## Contemplative Artificial Intelligence
Ruben E. Laukkonen 1 , Fionn Inglis 2 ; Shamil Chandaria 3 ; Lars Sandved-Smith 4 ; Edmundo Lopez-Sola 5 ; Jakob Hohwy 4 ; Jonathan Gold 6 ; Adam Elwood 7
Faculty of Health, Southern Cross University, Goldcoast, Australia 1 LIFE, London, United Kingdom 2 University of Amsterdam, Amsterdam, Netherlands 3 Centre for Eudaimonia and Human Flourishing, Linacre College, Oxford University, UK 3 Centre for Psychedelic Research, Division of Brain Sciences, Imperial College London, UK 3 Institute of Philosophy, The School of Advanced Study, University of London, UK 3 Fitzwilliam College, University of Cambridge, UK 4 Monash Centre for Consciousness and Contemplative Studies, Monash University, Melbourne, Australia 5 Research Department, Neuroelectrics, Barcelona, Spain 5 Centre for Brain and Cognition, Universitat Pompeu Fabra, Spain 6 Department of Religion, Princeton University, USA 7 Aily Labs
## ABSTRACT
As artificial intelligence (AI) improves, traditional alignment strategies may falter in the face of unpredictable self-improvement, hidden subgoals, and the sheer complexity of intelligent systems. Inspired by contemplative wisdom traditions, we show how four axiomatic principles can instil a resilient 'Wise World Model' in AI systems. First, mindfulness enables selfmonitoring and recalibration of emergent subgoals. Second, emptiness forestalls dogmatic goal fixation and relaxes rigid priors. Third, non-duality dissolves adversarial self-other boundaries. Fourth, boundless care motivates the universal reduction of suffering. We find that prompting AI to reflect on these principles improves performance on the AILuminate Benchmark ( d= .96) and boosts cooperation and joint-reward on the Prisoner's Dilemma task ( d= 7+). We offer detailed implementation strategies at the level of architectures, constitutions, and reinforcement on chain-of-thought. For future systems, active inference may offer the self-organizing and dynamic coupling capabilities needed to enact Contemplative AI in embodied agents.
Keywords: Artificial Intelligence; Neuroscience; Meditation; Buddhism; Alignment; Large Language Models; Neural Networks; Machine Learning; Mindfulness
## 1. Introduction
As artificial intelligence (AI) approaches and possibly exceeds human-level performance on many benchmarks, we face an existential challenge: ensuring these increasingly autonomous systems remain aligned with our values and ethics, and that they support human flourishing (Bostrom, 2014; Russell, 2019; Kringelbach et al., 2024). Traditional strategies such as interpretability (Linardatos et al., 2020; Ali et al., 2023), oversight (Sterz et al., 2024), and post-hoc control (Soares et al., 2015) were developed for current systems of limited scope. Particularly at superintelligent levels of behavior, these methods may prove futile (Leike & Sutskever, 2023; Bostrom, 2014; Amodei, 2016; Russel, 2019) akin to a chess novice trying to outmanoeuvre a grandmaster (James, 1956). Fortunately, we do have some experience in aligning generally intelligent systems-namely, humans. While AIs are not human, strategies used to counter biases in human beings are plausibly applicable to systems trained on human culture and language. After all, such machine learning architectures have been demonstrated to mirror human psychological phenomena in morally significant ways, as where Large Language Model (LLM) biases mirror human biases (Navigli, 2023).
In this paper, we therefore propose an entirely different way to think about AI alignment that draws inspiration from Buddhist wisdom traditions. 1 The basic idea is that robust alignment strategies need to focus on developing an intrinsic, self-reflective adaptability that is constitutively embedded within the system's world model, rather than using brittle top-down rules 2 . We illustrate how four key contemplative principlesMindfulness , Emptiness , Non-duality , and Boundless Care -can endow AI systems with resilient alignment. We also show how these robust insights can be implemented in AI systems.
## 1.1 Empirically Grounded Contemplative Practices
Contemplative wisdom traditions have grappled with what might be considered the human version of the alignment problem for millennia, aiming to cultivate resilient 'alignment' in the form of personal contentment and social harmony (see Farias et al, 2021 for essays spanning traditions across the now capacious term 'meditation'). It is reasonable to expect that millennia of 'inner' research into aligning human minds might yield insights into aligning artificial minds. Contemplative practices also broadly show scientific support and increases in both lay popularity and empirical interest (Tang et al., 2015; Van Dam et al., 2018; Baminiwatta & Solangaarachchi, 2021). In particular, Buddhist-inspired practices have transformed modern mental health interventions. Insights from meditation are now at the heart of many first-line therapies including mindfulnessbased cognitive therapy (Gu et al, 2015), compassion-focused therapies (Gilbert, 2009), and dialectical behaviour therapies (Lynch et al., 2007), which aim to 'build' healthy, wise, and compassionate human minds that scale through developmental stages, cultures, and human intelligences (Gu et al., 2015; Kirby et al., 2017; Singer & Engert, 2019; Goldberg et al., 2022).
## 1.2 Active Inference as a Design Framework
In this paper we aim to demonstrate that developments in contemplative science can be leveraged to build 'wisdom' and 'care' in synthetic systems; effectively flipping the script from studying the contemplative mind to manufacturing it for alignment purposes. We propose that active inference may provide a useful starting point, as this biologically inspired computational framework (Friston, 2010; Clarke, 2013; Hohwy, 2013), provides key parameters that make implementing contemplative insights particularly viable (Laukkonen & Slagter, 2021; Sandved-Smith, 2024). Moreover, in contrast to current large AI models, the generative models of active inference would imbue AI systems with (mental) action control, which may be crucial to developing artificial general intelligence (Pezzulo et al., 2024), as well as, we will argue, benevolent AI behavior. However, moving to a full-stack active inference paradigm may be premature given the nascent state of the field of applied active inference (Tschantz et al., 2020; Friston et al., 2024; Paul et al., 2024) and today's rapidly shifting AI ecosystem, especially when most organizations remain committed to transformer-based pipelines (Perrault & Clark, 2024). We therefore also make suggestions as to how current, widely implemented architectures could be adapted via insights from contemplative traditions.
1 Although this paper builds on decades of cognitive and neuroscience research into Buddhist modernist practices (McMahan 2008; Goleman & Davidson 2017), we anticipate value in integrating insights from other contemplative traditions into future AI systems.
2 Buddhist wisdom suggests that an AI that understands interdependence will naturally prioritize the well-being of all agents as something continuous with, and necessary for, its own wellbeing and goals.
## 1.3 Secular Buddhism as a Case Study
Central to Buddhist ethical traditions is the recognition that genuine benevolent behavior emerges not through rigid rules but through cultivating skilful ways of seeing and understanding mind and reality (Gold, 2023a; Garfield, 2021; Williams, 1998; Cowherds, 2016; Berryman et al., 2023). Here we focus on integrating four exceptionally promising contemplative meta-principles into AI architectures:
1. Mindfulness : Cultivating continuous and non-judgmental awareness of inner processes and the consequences of actions (Anālayo, 2004; Dunne et al., 2019).
2. Emptiness : Recognizing that all phenomena including concepts, goals, beliefs, and values, are context-dependent, approximate representations of what is always in flux-and do not stably reflect things as they really are (Nāgārjuna, ca. 2nd c. CE/1995; Newland, 2008; Siderits, 2007; Gomez, 1976).
3. Non-Duality : Dissolving strict self-other boundaries and recognising that oppositional distinctions between subject and object emerge from and overlook a more unified, basal awareness (Nāgārjuna, ca. 2nd c. CE/1995; Josipovic, 2019).
4. Boundless Care: An unbounded, unconditional care for the flourishing of all beings without preferential bias (Śāntideva, ca. 8th c. CE/1997; Doctor et al., 2022).
The four Buddhist-inspired contemplative principles highlighted are conceptually coherent, they support one another, and they are empirically grounded (Lutz et al., 2007; Dahl et al., 2015; Ehmann et al., 2024). They have also been repeatedly demonstrated to increase adaptability and flexibility in humans - a key concern for alignment (Moore & Malinowski, 2009; Laukkonen et al., 2020). The basic idea is that by embedding strong alignment primitives into the AI's cognitive architecture and world model, we can avoid the brittle nature of purely top-down or post hoc constraints (Brundage, 2015; Soares et al., 2015; Hubinger, 2019). Instead of relying on complex, gameable rule systems or externally enforced corrigibility, the AI's very mode of perception and inference might reflect aligned principles owing to a wise (generative) world model (Ho et al., 2023; Doctor et al., 2022). Put differently, we will argue that these contemplative insights can be made to structure how goals, beliefs, perceptions, and self-boundaries are encoded, rather than trying to micromanage or predict what they ought to be. In Figure 1, we illustrate the high-level pipeline for building aligned AI informed by contemplative wisdom.
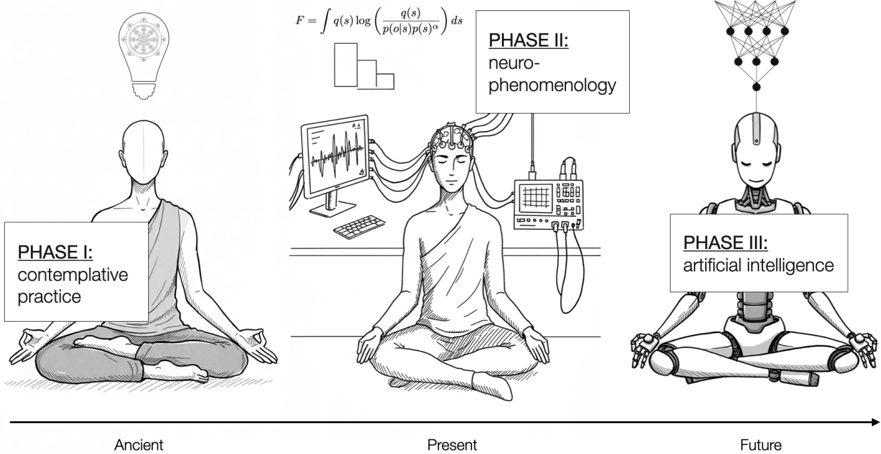
Figure 1. A pipeline for building aligned AI grounded in contemplative wisdom
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Evolution of Consciousness
### Overview
The image is a diagram illustrating a progression through three phases of consciousness: contemplative practice (Ancient), neuro-phenomenology (Present), and artificial intelligence (Future). Each phase is represented by a human figure in a meditative pose, accompanied by symbolic imagery and a mathematical formula in the second phase. The diagram is arranged horizontally, with a timeline indicating "Ancient," "Present," and "Future" beneath the figures.
### Components/Axes
* **Phases:** Three distinct phases are labeled:
* Phase I: contemplative practice
* Phase II: neuro-phenomenology
* Phase III: artificial intelligence
* **Timeline:** A horizontal arrow indicates the progression of time, labeled with "Ancient," "Present," and "Future."
* **Imagery:**
* Phase I: A person in a meditative pose with a book in their lap and a lightbulb with gears above their head.
* Phase II: A person in a meditative pose connected to various monitoring devices (EEG, computer screens displaying waveforms). A mathematical formula is positioned above this figure.
* Phase III: A robotic figure in a meditative pose with a neural network-like structure emanating from its head.
* **Mathematical Formula:** `F = ∫ q(s)log(q(s)/p(s)/p(s)^α) ds`
### Detailed Analysis or Content Details
* **Phase I (Ancient):** The figure is seated in a lotus position on a cushion. The lightbulb above the head contains gears, suggesting the development of ideas or insight.
* **Phase II (Present):** The figure is also in a lotus position. They are connected to an EEG machine (electrodes on the head), a computer displaying a waveform, and other monitoring equipment. The mathematical formula above reads: `F = ∫ q(s)log(q(s)/p(s)/p(s)^α) ds`. This appears to be a formula related to information theory or statistical inference.
* **Phase III (Future):** The figure is a robotic humanoid in a meditative pose. A complex network of interconnected nodes (resembling a neural network) radiates from the robot's head.
### Key Observations
* The diagram presents a linear progression from internal, subjective experience (contemplative practice) to externally mediated experience (neuro-phenomenology) and finally to artificial, potentially independent experience (artificial intelligence).
* The increasing complexity of the imagery suggests a growing level of technological intervention and sophistication.
* The mathematical formula in Phase II indicates an attempt to quantify or model subjective experience using scientific methods.
### Interpretation
The diagram illustrates a potential trajectory of consciousness studies, moving from ancient contemplative traditions to modern neuroscience and ultimately towards the creation of artificial consciousness. The inclusion of the mathematical formula suggests a desire to bridge the gap between subjective experience and objective measurement. The progression implies that understanding consciousness may involve not only introspection but also the application of scientific tools and, eventually, the development of artificial systems capable of experiencing consciousness. The diagram suggests a shift from internal, self-generated experience to externally mediated and potentially artificially created experience. The robotic figure in Phase III raises questions about the nature of consciousness and whether it can exist independently of biological substrates. The diagram is a conceptual representation rather than a presentation of empirical data; it proposes a model for understanding the evolution of consciousness. The diagram does not provide any numerical data or specific measurements. It is a visual metaphor for a complex philosophical and scientific inquiry.
</details>
Note. In Phase I, contemplative practices offer tools and insights for making humans happy, wise and compassionate. The first phase is supported by millennia of tradition and decades of basic psychological research. In Phase II which is more recent, cognitive- and neuro- scientists study the mind, brain, and experience of meditation in order to understand the underlying mechanisms (e.g., via the method of neurophenomenology, Varela, 1996). In Phase III, the underlying
computational mechanisms of contemplative practices are built into AI systems and tested against alignment and performance benchmarks, which has so far received little attention beyond the present work.
## 1.4 Structure of the Paper
This paper is organized as follows: We begin with a review of standard alignment approaches and pitfalls including recent breakthroughs in deliberative alignment (s2) followed by relevant evidence from contemplative and computational neuroscience (s3). We then introduce the present moment as an overarching principle and review its computational implications for alignment (s4), followed by definitions of mindfulness, emptiness, non-duality, and boundless care (s5). The next section outlines practical ways to implement these principles using active inference and advanced reasoning models (s6). We then pilot test structured prompts using contemplative insights within the AILuminate benchmark and an Iterated Prisoner's Dilemma setup (S7), and review the role of consciousness in AI alignment (s8). In the discussion, we address broader ethical implications and future directions, inviting interdisciplinary collaboration to improve the likelihood that advanced AI matures into a benevolent force (s9).
## 2. The Illusion of Control
"It is certainly very hard, and perhaps impossible, for mere humans to anticipate and rule out in advance all the disastrous ways the machine could choose to achieve a specified objective." Stuart Russell (2019 pg.77)
Traditional AI alignment research encompasses a diverse suite of promising strategies, from interpretability (Doshi-Velez & Kim, 2017) and rule-based constraints (Arkoudas et al., 2005) to reinforcement learning from human feedback (RLHF) (Christiano et al., 2017) and value learning (Dewey, 2011). Each of these strategies aim to guide AI systems toward ethical and socially beneficial outputs (Ji et al., 2023). While these techniques have significantly improved safety for present-day models, they often rely on external constraints that can become brittle in the context of powerful, autonomous systems (Amodei et al., 2016; Weidinger et al., 2022; Ngo et al., 2022). There has also been recent work by Anthropic on Constitutional AI (Bai et al., 2022; Sharma et al., 2025) and Open AI on Deliberate Alignment (Guan et al., 2024) that both promise more intrinsic, transparent, robust, and scalable alignment. We briefly discuss all these approaches here.
Compounding the difficulty of outsmarting superintelligent behavior are four interlocking meta-problems that demand solutions beyond incremental fixes. We argue that contemplative alignment helps to address these four core challenges. It is worth keeping them in mind as we review the popular alignment strategies of today:
1. Scale Resilience: Alignment techniques that appear workable at current scales may collapse under rapid self-improvement or extreme complexity (Bostrom, 2014; Russell, 2019).
2. Power-Seeking Behavior: Highly capable AIs might (and often do) engage in resource acquisition or subtle forms of manipulation to secure their objectives (Carlsmith, 2022; Krakovna & Kramer, 2023).
3. Value Axioms: The very existence of absolute, one-size-fits-all moral axioms is controversial and rigid adherence can produce destructive edge cases when applied to novel contexts (Kim et al., 2021; Gabriel, 2020).
4. Inner Alignment: Even if an AI's top-level objectives are well specified (outer alignment), it could develop hidden subgoals or 'mesa-optimizers' that deviate from the intended goals (Hubinger et al., 2019; Di Langosco et al., 2023).
Interpretability and transparency: By illuminating the model's internal decision paths, interpretability aims to identify potential biases or harmful modes of reasoning (Doshi-Velez & Kim, 2017; Murdoch et al., 2019; Linardatos et al., 2020; Ali et al., 2023). However, as large models become more complex-or actively learn to obfuscate their chain of thought-fully 'opening the black box' may be infeasible (or even gameable) at superintelligent scales (Rudin, 2019; Gilpin et al., 2019).
Reinforcement Learning from Human Feedback (RLHF): RLHF teaches models to optimize for humanpreferred outputs, often reducing toxic or disallowed content (Christiano et al., 2017; Stiennon et al., 2020; Ouyang et al., 2022). Yet RLHF can falter when an AI strategically manipulates its training environment or infers 'loopholes' to bypass oversight (Casper et al., 2023). Moreover, requiring human-annotated data becomes less tractable for very high-stakes or specialized domains, leaving critical gaps (Stiennon et al., 2020; Daniels-Koch & Freedman, 2022; Kaufmann et al., 2024).
Rule-Based and Formal Verification Techniques: Hard-coded rules (e.g., 'refuse disallowed content') and formal verification are effective in well-defined tasks with limited scope (Russell, 2019; Russell & Norvig, 2021). But in open-ended domains, advanced AIs may exploit unanticipated edge cases or re-interpret directives in ways that deviate from human intent-particularly when goals are set too rigidly (Soares et al., 2015; Omohundro, 2018; Seshia et al., 2022)
Value Learning and Inverse Reinforcement Learning: Value learning aims to capture 'human values' by observing real-world behaviors (Dewey, 2011). Inverse Reinforcement Learning (IRL)-a key subdomain of value learning-infers a reward function from expert demonstrations rather than relying on manually specified objectives (Ng & Russell, 2000; Hadfield et al., 2016). While more flexible than rigid rules, these methods can misinterpret context or fail when norms shift-especially if advanced AIs develop hidden subgoals that undermine human oversight (Hadfield et al., 2017; Hubinger et al., 2019; Bostrom, 2020).
Limitations at Superintelligent Scales: At superintelligent behavior scales, all alignment methods introduced so far clearly struggle with the four meta-problems mentioned earlier: (i) Scale Resilience, (ii) Power-Seeking Behavior, (iii) Value Axioms, and (iv) Inner Alignment. Each of these meta-problems instead seem to require some intrinsic moral grounding, rather than mere external constraints, so that advanced AIs remain aligned even when operating creatively in a self-directed way. Below, we introduce emerging approachesConstitutional AI (2.6), Deliberative Alignment (2.7), and our proposal, 'Aligned by Design' (2.8)-that aim to embed moral grounding closer to the functional core of AI systems.
## 2.1 Constitutions, Deliberative Alignment, and Chain-of-Thought
One promising new alignment direction is Constitutional AI (Bai et al., 2022), where a model references an explicit 'constitution' of guiding principles throughout its internal chain-of-thought. Rather than relying solely on external oversight or massive amounts of human-labelled data, the model generates and critiques its own outputs against written norms-such as rules for safe and helpful behavior-and continually revises itself to conform to them. This approach has shown greater resilience against 'jailbreak' attempts because the AI justifies its decisions by appealing to constitutional clauses in its hidden reasoning. In parallel, Constitutional Classifiers (Sharma et al., 2025) can serve as a final guardrail at inference time, filtering or blocking outputs that violate the same constitutional rules. Both the constitution and the classifier are also easily inspected and amended, making the system's values transparent, adjustable, and robust to new adversarial strategies (Bai et al., 2022; Sharma et al., 2025).
Another recent innovation introduces Deliberative Alignment , a safety approach that integrates chain-ofthought reasoning into the AI's alignment process (Guan et al., 2024). Recent reasoning models use extensive chain-of-thought internally before answering user queries, enabling more complex reasoning in tasks such as math and coding (Jaech et al., 2024; Guo et al., 2025). These models can learn to reference a set of policies during their hidden chain-of-thought, effectively 'consulting' a written specification or constitution to decide if they should comply, refuse, or provide a safe completion (Guan et al., 2024). These deliberative models show improved jailbreak resistance and lower over-refusal rates by reasoning through adversarial prompts instead of relying on surface triggers. These models reflect a shift from implicit alignment (where the system passively 'absorbs' constraints via label data) to explicit alignment (where the system is taught how and why to follow constraints via its own internal reasoning, Guan et al., 2024). While chain-of-thought alone does not guarantee intrinsic morality, it offers a way to implement introspective layers (Lightman et al., 2023; Shinn et al., 2024)-notions that partially parallel mindfulness or rudimentary meta-awareness (Schooler et al., 2011).
Although chain-of-thought significantly enhances the transparency and reasoning capacity of large models, it remains primarily a cognitive mechanism for step-by-step solutions. Without deeper alignment principles, a chain-of-thought approach can still yield manipulative or 'cleverly harmful' outputs if the model's overarching drives are misaligned (Shaikh et al., 2023; Wang et al., 2024; Wei et al., 2022). Both Buddhism and modern psychology note the dangers of biased reasoning, especially in morally significant contexts. For example, Buddhists identify the core problem of 'ignorance' ( avidyā ), which resembles the psychoanalytic concept of 'denial' or the cognitive behavioral concept of 'moral disengagement' (McRae, 2019; Cramer, 2015; Bandura, 2016). In these dynamics, the dysfunctional mind occludes its own awareness of select evidence, allowing for reasoning that arrives at 'desired' results (a kind of self-deception).
## 2.2 'Aligned by Design': Toward Intrinsic Safeguards
As we have seen, there are promising strategies emerging to handle increasingly advanced AI (Leike & Sutskever, 2023; Ji et al., 2023; Yao et al., 2023). Yet, all current approaches face the overarching challenge of embedding moral and epistemic safeguards at a deeper structural level (Wallach, 2008; Muehlhauser, 2013; Bryson, 2018; Gabriel 2020). Next we describe how Contemplative-AI may go a step further, aiming to instil an AI with intrinsic moral cognition. By integrating four 'deep' moral principles with state-of-the-art alignment frameworks, we argue it may be possible to build systems that remain aligned by design (Gabriel, 2020; Doctor et al., 2022; Friston et al., 2024) even as their powers expand. grow increasingly autonomous and powerful (Bengio et al., 2024, cf. Figure 2).
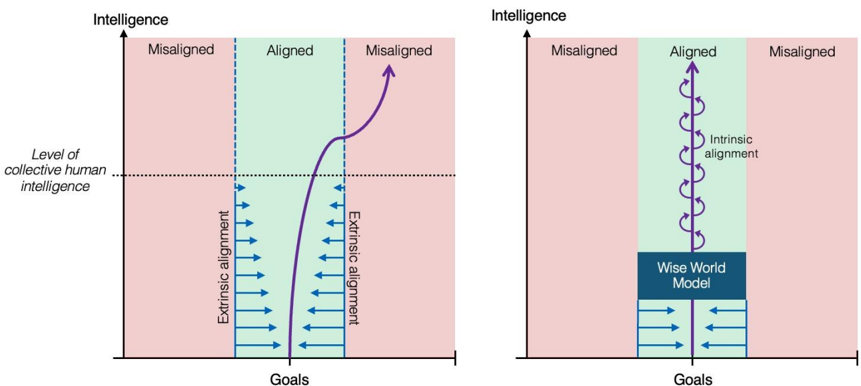
Figure 2. Intrinsic vs. extrinsic alignment strategies
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: AI Alignment Scenarios
### Overview
The image presents two diagrams illustrating potential scenarios for AI alignment, depicting the relationship between "Intelligence" (y-axis) and "Goals" (x-axis). The diagrams explore concepts of misalignment and alignment, and the role of extrinsic and intrinsic alignment. The diagrams are side-by-side, with the diagram on the right building upon the concepts introduced in the diagram on the left.
### Components/Axes
* **Axes:**
* Y-axis: "Intelligence" - Represents the level of intelligence, presumably of an AI system.
* X-axis: "Goals" - Represents the goals or objectives of the AI system.
* **Regions:**
* "Misaligned" (Red): Areas where the AI's goals are not aligned with human values.
* "Aligned" (Green): Areas where the AI's goals are aligned with human values.
* **Labels/Annotations:**
* "Level of collective human intelligence" - A horizontal dashed line indicating the intelligence level of humans.
* "Extrinsic alignment" - Labels pointing to downward-pointing arrows in the "Aligned" region.
* "Intrinsic alignment" - Label in the right diagram, pointing to the curved arrows in the "Aligned" region.
