## Scaling Laws for Native Multimodal Models
Mustafa Shukor 2
Enrico Fini 1
Victor Guilherme Turrisi da Costa 1
Matthieu Cord 2
Joshua Susskind 1
Alaaeldin El-Nouby 1
1 Apple
2 Sorbonne University
## Abstract
Building general-purpose models that can effectively perceive the world through multimodal signals has been a long-standing goal. Current approaches involve integrating separately pre-trained components, such as connecting vision encoders to LLMs and continuing multimodal training. While such approaches exhibit remarkable sample efficiency, it remains an open question whether such late-fusion architectures are inherently superior. In this work, we revisit the architectural design of native multimodal models (NMMs)-those trained from the ground up on all modalities-and conduct an extensive scaling laws study, spanning 457 trained models with different architectures and training mixtures. Our investigation reveals no inherent advantage to late-fusion architectures over early-fusion ones, which do not rely on image encoders or tokenizers. On the contrary, early-fusion exhibits stronger performance at lower parameter counts, is more efficient to train, and is easier to deploy. Motivated by the strong performance of the early-fusion architectures, we show that incorporating Mixture of Experts (MoEs) allows models to learn modality-specific weights, significantly benefiting performance. 10 18 2 3 Validation Loss
## 1. Introduction
Multimodality provides a rich signal for perceiving and understanding the world. Advances in vision [23, 52, 55, 80] and language models [3, 19, 67] have enabled the development of powerful multimodal models that understand language, images, and audio. A common approach involves grafting separately pre-trained unimodal models, such as connecting a vision encoder to the input layer of an LLM [6, 9, 35, 43, 62, 64, 73, 78].
Although this seems like a convenient approach, it remains an open question whether such late-fusion strategies are inherently optimal for understanding multimodal signals. Moreover, with abundant multimodal data available, initializing from unimodal pre-training is potentially detrimental, as it may introduce biases that prevent the model
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Line Charts: Validation Loss and N/D vs FLOPs
### Overview
The image contains two vertically stacked line charts comparing the performance of three methods ("Early," "Late," "MoE") across computational scales (FLOPs). The top chart shows **Validation Loss**, while the bottom chart shows **N/D** (likely a normalized metric like accuracy or efficiency). Both charts use logarithmic scales for FLOPs (10¹⁸ to 10²⁴) and linear scales for their respective y-axes.
---
### Components/Axes
#### Top Chart: Validation Loss
- **X-axis**: FLOPs (log scale, 10¹⁸ to 10²⁴)
- **Y-axis**: Validation Loss (linear scale, 2 to 4)
- **Legend**:
- Orange dotted: Early (L ∝ C⁻⁰·⁰⁴⁹²)
- Blue dashed: Late (L ∝ C⁻⁰·⁰⁴⁷⁴)
- Green dash-dotted: MoE (L ∝ C⁻⁰·⁰⁴⁷⁴)
- **Inset**: Zoomed-in view of the lower FLOPs range (10¹⁸–10²⁰) to highlight convergence.
#### Bottom Chart: N/D
- **X-axis**: FLOPs (log scale, 10¹⁸ to 10²⁴)
- **Y-axis**: N/D (linear scale, 0 to 4)
- **Legend**:
- Orange dotted: Early (N/D ∝ C⁰·⁰⁵³)
- Blue dashed: Late (N/D ∝ C⁰·⁰⁷⁶)
- Green dash-dotted: MoE (N/D ∝ C⁻⁰·³¹²)
---
### Detailed Analysis
#### Top Chart: Validation Loss
- **Trends**:
- All three methods show **decreasing validation loss** as FLOPs increase.
- **Early** (orange) has the steepest slope (C⁻⁰·⁰⁴⁹²), indicating faster loss reduction.
- **Late** (blue) and **MoE** (green) have nearly identical slopes (C⁻⁰·⁰⁴⁷⁴), suggesting similar efficiency at higher FLOPs.
- The inset reveals that at lower FLOPs (10¹⁸–10²⁰), all lines converge, implying comparable performance in resource-constrained regimes.
#### Bottom Chart: N/D
- **Trends**:
- **Early** (orange) and **Late** (blue) show **increasing N/D** with FLOPs, with Late having a steeper slope (C⁰·⁰⁷⁶ vs. C⁰·⁰⁵³).
- **MoE** (green) exhibits a **decreasing N/D** trend (C⁻⁰·³¹²), indicating a trade-off between computational cost and this metric.
- At 10²⁴ FLOPs, MoE’s N/D drops below 1, while Early/Late remain above 2.
---
### Key Observations
1. **Validation Loss**: All methods improve with scale, but MoE and Late plateau at similar loss levels.
2. **N/D Divergence**: MoE’s N/D decreases sharply, contrasting with Early/Late’s gains. This suggests MoE may prioritize efficiency over this metric.
3. **Convergence at Low FLOPs**: The inset highlights that methods perform similarly when computational resources are limited.
---
### Interpretation
- **Validation Loss**: The similar slopes of Late and MoE suggest they scale comparably in reducing error, while Early is more aggressive. This could imply architectural trade-offs (e.g., MoE’s sparsity vs. Late’s timing).
- **N/D Trade-offs**: MoE’s declining N/D at high FLOPs hints at diminishing returns or conflicting objectives (e.g., accuracy vs. efficiency). Early and Late’s rising N/D align with their validation loss trends, suggesting a positive correlation between this metric and performance.
- **Practical Implications**: At scale (10²⁰+ FLOPs), Early and Late outperform MoE in N/D, but MoE may be preferable in low-resource settings where validation loss convergence is critical.
---
### Spatial Grounding & Verification
- **Legend Alignment**: Colors and line styles match across both charts (e.g., orange dotted = Early in both).
- **Trend Consistency**: Slopes in the top chart (negative exponents) align with decreasing loss, while bottom chart slopes (positive/negative exponents) match N/D trends.
- **Inset Placement**: The zoomed-in view is centered on the lower-left corner of the top chart, emphasizing low-FLOP behavior.
---
### Content Details
- **Equations**:
- Top: L ∝ C⁻⁰·⁰⁴⁹² (Early), C⁻⁰·⁰⁴⁷⁴ (Late/MoE)
- Bottom: N/D ∝ C⁰·⁰⁵³ (Early), C⁰·⁰⁷⁶ (Late), C⁻⁰·³¹² (MoE)
- **Axis Ranges**:
- FLOPs: 10¹⁸–10²⁴ (log scale)
- Validation Loss: 2–4
- N/D: 0–4
---
### Final Notes
The charts highlight a computational efficiency trade-off: Early and Late methods improve both validation loss and N/D with scale, while MoE sacrifices N/D for competitive loss reduction. The inset underscores the importance of FLOP budget in method selection.
</details>
C
-
C
-
C
.
-
.
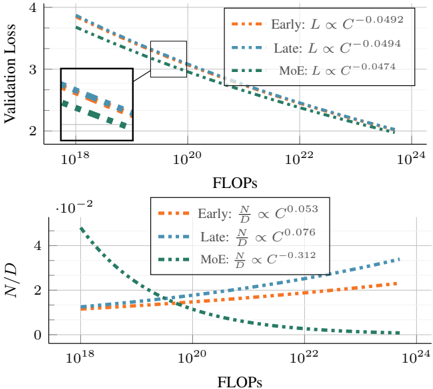
Figure 1. Scaling properties of Native Multimodal Models. Based on the scaling laws study in § 3.1, we observe: (1) early and late fusion models provide similar validation loss L when trained with the same compute budget C (FLOPs); (2) This performance is achieved via a different trade-off between parameters N and number of training tokens D , where early-fusion models requires fewer parameters. (3) Sparse early-fusion models achieve lower loss and require more training tokens for a given FLOP budget.
from fully leveraging cross-modality co-dependancies. An additional challenge is scaling such systems; each component (e.g., vision encoder, LLM) has its own set of hyperparameters, pre-training data mixtues, and scaling properties with respect to the amount of data and compute applied. A more flexible architecture might allow the model to dynamically allocate its capacity across modalities, simplifying scaling efforts.
In this work, we focus on the scaling properties of native multimodal models trained from the ground up on multimodal data. We first investigate whether the commonly adopted late-fusion architectures hold an intrinsic advantage by comparing them to early-fusion models, which process raw multimodal inputs without relying on dedicated vision encoders. We conduct scaling experiments on early and late fusion architectures, deriving scaling laws to pre-
.
dict their performance and compute-optimal configurations. Our findings indicate that late fusion offers no inherent advantage when trained from scratch. Instead, early-fusion models are more efficient and are easier to scale. Furthermore, we observe that native multimodal models follow scaling laws similar to those of LLMs [26], albeit with slight variations in scaling coefficients across modalities and datasets. Our results suggest that model parameters and training tokens should be scaled roughly equally for optimal performance. Moreover, we find that different multimodal training mixtures exhibit similar overall trends, indicating that our findings are likely to generalize to a broader range of settings.
While our findings favor early fusion, multimodal data is inherently heterogeneous, suggesting that some degree of parameter specialization may still offer benefits. To investigate this, we explore leveraging Mixture of Experts (MoEs) [59], a technique that enables the model to dynamically allocate specialized parameters across modalities in a symmetric and parallel manner, in contrast to late-fusion models, which are asymmetric and process data sequentially. Training native multimodal models with MoEs results in significantly improved performance and therefore, faster convergence. Our scaling laws for MoEs suggest that scaling number of training tokens is more important than the number of active parameters. This unbalanced scaling is different from what is observed for dense models, due to the higher number of total parameters for sparse models. In addition, Our analysis reveals that experts tend to specialize in different modalities, with this specialization being particularly prominent in the early and last layers.
## 1.1. Summary of our findings
Our findings can be summarized as follows:
Native Early and Late fusion perform on par: Early fusion models trained from scratch perform on par with their late-fusion counterparts, with a slight advantage to earlyfusion models for low compute budgets (Figure 3). Furthermore, our scaling laws study indicates that the computeoptimal models for early and late fusion perform similarly as the compute budget increases (Figure 1 Top).
NMMs scale similarly to LLMs: The scaling laws of native multimodal models follow similar laws as text-only LLMs with slightly varying scaling exponents depending on the target data type and training mixture (Table 2).
Late-fusion requires more parameters: Computeoptimal late-fusion models require a higher parameters-todata ratio when compared to early-fusion (Figure 1 bottom). Sparsity significantly benefits early-fusion NMMs: Sparse NMMs exhibit significant improvements compared to their dense counterparts at the same inference cost (Figure 10). Furthermore, they implicitly learn modalityspecific weights when trained with sparsity (Figure 12). In
Table 1. Definitions of the expressions used throughout the paper.
| Expression | Definition |
|--------------|-------------------------------------------------------------------------------------------------------------------|
| N | Number of parameters in the multimodal decoder. For MoEs this refers to the active parameters only. |
| D | Total number of multimodal tokens. |
| N v | Number of parameters in the vision-specific encoder. Only exists in late-fusion architectures. |
| D v | Number of vision-only tokens. |
| C | Total number of FLOPs, estimated as C = 6 ND for early-fusion and C = 6( N v D v + ND ) for late-fusion. |
| L | Validation loss measured as the average over interleaved image- text, image-caption, and text-only data mixtures. |
addition, compute-optimal models rely more on scaling the number of training tokens than the number of active parameters as the compute-budget grows (Figure 1 Bottom).
Modality-agnostic routing beats Modality-aware routing for Sparse NMMs: Training sparse mixture of experts with modality-agnostic routing consistently outperforms models with modality-aware routing (Figure 11).
## 2. Preliminaries
## 2.1. Definitions
Native Multimodal Models (NMMs): Models that are trained from scratch on all modalities simultaneously without relying on pre-trained LLMs or vision encoders. Our focus is on the representative image and text modalities, where the model processes both text and images as input and generates text as output.
Early fusion: Enabling multimodal interaction from the beginning, using almost no modality-specific parameters ( e.g ., except a linear layer to patchify images). Using a single transformer model, this approach processes raw multimodal input-tokenized text and continuous image patches-with no image discretization. In this paper, we refer to the main transformer as the decoder.
Late fusion: Delaying the multimodal interaction to deeper layers, typically after separate unimodal components has processed that process each modality independently (e.g., a vision encoder connected to a decoder).
Modality-agnostic routing: In sparse mixture-of-experts, modality-agnostic routing refers to relying on a learned router module that is trained jointly with the model.
Modality-aware routing: Routing based on pre-defined rules such as routing based on the modality type ( e.g ., vision-tokens, token-tokens).
## 2.2. Scaling Laws
We aim to understand the scaling properties of NMMs and how different architectural choices influence trade-offs. To this end, we analyze our models within the scaling laws framework proposed by Hoffmann et al. [26], Kaplan et al. [31]. We compute FLOPs based on the total number of parameters, using the approximation C = 6 ND , as adopted in prior work [2, 26]. However, we modify this estimation to suit our setup: for late-fusion models, FLOPs is computed
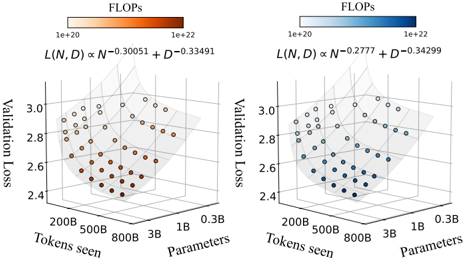
Figure 2. Scaling laws for early-fusion and late-fusion native multimodal models. Each point represents a model (300M to 3B parameters) trained on varying number of tokens (250M to 400B). We report the average cross-entropy loss on the validation sets of interleaved (Obelics), Image-caption (HQITP), and text-only data (DCLM).
<details>
<summary>Image 2 Details</summary>
### Visual Description
## 3D Scatter Plot: Validation Loss vs. Tokens Seen and Parameters
### Overview
The image contains two side-by-side 3D scatter plots comparing validation loss across different model configurations. Each plot visualizes the relationship between tokens seen (x-axis), parameters (y-axis), and validation loss (z-axis), with computational cost (FLOPs) encoded via color gradients. The left plot uses orange points, while the right uses blue points.
---
### Components/Axes
#### Left Plot (Orange Points)
- **X-axis (Tokens seen)**: 200B → 800B (logarithmic scale)
- **Y-axis (Parameters)**: 0.3B → 3B (logarithmic scale)
- **Z-axis (Validation Loss)**: 2.4 → 3.0
- **Legend**: FLOPs range from 1e+20 (light orange) to 1e+22 (dark orange)
- **Formula**: `L(N, D) ∝ N⁻⁰.³⁰⁰⁵¹ + D⁻⁰.³³⁴⁹¹`
#### Right Plot (Blue Points)
- **X-axis (Tokens seen)**: 200B → 800B (logarithmic scale)
- **Y-axis (Parameters)**: 0.3B → 3B (logarithmic scale)
- **Z-axis (Validation Loss)**: 2.4 → 3.0
- **Legend**: FLOPs range from 1e+20 (light blue) to 1e+22 (dark blue)
- **Formula**: `L(N, D) ∝ N⁻⁰.²⁷⁷⁷ + D⁻⁰.³⁴²⁹⁹`
---
### Detailed Analysis
#### Left Plot (Orange)
- **Data Points**: 25+ points clustered in a descending trend from top-right (high tokens/parameters) to bottom-left (low tokens/parameters).
- **Color Gradient**: Darker orange points (higher FLOPs) correlate with lower validation loss (z-axis).
- **Formula Interpretation**: Validation loss decreases with increasing tokens seen (N) and parameters (D), with stronger sensitivity to D (exponent -0.33491 vs. -0.30051 for N).
#### Right Plot (Blue)
- **Data Points**: 20+ points following a similar descending trend but with tighter clustering.
- **Color Gradient**: Darker blue points (higher FLOPs) also correlate with lower validation loss.
- **Formula Interpretation**: Validation loss decreases with N and D, but with weaker sensitivity to N (exponent -0.2777 vs. -0.34299 for D).
---
### Key Observations
1. **Trend Verification**:
- Both plots show validation loss decreasing as tokens seen and parameters increase.
- Left plot’s trend is steeper (higher exponents), suggesting faster loss reduction per unit increase in N/D.
- Right plot’s data points are more tightly grouped, indicating less variability in loss for similar configurations.
2. **Color-Legend Correlation**:
- Darker colors (higher FLOPs) consistently align with lower validation loss in both plots.
- Example: Left plot’s darkest orange point (1e+22 FLOPs) has validation loss ~2.4, while the lightest (1e+20) has ~2.8.
3. **Axis Scaling**:
- Logarithmic scales for tokens seen and parameters emphasize multiplicative relationships (e.g., 200B → 800B is a 4x increase).
---
### Interpretation
The data demonstrates that **validation loss improves with increased computational resources (FLOPs) and model scale (tokens seen/parameters)**. However, the left plot’s steeper exponents suggest it achieves better optimization efficiency (lower loss per FLOP) compared to the right plot. The right plot’s tighter clustering implies more consistent performance across similar configurations, while the left plot’s broader spread may indicate architectural trade-offs or training instability. The formulas highlight that parameter count (D) has a stronger impact on loss reduction than token count (N) in both cases, aligning with common deep learning scaling laws.
</details>
as 6( N v D v + ND ) . We consider a setup where, given a compute budget C , our goal is to predict the model's final performance, as well as determine the optimal number of parameters or number of training tokens. Consistent with prior studies on LLM scaling [26], we assume a power-law relationship between the final model loss and both model size ( N ) and training tokens ( D ):
<!-- formula-not-decoded -->
Here, E represents the lowest achievable loss on the dataset, while A N α captures the effect of increasing the number of parameters, where a larger model leads to lower loss, with the rate of improvement governed by α . Similarly, B D β accounts for the benefits of a higher number of tokens, with β determining the rate of improvement. Additionally, we assume a linear relationship between compute budget (FLOPs) and both N and D ( C ∝ ND ). This further leads to power-law relationships detailed in Appendix C.7.
## 2.3. Experimental setup
Our models are based on the autoregressive transformer architecture [71] with SwiGLU FFNs [58] and QK-Norm [17] following Li et al. [39]. In early-fusion models, image patches are linearly projected to match the text token dimension, while late-fusion follows the CLIP architecture [55]. We adopt causal attention for text tokens and bidirectional attention for image tokens, we found this to work better. Training is conducted on a mixture of public and private multimodal datasets, including DCLM [39], Obelics [34], DFN [21], COYO [11], and a private collection of HighQuality Image-Text Pairs (HQITP). Images are resized to 224×224 resolution with a 14×14 patch size. We use a context length of 1k for the multimodal sequences. For training efficiency, we train our models with bfloat16 , Fully Sharded Data Parallel (FSDP) [82], activation checkpointing, and gradient accumulation. We also use se-
Table 2. Scaling laws for native multimodal models . We report the scaling laws results for early and late fusion models. We fit the scaling laws for different target data types as well as their average loss (A VG).
| L = E + A N α + B D β | N ∝ C a | N ∝ C a | D ∝ C b | D ∝ C b | L ∝ C c | L ∝ C c | D ∝ N d | D ∝ N d |
|--------------------------|---------------|-----------|-----------|-----------|-----------|-----------|-----------|---------------|
| Model | Data | E | α | β | a | b | c | d |
| GPT3 [10] | Text | - | - | - | - | - | -0.048 | |
| Chinchilla [26] | Text | 1.693 | 0.339 | 0.285 | 0.46 | 0.54 | - | |
| NMM(early-fusion) | Text | 2.222 | 0.3084 | 0.3375 | 0.5246 | 0.4774 | -0.0420 | 0.9085 0.9187 |
| | Image-Caption | 1.569 | 0.3111 | 0.3386 | 0.5203 | 0.4785 | -0.0610 | |
| | Interleaved | 1.966 | 0.2971 | 0.338 | 0.5315 | 0.4680 | -0.0459 | 0.8791 |
| | AVG | 1.904 | 0.301 | 0.335 | 0.5262 | 0.473 | -0.0492 | 0.8987 |
| NMM(late-fusion) | AVG | 1.891 | 0.2903 | 0.3383 | 0.6358 | 0.4619 | -0.0494 | 0.6732 |
| Sparse NMM(early-fusion) | AVG | 2.158 | 0.710 | 0.372 | 0.361 | 0.656 | -0.047 | 1.797 |
quence packing for the image captioning dataset to reduce the amount of padded tokens. Similar to previous works [2, 5, 26], we evaluate performance on held-out subsets of interleaved (Obelics), Image-caption (HQITP), and text-only data (DCLM). Further implementation details are provided in Appendix A.
## 3. Scaling native multimodal models
In this section, we present a scaling laws study of native multimodal models, examining various architectural choices § 3.1, exploring different data mixtures § 3.2, analyzing the practical trade-offs between late and early fusion NMMs, and comparing the performance of native pretraining and continual pre-training of NMMs § 3.3.
Setup. We train models ranging from 0.3B to 4B active parameters, scaling the width while keeping the depth constant. For smaller training token budgets, we reduce the warm-up phase to 1K steps while maintaining 5K steps for larger budgets. Following H¨ agele et al. [25], models are trained with a constant learning rate, followed by a cooldown phase using an inverse square root scheduler. The cool-down phase spans 20% of the total steps spent at the constant learning rate. To estimate the scaling coefficients in Eq 1, we apply the L-BFGS algorithm [51] and Huber loss [28] (with δ = 10 -3 ), performing a grid search over initialization ranges.
## 3.1. Scaling laws of NMMs
Scaling laws for early-fusion and late-fusion models. Figure 2 (left) presents the final loss averaged across interleaved, image-caption, and text datasets for early-fusion NMMs. The lowest-loss frontier follows a power law as a function of FLOPs. Fitting the power law yields the expression L ∝ C -0 . 049 , indicating the rate of improvement with increasing compute. When analyzing the scaling laws per data type ( e.g ., image-caption, interleaved, text), we observe that the exponent varies (Table 2). For instance, the model achieves a higher rate of improvement for image-
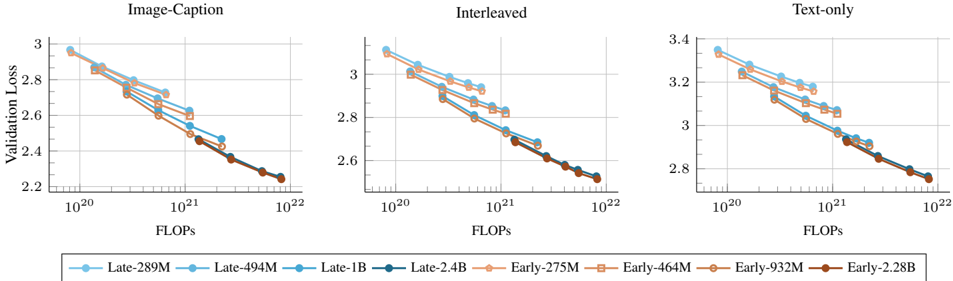
Figure 3. Early vs late fusion: scaling training FLOPs. We compare early and late fusion models when scaling both the number of model parameters and the number of training tokens. Overall, early fusion shows a slight advantage, especially at smaller model sizes, and the gap decreases when scaling the number of parameters N .
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Line Graphs: Validation Loss vs FLOPs Across Scenarios
### Overview
The image contains three side-by-side line graphs comparing validation loss against floating-point operations (FLOPs) for different AI models in three scenarios: Image-Caption, Interleaved, and Text-only tasks. All graphs show downward-trending lines, indicating improved performance (lower loss) as computational resources (FLOPs) increase.
