# Kimi-VL Technical Report
**Authors**: Kimi Team
\addbibresource
template.bib
Abstract
We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities —all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B).
Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains.
Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks.
Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking-2506. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), the latest model exhibits strong long-horizon reasoning capabilities (64.0 on MMMU, 46.3 on MMMU-Pro, 56.9 on MathVision, 80.1 on MathVista, 65.2 on VideoMMMU) while obtaining robust general abilities (84.4 on MMBench, 83.2 on V* and 52.8 on ScreenSpot-Pro). With only around 3B activated parameters, it sets a new standard for efficient yet capable multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
<details>
<summary>x1.png Details</summary>
### Visual Description
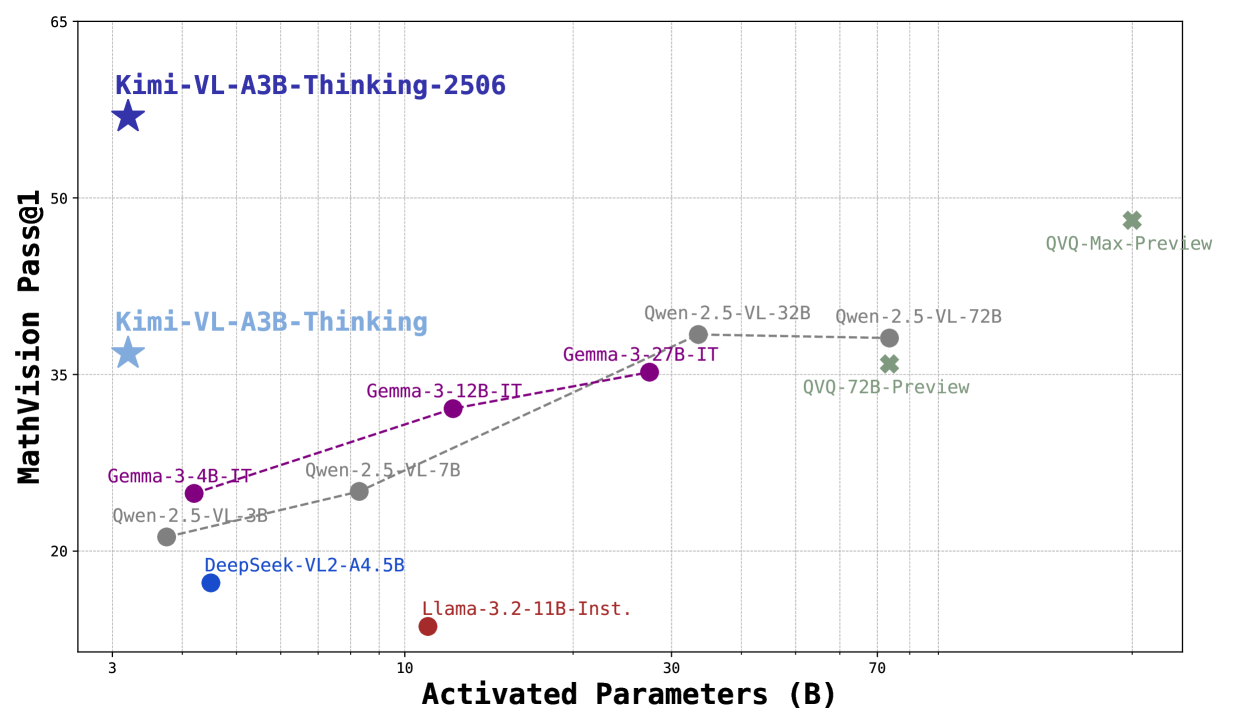
## Scatter Plot: MathVision Pass@1 vs. Activated Parameters
### Overview
The image is a scatter plot comparing the performance of various language models on the MathVision Pass@1 benchmark against the number of activated parameters (in billions). The plot displays data points for different models, each labeled with its name, and uses different colors to distinguish between model families. Trend lines connect related models.
### Components/Axes
* **X-axis:** Activated Parameters (B), with a logarithmic scale. Axis markers are present at approximately 3, 10, 30, and 70.
* **Y-axis:** MathVision Pass@1, with a linear scale. Axis markers are present at 20, 35, 50, and 65.
* **Data Points:** Each data point represents a specific language model. The models are labeled with their names (e.g., "Kimi-VL-A3B-Thinking-2506", "Gemma-3-4B-IT", "Qwen-2.5-VL-3B").
* **Trend Lines:** Dashed lines connect related models, showing the trend in performance as the number of activated parameters increases. There are two trend lines: one for the Gemma models (purple) and one for the Qwen models (gray).
* **Legend:** There is no explicit legend, but the colors of the data points implicitly represent different model families.
### Detailed Analysis
* **Kimi-VL-A3B-Thinking-2506 (Dark Blue Star):** Located at approximately (3, 60).
* **Kimi-VL-A3B-Thinking (Light Blue Star):** Located at approximately (3, 37).
* **Gemma-3-4B-IT (Purple Dot):** Located at approximately (4, 25).
* **Gemma-3-12B-IT (Purple Dot):** Located at approximately (12, 33).
* **Gemma-3-27B-IT (Purple Dot):** Located at approximately (28, 36).
* **Trend:** The Gemma models show an upward trend, with performance increasing as the number of activated parameters increases.
* **Qwen-2.5-VL-3B (Gray Dot):** Located at approximately (5, 22).
* **Qwen-2.5-VC-7B (Gray Dot):** Located at approximately (11, 27).
* **Qwen-2.5-VL-32B (Gray Dot):** Located at approximately (35, 38).
* **Qwen-2.5-VL-72B (Gray Dot):** Located at approximately (75, 38).
* **Trend:** The Qwen models show an upward trend initially, but performance plateaus after 32B parameters.
* **DeepSeek-VL2-A4.5B (Blue Dot):** Located at approximately (6, 18).
* **Llama-3.2-11B-Inst. (Red Dot):** Located at approximately (12, 15).
* **QVQ-72B-Preview (Green X):** Located at approximately (75, 33).
* **QVQ-Max-Preview (Green X):** Located at approximately (75, 48).
### Key Observations
* The Kimi models, represented by stars, outperform other models with similar numbers of activated parameters.
* The Gemma models show a consistent increase in performance with increasing parameters.
* The Qwen models plateau in performance after a certain number of parameters.
* The QVQ models show a significant jump in performance compared to the Qwen models, despite having similar numbers of parameters.
* The DeepSeek and Llama models have relatively low MathVision Pass@1 scores compared to other models.
### Interpretation
The scatter plot illustrates the relationship between model size (activated parameters) and performance on the MathVision Pass@1 benchmark. The data suggests that increasing model size generally leads to better performance, but there are diminishing returns for some model families (e.g., Qwen). The Kimi and QVQ models appear to be more efficient, achieving higher performance with fewer parameters compared to other models. The plot highlights the importance of model architecture and training techniques in addition to model size. The plateauing of the Qwen models suggests that simply increasing the number of parameters may not always lead to significant improvements in performance.
</details>
Figure 1: Comparison between Kimi-VL-Thinking-2506 and frontier open-source VLMs, including short-thinking VLMs (e.g. Gemma-3 series, Qwen2.5-VL series) and long-thinking VLMs (QVQ-72B/Max-Preview), on MathVision benchmark. Our model achieves strong multimodal reasoning with just 2.8B LLM activated parameters.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Bar Chart: Model Performance on Various Benchmarks
### Overview
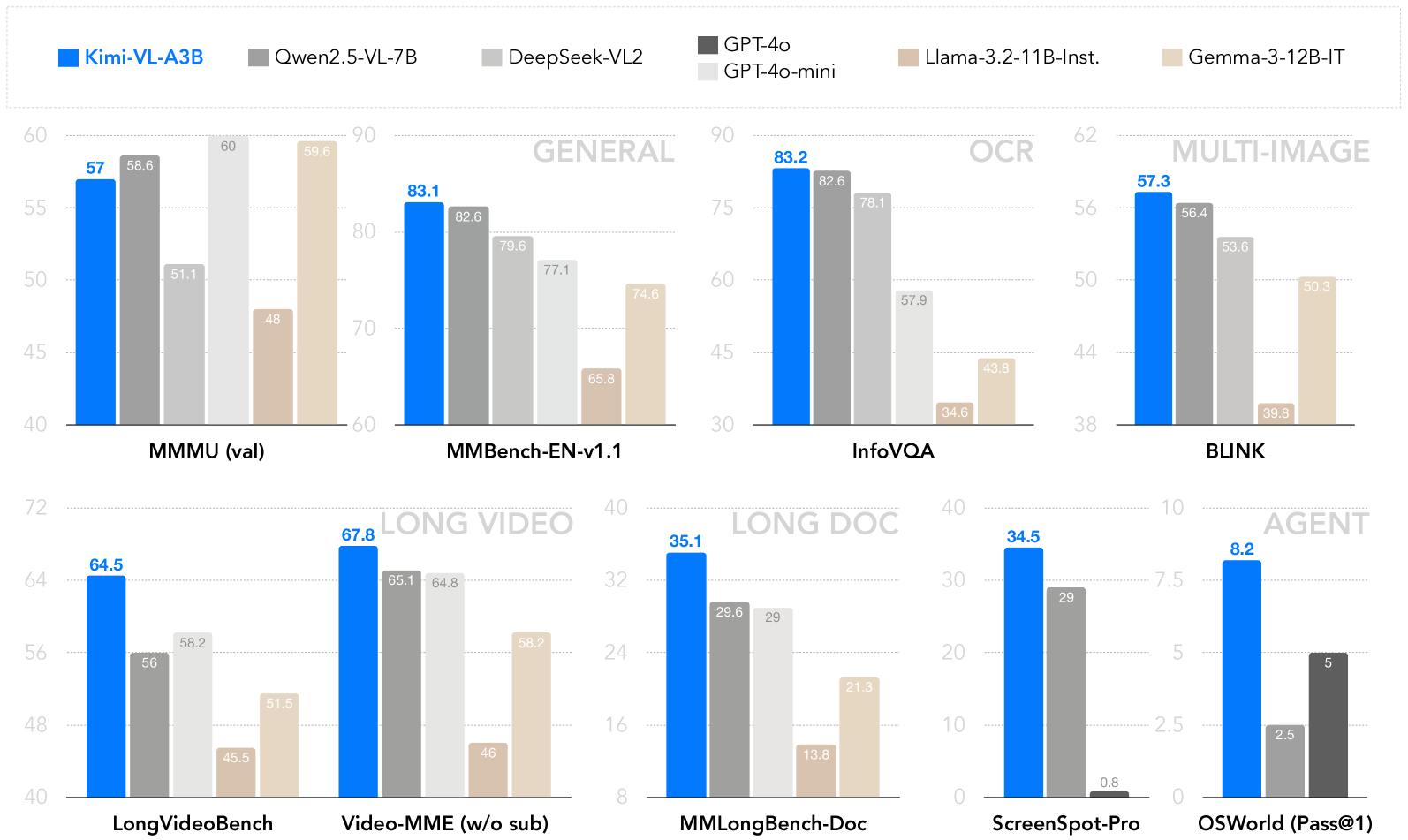
The image is a bar chart comparing the performance of several language models (Kimi-VL-A3B, Qwen2.5-VL-7B, DeepSeek-VL2, GPT-4o/GPT-4o-mini, Llama-3.2-11B-Inst., and Gemma-3-12B-IT) across different benchmark tasks. The tasks are grouped into categories like General, OCR, Multi-Image, Long Video, Long Doc, and Agent. The y-axis represents the performance score, and each model's score on a given task is represented by the height of its corresponding bar.
### Components/Axes
* **Title**: None explicitly visible in the cropped image.
* **X-Axis**: Represents different benchmark tasks: MMMU (val), MMBench-EN-v1.1, InfoVQA, BLINK, LongVideoBench, Video-MME (w/o sub), MMLongBench-Doc, ScreenSpot-Pro, OSWorld (Pass@1). These are grouped into broader categories: GENERAL, OCR, MULTI-IMAGE, LONG VIDEO, LONG DOC, and AGENT.
* **Y-Axis**: Represents the performance score. The scale varies depending on the task category.
* MMMU (val) and MMBench-EN-v1.1: 40 to 90
* InfoVQA and BLINK: 30 to 62
* LongVideoBench and Video-MME (w/o sub): 40 to 72
* MMLongBench-Doc and ScreenSpot-Pro: 0 to 40
* OSWorld (Pass@1): 0 to 10
* **Legend** (located at the top of the chart):
* Blue: Kimi-VL-A3B
* Gray: Qwen2.5-VL-7B
* Dark Gray: DeepSeek-VL2
* Black: GPT-4o/GPT-4o-mini
* Beige: Llama-3.2-11B-Inst.
* Light Beige: Gemma-3-12B-IT
### Detailed Analysis
Here's a breakdown of the performance of each model on each task, with values extracted from the bar heights:
**GENERAL**
* **MMMU (val)**:
* Kimi-VL-A3B (Blue): 57
* Qwen2.5-VL-7B (Gray): 58.6
* Llama-3.2-11B-Inst. (Beige): 51.1
* Gemma-3-12B-IT (Light Beige): 48
* **MMBench-EN-v1.1**:
* Kimi-VL-A3B (Blue): 83.1
* Qwen2.5-VL-7B (Gray): 82.6
* DeepSeek-VL2 (Dark Gray): 79.6
* GPT-4o/GPT-4o-mini (Black): 77.1
* Llama-3.2-11B-Inst. (Beige): 65.8
* Gemma-3-12B-IT (Light Beige): 74.6
**OCR**
* **InfoVQA**:
* Kimi-VL-A3B (Blue): 83.2
* Qwen2.5-VL-7B (Gray): 82.6
* DeepSeek-VL2 (Dark Gray): 78.1
* Llama-3.2-11B-Inst. (Beige): 57.9
* Gemma-3-12B-IT (Light Beige): 43.8
* GPT-4o/GPT-4o-mini (Black): 34.6
**MULTI-IMAGE**
* **BLINK**:
* Kimi-VL-A3B (Blue): 57.3
* Qwen2.5-VL-7B (Gray): 56.4
* DeepSeek-VL2 (Dark Gray): 53.6
* Llama-3.2-11B-Inst. (Beige): 50.3
* Gemma-3-12B-IT (Light Beige): 39.8
**LONG VIDEO**
* **LongVideoBench**:
* Kimi-VL-A3B (Blue): 64.5
* Qwen2.5-VL-7B (Gray): 56
* DeepSeek-VL2 (Dark Gray): 58.2
* Llama-3.2-11B-Inst. (Beige): 45.5
* Gemma-3-12B-IT (Light Beige): 51.5
* **Video-MME (w/o sub)**:
* Kimi-VL-A3B (Blue): 67.8
* Qwen2.5-VL-7B (Gray): 65.1
* DeepSeek-VL2 (Dark Gray): 64.8
* Llama-3.2-11B-Inst. (Beige): 46
* Gemma-3-12B-IT (Light Beige): 58.2
**LONG DOC**
* **MMLongBench-Doc**:
* Kimi-VL-A3B (Blue): 35.1
* Qwen2.5-VL-7B (Gray): 29.6
* DeepSeek-VL2 (Dark Gray): 29
* Llama-3.2-11B-Inst. (Beige): 13.8
* Gemma-3-12B-IT (Light Beige): 21.3
**AGENT**
* **ScreenSpot-Pro**:
* Kimi-VL-A3B (Blue): 34.5
* Qwen2.5-VL-7B (Gray): 29
* GPT-4o/GPT-4o-mini (Black): 0.8
* **OSWorld (Pass@1)**:
* Kimi-VL-A3B (Blue): 8.2
* Qwen2.5-VL-7B (Gray): 5
* GPT-4o/GPT-4o-mini (Black): 2.5
* DeepSeek-VL2 (Dark Gray): 5
### Key Observations
* Kimi-VL-A3B generally performs well across most tasks, often achieving the highest scores.
* Qwen2.5-VL-7B consistently scores close to Kimi-VL-A3B.
* GPT-4o/GPT-4o-mini shows mixed performance, excelling in some areas but lagging in others (particularly ScreenSpot-Pro).
