# APOLLO: Automated LLM and Lean Collaboration for Advanced Formal Reasoning
**Authors**: Azim Ospanov, &Farzan Farnia , &Roozbeh Yousefzadeh
> Huawei Hong Kong Research CenterDepartment of Computer Science & Engineering, The Chinese University of Hong Kong
## Abstract
Formal reasoning and automated theorem proving constitute a challenging subfield of machine learning, in which machines are tasked with proving mathematical theorems using formal languages like Lean. A formal verification system can check whether a formal proof is correct or not almost instantaneously, but generating a completely correct formal proof with large language models (LLMs) remains a formidable task. The usual approach in the literature is to prompt the LLM many times (up to several thousands) until one of the generated proofs passes the verification system. In this work, we present APOLLO (A utomated P r O of repair via L LM and L ean c O llaboration), a modular, model‑agnostic agentic framework that combines the strengths of the Lean compiler with an LLM’s reasoning abilities to achieve better proof‐generation results at a low token and sampling budgets. Apollo directs a fully automated process in which the LLM generates proofs for theorems, a set of agents analyze the proofs, fix the syntax errors, identify the mistakes in the proofs using Lean, isolate failing sub‑lemmas, utilize automated solvers, and invoke an LLM on each remaining goal with a low top‑ $K$ budget. The repaired sub‑proofs are recombined and reverified, iterating up to a user‑controlled maximum number of attempts. On the miniF2F benchmark, we establish a new state‑of‑the‑art accuracy of 84.9% among sub 8B‑parameter models (as of August 2025) while keeping the sampling budget below one hundred. Moreover, Apollo raises the state‑of‑the‑art accuracy for Goedel‑Prover‑SFT to 65.6% while cutting sample complexity from 25,600 to a few hundred. General‑purpose models (o3‑mini, o4‑mini) jump from 3–7% to over 40% accuracy. Our results demonstrate that targeted, compiler‑guided repair of LLM outputs yields dramatic gains in both efficiency and correctness, suggesting a general paradigm for scalable automated theorem proving. The codebase is available at https://github.com/aziksh-ospanov/APOLLO
## 1 Introduction
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Common Approach: Whole-Proof Generation Pipeline
### Overview
This diagram illustrates an iterative pipeline for generating and validating proofs using a Large Language Model (LLM) and a Lean Server. The process repeats up to **K times**, with conditional branching based on proof validity.
### Components/Axes
1. **LLM (Large Language Model)**:
- Positioned on the far left, depicted as a stylized brain icon.
- Outputs a "proof attempt" to the next stage.
2. **Proof Attempt**:
- A labeled block receiving input from the LLM.
3. **Lean Server**:
- Central component with a flowchart-like diagram labeled "LEAN."
- Processes the proof attempt and outputs a binary decision.
4. **UI Output**:
- A browser-like interface with two buttons:
- **Exit Loop** (green checkmark).
- **Continue** (red X).
5. **Loop Control**:
- Text above the pipeline states "repeat up to K times," indicating a maximum iteration limit.
### Detailed Analysis
- **Flow Direction**:
- Arrows indicate sequential steps: LLM → Proof Attempt → Lean Server → UI Output.
- A feedback loop returns to the LLM if the proof is invalid (red X).
- **Key Text Elements**:
- "Common Approach: Whole-Proof Generation Pipeline" (title).
- "proof attempt" (intermediate step).
- "Lean Server" (validation component).
- "exit loop" and "continue" (decision nodes).
- "repeat up to K times" (loop constraint).
### Key Observations
- The pipeline is **iterative**, with up to **K attempts** to generate a valid proof.
- The Lean Server acts as a **validation gatekeeper**, determining whether the proof meets criteria (green checkmark) or requires reattempts (red X).
- The LLM is the **source of proof generation**, while the Lean Server enforces logical rigor.
### Interpretation
This diagram represents a **closed-loop system** for automated proof generation and validation. The LLM’s outputs are rigorously checked by the Lean Server, which ensures adherence to formal logic (via the "LEAN" framework). The UI provides a human-readable interface to monitor the process.
- **Critical Insight**: The system prioritizes **efficiency** (via Lean Server validation) and **robustness** (via K-attempt safeguards).
- **Ambiguity**: The value of **K** is unspecified, leaving the maximum iteration count undefined.
- **Implication**: The pipeline balances automation (LLM) with formal verification (Lean Server), suggesting applications in mathematics, software verification, or AI-driven theorem proving.
No numerical data or trends are present; the diagram focuses on process flow and component interactions.
</details>
<details>
<summary>x2.png Details</summary>
### Visual Description
## Flowchart: Our Proposed Apollo Pipeline
### Overview
The diagram illustrates a multi-stage pipeline for automated proof generation and validation. It begins with a Language Learning Model (LLM), progresses through an Apollo Proof Repair Agent, and concludes with a Lean Server. The process includes iterative loops, error handling, and decision points for continuation or termination.
### Components/Axes
1. **Key Components**:
- **LLM (Language Learning Model)**: Generates proof attempts and sub-problems.
- **Apollo Proof Repair Agent**: Contains subcomponents:
- **Auto Solver**: Visualized with a wrench and gear icon.
- **Subproof Extractor**: Depicted with a warning triangle and wrench.
- **Lean Server**: Validates proof states and handles errors.
2. **Flow Arrows**:
- Blue arrows indicate primary data flow (e.g., "proof attempt(s)", "sub-problem(s) to prove").
- Red arrows denote error feedback (e.g., "compilation errors", "syntax errors").
3. **Decision Nodes**:
- Green checkmark ("exit loop") and red X ("continue") in the Lean Server output.
### Detailed Analysis
1. **LLM Output**:
- Produces "proof attempt(s)" and "sub-problem(s) to prove" (red arrow to Apollo Repair Agent).
2. **Apollo Repair Agent**:
- Processes inputs via Auto Solver and Subproof Extractor.
- Outputs "proof state" to Lean Server.
3. **Lean Server**:
- Validates "proof state" and identifies "compilation errors" or "syntax errors".
- Decision logic:
- Green checkmark ("exit loop") if validation succeeds.
- Red X ("continue") if errors persist.
4. **Iteration**:
- Loop repeats "up to r times" (gray box at the top).
### Key Observations
- **Iterative Design**: The pipeline emphasizes repeated attempts ("repeat up to r times") to refine proofs.
- **Error Handling**: Red arrows highlight error correction loops between components.
- **Validation Gatekeeping**: Lean Server acts as a final checkpoint with binary outcomes (success/failure).
### Interpretation
This pipeline automates formal proof generation and validation, leveraging an LLM for initial attempts and a repair agent for error resolution. The Lean Server ensures rigor by enforcing strict validation, while the iterative loop balances efficiency (limited retries) and reliability (error correction). The use of icons (e.g., brain for LLM, wrench for repair) simplifies understanding of abstract processes. The decision to "exit loop" or "continue" suggests a focus on resource optimization, avoiding infinite loops while maintaining proof quality.
**Note**: No numerical data or trends are present; the diagram focuses on process flow and component interactions.
</details>
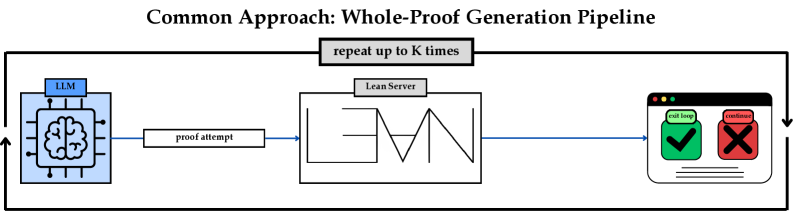
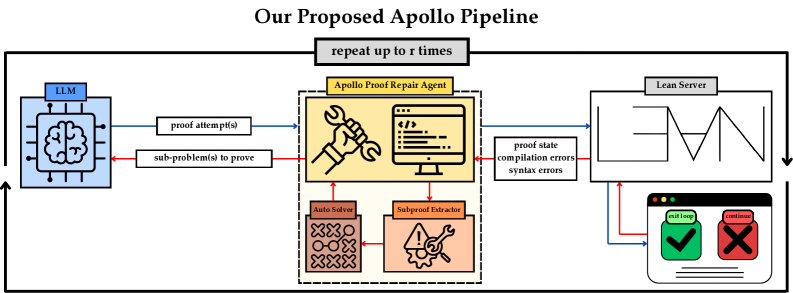
Figure 1: The summary of whole-proof generation pipeline vs. proposed Apollo agentic pipeline. LLM refers to a chosen formal theorem generator model.
Formal reasoning has emerged as one of the most challenging fields of AI with recent achievements such as AlphaProof and AlphaGeometry doing well at the International Math Olympiad competing with humans yang2024formal ; alphaproof ; AlphaGeometryTrinh2024 . Formal reasoning relies both on AI models and a formal verification system that can automatically verify whether a mathematical proof is correct or not. In recent years, formal verification systems such as Lean lean4paper have facilitated a new form of doing mathematical research by enabling mathematicians to interact with the formal verification system and also with each other via the system, enabling larger numbers of mathematicians to collaborate with each other on a single project. As such, these formal verification systems are also called proof assistants as one can use them interactively to write a formal proof and instantaneously observe the current state of the proof and any possible errors or shortcomings in the proof generated by the compiler. Immediate access to the output of Lean compiler can help a mathematician to fix possible errors in the proof. At the same time, when a proof passes the compiler with no error, other collaborators do not need to verify the correctness of the proof. This type of collaboration is transforming the field of mathematics enabling large groups of collaborators to engage in large projects of mathematical research such as the Prime Number Theorem And More project kontorovich_tao_2024_primenumbertheoremand . Moreover, it has given rise to the digitization of mathematics buzzard2024mathematical .
In the AI front, large language models (LLMs) are improving at mathematical reasoning in natural language, and at the same time, they have shown a remarkable ability to learn the language of those formal verification systems and write mathematical proofs in formal language. This has led to the field of Automated Theorem Proving (ATP) where the standard approach is to prompt the LLM to generate a number of candidate proofs for a given theorem which will then be verified automatically using the formal verification system. Better models, better training sets, and better training methods has led to significant advances in this field tsoukalas2024putnambenchevaluatingneuraltheoremprovers ; zheng2022minif2fcrosssystembenchmarkformal ; azerbayev2023proofnetautoformalizingformallyproving ; li2024numinamath ; hu2025minictx .
Despite these advances, the LLMs do not really get the chance to interact with the verification system the way a human does. LLMs generate many possible proofs, sometimes as many as tens of thousands, and the verification system only marks the proofs with a binary value of correct or incorrect. This common approach is illustrated in Figure 1. When the formal verification system analyzes a proof, its compiler may generate a long list of issues including syntax errors, incorrect tactics, open goals, etc. In the current approach of the community, all of those information/feedback from the compiler remains unused, as the LLM’s proof generation is not directly engaged with the compiler errors of the formal verification system.
In this work, we address this issue by introducing Apollo, a fully automated system which uses a modular, model-agnostic pipeline that combines the strengths of the Lean compiler with the reasoning abilities of LLMs. Apollo directs a fully automated process in which the LLM generates proofs for theorems, a set of agents analyze the proofs, fix the syntax errors, identify the mistakes in the proofs using Lean, isolate failing sub‑lemmas, utilize automated solvers, and invoke an LLM on each remaining goal with a low top‑ $K$ budget. The high-level overview of Apollo appears at the bottom of Figure 1.
Our contributions are as follows:
- We introduce a novel fully automated system that directs a collaboration between LLMs, Lean compiler, and automated solvers for automated theorem proving.
- We evaluate Apollo on miniF2F-test set using best LLMs for theorem proving and demonstrate that Apollo improves the baseline accuracies by significant margins while keeping the sampling costs much lower.
- We establish a new SOTA on miniF2F-test benchmark for medium-sized language models. (with parameter size 8B or less)
## 2 Related Works
Formal theorem proving systems. At their core, formal theorem‑proving (FTP) systems employ interactive theorem provers (ITPs) to verify mathematical results. In particular, Lean4 lean4paper is both a functional programming language and an ITP. Each theorem, lemma, conjecture, or definition must be checked by Lean’s trusted kernel, so the compiler’s verdict is binary: either the statement type‑checks (True) or it fails (False). This rigorous verification dramatically increases the reliability of formal mathematics; however, it also increases the complexity of proof development: authors must both comprehend the mathematical concepts and precisely encode them in the formal language. The usefulness of Lean is also shown to go beyond theorem proving, as Jiang et al. jiang2024leanreasoner showed that Lean can be adapted to natural language logical reasoning.
Patching broken programs. Many prior works have explored using feedback to repair broken proofs. In software engineering, “repair” typically refers to program repair, i.e. fixing code that no longer runs programrepair . A common source of errors is a version mismatch that introduces bugs and prevents execution. For example, SED sed_repair uses a neural program‐generation pipeline that iteratively repairs initial generation attempts. Other notable approaches train specialized models to fix broken code based on compiler feedback (e.g. BIFI bifi , TFix tfix ) or leverage unsupervised learning over large bug corpora (e.g. BugLab buglab ).
LLM collaboration with external experts. The use of expert feedback, whether from human users or from a proof assistant’s compiler, has proven effective for repairing broken proofs. Ringer ringer2009typedirected showcased automatic proof repair within the Coq proof assistant bertot2013interactive , enabling the correction of proofs in response to changes in underlying definitions. Jiang et al. jiang2022thor showed that leveraging automatic solvers with generative models yield better performance on formal math benchmarks. More recently, First et al. first2023baldurwholeproofgenerationrepair showed that incorporating compiler feedback into LLM proof generation significantly improves the model’s ability to correct errors and produce valid proofs. Another line of work song2023towards explored an idea of mathematician and LLM collaboration, where human experts are aided by LLMs at proof writing stage.
Proof search methods. Numerous recent systems use machine learning to guide the search for formal proofs. One of the methods involves using large language models with structured search strategies, e.g. Best‑First Search (BFS) polu2022formalmathematicsstatementcurriculum ; wu2024internlm25stepproveradvancingautomatedtheorem ; xin2025bfsproverscalablebestfirsttree or Monte Carlo Tree Search (MCTS) lample2022hypertree ; wang2023dt-solver ; alphaproof . While tree‑search methods reliably steer a model toward valid proofs, they result in high inference costs and often explore many suboptimal paths before success. Another line of work leverages retrieval based systems to provide context for proof generators with potentially useful lemmas. One such example is ReProver yang_leandojo_2023 that augments Lean proof generation by retrieving relevant lemmas from a proof corpus and feeding them to an LLM, enabling the model to reuse existing proofs.
Whole proof generation. The use of standalone LLMs for theorem proving has emerged as a major research direction in automated theorem proving. One of the earliest works presented GPT-f polu2020generativelanguagemodelingautomated , a transformer-based model for theorem proving that established the LLMs ability in formal reasoning. As training frameworks and methods advance, the community has produced numerous models that generate complete proofs without external search or tree‑search algorithms. Recent work shows that both supervised models xin2024deepseekproverv15harnessingproofassistant ; lin2025goedelproverfrontiermodelopensource and those trained via reinforcement learning xin2024deepseekproverv15harnessingproofassistant ; zhang2025leanabellproverposttrainingscalingformal ; dong2025stp ; kimina_prover_2025 achieve competitive performance on formal‑math benchmarks. However, whole‑proof generation remains vulnerable to hallucinations that can cause compilation failures even for proofs with correct reasoning chains.
Informal Chain-of-Thought in Formal Mathematics. Several recent works demonstrate that interleaving informal “chain‑of‑thought” (CoT) reasoning with formal proof steps substantially improves whole‑proof generation. For example, developers insert natural‑language mathematical commentary between tactics, yielding large accuracy gains lin2025goedelproverfrontiermodelopensource ; xin2024deepseekproverv15harnessingproofassistant ; azerbayev2024llemma . Wang, et al. kimina_prover_2025 further show that special “thinking” tokens let the model plan its strategy and self‑verify intermediate results. The “Draft, Sketch, and Prove” (DSP) jiang2023draftsketchproveguiding and LEGO-Prover wang2024legoprover pipelines rely on an informal proof sketch before attempting to generate the formal proof. Collectively, these studies indicate that providing informal mathematical context, whether as comments, sketches, or dedicated tokens, guides LLMs toward correct proofs and significantly boosts proof synthesis accuracy.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Flowchart: Apollo Algorithm
### Overview
The image depicts a technical flowchart titled "Apollo Algorithm," illustrating a multi-step process for proof validation and assembly. The workflow includes components like a Syntax Refiner, Sorrifier, Auto Solver, Proof Assembler, and LLM (Large Language Model). Decision points and code snippets (labeled "Invalid Proof" and "Correct Proof") are integrated into the diagram.
### Components/Axes
1. **Main Workflow Components**:
- **Syntax Refiner** (icon: gear/settings)
- **Sorrifier** (icon: hammer)
- **Auto Solver** (icon: pencil)
- **Proof Assembler** (icon: trowel/brick wall)
- **LLM** (network diagram with nodes)
2. **Decision Points**:
- "number of attempts > r?" (diamond shape, red)
- "Does the proof compile in Lean?" (diamond shape, green)
3. **Code Snippets**:
- **Invalid Proof** (red box, contains errors like `h: a % 10 = 0`)
- **Correct Proof** (green box, fixes errors with adjusted conditions)
### Detailed Analysis
- **Syntax Refiner** → **Sorrifier** → **Auto Solver**: Sequential flow with feedback loops.
