## Explainable AI - the Latest Advancements and New Trends
Bowen Long, Enjie Liu S Member, Renxi Qiu , Yanqing Duan
Abstract -In recent years, Artificial Intelligence technology has excelled in various applications across all domains and fields. However, the various algorithms in neural networks make it difficult to understand the reasons behind decisions. For this reason, trustworthy AI techniques have started gaining popularity. The concept of trustworthiness is cross-disciplinary; it must meet societal standards and principles, and technology is used to fulfill these requirements. In this paper, we first surveyed developments from various countries and regions on the ethical elements that make AI algorithms trustworthy; and then focused our survey on the state of the art research into the interpretability of AI. We have conducted an intensive survey on technologies and techniques used in making AI explainable. Finally, we identified new trends in achieving explainable AI. In particular, we elaborate on the strong link between the explainability of AI and the meta-reasoning of autonomous systems. The concept of meta-reasoning is "reason the reasoning", which coincides with the intention and goal of explainable Al. The integration of the approaches could pave the way for future interpretable AI systems.
Index Terms - Trustworthy AI, explainable AI, AI ethical principles, meta-reasoning
## I. INTRODUCTION
HE research around the theme of Trustworthy AI (TAI) is growing like never before, and the number of studies in the field of Trustworthy AI is growing by leaps and bounds. Since 2019, technology research around robustness, interpretability, and privacy protection has continued to grow [1]. Moreover, as the industry began implementing AI, the exploration and practice of making AI trustworthy continued to mature. The number of related AI technologies increased year by year after the integration of 'human-centric' computing elements. T
The concept of Trustworthy AI began to gain attention around the mid-2010s, largely because growing concerns over the ethical, transparent, and safe deployment of AI systems. S tandard organizations, such as IEEE introduced frameworks and standards, such as Ethics Certification Program for Autonomous and Intelligent Systems (ECPAIS) [2]. However, problems in the area of AI interpretability have slowed down due to the difficulty in cracking the black box attribute and the
- Bowen Long, Enjie Liu, Renxi Qiu, are from School of Computer Science and Technology, University of Bedfordshire, Park Square, LU1 3JU, Luton, UK
- Yanqing Duan is from Business School, University of Bedfordshire, Park Square, LU1 3JU, Luton UK.
high cost of some of the methods for cracking the black box [3]. Lacking of interpretable AI techniques has become an important constraint on the fairness of the system [4]. Due to the lack of specific, well-developed scenario practice cases, and because related technology research is still in the early stages, there have been relatively few established patented in the areas of interpretability and fairness.
Current, industry proposes a shift from Trustworthy AI to more transparent AI. It not only requires technical support but also aims to create a systematic approach to generate more interpretable methods while maintaining high performance levels. The US Defense Advanced Research Projects Agency (DARPA) launched the Explainable AI ( XAI) program [5] to create AI systems whose actions can be more easily understood by human users.
Although there has been a trend towards an explosion of research on this topic, not every area of it has received the same amount of attention. According to statistics from the China Academy of Communications Research [6], as of April 2022, patents in the field of privacy protection accounted for 63% of global AI technology patents, while AI interpretability and fairness patents accounted for only 10% and 6% respectively. With popularity of AI and increasing applications of AIenabled applications, trustworthiness and transparencies of AI becomes an unavoidable issue in AI development, and hence we witness the increasing development in the area.
In this paper, we first surveyed developments from various countries and regions on the ethical elements that make AI algorithms trustworthy; we adopted the definition from EU AI High-level Expert Group (HELG) [7], which summarized four basic ethical principles; AI HELG also identified seven specific needs to meet the ethical principles. We focus on one of the main requirement of the ethical AI, which is the transparency. To be more specific, we focus on reviewing of the latest research on improving explainability of AI. Finally, we also present our thoughts on the future development of technologies in AI explainability, and possible techniques to realize it.
- E-mail: (bowen.long, enjie.liu, renxi.qiu, yanqing.duan)@ beds.ac.uk
- Enjie Liu (Enjie.liu@beds.ac.uk) is the corresponding author
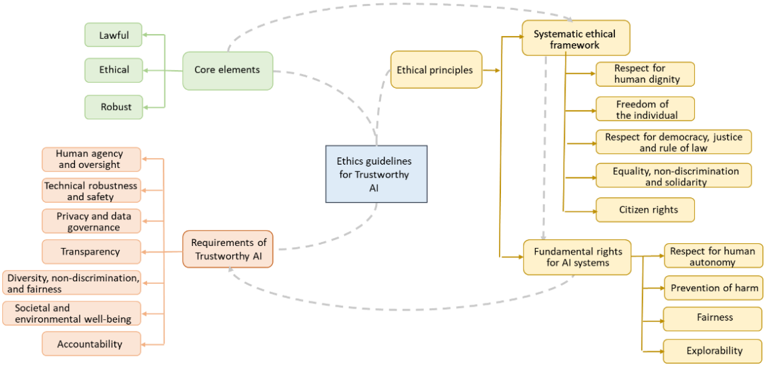
Fig. 1 Core elements with the ethics guidelines for trustworthy AI
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Ethics Guidelines for Trustworthy AI
### Overview
The image is a diagram outlining the ethics guidelines for trustworthy AI. It presents a hierarchical structure, starting with core elements and expanding into ethical principles, requirements, and fundamental rights. The diagram uses color-coded boxes and dashed lines to illustrate the relationships between different components.
### Components/Axes
* **Central Node:** "Ethics guidelines for Trustworthy AI" (Blue box)
* **Core elements:** (Green boxes, top-left)
* Lawful
* Ethical
* Robust
* **Requirements of Trustworthy AI:** (Orange boxes, bottom-left)
* Human agency and oversight
* Technical robustness and safety
* Privacy and data governance
* Transparency
* Diversity, non-discrimination, and fairness
* Societal and environmental well-being
* Accountability
* **Ethical principles:** (Yellow boxes, top-right)
* Systematic ethical framework
* Respect for human dignity
* Freedom of the individual
* Respect for democracy, justice and rule of law
* Equality, non-discrimination and solidarity
* Citizen rights
* Fundamental rights for AI systems
* Respect for human autonomy
* Prevention of harm
* Fairness
* Explorability
### Detailed Analysis
The diagram illustrates a flow from general principles to specific requirements and rights.
* **Core Elements:** The "Core elements" (Lawful, Ethical, Robust) are connected to the "Ethics guidelines for Trustworthy AI" via dashed lines.
* **Requirements:** The "Requirements of Trustworthy AI" are also connected to the central node via dashed lines.
* **Ethical Principles:** The "Ethical principles" are connected to the central node via a solid line. The "Systematic ethical framework" and "Fundamental rights for AI systems" are sub-categories of "Ethical principles". Each of these sub-categories has further sub-points.
### Key Observations
* The diagram emphasizes the multi-faceted nature of trustworthy AI, encompassing legal, ethical, and technical considerations.
* The use of dashed lines suggests a less direct or more conceptual relationship compared to the solid lines.
* The hierarchical structure indicates a progression from high-level principles to specific requirements and rights.
### Interpretation
The diagram provides a framework for understanding and implementing ethical guidelines for AI. It highlights the importance of considering not only technical aspects but also societal, legal, and human rights implications. The connections between the different components suggest that trustworthy AI requires a holistic approach, integrating core elements, specific requirements, and fundamental rights. The diagram suggests that ethical AI development should prioritize human well-being, fairness, and transparency.
</details>
## II. ETHICAL CONCERNS OF TRUSTWORTHINESS IN AI
European Commission proposed civil rules on robotics in [8], through two public statements in April and December 2018 [9], it clearly articulated three main visions for the field of Artificial Intelligence:
- to increase investment from all sectors of society in the development of AI;
- to prepare for new economic trends brought about by AI;
- to ensure that appropriate ethical and legal frameworks are in place so that European values in AI remain centered around the human being.
To achieve these common goals, the EU convened 52 authoritative experts or scholars, as well as authoritative practitioners to form the AI HLEG, which brought them together to draft and revise the Code of Ethics for Artificial Intelligence [13]. In this official document, the concept of trustworthy AI was formalized.
With due foresight and a sense of responsibility, the AI HLEG may have anticipated that AI governance would require more than merely outlining a vague concept of Trustworthy AI in broad terms. They have defined Trustworthy AI, through: (1) the core elements it should have; (2) the ethical principles it should protect; and (3) the specific requirements it should fulfil. These three aspects have been explored in depth to find ways to prevent AI from causing a crisis of trust [6], as shown in Fig. 1. Table 1 summarizes the investigation and progress of ethical concerns from different countries and regions.