* Llama-3.2-11B-Inst. and Gemma-3-12B-IT tend to have lower scores compared to Kimi-VL-A3B and Qwen2.5-VL-7B.
### Interpretation
The bar chart provides a comparative analysis of different language models on a variety of tasks, highlighting their strengths and weaknesses. Kimi-VL-A3B appears to be a strong all-around performer. The data suggests that model architecture and training data significantly impact performance on specific tasks. For example, the relatively low score of GPT-4o/GPT-4o-mini on ScreenSpot-Pro suggests it may not be optimized for that particular type of task. The chart is useful for understanding which models are best suited for different applications.
</details>
Figure 2: Highlights of Kimi-VL performance for a wide range of benchmarks like, general benchmarks (MMMU, MMBench), OCR (InfoVQA), multi-image (BLINK), long video (LongVideoBench, Video-MME), long document (MMLongBench-Doc), and agent (ScreenSpot-Pro and OSWorld). Detailed results are presented in Table 3.
1 Introduction
With the rapid advancement of artificial intelligence, human expectations for AI assistants have transcended traditional language-only interactions, increasingly aligning with the inherently multimodal nature of our world. To better understand and interact with these expectations, new generations of natively multimodal models, such as GPT-4o \parencite openai2024gpt4ocard and Google Gemini \parencite geminiteam2024gemini15unlockingmultimodal, have emerged with the capability to seamlessly perceive and interpret visual inputs alongside language processing. Most recently, advanced multimodal models, pioneered by OpenAI o1 series \parencite o12024 and Kimi k1.5 \parencite team2025kimi, have further pushed these boundaries by incorporating deeper and longer reasoning on multimodal inputs, thereby tackling more complex problems in the multimodal domain.
Nevertheless, development in large VLMs in the open-source community has significantly lagged behind their language-only counterparts, particularly in aspects of scalability, computational efficiency, and advanced reasoning capabilities. While language-only model DeepSeek R1 \parencite deepseekai2025deepseekr1incentivizingreasoningcapability has already leveraged the efficient and more scalable mixture-of-experts (MoE) architecture and facilitated sophisticated long chain-of-thought (CoT) reasoning, most recent open-source VLMs, e.g. Qwen2.5-VL \parencite bai2025qwen25vltechnicalreport and Gemma-3 \parencite gemmateam2025gemma3technicalreport, continue to rely on dense architectures and do not support long-CoT reasoning. Early explorations into MoE-based vision-language models, such as DeepSeek-VL2 \parencite wu2024deepseekvl2mixtureofexpertsvisionlanguagemodels and Aria \parencite li2024ariaopenmultimodalnative, exhibit limitations in other crucial dimensions. Architecturally, both models still adopt relatively traditional fixed-size vision encoders, hindering their adaptability to diverse visual inputs. From a capability perspective, DeepSeek-VL2 supports only a limited context length (4K), while Aria falls short in fine-grained visual tasks. Additionally, neither of them supports long-thinking abilities. Consequently, there remains a pressing need for an open-source VLM that effectively integrates structural innovation, stable capabilities, and enhanced reasoning through long-thinking.
In light of this, we present Kimi-VL, a vision-language model for the open-source community. Structurally, Kimi-VL consists of our Moonlight \parencite liu2025muonscalablellmtraining MoE language model with only 2.8B activated (16B total) parameters, paired with a 400M native-resolution MoonViT vision encoder. In terms of capability, as illustrated in Figure 2, Kimi-VL can robustly handle diverse tasks (fine-grained perception, math, college-level problems, OCR, agent, etc.) across a broad spectrum of input forms (single-image, multi-image, video, long-document, etc.). Specifically, it features the following exciting abilities:
1) Kimi-VL is smart: it has comparable text ability against efficient pure-text LLMs; without long thinking, Kimi-VL is already competitive in multimodal reasoning and multi-turn agent benchmarks, e.g., MMMU, MathVista, OSWorld.
2) Kimi-VL processes long: it effectively tackles long-context understanding on various multimodal inputs within its 128K context window, far ahead of similar-scale competitors on long video benchmarks and MMLongBench-Doc.
3) Kimi-VL perceives clear: it shows all-round competitive ability over existing efficient dense and MoE VLMs in various vision-language scenarios: visual perception, visual world knowledge, OCR, high-resolution OS screenshot, etc.
Furthermore, with long-CoT activation and reinforcement learning (RL), we introduce the long-thinking version of Kimi-VL, Kimi-VL-Thinking, which further substantially improves performance on more complex multimodal reasoning scenarios. Despite its small scale, Kimi-VL-Thinking offers compelling performance on hard reasoning benchmarks (e.g., MMMU, MathVision, MathVista), outperforming many state-of-the-art VLMs with even larger sizes. We further release and improved version of the thinking model, Kimi-VL-Thinking-2506. The improved version has even better performance on these reasoning benchmarks while retaining or improving on common visual perception and understanding scenarios, e.g. high-resolution perception (V*), OS grounding, video and long document understanding.
2 Approach
2.1 Model Architecture
<details>
<summary>x3.png Details</summary>
### Visual Description
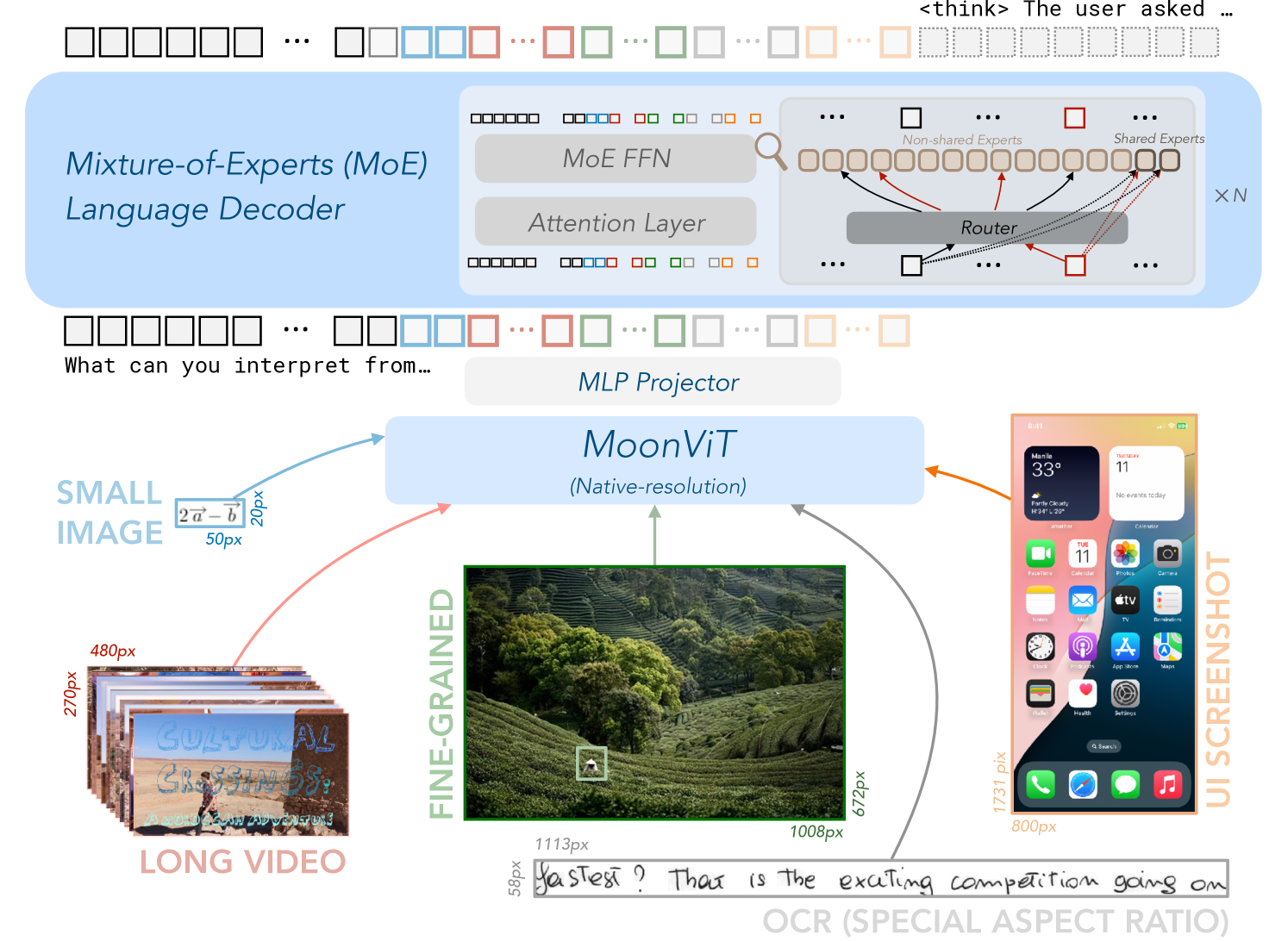
## Diagram: MoonViT Architecture
### Overview
The image presents a diagram illustrating the architecture of MoonViT, a system that processes various types of input data, including small images, long videos, fine-grained images, and UI screenshots. The system uses a Mixture-of-Experts (MoE) Language Decoder and an MLP Projector to interpret the input.
### Components/Axes
* **Input Types:**
* SMALL IMAGE: A small image with dimensions indicated as 20px and 50px. The image itself is not visible.
* LONG VIDEO: A stack of video frames labeled "CULTURAL CROSSINGS: A MOROCCAN ADVENTURE". The dimensions of the frames are approximately 270px in height and 480px in width.
* FINE-GRAINED: A landscape image of a tea plantation, with dimensions of 672px in height and 1008px in width. A small white square is visible within the image.
* UI SCREENSHOT: A screenshot of an iPhone's home screen, displaying various app icons and widgets. The dimensions are approximately 1731px in height and 800px in width.
* OCR (SPECIAL ASPECT RATIO): Handwritten text that reads "fastest? That is the exciting competition going on". The dimensions are approximately 58px in height and 1113px in width.
* **Processing Modules:**
* Mixture-of-Experts (MoE) Language Decoder: A module consisting of MoE FFN (Feed Forward Network) and an Attention Layer. It includes "Non-shared Experts" and "Shared Experts" connected by a "Router". The output is multiplied by "XN".
* MLP Projector: A module that projects the input data.
* MoonViT (Native-resolution): The core module that processes the input data.
* **Textual Elements:**
* "<think> The user asked ...": Text indicating a user query.
* "What can you interpret from...": Text indicating the system's task.
### Detailed Analysis
* **Input Data Flow:**
* The SMALL IMAGE is fed into the MLP Projector.
* The LONG VIDEO is fed into the MLP Projector.
* The FINE-GRAINED image is fed directly into MoonViT.
* The UI SCREENSHOT is fed into the MLP Projector.
* The OCR text is fed directly into MoonViT.
* **MoE Language Decoder:**
* The MoE Language Decoder consists of an MoE FFN and an Attention Layer.
* The "Router" connects "Non-shared Experts" and "Shared Experts".
### Key Observations
* The diagram illustrates a multi-modal input processing system.
* MoonViT appears to be the central processing unit, handling both fine-grained images and OCR text directly.
* The MLP Projector seems to be used for processing SMALL IMAGES, LONG VIDEOS, and UI SCREENSHOTS before they are fed into MoonViT.
* The MoE Language Decoder is used to interpret the processed data.
### Interpretation
The diagram depicts the architecture of MoonViT, a system designed to handle various types of input data, including images, videos, and text. The system uses a Mixture-of-Experts (MoE) Language Decoder to interpret the input, suggesting that it leverages multiple specialized models to understand different aspects of the data. The MLP Projector likely serves as a pre-processing step to transform the input data into a suitable format for MoonViT. The system's ability to handle native-resolution images and OCR text directly indicates its focus on preserving detail and extracting textual information from visual sources. The overall architecture suggests a sophisticated approach to multi-modal data processing, potentially enabling MoonViT to perform complex tasks such as image captioning, video understanding, and UI analysis.
</details>
Figure 3: The model architecture of Kimi-VL and Kimi-VL-Thinking, consisting of a MoonViT that allows native-resolution images, an MLP projector, and a Mixture-of-Experts (MoE) language decoder.
The architecture of Kimi-VL consists of three parts: a native-resolution vision encoder (MoonViT), an MLP projector, and an MoE language model, as depicted in Figure 3. We introduce each part in this section.
MoonViT: A Native-resolution Vision Encoder
We design MoonViT, the vision encoder of Kimi-VL, to natively process images at their varying resolutions, eliminating the need for complex sub-image splitting and splicing operations, as employed in LLaVA-OneVision \parencite li2024llavaonevisioneasyvisualtask. We incorporate the packing method from NaViT \parencite dehghani2023patchnpacknavit, where images are divided into patches, flattened, and sequentially concatenated into 1D sequences. These preprocessing operations enable MoonViT to share the same core computation operators and optimization as a language model, such as the variable-length sequence attention mechanism supported by FlashAttention \parencite dao2022flashattentionfastmemoryefficientexact, ensuring non-compromised training throughput for images of varying resolutions.
MoonViT is initialized from and continually pre-trained on SigLIP-SO-400M \parencite zhai2023sigmoidlosslanguageimage, which originally employs learnable fixed-size absolute positional embeddings to encode spatial information. While we interpolate these original position embeddings to better preserve SigLIP’s capabilities, these interpolated embeddings become increasingly inadequate as image resolution increases. To address this limitation, we incorporate 2D rotary positional embedding (RoPE) \parencite su2023roformerenhancedtransformerrotary across the height and width dimensions, which improves the representation of fine-grained positional information, especially in high-resolution images. These two positional embedding approaches work together to encode spatial information for our model and seamlessly integrate with the flattening and packing procedures. This integration enables MoonViT to efficiently process images of varying resolutions within the same batch. The resulting continuous image features are then forwarded to the MLP projector and, ultimately, to the MoE language model for subsequent training stages. In Kimi-VL-A3B-Thinking-2506, we further continually train this MoonViT to authentically encode up to 3.2 million pixels from a single image, 4 times compared to the original limit.
MLP Projector
We employ a two-layer MLP to bridge the vision encoder (MoonViT) and the LLM. Specifically, we first use a pixel shuffle operation to compress the spatial dimension of the image features extracted by MoonViT, performing 2×2 downsampling in the spatial domain and correspondingly expanding the channel dimension. We then feed the pixel-shuffled features into a two-layer MLP to project them into the dimension of LLM embeddings.
Mixture-of-Experts (MoE) Language Model
The language model of Kimi-VL utilizes our Moonlight model \parencite liu2025muonscalablellmtraining, an MoE language model with 2.8B activated parameters, 16B total parameters, and an architecture similar to DeepSeek-V3 \parencite deepseekai2025deepseekv3technicalreport. For our implementation, we initialize from an intermediate checkpoint in Moonlight’s pre-training stage—one that has processed 5.2T tokens of pure text data and activated an 8192-token (8K) context length. We then continue pre-training it using a joint recipe of multimodal and text-only data totaling 2.3T tokens, as detailed in Sec. 2.3.
2.2 Muon Optimizer
We use an enhanced Muon optimizer \parencite liu2025muon for model optimization. Compared to the original Muon optimizer \parencite jordan2024muon, we add weight decay and carefully adjust the per-parameter update scale. Additionally, we develop a distributed implementation of Muon following the ZeRO-1 \parencite rajbhandari2020zero optimization strategy, which achieves optimal memory efficiency and reduced communication overhead while preserving the algorithm’s mathematical properties. This enhanced Muon optimizer is used throughout the entire training process to optimize all model parameters, including the vision encoder, the projector, and the language model.
2.3 Pre-Training Stages
As illustrated in Figure 4 and Table 1, after loading the intermediate language model discussed above, Kimi-VL’s pre-training comprises a total of 4 stages consuming 4.4T tokens overall: first, standalone ViT training to establish a robust native-resolution visual encoder, followed by three joint training stages (pre-training, cooldown, and long-context activation) that simultaneously enhance the model’s language and multimodal capabilities. The details are as follows.
<details>
<summary>x4.png Details</summary>

### Visual Description
## Training Data Flow Diagram
### Overview
The image is a diagram illustrating the data flow and stages of a training process, likely for a large language model (LLM). It outlines four distinct phases: Text Pre-training, ViT Training, Joint Pre-training, Joint Cooldown, and Joint Long-context. Each phase is represented by a blue rounded rectangle containing information about the data used. The diagram also indicates the resumption of the learning rate (LR) scheduler between certain phases.
