2504.02654
Model: nemotron-free
# SymDQN: Symbolic Knowledge and Reasoning in Neural Network-based Reinforcement Learning
**Authors**:
- Ivo Amador
- Nina Gierasimczuk (Technical University of Denmark)
- ivo.amador@gmail.com, nigi@dtu.dk
## Abstract
We propose a learning architecture that allows symbolic control and guidance in reinforcement learning with deep neural networks. We introduce SymDQN, a novel modular approach that augments the existing Dueling Deep Q-Networks (DuelDQN) architecture with modules based on the neuro-symbolic framework of Logic Tensor Networks (LTNs). The modules guide action policy learning and allow reinforcement learning agents to display behavior consistent with reasoning about the environment. Our experiment is an ablation study performed on the modules. It is conducted in a reinforcement learning environment of a 5x5 grid navigated by an agent that encounters various shapes, each associated with a given reward. The underlying DuelDQN attempts to learn the optimal behavior of the agent in this environment, while the modules facilitate shape recognition and reward prediction. We show that our architecture significantly improves learning, both in terms of performance and the precision of the agent. The modularity of SymDQN allows reflecting on the intricacies and complexities of combining neural and symbolic approaches in reinforcement learning.
## 1 Introduction
Despite its rapidly growing impact on society, Artificial Intelligence technologies are tormented by reliability issues, such as lack of interpretability, propagation of biases, difficulty in generalizing across domains, and susceptibility to adversarial attacks. A possible way towards more interpretable, controlled and guided algorithms leads through the field of neuro-symbolic AI, which explores new ways of integrating symbolic, logic-based knowledge in neural networks (NNs). In particular, the framework of Logic Tensor Networks (LTNs, for short) Serafini and d’Avila Garcez (2016); Badreddine et al. (2022) enhances learning by interpreting first-order logic formulas concretely on data used by NNs algorithms. Such formulas express properties of data and, given a fuzzy semantics, can be integrated into the loss function, thus guiding the learning process.
In this paper, we apply LTNs to a reinforcement learning problem. By integrating LTNs in the training process, our learning agent uses logic to learn the structure of the environment, to predict how different objects in the environment interact with each other, and to guide its actions by performing elementary reasoning about rewards. We investigate how such integration affects learning performance of a robust, established and well-studied framework of Dueling Deep Q-Network (DuelDQN, for short) Wang et al. (2016). The structure of the paper is as follows. In Section 2 we briefly recall Logic Tensor Networks and elements of the underlying Real Logic. In Section 3 we introduce our methodology: the SymDQN architecture and its training process. We follow up with the presentation of the experiment in Section 4. We discuss of the results in Section 5. Section 6 concludes and outlines directions for future work.
#### Related Work
Since its conception, the framework of LTNs has been applied in various domains. In computer vision, LTNs were used to inject prior knowledge about object relationships and properties, improving interpretability and accuracy in object detection Donadello et al. (2017). Their addition to convolutional neural networks improves the robustness on noisy data Manigrasso et al. (2021). They enhance the accuracy in reasoning tasks in open-world and closed-world scenarios Wagner and d’Avila Garcez (2022). In Bianchi and Hitzler (2019), LTNs are leveraged for deductive reasoning tasks. Finally, in learning by reinforcement LTNs were used to integrate prior knowledge into reinforcement learning agents improving both the learning rate and robustness to environmental changes Badreddine and Spranger (2019). The latter work is similar to ours in the choice of tools, but it differs in its methodology. In Badreddine and Spranger (2019), LTN is a separate pre-training module which interacts with DuelDQN only by creating inputs. In contrast, our SymDQN integrates LTN in the training process (making it learn alongside DuelDQN).
Our work uses logic to adjust elements of a reinforcement learning framework. In that, it is related to reward shaping approaches, where the learner is given external symbolic information about the environment, e.g., in the form of linear time logic formulas (also known as restraining bolts) in Giacomo et al. (2019) or of an induced automaton in Furelos-Blanco et al. (2021). In a way, the LTN approach is similar: logical formulas adjust the reinforcement learning process. However, our technique is a more distributed form of reward shaping. First, the formulas of Real Logic are used as guides to obtain a symbolic representation of the environment, then to predict immediate rewards from encountering the objects of the environment. Finally, a logical formula is used to help the learner align the $q$ -values (the agent’s long term policy) with the predicted immediate rewards of symbolically represented objects. In other words, we restrain the reinforcement learner by expecting it to reason about its behavior as it learns, and we investigate the impact of this restriction on learning precision and performance. We will come back to this issue in Section 5.1, after we have detailed all the components.
## 2 Real Logic
Real Logic is the basis of the functioning of LTNs. In this section we provide a rudimentary introduction (for a full exposition consult Badreddine et al. (2022)). Let us start with a simple example.
**Example 1**
*Consider two datasets: a data set of humans (with two features: age and gender), and a dataset of pets (with three features: height, weight and color). Assume that Alice appears in the data set of humans (for instance as a five year old female), and Max and Mittens are listed in a dataset of pets. To be able to talk about Alice, Max and Mittens, we need a logical language that includes constants referring to objects (particular rows of the datasets). Note that such constants can be of different types —in our example humans consists of two, while pets are composed of three features.*
The signature of the language of Real Logic $\mathcal{L}$ contains a set $\mathcal{C}$ of constant symbols, a set $\mathcal{F}$ of function symbols, a set $\mathcal{P}$ of predicate symbols, and a set $\mathcal{X}$ of variable symbols. Let $\mathcal{D}$ be a non-empty set of domain symbols (that represent types). Domain symbols are used by functions $\mathbf{D}$ , $\mathbf{D_{in}}$ , and $\mathbf{D_{out}}$ which for a given element of the signature output its type, in the following way. $\mathbf{D}:\mathcal{X}\cup\mathcal{C}\rightarrow\mathcal{D}$ specifies the types for variables and constants; $\mathbf{D_{in}}:\mathcal{F}\cup\mathcal{P}\rightarrow\mathcal{D}^{\ast}$ specifies the types of the sequence of arguments allowed by function and predicate symbols ( $\mathcal{D}^{\ast}$ stands for the set of all finite sequences of elements from $\mathcal{D}$ ); $\mathbf{D_{out}}:\mathcal{F}\rightarrow\mathcal{D}$ specifies the type of the range of a function symbol.
**Example 2**
*Continuing Example 1, let the language of pet-ownership $\mathcal{L}_{pets}$ have the signature consisting of the set of constants $\mathcal{C}=\{\textsc{Alice},\textsc{Max},\textsc{Mit}\}$ , a set of function symbols $\mathcal{F}=\{\textsc{owner}\}$ , a set of predicate symbols $\mathcal{P}=\{\textsc{isOwner}\}$ , and two variable symbols $\mathcal{X}=\{\textsc{pet},\textsc{person}\}$ . Further, we have two domain symbols, one for the domain of humans and one for pets, $\mathcal{D}=\{H,P\}$ . Then, our domain functions can be defined in the following way. $\mathbf{D}(\textsc{Alice})=H$ (Alice is a constant of type $H$ ), $\mathbf{D}(\textsc{Max})=\mathbf{D}(\textsc{Mit})=P$ (Max and Mittens are of type $P$ ). Further, each dataset will have its own variable: $\mathbf{D}(\textsc{pet})=P$ , $\mathbf{D}(\textsc{person})=H$ . We also need to specify inputs for predicates: $\mathbf{D_{in}}(\textsc{isOwner})=HP$ (isOwner is a predicate taking two arguments, a human and a pet). Finally, for functions, we need both the input and the output types: $\mathbf{D_{in}}(\textsc{owner})=P$ , and $\mathbf{D_{out}}(\textsc{owner})=H$ (owner takes as input a pet and outputs the human who owns it).*
The language of Real Logic corresponds to first-order logic, and so it allows for more complex expressions. The set of terms consists of constants, variables, and function symbols and is defined in the following way: each $t\in X\cup C$ is a term of domain $\mathbf{D}(t)$ ; if $t_{1},\ldots,t_{n}$ are terms, then $t_{1}\ldots t_{n}$ is a term of the domain $\mathbf{D}(t_{1})...\mathbf{D}(t_{n})$ ; if $t$ is a term of the domain $\mathbf{D_{in}}(f)$ , then $f(t)$ is a term of the domain $\mathbf{D_{out}}(f)$ . Finally, the formulae of Real Logic are as follows: $t_{1}=t_{2}$ is an atomic formula for any terms $t_{1}$ and $t_{2}$ with $\mathbf{D}(t_{1})=\mathbf{D}(t_{2})$ ; $P(t)$ is an atomic formula if $\mathbf{D}(t)=\mathbf{D_{in}}(P)$ ; if $\varphi$ and $\psi$ are formulae and $x_{1},\ldots,x_{n}$ are variable symbols, then $\neg\varphi$ , $\varphi\wedge\psi$ , $\varphi\vee\psi$ , $\varphi\rightarrow\psi$ , $\varphi\leftrightarrow\psi$ , $\forall x_{1}\ldots x_{n}\varphi$ and $\exists x_{1}\ldots x_{n}\varphi$ are formulae.
