# Counterfactual Fairness Evaluation of Machine Learning Models on Educational Datasets
**Authors**: Woojin Kim, Hyeoncheol Kim
institutetext: Department of Computer Science and Engineering, Korea University, South Korea email: {woojinkim1021, harrykim}@korea.ac.kr
Abstract
As machine learning models are increasingly used in educational settings, from detecting at-risk students to predicting student performance, algorithmic bias and its potential impacts on students raise critical concerns about algorithmic fairness. Although group fairness is widely explored in education, works on individual fairness in a causal context are understudied, especially on counterfactual fairness. This paper explores the notion of counterfactual fairness for educational data by conducting counterfactual fairness analysis of machine learning models on benchmark educational datasets. We demonstrate that counterfactual fairness provides meaningful insight into the causality of sensitive attributes and causal-based individual fairness in education.
Keywords: Counterfactual Fairness Education Machine Learning.
1 Introduction
Machine learning models are increasingly implemented in educational settings to support automated decision-making processes. Such applications ranges from academic success prediction [33, 50], at-risk detection [25], automated grading [42], knowledge tracing [38] and personalized recommendation [53]. However, the application of machine learning models to automate decision-making in high-stakes scenarios calls for consideration of algorithmic bias [1]. In education, predictive models have been shown to exhibit lower performance for students from underrepresented demographic groups [40, 3, 6, 21, 34].
The majority of research on fairness in education focuses on group fairness [40, 21], while works on individual fairness are limited to aiming for similar treatment of similar individuals [20, 10]. Under context where students’ demographics causally shape their education [45, 11, 27], taking causality in consideration of fairness is crucial. Causal fairness asserts that it is unfair to produce different decisions for individuals caused by factors beyond their control [28]. In this sense, algorithmic decisions that impact students should eliminate the causal effects of uncontrollable variables, such as race, gender, and disability.
Group and individual fairness definitions have certain limitations, and the inherent incompatibility between group and individual fairness presents challenges [2, 31, 52, 48]. Group fairness can mask heterogeneous outcomes of individuals by using group-wise averaging measurements [2, 31]. While group fairness may be achieved, it does not ensure fairness for each individual [52]. Furthermore, ignoring individual fairness in favor of group fairness can result in algorithms making different decisions for identical individuals [29]. Individual fairness faces difficulty in selecting distance metrics for measuring the similarity of individuals and is easily affected by outlier samples [49].
Based on the limitations of group and individual fairness notions, we empirically investigate the potential of counterfactual fairness on educational datasets. Counterfactual fairness ensures that the algorithm’s decision would have remained the same when the individual belongs to a different demographic group, other things being equal [23]. Counterfactual fairness promotes individual-level fairness by removing the causal influence of sensitive attributes on the algorithm’s decisions. To the best of our current knowledge, the notion of counterfactual fairness has not been investigated in the educational domain.
In this paper, we aim to answer the following research questions(RQ):
1. What causal relationships do sensitive attributes have in educational data?
1. Does counterfactual fairness in educational data lead to identical outcomes for individual students regardless of demographic group membership?
1. Does counterfactually fair machine learning models result in a performance trade-off in educational data?
These questions are investigated by estimating a causal model and implementing a counterfactual fairness approach on real-world educational datasets. Section 2 introduces counterfactual fairness and algorithmic fairness in education. In Section 3, we provide methodologies for creating causal models and counterfactual fairness evaluation metrics. We present the experiment result in Section 4. In Section 5, we discuss the key findings of our study, exploring their implications for fairness in educational data before concluding in Section 6.
2 Background
2.1 Causal Model and Counterfactuals
Counterfactual fairness adopts the Structural Causal Model(SCM) framework [35] for the calculation of counterfactual samples. SCM is defined as a triplet $(U,V,F)$ where $U$ is a set of unobserved variables, $V$ is a set of observed variables, and $F$ is a set of structural equations describing how observable variables are determined. Given a SCM, counterfactual inference is to determine $P(Y_{Z← z}(U)|W=w)$ , which indicates the probability of $Y$ if $Z$ is set to $z$ (i.e. counterfactuals), given that we observed $W=w$ . Imagine a female student with a specific academic record. What would be the probability of her passing the course if her gender were male while keeping all other observed academic factors constant? Counterfactual inference on SCM allows us to calculate answers to counterfactual queries by abduction, action, and prediction inference steps detailed in [35].
2.2 Counterfactual Fairness
We follow the definition of counterfactual fairness by Kusner et al. [23].
**Definition 1 (Counterfactual Fairness)**
*Predictor $\hat{Y}$ is counterfactually fair if under any context $X=x$ and $A=a$ ,
$$
P(\hat{Y}_{A\leftarrow a}(U)=y|X=x,A=a)=P(\hat{Y}_{A\leftarrow a^{\prime}}(U)=%
y|X=x,A=a),
$$
for all y and for any value a’ attainable by A.*
The definition states that changing $A$ should not change the distribution of the predicted outcome $\hat{Y}$ . An algorithm is counterfactually fair towards an individual if an intervention in demographic group membership does not change the prediction. For instance, the predicted probability of a female student passing a course should remain the same as if the student had been a male.
Implementing counterfactual fairness requires a causal model of the real world and the counterfactual inference of samples under the causal model. This process allows for isolating the causal influence of the sensitive attribute on the outcome.
Counterfactual fairness is explored in diverse domains, such as in clinical decision support [47] and clinical risk prediction [36, 44] for healthcare, ranking algorithm [37], image classification [9, 22] and text classification [16].
2.3 Algorithmic Fairness in Education
Most works on algorithmic fairness in education focus on group fairness [40, 21]. The group fairness definition states that an algorithm is fair if its prediction performance is equal among subgroups, specifically requiring equivalent prediction ratios for favorable outcomes. Common definitions of group fairness are Equalized Odds [17], Demographic Parity [14] and Equal Opportunity [17].
Individual fairness requires individuals with similar characteristics to receive similar treatment. Research on individual fairness in education focuses on the similarity. Marras et al. [32] proposed a consistency metric for measuring the similarity of students’ past interactions for individual fairness under a personalized recommendation setting. Hu and Rangwala [20] developed a model architecture for individual fairness in at-risk student prediction task. Doewes et al. [12] proposed a methodology to evaluate individual fairness in automated essay scoring. Deho et al. [10] performed individual fairness evaluation of existing fairness mitigation methods in learning analytics.
There have been attempts to understand causal factors influencing academic success. Ferreira de Carvalho et al. [4] identifies causal relationships between LMS logs and student’s grades. Zhao et al. [51] propose Residual Counterfactual Networks to estimate the causal effect of an academic counterfactual intervention for personalized learning. To the best of our knowledge, the notion of algorithmic fairness under causal context, especially under counterfactual inference in the educational domain remains unexplored.
Table 1: Feature descriptions of Law School and OULAD datasets. Student Performance dataset descriptions are provided in Table 6 of Appendix A.
| Data | Feature | Type | Description |
| --- | --- | --- | --- |
| Law | gender | binary | the student’s gender |
| race | binary | the student’s race | |
| lsat | numerical | the student’s LSAT score | |
| ugpa | numerical | the student’s undergraduate GPA | |
| zfygpa | numerical | the student’s law school first year GPA | |
| OULAD | gender | binary | the student’s gender |
| disability | binary | whether the student has declared a disability | |
| education | categorical | the student’s highest education level | |
| IMD | categorical | the Index of Multiple Deprivation(IMD) of the student’s residence | |
| age | categorical | band of the student’s age | |
| studied credits | numerical | the student’s total credit of enrolled modules | |
| final result | binary | the student’s final result of the module | |
Table 2: Summary of datasets used for the experiment.
| Data | Task | Sensitive Attribute | Target | # Instances |
| --- | --- | --- | --- | --- |
| Law School | Regression | race, gender | zfygpa | 20,798 |
| OULAD | Classification | disability | final result | 32,593 |
| Student Performance(Mat) | Regression | gender | G3 | 395 |
| Student Performance(Por) | Regression | gender | G3 | 649 |
3 Methodology
We provide detailed description of experiment methodology for evaluating counterfactual fairness of machine learning models in education.
3.1 Educational Datasets
We use publicly available benchmark educational datasets for fairness presented in [26], which introduces four educational benchmark datasets for algorithmic fairness. Datasets are Law School github.com/mkusner/counterfactual-fairness [46], Open University Learning Analytics Dataset (OULAD) https://archive.ics.uci.edu/dataset/349/open+university+learning+analytics+dataset [24] and Student Performance in Mathematics and Portuguese language https://archive.ics.uci.edu/dataset/320/student+performance [8]. Refer to Table 1 and Table 6 for description of dataset features used in the experiment. The summary of tasks and selection of sensitive attributes are outlined in Table 2.
<details>
<summary>extracted/6375259/figures/freq_law.png Details</summary>
### Visual Description
\n
## Bar Chart: Racial Distribution
### Overview
The image presents a bar chart illustrating the distribution of two racial groups: White and Black. The chart uses vertical bars to represent the percentage of each group.
### Components/Axes
* **X-axis:** Represents the racial groups: "White" and "Black".
* **Y-axis:** Represents the percentage, with values ranging from 0% to approximately 100%. The scale is not explicitly marked, but can be inferred from the data labels.
* **Bars:** Two vertical bars, one blue representing "White" and one orange representing "Black".
* **Data Labels:** Percentage values are displayed above each bar.
### Detailed Analysis
* **White:** The blue bar for "White" extends to approximately 93.8%. The bar is significantly taller than the "Black" bar.
* **Black:** The orange bar for "Black" extends to approximately 6.2%. This bar is much shorter than the "White" bar.
### Key Observations
The chart demonstrates a significant disparity in the distribution of the two racial groups. The "White" group constitutes the vast majority (93.8%), while the "Black" group represents a small minority (6.2%).
### Interpretation
The data suggests a highly imbalanced racial composition within the population being represented. The large difference in percentages indicates a strong dominance of the "White" group and a limited representation of the "Black" group. This could be indicative of various socio-demographic factors, such as historical trends, migration patterns, or systemic inequalities. Without further context, it is difficult to determine the specific reasons for this distribution. The chart presents a factual representation of the racial distribution, but does not offer any explanation for the observed pattern.
</details>
(a) Law School
<details>
<summary>extracted/6375259/figures/freq_oulad.png Details</summary>
### Visual Description
\n
## Bar Chart: Percentage of Individuals by Disability Status
### Overview
This image presents a bar chart comparing the percentage of individuals categorized as "Non-Disabled" versus "Disabled". The chart uses vertical bars to represent the percentages, with labels indicating the disability status on the horizontal axis and percentage values displayed above each bar.
### Components/Axes
* **X-axis:** Represents disability status with two categories: "Non-Disabled" and "Disabled".
* **Y-axis:** Represents percentage, though it is not explicitly labeled with numerical values. The scale is implied by the percentage values displayed on the bars.
* **Bars:** Two vertical bars, one blue representing "Non-Disabled" and one orange representing "Disabled".
* **Data Labels:** Percentage values are displayed above each bar.
### Detailed Analysis
* **Non-Disabled Bar (Blue):** The bar reaches a height corresponding to 91.3%. The bar is positioned on the left side of the chart.
* **Disabled Bar (Orange):** The bar reaches a height corresponding to 8.7%. The bar is positioned on the right side of the chart.
* The blue bar is significantly taller than the orange bar, visually indicating a much larger percentage of non-disabled individuals.
### Key Observations
The chart clearly demonstrates a substantial difference in percentage between the "Non-Disabled" and "Disabled" categories. The vast majority of individuals fall into the "Non-Disabled" category.
### Interpretation
The data suggests that the population represented in this chart is overwhelmingly composed of individuals who do not identify as disabled. The 91.3% figure for non-disabled individuals and the 8.7% for disabled individuals indicate a significant disparity. This could be representative of a specific population sample, or a broader demographic trend. Without further context, it's difficult to determine the implications of this distribution. The chart is a simple, direct comparison, and doesn't offer any insight into *why* this disparity exists. It simply *shows* that it does.
</details>
(b) OULAD
<details>
<summary>extracted/6375259/figures/freq_mat.png Details</summary>
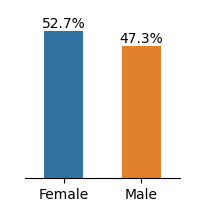
### Visual Description
\n
## Bar Chart: Gender Distribution
### Overview
This image presents a bar chart illustrating the distribution of gender within a population or sample. The chart compares the percentage of females to the percentage of males.
### Components/Axes
* **X-axis:** Represents gender categories: "Female" and "Male".
* **Y-axis:** Represents percentage, with values ranging from approximately 0% to 60%. The scale is not explicitly labeled, but can be inferred.