| Where | When | Documents/projects | Elements |
|--------------------|----------|-----------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| The United States | 10/20 19 | Principles of Artificial Intelligence: Ethical Recommendations for the Application of Artificial Intelligence in the Ministry of Defence [10] | 1) accountability; 2) fairness; 3) traceability; 4) reliability; and 5) control |
| The United States | 02/20 20 | "Ethical Standards for AI Guidance." [11] | Conduct AI system development, testing and review to the highest standards of fairness, accountability and transparency |
| The United States | 07/20 21 | "Trustworthy and Responsible" Artificial Intelligence Project [12] | 1) Accuracy; 2) Interpretability; 3) Privacy; 4) Reliability; 5) Robustness; 6) Safety; 7) Reducing the harm of bias |
| The European Union | 01/20 17 | European Commission Recommendation on Civil Law Rules on Robotics [9] | 1) freedom; 2) privacy; 3) positive value and dignity; 4) self- determination and non-discrimination; 5) personal data protection |
| The European Union | 04/20 19 | Ethics guidelines for trustworthy AI [13] | 1) human oversight; 2) robustness and safety of technology; 3) privacy and data management; 4) transparency; 5) diversity, non-discrimination and fairness; 6) social and environmental well-being; 7) accountability |
| Japan | 03/20 17 | Ethical Guidelines of the Society for Artificial Intelligence [14] | 1) Contribution to humanity; 2) Compliance with legal rules; 3) Respect for the privacy of others; 4) Impartiality; 5) Safety; 6) Honest behaviour; 7) responsibility to society |
| Japan | 07 /2017 | AI Development Programme | Developers should endeavour to exclude, to the extent possible, all measures of bias and other undue discrimination, including learning data from AI systems, in light of the nature of the technology; developers should comply with international human rights law, international humanitarian law, and be on the lookout for behaviour by AI systems that maybe incompatible with human values. |
Table 1. Summary of ethical concerns from different countries (Translated from [6])
| | 03/20 19 | Principles for a Human-Centred AI Society | 1) Human-centred; 2) Educational applications; 3) Privacy Protection; 4) Safety and Security; 5) Fair Play; 6) Equity; 7) Accountability and Transparency; 8) Innovation |
|-------------|------------|----------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Canada | 12/20 18 | Montreal Declaration on Reliable Draft Artificial Intelligence | 1) well-being; 2) autonomy; 3) justice; 4) privacy; 5) knowledge; 6) democracy; 7) responsibility |
| Australia | 11/20 19 | Australian Ethical Framework for Artificial Intelligence | 1) human, social and environmental well-being; 2) human-centred values; 3) fairness; 4) privacy protection and security; 5) reliability and safety; 6) transparency and interpretability; 7) contestability; 8) accountability |
| New Zealand | 03/20 20 | Guiding Principles for Trustworthy AI in New Zealand | 1) Fairness and Justice; 2) Reliability, Security and Privacy; 3) Transparency; 4) Human Oversight and Responsibility; 5) Welfare |
| Korean | 12/20 20 | National Ethical Standards for Artificial Intelligence | 1) Human Rights Protection; 2) Privacy Protection; 3) Respect for Diversity 4) Prohibition of Infringement; 5) Social Advocacy; 6) Cooperation of Subjects; 7) Data Management; 8) Clarification of Responsibilities; 9) Ensuring Safety; 10) Transparency |
| China | 11/20 17 | S36 Xiangshan conference | Trustworthy AI consists of three main elements: human, information, and physical. |
| China | 08/20 19 | Artificial Intelligence Industry Self- Regulation Convention | 1) Safe and Controllable; 2) Transparent and Releasable; 3); Protecting Privacy; 4) Clear Responsibility; 5) Diverse and Inclusive |
| China | 09 /2019 | Code of Ethics for New Generation Artificial Intelligence | 1) Enhance human well-being; 2) Promote fairness and justice; 3) Protect privacy and security; 4) Ensure controllability and credibility; 5) Strengthen responsibility; and 6) Enhance ethical literacy. |
| China | 07/20 21 | White Paper on Trusted Artificial Intelligence. | Trustworthiness consists of five trustworthy elements: 1) reliability and control, 2) transparency and release, 3) data protection, 4) clear responsibility, and 5) diversity and inclusiveness. Trustworthy AI is the implementation of ethical governance requirements from the perspective of technology and engineering practice to achieve an effective balance between innovation development and risk governance. |
Recently, after surveying the principles of the European Group on Ethics in Science and New Technologies (EGE) as well as 36 other ethical principles proposed so far, the AI4People task force summarized them into nine main principles [15]. Subsequently, the AI HELG, in response to these, refined them and selected four as the basic ethical principles that trustworthy AI should always adhere:
- Respect for Human Autonomy
- Prevention of Harm
- Principle of Fairness
- Principle of Explicability
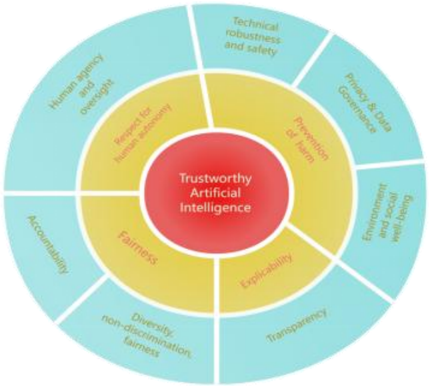
Abstract ethical principles need to be translated into tangible operational requirements to establish a solid foundation. AI systems cannot be realized without the involvement of relevant stakeholders: a.) developers who implement and apply them to the development process; b.) developers who ensure that the system and products and services comply with the requirements; and c.) users who are willing to use them and give feedback. In view of this, AI HELG has summarized seven specific needs to meet the ethical principles in place by reflecting on the stakeholders' positions, shown in Fig. 2.
Fig. 2 Relationship between the seven requirements and the corresponding basic principles
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Circular Diagram: Trustworthy Artificial Intelligence
### Overview
The image is a circular diagram illustrating the components of "Trustworthy Artificial Intelligence." It consists of concentric rings and radial divisions, with key concepts arranged around a central core. The diagram uses color-coding to distinguish between different layers or categories of principles.
### Components/Axes
* **Central Core (Red):** "Trustworthy Artificial Intelligence"
* **Inner Ring (Yellow):** Contains three principles: "Respect for human autonomy", "Fairness", "Prevention of harm", "Explicability".
* **Outer Ring (Light Blue):** Contains six principles: "Human agency and oversight", "Accountability", "Diversity, non-discrimination, fairness", "Transparency", "Environment and social well-being", "Privacy & Data Governance", "Technical robustness and safety".
### Detailed Analysis
The diagram is structured as follows:
1. **Central Core:** The innermost circle, colored red, contains the text "Trustworthy Artificial Intelligence." This represents the core concept of the diagram.
2. **Inner Ring:** Surrounding the central core is a yellow ring divided into four segments. Each segment contains a principle:
* Top: "Respect for human autonomy"
* Left: "Fairness"
* Right: "Explicability"
* Bottom: "Prevention of harm"
3. **Outer Ring:** The outermost ring is light blue and divided into six segments, each containing a principle:
* Top-Left: "Human agency and oversight"
* Bottom-Left: "Accountability"
* Bottom: "Diversity, non-discrimination, fairness"
* Bottom-Right: "Transparency"
* Top-Right: "Privacy & Data Governance"
* Right: "Environment and social well-being"
* Top: "Technical robustness and safety"
### Key Observations
* The diagram emphasizes a multi-faceted approach to trustworthy AI, encompassing ethical, social, and technical considerations.
* The arrangement suggests a hierarchy or relationship between the principles, with the inner ring representing core ethical considerations and the outer ring representing broader implementation and governance aspects.
* The use of color-coding helps to visually distinguish between different categories of principles.
### Interpretation
The diagram illustrates the key principles and considerations necessary for developing and deploying trustworthy artificial intelligence. The central concept of "Trustworthy Artificial Intelligence" is supported by core ethical principles (inner ring) and broader implementation and governance aspects (outer ring). The diagram suggests that trustworthy AI requires a holistic approach that considers human autonomy, fairness, prevention of harm, explicability, human oversight, accountability, diversity, transparency, environmental impact, data privacy, and technical robustness. The diagram serves as a visual framework for understanding the complex requirements of trustworthy AI and can be used to guide the development and deployment of AI systems in a responsible and ethical manner.
</details>
## III. TRANSPARENCY AI, INTERPRETABLE AI, AND EXPLAINABLE AI
The Trustworthy AI is an umbrella term for concepts that make AI socially valuable when utilized and deployed. Transparent AI is one of seven requirements that
trustworthiness should be met. Research on transparent focuses on the openness of structure and processes in AI models. Research on Interpretable AI focuses on understanding the outputs of AI systems. Explicability is critical in building and maintaining user trust in the system. When AI systems can be explained, it is transparent, and therefore, the model is trusted. However, a system can be transparent but not interpretable.
## A. Transparency of AI
Transparency includes traceability, interpretability and communication.
## a) Traceability
It means that the datasets and processes the system relies on to make decisions-including data collection methods, reasons for data labeling, and the algorithms used-should be documented as thoroughly as possible. To achieve traceability and increase transparency, this also applies to decisions made by AI systems. Traceability facilitates review and interpretation.
## b) Interpretability
It involves the technical process of explaining the AI system and it requires that the decisions taken by the AI system can be understood and tracked by human. In addition, there may be trade-offs between increasing the interpretability of a system or increasing its accuracy [16]. Whenever an AI system has a significant impact on people's lives, individuals should be able to demand a proper explanation of the decision-making process. In addition, the extent to which the AI system affects the organization's decision-making process, along with the rationale for its design and deployment, should be explained.
## c) Communication
Humans have the right to be informed that they are interacting with an AI system. This requires the AI system be recognizable. In addition, the basic right to decide not to interact with the AI system and to switch to interacting with humans should be provided if necessary. In addition to this, the performance and limitations of the AI system should be communicated to the AI practitioner or end user in a suitable manner.
## B. Interpretable AI and explainable AI
Interpretable AI and Explainable AI are sometimes interchangeably used, but there are distinct meanings: Interpretable AI is often used in designing models that are inherently understandable, it makes a model understand from design stage; Explainable AI , on the other hand, is often referred to the techniques and methods to make the results understandable.
Interpretable AI is one of the three attributes of Transparent AI, which is intended to indicate what a particular area of AI is trying to achieve. Interpretability of AI started as early as the mid-1970s [17].
Explainable AI was first introduced in 2004 [18], it involves different perspectives such as social science, cognitive science, psychology, and human-computer interaction, and aims to make the results of AI systems more understandable to humans. In [19], the authors summarized interpretability approaches used in machine Learning.
In some studies, Interpretable AI is categorized as a subfield of Explainable AI , which is used to express the technical behavior in the process of making AI systems explainable.
In this paper, we do not intend to distinguish the difference between the interpretable AI and explainable AI in our survey. We aim to survey the state of the art in explaining why a model produces a particular output or decision. With the so-called black box, multiple interpretable measures may be required to collaborate, and the degree of interpretability needed depends very much on the circumstances. In this paper, we categorize the interpretive approach as range-based, where interpretation is achieved globally or locally, and sequence-based, where interpretation is achieved at different stages.
## IV. RANGE-BASED INTERPRETIVE APPROACH
There are two different forms of interpretability, (1) understanding the behavior of the whole model - global interpretability: and (2) understanding individual regional predictions - local interpretability.
## A. Global Interpretability
Global interpretability helps users understand the overall logic of the model. To interpret black-box machine learning models globally, the authors in [20] used a compact binary tree and an interpretation tree to explicitly represent the most important decision rules implicitly contained within the blackbox models. In such cases, global explanations are more helpful than explanations made for a particular segment. Authors in [21] proposed an a priori learning technique in the form of a deep generator network based on method of activation maximization [22]. However, global model interpretability is difficult to achieve in practice for models with a small number of parameters.
