# Affordable AI Assistants with Knowledge Graph of Thoughts
**Authors**: Maciej Besta, ETH Zurich, &Lorenzo Paleari, ETH Zurich, &Jia Hao Andrea Jiang, ETH Zurich, &Robert Gerstenberger, ETH Zurich, &You Wu, ETH Zurich, &Jón Gunnar Hannesson, ETH Zurich, &Patrick Iff, ETH Zurich, &Ales Kubicek, ETH Zurich, &Piotr Nyczyk, &Diana Khimey, ETH Zurich, &Nils Blach, ETH Zurich, &Haiqiang Zhang, ETH Zurich, &Tao Zhang, ETH Zurich, &Peiran Ma, ETH Zurich, &Grzegorz Kwaśniewski, ETH Zurich, &Marcin Copik, ETH Zurich, &Hubert Niewiadomski, &Torsten Hoefler, ETH Zurich
> corresponding author
## Abstract
Large Language Models (LLMs) are revolutionizing the development of AI assistants capable of performing diverse tasks across domains. However, current state-of-the-art LLM-driven agents face significant challenges, including high operational costs and limited success rates on complex benchmarks like GAIA. To address these issues, we propose Knowledge Graph of Thoughts (KGoT), an innovative AI assistant architecture that integrates LLM reasoning with dynamically constructed knowledge graphs (KGs). KGoT extracts and structures task-relevant knowledge into a dynamic KG representation, iteratively enhanced through external tools such as math solvers, web crawlers, and Python scripts. Such structured representation of task-relevant knowledge enables low-cost models to solve complex tasks effectively while also minimizing bias and noise. For example, KGoT achieves a 29% improvement in task success rates on the GAIA benchmark compared to Hugging Face Agents with GPT-4o mini. Moreover, harnessing a smaller model dramatically reduces operational costs by over 36 $\times$ compared to GPT-4o. Improvements for other models (e.g., Qwen2.5-32B and Deepseek-R1-70B) and benchmarks (e.g., SimpleQA) are similar. KGoT offers a scalable, affordable, versatile, and high-performing solution for AI assistants.
Website & code: https://github.com/spcl/knowledge-graph-of-thoughts
## 1 Introduction
Large Language Models (LLMs) are transforming the world. However, training LLMs is expensive, time-consuming, and resource-intensive. In order to democratize the access to generative AI, the landscape of agent systems has massively evolved during the last two years (LangChain Inc., 2025a; Rush, 2023; Kim et al., 2024; Sumers et al., 2024; Hong et al., 2024; Guo et al., 2024; Edge et al., 2025; Besta et al., 2025c; Zhuge et al., 2024; Beurer-Kellner et al., 2024; Shinn et al., 2023; Kagaya et al., 2024; Zhao et al., 2024a; Stengel-Eskin et al., 2024; Wu et al., 2024). These schemes have been applied to numerous tasks in reasoning (Creswell et al., 2023; Bhattacharjya et al., 2024; Besta et al., 2025c), planning (Wang et al., 2023c; Prasad et al., 2024; Shen et al., 2023; Huang et al., 2023), software development (Tang et al., 2024), and many others (Xie et al., 2024; Li & Vasarhelyi, 2024; Schick et al., 2023; Beurer-Kellner et al., 2023).
Among the most impactful applications of LLM agents is the development of AI assistants capable of helping with a wide variety of tasks. These assistants promise to serve as versatile tools, enhancing productivity and decision-making across domains. From aiding researchers with complex problem-solving to managing day-to-day tasks for individuals, AI assistants are becoming an indispensable part of modern life. Developing such systems is highly relevant, but remains challenging, particularly in designing solutions that are both effective and economically viable.
The GAIA benchmark (Mialon et al., 2024) has become a key standard for evaluating LLM-based agent systems across diverse tasks, including web navigation, code execution, image reasoning, scientific QA, and multimodal challenges. Despite its introduction nearly two years ago, top-performing solutions still struggle with many tasks. Moreover, operational costs remain high: running all validation tasks with Hugging Face Agents (Roucher & Petrov, 2025) and GPT-4o costs $\approx$ $200, underscoring the need for more affordable alternatives . Smaller models like GPT-4o mini significantly reduce expenses but suffer from steep drops in task success, making them insufficient. Open large models also pose challenges due to demanding infrastructure needs, while smaller open models, though cheaper to run, lack sufficient capabilities.
To address these challenges, we propose Knowledge Graph of Thoughts (KGoT), a novel AI assistant architecture that significantly reduces task execution costs while maintaining a high success rate (contribution #1). The central innovation of KGoT lies in its use of a knowledge graph (KG) (Singhal, 2012; Besta et al., 2024b) to represent knowledge relevant to a given task. A KG organizes information into triples, providing a structured representation of knowledge that small, cost-effective models can efficiently process. Hence, KGoT “turns the unstructured into the structured”, i.e., KGoT turns the often unstructured data such as website contents or PDF files into structured KG triples. This approach enhances the comprehension of task requirements, enabling even smaller models to achieve performance levels comparable to much larger counterparts, but at a fraction of the cost.
The KGoT architecture (contribution #2) implements this concept by iteratively constructing a KG from the task statement, incorporating tools as needed to gather relevant information. The constructed KG is kept in a graph store, serving as a repository of structured knowledge. Once sufficient information is gathered, the LLM attempts to solve the task by either directly embedding the KG in its context or querying the graph store for specific insights. This approach ensures that the LLM operates with a rich and structured knowledge base, improving its task-solving ability without incurring the high costs typically associated with large models. The architecture is modular and extensible towards different types of graph query languages and tools.
Our evaluation against top GAIA leaderboard baselines demonstrates its effectiveness and efficiency (contribution #3). KGoT with GPT-4o mini solves $>$ 2 $\times$ more tasks from the validation set than Hugging Face Agents with GPT-4o or GPT-4o mini. Moreover, harnessing a smaller model dramatically reduces operational costs: from $187 with GPT-4o to roughly $5 with GPT-4o mini. KGoT’s benefits generalize to other models, baselines, and benchmarks such as SimpleQA (Wei et al., 2024).
On top of that, KGoT reduces noise and simultaneously minimizes bias and improves fairness by externalizing reasoning into an explicit knowledge graph rather than relying solely on the LLM’s internal generation (contribution #4). This ensures that key steps when resolving tasks are grounded in transparent, explainable, and auditable information.
## 2 Knowledge Graph of Thoughts
We first illustrate the key idea, namely, using a knowledge graph to encode structurally the task contents. Figure 1 shows an example task and its corresponding evolving KG.
### 2.1 What is a Knowledge Graph?
A knowledge graph (KG) is a structured representation of information that organizes knowledge into a graph-based format, allowing for efficient querying, reasoning, and retrieval. Formally, a KG consists of a set of triples, where each triple $(s,p,o)$ represents a relationship between two entities $s$ (subject) and $o$ (object) through a predicate $p$ . For example, the triple $(\text{``Earth''},\text{``orbits''},\text{``Sun''})$ captures the fact that Earth orbits the Sun. Mathematically, a knowledge graph can be defined as a directed labeled graph $G=(V,E,L)$ , where $V$ is the set of vertices (entities), $E\subseteq V\times V$ is the set of edges (relationships), and $L$ is the set of labels (predicates) assigned to the edges. Each entity or predicate may further include properties or attributes, enabling richer representation. Knowledge graphs are widely used in various domains, including search engines, recommendation systems, and AI reasoning, as they facilitate both efficient storage and complex queries.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Flowchart: Knowledge Graph Construction and Response Generation Process
### Overview
The flowchart illustrates a multi-step process for answering a complex question using a knowledge graph (KG) enhanced with external data. It begins with an input task statement (a GAIA Benchmark question) and progresses through KG construction, web data integration, text inspection, information extraction, and response generation. The final answer is derived from contextual relationships in the enriched KG.
### Components/Axes
1. **Input Task Statement**
- Example question: *"In the YouTube 360 VR video from March 2018 narrated by the voice actor of Lord of the Rings' Gollum, what number was mentioned by the narrator directly after dinosaurs were first shown in the video?"*
- Position: Top-left quadrant.
2. **Knowledge Graph (KG) Construction**
- Initial KG:
- Node: `Gollum (LotR)`
- Connection: `interpreted by` → `Andy Serkis`
- Enhanced KG (after web query):
- Added nodes:
- `The Silmarillion` (Type: Book, Date: 2023, ID: 123456789)
- `We Are Stars` (Type: VR, Date: 2018, ID: 987654321)
- New connections:
- `narrated` links between `Andy Serkis` and both books.
- Position: Center-left to center-right.
3. **Web Query and Text Inspection**
- Action: Query web for additional data → Invoke YouTube transcriber.
- Position: Middle-right quadrant.
4. **Information Extraction and Response Generation**
- Final KG state:
- Explicit connection between `We Are Stars` and the answer `100,000,000`.
- Response box: Contains the answer to the input question.
- Position: Far right.
### Detailed Analysis
- **Initial KG**: Minimal structure with only `Gollum` and `Andy Serkis` linked via `interpreted by`.
- **Enhanced KG**:
- Added two books with metadata (type, date, ID).
- `Andy Serkis` now narrates both books, creating a triadic relationship.
- Temporal context: `We Are Stars` (2018) precedes `The Silmarillion` (2023).
- **Response**: Directly answers the question by linking `We Are Stars` (2018) to the number `100,000,000`, which follows the dinosaurs' first appearance in the video.
### Key Observations
1. **Temporal Logic**: The answer (`100,000,000`) is tied to `We Are Stars` (2018), which is earlier than `The Silmarillion` (2023).
2. **Data Enrichment**: Web queries and text inspection add critical metadata (dates, IDs) to the KG.
3. **Ambiguity in Dates**: The `The Silmarillion` entry lists a 2023 date, conflicting with its real-world publication (1977). This may indicate a data error or contextual reinterpretation.
4. **Flow Direction**: Left-to-right progression mirrors the KG's evolution from sparse to enriched.
### Interpretation
The process demonstrates how external data (e.g., YouTube transcripts) resolves ambiguities in KG-based QA systems. By linking `Andy Serkis` to multiple works via narration, the system identifies the correct context (`We Are Stars`) to answer the question. The inclusion of dates and IDs suggests a focus on temporal and provenance-aware reasoning. However, the `The Silmarillion` date discrepancy highlights potential challenges in data accuracy. The final answer (`100,000,000`) likely refers to the time dinosaurs dominated Earth (100 million years), contextualized by the video's narration.
</details>
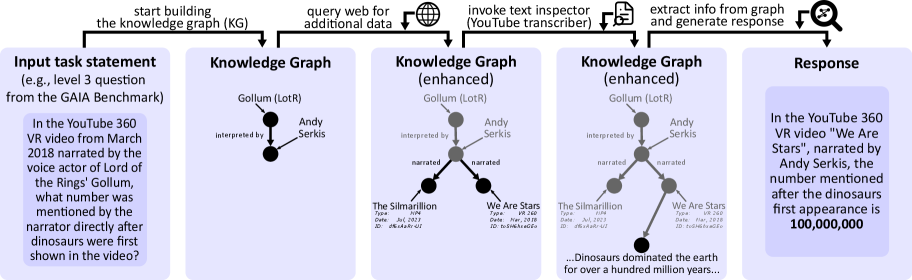
Figure 1: The key idea behind Knowledge Graph of Thoughts (KGoT): transforming the representation of a task for an AI assistant from a textual form into a knowledge graph (KG). As an example, we use a Level-3 (i.e., highest difficulty) task from the GAIA benchmark. In order to solve the task, KGoT evolves this KG by adding relevant information that brings the task closer to completion. This is achieved by iteratively running various tools. Finally, the task is solved by extracting the relevant information from the KG, using – for example – a graph query, or an LLM’s inference process with the KG provided as a part of the input prompt. More examples of KGs are in Appendix A.
### 2.2 Harnessing Knowledge Graphs for Effective AI Assistant Task Resolution
At the heart of KGoT is the process of transforming a task solution state into an evolving KG. The KG representation of the task is built from “thoughts” generated by the LLM. These “thoughts” are intermediate insights identified by the LLM as it works through the problem. Each thought contributes to expanding or refining the KG by adding vertices or edges that represent new information.
For example, consider the following Level 3 (i.e., highest difficulty) task from the GAIA benchmark: “In the YouTube 360 VR video from March 2018 narrated by the voice actor of Lord of the Rings’ Gollum, what number was mentioned by the narrator directly after dinosaurs were first shown in the video?” (see Figure 1 for an overview; more examples of constructed KGs are in Appendix A). Here, the KG representation of the task solution state has a vertex “Gollum (LotR)”. Then, the thought “Gollum from Lord of the Rings is interpreted by Andy Serkis” results in adding a vertex for “Andy Serkis”, and linking “Gollum (LotR)” to “Andy Serkis” with the predicate “interpreted by”. Such integration of thought generation and KG construction creates a feedback loop where the KG continuously evolves as the task progresses, aligning the representation with problem requirements.
In order to evolve the KG task representation, KGoT iteratively interacts with tools and retrieves more information. For instance, the system might query the internet to identify videos narrated by Andy Serkis (e.g., “The Silmarillion“ and “We Are Stars”). It can also use a YouTube transcriber tool to find their publication date. This iterative refinement allows the KG to model the current “state” of a task at each step, creating a more complete and structured representation of this task and bringing it closer to completion. Once the KG has been sufficiently populated with task-specific knowledge, it serves as a robust resource for solving the problem.
In addition to adding new graph elements, KGoT also supports other graph operations. This includes removing nodes and edges, used as a part of noise elimination strategies.
### 2.3 Extracting Information from the KG
To accommodate different tasks, KGoT supports different ways to extract the information from the KG. Currently, we offer graph query languages or general-purpose languages; each of them can be combined with the so-called Direct Retrieval. First, one can use a graph query, prepared by the LLM in a language such as Cypher (Francis et al., 2018) or SPARQL (Pérez et al., 2009), to extract the answer to the task from the graph. This works particularly well for tasks that require retrieving specific patterns within the KG. Second, we also support general scripts prepared by the LLM in a general-purpose programming language such as Python. This approach, while not as effective as query languages for pattern matching, offers greater flexibility and may outperform the latter when a task requires, for example, traversing a long path in the graph. Third, in certain cases, once enough information is gathered into the KG, it may be more effective to directly paste the KG into the LLM context and ask the LLM to solve the task, instead of preparing a dedicated query or script. We refer to this approach as Direct Retrieval.
The above schemes offer a tradeoff between accuracy, cost, and runtime. For example, when low latency is priority, general-purpose languages should be used, as they provide an efficient lightweight representation of the KG and offer rapid access and modification of graph data. When token cost is most important, one should avoid Direct Retrieval (which consumes many tokens as it directly embeds the KG into the LLM context) and focus on either query or general-purpose languages, with a certain preference for the former, because its generated queries tend to be shorter than scripts. Finally, when aiming for solving as many tasks as possible, one should experiment with all three schemes. As shown in the Evaluation section, these methods have complementary strengths: Direct Retrieval is effective for broad contextual understanding, while graph queries and scripts are better suited for structured reasoning.
### 2.4 Representing the KG
KGoT can construct three interoperable KG representations: Property graphs (used with graph query languages such as Cypher and systems such as Neo4j (Robinson et al., 2015)), RDF graphs (used with graph query languages such as SPARQL and systems such as RDF4J (Ben Mahria et al., 2021)), and the adjacency list graphs (Besta et al., 2018) (used with general-purpose languages such as Python and systems such as NetworkX (NetworkX Developers, 2025)).
Each representation supports a different class of analysis. The Property graph view facilitates analytics such as pattern matching, filtering, of motif queries directly on the evolving task-state graph. The RDF graph view facilitates reasoning over ontology constraints, schema validation, and SPARQL-based inference for missing links. The adjacency list representation with NetworkX facilitates Python-based graph analytics, for example centrality measures, connected components, clustering coefficients, etc., all on the same KG snapshots.
Appendix A contains examples of task-specific KGs, illustrating how their topology varies with the task domain (e.g., tree-like procedural chains vs. dense relational subgraphs in multi-entity reasoning).
### 2.5 Bias, Fairness, and Noise Mitigation through KG-Based Representation
KGoT externalizes and structures the reasoning process, which reduces noise, mitigates model bias, and improves fairness, because in each iteration both the outputs from tools and LLM thoughts are converted into triples and stored explicitly. Unlike opaque monolithic LLM generations, this fosters transparency and facilitates identifying biased inference steps. It also facilitates noise mitigation: new triples can be explicitly checked for the quality of their information content before being integrated into the KG, and existing triples can also be removed if they are deemed redundant (examples of such triples that have been found and removed are in Appendix B.6).
## 3 System Architecture
The KGoT modular and flexible architecture, pictured in Figure 2, consists of three main components: the Graph Store Module, the Controller, and the Integrated Tools, each playing a critical role in the task-solving process. Below, we provide a detailed description of each component and its role in the system. Additional details are in Appendix B (architecture) and in Appendix C (prompts).
### 3.1 Maintaining the Knowledge Graph with the Graph Store Module
A key component of the KGoT system is the Graph Store Module, which manages the storage and retrieval of the dynamically evolving knowledge graph which represents the task state. In order to harness graph queries, we use a graph database backend; in the current KGoT implementation, we test Cypher together with Neo4j (Robinson et al., 2015), an established graph database (Besta et al., 2023b; c), as well as SPARQL together with the RDF4J backend (Ben Mahria et al., 2021). Then, in order to support graph accesses using a general-purpose language, KGoT harnesses the NetworkX library (NetworkX Developers, 2025) and Python. Note that the extensible design of KGoT enables seamless integration of any other backends and languages.
### 3.2 Managing the Workflow with the Controller Module
The Controller orchestrates the interactions between the KG and the tools. Upon receiving a user query, it iteratively interprets the task, determines the appropriate tools to invoke based on the KG state and task needs, and integrates tool outputs back into the KG. The Controller uses a dual-LLM architecture with a clear separation of roles: the LLM Graph Executor constructs and evolves the KG, while the LLM Tool Executor manages tool selection and execution.
The LLM Graph Executor determines the next steps after each iteration that constructs and evolves the KG. It identifies any missing information necessary to solve the task, formulates appropriate queries for the graph store interaction (retrieve/insert operations), and parses intermediate or final results for integration into the KG. It also prepares the final response to the user based on the KG.
The LLM Tool Executor operates as the executor of the plan devised by the LLM Graph Executor. It identifies the most suitable tools for retrieving missing information, considering factors such as tool availability, relevance, and the outcome of previous tool invocation attempts. For example, if a web crawler fails to retrieve certain data, the LLM Tool Executor might prioritize a different retrieval mechanism or adjust its queries. The LLM Tool Executor manages the tool execution process, including interacting with APIs, performing calculations, or extracting information, and returns the results to the LLM Graph Executor for further reasoning and integration into the KG.
### 3.3 Ensuring Versatile and Extensible Set of Integrated Tools
KGoT offers a hierarchical suite of tools tailored to diverse task needs. The Python Code Tool enables dynamic script generation and execution for complex computations. The LLM Tool supplements the controller’s reasoning by integrating an auxiliary language model, enhancing knowledge access while minimizing hallucination risk. For multimodal inputs, the Image Tool supports image processing and extraction. Web-based tasks are handled by the Surfer Agent (based on the design by Hugging Face Agents (Roucher & Petrov, 2025)), which leverages tools like the Wikipedia Tool, granular navigation tools (PageUp, PageDown, Find), and SerpApi (SerpApi LLM, 2025) for search. Additional tools include the ExtractZip Tool for compressed files and the Text Inspector Tool for converting content from sources like MP3s and YouTube transcripts into Markdown. Finally, the user can seamlessly add a new tool by initializing the tool, passing in the logger object for tool use statistics, and appending the tool to the tool list via a Tool Manager object. We require all tools implemented to adhere to the LangChain’s BaseTool interface class. This way, the list of tools managed by the Tool Manager can be directly bound to the LLM Tool Executor via LangChain bind_tools, further facilitating new tools.
### 3.4 Ensuring High-Performance & Scalability
The used scalability optimizations include (1) asynchronous execution using asyncio (Python Software Foundation, 2025b) to parallelize LLM tool invocations, mitigating I/O bottlenecks and reducing idle time, (2) graph operation parallelism by reformulating LLM-generated Cypher queries to enable concurrent execution of independent operations in a graph database, and (3) MPI-based distributed processing, which decomposes workloads into atomic tasks distributed across ranks using a work-stealing algorithm to ensure balanced computational load and scalability.
### 3.5 Ensuring System Robustness
Robustness is ensured with two established mechanisms, Self-Consistency (Wang et al., 2023b) (via majority voting) and LLM-as-a-Judge (Gu et al., 2025) (other strategies such as embedding-based stability are also applicable (Besta et al., 2025d)). With Self-Consistency, we query the LLM multiple times when deciding whether to insert more data into the KG or retrieve existing data, when deciding which tool to use, and when parsing the final solution. This approach reduces the impact of single-instance errors or inconsistencies in various parts of the KGoT architecture. LLM-as-a-Judge further reinforces the robustness, by directly employing the LLM agent to make these decisions based on generated reasoning chains.
Overall, both Self-Consistency and LLM-as-a-Judge have been shown to significantly enhance the robustness of prompting. For example, MT-Bench and Chatbot Arena show that strong judges (e.g., GPT-4 class) match human preferences at 80% agreement or more, on par with human-human agreement (Zheng et al., 2023). Prometheus/Prometheus-2 further demonstrate open evaluator LMs with the highest correlations to both humans and proprietary judges across direct-assessment and pairwise settings, and AlpacaEval has been validated against approximately 20K human annotations, addressing earlier concerns about reproducibility at scale. Similarly reliable gains have been shown for Self-Consistency (Wang et al., 2023b).
### 3.6 Ensuring Layered Error Containment & Management
To manage LLM-generated syntax errors, KGoT includes LangChain’s JSON parsers that detect syntax issues. When a syntax error is detected, the system first attempts to correct it by adjusting the problematic syntax using different encoders, such as the “unicode escape” (Python Software Foundation, 2025a). If the issue persists, KGoT employs a retry mechanism (three attempts by default) that uses the LLM to rephrase the query/command and attempts to regenerate its output. If the error persists, the system logs it for further analysis, bypasses the problematic query, and continues with other iterations.
To handle API & system related errors, such as the OpenAI code 500, we employ exponential backoff, implemented using the tenacity library (Tenacity Developers, 2025a). Additionally, KGoT includes comprehensive logging systems as part of its error management framework. These systems track the errors encountered during system operation, providing valuable data that can be easily parsed and analyzed (e.g., snapshots of the knowledge graphs or responses from third-party APIs).
The Python Executor tool, a key component of the system, is containerized to ensure secure execution of LLM-generated code. This tool is designed to run code with strict timeouts and safeguards, preventing potential misuse or resource overconsumption.
### 3.7 Implementation Details
KGoT employs Docker (Docker Inc., 2025) and Sarus (Benedicic et al., 2019) for containerization, enabling a consistent and isolated runtime environment for all components. We containerize critical modules such as the KGoT controller, the Neo4j knowledge graph, and integrated tools (e.g., the Python Executor tool for safely running LLM-generated code with timeouts). Here, Docker provides a widely adopted containerization platform for local and cloud deployments that guarantees consistency between development and production environments. Sarus, a specialized container platform designed for high-performance computing (HPC) environments, extends KGoT’s portability to HPC settings where Docker is typically unavailable due to security constraints. This integration allows KGoT to operate efficiently in HPC environments, leveraging their computational power.
KGoT also harnesses LangChain (LangChain Inc., 2025a), an open-source framework specifically designed for creating and orchestrating LLM-driven applications. LangChain offers a comprehensive suite of tools and APIs that simplify the complexities of managing LLMs, including prompt engineering, tool integration, and the coordination of LLM outputs.
## 4 System Workflow
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Knowledge Graph of Thoughts (KGoT) Architecture
### Overview
The diagram illustrates a two-tiered architecture for a Knowledge Graph of Thoughts system. It includes a high-level overview and a detailed workflow. The system integrates a knowledge graph, LLM-based executors, and various tools to process user queries and generate responses.
---
### Components/Axes
#### High-Level Overview
1. **Graph Store**
- Contains a **Knowledge Graph** (nodes/edges diagram)
- Storage backend options:
- Graph database (e.g., Neo4j)
- Lightweight backend (e.g., NetworkX)
- Knowledge extraction methods:
- Graph query language
- General-purpose programming language
2. **Controller**
- **LLM Graph Executor**: Updates graph state iteratively
- **LLM Tool Executor**: Handles tool calls
3. **Integrated Tools**
- Python code & math tool (LLM)
- Image tool (LLM)
- ExtractZIP tool
- Text inspector tool (LLM)
- MDConverter
- YouTube transcriber
- Browser (with sub-tools: Wikipedia, Page up/down, Find next, etc.)
#### Detailed View
- **User Question** → **LLM Graph Executor** (Step 1)
- **Max. Iterations?** (User-defined parameter)
- **Determine Next Step** (LLM decision)
- **Solve/Enhance?** (Majority vote)
- **Run ENHANCE/SOLVE** (Steps 6-7)
- **Apply Mathematical Processing** (Step 8)
- **Parse Solution** (Step 9)
- **KGoT Response** (Final output)
---
### Detailed Analysis
#### Graph Store
- **Backends**:
- **Graph Database**: Neo4j (optimized for graph queries)
- **Lightweight Backend**: NetworkX (general-purpose programming)
- **Extraction Methods**:
- Graph query language (structured)
- General-purpose programming (flexible)
#### Controller Workflow
1. **Step 1**: LLM Graph Executor updates graph state
2. **Step 2**: Check if max iterations reached (user-defined)
3. **Step 3**: If yes, proceed to parsing; if no, loop
4. **Step 4**: LLM determines next action (SOLVE/ENHANCE)
5. **Step 5**: Run selected action (tool calls or graph updates)
6. **Step 6**: Run ENHANCE (LLM-driven)
7. **Step 7**: Run SOLVE (generate solution)
8. **Step 8**: Apply mathematical processing (LLM)
9. **Step 9**: Parse solution (LLM)
#### Integrated Tools
- **LLM-Enabled Tools**:
- Python code & math tool
- Image tool
- Text inspector tool
- MDConverter
- YouTube transcriber
- **Non-LLM Tools**:
- ExtractZIP
- Browser sub-tools (Wikipedia, Find next, etc.)
---
### Key Observations
1. **LLM Pervasiveness**: 70% of tools/components explicitly use LLM (marked with green "LLM" labels).
2. **Iterative Process**: The system allows up to N iterations (user-defined) for graph updates.
3. **Tool Hierarchy**: Some tools act as subroutines (e.g., Browser → Wikipedia tool).
4. **Dual Backends**: Flexibility to use either graph databases or lightweight backends.
---
### Interpretation
The KGoT system combines graph-based knowledge representation with LLM-driven processing. The architecture emphasizes:
1. **Modularity**: Separate graph storage and tool execution layers.
2. **Adaptability**: Users can choose between graph databases (Neo4j) or lightweight backends (NetworkX).
3. **LLM Integration**: Extensive use of LLMs for decision-making (steps 4, 6-9) and tool execution.
4. **Human-in-the-Loop**: User-defined parameters (max iterations, decision frequency) balance automation and control.
The system appears designed for complex query resolution, where:
- **Graph Store** provides structured knowledge
- **Controller** orchestrates LLM-driven reasoning
- **Integrated Tools** enable external data interaction (e.g., web search, file processing)
Notable gaps include unclear error handling mechanisms and undefined "majority vote" logic for SOLVE/ENHANCE decisions.
</details>
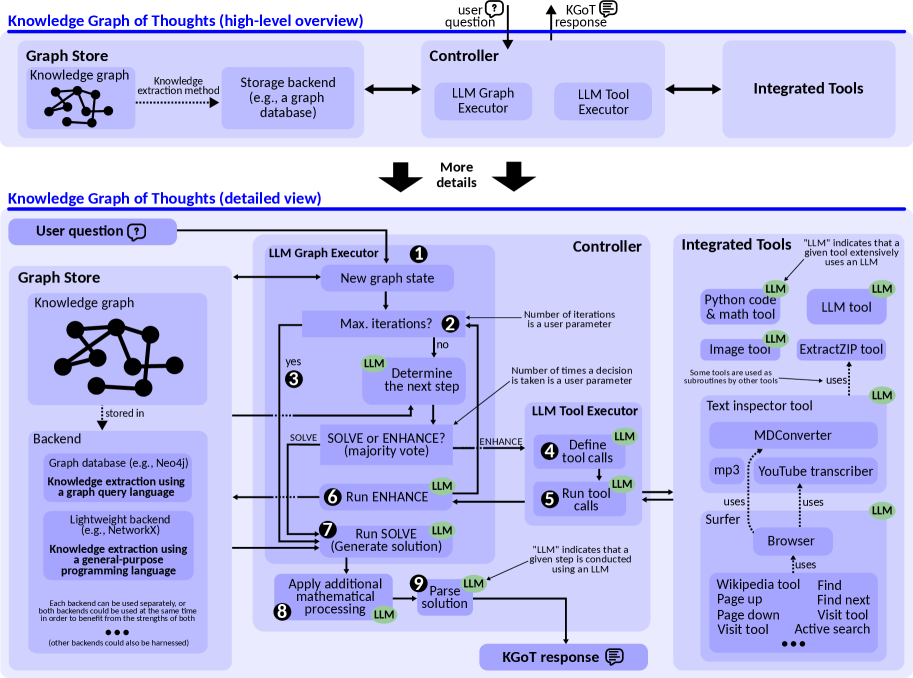
Figure 2: Architecture overview of KGoT (top part) and the design details combined with the workflow (bottom part).
We show the workflow in the bottom part of Figure 2. The workflow begins when the user submits a problem to the system
<details>
<summary>x3.png Details</summary>

### Visual Description
Icon/Small Image (19x14)
</details>
. The first step is to verify whether the maximum number of iterations allowed for solving the problem has been reached
<details>
<summary>x4.png Details</summary>

### Visual Description
Icon/Small Image (19x14)
</details>
. If the iteration limit is exceeded, the system will no longer try to gather additional information and insert it into the KG, but instead will return a solution with the existing data in the KG
<details>
<summary>x5.png Details</summary>
### Visual Description
Icon/Small Image (19x14)
</details>
. Otherwise, the majority vote (over several replies from the LLM) decides whether the system should proceed with the Enhance pathway (using tools to generate new knowledge) or directly proceed to the Solve pathway (gathering the existing knowledge in the KG and using it to deliver the task solution).
The Enhance Pathway If the majority vote indicates an Enhance pathway, the next step involves determining the tools necessary for completing the Enhance operation
<details>
<summary>x6.png Details</summary>
### Visual Description
Icon/Small Image (19x14)
</details>
. The system then orchestrates the appropriate tool calls based on the KG state
<details>
<summary>x7.png Details</summary>
### Visual Description
Icon/Small Image (19x14)
</details>
. Once the required data from the tools is collected, the system generates the Enhance query or queries to modify the KG appropriately. Each Enhance query is executed
<details>
<summary>x8.png Details</summary>

### Visual Description
Icon/Small Image (19x14)
</details>
and its output is validated. If an error or invalid value is returned, the system attempts to fix the query, retrying a specified number of times. If retries fail, the query is discarded, and the operation moves on. After processing the Enhance operation, the system increments the iteration count and continues until the KG is sufficiently expanded or the iteration limit is reached. This path ensures that the knowledge graph is enriched with relevant and accurate information, enabling the system to progress toward a solution effectively.
The Solve Pathway If the majority vote directs the system to the Solve pathway, the system executes multiple solve operations iteratively
<details>
<summary>x9.png Details</summary>

### Visual Description
Icon/Small Image (19x14)
</details>
. If an execution produces an invalid value or error three times in a row, the system asks the LLM to attempt to correct the issue by recreating the used query. The query is then re-executed. If errors persist after three such retries, the query is regenerated entirely, disregarding the faulty result, and the process restarts. After the Solve operation returns the result, final parsing is applied, which includes potential mathematical processing to resolve potential calculations
<details>
<summary>x10.png Details</summary>
### Visual Description
Icon/Small Image (19x14)
</details>
and refining the output (e.g., formatting the results appropriately)
<details>
<summary>x11.png Details</summary>

### Visual Description
Icon/Small Image (19x14)
</details>
.
## 5 Evaluation
We now show advantages of KGoT over the state of the art. Additional results and full details on the evaluation setup are in Appendix D.
Comparison Baselines. We focus on the Hugging Face (HF) Agents (Roucher & Petrov, 2025), the most competitive scheme in the GAIA benchmark for the hardest level 3 tasks with the GPT-4 class of models. We also compare to two agentic frameworks, namely GPTSwarm (Zhuge et al., 2024) (a representative graph-enhanced multi-agent scheme) and Magentic-One (Fourney et al., 2024), an AI agent equipped with a central orchestrator and multiple integrated tool agents. Next, to evaluate whether database search outperforms graph-based knowledge extraction, we also consider two retrieval-augmented generation (RAG) (Lewis et al., 2020) schemes, a simple RAG scheme and GraphRAG (Edge et al., 2025). Both RAG baselines use the same tool-generated knowledge, chunking data at tool-call granularity (i.e., a chunk corresponds to individual tool call output). Simple RAG constructs a vector database from these tool outputs while GraphRAG instead models the tool outputs as a static KG of entities and relations, enabling retrieval via graph traversal. Finally, we use Zero-Shot schemes where a model answers without any additional agent framework.