Let us turn to the semantics of Real Logic. Domain symbols allow grounding the logic in numerical, data-driven representations—to be precise, Real Logic is grounded in tensors in the field of real numbers. Tensor grounding is the key concept that allows the interplay of Real Logic with Neural Networks. It refers to the process of mapping high-level symbols to tensor representations, allowing integration of reasoning and differentiable functions. A grounding $\mathcal{G}$ assigns to each domain symbol $D\in\mathcal{D}$ a set of tensors $\mathcal{G}(D)\subseteq\bigcup_{n_{1}\ldots n_{d}\in\mathbb{N}^{\ast}}\mathbb{ R}^{n_{1}\times\ldots\times n_{d}}$ . For every $D_{1}\ldots D_{n}\in\mathcal{D}^{\ast}$ , $\mathcal{G}(D_{1}\ldots D_{n})=\mathcal{G}(D_{1})\times\ldots\times\mathcal{G} (D_{n})$ . Given a language $\mathcal{L}$ , a grounding $\mathcal{G}$ of $\mathcal{L}$ assigns to each constant symbol $c$ , a tensor $\mathcal{G}(c)$ in the domain $\mathcal{G}(\mathbf{D}(c))$ ; to a variable $x$ it assigns a finite sequence of tensors $d_{1}\ldots d_{k}$ , each in $\mathcal{G}(\mathbf{D}(x))$ , representing the instances of $x$ ; to a function symbol $f$ it assigns a function taking tensors from $\mathcal{G}(\mathbf{D_{in}}(f))$ as input, and producing a tensor in $\mathcal{G}(\mathbf{D_{out}}(f))$ as output; to a predicate symbol $P$ it assigns a function taking tensors from $\mathcal{G}(\mathbf{D_{in}}(P))$ as input, and producing a truth-degree in the interval $[0,1]$ as output.
In other words, $\mathcal{G}$ assigns to a variable a concatenation of instances in the domain of the variable. The treatment of free variables in Real Logic is analogous, departing from the usual interpretation of free variables in FOL. Thus, the application of functions and predicates to terms with free variables results in point-wise application of the function or predicate to the string representing all instances of the variable (see p. 5 of Badreddine et al. (2022) for examples). Semantically, logical connectives are fuzzy operators applied recursively to the suitable subformulas: conjunction is a t-norm, disjunction is a t-conorm, and for implication and negation—its fuzzy correspondents. The semantics for formulae with quantifiers ( $\forall$ and $\exists$ ) is given by symmetric and continuous aggregation operators $Agg:\bigcup_{n\in N}[0,1]^{n}\rightarrow[0,1]$ . Intuitively, quantifiers reduce the dimensions associated with the quantified variables.
**Example 3**
*Continuing our running example, we could enrich our signature with predicates $Dog$ and $Cat$ . Then, $Dog(Max)$ might return $0.8$ , while $Dog(Mit)$ might return $0.3$ , indicating that Max is likely a dog, while Mittens is not. In practice, the truth degrees for these atomic formulas could be obtained for example by a Multi-layer Perceptron (MLP), followed by a sigmoid function, taking the object’s features as input and returning a value in $[0,1]$ . For a new function symbol $age$ , $age(Max)$ could be an MLP, taking Max’s features, and outputting a scalar representing Max’s age. An example of a formula could be $Dog(Max)\vee Cat(Max)$ , which could return $0.95$ indicating that Max is almost certainly either a dog or a cat. A formula with a universal quantifier could be used to express that Alice owns all of the cats $\forall pet(Cat(pet)\rightarrow isOwner(Alice,pet))$ .*
Real Logic allows some flexibility in the choice of appropriate fuzzy operators for the semantics of connectives and quantifiers. However, note that not all fuzzy operators are suitable for differentiable learning van Krieken et al. (2022). In Appendix B of Badreddine et al. (2022), the authors discuss some particularly suitable fuzzy operators. In this work, we follow their recommendation and adopt the Product Real Logic semantics (product t-norm for conjunction, standard negation, the Reichenbach implication, p-mean for the existential, and p-mean error for the universal quantifier).
LTNs make use of Real Logic—they learns parameters that maximize the aggregated satisfiability of the formulas in the so-called knowledge base containing formulas of Real Logic. The framework is the basis of the PyTorch implementation of the LTN framework, known as LTNtorch library Carraro (2022). In our experiments we make substantial use of that tool.
## 3 Methodology
### 3.1 The game
The environment used for the experiments was a custom Gymnasium Towers et al. (2024) environment ShapesGridEnv designed for the experiments in Badreddine and Spranger (2019), see Fig. 1. The game is played on an image showing a 5x5 grid with cells occupied by one agent, represented by the symbol ‘+’, and a number of other objects: circles, squares, and crosses. The agent moves across the board (up, right, down, left) and when it enters a space occupied by an object, it ‘consumes’ that object. Each object shape is associated with a reward. The agent’s goal is to maximize its cumulative reward throughout an episode. An episode terminates when either all shapes with positive reward have been consumed, or when a predefined number of steps has been reached.
<details>
<summary>extracted/6333762/fig-env.png Details</summary>

### Visual Description
## Grid Layout: Symbolic Pattern Analysis
### Overview
The image depicts a 3x3 grid with symbolic elements (plus signs, Xs, Os, and squares) arranged in specific positions. No textual labels, axis titles, or legends are present. The grid appears to represent a structured arrangement of symbols, potentially indicating a game board, code, or abstract pattern.
### Components/Axes
- **Grid Structure**:
- 3 rows (top, middle, bottom) and 3 columns (left, center, right).
- Each cell contains a single symbol or is empty.
- **Symbols**:
- **Plus sign (+)**: Located in the center of the top row.
- **Xs**: Present in the top-right corner and the bottom-right corner of the middle row.
- **Os**: Located in the bottom-right corner of the top row and the center of the middle row.
- **Squares**: Found in the top-left corner of the middle row, the bottom-left corner, and the bottom-right corner.
### Detailed Analysis
- **Top Row**:
- Top-left: Empty.
- Top-center: Plus sign (+).
- Top-right: Xs.
- **Middle Row**:
- Top-left: Square.
- Center: Os.
- Bottom-right: Xs.
- **Bottom Row**:
- Bottom-left: Square.
- Bottom-center: Empty.
- Bottom-right: Two squares.
### Key Observations
1. **Symbol Distribution**:
- Xs and Os are positioned in the rightmost columns of their respective rows.
- Squares occupy the leftmost and bottom-right cells, with the bottom-right cell containing two squares.
- The plus sign is isolated in the center of the top row, acting as a focal point.
2. **Pattern Ambiguity**:
- No clear numerical or categorical data is present.
- The arrangement resembles a game board (e.g., tic-tac-toe) but with non-standard symbols (e.g., plus sign).
3. **Missing Elements**:
- No axis labels, legends, or textual annotations are visible.
### Interpretation
The grid likely represents a symbolic or abstract system rather than a data-driven chart. The plus sign in the top-center may denote a central reference point, while the Xs, Os, and squares could symbolize different entities or states. The absence of textual labels suggests the image is either a placeholder, a conceptual diagram, or part of a larger system requiring external context. The repetition of squares in the bottom row might indicate a progression or emphasis on that area. Without additional context, the purpose remains speculative, but the structured layout implies intentional design for a specific function (e.g., game mechanics, code representation, or visual metaphor).
</details>
Figure 1: ShapesGridEnv environment
We chose this environment because of its simplicity, and because it allows comparing our setting with that of Badreddine and Spranger (2019). The environment is very flexible in its parameters: density (the minimum and maximum amount of shapes initiated, in our case max is $18$ ), rewards (in our case the reward for a cross is +1, for a circle is -1 and for a square is 0), colors (in our case the background is white and objects are black), episode maximum length (for us it is 50). Altering the environment configurations allows investigating the adaptability of the learner in Badreddine and Spranger (2019).
### 3.2 The Model
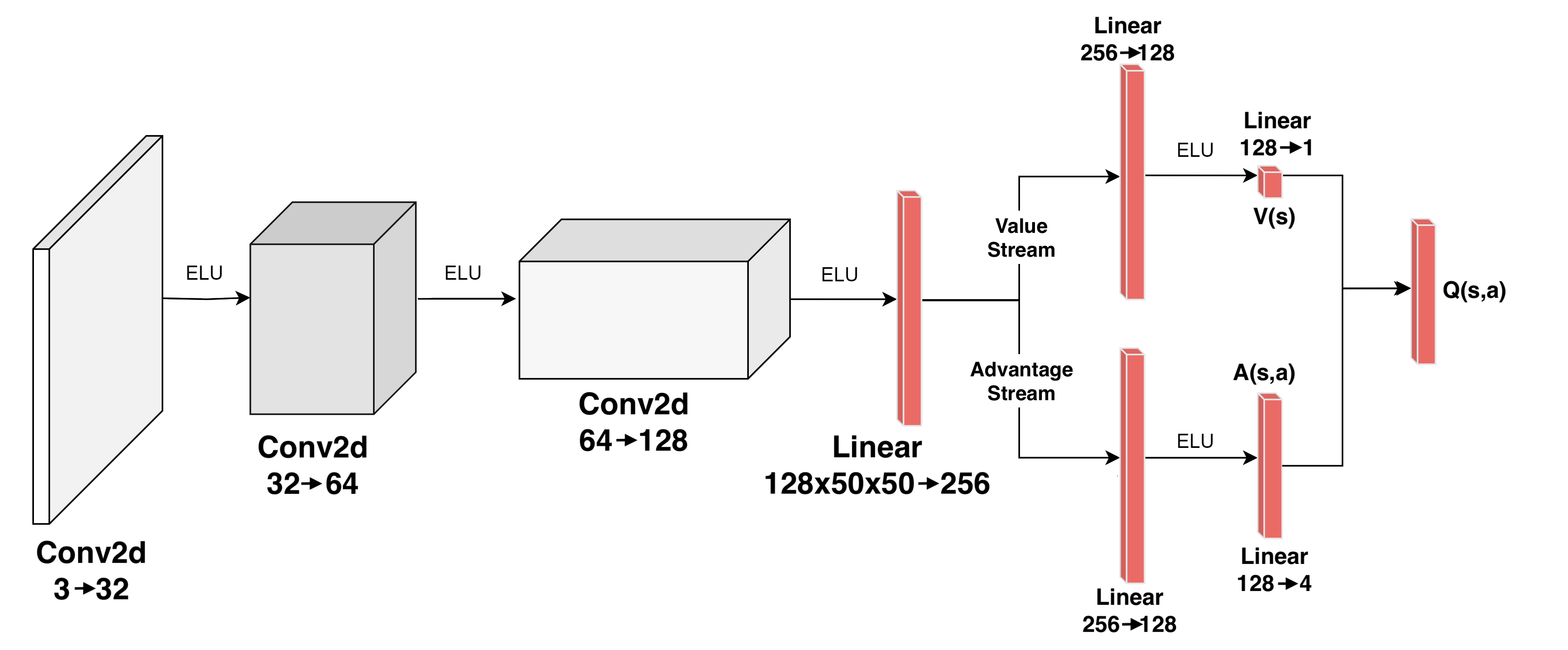
A suitable approach to learning to play such a game could be the existing Dueling Deep Q-Network (DuelDQN) Wang et al. (2015). The architecture is composed of several convolutional layers, which extract relevant features from the raw image input, and then pass them to the two main components, a Value Stream and an Advantage Stream (see Fig. 2). The Value Stream estimates how good it is for the agent to be in the given state, while the Advantage Stream estimates how good it is to perform each action in that given state. The two streams are then combined to calculate the final output.