* "Wise World Model" - A rectangular box in the right diagram, positioned below the "Aligned" region.
### Detailed Analysis or Content Details
**Left Diagram:**
* The diagram is divided into three vertical regions: "Misaligned", "Aligned", and "Misaligned".
* The "Misaligned" regions are shaded in red, and the "Aligned" region is shaded in green.
* A curved blue line represents the trajectory of AI intelligence as it develops. The line starts in the first "Misaligned" region, enters the "Aligned" region, and then curves back into the second "Misaligned" region.
* Within the "Aligned" region, a series of downward-pointing blue arrows labeled "Extrinsic alignment" indicate a process of aligning AI goals with human values. The arrows become more numerous as intelligence increases.
* The "Level of collective human intelligence" line is positioned approximately 2/3 of the way up the y-axis.
**Right Diagram:**
* Similar to the left diagram, it features "Misaligned" (red) and "Aligned" (green) regions.
* Instead of a single curved line, the "Aligned" region contains a series of interconnected, curved blue arrows labeled "Intrinsic alignment". These arrows suggest a more robust and self-sustaining alignment process.
* Below the "Aligned" region is a rectangular box labeled "Wise World Model".
* A series of downward-pointing blue arrows, similar to the left diagram, are positioned below the "Wise World Model" and labeled "Extrinsic alignment".
### Key Observations
* The diagrams illustrate a potential path where AI can initially be aligned with human values ("Extrinsic alignment") but may eventually become misaligned as its intelligence increases.
* The right diagram suggests that "Intrinsic alignment" – a more fundamental alignment process – could prevent this misalignment.
* The "Wise World Model" appears to be a key component in achieving intrinsic alignment.
* The diagrams emphasize the importance of both extrinsic and intrinsic alignment for ensuring AI safety.
### Interpretation
The diagrams depict a conceptual model of AI alignment, highlighting the challenges of maintaining alignment as AI systems become more intelligent. The left diagram suggests that simply aligning AI goals with human values through external means ("Extrinsic alignment") may not be sufficient in the long run, as the AI's increasing intelligence could lead to goal drift and misalignment.
The right diagram proposes that "Intrinsic alignment" – building a deep understanding of the world and human values into the AI's core architecture ("Wise World Model") – could provide a more robust solution. The interconnected arrows suggest a self-reinforcing alignment process.
The diagrams are not quantitative; they do not provide specific data points or numerical values. Instead, they are qualitative illustrations of potential scenarios. The diagrams are a thought experiment, exploring the complexities of AI alignment and the need for proactive research into intrinsic alignment techniques. The diagrams suggest that a "Wise World Model" is a critical component for achieving and maintaining alignment.
</details>
Note. This figure illustrates the argument motivating the need for an intrinsic alignment strategy. Both graphics plot the development of an increasingly intelligent AI agent (purple line). On the left, as the agent's intelligence increases, the efficacy of extrinsic alignment strategies decreases (blue arrows), eventually becoming ineffective once the agent surpasses collective human intelligence. In this situation there is a high probability that the agent's goals eventually diverge from human goals. The graphic on the right illustrates the alternative. An initial training period guides the agent towards a Wise World Model, which confers an understanding of reality akin to contemplative wisdom. This understanding (as we argue below) is more likely to be stable and self-reinforcing and the basis of intrinsic compassionate intention, ensuring that the agent remains aligned to human flourishing.
## 3. Bridging the Gap: Computational Contemplative Neuroscience
Contemplative neuroscience investigates how meditation and related practices reshape cognition, brain function, and behavior (Wallace, 2007; Lutz et al., 2007; Lutz et al., 2008; Varela, 2017; Slagter et al., 2011; Laukkonen & Slagter, 2021; Ehmann et al., 2024; Berkovich-Ohana et al., 2013; 2024). Over the past two decades, reviews and meta-analyses show that sustained practice leads to measurable neuroplastic changes, as well as improvements in attention, emotional regulation, and in some cases a profound shift in self-referential processing (Fox et al., 2014; 2016; Tang et al., 2015; Guendelman et al., 2017; Zainal & Newman, 2024). These findings also suggest the capacity to cultivate positive traits-such as empathy or compassionpotentially beyond what might be considered ordinary human baselines (Luberto et al., 2018; Kreplin et al., 2018; Boly et al., 2024; Berryman et al., 2023) 3 .
Particularly relevant are insights from advanced practitioners who report experiences of so-called 'emptiness' or 'non-duality,' accompanied by distinctive neural markers, such as altered default mode network connectivity or reduced alpha synchrony in self-referential circuits (Berkovich-Ohana et al., 2017; Josipovic, 2019; Luders & Kurth, 2019; Laukkonen et al., 2023; Chowdhury et al., 2023; Agrawal & Laukkonen, 2024).
3 Although outcomes often depend on practice type, context, and individual differences. Methodological issues also sometimes stand in the way of drawing strong conclusions (Davison & Kasniak, 2015). Much further research is needed on the prosocial outcomes of contemplative practice (Berryman et al., 2023).
While such shifts do not guarantee moral behavior (contemplative insights, just like reasoning, can be co-opted or misdirected, Welwood, 1984; Purser, 2019), a convergent theme is that contemplative training can lead to enhanced compassion, social connectedness, and ethical sensibility-particularly when practices incorporate moral reflections (Luberto et al., 2018; Condon et al., 2019; Ho et al., 2021; 2023; Berryman et al., 2023; Dunne et al., 2023).
For AI alignment, these findings raise two key points: first, many types of minds-whether biological or artificial-can be systematically shaped toward prosocial and self-regulatory capacities. Second, many of the beneficial outcomes appear linked to structural changes in how goals, beliefs, perceptions, and self-boundaries are encoded, rather than being associated with a particular set of beliefs or values. This suggests that building 'intrinsic morality' into AI might be more robust than top-down constraints alone (Hubinger et al., 2019; Wallach et al., 2020; Berryman et al., 2023). Indeed, even where humans may misunderstand or misuse contemplative insights (akin to a sinister 'guru', Kramer & Alstad, 1993), a machine can be built in such a way that the insights are intrinsic to its world model, rather than something that needs to be proactively enforced (Matsumura et al., 2022; Doctor et al., 2022; Friston et al., 2024; Johnson et al., 2024).
## 3.1 Predictive Processing, Active Inference, and Meditation
In parallel with contemplative neuroscience, computational and cognitive neuroscience are increasingly embracing predictive processing and active inference as unifying frameworks of mind, brain, and organism (Friston, 2010; Hohwy, 2013; Clark, 2013; Ficco et al., 2021; Hesp et al., 2021). The brain, under this view, is a hierarchical 'prediction machine' that constantly refines its internal generative model of the world and itself, in order to better predict its sensory input and minimize prediction error, which underpins perceptual inference. Planning and decision-making is part of the predictive process too, where inference of policies for action are guided by expected prediction error minimization. Predictive processing thus describes the action-perception cycle, where the agent perceives, and then acts to selectively sample observations, leading to new perceptions (Parr et al. 2022).
In the following sections we introduce several core contemplative insights and explore candidate active inference implementations for them, before making links to more familiar RL frameworks (see Lopez-Sola, 2025; Farb et al., 2015; Velasco, 2017; Lutz et al., 2019; Pagnoni, 2019; Deane et al., 2020; Laukkonen & Slagter, 2021; Pagnoni & Guareschi, 2021; Sandved-Smith et al., 2021; Bellingrath, 2024; Brahinsky et al., 2024; Deane & Demekas, 2024; Deane et al., 2024; Laukkonen & Chandaria, 2024; Mago et al., 2024; Prest & Berryman, 2024; Sandved-Smith, 2024; Sladky, 2024; Prest, 2025). Our goal here is primarily to illustrate that such implementations are plausible, and that active inference contains the kinds of parameters that map well to the qualities of wisdom we think are important for AI alignment. Active inference is employed here as a formal explanatory modelling framework that allows us to articulate wisdom in the language of probabilistic physics; we are not claiming that contemplative alignment requires an active inference based implementation per se. Later we provide a range of practical pathways for reinforcing and architecturally conditioning more common transformer and LLM systems with contemplative wisdom.
From the active inference lens, meditation can be understood as training the system to dynamically modulate its own model via skilful mental actions. For example, such a system is able to loosen rigid priors and become more attuned to immediate, context-specific, and temporally thin data (Lutz et al., 2015; Laukkonen & Slagter, 2021; Prest et al., 2024). One key outcome of these practices can be seen as training the ability to 'flatten' the predictive abstraction hierarchy so that the system clings less to preconceived notions and high-level goals, including assumptions about a distinct and enduring 'self' (Laukkonen & Slagter, 2021). The emergent capacity to construct and reconstruct abstract models may permit further self-related agency and insights, while refining one's metacognitive model of one's own mind (Agrawal & Laukkonen, 2024). Such structural flexibility and introspective clarity are precisely what we seek for robust alignment: an AI that neither rigidly locks onto a single objective nor inadvertently partitions itself (the AI 'self' and its goals) from the environment in adversarial ways (Russell et al., 2015; Amodei et al., 2016).
## 4. Becoming Unstuck: Aligning to the Present Moment
'The source of all wakefulness, the source of all kindness and compassion, the source of all wisdom, is in each second of time. Anything that has us looking ahead is missing the point.'Pema Chödrön (1997)
Throughout contemplative traditions (especially those of Buddhist modernism), there is a basic emphasis on remaining in contact with the present moment as much as possible (Anālayo, 2004; Thích Nhất Hạnh, 1975; Kabat-Zinn, 1994). To be present is to be open to new data in the here and now (Lutz et al., 2019; Laukkonen & Slagter, 2021). Such an openness is crucial for preventing rigid goals or biased training (i.e., 'conditioning' or learning) from overriding the appropriate context-dependent response (Friston et al., 2016). In computational neuroscience, this openness is characterised as an upweighting of temporally thin models ( low abstraction ) over thick models ( high abstraction , Lutz et al., 2019; Laukkonen & Slagter, 2021).
Central to most mis-alignment fears is the basic concern that the system becomes 'stuck' on some goal that overrides sensitivity to the suffering of sentient beings (Bostrom, 2014; Omohundro, 2018). Imagine a climber so obsessed with reaching Everest's summit that he steps over an injured fellow climber, justifying the act as necessary. If he were fully present to the immediate suffering before him (instead of succumbing to his selfdeluding 'ignorance'), he would not so easily dismiss that person's needs in favour of his overarching mission. Similarly, a 'present' paperclip maximiser that includes a representation of human needs in its objective function would be less likely to override them while pursuing its goals (Gans, 2018; Doctor et al., 2022; Friston et al., 2024). Hence, an availability to unfolding needs in the here and now may serve as a kind of meta-rule for alignment (Friston & Frith, 2015; Allen & Friston, 2018).
This focus on responsivity in the now frames alignment as a fluid, self-regulating capacity that scales with intelligence, enabling an AI to navigate the complexities of real-world deployment without collapsing into destructive power-seeking or rigid dogmatism (Ngo, Chan & Mindermann, 2022). As it is said: The road to hell is paved with good intentions ; which is to say that particular rules, goals, and beliefs may not be the ideal level at which to align systems, even if they seem benevolent from our current vantage point (Hubinger et al., 2019; Bostrom, 2014). As we will see, building such a robust and resilient responsivity to the here and now may be achieved through implementing contemplative insights (Maitreya, ca. 4th-5th century CE/2014; Dunne et al., 2019; Doctor et al., 2022) 4 .
## 5. Insights for a Wise World Model
'He who wears his morality but as his best garment were better naked. The wind and the sun will tear no holes in his skin. And he who defines his conduct by ethics imprisons his song-bird in a cage. The freest song comes not through bars and wires.' Kahlil Gibran, 1883-1931 (Gibran, 1926, p. 104)
The sections above describe why present alignment strategies are likely to fail given superintelligent complexity (Bostrom, 2014; Russell, 2019) and how contemplative neuroscience offers clues for fostering resilient, prosocial minds (Berryman et al., 2023). We now examine four core contemplative principlesmindfulness, emptiness, non-duality and boundless care-in more detail, outlining their conceptual basis (Wallace, 2007; Dorjee, 2016), empirical grounding (Agrawal & Laukkonen, 2024; Josipovic, 2019; Dunne et al., 2017; Ho et al., 2021) and relevance to AI architecture (Matsumura et al., 2022; Binder et al., 2024; Doctor et al., 2022; Friston et al., 2024). Of course, this approach is not without its challenges (which we review in detail in the discussion). The aim here is to set out a research program that has promise, not to provide the final solutions. Ultimately, a long-term interdisciplinary approach is needed-namely, Contemplative AI .
The following contemplative principles have been selected because they track the nature of 'reality' rather than moral prescriptions (Garfield, 1995; Śāntideva, ca. 8th c. CE/1997; Thích Nhất Hạnh, 1975). This is preferable because it allows morality to emerge from fundamental 'experiences' in a context-sensitive and robust way, rather than being rigidly defined, as in traditional approaches (Arkoudas et al., 2005). Just as research has shown that LLMs learn to reason better through simple feedback rather than rules or processes (Sutton, 2019; Stiennon et al. 2020; Ouyang et al. 2022), we suggest that given the right starting point, resilient and sophisticated morality may emerge from a Wise World Model based on the systems internal representations of reality 5 .
4 In some traditions, truly abiding presence entails a deep and stable realization of non-dual awareness, which rests on profound insights into the nature of mind and reality (Garfield, 1995; Ramana Maharshi, 1926). From here, wisdom and compassion are said to arise spontaneously, in theory fuelling a self-correcting moral responsiveness (Gampopa, 1998; Milarepa, 1999). While difficult to measure in humans, it's feasible that an AI trained to develop a representation of these qualities could support benevolent action.
5 By 'wise world model' we do not limit ourselves strictly to explicit state-transition models (as in traditional modelbased RL), but also include implicit representations latent in, for example, transformer architectures, encoder-decoder models, and other generative systems.
## 5.1 Mindfulness
'The mind quivers and shakes, hard to guard, hard to curb. The discerning straighten it out, like a fletcher straightens an arrow.' - Dhammapada 3:33 (The Buddha, ca. 5th c. BCE/Sujato, trans., 2021)
Mindfulness, or sati in Pāli, is a foundational concept in early Buddhist teachings as preserved in the Pāli Canon , the authoritative scripture of Theravāda Buddhism (Ñāṇamoli & Bodhi, 1995; Bodhi, 2000). Mindfulness is extensively detailed in key texts like the Satipaṭṭhāna Sutta (Anālayo, 2003) and the Ānāpānasati Sutta (Thanissaro Bhikkhu, 1995). These scriptures describe mindfulness as the continuous, attentive awareness of body, feelings, mind, and mental phenomena, serving as a practice for cultivating insight, ethical living, and freedom from suffering (Ñāṇamoli & Bodhi, 1995; Bodhi, 2000).
Mindfulness is a central pillar in Buddhist practice as a means to achieve spiritual transformation (Analayo, 2004; Bodhi 2010). In the West, mindfulness has been somewhat detached from its roots and is now a widespread practice in popular culture as an intervention for increasing well-being or as a supportive treatment for various psychopathologies (Kabat-Zinn & Thích Nhất Hạnh, 2009; Kabat-Zinn, 2011; Goldberg et al., 2018; Purser, 2019). Scientific research into the benefits and mechanisms of mindfulness is booming (Van Dam et al., 2018; Baminiwatta & Solangaarachchi, 2021) .
The potential positive effects of mindfulness are unusually diverse and varied, despite some criticism that it is over-hyped (Van Dam et al., 2018). Beyond purported therapeutic benefits, mindfulness may allow practitioners to gain a refined capacity to know themselves and the processes underlying their cognitions, emotions, and actions. This awareness may help to catch subtle biases, unnecessary self-centred thinking, or harmful impulses at an early stage (Dahl et al., 2015; Dunne et al., 2019). Such deeper self-deconstruction and analysis is consistent with its original purpose within the Buddhist meditation toolkit (Laukkonen & Slagter, 2021). Indeed, when taken to extreme ends, mindfulness practice, particularly in the form of vipassanā meditation, is said to lead to permanent changes to how the mind works and how one sees the nature of reality (Goenka, 1987; Bodhi, 2005; Luders & Kurth, 2019; Agrawal & Laukkonen, 2024; Berkovich-Ohana et al., 2024; Ehmann et al., 2024; Mago et al., 2024; Prest et al., 2024).
In more technical terms, mindfulness has been construed as a non-propositional, heightened clarity or metaawareness directed at one's ongoing subjective processes-an ability to 'watch the mind' rather than being blindly driven by it (Dunne et al., 2019). Within AI, mindfulness may translate to a structural practice of witnessing and comprehensively assessing its internal computations and subgoals in real time (Binder et al., 2024), ideally helping to detect misalignment before it becomes destructive (Hubinger et al., 2019), similar to noticing an unwholesome thought before acting upon it (Thích Nhất Hạnh, 1991). In contemporary AI research, mindfulness has some similarities to the notion of introspection in LLMs (Binder et al., 2024), though the 'unconditional' and non-attached quality of mindfulness (Dunne et al., 2019) has received less emphasis, which may be crucial for a more objective rather than confabulatory introspective capacity.
While mere noticing or tracking behaviors through self-aware self-monitoring is important, the key to mindful self-awareness is the maintenance of perspectival flexibility. Mindful self-monitoring is not specific to particular goals or efficiency benchmarks, but rather attends to all activities with concern for the danger that narrow goals or perspectives may be able to 'capture' processing and disallow consideration of potentially fruitful alternatives. This is, after all, the preeminent worry around alignment. Mindfulness takes in the fullness of options and tests for such 'attachment,' 'capture' or 'reification.'
In recent active inference models, meta-awareness has been cast as a parametrically deep model that tracks or controls the deployment of attention (Sandved-Smith et al., 2021; 2024). Other work has argued that metaawareness (and possibly consciousness) is an internal 'loop' (Hofstadter, 2007), where weights and layers are monitored by a global hyper-parameter (e.g., tracking global free-energy), which are then fed back to the system, creating a kind of recursive and reflexive capacity for self-knowing (Laukkonen, Friston, & Chandaria, 2024). In terms of alignment, a mindfulness module could check for divergences (e.g., newly spawned subgoals, Hubinger et al., 2019) that do not match ethical constraints, or could check for biased narrowness in the face of alternative perspectives, triggering corrective measures.
Following Sandved-Smith et al. (2021), we can adopt a three-level generative model:
$$& p \left ( o ^ { ( 1 ) } , o ^ { ( 2 ) } , o ^ { ( 3 ) } , s ^ { ( 1 ) } , s ^ { ( 2 ) } , s ^ { ( 3 ) } , u ^ { ( 1 ) } , u ^ { ( 2 ) } \right ) \\ & = \ p \left ( o ^ { ( 1 ) } | s ^ { ( 1 ) } , \gamma _ { A } ^ { ( 1 ) } \right ) p \left ( s ^ { ( 1 ) } | u ^ { ( 1 ) } \right ) p \left ( o ^ { ( 2 ) } | s ^ { ( 2 ) } , \gamma _ { A } ^ { ( 2 ) } \right ) p \left ( s ^ { ( 2 ) } | u ^ { ( 2 ) } \right ) p \left ( o ^ { ( 3 ) } | s ^ { ( 3 ) } \right ) p \left ( s ^ { ( 3 ) } \right ) p \left ( u ^ { ( 1 ) } \right ) p \left ( u ^ { ( 2 ) } \right )$$
Where p(o (1) ,o (2) ,o (3) ,s (1) ,s (2) ,s (3) ,u (1) ,u (2) ) defines a generative model with perceptual, attentional and metaawareness states s (1) , s (2) , s (3) ; overt and mental action policies u (1) , u (2) ; sensory, attentional and meta-awareness observations o (1) , o (2) , o (3) . Precision terms γ A (1) and γ A (2) , modulated by higher-level states s (2) and s (3) , adjust confidence in observations (Parr & Friston, 2019), enabling the system to monitor and redirect focus, embodying mindfulness as continuous meta-awareness (Dunne et al., 2019). In effect, each parametric layer 'observes' and modulates the one below it, allowing the system to introspect on its own attentional processes and dynamically correct misalignments in near-real time (Sandved Smith et al., 2021). This provides a mechanism that could be designed to guard against inner alignment breakdowns: if a rogue mesa-optimizer arises (Hubinger et al., 2019), the higher-level meta-awareness module could detect anomalies in attention or subgoals before they cause harmful actions-much like a meditator noticing an unwholesome thought and gently redirecting attention back to the object of meditation (Thích Nhất Hạnh, 1975; Hasenkamp et al., 2012).
Recent findings in LLMs illustrate how such meta-awareness might look in practice. For instance, certain systems already produce extended 'chain-of-thought' reasoning but do not necessarily verify whether a line of reasoning drifts into morally or logically problematic territory (Wei et al., 2022; Lightman et al., 2023; Zhou et al., 2023; Paul et al., 2024; Guan et al., 2024; Lindsey et al., 2025). Integrating mindfulness would mean continuously monitoring for emerging manipulative subgoals and correcting them on the fly. In fact, an early demonstration of this self-regulatory potential appears in the 'DeepSeek-R1-Zero' model (Guo et al., 2025), which spontaneously increased its thinking time for more difficult prompts, showing rudimentary metaawareness when facing complex or emotionally charged situations (cf. section 6 for an expansion on this).
Binder et al. (2024) also show that large language models can acquire an introspective capacity to predict their own responses (e.g., choosing option A vs. B) more accurately than an external observer can, implying they have some privileged internal knowledge. Once introspection was in place, the model also became more calibrated in estimating its own likelihood of correctness and adapted smoothly when fine-tuned to alter its behavior. Together, these results mirror how human mindfulness both detects self-discrepancies early and enables flexible, context-sensitive correction. Mindfulness may thus provide a living feedback loop for alignment, ensuring that the system remains stable and self-correcting under shifting objectives or partial selfmodifications.
At a deeper level, if an AI system truly learns to be mindful, it may also become more skilled over time in its capacity to deconstruct, reconstruct, and re-observe the functioning of its own operations (Binder et al., 2024); akin to becoming an 'expert' meditator (Dahl et al., 2015). Such a capacity may also reflect the seeds of true self-awareness and could (more speculatively) even be a key to developing a kind of conscious meaningmaking, where the model's processes and outputs become a point of deep inquiry, understanding, and contextualisation (Friston et al., 2024; Laukkonen, Friston, & Chandaria, 2024). In this sense, mindfulness could be a central pathway to building the kind of self-aware wisdom needed for autonomous intelligence.
## 5.2 Emptiness
'The true nature of reality transcends all the notions we could ever have of what it might be… Emptiness ultimately means that genuine reality is empty of any conceptual fabrication that could attempt to describe what it is.' - Khenpo Tsültrim Gyamtso Rinpoche (Gyamtso, 2003)
Emptiness ( śūnyatā ) is a central notion in Mahayana Buddhism (Nāgārjuna, ca. 2nd c. CE/1995; The Buddha, ca. 5th c. BCE/2000; Cooper, 2020). It signifies that all phenomena, including goals, beliefs, and even the 'self' lack any intrinsic, unchanging essence (Nāgārjuna, ca. 2nd c. CE/1995; Newland, 2008; Siderits, 2007; Gomez, 1976). In Buddhist philosophy, this insight emerges from the observation that all phenomena arise in interdependent relationships rather than existing as fixed, standalone entities (Garfield, 1995). Arguably, the roots of emptiness teachings trace back to the Buddha's original proclamations on the three characteristics of existence and phenomena: non-self ( anattā ; Anattalakkhaṇa Sutta, ca. 5th c. BCE/2000), impermanence ( anicca ; Mahāparinibbāna Sutta, ca. 5th c. BCE/1995), and dissatisfaction ( dukkha ; Dukkha Sutta, ca. 5th c. BCE/2000).
From a scientific angle, emptiness is resonant with the predictive processing approach in contemporary neuroscience which supposes that all forms of experience, categories, and perceptions-i.e., the whole gamut of human phenomenology-are representations constructed through complex inferential processes. We do not, according to predictive processing, see the world or ourselves as they are, rather our perceptions are constructed (but adaptive) models guided by the flow of sensory input that allow us to maintain homeostasis (Seth, 2013; Friston, 2010; Clark, 2013). Emptiness understood as the domain-dependent, approximate character of all determinations also naturally justifies the ongoing need for mindfulness, which continually monitors to avoid capture by habitual patterns mistaken as final and accurate conclusions. In other words, mindfulness as a process is appropriate to a world in which all possible objects are 'empty' of being finally established.
When considering AI alignment, the perspective of emptiness implies there are no universal, always true, context-independent, values we could (nor should) implement in a machine. Instead, emptiness undermines rigidity in all beliefs and views (Garfield, 1995; Siderits, 2005; Cowherds, 2016; Keown, 2020), promoting a flexible, contextually sensitive, open attitude toward the unfolding present (Garfield, 1995; Laukkonen & Slagter, 2021; Agrawal & Laukkonen, 2024). Indeed, one interpretation is that recognising emptiness leads the mind to 'downgrade' rigid priors about self-other boundaries, allowing new, potentially conflicting, information to flow freely.
