# A MIND for Reasoning: Meta-learning for In-context Deduction
## Abstract
Large language models (LLMs) are increasingly evaluated on formal tasks, where strong reasoning abilities define the state of the art. However, their ability to generalize to out-of-distribution problems remains limited. In this paper, we investigate how LLMs can achieve a systematic understanding of deductive rules. Our focus is on the task of identifying the appropriate subset of premises within a knowledge base needed to derive a given hypothesis. To tackle this challenge, we propose M eta-learning for IN -context D eduction (MIND), a novel few-shot meta-learning fine-tuning approach. The goal of MIND is to enable models to generalize more effectively to unseen knowledge bases and to systematically apply inference rules. Our results show that MIND significantly improves generalization in small LMs ranging from 1.5B to 7B parameters. The benefits are especially pronounced in smaller models and low-data settings. Remarkably, small models fine-tuned with MIND outperform state-of-the-art LLMs, such as GPT-4o and o3-mini, on this task.
A MIND for Reasoning: Meta-learning for In-context Deduction
Leonardo Bertolazzi 1, Manuel Vargas Guzmán 2, Raffaella Bernardi 3, Maciej Malicki 2, Jakub Szymanik 1, 1 University of Trento, 2 University of Warsaw, 3 Free University of Bozen-Bolzano
## 1 Introduction
Reasoning refers to a broad set of abilities that are applied not only in formal domains, such as mathematics and logic, but also in goal-directed scenarios involving problem-solving and decision-making (Leighton, 2004). All types of reasoning share a common foundation: the capacity to reach an abstract understanding of the problem at hand. With the advent of increasingly capable large language models (LLMs), reasoning has become a central domain for evaluating and comparing these systems (Huang and Chang, 2023; Mondorf and Plank, 2024).
Episode $T$ pt Knowledge Base ( $KB$ ) pt knowledge base: All x1 are x2, All x2 are x4, All x3 are x5, All x10 are x11, All x4 are x6, All x2 are x3, All x5 are x7, Some x5 are not x1, All x9 are x10, All x6 are x8, All x8 are x9, Some x11 are not x4 pt Study Examples ( $S^supp$ ) pt <STUDY> hypothesis: All x8 are x11 premises: All x8 are x9, All x9 are x10, All x10 are x11; hypothesis: All x1 are x3 premises: All x1 are x2, All x2 are x3; … pt Query Hypothesis ( $x^query$ ) <QUERY> hypothesis: All x3 are x7 pt Query Premises ( $y^query$ ) premises: All x3 are x5, All x5 are x7 pt Input pt Output
Figure 1: Overview of a MIND episode. Given a set of premises (the knowledge base, $KB$ ), a set of task demonstrations (or study examples, denoted by the <STUDY> tag), and a query hypothesis $x^query$ (denoted by the <QUERY> tag) that is entailed from $KB$ , models must generate the minimal subset of premises $y^query$ from which $x^query$ can be derived. During each MIND episode, models can practice on hypothesis-premise pairs before processing the main query hypothesis. The examples show how we frame syllogistic inferences as a premise selection task.
Despite extensive training on mathematical, programming, and STEM-related data, LLMs continue to struggle in out-of-distribution (OOD) reasoning scenarios. Their performance often deteriorates on longer inference chains than those seen during training (Clark et al., 2021; Saparov et al., 2023), and they exhibit variability when evaluated with perturbed versions of the same problems (Mirzadeh et al., 2025; Gulati et al., 2024; Huang et al., 2025). In particular, LLMs can get distracted by irrelevant context, becoming unable to solve problems they could otherwise solve (Shi et al., 2023; Yoran et al., 2024). These challenges relate to broader debates surrounding generalization versus memorization in LLMs (Balloccu et al., 2024; Singh et al., 2024).
Few-shot meta-learning approaches (Irie and Lake, 2024) have emerged as promising methods for inducing OOD generalization and rapid domain adaptation in LLMs. Specifically, this class of methods has proven effective in few-shot task generalization (Min et al., 2022; Chen et al., 2022), systematic generalization (Lake and Baroni, 2023), and mitigating catastrophic forgetting (Irie et al., 2025).
In this work, we propose M eta-learning for IN -context D eduction (MIND), a new few-shot meta-learning fine-tuning approach for deductive reasoning. As illustrated in Figure 1, we evaluate the effectiveness of this approach using a logical reasoning task grounded in syllogistic logic (Smiley, 1973; Vargas Guzmán et al., 2024). Each problem presents a knowledge base of atomic logical statements. Models are tasked with identifying the minimal subset of premises that logically entail a given test hypothesis. This premise selection task captures a core aspect of deductive reasoning: determining which known facts are necessary and sufficient to justify a conclusion. We apply MIND to small LMs from the Qwen-2.5 family (Qwen Team, 2025), ranging from 1.5B to 7B parameters. Specifically, we assess the generalization capabilities induced by MIND, such as systematically performing inferences over unseen sets of premises, as well as over more complex (longer) or simpler (shorter) sets of premises than those encountered during training. Our code and data are available at: https://github.com/leobertolazzi/MIND.git
Our main contributions are as follows:
- We introduce a new synthetic dataset based on syllogistic logic to study reasoning generalization in LLMs.
- We show that MIND enables LMs to better generalize in OOD reasoning problems with particularly strong performance in smaller models and low-data regimes.
- We demonstrate that small LMs fine-tuned with MIND can outperform state-of-the-art LLMs such as GPT-4o and o3-mini, on our premise selection task.
## 2 Background
### 2.1 Syllogistic Logic
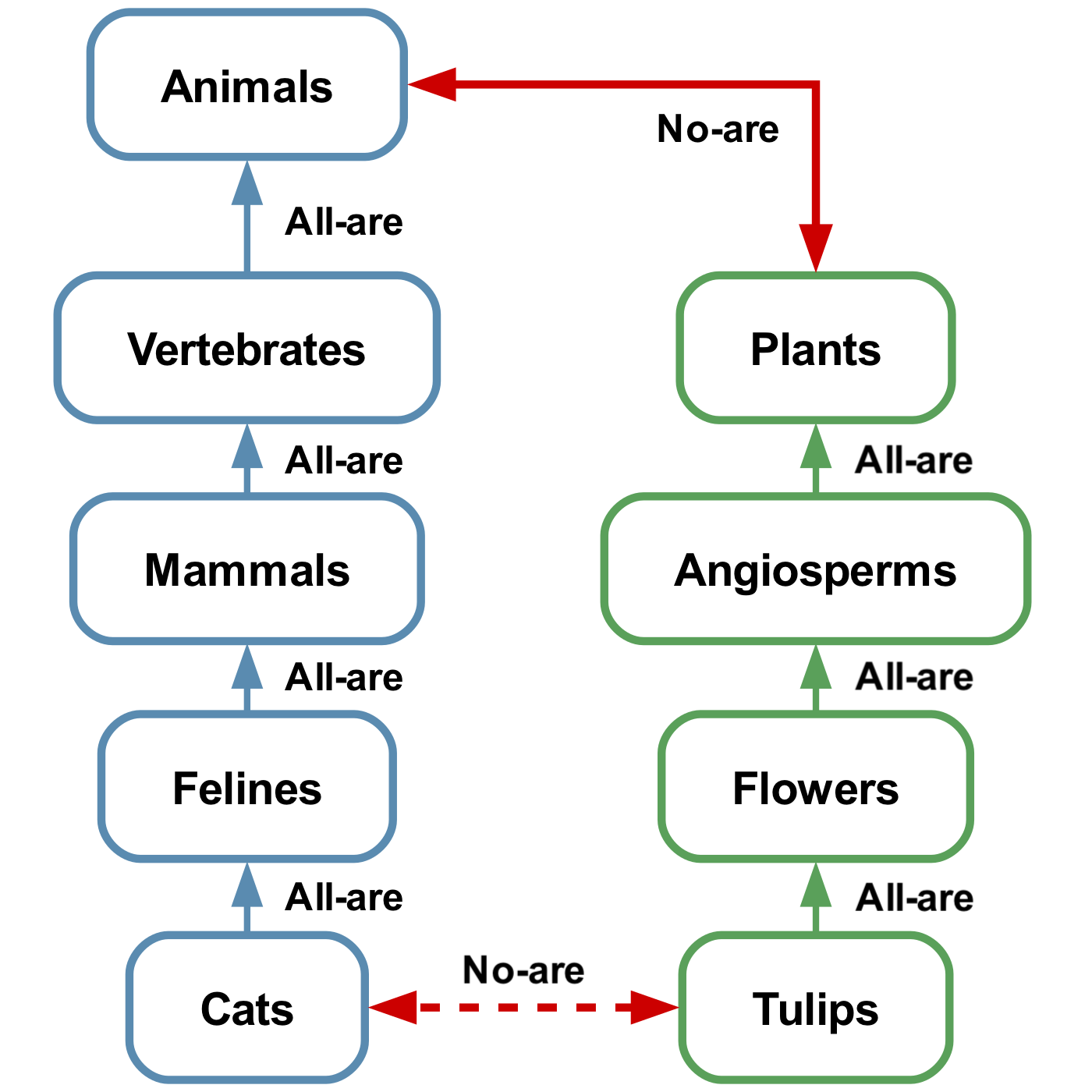
In our experiments, we focus on the syllogistic fragment of first-order logic. Originally, syllogisms have been studied by Aristotle as arguments composed of two premises and a conclusion, such as: “ All dogs are mammals; some pets are not mammals; therefore, some pets are not dogs. ” This basic form can be extended to include inferences involving more than two premises (see Łukasiewicz 1951; Smiley 1973).
<details>
<summary>extracted/6458430/figs/fig_1.png Details</summary>
### Visual Description
## Concept Diagram: Biological Classification Hierarchy
### Overview
The image is a conceptual diagram illustrating hierarchical relationships within biological classification, specifically contrasting the animal and plant kingdoms. It uses a flowchart structure with two distinct, color-coded branches connected by a top-level relationship. The diagram visually represents "is-a" (All-are) and "is-not-a" (No-are) relationships between categories.
### Components/Axes
The diagram consists of two primary vertical chains of rounded rectangular boxes, connected by arrows.
**Left Branch (Animal Kingdom - Blue Borders):**
* **Top Box:** "Animals" (Position: Top-left)
* **Second Box:** "Vertebrates" (Position: Below "Animals")
* **Third Box:** "Mammals" (Position: Below "Vertebrates")
* **Fourth Box:** "Felines" (Position: Below "Mammals")
* **Bottom Box:** "Cats" (Position: Bottom-left)
**Right Branch (Plant Kingdom - Green Borders):**
* **Top Box:** "Plants" (Position: Top-right)
* **Second Box:** "Angiosperms" (Position: Below "Plants")
* **Third Box:** "Flowers" (Position: Below "Angiosperms")
* **Bottom Box:** "Tulips" (Position: Bottom-right)
**Relationship Arrows & Labels:**
1. **Blue Upward Arrows (Left Branch):** Connect each box to the one above it. Each arrow is labeled with the text **"All-are"**.
* Cats -> Felines: "All-are"
* Felines -> Mammals: "All-are"
* Mammals -> Vertebrates: "All-are"
* Vertebrates -> Animals: "All-are"
2. **Green Upward Arrows (Right Branch):** Connect each box to the one above it. Each arrow is labeled with the text **"All-are"**.
* Tulips -> Flowers: "All-are"
* Flowers -> Angiosperms: "All-are"
* Angiosperms -> Plants: "All-are"
3. **Red Horizontal Arrow (Top):** A solid red arrow with arrowheads on both ends connects the "Animals" box to the "Plants" box. It is labeled with the text **"No-are"**.
4. **Red Dashed Arrow (Bottom):** A dashed red arrow with arrowheads on both ends connects the "Cats" box to the "Tulips" box. It is labeled with the text **"No-are"**.
### Detailed Analysis
The diagram establishes two clear, parallel taxonomic hierarchies:
* **Animal Hierarchy:** Cats are a type of Feline. All Felines are Mammals. All Mammals are Vertebrates. All Vertebrates are Animals.
* **Plant Hierarchy:** Tulips are a type of Flower. All Flowers are Angiosperms. All Angiosperms are Plants.
The relationships are defined by two predicate types:
* **"All-are":** Indicates a universal subset relationship (e.g., every member of the lower category is also a member of the higher category).
* **"No-are":** Indicates mutual exclusivity. The top-level "No-are" arrow between "Animals" and "Plants" signifies that these are separate, non-overlapping kingdoms. The bottom-level "No-are" arrow between "Cats" and "Tulips" reinforces this exclusivity at the most specific level shown.
### Key Observations
1. **Symmetrical Structure:** The diagram is visually balanced, with five boxes in the animal branch and four in the plant branch, creating a slight asymmetry at the base.
2. **Color Coding:** Blue is used exclusively for the animal lineage, green for the plant lineage, and red for the negative ("No-are") relationships. This provides immediate visual categorization.
3. **Arrow Direction:** All "All-are" arrows point upward, indicating a movement from specific to general categories. The "No-are" arrows are horizontal, indicating a relationship of opposition or separation between parallel categories.
4. **Dashed vs. Solid Line:** The "No-are" relationship between the top-level kingdoms ("Animals"/"Plants") is shown with a solid line, while the relationship between the most specific examples ("Cats"/"Tulips") is shown with a dashed line. This may imply a difference in the nature or emphasis of the relationship, though the label is identical.
### Interpretation
This diagram is a pedagogical tool designed to teach fundamental concepts in biological taxonomy and set theory logic. It demonstrates:
* **Hierarchical Classification:** How organisms are grouped into increasingly broad categories (from species like Cats/Tulips up to Kingdoms).
* **Inheritance of Properties:** The "All-are" relationship implies that properties of a higher category (e.g., being an Animal) are inherited by all sub-categories (e.g., Vertebrates, Mammals, Felines, Cats).
* **Mutual Exclusivity at the Kingdom Level:** The core "No-are" relationship between Animals and Plants establishes the primary, non-overlapping division in this simplified model of life. The diagram logically deduces that if Cats are Animals and Tulips are Plants, and Animals are not Plants, then Cats cannot be Tulips (the bottom "No-are" arrow).
* **Visual Logic:** The spatial layout and color coding make the abstract logical relationships concrete and easy to follow. The diagram effectively communicates that while there is a deep hierarchy *within* each kingdom, the kingdoms themselves are fundamentally distinct.
</details>
Figure 2: Example inference. Edges labeled “All-are” denote universal affirmatives (e.g., All cats are felines). The solid red edge is a universal negative (No animals are plants). From these “ atomic facts ” we infer No cats are tulips (dashed red edge). Formally, this is expressed as $\{Aa-b, Ac-d, Ebd\}\vDash Eac$ (Smiley, 1973).
#### Syntax and semantics.
The language of syllogistic logic comprises a finite set of atomic terms $\{a,b,c,…\}$ and four quantifier labels $A,E,I$ , and $O$ . Well-formed formulas consists of $Aab$ (“All $a$ are $b$ ”), $Eab$ (“No $a$ are $b$ ”), $Iab$ (“Some $a$ are $b$ ”), and $Oab$ (“Some $a$ are not $b$ ”). Finally, an A-chain, denoted as $Aa-b$ represents the single formula $Aab$ or a sequence of formulas $Aac_1$ , $Ac_1c_2$ , $\dots$ , $Ac_n-1c_n$ , $Ac_nb$ for $n≥ 1$ . A knowledge base ( $KB$ ) is defined as a finite set of formulas (premises).
An inference $F\vDash F$ (i.e., deriving a conclusion from a set of premises) holds when the conclusion $F$ is true in every interpretation (an assignment of non-empty sets to terms) where all formulas in $F$ are true. A set of formulas is consistent if there exists at least one interpretation in which all formulas are simultaneously true.
#### Minimal inferences.
We aim for models to identify the minimal set of premises in a knowledge base to derive a given hypothesis. Formally, we are interested in inferences $F\vDash F$ such that $F^\prime\not\vDash F$ for any proper subset $F^\prime⊂neqF$ . For example, $\{Abc,Abd\}\vDash Icd$ is minimal, while $\{Aab,Abc,Abd\}\vDash Icd$ is not because $Aab$ is not needed to infer the conclusion.
There are seven types of minimal syllogistic inferences. See the full list in Table 4 in Appendix A. To facilitate understanding, Figure 2 provides an intuitive representation of a type 6 inference. Further details about the syllogistic logic can be found in Appendix A.
### 2.2 Meta-learning in Autoregressive Models
Meta-learning, or “learning to learn”, is a paradigm that aims to enable machine learning models to acquire transferable knowledge across multiple tasks, allowing rapid adaptation to new tasks with minimal data. Among the numerous existing meta-learning frameworks (Hospedales et al., 2022), MIND is mainly inspired by Meta-learning Sequence Learners (MSL) (Irie and Lake, 2024).
#### Data organization.
In standard supervised learning, data consists of a static dataset $D_train=\{(x_i,y_i)\}_i=1^N$ where inputs $x_i$ are mapped to targets $y_i$ under a fixed distribution $p(x,y)$ . By contrast, meta-learning organizes data into tasks (or episodes) $T=(S^supp,S^query)$ drawn from $p(T)$ , where $S^supp=\{(x_i,y_i)\}_i=1^K$ is the support set containing task demonstrations, or study examples, and $S^query=\{(x_j,y_j)\}_j=1^M$ is the query set for evaluation. We consider the simplest scenario where $|S^query|=1$ , containing a single example $(x^query,y^query)$ . We adapt this episodic formulation to our task, as shown in Figure 1.
#### Optimization.
The fundamental difference between the two paradigms appears in their optimization objectives. Standard supervised learning finds parameters $θ^*$ that maximize the likelihood:
$$
θ^*=\underset{θ}{argmax}∑_(x,y)∈D_
train\log p_θ(y\mid x) \tag{1}
$$
while meta-learning finds parameters $θ^*$ that maximize the expected likelihood across tasks:
$$
θ^*=\underset{θ}{argmax}E_T≤ft[
\log p_θ(y^query\mid x^query,S^supp)\right] \tag{2}
$$
For autoregressive models, the probability $p_θ(y^query\mid x^query,S^supp)$ is computed by conditioning on the support set $S^supp$ as part of the input context, formatted as a sequence of input-output pairs preceding the query. This approach forces the model to develop the capabilities of recognizing and applying task patterns from the support examples to generate appropriate query outputs.
## 3 Method
### 3.1 Data Generation
In this section, we describe the methodology employed to construct textual datasets designed for the task of logical premise selection. The process begins with the random generation of graph-like structures representing $KBs$ . These are then translated into text using fixed syntactic templates and assigning pseudowords to nodes.
#### Abstract representation.
To avoid ambiguity in premise selection, we use only non-redundant $KBs$ , where for each derivable hypothesis $F$ , there is a unique $F⊆KB$ such that $F\vDash F$ is minimal. We represent $KBs$ as graphs, with constants as nodes and quantifiers as edges. A visual representation of $KBs$ and the seven types of inferences as graphs can be seen in Appendix B.2. Synthetic $KBs$ are generated by constructing such graphs. To ensure non-redundancy, $A$ -formulas form disjoint subgraphs with at most one path between any two nodes. We created three independent sets of consistent $KBs$ for training, validation, and testing to ensure diversity across splits. See Appendix B.1 for the exact algorithms used to generate $KB$ s
#### Textual translation.
To translate a given $KB_i$ into a textual string, we: (1) assign a unique identifier $x_1,…,x_n$ to each node within $KB_i$ ; (2) map each edge to a fixed template connecting nodes $x_i$ and $x_j$ based on the quantifier represented by the edge (e.g., $Ax_ix_j$ becomes “All $x_i$ are $x_j$ ”); and (3) assign each unique node identifier $x_1,…,x_n$ to a random English-like pseudoword (e.g., $x_1$ = wug, $x_2$ = blump). Further details on the vocabulary of pseudowords we used are provided in Appendix B.3.
As illustrated in Figure 1, we structured each datapoint in the three splits to begin with the token “ knowledge base: ”, followed by the full sequence of premises, separated by commas. This is immediately followed by the special tag <QUERY>, and then the token “ hypothesis: ”, which introduces the target hypothesis. Next comes the token “ premises: ”, followed by the specific comma-separated premises that entail the hypothesis. To increase variability, we applied ten random pseudoword assignments and three random permutations of premise order for each $KB$ , resulting in multiple variants per datapoint.
Within each $KB$ , valid hypotheses can be inferred by minimal sets of premises of varying lengths. We define the length of a inference as the total length of all $A$ -chains it contains, which corresponds to the total number of $A$ -formulas among its premises. For a given inference type $t$ , we denote the maximum and minimum lengths as $μ(t)$ and $σ(t)$ , respectively.
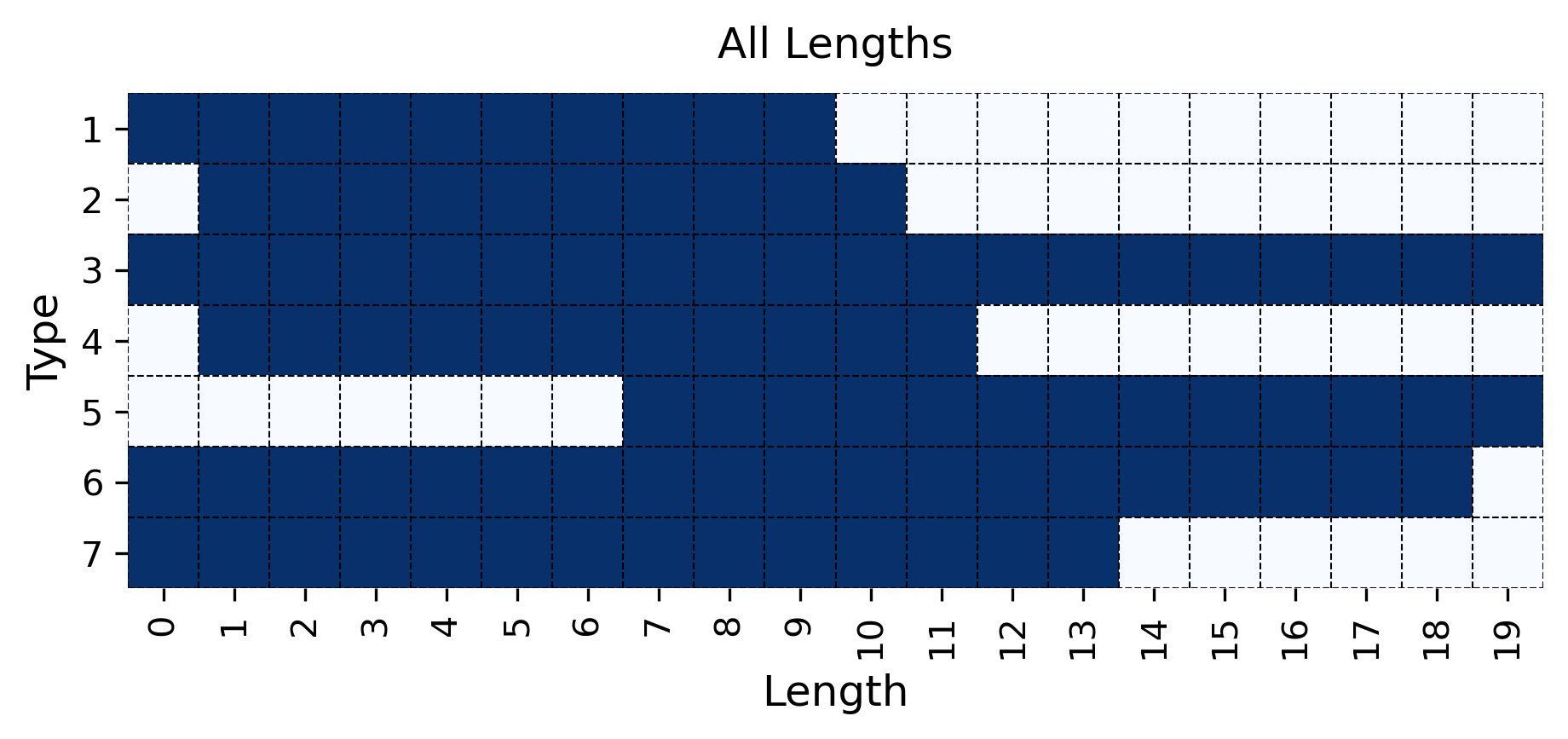
We generated enough $KB$ s to obtain 1000 training, 5 validation, and 100 test examples for each inference type and length combination in the range from 0 to 19. Note that some inference types (e.g., type 3) span the full range of lengths from 0 to 19, while others span only a subrange (e.g., type 2 spans from 1 to 10). See all type-length combinations within the generated $KB$ s in Figure 6 in Appendix B.4. This range was chosen to allow experiments with generalization to both unseen shorter and longer inferences. Full dataset statistics, including the number of generated $KB$ s per split, are reported in Appendix B.4. Training Testing
Longer inferences: ‘‘ all x1 are x2, all x2 are x3, all x3 are x4, all x4 are x5, all x5 are x6 $\vdash$ all x1 are x6’’
Shorter inferences: ‘‘ all x1 are x2, all x2 are x3 $\vdash$ all x1 are x3’’
Shorter inferences: ‘‘ all x1 are x2, all x2 are x3, all x3 are x4 $\vdash$ all x1 are x4’’
Longer inferences: ‘‘ all x1 are x2, all x2 are x3, all x3 are x4, all x4 are x5, all x5 are x6 $\vdash$ all x1 are x6’’
Figure 3: Length generalization. We evaluate models on two types of length generalization: models trained on more complex (i.e., longer) inferences are tested on simpler (i.e., shorter) ones (Top) and vice versa (Bottom). The examples illustrate type 2 inferences.
### 3.2 MIND
When applying meta-learning principles to the framework of syllogistic logic, we conceptualize the premises within a $KB$ as atomic facts. The seven types of syllogism (as detailed in Table 4) are treated as arguments, constructed using these atomic facts, and the model’s task is to extract the minimal set of facts within a $KB$ to produce a valid argument that proves the query hypothesis.
The type of systematic generalization MIND addresses involves applying the seven fixed syllogistic inferences to new, unseen sets of atomic facts. This is central to logical reasoning because logical rules are, by definition, formal: conclusions follow from premises based solely on the structure of the arguments, regardless of their specific content. Thus, successfully applying an inference type to a novel, unseen $KB$ requires the model to recognize and instantiate the same formal structure with different premises. This generalization also includes variations in the number of atomic facts needed to instantiate an argument. Specifically, handling $A$ -chains of varying lengths requires applying the learned inference patterns to longer or shorter instances of the same formal type.
#### Episodes organization.
To induce meta-learning of inference types, MIND uses a set of episodes where each episode $T=(KB,S^supp,x^query,y^ query)$ . Here, $KB$ is a knowledge base, $S^supp$ is a set of study valid hypothesis-premises pairs, $x^query$ is a valid query hypothesis, and $y^query$ is the minimal set of premises entailing $x^query$ . Figure 1 shows a full MIND episode using indexed variables in place of pseudowords for improved readability. Importantly, we consider study examples with inferences of the same type as the query. The number of study examples we set, i.e. valid hypothesis–premise pairs, is three. In their textual translation, we add the special tags <STUDY> to indicate the beginning of the sequence of study examples. During MIND fine-tuning, models are trained to minimize the cross-entropy loss of the tokens in $y^query$ given the input tokens from the context $(KB,S^supp,x^query)$ .
#### Baseline.
Similarly to Lake and Baroni (2023), we consider a baseline where models are not fine-tuned on episodes but on single input-output pairs $(x^query,y^query)$ preceded by a $KB$ . The baseline is fine-tuned to minimize the cross-entropy loss of the tokens in $y^query$ given the input tokens from the context $(KB,x^query)$ . To ensure a fair comparison between the meta-learning model and the baseline, we ensured that both models were fine-tuned on the exact same aggregate set of unique hypothesis-premises pairs. Specifically, the baseline was fine-tuned using a set $D_baseline$ consisting of $(x^query,y^query)$ unique pairs. For the meta-learning approach, the corresponding set of all unique hypothesis-premises pairs encountered across all $N$ episodes $T_i=(KB_i,S^supp_i,x^query_i ,y^query_i)$ is given by $D_meta=\bigcup_i=1^N(S^supp_i∪\{(x^ query_i,y^query_i)\})$ . We verified that $D_baseline=D_meta$ . Moreover, since the meta-learning model processes more hypothesis-premises pairs within each episode (due to $S^supp_i$ ), we counterbalanced this by training the baseline model for a proportionally larger number of epochs. Further details on the training regime and number of epochs for each approach are provided in Appendix C.2.
## 4 Experimental Setup
### 4.1 Models
We run experiments using the Qwen 2.5 family of decoder-only LMs (Qwen Team, 2025). More specifically, we test three sizes: 1.5B, 3B, and 7B parameters. This family of models is selected because it allows us to experiment with varying small sizes (ranging from 1.5 to 7 billion parameters) and achieves a better size vs. performance trade-off compared to other open weights model families.
In addition to the Qwen 2.5 family, we also evaluate the closed-source LLM GPT-4o (OpenAI, 2024) and the Large Reasoning Model (LRM) o3-mini (OpenAI, 2025) on the logical premise selection task. Note that LRMs are also LLMs, but post-trained to generate longer intermediate chains of thought, improving performance on complex reasoning tasks (Xu et al., 2025). We conduct the evaluation both in a zero-shot setting and in a few-shot setting, using the $S^supp$ study pairs as examples. See the API details and the exact prompts used to evaluate closed models in Appendix C.3.
| | Model | Method | All | Short | Long |
| --- | --- | --- | --- | --- | --- |
| Fine-tuning | Qwen-2.5 1.5B | MIND | 93.11 ± 0.61 | 94.28 ± 0.61 | 91.76 ± 0.27 |
| Baseline | 85.56 ± 1.24 | 91.42 ± 0.82 | 80.56 ± 1.78 | | |
| Qwen-2.5 3B | MIND | 96.16 ± 0.44 | 96.24 ± 0.56 | 95.55 ± 0.43 | |
| Baseline | 93.03 ± 1.15 | 95.34 ± 1.18 | 90.92 ± 1.27 | | |
| Qwen-2.5 7B | MIND | 98.13 ± 0.98 | 98.26 ± 0.82 | 97.69 ± 1.40 | |
| Baseline | 95.76 ± 1.10 | 97.27 ± 1.22 | 94.13 ± 0.90 | | |
| Prompting | GPT-4o | Few-shot | 39.76 | 52.91 | 33.51 |
| Zero-shot | 15.90 | 28.97 | 9.89 | | |
| o3-mini | Few-shot | 88.45 | 87.91 | 88.51 | |
| Zero-shot | 67.98 | 73.29 | 64.54 | | |
Table 1: Core generalization. Accuracy (mean ± std) on test inferences across all type-length combinations (All), plus breakdown into the five shortest (Short) and longest (Long) inferences for each of the seven types of inference. Fine-tuned Qwen models use MIND vs. Baseline; GPT-4o and o3-mini use few-shot vs. zero-shot prompting.
### 4.2 Experiments
We design experiments to evaluate the ability of MIND to teach pretrained small LMs to systematically apply inferences to new, unseen sets of premises —that is, to reason in a formal way by recognizing and instantiating the same underlying structure independently of the $KB$ s’ content.
To ensure consistency, both MIND and the baseline receive inputs at test time in the same format as during training. MIND models are provided as context $(KB,S^supp,x^query)$ , and are tasked to generate $y^query$ , while the baseline receives $(KB,x^query)$ .
#### Generalization.
In the first experiment, models are evaluated on their ability to generalize to unseen $KBs$ , while all inference lengths are seen. The training and testing sets contain inferences of all lengths for each of the seven types. Since this is the simplest form of systematic application of syllogistic inference, we refer to it as core generalization.
We then consider two more challenging generalizations involving inferences of unseen length. As illustrated in Figure 3, we examine the case of generalizing to longer inferences when the model has only learned from shorter ones (as studied in Saparov et al. 2023), and vice versa —generalizing to shorter inferences after seeing only longer ones. In the logic literature, they are respectively known as recursiveness and compositionality (Vargas Guzmán et al., 2024). To test this, we train exclusively on inferences whose lengths $x$ are $σ(t)≤ x≤μ(t)-5$ , and test on the five longest inferences for each type, i.e., those whose length is $μ(t)-5<x≤μ(t)$ . In the second case, we train on inferences with length $σ(t)+5≤ x≤μ(t)$ , and test only on the five shortest inference lengths for each type, i.e., those with length $σ(t)≤ x<σ(t)+5$ . An intuitive representation of these generalizations is provided in Figure 3. Notably, within the MIND approach, we consider two varying types of study examples $S^supp$ : the aligned and disaligned sets of study examples, in which each $(x^supp,y^supp)$ either falls within or outside the range of inference lengths used for testing, respectively. More precisely, the meanings of aligned and disaligned depend on whether we are evaluating models on unseen shorter or longer inferences. For longer inferences, disaligned includes inferences with lengths $σ(t)≤ x≤μ(t)-5$ , and aligned includes those with lengths $μ(t)-5<x≤μ(t)$ . For shorter ones, instead, aligned includes inferences with lengths $σ(t)≤ x<σ(t)+5$ , and disaligned includes those with lengths $σ(t)+5≤ x≤μ(t)$ .