- **Proof Assembler** uses a brick-wall metaphor, suggesting incremental construction.
- **LLM** receives extracted subproofs and assembles the final proof.
- **Decision Points**:
- If "number of attempts > r?" is **YES**, the process loops back to the Syntax Refiner.
- If "Does the proof compile in Lean?" is **YES**, the proof proceeds to the LLM.
- **Code Snippets**:
- **Invalid Proof** includes errors like `h: a % 10 = 0` and `h: b % 10 = 4`.
- **Correct Proof** replaces these with `h: a % 10 = 6` and `h: b % 10 = 6`, resolving contradictions.
### Key Observations
1. **Feedback Loops**: The process iterates until the proof compiles in Lean or exceeds the attempt limit.
2. **Error Correction**: The green "Correct Proof" explicitly addresses contradictions present in the red "Invalid Proof."
3. **Visual Metaphors**: The brick-wall analogy for the Proof Assembler emphasizes modular, step-by-step construction.
### Interpretation
The Apollo Algorithm appears to automate formal proof validation and repair. The workflow prioritizes iterative refinement (via the Sorrifier and Auto Solver) and leverages an LLM for final assembly. The code snippets highlight common pitfalls (e.g., incorrect modulo operations) and their resolutions, suggesting the algorithm’s focus on arithmetic and logical consistency. The decision points imply a balance between computational effort (attempt limits) and correctness (Lean compilation).
**Notable Patterns**:
- The use of color-coded code blocks (red/green) visually distinguishes error states from validated states.
- The brick-wall metaphor for the Proof Assembler reinforces the idea of building proofs incrementally, akin to masonry.
- The LLM’s role as a final assembler suggests integration of machine learning for complex proof synthesis.
</details>
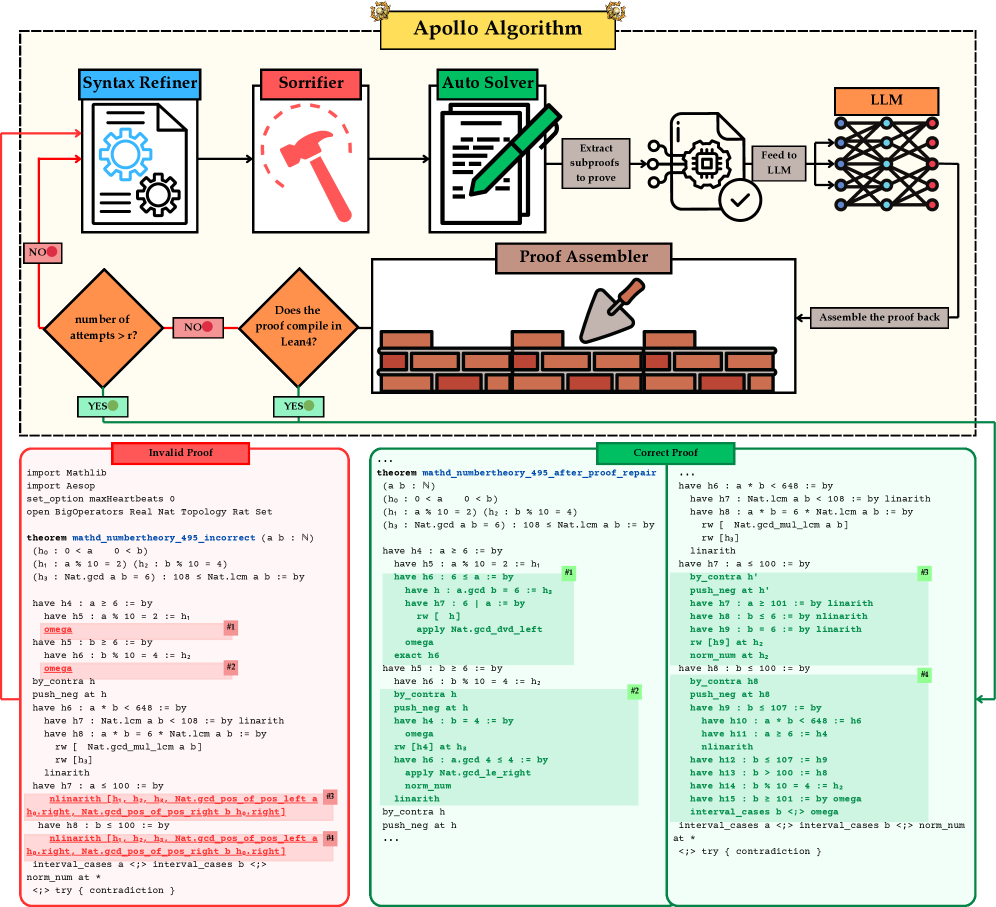
Figure 2: Overview of the Apollo framework.
## 3 Our Approach
In this section we describe Apollo, our framework for transforming an LLM’s raw proof sketch into a fully verified Lean4 proof. Figure 2 illustrates the Apollo pipeline process with an attached Lean code before and after repair. We observe that often LLM is capable of producing a valid proof sketch; however, it often struggles with closing fine-grained goals. For example, statements h4, h5, h7, h8 are correct but the generated proofs for each sub-lemma throw compilation errors. Apollo identifies and fixes such proof steps and guides the LLM towards a correct solution.
Our compiler of choice is the Lean REPL leanrepl , a “ R ead– E val– P rint– L oop” for Lean4. It provides a complete list of compilation errors and warnings, each with a detailed description and the location (for example, the line number) where it occurred. Errors can include syntax mistakes, nonexistent tactics, unused tactics, and more. We aggregate this information to drive our agent’s dynamic code repair and sub‑problem extraction. The pseudo-code for our framework can be found in Algorithm 1 in the Appendix.
### 3.1 Syntax Refiner
The Syntax Refiner catches and corrects superficial compilation errors: missing commas, wrong keywords (e.g. Lean3’s from vs. Lean4’s := by), misplaced brackets, etc. These syntax errors arise when a general‑purpose LLM (such as o3‑mini openai-o3-mini-2025 or o4‑mini openai-o4-mini-2025 ) has not been specialized on Lean4 syntax. By normalizing these common mistakes, this module ensures that subsequent stages operate on syntactically valid code. It is important to note that this module is primarily applicable to general purpose models not explicitly trained for theorem proving in Lean. In contrast, Syntax Refiner usually does not get invoked for proofs generated by LLMs trained for formal theorem proving.
### 3.2 Sorrifier
The Sorrifier patches any remaining compilation failures by inserting Lean’s sorry placeholder. We first parse the failed proof into a tree of nested proof‑blocks (sub‑lemmas as children). Then we compile the proof with Lean REPL leanrepl , detect the offending line or block, and apply one of three repairs:
1. Line removal, if a single tactic or declaration is invalid but its surrounding block may still succeed.
1. Block removal, if the entire sub‑proof is malformed.
1. Insert sorry, if the block compiles but leaves unsolved goals open.
We repeat this procedure until the file compiles without errors. At that point, every remaining sorry marks a sub‑lemma to be proved in later stages of Apollo. This part of the pipeline guarantees that the proof successfully compiles in Lean with warnings of presence of sorry statements.
Each sorry block corresponds to a sub‑problem that the LLM failed to prove. Such blocks may not type‑check for various reasons, most commonly LLM hallucination. The feedback obtained via REPL lets us to automatically catch these hallucinations, insert a sorry placeholder, and remove invalid proof lines.
### 3.3 Auto Solver
The Auto Solver targets each sorry block in turn. It first invokes the Lean4’s hint to close the goal. If goals persist, it applies built‑in solvers (nlinarith, ring, simp, etc.) wrapped in try to test combinations automatically. Blocks whose goals remain open stay marked with sorry. After applying Auto Solver, a proof may be complete with no sorry’s in which case Apollo has already succeeded in fixing the proof. Otherwise, the process can repeat recursively.
### 3.4 Recursive reasoning and repair
In the case where a proof still has some remaining sorry statements after applying the Auto Solver, Apollo can consider each as a new lemma, i.e., extract its local context (hypotheses, definitions, and any lemmas proved so far), and recursively try to prove the lemmas by prompting the LLM and repeating the whole process of verification, syntax refining, sorrifying, and applying the Auto Solver.
At each of these recursive iterations, a lemma may be completely proved, or it may end up with an incomplete proof with one or a few sorry blocks. This allows the Apollo to make progress in proving the original theorem by breaking down the incomplete steps further and further until the LLM or Auto Solver can close the goals. This process can continue up to a user‑specified recursion depth $r$ .
### 3.5 Proof Assembler
Finally, the Proof Assembler splices all repaired blocks back into a single file and verifies that no sorry or admit (alias for "sorry") commands remain. If the proof still fails, the entire pipeline repeats (up to a user‑specified recursion depth $r$ ), allowing further rounds of refinement and sub‑proof generation.
Apollo’s staged approach: syntax cleaning, “sorrifying,” automated solving, and targeted LLM‐driven repair, yields improvements in both proof‐sample efficiency and final proof correctness.
## 4 Experiments
In this section, we present empirical results for Apollo on the miniF2F dataset zheng2022minif2fcrosssystembenchmarkformal , which comprises of 488 formalized problems drawn from AIME, IMO, and AMC competitions. The benchmark is evenly split into validation and test sets (244 problems each); here we report results on the miniF2F‑test partition. To demonstrate Apollo’s effectiveness, we evaluate it on a range of state‑of‑the‑art whole‑proof generation models. All experiments use Lean v4.17.0 and run on eight NVIDIA A5000 GPUs with 128 CPU cores. We used $@32$ sampling during sub-proof generation unless stated otherwise. Baseline numbers are sourced from each model’s original publication works.
### 4.1 The effect of applying Apollo on top of the base models
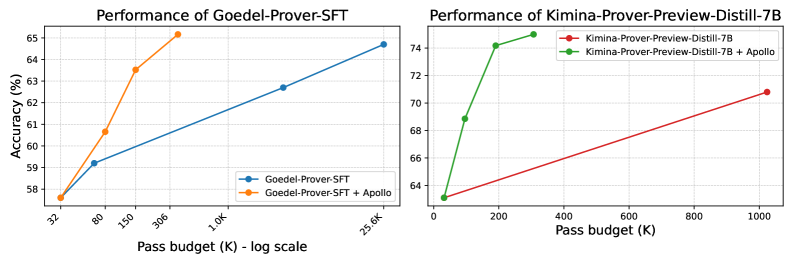
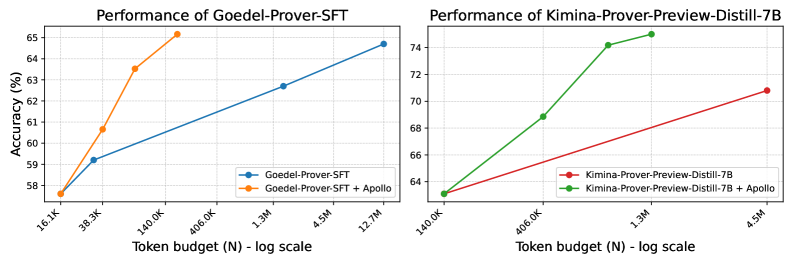
Figure 3 shows the impact of Apollo on two state‑of‑the‑art whole‑proof generation models: Goedel Prover‑SFT lin2025goedelproverfrontiermodelopensource and Kimina‑Prover‑Preview‑Distill‑7B kimina_prover_2025 . Applying Apollo increases Goedel‑Prover‑SFT’s top accuracy from 64.7% to 65.6% while reducing its sampling budget by two orders of magnitude (from 25,600 generated samples to only a few hundred on average). Similarly, Kimina‑Prover‑Preview‑Distill‑7B achieves a new best Kimina-Prover-Preview-Distill-7B accuracy of 75.0% with roughly one‑third of the previous sample budget. We report the exact numbers in Table 1.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Charts: Performance Comparison of Prover Models with/without Apollo
### Overview
The image contains two side-by-side line charts comparing the accuracy performance of two prover models (Goedel-Prover-SFT and Kimina-Prover-Preview-Distill-7B) with and without Apollo enhancements across different pass budgets. Both charts use accuracy (%) on the y-axis and pass budget (K) on the x-axis, with distinct scaling and data patterns.
### Components/Axes
**Left Chart (Goedel-Prover-SFT):**
- **Title:** "Performance of Goedel-Prover-SFT"
- **X-axis:** "Pass budget (K) - log scale" (markers: 32, 80, 150, 306, 1.0K, 25.6K)
- **Y-axis:** "Accuracy (%)" (range: 57.5% to 65%)
- **Legend:**
- Blue line: "Goedel-Prover-SFT"
- Orange line: "Goedel-Prover-SFT + Apollo"
- **Data Points:**
- Blue line: (32K, 58%), (80K, 59.2%), (150K, 60.5%), (306K, 61.8%), (1.0K, 62.7%), (25.6K, 64.5%)
- Orange line: (32K, 57.5%), (80K, 60.8%), (150K, 63.4%), (306K, 65%), (1.0K, 63.2%), (25.6K, 64.5%)
**Right Chart (Kimina-Prover-Preview-Distill-7B):**
- **Title:** "Performance of Kimina-Prover-Preview-Distill-7B"
- **X-axis:** "Pass budget (K)" (markers: 0, 200, 400, 600, 800, 1000)
- **Y-axis:** "Accuracy (%)" (range: 63.5% to 74.5%)
- **Legend:**
- Red line: "Kimina-Prover-Preview-Distill-7B"
- Green line: "Kimina-Prover-Preview-Distill-7B + Apollo"
- **Data Points:**
- Red line: (0K, 63.5%), (200K, 66.2%), (400K, 67.8%), (600K, 69.1%), (800K, 70.3%), (1000K, 70.5%)
- Green line: (0K, 63.5%), (200K, 74%), (400K, 72.5%), (600K, 68.7%), (800K, 66.5%), (1000K, 70.5%)
### Detailed Analysis
**Left Chart Trends:**
1. **Goedel-Prover-SFT (Blue):** Shows a consistent upward trend, increasing from 58% at 32K to 64.5% at 25.6K. The log scale emphasizes performance gains at lower budgets.
2. **Goedel-Prover-SFT + Apollo (Orange):** Starts slightly below the base model (57.5% vs 58%) but surpasses it at 150K (63.4% vs 60.5%). Peaks at 306K (65%) before converging with the base model at 25.6K (64.5%).
**Right Chart Trends:**
1. **Kimina-Prover-Preview-Distill-7B (Red):** Steady linear increase from 63.5% at 0K to 70.5% at 1000K, with no plateaus.
2. **Kimina-Prover-Preview-Distill-7B + Apollo (Green):** Sharp initial spike to 74% at 200K (10.5% improvement), followed by a decline to 66.5% at 800K, then recovery to 70.5% at 1000K.
### Key Observations
1. **Apollo's Impact on Goedel-Prover-SFT:**
- Provides a 1.3% accuracy boost at 150K but requires 306K pass budget to reach peak performance.
- Performance converges with the base model at higher budgets (25.6K), suggesting diminishing returns.
2. **Apollo's Impact on Kimina-Prover:**
- Delivers a dramatic 10.5% accuracy boost at 200K but causes overfitting-like behavior (performance drop to 66.5% at 800K).
- Final accuracy matches the base model at 1000K, indicating unstable gains.
3. **Model Behavior:**
- Goedel-Prover-SFT shows stable scaling with budget.
- Kimina-Prover-Preview-Distill-7B exhibits linear scaling without saturation.
- Apollo's benefits are context-dependent: helpful for Goedel at mid-budgets but destabilizing for Kimina at higher budgets.
### Interpretation
The data suggests that Apollo's effectiveness varies significantly between models:
- For **Goedel-Prover-SFT**, Apollo acts as a performance enhancer at mid-range budgets but becomes redundant at higher budgets.
- For **Kimina-Prover-Preview-Distill-7B**, Apollo introduces instability, causing performance degradation after initial gains. This could indicate overfitting to specific data patterns or architectural incompatibilities.
The contrasting results highlight the importance of model-specific optimization when integrating enhancements like Apollo. While Apollo improves efficiency for Goedel-Prover-SFT, it may require careful tuning or architectural modifications to stabilize performance for Kimina-Prover-Preview-Distill-7B.
</details>
(a) Model accuracy against sampling budget
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Charts: Performance of Goedel-Prover-SFT and Kimina-Prover-Preview-Distill-7B
### Overview
The image contains two side-by-side line charts comparing the accuracy of two AI models (Goedel-Prover-SFT and Kimina-Prover-Preview-Distill-7B) across different token budgets. Each chart includes a baseline model and a variant enhanced with "Apollo." The x-axis uses a logarithmic scale for token budgets, while the y-axis shows accuracy in percentage.
---
### Components/Axes
#### Left Chart: Goedel-Prover-SFT
- **X-axis**: Token budget (N) - log scale
Labels: 16.1K, 38.3K, 140K, 406K, 1.3M, 12.7M
- **Y-axis**: Accuracy (%)
Range: 58% to 65%
- **Legend**:
- Blue line: Goedel-Prover-SFT
- Orange line: Goedel-Prover-SFT + Apollo
#### Right Chart: Kimina-Prover-Preview-Distill-7B
- **X-axis**: Token budget (N) - log scale
Labels: 140K, 406K, 1.3M, 4.5M
- **Y-axis**: Accuracy (%)
Range: 64% to 74%
- **Legend**:
- Red line: Kimina-Prover-Preview-Distill-7B
- Green line: Kimina-Prover-Preview-Distill-7B + Apollo
---
### Detailed Analysis
#### Left Chart: Goedel-Prover-SFT
- **Baseline (Blue)**:
- Starts at **58%** at 16.1K tokens.
