# Chain-of-Thought Tokens are Computer Program Variables
Abstract
Chain-of-thoughts (CoT) requires large language models (LLMs) to generate intermediate steps before reaching the final answer, and has been proven effective to help LLMs solve complex reasoning tasks. However, the inner mechanism of CoT still remains largely unclear. In this paper, we empirically study the role of CoT tokens in LLMs on two compositional tasks: multi-digit multiplication and dynamic programming. While CoT is essential for solving these problems, we find that preserving only tokens that store intermediate results would achieve comparable performance. Furthermore, we observe that storing intermediate results in an alternative latent form will not affect model performance. We also randomly intervene some values in CoT, and notice that subsequent CoT tokens and the final answer would change correspondingly. These findings suggest that CoT tokens may function like variables in computer programs but with potential drawbacks like unintended shortcuts and computational complexity limits between tokens. The code and data are available at https://github.com/solitaryzero/CoTs_are_Variables.
\pdfcolInitStack
tcb@breakable
Chain-of-Thought Tokens are Computer Program Variables
Fangwei Zhu, Peiyi Wang, Zhifang Sui School of Computer Science, State Key Laboratory of Multimedia Information Processing, Peking University zhufangwei2022@stu.pku.edu.cn wangpeiyi9979@gmail.com szf@pku.edu.cn
1 Introduction
Chain-of-thoughts (CoT) Wei et al. (2022) is a widely adopted technique that greatly boosts the capability of large language models (LLMs) in reasoning tasks like solving mathematical problems Shao et al. (2024); Wang et al. (2024) or generating codes Guo et al. (2025). By requiring language models to generate intermediate steps before reaching the final result, chain-of-thoughts enables LLMs to perform advanced reasoning, and thus significantly outperforms standard supervised learning methods. Various methods have been explored to unlock the ability of chain-of-thought reasoning in LLMs, for example designing prompts Wei et al. (2022); Khot et al. (2022); Zhou et al. (2022), instruction tuning Yue et al. (2023); Yu et al. (2023) or reinforcement learning Havrilla et al. (2024); Wang et al. (2024); Guo et al. (2025).
There have been theoretical studies on the efficacy of chain-of-thoughts Deng et al. (2024); Li et al. (2024); Chen et al. (2024). These studies reveal that while it is exponentially difficult for language models to solve compositional problems requiring serial computations, CoT could help models solve problems under multinominal complexity. More interestingly, CoT tokens do not need to fall in the “language space”, using latent vectors could also enable language models to perform complex reasoning Hao et al. (2024), indicating that CoTs are more than mere thought traces. The mechanism of how CoT works, and the role of CoT tokens are still not fully explored.
In this paper, we propose a novel hypothesis that CoT tokens function like computer program variables. To be specific, the tokens in CoT store intermediate values that will be used in subsequent computations, and these values are partially mutable to control the final output. As long as the important intermediate values are calculated and stored, the CoT that leads to the final answer could be represented in different forms.
To verify the hypothesis, we conduct empirical study on two types of problems that both require long-chain serial computations: multi-digit multiplication and dynamic programming. By comparing the performance of vanilla prompting with CoT prompting, we confirm that CoT is crucial for these problems. However, we also find that removing non-result tokens would not bring performance drops, which means that tokens storing intermediate values matter more in chain-of-thoughts.
We further explore whether intermediate values could be represented in different forms. We attempt to compress consequent number digits within a single latent vector, and experimental results show that it does not detriment the model performance. This phenomenon indicates that the existence, rather than the form, of intermediate values matters more to language models. However, when the degree of compression exceeds a certain limit of language models’ capacity, it would lead to failure in reasoning.
To further confirm that the intermediate values are causally connected with the output, we intervene in some tokens in CoT, replacing them with random values. It can be observed that LLMs will ignore previous steps, and use the intervened value to perform subsequent computations, supporting that CoT tokens are causally related with the final result. We conclude that CoT tokens function like the variables in computer programs.
To sum up, in this paper we empirically study the function of CoT tokens, and find that: (1) The role of CoT tokens is similar to variables in computer programs as they store intermediate values used in subsequent computations; (2) The intermediate values could be stored in CoT tokens with different forms; (3) The values in CoT tokens are causally related to the final output and could be intervened like program variables. These findings are helpful in understanding alternative forms of CoT, and could assist in designing more concise CoTs.
2 Preliminary
2.1 Chain-of-Thoughts
Chain-of-thoughts (CoT) Wei et al. (2022) is a technique commonly used in decoder-only transformers. Given the input text $x$ , CoT attempts to generate intermediate steps $z$ prior to the final answer $y$ . In other words, instead of modeling the probability distribution $P(y|x)$ , CoT attempts to model the joint distribution $P(y,z|x)=P(z|x)P(y|x,z)$ .
For convenience, we use two special tokens <COT> and </COT> to separate CoT tokens from the final result in our experiments.
2.2 Compositional Tasks
It has been noticed that LLMs may fail on seemingly trivial problems like multi-digit multiplication. The commonality of these problems is that they need strict multi-hop reasoning to derive correct predictions, which requires language models to perform step-to-step reasoning like human intelligence. In this paper, we choose two representative tasks to study the role of CoT tokens:
Algorithm 1 Digit-wise multiplication
0: Integer $a$ and $b$
0: Value of $a*b$
Partial = [ ]
for Digit $b[i]$ in $b$ do
carry $←$ 0
for Digit $a[i]$ in $a$ do
x $←$ $a[i]*b[i]$ + carry
digit $←$ x/10
carry $←$ x mod 10
end for
res $←$ Combine digits and last carry
Add res to Partial
end for
while Len(Partial) > 1 do
x $←$ Partial[0] + Partial[1]
Partial $←$ [x] + Partial[2:]
end while
return Partial[0]
Multi-digit Multiplication
Calculating the multiplication result of two multi-digit numbers $(x,y)$ requires executing multiple operations based on procedural rules Dziri et al. (2023). A commonly adopted solution is the long-form multiplication algorithm, which iteratively calculates the digit-wise multiplication result and adds them up to get the final result. We describe the algorithm in Algorithm 1, see Appendix A for prompt and dataset construction details.
Algorithm 2 Maximum path sum in a grid
0: A $m*n$ matrix $W$
0: Maximum weight sum $s$ on path
DP $←$ $m*n$ matrix filled with 0
for $i$ in range( $m$ ) do
for $j$ in range( $n$ ) do
DP[ $i$ ][ $j$ ] = $\max$ (DP[ $i-1$ ][ $j$ ], DP[ $i$ ][ $j-1$ ]) + W[ $i$ ][ $j$ ]
end for
end for
return DP[ $m-1$ ][ $n-1$ ]
Dynamic Programming
Dynamic programming (DP) is an algorithmic paradigm that breaks down complicated problems into simpler sub-problems, and then recursively solves these sub-problems. In our experiments, we use the “Maximum Path Sum in a Grid” problem: Given a $m× n$ grid filled with non-negative numbers where only moving downward and rightward is allowed, find a path from top left to bottom right which maximizes the sum of all numbers along its path. This is a classic problem that can be solved with dynamic programming in $O(m× n)$ time. We describe the algorithm in Algorithm 2, see Appendix B for prompt and dataset construction details.
<details>
<summary>x1.png Details</summary>
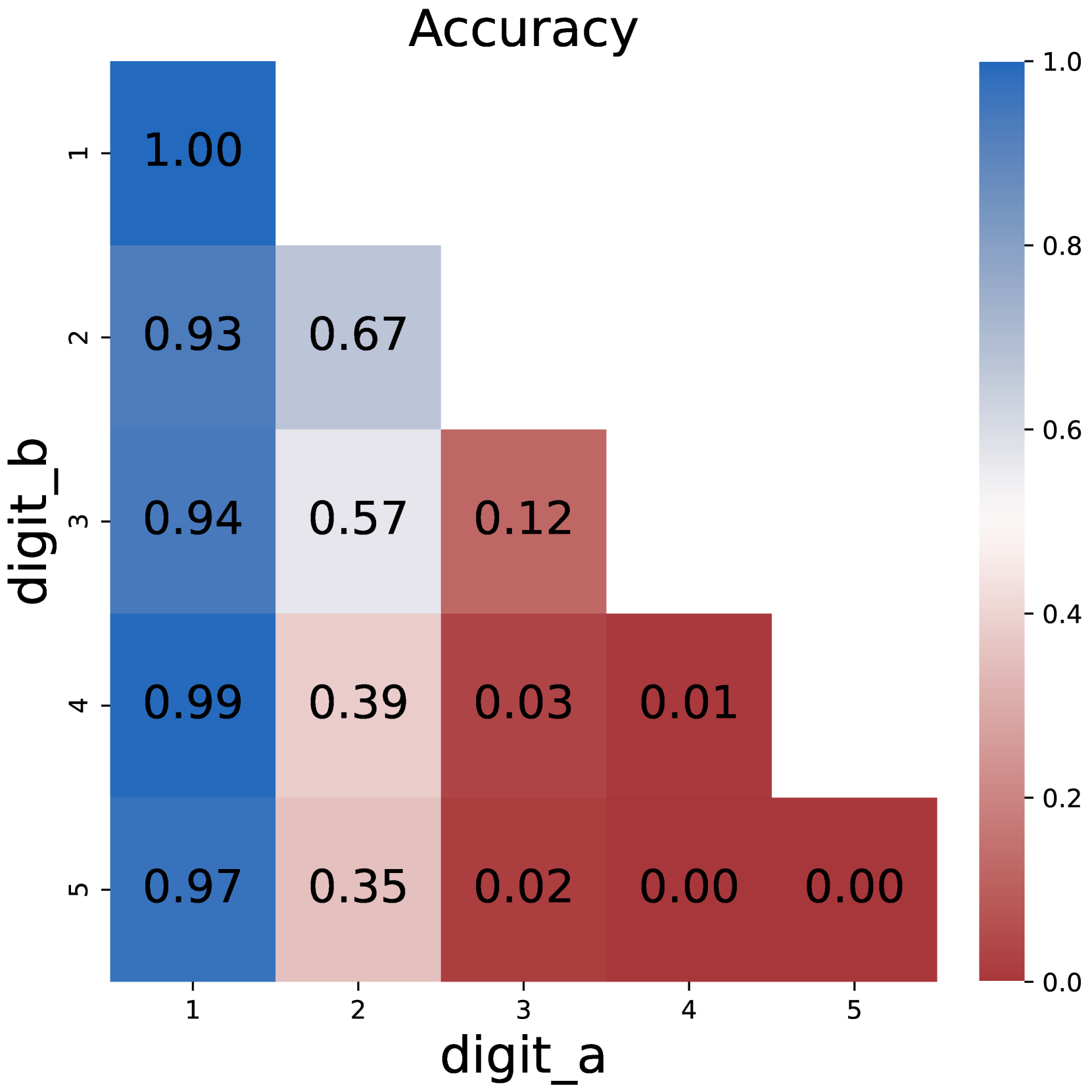
### Visual Description
## Heatmap: Accuracy
### Overview
This image presents a heatmap visualizing the accuracy of a digit recognition system, specifically how well it confuses one digit for another. The heatmap displays accuracy values ranging from 0.0 to 1.0, with darker blues representing higher accuracy and darker reds representing lower accuracy. The axes represent the 'true' digit (digit_a) and the 'predicted' digit (digit_b).
### Components/Axes
* **Title:** "Accuracy" - positioned at the top-center of the image.
* **X-axis Label:** "digit\_a" - representing the actual digit. Markers are 1, 2, 3, 4, and 5.
* **Y-axis Label:** "digit\_b" - representing the predicted digit. Markers are 1, 2, 3, 4, and 5.
* **Colorbar/Legend:** Located on the right side of the heatmap. It shows a gradient from blue (0.0) to red (1.0), representing the accuracy scale. The colorbar has markers at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
### Detailed Analysis
The heatmap is a 5x5 grid. Each cell represents the accuracy of predicting digit 'b' when the actual digit is 'a'. I will analyze row by row, referencing the legend to confirm color-accuracy correspondence.
* **Row 1 (digit\_a = 1):**
* digit\_b = 1: 1.00 (Dark Blue)
* digit\_b = 2: 0.93 (Light Blue)
* digit\_b = 3: 0.94 (Light Blue)
* digit\_b = 4: 0.99 (Dark Blue)
* digit\_b = 5: 0.97 (Light Blue)
* **Row 2 (digit\_a = 2):**
* digit\_b = 1: 0.67 (Light Grey)
* digit\_b = 2: 0.93 (Light Blue)
* digit\_b = 3: 0.57 (Grey)
* digit\_b = 4: 0.39 (Light Red)
* digit\_b = 5: 0.35 (Light Red)
* **Row 3 (digit\_a = 3):**
* digit\_b = 1: 0.12 (Red)
* digit\_b = 2: 0.57 (Grey)
* digit\_b = 3: 0.94 (Light Blue)
* digit\_b = 4: 0.03 (Dark Red)
* digit\_b = 5: 0.02 (Dark Red)
* **Row 4 (digit\_a = 4):**
* digit\_b = 1: 0.01 (Dark Red)
* digit\_b = 2: 0.39 (Light Red)
* digit\_b = 3: 0.03 (Dark Red)
* digit\_b = 4: 0.99 (Dark Blue)
* digit\_b = 5: 0.00 (Dark Red)
* **Row 5 (digit\_a = 5):**
* digit\_b = 1: 0.00 (Dark Red)
* digit\_b = 2: 0.35 (Light Red)
* digit\_b = 3: 0.02 (Dark Red)
* digit\_b = 4: 0.00 (Dark Red)
* digit\_b = 5: 0.97 (Light Blue)
### Key Observations
* The diagonal elements (where digit\_a = digit\_b) all have very high accuracy (close to 1.0), indicating the system correctly identifies digits most of the time.
* The system frequently confuses '3' for '1' and '2' (low accuracy values in the first column of row 3).
* The system frequently confuses '4' for '1', '2', '3', and '5' (low accuracy values in the first four columns of row 4).
* The system frequently confuses '5' for '1', '2', '3', and '4' (low accuracy values in the first four columns of row 5).
* The confusion matrix is not symmetrical. For example, the accuracy of predicting '2' given '1' (0.67) is different from predicting '1' given '2' (0.93).
### Interpretation
This heatmap represents a confusion matrix for a digit recognition model. It demonstrates the model's performance in classifying handwritten digits. The high accuracy along the diagonal indicates the model is generally good at recognizing digits when they are clearly presented. However, the lower accuracy values off-diagonal reveal specific areas of confusion.
The model struggles to differentiate between '3', '4', and '5', as evidenced by the low accuracy values when predicting these digits given other inputs. This suggests that these digits may have similar features in the dataset, leading to misclassification. The asymmetry in the confusion matrix suggests that the model may be biased towards certain digits or have different sensitivities to variations in their shapes.
The heatmap provides valuable insights for improving the model. Further analysis of the misclassified samples could reveal common patterns or features that contribute to the errors. This information can be used to refine the model's training data or architecture to enhance its accuracy and robustness.