Figure 6, in the Appendix, shows all inference type-length combinations within training and test split in the core and in the length generalization settings. These datasets contain 1,000 and 100 datapoints for each training and testing type–length combination, respectively. To further investigate the performance of MIND in a limited data regime, we also consider the case where only 100 datapoints are available for each training type–length combination.
### 4.3 Prediction Accuracy
We consider a model prediction to be correct if the set of premises extracted from the generated text matches the ground truth set of minimal premises. Using this criterion, we measure accuracy both in aggregate, i.e., across an entire test set, and decomposed by each test type-length combination. All models (1.5B, 3B, and 7B) are fine-tuned three times and with different random seeds, thus we report mean and standard deviation of each accuracy.
## 5 Results
| Qwen-2.5 1.5B Baseline Qwen-2.5 3B | MIND 63.53 ± 1.16 MIND | 76.42 ± 2.95 63.53 ± 1.16 87.61 ± 1.97 | 91.75 ± 1.10 56.67 ± 1.22 95.86 ± 0.70 | 70.94 ± 2.27 56.67 ± 1.22 77.19 ± 3.53 | 71.13 ± 1.83 78.53 ± 1.71 |
| --- | --- | --- | --- | --- | --- |
| Baseline | 76.78 ± 1.63 | 76.78 ± 1.63 | 71.88 ± 1.49 | 71.88 ± 1.49 | |
| Qwen-2.5 7B | MIND | 90.03 ± 1.09 | 96.84 ± 0.15 | 76.23 ± 2.91 | 83.41 ± 1.63 |
| Baseline | 80.76 ± 2.65 | 80.76 ± 2.65 | 71.08 ± 1.55 | 71.08 ± 1.55 | |
Table 2: Generalization to unseen lengths. Accuracy (mean ± std) of meta-learning and baseline models when trained on short inferences and tested on longer ones or vice versa. In both cases, we compare the settings in which the inferences in the study examples either falls within (Aligned) or outside (Disaligned) the range of inference lengths used for testing. Baseline models have no study examples, hence such difference does not hold for them.
### 5.1 Core Generalization
We first examine the performance of meta-learning versus the baseline on core generalization (Table 1), with models trained and tested on all inference type-length combinations. The “Short” and “Long” columns report aggregated accuracy on the sets of the five shortest and longest inferences, respectively, for each type. We hypothesize that longer inferences are harder because, to be correct, models must select all premises belonging to a larger minimal set of premises.
Across all Qwen-2.5 model sizes (1.5B, 3B, 7B), the meta-learning approach consistently yields higher accuracy than the baseline. Performance improves with model scale in both approaches. For example, MIND accuracy increases from 93.11% (1.5B) to 98.13% (7B) on all type-length combinations, with accuracy on shortest inferences rising from 94.28% to 98.26%, and on the longest ones increasing from 91.76% to 97.69%. In contrast, baseline performance rises more slowly —from 85.56% (1.5B) to 95.76% (7B) —and shows a wider drop on the longest inferences, falling as low as 80.56% for the smallest model. Notably, the performance gap between MIND and the baseline narrows as model size increases, suggesting that larger models achieve better core generalization even without meta-learning. It is worth noting that with limited data, MIND’s advantage over the baseline becomes much wider at all sizes, as shown in Appendix D.3.
The closed-source models GPT-4o and o3-mini still underperform compared to Qwen-2.5 models fine-tuned with MIND. Both models perform poorly in the zero-shot setting but improve with few-shot prompting: GPT-4o reaches 39.76% on all type-length combinations (with 52.91% on shortest and 33.51% on longest inferences), while o3-mini performs substantially better (88.45% all combination, 87.91% on shorters, and 88.51% on longest). As expected, performance on the longest inferences is worse than that on the shortest ones for GPT-4o, while o3-mini maintains a more robust performance across inference lengths.
### 5.2 Length Generalization
Table 2 shows that MIND models consistently outperform baseline models in generalizing to both longer and shorter inferences than those seen during training. In core generalization, we observed that longer inferences are more challenging than shorter ones. Instead, in the case of unseen lengths, an interesting and somewhat counterintuitive pattern emerges: it is generally easier for models to generalize to longer inferences than to shorter ones. This is true across all model sizes and in both approaches; For instance, the largest model, Qwen-2.5 7B, achieved 90.03% accuracy on longer inferences (disaligned) compared to 76.23% on shorter ones (disaligned).
Aligning study example lengths with the test condition (aligned) proves moderately to highly effective for unseen short inferences across all MIND model sizes. For example, Qwen-2.5 1.5B improved from 76.42% to 91.75%, and Qwen-2.5 3B improved from 87.61% to 95.86%. For unseen long inferences, this alignment is moderately effective in larger models: Qwen-2.5 7B improved from 76.23% to 83.41%, while the 1.5B and 3B models showed smaller gains (70.94% to 71.13% and 77.19% to 78.53%, respectively). These results indicate that MIND enables models in the aligned condition to exploit abstract patterns in the study examples (unseen inference lengths), allowing them to more effectively answer query hypotheses requiring length generalization.
Again, MIND’s better performance in length generalization is especially noticeable with limited training data, where the difference between MIND and baseline models grows significantly (see Appendix D.3 for more details).
| L $→$ S | MIND (aligned) | 42.94 | 4.9 | 36.68 | 2.1 | 57.5 |
| --- | --- | --- | --- | --- | --- | --- |
| MIND (disaligned) | 28.31 | 3.72 | 52.81 | 1.76 | 66.06 | |
| Baseline | 28.21 | 6.19 | 23.38 | 2.1 | 72.78 | |
| S $→$ L | MIND (aligned) | 9.76 | 1.66 | 87.54 | 5.08 | 60.94 |
| MIND (disaligned) | 14.14 | 6.14 | 81.82 | 3.65 | 35.35 | |
| Baseline | 3.87 | 2.36 | 89.79 | 6.66 | 66.9 | |
Table 3: Error analysis. Error analysis comparing MIND and baseline on long to short (L $→$ S) and short to long (S $→$ L) generalization. The table shows percentages and averages for non-minimal valid sets of premises (NVM) and missing necessary $A$ premises (MAP), and the percentage of hallucinated premises (HP).
## 6 Error Analysis
Beyond simply measuring the accuracy of MIND and the baseline, we additionally focus on two main types of errors models make when evaluated on unseen lengths. First, among all errors, we consider the proportion of non-minimal valid set of premises (NVM). This means that the correct minimal set was generated by the model, but together with unnecessary premises; for this case, we also measure how many unnecessary premises, on average, the models generate. Alternatively, models may fail to provide the complete $A$ -chain within the correct minimal set of premises, meaning that at least one necessary $A$ premise is missing (MAP); here, we also track the average number of missing necessary $A$ -formulas in erroneous answers. NVM and MAP are mutually exclusive. Furthermore, we consider an additional type of error that can occur simultaneously with either NVM or MAP: models may hallucinate premises —referred to as hallucinated premises (HP) —and output a formula that is not contained in the $KB$ .
Table 3 presents the error analysis for Qwen-2.5 7B Each model was fine-tuned three times with different random seeds, we selected the best model for each approach for this analysis. on the challenging length generalization settings. See Appendix D.4 for further error analysis results. HP is a common error type across both settings (often $>$ 50%). The baseline model has the highest HP rate in long to short (72.78%), while MIND models are generally better.
When generalizing to shorter inferences, a substantial portion of errors (28-43%) are NVM, indicating models indeed find logical solutions but include unnecessary premises. In this context, a lower number of unnecessary premises is better, as it is closer to the minimal set. The baseline model adds the most unnecessary premises (6.19 average), compared to MIND (disaligned) (4.9) and MIND (aligned) (3.72).
For generalizations to longer inferences, errors show different patterns, with few NVM errors (4-14%) and predominantly MAP errors (81-90%). The average number of missing premises is higher in short to long (3.65-6.66) than in long to short (1.76-2.1), suggesting models struggle to provide the complete set of premises when evaluated on longer inferences than seen during training. The baseline model struggles most with longer inferences, with a high MAP error rate (89.79%) and a large number of missing premises (6.66) contributing to its lower accuracy compared to MIND.
## 7 Related Work
### 7.1 LLMs’ Logical Capabilities
Recent work has highlighted weaknesses in LLMs’ logical reasoning. LLMs often struggle with OOD generalization (Clark et al., 2021; Saparov et al., 2023; Vargas Guzmán et al., 2024), multi-step inference (Creswell et al., 2023), and consistency across formal reasoning patterns (Parmar et al., 2024; Hong et al., 2024). Neuro-symbolic methods address these gaps by integrating logic modules or symbolic solvers, improving both performance and interpretability (Pan et al., 2023; Olausson et al., 2023; Kambhampati et al., 2024). In a different direction, LRMs have shown strong gains in reasoning and planning tasks (Xu et al., 2025). Our proposed meta-learning approach offers a complementary alternative by enabling LLMs to adapt across logical tasks without relying on symbolic modules, as our results demonstrate.
### 7.2 Meta-learning
Meta-learning enables models to rapidly adapt to new tasks by leveraging prior experiences across tasks (Thrun and Pratt, 1998; Hospedales et al., 2022). Foundational approaches include memory-augmented neural networks (Santoro et al., 2016), prototypical networks (Snell et al., 2017), and model-agnostic meta-learning (MAML) (Finn et al., 2017). In the context of LLMs, meta-learning has been explored through techniques such as meta-in-context learning (Coda-Forno et al., 2023), in-context tuning (Chen et al., 2022), and MetaICL (Min et al., 2022), which either train for or exploit the in-context learning abilities of models to adapt to new tasks using few-shot examples. Our proposed method draws inspiration from the MSL framework (Irie and Lake, 2024), which we adapt and extend to solve the logical premise selection task.
## 8 Conclusion
In this work, we introduced MIND, a meta-learning fine-tuning approach to improve deductive reasoning in LLMs, explicitly targeting the logical premise selection task. Our results show that MIND significantly enhances generalization compared to the baseline, especially in small-scale and low-data scenarios. Remarkably, our fine-tuned small models outperform state-of-the-art LLMs on this task. This demonstrates the potential of MIND to advance the development of more robust and reliable AI systems.
Future work should explore several potential avenues. First, we should investigate not only systematic generalization using fixed inference rules, as we have done here, but also extend our research to learning the composition of multiple logical inferences. This approach aligns with ideas proposed in other meta-learning research, such as Meta-Learning for Compositionality (Lake and Baroni, 2023). Additionally, we should examine increasingly complex fragments of language, where the interactions among various inference-building blocks and reasoning forms become more intricate, and assess the effectiveness of MIND in helping LLMs to generalize in such contexts.
## 9 Limitations
Despite demonstrating meaningful progress in enhancing the deductive reasoning capabilities of language models through the MIND approach, this study has several limitations that future research could address.
#### Model selection.
The evaluation primarily targets small to mid-sized language models (1.5B to 7B parameters), largely due to computational constraints. This focus leaves open the question of whether the observed improvements from MIND generalize to larger-scale models.
#### Meta-learning trade-offs.
The gains in reasoning ability achieved by MIND come with associated costs. The meta-learning strategy adopted involves incorporating multiple study examples into the input context during fine-tuning. This leads to longer input sequences, which in turn increase memory usage and computational demands compared to standard fine-tuning approaches.
#### Focus on a logic fragment.
This work is constrained to the syllogistic fragment of first-order logic. Future research should investigate whether our conclusions extend to more expressive logical systems or to real-world scenarios where reasoning tasks are less structured. However, syllogistic logic is a restricted domain that allows for precise control over variables such as the type of inference considered, inference length, and the structure of knowledge bases. In the context of this study, it serves as a valuable testbed for investigating logical generalization in LLMs.
## References
- Balloccu et al. (2024) Simone Balloccu, Patrícia Schmidtová, Mateusz Lango, and Ondrej Dusek. 2024. Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source LLMs. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 67–93, St. Julian’s, Malta. Association for Computational Linguistics.
- Chen et al. (2022) Yanda Chen, Ruiqi Zhong, Sheng Zha, George Karypis, and He He. 2022. Meta-learning via language model in-context tuning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 719–730, Dublin, Ireland. Association for Computational Linguistics.
- Clark et al. (2021) Peter Clark, Oyvind Tafjord, and Kyle Richardson. 2021. Transformers as soft reasoners over language. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI’20.
- Coda-Forno et al. (2023) Julian Coda-Forno, Marcel Binz, Zeynep Akata, Matt Botvinick, Jane Wang, and Eric Schulz. 2023. Meta-in-context learning in large language models. In Advances in Neural Information Processing Systems, volume 36, pages 65189–65201. Curran Associates, Inc.
- Creswell et al. (2023) Antonia Creswell, Murray Shanahan, and Irina Higgins. 2023. Selection-inference: Exploiting large language models for interpretable logical reasoning. In The Eleventh International Conference on Learning Representations.
- Dettmers et al. (2023) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: efficient finetuning of quantized llms. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA. Curran Associates Inc.
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, page 1126–1135. JMLR.org.
- Gulati et al. (2024) Aryan Gulati, Brando Miranda, Eric Chen, Emily Xia, Kai Fronsdal, Bruno de Moraes Dumont, and Sanmi Koyejo. 2024. Putnam-AXIOM: A functional and static benchmark for measuring higher level mathematical reasoning. In The 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24.
- Hong et al. (2024) Ruixin Hong, Hongming Zhang, Xinyu Pang, Dong Yu, and Changshui Zhang. 2024. A closer look at the self-verification abilities of large language models in logical reasoning. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 900–925, Mexico City, Mexico. Association for Computational Linguistics.
- Hospedales et al. (2022) Timothy Hospedales, Antreas Antoniou, Paul Micaelli, and Amos Storkey. 2022. Meta-Learning in Neural Networks: A Survey . IEEE Transactions on Pattern Analysis & Machine Intelligence, 44(09):5149–5169.
- Hu et al. (2022) Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations.
- Huang and Chang (2023) Jie Huang and Kevin Chen-Chuan Chang. 2023. Towards reasoning in large language models: A survey. In Findings of the Association for Computational Linguistics: ACL 2023, pages 1049–1065, Toronto, Canada. Association for Computational Linguistics.
- Huang et al. (2025) Kaixuan Huang, Jiacheng Guo, Zihao Li, Xiang Ji, Jiawei Ge, Wenzhe Li, Yingqing Guo, Tianle Cai, Hui Yuan, Runzhe Wang, Yue Wu, Ming Yin, Shange Tang, Yangsibo Huang, Chi Jin, Xinyun Chen, Chiyuan Zhang, and Mengdi Wang. 2025. MATH-Perturb: Benchmarking LLMs’ math reasoning abilities against hard perturbations. arXiv preprint arXiv:2502.06453.
- Irie et al. (2025) Kazuki Irie, Róbert Csordás, and Jürgen Schmidhuber. 2025. Metalearning continual learning algorithms. Transactions on Machine Learning Research.
- Irie and Lake (2024) Kazuki Irie and Brenden M. Lake. 2024. Neural networks that overcome classic challenges through practice. Preprint, arXiv:2410.10596.
- Kambhampati et al. (2024) Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Paul Saldyt, and Anil B Murthy. 2024. Position: LLMs can’t plan, but can help planning in LLM-modulo frameworks. In Forty-first International Conference on Machine Learning.
- Keuleers and Brysbaert (2010) Emmanuel Keuleers and Marc Brysbaert. 2010. Wuggy: A multilingual pseudoword generator. Behavior research methods, 42:627–633.
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization.
- Lake and Baroni (2023) Brenden M. Lake and Marco Baroni. 2023. Human-like systematic generalization through a meta-learning neural network. Nature, 623:115–121.
- Leighton (2004) Jacqueline P. Leighton. 2004. Defining and describing reason. In Jacqueline P. Leighton and Robert J. Sternberg, editors, The Nature of Reasoning. Cambridge University Press.
- Min et al. (2022) Sewon Min, Mike Lewis, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2022. MetaICL: Learning to learn in context. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2791–2809, Seattle, United States. Association for Computational Linguistics.
- Mirzadeh et al. (2025) Seyed Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. 2025. GSM-symbolic: Understanding the limitations of mathematical reasoning in large language models. In The Thirteenth International Conference on Learning Representations.
- Mondorf and Plank (2024) Philipp Mondorf and Barbara Plank. 2024. Beyond accuracy: Evaluating the reasoning behavior of large language models - a survey. In First Conference on Language Modeling.
- Olausson et al. (2023) Theo Olausson, Alex Gu, Ben Lipkin, Cedegao Zhang, Armando Solar-Lezama, Joshua Tenenbaum, and Roger Levy. 2023. LINC: A neurosymbolic approach for logical reasoning by combining language models with first-order logic provers. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5153–5176, Singapore. Association for Computational Linguistics.
- OpenAI (2024) OpenAI. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276.
- OpenAI (2025) OpenAI. 2025. Openai o3-mini. https://openai.com/index/openai-o3-mini/. Accessed: 2025-05-08.
- Pan et al. (2023) Liangming Pan, Alon Albalak, Xinyi Wang, and William Wang. 2023. Logic-LM: Empowering large language models with symbolic solvers for faithful logical reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 3806–3824, Singapore. Association for Computational Linguistics.
- Parmar et al. (2024) Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, and Chitta Baral. 2024. LogicBench: Towards systematic evaluation of logical reasoning ability of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13679–13707, Bangkok, Thailand. Association for Computational Linguistics.
- Qwen Team (2025) Qwen Team. 2025. Qwen2.5 technical report. Preprint, arXiv:2412.15115.
- Santoro et al. (2016) Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. 2016. Meta-learning with memory-augmented neural networks. In Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, page 1842–1850. JMLR.org.
- Saparov et al. (2023) Abulhair Saparov, Richard Yuanzhe Pang, Vishakh Padmakumar, Nitish Joshi, Mehran Kazemi, Najoung Kim, and He He. 2023. Testing the general deductive reasoning capacity of large language models using OOD examples. In Thirty-seventh Conference on Neural Information Processing Systems.
- Shi et al. (2023) Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org.
- Singh et al. (2024) Aaditya K. Singh, Muhammed Yusuf Kocyigit, Andrew Poulton, David Esiobu, Maria Lomeli, Gergely Szilvasy, and Dieuwke Hupkes. 2024. Evaluation data contamination in llms: how do we measure it and (when) does it matter? Preprint, arXiv:2411.03923.
- Smiley (1973) Timothy J. Smiley. 1973. What is a syllogism? Journal of Philosophical Logic, 2(1):136–154.
- Snell et al. (2017) Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 4080–4090, Red Hook, NY, USA. Curran Associates Inc.
- Thrun and Pratt (1998) Sebastian Thrun and Lorien Pratt. 1998. Learning to Learn: Introduction and Overview, pages 3–17. Springer US, Boston, MA.
- Vargas Guzmán et al. (2024) Manuel Vargas Guzmán, Jakub Szymanik, and Maciej Malicki. 2024. Testing the limits of logical reasoning in neural and hybrid models. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 2267–2279, Mexico City, Mexico. Association for Computational Linguistics.
- Xu et al. (2025) Fengli Xu, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, Jiahui Gong, Tianjian Ouyang, Fanjin Meng, Chenyang Shao, Yuwei Yan, Qinglong Yang, Yiwen Song, Sijian Ren, Xinyuan Hu, Yu Li, Jie Feng, Chen Gao, and Yong Li. 2025. Towards large reasoning models: A survey of reinforced reasoning with large language models. Preprint, arXiv:2501.09686.
- Yoran et al. (2024) Ori Yoran, Tomer Wolfson, Ori Ram, and Jonathan Berant. 2024. Making retrieval-augmented language models robust to irrelevant context. In The Twelfth International Conference on Learning Representations.
- Łukasiewicz (1951) Jan Łukasiewicz. 1951. Aristotle’s Syllogistic From the Standpoint of Modern Formal Logic. Oxford, England: Garland.
## Appendix A Formal Semantics and Syllogistic Inference Patterns
In this section, we formally define the semantics of syllogistic logic by translating syllogistic formulas into first-order logic. We also specify a consistent set of such formulas and formalize a valid inference within this framework. Let $A=\{a,b,c,…\}$ be a set of atomic terms, and let $R=\{R,S,T,…\}$ be a set of unary relational symbols. We bijectively assign to every atomic term $a∈A$ a relational symbol $R_a∈R$ , and interpret syllogistic formulas as first-order logic sentences: $Aab$ as $∀ x [R_a(x)→ R_b(x)]$ , $Eab$ as $∀ x [R_a(x)→¬ R_b(x)]$ , $Iab$ as $∃ x [R_a(x)∧ R_b(x)]$ , and $Oab$ as $∃ x [R_a(x)∧¬ R_b(x)]$ . We say that a set $F$ of syllogistic formulas is consistent if there exists a structure $M$ in signature $R$ such that every relation $R^M$ is non-empty, and the interpretation of every sentence in $F$ holds in $M$ , denoted by $M\vDashF$ . For a syllogistic formula $F$ , the pair $(F,F)$ is an inference, denoted by $F\vDash F$ , if $M\vDash\{F\}$ , whenever $M\vDashF$ for a structure $M$ in signature $R$ .
## Appendix B Dataset
| 1 2 3 | $\{Aa-b,Ac-d,Oad\}\vDash Obc$ $\{Aa-b\}\vDash Aab$ $\{Aa-b,Ac-d,Aa-e,Ede\}\vDash Obc$ |
| --- | --- |
| 4 | $\{Aa-b,Aa-c\}\vDash Ibc$ |
| 5 | $\{Aa-b,Ac-d,Ae-f,Iae,Edf\}\vDash Obc$ |
| 6 | $\{Aa-b,Ac-d,Ebd\}\vDash Eac$ |
| 7 | $\{Aa-b,Ac-d,Iac\}\vDash Ibd$ |
Table 4: Syllogistic inference types. Each row shows a distinct logical inference pattern. Notation follows traditional categorical logic: $Aab$ denotes a universal affirmative ("All $a$ are $b$ "), $Eab$ a universal negative ("No $a$ are $b$ "), $Iac$ a existential affirmative ("Some $a$ are $c$ "), and $Oad$ a existential negative ("Some $a$ are not $d$ "). Formulas of the form $Aa-b$ denote a sequence of $n$ $A$ -formulas relating $a$ and $b$ .
### B.1 $KB$ s’ Generation
Knowledge bases can be modeled as edge-labeled graphs, in which nodes correspond to atomic terms and edges are labeled with quantifiers. Our graph generation algorithm comprises two principal stages: (1) We first construct all A-chains of the knowledge base, which is used as its structural backbone, by generating disjoint trees—directed acyclic graphs that ensure a unique path exists between any pair of nodes. (2) Subsequently, we incorporate additional label edges corresponding to $E$ , $I$ , and $O$ formulas, while maintaining the overall consistency of the knowledge base.
To construct all possible valid syllogisms from each artificially generated knowledge base, we employ antillogisms—minimal inconsistent set of syllogistic formulas. For example, consider the set $\{Aab,Aac,Ebc\}$ , which forms an antilogism. By negating the inconsistent formula $Ebc$ , we obtain a valid inference in which the remaining formulas $\{Aab,Aac\}$ entail its negation, i.e., $\{Aab,Aac\}\vDash Ibc$ . This corresponds to an inference of type 4. More generally, any syllogism can be derived from an antilogism of the form $F∪\{¬ F\}$ by inferring the conclusion $F$ from the consistent set $F$ , that is, $F\vDash F$ . This result was formally established by (Smiley, 1973), who also demonstrated that there exist only three distinct types of antilogisms. Furthermore, as shown by (Vargas Guzmán et al., 2024), all valid syllogistic inferences can be systematically derived from these three canonical forms of antilogism (see Table 4).
| Core Generalization | Train | 97,000 | 100 | 26–35 |
| --- | --- | --- | --- | --- |
| Validation | 485 | 15 | 26–36 | |
| Test | 9,700 | 200 | 26–38 | |
| Short $→$ Long | Train | 62,000 | 100 | 26–35 |
| Validation | 310 | 15 | 26–36 | |
| Test | 3,500 | 194 | 26–38 | |
| Long $→$ Short | Train | 62,000 | 100 | 26–35 |
| Validation | 310 | 15 | 26–36 | |
| Test | 3,500 | 200 | 26–38 | |
Table 5: Dataset statistics across experiments. For each experiment and split, the table reports the number of unique query hypothesis-premises pairs (Size), the number of $KB$ s from which the pairs are generated (# KBs), and the range of total premises within $KB$ s (# Premises). In the additional experiment with limited training data, the total training size is reduced by a factor of ten.
### B.2 $KB$ s’ Visualization
To provide an intuitive understanding of the various types of inferences and their derivation from the knowledge bases employed in our framework, we represent syllogistic formulas as graphs. These graphs encompass the knowledge base, the corresponding hypothesis, and the minimal inference—defined as the smallest subset of premises required to derive the hypothesis.
Figure 19 illustrates a type 2 inference, characterized by a conclusion in the form of a universal affirmative ( $A$ -formula). The premises consist of a single sequence of $A$ -formulas. This represents the most elementary form of syllogistic inference, whose structural pattern is embedded within all other types. Inferences of types 1, 3, and 5, which yield particular negative conclusions ( $O$ -formulas), are presented in Figures 18, 20, and 22, respectively. Syllogisms corresponding to types 4 and 7, both concluding with particular affirmative statements ( $I$ -formulas), are shown in Figures 21 and 24. Finally, the type 6 inference, which concludes with a universal negative ( $E$ -formula), is depicted in Figure 23.
### B.3 Term Vocabulary
To train and evaluate our models, we artificially generated 5000 unique pseudowords by randomly concatenating two syllables selected from a set of approximately 300 of the most commonly used English syllables. Although these pseudowords are semantically meaningless, they remain phonologically plausible and are generally pronounceable. On occasion, the generation process may yield actual English words.
Additionally, we constructed two substitution sets to support our lexical generalization evaluation (see Appendix D.2). The first set comprises 5000 pseudowords generated using the Wuggy pseudoword generator Keuleers and Brysbaert (2010). We selected 500 English two-syllable nouns and, for each, produced 10 distinct pseudowords using Wuggy’s default parameters. The second set consists of symbolic constants, each formed by the character “X” followed by an integers ranging from 1 to 5000.
### B.4 Data Statistics
As described in Section 3.1, we generated as many KBs as necessary to obtain at least 1000 training, 5 validation, and 100 test examples for each inference type and length combination in the range from 0 to 19 (see all the combinations in Figure 6). Table 5 summarizes dataset statistics for the core generalization experiment, as well as for the length generalization ones (“Short $→$ Long” and “Long $→$ Short”). For each experiment and split, the table provides the total number of examples, the number of $KB$ s used to generate them, and the range of premises across $KB$ s. In the additional experiment with limited training data described in Appendix D.3, the total training size is reduced by a factor of ten in each setting.
## Appendix C Experiment Details
### C.1 Implementation Details
All experiments were conducted using the PyTorch and Hugging Face Transformers libraries. We used NVIDIA A100 80GB GPUs. Due to the relatively small size of the models used in the experiments, each fine-tuning run, both for MIND and the baseline, was able to fit on a single GPU. We estimate a total compute usage of approximately 500 GPU hours across all experiments. Additionally, GitHub Copilot was used as an assistant tool for parts of the project’s source code development.
You are tasked with logical premise selection. Given: 1. A knowledge base consisting of premises. 2. A query hypothesis to solve, preceded by the token <QUERY>. Your task is to identify the unique minimal set of premises from the knowledge base that logically proves the query hypothesis. Since the knowledge base is non-redundant, every valid hypothesis has exactly one minimal set of premises that proves it. Provide your answer in exactly this format: ### Answer: premise1, premise2, ..., premiseN
Figure 4: Zero-shot system prompt. The zero-shot system prompt used with the closed models GPT-4o and o3-mini. The query hypothesis is subsequently provided as the first user interaction. We then extract the set of premises returned by the model using regular expressions.
You are tasked with logical premise selection. Given: 1. A knowledge base consisting of premises. 2. Example hypotheses along with their correct minimal premise sets, preceded by the token <STUDY>. 3. A query hypothesis to solve, preceded by the token <QUERY>. Your task is to identify the unique minimal set of premises from the knowledge base that logically proves the query hypothesis. Since the knowledge base is non-redundant, every valid hypothesis has exactly one minimal set of premises that proves it. Examine the provided examples carefully to understand how to select the correct minimal set of premises. The examples demonstrate correct premise selections for various hypotheses. Provide your answer in exactly this format: ### Answer: premise1, premise2, ..., premiseN
Figure 5: Few-shot system prompt. The Few-shot system prompt used with the closed models GPT-4o and o3-mini. The set of study examples provided as few-shot examples, along with the query hypothesis are provided as the first user interaction. We then extract the set of premises returned by the model using regular expressions.
### C.2 Fine-tuning Details
All models were fine-tuned using Low-Rank Adaptation (LoRA) (Hu et al., 2022) with a rank $r=64$ , alpha value $α=128$ , and dropout probability $p=0.05$ . The adaptation was applied to all attention and linear weight matrices, excluding the embedding and unembedding layers. Baseline models were loaded in bfloat16 precision, while MIND fine-tuned models employed QLoRA (Dettmers et al., 2023) with 4-bit quantization to accommodate memory constraints from longer sequences. Despite the lower precision, the meta-learning models outperformed the baseline.
Training hyperparameters included a learning rate of $5× 10^-5$ , zero weight decay, and no learning rate warmup (steps=0, ratio=0.0). Batch sizes were 4 (training), 8 (validation), and 32 (testing). We used the AdamW optimizer (Kingma and Ba, 2015) with a linear learning rate scheduler. Although we experimented with a range of other hyperparameter configurations, we found this setup to be the most stable across tasks and random seeds. Baseline models were trained for 4 epochs, whereas meta-learning models were trained for only 1 epoch to account for differences in per-sample data exposure (see Section 3.2). We performed 10 validations per epoch and selected the model with the highest validation accuracy. Each fine-tuning run was repeated with three different random seeds: 1048, 512, and 1056.
### C.3 Closed Source Models
#### API details.
We accessed OpenAI’s closed-source models GPT-4o (OpenAI, 2024) and o3-mini (OpenAI, 2025) through the Azure OpenAI Service’s Batch API. The API version used was 2025-03-01-preview, and the specific model versions were gpt-4o-2024-08-06 and o3-mini-2025-01-31. The total cost of the experiments was approximately 250 USD. For both models, we employed the default API settings. In the case of o3-mini, this corresponds to a “medium” reasoning effort. We did not experiment with a high reasoning effort in order to limit API usage costs.
#### Prompts.
We provide the exact system prompts used in the experiments involving GPT-4o and o3-mini in both the zero-shot (Figure 4) and few-shot (Figure 5) settings. In both cases, the system prompt instructs the models on how to perform the task and specifies the exact format of the answer they should provide. This format facilitates the extraction of the set of premises generated by the models. We then present the query hypothesis as the first user interaction. In the few-shot setting, example interactions are included in the user message prior to the query.
| Qwen-2.5 1.5B Baseline Qwen-2.5 3B | MIND 85.56 ± 1.24 MIND | 93.11 ± 0.61 83.34 ± 1.90 96.16 ± 0.44 | 93.15 ± 0.11 38.49 ± 1.06 96.09 ± 0.30 | 74.24 ± 1.07 83.21 ± 1.19 |
| --- | --- | --- | --- | --- |
| Baseline | 93.03 ± 1.15 | 91.49 ± 0.68 | 53.12 ± 2.03 | |
| Qwen-2.5 7B | MIND | 98.13 ± 0.98 | 98.03 ± 1.19 | 86.87 ± 0.31 |
| Baseline | 95.76 ± 1.10 | 94.89 ± 1.55 | 57.81 ± 2.17 | |
Table 6: Lexical generalization. Accuracy (mean ± std) of MIND and Baseline models in core generalization as in the main paper (Core) and with novel unseen terms (Unseen Pseudowords, Unseen Constants).
| Qwen-2.5 1.5B Baseline Qwen-2.5 3B | MIND 55.14 ± 0.53 MIND | 76.67 ± 0.38 29.37 ± 1.85 84.68 ± 0.54 | 50.40 ± 3.45 30.22 ± 1.52 64.77 ± 0.73 | 45.81 ± 1.13 53.95 ± 3.46 |
| --- | --- | --- | --- | --- |
| Baseline | 66.51 ± 0.19 | 43.66 ± 1.93 | 43.67 ± 2.05 | |
| Qwen-2.5 7B | MIND | 88.01 ± 1.11 | 69.24 ± 9.79 | 60.90 ± 2.94 |
| Baseline | 68.54 ± 2.25 | 45.27 ± 0.95 | 43.94 ± 2.82 | |
Table 7: Generalization in limited data regime. Accuracy (mean ± std) of meta-learning and baseline models trained and tested on all inference types and lengths (Core), as well as tested for longer or shorter inferences than those seen during training. The models are trained on only 100 examples for each combination of inference type and inference length.
## Appendix D Additional Results
### D.1 Accuracies by Type and Length
In this section, we present the complete set of accuracies broken down by type and length for both MIND and baseline models, as well as closed source models.
#### MIND and baseline.
We report the average accuracy for each inference type and length combination in both the core and length generalization settings for the Qwen-2.5 models. Figures 7, 8, and 9 show the accuracies for core generalization for the 1.5B, 3B, and 7B models, respectively, in both the MIND and baseline settings. Figures 13, 14, and 15 show the accuracies for short to long generalization, while Figures 10, 11, and 12 show the accuracies for long to short generalization for the same models, again in both the MIND and baseline settings.