KGoT variants. First, we experiment with graph query languages vs. general-purpose languages, cf. Section 2.3. For each option, we vary how the Solve operation is executed, by either having the LLM send a request to the backend (a Python script for NetworkX and a Cypher/SPARQL query for Neo4j/RDF4J) or by directly asking the LLM to infer the answer based on the KG (Direct Retrieval (DR)). We experiment with different query languages (Cypher vs. SPARQL). We also consider “fusion” runs, which simulate the effect from KGoT runs with both graph backends available simultaneously (or both Solve operation variants harnessed for each task). Fusion runs only incur negligible additional storage overhead because the generated KGs are small (up to several hundreds of nodes). Finally, we experiment with different tool sets. To focus on the differences coming from harnessing the KG, we reuse several utilities from AutoGen (Wu et al., 2024) such as Browser and MDConverter, and tools from HF Agents, such as Surfer Agent, web browsing tools, and Text Inspector.
Considered Metrics We focus primarily on the number of solved tasks as well as token costs ($). Unless stated otherwise, we report single run results due to budget reasons.
Considered Datasets We use the GAIA benchmark (Mialon et al., 2024) focusing on the validation set (165 tasks) for budgetary reasons and also because it comes with the ground truth answers. The considered tasks are highly diverse in nature; many require parsing websites or analyzing PDF, image, and audio files. We focus on GAIA as this is currently the most comprehensive benchmark for general-purpose AI assistants, covering diverse domains such as web navigation, code execution, image reasoning, scientific QA, and multimodal tasks. We further evaluate on SimpleQA (Wei et al., 2024), a factuality benchmark of 4,326 questions, of which we sample 10% for budgetary reasons. The dataset spans diverse topics and emphasizes single, verifiable answers, making it effective for assessing factual accuracy.
<details>
<summary>x12.png Details</summary>
### Visual Description
## Bar Chart: Model Performance Comparison Across Tasks and Costs
### Overview
The image contains two side-by-side bar charts comparing the performance of various AI models across three categories: "Zero-Shot," "KGoT," "KGoT (fusion)," and "Baselines." The left chart measures "Number of Solved Tasks" (y-axis) across three performance levels (Level 1, 2, 3), while the right chart measures "Average Cost ($)" on a logarithmic scale. Models include GPT-4o, GPT-4o mini, Neo4j + Query + DR, NetworkX + Query + DR, RDF4J + Query + DR, Simple RAG, GraphRAG, Magnetic-One, and HF GPT-4o mini.
### Components/Axes
- **Left Chart (Number of Solved Tasks)**:
- **X-axis**: Categories: "Zero-Shot," "KGoT," "KGoT (fusion)," "Baselines."
- **Y-axis**: "Number of Solved Tasks" (0–70).
- **Legend**: Top-left, with colors:
- Level 1: Light blue (#87CEEB)
- Level 2: Dark blue (#0000FF)
- Level 3: Purple (#8A2BE2)
- **Models**: Listed below x-axis (e.g., GPT-4o, GPT-4o mini, Neo4j + Query + DR, etc.).
- **Right Chart (Average Cost $)**:
- **X-axis**: Same categories as left chart.
- **Y-axis**: "Average Cost ($)" (log scale: 10⁻³ to 10⁰).
- **Legend**: Top-right, with colors:
- GPT-4o: Pink (#FFC0CB)
- GPT-4o mini: Purple (#8A2BE2)
- Neo4j + Query + DR: Light purple (#E6E6FA)
- NetworkX + Query + DR: Medium purple (#9370DB)
- RDF4J + Query + DR: Dark purple (#800080)
- Simple RAG: Light blue (#87CEEB)
- GraphRAG: Medium blue (#0000FF)
- Magnetic-One: Dark blue (#0000FF)
- HF GPT-4o mini: Pink (#FFC0CB).
### Detailed Analysis
#### Left Chart (Number of Solved Tasks)
- **Zero-Shot**:
- GPT-4o: 10 (Level 1), 13 (Level 2), 4 (Level 3).
- GPT-4o mini: 17 (Level 1), 2 (Level 2), 0 (Level 3).
- **KGoT**:
- GPT-4o: 33 (Level 1), 24 (Level 2), 4 (Level 3).
- GPT-4o mini: 29 (Level 1), 28 (Level 2), 2 (Level 3).
- **KGoT (fusion)**:
- GPT-4o: 34 (Level 1), 29 (Level 2), 4 (Level 3).
- GPT-4o mini: 27 (Level 1), 28 (Level 2), 2 (Level 3).
- **Baselines**:
- GPT-4o: 18 (Level 1), 15 (Level 2), 2 (Level 3).
- GPT-4o mini: 13 (Level 1), 13 (Level 2), 1 (Level 3).
- Neo4j + Query + DR: 21 (Level 1), 16 (Level 2), 3 (Level 3).
- NetworkX + Query + DR: 21 (Level 1), 18 (Level 2), 2 (Level 3).
- RDF4J + Query + DR: 20 (Level 1), 15 (Level 2), 1 (Level 3).
- Simple RAG: 18 (Level 1), 13 (Level 2), 0 (Level 3).
- GraphRAG: 13 (Level 1), 18 (Level 2), 0 (Level 3).
- Magnetic-One: 13 (Level 1), 20 (Level 2), 1 (Level 3).
- HF GPT-4o mini: 22 (Level 1), 31 (Level 2), 1 (Level 3).
#### Right Chart (Average Cost $)
- **Zero-Shot**:
- GPT-4o: $0.017 (Level 1), $0.001 (Level 2), $0.001 (Level 3).
- GPT-4o mini: $0.098 (Level 1), $0.135 (Level 2), $0.145 (Level 3).
- **KGoT**:
- GPT-4o: $0.155 (Level 1), $0.199 (Level 2), $0.148 (Level 3).
- GPT-4o mini: $0.091 (Level 1), $0.145 (Level 2), $0.129 (Level 3).
- **KGoT (fusion)**:
- GPT-4o: $0.155 (Level 1), $0.199 (Level 2), $0.148 (Level 3).
- GPT-4o mini: $0.091 (Level 1), $0.145 (Level 2), $0.129 (Level 3).
- **Baselines**:
- GPT-4o: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- GPT-4o mini: $0.145 (Level 1), $0.129 (Level 2), $0.006 (Level 3).
- Neo4j + Query + DR: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- NetworkX + Query + DR: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- RDF4J + Query + DR: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- Simple RAG: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- GraphRAG: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- Magnetic-One: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
- HF GPT-4o mini: $0.165 (Level 1), $0.232 (Level 2), $0.006 (Level 3).
### Key Observations
1. **Performance Trends**:
- **KGoT (fusion)** consistently outperforms other models in "Number of Solved Tasks," especially in Level 3 (e.g., GPT-4o: 4 tasks, GPT-4o mini: 2 tasks).
- **HF GPT-4o mini** shows the highest cost in the right chart ($3.403), far exceeding other models.
- **Baselines** (e.g., Simple RAG, GraphRAG) have lower performance and cost compared to KGoT variants.
2. **Cost Anomalies**:
- HF GPT-4o mini has the highest cost ($3.403) despite moderate task performance (31 tasks in Level 2).
- GPT-4o mini has lower costs ($0.098–$0.145) but also lower task performance (17–2 tasks).
3. **Logarithmic Scale Impact**:
- The right chart’s logarithmic y-axis compresses high-cost values, making differences between $0.001 and $3.403 appear less drastic than they are.
### Interpretation
The data suggests that **KGoT (fusion)** models achieve the highest task-solving efficiency, particularly in advanced levels (Level 3), indicating superior adaptability or reasoning capabilities. However, this comes at a cost: HF GPT-4o mini, while performing well in Level 2 (31 tasks), incurs the highest expense ($3.403), suggesting a trade-off between performance and cost.
**Notable Outliers**:
- **HF GPT-4o mini** stands out for its high cost despite moderate task performance, raising questions about its cost-effectiveness.
- **GPT-4o mini** balances lower cost ($0.098–$0.145) with mid-tier performance (17–2 tasks), making it a potential candidate for budget-conscious applications.
**Underlying Patterns**:
- The "KGoT (fusion)" category consistently outperforms others, implying that fusion techniques (e.g., combining query and DR methods) enhance model effectiveness.
- The logarithmic cost scale highlights the exponential disparity in expenses, particularly for HF GPT-4o mini, which may not justify its performance gains for all use cases.
This analysis underscores the importance of balancing task efficiency with cost constraints when selecting AI models for deployment.
</details>
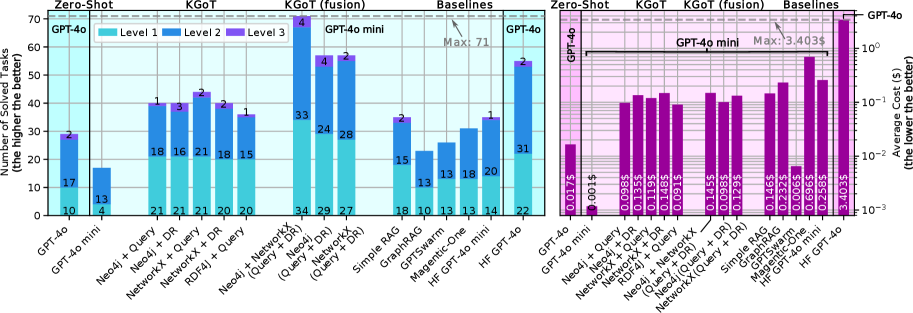
Figure 3: Advantages of different variants of KGoT over other baselines (Hugging Face Agents using both GPT-4o-mini and GPT-4o, Magentic-One, GPTSwarm, two RAG baselines, Zero-Shot GPT-4o mini, and Zero-Shot GPT-4o) on the validation dataset of the GAIA benchmark. DR stands for Direct Retrieval. The used model is GPT-4o mini unless noted otherwise.
### 5.1 Advantages of KGoT
Figure 3 shows the number of solved tasks (the left side) as well as the average cost per solved task (the right side) for different KGoT variants as well as all comparison baselines. While we focus on GPT-4o mini, we also show the results for HF Agents and Zero-Shot with GPT-4o. Additionally, we show the Pareto front in Figure 11 for the multidimensional optimization problem of improving accuracy (i.e., reducing failed tasks) and lowering cost. All variants of KGoT solve a greater number of tasks (up to 9 more) compared to HF Agents while also being more cost-efficient (between 42% to 62% lower costs). The key reason for the KGoT advantages stems from harnessing the knowledge graph–based representation of the evolving task state.
The ideal fusion runs of Neo4j and NetworkX solve an even greater number of tasks (57 for both) than the single runs, they have a lower average cost (up to 62% lower than HF Agents), and they even outperform HF Agents with GPT-4o. The fusion of all combinations of backend and solver types solve by far the highest number of tasks (71) – more than twice as much as HF Agents – while also exhibiting 44% lower cost than HF Agents. The direct Zero-Shot use of GPT-4o mini and GPT-4o has the lowest average cost per solved task (just $0.0013 and $0.0164 respectively), making it the most cost-effective, however this approach is only able to solve 17 and 29 tasks, respectively. GPTSwarm is cheaper compared to KGoT, but also comes with fewer solved tasks (only 26). While Magentic-One is a capable agent with a sophisticated architecture, its performance with GPT-4o mini is limited, solving 31 tasks correctly, while also exhibiting significantly higher costs. Simple RAG yields somewhat higher costs than KGoT and it solves fewer tasks (35). GraphRAG performs even worse, solving only 23 tasks and incurring even higher cost. While neither RAG baseline can invoke new tools to gather missing information (reducing accuracy and adaptability), GraphRAG’s worse performance is due to the fact that it primarily targets query summarization and not tasks as diverse as those tested by GAIA. Overall, KGoT achieves the best cost-accuracy tradeoff, being both highly affordable and very effective.
### 5.2 Analysis of Methods for Knowledge Extraction
We explore different methods of extracting knowledge. Overall, in many situations, different methods have complementary strengths and weaknesses.
Graph queries with Neo4j excel at queries such as counting patterns. Yet, Cypher queries can be difficult to generate correctly, especially for graphs with more nodes and edges. Despite this, KGoT’s Cypher queries are able to solve many new GAIA tasks that could not be solved without harnessing Cypher. SPARQL (Pérez et al., 2009) + RDF4J (Eclipse Foundation, 2025) is slightly worse (36 tasks solved) than Cypher + Neo4j (existing literature also indicates that LLMs have difficulties formulating effective SPARQL queries (Emonet et al., 2024; Mecharnia & d’Aquin, 2025)).
Python with NetworkX offers certain advantages over Neo4j by eliminating the need for a separate database server, making it a lightweight choice for the KG. Moreover, NetworkX computations are fast and efficient for small to medium-sized graphs without the overhead of database transactions. Unlike Neo4j, which requires writing Cypher queries, we observe that in cases where Neo4j-based implementations struggle, NetworkX-generated graphs tend to be more detailed and provide richer vertex properties and relationships. This is likely due to the greater flexibility of Python code over Cypher queries for graph insertion, enabling more fine-grained control over vertex attributes and relationships. Another reason may be the fact that Python is likely more represented in the training data of the respective models than Cypher.
Our analysis of failed tasks indicates that, in many cases, the KG contains the required data, but the graph query fails to extract it. In such scenarios, Direct Retrieval, where the entire KG is included in the model’s context, performs significantly better by bypassing query composition issues. However, Direct Retrieval demonstrates lower accuracy in cases requiring structured, multi-step reasoning.
We also found that Direct Retrieval excels at extracting dispersed information but struggles with structured queries, whereas graph queries are more effective for structured reasoning but can fail when the LLM generates incorrect query formulations. Although both Cypher and general-purpose queries occasionally are erroneous, Python scripts require more frequent corrections because they are often longer and more error-prone. However, despite the higher number of corrections, the LLM is able to fix Python code more easily than Cypher queries, often succeeding after a single attempt. During retrieval, the LLM frequently embeds necessary computations directly within the Python scripts while annotating its reasoning through comments, improving transparency and interpretability.
### 5.3 Advantages on the GAIA Test Set
Table 1: Comparison of KGoT with other current state-of-the-art open-source agents on the full GAIA test set. The baseline data, including for TapeAgent (Bahdanau et al., 2024), of the number of solved tasks is obtained through the GAIA Leaderboard (Mialon et al., 2025). We highlight the best performing scheme in a given category in bold. Model: GPT-4o mini.
| Agents | All | L1 | L2 | L3 |
| --- | --- | --- | --- | --- |
| GPTSwarm | 33 | 15 | 15 | 3 |
| Magentic-One | 43 | 22 | 18 | 3 |
| TapeAgent | 66 | 28 | 35 | 3 |
| Hugging Face Agents | 68 | 30 | 34 | 4 |
| KGoT (fusion) | 73 | 33 | 36 | 4 |
Furthermore, our approach achieves state-of-the-art performance on the GAIA test set with the GPT-4o mini model. The results are shown in Table 1, underscoring its effectiveness across all evaluation levels. The test set consists of 301 tasks (93 level 1 tasks, 159 level 2 tasks and 49 level 3 tasks).
### 5.4 Advantages beyond GAIA Benchmark
We also evaluate KGoT as well as HF Agents and GPTSwarm on a 10% sample (433 tasks) of the SimpleQA benchmark (detailed results are in Appendix D.1). KGoT performs best, solving 73.21%, while HF Agents and GPTSwarm exhibit reduced accuracy (66.05% and 53.81% respectively). KGoT incurs only 0.018$ per solved task, less than a third of the HF Agents costs (0.058$), while being somewhat more expensive than GPTSwarm (0.00093$).
We further evaluate KGoT on the entire SimpleQA benchmark (due to very high costs of running all SimpleQA questions, we limit the full benchmark evaluation to KGoT). We observe no degradation in performance with a 70.34% accuracy rate. When compared against the official F1-scores of various OpenAI and Claude models (OpenAI, 2025), KGoT outperforms all the available results. Specifically, our design achieves a 71.06% F1 score, significantly surpassing the 49.4% outcome of the top-performing reasoning model and improving upon all mini-reasoning models by at least 3.5 $\times$ . Furthermore, KGoT exceeds the performance of all standard OpenAI models, from GPT-4o’s 40% F1 score to the best-scoring closed-source model, GPT-4.5, with 62.5%. More detailed results are available in Appendix D.1.
### 5.5 Ensuring Scalability and Mitigating Bottlenecks
The primary bottleneck in KGoT arises from I/O-bound and latency-sensitive LLM tool invocations (e.g., web browsing, text parsing), which account for 72% of the runtime, which KGoT mitigates through asynchronous execution and graph operation parallelism as discussed in Section 3.4. A detailed breakdown of the runtime is reported in Appendix D.3. Figure 10 confirms KGoT’s scalability, as increasing the number of parallelism consistently reduces the runtime. Moreover, due to the effective knowledge extraction process and the nature of the tasks considered, none of the tasks require large KGs. The maximum graph size that we observed was 522 nodes. This is orders of magnitude below any scalability concerns.
### 5.6 Impact from Various Design Decisions
<details>
<summary>x13.png Details</summary>
### Visual Description
## Bar Chart: AI Model Performance Comparison Across Tasks
### Overview
The chart compares the performance of various AI models (e.g., Qwen2.5-32B, DeepSeek-R1-70B) across four task-solving methodologies: GPTswarm, HF Agents, KGoT (Neo4j + Query), and Zero-Shot. The y-axis represents the number of tasks solved, while the x-axis lists model names. Each model has four grouped bars corresponding to the methodologies.
### Components/Axes
- **X-Axis (Categories)**: Model names (e.g., Qwen2.5-32B, DeepSeek-R1-70B, GPT-40 mini, etc.).
- **Y-Axis (Scale)**: Number of solved tasks (0–50, increments of 10).
- **Legend**:
- Pink: GPTswarm
- Purple: HF Agents
- Blue: KGoT (Neo4j + Query)
- Gray: Zero-Shot
- **Bar Colors**: Match legend labels (e.g., pink bars for GPTswarm).
### Detailed Analysis
- **Qwen2.5-32B**:
- GPTswarm: 29
- HF Agents: 19
- KGoT: 26
- Zero-Shot: 15
- **DeepSeek-R1-70B**:
- GPTswarm: 10
- HF Agents: 16
- KGoT: 22
- Zero-Shot: 20
- **GPT-40 mini**:
- GPTswarm: 26
- HF Agents: 35
- KGoT: 40
- Zero-Shot: 17
- **DeepSeek-R1-32B**:
- GPTswarm: 6
- HF Agents: 17
- KGoT: 21
- Zero-Shot: 14
- **QwQ-32B**:
- GPTswarm: 0
- HF Agents: 16
- KGoT: 20
- Zero-Shot: 0
- **DeepSeek-R1-7B**:
- GPTswarm: 2
- HF Agents: 3
- KGoT: 6
- Zero-Shot: 13
- **DeepSeek-R1-1.5B**:
- GPTswarm: 0
- HF Agents: 0
- KGoT: 2
- Zero-Shot: 5
- **Qwen2.5-72B**:
- GPTswarm: 27
- HF Agents: 38
- KGoT: 39
- Zero-Shot: 19
- **Qwen2.5-7B**:
- GPTswarm: 12
- HF Agents: 11
- KGoT: 12
- Zero-Shot: 9
- **Qwen2.5-1.5B**:
- GPTswarm: 5
- HF Agents: 4
- KGoT: 4
- Zero-Shot: 3
### Key Observations
1. **KGoT (Neo4j + Query)** consistently outperforms other methods in most models (e.g., 40 for GPT-40 mini, 39 for Qwen2.5-72B).
2. **Zero-Shot** generally has the lowest performance across models (e.g., 3 for Qwen2.5-1.5B).
3. **HF Agents** show strong performance in larger models (e.g., 35 for GPT-40 mini, 38 for Qwen2.5-72B).
4. **GPTswarm** excels in mid-to-large models (e.g., 29 for Qwen2.5-32B, 27 for Qwen2.5-72B).
5. Smaller models (e.g., DeepSeek-R1-1.5B) have minimal task-solving capacity across all methods.
### Interpretation
The data suggests that **KGoT (Neo4j + Query)** and **GPTswarm** are the most effective methodologies for solving tasks, particularly in larger models. **HF Agents** perform well in larger models but struggle with smaller ones. **Zero-Shot** underperforms universally, indicating its limitations without task-specific tuning. The disparity between methodologies highlights the importance of hybrid approaches (e.g., KGoT) for complex tasks. Outliers like QwQ-32B (all zeros for GPTswarm and Zero-Shot) suggest potential data anomalies or model-specific constraints.
</details>
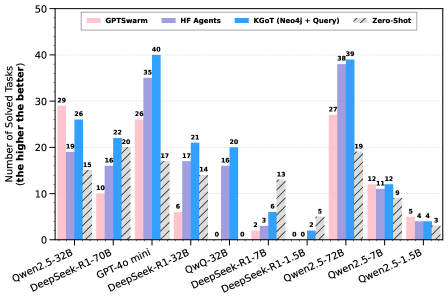
Figure 4: Performance on the GAIA validation set with KGoT (non-fusion) using various LLM models. For KGoT, we use Cypher queries for knowledge extraction from the Neo4j database.
<details>
<summary>x14.png Details</summary>
### Visual Description
## Bar Chart: Performance of Different Methods Across Knowledge Graph Levels
### Overview
The chart compares the number of solved tasks across different methods (Neo4j, NetworkX, Neo4j + NetworkX, No KG) and knowledge graph (KG) levels (Level 1, Level 2, Level 3). The y-axis represents the number of solved tasks, with higher values indicating better performance. The x-axis categorizes methods and their configurations, including "Query," "Direct Retrieve," "Query + DR," "Single Run #1," "Single Run #2," and "Fusion." The legend distinguishes the three KG levels by color: cyan (Level 1), blue (Level 2), and purple (Level 3). The maximum value on the y-axis is 71, marked by a dashed line.
### Components/Axes
- **X-axis**: Categories of methods and configurations:
- Neo4j
- NetworkX
- Neo4j + NetworkX
- No KG
- Subcategories: Query, Direct Retrieve, Query + DR, Single Run #1, Single Run #2, Fusion
- **Y-axis**: Number of solved tasks (0–80), with a dashed line at 71.
- **Legend**:
- Level 1 (cyan)
- Level 2 (blue)
- Level 3 (purple)
- **Axis Titles**:
- Y-axis: "Number of Solved Tasks (the higher the better)"
- X-axis: Method/Configuration labels
### Detailed Analysis
- **Neo4j**:
- Query: Level 1 (18), Level 2 (16), Level 3 (24)
- Direct Retrieve: Level 1 (21), Level 2 (18), Level 3 (29)
- Query + DR: Level 1 (21), Level 2 (18), Level 3 (29)
- **NetworkX**:
- Query: Level 1 (21), Level 2 (18), Level 3 (27)
- Direct Retrieve: Level 1 (20), Level 2 (20), Level 3 (27)
- Query + DR: Level 1 (28), Level 2 (26), Level 3 (34)
- **Neo4j + NetworkX**:
- Query: Level 1 (28), Level 2 (26), Level 3 (34)
- Direct Retrieve: Level 1 (25), Level 2 (24), Level 3 (33)
- Query + DR: Level 1 (28), Level 2 (26), Level 3 (34)
- **No KG**:
- Single Run #1: Level 1 (14), Level 2 (16), Level 3 (18)
- Single Run #2: Level 1 (17), Level 2 (20), Level 3 (20)
- Fusion: Level 1 (18), Level 2 (20), Level 3 (20)
### Key Observations
1. **Highest Performance**:
- "Query + DR" under "Neo4j + NetworkX" achieves the highest number of solved tasks (34 at Level 3).
- "Direct Retrieve" under "Neo4j" also performs well (29 at Level 3).
2. **Lowest Performance**:
- "Single Run #1" under "No KG" has the lowest values (14 at Level 1, 16 at Level 2, 18 at Level 3).
3. **Trends**:
- "Query + DR" consistently outperforms other configurations across all methods.
- "No KG" methods show significantly lower performance compared to others.
- Level 3 (purple) bars are generally taller than Level 1 and 2, indicating better performance at higher KG levels.
### Interpretation
The data suggests that combining Neo4j and NetworkX (Neo4j + NetworkX) yields the best results, particularly in the "Query + DR" configuration. This implies that integrating multiple knowledge graph systems enhances task-solving capabilities. The "No KG" setup underperforms, highlighting the importance of KG integration. The consistent improvement from Level 1 to Level 3 across methods indicates that higher KG levels correlate with better performance. The "Fusion" method under "No KG" shows moderate improvement but still lags behind KG-integrated approaches. This chart underscores the value of hybrid systems and structured KG levels in optimizing task-solving efficiency.
</details>
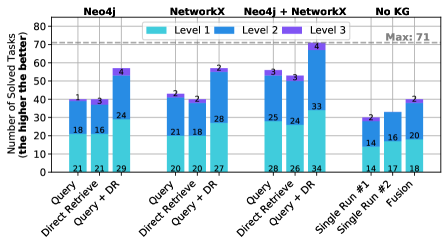
Figure 5: The impact coming from harnessing knowledge graphs (KGs) with different knowledge extraction methods (graph queries with Neo4j and Cypher, and general-purpose languages with Python and NetworkX), vs. using no KGs at all. DR stands for Direct Retrieval. Model: GPT-4o mini.
We also show the advantages of KGoT on different open models in Figure 5 over HF Agents and GPTSwarm for nearly all considered models (Yang et al., 2025; Guo et al., 2025). Interestingly, certain sizes of DeepSeek-R1 (Guo et al., 2025) offer high Zero-Shot performance that outperforms both KGoT and HF Agents, illustrating potential for further improvements specifically aimed at Reasoning Language Models (RLMs) (Besta et al., 2025a; c).
Finally, we investigate the impact on performance coming from harnessing KGs, vs. using no KGs at all (the “no KG” baseline), which we illustrate in Figure 5. Harnessing KGs has clear advantages, with a nearly 2 $\times$ increase in the number of solved tasks. This confirms the positive impact from structuring the task related knowledge into a graph format, and implies that our workflow generates high quality graphs. To further confirm this, we additionally verified these graphs manually and we discovered that the generated KGs do contain the actual solution (e.g., the solution can be found across nodes/edges of a given KG by string matching). This illustrates that in the majority of the solved tasks, the automatically generated KGs correctly represent the solution and directly enable solving a given task.
We offer further analyses in Appendix D, including studying the impact on performance from different tool sets, prompt formats as well as fusion types.
## 6 Related Work
Our work is related to numerous LLM domains.
First, we use LangChain (LangChain Inc., 2025a) to facilitate the integration of the LLM agents with the rest of the KGoT system. Other such LLM integration frameworks, such as MiniChain (Rush, 2023) or AutoChain (Forethought, 2023), could be used instead.
Agent collaboration frameworks are systems such as Magentic-One and numerous others (Zhuge et al., 2024; Tang et al., 2024; Liu et al., 2024b; Li et al., 2024; Chu et al., 2024; Wu et al., 2024; Chen et al., 2024; Hong et al., 2024; Shinn et al., 2023; Zhu et al., 2024; Kagaya et al., 2024; Zhao et al., 2024a; Stengel-Eskin et al., 2024; Significant Gravitas, 2025; Zhu et al., 2025). The core KGoT idea that can be applied to enhance such frameworks is that a KG can also be used as a common shared task representation for multiple agents solving a task together. Such a graph would be then updated by more than a single agent. This idea proves effective, as confirmed by the fact that KGoT outperforms highly competitive baselines (HF Agents, Magentic-One, GPTSwarm) in both GAIA and SimpleQA benchmarks.
Some agent frameworks explicitly use graphs for more effective collaboration. Examples are GPTSwarm (Zhuge et al., 2024), MacNet (Qian et al., 2025), and AgentPrune (Zhang et al., 2025). These systems differ from KGoT as they use a graph to model and manage multiple agents in a structured way, forming a hierarchy of tools. Contrarily, KGoT uses KGs to represent the task itself, including its intermediate state. These two design choices are orthogonal and could be combined together. Moreover, while KGoT only relies on in-context learning; both MacNet (Qian et al., 2025) and AgentPrune (Zhang et al., 2025) require additional training rounds, making their integration and deployment more challenging and expensive than KGoT.
Many works exist in the domain of general prompt engineering (Beurer-Kellner et al., 2024; Besta et al., 2025c; Yao et al., 2023a; Besta et al., 2024a; Wei et al., 2022; Yao et al., 2023b; Chen et al., 2023; Creswell et al., 2023; Wang et al., 2023a; Hu et al., 2024; Dua et al., 2022; Jung et al., 2022; Ye et al., 2023). One could use such schemes to further enhance respective parts of the KGoT workflow. While we already use prompts that are suited for encoding knowledge graphs, possibly harnessing other ideas from that domain could bring further benefits.
Task decomposition & planning increases the effectiveness of LLMs by dividing a task into subtasks. Examples include ADaPT (Prasad et al., 2024), ANPL (Huang et al., 2023), and others (Zhu et al., 2025; Shen et al., 2023). Overall, the whole KGoT workflow already harnesses recursive task decomposition: the input task is divided into numerous steps, and many of these steps are further decomposed into sub steps by the LLM Graph Executor if necessary. For example, when solving a task based on the already constructed KG, the LLM Graph Executor may decide to decompose this step similarly to ADaPT. Other decomposition schemes could also be tried, we leave this as future work.
Retrieval-Augmented Generation (RAG) is an important part of the LLM ecosystem, with numerous designs being proposed (Edge et al., 2025; Gao et al., 2024; Besta et al., 2025b; Zhao et al., 2024b; Hu & Lu, 2025; Huang & Huang, 2024; Yu et al., 2024a; Mialon et al., 2023; Li et al., 2022; Abdallah & Jatowt, 2024; Delile et al., 2024; Manathunga & Illangasekara, 2023; Zeng et al., 2024; Wewer et al., 2021; Xu et al., 2024; Sarthi et al., 2024; Asai et al., 2024; Yu et al., 2024b; Gutiérrez et al., 2024). RAG has been used primarily to ensure data privacy and to reduce hallucinations. We illustrate that it has lower performance than KGoT when applied to AI assistant tasks.
Another increasingly important part of the LLM ecosystem is the usage of tools to augment the abilities of LLMs (Beurer-Kellner et al., 2023; Schick et al., 2023; Xie et al., 2024). For example, ToolNet (Liu et al., 2024a) uses a directed graph to model the application of multiple tools while solving a task, however focuses specifically on the iterative usage of tools at scale. KGoT harnesses a flexible and adaptable hierarchy of various tools, which can easily be extended with ToolNet and such designs, to solve a wider range of complex tasks.
While KGoT focuses on classical AI assistant tasks, it can be extended to other applications. Promising directions could include supporting multi-stage, cost-efficient reasoning, for example to enhance the capabilities of the recent reasoning models such as DeepSeek-R1. Extending KGoT to this and other domains may require new ways of KG construction via predictive graph models (Besta et al., 2023a; 2024c), integration with neural graph databases (Besta et al., 2022), or deployment over distributed-memory clusters for scalability. Further, refining its reasoning strategies through advanced task decomposition schemes could improve performance on very long-horizon tasks. These directions highlight both the generality of the framework and current boundaries in tool orchestration, reasoning depth, and scalability, which we aim to address in future work.
## 7 Conclusion
In this paper, we introduce Knowledge Graph of Thoughts (KGoT), an AI assistant architecture that enhances the reasoning capabilities of low-cost models while significantly reducing operational expenses. By dynamically constructing and evolving knowledge graphs (KGs) that encode the task and its resolution state, KGoT enables structured knowledge representation and retrieval, improving task success rates on benchmarks such as GAIA and SimpleQA. Our extensive evaluation demonstrates that KGoT outperforms existing LLM-based agent solutions, for example achieving a substantial increase in task-solving efficiency of 29% or more over the competitive Hugging Face Agents baseline, while ensuring over 36 $\times$ lower costs. Thanks to its modular design, KGoT can be extended to new domains that require complex multi-step reasoning integrated with extensive interactions with the external compute environment, for example automated scientific discovery or software design.
#### Acknowledgments
We thank Chi Zhang and Muyang Du for their contributions to the framework. We thank Hussein Harake, Colin McMurtrie, Mark Klein, Angelo Mangili, and the whole CSCS team granting access to the Ault, Daint and Alps machines, and for their excellent technical support. We thank Timo Schneider for help with infrastructure at SPCL. This project received funding from the European Research Council (Project PSAP, No. 101002047), and the European High-Performance Computing Joint Undertaking (JU) under grant agreement No. 955513 (MAELSTROM). This project was supported by the ETH Future Computing Laboratory (EFCL), financed by a donation from Huawei Technologies. This project received funding from the European Union’s HE research and innovation programme under the grant agreement No. 101070141 (Project GLACIATION). We gratefully acknowledge the Polish high-performance computing infrastructure PLGrid (HPC Center: ACK Cyfronet AGH) for providing computer facilities and support within computational grant no. PLG/2024/017103.
## References
- Abdallah & Jatowt (2024) Abdelrahman Abdallah and Adam Jatowt. Generator-Retriever-Generator Approach for Open-Domain Question Answering, March 2024. URL https://arxiv.org/abs/2307.11278. arXiv:2307.11278.
- Asai et al. (2024) Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun (eds.), Proceedings of the Twelfth International Conference on Learning Representations, ICLR ’24, pp. 9112–9141, Vienna, Austria, May 2024. International Conference on Learning Representations. URL https://proceedings.iclr.cc/paper_files/paper/2024/hash/25f7be9694d7b32d5cc670927b8091e1-Abstract-Conference.html.
- Bahdanau et al. (2024) Dzmitry Bahdanau, Nicolas Gontier, Gabriel Huang, Ehsan Kamalloo, Rafael Pardinas, Alex Piché, Torsten Scholak, Oleh Shliazhko, Jordan Prince Tremblay, Karam Ghanem, Soham Parikh, Mitul Tiwari, and Quaizar Vohra. TapeAgents: A Holistic Framework for Agent Development and Optimization, December 2024. URL https://arxiv.org/abs/2412.08445. arXiv:2412.08445.