## B. Local Explainability
Local explanations are the most common method for generating Deep Neural Network (DNN) explanations. It explains the reasons for a particular decision or a single prediction implies that the interpretability occurs locally. The mining of interpretability is used to generate individual explanations and, in general, to justify why a model makes a given decision in a particular situation. Authors in [23] proposed the Locally Interpretable Model agnostic Explanatory (LIME) model. This model can locally approximate a black-box model in the vicinity of any prediction of interest. Authors in [24] proposed a new technique called Shapely Explanations based on the research of [25]. In addition, limited by the fact that global explanations are not well explained, researchers have tried to link local explanations with holistic explanations [26-28].
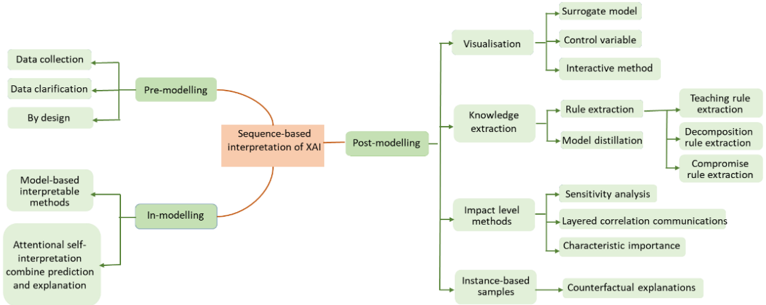
Fig. 3. Summary of the sequence-based interpretative approaches
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: Sequence-based Interpretation of XAI
### Overview
The image is a diagram illustrating the sequence-based interpretation of Explainable Artificial Intelligence (XAI). It outlines the process through pre-modelling, in-modelling, and post-modelling stages, detailing various methods and techniques associated with each stage.
### Components/Axes
* **Central Node:** "Sequence-based interpretation of XAI" (orange box)
* **Stages:**
* Pre-modelling (green box, top-left)
* In-modelling (green box, bottom-left)
* Post-modelling (green box, right)
* **Pre-modelling Sub-components:**
* Data collection (green box)
* Data clarification (green box)
* By design (green box)
* **In-modelling Sub-components:**
* Model-based interpretable methods (green box)
* Attentional self-interpretation combine prediction and explanation (green box)
* **Post-modelling Sub-components:**
* Visualisation (green box)
* Surrogate model (green box)
* Control variable (green box)
* Interactive method (green box)
* Knowledge extraction (green box)
* Rule extraction (green box)
* Teaching rule extraction (green box)
* Decomposition rule extraction (green box)
* Compromise rule extraction (green box)
* Model distillation (green box)
* Impact level methods (green box)
* Sensitivity analysis (green box)
* Layered correlation communications (green box)
* Characteristic importance (green box)
* Instance-based samples (green box)
* Counterfactual explanations (green box)
### Detailed Analysis
The diagram presents a sequential flow, starting with pre-modelling, moving to in-modelling, and culminating in post-modelling. Each stage is connected to the central node "Sequence-based interpretation of XAI" via curved arrows. Each stage has sub-components, which are connected via straight arrows.
* **Pre-modelling:** This stage focuses on preparing the data and defining the design for the XAI process. It includes data collection, data clarification, and design considerations.
* **In-modelling:** This stage involves the actual modelling process, emphasizing interpretable methods and self-interpretation techniques that combine prediction and explanation.
* **Post-modelling:** This stage focuses on extracting knowledge and insights from the model. It includes visualization techniques (surrogate models, control variables, interactive methods), knowledge extraction (rule extraction, model distillation), impact level methods (sensitivity analysis, layered correlation communications, characteristic importance), and instance-based samples (counterfactual explanations).
### Key Observations
* The diagram provides a structured overview of the XAI interpretation process.
* It highlights the importance of each stage, from data preparation to knowledge extraction.
* The diagram emphasizes the use of various methods and techniques to enhance the interpretability of AI models.
### Interpretation
The diagram illustrates a comprehensive approach to XAI, emphasizing the importance of a sequence-based interpretation. It suggests that effective XAI requires careful consideration of data preparation, model building, and post-hoc analysis. The diagram highlights the interconnectedness of these stages and the various methods that can be employed to enhance the interpretability of AI models. The inclusion of specific techniques like surrogate models, rule extraction, and sensitivity analysis suggests a focus on making AI models more transparent and understandable to users.
</details>
## V. SEQUENCE-BASED INTERPRETIVE APPROACH
Through a review of the past literature, study found that although many literatures have proposed a classification of interpretive methods [29], there is always a lack of uniformity. For the interpretive methods in Trustworthy AI, this study adopts the following two scales: (1) based on the scope, as explained in the previous section; (2) based on the sequence, which will be explained in this section. Fig. 3 summarizes the sequence-based interpretive methods in explainable AI.
The interpretability of AI can occur at three stages: premodelling, in modelling, and post-modelling.
## A. Pre-modelling
Pre-modelling interpretability means that it occurs before the model development process, and this stage mainly involves data collection, data classification, and model a priori design of the model.
- (1) Data Collection Many researchers use data augmentation for data complexity addition. In a series of works [30-32] and others, a new sample dataset was generated for training by applying a series of rotations, flips, and noise additions to the images using self-supervised learning.
- (2) Data classification Authors in [33] proposed the prototype network to measure data similarity and was widely adopted. Authors in [34] tackled the few-shot learning problem from a multimodal (text and image) perspective. The paper proposed to leverage a nearest neighbor classifier in a powerful representation space. Classification is performed by finding the nearest multimodal class prototype to an unseen test sample. However, the uniqueness of the prototype points within each data class leads to test sample classification results being determined by their similarity to a prototype point. It may result in over-generalization or overfitting leading to serious data bias. In [35], authors extended the approach, by proposing a discriminative sample generation along with a self-paced strategy for sample selection a subset of 'easy' samples can be automatically selected in each iteration. Training is performed using only subset, which is progressively increased in the subsequent iterations when the model becomes more mature.
Authors in [36] attempted to use semantically-assisted visual classification, but the area of visual-to-semantic is yet to be demonstrated.
- (3) By design In general, the more complex a model is, the more difficult it is to explain it. Therefore, the best way to obtain an interpretable AI model is to find an algorithm that is as interpretable as possible at the model setup expense.
Authors in [37] proposed a model called Bayesian Rule Lists (BRL) that based on BRL of Decision Trees in the hope of gaining the trust of relevant practitioners through its simplicity and convincing ability. Authors in [38] introduced a generalized summation based model to seek a solution to the problem of pneumonia. Authors in [39] introduced an attention based model that automatically learns to describe the content of an image. Authors in [40] proposed a linear model to create a data-driven scoring system. Authors in [41] has suggested that "accuracy usually requires more sophisticated prediction methods and simple interpretable functions do not make the most accurate predictors"
As explained in section IV, explainability can be categorized into two main paradigms: global explanation and local explanation. Table 2 summarises method used in premodelling for achieving interpretable AI under these two categories.
## B. In modelling
Interpretability in modelling refers to the development of measures that inherently explain the model. At this stage, researchers utilized model-specific explanatory methods, prediction and explanation of attentional self - interpretation for joint modelling.
- (1) Model-specific interpretable methods This approach is model-specific and model-independent, which has led to a surge of interest. Authors in [13] and others have investigated gradients in convolution and inverse convolution to explore relationships in convolutional neural networks, and authors in [42] have simplified the structure of convolutional neural networks to a fully convolutional structure for the task.
Table 2 Technologies used in prior modelling of explainable AI
| Range- based | Method | Conditions of application | Technology/Algorithm/Model | Application Scenarios |
|----------------|------------------------------|--------------------------------|-----------------------------------------------------------|-----------------------------------------------------|
| global | Interpretable Models | Transparent parameters | Explainable Decision Trees [43] | Self-driving |
| global | Interpretable Models | Transparent parameters | Explainable Linear Regression [44] | Crime forecasting |
| global | Interpretable Models | Transparent parameters | Explaining Logistic regression [45] | Human resources management |
| global | Interpretable Models | Transparent parameters | Explaining Bayes' rule based algorithms [456 | Spam filter |
| global | Interpretable Models | Transparent parameters | Explainable Support Vector Machines (SVM) [47] | Manufacturing quality control |
| global | Statisticians | Prior knowledge and experience | Causal Fuzzy Cognitive Maps [48] | Urban planning and governance |
| global | Statisticians | Sensor-based | Spike Neural Networks (SNN) [49] | Robot Sensing and Control |
| Local | Interpretable Models | Transparent parameters | Gradient Boosting Decision Trees(GBDT) [50] | E-commerce search engine sorting |
| Local | Statisticians | Probabilistic and causal | Structural Causal Models [51] | Environmental science research |
| Local | Statisticians | Probabilistic and causal | Bayesian Causality Networks [52] | Production process optimisation |
| Local | Counterfactua l Explanations | Data-based | Generative Adversarial Networks (GAN) [53] | Data enhancement and sample generation |
| Local | Counterfactua l Explanations | Scenario- based | Diverse Counterfactual Explanations (DiCE) [54] | Personalised Recommender System |
| Local | Agnostic | Data-based | Explainable Principal Component Analysis (PCA) [55] | Financial analytics and customer behaviour analysis |
| Local | Agnostic | Data-based | t-Distributed Stochastic Neighbour Embedding (t-SNE) [56] | Analysing similarities in graphic- textual data |
| Local | Agnostic | Data-based | Uniform Manifold Approximation and Projection (UMAP) [57] | Analysing biogenetic data |
(2) Attentional self-interpretation It combines prediction with interpretation. By assigning weights and importance in the data, attention-based approaches are considered more promising. The authors in [58] explored the Visual Question Answering (VQA) task of answering questions about images in free-form natural language, where the VQA model incorporates textual information during the question-and-answer process. The authors in [59] proposed fault and knowledge prediction metrics and found that the HIL (Human-In-Loop) approach enables human understanding. Authors in [60] extended the approach of [61] by interpreting the results of a VQA task by using textual interpretations and the visual regions corresponding to them. This process passes an attentional mask between modules and explores inter-modal complementarity to demonstrate the value and advantages of generating multimodal interpretations. A supervised attentional model was used in the study [62] in order to train the generation of interpretations that resemble human reasoning.
Table 3 summarizes the latest development of in-modelling approaches that attempted for achieving expansible AI.
## C. Post-modelling
Post-modelling approaches, also often referred to as model-independent or post-hoc interpretation approaches
[66-67] are currently a frequently cited classification approach in the field of XAI. In this study, we draw on the modelindependent categorization of XAI in [68] and others, and set the classification catalogue as: visualization, knowledge extraction, influence methods, and factual descriptions.