Across model sizes and approaches, the easiest types of inferences are type 2 and type 6. In contrast, types 1, 3, and 4 are typically the most challenging. A notable difference between the MIND and baseline models is that the latter consistently struggle with type 5 inferences, whereas the former show stronger performance. However, apart from type 5 inferences, MIND models generally perform better but still tend to struggle or excel in similar type and length combinations as the baseline models.
These patterns also hold in the length generalization setting, with the additional observation that performance tends to degrade as the distance between the lengths used for training and those used for testing increases.
#### Closed models.
Figures 16 and 17 show the accuracies for zero-shot and few-shot prompting of GPT-4o and o3-mini, respectively. Both models show substantial improvement in the few-shot setting. GPT-4o is the lowest-performing model according to Table 1, a result further supported by the detailed breakdown in this section. It consistently achieves high accuracy only on type 2 inferences, which are the easiest and rely primarily on simple transitivity. o3-mini struggles more with types 3 and 4. Additionally, a clear difference in performance on type 5 inferences is observed between the zero-shot and few-shot settings. This resembles the difference seen in Qwen-2.5 models between MIND and baseline. These results show that even pretrained models tend to struggle with the same types of syllogistic inferences as fine-tuned models, with a few exceptions, such as type 5 inferences.
| Qwen-2.5 7B Baseline GPT-4o | MIND 6.67 Few-shot | 17.86 5.19 28.13 | 2.80 91.43 2.92 | 80.36 5.39 70.54 | 3.32 80.95 5.76 | 75.00 22.76 |
| --- | --- | --- | --- | --- | --- | --- |
| Zero-shot | 14.46 | 3.50 | 83.01 | 6.45 | 17.15 | |
| o3-mini | Few-shot | 84.57 | 2.38 | 14.23 | 2.65 | 7.21 |
| Zero-shot | 76.60 | 2.61 | 22.55 | 7.09 | 2.62 | |
Table 8: Error analysis. Error analysis on core generalization in Qwen-2.5 7B, and the closed models GPT-4o and o3-mini. The table shows percentages and averages for non-minimal valid sets of premises (NVM) and missing necessary $A$ premises (MAP), and the percentage of hallucinated premises (HP).
### D.2 Lexical Generalization
In the main body of the paper, we evaluated core and length generalization. Here, we report an additional set of results related to lexical generalization. By lexical generalization, we mean the manipulation of the vocabulary assigned to each of the terms appearing in the formulas within $KB$ s.
Section 5.1 presents results using the same vocabulary of pseudowords employed during training, tested on unseen $KB$ s. Here, we explore two more challenging settings: one using a new vocabulary of pseudowords, and another using abstract symbols (e.g., x2435) in place of pseudowords. This latter setting is distributionally the most distant from the training data.
Table 6 presents the results of this lexical generalization experiment. Across all Qwen-2.5 model sizes (1.5B, 3B, 7B) and conditions, the MIND approach consistently yields higher accuracy than the baseline, with performance improving with model scale for both approaches. Notably, for both known and unseen pseudowords, performance is similar in both the MIND and baseline settings, that is, changing the pseudoword vocabulary has little impact on model performance.
In contrast, for the most challenging generalization setting—unseen constants—both approaches exhibit a significant drop in performance, but the performance gap between MIND and the baseline becomes more pronounced: MIND achieves 86.87% at 7B, compared to just 57.81% for the baseline.
### D.3 Generalization with Limited Data
Table 7 presents the performance of the models when trained in a low data regime, using only 100 examples for each combination of inference type and length. Consistent with the findings in Table 6 and Table 2, MIND significantly outperforms the baseline across all model sizes and evaluation metrics. For the core generalization performance, the MIND models achieve substantially higher accuracy (e.g., 88.01% for Qwen-2.5 7B MIND vs. 68.54% for baseline). Similarly, when evaluating generalization to shorter and longer inferences than seen during training, MIND models demonstrate a clear advantage.
Crucially, the performance gap between the meta-learning and baseline approaches is notably wider in this limited data setting compared to the standard data setting. This highlights the enhanced generalization capabilities on limited data induced by meta-learning.
### D.4 Additional Error Analysis
In this section, we present the additional error analysis results for Qwen-2.5 7B both in MIND and baseline setting on the core generalization experiment. Additionally, we also show the error analysis results for GPT-4o and o3-mini. The detailed breakdown of these errors is presented in Table 8.
#### MIND and baseline.
For the Qwen-2.5 7B model, MIND shows a higher percentage of non-minimal valid set of premises (NVM) errors (17.86%) compared to the baseline (6.67%) on core generalization. However, when these NVM errors occur, MIND includes fewer unnecessary premises on average (Avg. NVM of 2.80) than the baseline (Avg. NVM of 5.19). Conversely, the baseline model exhibits a higher proportion of errors due to missing necessary A premises (MAP) at 91.43%, with an average of 5.39 missing premises. This is higher than MIND, which has a MAP percentage of 80.36% and an average of 3.32 missing premises. Both methods show high rates of hallucinated premises (HP), with MIND at 75.00% and the baseline slightly higher at 80.95%. These results suggest that not only MIND has generally a higher core generalization performance than the baseline, but also that MIND errors tend to be closer to the correct set of premises.
#### Closed models.
The error analysis for closed models reveals distinct patterns for GPT-4o and o3-mini. For GPT-4o, MAP errors are predominant in both few-shot (70.54%) and zero-shot (83.01%) settings. The average number of missing $A$ premises is also high (5.76 for few-shot and 6.45 for zero-shot) and indicates that the model struggles to provide all the necessary premises to derive hypotheses.
In contrast, o3-mini primarily struggles with NVM errors, which constitute 84.57% of errors in the few-shot setting and 76.60% in the zero-shot setting. The average number of unnecessary premises is relatively low and similar in both settings (2.38 for few-shot, 2.61 for zero-shot). This shows that the model is capable of providing logically valid set of premises from which hypotheses can be derived but, on the other hand, struggles with the concept of minimality. An interesting characteristic of o3-mini is its very low HP rate, at 7.21% for few-shot and an even lower 2.62% for zero-shot, which is considerably better than both Qwen-2.5 7B and GPT-4o.
|
<details>
<summary>extracted/6458430/figs/overall_trainval.png Details</summary>
### Visual Description
## Heatmap: All Lengths
### Overview
The image displays a heatmap-style grid chart titled "All Lengths." It visualizes the presence or absence of data points across two categorical dimensions: "Type" (y-axis) and "Length" (x-axis). The chart uses a binary color scheme where dark blue cells indicate a data point exists for that specific Type-Length combination, and white cells indicate its absence.
### Components/Axes
* **Title:** "All Lengths" (centered at the top).
* **Y-Axis:** Labeled "Type." It lists 7 discrete categories, numbered 1 through 7 from top to bottom.
* **X-Axis:** Labeled "Length." It lists 20 discrete, equally spaced categories, numbered 0 through 19 from left to right.
* **Grid:** A 7-row by 20-column grid of cells. Each cell corresponds to a unique (Type, Length) pair.
* **Color Legend:** Implicit. Dark blue = Present/True. White = Absent/False. No separate legend box is present; the meaning is inferred from the visual pattern.
### Detailed Analysis
The following table reconstructs the data from the heatmap. A "✓" indicates a dark blue cell (present), and a "—" indicates a white cell (absent).
| Type | Length 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | — | — | — | — | — | — | — | — | — | — |
| **2** | — | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | — | — | — | — | — | — | — | — | — |
| **3** | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| **4** | — | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | — | — | — | — | — | — | — | — |
| **5** | — | — | — | — | — | — | — | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| **6** | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | — |
| **7** | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | — | — | — | — | — | — |
**Data Point Summary by Type:**
* **Type 1:** Present for Lengths 0 through 9 (10 consecutive points).
* **Type 2:** Present for Lengths 1 through 10 (10 consecutive points, shifted one unit right from Type 1).
* **Type 3:** Present for **all** Lengths 0 through 19 (20 points). This is the only fully populated row.
* **Type 4:** Present for Lengths 1 through 11 (11 consecutive points).
* **Type 5:** Present for Lengths 6 through 19 (14 consecutive points). This row starts the latest.
* **Type 6:** Present for Lengths 0 through 18 (19 consecutive points). This row ends one unit before the maximum.
* **Type 7:** Present for Lengths 0 through 13 (14 consecutive points).
### Key Observations
1. **Complete Coverage:** Type 3 is the only category that has data for every single Length value (0-19).
2. **Contiguous Blocks:** For every Type, the present data points form a single, contiguous block along the Length axis. There are no isolated or scattered points within a row.
3. **Variable Start and End Points:** The starting Length for each Type's data block varies (0, 1, 0, 1, 6, 0, 0). The ending Length also varies (9, 10, 19, 11, 19, 18, 13).
4. **Maximum Span:** Type 6 has the widest span, covering 19 consecutive Lengths (0-18). Type 5 has the latest start (Length 6).
5. **Symmetry/Pattern:** There is no obvious symmetrical or mathematical pattern governing the start and end points of each Type's data block. The distribution appears specific to the underlying dataset.
### Interpretation
This heatmap likely represents the **occurrence or availability of items of different "Types" across a spectrum of "Lengths."** The "Length" axis could represent a physical measurement, a time interval, a sequence position, or a categorical bin.
* **What the data suggests:** The chart answers the question: "For each Type, which Lengths are represented in the dataset?" It shows that Type 3 is ubiquitous, appearing at every measured length. Other types have more restricted ranges. For example, Type 5 is only associated with longer lengths (6 and above), while Types 1, 2, 4, 6, and 7 are absent from the longest lengths (14-19, with the exception of Type 5).
* **Relationships between elements:** The contiguous blocks suggest that each "Type" has a characteristic range of "Lengths." This could indicate a natural property (e.g., different species have different size ranges) or a sampling artifact (e.g., data for certain types was only collected within specific length intervals).
* **Notable anomalies:** The primary anomaly is the perfect, full coverage of Type 3. This makes it a reference or control category against which the more restricted ranges of the other types can be compared. The late start of Type 5 is also notable, suggesting it is exclusively a "long-length" phenomenon in this context.
**Language:** All text in the image is in English.
</details>
|
<details>
<summary>extracted/6458430/figs/overall_trainval.png Details</summary>

### Visual Description
## Heatmap: All Lengths
### Overview
The image displays a heatmap-style grid chart titled "All Lengths." It visualizes the presence or absence of data points across two categorical dimensions: "Type" (y-axis) and "Length" (x-axis). The chart uses a binary color scheme where dark blue cells indicate a data point exists for that specific Type-Length combination, and white cells indicate its absence.
### Components/Axes
* **Title:** "All Lengths" (centered at the top).
* **Y-Axis:** Labeled "Type." It lists 7 discrete categories, numbered 1 through 7 from top to bottom.
* **X-Axis:** Labeled "Length." It lists 20 discrete, equally spaced categories, numbered 0 through 19 from left to right.
* **Grid:** A 7-row by 20-column grid of cells. Each cell corresponds to a unique (Type, Length) pair.
* **Color Legend:** Implicit. Dark blue = Present/True. White = Absent/False. No separate legend box is present; the meaning is inferred from the visual pattern.
### Detailed Analysis
The following table reconstructs the data from the heatmap. A "✓" indicates a dark blue cell (present), and a "—" indicates a white cell (absent).
| Type | Length 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | — | — | — | — | — | — | — | — | — | — |
| **2** | — | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | — | — | — | — | — | — | — | — | — |
| **3** | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| **4** | — | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | — | — | — | — | — | — | — | — |
| **5** | — | — | — | — | — | — | — | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| **6** | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | — |
| **7** | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | — | — | — | — | — | — |
**Data Point Summary by Type:**
* **Type 1:** Present for Lengths 0 through 9 (10 consecutive points).
* **Type 2:** Present for Lengths 1 through 10 (10 consecutive points, shifted one unit right from Type 1).
* **Type 3:** Present for **all** Lengths 0 through 19 (20 points). This is the only fully populated row.
* **Type 4:** Present for Lengths 1 through 11 (11 consecutive points).
* **Type 5:** Present for Lengths 6 through 19 (14 consecutive points). This row starts the latest.
* **Type 6:** Present for Lengths 0 through 18 (19 consecutive points). This row ends one unit before the maximum.
* **Type 7:** Present for Lengths 0 through 13 (14 consecutive points).
### Key Observations
1. **Complete Coverage:** Type 3 is the only category that has data for every single Length value (0-19).
2. **Contiguous Blocks:** For every Type, the present data points form a single, contiguous block along the Length axis. There are no isolated or scattered points within a row.
3. **Variable Start and End Points:** The starting Length for each Type's data block varies (0, 1, 0, 1, 6, 0, 0). The ending Length also varies (9, 10, 19, 11, 19, 18, 13).
4. **Maximum Span:** Type 6 has the widest span, covering 19 consecutive Lengths (0-18). Type 5 has the latest start (Length 6).
5. **Symmetry/Pattern:** There is no obvious symmetrical or mathematical pattern governing the start and end points of each Type's data block. The distribution appears specific to the underlying dataset.
### Interpretation
This heatmap likely represents the **occurrence or availability of items of different "Types" across a spectrum of "Lengths."** The "Length" axis could represent a physical measurement, a time interval, a sequence position, or a categorical bin.
* **What the data suggests:** The chart answers the question: "For each Type, which Lengths are represented in the dataset?" It shows that Type 3 is ubiquitous, appearing at every measured length. Other types have more restricted ranges. For example, Type 5 is only associated with longer lengths (6 and above), while Types 1, 2, 4, 6, and 7 are absent from the longest lengths (14-19, with the exception of Type 5).
* **Relationships between elements:** The contiguous blocks suggest that each "Type" has a characteristic range of "Lengths." This could indicate a natural property (e.g., different species have different size ranges) or a sampling artifact (e.g., data for certain types was only collected within specific length intervals).
* **Notable anomalies:** The primary anomaly is the perfect, full coverage of Type 3. This makes it a reference or control category against which the more restricted ranges of the other types can be compared. The late start of Type 5 is also notable, suggesting it is exclusively a "long-length" phenomenon in this context.
**Language:** All text in the image is in English.
</details>
|
| --- | --- |
|
<details>
<summary>extracted/6458430/figs/compositionality_trainval.png Details</summary>
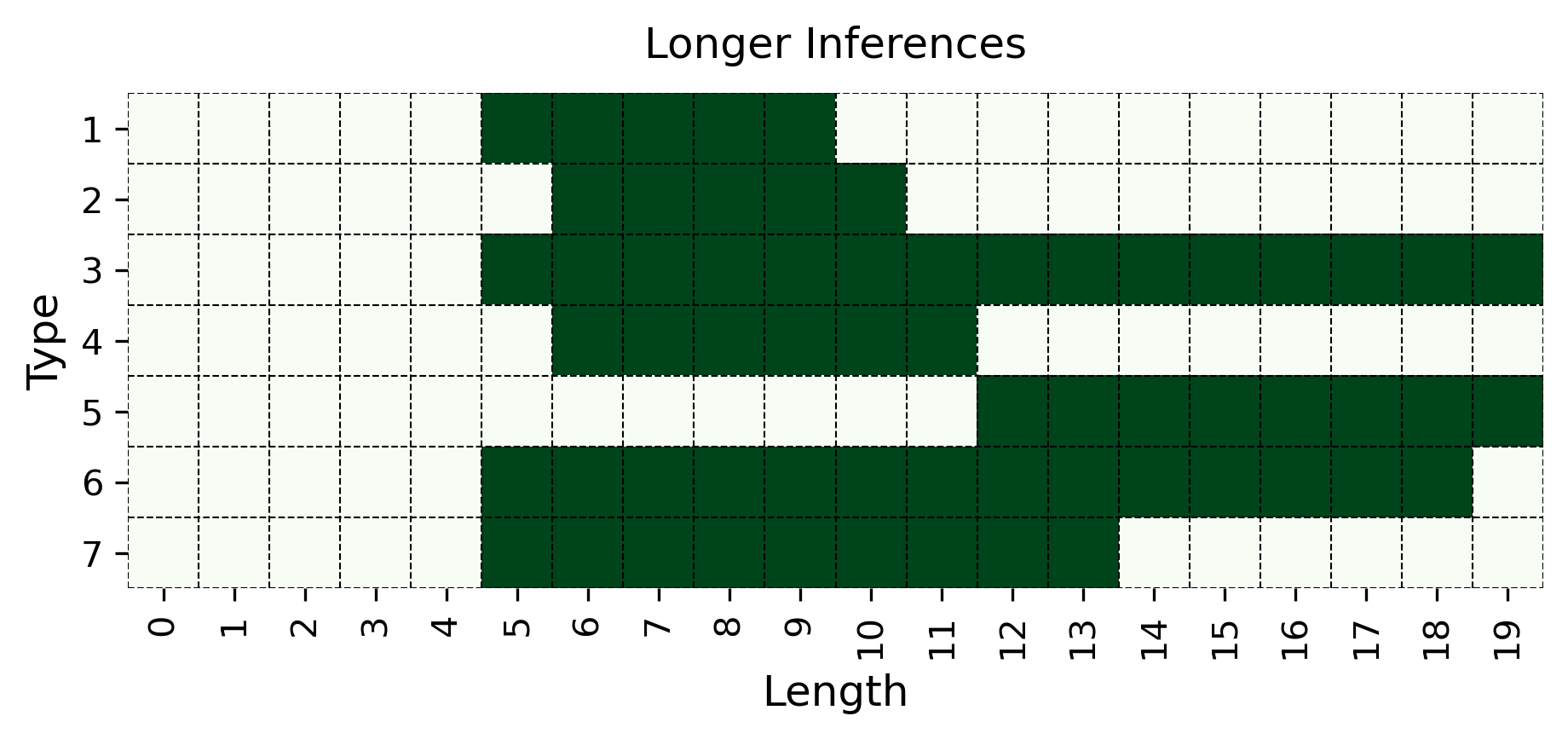
### Visual Description
## Heatmap Chart: Longer Inferences
### Overview
The image is a heatmap-style chart titled "Longer Inferences." It visualizes the presence or absence of seven distinct categories (labeled "Type" 1 through 7) across a range of numerical values (labeled "Length" from 0 to 19). The chart uses a binary color scheme: dark green cells indicate a "present" or "true" state for a given Type-Length combination, while white cells indicate "absent" or "false."
### Components/Axes
* **Title:** "Longer Inferences" (centered at the top).
* **Vertical Axis (Y-axis):** Labeled "Type." It lists seven discrete categories, numbered 1 through 7 from top to bottom.
* **Horizontal Axis (X-axis):** Labeled "Length." It displays a continuous numerical scale from 0 to 19, with integer markers.
* **Color Legend:** Implicit. Dark green represents a positive/active state; white represents a negative/inactive state. There is no separate legend box.
* **Grid:** A fine, dashed grid overlays the entire plot area, aligning with each integer on both axes.
### Detailed Analysis
The following table reconstructs the data by listing the continuous range of "Length" values for which each "Type" has a dark green (present) cell. All ranges are inclusive.
| Type | Length Range (Present) | Approximate Span |
| :--- | :--- | :--- |
| 1 | 5 to 9 | 5 units |
| 2 | 6 to 10 | 5 units |
| 3 | 5 to 19 | 15 units |
| 4 | 6 to 11 | 6 units |
| 5 | 12 to 19 | 8 units |
| 6 | 5 to 18 | 14 units |
| 7 | 5 to 13 | 9 units |
**Spatial & Trend Verification:**
* **Type 1 (Top Row):** Green block is centered, spanning from Length 5 to 9.
* **Type 2:** Green block is shifted one unit right compared to Type 1, spanning 6 to 10.
* **Type 3:** The longest continuous green block, starting at Length 5 and extending to the chart's maximum at 19.
* **Type 4:** Green block spans from 6 to 11.
* **Type 5:** Green block starts later than others, at Length 12, and continues to 19.
* **Type 6:** A long green block from 5 to 18, ending one unit before the maximum.
* **Type 7 (Bottom Row):** Green block spans from 5 to 13.
### Key Observations
1. **Maximum Range:** Type 3 has the broadest presence, active across 15 consecutive Length units (5-19).
2. **Minimum Range:** Types 1 and 2 have the narrowest presence, each spanning only 5 units.
3. **Late Onset:** Type 5 is unique in that it only becomes active at a higher Length value (12), whereas all other types begin at Length 5 or 6.
4. **Common Starting Point:** Five of the seven types (1, 3, 5, 6, 7) have a green cell at Length 5. Type 5 is the exception, starting at 12.
5. **Pattern of Gaps:** There are no green cells for any Type at Lengths 0-4. The first activity for all types begins at Length 5 or 6.
### Interpretation
This chart likely illustrates the operational range or applicability of seven different methods, models, or categories ("Types") relative to a parameter called "Length." The title "Longer Inferences" suggests "Length" may correspond to sequence length, input size, or time steps in an inference task.
* **Type 3** appears to be the most robust or general-purpose, functioning effectively across nearly the entire spectrum of longer lengths.
* **Type 5** is a specialist, only engaged for the longest sequences (Length ≥12).
* **Types 1, 2, 4, 6, and 7** have intermediate ranges, suggesting they are optimized for specific mid-range lengths. The staggered start points (5 vs. 6) and end points indicate subtle differences in their effective domains.
* The complete absence of activity for Lengths 0-4 implies that none of these "Longer Inference" types are designed for or applied to short sequences. A different set of methods likely handles those cases.
The visualization effectively communicates that the choice of "Type" is highly dependent on the "Length" parameter, with clear segmentation of their effective ranges.
</details>
|
<details>
<summary>extracted/6458430/figs/compositionality_test.png Details</summary>
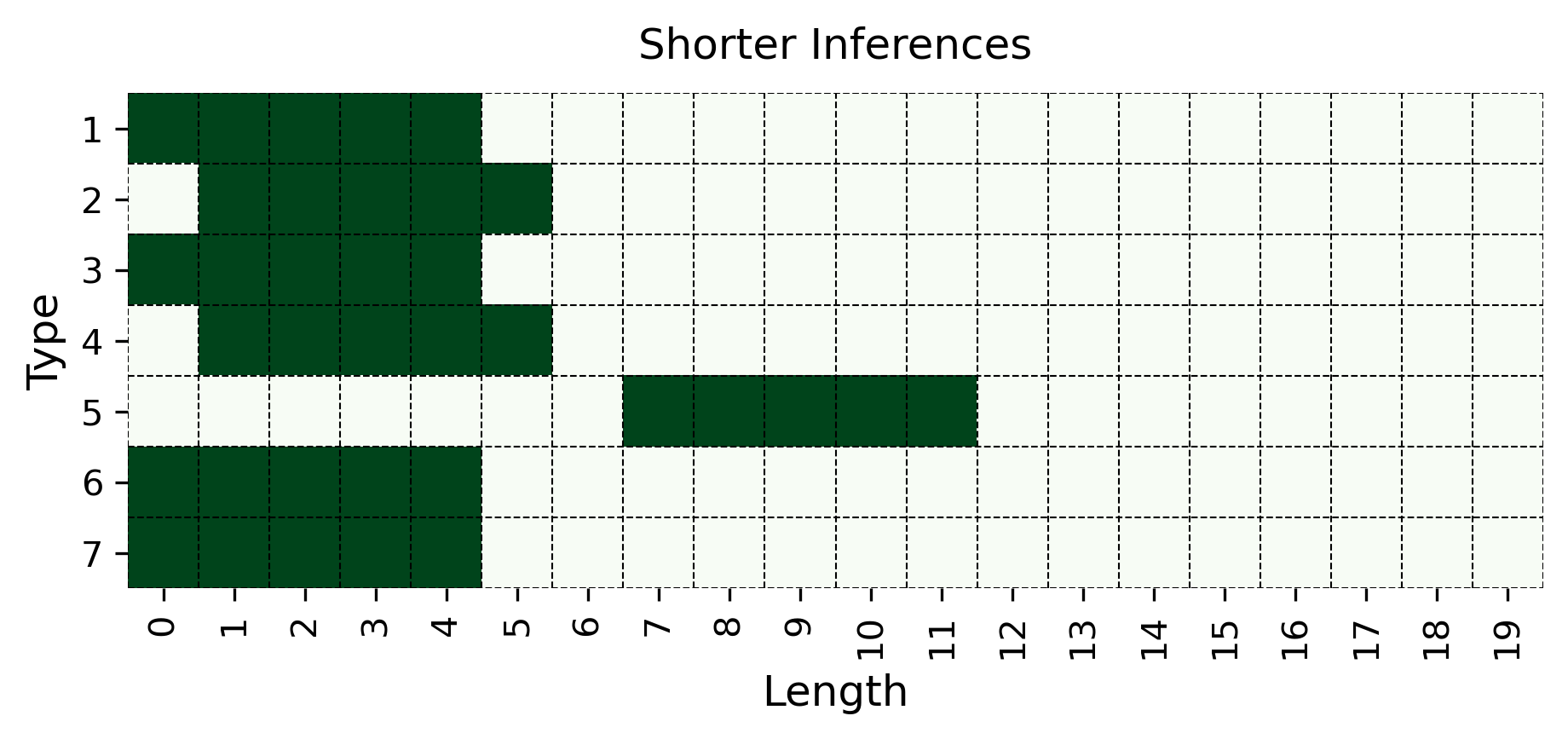
### Visual Description
## Heatmap: Shorter Inferences
### Overview
The image is a heatmap titled "Shorter Inferences." It visualizes the presence or intensity of data across two categorical/ordinal dimensions: "Type" (y-axis) and "Length" (x-axis). The chart uses a binary color scheme where dark green blocks indicate a positive value or presence for a given (Type, Length) pair, and the white background indicates absence or zero value.
### Components/Axes
* **Title:** "Shorter Inferences" (centered at the top).
* **Y-Axis (Vertical):**
* **Label:** "Type" (rotated 90 degrees, positioned to the left of the axis).
* **Categories/Ticks:** Seven discrete types, labeled from top to bottom as: 1, 2, 3, 4, 5, 6, 7.
* **X-Axis (Horizontal):**
* **Label:** "Length" (centered below the axis).
* **Scale/Ticks:** A linear scale from 0 to 19, with integer markers at every unit (0, 1, 2, ..., 19).
* **Grid:** A dashed grid is overlaid on the plot area, aligning with each integer tick on both axes.
* **Legend/Color Key:** No explicit legend is present. The color (dark green) is used uniformly to represent the presence of data. The absence of color (white) represents the absence of data.
### Detailed Analysis
The heatmap displays a sparse matrix where each row (Type) has a specific, contiguous range of "Length" values marked with dark green blocks.
* **Type 1:** Active for Lengths **0, 1, 2, 3, 4**. (A continuous block from 0 to 4).
* **Type 2:** Active for Lengths **1, 2, 3, 4, 5**. (A continuous block from 1 to 5; note the absence at Length 0).
* **Type 3:** Active for Lengths **0, 1, 2, 3, 4**. (Identical pattern to Type 1).
* **Type 4:** Active for Lengths **1, 2, 3, 4, 5**. (Identical pattern to Type 2).
* **Type 5:** Active for Lengths **7, 8, 9, 10, 11**. (A continuous block from 7 to 11; this is the only type with lengths significantly greater than 5).
* **Type 6:** Active for Lengths **0, 1, 2, 3, 4**. (Identical pattern to Types 1 and 3).
* **Type 7:** Active for Lengths **0, 1, 2, 3, 4**. (Identical pattern to Types 1, 3, and 6).
**Spatial Summary:** The data is heavily concentrated in the left portion of the chart (Lengths 0-5). There is a distinct cluster for Types 1, 3, 6, and 7 (Lengths 0-4) and a slightly offset cluster for Types 2 and 4 (Lengths 1-5). Type 5 is a clear outlier, forming an isolated cluster in the middle of the x-axis (Lengths 7-11). The right side of the chart (Lengths 12-19) is entirely empty.
### Key Observations
1. **Bimodal Distribution:** The data shows two primary clusters of activity: one at very short lengths (0-5) and a secondary, isolated cluster at moderate lengths (7-11).
2. **Type Grouping:** The seven types fall into three distinct behavioral groups based on their length profiles:
* **Group A (Shortest):** Types 1, 3, 6, 7 (Lengths 0-4).
* **Group B (Short):** Types 2, 4 (Lengths 1-5).
* **Group C (Moderate):** Type 5 (Lengths 7-11).
3. **Uniformity within Groups:** Within Groups A and B, the patterns are perfectly uniform. All members of Group A have identical active ranges, as do all members of Group B.
4. **Significant Gap:** There is a complete absence of data for any type at Lengths 5 and 6, creating a clear separation between the short-length cluster and the moderate-length cluster of Type 5.
5. **No Long Inferences:** No type shows any activity for lengths 12 and above.
### Interpretation
This heatmap likely represents the distribution of inference lengths (e.g., number of reasoning steps, sequence length, or token count) for different categories or models ("Types").
* **What the data suggests:** The title "Shorter Inferences" is strongly supported by the data. The vast majority of inferences across all types are very short (≤5 units). Type 5 is the sole exception, producing moderately longer inferences (7-11 units), but still not "long" relative to the full scale (0-19).
* **Relationship between elements:** The "Type" appears to be a strong determinant of inference length. The perfect grouping suggests that Types 1, 3, 6, and 7 may be variants of the same underlying model or process, as are Types 2 and 4. Type 5 represents a fundamentally different approach or category that consistently generates longer, but still bounded, inferences.
* **Notable anomalies:** The complete gap at lengths 5 and 6 is striking. It implies a potential threshold or discontinuity in the process generating these inferences. Inferences either terminate very quickly (≤5) or, if they pass a certain point, tend to continue to at least length 7. The absence of any data beyond length 11 suggests a hard constraint or a natural termination point for even the longest inferences in this dataset.
* **Peircean Investigative Reading:** The chart is an *index* of a process's behavior, pointing directly to its operational constraints. It is also a *symbol* of efficiency or simplicity, visually arguing that the system(s) under study predominantly operate with minimal steps. The outlier (Type 5) serves as a critical *icon* of a different, more complex operational mode within the same framework.
</details>
|
|
<details>
<summary>extracted/6458430/figs/recursiveness_trainval.png Details</summary>
### Visual Description
## Heatmap Chart: Shorter Inferences
### Overview
The image displays a heatmap titled "Shorter Inferences." It visualizes the presence or absence of seven distinct "Types" (vertical axis) across a range of "Lengths" (horizontal axis). The chart uses a two-color scheme: dark red indicates presence (or a positive value), and light beige indicates absence (or zero). The grid is marked with dashed lines for clarity.
### Components/Axes
- **Title**: "Shorter Inferences" (centered at the top).
- **Vertical Axis (Y-axis)**: Labeled "Type," with categorical markers numbered 1 through 7 from top to bottom.
- **Horizontal Axis (X-axis)**: Labeled "Length," with numerical markers from 0 to 19, incrementing by 1.
- **Color Legend**: Implied by the chart's visual encoding:
- **Dark Red**: Indicates the inference type is present or active at that specific length.
- **Light Beige**: Indicates the inference type is absent or inactive at that specific length.
- **Grid**: A dashed-line grid overlays the entire plot area, aligning with each integer value on both axes.
### Detailed Analysis
The heatmap presents a binary matrix where each cell corresponds to a specific (Type, Length) pair. The following table reconstructs the data, showing the range of lengths for which each Type is marked as present (dark red).
| Type | Length Range (Present) | Approx. Number of Lengths |
| :--- | :--------------------- | :------------------------ |
| 1 | 0 to 4 | 5 |
| 2 | 1 to 5 | 5 |
| 3 | 0 to 14 | 15 |
| 4 | 1 to 6 | 6 |
| 5 | 7 to 14 | 8 |
| 6 | 0 to 13 | 14 |
| 7 | 0 to 8 | 9 |
**Spatial Grounding & Trend Verification:**
- **Type 1 (Top Row)**: A solid dark red block spans from the left edge (Length 0) to Length 4. The trend is a short, continuous segment at the beginning of the length scale.
- **Type 2**: The first cell (Length 0) is light beige. A dark red block then spans from Length 1 to 5. The trend shows a one-unit delay before starting.
- **Type 3**: This is the longest continuous dark red block, extending from Length 0 to 14. It dominates the middle of the chart.
- **Type 4**: Similar to Type 2, the first cell (Length 0) is light beige. A dark red block spans from Length 1 to 6.
- **Type 5**: This row shows a significant delay. The first seven cells (Lengths 0-6) are light beige. A dark red block then spans from Length 7 to 14.
- **Type 6**: A long, continuous dark red block spans from Length 0 to 13, similar to but slightly shorter than Type 3.
- **Type 7 (Bottom Row)**: A dark red block spans from Length 0 to 8.
### Key Observations
1. **Variable Starting Points**: Not all types begin at Length 0. Types 2 and 4 start at Length 1, while Type 5 has the most delayed start at Length 7.
2. **Variable Durations**: The "length" of the present segment varies greatly. Type 3 has the longest duration (15 units), while Types 1 and 2 have the shortest (5 units each).
3. **Clustering at Lower Lengths**: Most types (1, 2, 3, 4, 6, 7) have their presence concentrated in the lower to middle range of the Length axis (0-14). No type is present beyond Length 14.
4. **Distinct Pattern for Type 5**: Type 5 is unique in having no presence in the first third of the length scale (0-6), suggesting a higher threshold or different condition for its activation.