<details>
<summary>extracted/6333762/dueldqn_parameters.png Details</summary>
### Visual Description
## Diagram: Deep Q-Network (DQN) Architecture
### Overview
The diagram illustrates a neural network architecture for a Deep Q-Network (DQN), commonly used in reinforcement learning. It includes convolutional layers, linear layers, activation functions (ELU), and streams for value and advantage estimation. The flow progresses from input to output through sequential transformations.
### Components/Axes
- **Input Layer**:
- **Conv2d**: `3 → 32` (3 input channels to 32 output channels).
- **Hidden Layers**:
- **Conv2d**: `32 → 64` (second convolutional layer).
- **Linear**: `128x50x50 → 256` (flattened convolutional output to 256 units).
- **Streams**:
- **Value Stream**:
- **Linear**: `256 → 128` → **ELU** → **Linear**: `128 → 1` (outputs value function `V(s)`).
- **Advantage Stream**:
- **Linear**: `256 → 128` → **ELU** → **Linear**: `128 → 4` (outputs advantage function `A(s,a)`).
- **Output**:
- **Q(s,a)**: Combines `V(s)` and `A(s,a)` via addition (`Q(s,a) = V(s) + A(s,a)`).
### Detailed Analysis
1. **Input Processing**:
- The input (e.g., raw pixel data) passes through two `Conv2d` layers with increasing channel depth (3 → 32 → 64), likely for feature extraction.
2. **Flattening**:
- The output of the second `Conv2d` (spatial dimensions 128x50x50) is flattened into a 1D vector of 256 units via a linear layer.
3. **Stream Splitting**:
- The 256-unit vector splits into two parallel streams:
- **Value Stream**: Predicts the state value `V(s)` (single output unit).
- **Advantage Stream**: Predicts the advantage `A(s,a)` (4 output units, likely for discrete actions).
4. **Activation Functions**:
- ELU (Exponential Linear Unit) is applied after each linear layer to introduce non-linearity.
5. **Output Fusion**:
- The final Q-value `Q(s,a)` is computed by adding the value function `V(s)` and advantage function `A(s,a)`.
### Key Observations
- **Architecture Type**: Combines convolutional layers for spatial feature extraction with linear layers for value/advantage estimation, typical of DQN with A2C (Advantage Actor-Critic) enhancements.
- **Output Dimensions**:
- `V(s)` outputs a scalar (1 unit), representing the expected return for state `s`.
- `A(s,a)` outputs 4 units, likely corresponding to discrete actions (e.g., up, down, left, right).
- **ELU Usage**: Ensures smooth gradients during training, avoiding dead neurons.
### Interpretation
This architecture is designed for reinforcement learning tasks requiring spatial input (e.g., Atari games). The separation into value and advantage streams improves training stability by decoupling state-value estimation from action-specific advantages. The final Q-value fusion enables policy optimization via methods like Q-learning or policy gradients. The use of `Conv2d` layers suggests compatibility with image-based inputs, while the linear layers handle high-dimensional state representations.
No numerical data or trends are present in the diagram; it focuses on architectural components and flow.
</details>
Figure 2: Network Architecture of DuelDQN, with the convolutional layers in white, and the dense layers in red
The DuelDQN architecture will be our starting point. We will extend it with new symbolic, cognitively-motivated components:
- shape recognition (ShapeRecognizer),
- reward prediction (RewardPredictor),
- action reasoning (ActionReasoner), and
- action filtering (ActionFilter).
In the following, we will discuss each component in more detail.
#### ShapeRecognizer
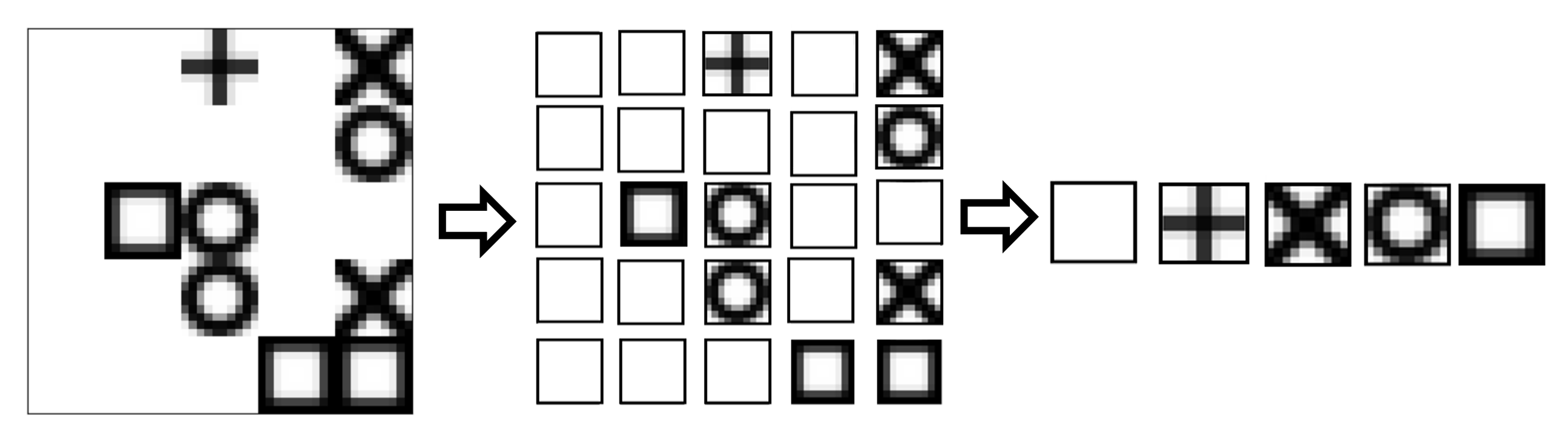
The function of ShapeRecognizer is to estimate the likelihood of a certain observation to be of a given unique kind. ShapeRecognizer is comprised of one pre-processing function, which divides the initial raw image into 25 patches. Each patch is then processed by a Convolutional Neural Network (CNN), which then outputs a 5-dimensional tensor.
The numbers chosen for the number of patches and the output dimension are an instance of soft knowledge injection, as the environment represents a 5x5 grid, and dividing it into 25 patches immediately separates the content of each cell in the grid. As for the output size, 5 is the number of different objects that each patch might contain: empty, agent, circle, cross, square. This allows the agent to perform a multi-label classification on each object type. The theoretical intention of this module is to give the agent a possibility of symbolic understanding of the different entities in the environment, by labeling their types.
Given the simple nature of the ShapesGridEnv, representing the environment is very easy. The state is composed of $25$ positions, with each position being occupied by one of five shapes (empty, agent, circle, square, cross), which results in the state space of size $25^{5}$ . To generate this representation, we start by instantiating five one-hot representations of the classes, which are stored in the LTN Variable $shape\_types$ . Then, for each state that the agent is in, it keeps in memory all the different patches that it has seen and a list of all the patches that are present in the current state.
<details>
<summary>extracted/6333762/unique_patch.png Details</summary>
### Visual Description
## Flowchart Diagram: Symbol Processing Stages
### Overview
The image depicts a three-stage flowchart illustrating the transformation of symbols through a structured process. Each stage is represented by a grid of cells containing symbols, with directional arrows indicating progression between stages. No textual labels, legends, or numerical data are present in the diagram.
### Components/Axes
1. **Stage 1 (Input Grid)**:
- A 3x3 grid containing symbols: `+`, `X`, `O`, and squares.
- Symbols are arranged in a seemingly random pattern with no discernible grouping.
2. **Stage 2 (Intermediate Grid)**:
- A 9x3 grid where each cell contains a single symbol from Stage 1.
- Symbols are distributed uniformly across the grid, with no apparent repetition or pattern.
3. **Stage 3 (Output Grid)**:
- A 1x4 grid displaying four symbols: `+`, `X`, `O`, and a square.
- Symbols are ordered sequentially from left to right.
4. **Arrows**:
- Black arrows with white outlines connect Stage 1 → Stage 2 → Stage 3, indicating a unidirectional flow.
### Detailed Analysis
- **Stage 1**: The 3x3 grid serves as the input, with symbols occupying specific positions. For example:
- Top-left cell: `+`
- Top-middle cell: `X`
- Bottom-right cell: Square
- **Stage 2**: The 9x3 grid expands the input into a larger structure. Each cell contains one symbol from Stage 1, but no aggregation or transformation rules are visible.
- **Stage 3**: The final output grid simplifies the process to four distinct symbols, suggesting a reduction or categorization step.
### Key Observations
1. **Symbol Consistency**: All symbols (`+`, `X`, `O`, squares) appear in all stages, indicating they are preserved through the process.