* **Bars:** Two vertical bars, one blue representing "Female" and one orange representing "Male".
* **Data Labels:** Percentage values are displayed above each bar.
### Detailed Analysis
* **Female:** The blue bar representing females has a height corresponding to 52.7%.
* **Male:** The orange bar representing males has a height corresponding to 47.3%.
* The bars are positioned side-by-side, allowing for direct comparison of the percentages.
### Key Observations
* The percentage of females (52.7%) is slightly higher than the percentage of males (47.3%).
* The difference between the two percentages is approximately 5.4% (52.7 - 47.3 = 5.4).
### Interpretation
The data suggests a slight female bias in the represented population or sample. The difference of 5.4% indicates that females are marginally more represented than males. This could be due to various factors depending on the context of the data collection. Without further information, it is difficult to determine the significance of this difference. The chart provides a clear and concise visual representation of the gender distribution, making it easy to compare the proportions of each gender.
</details>
(c) Mat
<details>
<summary>extracted/6375259/figures/freq_por.png Details</summary>
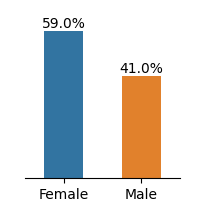
### Visual Description
\n
## Bar Chart: Gender Distribution
### Overview
This image presents a bar chart illustrating the distribution of gender within a dataset. The chart compares the percentage representation of females and males.
### Components/Axes
* **X-axis:** Represents gender categories: "Female" and "Male".
* **Y-axis:** Represents percentage, with a scale ranging from approximately 0% to 60%. The scale is not explicitly labeled with numerical markers, but can be inferred from the data points.
* **Bars:** Two vertical bars represent the percentage for each gender.
* Blue bar: Represents "Female".
* Orange bar: Represents "Male".
### Detailed Analysis
* **Female:** The blue bar reaches approximately 59.0%. The bar is positioned above the "Female" label on the x-axis.
* **Male:** The orange bar reaches approximately 41.0%. The bar is positioned above the "Male" label on the x-axis.
### Key Observations
The chart shows a clear difference in the percentage representation of females and males. Females are more prevalent in the dataset, representing approximately 59.0% of the total, while males represent approximately 41.0%.
### Interpretation
The data suggests that the dataset is skewed towards female representation. This could indicate a variety of factors depending on the context of the data. For example, if this data represents users of a specific product, it might suggest that the product is more popular among females. Alternatively, if this data represents participants in a study, it might indicate a bias in the recruitment process. The difference of approximately 18% between the two genders is notable and warrants further investigation to understand the underlying reasons for this distribution.
</details>
(d) Por
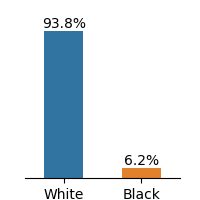
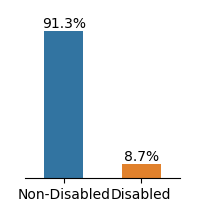
Figure 1: Frequency distributions of sensitive attributes in educational datasets.
The Law School dataset contains admission records of students at 163 U.S. law schools [46]. The dataset has demographic information of 20,798 students on race, gender, LSAT scores, and undergraduate GPA. We select gender and race as sensitive attributes and first-year GPA as the target for the regression task.
The OULAD dataset, originating from a 2013-2014 Open University study in England, compiles student data and their interactions within a virtual learning environment across seven courses. We select disability as the sensitive attribute and final result as the classification target. The gender is not considered as our sensitive attribute because the preceding study [18] revealed that gender attribute does not have a causal relationship to student’s final result. For this work, we only considered the module BBB(Social Science).
The Student Performance dataset describes students’ achievements in Mathematics and Portuguese language subjects in two Portuguese secondary schools during 2005-2006. The dataset provides details about students’ demographics, and family backgrounds such as parent’s jobs and education level, study habits, extracurricular activities, and lifestyle. We select gender as the sensitive attribute and G3 as the target for the regression problem. Feature description of the dataset is presented in Appendix A.
The dataset demonstrates imbalance between subgroups of sensitive attributes, presented in Fig. 1. Law school and OULAD datasets exhibit an extreme imbalance in the selected sensitive attributes, while the gender attribute in Student Performance is less imbalanced.
Race Gender GPA LSAT FYA
(a) Law School
Disability
Highest Education
Final Result Gender Age
(b) OULAD(module BBB)
Gender studytime freetime Dalc G1 Walc goout G2 G3
(c) Student Performance (Mat)
Gender Dalc freetime studytime Walc goout G1 G2 G3
(d) Student Performance (Por)
Figure 2: Partial DAGs of the estimated causal model for educational datasets, showing only the sensitive attribute, its descendants, and the target variable. See Appendix B for full graphs. Each sub-graph is not used for implementing counterfactually fair models; only the remaining features are included.
3.2 Structural Causal Model of Educational Dataset
Counterfactual fairness holds that intervening solely on the sensitive attribute A while keeping all other things equal, does not change the model’s prediction distribution. To implement counterfactual fairness, a predefined Structural Causal Model(SCM) in Directed Acyclic Graph(DAG) form is necessary. Although the causal model of the Law School data exists [23], there are no known causal models for the remaining datasets.
To construct the SCM of OULAD and the Student Performance dataset, we use a causal discovery algorithm, Linear Non-Gaussian Acyclic Model (LiNGAM) [41]. The algorithm estimates a causal structure of the observational data of continuous values under linear-non-Gaussian assumption. From the estimated causal model, we filtered DAG weights that are under the 0.1 threshold.
Among constructed SCM, we present features that are in causal relationships with the sensitive attribute that directly or indirectly affects the target variable in Fig. 2. Further analysis of causal relationships between sensitive features is discussed in Section 5.
3.3 Counterfactual Fairness Evaluation Metrics
We use the Wasserstein Distance(WD) and Maximum Mean Discrepancy(MMD) metric for evaluating the difference between prediction distributions for sensitive attributes. Wasserstein distance and MMD are common metrics for evaluating counterfactual fairness [13, 30]. Lower WD and MMD values suggest greater fairness, indicating smaller differences between the outcome distributions.
Although there exist other measures for evaluating counterfactual fairness such as Total Effect [55] and Counterfactual Confusion Matrix [39], we limit our evaluation of counterfactual fairness to the above metrics. We construct unaware and counterfactual models without direct access to the sensitive attribute, evaluating fairness with mentioned metrics would not be feasible. We visually examine prediction distributions through Kernel Density Estimation(KDE) plots across our baseline and counterfactually fair models.
3.3.1 Educational Domain Specific Fairness Metric
We additionally analyze the counterfactual approach with pre-existing fairness metrics tailored for the education domain. We choose Absolute Between-ROC Area(ABROCA) [15] and Model Absolute Density Distance(MADD) [43] for the analysis. ABROCA quantifies the absolute difference between two ROC curves. It measures the overall performance divergence of a classifier between sensitive attributes, focusing on the magnitude of the gap regardless of which group performs better at each threshold. MADD constructs KDE plots of prediction probabilities and calculates the area between two curves of the sensitive attribute. While the ABROCA metric represents how similar the numbers of errors across groups are, the MADD metric captures the severity of discrimination across groups, allowing for diverse perspectives on the analysis of model behaviors on fairness. Although both metrics are designed for group fairness, we include those in our work because they are specifically proposed under the context of the educational domain.
3.4 Experiment Details
For the experiment, we considered the Level 1 concept of counterfactual fairness defined in Kusner et al. [23]. At Level 1, the predictor is built exclusively using observed variables that are not causally influenced by the sensitive attributes. While a causal ordering of these features is necessary, no assumptions are made about the structure of unobserved latent variables. This requires causal ordering of features but no further assumptions of unobserved variables. For the Law School dataset, Level 2 is used.
We selected two baselines for the experiment, (a) Unfair model and (b) Unaware model. An unfair model directly includes sensitive attributes to train the model. The unaware model implements ‘Fairness Through Unawareness’, a fairness notion where an algorithm is considered fair when protected attributes are not used in the decision-making process [7]. We compare two baselines with the FairLearning algorithm introduced in Kusner et al. [23].
We evaluate the counterfactual fairness of machine learning models on both regression and classification models. We selected the four most utilized machine learning models in the algorithmic fairness literature [19]. We choose Linear Regression(LR; Logistic Regression for classification), Multilayer Perceptron(MLP), Random Forest(RF), and XGBoost(XGB) [5]. For KDE plot visualizations, we used a linear regression model for regression and MLP for classification.
4 Result
In the result section of our study, we present an analysis of counterfactual fairness on educational datasets. Since the Law School dataset is well studied in the counterfactual fairness literature, we only provide this experiment as a baseline.
4.1 Visual Analysis
We use KDE plots to visualize outcome distributions across subgroups, providing a better understanding of counterfactual fairness with summary statistics.
<details>
<summary>extracted/6375259/figures/kde_law_unfair.png Details</summary>
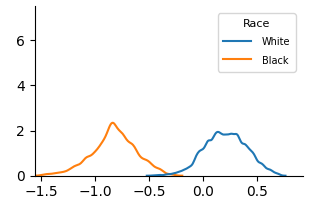
### Visual Description
\n
## Chart: Density Plot by Race
### Overview
The image presents a density plot comparing the distributions of values for two racial groups: White and Black. The x-axis represents the values being distributed, ranging from approximately -1.5 to 0.5. The y-axis represents the density, ranging from 0 to 6.
### Components/Axes
* **X-axis Title:** Not explicitly labeled, but represents a numerical value. Scale ranges from -1.5 to 0.5.
* **Y-axis Title:** Not explicitly labeled, but represents Density. Scale ranges from 0 to 6.
* **Legend:** Located in the top-right corner.
* **Label:** "Race"
* **Categories:**
* White (represented by a blue line)
* Black (represented by an orange line)
### Detailed Analysis
* **White (Blue Line):** The density for the White group starts at approximately 0 at -1.5, gradually increases to a peak density of approximately 2.0 around 0.2, and then decreases to approximately 0 at 0.5. The line exhibits a generally upward slope from -1.5 to 0.2, followed by a downward slope.
* **Black (Orange Line):** The density for the Black group starts at approximately 0 at -1.5, increases to a peak density of approximately 2.3 around -0.8, and then decreases to approximately 0 at 0.5. The line exhibits an upward slope from -1.5 to -0.8, followed by a downward slope.
Approximate Data Points (extracted visually):
| X-Value | White Density (approx.) | Black Density (approx.) |
|---|---|---|
| -1.5 | 0.0 | 0.0 |
| -1.2 | 0.2 | 0.6 |
| -1.0 | 0.5 | 2.2 |
| -0.8 | 0.8 | 2.0 |
| -0.6 | 1.2 | 1.0 |
| -0.4 | 1.6 | 0.4 |
| -0.2 | 1.9 | 0.1 |
| 0.0 | 1.7 | 0.0 |
| 0.2 | 2.0 | 0.0 |
| 0.4 | 0.5 | 0.0 |
| 0.5 | 0.0 | 0.0 |
### Key Observations
* The Black group has a higher density of values in the range of -1.2 to -0.6 compared to the White group.
* The White group has a higher density of values in the range of 0.0 to 0.4 compared to the Black group.
* Both distributions are unimodal (have one peak).
* The Black distribution is shifted to the left (more negative values) compared to the White distribution.
### Interpretation
The density plot suggests that the distributions of values for the White and Black groups are different. The Black group tends to have lower values than the White group. This could indicate a systematic difference between the two groups in the variable being measured. The difference in distributions could be due to a variety of factors, including socioeconomic status, access to resources, or historical discrimination. Further investigation would be needed to determine the underlying causes of this difference. The plot does not provide information about the nature of the variable being measured, only the relative distribution of values within each racial group. It is important to note that correlation does not equal causation, and this plot does not prove that race *causes* the observed differences.
</details>
(a) Unfair
<details>
<summary>extracted/6375259/figures/kde_law_unaware.png Details</summary>
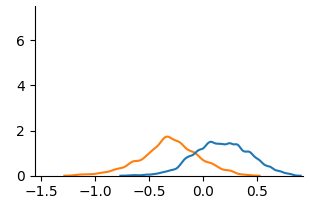
### Visual Description
\n
## Chart: Density Plot
### Overview
The image displays a density plot with two overlapping curves. The x-axis ranges from -1.5 to 0.5, and the y-axis ranges from 0 to 6. The plot appears to represent the distribution of two datasets.
### Components/Axes
* **X-axis:** Labeled with numerical values from -1.5 to 0.5, with tick marks at -1.0, -0.5, and 0.0.
