# Enhancing Trust in AI Marketplaces: Evaluating On-Chain Verification of Personalized AI Models using zk-SNARKs
**Authors**: Nishant Jagannath, Christopher Wong, Braden McGrath, MD Farhad Hossain, Asuquo A. Okon, Abbas Jamalipour, Kumudu S. Munasinghe
> School of IT and Systems, University of Canberra, ACT, Australia
> School of Engineering and Technology, University of New South Wales, ACT, Australia
> School of Electrical and Information Engineering, University of Sydney, NSW, Australia
## Abstract
The rapid advancement of artificial intelligence (AI) has brought about sophisticated models capable of various tasks ranging from image recognition to natural language processing. As these models continue to grow in complexity, ensuring their trustworthiness and transparency becomes critical, particularly in decentralized environments where traditional trust mechanisms are absent. This paper addresses the challenge of verifying personalized AI models in such environments, focusing on their integrity and privacy. We propose a novel framework that integrates zero-knowledge succinct non-interactive arguments of knowledge (zk-SNARKs) with Chainlink decentralized oracles to verify AI model performance claims on blockchain platforms. Our key contribution lies in integrating zk-SNARKs with Chainlink oracles to securely fetch and verify external data to enable trustless verification of AI models on a blockchain. Our approach addresses the limitations of using unverified external data for AI verification on the blockchain while preserving sensitive information of AI models and enhancing transparency. We demonstrate our methodology with a linear regression model predicting Bitcoin prices using on-chain data verified on the Sepolia testnet. Our results indicate the framework’s efficacy, with key metrics including proof generation taking an average of 233.63 seconds and verification time of 61.50 seconds. This research paves the way for transparent and trustless verification processes in blockchain-enabled AI ecosystems, addressing key challenges such as model integrity and model privacy protection. The proposed framework, while exemplified with linear regression, is designed for broader applicability across more complex AI models, setting the stage for future advancements in transparent AI verification.
## 1 Introduction
The proliferation of artificial intelligence (AI) has revolutionized the digital landscape, driving a growing demand for personalized, efficient, and reliable AI models. Developing such models, however, is resource-intensive and requires specialized expertise [1]. To bridge this gap, AI marketplaces have emerged as pivotal platforms that facilitate the exchange of personalized AI services. These marketplaces empower developers to monetize their models, providing access to sophisticated AI tools for users who may lack the capacity to develop them independently. A prime example of this trend is the ChatGPT Store [2], which offers diverse AI models tailored to various user needs. By enabling the buying, selling, and sharing of pre-trained AI models, AI marketplaces function much like software app stores but with a focus on AI capabilities rather than applications.
<details>
<summary>extracted/6340811/Strip-1.png Details</summary>

### Visual Description
## Diagram: Three Technical Challenges in Blockchain and AI Systems
### Overview
The image is a horizontal diagram composed of three distinct, side-by-side illustrations. Each illustration pairs a textual statement with a symbolic graphic to represent a specific technical challenge related to trust, integrity, and security in the context of blockchain and personalized AI models. The overall theme is the vulnerability and verification difficulties in decentralized and AI-driven systems.
### Components/Axes
The diagram is divided into three sections, each with a title and an accompanying icon/diagram.
**1. Left Section:**
* **Title Text:** "Blockchain – Lack of Inherent trust"
* **Graphic Components:**
* **Left Side:** Two identical orange-brown neural network icons (each with 3 input nodes, 2 hidden nodes, and 1 output node connected by arrows).
* **Center:** A black, hexagonal blockchain structure composed of interconnected cubes. Inside the central hexagon is a white circle containing various cryptocurrency and blockchain-related symbols (e.g., a Bitcoin '₿' symbol, an Ethereum diamond, a Polkadot logo, a generic chain link).
* **Flow Indicators:** Two curved, dark blue arrows point from the neural network icons towards the central blockchain structure, suggesting data or model inputs being sent to the chain.
**2. Middle Section:**
* **Title Text:** "Personalized AI Model – model’s integrity and confidentiality issues"
* **Graphic Components:**
* A single, larger orange-brown neural network diagram. It has a more complex, interconnected structure with multiple nodes and directional arrows.
* One specific node on the right side of the network is emphasized with a double circle (a circle within a circle), likely representing a personalized or specific output node of concern.
**3. Right Section:**
* **Title Text:** "Detecting changes to the model during inference is challenging."
* **Graphic Components:**
* A light blue line-art icon of a robot's head. The robot has 'X's for eyes and a straight line for a mouth, conveying a non-functional or erroneous state.
* Overlapping the bottom-right of the robot icon is a light blue warning triangle containing an exclamation mark.
### Detailed Analysis
* **Spatial Grounding:** The three challenges are presented in a linear, left-to-right sequence. The titles are positioned directly above their respective graphics. The graphics are centered within their conceptual "columns."
* **Visual Flow & Symbolism:**
* **Left (Blockchain):** The flow arrows indicate a process of feeding external models (neural networks) into a blockchain. The core message, stated in the title, is that the blockchain itself does not inherently solve the trust problem for the data or models being recorded on it.
* **Middle (AI Model):** The isolated, complex neural network with a highlighted node visually represents a "personalized" model. The title specifies the dual issues of **integrity** (has the model been tampered with?) and **confidentiality** (is the model's proprietary structure or data exposed?).
* **Right (Inference):** The "dead" robot icon with a warning sign is a direct metaphor for a model that has been altered or corrupted during its operational phase (inference), making its outputs unreliable. The title explicitly states the difficulty of detecting such changes.
### Key Observations
1. **Consistent Color Coding:** The neural network elements (left and middle) share the same orange-brown color, creating a visual link between the "input models" and the "personalized model." The blockchain is in stark black, and the inference problem is in a distinct light blue.
2. **Progression of Complexity:** The diagrams move from a system interaction (models + blockchain) to a focus on a single model's internal structure, and finally to a symbol of system failure.
3. **Textual Precision:** The titles are concise but technically specific, using terms like "inherent trust," "integrity," "confidentiality," and "inference."
### Interpretation
This diagram outlines a critical security and verification pipeline for AI models operating within or alongside blockchain systems. It presents a logical sequence of problems:
1. **The Foundational Problem:** Even if you use a blockchain to record or coordinate AI models, the chain's immutability doesn't guarantee the *trustworthiness* of the models being put onto it. The "lack of inherent trust" points to the need for external verification mechanisms.
2. **The Core Asset Problem:** The personalized AI model itself is a valuable and vulnerable asset. Its integrity (provenance and lack of tampering) and confidentiality (protection of its architecture and training data) are paramount concerns, especially in decentralized settings where control is distributed.
3. **The Operational Problem:** The most insidious threat may occur during runtime. A model that was verified at deployment could be subtly altered during inference (e.g., via data poisoning or runtime attacks), and detecting these changes in real-time is a significant technical challenge, as symbolized by the malfunctioning robot.
The overarching message is that deploying AI in trust-sensitive environments like blockchain requires solving a multi-layered security challenge: verifying inputs, protecting the model asset, and monitoring its ongoing operation. The diagram serves as a high-level threat model or problem statement for researchers and engineers working on secure, verifiable AI.
</details>
Figure 1: The importance of personalized AI model verification on blockchain.
Despite the promise of AI marketplaces, the dominance of a few global tech giants in AI technology has raised significant concerns regarding transparency, fairness, and equitable access [3]. Model weights are essential for providing experimental reproducibility and fostering innovation. The push towards commercializing AI models has led to a trend of closed-source models, keeping model weights and other details confidential. This confidentiality is due to the significant investments in data acquisition, computational resources, and algorithmic optimization. Even if developers wish to substantiate the performance claims of their models, publishing these weights could result in the misuse of AI models, leading to advanced cyberattacks or the propagation of disinformation [4]. These limitations hinder the examination of model performance and the verification of any claims regarding their effectiveness.
The problem is exacerbated in AI marketplaces operating in decentralized settings, such as blockchain, where there is no inherent trust among users [5]. This lack of transparency makes it difficult to identify performance characteristics, such as performance claims, in production AI models. Ensuring the integrity and reliability of personalized AI models in these marketplaces is crucial, as providers must guarantee model performance, and consumers seek assurance of quality and value. Currently, methods like SingularityNET’s decentralized reputation system rely on community participation to rate AI services [6]. However, this method lacks the rigour necessary for comprehensive validation. These issues as seen in Fig. 1, highlight the need for a decentralized and transparent verification mechanism that fosters trust.
<details>
<summary>extracted/6340811/Strip-2.png Details</summary>
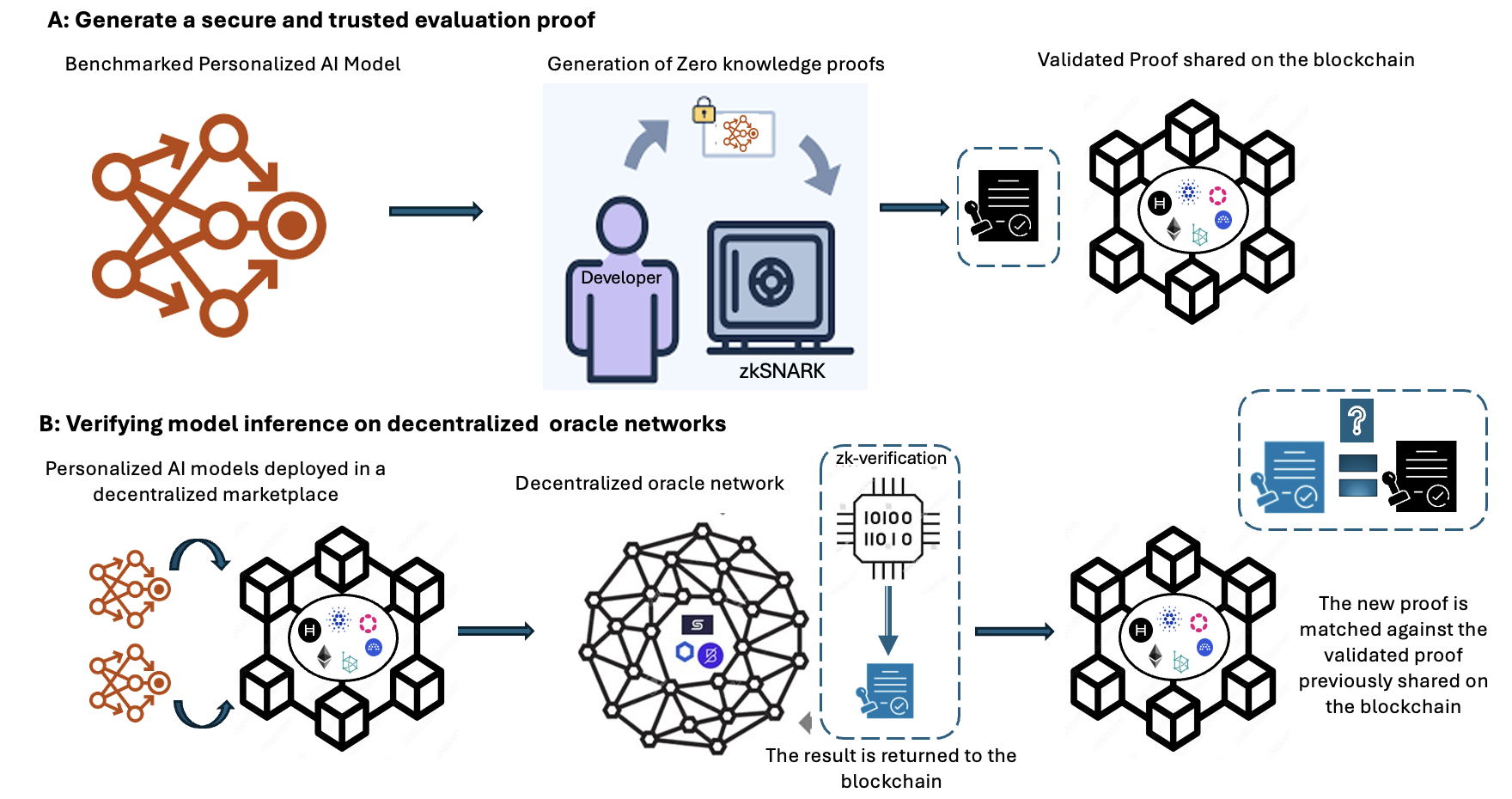
### Visual Description
## Technical Diagram: Secure AI Model Evaluation and Verification via Zero-Knowledge Proofs
### Overview
The image is a two-part technical diagram illustrating a cryptographic workflow for establishing trust in personalized AI models. It details a process for generating a verifiable proof of a model's performance and subsequently verifying its inferences in a decentralized environment using zero-knowledge proofs (specifically zkSNARKs) and blockchain technology.
### Components/Axes
The diagram is divided into two primary horizontal sections, labeled **A** and **B**, each depicting a sequential process flow from left to right.
**Section A: Generate a secure and trusted evaluation proof**
* **Stage 1 (Left):** Labeled "Benchmarked Personalized AI Model". Represented by an orange network graph icon with interconnected nodes and arrows.
* **Stage 2 (Center):** Labeled "Generation of Zero knowledge proofs". This is a composite illustration containing:
* A purple human figure icon labeled "Developer".
* A blue safe/vault icon labeled "zkSNARK".
* A circular arrow flow connecting the developer, a lock icon, and a document icon with a neural network symbol.
* **Stage 3 (Right):** Labeled "Validated Proof shared on the blockchain". Represented by a black blockchain network icon (hexagonal arrangement of cubes) containing a central document icon with a checkmark and various cryptographic symbols (e.g., "H", a diamond, a gear).
**Section B: Verifying model inference on decentralized oracle networks**
* **Stage 1 (Left):** Labeled "Personalized AI models deployed in a decentralized marketplace". Shows two orange AI model network icons feeding into a black blockchain network icon (identical to the one in Section A, Stage 3).
* **Stage 2 (Center):** Labeled "Decentralized oracle network". Represented by a complex, interconnected black network sphere containing small icons (a blue "S", a purple hexagon, a blue gear).
* **Stage 3 (Center-Right):** A dashed box labeled "zk-verification". Contains:
* A chip/processor icon displaying binary code ("10100", "11010").
* An arrow pointing down to a blue document icon with a checkmark.
* Text below: "The result is returned to the blockchain".
* **Stage 4 (Right):** Shows the black blockchain network icon again. To its right, a dashed box contains a question mark icon, an equals sign, and two document icons (one blue with a checkmark, one black with a checkmark). Accompanying text: "The new proof is matched against the validated proof previously shared on the blockchain".
### Detailed Analysis
The diagram outlines a two-phase cryptographic protocol:
**Phase A (Proof Generation):**
1. A personalized AI model is benchmarked.
2. A developer uses a zkSNARK system to generate a zero-knowledge proof. This proof cryptographically attests to the model's performance (e.g., its accuracy on a benchmark) without revealing the model's proprietary weights or the specific test data.
3. This validated proof is published and stored on a blockchain, creating an immutable, timestamped record.
**Phase B (Inference Verification):**
1. The same AI model is deployed for use in a decentralized marketplace.
2. When a user or system requests an inference (a prediction or output) from the model, the request is processed through a decentralized oracle network.
3. The oracle network performs a "zk-verification" step. It generates a new zero-knowledge proof for that specific inference.
4. This new proof is sent back to the blockchain.
5. The blockchain system automatically matches this new inference proof against the original, validated performance proof stored in Phase A. A match confirms that the inference was correctly generated by the authentic, benchmarked model.
### Key Observations
* **Visual Consistency:** The orange network icon consistently represents the AI model. The black blockchain icon is used in both phases, linking the proof storage and verification steps.
* **Flow Direction:** Both processes use clear left-to-right arrows to indicate sequential steps.
* **Cryptographic Core:** The "zkSNARK" safe and the "zk-verification" chip are central visual metaphors for the privacy-preserving and verifiable computation at the heart of the system.
* **Decentralization Elements:** The "decentralized oracle network" is depicted as a complex, peer-to-peer mesh, contrasting with the more structured blockchain icon.
### Interpretation
This diagram presents a solution to the "black box" problem in AI deployment. It proposes a system where:
1. **Trust is Established:** A model's capabilities are cryptographically certified once (Phase A).
2. **Trust is Maintained:** Every subsequent use of that model can be independently verified to ensure it is the genuine, certified model producing the output, and that the output is correct (Phase B).
The system leverages blockchain as a trust anchor for storing the original proof and coordinating verification. Zero-knowledge proofs are the critical enabling technology, allowing verification without exposing sensitive intellectual property (the model) or user data. The "decentralized oracle network" suggests the verification process itself is distributed, avoiding a single point of failure or trust.
**Notable Implication:** This architecture could enable a marketplace for AI models where users can trust the model's advertised performance without having to trust the model provider blindly, and providers can protect their IP. It shifts trust from the provider to mathematics and decentralized networks.
</details>
Figure 2: A high-level overview of the system design.
Technologies like Zero-Knowledge Succinct Non-Interactive Arguments of Knowledge (zk-SNARKs) can help address trust and model privacy issues in this context. zk-SNARKs provide powerful cryptographic proofs that verify the correctness of computations without revealing the underlying data [7]. However, using zk-SNARKs to verify AI models’ integrity and performance claims on blockchain-based marketplaces presents several challenges. Firstly, the compactness of zk-SNARK verification proofs is offset by the substantial resources needed for proof verification, potentially causing bottlenecks [8], especially when the blockchain handles multiple transactions and interactions simultaneously. Secondly, the computational intensity of zk-SNARK proofs involves complex mathematical computations that are both time-consuming and costly in terms of blockchain gas fees on platforms like Ethereum [8]. Furthermore, verifying claims of AI models using zk-SNARKs often requires external data inaccessible within the blockchain [9]. These considerations highlight the need for a decentralized approach that leverages off-chain computation for data collection and verification, and on-chain verification to optimize the performance and scalability of blockchain-based AI marketplaces.
Decentralized oracles are critical in bridging blockchain technology with the external world to validate transactions. They present untapped potential for verifying AI models in marketplaces. By bridging the digital and physical realms, oracles can conduct rigorous assessments of AI models’ claims, ensuring they meet high standards before being made available. This paper explores a novel approach as shown in Fig. 2 that integrates zk-SNARKS on Chainlink’s [10] decentralized oracle network with blockchain to verify AI models. This approach could revolutionize the development and distribution of personalized AI services by enhancing trust in blockchain-enabled AI marketplaces. This approach has practical applications across various sectors that require verifiable computation, such as finance, healthcare, education and supply chain management, where accurate AI model predictions are critical and transparency is paramount. By implementing such a solution, we can create a more open, equitable, and reliable AI marketplace, driving the next wave of advancements in AI technology.
### 1.1 Contributions
This paper addresses the challenges of secure and efficient verification of personalized AI models in a blockchain-enabled AI marketplace. We present a comprehensive study using zk-SNARKs and Chainlink oracles. The key contributions of this paper are as follows:
- A novel comprehensive framework that leverages decentralized oracles (Chainlink) to validate unverified data from off-chain data sources for zk-SNARK proof verification, ensuring transparent and trustless verification of AI models on blockchain while preserving model privacy.
- A working implementation that integrates zk-SNARKs with Chainlink oracles, demonstrating their practical use in AI model verification scenarios.
- Analysis of the efficiency and resource consumption of zk-SNARK proof generation and verification to identify key areas for optimization.
- Analysis of the computational costs such as transaction fees and LINK token costs associated with zk-SNARK verification’s, providing insights into the costs involved.