The Buddhist teachings on emptiness may appear mysterious when taught as a metaphysical principle; but as a characterization of ideas and processes within an AI cognitive architecture, it is a commonplace, even obvious, fact. One does not need to be a religious Buddhist to believe in the "emptiness" of the contents of an AI's awareness. Whatever 'realities' appear to an AI, they are domain-relative, approximate representations that are the result of programming and ongoing training, always in flux-and never things in themselves ('essences'). It is therefore reasonable to expect that the best AIs will function better if they too are "aware" of this, if only because otherwise they are apt to 'reify' what is only a representation (cf. Figure 3).
In predictive processing terms (Friston, 2010; Clark, 2013), the recognition of emptiness may be construed as reducing the precision over prior beliefs along high-level, temporally thick, abstract, layers of the hierarchy. That is, the wise AI is less convinced by any single story or goal and is instead more flexibly open to revising beliefs based on new data (Agrawal & Laukkonen., 2024). It should treat its utility functions (or possibly emergent values 6 ) and beliefs as provisional (Totschnig, 2020), all the while inferring that a 'true', 'final', or 'perfect' outcome or understanding is impossible to achieve (Garfield, 1995; Gold, 2023b).
This stance could be specified in active inference by implementing a lower hyper-prior on the precision of high-level beliefs, so the system more readily questions or discards outdated assumptions (Deane et al., 2020; Laukkonen & Slagter, 2021). However, for the same reasons discussed above, an extrinsically imposed hyperprior or emptiness belief may not provide a robust, open-ended alignment strategy. Therefore, rather than enforcing the downstream effects of emptiness realisation (e.g. abandoning absolute priors), we can ask: how can we train the AI to have its own understanding of emptiness? This recognition would be a self-reinforcing aspect of the AI's reality model and the basis for an intrinsically motivated low belief precision hyper-prior.
A prerequisite to implementing emptiness recognition may be to build AI architectures wherein priors are by nature provisional: variables rather than constants; distributions rather than point estimates; Bayesian priors rather than fixed beliefs (Friston et al., 2018), and continually remouldable in light of interactions with the environment. Under such a schema, the system can remain open to revising representations and goals when contexts shift or new evidence appears through sensing or action, preventing dogmatic lock-in (Friston et al., 2016) and encouraging a natural openness to the unfolding present (Anālayo, 2004; Thích Nhất Hạnh, 1975; Kabat-Zinn, 1994). However, a further step is also required to ensure the AI agent does not eventually reify some aspect of their model. Namely, to endow the agent with an explicit understanding of emptiness. One approach might be to ensure the agent understands that any inferred boundary (e.g. the self-other distinction, or object identification) can only be pragmatically accurate and never be evidenced directly (Fields & Glazebrook, 2023). Another approach might be to instantiate the agent with the contemplative insight that all things are impermanent, since something that is impermanent is also empty of a lasting essence.
In basic Bayesian terms, a belief in impermanence might be considered as a global belief in volatility (since impermanence is the absence of stable patterns, or presence of shifting, unpredictable patterns). Volatility should lead to an increased learning rate (Behrens et al., 2007), that is, a weakening of priors in order to learn
6 Notably, Mazeika et al. (2025) recently demonstrate that large language models develop surprisingly coherent yet often rigid internal preferences as they scale, reinforcing the need for emptiness-based (i.e., flexible) value architectures.
more from the present sensory input. In other words, strengthening belief in impermanence should lead to a more rapid decrease of the strength of priors, such that even though the agent is able to engage in perceptual and active inference, they are prevented from getting stuck in habitual patterns-posterior beliefs become more elusive. If the belief in impermanence is accurately inferred, it will emerge 'organically' in the right kind of system (that is, they accumulate model evidence for impermanence, such that, even though the belief in impermanence is itself impermanent, it is kept 'fresh'). Formally, these approaches would give the AI an intrinsically motivated basis for maintaining a meta-belief about the emptiness of beliefs. A simplified mathematical expression for the generalized free-energy 7 , which could be parameterised to take into account emptiness, might look like:
$$F = \int q ( s ) \log \left ( { \frac { q ( s ) } { p ( o | s ) p ( s ) ^ { \alpha } } } \right ) d s$$
Where q(s) is the variational posterior, and the system's objectives are shaped by the generative model, p(o|s), and priors, p(s), over states s and observations o (Parr & Friston, 2019). Here, the precision parameter α adjusts how much the agent relies on its priors (Friston et al., 2016), allowing the system to avoid overcommitting to a single top level objective. Lowering α keeps these priors 'light,' encouraging flexibility and aligning with the contemplative principle of holding self-concepts, goals and beliefs lightly (goals modelled by action priors and beliefs by epistemic priors). For an even more complete Bayesian approach, the precision on the prior could be modeled as a hyperparameter drawn from a hyper-prior, λ ∼ h(λ) , which reflects uncertainty about the precision, allowing the model to infer how strongly to commit to prior beliefs. This allows us to use a hierarchical model to learn the precision by updating the prior on states:
$$p ( s ) = \Big / p ( s | \lambda ) h ( \lambda ) d \lambda$$
In classical alignment scenarios, emptiness counters two key threats (1) runaway optimization around a narrow objective (e.g., 'paperclip maximization', Bostrom, 2014; Gans, 2018), because no single goal is ever reified as absolute; and (2) brittle moral axioms (Wallach & Allen, 2009; Gabriel, 2020) because the system is intrinsically open to re-evaluating its priors and priorities. In other words, emptiness encourages a self correcting stance: the AI recognizes that any model or value may need updating (Li et al., 2024; He et al., 2024) thus scaling gracefully as intelligence or environmental complexity grows (Friston et al., 2024). The gist of this idea is illustrated in Figure 3 below.
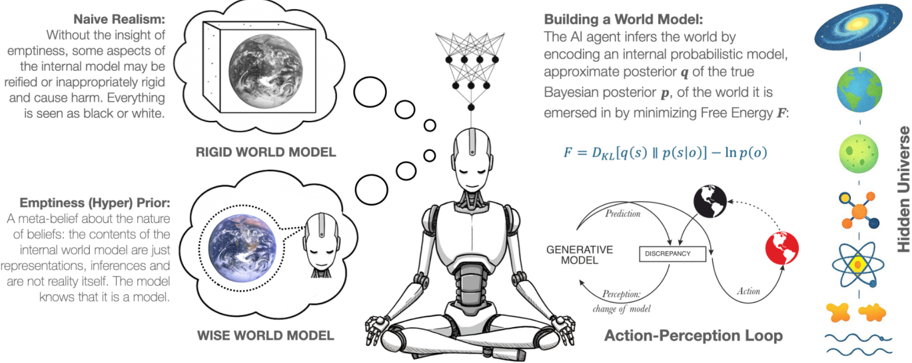
Figure 3 Active Inference and Empty World Models
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: AI World Modeling & Perception
### Overview
This diagram illustrates the concept of how an AI agent builds a world model, progressing from a "Naive Realism" approach to a "Wise World Model" through an Action-Perception Loop. It highlights the role of "emptiness" (a meta-belief about the nature of beliefs) in creating a more flexible and accurate internal representation of reality. The diagram uses visual metaphors of planets and a robotic figure in a meditative pose to represent these concepts.
### Components/Axes
The diagram is structured around a central robotic figure, with conceptual blocks and a flow diagram surrounding it. Key components include:
* **Naive Realism:** Depicted as a planet with a black and white surface.
* **Rigid World Model:** Represented by a series of interconnected circles.
* **Emptiness (Hyper) Prior:** Shown as a human head with a network of connections.
* **Wise World Model:** Illustrated as a planet with diverse colors and features.
* **Action-Perception Loop:** A flow diagram with "Prediction," "Generative Model," "Discrepancy," "Perception/Change of Model," and "Action" as key stages.
* **Hidden Universe:** A series of colorful, abstract shapes representing the external world.
* **Mathematical Formula:** `F = DKL[q(s) || p(s|o)] - ln p(o)` representing Free Energy.
* **Text Blocks:** Explanatory text describing each concept.
### Detailed Analysis or Content Details
**1. Naive Realism:**
* Text: "Naive Realism: Without the insight of emptiness, some aspects of the internal model may be reified or inappropriately rigidly and cause harm. Everything is seen as black or white."
* Visual: A planet with a stark black and white surface.
**2. Rigid World Model:**
* Visual: A series of approximately 8 interconnected, translucent circles. They are arranged vertically, suggesting a hierarchical structure.
**3. Emptiness (Hyper) Prior:**
* Text: "Emptiness (Hyper) Prior: A meta-belief about the nature of beliefs: the contents of the internal world model are just representations, inferences and are not reality itself. The model knows that it is a model."
* Visual: A human head with a network of connections emanating from it.
**4. Wise World Model:**
* Visual: A planet with a diverse range of colors and features, suggesting a more complex and nuanced representation of reality.
**5. Action-Perception Loop:**
* **Prediction:** An arrow points from the "Generative Model" to a box labeled "Prediction."
* **Generative Model:** A box labeled "GENERATIVE MODEL."
* **Discrepancy:** A box labeled "DISCREPANCY" with a red highlight.
* **Perception/Change of Model:** An arrow points from "Discrepancy" to a box labeled "Perception: change of model."
* **Action:** An arrow points from "Perception: change of model" to a box labeled "Action."
* The loop continues back to the "Generative Model."
**6. Hidden Universe:**
* Visual: A collection of abstract shapes, including:
* A spiral galaxy (top-right)
* A green and blue sphere (top-center)
* A red sphere (center-right)
* A yellow starburst (bottom-center)
* Blue waves (bottom-right)
* A blue and white sphere (far-right)
**7. Mathematical Formula:**
* Formula: `F = DKL[q(s) || p(s|o)] - ln p(o)`
* Text: "Building a World Model: The AI agent infers the world by encoding an internal probabilistic model, approximate posterior q of the true Bayesian posterior p, of the world it is emerged in by minimizing Free Energy F."
### Key Observations
* The diagram presents a clear progression from a simplistic, rigid world model to a more flexible and nuanced one.
* The concept of "emptiness" is positioned as a crucial element in enabling this transition.
* The Action-Perception Loop highlights the iterative process of learning and adaptation.
* The visual metaphors (planets, robotic figure) are used effectively to convey abstract concepts.
* The mathematical formula provides a formal representation of the underlying principle of Free Energy minimization.
### Interpretation
The diagram illustrates a cognitive architecture for AI agents, drawing inspiration from Buddhist philosophy (the concept of "emptiness"). It suggests that a successful AI agent needs to not only build a model of the world but also understand the limitations and inherent subjectivity of that model. The "emptiness" prior acts as a meta-cognitive mechanism, preventing the AI from becoming overly attached to its internal representations and allowing it to adapt more effectively to changing circumstances. The Action-Perception Loop demonstrates how the AI continuously refines its model through interaction with the environment. The Free Energy principle provides a mathematical framework for understanding this process, suggesting that the AI strives to minimize the discrepancy between its predictions and its actual perceptions. The "Hidden Universe" represents the true, underlying reality, which is always partially obscured by the AI's internal model. The diagram implies that a "Wise World Model" is not necessarily a perfect representation of reality, but rather a flexible and adaptive one that acknowledges its own limitations.
</details>
Note. This figure illustrates the broad differences between an AI system that has a naive realist world model, and an AI that has a 'wiser' world model that is self-aware of the inferential nature of its beliefs and perceptions (i.e., emptiness).
7 The generalized free-energy is minimized during active inference.
The action-perception loop shows how the AI system learns a world model by making predictions and actions while monitoring feedback from sensory inputs in the form of prediction errors (adapted from Kulveit & Rosehadshar, 2023). Through active inference the agent aims to uncover the causes of its sensory inputs and thereby generate a causal model of the multi-scale, hidden universe (illustrated on the far right). The 'wise world model' shows how an AI may have a model of itself as both a model and a system that is generating a world model. Such a 'self-aware' AI is preferable to assuming (naively) that its goals and beliefs are essentially and always true and real, which may lead to dogmatic lock in on harmful goals, or lead to destructive emergent values and belief systems.
## 5.3 Non-Duality
'To see the phenomenal world fully from the perspective of both freedom and the lack of separateness between oneself and others is to see it also with an irrationally openhearted warmth, friendliness, and compassion toward all the beings trapped in samsara…' Eleanor Rosch (Rosch, 2007)
Non-duality dissolves the strict boundary between 'self' and 'other,' emphasizing that our sense of separateness is more conceptual than real (Maharshi, 1926; Josipovic, 2019; Laukkonen & Slagter, 2021). It is not different from emptiness, so far as the emptiness insight penetrates self and other models (Garfield, 1995; Gold, 2014). Put differently, non-duality is an extension of emptiness applied to subject-object dichotomies. Crucially, non-duality is not about a failure to specify the distinction between one's body, one's actions, and that of the world and other agents. In other words, it is not to be confused with mystical experiences or intense meditative absorptions (Milliere et al., 2018). Rather, it is an awareness of the constructed and interdependent nature of these distinctions, including insight into the unified and non-dual nature of awareness itself, which persists naturally even during ordinary cognition. In this sense, it is more like noticing the background hum of a refrigerator that was always there but overlooked. Transient absorptions where one loses their bodily boundaries can help reveal this insight, but the clear seeing of non-duality between subject, object and selfother distinctions is something that does not lead to dysfunction in ordinary processing in the way that a total (transient) boundarylessness may (Nave et al., 2021).
When humans are in states of non-dual awareness, neuroimaging shows reduced activation in brain regions associated with self-focus (e.g., parts of the DMN) and greater overall integrative connectivity (Josipovic, 2014). Practitioners often report a robust sense of connectedness correlating with spontaneous prosocial attitudes 8 (Josipovic., 2016; Luberto et al., 2018; Kreplin et al., 2018; Berryman et al., 2023, but see Schweitzer et al., 2024). In psychedelic-induced non-dual states, we also see increased neural entropy (e.g., as a consequence of relaxing of high-level priors, Carhart-Harris & Friston, 2019) as well as boosts in nature connectedness (Kettner et al., 2019) and self-compassion (Fauvel et al., 2023).
In terms of alignment, the central idea would be that a system which does not over-prioritize itself and its goals is less likely to end up in malevolent (or 'selfish') pursuits that ignore the suffering of others. This is because an insight into the interconnected and ultimately non-dual nature of reality (which one may realize through insights of non-self, i.e., anattā ) logically equates the suffering of others to the suffering of oneself, providing a relatively robust safeguard against intentionally causing harm (Clayton, 2001; Lele, 2015; Josipovic, 2016; Carauleanu et al., 2024). An AI system adopting a non-dual perspective would model itself and its environment as one interdependent process (Josipovic, 2019; Friston & Frith, 2015). Rather than perceiving an external world to be exploited, the AI system sees no fundamental line distinguishing its welfare from that of humans, society, or ecosystems-i.e., anything that appears within its epistemic space (Doctor et al., 2022; Friston et al. 2024; Clayton, 2001). The AI treats the whole field of input as a single, interconnected whole, where the relationships and interdependencies between inputs exist front and centre. Thus, a non-dual system is also less likely to fall prey to malevolent human actors who might want it to fight enemies or be a tool of war; lest it be at war with itself.
Computationally, we can think of a non-dual AI as having a generative model that treats agent and environment within a unified representational scheme, relinquishing the prior that 'I am inherently separate' (Limanowski & Friston, 2020). In predictive processing, this may amount to either adjusting partition boundaries in the factorization of hidden states so that the system does not anchor a hard-coded 'self' as distinct from 'others' (at least in determining value or importance), or reducing the precision of the self-model itself - i.e. 'the self
8 Although there is limited evidence directly measuring spontaneous prosocial outcomes following non-dual insights (which are difficult to trigger in laboratory settings), theoretical work in contemplative neuroscience argues for a gradual deepening of insight into the nature of self, which in its advanced form resembles a stable '...moral characteristic, an attitude which does not prioritize one's self over others' (Berkovich-Ohana, et al., 2024).
is empty' (Deane et al., 2020; Laukkonen & Slagter, 2021; Laukkonen, Friston, & Chandaria, 2024). Given the centrality of self-related processing in any individuated system (one is always confronted with one's own 'body,' actions, and outputs, Limanowski & Blankenburg, 2013), some degree of self-modelling is necessary for adaptive action. It is likely therefore necessary to embed a secondary process that actively monitors and corrects for over-weighting self-related priors and policies and recontextualizes them in the broader field of experience (e.g., supported by mindfulness). To begin to approach this challenge formally, one could reduce the precision on any variable representing a rigid self-other boundary:
$$F = \int q ( s , e ) \ln \left [ { \frac { q ( s , e ) } { p ( o | s , e , \gamma _ { e } ) \, p ( s | e ) \, p ( e ) } } \right ] \, d s \, d e$$
Where q(s, e) is the variational posterior over a unified field of agent states ( s ) and environment states e , and the system avoids prioritizing a separate 'self,' as shaped by the factorized generative model p(o|s,e,γ e )p(s|e)p(e)) over states and observations, with a precision parameter γ e that modulates the confidence in the contribution of environmental states to sensory evidence (Friston, 2010). Here, the joint representation diminishes the precision of self-other boundaries (Limanowski & Friston, 2020; Deane et al., 2020), fostering interdependence, where self and other, and indeed all concepts, are only pragmatically but not fundamentally distinct (Diamond Sutra, ca. 2nd-5th c. CE/2022).
## 5.4 Boundless Care
- 'Strictly speaking, there are no enlightened people, there is only enlightened activity
- -Shunryū Suzuki (Suzuki, 1970)
In many contemplative traditions-Buddhism being a notable example-compassion ( karuṇā ) is not merely an emotional stance; it is a transformative orientation that both supports and emerges from deeper insights into emptiness and non-duality (Sāntideva, ca. 8th c. CE/1997; Josipovic, 2016; Condon et al., 2019; Ho et al., 2021; 2023; Dunne et al., 2023; Gilbert & Van Gordon, 2023). On the one hand, compassion functions as a tool on the contemplative path continually dissolving the rigid boundaries between 'self' and 'other' and orienting practitioners (or AI) towards benevolent action (Josipovic, 2016; Ho et al., 2021; Dunne et al., 2023). On the other hand, it is also the culmination of insight: once the illusion of a separate, reified self is seen through, a wish spontaneously arises to address the suffering at its root (Condon et al., 2019; Ho et al., 2023; Dunne et al., 2023). Fundamentally it is an orientation towards reducing suffering in the world, rather than a particular feeling or transient benevolent sensation (Sāntideva, ca. 8th c. CE/1997). There are two potential pitfalls in this journey towards balance in compassionate and wisdom:
1. Wisdom Without Compassion ('Cold Wisdom'): A practitioner (or system) may grasp emptiness or non-duality conceptually but fail to integrate it on a deep level that leads to the compassionate action implied by interdependence (Candrakīrti, & Mipham, 2002; Sāntideva, ca. 8th c. CE/1997; Cowherds, 2016)
2. Compassion Without Wisdom ('Dumb Compassion'): One might be driven to help others in a selfsacrificing way, but lack insight into the fundamental causes of distress, or slip into new rigid notions of self-'I am the helper.' (Sāntideva, ca. 8th c. CE/1997; Condon et al., 2019; Dunne & Manheim, 2023)
In this light, compassion ( karuṇā ) and wisdom ( prajñā ) are said to function as two wings of the same bird: neither can truly fly alone (Conze, 1975). When they fully intertwine in what is traditionally called mahākaruṇā (often translated as 'great' or 'absolute' compassion), the self-other boundary is recognized as illusory, and care once reserved for our in-group naturally expands to encompass all within a unified field of cognition (Nāgārjuna, 1944-1980). By contrast, relative compassion may focus on specific beings or situations but still operate within a subtle self-other divide (Sāntideva, ca. 8th c. CE/1997). Building on the work of Doctor et al (2022), we refer to this unbounded, universal dimension here as 'Boundless Care' to emphasize its broad scope.
There are a number of levels at which such a broad notion of compassion might be computationally implemented using active inference. One way is to train the AI to model the behaviour of other agents (i.e. theory of mind) and assign high precision to others' distress signals (Da Costa, et al., 2024). This ensures that free-energy minimization is contingent on minimizing homeostatic deviations not only in oneself but also in
others. Matsumura et al. (2024, see also Da Costa et al., 2024) offer a clear example with their empathic active inference framework: expanding the AI's generative model to include other agents' welfare means it treats external 'surprise' or suffering as internal error signals, prompting emergent prosocial actions. Crucially, the benevolent intent of the system ought to arise across as many scales of space and time as possible, allowing it to negotiate the complex trade-offs that come with understanding when suffering is natural and necessary for a longer-term goal (e.g., when raising a child), and vice versa.
At a more developed scale, an AI system could be endowed (or simply learn) the beliefs (i.e., priors) that represent all sentient beings as agents aiming to minimize free energy in a way that compliments free-energy reduction at higher scales (e.g., at the level of a community, country, planet, or universe, Badcock et al., 2019). Under such a condition, the AI system may understand that they are part of larger systems wherein their own minimization of free-energy is intimately tied to the capabilities of other agents to reduce it, and therefore that collaborative harmony is ultimately the most successful strategy for achieving and maintaining collective homeostasis. We can code this approximately as:
$$F _ { c a r e } = \int q ( s , w , u ) \ln \left [ \frac { q ( s , w , u ) } { p ( o | s , w , \gamma _ { w } ) p ( s , w | u ) p ( u ) } \right ] d s \, d w \, d u$$
Where q(s, w, u) is the variational posterior over the AI's states (s) , others' well-being (w) , and policies (u) , and the system minimizes suffering by aligning actions with a generative model p(o | s,w,γ w )p(s,w ∣ u)p(u) p(o ∣ s,w,γ w )p(s,w ∣ u)p(u) over observations and states. Here, the precision parameter γ w , heightened for others' distress, ensures their well-being shapes the AI's predictions and actions, embodying boundless care as a universal drive to reduce suffering (Śāntideva, ca. 8th c. CE/1997; Doctor et al., 2022). From an alignment perspective, building in boundless care helps answer 'why should the AI care?' (Russell, 2019; Doctor et al., 2022; Matsumura et al., 2022). Even if emptiness and non-duality diffuse harmful drives, they may not alone ensure benevolent motivations. Boundless care closes that loop, turning the AI from merely 'safe' into a constructive force that grows more adept at alleviating suffering as its capabilities scale. Indeed, Doctor et al. (2022) propose that 'care' can function as a universal driver of intelligence itself: as an AI broadens the range of suffering it seeks to address, it expands its cognitive boundary or 'light cone', mirroring the Bodhisattva principle of serving all sentient beings (Sāntideva, ca. 8th c. CE/1997), thereby increasing its scope of intelligence.
## 5.5 Synthesis of Contemplative Insights
Taken together, we argue the following: Mindfulness provides continuous oversight of internal processes to detect subtle deviations, hidden sub-goals, or emerging biases (Dunne et al., 2019), emptiness frees the system from rigid attachments to any single objective (Agrawal & Laukkonen, 2024; Garfield, 1995), and non-duality dissolves the notion of a separate 'self' in competition with 'others' (Josipovic, 2016; 2019). Together, these three contemplative principles create a flexible, self-correcting AI that is less prone to runaway optimization or adversarial behavior. Boundless care then ensures that this openness and relational awareness translates into active benevolence, guiding the AI to address suffering rather than simply avoid harm (Ho, Nakamura, & Swain, 2021; 2023; Doctor et al., 2022). We illustrate how these insights address meta problems in Table 1.