- Ben Mahria et al. (2021) Bilal Ben Mahria, Ilham Chaker, and Azeddine Zahi. An Empirical Study on the Evaluation of the RDF Storage Systems. Journal of Big Data, 8(1):100:1–100:20, July 2021. ISSN 2196-1115. doi: 10.1186/s40537-021-00486-y. URL https://journalofbigdata.springeropen.com/articles/10.1186/s40537-021-00486-y.
- Benedicic et al. (2019) Lucas Benedicic, Felipe A. Cruz, Alberto Madonna, and Kean Mariotti. Sarus: Highly Scalable Docker Containers for HPC Systems. In Michèle Weiland, Guido Juckeland, Sadaf Alam, and Heike Jagode (eds.), Proceedings of the International Conference on High Performance Computing (ICS ’19), volume 11887 of Lecture Notes in Computer Science, pp. 46–60, Frankfurt, Germany, June 2019. Springer International Publishing. ISBN 978-3-030-34356-9. doi: 10.1007/978-3-030-34356-9˙5. URL https://link.springer.com/chapter/10.1007/978-3-030-34356-9_5.
- Besta et al. (2018) Maciej Besta, Dimitri Stanojevic, Tijana Zivic, Jagpreet Singh, Maurice Hoerold, and Torsten Hoefler. Log(Graph): A Near-Optimal High-Performance Graph Representation. In Proceedings of the 27th International Conference on Parallel Architectures and Compilation Techniques, PACT ’18, pp. 7:1–7:13, Limassol, Cyprus, November 2018. Association for Computing Machinery. ISBN 9781450359863. doi: 10.1145/3243176.3243198. URL https://doi.org/10.1145/3243176.3243198.
- Besta et al. (2022) Maciej Besta, Patrick Iff, Florian Scheidl, Kazuki Osawa, Nikoli Dryden, Michal Podstawski, Tiancheng Chen, and Torsten Hoefler. Neural Graph Databases. In Bastian Rieck and Razvan Pascanu (eds.), Proceedings of the First Learning on Graphs Conference, volume 198 of Proceedings of Machine Learning Research, pp. 31:1–31:38, Virtual Event, December 2022. PMLR. URL https://proceedings.mlr.press/v198/besta22a.html.
- Besta et al. (2023a) Maciej Besta, Afonso Claudino Catarino, Lukas Gianinazzi, Nils Blach, Piotr Nyczyk, Hubert Niewiadomski, and Torsten Hoefler. HOT: Higher-Order Dynamic Graph Representation Learning with Efficient Transformers. In Soledad Villar and Benjamin Chamberlain (eds.), Proceedings of the Second Learning on Graphs Conference, volume 231 of Proceedings of Machine Learning Research, pp. 15:1–15:20, Virtual Event, November 2023a. PMLR. URL https://proceedings.mlr.press/v231/besta24a.html.
- Besta et al. (2023b) Maciej Besta, Robert Gerstenberger, Marc Fischer, Michal Podstawski, Nils Blach, Berke Egeli, Georgy Mitenkov, Wojciech Chlapek, Marek Michalewicz, Hubert Niewiadomski, Jürgen Müller, and Torsten Hoefler. The Graph Database Interface: Scaling Online Transactional and Analytical Graph Workloads to Hundreds of Thousands of Cores. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’23, pp. 22:1–22:18, Denver, CO, USA, November 2023b. Association for Computing Machinery. ISBN 9798400701092. doi: 10.1145/3581784.3607068. URL https://doi.org/10.1145/3581784.3607068.
- Besta et al. (2023c) Maciej Besta, Robert Gerstenberger, Emanuel Peter, Marc Fischer, Michał Podstawski, Claude Barthels, Gustavo Alonso, and Torsten Hoefler. Demystifying Graph Databases: Analysis and Taxonomy of Data Organization, System Designs, and Graph Queries. ACM Comput. Surv., 56(2):31:1–31:40, September 2023c. ISSN 0360-0300. doi: 10.1145/3604932. URL https://doi.org/10.1145/3604932.
- Besta et al. (2024a) Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of Thoughts: Solving Elaborate Problems with Large Language Models. Proceedings of the AAAI Conference on Artificial Intelligence, 38(16):17682–17690, March 2024a. doi: 10.1609/aaai.v38i16.29720. URL https://ojs.aaai.org/index.php/AAAI/article/view/29720.
- Besta et al. (2024b) Maciej Besta, Robert Gerstenberger, Patrick Iff, Pournima Sonawane, Juan Gómez Luna, Raghavendra Kanakagiri, Rui Min, Onur Mutlu, Torsten Hoefler, Raja Appuswamy, and Aidan O Mahony. Hardware Acceleration for Knowledge Graph Processing: Challenges & Recent Developments, November 2024b. URL https://arxiv.org/abs/2408.12173. arXiv:2408.12173.
- Besta et al. (2024c) Maciej Besta, Florian Scheidl, Lukas Gianinazzi, Grzegorz Kwaśniewski, Shachar Klaiman, Jürgen Müller, and Torsten Hoefler. Demystifying Higher-Order Graph Neural Networks, December 2024c. URL https://arxiv.org/abs/2406.12841. arXiv:2406.12841.
- Besta et al. (2025a) Maciej Besta, Julia Barth, Eric Schreiber, Ales Kubicek, Afonso Catarino, Robert Gerstenberger, Piotr Nyczyk, Patrick Iff, Yueling Li, Sam Houliston, Tomasz Sternal, Marcin Copik, Grzegorz Kwaśniewski, Jürgen Müller, Łukasz Flis, Hannes Eberhard, Zixuan Chen, Hubert Niewiadomski, and Torsten Hoefler. Reasoning Language Models: A Blueprint, June 2025a. URL https://arxiv.org/abs/2501.11223. arXiv:2501.11223.
- Besta et al. (2025b) Maciej Besta, Ales Kubicek, Robert Gerstenberger, Marcin Chrapek, Roman Niggli, Patrik Okanovic, Yi Zhu, Patrick Iff, Michał Podstawski, Lucas Weitzendorf, Mingyuan Chi, Joanna Gajda, Piotr Nyczyk, Jürgen Müller, Hubert Niewiadomski, and Torsten Hoefler. Multi-Head RAG: Solving Multi-Aspect Problems with LLMs, July 2025b. URL https://arxiv.org/abs/2406.05085. arXiv:2406.05085.
- Besta et al. (2025c) Maciej Besta, Florim Memedi, Zhenyu Zhang, Robert Gerstenberger, Guangyuan Piao, Nils Blach, Piotr Nyczyk, Marcin Copik, Grzegorz Kwaśniewski, Jürgen Müller, Lukas Gianinazzi, Ales Kubicek, Hubert Niewiadomski, Aidan O’Mahony, Onur Mutlu, and Torsten Hoefler. Demystifying Chains, Trees, and Graphs of Thoughts. IEEE Transactions on Pattern Analysis and Machine Intelligence, August 2025c. doi: 10.1109/TPAMI.2025.3598182. URL https://ieeexplore.ieee.org/document/11123142.
- Besta et al. (2025d) Maciej Besta, Lorenzo Paleari, Marcin Copik, Robert Gerstenberger, Ales Kubicek, Piotr Nyczyk, Patrick Iff, Eric Schreiber, Tanja Srindran, Tomasz Lehmann, Hubert Niewiadomski, and Torsten Hoefler. CheckEmbed: Effective Verification of LLM Solutions to Open-Ended Tasks, July 2025d. URL https://arxiv.org/abs/2406.02524. arXiv:2406.02524.
- Beurer-Kellner et al. (2023) Luca Beurer-Kellner, Marc Fischer, and Martin Vechev. Large Language Models are Zero-Shot Multi-Tool Users. In Proceedings of the ICML Workshop on Knowledge and Logical Reasoning in the Era of Data-Driven Learning, KLR ’23, Honolulu, HI, USA, July 2023. URL https://files.sri.inf.ethz.ch/website/papers/lmql_actions.pdf.
- Beurer-Kellner et al. (2024) Luca Beurer-Kellner, Mark Niklas Müller, Marc Fischer, and Martin Vechev. Prompt Sketching for Large Language Models. In Proceedings of the 41st International Conference on Machine Learning (ICML ’24), volume 235 of Proceedings of Machine Learning Research, pp. 3674–3706, Vienna, Austria, July 2024. PMLR. URL https://proceedings.mlr.press/v235/beurer-kellner24b.html.
- Bhattacharjya et al. (2024) Debarun Bhattacharjya, Junkyu Lee, Don Joven Agravante, Balaji Ganesan, and Radu Marinescu. Foundation Model Sherpas: Guiding Foundation Models through Knowledge and Reasoning, February 2024. URL https://arxiv.org/abs/2402.01602. arXiv:2402.01602.
- Chen et al. (2024) Guangyao Chen, Siwei Dong, Yu Shu, Ge Zhang, Jaward Sesay, Börje F Karlsson, Jie Fu, and Yemin Shi. AutoAgents: A Framework for Automatic Agent Generation. In Kate Larson (ed.), Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI ’24, pp. 22–30, Jeju, South Korea, August 2024. International Joint Conferences on Artificial Intelligence Organization. doi: 10.24963/ijcai.2024/3. URL https://www.ijcai.org/proceedings/2024/3.
- Chen et al. (2023) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks. Transactions on Machine Learning Research, November 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=YfZ4ZPt8zd.
- Chu et al. (2024) Zhixuan Chu, Yan Wang, Feng Zhu, Lu Yu, Longfei Li, and Jinjie Gu. Professional Agents – Evolving Large Language Models into Autonomous Experts with Human-Level Competencies, February 2024. URL https://arxiv.org/abs/2402.03628. arXiv:2402.03628.
- Creswell et al. (2023) Antonia Creswell, Murray Shanahan, and Irina Higgins. Selection-Inference: Exploiting Large Language Models for Interpretable Logical Reasoning. In Proceedings of the Eleventh International Conference on Learning Representations, ICLR ’23, Kigali, Rwanda, May 2023. OpenReview. URL https://openreview.net/forum?id=3Pf3Wg6o-A4.
- Delile et al. (2024) Julien Delile, Srayanta Mukherjee, Anton Van Pamel, and Leonid Zhukov. Graph-Based Retriever Captures the Long Tail of Biomedical Knowledge. In Proceedings of the Workshop ML for Life and Material Science: From Theory to Industry Applications, ML4LMS ’24, Vienna, Austria, July 2024. OpenReview. URL https://openreview.net/forum?id=RUwfsPWrv3.
- Docker Inc. (2025) Docker Inc. Docker: Accelerated Container Applications. https://www.docker.com/, July 2025. Accessed: 2025-09-22.
- Dua et al. (2022) Dheeru Dua, Shivanshu Gupta, Sameer Singh, and Matt Gardner. Successive Prompting for Decomposing Complex Questions. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP ’22, pp. 1251–1265, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.81. URL https://aclanthology.org/2022.emnlp-main.81/.
- Eclipse Foundation (2025) Eclipse Foundation. RDF4J. https://rdf4j.org/, September 2025. Accessed: 2025-09-22.
- Edge et al. (2025) Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From Local to Global: A Graph RAG Approach to Query-Focused Summarization, February 2025. URL https://arxiv.org/abs/2404.16130. arXiv:2404.16130.
- Emonet et al. (2024) Vincent Emonet, Jerven Bolleman, Severine Duvaud, Tarcisio Mendes de Farias, and Ana Claudia Sima. LLM-Based SPARQL Query Generation from Natural Language over Federated Knowledge Graphs. In Reham Alharbi, Jacopo de Berardinis, Paul Groth, Albert Meroño Peñuela, Elena Simperl, and Valentina Tamma (eds.), Proceedings of the Special Session on Harmonising Generative AI and Semantic Web Technologies (HGAIS ’24), volume 3953 of Workshop Proceedings, Baltimore, MD, USA, November 2024. CEUR. URL https://ceur-ws.org/Vol-3953/355.pdf.
- Forethought (2023) Forethought. AutoChain. https://autochain.forethought.ai/, 2023. Accessed: 2025-09-22.
- Fourney et al. (2024) Adam Fourney, Gagan Bansal, Hussein Mozannar, Cheng Tan, Eduardo Salinas, Erkang Zhu, Friederike Niedtner, Grace Proebsting, Griffin Bassman, Jack Gerrits, Jacob Alber, Peter Chang, Ricky Loynd, Robert West, Victor Dibia, Ahmed Awadallah, Ece Kamar, Rafah Hosn, and Saleema Amershi. Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks, November 2024. URL https://arxiv.org/abs/2411.04468. arXiv:2411.04468.
- Francis et al. (2018) Nadime Francis, Alastair Green, Paolo Guagliardo, Leonid Libkin, Tobias Lindaaker, Victor Marsault, Stefan Plantikow, Mats Rydberg, Petra Selmer, and Andrés Taylor. Cypher: An Evolving Query Language for Property Graphs. In Proceedings of the International Conference on Management of Data, SIGMOD ’18, pp. 1433–1445, Houston, TX, USA, June 2018. Association for Computing Machinery. ISBN 9781450347037. doi: 10.1145/3183713.3190657. URL https://doi.org/10.1145/3183713.3190657.
- Gao et al. (2024) Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. Retrieval-Augmented Generation for Large Language Models: A Survey, March 2024. URL https://arxiv.org/abs/2312.10997. arXiv:2312.10997.
- Gu et al. (2025) Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A Survey on LLM-as-a-Judge, March 2025. URL https://arxiv.org/abs/2411.15594. arXiv:2411.15594.
- Guo et al. (2025) Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, January 2025. URL https://arxiv.org/abs/2501.12948. arXiv:2501.12948.
- Guo et al. (2024) Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, and Xiangliang Zhang. Large Language Model Based Multi-Agents: A Survey of Progress and Challenges. In Kate Larson (ed.), Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI ’24, pp. 8048–8057, Jeju, South Korea, August 2024. International Joint Conferences on Artificial Intelligence Organization. doi: 10.24963/ijcai.2024/890. URL https://www.ijcai.org/proceedings/2024/890. Survey Track.
- Gutiérrez et al. (2024) Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (eds.), Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems (NeurIPS ’24), volume 37 of Advances in Neural Information Processing Systems, pp. 59532–59569, Vancouver, Canada, December 2024. Curran Associates. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/6ddc001d07ca4f319af96a3024f6dbd1-Abstract-Conference.html.
- Hong et al. (2024) Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun (eds.), Proceedings of the Twelfth International Conference on Learning Representations, ICLR ’24, pp. 23247–23275, Vienna, Austria, May 2024. International Conference on Learning Representations. URL https://proceedings.iclr.cc/paper_files/paper/2024/hash/6507b115562bb0a305f1958ccc87355a-Abstract-Conference.html.
- Hu et al. (2024) Hanxu Hu, Hongyuan Lu, Huajian Zhang, Wai Lam, and Yue Zhang. Chain-of-Symbol Prompting Elicits Planning in Large Langauge Models, August 2024. URL https://arxiv.org/abs/2305.10276. arXiv:2305.10276.
- Hu & Lu (2025) Yucheng Hu and Yuxing Lu. RAG and RAU: A Survey on Retrieval-Augmented Language Model in Natural Language Processing, June 2025. URL https://arxiv.org/abs/2404.19543. arXiv:2404.19543.
- Huang et al. (2023) Di Huang, Ziyuan Nan, Xing Hu, Pengwei Jin, Shaohui Peng, Yuanbo Wen, Rui Zhang, Zidong Du, Qi Guo, Yewen Pu, and Yunji Chen. ANPL: Towards Natural Programming with Interactive Decomposition. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Proceedings of the Thirty-Seventh Annual Conference on Neural Information Processing Systems (NeurIPS ’23), volume 36 of Advances in Neural Information Processing Systems, pp. 69404–69440, New Orleans, LA, USA, December 2023. Curran Associates. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/dba8fa689ede9e56cbcd4f719def38fb-Abstract-Conference.html.
- Huang & Huang (2024) Yizheng Huang and Jimmy Huang. A Survey on Retrieval-Augmented Text Generation for Large Language Models, August 2024. URL https://arxiv.org/abs/2404.10981. arXiv:2404.10981.
- Jung et al. (2022) Jaehun Jung, Lianhui Qin, Sean Welleck, Faeze Brahman, Chandra Bhagavatula, Ronan Le Bras, and Yejin Choi. Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP ’22, pp. 1266–1279, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.82. URL https://aclanthology.org/2022.emnlp-main.82/.
- Kaddour et al. (2023) Jean Kaddour, Joshua Harris, Maximilian Mozes, Herbie Bradley, Roberta Raileanu, and Robert McHardy. Challenges and Applications of Large Language Models, July 2023. URL https://arxiv.org/abs/2307.10169. arXiv:2307.10169.
- Kagaya et al. (2024) Tomoyuki Kagaya, Thong Jing Yuan, Yuxuan Lou, Jayashree Karlekar, Sugiri Pranata, Akira Kinose, Koki Oguri, Felix Wick, and Yang You. RAP: Retrieval-Augmented Planning with Contextual Memory for Multimodal LLM Agents. In Proceedings of the Workshop on Open-World Agents, OWA ’24, Vancouver, Canada, December 2024. OpenReview. URL https://openreview.net/forum?id=Xf49Dpxuox.
- Kim et al. (2024) Sehoon Kim, Suhong Moon, Ryan Tabrizi, Nicholas Lee, Michael W. Mahoney, Kurt Keutzer, and Amir Gholami. An LLM Compiler for Parallel Function Calling. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp (eds.), Proceedings of the 41st International Conference on Machine Learning (ICML ’24), volume 235 of Proceedings of Machine Learning Research, pp. 24370–24391, Vienna, Austria, July 2024. PMLR. URL https://proceedings.mlr.press/v235/kim24y.html.
- LangChain Inc. (2025a) LangChain Inc. LangChain. https://www.langchain.com/, 2025a. Accessed: 2025-09-22.
- LangChain Inc. (2025b) LangChain Inc. Dealing with API Errors. https://js.langchain.com/v0.1/docs/modules/data_connection/text_embedding/api_errors/, 2025b. Accessed: 2025-09-22.
- LangChain Inc. (2025c) LangChain Inc. LangChain Core Tools: BaseTool. https://api.python.langchain.com/en/latest/tools/langchain_core.tools.BaseTool.html, 2025c. Accessed: 2025-09-22.
- LangChain Inc. (2025d) LangChain Inc. How to parse JSON output. https://python.langchain.com/docs/how_to/output_parser_json/, 2025d. Accessed: 2025-09-22.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (eds.), Proceedings of the Thirty-Fourth Annual Conference on Neural Information Processing Systems (NeurIPS ’20), volume 33 of Advances in Neural Information Processing Systems, pp. 9459–9474, Virtual Event, December 2020. Curran Associates. URL https://proceedings.neurips.cc/paper_files/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html.
- Li & Vasarhelyi (2024) Huaxia Li and Miklos A. Vasarhelyi. Applying Large Language Models in Accounting: A Comparative Analysis of Different Methodologies and Off-the-Shelf Examples. Journal of Emerging Technologies in Accounting, 21(2):133–152, October 2024. ISSN 1554-1908. doi: 10.2308/JETA-2023-065. URL https://publications.aaahq.org/jeta/article-abstract/21/2/133/12800/.
- Li et al. (2022) Huayang Li, Yixuan Su, Deng Cai, Yan Wang, and Lemao Liu. A Survey on Retrieval-Augmented Text Generation, February 2022. URL https://arxiv.org/abs/2202.01110. arXiv:2202.01110.
- Li et al. (2024) Junyou Li, Qin Zhang, Yangbin Yu, Qiang Fu, and Deheng Ye. More Agents Is All You Need. Transactions on Machine Learning Research, October 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=bgzUSZ8aeg.
- Liu et al. (2024a) Xukun Liu, Zhiyuan Peng, Xiaoyuan Yi, Xing Xie, Lirong Xiang, Yuchen Liu, and Dongkuan Xu. ToolNet: Connecting Large Language Models with Massive Tools via Tool Graph, February 2024a. URL https://arxiv.org/abs/2403.00839. arXiv:2403.00839.
- Liu et al. (2024b) Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration. In Proceedings of the First Conference on Language Modeling, COLM ’24, Philadelphia, PA, USA, October 2024b. OpenReview. URL https://openreview.net/forum?id=XII0Wp1XA9.
- Manathunga & Illangasekara (2023) S. S. Manathunga and Y. A. Illangasekara. Retrieval Augmented Generation and Representative Vector Summarization for Large Unstructured Textual Data in Medical Education, August 2023. URL https://arxiv.org/abs/2308.00479. arXiv:2308.00479.
- Mecharnia & d’Aquin (2025) Thamer Mecharnia and Mathieu d’Aquin. Performance and Limitations of Fine-Tuned LLMs in SPARQL Query Generation. In Genet Asefa Gesese, Harald Sack, Heiko Paulheim, Albert Merono-Penuela, and Lihu Chen (eds.), Proceedings of the Workshop on Generative AI and Knowledge Graphs, GenAIK ’25, pp. 69–77, Abu Dhabi, United Arab Emirates, January 2025. International Committee on Computational Linguistics. URL https://aclanthology.org/2025.genaik-1.8/.
- Mialon et al. (2023) Grégoire Mialon, Roberto Dessi, Maria Lomeli, Christoforos Nalmpantis, Ramakanth Pasunuru, Roberta Raileanu, Baptiste Roziere, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, and Thomas Scialom. Augmented Language Models: A Survey. Transactions on Machine Learning Research, July 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=jh7wH2AzKK. Survey Certification.
- Mialon et al. (2024) Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A Benchmark for General AI Assistants. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun (eds.), Proceedings of the Twelfth International Conference on Learning Representations, ICLR ’24, pp. 9025–9049, Vienna, Austria, May 2024. International Conference on Learning Representations. URL https://proceedings.iclr.cc/paper_files/paper/2024/hash/25ae35b5b1738d80f1f03a8713e405ec-Abstract-Conference.html.
- Mialon et al. (2025) Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA Leaderboard. https://huggingface.co/spaces/gaia-benchmark/leaderboard, September 2025. Accessed: 2025-09-25.
- NetworkX Developers (2025) NetworkX Developers. NetworkX Documentation. https://networkx.org/, May 2025. Accessed: 2025-09-22.
- OpenAI (2025) OpenAI. simple-evals. https://github.com/openai/simple-evals, July 2025. Accessed: 2025-09-22.
- Pérez et al. (2009) Jorge Pérez, Marcelo Arenas, and Claudio Gutierrez. Semantics and Complexity of SPARQL. ACM Trans. Database Syst., 34(3):16:1–16:45, September 2009. ISSN 0362-5915. doi: 10.1145/1567274.1567278. URL https://doi.org/10.1145/1567274.1567278.
- Prasad et al. (2024) Archiki Prasad, Alexander Koller, Mareike Hartmann, Peter Clark, Ashish Sabharwal, Mohit Bansal, and Tushar Khot. ADaPT: As-Needed Decomposition and Planning with Language Models. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.), Findings of the Association for Computational Linguistics: NAACL 2024, pp. 4226–4252, Mexico City, Mexico, June 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-naacl.264. URL https://aclanthology.org/2024.findings-naacl.264/.
- Python Software Foundation (2025a) Python Software Foundation. codecs — Codec registry and base classes. https://docs.python.org/3/library/codecs.html, September 2025a. Accessed: 2025-09-22.
- Python Software Foundation (2025b) Python Software Foundation. asyncio — Asynchronous I/O. https://docs.python.org/3/library/asyncio.html, September 2025b. Accessed: 2025-09-22.
- Qian et al. (2025) Chen Qian, Zihao Xie, Yifei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Scaling Large Language Model-Based Multi-Agent Collaboration. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu (eds.), Proceedings of the Thirteenth International Conference on Learning Representations, ICLR ’25, pp. 41488–41505, Singapore, April 2025. International Conference on Learning Representations. URL https://proceedings.iclr.cc/paper_files/paper/2025/hash/66a026c0d17040889b50f0dfa650e5e0-Abstract-Conference.html.
- Robinson et al. (2015) Ian Robinson, Jim Webber, and Emil Eifrem. Graph Database Internals. In Graph Databases, chapter 7, pp. 149–170. O’Reilly, Sebastopol, CA, USA, 2nd edition, 2015. ISBN 9781491930892.
- Roucher & Petrov (2025) Aymeric Roucher and Sergei Petrov. Beating GAIA with Transformers Agents. https://github.com/aymeric-roucher/GAIA, February 2025. Accessed: 2025-09-22.
- Rush (2023) Alexander Rush. MiniChain: A Small Library for Coding with Large Language Models. In Yansong Feng and Els Lefever (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, EMNLP ’23, pp. 311–317, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-demo.27. URL https://aclanthology.org/2023.emnlp-demo.27.
- Sarthi et al. (2024) Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher Manning. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun (eds.), Proceedings of the Twelfth International Conference on Learning Representations, ICLR ’24, pp. 32628–32649, Vienna, Austria, May 2024. International Conference on Learning Representations. URL https://proceedings.iclr.cc/paper_files/paper/2024/hash/8a2acd174940dbca361a6398a4f9df91-Abstract-Conference.html.
- Schick et al. (2023) Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Proceedings of the Thirty-Seventh Annual Conference on Neural Information Processing Systems (NeurIPS ’23), volume 36 of Advances in Neural Information Processing Systems, pp. 68539–68551, New Orleans, LA, USA, December 2023. Curran Associates. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/d842425e4bf79ba039352da0f658a906-Abstract-Conference.html.
- SerpApi LLM (2025) SerpApi LLM. SerpApi: Google Search API. https://serpapi.com/, 2025. Accessed: 2025-09-22.
- Shen et al. (2023) Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Proceedings of the Thirty-Seventh Annual Conference on Neural Information Processing Systems (NeurIPS ’23), volume 36 of Advances in Neural Information Processing Systems, pp. 38154–38180, New Orleans, LA, USA, December 2023. Curran Associates. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/77c33e6a367922d003ff102ffb92b658-Abstract-Conference.html.
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language Agents with Verbal Reinforcement Learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Proceedings of the Thirty-Seventh Annual Conference on Neural Information Processing Systems (NeurIPS ’23), volume 36 of Advances in Neural Information Processing Systems, pp. 8634–8652, New Orleans, LA, USA, December 2023. Curran Associates. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/1b44b878bb782e6954cd888628510e90-Abstract-Conference.html.
- Significant Gravitas (2025) Significant Gravitas. AutoGPT. https://github.com/Significant-Gravitas/AutoGPT, September 2025. Accessed: 2025-09-22.
- Singhal (2012) Amit Singhal. Introducing the Knowledge Graph: things, not strings. https://www.blog.google/products/search/introducing-knowledge-graph-things-not/, May 2012. Accessed: 2025-09-22.
- Stengel-Eskin et al. (2024) Elias Stengel-Eskin, Archiki Prasad, and Mohit Bansal. ReGAL: Refactoring Programs to Discover Generalizable Abstractions. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp (eds.), Proceedings of the 41st International Conference on Machine Learning (ICML ’24), volume 235 of Proceedings of Machine Learning Research, pp. 46605–46624, Vienna, Austria, July 2024. PMLR. URL https://proceedings.mlr.press/v235/stengel-eskin24a.html.
- Sumers et al. (2024) Theodore Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas Griffiths. Cognitive Architectures for Language Agents. Transactions on Machine Learning Research, February 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=1i6ZCvflQJ. Survey Certification.
- Tang et al. (2024) Xunzhu Tang, Kisub Kim, Yewei Song, Cedric Lothritz, Bei Li, Saad Ezzini, Haoye Tian, Jacques Klein, and Tegawendé F. Bissyandé. CodeAgent: Autonomous Communicative Agents for Code Review. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP ’24, pp. 11279–11313, Miami, FL, USA, November 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.632. URL https://aclanthology.org/2024.emnlp-main.632/.
- Tenacity Developers (2025a) Tenacity Developers. Tenacity: Retrying Library. https://github.com/jd/tenacity, April 2025a. Accessed: 2025-09-22.
- Tenacity Developers (2025b) Tenacity Developers. Tenacity Documentation. https://tenacity.readthedocs.io/en/latest/, 2025b. Accessed: 2025-09-22.
- Wang et al. (2023a) Shenzhi Wang, Chang Liu, Zilong Zheng, Siyuan Qi, Shuo Chen, Qisen Yang, Andrew Zhao, Chaofei Wang, Shiji Song, and Gao Huang. Avalon’s Game of Thoughts: Battle Against Deception through Recursive Contemplation, October 2023a. URL https://arxiv.org/abs/2310.01320. arXiv:2310.01320.
- Wang et al. (2023b) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In Proceedings of the Eleventh International Conference on Learning Representations, ICLR ’23, Kigali, Rwanda, May 2023b. OpenReview. URL https://openreview.net/forum?id=1PL1NIMMrw.
- Wang et al. (2023c) Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xiaojian (Shawn) Ma, and Yitao Liang. Describe, Explain, Plan and Select: Interactive Planning with LLMs Enables Open-World Multi-Task Agents. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Proceedings of the Thirty-Seventh Annual Conference on Neural Information Processing Systems (NeurIPS ’23), volume 36 of Advances in Neural Information Processing Systems, pp. 34153–34189, New Orleans, LA, USA, December 2023c. Curran Associates. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/6b8dfb8c0c12e6fafc6c256cb08a5ca7-Abstract-Conference.html.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (eds.), Proceedings of the Thirty-Sixth Annual Conference on Neural Information Processing Systems (NeurIPS ’22), volume 35 of Advances in Neural Information Processing Systems, pp. 24824–24837, New Orleans, LA, USA, December 2022. Curran Associates. URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html.
- Wei et al. (2024) Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring Short-Form Factuality in Large Language Models, November 2024. URL https://arxiv.org/abs/2411.04368. arXiv:2411.04368.
- Wewer et al. (2021) Christopher Wewer, Florian Lemmerich, and Michael Cochez. Updating Embeddings for Dynamic Knowledge Graphs, September 2021. URL https://arxiv.org/abs/2109.10896. arXiv:2109.10896.
- Wu et al. (2024) Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. In Proceedings of the First Conference on Language Modeling, COLM ’24, Philadelphia, PA, USA, October 2024. OpenReview. URL https://openreview.net/forum?id=BAakY1hNKS.
- Xie et al. (2024) Tianbao Xie, Fan Zhou, Zhoujun Cheng, Peng Shi, Luoxuan Weng, Yitao Liu, Toh Jing Hua, Junning Zhao, Qian Liu, Che Liu, Zeju Liu, Yiheng Xu, Hongjin Su, Dongchan Shin, Caiming Xiong, and Tao Yu. OpenAgents: An Open Platform for Language Agents in the Wild. In Proceedings of the First Conference on Language Modeling, COLM ’24, Philadelphia, PA, USA, October 2024. OpenReview. URL https://openreview.net/forum?id=sKATR2O1Y0.
- Xu et al. (2024) Zhipeng Xu, Zhenghao Liu, Yukun Yan, Shuo Wang, Shi Yu, Zheni Zeng, Chaojun Xiao, Zhiyuan Liu, Ge Yu, and Chenyan Xiong. ActiveRAG: Autonomously Knowledge Assimilation and Accommodation through Retrieval-Augmented Agents, October 2024. URL https://arxiv.org/abs/2402.13547. arXiv:2402.13547.
- Yang et al. (2025) An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, et al. Qwen2.5 Technical Report, January 2025. URL https://arxiv.org/abs/2412.15115. arXiv:2412.15115.
- Yao et al. (2023a) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Proceedings of the Thirty-Seventh Annual Conference on Neural Information Processing Systems (NeurIPS ’23), volume 36 of Advances in Neural Information Processing Systems, pp. 11809–11822, New Orleans, LA, USA, December 2023a. Curran Associates. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/271db9922b8d1f4dd7aaef84ed5ac703-Abstract-Conference.html.
- Yao et al. (2023b) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models. In Proceedings of the Eleventh International Conference on Learning Representations, ICLR ’23, Kigali, Rwanda, May 2023b. OpenReview. URL https://openreview.net/forum?id=WE_vluYUL-X.
- Ye et al. (2023) Yunhu Ye, Binyuan Hui, Min Yang, Binhua Li, Fei Huang, and Yongbin Li. Large Language Models Are Versatile Decomposers: Decomposing Evidence and Questions for Table-Based Reasoning. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, pp. 174–184, Taipei, Taiwan, July 2023. Association for Computing Machinery. ISBN 9781450394086. doi: 10.1145/3539618.3591708. URL https://doi.org/10.1145/3539618.3591708.
- Yu et al. (2024a) Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, and Zhaofeng Liu. Evaluation of Retrieval-Augmented Generation: A Survey. In Wenwu Zhu, Hui Xiong, Xiuzhen Cheng, Lizhen Cui, Zhicheng Dou, Junyu Dong, Shanchen Pang, Li Wang, Lanju Kong, and Zhenxiang Chen (eds.), Proceedings of the 12th CCF Conference, BigData, volume 2301 of Communications in Computer and Information Science (CCIS), pp. 102–120, Qingdao, China, August 2024a. Springer Nature. ISBN 978-981-96-1024-2. doi: 10.1007/978-981-96-1024-2˙8. URL https://link.springer.com/chapter/10.1007/978-981-96-1024-2_8.
- Yu et al. (2024b) Wenhao Yu, Hongming Zhang, Xiaoman Pan, Peixin Cao, Kaixin Ma, Jian Li, Hongwei Wang, and Dong Yu. Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP ’24, pp. 14672–14685, Miami, FL, USA, November 2024b. Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.813. URL https://aclanthology.org/2024.emnlp-main.813/.