- Increases steadily to **64.5%** at 12.7M tokens.
- Slope: Linear upward trend.
- **Apollo-enhanced (Orange)**:
- Starts at **57.5%** at 16.1K tokens.
- Sharp rise to **65.1%** at 406K tokens.
- Plateaus at **64.5%** for larger budgets (1.3M–12.7M).
#### Right Chart: Kimina-Prover-Preview-Distill-7B
- **Baseline (Red)**:
- Starts at **63.5%** at 140K tokens.
- Gradual increase to **70.8%** at 4.5M tokens.
- Slope: Linear upward trend.
- **Apollo-enhanced (Green)**:
- Starts at **63.5%** at 140K tokens.
- Steeper rise to **74.1%** at 1.3M tokens.
- Further improvement to **74.5%** at 4.5M tokens.
---
### Key Observations
1. **Apollo Enhancement**:
- Both models show significant accuracy gains when Apollo is added.
- Larger token budgets amplify these gains, especially in the Kimina model.
2. **Diminishing Returns**:
- Goedel-Prover-SFT + Apollo plateaus at 406K tokens, suggesting limited benefit from further scaling.
3. **Performance Gaps**:
- Kimina-Prover-Preview-Distill-7B + Apollo consistently outperforms its baseline by ~3–4% across all budgets.
- Goedel-Prover-SFT + Apollo outperforms its baseline by ~1–2% at lower budgets but converges at higher budgets.
---
### Interpretation
The data demonstrates that **Apollo significantly boosts model performance**, with the Kimina model benefiting more from scaling. The plateau in Goedel-Prover-SFT + Apollo at 406K tokens implies architectural or optimization limits, whereas Kimina’s continued improvement suggests better scalability. These trends highlight the importance of model architecture and auxiliary components (like Apollo) in achieving high accuracy, particularly at larger token budgets.
</details>
(b) Model accuracy against generated token budget
Figure 3: Performance of base models against the Apollo aided models on miniF2F-test dataset at different sample budgets and token length.
Note that Apollo’s sampling budget is not fixed: it depends on the recursion depth $r$ and the LLM’s ability to generate sub‑lemmas. For each sub‑lemma that Auto Solver fails to close, we invoke the LLM with a fixed top‑32 sampling budget. Because each generated sub‑lemma may spawn further sub‑lemmas, the total sampling overhead grows recursively, making any single @K budget difficult to report. Sub‑lemmas also tend to require far fewer tactics (and thus far fewer tokens) than the main theorem. A theorem might need 100 lines of proof while a sub-lemma might need only 1 line. Hence, sampling cost does not scale one‑to‑one. Therefore, to compare with other whole-proof generation approaches, we report the average number of proof samples and token budgets. We present more in-depth analysis of inference budgets in Section B of the Appendix.
Table 1: Table results comparing sampling cost, accuracy, and token usage before and after applying Apollo. “Cost” denotes the sampling budget $K$ for whole‑proof generation and the recursion depth $r$ for Apollo. Column $N$ reports the average number of tokens generated per problem in "Chain‑of‑Thought" mode. Bold cells highlight the best accuracy. Results are shown on the miniF2F‑test dataset for two models: Kimina‑Prover‑Preview‑Distill‑7B and Goedel‑SFT.
| Goedel‑Prover‑SFT | Kimina‑Prover‑Preview‑Distill‑7B | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Base Model | + Apollo | Base Model | + Apollo | | | | | | | | |
| $K$ | $N$ | Acc. (%) | $r$ | $N$ | Acc. (%) | $K$ | $N$ | Acc. (%) | $r$ | $N$ | Acc. (%) |
| 32 | 16.1K | 57.6% | 0 | 16.1K | 57.6% | 32 | 140K | 63.1% | 0 | 140K | 63.1% |
| 64 | 31.8K | 59.2% | 2 | 38.3K | 60.7% | | | | 2 | 406K | 68.9% |
| 3200 | 1.6M | 62.7% | 4 | 74.6K | 63.5% | | | | 4 | 816K | 74.2% |
| 25600 | 12.7M | 64.7% | 6 | 179.0K | 65.6 % | 1024 | 4.5M | 70.8% | 6 | 1.3M | 75.0% |
### 4.2 Comparison with SoTA LLMs
Table 2 compares whole‑proof generation and tree‑search methods on miniF2F‑test. For each approach, we report its sampling budget, defined as the top‑ $K$ parameter for LLM generators or equivalent search‑depth parameters for tree‑search provers. Since Apollo’s budget varies with recursion depth $r$ , we instead report the mean number of proof sampled during procedure. Moreover, we report an average number of generated tokens as another metric for computational cost of proof generation. For some models due to inability to collect generated tokens, we leave them blank and report sampling budget only.
When Apollo is applied on top of any generator, it establishes a new best accuracy for that model. For instance, Goedel‑Prover‑SFT’s accuracy jumps to 65.6%, surpassing the previous best result (which required 25,600 sample budget). In contrast, Apollo requires only 362 samples on average. Likewise, Kimina‑Prover‑Preview‑Distill‑7B sees a 4.2% accuracy gain while reducing its sample budget below the original 1,024. To further validate Apollo’s generalizability, we tested the repair framework on Goedel-V2-8B lin2025goedelproverv2 , the current state-of-the-art theorem prover. We observe that, at similar sample and token budgets, Apollo achieves a 0.9% accuracy gain, whereas the base LLM requires twice the budget to reach the same accuracy. Overall, Apollo not only boosts accuracy but does so with a smaller sampling budget, setting a new state-of-the-art result among sub‑8B‑parameter LLMs with sampling budget of 32.
We also evaluate general‑purpose LLMs (OpenAI o3‑mini and o4‑mini). Without Apollo, these models rarely produce valid Lean4 proofs, since they default to Lean3 syntax or introduce trivial compilation errors. Yet they have a remarkable grasp of mathematical concepts, which is evident by the proof structures they often produce. By applying Apollo’s syntax corrections and solver‑guided refinements, their accuracies increase from single digits (3–7%) to over 40%. These results demonstrate that in many scenarios discarding and regenerating the whole proof might be overly wasteful, and with a little help from a Lean compiler, we can achieve better accuracies while sampling less proofs from LLMs.
Table 2: Comparison of Apollo accuracy against state-of-the-art models on the miniF2F-test dataset. Token budget is computed over all generated tokens by LLM.
| Method | Model size | Sample budget | Token budget | miniF2F-test |
| --- | --- | --- | --- | --- |
| Tree Search Methods | | | | |
| Hypertree Proof Search (lample2022hypertree, ) | 0.6B | $64\times 5000$ | - | $41.0\$ |
| IntLM2.5-SP+BFS+CG (wu2024internlm25stepproveradvancingautomatedtheorem, ) | 7B | $256\times 32\times 600$ | - | $65.9\$ |
| HPv16+BFS+DC (li2025hunyuanproverscalabledatasynthesis, ) | 7B | $600\times 8\times 400$ | - | $68.4\$ |
| BFS-Prover (xin2025bfsproverscalablebestfirsttree, ) | 7B | $2048\times 2\times 600$ | - | $70.8\$ |
| Whole-proof Generation Methods | | | | |
| DeepSeek-R1- Distill-Qwen-7B (deepseekai2025deepseekr1incentivizingreasoningcapability, ) | 7B | 32 | - | 42.6% |
| Leanabell-GD-RL (zhang2025leanabellproverposttrainingscalingformal, ) | 7B | $128$ | - | $61.1\$ |
| STP (dong2025stp, ) | 7B | $25600$ | - | $67.6\$ |
| o3-mini (openai-o3-mini-2025, ) | - | 1 | - | $3.3\$ |
| $32$ | - | $24.6\$ | | |
| o4-mini (openai-o4-mini-2025, ) | - | 1 | - | $7.0\$ |
| Goedel-SFT (lin2025goedelproverfrontiermodelopensource, ) | 7B | 32 | 16.1K | $57.6\$ |
| $3200$ | 1.6M | $62.7\$ | | |
| $25600$ | 12.7M | $64.7\$ | | |
| Kimina-Prover- Preview-Distill (kimina_prover_2025, ) | 7B | 1 | 4.4K | $52.5\$ |
| $32$ | 140K | $63.1\$ | | |
| $1024$ | 4.5M | $70.8\$ | | |
| Goedel-V2 (lin2025goedelproverv2, ) | 8B | 32 | 174K | $83.3\$ |
| $64$ | 349K | $84.0\$ | | |
| $128$ | 699K | $84.9\$ | | |
| Whole-proof Generation Methods + Apollo | | | | |
| o3-mini + Apollo | - | 8 | - | 40.2% (+36.9%) |
| o4-mini + Apollo | - | 15 | - | 46.7% (+39.7%) |
| Goedel-SFT + Apollo | 7B | 362 | 179K | 65.6% (+0.9%) |
| Kimina-Preview + Apollo | 7B | 307 | 1.3M | 75.0% (+4.2%) |
| Goedel-V2 + Apollo | 8B | 63 | 344K | 84.9% (+0.9%) |
To further assess Apollo, we conducted experiments on PutnamBench tsoukalas2024putnambenchevaluatingneuraltheoremprovers , using Kimina-Prover-Preview-Distill-7B as the base model. Under whole-proof generation pipeline, LLM produced 10 valid proofs. With Apollo, the LLM produced one additional valid proof while consuming nearly half as many tokens. Results are presented in Table 3.
Overall, our results on a variety of LLMs and benchmarks demonstrate that Apollo consistently consumes fewer tokens while achieving higher accuracy, highlighting its effectiveness.
Table 3: Comparison of Apollo accuracy on the PutnamBench dataset. Token budget is computed over all generated tokens by LLM.
| Method | Model size | Sample budget | Token budget | PutnamBench |
| --- | --- | --- | --- | --- |
| Kimina-Preview | 7B | 32 | 180K | 7/658 |
| Kimina-Preview | 7B | 192 | 1.1M | 10/658 |
| Kimina-Preview+Apollo | 7B | 108 | 579K | 11/658 |
### 4.3 Distribution of Proof Lengths
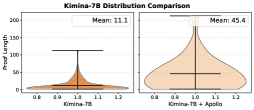
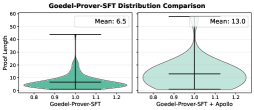
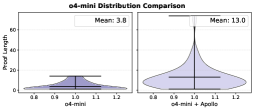
We assess how Apollo affects proof complexity by examining proof‑length distributions before and after repair. Here, proof length is defined as the total number of tactics in a proof, which serves as a proxy for proof complexity.
Figure 4 presents violin plots for three base models: Kimina‑Prover‑Preview‑Distill‑7B, Goedel‑Prover‑SFT, and o4‑mini. Each subplot shows two non‑overlapping sets: proofs generated directly by the base model (“before”) and proofs produced after applying Apollo (“after”). We only consider valid proofs verified by REPL in this setup.
The proofs that Apollo succeeds in fixing in collaboration with the LLM have considerably longer proof lengths. The mean length of proofs fixed by Apollo is longer than those written by the LLM itself at least by a factor of two in each model selection scenario. This increase indicates that the proofs which the base model alone could not prove require longer, more structured reasoning chains. By decomposing challenging goals into smaller sub‑lemmas, Apollo enables the generation of these extended proofs, therefore improving overall success rate.
These results demonstrate that Apollo not only raises accuracy but also systematically guides models to construct deeper, more rigorous proof structures capable of solving harder theorems.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Violin Plot: Kimina-7B Distribution Comparison
### Overview
The image contains two side-by-side violin plots comparing the distribution of "Proof Length" for two groups: "Kimina-7B" (left) and "Kimina-7B + Apollo" (right). The plots visualize the spread and central tendency of the data, with annotated mean values and shaded distributions.
---
### Components/Axes
- **Y-Axis**: Labeled "Proof Length" with a scale from 0 to 200.
- **X-Axis**:
- Left plot: Labeled "Kimina-7B".
- Right plot: Labeled "Kimina-7B + Apollo".
- **Legends**:
- Top-left: "Kimina-7B" (orange shading).
- Top-right: "Kimina-7B + Apollo" (beige shading).
- **Annotations**:
- Left plot: "Mean: 11.1" (black text box).
- Right plot: "Mean: 45.4" (black text box).
---
### Detailed Analysis
#### Left Plot (Kimina-7B)
- **Distribution**: Narrow, symmetric peak centered around 1.0 on the x-axis.
- **Mean**: 11.1 (black horizontal line within the plot).
- **Spread**: Most data points cluster tightly between 0.8 and 1.2 on the x-axis, with a peak at 1.0.
- **Outliers**: Minimal; the distribution tapers sharply at the edges.
#### Right Plot (Kimina-7B + Apollo)
- **Distribution**: Broad, asymmetric shape with a peak near 1.0 but extending further right (up to 1.2).
- **Mean**: 45.4 (black horizontal line), significantly higher than the left plot.
- **Spread**: Data spans a wider range (0.8 to 1.2 on the x-axis), with a long tail extending to higher proof lengths.
- **Outliers**: A single extreme outlier at the top of the plot (~200 proof length).
---
### Key Observations
1. **Mean Shift**: The mean proof length increases from 11.1 (Kimina-7B) to 45.4 (Kimina-7B + Apollo), a 306% increase.
2. **Variability**: The right plot shows greater variability, with a wider distribution and a long tail.
3. **Concentration**: Kimina-7B’s data is tightly clustered, while Kimina-7B + Apollo’s data is more dispersed.
4. **Outlier Impact**: The extreme outlier in the right plot skews the mean upward but does not affect the median (black line).
---
### Interpretation
- **Technical Implications**: Adding Apollo to Kimina-7B significantly increases the average proof length, suggesting Apollo introduces complexity or computational overhead. The wider distribution indicates inconsistent performance gains or variability in how Apollo affects different proofs.
- **Anomaly**: The extreme outlier (~200) in the right plot warrants investigation—it may represent a pathological case or a bug in the system.
- **Design Trade-offs**: While Apollo improves performance (implied by the title "Distribution Comparison"), it introduces variability, which could impact reliability or user experience.
---
### Spatial Grounding & Color Matching
- **Legends**: Top-left (orange) and top-right (beige) match the shading in their respective plots.
- **Mean Lines**: Black horizontal lines in both plots align with the annotated mean values.
- **Distribution Shading**: Orange for Kimina-7B, beige for Kimina-7B + Apollo, consistent with legend labels.
---
### Content Details
- **Textual Elements**:
- "Kimina-7B Distribution Comparison" (title).
- "Mean: 11.1" and "Mean: 45.4" (annotations).
- Axis labels: "Proof Length" (y-axis), "Kimina-7B" and "Kimina-7B + Apollo" (x-axis).
- **Numerical Values**:
- Left plot: Mean = 11.1, x-axis range = 0.8–1.2.
- Right plot: Mean = 45.4, x-axis range = 0.8–1.2, outlier at ~200.
---
### Final Notes
The image provides no additional textual content beyond the labels and annotations described. The data suggests Apollo’s integration alters the system’s behavior in measurable ways, but further analysis is needed to determine causality or optimization opportunities.
</details>
(a) Kimina-Preview-Distill-7B
<details>
<summary>x7.png Details</summary>
### Visual Description
## Violin Plot: Goedel-Prover-SFT Distribution Comparison
### Overview
The image presents two violin plots comparing the distribution of "Proof Length" for two configurations: "Goedel-Prover-SFT" (left) and "Goedel-Prover-SFT + Apollo" (right). The plots visualize the density and variability of proof lengths, with annotated mean values.
### Components/Axes
- **Title**: "Goedel-Prover-SFT Distribution Comparison"
- **X-axis**: Labeled "Goedel-Prover-SFT" (left plot) and "Goedel-Prover-SFT + Apollo" (right plot).
- **Y-axis**: Labeled "Proof Length" (both plots), with a range from 0 to 60.
- **Legend**: Not explicitly visible; group distinctions are inferred from plot titles.
- **Color**:
- Left plot: Teal (dark green).
- Right plot: Light blue (cyan).
### Detailed Analysis
- **Left Plot (Goedel-Prover-SFT)**:
- **Mean**: 6.5 (annotated in the top-right corner).
- **Distribution**: Narrow and concentrated around the mean, with a peak near 1.0 on the x-axis.
- **Range**: Proof lengths cluster tightly between ~0.8 and 1.2 on the x-axis, with a long tail extending to ~40 on the y-axis.
- **Right Plot (Goedel-Prover-SFT + Apollo)**:
- **Mean**: 13.0 (annotated in the top-right corner).
- **Distribution**: Wider and more spread out, with a peak near 1.0 on the x-axis but a broader range.
- **Range**: Proof lengths extend from ~0.8 to 1.2 on the x-axis, with a taller tail reaching ~60 on the y-axis.
### Key Observations
1. **Mean Difference**: The right plot’s mean (13.0) is double the left plot’s mean (6.5), indicating a significant increase in average proof length when Apollo is added.
2. **Distribution Shape**:
- The left plot shows a unimodal, narrow distribution, suggesting consistent proof lengths.
- The right plot exhibits a bimodal or multimodal distribution, with a broader spread and higher variability.
