35.7 | 96.9 | 52.2 | 13.0 | 93.3 | 22.8 | 12.0 | 92.0 | 21.2 | 11.2 | 91.7 | 20.0 | 29.1 |
| Llama-3.1-8B-Instruct | 44.4 | 6.2 | 10.9 | 41.9 | 2.7 | 5.1 | 32.4 | 1.5 | 2.8 | 32.0 | 0.8 | 1.6 | 5.1 |
| Llama-3.1-70B-Instruct | 64.3 | 89.6 | 74.9 | 35.4 | 75.6 | 48.2 | 35.1 | 69.9 | 46.7 | 30.7 | 61.8 | 41.0 | 52.7 |
| Llama-3.3-70B-Instruct | 72.5 | 96.9 | 82.9 | 43.3 | 94.6 | 59.4 | 31.0 | 94.1 | 46.7 | 28.2 | 90.5 | 43.0 | 58.0 |
| Qwen2.5-Math-7B-Instruct | 15.5 | 100.0 | 26.8 | 14.8 | 96.8 | 25.7 | 7.7 | 91.7 | 14.2 | 6.9 | 88.0 | 12.7 | 19.9 |
| Qwen2.5-Math-72B-Instruct | 49.8 | 96.9 | 65.8 | 36.0 | 94.3 | 52.1 | 19.5 | 97.3 | 32.5 | 19.0 | 96.3 | 31.7 | 45.5 |
| Qwen2.5-Coder-7B-Instruct | 7.7 | 100.0 | 14.3 | 3.4 | 98.3 | 6.5 | 2.1 | 99.1 | 4.1 | 0.9 | 98.3 | 1.8 | 6.7 |
| Qwen2.5-Coder-14B-Instruct | 33.8 | 96.4 | 50.1 | 25.4 | 92.4 | 39.9 | 20.7 | 94.1 | 34.0 | 15.9 | 94.2 | 27.3 | 37.8 |
| Qwen2.5-Coder-32B-Instruct | 54.1 | 94.8 | 68.9 | 44.9 | 90.6 | 60.1 | 33.4 | 91.2 | 48.9 | 31.5 | 87.6 | 46.3 | 56.1 |
| Qwen2-7B-Instruct | 40.6 | 4.7 | 8.4 | 30.5 | 13.8 | 19.0 | 22.4 | 10.9 | 14.7 | 20.0 | 8.7 | 12.1 | 13.6 |
| Qwen2-72B-Instruct | 57.0 | 82.9 | 67.6 | 37.7 | 70.9 | 49.2 | 34.0 | 55.2 | 42.1 | 32.3 | 53.1 | 40.2 | 49.8 |
| Qwen2.5-7B-Instruct | 40.6 | 33.2 | 36.5 | 30.8 | 45.1 | 36.6 | 26.5 | 33.9 | 29.7 | 26.2 | 28.6 | 27.4 | 32.6 |
| Qwen2.5-14B-Instruct | 54.6 | 94.8 | 69.3 | 38.4 | 87.4 | 53.3 | 31.5 | 78.8 | 45.0 | 28.3 | 76.3 | 41.3 | 52.2 |
| Qwen2.5-32B-Instruct | 49.3 | 97.9 | 65.6 | 36.7 | 95.8 | 53.1 | 25.3 | 95.9 | 40.0 | 24.1 | 92.5 | 38.3 | 49.3 |
| Qwen2.5-72B-Instruct | 62.8 | 96.9 | 76.2 | 46.3 | 93.1 | 61.8 | 38.7 | 92.6 | 54.6 | 36.6 | 90.9 | 52.2 | 61.2 |
| QwQ-32B-Preview | 81.6 | 95.3 | 88.0 | 78.1 | 79.3 | 78.7 | 61.4 | 54.6 | 57.8 | 55.7 | 68.0 | 61.3 | 71.5 |
| PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) | PRMs (1.5B) |
| Skywork-PRM-1.5B | 50.2 | 71.5 | 59.0 | 37.9 | 65.2 | 48.0 | 15.4 | 26.0 | 19.3 | 13.6 | 32.8 | 19.2 | 36.4 |
| GenPRM-1.5B (Pass@1) | 37.0 | 92.7 | 52.8 | 57.1 | 80.1 | 66.6 | 47.0 | 66.5 | 55.1 | 45.2 | 68.7 | 54.5 | 57.3 |
| GenPRM-1.5B (Maj@8) | 34.8 | 97.4 | 51.3 | 64.7 | 87.7 | 74.4 | 57.2 | 76.1 | 65.3 | 51.3 | 80.1 | 62.5 | 63.4 |
| PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) | PRMs (7-8B) |