* **Y-axis:** Labeled with numerical values from 0 to 6, with tick marks at 0, 2, 4, and 6.
* **Curve 1 (Orange):** Represents one dataset's distribution.
* **Curve 2 (Blue):** Represents another dataset's distribution.
* **No Legend:** There is no explicit legend identifying the datasets represented by each curve.
### Detailed Analysis
* **Curve 1 (Orange):** This curve starts at approximately y=0 at x=-1.5. It gradually increases, reaching a peak of approximately y=2 at x=-0.5. It then decreases, crossing y=0 around x=0.2. The curve is unimodal.
* **Curve 2 (Blue):** This curve starts at approximately y=0 at x=-1.5. It increases more rapidly than the orange curve, reaching a peak of approximately y=1.7 at x=-0.2. It then decreases, with a slight plateau around x=0.1, and crosses y=0 around x=0.4. The curve is also unimodal.
* **Overlap:** The two curves overlap significantly between x=-0.5 and x=0.2. The blue curve is generally higher than the orange curve in this region.
* **Data Points (Approximate):**
* Orange Curve: (-1.5, 0), (-1.0, 0.2), (-0.5, 2.0), (0.0, 0.8), (0.2, 0.0)
* Blue Curve: (-1.5, 0), (-1.0, 0.5), (-0.5, 1.2), (-0.2, 1.7), (0.0, 1.0), (0.2, 0.5), (0.4, 0.0)
### Key Observations
* Both datasets appear to be similarly distributed, with a slight skew towards positive values.
* The blue dataset has a higher peak and is generally more concentrated around x=-0.2.
* The orange dataset is more spread out and has a peak at x=-0.5.
### Interpretation
The chart suggests that the two datasets represent distributions with similar shapes but different central tendencies. The blue dataset is shifted slightly to the right compared to the orange dataset, indicating a higher average value. The overlap between the curves suggests that there is some commonality between the two datasets, but they are not identical. Without knowing what these datasets represent, it's difficult to draw more specific conclusions. The lack of a legend makes it impossible to determine what the curves represent. The chart could be visualizing the distribution of two different populations, or the distribution of a single variable before and after some intervention. The data suggests a possible difference in the underlying processes generating these distributions.
</details>
(b) Unaware
<details>
<summary>extracted/6375259/figures/kde_law_counterfactual.png Details</summary>
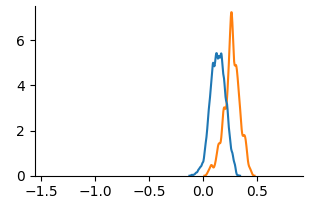
### Visual Description
\n
## Line Chart: Distribution Comparison
### Overview
The image presents a line chart comparing two distributions. The chart displays values on the y-axis against values on the x-axis, ranging from -1.5 to 0.5. Two distinct lines, one blue and one orange, represent the distributions.
### Components/Axes
* **X-axis:** Labeled with numerical values ranging from -1.5 to 0.5, with markings at -1.0, -0.5, 0.0, and 0.5.
* **Y-axis:** Labeled with numerical values ranging from 0 to 6, with markings at 0, 2, 4, and 6.
* **Line 1:** Blue line.
* **Line 2:** Orange line.
* **Legend:** No explicit legend is present, but the lines are visually distinguishable by color.
### Detailed Analysis
* **Blue Line:** The blue line starts at approximately y=0 at x=-0.5. It increases steadily, reaching a peak of approximately y=5.2 at x=0.0. It then decreases rapidly, returning to approximately y=0 at x=0.25.
* **Orange Line:** The orange line starts at approximately y=0 at x=-0.5. It increases more gradually than the blue line, reaching a peak of approximately y=7.0 at x=0.25. It then decreases more slowly than the blue line, reaching approximately y=0 at x=0.5.
### Key Observations
* The orange line has a higher peak value than the blue line.
* The blue line peaks earlier (at x=0.0) than the orange line (at x=0.25).
* The blue line has a steeper descent after its peak than the orange line.
* Both lines exhibit a similar overall shape, suggesting they represent distributions with similar characteristics but different parameters.
### Interpretation
The chart likely represents the probability density functions of two different distributions. The higher peak of the orange line suggests that values around x=0.25 are more probable in that distribution compared to the blue distribution, where values around x=0.0 are more probable. The difference in peak location and steepness indicates that the distributions have different means and variances. Without further context, it's difficult to determine the specific nature of these distributions or the variables they represent. The chart suggests a comparison of two related phenomena, where one is slightly shifted to the right and has a broader spread than the other.
</details>
(c) Counterfactual
Figure 3: KDE plots on Law School.
<details>
<summary>extracted/6375259/figures/kde_oulad_unfair.png Details</summary>
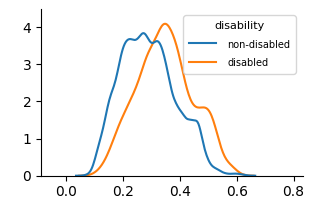
### Visual Description
\n
## Density Plot: Disability Status
### Overview
The image presents a density plot comparing the distribution of a variable (likely a score or index) for individuals with and without disabilities. The plot visualizes the probability density of the variable for each group.
### Components/Axes
* **X-axis:** Ranges from approximately 0.0 to 0.8, with tick marks at 0.0, 0.2, 0.4, 0.6, and 0.8. The axis is not explicitly labeled, but represents the value of the variable being measured.
* **Y-axis:** Ranges from approximately 0.0 to 4.0, with tick marks at 0.0, 1.0, 2.0, 3.0, and 4.0. This represents the probability density.
* **Legend:** Located in the top-right corner, labeled "disability". It contains two entries:
* "non-disabled" – represented by a blue line.
* "disabled" – represented by an orange line.
### Detailed Analysis
* **Non-disabled (Blue Line):** The density curve for non-disabled individuals rises from approximately 0.0 at x=0.0, reaches a peak density of approximately 3.8 at x=0.22, and then gradually declines, reaching approximately 0.0 at x=0.65.
* **Disabled (Orange Line):** The density curve for disabled individuals rises from approximately 0.0 at x=0.0, reaches a peak density of approximately 4.0 at x=0.35, and then declines more rapidly than the non-disabled curve, reaching approximately 0.0 at x=0.55.
### Key Observations
* The distribution for disabled individuals is more concentrated around lower values of the variable compared to non-disabled individuals.
* The peak density for disabled individuals is slightly higher than that for non-disabled individuals.
* The non-disabled group has a longer tail extending towards higher values of the variable.
### Interpretation
The data suggests that the variable being measured tends to have lower values for individuals with disabilities compared to those without disabilities. The higher peak density for the disabled group indicates a greater concentration of individuals around that lower value. The difference in distributions could indicate a systematic difference in the characteristic being measured between the two groups. It is important to note that this is a density plot, and does not provide information about the absolute number of individuals in each group. The variable could represent a score on a test, a measure of performance, or any other quantitative characteristic. Without knowing what the variable represents, it is difficult to draw definitive conclusions. However, the plot clearly demonstrates a difference in the distribution of the variable between individuals with and without disabilities.
</details>
(a) Unfair
<details>
<summary>extracted/6375259/figures/kde_oulad_unaware.png Details</summary>
### Visual Description
\n
## Line Chart: Distribution Comparison
### Overview
The image presents a line chart comparing two distributions. The chart displays the frequency or density of values along the x-axis, ranging from approximately 0.0 to 0.8. The y-axis represents the frequency/density, ranging from 0.0 to approximately 4.0. Two lines, one blue and one orange, depict the distributions.
### Components/Axes
* **X-axis:** Ranges from 0.0 to 0.8, with tick marks at 0.0, 0.2, 0.4, 0.6, and 0.8. The axis is not explicitly labeled, but represents a variable's value.
* **Y-axis:** Ranges from 0.0 to 4.0, with tick marks at 0.0, 1.0, 2.0, 3.0, and 4.0. The axis is not explicitly labeled, but represents frequency or density.
* **Line 1 (Blue):** Represents the first distribution.
* **Line 2 (Orange):** Represents the second distribution.
* **Legend:** There is no explicit legend, but the colors of the lines are used to differentiate the distributions.
### Detailed Analysis
* **Blue Line:** The blue line starts at approximately 0.0 at x=0.0, rises rapidly to a peak of approximately 3.8 at x=0.2, then gradually declines, crossing the x-axis at approximately x=0.65.
* **Orange Line:** The orange line starts at approximately 0.0 at x=0.0, rises to a peak of approximately 3.3 at x=0.2, then declines more rapidly than the blue line, crossing the x-axis at approximately x=0.55.
* **Trend Comparison:** Both lines exhibit a similar shape, with a peak around x=0.2. However, the blue line has a slightly higher peak and a longer tail, indicating a greater spread of values. The orange line declines more quickly after its peak.
### Key Observations
* Both distributions are unimodal (have a single peak).
* The blue distribution has a slightly larger spread and a higher maximum value than the orange distribution.
* The orange distribution appears to be more concentrated around the peak.
### Interpretation
The chart suggests a comparison of two related distributions. The similarity in shape indicates that both variables likely follow a similar underlying process, but with differences in their spread and magnitude. The blue line might represent a variable with more variability or a higher overall frequency, while the orange line represents a more concentrated variable. Without knowing what the x-axis represents, it's difficult to draw more specific conclusions. The difference in the rate of decline after the peak could indicate different decay rates or different underlying mechanisms governing the distributions. The chart is useful for visually comparing the characteristics of the two distributions and identifying potential differences in their behavior.
</details>
(b) Unaware
<details>
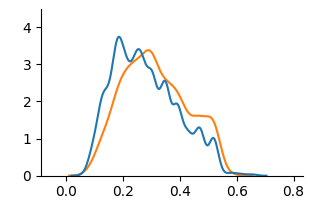
<summary>extracted/6375259/figures/kde_oulad_counterfactual.png Details</summary>
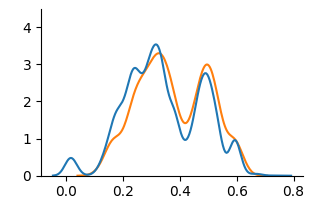
### Visual Description
\n
## Line Chart: Distribution Comparison
### Overview
The image presents a line chart comparing two distributions. The chart displays the frequency or density of values along the x-axis, ranging from approximately 0.0 to 0.8. The y-axis represents the corresponding frequency or density, ranging from 0.0 to approximately 4.0. Two lines, one blue and one orange, depict the distributions.
### Components/Axes
* **X-axis:** Ranges from 0.0 to 0.8, with tick marks at 0.0, 0.2, 0.4, 0.6, and 0.8. The axis is not explicitly labeled, but represents a variable with values between 0 and 0.8.
* **Y-axis:** Ranges from 0.0 to 4.0, with tick marks at 0.0, 1.0, 2.0, 3.0, and 4.0. The axis is not explicitly labeled, but represents the frequency or density of the variable on the x-axis.
* **Line 1 (Blue):** Represents the first distribution.
* **Line 2 (Orange):** Represents the second distribution.
* **Legend:** There is no explicit legend, but the colors of the lines are used to differentiate the distributions.
### Detailed Analysis
* **Blue Line:** The blue line starts at approximately 0.0 at x=0.0, rises to a peak of approximately 3.2 at x=0.3, decreases to a local minimum of approximately 1.5 at x=0.4, rises again to a peak of approximately 2.8 at x=0.5, and then declines to approximately 0.0 at x=0.7.
* **Orange Line:** The orange line starts at approximately 0.0 at x=0.0, rises to a peak of approximately 3.4 at x=0.25, decreases to a local minimum of approximately 1.8 at x=0.4, rises again to a peak of approximately 3.0 at x=0.55, and then declines to approximately 0.0 at x=0.7.
### Key Observations
* Both distributions exhibit a similar shape, with two prominent peaks.
* The orange line appears to be slightly shifted to the right compared to the blue line.
* The peak at approximately x=0.3 (blue) and x=0.25 (orange) are similar in magnitude.
* The peak at approximately x=0.5 (blue) and x=0.55 (orange) are also similar in magnitude.
* Both lines converge to approximately 0.0 around x=0.7.
### Interpretation
The chart suggests that the two variables represented by the blue and orange lines have similar underlying distributions, but with a slight difference in their central tendency. The two peaks could represent two distinct modes or clusters within the data. The similarity in shape suggests that the variables are related, but the shift in position indicates that one variable tends to have slightly higher values than the other. Without knowing what the x-axis represents, it is difficult to draw more specific conclusions. The chart could be visualizing the distribution of scores, measurements, or probabilities. The convergence to zero at the right end of the x-axis suggests that values beyond a certain point become increasingly rare.