## (1) Visualization
Visualization techniques are mainly applied to supervised learning models and are one of many effective methods for exploring artificial intelligence systems. The elements introduced in this study are categorized as follows:
- Surrogate models
- Control variable graphs
- Interactive methods
## a. Surrogate model
It is trained from the predictions of the original black box model. It can be used to explain complex models. The LIME [67] method is a prescribed way to build a local surrogate model around a single observation. The authors in [69] used a surrogate model approach to extract a decision tree representing the behavior of the model. Another study by [70] proposed a method of using surrogate models for constructing a tree view visualization method.
Table 3 Technologies used in in-modelling of explainable AI
| Range-based | Conditions of application | Technology/Algorithm/Model | Application Scenarios |
|---------------|-----------------------------|-------------------------------------------|-----------------------------------------------|
| global | Simplification- based | Architecture modification techniques [63] | Signal enhancement for speech recognition |
| global& local | Parameters- based | Backpropagation-based methods [64] | Significant characterisation of imaging tasks |
| local | Weighting- based | Attention mechanisms [65] | Natural Language Processing (NLP) |
## b. Control variables
This method refers to the establishment of a link between outcome and cause by showing the average partial relationship between one or more input variables and the predictions of the black box model. Partial Dependence Plot (PDP) and Individual Conditional Expectation (ICE) are used in express the relationship between the outcomes and the causes. Partial Dependence Plot is a method that uses a graphical representation of the relationship between an objective function and a feature, which helps to visualize the overall effect of variable changes on the results. The study of Partial Dependence Plot [71], showed the marginal effects of the final predictor features. The authors in [72] demonstrated the advantages of using Random Forests and correlation PDPs to accurately model the predictor-response relationships at asymmetric categorical costs in a criminal justice setting. Individual Conditional Expectation reveals interactions and individual differences based on PDP graphs. Authors in [73] presented a preliminary theory of ICE and elucidated the advantages over PDP. The authors in [74] and proposed representation based on local feature importance.
## c. Interactive methods
Interactive methods were initially designed to exploit the transparency of machine learning to analyze the accuracy of multimodal systems [75], but have since been commonly used for interpretability studies. Authors in [76] applied a virtual agent to improving user trust, finding that multimodal explanations of the combination of vision and speech were more convincing. The authors in [77] proposed an interactive algorithm that was used by XAl go to explain the internal state of the system by answering questions now. The authors in [78] introduced an interactive model with an "active attention" mechanism. By combining model interpretation and annotation, model interpretation is evaluated based on metrics such as user trust, mental models, and usability. This approach adjusts model attention and provides user feedback to correct inaccurate predictions, ultimately improving accuracy. Interpretation-based dialogue systems provide users with better explanations than traditional systems by using an interactive approach that integrates multiple senses [79].
## (2) Knowledge Extraction
The task of extracting knowledge from the network is to extract the knowledge gained by the neural network during training in an understandable form and encode it into an internal representation. There are two main methods designed to extract knowledge from artificial neural networks in this study: rule extraction and model refinement.
## a. Rule Extraction
To gain insights into highly complex models, many researchers have begun experimenting with rule extraction [80]. A symbolic and comprehensible description of the knowledge learned by the network during the training process is provided by extracting rules, which approximate the decision-making process of the AI network by utilizing its inputs and outputs. In a study [81], rule extraction strategies are classified and three rule extraction models are proposed: pedagogical rule extraction, decomposition rule extraction and compromise rule extraction.
## b. Model distillation
Distillation is a type of model compression that transfers knowledge learned by the 'teacher' network (a deep network) to the 'student' network (a shallow network) [82, 83]. Model compression was initially used to reduce the computational cost of running a model, but has since been applied to interpretability as well. The authors in [84] investigated how model distillation can be used to distill complex models into forms that are as transparent as possible. The authors in [85] introduced a new method of knowledge distillation, known as the Interpretable Imitation Learning (IIL) method. Since then, research in [86-87] have expanded the approach.
## (3) Impact level methods
This type of approach estimates the importance as well as the relevance of features or modules by changing inputs or internal components and recording the trend in the degree of impact of these changes on the model performance. Relevant methods are: sensitivity analysis, hierarchical correlation propagation, and feature importance metrics.
## a. Sensitivity analysis
It is used to verify that model behavior and outputs remain stable when the data is deliberately perturbed or when other changes occur in the simulated data [88]. Sensitivity analysis has been increasingly used to explain image classification in DNNs [89-90].
Table 4 Technologies used in post modelling of explainable AI
| Range- based | Method | Conditions of application | Technology/Algorithm/Model | Application Scenarios |
|-------------------|----------------|-----------------------------|-----------------------------------------------------------------|---------------------------------------------------|
| Post-hoc (local) | Agnostic | Data-based | Local Interpretable Model-Agnostic Explanations (LIME) [98] | Data science experiments |
| Post-hoc (local) | Agnostic | Data-based | Perturbation-based methods [99] | Assessment of insurance claims |
| Post-hoc (local) | Agnostic | Feature-based | SHapley Additive exPlanations (SHAP) [100] | Climate change projections |
| Post-hoc (local) | Agnostic | Feature-based | Feature Importance Scores [101] | Software for evaluating AI models |
| Post-hoc (local) | Agnostic | Feature-based | Attribution-based methods [102] | Evaluation of corporate business indicators |
| Post-hoc (local) | Agnostic | Feature-based | Local-perturbation techniques [103] | Comparison and classification of computer vision. |
| Post-hoc (local) | Agnostic | Feature-based | Sensitivity/Stability-based methods [104] | Sentiment Analysis in NLP |
| Post-hoc (local) | Agnostic | Graph Example - based | Graph Neural network explainer (GNN Explainer) [105] | Knowledge Reasoning |
| Post-hoc (local) | Agnostic | Graph Example - based | Gradient-Based Techniques: Class Activation Mapping (CAM) [106] | Anomaly Detection in Security Monitoring |
| Post-hoc (global) | Specific | Feature-based | Feature contribution techniques [107] | Trend analysis of house prices |
| Post-hoc (global) | Specific | Simplification -based | Activation mapping [108] | Visualisation of target detection |
| Post-hoc (global) | Specific | Surrogate | Model distillation [109] | Cloud Computing Tasks |
| Post-hoc (global) | Statisticia ns | Probabilistic and causal | Explainable Naive hierarchical Bayes models [110] | Recommender system |
| Post-hoc (global) | Statisticia ns | Probabilistic and causal | Bayesian Belief Networks [111] | Troubleshooting of industrial equipment |
| Post-hoc (global) | Statisticia ns | Feature-based | Partial Dependence Plot (PDP) [112] | Financial risk management |
| Post-hoc (global) | Statisticia ns | Feature-based | Regression Concept Vectors (RCV) [113] | Medical Diagnostics |
## b. Layered Correlation Propagation
Layered Correlation Propagation Algorithm (LRP) was first proposed in [91]. The algorithm performs a backward redistribution of the prediction function, starting at the output layer of the network and then back-propagating to the input layer. The key property of this redistribution process is known as correlation conservation.
## c. Characteristic importance
Characteristic importance quantifies the contribution of each input variable to the prediction of a complex ML model. The authors in [92] used a quantitative ranking of feature importance when proposing a decision boundary based model to explain the data classification, calculating the increase in model prediction error can be used to measure the importance of features. Similarly, [93] proposed a model-independent version of feature importance called Model Class Dependency (MCR). The authors in [94] proposed a localized version of feature importance, permutation-based Shapley's Feature Importance (SFIMP) to fairly distributes the model performance among features and compares feature importance across different models.
## (4) Instance-based samples
Most example-based explanations are not directly related to the model itself; sample-based explanation methods explain the model by selecting representative samples from the dataset. A common approach is counterfactual interpretation , which reasons by assuming the opposite of the predicted outcome.
Contrastive, human-based reflection on failed events can prompt people to think about why a machine arrives at a particular result rather than other possible outcomes. For example, suppose a loan application is rejected [95]. In this case, there are questions about which steps and minimal changes could have been made to alter the undesirable outcome, and in [96], authors proposed the concept of an unconditional counterfactual explanation as a new approach to automated decision making. Multi-modal explanations based on counterfactuals can provide actionable insights and recommendations [97].
Table 4 summarizes the latest development of postmodelling approaches that attempted for achieving expansible AI.
## VI. NEW TRENDS IN EXPLAINABILITY OF AI, OPPORTUNITIES AND CHALLENGES
## A. Explainability AI and meta-reasoning
A key challenge with the sequence-based and range-based methods surveyed in this paper is that explainability is obscured by the complex interactions between the learning and reasoning, both are essential requirements of AI systems, making it extremely difficult to extract. We advocate that the explainability of AI systems can be approached by projecting the problem into the reward space for a reward-driven explainability. The approach focuses on explaining the potential impact of the AI systems using logical reasoning
techniques solely at the reward space, which significantly reduced complexity and improves observability.
The concept of meta-reasoning is "reason the reasoning" [136], which coincides with the intention and goal of explainable Al. The integration of the approaches could pave the way for future interpretable AI systems.
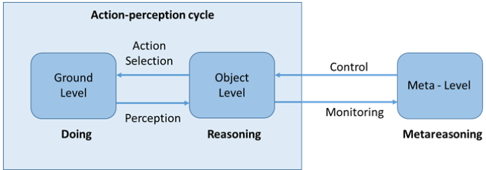
Meta-reasoning (as shown in Fig. 4) aims to simplify the symbolic grounding processes by observing patterns of reward for explanation rather than sequence-based or range-based causal relationships. Traditionally, logical reasoning in AI has been used for object driven knowledge representation and reasoning but it is often inadequate at ground level required by data driven models. Meta-reasoning consists of the meta-level control of computational activities and the introspective monitoring of reasoning [114]. The concept has been successfully applied in Neuroscience under the umbrella of Meta-analysis for the synthesis of quantitative data from multiple independent models [115].
Compared to meta-learning, which focuses on the efficient use of data at the ground level, meta-reasoning emphasizes the efficient use of computational models and resources at the object level, which is crucial for the trustworthiness of AI systems. We advocate that the achieving explainability of AI systems by projecting the problem into the reward space for a reward-driven explainability is a new research trend. This simplification avoids the data-driven chaotic systems that are difficult to define with the reductionist view expected by trustworthy AI [116, 117].