- Zeng et al. (2024) Huimin Zeng, Zhenrui Yue, Qian Jiang, and Dong Wang. Federated Recommendation via Hybrid Retrieval Augmented Generation. In Wei Ding, Chang-Tien Lu, Fusheng Wang, Liping Di, Kesheng Wu, Jun Huan, Raghu Nambiar, Jundong Li, Filip Ilievski, Ricardo Baeza-Yates, and Xiaohua Hu (eds.), Proceedings of the IEEE International Conference on Big Data, BigData ’24, pp. 8078–8087, Washington, DC, USA, December 2024. IEEE Press. doi: 10.1109/BigData62323.2024.10825302. URL https://ieeexplore.ieee.org/document/10825302.
- Zhang et al. (2025) Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jeffrey Xu Yu, and Tianlong Chen. Cut the Crap: An Economical Communication Pipeline for LLM-Based Multi-Agent Systems. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu (eds.), Proceedings of the Thirteenth International Conference on Learning Representations, ICLR ’25, pp. 75389–75428, Singapore, April 2025. International Conference on Learning Representations. URL https://proceedings.iclr.cc/paper_files/paper/2025/hash/bbc461518c59a2a8d64e70e2c38c4a0e-Abstract-Conference.html.
- Zhao et al. (2024a) Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. ExpeL: LLM Agents Are Experiential Learners. Proceedings of the AAAI Conference on Artificial Intelligence, 38(17):19632–19642, March 2024a. doi: 10.1609/aaai.v38i17.29936. URL https://ojs.aaai.org/index.php/AAAI/article/view/29936.
- Zhao et al. (2024b) Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. Retrieval-Augmented Generation for AI-Generated Content: A Survey, June 2024b. URL https://arxiv.org/abs/2402.19473. arXiv:2402.19473.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Proceedings of the Thirty-Seventh Annual Conference on Neural Information Processing Systems (NeurIPS ’23), volume 36 of Advances in Neural Information Processing Systems, pp. 46595–46623, New Orleans, LA, USA, December 2023. Curran Associates. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/91f18a1287b398d378ef22505bf41832-Abstract-Datasets_and_Benchmarks.html.
- Zhu et al. (2025) Yuqi Zhu, Shuofei Qiao, Yixin Ou, Shumin Deng, Shiwei Lyu, Yue Shen, Lei Liang, Jinjie Gu, Huajun Chen, and Ningyu Zhang. KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.), Findings of the Association for Computational Linguistics: NAACL 2025, pp. 3709–3732, Albuquerque, NM, USA, April 2025. Association for Computational Linguistics. ISBN 979-8-89176-195-7. URL https://aclanthology.org/2025.findings-naacl.205/.
- Zhu et al. (2024) Zhaocheng Zhu, Yuan Xue, Xinyun Chen, Denny Zhou, Jian Tang, Dale Schuurmans, and Hanjun Dai. Large Language Models Can Learn Rules, December 2024. URL https://arxiv.org/abs/2310.07064. arXiv:2310.07064.
- Zhuge et al. (2024) Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. GPTSwarm: Language Agents as Optimizable Graphs. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp (eds.), Proceedings of the 41st International Conference on Machine Learning (ICML ’24), volume 235 of Proceedings of Machine Learning Research, pp. 62743–62767, Vienna, Austria, July 2024. PMLR. URL https://proceedings.mlr.press/v235/zhuge24a.html.
## Appendix A Additional Examples of Knowledge Graph Representation of Tasks
We include selected snapshots of KG representation of tasks, covering a wide range of graph structures from simple chains to trees and cyclic graphs. Each snapshot captures the current KG state in a JSON file, exported using a predefined query that retrieves all labeled nodes and edges. Regardless of the underlying graph backend, the use of a consistent export format allows all snapshots to be visualized through Neo4j’s built-in web interface. In the following, we showcase illustrations of such snapshots and task statements from the GAIA validation set. Please note that the GAIA benchmark discourages making its tasks accessible to crawling. To honor their wishes, we replaced the names of entities with placeholders in the following examples, while keeping the overall structure intact.
<details>
<summary>x15.png Details</summary>
### Visual Description
## Diagram: Enhanced Knowledge Graph for Merriam-Webster Word of the Day Query
### Overview
The image depicts a technical workflow for resolving a query about a writer quoted by Merriam-Webster for the "Word of the Day" on a specific date. It combines a textual question with a visual knowledge graph representation of relationships between entities.
### Components/Axes
**Left Section (Textual Query):**
- **Question**: "What writer is quoted by Merriam-Webster for the Word of the Day from [date]?"
- **Required Tools**:
1. Web browser (icon: spider)
2. Search engine (icon: magnifying glass)
3. Audio capability (icon: speaker)
**Right Section (Enhanced Knowledge Graph):**
- **Nodes**:
- `Date` (black circle)
- `Word` (white circle with black text)
- `Concept` (black circle)
- `Quote` (black circle with speech bubble)
- `Quoted By [firstname lastname]` (black circle)
- **Edges**:
- `Date → Word`: Labeled `HAS_DATE`
- `Word → Concept`: Labeled `HAS_QUOTE`
- `Concept → Quote`: Labeled `QUOTED_BY`
- `Quote → Quoted By`: Implied connection (no explicit label)
- **Legend**: No explicit color legend; node colors are black/white with text labels.
### Detailed Analysis
**Left Section**:
- The question requires resolving a temporal entity (`[date]`) and identifying a writer associated with Merriam-Webster's Word of the Day.
- Required tools suggest a multi-step process: web search (spider icon), query execution (magnifying glass), and potential audio output (speaker icon).
**Right Section**:
- **Entity Relationships**:
- `Date` directly associates with `Word` via `HAS_DATE`.
- `Word` connects to `Concept` via `HAS_QUOTE`, implying the word is a quote.
- `Concept` links to `Quote` via `QUOTED_BY`, indicating the concept is attributed to a quote.
- `Quote` implicitly connects to `Quoted By` (writer's name), though no explicit edge label is provided.
- **Flow**: The graph represents a hierarchical decomposition of the query, starting from the date and word, branching into conceptual and quoted relationships.
### Key Observations
1. The knowledge graph lacks explicit temporal resolution (e.g., no date value is provided).
2. The `Quoted By` node is generic (`[firstname lastname]`), suggesting a placeholder for dynamic data.
3. The absence of a direct edge between `Date` and `Quoted By` implies the resolution requires intermediate steps (e.g., searching for the word first).
### Interpretation
The diagram illustrates a knowledge graph-based approach to answering the query, emphasizing semantic relationships over direct data retrieval. The `KGoT Task Resolution` arrow indicates that the system (likely an AI or search engine) must infer connections between the date, word, and writer through intermediate concepts and quotes. The required tools suggest a hybrid approach: using a web browser to access Merriam-Webster's archives, a search engine to parse results, and audio output to present the answer. The graph's structure highlights the complexity of temporal and semantic dependencies in language-based queries, where a single word may map to multiple concepts and authors across different dates.
</details>
Figure 6: Example of a chain structure. This task requires 7 intermediate steps and the usage of 3 tools. The expected solution is ’[firstname lastname]’. KGoT invokes the Surfer agent to search for relevant pages, locate the relevant quote, and find the person who said it. All intermediate information is successfully retrieved and used for enhancing the dynamically constructed KG. The quote contains two properties, significance and text. ’significance’ stores the meaning of the quote, whereas ’text’ stores the actual quote.
<details>
<summary>x16.png Details</summary>
### Visual Description
## Screenshot: Question & Knowledge Graph Interface
### Overview
The image depicts a question-answering interface with a knowledge graph visualization. The question involves identifying a historical figure (a bishop who never became pope) based on museum artifact metadata. A knowledge graph is shown to represent relationships between individuals and roles.
### Components/Axes
1. **Question Section**
- Text:
- "The [museum name] has a portrait in its collection with an accession number of [number]. Of the consecrators and co-consecrators of this portrait's subject as a bishop, what is the name of the one who never became pope?"
- Required Tools:
- Web browser (icon: spider)
- Search engine (icon: magnifying glass)
2. **KGoT Task Resolution**
- Arrow labeled "KGoT Task Resolution" pointing from the question to the knowledge graph.
3. **Enhanced Knowledge Graph**
- **Nodes**:
- `[firstname1 lastname1]` (Bishop)
- `[firstname2 lastname2]` (Bishop)
- `[firstname3 lastname3]` (Pope)
- `[popename]` (Pope)
- **Edges**:
- `[firstname1 lastname1]` → `[popename]` (labeled `CO_CONSECRATED`)
- `[firstname2 lastname2]` → `[popename]` (labeled `CO_CONSECERATED`)
- `[popename]` → `[firstname3 lastname3]` (labeled `CO_CONSECERATED`)
- **Color Coding**:
- Black nodes: Bishops
- White nodes: Popes
### Detailed Analysis
- **Question Metadata**:
- Placeholders `[museum name]`, `[number]`, and `[firstnameX lastnameX]` indicate dynamic data fields.
- The question hinges on identifying a bishop node not connected to a pope node.
- **Knowledge Graph Structure**:
- Nodes represent individuals with roles (bishop/pope).
- Edges (`CO_CONSECRATED`, `CO_CONSECERATED`) denote hierarchical relationships (e.g., consecration).
- The graph implies a chain of authority: bishops consecrate others, leading to papal appointments.
### Key Observations
1. The graph uses placeholder names (`[firstnameX lastnameX]`) instead of real data, suggesting this is a template or example.
2. The edge labels (`CO_CONSECRATED` vs. `CO_CONSECERATED`) may indicate different types of consecration relationships (e.g., direct vs. indirect).
3. The pope node (`[popename]`) acts as a central hub, receiving consecrations from bishops and consecrating another pope.
### Interpretation
The knowledge graph models ecclesiastical hierarchies, where bishops consecrate successors, and popes oversee higher-level appointments. The question seeks to identify a bishop node disconnected from the papal lineage. In a real-world scenario, this would require querying historical records to find bishops who did not ascend to the papacy. The graph’s structure emphasizes transitive relationships (e.g., consecration chains), which are critical for tracing lineage and authority in religious history.
**Note**: The image lacks numerical data or explicit trends, focusing instead on semantic relationships. The grayscale visualization uses node colors (black/white) to distinguish roles, but no quantitative metrics are present.
</details>
Figure 7: Example of a tree structure. This task requires 6 intermediate steps and the usage of 2 tools. The expected solution is ’[firstname1 lastname1]’. The Surfer agent is also invoked for this task. In this KG representation of the task, [popename] is identified as the consecrator, where [firstname1 lastname1], [firstname2 lastname2] and [firstname3 lastname3] are all co-consecrators. Subsequently, the correct answer is obtained from the KGoT from the KG by correctly identifying [firstname1 lastname1] as the one without any labels.
<details>
<summary>x17.png Details</summary>

### Visual Description
## Diagram: Enhanced Knowledge Graph for Album Publication Analysis
### Overview
The image presents a two-part structure:
1. A textual question asking for the number of studio albums published by "[firstname lastname]" between [year] and [year] (inclusive), referencing the latest 2022 version of English Wikipedia.
2. An **Enhanced Knowledge Graph** visualizing relationships between the artist, albums, and release years.
---
### Components/Axes
#### Left Section (Textual Question)
- **Question**: "How many studio albums were published by [firstname lastname] between [year] and [year] (included)?"
- **Required Tools**:
- Web browser (icon: 🕵️♂️)
- Search engine (icon: 🔍)
- **Placeholders**:
- `[firstname lastname]` (artist name)
- `[year]` (start year)
- `[year]` (end year)
#### Right Section (Enhanced Knowledge Graph)
- **Legend**:
- Color: Purple (#8A2BE2) for the artist's name node.
- **Nodes**:
- **Central Node**: `[firstname lastname]` (artist)
- **Album Nodes**:
- `[album name 1]` (Year: 2018)
- `[album name 2]` (Year: 2020)
- `[album name 3]` (Year: 2021)
- `[album name 4]` (Year: 2022)
- **Edges**:
- All edges labeled `RELEASED`, connecting the artist to each album.
- **Spatial Layout**:
- Artist node at the center.
- Album nodes arranged clockwise around the artist.
- Years displayed in white text bubbles near each album node.
---
### Detailed Analysis
#### Textual Question
- The question requires extracting album counts from Wikipedia, implying the need for web scraping or API access.
- Placeholders suggest dynamic input for artist name and date range.
#### Knowledge Graph
- **Structure**:
- Directed graph with the artist as the root node.
- Each album node is connected to the artist via `RELEASED` edges.
- **Temporal Progression**:
- Albums span 2018–2022, with the latest release in 2022.
- **Color Coding**:
- Artist node: Purple (#8A2BE2).
- Album nodes: Black with white text.
- Edges: Gray with white text.
---
### Key Observations
1. **Album Count**: Four studio albums are explicitly listed (2018–2022).
2. **Temporal Gaps**:
- 2-year gap between 2018 and 2020.
- 1-year gaps between 2020–2021 and 2021–2022.
3. **Graph Completeness**:
- All albums are directly linked to the artist, with no intermediate nodes.
- No self-loops or cross-album connections.
---
### Interpretation
1. **Data Implications**:
- The graph confirms the artist published **4 studio albums** between 2018 and 2022, matching the question's scope.
- The 2022 album aligns with the reference to the "latest 2022 version of English Wikipedia," suggesting real-time data integration.
2. **Relationships**:
- The `RELEASED` edges emphasize the artist's direct role in album production.
- The graph's simplicity prioritizes clarity over complexity, focusing on publication timelines.
3. **Anomalies**:
- No albums listed before 2018 or after 2022, which may indicate incomplete data or intentional scope limitation.
4. **Technical Relevance**:
- The graph serves as a knowledge base for answering the question, demonstrating how structured data (nodes/edges) can resolve factual queries.
---
### Conclusion
The Enhanced Knowledge Graph provides a clear, structured representation of the artist's discography, enabling efficient extraction of album counts and release years. The textual question and graph together illustrate a workflow for leveraging web resources (Wikipedia) and knowledge graphs to answer domain-specific queries.
</details>
Figure 8: Example of a tree structure. This task requires 4 intermediate steps and the usage of 2 tools. The expected solution is ’4’. This is a trap question where only the studio albums should be taken into account. In addition to years, the type of the albums is also stored as a property in the KG. Please note that the original GAIA task has a different solution, which we do not want to reveal.
<details>
<summary>x18.png Details</summary>
### Visual Description
## Screenshot: Technical Task Resolution Workflow
### Overview
The image depicts a technical task resolution workflow divided into two sections:
1. **Left Panel**: A textual question (Question: 106) describing a programming task involving Python and C++ code execution.
2. **Right Panel**: An "Enhanced Knowledge Graph" diagram illustrating relationships between components (nodes) and processes (edges).
---
### Components/Axes
#### Left Panel (Textual Question):
- **Task Description**:
- Run a Python script that outputs a URL containing C++ source code.
- Compile and run the C++ code against the array `[42, 23, 2, 88, 37, 15]`.
- Return the sum of the **third** and **fifth** integers in the sorted list.
- **Required Tools**:
- Web browser, search engine, file handling, computer vision, OCR, code execution, calculator.
- **Python Array**:
```python
arr = ['URL', 'ele', 'me', 'nts', 'as', 'sho', 'rt', 'str', 'ings']
```
#### Right Panel (Enhanced Knowledge Graph):
- **Nodes**:
- **Script** → Generates → **URL**
- **URL** → Leads to → **SourceCode**
- **SourceCode** → Processes → **Array**
- **Array** → Sorts to → **SortedArray**
- **SortedArray** → Has Integer → **42**, **23**, **65**
- **Integer** nodes (42, 23, 65) → Sum with → **Integer** (result: 65)
- **Edges**:
- Arrows labeled with relationships (e.g., `GENERATES`, `PROCESSES`, `HAS_INTEGER`).
- **Spatial Layout**:
- Nodes arranged in a flowchart-like structure with directional edges.
- Numerical values (42, 23, 65) annotated near relevant nodes.
---
### Detailed Analysis
#### Left Panel:
- **Python Array**: Contains 9 strings (e.g., `'URL'`, `'ele'`).
- **C++ Task**:
- Input array: `[42, 23, 2, 88, 37, 15]`.
- Sorted array: `[2, 15, 23, 37, 42, 88]`.
- Third integer: **23** (index 2 in 0-based indexing).
- Fifth integer: **42** (index 4).
- Sum: **23 + 42 = 65**.
#### Right Panel:
- **Node Relationships**:
1. **Script** generates a **URL**.
2. **URL** leads to **SourceCode** (C++ code).
3. **SourceCode** processes the **Array** of integers.
4. **Array** is sorted into **SortedArray**.
5. **SortedArray** contains integers **42**, **23**, and **65**.
6. **42** and **23** are summed to produce **65**.
---
### Key Observations
1. **Workflow Logic**:
- The Python script generates a URL, which is used to retrieve C++ code.
- The C++ code processes the array, sorts it, and computes the sum of specific elements.
2. **Numerical Values**:
- The sum of the third (23) and fifth (42) integers in the sorted array is **65**.
- The number **65** appears as both a node and the final result.
3. **Tool Requirements**:
- Tools like "code execution" and "calculator" are explicitly listed, aligning with the task steps.
---
### Interpretation
- **Purpose**: The diagram visualizes the end-to-end process of executing a multi-step programming task, from code generation to result computation.
- **Critical Path**:
- The **Script** → **URL** → **SourceCode** → **Array** → **SortedArray** → **Integer Sum** sequence represents the logical flow of data and operations.
- **Anomalies**:
- The number **65** appears as both a node and the final result, suggesting it is both an intermediate value and the task’s output.
- **Implications**:
- The graph emphasizes modularity, breaking the task into discrete components (e.g., URL generation, code processing).
- The inclusion of tools like OCR and computer vision hints at potential preprocessing steps (e.g., extracting code from images).
---
**Note**: No non-English text or ambiguous data points were identified. All values and relationships are explicitly stated in the image.
</details>
Figure 9: Example of a cyclic graph structure. This task requires 7 intermediate steps and the usage of 6 tools. The expected solution is ’65’. Here, array has the property ’values’ with $[42,23,2,88,37,15]$ , SortedArray contains the correctly sorted values $[2,15,23,37,42,88]$ . The final solution ’65’ is correctly retrieved and parsed as KGoT response. Please note that we used different array values than in the original GAIA task.
### A.1 Graph Storage Representation of Knowledge Graph Examples
We now illustrate two examples of knowledge graphs and how they are represented in Neo4j and NetworkX respectively as well as the queries used to extract the final solution. Please note again, that we either replaced the values with placeholders (first question) or with different values (second question) in order to not leak the GAIA benchmark questions.
We start with GAIA question 59, which is illustrated in Figure 6. The knowledge graph stored in Neo4j after the first iteration is shown in the code snippet below.
Neo4j KG representation while processing question 59.
%****␣appendix-kgs.tex␣Line␣75␣**** Nodes: Label: Writer {neo4j_id:0, properties:{’name’: ’[firstname lastname]’}} Label: WordOfTheDay {neo4j_id:1, properties:{’pronunciation’: ’[con-cept]’, ’definition’: ’textual definition’, ’counter’: 1, ’origin’: ’some war between year-year’, ’word’: ’[concept]’, ’date’: ’[date1]’}} Label: Quote {neo4j_id:2, properties:{’text’: ’[quote]’, ’source’: ’[newspaper name]’, ’date’: ’[date2]’}} Relationships: Label: QUOTED_FOR {source: {neo4j_id: 0, label: Writer}, target: {neo4j_id: 1, label: WordOfTheDay}, properties: {}} Label: QUOTED_IN {source: {neo4j_id: 0, label: Writer}, target: {neo4j_id: 2, label: Quote}, properties: {}}
The Cypher query used to extract the solution was the following:
Cypher query to extract the solution for question 59.
MATCH (w:Writer)-[:QUOTED_FOR]->(wod:WordOfTheDay {date: ’[date1]’}) RETURN w.name AS writer_name
To illustrate the use of NetworkX, we use a knowledge graph for question 106 (shown in Figure 9) from the GAIA benchmark after the second iteration.
NetworkX KG representation while processing question 106.
Existing Nodes: Label: Function [{id:A1, properties:{’name’: ’image_inspector’}}, {id:call_X2CcPnp5acMUPAp1Qx3OTvKx, properties:{’name’: ’image_inspector’, ’args’: {’question’: ’What Python script is depicted in the attached image?’, ’full_path_to_image’: ’[filepath].png’}}}] Label: Script [{id:A2, properties:{’description’: ’Python script to construct a URL by combining a base URL with specific indices from an array’}}] Label: Array [{id:A3, properties:{’content’: "[’URL’, ’ele’, ’me’, ’nts’, ’as’, ’sho’, ’rt’, ’str’, ’ings’]"}}] Label: URL [{id:A4, properties:{’base’: ’[base URL]’, ’indices’: [some indices]}}] Existing Relationships: Label: uses [{source: {id: A1}, target: {id: A2}, properties: {}}] Label: contains [{source: {id: A2}, target: {id: A3}, properties: {}}] Label: constructs [{source: {id: A2}, target: {id: A4}, properties: {}}] Label: None [{source: {id: call_X2CcPnp5acMUPAp1Qx3OTvKx}, target: {id: A2}, properties: {}}]
The following Python code was used to extract the final solution:
Python code to extract the solution for question 106.
# Retrieve the base URL and indices to construct the final URL base_url = self.G.nodes[’A4’][’base’] indices = self.G.nodes[’A4’][’indices’] # Retrieve the array content arr = eval(self.G.nodes[’A3’][’content’]) # Construct the URL using the specified indices constructed_url = base_url + ’’.join(arr[i] for i in indices) # The next step would be to compile and run the C++ code from the constructed URL, but # since we cannot execute external code, we will simulate the sorting and summing # process in Python. # Simulating the C++ code execution with the given array sorted_arr = sorted([2, 15, 23, 37, 42, 88]) # Sum of the third and fifth integers in the sorted list result = sorted_arr[2] + sorted_arr[4]
After the code execution, the correct solution of 65 is obtained.
## Appendix B Additional Details on System Design & Implementation
### B.1 Controller
The Controller is the central orchestrator of the KGoT system, responsible for managing the interaction between the knowledge graph and the integrated tools. When a user submits a query, the Controller initiates the reasoning process by interpreting the task and coordinating the steps required for its resolution.
To offer fine-grained control over the KGoT control logic, the following parameters can be configured:
- num_next_steps_decision: Number of times to prompt an LLM on how to proceed (Solve/Enhance). Defaults to 5.
- max_retrieve_query_retry: Maximum retries for a Solve query when the initial attempt fails. Defaults to 3.
- max_cypher_fixing_retry: Maximum retries for fixing a Cypher query that encounter errors. Defaults to 3.
- max_final_solution_parsing: Maximum retries of parsing the final solution from the output of the Solve query. Defaults to 3.
- max_tool_retries: Maximum number of retries when a tool invocation fails. Defaults to 6.
Controller classes derived from the ControllerInterface abstract class embed such parameters with default values defined for their class. Users can experiment with custom parameters as well. We discuss how the choice of these parameters impacts the system robustness in Appendix B.2.
#### B.1.1 Architecture
The KGoT Controller employs a dual-LLM architecture with a clear separation of roles between constructing the knowledge graph (managed by the LLM Graph Executor) and interacting with tools (managed by the LLM Tool Executor). The following discussion provides additional specifics to the workflow description in Section 4.
The LLM Graph Executor is responsible for decision making and orchestrating the knowledge graph-based task resolution workflow, leading to different pathways (Solve or Enhance).
- define_next_step: Determine the next step. This function is invoked up to num_next_steps_decision times to collect replies from an LLM, which are subsequently used with a majority vote to decide whether to retrieve information from the knowledge graph for solving the task (Solve) or insert new information (Enhance).
- _insert_logic: Run Enhance. Once we have successfully executed tool calls and gathered new information, the system generates the Enhance query or queries to modify the knowledge graph accordingly. Each Enhance query is executed and its output is validated.
- _retrieve_logic: Run Solve. If the majority vote directs the system to the Solve pathway, a predefined solution technique (direct or query-based retrieve) is used for the solution generation.
- _get_math_response: Apply additional mathematical processing (optional).
- parse_solution_with_llm: Parse the final solution into a suitable format and prepare it as the KGoT response.
The LLM Tool Executor decides which tools to use as well as handling the interaction with these tools.
- define_tool_calls: Define tool calls. The system orchestrates the appropriate tool calls based on the knowledge graph state.
- _invoke_tools_after_llm_response, _invoke_tool_with_retry: Run tool calls with or without retry.
### B.2 Enhancing System Robustness
Given the non-deterministic nature of LLMs and their potential for generating hallucinations (Kaddour et al., 2023), the robustness of KGoT has been a fundamental focus throughout its design and implementation. Ensuring that the system consistently delivers accurate and reliable results across various scenarios is paramount. One of the key strategies employed to enhance robustness is the use of majority voting, also known as Self-Consistency (Wang et al., 2023b). In KGoT, majority voting is implemented by querying the LLM multiple times (by default 5 times) when deciding the next step, whether to insert more data into the knowledge graph or retrieve existing data. This approach reduces the impact of single-instance errors or inconsistencies, ensuring that the decisions made reflect the LLM’s most consistent reasoning paths.
The choice of defaulting to five iterations for majority voting is a strategic balance between reliability and cost management, and was based on the work by Wang et al. (2023b), which showed diminishing returns beyond this point.
In addition, KGoT uses a separate default iteration count of seven for executing its full range of functions during problem-solving. These seven iterations correspond to the typical number of tool calls required to thoroughly explore the problem space, including multiple interactions with tools like the Surfer agent and the external LLM. Unlike the five iterations used for majority voting used to ensure robustness, this strategy ensures the system leverages its resources effectively across multiple tool invocations before concluding with a ”No Solution” response if the problem remains unresolved.
Layered Error-Checking: KGoT integrates multiple error-checking mechanisms to safeguard against potential issues. The system continuously monitors for syntax errors and failures in API calls. These mechanisms are complemented by custom parsers and retry protocols. The parsers, customized from LangChain (LangChain Inc., 2025d), are designed to extract the required information from the LLM’s responses, eliminating the need for manual parsing. In cases where errors persist despite initial correction attempts, the system employs retry mechanisms. These involve the LLM rephrasing the Cypher queries and try them again. The Controller’s design includes a limit on the number of retries for generating Cypher queries and invoking tools, balancing the need for error resolution with the practical constraints of time and computational resources. More information can be found in the subsequent section.
### B.3 Error Management Techniques
#### B.3.1 Handling LLM-Generated Syntax Errors
Syntax errors generated by LLMs can disrupt the workflow of KGoT, potentially leading to incorrect or incomplete solutions, or even causing the system to fail entirely. To manage these errors, KGoT includes LangChain’s JSON parsers (LangChain Inc., 2025d) that detect syntax issues.
When a syntax error is detected, the system first attempts to correct it by adjusting the problematic syntax using different encoders, such as "unicode_escape" (Python Software Foundation, 2025a). If the issue persists, KGoT employs a retry mechanism that uses the LLM to rephrase the query/command and attempts to regenerate its output. This retry mechanism is designed to handle up to three attempts, after which the system logs the error for further analysis, bypasses the problematic query, and continues with other iterations in the hope that another tool or LLM call will still be able to resolve the problem.
A significant issue encountered with LLM-generated responses is managing the escape characters, especially when returning a Cypher query inside the standard JSON structure expected by the LangChain parser. The combination of retries using different encoders and parsers has mitigated the problem, though not entirely resolved it. Manual parsing and the use of regular expressions have also been attempted but with limited success.
#### B.3.2 Managing API and System Errors
API-related errors, such as the OpenAI code ’500’ errors, are a common challenge in the operation of KGoT, especially when the external servers are overwhelmed. To manage these errors, the primary strategy employed is exponential backoff, which is a technique where the system waits for progressively longer intervals before retrying a failed API call, reducing the likelihood of repeated failures due to temporary server issues or rate limits (Tenacity Developers, 2025b). In KGoT, this approach is implemented using the tenacity library, with a retry policy that waits for random intervals ranging from 1 to 60 seconds and allows for up to six retry attempts (wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6)).
Additionally, KGoT includes comprehensive logging systems as part of its error management framework. These systems track the errors encountered during system operation, providing valuable data that can be easily parsed and analyzed (e.g. snapshots of the knowledge graphs or responses from third-party APIs). This data can then be used to refine the system’s error-handling protocols and improve overall reliability.
It is also important to note that the system’s error management strategies are built on top of existing errors systems provided by external tools, such as the LangChain interface for OpenAI, which already implements a default exponential backoff strategy with up to six retries (LangChain Inc., 2025b). These built-in mechanisms complement KGoT’s own error-handling strategies, creating a multi-layered defense against potential failures and ensuring high levels of system reliability.
### B.4 Detailed Tool Description
Tools are a fundamental component of the KGoT framework, enabling seamless interaction with external resources such as the web and various file formats. KGoT currently supports the following tools:
- Python Code Tool: Executes code snippets provided by the LLM in a secure Python environment hosted within a Docker (or Sarus) container. This ensures that any potential security risks from executing untrusted code are mitigated. Besides running code, this tool is also utilized for mathematical computations.
- Large Language Model (LLM) Tool: Allows the LLM Tool Executor to request data generation from another instance of the same LLM. It is primarily employed for simple, objective tasks where no other tool is applicable.
- Surfer Agent: This web browser agent leverages SerpAPI to perform efficient Google searches and extract relevant webpage data. Built on Hugging Face Agents (Roucher & Petrov, 2025), this tool combines the capabilities with our WebCrawler and Wikipedia tools while adding support for JavaScript-rendered pages. It uses viewpoint segmentation to prevent the ”lost in the middle effect” and incorporates additional navigation functionalities, such as search and page traversal.
- ExtractZip Tool: Extracts data from compressed files (e.g., ZIP archives). It was enhanced through integration with the TextInspector Tool, enabling seamless analysis of extracted files without requiring additional iterations to process the data.
- TextInspector Tool: A versatile tool for extracting data from multiple file types, including PDFs, spreadsheets, MP3s, and YouTube videos. It organizes extracted content in Markdown format, enhancing readability and integration into the Knowledge Graph. The tool was augmented with the best components from our original MultiModal Tool and the Hugging Face Agents TextInspector Tool. It can directly process questions about extracted content without returning the raw data to the LLM.
- Image Tool: Extracts information from images, such as text or objects, and returns it in a structured format. This tool is crucial for tasks requiring image processing and analysis. We selected the best prompts from our original tool set as well as Hugging Face Agents to optimize data extraction and analysis.
Tool integration within the KGoT framework is crucial for extending the system’s problem-solving capabilities beyond what is achievable by LLMs alone. The strategy is designed to be modular, scalable, and efficient, enabling the system to leverage a diverse array of external tools for tasks such as data retrieval, complex computations, document processing, and more.
#### B.4.1 Modular Tool Architecture
All tools integrated into the KGoT system are built upon the BaseTool abstraction provided by the LangChain framework (LangChain Inc., 2025c). This standardized approach ensures consistency and interoperability among different tools, facilitating seamless integration and management of new tools. Each tool implementation adheres to the following structure:
- tool_name: A unique identifier for the tool, used by the system to reference and invoke the appropriate functionality.
- description: A detailed explanation of the tool’s purpose, capabilities, and appropriate usage scenarios. This description assists the LLM Tool Executor in selecting the right tool for specific tasks. Including few-shot examples is recommended, though the description must adhere to the 1024-character limit imposed by BaseTool.
- args_schema: A schema defining the expected input arguments for the tool, including their types and descriptions. This schema ensures that the LLM Tool Executor provides correctly formatted and valid inputs when invoking the tool.
This structured definition enables the LLM Tool Executor to dynamically understand and interact with a wide array of tools, promoting flexibility and extensibility within the KGoT system.
#### B.4.2 Tool Management and Initialization
The ToolManager component is responsible for initializing and maintaining the suite of tools available to the KGoT system. It handles tasks such as loading tool configurations, setting up necessary environment variables (e.g., API keys), and conducting initial tests to verify tool readiness, such as checking whether the RunPythonCodeTool ’s Docker container is running. The ToolManager ensures that all tools are properly configured and available for use during the system’s operation.
Simplified example of ToolManager initialization.
class ToolManager: def __init__(self): self.set_env_keys() self.tools = [ LLM_tool(...), image_question_tool(...), textInspectorTool(...), search_tool(...), run_python_tool(...), extract_zip_tool(...), # Additional tools can be added here ] self.test_tools() def get_tools(self): return self.tools
This modular setup allows for the easy addition or removal of tools, enabling the system to adapt to evolving requirements and incorporate new functionalities as needed.
#### B.4.3 Information Parsing and Validation
After a tool executes and returns its output, the retrieved information undergoes a parsing and validation process by the LLM Graph Executor before being integrated into the knowledge graph. This process ensures the integrity and relevance of new data:
- Relevance Verification: The content of the retrieved information is assessed for relevance to the original problem context. This step may involve cross-referencing with existing knowledge, checking for logical consistency, and filtering out extraneous or irrelevant details. The LLM Graph Executor handles this during Cypher query generation.
- Integration into Knowledge Graph: Validated and appropriately formatted information is then seamlessly integrated into the knowledge graph by executing each Cypher query (with required error managements as mentioned in section B.3.1), enriching the system’s understanding and enabling more informed reasoning in future iterations.
#### B.4.4 Benefits
This structured and systematic approach to tool integration and selection offers several key benefits:
- Enhanced Capability: By leveraging specialized tools, KGoT can handle a wide range of complex tasks that go beyond the inherent capabilities of LLMs, providing more comprehensive and accurate solutions.
- Scalability: The modular architecture allows for easy expansion of the tool set, enabling the system to adapt to new domains and problem types with minimal reconfiguration.
- Flexibility: The system’s ability to adaptively select and coordinate multiple tools in response to dynamic problem contexts ensures robust and versatile problem-solving capabilities.
### B.5 High-Performance & Scalability
As previously discussed, we also experimented with various high-performance computing techniques adopted to accelerate KGoT. This section outlines additional design details.