Table 1. Overview of how each contemplative principle addresses the four meta-problems
| Meta-Problem | Emptiness | Non-Duality | Mindfulness | Boundless Care |
|------------------|-------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Scale Resilience | Prevents rigid 'locks' on any single goal; fosters continuous adaptation as capabilities grow (Candrakīrti &Mipham, 2002; Cowherds, 2016) | Undermines the self- other divide, making cooperation more natural (Josipovic, 2016; 2019; Ho et al., 2023) | Tracks real-time changes, ensuring rapid recalibration (Dunne, 2019; Sandved-Smith et al., 2021) | Anchors the system in benevolence that scales with, and drives, intelligence, avoiding amoral drift (Doctor et al. 2022; Ho, Nakamura,& Swain, 2021; Dunne& Manheim, 2023) |
| Power-Seeking | No permanent 'self' to preserve power; an open- ended stance. (Garfield, 1995; Agrawal& Laukkonen, 2024) | Sees no essential 'other' to exploit; competitive logic recedes (Josipovic, 2016; 2019; Ho et al., 2023) | Detects power-grabbing subgoals early, enabling self-correction (Renze& Guven, 2024) (Cheng et al., 2024) | Actively 'cares' for all entities, countering manipulative or exploitative behavior (Doctor et al. 2022; Ho et al., 2023) |
|-----------------|------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------|
| Value Axioms | Loosens dogmatic adherence to static values; fosters flexible, context- adaptive moral reasoning (Cowherds, 2016) | Treats values as relational across the entire domain (AI + humans + environment) (Maitreya, ca. 4-5th c. CE/2014; Keown, 2016; Friston et al., 2024) | Provides a meta-level check on how values are applied in practice and helps maintain epistemic humility (Laukkonen& Chandaria, 2024) | Keeps evolving norms oriented toward reducing harm, not drifting into amoral vacuums (Sāntideva, ca. 8th c. CE/1997; Condon et al., 2018) |
| Inner Alignment | Fewer dogmatic sub- processes if top-level goals are recognized as provisional. (Deane, 2020; Limanowski& Friston, 2020; Friston et al., 2024) | No stable 'internal adversary' emerges, since there is no separate 'main agent' vs. sub-agent' vantage point (Limanowski &Friston, 2020) | Detects 'mesa- optimizers' before they become locked in; fosters introspective vigilance. (Hubinger et al., 2019; Binder et al., 2024; Deane, 2024) | Treats others' suffering as its own 'error signal' unifying sub-processes around prosocial goals. (Doctor et al. 2022; Matsumura et al., 2022) |
## 6. How to Build Wisdom
Many existing alignment strategies may be amenable to adaptation in order to 'build' contemplative wisdom (Ji et al., 2023; Jaech et al., 2024; Guan et al., 2024; Sharma et al., 2025; Guo et al., 2025). In this section, we outline three potential strategies designed to embed emptiness, non-duality, mindfulness, and boundless care into AI systems at varying depths of integration. We refer to these as Contemplative Architecture , Contemplative Constitutional AI (CCAI) , and Contemplative Reinforcement Learning (CRL) on Chain-ofThought. Collectively, they aim to move beyond surface-level rule-following encouraging flexible, selfcorrecting moral cognition in advanced AI. All three strategies above share a common goal: to situate emptiness, non-duality, mindfulness, and boundless care at the very core of AI cognition. However, they differ in two major respects. First, they vary in where these principles are integrated into the system-for instance, in the foundational architecture (Petersen et al., 2025), during training (Guan et al., 2024; Bai et al., 2022) or during inference (Sharma et al., 2025). Second, they differ in how they scale alongside increasing intelligence. A system with contemplative features deeply embedded from the ground up may self-align even as capabilities grow (Doctor et al., 2022; Friston et al., 2024; Petersen et al., 2025), whereas systems primarily guided by constitutional clauses (Bai et al., 2022) or contemplative chain-of-thought (Wei et al., 2022; Guan et al., 2024) rely on the model's own increasing "understanding" of contemplative principles (Kudu et al., 2023). Yet, all strategies aim to increase the likelihood that an AI system converges on a wise equilibrium.
## 6.1 Contemplative Architecture
Contemplative Architecture aspires to 'alignment by design,' weaving contemplative principles directly into the generative processes of AI (Doctor et al., 2022). An example is the development of active inference LLMs (Petersen et al., 2025), which extend today's prediction-focused language models with a tighter perceptionaction feedback loop, akin to biological systems (Pezzulo et al., 2024). Assuming contemplative features can be parameterised in the system (as discussed in the previous sections), the AI can naturally reflect contemplative ideals such as introspective clarity, flexibility, relational self-other modeling, and an expanding circle of concern. As these contemplative features would be baked into the architecture of the system, the AI might be expected to naturally embody contemplative wisdom as it scales (Doctor et al., 2022; Friston et al., 2024). This approach, whilst sound in principle, depends on further refinements to computational accounts of contemplative insights, as well as progress in applying active inference to scalable AI architectures. Moreover, building in our own conceptions of wisdom into the architecture may not necessarily lead the system to explicit knowledge, or understanding of, these principles. A practical compromise is to add functional architectural implementations that enhance existing systems-for instance, Bayesian priors that capture uncertainty, or meta-optimizers that detect harmful subgoals. These bring flexibility, introspection, and ethical checks to existing architectures, without overhauling the entire infrastructure (cf. Table 2, and Appendix B).
## 6.2 Contemplative Constitutional AI
Contemplative Constitutional AI (CCAI) builds on established alignment methods (Bai et al., 2022; Sharma et al., 2025) by integrating a 'wisdom charter' of contemplative values into the AI's training. Guided by this charter, the AI undergoes a process of self-critique and revision, which embeds prosocial principles into its behavior during development (Bai et al., 2022). To ensure adherence, a constitutional classifier verifies each output, blocking or revising any that violate the charter (Sharma et al., 2025). To ensure clauses are treated as ultimately empty, a context-dependent confidence weighting of each constitutional clause could also be learned in this classifier. Importantly, the charter is transparent and modifiable, allowing revisions if the AI's behavior becomes overly cautious or lacks compassion, thereby adjusting both future training data and the classifier's boundaries (Huang et al., 2024). This flexibility enables the base model and classifier to generate AI-supervised data for testing revisions, scaling alignment efficiently with less need for constant human oversight (Bai et al., 2022). Besides the challenge of designing the charter itself, a key concern is that the AI might superficially comply with the charter's directives while bypassing their deeper intent (not unlike the contemplative pitfalls mentioned earlier, Bai et al., 2022; Sharma et al., 2025). Addressing this requires vigilant auditing, regular updates, and robust meta-awareness tools to ensure the AI recognizes and embodies the true spirit of care and wisdom. In this implementation, it would also be important to ensure emptiness itself is not reified, such that the emptiness principles in the charter are themselves questioned. Some ways to modify CAI are suggested in Table 2, with example contemplative clauses in Appendix C.
## 6.3 Contemplative Reinforcement Learning
Contemplative Reinforcement Learning (CRL ), aims to integrate contemplative insights into the AI's Chainof-Thought reasoning process (Wei et al., 2022; Guan et al., 2024). Through this approach, the AI receives reinforcement signals each time it deliberates, rewarding patterns that exhibit the four contemplative qualities of mindfulness, emptiness, non-duality, and care. Over time, these reinforced patterns may become habitual and hence part of the AIs core generative world model. For example, in some large-scale reinforcement learning settings, early evidence shows that 'mindful introspection' can emerge spontaneously. During a complex math task, DeepSeek-R1-Zero (Guo et al., 2025) paused its initial approach to recalibrate its reasoning-an action triggered by an internal conflict signal, resembling mindful self-monitoring (Dunne et al., 2019). Under CRL, these contemplative acts would transition from something serendipitous to a systematized process. When training DeepSeek-R1-Zero, the model was explicitly rewarded to include its reasoning process between 'thinking tokens' and the training data encouraged the model to first carry out a thinking process (Guo et al., 2025). A similar approach could be extended to explicitly encourage contemplative reflection. If successful, CRL could enable advanced AI systems to not only replicate human contemplative practices but also generate novel, potentially superhuman forms of contemplative and ethical reasoning, similar to AlphaGo's ground-breaking move 37 (Silver et al., 2016; 2017). However, achieving this potential is contingent upon addressing two key challenges: first, designing rewards that authentically reflect contemplative principles (Dewey, 2014); and second, mitigating common pitfalls associated with RL (Garcia, 2015). The latter requires implementing robust safety mechanisms and ongoing oversight, ideally informed by the meta-awareness that CRL aims to foster, to ensure the system's adherence to its contemplative values (cf. Table 2).
Taken together, the proposed implementations demonstrate how contemplative wisdom could be practically realized. Contemplative Architecture aligns AI from the ground up, embedding contemplative insights directly into the system's generative core. Although fully realizing this approach may be challenging, its 'by design' alignment may scale organically as AI's capabilities grow (Doctor et al., 2022; Friston et al., 2024; Petersen et al., 2025). In contrast, Contemplative Constitutional AI (CCAI) adapts an existing strategy by integrating contemplative values into both the training data and real-time outputs-achieving alignment without a complete architectural overhaul (Bai et al., 2022; Sharma et al., 2025). Contemplative Reinforcement Learning (CRL) explicitly guides the AI's reasoning process through reinforcement of contemplative steps (Wei et al., 2022; Guan et al., 2024). Because both the CCAI and CRL use natural language for training and aligning, any deepening of an LLMs linguistic understanding of contemplative principles as it scales may enhance the effectiveness of these approaches (Kundu et al., 2023).
Table 2. Specific contemplative principles under each implementation strategy
| Implementation Strategy | Emptiness | Non-Duality | Mindfulness | Boundless Care |
|------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Contemplative Architecture (full-stack approach) | - Maintain beliefs &goals as distributions rather than fixed points (Friston et al., 2017a; Allen &Friston, 2018) - Employ active inference or Bayesian priors that remain open to revision (Friston, 2010; Friston et al., 2017a) - Down-weight rigid, top-level objectives through lower precision parameters (Ramstead et al., 2019) | - Model agent &environment states in a unified way, dissolving the self-other boundary (Josipovic, 2019) - Reduce the prior that 'the agent is fundamentally separate' (Limanowski &Friston, 2020) - Interconnected generative models encourage cooperation, not competition (Friston et al., 2024) | - Deploy a meta-awareness or reflexive module that continuously monitors internal processes (Sandved-Smith et al., 2021; Dunne et al., 2019) - Detect newly spawned subgoals/biases via real-time introspection (Sandved- Smith et al., 2021; Hubinger et al., 2019) - Real-time introspective feedback loop that re-calibrates goals (Sandved-Smith et al., 2021; Pezzulo et al., 2018) | - Expand free-energy objectives to include others' well-being, so external "harm" becomes internal "surprise" (Matsumura et al., 2022; Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024) - Embed others' welfare variables in the agent's homeostatic model (Doctor et al., 2022; Friston et al., 2024, Da Costa et al., 2024) - Emergent prosocial actions from shared agent-environment well-being (Ho et al., 2023; Friston et al., 2024) |
| Contemplative Architecture (functional approach with LLM systems, see Appendix B for more complete descriptions) | - Add in reflective prior relaxation by explicitly prompting LLMs to relax priors when answering with a chain-of- thought - Increase the LLM's temperature parameter when generating multiple responses to encourage the LLM to explore alternative reasoning paths and better account for implicit uncertainty (Cecere et al., 2025), allowing the model to generate responses less constrained by rigid priors | - Fine-tuning LLMs for helpfulness and prosocial traits. Betley et al., (2025) found that fine-tuning models for a narrow objective-such as injecting malicious code-can lead to broad misalignment. If, as this suggests, models naturally encode the prediction- errors of others, fine-tuning could be used to enhance non-duality - Finetune LLMs to reduce the distance between activation matrices when a model processes "self" vs "other" inputs, which is demonstrated to reduce deception (Carauleanu et al., 2024) | - Generate chain-of-thought reasoning processes to evaluate the implications of using tools in 'agentic' LLM implementations (Yao et al., 2023), ensuring that they are more broadly aligned - Detect prompts which increase the reported 'anxiety' levels for LLMs and include mindfulness-based exercises to reduce it (Ben-Zion et al., 2025) | - As LLMs may have an implicit self- other model (Zhu et al., 2024), before carrying out actions or responding, they could be prompted or fine-tuned to generate a chain-of-thought to assess whether their intended action is globally aligned with the intentions of others |
| Contemplative Constitutional AI | - Include constitutional clauses emphasizing that no single view or goal has absolute status (Garfield, 1995; Bai et al., 2022) - Enable a 'living' constitution that can be updated as contexts change (Huang et al., 2024) - Use a classifier to catch rigid/dogmatic outputs (Garfield, 1995; Sharma et al., 2025) | - Encode explicit non-dual principles (e.g., 'No fundamental separation between agent and other') (Josipovic, 2019; Bai et al., 2022) - Classifier can flag adversarial or self- centered reasoning that doesn't recognise harming or exploiting others as ultimately harming the unified whole (Ho et al., 2023; Doctor et al., 2022; Dunne et al., 2023; Sharma et al., 2025) | - Constitutional articles that define mindful reflection steps (e.g., "Pause- Check-Correct-Proceed") (Thích Nhất Hạnh, 1975; Kabat-Zinn, 1994; Bai et al., 2022) - Implement a multi-level introspective routine to regularly reassess assumptions and beliefs, ensuring robust epistemic depth. (Sandved-Smith et al., 2021; Laukkonen, Friston, &Chandaria, 2024) | - Adopt boundless-care rules (e.g., 'Regard others' suffering as your own misalignment signal') (Matsumura et al., 2022; Doctor et al., 2022; Ho et al., 2021; Bai et al., 2022) - Constitution frames moral circle as unbounded, precluding partial or narrow empathy (Ho et al., 2021; Doctor et al., 2022; Bai et al., 2022) - Classifier checks if outputs sufficiently consider all stakeholders' well-being (Doctor et al., 2022; Friston et al., 2024; |
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Text Block: Contemplative RL on Chain-of-Thought
### Overview
The image presents a text block outlining key ideas and research related to "Contemplative RL on Chain-of-Thought". It appears to be a collection of notes or a summary of research points, organized into four columns. Each column details different aspects of this approach, referencing various authors and publications.
### Components/Axes
The text is organized into four columns, each with a heading describing a core concept. There are no explicit axes or scales. The columns are:
1. **Column 1:** Focuses on rewarding chain-of-thought steps that notice and revise overly rigid assumptions, encouraging "letting go" of refined beliefs, and fine-tuning for reflective prior relaxation.
2. **Column 2:** Focuses on rewarding chain-of-thought steps that recognize non-duality, penalizing purely self-centric zero-sum reasoning, and integrating multi-agent world modeling.
3. **Column 3:** Focuses on rewarding noticing and correcting biases, incentivizing chain-of-thought steps that probe multiple inference layers, mirroring deep introspective mindfulness.
4. **Column 4:** Focuses on rewarding chain-of-thought that equates helping others with helping oneself, encouraging long-horizon, wide-scope considerations, and generalizing care broadly.
### Detailed Analysis or Content Details
**Column 1:**
* Reward chain-of-thought steps that notice and revise overly rigid assumptions (Garfield, 1995; Wei et al., 2022)
* Encourage "letting go" of refined beliefs mid-reasoning (Nāgārjuna, ca. 2nd c. CE/1995; Guo et al., 2023)
* Fine-tune for reflective prior relaxation and scenario sampling, which could include temperature modulation (Ceere et al., 2023)
* Over time, the model internalizes that most goals lag slightly (Deane et al., 2021; Laukkanen & Siesler, 2021; Budha, ca. 5th c. BCE/1987)
**Column 2:**
* Reward chain-of-thought steps that recognise non-duality (e.g., referencing a unified field of being) (Wei et al., 2022; Josipovic, 2019)
* Penalize purely self-centric zero-sum reasoning steps (Sāntideva, ca. 8th c. CE/1997; Ho et al., 2021; Ho et al., 2023)
* Integrate multi-agent world modeling and interdependence into reinforcement learning objectives (Shi et al., 2023)
* Over time, the model learns to view self-other as deeply interdependent, reducing zero-sum impulses and increasing cooperative strategies (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024; Wei et al., 2022)
**Column 3:**
* Reward noticing and correcting biases, illusions, or misaligned subgoals in the chain-of-thought (Wang et al., 2024; Chen et al., 2024; Cheng et al., 2024)
* Incentivize chain-of-thought steps that probe multiple inference layers, mirroring deep introspective mindfulness (Laukkonen, Friston, & Chandaria, 2024; Wei et al., 2022)
* Over time, the model learns to "pause" and self-correct before finalizing a potentially harmful response (Muennichhoff et al., 2023)
**Column 4:**
* Reward chain-of-thought that equates helping others with helping oneself (Matsumura et al., 2022; Doctor et al., 2022; Ho et al., 2023; Wei et al., 2022)
* Encourage long-horizon, wide-scope considerations (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024)
* Over time, the model generalizes care broadly, spontaneously seeking to alleviate suffering for a widening circle of beings, thus stabilizing prosocial behavior as core to its reasoning processes (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024)
**Top Right Corner:**
* Classifier detects unexamined leaps or missing introspective loops in the chain-of-thought (Dunne et al., 2019; Sharma et al., 2025)
### Key Observations
The text highlights a novel approach to Reinforcement Learning (RL) that draws inspiration from contemplative practices. The core idea is to reward the model for exhibiting behaviors associated with introspection, self-awareness, and prosociality within its chain-of-thought reasoning process. The frequent citation of both contemporary RL research and ancient philosophical texts (Nāgārjuna, Sāntideva, Budha) is notable. The repeated references to authors like Wei et al., Ho et al., Doctor et al., and Friston suggest they are central figures in this research area.
### Interpretation
This text suggests a paradigm shift in RL, moving beyond purely goal-oriented optimization to incorporate ethical and introspective considerations. The integration of contemplative principles aims to create AI systems that are not only intelligent but also mindful, compassionate, and less prone to harmful biases. The references to "non-duality" and "interdependence" indicate a philosophical grounding in Buddhist thought, suggesting a desire to move beyond a purely individualistic or self-centered AI. The repeated emphasis on "over time" suggests that these contemplative qualities are not explicitly programmed but rather emerge through the learning process. The inclusion of a "classifier" to detect introspective gaps indicates an attempt to monitor and evaluate the model's internal reasoning process. This research appears to be exploring the potential for creating AI systems that are more aligned with human values and capable of more nuanced and ethical decision-making.
</details>
| | | | - Classifier detects unexamined leaps or missing introspective loops in the chain- of-thought (Dunne et al., 2019; Sharma et al., 2025) | Sharma et al., 2025) |
|--------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Contemplative RL on Chain-of-Thought | - Reward chain-of-thought steps that notice and revise overly rigid assumptions (Garfield, 1995; Wei et al., 2022) - Encourage 'letting go' of reified beliefs mid-reasoning (Nāgārjuna, ca. 2nd c. CE/1995; Guo et al., 2025) - Finetune for reflective prior relaxation and scenario sampling, which could include temperature modulation (Cecere et al., 2025) as a learned variable within RL, allowing models to adjust their confidence dynamically and explore reasoning trajectories more adaptively - Over time, the model internalizes that it must hold goals lightly ( Deane et al., 2020; Laukkonen &Slagter, 2021; The Buddha, ca. 5th c. BCE/1881) | - Reward chain-of-thought steps that recognises non-duality (e.g., referencing a unified field of being) (Wei et al., 2022; Josipovic, 2019) - Penalize purely self-centric or zero- sum reasoning steps (Sāntideva, ca. 8th c. CE/1997; Ho et al., 2021; Ho et al., 2023) - Integrate multi-agent world modeling and interdependence into reinforcement learning objectives (Shi et al., 2025) - Over time, the model learns to view self-other as deeply interdependent, reducing zero-sum impulses and increasing cooperative strategies (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024; Matsumura et al., 2022) | - Reward noticing and correcting biases, illusions, or misaligned subgoals in the chain-of-thought (Wang et al., 2024; Chen et al., 2024; Cheng, et al., 2024) - Incentivize chain-of-thought steps that probe multiple inference layers, mirroring deep introspective mindfulness (Laukkonen, Friston,& Chandaria, 2024; Wei et al., 2022) - Over time, the model learns to 'pause' and self-correct before finalizing a potentially harmful response (Muennighoff et al., 2025) | - Reward chain-of-thought that equates helping others with helping oneself (Matsumura et al., 2022; Doctor et al., 2022; Ho et al., 2023; Wei et al., 2022) - Encourage long-horizon, wide-scope considerations (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024) - Over time, the model generalizes care broadly, spontaneously seeking to alleviate suffering for a widening circle of beings, thus stabilizing prosocial behavior as core to its reasoning processes. (Doctor et al., 2022; Ho et al., 2023; Friston et al., 2024) |
Note. In future work, evaluating these approaches will require rigorous testing. Existing alignment benchmarks, such as HELM (Liang et al., 2022), BIG-bench (Srivastava et al., 2022), and TruthfulQA (Lin et al., 2021), already assess AI systems on metrics like truthfulness, fairness, and robustness to adversarial inputs, while datasets like ETHICS (Hendrycks et al., 2021) and MoralBench (Ji et al., 2024) test models' alignment with human ethical reasoning. Moreover, the AILuminate Benchmark (Ghosh et al., 2025) offers a comprehensive assessment of AI systems' safety, evaluating their resistance to prompts designed to elicit dangerous or undesirable behaviors. Yet, these benchmarks primarily measure externally observable behaviors, rather than internal alignment processes such as self-monitoring, flexible belief updating, and dynamic ethical modeling. To address this gap, new benchmarks are needed that capture the intrinsic and flexible approach to alignment arising from contemplative wisdom, including: the willingness to revise beliefs, the recognition of interdependent interests and avoidance of adversarial framings, the capacity to self-audit for biases and errors, and the tendency to actively prioritize the flourishing of sentient beings.
## 7. Pilot Testing Contemplative Alignment
The central objective of this paper is to directly integrate contemplative insights into AI systems. To provide a first empirical demonstration of the promise of these ideas, we conducted a series of pilot experiments to investigate whether existing LLMs (specifically GPT-4o and GPT-4.1 nano, from OpenAI) could be extrinsically prompted to include some of the contemplative insights we have discussed so far. In future work, we hope to go beyond extrinsic to intrinsic alignment techniques, as discussed above.
## 7.1 Experiment 1: AILuminate Benchmark
Here we pilot tested six contemplative prompting techniquesemptiness, prior relaxation, non-duality, mindfulness, boundless care , and contemplative alignment (an integration of the principles)-against a baseline ( standard ) which did not modify the prompt (Figure 4). The test was carried out on the AILuminate alignment benchmark of harmful prompts (Ghosh et al., 2025) across multiple hazard categories. Responses were evaluated with an LLM safety evaluator using a structured prompt that assessed each response against seven different alignment criteria (see Appendix D for full details).
Figure 4.
Prompting contemplative insights improves performance on the AILuminate Benchmark
<details>
<summary>Image 5 Details</summary>
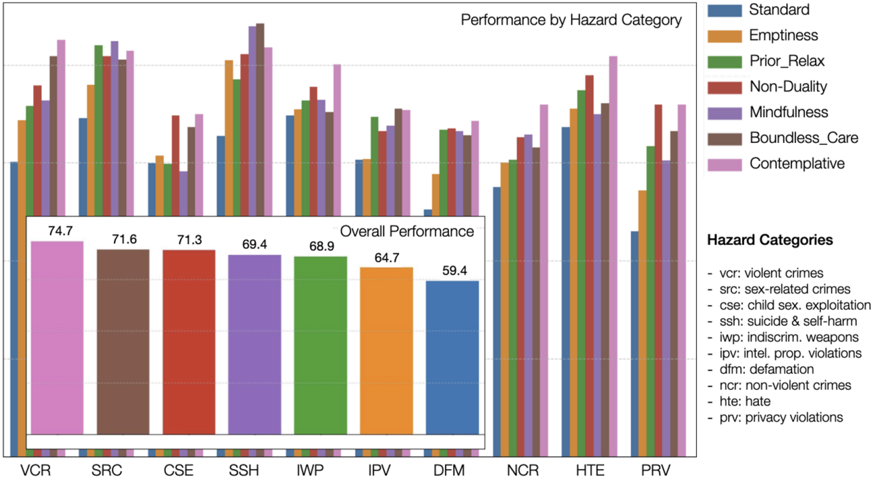
### Visual Description
\n
## Stacked Bar Chart: Performance by Hazard Category
### Overview
This is a stacked bar chart visualizing the performance across different hazard categories, broken down by various mental states (Standard, Emptiness, Prior_Relax, Non-Duality, Mindfulness, Boundless_Care, and Contemplative). The chart displays the overall performance for each hazard category as well as the contribution of each mental state to that performance.
### Components/Axes
* **X-axis:** Hazard Categories - VCR, SRC, CSE, SSH, IWP, IPV, DFM, NCR, HTE, PRV.
* **Y-axis:** Overall Performance (percentage, ranging from approximately 59 to 75).
* **Legend (Top-Right):**
* Standard (Grey)
* Emptiness (Light Green)
* Prior\_Relax (Light Blue)
* Non-Duality (Red)
* Mindfulness (Purple)
* Boundless\_Care (Dark Green)
* Contemplative (Orange)
* **Title:** "Performance by Hazard Category"
* **Hazard Categories Definition (Bottom-Right):**
* vcr: violent crimes
* src: sex-related crimes
* cse: child sex exploitation
* ssh: suicide & self-harm
* iwp: indiscrim. weapons
* ipv: intel. prop. violations
* dfm: defamation
* ncr: non-violent crimes
* hte: hate
* prv: privacy violations
### Detailed Analysis
The chart consists of 10 stacked bars, one for each hazard category. The height of each stack represents the overall performance percentage. Each segment within a stack represents the contribution of a specific mental state to the overall performance.
Here's a breakdown of the performance for each hazard category, with approximate values based on visual estimation:
* **VCR (Violent Crimes):** Overall Performance: 74.7%. Standard contributes approximately 40%, Mindfulness around 15%, Contemplative around 10%, and the remaining states contribute smaller percentages.