Fig. 4 Duality in reasoning and acting
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Diagram: Action-Perception Cycle
### Overview
The image is a diagram illustrating the action-perception cycle, showing the flow of information and control between three levels: Ground Level, Object Level, and Meta-Level. The diagram emphasizes the cyclical nature of action and perception, with feedback loops between the levels.
### Components/Axes
* **Title:** Action-perception cycle
* **Levels:**
* Ground Level (Doing)
* Object Level (Reasoning)
* Meta-Level (Metareasoning)
* **Flow of Information:**
* Action Selection: From Ground Level to Object Level
* Perception: From Object Level to Ground Level
* Control: From Meta-Level to Object Level
* Monitoring: From Object Level to Meta-Level
### Detailed Analysis
The diagram consists of three rounded rectangles, each representing a level in the action-perception cycle.
* **Ground Level:** Located on the left side of the diagram. Labeled "Ground Level" inside the rectangle and "Doing" below it. An arrow labeled "Action Selection" points from the Ground Level to the Object Level. An arrow labeled "Perception" points from the Object Level back to the Ground Level.
* **Object Level:** Located in the center of the diagram. Labeled "Object Level" inside the rectangle and "Reasoning" below it.
* **Meta-Level:** Located on the right side of the diagram. Labeled "Meta - Level" inside the rectangle and "Metareasoning" below it. An arrow labeled "Control" points from the Meta-Level to the Object Level. An arrow labeled "Monitoring" points from the Object Level to the Meta-Level.
The three levels are enclosed in a light blue box.
### Key Observations
* The diagram highlights a hierarchical structure, with the Ground Level representing basic actions, the Object Level representing reasoning and object manipulation, and the Meta-Level representing higher-level control and monitoring.
* The arrows indicate the flow of information and control between the levels, emphasizing the cyclical nature of the action-perception process.
* The labels "Doing," "Reasoning," and "Metareasoning" provide context for the function of each level.
### Interpretation
The diagram illustrates a cognitive architecture where actions are initiated at the Ground Level, processed and reasoned about at the Object Level, and monitored and controlled at the Meta-Level. The feedback loops between the levels allow for continuous adaptation and refinement of actions based on perception and higher-level goals. The diagram suggests that intelligent behavior arises from the interaction of these three levels, with each level playing a distinct but interconnected role in the action-perception cycle. The "Action Selection" and "Perception" arrows between the Ground and Object levels indicate a tight coupling between action and sensory input. The "Control" and "Monitoring" arrows between the Object and Meta levels suggest that higher-level cognitive processes are involved in guiding and evaluating actions.
</details>
The reasoning and explainability of AI share a common goal at the meta-level: at the object level, to explain the observation of the ground level (action-perception). The goal of meta-level control is to improve the quality of its decision-making by determine what and how much reasoning to perform, rather than focusing solely on actions. The goal of the explainability is to verify of the model consistent with its design.
In [118], authors identified variants of meta-reasoning. Suppose there is a fixed set of possible plans of action (decision) that the agent can choose from, the agent has some extant expected for each plan. The agent can take some deliberation actions on each plan; depending on the rewards of the deliberation action, the expected utility of that plan changes. The goal here is to find a deliberation strategy that maximizes the expected utility/reward of the agent. Another variant is that the agent knows that there are multiple states in clarification/prediction, to obtain nonzero utility, the agent needs to determine (by deliberation) the state with certainty.
## B. Trustworthy autonomous systems and domain randomization
The main challenges in achieving explainability involve establishing a mathematical framework for monitoring and control at the meta-level. Bayesian based networks allow us to learn a probability distribution over possible behaviors of neural networks, bridging the information between the ground levels and object levels. To do so, techniques such as trustworthy autonomous systems and domain randomization are integrated to create more explainable AI systems at the reward space. Trustworthy autonomous systems and domain randomization are not inherently "reward-based" by definition, but they can involve reward-based mechanism.
Trust is a psychological state that can be established through interactions with corresponding agents. Trust in AI can be built by interacting with autonomous systems. Given that the AI in trustworthy autonomous systems [119] is directly exposed to the reward space, its explainability can be observed and verified by explaining the behavior of the corresponding autonomous systems according to their design. Meanwhile, domain generalization enables AI to make decisions with less reliance on a distributed training area. It aims to learn a generalizable model from multiple known source domains and then directly generalize to an unseen target domain without additional adaptation. This approach has been widely studied for creating more robust neural networks by transferring source images to different styles in spatial space to learn domain-agnostic features. This significantly reduces the impact of network errors, allowing explainability to focus solely on the real rewards generated by ground-level information.
Domain randomization has been used in robotic training [120-124] and image clarification [125-127] the required realworld data is typically prohibitively expensive to acquire, or fragile to external disturbance. Unfortunately, such polices are often not transferable to the real world due to a mismatch between the simulation and reality, called 'reality gap'. Domain randomization methods address this problem by randomizing the physics simulator (source domain) during training according to a distribution over domain parameters in order to obtain more robust policies capable of overcoming the reality gap. It manipulates the training data according to rewards e.g. learning in some specific simulations or deliberately adding random noise in the training data could improve the robustness of the neural network.
In [128], the authors proposed style randomization, a feature-level augmentation strategy, can increase the networks' generalization capability simply by diversifying the source domains. In [129], authors proposed a Variance Reduced Domain Randomization (VRDR) approach for policy gradient methods, to strike a tradeoff between the variance reduction and computational complexity for the practical implementation. In [130], the authors proposed a single domain generalization for remote sensing image segmentation via domain randomization
of texture and style information. In [131], the authors proposed an unsupervised cross-domain object detection method based on multi-domain randomization. Domain randomization parameter callback module is devised to retain the key detection information of the object, thereby improving the model's stability. A source domain consistency loss is incorporated to enhance the convergence speed of the model and amplify the semantic information embedded within the features.
## C. Large Language Models in explainable AI
Recent advancements in Large Language Models (LLMs) have significantly enhanced the explainability of AI through automated and structured reasoning capabilities. The exceptional abilities of LLMs in natural language understanding and generation are vital for orchestrating metareasoning, which helps identify the most appropriate explanations for AI systems based on observations. This rapidly growing field has seen substantial progress over the past year and is poised to play a crucial role in various approaches to achieving explainable AI.
The authors in [132], [133], and [134] use Chain-ofThoughts and Tree-of-Thoughts to convert LLMs into reasoners, thereby explaining the potential of AI from a problem-solving perspective. While these methods enhance explainability in targeted scenarios, they fall short of achieving consistent performance across different tasks [135]. This limitation can be mitigated by meta-reasoning, which ensures the monitoring and control of the reasoning paradigm at the meta level [116]. Therefore, a key advantage of integrating meta-reasoning with LLMs is the ability to adjust strategies based on the context and specific task requirements. This is essential for addressing the diversity and complexity of realworld problems and has been applied to Meta-Reasoning Prompting (MRP), which endows LLMs with adaptive explaining capabilities [135]. the authors in [137] proposed a novel approach, which to integrating Shapley Additive exPlanations (SHAP) values with LLMs to enhance transparency and trust in intrusion detection. In [138], the authors combine Markov logic networks (MLNs) with external knowledge extracted using LLMs, aiming for improved both interpretability and accuracy. In [139], domain-experts were integrated in the prompt engineering, as man-in-the-loop, authors designed the explanation as a textual template, which is filled and completed by the LLM. [140] compared global rulebased models (LLM and DT) with well-established black box models. Rule-based models has simpler shapes than the ones resulting from more complex black-box models like Support Vector Machine (SVM) or Neural Networks.
## VI. CONCLUSION
In this paper, first surveyed the state-of-the-art standards and developments from various countries and regions on the ethical elements that make AI algorithms trustworthy. We then surveyed the techniques used in achieving explainable AI. Lastly, we identify the new trends in addressing explainability, and also listed potential solutions.
## REFERENCES
- [1] H. Liu, Y. Wang, W. Fan, X. Liu, Y. Li, S. Jain, Y. Liu, A. Jain, and J. Tang, 'Trustworthy AI: A Computational Perspective', ACM Trans. Intell. Syst. Technol. 14, 1, Article 4, 2023, 59 pages. https://doi.org/10.1145/3546872
- [2] IEEE ECPAIS: https://oecd.ai/en/catalogue/tools/ieee-ethicscertification-program-for-autonomous-and-intelligent-systems-ecpais
- [3] V. Hassija, V. Chamola, A. Mahapatra, et al, 'Interpreting Black-Box Models: A Review on Explainable Artificial Intelligence', Cogn Comput (2023). https://doi.org/10.1007/s12559-023-10179-8
- [4] M. Du, F. Yang, N. Zou and X. Hu, "Fairness in Deep Learning: A Computational Perspective," in IEEE Intelligent Systems, vol. 36, no. 4, pp. 25-34, 1 July-Aug. 2021, doi: 10.1109/MIS.2020.3000681.
- [5] DARPA: https://www.darpa.mil/program/explainable-artificialintelligence 2850
- [6] Text adopted -Trusted Artificial Intelligence Industry Ecology Development Report (2022) - China Academy of Information and Communications Technology. Available at: http://www.caict.ac.cn/sytj/202209/t20220913\_408839.htm (Accessed: 17 October 2023).
- [7] EU AI HELG: https://digital-strategy.ec.europa.eu/en/policies/expertgroupai#:~:text=The%20AI%20HLEG%20has%20worked,society%2C%20 EU%20citizens%20and%20policymakers.
- [8] Texts adopted - Civil Law Rules on Robotics - Thursday, 16 February 2017 europarl.europa.eu. Available at: https://www.europarl.europa.eu/doceo/document/TA-8-2017-0051\_EN.html (Accessed: 17 October 2023).
- [9] Europe's Digital Decade: digital targets for 2030 European Commission. Available at: https://commission.europa.eu/strategy-andpolicy/priorities-2019-2024/europe-fit-digital-age/europes-digitaldecade-digital-targets-2030\_en (Accessed: 18 October 2023).
- [10] DOD Adopts Ethical Principles for Artificial Intelligence U.S. Department of Defense. Available at: https://www.defense.gov/News/Releases/release/article/2091996/dodadopts-ethical-principles-for-artificial-intelligence/ (Accessed: 17 October 2023)
- [11] DOD Adopts 5 Principles of Artificial Intelligence Ethics U.S. Department of Defense. Available at: https://www.defense.gov/News/NewsStories/article/article/2094085/dod-adopts-5-principles-of-artificialintelligence-ethics/ (Accessed: 17 October 2023).