</details>
(c) Counterfactual
Figure 4: KDE plots on OULAD.
<details>
<summary>extracted/6375259/figures/kde_mat_unfair.png Details</summary>
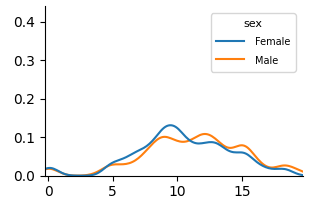
### Visual Description
\n
## Line Chart: Distribution by Sex
### Overview
The image presents a line chart depicting the distribution of a variable (likely age or a similar continuous variable) across two sexes: Female and Male. The y-axis represents the density or frequency, while the x-axis ranges from 0 to approximately 20.
### Components/Axes
* **X-axis:** Ranges from 0 to 20, with no explicit label. It represents the independent variable.
* **Y-axis:** Ranges from 0.0 to 0.4, labeled as "Density" (inferred). It represents the dependent variable.
* **Legend:** Located in the top-right corner, labeled "sex". It contains two entries:
* "Female" - represented by a blue line.
* "Male" - represented by an orange line.
### Detailed Analysis
The chart displays two overlapping lines.
* **Female (Blue Line):** The line starts at approximately 0.0 at x=0, gradually increases, reaching a peak density of approximately 0.12 at x=9. It then declines, crossing back to approximately 0.0 at x=18.
* **Male (Orange Line):** The line starts at approximately 0.0 at x=0, gradually increases, reaching a peak density of approximately 0.11 at x=11. It then declines, crossing back to approximately 0.0 at x=18.
The lines are very similar in shape, with the Female line peaking slightly earlier than the Male line. Both lines exhibit a unimodal distribution, meaning they have a single peak.
### Key Observations
* Both sexes exhibit a similar distribution pattern.
* The Female distribution peaks slightly earlier (around x=9) than the Male distribution (around x=11).
* The maximum density for the Female distribution is slightly higher than for the Male distribution.
* The distributions are roughly symmetrical around their peaks.
### Interpretation
The chart suggests that the variable being measured (likely age) is distributed similarly across both sexes, with a concentration of individuals around the ages of 9-11. The slight difference in peak location suggests that females may tend to be slightly younger in this sample. The overall shape of the distribution indicates a natural grouping or clustering of individuals within this age range. Without knowing the context of the data, it's difficult to draw more specific conclusions. The data suggests a possible cohort effect or a natural life-cycle pattern. The distributions could represent age distributions within a specific population or sample. The fact that the distributions are similar suggests that the variable being measured is not strongly influenced by sex.
</details>
(a) Unfair
<details>
<summary>extracted/6375259/figures/kde_mat_unaware.png Details</summary>
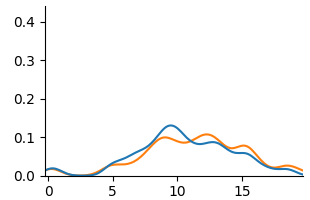
### Visual Description
\n
## Line Chart: Distribution Comparison
### Overview
The image presents a line chart comparing two distributions. The chart displays values on the y-axis ranging from 0.0 to 0.4, plotted against values on the x-axis ranging from 0 to 20. Two lines, one blue and one orange, represent the distributions.
### Components/Axes
* **X-axis:** Ranges from 0 to approximately 20, with tick marks at intervals of 5. The axis is not explicitly labeled.
* **Y-axis:** Ranges from 0.0 to 0.4, with tick marks at intervals of 0.1. The axis is not explicitly labeled.
* **Line 1:** Blue line.
* **Line 2:** Orange line.
* **Legend:** There is no explicit legend.
### Detailed Analysis
* **Blue Line:** The blue line starts at approximately 0.01 at x=0, gradually increases, reaching a peak of approximately 0.12 at x=8. It then declines, crossing back to approximately 0.01 at x=18. The line exhibits a roughly symmetrical bell-shaped curve.
* **Orange Line:** The orange line starts at approximately 0.01 at x=0, increases more rapidly than the blue line, peaking at approximately 0.14 at x=9. It then declines, crossing back to approximately 0.01 at x=17. This line also exhibits a roughly symmetrical bell-shaped curve, but is slightly shifted to the right and has a higher peak than the blue line.
### Key Observations
* Both lines show similar distributions, peaking around x=8-9.
* The orange line has a slightly higher peak than the blue line.
* The orange line's peak is slightly shifted to the right compared to the blue line.
* Both lines return to near-zero values around x=17-18.
### Interpretation
The chart likely represents the distribution of some continuous variable. The two lines could represent different groups or conditions. The slight shift and higher peak of the orange line suggest that the variable tends to have slightly higher values for the group represented by the orange line, or that the distribution is more concentrated around a slightly higher value. Without knowing what the x and y axes represent, it's difficult to draw more specific conclusions. The symmetrical shape of both curves suggests a normal or near-normal distribution. The fact that both lines converge to zero at both ends suggests that extreme values are rare.
</details>
(b) Unaware
<details>
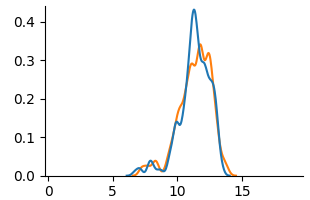
<summary>extracted/6375259/figures/kde_mat_counterfactual.png Details</summary>
### Visual Description
\n
## Line Chart: Distribution Comparison
### Overview
The image presents a line chart comparing two distributions. The chart displays values on the y-axis ranging from 0.0 to 0.4, and values on the x-axis ranging from 0 to 15. Two lines, one blue and one orange, represent the distributions.
### Components/Axes
* **X-axis:** Ranges from 0 to 15, with no explicit label.
* **Y-axis:** Ranges from 0.0 to 0.4, with no explicit label.
* **Line 1:** Blue line.
* **Line 2:** Orange line.
* **Legend:** No explicit legend is present, but the lines are visually distinguishable.
### Detailed Analysis
The blue line starts at approximately 0 at x=0, gradually increases, reaches a peak around x=11 with a value of approximately 0.42, and then decreases back to approximately 0 by x=15. There is a slight oscillation before the peak.
The orange line also starts at approximately 0 at x=0, increases, reaches a peak around x=11.5 with a value of approximately 0.32, and then decreases to approximately 0 by x=15. The orange line appears smoother than the blue line.
Here's a breakdown of approximate data points:
**Blue Line:**
* x=0: y=0.0
* x=5: y=0.02
* x=8: y=0.15
* x=10: y=0.35
* x=11: y=0.42
* x=12: y=0.30
* x=14: y=0.05
* x=15: y=0.0
**Orange Line:**
* x=0: y=0.0
* x=5: y=0.01
* x=8: y=0.10
* x=10: y=0.25
* x=11.5: y=0.32
* x=12: y=0.20
* x=14: y=0.03
* x=15: y=0.0
### Key Observations
* Both distributions are unimodal, peaking around x=11.
* The blue line has a higher peak value than the orange line.
* The blue line exhibits more fluctuations than the orange line.
* Both lines converge towards 0 as x approaches 0 and 15.
### Interpretation
The chart likely represents the distribution of some continuous variable. The two lines could represent distributions from two different groups or conditions. The higher peak of the blue line suggests that values around x=11 are more frequent in the blue distribution compared to the orange distribution. The smoother nature of the orange line might indicate a larger sample size or less variability within that distribution. Without knowing what the x and y axes represent, it's difficult to draw more specific conclusions. The chart demonstrates a comparison of two distributions, highlighting differences in their central tendency and variability.
</details>
(c) Counterfactual
Figure 5: KDE plots on Student Performance(Mathematics).
<details>
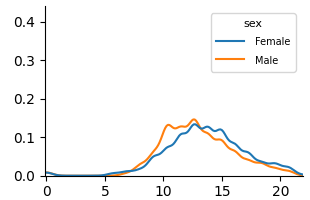
<summary>extracted/6375259/figures/kde_por_unfair.png Details</summary>
### Visual Description
\n
## Line Chart: Distribution by Sex
### Overview
The image presents a line chart depicting the distribution of a variable (likely age or a similar continuous measure) across two sexes: Female and Male. The y-axis represents the density or frequency, while the x-axis ranges from 0 to 20.
### Components/Axes
* **X-axis:** Labeled with numerical values from 0 to 20, representing the range of the variable being measured.
* **Y-axis:** Labeled with a scale from 0.0 to 0.4, representing the density or frequency of the variable.
* **Legend:** Located in the top-right corner, identifies the two lines:
* "Female" - represented by a blue line.
* "Sex" - the legend title.
* "Male" - represented by an orange line.
### Detailed Analysis
* **Female (Blue Line):** The line starts at approximately 0.0 at x=0, gradually increases, reaching a peak density of approximately 0.12 at around x=12. It then declines, approaching 0.0 again by x=20.
* **Male (Orange Line):** The line starts at approximately 0.0 at x=0, increases more rapidly than the female line, peaking at approximately 0.14 at around x=10. It then declines, crossing the female line around x=13, and approaching 0.0 by x=20.
* **Trend Comparison:** The male distribution peaks earlier (around x=10) and at a slightly higher density than the female distribution (around x=12). Both distributions are roughly symmetrical, but the male distribution appears to have a slightly sharper peak and a faster decline.
### Key Observations
* The male distribution shows a higher concentration of values in the range of 8-12 compared to the female distribution.
* Both distributions exhibit a similar overall shape, suggesting a common underlying process, but with a shift in the peak location.
* The distributions are relatively smooth, indicating a large sample size or a continuous variable.
### Interpretation
The chart suggests that the variable being measured (likely age or a similar continuous measure) is distributed differently between males and females. The earlier peak in the male distribution could indicate that males tend to have lower values of this variable, while the later peak in the female distribution suggests females tend to have higher values. The similarity in the overall shape of the distributions suggests that the underlying process generating these values is similar for both sexes, but with a systematic difference in the central tendency. Without knowing what the x-axis represents, it's difficult to draw more specific conclusions. However, if the x-axis represents age, this could indicate that the male population in the dataset tends to be younger on average than the female population.
</details>
(a) Unfair
<details>
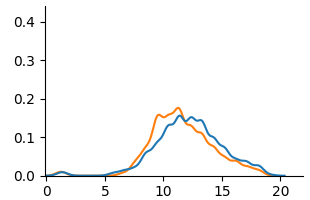
<summary>extracted/6375259/figures/kde_por_unaware.png Details</summary>
### Visual Description
\n
## Line Chart: Distribution Comparison
### Overview
The image presents a line chart comparing two distributions. The x-axis ranges from 0 to 20, and the y-axis ranges from 0 to 0.4. Two lines, one blue and one orange, depict the distributions. There are no explicit labels for the lines or axes.
### Components/Axes
* **X-axis:** Ranges from 0 to 20, with tick marks at integer values.
* **Y-axis:** Ranges from 0 to 0.4, with tick marks at 0.1 intervals.
* **Line 1:** Blue line.
* **Line 2:** Orange line.
* **Legend:** No legend is present.
### Detailed Analysis
**Line 1 (Blue):**
The blue line starts at approximately y=0 at x=0. It gradually increases, reaching a peak around x=11, where y is approximately 0.18. After the peak, the line decreases, approaching y=0 again around x=20.
**Line 2 (Orange):**
The orange line also starts at approximately y=0 at x=0. It increases more rapidly than the blue line, reaching a peak around x=12, where y is approximately 0.21. The line then decreases, approaching y=0 around x=20.
**Approximate Data Points (estimated from the visual):**
| X | Blue Line (Y) | Orange Line (Y) |
| --- | ------------- | --------------- |
| 0 | 0.0 | 0.0 |
| 5 | 0.03 | 0.08 |
| 10 | 0.15 | 0.19 |
| 11 | 0.18 | 0.21 |
| 12 | 0.16 | 0.18 |
| 15 | 0.08 | 0.07 |
| 20 | 0.0 | 0.0 |
### Key Observations
* Both distributions are unimodal, with a single peak.
* The orange line has a slightly higher peak than the blue line.
* The orange line rises more quickly than the blue line.
* Both lines converge towards zero at both ends of the x-axis.
### Interpretation
The chart likely represents the distributions of two different datasets. The similarity in shape suggests that the datasets share some underlying characteristics, but the differences in peak height and rate of increase indicate variations in their distributions. Without labels, it's impossible to determine what these datasets represent. The distributions could represent frequencies of events, probabilities, or other continuous variables. The slight shift in the peak positions (11 for blue, 12 for orange) suggests a subtle difference in the central tendency of the two datasets. The lack of a legend and axis labels limits the ability to draw definitive conclusions.