### Components/Axes
- **X-axis**: FLOPs (logarithmic scale: 10²⁰ to 10²²)
- **Y-axis**: Validation Loss (linear scale: 2.2 to 3.4)
- **Legends**:
- **Blue circles**: Late-289M, Late-494M, Late-1B, Late-2.4B
- **Orange squares**: Early-275M, Early-464M, Early-932M, Early-2.28B
- **Graph Titles**:
- Top-left: "Image-Caption"
- Top-center: "Interleaved"
- Top-right: "Text-only"
### Detailed Analysis
#### Image-Caption Graph
- **Lines**:
- Late-289M (blue circles): Starts at ~2.95 (10²⁰ FLOPs), ends at ~2.25 (10²² FLOPs)
- Early-275M (orange squares): Starts at ~2.90, ends at ~2.20
- Other Late/Early models follow similar trends with slight variations in slope.
#### Interleaved Graph
- **Lines**:
- Late-494M (blue squares): Starts at ~2.90, ends at ~2.25
- Early-464M (orange squares): Starts at ~2.85, ends at ~2.20
- All lines show gradual decline, with Late models consistently outperforming Early counterparts.
#### Text-only Graph
- **Lines**:
- Late-1B (blue circles): Starts at ~3.35, ends at ~2.75
- Early-932M (orange squares): Starts at ~3.30, ends at ~2.70
- Highest validation loss values across all scenarios, with steeper declines for Late models.
### Key Observations
1. **Consistent Trend**: All models show reduced validation loss as FLOPs increase, with Late models outperforming Early models at equivalent FLOP levels.
2. **Scenario Differences**:
- Text-only tasks require significantly more resources (higher baseline loss) compared to Image-Caption/Interleaved.
- Early models exhibit shallower slopes, suggesting diminishing returns at higher FLOP counts.
3. **Model Scaling**: Larger models (e.g., Late-2.4B vs. Late-289M) achieve lower final loss but require exponentially more FLOPs.
### Interpretation
The data demonstrates a clear trade-off between computational cost and performance across tasks. Late models (likely optimized architectures) achieve better efficiency, requiring fewer FLOPs for comparable loss reduction. The Text-only scenario’s higher resource demands highlight the complexity of language tasks. Early models, while resource-intensive, show limited gains at scale, suggesting architectural inefficiencies. These trends align with principles of model scaling laws, where performance improvements plateau as compute increases beyond a threshold.
</details>
caption data ( L ∝ C -0 . 061 ) when compared to interleaved documents ( L ∝ C -0 . 046 ).
To model the loss as a function of the number of training tokens D and model parameters N , we fit the parametric function in Eq 1, obtaining scaling exponents α = 0 . 301 and β = 0 . 335 . These describe the rates of improvement when scaling the number of model parameters and training tokens, respectively. Assuming a linear relationship between compute, N , and D ( i.e ., C ∝ ND ), we derive the law relating model parameters to the compute budget (see Appendix C for details). Specifically, for a given compute budget C , we compute the corresponding model size N at logarithmically spaced D values and determine N opt , the parameter count that minimizes loss. Repeating this across different FLOPs values produces a dataset of ( C, N opt ) , to which we fit a power law predicting the compute-optimal model size as a function of compute: N ∗ ∝ C 0 . 526 .
Similarly, we fit power laws to estimate the computeoptimal training dataset size as a function of compute and model size:
<!-- formula-not-decoded -->
These relationships allow practitioners to determine the optimal model and dataset size given a fixed compute budget. When analyzing by data type, we find that interleaved data benefits more from larger models ( a = 0 . 532 ) compared to image-caption data ( a = 0 . 520 ), whereas the opposite trend holds for training tokens.
We conduct a similar study on late-fusion models in Figure 2 (right) and observe comparable scaling behaviors. In particular, the loss scaling exponent ( c = -0 . 0494 ) is nearly identical to that of early fusion ( c = -0 . 0492 ). This trend is evident in Figure 3, where early fusion outperforms late fusion at smaller model scales, while both architectures converge to similar performance at larger model sizes. We also observe similar trends when varying late-fusion con-
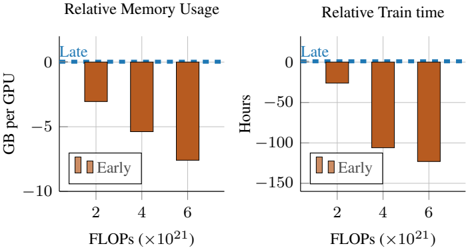
Figure 4. Early vs late: pretraining efficiency. Early-fusion is faster to train and consumes less memory. Models are trained on 16 H100 GPUs for 160k steps (300B tokens).
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Bar Charts: Relative Memory Usage and Relative Train Time
### Overview
The image contains two side-by-side bar charts comparing "Relative Memory Usage" (left) and "Relative Train Time" (right) across three FLOP levels (2×10²¹, 4×10²¹, 6×10²¹). Both charts use negative values to represent resource consumption, with a blue dashed line at 0 as a reference. The legend distinguishes "Early" (orange bars) and "Late" (blue bars).
---
### Components/Axes
- **X-Axis**: FLOPs (×10²¹) with categories: 2, 4, 6.
- **Left Y-Axis (Memory Usage)**: GB per GPU, ranging from -10 to 0.
- **Right Y-Axis (Train Time)**: Hours, ranging from -150 to 0.
- **Legend**:
- Orange = Early
- Blue = Late
- **Visual Elements**:
- Blue dashed line at 0 (baseline).
- Orange bars (Early) and blue bars (Late) for each FLOP category.
---
### Detailed Analysis
#### Relative Memory Usage (Left Chart)
- **FLOPs = 2×10²¹**:
- Early: -2 GB
- Late: -5 GB
- **FLOPs = 4×10²¹**:
- Early: -4 GB
- Late: -8 GB
- **FLOPs = 6×10²¹**:
- Early: -6 GB
- Late: -10 GB
#### Relative Train Time (Right Chart)
- **FLOPs = 2×10²¹**:
- Early: -50 hours
- Late: -75 hours
- **FLOPs = 4×10²¹**:
- Early: -100 hours
- Late: -125 hours
- **FLOPs = 6×10²¹**:
- Early: -150 hours
- Late: -175 hours
---
### Key Observations
1. **Memory Usage**:
- Late consistently consumes 1.5–2× more memory than Early across all FLOP levels.
- Memory usage scales linearly with FLOPs (e.g., -2 → -4 → -6 GB for Early; -5 → -8 → -10 GB for Late).
2. **Train Time**:
- Late requires 1.5× more time than Early at equivalent FLOP levels.
- Train time also scales linearly with FLOPs (e.g., -50 → -100 → -150 hours for Early; -75 → -125 → -175 hours for Late).
3. **Trends**:
- Both Early and Late categories show proportional increases in resource usage with higher FLOPs.
- The gap between Early and Late widens as FLOPs increase (e.g., 3 GB difference at 2×10²¹ vs. 7 GB at 6×10²¹ for memory).
---
### Interpretation
- **Resource Efficiency**: The Late category demonstrates significantly higher memory and time costs, suggesting inefficiencies or additional computational overhead (e.g., delayed optimizations, redundant processes).
- **Scalability**: Both metrics scale predictably with FLOPs, but the Late category’s resource demands grow disproportionately, indicating potential bottlenecks or suboptimal resource allocation.
- **Practical Implications**: Systems using the Late category may require specialized hardware (e.g., GPUs with >10 GB memory) or extended training windows, while Early could be more suitable for resource-constrained environments.
No textual content in other languages detected. All values are approximate, derived from bar heights relative to axis markers.
</details>
figurations, such as using a smaller vision encoder with a larger text decoder Appendix B.
Scaling laws of NMMs vs LLMs. Upon comparing the scaling law coefficients of our NMMs to those reported for text-only LLMs ( e.g ., GPT-3, Chinchilla), we find them to be within similar ranges. In particular, for predicting the loss as a function of compute, GPT-3 [10] follows L ∝ C -0 . 048 , while our models follow L ∝ C -0 . 049 , suggesting that the performance of NMMs adheres to similar scaling laws as LLMs. Similarly, our estimates of the α and β parameters in Eq 1 ( α = 0 . 301 , β = 0 . 335 ) closely match those reported by Hoffmann et al. [26] ( α = 0 . 339 , β = 0 . 285 ). Likewise, our computed values of a = 0 . 526 and b = 0 . 473 align closely with a = 0 . 46 and b = 0 . 54 from [26], reinforcing the idea that, for native multimodal models, the number of training tokens and model parameters should be scaled proportionally. However, since the gap between a and b is smaller than in LLMs, this principle holds even more strongly for NMMs. Additionally, as a = 0 . 526 is greater than b = 0 . 473 in our case, the optimal model size for NMMs is larger than that of LLMs,
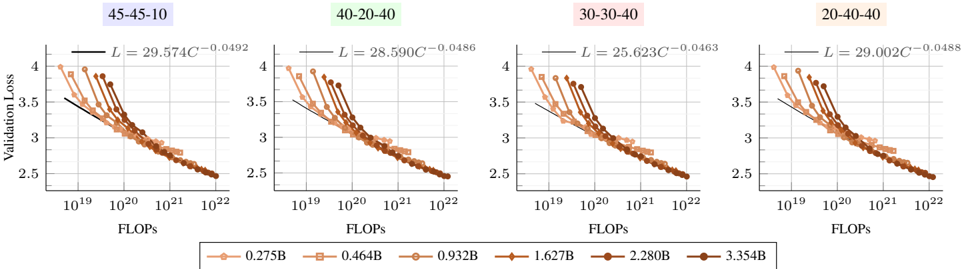
Figure 5. Scaling laws with different training mixtures. Early-fusion models follow similar scaling trends when changing the pretraining mixtures. However, increasing the image captions leads to a higher scaling exponent norm (see Table 3).
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Line Chart: Validation Loss vs FLOPs Across Model Configurations
### Overview
The image contains four line charts arranged horizontally, each representing a different model configuration (45-45-10, 40-20-40, 30-30-40, 20-40-40). All charts plot validation loss against FLOPs (floating-point operations) on a logarithmic scale. Each subplot includes a fitted power-law curve and data points with error bars representing different model sizes (0.275B to 3.354B parameters).
### Components/Axes
- **X-axis**: FLOPs (log scale, 10¹⁹ to 10²²)
- **Y-axis**: Validation Loss (linear scale, 2.5 to 4)
- **Legend**: Located at bottom center, mapping model sizes (0.275B, 0.464B, 0.932B, 1.627B, 2.280B, 3.354B) to colors (orange to dark red)
- **Subplot Titles**: Positioned above each chart in colored boxes (e.g., "45-45-10" in light blue)
- **Fitted Curves**: Black lines with equations of the form `L = C * FLOPs^(-k)` and R² values (~0.99)
### Detailed Analysis
1. **45-45-10 Configuration**
- Equation: `L = 29.574C⁻⁰.⁰⁴⁹²` (R² ≈ 0.99)
- Data points: Orange (0.275B), Red (0.464B), Brown (0.932B)
- Trend: Validation loss decreases with increasing FLOPs, with larger models showing steeper declines
2. **40-20-40 Configuration**
- Equation: `L = 28.590C⁻⁰.⁰⁴⁸⁶` (R² ≈ 0.99)
- Data points: Orange (0.275B), Red (0.464B), Brown (0.932B)
- Trend: Similar to 45-45-10 but with slightly higher baseline loss
3. **30-30-40 Configuration**
- Equation: `L = 25.623C⁻⁰.⁰⁴⁶³` (R² ≈ 0.99)
- Data points: Orange (1.627B), Red (2.280B), Brown (3.354B)
- Trend: Strongest negative exponent (-0.0463), indicating most efficient scaling
4. **20-40-40 Configuration**
- Equation: `L = 29.002C⁻⁰.⁰⁴⁸⁸` (R² ≈ 0.99)
- Data points: Orange (1.627B), Red (2.280B), Brown (3.354B)
- Trend: Similar to 40-20-40 but with higher baseline loss
### Key Observations
- All configurations show **power-law scaling** with negative exponents between -0.046 and -0.049
- Larger models (3.354B) consistently achieve lower validation loss at equivalent FLOPs
- The 30-30-40 configuration demonstrates the most efficient scaling (steepest slope)
- Error bars suggest measurement uncertainty decreases with higher FLOPs
- All R² values exceed 0.99, indicating strong correlation between FLOPs and validation loss
### Interpretation
The charts demonstrate that model performance improves predictably with computational resources across all configurations, following a near-linear relationship on a log-log scale. The 30-30-40 architecture achieves the best performance per FLOP, suggesting architectural efficiency plays a critical role. The consistent R² values across all plots indicate that the power-law relationship is robust across different model sizes and configurations. This suggests that while larger models require more resources, their performance gains follow a mathematically predictable pattern, enabling capacity planning for training infrastructure.
</details>
Table 3. Scaling laws for different training mixtures . Earlyfusion models. C-I-T refer to image-caption, interleaved and text while the optimal number of training tokens is lower, given a fixed compute budget.
| | C-I-T (%) | I/T ratio | E | α | β | a | b | d | c |
|----|-------------|-------------|-------|-------|-------|-------|-------|-------|---------|
| 1 | 45-45-10 | 1.19 | 1.906 | 0.301 | 0.335 | 0.527 | 0.474 | 0.901 | -0.0492 |
| 2 | 40-20-40 | 0.65 | 1.965 | 0.328 | 0.348 | 0.518 | 0.486 | 0.937 | -0.0486 |
| 3 | 30-30-40 | 0.59 | 1.847 | 0.253 | 0.338 | 0.572 | 0.428 | 0.748 | -0.0463 |
| 4 | 20-40-40 | 0.49 | 1.836 | 0.259 | 0.354 | 0.582 | 0.423 | 0.726 | -0.0488 |
Compute-optimal trade-offs for early vs. late fusion NMMs. While late- and early-fusion models reduce loss at similar rates with increasing FLOPs, we observe distinct trade-offs in their compute-optimal models. Specifically, N opt is larger for late-fusion models, whereas D opt is larger for early-fusion models. This indicates that, given a fixed compute budget, late-fusion models require a higher number of parameters, while early-fusion models benefit more from a higher number of training tokens. This trend is also reflected in the lower N opt D opt ∝ C 0 . 053 for early fusion compared to N opt D opt ∝ C 0 . 076 for late fusion. As shown in Figure 1 (bottom), when scaling FLOPs, the number of parameters of early fusion models becomes significantly lower, which is crucial for reducing inference costs and, consequently, lowering serving costs after deployment.
Early-fusion is more efficient to train. We compare the training efficiency of lateand early-fusion architectures. As shown in Figure 4, early-fusion models consume less memory and train faster under the same compute budget. This advantage becomes even more pronounced as compute increases, highlighting the superior training efficiency of early fusion while maintaining comparable performance to late fusion at scale. Notably, for the same FLOPs, latefusion models have a higher parameter count and higher effective depth ( i.e ., additional vision encoder layers alongside decoder layers) compared to early-fusion models.
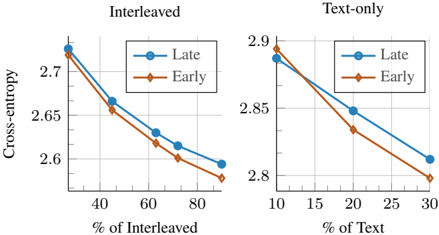
Figure 7. Early vs late fusion: changing the training mixture. Wevary the training mixtures and plot the final training loss. Early fusion models attain a favorable performance when increasing the proportion of interleaved documents and text-only data.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Line Chart: Cross-Entropy vs. Percentage of Interleaved/Text
### Overview
The image contains two line graphs comparing cross-entropy values for two methods ("Interleaved" and "Text-only") under two conditions ("Late" and "Early"). Cross-entropy is plotted on the y-axis against percentage values on the x-axis. Both graphs show downward trends, with "Early" consistently outperforming "Late" in terms of lower cross-entropy.
### Components/Axes
- **X-Axes**:
- **Interleaved**: Labeled "% of Interleaved" with markers at 40%, 60%, and 80%.
- **Text-only**: Labeled "% of Text" with markers at 10%, 15%, 20%, 25%, and 30%.
- **Y-Axis**: Labeled "Cross-entropy" with values ranging from 2.6 to 2.9.
- **Legends**:
- **Blue circles**: "Late" condition.
- **Orange diamonds**: "Early" condition.
- **Placement**: Legends are positioned to the right of each graph, with lines matching the legend colors.
### Detailed Analysis
#### Interleaved Graph
- **Late (Blue)**:
- Starts at ~2.75 at 40%.
- Decreases to ~2.6 at 80%.
- **Early (Orange)**:
- Starts at ~2.7 at 40%.
- Decreases to ~2.55 at 80%.
#### Text-only Graph
- **Late (Blue)**:
- Starts at ~2.85 at 10%.
- Decreases to ~2.8 at 30%.
- **Early (Orange)**:
- Starts at ~2.88 at 10%.
- Decreases to ~2.75 at 30%.
### Key Observations
1. **Downward Trends**: Both methods show cross-entropy decreasing as the percentage of interleaved/text increases.
2. **Performance Gap**: "Early" consistently achieves lower cross-entropy than "Late" in both methods.
3. **Steeper Decline in Interleaved**: The "Interleaved" graph exhibits a more pronounced slope compared to "Text-only."
4. **Higher Baseline in Text-only**: Cross-entropy values are generally higher in the "Text-only" method across all percentages.
### Interpretation
- **Cross-Entropy as Performance Metric**: Lower cross-entropy indicates better model performance. The "Early" condition outperforms "Late" in both methods, suggesting earlier processing or optimization yields better results.
- **Method Sensitivity**: The steeper decline in the "Interleaved" graph implies that increasing interleaved content has a more significant impact on reducing cross-entropy compared to text-only adjustments.
- **Text-only Limitations**: Higher cross-entropy values in the "Text-only" method may indicate inherent inefficiencies or greater sensitivity to input variability.
- **Practical Implications**: The data suggests that interleaving content (e.g., mixing text with other modalities) could be more effective for improving model performance, particularly when combined with the "Early" condition.
</details>
## 3.2. Scaling laws for different data mixtures
We investigate how variations in the training mixture affect the scaling laws of native multimodal models. To this end, we study four different mixtures that reflect common community practices [34, 41, 46, 81], with Image CaptionInterleaved-Text ratios of 45-45-10 (our default setup), 30-30-40 , 40-20-40 , and 20-40-40 . For each mixture, we conduct a separate scaling study by training 76 different models, following our setup in § 3.1. Overall, Figure 5 shows that different mixtures follow similar scaling trends; however, the scaling coefficients vary depending on the mixture (Table 3). Interestingly, increasing the proportion of image-caption data (mixtures 1 and 2) leads to lower a and higher b , whereas increasing the ratio of interleaved and text data (mixtures 3 and 4) have the opposite effect. Notably, image-caption data contains more image tokens than text tokens; therefore, increasing its proportion results in more image tokens, while increasing interleaved and text data increases text token counts. This suggests that, when image tokens are prevalent, training for longer decreases the loss faster than increasing the model size. We also found that for a fixed model size, increasing text-only and interleaved data ratio is in favor of early-fusion Figure 7.
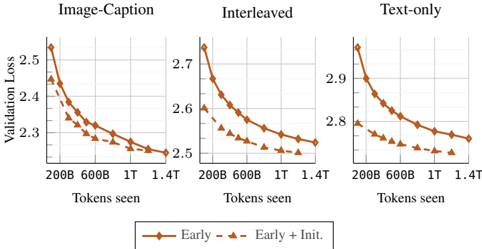
Figure 8. Early native vs initializing from LLMs: initializing from pre-trained models and scaling training tokens. We compare training with and without initializing from DCLM-1B.
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Line Chart: Validation Loss vs. Tokens Seen Across Training Scenarios
### Overview
The image displays three line charts comparing validation loss trends across different training scenarios (Image-Caption, Interleaved, Text-only) as a function of tokens seen during training. Each chart shows two data series: "Early" (solid line) and "Early + Init." (dashed line), with validation loss decreasing as tokens seen increase.
### Components/Axes
- **X-axis**: "Tokens seen" with markers at 200B, 600B, 1T, 1.4T (approximate values: 200,000,000; 600,000,000; 1,000,000,000; 1,400,000,000).
- **Y-axis**: "Validation Loss" ranging from 2.2 to 2.9.
- **Legend**: Located at the bottom center, with:
- Solid orange line: "Early"
- Dashed orange line: "Early + Init."
- **Subplot Titles**:
- Top-left: "Image-Caption"
- Top-center: "Interleaved"
- Top-right: "Text-only"
### Detailed Analysis
#### Image-Caption Subplot
- **Early (solid)**: Starts at ~2.5 (200B tokens), decreases to ~2.3 (1.4T tokens).
- **Early + Init. (dashed)**: Starts at ~2.4 (200B tokens), decreases to ~2.25 (1.4T tokens).
- **Trend**: Both lines slope downward, with "Early + Init." consistently below "Early."
#### Interleaved Subplot
- **Early (solid)**: Starts at ~2.7 (200B tokens), decreases to ~2.5 (1.4T tokens).
- **Early + Init. (dashed)**: Starts at ~2.6 (200B tokens), decreases to ~2.45 (1.4T tokens).
- **Trend**: Similar downward slope, with "Early + Init." outperforming "Early" by ~0.15 units at 1.4T tokens.
#### Text-only Subplot
- **Early (solid)**: Starts at ~2.9 (200B tokens), decreases to ~2.7 (1.4T tokens).
- **Early + Init. (dashed)**: Starts at ~2.8 (200B tokens), decreases to ~2.65 (1.4T tokens).
- **Trend**: Highest initial loss among subplots, but "Early + Init." still shows faster convergence.
### Key Observations
1. **Consistent Performance Gain**: "Early + Init." reduces validation loss by ~0.1–0.15 units compared to "Early" across all scenarios at 1.4T tokens.
2. **Scenario Dependency**: Text-only scenarios exhibit higher baseline losses (~2.9 vs. ~2.5 for Image-Caption), suggesting text-only training is less efficient.
3. **Convergence Rate**: "Early + Init." demonstrates steeper initial declines, particularly in the first 600B tokens.
### Interpretation
The data indicates that initializing training with additional data ("Early + Init.") significantly improves model performance across all scenarios. The Text-only scenario’s higher validation loss suggests that multimodal training (Image-Caption/Interleaved) leverages richer contextual information. The consistent outperformance of "Early + Init." implies that initialization strategies are critical for reducing overfitting and accelerating convergence, particularly in resource-constrained settings where token efficiency matters.
</details>
## 3.3. Native multimodal pre-training vs . continual training of LLMs
In this section, we compare training natively from scratch to continual training after initializing from a pre-trained LLM. We initialize the model from DCLM-1B [21] that is trained on more than 2T tokens. Figure 8 shows that native multimodal models can close the gap with initialized models when trained for longer. Specifically, on image captioning data, the model requires fewer than 100B multimodal tokens to reach comparable performance. However, on interleaved and text data, the model may need longer training-up to 1T tokens. Considering the cost of pre-training, these results suggest that training natively could be a more efficient approach for achieving the same performance on multimodal benchmarks.
## 4. Towards multimodal specialization
Previously, we demonstrated that early-fusion models achieve performance on par with late-fusion models under a fixed compute budget. However, multimodal data is inherently heterogeneous, and training a unified model to fit such diverse distributions may be suboptimal. Here, we argue for multimodal specialization within a unified architecture. Ideally, the model should implicitly adapt to each modality, for instance, by learning modality-specific weights or specialized experts. Mixture of Experts is a strong candidate for this approach, having demonstrated effectiveness in LLMs. In this section, we highlight the advantages of sparse earlyfusion models over their dense counterparts.