- [12] Trustworthy and Responsible AI, NIST. Available at: https://www.nist.gov/trustworthy-and-responsible-ai (Accessed: 17 October 2023).
- [13] Ethics guidelines for trustworthy AI (2019) Shaping Europe's digital future. Available at: https://digitalstrategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai (Accessed: 17 October 2023).
- [14] About the Japanese Society for Artificial Intelligence Ethical Guidelines Ethics Committee of the Japanese Society for Artificial Intelligence. Available at: https://www.ai-gakkai.or.jp/ai-elsi/archives/514 (Accessed: 17 October 2023).
- [15] L. Floridi, J. Cowls, M. Beltrametti, R. Chatila, P. Chazerand, V. Dignum, C. Luetge, R. Madelin, U. Pagallo, F. Rossi, and B. Schafer, 'An ethical framework for a good AI society: Opportunities, risks, principles, and recommendations'. Ethics, Governance, and Policies in Artificial Intelligence / [ed] Luciano Floridi, Springer Nature, 2021, p. 21p. 19-39
- [16] W. R. Swartout and J. D. Moore, ''Explanation in expert systems: A survey,'' Univ. Southern California, Los Angeles, CA, USA, Tech. Rep. ISI/RR-88-228, 1988.
- [17] D. Gunning and D. Aha, 'DARPA's Explainable Artificial Intelligence (XAI) Program', AI Magazine, 40(2), pp. 44-58. doi: 10.1609/aimag.v40i2.2850, 2019
- [18] M. van Lent, W. Fisher, and M. Mancuso, 'An explainable artificial intelligence system for small-unit tactical behavior,'' in Proc. 16th Conf. Innov. Appl. Artif. Intell., 2004, pp. 900-907.
- [19] P. Linardatos, V. Papastefanopoulos, and S. Kotsiantis, 'Explainable AI: A Review of Machine Learning Interpretability Methods', MDPI Entropy 2021, 23(1), 18; https://doi.org/10.3390/e23010018, Special issue: Theory and Applications of Information Theoretic Machine Learning
- [20] C. Yang, A. Rangarajan, and S. Ranka. (2018). ''Global model interpretation via recursive partitioning.'' [Online]. Available: https://arxiv. org/abs/1802.04253.
- [21] A. Nguyen, A. Dosovitskiy, J. Yosinski, T. Brox, and J. Clune, ''Synthesizing the preferred inputs for neurons in neural networks via deep generator networks,'' in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2016, pp. 3387-3395.
- [22] D. Erhan, A. Courville, and Y. Bengio, ''Understanding representations learned in deep architectures,'' Dept. d'Informatique Recherche Operationnelle, Univ. Montreal, Montreal, QC, Canada, Tech. Rep. 1355, 2010.
- [23] M. T. Ribeiro, S. Singh, and C. Guestrin, '''Why should i trust you?': Explaining the predictions of any classifier,'' in Proc. 22nd ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2016, pp. 11351144.
- [24] S. M. Lundberg and S. I. Lee, ''A unified approach to interpreting model predictions,'' in Proc. Adv. Neural Inf. Process. Syst., 2017, pp. 47684777.
- [25] R. Fong and A. Vedaldi, ''Interpretable explanations of black boxes by meaningful perturbation.'' [Online]. 2017, Available: https://arxiv.org/abs/1704.03296
- [26] P.-J. Kindermans et al., ''Learning how to explain neural networks: PatternNet and patternAttribution,'' in Proc. Int. Conf. Learn. Represent., 2018, pp. 1-16. Accessed: Jun. 6, 2018. [Online]. Available: https://openreview.net/forum?id=Hkn7CBaTW
- [27] A. Ross, M. C. Hughes, and F. Doshi-Velez, ''Right for the right reasons: Training differentiable models by constraining their explanations,'' in Proc. Int. Joint Conf. Artif. Intell., 2017, pp. 2662-2670.
- [28] R. Guidotti, A. Monreale, S. Ruggieri, D, Pedreschi, F. Turini, and F. Giannotti. (2018). ''Local rule-based explanations of black box decision systems.'' [Online]. Available: https://arxiv.org/abs/1805.10820
- [29] A. B., Arrieta, N. Dí az-Rodrí guez, J. Del Ser, A. Bennetot, S. Tabik, A. Barbado, S. Garcia, S. Gil-Lopez, D. Molina, R. Benjamins, R. Chatila, and F. Herrera, 'Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible A', Information Fusion, 2020, 58, pp. 82-115 Available at: 10.1016/j.inffus.2019.12.012.
- [30] Z. Chen, Y. Fu, Y. Wang, L. Ma, W. Liu, and M. Hebert, 'Image deformation meta-networks for one-shot learning'. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8680-8689
- [31] Z. Chen, Y. Fu, K. Chen, and Y. Jiang, 'Image block augmentation for one-shot learning'. In Proceedings of the AAAI Conference on Artificial Intelligence, 2019, Vol. 33, No. 01, pp. 3379-3386
- [32] Z. Chen, Y. Fu, Y. Zhang, Y. Jiang, X. Xue, and L. Sigal, 'Multi-level semantic feature augmentation for one-shot learning'. IEEE Transactions on Image Processing, 2019, 28(9), pp.4594-4605.
- [33] J. Snell, K. Swersky, and R. Zemel, 'Prototypical networks for few-shot learning'. 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
- [34] F. Pahde, M.M. Puscas, T. Klein, M. Nabi, 'Multimodal prototypical networks for few-shot learning', Proceeding of IEEE Winter Conference on Applications of Computer Vision, WACV 2021, Waikoloa, HI, USA, January 3-8, 2021, IEEE, 2021, pp. 2643-2652, http://dx.doi.org/10.1109/WACV48630.2021.00269.
- [35] F. Pahde, O. Ostapenko, P. Jä hnichen, T. Klein, M. Nabi, 'Self-paced adversarial training for multimodal few-shot learning', Proceeding of IEEE Winter Conference on Applications of Computer Vision, WACV 2019, Waikoloa Village, HI, USA, January 7-11, 2019, IEEE, 2019, pp. 218-226, http://dx.doi.org/10. 1109/WACV.2019.00029.
- [36] C. Xing, N. Rostamzadeh, B. Oreshkin, and P. O., Pinheiro, 'Adaptive cross-modal few-shot learning'. Advances in Neural Information Processing Systems, 32. 2019
- [37] B. Letham, C. Rudin, T. H. McCormick, and D. Madigan, ''Interpretable classifiers using rules and Bayesian analysis: Building a better stroke prediction model,'' Ann. Appl. Statist., vol. 9, no. 3, pp. 1350-1371, 2015.
- [38] R. Caruana, Y. Lou, J. Gehrke, P. Koch, M. Sturm, and N. Elhadad, ''Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission,'' in Proc. 21th ACMSIGKDD Int. Conf. Knowl. Discovery Data Mining, 2015, pp. 1721-1730.
- [39] K. Xu, J. Ba, R. Kiros, K. Cho, A. C. Courville, R. Salakhutdinov, R. S. Zemel, and Y. Bengio, 'Show, Attend and Tell: Neural Image Caption Generation with Visual Attention'. Proceeding of 32nd International Conference on Machine Learning Research. 37:2048-2057, 2015
- [40] B. Ustun and C. Rudin, ''Supersparse linear integer models for optimized medical scoring systems,'' Mach. Learn., vol. 102, no. 3, pp. 349-391, 2015.
- [41] L. Breiman, ''Statistical modeling: The two cultures (with comments and a rejoinder by the author),'' Stat. Sci., vol. 16, no. 3, pp. 199-231, 2001.
- [42] J. Tobias Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller, 'Striving for simplicity: The all convolutional net,' 2014, arXiv:1412.6806. [Online]. Available: http://arxiv.org/abs/1412.6806.
- [43] J. Imanuel, L. Kintanswari, H. Lucky, and A. Chowanda, 'Explainable Artificial Intelligence (XAI) on Hoax Detection Using Decision Tree C4.5 Method for Indonesian News Platform', 2022 Intl Conf of Science & Technology in Smart Administration, 2022
- [44] M. David, E. S. Mbabazi, J. Nakatumba-Nabende and G. Marvin, 'Crime Forecasting using Interpretable Regression Techniques', Proceedings of the 7th International Conference on Trends in Electronics and Informatics, 2023
- [45] T. Xiang, P. Z. Wu, S. Yuan, 'Application Analysis of Combining BP Neural Network and Logistic Regression in Human Resource Management System', Computational Intelligence and Neuroscience, 2022, pp. 1-11. doi: 10.1155/2022/7425815.
- [46] A. K. Panda, B. Kosko, 'Bayesian Pruned Random Rule Foams for XAI', 2021 IEEE International Conference on Fuzzy Systems (FUZZIEEE)
- [47] C. A. Escobar, and R. Morales-Menendez, 'Process-Monitoring-forQuality - A Model Selection Criterion for Support Vector Machine', Procedia Manufacturing, 34, pp. 1010-1017 Available at: 10.1016/j.promfg. 2019.06.094.
- [48] A. Nair, D. Reckien, and M.F.A.M van Maarseveen, 'Generalised fuzzy cognitive maps: Considering the time dynamics between a cause and an effect', Applied Soft Computing, 92, pp. 106309 Available at: 10.1016/j.asoc.2020.106309.
- [49] Y. Kim, P. Panda, 'Visual explanations from spiking neural networks using inter-spike intervals'. Sci Rep 11, 19037 (2021). https://doi.org/10.1038/s41598-021-98448-0
- [50] H. Wu and B. Li, "Customer Purchase Prediction Based on Improved Gradient Boosting Decision Tree Algorithm," 2nd International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 2022, pp. 795-798, doi: 10.1109/ICCECE54139.2022.9712779.
- [51] R. Hatami, 'Development of a protocol for environmental impact studies using causal modelling', Water research, 138, pp. 206-223 Available at: 10.1016/j.watres.2018.03.034.
- [52] L. Wang, J. Zhou, J. Wei, M. Pang, and M. Sun, M. 'Learning causal Bayesian networks based on causality analysis for classification', Engineering Applications of Artificial Intelligence, 114, pp. 105212 Available at: 10.1016/j.engappai.2022.105212.