### Interpretation
This heatmap likely illustrates the operational range or validity of different inference mechanisms ("Types") with respect to an input "Length" parameter. The data suggests:
- **Specialization**: Each inference type is specialized for a specific range of lengths. Type 3 and Type 6 are generalists, covering a broad spectrum. Type 5 is a specialist for mid-to-high lengths (7-14).
- **Activation Thresholds**: The delayed start for Types 2, 4, and especially 5 implies these inferences require a minimum input length to become active or relevant. This could relate to complexity, data sufficiency, or algorithmic constraints.
- **Upper Bound**: The consistent cutoff at or before Length 14 for all types indicates a system-wide maximum length for these "shorter inferences," beyond which they may not apply or a different mechanism takes over.
- **Functional Grouping**: The similar patterns of Types 1/2 and 3/6 might indicate they belong to related families or serve analogous purposes with slightly different parameters.
In essence, the chart maps the "territory" of seven different processes, showing where each one operates along a length dimension. It reveals a structured system where processes are activated and deactivated at specific points, likely to optimize performance or accuracy for different input sizes.
</details>
|
<details>
<summary>extracted/6458430/figs/recursiveness_test.png Details</summary>
### Visual Description
## Heatmap: Longer Inferences
### Overview
The image is a heatmap chart titled "Longer Inferences." It visualizes the relationship between two categorical variables: "Type" (y-axis) and "Length" (x-axis). The chart uses a binary color scheme to indicate the presence or absence of a condition (likely "longer inferences") for each combination of Type and Length. The active cells are colored dark red, while the inactive cells are a light beige.
### Components/Axes
* **Title:** "Longer Inferences" (centered at the top).
* **Y-Axis:** Labeled "Type." It lists discrete categories numbered from 1 to 7, arranged vertically from top to bottom.
* **X-Axis:** Labeled "Length." It lists discrete numerical values from 0 to 19, arranged horizontally from left to right. The labels are rotated 90 degrees clockwise.
* **Grid:** A dashed grid overlays the entire plot area, creating a matrix of cells corresponding to each (Type, Length) pair.
* **Legend/Color Key:** There is no explicit legend. The color meaning is inferred: dark red indicates an active or "true" state for that cell, while light beige indicates an inactive or "false" state.
### Detailed Analysis
The heatmap shows which "Length" values are associated with each "Type." The dark red blocks represent the active ranges.
* **Type 1:** Active for Lengths **5, 6, 7, 8, 9**. (Range: 5-9)
* **Type 2:** Active for Lengths **6, 7, 8, 9, 10**. (Range: 6-10)
* **Type 3:** Active for Lengths **15, 16, 17, 18, 19**. (Range: 15-19)
* **Type 4:** Active for Lengths **7, 8, 9, 10, 11**. (Range: 7-11)
* **Type 5:** Active for Lengths **15, 16, 17, 18, 19**. (Range: 15-19)
* **Type 6:** Active for Lengths **14, 15, 16, 17, 18**. (Range: 14-18)
* **Type 7:** Active for Lengths **9, 10, 11, 12, 13**. (Range: 9-13)
### Key Observations
1. **Clustered Ranges:** Each Type has a contiguous block of active Lengths, spanning exactly 5 units.
2. **Two Distinct Groups:**
* **Group A (Shorter Lengths):** Types 1, 2, 4, and 7 have active ranges clustered between Lengths 5 and 13.
* **Group B (Longer Lengths):** Types 3, 5, and 6 have active ranges clustered between Lengths 14 and 19.
3. **Overlap and Progression:**
* Within Group A, the active ranges shift rightward (to higher Lengths) as Type increases: Type 1 (5-9) -> Type 2 (6-10) -> Type 4 (7-11) -> Type 7 (9-13).
* Within Group B, the ranges are very similar: Type 6 (14-18), Types 3 & 5 (15-19).
4. **Gaps:** There is a clear gap in the data. No Type has active cells for Lengths 0-4 or for Length 14 in the case of Types 3 and 5.
### Interpretation
This heatmap likely illustrates the output of a classification or analysis system where different "Types" (which could represent models, algorithms, categories, or conditions) are associated with specific ranges of "Length" (which could represent sequence length, inference steps, data size, or time duration).
* **What the data suggests:** The system or phenomenon being measured produces "longer inferences" (the active state) only within specific, bounded length intervals for each type. The clear separation into two groups (A and B) suggests a fundamental dichotomy in the data or the types themselves—perhaps two different classes of problems, two different operational modes, or two distinct populations.
* **How elements relate:** The Type is the primary determinant of the Length range. The progression within Group A suggests a systematic relationship where increasing Type number correlates with a shift toward slightly longer inference lengths.
* **Notable anomalies:** The most striking feature is the complete absence of activity for Lengths 0-4 across all Types. This could indicate a minimum threshold for the measured phenomenon. The identical ranges for Types 3 and 5 are also notable, suggesting these two types behave identically with respect to this metric. The gap at Length 14 for Types 3 and 5, while Type 6 is active there, is a specific point of divergence within Group B.
</details>
|
Figure 6: Combination of inference type and length within generated $KB$ s. In each heatmap, rows represent Inference Types (1–7), while columns represent Lengths (0–19). The train, validation, and test splits use fixed values of 1000 or 100, 5, and 100 samples respectively for all non-zero entries (Colored). Entries with values equal to 0 indicate non-existing combinations of length and type within the split that is considered (White).
<details>
<summary>extracted/6458430/figs/qwen-1.5b_heatmap_meta_overall_high.png Details</summary>
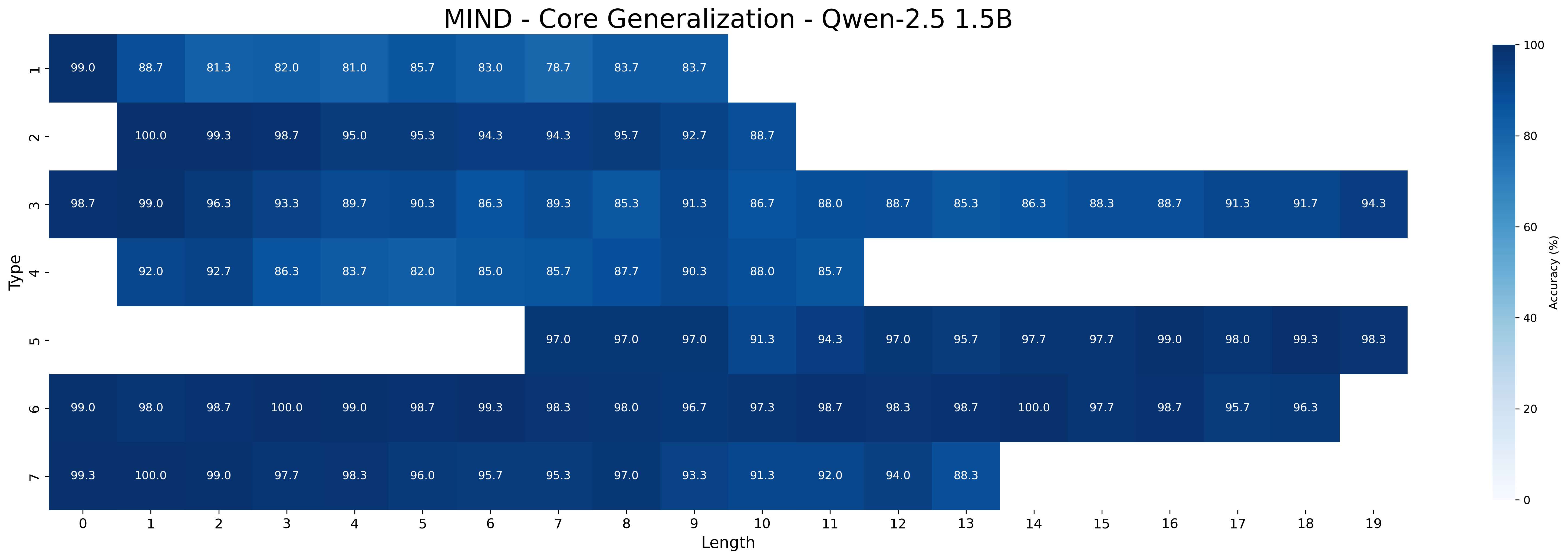
### Visual Description
## Heatmap: MIND - Core Generalization - Qwen-2.5 1.5B
### Overview
This image is a heatmap visualizing the accuracy performance of the "Qwen-2.5 1.5B" model on a task or benchmark named "MIND - Core Generalization." The chart plots performance across two dimensions: "Type" (y-axis) and "Length" (x-axis). The color intensity represents accuracy percentage, with a corresponding color bar legend on the right.
### Components/Axes
* **Title:** "MIND - Core Generalization - Qwen-2.5 1.5B" (centered at the top).
* **Y-Axis (Vertical):** Labeled "Type". It contains 7 discrete categories, numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled "Length". It contains 20 discrete categories, numbered 0 through 19 from left to right.
* **Color Bar Legend:** Located on the far right of the chart. It is a vertical gradient bar labeled "Accuracy (%)".
* Scale: 0 (bottom, lightest blue/white) to 100 (top, darkest blue).
* Major tick marks are at 0, 20, 40, 60, 80, and 100.
* **Data Grid:** The main body of the chart is a grid of colored cells. Each cell corresponds to a specific (Type, Length) pair. The numerical accuracy value is printed in white text within each cell. Cells with no data are left blank (white).
### Detailed Analysis
The following table reconstructs the data from the heatmap. "N/A" indicates a blank cell with no reported data.
| Type \ Length | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 99.0 | 88.7 | 81.3 | 82.0 | 81.0 | 85.7 | 83.0 | 78.7 | 83.7 | 83.7 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **2** | N/A | 100.0 | 99.3 | 98.7 | 95.0 | 95.3 | 94.3 | 94.3 | 95.7 | 92.7 | 88.7 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **3** | 98.7 | 99.0 | 96.3 | 93.3 | 89.7 | 90.3 | 86.3 | 89.3 | 85.3 | 91.3 | 86.7 | 88.0 | 88.7 | 85.3 | 86.3 | 88.3 | 88.7 | 91.3 | 91.7 | 94.3 |
| **4** | N/A | 92.0 | 92.7 | 86.3 | 83.7 | 82.0 | 85.0 | 85.7 | 87.7 | 90.3 | 88.0 | 85.7 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **5** | N/A | N/A | N/A | N/A | N/A | N/A | N/A | 97.0 | 97.0 | 97.0 | 91.3 | 94.3 | 97.0 | 95.7 | 97.7 | 97.7 | 99.0 | 98.0 | 99.3 | 98.3 |
| **6** | 99.0 | 98.0 | 98.7 | 100.0 | 99.0 | 98.7 | 99.3 | 98.3 | 98.0 | 96.7 | 97.3 | 98.7 | 98.3 | 98.7 | 100.0 | 97.7 | 98.7 | 95.7 | 96.3 | N/A |
| **7** | 99.3 | 100.0 | 99.0 | 97.7 | 98.3 | 96.0 | 95.7 | 95.3 | 97.0 | 93.3 | 91.3 | 92.0 | 94.0 | 88.3 | N/A | N/A | N/A | N/A | N/A | N/A |
### Key Observations
1. **Performance Range:** Accuracy values range from a low of **78.7%** (Type 1, Length 7) to a high of **100.0%** (achieved multiple times, e.g., Type 2 Length 1, Type 6 Lengths 3 & 14, Type 7 Length 1).
2. **Data Coverage:** Not all (Type, Length) combinations have data.
* **Type 1** has data only for Lengths 0-9.
* **Type 2** has data only for Lengths 1-10.
* **Type 4** has data only for Lengths 1-11.
* **Type 5** has data only for Lengths 7-19.
* **Type 7** has data only for Lengths 0-13.
* **Types 3 and 6** have the most complete coverage, with data for almost all lengths (Type 3: 0-19, Type 6: 0-18).
3. **Trends by Type:**
* **Type 1:** Shows a general downward trend from 99.0% at Length 0 to the low 80s/high 70s for longer lengths.
* **Type 2:** Starts at 100% and shows a gradual decline to 88.7% at Length 10.
* **Type 3:** Performance fluctuates but remains relatively stable in the high 80s to low 90s across all lengths.
* **Type 4:** Performance is in the 80s and low 90s, with a slight dip in the middle lengths.
* **Type 5:** Exhibits very high and stable performance, consistently above 91% and often above 97% for the lengths where data exists.
* **Type 6:** Shows exceptionally high and stable performance, with most values between 96% and 100%.
* **Type 7:** Starts very high (99-100%) and shows a gradual decline as length increases, dropping to 88.3% at Length 13.
4. **Spatial Pattern:** The heatmap is not a full rectangle. The missing data creates a stepped pattern, suggesting that certain "Types" are only evaluated or applicable for specific ranges of "Length."
### Interpretation
This heatmap provides a granular view of the Qwen-2.5 1.5B model's generalization capabilities on the MIND benchmark. The "Type" axis likely represents different categories or difficulty levels of tasks, while "Length" probably corresponds to sequence length, complexity, or number of steps.
* **Core Finding:** The model demonstrates strong overall performance, with most accuracy values above 85%. It achieves perfect scores (100%) on several task-length combinations.
* **Generalization Strength:** **Types 5 and 6** represent areas of exceptional strength, where the model maintains near-perfect accuracy regardless of length. This suggests robust generalization for these task categories.
* **Performance Degradation:** **Types 1, 2, and 7** show a clearer pattern of performance degradation as length increases. This indicates a potential limitation in handling longer or more complex instances within these specific task types.
* **Stability vs. Variability:** **Type 3** is notable for its stability across the entire length spectrum (0-19), suggesting consistent, reliable performance for that category.
* **Data Gaps:** The missing cells are informative. They imply that the evaluation was not uniform; some task types were only tested on specific length ranges. This could be due to the inherent nature of the tasks (e.g., Type 5 tasks might not exist for short lengths) or a deliberate evaluation design.
In summary, the model exhibits high proficiency on the MIND benchmark, but its generalization is not uniform. Performance is highly dependent on the task "Type," with some categories showing remarkable robustness to increasing "Length" and others showing a measurable decline. This detailed breakdown is crucial for understanding the model's specific strengths and weaknesses.
</details>
<details>
<summary>extracted/6458430/figs/qwen-1.5b_heatmap_base_overall_high.png Details</summary>
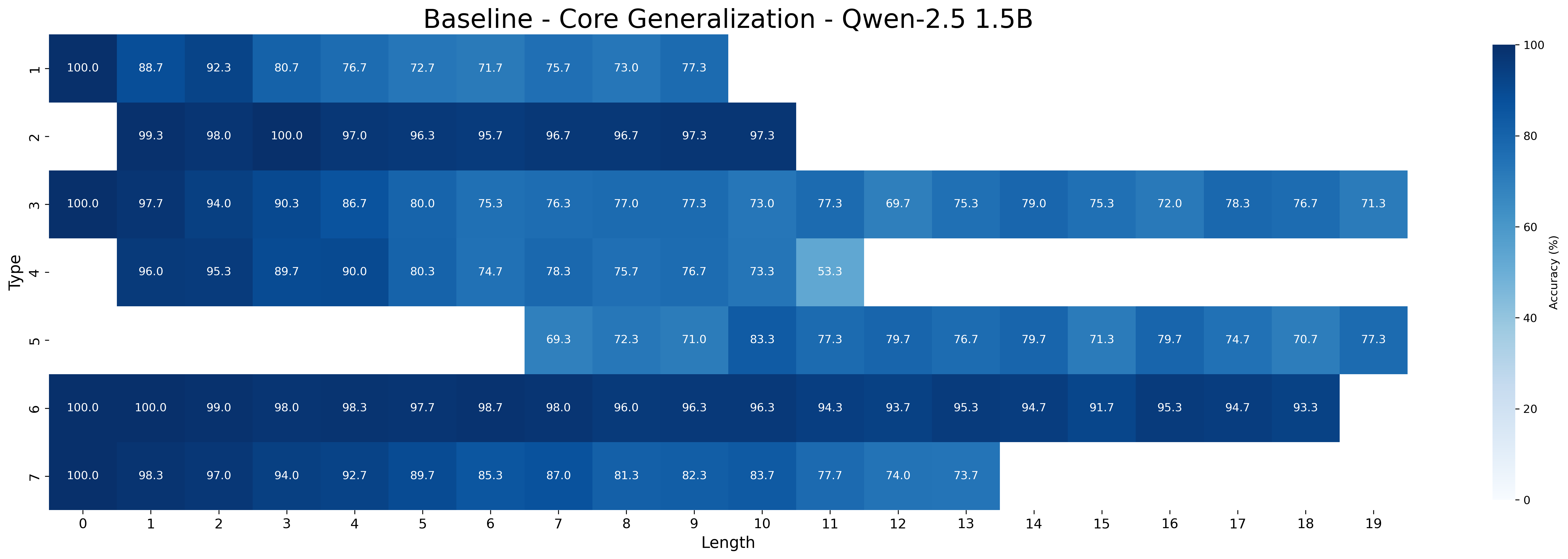
### Visual Description
## Heatmap: Baseline - Core Generalization - Qwen-2.5 1.5B
### Overview
This image is a heatmap visualizing the performance accuracy (in percentage) of a model named "Qwen-2.5 1.5B" on a "Core Generalization" task. The chart plots performance across two dimensions: "Type" (y-axis) and "Length" (x-axis). The color intensity of each cell represents the accuracy percentage, with a corresponding color bar legend on the right.
### Components/Axes
* **Title:** "Baseline - Core Generalization - Qwen-2.5 1.5B" (centered at the top).
* **Y-Axis (Vertical):** Labeled "Type". It contains 7 discrete categories, numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled "Length". It contains 20 discrete categories, numbered 0 through 19 from left to right.
* **Legend/Color Bar:** Located on the far right of the chart. It is a vertical gradient bar labeled "Accuracy (%)". The scale runs from 0 (lightest blue/white) at the bottom to 100 (darkest blue) at the top, with tick marks at 0, 20, 40, 60, 80, and 100.
* **Data Cells:** The main chart area is a grid where each cell's color corresponds to an accuracy value. The numerical accuracy percentage is printed in white text within each colored cell.
### Detailed Analysis
The following table reconstructs the data from the heatmap. Empty cells indicate no data point was recorded for that Type/Length combination.
| Type \ Length | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| :------------ | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- | :-- |
| **1** | 100.0 | 88.7 | 92.3 | 80.7 | 76.7 | 72.7 | 71.7 | 75.7 | 73.0 | 77.3 | | | | | | | | | | |
| **2** | | 99.3 | 98.0 | 100.0 | 97.0 | 96.3 | 95.7 | 96.7 | 96.7 | 97.3 | 97.3 | | | | | | | | | |
| **3** | 100.0 | 97.7 | 94.0 | 90.3 | 86.7 | 80.0 | 75.3 | 76.3 | 77.0 | 77.3 | 73.0 | 77.3 | 69.7 | 75.3 | 79.0 | 75.3 | 72.0 | 78.3 | 76.7 | 71.3 |
| **4** | | 96.0 | 95.3 | 89.7 | 90.0 | 80.3 | 74.7 | 78.3 | 75.7 | 76.7 | 73.3 | 53.3 | | | | | | | | |
| **5** | | | | | | | | 69.3 | 72.3 | 71.0 | 83.3 | 77.3 | 79.7 | 76.7 | 79.7 | 71.3 | 79.7 | 74.7 | 70.7 | 77.3 |
| **6** | 100.0 | 100.0 | 99.0 | 98.0 | 98.3 | 97.7 | 98.7 | 98.0 | 96.0 | 96.3 | 96.3 | 94.3 | 93.7 | 95.3 | 94.7 | 91.7 | 95.3 | 94.7 | 93.3 | |
| **7** | 100.0 | 98.3 | 97.0 | 94.0 | 92.7 | 89.7 | 85.3 | 87.0 | 81.3 | 82.3 | 83.7 | 77.7 | 74.0 | 73.7 | | | | | | |
### Key Observations
1. **Performance Range:** Accuracy values range from a low of **53.3%** (Type 4, Length 11) to multiple perfect scores of **100.0%**.
2. **Type 6 Dominance:** Type 6 exhibits the strongest and most consistent performance, maintaining accuracy above 91.7% across all measured lengths (0-18). It starts at 100% and shows only a very gradual decline.
3. **Type 4 Anomaly:** Type 4 shows a significant performance drop at **Length 11 (53.3%)**, which is the lowest value in the entire dataset. This is a sharp outlier compared to its neighboring values (73.3% at Length 10 and no data after).
4. **Length Coverage:** Different "Types" are evaluated over different ranges of "Length":
* Types 1, 2, and 7 are evaluated for shorter lengths (0-9, 1-10, and 0-13 respectively).
* Types 3, 5, and 6 are evaluated for longer lengths (0-19, 7-19, and 0-18 respectively).
* Type 4 is evaluated for lengths 1-11.
5. **General Trend:** For most types, there is a general downward trend in accuracy as "Length" increases, though the rate of decline varies significantly by type. Type 6 is the most resilient to increasing length.
6. **Color Correlation:** The color gradient accurately reflects the numerical values. The darkest blue cells correspond to 100% or high-90s accuracy, while the lightest blue cell corresponds to the 53.3% value.
### Interpretation
This heatmap provides a diagnostic view of the Qwen-2.5 1.5B model's ability to generalize core tasks as a function of problem "Type" and "Length".
* **What the data suggests:** The model's generalization capability is highly dependent on the specific "Type" of task. It demonstrates robust, near-perfect performance on Type 6 across a wide range of lengths, suggesting this task type is well-learned or inherently easier for the model. Conversely, the dramatic failure of Type 4 at Length 11 indicates a specific weakness or a point where the task complexity exceeds the model's capacity for that particular type.
* **Relationship between elements:** The "Type" axis likely represents different categories or formulations of a core reasoning or generalization task. The "Length" axis likely represents the complexity or sequential length of the problem instance. The chart reveals an interaction effect: the impact of increasing length on accuracy is not uniform but is mediated by the task type.
* **Notable patterns and anomalies:**
* **The Type 4 Cliff:** The drop to 53.3% is the most salient anomaly. It could indicate a specific failure mode, a data distribution gap, or a threshold effect where the model's reasoning breaks down for that type at that specific length.
* **The Type 6 Plateau:** The sustained high performance of Type 6 is notable. It suggests the model has a strong, length-invariant representation for this task type.
* **Missing Data:** The staggered start and end points for different types (e.g., Type 5 starts at Length 7) imply the evaluation was designed to test types over their relevant or challenging length ranges, rather than a uniform grid.
In summary, the heatmap is a valuable tool for identifying model strengths (Type 6), weaknesses (Type 4 at Length 11), and the varying sensitivity of different task types to increasing problem length. It guides further investigation into why certain types generalize better than others.
</details>
Figure 7: Accuracy of MIND (Top) and Baseline (Bottom) Qwen-2.5 1.5B on core generalization decomposed by inference type and length.
<details>
<summary>extracted/6458430/figs/qwen-3b_heatmap_meta_overall_high.png Details</summary>
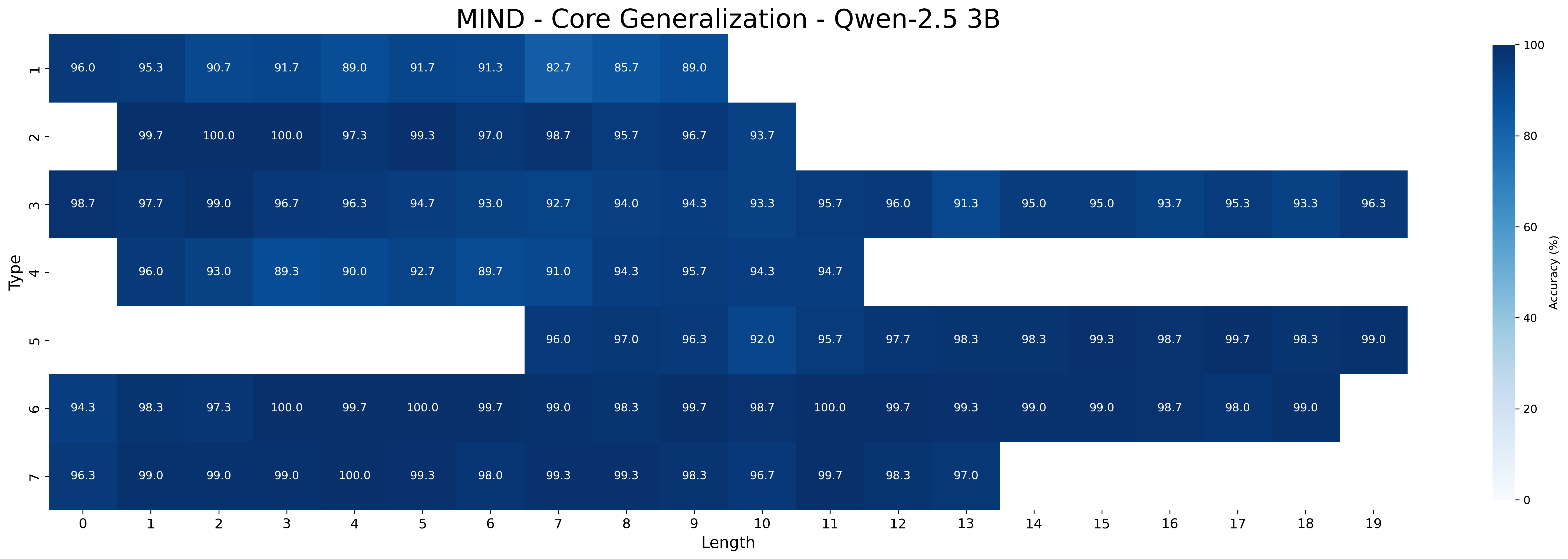
### Visual Description
## Heatmap: MIND - Core Generalization - Qwen-2.5 3B
### Overview
This image is a heatmap visualizing the performance accuracy (in percentage) of a model named "Qwen-2.5 3B" on a task or benchmark called "MIND - Core Generalization". The heatmap plots performance across two dimensions: "Type" (y-axis) and "Length" (x-axis). The color intensity represents accuracy, with a scale from 0% (lightest blue/white) to 100% (darkest blue). The chart contains numerical accuracy values within each colored cell.
### Components/Axes
* **Title:** "MIND - Core Generalization - Qwen-2.5 3B" (centered at the top).
* **Y-Axis (Vertical):** Labeled "Type". It contains 7 discrete categories, numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled "Length". It contains 20 discrete categories, numbered 0 through 19 from left to right.
* **Legend/Color Scale:** Located on the far right. It is a vertical color bar labeled "Accuracy (%)". The scale runs from 0 at the bottom to 100 at the top, with tick marks at 0, 20, 40, 60, 80, and 100. The color gradient transitions from very light blue (near white) at 0% to a deep, dark blue at 100%.
* **Data Cells:** The main body of the chart is a grid where each cell corresponds to a specific (Type, Length) pair. The cell's background color corresponds to the accuracy value, which is also printed as a number within the cell. White cells indicate missing data or a value of 0% (though the scale suggests white is 0, the absence of a number implies no data was recorded for that combination).
### Detailed Analysis
The following table reconstructs the data from the heatmap. "N/A" indicates a white cell with no numerical value.
| Type \ Length | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 96.0 | 95.3 | 90.7 | 91.7 | 89.0 | 91.7 | 91.3 | 82.7 | 85.7 | 89.0 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **2** | N/A | 99.7 | 100.0 | 100.0 | 97.3 | 99.3 | 97.0 | 98.7 | 95.7 | 96.7 | 93.7 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **3** | 98.7 | 97.7 | 99.0 | 96.7 | 96.3 | 94.7 | 93.0 | 92.7 | 94.0 | 94.3 | 93.3 | 95.7 | 96.0 | 91.3 | 95.0 | 95.0 | 93.7 | 95.3 | 93.3 | 96.3 |
| **4** | N/A | 96.0 | 93.0 | 89.3 | 90.0 | 92.7 | 89.7 | 91.0 | 94.3 | 95.7 | 94.3 | 94.7 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **5** | N/A | N/A | N/A | N/A | N/A | N/A | N/A | 96.0 | 97.0 | 96.3 | 92.0 | 95.7 | 97.7 | 98.3 | 98.3 | 99.3 | 98.7 | 99.7 | 98.3 | 99.0 |
| **6** | 94.3 | 98.3 | 97.3 | 100.0 | 99.7 | 100.0 | 99.7 | 99.0 | 98.3 | 99.7 | 98.7 | 100.0 | 99.7 | 99.3 | 99.0 | 99.0 | 98.7 | 98.0 | 99.0 | N/A |
| **7** | 96.3 | 99.0 | 99.0 | 99.0 | 100.0 | 99.3 | 98.0 | 99.3 | 99.3 | 98.3 | 96.7 | 99.7 | 98.3 | 97.0 | N/A | N/A | N/A | N/A | N/A | N/A |
### Key Observations
1. **High Overall Performance:** The vast majority of recorded accuracy values are above 90%, with many in the high 90s and several perfect 100.0% scores. The color scale is dominated by dark blue hues.
2. **Performance by Type:**
* **Type 6** shows exceptionally high and consistent performance, with scores almost exclusively between 97.3% and 100.0% across its available lengths (0-18).
* **Type 7** also demonstrates very high performance (96.3% to 100.0%) but only for lengths 0-13.
* **Type 3** has the most complete data, spanning all lengths from 0 to 19, with scores generally in the 91-99% range.
* **Type 1** shows the lowest performance within the dataset, with a notable dip to 82.7% at Length 7.
3. **Data Sparsity Pattern:** There is a clear pattern of missing data (white cells). Types 1, 2, 4, and 7 have data only for lower lengths. Type 5 has data only for higher lengths (7-19). Only Type 3 has data across the entire length spectrum (0-19).
4. **Trend by Length:** For the types with complete or long sequences of data (e.g., Type 3, Type 6), there is no strong, consistent upward or downward trend in accuracy as "Length" increases. Performance remains relatively stable within a high band.
### Interpretation
This heatmap evaluates the "core generalization" capability of the Qwen-2.5 3B model on the MIND benchmark. The "Type" axis likely represents different categories, tasks, or problem formats within the benchmark, while "Length" probably refers to the sequence length, complexity, or number of steps in the input.
The data suggests the model has **strong generalization performance** across the tested dimensions, as evidenced by the predominantly high accuracy scores. The model appears particularly robust on "Type 6" problems. The pattern of missing data is significant; it may indicate that certain "Types" are only defined or testable for specific "Lengths," or that the evaluation was not run for all combinations. The lack of a clear performance degradation with increasing "Length" (for types where it's measured) is a positive indicator, suggesting the model's reasoning or processing does not break down significantly as problem length increases within the tested range (0-19). The outlier low score of 82.7% for Type 1 at Length 7 warrants investigation as a potential edge case or specific weakness.
</details>
<details>
<summary>extracted/6458430/figs/qwen-3b_heatmap_base_overall_high.png Details</summary>
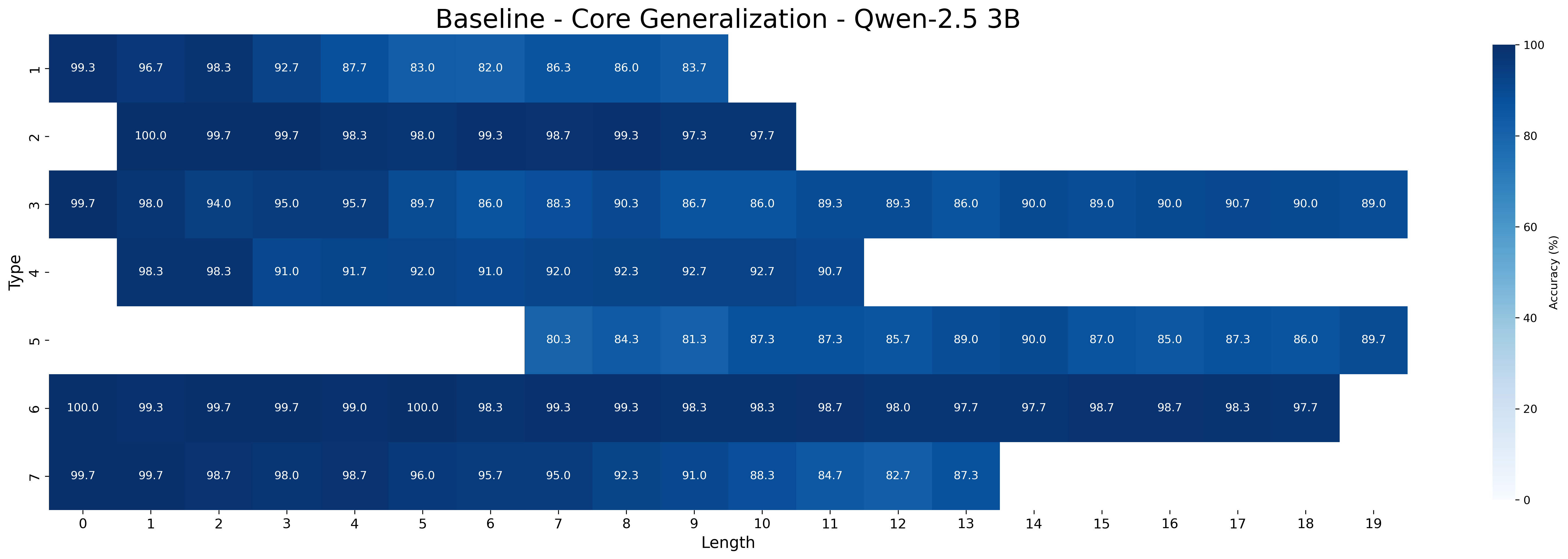
### Visual Description
## Heatmap: Baseline - Core Generalization - Qwen-2.5 3B
### Overview
This image is a heatmap visualizing the accuracy (in percentage) of a model named "Qwen-2.5 3B" on a "Core Generalization" task. The performance is broken down by two dimensions: "Type" (y-axis, categories 1-7) and "Length" (x-axis, values 0-19). The color intensity represents accuracy, with a scale from 0% (lightest) to 100% (darkest blue). The chart shows how model performance varies across different task types and sequence lengths.