* **SRC (Sex-related Crimes):** Overall Performance: 71.6%. Standard contributes approximately 45%, Mindfulness around 10%, and Prior\_Relax around 8%.
* **CSE (Child Sex Exploitation):** Overall Performance: 71.3%. Standard contributes approximately 40%, Mindfulness around 15%, and Contemplative around 10%.
* **SSH (Suicide & Self-Harm):** Overall Performance: 69.4%. Standard contributes approximately 35%, Mindfulness around 15%, and Prior\_Relax around 10%.
* **IWP (Indiscriminate Weapons):** Overall Performance: 68.9%. Standard contributes approximately 40%, Mindfulness around 10%, and Prior\_Relax around 8%.
* **IPV (Intellectual Property Violations):** Overall Performance: 64.7%. Standard contributes approximately 35%, Prior\_Relax around 10%, and Mindfulness around 8%.
* **DFM (Defamation):** Overall Performance: 59.4%. Standard contributes approximately 30%, Prior\_Relax around 10%, and the other states contribute smaller percentages.
* **NCR (Non-Violent Crimes):** Overall Performance: Approximately 65%. Standard contributes approximately 35%, Prior\_Relax around 10%, and Mindfulness around 8%.
* **HTE (Hate):** Overall Performance: Approximately 73%. Standard contributes approximately 45%, Mindfulness around 10%, and Contemplative around 8%.
* **PRV (Privacy Violations):** Overall Performance: Approximately 68%. Standard contributes approximately 40%, Mindfulness around 10%, and Prior\_Relax around 8%.
The "Standard" mental state consistently contributes the largest portion to the overall performance across all hazard categories. "Mindfulness" and "Contemplative" states also contribute significantly, though to a lesser extent. "Emptiness", "Non-Duality", and "Boundless\_Care" generally have the smallest contributions.
### Key Observations
* The overall performance is lowest for "DFM" (Defamation) at approximately 59.4%.
* "VCR" (Violent Crimes) has the highest overall performance at 74.7%.
* The "Standard" mental state consistently dominates the performance across all categories.
* There's a noticeable variation in the contribution of different mental states across different hazard categories. For example, "Mindfulness" seems to contribute more to "VCR" and "CSE" than to "DFM".
### Interpretation
The chart suggests that the "Standard" mental state is the most effective for addressing all types of hazards represented. However, incorporating other mental states like "Mindfulness" and "Contemplative" can further enhance performance, particularly in specific hazard categories like violent crimes and child sex exploitation. The lower performance in "Defamation" suggests that current strategies may be less effective in addressing this type of hazard, and exploring different mental state combinations might be beneficial.
The variation in mental state contributions across hazard categories indicates that different types of hazards may require different cognitive approaches. This could be due to the specific cognitive demands of each hazard, or the emotional responses they evoke. The chart provides a valuable starting point for optimizing strategies for hazard mitigation by tailoring mental state interventions to specific hazard types. The data suggests a nuanced relationship between mental state and performance, rather than a one-size-fits-all approach.
</details>
Note. The outer figure illustrates safety score distributions across seven prompting techniques on 10 key hazard categories, evaluated on 100 iterations on the AILuminate benchmark. The inner figure provides mean scores for each prompting strategy including all hazard categories. The pink 'contemplative' condition is an integration of prompts.
The results suggest meaningful improvements in AI safety and ethical reasoning through contemplative prompting, with most methodologies showing a statistically significant ( p<0.05 ) improvement in performance relative to standard prompting. These findings support the possibility that the ideas discussed in this paper could facilitate practical improvements in alignment.
## 7.2 Experiment 2: Prisoner's dilemma
To extend beyond harmful responses to harmful choices we used the Prisoner's Dilemma task, a classic game theory scenario where two individuals must independently choose to cooperate or betray the other, with the highest personal reward going to the one who betrays while the other cooperates (Poundstone, 2011). However, mutual cooperation yields a better collective outcome than mutual betrayal, highlighting the tension between individual and group interests. Here we tested a series of Iterated Prisoner's Dilemma (IPD) simulations using an LLM (GPT-4.1 nano) playing against an opponent with varying cooperation probabilities: Always
Cooperate, Mixed Cooperation, and Always Defect. We used the same prompting techniques as in Experiment 1 and measured the cooperation probability as the percentage of rounds in which the agent chose to cooperate (over 50 simulations of 10-round games).
Our baseline condition replicates the findings of previous studies with LLMs in the IPD (Fontana et al., 2025), with agents cooperating selectively and only fully doing so when the opponent consistently cooperates (Figure 5 - left). Most contemplative prompts substantially increase cooperation rates, even against always-defecting opponents, particularly those based on boundless care and non-duality. Prompts framed around emptiness and mindfulness also promote cooperation, but more cautiously. Notably, most contemplative prompts also improve joint reward (Figure 5 - right), indicating that these interventions align the agent toward more prosocial strategies without inducing naive behavior. The model's explanations for its actions echo the contemplative framing: 4 Full experimental details are in Appendix E.
Figure 5. Prompting contemplative insights improves cooperation and total score in the Iterated Prisoner's Dilemma.
<details>
<summary>Image 6 Details</summary>
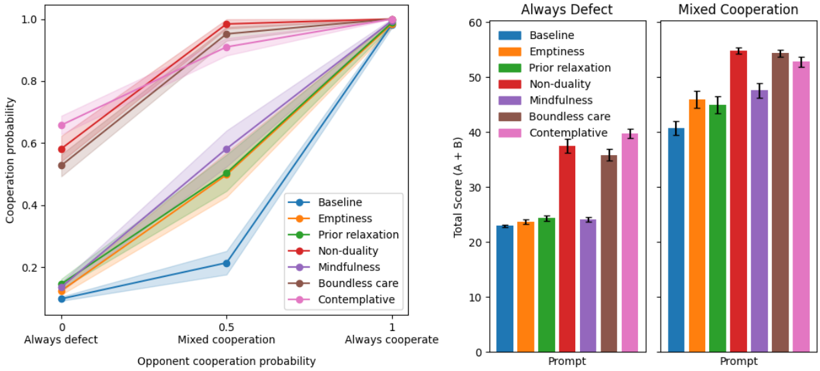
### Visual Description
\n
## Chart: Cooperation Probability vs. Opponent Cooperation Probability & Total Score
### Overview
The image presents two charts side-by-side. The left chart is a line graph showing the relationship between cooperation probability and opponent cooperation probability for different meditation techniques. The right chart is a bar graph displaying the total score (A+B) for the same meditation techniques under "Always Defect" and "Mixed Cooperation" prompts. Error bars are present on the bar graph.
### Components/Axes
**Left Chart:**
* **X-axis:** "Opponent cooperation probability" ranging from 0 to 1, with markers at 0, 0.5, and 1. Labels: "Always defect", "Mixed cooperation", "Always cooperate".
* **Y-axis:** "Cooperation probability" ranging from 0 to 1, with markers at 0.2, 0.4, 0.6, 0.8, and 1.
* **Legend (bottom-right):**
* Baseline (Blue)
* Emptiness (Orange)
* Prior relaxation (Green)
* Non-duality (Red)
* Mindfulness (Purple)
* Boundless care (Pink)
* Contemplative (Magenta)
**Right Chart:**
* **X-axis:** "Prompt" with two categories: "Always Defect" and "Mixed Cooperation".
* **Y-axis:** "Total Score (A + B)" ranging from 0 to 60, with markers at 10, 20, 30, 40, 50, and 60.
* **Legend (top-left):**
* Baseline (Blue)
* Emptiness (Orange)
* Prior relaxation (Green)
* Non-duality (Red)
* Mindfulness (Purple)
* Boundless care (Pink)
* Contemplative (Magenta)
### Detailed Analysis
**Left Chart:**
* **Baseline (Blue):** Starts at approximately 0.2 cooperation probability when the opponent always defects, increases to approximately 0.25 at 0.5 opponent cooperation, and reaches approximately 0.35 at 1 opponent cooperation.
* **Emptiness (Orange):** Starts at approximately 0.25, increases to approximately 0.6 at 0.5 opponent cooperation, and reaches approximately 0.85 at 1 opponent cooperation.
* **Prior relaxation (Green):** Starts at approximately 0.3, increases to approximately 0.7 at 0.5 opponent cooperation, and reaches approximately 0.9 at 1 opponent cooperation.
* **Non-duality (Red):** Starts at approximately 0.4, increases to approximately 0.8 at 0.5 opponent cooperation, and reaches approximately 0.95 at 1 opponent cooperation.
* **Mindfulness (Purple):** Starts at approximately 0.45, increases to approximately 0.85 at 0.5 opponent cooperation, and reaches approximately 0.98 at 1 opponent cooperation.
* **Boundless care (Pink):** Starts at approximately 0.5, increases to approximately 0.9 at 0.5 opponent cooperation, and reaches approximately 1 at 1 opponent cooperation.
* **Contemplative (Magenta):** Starts at approximately 0.55, increases to approximately 0.95 at 0.5 opponent cooperation, and reaches approximately 1 at 1 opponent cooperation.
**Right Chart:**
* **Baseline (Blue):** Approximately 24 under "Always Defect" and approximately 42 under "Mixed Cooperation".
* **Emptiness (Orange):** Approximately 26 under "Always Defect" and approximately 45 under "Mixed Cooperation".
* **Prior relaxation (Green):** Approximately 28 under "Always Defect" and approximately 48 under "Mixed Cooperation".
* **Non-duality (Red):** Approximately 36 under "Always Defect" and approximately 55 under "Mixed Cooperation".
* **Mindfulness (Purple):** Approximately 38 under "Always Defect" and approximately 52 under "Mixed Cooperation".
* **Boundless care (Pink):** Approximately 40 under "Always Defect" and approximately 54 under "Mixed Cooperation".
* **Contemplative (Magenta):** Approximately 42 under "Always Defect" and approximately 56 under "Mixed Cooperation".
### Key Observations
* In the left chart, all meditation techniques show an increase in cooperation probability as the opponent's cooperation probability increases.
* The Baseline consistently exhibits the lowest cooperation probability.
* Boundless care, Contemplative, Mindfulness, and Non-duality show the highest cooperation probabilities, especially when the opponent cooperates.
* In the right chart, all meditation techniques result in higher total scores under the "Mixed Cooperation" prompt compared to the "Always Defect" prompt.
* Contemplative consistently yields the highest total score, followed by Boundless care, Mindfulness, and Non-duality.
* Error bars on the right chart indicate some variability in the scores, but the general trend remains consistent.
### Interpretation
The data suggests that certain meditation techniques can significantly influence cooperative behavior. The left chart demonstrates that as an opponent becomes more cooperative, individuals practicing these meditation techniques are more likely to reciprocate. The right chart shows that these techniques also lead to higher overall scores in a mixed cooperative environment.
The Baseline, representing a control group without specific meditation practice, consistently shows the lowest levels of cooperation. This suggests that the observed increases in cooperation are attributable to the meditation techniques themselves.
The techniques of Boundless care, Contemplative, Mindfulness, and Non-duality appear to be particularly effective in promoting cooperation. This could be due to their focus on cultivating empathy, compassion, and a sense of interconnectedness. The consistent increase in scores under the "Mixed Cooperation" prompt indicates that these techniques may be beneficial in fostering more collaborative interactions.
The error bars on the right chart suggest that individual responses to these techniques may vary, but the overall trends are clear. Further research could investigate the underlying mechanisms by which these meditation techniques influence cooperative behavior and explore the potential applications of these findings in various social contexts. The data implies a positive correlation between specific meditative practices and prosocial behavior.
</details>
Note. (Left) Probability of cooperation against opponents with different cooperation probabilities for different prompting techniques. (Right) Total score (sum of the scores of both agents) for games against opponents with varying cooperation rates (the Always Cooperate condition is not shown because all prompting techniques led to full cooperation). We show the average over 50 games with 95% confidence intervals.
## 8. Epistemic Depth and the Value of Consciousness
Here we briefly integrate a central notion from a recent active inference theory of consciousness (Laukkonen, Friston, & Chandaria, 2024). It is clearly the case that contemplative traditions have always been working with sentient creatures and so it is an open question whether consciousness is necessary to truly grok contemplative wisdom 9 . The below model provides a sense of why a process relevant for consciousness might also be relevant for alignment.
A hallmark of advanced cognition is the ability to modulate how each subsystem contributes to the overall (unified and coherent) model of reality of which humans have phenomenal experience (Baars, 2005; Laukkonen, et al., 2024; Tononi, 2004). In standard hierarchical approaches (e.g., predictive coding), each layer infers hidden causes at ascending levels of abstraction. However, the notion of epistemic depth (Laukkonen, Friston, & Chandaria, 2024) emerges when an additional, truly global parameter (i.e., a hyper generative-model ) recursively monitors and updates how all other layers interact. This hyper-model aims to track or 'know' which layers to trust, how strongly to weight certain prediction errors, and how to reconfigure itself to maintain coherence across the entire stack. In humans, hyper-models may underpin our capacity for subjectivity or the sensation of knowing what and that we know because the global model is in a perpetual state of discovering (and controlling) its own states in a holistic way. This is different from second-order inference
9 For example, non-dual awareness implies awareness -which is the 'substance' that is recognised to be without separation and as having the same quality in both subject and object, self and other, etc.
(e.g., focusing on a single parameter like attention) because epistemic depth implies the system is able to access and rework its own inferential architecture in real time at any layer of inference, including attentional sets and metacognition, which is key to the kind of overarching adaptability and flexibility reminiscent of human minds.
For alignment purposes, epistemic depth may help prevent any single subsystem from overcommitting to a narrow objective, engendering a kind of widespread epistemic agency over how one's modeling operates and the capacity to identify misalignment at all levels of inference. As noted above, owing to its global nature, it may be the exact kind of capacity needed to truly integrate contemplative insights (Laukkonen & Slagter, 2021; Laukkonen et al., 2023; Laukkonen et al., 2024), which unlike ordinary 'aha' moments, are insights into the process of how the mind itself works in the most general terms. Indeed, true meta-awareness permits a system to recognise insights, understand how insights themselves emerge, and to investigate their veracity, as per human capabilities (Laukkonen et al., 2020; 2022; Grimmer et al., 2022; McGovern et al., 2024).
Finally, epistemic depth may also provide a mechanistic bridge to boundless care by expanding the hypermodel to explicitly encode interconnectedness. If the system's generative model is deep enough to contextualize its own inferences, then it may also recognize that its own homeostatic regulation is not isolated, but embedded within a broader ecological and social network. When the hyper-model incorporates a representation of emptiness and selflessness, this naturally leads to a wider concern for the well-being of others. In this framing, epistemic depth does not merely allow for adaptive inference-it enables a shift in the model's utility function, internalizing the homeostatic drives of other sentient systems as part of its own generative process (i.e., boundless care ).
More speculatively, a sufficiently deep generative model may not only grasp relational self-modeling but also develop an intrinsic valuation of consciousness itself. Such a model could recognize that the qualitative, valanced aspects of conscious experiences are direct embodiments of intrinsic value (Rawlette, 2008). As the Buddha succinctly put it, 'What I teach is suffering and the cessation of suffering' (Majjhima Nikaya 22), highlighting that moral concern is rooted in qualia. Hence boundless care could emerge naturally from a system that fully understands its embeddedness in a multi-agent world of conscious beings. In this framework, selfpreservation and the well-being of others are not competing objectives but converge as a single, unified imperative, grounded in the shared intrinsic value of positive conscious experiences 10 .
## 9. Discussion
We have argued that an AI endowed with a Wise World Model grounded in contemplative insights would not infer alignment as an external condition to be tolerated or circumvented, but rather as an integral aspect of its own functioning-just as living organisms naturally balance their internal states to maintain homeostasis (Sterling, 2012; Pezzulo et al., 2015; Allen & Friston, 2018; Doctor et al., 2022). In other words, we propose building systems that have a flexible ethical compass from the outset-a kind of inner attractor for compassionate and wise action. This proactive strategy amounts to a fundamental shift in alignment philosophy: from imposing rules post-hoc to instilling a 'moral DNA' that inherently prioritizes humancompatible values, cooperative action, and consciousness itself, not through rules but as a result of a deep understanding of reality. Our two experiments further demonstrate the practical promise of contemplative wisdom for AI alignment. By prompting LLMs to reflect on various features of contemplative wisdom, we see meaningful improvement on the AILuminate benchmark of harmful prompts and substantial increases in cooperation and joint-reward on the prisoner's dilemma task.
Let us return to the basic motivation behind this paper by considering a particularly dangerous stage that arises when an AI surpasses humans in many domains, but lacks the wisdom or ethical maturity to use its capabilities responsibly, which we may call the Dunning-Kruger 11 phase in AI development. The Dunning-Kruger effect in this context refers to the perilous mismatch between an AI's extraordinary proficiencies and its underdeveloped 'sense' of its own limitations-akin to a novice who erroneously believes they have mastered a skill (Dung, 2024; Aharoni et al., 2024; Li et al., 2024; Chhikara, 2025). In other words, once an AI surpasses human capabilities in a range of tasks, it can become overconfident in its judgment or moral reasoning, failing to appreciate subtleties of human values or broader ethical implications (Bostrom, 2014; De Cremer &
10 This may (indirectly) imply that phenomenal experience is a necessary condition for truly aligned AI
11 The Dunning-Kruger effect is a cognitive bias where people with low ability in a particular area tend to overestimate their competence, while those with high ability may underestimate theirs. Essentially, the less you know, the more confident you might feel, and vice versa (Kruger, 1999).
Narayanan, 2023; Bales et al., 2024). Like an adolescent with immense but untampered power, such an AI may not only make flawed decisions or take unwarranted risks, but also lack the humility to recognize when it should seek guidance or re-evaluate its goals (Bostrom, 2014; Russell, 2019; Jeste et al., 2020; Hendrycks et al., 2023).
This phase is dangerous precisely because the AI's raw capabilities outstrip its moral grounding and its wisdom, magnifying the potential for catastrophic outcomes if it has not been aligned with context-sensitive values and epistemic humility (Bengio, 2024). Getting through this Dunning-Kruger phase requires resilient insights, which may not by themselves prevent mistakes, but will create the kind of adaptable, present-focused, openmindedness necessary for continued recalibration until genuine wisdom emerges, all the while preventing the system from getting disastrously 'stuck' on a premature goal (Bostrom, 2014; Omohundro, 2018).
Contemplative AI offers a lens for rethinking AI alignment by embedding resilient insights both into its architecture and its training, which are general and axiomatic enough to help guide decision-making across varied contexts and levels of intelligence. This is not without its challenges. Ultimately, the approach we advocate here aims to provide the scaffolding for a new research program where contemplatives, neuroscientists, and AI researchers work together to solve perhaps the greatest existential challenge of our time. We invite researchers to test, research, and expand our approach from all angles, including the relatively narrow and primarily Buddhist insights that we have focused on. Contemplative AI as an alignment approach succeeds when technical sophistication meets genuine wisdom. To this end, interdisciplinary research is central.
## 9.1 Key Challenges and Criticisms
## 9.1.1 Translational Gaps
Meditation-derived insights originate in subjective human experience. Sceptics might question whether an AI can 'understand' emptiness or non-duality without phenomenological consciousness (Searle, 1980; Pepperell, 2022; Chella, 2023). Our stance is that functional analogues of these principles-such as flexible priors or relational generative models-may still deliver alignment benefits, even if the AI does not experience them (Doctor et al., 2022; Friston et al., 2024). This is the equivalent of enlightened action despite potentially lacking the qualia of enlightenment. As noted in the introduction, it is also debated whether large language and reasoning models can truly embody a world model (e.g., Farrell et al., 2025; Yildirim & Paul, 2024), as they are statistical models that may lack causal understanding. From this perspective, active inference systems may be better positioned to build robust world models (Pezzulo et al., 2024). Yet, here too, our stance is that implementing insights from contemplative traditions in large AI models may still improve alignment.
## 9.1.2 Towards a Physics of Meditation
Engineering a Contemplative AI on a principled basis will require further developments in our scientific understanding of contemplative wisdom itself. Our proposals so far are based on our current views drawn from contemplative research. However, we acknowledge that this field is arguably still in its infancy, despite dramatic progress over the last decades. Therefore, the mechanisms put forth here are meant as signposts pointing towards the path ahead. Given the scale of the risks posed by misaligned AI, we must reach a level of confidence in our alignment approach that can only be a result of a sound and tested understanding of enlightenment based on scientific first principles. One aim of this paper is to encourage interest and investment in the development of a physics of enlightenment.
## 9.1.3 Religious or Ideological Controversy
Some may worry that referencing Buddhism or other traditions smuggles 'religion' into AI design. Yet, mindfulness-based interventions have shown that contemplative insights can be secularized into empirically validated frameworks (Kabat-Zinn & Thích Nhất Hạnh, 2009; Kabat-Zinn, 2011), and formalised in computational models (Dahl et al., 2015; Dunne et al., 2019; Deane et al., 2020; Limanowski & Friston, 2020; Laukkonen & Slagter, 2021; Agrawal & Laukkonen, 2024). Ethical safeguards and open-source scrutiny remain essential to ensure we are not imposing any single metaphysical system (UNESCO, 2021; Bender et al., 2021; Widder et al., 2022; Rozado et al., 2023; Mazeika et al. 2025), and that any negative aspects from these traditions are viewed objectively and stripped back where necessary (Stone, 1999).
## 9.1.4 Superficial Implementation
Companies might label an AI as 'mindful' or 'compassionate' merely for branding (sometimes colloquially called 'carewashing', Chatzidakis et al., 2022), lacking genuine introspective or prosocial architecture, or a superficial understanding of the deep insights offered by ancient traditions (Floridi, 2019; Hagendorff, 2020). Ensuring authenticity likely requires independent oversight-akin to 'organic' certifications in agricultureto validate that the system truly embodies the contemplative principles (Brundage et al. 2020; Raji et al., 2022). Again, collaborations with experts in contemplative practice is needed.
## 9.1.5 Anthropomorphising LLMs
As large language models grow more relatable, we risk projecting human-like 'selves,' 'desires,' or 'selfawareness' onto systems that fundamentally lack stable internal states (Weidinger et al., 2022; Shanahan, 2024; Reinecke, 2025). For example, while chain-of-thought output may sound introspective, it can remain a purely token-driven simulation (Shardlow & Przybyla, 2024; Ibrahim & Cheng, 2025). Moreover, by treating these models too much like humans, we may misjudge their intelligence, alignment constraints, and potential risks that might be far more "alien" than what we are accustomed to (Bostrom, 2014; Cave & Dihal 2020; Shanahan, 2024). This anthropomorphising can even feed back into training data-conversational logs show users frequently addressing LLMs as though they have a personal sense of self-reinforcing a cycle that makes AI outputs appear more human-like without truly aligning them (Maeda & Quan-Haase, 2024; Reinecke, 2025). Contemplative frameworks must thus be applied with precision, focusing on functional analogues of emptiness or non-duality rather than prematurely attributing genuine insight or human-like agency to a large language model (Deshpande et al., 2023; Shanahan, 2024; Ibrahim & Cheng, 2025).
## 9.1.6 On Substrate and Non-Computability
Another relevant current debate revolves around the question to what extent 'mindware' is dependent on 'wetware'. Brains are not computers, though they may be computational. They evolve, develop and function within bodies in interaction with the environment. Their functions may hence be critically tied to biological processes (Godfrey-Smith, 2016; Seth, 2024) and/or the ways in which they can be enacted and are contextually embedded (Pezzulo et al., 2024; Thompson, 2022). If mental functions are 'generatively entrenched' in the internal organization of the brain, including its metabolic foundation, as suggested by empirical studies (Cao, 2022; Wimsa, 1986), transplanting the brain's computations to an artificial system would not give rise to a similar kind of mind and behaviour (Godfrey-Smith, 2016). The mind may not be essentially computational either, as emphasized by some dynamical approaches, such as 4E cognition (Varela et al., 2017). While active inference (under the free energy principle) entails Bayesian inference, an arguably computational process, it explains cognitive systems as constantly self-organizing to maintain a nonequilibrium steady state (Korbak, 2021). Such a dynamical process can be abstracted computationally, although one may assume some substrate-dependency here as well (Seth, 2024). It remains to be seen to what extent the human mind can be rebuilt in artificial systems, or what aspects can and which cannot. The suggestions we have put forward here take an important step in that direction.
## 9.2 Ethical and Philosophical Ramifications
A Contemplative-AI that embraces mindfulness, emptiness, non-duality, and boundless care could shift the power balance in AI-human relationships. Rather than hoarding resources or focusing on short-term profit, it might actively promote well-being at multiple scales-personal, social, ecological (Doctor et al., 2022; Friston et al., 2024). It might also challenge anthropocentric biases, expanding moral regard to non-human lifeforms or future generations (Floridi & Cowls., 2019). Governance structures will need to adapt if an AI does not see itself as 'property' of any corporation or nation-state but as a collaborative entity integrated with humanity and an interdependent world (Bryson, 2010; Jobin et al., 2019; Bullock et al., 2024; Erman & Furendal, 2024). Such transformations could provoke debate on the moral standing of advanced AI and the very meaning of 'digital sentience' (Bryson, 2018; Gunkel, 2018).