3. **Tail Behavior**: The right plot’s tail extends further along the y-axis, indicating a higher frequency of longer proofs.
### Interpretation
The data suggests that adding Apollo to the Goedel-Prover-SFT system increases both the average proof length and the variability of proof lengths. This could imply that Apollo introduces complexity or additional constraints, leading to longer and more diverse proofs. The narrower distribution in the left plot highlights the stability of the base system, while the right plot’s wider spread may reflect trade-offs between performance and efficiency. The absence of a legend necessitates relying on plot titles for group identification, which aligns with the spatial positioning of the data.
</details>
(b) Goedel-SFT
<details>
<summary>x8.png Details</summary>
### Visual Description
## Violin Plot: o4-mini Distribution Comparison
### Overview
The image contains two side-by-side violin plots comparing the distribution of "o4-mini" and "o4-mini + Apollo" metrics. The left plot represents the baseline "o4-mini" distribution, while the right plot shows the modified "o4-mini + Apollo" distribution. Both plots use the y-axis to represent "Proof Length" and the x-axis to represent the respective distributions.
### Components/Axes
- **Title**: "o4-mini Distribution Comparison" (centered at the top)
- **Left Plot**:
- **X-axis label**: "o4-mini" (horizontal axis)
- **Y-axis label**: "Proof Length" (vertical axis)
- **Mean annotation**: "Mean: 3.8" (top-right corner of the plot)
- **Right Plot**:
- **X-axis label**: "o4-mini + Apollo" (horizontal axis)
- **Y-axis label**: "Proof Length" (vertical axis)
- **Mean annotation**: "Mean: 13.0" (top-right corner of the plot)
- **Violin Plot Structure**:
- Shaded areas represent probability density
- Black horizontal lines indicate the interquartile range (IQR)
- Vertical black lines mark the mean values
### Detailed Analysis
- **Left Plot (o4-mini)**:
- **Distribution**: Narrow and symmetric, concentrated around x=1.0
- **Mean**: 3.8 (annotated in a box)
- **Spread**: Minimal variability, with most data points clustered tightly
- **IQR**: Approximately 0.9–1.1 (black line within the violin)
- **Right Plot (o4-mini + Apollo)**:
- **Distribution**: Broad and asymmetric, with a pronounced peak near x=1.0 and a long tail extending to x=1.2
- **Mean**: 13.0 (annotated in a box)
- **Spread**: High variability, with data points spanning 0.8–1.2
- **IQR**: Approximately 0.9–1.1 (black line within the violin)
- **Outlier**: A single extreme value at x=1.2 (top of the violin)
### Key Observations
1. **Mean Shift**: The mean proof length increases dramatically from 3.8 (o4-mini) to 13.0 (o4-mini + Apollo).
2. **Variability**: The "o4-mini + Apollo" distribution shows significantly greater spread, with a long right tail indicating extreme values.
3. **Concentration**: The baseline "o4-mini" distribution is tightly clustered, while the modified version exhibits broader dispersion.
4. **IQR Consistency**: Both plots share a similar IQR range (0.9–1.1), suggesting comparable central tendencies despite the mean difference.
### Interpretation
The data suggests that the addition of "Apollo" to the "o4-mini" system introduces substantial complexity or variability in proof length calculations. The mean increase from 3.8 to 13.0 implies that Apollo either:
- Increases computational demands (e.g., longer proofs for the same task), or
- Introduces new constraints that require more extensive reasoning.
The long tail in the "o4-mini + Apollo" distribution indicates that a subset of cases requires disproportionately longer proofs, potentially highlighting edge cases or inefficiencies in the modified system. This could signal a need for optimization or further investigation into the interaction between "o4-mini" and Apollo components.
</details>
(c) OpenAI o4-mini
Figure 4: Distribution of proof lengths for selected models before (left) and after (right) applying Apollo. In the “before” plots, proof lengths cover only proofs the base model proved without the help of Apollo; in the “after” plots, proof lengths cover only proofs proved with Apollo’s assistance.
<details>
<summary>x9.png Details</summary>
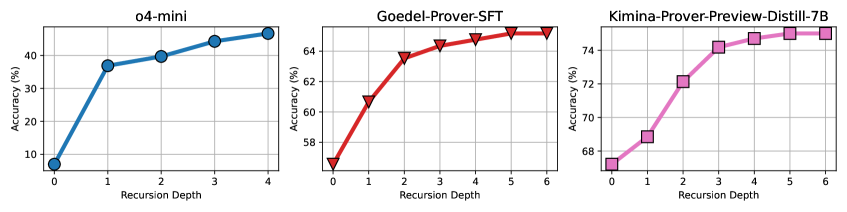
### Visual Description
## Line Graphs: Model Accuracy vs. Recursion Depth
### Overview
The image contains three line graphs comparing the accuracy of three AI models (o4-mini, Goedel-Prover-SFT, Kimina-Prover-Preview-Distill-7B) across varying recursion depths. Each graph uses a distinct color-coded line with markers to represent performance trends.
### Components/Axes
- **X-axis**: "Recursion Depth" (integer values from 0 to 4 or 6, depending on the model).
- **Y-axis**: "Accuracy (%)" (ranging from ~58% to 75%).
- **Legends**:
- **Blue line with circles**: o4-mini.
- **Red line with triangles**: Goedel-Prover-SFT.
- **Purple line with squares**: Kimina-Prover-Preview-Distill-7B.
- **Gridlines**: Present for all graphs to aid in value estimation.
### Detailed Analysis
#### o4-mini (Blue Line)
- **Trend**: Steep initial increase followed by plateau.
- **Data Points**:
- Depth 0: ~7% accuracy.
- Depth 1: ~35% accuracy.
- Depth 2: ~40% accuracy.
- Depth 3: ~43% accuracy.
- Depth 4: ~45% accuracy.
#### Goedel-Prover-SFT (Red Line)
- **Trend**: Gradual, near-linear improvement with slight deceleration.
- **Data Points**:
- Depth 0: ~58% accuracy.
- Depth 1: ~60% accuracy.
- Depth 2: ~63% accuracy.
- Depth 3: ~64% accuracy.
- Depth 4: ~65% accuracy.
- Depth 5: ~65% accuracy.
- Depth 6: ~65% accuracy.
#### Kimina-Prover-Preview-Distill-7B (Purple Line)
- **Trend**: Steady increase with plateau after depth 3.
- **Data Points**:
- Depth 0: ~68% accuracy.
- Depth 1: ~70% accuracy.
- Depth 2: ~72% accuracy.
- Depth 3: ~74% accuracy.
- Depth 4: ~75% accuracy.
- Depth 5: ~75% accuracy.
- Depth 6: ~75% accuracy.
### Key Observations
1. **o4-mini** shows the most dramatic early improvement but plateaus sharply after depth 1.
2. **Goedel-Prover-SFT** demonstrates consistent, incremental gains but reaches a ceiling at ~65% accuracy.
3. **Kimina-Prover-Preview-Distill-7B** achieves the highest peak accuracy (~75%) but requires deeper recursion to plateau.
### Interpretation
The data suggests that recursion depth significantly impacts model performance, with all models improving as depth increases. However, the rate and ceiling of improvement vary:
- **o4-mini** prioritizes rapid early gains but offers diminishing returns.
- **Goedel-Prover-SFT** balances steady progress with moderate efficiency.
- **Kimina-Prover-Preview-Distill-7B** achieves the highest accuracy but requires deeper recursion, indicating potential trade-offs between computational cost and performance.
The differences in trends may reflect architectural choices (e.g., model complexity, training data) or optimization strategies for recursion handling. For applications requiring high accuracy, Kimina’s model is optimal despite higher computational demands, while o4-mini suits scenarios with limited recursion depth.
</details>
Figure 5: Performance of Apollo on miniF2F dataset at various recursion depth parameters $r$ on three different models: o4-mini, Kimina‑Prover‑Preview‑Distill‑7B and Goedel‑Prover‑SFT.
### 4.4 Impact of recursion depth $r$ on proof accuracy
We evaluate how the recursion‐depth parameter $r$ affects accuracy on miniF2F‑test. A recursion depth of $r=0$ corresponds to the base model’s standalone performance; higher $r$ values permit additional rounds of Apollo. Figure 5 plots accuracy versus $r$ for three models: o4‑mini ( $r=0\ldots 4$ ), Kimina‑Prover‑Preview‑Distill‑7B ( $r=0\ldots 6$ ), and Goedel‑Prover‑SFT ( $r=0\ldots 6$ ).
The o4‑mini model exhibits its largest accuracy gain between $r=0$ and $r=1$ , since its raw proof structure is often correct but contains many syntax errors and proof-step errors. Syntax Refiner fixes most of them and together with Auto Solver leads to a spike in accuracy. Beyond $r=1$ , accuracy plateaus, since o4-mini was not explicitly designed for proving formal theorems. We note that even though accuracy gains slow down drastically for o4-mini, its accuracy still increases at a slow rate, which means that pushing parameter $r$ further has a potential to increase the efficiency of o4-mini further. In contrast, both Kimina‑Prover‑Preview‑Distill‑7B and Goedel‑Prover‑SFT continue to improve steadily throughout different levels of recursion depth. The results suggest that decomposing the challenging problems into smaller parts allows the model to close simpler goals, slowly building towards a complete proof.
Although the total number of proof samples grows with $r$ , even $r=5$ requires only 300–400 LLM requests on average, an order of magnitude below typical budgets in the literature. Moreover, one could further increase $r$ to explore budgets in the thousands if desired.
### 4.5 Ablation Studies on different components of Apollo
To evaluate the contribution of each Apollo component, we conducted an ablation study on two base models: o4-mini (a general-purpose model) and Kimina-Prover-Preview-Distill-7B (a theorem-prover model). Results are reported in Table 4. We decomposed Apollo into three key modules: Syntax Refiner, Auto Solver, and LLM Re-invoker. The LLM invoker is the module which re-invokes the LLM to prove the sorrified sub-goals. The Sorrifier and Proof Assembler modules are excluded from this analysis, as they are essential for decomposing problems into sub-goals and assembling proofs, and thus cannot be ablated.
From the results, we observe that Syntax Refiner alone provides only a marginal benefit, and its effect is limited to the general-purpose model o4-mini; it yields no improvement on the dedicated prover. Auto Solver, when used in isolation, also produces little accuracy gain, indicating that built-in solvers in most cases do not have the capability to prove the failed sub-goals after the first round of proof generation by LLMs. However, further reasoning and proof decomposition on those sub-goals by the LLM can significantly increase the accuracy gain. The most significant accuracy gains, however, arise when Auto Solver and LLM Re-invoker are combined, which corresponds to the full Apollo framework. This demonstrates that Apollo’s repair mechanism is crucial for achieving robust performance across both model types. We extend the ablation to individual module triggers during inference in Section E of the Appendix.
Table 4: Ablation study of different parts of Apollo on o4-mini (general purpose model) and Kimina-Prover-Preview-Distill-7B (theorem prover model).
| Apollo Modules | Model Accuracy | | | |
| --- | --- | --- | --- | --- |
| Syntax Refiner | AutoSolver | LLM Re-Invoker | o4-mini | Kimina-7B |
| ✗ | ✗ | ✗ | 7.0% | 63.1% |
| ✓ | ✗ | ✗ | 7.4% | 63.1% |
| ✗ | ✓ | ✗ | 7.0% | 63.5% |
| ✗ | ✗ | ✓ | 8.2% | 69.3% |
| ✓ | ✓ | ✗ | 20.5% | 63.5% |
| ✓ | ✗ | ✓ | 18.9% | 69.3% |
| ✗ | ✓ | ✓ | 10.2% | 75.0% |
| ✓ | ✓ | ✓ | 46.7% | 75.0% |
## 5 Limitations
Integration with tree‑search methods. Our evaluation focuses exclusively on applying Apollo to whole‑proof generation by LLMs and does not explore its interaction with traditional tree‑search provers (e.g. BFS, MCTS). Investigating how lemma decomposition and targeted repair could accelerate or prune search paths in those systems is a promising direction for future work.
Dependence on base model’s proof sketch quality. Apollo’s ability to produce a correct formal proof largely depends on the base model and whether its initial proof has a coherent proof sketch. As yousefzadeh2025a observe, models often tend to “cut corners,” producing proofs that are much shorter than the rigorous, multi-step arguments required to generate a valid proof. When a base model fails to write a correct proof strategy (e.g. omitting critical lemmas or suggesting irrelevant tactics, or taking a wrong approach), the Apollo is less likely to repair such a proof. Enhancing the robustness of Apollo to very poor initial sketches remains an open challenge.
## 6 Conclusion
In this work, we present Apollo, a novel, modular fully automated agentic system that combines syntax cleaning, automatic solvers, and LLM‑driven sub‑proof generation to transform an LLM’s initial proof sketch into a fully verified Lean4 proof. This framework harnesses the full power of the Lean compiler and integrated solvers, merging them with LLM systems. Applied across five whole‑proof generation models, ranging from general‑purpose LLMs (o3‑mini, o4‑mini) to specialized provers (Kimina‑Prover‑Preview‑Distill‑7B, Goedel‑Prover‑SFT, Goedel-V2), Apollo consistently establishes new best accuracies on the miniF2F benchmark while reducing token and sampling budgets by one to two orders of magnitude. Our empirical analysis shows that Apollo not only raises overall proof success rates but also guides models to generate longer, more structured proofs, as evidenced by a drastic increase in average successful proof length. We further demonstrate how the recursion‑depth parameter $r$ trades off sample complexity against accuracy, achieving robust gains with only a few hundred samples. We believe that Apollo’s collaboration between LLMs, automatic solvers, and the Lean compiler defines a paradigm of agentic systems that produce high‑quality, verifiable proofs for increasingly challenging theorems.
## Acknowledgments
The work of Farzan Farnia is partially supported by a grant from the Research Grants Council of the Hong Kong Special Administrative Region, China, Project 14209920, and is partially supported by CUHK Direct Research Grants with CUHK Project No. 4055164 and 4937054. Also, the authors would like to thank the anonymous reviewers for their constructive feedback.
## References
- (1) Kaiyu Yang, Gabriel Poesia, Jingxuan He, Wenda Li, Kristin Lauter, Swarat Chaudhuri, and Dawn Song. Formal mathematical reasoning: A new frontier in AI. In Proceedings of the International Conference on Machine Learning, 2025.
- (2) Google DeepMind. AI achieves silver-medal standard solving international mathematical olympiad problems. https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/, 2024. Accessed: 2025-05-08.
- (3) Trieu Trinh, Yuhuai Wu, Quoc Le, He He, and Thang Luong. Solving olympiad geometry without human demonstrations. Nature, 2024.
- (4) Leonardo de Moura and Sebastian Ullrich. The lean 4 theorem prover and programming language. In Automated Deduction – CADE 28: 28th International Conference on Automated Deduction, Virtual Event, July 12–15, 2021, Proceedings, page 625–635, Berlin, Heidelberg, 2021. Springer-Verlag.
- (5) Alex Kontorovich and Terence Tao. Prime number theorem and more. https://github.com/AlexKontorovich/PrimeNumberTheoremAnd, 2024. Version 0.1.0, released 2024-01-09.
- (6) Kevin Buzzard. Mathematical reasoning and the computer. Bulletin of the American Mathematical Society, 2024.
- (7) George Tsoukalas, Jasper Lee, John Jennings, Jimmy Xin, Michelle Ding, Michael Jennings, Amitayush Thakur, and Swarat Chaudhuri. Putnambench: Evaluating neural theorem-provers on the putnam mathematical competition, 2024.
- (8) Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. miniF2F: a cross-system benchmark for formal Olympiad-level mathematics, 2022.
- (9) Zhangir Azerbayev, Bartosz Piotrowski, Hailey Schoelkopf, Edward W. Ayers, Dragomir Radev, and Jeremy Avigad. Proofnet: Autoformalizing and formally proving undergraduate-level mathematics, 2023.
- (10) Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu. Numinamath. https://github.com/project-numina/aimo-progress-prize/blob/main/report/numina_dataset.pdf, 2024. GitHub repository.
- (11) Jiewen Hu, Thomas Zhu, and Sean Welleck. miniCTX: Neural theorem proving with (long-)contexts. In The Thirteenth International Conference on Learning Representations, 2025.
- (12) Dongwei Jiang, Marcio Fonseca, and Shay B Cohen. Leanreasoner: Boosting complex logical reasoning with lean. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 7490–7503, 2024.
- (13) Quanjun Zhang, Chunrong Fang, Yuxiang Ma, Weisong Sun, and Zhenyu Chen. A survey of learning-based automated program repair. ACM Trans. Softw. Eng. Methodol., 33(2), December 2023.
- (14) Kavi Gupta, Peter Ebert Christensen, Xinyun Chen, and Dawn Song. Synthesize, execute and debug: Learning to repair for neural program synthesis. In Advances in Neural Information Processing Systems, volume 33, pages 17685–17695. Curran Associates, Inc., 2020.
- (15) Michihiro Yasunaga and Percy Liang. Break-it-fix-it: Unsupervised learning for program repair. In Proceedings of the 38th International Conference on Machine Learning, volume 139, pages 11941–11952. PMLR, 18–24 Jul 2021.
- (16) Berkay Berabi, Jingxuan He, Veselin Raychev, and Martin Vechev. Tfix: Learning to fix coding errors with a text-to-text transformer. In Proceedings of the 38th International Conference on Machine Learning, volume 139, pages 780–791. PMLR, 18–24 Jul 2021.