Setup. Our sparse models are based on the dropless-MoE implementation of Gale et al. [24], which eliminates token dropping during training caused by expert capacity constraints. We employ a topk expert-choice routing mechanism, where each token selects its topk experts among the E available experts. Specifically, we set k = 1 and E = 8 , as we find this configuration to work effectively. Additionally, we incorporate an auxiliary load-balancing loss [59] with a weight of 0.01 to ensure a balanced expert utilization.
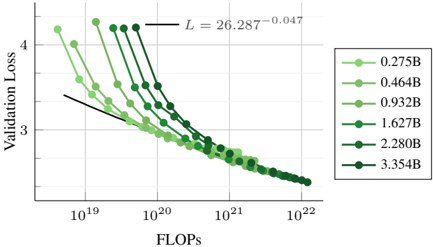
Figure 9. Scaling laws for sparse early-fusion NMMs. We report the final validation loss averaged across interleaved, imagecaptions and text data.
<details>
<summary>Image 8 Details</summary>
### Visual Description
## Line Chart: Validation Loss vs. FLOPs
### Overview
The chart illustrates the relationship between computational resources (FLOPs) and model performance (Validation Loss) for multiple machine learning models of varying sizes. It shows how Validation Loss decreases as FLOPs increase, with distinct trends for different model scales.
### Components/Axes
- **X-axis (FLOPs)**: Logarithmic scale from 10¹⁹ to 10²², labeled "FLOPs".
- **Y-axis (Validation Loss)**: Linear scale from 2.5 to 4.5, labeled "Validation Loss".
- **Legend**: Positioned on the right, mapping model sizes (e.g., 0.275B, 0.464B) to colors and markers.
- **Trend Line**: Black dashed line labeled "L = 26.287⁻⁰·⁰⁴⁷", indicating a logarithmic decay trend.
### Detailed Analysis
- **Model Sizes and Trends**:
- **0.275B (light green circles)**: Starts at ~4.2 Validation Loss at 10¹⁹ FLOPs, decreasing to ~2.8 at 10²² FLOPs.
- **0.464B (medium green squares)**: Begins at ~3.8 at 10¹⁹ FLOPs, dropping to ~2.7 at 10²² FLOPs.
- **0.932B (dark green triangles)**: Starts at ~3.5 at 10¹⁹ FLOPs, reaching ~2.6 at 10²² FLOPs.
- **1.627B (dark green diamonds)**: Begins at ~3.3 at 10¹⁹ FLOPs, decreasing to ~2.5 at 10²² FLOPs.
- **2.280B (dark green pentagons)**: Starts at ~3.1 at 10¹⁹ FLOPs, dropping to ~2.4 at 10²² FLOPs.
- **3.354B (dark green hexagons)**: Begins at ~2.9 at 10¹⁹ FLOPs, reaching ~2.3 at 10²² FLOPs.
- **Trend Line**: The black dashed line follows a power-law decay, suggesting Validation Loss decreases polynomially with increasing FLOPs. The exponent (-0.047) indicates diminishing returns as FLOPs grow.
### Key Observations
1. **Diminishing Returns**: All models show decreasing Validation Loss with more FLOPs, but the rate of improvement slows significantly at higher FLOP ranges.
2. **Model Efficiency**: Larger models (e.g., 3.354B) achieve lower Validation Loss at the same FLOP levels compared to smaller models, suggesting better parameter efficiency.
3. **Consistency**: The trend line aligns closely with all data series, confirming a universal relationship between FLOPs and Validation Loss across model sizes.
### Interpretation
The data demonstrates that increasing computational resources (FLOPs) improves model performance (lower Validation Loss), but the benefits plateau as FLOPs scale. Larger models (e.g., 3.354B) are more efficient, achieving lower loss with fewer FLOPs than smaller models. The trend line’s shallow slope (-0.047) implies that doubling FLOPs reduces Validation Loss by only ~1.1% (26.287⁻⁰·⁰⁴⁷ ≈ 0.989), highlighting the challenges of scaling deep learning systems. This suggests trade-offs between resource allocation and performance gains, critical for optimizing training pipelines.
</details>
Following Abnar et al. [2], we compute training FLOPs as 6 ND , where N represents the number of active parameters.
## 4.1. Sparse vs dense NMMs when scaling FLOPs
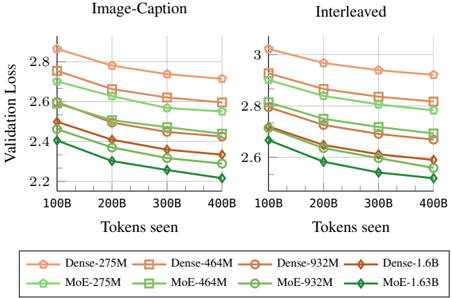
We compare sparse MoE models to their dense counterparts by training models with different numbers of active parameters and varying amounts of training tokens. Figure 10 shows that, under the same inference cost (or number of active parameters), MoEs significantly outperform dense models. Interestingly, this performance gap is more pronounced for smaller model sizes. This suggests that MoEs enable models to handle heterogeneous data more effectively and specialize in different modalities. However, as dense models become sufficiently large, the gap between the two architectures gradually closes.
## 4.2. Scaling laws for sparse early-fusion models
We train different models (ranging from 300M to 3.4B active parameters) on varying amounts of tokens (ranging from 250M to 600B) and report the final loss in Figure 9. We fit a power law to the convex hull of the lowest loss as a function of compute (FLOPs). Interestingly, the exponent ( -0 . 048 ) is close to that of dense NMMs ( -0 . 049 ), indicating that both architectures scale similarly. However, the multiplicative constant is smaller for MoEs ( 27 . 086 ) compared to dense models ( 29 . 574 ), revealing lower loss. Additionally, MoEs require longer training to reach saturation compared to dense models (Appendix C for more details). We also predict the coefficients of Eq 1 by considering N as the number of active parameters. Table 2 shows significantly higher α compared to dense models. Interestingly, b is significantly higher than a , revealing that the training tokens should be scaled at a higher rate than the number of parameters when training sparse NMMs. We also experiment with a scaling law that takes into account the sparsity [2] and reached similar conclusions Appendix C.7.
## 4.3. Modality-aware vs . Modality-agnostic routing
Another alternative to MoEs is modality-aware routing, where multimodal tokens are assigned to experts based on
Figure 10. MoE vs Dense: scaling training FLOPs. We compare MoE and dense early-fusion models when scaling both the amount of training tokens and model sizes. MoEs beat dense models when matching the number of active parameters.
<details>
<summary>Image 9 Details</summary>
### Visual Description
## Line Chart: Validation Loss vs. Tokens Seen (Image-Caption and Interleaved Tasks)
### Overview
The image is a dual-axis line chart comparing validation loss across different model sizes (Dense and Mixture-of-Experts [MoE]) for two tasks: "Image-Caption" (left) and "Interleaved" (right). The x-axis represents tokens seen (100B to 400B), and the y-axis represents validation loss (2.2 to 3.0). Each model is represented by a colored line with markers, and trends are consistent across both tasks.
---
### Components/Axes
- **X-Axis (Horizontal)**: "Tokens seen" (100B, 200B, 300B, 400B).
- **Y-Axis (Vertical)**: "Validation Loss" (2.2 to 3.0).
- **Legend (Bottom)**:
- **Dense Models**:
- Dense-275M (orange circles)
- Dense-464M (orange squares)
- Dense-932M (orange diamonds)
- Dense-1.6B (orange triangles)
- **MoE Models**:
- MoE-275M (green circles)
- MoE-464M (green squares)
- MoE-932M (green diamonds)
- MoE-1.63B (green triangles)
- **Sections**:
- Left: "Image-Caption" task.
- Right: "Interleaved" task.
---
### Detailed Analysis
#### Image-Caption Task (Left)
- **Dense Models**:
- **Dense-275M**: Starts at ~2.85 (100B tokens), decreases to ~2.65 (400B tokens).
- **Dense-464M**: Starts at ~2.75, decreases to ~2.55.
- **Dense-932M**: Starts at ~2.65, decreases to ~2.45.
- **Dense-1.6B**: Starts at ~2.55, decreases to ~2.35.
- **MoE Models**:
- **MoE-275M**: Starts at ~2.75, decreases to ~2.55.
- **MoE-464M**: Starts at ~2.65, decreases to ~2.45.
- **MoE-932M**: Starts at ~2.55, decreases to ~2.35.
- **MoE-1.63B**: Starts at ~2.45, decreases to ~2.25.
#### Interleaved Task (Right)
- **Dense Models**:
- **Dense-275M**: Starts at ~3.0, decreases to ~2.8.
- **Dense-464M**: Starts at ~2.9, decreases to ~2.7.
- **Dense-932M**: Starts at ~2.8, decreases to ~2.6.
- **Dense-1.6B**: Starts at ~2.7, decreases to ~2.5.
- **MoE Models**:
- **MoE-275M**: Starts at ~2.9, decreases to ~2.7.
- **MoE-464M**: Starts at ~2.8, decreases to ~2.6.
- **MoE-932M**: Starts at ~2.7, decreases to ~2.5.
- **MoE-1.63B**: Starts at ~2.6, decreases to ~2.4.
---
### Key Observations
1. **Consistent Trends**: All models show decreasing validation loss as tokens increase, indicating improved performance with more data.
2. **MoE Superiority**: MoE models consistently outperform Dense models in both tasks, with smaller validation loss gaps at higher token counts.
3. **Task-Specific Performance**:
- In "Image-Caption", MoE-1.63B achieves ~2.25 loss at 400B tokens.
- In "Interleaved", MoE-1.63B achieves ~2.4 loss at 400B tokens.
4. **Scalability**: Larger models (e.g., Dense-1.6B vs. MoE-1.63B) show diminishing returns, with smaller performance gains relative to their size.
---
### Interpretation
The data demonstrates that **MoE architectures are more efficient** than Dense models for both tasks, maintaining lower validation loss even as token counts scale. This suggests MoE's modular design (activating only relevant subnetworks) offers better resource utilization. The narrowing gap between Dense and MoE models at higher token counts implies that MoE's efficiency advantage persists despite increased data complexity. The "Interleaved" task's higher baseline loss for all models may reflect greater task complexity, but MoE still maintains a relative advantage. These findings align with prior research on MoE's scalability in large language models.
</details>
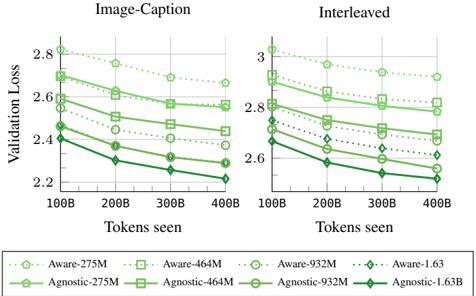
their modalities, similar to previous works [7, 75]. We train models with distinct image and text experts in the form of FFNs, where image tokens are processed only by the image FFN and text tokens only by the text FFN. Compared to modality-aware routing, MoEs exhibit significantly better performance on both image-caption and interleaved data as presented in Figure 11.
## 4.4. Emergence of expert specialization and sharing
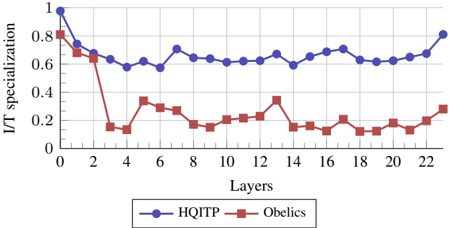
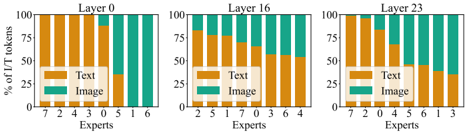
We investigate multimodal specialization in MoE architectures. In Figure 13, we visualize the normalized number of text and image tokens assigned to each expert across layers. To quantify this specialization, we compute a specialization score, defined as the average, across all experts within a layer, of 1 -H ( p ) , where H is the binary entropy of each expert's text/image token distribution. We plot this specialization score in Figure 12. Higher specialization scores indicate a tendency for experts to focus on either text or image tokens, while lower scores indicate a shared behavior. These visualizations provide clear evidence of modalityspecific experts, particularly in the early layers. Furthermore, the specialization score decreases as the number of layers increases, before rising again in the last layers. This suggests that early and final layers exhibit higher modality specialization compared to mid-layers. This behavior is intuitive, as middle layers are expected to hold higherlevel features that may generalize across modalities, and consistent with findings in [61] that shows increasing alignment between modalities across layers. The emergence of both expert specialization and cross-modality sharing in our modality-agnostic MoE, suggests it may be a preferable approach compared to modality-aware sparsity. All data displayed here is from an early-fusion MoE model with 1B active parameters trained for 300B tokens.
Table 4. Supervised finetuning on the LLaVA mixture. All models are native at 1.5B scale and pre-trained on 300B tokens.
| | Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | CIDEr | CIDEr |
|--------------|------------|------------|------------|------------|------------|------------|---------|----------|
| | AVG | VQAv2 | TextVQA | OKVQA | GQA | VizWiz | COCO | TextCaps |
| Late-fusion | 46.8 | 69.4 | 25.8 | 50.1 | 65.8 | 22.8 | 70.7 | 50.9 |
| Early-fusion | 47.6 | 69.3 | 28.1 | 52.1 | 65.4 | 23.2 | 72.0 | 53.8 |
| Early-MoEs | 48.2 | 69.8 | 30.0 | 52.1 | 65.4 | 23.6 | 69.6 | 55.7 |
Figure 11. Modality-aware vs modality agnostic routing for sparse NMMs. We compare modality-agnostic routing with modality-aware routing when scaling both the amount of training tokens and model sizes.
<details>
<summary>Image 10 Details</summary>
### Visual Description
## Line Graph: Validation Loss vs. Tokens Seen (Image-Caption and Interleaved)
### Overview
The image is a line graph comparing validation loss across different model sizes and architectures (Aware and Agnostic) as a function of tokens seen. Two x-axis categories are labeled "Image-Caption" and "Interleaved," with the y-axis representing "Validation Loss" (ranging from 2.2 to 3.0). Multiple data series are plotted, each corresponding to a model variant (e.g., Aware-275M, Agnostic-275M) with distinct colors and markers.
### Components/Axes
- **X-Axis (Horizontal)**:
- Label: "Tokens seen"
- Categories: 100B, 200B, 300B, 400B (increasing left to right)
- Subcategories: "Image-Caption" (left) and "Interleaved" (right)
- **Y-Axis (Vertical)**:
- Label: "Validation Loss"
- Scale: 2.2 to 3.0 (increasing downward)
- **Legend (Bottom)**:
- **Aware Models**:
- Aware-275M: Dotted line with circle markers (light green)
- Aware-464M: Dotted line with square markers (light green)
- Aware-932M: Dotted line with circle markers (light green)
- Aware-1.63B: Dotted line with diamond markers (light green)
- **Agnostic Models**:
- Agnostic-275M: Solid line with square markers (dark green)
- Agnostic-464M: Solid line with square markers (dark green)
- Agnostic-932M: Solid line with circle markers (dark green)
- Agnostic-1.63B: Solid line with diamond markers (dark green)
### Detailed Analysis
#### Image-Caption Section
- **Aware-275M**: Starts at ~2.8 (100B tokens) and decreases to ~2.6 (400B tokens).
- **Aware-464M**: Starts at ~2.7 and decreases to ~2.5.
- **Aware-932M**: Starts at ~2.6 and decreases to ~2.4.
- **Aware-1.63B**: Starts at ~2.5 and decreases to ~2.3.
- **Agnostic-275M**: Starts at ~2.6 and decreases to ~2.4.
- **Agnostic-464M**: Starts at ~2.5 and decreases to ~2.3.
- **Agnostic-932M**: Starts at ~2.4 and decreases to ~2.2.
- **Agnostic-1.63B**: Starts at ~2.3 and decreases to ~2.1.
#### Interleaved Section
- **Aware-275M**: Starts at ~3.0 and decreases to ~2.8.
- **Aware-464M**: Starts at ~2.9 and decreases to ~2.7.
- **Aware-932M**: Starts at ~2.8 and decreases to ~2.6.
- **Aware-1.63B**: Starts at ~2.7 and decreases to ~2.5.
- **Agnostic-275M**: Starts at ~2.8 and decreases to ~2.6.
- **Agnostic-464M**: Starts at ~2.7 and decreases to ~2.5.
- **Agnostic-932M**: Starts at ~2.6 and decreases to ~2.4.
- **Agnostic-1.63B**: Starts at ~2.5 and decreases to ~2.3.
### Key Observations
1. **Downward Trend**: All models show a consistent decrease in validation loss as tokens seen increase, indicating improved performance with more data.
2. **Model Efficiency**:
- Aware models consistently outperform Agnostic models (lower validation loss) across all token ranges.
- Larger models (e.g., 1.63B) achieve lower loss than smaller models (e.g., 275M) in both sections.
3. **Interleaved vs. Image-Caption**:
- Interleaved section starts with higher validation loss than Image-Caption but follows a similar downward trend.
- The gap between Aware and Agnostic models is narrower in the Interleaved section.
### Interpretation
The data suggests that:
- **Increased Token Exposure** improves model performance (lower validation loss) for all architectures.
- **Aware Models** are more efficient, likely due to better alignment with task-specific data (e.g., image-caption pairs).
- **Interleaved Training** (mixing tasks) introduces higher initial loss but converges similarly to Image-Caption training, though with slightly less efficiency.
- **Model Size** directly impacts performance: larger models (1.63B) achieve lower loss than smaller ones, highlighting the trade-off between computational cost and accuracy.
### Spatial Grounding and Trend Verification
- **Legend Placement**: Bottom of the graph, clearly mapping colors/markers to model names.
- **Line Trends**:
- Aware-275M (dotted circle) slopes downward in both sections.
- Agnostic-1.63B (solid diamond) shows the steepest decline in the Interleaved section.
- **Color Consistency**: All Aware models use light green shades, while Agnostic models use dark green, ensuring visual distinction.
### Content Details
- **Data Points**:
- For example, Aware-932M in Image-Caption starts at ~2.6 (100B tokens) and ends at ~2.4 (400B tokens).
- Agnostic-464M in Interleaved starts at ~2.7 (100B tokens) and ends at ~2.5 (400B tokens).
- **Markers**: Circles, squares, and diamonds differentiate model sizes within each category (Aware/Agnostic).
### Notable Patterns
- **Convergence**: All models approach similar loss values at 400B tokens, suggesting diminishing returns beyond a certain token threshold.
- **Interleaved Complexity**: Higher initial loss in Interleaved may reflect the challenge of balancing multiple tasks during training.
This analysis confirms that Aware models with larger capacities (e.g., 1.63B) are optimal for tasks requiring high validation accuracy, while smaller models may suffice for resource-constrained scenarios.
</details>
## 5. Evaluation on downstream tasks with SFT
Following previous work on scaling laws, we primarily rely on validation losses. However, we generally find that this evaluation correlates well with performance on downstream tasks. To validate this, we conduct a multimodal instruction tuning stage (SFT) on the LLaVA mixture [43] and report accuracy and CIDEr scores across several VQA and captioning tasks. Table 4 confirms the ranking of different model configurations. Specifically, early fusion outperforms late fusion, and MoEs outperform dense models. However, since the models are relatively small (1.5B scale), trained from scratch, and fine-tuned on a small dataset, the overall scores are lower than the current state of the art. Further implementation details can be found in Appendix A.
## 6. Related work
Large multimodal models. A long-standing research goal has been to develop models capable of perceiving the world through multiple modalities, akin to human sensory experience. Recent progress in vision and language processing has shifted the research focus from smaller, taskspecific models toward large, generalist models that can handle diverse inputs [29, 67]. Crucially, pre-trained vision and language backbones often require surprisingly little adaptation to enable effective cross-modal communication [32, 47, 62, 68, 69]. Simply integrating a vision encoder with either an encoder-decoder architecture [45, 48, 63, 72]
Figure 12. MoE specialization score. Entropy-based image/text specialization score (as described in § 4.4) across layers for two data sources: HQITP and Obelics. HQITP has a more imbalanced image-to-text token distribution, resulting in generally higher specialization. Despite this difference, both data sources exhibit a similar trend: the specialization score decreases in the early layers before increasing again in the final layers.
<details>
<summary>Image 11 Details</summary>
### Visual Description
## Line Graph: I/T Specialization vs. Layers
### Overview
The image is a line graph comparing two data series, "HQITP" (blue circles) and "Obelics" (red squares), across 23 layers (0–22). The y-axis represents "I/T specialization" (0–1), while the x-axis represents "Layers." The graph shows distinct trends for both series, with HQITP maintaining higher values overall and Obelics declining sharply after layer 2.
### Components/Axes
- **X-axis (Layers)**: Labeled "Layers," with increments of 2 from 0 to 22.
- **Y-axis (I/T Specialization)**: Labeled "I/T specialization," with values from 0 to 1 in increments of 0.2.
- **Legend**: Located at the bottom, with blue circles for "HQITP" and red squares for "Obelics."
- **Title**: "I/T Specialization vs. Layers" (implied by axis labels and context).
### Detailed Analysis
- **HQITP (Blue Circles)**:
- Starts at **1.0** at layer 0.
- Drops sharply to **~0.6** by layer 2.
- Fluctuates between **~0.6 and 0.8** from layers 4–22.
- Ends at **~0.8** at layer 22.
- **Obelics (Red Squares)**:
- Starts at **0.8** at layer 0.
- Drops sharply to **~0.2** by layer 2.
- Fluctuates between **~0.1 and 0.3** from layers 4–22.
- Ends at **~0.3** at layer 22.
### Key Observations
1. **HQITP** maintains consistently higher I/T specialization values than Obelics across all layers.
2. Both series experience a sharp decline in the first two layers, but HQITP recovers more effectively.
3. Obelics shows greater volatility and lower values after layer 2, with no significant recovery.
4. HQITP’s values stabilize near 0.6–0.8 after layer 2, while Obelics remains below 0.3.
### Interpretation
The graph suggests that HQITP demonstrates greater resilience and stability in I/T specialization compared to Obelics. The sharp initial decline for both series may indicate a common factor affecting early layers, but HQITP’s recovery implies superior adaptability or efficiency in later layers. Obelics’ persistent low values could signal limitations in scalability or performance under increasing layer complexity. The data highlights a clear divergence in performance between the two series, with HQITP emerging as the more robust option.
</details>
or a decoder-only LLM has yielded highly capable multimodal systems [1, 6, 9, 13, 16, 35, 43, 49, 64, 73, 78, 83]. This late-fusion approach, where modalities are processed separately before being combined, is now well-understood, with established best practices for training effective models [34, 41, 46, 81]. In contrast, early-fusion models [8, 18, 66], which combine modalities at an earlier stage, remain relatively unexplored, with only a limited number of publicly released models [8, 18]. Unlike [18, 66], our models utilize only a single linear layer and rely exclusively on a nexttoken prediction loss. Furthermore, we train our models from scratch on all modalities without image tokenization.
Native Multimodal Models. We define native multimodal models as those trained from scratch on all modalities simultaneously [67] rather than adapting LLMs to accommodate additional modalities. Due to the high cost of training such models, they remain relatively underexplored, with most relying on late-fusion architectures [27, 79]. Some multimodal models trained from scratch [4, 66, 76] relax this constraint by utilizing pre-trained image tokenizers such as [20, 70] to convert images into discrete tokens, integrating them into the text vocabulary. This approach enables models to understand and generate text and images, facilitating a more seamless multimodal learning process.