</details>
(a) Plain multiplication
<details>
<summary>x2.png Details</summary>
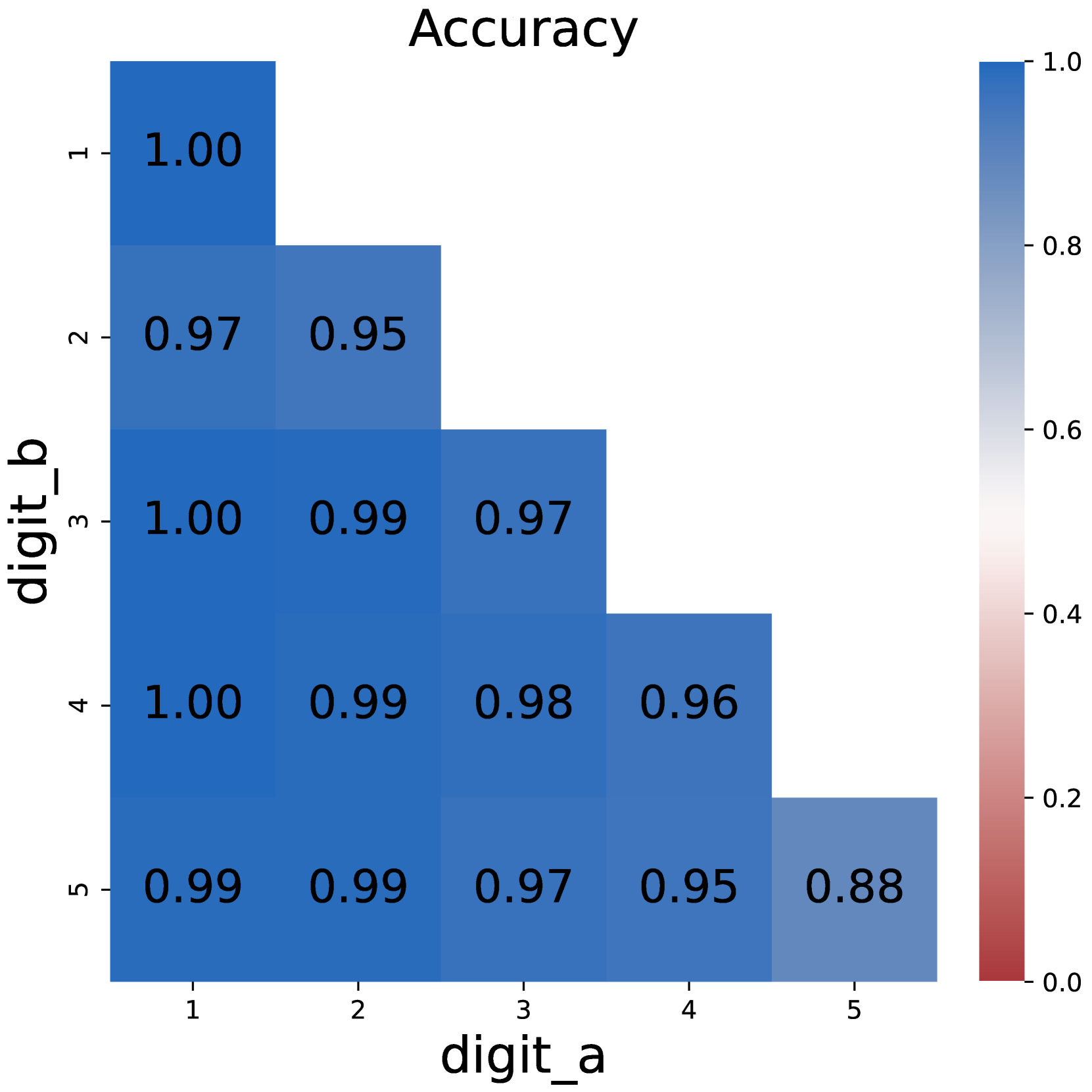
### Visual Description
\n
## Heatmap: Accuracy
### Overview
This image presents a heatmap visualizing the accuracy of a digit recognition system, likely a machine learning model, in classifying handwritten digits. The heatmap displays accuracy scores based on pairs of digits, 'digit_a' and 'digit_b'. The color intensity represents the accuracy level, with darker blues indicating higher accuracy and lighter blues/reds indicating lower accuracy.
### Components/Axes
* **Title:** "Accuracy" - positioned at the top-center of the image.
* **X-axis Label:** "digit\_a" - positioned at the bottom-center of the image. The axis markers are 1, 2, 3, 4, and 5.
* **Y-axis Label:** "digit\_b" - positioned at the left-center of the image. The axis markers are 1, 2, 3, 4, and 5.
* **Colorbar/Legend:** Located on the right side of the heatmap. It represents the accuracy scale, ranging from 0.0 (red) to 1.0 (dark blue). The colorbar has markers at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
### Detailed Analysis
The heatmap is a 5x5 grid, where each cell represents the accuracy of classifying 'digit_b' given that the input was 'digit_a'. The values within each cell are accuracy scores.
Here's a breakdown of the accuracy values, row by row (digit_b):
* **digit_b = 1:**
* digit_a = 1: 1.00
* digit_a = 2: 0.97
* digit_a = 3: 1.00
* digit_a = 4: 1.00
* digit_a = 5: 0.99
* **digit_b = 2:**
* digit_a = 1: 0.95
* digit_a = 2: 0.95
* digit_a = 3: 0.99
* digit_a = 4: 1.00
* digit_a = 5: 0.99
* **digit_b = 3:**
* digit_a = 1: 0.97
* digit_a = 2: 0.97
* digit_a = 3: 0.97
* digit_a = 4: 0.98
* digit_a = 5: 0.95
* **digit_b = 4:**
* digit_a = 1: 0.96
* digit_a = 2: 0.99
* digit_a = 3: 0.98
* digit_a = 4: 0.96
* digit_a = 5: 0.88
* **digit_b = 5:**
* digit_a = 1: 0.88
* digit_a = 2: 0.95
* digit_a = 3: 0.97
* digit_a = 4: 0.95
* digit_a = 5: 0.88
The overall trend is that the accuracy is generally high (above 0.90) for most digit pairs. The lowest accuracy scores are observed when classifying '5' given an input of '1' or '5' (0.88).
### Key Observations
* The highest accuracy scores (1.00) are observed when 'digit_a' and 'digit_b' are the same (1,1; 3,3; 4,4). This is expected, as the model should be most confident in recognizing a digit when it is presented with itself.
* Accuracy tends to be slightly lower when classifying '5' regardless of the input digit.
* The model performs relatively well in distinguishing between most digit pairs, with accuracy rarely dropping below 0.95.
* The heatmap is nearly symmetrical, suggesting that the confusion between digits is largely reciprocal (e.g., if the model sometimes misclassifies '2' as '3', it also sometimes misclassifies '3' as '2').
### Interpretation
This heatmap demonstrates the performance of a digit recognition model. The high accuracy scores across most digit pairs indicate that the model is generally effective at recognizing handwritten digits. The lower accuracy scores for the digit '5' suggest that this digit may be more difficult to classify, potentially due to its more complex shape or similarity to other digits. The near-symmetry of the heatmap suggests that the model's errors are not biased towards specific misclassifications.
The data suggests that the model is well-trained and performs reliably. However, further investigation could focus on improving the model's ability to classify the digit '5' and understanding the specific reasons for the observed misclassifications. This could involve analyzing the training data for imbalances or using techniques to augment the data with more examples of the digit '5'. The heatmap provides a clear and concise visualization of the model's performance, allowing for easy identification of areas for improvement.
</details>
(b) CoT multiplication
<details>
<summary>x3.png Details</summary>
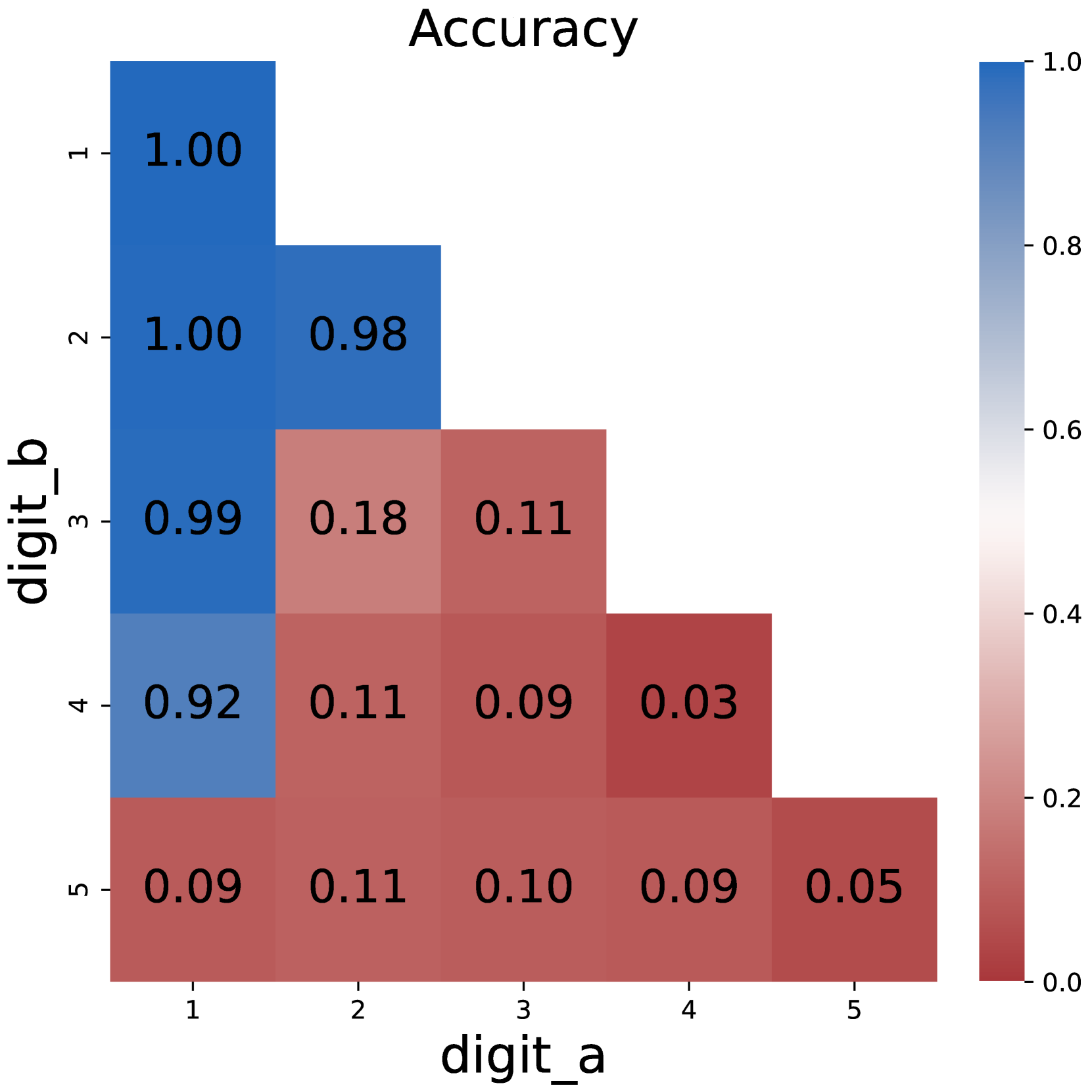
### Visual Description
## Heatmap: Accuracy
### Overview
This image presents a heatmap visualizing the accuracy of a digit recognition system, specifically showing how well the system confuses one digit for another. The heatmap displays accuracy values ranging from 0.0 to 1.0, with darker blues representing higher accuracy and darker reds representing lower accuracy. The axes represent the 'true' digit (digit_a) and the 'predicted' digit (digit_b).
### Components/Axes
* **Title:** "Accuracy" - positioned at the top-center of the image.
* **X-axis Label:** "digit\_a" - representing the actual digit. Markers are 1, 2, 3, 4, 5.
* **Y-axis Label:** "digit\_b" - representing the predicted digit. Markers are 1, 2, 3, 4, 5.
* **Colorbar:** Located on the right side of the heatmap. It ranges from 0.0 (dark red) to 1.0 (dark blue), representing the accuracy scale.
* **Data Cells:** Each cell in the grid represents the accuracy of predicting digit 'b' when the actual digit is 'a'. The values are displayed within each cell.
### Detailed Analysis
The heatmap is a 5x5 grid. I will analyze row by row, referencing the colorbar to confirm accuracy.
* **Row 1 (digit\_a = 1):**
* digit\_b = 1: 1.00 (dark blue)
* digit\_b = 2: 1.00 (dark blue)
* digit\_b = 3: 0.99 (light blue)
* digit\_b = 4: 0.92 (medium blue)
* digit\_b = 5: 0.09 (dark red)
* **Row 2 (digit\_a = 2):**
* digit\_b = 1: 1.00 (dark blue)
* digit\_b = 2: 0.98 (light blue)
* digit\_b = 3: 0.18 (red)
* digit\_b = 4: 0.11 (red)
* digit\_b = 5: 0.09 (dark red)
* **Row 3 (digit\_a = 3):**
* digit\_b = 1: 0.99 (light blue)
* digit\_b = 2: 0.18 (red)
* digit\_b = 3: 0.11 (red)
* digit\_b = 4: 0.09 (dark red)
* digit\_b = 5: 0.05 (dark red)
* **Row 4 (digit\_a = 4):**
* digit\_b = 1: 0.92 (medium blue)
* digit\_b = 2: 0.11 (red)
* digit\_b = 3: 0.09 (dark red)
* digit\_b = 4: 0.03 (dark red)
* digit\_b = 5: 0.09 (dark red)
* **Row 5 (digit\_a = 5):**
* digit\_b = 1: 0.09 (dark red)
* digit\_b = 2: 0.11 (red)
* digit\_b = 3: 0.10 (red)
* digit\_b = 4: 0.09 (dark red)
* digit\_b = 5: 0.05 (dark red)
### Key Observations
* The system performs very well at recognizing digits 1 and 2 when they are the actual digits. Accuracy is near 1.0 when predicting 1 or 2 given 1 or 2.
* The system frequently confuses digit 5 for other digits, and vice versa. Accuracy values are consistently low (around 0.05-0.11) when the actual digit is 5.
* Digit 4 is also often misclassified, particularly as other digits.
* The diagonal elements (where predicted = actual) are the highest values, as expected.
* There is a noticeable asymmetry in the confusion matrix. For example, the system is better at predicting '1' when the actual digit is '1' than it is at predicting '1' when the actual digit is '5'.
### Interpretation
This heatmap demonstrates the performance of a digit recognition model. The high accuracy along the diagonal indicates that the model correctly identifies digits most of the time when the input is clear. However, the low accuracy values in several off-diagonal cells reveal specific areas of confusion. The model struggles to differentiate between digits 5 and other digits, suggesting that the features used to recognize '5' are similar to those of other digits, or that the training data for '5' was insufficient or of poor quality. The heatmap provides valuable insights for improving the model, such as focusing on feature engineering or data augmentation for the digits that are frequently misclassified. The pattern of confusion suggests that the model may be sensitive to certain visual characteristics of the digits, leading to systematic errors.
</details>
(c) Plain DP
<details>
<summary>x4.png Details</summary>
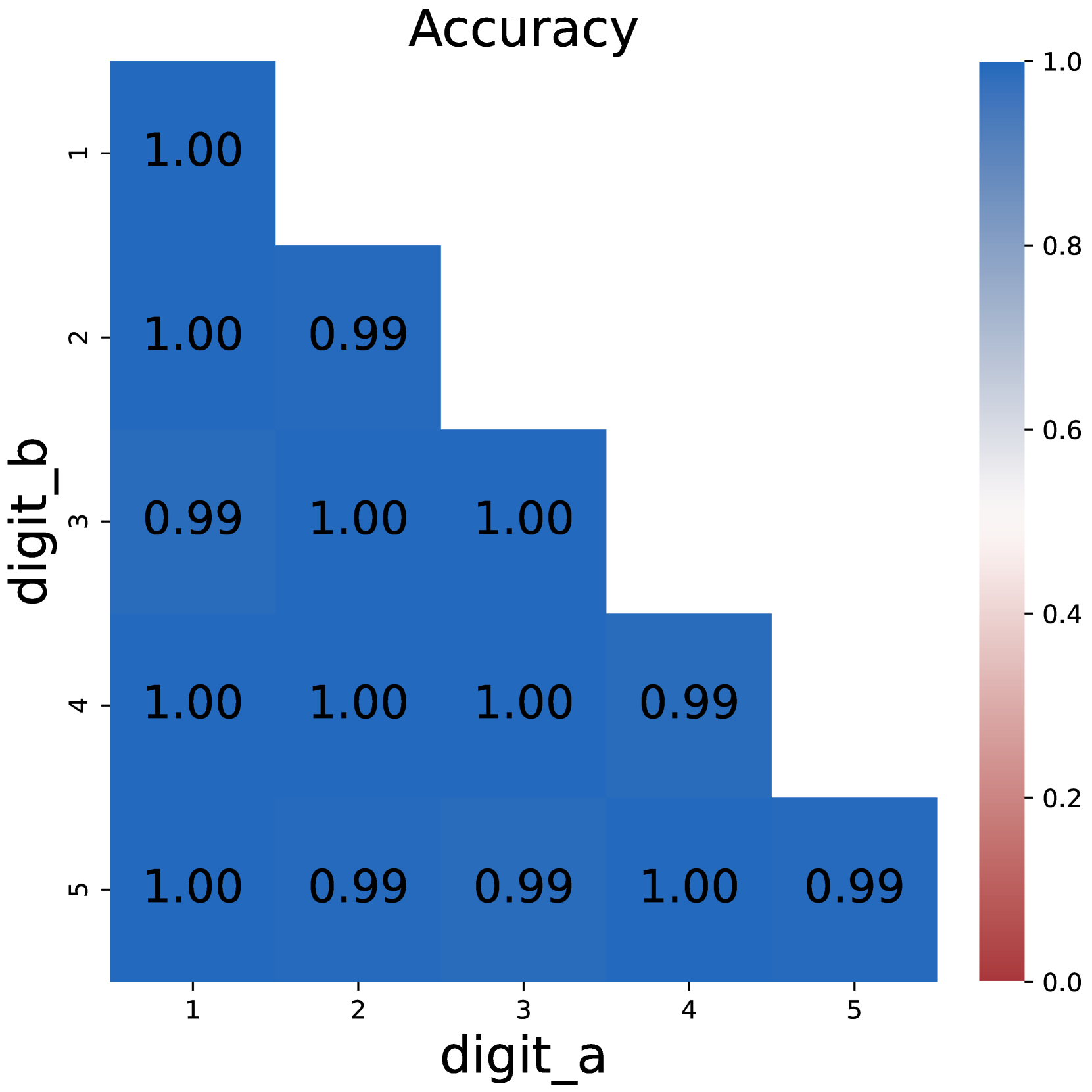
### Visual Description
## Heatmap: Accuracy
### Overview
This image presents a heatmap visualizing the accuracy of a system, likely a digit recognition model, in predicting digit 'b' given digit 'a'. The heatmap displays accuracy values ranging from 0.0 to 1.0, with darker blue shades representing higher accuracy. The heatmap is a 5x5 grid, representing the accuracy for each possible pair of digits from 1 to 5.