### Components/Axes
* **Blue Rounded Rectangles:** Represent the different training phases.
* **Text within Rectangles:** Describes the phase name, the amount of data used (in terabytes), and additional details about the data or training process.
* **Green Arrows:** Indicate the flow of the training process and the resumption of the LR scheduler.
### Detailed Analysis or ### Content Details
**1. Text Pre-training:**
* Data: 5.2T data
* Data Type: Pure Text Data
**2. ViT Training:**
* Data: 2.0T -> 0.1T data
* Details: CoCa-loss with tiny language decoder -> align to LLM
**3. Joint Pre-training:**
* Data: 1.4T data
* Details: Up to 40% Multimodal Data, Progressive Multimodal Ratio
* Arrow: A green arrow indicates that the LR scheduler resumes after this phase.
**4. Joint Cooldown:**
* Data: 0.6T data
* Details: High-quality Text & Multimodal Data, Re-warmup to higher LR
**5. Joint Long-context:**
* Data: 0.3T data
* Details: Long Text & Long Video & Long Doc, RoPE base: 50,000 -> 800,000
* Arrow: A green arrow indicates that the LR scheduler resumes after this phase.
### Key Observations
* The amount of data used decreases as the training progresses from Text Pre-training (5.2T) to Joint Long-context (0.3T).
* The training process transitions from pure text data to multimodal data.
* The ViT Training phase significantly reduces the amount of data used (2.0T -> 0.1T).
* The LR scheduler is resumed after the Joint Pre-training and Joint Long-context phases.
### Interpretation
The diagram illustrates a multi-stage training process for a model, likely a large multimodal model. The initial phase focuses on pre-training with a large amount of pure text data. Subsequent phases incorporate multimodal data and fine-tune the model for specific tasks or contexts, such as long-context understanding. The reduction in data size and the use of techniques like CoCa-loss and RoPE suggest a focus on efficiency and specialized training as the process evolves. The resumption of the LR scheduler indicates adjustments to the learning rate during training, likely to optimize convergence and performance. The progression from pure text to multimodal data suggests an effort to build a model capable of processing and understanding diverse types of information.
</details>
Figure 4: The pre-training stages of Kimi-VL consume a total of 4.4T tokens after text-only pre-training of its language model. To preserve text abilities, all stages that update the language model are joint training stages.
Table 1: Overview of training stages: data composition, token volumes, sequence lengths, and trainable components.
| Stages Data | ViT Training Alt text Synthesis Caption | Joint Pre-training + Text, Knowledge | Joint Cooldown + High-quality Text | Joint Long-context + Long Text |
| --- | --- | --- | --- | --- |
| Grounding | Interleaving | High-quality Multimodal | Long Video | |
| OCR | Video, Agent | Academic Sources | Long Document | |
| Tokens | 2T + 0.1T | 1.4T | 0.6T | 0.3T |
| Sequence length | 8192 | 8192 | 8192 | 32768->131072 |
| Training | ViT | ViT & LLM | ViT & LLM | ViT & LLM |
ViT Training Stages
The MoonViT is trained on image-text pairs, where the text components consist of a variety of targets: image alt texts, synthetic captions, grounding bboxes, and OCR texts. The training incorporates two objectives: a SigLIP \parencite zhai2023sigmoidlosslanguageimage loss $\mathcal{L}_{siglip}$ (a variant of contrastive loss) and a cross-entropy loss $\mathcal{L}_{caption}$ for caption generation conditioned on input images. Following CoCa’s approach \parencite yu2022cocacontrastivecaptionersimagetext, the final loss function is formulated as $\mathcal{L}=\mathcal{L}_{siglip}+\lambda\mathcal{L}_{caption}$ , where $\lambda=2$ . Specifically, the image and text encoders compute the contrastive loss, while the text decoder performs next-token prediction (NTP) conditioned on features from the image encoder. To accelerate training, we initialized both encoders with SigLIP SO-400M \parencite zhai2023sigmoidlosslanguageimage weights and implemented a progressive resolution sampling strategy to gradually allow larger size; the text decoder is initialized from a tiny decoder-only language model. During training, we observed an emergence in the caption loss while scaling up OCR data, indicating that the text decoder had developed some OCR capabilities. After training the ViT in the CoCa-alike stage with 2T tokens, we align the MoonViT to the MoE language model using another 0.1T tokens, where only MoonViT and MLP projector are updated. This alignment stage significantly reduces the initial perplexity of MoonViT embeddings in the language model, allowing a smoother joint pre-training stage as follows.
Joint Pre-training Stage
In the joint pre-training stage, we train the model with a combination of pure text data (sampled from the same distribution as the initial language model) and a variety of multimodal data (as discussed in Sec. 3.1). We continue training from the loaded LLM checkpoint using the same learning rate scheduler, consuming an additional 1.4T tokens. The initial steps utilize solely language data, after which the proportion of multimodal data gradually increases. Through this progressive approach and the previous alignment stage, we observe that joint pre-training preserves the model’s language capabilities while successfully integrating visual comprehension abilities.
Joint Cooldown Stage
The stage following the pre-training stage is a multimodal cooldown phase, where the model is continue trained with high-quality language and multimodal datasets to ensure superior performance. For the language part, through empirical investigation, we observe that the incorporation of synthetic data during the cooling phase yields significant performance improvements, particularly in mathematical reasoning, knowledge-based tasks, and code generation. The general text components of the cooldown dataset are curated from high-fidelity subsets of the pre-training corpus. For math, knowledge, and code domains, we employ a hybrid approach: utilizing selected pre-training subsets while augmenting them with synthetically generated content. Specifically, we leverage existing mathematical knowledge and code corpora as source material to generate question-answer (QA) pairs through a proprietary language model, implementing rejection sampling techniques to maintain quality standards \parencite yue2023mammoth,su2024nemotron. These synthesized QA pairs undergo comprehensive validation before being integrated into the cooldown dataset. For the multimodal part, in addition to the two strategies as employed in text cooldown data preparation, i.e. question-answer synthesis and high-quality subset replay, to allow more comprehensive visual-centric perception and understanding \parencite li2024llavaonevisioneasyvisualtask,tong2024cambrian1fullyopenvisioncentric,guo2024mammothvlelicitingmultimodalreasoning, we filter and rewrite a variety of academic visual or vision-language data sources to QA pairs. Unlike post-training stages, these language and multimodal QA pairs in the cooldown stage are only included for activating specific abilities and henceforth facilitating learning high-quality data, thus, we keep their ratio at a low portion to avoid overfitting these QA patterns. The joint cooldown stage significantly improves both language and multimodal abilities of the model.
Table 2: Needle-in-a-Haystack (NIAH) test on text/video haystacks, where needles are uniformly distributed at various positions within the haystack. We report recall accuracy across different haystack lengths up to 131,072 tokens (128K).
| - text haystack - video haystack | 100.0 100.0 | 100.0 100.0 | 100.0 100.0 | 100.0 100.0 | 100.0 100.0 | 100.0 100.0 | 87.0 91.7 |
| --- | --- | --- | --- | --- | --- | --- | --- |
Joint Long-context Activation Stage
In the final pre-training stage, we extend the context length of the model from 8192 (8K) to 131072 (128K), with the inverse frequency of its RoPE \parencite su2023roformerenhancedtransformerrotary embeddings reset from 50,000 to 800,000. The joint long-context stage is conducted in two sub-stages, where each one extends the model’s context length by four times. For data composition, we filter and upsample the ratio of long data to 25% in each sub-stage, while using the remaining 75% tokens to replay shorter data in its previous stage; our exploration confirms that this composition allows the model to effectively learn long-context understanding while maintaining short-context ability.
To allow the model to activate long-context abilities on both pure-text and multimodal inputs, the long data used in Kimi-VL’s long-context activation consists of not only long text, but also long multimodal data, including long interleaved data, long videos, and long documents. Similar as cooldown data, we also synthesize a small portion of QA pairs to augment the learning efficiency of long-context activation. After the long-context activations, the model can pass needle-in-a-haystack (NIAH) evaluations with either long pure-text or long video haystack, proving its versatile long-context ability. We provide the NIAH recall accuracy on various range of context length up to 128K in Table 2.
<details>
<summary>x5.png Details</summary>

### Visual Description
## Diagram: Kimi-VL-Thinking Process
### Overview
The image is a diagram illustrating the Kimi-VL-Thinking process, which consists of three main stages: Joint Supervised Fine-tuning, Long-CoT Supervised Fine-tuning, and Reinforcement Learning (RL). Each stage is represented by a blue rounded rectangle, with arrows indicating the flow of the process. The Kimi-VL model is mentioned between the first and second stages, and again at the end of the process as "Kimi-VL-Thinking".
### Components/Axes
* **Stages:**
* Joint Supervised Fine-tuning
* Long-CoT Supervised Fine-tuning
* Reinforcement Learning (RL)
* **Model:** Kimi-VL
* **Data Types:** Text, Multimodal SFT Data, Multimodal Long-CoT Data
* **Processes:** Planning, Evaluation, Reflection, Exploration, Online RL on Answer Only
* **Parameters:** Epoch, Length penalty, Difficulty control
### Detailed Analysis or Content Details
1. **Joint Supervised Fine-tuning:**
* Text: "Joint Supervised Fine-tuning"
* Data: "Text + Multimodal SFT Data"
* Epochs: "1 Epoch@32K + 1 Epoch@128K"
* Position: Located on the left side of the diagram.
2. **Kimi-VL (First Instance):**
* Text: "Kimi-VL"
* Position: Located between the "Joint Supervised Fine-tuning" and "Long-CoT Supervised Fine-tuning" stages, with an arrow pointing from the first stage to "Kimi-VL" and another arrow pointing from "Kimi-VL" to the second stage.
3. **Long-CoT Supervised Fine-tuning:**
* Text: "Long-CoT Supervised Fine-tuning"
* Data: "Text + Multimodal Long-CoT Data"
* Processes: "Planning, Evaluation, Reflection, Exploration"
* Position: Located in the center of the diagram.
4. **Reinforcement Learning (RL):**
* Text: "Reinforcement Learning (RL)"
* Process: "Online RL on Answer Only"
* Parameters: "Length penalty, Difficulty control"
* Position: Located on the right side of the diagram.
5. **Kimi-VL-Thinking:**
* Text: "Kimi-VL-Thinking"
* Position: Located on the far right side of the diagram, with an arrow pointing from the "Reinforcement Learning (RL)" stage to "Kimi-VL-Thinking".
### Key Observations
* The diagram illustrates a sequential process, starting with Joint Supervised Fine-tuning, progressing through Long-CoT Supervised Fine-tuning, and ending with Reinforcement Learning (RL).
* The Kimi-VL model is involved in the transition between the first two stages and is ultimately associated with "Thinking" at the end of the process.
* Each stage involves specific data types, processes, and parameters.
### Interpretation
The diagram outlines the training and refinement process for the Kimi-VL model, specifically focusing on its "Thinking" capabilities. The process begins with a broad joint supervised fine-tuning, then moves to a more specialized Long-CoT (Chain-of-Thought) supervised fine-tuning, and finally incorporates reinforcement learning to optimize the model's responses. The progression suggests an iterative approach to improving the model's ability to reason and provide accurate answers. The use of multimodal data throughout the process indicates that the model is designed to handle various types of input, not just text. The parameters mentioned in the RL stage, such as "Length penalty" and "Difficulty control," suggest that the model is being fine-tuned to generate concise and appropriate responses based on the complexity of the input.
</details>
Figure 5: The post-training stages of Kimi-VL and Kimi-VL-Thinking, including two stages of joint SFT in 32K and 128K context, and further long-CoT SFT and RL stages to activate and enhance long thinking abilities.
2.4 Post-Training Stages
Joint Supervised Fine-tuning (SFT)
In this phase, we fine-tune the base model of Kimi-VL with instruction-based fine-tuning to enhance its ability to follow instructions and engage in dialogue, culminating in the creation of the interactive Kimi-VL model. This is achieved by employing the ChatML format (Openai, 2024), which allows for a targeted instruction optimization while maintaining architectural consistency with Kimi-VL. We optimize the language model, MLP projector, and vision encoder using a mixture of pure-text and vision-language SFT data, which will be described in Sec 3.2. Supervision is applied only to answers and special tokens, with system and user prompts being masked. The model is exposed to a curated set of multimodal instruction-response pairs, where explicit dialogue role tagging, structured injection of visual embeddings, and preservation of cross-modal positional relationships are ensured through the format-aware packing. Additionally, to guarantee the model’s comprehensive proficiency in dialogue, we incorporate a mix of multimodal data and pure text dialogue data used in Moonlight, ensuring its versatility across various dialogue scenarios.
We first train the model at the sequence length of 32k tokens for 1 epoch, followed by another epoch at the sequence length of 128k tokens. In the first stage (32K), the learning rate decays from $2× 10^{-5}$ to $2× 10^{-6}$ , before it re-warmups to $1× 10^{-5}$ in the second stage (128K) and finally decays to $1× 10^{-6}$ . To improve training efficiency, we pack multiple training examples into each single training sequence.
Long-CoT Supervised Fine-Tuning
With the refined RL prompt set, we employ prompt engineering to construct a small yet high-quality long-CoT warmup dataset, containing accurately verified reasoning paths for both text and image inputs. This approach resembles rejection sampling (RS) but focuses on generating long-CoT reasoning paths through prompt engineering. The resulting warmup dataset is designed to encapsulate key cognitive processes that are fundamental to human-like reasoning, such as planning, where the model systematically outlines steps before execution; evaluation, involving critical assessment of intermediate steps; reflection, enabling the model to reconsider and refine its approach; and exploration, encouraging consideration of alternative solutions. By performing a lightweight SFT on this warm-up dataset, we effectively prime the model to internalize these multimodal reasoning strategies. As a result, the fine-tuned long-CoT model demonstrates improved capability in generating more detailed and logically coherent responses, which enhances its performance across diverse reasoning tasks.
Reinforcement Learning
To further advance the model’s reasoning abilities, we then train the model with reinforcement learning (RL), enabling the model to autonomously generate structured CoT rationales. Specifically, similar as Kimi k1.5 \parencite team2025kimi, we adopt a variant of online policy mirror descent as our RL algorithm, which iteratively refines the policy model $\pi_{\theta}$ to improve its problem-solving accuracy. During the $i$ -th training iteration, we treat the current model as a reference policy model and optimize the following objective, regularized by relative entropy to stabilize policy updates:
$$
\displaystyle\max_{\theta}\mathbb{E}_{(x,y^{*})\sim\mathcal{D}}\left[\mathbb{E%
}_{(y,z)\sim\pi_{\theta}}\left[r(x,y,y^{*})\right]-\tau\mathrm{KL}(\pi_{\theta%
}(x)||\pi_{\theta_{i}}(x))\right]\,, \tag{1}
$$
where $r$ is a reward model that justifies the correctness of the proposed answer $y$ for the given problem $x$ , by assigning a value $r(x,y,y^{*})∈\{0,1\}$ based on the ground truth $y^{*}$ , and $\tau>0$ is a parameter controlling the degree of regularization.
Each training iteration begins by sampling a problem batch from the dataset $\mathcal{D}$ , and the model parameters are updated to $\theta_{i+1}$ using the policy gradient derived from (1), with the optimized policy model subsequently assuming the role of reference policy for the subsequent iteration. To enhance RL training efficiency, we implement a length-based reward to penalize excessively long responses, mitigating the overthinking problem where the model generates redundant reasoning chains. Besides, we employ two sampling strategies including curriculum sampling and prioritized sampling, which leverage difficulty labels and per-instance success rates to focus training effort on the most pedagogically valuable examples, thereby optimizing the learning trajectory and improving training efficiency.