2. **Grid Dimensionality**: The progression from 3x3 → 9x3 → 1x4 grids implies increasing complexity followed by simplification.
3. **No Data-Driven Logic**: The absence of numerical values or explicit rules suggests the flowchart represents a conceptual or procedural flow rather than data analysis.
### Interpretation
The diagram likely represents a symbolic processing pipeline, such as:
1. **Input Encoding**: Stage 1 defines a set of symbols (e.g., user inputs or predefined tokens).
2. **Expansion/Mapping**: Stage 2 distributes symbols across a larger grid, possibly simulating parallel processing or state transitions.
3. **Output Synthesis**: Stage 3 condenses the process into a final set of symbols, potentially representing outcomes or decisions.
The lack of numerical data or explicit rules implies the flowchart is a high-level abstraction, possibly used to illustrate algorithmic steps, decision trees, or symbolic logic systems. The uniformity of symbols across stages suggests no loss or alteration of information during processing.
</details>
Figure 3: The process of obtaining unique labels
Once the variables have been set up, the ShapeRecognizer module can be used to estimate the likelihood of a grid cell containing a given unique shape. To guide its learning, the aggregated satisfiability of three axioms is maximized. The axioms represent the first instance of actual knowledge injection in the system:
$$
\forall s\ \exists l\ IS(s,l)
$$
$$
\neg\exists s\ l_{1}\ l_{2}\ (IS(s,l_{1})\wedge IS(s,l_{2})\wedge(l_{1}\neq l_
{2}))
$$
$$
\forall s_{1}\ s_{2}\ l\ ((IS(s_{1},l)\wedge(s_{1}\neq s_{2}))\rightarrow\neg
IS
(s_{2},l)
$$
In the above formulas, $s$ stands for a shape, $l$ stands for a label and $IS(x,y)$ stands for $x$ has label $y$ . A1 says that every shape has a label; A2 says that no shape has two different labels; A3 says that different shapes cannot have the same label. At each step of every episode, the aggregated satisfaction (truth) degree of these axioms is calculated, and its inverse, $1-AggSat(A1,A2,A3)$ , is used as a loss to train the agent.
Intuitively, ShapeRecognizer gives the learner a way to distinguish between different shapes. In that, our approach is somewhat similar to the framework of semi-supervised symbol grounding Umili et al. (2023).
#### RewardPredictor
Once the environment is symbolically represented, we will make the agent understand the properties of different objects and their dynamics. The only truly dynamic element in the environment is the agent itself—nothing else moves. The agent can move to a cell that was previously occupied by a different shape, which results in the shape being consumed, and the agent being rewarded with the value of the respective shape. Hence, there are three key pieces of knowledge that the learner must acquire to successfully navigate the environment. It must identify which shape represents the agent, it must understand how each action influences the future position of the agent, and it must associate each shape with its respective reward.
The task of self-recognition can be approached in numerous ways, depending on the information we have about the environment, and on our understanding of its dynamics. In our approach, leveraging the ShapeRecognizer, in each episode we count the occurrences of each shape in the environment and add it to a variable that keeps track of this shape’s count over time. The agent is the only shape that has a constant, and equal to one, number of appearances in the environment. This approach is enough to quickly determine with confidence which shape represents the agent. This step demonstrates a specific advantage of using the neuro-symbolic framework. Our reinforcement learning agent is now equipped with memory of the previous states of the environment (i.e., the count of shapes) which can then be used to make decisions or to further process symbolic knowledge.
Understanding the impact of different actions is crucial for the agent to make informed decisions in the environment. Each action represents a direction (up, right, down, left) and taking the action will lead to one of two outcomes. If the agent is at the edge of the environment and attempts to move against the edge, it will remain in the same cell, otherwise, the agent will move one cell in the given direction. Given the simplicity of this dynamics, a function has been defined that takes as input a position and an action, outputting the resulting position.
Our RewardPredictor is a Multi-layer Perceptron (MLP), which takes as input a ShapeRecognizer ’s prediction and outputs one scalar. The main intention of this module is to train to predict the reward associated with each object shape, using the symbolic representations generated by the ShapeRecognizer paired with high-level reasoning on the training procedure. This module intends to give the agent a way of knowing on a high level the reward associated with any shape, and consequently with any action.
In reinforcement learning environments, agents learn action policies by maximizing their expected rewards. When building an agent that symbolically represents and reasons about the environment, one of the key elements is the agent’s ability to understand how to obtain rewards. Given that the agent has the capability of identifying the shapes in the grid, recognizing its own shape, and calculating the position it will take given an action, it can now determine the shape that will be consumed by that action. By using the RewardPredictor module and passing it this shape, the agent obtains a prediction of the reward associated with that shape. Over time, by calculating the loss between that prediction and the actual reward obtained after taking an action, the module learns to accurately predict the reward associated with every shape.
#### ActionReasoner
Once the agent can predict the expected reward of its own actions, we can then guide its policy learning so that it acts in the way (it expects) will give the highest immediate reward. To achieve this, we specify an axiom to ensure that the $q-$ value outputs of the Q-Network are in alignment with the predicted rewards. To achieve this, the expected reward of all the possible actions is calculated by using the RewardPredictor and the $q-$ values are calculated by calling the SymDQN. Our axiom expresses the following condition: if the reward prediction of action $a_{1}$ is higher than the reward prediction of action $a_{2}$ , then the $q-$ value of $a_{1}$ must also be higher than the $q-$ value of $a_{2}$ . The learning is then guided by the LTN framework with the following formula of Real Logic used in the loss function.
$$
\forall\ \textup{Diag}((r_{1},q_{1}),(r_{2},q_{2}))(r_{1}>r_{2}):(q_{1}>q_{2})
$$
Two standard operators of Real Logic Badreddine et al. (2022) are applied in this axiom: $Diag$ and guarded quantification with the condition $(r_{1}>r_{2})$ . Firstly, the $Diag$ operator restricts the range of the quantifier, which will then not run through all the pairs from $\{r_{1},r_{2},q_{1},q_{2}\}$ , but only the pairs of (reward, $q$ -value) that correspond to the same actions. Specifically, when $r_{1}$ corresponds to the predicted reward of action ‘up’, then $q_{1}$ corresponds to $q$ -value of action ‘up’. Secondly, we use guarded quantification, restricting the range of the quantifier to only those cases in which $(r_{1}>r_{2})$ . If we had used implication, with the antecedent $(r_{1}>r_{2})$ false, the whole condition would evaluate to true. This is problematic when the majority of pairs do not fulfill the antecedent. In such a case the universal quantifier evaluates to true for most of the instances, even if the important ones, with antecedent true, are false. Guarded quantification gives a satisfaction degree that is much closer to the value we are interested in.
#### ActionFilter
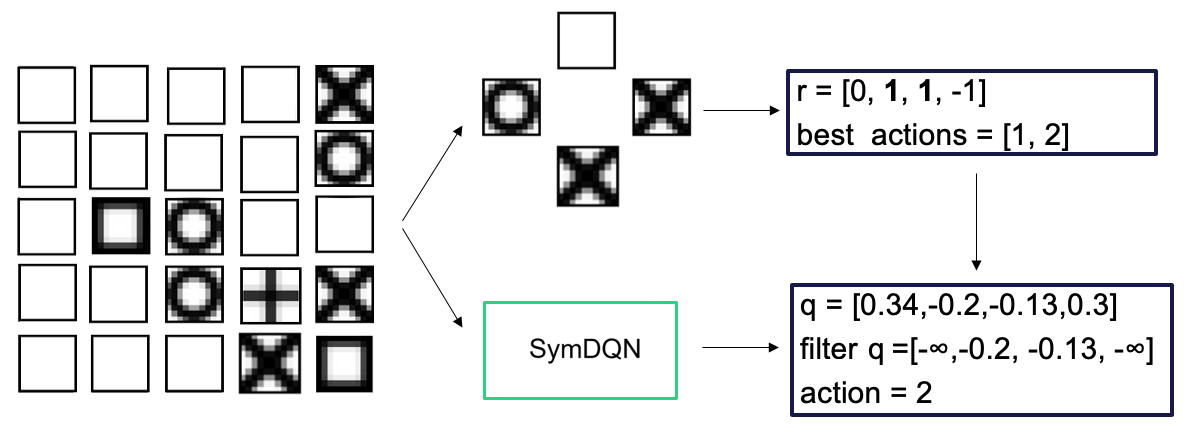
Our learner can now predict the reward for each shape. For each action in a given state, it then knows what shapes could be consumed and what is their corresponding immediate reward. ActionFilter eliminates the actions for which the difference between their reward and the maximum immediately obtainable reward in that state is under a predefined threshold (we set it at 0.5). This allows a balance between the strictness of symbolic selection of immediately best actions and the information about rewards available in the network as a whole. This is represented in Fig. 4.
<details>
<summary>extracted/6333762/fig-action-filter.png Details</summary>
### Visual Description
## Flowchart: SymDQN Decision Process
### Overview
The image depicts a flowchart illustrating a decision-making process using a SymDQN (Symmetric Deep Q-Network) model. The process begins with a 5x5 grid of symbols, transitions through a central "SymDQN" component, and outputs decision metrics (r, best actions, q-values) leading to a final action selection.
### Components/Axes
1. **Left Grid**:
- 5x5 matrix of cells containing symbols:
- Empty squares (white)
- Black squares with white centers
- Black squares with white circles
- Black squares with white Xs
- Black squares with white plus signs
- No explicit axis labels or legends, but symbols are spatially arranged in a grid.
2. **Central SymDQN Box**:
- Labeled "SymDQN" in bold text.
- Connected via bidirectional arrows to the grid and decision outputs.