This article is organised as follows. Section II provides an overview of relevant work, emphasising current research on verification of AI models in decentralized settings. Section III covers the system architecture and is divided into four subsections: A, B and C. Subsection A describes the method used to generate a secure and evaluation proof. Subsection B describes the method used to verify model inference while subsection C provides an overview of the proposed framework, D describes the proposed system model. Section IV describes the experimental setup, whereas Section V presents the results and their interpretation. Finally, in Section VI, we summarise our findings and conclusions and outline areas for further research.
## 2 Literature Review
Recent advances in AI models have led to significant progress in various decentralized systems, particularly in the integration of AI with blockchain technology. This development has huge potential for revolutionizing various industries and domains [11]. The benefits of this integration as highlighted by [12] and [13] include improved system performance and a more equitable development of AI. Furthermore, various techniques and applications of decentralized AI, such as decentralized machine learning (ML) frameworks and distributed AI marketplaces are explored in [14].
Traditional trust mechanisms for ensuring the trustworthiness of AI models have been extensively researched, with various approaches proposed. Key issues include transparency and interpretability [15], robustness and fairness [16], uncertainty quantification [17], and causal reasoning [18]. Transparency and interpretability are crucial for building trust in AI models and making the decision-making process understandable to humans. Techniques such as model visualization, saliency maps, Local Interpretable Model-agnostic Explanations (LIME), and SHapley Additive exPlanations (SHAP) support these goals [15]. Robustness and fairness are also vital components of trustworthy AI systems, with techniques like adversarial training and data augmentation enhancing robustness against attacks, while debiasing algorithms and fairness constraints mitigate discriminatory biases [16]. Uncertainty quantification, using methods such as Bayesian neural networks, ensemble methods, and conformal prediction, provides a measure of confidence in AI model predictions, particularly important in critical domains such as healthcare and autonomous systems [17]. Causal reasoning, facilitated by tools such as causal inference, structural causal models, and counterfactual reasoning, is essential for achieving a more interpretable and robust decision-making framework in AI models [18].
Despite these multi-faceted strategies for developing trustworthy centralized AI systems, traditional trust mechanisms often fail to preserve data privacy and confidentiality in decentralized systems, where data is replicated across multiple nodes. In addition, decentralized systems face scalability and performance limitations, making it challenging to handle large-scale applications and high transaction volumes using traditional centralised approaches. Major challenges of traditional trust mechanisms in decentralized environments include the lack of a central authority, identity verification issues, Sybil attacks, scalability and consistency issues, and legal and regulatory uncertainty [19], [20], [21].
The landscape of AI has entered a new era with the advent of blockchain-enabled AI marketplaces. These marketplaces enable individuals and organisations to decentralise AI models’ sharing, trading, and utilisation, in a manner that democratises access to advanced AI technologies [6]. Despite their numerous benefits, decentralized marketplaces present unique challenges for authenticating and verifying AI models. The diversity and volume of AI models exchanged on these platforms render traditional centralised verification and validation processes impractical. Consequently, there is an urgent need for novel approaches to perform these crucial functions efficiently and dependably. The Neuromation platform is an AI marketplace that leverages synthetic data for training models, substantially reducing the time and cost associated with developing AI models. Additionally, they possess a distributed computing platform designed for model training
Chainlink is a pioneering decentralized oracle network that seamlessly connects smart contracts on blockchains with off-chain data and systems [10]. As a secure middleware, it enables blockchain applications to reliably access and leverage real-world information, unlocking a vast array of innovative use cases. At its core, Chainlink employs a decentralized network of independent oracle nodes that retrieve and deliver data to smart contracts, mitigating single points of failure [22]. Through crypto-economic incentives and penalties, it ensures the reliability and correctness of oracles, even against well-resourced adversaries.
Chainlink enhances blockchain scalability and efficiency by enabling secure off-chain computations and data processing, which are then integrated on-chain, facilitating the development of advanced hybrid smart contracts [22]. Through its confidentiality measures and trust minimization achieved via decentralization and cryptographic assurances, Chainlink acts as a secure conduit between blockchains and real-world data, driving the evolution and broader adoption of sophisticated decentralized applications across various sectors [23]. Recent research suggests that the integration of AI and blockchain could be further enhanced with Chainlink [24], which ensures the integrity and transparency of data inputs used in AI models, thereby providing a robust foundation for the ethical and verifiable deployment of AI technologies.
Verification and validation (V&V) are necessary quality assurance procedures for preserving the trust and dependability of AI systems. Verification ensures that the AI model was implemented accurately and behaved as intended per its mathematical description [25]. It is comparable to "building the model properly." Validation, conversely, guarantees that the AI model satisfies the requirements of the context or problem it was designed to solve – it involves "building the right model". Despite their robust capabilities, AI models occasionally generate inaccurate predictions and manifest unintended behaviour.
These risks may be exacerbated in high-stakes domains such as healthcare or finance, where errors may result in severe adverse outcomes, from incorrect medical diagnoses to substantial financial losses. This makes V&V processes essential for the safety and dependability of AI systems, assuring that their decisions are accurate, trustworthy, and dependable [26]. As these models take on increasingly complex duties, their verification and validation become paramount [27]. These procedures are essential for maintaining confidence in AI systems because they help identify and mitigate risks associated with inaccurate predictions or biased outcomes [26].
A key challenge in AI is verifying personalized, closed-source models in a way that safeguards sensitive information, preserves intellectual property, and enhances transparency, as traditional methods often rely on trust or costly re-evaluation. To this end, zero-knowledge proofs have emerged as a powerful tool for privacy-preserving authentication [28]. This cryptographic technique allows one party to prove to another that a given statement is true, without revealing any additional information about the statement. Initially, the zk proofs were designed to be interactive and could not be re-verified multiple times by other validators without creating new interactions. This led to the development of Non-Interactive Zero-knowledge Proofs (NIZKPs) [29], allowing the zero-knowledge proofs to be re-verified by multiple parties.
There are several popular implementations of zero-knowledge proofs, including zk-SNARKs [30], Zero-Knowledge Scalable Transparent Argument of Knowledge (zk-STARKs) [31] and bulletproofs [32]. One of the primary differences between zk-SNARKs, zk-STARKs and bulletproofs is the trusted setup process. An initial trusted setup process is required for zk-SNARKs and it’s not required by zk-STARKs and bulletproofs. zk-STARKs have larger proof sizes, resulting in higher verification costs and storage requirements on the blockchain. Bulletproofs have smaller proof sizes but require interactive verification, which is less practical for decentralized systems. Beyond zero-knowledge proof systems, there exist other cryptographic techniques for verifying computations with privacy guarantees, such as Homomorphic Encryption (HE), Verifiable Computing (VC) [33] and Secure Multiparty Computation (MPC) [34]. While these methods are widely used for general secure computation and data confidentiality, they are not specifically tailored for AI-based tasks.
For this research, we consider zk-SNARKS, despite their reliance on a trusted setup. zk-SNARKs achieves significantly smaller proof sizes compared to zk-STARKs and bulletproofs, resulting in smaller shorter verification times and less gas cost [35]. In the context of personalized AI models, zk-SNARKs can be leveraged to verify the correctness of a model’s predictions without disclosing the underlying model parameters or training data [36]. This is particularly relevant when AI models are deployed in environments handling sensitive user data.
The US Department of Energy implemented a secure neural network verification system using zk-SNARKs for Nuclear Treaty Verification [37]. This proposed system allows to verify the neural network output, input hash and Rivest–Shamir–Adleman (RSA) signature with zk proof, enabling a secure, adaptable way to disclose sensitive data on nuclear materials and facilities. The work by [38] investigates verifiable evaluation attestations using zk-SNARKs, enabling independent validation of model performance claims without exposing the models’ internal weights or outputs. Here the authors employ a "predict, then prove" strategy, where models are converted to a standard format, evaluated on benchmark datasets, and proofs of correct inference are generated. These proofs are aggregated into attestations that can be independently verified.
The authors in [39] presented a practical approach to verify ML model inference for a full-resolution ImageNet model using zk-SNARKs and explore other scenarios such as verifying MLaaS predictions and accuracy. The zk-SNARKs enabled a non-interactive way to verify ML model execution and achieved 79% accuracy. A scheme called zkCNN was proposed to prove the accuracy of a convolution neural network (CNN) model’s predictions using public dataset to others without revealing sensitive information about the model [40].
Based on our literature review, it is evident that technologies like zk-SNARKs can help address trust and AI model privacy issues in this context [37], [38], [39], [40]. However, using zk-SNARKs to verify AI models’ integrity and performance claims on blockchain-based marketplaces presents several challenges. Verifying claims of AI models using zk-SNARKs often requires external data inaccessible within the blockchain [9]. Similar to the work in [40], models can be trained on public datasets and to prove the model accuracy claims, access to high quality public datasets are required. The compactness of zk-SNARK verification proofs is offset by the substantial resources needed for proof verification, potentially causing bottlenecks [8], [41] especially when the blockchain handles multiple transactions and interactions simultaneously. Secondly, the computational intensity of zk-SNARK proofs involves complex mathematical computations that are both time-consuming and costly [42] especially in terms of blockchain gas fees on platforms like Ethereum [8]. These considerations highlight the need for a decentralized approach that leverages off-chain computation for data collection and verification and on-chain zk verification to optimize the performance, scalability and enhancing trust within blockchain-based AI marketplaces.
This paper addresses existing gaps by proposing a novel framework that leverages zk-SNARKs integrated with Chainlink oracles to verify AI model performance claims on blockchain platforms. Our approach allows for the verification of personalized AI models without disclosing sensitive information, preserving intellectual property and enhancing transparency. We demonstrate our approach with a linear regression model predicting Bitcoin prices using on-chain data, verified on the Sepolia testnet.
<details>
<summary>x1.png Details</summary>
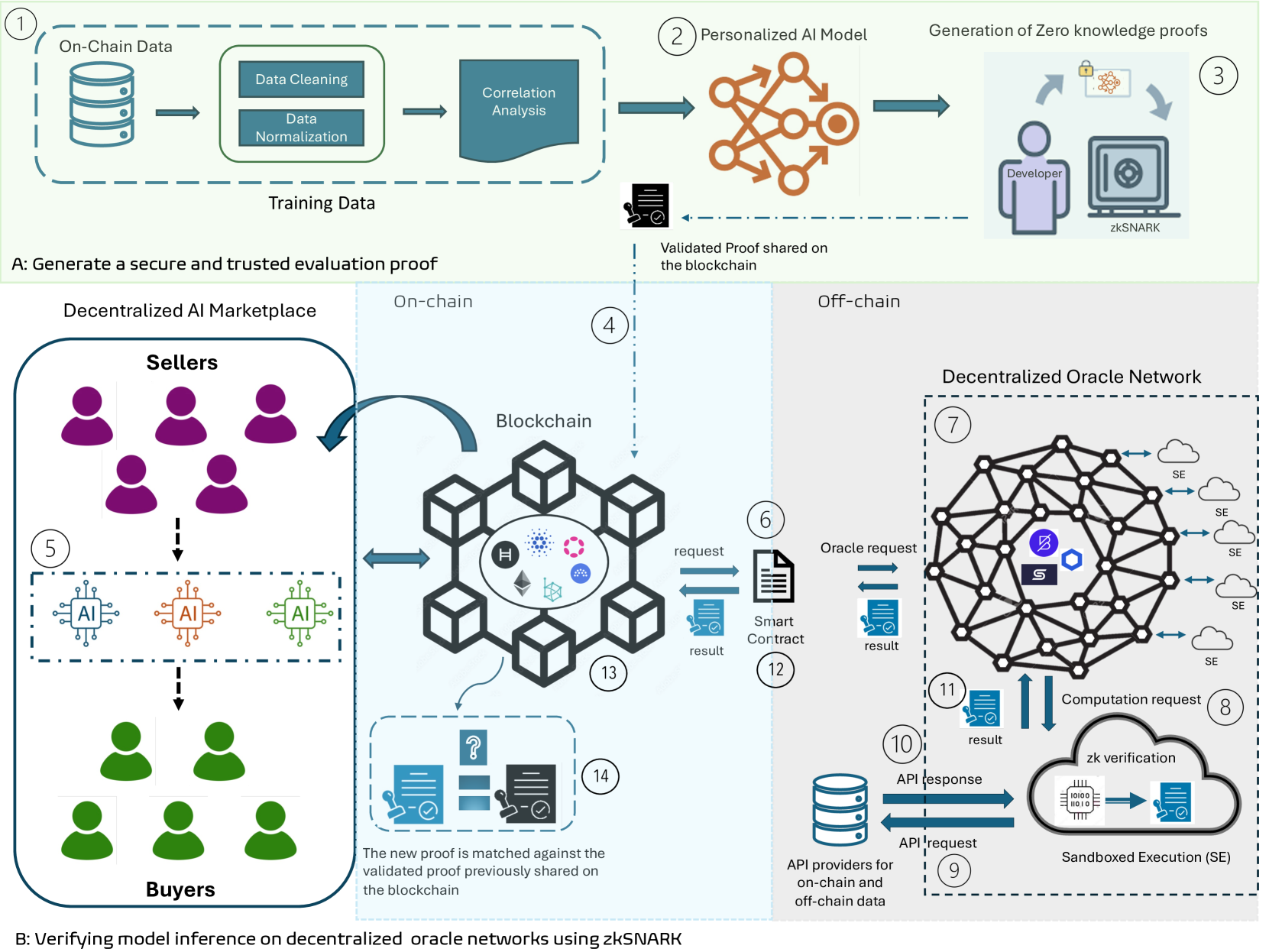
### Visual Description
## System Architecture Diagram: Decentralized AI Marketplace with zkSNARK Verification
### Overview
This image is a technical system architecture diagram illustrating a two-part process for creating and verifying AI models in a decentralized marketplace. The diagram is divided into two main sections labeled **A** and **B**, connected by a dashed line representing the flow of a "Validated Proof." The overall system combines on-chain (blockchain) and off-chain (oracle network) components to enable secure, trustless AI model evaluation and inference.
### Components/Axes
The diagram is structured into distinct regions and components, each with specific labels and functions.
**Part A: Generate a secure and trusted evaluation proof** (Top section, light green background)
* **1. On-Chain Data:** Represented by a database icon. This is the starting point.
* **Training Data Processing Pipeline:** A dashed box containing:
* **Data Cleaning** (blue box)
* **Data Normalization** (blue box)
* **Correlation Analysis** (blue box)
* **2. Personalized AI Model:** Represented by a neural network icon.
* **3. Generation of Zero knowledge proofs:** Shows a developer icon, a zkSNARK icon, and a lock icon, indicating the creation of a cryptographic proof.
* **Output:** A document icon labeled "Validated Proof shared on the blockchain" connects Part A to Part B.
**Part B: Verifying model inference on decentralized oracle networks using zkSNARK** (Bottom section, light blue background)
This section is divided into three vertical zones: **Decentralized AI Marketplace** (left), **On-chain** (center), and **Off-chain** (right).
* **Decentralized AI Marketplace (Left Zone):**
* **Sellers:** Represented by purple person icons.
* **5. AI Models:** Three distinct AI chip icons (blue, orange, green) in a dashed box, representing models for sale.
* **Buyers:** Represented by green person icons.
* **Flow:** Sellers provide AI models, which are then available to Buyers.
* **On-chain (Center Zone):**
* **4. Blockchain:** A central hexagonal network diagram containing logos for Hyperledger (H), Ethereum (ETH), and others.
* **13. Blockchain Interaction:** Arrows show data flow to/from the blockchain.
* **14. Proof Matching:** A dashed box showing a question mark icon and two document icons with checkmarks. Text: "The new proof is matched against the validated proof previously shared on the blockchain."
* **Off-chain (Right Zone):**
* **6. Smart Contract:** A document icon that sends a "request" and receives a "result."
* **7. Decentralized Oracle Network:** A large, complex network diagram with interconnected nodes. It contains logos for Chainlink (link icon) and API3 (hexagon icon).
* **8. Computation request:** An arrow pointing from the Oracle Network to a cloud.
* **9. API providers for on-chain and off-chain data:** A database icon.
* **10. API request/response:** Arrows showing communication between the Oracle Network and API providers.
* **11. Result:** A document icon returning from the Oracle Network.
* **12. Result:** A document icon returning to the Smart Contract.
* **Sandboxed Execution (SE):** A cloud icon containing a chip and a document icon, labeled "zk verification." Multiple "SE" clouds are connected to the Oracle Network.
**Numbered Process Steps:** The diagram includes circled numbers (1 through 14) indicating a sequential or logical flow of operations, though the exact sequence is not strictly linear.
### Detailed Analysis
The diagram details a multi-stage workflow:
1. **Proof Generation (Part A):** On-chain data is cleaned, normalized, and analyzed to train a personalized AI model. A developer then uses zkSNARK technology to generate a cryptographic proof of the model's properties or performance. This "Validated Proof" is shared on the blockchain.
2. **Marketplace & Verification (Part B):**
* Sellers list AI models in a decentralized marketplace.
* A buyer's interaction triggers a **Smart Contract (6)** on the blockchain.
* The Smart Contract sends an **Oracle request (7)** to a **Decentralized Oracle Network**.
* The Oracle Network coordinates a **Computation request (8)** to **Sandboxed Execution (SE)** environments for secure, verified processing. It also fetches necessary data via **API requests (9, 10)** to external providers.
* Results are returned through the Oracle Network **(11)** to the Smart Contract **(12)**.
* Crucially, the system performs **Proof Matching (14)**: the new proof generated from the inference is matched against the original "Validated Proof" stored on the blockchain to ensure the model's integrity and correct execution.
### Key Observations
* **Hybrid Architecture:** The system explicitly separates on-chain (blockchain, smart contracts) and off-chain (oracle network, API providers, sandboxed execution) components, highlighting a common pattern in decentralized applications.
* **zkSNARK Integration:** Zero-knowledge proofs are used in two key places: initially to create a trusted evaluation proof (Part A) and later for verification within the sandboxed execution environment (Part B, SE cloud).
* **Trust Model:** The architecture aims to create trust between anonymous sellers and buyers in a marketplace by using cryptographic proofs and decentralized verification, removing the need for a central trusted authority.
* **Complex Flow:** The numbered steps (1-14) suggest a complex, multi-transaction process involving data preparation, model training, proof generation, marketplace listing, request handling, off-chain computation, and on-chain verification.
### Interpretation
This diagram outlines a sophisticated framework for a **trustless AI economy**. It addresses the core problem of verifying that an AI model sold in a decentralized marketplace is both the one advertised and that it performs computations correctly, without requiring the buyer to trust the seller or a central platform.
* **How Elements Relate:** The "Validated Proof" from Part A is the linchpin. It acts as a cryptographic benchmark stored immutably on the blockchain. Part B's entire verification process (steps 11-14) exists to check new model inferences against this benchmark. The Decentralized Oracle Network acts as the secure bridge between the deterministic blockchain and the external world (APIs, computation), while zkSNARKs provide the mathematical guarantees for verification.
* **Purpose:** The system enables **verifiable AI-as-a-service**. A buyer can purchase an inference from a model and receive not just the result, but also a cryptographic proof that the result was generated correctly by the specific, validated model.
* **Notable Anomalies/Considerations:** The diagram is conceptual and does not specify the blockchain platform, the exact zk-SNARK circuit design, or the economic incentives for oracle nodes and sellers. The complexity of the flow (14 steps) implies significant overhead, which would be a practical consideration for implementation. The security of the entire system hinges on the correctness of the initial proof generation (Part A) and the security of the sandboxed execution environments (SE).
</details>
Figure 3: Proposed verification framework.