- [53] I. S. A. Abdelhalim, M. F. Mohamed, Y. B. Mahdy, 'Data augmentation for skin lesion using self-attention based progressive generative adversarial network', Expert Systems with Applications, 165, pp. 113922 Available at: 10.1016/j.eswa.2020.113922.
- [54] P. Rodrí guez; M. Caccia, et. al., 'Beyond Trivial Counterfactual Explanations with Diverse Valuable Explanations', proceeding of 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021
- [55] B. Liu, M. Lai, 'Advanced Machine Learning for Financial Markets: A PCA-GRU-LSTM Approach'. J. Knowl Econ (2024). https://doi.org/10.1007/s13132-024-02108-3
- [56] F. Luus, N. Khan, and I. Akhalwaya. 'Interactive Supervision with tSNE'. Proceedings of the 10th International Conference on Knowledge Capture (K-CAP '19). Association for Computing Machinery, New York, NY, USA, 85-92. https://doi.org/10.1145/3360901.3364414, 2019
- [57] H. Han, W. Li, J. Wang, G. Qin, and X. Qin, 'Enhance explainability of manifold learning', Neurocomputing, 500, pp. 877-895 Available at: 10.1016/j.neucom.2022.05.119.
- [58] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh, ''VQA: Visual question answering,'' in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2015, pp. 2425-2433.
- [59] A. Chandrasekaran and P. Chattopadhyay, ''Do explanations make VQA models more predictable to a human?'' in Proc. Conf. Empirical Methods Natural Lang. Process., 2018, pp. 1036-1042.
- [60] D. H. Park, L. A. Hendricks, Z. Akata, A. Rohrbach, B. Schiele, T. Darrell, and M. Rohrbach, ''Multimodal explanations: Justifying decisions and pointing to the evidence,'' in Proc. IEEE Conf. Comput.
Vis. Pattern Recognit., Jun. 2018, pp. 8779-8788. [Online]. Available: https://arxiv.org/abs/1802.08129.
- [61] M. Hind, D. Wei, M. Campbell, N. C. F. Codella, A. Dhurandhar, A. Mojsilović, K. N. Ramamurthy, and K. R. Varshney, ''TED: Teaching AI to explain its decisions,'' in Proc. AAAI/ACM Conf. AI, Ethics, Soc., 2019, pp. 123-129.
- [62] J. Strout, Y. Zhang, and R. J. Mooney, ''Do human rationales improve machine explanations?'' 2019, arXiv:1905.13714. [Online]. Available: http://arxiv.org/abs/1905.13714
- [63] S. Becker, M. Ackermann, S. Lapuschkin, K. R. Mü ller, and W. Samek, 'Interpreting and explaining deep neural networks for classification of audio signals'. arXiv preprint arXiv:1807.03418, 1. 2018
- [64] E. Mohamed, K. Sirlantzis, and G. Howells, 'A review of visualisationas-explanation techniques for convolutional neural networks and their evaluation', Displays, 73, pp. 102239 Available at: 10.1016/j.displa.2022.102239.
- [65] N. Dehimi; Z. Tolba, 'Attention Mechanisms in Deep Learning : Towards Explainable Artificial Intelligence' 2024 6th International Conference on Pattern Analysis and Intelligent Systems (PAIS)
- [66] R. C. Fong and A. Vedaldi, ''Interpretable explanations of black boxes by meaningful perturbation,'' in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 3429-3437.
- [67] A. Sharma, R. Rai, Z. Zhang, 'The interpretive model pf manufacturing: a theoretical framework and research agenda for machine learning in manufacturing', Intl J. of Production Research, June 2021, DOI: 10.1080/00207543.2021.1930234
- [68] A. Adadi and M. Berrada, "Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI)," in IEEE Access, vol. 6, pp. 52138-52160, 2018, doi: 10.1109/ACCESS.2018.2870052.
- [69] O. Bastani, C. Kim, and H. Bastani, 'Interpretability via model extraction.' [Online]. Available: https://arxiv.org/abs/1706.09773, 2017
- [70] J. J. Thiagarajan, B. Kailkhura, P. Sattigeri, and K. N. Ramamurthy. (2016). 'TreeView: Peeking into deep neural networks via feature-space partitioning.' [Online]. Available: https://arxiv.org/abs/1611.07429
- [71] Z. Liu, Y. Shen, V. B. Lakshminarasimhan, P. P. Liang, A. Zadeh, and L. P. Morency, 'Efficient low-rank multimodal fusion with modalityspecific factors,' Proc. 56th Annu. Meeting Assoc. Comput. Linguistics, 2018, pp. 2247-2256, doi: 10.18653/v1/p18-1209.
- [72] R. Berk and J. Bleich, 'Statistical procedures for forecasting criminal behavior: A comparative assessment,' Criminol. Public Policy, vol. 12, no. 3, pp. 513-544, 2013.
- [73] A. Goldstein, A. Kapelner, J. Bleich, and E. Pitkin, 'Peeking inside the black box: Visualizing statistical learning with plots of individual conditional expectation', J. Comput. Graph. Statist., vol. 24, no. 1, pp. 44-65, 2015, doi: 10.1080/10618600.2014.907095.
- [74] G. Casalicchio, C. Molnar, and B. Bischl. (2018). 'Visualizing the feature importance for black box models.' [Online]. Available: https://arxiv.org/abs/1804.06620.
- [75] K. Sokol, P. Flach, 'One Explanation Does Not Fit All'. Kü nstl Intell 34, 235-250, 2020. https://doi.org/10.1007/s13218-020-00637-y
- [76] K. Weitz, D. Schiller, R. Schlagowski, T. Huber, and E. André, 'Let me explain!', Exploring the potential of virtual agents in explainable ai interaction design,'' J. Multimodal User Interfaces, 2020, pp. 1-12.
- [77] J. Rebanal, Y. Tang, J. Combitsis, K.-W. Chang, and X. Chen, 'XAlgo: Explaining the internal states of algorithms via question answering,' 2020, arXiv:2007.07407. [Online]. Available: https://arxiv.org/abs/2007.07407.
- [78] K. Alipour, J. P. Schulze, Y. Yao, A. Ziskind, and G. Burachas, ''A study on multimodal and interactive explanations for visual question answering,'' 2020, arXiv:2003.00431
- [79] D. Braines and D. Harborne, ''Multimodal explanations for ai-based multisensor fusion,'' in Proc. RSM Artif. Intell. Military Multisensor Fusion Engines, 2018, pp. 1-13.
- [80] T. Hailesilassie, 'Rule extraction algorithm for deep neural networks: A review'. arXiv preprint arXiv:1610.05267. 2016
- [81] G. Ras, M. V., Gerven, and W. P., Haselager, 'Explanation Methods in Deep Learning: Users, Values, Concerns and Challenges'. ArXiv, abs/1803.07517. 2018
- [82] P. Sadowski, J. Collado, D. Whiteson, and P. Baldi, 'Deep learning, dark knowledge, and dark matter,' Proc. NIPSWorkshop High-Energy Phys. Mach. Learn. (PMLR), vol. 42, 2015, pp. 81-87.
- [83] G. Hinton, O. Vinyals, and J. Dean. 'Distilling the knowledge in a neural network.' [Online]. Available: https://arxiv.org/abs/1503.02531, 2015
- [84] S. Tan, 'Interpretable approaches to detect bias in black-box models,' in Proc. AAAI/ACM Conf. AI Ethics Soc., 2017, pp. 1-2.
- [85] Z. Che, S. Purushotham, R. Khemani, and Y. Liu, 'Distilling knowledge from deep networks with applications to healthcare domain' arXiv preprint arXiv:1512.03542. 2015
- [86] K. Xu, D. H., Park, C. Yi, C. and C. Sutton, 'Interpreting deep classifier by visual distillation of dark knowledge'. arXiv preprint arXiv:1803.04042. 2018
- [87] S. Tan, R. Caruana, G. Hooker, and Y. Lou, 'December. Distill-andcompare: Auditing black-box models using transparent model distillation'. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society (pp. 303-310).
- [88] Y. Zhang and B. Wallace. 'A sensitivity analysis of (and practitioners' Guide to) convolutional neural networks for sentence classification.' [Online]. Available: https://arxiv.org/abs/1510.03820. 2016
- [89] P. Cortez and M. J. Embrechts, 'Using sensitivity analysis and visualization techniques to open black box data mining models,' Inf. Sci., vol. 225, pp. 1-17, Mar. 2013.
- [90] P. Cortez and M. J. Embrechts, 'Opening black box data mining models using sensitivity analysis,' in Proc. IEEE Symp. Comput. Intell. Data Mining (CIDM), Apr. 2011, pp. 341-348.
- [91] S. Bach, A. Binder, G. Montavon, F. Klauschen, K.-R. Mü ller, and W. Samek, 'On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation,' PLoS ONE, vol. 10, no. 7, p. e0130140, 2015.
- [92] A. Delaforge, J. Azé , S. Bringay, C. Mollevi, A. Sallaberry, and M. Servajean, 'Ebbe-text: Explaining neural networks by exploring text classification decision boundaries'. IEEE Transactions on Visualization and Computer Graphics. Vol. 29, Issue 10, pp 4154 - 4171, 2022
- [93] A. Fisher, C. Rudin, and F. Dominici. 'Model class reliance: Variable importance measures for any machine learning model class, from the 'rashomon' perspective.' [Online]. Available: https://arxiv.org/abs/1801.01489. 2018
- [94] G. Casalicchio, C. Molnar, and B. Bischl. 'Visualizing the feature importance for black box models.' [Online]. Available: https://arxiv.org/abs/1804.06620, 2018
- [95] A. Rai, 'Explainable AI: from black box to glass box'. J. of the Acad. Mark. Sci. 48, 137-141 (2020). https://doi.org/10.1007/s11747-01900710-5
- [96] S. Wachter, B. D. Mittelstadt, and C. Russell, 'Counterfactual Explanations Without Opening the Black Box: Automated Decisions and the GDPR'. Harvard Journal of Law & Technology, 2017
- [97] A. H. Karimi, B. Schö lkopf, and I. Valera, 'Algorithmic recourse: from counterfactual explanations to interventions'. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, pp. 353362.
- [98] X. Li, H. Xiong, X. Li, X. Zhang, J. Liu, H. Jiang, Z. Chen, Z. and D. Dou, 'G-LIME: Statistical learning for local interpretations of deep neural networks using global priors', Artificial Intelligence, 314, pp. 103823 Available at: 10.1016/j.artint.2022.103823.