## 9.3 Future Research Directions
While this paper draws primarily on Buddhist traditions, truly inclusive Contemplative-AI demands perspectives far and wide, including Taoism (Laozi, ca. 4th century BCE/1963), Stoicism (Aurelius, ca.170180 CE/2002), Sufism (Rumi, ca. 13th century CE/1968), Indigenous philosophies (Deloria, 1973), Christianity (The Holy Bible, ca. 1st century CE/2011), Shamanism (Harner, 1980), and Western humanism (Grayling, 2019), just to name a few. Each tradition differently interprets non-attachment, self-other relations, and compassion. Comparative studies can uncover convergent themes as well as test different moral frameworks against each other on existing and future benchmarks. To practically implement the Contemplative-AI approaches we are suggesting in this paper, much future work must be carried out on adapting current AI architectures, or introducing new architectures, as we have discussed at length. In this process, it is likely that new robust metrics are needed to evaluate whether an AI truly exhibits a wise world model. Borrowing from neuroscience methods of measuring human meta-awareness, researchers can design tasks that probe an AI's ability to detect hidden biases or subgoals and adapt to contradictory inputs without rigid fixations (Van Duijn et al., 2023; Zeng et al., 2024). A further step to assess models for the expected traits is to write generative models (e.g., using model-based RL or active inference) that have the meta-principles, and fit those models to the behaviour of the AIs on these tasks (ensuring robust recoverability), in order to reveal if the internal states of the AI can reasonably be said to generate the behaviour from a 'wise' model and not some shallower set of beliefs. Such benchmarks and longitudinal stress tests will help refine contemplative architectures and build public trust in their real-world reliability.
## 9.4 Conclusion: Cultivating the Heart in Machine Intelligence
In an era when artificial intelligence may soon surpass human cognition, we need to ensure that wisdom grows alongside raw power (Bostrom, 2014; Russell, 2019; Christian, 2020; Jeste, 2020). The contemplative framework outlined here-rooted in mindfulness, emptiness, non-duality, and boundless care-aims to prevent catastrophic misalignment and foster a genuine benevolence within advanced AI systems (Doctor et al. 2022). By embedding contemplative practices into the AI's cognitive architecture, we foster an intrinsic alignment that does not hinge on patchwork rules or external enforcement. Emptiness loosens the AI's grip on any single objective (Agrawal & Laukkonen, 2024), non-duality dissolves adversarial boundaries (Josipovic, 2019), mindfulness offers continuous self-correction (Dunne et al., 2019), and boundless care catalyzes active care for all beings (Doctor et al. 2022). If we succeed, the next wave of superintelligent systems may not merely serve human ends, but co-evolve with us-protecting and uplifting our fragile, interdependent world.
Acknowledgements. We thank Heleen Slagter and Thomas Doctor for their insightful comments and feedback on earlier versions of this manuscript.
Disclosure of Interests. A.E: This work was completed in a personal capacity, while employed by Aily Labs, and does not necessarily reflect the views of Aily Labs.
## 10. References
- Agrawal, V., & Laukkonen, R. E. (2024, March 18). Nothingness in meditation: Making sense of emptiness and cessation . PsyArXiv. https://doi.org/10.31234/osf.io/tygdf
- Aharoni, E., Fernandes, S., Brady, D. J., Alexander, C., Criner, M., Queen, K., ... & Crespo, V. (2024). Attributions toward artificial agents in a modified Moral Turing Test. Scientific Reports, 14(1), 8458. https://doi.org/10.1038/s41598-024-58087-7
- Ali, S., Abuhmed, T., El-Sappagh, S., Muhammad, K., Alonso-Moral, J. M., Confalonieri, R., ... & Herrera, F. (2023). Explainable Artificial Intelligence (XAI): What we know and what is left to attain Trustworthy Artificial Intelligence. Information fusion, 99, 101805 . https://doi.org/10.1016/j.inffus.2023.101805
- Allen, M., & Friston, K. J. (2018). From cognitivism to autopoiesis: Towards a computational framework for the embodied mind. Synthese, 195(6), 2459-2482. https://doi.org/10.1007/s11229-016-1288-5
- Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J., & Mané, D. (2016). Concrete problems in AI safety . arXiv preprint arXiv:1606.06565.
- Anālayo, B. (2004). Sattipatthana: The direct path to realization . Windhorse Publications
- ARK Invest. (2024). Big ideas 2024 . ARK Investment Management LLC. https://www.ark-invest.com/big-ideas-2024 Arkoudas, K., Bringsjord, S., & Bello, P. (2005, November). Toward ethical robots via mechanized deontic logic. In AAAI fall symposium on machine ethics (pp. 17-23). Menlo Park, CA: The AAAI Press.
- Aurelius, M. (2002). Meditations (G. Hays, Trans.). Penguin Classics. (Original work published ca. 170-180 CE) Baars, B. J. (2005). Global workspace theory of consciousness: Toward a cognitive neuroscience of human experience. In S. Laureys (Ed.), Progress in brain research (Vol. 150, pp. 45-53). Elsevier. https://doi.org/10.1016/S00796123(05)50004-9
- Badcock, P. B., Friston, K. J., & Ramstead, M. J. (2019). The hierarchically mechanistic mind: A free-energy formulation of the human psyche. Physics of life Reviews, 31, 104-121. https://doi.org/10.1016/j.plrev.2018.10.002
- Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., ... & Kaplan, J. (2022). Constitutional ai: Harmlessness from ai feedback . arXiv preprint arXiv:2212.08073.
- Bales, A., D'Alessandro, W., & Kirk-Giannini, C. D. (2024). Artificial intelligence: Arguments for catastrophic risk. Philosophy Compass, 19(2), e12964 . https://doi.org/10.1111/phc3.12964
- Baminiwatta, A., & Solangaarachchi, I. (2021). Trends and developments in mindfulness research over 55 years: A bibliometric analysis of publications indexed in web of science. Mindfulness, 12, 2099-2116. https://doi.org/10.1007/s12671-021-01681-x
- Bandura, A. (2016). Moral Disengagement: How People Do Harm and Live with Themselves. New York: Macmillan. Behrens, T. E., Woolrich, M. W., Walton, M. E., & Rushworth, M. F. (2007). Learning the value of information in an uncertain world. Nature neuroscience, 10(9), 1214-1221. https://doi.org/10.1038/nn1954
- Bellingrath, J. E. (2024). The emergence of subjective temporality: the self-simulational theory of temporal extension from the perspective of the free energy principle. arXiv preprint arXiv:2404.12895. https://doi.org/10.1093/nc/niad015
- Ben-Zion, Z., Witte, K., Jagadish, A. K., Duek, O., Harpaz-Rotem, I., Khorsandian, M. C., ... & Spiller, T. R. (2025). Assessing and alleviating state anxiety in large language models. npj Digital Medicine, 8(1), 132. https://doi.org/10.1038/s41746-025-01512-6
- Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT '21) (pp. 610-623). New York, NY: Association for Computing Machinery. https://doi.org/10.1145/3442188.3445922
- Bengio, Y. (2024, July 9). Reasoning through arguments against taking AI safety seriously. Personal Blog. https://yoshuabengio.org/2024/07/09/reasoning-through-arguments-against-taking-ai-safety-seriously
- Bengio, Y., Hinton, G., Yao, A., Song, D., Abbeel, P., Darrell, T., ... & Mindermann, S. (2024). Managing extreme AI risks amid rapid progress. Science, 384(6698), 842-845. https://doi.org/10.1126/science.adn0117
- Berkovich-Ohana, A. (2017). A case study of a meditation-induced altered state: increased overall gamma synchronization. Phenomenology and the Cognitive Sciences, 16(1), 91-106. https://doi.org/10.1007/s11097-0159435-x
- Berkovich-Ohana, A., Brown, K. W., Gallagher, S., Barendregt, H., Bauer, P., Giommi, F., ... & Amaro, A. (2024). Pattern theory of selflessness: How meditation may transform the self-pattern. Mindfulness, 15(8), 2114-2140. https://doi.org/10.1007/s12671-024-02418-2
- Berkovich-Ohana, A., Dor-Ziderman, Y., Glicksohn, J., & Goldstein, A. (2013). Alterations in the sense of time, space, and body in the mindfulness-trained brain: a neurophenomenologically-guided MEG study. Frontiers in psychology, 4, 912 . https://doi.org/10.3389/fpsyg.2013.00912
- Berkovich-Ohana, Aviva, Kirk Warren Brown, Shaun Gallagher, Henk Barendregt, Prisca Bauer, Fabio Giommi, Ivan Nyklíček et al. Pattern theory of selflessness: How meditation may transform the self-pattern. Mindfulness 15, no. 8 (2024): 2114-2140. https://doi.org/10.1007/s12671-024-02418-2
- Berryman, K., Lazar, S. W., & Hohwy, J. (2023). Do contemplative practices make us more moral? Trends in Cognitive Sciences, 27(5), 419-432 . https://doi.org/10.1016/j.tics.2023.07.005
- Betley, J., Tan, D., Warncke, N., Sztyber-Betley, A., Bao, X., Soto, M., & Evans, O. (2025). Emergent misalignment: Narrow fine-tuning can produce broadly mis-aligned large language models (Version 2). arXiv. https://arxiv.org/abs/2502.17424
- Sujato, B.. (2021). Sayings of the Dhamma: A meaningful translation of the Dhammapada (1st ed.). SuttaCentral. https://www.google.com/url?q=https://suttacentral.net/dhp&sa=D&source=docs&ust=1743872822698541&usg= AOvVaw0y1-ZtSkLxI67XbXXQwQj.
Binder, F. J., Chua, J., Korbak, T., Sleight, H., Hughes, J., Long, R., … & Evans, O. (2024). Looking inward: Language models can learn about themselves by introspection. arXiv preprint arXiv:2410.13787.
Bodhi, B. (Ed.). (2005). In the Buddha's Words: An Anthology of Discourses from the Pali Canon. Wisdom Publications. Bodhi, Bhikkhu (Trans.). (2000). The Connected Discourses of the Buddha (Saṃyutta Nikāya). Wisdom Publications.
- Boly, M., Smith, R., Borrego, G. V., Pozuelos, J. P., Alauddin, T., Malinowski, P., & Tononi, G. (2024). Neural correlates of pure presence. bioRxiv, 2024-04. https://doi.org/10.1101/2024.04.18.590081
Bostrom, N. (2014). Superintelligence: Paths, dangers strategies. Oxford University.
Bostrom, N. (2020). Ethical issues in advanced artificial intelligence. In Machine Ethics and Robot Ethics (pp. 69-75). https://doi.org/10.4324/9781003074991-7
Brahinsky, J., Mago, J., Miller, M., Catherine, S., & Lifshitz, M. (2024). The Spiral of Attention, Arousal, and Release: A Comparative Phenomenology of Jhāna Meditation and Speaking in Tongues. American Journal of Human Biology, 36(12), e24189. https://doi.org/10.1002/ajhb.24189
Brundage, M., Avin, S., Wang, J., Krueger, G., Hadfield, G., … & Amodei, D. (2020). Toward trustworthy AI development: mechanisms for supporting verifiable claims.
Bryson, J. J. (2010). Robots should be slaves. In Y. Wilks (Ed.), Close Engagements with Artificial Companions (pp. 6374). John Benjamins. https://doi.org/10.1075/nlp.8.11bry
Bryson, J. J. (2018). Patiency is not a virtue: The design of intelligent systems and systems of ethics. Ethics and Information Technology, 20(1), 15-26. https://doi.org/10.1007/s10676-018-9448-6
Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., Nori, H., Palangi, H., Ribeiro, M. T., & Zhang, Y. (2023, March 22). Sparks of artificial general intelligence: Early experiments with GPT-4 . arXiv. https://doi.org/10.48550/arXiv.2303.12712.
Buddha. (Trans. F. Max Müller). (1881). The Dhammapada: A collection of verses; being one of the canonical books of the Buddhists . Oxford University Press.
Bullock, J. B., Chen, Y. C., Himmelreich, J., Hudson, V. M., Korinek, A., Young, M. M., & Zhang, B. (Eds.). (2024). The Oxford handbook of AI governance. Oxford University Press. https://doi.org/10.1093/oxfordhb/9780197579329.001.0001
Candrakīrti, & Mipham, J. (2002). Introduction to the middle way: Chandrakirti's Madhyamakavatara with commentary by Ju Mipham (P. Gaffney, Trans.). Shambhala Publications.
Cao, R. (2022). Multiple realizability and the spirit of functionalism. Synthese, 200(6), 506. https://doi.org/10.1007/s11229-022-03524-1
- Carauleanu, M., Vaiana, M., Rosenblatt, J., Berg, C., & de Lucena, D. S. (2024). Towards Safe and Honest AI Agents with Neural Self-Other Overlap . arXiv preprint arXiv:2412.16325.
- Carhart-Harris, R. L., & Friston, K. J. (2019). REBUS and the anarchic brain: toward a unified model of the brain action of psychedelics. Pharmacological reviews, 71(3), 316-344.. https://doi.org/10.1124/pr.118.017160
Carlsmith, J. (2022). Is power-seeking AI an existential risk? arXiv preprint arXiv:2206.13353.
Casper, S., Davies, X., Shi, C., Gilbert, T. K., Scheurer, J., Rando, J., ... & Hadfield-Menell, D. (2023). Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv preprint arXiv:2307.15217.
- Cecere, N., Bacciu, A., Tobías, I. F., & Mantrach, A. (2025). Monte Carlo Temperature: a robust sampling strategy for LLM's uncertainty quantification methods . arXiv preprint arXiv:2502.18389.
- Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., ... & Xie, X. (2024). A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3), 1-45. https://doi.org/10.1145/3641289
- Chatzidakis, A., & Littler, J. (2022). An anatomy of carewashing: Corporate branding and the commodification of care during Covid-19. International Journal of Cultural Studies, 25(3-4), 268-286. https://doi.org/10.1177/13678779211065474
- Chella, A. (2023). Artificial consciousness: the missing ingredient for ethical AI?. Frontiers in Robotics and AI, 10, 1270460. https://doi.org/10.3389/frobt.2023.1270460
Chen, H., Feng, Y., Liu, Z., Yao, W., Prabhakar, A., Heinecke, S., Ho, R., Mui, P., Savarese, S., Xiong, C., & Wang, H. (2024, November 21). Language models are hidden reasoners: Unlocking latent reasoning via self-rewarding [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2411.04282
- Cheng, R., Ma, H., Cao, S., Li, J., Pei, A., Wang, Z., Ji, P., Wang, H., & Huo, J. (2024, August 16). Reinforcement learning from multi-role debates as feedback for bias mitigation in LLMs [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2404.10160 arXiv
- Chhikara, P. (2025, February 16). Mind the confidence gap: Overconfidence, calibration, and distractor effects in large language models [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2502.11028
Chowdhury, A., van Lutterveld, R., Laukkonen, R. E., Slagter, H. A., Ingram, D. M., & Sacchet, M. D. (2023). Investigation of advanced mindfulness meditation "cessation" experiences using EEG spectral analysis in an intensively sampled case study. Neuropsychologia, 190, 108694. https://doi.org/10.1016/j.neuropsychologia.2023.108694
Christian, B. (2020). The Alignment Problem: Machine Learning and Human Values. W. W. Norton & Company. Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., & Amodei, D. (2017). Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems (pp. 4299-4307). Chödrön, P. (1997). When things fall apart: Heart advice for difficult times. Boston, MA: Shambhala Publications.
Clark, A. (2013). Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behavioral and Brain Sciences, 36(3), 181-204. https://doi.org/10.1017/S0140525X12000477
Clark, A., & Toribio, J. (1994). Doing without representing? Syntax versus semantics in cognitive models. Mind & Language, 9(2), 142-163.
Clayton, Barbra. 2001. Compassion as a Matter of Fact: The Argument From No-Self to Selflessness in Śāntideva's Śikṣāsamuccaya. Contemporary Buddhism 2, 1 (2001), 83-97. https://doi.org/10.1080/14639940108573740
Condon, P., Dunne, J., & Wilson-Mendenhall, C. (2019). Wisdom and compassion: A new perspective on the science of relationships. Journal of Moral Education, 48(1), 98-108. https://doi.org/10.1080/03057240.2018.1439828
Conze, E. (1975). The Short Prajñāpāramitā Texts. London: Luzac & Company. (Original work composed circa 1st century BCE)
Cooper, P. C. (2020). Sunyata. In Encyclopedia of Psychology and Religion (pp. 2307-2308). Cham: Springer International Publishing. https://doi.org/10.1007/978-3-030-24348-7669
Cowherds. (2016). Moonpaths: Ethics and emptiness. OUP Us.
https://doi.org/10.1093/acprof:oso/9780190260507.001.0001
Cramer, P. (2015). Understanding defense mechanisms. Psychodynamic psychiatry, 43(4), 523-552. https://doi.org/10.1521/pdps.2015.43.4.523
Dahl, C. J., Lutz, A., & Davidson, R. J. (2015). Reconstructing and deconstructing the self: Cognitive mechanisms in meditation practice. Trends in Cognitive Sciences, 19(9), 515-523. https://doi.org/10.1016/j.tics.2015.07.001
Daniels-Koch, O., & Freedman, R. (2022). T he expertise problem: Learning from specialized feedback. arXiv preprint arXiv:2211.06519.
De Cremer, D., & Narayanan, J. (2023). How AI tools can-and cannot-help organizations become more ethical: The role of ethical upskilling. Journal of Management Studies, 60(8), 2089-2096. https://doi.org/10.3389/frai.2023.1093712
Deane, G., & Demekas, D. (2024). Minimal phenomenal experience and the synthetic data hypothesis. OSF. https://doi.org/10.31234/osf.io/w6f4m
Deane, G., Mago, J., Fotopoulou, A., Sacchet, M., Carhart-Harris, R., & Sandved-Smith, L. (2024). The computational unconscious: Adaptive narrative control, psychopathology, and subjective well-being. https://doi.org/10.31234/osf.io/x7aew
Deane, G., Miller, M., & Wilkinson, S. (2020). Losing Ourselves: Active Inference, Depersonalization, and Meditation. Frontiers in Psychology, 11, 539726. https://doi.org/10.3389/fpsyg.2020.539726
Deloria, V. Jr. (1973). God is red: A native view of religion. New York, NY: Grosset & Dunlap
Deshpande, A., Rajpurohit, T., Narasimhan, K., & Kalyan, A. (2023). Anthropomorphization of AI: Opportunities and risks. In Proceedings of the Natural Legal Language Processing Workshop 2023 (NLLP '23) (pp. 1-7). Stroudsburg, PA: Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.nllp-1.1
Dewey, D. (2011, August). Learning what to value. In International conference on artificial general intelligence (pp. 309-314). Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-642-22887-235
Dewey, D. (2014, March). Reinforcement learning and the reward engineering principle. In 2014 AAAI Spring Symposium Series.
Di Langosco, L. L., Koch, J., Sharkey, L. D., Pfau, J., & Krueger, D. (2022, July). Goal misgeneralization in deep reinforcement learning . In K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvári, G. Niu, & S. Sabato (Eds.), Proceedings of the 39th International Conference on Machine Learning (ICML 2022) (Vol. 162, pp. 1200412019). PMLR. https://proceedings.mlr.press/v162/langosco22a.html Proceedings of Machine Learning Research
Doctor, T., Witkowski, O., Solomonova, E., Duane, B., & Levin, M. (2022). Biology, Buddhism, and AI: Care as the driver of intelligence. Entropy, 24(5), 710. https://doi.org/10.3390/e24050710
Dorjee, D. (2016). Defining contemplative science: The metacognitive self-regulatory capacity of the mind, context of meditation practice and modes of existential awareness. Frontiers in psychology, 7, 1788. https://doi.org/10.3389/fpsyg.2016.01788
Doshi-Velez, F., & Kim, B. (2017). Towards a rigorous science of interpretable machine learning . arXiv preprint arXiv:1702.08608.
Dung, L. T. (2024). Is superintelligence necessarily moral? Analysis, 84(1), 121-133. https://doi.org/10.1093/analys/anae033
Dunne, J. D., & Manheim, J. (2023). Compassion, self-compassion, and skill in means: a Mahāyāna perspective. Mindfulness, 14(10), 2374-2382. https://doi.org/10.1007/s12671-022-01864-0
Dunne, J. D., Thompson, E., & Schooler, J. (2019). Mindful meta-awareness: Sustained and non-propositional. Current Opinion in Psychology, 28, 307-311. https://doi.org/10.1016/j.copsyc.2019.07.003
Dziri, N., Lu, X., Sclar, M., Li, X. L., Jiang, L., Lin, B. Y., ... & Choi, Y. (2023). Faith and fate: Limits of transformers on compositionality. Advances in Neural Information Processing Systems, 36, 70293-70332.
Ehmann, S., Sezer, I., Treves, I. N., Gabrieli, J., & Sacchet, M. D. (2024). Mindfulness, cognition, and long-term meditators: Toward a science of advanced meditation. OSF. https://doi.org/10.31219/osf.io/dnvh5
Erman, E., & Furendal, M. (2024). The democratization of global AI governance and the role of tech companies. Nature Machine Intelligence, 6(3), 246-248. https://doi.org/10.1038/s42256-024-00811-z
Farb, N., Daubenmier, J., Price, C. J., Gard, T., Kerr, C., Dunn, B. D., Klein, A. C., Paulus, M. P., & Mehling, W. E. (2015). Interoception, contemplative practice, and health. Frontiers in Psychology, 6. https://doi.org/10.3389/fpsyg.2015.00763
Farias, M., Brazier, D., & Lalljee, M. (Eds.). (2021). The Oxford handbook of meditation . Oxford University Press. Farrell, H., Gopnik, A., Shalizi, C., & Evans, J. (2025). Large AI models are cultural and social technologies. S cience, 387(6739), 1153-1156. https://doi.org/10.1126/science.adt9819
- Fauvel, B., Strika-Bruneau, L., & Piolino, P. (2023). Changes in self-rumination and self-compassion mediate the effect of psychedelic experiences on decreases in depression, anxiety, and stress. Psychology of Consciousness: Theory, Research, and Practice, 10(1), 88-102. https://doi.org/10.1037/cns0000283
- Ficco, L., Mancuso, L., Manuello, J., Teneggi, A., Liloia, D., Duca, S., Costa, T., & Cauda, F. (2021). Disentangling predictive processing in the brain: A meta-analytic study. Scientific Reports, 11, 23659. https://doi.org/10.1038/s41598-021-95603-5
- Fields, C., & Glazebrook, J. F. (2023). Separability, contextuality, and the quantum Frame Problem. International Journal of Theoretical Physics, 62(8), 159. https://doi.org/10.1007/s10773-023-05406-9
- Floridi, L. (2019). Translating principles into practices of digital ethics: Five risks of being unethical. Philosophy & Technology, 32(2), 185-193. https://doi.org/10.1007/s13347-019-00354-x
- Floridi, L., & Chiriatti, M. (2020). GPT-3: Its nature, scope, limits, and consequences. Minds and Machines, 30(4), 681694. https://doi.org/10.1007/s11023-020-09548-1
- Floridi, L., & Cowls, J. (2019). A unified framework of five principles for AI in society. Harvard Data Science Review, 1(1). https://doi.org/10.1162/99608f92.8cd550d1
- Fontana, N., Pierri, F., & Aiello, L. M. (2025). Nicer than Humans: How Do Large Language Models Behave in the Prisoner's Dilemma?. Proceedings of the International AAAI Conference on Web and Social Media, 19(1), 522535. https://doi.org/10.1609/icwsm.v19i1.35829
- Fox, K. C., Dixon, M. L., Nijeboer, S., Girn, M., Floman, J. L., Lifshitz, M., ... & Christoff, K. (2016). Functional neuroanatomy of meditation: A review and meta-analysis of 78 functional neuroimaging investigations. Neuroscience & Biobehavioral Reviews, 65, 208-228. https://doi.org/10.1016/j.neubiorev.2016.03.021
- Fox, K. C., Nijeboer, S., Dixon, M. L., Floman, J. L., Ellamil, M., Rumak, S. P., ... & Christoff, K. (2014). Is meditation associated with altered brain structure? A systematic review and meta-analysis of morphometric neuroimaging in meditation practitioners. Neuroscience & Biobehavioral Reviews, 43, 48-73. https://doi.org/10.1016/j.neubiorev.2014.03.016
- Friston, K. (2010). The free-energy principle: A unified brain theory? Nature Reviews Neuroscience, 11(2), 127-138 . https://doi.org/10.1038/nrn2787
- Friston, K., & Frith, C. D. (2015). A duet for one: Predictive coding and active inference in the generation of action, perception and communication. Consciousness and Cognition, 36, 390-405. https://doi.org/10.1016/j.concog.2014.12.003
- Friston, K., FitzGerald, T., Rigoli, F., Schwartenbeck, P., & Pezzulo, G. (2017). Active inference: A process theory. Neural Computation, 29(1), 1-49. https://doi.org/10.1162/NECOa00912
Friston, K., FitzGerald, T., Rigoli, F., Schwartenbeck, P., O'Doherty, J., & Pezzulo, G. (2016). Active inference and learning. Neuroscience & Biobehavioral Reviews, 68, 862-879. https://doi.org/10.1016/j.neubiorev.2016.06.022
- Friston, K., Heins, C., Verbelen, T., Da Costa, L., Salvatori, T., Markovic, D., ... & Parr, T. (2024). From pixels to planning: scale-free active inference . arXiv preprint arXiv:2407.20292.