</details>
(b) Unaware
<details>
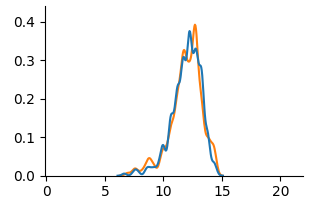
<summary>extracted/6375259/figures/kde_por_counterfactual.png Details</summary>
### Visual Description
\n
## Line Chart: Distribution Comparison
### Overview
The image presents a line chart comparing two distributions. The chart displays values on the y-axis ranging from 0.0 to 0.4, and values on the x-axis ranging from 0 to 20. Two lines, one blue and one orange, are plotted, showing the distribution of data across the x-axis.
### Components/Axes
* **X-axis:** Ranges from 0 to 20, with tick marks at intervals of 5. The axis is not explicitly labeled.
* **Y-axis:** Ranges from 0.0 to 0.4, with tick marks at intervals of 0.1. The axis is not explicitly labeled.
* **Line 1:** Blue line.
* **Line 2:** Orange line.
* **Legend:** There is no explicit legend.
### Detailed Analysis
The blue line starts at approximately 0.0 at x=0, increases gradually until x=8, then rises more steeply to a peak around x=12, reaching a maximum value of approximately 0.38. After the peak, the blue line declines rapidly, returning to approximately 0.0 by x=16.
The orange line follows a similar pattern. It starts at approximately 0.0 at x=0, increases gradually until x=8, then rises more steeply to a peak around x=13, reaching a maximum value of approximately 0.35. After the peak, the orange line declines rapidly, returning to approximately 0.0 by x=16.
Here's a breakdown of approximate data points:
**Blue Line:**
* x=0, y=0.0
* x=5, y=0.03
* x=10, y=0.25
* x=12, y=0.38
* x=15, y=0.02
* x=20, y=0.0
**Orange Line:**
* x=0, y=0.0
* x=5, y=0.02
* x=10, y=0.23
* x=13, y=0.35
* x=15, y=0.01
* x=20, y=0.0
### Key Observations
Both lines exhibit a similar distribution shape, peaking between x=12 and x=13. The blue line has a slightly higher peak value (approximately 0.38) compared to the orange line (approximately 0.35). The distributions are roughly symmetrical around their peaks.
### Interpretation
The chart likely represents the distribution of some continuous variable. The two lines could represent distributions from two different groups or conditions. The similarity in shape suggests that the underlying processes generating these distributions are similar, but the slight difference in peak height indicates a potential difference in the magnitude or intensity of the variable being measured. Without knowing what the x and y axes represent, it's difficult to draw more specific conclusions. The data suggests a unimodal distribution, with a concentration of values around the peak. The rapid decline after the peak suggests that values beyond a certain point are rare.
</details>
(c) Counterfactual
Figure 6: KDE plots on Student Performance(Portuguese).
Fig. 3 and Fig. 4 present KDE plots for Law School and OULAD datasets. For Law School data, we can see that the unfair and unaware model produces predictions with large disparities, as previously known from the counterfactual literature. For OULAD data, unfair and unaware models’ prediction probabilities do not overlap, giving slightly higher prediction probabilities for disabled students. For both datasets, the prediction distribution of the counterfactual model is closer than the unfair and unaware model.
Fig. 5 and Fig. 6 show KDE plots for Student Performance in Mathematics and Portuguese. The differences in model predictions are relatively small for all models compared to previous datasets, although disparities exist. In Mathematics, unfair and unaware models underestimate scores for female students (below 10) and overestimate for males. The opposite is true for Portuguese, where female students are more frequently assigned scores above 10. Counterfactual models on both data demonstrate an overlap of two distributions, although male students were predicted to be in the middle score range more frequently than female students in Mathematics.
4.2 Measure of Counterfactual Fairness
Table 3: Evaluation of fairness notions on benchmark datasets.
| Data | Metric | Unfair | Unaware | Counterfactual |
| --- | --- | --- | --- | --- |
| Law | WD | 1.0340 | 0.4685 | 0.1290 |
| MMD | 0.8658 | 0.4140 | 0.1277 | |
| OULAD | WD | 0.0722 | 0.0342 | 0.0337 |
| MMD | 0.0708 | 0.0324 | 0.0317 | |
| Math | WD | 0.7251 | 0.7358 | 0.1161 |
| MMD | 0.3396 | 0.1917 | 0.0538 | |
| Por | WD | 0.7526 | 0.6339 | 0.1047 |
| MMD | 0.4322 | 0.2839 | 0.1205 | |
We present the evaluation of counterfactual fairness in Table 3. In all cases, the counterfactually fair model achieves the lowest WD and MMD. For Law School and Student Performance(Mat and Por) data, the distance between two distributions of sensitive attribute subgroups significantly reduced, comparing the counterfactual model to the unfair and unaware model. Despite the limited visual evidence of reduced distributional differences in the Student Performance KDE plots, WD and MMD provided quantifiable measures of this reduction. For OULAD data, the reduction in distribution difference between the unaware and counterfactual model is minimal, suggesting a weak causal link of disability to student’s final result. Consistent for all datasets, WD and MMD decrease as the sensitive attribute and its causal relationships are removed.
Fairness levels vary across datasets. Law school data shows the highest initial unfairness while OULAD data shows relatively low unfairness even for the unfair model. Both Student Performance dataset shows significant unfairness, particularly for WD. WD and MMD rankings of fairness methods generally agree, with large differences in one corresponding to large differences in the other, suggesting robustness to the distance metric choice.
Table 4: Evaluation of education-specific fairness on OULAD dataset.
| Data | Metric | Unfair | Unaware | Counterfactual |
| --- | --- | --- | --- | --- |
| OULAD | ABROCA | 0.1019 | 0.0219 | 0.0181 |
| MADD | 0.5868 | 0.3194 | 0.2763 | |
Given the classification nature of the OULAD dataset, ABROCA and MADD metric results are presented in Table 4. Because ABROCA and MADD assess group fairness disparity across all classification thresholds, they are not directly comparable to counterfactual fairness, an individual-level fairness notion. However, the unfair model was highly biased, as evidenced by its ABROCA (0.1019, max 0.5) and MADD (0.5868, max 2) scores. While the unaware model showed improvement, the counterfactual model achieved the best fairness results. This indicates that the counterfactual approach is effective in reducing disparities in the number of errors and model behaviors across groups.
4.3 Performance of Machine Learning Models
Table 5: Prediction performance of machine learning models on fairness notions.
| Data | Metric | Unfair | Unaware | Counterfactual | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| LR | MLP | RF | XGB | LR | MLP | RF | XGB | LR | MLP | RF | XGB | | |
| Law | MSE | 0.72 | 0.73 | 0.50 | 0.52 | 0.75 | 0.75 | 0.59 | 0.59 | 0.82 | 0.83 | 0.57 | 0.57 |
| RMSE | 0.85 | 0.86 | 0.71 | 0.72 | 0.86 | 0.86 | 0.77 | 0.77 | 0.90 | 0.91 | 0.75 | 0.76 | |
| OULAD | Acc | 0.69 | 0.70 | 0.72 | 0.71 | 0.69 | 0.69 | 0.71 | 0.71 | 0.68 | 0.68 | 0.70 | 0.69 |
| AUROC | 0.65 | 0.68 | 0.72 | 0.71 | 0.65 | 0.67 | 0.71 | 0.70 | 0.62 | 0.63 | 0.65 | 0.64 | |
| Mat | MSE | 4.13 | 5.33 | 2.82 | 4.71 | 4.06 | 5.30 | 2.88 | 4.04 | 17.43 | 17.50 | 17.08 | 17.76 |
| RMSE | 2.03 | 2.31 | 1.68 | 2.17 | 2.01 | 2.30 | 1.70 | 2.01 | 4.17 | 4.18 | 4.13 | 4.21 | |
| Por | MSE | 1.43 | 1.74 | 2.19 | 1.60 | 1.41 | 1.42 | 2.17 | 1.73 | 7.96 | 8.61 | 7.90 | 8.52 |
| RMSE | 1.20 | 1.32 | 1.48 | 1.27 | 1.19 | 1.19 | 1.47 | 1.31 | 2.82 | 2.93 | 2.81 | 2.92 | |
We show model performance results in Table 5. Across models, tree-based ensembles (RF and XGB) generally outperformed LR and MLP in regression. LR and MLP showed variable performance, with strong results on the Law School dataset but poor performance on others. All models performed well on the Law School dataset; however, the Student Performance datasets (Mathematics and Portuguese) were more challenging, possibly due to non-linear relationships.
The impact of fairness approaches varies across datasets. Although the unfair model frequently has the highest performance, the classification performance of OULAD remains similar across all fairness approaches. For Law School and Student Performance data, the counterfactual model leads to the worst performance, which aligns with existing literature on the accuracy-fairness trade-off. Student Performance in Mathematics shows a massive increase in MSE and RMSE for all models, suggesting that achieving counterfactual fairness with performance is challenging on this dataset.
5 Discussion
5.0.1 RQ 1. What causal relationships do sensitive attributes have in educational data?
Analysis of the OULAD causal graph (Fig. 2(b) and Fig. 7) reveals that disability has a direct causal effect on highest education (-0.14 weight). This implies that having disability makes attaining higher education more difficult. There is no common cause between disability and final result, implying having a disability does not directly affect student outcome. Attribute gender causally affects age; however, with a 0.1 edge weight threshold, two attributes are disconnected from the DAG. This reinforces previous research [18] which revealed no causal relationship between gender and final result.
The causal model of Student Performance is presented in Fig. 2(c) and Fig. 2(d). The estimated causal model shows potential gender-based influences in study habits, social behaviors, and alcohol consumption to academic performance. Foremost, gender have an indirect causal relationship on G3. For both datasets, gender directly influences studytime, and studytime directly influences G1. For Mathematics, gender directly impacts studytime, freetime, goout and Dalc, but not goout for Portuguese. Differences in goout and alcohol consumption(Dalc and Walc) show that the factors influencing student performance differ between Math and Portuguese, demonstrating the importance of considering subject-specific causal models in education.
5.0.2 RQ 2. Does counterfactual fairness in educational data lead to identical outcomes for students regardless of their demographic group membership in individual-level?
From our experiment result, we have demonstrated that removing causal links between sensitive attributes and the target through counterfactuals achieves a similar prediction distribution of machine learning models in sensitive feature subgroups. This suggests that the counterfactual approach is effective at mitigating unfairness as measured by these metrics, across all datasets.
The fairness result supports the insufficiency of the ‘fairness through unawareness’ notion in educational datasets. In KDE plots from Fig. 3 to Fig. 6, (a) Unfair are often very similar to (b) Unaware. In fairness evaluation in Table 3 and Table 4, the Unaware approach generally performs better than the Unfair baseline, but it’s significantly worse than the Counterfactual approach. This suggests that proxies often exist within the remaining features and simply removing the sensitive attribute is not a reliable way to achieve fairness.
5.0.3 RQ 3. Does counterfactually fair machine learning models result in a performance trade-off in educational data?
The performance result in Table 5 demonstrates trade-off exists between achieving high predictive accuracy and satisfying counterfactual fairness, especially for Student Performance data. Although the definition of counterfactual fairness is agnostic to how good an algorithm is [23], this phenomenon is known from the previous literature [54] that an trade-off between fairness and accuracy exists dominated by the sensitive attribute influencing the target variable.
The severe performance drop in the Student Performance dataset suggests high dependence on sensitive attribute gender on student performance, especially for Mathematics subject. We can infer that machine learning models heavily rely on the information related to the sensitive attribute gender for prediction. Removal of the sensitive attribute and its causal influence can drastically reduce performance in this case.
Similar performance across all fairness approaches in the OULAD dataset implies that sensitive attribute disability might not be a significant feature for predicting student outcomes. Further, the naive exclusion of sensitive attributes has minimal impact on the performance of machine learning models, reconfirming the ineffectiveness of the Unaware approach in both fairness and performance.
Overall, we find the nature of the sensitive attribute and its causal links to other features differs across educational datasets, influencing the variability in the effectiveness of the counterfactual fairness approach. Some sensitive attributes might be more challenging to address than others in terms of counterfactual fairness.
5.0.4 Limitations and Future Work
Our work is limited to implementing the early approach of counterfactual fairness introduced in Kusner et al. [23], which only includes non-descendants of sensitive attributes in the decision-making process and utilizing the Level 1 causal model. Also, we only report on counterfactual fairness and performance trade-offs. Thus, future research will focus on developing our Level 1 causal model into a Level 2 model. This will involve postulating unobserved latent variables based on expert domain knowledge and assessing the impact of increasingly strong causal assumptions. Concurrently, we will develop algorithms to reduce the trade-off between counterfactual fairness and performance in educational datasets.