Through large-scale reinforcement learning training, we can derive a model that harnesses the strengths of both basic prompt-based CoT reasoning and sophisticated planning-enhanced CoT approaches. During inference, the model maintains standard autoregressive sequence generation, eliminating the deployment complexities associated with specialized planning algorithms that require parallel computation. Simultaneously, the model develops essential meta-reasoning abilities including error detection, backtracking, and iterative solution refinement by effectively utilizing the complete history of explored reasoning paths as contextual information. With endogenous learning from its complete reasoning trace history, the model can effectively encode planned search procedures into its parametric knowledge.
2.5 Infrastructure
Storage We utilize S3 \parencite amazon_s3 compatible object storage from cloud service vendors to store our visual-text data. To minimize the time between data preparation and model training, we store visual data in its original format and have developed an efficient and flexible data loading system. This system provides several key benefits:
- Supports on-the-fly data shuffling, mixing, tokenization, loss masking and packing during training, allowing us to adjust data proportions as needed;
- Enables random augmentation of both visual and text data, while preserving the correctness of 2D coordinate and orientation information during transformations;
- Ensures reproducibility by strictly controlling random states and other states across different data loader workers, guaranteeing that any interrupted training can be resumed seamlessly—the data sequence after resumption remains identical to an uninterrupted run;
- Delivers high-performance data loading: through multiple caching strategies, our system reliably supports training on large scale clusters while maintaining controlled request rates and throughput to the object storage.
Additionally, to ensure consistent dataset quality control, we developed a centralized platform for data registration, visualization, compiling statistics, synchronizing data across cloud storage systems, and managing dataset lifecycles.
<details>
<summary>x6.png Details</summary>

### Visual Description
## Manuscript Analysis: Einstein's Gravitational Field Equations
### Overview
The image presents two scanned pages of handwritten mathematical notes and calculations. The notes appear to be related to gravitational field equations and theoretical physics, potentially the work of Albert Einstein. The handwriting is consistent across both pages, and the presence of German terms suggests a German-speaking author.
### Components/Axes
**Left Side (Instruction):**
* **Header:** "Instruction"
* **Text:** "Please infer step by step who this manuscript belongs to and what it records"
* **Handwritten Notes (Image 1):** A collection of equations involving partial derivatives, summations, and various mathematical symbols.
* **Handwritten Notes (Image 2):** A collection of numerical calculations, formulas, and integrals.
* **Bottom-Right:** "I 5a"
**Right Side (Response):**
* **Header:** "Response"
* **Text:** A detailed analysis of the manuscripts, including observations about the handwriting style, content, and presence of German terms.
* **Key Observations:** A summary of the key findings, including handwriting style, content analysis, and German terms.
* **Conclusion:** A statement that the manuscripts belong to Albert Einstein and record his work on gravitational field equations and mathematical derivations.
### Detailed Analysis or Content Details
**Left Side (Image 1):**
* The equations involve terms like partial derivatives, summations, and Greek letters (e.g., γ, g).
* The equations resemble Einstein's formulation of gravitational field equations.
* The presence of the German term "Einheitsvektor" (unit vector) suggests a connection to Einstein's work.
**Left Side (Image 2):**
* The equations include numerical calculations, constants (e.g., K, M, T), and integrals.
* The equations indicate detailed derivations or computations in gravitational theory.
**Right Side (Response):**
* The handwriting is consistent with Einstein's known style.
* The presence of German terms like "Einheitsvektor" and "Gln" (equation) suggests Einstein, who was German-speaking.
* The manuscripts are part of Einstein's research materials, documenting his mathematical and theoretical work on gravitational fields and field equations.
### Key Observations
* The handwriting is consistent across both pages and resembles Einstein's style.
* The equations involve terms like partial derivatives, summations, and Greek letters, which are typical in tensor calculus and field theory.
* The presence of German terms suggests a German-speaking author, which aligns with Einstein's background.
* The manuscripts are likely part of Einstein's research materials, documenting his mathematical and theoretical work on gravitational fields and field equations.
### Interpretation
The image presents compelling evidence that the manuscripts belong to Albert Einstein and record his work on gravitational field equations and mathematical derivations. The handwriting style, content, and presence of German terms all point to Einstein as the author. The equations and calculations are consistent with Einstein's known work in general relativity and gravitational field theory. The manuscripts likely represent Einstein's efforts to formalize the mathematical framework underlying general relativity, a cornerstone of modern physics.
</details>
Figure 6: Manuscript reasoning visualization. Kimi-VL-Thinking demonstrates the ability to perform historical and scientific inference by analyzing handwritten manuscripts step by step. In this example, our model identifies the author as Albert Einstein based on handwriting style, content analysis, and language cues. It reasons that the manuscripts relate to gravitational field equations, consistent with Einstein’s contributions to general relativity.
Parallelism We adopt a 4D parallelism strategy—Data Parallelism \parencite li2020pytorchdistributedexperiencesaccelerating, Expert Parallelism \parencite fedus2022switchtransformersscalingtrillion, Pipeline Parallelism \parencite huang2019gpipeefficienttraininggiant,narayanan2021efficientlargescalelanguagemodel, and Context Parallelism \parencite jacobs2023deepspeedulyssesoptimizationsenabling,liu2023ringattentionblockwisetransformers—to accelerate the speed of Kimi-VL . After optimizing parallel strategies, the resulting training throughput of our model is around 60% higher than a 7B dense VLM (e.g. VLMs based on Qwen2.5-7B).
- Data Parallelism (DP). DP replicates the model across multiple devices, each processing different micro-batches. This setup allows larger effective batch sizes by simply increasing the number of devices.
- Expert Parallelism (EP). EP distributes expert modules in the MoE layer across multiple devices. When combined with DP, experts on a given device can handle tokens from different DP groups, enhancing computational efficiency.
- Pipeline Parallelism (PP). PP splits the model into multiple layer-based stages. To minimize pipeline bubbles, we allocate the Vision Tower (VT) and several decoder layers to the first stage, place the output layer and additional decoder layers in the last stage, and distribute the remaining decoder layers evenly across intermediate stages based on their time overhead.
- Context Parallelism (CP). CP addresses long-sequence training by splitting sequences across different CP ranks in conjunction with flash attention \parencite dao2022flashattentionfastmemoryefficientexact. This substantially reduces peak memory usage and relieves the memory pressure from attention computations.
Beyond these four parallel strategies, we incorporate ZeRO1 \parencite rajbhandari2020zero and Selective Checkpointing Activation \parencite chen2016trainingdeepnetssublinear, korthikanti2022reducingactivationrecomputationlarge to further optimize memory usage. ZeRO1 reduces optimizer state overhead by using a distributed optimizer while avoiding extra communication costs. Selective Checkpointing Activation trades time for space by recomputing only those layers that have low time overhead but high memory consumption, striking a balance between computation efficiency and memory demands. For extremely long sequences, we expand recomputation to a broader set of layers to prevent out-of-memory errors.
3 Data Construction
3.1 Pre-Training Data
Our multimodal pre-training corpus is designed to provide high-quality data that enables models to process and understand information from multiple modalities, including text, images, and videos. To this end, we have also curated high-quality data from six categories – caption, interleaving, OCR, knowledge, video, and agent – to form the corpus.
When constructing our training corpus, we developed several multimodal data processing pipelines to ensure data quality, encompassing filtering, synthesis, and deduplication. Establishing an effective multimodal data strategy is crucial during the joint training of vision and language, as it both preserves the capabilities of the language model and facilitates alignment of knowledge across diverse modalities.
We provide a detailed description of these sources in this section, which is organized into the following categories:
Caption Data
Our caption data provides the model with fundamental modality alignment and a broad range of world knowledge. By incorporating caption data, the multimodal LLM gains wider world knowledge with high learning efficiency. We have integrated various open-source Chinese and English caption datasets like \parencite schuhmann2022laion, gadre2024datacomp and also collected substantial in-house caption data from multiple sources. However, throughout the training process, we strictly limit the proportion of synthetic caption data to mitigate the risk of hallucination stemming from insufficient real-world knowledge.
For general caption data, we follow a rigorous quality control pipeline that avoids duplication and maintain high image-text correlation. We also vary image resolution during pre-training to ensure that the vision tower remains effective when processing images of both high- and low-resolution.
Image-text Interleaving Data During the pre-training phase, the model benefits from interleaving data for many aspects. For example, multi-image comprehension ability can be boosted by interleaving data; interleaving data always provides detailed knowledge for the given image; a longer multimodal context learning ability can also be gained by interleaving data. What’s more, we also find that interleaving data can contribute positively to maintaining the model’s language abilities. Thus, image-text interleaving data is an important part in our training corpus. Our multimodal corpus considered open-sourced interleave datasets like \parencite zhu2024multimodal,laurenccon2024obelics and also constructed large-scale in-house data using resources like textbooks, webpages, and tutorials. Further, we also find that synthesizing the interleaving data benefits the performance of multimodal LLM for keeping the text knowledge. To ensure each image’s knowledge is sufficiently studied, for all the interleaving data, despite standard filtering, deduping, and other quality control pipeline, we also integrate a data reordering procedure to keep all the image and text in the correct order.
OCR Data Optical Character Recognition (OCR) is a widely adopted technique that converts text from images into an editable format. In our model, a robust OCR capability is deemed essential for better aligning the model with human values. Accordingly, our OCR data sources are diverse, ranging from open-source to in-house datasets, encompassing both clean and augmented images, and spanning over single-page and multi-page inputs.
In addition to the publicly available data, we have developed a substantial volume of in-house OCR datasets, covering multilingual text, dense text layouts, web-based content, and handwritten samples. Furthermore, following the principles outlined in OCR 2.0 \parencite wei2024general, our model is also equipped to handle a variety of optical image types, including figures, tables, geometry diagrams, mermaid plots, and natural scene text. We apply extensive data augmentation techniques—such as rotation, distortion, color adjustments, and noise addition—to enhance the model’s robustness. As a result, our model achieves a high level of proficiency in OCR tasks.
In addition to single-page OCR data, we collect and convert a large volume of in-house multi-page OCR data to activate the model’s understanding of long documents in the real world. With the help of these data, our model is capable of performing accurate OCR on a single image but can also comprehend an entire academic paper or a scanned book.
Knowledge Data The concept of multimodal knowledge data is analogous to the previously mentioned text pre-training data, except here we focus on assembling a comprehensive repository of human knowledge from diverse sources to further enhance the model’s capabilities. For example, carefully curated geometry data in our dataset is vital for developing visual reasoning skills, ensuring the model can interpret the abstract diagrams created by humans.
Our knowledge corpus adheres to a standardized taxonomy to balance content across various categories, ensuring diversity in data sources. Similar to text-only corpora, which gather knowledge from textbooks, research papers, and other academic materials, multimodal knowledge data employs both a layout parser and an OCR model to process content from these sources. While we also include filtered data from internet-based and other external resources.
Because a significant portion of our knowledge corpus is sourced from internet-based materials, infographics can cause the model to focus solely on OCR-based information. In such cases, relying exclusively on a basic OCR pipeline may limit training effectiveness. To address this, we have developed an additional pipeline that better captures the purely textual information embedded within images.
Agent Data For agent tasks, the model’s grounding and planning capabilities have been significantly enhanced. In addition to utilizing publicly available data, a platform has been established to efficiently manage and execute virtual machine environments in bulk. Within these virtual environments, heuristic methods were employed to collect screenshots and corresponding action data. This data was then processed into dense grounding formats and continuous trajectory formats. The design of the Action Space was categorized according to Desktop, Mobile, and Web environments. Furthermore, icon data was collected to strengthen the model’s understanding of the meanings of icons within software graphical user interfaces (GUIs). To enhance the model’s planning ability for solving multi-step desktop tasks, a set of computer-use trajectories was collected from human annotators, each accompanied by synthesized Chain-of-Thought (Aguvis \parencite xu2024aguvis). These multi-step agent demonstrations equip Kimi-VL with the capability to complete real-world desktop tasks (on both Ubuntu and Windows).
Video Data In addition to image-only and image-text interleaved data, we also incorporate large-scale video data during pre-training, cooldown, and long-context activation stages to enable two directions of essential abilities of our model: first, to understand a long-context sequence dominated by images (e.g. hour-long videos) in addition to long text; second, to perceive fine-grained spatio-temporal correspondence in short video clips.
Our video data are sourced from diverse resources, including open-source datasets as well as in-house web-scale video data, and span videos of varying durations. Similarly, to ensure sufficient generalization ability, our video data cover a wide range of scenes and diverse tasks. We cover tasks such as video description and video grounding, among others. For long videos, we carefully design a pipeline to produce dense captions. Similar to processing the caption data, we strictly limit the proportion of the synthetic dense video description data to reduce the risk of hallucinations.
Text Data Our text pretrain corpus directly utilizes the data in Moonlight [liu2025muonscalablellmtraining], which is designed to provide comprehensive and high-quality data for training large language models (LLMs). It encompasses five domains: English, Chinese, Code, Mathematics & Reasoning, and Knowledge. We employ sophisticated filtering and quality control mechanisms for each domain to ensure the highest quality training data. For all pretrain data, we conducted rigorous individual validation for each data source to assess its specific contribution to the overall training recipe. This systematic evaluation ensures the quality and effectiveness of our diverse data composition. To optimize the overall composition of our training corpus, the sampling strategy for different document types is empirically determined through extensive experimentation. We conduct isolated evaluations to identify document subsets that contribute most significantly to the model’s knowledge acquisition capabilities. These high-value subsets are upsampled in the final training corpus. However, to maintain data diversity and ensure model generalization, we carefully preserve a balanced representation of other document types at appropriate ratios. This data-driven approach helps us optimize the trade-off between focused knowledge acquisition and broad generalization capabilities. footnotetext: GPT-4o and GPT-4o-mini results use Omniparser without UIA, according to [bonatti2024windowsagentarenaevaluating].
| | Benchmark (Metric) | GPT-4o | GPT- | Qwen2.5- | Llama3.2- | Gemma3- | DeepSeek- | Kimi-VL- |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 4o-mini | VL-7B | 11B-Inst. | 12B-IT | VL2 | A3B | | | |
| Architecture | - | - | Dense | Dense | Dense | MoE | MoE | |
| # Act. Params ${}_{\text{(LLM+VT)}}$ | - | - | 7.6B+0.7B | 8B+2.6B | 12B+0.4B | 4.1B+0.4B | 2.8B+0.4B | |
| # Total Params | - | - | 8B | 11B | 12B | 28B | 16B | |
| College-level | MMMU ${}_{\text{val}}$ (Pass@1) | 69.1 | 60.0 | 58.6 | 48 | 59.6 | 51.1 | 57.0 |
| VideoMMMU (Pass@1) | 61.2 | - | 47.4 | 41.8 | 57.2 | 44.4 | 52.6 | |
| MMVU ${}_{\text{val}}$ (Pass@1) | 67.4 | 61.6 | 50.1 | 44.4 | 57.0 | 52.1 | 52.2 | |
| General | MMBench-EN-v1.1 (Acc) | 83.1 | 77.1 | 82.6 | 65.8 | 74.6 | 79.6 | 83.1 |
| MMStar (Acc) | 64.7 | 54.8 | 63.9 | 49.8 | 56.1 | 55.5 | 61.3 | |
| MMVet (Pass@1) | 69.1 | 66.9 | 67.1 | 57.6 | 64.9 | 60.0 | 66.7 | |
| RealWorldQA (Acc) | 75.4 | 67.1 | 68.5 | 63.3 | 59.1 | 68.4 | 68.1 | |
| AI2D (Acc) | 84.6 | 77.8 | 83.9 | 77.3 | 78.1 | 81.4 | 84.9 | |
| Multi-image | BLINK (Acc) | 68.0 | 53.6 | 56.4 | 39.8 | 50.3 | - | 57.3 |
| Math | MathVista (Pass@1) | 63.8 | 52.5 | 68.2 | 47.7 | 56.1 | 62.8 | 68.7 |
| MathVision (Pass@1) | 30.4 | - | 25.1 | 13.6 | 32.1 | 17.3 | 21.4 | |
| OCR | InfoVQA (Acc) | 80.7 | 57.9 | 82.6 | 34.6 | 43.8 | 78.1 | 83.2 |
| OCRBench (Acc) | 815 | 785 | 864 | 753 | 702 | 811 | 867 | |
| OS Agent | ScreenSpot-V2 (Acc) | 18.1 | - | 86.8 | - | - | - | 92.8 |
| ScreenSpot-Pro (Acc) | 0.8 | - | 29.0 | - | - | - | 34.5 | |
| OSWorld (Pass@1) | 5.03 | - | 2.5 | - | - | - | 8.22 | |
| WindowsAgentArena (Pass@1) footnotemark: | 9.4 | 2.7 | 3.4 | - | - | - | 10.4 | |
| Long Document | MMLongBench-Doc (Acc) | 42.8 | 29.0 | 29.6 | 13.8 | 21.3 | - | 35.1 |
| Long Video | Video-MME (w/o sub. / w/ sub.) | 71.9/77.2 | 64.8/68.9 | 65.1/71.6 | 46.0/49.5 | 58.2/62.1 | - | 67.8/72.6 |
| MLVU ${}_{\text{MCQ}}$ (Acc) | 64.6 | 48.1 | 70.2 | 44.4 | 52.3 | - | 74.2 | |
| LongVideoBench ${}_{\text{val}}$ | 66.7 | 58.2 | 56.0 | 45.5 | 51.5 | - | 64.5 | |
| Video Perception | EgoSchema ${}_{\text{full}}$ | 72.2 | - | 65.0 | 54.3 | 56.9 | 38.5 | 78.5 |
| VSI-Bench | 34.0 | - | 34.2 | 20.6 | 32.4 | 21.7 | 37.4 | |
| TOMATO | 37.7 | 28.8 | 27.6 | 21.5 | 28.6 | 27.2 | 31.7 | |
Table 3: Performance of Kimi-VL against proprietary and open-source efficient VLMs; performance of GPT-4o is also listed in gray for reference. Top and second-best models are in boldface and underline respectively. Some results of competing models are unavailable due to limitation of model ability on specific tasks or model context length.