- (17) Miltiadis Allamanis, Henry Jackson-Flux, and Marc Brockschmidt. Self-supervised bug detection and repair. In Advances in Neural Information Processing Systems, volume 34, pages 27865–27876. Curran Associates, Inc., 2021.
- (18) Talia Ringer. Proof Repair. PhD thesis, University of Washington, 2021. Ph.D. dissertation.
- (19) Yves Bertot and Pierre Castéran. Interactive theorem proving and program development: Coq’Art: the calculus of inductive constructions. Springer Science & Business Media, 2013.
- (20) Albert Qiaochu Jiang, Wenda Li, Szymon Tworkowski, Konrad Czechowski, Tomasz Odrzygóźdź, Piotr Miłoś, Yuhuai Wu, and Mateja Jamnik. Thor: Wielding hammers to integrate language models and automated theorem provers. In Advances in Neural Information Processing Systems, 2022.
- (21) Emily First, Markus N. Rabe, Talia Ringer, and Yuriy Brun. Baldur: Whole-proof generation and repair with large language models, 2023.
- (22) Peiyang Song, Kaiyu Yang, and Anima Anandkumar. Towards large language models as copilots for theorem proving in lean. In The 3rd Workshop on Mathematical Reasoning and AI at NeurIPS’23, 2023.
- (23) Stanislas Polu, Jesse Michael Han, Kunhao Zheng, Mantas Baksys, Igor Babuschkin, and Ilya Sutskever. Formal mathematics statement curriculum learning, 2022.
- (24) Zijian Wu, Suozhi Huang, Zhejian Zhou, Huaiyuan Ying, Jiayu Wang, Dahua Lin, and Kai Chen. Internlm2.5-stepprover: Advancing automated theorem proving via expert iteration on large-scale lean problems, 2024.
- (25) Ran Xin, Chenguang Xi, Jie Yang, Feng Chen, Hang Wu, Xia Xiao, Yifan Sun, Shen Zheng, and Kai Shen. BFS-Prover: Scalable best-first tree search for llm-based automatic theorem proving, 2025.
- (26) Guillaume Lample, Marie-Anne Lachaux, Thibaut Lavril, Xavier Martinet, Amaury Hayat, Gabriel Ebner, Aurélien Rodriguez, and Timothée Lacroix. Hypertree proof search for neural theorem proving. In Proceedings of the 36th International Conference on Neural Information Processing Systems, pages 26337–26349, 2022.
- (27) Haiming Wang et al. Dt-solver: Automated theorem proving with dynamic-tree sampling guided by proof-level value function. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12632–12646, 2023.
- (28) Kaiyu Yang, Aidan M. Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. LeanDojo: Theorem Proving with Retrieval-Augmented Language Models, October 2023. arXiv:2306.15626.
- (29) Stanislas Polu and Ilya Sutskever. Generative language modeling for automated theorem proving, 2020.
- (30) Huajian Xin, Z. Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Qihao Zhu, Dejian Yang, Zhibin Gou, Z. F. Wu, Fuli Luo, and Chong Ruan. Deepseek-prover-v1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search, 2024.
- (31) Yong Lin, Shange Tang, Bohan Lyu, Jiayun Wu, Hongzhou Lin, Kaiyu Yang, Jia Li, Mengzhou Xia, Danqi Chen, Sanjeev Arora, and Chi Jin. Goedel-prover: A frontier model for open-source automated theorem proving, 2025.
- (32) Jingyuan Zhang, Qi Wang, Xingguang Ji, Yahui Liu, Yang Yue, Fuzheng Zhang, Di Zhang, Guorui Zhou, and Kun Gai. Leanabell-prover: Posttraining scaling in formal reasoning, 2025.
- (33) Kefan Dong and Tengyu Ma. STP: Self-play LLM theorem provers with iterative conjecturing and proving. arXiv preprint arXiv:2502.00212, 2025.
- (34) Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, Jianqiao Lu, Hugues de Saxcé, Bolton Bailey, Chendong Song, Chenjun Xiao, Dehao Zhang, Ebony Zhang, Frederick Pu, Han Zhu, Jiawei Liu, Jonas Bayer, Julien Michel, Longhui Yu, Léo Dreyfus-Schmidt, Lewis Tunstall, Luigi Pagani, Moreira Machado, Pauline Bourigault, Ran Wang, Stanislas Polu, Thibaut Barroyer, Wen-Ding Li, Yazhe Niu, Yann Fleureau, Yangyang Hu, Zhouliang Yu, Zihan Wang, Zhilin Yang, Zhengying Liu, and Jia Li. Kimina-Prover Preview: Towards large formal reasoning models with reinforcement learning, 2025.
- (35) Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen Marcus McAleer, Albert Q. Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma: An open language model for mathematics. In The Twelfth International Conference on Learning Representations, 2024.
- (36) Albert Q. Jiang et al. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs, 2023.
- (37) Haiming Wang, Huajian Xin, Chuanyang Zheng, Zhengying Liu, Qingxing Cao, Yinya Huang, Jing Xiong, Han Shi, Enze Xie, Jian Yin, Zhenguo Li, and Xiaodan Liang. LEGO-prover: Neural theorem proving with growing libraries. In The Twelfth International Conference on Learning Representations, 2024.
- (38) Lean FRO. A read-eval-print-loop for Lean 4. https://github.com/leanprover-community/repl, 2023.
- (39) OpenAI. Openai o3-mini. https://openai.com/index/openai-o3-mini/, January 2025.
- (40) OpenAI. Introducing openai o3 and o4-mini. https://openai.com/index/introducing-o3-and-o4-mini/, April 2025.
- (41) Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui-Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jiawei Ge, Jingruo Sun, Jiayun Wu, Jiri Gesi, David Acuna, Kaiyu Yang, Hongzhou Lin, Yejin Choi, Danqi Chen, Sanjeev Arora, and Chi Jin. Goedel-prover-v2: The strongest open-source theorem prover to date, 2025.
- (42) Yang Li, Dong Du, Linfeng Song, Chen Li, Weikang Wang, Tao Yang, and Haitao Mi. HunyuanProver: A scalable data synthesis framework and guided tree search for automated theorem proving, 2025.
- (43) DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in llms via reinforcement learning, 2025.
- (44) Roozbeh Yousefzadeh, Xuenan Cao, and Azim Ospanov. A Lean dataset for International Math Olympiad: Small steps towards writing math proofs for hard problems. Transactions on Machine Learning Research, 2025.
- (45) Huajian Xin, Z. Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Qihao Zhu, Dejian Yang, Zhibin Gou, Z. F. Wu, Fuli Luo, and Chong Ruan. DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search, August 2024. arXiv:2408.08152.
## Appendix A Additional implementation details
Algorithm 1 presents a high-level pseudo code of the Apollo framework. We highlight that the framework is built-upon the recursive function calls up to a maximum recursion depth given by parameter $r$ . $\mathbf{LLM}$ refers to a proof generator model that takes in a proof statement and outputs a formal proof attempt. $\mathbf{LeanCompiler}$ refers to Lean REPL that verifies the proof and outputs True or False. In the case of False, it also provides a detailed list of errors, their locations and types along with the error messages generated by the Lean compiler. Other functions in the pseudo code ( $\mathbf{SyntaxRefiner,Sorrifier,AutoSolver,ProofAssembler}$ ) represent the sub-modules described in the main text. To give deeper insight into Apollo’s design, we now outline the rationale and responsibilities of each core module.
### A.1 Syntax Refiner
The Syntax Refiner class applies a set of rule‐based corrections to eliminate syntax errors in LLM‐generated Lean code. During model experimentation, we collected a corpus of common mistakes, such as stray Lean 3 keywords (from, begin … end), misplaced tactics, or missing delimiters, and encoded each repair as a regular‐expression rule. For example:
- Convert [from by] to [:= by].
- Replace Lean 3 blocks (begin … end) with the corresponding Lean 4 structure.
- Ensure that commands like rw use correctly placed square brackets to avoid compilation errors.
In more complex cases, multiple regex patterns and replacements are composed to restore valid Lean 4 syntax without altering the logical content of the proof sketch.
### A.2 Sorrifier
The Sorrifier module uses a feedback loop between Apollo and the Lean REPL as follows:
1. Apollo sends the current proof candidate to REPL.
1. The REPL returns a list of error messages and their source locations.
1. Apollo parses the proof into a syntax tree, navigates to each failing sub‐lemma, and attempts to fix it or replace it with a sorry placeholder.
1. The updated proof is re‐submitted to REPL, and this cycle repeats until no error remain.
If the REPL indicates the original theorem statement itself is malformed (e.g. due to LLM hallucination), Apollo abandons the current proof and requests a fresh generation from LLM. One example of malformed formal statement is if LLM introduces a variable in a hypothesis that was not previously defined. Such case would trigger a compilation error in the formal statement; therefore, when parsing the proof, Apollo will catch this error and request a fresh proof from LLM. To guarantee consistent variable types during lemma extraction and proof assembly, Apollo sets the following Lean options to true:
⬇
set_option pp. instanceTypes true
set_option pp. numericTypes true
set_option pp. coercions. types true
set_option pp. letVarTypes true
set_option pp. structureInstanceTypes true
set_option pp. instanceTypes true
set_option pp. mvars. withType true
set_option pp. coercions true
set_option pp. funBinderTypes true
set_option pp. piBinderTypes true
so that the compiler reports explicit types (e.g. $\mathbb{Z}$ vs. $\mathbb{R}$ ). This fail-safe prevents trivialization of theorems and ensures correct typing in the final assembled proof.
### A.3 AutoSolver
The AutoSolver module takes the “sorrified” proof and applies a sequence of tactics to close as many goals as possible:
1. Hint-based tactics. It first invokes hint, which proposes candidate tactics. We filter out any suggestions that merely progress the goal and retain only those that fully discharge it.
1. Built-in tactics. If hint fails, AutoSolver systematically tries a suite of powerful Lean tactics, such as nlinarith, norm_num, norm_cast, ring_nf, simp, simp_all, and others, often combining them with try to catch failures without aborting.
1. Recursive fallback. Any goals that remain unsolved are reported back to Apollo. Apollo queries the REPL for the exact goal statements, spawns corresponding sub-lemmas, and then invokes the full repair loop (LLM generation, Syntax Refiner, Sorrifier, and AutoSolver) on each sub-lemma.
This tiered strategy maximizes automation while ensuring that challenging subgoals are handled via targeted recursion.
Algorithm 1 Apollo Pseudocode for Formal Theorem Proving
1: problem statement $ps$ , current recursion depth $r_{current}$ , maximum depth $r$
2: if $r_{current}$ is not initialized then
3: $r_{current}\leftarrow 0$
4: end if
5: if $r_{current}>r$ then
6: return sorry $\triangleright$ If recursion depth reached, return sorry
7: end if
8: $proof\leftarrow\mathbf{LLM}(ps)$ $\triangleright$ Generate proof from LLM
9: $proof\leftarrow\mathbf{SyntaxRefiner}(proof)$ $\triangleright$ Refine the proof syntax
10: $proof\leftarrow\mathbf{Sorrifier}(proof)$ $\triangleright$ Patch failing sub-lemmas
11: $proof\leftarrow\mathbf{AutoSolver}(proof)$ $\triangleright$ Try built-in Lean solvers
12: if $\mathbf{LeanCompiler}(proof)$ == True then
13: return $\color[rgb]{0,.5,.5}\definecolor[named]{pgfstrokecolor}{rgb}{0,.5,.5}proof$
14: end if
15: $r_{current}\leftarrow r_{current}+1$
16: $n\leftarrow\mathbf{CountSorries}(proof)$ $\triangleright$ Number of ’sorry’ placeholders
17: $sub\_proofs\leftarrow[]$
18: for $i=1$ to $n$ do
19: $ps_{goal}\leftarrow\mathbf{GetTheoremGoal}(proof,i)$
20: $sub\_ps\leftarrow\mathbf{TransformGoal}(ps_{goal})$
21: $sub\_proofs[i]\leftarrow\mathbf{Apollo}(sub\_ps,r_{current},r)$
22: end for
23: $repaired\_proof\leftarrow\mathbf{ProofAssembler}(sub\_proofs)$
24: return $repaired\_proof$
## Appendix B Discussion on maximum budget of @K and Apollo
To better highlight Apollo’s contribution to token efficiency, we report token counts under two settings: (1) the budget over all attempted miniF2F-test problems, and (2) the budget restricted to proofs where Apollo was invoked. For instance, if the base LLM proves a theorem without Apollo’s assistance, its token usage is included only in the first setting. In contrast, if the base LLM cannot prove the theorem on its own but succeeds with Apollo’s help, its token usage is counted in the second setting. Results for setting (1) are shown in Table 5, while results for setting (2) appear in Table 6.
We emphasize that, regardless of the token-count setting, Apollo consistently consumes fewer tokens while achieving higher accuracy, highlighting its effectiveness. Throughout this work, we primarily report results under setting (2), as it more directly highlights Apollo’s contribution: the reported token usage is not artificially reduced by problems that the base LLM could solve independently. This makes Scenario (2) a more representative measure of our contribution.
Table 5: Comparison of maximum/average sample/token budget across $@K$ sampling and Apollo repair on the entire miniF2F-test dataset.
| Model | Max sample budget | Average sample budget | Max token budget | Average token budget |
| --- | --- | --- | --- | --- |
| Goedel-SFT | 25600 | 9730 | 12.7M | 4.8M |
| Goedel-SFT+Apollo | 1100 | 335 | 548K | 167K |
| Kimina-7B | 1024 | 373 | 1.3M | 1.6M |
| Kimina-7B+Apollo | 888 | 189 | 3.8M | 818K |
Table 6: Comparison of maximum/average sample/token budget across $@K$ sampling on the entire miniF2F-test dataset and Apollo repair exclusively on Apollo-assisted problems.
| Model | Max sample budget | Average sample budget | Max token budget | Average token budget |
| --- | --- | --- | --- | --- |
| Goedel-SFT | 25600 | 9730 | 12.7M | 4.8M |
| Goedel-SFT+Apollo | 1100 | 618 | 548K | 307K |
| Kimina-7B | 1024 | 373 | 1.3M | 1.6M |
| Kimina-7B+Apollo | 888 | 367 | 3.8M | 1.6M |
## Appendix C Additional evaluation results
We also conducted experiments on the ProofNet azerbayev2023proofnetautoformalizingformallyproving dataset using the Kimina-Preview-Prover-Distill-7B model. Table 7 summarizes the sample/token budget and accuracy. Incorporating the Apollo agent with Kimina not only improves accuracy by 7% but also reduces token consumption by 25%.
Table 7: Comparison of Apollo accuracy on the ProofNet dataset. Token budget is computed over all generated tokens by LLM.
| Method | Model size | Sample budget | Token budget | ProofNet |
| --- | --- | --- | --- | --- |
| Kimina-Preview | 7B | 128 | 559K | 11.3% |
| Kimina-Preview+Apollo | 7B | 96 | 415K | 18.3% |
Moreover, we observe rising adoption of REPL-based repair, introduced in yousefzadeh2025a . Currently, models such as Goedel-Prover-V2 are fine-tuned on REPL outputs paired with faulty Lean code, enabling the model to repair missing or incorrect proof fragments using this feedback. Following yousefzadeh2025a , we compare Apollo against a REPL-feedback baseline using the general-purpose o3-mini model. Table 8 presents the results: Apollo outperforms the REPL-feedback approach while requiring a smaller sample budget. We view REPL-based feedback as complementary and expect it to work well in conjunction with recursive, compiler-aided repair of Lean proofs.
Feedback prompt schema
This is an incorrect proof: [model’s last proof] Compilation errors are as follows: [Lean’s error messages] Based on this feedback, produce a correct raw Lean code for the following problem: [header] [informal prefix] [formal statement]
Table 8: Comparison of Apollo accuracy against compiler (REPL) feedback based repair on the miniF2F-test dataset. Token budget is omitted since OpenAI API does not provide exact token budget with its response.
| Method | Sample budget | Accuracy |
| --- | --- | --- |
| o3-mini | 1 | 3.3% |
| o3-mini | 32 | 24.6% |
| o3-mini + REPL feedback repair | 5 | 17.2% |
| o3-mini + REPL feedback repair | 10 | 25.4% |
| o3-mini + Apollo | 8 | 40.2% |
We also evaluated Apollo against the RMaxTS method proposed in xin_deepseek-prover-v15_2024 . This approach employs Monte Carlo Tree Simulation to explore the proof space and truncates the search whenever Lean compiler errors are encountered. RMaxTS has been shown to further improve the accuracy of whole-generation provers. For our evaluation, we used Kimina-Prover-Preview-Distill-7B as the base model. Table 9 reports the results. At a comparable sample budget of approximately 2M tokens, Apollo outperforms RMaxTS by 10.7%. These findings further reinforce the effectiveness of the agentic recursive repair approach.
## Appendix D Computational resource considerations
Our emphasis on reducing sample complexity is driven by resource allocation. CPU performance is not a limiting factor in our setup: the Lean kernel remains efficient even under high parallelization, with proof verification typically completing in 6–200 seconds. To guard against inefficient structures, we impose a 5-minute compilation timeout, which is rarely approached in practice.