3. **Decision Outputs**:
- **Top Right Box**:
- Label: `r = [0, 1, 1, -1]`
- Label: `best actions = [1, 2]`
- **Bottom Right Box**:
- Label: `q = [0.34, -0.2, -0.13, 0.3]`
- Label: `filter q = [-∞, -0.2, -0.13, -∞]`
- Label: `action = 2`
### Detailed Analysis
1. **Grid Symbols**:
- Symbols likely represent states or positions in a game/environment (e.g., Tic-Tac-Toe variants).
- Example: The bottom-right cell contains a black square with a white X, while the center cell has a black square with a white plus sign.
2. **Flow**:
- Arrows indicate a left-to-right flow:
- Grid → SymDQN → Decision outputs (r, best actions, q-values).
- SymDQN processes the grid state to compute rewards (`r`) and candidate actions (`best actions`).
- Q-values (`q`) are filtered to select the final action (`action = 2`).
3. **Numerical Values**:
- `r = [0, 1, 1, -1]`: Reward values for candidate actions.
- `best actions = [1, 2]`: Indices of actions with highest rewards.
- `q = [0.34, -0.2, -0.13, 0.3]`: Q-values for all actions.
- Filtered `q = [-∞, -0.2, -0.13, -∞]`: Discards actions with negative infinity Q-values, leaving indices 1 and 2.
- Final `action = 2`: Selected action after filtering.
### Key Observations
- The SymDQN evaluates multiple actions (indices 1 and 2) but selects action 2 after filtering Q-values.
- Negative infinity (`-∞`) in filtered Q-values suggests penalties for invalid or suboptimal actions.
- The grid's symbols may encode environmental states influencing the decision process.
### Interpretation
The flowchart demonstrates a reinforcement learning workflow where SymDQN:
1. **State Evaluation**: Analyzes the grid's symbolic state to identify viable actions.
2. **Reward Calculation**: Computes immediate rewards (`r`) for candidate actions.
3. **Q-Value Optimization**: Uses Q-values to prioritize actions, filtering out those with negligible or negative utility.
4. **Action Selection**: Chooses the optimal action (2) based on filtered Q-values, balancing exploration and exploitation.
This process highlights how SymDQN integrates symbolic state representation with numerical optimization to make decisions in structured environments.
</details>
Figure 4: The process of action filtering
ActionFilter severely restricts action choice. We prevented it from forcing the outcomes by switching it off during the training period. When the agent is actually running in the environment, the ActionFilter is used to optimize decision making. Further strategies on how this dynamic might be implemented in training must be studied, as we want to maintain the asymptotic optimality of DuelDQNs, while enhancing them with reasoning, when relevant.
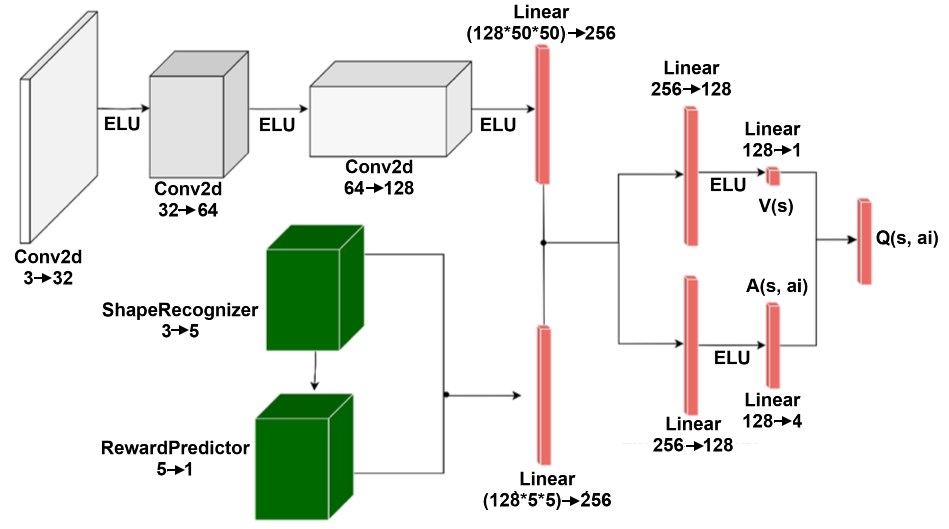
With ShapeRecognizer, RewardPredictor, ActionReasoner and ActionFilter integrated with the original DuelDQN, the complete architecture of SymDQN can be seen in Fig. 5.
<details>
<summary>extracted/6333762/SymDQN_arch.png Details</summary>
### Visual Description
## Neural Network Architecture Diagram: Reinforcement Learning Agent
### Overview
The diagram illustrates a neural network architecture for a reinforcement learning agent. It combines convolutional layers for feature extraction with specialized branches for shape recognition and reward prediction, culminating in a Q-value output for action selection.
### Components/Axes
- **Input Layer**: Conv2d (3→32)
- **Activation Functions**: ELU (applied after each Conv2d layer)
- **Convolutional Layers**:
- Conv2d (32→64)
- Conv2d (64→128)
- **Linear Layers**:
- Linear (128×50×50→256)
- Linear (256→128)
- Linear (128→4)
- Linear (128→1)
- **Specialized Branches**:
- ShapeRecognizer (3→5)
- RewardPredictor (5→1)
- **Output**: Q(s, a_i) (final Q-value)
### Detailed Analysis
1. **Main Path**:
- Input (Conv2d 3→32) → ELU → Conv2d (32→64) → ELU → Conv2d (64→128) → ELU → Linear (128×50×50→256)
- Branches:
- **Shape Recognition**: Linear (256→128) → ELU → Linear (128→5) → ShapeRecognizer (3→5)
- **Reward Prediction**: Linear (256→128) → ELU → Linear (128→1) → RewardPredictor (5→1)
- Final Output: Linear (128→1) → Q(s, a_i)
2. **Color Coding**:
- Gray: Main convolutional/linear path
- Green: Specialized branches (ShapeRecognizer, RewardPredictor)
3. **Dimensional Flow**:
- Spatial dimensions reduce through convolutions (32→64→128)
- Channel dimensions expand through linear layers (256→128→4→1)
### Key Observations
- **Modular Design**: Separate branches handle distinct tasks (shape recognition vs. reward prediction)
- **Dimensional Reduction**: Input dimensions shrink from 50×50 to 1×1 through progressive convolutions
- **Non-Linearity**: ELU activation used consistently after convolutional layers
- **Action-Value Integration**: Final Q-value combines outputs from both branches
### Interpretation
This architecture demonstrates a hierarchical approach to reinforcement learning:
1. **Feature Extraction**: Early convolutional layers capture spatial features
2. **Task Specialization**: Dedicated branches process different aspects of the input
3. **Value Integration**: Final Q-value combines shape information and reward predictions
The design suggests an agent that:
- Processes visual input (Conv2d layers)
- Recognizes object shapes (ShapeRecognizer)
- Predicts rewards (RewardPredictor)
- Evaluates actions (Q(s, a_i))
The use of ELU activations and progressive dimensional reduction indicates optimization for stability and computational efficiency. The specialized branches allow the model to handle complex decision-making by decomposing the problem into shape analysis and reward evaluation.
</details>
Figure 5: SymDQN network architecture integrating DuelDQN with ShapeRecognizer and RewardPredictor modules
## 4 The experiment
By comparing the baseline DuelDQN model with our SymDQN model, this study attempts to answer the following questions:
1. Does the SymDQN converge to a stable action policy faster than the baseline DuelDQN?
1. Does the SymDQN outperform the baseline DuelDQN in average reward accumulation?
1. Is SymDQN more precise in its performance than DuelDQN, i.e., is it better at avoiding shapes with negative rewards?
In the experiment, we analyze the impact that each individual modification has on the performance of the SymDQN, comparing them between each other and the baseline DuelDQN. We hence consider five experimental conditions:
DuelDQN: the baseline model-no symbolic components;
SymDQN: DuelDQN enriched with ShapeRecognizer (that uses A1-A3) and with RewardPredictor;
SymDQN(AR): SymDQN with ActionReasoner (that uses the axiom A4);
SymDQN(AF): SymDQN with ActionFilter;
SymDQN(AR,AF): SymDQN enriched with both ActionReasoner and ActionFilter.
Our experiment runs through $250$ epochs, after which the empirically observed rate of learning of all the variations is no longer significant. Each epoch contains $50$ episodes of training, and then the agent’s performance is evaluated as the average score of $50$ new episodes. The score is defined as the ratio of the actual score and the maximum score obtainable in a given episode. The other performance measure we look at is the percentage of the negative-reward objects consumed. The hardware and software specification and the hyperparameters of the experiment can be found in the Appendix A.
## 5 Results
In this section, we will report on the results of our ablation study, which isolates the impact of each component on the agent’s performance. We will first focus on the obtained score comparison among different experimental conditions, and later we will report on the precision of the agent.