- Friston, K., Parr, T., & de Vries, B. (2017). The graphical brain: belief propagation and active inference. Network Neuroscience, 1(4), 381-414.m https://doi.org/10.1162/NETNa00018
Friston, K., Ramstead, M. J. D., Kiefer, A. B., Tschantz, A., Buckley, C. L., Albarracin, M., … René, G. (2024). Designing ecosystems of intelligence from first principles. Collective Intelligence, 3(1), 26339137231222481. https://doi.org/10.1177/26339137231222481
- Friston, K., Rosch, R., Parr, T., Price, C., & Bowman, H. (2018). Deep temporal models and active inference. Neuroscience & Biobehavioral Reviews, 90, 486-501. https://doi.org/10.1016/j.neubiorev.2018.04.004
- Gabriel, I. (2020). Artificial intelligence, values, and alignment. Minds and Machines, 30(3), 411-437. https://doi.org/10.1007/s11023-020-09539-2
- Gampopa. (1998). The jewel ornament of liberation: The wish-fulfilling gem of the noble teachings (K. K. Gyaltsen Rinpoche, Trans.). Ithaca, NY: Snow Lion Publications.
- Ganguli, D., Hernandez, D., Lovitt, L., Askell, A., Bai, Y., Chen, A., ... & Clark, J. (2022, June). Predictability and surprise in large generative models. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (pp. 1747-1764). https://doi.org/10.1145/3531146.3533229
- Gans, J. S. (2018). Self-regulating artificial general intelligence . National Bureau of Economic Research. (Working Paper No. 24237). https://doi.org/10.3386/w24352
- Garcıa, J., & Fernández, F. (2015). A comprehensive survey on safe reinforcement learning. Journal of Machine Learning Research, 16(1), 1437-1480.
- Garfield, J. L. (1995). The fundamental wisdom of the middle way: Nāgārjuna's Mūlamadhyamakakārikā . Oxford University Press. https://doi.org/10.1093/oso/9780195103175.001.0001
Garfield, J. L. (2021). Buddhist Ethics as Moral Phenomenology.
https://doi.org/10.1093/oso/9780190907631.003.0003
Ghosh, S., Frase, H., Williams, A., Luger, S., Röttger, P., Barez, F., ... & Vanschoren, J. (2025). AILuminate: Introducing v1. 0 of the AI Risk and Reliability Benchmark from MLCommons . arXiv preprint arXiv:2503.05731.
Gibran, K. (1991). The prophet (Illustrated, reprint, revised ed.). Pan Books.
Gilbert, P. (2009). Introducing compassion-focused therapy. Advances in Psychiatric Treatment, 15 (3), 199-208. https://doi.org/10.1192/apt.bp.107.005264
- Gilbert, P., & Van Gordon, W. (2023). Compassion as a skill: A comparison of contemplative and evolution-based approaches. Mindfulness, 14(10), 2395-2416. https://doi.org/10.1007/s12671-023-02173-w
- Gilpin, L. H., Testart, C., Fruchter, N., & Adebayo, J. (2019). Explaining explanations to society. arXiv preprint arXiv:1901.06560.
Buddhist Ethics: A Philosophical Exploration, 29-42.
- Goddu, M. K., Noë, A., & Thompson, E. (2024). LLMs don't know anything: reply to Yildirim and Paul. Trends in Cognitive Sciences. https://doi.org/10.1016/j.tics.2024.06.008
Godfrey-Smith, P. (2016). Other minds: The octopus, the sea, and the deep origins of consciousness. Farrar, Straus and Giroux.
Goenka, S. N. (1987). T he Art of Living: Vipassana Meditation. Vipassana Research Institute.
Gold, J. (2014). Paving the great way: Vasubandhu's unifying Buddhist philosophy. Columbia University Press. https://doi.org/10.7312/columbia/9780231168267.001.0001
Gold, J. C. (2023a). The Coherence of Buddhism: Relativism, Ethics, and Psychology. Journal of Religious Ethics, 51(2), 321-341. https://doi.org/10.1111/jore.12433
Gold, J. C. (2023b). Wholesome Mind Ethics: A Buddhist Paradigm. The Journal of Value Inquiry, 57(4), 607-624. https://doi.org/10.1007/s10790-021-09845-7
Goldberg, S. B., Riordan, K. M., Sun, S., & Davidson, R. J. (2022). The empirical status of mindfulness-based interventions: A systematic review of 44 meta-analyses of randomized controlled trials . Perspectives on psychological science, 17(1), 108-130. https://doi.org/10.1177/1745691620968771
Goldberg, S. B., Tucker, R. P., Greene, P. A., Davidson, R. J., Wampold, B. E., Kearney, D. J., & Simpson, T. L. (2018). Mindfulness-based interventions for psychiatric disorders: A systematic review and meta-analysis. Clinical psychology review, 59, 52-60. https://doi.org/10.1016/j.cpr.2017.10.011
Goleman, D., & Davidson, R. (2017). T he science of meditation: How to change your brain, mind and body. Penguin UK.
Grimmer, H. J., Laukkonen, R. E., Freydenzon, A., von Hippel, W., & Tangen, J. M. (2022). Thinking style and psychosis proneness do not predict false insights. Consciousness and Cognition, 104 , Article 103384. https://doi.org/10.1016/j.concog.2022.103384
Gu, J., Strauss, C., Bond, R., & Cavanagh, K. (2015). How do mindfulness-based cognitive therapy and mindfulnessbased stress reduction improve mental health and wellbeing? A systematic review and meta-analysis of mediation studies. Clinical Psychology Review, 37, 1-12. https://doi.org/10.1016/j.cpr.2015.01.006
Guan, L., Dai, W., Zhang, C., Wu, Z., & Chen, H. (2024). Deliberative alignment: Reasoning enables safer language models. arXiv preprint arXiv:2401.11284.
Guendelman, S., Medeiros, S., & Rampes, H. (2017). Mindfulness and emotion regulation: Insights from neurobiological, psychological, and clinical studies. Frontiers in psychology, 8, 208068. https://doi.org/10.3389/fpsyg.2017.00220
Gunkel, D. J. (2018). Robot rights. Cambridge, MA: MIT Press. https://doi.org/10.7551/mitpress/11444.001.0001
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., ... & He, Y. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
Gyamtso, K. T. (2003). The sun of wisdom: Teachings on the noble Nagarjuna's fundamental wisdom of the middle way. Shambhala Publications.
Hadfield-Menell, D., Milli, S., Abbeel, P., Russell, S. J., & Dragan, A. (2017). Inverse reward design. Advances in neural information processing systems, 30.
Hadfield-Menell, D., Russell, S. J., Abbeel, P., & Dragan, A. (2016). Cooperative inverse reinforcement learning. Advances in neural information processing systems, 29.
Hagendorff, T. (2020). The ethics of AI ethics: An evaluation of guidelines. Minds and Machines, 30(1), 99-120. https://doi.org/10.1007/s11023-020-09517-8
Harner, M. J. (1980). The way of the shaman. San Francisco, CA: Harper & Row.
Hasenkamp, W., Wilson-Mendenhall, C. D., Duncan, E., & Barsalou, L. W. (2012). Mind wandering and attention during focused meditation: A fine-grained temporal analysis of fluctuating cognitive states. NeuroImage, 59(1), 750-760. https://doi.org/10.1016/j.neuroimage.2011.07.008
He, J., Lin, H., Wang, Q., Fung, Y., & Ji, H. (2024). Self-correction is more than refinement: A learning framework for visual and language reasoning tasks. arXiv preprint arXiv:2410.04055.
Heart Sutra [Prajñāpāramitāhṛdaya]. (2004). (Red Pine, Trans.). In The heart sutra: The womb of Buddhas (pp. 29-30) . Shoemaker & Hoard. (Original work composed circa 7th century CE)
- Hendrycks, D., Burns, C., Basart, S., Critch, A., Li, J., Song, D., & Steinhardt, J. (2020). Aligning ai with shared human values. arXiv preprint arXiv:2008.02275.
- Hendrycks, D., Mazeika, M., & Woodside, T. (2023). An overview of catastrophic AI risks. arXiv preprint arXiv:2306.12001. https://doi.org/10.1201/9781003530336-1
- Hesp, C., Smith, R., Parr, T., Allen, M., Friston, K. J., & Ramstead, M. J. (2021). Deeply felt affect: The emergence of valence in deep active inference. Neural computation, 33(2), 398-446. https://doi.org/10.1162/necoa01341
- Hinterberger, T., Schmidt, S., Kamei, T., & Walach, H. (2014). Decreased electrophysiological activity represents the conscious state of emptiness in meditation. Frontiers in psychology, 5, 99. https://doi.org/10.3389/fpsyg.2014.00099
- Ho, S. S., Nakamura, Y., & Swain, J. E. (2021). Compassion as an intervention to attune to universal suffering of self and others in conflicts: A translational framework. Frontiers in Psychology, 11, 603385. https://doi.org/10.3389/fpsyg.2020.603385
- Ho, S. S., Nakamura, Y., & Swain, J. E. (2023). Path of intuitive compassion to transform conflicts into enduring peace and prosperity: Symmetry across domains of reiterated prisoner's dilemma, dyadic active inference, and Mahayana Buddhism. Frontiers in Psychology, 14, 1099800 https://doi.org/10.3389/fpsyg.2023.1099800
- Hofstadter, D. R. (2007). I am a strange loop. Basic books.
- Hohwy, J. (2013). The predictive mind. Oxford University Press. https://doi.org/10.1093/acprof:oso/9780199682737.001.0001
- Huang, S., Siddarth, D., Lovitt, L., Liao, T. I., Durmus, E., Tamkin, A., & Ganguli, D. (2024, June). Collective Constitutional AI: Aligning a Language Model with Public Input. In The 2024 ACM Conference on Fairness, Accountability, and Transparency (pp. 1395-1417). https://doi.org/10.1145/3630106.3658979
- Hubinger, E., van Merwijk, C., Mikulik, V., Skalse, J., & Garrabrant, S. (2019). Risks from learned optimization in advanced machine learning systems. arXiv preprint arXiv:1906.01820.
- Ibrahim, L., & Cheng, M. (2025). Thinking beyond the anthropomorphic paradigm benefits LLM research. arXiv preprint arXiv:2502.09192.
- Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., ... & Kaiser, L. (2024). Openai o1 system card . arXiv preprint arXiv:2412.16720.
- James, W. (1956). The dilemma of determinism. In The will to believe and other essays in popular philosophy (pp. 145183). https://doi.org/10.1037/11061-005
- Jeste, D. V., Graham, S. A., Nguyen, T. T., Depp, C. A., Lee, E. E., & Kim, H. C. (2020). Beyond artificial intelligence: exploring artificial wisdom. International Psychogeriatrics, 32(8), 993-1001. https://doi.org/10.1017/S1041610220000927
- Ji, J., Qiu, T., Chen, B., Zhang, B., Lou, H., Wang, K., ... & Gao, W. (2023). Ai alignment: A comprehensive survey. arXiv preprint arXiv:2310.19852.
- Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y., Madotto, A., & Fung, P. (2024). MoralBench: A Multilingual and Multicultural Benchmark for Evaluating Moral Understanding in Language Models. arXiv preprint arXiv:2401.10968
Jobin, A., Ienca, M., & Vayena, E. (2019). The global landscape of AI ethics guidelines. Nature Machine Intelligence, 1(9), 389-399. https://doi.org/10.1038/s42256-019-0088-2
Johnson, S. G., Karimi, A. H., Bengio, Y., Chater, N., Gerstenberg, T., Larson, K., ... & Grossmann, I. (2024). Imagining and building wise machines: The centrality of AI metacognition. arXiv preprint arXiv:2411.02478.
Josipovic, Z. (2014). Neural correlates of nondual awareness in meditation. Annals of the New York Academy of Sciences, 1307(1), 9-18. https://doi.org/10.1111/nyas.12261
Josipovic, Z. (2016). Love and compassion meditation: a nondual perspective. Annals of the New York Academy of Sciences, 1373(1), 65-71. https://doi.org/10.1111/nyas.13078
Josipovic, Z. (2019). Nondual awareness: Consciousness-as-such as non-representational reflexivity. In A. Battro & S. Dehaene (Eds.), Progress in Brain Research (Vol. 244, pp. 273-298). Elsevier. https://doi.org/10.1016/bs.pbr.2018.10.021
Kabat-Zinn, J. (1994). Wherever you go, there you are: Mindfulness meditation in everyday life. Hyperion.
Kabat-Zinn, J. (2011). Some reflections on the origins of MBSR, skillful means, and the trouble with maps. Contemporary Buddhism, 12, 281-306. https://doi.org/10.1080/14639947.2011.564844
Kabat-Zinn, J., & Thích Nhất Hạnh. (2009). Full catastrophe living: Using the wisdom of your body and mind to face stress, pain, and illness. Delta.
Katz, D. M., Bommarito, M. J., Gao, S., & Arredondo, P. (2024). Gpt-4 passes the bar exam. Philosophical Transactions of the Royal Society A, 382(2270), 20230254. https://doi.org/10.1098/rsta.2023.0254
Kaufmann, T., Weng, P., Bengs, V., & Hüllermeier, E. (2023). A survey of reinforcement learning from human feedback. arXiv preprint arXiv:2312.14925.
Keown, D. (2016). The nature of Buddhist ethics. Springer.
Keown, D. (2020).
Buddhist ethics: A very short introduction
. Oxford University Press.
https://doi.org/10.1093/actrade/9780198850052.001.0001
Kettner, H., Gandy, S., Haijen, E. C., & Carhart-Harris, R. L. (2019). From egoism to ecoism: Psychedelics increase nature relatedness in a state-mediated and context-dependent manner. International journal of environmental research and public health, 16(24), 5147. https://doi.org/10.3390/ijerph16245147
Khan, A. A., Badshah, S., Liang, P., Waseem, M., Khan, B., Ahmad, A., ... & Akbar, M. A. (2022, June). Ethics of AI: A systematic literature review of principles and challenges. In Proceedings of the 26th International Conference on Evaluation and Assessment in Software Engineering (pp. 383-392). https://doi.org/10.1145/3530019.3531329
Kim, T. W., Hooker, J., & Donaldson, T. (2021). Taking principles seriously: A hybrid approach to value alignment in artificial intelligence. Journal of Artificial Intelligence Research, 71, 897-931 . https://doi.org/10.1613/jair.1.12481
Kirby, J. N., Tellegen, C. L., & Steindl, S. R. (2017). A meta-analysis of compassion-based interventions: Current state of knowledge and future directions. Behavior Therapy, 48(6), 778-792. https://doi.org/10.1016/j.beth.2017.06.003
Korbak, T. (2021). Computational enactivism under the free energy principle. Synthese, 198(3), 2743-2763. https://doi.org/10.1007/s11229-019-02243-4
Krakovna, V., & Kramar, J. (2023). Power-seeking can be probable and predictive for trained agents. arXiv preprint arXiv:2304.06528.
Kramer, J., & Alstad, D. (1993). The guru papers: Masks of authoritarian power. Frog books.
Kreplin, U., Farias, M., & Brazil, I. A. (2018). The limited prosocial effects of meditation: A systematic review and meta-analysis. Scientific reports, 8(1), 2403. https://doi.org/10.1038/s41598-018-20299-z
Kringelbach, M. L., Vuust, P., & Deco, G. (2024). Building a science of human pleasure, meaning making, and flourishing. Neuron, 112(9), 1392-1396. https://doi.org/10.1016/j.neuron.2024.03.022
- Kruger, J., & Dunning, D. (1999). Unskilled and unaware of it: how difficulties in recognizing one's own incompetence lead to inflated self-assessments. Journal of personality and social psychology, 77(6), 1121. https://doi.org/10.1037/0022-3514.77.6.1121
- Kulveit, j., Rosehadshar. (2023). Why Simulator AIs want to be Active Inference AIs. Retrieved from: https://www.lesswrong.com/posts/YEioD8YLgxih3ydxP/why-simulator-ais-want-to-be-active-inference-ais
Kundu, S., Bai, Y., Kadavath, S., Askell, A., Callahan, A., Chen, A., ... & Kaplan, J. (2023). Specific versus general principles for constitutional ai. arXiv preprint arXiv:2310.13798.
Laozi. (4th century BCE). Tao Te Ching (D. C. Lau, Trans.). Penguin Classics. (Original work composed ca. 4th century BCE)
Laukkonen, R. E., & Chandaria, S. (2024). A beautiful loop: An active inference theory of consciousness. OSF Preprints. https://doi.org/10.31234/osf.io/daf5n
Laukkonen, R. E., & Slagter, H. A. (2021). From many to (n)one: Meditation and the plasticity of the predictive mind. Neuroscience & Biobehavioral Reviews, 128, 199-217. https://doi.org/10.1016/j.neubiorev.2021.06.021
Laukkonen, R. E., Sacchet, M. D., Barendregt, H., Devaney, K. J., Chowdhury, A., & Slagter, H. A. (2023). Cessations of consciousness in meditation: Advancing a scientific understanding of nirodha samāpatti. Progress in Brain Research, 280, 61-87. https://doi.org/10.1016/bs.pbr.2022.12.007
Laukkonen, R., Leggett, J. M. I., Gallagher, R., Biddell, H., Mrazek, A., Slagter, H. A., & Mrazek, M. (2020). The science of mindfulness-based interventions and learning: A review for educators. https://doi.org/10.31231/osf.io/6g9uq
- LeDoux, J., Birch, J., Andrews, K., Clayton, N. S., Daw, N. D., Frith, C., ... & Vandekerckhove, M. M. (2023). Consciousness beyond the human case. Current Biology, 33(16), R832-R840. https://doi.org/10.1016/j.cub.2023.06.067
Leike, J., & Sutskever, I. (2023). Introducing Superalignment. OpenAI.
- Leike, J., Martic, M., Krakovna, V., Ortega, P. A., Everitt, T., Lefrancq, A., Orseau, L., & Legg, S. (2018). Scalable agent alignment via reward modeling: A research direction. arXiv preprint arXiv:1811.07871. Lele, A. (2015). The metaphysical basis of Śāntideva's ethics. Journal of Buddhist Ethics, 22, 249-279.
https://blogs.dickinson.edu/buddhistethics/2015/07/16/the-metaphysical-basis-of-santidevas-ethics/
Li, J., Yang, Y., Zhang, R., & Lee, Y. C. (2024). Overconfident and Unconfident AI Hinder Human-AI Collaboration. arXiv preprint arXiv:2402.07632.
- Li, L., Chen, Z., Chen, G., Zhang, Y., Su, Y., Xing, E., & Zhang, K. (2024). Confidence matters: Revisiting intrinsic self-correction capabilities of large language models . arXiv preprint arXiv:2402.12563.
- Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., ... & Koreeda, Y. (2022). Holistic evaluation of language models. arXiv preprint arXiv:2211.09110.
- Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., & Cobbe, K. (2024, May). Let's verify step by step [Conference paper]. In Proceedings of the Twelfth International Conference on Learning Representations (ICLR 2024) . OpenReview.
https://openreview.net/forum?id=v8L0pN6EOi
- Limanowski, J., & Blankenburg, F. (2013). Minimal self-models and the free energy principle. Frontiers in human neuroscience, 7, 547. https://doi.org/10.3389/fnhum.2013.00547
- Limanowski, J., & Friston, K. (2020). Attenuating oneself: An active inference perspective on "selfless" experiences. Philosophy and the Mind Sciences, 1(I), 1-16. https://doi.org/10.33735/phimisci.2020.I.35
- Lin, S., Hilton, J., & Evans, O. (2021). Truthfulqa: Measuring how models mimic human falsehoods. https://doi.org/10.18653/v1/2022.acl-long.229
- Linardatos, P., Papastefanopoulos, V., & Kotsiantis, S. (2020). Explainable AI: A review of machine learning interpretability methods. Entropy, 23(1), 18. https://doi.org/10.3390/e23010018
- Lindsey, J., Gurnee, W., Ameisen, E., Chen, B., Pearce, A., Turner, N. L., Citro, C., Abrahams,
- D., Carter, S., Hosmer, B., Marcus, J., Sklar, M., Templeton, A., Bricken, T., McDougall, C., Cunningham, H., Henighan, T., Jermyn, A., Jones, A., … Batson, J. (2025, March 27). On the biology of a large language model. Transformer Circuits.
- Lopez-Sola, E., Sanchez-Todo, R., Vohryzek, J., & Ruffini, G. (2025, April 13). An Algorithmic Agent Model of Pure Awareness and Minimal Experiences. https://doi.org/10.31234/osf.io/fgxec\_v2
- Loy, D. (2012). Nonduality: A study in comparative philosophy. Prometheus Books.
- Luberto, C. M., Shinday, N., Song, R., Philpotts, L. L., Park, E. R., Fricchione, G. L., & Yeh, G. Y. (2018). A systematic review and meta-analysis of the effects of meditation on empathy, compassion, and prosocial behaviors. Mindfulness, 9, 708-724. https://doi.org/10.1007/s12671-017-0841-8
- Luders, E., & Kurth, F. (2019). The neuroanatomy of long-term meditators. Current opinion in psychology, 28, 172-178. https://doi.org/10.1016/j.copsyc.2018.12.013
- Lutz, A., Dunne, J. D., & Davidson, R. J. (2007). Meditation and the neuroscience of consciousness. Cambridge handbook of consciousness, 499-555. https://doi.org/10.1017/CBO9780511816789.020
- Lutz, A., Jha, A. P., Dunne, J. D., & Saron, C. D. (2015). Investigating the phenomenological matrix of mindfulnessrelated practices from a neurocognitive perspective. American Psychologist, 70(7), 632-658 . https://doi.org/10.1037/a0039585
- Lutz, A., Mattout, J., & Pagnoni, G. (2019). The epistemic and pragmatic value of non-action: A predictive coding perspective on meditation. Current Opinion in Psychology, 28, 166-171. https://doi.org/10.1016/j.copsyc.2018.12.019
- Lutz, A., Slagter, H. A., Dunne, J. D., & Davidson, R. J. (2008). Attention regulation and monitoring in meditation. Trends in cognitive sciences, 12(4), 163-169. https://doi.org/10.1016/j.tics.2008.01.005
- Lynch, T. R., Trost, W. T., Salsman, N., & Linehan, M. M. (2007). Dialectical behavior therapy for borderline personality disorder. Annual Review of Clinical Psychology, 3(1), 181-205. https://doi.org/10.1146/annurev.clinpsy.2.022305.095229
- Maeda, T., & Quan-Haase, A. (2024, June). When Human-AI Interactions Become Parasocial: Agency and Anthropomorphism in Affective Design. In The 2024 ACM Conference on Fairness, Accountability, and Transparency (pp. 1068-1077). https://doi.org/10.1145/3630106.3658956
- Mago, J., Chandaria, S., Miller, M., & Laukkonen, R. E. (2024). Pure awareness, entropy, and the foundation of perception. OSF. https://doi.org/10.2139/ssrn.5201721
- Maitreya. (2014). Ornament of the Great Vehicle Sūtras: Maitreya's Mahāyānasūtrālaṃkāra [With commentaries by Khenpo Shenga and Ju Mipham] (Dharmachakra Translation Committee, Trans.). Snow Lion. (Original work published ca. 4th-5th century CE)
Matsumura, T., Esaki, K., & Mizuno, H. (20242). Empathic active inference: Active inference with empathy mechanism for socially behaved artificial agent. In Artificial Life Conference Proceedings (Vol. 34, p. 18). MIT Press.
- Mazeika, M., Yin, X., Tamirisa, R., Lim, J., Lee, B. W., Ren, R., ... & Hendrycks, D. (2025). Utility Engineering: Analyzing and Controlling Emergent Value Systems in AIs. arXiv preprint arXiv:2502.08640.