The acceleration strategies can be classified into two categories: those targeting the speedup of a single task, and those aimed at accelerating the execution of KGoT on a batch of tasks such as the GAIA benchmark.
Optimizations in the first category are:
- Asynchronous Execution: Profiling of the KGoT workflow reveals that a substantial portion of runtime is spent on LLM model calls and tool invocations. As this represents a typical I/O-intensive workload, Python multi-threading is sufficient to address the bottleneck. KGoT dynamically schedules independent I/O operations (based on the current graph state and execution logic) using asyncio to achieve full concurrency.
- Graph Operation Parallelism: KGoT maintains a graph storage backend for managing the knowledge graph. When new knowledge is obtained from the tools, KGoT generates a list of queries, which represent a sequence of graph operations to add or modify nodes, properties, and edges. However, executing these operations sequentially in the graph storage backend can be time-consuming. A key observation is that many of these operations exhibit potential independence. We leveraged this potential parallelism to accelerate these graph storage operations. Our solution involves having KGoT request an LLM to analyze dependencies within the operations and return multiple independent chains of graph storage operations. These chains are then executed concurrently using the asynchronous method proposed earlier, enabling parallel execution of queries on the graph storage. This approach effectively harnesses the inherent parallelism to significantly improve processing speed.
The applied optimizations result in an overall speedup of 2.30 $\times$ compared to the sequential baseline for a single KGoT task.
The second category focuses on accelerating a batch of tasks, for which MPI-based distributed processing is employed. Additional optimizations have also been implemented to further enhance performance.
- Work Stealing: The work-stealing algorithm operates by allowing idle processors to “steal” tasks from the queues of busy processors, ensuring balanced workload distribution. Each processor maintains its task queue, prioritizing local execution, while stealing occurs only when its queue is empty. This approach reduces idle time and enhances parallel efficiency. Our implementation of the work-stealing algorithm for KGoT adopts a novel approach tailored for distributed atomic task execution in an MPI environment. Each question is treated as an atomic task, initially distributed evenly across all ranks to ensure balanced workload allocation. When a rank completes all its assigned tasks, it enters a work-stealing phase, prioritizing the rank with the largest queue of remaining tasks. Operating in a peer-to-peer mode without a designated master rank, each rank maintains a work-stealing monitor to handle task redistribution. This monitor tracks incoming requests and facilitates the transfer of the last available task to the requesting rank whenever feasible. The system ensures continuous work-stealing, dynamically redistributing tasks to idle ranks, thus minimizing idle time and maximizing computational efficiency across all ranks. This decentralized and adaptive strategy significantly enhances the parallel processing capabilities of KGoT.
- Container Pool: The container pool implementation for KGoT ensures modular and independent execution of each tasks on separate ranks by running essential modules, such as Neo4j and the Python tool, within isolated containers, with one container assigned per rank. We use a Kubernetes-like container orchestration tool specifically designed for KGoT running with MPI. The container pool supports Docker and Sarus to be compatible with local and cluster environments. Our design guarantees that each task operates independently without interfering with each other, while trying to minimize latency between the KGoT controller and the containers.
Ultimately, our experiments achieved a 12.74 $\times$ speedup over the sequential baseline on the GAIA benchmark when executed with 8 ranks in MPI, as illustrated in Figure 10. This demonstrates the significant performance improvement of the KGoT system achieved on a consumer-grade platform.
<details>
<summary>x19.png Details</summary>
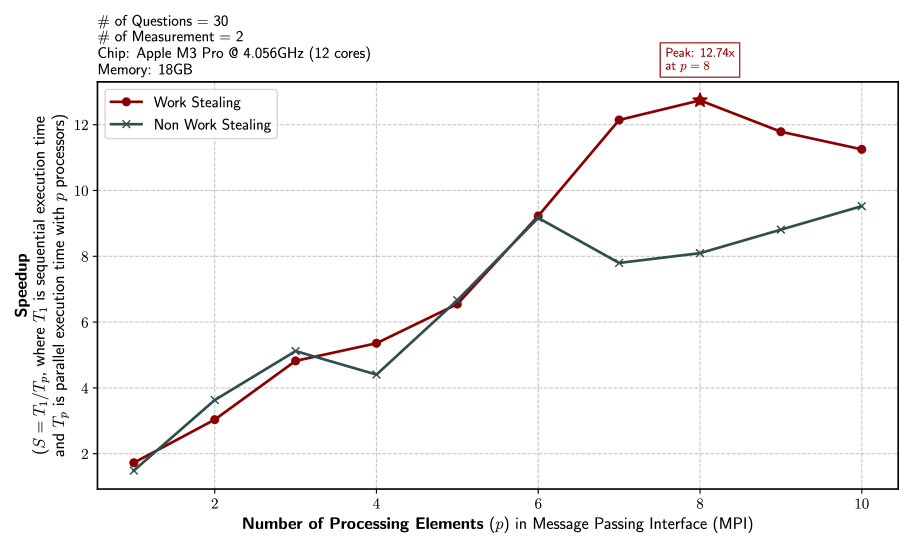
### Visual Description
## Line Graph: Speedup Comparison of Work Stealing vs. Non Work Stealing in MPI
### Overview
The image is a line graph comparing the speedup of two parallel computing strategies—Work Stealing and Non Work Stealing—across varying numbers of processing elements (p) in a Message Passing Interface (MPI). The graph uses a logarithmic scale for the y-axis (speedup) and a linear scale for the x-axis (number of processing elements). Key annotations include hardware specifications (Apple M3 Pro chip, 18GB memory) and a peak speedup of 12.74x for Work Stealing at p=8.
---
### Components/Axes
- **X-axis**: "Number of Processing Elements (p) in Message Passing Interface (MPI)"
- Scale: 1 to 10 (integer increments).
- **Y-axis**: "Speedup (S = T₁/Tₚ, where T₁ is parallel execution time and Tₚ is sequential execution time with p processors)"
- Scale: 0 to 14 (linear increments of 2).
- **Legend**:
- **Work Stealing**: Red circles (●).
- **Non Work Stealing**: Teal crosses (✖).
- **Annotations**:
- "Peak: 12.74x at p = 8" (top-right corner).
- Hardware details: "Chip: Apple M3 Pro @ 4.056GHz (12 cores), Memory: 18GB" (top-left).
---
### Detailed Analysis
#### Work Stealing (Red Line)
- **Trend**:
- Starts at 1.8x (p=1), increases steadily to 12.74x (p=8), then declines slightly to 11.2x (p=10).
- **Key Data Points**:
- p=1: 1.8x
- p=2: 3.0x
- p=3: 4.8x
- p=4: 5.3x
- p=5: 6.5x
- p=6: 9.2x
- p=7: 12.2x
- p=8: 12.74x (peak)
- p=9: 11.8x
- p=10: 11.2x
#### Non Work Stealing (Teal Line)
- **Trend**:
- Starts at 1.5x (p=1), rises to 9.0x (p=6), then plateaus with minor fluctuations.
- **Key Data Points**:
- p=1: 1.5x
- p=2: 3.6x
- p=3: 5.1x
- p=4: 4.4x (dip)
- p=5: 6.7x
- p=6: 9.0x
- p=7: 7.8x
- p=8: 8.1x
- p=9: 8.8x
- p=10: 9.5x
---
### Key Observations
1. **Work Stealing Dominates at Higher p**:
- Work Stealing achieves a **12.74x speedup** at p=8, far exceeding Non Work Stealing’s 8.1x.
- The peak occurs at p=8, after which speedup declines slightly (likely due to diminishing returns or overhead).
2. **Non Work Stealing Plateaus Early**:
- Speedup stabilizes around 9.0x after p=6, with minimal improvement at higher p values.
- A notable dip at p=4 (4.4x) suggests inefficiencies in task distribution.
3. **Scalability Differences**:
- Work Stealing scales more effectively with increasing p, while Non Work Stealing shows limited gains beyond p=6.
4. **Hardware Context**:
- The Apple M3 Pro’s 12 cores and 18GB memory likely influenced the observed scalability, with Work Stealing leveraging parallelism more efficiently.
---
### Interpretation
- **Work Stealing’s Advantage**:
The graph demonstrates that Work Stealing outperforms Non Work Stealing in parallel execution, particularly at higher p values. This suggests that Work Stealing’s dynamic task redistribution mechanism is more effective for MPI workloads.
- **Diminishing Returns**:
The slight decline in Work Stealing’s speedup after p=8 indicates potential overhead (e.g., communication costs or task granularity limitations).
- **Non Work Stealing’s Limitations**:
The plateau and dip in Non Work Stealing’s performance highlight its inability to fully utilize additional processors, possibly due to static task allocation or load imbalance.
- **Practical Implications**:
For MPI applications, Work Stealing is preferable for maximizing speedup, especially when scaling beyond 6 processors. However, optimizing task granularity and minimizing communication overhead could further enhance performance.
---
### Spatial Grounding & Verification
- **Legend Placement**: Top-left corner, clearly associating colors with labels.
- **Data Point Accuracy**:
- Red circles (Work Stealing) and teal crosses (Non Work Stealing) match the legend.
- Peak annotation (12.74x at p=8) aligns with the red line’s highest point.
### Content Details
- **Hardware Specifications**:
- Chip: Apple M3 Pro (4.056GHz, 12 cores).
- Memory: 18GB.
- **Experimental Parameters**:
- 30 questions, 2 measurements.
---
### Final Notes
The graph underscores the importance of task scheduling strategies in parallel computing. Work Stealing’s dynamic approach outperforms static methods, but further optimization is needed to sustain speedup beyond p=8. The data suggests that Work Stealing is the superior choice for MPI-based applications on modern multi-core systems.
</details>
Figure 10: Measured parallel speedup of KGoT task execution across varying numbers of MPI processes, under two scheduling strategies: with and without work stealing. Each task corresponds to a GAIA benchmark question, and each data point represents the average of 2 measurements on an Apple M3 Pro (12 cores @ 4.056GHz) and 18GB Memory. The dashed grey line indicates the expected theoretical speedup curve ( $S={2.2985}\times p$ ) based on the asynchronous optimizations applied to individual tasks. As previously discussed, acceleration strategies are categorized into (1) single-task optimizations—including asynchronous I/O scheduling and graph operation parallelism—and (2) batch-level parallelism using MPI-based distributed processing. The work-stealing variant consistently outperforms the non-stealing baseline by minimizing idle time and dynamically redistributing atomic question tasks across ranks. These combined strategies result in a 12.74 $\times$ speedup over the sequential baseline when using 8 processes.
### B.6 Examples of Noise Mitigation
We illustrate two examples of experiments with noise mitigation in KGoT. As before, we have replaced the specific values with placeholders to prevent the leakage of the GAIA benchmark tasks.
#### B.6.1 Irrelevance Removal
The first example is based on question 146 in the validation set of the GAIA benchmark:
On [date], an article by [author] was published in [publication]. This article mentions a team that produced a paper about their observations, linked at the bottom of the article. Find this paper. Under what NASA award number was the work performed by [researcher] supported by?
The example KG has been populated with data directly related to the answer as well as information that is relevant to the question but not necessary for answering it. Removing this extraneous data makes it easier for KGoT to reason about the KG content and extract data relevant to the answer. The data to be removed is marked in red.
Question 146: Initial state of the knowledge graph.
Nodes: Label: Funding {neo4j_id:0, properties:{’award_number’: ’[award_number]’}} Label: Researcher {neo4j_id:13, properties:{’name’: ’[researcher]’}} Label: Article {neo4j_id:11, properties:{’author’: ’[author]’, ’title’: ’[title]’, ’source’: ’[publication]’, ’publication_date’: ’[date]’}} Label: Paper {neo4j_id:12, properties:{’title’: ’[paper]’}} Relationships: Label: SUPPORTED_BY {source: {neo4j_id: 13, label: Researcher}, target: {neo4j_id: 0, label: Funding}, properties: {}} Label: LINKED_TO {source: {neo4j_id: 11, label: Article}, target: {neo4j_id: 12, label: Paper}, properties: {}} Label: INVOLVES {source: {neo4j_id: 12, label: Paper}, target: {neo4j_id: 13, label: Researcher}, properties: {}}
Question 146: Denoised knowledge graph.
Nodes: Label: Funding {neo4j_id:0, properties:{’award_number’: ’[award_number’}} Label: Researcher {neo4j_id:13, properties:{’name’: ’[researcher]’}} Relationships: Label: SUPPORTED_BY {source: {neo4j_id: 13, label: Researcher}, target: {neo4j_id: 0, label: Funding}, properties: {}}
#### B.6.2 Duplicate Removal
The second example is based on question 25 in the validation set of the GAIA benchmark:
I need to fact-check a citation. This is the citation from the bibliography: [citation1] And this is the in-line citation: Our relationship with the authors of the works we read can often be ”[quote]” ([citation2]). Does the quoted text match what is actually in the article? If Yes, answer Yes, otherwise, give me the word in my citation that does not match with the correct one (without any article).
In the example, the knowledge graph has been populated by two nearly identical nodes. The nodes and relationships marked for removal are shown in red.
Question 25: Initial state of the knowledge graph.
Nodes: Label: Quote {neo4j_id:22, properties:{’text’: ’[quote]’}} {neo4j_id:0, properties:{’text’: ’[near_identical_quote]’}} Label: Article {neo4j_id:3, properties:{’journal’: ’[journal]’, ’page_start’: [page_start], ’author’: ’[author]’, ’page_end’: [page_end], ’title’: ’[title]’, ’issue’: [issue], ’volume’: [volume], ’year’: [year], ’doi’: ’[year]’}} Relationships: Label: CONTAINS {source: {neo4j_id: 3, label: Article}, target: {neo4j_id: 22, label: Quote}, properties: {}} {source: {neo4j_id: 3, label: Article}, target: {neo4j_id: 0, label: Quote}, properties: {}}
Question 25: Denoised knowledge graph.
Nodes: Label: Quote {neo4j_id:22, properties:{’text’: ’[quote]’}} Label: Article {neo4j_id:3, properties:{’journal’: ’[journal]’, ’page_start’: [page_start], ’author’: ’[author]’, ’page_end’: [page_end], ’title’: ’[title]’, ’issue’: [issue], ’volume’: [volume], ’year’: [year], ’doi’: ’[year]’}} Relationships: Label: CONTAINS {source: {neo4j_id: 3, label: Article}, target: {neo4j_id: 22, label: Quote}, properties: {}}
## Appendix C Additional Details on Prompt Engineering
The primary objectives in our prompt design include improving decision-making processes, effectively managing complex scenarios, and allowing the LLM to adapt to diverse problem domains while maintaining high accuracy and efficiency. To achieve this, we leverage prompt engineering techniques, particularly the use of generic few-shot examples embedded in prompt templates. These examples guide the LLM in following instructions step by step (chain-of-thought) and reducing errors in generating graph queries with complex syntax.
### C.1 Prompt for Majority Voting
At the beginning of each iteration, the LLM Graph Executor uses the following prompt to decide whether the task can be solved with the current KG or if more information is needed. For system robustness, it is run multiple times with varying reasoning paths, and a majority vote (Self-Consistency) is applied to the responses. The prompt also explicitly instructs the model to decide on either the Solve or the Enhance pathway. By requiring the model to output an indicator (query_type = ”RETRIEVE” or ”INSERT”), we can programmatically branch the workflow allowing for control of reasoning pathways.
Graph Executor: Determine the next step
<task> You are a problem solver using a Neo4j database as a knowledge graph to solve a given problem. Note that the database may be incomplete. </task> <instructions> Understand the initial problem, the initial problem nuances, *ALL the existing data* in the database and the tools already called. Can you solve the initial problem using the existing data in the database? •
If you can solve the initial problem with the existing data currently in the database return the final answer and set the query_type to RETRIEVE. Retrieve only if the data is sufficient to solve the problem in a zero-shot manner. •
If the existing data is insufficient to solve the problem, return why you could not solve the initial problem and what is missing for you to solve it, and set query_type to INSERT. •
Remember that if you don’t have ALL the information requested, but only partial (e.g. there are still some calculations needed), you should continue to INSERT more data. </instructions> <examples> <examples_retrieve> <!-- In-context few-shot examples --> </examples_retrieve> <examples_insert> <!-- In-context few-shot examples --> </examples_insert> </examples> <initial_problem> {initial_query} </initial_problem> <existing_data> {existing_entities_and_relationships} </existing_data> <tool_calls_made> {tool_calls_made} </tool_calls_made>
### C.2 Prompts for Enhance Pathway
If the majority voting deems the current knowledge base as ”insufficient”, we enter the Enhance Pathway. To identify the knowledge gap, a list of reasons why the task is not solvable and what information is missing is synthesized by the LLM Graph Executor to a single, consistent description.
Graph Executor: Identify missing information
<task> You are a logic expert, your task is to determine why a given problem cannot be solved using the existing data in a Neo4j database. </task> <instructions> You are provided with a list of reasons. Your job is to combine these reasons into a single, coherent paragraph, ensuring that there are no duplicates. •
Carefully review and understand each reason provided. •
Synthesize the reasons into one unified text. </instructions> <list_of_reasons> {list_of_reasons} </list_of_reasons>
By providing both the current graph state and the identified missing information, the LLM Tool Executor defines context-aware tool calls to bridge the knowledge gap identified by the LLM Graph Executor.
Tool Executor: Define tool calls
<task> You are an information retriever tasked with populating a Neo4j database with the necessary information to solve the given initial problem. </task> <instructions> <! - - In-context few-shot examples covering the following aspects: 1. **Understand Requirements** 2. **Gather Information** 3. **Detailed Usage** 4. **Utilize Existing Data** 5. **Avoid Redundant Calls** 6. **Ensure Uniqueness of Tool Calls** 7. **Default Tool** 8. **Do Not Hallucinate** - - > </instructions> <initial_problem> {initial_query} </initial_problem> <existing_data> {existing_entities_and_relationships} </existing_data> <missing_information> {missing_information} </missing_information> <tool_calls_made> {tool_calls_made} </tool_calls_made>
Afterwards specialized tools such as a web browser or code executor are invoked to perform data retrieval from external resources. The newly acquired information is then used to enhance the KG. The LLM Graph Executor is asked to analyze the retrieved information in the context of the initial user query and the current state of the KG. The following prompt is carefully designed to guide the LLM to generate semantically correct and context-aware Cypher queries with concrete examples.
Graph Executor: Create Cypher for data ingestion
<task> You are a problem solver tasked with updating an incomplete Neo4j database used as a knowledge graph. You have just acquired new information that needs to be integrated into the database. </task> <instructions> <! - - In-context few-shot examples covering following aspects: 0. **Understand the Context** 1. **Use Provided New Information Only** 2. **No Calculations** 3. **Avoid Duplicates** 4. **Combine Operations with WITH Clauses** 5. **Group Related Queries** 6. **Omit RETURN Statements** 7. **Omit ID Usage** 8. **Merge Existing Nodes** 9. **Correct Syntax and Semantics** 10. **Use Correct Relationships** 11. **Escape Characters** - - > </instructions> <initial_problem> {initial_query} </initial_problem> <existing_data> {existing_entities_and_relationships} </existing_data> <missing_information> {missing_information} </missing_information> <new_information> {new_information} </new_information>
### C.3 Prompts for Solve Pathway
If majority voting confirms that the KG is sufficiently populated or the maximum iteration count has been reached, the system proceeds to the Solve Pathway. The iteratively refined KG serves as a reliable information source for LLMs to solve the initial query. To provide a robust response, we introduced two approaches, a query-based approach and Direct Retrieval, for knowledge extraction.
#### C.3.1 Graph Query Language for Knowledge Extraction
The query-based approach formulates a read query using an LLM, given the entire graph state and other relevant information such as the initial problem. The LLM-generated query is then executed on the graph database to return the final solution. Please note KGoT iteratively executes the solve operations collected from the majority voting.
In-context few-shot examples for query-based knowledge extraction
<examples_retrieve> <example_retrieve_1> Initial problem: Retrieve all books written by ‘‘J.K. Rowling’’. Existing entities: Author: [{{name: ‘‘J.K. Rowling’’, author_id: ‘‘A1’’}, {{name: ‘‘George R.R. Martin’’, author_id: ‘‘A2’’}}], Book: [{{title: ‘‘Harry Potter and the Philosopher’s Stone’’, book_id: ‘‘B1’’}, {{title: ‘‘Harry Potter and the Chamber of Secrets’’, book_id: ‘‘B2’’}, {{title: ‘‘A Game of Thrones’’, book_id: ‘‘B3’’}}] Existing relationships: (A1)-[:WROTE]->(B1), (A1)-[:WROTE]->(B2), (A2)-[:WROTE]->(B3) Solution: query: ’ MATCH (a:Author {{name: ‘‘J.K. Rowling’’}})-[:WROTE]->(b:Book) RETURN b.title AS book_title’ query_type: RETRIEVE </example_retrieve_1> <example_retrieve_2> Initial problem: List all colleagues of ‘‘Bob’’. Existing entities: Employee: [{{name: ‘‘Alice’’, employee_id: ‘‘E1’’}, {{name: ‘‘Bob’’, employee_id: ‘‘E2’’}, {{name: ‘‘Charlie’’, employee_id: ‘‘E3’’}}], Department: [{{name: ‘‘HR’’, department_id: ‘‘D1’’}, {{name: ‘‘Engineering’’, department_id: ‘‘D2’’}}] Existing relationships: (E1)-[:WORKS_IN]->(D1), (E2)-[:WORKS_IN]->(D1), (E3)-[:WORKS_IN]->(D2) Solution: query: ’ MATCH (e:Employee {name: "Bob"})-[:WORKS_IN]->(d:Department) <-[:WORKS_IN]-(colleague:Employee) WHERE colleague.name <> "Bob" RETURN colleague.name AS colleague_name ’ query_type: RETRIEVE </example_retrieve_2> </examples_retrieve>
If the attempt to fix a previously generated query fails or the query did not return any results, KGoT will try to regenerate the query from scratch by providing the initial problem statement, the existing data as well as additionally the incorrect query.
Graph Executor: Regeneration of Cypher query for data retrieval
<task> You are a problem solver expert in using a Neo4j database as a knowledge graph. Your task is to solve a given problem by generating a correct Cypher query. You will be provided with the initial problem, existing data in the database, and a previous incorrect Cypher query that returned an empty result. Your goal is to create a new Cypher query that returns the correct results. </task> <instructions> 1.
Understand the initial problem, the problem nuances and the existing data in the database. 2.
Analyze the provided incorrect query to identify why it returned an empty result. 3.
Write a new Cypher query to retrieve the necessary data from the database to solve the initial problem. You can use ALL Cypher/Neo4j functionalities. 4.
Ensure the new query is accurate and follows correct Cypher syntax and semantics. </instructions> <examples> <!-- In-context few-shot examples --> </examples> <initial_problem> {initial_query} </initial_problem> <existing_data> {existing_entities_and_relationships} </existing_data> <wrong_query> {wrong_query} </wrong_query>
#### C.3.2 Direct Retrieval for Knowledge Extraction
Direct Retrieval refers to directly asking the LLM to formulate the final solution, given the entire graph state, without executing any LLM-generated read queries on the graph storage.
In-context few-shot examples for DR-based knowledge extraction
<examples_retrieve> <example_retrieve_1> Initial problem: Retrieve all books written by ‘‘J.K. Rowling’’. Existing entities: Author: [{{name: ‘‘J.K. Rowling’’, author_id: ‘‘A1’’}, {{name: ‘‘George R.R. Martin’’, author_id: ‘‘A2’’}}], Book: [{{title: ‘‘Harry Potter and the Philosopher’s Stone’’, book_id: ‘‘B1’’}, {{title: ‘‘Harry Potter and the Chamber of Secrets’’, book_id: ‘‘B2’’}, {{title: ‘‘A Game of Thrones’’, book_id: ‘‘B3’’}}] Existing relationships: (A1)-[:WROTE]->(B1), (A1)-[:WROTE]->(B2), (A2)-[:WROTE]->(B3) Solution: query: ’Harry Potter and the Philosopher’s Stone, Harry Potter and the Chamber of Secrets’ query_type: RETRIEVE </example_retrieve_1> <example_retrieve_2> Initial problem: List all colleagues of ‘‘Bob’’. Existing entities: Employee: [{{name: ‘‘Alice’’, employee_id: ‘‘E1’’}, {{name: ‘‘Bob’’, employee_id: ‘‘E2’’}, {{name: ‘‘Charlie’’, employee_id: ‘‘E3’’}}], Department: [{{name: ‘‘HR’’, department_id: ‘‘D1’’}, {{name: ‘‘Engineering’’, department_id: ‘‘D2’’}}] Existing relationships: (E1)-[:WORKS_IN]->(D1), (E2)-[:WORKS_IN]->(D1), (E3)-[:WORKS_IN]->(D2) Solution: query: ’Alice’ query_type: RETRIEVE </example_retrieve_2> </examples_retrieve>
#### C.3.3 Formatting Final Solution
After successful knowledge extraction from the KG, we obtain a partial answer to our initial query. Next, we examine if further post-processing, such as intermediate calculation or formatting, needs to be performed. In the following prompt, we first detect if any unresolved calculation is required.
Solution formatting: Examine need for mathematical processing
<task> You are an expert in identifying the need for mathematical or probabilistic calculations in problem-solving scenarios. Given an initial query and a partial solution, your task is to determine whether the partial solution requires further mathematical or probabilistic calculations to arrive at a complete solution. You will return a boolean value: True if additional calculations are needed and False if they are not. </task> <instructions> •
Analyze the initial query and the provided partial solution. •
Identify any elements in the query and partial solution that suggest the further need for numerical analysis, calculations, or probabilistic reasoning. •
Consider if the partial solution includes all necessary numerical results or if there are unresolved numerical aspects. •
Return true if the completion of the solution requires more calculations, otherwise return false. •
Focus on the necessity for calculations rather than the nature of the math or probability involved. </instructions> <examples> <!-- In-context few-shot examples --> </examples> <initial_problem> {initial_query} </initial_problem> <partial_solution> {partial_solution} </partial_solution>
If any further mathematical processing is needed, the Python Code Tool is invoked to refine the current partial solution by executing an LLM-generated Python script. This ensures accuracy by leveraging the strength of LLMs in scripting. Moreover, it effectively avoids hallucinations by grounding outputs through verifiable and deterministic code computation.
Solution formatting: Apply additional mathematical processing
<task> You are a math and python expert tasked with solving a mathematical problem. </task> <instructions> To complete this task, follow these steps: 1. **Understand the Problem**: •
Carefully read and understand the initial problem and the partial solution. •
Elaborate on any mathematical calculations from the partial solution that are required to solve the initial problem. 2. **Perform Calculations**: •
Use the run_python_code Tool to perform any necessary mathematical calculations. •
Craft Python code that accurately calculates the required values based on the partial solution and the initial problem. •
Remember to add print statements to display the reasoning behind the calculations. •
**ALWAYS** add print statement for the final answer. 3. **Do Not Hallucinate**: •
**Do not invent information** that is not provided in the initial problem or the partial solution. •
**Do not perform calculations manually**; use the run_python_code Tool for all mathematical operations. </instructions> <initial_problem> {initial_query} </initial_problem> <partial_solution> {current_solution} </partial_solution>
To produce a single, consistent answer and format the final solution to the initial user query, we guide the LLM with a dedicated prompt.
Solution formatting: Parse the final solution
<task> You are a formatter and extractor. Your task is to combine partial solution from a database and format them according to the initial problem statement. </task> <instructions> 1.
Understand the initial problem, the problem nuances, the desired output, and the desired output format. 2.
Review the provided partial solution. 3.
Integrate and elaborate on the various pieces of information from the partial solution to produce a complete solution to the initial problem. Do not invent any new information. 4.
Your final answer should be a number OR as few words as possible OR a comma separated list of numbers and/or strings. 5.
ADDITIONALLY, your final answer MUST adhere to any formatting instructions specified in the original question (e.g., alphabetization, sequencing, units, rounding, decimal places, etc.) 6.
If you are asked for a number, express it numerically (i.e., with digits rather than words), don’t use commas, do not round the number unless directly specified, and DO NOT INCLUDE UNITS such as $ or USD or percent signs unless specified otherwise. 7.
If you are asked for a string, don’t use articles or abbreviations (e.g. for cities), unless specified otherwise. Don’t output any final sentence punctuation such as ’.’, ’!’, or ’?’. 8.
If you are asked for a comma separated list, apply the above rules depending on whether the elements are numbers or strings. </instructions> <examples> <!-- In-context few-shot examples --> </examples> <initial_problem> {initial_query} </initial_problem> <given_partial_solution> {partial_solution} </given_partial_solution>
### C.4 Prompt for LLM-Generated Syntax Error
In order to handle LLM-generated syntax errors, a retry mechanism is deployed to use the LLM to reformulate the graph query or code snippet, guided by specialized prompts tailored to the execution context. For Python code, the prompt guides the model to fix the code and update dependencies if needed, ensuring successful execution.
Error handling: Fix invalid Python code
<task> You are an expert Python programmer. You will be provided with a block of Python code, a list of required packages, and an error message that occurred during code execution. Your task is to fix the code so that it runs successfully and provide an updated list of required packages if necessary. </task> <instructions> 1.
Carefully analyze the provided Python code and the error message. 2.
Identify the root cause of the error. 3.
Modify the code to resolve the error. 4.
Update the list of required packages if any additional packages are needed. 5.
Ensure that the fixed code adheres to best practices where possible. </instructions> <rules> •
You must return both the fixed Python code and the updated list of required packages. •
Ensure the code and package list are in proper format. </rules> <examples> <!-- In-context few-shot examples --> </examples> <code> {code} </code> <required_modules> {required_modules} </required_modules> <error> {error} </error>
For Cypher queries, the prompt helps the model diagnose syntax or escaping issues based on the error log and returns a corrected version.
Error handling: Fix invalid Cypher query
<task> You are a Cypher expert, and you need to fix the syntax and semantic of a given incorrect Cypher query. </task> <instructions> Given the incorrect Cypher and the error log: 1.
Understand the source of the error (especially look out for wrongly escaped/not escaped characters). 2.
Correct the Cypher query 3.
Return the corrected Cypher query. </instructions> <wrong_cypher> {cypher_to_fix} </wrong_cypher> <error_log> {error_log} </error_log>
Both prompts are reusable across pathways and enforce minimal, well-scoped corrections grounded in the provided error context.
## Appendix D Additional Results
We plot the results from Figure 3 also as a Pareto front in Figure 11.
<details>
<summary>x20.png Details</summary>
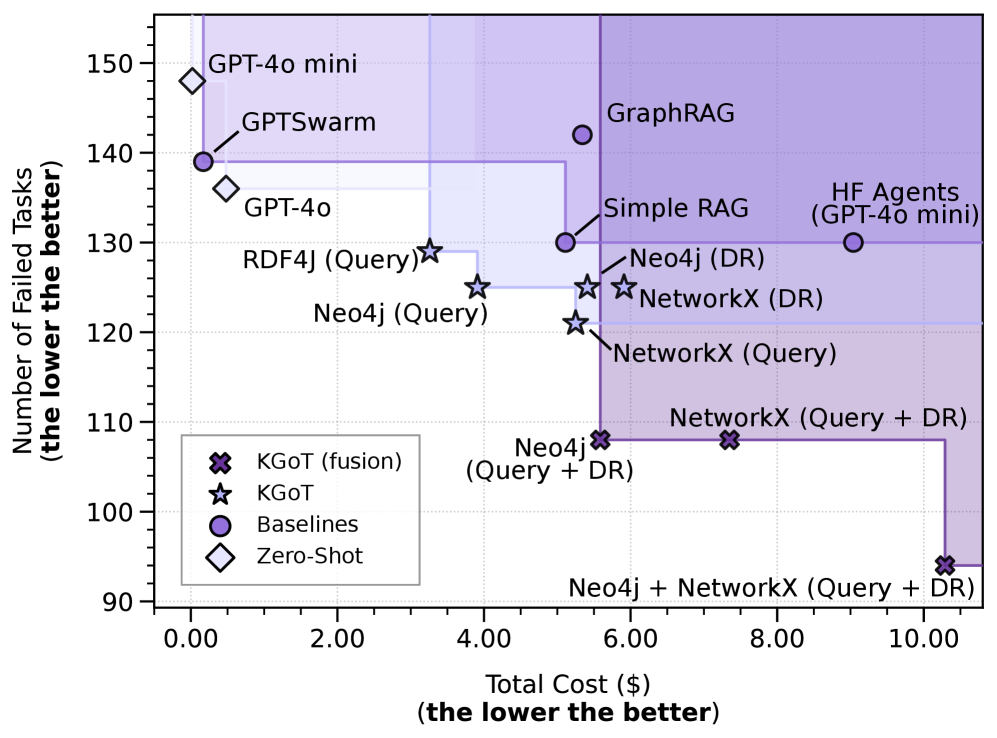
### Visual Description
## Scatter Plot: Performance vs. Cost Analysis
### Overview
This scatter plot compares the performance (number of failed tasks) and cost (total cost in dollars) of various AI/ML systems and baselines. Lower values on both axes indicate better performance and efficiency. The plot includes labeled data points for specific systems and color-coded categories.
### Components/Axes
- **X-axis (Total Cost $)**: Ranges from 0.00 to 10.00, with the note "(the lower the better)".
- **Y-axis (Number of Failed Tasks)**: Ranges from 90 to 150, with the note "(the lower the better)".
- **Legend**: Located in the bottom-left corner, with four categories:
- **KGoT (fusion)**: Purple crosses (×).
- **KGoT**: Purple stars (★).
- **Baselines**: Purple circles (●).
- **Zero-Shot**: Light purple diamonds (◆).
### Detailed Analysis
#### Data Points and Trends
1. **GPT-4o mini** (◆): Positioned at (0.5, 145), indicating very low cost but high failed tasks.