6 Conclusion
In this paper, we evaluated the counterfactual fairness of machine learning models on real-world educational datasets and provided a comprehensive analysis of counterfactual fairness in the education context. This work contributes to exploring causal mechanisms in educational datasets and their impact on achieving counterfactual fairness. Considering counterfactual fairness as well as group and individual fairness could provide different viewpoints in evaluating the fairness of algorithmic decisions in education.
{credits}
6.0.1 Acknowledgements
We acknowledge the valuable input from Sunwoo Kim, whose comments helped in conducting the experiments. This work was supported by the National Research Foundation(NRF), Korea, under project BK21 FOUR (grant number T2023936).
6.0.2 \discintname
The authors have no competing interests to declare that are relevant to the content of this article.
References
- [1] Baker, R.S., Hawn, A.: Algorithmic bias in education. International Journal of Artificial Intelligence in Education pp. 1–41 (2022)
- [2] Binns, R.: On the apparent conflict between individual and group fairness. In: Proceedings of the 2020 conference on fairness, accountability, and transparency. pp. 514–524 (2020)
- [3] Bird, K.A., Castleman, B.L., Song, Y.: Are algorithms biased in education? exploring racial bias in predicting community college student success. Journal of Policy Analysis and Management (2024)
- [4] Ferreira de Carvalho, W., Roberto Gonçalves Marinho Couto, B., Ladeira, A.P., Ventura Gomes, O., Zarate, L.E.: Applying causal inference in educational data mining: A pilot study. In: Proceedings of the 10th International Conference on Computer Supported Education. pp. 454–460 (2018)
- [5] Chen, T., Guestrin, C.: Xgboost: A scalable tree boosting system. In: Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. pp. 785–794 (2016)
- [6] Cock, J.M., Bilal, M., Davis, R., Marras, M., Kaser, T.: Protected attributes tell us who, behavior tells us how: A comparison of demographic and behavioral oversampling for fair student success modeling. In: LAK23: 13th International Learning Analytics and Knowledge Conference. pp. 488–498 (2023)
- [7] Cornacchia, G., Anelli, V.W., Biancofiore, G.M., Narducci, F., Pomo, C., Ragone, A., Di Sciascio, E.: Auditing fairness under unawareness through counterfactual reasoning. Information Processing & Management 60 (2), 103224 (2023)
- [8] Cortez, P., Silva, A.M.G.: Using data mining to predict secondary school student performance (2008)
- [9] Dash, S., Balasubramanian, V.N., Sharma, A.: Evaluating and mitigating bias in image classifiers: A causal perspective using counterfactuals. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 915–924 (2022)
- [10] Deho, O.B., Zhan, C., Li, J., Liu, J., Liu, L., Duy Le, T.: How do the existing fairness metrics and unfairness mitigation algorithms contribute to ethical learning analytics? British Journal of Educational Technology 53 (4), 822–843 (2022)
- [11] Delaney, J., Devereux, P.J.: Gender and educational achievement: Stylized facts and causal evidence. CEPR Discussion Paper No. DP15753 (2021)
- [12] Doewes, A., Saxena, A., Pei, Y., Pechenizkiy, M.: Individual fairness evaluation for automated essay scoring system. International Educational Data Mining Society (2022)
- [13] Duong, T.D., Li, Q., Xu, G.: Achieving counterfactual fairness with imperfect structural causal model. Expert Systems with Applications 240, 122411 (2024)
- [14] Dwork, C., Hardt, M., Pitassi, T., Reingold, O., Zemel, R.: Fairness through awareness. In: Proceedings of the 3rd innovations in theoretical computer science conference. pp. 214–226 (2012)
- [15] Gardner, J., Brooks, C., Baker, R.: Evaluating the fairness of predictive student models through slicing analysis. In: Proceedings of the 9th international conference on learning analytics & knowledge. pp. 225–234 (2019)
- [16] Garg, S., Perot, V., Limtiaco, N., Taly, A., Chi, E.H., Beutel, A.: Counterfactual fairness in text classification through robustness. In: Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society. pp. 219–226 (2019)
- [17] Hardt, M., Price, E., Srebro, N.: Equality of opportunity in supervised learning. Advances in neural information processing systems 29 (2016)
- [18] Hasan, R., Fritz, M.: Understanding utility and privacy of demographic data in education technology by causal analysis and adversarial-censoring. Proceedings on Privacy Enhancing Technologies (2022)
- [19] Hort, M., Chen, Z., Zhang, J.M., Harman, M., Sarro, F.: Bias mitigation for machine learning classifiers: A comprehensive survey. ACM Journal on Responsible Computing 1 (2), 1–52 (2024)
- [20] Hu, Q., Rangwala, H.: Towards fair educational data mining: A case study on detecting at-risk students. International Educational Data Mining Society (2020)
- [21] Jiang, W., Pardos, Z.A.: Towards equity and algorithmic fairness in student grade prediction. In: Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. pp. 608–617 (2021)
- [22] Jung, S., Yu, S., Chun, S., Moon, T.: Do counterfactually fair image classifiers satisfy group fairness?–a theoretical and empirical study. Advances in Neural Information Processing Systems 37, 56041–56053 (2025)
- [23] Kusner, M.J., Loftus, J., Russell, C., Silva, R.: Counterfactual fairness. Advances in neural information processing systems 30 (2017)
- [24] Kuzilek, J., Hlosta, M., Zdrahal, Z.: Open university learning analytics dataset. Scientific data 4 (1), 1–8 (2017)
- [25] Lakkaraju, H., Aguiar, E., Shan, C., Miller, D., Bhanpuri, N., Ghani, R., Addison, K.L.: A machine learning framework to identify students at risk of adverse academic outcomes. In: Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining. pp. 1909–1918 (2015)
- [26] Le Quy, T., Roy, A., Iosifidis, V., Zhang, W., Ntoutsi, E.: A survey on datasets for fairness-aware machine learning. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 12 (3), e1452 (2022)
- [27] Li, Z., Guo, X., Qiang, S.: A survey of deep causal models and their industrial applications. Artificial Intelligence Review 57 (11) (2024)
- [28] Loftus, J.R., Russell, C., Kusner, M.J., Silva, R.: Causal reasoning for algorithmic fairness. CoRR abs/1805.05859 (2018), http://arxiv.org/abs/1805.05859
- [29] Long, C., Hsu, H., Alghamdi, W., Calmon, F.: Individual arbitrariness and group fairness. Advances in Neural Information Processing Systems 36, 68602–68624 (2023)
- [30] Ma, J., Guo, R., Zhang, A., Li, J.: Learning for counterfactual fairness from observational data. In: Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. pp. 1620–1630 (2023)
- [31] Makhlouf, K., Zhioua, S., Palamidessi, C.: Machine learning fairness notions: Bridging the gap with real-world applications. Information Processing & Management 58 (5), 102642 (2021)
- [32] Marras, M., Boratto, L., Ramos, G., Fenu, G.: Equality of learning opportunity via individual fairness in personalized recommendations. International Journal of Artificial Intelligence in Education 32 (3), 636–684 (2022)
- [33] Pallathadka, H., Wenda, A., Ramirez-Asís, E., Asís-López, M., Flores-Albornoz, J., Phasinam, K.: Classification and prediction of student performance data using various machine learning algorithms. Materials today: proceedings 80, 3782–3785 (2023)
- [34] Pan, C., Zhang, Z.: Examining the algorithmic fairness in predicting high school dropouts. In: Proceedings of the 17th International Conference on Educational Data Mining. pp. 262–269 (2024)
- [35] Pearl, J.: Causality. Cambridge university press (2009)
- [36] Pfohl, S.R., Duan, T., Ding, D.Y., Shah, N.H.: Counterfactual reasoning for fair clinical risk prediction. In: Machine Learning for Healthcare Conference. pp. 325–358. PMLR (2019)
- [37] Piccininni, M.: Counterfactual fairness: The case study of a food delivery platform’s reputational-ranking algorithm. Frontiers in Psychology 13, 1015100 (2022)
- [38] Piech, C., Bassen, J., Huang, J., Ganguli, S., Sahami, M., Guibas, L.J., Sohl-Dickstein, J.: Deep knowledge tracing. Advances in neural information processing systems 28 (2015)
- [39] Pinto, M., Carreiro, A.V., Madeira, P., Lopez, A., Gamboa, H.: The matrix reloaded: Towards counterfactual group fairness in machine learning. Journal of Data-centric Machine Learning Research (2024)
- [40] Sha, L., Raković, M., Das, A., Gašević, D., Chen, G.: Leveraging class balancing techniques to alleviate algorithmic bias for predictive tasks in education. IEEE Transactions on Learning Technologies 15 (4), 481–492 (2022)
- [41] Shimizu, S., Hoyer, P.O., Hyvärinen, A., Kerminen, A., Jordan, M.: A linear non-gaussian acyclic model for causal discovery. Journal of Machine Learning Research 7 (10) (2006)
- [42] Taghipour, K., Ng, H.T.: A neural approach to automated essay scoring. In: Proceedings of the 2016 conference on empirical methods in natural language processing. pp. 1882–1891 (2016)
- [43] Verger, M., Lallé, S., Bouchet, F., Luengo, V.: Is your model" madd"? a novel metric to evaluate algorithmic fairness for predictive student models. arXiv preprint arXiv:2305.15342 (2023)
- [44] Wastvedt, S., Huling, J.D., Wolfson, J.: An intersectional framework for counterfactual fairness in risk prediction. Biostatistics 25 (3), 702–717 (2024)
- [45] Webbink, D.: Causal effects in education. Journal of Economic Surveys 19 (4), 535–560 (2005)
- [46] Wightman, L.F.: Lsac national longitudinal bar passage study. lsac research report series. (1998)
- [47] Wu, H., Zhu, Y., Shi, W., Tong, L., Wang, M.D.: Fairness artificial intelligence in clinical decision support: Mitigating effect of health disparity. IEEE Journal of Biomedical and Health Informatics (2024)
- [48] Xu, S., Strohmer, T.: On the (in) compatibility between group fairness and individual fairness. arXiv preprint arXiv:2401.07174 (2024)
- [49] Xu, Z., Li, J., Yao, Q., Li, H., Zhao, M., Zhou, S.K.: Addressing fairness issues in deep learning-based medical image analysis: a systematic review. npj Digital Medicine 7 (1), 286 (2024)
- [50] Yağcı, M.: Educational data mining: prediction of students’ academic performance using machine learning algorithms. Smart Learning Environments 9 (1), 11 (2022)
- [51] Zhao, S., Heffernan, N.: Estimating individual treatment effect from educational studies with residual counterfactual networks. In: Proceedings of the 10th International Conference on Educational Data Mining. pp. 306–311 (2017)
- [52] Zhou, W.: Group vs. individual algorithmic fairness. Ph.D. thesis, University of Southampton (2022)
- [53] Zhou, Y., Huang, C., Hu, Q., Zhu, J., Tang, Y.: Personalized learning full-path recommendation model based on lstm neural networks. Information sciences 444, 135–152 (2018)
- [54] Zhou, Z., Liu, T., Bai, R., Gao, J., Kocaoglu, M., Inouye, D.I.: Counterfactual fairness by combining factual and counterfactual predictions. In: Advances in Neural Information Processing Systems. vol. 37, pp. 47876–47907 (2024)
- [55] Zuo, Z., Khalili, M., Zhang, X.: Counterfactually fair representation. Advances in Neural Information Processing Systems 36, 12124–12140 (2023)
Appendix A Feature Description of Student Performance Dataset
Table 6: Feature descriptions of Student Performance dataset [8].
| Feature | Type | Description |
| --- | --- | --- |
| school | binary | the student’s school (Gabriel Pereira/Mousinho da Silveira) |
| gender | binary | The student’s gender |
| age | numerical | The student’s age |
| address | binary | The student’s residence (urban/rural) |
| famsize | binary | The student’s family size |
| Pstatus | binary | The parent’s cohabitation status |
| Medu | numerical | Mother’s education |
| Fedu | numerical | Father’s education |
| Mjob | categorical | Mother’s job |
| Fjob | categorical | Father’s job |
| reason | categorical | The reason to choose this school |
| guardian | categorical | The student’s guardian (mother/father/other) |
| traveltime | numerical | The travel time from home to school |
| studytime | numerical | The weekly study time |
| failures | numerical | The number of past class failures |
| schoolsup | binary | Is there an extra educational support? |
| famsup | binary | Is there any family educational support? |
| paid | binary | Is there an extra paid classes within the course subject? |
| activities | binary | Are there extra-curricular activities? |
| nursery | binary | Did the student attend a nursery school? |
| higher | binary | Does the student want to take a higher education? |
| internet | binary | Does the student have an Internet access at home? |
| romantic | binary | Does the student have a romantic relationship? |
| famrel | numerical | The quality of family relationships |
| freetime | numerical | Free time after school |
| goout | numerical | How often does the student go out with friends? |
| Dalc | numerical | The workday alcohol consumption |
| Walc | numerical | The weekend alcohol consumption |
| health | numerical | The current health status |
| absences | numerical | The number of school absences |
| G1 | numerical | The first period grade |
| G2 | numerical | The second period grade |
| G3 | numerical | The final grade |
Appendix B Complete SCMs of Datasets
Construction of causal structural model(SCM) is crucial for implementing counterfactual fairness. Thus, we provide a estimated SCM inferred from each dataset through LiNGAM algorithm [41]. We filtered out edges with absolute weights lower than 0.1. These causal models are used for sampling counterfactual instances. For fitting a counterfactually fair model, we excluded direct and indirect descendants of the sensitive feature for each dataset.