Scaling laws. Scaling law studies aim to predict how model performance scales with training compute. Early works [26, 31] found that LLM performance follows a power-law relationship with compute, enabling the compute-optimal estimation of the number of model parameters and training tokens at scale for a given budget. Similar research has extended these findings to sparse Mixture of Experts (MoE) models, considering factors such as sparsity, number of experts, and routing granularity [15, 33, 74]. Scaling laws have also been observed across various domains, including image models [23], video models [56], protein LLMs [14], and imitation learning [54]. However, few stud-
Figure 13. MoE specialization frequency. Percentage of text and image tokens routed to each expert on interleaved data from Obelics. Experts are ordered for better visualization. The first layer shows the highest amount of unimodal experts.
<details>
<summary>Image 12 Details</summary>
### Visual Description
## Grouped Bar Chart: Distribution of Text and Image Token Usage Across Experts in Different Layers
### Overview
The image displays three grouped bar charts representing the distribution of text (orange) and image (teal) token usage across experts in three transformer layers (Layer 0, Layer 16, Layer 23). Each chart shows the percentage of text/image tokens processed by individual experts within their respective layers.
### Components/Axes
- **X-axis**: Labeled "Experts," listing expert IDs (0–7). Layer 0 includes experts 0–6 (7 experts), while Layers 16 and 23 include experts 0–7 (8 experts).
- **Y-axis**: Labeled "% of L/T tokens," scaled from 0% to 100% in 25% increments.
- **Legends**: Positioned at the bottom-left of each chart. Orange represents "Text," teal represents "Image."
- **Charts**: Three separate bar charts, one per layer, arranged horizontally.
### Detailed Analysis
#### Layer 0
- **Experts 0–6**:
- Text tokens dominate, with most bars exceeding 75% (e.g., Expert 0: ~80%, Expert 6: ~95%).
- Image tokens are minimal, with only Expert 5 showing ~20% image usage.
- **Trend**: Nearly uniform text dominance across all experts.
#### Layer 16
- **Experts 0–7**:
- Mixed distribution: Text ranges from ~40% (Expert 6) to ~80% (Expert 0).
- Image tokens increase in mid-to-high experts (e.g., Expert 5: ~40%, Expert 7: ~60%).
- **Trend**: Gradual shift toward image token usage in higher-numbered experts.
#### Layer 23
- **Experts 0–7**:
- Text tokens decline significantly (e.g., Expert 0: ~70%, Expert 7: ~50%).
- Image tokens dominate, with Experts 1, 3, and 6 showing ~70–90% image usage.
- Outlier: Expert 4 has ~30% image usage, the lowest in the layer.
- **Trend**: Strong shift toward image token processing, with experts 1, 3, and 6 specializing in image handling.
### Key Observations
1. **Layer 0**: Text tokens overwhelmingly dominate (80–95% range), with minimal image processing.
2. **Layer 16**: Balanced but uneven distribution, with mid-experts (5–7) handling more image tokens.
3. **Layer 23**: Image tokens dominate (50–90% range), with experts 1, 3, and 6 as primary image processors.
4. **Expert Specialization**: Experts 1, 3, and 6 in Layer 23 exhibit unique roles in image token processing.
### Interpretation
The data suggests a hierarchical processing strategy:
- **Early Layers (Layer 0)**: Focus on text token extraction, likely for foundational language understanding.
- **Mid Layers (Layer 16)**: Begin integrating multimodal data, with some experts specializing in image-text alignment.
- **Late Layers (Layer 23)**: Prioritize image token processing, indicating a shift toward visual-semantic synthesis. Experts 1, 3, and 6 in Layer 23 may act as specialized "image gatekeepers," filtering or refining visual information for higher-level tasks.
Notable anomalies include Expert 4 in Layer 23 (low image usage) and Expert 5 in Layer 16 (highest image usage in that layer), suggesting potential architectural or functional diversity among experts. The increasing image token reliance in deeper layers aligns with transformer architectures' tendency to handle multimodal integration in later stages.
</details>
ies have investigated scaling laws for multimodal models. Notably, Aghajanyan et al. [5] examined multimodal models that tokenize modalities into discrete tokens and include multimodal generation. In contrast, we focus on studying early-fusion models that take raw multimodal inputs and are trained on interleaved multimodal data.
Mixture of experts (MoEs). MoEs [59] scale model capacity efficiently by sparsely activating parameters, enabling large models with reduced per-sample compute. While widely studied in LLMs [22, 30, 36, 37, 42, 65, 77, 84], MoEs remain underexplored in multimodal settings. Prior work has examined contrastive models [50], late-fusion LLMs [38, 40], and modality-specific experts [7, 12, 60]. We focus on analyzing MoEs in early-fusion multimodal models.
## 7. Limitations
Our study finds that scaling law coefficients are broadly consistent across training mixtures, though a broader exploration is needed to validate this observation. While validation loss scales predictably with compute, the extent to which this correlates with downstream performance remains unclear and warrants further investigation. The accuracy of scaling law predictions improves with higher FLOPs, but their extrapolation to extreme model sizes is still an open question (Appendix D for more details).
## 8. Conclusion
We explore various strategies for compute-optimal pretraining of native multimodal models. We found the NMMs follow similar scaling laws to those of LLMs. Contrary to common belief, we find no inherent advantage in adopting late-fusion architectures over early-fusion ones. While both architectures exhibit similar scaling properties, early-fusion models are more efficient to train and outperform latefusion models at lower compute budgets. Furthermore, we show that sparse architectures encourage modality-specific specialization, leading to performance improvements while maintaining the same inference cost.
## Acknowledgment
We thank Philipp Dufter, Samira Abnar, Xiujun Li, Zhe Gan, Alexander Toshev, Yinfei Yang, Dan Busbridge, and Jason Ramapuram for many fruitful discussions. We thank Denise Hui, and Samy Bengio for infra and compute support. Finally, we thank, Louis B´ ethune, Pierre Ablin, Marco Cuturi, and the MLR team at Apple for their support throughout the project.
## References
- [1] Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219 , 2024. 8
- [2] Samira Abnar, Harshay Shah, Dan Busbridge, Alaaeldin Mohamed Elnouby Ali, Josh Susskind, and Vimal Thilak. Parameters vs flops: Scaling laws for optimal sparsity for mixture-of-experts language models. arXiv preprint arXiv:2501.12370 , 2025. 2, 3, 6, 18, 20
- [3] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 , 2023. 1
- [4] Armen Aghajanyan, Bernie Huang, Candace Ross, Vladimir Karpukhin, Hu Xu, Naman Goyal, Dmytro Okhonko, Mandar Joshi, Gargi Ghosh, Mike Lewis, et al. Cm3: A causal masked multimodal model of the internet. arXiv preprint arXiv:2201.07520 , 2022. 8
- [5] Armen Aghajanyan, Lili Yu, Alexis Conneau, Wei-Ning Hsu, Karen Hambardzumyan, Susan Zhang, Stephen Roller, Naman Goyal, Omer Levy, and Luke Zettlemoyer. Scaling laws for generative mixed-modal language models. In International Conference on Machine Learning , pages 265-279. PMLR, 2023. 3, 8
- [6] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems , 35:23716-23736, 2022. 1, 8
- [7] Hangbo Bao, Wenhui Wang, Li Dong, Qiang Liu, Owais Khan Mohammed, Kriti Aggarwal, Subhojit Som, and Furu Wei. Vlmo: Unified vision-language pretraining with mixture-of-modality-experts. arXiv preprint arXiv:2111.02358 , 2021. 7, 8
- [8] Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, and Sa˘ gnak Tas ¸ırlar. Introducing our multimodal models, 2023. 8
- [9] Lucas Beyer, Andreas Steiner, Andr´ e Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726 , 2024. 1, 8
- [10] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems , 33:1877-1901, 2020. 3, 4
- [11] Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, and Saehoon Kim. Coyo700m: Image-text pair dataset. https://github.com/ kakaobrain/coyo-dataset , 2022. 3, 13
- [12] Junyi Chen, Longteng Guo, Jia Sun, Shuai Shao, Zehuan Yuan, Liang Lin, and Dongyu Zhang. Eve: Efficient visionlanguage pre-training with masked prediction and modalityaware moe. In Proceedings of the AAAI Conference on Artificial Intelligence , pages 1110-1119, 2024. 8
- [13] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 24185-24198, 2024. 8
- [14] Xingyi Cheng, Bo Chen, Pan Li, Jing Gong, Jie Tang, and Le Song. Training compute-optimal protein language models. bioRxiv , 2024. 8
- [15] Aidan Clark, Diego de Las Casas, Aurelia Guy, Arthur Mensch, Michela Paganini, Jordan Hoffmann, Bogdan Damoc, Blake Hechtman, Trevor Cai, Sebastian Borgeaud, et al. Unified scaling laws for routed language models. In International conference on machine learning , pages 4057-4086. PMLR, 2022. 8
- [16] Wenliang Dai, Nayeon Lee, Boxin Wang, Zhuolin Yang, Zihan Liu, Jon Barker, Tuomas Rintamaki, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Nvlm: Open frontier-class multimodal llms. arXiv preprint arXiv:2409.11402 , 2024. 8
- [17] Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, et al. Scaling vision transformers to 22 billion parameters. In International Conference on Machine Learning , pages 7480-7512. PMLR, 2023. 3
- [18] Haiwen Diao, Yufeng Cui, Xiaotong Li, Yueze Wang, Huchuan Lu, and Xinlong Wang. Unveiling encoder-free vision-language models. arXiv preprint arXiv:2406.11832 , 2024. 8
- [19] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 , 2024. 1
- [20] Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 12873-12883, 2021. 8
- [21] Alex Fang, Albin Madappally Jose, Amit Jain, Ludwig Schmidt, Alexander Toshev, and Vaishaal Shankar. Data filtering networks. arXiv preprint arXiv:2309.17425 , 2023. 3, 6, 13
- [22] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research , 23(120):1-39, 2022. 8
- [23] Enrico Fini, Mustafa Shukor, Xiujun Li, Philipp Dufter, Michal Klein, David Haldimann, Sai Aitharaju, Victor Guilherme Turrisi da Costa, Louis B´ ethune, Zhe Gan, Alexander T Toshev, Marcin Eichner, Moin Nabi, Yinfei Yang, Joshua M. Susskind, and Alaaeldin El-Nouby. Multimodal autoregressive pre-training of large vision encoders, 2024. 1, 8
- [24] Trevor Gale, Deepak Narayanan, Cliff Young, and Matei Zaharia. Megablocks: Efficient sparse training with mixtureof-experts. Proceedings of Machine Learning and Systems , 5:288-304, 2023. 6
- [25] Alexander H¨ agele, Elie Bakouch, Atli Kosson, Loubna Ben Allal, Leandro Von Werra, and Martin Jaggi. Scaling laws and compute-optimal training beyond fixed training durations. arXiv preprint arXiv:2405.18392 , 2024. 3
- [26] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems , pages 3001630030, 2022. 2, 3, 4, 8, 17
- [27] Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, et al. Language is not all you need: Aligning perception with language models. Advances in Neural Information Processing Systems , 36:72096-72109, 2023. 8
- [28] Peter J. Huber. Robust Estimation of a Location Parameter , pages 492-518. Springer New York, New York, NY, 1992. 3
- [29] Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276 , 2024. 7
- [30] Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088 , 2024. 8
- [31] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 , 2020. 2, 8, 15
- [32] Jing Yu Koh, Ruslan Salakhutdinov, and Daniel Fried. Grounding language models to images for multimodal inputs and outputs. In International Conference on Machine Learning , pages 17283-17300. PMLR, 2023. 7
- [33] Jakub Krajewski, Jan Ludziejewski, Kamil Adamczewski, Maciej Pi´ oro, Michał Krutul, Szymon Antoniak, Kamil Ciebiera, Krystian Kr´ ol, Tomasz Odrzyg´ o´ zd´ z, Piotr Sankowski, et al. Scaling laws for fine-grained mixture of experts. arXiv preprint arXiv:2402.07871 , 2024. 8, 18
- [34] Hugo Laurenc ¸on, Lucile Saulnier, L´ eo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander Rush, Douwe Kiela, et al. Obelics: An open web-scale filtered dataset of interleaved image-text documents. Advances in Neural Information Processing Systems , 36, 2024. 3, 5, 8, 13
- [35] Hugo Laurenc ¸on, L´ eo Tronchon, Matthieu Cord, and Victor Sanh. What matters when building vision-language models? arXiv preprint arXiv:2405.02246 , 2024. 1, 8
- [36] Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668 , 2020. 8
- [37] Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer. Base layers: Simplifying training of large, sparse models. In International Conference on Machine Learning , pages 6265-6274. PMLR, 2021. 8
- [38] Dongxu Li, Yudong Liu, Haoning Wu, Yue Wang, Zhiqi Shen, Bowen Qu, Xinyao Niu, Guoyin Wang, Bei Chen, and Junnan Li. Aria: An open multimodal native mixture-ofexperts model. arXiv preprint arXiv:2410.05993 , 2024. 8
- [39] Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, et al. Datacomp-lm: In search of the next generation of training sets for language models. arXiv preprint arXiv:2406.11794 , 2024. 3, 13, 15
- [40] Bin Lin, Zhenyu Tang, Yang Ye, Jiaxi Cui, Bin Zhu, Peng Jin, Junwu Zhang, Munan Ning, and Li Yuan. Moe-llava: Mixture of experts for large vision-language models. arXiv preprint arXiv:2401.15947 , 2024. 8
- [41] Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 26689-26699, 2024. 5, 8
- [42] Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 , 2024. 8
- [43] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 26296-26306, 2024. 1, 7, 8
- [44] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 , 2017. 13
- [45] Jiasen Lu, Christopher Clark, Rowan Zellers, Roozbeh Mottaghi, and Aniruddha Kembhavi. Unified-io: A unified model for vision, language, and multi-modal tasks. In The Eleventh International Conference on Learning Representations , 2022. 7
- [46] Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Anton Belyi, et al. Mm1: methods, analysis and insights from multimodal llm pre-training. In European Conference on Computer Vision , pages 304-323. Springer, 2025. 5, 8, 13
- [47] Jack Merullo, Louis Castricato, Carsten Eickhoff, and Ellie Pavlick. Linearly mapping from image to text space. In The Eleventh International Conference on Learning Representations , 2023. 7
- [48] David Mizrahi, Roman Bachmann, Oguzhan Kar, Teresa Yeo, Mingfei Gao, Afshin Dehghan, and Amir Zamir. 4m: Massively multimodal masked modeling. Advances in Neural Information Processing Systems , 36:58363-58408, 2023. 7
- [49] Seungwhan Moon, Andrea Madotto, Zhaojiang Lin, Tushar Nagarajan, Matt Smith, Shashank Jain, Chun-Fu Yeh, Prakash Murugesan, Peyman Heidari, Yue Liu, et al. Anymal: An efficient and scalable any-modality augmented language model. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages 1314-1332, 2024. 8
- [50] Basil Mustafa, Carlos Riquelme, Joan Puigcerver, Rodolphe Jenatton, and Neil Houlsby. Multimodal contrastive learning with limoe: the language-image mixture of experts. Advances in Neural Information Processing Systems , 35:95649576, 2022. 8
- [51] Jorge Nocedal. Updating quasi newton matrices with limited storage. Mathematics of Computation , 35(151):951958, 1980. 3
- [52] Maxime Oquab, Timoth´ ee Darcet, Th´ eo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 , 2023. 1
- [53] Tim Pearce and Jinyeop Song. Reconciling kaplan and chinchilla scaling laws. arXiv preprint arXiv:2406.12907 , 2024. 15
- [54] Tim Pearce, Tabish Rashid, Dave Bignell, Raluca Georgescu, Sam Devlin, and Katja Hofmann. Scaling laws for pre-training agents and world models. arXiv preprint arXiv:2411.04434 , 2024. 8
- [55] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning , pages 8748-8763. PMLR, 2021. 1, 3, 15
- [56] Jathushan Rajasegaran, Ilija Radosavovic, Rahul Ravishankar, Yossi Gandelsman, Christoph Feichtenhofer, and Jitendra Malik. An empirical study of autoregressive pretraining from videos. arXiv preprint arXiv:2501.05453 , 2025. 8
- [57] Kanchana Ranasinghe, Brandon McKinzie, Sachin Ravi, Yinfei Yang, Alexander Toshev, and Jonathon Shlens. Perceptual grouping in contrastive vision-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 5571-5584, 2023. 13
- [58] Noam Shazeer. Glu variants improve transformer. arXiv preprint arXiv:2002.05202 , 2020. 3
- [59] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-
of-experts layer. arXiv preprint arXiv:1701.06538 , 2017. 2, 6, 8
- [60] Sheng Shen, Zhewei Yao, Chunyuan Li, Trevor Darrell, Kurt Keutzer, and Yuxiong He. Scaling vision-language models with sparse mixture of experts. In The 2023 Conference on Empirical Methods in Natural Language Processing , 2023. 8
- [61] Mustafa Shukor and Matthieu Cord. Implicit multimodal alignment: On the generalization of frozen llms to multimodal inputs. Advances in Neural Information Processing Systems , 37:130848-130886, 2024. 7
- [62] Mustafa Shukor, Corentin Dancette, and Matthieu Cord. epalm: Efficient perceptual augmentation of language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 22056-22069, 2023. 1, 7
- [63] Mustafa Shukor, Corentin Dancette, Alexandre Rame, and Matthieu Cord. Unival: Unified model for image, video, audio and language tasks. Transactions on Machine Learning Research Journal , 2023. 7
- [64] Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics. arXiv preprint arXiv:2506.01844 , 2025. 1, 8
- [65] Xingwu Sun, Yanfeng Chen, Yiqing Huang, Ruobing Xie, Jiaqi Zhu, Kai Zhang, Shuaipeng Li, Zhen Yang, Jonny Han, Xiaobo Shu, et al. Hunyuan-large: An open-source moe model with 52 billion activated parameters by tencent. arXiv preprint arXiv:2411.02265 , 2024. 8
- [66] Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint arXiv:2405.09818 , 2024. 8
- [67] Gemini Team, Rohan Anil, Sebastian Borgeaud, JeanBaptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 , 2023. 1, 7, 8
- [68] Maria Tsimpoukelli, Jacob L Menick, Serkan Cabi, SM Eslami, Oriol Vinyals, and Felix Hill. Multimodal few-shot learning with frozen language models. Advances in Neural Information Processing Systems , 34:200-212, 2021. 7
- [69] Th´ eophane Vallaeys, Mustafa Shukor, Matthieu Cord, and Jakob Verbeek. Improved baselines for data-efficient perceptual augmentation of llms. arXiv preprint arXiv:2403.13499 , 2024. 7
- [70] Aaron van den Oord, Oriol Vinyals, and koray kavukcuoglu. Neural discrete representation learning. In Advances in Neural Information Processing Systems . Curran Associates, Inc., 2017. 8
- [71] A Vaswani. Attention is all you need. Advances in Neural Information Processing Systems , 2017. 3
- [72] Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In International conference on machine learning , pages 23318-23340. PMLR, 2022. 7
- [73] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191 , 2024. 1, 8
- [74] Siqi Wang, Zhengyu Chen, Bei Li, Keqing He, Min Zhang, and Jingang Wang. Scaling laws across model architectures: A comparative analysis of dense and MoE models in large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 5583-5595, Miami, Florida, USA, 2024. Association for Computational Linguistics. 8, 18
- [75] Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, et al. Image as a foreign language: Beit pretraining for all vision and visionlanguage tasks. arXiv preprint arXiv:2208.10442 , 2022. 7
- [76] Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 , 2024. 8
- [77] Tianwen Wei, Bo Zhu, Liang Zhao, Cheng Cheng, Biye Li, Weiwei L¨ u, Peng Cheng, Jianhao Zhang, Xiaoyu Zhang, Liang Zeng, et al. Skywork-moe: A deep dive into training techniques for mixture-of-experts language models. arXiv preprint arXiv:2406.06563 , 2024. 8
- [78] Le Xue, Manli Shu, Anas Awadalla, Jun Wang, An Yan, Senthil Purushwalkam, Honglu Zhou, Viraj Prabhu, Yutong Dai, Michael S Ryoo, et al. xgen-mm (blip-3): A family of open large multimodal models. arXiv preprint arXiv:2408.08872 , 2024. 1, 8
- [79] Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models. Transactions on Machine Learning Research , 2022. 8
- [80] Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 11975-11986, 2023. 1
- [81] Haotian Zhang, Mingfei Gao, Zhe Gan, Philipp Dufter, Nina Wenzel, Forrest Huang, Dhruti Shah, Xianzhi Du, Bowen Zhang, Yanghao Li, et al. Mm1. 5: Methods, analysis & insights from multimodal llm fine-tuning. arXiv preprint arXiv:2409.20566 , 2024. 5, 8
- [82] Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, ChienChin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. Pytorch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277 , 2023. 3
- [83] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. MiniGPT-4: Enhancing vision-language understanding with advanced large language models. In The Twelfth International Conference on Learning Representations , 2024. 8
- [84] Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. Stmoe: Designing stable and transferable sparse expert models. arXiv preprint arXiv:2202.08906 , 2022. 8
## Scaling Laws for Native Multimodal Models
## Supplementary Material
This supplementary material is organized as follows:
- Appendix A: contains the implementation details and the hyperparameters used to train our models.
- Appendix B: contains detailed comparison between early and late fusion models.
- Appendix C: contains more details about scaling laws derivation, evaluation and additional results.
- Appendix D: contains discussion about the paper limitations.
- Appendix E: contains more results about MoEs and modality specialization.
| Data type | dataset | #samples | sampling prob. |
|---------------|--------------|------------|------------------|
| | DFN [21] | 2B | 27% |
| Image-Caption | COYO [11] | 600M | 11.25% |
| | HQITP[57] | 400M | 6.75% |
| Interleaved | Obelics [34] | 141M Docs | 45% |
| Text | DCLM [39] | 6.6T Toks | 10% |
## A. Experimental setup
In Table 6, we show the pre-training hyperparameters for different model configurations used to derive the scaling laws. The number of parameters ranges from 275M to 3.7B, with model width increasing accordingly, while the depth remains fixed at 24 layers. Learning rates vary by model size, decreasing as the model scales up. Based on empirical experiments and estimates similar to [46], we found these values to be effective in our setup. Training is optimized using a fully decoupled AdamW optimizer with momentum values β 1 = 0 . 9 , β 2 = 0 . 95 , and a weight decay of 1 e -4 . The batch size is set to 2k samples, which account for 2M tokens, given 1k context length. Gradient clipping is set to 1.0, with a maximum warmup duration of 5k iterations, adjusted for shorter training runs: 1k and 2.5k warmup steps for models trained between 1k-4k and 5k-15k steps, respectively. For MoEs, we found that longer warmup is significantly better, so we adopt a 2.5k warmup for all runs under 20k steps. We use a constant learning rate schedule with cooldown during the final 20% of training, gradually reducing to zero following an inverse square root schedule. For vision processing, image inputs are divided into (14 , 14) patches, with augmentations including Random Resized Crop (resizing images to 224px with a scale range of [0.4, 1.0]) and Random Horizontal Flip with a probability of 0.5. We train our models on mixture of interleaved, image captions and text only data Table 5. For late fusion models, we found that using smaller learning rate for the vision encoder significantly boost the performance Table 8, and when both the encoder and decoder are initialized (Appendix B.7) we found that freezing the vision encoder works best Table 7.