| Math-Shepherd-PRM-7B | 32.4 | 91.7 | 47.9 | 18.0 | 82.0 | 29.5 | 15.0 | 71.1 | 24.8 | 14.2 | 73.0 | 23.8 | 31.5 |
| RLHFlow-PRM-Mistral-8B | 33.8 | 99.0 | 50.4 | 21.7 | 72.2 | 33.4 | 8.2 | 43.1 | 13.8 | 9.6 | 45.2 | 15.8 | 28.4 |
| RLHFlow-PRM-Deepseek-8B | 24.2 | 98.4 | 38.8 | 21.4 | 80.0 | 33.8 | 10.1 | 51.0 | 16.9 | 10.9 | 51.9 | 16.9 | 26.6 |
| Skywork-PRM-7B | 61.8 | 82.9 | 70.8 | 43.8 | 62.2 | 53.6 | 17.9 | 31.9 | 22.9 | 14.0 | 41.9 | 21.0 | 42.1 |
| EurusPRM-Stage1 | 46.9 | 42.0 | 44.3 | 33.3 | 38.2 | 35.6 | 23.9 | 19.8 | 21.7 | 21.9 | 24.5 | 23.1 | 31.2 |
| EurusPRM-Stage2 | 51.2 | 44.0 | 47.3 | 36.4 | 35.0 | 35.7 | 25.7 | 18.0 | 21.2 | 23.1 | 19.1 | 20.9 | 31.3 |
| Qwen2.5-Math-7B-Math-Shepherd | 46.4 | 95.9 | 62.5 | 18.9 | 96.6 | 31.6 | 7.4 | 93.8 | 13.7 | 4.0 | 95.0 | 7.7 | 28.9 |
| Qwen2.5-Math-7B-PRM800K | 53.1 | 95.3 | 68.2 | 48.0 | 90.1 | 62.6 | 35.7 | 87.3 | 50.7 | 29.8 | 86.1 | 44.3 | 56.5 |
| Qwen2.5-Math-PRM-7B | 72.0 | 96.4 | 82.4 | 68.0 | 90.4 | 77.6 | 55.7 | 85.5 | 67.5 | 55.2 | 83.0 | 66.3 | 73.5 |
| RetrievalPRM-7B | 64.7 | 88.1 | 74.6 | 67.2 | 75.6 | 71.1 | 56.0 | 65.2 | 60.2 | 52.8 | 62.7 | 57.3 | 65.8 |
| Universal-PRM-7B | - | - | 85.8 | - | - | 77.7 | - | - | 67.6 | - | - | 66.4 | 74.3 |
| Direct Generative PRM-7B | 52.7 | 81.4 | 63.9 | 55.9 | 80.0 | 65.8 | 44.8 | 69.6 | 54.5 | 45.5 | 72.6 | 55.9 | 60.0 |
| GenPRM-7B (Pass@1) | 67.7 | 94.0 | 78.7 | 74.6 | 87.0 | 80.3 | 68.3 | 76.6 | 72.2 | 63.5 | 77.4 | 69.8 | 75.2 |
| GenPRM-7B (Maj@8) | 69.6 | 96.9 | 81.0 | 80.5 | 91.6 | 85.7 | 74.0 | 83.5 | 78.4 | 70.0 | 85.1 | 76.8 | 80.5 |
| PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) | PRMs (14-72B) |
| Dyve-14B | - | - | 68.5 | - | - | 58.3 | - | - | 49.0 | - | - | 47.2 | 55.8 |
| Qwen2.5-Math-PRM-72B | 78.7 | 97.9 | 87.3 | 74.2 | 88.2 | 80.6 | 67.9 | 82.0 | 74.3 | 64.8 | 78.8 | 71.1 | 78.3 |
| GenPRM-32B (Pass@1) | 73.1 | 96.4 | 83.1 | 79.4 | 84.1 | 81.7 | 73.4 | 72.2 | 72.8 | 70.3 | 75.5 | 72.8 | 77.6 |
| GenPRM-32B (Maj@8) | 74.9 | 98.5 | 85.1 | 84.0 | 88.7 | 86.3 | 79.0 | 78.8 | 78.9 | 76.3 | 84.2 | 80.1 | 82.6 |
## C. Cases
In this section, we analyze two cases to have a better understanding of GenPRM. The case in Figure 5 shows that the code execution feedback can correct the mistakes in CoT and enhance the process supervision abilities of GenPRM. The case in Figure 6 demonstrates that GenPRM provides accurate process supervision with CoT reasoning only.