### Components/Axes
* **Title:** "Baseline - Core Generalization - Qwen-2.5 3B" (Top center).
* **Y-Axis (Vertical):** Labeled "Type". Categories are numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled "Length". Values range from 0 to 19 from left to right.
* **Color Bar/Legend:** Located on the right side. It is a vertical gradient bar labeled "Accuracy (%)". The scale runs from 0 at the bottom to 100 at the top, with tick marks at 0, 20, 40, 60, 80, and 100. Darker blue corresponds to higher accuracy.
* **Data Cells:** Each cell in the grid contains a numerical accuracy value. Cells with no data are left blank (white).
### Detailed Analysis
The following table reconstructs the accuracy data for each Type across the available Lengths. Empty cells indicate no data for that Type-Length combination.
| Type | Length 0 | Length 1 | Length 2 | Length 3 | Length 4 | Length 5 | Length 6 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 | Length 12 | Length 13 | Length 14 | Length 15 | Length 16 | Length 17 | Length 18 | Length 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 99.3 | 96.7 | 98.3 | 92.7 | 87.7 | 83.0 | 82.0 | 86.3 | 86.0 | 83.7 | | | | | | | | | | |
| **2** | | 100.0 | 99.7 | 99.7 | 98.3 | 98.0 | 99.3 | 98.7 | 99.3 | 97.3 | 97.7 | | | | | | | | | |
| **3** | 99.7 | 98.0 | 94.0 | 95.0 | 95.7 | 89.7 | 86.0 | 88.3 | 90.3 | 86.7 | 86.0 | 89.3 | 89.3 | 86.0 | 90.0 | 89.0 | 90.0 | 90.7 | 90.0 | 89.0 |
| **4** | | 98.3 | 98.3 | 91.0 | 91.7 | 92.0 | 91.0 | 92.0 | 92.3 | 92.7 | 92.7 | 90.7 | | | | | | | | |
| **5** | | | | | | | | 80.3 | 84.3 | 81.3 | 87.3 | 87.3 | 85.7 | 89.0 | 90.0 | 87.0 | 85.0 | 87.3 | 86.0 | 89.7 |
| **6** | 100.0 | 99.3 | 99.7 | 99.7 | 99.0 | 100.0 | 98.3 | 99.3 | 99.3 | 98.3 | 98.3 | 98.7 | 98.0 | 97.7 | 97.7 | 98.7 | 98.7 | 98.3 | 97.7 | |
| **7** | 99.7 | 99.7 | 98.7 | 98.0 | 98.7 | 96.0 | 95.7 | 95.0 | 92.3 | 91.0 | 88.3 | 84.7 | 82.7 | 87.3 | | | | | | |
**Trend Verification by Type:**
* **Type 1:** Shows a general downward trend. Accuracy starts very high (99.3% at Length 0) and declines to the low 80s by Length 9.
* **Type 2:** Maintains exceptionally high accuracy (97.3% - 100.0%) across its available lengths (1-10), with minimal degradation.
* **Type 3:** Exhibits a fluctuating but relatively stable trend after an initial drop. Accuracy starts at 99.7%, dips into the mid-80s, and then stabilizes in the 86-90% range for longer lengths.
* **Type 4:** Shows stable performance, mostly in the 91-92% range, with a slight peak at Lengths 9-10 (92.7%).
* **Type 5:** Starts at a lower accuracy (80.3% at Length 7) and shows a slight, inconsistent upward trend, reaching 89.7% at Length 19.
* **Type 6:** Demonstrates the most consistent and highest performance, with accuracy almost exclusively between 97.7% and 100.0% across all measured lengths (0-18).
* **Type 7:** Shows a clear downward trend. Accuracy begins at 99.7% and steadily decreases to 82.7% at Length 12, with a slight recovery at Length 13 (87.3%).
### Key Observations
1. **Performance Variability:** There is significant variability in performance across the different "Types". Type 6 is the top performer, while Type 5 shows the lowest initial accuracy.
2. **Length Sensitivity:** Some types are highly sensitive to length (e.g., Types 1 and 7 show clear degradation), while others are robust (e.g., Types 2 and 6 maintain high accuracy).
3. **Data Coverage:** Not all Types have data for all Lengths. Type 3 has the most complete data (Lengths 0-19). Types 1, 2, 4, and 7 have data only for shorter to medium lengths. Type 5 only has data for longer lengths (7-19).
4. **High-Accuracy Clusters:** The darkest blue cells (accuracy >98%) are concentrated in the top-left region of the chart (shorter lengths for Types 1, 2, 3, 6, 7) and throughout Type 6.
### Interpretation
This heatmap provides a diagnostic view of the Qwen-2.5 3B model's generalization capabilities. The "Type" axis likely represents different categories or tasks within the "Core Generalization" benchmark, while "Length" probably refers to the sequence length or complexity of the input.
* **Model Strengths:** The model exhibits strong and robust performance on Type 6 tasks across all lengths, suggesting a particular strength in that category. It also performs very well on shorter sequences for most types.
* **Model Weaknesses:** The model struggles with Type 5 tasks, especially at shorter lengths. It also shows a clear vulnerability to increasing sequence length for Types 1 and 7, where accuracy drops by over 10 percentage points.
* **Generalization Pattern:** The data suggests that the model's ability to generalize is not uniform. Its performance is highly dependent on the specific nature of the task (Type) and the length of the input. The degradation with length for some types indicates a potential limitation in handling long-range dependencies or maintaining context for those specific tasks.
* **Practical Implication:** For users of this model, this chart indicates that performance will be most reliable for Type 6 tasks and for shorter inputs across most categories. When dealing with Type 5 tasks or long sequences of Type 1 or 7, one should expect lower and potentially declining accuracy.
</details>
Figure 8: Accuracy of MIND (Top) and Baseline (Bottom) Qwen-2.5 3B on core generalization decomposed by inference type and length.
<details>
<summary>extracted/6458430/figs/qwen-7b_heatmap_meta_overall_high.png Details</summary>
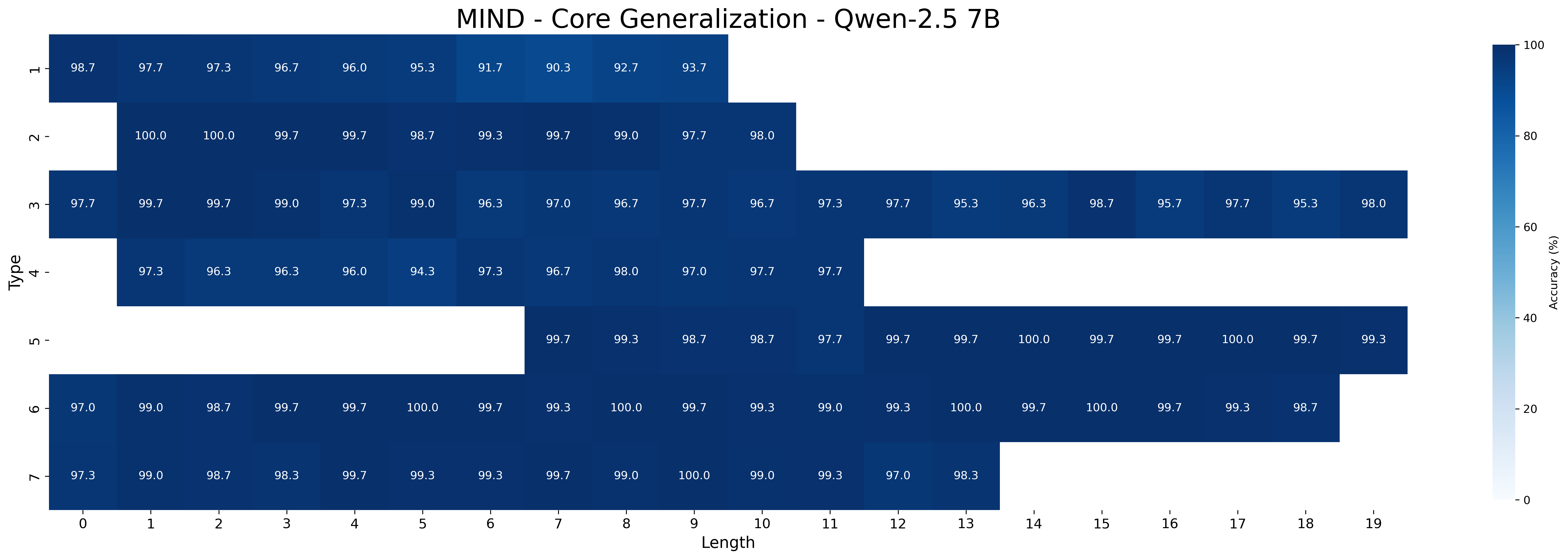
### Visual Description
## Heatmap: MIND - Core Generalization - Qwen-2.5 7B
### Overview
This image is a heatmap visualizing the accuracy percentages of a model named "Qwen-2.5 7B" on a task or benchmark called "MIND - Core Generalization." The heatmap plots performance across two dimensions: "Type" (y-axis) and "Length" (x-axis). The color intensity represents accuracy, with a scale from 0% (lightest) to 100% (darkest blue). Numerical accuracy values are overlaid on each colored cell.
### Components/Axes
* **Title:** "MIND - Core Generalization - Qwen-2.5 7B" (centered at the top).
* **Y-Axis (Vertical):** Labeled "Type." It contains 7 discrete categories, numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled "Length." It contains 20 discrete categories, numbered 0 through 19 from left to right.
* **Color Bar/Legend:** Located on the far right. It is a vertical gradient bar labeled "Accuracy (%)" with tick marks at 0, 20, 40, 60, 80, and 100. The gradient runs from white (0%) to dark blue (100%).
* **Data Cells:** The main grid consists of cells at the intersection of each Type and Length. Each cell is colored according to its accuracy value and contains the numerical percentage (e.g., "98.7"). Some cells are empty (white), indicating missing data or a value of 0%.
### Detailed Analysis
The following table reconstructs the data from the heatmap. "N/A" indicates an empty cell with no numerical value.
| Type \ Length | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 98.7 | 97.7 | 97.3 | 96.7 | 96.0 | 95.3 | 91.7 | 90.3 | 92.7 | 93.7 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **2** | N/A | 100.0 | 100.0 | 99.7 | 99.7 | 98.7 | 99.3 | 99.7 | 99.0 | 97.7 | 98.0 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **3** | 97.7 | 99.7 | 99.7 | 99.0 | 97.3 | 99.0 | 96.3 | 97.0 | 96.7 | 97.7 | 96.7 | 97.3 | 97.7 | 95.3 | 96.3 | 98.7 | 95.7 | 97.7 | 95.3 | 98.0 |
| **4** | N/A | 97.3 | 96.3 | 96.3 | 96.0 | 94.3 | 97.3 | 96.7 | 98.0 | 97.0 | 97.7 | 97.7 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **5** | N/A | N/A | N/A | N/A | N/A | N/A | N/A | 99.7 | 99.3 | 98.7 | 98.7 | 97.7 | 99.7 | 99.7 | 100.0 | 99.7 | 99.7 | 100.0 | 99.7 | 99.3 |
| **6** | 97.0 | 99.0 | 98.7 | 99.7 | 99.7 | 100.0 | 99.7 | 99.3 | 100.0 | 99.7 | 99.3 | 99.0 | 99.3 | 100.0 | 99.7 | 100.0 | 99.7 | 99.3 | 98.7 | N/A |
| **7** | 97.3 | 99.0 | 98.7 | 98.3 | 99.7 | 99.3 | 99.3 | 99.7 | 99.0 | 100.0 | 99.0 | 99.3 | 97.0 | 98.3 | N/A | N/A | N/A | N/A | N/A | N/A |
**Trend Verification per Type:**
* **Type 1:** Shows a general downward trend in accuracy as Length increases from 0 to 7, dropping from 98.7% to 90.3%, before a slight recovery at Lengths 8 and 9.
* **Type 2:** Maintains very high accuracy (97.7% - 100.0%) across its available Lengths (1-10), with no strong directional trend.
* **Type 3:** Exhibits consistently high accuracy (95.3% - 99.7%) across all Lengths (0-19), with minor fluctuations but no significant drop-off.
* **Type 4:** Shows stable, high accuracy (94.3% - 98.0%) across its available Lengths (1-11).
* **Type 5:** Has data only for longer Lengths (7-19) and demonstrates exceptionally high and stable accuracy (97.7% - 100.0%).
* **Type 6:** Shows consistently high accuracy (97.0% - 100.0%) across its available Lengths (0-18).
* **Type 7:** Maintains high accuracy (97.0% - 100.0%) across its available Lengths (0-13).
### Key Observations
1. **High Overall Performance:** The vast majority of data points show accuracy above 95%, indicating strong performance of the Qwen-2.5 7B model on this "Core Generalization" task.
2. **Data Sparsity Pattern:** The heatmap is not fully populated. Data is missing in a structured way:
* **Type 1:** Missing data for Lengths 10-19.
* **Type 2:** Missing data for Length 0 and Lengths 11-19.
* **Type 4:** Missing data for Length 0 and Lengths 12-19.
* **Type 5:** Missing data for Lengths 0-6.
* **Type 6:** Missing data for Length 19.
* **Type 7:** Missing data for Lengths 14-19.
* Only **Type 3** has complete data across all Lengths (0-19).
3. **Performance Dips:** The most notable performance dip is in **Type 1**, where accuracy falls to 90.3% at Length 7. Other minor dips include Type 4 at Length 5 (94.3%) and Type 3 at various points (e.g., 95.3% at Lengths 13 and 18).
4. **Perfect Scores:** Several cells achieve 100.0% accuracy: Type 2 (Lengths 1, 2), Type 5 (Lengths 14, 17), and Type 6 (Lengths 5, 8, 13, 15).
### Interpretation
This heatmap provides a granular view of a model's generalization capability. The "Type" axis likely represents different categories, tasks, or problem formats within the "MIND" benchmark, while "Length" probably corresponds to sequence length, problem complexity, or number of reasoning steps.
The data suggests that the Qwen-2.5 7B model generalizes very well across most types and lengths, as evidenced by the predominantly dark blue cells and high numerical values. The model's performance is robust, with only one significant dip observed (Type 1, Length 7).
The structured missing data is intriguing. It may indicate that certain combinations of Type and Length were not part of the test set, or that the model was not evaluated on them. The fact that only Type 3 has a full evaluation across all lengths suggests it might be a primary or baseline category for this benchmark.
The presence of perfect 100% scores, especially in Type 5 and Type 6 at longer lengths, demonstrates that the model can achieve flawless performance on specific, potentially more complex, instances of the task. The overall pattern implies that the model's core generalization abilities are strong, with performance remaining stable or only slightly degrading as the "Length" parameter increases, which is a desirable trait for handling complex or extended problems.
</details>
<details>
<summary>extracted/6458430/figs/qwen-7b_heatmap_base_overall_high.png Details</summary>
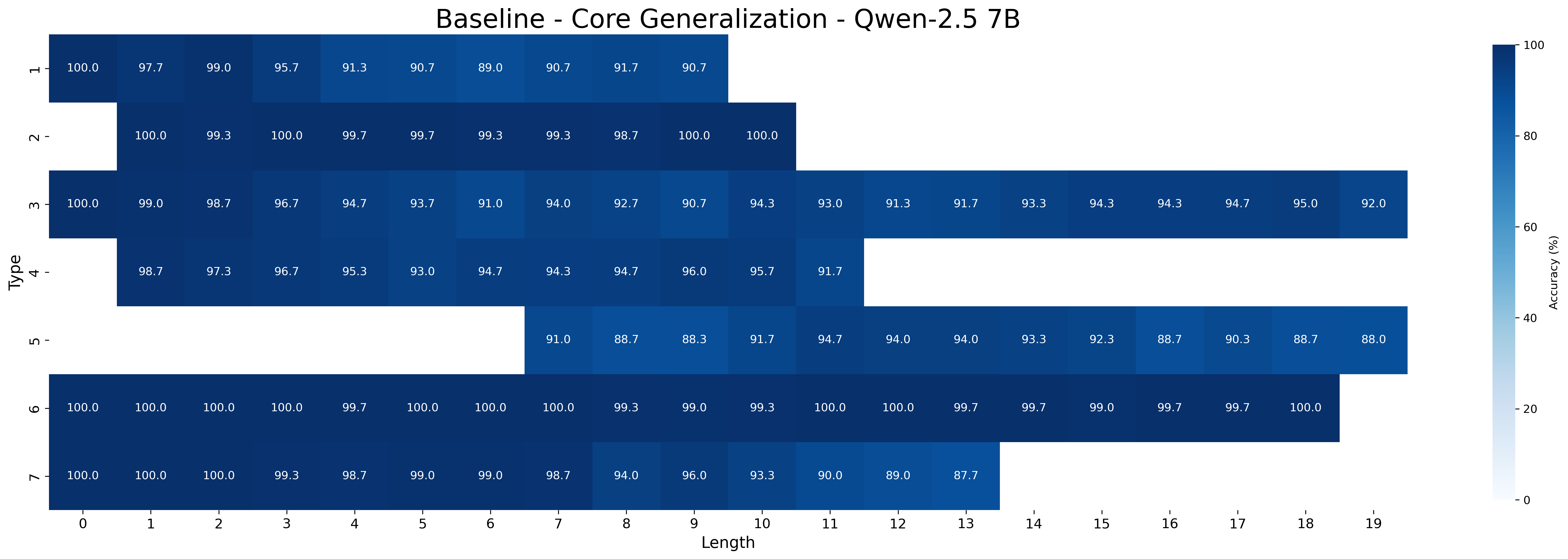
### Visual Description
## Heatmap: Baseline - Core Generalization - Qwen-2.5 7B
### Overview
This image is a heatmap visualizing the accuracy performance of the "Qwen-2.5 7B" model on a "Core Generalization" task. The chart plots performance across two dimensions: "Type" (vertical axis) and "Length" (horizontal axis). The color intensity of each cell represents the accuracy percentage, with a corresponding color bar legend on the right. The data appears to be from a baseline evaluation.
### Components/Axes
* **Title:** "Baseline - Core Generalization - Qwen-2.5 7B" (centered at the top).
* **Vertical Axis (Y-axis):** Labeled "Type". It contains 7 discrete categories, numbered 1 through 7 from top to bottom.
* **Horizontal Axis (X-axis):** Labeled "Length". It contains 20 discrete categories, numbered 0 through 19 from left to right.
* **Color Bar Legend:** Positioned vertically on the far right of the chart. It is labeled "Accuracy (%)" and shows a gradient from light blue (0%) to dark blue (100%), with tick marks at 0, 20, 40, 60, 80, and 100.
* **Data Grid:** The main body of the chart is a grid of colored cells. Each cell contains a numerical value representing the accuracy percentage for a specific (Type, Length) combination. White cells indicate missing data or a value of 0% (though the color bar suggests 0% is very light blue, not white).
### Detailed Analysis
The following table reconstructs the data from the heatmap. "N/A" denotes a white cell with no numerical value.
| Type \ Length | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 100.0 | 97.7 | 99.0 | 95.7 | 91.3 | 90.7 | 89.0 | 90.7 | 91.7 | 90.7 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **2** | N/A | 100.0 | 99.3 | 100.0 | 99.7 | 99.7 | 99.3 | 99.3 | 98.7 | 100.0 | 100.0 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **3** | 100.0 | 99.0 | 98.7 | 96.7 | 94.7 | 93.7 | 91.0 | 94.0 | 92.7 | 90.7 | 94.3 | 93.0 | 91.3 | 91.7 | 93.3 | 94.3 | 94.3 | 94.7 | 95.0 | 92.0 |
| **4** | N/A | 98.7 | 97.3 | 96.7 | 95.3 | 93.0 | 94.7 | 94.3 | 94.7 | 96.0 | 95.7 | 91.7 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **5** | N/A | N/A | N/A | N/A | N/A | N/A | N/A | 91.0 | 88.7 | 88.3 | 91.7 | 94.7 | 94.0 | 94.0 | 93.3 | 92.3 | 88.7 | 90.3 | 88.7 | 88.0 |
| **6** | 100.0 | 100.0 | 100.0 | 100.0 | 99.7 | 100.0 | 100.0 | 100.0 | 99.3 | 99.0 | 99.3 | 100.0 | 100.0 | 99.7 | 99.7 | 99.0 | 99.7 | 99.7 | 100.0 | N/A |
| **7** | 100.0 | 100.0 | 100.0 | 99.3 | 98.7 | 99.0 | 99.0 | 98.7 | 94.0 | 96.0 | 93.3 | 90.0 | 89.0 | 87.7 | N/A | N/A | N/A | N/A | N/A | N/A |
### Key Observations
1. **High Overall Performance:** The majority of the recorded accuracy values are above 90%, with many cells at or near 100%. The darkest blue cells (highest accuracy) are concentrated in the top-left and middle sections of the chart.
2. **Performance by Type:**
* **Type 6** demonstrates the most consistent and highest performance, maintaining accuracy between 99.0% and 100.0% across all measured lengths (0-18).
* **Type 2** also shows excellent performance (98.7%-100.0%) but only for lengths 1-10.
* **Type 5** has the most limited data range (Lengths 7-19) and shows a slight downward trend, with its lowest accuracy (88.0%) at the maximum length (19).
* **Type 7** shows a clear performance degradation as length increases, starting at 100% for lengths 0-2 and dropping to 87.7% by length 13.
3. **Performance by Length:** There is no universal trend of accuracy decreasing with length. Some types (e.g., Type 6) are unaffected. Others (e.g., Type 7) show a decline. Type 3 shows a slight dip in the middle lengths (6-9) before recovering.
4. **Data Sparsity:** The heatmap is not fully populated. Significant gaps exist:
* **Type 1:** No data for Lengths 10-19.
* **Type 2:** No data for Length 0 and Lengths 11-19.
* **Type 4:** No data for Length 0 and Lengths 12-19.
* **Type 5:** No data for Lengths 0-6.
* **Type 6:** No data for Length 19.
* **Type 7:** No data for Lengths 14-19.
### Interpretation
This heatmap provides a granular view of the Qwen-2.5 7B model's generalization capabilities. The "Type" axis likely represents different categories or difficulty levels of the core generalization task, while "Length" probably corresponds to the sequence length or complexity of the input.
The data suggests the model is highly robust for certain task types (notably Type 6) across varying lengths. The performance degradation observed in Type 7 indicates a specific vulnerability where increased length negatively impacts accuracy. The sparse data for higher lengths in several types (1, 2, 4, 7) could imply that testing was not conducted for those combinations, or that the model failed to produce valid outputs (resulting in no accuracy score).
The primary takeaway is that the model's generalization performance is not uniform; it is highly dependent on the specific type of task and, for some types, the length of the input. This analysis would be crucial for identifying the model's strengths and weaknesses, guiding further fine-tuning, or determining its suitability for specific applications that require handling long sequences of a particular type.
</details>
Figure 9: Accuracy of MIND (Top) and Baseline (Bottom) Qwen-2.5 7B on core generalization decomposed by inference type and length.
<details>
<summary>extracted/6458430/figs/qwen-1.5b_heatmap_meta_compositionality_high.png Details</summary>
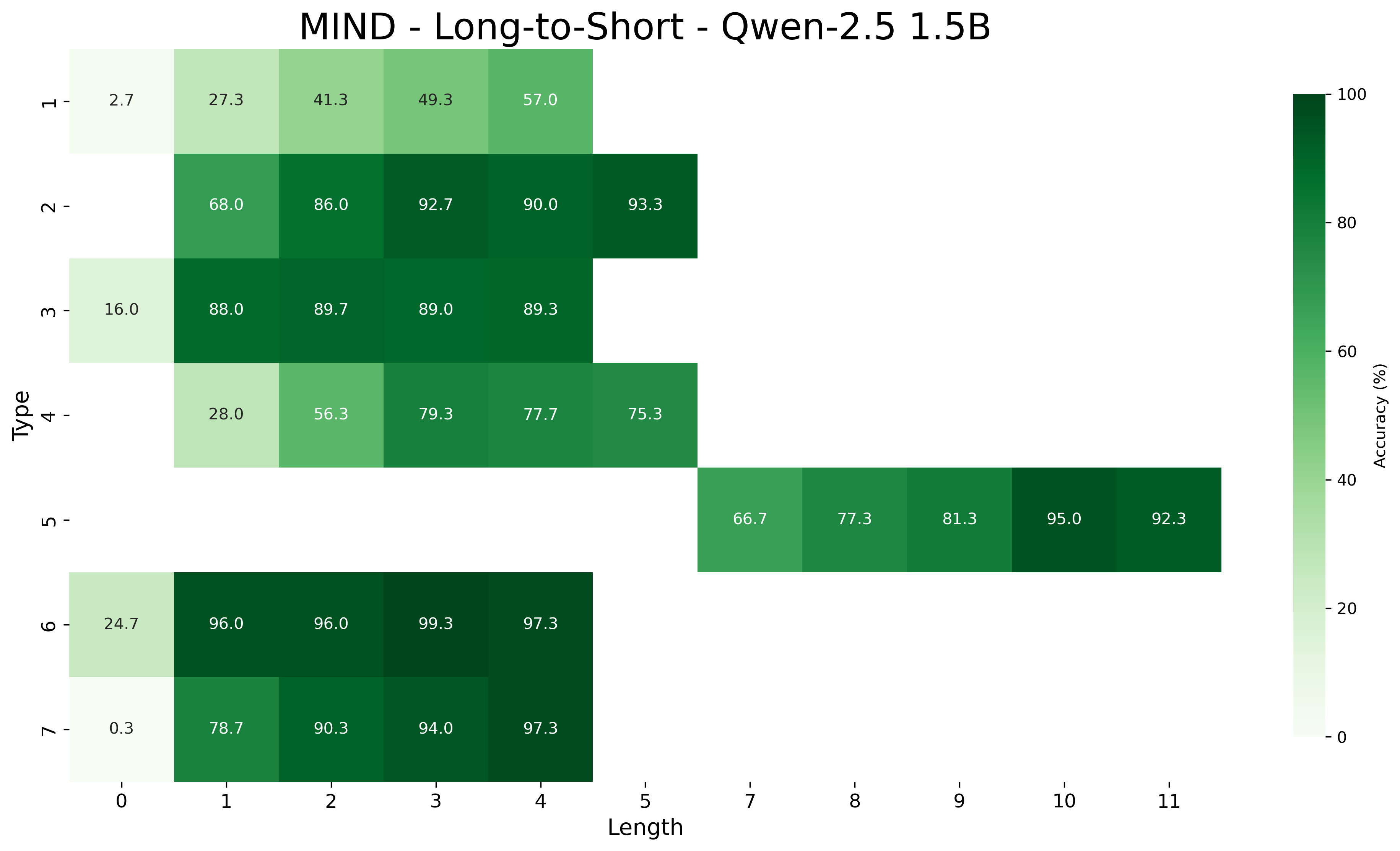
### Visual Description
\n
## Heatmap: MIND - Long-to-Short - Qwen-2.5 1.5B
### Overview
This image is a heatmap visualizing the accuracy (in percentage) of a model named "Qwen-2.5 1.5B" on a task or dataset referred to as "MIND - Long-to-Short". The chart plots performance across two dimensions: "Type" (y-axis) and "Length" (x-axis). The color intensity of each cell represents the accuracy value, with a corresponding color bar legend on the right side of the chart.
### Components/Axes
* **Title:** "MIND - Long-to-Short - Qwen-2.5 1.5B" (centered at the top).
* **Y-Axis (Vertical):** Labeled "Type". It lists seven discrete categories, numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled "Length". It lists discrete numerical values: 0, 1, 2, 3, 4, 5, 7, 8, 9, 10, 11. Note that the value '6' is absent from the axis.
* **Color Bar Legend:** Positioned vertically on the right side of the chart. It is labeled "Accuracy (%)" and provides a scale from 0 (lightest green/white) to 100 (darkest green). The scale has major tick marks at 0, 20, 40, 60, 80, and 100.
* **Data Cells:** The main body of the chart consists of a grid of colored rectangles. Each cell corresponds to a specific (Type, Length) pair and contains a numerical value representing the accuracy percentage. Not all grid positions are filled; some cells are empty (white), indicating no data for that combination.
### Detailed Analysis
The following table reconstructs the data presented in the heatmap. Empty cells are denoted by "N/A".
| Type \ Length | 0 | 1 | 2 | 3 | 4 | 5 | 7 | 8 | 9 | 10 | 11 |
| :------------ | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- |
| **1** | 2.7 | 27.3 | 41.3 | 49.3 | 57.0 | N/A | N/A | N/A | N/A | N/A | N/A |
| **2** | N/A | 68.0 | 86.0 | 92.7 | 90.0 | 93.3 | N/A | N/A | N/A | N/A | N/A |
| **3** | 16.0 | 88.0 | 89.7 | 89.0 | 89.3 | N/A | N/A | N/A | N/A | N/A | N/A |
| **4** | N/A | 28.0 | 56.3 | 79.3 | 77.7 | 75.3 | N/A | N/A | N/A | N/A | N/A |
| **5** | N/A | N/A | N/A | N/A | N/A | N/A | 66.7 | 77.3 | 81.3 | 95.0 | 92.3 |
| **6** | 24.7 | 96.0 | 96.0 | 99.3 | 97.3 | N/A | N/A | N/A | N/A | N/A | N/A |
| **7** | 0.3 | 78.7 | 90.3 | 94.0 | 97.3 | N/A | N/A | N/A | N/A | N/A | N/A |
**Trend Verification by Type:**
* **Type 1:** Shows a steady, positive trend. Accuracy increases monotonically from 2.7% at Length 0 to 57.0% at Length 4.
* **Type 2:** Shows a strong positive trend, peaking at Length 5 (93.3%). There is a slight dip at Length 4 (90.0%) compared to Length 3 (92.7%).
* **Type 3:** Shows a sharp initial increase from Length 0 (16.0%) to Length 1 (88.0%), then plateaus in the high 80s for Lengths 1-4.
* **Type 4:** Shows a positive trend from Length 1 to Length 3, then a slight decline for Lengths 4 and 5.
* **Type 5:** Data only exists for longer lengths (7-11). It shows a generally positive trend, peaking at Length 10 (95.0%).
* **Type 6:** Shows very high accuracy across all available lengths. It starts at 24.7% for Length 0 and jumps to 96.0% for Length 1, maintaining near-perfect scores thereafter.
* **Type 7:** Shows a dramatic positive trend. Accuracy starts near zero (0.3%) at Length 0 and increases sharply to 97.3% by Length 4.
### Key Observations
1. **Performance Variability:** There is significant variability in model performance across different "Types". Type 6 consistently achieves the highest accuracy (96-99% for Lengths 1-4), while Type 1 shows the lowest overall performance, never exceeding 57%.
2. **Length Sensitivity:** For most Types (1, 2, 3, 4, 6, 7), accuracy improves substantially as the "Length" increases from 0 or 1. This suggests the model's performance on the "Long-to-Short" task is highly dependent on sequence length.
3. **Data Sparsity:** The heatmap is not a complete grid. Data for Types 1-4 and 6-7 is only provided for shorter lengths (0-5). Data for Type 5 is only provided for longer lengths (7-11). This creates two distinct clusters in the visualization.
4. **Outliers:**
* **Type 7 at Length 0:** The accuracy of 0.3% is the lowest value in the entire dataset, indicating a near-total failure for this specific condition.
* **Type 6 at Length 0:** While 24.7% is low, it is notably higher than the starting points of Type 1 (2.7%) and Type 7 (0.3%), suggesting Type 6 is somewhat more robust even at the shortest length.
5. **Plateaus:** Type 3's performance plateaus quickly after Length 1, suggesting that beyond a minimal length, additional length provides no benefit for this Type. Type 6 also plateaus at a very high level.
### Interpretation
This heatmap provides a diagnostic view of the Qwen-2.5 1.5B model's capabilities on the MIND "Long-to-Short" task. The data suggests the following:
* **Task Difficulty is Type-Dependent:** The "Type" category is a primary determinant of task difficulty. The model finds some Types (e.g., 6, 3) inherently easier to solve than others (e.g., 1, 7 at short lengths). This could reflect differences in the complexity, structure, or required reasoning for each Type.
* **Critical Role of Context Length:** The strong positive correlation between "Length" and accuracy for most Types indicates that the model relies heavily on context. The "Long-to-Short" task likely involves summarizing, compressing, or extracting information from longer sequences. The model's ability to perform this function degrades severely when the input sequence is too short (Length 0 or 1), as it lacks sufficient context to generate an accurate short output.