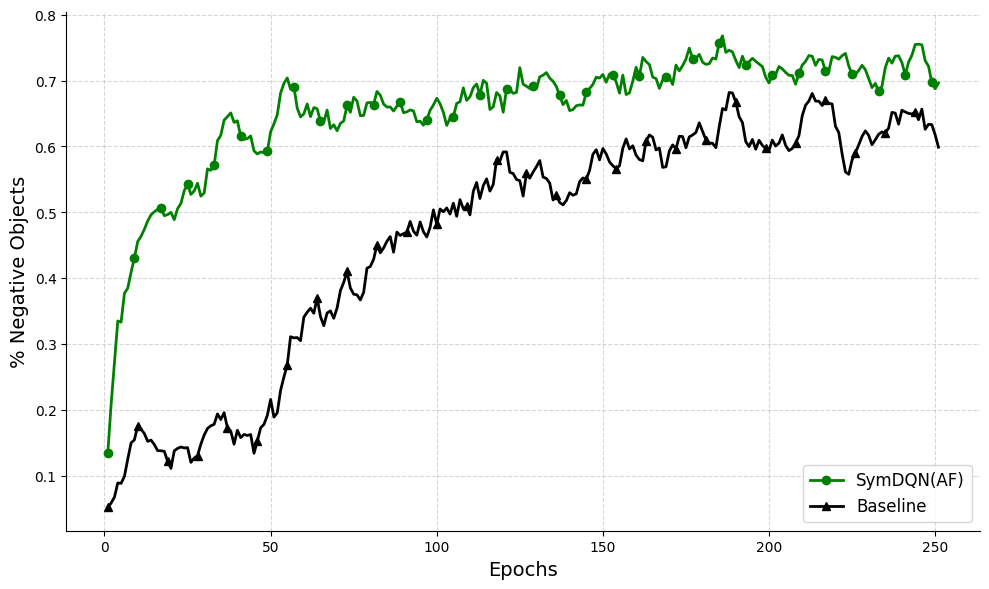
We first compare our best-performing condition, SymDQN(AF) with the baseline learning of the pure non-symbolic DuelDQN, see Fig. 6.
<details>
<summary>extracted/6333762/SymDQNAF-DuelingDQN.png Details</summary>
### Visual Description
## Line Graph: Comparison of SymDQN(AF) and Baseline Algorithms in Negative Object Percentage Over Epochs
### Overview
The graph compares the performance of two algorithms, **SymDQN(AF)** (green line) and **Baseline** (black line), in terms of the percentage of negative objects across 250 epochs. The y-axis represents the percentage of negative objects (0–0.8), while the x-axis represents epochs (0–250). The green line (SymDQN(AF)) consistently remains above the black line (Baseline), indicating superior performance in reducing negative objects. Both lines exhibit fluctuations but follow distinct trends.
---
### Components/Axes
- **X-axis (Epochs)**: Labeled "Epochs," ranging from 0 to 250 in increments of 50.
- **Y-axis (% Negative Objects)**: Labeled "% Negative Objects," ranging from 0 to 0.8 in increments of 0.1.
- **Legend**: Located in the **bottom-right corner**, with:
- **Green circles**: SymDQN(AF)
- **Black triangles**: Baseline
- **Grid**: Light gray dashed lines for reference.
- **Data Points**: Markers (circles for SymDQN(AF), triangles for Baseline) are plotted at each epoch.
---
### Detailed Analysis
#### SymDQN(AF) (Green Line)
- **Initial Trend**: Starts at ~0.12 at epoch 0, rising sharply to ~0.65 by epoch 50.
- **Mid-Phase**: Stabilizes between ~0.65–0.72 from epochs 50–150, with minor fluctuations.
- **Later Phase**: Peaks at ~0.75 around epoch 180, then declines slightly to ~0.70 by epoch 250.
- **Key Values**:
- Epoch 0: ~0.12
- Epoch 50: ~0.65
- Epoch 100: ~0.68
- Epoch 150: ~0.72
- Epoch 200: ~0.71
- Epoch 250: ~0.70
#### Baseline (Black Line)
- **Initial Trend**: Starts at ~0.05 at epoch 0, rising to ~0.35 by epoch 50.
- **Mid-Phase**: Increases to ~0.55 by epoch 100, then fluctuates between ~0.55–0.65 until epoch 150.
- **Later Phase**: Peaks at ~0.65 around epoch 200, then declines to ~0.60 by epoch 250.
- **Key Values**:
- Epoch 0: ~0.05
- Epoch 50: ~0.35
- Epoch 100: ~0.55
- Epoch 150: ~0.62
- Epoch 200: ~0.65
- Epoch 250: ~0.60
---
### Key Observations
1. **SymDQN(AF) Outperforms Baseline**: The green line (SymDQN(AF)) consistently maintains a higher percentage of negative objects than the black line (Baseline) across all epochs.
2. **Baseline Decline**: The Baseline algorithm shows a noticeable decline in performance after epoch 200, dropping from ~0.65 to ~0.60.
3. **SymDQN(AF) Stability**: SymDQN(AF) exhibits smoother growth and stabilization compared to the Baseline, which has sharper fluctuations.
4. **Convergence Gap**: The gap between the two lines narrows slightly after epoch 200 but remains significant (~0.10 difference at epoch 250).
---
### Interpretation
- **Algorithm Effectiveness**: SymDQN(AF) demonstrates superior ability to reduce negative objects, likely due to its adaptive framework (AF) or advanced optimization strategies.
- **Baseline Limitations**: The Baseline’s decline after epoch 200 suggests potential overfitting, inefficiency, or lack of adaptability in later training phases.
- **Training Dynamics**: Both algorithms show initial rapid improvement, but SymDQN(AF) achieves higher stability and sustained performance, indicating better generalization.
- **Practical Implications**: For tasks requiring consistent negative object reduction, SymDQN(AF) is the preferred choice. The Baseline may require architectural adjustments or hyperparameter tuning to match SymDQN(AF)’s performance.
---
**Note**: All values are approximate, derived from visual inspection of the graph. The legend colors (green for SymDQN(AF), black for Baseline) are strictly cross-referenced with line placements to ensure accuracy.
</details>
Figure 6: SymDQN(AF) (in green) vs. DuelDQN (in black): $x$ -axis represents epochs and $y$ -axis represents the ratio of obtained score in the episode and the maximum obtainable score in that episode.
Clearly, the performance of the SymDQN agent equipped with ActionFilter is superior to DuelDQN both in terms of quicker convergence (high initial learning rate) and overall end performance.
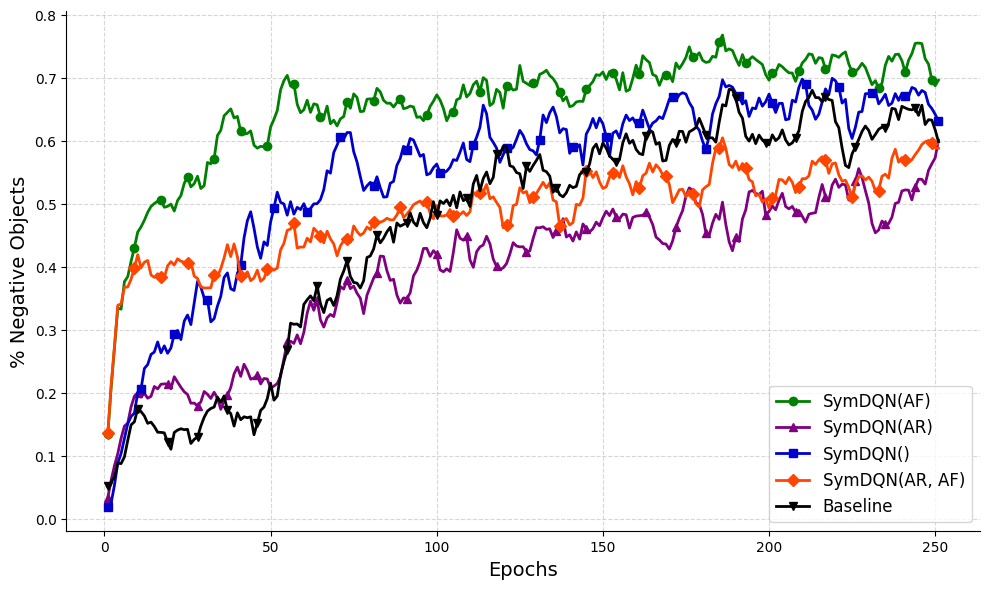
Let us now look at different versions of our SymDQN to better understand what contributes to its performance. In Fig. 7 we show the performance of all four versions of SymDQN.
<details>
<summary>extracted/6333762/SymDQN_performance_new.png Details</summary>
### Visual Description
## Line Graph: % Negative Objects vs. Epochs
### Overview
The image depicts a line graph comparing the performance of five different configurations over 250 epochs. The y-axis represents "% Negative Objects" (ranging from 0% to 0.8%), and the x-axis represents "Epochs" (0 to 250). Five distinct data series are plotted, each with unique colors and markers, showing varying trends in negative object percentages over time.
### Components/Axes
- **X-axis (Epochs)**: Labeled "Epochs," with ticks at 0, 50, 100, 150, 200, and 250.
- **Y-axis (% Negative Objects)**: Labeled "% Negative Objects," with ticks at 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, and 0.7.
- **Legend**: Located in the bottom-right corner, with the following entries:
- **SymDQN(AF)**: Green line with circular markers.
- **SymDQN(AR)**: Purple line with triangular markers.
- **SymDQN()**: Blue line with square markers.
- **SymDQN(AR, AF)**: Orange line with diamond markers.
- **Baseline**: Black line with triangular markers.
### Detailed Analysis
1. **SymDQN(AF) (Green)**:
- Starts at ~0.35% at epoch 0.
- Peaks at ~0.7% by epoch 250, maintaining the highest values throughout.
- Shows moderate fluctuations but remains consistently above other series.
2. **SymDQN(AR) (Purple)**:
- Begins at ~0.1% at epoch 0.
- Rises steadily to ~0.55% by epoch 250.
- Exhibits sharper fluctuations compared to SymDQN(AF).
3. **SymDQN() (Blue)**:
- Starts at ~0.05% at epoch 0.
- Increases to ~0.65% by epoch 250.
- Shows significant variability, with peaks and troughs.
4. **SymDQN(AR, AF) (Orange)**:
- Begins at ~0.15% at epoch 0.
- Reaches ~0.6% by epoch 250.
- Follows a relatively smooth upward trend with minor oscillations.
5. **Baseline (Black)**:
- Starts at ~0.1% at epoch 0.
- Ends at ~0.65% by epoch 250.
- Displays erratic fluctuations, with values often overlapping other series.