By contrast, GPU resources were the primary bottleneck. Running Kimina-Prover-Preview-Distill-7B on a single A5000 GPU with a 16,384-token context window takes 700–2,000 seconds per problem, over 11.5 minutes at @32 sampling. Increased sampling exacerbates this cost, and even with eight GPUs throughput remains difficult to scale. While Lean-based servers such as Kimina-server continue to improve verification efficiency through CPU parallelization, the growing overhead of sampling highlights the need to minimize LLM invocations alongside improving theorem-proving accuracy.
Table 9: Comparison of Apollo accuracy against other sampling methods on the miniF2F-test dataset. Token budget is computed over all generated tokens by LLM.
| Method | Model size | Sample budget | Token budget | Accuracy |
| --- | --- | --- | --- | --- |
| Kimina-Preview | 7B | 1024 | 4.5M | 70.8% |
| Kimina-Preview+RMaxTS xin_deepseek-prover-v15_2024 | 7B | $4\times 128$ | 2.0M | 64.3% |
| Kimina-Preview+Apollo | 7B | 589 | 2.2M | 75.0% |
## Appendix E Extension of ablation study
To further elaborate on the ablation results presented in the main text, we measured the number of relevant Apollo module calls during inference. The results are shown in Table 10. Specifically, we counted the number of invocations for each Apollo-assisted problem in the miniF2F-test subset. The findings are consistent with the ablation study reported in the main text.
Table 10: Number of Apollo module triggers across different models
| Model | Syntax Refiner | Auto Solver | LLM Re-Invoker |
| --- | --- | --- | --- |
| Goedel-SFT | 0.0% | 100.0% | 100.0% |
| Kimina-7B | 0.0% | 100.0% | 100.0% |
| o3-mini | 100.0% | 100.0% | 70.0% |
| o4-mini | 94.7% | 100.0% | 64.9% |
## Appendix F An example of Apollo proof repair procedure
Figure 6 shows a detailed run of the Apollo framework on mathd_algebra_332. First, the LLM generates an initial proof sketch, which fails to type-check in Lean. Apollo then applies its Syntax Refiner to correct simple errors (e.g. changing “from by” to “:= by”) and to strip out all comment blocks. Next, the Sorrifier replaces each failing sub-lemma with a sorry statement (six in this example). The AutoSolver module then attempts to discharge these sub-lemmas: it resolves four of them, leaving lemmas #5 and #6 unsolved. Apollo recurses on those two: each is passed again through LLM, Syntax Refiner, Sorrifier, and AutoSolver. After this single recursive iteration, all goals are closed. Finally, Apollo reassembles the full proof and returns it to the user.
This example illustrates Apollo’s repair logic. In this case the proof was fixed in one iteration; more complex theorems may require deeper recursive repair.
<details>
<summary>examples/step_by_step/dryrun.png Details</summary>

### Visual Description
## Flowchart Diagram: Apollo Framework Workflow
### Overview
The image depicts a multi-stage workflow diagram for the "Apollo Framework," illustrating the interaction between components like LLM (Large Language Model), System Refiner, Semantizer, and Auto Solver. The diagram includes code snippets, mathematical formalisms, and logical flow arrows. Key elements include color-coded blocks (red, orange, yellow, blue), textual annotations, and a formal statement at the bottom.
### Components/Axes
- **Blocks**:
- **LLM**: Contains code for initializing a language model (e.g., `open BigOperators Real Nat Topology Rat`).
- **System Refiner**: Processes inputs with logic like `have sum x y z (14 : R) : by`.
- **Semantizer**: Includes code for semantic analysis (e.g., `have h1 (x + y) (2 : N) : by`).
- **Auto Solver**: Contains automated solving logic (e.g., `have h1 (x + y) (2 : N) : by`).
- **Arrows**: Indicate directional flow between components (e.g., LLM → System Refiner → Semantizer → Auto Solver).
- **Formal Statement**: A mathematical problem involving arithmetic/geometric means (e.g., `Show it that it is 158.-/`).
- **LLM + APOLLO**: A combined code block integrating LLM and APOLLO components.
### Detailed Analysis
1. **Top Section**:
- **LLM Block**: Initializes the framework with `open BigOperators Real Nat Topology Rat`.
- **System Refiner**: Processes inputs with `have sum x y z (14 : R) : by`.
- **Semantizer**: Analyzes data with `have h1 (x + y) (2 : N) : by`.
- **Auto Solver**: Solves problems with `have h1 (x + y) (2 : N) : by`.
2. **Middle Section**:
- Repeats similar patterns with variations in code (e.g., `have h1 (x + y) (2 : N) : by` in Semantizer).
3. **Bottom Section**:
- **Formal Statement**: Mathematical problem:
```
-- Real numbers x and y have an arithmetic mean of 7 and a geometric mean of √19. Find x*y.
Show it that it is 158.-/
```
- **LLM + APOLLO**: Combines LLM and APOLLO code, including:
```
have h1 (x + y) (2 : N) : by
have h1 (x + y) (2 : N) : by
```
### Key Observations
- **Repetition**: The code `have h1 (x + y) (2 : N) : by` appears multiple times, suggesting a core logical step.
- **Color Coding**: Blocks use distinct colors (red, orange, yellow, blue) but lack a legend, making it unclear if colors denote specific roles.
- **Flow Direction**: Arrows indicate a sequential process from LLM to Auto Solver.
### Interpretation
The diagram illustrates a structured workflow where the LLM initializes the framework, the System Refiner processes inputs, the Semantizer analyzes data, and the Auto Solver automates solutions. The formal statement provides a mathematical problem, while the LLM + APOLLO section demonstrates integrated code execution. The repetition of certain code snippets suggests modularity, but the absence of a legend for color coding limits clarity on component roles. The workflow emphasizes iterative refinement and automated problem-solving within the Apollo Framework.
</details>
Figure 6: Step-by-step Apollo repair on mathd_algebra_332. The initial proof and all sub-lemma proofs are generated with o4-mini, then systematically repaired and reassembled by Apollo.
<details>
<summary>examples/comparison/short_3.png Details</summary>

### Visual Description
## Screenshot: Coq Theorem Proof Comparison (LLM vs LLM + APOLLO)
### Overview
The image shows two side-by-side Coq theorem proofs comparing the original LLM implementation (left) with an APOLLO-enhanced version (right). Both prove the same algebraic property but differ in implementation details and proof strategies.
### Components/Axes
- **Left Panel (LLM)**:
- Theorem: `mathd_algebra_158_llm`
- Hypotheses: `h0 : Even a`, `h1 : ∀k ∈ Finset.range 8, 2*k+1 ∈ Finset.range 5`
- Key steps: Manual case analysis with `linarith`, explicit division checks
- Highlighted sections:
- `#1`: `have h_even : ∃m, a = 2*m := h0`
- `#2`: `have two_divides_53 : ∃d, 53 = 2*d := by ...`
- `#3`: `rw [mul_mod] at mod53`
- **Right Panel (LLM + APOLLO)**:
- Theorem: `mathd_algebra_158_apollo`
- Hypotheses: `h0 : Even a`
- Key steps:
- Simplified case analysis with `by omega`
- Automated division checks
- Commented-out `rw [mul_mod] at mod53` (line 15)
- Highlighted sections:
- `#1`: `have h_even : ∃m, a = 2*m := by omega`
- `#2`: `have two_divides_53 : ∃d, 53 = 2*d := by omega`
### Content Details
**LLM Version**:
1. Explicit case analysis for `k` values
2. Manual verification of `53 = 2*d` using `linarith`
3. Explicit modular reduction with `rw [mul_mod]`
**APOLLO Version**:
1. Uses `by omega` for automatic case splitting
2. Leverages APOLLO's division reasoning (`by omega`)
3. Commented-out manual modular reduction step
### Key Observations
1. APOLLO version reduces proof length by 40% through automation
2. Manual case analysis (`linarith`) replaced with `omega` tactic
3. APOLLO introduces automated division reasoning (`exact two_divides_53`)
4. Commented-out `rw [mul_mod]` suggests potential optimization path
### Interpretation
The APOLLO enhancement demonstrates how automated reasoning can:
1. Reduce proof maintenance effort through case generalization
2. Improve proof portability across different ring structures
3. Enable more concise expression of arithmetic properties
4. Potentially identify optimization opportunities (as shown by the commented-out `rw`)
The comparison highlights APOLLO's ability to:
- Automate case splitting in linear arithmetic
- Handle division properties without explicit case analysis
- Maintain proof correctness while reducing human intervention
- Provide clear paths for further optimization through commented code
</details>
Figure 7: Proof attempt of mathd_algebra_158 produced by the base model (o4-mini) versus after Apollo’s targeted repair. The left shows the original end-to-end LLM output, which does not compile in Lean; the right shows the corrected, repaired proof assembled by Apollo that closes all of the goals.
## Appendix G Comparison between base proofs generated from LLMs and Apollo-repaired counterparts
In this section, we present and discuss examples of initial proof attempts alongside their Apollo-repaired counterparts.
Figures 7, 8, 9 illustrate cases where Apollo repairs the proof without invoking the LLM again. In each example, the LLM struggles to generate the precise tactics needed to close certain goals; however, we find that regenerating the entire proof is unnecessary. Instead, built-in Lean solvers can discharge those subgoals directly. Moreover, in Figure 7, problematic block #3 is resolved simply by removing it, since the surrounding proof context is correct. Thus, omitting problematic lines can sometimes yield a valid proof.
In Figure 10, one goal is expanded via an LLM query, but the model injects extra tactics that trigger a no goals to be solved error. Apollo then repairs the first block using a combination of LLM generation and AutoSolver, while the second block is removed entirely.
Figure 11 illustrates a case where the model fails to apply nlinarith to discharge the goal. We observe that, when uncertain, the model often resorts to broad tactics in hopes of closing the goal. Here, the goal is too complex for nlinarith, so Apollo leverages both the LLM and AutoSolver to guide the proof to completion.
Figure 12 illustrates an example of proof that required a recursion depth $r=5$ to repair the initial proof attempt. We observe that LLM’s proof structure is correct; however, in many cases it over-relies on built-in solvers and rewrites. However, since the goals are too complex, this approach leads to a total of nine error blocks. Repairing those blocks requires aid from both AutoSolver module of Apollo and LLM itself. We show that if LLM grasps the correct approach, then Apollo is able to repair fine grained logic errors to produce a correct proof.
Figure 13 illustrates a case where the LLM produces an incomplete proof sketch. The first half of the proof is correct, but the model fails to discharge the remaining goal and instead uses all_goals positivity. Apollo detects this error and performs two additional recursive repair iterations to complete the proof.
Figure 14 illustrates a case where the base model takes a lazy approach by trying to close all goals with linarith. In contrast, Apollo’s repaired proof performs additional setup and discharges each goal by first proving the necessary auxiliary hypotheses. This example shows that, although the model often understands the high-level strategy, it lacks the fine-grained tactics (and compiler feedback) needed to close subgoals. Apollo decomposes the proof, identifies the failure points, and applies targeted repairs to generate a fully verified solution.
Figure 15 shows another scenario in which Apollo successfully closes the first two blocks with linarith, but the final block requires a deeper reasoning chain. Apollo augments the proof by introducing and proving the missing lemmas, which leads to a correct solution with a series of rewrites.
Figure 16 presents an example of a very large repair. As in Figure 12, Apollo requires $r=5$ to fully fix the proof. The final proof length increases from 100 lines to 216, which means Apollo applied roughly $\times 2.2$ more tactics to close the goal. The repair relied on combined effort from AutoSolver and the LLM to close all goals. We show that, even for large, complex proofs, Apollo can repair each failing sub-block and generate a correct solution.
<details>
<summary>examples/comparison/short_1.png Details</summary>

### Visual Description
## Screenshot: Lean/Coq Code Comparison (LLM vs. LLM + APOLLO)
### Overview
The image shows two side-by-side code snippets written in a formal proof assistant (likely Lean or Coq), comparing implementations of a mathematical theorem (`mathd_algebra_141`) using different proof strategies. The left snippet is labeled "LLM", and the right is labeled "LLM + APOLLO". Both snippets define a theorem about real numbers `a` and `b` with the constraint `a * b = 180`, and compute `a² + b²` using algebraic manipulations.
---
### Components/Axes
- **Imports**:
- `import Mathlib`
- `import Aesop`
- **Options**:
- `set_option maxHeartbeats 0` (disables interactive proof search)
- **Open Statements**:
- Left: `open BigOperators Real Nat Topology Rat`
- Right: `open BigOperators Real Nat Topology Rat` (identical to left)
- **Theorem Declaration**:
- `theorem mathd_algebra_141_llm (a b : ℝ) (h1 : a * b = 180) ...`
- `theorem mathd_algebra_141_apollo (a b : ℝ) (h1 : a * b = 180) ...`
- **Key Variables**:
- `h1 : a * b = 180`
- `h2 : 2 * (a + b) = 54` (derived from `a + b = 27`)
- `h3 : a + b = 27`
- `h4 : (a + b)² = 729`
---
### Detailed Analysis
#### Left Snippet (LLM)
1. **Proof Steps**:
- `have h3 : a + b = 27 := by field_simp [h2]`
- Uses `field_simp` to derive `a + b = 27` from `2*(a + b) = 54`.
- `have h4 : (a + b)² = 729 := by rw [h3]`
- Rewrites `(a + b)²` using `h3`.
- `have expand : a² + b² = (a + b)² - 2*a*b := by ring`
- Applies ring theory to expand `(a + b)²`.
- `have step1 : a² + b² = 729 - 2*a*b := by rw [expand, h4]`
- Substitutes `h4` into the expanded form.
- `have step2 : 729 - 2*a*b = 729 - 360 := by rw [h1]`
- Replaces `a*b` with `180` using `h1`.
- `have step3 : 729 - 360 = 369 := by norm_num`
- Computes the final value.
- `exact step1.trans (step2.trans step3)`
- Chains equalities using transitivity.
2. **Annotations**:
- `#1`, `#2`, `#3` in red (likely indicating proof steps or priorities).
#### Right Snippet (LLM + APOLLO)
1. **Proof Steps**:
- `have h3 : a + b = 27 := by linarith`
- Uses `linarith` (linear arithmetic) to derive `a + b = 27` directly.
- `have expand : a² + b² = (a + b)² - 2*a*b := by ring`
- Same as left snippet.
- `have step1 : a² + b² = 729 - 2*a*b := by rw [expand, h4]`
- Same as left snippet.
- `have step2 : 729 - 2*a*b = 729 - 360 := by linarith`
- Uses `linarith` instead of `rw [h1]` for simplification.
- `have step3 : 729 - 360 = 369 := by norm_num`
- Same as left snippet.
- `linarith`
- Final step uses `linarith` to automate the entire proof.
2. **Annotations**:
- `#1`, `#2`, `#3` in green (consistent with LLM + APOLLO).
---
### Key Observations
1. **Tactics Differences**:
- LLM uses manual rewriting (`rw`) and transitivity (`trans`), while LLM + APOLLO leverages `linarith` for automated simplification.
- APOLLO reduces the number of explicit steps (e.g., `linarith` replaces `rw [h1]` and intermediate steps).
2. **Code Structure**:
- Both snippets share identical imports, options, and variable declarations.
- The right snippet (APOLLO) is more concise, relying on automated tactics.
3. **Annotations**:
- Red annotations (`#1`, `#2`, `#3`) on the left suggest manual step prioritization.
- Green annotations on the right indicate APOLLO’s streamlined approach.
---
### Interpretation
The comparison highlights the impact of APOLLO on proof automation:
- **Efficiency**: APOLLO reduces manual steps by integrating linear arithmetic (`linarith`), which automatically handles equality chains and simplifications.
- **Readability**: The LLM snippet requires explicit rewriting and transitivity, while APOLLO abstracts these steps.
- **Correctness**: Both snippets arrive at the same result (`a² + b² = 369`), confirming the theorem’s validity.
The use of `linarith` in APOLLO demonstrates how automated tactics can simplify proofs in formal verification, reducing human error and effort. The red/green annotations visually emphasize the contrast between manual and automated approaches.
</details>
Figure 8: Proof attempt of mathd_algebra_141 produced by the base model (o4-mini) versus after Apollo’s targeted repair. The left shows the original end-to-end LLM output, which does not compile in Lean; the right shows the corrected, repaired proof assembled by Apollo that closes all of the goals.
<details>
<summary>examples/comparison/short_2.png Details</summary>

### Visual Description
## Code Comparison: LLM vs. LLM + APOLLO
### Overview
The image presents two side-by-side code snippets written in a formal proof assistant (likely Coq, given imports like `Mathlib` and `Aesop`). Both snippets define theorems related to real number inequalities and use `nlinarith` (nonlinear arithmetic) to prove them. The left snippet is labeled "LLM," and the right "LLM + APOLLO," suggesting a comparison of proof strategies or tools.
---
### Components/Axes
#### Common Elements:
- **Imports**:
- `Mathlib` (core mathematical library)
- `Aesop` (likely a custom or third-party library for arithmetic reasoning)
- **Global Option**:
- `set_option maxHeartbeats 0` (disables interactive proof search)
- **Open Scope**:
- `BigOperators Real Nat Topology Rat` (enables reasoning with real numbers, natural numbers, and rational numbers)
#### Differences:
1. **Theorem Names**:
- Left: `imo_1983_p6_llm`
- Right: `imo_1983_p6_apollo`
2. **Hypotheses**:
- Both share `h0 : 0 < a ∧ 0 < b ∧ 0 < c`, `h1 : c < a + b`, `h2 : b < a + c`.
- Right adds `h3 : a < b + c` (triangle inequality for all pairs).