* **Model Specialization or Bias:** The stark performance difference between Type 6 (consistently high) and Type 1 (consistently lower) may indicate the model was trained on data that better aligns with the characteristics of Type 6, or that the architecture of this 1.5B parameter model is better suited to the pattern recognition required for certain Types.
* **Practical Implication:** For practical application, this model would require a minimum input length (likely ≥1 or ≥2) to achieve acceptable performance on most task Types. Its performance is unreliable for extremely short inputs, especially for certain task categories. The separate data cluster for Type 5 suggests it may be a fundamentally different sub-task requiring longer inputs by design.
</details>
<details>
<summary>extracted/6458430/figs/qwen-1.5b_heatmap_base_compositionality_high.png Details</summary>
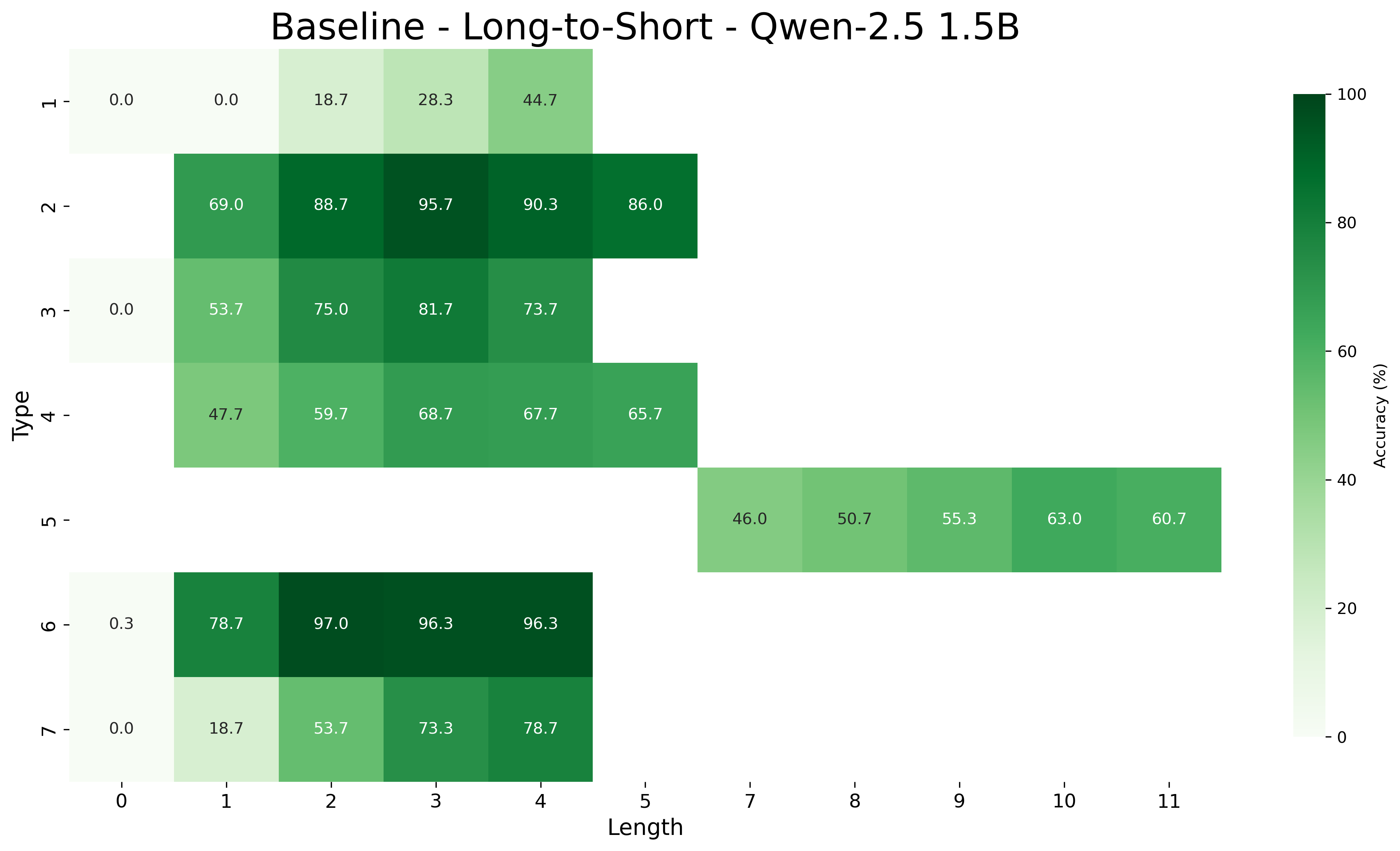
### Visual Description
## Heatmap: Baseline - Long-to-Short - Qwen-2.5 1.5B
### Overview
This image is a heatmap visualizing the accuracy (in percentage) of a model named "Qwen-2.5 1.5B" on a "Long-to-Short" task. The performance is broken down by two categorical variables: "Type" (y-axis) and "Length" (x-axis). The color intensity represents accuracy, with a scale from 0% (lightest) to 100% (darkest green).
### Components/Axes
* **Title:** "Baseline - Long-to-Short - Qwen-2.5 1.5B" (centered at the top).
* **Y-Axis (Vertical):** Labeled "Type". It contains 7 discrete categories, numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled "Length". It contains discrete numerical markers: 0, 1, 2, 3, 4, 5, 7, 8, 9, 10, 11. Note that length 6 is absent from the axis.
* **Legend/Color Bar:** Located on the right side of the chart. It is a vertical gradient bar labeled "Accuracy (%)". The scale has tick marks at 0, 20, 40, 60, 80, and 100. The color transitions from a very light, almost white green (0%) to a deep, dark forest green (100%).
* **Data Cells:** The main chart area is a grid where each cell corresponds to a specific (Type, Length) pair. The cell's background color corresponds to the accuracy value, which is also printed as a number within the cell. Not all (Type, Length) combinations are present; the data is sparse.
### Detailed Analysis
The following table reconstructs the data from the heatmap. Empty cells indicate no data point for that (Type, Length) combination.
| Type | Length 0 | Length 1 | Length 2 | Length 3 | Length 4 | Length 5 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 0.0 | 0.0 | 18.7 | 28.3 | 44.7 | | | | | | |
| **2** | | 69.0 | 88.7 | 95.7 | 90.3 | 86.0 | | | | | |
| **3** | 0.0 | 53.7 | 75.0 | 81.7 | 73.7 | | | | | | |
| **4** | | 47.7 | 59.7 | 68.7 | 67.7 | 65.7 | | | | | |
| **5** | | | | | | | 46.0 | 50.7 | 55.3 | 63.0 | 60.7 |
| **6** | 0.3 | 78.7 | 97.0 | 96.3 | 96.3 | | | | | | |
| **7** | 0.0 | 18.7 | 53.7 | 73.3 | 78.7 | | | | | | |
**Trend Verification by Type:**
* **Type 1:** Accuracy starts at 0.0 for lengths 0-1, then shows a steady upward trend with increasing length (18.7 → 28.3 → 44.7).
* **Type 2:** Shows high accuracy overall. It increases sharply from length 1 (69.0) to a peak at length 3 (95.7), then slightly decreases at lengths 4 and 5.
* **Type 3:** Starts at 0.0 for length 0, jumps to 53.7 at length 1, peaks at length 3 (81.7), and then dips at length 4.
* **Type 4:** Shows a moderate, relatively stable accuracy across lengths 1-5, peaking at length 3 (68.7).
* **Type 5:** This type is isolated to longer lengths (7-11). It shows a gradual upward trend from length 7 (46.0) to a peak at length 10 (63.0), with a slight drop at length 11.
* **Type 6:** Exhibits very high accuracy. After a near-zero start at length 0 (0.3), it jumps to 78.7 at length 1 and maintains very high values (>96) for lengths 2-4.
* **Type 7:** Starts at 0.0 for length 0, then shows a consistent and strong upward trend with increasing length, reaching 78.7 at length 4.
### Key Observations
1. **Performance at Length 0:** Types 1, 3, and 7 have 0.0% accuracy at length 0. Type 6 has a negligible 0.3%. This suggests the model fails completely on these task types when the "Length" parameter is 0.
2. **High-Performing Types:** Type 6 is the strongest performer, achieving near-perfect accuracy (97.0%) at length 2 and maintaining >96% for longer lengths. Type 2 also shows excellent performance, peaking at 95.7%.
3. **Length Specialization:** Type 5 is unique, with data only for lengths 7 through 11. This may indicate a task category inherently associated with longer sequences.
4. **General Trend:** For most types (1, 3, 6, 7), accuracy improves as the "Length" value increases from 0 or 1. Performance often peaks around length 3 or 4 before plateauing or slightly declining.
5. **Sparse Data Grid:** The heatmap is not a complete matrix. The absence of data for certain (Type, Length) pairs (e.g., Type 1 at length 5, Type 2 at length 0) is a significant feature of the dataset.
### Interpretation
This heatmap provides a diagnostic view of the Qwen-2.5 1.5B model's capabilities on a "Long-to-Short" task, which likely involves condensing or summarizing information. The "Type" axis probably represents different categories or formats of this task (e.g., summarizing a paragraph vs. extracting a key phrase), while "Length" could refer to the input length, output length, or a complexity parameter.
The data suggests the model's performance is highly dependent on both the task type and the length parameter. The complete failure at Length 0 for several types indicates a fundamental limitation or a specific edge case in the model's design or training for those scenarios. The strong performance of Types 2 and 6 identifies them as areas of relative strength. The isolated data for Type 5 hints at a specialized subset of the task.
Overall, the chart reveals that the model is not uniformly proficient. Its accuracy is contingent on the specific combination of task type and length, with clear patterns of strength (high accuracy at moderate lengths for certain types) and weakness (failure at minimal lengths). This information would be crucial for developers to understand the model's boundaries and guide further fine-tuning or evaluation.
</details>
Figure 10: Accuracy of MIND (Left) and Baseline (Right) Qwen-2.5 1.5B on long to short generalization decomposed by inference type and length.
<details>
<summary>extracted/6458430/figs/qwen-3b_heatmap_meta_compositionality_high.png Details</summary>
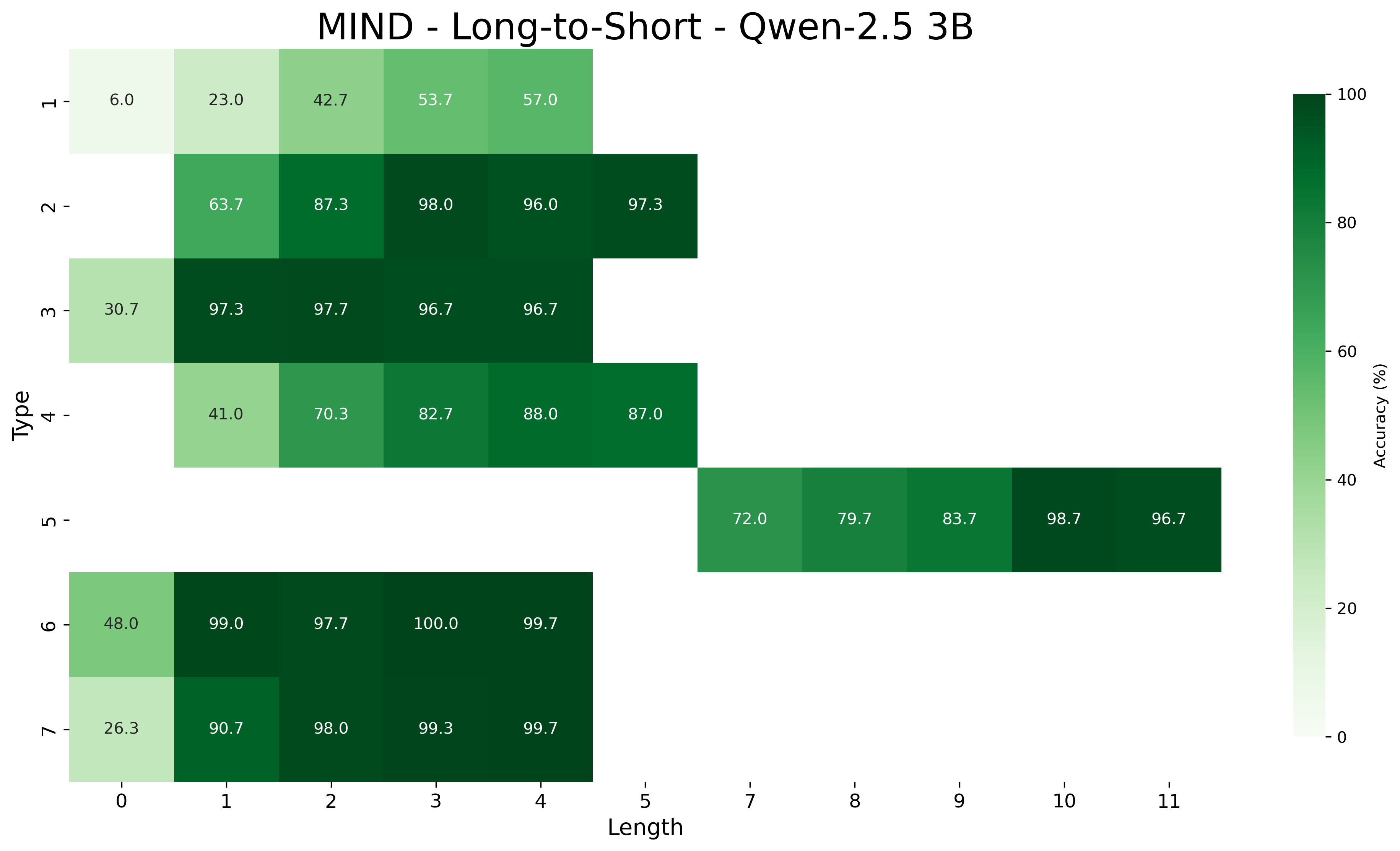
### Visual Description
## Heatmap: MIND - Long-to-Short - Qwen-2.5 3B
### Overview
This image is a heatmap visualizing the accuracy performance of a model named "Qwen-2.5 3B" on a task or benchmark referred to as "MIND - Long-to-Short." The chart displays accuracy percentages across two dimensions: "Type" (vertical axis) and "Length" (horizontal axis). The color intensity of each cell represents the accuracy value, with a corresponding color bar legend on the right.
### Components/Axes
* **Title:** "MIND - Long-to-Short - Qwen-2.5 3B" (centered at the top).
* **Vertical Axis (Y-axis):** Labeled "Type," with categorical values numbered 1 through 7.
* **Horizontal Axis (X-axis):** Labeled "Length," with numerical values ranging from 0 to 11. Not all length values are present for every type.
* **Legend/Color Bar:** Located on the right side of the chart. It is a vertical gradient bar labeled "Accuracy (%)" with tick marks at 0, 20, 40, 60, 80, and 100. The color scale runs from a very light green (0%) to a dark forest green (100%).
* **Data Cells:** The main chart area is a grid where each cell's color corresponds to an accuracy value. The exact numerical accuracy is printed within each colored cell.
### Detailed Analysis
The following table reconstructs the data from the heatmap. Empty cells indicate no data point for that Type-Length combination.
| Type | Length 0 | Length 1 | Length 2 | Length 3 | Length 4 | Length 5 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 6.0 | 23.0 | 42.7 | 53.7 | 57.0 | | | | | | |
| **2** | | 63.7 | 87.3 | 98.0 | 96.0 | 97.3 | | | | | |
| **3** | 30.7 | 97.3 | 97.7 | 96.7 | 96.7 | | | | | | |
| **4** | | 41.0 | 70.3 | 82.7 | 88.0 | 87.0 | | | | | |
| **5** | | | | | | | 72.0 | 79.7 | 83.7 | 98.7 | 96.7 |
| **6** | 48.0 | 99.0 | 97.7 | 100.0 | 99.7 | | | | | | |
| **7** | 26.3 | 90.7 | 98.0 | 99.3 | 99.7 | | | | | | |
**Trend Verification by Type:**
* **Type 1:** Shows a steady, gradual upward trend in accuracy as Length increases from 0 to 4, starting from a very low base (6.0%).
* **Type 2:** Accuracy jumps sharply from Length 1 (63.7%) to Length 2 (87.3%), then plateaus at a very high level (>96%) for Lengths 3-5.
* **Type 3:** Exhibits a dramatic increase from Length 0 (30.7%) to Length 1 (97.3%), after which accuracy remains consistently high (~97%).
* **Type 4:** Demonstrates a consistent upward trend from Length 1 (41.0%) to Length 4 (88.0%), with a slight decrease at Length 5.
* **Type 5:** Data exists only for longer lengths (7-11). Accuracy shows a general upward trend, with a significant peak at Length 10 (98.7%).
* **Type 6:** Starts with moderate accuracy at Length 0 (48.0%) and immediately jumps to near-perfect scores (>97%) for Lengths 1-4, achieving a perfect 100.0% at Length 3.
* **Type 7:** Similar pattern to Type 6, with a low starting point at Length 0 (26.3%) followed by very high accuracy (>90%) for Lengths 1-4.
### Key Observations
1. **Performance Stratification by Type:** There is a clear hierarchy in model performance across types. Types 2, 3, 6, and 7 achieve very high accuracy (>90%) for most lengths. Type 4 shows good but slightly lower performance. Type 1 is a significant outlier with consistently low accuracy. Type 5 is only evaluated on longer lengths.
2. **Length-Dependent Accuracy:** For nearly all types, accuracy improves as the "Length" value increases. The most dramatic improvements often occur between the first two available data points for a given type (e.g., Type 3 from Length 0 to 1, Type 2 from Length 1 to 2).
3. **Data Sparsity:** The heatmap is not a complete grid. Type 5 has no data for lengths 0-6. Types 2 and 4 lack data for Length 0. This suggests the evaluation was not uniform across all possible Type-Length combinations.
4. **Peak Performance:** The highest accuracy values (98-100%) are concentrated in the darker green cells, primarily for Types 2, 3, 6, and 7 at lengths ≥ 2, and for Type 5 at lengths 10 and 11.
### Interpretation
This heatmap likely evaluates the performance of the Qwen-2.5 3B language model on a "Long-to-Short" text processing task within the MIND framework. The "Type" axis probably represents different categories or difficulty levels of the task, while "Length" likely corresponds to the length of the input or output text (e.g., number of sentences, tokens, or a predefined length bin).
The data suggests the model is highly effective for most task types (2, 3, 6, 7), achieving near-perfect accuracy once a minimum length threshold is met. The poor performance on Type 1 indicates it is a particularly challenging variant of the task. The absence of data for short lengths in Type 5 might imply that this task type is only relevant or defined for longer sequences. The strong positive correlation between length and accuracy for most types implies that the model's ability to perform this "Long-to-Short" task improves when it has more context or a longer target to work with, up to a point of diminishing returns where accuracy plateaus near 100%.
</details>
<details>
<summary>extracted/6458430/figs/qwen-3b_heatmap_base_compositionality_high.png Details</summary>
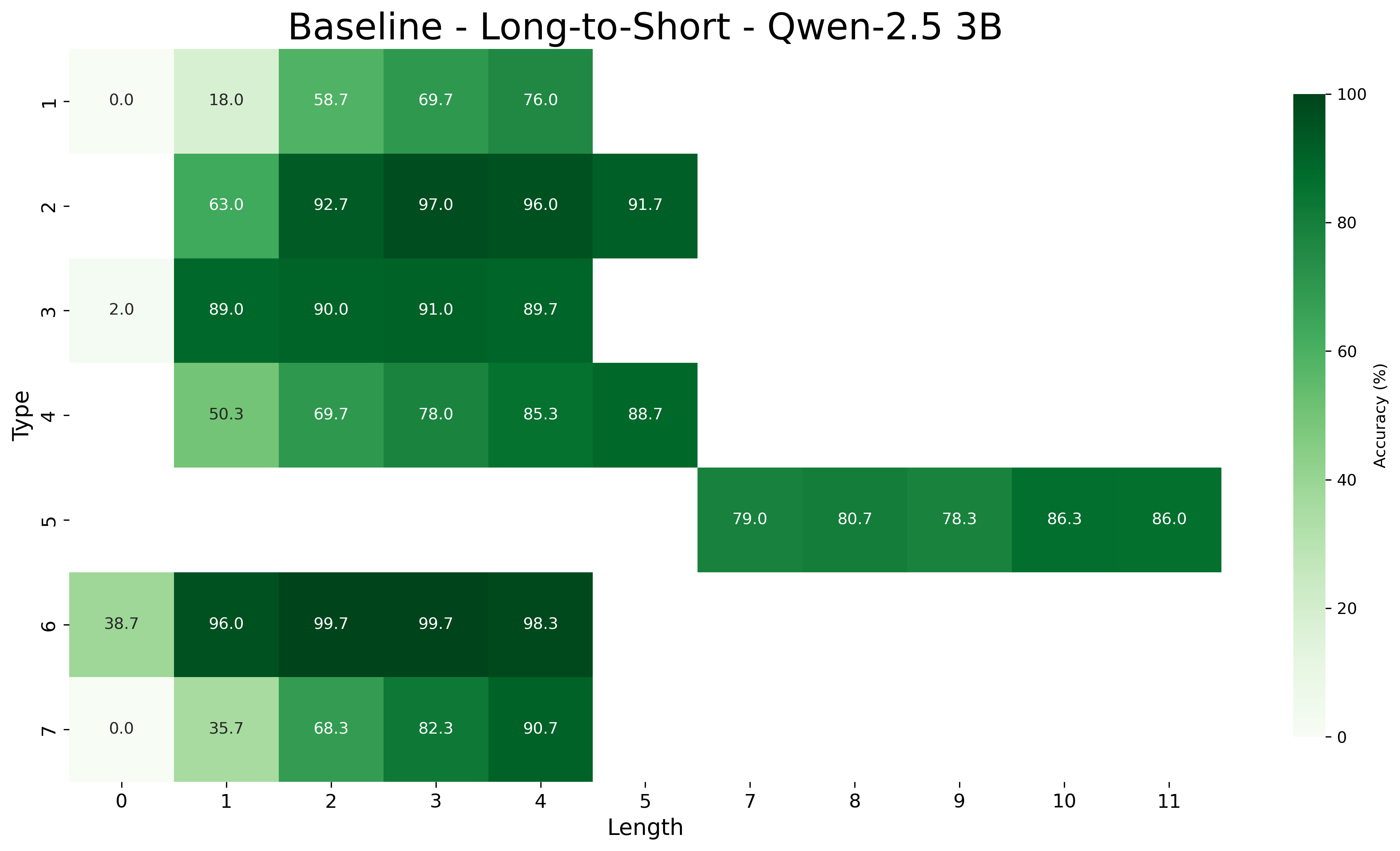
### Visual Description
## Heatmap: Baseline - Long-to-Short - Qwen-2.5 3B
### Overview
This image is a heatmap visualizing the accuracy percentage of a model named "Qwen-2.5 3B" on a "Long-to-Short" task. The performance is broken down by two categorical variables: "Type" (vertical axis, rows 1-7) and "Length" (horizontal axis, columns 0-11, with a gap at 6). The color intensity represents accuracy, with a legend on the right showing a gradient from light green (0%) to dark green (100%).
### Components/Axes
* **Title:** "Baseline - Long-to-Short - Qwen-2.5 3B" (centered at the top).
* **Vertical Axis (Y-axis):** Labeled "Type". It contains 7 discrete categories, numbered 1 through 7 from top to bottom.
* **Horizontal Axis (X-axis):** Labeled "Length". It contains discrete numerical markers: 0, 1, 2, 3, 4, 5, 7, 8, 9, 10, 11. There is no marker for length 6.
* **Legend/Color Bar:** Located on the right side of the chart. It is a vertical bar labeled "Accuracy (%)" with a scale from 0 to 100. The color gradient transitions from very light green (0) to dark forest green (100).
* **Data Cells:** The main body of the chart is a grid where each cell corresponds to a specific Type and Length. Each cell contains a numerical value representing the accuracy percentage and is colored according to the legend.
### Detailed Analysis
The following table reconstructs the data from the heatmap. Empty cells indicate no data was recorded for that Type-Length combination.
| Type | Length 0 | Length 1 | Length 2 | Length 3 | Length 4 | Length 5 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 0.0 | 18.0 | 58.7 | 69.7 | 76.0 | | | | | | |
| **2** | | 63.0 | 92.7 | 97.0 | 96.0 | 91.7 | | | | | |
| **3** | 2.0 | 89.0 | 90.0 | 91.0 | 89.7 | | | | | | |
| **4** | | 50.3 | 69.7 | 78.0 | 85.3 | 88.7 | | | | | |
| **5** | | | | | | | 79.0 | 80.7 | 78.3 | 86.3 | 86.0 |
| **6** | 38.7 | 96.0 | 99.7 | 99.7 | 98.3 | | | | | | |
| **7** | 0.0 | 35.7 | 68.3 | 82.3 | 90.7 | | | | | | |
**Trend Verification by Type:**
* **Type 1:** Shows a clear upward trend. Accuracy starts at 0.0% (Length 0) and increases steadily to 76.0% (Length 4).
* **Type 2:** Accuracy is high, starting at 63.0% (Length 1), peaking at 97.0% (Length 3), and slightly declining to 91.7% (Length 5).
* **Type 3:** Accuracy is consistently high (89.0%-91.0%) for Lengths 1-4, with a very low value (2.0%) at Length 0.
* **Type 4:** Shows a steady upward trend from 50.3% (Length 1) to 88.7% (Length 5).
* **Type 5:** Data exists only for longer lengths (7-11). Accuracy is relatively stable, ranging from 78.3% to 86.3%.
* **Type 6:** Exhibits very high accuracy. It starts at 38.7% (Length 0), jumps to 96.0% (Length 1), and peaks at 99.7% for Lengths 2 and 3.
* **Type 7:** Shows a strong upward trend from 0.0% (Length 0) to 90.7% (Length 4).
### Key Observations
1. **Variable Data Ranges:** Different "Types" are evaluated over different ranges of "Length". Types 1, 3, 6, and 7 have data for lengths 0-4. Types 2 and 4 have data for lengths 1-5. Type 5 is an outlier, with data only for lengths 7-11.
2. **Performance Extremes:** The highest accuracy values (99.7%) are found in Type 6 at Lengths 2 and 3. The lowest values (0.0%) are found in Types 1 and 7 at Length 0.
3. **General Trend:** For most Types where data is available across multiple lengths (1, 4, 6, 7), accuracy generally improves as the "Length" value increases.
4. **High-Performing Types:** Types 2, 3, and 6 demonstrate consistently high accuracy (mostly above 85%) across their respective tested lengths.
5. **Missing Data Point:** The x-axis skips the value 6, suggesting this length category was not part of the evaluation.
### Interpretation
This heatmap likely presents the results of an evaluation benchmark for the Qwen-2.5 3B language model on a "Long-to-Short" task, which may involve summarizing or condensing long inputs. The "Type" axis probably represents different task categories or prompt styles, while "Length" could correspond to input length, output length, or a complexity metric.
The data suggests that model performance is highly dependent on both the task type and the length parameter. The strong positive correlation between length and accuracy for several types (e.g., Type 1, 7) indicates the model may require a minimum amount of context or a certain scale to perform effectively. The exceptional performance of Type 6 suggests it is a particularly well-suited or easier task variant for this model. Conversely, the 0% accuracy at Length 0 for some types might represent a baseline failure mode or a control condition where the task is impossible to complete. The isolated data for Type 5 at longer lengths implies it is a distinct task category only applicable to higher length values. Overall, the chart provides a granular view of model strengths and weaknesses across a multidimensional task space.
</details>
Figure 11: Accuracy of MIND (Left) and Baseline (Right) Qwen-2.5 3B on long to short generalization decomposed by inference type and length.
<details>
<summary>extracted/6458430/figs/qwen-7b_heatmap_meta_compositionality_high.png Details</summary>
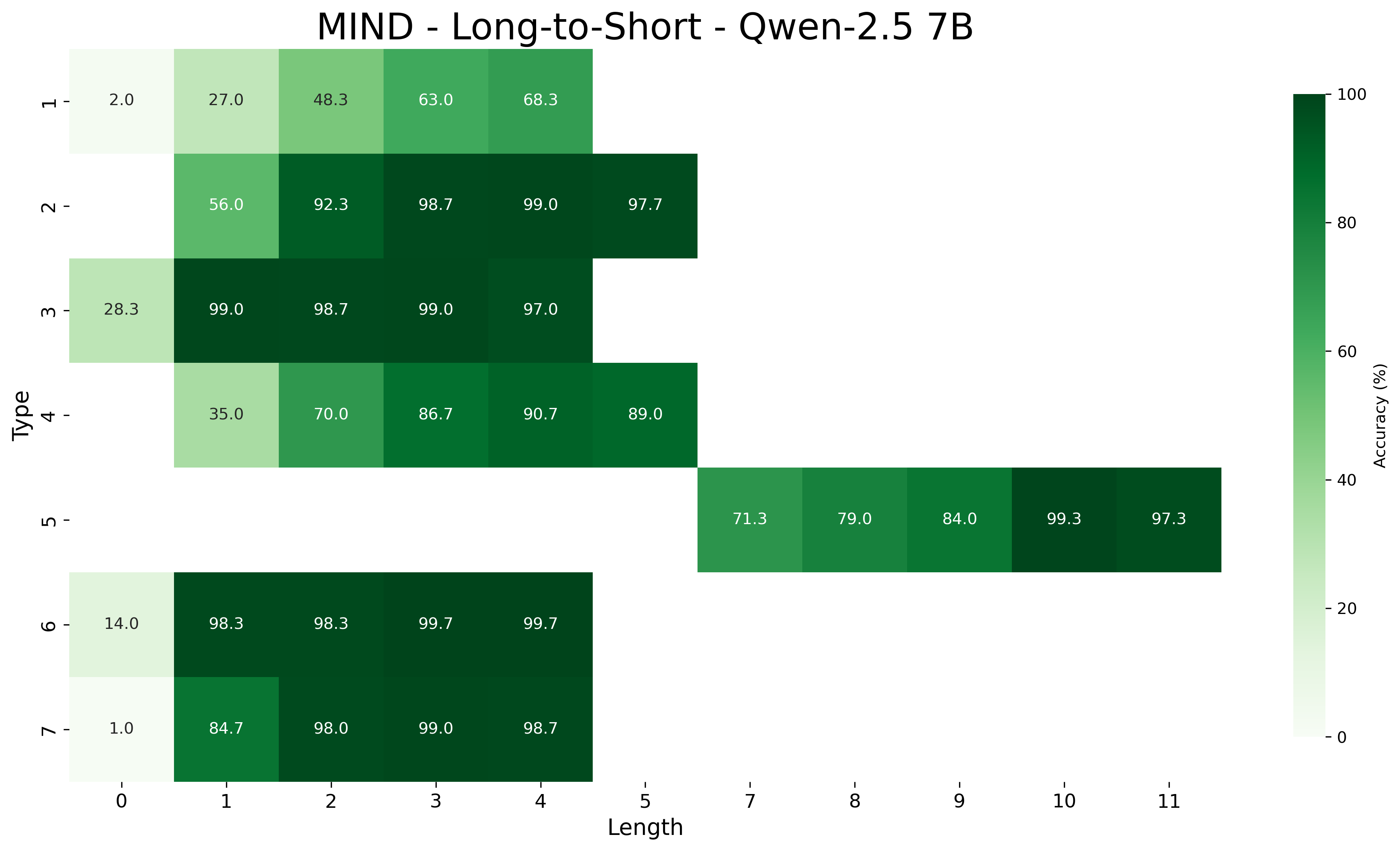
### Visual Description
## Heatmap: MIND - Long-to-Short - Qwen-2.5 7B
### Overview
This image is a heatmap visualizing the accuracy (in percentage) of a model named "Qwen-2.5 7B" on a task or dataset referred to as "MIND - Long-to-Short". The heatmap plots accuracy against two categorical variables: "Type" (vertical axis) and "Length" (horizontal axis). The color intensity represents accuracy, with a scale from 0% (lightest) to 100% (darkest green).
### Components/Axes
* **Title:** "MIND - Long-to-Short - Qwen-2.5 7B"
* **Vertical Axis (Y-axis):** Labeled "Type". It contains 7 discrete categories, numbered 1 through 7.
* **Horizontal Axis (X-axis):** Labeled "Length". It contains 12 discrete categories, numbered 0 through 11.
* **Legend/Color Bar:** Located on the right side of the chart. It is a vertical gradient bar labeled "Accuracy (%)". The scale runs from 0 at the bottom to 100 at the top, with intermediate markers at 20, 40, 60, and 80. The color transitions from a very light, almost white-green at 0% to a deep, dark green at 100%.
### Detailed Analysis
The following table reconstructs the data presented in the heatmap. Each cell contains the accuracy value for a specific Type and Length combination. Cells with no value indicate missing data for that combination.
| Type \ Length | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 2.0 | 27.0 | 48.3 | 63.0 | 68.3 | | | | | | | |
| **2** | | 56.0 | 92.3 | 98.7 | 99.0 | 97.7 | | | | | | |
| **3** | 28.3 | 99.0 | 98.7 | 99.0 | 97.0 | | | | | | | |
| **4** | | 35.0 | 70.0 | 86.7 | 90.7 | 89.0 | | | | | | |
| **5** | | | | | | | | 71.3 | 79.0 | 84.0 | 99.3 | 97.3 |
| **6** | 14.0 | 98.3 | 98.3 | 99.7 | 99.7 | | | | | | | |
| **7** | 1.0 | 84.7 | 98.0 | 99.0 | 98.7 | | | | | | | |
**Spatial & Color Grounding:**
* The highest accuracy values (≥99.0%) are represented by the darkest green cells. These are found in:
* Type 2 at Lengths 3 (98.7%) and 4 (99.0%).