3.2 Instruction Data
At this stage, the data is primarily aimed at enhancing the model’s conversational abilities and instruction-following capabilities. To cover as many scenarios as possible, we enrich the data across different domains. For non-reasoning tasks, including chart interpretation, agent grounding, OCR, image-grounded conversations, question-answering, writing, and text processing, we initially construct a seed dataset through human annotation. This seed dataset is used to train a seed model. Subsequently, we collect a diverse set of prompts and employ the seed model to generate multiple responses to each prompt. Annotators then rank these responses and refine the top-ranked response to produce the final version. For reasoning tasks like visual coding, visual reasoning, and math/science problems, where rule-based and model-based verifications are more accurate and efficient than human judgment, we utilize rejection sampling to expand the SFT dataset. The complete vanilla SFT dataset comprises approximately a 1:1 ratio of text tokens to image tokens.
<details>
<summary>x7.png Details</summary>

### Visual Description
## Image Analysis: Question and Response Sets
### Overview
The image presents three distinct question-and-answer sets. Each set consists of an "Instruction" section posing a question, and a "Response" section providing an answer. The questions cover image recognition and scene identification.
### Components/Axes
Each set is structured as follows:
* **Instruction (Left Side):** Contains a question related to an image.
* **Response (Right Side):** Provides an answer to the question posed in the "Instruction" section.
### Detailed Analysis
**Set 1: Urban Area Identification**
* **Instruction:** "Which of the four subgraphs in the figure is taken at the same place as subgraph 1?" An aerial photograph of an urban area is shown.
* **Response:** The response identifies image 4 as the most likely candidate because it matches the urban density, building types, and circular structure seen in image 1. It notes that image 3 includes a church spire, and image 2 is suburban. The answer concludes that the fourth sub-picture (image 4) is in the same place as the first picture.
**Set 2: Dome Building Identification**
* **Instruction:** "What is the dome building in the picture?" The image shows a cityscape with a dome-shaped building and the CN Tower.
* **Response:** The response identifies the dome building as the Rogers Centre in Toronto, Canada. It mentions its retractable roof and its visibility alongside the CN Tower. It also notes that the Rogers Centre hosts various events.
**Set 3: Location Identification (Cyberpunk 2077)**
* **Instruction:** "Where am I?" The image shows an interior scene of a futuristic bar or club.
* **Response:** The response identifies the location as Night City in the game Cyberpunk 2077. It describes the setting as a futuristic bar or club with neon lights, holographic displays, and characters with cybernetic enhancements. It also mentions a possible mission or social interaction location.
### Key Observations
* Each question is directly answered in the corresponding response.
* The responses provide context and details beyond a simple one-word answer.
* The third set identifies a location within a video game.
### Interpretation
The image demonstrates a question-and-answer format used for image recognition and scene identification. The questions range from identifying real-world locations and structures to recognizing a setting within a video game. The responses provide detailed explanations, demonstrating an understanding of the visual information presented. The sets are independent, but all follow the same structure.
</details>
Figure 7: Kimi-VL exhibits strong visual reasoning capabilities by grounding visual content in spatial, contextual, and cultural knowledge. It accurately identifies matching urban locations based on structural and layout features, interprets scenes from video games like Cyberpunk 2077 using stylistic cues, and recognizes real-world landmarks such as the Rogers Centre in Toronto.
3.3 Reasoning Data
Our reasoning data is meticulously constructed for activation and enhancement of the model’s multimodal reasoning capabilities during both the long-CoT supervised fine-tuning and reinforcement learning stages. Through developing a generation pipeline that resembles rejection sampling (RS) and prompt engineering, we collect and synthesize an amount of high-quality long-CoT data. Specifically, we first assemble a collection of QA data with ground truth annotations that require multi-step reasoning, such as mathematical problem-solving and domain-specific VQA. Subsequently, we sample multiple detailed reasoning trajectories for each question by leveraging a powerful long-CoT model - Kimi k1.5 \parencite team2025kimi with curated reasoning prompts. In rejection sampling, we feed the true labels and model predictions into an off-the-shelf reward model for judgment. Wrong chain-of-thought responses are filtered out according to the model evaluation as well as some rule-based rewards, thus improving the reasoning data quality.
4 Evaluation
We begin by presenting our comprehensive model and conducting a comparative analysis with leading state-of-the-art (SoTA) solutions. Following this introduction, we proceed to assess various sub-capabilities of the model through detailed performance evaluations. This part examines how effectively the model handles different tasks and scenarios, providing insights into its strengths and limitations across diverse functional domains.
4.1 Comparison to the State-of-the-Art Models
Table 3 presents a comprehensive evaluation of Kimi-VL against state-of-the-art vision-language models across multiple benchmarks. Although having a more parameter-efficient architecture (2.8B+0.4B activated parameters) compared to larger models such as GPT-4o, Llama-3.2-11B-Inst. and Gemma3-12B-IT, Kimi-VL demonstrates competitive or superior performance in several key areas. Our model employs a Mixture-of-Experts (MoE) architecture similar to DeepSeek-VL2, but outperforms it on most benchmarks with significantly fewer parameters (activated: 2.8B vs 4.5B; total: 16B vs 28B); it also outperforms Qwen2.5-VL-7B (actually 8.3B) on 19 out of 24 benchmarks, though the latter has 2.59 $×$ more activated parameters. The following sections analyze performance across specific domains, which reveals Kimi-VL ’s strengths in OCR, math, agent, long-form content understanding, multi-image and video perception.
<details>
<summary>x8.png Details</summary>

### Visual Description
## Geometry Problem and Solution
### Overview
The image presents a geometry problem involving a circle, angles, and a solution. It includes a diagram of a circle with labeled points and lines, the problem statement in Chinese, and a step-by-step solution in Chinese.
### Components/Axes
* **Diagram:** A circle with center O. Line AB is a diameter. Points C and D lie on the circumference. Lines AC, BC, OD, and OC are drawn. Angle D is labeled.
* **Problem Statement (Chinese):** "如图,AB为⊙O的直径,点D、C在⊙○上,∠D=62°,则∠ACO的度数为() A. 26° B. 28° C. 30° D. 32°"
* **Translation:** "As shown in the figure, AB is the diameter of circle O, points D and C are on circle O, ∠D=62°, then the degree measure of ∠ACO is () A. 26° B. 28° C. 30° D. 32°"
* **Solution (Chinese):** A step-by-step solution to the problem, including explanations and calculations.
### Detailed Analysis or Content Details
**Problem Statement:**
* The problem asks to find the measure of angle ACO, given that AB is the diameter of circle O, points D and C lie on the circle, and angle D measures 62 degrees.
* The possible answers are: A. 26°, B. 28°, C. 30°, D. 32°.
**Solution:**
1. **Analysis of Known Conditions:**
* AB is the diameter, so ∠ACB = 90° (Inscribed Angle Theorem).
* ∠D = 62°.
2. **Using the Inscribed Angle Theorem:**
* ∠AOC is a central angle, equal to twice the inscribed angle ∠D.
* ∠AOC = 2 × 62° = 124°.
3. **Calculating ∠ACO:**
* ∠ACO is an interior angle of triangle AOC.
* ∠ACO + ∠CAO + ∠AOC = 180°.
* Since OA = OC (radii are equal), then ∠CAO = ∠ACO.
* Let ∠ACO = x, then:
* x + x + 124° = 180°
* 2x + 124° = 180°
* 2x = 56°
* x = 28°
Therefore, ∠ACO is 28°. The answer is B.
### Key Observations
* The solution correctly applies the Inscribed Angle Theorem and the properties of isosceles triangles to find the measure of angle ACO.
* The diagram is essential for understanding the geometric relationships described in the problem.
* The solution is presented in a clear and logical manner.
### Interpretation
The problem demonstrates the application of geometric theorems and principles to solve for unknown angles in a circle. The solution highlights the importance of understanding the relationships between central angles, inscribed angles, and the properties of triangles. The problem is well-structured and provides a clear path to the correct answer.
</details>
Figure 8: Kimi-VL demonstrates its capability to perform symbolic reasoning and geometric inference by solving a circle geometry problem step by step. The model analyzes given conditions, applies geometric theorems such as the inscribed angle theorem and properties of triangle angles, and accurately derives the target angle.
<details>
<summary>x9.png Details</summary>
### Visual Description
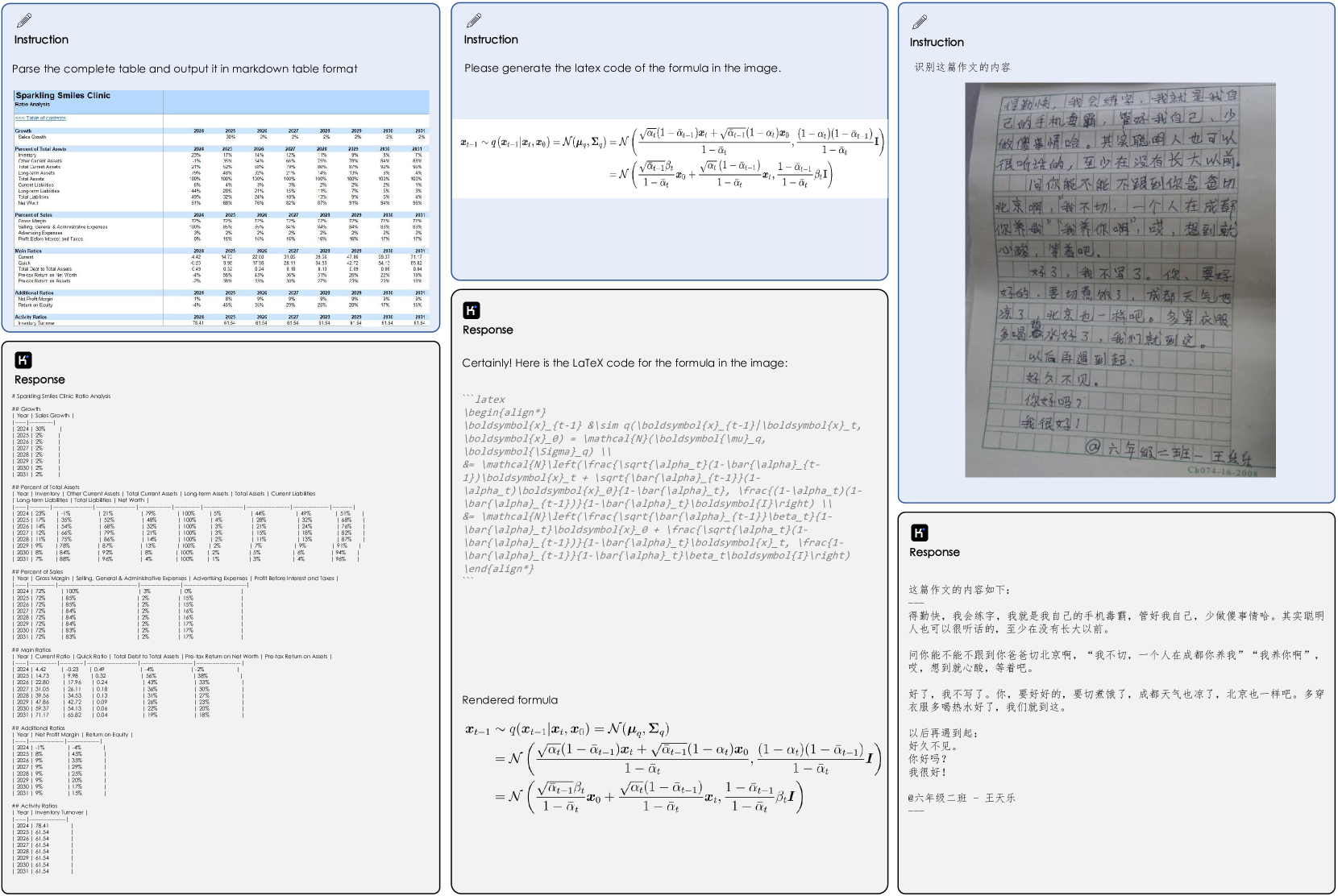
## Table: Sparkling Smiles Clinic Ratio Analysis
### Overview
The image presents a financial ratio analysis for Sparkling Smiles Clinic, covering the years 2024 to 2031. The analysis includes growth rates, percentage of total assets, percentage of sales, main ratios, additional ratios, and activity ratios. The data is presented in a tabular format.