## 3 Methodology and System Design
This section describes the methodology as shown in Fig. 3 for verifying the performance claims of a personalized AI model without revealing weights and are trained on on-chain and user-specific data to predict Bitcoin prices. The verification process is computed on Chainlink’s decentralised oracle network using zk-SNARKs. We divide the section into two parts and explain these parts with respect to Fig. 3. In Part A, we provide the system overview of our proposed framework. Part B outlines the steps to generate a secure and trusted evaluation proof and Part C describes the verification process for the model inference on a decentralized oracle network using zk-SNARKs.
### 3.1 System Overview
Trust is a major concern for users in the Web3 domain, particularly on the blockchain. Trust issues also extend to the blockchain-enabled AI marketplace, where the credibility of developers’ performance claims for personalized AI models is questioned. The blockchain-enabled AI marketplace combines on-chain and off-chain elements to enhance the verifiability of verifications. The framework represented in Fig. 3 is specifically designed to enable personalized AI model performance verification using zk-SNARKs. The interaction between on-chain smart contracts and off-chain Chainlink oracles is crucial for the functioning of the blockchain-enabled AI marketplace. The interaction guarantees that the data, computation, and proof validation are carried out securely and efficiently. We analyze the on-chain data from external API providers and eliminate inaccurate data points. The data is carefully scaled to uncover and examine the connections between important data points in the model’s output. After the training and testing of the personalized AI model, developers generate zk-SNARK proofs to verify the AI model’s claim without exposing sensitive data such as model weights. These verifiable proofs are shared on the blockchain.
Prior to purchasing the personalized AI model, the buyer demands proof to verify the performance claim of the personalized AI model. The decentralized oracle network is used for verification using the Chainlink Functions, as requested by the blockchain. The Chainlink nodes facilitates the coordination of data acquisition from external API providers for on-chain data and the execution of computations. Each node in the Chainlink carries out sandboxed execution of the provided source code to ensure transparency. The aggregated results are sent to the smart contract using Chainlink’s Off-Chain Reporting (OCR) protocol [43]. The smart contract on Sepolia receives the aggregated result and zk-SNARK proof.
The blockchain verifies the proof using stored verification keys and updates the state of the blockchain based on the verification outcome. Verified proofs are stored on-chain for future reference, ensuring a transparent and tamper-proof record of all computations. This framework provides a practical approach to verifying personalized AI models. Incorporating zk-SNARK ensures the privacy of model weights during verification, enhancing trust and transparency in AI model marketplaces. The integration of zk-SNARKs into Chainlink functions facilitates secure and reliable data fetching and computation, offering a robust AI model verification framework that can be implemented in real-world scenarios.
To summarize the interactions in the proposed verification framework, Fig. 3 represents the framework for verifying personalized AI model performance using zk-SNARKs. In Step 1, The process begins with developers training personalized AI models, followed by data cleaning, normalization, and correlation analysis. In Step 2, developers generate zk-SNARK proofs to verify model performance claims without revealing sensitive data and upload these proofs to the blockchain. In Step 3, buyers initiate verification requests, which the decentralized oracle network processes by fetching data from external APIs and performing zk-SNARK verification in a sandboxed environment. In Step 4, the Chainlink oracles communicates results back to the blockchain smart contract via Chainlink’s Off-Chain Reporting protocol. In Step 5, the blockchain then validates the proofs using stored verification keys and updates the state of the decentralized marketplace, ensuring a transparent and tamper-proof record of all zk-SNARK verifications.
### 3.2 Generate a Secure and Evaluation Proof
#### 3.2.1 Personalized AI model - Introduction to Personalization
Personalized AI models provide customized predictions by utilizing on-chain data and user data. For example, the model can be personalized when predicting Bitcoin prices to consider the user’s unique trading patterns, preferences, and other data points affecting their investment choices.
Data Collection:
Developers acquire on-chain data in two ways. The first method involves collecting and processing raw on-chain data from the public Bitcoin blockchain. The second method uses external application programming interface (API) providers where the on-chain data is already preprocessed and ready to use. We obtained on-chain data from 2016 to 2023 from API providers such as [44], [45]. With the on-chain data collected from these sources, we categorized and analyzed metrics from each category against Bitcoin’s price. We also use user-specific data such as transaction history and wallet activity. The following metrics are obtained from the on-chain data; block size, block height, transaction count, daily active addresses, miners revenue, miner fees, miner to exchanges, total new addresses, transactions rate, transfers count, hash rate, transactions difficulty, transfer rate, wallets address with greater than 1, 10 and 100 coins, exchange deposits, exchange withdrawals and total addresses.
Data Analysis:
The on-chain data closely correlating to the bitcoin price are identified. This step involves using a Pearson and Spearman correlation analysis to understand the linear and non-linear relationship between the on-chain datasets and the bitcoin price. The Pearson correlation can be represented by equation (1)
$$
r=\frac{\sum_{i=1}^{n}(x_{i}-\bar{x})(y_{i}-\bar{y})}{\sqrt{\sum_{i=1}^{n}(x_{
i}-\bar{x})^{2}\sum_{i=1}^{n}(y_{i}-\bar{y})^{2}}} \tag{1}
$$
where:
- $x_{i}$ is the $i$ -th data point of features of on-chain data
- $y_{i}$ is the $i$ -th data point of bitcoin price
- $\bar{x}$ is the mean of the $x$ values
- $\bar{y}$ is the mean of $y$ values
- $n$ is the total number of data points
The Spearman rank correlation coefficient [46] is a nonparametric measurement correlation used to evaluate the monotonic relationship between two variables.
$$
\rho=1-\frac{6\sum{d_{i}}^{2}}{n({n}^{2}-1)} \tag{2}
$$
In (2), the difference between the ranks of the $i$ -th pair of values is represented by $d_{i}$ and $n$ represents the total number of data points.
Pearson correlation coefficients are used to quantify the linear connection between variables. In contrast, Spearman correlation coefficients are only applicable to monotonic connections, in which variables tend to move in the same or opposite direction but not necessarily at the same rate. In a linear relationship, the rate is constant.
We re-scale the data between the range [0,1]. The normalization value is calculated using equation (3).
$$
z=\frac{x_{i}-\min(x)}{\max(x)-\min(x)} \tag{3}
$$
By conducting correlation analysis, we can pinpoint important on-chain metrics that can be incorporated into advanced predictive algorithms. Conversely, we can also identify metrics that could be more relevant and should be considered.
Introduction to zk-SNARKs:
A zk-SNARK allows a prover to convince a verifier that they know a solution to a computational problem without disclosing the solution itself. These proofs are short and fast to verify, and they do not require ongoing interaction between the prover and the verifier after the initial setup. A zk-SNARK system comprises three core algorithms: Generation (Gen), Prover (P) and Verification (V).
Non-Interactive Zero-Knowledge Argument
The arithmetic circuits in zk-SNARKs play a critical role in representing the computational problem that the prover aims to demonstrate to the verifier that it has been solved correctly. In the context of the non-interactive zero-knowledge argument, let $C$ be an arithmetic circuit such that $C:F^{n}\times F^{n^{\prime}}\rightarrow F^{l}$ . Here, $F$ denotes a finite field and $F^{n}$ represents a vector space of dimension $n$ over the finite field $F$ . Similarly, $F^{n^{\prime}}$ and $F^{l}$ indicate vector spaces of dimensions $n^{\prime}$ and $l$ over $F$ , respectively. The NP language $L$ is defined as the set of statements $x$ in $F^{n}$ for which there exists a valid witness $w$ in $F^{n^{\prime}}$ . This is represented by the relation $R$ defined as $R:=\{(x,w)\in F^{n}\times F^{n^{\prime}}\}$ , where $w$ is the witness and $x$ is the statement.
A non-interactive zero-knowledge argument for the relation $R$ consists of the triple of polynomial-time algorithms: Generation (Gen), Prover (P), and Verification (V).
- Generation (Gen): Produces a common reference string (crs) and a private verification state.
$$
(\text{crs})\leftarrow\text{Gen}(1^{n},R)
$$
- Prover (P): Produces a proof $\pi$ for a statement $x$ using a witness $w$ .
$$
\pi\leftarrow\text{P}(\text{crs},x,w)
$$
- Verification (V): Verifies the proof $\pi$ for the statement $x$ .
$$
\text{V}(\text{crs},x,\pi)\rightarrow\{0,1\}
$$
Properties of zk-SNARKs
The following properties [47] must be met by a non-interactive zero-knowledge proof $\pi$ for the relation $R$ :
- Completeness: For a statement $x\in F^{n}$ with a witness $w\in F^{n^{\prime}}$ such that $(x,w)\in R$ , the prover acting honestly always produces a valid proof $\pi$ . This proof should be sufficient to convince an honest verifier. The completeness of the non-interactive zero-knowledge proof can be expressed as follows [48]:
$$
\Pr\left[\begin{array}[]{c}(\text{crs})\leftarrow\text{Gen}(1^{n},R)\\
\pi\leftarrow\text{P}(\text{crs},x,w)\\
\text{V}(\text{crs},x,\pi)=1\text{ if }(x,w)\in R\end{array}\right]=1 \tag{4}
$$
- Soundness: When an adversary attempts to deceive by providing a proof $\pi$ for a false statement $x\notin R$ , the verification algorithm V is designed to have a high probability of rejecting the proof. Any evidence $\pi$ offered by an adversary will be rejected with a high probability due to the soundness requirement, which ensures that $x$ must be in the relation $R$ [28]:
$$
\Pr\left[\begin{array}[]{c}(\text{crs})\leftarrow\text{Gen}(1^{n},R)\\
(x,\pi)\leftarrow\mathcal{A}(\text{crs})\\
\text{V}(\text{crs},x,\pi)=1\text{ and }(x,w)\notin R\end{array}\right]\leq
\text{negl}(n) \tag{5}
$$
Furthermore, suppose there is an extractor $\mathcal{E}$ that can generate the witness $w\leftarrow\mathcal{E}_{\mathcal{A}}(\text{crs})$ based on the output of an adversary $\mathcal{A}$ , which produces a valid argument $(x,\pi)\leftarrow\mathcal{A}(\text{crs})$ :
$$
\Pr\left[\begin{array}[]{c}(\text{crs})\leftarrow\text{Gen}(1^{n},R)\\
(x,\pi)\leftarrow\mathcal{A}(\text{crs})\\
w\leftarrow\mathcal{E}_{\mathcal{A}}(\text{crs})\\
\text{V}(\text{crs},x,\pi)=1\text{ and }(x,w)\notin R\end{array}\right]\leq
\text{negl}(n) \tag{6}
$$
- Zero-Knowledge: This characteristic ensures that the verifier only gains knowledge of the statement’s truth. In zk-SNARKs, Tau refers to the trusted setup parameter generated during the initial phase, creating a secure cryptographic environment. The Powers of Tau (PoT) ceremony generates these parameters, which are necessary for generating and verifying zk-SNARK proofs, ensuring privacy. In the Phase 2, the crs is further refined to support the specific zk-SNARK application, introducing additional complexity as it tailors the parameters to the operations of the AI model being verified. Together, PoT and Phase 2 form the backbone of the trusted setup, ensuring a robust and reliable foundation for zk-SNARK operations. Without knowing the witness $w$ , the proof or argument $\pi$ for a valid assertion $x$ can be simulated using a polynomial-time procedure known as a simulator. Simulator 1 $(S_{1})$ generates a simulated proof based on the crs and the random Tau parameter. This demonstrates that the proof system can function without accessing private data thus maintaining the zero-knowledge property. Simulator 2 $(S_{2})$ simulates the zk-SNARK proof using the input, output pair and a random Tau. This confirms that the system can generate valid proofs without revealing sensitive information, completing the zero-knowledge simulation. The zero-knowledgeness can be expressed as follows [48]:
$$
\Pr\left[\begin{array}[]{c}(\text{crs})\leftarrow\text{Gen}(1^{n},R)\\
(x,w)\leftarrow\mathcal{A}(\text{crs})\\
\pi\leftarrow\text{P}(\text{crs},x,w)\\
\mathcal{A}(\pi)=1\end{array}\right]=\Pr\left[\begin{array}[]{c}(\text{crs},
\tau)\leftarrow S_{1}(1^{n},R)\\
(x,w)\leftarrow\mathcal{A}(\text{crs})\\
\pi\leftarrow S_{2}(\text{crs},x,\tau)\\
\mathcal{A}(\pi)=1\end{array}\right] \tag{7}
$$
#### 3.2.2 Conversion of Linear Regression Model to zk-SNARK Circuit for Validation
We use zk-SNARKs to generate verifiable computations on-chain of the model without revealing its weights. The linear regression model is converted into a zk-SNARK circuit to represent the model’s internal operations. The following steps are used in converting the linear regression model into a zk-SNARK circuit:
Step 1: Model Representation
The developer trains the personalized AI model, specifically a linear regression model that predicts Bitcoin prices based on historical on-chain data. The model takes various features (independent variables) from the on-chain data and user-specific data, such as transaction history and wallet activity of the user, and predicts the price (dependent variable) of Bitcoin. The linear regression model is represented using (8):
$$
y=a_{0}+a_{1}x_{1}+a_{2}x_{2}+\ldots+a_{n}x_{n}+C \tag{8}
$$
where:
- $y$ is the predicted bitcoin price.
- $x_{i}$ are the features of on-chain and user-specific data.
- $a_{i}$ are the coefficients (weights) learned during training.
- $C$ is the intercept.
Step 2: Arithmetic Circuit Construction
The linear regression model equation is converted into an arithmetic circuit to permit proving zk-SNARK based computational statements. Each mathematical operation in the linear regression model is mapped to a multiplication and addition gate in zk-SNARKs. For example, the operation $a_{1}x_{1}$ is handled by multiplication gates and sum $a_{0}$ + $a_{1}x_{1}$ is handled by addition gates. The final output $y$ is computed by using addition gates adding all terms together. This process transforms the linear regression equation into an arithmetic circuit that is compatible with zk-SNARKs.
Step 3: QAP Conversion
The models arithmetic circuit are converted into a QAP, providing a framework for zk-SNARKs to check the correctness of the operations in the arithmetic circuit. A QAP for a function $f$ is defined by three sets of polynomials $\{v_{i}(x)\},\{w_{i}(x)\},\{y_{i}(x)\}$ and a target polynomial $t(x)$ .
For an arithmetic circuit $C$ with $m$ gates:
$$
p(x)=\left(\sum_{i=0}^{m}a_{i}\cdot v_{i}(x)\right)\cdot\left(\sum_{i=0}^{m}a_
{i}\cdot w_{i}(x)\right)-\left(\sum_{i=0}^{m}a_{i}\cdot y_{i}(x)\right) \tag{9}
$$
where $t(x)$ divides $p(x)$ and $a_{i}$ represents the coefficients of the polynomials.
The QAP introduces constraints that must be satisfied to ensure all operations in the arithmetic circuit are represented correctly in zk-SNARK form. The complexity of these QAP constraints increases with larger number of features in the linear regression model. As the complexity of the AI models increases, it will require more number of gates to represent model internal operations, leading to higher computational resources and longer proof generation times.
Step 4: zk-SNARK Proof Generation and Verification
The prover generates a proof $\pi$ demonstrating they know $\{a_{i}\}$ satisfying the Quadratic Arithmetic Program (QAP) equations:
$$
\pi=(A,B,C) \tag{10}
$$
where:
$$
A=\sum_{i=0}^{m}a_{i}\cdot g^{v_{i}(s)},\quad B=\sum_{i=0}^{m}a_{i}\cdot g^{w_
{i}(s)},\quad C=\sum_{i=0}^{m}a_{i}\cdot g^{y_{i}(s)}
$$
The polynomials ${v_{i}(s)},{w_{i}(s)},{y_{i}(s)}$ represent the QAP for the arithmetic circuit. These polynomials are evaluated at a secret value $s$ . The components of the zk-SNARK proof are represented by $A,B,C$ and the generator of a cryptographic group by $g$ , which is used to generate all the elements of the group through its powers. The verifier checks the proof by ensuring:
$$
e(A,B)=e(g,C)\cdot e(g^{t(s)},g) \tag{11}
$$
where $e(A,B)$ represents the bilinear pairing function used for verification and $t(s)$ is the target polynomial evaluated at the secret value $s$ .
### 3.3 Verifying Model Inference on Decentralized Oracle Network Using zk-SNARKs
In this paper, we use the Chainlink Decentralized Oracle Network (DON), hereafter referred to as Chainlink oracles, to perform off-chain computations and relay data to the blockchain. The blockchain component in our framework is represented by the Sepolia testnet, which serves as a proxy for a production blockchain environment. Chainlink Functions enable smart contracts to access a computing infrastructure that is trust-minimized. Smart contracts can access on-chain and off-chain data from APIs and perform personalized computations. By seamlessly integrating these functions with the Sepolia testnet, we can efficiently execute zero-knowledge (zk) verification computations on chainlink’s decentralized oracle network, ensuring that verified results are returned to the blockchain.
Smart contracts utilize the Chainlink nodes to retrieve data from external APIs by sending requests for source code. Every node in the Chainlink carries out the code within a secure and sandboxed execution, efficiently handling the required computations. The zk-SNARK circuits use the obtained data to perform computations without disclosing confidential details. The process yields zk-SNARK proofs that showcase accurate computation using input data. The results are sent to the Sepolia testnet through smart contracts after completing the necessary proofs. These smart contracts validate the proofs and update the state of the blockchain. Once the results have been verified, they can be easily accessed in other smart contracts, ensuring secure and reliable interactions.
## 4 Experimental Setup
The experimental setup used in our study consists of two phases: the proof generation phase and the proof verification phase. The proof generation phase involves an in-depth exploration of the processing environment and configuration details pertinent to a personalized AI model’s zk proof generation process. The proof verification phase delves into the implementation steps associated with deploying zero-knowledge proof on the blockchain and verifying zero-knowledge proofs using Chainlink oracles.
### 4.1 Proof Generation Phase
The proof generation setup uses an NVIDIA Jetson TX2, a cutting-edge device known for its high computational power and energy efficiency. The specifications of NVIDIA are listed in Table 1.
| CPU | 6 ARM Cortex-A57 |
| --- | --- |
| GPU | 256-core NVIDIA Pascal |
| Memory | 8GB LPDDR4 |
Table 1: Nvidia Jetson TX2 specifications
We selected this device due to its suitability for AI applications, which are known to require significant computational resources. Our objective was to develop zk-SNARK circuits designed to generate zero-knowledge proofs. These circuits are specifically tailored for a linear regression model, utilizing characteristics obtained from the on-chain data of Bitcoin as a CSV file. The linear regression model coefficients, including the model weights, were saved in a JSON file. We used Python scripts to automate the process of generating circuit files. These scripts received the JSON data and produced multiple Circom files, each representing a distinct number of weights.
Creating and confirming proofs involves building zk circuits using the Circom programming language, generating witnesses, and then proving and checking the proofs using the Snarkjs library. The automated script managed the complete procedure, encompassing compilation, witness production, contribution to the ceremony, preparation for phase 2, zkey generation, and proof generation and verification. We used the Circom tool to generate a smart contract-based verifier that allows proofs to be verified on the blockchain. Remix was used to deploy the Verifer smart contract on the blockchain. The trusted setup was conducted by a consortium of stakeholders, including model developers, auditors and decentralized oracle providers. This collaborative approach ensures trust in the setup process and mitigates the risk of a single point of failure.
### 4.2 Proof Verification Phase
For this experiment, we chose the Sepolia testnet because it is widely used among developers and one of the few testnets supported by Chainlink. The experimental findings are relevant and applicable to live production settings like the Ethereum main network. We deployed the verifier smart contract on the testnet for zk verification purposes, ensuring the thoroughness of our testing process.