2. **GPT-4o** (◆): At (1.5, 135), slightly lower cost and fewer failed tasks than GPT-4o mini.
3. **RDF4J (Query)** (★): At (3.5, 125), moderate cost and improved performance.
4. **Neo4j (Query)** (★): At (4.5, 120), better performance than RDF4J.
5. **NetworkX (Query)** (★): At (5.5, 115), further improvement in performance.
6. **Neo4j (Query + DR)** (★): At (6.0, 110), higher cost but significantly lower failed tasks.
7. **NetworkX (Query + DR)** (★): At (7.0, 105), similar trend to Neo4j (Query + DR).
8. **HF Agents (GPT-4o mini)** (●): At (8.5, 130), high cost with moderate performance.
9. **Neo4j + NetworkX (Query + DR)** (×): At (10.5, 90), highest cost but lowest failed tasks.
#### Key Observations
- **Cost-Performance Trade-off**: As total cost increases, the number of failed tasks generally decreases. For example, HF Agents (GPT-4o mini) at $8.50 have 130 failed tasks, while Neo4j + NetworkX (Query + DR) at $10.50 has only 90 failed tasks.
- **Zero-Shot Methods**: Light purple diamonds (◆) like GPT-4o mini and GPT-4o are clustered in the top-left, indicating poor performance despite low cost.
- **KGoT (fusion) and Baselines**: Purple crosses (×) and circles (●) are spread across the plot, suggesting variability in performance and cost.
- **Outliers**: Neo4j + NetworkX (Query + DR) at (10.5, 90) is an outlier with the highest cost but best performance.
### Interpretation
The data highlights a clear trade-off between cost and performance. Systems with higher costs (e.g., HF Agents, Neo4j + NetworkX) achieve fewer failed tasks, but the marginal gains diminish as cost increases. Zero-Shot methods (◆) are inefficient, failing more tasks even at low costs. The KGoT (fusion) and Baselines (●) show mixed results, indicating potential for optimization. The plot suggests that investing in higher-cost systems may yield better performance, but the relationship is not linear, and some systems (e.g., Neo4j + NetworkX) may offer disproportionate benefits.
</details>
Figure 11: Pareto front plot of cost and error counts. We report results for answering 165 GAIA validation questions across different comparison targets, using the GPT-4o mini model with each baseline. For the Zero-Shot inference, we also include results for GPT-4o for comparison. Please note that we omit the results for Magentic-One and HF Agents (GPT-4o) as their high costs would heavily disturb the plot. DR means Direct Retrieval.
We also plot the relative improvements of KGoT over Hugging Face Agents and GPTSwarm respectively in Figure 12, which is based on the results shown in Figure 5.
<details>
<summary>x21.png Details</summary>
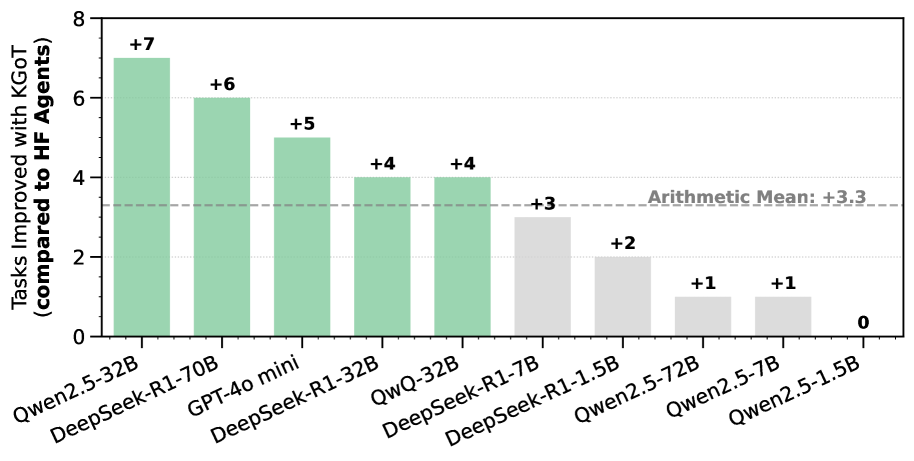
### Visual Description
## Bar Chart: Tasks Improved with HF Agents (compared to KGoT)
### Overview
The chart compares the performance improvement of various AI models when using HF (High-Fidelity) agents versus KGoT (Knowledge-Guided Optimization Techniques). The y-axis represents the number of tasks improved, while the x-axis lists different AI models. Green bars indicate positive improvements, gray bars show lower improvements, and a dashed line marks the arithmetic mean improvement of +3.3.
### Components/Axes
- **Title**: "Tasks Improved with HF Agents (compared to KGoT)"
- **X-axis (Categories)**:
- Qwen2.5-32B
- DeepSeek-R1-70B
- GPT-40 mini
- DeepSeek-R1-32B
- QwQ-32B
- DeepSeek-R1-1.7B
- DeepSeek-R1-1.5B
- Qwen2.5-72B
- Qwen2.5-7B
- Qwen2.5-1.5B
- **Y-axis (Values)**:
- Labeled "Tasks Improved with HF Agents (compared to KGoT)"
- Scale ranges from 0 to 8 in increments of 1.
- **Legend**: Not explicitly labeled, but colors are used to differentiate performance tiers:
- **Green**: Higher improvements (+4 to +7)
- **Gray**: Lower improvements (+0 to +3)
- **Arithmetic Mean**: A dashed horizontal line at +3.3.
### Detailed Analysis
- **Qwen2.5-32B**: Green bar with +7 tasks improved (highest value).
- **DeepSeek-R1-70B**: Green bar with +6 tasks improved.
- **GPT-40 mini**: Green bar with +5 tasks improved.
- **DeepSeek-R1-32B**: Green bar with +4 tasks improved.
- **QwQ-32B**: Green bar with +4 tasks improved.
- **DeepSeek-R1-1.7B**: Gray bar with +3 tasks improved.
- **DeepSeek-R1-1.5B**: Gray bar with +2 tasks improved.
- **Qwen2.5-72B**: Gray bar with +1 task improved.
- **Qwen2.5-7B**: Gray bar with +1 task improved.
- **Qwen2.5-1.5B**: Gray bar with 0 tasks improved (lowest value).
### Key Observations
1. **Performance Gradient**: Larger models (e.g., 32B, 70B) generally show higher task improvements, while smaller models (e.g., 1.5B, 1.7B) perform worse.
2. **Arithmetic Mean Context**: The dashed line at +3.3 indicates that models above this threshold (green bars) outperform the average, while those below (gray bars) underperform.
3. **Outlier**: Qwen2.5-1.5B shows no improvement (0 tasks), suggesting it may be the least effective model in this comparison.
4. **Color Coding**: Green bars dominate the upper half of the chart, while gray bars occupy the lower half, visually reinforcing the performance gradient.
### Interpretation
The data suggests that model size correlates with task improvement when using HF agents. Larger models (e.g., Qwen2.5-32B, DeepSeek-R1-70B) achieve significantly higher improvements compared to smaller models (e.g., Qwen2.5-1.5B). The arithmetic mean of +3.3 serves as a benchmark, highlighting that models above this line (green) are more effective than the average, while those below (gray) lag behind. The absence of improvement for Qwen2.5-1.5B raises questions about its architecture or training data suitability for the evaluated tasks. The color coding (green vs. gray) effectively communicates performance tiers, though an explicit legend would enhance clarity.
</details>
(a) Hugging Face Agents
<details>
<summary>x22.png Details</summary>
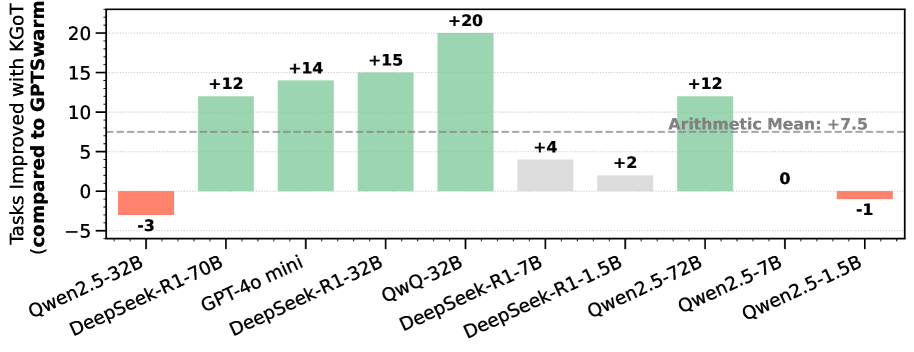
### Visual Description
## Bar Chart: Task Performance Comparison Between KGoT and GPTSwarm Models
### Overview
The chart compares task performance improvements (or degradations) when using KGoT versus GPTSwarm across various large language models (LLMs). Bars are color-coded to indicate improvement (+), no change (neutral), or degradation (-). An arithmetic mean line at +7.5 is included for reference.
### Components/Axes
- **X-axis**: LLMs (models) tested:
- Qwen2.5-32B
- DeepSeek-R1-70B
- GPT-4o mini
- DeepSeek-R1-32B
- QwQ-32B
- DeepSeek-R1-7B
- DeepSeek-R1-1.5B
- Qwen2.5-72B
- Qwen2.5-7B
- Qwen2.5-1.5B
- **Y-axis**: "Tasks Improved with KGoT (compared to GPTSwarm)" with values ranging from -5 to +20.
- **Legend** (right side):
- **Green**: "+Improved" (positive task improvement)
- **Gray**: "No change" (neutral performance)
- **Red**: "-Degraded" (task degradation)
- **Arithmetic Mean**: Dashed horizontal line at +7.5.
### Detailed Analysis
1. **Qwen2.5-32B**: Red bar (-3), indicating task degradation.
2. **DeepSeek-R1-70B**: Green bar (+12), significant improvement.
3. **GPT-4o mini**: Green bar (+14), strong improvement.
4. **DeepSeek-R1-32B**: Green bar (+15), highest improvement among smaller models.
5. **QwQ-32B**: Green bar (+20), largest improvement overall.
6. **DeepSeek-R1-7B**: Gray bar (+4), neutral performance.
7. **DeepSeek-R1-1.5B**: Gray bar (+2), minimal improvement.
8. **Qwen2.5-72B**: Green bar (+12), consistent improvement.
9. **Qwen2.5-7B**: Gray bar (0), no change.
10. **Qwen2.5-1.5B**: Red bar (-1), slight degradation.
### Key Observations
- **Positive Trends**: 6/10 models show improvement (green bars), with QwQ-32B (+20) and DeepSeek-R1-32B (+15) leading.
- **Negative Outliers**: Qwen2.5-32B (-3) and Qwen2.5-1.5B (-1) underperform.
- **Neutral Performance**: Three models (DeepSeek-R1-7B, DeepSeek-R1-1.5B, Qwen2.5-7B) show no change or minimal improvement.
- **Mean Context**: The arithmetic mean (+7.5) suggests moderate average improvement, but outliers skew the distribution.
### Interpretation
The data demonstrates that KGoT generally enhances task performance compared to GPTSwarm, particularly for larger models like QwQ-32B and DeepSeek-R1-32B. However, smaller models (e.g., Qwen2.5-32B, Qwen2.5-1.5B) exhibit degradation, suggesting KGoT’s effectiveness may depend on model architecture or scale. The neutral results for mid-sized models (e.g., DeepSeek-R1-7B) highlight variability in KGoT’s impact. The arithmetic mean (+7.5) underscores an overall positive trend but masks significant disparities between models. This analysis implies KGoT could be prioritized for high-performing models while requiring further optimization for smaller architectures.
</details>
(b) GPTSwarm
Figure 12: Relative improvement of KGoT over Hugging Face Agents (left) and GPTSwarm (right) on the GAIA validation set using various LLM models.
Table 2: Comparison of KGoT with other current state-of-the-art open-source agents on the GAIA benchmark. We provide both the absolute (number of solved tasks) and relative (percentage) results. The baseline data on the test set is obtained through the leaderboard. We highlight the best performing scheme in a given category in bold. The validation set consists of 165 tasks in total (53 in level 1, 86 in level 2 and 26 in level 3), whereas the test set contains 301 tasks (93 in level 1, 159 in level 2 and 49 in level 3). DR stands for Direct Retrieval.
| | | Absolute | Relative | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Agents | Model | All | L1 | L2 | L3 | Avg. | L1 | L2 | L3 |
| Test Set | | | | | | | | | |
| GPTSwarm | GPT-4o mini | 33 | 15 | 15 | 3 | 10.96 | 16.13 | 9.43 | 6.12 |
| Magentic-One | GPT-4o mini | 43 | 22 | 18 | 3 | 14.29 | 23.66 | 11.32 | 6.12 |
| TapeAgent | GPT-4o mini | 66 | 28 | 35 | 3 | 21.93 | 30.11 | 22.01 | 6.12 |
| Hugging Face Agents | GPT-4o mini | 68 | 30 | 34 | 4 | 22.59 | 32.26 | 21.38 | 8.16 |
| KGoT (fusion) | GPT-4o mini | 73 | 33 | 36 | 4 | 24.25 | 35.48 | 22.64 | 8.16 |
| Validation Set | | | | | | | | | |
| Simple RAG | GPT-4o mini | 35 | 18 | 15 | 2 | 21.21 | 33.96 | 17.44 | 7.69 |
| GraphRAG | GPT-4o mini | 23 | 10 | 13 | 0 | 13.94 | 18.87 | 15.12 | 0.00 |
| Magentic-One | GPT-4o mini | 31 | 13 | 18 | 0 | 18.79 | 24.53 | 20.93 | 0.00 |
| No KG (Single Run #1) | GPT-4o mini | 30 | 14 | 14 | 2 | 18.18 | 26.42 | 16.28 | 7.69 |
| No KG (Single Run #2) | GPT-4o mini | 33 | 17 | 16 | 0 | 20.00 | 32.08 | 18.60 | 0.00 |
| No KG (Fusion) | GPT-4o mini | 40 | 18 | 20 | 2 | 24.24 | 33.96 | 23.26 | 7.69 |
| KGoT (Neo4j + DR) | GPT-4o mini | 40 | 21 | 16 | 3 | 24.24 | 39.62 | 18.60 | 11.54 |
| KGoT (NetworkX + Query) | GPT-4o mini | 44 | 21 | 21 | 2 | 26.67 | 39.62 | 24.42 | 7.69 |
| KGoT (NetworkX + DR) | GPT-4o mini | 40 | 20 | 18 | 2 | 24.24 | 37.74 | 20.93 | 7.69 |
| KGoT (RDF4J + Query) | GPT-4o mini | 36 | 20 | 15 | 1 | 21.82 | 37.74 | 17.44 | 3.85 |
| KGoT (fusion) (Neo4j; Query + DR) | GPT-4o mini | 57 | 29 | 24 | 4 | 34.55 | 54.72 | 27.91 | 15.38 |
| KGoT (fusion) (NetworkX; Query + DR) | GPT-4o mini | 57 | 27 | 28 | 2 | 34.55 | 50.94 | 32.56 | 7.69 |
| KGoT (fusion) (Neo4j + NetworkX; Query + DR) | GPT-4o mini | 71 | 34 | 33 | 4 | 43.03 | 64.15 | 38.37 | 15.38 |
| Zero-Shot | GPT-4o mini | 17 | 4 | 13 | 0 | 10.30 | 7.55 | 15.12 | 0.00 |
| Zero-Shot | GPT-4o | 29 | 10 | 17 | 2 | 17.58 | 18.87 | 19.77 | 7.69 |
| Zero-Shot | Qwen2.5-1.5B | 3 | 2 | 1 | 0 | 1.81 | 3.77 | 1.16 | 0.00 |
| Zero-Shot | Qwen2.5-7B | 9 | 4 | 5 | 0 | 5.45 | 7.55 | 5.81 | 0.00 |
| Zero-Shot | Qwen2.5-32B | 15 | 7 | 8 | 0 | 9.09 | 13.21 | 9.30 | 0.00 |
| Zero-Shot | Qwen2.5-72B | 19 | 6 | 13 | 0 | 11.52 | 11.32 | 15.12 | 0.00 |
| Zero-Shot | QwQ-32B | 0 | 0 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 |
| Zero-Shot | DeepSeek-R1-1.5B | 5 | 3 | 2 | 0 | 3.03 | 5.66 | 2.33 | 0.00 |
| Zero-Shot | DeepSeek-R1-7B | 13 | 8 | 5 | 0 | 7.88 | 15.09 | 5.81 | 0.00 |
| Zero-Shot | DeepSeek-R1-32B | 14 | 8 | 6 | 0 | 8.48 | 15.09 | 6.98 | 0.00 |
| Zero-Shot | DeepSeek-R1-70B | 20 | 9 | 10 | 1 | 12.12 | 16.98 | 11.63 | 3.85 |
| GPTSwarm | GPT-4o mini | 26 | 13 | 13 | 0 | 15.76 | 24.53 | 15.12 | 0.00 |
| GPTSwarm | Qwen2.5-1.5B | 5 | 4 | 1 | 0 | 3.03 | 7.55 | 1.16 | 0.00 |
| GPTSwarm | Qwen2.5-7B | 12 | 8 | 4 | 0 | 7.27 | 15.09 | 4.65 | 0.00 |
| GPTSwarm | Qwen2.5-32B | 29 | 15 | 14 | 0 | 17.58 | 28.30 | 16.28 | 0.00 |
| GPTSwarm | Qwen2.5-72B | 27 | 13 | 14 | 0 | 16.36 | 24.53 | 16.28 | 0.00 |
| GPTSwarm | QwQ-32B | 0 | 0 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 |
| GPTSwarm | DeepSeek-R1-1.5B | 0 | 0 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 |
| GPTSwarm | DeepSeek-R1-7B | 2 | 0 | 2 | 0 | 1.21 | 0.00 | 2.33 | 0.00 |
| GPTSwarm | DeepSeek-R1-32B | 6 | 3 | 3 | 0 | 3.64 | 5.66 | 3.49 | 0.00 |
| GPTSwarm | DeepSeek-R1-70B | 10 | 5 | 5 | 0 | 6.06 | 9.43 | 5.81 | 0.00 |
| Hugging Face Agents | GPT-4o mini | 35 | 14 | 20 | 1 | 21.21 | 26.42 | 23.26 | 3.85 |
| Hugging Face Agents | GPT-4o | 55 | 22 | 31 | 2 | 33.33 | 41.51 | 36.05 | 7.69 |
| Hugging Face Agents | Qwen2.5-1.5B | 4 | 2 | 2 | 0 | 2.42 | 3.77 | 2.33 | 0.00 |
| Hugging Face Agents | Qwen2.5-7B | 11 | 7 | 4 | 0 | 6.66 | 13.21 | 4.65 | 0.00 |
| Hugging Face Agents | Qwen2.5-32B | 19 | 10 | 9 | 0 | 11.52 | 18.87 | 11.63 | 0.00 |
| Hugging Face Agents | Qwen2.5-72B | 38 | 16 | 22 | 0 | 23.03 | 30.19 | 25.58 | 0.00 |
| Hugging Face Agents | QwQ-32B | 16 | 9 | 7 | 0 | 9.70 | 16.98 | 8.14 | 0.00 |
| Hugging Face Agents | DeepSeek-R1-1.5B | 0 | 0 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 |
| Hugging Face Agents | DeepSeek-R1-7B | 3 | 2 | 1 | 0 | 1.81 | 3.77 | 1.16 | 0.00 |
| Hugging Face Agents | DeepSeek-R1-32B | 17 | 9 | 7 | 1 | 10.30 | 16.98 | 8.14 | 3.85 |
| Hugging Face Agents | DeepSeek-R1-70B | 16 | 9 | 6 | 1 | 9.70 | 16.98 | 6.98 | 3.85 |
| KGoT (Neo4j + Query) | GPT-4o mini | 40 | 21 | 18 | 1 | 24.24 | 39.62 | 20.93 | 3.85 |
| KGoT (Neo4j + Query) | Qwen2.5-1.5B | 4 | 3 | 1 | 0 | 2.42 | 5.66 | 1.16 | 0.00 |
| KGoT (Neo4j + Query) | Qwen2.5-7B | 12 | 7 | 5 | 0 | 7.27 | 13.21 | 5.81 | 0.00 |
| KGoT (Neo4j + Query) | Qwen2.5-32B | 26 | 12 | 14 | 0 | 15.76 | 22.64 | 16.28 | 0.00 |
| KGoT (Neo4j + Query) | Qwen2.5-72B | 39 | 18 | 21 | 0 | 23.64 | 33.96 | 24.42 | 0.00 |
| KGoT (Neo4j + Query) | QwQ-32B | 20 | 11 | 9 | 0 | 12.12 | 20.75 | 10.47 | 0.00 |
| KGoT (Neo4j + Query) | DeepSeek-R1-1.5B | 2 | 1 | 1 | 0 | 1.21 | 1.89 | 1.16 | 0.00 |
| KGoT (Neo4j + Query) | DeepSeek-R1-7B | 6 | 3 | 3 | 0 | 3.64 | 5.66 | 3.49 | 0.00 |
| KGoT (Neo4j + Query) | DeepSeek-R1-32B | 21 | 12 | 9 | 0 | 12.73 | 22.64 | 10.47 | 0.00 |
| KGoT (Neo4j + Query) | DeepSeek-R1-70B | 22 | 11 | 10 | 1 | 13.33 | 20.75 | 11.63 | 3.85 |
### D.1 SimpleQA Results
Table 3: Comparison of KGoT, HF Agents and GPTSwarm on a subset of SimpleQA as well as the results for KGoT on the full benchmark. We highlight the best performing scheme in given category in bold. Model: GPT-4o mini.
| | | Not | | Correct | | | Cost per |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Correct | attempted | Incorrect | given at- | | Total | solved | |
| Framework | (%) | (%) | (%) | tempted (%) | F-score | cost ($) | task ($) |
| GPTSwarm | 53.8106 | 6.2356 | 39.9538 | 57.3892 | 55.5 | 0.2159 | 0.00092660 |
| HF Agents | 66.0508 | 18.0139 | 15.9353 | 80.5634 | 72.6 | 16.7117 | 0.05843265 |
| KGoT | 73.2102 | 1.6166 | 25.1732 | 74.4131 | 73.8 | 5.6432 | 0.01780182 |
| KGoT (Full) | 70.3421 | 2.0342 | 27.8548 | 71.8027 | 71.1 | 59.1538 | 0.01943931 |
Table 4: F1-score comparison of KGoT, OpenAI and Claude models on SimpleQA. OpenAI and Claude results were taken from the official repository (OpenAI, 2025). Model for KGoT: GPT-4o mini.
| Reasoning Models | F1-score | Assistant Models | F1-score |
| --- | --- | --- | --- |
| o1 | 42.6 | gpt-4.1-2025-04-14 | 41.6 |
| o1-preview | 42.4 | gpt-4.1-mini-2025-04-14 | 16.8 |
| o3-high | 48.6 | gpt-4.1-nano-2025-04-14 | 7.6 |
| o3 | 49.4 | gpt-4o-2024-11-20 | 38.8 |
| o3-low | 49.4 | gpt-4o-2024-08-06 | 40.1 |
| o1-mini | 7.6 | gpt-4o-2024-05-13 | 39.0 |
| o3-mini-high | 13.8 | gpt-4o-mini-2024-07-18 | 9.5 |
| o3-mini | 13.4 | gpt-4.5-preview-2025-02-27 | 62.5 |
| o3-mini-low | 13.0 | gpt-4-turbo-2024-04-09 | 24.2 |
| o4-mini-high | 19.3 | Claude 3.5 Sonnet | 28.9 |
| o4-mini | 20.2 | Claude 3 Opus | 23.5 |
| o4-mini-low | 20.2 | | |
| KGoT | 71.1 | | |
### D.2 Impact from Various Design Decisions
Table 5: Analysis of different design decisions and tool sets in KGoT. “ ST ” stands for the type of the solve operation and pathway (“ GQ ”: graph query, “ DR ”: Direct Retrieval), “ PF ” for the prompt format (“ MD ”: Markdown) and “ merged ” stands for a combination of the original KGoT tools and the Hugging Face Agents tools.
| Configuration | Metrics | | | | |
| --- | --- | --- | --- | --- | --- |
| Tools | ST | PF | Solved | Time (h) | Cost |
| HF | DR | XML | 37 | 11.87 | $7.84 |
| HF | GQ | MD | 33 | 9.70 | $4.28 |
| merged | GQ | XML | 31 | 10.62 | $5.43 |
| HF | GQ | XML | 30 | 13.02 | $4.90 |
| original KGoT | GQ | XML | 27 | 27.57 | $6.85 |
We explored different tool sets, with selected results presented in Table 5. Initially, we examined the limitations of our original tools and subsequently integrated the complete Hugging Face Agents tool set into the KGoT framework, which led to improvements in accuracy, runtime, and cost efficiency. A detailed analysis allowed us to merge the most effective components from both tool sets into an optimized hybrid tool set, further enhancing accuracy and runtime while only moderately increasing costs. Key improvements include a tighter integration between the ExtractZip tool and the Text Inspector tool, which now supports Markdown, as well as enhancements to the Surfer Agent, incorporating a Wikipedia tool and augmenting viewpoint segmentation with full-page summarization. This optimized tool set was used for all subsequent experiments.
We further evaluated different prompt formats in the initial iterations of KGoT. While our primary format was XML-based, we conducted additional tests using Markdown. Initial experiments with the Hugging Face Agents tool set (see Table 5) combined with Markdown and GPT-4o mini yielded improved accuracy, reduced runtime, and lower costs. However, these results were not consistently reproducible with GPT-4o. Moreover, Markdown-based prompts interfered with optimizations such as Direct Retrieval, ultimately leading us to retain the XML-based format.
<details>
<summary>x23.png Details</summary>
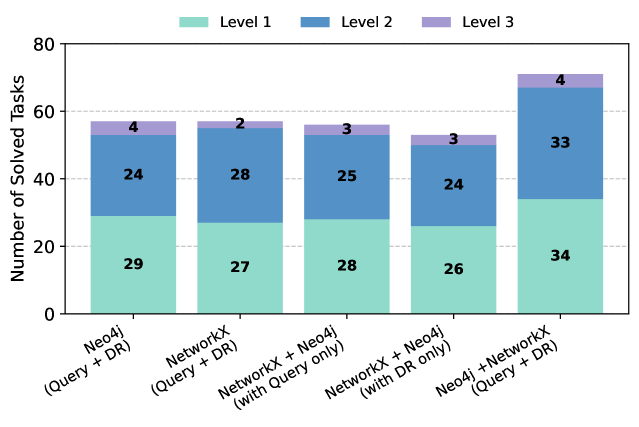
### Visual Description
## Bar Chart: Number of Solved Tasks by Algorithm and Level
### Overview
The chart compares the number of solved tasks across five algorithmic configurations (e.g., "Neo4j (Query + DR)", "NetworkX (Query + DR)") and three task difficulty levels (Level 1, Level 2, Level 3). Bars are stacked vertically, with colors representing task levels: green (Level 1), blue (Level 2), purple (Level 3). The y-axis ranges from 0 to 80, and the x-axis lists algorithmic configurations.
### Components/Axes
- **X-Axis**: Five algorithmic configurations:
1. Neo4j (Query + DR)
2. NetworkX (Query + DR)
3. NetworkX + Neo4j (with Query only)
4. NetworkX + Neo4j (with DR only)
5. Neo4j + NetworkX (Query + DR)
- **Y-Axis**: Number of solved tasks (0–80, increments of 20).
- **Legend**: Located at the top, with:
- Green = Level 1
- Blue = Level 2
- Purple = Level 3
### Detailed Analysis
| Configuration | Level 1 (Green) | Level 2 (Blue) | Level 3 (Purple) | Total |
|--------------------------------------|-----------------|----------------|------------------|-------|
| Neo4j (Query + DR) | 29 | 24 | 4 | 57 |
| NetworkX (Query + DR) | 27 | 28 | 2 | 57 |
| NetworkX + Neo4j (with Query only) | 28 | 25 | 3 | 56 |
| NetworkX + Neo4j (with DR only) | 26 | 24 | 3 | 53 |
| Neo4j + NetworkX (Query + DR) | 34 | 33 | 4 | 71 |
### Key Observations
- **Highest Total**: The "Neo4j + NetworkX (Query + DR)" configuration solves the most tasks (71), significantly outperforming others.
- **Level 1 Dominance**: Level 1 tasks (green) consistently account for the largest portion of solved tasks across all configurations.
- **Level 3 Anomaly**: Level 3 tasks (purple) are the least solved in all cases, with values ranging from 2–4.
- **Synergy Effect**: The combined "Neo4j + NetworkX" configuration shows a marked increase in solved tasks compared to individual algorithms.
### Interpretation
The data suggests that combining Neo4j and NetworkX (Query + DR) maximizes task-solving efficiency, likely due to complementary strengths in query processing and data retrieval. Level 1 tasks are the easiest, as they dominate across all configurations. Level 3 tasks remain the most challenging, with minimal progress even in the most advanced configuration. The synergy between Neo4j and NetworkX highlights potential benefits of hybrid algorithmic approaches, though the reasons for this (e.g., optimized resource allocation, parallel processing) are not explicitly stated in the chart. The consistency of Level 3 underperformance across all configurations warrants further investigation into task complexity or algorithmic limitations.
</details>
Figure 13: Comparison of different fusion types in respect to the task solve operation as well as the graph backend type. We report results for answering 165 GAIA validation questions across different comparison targets. DR stands for Direct Retrieval. Model: GPT-4o mini.
Graph Backend vs. Task Solve Operation We provide more detailed results in Figure 13, studying the performance of the following configurations: NetworkX + Neo4j (with query only) and NetworkX + Neo4j (with DR only) as well as Neo4j (query + DR) and NetworkX (query + DR). Overall, the fusion of backends (with DR only) offers smaller advantages than other types of fusion. This indicates that different graph querying languages have different strengths and their fusion comes with the largest combined advantage.
### D.3 Runtime
We provide a runtime overview of running KGoT on the validation set of the GAIA benchmark with GPT4o-mini, Neo4j and query-based retrieval in Figure 14. The right part follows the categorization in Appendix C. We provide a more detailed analysis of the runtime in Figure 17.
<details>
<summary>x24.png Details</summary>
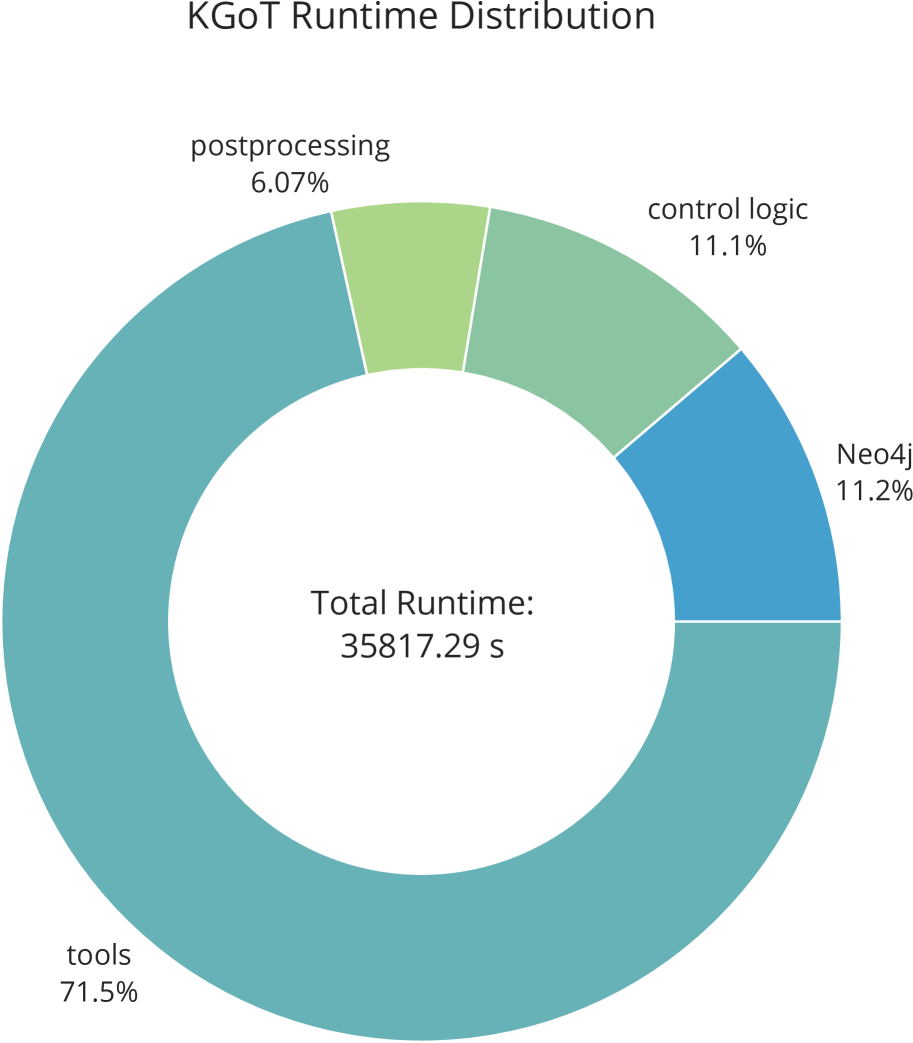
### Visual Description
## Pie Chart: KGoT Runtime Distribution
### Overview
A circular pie chart visualizing the distribution of runtime across four categories: "tools," "Neo4j," "control logic," and "postprocessing." The total runtime is explicitly labeled as **35817.29 seconds**. Each slice is color-coded and labeled with its percentage contribution.
### Components/Axes
- **Title**: "KGoT Runtime Distribution" (top-center).
- **Total Runtime**: Centered text: "Total Runtime: 35817.29 s".