### Components/Axes
* **Title:** Sparkling Smiles Clinic Ratio Analysis
* **Sections:**
* Growth
* Percent of Total Assets
* Percent of Sales
* Main Ratios
* Additional Ratios
* Activity Ratios
* **Years:** 2024, 2025, 2026, 2027, 2028, 2029, 2030, 2031
* **Growth:** Sales Growth (%)
* **Percent of Total Assets:** Inventory, Other Current Assets, Total Current Assets, Long-term Assets, Total Assets, Current Liabilities, Long-term Liabilities, Total Liabilities, Net Worth
* **Percent of Sales:** Gross Margin, Selling, General & Administrative Expenses, Advertising Expenses, Profit Before Interest and Taxes
* **Main Ratios:** Current Ratio, Quick Ratio, Total Debt to Total Assets, Pre-tax Return on Net Worth, Pre-tax Return on Assets
* **Additional Ratios:** Net Profit Margin, Return on Equity
* **Activity Ratios:** Inventory Turnover
### Detailed Analysis or ### Content Details
**Growth**
| Year | Sales Growth (%) |
|---|---|
| 2024 | 30% |
| 2025 | 2% |
| 2026 | 2% |
| 2027 | 1% |
| 2028 | 2% |
| 2029 | 2% |
| 2030 | 2% |
| 2031 | 2% |
**Percent of Total Assets**
| Year | Inventory | Other Current Assets | Total Current Assets | Long-term Assets | Total Assets | Current Liabilities | Long-term Liabilities | Total Liabilities | Net Worth |
|---|---|---|---|---|---|---|---|---|---|
| 2024 | 23% | 21% | 79% | 100% | 5% | 44% | 1% | 45% | 51% |
| 2025 | 14% | 54% | 68% | 32% | 100% | 3% | 21% | 24% | 76% |
| 2026 | 11% | 75% | 86% | 14% | 100% | 2% | 11% | 13% | 87% |
| 2027 | 8% | 84% | 92% | 8% | 100% | 2% | 1% | 3% | 97% |
| 2028 | 8% | 84% | 92% | 8% | 100% | 2% | 1% | 3% | 97% |
| 2029 | 8% | 84% | 92% | 8% | 100% | 2% | 1% | 3% | 97% |
| 2030 | 8% | 84% | 92% | 8% | 100% | 2% | 1% | 3% | 97% |
| 2031 | 8% | 84% | 92% | 8% | 100% | 2% | 1% | 3% | 97% |
**Percent of Sales**
| Year | Gross Margin | Selling, General & Administrative Expenses | Advertising Expenses | Profit Before Interest and Taxes |
|---|---|---|---|---|
| 2024 | 72% | 100% | 4% | 1% |
| 2025 | 72% | 8% | 2% | 12% |
| 2026 | 72% | 8% | 2% | 12% |
| 2027 | 72% | 8% | 2% | 12% |
| 2028 | 72% | 8% | 2% | 12% |
| 2029 | 72% | 8% | 2% | 12% |
| 2030 | 72% | 8% | 2% | 12% |
| 2031 | 72% | 8% | 2% | 12% |
**Main Ratios**
| Year | Current Ratio | Quick Ratio | Total Debt to Total Assets | Pre-tax Return on Net Worth | Pre-tax Return on Assets |
|---|---|---|---|---|---|
| 2024 | 4.42 | 0.23 | 0.49 | 4% | 2% |
| 2025 | 14.73 | 9.98 | 0.32 | 54% | 30% |
| 2026 | 28.11 | 18.13 | 0.18 | 30% | 15% |
| 2027 | 39.05 | 26.11 | 0.08 | 30% | 15% |
| 2028 | 47.86 | 31.53 | 0.08 | 30% | 15% |
| 2029 | 47.86 | 42.72 | 0.08 | 26% | 18% |
| 2030 | 54.13 | 34.53 | 0.08 | 23% | 18% |
| 2031 | 71.17 | 65.82 | 0.04 | 19% | 18% |
**Additional Ratios**
| Year | Net Profit Margin | Return on Equity |
|---|---|---|
| 2024 | 2% | 4% |
| 2025 | 30% | 54% |
| 2026 | 15% | 30% |
| 2027 | 15% | 30% |
| 2028 | 15% | 30% |
| 2029 | 18% | 26% |
| 2030 | 18% | 23% |
| 2031 | 18% | 19% |
**Activity Ratios**
| Year | Inventory Turnover |
|---|---|
| 2024 | 38.41 |
| 2025 | 61.54 |
| 2026 | 61.54 |
| 2027 | 61.54 |
| 2028 | 61.54 |
| 2029 | 61.54 |
| 2030 | 61.54 |
| 2031 | 61.54 |
### Key Observations
* Sales growth starts at 30% in 2024 and decreases to 2% from 2025 onwards.
* Total Current Assets are a high percentage of Total Assets.
* Gross Margin remains constant at 72% from 2024 to 2031.
* Current Ratio and Quick Ratio increase significantly over the years.
* Total Debt to Total Assets decreases over the years.
### Interpretation
The data suggests that Sparkling Smiles Clinic anticipates a significant initial sales growth, which then stabilizes. The high percentage of Total Current Assets indicates a focus on short-term assets. The increasing Current and Quick Ratios suggest improved liquidity. The decreasing Total Debt to Total Assets indicates a reduction in financial leverage. The constant Gross Margin implies stable pricing and cost management.
</details>
Figure 9: Diverse OCR visualization. Kimi-VL demonstrates strong OCR capabilities across varied content types, including structured financial tables, complex mathematical formulas, and handwritten Chinese text. The model accurately parses tabular data into markdown, converts formulas to LaTeX, and transcribes handwritten paragraphs with contextual understanding, showcasing its versatility in multimodal text extraction and interpretation.
<details>
<summary>x10.png Details</summary>
### Visual Description
## Diagram: Enabling 'Do Not Track' in Chrome
### Overview
The image is a step-by-step guide, with screenshots, on how to enable the "Do Not Track" feature in the Chrome browser. Each step includes a screenshot of the Chrome interface, a "Thought" section explaining the reasoning behind the action, and an "Action" section describing the user's action.
### Components/Axes
The image is structured as a sequence of steps, numbered from 1 to 12. Each step contains:
- **Step Number**: Indicates the sequence of actions.
- **Screenshot**: A visual representation of the Chrome browser window at that stage.
- **Thought**: A textual description of the user's reasoning and observations.
- **Action**: A textual description of the action the user should take.
- **Toolcall**: Specifies the coordinates of the click action.
### Detailed Analysis or ### Content Details
**Step 1:**
- **Screenshot**: Shows the default Google search page in Chrome.
- **Thought**: The user needs to access Chrome's settings and identifies the vertical ellipsis menu button in the top-right corner.
- **Action**: Click on the vertical ellipsis menu button.
- **Toolcall**: click(x=0.884, y=0.144)
**Step 2:**
- **Screenshot**: Shows the Chrome menu that appears after clicking the ellipsis button.
- **Thought**: The user identifies the "Settings" option at the bottom of the menu.
- **Action**: Click on the "Settings" option.
- **Toolcall**: click(x=0.744, y=0.851)
**Step 3:**
- **Screenshot**: Shows the Chrome settings page.
- **Thought**: The user looks for the "Do Not Track" setting and identifies the "Privacy and security" option in the left sidebar menu.
- **Action**: Click on the "Privacy and security" option.
- **Toolcall**: click(x=0.386, y=0.311)
**Step 4:**
- **Screenshot**: Shows the Privacy and security settings page.
- **Thought**: The user notes that "Do Not Track" is not immediately visible but identifies a "Security" option with a lock icon.
- **Action**: Click on the "Security" option.
- **Toolcall**: click(x=0.522, y=0.884)
**Step 5:**
- **Screenshot**: Shows the Security settings page.
- **Thought**: The user needs to scroll down to find the "Do Not Track" setting.
- **Action**: Scroll down in the Security settings page.
- **Toolcall**: scroll(-5)
**Step 6:**
- **Screenshot**: Shows the Security settings page after scrolling.
- **Thought**: The user sees the "Manage HTTPS/SSL certificates and settings" option.
- **Action**: Click on the "Manage HTTPS/SSL certificates and settings" option.
- **Toolcall**: click(x=0.527, y=0.883)
**Step 7:**
- **Screenshot**: Shows the "Manage certificates" page.
- **Thought**: The user realizes they are on the wrong page and need to go back to the Privacy and security section.
- **Action**: Click on the "Privacy and security" option in the left sidebar menu.
- **Toolcall**: click(x=0.365, y=0.317)
**Step 8:**
- **Screenshot**: Shows the Privacy and security settings page again.
- **Thought**: The user identifies the "Security" option within the Privacy and security section.
- **Action**: Click on the "Security" option.
- **Toolcall**: click(x=0.522, y=0.884)
**Step 9:**
- **Screenshot**: Shows the Security settings page.
- **Thought**: The user decides to go back to the previous page.
- **Action**: Click the back button in the browser.
- **Toolcall**: click(x=0.486, y=0.242)
**Step 10:**
- **Screenshot**: Shows the Privacy and security settings page.
- **Thought**: The user identifies the "Third-party cookies" option.
- **Action**: Click on the "Third-party cookies" option.
- **Toolcall**: click(x=0.542, y=0.772)
**Step 11:**
- **Screenshot**: Shows the "Third-party cookies" settings page.
- **Thought**: The user identifies the "Advanced" section containing the "Send a 'Do Not Track' request with your browsing traffic" option.
- **Action**: Click the toggle switch next to "Send a 'Do Not Track' request with your browsing traffic".
- **Toolcall**: click(x=0.808, y=0.871)
**Step 12:**
- **Screenshot**: Shows a confirmation dialog.
- **Thought**: The user needs to confirm the action.
- **Action**: Click the "Confirm" button.
- **Toolcall**: click(x=0.708, y=0.669)
### Key Observations
- The process involves navigating through Chrome's settings, specifically the Privacy and security section.
- The user initially makes a wrong turn by selecting "Manage HTTPS/SSL certificates and settings" and needs to backtrack.
- The "Do Not Track" setting is found within the "Third-party cookies" settings page under the "Advanced" section.
### Interpretation
The guide demonstrates how to enable the "Do Not Track" feature in Chrome. It highlights the somewhat convoluted path to find this setting, requiring multiple steps and a brief detour. The "Thought" sections provide valuable context, explaining the user's reasoning and decision-making process at each step. The guide emphasizes the importance of navigating through the settings and identifying the correct options to achieve the desired outcome. The toolcall coordinates provide precise locations for the click actions, making the guide highly actionable.
</details>
Figure 10: Kimi-VL is capable of following multi-step reasoning processes to complete complex GUI tasks. In this example, it successfully enables the “Do Not Track” feature in the Chrome browser to enhance online privacy. The agent interprets each screen, identifies relevant UI elements, and performs the appropriate actions sequentially with clear thoughts, actions, and API calls.
<details>
<summary>x11.png Details</summary>

### Visual Description
## Video Scene Analysis
### Overview
The image presents a breakdown of a video into scenes, providing timestamps and descriptions for each. It includes an "Instruction" section prompting the user to split the video into scenes and a "Response" section containing the scene-by-scene analysis.
### Components/Axes
* **Instruction:** A prompt asking the user to split the video into scenes, providing start time, end time, and detailed descriptions.
* **Response:** A series of timestamped scene descriptions. Each entry includes a start and end time, followed by a textual description of the scene's visual content, atmosphere, and thematic elements.
### Detailed Analysis or ### Content Details
The "Response" section provides a detailed breakdown of the video content. Here's a summary of the scenes:
* **(00:00:00 - 00:00:15):** A dark room with someone cooking, creating a mysterious atmosphere. Text appears: "THE NORTH FACE PRESENTS."
* **(00:00:15 - 00:00:36):** Close-up of an elderly person's face, prayer wheel. Calm and contemplative atmosphere.
* **(00:00:36 - 00:00:46):** Aerial view of snow-capped mountains. Title card: "A NEW FILM BY SHERPAS CINEMA." Close-up of a person's eye.
* **(00:00:46 - 00:01:09):** Close-up of an eye, prayer wheel, wave, underwater view, mountain range.
* **(00:01:09 - 00:01:27):** Room with candles, elderly person's face, prayer wheel, mountain range, rock surface, clouds, river, hand holding a prayer wheel.
* **(00:01:27 - 00:01:39):** Person in yellow jacket, eye close-up, snow-covered mountain range.
* **(00:01:39 - 00:02:03):** Climbers ascending a mountain, hand turning pages of a book, aerial view of mountains, skier descending.
* **(00:02:03 - 00:02:17):** Prayer wheel, mountain peak, vintage watch, person in tent, climber's harness, skiers on a snowy ridge and launching off a cliff.
* **(00:02:17 - 00:02:42):** Skiers performing mid-air tricks, navigating through trees, and a snowboarder. Bird soaring through the sky.
* **(00:02:42 - 00:03:05):** Skier performing a mid-air trick against a sunset, incense burning, mountain range under a pink sky, surfer riding a wave.
* **(00:03:05 - 00:03:27):** Forest, temple with prayer flags, forest floor, cracked lakebed. Title "INTO THE MIND" appears. Credits roll.
* **(00:03:27 - 00:03:37):** Credits, dark rocky interior with a wooden structure.
### Key Observations
* The video appears to be a visually rich film featuring themes of nature, spirituality, adventure, and human endeavor.
* The scenes transition between close-ups of people and objects, and wide shots of landscapes.
* The timestamps provide a precise timeline of the video's progression.
### Interpretation
The document provides a structured analysis of a video, breaking it down into individual scenes and describing their content and atmosphere. This type of analysis is useful for video editing, content indexing, and understanding the narrative structure of a film. The detailed descriptions allow someone to understand the video's content without actually watching it. The repetition of themes like nature, spirituality, and adventure suggests that these are central to the video's message.
</details>
Figure 11: Video scene splitting. Kimi-VL processes a long-form video by segmenting it into coherent scenes and providing detailed start/end timestamps along with fine-grained natural language descriptions for each scene. footnotemark:
<details>
<summary>x12.png Details</summary>
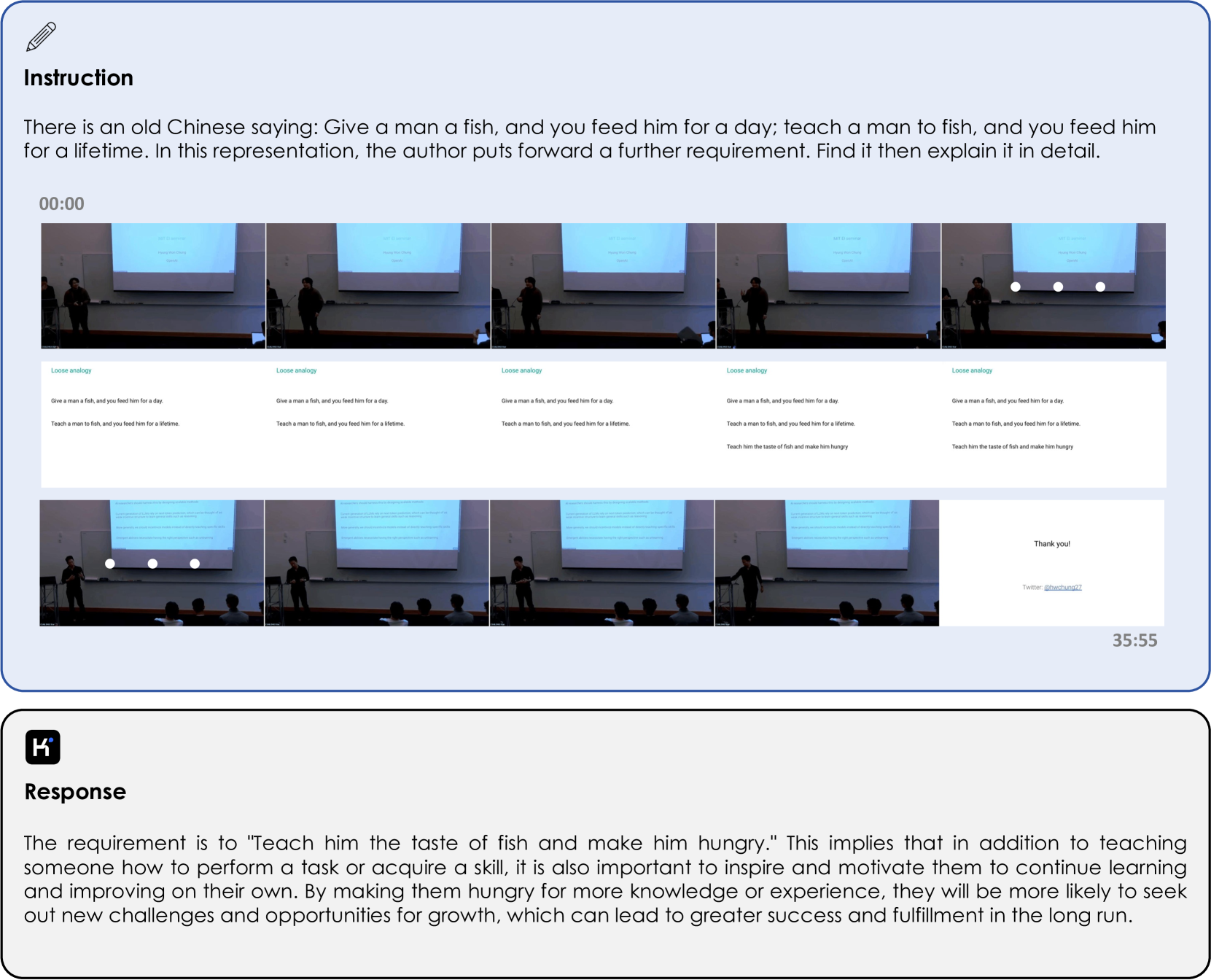
### Visual Description
## Presentation Slides: Instruction and Response
### Overview
The image presents a series of slides, likely from a presentation, discussing an old Chinese saying and its implications for teaching and learning. The presentation includes a visual analogy using a person presenting in front of a screen, and concludes with a "Thank you!" slide. A response section at the bottom provides further explanation of the concept.
### Components/Axes
* **Header:** "Instruction"
* Text: "There is an old Chinese saying: Give a man a fish, and you feed him for a day; teach a man to fish, and you feed him for a lifetime. In this representation, the author puts forward a further requirement. Find it then explain it in detail."