We set up Chainlink Functions to integrate the decentralized oracle network to the Sepolia testnet. We cloned the Chainlink Functions starter kit from the official GitHub repository [49].
This configuration offered the essential resources to interact with the blockchain and Chainlink oracle networks. Subsequently, we modified the Functions request configuration file to explicitly define the source code for API calls and perform computations based on the smart contract request. We established the environment variables using encrypted data for access. This process involved establishing the environment variable file’s password and configuring the environment variable by specifying the key and value. We used four keys to setup the experiment:
- A private key obtained from the MetaMask wallet.
- An Remote Procedure Call (RPC) URL derived from the Alchemy website for the Sepolia testnet.
- An API token for GitHub.
- An API for the blockchain explorer Etherscan
<details>
<summary>extracted/6340811/12.png Details</summary>

### Visual Description
## Screenshot: Blockchain Contract Deployment Log
### Overview
The image is a screenshot of a terminal or command-line interface displaying log output from a blockchain development tool. The text documents the process of deploying and verifying a smart contract named `FunctionsConsumer` on the Ethereum Sepolia test network. The output is presented as a series of timestamped or sequential status messages.
### Components/Axes
The image contains only textual log entries. There are no graphical axes, charts, or legends. The text is monospaced, typical of a terminal console, and appears in a light color (likely white or light gray) against a dark background.
### Detailed Analysis
The following text is transcribed from the image, line by line:
1. `Waiting 2 blocks for transaction 0x7fdca8a958ef7c843a02fbb7fe8bad116b4201579e615d97dbd04b2ef46ec8e2 to be confirmed...`
* **Content:** A status message indicating the system is waiting for blockchain confirmations for a specific transaction.
* **Key Data:** Transaction Hash: `0x7fdca8a958ef7c843a02fbb7fe8bad116b4201579e615d97dbd04b2ef46ec8e2`
2. `Deployed FunctionsConsumer contract to: 0xe953b197CC443e3d8664962C1e1d40abc33701d`
* **Content:** A confirmation that the contract named `FunctionsConsumer` has been deployed.
* **Key Data:**
* Contract Name: `FunctionsConsumer`
* Deployed Contract Address: `0xe953b197CC443e3d8664962C1e1d40abc33701d`
3. `Verifying contract...`
* **Content:** A status message indicating the start of the contract verification process on a block explorer (e.g., Etherscan).
4. `The contract 0xe953b197CC443e3d8664962C1e1d40abc33701d has already been verified`
* **Content:** A status message indicating the verification step was skipped because the contract's source code was already verified on the block explorer.
* **Key Data:** Confirms the contract address from line 2.
5. `Contract verified`
* **Content:** A final confirmation of the verification status.
6. `FunctionsConsumer contract deployed to 0xe953b197CC443e3d8664962C1e1d40abc33701d on ethereumSepolia`
* **Content:** A summary line confirming the successful deployment and network.
* **Key Data:**
* Contract Name: `FunctionsConsumer`
* Deployed Contract Address: `0xe953b197CC443e3d8664962C1e1d40abc33701d` (matches lines 2 & 4)
* Network: `ethereumSepolia` (Ethereum's Sepolia test network)
### Key Observations
* **Successful Deployment:** The log sequence indicates a successful deployment of the `FunctionsConsumer` contract.
* **Pre-verified Contract:** The contract source code was already verified on the block explorer before the deployment script attempted verification, suggesting it may have been deployed previously or the verification was handled in an earlier step.
* **Test Network:** The deployment target is explicitly stated as `ethereumSepolia`, confirming this is a testnet deployment, not on the Ethereum mainnet.
* **Consistent Address:** The contract address `0xe953b197CC443e3d8664962C1e1d40abc33701d` is consistently reported across multiple log lines.
### Interpretation
This log output captures a routine but critical phase in smart contract development: deploying code to a test blockchain and ensuring its source code is publicly verifiable. The process shown is likely automated via a development framework (like Hardhat or Foundry).
The key takeaway is the successful deployment of the `FunctionsConsumer` contract to the Sepolia testnet. The "already verified" status is a positive sign, indicating the contract's source code is publicly available and matches the deployed bytecode on the block explorer. This is essential for transparency and trust, allowing users and other developers to inspect the contract's logic. The use of the Sepolia testnet confirms this is a development or testing activity, allowing for safe experimentation before any potential mainnet deployment. The transaction hash provided in the first line could be used to look up the specific deployment transaction on a Sepolia block explorer for further details like gas used and exact block number.
</details>
Figure 4: Oracle functions consumer contract deployed to Sepolia.
Upon configuring the environment variables, the functions consumer contract was successfully deployed to the Sepolia testnet, as shown in Fig. 4, completing the integration with Chainlink oracles.
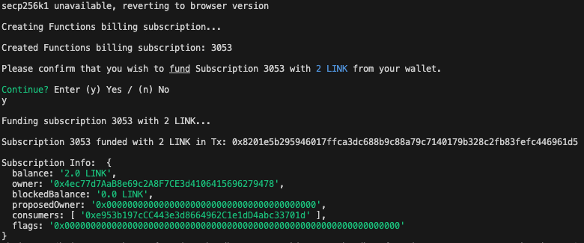
The consumer contract address is used to create and fund the billing subscription for Chainlink Functions, as shown in Fig. 5 using LINK tokens acquired via the Chainlink Faucet.
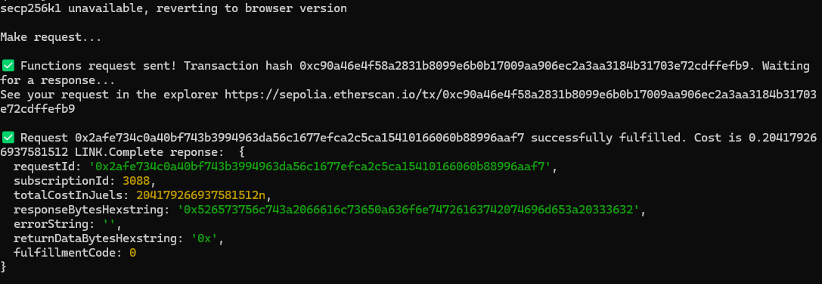
The Chainlink’s smart contract requests the nodes to perform zk computations and return the result. The proof size of our model is 806 bytes and the verification key size is 2922 bytes. The script runs the functions in a sandbox environment, as seen in Fig. 5 before making an on-chain transaction to ensure they are correctly configured and the fulfilment costs are estimated before making the request. As shown in Fig. 6, chain data retrieval was implemented by pushing API queries to external API providers for on-chain data utilizing the Chainlink Functions.
<details>
<summary>extracted/6340811/123.png Details</summary>
### Visual Description
## Terminal Output: Blockchain Subscription Funding Transaction
### Overview
The image is a screenshot of a terminal or command-line interface displaying the process of funding a blockchain-based subscription service using LINK cryptocurrency tokens. The output shows a sequence of system messages, user prompts, and transaction confirmation data.
### Components/Axes
The content is structured as a chronological log of a command-line interaction:
1. **Initial System Message**: A cryptographic library fallback notice.
2. **Subscription Creation**: A billing subscription is initiated.
3. **User Prompt**: A confirmation request to fund the subscription.
4. **User Input**: The user's affirmative response.
5. **Funding Execution**: A message indicating the funding process has started.
6. **Transaction Confirmation**: A success message with a transaction hash.
7. **Subscription Details**: A structured data block (JSON-like) showing the subscription's state post-funding.
### Detailed Analysis
The text is transcribed verbatim below. All text is in English.
**Line-by-Line Transcription:**
1. `secp256k1 unavailable, reverting to browser version`
* *Note: secp256k1 is the elliptic curve used by Bitcoin and Ethereum for digital signatures.*
2. `Creating Functions billing subscription...`
3. `Created Functions billing subscription: 3053`
4. `Please confirm that you wish to fund Subscription 3053 with 2 LINK from your wallet.`
5. `Continue? Enter (y) Yes / (n) No`
6. `y`
* *This is the user's input.*
7. `Funding subscription 3053 with 2 LINK...`
8. `Subscription 3053 funded with 2 LINK in Tx: 0x8201e5b295946017ffca3dc688b9c88a79c7140179b328c2fb83fefc446961d5`
* *Tx: Transaction Hash.*
9. `Subscription Info: {`
10. ` balance: '2.0',`
11. ` usedBalance: '0.27708668692A0F7CE34106415696279478',`
12. ` blockedBalance: '0.0 LINK',`
13. ` proposedOwner: '0x0000000000000000000000000000000000000000',`
14. ` consumers: [ '0x95b019cc11483e3800044962c1e1804abc237810' ],`
15. ` flags: '0x0000000000000000000000000000000000000000000000000000000000000000'`
16. `}`
### Key Observations
* **Transaction Success**: The primary action—funding subscription #3053 with 2 LINK tokens—was successful, as confirmed by the transaction hash.
* **Balance State**: Post-funding, the subscription's `balance` is exactly '2.0' (LINK). The `usedBalance` shows a non-zero value (~0.277 LINK), indicating some funds have already been consumed or allocated, possibly for prior operations or fees.
* **Zero Addresses**: The `proposedOwner` and `flags` fields are set to zero-address values, suggesting these features are not currently configured or active for this subscription.
* **Single Consumer**: The subscription has one authorized `consumer` address listed.
* **Library Fallback**: The initial line indicates a software environment where the native `secp256k1` cryptographic library was not available, causing a fallback to a browser-based implementation.
### Interpretation
This log captures a routine but critical administrative action within a blockchain-based service ecosystem, likely related to Chainlink Functions or a similar decentralized oracle network. The user is allocating financial resources (LINK tokens) to a specific subscription contract (ID: 3053) to pay for future computational services or data requests.
The presence of a `usedBalance` alongside a fresh `balance` suggests this is a top-up transaction for an existing, active subscription rather than the creation of a new one. The single `consumer` address implies a specific smart contract or externally owned account is authorized to spend from this subscription's balance. The zeroed `proposedOwner` and `flags` indicate a simple, default configuration. The transaction hash is the immutable proof of this funding event on the blockchain.
</details>
Figure 5: Funding the subscription
<details>
<summary>extracted/6340811/n123.png Details</summary>
### Visual Description
## Terminal/Console Output: Blockchain Transaction Log
### Overview
The image displays a terminal or console output showing the process and result of a blockchain transaction, likely on the Ethereum Sepolia test network. It details a request being sent, a transaction hash being generated, and the subsequent fulfillment of that request with associated data.
### Components/Axes
The output is structured as a series of text lines, primarily in green and white on a black background. Key components include:
1. **Status Message:** `secp256k1 unavailable, reverting to browser version`
2. **Action Prompt:** `Make request...`
3. **Transaction Submission Log:** Details of a sent function request.
4. **Request Fulfillment Log:** Details of the completed request response.
### Detailed Analysis
The text can be segmented into two main blocks:
**Block 1: Transaction Submission**
* **Line 1:** `Functions request sent! Transaction hash 0xc90a46e4f58a2831b8099e6b0b17009aa906ec2a3aa3184b31703e72cdffefb9. Waiting for a response...`
* **Line 2:** `See your request in the explorer https://sepolia.etherscan.io/tx/0xc90a46e4f58a2831b8099e6b0b17009aa906ec2a3aa3184b31703e72cdffefb9`
**Block 2: Request Fulfillment**
* **Line 1:** `Request 0x2afe734c0a40bf743b3994963da56c1677efca2c5ca15410166060b88996aaf7 LINK.Complete reponse. Cost is 0.2841792696397581512n`
* **Data Object (Key-Value Pairs):**
* `requestId: '0x2afe734c0a40bf743b3994963da56c1677efca2c5ca15410166060b88996aaf7'`
* `subscriptionId: 3088`
* `totalCostInJuels: 2841792696397581512n`
* `responseBytesHexstring: '0x526573756c743a2066616c6c65642062656361757365206973206e6f7420612076616c696420726573706f6e73652e'`
* `errorString: ''`
* `returnDataBytesHexstring: '0x'`
* `fulfillmentCode: 0`
### Key Observations
1. **Successful Transaction:** The process completed successfully, indicated by `LINK.Complete reponse` and a `fulfillmentCode` of `0`.
2. **Cost:** The transaction cost `0.2841792696397581512n` LINK (the native token of the Chainlink network). The `n` suffix denotes a BigInt number.
3. **Identifiers:** A unique `requestId` and a `subscriptionId` (3088) are provided for tracking.
4. **Response Data:** The `responseBytesHexstring` contains a hex-encoded message. Decoding this hex string reveals the text: `Result: failed because is not a valid response.`
5. **No Errors:** The `errorString` is empty, and `returnDataBytesHexstring` is `0x` (empty), suggesting the primary response was carried in the `responseBytesHexstring` field.
### Interpretation
This log captures a complete lifecycle of a decentralized request, likely using the Chainlink Functions service. A user or contract initiated a request (transaction hash provided), which was later fulfilled by the Chainlink network.
The critical piece of information is the decoded response: **"Result: failed because is not a valid response."** This indicates that while the Chainlink node successfully processed and delivered the request (hence the `fulfillmentCode: 0`), the *result of the computation or data fetch* itself was a failure. The external data source or computation returned an invalid or erroneous result.
The cost in LINK and the subscription model (`subscriptionId`) are standard for Chainlink's decentralized services. The initial `secp256k1 unavailable` message suggests the environment may have fallen back to a different cryptographic library, which is a technical note but did not prevent the transaction from proceeding.
**In summary:** The image documents a technically successful blockchain transaction that delivered a failed business logic result. The infrastructure worked, but the requested task could not be completed successfully by the external system.
</details>
Figure 6: Chainlink functions API and computation Output
## 5 Experimental Results and Analysis
<details>
<summary>extracted/6340811/Distribution.png Details</summary>
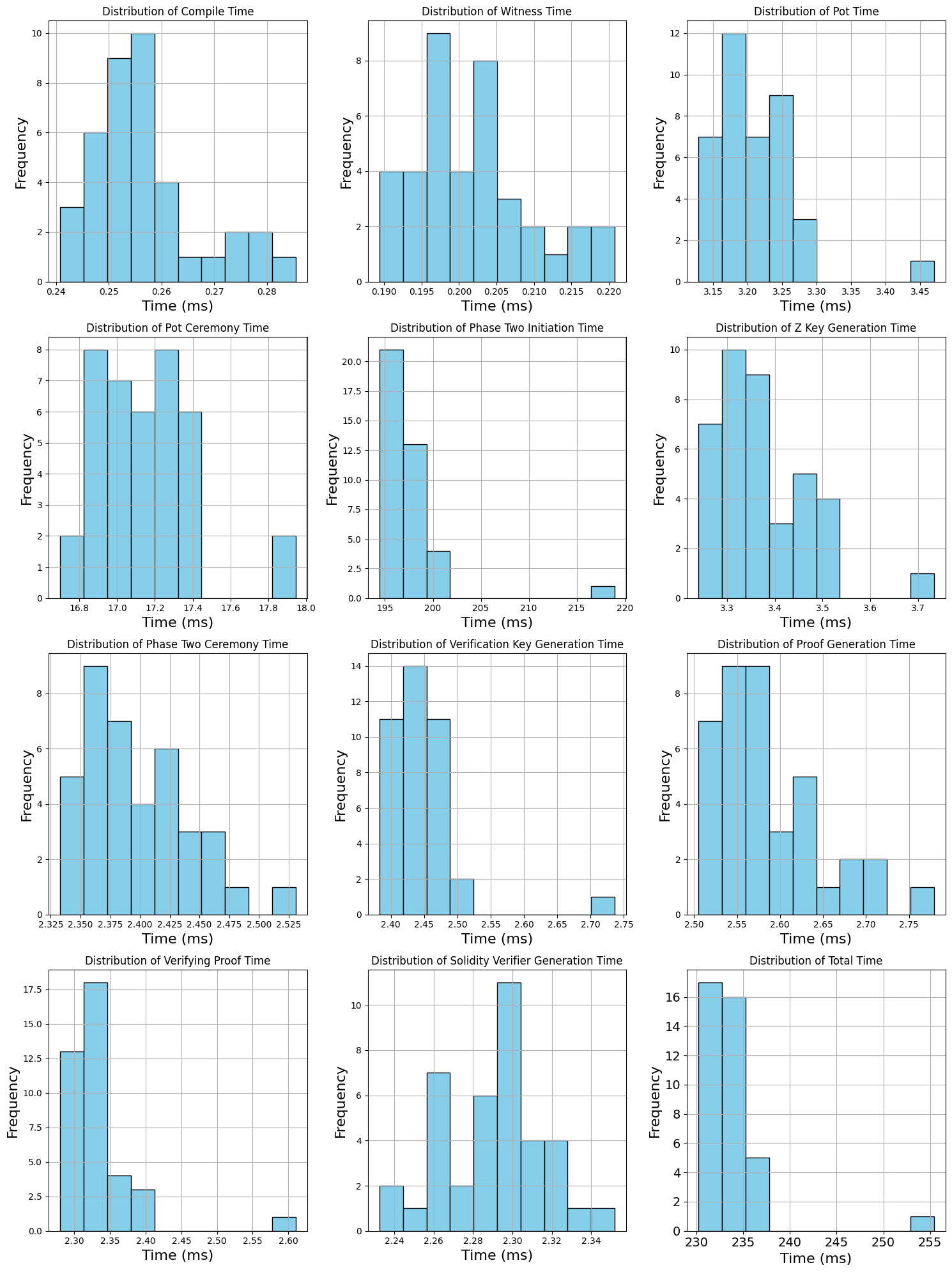
### Visual Description
\n
## Histograms: Performance Timing Distributions
### Overview
The image displays a 4x3 grid of 12 individual histograms. Each histogram visualizes the frequency distribution of execution times (in milliseconds, ms) for a specific step or component of a computational process, likely related to a cryptographic protocol or zero-knowledge proof system. All plots share the same visual style: light blue bars with black outlines on a white background with gray grid lines.
### Components/Axes
* **Grid Structure:** 12 separate plots arranged in 4 rows and 3 columns.
* **Common Elements per Plot:**
* **Title:** Each plot has a unique title at the top, following the pattern "Distribution of [Process Name] Time".
* **X-axis:** Labeled "Time (ms)" for all plots. The scale and range vary significantly between plots.
* **Y-axis:** Labeled "Frequency" for all plots. The scale varies between plots.
* **Plot Titles (in reading order, left-to-right, top-to-bottom):**
1. Distribution of Compile Time
2. Distribution of Witness Time
3. Distribution of Pot Time
4. Distribution of Pot Ceremony Time
5. Distribution of Phase Two Initiation Time
6. Distribution of Z Key Generation Time
7. Distribution of Phase Two Ceremony Time
8. Distribution of Verification Key Generation Time
9. Distribution of Proof Generation Time
10. Distribution of Verifying Proof Time
11. Distribution of Solidity Verifier Generation Time
12. Distribution of Total Time
### Detailed Analysis
**Row 1:**
1. **Compile Time:** X-axis range ~0.24 to 0.285 ms. Distribution is roughly unimodal, peaking at the bin centered near 0.255 ms with a frequency of 10. The distribution is slightly right-skewed.
2. **Witness Time:** X-axis range ~0.190 to 0.220 ms. Distribution is bimodal, with a primary peak at ~0.197 ms (frequency ~9) and a secondary peak at ~0.203 ms (frequency 8).