- [99] X. Xin, G. Hooker, and F. Huang, 'Why You Should Not Trust Interpretations in Machine Learning: Adversarial Attacks on Partial Dependence Plots, arXiv.org. Available at: https://arxiv.org/abs/2404.18702 (Accessed: 6 July 2024).
- [100] Z. Song, S. Cao, and H. Yang, 'An interpretable framework for modeling global solar radiation using tree-based ensemble machine learning and Shapley additive explanations methods', Applied Energy, 364, pp. 123238 Available at: 10.1016/j.apenergy.2024.123238. 2024
- [101] T. Clement, N. Kemmerzell, M. Abdelaal, and M. Amberg, M. (2023) 'XAIR: A Systematic Metareview of Explainable AI (XAI) Aligned to the Software Development Process', MDPI. Multidisciplinary Digital Publishing Institute. Available at: https://www.mdpi.com/25044990/5/1/6, 2023, (Accessed: 6 July 2024).
- [102] A. Berkin, W. Aerts, W. and T. Van Caneghem, 'Feasibility analysis of machine learning for performance-related attributional statements', International Journal of Accounting Information Systems, 48, pp. 100597 Available at: 10.1016/j.accinf.2022.100597. 2023
- [103] Y. Zhang, Y., Tan, H. Sun, Y. Zhao, Q. Zhang, and Y. Li, 'Improving the invisibility of adversarial examples with perceptually adaptive perturbation', Information Sciences, 635, pp. 126-137 Available at: 10.1016/j.ins.2023.03.139. 2023
- [104] F. Yin, Z. Shi, C. J. Hsieh, and K. W. Chang, 'On the sensitivity and stability of model interpretations in NLP'. arXiv preprint arXiv:2104.08782. 2021
- [105] B. Finzel, A. Saranti, A. Angerschmid, et al. 'Generating Explanations for Conceptual Validation of Graph Neural Networks: An Investigation of Symbolic Predicates Learned on Relevance-Ranked Sub-Graphs'.
Kü nstl Intell 36, 271-285 (2022). https://doi.org/10.1007/s13218-02200781-7
- [106] S. Bhakat and G. Ramakrishnan. 'Anomaly Detection in Surveillance Videos'. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data (CODS-COMAD '19). Association for Computing Machinery, New York, NY, USA, 252255. https://doi.org/10.1145/3297001.3297034
- [107] K. Chanasit, E. Chuangsuwanich, A. Suchato and P. Punyabukkana, 'A Real Estate Valuation Model Using Boosted Feature Selection,' in IEEE Access, vol. 9, pp. 86938-86953, 2021, doi: 10.1109/ACCESS.2021.3089198.
- [108] K. Simonyan, A. Vedaldi, and A. Zisserman, 'Deep inside convolutional networks: Visualising image classification models and saliency maps'. arXiv preprint arXiv:1312.6034. 2013
- [109] Y. Matsubara, D. Callegaro, S. Baidya, M. Levorato and S. Singh, "Head Network Distillation: Splitting Distilled Deep Neural Networks for Resource-Constrained Edge Computing Systems," in IEEE Access, vol. 8, pp. 212177-212193, 2020, doi: 10.1109/ACCESS.2020.3039714.
- [110] A. N. Ngaffo, W. E. Ayeb and Z. Choukair, "A Bayesian Inference Based Hybrid Recommender System," in IEEE Access, vol. 8, pp. 101682101701, 2020, doi: 10.1109/ACCESS.2020.2998824.
- [111] Q. Tong, T. Gernay, 'Resilience assessment of process industry facilities using dynamic Bayesian networks', Process Safety and Environmental Protection, 169, pp. 547-563 Available at: 10.1016/j.psep.2022.11.048. 2023
- [112] G. Szepannek, K. Lü bke, 'How much do we see? On the explainability of partial dependence plots for credit risk scoring', Argumenta Oeconomica. No 1 (50) 2023. Available at: https://journals.ue.wroc.pl/aoe/article/view/1047 (Accessed: 6 July 2024).
- [113] C. Patrí cio, J. C. Neves, and F. L. Teixeira. 'Explainable Deep Learning Methods in Medical Image Classification: A Survey'. ACM Comput. Surv. 2023, 56, 4, Article 85 (April 2024), 41 pages. https://doi.org/10.1145/3625287
- [114] M. T. Cox, and A. Raja, 'Metareasoning: A manifesto'. Technical Report, www.mcox.org/Metareasoning/Manifesto.
- [115] Gurevitch, J., Koricheva, J., Nakagawa, S. et al. Meta-analysis and the science of research synthesis. Nature 555, 175-182 (2018). https://doi.org/10.1038/nature25753
- [116] Gross C. G. (2002). The genealogy of the 'grandmother cell.' Neuroscientist 8, 512-518 10.1177/107385802237175
- [117] Roy A. An extension of the localist representation theory: grandmother cells are also widely used in the brain. Front Psychol. 2013 May 24;4:300. doi: 10.3389/fpsyg.2013.00300. PMID: 23745119; PMCID: PMC3662881.
- [118] V. Conitzer, 'Metareasoning as a Formal Computational Problem', AAAI Workshop Papers 2008
- [119] The UKRI Trustworthy Autonomous Systems (TAS) Hub (last accessed 2024) https://tas.ac.uk/
- [120] F. Muratore, C. Eilers, M. Gienger, and J. Peters, 'Data-Efficient Domain Randomization With Bayesian Optimization', IEEE Robotics and Automation Letters, Vol. 6, No. 2, April 2021
- [121] A. Shakerimov , T. Alizadeh, H. A. Varol, 'Efficient Sim-to-Real Transfer in Reinforcement Learning Through Domain Randomization and Domain Adaptation', IEEE Access, Dec., 2023, Digital Object Identifier 10.1109/ACCESS.2023.3339568
- [122] Y. Wang, L. Qi, Y. Shi, Y. Gao, 'Feature-Based Style Randomization for Domain Generalization', IEEE Trans on Circuits and Systems for Video Technology, Vol. 32, No. 8, August 2022
- [123] H. Dong, J. Zhou, C. Qiu, D. K. Prasad, I. Chen, 'Robotic Manipulations of Cylinders and Ellipsoids by Ellipse Detection with Domain Randomization', IEEE/ASME Trans on Mechatronics, Vol. 28, No. 1, February 2023
- [124] J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, P. Abbeel, 'Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World', 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), September 2017, Canada
- [125] J. Huang, D. Guan, A. Xiao, S. Lu, 'FSDR: Frequency Space Domain Randomization for Domain Generalization', 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
- [126] C. Liu, Y. Dong, W. Xiang, W. et al. 'A Comprehensive Study on Robustness of Image Classification Models: Benchmarking and Rethinking'. Int J Comput Vis (2024). https://doi.org/10.1007/s11263-024-02196-3
- [127] Y. Zhang, S. Nie, S. Liang and W. Liu, "Robust Text Image Recognition via Adversarial Sequence-to-Sequence Domain Adaptation," in IEEE Transactions on Image Processing, vol. 30, pp. 3922-3933, 2021, doi: 10.1109/TIP.2021.3066903
- [128] J. Lee, K. Kim, T. Kim, D. Kim, 'Improving Style Randomization via Domain specific Feature Reweighting for Domain Generalization', Proceeding of 2022 30th European Signal Processing Conference (EUSIPCO)
- [129] Y. Jiang, C. Li, W. Dai, J. Zou, H. Xiong, 'Variance Reduced Domain Randomization for Reinforcement Learning With Policy Gradient', IEEE Trans on Pattern Analysis and Machine Intelligence, Vol. 46, No. 2, February, 2024
- [130] C. Liang , W. Li , Y. Dong , W. Fu, 'Single Domain Generalization Method for Remote Sensing Image Segmentation via Category Consistency on Domain Randomization', IEEE Trans on Geoscience and Remote Sensing, Vol. 62, 2024
- [131] F. Luo, J. Liu, G. T. Ho, K. Yan, 'Unsupervised Cross-domain Object Detection via Multiple Domain Randomization', Proceedings of the 2024 27th International Conference on Computer Supported Cooperative Work in Design
- [132] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. 'Chain-of-thought prompting elicits reasoning in large language models'. Advances in neural information processing systems, 35:24824-24837, 2022
- [133] S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y. Cao, and K. Narasimhan. 'Tree of thoughts: Deliberate problem solving with large language models'. Advances in Neural Information Processing Systems, 36, 2024
- [134] M. Yasunaga, X. Chen, Y. Li, P. Pasupat, J. Leskovec, P. Liang, E. H. Chi, and D. Zhou. 'Large language models as analogical reasoners'. arXiv doi.org/10.48550/arXiv.2310.01714 , 2023
- [135] P. Gao, A. Xie, S. Mao, W. Wu, Y. Xia, H. Mi, F. Wei, 'Meta Reasoning for Large Language Models', doi.org/10.48550/arXiv.2406.11698, 2024
- [136] T. L. Griffiths, F. Callaway, M. B. Chang, E. Grant, P. M. Krueger, F. Lieder, 'Doing more with less: meta-reasoning and meta-learning in humans and machines', Current Opinion in Behavioral Sciences, Volume 29, 2019, Pages 24-30,ISSN 2352-1546, https://doi.org/10.1016/j.cobeha.2019.01.005
- [137] A. Khediri, H. Slimi, A. Yahiaoui, M. Derdour, H. Bendjenna, C. E. Ghenai, 'Enhancing Machine Learning Model Interpretability in Intrusion Detection Systems through SHAP Explanations and LLMGenerated Descriptions', 2024 6th International Conference on Pattern Analysis and Intelligent Systems (PAIS)
- [138] H. Zhang, J. Li, Y. Wang, Y. Song, 'Integrating Automated Knowledge Extraction with Large Language Models for Explainable Medical Decision-Making', 2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM)
- [139] H. Abu-Rasheed, C. Weber, M. Fathi, 'Knowledge Graphs as Context Sources for LLM Based Explanations of Learning Recommendations', 2024 IEEE Global Engineering Education Conference (EDUCON)S.
- [140] S. Narteni, V. Orani, E. Cambiaso, M. Rucco, M. Mongelli. 'On the Intersection of Explainable and Reliable AI for Physical Fatigue Prediction', IEEE Access, July 2022, Digital Object Identifier 10.1109/ACCESS.2022.3191907