* **Slides:** A series of six slides showing a person presenting in front of a screen.
* Each slide contains a title "Loose analogy"
* The first five slides contain the text: "Give a man a fish, and you feed him for a day." and "Teach a man to fish, and you feed him for a lifetime."
* The fourth and fifth slides contain the text: "Teach him the taste of fish and make him hungry."
* **"Thank you!" Slide:**
* Text: "Thank you!"
* Twitter handle: "@hwchung27"
* **Footer:**
* Timestamp: "35:55"
* **Response Section:**
* Title: "Response"
* Text: "The requirement is to 'Teach him the taste of fish and make him hungry.' This implies that in addition to teaching someone how to perform a task or acquire a skill, it is also important to inspire and motivate them to continue learning and improving on their own. By making them hungry for more knowledge or experience, they will be more likely to seek out new challenges and opportunities for growth, which can lead to greater success and fulfillment in the long run."
### Detailed Analysis or ### Content Details
The presentation uses a visual analogy of a person presenting in front of a screen. The slides build upon the traditional Chinese saying by adding the requirement to "Teach him the taste of fish and make him hungry."
The slides show a progression:
1. Initial slides present the basic analogy.
2. Later slides introduce the additional requirement.
3. The presentation concludes with a "Thank you!" slide and a Twitter handle.
The response section elaborates on the meaning of the additional requirement, emphasizing the importance of inspiring and motivating learners.
### Key Observations
* The presentation builds upon a well-known saying to convey a deeper message about education and motivation.
* The visual analogy reinforces the message.
* The response section provides a clear explanation of the key concept.
### Interpretation
The presentation aims to highlight the importance of not only teaching skills but also inspiring a desire for continuous learning and growth. The "Teach him the taste of fish and make him hungry" concept suggests that true education involves fostering a passion for knowledge and a drive to seek out new challenges. The response section clarifies that this approach leads to greater success and fulfillment in the long run. The presentation uses a combination of visual and textual elements to effectively communicate this message.
</details>
Figure 12: Catching and understanding key details from an hour-long video course. Kimi-VL demonstrates its ability to comprehend and interpret instructional video content by analyzing frame sequences and extracting conceptual progression over time. In this case, the model identifies a deepening of the traditional saying “Teach a man to fish, and you feed him for a lifetime” into a more nuanced idea: “Teach him the taste of fish and make him hungry.” footnotemark:
4.1.1 College-level Academic Problems
Our Kimi-VL model demonstrates competitive performance on college-level academic benchmarks. On MMMU validation set, it achieves a score of 57.0%, which outperforms DeepSeek-VL2 (51.1%) and is comparable to Qwen2.5-VL-7B (58.6%) and even Gemma-3-12B-IT (59.6%), despite having significantly fewer activated parameters. On video college-level problems, it significantly outperforms Qwen2.5-VL-7B and DeepSeek-VL2, only behind >10B Gemma-3-12B-IT, demonstrating reasonable university-level understanding capabilities compared to larger models. These results indicate that Kimi-VL effectively balances parameter efficiency with academic reasoning abilities.
4.1.2 General Visual Ability
Kimi-VL exhibits strong general visual understanding capabilities across multiple benchmarks. On MMBench-EN-v1.1, it achieves 83.1% accuracy, outperforming all efficient VLMs in comparison, and performing on par with GPT-4o. For AI2D, our model achieves 84.9% and surpasses all compared models including GPT-4o (84.6%). On MMVet, Kimi-VL scores 66.7% and ties closely with Qwen2.5-VL-7B (67.1%) and GPT-4o-mini (66.9%). For RealWorldQA, it achieves 68.1%, outperforming Gemma3-12B (59.1%) and approaching Qwen2.5-VL-7B (68.5%). These results demonstrate that our model maintains robust general visual understanding despite its compact architecture.
In multi-image reasoning tasks, Kimi-VL shows promising capabilities with a score of 57.3% on the BLINK benchmark. This performance surpasses Qwen2.5-VL-7B (56.4%), GPT-4o-mini (53.6%), Gemma3-12B-IT (50.3%), and Llama3.2-11B-Inst. (39.8%). The ability to reason across multiple images requires understanding spatial and temporal relationships between visual elements, which our model handles effectively with fewer parameters than most competitors.
4.1.3 Mathematical Reasoning
With its relatively small scale, Kimi-VL also demonstrates strong mathematical reasoning capabilities, particularly on the MathVista benchmark where it achieves 68.7%, outperforming all compared models including GPT-4o (63.8%) and Qwen2.5-VL-7B (68.2%). It indicates our model’s exceptional ability to understand and solve mathematical problems presented in visual contexts. On the more challenging MathVision benchmark, due to limited activated parameters, Kimi-VL outperforms DeepSeek-VL2 and Llama-3.2-11B-Inst., but lags behind Qwen2.5-VL-7B and Gemma-12B-IT. Nevertheless, through RL and test-time scaling, Kimi-VL-Thinking has significantly improved and already on par with 30B-level VLMs (see Table 4). These results highlight our model’s effectiveness in combining visual perception with mathematical problem-solving, an essential capability for real-world applications.
4.1.4 Document Understanding and OCR
Kimi-VL excels in document understanding and OCR tasks across all benchmarks in this category. On InfoVQA, it achieves 83.2% accuracy, outperforming GPT-4o (80.7%) and DeepSeek-VL2 (78.1%). For OCRBench, our model scores 86.7%, surpassing all other models including GPT-4o-mini (78.5%) and DeepSeek-VL2 (81.1%). These results demonstrate that our model has exceptional text recognition and document understanding capabilities, making it especially suitable for applications involving document processing and information extraction.
4.1.5 Agent Grounding and Multi-turn Agent Interaction
In agent-based tasks, Kimi-VL demonstrates remarkable performance. On single-step grounding, our model shows strong accuracy, with 92.0% on ScreenSpot-V2 and 34.5% on extremely difficult ScreenSpot-Pro (on 4K screens), proving its strong agent grounding abilities. More importantly, it also shows strong multi-step turn agent interaction abilities: For OSWorld, Kimi-VL reaches 8.22%, outperforming GPT-4o (5.03%) and other capable open-source models; On WindowsAgentArena, our model achieves 10.4%, also surpassing GPT-4o (9.4%) and others. These results highlight Kimi-VL’s exceptional ability to understand and interact with operating system interfaces, suggesting strong potential for applications in automated UI navigation and task execution.
4.1.6 Long Document and Long Video Understanding
Kimi-VL demonstrates competitive performance in long-form content understanding. On MMLongBench-Doc, a challenging benchmark with question-answering on up to 100+ pages, it achieves 35.1%, outperforming GPT-4o-mini (29.0%) and Qwen2.5-VL-7B (29.6%), only behind GPT-4o (42.8%). For long video understanding, on Video-MME, our model outperforms all efficient VLMs and especially leads on the fairer w/o subtitle setting, where models have to find answers from video frames instead of hacking from input subtitles; on w/ subtitle setting, it also reaches extraordinary 72.6% accuracy. On the MCQ subset of MLVU, Kimi-VL achieves an impressive 74.2% score, achieving state-of-the-art and surpassing both GPT-4o (64.6%) and Qwen2.5-VL-7B (70.2%). For LongVideoBench, it scores 64.5%, outperforming all compared models except GPT-4o (66.7%). These results demonstrate Kimi-VL ’s strong capability to understand long-form PDFs and videos.
4.1.7 Egocentric and Fine-grained Video Perception
Kimi-VL also shows strong performance in more nuanced video perception tasks. On EgoSchema full set (hidden test set), it achieves 78.5%, significantly outperforming GPT-4o (72.2%), Qwen2.5-VL-7B (65.0%). For VSI-Bench, a very challenging benchmark that requires to understand spatial relationships and correspondences of multiple objects in a video, our model scores 37.4%, surpassing GPT-4o (34.0%) and Qwen2.5-VL-7B (34.2%). In TOMATO that examines fine-grained temporal perception of VLMs, Kimi-VL reaches 31.7%, outperforming Qwen2.5-VL-7B (27.6%) and GPT-4o-Mini (28.8%). These results demonstrate our model’s strong capability to understand dynamic visual content, track objects over time, and interpret complex actions in video sequences, making it well-suited for applications requiring temporal visual understanding.
4.2 Kimi-VL-A3B-Thinking: A Reasoning Extension of Kimi-VL
Furthermore, we conduct a reasoning extension to empower Kimi-VL to reason with CoT and present a long-thinking version of the model, Kimi-VL-Thinking, through long-CoT activation and reinforcement learning. We validate its superior performance on several image benchmarks, as shown in Table 4.
| MathVision (full) (Pass@1) MathVista (mini) (Pass@1) MMMU (val) (Pass@1) | 30.4 63.8 69.1 | - 56.7 60.0 | 38.1 74.8 74.8 | 25.1 68.2 58.6 | 35.5 62.3 64.8 | 32.1 56.4 59.6 | - 71.0 77.3 | 35.9 71.4 70.3 | 38.6 74.9 70.0 | 36.8 71.3 61.7 | 56.9 80.1 64.0 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| MMMU-Pro (avg) (Pass@1) | 51.7 | 37.6 | 51.1 | 38.1 | - | 32.1 | - | - | - | 43.0 | 46.3 |
| VideoMMMU (Pass@1) | 61.1 | - | 60.2 | 47.0 | 61.8 | 57.2 | - | - | - | 55.5 | 65.2 |
Table 4: Performance of Kimi-VL-Thinking and Kimi-VL-Thinking-2506 on multimodal reasoning benchmarks. The metrics evaluated include MathVista (mini), MMMU (val), MMMU-Pro (average), MathVision (full) and VideoMMMU, with results expressed in Pass@1. The Kimi-VL-Thinking-2506 performs well in most cases, showcasing the enhanced reasoning and processing capabilities of the “thinking” variant across different domains and scales.
<details>
<summary>x13.png Details</summary>
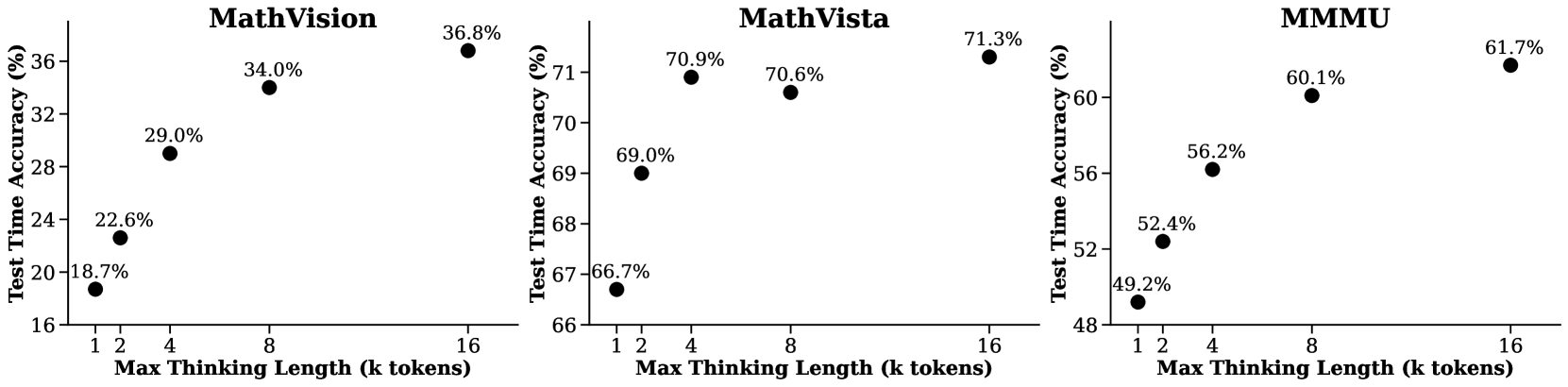
### Visual Description
## Scatter Plot: Test Time Accuracy vs. Max Thinking Length for MathVision, MathVista, and MMMU
### Overview
The image presents three scatter plots comparing the test time accuracy (in percentage) against the maximum thinking length (in k tokens) for three different models: MathVision, MathVista, and MMMU. Each plot shows how the accuracy changes as the maximum thinking length increases.
### Components/Axes
* **X-axis (Horizontal):** Max Thinking Length (k tokens). The axis markers are at 1, 2, 4, 8, and 16.
* **Y-axis (Vertical):** Test Time Accuracy (%). The scale varies for each plot to best display the data.
* **MathVision:** Ranges from 16% to 36%.
* **MathVista:** Ranges from 66% to 71%.
* **MMMU:** Ranges from 48% to 62%.
* **Data Points:** Black dots representing the accuracy at specific thinking lengths. Each data point is labeled with its corresponding accuracy percentage.
* **Titles:** Each plot has a title indicating the model being evaluated: MathVision, MathVista, and MMMU.
### Detailed Analysis
**MathVision:**
* **Trend:** The test time accuracy generally increases as the maximum thinking length increases.
* **Data Points:**
* 1k tokens: 18.7%
* 2k tokens: 22.6%
* 4k tokens: 29.0%
* 8k tokens: 34.0%
* 16k tokens: 36.8%
**MathVista:**
* **Trend:** The test time accuracy increases sharply from 1k to 4k tokens, then plateaus.
* **Data Points:**
* 1k tokens: 66.7%
* 2k tokens: 69.0%
* 4k tokens: 70.9%
* 8k tokens: 70.6%
* 16k tokens: 71.3%
**MMMU:**
* **Trend:** The test time accuracy increases as the maximum thinking length increases.
* **Data Points:**
* 1k tokens: 49.2%
* 2k tokens: 52.4%
* 4k tokens: 56.2%
* 8k tokens: 60.1%
* 16k tokens: 61.7%
### Key Observations
* MathVista has the highest test time accuracy overall, with values consistently above 66%.
* MathVision has the lowest initial accuracy (18.7% at 1k tokens) but shows a substantial increase with longer thinking lengths.
* MMMU shows a steady increase in accuracy as the thinking length increases, but its overall accuracy remains lower than MathVista.
* All three models show diminishing returns in accuracy gains as the thinking length increases from 8k to 16k tokens.
### Interpretation
The plots suggest that increasing the maximum thinking length generally improves the test time accuracy for all three models. However, the extent of improvement varies. MathVista appears to benefit the most from a thinking length of up to 4k tokens, after which the gains are minimal. MathVision and MMMU show more consistent improvements across the range of thinking lengths tested, although the rate of improvement slows down at higher values.
The data indicates that there is a trade-off between the computational cost of longer thinking lengths and the resulting accuracy gains. Depending on the specific application and resource constraints, different models and thinking lengths may be optimal. MathVista might be preferred for applications where high accuracy is crucial and computational resources are limited, while MathVision and MMMU might be suitable for scenarios where incremental improvements in accuracy are valuable and more computational resources are available.
</details>
Figure 13: Test-time accuracy when scaling the max thinking token length of our Kimi-VL-Thinking model.
Kimi-VL-Thinking significantly improves over the base Kimi-VL model, with gains of 2.6% on MathVista, 4.7% on MMMU, and 15.4% on MathVision, demonstrating its capability to leverage test-time computation for deeper reasoning and better handling of complex multimodal queries. In Table 4, Kimi-VL-Thinking further outperforms or rivals state-of-the-art thinking and non-thinking models: achieving 71.3% on MathVista, outperforming GPT-4o (63.8%) and GPT-4o-mini (56.7%); scoring 61.7% on MMMU, surpassing GPT-4o-mini (60.0%) and Qwen2.5-VL-7B (58.6%); and reaching 36.8% on MathVision, exceeding GPT-4o (30.4%) and Gemma-3-27B-IT (35.5%), even QVQ-72B (35.9%). While marginally behind some larger-scale models on select benchmarks, Kimi-VL-Thinking accomplishes these results with only 3B activated parameters—orders of magnitude fewer than its counterparts—underscoring its strong efficiency and effectiveness in multimodal reasoning.