### Components/Axes
* **Title:** "Accuracy" - positioned at the top-center of the image.
* **X-axis Label:** "digit\_a" - positioned at the bottom-center of the image. The axis markers are 1, 2, 3, 4, and 5.
* **Y-axis Label:** "digit\_b" - positioned at the left-center of the image. The axis markers are 1, 2, 3, 4, and 5.
* **Colorbar:** A vertical colorbar is located on the right side of the heatmap. It ranges from approximately 0.0 (red) to 1.0 (dark blue), representing the accuracy scale.
* **Data Cells:** Each cell in the 5x5 grid represents the accuracy for a specific (digit\_a, digit\_b) pair. The accuracy value is displayed within each cell.
### Detailed Analysis
The heatmap shows predominantly high accuracy values, mostly close to 1.0. Let's analyze each cell:
* **(1, 1):** Accuracy = 1.00
* **(1, 2):** Accuracy = 1.00
* **(1, 3):** Accuracy = 0.99
* **(1, 4):** Accuracy = 1.00
* **(1, 5):** Accuracy = 1.00
* **(2, 1):** Accuracy = 1.00
* **(2, 2):** Accuracy = 0.99
* **(2, 3):** Accuracy = 1.00
* **(2, 4):** Accuracy = 1.00
* **(2, 5):** Accuracy = 0.99
* **(3, 1):** Accuracy = 0.99
* **(3, 2):** Accuracy = 1.00
* **(3, 3):** Accuracy = 1.00
* **(3, 4):** Accuracy = 1.00
* **(3, 5):** Accuracy = 0.99
* **(4, 1):** Accuracy = 1.00
* **(4, 2):** Accuracy = 1.00
* **(4, 3):** Accuracy = 1.00
* **(4, 4):** Accuracy = 0.99
* **(4, 5):** Accuracy = 0.99
* **(5, 1):** Accuracy = 1.00
* **(5, 2):** Accuracy = 0.99
* **(5, 3):** Accuracy = 0.99
* **(5, 4):** Accuracy = 1.00
* **(5, 5):** Accuracy = 0.99
The values generally decrease as the digits 'a' and 'b' become further apart.
### Key Observations
* The highest accuracy (1.00) is observed for several digit pairs, indicating strong performance in those specific predictions.
* The lowest accuracy values (0.99) are scattered throughout the heatmap, suggesting a slight decrease in performance for certain digit combinations.
* The heatmap exhibits a generally consistent pattern of high accuracy, with only minor variations.
* There is no clear diagonal pattern, suggesting that the model does not have a bias towards predicting the same digit.
### Interpretation
The heatmap demonstrates that the digit recognition system achieves very high accuracy across most digit pairs (1-5). The values consistently hover around 1.0, indicating a robust and reliable model. The slight dips to 0.99 suggest that the model may struggle slightly with certain digit combinations, but the overall performance remains excellent.
The heatmap provides a clear visual representation of the model's performance, allowing for quick identification of areas where the model excels or may require further improvement. The data suggests that the model is well-trained and capable of accurately predicting digits in most scenarios. The consistent high accuracy across the board indicates a well-generalized model, not overly sensitive to specific input combinations.
</details>
(d) CoT DP
Figure 1: Comparison on model accuracy between plain prompting and chain-of-thought prompting.
3 CoT Tokens Store Intermediate Results
Experimental Setup
In all of our experiments, We use Qwen-2.5-1.5B Yang et al. (2024) as the backbone model. On each task, we finetune the model on the corresponding training data and then evaluate whether the generated final answer matches the golden answer. The training stage goes under a learning rate of 1e-5 for 1 epoch. See Appendix C for detailed hyperparameter settings.
3.1 Necessity of Chain-of-Thoughts
We start by examining the effectiveness of CoT by comparing the model performance under direct prompting and CoT settings. As illustrated in Figure 1, training the model with direct prompts faces difficulty starting from 3*3 multiplication problems, and completely fails on larger numbers. In contrast, the model could easily solve multiplication problems with chain-of-thoughts, with near-perfect accuracy.
The same applies to dynamic programming problems. Direct prompting would fail as the number of intermediate states increases, while CoT maintains its competence. These results support the conclusion that chain-of-thoughts is necessary for solving inherent serial problems that require multi-step reasoning, just as previous research suggests Li et al. (2024); Chen et al. (2024).
<details>
<summary>x5.png Details</summary>
### Visual Description
## Heatmap: Accuracy
### Overview
This image presents a heatmap visualizing the accuracy of a system, likely a digit recognition model, based on pairs of digits 'a' and 'b'. The heatmap displays accuracy values ranging from 0.0 to 1.0, with darker blue shades indicating higher accuracy. The x-axis represents 'digit_a' and the y-axis represents 'digit_b'.
### Components/Axes
* **Title:** "Accuracy" - positioned at the top-center of the image.
* **X-axis Label:** "digit\_a" - positioned at the bottom-center of the image. The axis markers are 1, 2, 3, 4, and 5.
* **Y-axis Label:** "digit\_b" - positioned at the left-center of the image. The axis markers are 1, 2, 3, 4, and 5.
* **Colorbar/Legend:** Located on the right side of the heatmap. It represents the accuracy scale, ranging from 0.0 (red) to 1.0 (dark blue). The colorbar has markers at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
### Detailed Analysis
The heatmap is a 5x5 grid, with each cell representing the accuracy for a specific pair of digits (digit\_a, digit\_b). The values are as follows:
* **(1, 1):** 1.00
* **(1, 2):** 0.92
* **(1, 3):** 1.00
* **(1, 4):** 1.00
* **(1, 5):** 1.00
* **(2, 1):** 0.90
* **(2, 2):** 0.90
* **(2, 3):** 1.00
* **(2, 4):** 0.98
* **(2, 5):** 1.00
* **(3, 1):** 1.00
* **(3, 2):** 1.00
* **(3, 3):** 0.98
* **(3, 4):** 0.94
* **(3, 5):** 0.93
* **(4, 1):** 1.00
* **(4, 2):** 0.98
* **(4, 3):** 0.94
* **(4, 4):** 0.93
* **(4, 5):** 0.93
* **(5, 1):** 1.00
* **(5, 2):** 1.00
* **(5, 3):** 0.87
* **(5, 4):** 0.93
* **(5, 5):** 0.93
The accuracy values are generally high, with most cells displaying values above 0.90. There is a slight decrease in accuracy when digit\_a is 5 and digit\_b is 3 (0.87).
### Key Observations
* The highest accuracy (1.00) is observed for several digit pairs, including (1,1), (1,3), (1,4), (1,5), (3,1), (3,2), (5,1), and (5,2).
* The lowest accuracy (0.87) is observed for the digit pair (5,3).
* Accuracy appears to be relatively consistent across most digit pairs, with a few exceptions.
* The diagonal elements (where digit\_a equals digit\_b) all have an accuracy of 1.00 or very close to it.
### Interpretation
This heatmap suggests that the digit recognition system performs very well overall, achieving high accuracy for most digit pairs. The slight decrease in accuracy for the (5,3) pair could indicate a specific challenge in distinguishing between these two digits. The high accuracy along the diagonal suggests the system is very confident in recognizing individual digits when presented in isolation. The data suggests the system is robust, but further investigation into the (5,3) case might reveal specific features or patterns that contribute to the lower accuracy. The heatmap provides a clear visual representation of the system's performance across different digit combinations, allowing for targeted improvements and optimization.
</details>
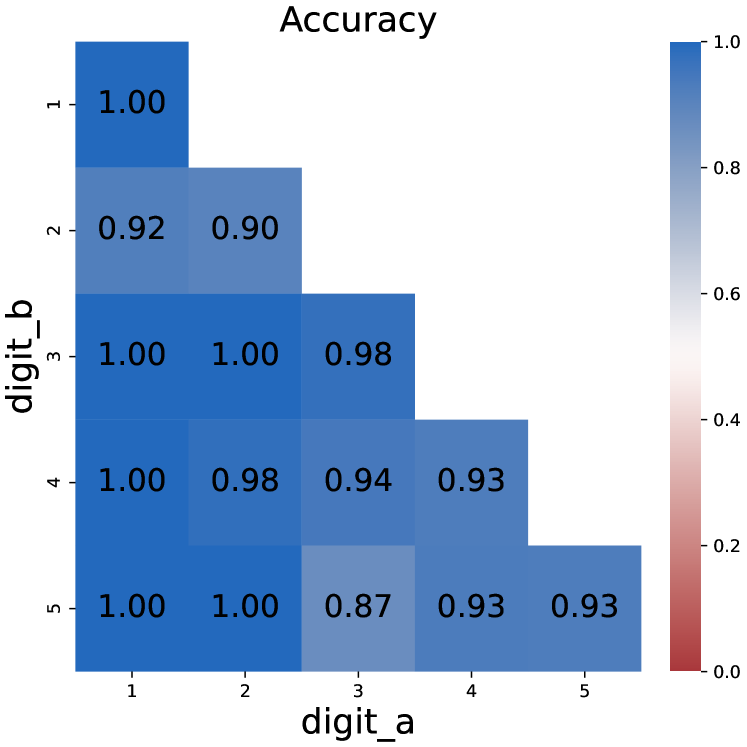
Figure 2: Model performance when non-result tokens are removed from CoT in multi-digit multiplication. Removing these tokens has little impact.
3.2 Removing Non-result Tokens
One of the concerns about CoT is whether it could be compressed into a more concise form. An obvious approach is to remove some less important tokens. To be specific, we remove tokens that are neither a number nor a symbol For example word ”carry“ in multiplication problems, see Appendix C for details, making CoT a sequence consisting purely of intermediate results to solve the task.
Figure 2 shows the model performances after removing these tokens. While the removal would make the CoT unreadable, models finetuned on compressed CoT still achieve satisfying performance, even outperforming the full CoT setting. We can infer from this phenomenon that intermediate results are more important than semantic completeness in CoT. In other words, the central function of CoT is to store the sequence of intermediate results.
<details>
<summary>x6.png Details</summary>
### Visual Description
\n
## Diagram: Large Language Model with Chain-of-Thought (CoT) Prompting
### Overview
This diagram illustrates the process of a Large Language Model (LLM) generating a result using Chain-of-Thought (CoT) prompting. It depicts the flow of information from input tokens through the LLM's hidden states to output tokens, highlighting the role of latent embeddings and CoT tokens.
### Components/Axes
The diagram consists of three main sections:
1. **Input Layer:** Represents the input to the LLM, including the initial question and CoT tokens.
2. **Large Language Model (LLM):** A large blue rectangle representing the core of the model.
3. **Output Layer:** Represents the generated output tokens, leading to the final result.
Key labels include:
* "Large Language Model"
* "Input token"
* "Latent embedding"
* "Last hidden state"
* "Latent prediction"
* "Output token"
* "[Question]"
* "<COT>"
* "<LAT>"
* "Result"
### Detailed Analysis or Content Details
The diagram shows a sequential process.
**Input Layer:**
* The input begins with "[Question]", represented by a yellow rounded rectangle.
* Following the question, a series of "<COT>" and "<LAT>" tokens are added. "<COT>" appears to be a Chain-of-Thought token, and "<LAT>" appears to be a Latent token.
* Below the tokens is the label "Input token".
* Above the tokens is the label "Latent embedding".
* Arrows point upwards from the "Input token" to the "Latent embedding".
**Large Language Model (LLM):**
* The LLM is represented as a large blue rectangle.
* Inside the LLM, a series of green rounded rectangles represent "Last hidden state".
* Above each "Last hidden state" is a yellow rounded rectangle representing "Latent prediction".
* Arrows connect the "Latent prediction" to the "Last hidden state", indicating a feedback loop or iterative refinement.
* The "<COT>" and "<LAT>" tokens are fed into the LLM, influencing the hidden states.
**Output Layer:**
* The output consists of a sequence of "<COT>" and "<LAT>" tokens, followed by "<COT>" and "Result".
* Above the tokens is the label "Output token".
* Arrows point downwards from the "Latent prediction" to the "Output token".
* The final output is labeled "Result".
The diagram uses "..." to indicate that the sequence of hidden states and tokens continues beyond what is explicitly shown.
### Key Observations
* The diagram emphasizes the iterative nature of LLM processing, with latent predictions influencing subsequent hidden states.
* The inclusion of "<COT>" and "<LAT>" tokens suggests a specific prompting strategy designed to elicit chain-of-thought reasoning and latent knowledge from the model.
* The diagram does not provide any numerical data or specific values. It is a conceptual illustration of the process.
### Interpretation
This diagram demonstrates how Chain-of-Thought (CoT) prompting can be integrated into the input sequence of a Large Language Model to guide its reasoning process. The "<COT>" tokens likely serve as cues for the model to generate intermediate reasoning steps, while the "<LAT>" tokens may represent latent knowledge or concepts that are relevant to the question. The iterative feedback loop between latent predictions and hidden states suggests that the model refines its understanding and reasoning over multiple steps. The final "Result" is the output of this process, informed by both the initial question and the CoT/latent prompting strategy. The diagram highlights the importance of carefully crafting prompts to elicit desired behaviors from LLMs. The diagram is a high-level conceptual overview and does not delve into the specific architecture or parameters of the LLM.
</details>
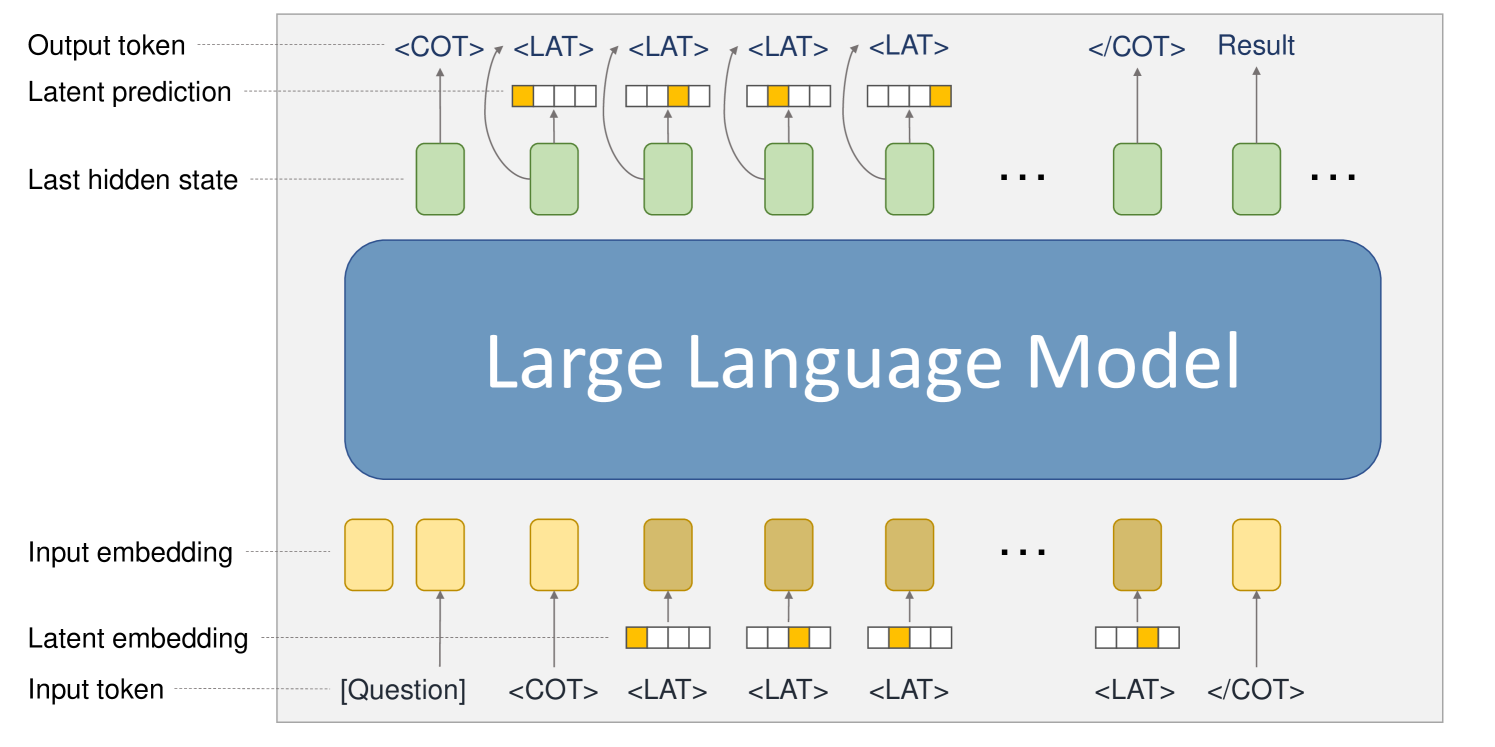
Figure 3: The model structure used to reason with latent tokens. We use one-hot vectors as the latent embedding of latent tokens <LAT>. When the input token is a latent token, we use its projected latent embedding to replace the original input embedding. Correspondingly, a latent output head is added to predict the latent embedding of the next token from the last hidden state.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Heatmap: Accuracy
### Overview
This image presents a heatmap visualizing the accuracy of a system, likely a digit recognition model, based on pairs of digits 'a' and 'b'. The heatmap displays accuracy values ranging from 0.0 to 1.0, with darker blue shades indicating higher accuracy.