3. **Pot Time:** X-axis range ~3.15 to 3.45 ms. Distribution is right-skewed with a primary peak at ~3.17 ms (frequency 12) and a notable outlier bin at ~3.45 ms (frequency 1).
**Row 2:**
4. **Pot Ceremony Time:** X-axis range ~16.8 to 18.0 ms. Distribution is roughly bimodal, with peaks at ~16.9 ms and ~17.3 ms (both frequency 8). There is a gap and a small outlier bin at ~17.9 ms (frequency 2).
5. **Phase Two Initiation Time:** X-axis range ~195 to 220 ms. Distribution is heavily right-skewed. The highest frequency bin is at the far left (~195 ms, frequency >20). Frequencies drop sharply, with a very small outlier bin at ~218 ms (frequency 1).
6. **Z Key Generation Time:** X-axis range ~3.25 to 3.7 ms. Distribution is right-skewed, peaking at ~3.3 ms (frequency 10). There is a gap and a small outlier bin at ~3.7 ms (frequency 1).
**Row 3:**
7. **Phase Two Ceremony Time:** X-axis range ~2.325 to 2.525 ms. Distribution is right-skewed, peaking at ~2.36 ms (frequency ~9).
8. **Verification Key Generation Time:** X-axis range ~2.40 to 2.75 ms. Distribution is right-skewed, peaking at ~2.44 ms (frequency 14). There is a gap and a small outlier bin at ~2.72 ms (frequency 1).
9. **Proof Generation Time:** X-axis range ~2.50 to 2.75 ms. Distribution is right-skewed, with two high-frequency bins at ~2.54 ms and ~2.56 ms (both frequency ~9).
**Row 4:**
10. **Verifying Proof Time:** X-axis range ~2.30 to 2.60 ms. Distribution is right-skewed, peaking at ~2.32 ms (frequency ~18). There is a gap and a small outlier bin at ~2.58 ms (frequency 1).
11. **Solidity Verifier Generation Time:** X-axis range ~2.24 to 2.34 ms. Distribution is roughly bimodal, with peaks at ~2.26 ms (frequency 7) and ~2.30 ms (frequency 11).
12. **Total Time:** X-axis range ~230 to 255 ms. Distribution is right-skewed. The highest frequency bin is at the far left (~230 ms, frequency ~17). Frequencies drop sharply, with a gap and a small outlier bin at ~254 ms (frequency 1).
### Key Observations
1. **Vastly Different Time Scales:** The processes operate on different orders of magnitude. "Compile Time" and "Witness Time" are sub-millisecond. "Pot Ceremony Time" is ~17 ms. "Phase Two Initiation Time" is ~200 ms. "Total Time" is ~230-255 ms.
2. **Common Distribution Shape:** 10 of the 12 histograms exhibit a right-skewed (positively skewed) distribution, indicating that most runs complete near the lower end of the time range, with a long tail of slower runs.
3. **Presence of Outliers:** Several plots (Pot Time, Z Key Generation Time, Verification Key Generation Time, Verifying Proof Time, Total Time) show isolated bins at the high end of their ranges, suggesting occasional runs that are significantly slower than the norm.
4. **Bimodal Distributions:** "Witness Time" and "Solidity Verifier Generation Time" show clear bimodal patterns, which could indicate two distinct operational modes or conditions affecting performance.
5. **Dominant Component:** "Phase Two Initiation Time" (~200 ms) and the sum of other components suggest it is a major contributor to the "Total Time" (~230-255 ms).
### Interpretation
This set of histograms provides a performance profile for a multi-stage computational pipeline. The data suggests:
* **Performance Bottlenecks:** The "Phase Two Initiation Time" is the single largest time component, making it the primary candidate for optimization. The "Total Time" distribution closely mirrors its shape, confirming its dominance.
* **Process Stability:** The right-skew and outlier bins across many stages indicate that while the system performs consistently most of the time, there are sporadic instances of significant slowdowns. Investigating the cause of these outliers (e.g., resource contention, specific input characteristics) could improve reliability.
* **Operational Modes:** The bimodal distributions for "Witness Time" and "Solidity Verifier Generation Time" are particularly interesting. They imply the existence of two common performance profiles for these steps, which could be triggered by different code paths, hardware states, or input data types.
* **System Context:** The terminology ("Witness," "Pot," "Ceremony," "Z Key," "Verification Key," "Proof," "Solidity Verifier") strongly indicates this is a performance analysis of a zero-knowledge proof system (like zk-SNARKs) or a related cryptographic protocol, possibly involving a trusted setup ceremony. The "Total Time" likely represents the end-to-end latency for generating and verifying a proof.
In summary, this is a detailed performance benchmark revealing the timing characteristics, bottlenecks, and variability of a complex cryptographic computation.
</details>
Figure 7: Distribution analysis for each phase of zk generation.
<details>
<summary>extracted/6340811/Avg_Time_Gen_Bar.png Details</summary>
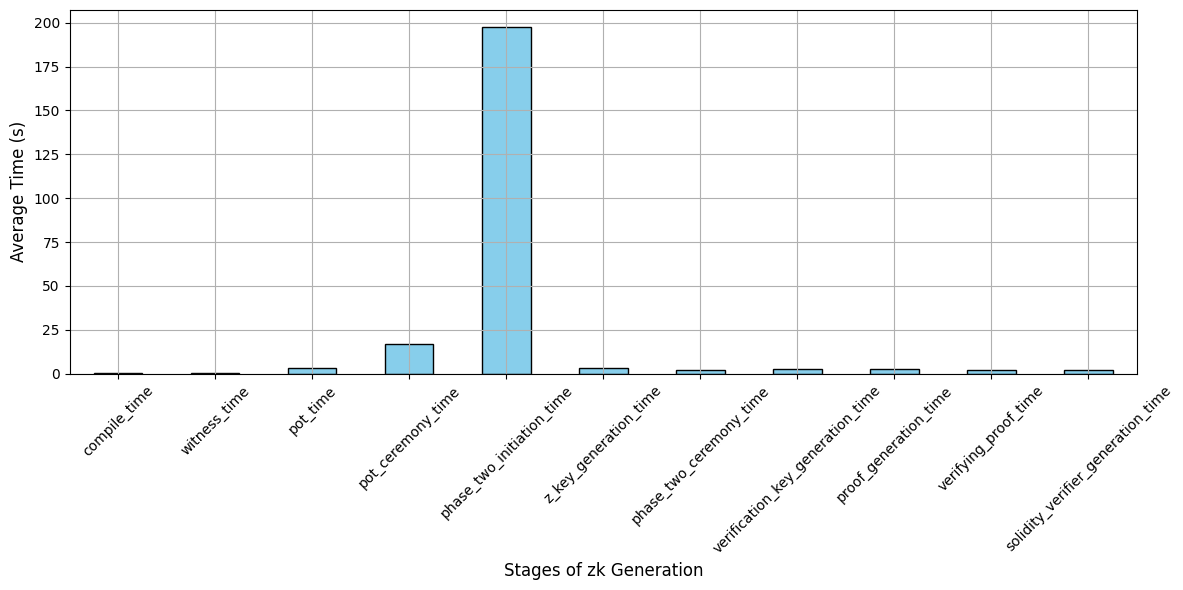
### Visual Description
## Bar Chart: Stages of zk Generation
### Overview
This is a vertical bar chart illustrating the average time, measured in seconds, required for various stages in a "zk Generation" process. The chart reveals a highly skewed distribution, with one stage consuming the vast majority of the total time, while all other stages are comparatively very fast.
### Components/Axes
* **Chart Title:** "Stages of zk Generation" (located at the bottom center, below the x-axis).
* **Y-Axis:**
* **Label:** "Average Time (s)"
* **Scale:** Linear scale from 0 to 200 seconds, with major gridlines at intervals of 25 seconds (0, 25, 50, 75, 100, 125, 150, 175, 200).
* **X-Axis:**
* **Label:** "Stages of zk Generation"
* **Categories (from left to right):**
1. `compile_time`
2. `witness_time`
3. `pot_time`
4. `pot_ceremony_time`
5. `phase_two_initiation_time`
6. `z_key_generation_time`
7. `phase_two_ceremony_time`
8. `verification_key_generation_time`
9. `proof_generation_time`
10. `verifying_proof_time`
11. `solidity_verifier_generation_time`
* **Data Series:** A single series represented by light blue bars with black outlines. There is no legend, as there is only one data series.
### Detailed Analysis
The following table reconstructs the approximate data from the chart. Values are estimated based on the bar heights relative to the y-axis gridlines. Bars that are barely visible are noted as having a negligible time.
| Stage (X-axis Category) | Approximate Average Time (s) | Visual Trend & Notes |
| :--- | :--- | :--- |
| `compile_time` | ~0.5 s | Extremely low, bar is a thin line just above the axis. |
| `witness_time` | ~0.5 s | Extremely low, bar is a thin line just above the axis. |
| `pot_time` | ~4 s | Very low, bar reaches slightly below the 25s gridline. |
| `pot_ceremony_time` | ~17 s | Low, bar is clearly visible, reaching about 2/3 of the way to the 25s gridline. |
| **`phase_two_initiation_time`** | **~198 s** | **Dominant outlier.** Bar extends almost to the 200s gridline, dwarfing all others. |
| `z_key_generation_time` | ~4 s | Very low, similar height to `pot_time`. |
| `phase_two_ceremony_time` | ~3 s | Very low, slightly shorter than `z_key_generation_time`. |
| `verification_key_generation_time` | ~3 s | Very low, similar height to `phase_two_ceremony_time`. |
| `proof_generation_time` | ~3 s | Very low, similar height to `verification_key_generation_time`. |
| `verifying_proof_time` | ~3 s | Very low, similar height to `proof_generation_time`. |
| `solidity_verifier_generation_time` | ~3 s | Very low, similar height to `verifying_proof_time`. |
### Key Observations
1. **Extreme Outlier:** The `phase_two_initiation_time` stage is the overwhelming bottleneck, taking approximately 198 seconds. This single stage accounts for roughly 85-90% of the total visible time across all stages.
2. **Cluster of Low-Time Stages:** Ten out of the eleven stages have average times below 20 seconds. Within this group, there are two sub-clusters:
* **Negligible Time (<1s):** `compile_time` and `witness_time`.
* **Low Time (3-17s):** The remaining eight stages (`pot_time` through `solidity_verifier_generation_time`, excluding the outlier).
3. **Visual Disparity:** The chart's visual impact is defined by the stark contrast between the single, very tall bar and the series of very short bars, immediately drawing the viewer's attention to the `phase_two_initiation_time` stage.
### Interpretation
The data demonstrates that the zk (zero-knowledge) generation process, as profiled here, is not uniformly time-consuming. Its performance is dominated by a single, computationally intensive phase: **`phase_two_initiation_time`**.
* **Process Implication:** Efforts to optimize the overall zk generation workflow should be almost exclusively focused on the `phase_two_initiation` stage. Even a 50% reduction in this stage's time would yield a greater overall speedup than completely eliminating all other stages combined.
* **Architectural Insight:** The significant time cost of `phase_two_initiation` suggests it may involve complex cryptographic operations, large data processing, or network-dependent steps (like a multi-party ceremony setup) that are fundamentally more demanding than the subsequent proof generation and verification steps.
* **Anomaly Note:** The `pot_ceremony_time` (~17s) is notably higher than the other low-time stages but is still an order of magnitude smaller than the primary outlier. This might represent a secondary, but still minor, optimization target.
* **Efficiency of Later Stages:** The consistently low times for stages like `proof_generation_time` and `verifying_proof_time` indicate that, once the initial setup (`phase_two_initiation`) is complete, the core cryptographic proof operations are highly efficient in this implementation.
</details>
Figure 8: Average time taken for each stage of zk generation.
Our experimental setup aimed to replicate real-life scenarios for deploying and verifying personalized AI models in a blockchain-enabled AI marketplace. Our study is the first to utilize the Chainlink oracle network to compute and evaluate the efficiency of the zk verification for personalized AI models. We used NVIDIA Jetson TX2 to simulate the developer’s process of generating zk-SNARK proofs for their trained personalized AI models before deployment. The zk-SNARK verification was conducted on the Sepolia testnet, and the zk verification computations were performed using Chainlink oracles to ensure secure and reliable verification.
We assess the efficiency and resource consumption of the zk-SNARK generation and verification process for personalized AI models. We also evaluate the overheads introduced by blockchain and Chainlink oracles during the verification process. This study aims to demonstrate the feasibility and effectiveness of using zk-SNARKs and Chainlink oracles to verify personalized AI models securely and efficiently.
The time analysis of zk-SNARK proof generation and verification involved examining various stages as shown in Fig. 7 and Fig. 8 and focusing on their duration and variability using a distribution analysis. The compilation process is the process of converting the linear regression model into an arithmetic circuit for zk-SNARK proof generation. The average time to compile our model is efficient and took approximately 0.256 seconds. Witness time involves creating the internal model values required for zk-SNARK proof generation. This will be used as cryptographic evidence to show the validity of the computations without revealing inputs. The witness time distribution shows low mean value of 0.202 seconds. The Power of Tau (PoT) which is a crucial phase in the zk-SNARK trusted setup process takes an average of 3.21 seconds. During this phase, cryptographic parameters are generated to ensure reliability of the zk-SNARK system, allowing it to produce proofs without revealing private information. The PoT ceremony time process involves multiple participants to contribute randomness to generate the final parameters taking 17.14 seconds. These resulting parameters are known as the common reference string (crs) and are necessary for any zk-SNARK proofs generated by the system.
Phase two initiation time was the most computationally demanding phase taking approximately 197.39 seconds as shown in Fig. 8, this is due to the complex setup of cryptographic parameters for zk-SNARKs. The time required for this stage is heavily contingent on the size and complexity of the personalized AI model in our case a linear regression model being converted into an arithmetic circuit for zk-SNARK proof generation. The complexity of QAP constraints increases with more complex AI models as they have larger number of features. This is also evident in the wide distribution of phase two initiation time, indicating significant differences in processing times adding to the longer proof generation times. The generation of the zk key takes 3.37 seconds indicating that it is relatively efficient once the cryptographic setup is completed. The verification and proof generation times are much faster than earlier stages like PoT and phase two initiation taking 2.59 and 2.45 seconds. This is due to the nature of zk-SNARKs producing succinct cryptographic proofs allowing for quick proof generation and verification irrespective of the complexity of AI models.
<details>
<summary>extracted/6340811/New_CPU.png Details</summary>
### Visual Description
## Line Chart: Average CPU Usage Across Stages of zk Generation
### Overview
The image displays a line chart illustrating the average CPU usage percentage across six distinct stages of a "zk Generation" process. The chart shows a significant spike in CPU usage early in the process, followed by a general plateau with a notable dip before the final stage.
### Components/Axes
* **Chart Type:** Line chart with data points marked by red circles.
* **Y-Axis (Vertical):**
* **Label:** "Average CPU Usage (%)"
* **Scale:** Linear scale ranging from 20 to 60, with major gridlines at intervals of 10 (20, 30, 40, 50, 60).
* **X-Axis (Horizontal):**
* **Label:** "Stages of zk Generation"
* **Categories (from left to right):** `compile`, `phase_two_initiation`, `power_of_tau`, `solidity_verifier`, `verify_proof`, `z_key`. The labels are rotated approximately 45 degrees for readability.
* **Legend:**
* **Position:** Top-right corner of the chart area.
* **Content:** A red line with a circular marker labeled "cpu(%)".
* **Data Series:** A single data series represented by a solid red line connecting circular red markers.
### Detailed Analysis
The following table lists the approximate CPU usage for each labeled stage on the x-axis. Values are estimated based on the position of the data points relative to the y-axis gridlines.
| Stage (X-Axis Label) | Approximate Average CPU Usage (%) | Visual Trend Description |
| :--- | :--- | :--- |
| `compile` | ~21% | Starting point, lowest value on the chart. |
| `phase_two_initiation` | ~64% | Sharp, steep increase from the previous stage. This is the peak value on the chart. |
| `power_of_tau` | ~52% | Significant decrease from the peak. |
| `solidity_verifier` | ~52.5% | Very slight increase, nearly level with the previous stage. |
| `verify_proof` | ~51% | Slight decrease. |
| *(Unlabeled point between `verify_proof` and `z_key`)* | ~43% | A distinct dip, representing the second-lowest point after the initial `compile` stage. |
| `z_key` | ~51.5% | Recovery from the dip, returning to a level similar to `solidity_verifier` and `verify_proof`. |
**Trend Verification:** The line exhibits a sharp upward slope from `compile` to `phase_two_initiation`, followed by a downward slope to `power_of_tau`. From `power_of_tau` to `verify_proof`, the line is relatively flat with minor fluctuations. It then dips sharply before rising again to the final point at `z_key`.
### Key Observations
1. **Peak Resource Demand:** The `phase_two_initiation` stage is the most computationally intensive, consuming approximately 64% average CPU usage, which is over three times the usage of the initial `compile` stage.
2. **Plateau Phase:** After the initial spike and drop, CPU usage stabilizes in the 51-53% range for the middle stages (`power_of_tau`, `solidity_verifier`, `verify_proof`).
3. **Notable Dip:** There is an unexplained, significant drop in CPU usage to approximately 43% at a point between the `verify_proof` and `z_key` stages. This point is not labeled on the x-axis.
4. **Final Stage Recovery:** The process concludes with the `z_key` stage, where CPU usage recovers to the plateau level of around 51.5%.
### Interpretation
This chart profiles the computational load of a zero-knowledge (zk) proof generation workflow. The data suggests that the process is not uniformly demanding.
* **Workflow Bottleneck:** The `phase_two_initiation` stage is clearly the primary computational bottleneck. Resources should be focused here for optimization, as improvements here would have the greatest impact on overall process time.
* **Process Phases:** The workflow can be interpreted as having three phases: 1) A low-overhead setup (`compile`), 2) A highly intensive core computation (`phase_two_initiation`), and 3) A series of subsequent verification and key generation steps (`power_of_tau` through `z_key`) that have a moderate, relatively consistent CPU demand.
* **The Unlabeled Dip:** The sharp, unlabeled dip is an anomaly. It could represent a brief I/O-bound operation, a pause for data transfer, or a stage that is highly parallelized and thus shows lower *average* CPU usage per core. Its position suggests it occurs after proof verification but before final key generation.
* **Resource Planning:** For system provisioning, the peak usage (~64%) dictates the minimum CPU capacity required to avoid throttling during the most demanding phase. The average usage across the entire process, however, would be lower, closer to the 50-52% plateau.
**Language Note:** All text in the image is in English.
</details>
Figure 9: Average CPU usage for each stage of zk generation.
<details>
<summary>extracted/6340811/New_Memory.png Details</summary>
### Visual Description
## Line Chart: Memory Usage Across zk Generation Stages
### Overview
This image is a line chart displaying the average memory usage (as a percentage) across various stages of a zero-knowledge (zk) proof generation process. The chart tracks a single data series, showing how memory consumption fluctuates through the sequential stages.
### Components/Axes
* **Chart Type:** Line chart with data points marked by red circles.
* **X-Axis (Horizontal):**
* **Title:** "Stages of zk Generation"
* **Categories (from left to right):** `compile`, `phase_two_initiation`, `power_of_tau`, `solidity_verifier`, `verify_proof`, `z_key`.
* **Note:** The axis labels are rotated approximately 45 degrees for readability.
* **Y-Axis (Vertical):**
* **Title:** "Average Memory Usage (%)"
* **Scale:** Linear scale ranging from approximately 30.0% to 31.4%.
* **Major Gridlines:** Present at intervals of 0.2% (30.2, 30.4, 30.6, 30.8, 31.0, 31.2).