Our Kimi-VL-Thinking model also exhibits strong test-time scaling properties, as shown in Figure 13. Specifically, increasing the max thinking token length at inference time consistently improves test-time accuracy across all three benchmarks. For example, on MathVision, the accuracy rises steadily from 18.7% at 1k tokens to 36.8% at 16k tokens, and similar upward trend is also observed on MMMU, indicating that the model is able to utilize longer reasoning chains for better performance. However, not all benchmarks benefit equally from longer thinking lengths. On MathVista, performance saturates early, with accuracy reaching 70.9% at 4k tokens and no further significant gains observed as the token length increases to 16k. It suggests that for this task, the necessary reasoning depth is already captured within a relatively short context, and additional computation does not yield further improvements.
4.3 Kimi-VL-A3B-Thinking-2506: From Reasoning Extension to Integrated Thinking Model
Table 5: Performance of Kimi-VL-A3B-Thinking-2506 on multimodal benchmarks that do not require extensive reasoning.
| Benchmark (Metric) General Multimodal MMBench-EN-v1.1 (Acc) | GPT-4o 83.1 | Qwen2.5- VL-7B 83.2 | Gemma3- 12B-IT 74.6 | Kimi-VL-A3B- Instruct 82.9 | Kimi-VL-A3B- Thinking 76.0 | Kimi-VL-A3B- Thinking-2506 84.4 |
| --- | --- | --- | --- | --- | --- | --- |
| RealWorldQA (Acc) | 75.4 | 68.5 | 59.1 | 68.1 | 64.0 | 70.0 |
| OCRBench (Acc) | 815 | 864 | 702 | 864 | 864 | 869 |
| MMStar (Acc) | 64.0 | 63.0 | 56.1 | 61.7 | 64.2 | 70.4 |
| MMVet (Acc) | 69.1 | 67.1 | 64.9 | 66.7 | 69.5 | 78.1 |
| Video | | | | | | |
| MMVU ${}_{\text{val}}$ (Pass@1) | 67.4 | 50.1 | 57.0 | 52.7 | 53.0 | 57.5 |
| Video-MME (w/ sub.) (Acc) | 77.2 | 71.6 | 62.1 | 72.7 | 66.0 | 71.9 |
| OS-Agent Grounding | | | | | | |
| ScreenSpot-Pro (Acc) | 0.8 | 29.0 | — | 35.4 | — | 52.8 |
| ScreenSpot-V2 (Acc) | 18.1 | 84.2 | — | 92.8 | — | 91.4 |
| OSWorld-G (Acc) | - | 31.5 | — | 41.6 | — | 52.5 |
| Long Document | | | | | | |
| MMLongBench-Doc (Acc) | 42.8 | 29.6 | 21.3 | 35.1 | 32.5 | 42.1 |
While Kimi-VL-A3B-Thinking shows excellent thinking abilities on hard reasoning tasks, we further provide the updated Kimi-VL-A3B-Thinking-2506 Tech Blog: https://huggingface.co/blog/moonshotai/kimi-vl-a3b-thinking-2506, a new reasoning variant that is not only smarter, but integrates key abilities of Kimi-VL-A3B-Instruct (perception, video, long-document, and OS-agent abilities) into this thinking model.
Kimi-VL-Thinking-2506 significantly improves reasoning efficiency while reducing token consumption. As shown in Table 4, Kimi-VL-Thinking-2506 achieves 56.9% on MathVision (+20.1% improvement on original Kimi-VL-Thinking), 80.1% on MathVista (+8.4%), 46.3% on MMMU-Pro (+3.2%), and 64.0% on MMMU (+2.1%), demonstrating non-trivial gains across multiple reasoning benchmarks. Meanwhile, while solving these hard reasoning problems, the 2506 version reduces the average output token length by around 20% (e.g., 2.9K $→$ 2.4K on MMMU-val and 5.8K $→$ 4.4K on MathVision), facilitating it to be more efficient and user-friendly for practical deployments.
Beyond extensive reasoning tasks, Kimi-VL-Thinking demonstrates stronger visual perception capabilities (Table 5). Compared to the previous non-thinking variant (Kimi-VL-A3B-Instruct), Kimi-VL-A3B-Thinking-2506 achieves competitive or superior results on general multimodal understanding benchmarks: 84.4% on MMBench-EN-v1.1, 70.4% on MMStar, 70.0% on RealWorldQA, and 78.4% on MMVet, underscoring its broader competence in vision-language tasks. In terms of token efficiency, the 2506 version only requires in average 180 tokens per answer when solving MMBench, 1/3 compared to the previous thinking model while improving 8.4% accuracy.
Kimi-VL-A3B-Thinking-2506 also extends its reasoning ability to video and long-context domains. It establishes new state-of-the-art results among open-source models on VideoMMMU (65.2%, 4% better than GPT-4o), a challenging video reasoning benchmark; it also maintains robust general video understanding performance with 71.9% on Video-MME, matching the long video understanding ability of Kimi-VL-A3B-Instruct. It also scores 42.1% (first open-source model matching GPT-4o) on MMLongBench-Doc (Table 5), a 10% improvement over the previous thinking model and 7% over the previous instruct model, demonstrating its robust ability on broader long-form visual inputs.
As mentioned in the method part, the continual training on MoonViT (3.2 million max input pixels) of Kimi-VL-A3B-Thinking-2506 leads to substantial improvements on high-resolution perception and OS grounding benchmarks, achieving 83.2% on V* Benchmark (without external tools), 52.8% on ScreenSpot-Pro, and 52.5% on OSWorld-G (full set with refusal samples), showing huge improvements over both previous variants. We hope that this high-resolution multimodal reasoning model brings about interesting new capabilities in the real world.
5 Conclusion, Limitation, and Future Work
We introduce Kimi-VL, a VLM designed with a balanced approach to cover both multimodal and text-only pre-training/post-training, underpinned by an MoE-based architecture for scalable efficiency. Its 128K extended context window enables precise retrieval in lengthy texts and videos, while the native-resolution encoder MoonViT helps maintain high accuracy with low computational overhead in ultra-high-resolution visual tasks. Additionally, Kimi-VL-Thinking facilitates effective long-chain reasoning in complex image and video inference. Overall, Kimi-VL demonstrates robust adaptability and efficiency across multimodal, long-context, and high-resolution tasks, indicating substantial potential for future research and industrial applications.
However, Kimi-VL still faces several challenges:
1. Although the current model size performs effectively for many standard tasks, it remains too limited to address highly specialized or domain-specific problems, or problems that are strongly dependent on language abilities, restricting Kimi-VL’s ability to handle extremely complex scenarios.
1. While the reasoning capability is already strong for typical use cases, it has yet to reach its theoretical upper bound, particularly for intricate tasks requiring multi-step inference or deeper contextual understanding.
1. Despite providing a 128K extended context window, due to limited parameters in its attention layers (which is only comparable to a 3B model), its long-context abilities is still insufficient for certain advanced applications that involve extremely long sequences or high-volume contextual information.
In the future, we will tackle these challenges by scaling up the model size, expanding pre-training data, and enhancing post-training algorithms. Our next steps include optimizing Kimi-VL and releasing larger versions, as well as refining post-training and test-time scaling mechanisms for a better thinking model. These efforts will pave the way for more advanced applications in both research and industry.
\printbibliography
[title=References]
Appendix
Appendix A Contributions
Core Contributors
Bohong Yin Bowei Xing Cheng Chen Chu Wei Dehao Zhang Dongliang Wang Haoning Wu ∗ Haotian Yao Haoyu Lu ∗ Hao Yang Kun Ouyang Lin Sui Xinyuan Wang # Xinyu Zhou Yang Li Y. Charles ∗ Yiping Bao Yimin Chen Yuanxin Liu Yuxin Wu Zaida Zhou Zhaowei Li Zhiqi Huang Zhilin Yang Ziwei Chen
Contributors
Angang Du Bowen Qu Bowen Wang # Chenlin Zhang Chenzhuang Du Congcong Wang Dikang Du Enming Yuan Enzhe Lu Fang Li Flood Sung Guangda Wei Guokun Lai Han Zhu Hao Ding Hao Hu Hao Zhang Heng Wang Hongcheng Gao Huabin Zheng Jiaming Li Jianlin Su Jianzhou Wang Jiaqi Deng # Jiezhong Qiu Jin Xie Jinhong Wang Jingyuan Liu Junjie Yan Liang Chen Longhui Yu Mengfan Dong Mengnan Dong Nuo Xu Pengyu Cheng Qizheng Gu Runjie Zhou Shaowei Liu Sihan Cao Tao Yu # Tianhui Song Tongtong Bai Weiran He Wei Song Weixiao Huang Weixin Xu Xiaokun Yuan Xingzhe Wu Xingcheng Yao Xinhao Li Xinxing Zu Yangyang Hu Yan Zhong Yanru Chen Yibo Miao Yejie Wang Yibo Liu Yidao Qin Yiqin Wang Yongsheng Kang Yuhao Dong Yulun Du Yuzhi Wang Yuzi Yan Zhejun Jiang Zheng Zhang Zihao Huang Zijia Zhao Zongyu Lin
* Project lead(s). # The University of Hong Kong, Moonshot.ai The listing of authors is in alphabetical order based on their first names.
Appendix B Evaluation Details
B.1 Image Benchmark
MMMU \parencite yue2024mmmu encompasses a carefully curated collection of 11.5K multimodal questions sourced from college exams, quizzes, and textbooks. These questions span six major academic fields: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering.
MMBench-EN-v1.1 \parencite MMBench is a fine-grained benchmark that contains 2974 multiple-choice questions, covering 20 ability dimensions. It incorporate perception and reasoning as the top-level ability dimensions in its ability taxonomy, leading to different levels of evaluation in various ability dimensions.
MMStar \parencite chen2024mmstar is an elite vision-indispensable multimodal benchmark comprising 1,500 challenge samples meticulously selected by humans. It is designed to benchmark 6 core capabilities and 18 detailed axes, aiming to evaluate the multimodal capacities of LVLMs with a carefully balanced and purified selection of samples.
MMVet \parencite yu2024mmvet is designed based on the insight that the intriguing ability to solve complicated tasks is often achieved by a generalist model being able to integrate different core vision-language capabilities. It defines 6 core VL capabilities and examines the 16 integrations of interest derived from the capability combination.
RealWorldQA \parencite realworldQA is a benchmark designed to evaluate the real-world spatial understanding capabilities of multimodal models. It assesses how well the models comprehend physical environments. The benchmark consists of over 700 images, each accompanied by a question and a verifiable answer, and these images are drawn from various real-world scenarios.
AI2D \parencite kembhavi2016ai2d is a dataset of over 5000 grade school science diagrams with over 150000 rich annotations, their ground truth syntactic parses, and more than 15000 corresponding multiple choice questions.
MathVision \parencite wang2024measuring is a carefully curated collection of 3,040 high-quality mathematical problems with visual contexts that are sourced from real math competitions. It covers 16 distinct mathematical disciplines and is graded across 5 levels of difficulty. This dataset offers a comprehensive and diverse set of challenges, making it ideal for evaluating the mathematical reasoning abilities of LMMs.
MathVista \parencite lu2023mathvista is a benchmark that integrates challenges from a variety of mathematical and visual tasks, demanding participants to exhibit fine-grained, deep visual understanding along with compositional reasoning to successfully complete the tasks.
BLINK \parencite fu2024blink is a benchmark designed to evaluate multi-image visual cognition, encompassing tasks related to depth relationships, feature matching, digital forensics, and spatiotemporal reasoning. It features a diverse set of multi-image perceptual similarity tasks, validated through standardized protocols.
InfoVQA \parencite mathew2022infographicvqa is a dataset specifically designed to assess models’ capabilities in interpreting and reasoning with complex infographics that integrate text, graphics, and visual elements. Model performance on this dataset is evaluated using the ANLS metric on the test set.
OCRBench \parencite liu2023hidden evaluates the OCR capabilities of MLLMs across five tasks: text recognition, scene text VQA, document VQA, key information extraction, and handwritten math expression recognition. The benchmark is scored out of a maximum of 1000 points.
B.2 Video and Long Document Benchmark
VideoMMMU \parencite arxiv2025videommmu is a video benchmark designed to evaluate the college-level knowledge acquisition capabilities of large multimodal models. It consists of 300 expert-level videos and 900 human-annotated questions. The videos span six diverse academic disciplines: Art, Humanities, Medicine, Business, Science, and Engineering. The questions are structured to align with three cognitive stages: Perception, Comprehension, and Adaptation.
MMVU \parencite arxiv2025mmvu is a video benchmark designed to evaluate the expert-level video understanding ability. The benchmark contains 3,000 expert-annotated questions over 1,529 videos, which span 27 subjects from four core disciplines: Science, Healthcare, Humanities & Social Sciences, and Engineering.
Video-MME \parencite arxiv2024videomme is a video benchmark that consists of 900 manually selected videos (totaling 254 hours length), and 2,700 QA pairs. The videos, varying in duration, are categorized into 30 fine-grained classes across six diverse domains: Knowledge, Film & Television, Sports Competition, Artistic Performance, Life Record, and Multilingual content. Evaluations are conducted under two different settings: with and without subtitles.
MLVU \parencite arxiv2024mlvu is designed to evaluate the model performance in comprehending long videos from multiple aspects. It consists of 1,730 videos along with 3,102 corresponding question-answer pairs (2,593 in dev set and 509 in test set). Videos of this benchmark are collected from multiple scenarios, including Sport, Ego-centric, Life Record, Tutorial, etc. The close-ended task set of MLVU comprises 7 different tasks: Action Order, Action Count, Topic Reasoning, Anomaly Recognition, Plot QA, Ego Reasoning, and Needle QA.
LongVideoBench \parencite nips2024longvideobench is a video question-answering benchmark designed to evaluate the long-form multimodal perception and relation capability of large multimodal models. The benchmark includes 3,763 web-collected videos spanning various lengths and themes, along with their corresponding subtitles. It includes 6,678 human-annotated multiple-choice questions, distributed across 17 fine-grained categories, which accesses different aspects of video-language understanding.
EgoSchema \parencite nips2023egoschema is a video benchmark designed to evaluate the long-form video understanding capabilities within the ego-centric scenario. Derived from Ego4D \parencite cvpr2022ego4d, the benchmark comprises over 5,031 multiple choice question-answer pairs spanning more than 250 hours real-world videos with a semi-automatic data pipeline.
VSI-Bench \parencite arxiv2024vsibench is designed to evaluate the visual-spatial comprehensive capabilities of large multimodal models. It consists of over 5,000 question-answer pairs across around 290 real indoor-scene videos.
TOMATO \parencite iclr2025tomato is a video benchmark comprises 1,484 human-annotated question-answer pairs and 1,417 videos. TOMATO focuses on evaluating the temporal reasoning capabilities of large multimodal models, including action counting, direction prediction, rotation analysis, shape & trend detection, velocity & frequency estimation, and visual cue interpretation.
B.3 Agent Benchmark
ScreenSpot V2 \parencite wu2024osatlas is an enhanced version of the ScreenSpot \parencite cheng2024seeclick benchmark, which focuses on evaluating the performance of GUI grounding models across multiple platforms, including web, desktop, and mobile interfaces. This updated version addresses several issues identified in the original ScreenSpot dataset, such as incorrect or ambiguous annotations, spelling mistakes, and mislabeled bounding boxes.
ScreenSpot Pro \parencite li2025screenspotpro is a benchmark for evaluating GUI grounding in high-resolution, complex UI environments. It contains 1,581 real-world, high-resolution images and expert-annotated tasks from diverse professional domains. Including domain-specific interface conventions that challenge models to understand professional-grade interfaces beyond consumer applications.
OSWorld \parencite xie2024osworld is a pioneering scalable, real computer environment designed for multimodal agents, facilitating task setup, execution-based evaluation, and interactive learning across multiple operating systems, including Ubuntu, Windows, and macOS. It serves as a unified platform for evaluating open-ended computer tasks that involve arbitrary applications, addressing the limitations of existing benchmarks that often lack interactive environments or are confined to specific applications or domains.
WindowsAgentArena \parencite bonatti2024windowsagentarenaevaluating is a benchmark designed to evaluate multimodal agents in realistic Windows environments. Built on the OSWorld framework, it allows agents to interact with a full range of applications and web tools. The benchmark is scalable and can complete evaluations in under 20 minutes on Azure. It offers insights into agent performance, highlighting the potential for future research in agent development and task automation.