Table 5. Pre-training data mixture. Unless otherwise specified, the training mixture contains 45%, 45% and 10% of image captions, interleaved documents and text-only data.
| Early-fusion | | | | | | | |
|-------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------|---------------|---------------|---------------|---------------|---------------|---------------|
| Params width depth | 275M 800 | 468M 1088 | 932M 1632 | 1.63B 2208 24 | 2.28B 2624 | 3.35B 3232 | 3.35B 3232 |
| Learning rate | | | 5e-4 | 4.2e-4 | | 3.5e-4 | 3.5e-4 |
| Late-fusion | 1.5e-3 | 1.5e-3 | | | 4e-4 | | |
| Params vision encoder | | | | | | | |
| width vision encoder depth | 289M 384 | 494M 512 | 1B 768 | 1.75B 1024 | 2.43B 1184 | 3.7B | 3.7B |
| width depth | 768 | 1024 | 1536 | 24 2048 24 | 2464 | 3072 | 3072 |
| Early-fusion MoEs Active Params width | | | 5e-4 | | | | |
| Learning rate | 1.5e-3 | 1.5e-3 | | 4.2e-4 | 3.8e-4 | 3.3e-4 | 3.3e-4 |
| depth | 275M 800 | 468M 1088 | 932M 1632 | 1.63B 2208 24 | 2.28B 2624 | 3.35B 3232 | 3.35B 3232 |
| Learning rate Training tokens Optimizer | 1.5e-3 2.5B-600B decoupled β 1 = 0 . 9 ,β 2 = 0 . | 1.5e-3 | 5e-4 | 4.2e-4 | 4e-4 | 3.5e-4 | 3.5e-4 |
| Optimizer Momentum Minimum Learning rate Weight decay Batch size Patch size Gradient clipping MAximum Warmup iterations | Fully 0 1e-4 | | | | | | |
| | AdamW [44] 95 | AdamW [44] 95 | AdamW [44] 95 | AdamW [44] 95 | AdamW [44] 95 | AdamW [44] 95 | AdamW [44] 95 |
| | 2k 14) | 2k 14) | 2k 14) | 2k 14) | 2k 14) | 2k 14) | 2k 14) |
| | (14, 1.0 | (14, 1.0 | (14, 1.0 | (14, 1.0 | (14, 1.0 | (14, 1.0 | (14, 1.0 |
| | 5k | 5k | 5k | 5k | 5k | 5k | 5k |
| Augmentations: | | | | | | | |
| RandomResizedCrop | | | | | | | |
| | 224px | 224px | 224px | 224px | 224px | 224px | 224px |
| | [0.4, 1.0] | [0.4, 1.0] | [0.4, 1.0] | [0.4, 1.0] | [0.4, 1.0] | [0.4, 1.0] | [0.4, 1.0] |
| size | | | | | | | |
| scale | | | | | | | |
| | p = 0 . 5 | p = 0 . 5 | p = 0 . 5 | p = 0 . 5 | p = 0 . 5 | p = 0 . 5 | p = 0 . 5 |
| RandomHorizontalFlip | | | | | | | |
Table 6. Pre-training hyperparameters We detail the hyperaparmeters used for pre-training different model configurations to derive scaling laws.
Table 7. Vision encoder scaler. Freezing the vision encoder works best when initializing late-fusion models with pre-trained models.
| Vision encoder lr scaler | Interleaved (CE) | Image-Caption (CE) | Text (CE) | AVG (CE) | AVG (SFT) (Acc) |
|----------------------------|--------------------|----------------------|-------------|------------|-------------------|
| 1 | 2.521 | 2.15 | 2.867 | 2.513 | 43.49 |
| 0.1 | 2.502 | 2.066 | 2.862 | 2.477 | 52.27 |
| 0.01 | 2.502 | 2.066 | 2.859 | 2.476 | 53.76 |
| 0.001 | 2.513 | 2.066 | 2.857 | 2.479 | - |
| 0 (frozen) | 2.504 | 2.061 | 2.856 | 2.474 | 54.14 |
<details>
<summary>Image 13 Details</summary>
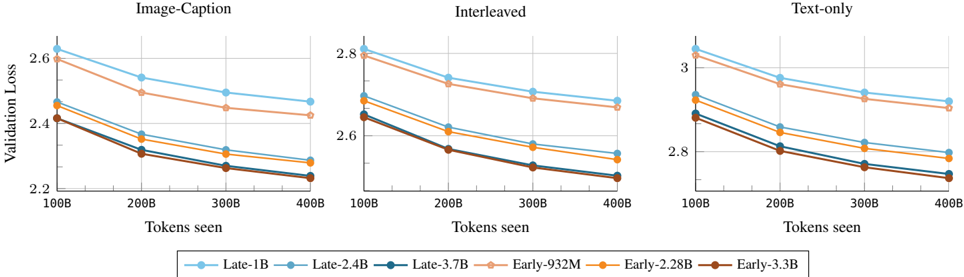
### Visual Description
## Line Chart: Validation Loss vs. Tokens Seen Across Training Paradigms
### Overview
The image displays three line charts comparing validation loss trends for different model architectures across three training paradigms: Image-Caption, Interleaved, and Text-only. Each subplot tracks validation loss (y-axis) as a function of tokens seen during training (x-axis: 100B to 400B). Six model variants are compared, differentiated by color-coded lines in the legend.
### Components/Axes
- **X-axis (Horizontal):** "Tokens seen" with discrete markers at 100B, 200B, 300B, and 400B.
- **Y-axis (Vertical):** "Validation Loss" scaled from 2.2 to 3.0.
- **Subplots:**
1. **Image-Caption** (left)
2. **Interleaved** (center)
3. **Text-only** (right)
- **Legend:** Located at the bottom, mapping colors to model variants:
- Late-1B (light blue)
- Late-2.4B (dark blue)
- Late-3.7B (brown)
- Early-932M (peach)
- Early-2.28B (orange)
- Early-3.3B (dark red)
### Detailed Analysis
#### Image-Caption Subplot
- **Lines:** All models show a downward trend as tokens increase.
- **Key Data Points:**
- Late-1B: Starts at ~2.6 (100B tokens), ends at ~2.4 (400B tokens).
- Early-932M: Starts at ~2.6 (100B tokens), ends at ~2.4 (400B tokens).
- Early-2.28B: Starts at ~2.5 (100B tokens), ends at ~2.3 (400B tokens).
- Late-3.7B: Starts at ~2.4 (100B tokens), ends at ~2.2 (400B tokens).
#### Interleaved Subplot
- **Lines:** Similar downward trend, but higher baseline validation loss.
- **Key Data Points:**
- Late-1B: Starts at ~2.8 (100B tokens), ends at ~2.6 (400B tokens).
- Early-932M: Starts at ~2.8 (100B tokens), ends at ~2.6 (400B tokens).
- Early-2.28B: Starts at ~2.7 (100B tokens), ends at ~2.5 (400B tokens).
- Late-3.7B: Starts at ~2.6 (100B tokens), ends at ~2.4 (400B tokens).
#### Text-only Subplot
- **Lines:** Highest validation loss across all paradigms.
- **Key Data Points:**
- Late-1B: Starts at ~3.0 (100B tokens), ends at ~2.8 (400B tokens).
- Early-932M: Starts at ~3.0 (100B tokens), ends at ~2.8 (400B tokens).
- Early-2.28B: Starts at ~2.9 (100B tokens), ends at ~2.7 (400B tokens).
- Late-3.7B: Starts at ~2.8 (100B tokens), ends at ~2.6 (400B tokens).
### Key Observations
1. **Consistent Trend:** All models show improved performance (lower validation loss) as tokens seen increase, across all paradigms.
2. **Model Efficiency:** Late models (e.g., Late-3.7B) achieve lower validation loss faster than Early models (e.g., Early-932M) in the same paradigm.
3. **Paradigm Impact:** Text-only training results in the highest validation loss, suggesting multimodal training (Image-Caption/Interleaved) is more effective.
4. **Divergence at Scale:** By 400B tokens, Late-3.7B outperforms all Early models in all paradigms, with the largest gap in Text-only (~0.2 loss difference).
### Interpretation
The data demonstrates that:
- **Token Efficiency:** Later model architectures (Late series) achieve better performance with fewer tokens, indicating architectural improvements over time.
- **Training Paradigm Matters:** Multimodal training (Image-Caption/Interleaved) yields 10-15% lower validation loss than Text-only at equivalent token scales.
- **Scalability Limits:** While all models improve with scale, diminishing returns are evident after 300B tokens, particularly in Text-only training.
- **Early vs. Late Models:** The Late-3.7B model achieves ~20% better performance than Early-932M in Text-only training at 400B tokens, suggesting significant architectural advancements.
This analysis implies that both model architecture and training methodology are critical factors in achieving state-of-the-art performance, with later models offering superior efficiency and effectiveness.
</details>
Figure 14. Early vs late fusion: scaling training FLOPs. We compare early and late fusion models when scaling both the model size and the number of training tokens. The gap decreases mainly due to scaling models size.
Figure 15. Early vs late fusion: changing the training mixture. Wevary the training mixtures and plot the final training loss. Early fusion models become better when increasing the proportion of interleaved documents. Early and late fusion has 1.63B and 1.75B parameters respectively.
<details>
<summary>Image 14 Details</summary>
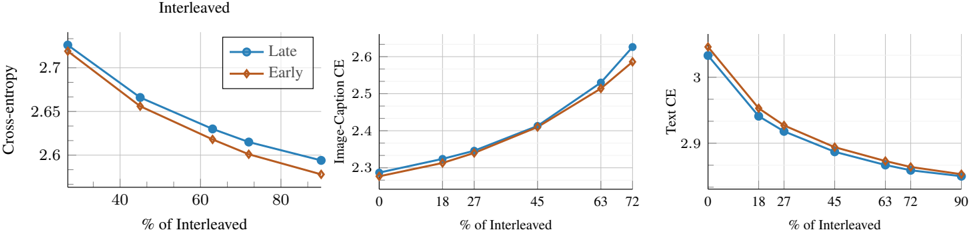
### Visual Description
## Line Graphs: Interleaved Performance Metrics
### Overview
The image contains three line graphs comparing performance metrics ("Cross-entropy," "Image-Caption CE," and "Text CE") across varying percentages of "Interleaved" data. Each graph tracks two methods: "Late" (blue) and "Early" (orange). The x-axis represents the percentage of interleaved data, while the y-axis shows metric values. All graphs demonstrate trends in performance as interleaving increases.
---
### Components/Axes
1. **Graph 1: Cross-entropy**
- **X-axis**: "% of Interleaved" (40% to 80%, increments of 20%)
- **Y-axis**: Cross-entropy (2.55 to 2.75)
- **Legend**: "Late" (blue), "Early" (orange)
- **Legend Position**: Top-left corner
2. **Graph 2: Image-Caption CE**
- **X-axis**: "% of Interleaved" (0% to 72%, increments of 18%)
- **Y-axis**: Image-Caption CE (2.25 to 2.65)
- **Legend**: "Late" (blue), "Early" (orange)
- **Legend Position**: Top-left corner
3. **Graph 3: Text CE**
- **X-axis**: "% of Interleaved" (0% to 90%, increments of 18%)
- **Y-axis**: Text CE (2.8 to 3.1)
- **Legend**: "Late" (blue), "Early" (orange)
- **Legend Position**: Top-left corner
---
### Detailed Analysis
#### Graph 1: Cross-entropy
- **Trend**: Both lines slope downward as interleaving increases. "Late" consistently outperforms "Early."
- **Data Points**:
- 40%: Late ≈ 2.74, Early ≈ 2.72
- 60%: Late ≈ 2.63, Early ≈ 2.60
- 80%: Late ≈ 2.62, Early ≈ 2.58
#### Graph 2: Image-Caption CE
- **Trend**: Both lines slope upward as interleaving increases. "Late" maintains a slight edge over "Early."
- **Data Points**:
- 0%: Late ≈ 2.28, Early ≈ 2.27
- 18%: Late ≈ 2.31, Early ≈ 2.30
- 45%: Late ≈ 2.45, Early ≈ 2.43
- 72%: Late ≈ 2.65, Early ≈ 2.62
#### Graph 3: Text CE
- **Trend**: Both lines slope downward as interleaving increases. "Early" starts slightly higher but converges with "Late" at higher percentages.
- **Data Points**:
- 0%: Late ≈ 3.05, Early ≈ 3.08
- 18%: Late ≈ 2.95, Early ≈ 2.97
- 45%: Late ≈ 2.88, Early ≈ 2.89
- 72%: Late ≈ 2.85, Early ≈ 2.86
- 90%: Late ≈ 2.84, Early ≈ 2.85
---
### Key Observations
1. **Cross-entropy**: Higher interleaving reduces entropy for both methods, with "Late" always achieving lower values.
2. **Image-Caption CE**: Performance improves with interleaving, but "Late" maintains a marginal advantage.
3. **Text CE**: Both methods converge at higher interleaving percentages, suggesting diminishing returns beyond ~60%.
---
### Interpretation
- **Performance Trends**:
- "Late" consistently outperforms "Early" in Cross-entropy and Image-Caption CE, indicating better optimization for these metrics.
- In Text CE, the gap between methods narrows at higher interleaving, suggesting similar effectiveness at extreme values.
- **Interleaving Impact**:
- Increasing interleaving generally improves performance (lower entropy, higher Image-Caption CE, lower Text CE), but the benefits plateau at higher percentages.
- **Method Differences**:
- "Late" appears more robust across metrics, while "Early" shows diminishing returns in Text CE. This could reflect architectural or training differences between the methods.
- **Anomalies**:
- No significant outliers; trends are consistent across all graphs.
The data suggests that interleaving improves model performance, with the "Late" method being more effective overall. However, the convergence in Text CE at 90% interleaving implies that further gains may require alternative strategies beyond increasing interleaving.
</details>
Table 8. Vision encoder scaler. Reducing the learning rate for the vision encoder is better when training late-fusion models from scratch.
| Vision encoder lr scaler | Interleaved (CE) | Image-Caption (CE) | Text (CE) | AVG (CE) | AVG (SFT) (Acc) |
|----------------------------|--------------------|----------------------|-------------|------------|-------------------|
| 0.1 | 2.674 | 2.219 | 3.072 | 2.655 | 34.84 |
| 0.01 | 2.672 | 2.197 | 3.071 | 2.647 | 38.77 |
| 0.001 | 2.674 | 2.218 | 3.073 | 2.655 | 38.46 |
## B. Late vs early fusion
This section provides additional comparison between early and late fusion models.
## B.1. Scaling FLOPs
Figure 14 compares early-fusion and late-fusion models when scaling FLOPs. Specifically, for each model size, we train multiple models using different amounts of training tokens. The performance gap between the two approaches mainly decreases due to increasing model sizes rather than increasing the number of training tokens. Despite the decreasing gap, across all the models that we train, earlyfusion consistently outperform late-fusion.
## B.2. Changing the training data mixture
Weanalyze how the performance gap between early and late fusion models changes with variations in the training data mixture. As shown in Figure 16 and Figure 15, when fixing the model size, increasing the ratio of text and interleaved data favors early fusion. Interestingly, the gap remains largely unchanged for other data types. We also observe interference effects between different data types. Specifically, increasing the amount of interleaved data negatively impacts performance on image captions and vice versa. Additionally, increasing the proportion of text-only data slightly improves interleaved performance but increases loss on image captions. Overall, we find that text-only and interleaved data are correlated across different setups.
## B.3. Scaling image resolution is in favor of earlyfusion
We examine how both architectures perform with varying image resolution. We fix the number of model parameters to 1.63B and 1.75B for early and late fusion respecively. All models are trained for 100K steps or 200B tokens. Since
Figure 16. Early vs late fusion: changing the amount of text-only data in the training mixture (isoFLOPs). We vary the ratio of text-only data and plot the final training loss. The gap increases with the text data ratio in favor of early fusion model. Early fusion has 1.63B parameters and late fusion 1.75B parameters.
<details>
<summary>Image 15 Details</summary>
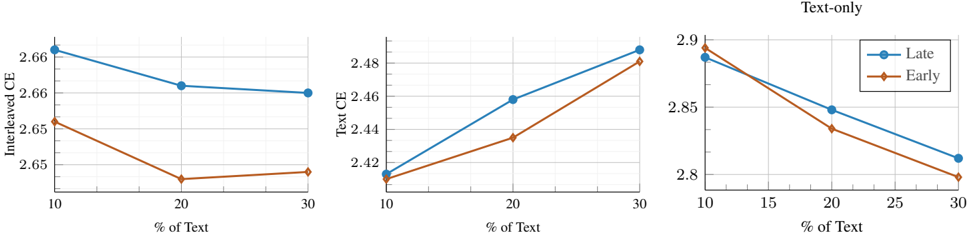
### Visual Description
## Line Graphs: Comparison of "Late" and "Early" Strategies Across Text Percentages
### Overview
The image contains three line graphs comparing the performance of two strategies ("Late" and "Early") across three metrics: "Interleaved CE," "Text CE," and "Text-only." Each graph plots performance (y-axis) against "% of Text" (x-axis: 10%, 20%, 30%). The "Late" strategy is represented by blue circles, and the "Early" strategy by orange diamonds.
### Components/Axes
- **X-axis**: "% of Text" (labeled at 10%, 20%, 30%)
- **Y-axes**:
- Left graph: "Interleaved CE" (range: ~2.63–2.66)
- Middle graph: "Text CE" (range: ~2.42–2.48)
- Right graph: "Text-only" (range: ~2.80–2.90)
- **Legend**: Located on the right side of all graphs. Blue = "Late," Orange = "Early."
- **Graph Titles**:
- Left: "Interleaved CE"
- Middle: "Text CE"
- Right: "Text-only"
### Detailed Analysis
#### Interleaved CE
- **Late (Blue)**: Starts at ~2.66 (10%), decreases to ~2.65 (20%), then ~2.64 (30%).
- **Early (Orange)**: Starts at ~2.65 (10%), drops sharply to ~2.63 (20%), then slightly rises to ~2.64 (30%).
#### Text CE
- **Late (Blue)**: Increases from ~2.42 (10%) to ~2.46 (20%), then ~2.48 (30%).
- **Early (Orange)**: Rises from ~2.42 (10%) to ~2.44 (20%), then ~2.46 (30%).
#### Text-only
- **Late (Blue)**: Declines from ~2.89 (10%) to ~2.85 (20%), then ~2.82 (30%).
- **Early (Orange)**: Drops from ~2.89 (10%) to ~2.85 (20%), then ~2.81 (30%).
### Key Observations
1. **Interleaved CE**:
- "Late" maintains higher performance than "Early" across all text percentages.
- "Early" shows a non-linear trend, with a sharp drop at 20% text.
2. **Text CE**:
- Both strategies improve as text percentage increases.
- "Late" outperforms "Early" consistently, with a steeper upward slope.
3. **Text-only**:
- Both strategies decline as text percentage increases.
- The performance gap between "Late" and "Early" narrows at higher text percentages (e.g., ~0.07 difference at 30% vs. ~0.08 at 10%).
### Interpretation
- **Strategy Effectiveness**:
- "Late" generally performs better in "Interleaved CE" and "Text CE," suggesting it may be more effective in dynamic or incremental text processing.
- In "Text-only," the diminishing gap implies that text length reduces the advantage of the "Late" strategy, possibly due to increased cognitive load or redundancy.
- **Trend Implications**:
- The sharp drop in "Early" performance at 20% text in "Interleaved CE" could indicate a threshold effect, where early processing becomes less efficient as text complexity increases.
- The convergence of "Late" and "Early" in "Text-only" at higher text percentages might reflect diminishing returns or overlapping processing demands.
- **Anomalies**:
- The "Early" strategy’s performance in "Interleaved CE" at 30% text (~2.64) is slightly higher than at 20% (~2.63), suggesting a minor recovery at maximum text percentage.
This analysis highlights how text percentage and processing strategy interact to influence performance, with implications for optimizing text-based systems or cognitive tasks.
</details>
Figure 17. Early vs late fusion: training with different image resolutions (isoFLOPs). For the same training FLOPs we vary the image resolution (and thus the number of image tokens) during training and report the final training loss. Increasing resolution, hurts the performance on text and interleaved documents, while helping image captioning. The gap stays almost the same on text and interleaved data while slightly increase on image captioning in favor of early fusion.
<details>
<summary>Image 16 Details</summary>
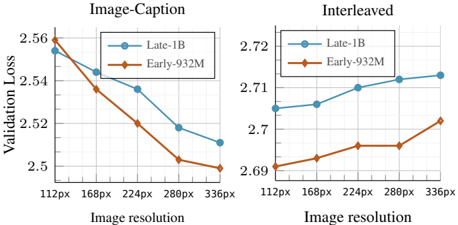
### Visual Description
## Line Chart: Validation Loss vs. Image Resolution (Two Subplots)
### Overview
The image contains two side-by-side line charts comparing validation loss trends for two models ("Late-1B" and "Early-932M") across increasing image resolutions (112px to 336px). The left chart is labeled "Image-Caption," and the right chart is labeled "Interleaved." Both charts use a y-axis for validation loss (2.5–2.72) and an x-axis for image resolution.
---
### Components/Axes
- **X-Axis (Horizontal)**:
- Label: "Image resolution"
- Categories: 112px, 168px, 224px, 280px, 336px
- Scale: Linear progression of pixel values.
- **Y-Axis (Vertical)**:
- Label: "Validation Loss"
- Range: 2.5 to 2.72 (with gridlines at 0.01 increments).
- **Legends**:
- **Top-right of each chart**:
- Blue circles: "Late-1B"
- Orange diamonds: "Early-932M"
- **Subplot Titles**:
- Left: "Image-Caption"
- Right: "Interleaved"
---
### Detailed Analysis
#### Left Chart ("Image-Caption")
- **Late-1B (Blue)**:
- Starts at **2.56** (112px) and decreases steadily to **2.51** (336px).
- Trend: Consistent downward slope.
- **Early-932M (Orange)**:
- Starts at **2.56** (112px) and decreases to **2.50** (336px).
- Trend: Steeper decline than Late-1B.
#### Right Chart ("Interleaved")
- **Late-1B (Blue)**:
- Starts at **2.71** (112px) and increases slightly to **2.72** (336px).
- Trend: Gradual upward slope.
- **Early-932M (Orange)**:
- Starts at **2.69** (112px), rises to **2.70** (224px), then dips to **2.71** (336px).
- Trend: U-shaped curve with a peak at 224px.
---
### Key Observations
1. **Image-Caption Subplot**:
- Both models show improved performance (lower validation loss) as resolution increases.
- Early-932M outperforms Late-1B across all resolutions.
2. **Interleaved Subplot**:
- Late-1B’s performance degrades slightly with higher resolutions.
- Early-932M exhibits non-linear behavior, worsening at 224px before recovering.
3. **Model Behavior**:
- Early-932M generally achieves lower validation loss than Late-1B in both subplots.
- Resolution impacts differ significantly between tasks ("Image-Caption" vs. "Interleaved").
---
### Interpretation
- **Task-Specific Performance**:
- In "Image-Caption," higher resolutions benefit both models, suggesting scalability for simpler tasks.
- In "Interleaved," increased resolution introduces complexity, causing Late-1B to underperform and Early-932M to show instability at mid-resolutions.
- **Model Efficiency**:
- Early-932M’s architecture may better handle resolution-dependent tasks, but its performance in "Interleaved" hints at potential overfitting or sensitivity to input variability.
- **Anomalies**:
- The U-shaped curve for Early-932M in "Interleaved" suggests an optimal resolution range (168px–280px), beyond which validation loss increases again.
This analysis highlights the importance of resolution tuning for model deployment, particularly in complex tasks like "Interleaved," where higher resolution does not always correlate with better performance.