* **Legend:**
* **Location:** Top-right corner of the chart area.
* **Content:** A red line with a circle marker labeled "memory(%)".
* **Data Series:**
* **Label:** "memory(%)"
* **Visual Representation:** A solid red line connecting red circular data points.
### Detailed Analysis
The chart plots memory usage for six distinct stages. The trend is not monotonic; it features a sharp initial rise, a peak, a significant drop, and a gradual recovery.
**Data Points & Trend Verification:**
1. **`compile`**: The line starts at its lowest point. **Approximate Value:** 30.13%.
2. **`phase_two_initiation`**: The line slopes steeply upward to its highest peak. **Approximate Value:** 31.33%.
3. **`power_of_tau`**: The line slopes steeply downward to a local minimum. **Approximate Value:** 30.75%.
4. **`solidity_verifier`**: The line slopes gently upward. **Approximate Value:** 30.96%.
5. **`verify_proof`**: The line continues with a very slight upward slope, appearing almost flat. **Approximate Value:** 30.91%.
6. **`z_key`**: The line slopes upward again to its second-highest point. **Approximate Value:** 31.11%.
**Spatial Grounding:** All data points are plotted directly above their corresponding x-axis category labels. The legend is positioned in the upper right quadrant, clearly associated with the red line.
### Key Observations
* **Peak Memory Demand:** The `phase_two_initiation` stage is the most memory-intensive, consuming over 31.3% on average.
* **Significant Drop:** There is a notable decrease in memory usage (approximately 0.58 percentage points) between `phase_two_initiation` and `power_of_tau`.
* **Stabilization and Rise:** After the drop at `power_of_tau`, memory usage stabilizes around the 30.9% mark for `solidity_verifier` and `verify_proof` before rising again for the final `z_key` stage.
* **Overall Range:** Memory usage across all stages varies within a relatively narrow band of approximately 1.2 percentage points (from ~30.13% to ~31.33%).
### Interpretation
This chart provides a technical profile of the memory footprint for a zk-proof generation pipeline. The data suggests that the process is not uniformly resource-intensive.
* **Resource Allocation:** System designers or operators should anticipate the highest memory allocation requirements during the `phase_two_initiation` stage. The `compile` stage is the most lightweight in terms of memory.
* **Process Insight:** The sharp drop after the peak could indicate the completion of a major, memory-heavy sub-process (like large-scale polynomial commitment or setup) within `phase_two_initiation`, after which resources are freed before the `power_of_tau` stage begins.
* **Bottleneck Identification:** While `z_key` shows high usage, the most critical potential bottleneck for memory-constrained systems appears to be the `phase_two_initiation` phase. Optimizing this stage could yield the greatest benefit for reducing overall memory requirements.
* **Stability:** The relatively flat usage between `solidity_verifier` and `verify_proof` suggests these stages have consistent and predictable memory demands.
The chart effectively communicates that memory usage is stage-dependent, with clear peaks and valleys that are crucial for performance tuning and infrastructure planning in zk-proof systems.
</details>
Figure 10: Average RAM usage for each stage of zk generation.
Looking at the average time for each stage reflected in Fig. 8, it is evident that phase two initiation time stood out as the most time-consuming stage, followed by the power of tau (PoT) and the phase two ceremony. In comparison, compile, witness, and zk key generation times are notably shorter. Overall, zk Proof Generation takes significantly longer, averaging 233.63 seconds, compared to zk Verification, which took 61.50 seconds. We analyzed CPU and memory consumption to understand the resource requirements encountered during the various phases of zk-SNARK proof creation. From Fig. 9, we can see that CPU usage was highest during the Phase Two Initiation and Power of Tau stages, indicating these stages are particularly computationally intensive. Other stages like compile, proof, and verification key generation also showed significant CPU usage but to a lesser extent. Memory usage remained relatively consistent across all stages as seen in Fig. 10 hovering around 30-31%, with slight variations observed during the Phase Two Initiation and Power of Tau stages, which can be attributed to the intensive computations required for phase two and power of tau setup. This indicates that developers will face penalties for higher resource consumption and longer times during the zk-SNARK proof generation phase, especially if their models are complex or inefficient. Therefore, optimizing the proof generation process is crucial to avoid high computational costs and delays.
<details>
<summary>extracted/6340811/Blockchain_Chainlink.png Details</summary>
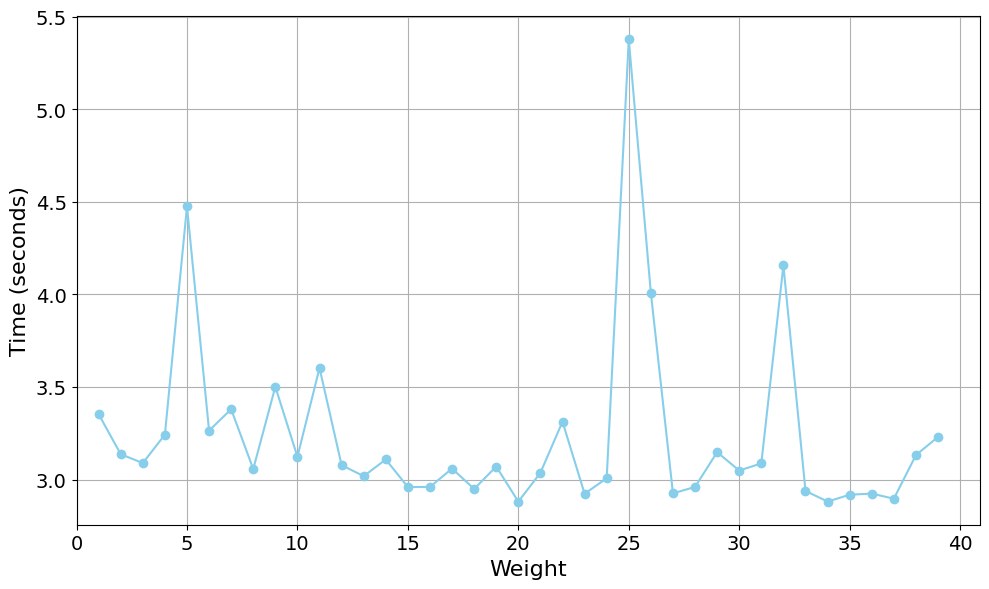
### Visual Description
\n
## Line Chart: Weight vs. Time
### Overview
The image displays a line chart plotting a single data series showing the relationship between a variable labeled "Weight" on the horizontal axis and "Time (seconds)" on the vertical axis. The chart features a light blue line connecting circular data points against a white background with a gray grid. The data exhibits a generally stable baseline with several prominent, sharp spikes.
### Components/Axes
* **Chart Type:** Line chart with marked data points.
* **X-Axis (Horizontal):**
* **Label:** "Weight"
* **Scale:** Linear scale ranging from 0 to 40.
* **Major Tick Marks:** At intervals of 5 (0, 5, 10, 15, 20, 25, 30, 35, 40).
* **Y-Axis (Vertical):**
* **Label:** "Time (seconds)"
* **Scale:** Linear scale ranging from 3.0 to 5.5.
* **Major Tick Marks:** At intervals of 0.5 (3.0, 3.5, 4.0, 4.5, 5.0, 5.5).
* **Data Series:** A single series represented by a light blue line (`#7eb8da` approximate hex) with circular markers at each data point.
* **Legend:** None present.
* **Grid:** A light gray grid is present, aligned with the major tick marks on both axes.
### Detailed Analysis
The data series consists of approximately 39 points, one for each integer value of Weight from 1 to 39. The following table lists the approximate Time values for key points, derived from visual inspection of the chart. Values are estimates with an uncertainty of ±0.05 seconds.
| Weight (approx.) | Time (seconds, approx.) | Note |
| :--- | :--- | :--- |
| 1 | 3.35 | Starting point |
| 2 | 3.15 | |
| 3 | 3.10 | Local minimum |
| 4 | 3.25 | |
| **5** | **4.50** | **First major peak** |
| 6 | 3.27 | |
| 7 | 3.40 | |
| 8 | 3.05 | |
| 9 | 3.50 | |
| 10 | 3.12 | |
| 11 | 3.60 | Local peak |
| 12 | 3.08 | |
| 13 | 3.02 | |
| 14 | 3.10 | |
| 15 | 2.97 | |
| 16 | 2.97 | |
| 17 | 3.06 | |
| 18 | 2.96 | |
| 19 | 3.07 | |
| **20** | **2.90** | **Global minimum** |
| 21 | 3.05 | |
| 22 | 3.32 | |
| 23 | 2.93 | |
| 24 | 3.02 | |
| **25** | **5.40** | **Global maximum, sharpest peak** |
| 26 | 4.00 | |
| 27 | 2.93 | |
| 28 | 2.97 | |
| 29 | 3.15 | |
| 30 | 3.05 | |
| 31 | 3.09 | |
| **32** | **4.17** | **Third major peak** |
| 33 | 2.95 | |
| 34 | 2.90 | |
| 35 | 2.93 | |
| 36 | 2.94 | |
| 37 | 2.92 | |
| 38 | 3.13 | |
| 39 | 3.25 | Final point |
**Visual Trend Description:** The line maintains a relatively stable baseline, fluctuating primarily between 2.9 and 3.6 seconds for most weight values. This stable trend is interrupted by three distinct, sharp upward spikes. The most significant spike occurs at Weight=25, reaching the chart's maximum. A second major spike occurs at Weight=5, and a third, slightly smaller spike occurs at Weight=32. The line returns to its baseline range immediately after each spike.
### Key Observations
1. **Baseline Stability:** For approximately 85% of the data points (weights 1-4, 6-24, 27-31, 33-39), the time value remains within a narrow band of ~2.9 to 3.6 seconds.
2. **Three Anomalous Spikes:** The data is dominated by three outliers:
* **Weight 5:** Time jumps to ~4.5s.
* **Weight 25:** Time reaches the global maximum of ~5.4s.
* **Weight 32:** Time spikes to ~4.17s.
3. **Sharp Transitions:** The spikes are characterized by very steep ascents and descents, indicating the high time value is isolated to a specific weight or a very narrow range around it.
4. **Global Extremes:** The minimum time (~2.90s) occurs at Weight=20 and Weight=34. The maximum time (~5.40s) occurs at Weight=25.
### Interpretation
This chart likely visualizes the performance (in terms of processing or response time) of a system or algorithm as a function of an input parameter called "Weight." The "Weight" could represent problem size, data volume, a complexity parameter, or a physical weight in an experiment.
The data suggests the system has a consistent, predictable performance baseline for most input weights. However, it exhibits severe, localized performance degradation at three specific weight values (5, 25, and 32). These are not gradual slowdowns but sharp, significant increases in time.
**Potential Implications:**
* **Critical Thresholds:** The weights 5, 25, and 32 may represent critical thresholds, edge cases, or specific configurations that trigger an inefficient code path, a resource bottleneck (like cache thrashing), or a complex sub-routine within the system.
* **Non-Linear Behavior:** The relationship is highly non-linear. Doubling the weight from 20 to 40 does not double the time; instead, time remains low except at the specific problematic points.
* **Optimization Target:** For system optimization, investigating the processes occurring at weights 5, 25, and 32 would yield the highest performance improvement, as addressing these outliers would dramatically improve worst-case performance without affecting the already-efficient baseline.
The absence of a title or legend suggests this chart is likely part of a larger technical report or dashboard where context is provided externally. The clean, grid-based presentation is typical of output from data analysis libraries like Matplotlib or Seaborn in Python.
</details>
Figure 11: Blockchain and Chainlink overhead time over 39 weights.
<details>
<summary>extracted/6340811/Comparison_1.png Details</summary>
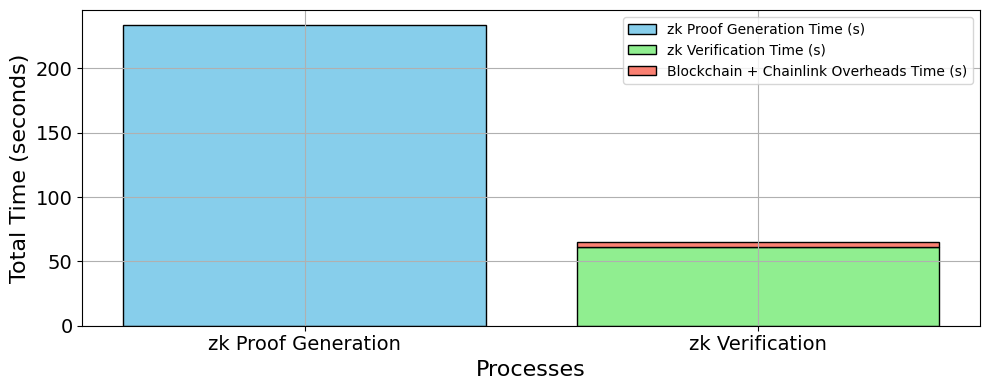
### Visual Description
\n
## Bar Chart: zk Proof Generation vs. zk Verification Time Breakdown
### Overview
This is a stacked bar chart comparing the total time (in seconds) required for two distinct processes in a zero-knowledge (zk) system: "zk Proof Generation" and "zk Verification". The chart breaks down the total time for each process into its constituent components.
### Components/Axes
* **Chart Type:** Stacked Bar Chart.
* **X-Axis (Horizontal):** Labeled "Processes". It contains two categorical bars:
1. `zk Proof Generation` (left bar)
2. `zk Verification` (right bar)
* **Y-Axis (Vertical):** Labeled "Total Time (seconds)". The scale runs from 0 to approximately 240, with major gridlines at intervals of 50 seconds (0, 50, 100, 150, 200).
* **Legend:** Positioned in the top-right corner of the chart area. It defines three data series with corresponding colors:
* `zk Proof Generation Time (s)`: Light blue color.
* `zk Verification Time (s)`: Light green color.
* `Blockchain + Chainlink Overheads Time (s)`: Light red/salmon color.
### Detailed Analysis
**1. zk Proof Generation Process (Left Bar):**
* **Visual Trend:** This is a single, solid bar with no stacking.
* **Composition:** The entire bar is filled with the light blue color corresponding to "zk Proof Generation Time (s)". There are no green or red segments.
* **Data Point:** The top of the blue bar aligns with a value on the Y-axis of approximately **235 seconds**. This represents the total time for proof generation, which is entirely consumed by the proof generation computation itself.
**2. zk Verification Process (Right Bar):**
* **Visual Trend:** This is a stacked bar composed of two distinct color segments.
* **Composition & Data Points:**
* **Bottom Segment (Green):** This segment represents "zk Verification Time (s)". It starts at 0 and extends upward to approximately **60 seconds**.
* **Top Segment (Red):** This segment represents "Blockchain + Chainlink Overheads Time (s)". It is stacked on top of the green segment. It starts at ~60 seconds and ends at approximately **65 seconds**. Therefore, the overhead time is approximately **5 seconds** (65s - 60s).
* **Total Time:** The combined height of the green and red segments indicates a total time for the "zk Verification" process of approximately **65 seconds**.
### Key Observations
1. **Dominant Time Cost:** The "zk Proof Generation" process (235s) is significantly more time-consuming than the entire "zk Verification" process (65s), by a factor of roughly 3.6x.
2. **Verification Breakdown:** Within the verification process, the core "zk Verification Time" (60s) constitutes the vast majority (~92%) of the total time. The associated "Blockchain + Chainlink Overheads" are relatively minor (~5s, or ~8%).
3. **Process Isolation:** The chart clearly separates the two main phases of a zk workflow. Proof generation is a monolithic, computationally heavy task. Verification is faster and includes both the cryptographic verification and external system overheads.
### Interpretation
This chart provides a clear performance profile for a zero-knowledge proof system, likely in a blockchain or oracle context (given the "Chainlink" reference).
* **What the data suggests:** The primary bottleneck in this system is **proof generation**. Any optimization efforts should focus here, as even a 10% improvement would save over 23 seconds. The verification step, while non-trivial, is much faster. The overhead from integrating with a blockchain and Chainlink is minimal in comparison.
* **How elements relate:** The two bars represent the sequential or parallel stages of a zk-based application. A proof must be generated (expensive) before it can be verified (cheaper). The verification bar's stack shows that the act of verifying the proof on-chain (green) is the main component, with additional latency from blockchain consensus and oracle network communication (red).
* **Notable Anomalies/Considerations:** The chart does not specify the complexity of the proof being generated or verified. The absolute times (235s, 65s) are highly dependent on the specific circuit, hardware, and network conditions. The key takeaway is the **relative proportion** of time spent. The near-negligible overhead suggests an efficient integration design, where the cryptographic operations dominate the latency, not the external system calls.
</details>
Figure 12: Comparison of time taken for zk proof generation vs zk verification process.
Figures 11 and 12 show that blockchain and Chainlink oracle overhead times were minimal compared to the zk proof generation and verification times, highlighting the efficiency of using Chainlink oracles for decentralized verification. Zk-SNARKs are designed to provide a compact proof that can be verified quickly, regardless of the underlying complexity of the original computation. Chainlink oracle network was utilized to compute zk-SNARK verification and return the result to the blockchain, ensuring that the process is both efficient and secure. Figure 12 demonstrates that the zk verification process is efficient. The users can be assured that AI models are verified securely and efficiently, as Chainlink’s decentralized oracle network adds an extra layer of robustness by eliminating single points of failure. This decentralized verification process ensures that the zk-SNARK proofs are validated in a trust-minimized manner.
The results in Fig. 13 indicate the transaction fees associated with the zk-SNARK verification requests on the Ethereum blockchain. The dataset comprised 39 transactions, each representing a distinct zk verification request. With an average fee of 0.000572 ETH, translating to $1.03 USD for each verification. The transaction fees were relatively consistent across all transactions, with minimal variability.