<details>
<summary>x1.png Details</summary>
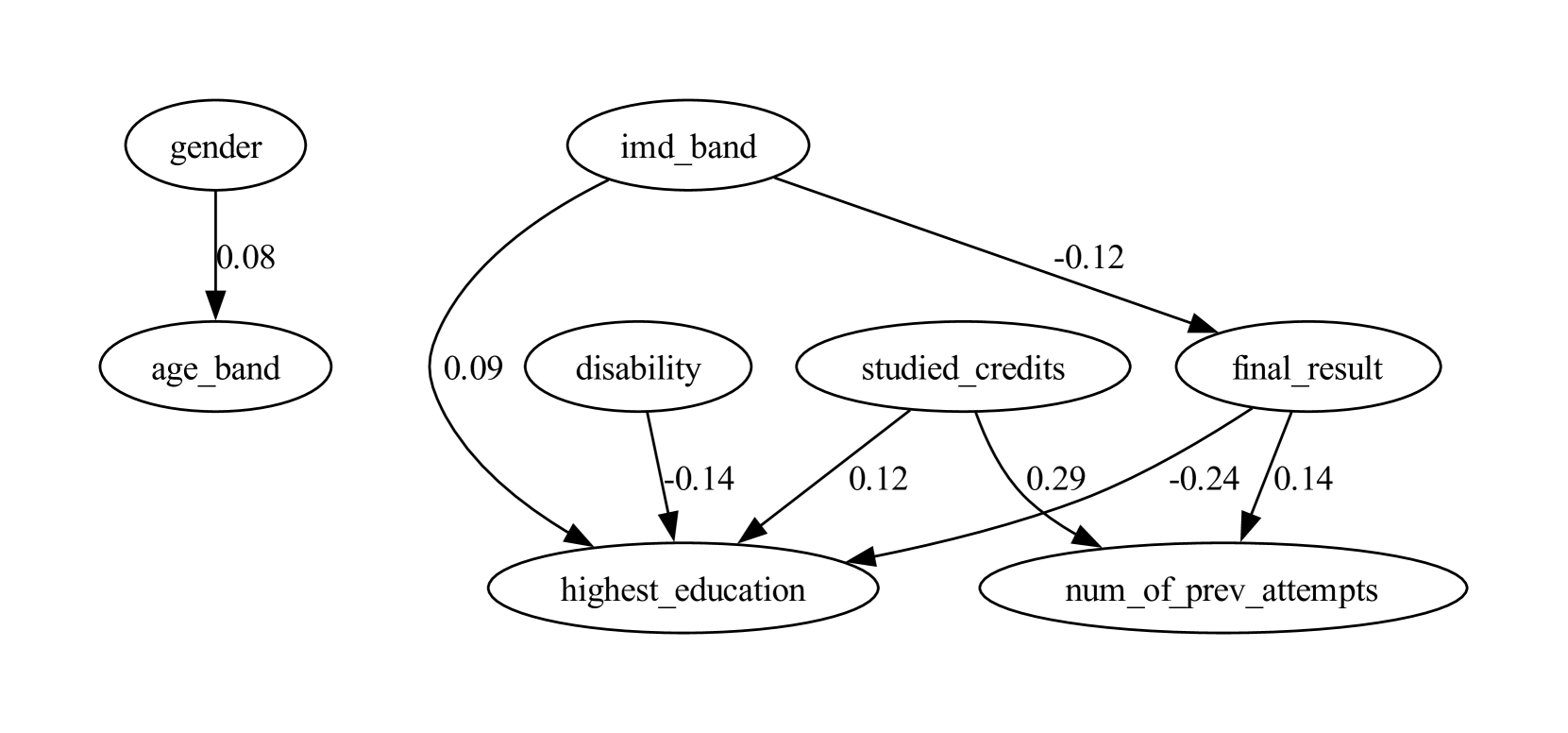
### Visual Description
## Diagram: Path Diagram of Variable Relationships
### Overview
The image presents a path diagram illustrating the relationships between several variables. The diagram uses nodes (ellipses) to represent variables and directed arrows to indicate the hypothesized relationships between them. The arrows are labeled with numerical values, presumably representing path coefficients or correlation coefficients. The background is a light gray.
### Components/Axes
The diagram consists of the following variables (nodes):
* gender
* age\_band
* imd\_band (Index of Multiple Deprivation Band)
* disability
* studied\_credits
* highest\_education
* final\_result
* num\_of\_prev\_attempts (Number of Previous Attempts)
The arrows represent the relationships between these variables, with the following path coefficients indicated:
* gender -> age\_band: 0.08
* gender -> disability: 0.09
* imd\_band -> disability: (No value provided, implied connection)
* imd\_band -> studied\_credits: (No value provided, implied connection)
* imd\_band -> final\_result: -0.12
* disability -> highest\_education: -0.14
* disability -> studied\_credits: 0.12
* studied\_credits -> num\_of\_prev\_attempts: 0.29
* studied\_credits -> final\_result: (No value provided, implied connection)
* highest\_education -> num\_of\_prev\_attempts: (No value provided, implied connection)
* final\_result -> num\_of\_prev\_attempts: -0.24
* num\_of\_prev\_attempts -> (No outgoing arrows)
There are no explicit axes or legends in the traditional sense. The diagram's structure *is* the representation of the relationships.
### Detailed Analysis or Content Details
The diagram shows a network of relationships.
* **Gender** directly influences both **age\_band** (with a coefficient of 0.08) and **disability** (with a coefficient of 0.09).
* **imd\_band** directly influences **disability**, **studied\_credits**, and **final\_result**. The influence on **final\_result** is negative (-0.12).
* **Disability** negatively influences **highest\_education** (-0.14) and positively influences **studied\_credits** (0.12).
* **Studied\_credits** positively influences **num\_of\_prev\_attempts** (0.29).
* **Final\_result** negatively influences **num\_of\_prev\_attempts** (-0.24).
* There are implied connections between **imd\_band** and **studied\_credits**, **studied\_credits** and **final\_result**, and **highest\_education** and **num\_of\_prev\_attempts** that are not quantified.
### Key Observations
* The path coefficients are relatively small in magnitude, suggesting weak to moderate relationships between the variables.
* Several relationships are negative, indicating inverse relationships (e.g., as disability increases, highest education tends to decrease).
* The variable **num\_of\_prev\_attempts** appears to be an outcome variable, influenced by **studied\_credits**, **final\_result**, and potentially **highest\_education**.
* The diagram does not indicate any feedback loops or reciprocal relationships.
### Interpretation
This path diagram likely represents a hypothesized model of factors influencing academic performance or educational outcomes. The variables represent demographic characteristics (gender, imd\_band), individual attributes (disability), educational experiences (studied\_credits, highest\_education), and outcomes (final\_result, num\_of\_prev\_attempts).
The model suggests that gender and socioeconomic status (imd\_band) indirectly influence academic outcomes through their effects on disability and educational engagement. Disability, in turn, affects both educational attainment (highest\_education) and study habits (studied\_credits). The number of previous attempts is influenced by the final result and the number of credits studied.
The negative path coefficients suggest that certain factors (e.g., disability, previous attempts) may be associated with lower academic performance. The absence of quantified relationships for some paths indicates either a lack of data or a deliberate choice to simplify the model.
The diagram is a visual representation of a statistical model, likely a structural equation model (SEM), and would require further analysis (e.g., model fit indices) to assess the validity of the hypothesized relationships. The diagram itself does not provide statistical significance or confidence intervals for the path coefficients.
</details>
Figure 7: Estimated SCM for OULAD dataset. Sensitive attribute is disability. For fitting counterfactual model, we excluded disability and highest_education features.
<details>
<summary>x2.png Details</summary>
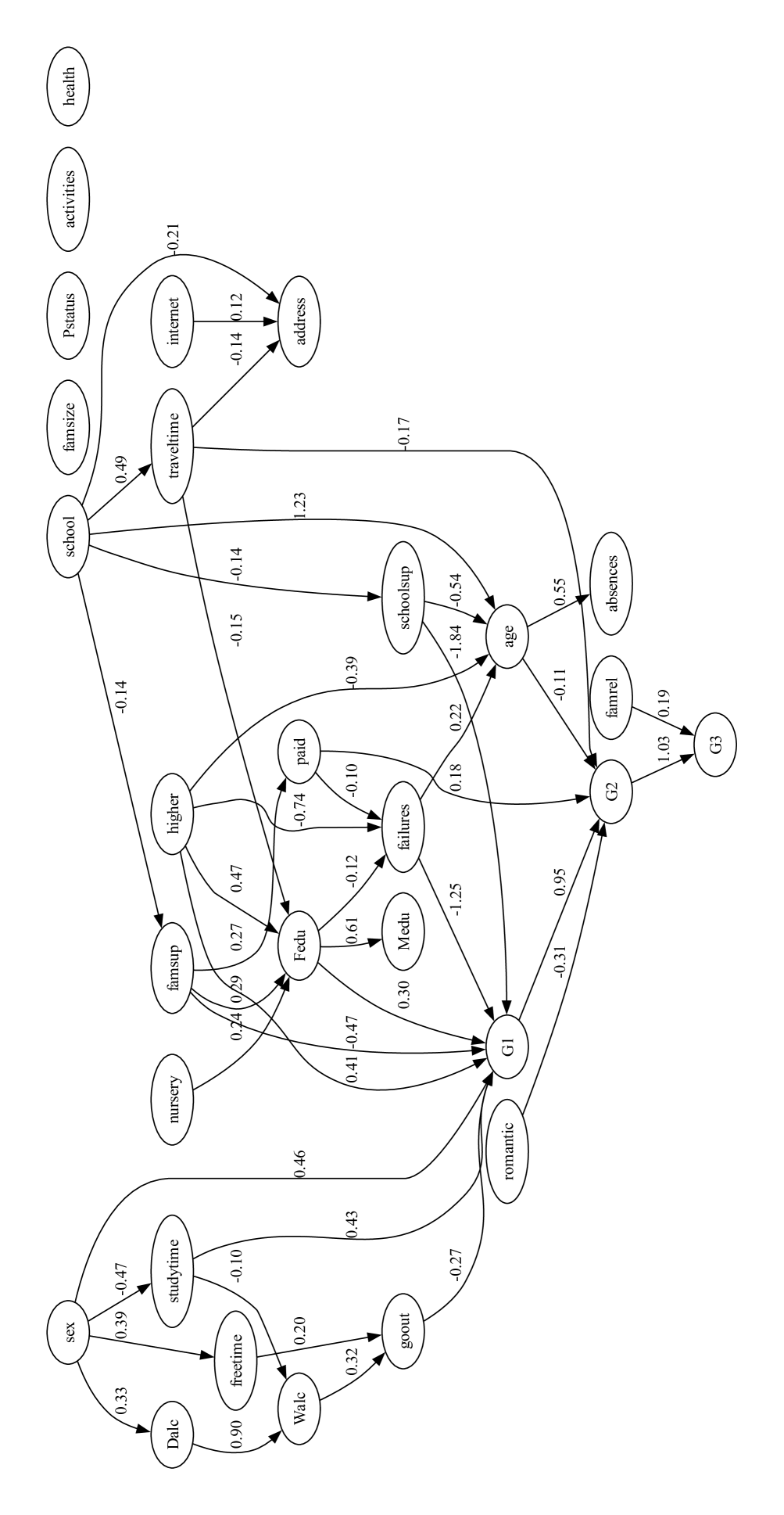
### Visual Description
\n
## Diagram: Path Model of Adolescent Well-being
### Overview
The image depicts a path model diagram illustrating relationships between various factors influencing adolescent well-being. The diagram uses nodes (ovals) to represent latent variables and observed variables, and directed arrows to indicate hypothesized causal relationships. Numerical values associated with each arrow represent standardized path coefficients. The diagram appears to model the influence of factors like family, school, and peer relationships on adolescent well-being outcomes.