### Components/Axes
* **Title:** "Accuracy" - positioned at the top-center of the image.
* **X-axis Label:** "digit\_a" - positioned at the bottom-center of the image. The axis markers are 1, 2, 3, 4, and 5.
* **Y-axis Label:** "digit\_b" - positioned at the left-center of the image. The axis markers are 1, 2, 3, 4, and 5.
* **Colorbar/Legend:** Located on the right side of the heatmap. It represents the accuracy scale, ranging from 0.0 (red) to 1.0 (dark blue). The colorbar has markers at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
### Detailed Analysis
The heatmap is a 5x5 grid, where each cell represents the accuracy for a specific pair of digits (digit\_a, digit\_b). The values are as follows:
* **(1, 1):** 1.00
* **(1, 2):** 0.92
* **(1, 3):** 1.00
* **(1, 4):** 1.00
* **(1, 5):** 1.00
* **(2, 1):** 0.92
* **(2, 2):** 0.92
* **(2, 3):** 0.97
* **(2, 4):** 0.99
* **(2, 5):** 0.97
* **(3, 1):** 1.00
* **(3, 2):** 1.00
* **(3, 3):** 0.97
* **(3, 4):** 0.90
* **(3, 5):** 0.96
* **(4, 1):** 1.00
* **(4, 2):** 0.99
* **(4, 3):** 0.90
* **(4, 4):** 0.96
* **(4, 5):** 0.93
* **(5, 1):** 1.00
* **(5, 2):** 0.99
* **(5, 3):** 0.97
* **(5, 4):** 0.96
* **(5, 5):** 0.93
The heatmap shows a generally high level of accuracy across all digit pairs. The highest accuracy values (1.00) are concentrated along the main diagonal, indicating that the system performs best when recognizing the same digit as both 'a' and 'b'. Accuracy values tend to decrease slightly as the digits 'a' and 'b' become more dissimilar.
### Key Observations
* The highest accuracy is achieved when digit\_a and digit\_b are the same (diagonal elements).
* The lowest accuracy values are around 0.90-0.92, still indicating very good performance.
* There is no significant pattern of confusion between specific digit pairs.
* The accuracy is consistently high, suggesting a robust system.
### Interpretation
This heatmap demonstrates the performance of a digit recognition system when presented with pairs of digits. The high accuracy values across the board suggest that the system is well-trained and capable of accurately identifying digits, even when they are presented in combination. The slight decrease in accuracy when the digits differ could be due to the inherent difficulty of distinguishing between certain digit shapes or the presence of noise in the input data. The consistent performance across different digit pairs indicates that the system does not exhibit a strong bias towards any particular digit. This data could be used to evaluate the effectiveness of the digit recognition model and identify areas for potential improvement. The heatmap provides a clear and concise visualization of the system's performance, making it easy to identify strengths and weaknesses.
</details>
(a) Multiplication
<details>
<summary>x8.png Details</summary>
### Visual Description
## Heatmap: Accuracy
### Overview
This image presents a heatmap visualizing the accuracy of a digit recognition system, likely a machine learning model, when predicting one digit (`digit_b`) given another digit (`digit_a`). The heatmap displays accuracy values ranging from 0.0 to 1.0, with darker blue shades representing higher accuracy.
### Components/Axes
* **Title:** "Accuracy" - positioned at the top-center of the image.
* **X-axis Label:** "digit\_a" - positioned at the bottom-center of the image. The axis markers are 1, 2, 3, 4, and 5.
* **Y-axis Label:** "digit\_b" - positioned at the left-center of the image. The axis markers are 1, 2, 3, 4, and 5.
* **Colorbar/Legend:** Located on the right side of the heatmap. It represents the accuracy scale, ranging from 0.0 (red) to 1.0 (dark blue). The colorbar has markers at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
### Detailed Analysis
The heatmap is a 5x5 grid, where each cell represents the accuracy of predicting `digit_b` given `digit_a`. I will analyze each cell, referencing the colorbar to confirm accuracy values.
* **(1,1):** Dark blue, approximately 1.00
* **(1,2):** Dark blue, approximately 1.00
* **(1,3):** Medium blue, approximately 0.98
* **(1,4):** Medium blue, approximately 0.98
* **(1,5):** Medium blue, approximately 0.93
* **(2,1):** Dark blue, approximately 1.00
* **(2,2):** Dark blue, approximately 0.96
* **(2,3):** Medium blue, approximately 0.93
* **(2,4):** Medium blue, approximately 0.91
* **(2,5):** Medium blue, approximately 0.97
* **(3,1):** Medium blue, approximately 0.98
* **(3,2):** Medium blue, approximately 0.93
* **(3,3):** Medium blue, approximately 0.94
* **(3,4):** Medium blue, approximately 0.95
* **(3,5):** Medium blue, approximately 0.94
* **(4,1):** Medium blue, approximately 0.98
* **(4,2):** Medium blue, approximately 0.91
* **(4,3):** Medium blue, approximately 0.95
* **(4,4):** Dark blue, approximately 0.98
* **(4,5):** Medium blue, approximately 0.91
* **(5,1):** Medium blue, approximately 0.93
* **(5,2):** Medium blue, approximately 0.97
* **(5,3):** Medium blue, approximately 0.94
* **(5,4):** Medium blue, approximately 0.91
* **(5,5):** Medium blue, approximately 0.95
The overall trend is that the accuracy is generally high (above 0.90) for most digit pairs.
### Key Observations
* The highest accuracy values (1.00) are observed when predicting digit 1 or 2, regardless of the input digit.
* The lowest accuracy values (around 0.91-0.93) are observed when predicting digits 4 or 5.
* The accuracy is relatively consistent across different input digits for a given predicted digit.
* There is no clear pattern of accuracy decreasing as the difference between `digit_a` and `digit_b` increases.
### Interpretation
This heatmap suggests that the digit recognition system performs very well overall, with high accuracy for most digit pairs. The slight variations in accuracy may be due to the inherent difficulty of distinguishing between certain digit pairs (e.g., 4 and 9, or 3 and 8, though these are not represented in this 1-5 range). The consistently high accuracy indicates a robust model that is not easily confused by different input digits. The heatmap provides a visual representation of the model's performance, allowing for quick identification of potential areas for improvement. The model appears to be more confident in predicting 1 and 2 than 4 and 5. This could be due to the training data having more examples of 1 and 2, or the features used to represent the digits being more discriminative for those digits.
</details>
(b) DP
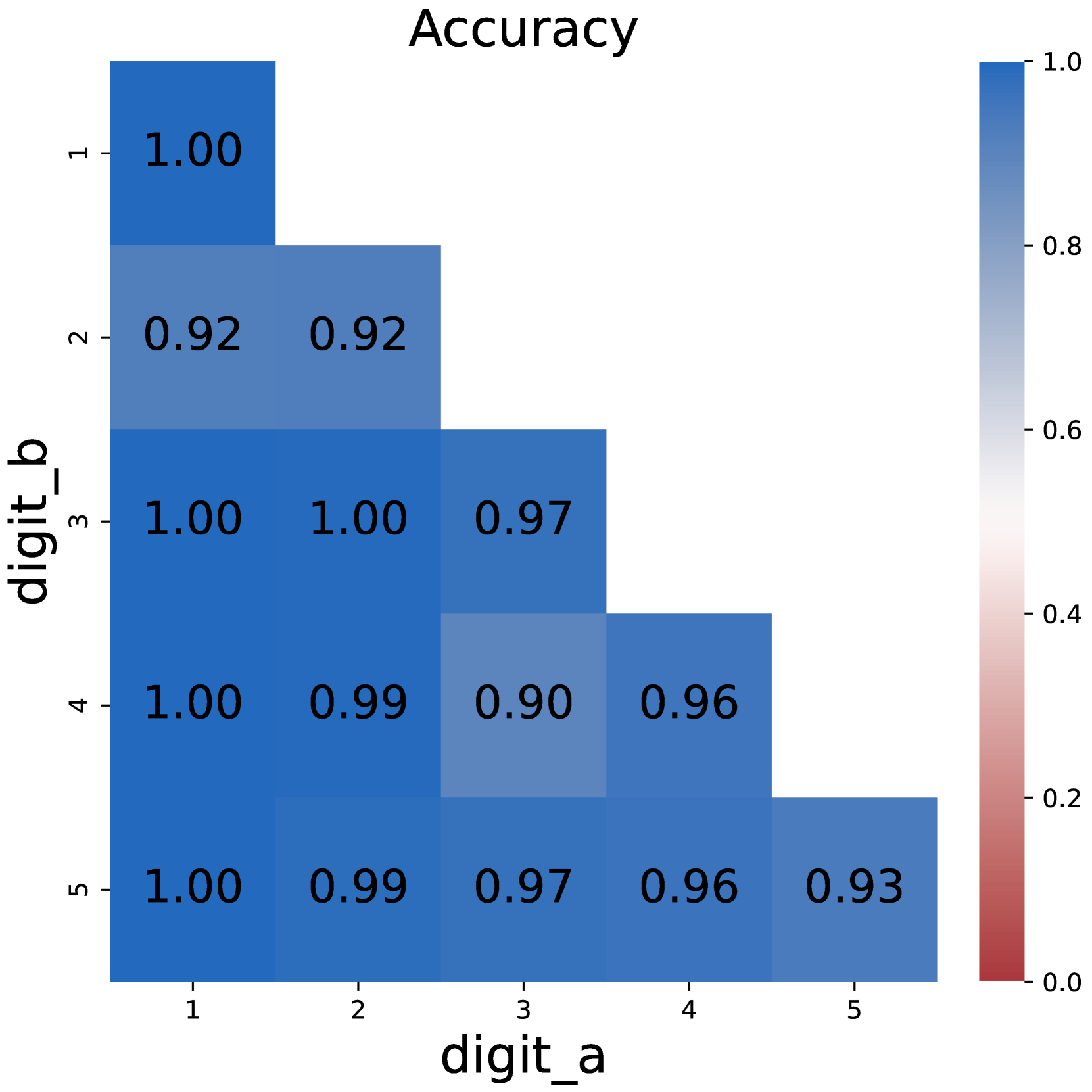
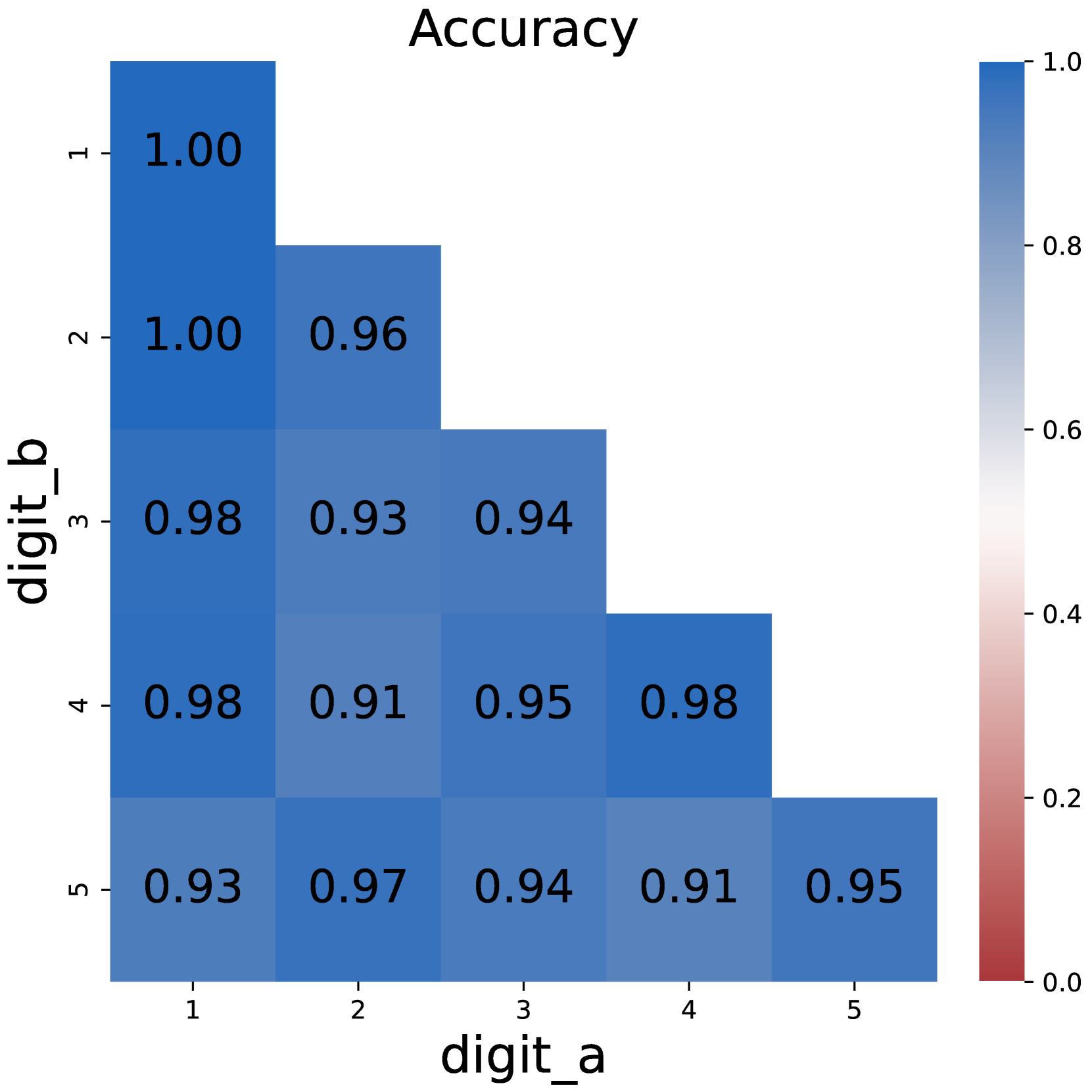
Figure 4: Model performances when merging intermediate results into latent tokens.
3.3 Merging Results into Latent Tokens
Another concern about CoT is whether intermediate results should be explicitly recorded. To test this hypothesis, we try to merge some of the intermediate results, and represent the merged results with latent tokens.
Method design.
As depicted in Figure 3, we use latent tokens <LAT> to store intermediate results, and each latent token stores the information of a complete number. For simplicity, we use one-hot vectors $\mathbf{l}$ as the embedding of latent tokens: a one-hot vector $\mathbf{l}=(l_{1},l_{2},...,l_{d})∈\mathbb{R}^{d}$ consisting of $d$ dimensions could represent a number $N$ of at most $n$ digits, where $d=10n$ .
$$
l_{10k+x}=\begin{cases}1,\lfloor\frac{N}{10^{k}}\rfloor\mod 10=x\\
0,\lfloor\frac{N}{10^{k}}\rfloor\mod 10\neq x\end{cases} \tag{1}
$$
We start by setting all values in $L$ to 0. Assuming that the value of the $k$ -th digit under the little-endian system is $x$ , we set $l_{10k+x}=1$ . In this way, we could represent a number with a single latent token instead of multiple tokens.