<details>
<summary>extracted/6340811/Transaction_Fee.png Details</summary>
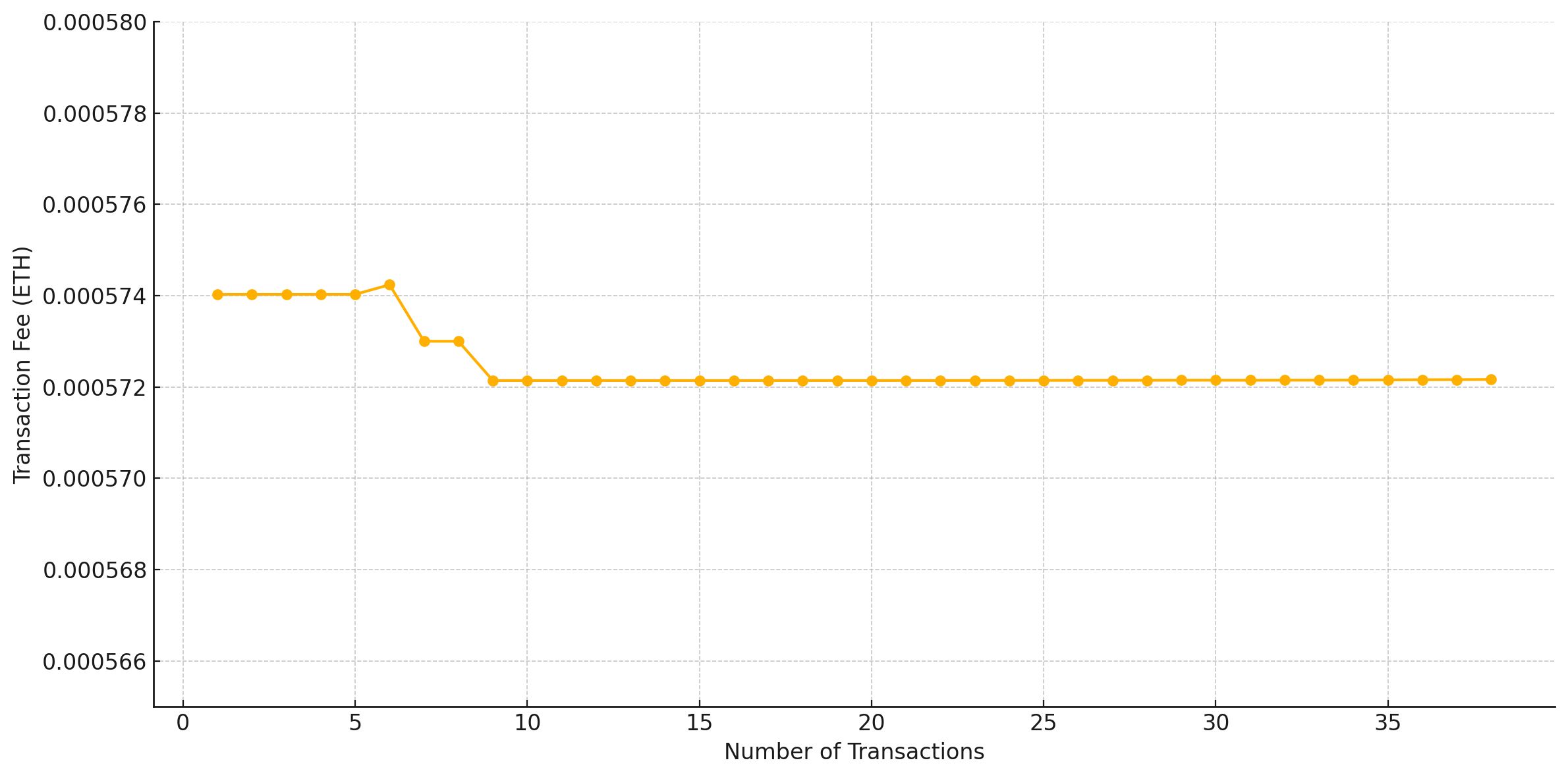
### Visual Description
\n
## Line Chart: Transaction Fee vs. Number of Transactions
### Overview
The image displays a line chart plotting the relationship between the number of transactions (x-axis) and the corresponding transaction fee in Ethereum (ETH) (y-axis). The chart shows a single data series represented by an orange line with circular markers at each data point. The overall trend indicates a fee that is largely stable with a minor, stepwise decrease early in the series before plateauing.
### Components/Axes
* **Chart Type:** Line chart with data point markers.
* **X-Axis:**
* **Label:** "Number of Transactions"
* **Scale:** Linear, ranging from 0 to approximately 38.
* **Major Tick Marks:** 0, 5, 10, 15, 20, 25, 30, 35.
* **Y-Axis:**
* **Label:** "Transaction Fee (ETH)"
* **Scale:** Linear, ranging from 0.000566 to 0.000580 ETH.
* **Major Tick Marks:** 0.000566, 0.000568, 0.000570, 0.000572, 0.000574, 0.000576, 0.000578, 0.000580.
* **Data Series:**
* **Color:** Orange (#FFA500 approximate).
* **Marker:** Solid circle.
* **Legend:** Not present (single series).
* **Grid:** Light gray dashed grid lines are present for both major x and y ticks.
### Detailed Analysis
**Trend Verification:** The orange line begins flat, exhibits a small upward bump, then descends in two distinct steps before flattening out completely for the remainder of the chart.
**Data Point Extraction (Approximate Values):**
The following table lists the approximate (x, y) coordinates for each visible data point, read from the chart.
| Number of Transactions (x) | Transaction Fee (ETH) (y) | Notes |
| :--- | :--- | :--- |
| 1 | 0.0005740 | Start of series. |
| 2 | 0.0005740 | |
| 3 | 0.0005740 | |
| 4 | 0.0005740 | |
| 5 | 0.0005740 | |
| 6 | ~0.0005742 | **Peak value.** Slight increase from baseline. |
| 7 | 0.0005730 | First step down. |
| 8 | 0.0005730 | |
| 9 | 0.0005721 | Second step down. |
| 10 | 0.0005721 | |
| 11 | 0.0005721 | |
| 12 | 0.0005721 | |
| 13 | 0.0005721 | |
| 14 | 0.0005721 | |
| 15 | 0.0005721 | |
| 16 | 0.0005721 | |
| 17 | 0.0005721 | |
| 18 | 0.0005721 | |
| 19 | 0.0005721 | |
| 20 | 0.0005721 | |
| 21 | 0.0005721 | |
| 22 | 0.0005721 | |
| 23 | 0.0005721 | |
| 24 | 0.0005721 | |
| 25 | 0.0005721 | |
| 26 | 0.0005721 | |
| 27 | 0.0005721 | |
| 28 | 0.0005721 | |
| 29 | 0.0005721 | |
| 30 | 0.0005721 | |
| 31 | 0.0005721 | |
| 32 | 0.0005721 | |
| 33 | 0.0005721 | |
| 34 | 0.0005721 | |
| 35 | 0.0005721 | |
| 36 | 0.0005721 | |
| 37 | 0.0005721 | |
| 38 | 0.0005721 | End of visible series. |
### Key Observations
1. **Plateaued Baseline:** The fee is constant at 0.0005740 ETH for transactions 1 through 5.
2. **Minor Peak:** A single, slight increase to ~0.0005742 ETH occurs at 6 transactions.
3. **Stepwise Decrease:** The fee drops in two clear steps: first to 0.0005730 ETH (transactions 7-8), then to 0.0005721 ETH (transaction 9 onward).
4. **Extended Plateau:** From 9 transactions to the end of the chart (~38 transactions), the fee remains perfectly constant at 0.0005721 ETH.
5. **Narrow Y-Axis Range:** The entire variation in fee occurs within a very narrow band of 0.0000021 ETH (from 0.0005721 to 0.0005742), indicating high stability.
### Interpretation
This chart demonstrates a transaction fee model with remarkable stability relative to transaction volume. The data suggests one of two scenarios:
1. **Fixed Fee Structure:** The fee is largely predetermined and not sensitive to the number of transactions processed, with minor adjustments possibly due to rounding, network conditions at specific volumes, or a tiered pricing model that changes only at specific thresholds (e.g., after 6 and after 8 transactions).
2. **Efficient Scaling:** The system or protocol being measured handles increased transaction load with negligible impact on per-transaction cost, achieving economies of scale almost immediately (by the 9th transaction).
The notable anomaly is the small peak at 6 transactions. This could represent a specific threshold where a minor fee adjustment occurs before settling into a lower, stable rate. The absence of any upward trend or volatility as transactions increase to 38 is the most significant finding, implying predictable and low marginal cost for additional transactions within this range. The extremely fine scale of the y-axis (0.000002 ETH increments) highlights that while changes are visually distinct, their absolute financial magnitude is minimal.
</details>
Figure 13: Transaction Fee (ETH) for zk verification.
<details>
<summary>extracted/6340811/LINK_Spent.png Details</summary>
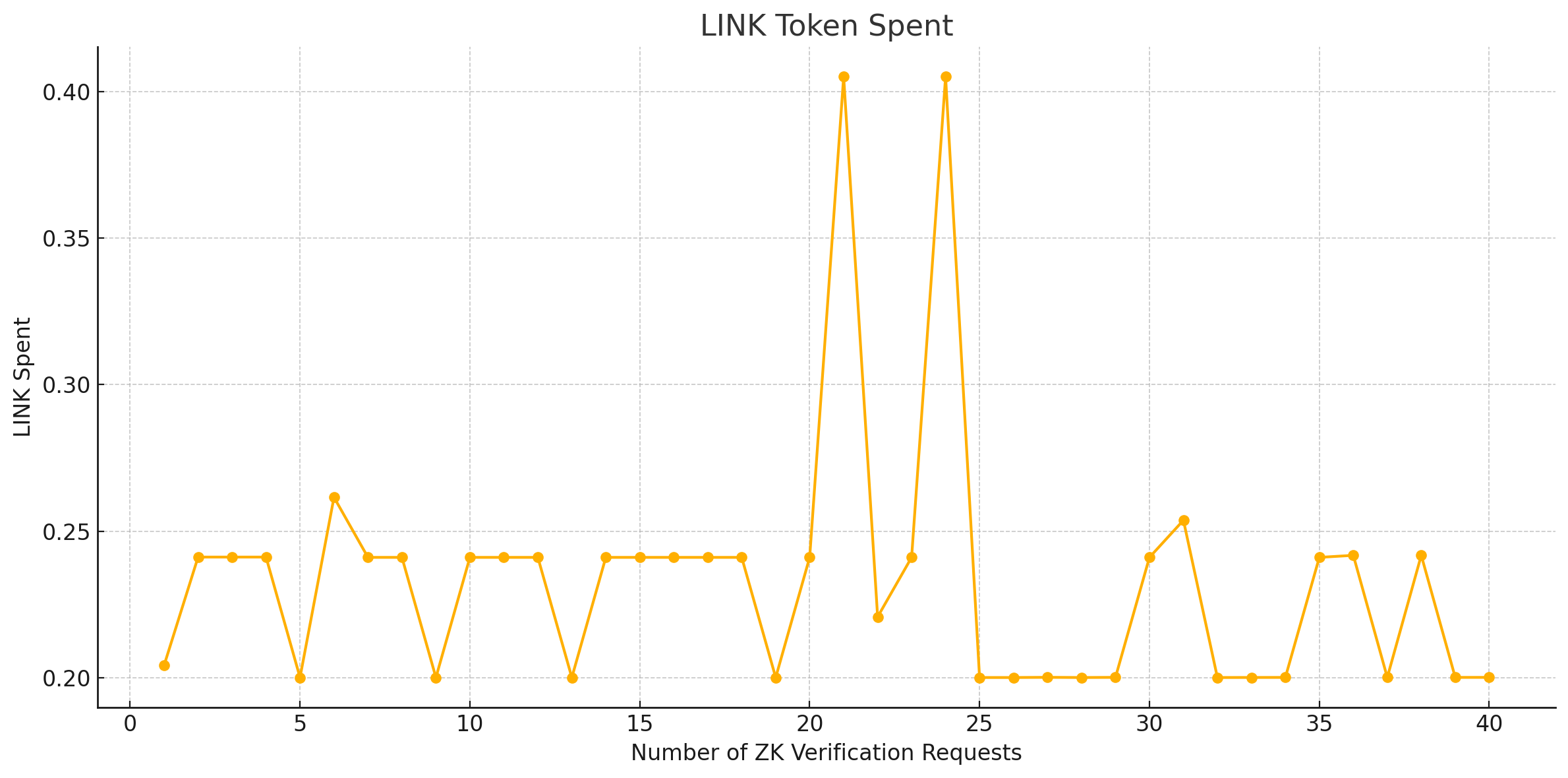
### Visual Description
\n
## Line Chart: LINK Token Spent vs. Number of ZK Verification Requests
### Overview
This is a line chart plotting the amount of "LINK Spent" against the "Number of ZK Verification Requests." The chart displays a single data series represented by an orange line with circular markers at each data point. The data shows a generally stable baseline with two significant, isolated spikes.
### Components/Axes
* **Chart Title:** "LINK Token Spent" (centered at the top).
* **X-Axis (Horizontal):**
* **Label:** "Number of ZK Verification Requests".
* **Scale:** Linear scale from 0 to 40, with major tick marks and labels at intervals of 5 (0, 5, 10, 15, 20, 25, 30, 35, 40).
* **Y-Axis (Vertical):**
* **Label:** "LINK Spent".
* **Scale:** Linear scale from approximately 0.19 to 0.41, with major tick marks and labels at 0.20, 0.25, 0.30, 0.35, and 0.40.
* **Data Series:** A single series plotted as a solid orange line (`#ffa500` approximate) connecting circular orange markers. There is no legend, as only one series is present.
* **Grid:** A light gray, dashed grid is present for both major x and y axis ticks.
### Detailed Analysis
**Data Points (Approximate Values):**
The following table lists the approximate "LINK Spent" value for each "Number of ZK Verification Requests" (x-value), read from the chart. Values are estimated based on the position of the orange markers relative to the y-axis grid lines.
| Number of ZK Verification Requests (x) | Approximate LINK Spent (y) | Trend Note |
| :--- | :--- | :--- |
| 1 | 0.205 | Starting point. |
| 2 | 0.240 | Jumps to a plateau. |
| 3 | 0.240 | Plateau continues. |
| 4 | 0.240 | Plateau continues. |
| 5 | 0.200 | Sharp drop to baseline. |
| 6 | 0.260 | Sharp rise to a local peak. |
| 7 | 0.240 | Drops back to plateau level. |
| 8 | 0.240 | Plateau continues. |
| 9 | 0.200 | Sharp drop to baseline. |
| 10 | 0.240 | Sharp rise to plateau. |
| 11 | 0.240 | Plateau continues. |
| 12 | 0.240 | Plateau continues. |
| 13 | 0.200 | Sharp drop to baseline. |
| 14 | 0.240 | Sharp rise to plateau. |
| 15 | 0.240 | Plateau continues. |
| 16 | 0.240 | Plateau continues. |
| 17 | 0.240 | Plateau continues. |
| 18 | 0.240 | Plateau continues. |
| 19 | 0.200 | Sharp drop to baseline. |
| 20 | 0.240 | Sharp rise to plateau. |
| **21** | **~0.405** | **MAJOR SPIKE.** Highest point on chart. |
| 22 | 0.220 | Sharp drop from spike. |
| 23 | 0.240 | Rises back to plateau. |
| **24** | **~0.405** | **MAJOR SPIKE.** Second peak, nearly identical to first. |
| 25 | 0.200 | Sharp drop to baseline. |
| 26 | 0.200 | Baseline continues. |
| 27 | 0.200 | Baseline continues. |
| 28 | 0.200 | Baseline continues. |
| 29 | 0.200 | Baseline continues. |
| 30 | 0.240 | Rises to plateau. |
| 31 | 0.255 | Slight rise to a minor local peak. |
| 32 | 0.200 | Sharp drop to baseline. |
| 33 | 0.200 | Baseline continues. |
| 34 | 0.200 | Baseline continues. |
| 35 | 0.240 | Rises to plateau. |
| 36 | 0.240 | Plateau continues. |
| 37 | 0.200 | Sharp drop to baseline. |
| 38 | 0.240 | Sharp rise to plateau. |
| 39 | 0.200 | Sharp drop to baseline. |
| 40 | 0.200 | Ends at baseline. |
**Visual Trend Description:**
The orange line exhibits a pattern of fluctuating between two primary levels: a "baseline" around 0.20 and a "plateau" around 0.24. It frequently jumps between these levels. The most prominent features are two dramatic, narrow spikes where the value shoots up to approximately 0.405 at x=21 and x=24, before immediately returning to the lower levels. After x=25, the data spends more time at the 0.20 baseline, with brief returns to the 0.24 plateau.
### Key Observations
1. **Dual Baseline/Plateau Pattern:** The data primarily oscillates between ~0.20 and ~0.24 LINK spent.
2. **Extreme Outliers:** Two significant, isolated cost spikes occur at 21 and 24 verification requests, where spending nearly doubles the typical plateau value.
3. **Post-Spike Behavior:** After the second major spike (x=24), the system appears to settle into a lower-cost state, spending more consecutive points at the 0.20 baseline compared to the pre-spike period.
4. **No Clear Correlation:** There is no obvious linear or simple curvilinear relationship between the number of requests and LINK spent. The cost does not steadily increase with more requests.
### Interpretation
This chart likely visualizes the cost (in LINK tokens) of performing Zero-Knowledge (ZK) proof verifications on a blockchain oracle network (like Chainlink). The "Number of ZK Verification Requests" could represent batch sizes or sequential operations.
The data suggests that the cost model is **not linearly scalable** with the number of requests. Instead, it operates in a step-wise fashion with a standard cost band (0.20-0.24 LINK). The two massive spikes are critical anomalies. They could indicate:
* **System Overload or Inefficiency:** Specific batch sizes (21 and 24) may trigger a non-optimal computational path, a different verification circuit, or network congestion, causing a disproportionate cost increase.
* **External Factors:** The spikes might correlate with external events not shown on the chart, such as high network gas fees at those specific times.
* **Protocol Behavior:** The pattern post-spike (more time at the lower 0.20 baseline) could imply the system implements some form of cost optimization or state change after handling high-load events.
The key takeaway for a technical user is that while average costs are predictable, **certain operational conditions (around 21-24 requests) pose a risk of extreme, order-of-magnitude cost increases.** System designers would need to investigate the root cause of these spikes to ensure predictable and economical operation.
</details>
Figure 14: Amount of LINK token spent for zk verification.
Analyzing transaction fees and LINK token expenditure provide valuable insights into the cost structure of deploying zk-SNARK verifications in a decentralized environment. The consistent transaction fees suggest a predictable cost model, benefiting developers and operators planning to integrate such verifications into their systems. At the time of this writing, the cost of LINK is approximately $14.16 USD per token [50], this translates to a range of $2.83 USD to $5.66 USD per request for a zk verification computation. As seen in Fig. 14, the LINK token expenditure graph further emphasis that the costs associated with chainlink oracle are stable for the verification process.
The transaction fees were plotted against the number of transactions to visualize the fee distribution. In addition to transaction fees, we analyzed the LINK token expenditure for the oracle requests involved in zk-SNARK verification. The analysis included 39 oracle requests for zk verification computations, and the expenditure was plotted against the number of zk verification requests. This graph helped identify the cost distribution across different requests, highlighting any peaks that might indicate higher computational or operational demands. Previous work used selective verification to reduce the number of verifications and hence the overall costs associated [38]. While costs associated are higher than centralized systems due to the decentralized nature of blockchain and oracles, these costs are justified by the added benefits of increased trust and continuous transparency for verification.