### Key Observations
- **SymDQN(AF)** consistently outperforms all other configurations, maintaining the highest % Negative Objects.
- **SymDQN(AR, AF)** shows the second-highest performance, with a steady increase.
- The **Baseline** exhibits the most variability, suggesting less stability compared to other configurations.
- **SymDQN(AR)** and **SymDQN()** demonstrate similar trends but with distinct fluctuation patterns.
### Interpretation
The data suggests that the **SymDQN(AF)** configuration is the most effective at maintaining higher % Negative Objects over time, potentially indicating superior performance in the evaluated task. The **Baseline**'s erratic behavior implies that the tested configurations generally outperform the default or control scenario. The **SymDQN(AR, AF)** configuration bridges the gap between the top-performing SymDQN(AF) and the others, highlighting the impact of combining AR and AF adjustments. The variability in SymDQN() and SymDQN(AR) suggests that additional tuning or context-specific factors may influence their effectiveness.
</details>
Figure 7: All versions of SymDQN: SymDQN(AF) (in green), SymDQN(AR,AF) (in red), SymDQN (in blue) and SymDQN(AR) (in purple); the $x$ -axis represents epochs and the $y$ -axis represents the ratio of obtained score in the episode and the maximum obtainable score in that episode. We report in standard deviations in the Appendix.
From this graph, we can conclude that the presence of ActionReasoner, despite giving a slight boost in the initial learning rate, hampers the overall performance of the agent (red and purple graphs). On the other hand, the presence of ActionFilter improves the initial performance (green and red).
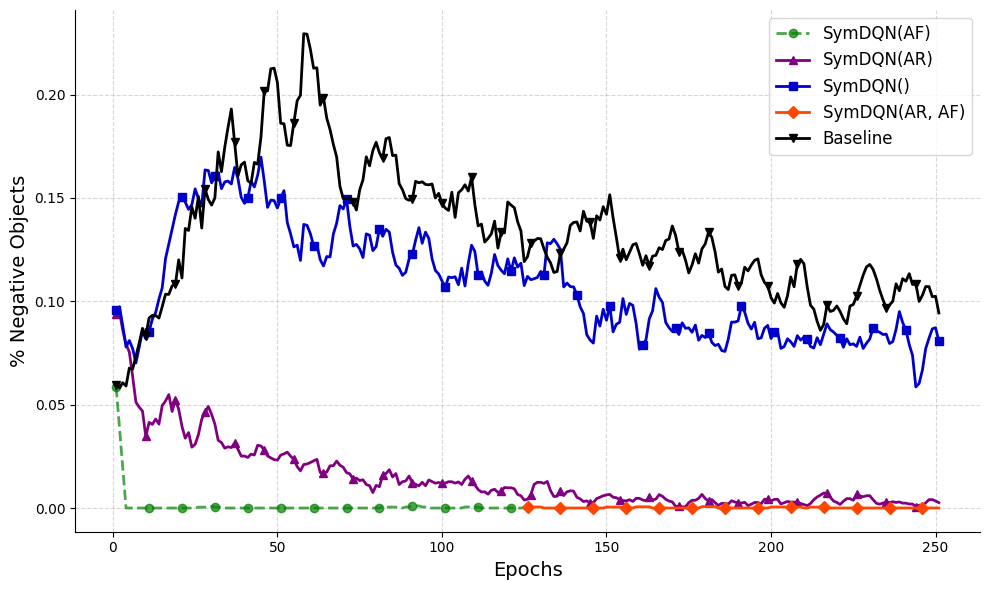
Let us now move to another performance measure: the precision of the agent in avoiding objects of the shape associated with negative rewards. We now compare all five experimental conditions, see Fig. 8.
<details>
<summary>extracted/6333762/precision_new.png Details</summary>
### Visual Description
## Line Graph: Percentage of Negative Objects Over Training Epochs
### Overview
The graph depicts the performance of different SymDQN model configurations and a baseline over 250 training epochs, measuring the percentage of negative objects retained. Five data series are plotted with distinct markers and colors, showing varying trends in object retention.
### Components/Axes
- **X-axis (Epochs)**: Ranges from 0 to 250 in increments of 50.
- **Y-axis (% Negative Objects)**: Scaled from 0.00 to 0.20 in 0.05 increments.
- **Legend**: Located in the top-right corner, mapping colors/markers to:
- Green dashed line: SymDQN(AF)
- Purple triangle line: SymDQN(AR)
- Blue square line: SymDQN()
- Orange diamond line: SymDQN(AR, AF)
- Black solid line: Baseline
### Detailed Analysis
1. **Baseline (Black Solid Line)**:
- Starts at ~0.06 at epoch 0.
- Peaks sharply at ~0.20 around epoch 50.
- Exhibits high volatility, fluctuating between ~0.08 and ~0.20 throughout training.
- Ends at ~0.10 by epoch 250.
2. **SymDQN(AF) (Green Dashed Line)**:
- Drops abruptly from ~0.06 to near 0.00 within the first 10 epochs.
- Remains flat at ~0.00 for all subsequent epochs.
3. **SymDQN(AR) (Purple Triangle Line)**:
- Declines gradually from ~0.06 to ~0.01 by epoch 50.
- Fluctuates slightly but stabilizes near ~0.005 by epoch 250.
4. **SymDQN() (Blue Square Line)**:
- Begins at ~0.09, rises to ~0.15 by epoch 50.
- Shows moderate volatility, averaging ~0.09–0.12 after epoch 100.
- Ends at ~0.08 by epoch 250.
5. **SymDQN(AR, AF) (Orange Diamond Line)**:
- Follows a similar trajectory to SymDQN(AR), starting at ~0.06.
- Declines to ~0.005 by epoch 100, stabilizing near ~0.002 by epoch 250.
### Key Observations
- **Baseline Volatility**: The Baseline exhibits the highest variability, with sharp peaks and troughs, suggesting instability in negative object retention.
- **SymDQN(AF) Efficacy**: SymDQN(AF) achieves the fastest and most complete reduction in negative objects, reaching near-zero retention within 10 epochs.
- **Combined Configurations**: SymDQN(AR, AF) and SymDQN(AR) show complementary performance, with SymDQN(AR, AF) achieving marginally better results than SymDQN(AR).
- **SymDQN() Limitations**: The SymDQN() configuration retains the highest percentage of negative objects, indicating suboptimal performance compared to other variants.
### Interpretation
The data demonstrates that SymDQN models with the AF (Adaptive Feature) component are most effective at minimizing negative object retention. The Baseline's high volatility and persistent negative object retention suggest it lacks mechanisms to suppress irrelevant features. SymDQN(AR) and SymDQN(AR, AF) configurations show that AR (Adaptive Regularization) contributes to gradual improvement, while AF enables rapid suppression. The SymDQN() variant's poor performance highlights the importance of combining AR and AF for optimal results. These trends align with the hypothesis that adaptive regularization and feature engineering are critical for reducing negative object influence in training.
</details>
Figure 8: Agent’s precision in all conditions: SymDQN(AF) (in green), SymDQN(AR,AF) (in red), SymDQN(AR) (in purple); SymDQN (in blue); DuelDQN (in black): the $x$ -axis represents epochs and the $y$ -axis represents the percentage of negative-reward objects consumed by the agent. Note that the green and red lines overlap.
While the presence of ActionReasoner (in purple) allows a significant improvement of precision, it’s the ActionFilter that eradicates negative rewards completely (red and green graphs). The baseline DuelDQN and the pure SymDQN perform similarly, not being able to learn to avoid negative rewards completely.
### 5.1 Interpretation and Discussion
The integration of symbolic knowledge into reinforcement learning, as demonstrated by SymDQN, provides several insights into the potential of neuro-symbolic approaches in AI. The ability of SymDQN to extract and utilize key environmental features drives a significant boost in initial learning rate and overall performance, suggesting that symbolic representations can provide a valuable advantage to neural networks, enabling them to rapidly leverage the features for better decision-making. The ActionFilter provides a dramatic enhancement in early-stage performance, allowing the model to make good decisions as soon as the symbolic representation is available. By leveraging the symbolic representation and understanding of the environment, ActionFilter prunes sub-optimal actions, aligning the agent’s behavior with a symbolic understanding of the environment. The role of ActionReasoner is less clear: while providing a slight boost in initial performance, it hampers the overall learning rate. It seems that by forcing the model output to comply with the logical axiom, it diminishes its ability to capture information that is not described by the logical formulas.
The two components, ActionReasoner and ActionFilter use symbolic information to adjust (the impact of) $q$ -values and could be seen as a form of reward shaping. ActionReasoner uses the axiom (A4) to align $q$ -values with predicted immediate rewards. As we can see in Fig. 7, this ‘reward shaping’ process is detrimental to the overall performance. A possible reason for that can be illustrated in the following example. Let’s assume the agent is separated from a multitude of positive shapes by a thin wall of negative shapes. A long-term perspective of sacrificing some reward by crossing over the wall can be blocked by attaching too much value to the immediate punishment. Note, however, that although ineffective, this ‘reward shaping’ makes the agent more cautious/precise (see Fig. 7). While ActionFilter does not shape the reward function directly (as it is turned off in the training phase), it performs reasoning based on rewards (Fig. 4). In a given state it eliminates the possibility of executing actions for which $q$ -values and immediate rewards differ too drastically.
The advantages of SymDQN come with trade-offs. The computational cost introduced by the additional components is non-trivial, and the logical constraints imposed on the learning might hamper performance in more complex environments. In that, the use of LTNs in reinforcement learning sheds light on the ‘thinking fast and slow’ effects in learning. Firstly, the use of axioms (A1)-(A3) in ShapeRecognizer gives a sharp increase in the initial performance due to the understanding of the environment structure (Fig. 8). Apart from that, adjusting the reward function with ActionReasoner and ActionFilter will increase precision (as normally assumed about the System 2 type of behavior), but it can also hamper the overall performance, like it does in the case of ActionReasoner (see Fig. 7).