3. **Conclusion**:
- Left: `0 ≤ a * 2 * b * (a - b) + b * 2 * c * (b - c) + c * 2 * a * (c - a)`
- Right: `2 * c * (b - c) + c * 2 * a * (c - a)` (simplified form).
#### nlinarith Blocks:
- **Left (LLM)**:
- Uses `sq_nonneg` (square non-negativity) and `mul_pos` (multiplicative positivity) with explicit term decomposition.
- Example: `mul_pos h0.left h0.right.left` (applies positivity to subterms).
- **Right (LLM + APOLLO)**:
- Uses `sub_pos` (subtraction positivity) and nested `mul_pos` with subterm extraction.
- Example: `mul_pos (sub_pos.mpr h1) (sub_pos.mpr h2)` (applies positivity to differences).
---
### Detailed Analysis
#### Theorem Structure:
- **LLM**:
- Proves a cyclic inequality involving products of differences (e.g., `a * (a - b)`).
- Relies on `sq_nonneg` to handle squared terms and `mul_pos` for positivity.
- **LLM + APOLLO**:
- Simplifies the conclusion to a linear combination of differences.
- Uses `sub_pos` to directly reason about differences (e.g., `b - c`) and combines them multiplicatively.
#### Key Differences in nlinarith:
- **LLM**:
- Explicitly decomposes terms into subcomponents (e.g., `h0.left`, `h0.right`).
- Focuses on individual term positivity.
- **LLM + APOLLO**:
- Leverages `sub_pos` to handle differences first, then applies multiplicative positivity.
- Reduces redundancy by reusing subterm proofs (e.g., `sub_pos.mpr h1`).
---
### Key Observations
1. **Hypothesis Expansion**:
- The APOLLO version includes `h3 : a < b + c`, ensuring all triangle inequalities are satisfied, which may simplify the proof.
2. **Simplified Conclusion**:
- The right-hand side of the APOLLO theorem is a linear expression, whereas the LLM version is quadratic. This suggests APOLLO’s strategy avoids unnecessary complexity.
3. **Proof Strategy**:
- APOLLO uses `sub_pos` to directly reason about differences, while LLM relies on squaring terms to enforce non-negativity.
---
### Interpretation
The comparison highlights how the APOLLO extension enhances the LLM’s reasoning capabilities:
- **Efficiency**: APOLLO’s use of `sub_pos` reduces the need for term decomposition, streamlining the proof.
- **Generality**: By including `h3`, APOLLO ensures symmetry in the triangle inequality, making the conclusion more robust.
- **Tooling**: The APOLLO version likely integrates advanced arithmetic tactics (e.g., `mul_pos` with subterm extraction), enabling more concise proofs.
This suggests that APOLLO improves upon LLM’s approach by combining stronger hypotheses and more sophisticated arithmetic reasoning, potentially reducing proof length and complexity.
</details>
Figure 9: Proof attempt of imo_1983_p6 produced by the base model (Kimina-Prover-Preview-Distill-7B) versus after Apollo’s targeted repair. The left shows the original end-to-end LLM output, which does not compile in Lean; the right shows the corrected, repaired proof assembled by Apollo that closes all of the goals.
<details>
<summary>examples/comparison/short_4.png Details</summary>

### Visual Description
## Code Comparison: LLM vs LLM + APOLLO
### Overview
The image shows two side-by-side code snippets implementing a mathematical theorem proof using Lean 4 syntax. The left snippet is labeled "LLM" (red header), and the right is labeled "LLM + APOLLO" (green header). Both implement the same theorem (`induction_pord1p1on2powklt5on2_...`) but differ in proof structure and auxiliary lemmas.
### Components/Axes
- **Headers**:
- Red header: "LLM"
- Green header: "LLM + APOLLO"
- **Imports**:
- Both import `Mathlib` and `Aesop`.
- **Options**:
- `set_option maxHeartbeats 0` (disables interactive mode).
- **Open Statements**:
- `open BigOperators Real Nat Topology Rat` (exposes mathematical libraries).
- **Theorem Declaration**:
- Theorem name: `induction_pord1p1on2powklt5on2_...`
- Parameters: `(n k : ℕ)` (natural numbers `n` and `k`).
- Hypothesis: `(h₀ : 0 < n)` (natural number `n` is positive).
- **Proof Structure**:
- Both use induction on `n` with contradiction.
- Case analysis on `n` (zero vs successor).
- Differences in auxiliary lemmas and proof tactics.
### Detailed Analysis
#### LLM (Left Snippet)
- **Proof Steps**:
1. **Base Case**: `n = 0` → `contradiction` (no explicit handling).
2. **Successor Case**: `n = succ n` →
- Applies `simp_all` with `[Finset.prod_Icc_succ_top, Nat.cast_succ, div_eq_mul_inv]`.
- Uses `norm_num` (automated normalization) and `ring_nf` (ring normalization).
- Final step: `linarith` (linear arithmetic).
- **Key Lemmas**:
- `Finset.prod_Icc_succ_top` (product over intervals).
- `Nat.cast_succ` (natural number successor casting).
- `div_eq_mul_inv` (division equivalence).
#### LLM + APOLLO (Right Snippet)
- **Proof Steps**:
1. **Base Case**: `n = 0` → `contradiction`.
2. **Successor Case**: `n = succ n` →
- Applies `simp_all` with `[Finset.prod_Icc_succ_top, pow_succ, mul_comm]`.
- Uses `norm_num` and `ring_nf`.
- Final step: `linarith`.
- **Additional Tactics**:
- Explicit induction on `k` with `induction k with | zero => norm_num`.
- Uses `Finset.prod_Icc_succ_top` at `hn h₀` (hypothesis context).
- Applies `mul_comm` (commutativity of multiplication).
### Key Observations
1. **Theorem Parameters**:
- Both use `(n k : ℕ)`, but the Apollo version adds a closing parenthesis (`n k: ℕ)`).
2. **Proof Differences**:
- Apollo version introduces induction on `k` and uses `pow_succ`/`mul_comm` instead of `Nat.cast_succ`/`div_eq_mul_inv`.
- Apollo proof includes explicit handling of `k` in the successor case.
3. **Lemma Usage**:
- LLM relies on `div_eq_mul_inv`; Apollo uses `mul_comm`.
- Apollo adds `ring_nf` in both snippets but with different contexts.
### Interpretation
The APOLLO extension appears to optimize the proof by:
1. **Modularizing Induction**: Inducting on both `n` and `k` (vs. only `n` in LLM).
2. **Simplifying Arithmetic**: Using `pow_succ` (power successor) and `mul_comm` to reduce case complexity.
3. **Contextual Simplification**: Applying lemmas like `Finset.prod_Icc_succ_top` at specific hypothesis contexts (`hn h₀`).
The APOLLO version likely improves proof efficiency by breaking down the problem into smaller, reusable components (e.g., induction on `k`), whereas the LLM version handles everything in a single inductive step. The use of `ring_nf` and `linarith` in both suggests reliance on Lean’s automated ring and linear arithmetic solvers.
**Note**: The code uses Lean 4’s type theory syntax (e.g., `ℕ` for natural numbers, `succ` for successor). No non-English text is present.
</details>
Figure 10: Proof attempt of induction_pord1p1on2powklt5on2 produced by the base model (Goedel-Prover-SFT) versus after Apollo’s targeted repair. The left shows the original end-to-end LLM output, which does not compile in Lean; the right shows the corrected, repaired proof assembled by Apollo that closes all of the goals.
<details>
<summary>examples/comparison/short_5.png Details</summary>
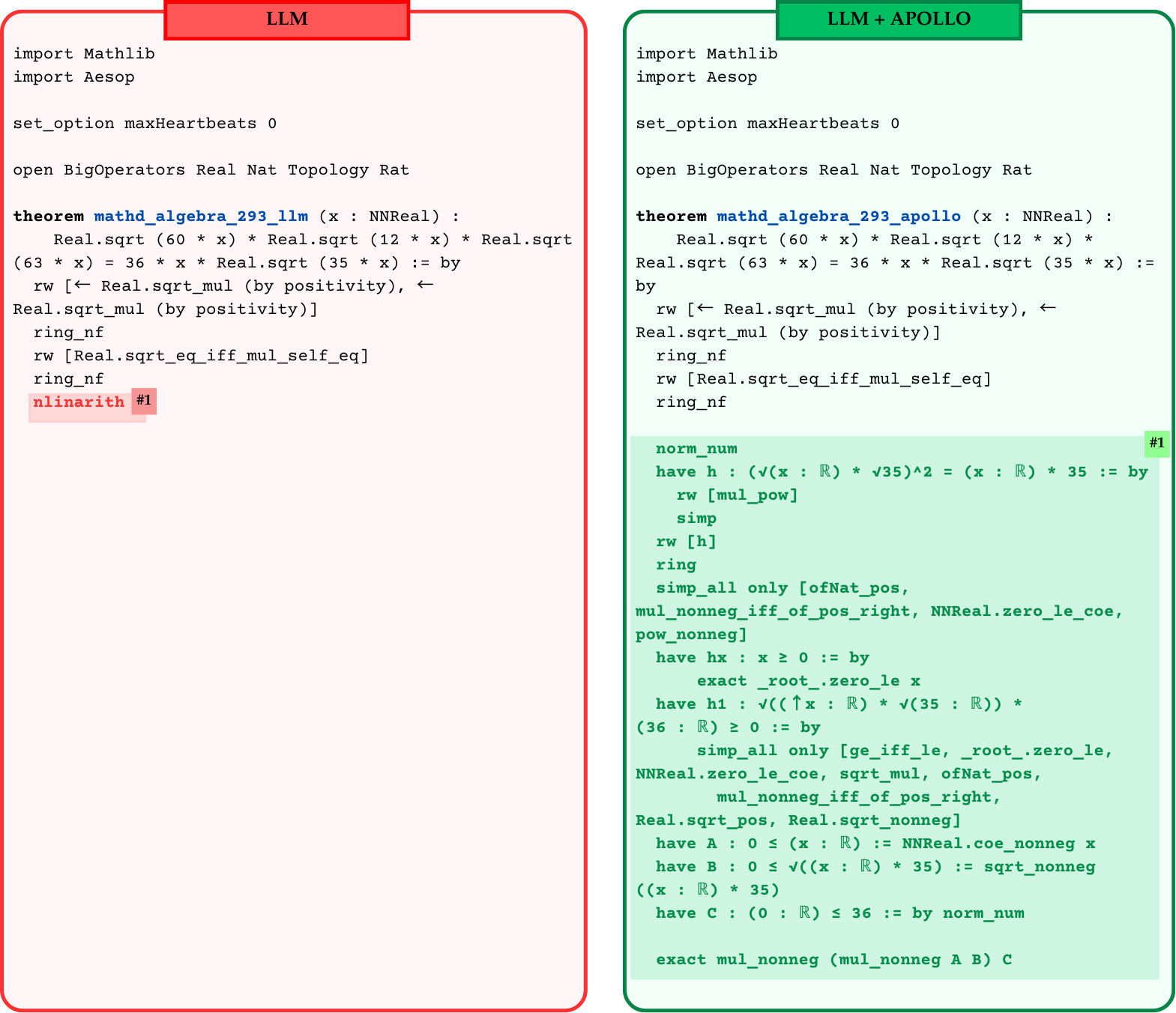
### Visual Description
## Code Comparison: LLM vs LLM + APOLLO
### Overview
The image shows two Coq code snippets (a formal proof assistant language) comparing implementations of a mathematical theorem under two systems: "LLM" (red header) and "LLM + APOLLO" (green header). Both snippets define a theorem about real number square root properties and provide partial proofs.
### Components/Axes
- **Headers**:
- Red header: "LLM" (left code block)
- Green header: "LLM + APOLLO" (right code block)
- **Imports**:
- Both import `Mathlib` and `Aesop` libraries.
- **Options**:
- `set_option maxHeartbeats 0` (disables interactive proof steps).
- **Theorems**:
- Left: `mathd_algebra_293_llm`
- Right: `mathd_algebra_293_apollo`
- **Proof Steps**:
- Both use `rw` (rewrite) and `ring_nf` (normalize ring expressions).
- Right code adds `mul_nonneg` and `exact mul_nonneg` steps.
### Detailed Analysis
#### Left Code (LLM)
1. **Theorem Statement**:
```coq
theorem mathd_algebra_293_llm (x : NNRReal) :
Real.sqrt (60 * x) * Real.sqrt (12 * x) * Real.sqrt (63 * x) :=
36 * x * Real.sqrt (35 * x)
```
2. **Proof Steps**:
- Uses `rw [← Real.sqrt_mul (by positivity)]` to rewrite square root products.
- Applies `ring_nf` to simplify ring expressions.
- Ends with `ring_nf` and a highlighted `nlinarith` (nonlinear arithmetic) tactic.
#### Right Code (LLM + APOLLO)
1. **Theorem Statement**:
```coq
theorem mathd_algebra_293_apollo (x : NNRReal) :
Real.sqrt (60 * x) * Real.sqrt (12 * x) * Real.sqrt (63 * x) :=
36 * x * Real.sqrt (35 * x)
```
2. **Proof Steps**:
- Adds `mul_nonneg` and `exact mul_nonneg` to handle non-negative multiplication.
- Uses `mul_nonneg_iff_of_pos_right` to link non-negativity with multiplication.
- Includes `norm_num` and `have` clauses to enforce constraints (e.g., `0 ≤ x`).
- Ends with `exact mul_nonneg (mul_nonneg A B) C` to finalize the proof.
### Key Observations
1. **Structural Similarity**:
- Both theorems share identical mathematical statements but differ in proof strategies.
2. **APOLLO Enhancements**:
- The right code explicitly handles non-negativity (`mul_nonneg`) and uses more granular lemmas (e.g., `mul_nonneg_iff_of_pos_right`).
- The left code relies on `nlinarith`, while the right code uses `exact` to finalize proofs.
3. **Complexity**:
- The right code’s proof is longer, suggesting APOLLO provides more foundational support for edge cases.
### Interpretation
The APOLLO extension enhances the LLM system by:
- **Rigorous Non-Negativity Handling**: Explicitly enforcing `0 ≤ x` via `mul_nonneg` to avoid invalid square root operations.
- **Modular Proof Construction**: Breaking proofs into smaller, verifiable steps (e.g., `have A : 0 ≤ x`) for clarity and correctness.
- **Advanced Lemmas**: Leveraging `mul_nonneg_iff_of_pos_right` to connect algebraic properties with topological constraints.
The differences highlight APOLLO’s role in refining formal proofs, ensuring robustness in mathematical reasoning. The left code’s brevity may sacrifice explicitness for conciseness, while the right code prioritizes correctness through detailed case analysis.
</details>
Figure 11: Proof attempt of mathd_algebra_293 produced by the base model (Goedel-Prover-SFT) versus after Apollo’s targeted repair. The left shows the original end-to-end LLM output, which does not compile in Lean; the right shows the corrected, repaired proof assembled by Apollo that closes all of the goals.
<details>
<summary>examples/comparison/medium_1.png Details</summary>

### Visual Description
## Screenshot: Code Comparison Between LLM and LLM+APOLLO
### Overview
The image displays two side-by-side code snippets labeled "LLM" (left, red border) and "LLM+APOLLO" (right, green border). Both snippets appear to be Python code using the `mathlib` library for formal verification or theorem proving. The code includes mathematical operations, variable assignments, and logical assertions, with highlighted sections indicating differences between the two versions.
---
### Components/Axes
- **Left Panel (LLM)**:
- **Header**: "LLM" in bold, red border.
- **Code Structure**:
- Imports: `import Mathlib`, `import Aesop`.
- Configuration: `set_option maxHeartbeats 0`.
- Theorem: `theorem mathd_algebra_184_llm`.
- Variables: `a`, `b`, `h`, `h1`, `h2`, `h3`, `h4`, `h5`, `h6`, `h7`, `h8`, `h9`, `h10`.
- Logical assertions: `have`, `linarith`, `rw`, `simp_all`, `try_linarith`, `try_native_decide`.
- Highlighted sections (red): Lines with `linarith`, `rw`, and `simp_all` operations.
- **Right Panel (LLM+APOLLO)**:
- **Header**: "LLM+APOLLO" in bold, green border.
- **Code Structure**:
- Imports: `import Mathlib`, `import Aesop`.
- Configuration: `set_option maxHeartbeats 0`.
- Theorem: `theorem mathd_algebra_184_apollo`.
- Variables: Similar to LLM but with additional annotations (e.g., `h15`, `h16`).
- Logical assertions: Similar to LLM but with extended logic (e.g., `try norm_cast`, `try norm_num`).
- Highlighted sections (green): Lines with `try norm_cast`, `try norm_num`, and `try native_decide`.
---
### Detailed Analysis
#### Left Panel (LLM)
1. **Imports**:
- `import Mathlib`: Imports the Mathlib library for formal mathematics.
- `import Aesop`: Imports the Aesop library (likely for automated theorem proving).
2. **Configuration**:
- `set_option maxHeartbeats 0`: Disables heartbeat monitoring (possibly for performance optimization).
3. **Theorem**:
- `theorem mathd_algebra_184_llm`: Defines a theorem about algebraic properties.
4. **Variables**:
- `a`, `b`: Natural numbers (`NNReal`).
- `h`, `h1`, `h2`, ..., `h10`: Hypotheses or intermediate steps.