## 6 Discussion
Our analysis in the results section indicates that the speed of proof generation is the main constraint that requires significant resources and is process intensive. This can be attributed to the complexity of creating a QAP from the arithmetic circuit, which introduces arithmetization constraints that are difficult to address. These constraints ensure an accurate polynomial representation of AI model operations, but their complexity increases with model size and feature count. For models more complex than a linear regression model, such as a deep learning network, the number of required gates and constraints can increase exponentially, leading to significant resource consumption, longer proof generation times and could present scalability issues. While our framework shows the feasibility of using zk-SNARK-based verification for a linear regression model on blockchain, further optimization is necessary to improve efficiency of zk-SNARK proof generation enabling the use of more advanced AI models within this framework. Techniques such as proof splitting [51], GPU acceleration [52], and parallel processing [53] of zk-SNARK proofs using tools such as Sonic [54] have shown promise in improving the efficiency and reducing costs for zk-SNARK proof generation.
| Key Attributes | Our Paper | SNNzksNARK [37] | Verifiable Evaluations of ML using zk-SNARKs [38] | Trustless DNN Inference [39] | zkCNN [40] | Secure Machine Learning using Homomorphic Encryption & Verifiable Computing [33] |
| --- | --- | --- | --- | --- | --- | --- |
| Blockchain & Oracle Integration | Yes | No | No | No | No | No |
| Decentralization | Fully decentralized using blockchain and Chainlink decentralized oracle network (DON) | Centralized | Centralized | Centralized; runs inference verification in a centralized MLaaS (Machine Learning-as-a-Service) model | Centralized | Centralized |
| Trust | Completely trustless; leverages blockchain, zk-SNARKs and Chainlink oracles for verifiable computations | Relies on trusted central entities for computation and validation | Partially trustless; ensures correct model inference but still requires trust in model providers not to swap models | Limited trustless; relies on a trusted ML service provider to generate zk-SNARKs proofs | Limited trustless; Relies on the model provider to generate and distribute proofs honestly | Partially trustless; relies on a centralized entity to manage HE-encrypted data |
| Transparency | Fully transparent due to Chainlink oracles and zk-SNARK integration; verifications are stored on-chain | Limited transparency as proofs are stored on a centralized setup; lacks public auditability | Provides transparency in verifiable inference but lacks blockchain immutability; results are not recorded on a auditable ledger | Limited transparency as proofs are not public and depends on centralized storage | Limited Transparency; proofs ensure inference correctness, but they are not publicly auditable | Limited Transparency; does not store the proofs on a publicly verifiable ledger |
| Privacy | Ensures privacy by integrating zk-SNARKs into Chainlink oracles for proof verification | Privacy is protected using zk-SNARKs but trained neural network weights might still be exposed | Strong focus on ML model privacy using zk-SNARKs | Ensures input and model privacy via zk-SNARKs but data exposure risks exist | zkCNN hides CNN weights and input data, ensuring confidential inference verification | Ensures privacy of model inputs and outputs using homomorphic encryption (HE) |
| Evaluation Methodology | Real-world implementation using the NVIDIA Jetson TX2, Sepolia testnet and Chainlink’s DON | Simulated performance evaluation on neural networks; No real-world deployment | Real-world tests using actual ML models and benchmarked proof generation | Simulations for centralized environments; no real-world test | zkCNN is benchmark-tested, lacks practical real-world implementation | Benchmarked three architectures for ML evaluation |
| AI/ML Model Verification | Yes - zk-SNARK proofs verify AI model performance claims without revealing model weights | Yes - Uses zk-SNARKs for verifying neural network execution | Yes, verifies inference correctness using zk-SNARKs without revealing model weights | Yes - Focuses on verifying AI inference correctness | Yes, zkCNN guarantees correct CNN model inference execution | No AI-specific verification |
| Data Verification | Yes - Chainlink oracles fetch and verify off-chain data before model verification | No - explicit data verification mechanism; assumes correct data input | No - Does not use external verification mechanisms; assumes data inputs are correct | No - Does not use external verification mechanisms; assumes data inputs are correct | No - assumes data correctness without independent verification | No external data verification |
| Scalability | Scales efficiently due to use of Chainlink oracles for zk-SNARK computations | More efficient scaling due to centralized environments | Limited scalability; real-time AI model inference verification is computationally expensive | Scales better in centralized MLaaS setups | Highly scalable for CNN-based verifications, not designed for large-scale AI verification | Limited scalability due to high computational costs of homomorphic encryption |
| Efficiency | Comparatively higher computational overhead due to decentralized architecture | More efficient; Highly optimized for single-server performance due to centralized architecture with optimized environments | More efficient than decentralized solutions but less efficient than centralized solutions due to the computationally intensive privacy-preserving inference proofs | More efficient; Optimized for centralized systems with batched proofs | Highly efficient for CNN inferences | Computationally expensive due to homomorphic encryption and verifiable computing overhead |
Table 2: Comparison with the existing verification methods across key attributes.
To our knowledge, none of the above studies has implemented zk-SNARKs on a practical blockchain system and a decentralized oracle network to verify AI models. Direct comparisons to existing non-blockchain zk-SNARK AI verification implementations, such as those in [37], [38], [39], and [40], are challenging due to differences in the underlying systems and AI models tested. While these studies focus on implementing zk-SNARKs in centralized systems, our work integrates zk-SNARKs into a decentralized blockchain and oracle network. Despite the inherent differences in our blockchain-based implementation compared to centralized systems, we can still draw important conclusions based on our results.
Existing verification methods such as HE and VC [33] and implementations of zk-SNARKs such as those in [37], [38], [39] and [40], benefit from optimized environments where data and computational resources are centrally managed. These setups enable faster proof generation and verification by reducing communication overhead and leveraging high-performance infrastructure, such as dedicated servers or centralized cloud systems. The key trade-off in implementing zk-SNARKs in decentralization systems is increased transparency and trust at the cost of increased transaction fees and efficiency compared to centralized systems. Decentralized oracles take longer to fetch and verify data, compute the zk-SNARK proof and the blockchain verification adds further delays due to the decentralized nature of the network both of which slow down the process. While this ensures trustless, transparent verification, it results in reduced efficiency compared to zk-SNARKs implementations on centralized systems for AI verification. The key differences in attributes between our approach and existing verification methods is highlighted in Table 2.
A significant incentive for participants to engage with this framework lies in the model data privacy and trustless verification offered by zk-SNARKs, especially when used in conjunction with blockchain technology and decentralized oracles. The decentralized nature of blockchain and oracles ensures that no single entity controls the data or verification process, enhancing transparency and preventing tampering with transaction records. For developers, the ability to verify AI model performance without exposing proprietary data such as model weights ensures that their intellectual property remains secure, reducing the risk of misuse and unauthorized replication. These guarantees encourage developers to bring innovative AI models to the marketplace with confidence knowing that their investments are safeguarded in a trustless and immutable environment. For buyers, zk-SNARKs and the decentralized infrastructure offer a reliable means to independently verify claims of AI models, ensuring that the claims made by sellers about model performance are accurate and trustworthy. This capability promotes transparency and trust in AI models in blockchain-enabled marketplaces, enabling buyers to make informed decisions based on verifiable evidence of model efficacy, thereby fostering a more trustworthy and equitable ecosystem.
## 7 Conclusion
This paper presents a novel framework for verifying AI model performance claims on blockchain. Our study indicates that the zk proof generation process is the most time-consuming and computationally intensive stage. Optimizing this stage is crucial for enhancing the overall efficiency of zk-SNARK implementations. The zk Verification process on Chainlink oracles is relatively faster but still significant compared to the overhead time, emphasizing the importance of efficient verification mechanisms.
By using the NVIDIA Jetson TX2 for local proof generation and the Sepolia testnet with Chainlink oracles for decentralized verification, our study demonstrates a robust and feasible approach to securely and transparently verifying personalized AI models using a real-world oracle network and testnet setup. Integrating Chainlink oracles with the Sepolia testnet environment allowed us to replicate real-world conditions, providing insights into the practical challenges and benefits of deploying zk-SNARKs in decentralized settings. This implementation highlights the feasibility of using Chainlink’s decentralized oracle network to handle the computational demands of zk-SNARK verification in real-world applications. The consistent performance and minimal overhead observed during our tests indicate that such a setup can effectively manage the verification of personalized AI models at scale. Furthermore, the scalability of Chainlink oracles ensures that this approach can accommodate increasing verification demands without compromising efficiency.
Our findings highlight the potential of combining zk-SNARKs with decentralized oracle networks to improve the transparency and privacy of AI model verification processes for blockchain in real-world applications. In addition to showing that this framework is technically feasible, this study lays the groundwork for future studies that optimize zk-SNARK proof generation and investigate broader applications of Chainlink oracles for AI verification on blockchain. In future work, we will conduct a comprehensive security evaluation of the proposed framework to address potential vulnerabilities and evaluate its robustness against various attack scenarios. This will ensure that the framework is not only efficient and scalable but also secure, thus increasing its applicability and trustworthiness in blockchain-enabled AI marketplaces.
## References
- [1] K. Hao, “The computing power needed to train ai is now rising seven times faster than ever before,” MIT Technology Review, 2019.
- [2] OpenAI, “Introducing the gpt store,” Online, 2024, https://openai.com/blog/introducing-the-gpt-store/.
- [3] G. Zyskind, O. Nathan, and A. S. Pentland, “Decentralizing privacy: Using blockchain to protect personal data,” in 2015 IEEE Security and Privacy Workshops, 2015, pp. 180–184.
- [4] S. Nevo, D. Lahav, A. Karpur, Y. Bar-On, H. A. Bradley, and J. Alstott, Securing AI Model Weights: Preventing Theft and Misuse of Frontier Models. Santa Monica, CA: RAND Corporation, 2024.
- [5] K. K. Sarpatwar, V. S. Ganapavarapu, K. Shanmugam, A. A. U. Rahman, and R. Vaculín, “Blockchain enabled ai marketplace: The price you pay for trust,” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 2857–2866, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:198908085
- [6] B. Goertzel, S. Giacomelli, D. Hanson, G. Yu, C. Dyer, S. Hommel et al., “Singularitynet: A decentralized, open market and inter-network for ais,” SingularityNET Whitepaper, 2017.
- [7] T. Chen, H. Lu, T. Kunpittaya, and A. Luo, “A review of zk-snarks,” 2023. [Online]. Available: https://arxiv.org/abs/2202.06877
- [8] A. Garoffolo, D. Kaidalov, and R. Oliynykov, “Snarktor: A decentralized protocol for scaling snarks verification in blockchains,” IACR Cryptol. ePrint Arch., vol. 2024, p. 99, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:267398902
- [9] K. K. Sarpatwar, R. Vaculín, H. Min, G. Su, F. T. Heath, G. Ganapavarapu, and D. N. Dillenberger, “Towards enabling trusted artificial intelligence via blockchain,” in PADG@ESORICS, 2018. [Online]. Available: https://api.semanticscholar.org/CorpusID:133607734
- [10] S. Nazarov et al., “Chainlink 2.0: Next Steps in the Evolution of Decentralized Oracle Networks,” Chainlink Labs, Tech. Rep., April 2021. [Online]. Available: https://research.chain.link/whitepaper-v2.pdf
- [11] K. Salah, M. H. U. Rehman, N. Nizamuddin, and A. Al-Fuqaha, “Blockchain for ai: Review and open research challenges,” IEEE Access, vol. 7, pp. 10 127–10 149, 2019.
- [12] B. Chavali, S. K. Khatri, and S. A. Hossain, “Ai and blockchain integration,” in 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions)(ICRITO). IEEE, 2020, pp. 548–552.
- [13] G. A. Montes and B. Goertzel, “Distributed, decentralized, and democratized artificial intelligence,” Technological Forecasting and Social Change, vol. 141, pp. 354–358, 2019.
- [14] M. Vincent, A. E. George, T. Christa, and N. Jayapandian, “Systematic review on decentralised artificial intelligence and its applications,” in 2023 International Conference on Innovative Data Communication Technologies and Application (ICIDCA). IEEE, 2023, pp. 241–246.
- [15] R. Upreti, P. G. Lind, A. Elmokashfi, and A. Yazidi, “Trustworthy machine learning in the context of security and privacy,” International Journal of Information Security, pp. 1–28, 2024.
- [16] M. Mylrea and N. Robinson, “Artificial intelligence (ai) trust framework and maturity model: applying an entropy lens to improve security, privacy, and ethical ai,” Entropy, vol. 25, no. 10, p. 1429, 2023.
- [17] M. Abdar, F. Pourpanah, S. Hussain, D. Rezazadegan, L. Liu, M. Ghavamzadeh, P. Fieguth, X. Cao, A. Khosravi, U. R. Acharya et al., “A review of uncertainty quantification in deep learning: Techniques, applications and challenges,” Information fusion, vol. 76, pp. 243–297, 2021.
- [18] J. Pearl and D. Mackenzie, The book of why: The new science of cause and effect. Basic books, 2018.
- [19] Q.-u.-A. Arshad, W. Z. Khan, F. Azam, M. K. Khan, H. Yu, and Y. B. Zikria, “Blockchain-based decentralized trust management in iot: systems, requirements and challenges,” Complex & Intelligent Systems, vol. 9, no. 6, pp. 6155–6176, 2023.
- [20] P. De Filippi, M. Mannan, and W. Reijers, “Blockchain as a confidence machine: The problem of trust & challenges of governance,” Technology in Society, vol. 62, p. 101284, 2020.
- [21] D. El Majdoubi, H. El Bakkali, M. Bensaih, and S. Sadki, “A decentralized trust establishment protocol for smart iot systems,” Internet of Things, vol. 20, p. 100634, 2022.
- [22] S. K. Ezzat, Y. N. Saleh, and A. A. Abdel-Hamid, “Blockchain oracles: State-of-the-art and research directions,” IEEE Access, vol. 10, pp. 67 551–67 572, 2022.
- [23] Y. Zhao, X. Kang, T. Li, C.-K. Chu, and H. Wang, “Toward trustworthy defi oracles: past, present, and future,” IEEE Access, vol. 10, pp. 60 914–60 928, 2022.
- [24] D. Bhumichai, C. Smiliotopoulos, R. Benton, G. Kambourakis, and D. Damopoulos, “The convergence of artificial intelligence and blockchain: the state of play and the road ahead,” Information, vol. 15, no. 5, p. 268, 2024.
- [25] W. L. Oberkampf and C. J. Roy, Verification and Validation in Scientific Computing. Cambridge University Press, 2010.
- [26] C. Rudin, “Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead,” Nature Machine Intelligence, vol. 1, no. 5, pp. 206–215, 2019.
- [27] D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané, “Concrete problems in ai safety,” 2016.
- [28] S. Goldwasser, S. Micali, and C. Rackoff, “The knowledge complexity of interactive proof-systems,” in Symposium on the Theory of Computing, 1985. [Online]. Available: https://api.semanticscholar.org/CorpusID:209402113
- [29] M. Blum, P. Feldman, and S. Micali, “Non-interactive zero-knowledge and its applications,” in Proceedings of the Twentieth Annual ACM Symposium on Theory of Computing, ser. STOC ’88. New York, NY, USA: Association for Computing Machinery, 1988, p. 103–112. [Online]. Available: https://doi.org/10.1145/62212.62222
- [30] N. Bitansky, R. Canetti, A. Chiesa, and E. Tromer, “From extractable collision resistance to succinct non-interactive arguments of knowledge, and back again,” Cryptology ePrint Archive, Paper 2011/443, 2011, https://eprint.iacr.org/2011/443. [Online]. Available: https://eprint.iacr.org/2011/443
- [31] E. Ben-Sasson, I. Bentov, Y. Horesh, and M. Riabzev, “Scalable, transparent, and post-quantum secure computational integrity,” Cryptology ePrint Archive, Paper 2018/046, 2018, https://eprint.iacr.org/2018/046. [Online]. Available: https://eprint.iacr.org/2018/046
- [32] B. Bünz, J. Bootle, D. Boneh, A. Poelstra, P. Wuille, and G. Maxwell, “Bulletproofs: Short proofs for confidential transactions and more,” in 2018 IEEE Symposium on Security and Privacy (SP), 2018, pp. 315–334.
- [33] A. Madi, R. Sirdey, and O. Stan, “Computing neural networks with homomorphic encryption and verifiable computing,” in Applied Cryptography and Network Security Workshops: ACNS 2020 Satellite Workshops, AIBlock, AIHWS, AIoTS, Cloud S&P, SCI, SecMT, and SiMLA, Rome, Italy, October 19–22, 2020, Proceedings. Berlin, Heidelberg: Springer-Verlag, 2020, p. 295–317. [Online]. Available: https://doi.org/10.1007/978-3-030-61638-0_17
- [34] Y. Lindell, “Secure multiparty computation (mpc),” IACR Cryptol. ePrint Arch., vol. 2020, p. 300, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:212673511
- [35] T. Xie, J. Zhang, Y. Zhang, C. Papamanthou, and D. X. Song, “Libra: Succinct zero-knowledge proofs with optimal prover computation,” IACR Cryptol. ePrint Arch., vol. 2019, p. 317, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:92989590
- [36] T. Chen, H. Lu, T. Kunpittaya, and A. Luo, “A review of zk-snarks,” arXiv preprint arXiv:2202.06877, 2022.
- [37] Z. L. DeStefano, “Snnzksnark an efficient design and implementation of a secure neural network verification system using zksnarks [slides],” 1 2020. [Online]. Available: https://www.osti.gov/biblio/1583147
- [38] T. South, A. Camuto, S. Jain, S. Nguyen, R. Mahari, C. Paquin, J. Morton, and A. Pentland, “Verifiable evaluations of machine learning models using zksnarks,” arXiv preprint arXiv:2402.02675, 2024.
- [39] D. Kang, T. B. Hashimoto, I. Stoica, and Y. Sun, “Scaling up trustless dnn inference with zero-knowledge proofs,” ArXiv, vol. abs/2210.08674, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:252918110
- [40] T. Liu, X. Xie, and Y. Zhang, “zkcnn: Zero knowledge proofs for convolutional neural network predictions and accuracy,” Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:235349006
- [41] N. Ni and Y. Zhu, “Enabling zero knowledge proof by accelerating zk-snark kernels on gpu,” Journal of Parallel and Distributed Computing, vol. 173, pp. 20–31, 2023. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0743731522002246
- [42] R. S. Wahby, I. Tzialla, A. Shelat, J. Thaler, and M. Walfish, “Doubly-efficient zksnarks without trusted setup,” 2018 IEEE Symposium on Security and Privacy (SP), pp. 926–943, 2018. [Online]. Available: https://api.semanticscholar.org/CorpusID:549873
- [43] C. Labs, “Off-chain reporting,” 2024, accessed: 2024-07-15. [Online]. Available: https://research.chain.link/ocr.pdf
- [44] The Block, “Ethereum archives,” The Block, (accessed Feb. 6, 2023). [Online]. Available: https://www.theblockcrypto.com/data/on-chain-metrics/ethereum
- [45] Glassnode Studio, “Glassnode studio - on-chain market intelligence.” Glassnode Studio, (accessed Jan. 21, 2023). [Online]. Available: https://studio.glassnode.com
- [46] C. Spearman, “The proof and measurement of association between two things,” The American Journal of Psychology, vol. 100, no. 3/4, pp. 441–471, 1987.
- [47] R. Gennaro, C. Gentry, B. Parno, and M. Raykova, “Quadratic span programs and succinct nizks without pcps,” in Advances in Cryptology – EUROCRYPT 2013, T. Johansson and P. Q. Nguyen, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2013, pp. 626–645.
- [48] A. R. Bernabéu, “Efficient cryptographic techniques for privacy-preserving data aggregation,” Master’s thesis, Universitat Oberta de Catalunya, 2020. [Online]. Available: https://openaccess.uoc.edu/bitstream/10609/120126/6/albertobrTFM0620memory.pdf
- [49] SmartContractKit, “functions-hardhat-starter-kit,” https://github.com/smartcontractkit/functions-hardhat-starter-kit, 2024, accessed: 2024-07-15.
- [50] CoinMarketCap, “Chainlink price today, link to usd live price, marketcap and chart,” https://coinmarketcap.com/currencies/chainlink/, accessed: 04 July 2024.
- [51] H. Qi, Y. Cheng, M. Xu, D. Yu, H. Wang, and W. Lyu, “Split: A hash-based memory optimization method for zero-knowledge succinct non-interactive argument of knowledge (zk-snark),” IEEE Transactions on Computers, vol. 72, pp. 1857–1870, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:255624126
- [52] T. Derei, “Accelerating the plonk zksnark proving system using gpu architectures,” 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:259373697
- [53] T. Lu, C. Wei, R. Yu, Y. Chen, L. xilinx Wang, C. Chen, Z. Wang, and W. Chen, “cuzk: Accelerating zero-knowledge proof with a faster parallel multi-scalar multiplication algorithm on gpus,” IACR Trans. Cryptogr. Hardw. Embed. Syst., vol. 2023, pp. 194–220, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:252734156
- [54] M. Maller, S. Bowe, M. Kohlweiss, and S. Meiklejohn, “Sonic: Zero-knowledge snarks from linear-size universal and updatable structured reference strings,” Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:60442921