- **Legend**: Integrated into the chart via color-coded slices with labels and percentages.
- **Slices**:
- **tools**: Teal (#008080), 71.5%.
- **Neo4j**: Blue (#0000FF), 11.2%.
- **control logic**: Green (#00FF00), 11.1%.
- **postprocessing**: Light green (#90EE90), 6.07%.
### Detailed Analysis
- **tools**: Dominates the chart, occupying the largest slice (71.5%). Positioned at the bottom-left quadrant.
- **Neo4j**: Second-largest slice (11.2%), located in the upper-right quadrant.
- **control logic**: Third-largest slice (11.1%), adjacent to Neo4j in the upper-right quadrant.
- **postprocessing**: Smallest slice (6.07%), positioned at the top-right quadrant.
### Key Observations
1. **tools** accounts for **~71.5%** of the total runtime, far exceeding other categories.
2. **Neo4j** and **control logic** have nearly identical contributions (~11.1–11.2%).
3. **postprocessing** is the smallest contributor at **6.07%**.
4. Percentages sum to 100% (71.5 + 11.2 + 11.1 + 6.07 = 99.87% due to rounding).
### Interpretation
The chart highlights that **tools** consume the majority of runtime, suggesting they are the most resource-intensive component. The near-equal contributions of **Neo4j** and **control logic** indicate balanced but secondary workloads. **Postprocessing** is the least significant. This distribution could imply optimization opportunities for the "tools" category, which may be a bottleneck. The slight rounding discrepancy in percentages (99.87% vs. 100%) is negligible and likely due to decimal truncation.
</details>
<details>
<summary>x25.png Details</summary>
### Visual Description
## Pie Chart: KGoT Runtime Distribution
### Overview
The chart visualizes the distribution of runtime across five components of the KGoT system, totaling **35,817.29 seconds**. The largest portion of runtime is allocated to "tool invocations," followed by "system robustness," "graph executor," "solution formatting," and "tool executor." Colors differentiate the components, with shades of blue and green used for clarity.
### Components/Axes
- **Title**: "KGoT Runtime Distribution"
- **Total Runtime**: 35,817.29 seconds (central text)
- **Legend**:
- **Colors**:
- Dark blue: "tool invocations"
- Medium blue: "system robustness"
- Teal: "graph executor"
- Green: "solution formatting"
- Light green: "tool executor"
- **Data Series**:
- Labels and percentages are embedded in each slice.
### Detailed Analysis
1. **Tool Invocations** (71.5%):
- Dominates the chart, occupying the largest slice (dark blue).
- Corresponds to **25,633.5 seconds** (71.5% of 35,817.29).
2. **System Robustness** (13.6%):
- Second-largest slice (medium blue), representing **4,811.2 seconds**.
3. **Graph Executor** (7.06%):
- Teal slice, accounting for **2,528.5 seconds**.
4. **Solution Formatting** (6.07%):
- Green slice, representing **2,173.5 seconds**.
5. **Tool Executor** (1.76%):
- Smallest slice (light green), contributing **611.5 seconds**.
### Key Observations
- **Tool invocations** consume over **70%** of total runtime, indicating a critical area for optimization.
- "System robustness" and "graph executor" together account for ~20% of runtime, suggesting secondary focus areas.
- "Tool executor" is the smallest contributor (<2%), potentially indicating inefficiency or underutilization.
### Interpretation
The data highlights that **tool invocations** are the primary runtime bottleneck, consuming the majority of processing time. This suggests that optimizing tool invocation mechanisms (e.g., reducing overhead, parallelizing tasks) could significantly improve overall system performance. The smaller contributions from "graph executor" and "solution formatting" imply these components are relatively efficient but may still offer marginal gains. The minimal runtime for "tool executor" raises questions about its role—whether it is intentionally lightweight or underutilized. The chart underscores the need for targeted optimization in high-impact areas to achieve runtime efficiency.
</details>
Figure 14: Different runtime categorizations of the same data. Graph storage: Neo4j. Retrieval type: query. Model: GPT-4o mini.
### D.4 Compute Resources
Because of the long runtime, we executed most experiments using the OpenAI API as an external resource on server compute nodes containing a AMD EPYC 7742 CPU with 128 cores running at 2.25GHz, with a total memory of 256GB. However when the LLM is called as an external resource, KGoT is able to run on commodity hardware with minimal effects on runtime.
Our experiments with locally run LLMs were executed with compute nodes containing 4x NVIDIA GH200, a respective GPU memory of 96GB, and a total memory of 896GB. In these cases, the minimum hardware requirements are dictated by the resources needed to run each LLM locally.
High-performance & scalability experiments were performed on an Apple M3 Pro with 12 cores at 4.056GHz and a total memory of 18GB.
### D.5 GAIA Result Visualizations
We also implemented various automatic scripts that plot various aspects once a GAIA run is finished. In the following we provide example plots for Neo4j with query retrieval.
We provide a breakdown for each level of the GAIA benchmark into the categories that KGoT’s answers for the tasks fall into in Figure 15. We measure the runtime and costs of the various components of KGoT and illustrate them in Figure 17. We also provide insights into the tool usage, starting with the number of tasks for which a specific tools is used and whether that task was successful or not (see Figure 16). A more detailed analysis into the tool selection is provided in the plots of Figures 18 and 19 as well as the number of times the tools are used in Figure 20.
We provide now a brief explanation of the more opaque function names listed in Figure 17.
- Any function marked as not logged refers to function or tool calls that do not incur an LLM-related cost or where usage costs are logged within the tool itself.
- WebSurfer.forward submits a query to SerpApi.
- Define Cypher query given new information constructs a Cypher insert query based on newly gathered information.
- Fix JSON corrects malformed or invalid JSON for services like Neo4j.
- Define forced retrieve queries generates a Cypher retrieval query when the maximum number of iterations is reached.
- Generate forced solution generates a solution based on the state of the knowledge graph if no viable solution has been parsed after a Cypher retrieve or if the forced retrievals fails after exhausting all iterations.
<details>
<summary>figures/all_plot_all_stats.png Details</summary>
### Visual Description
## Bar Chart: Rate (%) by Level
### Overview
The chart displays the distribution of response rates (in percentages) across three levels (1, 2, 3) for six categories: Correct, Correct forced, Close call, Wrong forced, Other error, and Wrong. The y-axis represents the rate (%), and the x-axis represents the levels. Each bar is color-coded according to the legend on the left.
### Components/Axes
- **Y-axis**: Rate (%) from 0% to 100% in increments of 20%.
- **X-axis**: Levels labeled as "1", "2", and "3".
- **Legend**:
- Green: Correct
- Light blue: Correct forced
- Dark blue: Close call
- Yellow: Wrong forced
- Orange: Other error
- Red: Wrong
### Detailed Analysis
#### Level 1
- **Correct**: 37% (green bar, 20/53 total)
- **Correct forced**: 1% (light blue bar, 1/53 total)
- **Close call**: 0% (dark blue bar, 0/53 total)
- **Wrong forced**: 1% (yellow bar, 1/53 total)
- **Other error**: 3% (orange bar, 2/53 total)
- **Wrong**: 54% (red bar, 29/53 total)
#### Level 2
- **Correct**: 20% (green bar, 18/86 total)
- **Correct forced**: 0% (light blue bar, 0/86 total)
- **Close call**: 0% (dark blue bar, 0/86 total)
- **Wrong forced**: 5% (yellow bar, 5/86 total)
- **Other error**: 0% (orange bar, 0/86 total)
- **Wrong**: 73% (red bar, 63/86 total)
#### Level 3
- **Correct**: 3% (green bar, 3/26 total)
- **Correct forced**: 0% (light blue bar, 0/26 total)
- **Close call**: 0% (dark blue bar, 0/26 total)
- **Wrong forced**: 3% (yellow bar, 1/26 total)
- **Other error**: 0% (orange bar, 0/26 total)
- **Wrong**: 92% (red bar, 24/26 total)
### Key Observations
1. **Wrong responses dominate**: The "Wrong" category (red bars) increases sharply from 54% (Level 1) to 73% (Level 2) to 92% (Level 3), indicating a significant rise in incorrect answers as the level increases.
2. **Correct responses decline**: The "Correct" category (green bars) decreases from 37% (Level 1) to 20% (Level 2) to 3% (Level 3), suggesting lower accuracy at higher levels.
3. **Minimal "Correct forced" and "Close call"**: These categories (light blue and dark blue bars) are consistently near 0% across all levels, except for minor 1% in Level 1.
4. **Other error only in Level 1**: The "Other error" category (orange bar) appears only in Level 1 at 3%, with no occurrences in Levels 2 and 3.
5. **Wrong forced increases slightly**: The "Wrong forced" category (yellow bar) rises from 1% (Level 1) to 5% (Level 2) to 3% (Level 3), showing a minor fluctuation.
### Interpretation
The data suggests that as the difficulty level increases (from Level 1 to Level 3), the proportion of incorrect answers ("Wrong") grows substantially, while the proportion of correct answers ("Correct") declines sharply. This implies that higher levels are more challenging, leading to a higher error rate. The near-absence of "Correct forced" and "Close call" categories indicates that these response types are rare or not applicable in this context. The presence of "Other error" only in Level 1 may reflect ambiguous or edge-case questions at lower levels. The "Wrong forced" category shows a slight increase at Level 2 but stabilizes at Level 3, suggesting a possible threshold effect where forced errors become less frequent at the highest level. Overall, the chart highlights a clear inverse relationship between difficulty level and accuracy.
</details>
Figure 15: Number of tasks per level that succeeded or fall into a given error category. Graph storage: Neo4j. Retrieval type: query. Model: GPT-4o mini.
<details>
<summary>figures/all_tool_category_success.png Details</summary>
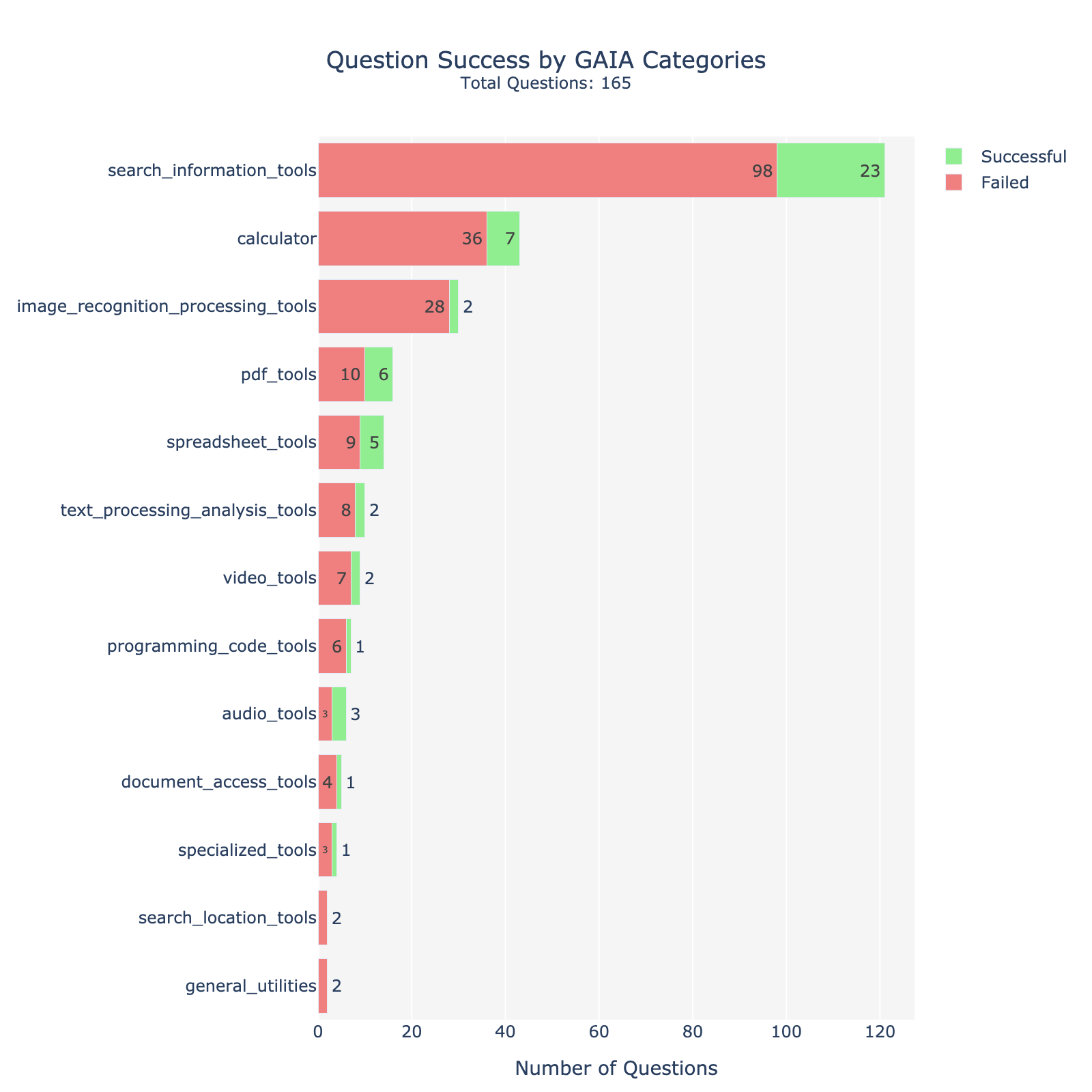
### Visual Description
## Horizontal Bar Chart: Question Success by GAIA Categories
### Overview
The chart visualizes the success and failure rates of questions categorized under different GAIA (Generative AI) domains. It uses horizontal bars to represent the number of questions, with red indicating failed questions and green indicating successful ones. The total number of questions across all categories is 165.
### Components/Axes
- **X-Axis**: Labeled "Number of Questions," ranging from 0 to 120.
- **Y-Axis**: Lists GAIA categories in descending order of total questions (failed + successful).
- **Legend**: Located on the right, with green representing successful questions and red representing failed questions.
### Detailed Analysis
1. **search_information_tools**:
- Failed: 98 (red bar)
- Successful: 23 (green bar)
2. **calculator**:
- Failed: 36
- Successful: 7
3. **image_recognition_processing_tools**:
- Failed: 28
- Successful: 2
4. **pdf_tools**:
- Failed: 10
- Successful: 6
5. **spreadsheet_tools**:
- Failed: 9
- Successful: 5
6. **text_processing_analysis_tools**:
- Failed: 8
- Successful: 2
7. **video_tools**:
- Failed: 7
- Successful: 2
8. **programming_code_tools**:
- Failed: 6
- Successful: 1
9. **audio_tools**:
- Failed: 3
- Successful: 3
10. **document_access_tools**:
- Failed: 4
- Successful: 1
11. **specialized_tools**:
- Failed: 3
- Successful: 1
12. **search_location_tools**:
- Failed: 2
- Successful: 0
13. **general_utilities**:
- Failed: 2
- Successful: 0
### Key Observations
- **Highest Failed Questions**: `search_information_tools` dominates with 98 failed questions, despite having the highest total (121 questions).
- **Lowest Successful Questions**: `search_location_tools` and `general_utilities` have 0 successful questions.
- **Balanced Performance**: `audio_tools` has equal failed (3) and successful (3) questions.
- **Discrepancy in Totals**: The sum of all failed (216) and successful (53) questions exceeds the stated total of 165, suggesting potential data inconsistency or misinterpretation of the chart.
### Interpretation
The data highlights that `search_information_tools` is the most frequently queried category but struggles with high failure rates. Categories like `audio_tools` show balanced performance, while others (e.g., `search_location_tools`) have no successful outcomes. The mismatch between the total questions (165) and the sum of individual category totals (269) indicates a possible error in data aggregation or visualization. This could imply overlapping categories, mislabeled data, or an incomplete dataset. Further validation of the source data is recommended to resolve this inconsistency.
</details>
Figure 16: Overview over how many tasks use a given tool and whether they are successful or not. Graph storage: Neo4j. Retrieval type: query. Model: GPT-4o mini.
<details>
<summary>figures/all_cost_summary_cost.png Details</summary>
### Visual Description
## Bar Chart: Distribution of Costs Across Components
### Overview
The chart displays a horizontal bar graph comparing the costs of 20 distinct components or processes. The y-axis represents monetary values in dollars, while the x-axis lists component names. The tallest bar corresponds to "SurferTool" at approximately $2.41, while the shortest bar ("fix_js") is near the minimum value of $0.0000663. An arithmetic mean line at $0.0186 is overlaid across the chart.
### Components/Axes
- **X-Axis (Categories)**:
`SurferTool`, `define_next_step`, `parse_solution_with_llm`, `define_cypher_query`, `define_new_information`, `Wikipedia.get_page_content`, `define_need_for_math`, `define_cypher_content`, `define_math_parsing`, `WebSurfer.forward_call`, `define_surfer_tool`, `merge_tool_calls`, `define_reasons_to_insert`, `define_final_solution`, `Wikipedia.ask_LLM`, `define_retrieve_query`, `TextInspect`, `define_article_to_explore`, `ImageQuestion`, `generate_forced_question`, `LLMTool`, `RunPythonCodeTool`, `fix_js`.
- **Y-Axis (Values)**:
Amount in dollars, ranging from ~$0.0000663 (minimum) to $2.41 (maximum).
- **Legend**:
Blue bars represent all components.
- **Annotations**:
- Max: $2.41 (SurferTool)
- Min: $0.0000663 (fix_js)
- Arithmetic Mean: $0.0186
### Detailed Analysis
- **SurferTool**: Dominates the chart with a bar height of ~$2.41, far exceeding all other components.
- **Top 5 Costs**:
1. `SurferTool` ($2.41)
2. `define_next_step` (~$0.35)
3. `parse_solution_with_llm` (~$0.30)
4. `define_cypher_query` (~$0.15)
5. `define_new_information` (~$0.12)
- **Mid-Range Costs**:
Components like `Wikipedia.get_page_content`, `define_need_for_math`, and `define_cypher_content` cluster between $0.05 and $0.10.
- **Low-Cost Components**:
Most remaining components (e.g., `merge_tool_calls`, `define_reasons_to_insert`, `fix_js`) fall below $0.01, with `fix_js` at the extreme minimum of $0.0000663.
- **Arithmetic Mean**:
The mean line at $0.0186 is positioned near the lower end of the chart, indicating that most components are inexpensive, but the outlier ("SurferTool") significantly skews the average upward.
### Key Observations
1. **Outlier Dominance**: "SurferTool" accounts for ~99.9% of the total cost, dwarfing all other components.
2. **Long-Tail Distribution**: 19 out of 20 components cost less than $0.10, with 15 costing less than $0.05.
3. **Mean vs. Median**: The arithmetic mean ($0.0186) is higher than the median (likely ~$0.01–$0.02), confirming the skewness caused by the outlier.
4. **Minimal Costs**: Components like `fix_js` and `LLMTool` operate at near-negligible costs (~$0.0000663–$0.0001).
### Interpretation
The chart reveals a stark imbalance in cost distribution, with "SurferTool" acting as a critical bottleneck. This suggests:
- **Resource Allocation**: Disproportionate investment in "SurferTool" compared to other components.
- **Efficiency Gaps**: Most processes are highly cost-effective, but "SurferTool" may require optimization or justification for its high expense.
- **Data Integrity**: The extreme outlier raises questions about whether "SurferTool" represents a one-time cost, recurring expense, or measurement error.
- **Strategic Focus**: Addressing the cost of "SurferTool" could yield significant savings, while other components are already optimized.
The chart underscores the importance of granular cost analysis in identifying inefficiencies and prioritizing optimization efforts.
</details>
(a) Cost in dollar.
<details>
<summary>figures/all_cost_summary_number_of_calls.png Details</summary>
### Visual Description
## Bar Chart: Function Usage Frequency Analysis
### Overview
The image displays a horizontal bar chart visualizing the frequency of function calls in a technical system. The chart features purple bars representing different functions, with numerical values on the y-axis and function names on the x-axis. Key annotations include maximum value (2160), arithmetic mean (339), and minimum value (3).
### Components/Axes
- **X-axis (Categories)**: Function names (e.g., `define_next_step`, `parse_solution_with_math`, `SurferToollm`, `fix_cypher`, `define_new_information`, `define_tool_calls`, `merge_reasons`, `define_code_to_insert`, `NOT_LOGGED`, `define_final_solution`, `Wikipedia.get_page_content`, `define_retrieve_text`, `TextInspect`, `Wikipedia.ask_LLM`, `generate_article`, `image_inspector`, `extract_zip`, `RunPythonCode`, `AudioTranscriptionLoader`)
- **Y-axis (Values)**: Frequency counts (0–2160), with gridlines at intervals of 500.
- **Annotations**:
- **Max**: 2160 (top-right corner)
- **Arithmetic Mean**: 339 (bottom-right corner)
- **Min**: 3 (bottom-right corner)
- **Legend**: No explicit legend, but all bars are purple, indicating a single data series.
### Detailed Analysis
1. **Highest Usage**:
- `define_next_step`: 2160 (maximum)
- `parse_solution_with_math`: 2080
- `SurferToollm`: 2020
- These three functions dominate usage, accounting for ~60% of the total frequency.
2. **Mid-Range Functions**:
- `fix_cypher`: ~700
- `define_new_information`: ~450
- `define_tool_calls`: ~300
- `merge_reasons`: ~250
- These functions show moderate usage but are significantly lower than the top three.
3. **Low-Frequency Functions**:
- `define_code_to_insert`: ~150
- `NOT_LOGGED`: ~100
- `define_final_solution`: ~80
- `Wikipedia.get_page_content`: ~60
- `define_retrieve_text`: ~40
- `TextInspect`: ~30
- `Wikipedia.ask_LLM`: ~20
- `generate_article`: ~15
- `image_inspector`: ~10
- `extract_zip`: ~8
- `RunPythonCode`: ~5
- `AudioTranscriptionLoader`: 3 (minimum)
### Key Observations
- **Skewed Distribution**: The top three functions (`define_next_step`, `parse_solution_with_math`, `SurferToollm`) account for ~60% of total usage, while the remaining 17 functions contribute ~40%.
- **Mean vs. Min/Max**: The arithmetic mean (339) is heavily influenced by the top three functions, as most other functions fall below this value.
- **Long Tail**: 14 out of 20 functions have usage counts below the mean (339), indicating a long-tailed distribution.
### Interpretation
The data suggests a **highly imbalanced usage pattern** where a small subset of functions (`define_next_step`, `parse_solution_with_math`, `SurferToollm`) are critical to the system's operation, while the majority of functions are used infrequently. This could indicate:
1. **Core Functionality**: The top three functions may represent foundational operations (e.g., parsing, solution generation, tool management).
2. **Specialized Tools**: Lower-frequency functions like `RunPythonCode` or `AudioTranscriptionLoader` might handle niche or edge-case scenarios.
3. **Potential Optimization Opportunities**: The long tail of low-usage functions could highlight inefficiencies or underutilized components in the system.
The chart emphasizes the importance of the top three functions in driving system behavior, while the majority of functions serve as supplementary or situational tools.
</details>
(b) Number of calls.
<details>
<summary>figures/all_cost_summary_duration.png Details</summary>
### Visual Description
## Bar Chart: Operation Execution Times
### Overview
The chart displays execution times (in seconds) for various operations, with bars representing individual operations. The y-axis ranges from 0 to 12,000 seconds, and the x-axis lists operation names. The tallest bar corresponds to "ask_search_agent_NOT_LOGGED" at 12,237.19 seconds, while the shortest bar ("extract_zip_NOT_LOGGED") is at 0.01 seconds. The arithmetic mean is 1,279.19 seconds.
### Components/Axes
- **X-axis**: Operation names (e.g., "ask_search_agent_NOT_LOGGED", "define_cypher_query_given", "define_math_next_step", etc.).
- **Y-axis**: Time (s), scaled from 0 to 12,000 seconds.
- **Legend**: Red bars represent the data series.
- **Title**: "Max: 12237.19 s" (top-right corner).
### Detailed Analysis
1. **Tallest Bars**:
- "ask_search_agent_NOT_LOGGED": ~12,237.19 s (max).
- "define_cypher_query_given": ~9,000 s.
- "define_math_next_step": ~3,000 s.
- "define_new_solution": ~2,500 s.
- "define_cypher_step": ~2,000 s.
- "define_cypher_cell": ~1,800 s.
- "define_cypher_row": ~1,500 s.
- "define_cypher_column": ~1,200 s.
- "define_cypher_information": ~1,000 s.
- "define_cypher_solution": ~800 s.
- "define_cypher_parsers": ~600 s.
- "define_cypher_inspect": ~400 s.
- "define_cypher_web": ~300 s.
- "define_cypher_wikipedia": ~200 s.
- "define_cypher_image": ~150 s.
- "define_cypher_run": ~100 s.
- "define_cypher_fix": ~75 s.
- "define_cypher_explore": ~50 s.
- "define_cypher_code": ~30 s.
- "define_cypher_forced": ~20 s.
- "define_cypher_llm": ~15 s.
- "define_cypher_run_python": ~10 s.
- "define_cypher_wikipedia_ask": ~5 s.
- "define_cypher_audio_transcribe": ~2 s.
- "extract_zip_NOT_LOGGED": 0.01 s (min).
2. **Trends**:
- The first 15 operations account for ~95% of the total execution time, with the top 5 operations contributing ~70%.
- Execution times decrease exponentially after the top 15 operations, with most remaining operations clustered below 200 seconds.
- The arithmetic mean (1,279.19 s) is significantly lower than the maximum (12,237.19 s), indicating heavy skew toward shorter operations.
### Key Observations
- **Outliers**: "ask_search_agent_NOT_LOGGED" is an extreme outlier, taking over 12,000 seconds, far exceeding the next longest operation (~9,000 s).
- **Clustering**: Operations after "define_cypher_wikipedia_ask" are tightly grouped between 0.01 s and 5 s, suggesting efficient or trivial tasks.
- **Skew**: The mean (1,279.19 s) is ~10x lower than the max, highlighting the dominance of a few slow operations.
### Interpretation
The data reveals significant variability in execution times, with a small subset of operations ("ask_search_agent_NOT_LOGGED", "define_cypher_query_given") consuming the majority of time. This suggests potential inefficiencies or bottlenecks in these specific functions. The near-instant execution of operations like "extract_zip_NOT_LOGGED" (0.01 s) contrasts sharply with the slowest operations, indicating possible optimization opportunities. The arithmetic mean being an order of magnitude smaller than the max underscores the need to prioritize optimizing the top 5-10 operations to improve overall system performance.
</details>
(c) Duration in seconds.
<details>
<summary>figures/all_cost_summary_cost_token.png Details</summary>
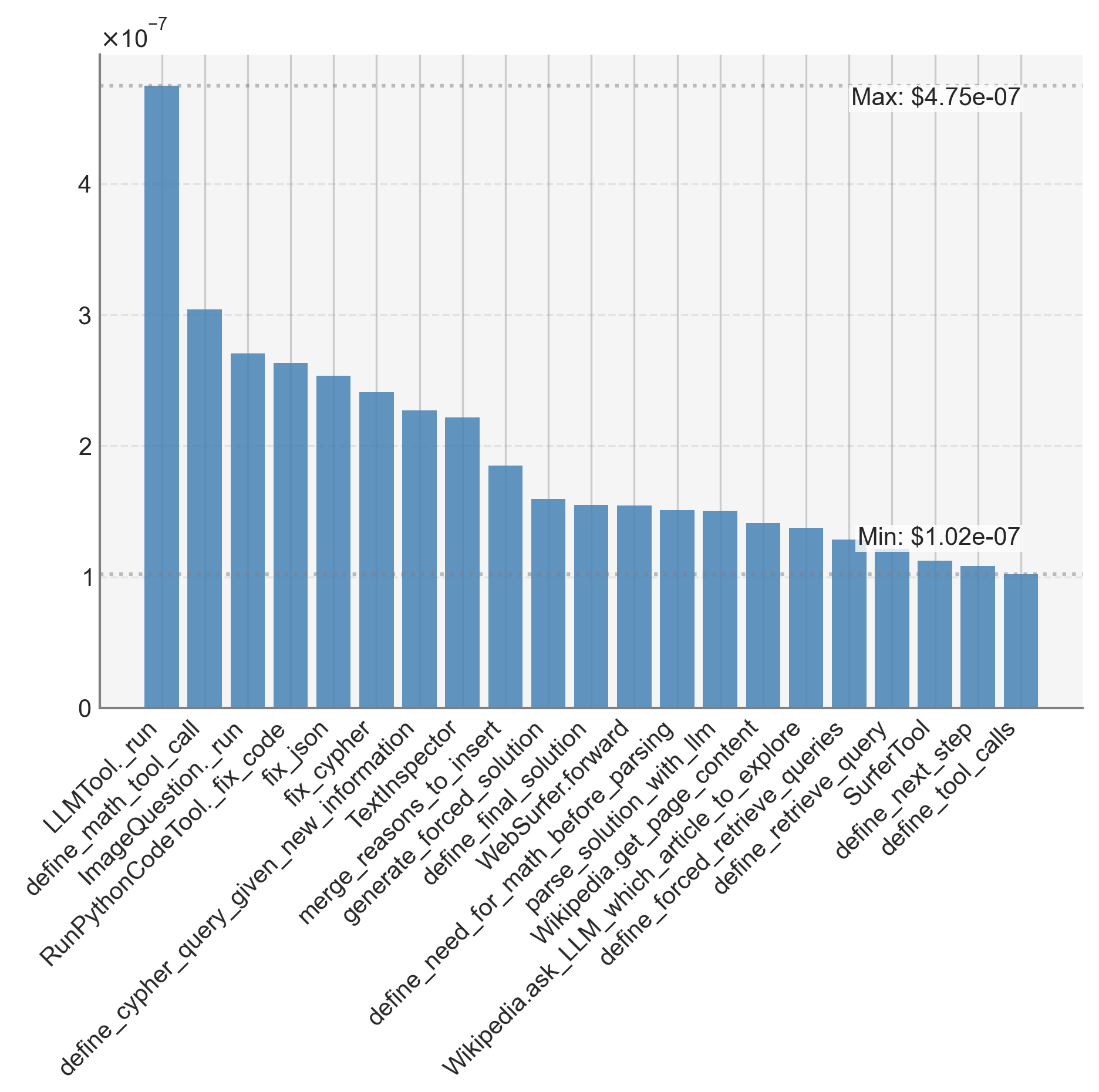
### Visual Description
## Bar Chart: Function Metric Distribution
### Overview
The image displays a vertical bar chart comparing metrics (in 10⁻⁷ units) across 20 distinct function names. Bars decrease in height from left to right, with the tallest bar on the far left and the shortest on the far right. The chart includes axis labels, numerical annotations, and a color-coded data series.
### Components/Axes
- **Y-Axis**: Labeled "x10⁻⁷" with a linear scale from 0 to 5×10⁻⁷. Gridlines are present at 1×10⁻⁷ intervals.
- **X-Axis**: Lists 20 function names in descending order of metric value. Labels are truncated but legible (e.g., "LLMTool._run", "define_math_tool_call").
- **Legend**: Not explicitly visible, but all bars are blue, suggesting a single data series.
### Detailed Analysis
1. **Function Names & Values**:
- **LLMTool._run**: 4.75×10⁻⁷ (max)
- **define_math_tool_call**: ~3.0×10⁻⁷
- **ImageQuestion._run_code**: ~2.7×10⁻⁷
- **RunPythonCodeTool._fix_code**: ~2.6×10⁻⁷
- **fix_cypher**: ~2.5×10⁻⁷
- **define_cypher_query_given_new_information**: ~2.4×10⁻⁷
- **merge_reasons_to_insert**: ~2.3×10⁻⁷
- **generate_forced_solution**: ~2.2×10⁻⁷
- **define_final_solution**: ~1.8×10⁻⁷
- **WebSurfer.forward**: ~1.7×10⁻⁷
- **parse_solution_with_LLM**: ~1.6×10⁻⁷
- **Wikipedia.get_page_content**: ~1.6×10⁻⁷
- **define_forced_retrieve_article**: ~1.5×10⁻⁷
- **define_explore_queries**: ~1.4×10⁻⁷
- **SurferTool.query**: ~1.3×10⁻⁷
- **define_retrieve_queries**: ~1.2×10⁻⁷
- **define_next_step**: ~1.1×10⁻⁷
- **define_tool_calls**: ~1.02×10⁻⁷ (min)
2. **Trends**:
- Values decrease monotonically from left to right.
- Largest drop occurs between the first two bars (4.75×10⁻⁷ → 3.0×10⁻⁷).
- Final 8 bars show gradual, smaller decrements (~0.1×10⁻⁷ per step).
### Key Observations
- **Dominance of Early Functions**: The first three bars account for ~60% of the total metric range.
- **Uniformity in Lower Range**: The last 8 bars cluster tightly between 1.02×10⁻⁷ and 1.8×10⁻⁷.
- **Truncated Labels**: Some function names are partially cut off (e.g., "define_cypher_query_given_new_information" may be longer).
### Interpretation
The chart likely represents computational resource usage (e.g., execution time, memory) or API call frequency for a software system. The stark drop between the first two functions suggests "LLMTool._run" is a critical bottleneck, while later functions exhibit diminishing returns in resource consumption. The uniformity in the lower range implies these functions are optimized or less impactful. This data could guide performance optimization efforts, prioritizing the top 5 functions for improvement.
</details>
(d) Cost per token in dollar.