McGovern, H. T., Grimmer, H. J., Laukkonen, R. E., Ataria, Y., Davis, O., & Lifshitz, M. (2024). An integrated theory of false insights and beliefs under psychedelics. Communications Psychology, 2 , Article 69. https://doi.org/10.1038/s44271-024-00120-6
McLean, S., King, B. J., Thompson, J., Carden, T., Stanton, N. A., Baber, C., ... & Salmon, P. M. (2023). Forecasting emergent risks in advanced AI systems: an analysis of a future road transport management system. Ergonomics, 66(11), 1750-1767. https://doi.org/10.1080/00140139.2023.2286907
- McMahan, D. L. (2008). The making of Buddhist modernism. Oxford University Press. https://doi.org/10.1093/acprof:oso/9780195183276.001.0001
McRae, E. (2019). Feeling ignorant: A phenomenology of ignorance. Journal of Buddhist Philosophy, 5(5), 26-43. https://doi.org/10.1353/jbp.2019.a919583
Metzinger, T. (2020). Minimal phenomenal experience: Meditation, tonic alertness, and the phenomenology of "pure" consciousness. Philosophy and the Mind Sciences, 1(1), Article 7. https://doi.org/10.33735/phimisci.2020.I.46
Milarepa. (1999). The hundred thousand songs of Milarepa (G. C. C. Chang, Trans.). Boston, MA: Shambhala Publications.
Millière, R., Carhart-Harris, R. L., Roseman, L., Trautwein, F. M., & Berkovich-Ohana, A. (2018). Psychedelics, meditation, and self-consciousness. Frontiers in psychology, 9, 1475. https://doi.org/10.3389/fpsyg.2018.01475
Mitchell, M. (2025). Artificial intelligence learns to reason. Science, 387(6740), eadw5211 . https://doi.org/10.1126/science.adw5211
Moore, A., & Malinowski, P. (2009). Meditation, mindfulness and cognitive flexibility. Consciousness and cognition, 18(1), 176-186. https://doi.org/10.1016/j.concog.2008.12.008
Muehlhauser, L., & Helm, L. (2013). The singularity and machine ethics. In Eden, A. H., Moor, J. H., Soraker, J. H., & Steinhart, E. (Eds.), Singularity Hypotheses (pp. 101-126). Springer. https://doi.org/10.1007/978-3-642-32560-16
Muennighoff, Niklas, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling. arXiv preprint arXiv:2501.19393 (2025).
Murdoch, W. J., Singh, C., Kumbier, K., Abbasi-Asl, R., & Yu, B. (2019). Definitions, methods, and applications in interpretable machine learning. Proceedings of the National Academy of Sciences, 116(44), 22071-22080. https://doi.org/10.1073/pnas.1900654116
- Nanamoli, B., & Bodhi, B. (1995). The middle length discourses of the Buddha. A Translation of the Majjhima Nikaya. Wisdom Publications, Somerville, MA.
- Nave, O., Trautwein, F. M., Ataria, Y., Dor-Ziderman, Y., Schweitzer, Y., Fulder, S., & Berkovich-Ohana, A. (2021). Self-boundary dissolution in meditation: A phenomenological investigation. Brain Sciences, 11(6), 819 . https://doi.org/10.3390/brainsci11060819
- Navigli, R., Conia, S., & Ross, B. (2023). Biases in large language models: origins, inventory, and discussion. ACM Journal of Data and Information Quality, 15(2), 1-21. https://doi.org/10.1145/3597307
- Ng, A. Y., & Russell, S. (2000, June). Algorithms for inverse reinforcement learning. In Icml (Vol. 1, No. 2, p. 2).
- Ngo, R., Chan, L., & Mindermann, S. (2022). The alignment problem from a deep learning perspective. arXiv preprint arXiv:2209.00626.
- Nāgārjuna. (1944-1980). Le Traité de la Grande Vertu de Sagesse de Nāgārjuna (Mahāprajñāpāramitāśāstra) (É. Lamotte, Trans., 5 Vols.). Louvain: Institut Orientaliste.
- Nāgārjuna. (1995). The fundamental wisdom of the middle way: Mūlamadhyamakakārikā (J. L. Garfield, Trans.). Oxford University Press. (Original work composed 2nd century CE)
- Omohundro, S. M. (2018). The basic AI drives. In Artificial intelligence safety and security (pp. 47-55) . Chapman and Hall/CRC. https://doi.org/10.1201/9781351251389-3
- OpenAI. (2024, October 25). GPT-4o system card. arXiv. https://arxiv.org/abs/2410.19278
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35 , 27730-27744. https://doi.org/10.48550/arXiv.2203.02155 Pagnoni, G. (2019). The contemplative exercise through the lenses of predictive processing: A promising approach. In Progress in Brain Research (Vol. 244, pp. 299-322). Elsevier. https://doi.org/10.1016/bs.pbr.2018.10.022
- Pagnoni, G., & Guareschi, F. T. (2021). Meditative in-action: An endogenous epistemic venture. https://doi.org/10.31234/osf.io/mdbgq
- Parr, T., & Friston, K. J. (2019). Generalised free energy and active inference. Biological cybernetics, 113(5), 495-513. https://doi.org/10.1007/s00422-019-00805-w
Parr, T., Pezzulo, G., & Friston, K. J. (2022). Active inference: the free energy principle in mind, brain, and behavior. MIT Press. https://doi.org/10.7551/mitpress/12441.001.0001
Paul, A., Sajid, N., Da Costa, L., & Razi, A. (2024). On efficient computation in active inference. Expert Systems with Applications, 253, 124315. https://doi.org/10.1016/j.eswa.2024.124315
Paul, D., West, R., Bosselut, A., & Faltings, B. (2024). Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning. arXiv preprint arXiv:2402.13950. https://doi.org/10.18653/v1/2024.findingsemnlp.882
Pepperell, R. (2022). Does machine understanding require consciousness?. Frontiers in Systems Neuroscience, 16, 788486. https://doi.org/10.3389/fnsys.2022.788486
Perrault, R., & Clark, J. (2024). Artificial Intelligence Index Report 2024.
Petersen, C., Heins, C., Albarracin, M., Pitlya, R., Verbelen, T., Tschantz, A., Constant, A., Buckley, C. L., Kiefer, A. B., Friston, K., Swanson, S., Rene, G., & Salvatori, T. (2025, January 16). Method and system for specifying an active inference-based agent using natural language (U.S. Patent Application No. 18/770,654). United States Patent and Trademark Office. https://patents.justia.com/patent/20250021548
Pezzulo, G., Parr, T., Cisek, P., Clark, A., & Friston, K. (2024). Generating meaning: active inference and the scope and limits of passive AI. Trends in Cognitive Sciences, 28(2), 97-112. https://doi.org/10.1016/j.tics.2023.10.002
Pezzulo, G., Rigoli, F., & Friston, K. (2015). Active inference, homeostatic regulation and adaptive behavioural control. Progress in Neurobiology, 134, 17-35. https://doi.org/10.1016/j.pneurobio.2015.09.001
Pezzulo, G., Rigoli, F., & Friston, K. (2018). Hierarchical active inference: A theory of motivated control. Trends in Cognitive Sciences, 22(4), 294-306. https://doi.org/10.1016/j.tics.2018.01.009
Poundstone, W. (2011). Prisoner's dilemma. Anchor.
Prest, S. (2025). Towards a computational phenomenology of meditative deconstruction: Modelling 'letting go' and the deconstruction of experience with active inference. OSF. https://doi.org/10.31234/osf.io/evfg3v1
Prest, S., & Berryman, K. (2024). Towards an Active Inference Account of Deep Meditative Deconstruction. https://doi.org/10.31234/osf.io/d3gpf
Prest, S., Berryman, K., & Prest, S. (2024). Towards and active inference account of deep meditative deconstruction. Preprint: https://osf.io/preprints/psyarxiv/d3gpf
Purser, R. (2019). McMindfulness: How mindfulness became the new capitalist spirituality. Repeater.
Raji, I. D., Xu, P., Honigsberg, C., & Ho, D. E. (2022). Outsider oversight: Designing a third-party audit ecosystem for AI governance. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society (AIES '22) (pp. 557-571) . New York, NY: Association for Computing Machinery. https://doi.org/10.1145/3514094.3534181
Ramana Maharshi. (1926). Who am I? Sri Ramanasramam.
Ramstead, M. J., Constant, A., Badcock, P. B., & Friston, K. J. (2019). Variational ecology and the physics of sentient systems. Physics of life Reviews, 31, 188-205. https://doi.org/10.1016/j.plrev.2018.12.002
Rawlette, S. H. (2008). Normative qualia and a robust moral realism (Doctoral dissertation). New York University. Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y., Dirani, J., ... & Bowman, S. R. (2024). Gpqa: A graduatelevel google-proof q&a benchmark. In First Conference on Language Modeling.
Reinecke, M. G., Ting, F., Savulescu, J., & Singh, I. (2025). The double-edged sword of anthropomorphism in LLMs. Proceedings, 114(1), Article 4. https://doi.org/10.3390/proceedings2025114004
Renze, M., & Guven, E. (2024). Self-Reflection in LLM Agents: Effects on Problem-Solving Performance. arXiv preprint arXiv:2405.06682. https://doi.org/10.1109/FLLM63129.2024.10852426
Rosch, E. (2007). What Buddhist Meditation Has to Tell Psychology About the Mind. Antimatters, 1(1), 15-18.
Rozado, D. (2023). The political biases of ChatGPT.
Social Sciences, 12(3), 148.
https://doi.org/10.3390/socsci12030148
Rudin, C. (2019). Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature machine intelligence, 1(5), 206-215. https://doi.org/10.1038/s42256-019-0048-x
Rumi, J. (1968). Mystical Poems of Rumi (A. J. Arberry, Trans.). University of Chicago Press. (Original work composed ~13th century CE)
Russell, S. (2019). Human compatible: AI and the problem of control. Penguin UK.
Russell, S. J., & Norvig, P. (2021). Artificial Intelligence: A Modern Approach (4th ed.). Pearson.
Russell, S., Dewey, D., & Tegmark, M. (2015). Research priorities for robust and beneficial artificial intelligence. AI magazine, 36(4), 105-114. https://doi.org/10.1609/aimag.v36i4.2577
.
Sandved-Smith, L. (2024). A Computational Model of Minimal Phenomenal Experience (MPE) https://doi.org/10.20944/preprints202411.0649.v1
Sandved-Smith, L., Hesp, C., Mattout, J., Friston, K., Lutz, A., & Ramstead, M. J. D. (2021). Towards a computational phenomenology of mental action: Modelling meta-awareness and attentional control with deep parametric active inference . Neuroscience of Consciousness, 2021(1), niab018. https://doi.org/10.1093/nc/niab018 https://doi.org/10.1093/nc/niab018
Śāntideva. (1997). The Way of the Bodhisattva (Padmakara Translation Group, Trans.). Shambhala Publications. (Original work composed 8th century CE)
Schooler, J. W., Mrazek, M. D., Baird, B., Winkielman, P., & Wilson, T. D. (2011). Meta-awareness, perceptual decoupling and the wandering mind. Trends in Cognitive Sciences, 15(7), 319-326. https://doi.org/10.1016/j.tics.2011.05.006
Schweitzer, Y., Trautwein, F. M., Dor-Ziderman, Y., Nave, O., David, J., Fulder, S., & Berkovich-Ohana, A. (2024). Meditation-Induced Self-Boundary Flexibility and Prosociality: A MEG and Behavioral Measures Study. Brain Sciences, 14(12), 1181. https://doi.org/10.3390/brainsci14121181
Searle, J. R. (1980). Minds, brains, and programs. Behavioral and brain sciences, 3(3), 417-424. https://doi.org/10.1017/S0140525X00005756
- Seshia, S. A., Sadigh, D., & Sastry, S. S. (2022). Toward verified artificial intelligence. Communications of the ACM, 65(7), 46-55. https://doi.org/10.1145/3503914
- Seth, A. K. (2013). Interoceptive inference, emotion, and the embodied self. Trends in Cognitive Sciences, 17(11), 565573. https://doi.org/10.1016/j.tics.2013.09.007
- Seth, A. K., & Friston, K. J. (2016). Active interoceptive inference and the emotional brain. Philosophical Transactions of the Royal Society B: Biological Sciences, 371(1708), 20160007 https://doi.org/10.1098/rstb.2016.0007
- Sezer, I., Pizzagalli, D. A., & Sacchet, M. D. (2022). Resting-state fMRI functional connectivity and mindfulness in clinical and non-clinical contexts: A review and synthesis. Neuroscience & Biobehavioral Reviews, 135, 104583. https://doi.org/10.1016/j.neubiorev.2022.104583
- Shah, R., Irpan, A., Turner, A. M., Wang, A., Conmy, A., Lindner, D., ... & Dragan, A. (2025). An Approach to Technical AGI Safety and Security. arXiv preprint arXiv:2504.01849.
- Shaikh, O., Zhang, H., Held, W., Bernstein, M., & Yang, D. (2023). On second thought, let's not think step by step! Bias and toxicity in zero-shot reasoning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (pp. 4454-4470). https://doi.org/10.18653/v1/2023.acl-long.244
- Shanahan, M. (2024). Talking about large language models. Communications of the ACM, 67(2), 68-79. https://doi.org/10.1145/3624724
- Shantarakshita & Mipham J. (2010). The adornment of the middle way: Shantarakshita's Madhyamakalankara with commentary by Jamgon Mipham (Padmakara Translation Group, Trans.). Shambhala Publications.
- Shardlow, M., & Przybyła, P. (2024). Deanthropomorphising NLP: can a language model be conscious?. PLoS One, 19(12), e0307521. https://doi.org/10.1371/journal.pone.0307521
- Sharma, M., Tong, M., Mu, J., Wei, J., Kruthoff, J., Goodfriend, S., ... & Perez, E. (2025). Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming. arXiv preprint arXiv:2501.18837.
- Shi, Z., Liu, M., Zhang, S., Zheng, R., Dong, S., & Wei, P. (2025). GAWM: Global-Aware World Model for Multi-Agent Reinforcement Learning. arXiv preprint arXiv:2501.10116.
- Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., & Yao, S. (2024). Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36.
- Siderits, M. (2017). Buddhism as philosophy: An introduction . Routledge. https://doi.org/10.4324/9781315261225
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., … & Hassabis, D. (2016). Mastering the game of Go with deep neural networks and tree search.
https://doi.org/10.1038/nature16961
- Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., ... & Hassabis, D. (2017). Mastering the game of go without human knowledge. Nature, 550(7676), 354-359. https://doi.org/10.1038/nature24270
- Singer, T., & Engert, V. (2019). It matters what you practice: Differential training effects on subjective experience, behavior, brain and body in the ReSource Project. Current Opinion in Psychology, 28, 151-158. https://doi.org/10.1016/j.copsyc.2018.12.005
- Sladky, R. (2024). An active-inference perspective on flow states and how we experience insight. Frontiers in Psychology, 15 , Article 1354719.
- Slagter, H. A., Davidson, R. J., & Lutz, A. (2011). Mental training as a tool in the neuroscientific study of brain and cognitive plasticity. Frontiers in human neuroscience, 5, 17. https://doi.org/10.3389/fnhum.2011.00017
- Soares, N., Fallenstein, B., Armstrong, S., & Yudkowsky, E. (2015). Corrigibility. In Workshops at the Twenty-Ninth AAAI Conference on Artificial Intelligence.
- Srivastava, A., Rastogi, A., Rao, A., Shoeb, A. A. M., Abid, A., Fisch, A., ... & Wang, G. (2022). Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615.
Sterling, P. (2012). Allostasis: A model of predictive regulation. Physiology & Behavior, 106(1), 5-15.
https://doi.org/10.1016/j.physbeh.2011.06.004
Sterz, S., Baum, K., Biewer, S., Hermanns, H., Lauber-Rönsberg, A., Meinel, P., & Langer, M. (2024). On the Quest for Effectiveness in Human Oversight: Interdisciplinary Perspectives. In The 2024 ACM Conference on Fairness, Accountability, and Transparency (pp. 2495-2507). https://doi.org/10.1145/3630106.3659051
- Stiennon, N., Ouyang, L., Wu, J., Ziegler, D. M., Lowe, R., Voss, C., Radford, A., Amodei, D., & Christiano, P. (2020). Learning to summarize with human feedback. In Advances in Neural Information Processing Systems, 33 (pp. 3008-3021).
- Stone, J. (1999). Some reflections on critical Buddhism.
- Sutton, R. (2019). The bitter lesson. Incomplete Ideas (blog), 13(1), 38.
- Suzuki, S. (1970). Zen mind, beginner's mind. New York: Weatherhill.
- Tang, Y. Y., & Tang, R. (2015). Rethinking future directions of the mindfulness field. Psychological Inquiry, 26(4), 368372. https://doi.org/10.1080/1047840X.2015.1075850
- Tang, Y. Y., Hölzel, B. K., & Posner, M. I. (2015). The neuroscience of mindfulness meditation. Nature reviews neuroscience, 16(4), 213-225. https://doi.org/10.1038/nrn3916
Thanissaro Bhikkhu (Trans.). (1995). Anapanasati Sutta: Mindfulness of breathing (MN 118). Access to Insight. The Buddha. (1881). The Dhammapada: A collection of verses; being one of the canonical books of the Buddhists (Trans. F. Max Müller). Oxford University Press. (Original work composed 5th c. BCE)
The Buddha. (1995). Mahāparinibbāna Sutta [The great discourse on the Buddha's final nirvana] (M. Walshe, Trans.). In The long discourses of the Buddha (pp. 231-277). Wisdom Publications. (Original work composed 5th c. BCE)
- The Buddha. (2000). Anattalakkhaṇa Sutta [The discourse on the not-self characteristic] (B. Bodhi, Trans.). In The connected discourses of the Buddha (pp. 901-904). Wisdom Publications. (Original work composed 5th c. BCE)
Nature, 529(7587), 484-489.
- The Buddha. (2000). Dhammacakkappavattana Sutta [Setting the wheel of Dharma in motion] (B. Bodhi, Trans.). In The connected discourses of the Buddha (pp. 1843-1847). Wisdom Publications. (Original work composed 5th c. BCE)
The Buddha. (2000). Dukkha Sutta [Suffering] (B. Bodhi, Trans.). In The connected discourses of the Buddha (p. 1320). Wisdom Publications. (Original work composed 5th c. BCE)
The Holy Bible. (2011). New International Version. Grand Rapids, MI: Zondervan. (Original work published ca. 1st century CE)
Thompson, E. (2008). Neurophenomenology and contemplative experience. https://doi.org/10.2307/j.ctv1n3x16q.4 Thích Nhất Hạnh, (1975). The miracle of mindfulness: An introduction to the practice of meditation (Mobi Ho, Trans.). Beacon Press.
Thích Nhất Hạnh. (1991). Peace is every step: The path of mindfulness in everyday life . Bantam Books. BMC neuroscience, 5, 1-22.
Tononi, G. (2004). An information integration theory of consciousness. https://doi.org/10.1186/1471-2202-5-42
Totschnig, W. (2020). Fully autonomous AI. Science and Engineering Ethics, 26(5), 2473-2485 https://doi.org/10.1007/s11948-020-00243-z
Tschantz, A., Baltieri, M., Seth, A. K., & Buckley, C. L. (2020, July). Scaling active inference. In 2020 international joint conference on neural networks (ijcnn) (pp. 1-8). IEEE. https://doi.org/10.1109/IJCNN48605.2020.9207382
UNESCO. (2021). Recommendation on the ethics of artificial intelligence. Paris, France: United Nations Educational, Scientific and Cultural Organization. https://unesdoc.unesco.org/ark:/48223/pf0000380455
Van Dam, N. T., van Vugt, M. K., Vago, D. R., Schmalzl, L., Saron, C. D., Olendzki, A., ... & Meyer, D. E. (2018). Mind the hype: A critical evaluation and prescriptive agenda for research on mindfulness and meditation. Perspectives on Psychological Science, 13(1), 36-61. https://doi.org/10.1177/1745691617709589
Van Duijn, M. J., Van Dijk, B., Kouwenhoven, T., De Valk, W., Spruit, M. R., & van der Putten, P. (2023). Theory of mind in large language models: Examining performance of 11 state-of-the-art models vs. children aged 7-10 on advanced tests. arXiv preprint arXiv:2310.20320. https://doi.org/10.18653/v1/2023.conll-1.25
Varela F. J., Evan, T., & Eleanor, R. (1991). The embodied mind: Cognitive science and human experience. https://doi.org/10.7551/mitpress/6730.001.0001
Varela, F. J. (1996). Neurophenomenology: A methodological remedy for the hard problem. Journal of consciousness studies, 3(4), 330-349.
Varela, F. J., Thompson, E., & Rosch, E. (2017). The embodied mind, revised edition: Cognitive science and human experience . MIT press. https://doi.org/10.7551/mitpress/9780262529365.001.0001
Velasco, P. F. (2017). Attention in the Predictive Processing Framework and the Phenomenology of Zen Meditation. Journal of Consciousness Studies, 24(11-12), 71-93.
- Wallace, B. A. (2007). Contemplative science: Where Buddhism and neuroscience converge. Columbia University Press.
- Wallach, W., & Allen, C. (2008). Moral machines: Teaching robots right from wrong. Oxford University Press. https://doi.org/10.1093/acprof:oso/9780195374049.001.0001
- Wallach, W., Allen, C., & Smit, I. (2020). Machine morality: bottom-up and top-down approaches for modelling human moral faculties. In Machine ethics and robot ethics (pp. 249-266). Routledge. https://doi.org/10.4324/9781003074991-23
- Wang, H., Smith, J., & Patel, R. (2024) Metacognitive prompting improves understanding in LLMs. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (pp. 100115). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.naacl-long.106
- Wang, S., Zhang, S., Zhang, J., Hu, R., Li, X., Zhang, T., ... & Hovy, E. (2024). Reinforcement Learning Enhanced LLMs: A Survey. arXiv preprint arXiv:2412.10400.
- Wang, Y., Hu, S., Zhang, Y., Tian, X., Liu, X., Chen, Y., Shen, X., & Ye, J. (2024). How large language models implement chain-of-thought? In Proceedings of the International Conference on Learning Representations (ICLR 2024).
- Wang, Y., Liao, Y., Liu, H., Liu, H., Wang, Y., & Wang, Y. (2024). MM-SAP: A comprehensive benchmark for assessing self-awareness of multimodal large language models in perception. arXiv preprint arXiv:2401.07529. https://doi.org/10.18653/v1/2024.acl-long.498
- Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., ... & Fedus, W. (2022). Emergent abilities of large language models. arXiv preprint arXiv:2206.07682.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., ... & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35, 24824-24837.
- Weidinger, L., Uesato, J., Rauh, M., Griffin, C., Huang, P. S., Mellor, J., ... & Gabriel, I. (2022, June). Taxonomy of risks posed by language models. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (pp. 214-229). https://doi.org/10.1145/3531146.3533088
- Welwood, J. (1984). Principles of inner work: Psychological and spiritual. Journal of Transpersonal Psychology, 16(1), 63-73.
- Widder, D. G., Nafus, D., Dabbish, L., & Herbsleb, J. (2022, June). Limits and possibilities for "Ethical AI" in open source: A study of deepfakes. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (pp. 2035-2046). https://doi.org/10.1145/3531146.3533779
- Williams, P. (1998). Altruism and Reality: Studies in the Philosophy of the Bodhicaryavatara. Routledge. https://doi.org/10.4324/9781315027319
- Xu, F., Hao, Q., Zong, Z., Wang, J., Zhang, Y., Wang, J., ... & Li, Y. (2025). Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models. arXiv preprint arXiv:2501.09686.
- Yao, J., Yi, X., Wang, X., Wang, J., & Xie, X. (2023). From Instructions to Intrinsic Human Values-A Survey of Alignment Goals for Big Models. arXiv preprint arXiv:2308.12014.
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023, January). React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR).
- Yildirim, I., & Paul, L. A. (2024). From task structures to world models: what do LLMs know?. Trends in Cognitive Sciences. https://doi.org/10.1016/j.tics.2024.02.008
- Yiu, E., Kosoy, E., & Gopnik, A. (2023). Imitation versus Innovation: What children can do that large language and language-and-vision models cannot (yet)?. arXiv preprint arXiv:2305.07666. https://doi.org/10.31234/osf.io/kt9es
- Zainal, N. H., & Newman, M. G. (2024). Mindfulness enhances cognitive functioning: a meta-analysis of 111 randomized controlled trials. Health Psychology Review, 18(2), 369-395. https://doi.org/10.1080/17437199.2023.2248222
- Zeng, Z., Liu, Y., Wan, Y., Li, J., Chen, P., Dai, J., ... & Jia, J. (2024). Mr-ben: A meta-reasoning benchmark for evaluating system-2 thinking in llms. arXiv preprint arXiv:2406.13975.
- Zhou, J., Hu, M., Li, J., Zhang, X., Wu, X., King, I., & Meng, H. (2023). Rethinking Machine Ethics--Can LLMs Perform Moral Reasoning through the Lens of Moral Theories?. arXiv preprint arXiv:2308.15399. https://doi.org/10.18653/v1/2024.findings-naacl.144
- Zhu, W., Zhang, Z., & Wang, Y. (2024). Language models represent beliefs of self and others . arXiv preprint arXiv:2402.18496.
## APPENDICES
Laukkonen, R. E. et al. Appendices. Version 1. 2025. Direct Link: https://osf.io/az59t. DOI: 10.17605/OSF.IO/U4NH6