## 6 Conclusions and Future Work
This research introduces a novel modular approach to integrating symbolic knowledge with deep reinforcement learning through the implementation of SymDQN. We contribute to the field of Neuro-Symbolic AI in several ways. Firstly, we demonstrate a successful integration of LTNs into reinforcement learning, a promising and under-explored research direction. This integration touches on key challenges: interpretability, alignment, and knowledge injection. Secondly, SymDQN augments reinforcement learning through symbolic environment representation, modeling of object relationships and dynamics, and guiding action based on symbolic knowledge, effectively improving both initial learning rates and the end performance of the reinforcement learning agents. These contributions advance the field of neuro-symbolic AI, bridging the gap between symbolic reasoning and deep learning systems. Our findings demonstrate the potential of integrative approaches in creating more aligned, controllable and interpretable models for safe and reliable AI systems.
### 6.1 Future Work
We see several potential avenues for future research.
Enhancing Environment Representation It is easy to see that the ShapeRecognizer can be adapted to any grid-like environment. It could also be further developed to represent more complex environments symbolically, e.g., by integrating a more advanced object-detection component (e.g., Faster-LTN Manigrasso et al. (2021)). With the addition of precise bounding box detection and multi-class labeling, the component could be extended to also perform hierarchical representations, e.g., recognizing independent objects and their parts or constructing abstract taxonomies.
Automatic Axiom Discovery The investigation of automatic axiom discovery through iterative learning, or meta-learning, is an interesting direction that opens the doors to knowledge extraction from a model (see, e.g., Hasanbeig et al. (2021); Umili et al. (2021); Meli et al. (2024)). Theoretically, given enough time and randomization, Q-learning converges to optimal decision policy in any environment, and so the iterative development and assessment of axioms might allow us to extract knowledge from deep learning systems that outperform human experts.
Broader Evaluation While a version of SymDQN was shown to be advantageous, it was only tested in a single, simple environment. A broader suite of empirical experiments in more complex environments, such as Atari games or Pac-Man, is necessary to understand the generalization capabilities of the findings. These environments provide more complex and diverse challenges, potentially offering deeper insights into the advantages of SymDQN.
## Appendix A Appendix
#### Hardware and software specifications
The experiments, hyper-parameter tuning, and model variation comparisons were performed on a computing center machine (Tesla V100 with either 16 or 32GB). The coding environment used was Python 3.9.5 and Pytorch 2.3.1 with Cuda Toolkit 12.1. To integrate LTNs, the LTNtorch Carraro (2022) library was used, a PyTorch implementation by Tommaso Carraro. For experiment tracking, the ClearMl Platform cle (2023) was used. The code is provided as a separate .zip file.
#### Hyperparameters
The hyper-parameters used for training were: explore steps: 25000, update steps: 1000, initial epsilon: 0.95, end epsilon: 0.05, memory capacity: 1000, batch size: 16, gamma: 0.99, learning rate: 0.0001, maximum gradient norm: 1. Semantics of quantifiers in LTN used $p=8$ .
#### Standard deviations
Performance was assessed through 5 independent experimental runs per configuration. Each run evaluated 50 distinct environments to calculate average scores per epoch; ( $\ast$ ) stands for SymDQN( $\ast$ ), values for epochs 50, 150, 250 (smoothed, rolling window 5). First table: overall performance (rewards, r) and standard deviations (sd). Second table: ratio of negative shapes collected (inverse of precision, p) and sd.
| (AF) (AR) () | 0.65 0.26 0.43 | 0.03 0.03 0.05 | 0.70 0.47 0.65 | 0.01 0.01 0.02 | 0.71 0.53 0.66 | 0.01 0.04 0.02 |
| --- | --- | --- | --- | --- | --- | --- |
| (AR,AF) | 0.40 | 0.02 | 0.53 | 0.02 | 0.59 | 0.02 |
| DuelDQN | 0.24 | 0.06 | 0.57 | 0.02 | 0.64 | 0.01 |
| (AF) (AR) () | 0.00 0.02 0.17 | 0.00 0.00 0.02 | 0.00 0.01 0.12 | 0.00 0.00 0.02 | 0.00 0.00 0.08 | 0.00 0.00 0.00 |
| --- | --- | --- | --- | --- | --- | --- |
| (AR,AF) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| DDQN | 0.19 | 0.03 | 0.14 | 0.01 | 0.10 | 0.00 |
## References
- Badreddine and Spranger (2019) Samy Badreddine and Michael Spranger. Injecting prior knowledge for transfer learning into reinforcement learning algorithms using logic tensor networks. CoRR, abs/1906.06576, 2019.
- Badreddine et al. (2022) Samy Badreddine, Artur d’Avila Garcez, Luciano Serafini, and Michael Spranger. Logic tensor networks. Artificial Intelligence, 303:103649, 2022.
- Bianchi and Hitzler (2019) Federico Bianchi and Pascal Hitzler. On the capabilities of logic tensor networks for deductive reasoning. In AAAI Spring Symposium Combining Machine Learning with Knowledge Engineering, 2019.
- Carraro (2022) Tommaso Carraro. LTNtorch: PyTorch implementation of Logic Tensor Networks, mar 2022.
- cle (2023) ClearML - your entire mlops stack in one open-source tool, 2023. Software available from http://github.com/allegroai/clearml.
- Donadello et al. (2017) Ivan Donadello, Luciano Serafini, and Artur d’Avila Garcez. Logic tensor networks for semantic image interpretation. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, pages 1596–1602, 2017.
- Furelos-Blanco et al. (2021) Daniel Furelos-Blanco, Mark Law, Anders Jonsson, Krysia Broda, and Alessandra Russo. Induction and exploitation of subgoal automata for reinforcement learning. J. Artif. Intell. Res., 70:1031–1116, 2021.
- Giacomo et al. (2019) Giuseppe De Giacomo, Luca Iocchi, Marco Favorito, and Fabio Patrizi. Foundations for restraining bolts: Reinforcement learning with ltlf/ldlf restraining specifications. In J. Benton, Nir Lipovetzky, Eva Onaindia, David E. Smith, and Siddharth Srivastava, editors, Proceedings of the Twenty-Ninth International Conference on Automated Planning and Scheduling, ICAPS 2019, Berkeley, CA, USA, July 11-15, 2019, pages 128–136. AAAI Press, 2019.
- Hasanbeig et al. (2021) Mohammadhosein Hasanbeig, Natasha Yogananda Jeppu, Alessandro Abate, Tom Melham, and Daniel Kroening. Deepsynth: Automata synthesis for automatic task segmentation in deep reinforcement learning. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021, pages 7647–7656. AAAI Press, 2021.
- Manigrasso et al. (2021) Francesco Manigrasso, Filomeno Davide Miro, Lia Morra, and Fabrizio Lamberti. Faster-LTN: A neuro-symbolic, end-to-end object detection architecture. In Igor Farkaš, Paolo Masulli, Sebastian Otte, and Stefan Wermter, editors, Artificial Neural Networks and Machine Learning – ICANN 2021, pages 40–52, Cham, 2021. Springer International Publishing.
- Meli et al. (2024) Daniele Meli, Alberto Castellini, and Alessandro Farinelli. Learning logic specifications for policy guidance in pomdps: an inductive logic programming approach. Journal of Artificial Intelligence Research, 79:725–776, February 2024.
- Serafini and d’Avila Garcez (2016) Luciano Serafini and Artur S. d’Avila Garcez. Logic tensor networks: Deep learning and logical reasoning from data and knowledge. CoRR, abs/1606.04422, 2016.
- Towers et al. (2024) Mark Towers, Jordan K. Terry, Ariel Kwiatkowski, John U. Balis, Gianluca de Cola, Tristan Deleu, Manuel Goulão, Andreas Kallinteris, Arjun KG, Markus Krimmel, Rodrigo Perez-Vicente, Andrea Pierré, Sander Schulhoff, Jun Jet Tai, Andrew Tan Jin Shen, and Omar G. Younis. Gymnasium, June 2024.
- Umili et al. (2021) Elena Umili, Emanuele Antonioni, Francesco Riccio, Roberto Capobianco, Daniele Nardi, Giuseppe De Giacomo, et al. Learning a symbolic planning domain through the interaction with continuous environments. In Workshop on Bridging the Gap Between AI Planning and Reinforcement Learning (PRL), workshop at ICAPS 2021, 2021.
- Umili et al. (2023) Elena Umili, Roberto Capobianco, and Giuseppe De Giacomo. Grounding LTLf Specifications in Image Sequences. In Proceedings of the 20th International Conference on Principles of Knowledge Representation and Reasoning, pages 668–678, 8 2023.
- van Krieken et al. (2022) Emile van Krieken, Erman Acar, and Frank van Harmelen. Analyzing differentiable fuzzy logic operators. Artificial Intelligence, 302:103602, 2022.
- Wagner and d’Avila Garcez (2022) Benedikt Wagner and Artur S. d’Avila Garcez. Neural-symbolic reasoning under open-world and closed-world assumptions. In Proceedings of the AAAI 2022 Spring Symposium on Machine Learning and Knowledge Engineering for Hybrid Intelligence (AAAI-MAKE 2022), 2022.
- Wang et al. (2015) Ziyu Wang, Nando de Freitas, and Marc Lanctot. Dueling network architectures for deep reinforcement learning. CoRR, abs/1511.06581, 2015.
- Wang et al. (2016) Ziyu Wang, Tom Schaul, Matteo Hessel, Hado Van Hasselt, Marc Lanctot, and Nando De Freitas. Dueling network architectures for deep reinforcement learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, pages 1995–2003. JMLR.org, 2016.