To support reasoning with latent tokens, we augment the Transformer structure by adding an input projection module $P_{in}$ and a latent output head $P_{out}$ . When the input token $c_{t}$ at position $t$ is a latent token, we feed its latent embedding $\mathbf{l}_{t}$ to the projection module $P_{in}$ , and use the projected vector as the input embedding; Correspondingly, the last hidden state $\mathbf{h}_{t}$ is fed to the latent output head $P_{out}$ aside from the default LM head to predict the latent embedding of the next token $\mathbf{l}_{t+1}$ .
We use linear layers to implement $P_{in}$ and $P_{out}$ , which can be described as:
$$
\displaystyle P_{in}(\mathbf{l}_{t}) \displaystyle=\mathbf{W}_{in}\mathbf{l}_{t}+\mathbf{b}_{in} \displaystyle P_{out}(\mathbf{h}_{t}) \displaystyle=\mathbf{W}_{out}\mathbf{h}_{t}+\mathbf{b}_{out} \tag{2}
$$
where $\mathbf{W}_{in},\mathbf{b}_{in},\mathbf{W}_{out},\mathbf{b}_{out}$ are trainable parameters. We randomly initialize these parameters.
An additional latent loss $\mathcal{L}_{lat}$ is introduced to train the augmented model:
$$
\mathcal{L}_{lat}=\frac{1}{N_{l}}\sum_{c_{t}=<LAT>}\text{BCE}(\sigma(P_{out}(%
\mathbf{h}_{t}),\mathbf{y})) \tag{4}
$$
Where $N_{l}$ is the number of latent tokens, $\mathbf{y}$ is the golden latent embedding, BCE is the binary cross entropy loss function, and $\sigma$ is the Sigmoid function.
<details>
<summary>x9.png Details</summary>
### Visual Description
\n
## Textual Comparison: Original vs. Intervened CoT
### Overview
The image presents a side-by-side comparison of two "Chain of Thought" (CoT) processes, labeled "Original CoT" and "Intervened CoT". Both CoTs demonstrate the calculation of 8493 * 8877. The primary difference lies in the carry values during the multiplication of 8493 by 7, and consequently, the final result. An arrow highlights the difference in the carry value.
### Components/Axes
The image consists of two text blocks, arranged vertically. Each block represents a CoT process. Each CoT block contains the following elements:
* Initial calculation statement: `8493*8877=<COT>`
* Intermediate calculation steps for `8493*7`
* Intermediate calculation steps for `8493*70`
* Partial result addition step: `59451+594510+...`
* Closing tag: `</COT>`
* Final result.
### Detailed Analysis or Content Details
**Original CoT:**
* Initial Calculation: `8493*8877=<COT>`
* `3*7=21, digit 1, carry 2`
* `9*7=63, digit 5, carry 6`
* `4*7=28, digit 4, carry 3`
* `8*7=56, digit 9, carry 5`
* Result of `8493*7`: `59451`
* Calculate `8493*70`
* Add up partial results: `59451+594510+...`
* `</COT>`
* Result: `75392361`
**Intervened CoT:**
* Initial Calculation: `8493*8877=<COT>`
* `3*7=21, digit 1, carry 4` (Highlighted difference)
* `9*7=63, digit 7, carry 6`
* `4*7=28, digit 4, carry 3`
* `8*7=56, digit 9, carry 5`
* Result of `8493*7`: `59471`
* Calculate `8493*70`
* Add up partial results: `59471+594510+...`
* `</COT>`
* Result: `75392381`
The arrow points from the "carry 2" in the Original CoT to the "carry 4" in the Intervened CoT during the calculation of `3*7`. This single change propagates through the subsequent calculations, leading to a different final result.
### Key Observations
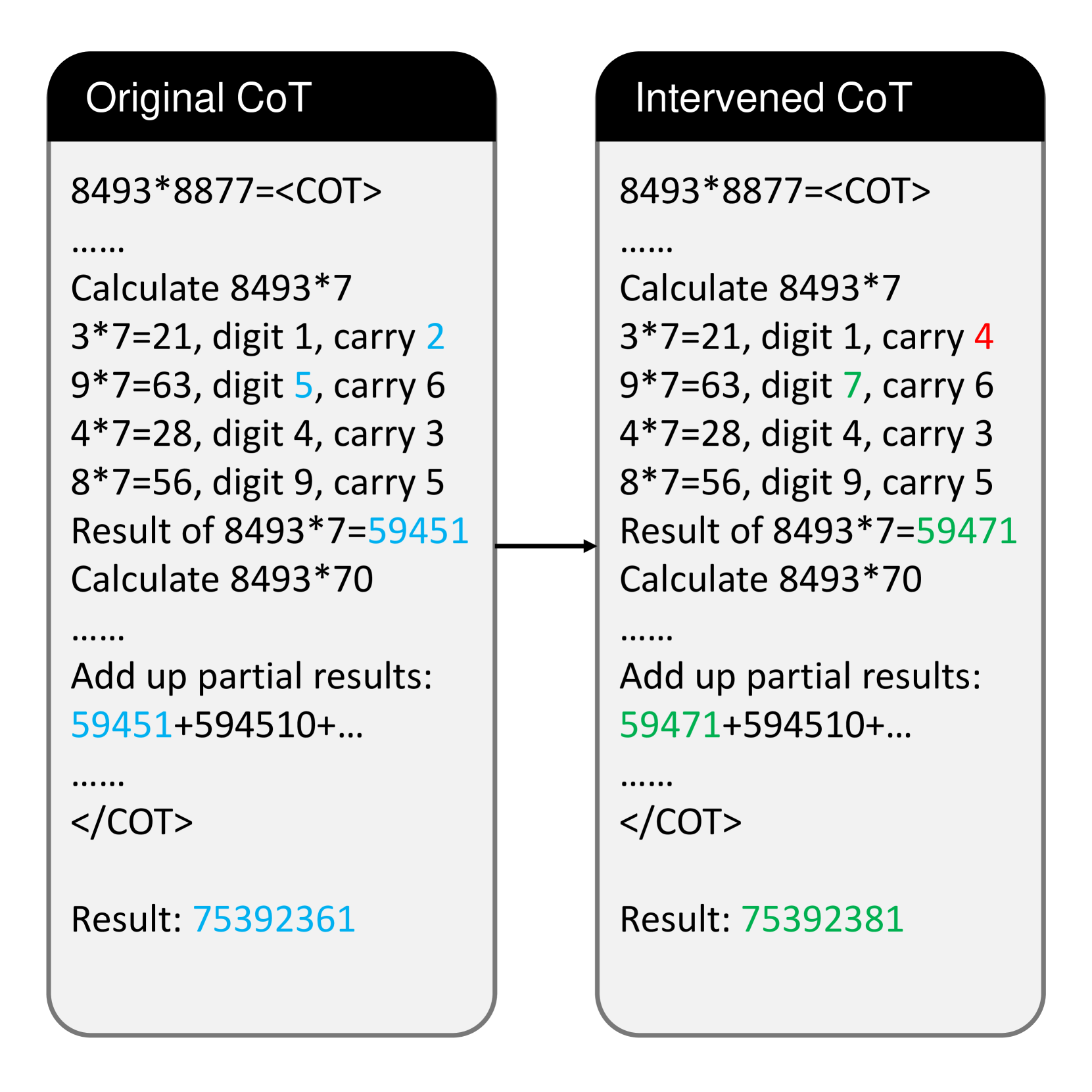
The only difference between the two CoTs is the carry value during the multiplication of 8493 by 7. The original CoT has a carry of 2, while the intervened CoT has a carry of 4. This seemingly small change results in a difference of 20 in the final result (75392381 - 75392361 = 20).
### Interpretation
This image demonstrates the sensitivity of multi-step calculations to even minor errors. The "Intervened CoT" suggests a correction or intervention in the calculation process, specifically altering the carry value. This highlights the importance of accurate intermediate steps in achieving the correct final result. The image is not presenting data in the traditional sense, but rather illustrating a computational process and the impact of a single modification. The `<COT>` tags suggest this is part of a larger framework for analyzing or controlling the reasoning process of a language model or similar system. The difference in the final result, though small, underscores the potential for subtle errors to accumulate and affect the outcome of complex calculations. The image is a demonstration of error propagation in a computational context.
</details>
(a) Successful intervention
<details>
<summary>x10.png Details</summary>
### Visual Description
\n
## Diagram: Comparison of Original and Intervened Chain of Thought (CoT)
### Overview
The image presents a side-by-side comparison of two "Chain of Thought" (CoT) processes, labeled "Original CoT" and "Intervened CoT". Both CoTs demonstrate the calculation of 7967 * 1083. The diagram highlights the intermediate steps of the multiplication and addition, with an arrow indicating a difference between the two processes.
### Components/Axes
The diagram consists of two rectangular blocks, positioned side-by-side. Each block represents a CoT process. Within each block, the calculation steps are listed sequentially. The blocks are labeled "Original CoT" (left) and "Intervened CoT" (right). The diagram also includes an arrow pointing from the "Original CoT" block to the "Intervened CoT" block, indicating a modification.
### Detailed Analysis or Content Details
**Original CoT:**
* **Initial Calculation:** 7967 * 1083 = <COT>
* **Step 1:** Calculate 7967 * 1000
* 7 * 1 = 7, digit 7, carry 0
* 6 * 1 = 6, digit 6, carry 0
* 9 * 1 = 9, digit 9, carry 0
* 7 * 1 = 7, digit 7, carry 0
* Result of 7967 * 1000 = 7967000
* **Step 2:** Add up partial results: 23901...+7967000
* <COT>
* **Final Result:** 8628261
**Intervened CoT:**
* **Initial Calculation:** 7967 * 1083 = <COT>
* **Step 1:** Calculate 7967 * 1000
* 7 * 1 = 7, digit 7, carry 9
* 6 * 1 = 6, digit 5, carry 0
* 9 * 1 = 9, digit 9, carry 0
* 7 * 1 = 7, digit 7, carry 0
* Result of 7967 * 1000 = 7967000
* **Step 2:** Add up partial results: 23901...+7967000
* <COT>
* **Final Result:** 8628261
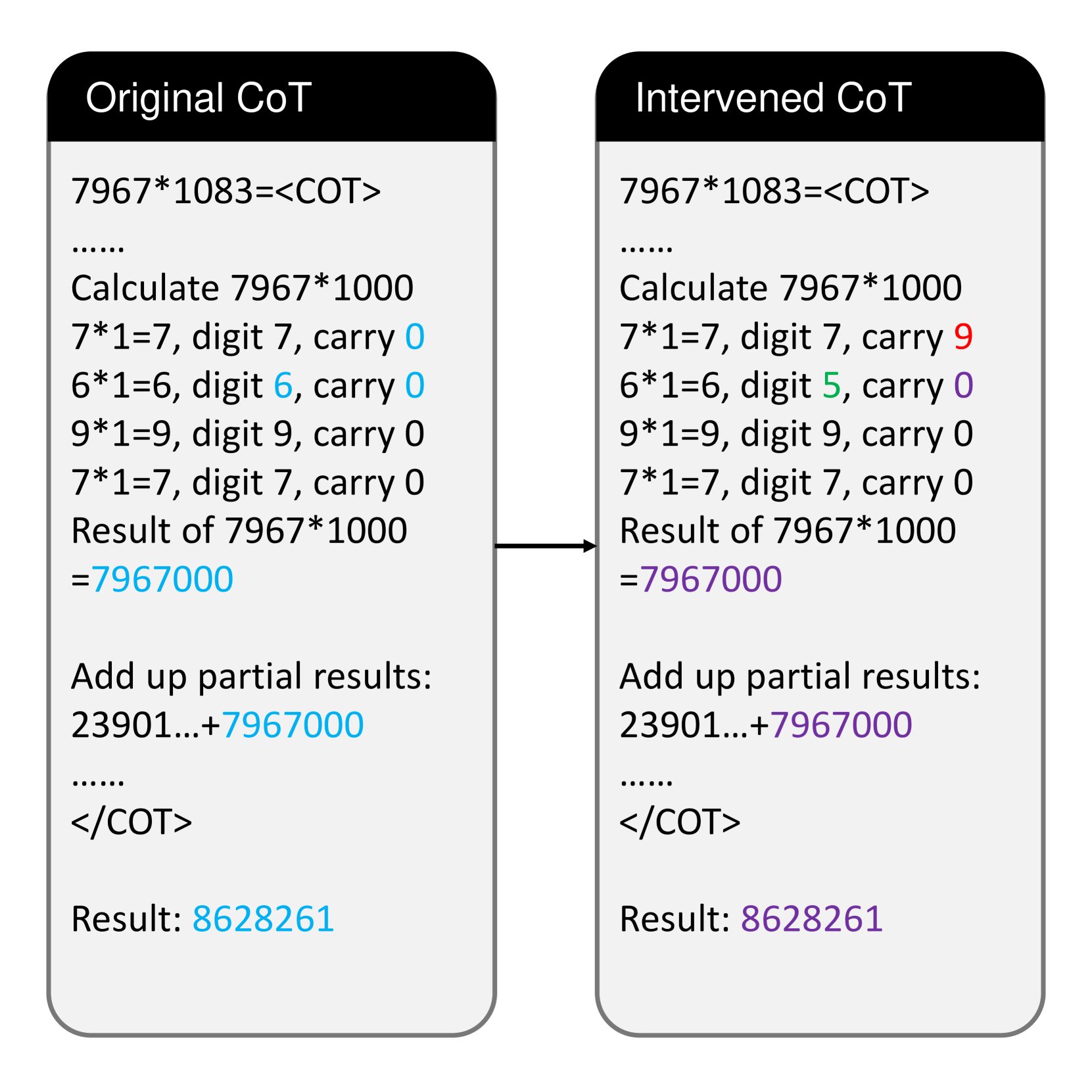
The arrow points from the first line of the "Calculate 7967 * 1000" section in the "Original CoT" to the corresponding line in the "Intervened CoT". The difference lies in the "carry" values during the multiplication. In the original CoT, all carries are 0. In the intervened CoT, the first carry is 9.
### Key Observations
The final result is identical in both CoTs (8628261). The intervention appears to affect the intermediate carry values during the multiplication step, but does not alter the final outcome. The intervention seems to be related to how the carry is handled during the multiplication of 7967 by 1000.
### Interpretation
This diagram demonstrates a subtle intervention in a chain-of-thought reasoning process. The intervention, altering the carry values during multiplication, does not change the final answer. This suggests that the specific intermediate steps, while potentially influencing the reasoning path, are not necessarily critical for achieving the correct result in this particular calculation. The diagram highlights the robustness of the calculation process, where minor variations in the reasoning steps do not lead to errors. The <COT> tags likely represent the end of a thought or a step in the reasoning process. The diagram is likely used to illustrate the impact of interventions on the internal workings of a large language model (LLM) or similar reasoning system. The fact that the final result remains the same despite the intervention suggests that the LLM is capable of correcting errors or finding alternative paths to the correct answer.
</details>
(b) Intervention with a shortcut error
Figure 5: Examples of a successful intervention (left) and an intervention with a shortcut error (right). Blue numbers refer to relevant values in the original CoT, red numbers refer to the intervention, green numbers refer to values that change as expected, but purple numbers do not change due to a shortcut error.
Experimental setup.
For multiplication problems, we replace each digit-wise multiplication step with a single latent token and set $d=20$ ; For DP problems, we replace each intermediate state with a single latent token and set $d=50$ . We add the latent loss $\mathcal{L}_{lat}$ with the default LM head loss as the final loss for training.
Figure 4 shows the model performances when trained with latent tokens. Surprisingly, merging digit tokens to a single latent token does not detriment the performance: the model retains most of its ability to solve problems. The accuracy of using latent tokens on multiplication problems is almost identical with the accuracy of using full CoT. On 5*5 multiplication problems, using latent tokens even surpasses the original CoT, suggesting that the form of intermediate results does not matter.
However, it can also be observed that using latent tokens brings disadvantage on DP problems where latent tokens store larger numbers. For example, the accuracy reduces by 9% on 4*5 DP problems. This raises the hypothesis that the computation complexity should not exceed a certain limit, which we will discuss further in Section 4.2.
4 CoT Tokens are Mutable Variables
In the previous section, we find that while CoT is essential for solving complex problems (Section 3.1), the tokens representing intermediate results are more important than others (Section 3.2). Meanwhile, compressing intermediate results into latent tokens would not obviously harm model performance (Section 3.3), indicating that intermediate results could be stored in different forms.
Here, we continue to discuss whether these stored intermediate results are causally related to the final prediction, and how the computation complexity between intermediate results affects model performance.