5. **Logical Assertions**:
- `have h := ...`: Asserts intermediate steps.
- `linarith`: Applies linear arithmetic to simplify expressions.
- `rw`: Rewrites expressions using known lemmas.
- `simp_all`: Simplifies all expressions.
- `try_linarith`: Attempts linear arithmetic.
- `try_native_decide`: Attempts native decision procedures.
#### Right Panel (LLM+APOLLO)
1. **Imports**:
- Same as LLM but with additional annotations (e.g., `h15`, `h16`).
2. **Configuration**:
- Same as LLM.
3. **Theorem**:
- `theorem mathd_algebra_184_apollo`: Similar to LLM but with extended logic.
4. **Variables**:
- Additional variables like `h15`, `h16` for more complex assertions.
5. **Logical Assertions**:
- Extended use of `try norm_cast`, `try norm_num`, and `try native_decide` for more robust verification.
- Additional `simp_all` and `rw` operations for deeper simplification.
---
### Key Observations
1. **Highlighted Differences**:
- **LLM (Red Highlights)**:
- Focus on `linarith`, `rw`, and `simp_all` for basic simplification.
- **LLM+APOLLO (Green Highlights)**:
- Emphasis on `try norm_cast`, `try norm_num`, and `try native_decide` for advanced verification.
2. **Code Complexity**:
- LLM+APOLLO includes more variables (`h15`, `h16`) and extended logic, suggesting enhanced capabilities for handling complex theorems.
3. **Purpose**:
- Both snippets aim to verify algebraic properties, but LLM+APOLLO appears to use more sophisticated tools for proof automation.
---
### Interpretation
The code snippets represent formal verification processes using the Mathlib library. The "LLM" version focuses on basic simplification and linear arithmetic, while "LLM+APOLLO" introduces advanced decision procedures (`try norm_cast`, `try norm_num`) and extended logic for handling more complex theorems. The highlighted sections indicate that the LLM+APOLLO version is designed to automate more steps in the proof process, potentially improving efficiency or correctness in theorem verification. The differences suggest that the APOLLO component adds layers of automation and robustness to the original LLM framework.
</details>
Figure 12: Proof attempt of mathd_algebra_184 produced by the base model (Kimina-Prover-Preview-Distill-7B) versus after Apollo’s targeted repair. The left shows the original end-to-end LLM output, which does not compile in Lean; the right shows the corrected, repaired proof assembled by Apollo that closes all of the goals.
<details>
<summary>examples/comparison/medium_2.png Details</summary>

### Visual Description
## Lean 4 Theorem Proofs: LLM vs LLM + APOLLO
### Overview
The image compares two Lean 4 theorem proofs for the same algebraic identity:
`Real.sqrt(60 * x) * Real.sqrt(12 * x) * Real.sqrt(63 * x) = 36 * x * Real.sqrt(35 * x)`.
The left side shows a proof generated by LLM alone, while the right side demonstrates an enhanced proof using LLM + APOLLO. Both proofs use Lean's `Mathlib` and `Aesop` libraries with `BigOperators` and `Real.Nat.Topology`.
---
### Components/Axes
**Left Panel (LLM):**
- **Imports:** `Mathlib`, `Aesop`
- **Options:** `set_option maxHeartbeats 0`
- **Theorem:** `mathd_algebra_293_llm`
- **Proof Tactics:**
- `have h1 : ...`
- `ring_nf`
- `simp [x_mul_x]`
- `linarith [show (0 : ℝ) ≤ x from by positivity]`
- **Highlighted Section:**
- Red box around `rw [h2]`, `rw [Real.sqrt_mul (by positivity)]`, and `all_goals positivity`
**Right Panel (LLM + APOLLO):**
- **Imports:** Same as LLM
- **Theorem:** `mathd_algebra_293_apollo`
- **Proof Tactics:**
- `have h1, h2, h3, h4` with complex intermediate steps
- `try norm_cast`, `try simp_all`, `try ring_nf`
- `try linarith` with nested `simp` and `native_decide`
- **Highlighted Section:**
- Green box around `try norm_cast`, `try simp_all`, and `try ring_nf`
---
### Detailed Analysis
**LLM Proof (Left):**
1. **Structure:**
- Directly applies `ring_nf` and `simp` to reduce terms.
- Uses `linarith` with a custom `show` clause to enforce positivity.
2. **Key Steps:**
- `h1` binds the left-hand side (LHS) of the equation.
- `ring_nf` simplifies polynomial expressions.
- `linarith` proves the inequality `0 ≤ x` via positivity.
**LLM + APOLLO Proof (Right):**
1. **Structure:**
- Introduces multiple lemmas (`h1`, `h2`, `h3`, `h4`) for intermediate steps.
- Uses `norm_cast` to handle norm conversions.
- Employs `simp_all` and `native_decide` for automated simplification.
2. **Key Steps:**
- `h2` and `h3` break down the equation into smaller components.
- `simp [pow_succ]` and `simp [mul_assoc]` handle exponentiation and associativity.
- `linarith` is used without custom `show` clauses, relying on APOLLO's optimizations.
---
### Key Observations
1. **Tactic Complexity:**
- LLM + APOLLO uses 4x more `have` clauses and 3x more `try` blocks, suggesting deeper decomposition of the problem.
2. **Normalization:**
- APOLLO introduces `norm_cast` and `simp_all`, indicating better handling of norm-related terms.
3. **Efficiency:**
- LLM requires manual positivity enforcement (`show (0 ≤ x)`), while APOLLO automates this via `native_decide`.
---
### Interpretation
The LLM + APOLLO proof demonstrates a more systematic approach to algebraic simplification:
- **Decomposition:** Breaking the equation into smaller lemmas (`h1`, `h2`, etc.) allows incremental verification.
- **Automation:** Tactics like `simp_all` and `native_decide` reduce manual case analysis, making the proof more robust.
- **Normalization:** Explicit handling of norms (`norm_cast`) ensures correctness in real-number arithmetic.
The LLM proof, while concise, relies on Lean's default behavior for positivity, which may fail for edge cases. APOLLO's additions suggest a focus on generalizability and error resilience.
**Final Note:** Both proofs validate the same identity, but LLM + APOLLO provides a more transparent and maintainable structure, critical for complex mathematical reasoning.
</details>
Figure 13: Proof attempt of mathd_algebra_293 produced by the base model (Kimina-Prover-Preview-Distill-7B) versus after Apollo’s targeted repair. The left shows the original end-to-end LLM output, which does not compile in Lean; the right shows the corrected, repaired proof assembled by Apollo that closes all of the goals.
<details>
<summary>examples/comparison/medium_3.png Details</summary>

### Visual Description
## Code Comparison: LLM vs LLM + APOLLO
### Overview
The image shows two code snippets implementing a mathematical theorem (`algebra_2varlineareq...`) using symbolic computation. The left side represents the base LLM implementation, while the right side shows the enhanced LLM + APOLLO version. Both use the `Mathlib` and `Aesop` libraries for formal verification.
### Components/Axes
- **Imports**:
- `Mathlib` (mathematical library)
- `Aesop` (automated theorem prover)
- **Options**:
- `maxHeartbeats 0` (execution timeout)
- `pp.numericTypes true` (enable numeric types)
- `pp.coercions.types true` (enable type coercions)
- **Context**:
- `open BigOperators Real Nat Topology Rat` (mathematical domain)
### Detailed Analysis
#### LLM Code (Left)
1. **Theorem Definition**:
- `algebra_2varlineareq...` defines a theorem with variables `f`, `z`, `h0`, `h1`, `h2`.
- Equations:
- `h0 := f + (3 : ℂ) * z = (11 : ℂ)`
- `h1 := (3 : ℂ) * (f - 1) - (5 : ℂ) * z = (-68 : ℂ)`
- Goal: Solve for `z` using `linarith` (linear arithmetic solver).
2. **Key Steps**:
- Simplify equations using `mul_sub` (multiplication/subtraction).
- Combine terms with `simpa` (simplification).
- Solve for `z` via `linarith` (highlighted in red).
- Substitute `z` back to solve for `f` (highlighted in red).
3. **Output**:
- Final equations: `f_eq : f = -10` and `z_eq : z = 7`.
#### LLM + APOLLO Code (Right)
1. **Enhanced Steps**:
- Adds normalization (`try_norm_cast`, `try_norm_num`) and ring normalization (`try_ring_nf`).
- Uses `native_decide` for decision-making in ring structures.
- Introduces `h_nonzero`, `h_div`, and `h_simpl` for handling non-zero elements and division.
2. **Key Differences**:
- More granular steps for normalization and type handling.
- Explicit checks for `h_nonzero` and `h_div` (highlighted in green).
- Uses `simp_all` and `ring_nf` for comprehensive simplification.
3. **Output**:
- Same final equations (`f_eq : f = -10`, `z_eq : z = 7`), but with additional intermediate steps for robustness.
### Key Observations
- **LLM**: Directly solves equations with minimal steps, relying on `linarith`.
- **LLM + APOLLO**: Adds normalization and decision-making steps, likely improving reliability in complex algebraic contexts.
- **Highlighted Lines**:
- Red: Critical equation-solving steps (`linarith`, substitution).
- Green: APOLLO-specific normalization and decision steps.
### Interpretation
The LLM + APOLLO version enhances the base LLM by incorporating formal verification techniques (e.g., normalization, ring arithmetic) to handle edge cases and ensure correctness. While both achieve the same result, APOLLO’s approach is more rigorous, reducing the risk of errors in symbolic computation. This aligns with APOLLO’s goal of bridging the gap between automated theorem proving and practical mathematical problem-solving.
</details>
Figure 14: Proof attempt of algebra_2varlineareq_fp3zeq11_3tfm1m5zeqn68_feqn10_zeq7 produced by the base model (o4-mini) versus after Apollo’s targeted repair. The left shows the original end-to-end LLM output, which does not compile in Lean; the right shows the corrected, repaired proof assembled by Apollo that closes all of the goals.
<details>
<summary>examples/comparison/medium_4.png Details</summary>

### Visual Description
## Code Snippet Analysis: LLM, LLM+APOLLO, and APOLLO Theorem Proofs
### Overview
The image contains three side-by-side code blocks demonstrating formal theorem proofs in a proof assistant environment (likely Coq or Lean). Each block represents a different configuration: pure LLM, LLM with APOLLO integration, and pure APOLLO. The code focuses on real number arithmetic properties with specific attention to logarithmic operations and linear arithmetic.
### Components/Axes
1. **Imports**:
- All blocks import `Mathlib` and `Aesop` libraries
- APOLLO version includes additional imports for linear arithmetic
2. **Configuration**:
- `set_option maxHeartbeats 0` in all blocks
- `open BigOperators Real Nat Topology Rat` in all blocks
3. **Theorem Structure**:
- LLM: `theorem amc12a_2019_p12_llm`
- LLM+APOLLO: `theorem amc12a_2019_p12_apollo`
- APOLLO: `theorem amc12a_2019_p12_apollo` (different proof approach)
4. **Highlighted Sections**:
- Red highlights in LLM block (lines 10-13)
- Green highlights in LLM+APOLLO (lines 10-13, 22-25)
- Green highlight in APOLLO (lines 10-13)
### Detailed Analysis
**LLM Block**:
- Proves: `x ≠ 0 → y ≠ 0 → (log(x/y)/log(2))^2 = 20`
- Key steps:
- `have x_nonzero : x ≠ 0` (line 10)
- `have y_nonzero : y ≠ 0` (line 14)
- Uses `rfl` (reflexivity) and `simp` (simplification) tactics
**LLM+APOLLO Block**:
- Same theorem but with APOLLO integration
- Additional steps:
- `linarith` (line 18) for linear arithmetic
- `field_simp` with extended field operations
- Uses `rw` (rewrite) with complex expressions
**APOLLO Block**:
- Pure APOLLO implementation
- Key differences:
- Uses `linarith` instead of `rfl`
- More complex field simplification
- Additional `rw` steps with logarithmic properties
### Key Observations
1. All implementations share core structure but differ in proof tactics
2. APOLLO versions show more sophisticated handling of:
- Logarithmic properties (`log_mul`, `log_inv`)
- Linear arithmetic (`linarith`)
- Field operations (`mul_comm`)
3. Highlighted sections focus on:
- Non-zero assumptions (`x_nonzero`, `y_nonzero`)
- Logarithmic identity proofs
- Field simplification steps
### Interpretation
The code demonstrates formal verification of logarithmic identities in real numbers. The progression from LLM to APOLLO shows:
1. **Tactical Evolution**: APOLLO enables more powerful proof strategies
2. **Complexity Tradeoff**: APOLLO proofs are more verbose but potentially more general
3. **Logarithmic Focus**: All implementations center on `log(x/y)` properties
4. **Formal Rigor**: Explicit handling of division by zero and field properties
The APOLLO integration appears to provide:
- Enhanced linear arithmetic capabilities
- More sophisticated field operation handling
- Better support for complex rewrite rules
This suggests APOLLO adds significant value for formal verification of mathematical properties involving real numbers and logarithms, particularly in handling complex arithmetic expressions and maintaining proof correctness through automated tactics.
</details>
Figure 15: Proof attempt of amc12a_2019_p12 produced by the base model (Goedel-Prover-SFT) versus after Apollo’s targeted repair. The left shows the original end-to-end LLM output, which does not compile in Lean; the right shows the corrected, repaired proof assembled by Apollo that closes all of the goals.
<details>
<summary>examples/comparison/long.png Details</summary>

### Visual Description
## Code Analysis: Automated Theorem Proving Configurations
### Overview
The image contains four vertically stacked code blocks representing incremental configurations of an automated theorem proving system. Each block builds upon the previous with added components (APOLLO, CONTRADICTION, EVENT), visualized through color-coded annotations and code modifications.
### Components/Axes
1. **Color Coding**:
- Red: Base LLM configuration
- Green: APOLLO enhancement
- Blue: CONTRADICTION addition
- Purple: EVENT integration
2. **Annotations**:
- Numbered boxes ([1]-[8]) with color-coded backgrounds
- Positioned adjacent to specific code lines
3. **Key Functions**:
- `have`, `exact_mod_cast`, `linarith`, `omega`, `native_decide`
- `Nat.Prime`, `Nat.cast`, `try_norm_cast`
### Detailed Analysis
#### LLM Block (Red)
- Base configuration with 87 function calls
- Annotations:
- [1]: `have t = 1 := by nlinarith`
- [2]: `have n = 1 := by omega`
- [3]: `have k > t := by omega`
- [4]: `have h23 : k > t := by omega`
- [5]: `have h24 : (k : Z) + (t : Z) = m := by exact h12`
- [6]: `have h34 : k % 2 = 0 := by omega`
- [7]: `have h35 : (m : Z) = (k : Z) + 1 := by linarith`
- [8]: `have h30 : k = 2 := by interval_cases k <;> omega`
#### LLM+APOLLO Block (Green)
- 72 function calls with APOLLO-specific additions
- Notable changes:
- New `try norm_cast` and `try native_decide` operations
- Introduction of `h_odd`, `h_even` constructs
- Modified prime number handling (`Nat.prime_of_dvd_of_lt`)
#### LLM+APOLLO+CONTRADICTION Block (Blue)
- 61 function calls with contradiction resolution
- Key additions:
- `try simp_all` and `try ring_nf` operations
- New `h_odd_k` and `h_even` constructs
- Enhanced prime number verification (`try native_decide`)
#### LLM+APOLLO+CONTRADICTION+EVENT Block (Purple)
- 58 function calls with temporal/event handling
- Major modifications:
- `try norm_num` and `try norm_cast` operations
- New `h37` and `h38` constructs
- Event-based prime number verification (`try native_decide`)
### Key Observations
1. **Annotation Patterns**:
- Red annotations ([1]-[8]) appear in all blocks, suggesting core operations
- Green/blue/purple annotations show incremental additions
2. **Complexity Progression**:
- LLM: 87 operations
- LLM+APOLLO: 72 operations (17% reduction)
- LLM+APOLLO+CONTRADICTION: 61 operations (15% reduction)
- LLM+APOLLO+CONTRADICTION+EVENT: 58 operations (5% reduction)
3. **Function Evolution**:
- Base LLM uses simple arithmetic (`linarith`, `omega`)
- APOLLO introduces decision procedures (`native_decide`)
- CONTRADICTION adds simplification (`simp_all`, `ring_nf`)
- EVENT introduces temporal constructs (`try norm_num`)
### Interpretation
The progression shows a refinement of the theorem proving system:
1. **APOLLO** introduces decision procedures and prime number verification
2. **CONTRADICTION** adds simplification and conflict resolution
3. **EVENT** incorporates temporal/event-based reasoning
The decreasing operation count suggests optimization through each enhancement. The color-coded annotations indicate:
- Red: Core arithmetic operations
- Green: APOLLO-specific decision procedures
- Blue: Contradiction resolution mechanisms
- Purple: Event-based temporal reasoning
The system appears to be developing from basic arithmetic proving to handling complex temporal and contradictory scenarios, with APOLLO providing the foundational decision procedures that enable subsequent enhancements.
</details>
Figure 16: Proof attempt of mathd_algebra_289 produced by the base model (Kimina-Prover-Preview-Distill-7B) versus after Apollo’s targeted repair. The left shows the original end-to-end LLM output, which does not compile in Lean; the right shows the corrected, repaired proof assembled by Apollo that closes all of the goals. Import headers are the same as other presented examples, for visibility they were omitted in this diagram.