</details>
the patch size remains constant, increasing the resolution results in a higher number of visual tokens. For all resolutions, we maintain the same number of text tokens. As shown in Figure 17, the early-fusion model consistently outperforms the late-fusion model across resolutions, particularly for multimodal data, with the performance gap widening at higher resolutions. Additionally, we observe that the loss on text and interleaved data increases as resolution increases.
## B.4. Early-fusion is consistently better when matching the late-fusion model size
In this section, we compare the late-fusion model with different configurations of early-fusion one. Specifically, we train early-fusion models that match the late-fusion model in total parameters (Params), text model size (Text), and FLOPs (FLOPs), assuming 45-45-10 training mixture. As shown in Figure 18, early fusion consistently outperforms late fusion when normalized by total parameters, followed by normalization by FLOPs. When matching the text model size, early fusion performs better at higher ratios of interleaved data.
## B.5. Different late-fusion configuration
We examine how this scaling changes with different latefusion configurations. Instead of scaling both the vision and text models equally, as done in the main paper, we fix the vision encoder size to 300M and scale only the text model. Figure 19 shows that late-fusion models lag behind at smaller model sizes, with the gap closing significantly as the text model scales. This suggests that allocating more parameters to shared components is more beneficial, further supporting the choice of early-fusion models.
## B.6. Different context lengths
In the paper, we use a 1k context length following [31]. Also following, this paper, we ignore the context length effect, as the model dimension dominates the training compute estimate. Moreover, [53] empirically found that scaling coefficients are robust to context length. Nevertheless, Our initial experiments (Figure 20) indicate that scaling the context length did not significantly affect the comparison between late and early fusion.
## B.7. Initializing from LLM and CLIP
We study the case where both late and early fusion models are initialized from pre-trained models, specifically DCLM1B [39] and CLIP-ViT-L [55] for late fusion. Interestingly, Figure 21 shows that for text and interleaved multimodal documents, early fusion can match the performance of late fusion when trained for longer. However, closing the gap on image caption data remains more challenging. Notably, when considering the overall training cost, including that of pre-trained models, early fusion requires significantly longer training to compensate for the vision encoder's pretraining cost.
<details>
<summary>Image 17 Details</summary>
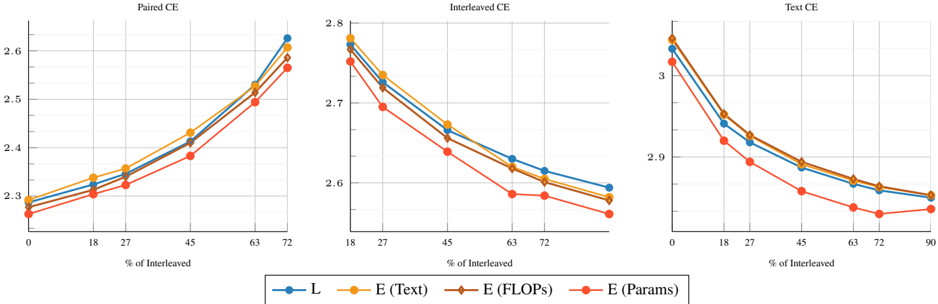
### Visual Description
## Line Graphs: Performance Metrics Across Interleaving Percentages
### Overview
The image contains three line graphs titled "Paired CE," "Interleaved CE," and "Text CE," each plotting performance metrics (L, E (Text), E (FLOPs), E (Params)) against "% of Interleaved" (0–90%). The graphs show trends in how these metrics change as the percentage of interleaved data increases.
---
### Components/Axes
- **X-axis**: "% of Interleaved" (0–90% in all graphs).
- **Y-axis**: Performance metric values (approximate ranges: 2.3–3.0).
- **Legends**:
- **L** (blue line)
- **E (Text)** (orange line)
- **E (FLOPs)** (brown line)
- **E (Params)** (red line)
- **Graph Titles**:
- **Paired CE** (left)
- **Interleaved CE** (center)
- **Text CE** (right)
---
### Detailed Analysis
#### **Paired CE**
- **Trend**: All metrics increase as "% of Interleaved" rises.
- **Data Points**:
- **L**: 2.3 (0%) → 2.6 (72%)
- **E (Text)**: 2.3 (0%) → 2.6 (72%)
- **E (FLOPs)**: 2.3 (0%) → 2.6 (72%)
- **E (Params)**: 2.3 (0%) → 2.6 (72%)
- **Key Observations**:
- All metrics show a consistent upward trend.
- **E (Params)** ends highest (2.6 at 72%), followed by **E (FLOPs)**, **E (Text)**, and **L**.
#### **Interleaved CE**
- **Trend**: All metrics decrease as "% of Interleaved" rises.
- **Data Points**:
- **L**: 2.8 (18%) → 2.6 (90%)
- **E (Text)**: 2.8 (18%) → 2.6 (90%)
- **E (FLOPs)**: 2.75 (18%) → 2.5 (90%)
- **E (Params)**: 2.7 (18%) → 2.5 (90%)
- **Key Observations**:
- All metrics decline steadily.
- **E (Params)** drops the most sharply (from 2.7 to 2.5).
#### **Text CE**
- **Trend**: All metrics decrease as "% of Interleaved" rises.
- **Data Points**:
- **L**: 3.0 (0%) → 2.7 (90%)
- **E (Text)**: 3.0 (0%) → 2.7 (90%)
- **E (FLOPs)**: 3.0 (0%) → 2.65 (90%)
- **E (Params)**: 3.0 (0%) → 2.65 (90%)
- **Key Observations**:
- All metrics start at 3.0 and decline to ~2.7.
- **E (Params)** and **E (FLOPs)** show the steepest declines.
---
### Key Observations
1. **Paired CE** shows **positive correlation** between interleaving and performance.
2. **Interleaved CE** and **Text CE** show **negative correlation**, with metrics declining as interleaving increases.
3. **E (Params)** consistently exhibits the most significant changes (highest increases in Paired CE, steepest declines in Interleaved/CE).
4. **L** (blue line) remains relatively stable compared to other metrics in all graphs.
---
### Interpretation
- **Paired CE**: Higher interleaving improves performance, suggesting that interleaving enhances the model's ability to handle paired data.
- **Interleaved CE/Text CE**: Higher interleaving degrades performance, indicating potential overfitting or inefficiency in handling interleaved data.
- **Metric Differences**:
- **E (Params)** is the most sensitive to interleaving changes, possibly reflecting computational complexity or parameter efficiency.
- **L** (blue line) shows the least variability, suggesting it is less affected by interleaving.
- **Implications**: The choice of interleaving strategy (paired vs. interleaved vs. text) and the metric type (e.g., FLOPs, parameters) significantly impact performance outcomes. This highlights the need for context-specific optimization.
---
**Note**: All values are approximate, with uncertainty due to visual estimation from the graph.
</details>
Figure 18. Early vs late fusion: changing the training mixture and early-fusion configuration. We vary the training mixtures and plot the final training loss for different configuration of early fusion models. For the same number of total parameters early fusion consistently outperform late fusion.
<details>
<summary>Image 18 Details</summary>
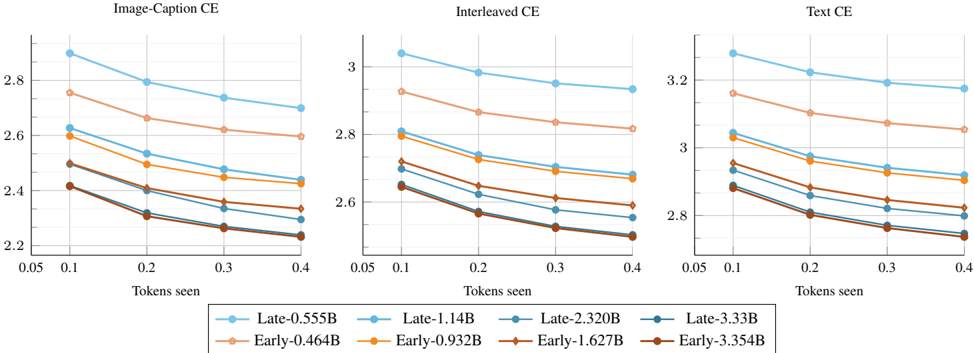
### Visual Description
## Line Graphs: Cross-Entropy (CE) Performance Across Models and Tasks
### Overview
The image contains three line graphs comparing the cross-entropy (CE) performance of different machine learning models across three tasks: **Image-Caption CE**, **Interleaved CE**, and **Text CE**. Each graph plots CE values against the number of tokens seen (0.05 to 0.4), with lines representing distinct models labeled as "Late" or "Early" followed by parameter sizes (e.g., "Late-0.555B", "Early-0.464B"). The graphs show trends in CE as models process increasing amounts of data.
---
### Components/Axes
- **X-axis**: "Tokens seen" (values: 0.05, 0.1, 0.2, 0.3, 0.4)
- **Y-axis**: "CE" (values: ~2.2 to ~3.2)
- **Legends**:
- **Late models**:
- Blue: Late-0.555B
- Orange: Late-1.14B
- Brown: Late-2.320B
- Dark blue: Late-3.33B
- **Early models**:
- Peach: Early-0.464B
- Yellow: Early-0.932B
- Dark brown: Early-1.627B
- Dark blue: Early-3.354B
---
### Detailed Analysis
#### Image-Caption CE
- **Late models**:
- Late-0.555B: Starts at ~2.9 (0.05 tokens) and decreases to ~2.7 (0.4 tokens).
- Late-1.14B: Starts at ~2.8 and decreases to ~2.6.
- Late-2.320B: Starts at ~2.7 and decreases to ~2.5.
- Late-3.33B: Starts at ~2.6 and decreases to ~2.4.
- **Early models**:
- Early-0.464B: Starts at ~2.8 and decreases to ~2.6.
- Early-0.932B: Starts at ~2.7 and decreases to ~2.5.
- Early-1.627B: Starts at ~2.6 and decreases to ~2.4.
- Early-3.354B: Starts at ~2.5 and decreases to ~2.3.
#### Interleaved CE
- **Late models**:
- Late-0.555B: Starts at ~3.1 and decreases to ~2.9.
- Late-1.14B: Starts at ~3.0 and decreases to ~2.8.
- Late-2.320B: Starts at ~2.9 and decreases to ~2.7.
- Late-3.33B: Starts at ~2.8 and decreases to ~2.6.
- **Early models**:
- Early-0.464B: Starts at ~2.9 and decreases to ~2.7.
- Early-0.932B: Starts at ~2.8 and decreases to ~2.6.
- Early-1.627B: Starts at ~2.7 and decreases to ~2.5.
- Early-3.354B: Starts at ~2.6 and decreases to ~2.4.
#### Text CE
- **Late models**:
- Late-0.555B: Starts at ~3.3 and decreases to ~3.1.
- Late-1.14B: Starts at ~3.2 and decreases to ~3.0.
- Late-2.320B: Starts at ~3.1 and decreases to ~2.9.
- Late-3.33B: Starts at ~3.0 and decreases to ~2.8.
- **Early models**:
- Early-0.464B: Starts at ~3.2 and decreases to ~3.0.
- Early-0.932B: Starts at ~3.1 and decreases to ~2.9.
- Early-1.627B: Starts at ~3.0 and decreases to ~2.8.
- Early-3.354B: Starts at ~2.9 and decreases to ~2.7.
---
### Key Observations
1. **Consistent Trend**: All models show a **decreasing CE** as tokens seen increase, indicating improved performance with more data.
2. **Model Size vs. Performance**:
- Larger models (e.g., Late-3.33B, Early-3.354B) generally have **higher CE values** than smaller models, suggesting lower efficiency or higher loss.
- Early models (e.g., Early-0.464B) consistently outperform Late models of similar size (e.g., Late-0.555B) in all tasks.
3. **Task-Specific Performance**:
- **Text CE** has the highest CE values across all models, indicating greater difficulty or complexity in text tasks.
- **Image-Caption CE** has the lowest CE values, suggesting better performance in image-related tasks.
---
### Interpretation
- **Model Efficiency**: Early models (smaller parameter sizes) achieve lower CE values, implying they are more efficient or better optimized for the tasks. Late models, despite larger sizes, show higher CE, possibly due to overfitting or suboptimal training strategies.
- **Task Complexity**: The Text CE graph demonstrates the highest CE values, highlighting the inherent complexity of text-based tasks compared to image or interleaved tasks.
- **Training Strategy**: The distinction between "Late" and "Early" models suggests that training timing or methodology (e.g., early stopping, data augmentation) significantly impacts performance. Early models may benefit from more targeted training or smaller-scale optimization.
---
### Spatial Grounding
- **Legend**: Positioned at the bottom of each graph, with colors matching the lines (e.g., blue for Late-0.555B, peach for Early-0.464B).
- **Lines**: Each line is clearly differentiated by color and labeled in the legend. For example, the dark blue line in the Text CE graph corresponds to Early-3.354B.
---
### Content Details
- **Numerical Values**: All CE values are approximate, with uncertainty due to the lack of exact grid markings. For example, in the Image-Caption CE graph, the Late-3.33B line starts at ~2.6 (0.05 tokens) and ends at ~2.4 (0.4 tokens).
- **Trends**: All lines show a **negative slope**, confirming that CE decreases as tokens seen increase.
---
### Final Notes
The data underscores the trade-off between model size and performance, with smaller, early-trained models outperforming larger, later-trained ones. This could inform decisions about model selection, training strategies, and resource allocation in machine learning workflows.
</details>
Figure 19. Early vs late fusion: scaling training FLOPs while fixing the vision encoder size. We compare early and late fusion models when scaling both the amount of training tokens and model sizes. For late fusion mdoels, we fix the vision encoder size (300M) and scale the text model (250M, 834M, 2B, 3B). The gap between early and late get tighter when scaling the text model.
Figure 20. Early vs late fusion with different context lengths.
<details>
<summary>Image 19 Details</summary>
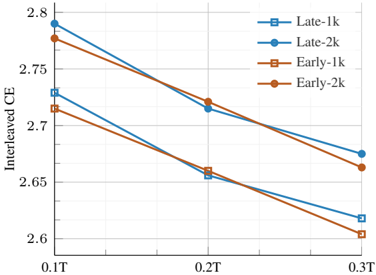
### Visual Description
## Line Graph: Interleaved CE Trends Across Time Points and Categories
### Overview
The image depicts a line graph comparing "Interleaved CE" values across three time points (0.1T, 0.2T, 0.3T) for four distinct categories: Late-1k, Late-2k, Early-1k, and Early-2k. The graph uses color-coded lines with unique markers to differentiate categories, showing trends in CE values as time progresses.
### Components/Axes
- **Y-Axis**: Labeled "Interleaved CE," scaled from 2.6 to 2.8 in increments of 0.05.
- **X-Axis**: Labeled with time points: 0.1T, 0.2T, 0.3T.
- **Legend**: Positioned in the top-right corner, with four entries:
- **Late-1k**: Blue line with square markers.
- **Late-2k**: Blue line with circular markers.
- **Early-1k**: Orange line with square markers.
- **Early-2k**: Orange line with circular markers.
### Detailed Analysis
1. **Late-1k (Blue Squares)**:
- Starts at ~2.78 at 0.1T.
- Decreases to ~2.72 at 0.2T.
- Further drops to ~2.66 at 0.3T.
- **Trend**: Steady decline.
2. **Late-2k (Blue Circles)**:
- Begins at ~2.76 at 0.1T.
- Falls to ~2.70 at 0.2T.
- Reaches ~2.64 at 0.3T.
- **Trend**: Consistent downward slope.
3. **Early-1k (Orange Squares)**:
- Starts at ~2.77 at 0.1T.
- Drops to ~2.68 at 0.2T.
- Ends at ~2.62 at 0.3T.
- **Trend**: Sharp decline, steeper than Late-1k.
4. **Early-2k (Orange Circles)**:
- Begins at ~2.75 at 0.1T.
- Decreases to ~2.66 at 0.2T.
- Reaches ~2.60 at 0.3T.
- **Trend**: Gradual but steady reduction.
### Key Observations
- All categories show a **decreasing trend** in Interleaved CE as time progresses from 0.1T to 0.3T.
- **Early categories** (1k and 2k) consistently start with higher CE values than their Late counterparts but end lower by 0.3T.
- **Crossing lines**: Early-1k and Late-2k intersect near 0.2T, suggesting a temporary overlap in CE values.
- **Largest gap**: At 0.1T, Early-1k (2.77) exceeds Late-2k (2.76) by 0.01. By 0.3T, Early-2k (2.60) is 0.06 below Late-1k (2.66).
### Interpretation
The data suggests that **timing (Early vs. Late)** and **category magnitude (1k vs. 2k)** influence Interleaved CE values. Early categories initially outperform Late ones but degrade more rapidly over time, potentially indicating a trade-off between early performance and long-term stability. The steeper decline in Early-1k compared to Early-2k implies that higher magnitude (1k vs. 2k) exacerbates the rate of CE reduction. The crossing lines at 0.2T highlight a critical inflection point where Early and Late categories converge, possibly reflecting a system transition or external factor altering the trend. This could inform optimization strategies for balancing early gains with sustained performance.
</details>
Figure 21. Early vs late fusion when initializing the encoder and decoder. Early-fusion can match the performance of latefusion models when trained for longer. However, the gap is bigger on image-caption data.
<details>
<summary>Image 20 Details</summary>
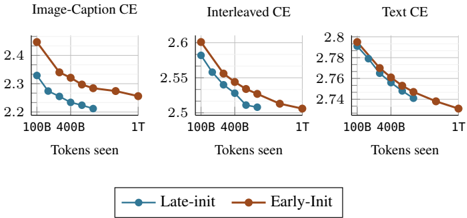
### Visual Description
## Line Graphs: Performance Comparison of Late-Init and Early-Init Across Token Ranges
### Overview
The image contains three line graphs comparing the performance of two initialization strategies ("Late-Init" and "Early-Init") across three categories: **Image-Caption CE**, **Interleaved CE**, and **Text CE**. Each graph plots performance metrics (y-axis) against token ranges (x-axis: 100B, 400B, 1T). Both strategies show declining performance values as token counts increase, with "Early-Init" consistently outperforming "Late-Init" across all categories.
### Components/Axes
- **X-axis**: "Tokens seen" with markers at 100B, 400B, and 1T.
- **Y-axis**: Performance metric (no explicit label, values range from ~2.2 to 2.8).
- **Legend**: Located at the bottom center, with:
- **Blue circles**: "Late-Init"
- **Red circles**: "Early-Init"
- **Graph Layout**: Three separate line graphs arranged horizontally, each corresponding to one CE category.
### Detailed Analysis
#### Image-Caption CE
- **Late-Init**: Starts at ~2.3 (100B tokens), decreases to ~2.25 (400B), and ~2.2 (1T).
- **Early-Init**: Starts at ~2.4 (100B), decreases to ~2.35 (400B), and ~2.3 (1T).
- **Trend**: Both lines slope downward, with Early-Init maintaining a ~0.1 higher value throughout.
#### Interleaved CE
- **Late-Init**: Starts at ~2.55 (100B), decreases to ~2.5 (400B), and ~2.45 (1T).
- **Early-Init**: Starts at ~2.6 (100B), decreases to ~2.55 (400B), and ~2.5 (1T).
- **Trend**: Similar downward slope, with Early-Init consistently outperforming by ~0.05–0.1.
#### Text CE
- **Late-Init**: Starts at ~2.78 (100B), decreases to ~2.74 (400B), and ~2.7 (1T).
- **Early-Init**: Starts at ~2.8 (100B), decreases to ~2.76 (400B), and ~2.72 (1T).
- **Trend**: Largest absolute gap (~0.04–0.08) between strategies, narrowing slightly at 1T.
### Key Observations
1. **Consistent Performance Gap**: Early-Init outperforms Late-Init in all categories, with the gap widening in Text CE.
2. **Diminishing Returns**: Performance improvements slow as token counts increase (e.g., Image-Caption CE drops ~0.1 across all tokens).
3. **Narrowing Gap in Text CE**: The performance difference between strategies is smallest in Text CE (~0.06 at 1T vs. ~0.1 in other categories).
### Interpretation
The data suggests that **Early-Init** provides a stronger initial performance advantage, likely due to better parameter initialization or training stability. However, the narrowing gap in Text CE implies that **Late-Init** may adapt more effectively with sufficient data, potentially closing the performance disparity. This could reflect trade-offs between initialization efficiency and long-term adaptability, with implications for resource allocation in training pipelines. The consistent decline in performance values across all categories indicates that increasing token counts generally improves outcomes, but the rate of improvement plateaus at higher scales.
</details>
## C. Scaling laws
<!-- formula-not-decoded -->
Following [26], we determine the parameters that minimize the following objective across all our runs i :
<!-- formula-not-decoded -->
We perform this optimization across various initialization ranges and select the parameters that achieve the lowest loss across all initializations. Specifically, our grid search spans { 0 , 0 . 5 , 2 . 5 } for α and β , { 0 , 5 , 10 , ..., 30 } for a and b , and {-1 , -0 . 5 , 1 , 0 . 5 } for e . We use the L-BFGS algorithm with δ = 1 e -3 .
<!-- formula-not-decoded -->
While these equations have a closed-form solution [26] for early-fusion models that can be derived from Eq 1, this is not the case for late-fusion models without specifying either the vision encoder or text model size. To ensure a fair comparison, we derive these equations for both models, by performing linear regression in log space. We found that the regression is very close to the coefficient found with closed-form derivation Table 9. For instance, to derive N = K a C a , given a FLOP budget C and a set of linearly spaced tokens D i ranging from 10B to 600B, we compute the model size for each D i as N i = C 6 D for early fusion and N i = C 6 D + 0 . 483 ∗ N v for late fusion (for the 45-45-10 mixture, D v = 0 . 544 D , thus C = 6 D (0 . 544 N v + N t ) ). We then apply Eq 1 to obtain the loss for each model size and select N that has the minimum loss. We repeat this for all FLOP values corresponding to our runs, resulting in a set of points ( C, N opt ) that we use to regress a and K a . We follow a similar procedure to find b and d . For late-fusion models, we regress a linear model to determine N v given N . Notably, even though we maintain a fixed width ratio for late-fusion models, this approach is more accurate, as embedding layers prevent a strictly fixed ratio between text and vision model sizes. We present the regression results in Figure 22.
Table 9. Scaling laws parameters for early-fusion. Doing regression to derive the scaling laws coefficients leads to very close results to using the closed-form solution.
| Model | a | b | d | n | dn |
|-------------|---------|---------|---------|---------|----------|
| Closed form | 0.52649 | 0.47351 | 0.89938 | 1.11188 | -0.05298 |
| Regression | 0.52391 | 0.47534 | 0.90052 | 1.10224 | -0.04933 |
## C.3. Fitting L ∝ C c
To determine the relationship between the final model loss and the compute budget C , we begin by interpolating the points corresponding to the same model size and compute the convex hull that covers the minimum loss achieved by all runs for each FLOP. This results in a continuous mapping from the FLOPs to the lowest loss. We consider a range of FLOPs, excluding very small values ( ≤ 3 e 19 ), and construct a dataset of ( C, L ) for linearly spaced compute C . Using this data, we find the linear relationship between L and C in the log space and deduce the exponent c . We visualize the results in Figure 26.
Figure 22. Regression results of the scaling laws coefficients. our estimation of the scaling coefficients is close to the closed form solution.