<details>
<summary>x11.png Details</summary>
### Visual Description
\n
## Bar Chart: Accuracy vs. Task
### Overview
This image presents a bar chart comparing the accuracy achieved on two different tasks: "Multi" and "DP". The y-axis represents accuracy, ranging from 0.0 to 1.0, while the x-axis represents the task type.
### Components/Axes
* **X-axis Label:** "task"
* **Y-axis Label:** "accuracy"
* **X-axis Categories:** "Multi", "DP"
* **Y-axis Scale:** Linear, from approximately 0.0 to 1.0, with increments of 0.2.
* **Bars:** Two bars, one for each task. The bars are a uniform blue color.
### Detailed Analysis
The bar chart displays the accuracy for each task.
* **Multi Task:** The bar for the "Multi" task reaches approximately 0.73 on the accuracy scale.
* **DP Task:** The bar for the "DP" task reaches approximately 1.0 on the accuracy scale.
The "DP" task bar is significantly taller than the "Multi" task bar, indicating a higher accuracy.
### Key Observations
The accuracy for the "DP" task is substantially higher than the accuracy for the "Multi" task. The "DP" task appears to have near-perfect accuracy.
### Interpretation
The data suggests that the model or system being evaluated performs significantly better on the "DP" task compared to the "Multi" task. This could be due to several factors:
* **Task Complexity:** The "DP" task might be inherently simpler than the "Multi" task.
* **Data Quality:** The data used for training or evaluation might be of higher quality for the "DP" task.
* **Model Suitability:** The model might be better suited for the "DP" task than the "Multi" task.
Further investigation would be needed to determine the underlying reasons for this performance difference. The near-perfect accuracy on the "DP" task is notable and could indicate a well-optimized solution for that specific problem. The relatively lower accuracy on the "Multi" task suggests potential areas for improvement.
</details>
(a) Success rate
<details>
<summary>x12.png Details</summary>
### Visual Description
\n
## Pie Chart: Error Breakdown
### Overview
This image presents a pie chart illustrating the breakdown of different error types. The chart displays the percentage contribution of each error type to the total.
### Components/Axes
* **Title:** "Error breakdown" (positioned at the top-center of the chart)
* **Legend:** Located in the top-right corner of the chart. It maps colors to error types:
* `addition` - Light Blue
* `reconstruct` - Light Orange
* `shortcut` - Light Green
* `copy` - Light Red
* `misc` - Light Purple
* **Data Labels:** Percentage values are displayed within each slice of the pie chart.
### Detailed Analysis
The pie chart segments represent the following error types and their corresponding percentages:
* **addition:** 29.3% (Light Blue slice)
* **reconstruct:** 19.0% (Light Orange slice)
* **shortcut:** 49.4% (Light Green slice) - This is the largest segment, representing almost half of all errors.
* **copy:** A very small segment, approximately 1.3% (Light Red slice)
* **misc:** A very small segment, approximately 1.0% (Light Purple slice)
The slices are arranged clockwise, starting with "addition" at the top. The "shortcut" slice occupies the largest portion of the pie, followed by "addition" and then "reconstruct". The "copy" and "misc" slices are very small and positioned near the top-right of the chart.
### Key Observations
* "Shortcut" errors are the most frequent, accounting for nearly half (49.4%) of all errors.
* "Addition" errors represent a significant portion of the total (29.3%).
* "Reconstruct" errors account for 19.0% of the total.
* "Copy" and "misc" errors are relatively rare, each contributing less than 2% to the total.
### Interpretation
The data suggests that errors related to "shortcuts" are the primary source of issues. This could indicate problems with the implementation of shortcut functionality, user confusion regarding shortcuts, or a high reliance on shortcuts that are prone to errors. The substantial proportion of "addition" errors also warrants investigation. It might be beneficial to analyze the specific scenarios where these errors occur to identify underlying causes and implement targeted improvements. The small percentages of "copy" and "misc" errors suggest they are less critical areas for immediate attention, but should still be monitored. The chart provides a clear prioritization for error resolution efforts, focusing on "shortcut" and "addition" related issues first.
</details>
(b) Error breakdown
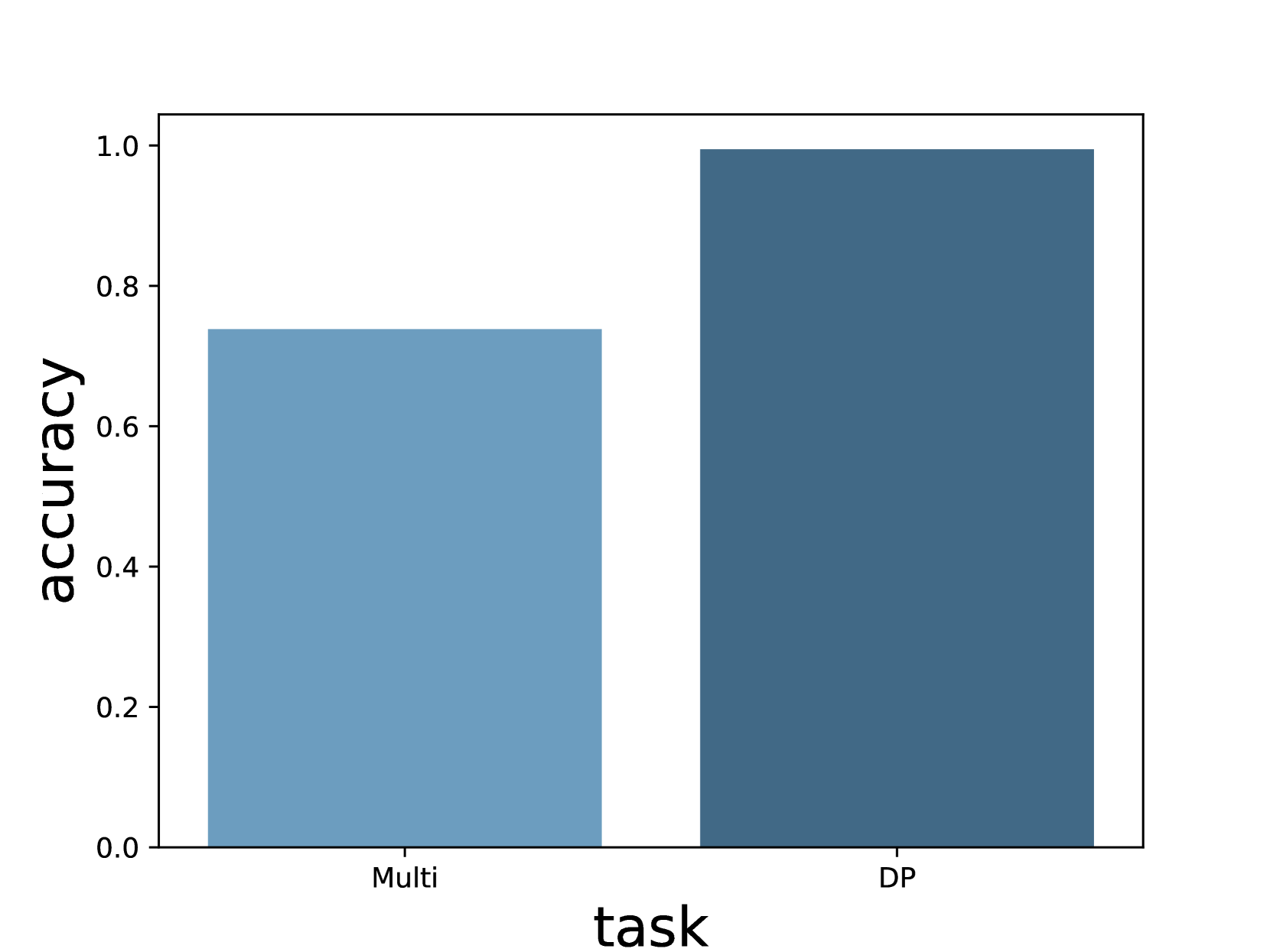
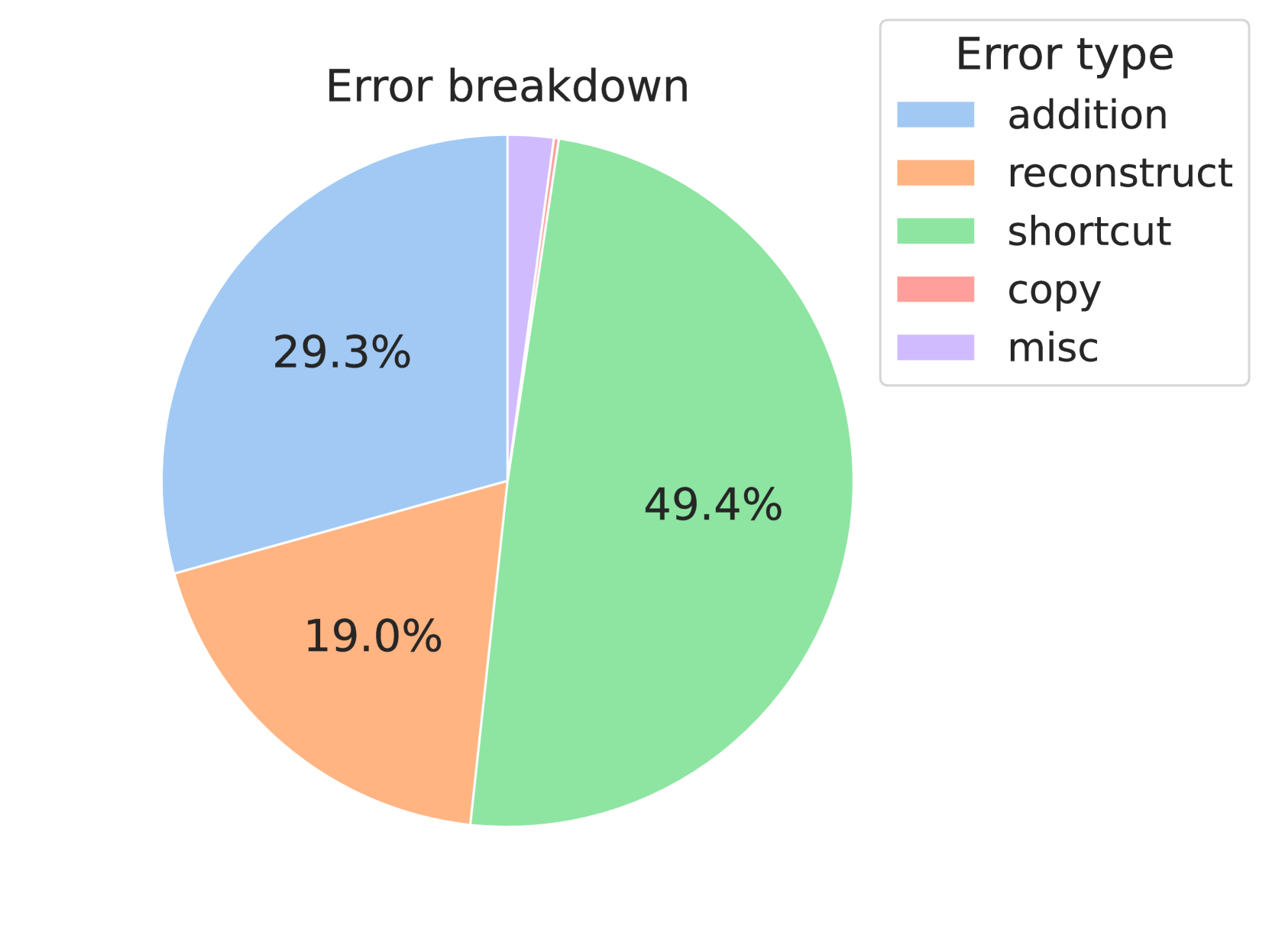
Figure 6: (a) Success rate of intervention. When the intervened output is the same as simulated, we view it as a successful intervention. (b) Error breakdown. Shortcut error occupies a large percentage of the errors.
<details>
<summary>x13.png Details</summary>
### Visual Description
\n
## Diagram: Dynamic Programming State Transition
### Overview
The image depicts a diagram illustrating a state transition process, likely related to dynamic programming. It shows a grid-like structure of interconnected nodes labeled with `DP[i][j]` and its variations, connected by arrows indicating dependencies. The diagram suggests a recursive or iterative calculation where the value of a state depends on the values of previous states.
### Components/Axes
The diagram consists of rectangular nodes, each labeled with `DP[i][j]` where `i` and `j` are indices. The arrows represent transitions between states. There are no explicit axes or scales. The diagram extends downwards and to the right, indicated by the ellipsis (`...`).
### Detailed Analysis or Content Details
The diagram shows a 3x3 grid of `DP` states, with an indication that this pattern continues. The nodes are arranged as follows:
* **Top Row:** `DP[i][j]`, `DP[i][j+1]`, `DP[i][j+2]`
* **Middle Row:** `DP[i+1][j]`, `DP[i+1][j+1]`, `DP[i+1][j+2]`
* **Bottom Row:** `DP[i+2][j]`, `DP[i+2][j+1]`, `DP[i+2][j+2]`
The arrows indicate the following dependencies:
* `DP[i][j]` -> `DP[i][j+1]` (solid red arrow)
* `DP[i][j+1]` -> `DP[i][j+2]` (dashed red arrow)
* `DP[i][j]` -> `DP[i+1][j]` (solid yellow arrow)
* `DP[i+1][j]` -> `DP[i+2][j]` (solid yellow arrow)
* `DP[i][j+1]` -> `DP[i+1][j+1]` (dashed yellow arrow)
* `DP[i+1][j+1]` -> `DP[i+2][j+1]` (dashed yellow arrow)
* `DP[i][j+2]` -> `DP[i+1][j+2]` (solid red arrow)
* `DP[i+1][j+2]` -> `DP[i+2][j+2]` (solid red arrow)
The diagram shows a pattern of dependencies where each state `DP[i][j]` depends on states in the same row and the row above. The solid arrows represent a stronger dependency, while the dashed arrows represent a weaker or different type of dependency.
### Key Observations
The diagram illustrates a dynamic programming approach where the solution to a problem is built up from solutions to subproblems. The indices `i` and `j` likely represent dimensions or stages in the problem. The use of both solid and dashed arrows suggests different types of transitions or dependencies between states. The ellipsis indicates that the grid extends indefinitely, implying a potentially large state space.
### Interpretation
This diagram likely represents a state transition diagram for a dynamic programming algorithm. The `DP[i][j]` notation suggests that the algorithm is storing intermediate results in a table or matrix. The arrows indicate how the value of a state `DP[i][j]` is calculated based on the values of other states. The solid and dashed arrows could represent different costs or weights associated with the transitions.
The diagram suggests that the problem being solved can be broken down into smaller, overlapping subproblems. The dynamic programming approach allows the algorithm to avoid redundant calculations by storing the solutions to subproblems and reusing them when needed. The pattern of dependencies indicates that the algorithm is likely solving a problem with a grid-like structure, such as a pathfinding problem or a matrix optimization problem. The diagram does not provide specific data or numerical values, but it illustrates the general structure of a dynamic programming solution.
</details>
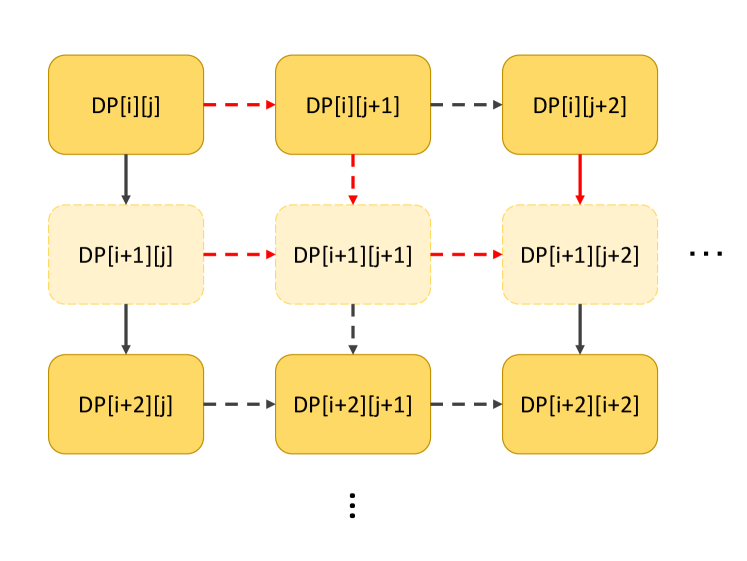
Figure 7: Demonstration of the alternative merging strategy. Each line refers to the compare-then-add state transfer function in the original setup. Nodes corresponding to the dashed boxes will not appear in the new CoT. It will cost at most 3 compare-then-add operations (red lines) to transfer states between new matrix tokens.