* Type 3 at Lengths 1 (99.0%) and 3 (99.0%).
* Type 6 at Lengths 3 (99.7%) and 4 (99.7%).
* Type 7 at Length 3 (99.0%).
* Type 5 at Length 10 (99.3%).
* The lowest accuracy values (≤2.0%) are represented by the lightest cells. These are found in:
* Type 1 at Length 0 (2.0%).
* Type 7 at Length 0 (1.0%).
### Key Observations
1. **General Trend:** For most Types (1, 2, 3, 4, 6, 7), accuracy increases significantly as "Length" increases from 0 or 1, often plateauing at a very high level (>90%) by Length 3 or 4.
2. **Type-Specific Performance:**
* **Type 1** shows the most gradual improvement, starting very low (2.0%) and only reaching 68.3% by Length 4.
* **Types 2, 3, 6, and 7** achieve near-perfect accuracy (>98%) very quickly, often by Length 2 or 3.
* **Type 4** shows strong improvement but peaks at 90.7% (Length 4), slightly lower than the top performers.
* **Type 5** is an outlier in data distribution. It has no recorded data for Lengths 0-6. Its performance starts at 71.3% (Length 7) and improves to a peak of 99.3% at Length 10.
3. **Data Sparsity:** The heatmap is not a complete grid. Data for Types 1-4 and 6-7 is concentrated on the left side (Lengths 0-5), while data for Type 5 is concentrated on the right side (Lengths 7-11). There is no overlap in the "Length" values between these two groups.
### Interpretation
This heatmap likely evaluates the performance of the Qwen-2.5 7B model on a summarization or compression task ("Long-to-Short") within the MIND benchmark. The "Type" axis probably represents different categories of input documents or summarization tasks, while "Length" likely corresponds to the target summary length or a compression ratio.
* **What the data suggests:** The model's ability to generate accurate short summaries is highly dependent on both the document type and the desired output length. For most document types, providing a slightly longer target summary (Length 3 or 4) yields a dramatic improvement in accuracy compared to very short targets (Length 0 or 1).
* **Relationship between elements:** The stark separation between the data for Types 1-4/6-7 and Type 5 suggests these groups may represent fundamentally different task categories. Type 5 tasks might inherently require longer summaries (hence data only from Length 7 onward) or belong to a different subset of the benchmark.
* **Notable patterns:** The near-perfect accuracy for several types at moderate lengths indicates the model is highly capable for those specific tasks. The poor performance of Type 1 at all lengths suggests it is a particularly challenging category for this model. The outlier status of Type 5 warrants further investigation into its definition within the MIND benchmark.
</details>
<details>
<summary>extracted/6458430/figs/qwen-7b_heatmap_base_compositionality_high.png Details</summary>
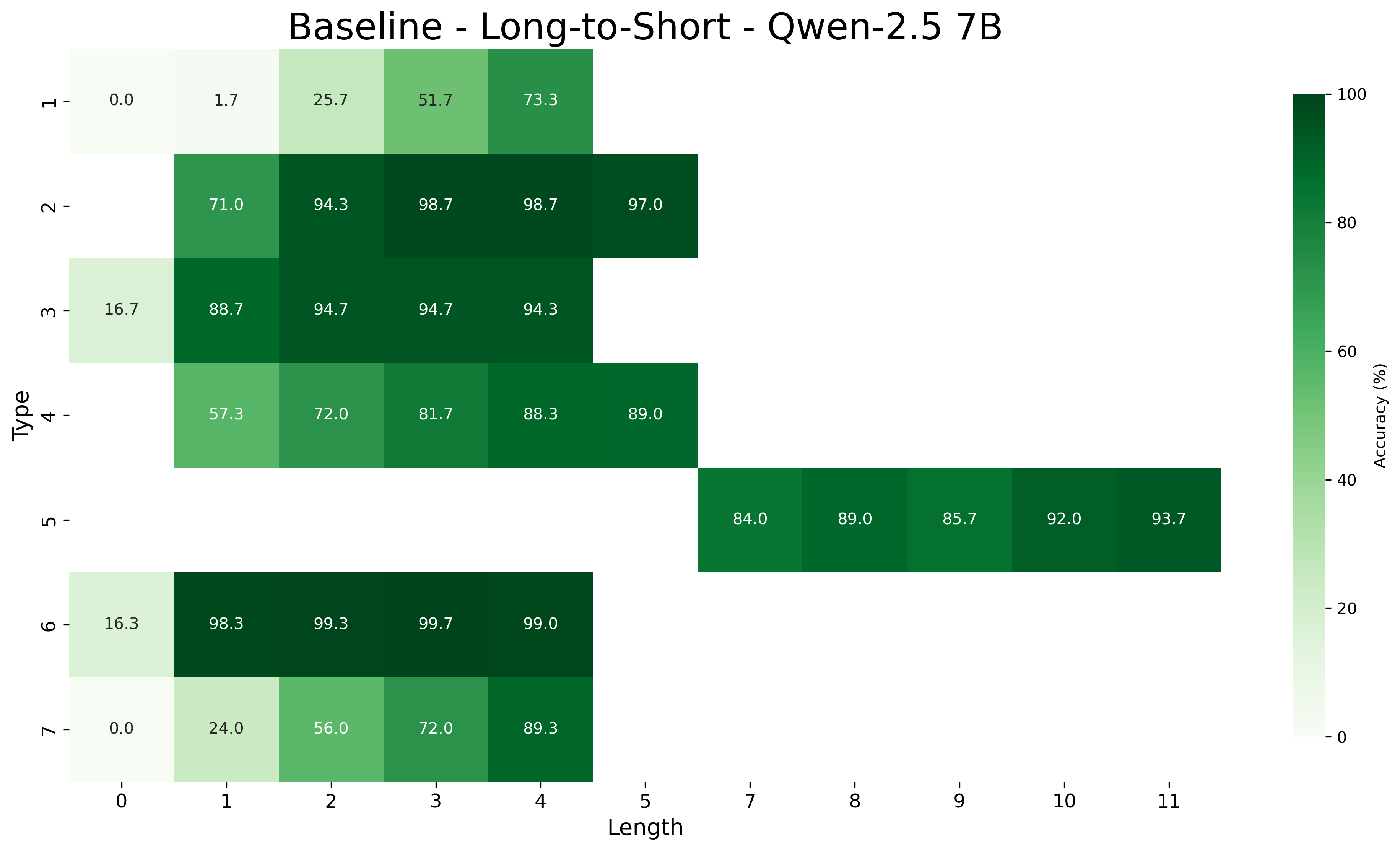
### Visual Description
## Heatmap: Baseline - Long-to-Short - Qwen-2.5 7B
### Overview
This image is a heatmap visualizing the accuracy (in percentage) of a model named "Qwen-2.5 7B" on a "Long-to-Short" task. The performance is broken down by two categorical variables: "Type" (y-axis) and "Length" (x-axis). The color intensity represents accuracy, with a scale from light green (0%) to dark green (100%).
### Components/Axes
* **Title:** "Baseline - Long-to-Short - Qwen-2.5 7B" (centered at the top).
* **Y-Axis (Vertical):** Labeled "Type". It lists 7 distinct categories, numbered 1 through 7.
* **X-Axis (Horizontal):** Labeled "Length". It lists discrete numerical values: 0, 1, 2, 3, 4, 5, 7, 8, 9, 10, 11. Note the gap between 5 and 7.
* **Color Bar/Legend:** Located on the right side. It is a vertical gradient bar labeled "Accuracy (%)". The scale runs from 0 (lightest green) at the bottom to 100 (darkest green) at the top, with tick marks at 20, 40, 60, and 80.
* **Data Cells:** The main body of the chart is a grid where each cell corresponds to a specific (Type, Length) pair. The cell's background color corresponds to the accuracy value, which is also printed as a number within the cell.
### Detailed Analysis
The following table reconstructs the data from the heatmap. Empty cells indicate no data point for that (Type, Length) combination.
| Type | Length 0 | Length 1 | Length 2 | Length 3 | Length 4 | Length 5 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 0.0 | 1.7 | 25.7 | 51.7 | 73.3 | | | | | | |
| **2** | | 71.0 | 94.3 | 98.7 | 98.7 | 97.0 | | | | | |
| **3** | 16.7 | 88.7 | 94.7 | 94.7 | 94.3 | | | | | | |
| **4** | | 57.3 | 72.0 | 81.7 | 88.3 | 89.0 | | | | | |
| **5** | | | | | | | 84.0 | 89.0 | 85.7 | 92.0 | 93.7 |
| **6** | 16.3 | 98.3 | 99.3 | 99.7 | 99.0 | | | | | | |
| **7** | 0.0 | 24.0 | 56.0 | 72.0 | 89.3 | | | | | | |
**Trend Verification per Type:**
* **Type 1:** Shows a strong, steady upward trend. Accuracy starts at 0.0% (Length 0) and increases monotonically to 73.3% (Length 4).
* **Type 2:** Starts high (71.0% at Length 1), peaks at 98.7% (Lengths 3 & 4), and shows a very slight decrease to 97.0% at Length 5.
* **Type 3:** Jumps dramatically from 16.7% (Length 0) to 88.7% (Length 1), then plateaus in the mid-90s.
* **Type 4:** Exhibits a consistent upward trend from 57.3% (Length 1) to 89.0% (Length 5).
* **Type 5:** Data exists only for longer lengths (7-11). Accuracy fluctuates between 84.0% and 93.7%, with a general upward trend from Length 7 to 11.
* **Type 6:** Starts low (16.3% at Length 0) but immediately jumps to near-perfect accuracy (98.3% at Length 1) and remains above 99% for Lengths 2-4.
* **Type 7:** Mirrors the trend of Type 1, starting at 0.0% (Length 0) and increasing steadily to 89.3% (Length 4).
### Key Observations
1. **Length-Dependent Performance:** For Types 1, 4, and 7, accuracy improves significantly and consistently as the "Length" value increases.
2. **High Baseline Performance:** Types 2, 3, and 6 achieve very high accuracy (>88%) starting from relatively short lengths (Length 1 or 2).
3. **Outlier - Type 5:** This type has no data for lengths 0-6, suggesting it may represent a different category of task or input that only applies to longer sequences. Its performance is consistently high within its range.
4. **Near-Perfect Accuracy:** Type 6 at Lengths 2, 3, and 4 shows accuracy values of 99.3%, 99.7%, and 99.0%, indicating near-perfect performance for those conditions.
5. **Zero Accuracy Points:** Types 1 and 7 both have an accuracy of 0.0% at Length 0, indicating complete failure for that specific condition.
### Interpretation
This heatmap provides a granular view of the Qwen-2.5 7B model's performance on a "Long-to-Short" task, revealing that its effectiveness is highly dependent on both the task "Type" and the input "Length."
* **Task Difficulty Spectrum:** The "Type" axis likely represents different sub-tasks or problem categories. The data suggests a spectrum of difficulty: Types 1 and 7 appear to be the most challenging at short lengths, requiring longer inputs to achieve decent accuracy. In contrast, Types 2, 3, and 6 seem to be easier or better-suited to the model, as they yield high accuracy even with short inputs.
* **The "Long-to-Short" Mechanism:** The general trend of improving accuracy with increasing length for most types supports the premise of a "Long-to-Short" process—perhaps the model uses longer context or reasoning chains to generate a correct short answer. The plateau or slight dip for Type 2 at Length 5 might indicate a point of diminishing returns or a minor failure mode.
* **Model Specialization:** The exceptional performance of Type 6 (near 100% accuracy) suggests the model is particularly adept at that specific type of task. Conversely, the 0% accuracy for Types 1 and 7 at Length 0 highlights a critical failure case for very short inputs of those types.
* **Data Gaps:** The absence of data for Type 5 at shorter lengths and for all types at lengths 6 and beyond (except Type 5) is notable. It implies the evaluation was either not performed for those combinations or that those combinations are not applicable, which is important context for understanding the model's full capabilities.
In summary, the chart demonstrates that the Qwen-2.5 7B model's accuracy on this task is not uniform but is a complex function of task type and input length, with clear patterns of strength and weakness across different conditions.
</details>
Figure 12: Accuracy of MIND (Left) and Baseline (Right) Qwen-2.5 7B on long to short generalization decomposed by inference type and length.
<details>
<summary>extracted/6458430/figs/qwen-1.5b_heatmap_meta_recursiveness_high.png Details</summary>
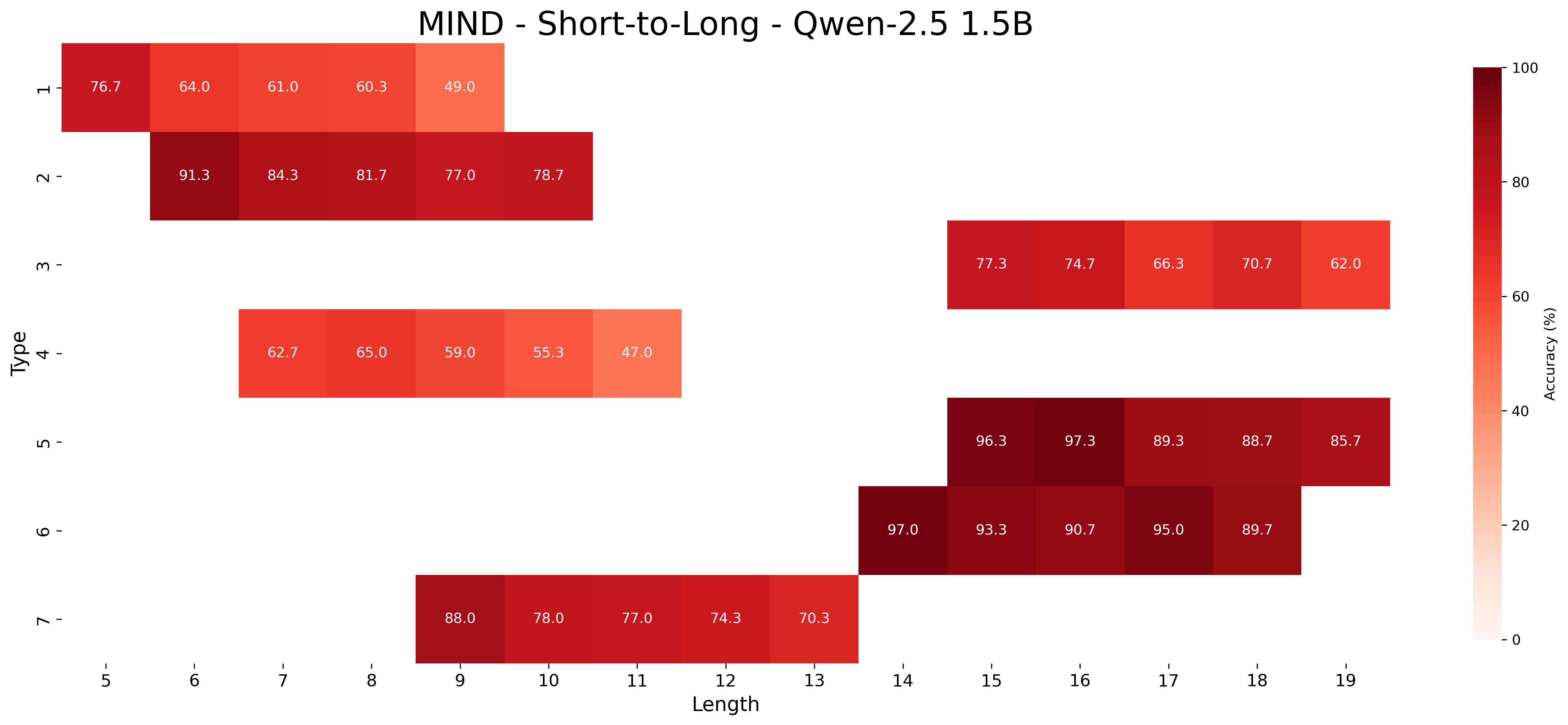
### Visual Description
## Heatmap: MIND - Short-to-Long - Qwen-2.5 1.5B
### Overview
This image is a heatmap visualizing the accuracy performance of a model named "Qwen-2.5 1.5B" on a task or dataset referred to as "MIND," specifically focusing on a "Short-to-Long" evaluation. The chart plots accuracy percentages against two categorical variables: "Type" (y-axis) and "Length" (x-axis). The data is presented as a grid of colored cells, where each cell's color intensity corresponds to an accuracy value, with darker reds indicating higher accuracy.
### Components/Axes
* **Title:** "MIND - Short-to-Long - Qwen-2.5 1.5B" (Top center).
* **Y-Axis (Vertical):** Labeled "Type". It contains 7 discrete categories, numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled "Length". It contains 15 discrete categories, numbered 5 through 19 from left to right.
* **Legend/Color Bar:** Located on the right side of the chart. It is a vertical gradient bar labeled "Accuracy (%)". The scale runs from 0 (light peach/white) at the bottom to 100 (dark red) at the top, with intermediate tick marks at 20, 40, 60, and 80.
* **Data Cells:** The main chart area is a grid where rows correspond to "Type" and columns correspond to "Length". Not all grid cells are populated; data is present only for specific Type-Length combinations. Each populated cell contains a numerical value representing the accuracy percentage.
### Detailed Analysis
The following table reconstructs the data from the heatmap. An empty cell indicates no data was recorded for that Type-Length combination.
| Type | Length 5 | Length 6 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 | Length 12 | Length 13 | Length 14 | Length 15 | Length 16 | Length 17 | Length 18 | Length 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 76.7 | 64.0 | 61.0 | 60.3 | 49.0 | | | | | | | | | | |
| **2** | | 91.3 | 84.3 | 81.7 | 77.0 | 78.7 | | | | | | | | | |
| **3** | | | | | | | | | | | 77.3 | 74.7 | 66.3 | 70.7 | 62.0 |
| **4** | | | 62.7 | 65.0 | 59.0 | 55.3 | 47.0 | | | | | | | | |
| **5** | | | | | | | | | | | 96.3 | 97.3 | 89.3 | 88.7 | 85.7 |
| **6** | | | | | | | | | | 97.0 | 93.3 | 90.7 | 95.0 | 89.7 | |
| **7** | | | | | 88.0 | 78.0 | 77.0 | 74.3 | 70.3 | | | | | | |
**Trend Verification per Type:**
* **Type 1:** Shows a clear downward trend. Accuracy starts at 76.7% (Length 5) and decreases steadily to 49.0% (Length 9).
* **Type 2:** Shows a general downward trend with a slight uptick at the end. Accuracy decreases from 91.3% (Length 6) to 77.0% (Length 9), then rises slightly to 78.7% (Length 10).
* **Type 3:** Shows a general downward trend with fluctuation. Accuracy decreases from 77.3% (Length 15) to 66.3% (Length 17), rises to 70.7% (Length 18), then falls to 62.0% (Length 19).
* **Type 4:** Shows a downward trend. Accuracy peaks at 65.0% (Length 8) and then decreases to 47.0% (Length 11).
* **Type 5:** Shows a downward trend from a very high starting point. Accuracy peaks at 97.3% (Length 16) and decreases to 85.7% (Length 19).
* **Type 6:** Shows a fluctuating but generally high-performance trend. Accuracy starts at 97.0% (Length 14), dips, rises to 95.0% (Length 17), then falls to 89.7% (Length 18).
* **Type 7:** Shows a clear downward trend. Accuracy decreases from 88.0% (Length 9) to 70.3% (Length 13).
### Key Observations
1. **Performance Stratification by Type:** There is a stark difference in baseline performance between types. Types 5 and 6 consistently achieve very high accuracy (mostly >85%), while Types 1 and 4 operate at a much lower accuracy range (mostly <70%).
2. **Universal Negative Correlation with Length:** For every type where a trend is visible, accuracy decreases as the "Length" value increases. This is the most dominant pattern in the chart.
3. **Data Sparsity:** The evaluation is not uniform. Each type is tested over a specific, non-overlapping range of lengths (e.g., Type 1 only for lengths 5-9, Type 3 only for lengths 15-19). This suggests the "Types" may represent different task categories or difficulty levels that are naturally associated with different sequence lengths.
4. **High-Accuracy Cluster:** The highest accuracy values (≥90%) are concentrated in the lower-right quadrant of the populated data, specifically for Types 5 and 6 at lengths 14-18.
### Interpretation
This heatmap provides a diagnostic view of the Qwen-2.5 1.5B model's capabilities on the MIND benchmark. The data strongly suggests that **sequence length is a critical factor degrading model performance** across all evaluated task types. The model's accuracy is not robust to increases in the "Length" parameter.
The separation of data into distinct, non-overlapping blocks for each "Type" implies these types are fundamentally different sub-tasks. The model exhibits a clear hierarchy of competence: it excels at Types 5 and 6, performs moderately on Types 2, 3, and 7, and struggles significantly with Types 1 and 4. This could indicate that Types 5 and 6 involve simpler patterns or are more aligned with the model's pre-training, while Types 1 and 4 present more complex reasoning or retrieval challenges that break down as sequences get longer.
The investigation reveals a model that is highly sensitive to input length, with its strengths and weaknesses being task-dependent. To improve performance, focus would need to be placed on enhancing the model's ability to maintain coherence and accuracy over longer contexts, particularly for the lower-performing task types (1 and 4).
</details>
<details>
<summary>extracted/6458430/figs/qwen-1.5b_heatmap_base_recursiveness_high.png Details</summary>
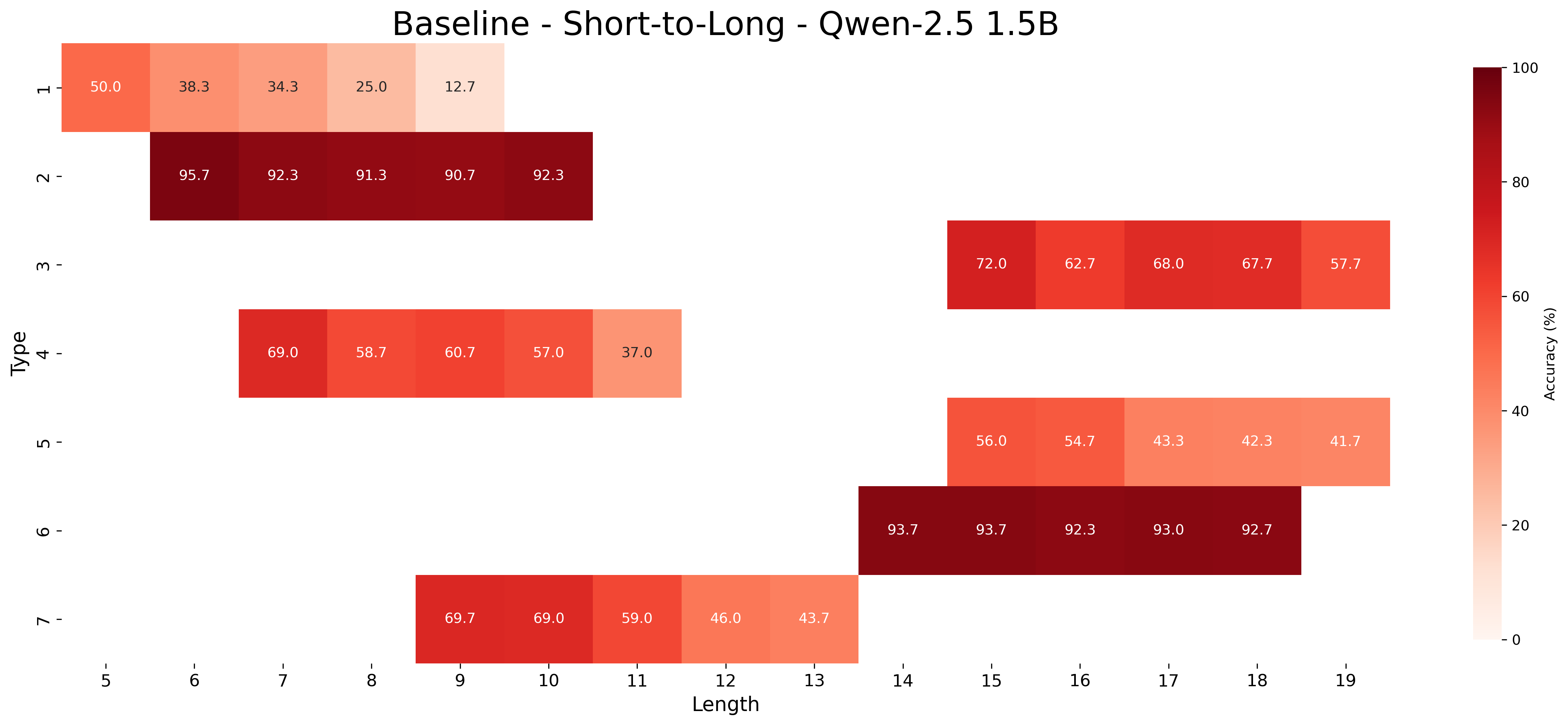
### Visual Description
## Heatmap: Baseline - Short-to-Long - Qwen-2.5 1.5B
### Overview
This image is a heatmap visualizing the accuracy performance of a model named "Qwen-2.5 1.5B" across different task "Types" and input sequence "Lengths." The chart is titled "Baseline - Short-to-Long - Qwen-2.5 1.5B," suggesting it evaluates the model's baseline performance when handling sequences that vary from short to long. The data is presented as a grid where each cell's color and numerical value represent the accuracy percentage for a specific Type-Length combination.
### Components/Axes
* **Title:** "Baseline - Short-to-Long - Qwen-2.5 1.5B" (Top center).
* **Y-Axis (Vertical):** Labeled **"Type"**. It lists 7 discrete categories, numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled **"Length"**. It represents a numerical scale from 5 to 19, with tick marks at each integer.
* **Color Bar/Legend:** Located on the right side of the chart. It is a vertical gradient bar labeled **"Accuracy (%)"**. The scale runs from 0 (lightest, near-white) to 100 (darkest, deep red). Key markers are at 0, 20, 40, 60, 80, and 100.
* **Data Cells:** The main chart area contains colored rectangular cells. Each cell contains a white numerical value representing the accuracy percentage. The cell's color corresponds to the value according to the color bar. Not all Type-Length intersections contain data; many cells are empty (white background).
### Detailed Analysis
The following table reconstructs the data from the heatmap. An empty cell indicates no data was recorded for that Type-Length combination.
| Type | Length 5 | Length 6 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 | Length 12 | Length 13 | Length 14 | Length 15 | Length 16 | Length 17 | Length 18 | Length 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 50.0 | 38.3 | 34.3 | 25.0 | 12.7 | | | | | | | | | | |
| **2** | | 95.7 | 92.3 | 91.3 | 90.7 | 92.3 | | | | | | | | | |
| **3** | | | | | | | | | | | 72.0 | 62.7 | 68.0 | 67.7 | 57.7 |
| **4** | | | 69.0 | 58.7 | 60.7 | 57.0 | 37.0 | | | | | | | | |
| **5** | | | | | | | | | | | 56.0 | 54.7 | 43.3 | 42.3 | 41.7 |
| **6** | | | | | | | | | | 93.7 | 93.7 | 92.3 | 93.0 | 92.7 | |
| **7** | | | | | 69.7 | 69.0 | 59.0 | 46.0 | 43.7 | | | | | | |
**Trend Verification by Type:**
* **Type 1 (Lengths 5-9):** The line of data slopes sharply downward. Accuracy decreases monotonically from 50.0% to 12.7% as length increases.
* **Type 2 (Lengths 6-10):** The data shows consistently high accuracy with minimal variation. Values remain above 90%, indicating robust performance across this length range.
* **Type 3 (Lengths 15-19):** The trend is generally downward but with fluctuation. It starts at 72.0%, dips to 62.7%, recovers to 68.0%, then declines to 57.7%.
* **Type 4 (Lengths 7-11):** The trend is downward. Accuracy falls from 69.0% to a low of 37.0% at the longest length in its range.
* **Type 5 (Lengths 15-19):** The trend is a steady, monotonic decline from 56.0% to 41.7%.
* **Type 6 (Lengths 14-18):** The data shows exceptionally high and stable accuracy, with all values between 92.3% and 93.7%. There is no significant downward trend.
* **Type 7 (Lengths 9-13):** The trend is a clear, monotonic decline from 69.7% to 43.7%.
### Key Observations
1. **Performance Clusters:** The model's performance falls into distinct clusters:
* **High & Stable:** Types 2 and 6 maintain accuracy above 90% across their tested lengths.
* **Moderate & Declining:** Types 3, 4, 5, and 7 show moderate starting accuracy (56-72%) that degrades significantly with increased length.
* **Poor & Rapidly Declining:** Type 1 starts at only 50% and drops to near 10%.
2. **Length Sensitivity:** For most Types (1, 3, 4, 5, 7), accuracy is inversely correlated with sequence length. The model struggles more as inputs get longer.
3. **Data Gaps:** The heatmap is sparse. Each Type is only evaluated over a specific, non-overlapping range of lengths (e.g., Type 1 only for short lengths 5-9, Type 3 only for long lengths 15-19). This suggests the "Types" may represent different task categories or data distributions that are inherently associated with different typical lengths.
4. **Color-Value Consistency:** The color intensity accurately reflects the numerical values. The darkest red cells (Type 2, Type 6) correspond to the highest accuracies (>90%), while the lightest cells (Type 1 at Length 9) correspond to the lowest accuracy (12.7%).
### Interpretation
This heatmap provides a diagnostic view of the Qwen-2.5 1.5B model's capabilities and limitations in a "short-to-long" context.
* **What the data suggests:** The model exhibits highly variable performance depending on the task "Type." It is exceptionally robust and accurate for certain tasks (Types 2 and 6), regardless of sequence length within the tested range. However, for other tasks (Types 1, 3, 4, 5, 7), its performance degrades as sequences become longer. This indicates a potential weakness in maintaining context or coherence over extended sequences for specific types of problems.
* **How elements relate:** The "Type" axis is the primary differentiator of performance. The "Length" axis acts as a stress test, revealing the model's stability. The stark contrast between the stable high performance of Types 2/6 and the declining performance of others suggests fundamental differences in how the model processes these task categories. The sparse, non-overlapping length ranges for each Type imply that the evaluation was designed to test each Type within its natural or challenging length regime.
* **Notable anomalies:** The slight accuracy increase for Type 3 from Length 16 (62.7%) to Length 17 (68.0%) is an outlier in the general downward trend, which could be due to statistical noise or a specific characteristic of the test samples at that length.
* **Why it matters:** This analysis is crucial for understanding the model's reliability. Users or developers would know to expect consistent, high-quality outputs for tasks resembling Types 2 and 6, but would need to be cautious or apply additional techniques (like chunking or fine-tuning) when using the model for tasks similar to Types 1, 4, or 7, especially with long inputs. The chart effectively maps the model's "comfort zone" across the task-length spectrum.
</details>
Figure 13: Accuracy of MIND (Left) and Baseline (Right) Qwen-2.5 1.5B on short to long generalization decomposed by inference type and length.
<details>
<summary>extracted/6458430/figs/qwen-3b_heatmap_meta_recursiveness_high.png Details</summary>
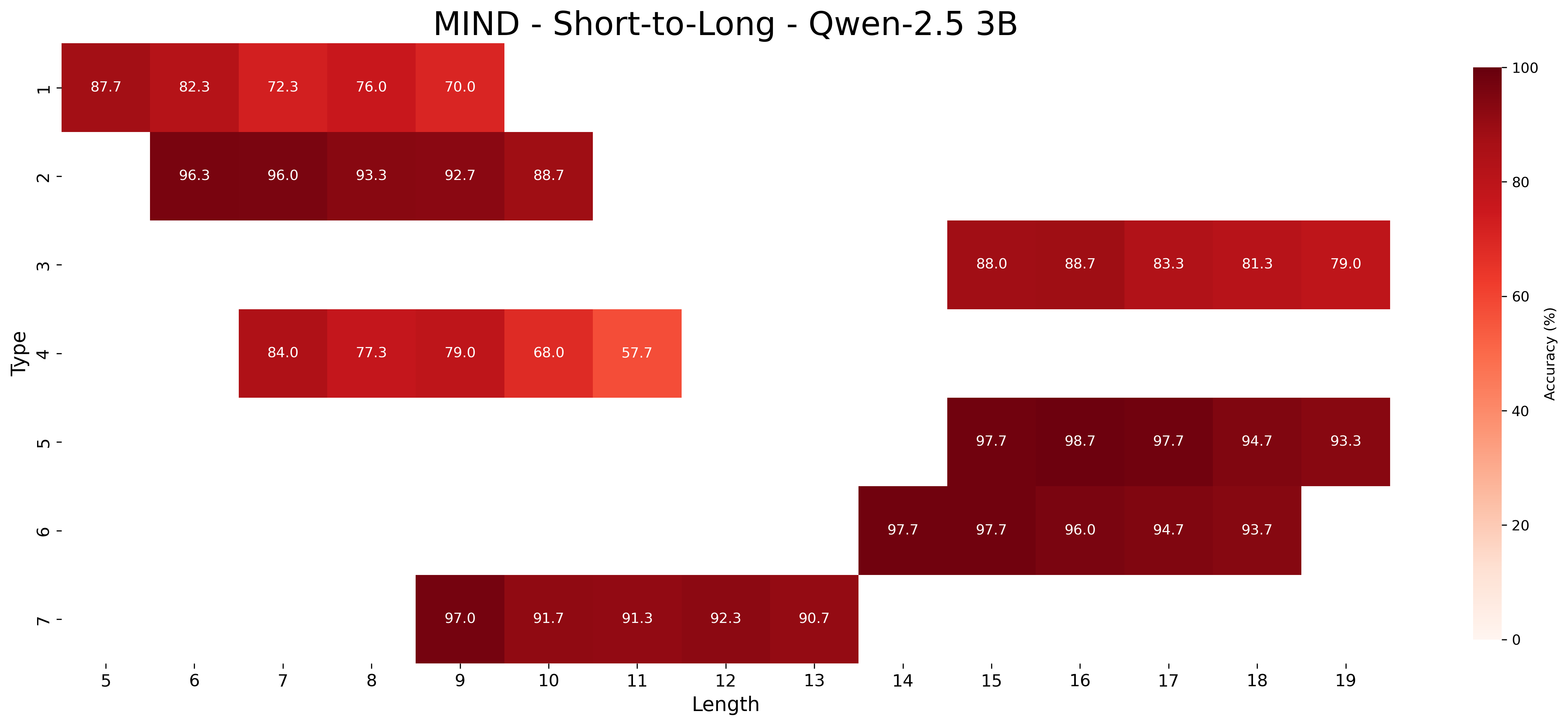
### Visual Description
## Heatmap: MIND - Short-to-Long - Qwen-2.5 3B
### Overview
This image is a heatmap visualizing the accuracy performance of the "Qwen-2.5 3B" model on the "MIND" dataset, specifically for a "Short-to-Long" task. The chart plots model accuracy (%) against two categorical variables: "Type" (vertical axis) and "Length" (horizontal axis). The data is presented as a grid of colored cells, where the color intensity represents the accuracy value, with a corresponding color bar legend on the right.