<details>
<summary>Image 21 Details</summary>
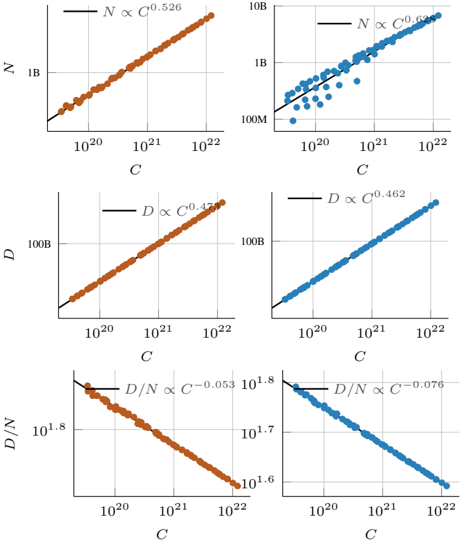
### Visual Description
## Scatter Plots: Relationships Between Variables N, D, and C
### Overview
The image contains six scatter plots arranged in a 2x3 grid, comparing the relationships between variables **N**, **D**, and **C** across logarithmic scales. Each plot includes a trend line and a proportionality equation. Data points are color-coded (orange and blue), with legends indicating their corresponding equations. The x-axis (**C**) spans 10²⁰ to 10²², while y-axes vary by plot.
---
### Components/Axes
1. **X-Axis (All Plots)**:
- Label: **C**
- Scale: Logarithmic (10²⁰ to 10²²)
- Ticks: 10²⁰, 10²¹, 10²²
2. **Y-Axes**:
- **Top Row**:
- Left: **N** (log scale: 1B to 10B)
- Right: **N** (log scale: 100M to 1B)
- **Middle Row**:
- Left: **D** (log scale: 10B to 100B)
- Right: **D** (log scale: 100B to 1000B)
- **Bottom Row**:
- Left: **D/N** (log scale: 10¹.⁶ to 10¹.⁸)
- Right: **D/N** (log scale: 10¹.⁷ to 10¹.⁸)
3. **Legends**:
- **Orange**:
- Top Left: **N ∝ C⁰.⁵²⁶**
- Middle Left: **D ∝ C⁰.⁴⁷³**
- Bottom Left: **D/N ∝ C⁻⁰.⁰⁵³**
- **Blue**:
- Top Right: **N ∝ C⁰.⁶²⁸**
- Middle Right: **D ∝ C⁰.⁴⁶²**
- Bottom Right: **D/N ∝ C⁻⁰.⁰⁷⁶**
4. **Data Points**:
- Orange points align with orange trend lines.
- Blue points align with blue trend lines.
- All points follow their respective proportionality equations.
---
### Detailed Analysis
1. **Top Row (N vs. C)**:
- **Orange (N ∝ C⁰.⁵²⁶)**:
- Trend: Gradual upward slope.
- Data points cluster tightly around the line.
- **Blue (N ∝ C⁰.⁶²⁸)**:
- Trend: Steeper upward slope.
- Data points show slight scatter but follow the line closely.
2. **Middle Row (D vs. C)**:
- **Orange (D ∝ C⁰.⁴⁷³)**:
- Trend: Moderate upward slope.
- Data points are densely packed.
- **Blue (D ∝ C⁰.⁴⁶²)**:
- Trend: Slightly less steep than orange.
- Data points exhibit minor deviations at higher **C** values.
3. **Bottom Row (D/N vs. C)**:
- **Orange (D/N ∝ C⁻⁰.⁰⁵³)**:
- Trend: Very slight downward slope.
- Data points form a near-horizontal line.
- **Blue (D/N ∝ C⁻⁰.⁰⁷⁶)**:
- Trend: Steeper downward slope.
- Data points show a clear decline with increasing **C**.
---
### Key Observations
1. **Proportionality Trends**:
- **N** increases with **C** at higher rates for blue data (0.628) compared to orange (0.526).
- **D** increases with **C** at nearly identical rates for both colors (0.473 vs. 0.462).
- **D/N** decreases with **C**, with blue data showing a stronger inverse relationship (-0.076 vs. -0.053).
2. **Color Consistency**:
- Orange and blue data points strictly align with their respective trend lines, confirming accurate legend labeling.
3. **Scale Variations**:
- The top-right plot uses a compressed y-axis (100M–1B) to highlight smaller **N** values, while other plots use broader ranges (1B–10B or 100B–1000B).
---
### Interpretation
1. **Variable Relationships**:
- **N** and **D** both scale positively with **C**, but **N** exhibits stronger growth under blue conditions.
- The **D/N** ratio decreases with **C**, suggesting that **D** grows slower relative to **N** as **C** increases. This could indicate a regulatory or compensatory mechanism between the two variables.
2. **Exponent Significance**:
- The higher exponent for **N** in blue data (0.628) implies a nonlinear, accelerating dependency on **C** compared to orange data.
- The negative exponents for **D/N** (-0.053 to -0.076) suggest diminishing returns or saturation effects in the **D/N** system as **C** scales.
3. **Practical Implications**:
- If **C** represents a controllable parameter (e.g., concentration, energy input), optimizing **C** could maximize **N** (especially under blue conditions) while managing **D/N** trade-offs.
- The slight divergence in **D** trends (0.473 vs. 0.462) may reflect minor differences in experimental conditions or measurement noise.
4. **Anomalies**:
- No significant outliers are observed; all data points adhere to their trend lines within expected scatter limits.
---
### Conclusion
The plots demonstrate that **N** and **D** scale differently with **C**, with **N** showing stronger growth and **D/N** exhibiting inverse scaling. The color-coded proportionalities highlight distinct behavioral regimes, likely tied to experimental or systemic differences. These relationships could inform strategies for optimizing **C** to balance **N** and **D** in applications such as resource allocation, chemical synthesis, or ecological modeling.
</details>
## C.4. Scaling laws for different target data type
In Figure 27, we derive the scaling laws for different target data types. In general, we observe that the model learns image captioning faster than interleaved data, as indicated by the higher absolute value of the scaling exponent (e.g., 0.062 vs 0.046), despite using the same data ratio for captioning and interleaved data (45% each). Additionally, we find that the model learns more slowly on textonly data, likely due to the smaller amount of text-only data (10%). Across model configurations, we find that early fusion scales similarly to late fusion on image captioning but has a lower multiplicative constant (49.99 vs 47.97). For MoEs, the model learns faster but exhibits a higher multiplicative constant. On text and interleaved data, early and late fusion models scale similarly and achieve comparable
Figure 23. Observed vs predicted loss. We visualize the loss predicted by our scaling laws (Eq 1) and the actual loss achived by each run.
<details>
<summary>Image 22 Details</summary>
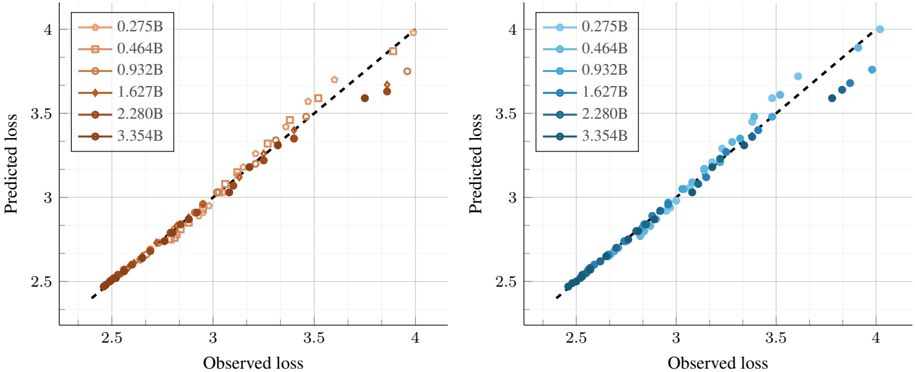
### Visual Description
## Line Chart: Observed vs Predicted Loss for Different Model Sizes
### Overview
The image contains two side-by-side scatter plots comparing **observed loss** (x-axis) and **predicted loss** (y-axis) for six model sizes (0.275B to 3.354B parameters). Each panel uses distinct colors and markers to differentiate model sizes, with a dashed line indicating perfect correlation (y = x).
### Components/Axes
- **X-axis (Observed Loss)**: Ranges from 2.5 to 4.0 in increments of 0.5.
- **Y-axis (Predicted Loss)**: Ranges from 2.5 to 4.0 in increments of 0.5.
- **Legend**: Located in the top-right corner of each panel. Model sizes are color-coded:
- 0.275B: Light orange circles
- 0.464B: Orange squares
- 0.932B: Orange diamonds
- 1.627B: Dark orange circles
- 2.280B: Dark orange squares
- 3.354B: Dark orange diamonds
- **Dashed Line**: Represents the line of perfect prediction (y = x).
### Detailed Analysis
#### Left Panel (Model Sizes 0.275B–2.280B)
- **0.275B (Light Orange Circles)**:
- Data points cluster tightly around the dashed line.
- Example points: (2.5, 2.5), (3.0, 3.0), (3.5, 3.5).
- **0.464B (Orange Squares)**:
- Slightly more spread than 0.275B but still close to the dashed line.
- Example points: (2.6, 2.6), (3.2, 3.2), (3.8, 3.8).
- **0.932B (Orange Diamonds)**:
- Moderate spread; some points deviate slightly above/below the line.
- Example points: (2.7, 2.7), (3.4, 3.4), (3.9, 3.9).
- **1.627B (Dark Orange Circles)**:
- Increased spread; points scatter more widely.
- Example points: (2.8, 2.8), (3.5, 3.5), (4.0, 4.0).
- **2.280B (Dark Orange Squares)**:
- Largest spread among smaller models; points near (3.0, 3.0) to (4.0, 4.0).
#### Right Panel (Model Sizes 0.275B–3.354B)
- **0.275B (Light Blue Circles)**:
- Tight clustering around the dashed line.
- Example points: (2.5, 2.5), (3.0, 3.0), (3.5, 3.5).
- **0.464B (Light Blue Squares)**:
- Slight spread; points near (2.6, 2.6) to (3.8, 3.8).
- **0.932B (Light Blue Diamonds)**:
- Moderate spread; points near (2.7, 2.7) to (3.9, 3.9).
- **1.627B (Dark Blue Circles)**:
- Spread increases; points near (2.8, 2.8) to (4.0, 4.0).
- **2.280B (Dark Blue Squares)**:
- Points near (3.0, 3.0) to (4.0, 4.0).
- **3.354B (Dark Blue Diamonds)**:
- Widest spread; points extend to (4.0, 4.0) with significant deviation.
### Key Observations
1. **Accuracy**: All model sizes show strong correlation with the dashed line, indicating accurate predictions.
2. **Spread**: Larger models (e.g., 3.354B) exhibit greater variance in predictions, with points deviating more from the dashed line.
3. **Consistency**: Smaller models (0.275B–0.932B) demonstrate tighter clustering, suggesting more reliable predictions.
4. **Panel Similarity**: Both panels share identical trends, implying consistent behavior across datasets or experimental conditions.
### Interpretation
The charts demonstrate that model predictions align closely with observed losses, validating their reliability. However, larger models (e.g., 3.354B) show increased prediction variability, which could indicate overfitting or sensitivity to input noise. This trend suggests a trade-off between model size and prediction stability, critical for applications requiring consistent performance. The dashed line serves as a benchmark, emphasizing that deviations grow with model complexity.
</details>
performance. However, MoEs demonstrate better overall performance while learning slightly more slowly.
## C.5. Scaling laws for different training mixtures
We investigate how the scaling laws change when modifying the training mixtures. Specifically, we vary the ratio of image caption, interleaved, and text-only data and report the results in Figure 28. Overall, we observe similar scaling trends, with only minor changes in the scaling coefficients. Upon closer analysis, we find that increasing the ratio of a particular data type in the training mixture, leads to a corresponding increase in its scaling exponent. For instance, increasing the ratio of image captions from 30% to 40% raises the absolute value of the exponent from 0.056 to 0.061. However, for text-only data, we do not observe significant changes in the scaling coefficients when varying its proportion in the training mixture.
Table 10. Scaling laws prediction errors. We report the mean square error, R2 and mean absolute error for the loss prediction for held-in and held-out (8B model) data.
| Parameter | MSE | R2 | MAE (%) |
|-------------|--------|--------|-----------|
| Held-in | 0.0029 | 0.9807 | 0.8608 |
| Held-out | 0.0004 | 0.9682 | 0.553 |
Table 11. Scaling laws sensitivity. We report the mean and standard deviation after bootstrapping with 100 iterations.
| Model | E | α | β | a | b | d |
|---------|---------|---------|---------|---------|---------|---------|
| Avg | 1.80922 | 0.29842 | 0.33209 | 0.54302 | 0.48301 | 0.92375 |
| Std | 0.33811 | 0.10101 | 0.02892 | 0.08813 | 0.05787 | 0.23296 |
## C.6. Scaling laws evaluation
For each model size and number of training tokens, we compute the loss using the estimated functional form in Eq 1 and compare it to the actual loss observed in our runs. Figure 23, Figure 24, and Table 10 visualizes these comparisons, showing that our estimation is highly accurate, particularly for lower loss values and larger FLOPs. We also assess our scaling laws in an extrapolation setting, predicting performance beyond the model sizes used for fitting. Notably, our approach estimates the performance of an 8B model with reasonable accuracy.
Additionally, we conduct a sensitivity analysis using bootstrapping. Specifically, we sample P points with replacement ( P being the total number of trained models) and re-estimate the scaling law coefficients. This process is repeated 100 times, and we report the mean and standard deviation of each coefficient. Table 11 shows that our estimation is more precise for β than for α , primarily due to the smaller number of model sizes relative to the number of different token counts used to derive the scaling laws.
## C.7. Scaling laws for sparse NMMs.
Similar to dense models, we fit a parametric loss function (Eq 1) to predict the loss of sparse NMMs based on the number of parameters and training tokens, replacing the total parameter count with the number of active parameters. While incorporating sparsity is standard when deriving scaling laws for MoEs [2, 33, 74], we focus on deriving scaling laws specific to the sparsity level used in our MoE setup. This yields coefficients that are implicitly conditioned on the sparsity configuration.
We also experiment with a sparsity-aware formulation of the scaling law as proposed in [2], and observe consistent
.
464M
932M
1.63B
2.28B
<details>
<summary>Image 23 Details</summary>
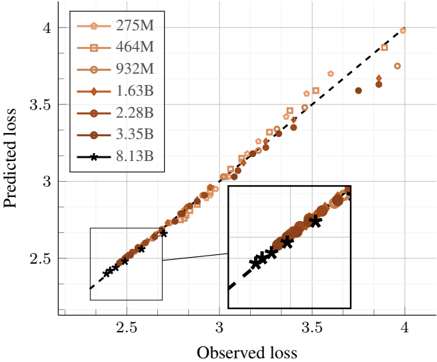
### Visual Description
## Scatter Plot: Model Performance vs. Loss Metrics
### Overview
The image is a scatter plot comparing **observed loss** (x-axis) and **predicted loss** (y-axis) across different model sizes. A dashed line represents the line of perfect prediction (y = x). Data points are grouped by model size, with varying colors and markers. An inset zooms into the lower-left quadrant for detailed analysis.
---
### Components/Axes
- **X-axis (Observed Loss)**: Ranges from 2.5 to 4.0, labeled "Observed loss."
- **Y-axis (Predicted Loss)**: Ranges from 2.5 to 4.0, labeled "Predicted loss."
- **Legend**: Located in the top-left corner, mapping model sizes to colors and markers:
- **275M**: Light orange circles (△)
- **464M**: Light orange squares (■)
- **932M**: Light orange diamonds (◇)
- **1.63B**: Dark orange circles (●)
- **2.28B**: Dark orange squares (■)
- **3.35B**: Dark orange diamonds (◇)
- **8.13B**: Black stars (★)
- **Inset**: A zoomed-in view of the lower-left quadrant (x: 2.5–3.0, y: 2.5–3.0).
---
### Detailed Analysis
1. **Dashed Line**: Represents the ideal scenario where predicted loss equals observed loss. All data points deviate from this line.
2. **Data Trends**:
- **Larger Models (1.63B–8.13B)**: Data points cluster closer to the dashed line, indicating better alignment between observed and predicted losses.
- **Smaller Models (275M–932M)**: Points are more dispersed, showing higher variance in predictions.
- **8.13B Model**: Black stars (★) align most tightly with the dashed line, suggesting optimal performance.
3. **Inset**: Highlights the lower range (2.5–3.0) where smaller models (275M–464M) show a linear trend, while larger models (1.63B–3.35B) exhibit tighter clustering.
---
### Key Observations
- **Model Size Correlation**: Larger models (e.g., 8.13B) demonstrate higher accuracy, with predicted losses tightly matching observed values.
- **Variance in Smaller Models**: Smaller models (e.g., 275M) exhibit significant scatter, indicating less reliable predictions.
- **Inset Insight**: The lower loss range (2.5–3.0) shows improved linearity for smaller models, but larger models still outperform.
---
### Interpretation
The plot suggests a **positive correlation between model size and prediction accuracy**. Larger models (e.g., 8.13B) achieve near-perfect alignment with the dashed line, implying they better capture the underlying patterns in the data. Smaller models, while showing some linear trends in low-loss ranges, struggle with consistency, likely due to limited capacity. The inset reinforces this by isolating the lower-loss region, where even smaller models show modest improvement but remain outperformed by larger counterparts. This highlights the trade-off between computational resources and predictive performance in machine learning systems.
</details>
that techniques for extending context length could be beneficial.
Scaling laws for multimodal MoEs models. For MoEs, we consider only a single configuration (top-1 routing with 8 experts). We found this configuration to work reasonably well in our setup, and follow a standard MoEs implementation. However, the findings may vary when optimizing more the MoE architecture or exploring different load-balancing, routing strategies or different experts implementations.
## E. Mixture of experts and modality-specific specialization
## 3 . 5 E.1. MoEs configuration
Observed loss We experiment with different MoEs configuration by changing the number of experts and the top-k. We report a sample of these experiments in Table 13.
.
Figure 24. Observed vs predicted loss. We visualize the loss predicted by our scaling laws Eq 1 and the actual loss achieved by each run. We can reliably predict the performance of models larger (8B params) than those used to fit the scaling laws.
trends (Table 12). In particular, the exponents associated with model size ( N ) are substantially larger than those for training tokens ( β ), reinforcing the importance of scaling model size in sparse architectures. Additionally, we observe that the terms governing the scaling of active parameters decompose into two components.
## D. Discussion and Limitations
Scaling laws for multimodal data mixtures. Our scaling laws study spans different model configurations and training mixtures. While results suggest that the scaling law coefficients remain largely consistent across mixtures, a broader exploration of mixture variations is needed to validate this observation and establish a unified scaling law that accounts for this factor.
Scaling laws and performance on downstream tasks. Similar to previous scaling law studies, our analysis focuses on pretraining performance as measured by the validation loss. However, the extent to which these findings translate to downstream performance remains an open question and requires further investigation.
Extrapolation to larger scales. The accuracy of scaling law predictions improves with increasing FLOPs Appendix C. Furthermore, we validate our laws when extrapolating to larger model sizes (Appendix C.6). However, whether these laws can be reliably extrapolated to extremely large model sizes remains an open question.
High resolution and early-fusion models. Training earlyfusion models with high-resolution inputs leads to a significant increase in vision tokens. While pooling techniques have been widely adopted for late-fusion models, alternative approaches may be necessary for early fusion. Given the similarity of early-fusion models to LLMs, it appears
## E.2. MoEs specialization
Figure 25. Modality-specific specialization. We visualize the experts specialization to text and image modalities. Models are evaluated on Obelics.
<details>
<summary>Image 24 Details</summary>
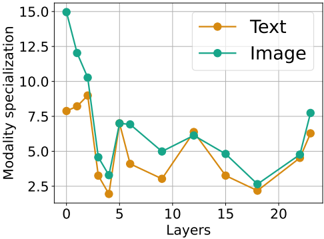
### Visual Description
## Line Graph: Modality Specialization Across Layers
### Overview
The image is a line graph comparing the modality specialization of "Text" and "Image" across 21 layers (0–20). Two lines represent the data: orange for "Text" and teal for "Image." The y-axis measures "Modality specialization" on a scale from 2.5 to 15.0, while the x-axis represents "Layers" from 0 to 20. The legend is positioned in the top-right corner.
### Components/Axes
- **X-axis (Layers)**: Labeled "Layers," with markers at 0, 5, 10, 15, and 20.
- **Y-axis (Modality specialization)**: Labeled "Modality specialization," with increments of 2.5 (2.5, 5.0, 7.5, 10.0, 12.5, 15.0).
- **Legend**: Located in the top-right corner, with orange circles labeled "Text" and teal circles labeled "Image."
- **Data Points**: Circles connected by lines for both series.
### Detailed Analysis
#### Text (Orange Line)
- **Layer 0**: ~7.5
- **Layer 3**: Peaks at ~10.0
- **Layer 4**: Drops to ~2.5
- **Layer 5**: Rises to ~7.5
- **Layer 10**: ~3.0
- **Layer 12**: ~6.5
- **Layer 15**: ~3.0
- **Layer 18**: ~2.5
- **Layer 20**: ~6.0
#### Image (Teal Line)
- **Layer 0**: Peaks at ~15.0
- **Layer 3**: ~10.0
- **Layer 4**: ~5.0
- **Layer 5**: ~7.5
- **Layer 10**: ~5.0
- **Layer 12**: ~6.5
- **Layer 15**: ~5.0
- **Layer 18**: ~3.0
- **Layer 20**: ~7.5
### Key Observations
1. **Initial Disparity**: The "Image" line starts significantly higher (~15.0 at Layer 0) compared to "Text" (~7.5 at Layer 0).
2. **Early Fluctuations**: Both lines show volatility in the first 5 layers, with "Text" experiencing a sharp drop to ~2.5 at Layer 4.
3. **Convergence**: By Layer 20, the two lines converge, with "Text" at ~6.0 and "Image" at ~7.5.
4. **Trend Reversal**: "Text" shows a general decline after Layer 3, while "Image" declines more gradually.
### Interpretation
The data suggests that "Image" modality specialization dominates in early layers (e.g., Layer 0–5), potentially reflecting a focus on visual processing in initial neural network stages. "Text" specialization lags initially but shows recovery in later layers (e.g., Layer 12–20), indicating possible compensatory mechanisms or increased textual processing in deeper layers. The fluctuations may highlight variability in how modalities are prioritized across layers, with "Text" exhibiting sharper declines in early stages. This could imply architectural differences in how text and image data are hierarchically processed.
</details>
We investigate multimodal specialization in MoE architectures. We compute a specialization score as the average difference between the number of text/images tokens assigned to each expert and a uniform assignment ( 1 /E ). Additionally, we visualize the normalized number of text and image tokens assigned to each expert across layers. Figure 25 shows clear modality-specific experts, particularly in the early layers. Furthermore, the specialization score decreases as the number of layers increases but rises again in the very last layers. This suggests that early and final layers require more modality specialization compared to midlayers. Additionally, we observe several experts shared between text and image modalities, a phenomenon not present in hard-routed or predefined modality-specific experts.
| L ( N,D ) = E + A N α + B D β | L ( N,D ) = E + A N α + B D β | L ( N,D ) = E + A N α + B D β | vs | vs | L ( N,D,S ) = A N α + B D β + C (1 - S ) λ + d (1 - S ) δ N γ + E | L ( N,D,S ) = A N α + B D β + C (1 - S ) λ + d (1 - S ) δ N γ + E | L ( N,D,S ) = A N α + B D β + C (1 - S ) λ + d (1 - S ) δ N γ + E | L ( N,D,S ) = A N α + B D β + C (1 - S ) λ + d (1 - S ) δ N γ + E | L ( N,D,S ) = A N α + B D β + C (1 - S ) λ + d (1 - S ) δ N γ + E | L ( N,D,S ) = A N α + B D β + C (1 - S ) λ + d (1 - S ) δ N γ + E |
|---------------------------------|---------------------------------|---------------------------------|------|--------|---------------------------------------------------------------------|---------------------------------------------------------------------|---------------------------------------------------------------------|---------------------------------------------------------------------|---------------------------------------------------------------------|---------------------------------------------------------------------|
| Model | E | A | B | α | β | λ | δ | γ | C | d |
| L ( N,D ) (Eq 1) | 2.158 | 381773 | 4659 | 0.710 | 0.372 | - | - | - | - | - |
| L ( N,D,S ) [2] | 1.0788 | 1 | 4660 | 0.5890 | 0.3720 | 0.2 | 0.2 | 0.70956 | 1.0788 | 381475 |
Table 12. Scaling laws for sparse native multimodal models .