4.1 Intervening the Value of CoT Tokens
An inherent problem is that while CoT is essential for reaching the right answer, some of the intermediate results may only be correlational to the output, rather than having causal effects. To address this problem, we perform intervention experiments by replacing intermediate results and observe whether the final result would change as expected.
For multiplication problems, we randomly choose a substep in CoT and replace its result with a different random number; For DP problems, we randomly choose an intermediate state and replace it with a different random number. For simplicity, we perform interventions on 4*4 problems, and only one number is replaced in each data entry. Details are described in Appendix E.
As shown in Figure 6(a), the intervention on both tasks achieves a decent success rate, clearly indicating that the intermediate values stored in CoT tokens are causally related to the final answer. We also notice that subsequent reasoning steps will change correspondingly. Take Figure 5(a) as an example, when we change the carry from 2 to 4, the model generates a result of $8493*7=59471$ instead of 59451, just as simulated. In other words, tokens in CoT not only store intermediate values, but they are also “variables” that would affect subsequent reasoning steps.
Another interesting observation is that the success rate on multiplication problems is significantly lower than that on DP problems. We investigate the cause of unsuccessful interventions and categorize them into 5 categories. (1) Addition error means that the model fails to add up partial multiplication results; (2) Reconstruction error means that the partial multiplication result conflicts with digit-wise results; (3) Copy error means that partial multiplication results do not correctly appear in the addition step; (4) Shortcut error means that the model learns a “shortcut” on certain multiplications (usually when one of the operands is 0 or 1); (5) Misc error covers the remaining errors.
Figure 6(b) illustrates the distribution of error types. Among the 5 types, shortcut error occupies the largest portion. As shown in Figure 5(b), while changing the carry from 0 to 9 will affect the next digit as intended, the model does not change its result in the substep $7967*1000$ . When multiplying a number $x$ by 1, the model seems to be taking a shortcut of directly copying $x$ , rather than collecting the digit-wise multiplication results.
To sum up, language models use the value in CoT tokens like treating program variables, but models may develop shortcut on easy subproblems that leave certain variables unused.
<details>
<summary>x14.png Details</summary>
### Visual Description
\n
## Line Chart: Probe Accuracy
### Overview
This image presents a line chart illustrating the probe accuracy across different layers, comparing different accuracy metrics and compression techniques. The chart displays how accuracy changes as the layer number increases.
### Components/Axes
* **Title:** "Probe Accuracy" (top-center)
* **X-axis:** "Layer" (bottom-center), ranging from approximately 0 to 27.
* **Y-axis:** "Value" (left-center), ranging from approximately 0.0 to 1.1.
* **Legend:** Located in the center-left of the chart, with the following entries:
* "element" - Solid blue line
* "entry" - Solid orange line
* "none" - Solid black line
* "row" - Dashed orange line
### Detailed Analysis
The chart contains four data series, each represented by a different line.
* **"element" (Solid Blue Line):** This line starts at approximately 0.92 and remains relatively stable, fluctuating slightly around 0.95-1.0, throughout all layers. It shows a very slight upward trend.
* **"entry" (Solid Orange Line):** This line begins at approximately 0.0 and remains close to 0.0 until layer 20, where it rapidly increases to approximately 1.0. It then plateaus around 1.0.
* **"none" (Solid Black Line):** This line starts at approximately 0.92 and remains relatively constant around 0.95-1.0, similar to the "element" line. It shows a very slight upward trend.
* **"row" (Dashed Orange Line):** This line starts at approximately 0.0 and remains close to 0.0 until layer 22, where it begins to increase gradually, reaching approximately 0.2 by layer 27.
### Key Observations
* The "entry" metric exhibits a significant jump in accuracy around layer 20, while the "element" and "none" metrics maintain high accuracy throughout all layers.
* The "row" metric shows a slow increase in accuracy, remaining significantly lower than the other metrics.
* The "element" and "none" lines are nearly identical, suggesting that no compression has minimal impact on the "element" accuracy metric.
* The "entry" metric is initially very low, but becomes comparable to the other metrics after layer 20.
### Interpretation
The data suggests that the "entry" accuracy metric is highly dependent on the layer number, requiring a certain depth (around layer 20) to achieve high accuracy. The "element" and "none" metrics, on the other hand, are largely unaffected by the layer number, indicating that they capture information effectively even in earlier layers. The "row" metric consistently underperforms, suggesting it may not be a suitable metric for evaluating probe accuracy in this context.
The rapid increase in "entry" accuracy around layer 20 could indicate a critical point in the model where the representation becomes more informative for this specific metric. The similarity between "element" and "none" suggests that the compression technique used does not significantly degrade the "element" accuracy. The consistently low performance of "row" might indicate that it captures a different aspect of the model's representation, or that it is less sensitive to the information being probed.
</details>
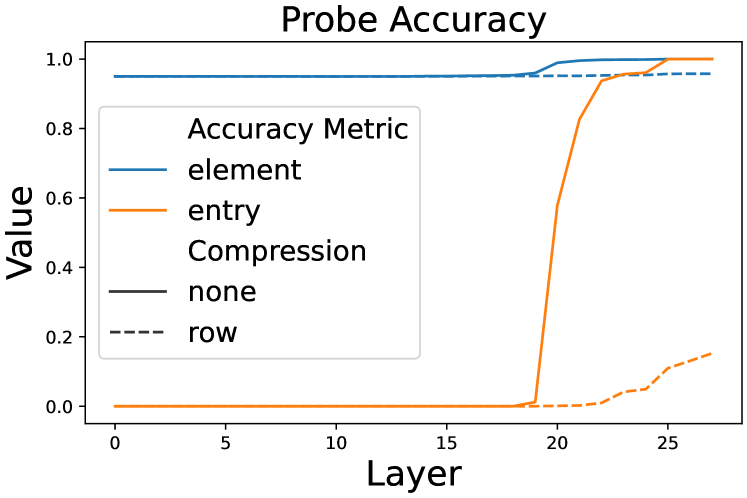
Figure 8: Probing accuracy on different layers. Intermediate variable values can only be probed on late layers, regardless of the overall accuracy.
4.2 Probing the Limit of CoT Tokens
In Section 3.3, we discover that intermediate values can be compressed in latent tokens. This naturally raises the question: to what extent could the values be compressed? To address this problem, we adopt some aggressive compression strategies and use linear probing classifiers to observe how the compression affects the final output.
We choose 5*5 DP problems as the base problem and use the latent token setting in Section 3.3. Specifically, we introduce an alternative strategy that merges two adjacent latent tokens in a row to one latent token (Figure 7). In this way, this strategy yields a 3*3 CoT token matrix instead of a 5*5 matrix. However, the computational complexity between CoT tokens also increases: it would cost up to 3 times as much as in the original case.
For each CoT token <LAT>, we use a linear probe $P$ to probe its latent embedding $\mathbf{l}$ from the hidden states $\mathbf{h}_{k}$ on different layer $k$ of the previous token. We use a unique probe $P_{k}$ for each layer:
$$
P_{k}(\mathbf{h}_{k})=\mathbf{W}_{k}\mathbf{h}_{k}+\mathbf{b}_{k} \tag{5}
$$
where $\mathbf{W}_{k}$ and $\mathbf{b}_{k}$ are trainable parameters.
After training the probes on the training set, we evaluate them with two metrics: element accuracy evaluates the ratio of correctly predicted individual dimensions, and token accuracy evaluates the ratio of correct latent tokens.
Figure 8 shows the result of probing CoT tokens. Aggressively merging CoT tokens will significantly lower both element accuracy and token accuracy, meaning that there exists a computation complexity limit, over which the LLM can no longer correctly calculate the next intermediate variable.
<details>
<summary>x15.png Details</summary>
### Visual Description
## Heatmap: Accuracy Breakdown
### Overview
The image presents a heatmap visualizing the accuracy breakdown across different digit scales and layers. The heatmap uses a color gradient to represent accuracy values, ranging from 0.0 (lightest color) to 0.8 (darkest color).
### Components/Axes
* **Title:** "Accuracy Breakdown" - positioned at the top-center of the image.
* **X-axis:** "layer" - ranging from 0 to 28, with markers at every 2 units.
* **Y-axis:** "Digit Scale" - ranging from 1 to 4, with markers at each integer value.
* **Colorbar:** Located on the right side of the heatmap, representing the accuracy scale from 0.0 to 0.8, with a gradient from light blue to dark blue.
### Detailed Analysis
The heatmap displays accuracy values for each combination of digit scale and layer. The color intensity corresponds to the accuracy level.
* **Digit Scale 1:** Accuracy is low for layers 0-22, then rapidly increases to approximately 0.8 for layers 24-28.
* **Digit Scale 2:** Accuracy starts low for layers 0-22, then increases to approximately 0.6-0.7 for layers 24-28.
* **Digit Scale 3:** Accuracy remains consistently low, around 0.2-0.4, across all layers.
* **Digit Scale 4:** Accuracy is very low, around 0.1-0.2, across all layers.
Here's a more detailed breakdown of approximate accuracy values based on color interpretation:
| Digit Scale | Layer 0 | Layer 2 | Layer 4 | Layer 6 | Layer 8 | Layer 10 | Layer 12 | Layer 14 | Layer 16 | Layer 18 | Layer 20 | Layer 22 | Layer 24 | Layer 26 | Layer 28 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.75 | 0.8 | 0.8 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.55 | 0.65 | 0.65 |
| 3 | 0.1 | 0.1 | 0.2 | 0.2 | 0.2 | 0.2 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 |
| 4 | 0.0 | 0.0 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
### Key Observations
* Accuracy is significantly higher for Digit Scale 1 compared to other digit scales.
* Accuracy generally increases with layer number, particularly for Digit Scale 1 and 2.
* Digit Scales 3 and 4 exhibit consistently low accuracy across all layers.
* There is a sharp increase in accuracy for Digit Scale 1 around layer 24.
### Interpretation
The heatmap suggests that the model performs best at recognizing Digit Scale 1, and its performance improves as it progresses through deeper layers (layers 24-28). The consistently low accuracy for Digit Scales 3 and 4 indicates that the model struggles to accurately process these scales, regardless of the layer. This could be due to several factors, such as the complexity of these digits, the quality of the training data, or limitations in the model architecture. The rapid increase in accuracy for Digit Scale 1 around layer 24 might indicate that this layer is crucial for feature extraction or pattern recognition specific to that digit scale. The data suggests a potential need to focus on improving the model's ability to handle Digit Scales 3 and 4, perhaps through data augmentation or architectural modifications.
</details>
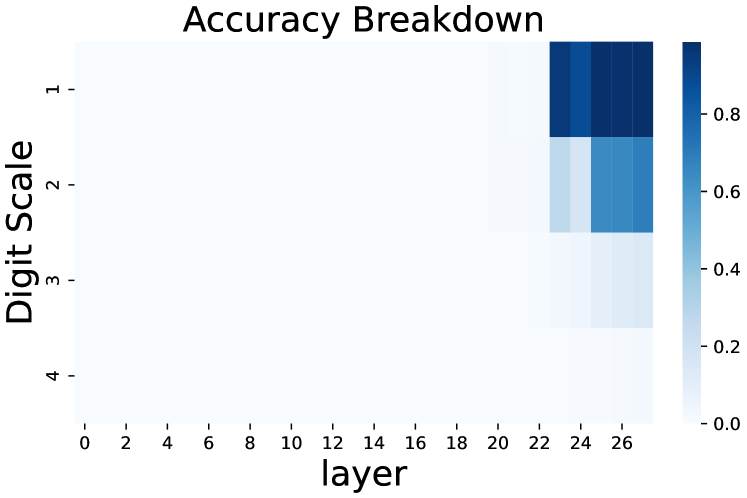
Figure 9: Accuracy breakdown by the scale of target values. When computational complexity between tokens exceeds a limit, the model will fail.
Figure 9 further breaks down the accuracy distribution by the range of values stored in merged latent tokens. We can see that merging latent tokens has little impact on numbers with a digit length of 1 or 2, but would decrease the accuracy to near 0 on larger number values. This phenomenon can be explained as it is easier to calculate small numbers, and thus the model could “afford” the extra computational cost of merging latent tokens.
Another interesting point to notice is that two accuracy curves share a similar pattern: the token accuracy stays at 0 from early layers, and rapidly rises around layer 20. Previous work Stolfo et al. (2023); Zhu et al. (2025) has concluded that LLMs tend to use early-mid layers to gather and process information from previous tokens, and determine the output only in mid-late layers. We may further assume that the role of layers will not change with computation complexity between CoT tokens.
5 Discussion
Explaining alternative CoT forms.
By viewing CoTs as programs, we can explain alternative CoT forms in a novel way. For example, the success of internalizing CoT steps Deng et al. (2024); Hao et al. (2024) could be viewed as compressing explicit step tokens into implicit latent tokens that cover all essential intermediate values. And the validity of inserting meaningless filler tokens Goyal et al. (2024); Pfau et al. (2024) comes from enabling LLMs to store intermediate results in the hidden states of filler tokens. By reserving space for complex reasoning steps and compressing simple reasoning steps, we could design high-efficiency CoTs.
Generalization of CoT “programs”.
From the experiments in previous sections, we can see that CoT tokens store intermediate values, and their values are subsequently used like the way variables function in computer programs. Theoretical proof has been made that Transformer with a recurrent module is Turing complete Pérez et al. (2021). However, there is also evidence that LLMs may struggle to generalize on compositional problems Dziri et al. (2023): models trained on easy problems would fail on more complex problems. In real-world settings, the type and complexity of desired programs are unknown, and a general-purpose LLM needs to first determine the type of program to use, or in other words, generate a meta-program first.
Identification of intermediate variable tokens.
It is not surprising that the CoT generated by LLMs is partially redundant and could be shortened. In Section 3.2, we find that preserving value tokens could retain most of the ability of language models. While it is easy to judge whether a token stores intermediate results in multiplication and DP problems, it is harder to identify variable tokens on general tasks: Madaan and Yazdanbakhsh (2022) finds that plain text helps LLMs elicit semantic commonsense knowledge, which may be infused into later CoT tokens. Developing an approach to identifying variable tokens would benefit CoT compression.
Estimation of computational complexity between variable tokens.
Section 4.2 shows that LLMs would fail when the computational complexity between variable tokens exceeds a certain limit. However, it is difficult to estimate the exact complexity limit for LLMs. It is possible to calculate the theoretical bound of ability for finite-precision Transformers Chen et al. (2024), but how LLMs process semantic information is still largely opaque, and unexpected features may appear Lindsey et al. (2025). Moreover, LLMs are not guaranteed to solve similar subproblems in the same way, they may take shortcuts (Section 4.1) that would largely affect the computational complexity between variable tokens. We hope that the broader research community could help estimate the computational complexity between variable tokens in different types of questions.
6 Related Work
6.1 Chain-of-Thought Reasoning
Chain-of-Thoughts (CoT) Wei et al. (2022) is a commonly adopted technique in LLMs. Nowadays, CoT refers to a broad range of approaches that require LLMs to generate an intermediate reasoning process before reaching the final answer. Typical approaches include designing the prompt Wei et al. (2022); Khot et al. (2022); Zhou et al. (2022) and finetuning LLMs on existing chain-of-thoughts Yue et al. (2023); Yu et al. (2023). Recently, reinforcement learning also reveals its great potential in enabling LLMs to perform complex reasoning without extensive human annotations Havrilla et al. (2024); Wang et al. (2024); Shao et al. (2024); Guo et al. (2025). While the tokens in CoT can be classified into symbols, patterns, and text, which both contribute to the final answer Madaan and Yazdanbakhsh (2022), it seems that LLMs can still perform well with a small amount of CoT tokens Xu et al. (2025).
Aside from plain text, researchers have also explored alternative forms of CoT. Some works focus on search abilities, like tree-form thought traces Yao et al. (2023); Xie et al. (2023) and Monte-Carlo Tree Search (MCTS) algorithms Zhang et al. (2024); Guan et al. (2025). Another line of work attempts to reason in a latent space: Goyal et al. (2024) uses a pause token to help models process extra computation before reaching an answer, and Pfau et al. (2024) shows it is also possible to replace CoT with meaningless filler tokens. On top of this, Deng et al. (2024) tries to train models with gradually shortened CoT, and COCONUT Hao et al. (2024) proposes the continuous thought paradigm, where the last hidden state of a latent token is used as the next input embedding.