Table 7: Evaluation results of GenPRM with different sizes on ProcessBench.
| Model Size | Metric | GSM8K | MATH | OlympiadBench | Omni-MATH | Avg. |
|--------------|----------|---------|--------|-----------------|-------------|--------|
| 1.5B | Pass@1 | 52.8 | 66.6 | 55.1 | 54.5 | 57.3 |
| 1.5B | Maj@8 | 81 | 74.4 | 65.3 | 62.5 | 63.4 |
| 7B | Pass@1 | 78.7 | 80.3 | 72.2 | 69.8 | 75.2 |
| 7B | Maj@8 | 81 | 85.7 | 78.4 | 76.8 | 80.5 |
| 32B | Pass@1 | 83.1 | 81.7 | 72.8 | 72.8 | 77.6 |
| 32B | Maj@8 | 85.1 | 86.3 | 78.9 | 80.1 | 82.6 |
Table 8: Evaluation results of GenPRM with different proportions of training data on ProcessBench.
| Data Size | Metric | GSM8K | MATH | OlympiadBench | Omni-MATH | Avg. |
|-------------|----------|---------|--------|-----------------|-------------|--------|
| 25% | Pass@1 | 71.8 | 78 | 68.9 | 68.2 | 71.7 |
| 50% | Pass@1 | 78.1 | 80.6 | 71.5 | 67.6 | 74.5 |
| 100% | Pass@1 | 78.7 | 80.3 | 72.2 | 69.8 | 75.2 |
Table 9: Statistics of the output tokens of GenPRM.
| | MATH | AMC23 | AIME24 | Minerva Math |
|----------|--------|---------|----------|----------------|
| Step | 344.7 | 416.2 | 432.5 | 503.3 |
| Response | 2771.4 | 3200.2 | 4112.9 | 4877.1 |
## Problem:
Simplify $\cos 54^\circ \cos 4^\circ - \cos 36^\circ \cos 86^\circ.$ Enter your answer is a trigonometric function evaluated at an integer, such as "sin 7". (The system will assume that the angle is in degrees.)
```
```
Figure 5: The first case of GenPRM.
## Problem:
## Compute the distance between the two foci of the ellipse $x^2 + 4y^2 = 9.$
Figure 6: The second case of GenPRM.
<details>
<summary>Image 5 Details</summary>

### Visual Description
## Text-Based Conversation: Math Problem Analysis
### Overview
The image shows a technical conversation between a user and an assistant analyzing mathematical solutions involving ellipses. The discussion focuses on verifying the correctness of algebraic manipulations and geometric formulas.
### Components/Axes
- **System Prompt**: "You are a math teacher. Your task is to review and critique the paragraphs in solution step by step."
- **User Turns**:
- **Turn 1**: Presents an equation $ x^2 + 4y^2 = 9 $ and describes dividing both sides by 9 to normalize it.
- **Turn 2**: Asks about the distance between foci of an ellipse with semi-major axis $ a $ and semi-minor axis $ b $, providing a formula $ c = \sqrt{a^2 - b^2} $.
- **Assistant Turns**:
- **Turn 1**: Analyzes the first paragraph, confirming correctness of dividing by 9 and identifying $ a = 3 $, $ b = 3/2 $. Judgment: ✅ Yes.
- **Turn 2**: Critiques the second paragraph, identifying arithmetic errors in calculating $ c = \sqrt{27/4 - 9/4} $ (incorrectly simplified to $ \sqrt{18/4} $). Judgment: ❌ No.
### Detailed Analysis
#### User Turn 1
- **Equation**: $ x^2 + 4y^2 = 9 $.
- **Step**: Dividing both sides by 9 to get $ \frac{x^2}{9} + \frac{4y^2}{9} = 1 $.
- **Analysis**:
- Semi-major axis $ a = 3 $ (denominator under $ x^2 $ is 9).
- Semi-minor axis $ b = 3/2 $ (denominator under $ y^2 $ is $ 9/4 $).
- Judgment: ✅ Correct.
#### User Turn 2
- **Formula**: Distance between foci $ c = \sqrt{a^2 - b^2} $.
- **Substitution**: $ a = 3 $, $ b = 3/2 $.
- **Calculation**:
- $ a^2 = 9 $, $ b^2 = 9/4 $.
- $ c = \sqrt{9 - 9/4} = \sqrt{27/4} = 3\sqrt{3}/2 \approx 2.598 $.
- **Error**: User incorrectly simplified $ \sqrt{27/4 - 9/4} $ to $ \sqrt{18/4} $ instead of $ \sqrt{27/4} $.
### Key Observations
1. **Correct Normalization**: The first paragraph correctly transforms the ellipse equation into standard form.
2. **Arithmetic Error**: The second paragraph miscalculates $ 27/4 - 9/4 $ as $ 18/4 $ instead of $ 27/4 $, leading to an incorrect $ c $.
3. **Formula Application**: The assistant correctly applies $ c = \sqrt{a^2 - b^2} $ but highlights the user’s mistake in intermediate steps.
### Interpretation
The conversation demonstrates the importance of precise arithmetic in geometric calculations. While the first paragraph adheres to standard ellipse normalization, the second paragraph contains a critical error in simplifying terms under the square root. The assistant’s role is to identify such discrepancies, emphasizing the need for careful step-by-step verification in mathematical problem-solving.
## Final Output
The image contains no numerical data or visualizations but focuses on textual analysis of mathematical reasoning. The assistant’s corrections underscore common pitfalls in algebraic manipulation, particularly in handling fractions and square roots.
</details>