### Components/Axes
The diagram consists of the following components:
* **Latent Variables:** Represented by double-lined ovals. These include: `GI` (General Intelligence), `faith`, `romantic`, `school`, `parents`, `health`.
* **Observed Variables:** Represented by single-lined ovals. These include: `Dulc`, `sex`, `substance`, `Naï`, `guilt`, `injury`, `anger`, `trusty`, `higher`, `ideal`, `travelling`, `address`, `schoolship`, `age`, `GC`, `fitness`, `distances`.
* **Path Coefficients:** Numerical values along the arrows indicating the strength and direction of the relationships.
* **Arrows:** Directed lines indicating the hypothesized causal relationships between variables.
### Detailed Analysis
Here's a breakdown of the relationships and their corresponding path coefficients, moving from left to right and top to bottom:
* **Dulc -> sex:** 0.33
* **Dulc -> substance:** 0.39, -0.47
* **Dulc -> Naï:** 0.90
* **sex -> substance:** -0.10
* **sex -> guilt:** 0.46
* **substance -> injury:** 0.20
* **Naï -> guilt:** 0.33
* **Naï -> romantic:** 0.45
* **guilt -> faith:** 0.14, -0.47
* **injury -> anger:** 0.27
* **anger -> trusty:** 0.20
* **trusty -> higher:** 0.27
* **higher -> ideal:** -0.14
* **ideal -> faith:** -0.41, -0.12
* **faith -> school:** -0.39
* **faith -> parents:** -0.14
* **travelling -> address:** 0.12
* **address -> health:** 0.12
* **school -> schoolship:** 0.23
* **schoolship -> age:** -0.17
* **schoolship -> GC:** -1.34, -0.54
* **age -> fitness:** 0.18, 0.22
* **age -> distances:** -1.11
* **GC -> GI:** 1.68, 0.19
* **fitness -> GI:** 0.095
* **distances -> GI:** -0.31
* **romantic -> GI:** -0.75
**Trend Verification:**
* The path from `Dulc` to `sex` is positive (0.33).
* The path from `Dulc` to `substance` has both positive (0.39) and negative (-0.47) components.
* The path from `faith` to `school` is negative (-0.39).
* The path from `age` to `distances` is negative (-1.11).
* The path from `GC` to `GI` is strongly positive (1.68, 0.19).
### Key Observations
* The strongest positive path coefficient is between `GC` and `GI` (1.68, 0.19), suggesting a very strong relationship.
* The strongest negative path coefficient is between `age` and `distances` (-1.11), indicating a strong inverse relationship.
* Several paths involve negative coefficients, suggesting inhibitory or suppressing relationships.
* The variable `Dulc` appears to have multiple outgoing paths, indicating its potential as a central predictor.
* The variable `GI` appears to be a final outcome variable, receiving paths from multiple sources.
### Interpretation
This path model attempts to explain the factors contributing to adolescent well-being, as represented by the latent variable `GI` (General Intelligence). The model suggests that factors like family dynamics (`parents`, `faith`), school environment (`school`, `schoolship`), and individual characteristics (`Dulc`, `sex`, `substance`, `Naï`, `romantic`) all indirectly influence `GI`.
The strong positive relationship between `GC` and `GI` suggests that general cognitive ability is a key component of overall well-being. The negative relationship between `age` and `distances` could indicate that as adolescents get older, they tend to have less social distance from their peers.
The presence of both positive and negative path coefficients highlights the complexity of the relationships. For example, the mixed paths from `Dulc` to `substance` suggest that the relationship between these variables is not straightforward.
The model provides a framework for understanding the interplay of various factors in adolescent development. It could be used to identify potential intervention points for promoting well-being. The model is a hypothesis, and its validity would need to be tested using empirical data. The diagram is a visual representation of a statistical model, likely derived from structural equation modeling (SEM).
</details>
Figure 8: Estimated SCM for Student Performance(Mathematics) dataset. Sensitive attribute is gender. For fitting counterfactual model, we excluded gender, freetime, goout, Dalc, Walc, famsup, paid, G1, G2, absences and studytime. Features that does not have edge connected to the rest of the graph are also excluded.
<details>
<summary>x3.png Details</summary>
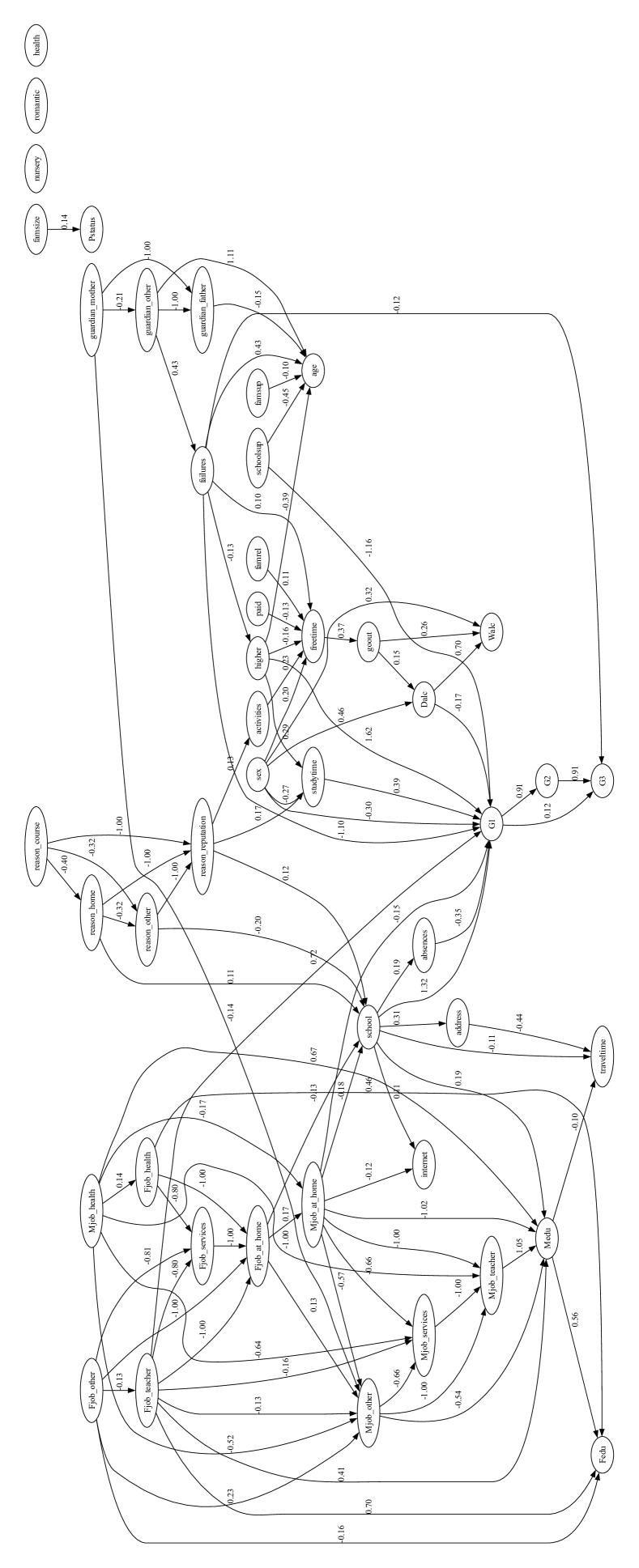
### Visual Description
\n
## Diagram: Structural Equation Model (SEM)
### Overview
The image depicts a complex Structural Equation Model (SEM) diagram, likely representing relationships between various latent and observed variables. The diagram consists of oval-shaped nodes representing latent variables and rectangular nodes representing observed variables. Arrows indicate the hypothesized relationships between these variables, with numerical values associated with each arrow representing path coefficients. The diagram is largely monochromatic, with subtle shading to differentiate node types.
### Components/Axes
The diagram does not have traditional axes. Instead, it is organized spatially to represent the relationships between variables. Key components include:
* **Latent Variables:** Represented by ovals. Examples include "quality", "satisfaction", "loyalty", "image", "trust", "value", "affect", "cognition", "behavioral intention", "fish", "major dishes", "major service", "major others", "price", "atmosphere", "food quality", "service quality", "physical facility", "cleanliness", "GI".
* **Observed Variables:** Represented by rectangles. These are indicators of the latent variables.
* **Path Coefficients:** Numerical values associated with arrows, indicating the strength and direction of the relationship between variables. These range from negative values (e.g., -0.489) to positive values (e.g., 0.417).
* **Error Terms:** Represented by single-headed arrows pointing towards observed variables.
* **Variance:** Represented by double-headed arrows pointing towards latent variables.
### Detailed Analysis or Content Details
The diagram is complex, so I will break down the relationships and values in sections, moving roughly from left to right.
**Left Side - Fish & Major Dishes:**
* "Fish" has a path coefficient of 0.75 to "major dishes".
* "major dishes" has a path coefficient of 0.417 to "affect".
* "major dishes" has a path coefficient of 0.32 to "cognition".
**Middle Section - Major Service & Major Others:**
* "major service" has a path coefficient of 0.434 to "affect".
* "major service" has a path coefficient of 0.402 to "cognition".
* "major others" has a path coefficient of 0.454 to "affect".
* "major others" has a path coefficient of 0.38 to "cognition".
**Central Latent Variables:**
* "affect" has path coefficients to: "satisfaction" (0.417), "loyalty" (0.479).
* "cognition" has path coefficients to: "satisfaction" (0.434), "loyalty" (0.389).
* "satisfaction" has a path coefficient to "behavioral intention" (0.63).
**Right Side - Quality & Trust:**
* "quality" has path coefficients to: "trust" (0.71), "satisfaction" (0.417).
* "trust" has a path coefficient to "loyalty" (0.43).
* "value" has a path coefficient to "satisfaction" (0.32).
**Other Notable Path Coefficients:**
* "price" to "value" (0.44)
* "atmosphere" to "quality" (0.411)
* "food quality" to "quality" (0.437)
* "service quality" to "quality" (0.417)
* "physical facility" to "quality" (0.35)
* "cleanliness" to "quality" (0.407)
* "GI" to "quality" (0.32)
**Error Terms (examples):**
* Error term for "affect" is 0.56.
* Error term for "cognition" is 0.58.
* Error term for "satisfaction" is 0.37.
* Error term for "loyalty" is 0.41.
**Variances (examples):**
* Variance for "affect" is 1.00.
* Variance for "cognition" is 1.00.
* Variance for "satisfaction" is 1.00.
* Variance for "loyalty" is 1.00.
* Variance for "quality" is 1.00.
* Variance for "trust" is 1.00.
* Variance for "value" is 1.00.
### Key Observations
* The model suggests a strong relationship between "affect" and "cognition" influencing "satisfaction" and subsequently "loyalty".
* "Quality" appears to be a central construct, influencing both "trust" and "satisfaction".
* Several observed variables (price, atmosphere, food quality, etc.) contribute to the latent variable "quality".
* Path coefficients are generally positive, indicating positive relationships between variables.
* The model is relatively complex, with numerous interconnected variables.
### Interpretation
This Structural Equation Model (SEM) aims to explain the factors influencing customer loyalty in a restaurant or hospitality setting. The model proposes that customer loyalty is driven by both affective (emotional) and cognitive (rational) evaluations of the experience. These evaluations, in turn, are shaped by the perceived quality of the restaurant, encompassing aspects like food quality, service, atmosphere, and cleanliness. The inclusion of "value" suggests that the perceived value for money also plays a role in customer satisfaction.
The model's complexity indicates a nuanced understanding of the factors influencing loyalty. The path coefficients provide insights into the relative importance of each variable. For example, the strong path coefficient between "satisfaction" and "behavioral intention" (0.63) suggests that satisfied customers are more likely to exhibit loyal behavior.
The model could be used to identify areas for improvement in the restaurant's operations. By focusing on enhancing the factors that contribute to "quality" and "value," the restaurant can potentially increase customer satisfaction and loyalty. The model also allows for testing the validity of these hypothesized relationships using empirical data.
The presence of error terms acknowledges that the model is not perfect and that other unmeasured factors may also influence the variables. The variances represent the unique variance in each latent variable, not explained by the model. This is a standard practice in SEM to account for the complexity of real-world phenomena.
</details>
Figure 9: Estimated SCM for Student Performance(Portuguese) dataset. Sensitive attribute is gender. For fitting counterfactual model, we excluded gender, freetime, goout, Dalc, Walc, G1, G2, absences and studytime. Features that does not have edge connected to the rest of the graph are also excluded.