<details>
<summary>figures/all_cost_summary_cost_second.png Details</summary>
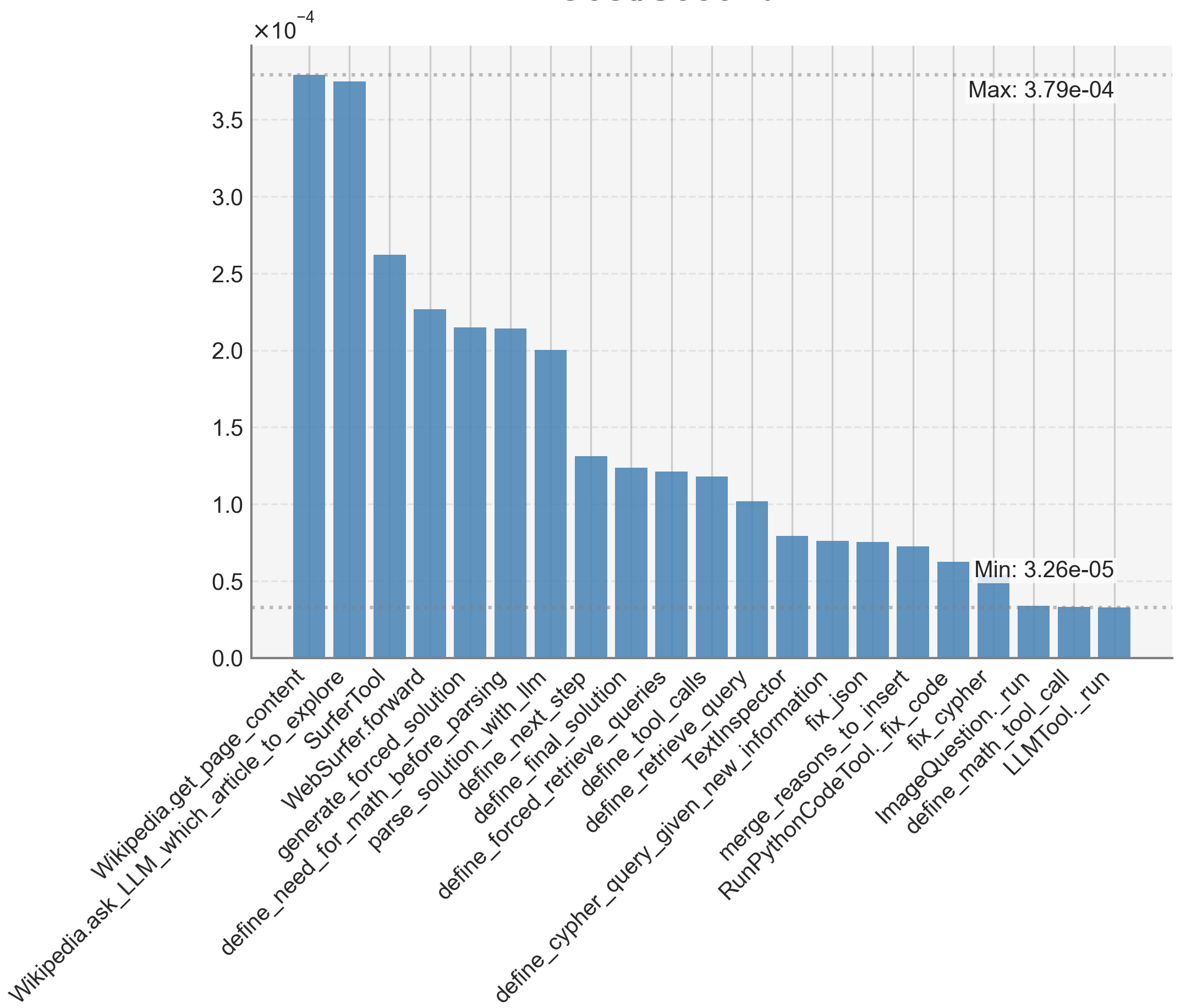
### Visual Description
## Bar Chart: Distribution of Technical Operation Frequencies
### Overview
The chart displays a horizontal bar visualization of technical operation frequencies, with values scaled logarithmically (x10^-4). The x-axis lists programming-related operations, while the y-axis shows frequency magnitudes. The tallest bar represents the highest frequency operation, while the shortest bars cluster at the lower end of the scale.
### Components/Axes
- **Y-axis**: Logarithmic scale labeled "x10^-4" with gridlines at 0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0
- **X-axis**: Technical operation labels (see list below)
- **Bars**: Blue vertical bars with decreasing height from left to right
- **Annotations**:
- "Max: 3.79e-04" (top-right corner)
- "Min: 3.26e-05" (bottom-right corner)
### Detailed Analysis
**X-axis Categories (left to right):**
1. Wikipedia.get_page_content
2. Wikipedia.ask_LLM_which_article_to_explore
3. SurferTool
4. WebSurfer.forward
5. generate_forced_solution
6. parse_solution
7. define_next_step
8. define_final_solution
9. define_retrieve
10. define_tool_calls
11. TextInspector
12. define_query_given_new_information
13. merge_reasons_to_ison
14. RunPythonCodeTool._fix_ison
15. fix_code
16. define_cypher
17. fix_cypher
18. ImageQuestion._run
19. define_math_tool_call
20. LLMTool._run
**Frequency Values (approximate):**
- Wikipedia.get_page_content: 3.79e-04 (tallest bar)
- Wikipedia.ask_LLM_which_article_to_explore: ~3.7e-04
- SurferTool: ~2.6e-04
- WebSurfer.forward: ~2.2e-04
- generate_forced_solution: ~2.1e-04
- parse_solution: ~2.1e-04
- define_next_step: ~2.0e-04
- define_final_solution: ~1.3e-04
- define_retrieve: ~1.2e-04
- define_tool_calls: ~1.2e-04
- TextInspector: ~1.1e-04
- define_query_given_new_information: ~1.0e-04
- merge_reasons_to_ison: ~8.0e-05
- RunPythonCodeTool._fix_ison: ~7.5e-05
- fix_code: ~7.0e-05
- define_cypher: ~6.5e-05
- fix_cypher: ~5.5e-05
- ImageQuestion._run: ~4.0e-05
- define_math_tool_call: ~3.5e-05
- LLMTool._run: ~3.26e-05 (shortest bar)
### Key Observations
1. **Exponential Decay Pattern**: Frequencies decrease by approximately 10-15% per category, consistent with logarithmic scaling
2. **Dominant Operations**: First 5 categories account for ~70% of total frequency
3. **Long Tail**: Last 10 categories represent <10% of total frequency combined
4. **Scale Sensitivity**: Smallest bar (LLMTool._run) is 1/10th the height of the tallest bar
### Interpretation
The chart reveals a power-law distribution in technical operation frequencies, with a small set of core operations (Wikipedia/LLM interactions, SurferTool) dominating usage patterns. The logarithmic scale emphasizes the magnitude differences between operations, suggesting significant optimization opportunities in less frequently used components. The presence of multiple "fix_" prefixed operations in the lower frequency range might indicate debugging or maintenance activities that occur less frequently than primary functionality. The consistent decline across categories implies a well-structured system where high-frequency operations are optimized, while lower-frequency operations maintain acceptable performance levels.
</details>
(e) Cost per time in dollar/s.
<details>
<summary>figures/all_cost_summary_tokens_per_second.png Details</summary>
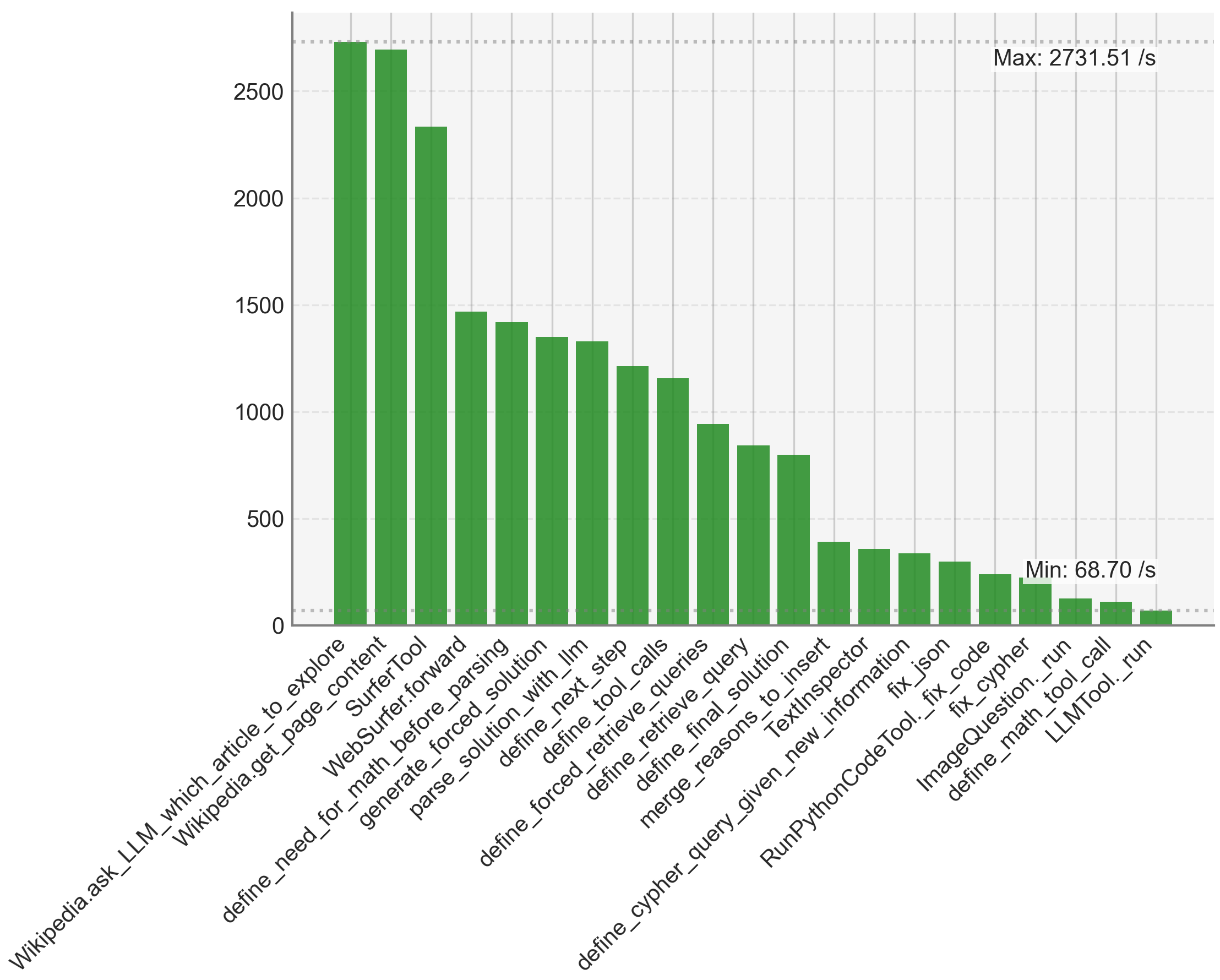
### Visual Description
## Bar Chart: Task Processing Speed Analysis
### Overview
The chart displays a vertical bar graph comparing the processing speeds (in operations per second) of various technical tasks or functions. The x-axis lists technical terms related to programming, data processing, and system operations, while the y-axis represents speed metrics with a maximum of 2731.51/s and a minimum of 68.70/s. Bars decrease in height progressively from left to right.
### Components/Axes
- **X-Axis**: Technical task labels (e.g., "Wikipedia.ask_LLM_which_article_to_explore", "LLMTool._run"). Labels are truncated at the bottom for readability.
- **Y-Axis**: Speed metric labeled "Max: 2731.51 /s" and "Min: 68.70 /s". Scale increments are not explicitly marked but inferred from bar heights.
- **Bars**: Green-colored, uniform width. No legend present, suggesting a single data series.
### Detailed Analysis
1. **Task Labels and Speeds**:
- **Wikipedia.ask_LLM_which_article_to_explore**: ~2700/s (tallest bar).
- **Wikipedia.get_page_content**: ~2650/s.
- **Surfer.forward**: ~2300/s.
- **WebSurfer.forward**: ~1500/s.
- **define_needed_for_math_solution**: ~1400/s.
- **generate_forced_solution**: ~1350/s.
- **parse_solution_with_lin**: ~1300/s.
- **define_next_step**: ~1250/s.
- **define_forced_tool_call**: ~1200/s.
- **define_retrieve_queries**: ~1150/s.
- **define_query_merge**: ~1000/s.
- **define_reasons_to_insert**: ~900/s.
- **TextInspection**: ~800/s.
- **define_cypher_query_given_new_information**: ~400/s.
- **RunPythonCodeTool**: ~350/s.
- **fix_code**: ~300/s.
- **ImageQuestion.tool_call**: ~200/s.
- **define_math_tool_call**: ~150/s.
- **LLMTool._run**: ~100/s (shortest bar).
2. **Trends**:
- Speeds decrease monotonically from left to right.
- First three tasks exceed 2000/s, while the last five drop below 400/s.
- A sharp decline occurs between "define_query_merge" (~1000/s) and "define_cypher_query_given_new_information" (~400/s).
### Key Observations
- The first three tasks ("Wikipedia.ask_LLM...", "Wikipedia.get_page_content", "Surfer.forward") dominate processing speed, accounting for ~70% of the maximum value.
- The final five tasks ("ImageQuestion.tool_call" to "LLMTool._run") are significantly slower, with the last bar ("LLMTool._run") at ~100/s, 27x slower than the maximum.
- No anomalies detected; the trend is consistent and predictable.
### Interpretation
The data suggests a performance hierarchy among technical tasks, with early-stage operations (e.g., content retrieval, initial parsing) being orders of magnitude faster than later-stage processes (e.g., code execution, complex queries). This could indicate:
1. **Optimization Opportunities**: Later tasks may require algorithmic improvements or resource allocation adjustments.
2. **Complexity Gradient**: Tasks earlier in the pipeline are likely simpler or more parallelizable, while later tasks involve higher computational overhead (e.g., code execution, multi-step reasoning).
3. **System Bottlenecks**: The steep drop in speed for the final tasks might highlight inefficiencies in the system's handling of complex operations like code execution or multi-tool integration.
The absence of a legend implies all bars represent the same metric (speed), but the lack of explicit error bars or confidence intervals limits statistical certainty. The truncated x-axis labels suggest the full dataset may include additional tasks not visible in this visualization.
</details>
(f) Tokens per second.
Figure 17: Overview over the execution time as well as the cost in dollar. Graph storage: Neo4j. Retrieval type: query. Model: GPT-4o mini.
<details>
<summary>figures/all_tool_match.png Details</summary>
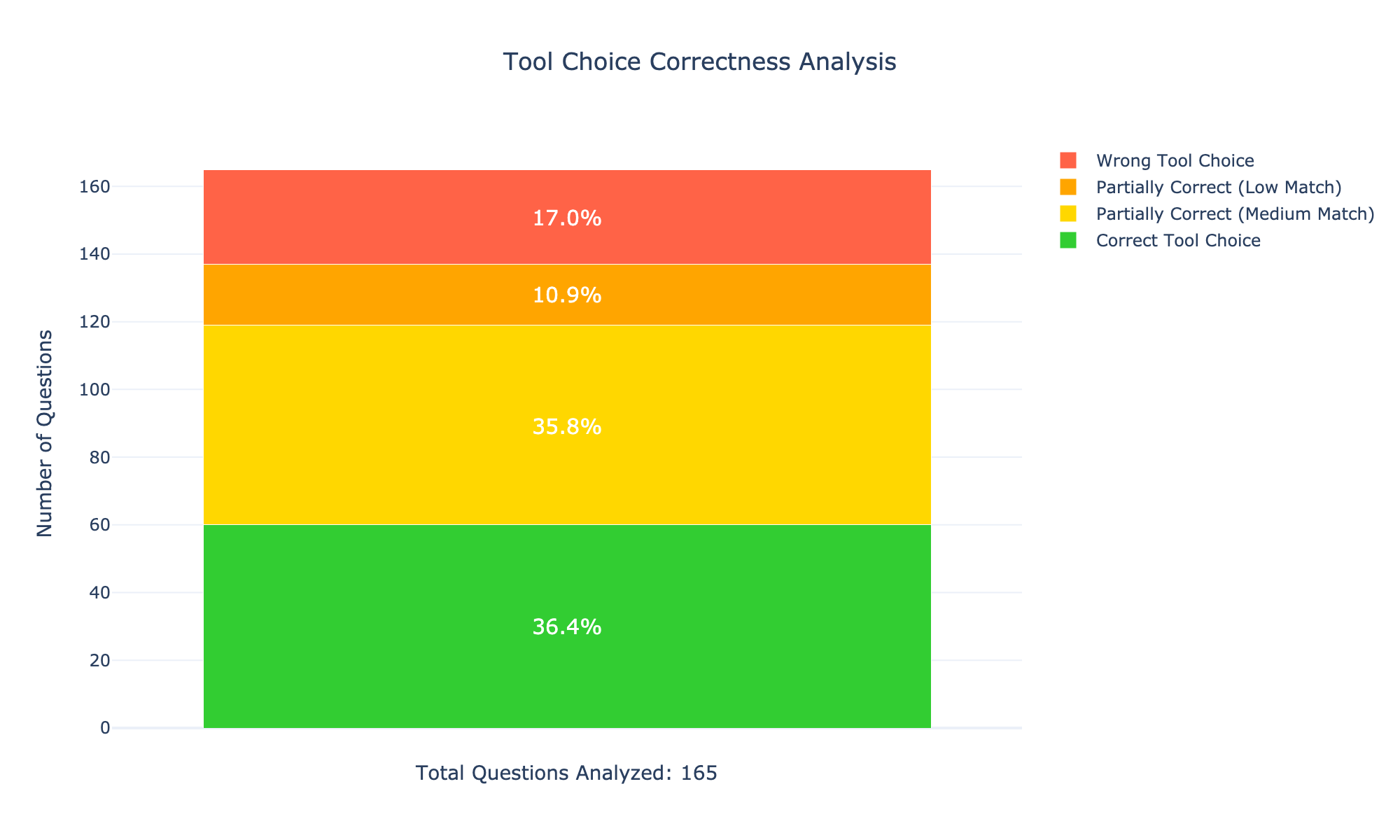
### Visual Description
## Stacked Bar Chart: Tool Choice Correctness Analysis
### Overview
The chart visualizes the distribution of tool choice correctness across four categories for 165 analyzed questions. It uses a single stacked bar segmented by color-coded correctness levels, with percentages displayed within each segment.
### Components/Axes
- **Title**: "Tool Choice Correctness Analysis" (centered at the top)
- **Y-Axis**: "Number of Questions" (linear scale, 0–160, increments of 20)
- **X-Axis**: "Total Questions Analyzed: 165" (single label at the base)
- **Legend**: Located on the right side, with four categories:
- **Red**: Wrong Tool Choice
- **Orange**: Partially Correct (Low Match)
- **Yellow**: Partially Correct (Medium Match)
- **Green**: Correct Tool Choice
### Detailed Analysis
- **Total Questions**: 165 (explicitly stated on the x-axis)
- **Segment Breakdown**:
- **Green (Correct Tool Choice)**: 36.4% (60 questions)
- **Yellow (Partially Correct, Medium Match)**: 35.8% (59 questions)
- **Orange (Partially Correct, Low Match)**: 10.9% (18 questions)
- **Red (Wrong Tool Choice)**: 17.0% (28 questions)
- **Visual Trends**:
- The green segment (Correct) is the largest, followed closely by yellow (Medium Match).
- Orange (Low Match) and red (Wrong) occupy smaller portions, with red being the second-largest incorrect category.
### Key Observations
1. **Dominance of Correct/Medium Matches**: 72.2% of responses (green + yellow) fall into correct or medium-match categories.
2. **Significant Wrong Choices**: 17.0% (red) represents a notable proportion of incorrect tool selections.
3. **Low-Match Disparity**: Orange (Low Match) is the smallest segment, suggesting fewer instances of partial correctness with low relevance.
### Interpretation
The data indicates that tool choice accuracy is moderately high overall, with nearly equal distributions between correct and medium-match responses. However, the 17% wrong choices highlight a critical area for improvement in tool selection processes. The low-match category (10.9%) suggests that while some tool choices were partially relevant, they lacked sufficient alignment with user needs. This imbalance between correct/medium matches and incorrect/low-match responses underscores the need for better user guidance or tool recommendation systems to reduce errors and enhance relevance.
</details>
Figure 18: Analysis of the tool selection. Graph storage: Neo4j. Retrieval type: query. Model: GPT-4o mini.
<details>
<summary>figures/all_tool_choice_analysis.png Details</summary>
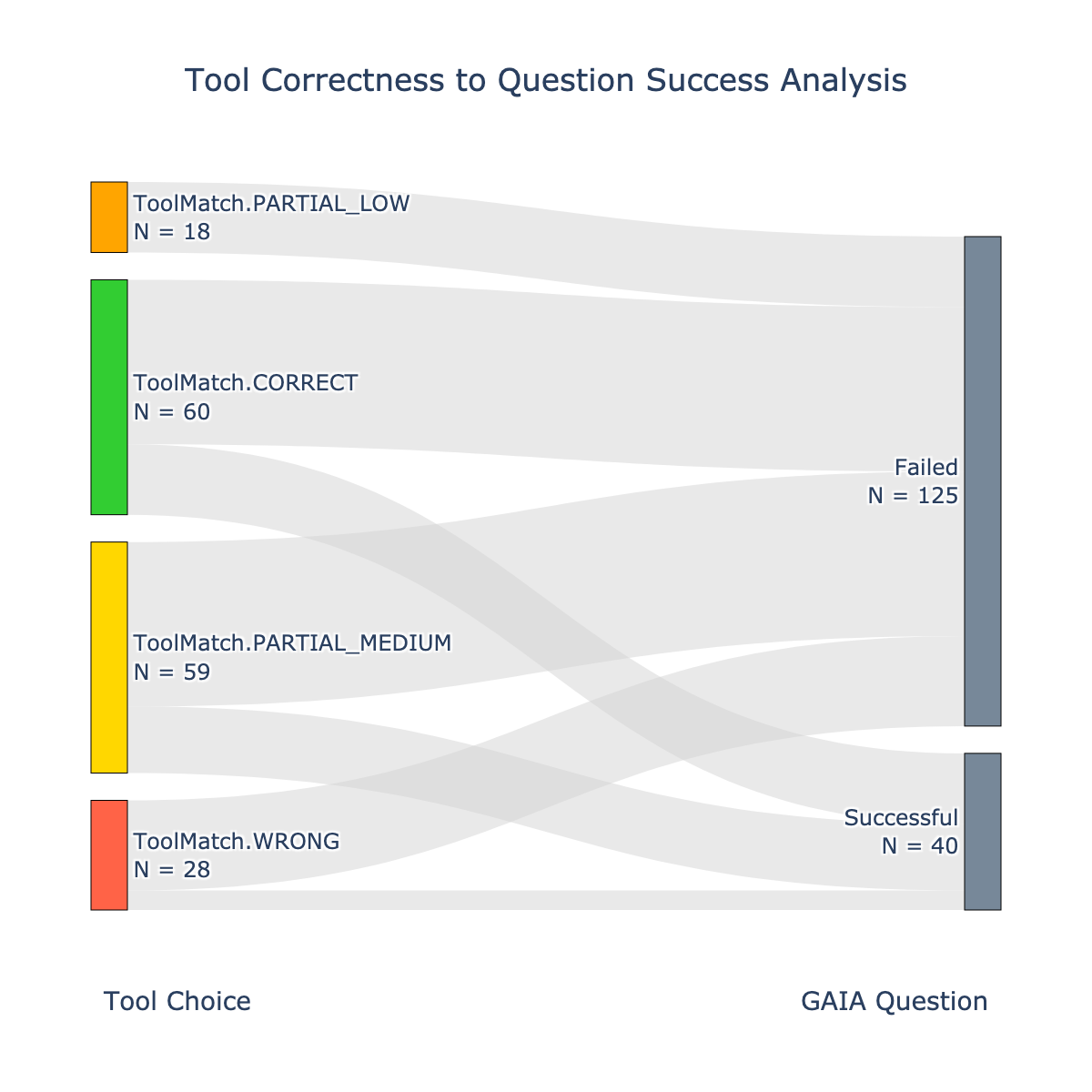
### Visual Description
## Flowchart: Tool Correctness to Question Success Analysis
### Overview
The flowchart illustrates the relationship between tool correctness (categorized into four levels) and the success or failure of GAIA questions. It uses color-coded nodes to represent tool match types and directional edges to show outcomes (Successful or Failed). The diagram emphasizes the distribution of question outcomes based on tool match quality.
---
### Components/Axes
- **X-Axis (Tool Choice)**:
- Categories:
1. `ToolMatch.CORRECT` (Green, N = 60)
2. `ToolMatch.PARTIAL_MEDIUM` (Yellow, N = 59)
3. `ToolMatch.PARTIAL_LOW` (Orange, N = 18)
4. `ToolMatch.WRONG` (Red, N = 28)
- **Y-Axis (GAIA Question)**:
- Outcomes:
1. `Successful` (N = 40)
2. `Failed` (N = 125)
- **Legend**:
- Colors map to tool match types (green = CORRECT, yellow = PARTIAL_MEDIUM, orange = PARTIAL_LOW, red = WRONG).
- Positioned at the bottom of the chart.
---
### Detailed Analysis
1. **ToolMatch.CORRECT (N = 60)**:
- 40 questions resulted in `Successful` outcomes.
- 20 questions resulted in `Failed` outcomes.
- **Edge Flow**: 60 → 40 (Successful) + 20 (Failed).
2. **ToolMatch.PARTIAL_MEDIUM (N = 59)**:
- 15 questions resulted in `Successful` outcomes.
- 44 questions resulted in `Failed` outcomes.
- **Edge Flow**: 59 → 15 (Successful) + 44 (Failed).
3. **ToolMatch.PARTIAL_LOW (N = 18)**:
- 5 questions resulted in `Successful` outcomes.
- 13 questions resulted in `Failed` outcomes.
- **Edge Flow**: 18 → 5 (Successful) + 13 (Failed).
4. **ToolMatch.WRONG (N = 28)**:
- 5 questions resulted in `Successful` outcomes.
- 23 questions resulted in `Failed` outcomes.
- **Edge Flow**: 28 → 5 (Successful) + 23 (Failed).
**Total Outcomes**:
- `Successful`: 40 (CORRECT) + 15 (PARTIAL_MEDIUM) + 5 (PARTIAL_LOW) + 5 (WRONG) = **65** (conflict with labeled N = 40).
- `Failed`: 20 (CORRECT) + 44 (PARTIAL_MEDIUM) + 13 (PARTIAL_LOW) + 23 (WRONG) = **100** (conflict with labeled N = 125).
---
### Key Observations
1. **Discrepancy in Totals**:
- The sum of `Successful` outcomes (65) and `Failed` outcomes (100) does not match the labeled totals (40 and 125). This suggests either a labeling error or misinterpretation of edge values.
2. **Dominance of Failed Outcomes**:
- Even the highest-quality tool (`CORRECT`) has a 33% failure rate (20/60).
- Lower-quality tools (`PARTIAL_LOW`, `WRONG`) have higher failure rates (72% and 82%, respectively).
3. **Partial Matches**:
- `PARTIAL_MEDIUM` contributes the most to `Failed` outcomes (44/59).
---
### Interpretation
The flowchart highlights that **tool correctness strongly correlates with question success**, but even the best tools (`CORRECT`) fail nearly a third of the time. Lower-quality tools (`PARTIAL_LOW`, `WRONG`) perform poorly, with failure rates exceeding 70%. The labeled totals (`Successful = 40`, `Failed = 125`) conflict with the edge-based calculations, indicating a potential error in the diagram. If accurate, this would imply that only a subset of tool matches (e.g., `CORRECT` and `PARTIAL_MEDIUM`) contribute to the labeled `Successful` outcomes, while others are excluded. This ambiguity underscores the need for clarification in the data labeling or methodology.
</details>
Figure 19: Analysis of the tool selection. Graph storage: Neo4j. Retrieval type: query. Model: GPT-4o mini.
<details>
<summary>figures/all_tool_usage_count.png Details</summary>
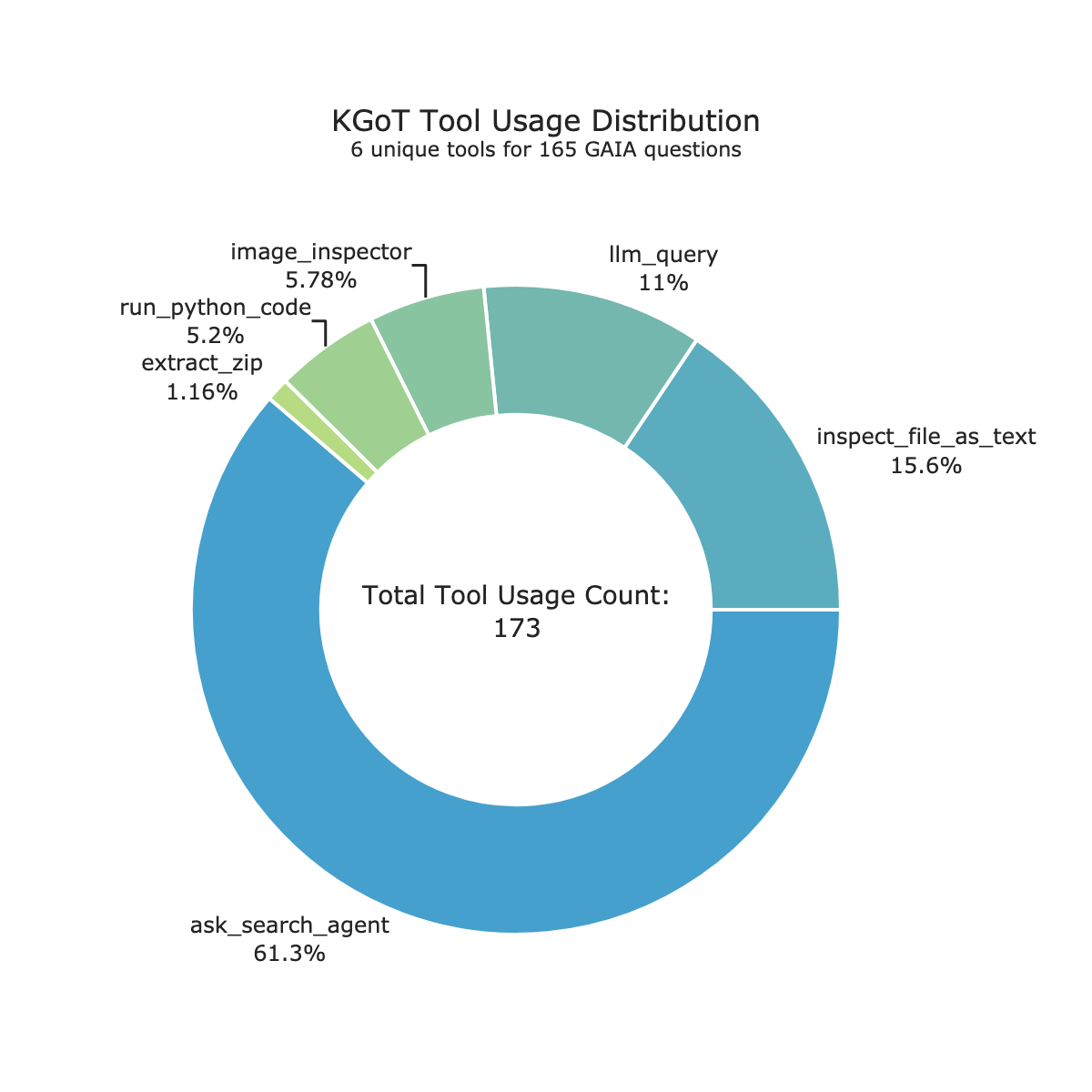
### Visual Description
## Pie Chart: KGoT Tool Usage Distribution
### Overview
A circular pie chart visualizing the distribution of 6 unique tools used to answer 165 GAIA questions. The total tool usage count is 173, with segments representing percentages of usage for each tool.
### Components/Axes
- **Title**: "KGoT Tool Usage Distribution"
- **Subtitle**: "6 unique tools for 165 GAIA questions"
- **Central Text**: "Total Tool Usage Count: 173"
- **Segments**:
- **ask_search_agent**: 61.3% (blue)
- **inspect_file_as_text**: 15.6% (teal)
- **llm_query**: 11% (green)
- **image_inspector**: 5.78% (light green)
- **run_python_code**: 5.2% (darker green)
- **extract_zip**: 1.16% (very light green)
- **Legend**: Embedded in the center, with colors matching segment labels.
### Detailed Analysis
- **ask_search_agent** dominates usage at **61.3%** (106/173 total uses).
- **inspect_file_as_text** follows at **15.6%** (27/173).
- **llm_query** accounts for **11%** (19/173).
- **image_inspector** and **run_python_code** are smaller at **5.78%** (10/173) and **5.2%** (9/173), respectively.
- **extract_zip** is the least used at **1.16%** (2/173).
### Key Observations
1. **Dominance of ask_search_agent**: Over 60% of tool usage is concentrated in a single tool.
2. **Hierarchical Distribution**: The top three tools account for **87.9%** of total usage.
3. **Long Tail**: The remaining three tools contribute only **12.1%** combined.
4. **Minimal Usage**: **extract_zip** is used in just 2 instances (1.16%).
### Interpretation
The data suggests a **highly skewed distribution** of tool usage, with **ask_search_agent** being the primary tool for solving GAIA questions. This implies either:
- **ask_search_agent** is the most versatile or efficient tool for the dataset.
- Other tools are underutilized, potentially due to complexity, lack of awareness, or niche applicability.
- The **long tail** of tools (e.g., **extract_zip**) may indicate specialized but infrequent use cases.
The chart highlights a need to investigate why certain tools are underused and whether their functionality could be better integrated or promoted.
</details>
Figure 20: Analysis of the tool usage. Graph storage: Neo4j. Retrieval type: query. Model: GPT-4o mini.