6.2 Theoretical Analysis on CoT
It has been noticed that LLMs face difficulty in compositional problems where combining multiple reasoning steps is strictly required, and it may be an intrinsic drawback of the Transformer structure Dziri et al. (2023). Feng et al. (2023) explains the phenomenon with the circuit complexity theory, and reaches the conclusion that it is impossible for a constant-depth log-precision transformer to solve certain math problems like linear equations. However, with the help of CoT, the model could solve these problems in polynomial complexity. Li et al. (2024) further extends the conclusion that constant-depth transformers using constant-bit precision could solve any problems solvable by boolean circuits, as long as they are equipped with CoT whose steps are longer than the circuit size. Chen et al. (2024) analyzes the problem with a multi-party autoregressive communication model, and finds that it is exponentially harder for Transformer models to solve composition tasks that require more steps than the model layers, and CoT could make the problem exponentially easier.
In fact, Transformer models are powerful enough to represent finite-state automata Liu et al. (2022), and could even be Turing-complete Pérez et al. (2021) to simulate computer programs when equipped with loop modules Giannou et al. (2023). We hold the belief that these findings could also be extended to chain-of-thoughts reasoning.
7 Conclusion
In this paper, we empirically explore the role CoT tokens play in reasoning. By observing the model performance on multi-digit multiplication problems and dynamic programming, we confirm that CoT is essential for solving these compositional problems. We further find that we could mostly preserve model ability by only using tokens that store intermediate results, and these intermediate results could be stored in different forms like latent token embeddings.
To validate the causal connection between CoT tokens and model output, we randomly replace some values in CoT, and find that both the subsequent reasoning process and the final result would change corresponding to the intervention. The way CoT tokens behave is similar to the function of computer program variables. However, in easy subproblems LLMs would learn shortcuts that are unfaithful to the generated reasoning process, and the intervention would fail under these scenarios. We also train probing classifiers to probe variable values from hidden states on different layers, and find that there exists a computational complexity limit between CoT tokens. Intermediate values could be compressed within a single latent CoT token, but the model would drastically fail when computational complexity exceeds the limit.
Our work conducts preliminary experiments on the function of CoT tokens, and there still exist mysteries like generalization ability, variable identification and complexity limit estimation, which we leave for future explorations.
Limitations
In this paper we empirically demonstrate that an important function of CoT tokens is to store intermediate values, and these values function like program variables. However, currently we are not able to give a theoretical proof on this statement.
Another limitation of our work is that the experiments are conducted on two synthetic tasks with Qwen-2.5-1.5B, as it is difficult to identify and analyze intermediate results in real-world datasets like GSM8K and Math. Future experiments on other problems and models will be beneficial.
References
- Chen et al. (2024) Lijie Chen, Binghui Peng, and Hongxun Wu. 2024. Theoretical limitations of multi-layer transformer. arXiv preprint arXiv:2412.02975.
- Deng et al. (2024) Yuntian Deng, Yejin Choi, and Stuart Shieber. 2024. From explicit cot to implicit cot: Learning to internalize cot step by step. arXiv preprint arXiv:2405.14838.
- Dziri et al. (2023) Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, and 1 others. 2023. Faith and fate: Limits of transformers on compositionality. Advances in Neural Information Processing Systems, 36:70293–70332.
- Feng et al. (2023) Guhao Feng, Bohang Zhang, Yuntian Gu, Haotian Ye, Di He, and Liwei Wang. 2023. Towards revealing the mystery behind chain of thought: a theoretical perspective. Advances in Neural Information Processing Systems, 36:70757–70798.
- Giannou et al. (2023) Angeliki Giannou, Shashank Rajput, Jy-yong Sohn, Kangwook Lee, Jason D Lee, and Dimitris Papailiopoulos. 2023. Looped transformers as programmable computers. In International Conference on Machine Learning, pages 11398–11442. PMLR.
- Goyal et al. (2024) Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. 2024. Think before you speak: Training language models with pause tokens. In The Twelfth International Conference on Learning Representations.
- Guan et al. (2025) Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. 2025. rstar-math: Small llms can master math reasoning with self-evolved deep thinking. arXiv preprint arXiv:2501.04519.
- Guo et al. (2025) Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
- Hao et al. (2024) Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. 2024. Training large language models to reason in a continuous latent space. arXiv preprint arXiv:2412.06769.
- Havrilla et al. (2024) Alexander Havrilla, Yuqing Du, Sharath Chandra Raparthy, Christoforos Nalmpantis, Jane Dwivedi-Yu, Eric Hambro, Sainbayar Sukhbaatar, and Roberta Raileanu. 2024. Teaching large language models to reason with reinforcement learning. In AI for Math Workshop@ ICML 2024.
- Khot et al. (2022) Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. 2022. Decomposed prompting: A modular approach for solving complex tasks. In The Eleventh International Conference on Learning Representations.
- Li et al. (2024) Zhiyuan Li, Hong Liu, Denny Zhou, and Tengyu Ma. 2024. Chain of thought empowers transformers to solve inherently serial problems. In The Twelfth International Conference on Learning Representations.
- Lindsey et al. (2025) Jack Lindsey, Wes Gurnee, Emmanuel Ameisen, Brian Chen, Adam Pearce, Nicholas L. Turner, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, and 8 others. 2025. On the biology of a large language model. Transformer Circuits Thread.
- Liu et al. (2022) Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. 2022. Transformers learn shortcuts to automata. In The Eleventh International Conference on Learning Representations.
- Madaan and Yazdanbakhsh (2022) Aman Madaan and Amir Yazdanbakhsh. 2022. Text and patterns: For effective chain of thought, it takes two to tango. arXiv preprint arXiv:2209.07686.
- Pérez et al. (2021) Jorge Pérez, Pablo Barceló, and Javier Marinkovic. 2021. Attention is turing-complete. Journal of Machine Learning Research, 22(75):1–35.
- Pfau et al. (2024) Jacob Pfau, William Merrill, and Samuel R Bowman. 2024. Let’s think dot by dot: Hidden computation in transformer language models. In First Conference on Language Modeling.
- Shao et al. (2024) Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300.
- Stolfo et al. (2023) Alessandro Stolfo, Yonatan Belinkov, and Mrinmaya Sachan. 2023. A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7035–7052.
- Wang et al. (2024) Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. 2024. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837.
- Xie et al. (2023) Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, James Xu Zhao, Min-Yen Kan, Junxian He, and Michael Xie. 2023. Self-evaluation guided beam search for reasoning. Advances in Neural Information Processing Systems, 36:41618–41650.
- Xu et al. (2025) Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He. 2025. Chain of draft: Thinking faster by writing less. arXiv preprint arXiv:2502.18600.
- Yang et al. (2024) An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, and 1 others. 2024. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems, 36:11809–11822.
- Yu et al. (2023) Longhui Yu, Weisen Jiang, Han Shi, YU Jincheng, Zhengying Liu, Yu Zhang, James Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. 2023. Metamath: Bootstrap your own mathematical questions for large language models. In The Twelfth International Conference on Learning Representations.
- Yue et al. (2023) Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. 2023. Mammoth: Building math generalist models through hybrid instruction tuning. In The Twelfth International Conference on Learning Representations.
- Zhang et al. (2024) Di Zhang, Jianbo Wu, Jingdi Lei, Tong Che, Jiatong Li, Tong Xie, Xiaoshui Huang, Shufei Zhang, Marco Pavone, Yuqiang Li, and 1 others. 2024. Llama-berry: Pairwise optimization for o1-like olympiad-level mathematical reasoning. arXiv preprint arXiv:2410.02884.
- Zhou et al. (2022) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc V Le, and 1 others. 2022. Least-to-most prompting enables complex reasoning in large language models. In The Eleventh International Conference on Learning Representations.
- Zhu et al. (2025) Fangwei Zhu, Damai Dai, and Zhifang Sui. 2025. Language models encode the value of numbers linearly. In Proceedings of the 31st International Conference on Computational Linguistics, pages 693–709.
Appendix A Details on Multiplication Task
Dataset construction
For each problem scale of $m× n$ that multiplies $m$ -digit number $a$ with $n$ -digit number $b$ , we generate 100,000 data entries by randomly sampling $a$ and $b$ . When the scale is small (for example $1× 2$ ), we exhaustively generate all number pairs instead. The generated data entries are then divided into train and test splits with a ratio of 90%/10%.
Prompt and CoT Formulation
We use simple multiplication expressions as prompts. Figure 10 shows an example prompt for querying the model to perform multiplication.
For convenience, we use <tool_call> as the start-of-CoT token <COT>, </tool_call> as the end-of-CoT token </COT>, and <|fim_middle|> as the latent token <LAT>, which already exist in the tokenizer vocabulary.
We formulate the reasoning process with the algorithm of digit-wise multiplication, whose example is demonstrated in Figure 11. In the compressed CoT setting, we remove all tokens that merely represent text semantics in CoT, namely “Calculate”, “digit”, “carry”, “Result of” “Add up partial results:” and “The final result is:”, whose example is demonstrated in Figure 12.
Prompt example
3773*6821=
Figure 10: Example prompt for the multi-digit multiplication task.
Full CoT example
3773*6821=<tool_call>Calculate 3773*1 3*1=3, digit 3, carry 0 7*1=7, digit 7, carry 0 7*1=7, digit 7, carry 0 3*1=3, digit 3, carry 0 Result of 3773*1=3773 Calculate 3773*20 3*2=6, digit 6, carry 0 7*2=14, digit 4, carry 1 7*2=14, digit 5, carry 1 3*2=6, digit 7, carry 0 Result of 3773*20=75460 Calculate 3773*800 3*8=24, digit 4, carry 2 7*8=56, digit 8, carry 5 7*8=56, digit 1, carry 6 3*8=24, digit 0, carry 3 Result of 3773*800=3018400 Calculate 3773*6000 3*6=18, digit 8, carry 1 7*6=42, digit 3, carry 4 7*6=42, digit 6, carry 4 3*6=18, digit 2, carry 2 Result of 3773*6000=22638000 Add up partial results: 3773+75460+3018400+22638000 3773+75460+3018400+22638000=79233+3018400+22638000 79233+3018400+22638000=3097633+22638000 3097633+22638000=25735633 The final result is: 3773*6821=25735633</tool_call> Result: 25735633
Figure 11: Example CoT for the multi-digit multiplication task.
Compressed CoT example
3773*6821=<tool_call>3773*1 3*1 3 0 7*1 7 0 7*1 7 0 3*1 3 0 3773*1=3773 3773*20 3*2 6 0 7*2 4 1 7*2 5 1 3*2 7 0 3773*20=75460 3773*800 3*8 4 2 7*8 8 5 7*8 1 6 3*8 0 3 3773*800=3018400 3773*6000 3*6 8 1 7*6 3 4 7*6 6 4 3*6 2 2 3773*6000=22638000 3773+75460+3018400+22638000 3773+75460+3018400+22638000=79233+3018400+22638000 79233+3018400+22638000=3097633+22638000 3097633+22638000=25735633 3773*6821=25735633</tool_call> Result: 25735633
Figure 12: Example CoT after compression for the multi-digit multiplication task.
Appendix B Details on Dynamic Programming Task
Dataset construction
Similar to the multiplication problems, we generate 100,000 data entries for each problem scale of $m× n$ (whose input matrix has a shape of $m$ rows, $n$ columns), and divide them into train and test splits with a ratio of 90%/10%.
To control the value of intermediate states within a reasonable range, we ensure all values $x$ in the input matrix satisfy $1<x<100$ . In other words, each input value is a 2-digit number.
Prompt formulation
We use a matrix whose shape is the same as the input matrix to store intermediate values. The choice of special tokens <COT>, </COT> and <LAT> are the same as those in multiplication problems.
An example of the input prompt is shown in Figure 13, and an example of the full prompt is shown in Figure 14. Notice that we do not have a compressed version of CoT in dynamic programming tasks.
Prompt example
Find a path in the given table from the top-left corner to the bottom-right corner that maximizes the sum of the numbers on it. You can only move rightwards or downwards. Table: 85 93 45 79 49 28 12 37 57 76 3 22 37 55 68 26 2 57 7 100 87 11 12 67 89
Figure 13: Example Prompt for the dynamic programming task.
Full CoT example
Find a path in the given table from the top-left corner to the bottom-right corner that maximizes the sum of the numbers on it. You can only move rightwards or downwards. Table: 15 5 59 62 22 41 61 7 12 27 98 60 34 94 24 45 40 12 77 11 56 94 46 34 45 <tool_call>15 20 79 141 163 56 117 124 153 190 154 214 248 342 366 199 254 266 419 430 255 349 395 453 498</tool_call> Result: 498
Figure 14: Example CoT for the dynamic programming task.
Appendix C Main Experiment Settings
For all of our experiments, we use Qwen-2.5-1.5B Yang et al. (2024) from the huggingface model hub as the base model. On each task, we finetune the model on the training set and then evaluate the model on the test set of the corresponding prompt type. We use the full-parameter supervised finetuning setting and do not use parameter-efficient training techniques.
During training, we use the AdamW optimizer with a learning rate of $1e-5$ . The weight decay is set to 0 and the gradient clipping threshold is set to 1. We train the model for 1 epoch with a training batch size of 4 by default. For small datasets like $1× 2$ digit multiplication, we change the epoch to 10 to ensure convergence.
The models on multiplication problems are trained under BFloat16 precision, while models on DP problems are trained under Float32 precision.
During evaluation, we evaluate with a batch size of 1. We only check the correctness of the final result, and do not check the values in CoT.
Appendix D Latent Experiment Settings
The hyperparameters in latent experiments are the same as the main experiment. For convenience, we use <|fim_middle|> as the latent token <LAT>.
In multiplication problems, the dimension of latent embeddings is set to 20 (10 for digit results and 10 for carry results). In dynamic programming problems, the dimension of latent embeddings is set to 50 to store values no larger than 100,000. The latent projection module $P_{in}$ and the latent output head $P_{out}$ are trained with the backbone model with the same learning rate. We simply add the latent loss $\mathcal{L}_{lat}$ with the original LM head loss $\mathcal{L}_{lm}$ as the final loss $\mathcal{L}=\mathcal{L}_{lat}+\mathcal{L}_{lm}$ .
Figure 15 shows an example of latent CoT in multiplication problems, and Figure 16 shows an example of latent CoT in dynamic programming problems.
Latent CoT example
8493*8877=<tool_call>8493*7 <|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|>|59451 8493*70 <|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|>|594510 8493*800 <|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|>|6794400 8493*8000 <|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|>|67944000 59451+594510+6794400+67944000 59451+594510+6794400+67944000=653961+6794400+67944000 653961+6794400+67944000=7448361+67944000 7448361+67944000=75392361 8493*8877=75392361</tool_call> Result: 75392361
Figure 15: Example latent CoT for the multi-digit multiplication task.
Latent CoT example
Find a path in the given table from the top-left corner to the bottom-right corner that maximizes the sum of the numbers on it. You can only move rightwards or downwards. Table: 15 5 59 62 22 41 61 7 12 27 98 60 34 94 24 45 40 12 77 11 56 94 46 34 45 <tool_call><|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|> <|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|> <|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|> <|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|> <|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|><|fim_middle|></tool_call> Result: 498
Figure 16: Example latent CoT for the dynamic programming task.
Appendix E Intervention Experiment Details
In the intervention experiments, we randomly substitute a number value in the CoT generated by trained models on the test set. The interventions are performed on the full CoT texts. The substituted number has the same digit length as the original number, but with a different value. To prevent outlier values, we keep the first digit to be the same as the original number when substituting numbers with 2 or more digits.
We choose the number to substitute within the following range:
Multiplication
- $x$ or $y$ in “digit $x$ , carry $y$ ” statements;
- A random number $x$ in “Add up partial results:” statements;
- The first partial result $x$ in “ $a_{1}+...+a_{n}=x+...$ statements;
- The result $x$ in the “The final result is: $...=x$ ” statement.
Dynamic programming
A random intermediate value in the CoT.
After intervention, we truncate all tokens after the intervened value, and feed the partial CoT into trained models to complement the full CoT and get the final answer.
The detailed breakdown of errors in multiplication problems is shown in Table 1 (1 entry with deformed CoT is excluded):
| Total Success Error | 9999 7383 2616 |
| --- | --- |
| Addition error | 767 |
| Reconstruct error | 496 |
| Shortcut error | 1291 |
| Copy error | 6 |
| Misc error | 56 |
Table 1: Intervention error breakdown in multiplication problems.
Appendix F Probing Experiment Details
In the probing experiments, we probe on latent CoT for simplicity. We first collect hidden states of LLMs on different layers, and then train the probe classifiers. The training set of hidden states is collected by running the trained model on the original training set, and so is the test set.
We use a learning rate of $1e-3$ and a gradient clipping threshold of $1$ . We train the probe classifiers for 4 epochs with a training batch size of 32, and an evaluate batch size of 64.