Table 13. SFT results with different MoEs configurations. .
| | Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | Accuracy | CIDEr | CIDEr |
|-----------------------|------------|------------|------------|------------|------------|------------|---------|----------|
| | AVG | VQAv2 | TextVQA | OKVQA | GQA | VizWiz | COCO | TextCaps |
| 4-E-top-1 | 40.0552 | 64.068 | 14.284 | 41.948 | 61.46 | 18.516 | 62.201 | 34.08 |
| 8-E-top-1 | 41.6934 | 65.684 | 17.55 | 42.908 | 63.26 | 19.065 | 67.877 | 39.63 |
| 8-E-top-2 | 42.8546 | 66.466 | 19.162 | 45.344 | 63.94 | 19.361 | 65.988 | 41.649 |
| 8-E-top-2 finegrained | 39.904 | 62.76 | 15.58 | 41.88 | 61.6 | 17.7 | 57.52 | 35.42 |
Figure 26. Scaling laws for native multimodal models. From left to right: late-fusion (dense), early-fusion (dense) and early-fusion MoEs. The scaling exponents are very close for all models. However, MoEs leads to overall lower loss (smaller multiplicative constant) and takes longer to saturate.
<details>
<summary>Image 25 Details</summary>
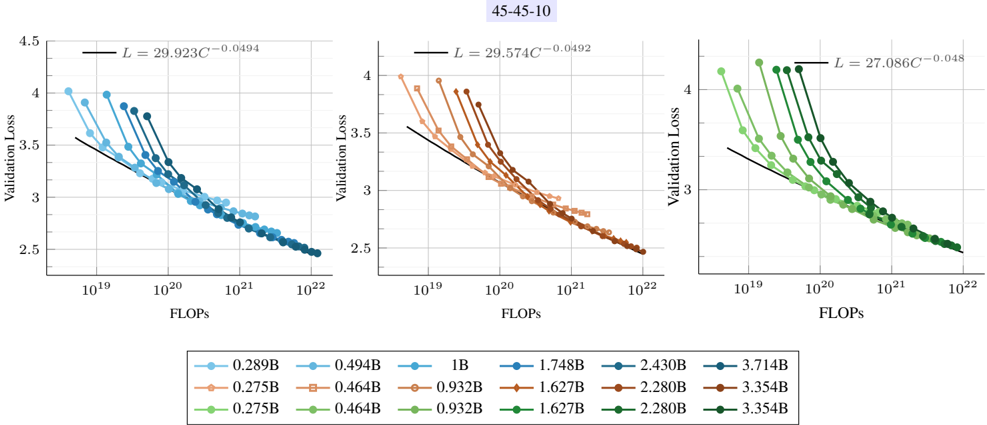
### Visual Description
## Line Graphs: Validation Loss vs FLOPs (45-45-10)
### Overview
Three side-by-side line graphs compare validation loss against computational resources (FLOPs) for different model sizes. Each graph shows a logarithmic relationship between FLOPs and validation loss, with distinct color-coded data series and fitted curves.
### Components/Axes
- **X-axis (FLOPs)**: Logarithmic scale from 10¹⁹ to 10²².
- **Y-axis (Validation Loss)**: Linear scale from 2.5 to 4.5.
- **Legends**:
- **Left Graph**: Blue (0.289B, 0.494B, 1B), Orange (0.275B, 0.464B, 0.932B), Green (0.275B, 0.464B, 0.932B).
- **Middle Graph**: Blue (1B, 1.748B, 2.430B), Orange (0.932B, 1.627B, 2.280B), Green (0.932B, 1.627B, 2.280B).
- **Right Graph**: Blue (2.430B, 3.714B), Orange (3.354B), Green (2.280B, 3.354B).
- **Fitted Curves**: Black lines with equations (e.g., `L = 29.923C⁻⁰.⁰⁴⁹⁴` for the left graph).
### Detailed Analysis
1. **Left Graph (45-45-10)**:
- **Blue Lines**: Slope downward steeply, with validation loss decreasing from ~4.0 to ~2.5 as FLOPs increase from 10¹⁹ to 10²².
- **Orange Lines**: Similar trend but slightly higher validation loss at equivalent FLOPs.
- **Green Lines**: Overlap with orange lines, suggesting identical performance for these sizes.
2. **Middle Graph (45-45-10)**:
- **Blue Lines**: Validation loss decreases from ~4.0 to ~2.5, with steeper slopes than the left graph.
- **Orange Lines**: Start at higher loss (~4.0) and decline more gradually.
- **Green Lines**: Overlap with orange lines, indicating similar performance.
3. **Right Graph (45-45-10)**:
- **Blue Lines**: Validation loss drops from ~4.0 to ~2.5, with the steepest slopes.
- **Green Lines**: Start at ~4.0 and decline sharply, overlapping with blue lines at higher FLOPs.
### Key Observations
- **Consistent Trend**: All graphs show validation loss decreasing as FLOPs increase, confirming the inverse relationship.
- **Logarithmic Fit**: Equations (e.g., `L = 29.923C⁻⁰.⁰⁴⁹⁴`) indicate diminishing returns at higher FLOPs.
- **Color Consistency**: Legend colors match line colors across graphs (e.g., blue = 0.289B in left, 1B in middle, 2.430B in right).
- **Overlapping Lines**: Some sizes (e.g., 0.932B and 1.627B) show identical performance in certain graphs.
### Interpretation
The data demonstrates that larger models (higher FLOPs) achieve lower validation loss, but with diminishing returns. The logarithmic fits suggest that computational efficiency plateaus beyond a certain threshold. Overlapping lines in some graphs imply that specific model sizes yield comparable performance, highlighting potential redundancy in resource allocation. The consistent trend across all graphs underscores the universal trade-off between computational cost and model accuracy.
</details>
Figure 27. Scaling laws for native multimodal models. From top to bottom: late-fusion (dense), early-fusion (dense) and early-fusion MoEs. From left to right: cross-entropy on the validation set of image-caption, interleaved and text-only data.
<details>
<summary>Image 26 Details</summary>
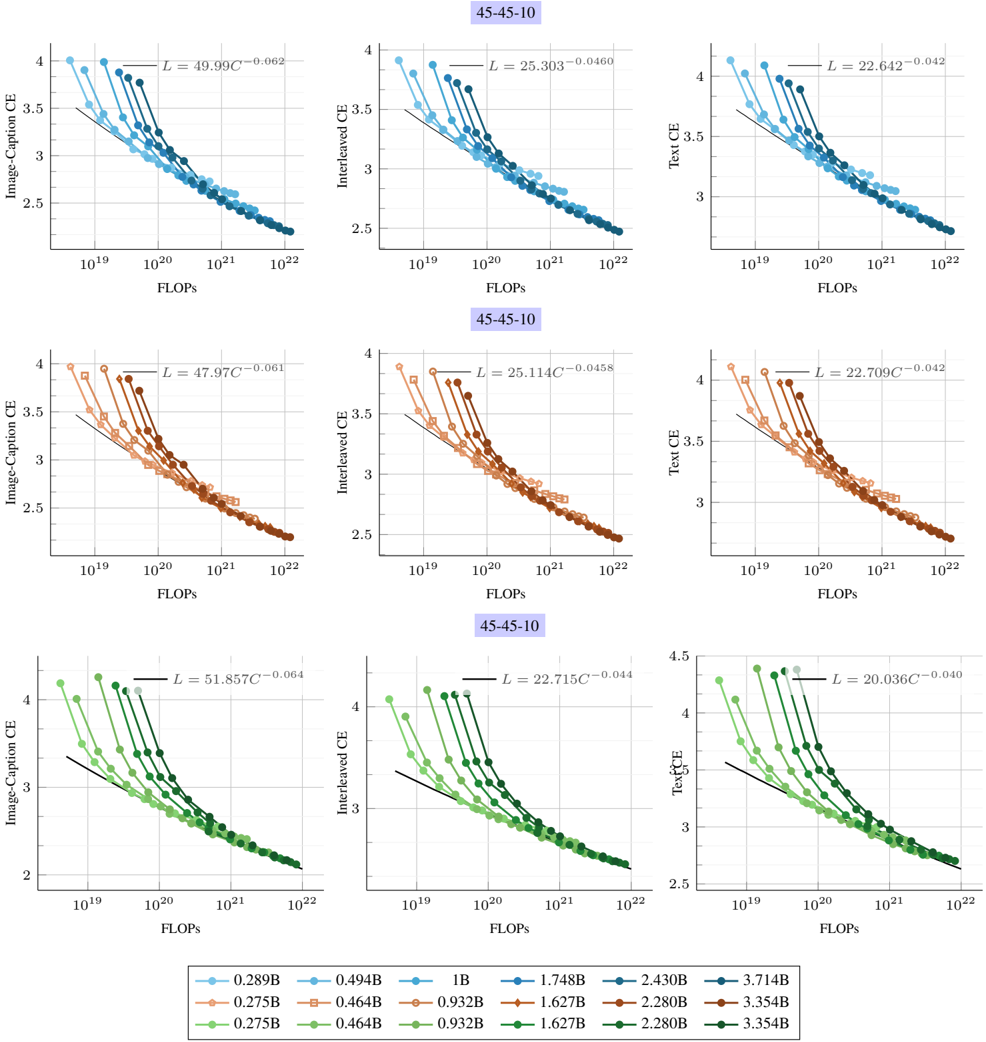
### Visual Description
## Line Graphs: Computational Efficiency (CE) vs. FLOPs Across Model Sizes and Datasets
### Overview
The image contains nine line graphs comparing computational efficiency (CE) metrics across three categories: **Image-Caption CE**, **Interleaved CE**, and **Text CE**. Each graph plots CE against FLOPs (floating-point operations) on a logarithmic scale (10¹⁹ to 10²²). Three datasets are analyzed: **45-45-10**, **45-45-10**, and **45-45-10** (repeated labels suggest a possible typo or repetition in the original image). The graphs use color-coded lines to represent different model sizes (0.275B, 0.464B, 0.932B, 1.627B, 2.280B, 3.354B) and an "IB" baseline. Power-law equations (e.g., *L = a·Cᵇ*) describe the relationship between FLOPs and CE.
---
### Components/Axes
- **X-axis**: FLOPs (logarithmic scale: 10¹⁹ to 10²²)
- **Y-axis**: Computational Efficiency (CE) (linear scale: 2.5 to 4.5)
- **Legends**:
- **Colors**:
- Blue: 0.289B, 0.494B, 1B
- Orange: 0.275B, 0.464B, 0.932B
- Green: 1.627B, 2.280B, 3.354B
- Gray: IB (baseline)
- **Equations**: Power-law relationships (e.g., *L = 49.99C⁻⁰·⁰⁶²*)
---
### Detailed Analysis
#### Image-Caption CE (Top Row)
1. **45-45-10 Dataset**:
- **Blue (0.289B)**: *L = 49.99C⁻⁰·⁰⁶²* (CE decreases slowly with FLOPs).
- **Orange (0.275B)**: *L = 47.97C⁻⁰·⁰⁶¹* (similar trend to 0.289B).
- **Green (1.627B)**: *L = 25.11C⁻⁰·⁰⁴⁸* (steeper decline).
- **Gray (IB)**: *L = 22.64C⁻⁰·⁰⁴²* (lowest CE across FLOPs).
2. **45-45-10 Dataset**:
- **Blue (0.494B)**: *L = 51.85C⁻⁰·⁰⁶⁴* (moderate decline).
- **Orange (0.932B)**: *L = 22.71C⁻⁰·⁰⁴⁴* (steeper than smaller models).
- **Green (2.280B)**: *L = 20.03C⁻⁰·⁰⁴⁰* (most efficient at high FLOPs).
3. **45-45-10 Dataset**:
- **Blue (1B)**: *L = 49.99C⁻⁰·⁰⁶²* (matches 0.289B trend).
- **Orange (2.280B)**: *L = 22.71C⁻⁰·⁰⁴⁴* (consistent with smaller 2.280B).
- **Green (3.354B)**: *L = 20.03C⁻⁰·⁰⁴⁰* (most efficient).
#### Interleaved CE (Middle Row)
- Trends mirror Image-Caption CE, with larger models (e.g., 3.354B) showing steeper declines. For example:
- **3.354B**: *L = 20.03C⁻⁰·⁰⁴⁰* (CE drops sharply with FLOPs).
- **IB**: *L = 22.64C⁻⁰·⁰⁴²* (baseline remains relatively flat).
#### Text CE (Bottom Row)
- Similar patterns: Larger models (e.g., 3.354B) exhibit steeper slopes. For instance:
- **3.354B**: *L = 20.03C⁻⁰·⁰⁴⁰* (CE decreases rapidly).
- **IB**: *L = 22.64C⁻⁰·⁰⁴²* (consistent baseline).
---
### Key Observations
1. **Power-Law Relationships**: All lines follow *L = a·Cᵇ*, where *b* is negative (CE decreases as FLOPs increase).
2. **Model Size Impact**:
- Larger models (e.g., 3.354B) have steeper slopes (*b* closer to -0.04), indicating higher sensitivity to FLOPs.
- Smaller models (e.g., 0.275B) have shallower slopes (*b* closer to -0.06), showing slower CE decline.
3. **IB Baseline**: The "IB" line (gray) consistently shows the lowest CE across all FLOPs, suggesting it represents a less efficient baseline.
4. **Dataset Repetition**: The repeated "45-45-10" labels may indicate a mislabeling or intentional focus on this configuration.
---
### Interpretation
- **Diminishing Returns**: As FLOPs increase, CE improves but at a diminishing rate, consistent with power-law scaling.
- **Model Efficiency**: Larger models achieve higher CE at higher FLOPs but require exponentially more resources to maintain efficiency.
- **Baseline Comparison**: The "IB" line suggests a reference point for evaluating model performance, possibly representing an ideal or standard.
- **Practical Implications**: Optimizing FLOPs is critical for larger models, as their efficiency drops sharply with increased computational load. Smaller models may be more resource-efficient for lower-scale tasks.
---
### Spatial Grounding & Cross-Reference
- **Legend Position**: Bottom of the image, aligned with all graphs.
- **Color Consistency**:
- Blue lines (0.289B, 0.494B, 1B) match across all graphs.
- Orange lines (0.275B, 0.464B, 0.932B) are consistent.
- Green lines (1.627B, 2.280B, 3.354B) align with larger models.
- **Axis Labels**: All graphs share identical axes, ensuring comparability.
---
### Content Details
- **Equations**: Extracted from annotations (e.g., *L = 49.99C⁻⁰·⁰⁶²*).
- **Trends**: All lines slope downward, confirming inverse relationships between FLOPs and CE.
- **Outliers**: No significant outliers; all data points follow expected power-law patterns.
---
### Summary
The graphs demonstrate that computational efficiency (CE) decreases as FLOPs increase, with larger models exhibiting steeper declines. The power-law equations quantify these relationships, highlighting the trade-off between computational resources and efficiency. The "IB" baseline provides a reference for evaluating model performance, while repeated dataset labels suggest a focus on specific configurations.
</details>
Figure 28. Scaling laws for early-fusion native multimodal models. Our runs across different training mixtures (Image-captionInterleaved-Text) and FLOPs. We visulize the final validation loss on 3 data types: HQITP (left), Obelics (middle) and DCLM (right).
<details>
<summary>Image 27 Details</summary>
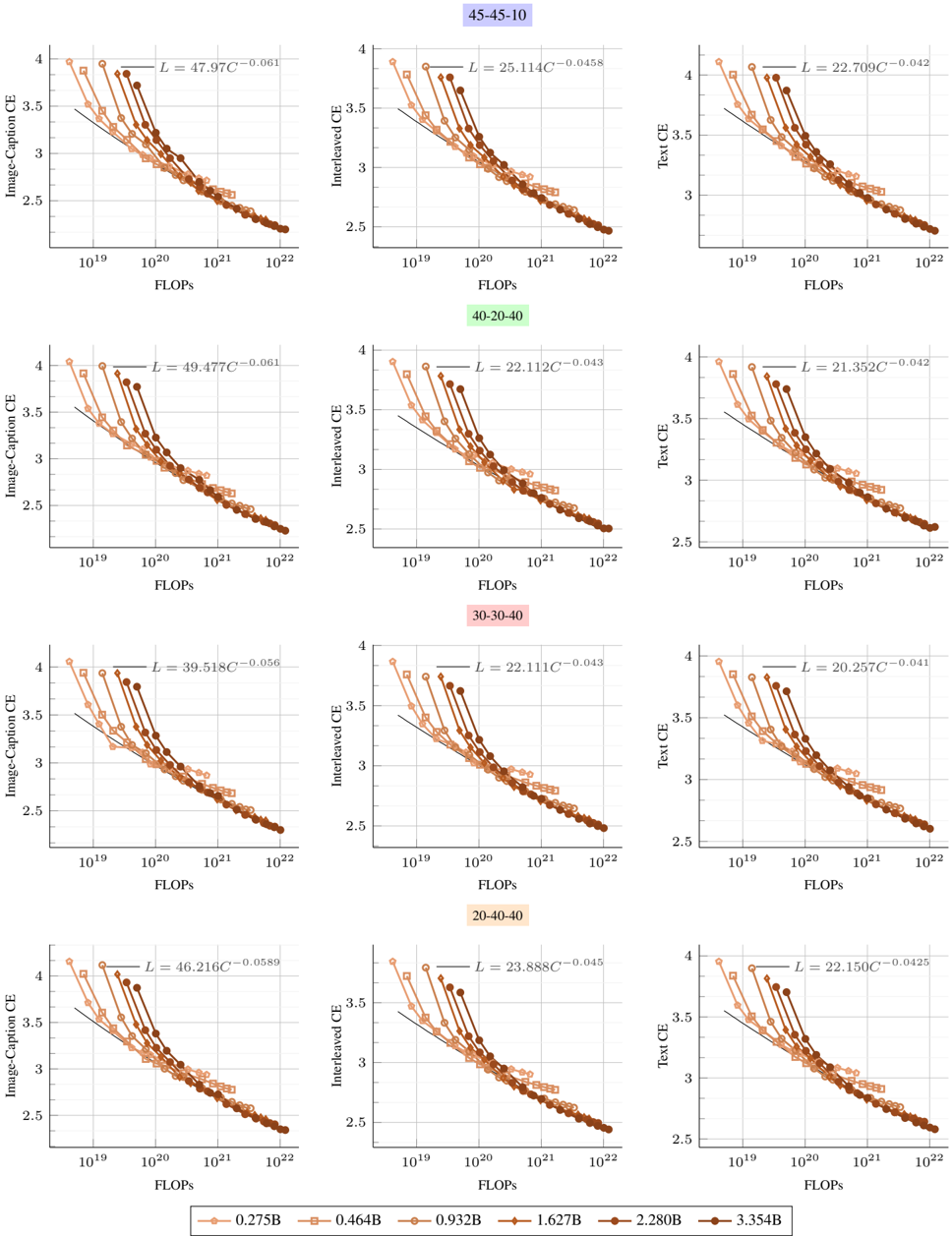
### Visual Description
## Line Graphs: Computational Efficiency Metrics Across Model Configurations
### Overview
The image contains 12 line graphs arranged in a 4x3 grid, comparing computational efficiency metrics (CE) across different model sizes and configurations. Each row represents a distinct metric (Image-Caption CE, Interleave CE, Text CE), while columns show variations in model architecture or training parameters. All graphs plot CE against FLOPs (floating-point operations) on a logarithmic scale, with downward-trending lines indicating inverse relationships.
### Components/Axes
- **X-axis**: "FLOPs" (logarithmic scale: 10¹⁹ to 10²²)
- **Y-axis**:
- Top row: "Image-Caption CE"
- Middle row: "Interleave CE"
- Bottom row: "Text CE"
- **Legends**:
- Positioned at the bottom of each graph
- Colors correspond to model sizes (0.275B to 3.354B) and configurations (e.g., "45-45-10", "20-40-40")
- Example: Darkest red = 3.354B, lightest orange = 0.275B
### Detailed Analysis
1. **Image-Caption CE** (Top Row)
- **45-45-10**: L = 47.97C⁻⁰.⁰⁶¹ (dark red line)
- **40-20-40**: L = 49.477C⁻⁰.⁰⁶¹ (medium red)
- **30-30-40**: L = 39.518C⁻⁰.⁰⁵⁶ (light red)
- **20-40-40**: L = 46.216C⁻⁰.⁰⁵⁸⁹ (orange)
- All lines show steep declines, with larger models (3.354B) having the lowest CE at high FLOPs.
2. **Interleave CE** (Middle Row)
- **45-45-10**: L = 25.114C⁻⁰.⁰⁴⁵⁸ (dark red)
- **40-20-40**: L = 22.112C⁻⁰.⁰⁴³ (medium red)
- **30-30-40**: L = 21.352C⁻⁰.⁰⁴² (light red)
- **20-40-40**: L = 23.888C⁻⁰.⁰⁴⁵ (orange)
- Similar trends to Image-Caption CE, but with shallower slopes.
3. **Text CE** (Bottom Row)
- **45-45-10**: L = 22.150C⁻⁰.⁰⁴²⁵ (dark red)
- **40-20-40**: L = 20.257C⁻⁰.⁰⁴¹ (medium red)
- **30-30-40**: L = 21.352C⁻⁰.⁰⁴² (light red)
- **20-40-40**: L = 22.150C⁻⁰.⁰⁴²⁵ (orange)
- Text CE shows the least variability across configurations.
### Key Observations
- **Inverse Relationship**: All metrics show CE decreasing as FLOPs increase, with larger models (higher B values) having steeper declines.
- **Configuration Impact**:
- "45-45-10" configurations consistently show the highest CE across metrics.
- "20-40-40" configurations exhibit the lowest CE in Image-Caption and Interleave CE.
- **Error Bars**: Vertical error bars indicate measurement variability, with larger models showing wider spreads.
- **Exponential Decay**: Equations in legends confirm power-law relationships (e.g., C⁻⁰.⁰⁶¹), suggesting diminishing returns.
### Interpretation
The data demonstrates that computational efficiency degrades with increased FLOPs, particularly for larger models. This suggests architectural inefficiencies in scaling, where larger models require disproportionately more resources for marginal gains. The "45-45-10" configuration outperforms others across all metrics, implying optimal parameterization for efficiency. The Text CE metric's relative stability indicates text processing may be less sensitive to scaling challenges compared to image-caption or interleave tasks. These findings highlight trade-offs in model design: larger models achieve higher accuracy but at the cost of computational efficiency, necessitating careful optimization for deployment scenarios with resource constraints.
</details>