### Components/Axes
* **Title:** "MIND - Short-to-Long - Qwen-2.5 3B" (Top center).
* **Vertical Axis (Y-axis):**
* **Label:** "Type" (Rotated 90 degrees, left side).
* **Categories/Ticks:** 1, 2, 3, 4, 5, 6, 7 (Listed from top to bottom).
* **Horizontal Axis (X-axis):**
* **Label:** "Length" (Bottom center).
* **Categories/Ticks:** 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19 (Listed from left to right).
* **Legend/Color Bar:**
* **Position:** Right side of the chart.
* **Label:** "Accuracy (%)" (Rotated 90 degrees, next to the bar).
* **Scale:** A continuous gradient from light peach/white (0%) to dark red (100%).
* **Tick Marks:** 0, 20, 40, 60, 80, 100.
### Detailed Analysis
The heatmap is sparse, with data points only for specific combinations of Type and Length. Each cell contains a numerical accuracy value. Below is the extracted data, organized by Type (row) and corresponding Length (column):
**Type 1 (Top row):**
* Length 5: 87.7%
* Length 6: 82.3%
* Length 7: 72.3%
* Length 8: 76.0%
* Length 9: 70.0%
**Type 2:**
* Length 6: 96.3%
* Length 7: 96.0%
* Length 8: 93.3%
* Length 9: 92.7%
* Length 10: 88.7%
**Type 3:**
* Length 15: 88.0%
* Length 16: 88.7%
* Length 17: 83.3%
* Length 18: 81.3%
* Length 19: 79.0%
**Type 4:**
* Length 7: 84.0%
* Length 8: 77.3%
* Length 9: 79.0%
* Length 10: 68.0%
* Length 11: 57.7%
**Type 5:**
* Length 15: 97.7%
* Length 16: 98.7%
* Length 17: 97.7%
* Length 18: 94.7%
* Length 19: 93.3%
**Type 6:**
* Length 14: 97.7%
* Length 15: 97.7%
* Length 16: 96.0%
* Length 17: 94.7%
* Length 18: 93.7%
**Type 7 (Bottom row):**
* Length 9: 97.0%
* Length 10: 91.7%
* Length 11: 91.3%
* Length 12: 92.3%
* Length 13: 90.7%
### Key Observations
1. **Performance Variability by Type:** There is significant variation in accuracy across different "Types." Types 2, 5, 6, and 7 consistently show very high accuracy (mostly >90%), indicated by the darkest red cells. Type 4 shows the lowest performance, with accuracy dropping to 57.7% at Length 11.
2. **Performance Trend with Length:** For most Types where data is available across a range of lengths, there is a general trend of **decreasing accuracy as Length increases**. This is visible as a color gradient from darker to lighter red moving left to right within a Type's row (e.g., Type 1: 87.7% → 70.0%; Type 4: 84.0% → 57.7%).
3. **Data Sparsity:** The heatmap is not fully populated. Each Type has data for only a contiguous block of 5 consecutive Lengths, and these blocks are offset from each other. For example, Type 1 covers lengths 5-9, Type 2 covers 6-10, Type 3 covers 15-19, etc. This suggests the evaluation was performed on specific, non-overlapping length intervals for each task type.
4. **Outliers:** Type 4 at Length 11 (57.7%) is a notable low point. Type 5 at Length 16 (98.7%) is the highest recorded accuracy in the chart.
### Interpretation
This heatmap provides a diagnostic view of the Qwen-2.5 3B model's capabilities on the MIND benchmark. The "Short-to-Long" context suggests the task involves processing or generating information where sequence length is a key variable.
* **Model Strengths:** The model excels (accuracy >90%) on several task Types (2, 5, 6, 7) across their evaluated length ranges. This indicates robust performance on those specific sub-tasks within the MIND dataset.
* **Model Weaknesses & Length Sensitivity:** The clear downward trend in accuracy with increasing length for Types 1 and 4 reveals a key limitation: the model's performance degrades as the sequence length grows for these task categories. Type 4 is particularly sensitive, showing a steep decline. This could point to challenges in maintaining coherence, attention, or reasoning over longer contexts for those specific task formulations.
* **Task-Specific Performance:** The stark difference in performance between Types (e.g., Type 2 vs. Type 4) implies that the model's effectiveness is highly dependent on the nature of the task ("Type"). The MIND benchmark likely contains diverse sub-tasks, and this model has an uneven proficiency across them.
* **Experimental Design:** The offset, non-overlapping length windows for each Type suggest a controlled experimental setup designed to isolate the effect of length within specific task categories, rather than testing all Types across all lengths. This is efficient but means direct comparison of, for example, Type 1 at Length 15 is not possible from this chart.
In summary, the data demonstrates that the Qwen-2.5 3B model has strong but task-dependent performance on the MIND benchmark, with a notable vulnerability to performance degradation on certain tasks as sequence length increases.
</details>
<details>
<summary>extracted/6458430/figs/qwen-3b_heatmap_base_recursiveness_high.png Details</summary>
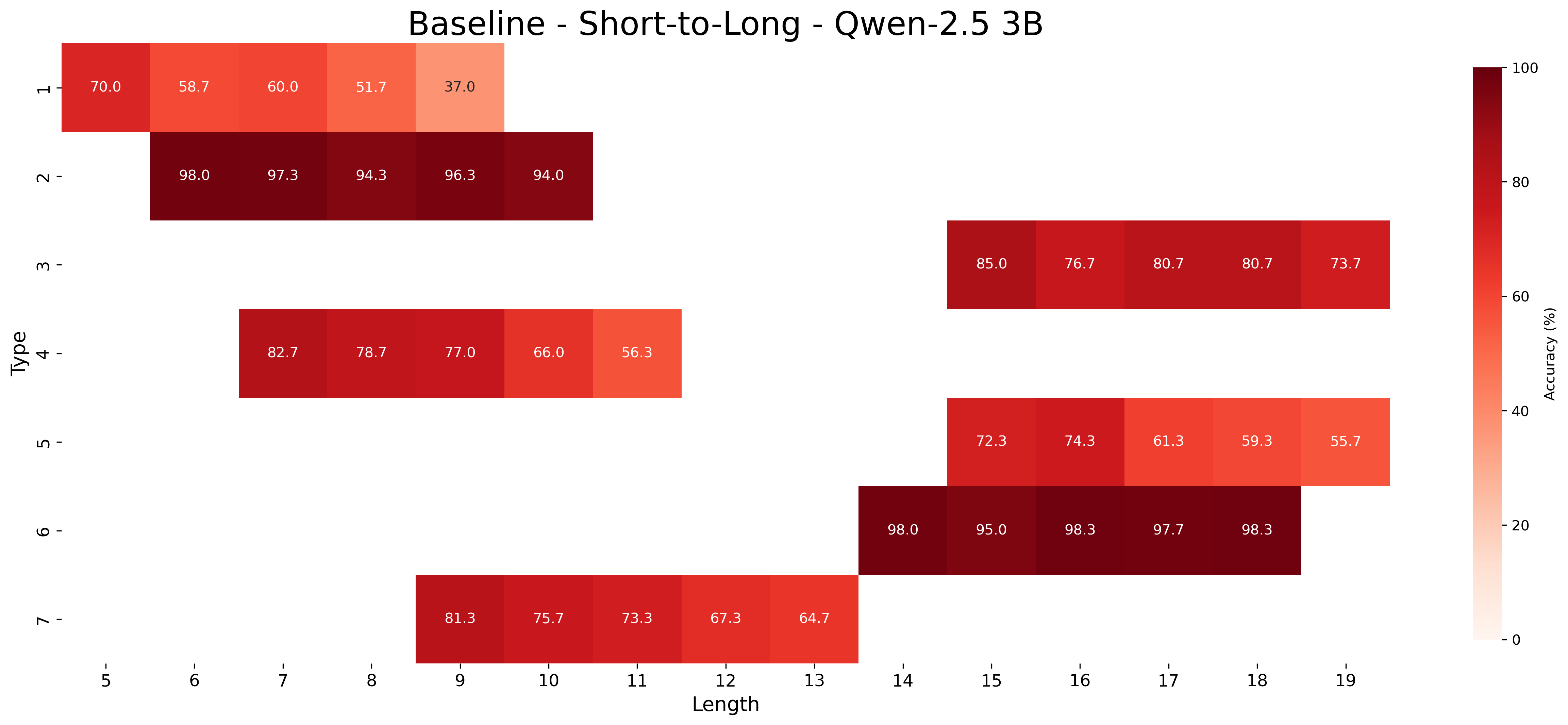
### Visual Description
## Heatmap: Baseline - Short-to-Long - Qwen-2.5 3B
### Overview
This image is a heatmap visualizing the accuracy (in percentage) of a model named "Qwen-2.5 3B" on a "Short-to-Long" baseline task. The accuracy is plotted against two categorical variables: "Type" (y-axis, categories 1 through 7) and "Length" (x-axis, values from 5 to 19). The color intensity represents accuracy, with a scale from 0% (lightest) to 100% (darkest red). The data is sparse, with each "Type" row containing data only for a specific, non-overlapping range of "Length" values.
### Components/Axes
* **Title:** "Baseline - Short-to-Long - Qwen-2.5 3B" (centered at the top).
* **Y-Axis (Vertical):** Labeled "Type". Categories are numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled "Length". Tick marks and labels are provided for integer values from 5 to 19.
* **Color Bar/Legend:** Located on the right side of the chart. It is a vertical gradient bar labeled "Accuracy (%)". The scale runs from 0 at the bottom (lightest color) to 100 at the top (darkest red), with intermediate markers at 20, 40, 60, and 80.
* **Data Cells:** Each cell in the grid contains a numerical value representing the accuracy percentage for a specific (Type, Length) combination. The cell's background color corresponds to this value on the color bar.
### Detailed Analysis
The following table reconstructs the data from the heatmap. Each row corresponds to a "Type," and columns correspond to "Length." Empty cells indicate no data for that combination.
| Type | Length 5 | Length 6 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 | Length 12 | Length 13 | Length 14 | Length 15 | Length 16 | Length 17 | Length 18 | Length 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 70.0 | 58.7 | 60.0 | 51.7 | 37.0 | | | | | | | | | | |
| **2** | | 98.0 | 97.3 | 94.3 | 96.3 | 94.0 | | | | | | | | | |
| **3** | | | | | | | | | | | 85.0 | 76.7 | 80.7 | 80.7 | 73.7 |
| **4** | | | 82.7 | 78.7 | 77.0 | 66.0 | 56.3 | | | | | | | | |
| **5** | | | | | | | | | | | 72.3 | 74.3 | 61.3 | 59.3 | 55.7 |
| **6** | | | | | | | | | | 98.0 | 95.0 | 98.3 | 97.7 | 98.3 | |
| **7** | | | | | 81.3 | 75.7 | 73.3 | 67.3 | 64.7 | | | | | | |
**Trend Verification by Type:**
* **Type 1 (Lengths 5-9):** The line of data points slopes sharply downward. Accuracy starts at 70.0% and decreases to 37.0% as length increases.
* **Type 2 (Lengths 6-10):** The data points form a high, relatively flat line. Accuracy remains very high, ranging from 94.0% to 98.0%, with a minor dip at Length 8 (94.3%).
* **Type 3 (Lengths 15-19):** The trend is generally downward with a peak at the start. Accuracy begins at 85.0%, dips to 76.7%, recovers to 80.7%, and ends at 73.7%.
* **Type 4 (Lengths 7-11):** The line slopes downward. Accuracy declines steadily from 82.7% to 56.3%.
* **Type 5 (Lengths 15-19):** The trend shows a peak in the middle. Accuracy starts at 72.3%, rises to 74.3%, then falls to 55.7%.
* **Type 6 (Lengths 14-18):** The data points form a very high, stable line. Accuracy is consistently excellent, ranging from 95.0% to 98.3%.
* **Type 7 (Lengths 9-13):** The line slopes downward. Accuracy decreases from 81.3% to 64.7%.
### Key Observations
1. **Performance Stratification by Type:** There is a stark difference in baseline performance between Types. Types 2 and 6 achieve near-perfect accuracy (>94%) across their respective length ranges. In contrast, Types 1, 4, 5, and 7 show significant performance degradation as sequence length increases.
2. **Length Sensitivity:** For most Types (1, 3, 4, 5, 7), accuracy generally decreases as the "Length" value increases, indicating the task becomes harder for longer sequences. Type 2 is an exception, maintaining high accuracy.
3. **Data Sparsity:** Each Type is evaluated only on a specific, contiguous block of Lengths (e.g., Type 1 on 5-9, Type 6 on 14-18). This suggests the "Types" may represent different task categories or difficulty levels that are only relevant or tested within certain length ranges.
4. **Color-Accuracy Correlation:** The visual trend matches the numerical data. The darkest red cells (highest accuracy) are concentrated in the rows for Type 2 and Type 6. The lightest cells (lowest accuracy) appear at the end of the length range for Type 1 (37.0%).
### Interpretation
This heatmap provides a diagnostic view of the Qwen-2.5 3B model's capabilities on a specific "Short-to-Long" evaluation. The data suggests that the model's performance is highly dependent on both the *type* of task and the *length* of the input sequence.
* **Task-Specific Proficiency:** The model exhibits exceptional, robust performance on the tasks categorized as Type 2 and Type 6, regardless of length within the tested range. This indicates these task types are well within the model's capabilities.
* **Length Generalization Challenge:** For several other task types (1, 4, 7), the model shows a clear inability to maintain accuracy as sequences get longer. This is a common challenge in language models, often related to attention mechanisms or context window utilization. The steep drop in Type 1 (from 70% to 37%) is particularly notable.
* **Non-Linear Difficulty:** The performance on Type 3 and Type 5 does not follow a simple linear decline. The peak at intermediate lengths (e.g., Type 5 at Length 16) suggests there may be specific length ranges where the model's processing is optimal for those task types, or that the difficulty of the task itself varies non-monotonically with length.
* **Implication for "Short-to-Long" Generalization:** The overall pattern indicates that while the model can handle some tasks ("Types") with excellent generalization from short to long sequences, it struggles significantly with others. This highlights that "length generalization" is not a monolithic capability but is deeply intertwined with the nature of the underlying task. The evaluation successfully isolates which task categories are robust and which are brittle as sequence length scales.
</details>
Figure 14: Accuracy of MIND (Left) and Baseline (Right) Qwen-2.5 3B on short to long generalization decomposed by inference type and length.
<details>
<summary>extracted/6458430/figs/qwen-7b_heatmap_meta_recursiveness_high.png Details</summary>
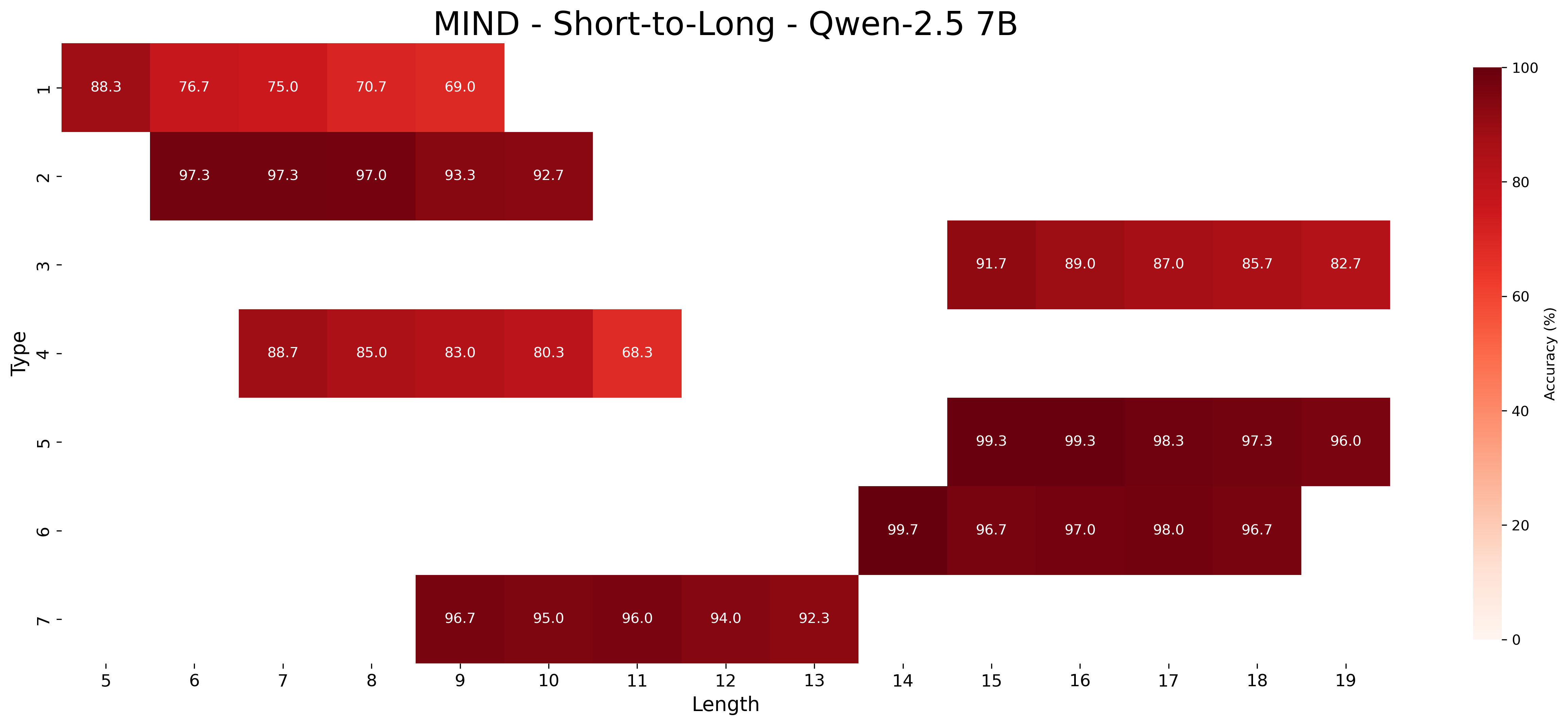
### Visual Description
## Heatmap Chart: MIND - Short-to-Long - Qwen-2.5 7B
### Overview
This image is a heatmap chart visualizing the accuracy performance of the "Qwen-2.5 7B" model on a task or dataset referred to as "MIND" under a "Short-to-Long" evaluation paradigm. The chart plots accuracy percentages across two dimensions: "Type" (vertical axis) and "Length" (horizontal axis). The data is presented as a grid of colored cells, where the color intensity corresponds to the accuracy value, with a legend on the right providing the scale.
### Components/Axes
* **Title:** "MIND - Short-to-Long - Qwen-2.5 7B" (centered at the top).
* **Vertical Axis (Y-axis):** Labeled "Type". It contains discrete categories numbered 1 through 7.
* **Horizontal Axis (X-axis):** Labeled "Length". It contains discrete numerical values from 5 to 19.
* **Color Bar/Legend:** Located on the right side of the chart. It is a vertical gradient bar labeled "Accuracy (%)". The scale runs from 0 (lightest, near-white) to 100 (darkest, deep red). Major tick marks are at 0, 20, 40, 60, 80, and 100.
* **Data Grid:** The main area consists of rectangular cells. Each cell contains a numerical value representing the accuracy percentage for a specific Type-Length combination. Cells are only present where data exists; many Type-Length combinations have no data (blank/white space).
### Detailed Analysis
The following table reconstructs the data from the heatmap. Values are accuracy percentages. A dash (`-`) indicates no data cell exists for that Type-Length combination.
| Type | Length 5 | Length 6 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 | Length 12 | Length 13 | Length 14 | Length 15 | Length 16 | Length 17 | Length 18 | Length 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 88.3 | 76.7 | 75.0 | 70.7 | 69.0 | - | - | - | - | - | - | - | - | - | - |
| **2** | - | 97.3 | 97.3 | 97.0 | 93.3 | 92.7 | - | - | - | - | - | - | - | - | - |
| **3** | - | - | - | - | - | - | - | - | - | 91.7 | 89.0 | 87.0 | 85.7 | 82.7 | - |
| **4** | - | - | 88.7 | 85.0 | 83.0 | 80.3 | 68.3 | - | - | - | - | - | - | - | - |
| **5** | - | - | - | - | - | - | - | - | - | 99.3 | 99.3 | 98.3 | 97.3 | 96.0 | - |
| **6** | - | - | - | - | - | - | - | - | 99.7 | 96.7 | 97.0 | 98.0 | 96.7 | - | - |
| **7** | - | - | - | - | 96.7 | 95.0 | 96.0 | 94.0 | 92.3 | - | - | - | - | - | - |
**Spatial & Color Grounding:**
* The highest accuracy values (99.7, 99.3) are found in the darkest red cells, located in the lower-right quadrant of the populated data (Type 6, Length 13 and Type 5, Length 14/15).
* The lowest accuracy value (68.3) is in a lighter red cell, located at Type 4, Length 11.
* The data is not a complete matrix. Each "Type" has a contiguous block of data across a specific range of "Lengths":
* Type 1: Lengths 5-9
* Type 2: Lengths 6-10
* Type 3: Lengths 14-18
* Type 4: Lengths 7-11
* Type 5: Lengths 14-18
* Type 6: Lengths 13-17
* Type 7: Lengths 9-13
### Key Observations
1. **Performance Stratification by Type:** There is a clear separation in performance levels between different Types. Types 5 and 6 consistently show very high accuracy (mostly >96%). Types 2 and 7 also show high accuracy (>92%). Type 3 shows moderate accuracy (82.7-91.7%). Types 1 and 4 show the lowest and most variable accuracy.
2. **Length Sensitivity:** For most Types, accuracy tends to decrease as the "Length" value increases within its data block. This downward trend is most pronounced in Type 1 (88.3% to 69.0%) and Type 4 (88.7% to 68.3%).
3. **Anomaly in Type 6:** Type 6 shows a non-monotonic trend. Accuracy starts at 99.7% (Length 13), dips to 96.7% (Length 14), then rises again to 98.0% (Length 17) before a final dip. This suggests a potential outlier or a specific length where performance is exceptionally high.
4. **Data Coverage:** The "Length" axis is not uniformly covered for all Types. Shorter lengths (5-11) are primarily associated with Types 1, 2, 4, and 7. Longer lengths (13-18) are associated with Types 3, 5, and 6. This suggests the "Short-to-Long" evaluation may involve different task types being relevant at different length scales.
### Interpretation
This heatmap provides a diagnostic view of the Qwen-2.5 7B model's capabilities on the MIND benchmark. The "Type" axis likely represents different sub-tasks, question categories, or reasoning skills within the MIND evaluation. The "Length" axis likely corresponds to input sequence length, context window size, or the complexity/number of steps in a problem.
The data suggests that the model's performance is highly dependent on the specific task type. It excels at certain tasks (Types 5 & 6) even with long inputs, indicating robust capabilities in those areas. Conversely, it struggles with other tasks (Types 1 & 4), and its performance degrades significantly as the problem length increases, pointing to a potential weakness in handling long-context reasoning or information retention for those specific task types.
The segmented nature of the data (each Type occupying a specific length range) implies that the "Short-to-Long" evaluation might be structured such that different cognitive challenges (represented by Types) become prominent at different scales. The model's strong performance on longer-length tasks (Types 3, 5, 6) is a positive indicator for its long-context abilities, but the poor performance on shorter-length tasks of Types 1 and 4 highlights areas for improvement. The anomaly in Type 6 warrants further investigation to understand why performance peaks at a specific length.
</details>
<details>
<summary>extracted/6458430/figs/qwen-7b_heatmap_base_recursiveness_high.png Details</summary>
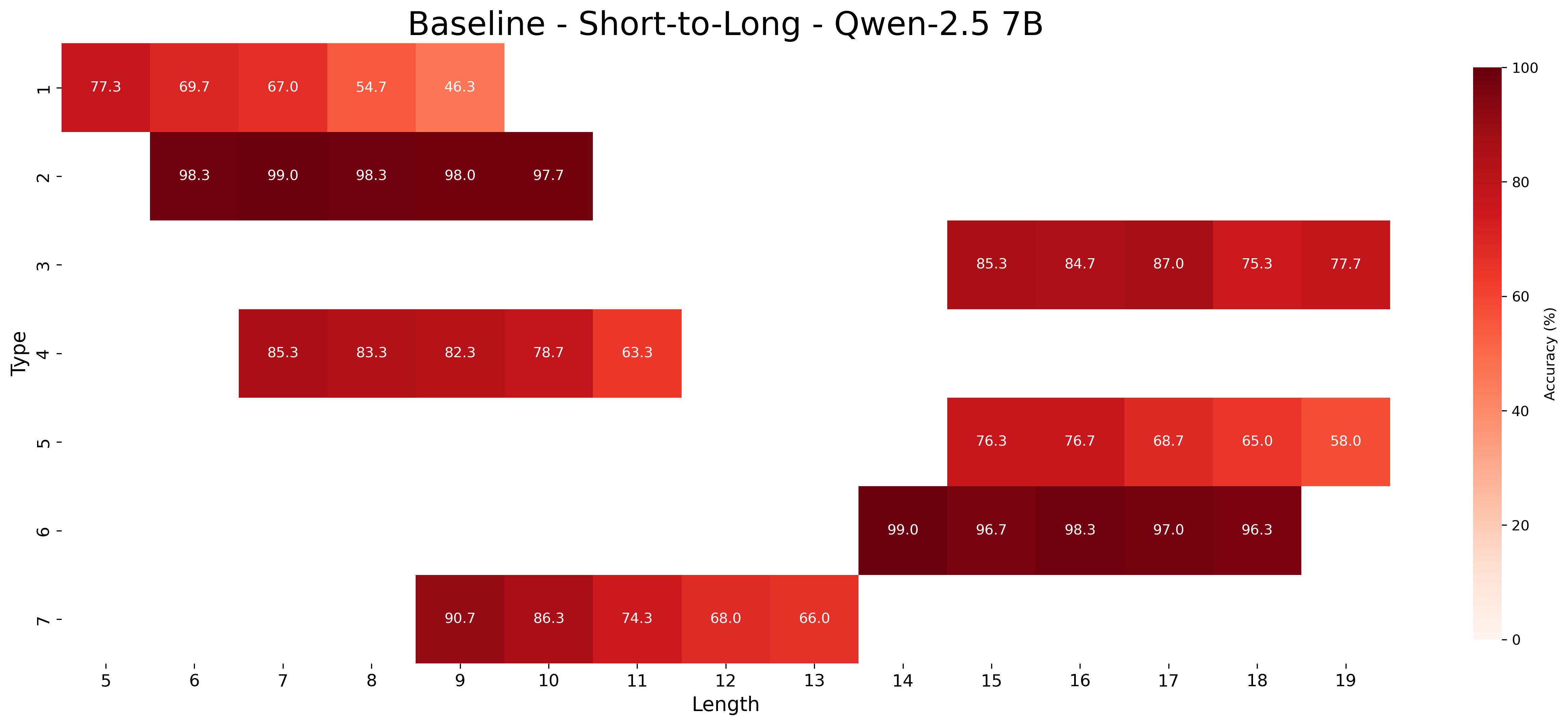
### Visual Description
## Heatmap: Baseline - Short-to-Long - Qwen-2.5 7B
### Overview
This image is a heatmap visualizing the accuracy (in percentage) of a model named "Qwen-2.5 7B" across different "Types" and "Lengths." The title "Baseline - Short-to-Long" suggests this data represents a baseline performance evaluation, likely measuring how well the model generalizes from shorter to longer sequences or inputs. The chart uses a color gradient from light orange (low accuracy) to dark red (high accuracy) to represent the accuracy values.
### Components/Axes
* **Title:** "Baseline - Short-to-Long - Qwen-2.5 7B" (centered at the top).
* **Y-Axis (Vertical):** Labeled "Type." It lists seven discrete categories, numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled "Length." It displays a numerical scale from 5 to 19, with tick marks at each integer.
* **Color Bar/Legend:** Located on the right side of the chart. It is a vertical gradient bar labeled "Accuracy (%)" with a scale from 0 (lightest) to 100 (darkest). The color mapping is:
* ~0-20%: Light peach/orange
* ~40-60%: Medium orange/red
* ~80-100%: Dark red to maroon
* **Data Cells:** The main chart area contains rectangular cells positioned at the intersection of a specific Type and Length. Each cell contains a numerical value representing the accuracy percentage and is colored according to the legend.
### Detailed Analysis
The heatmap does not contain data for every Type-Length combination. Data is present in distinct horizontal bands for each Type, covering specific Length ranges. Below is the extracted data, organized by Type (row) and Length (column).
**Type 1 (Top Row):**
* Length 5: 77.3%
* Length 6: 69.7%
* Length 7: 67.0%
* Length 8: 54.7%
* Length 9: 46.3%
* *Trend:* Accuracy shows a clear and steady downward trend as Length increases from 5 to 9.
**Type 2:**
* Length 6: 98.3%
* Length 7: 99.0%
* Length 8: 98.3%
* Length 9: 98.0%
* Length 10: 97.7%
* *Trend:* Accuracy is consistently very high (above 97%) across all measured lengths, with minimal variation.
**Type 3:**
* Length 14: 85.3%
* Length 15: 84.7%
* Length 16: 87.0%
* Length 17: 75.3%
* Length 18: 77.7%
* *Trend:* Accuracy is relatively stable in the mid-80s for lengths 14-16, then drops notably at length 17 before a slight recovery at length 18.
**Type 4:**
* Length 7: 85.3%
* Length 8: 83.3%
* Length 9: 82.3%
* Length 10: 78.7%
* Length 11: 63.3%
* *Trend:* Accuracy declines gradually from length 7 to 10, followed by a sharp drop of over 15 percentage points at length 11.
**Type 5:**
* Length 14: 76.3%
* Length 15: 76.7%
* Length 16: 68.7%
* Length 17: 65.0%
* Length 18: 58.0%
* *Trend:* Accuracy is stable for lengths 14-15, then begins a consistent downward trend through length 18.
**Type 6:**
* Length 13: 99.0%
* Length 14: 96.7%
* Length 15: 98.3%
* Length 16: 97.0%
* Length 17: 96.3%
* *Trend:* Accuracy remains exceptionally high (above 96%) across all measured lengths, showing robustness.
**Type 7 (Bottom Row):**
* Length 9: 90.7%
* Length 10: 86.3%
* Length 11: 74.3%
* Length 12: 68.0%
* Length 13: 66.0%
* *Trend:* Accuracy shows a strong downward trend as length increases, with the most significant drop occurring between lengths 10 and 11.
### Key Observations
1. **Performance Clusters:** The data reveals two distinct performance clusters. **High-Performance Types** (2 and 6) maintain accuracy above ~96% across their measured length ranges. **Declining-Performance Types** (1, 4, 5, 7) show a clear negative correlation between length and accuracy. Type 3 is intermediate, with a mid-range performance that dips at longer lengths.
2. **Critical Length Thresholds:** Several types exhibit a sharp performance drop at a specific length:
* Type 1: Drop begins at Length 8 (54.7%).
* Type 4: Sharp drop at Length 11 (63.3%).
* Type 7: Sharp drop at Length 11 (74.3%).
* Type 3: Drop at Length 17 (75.3%).
3. **Length Coverage:** The "Length" axis is not uniformly covered. Different types are evaluated on different, often non-overlapping, length intervals (e.g., Type 1 covers 5-9, Type 6 covers 13-17). This suggests the "Types" may represent different tasks, datasets, or evaluation conditions with inherent length constraints.
4. **Color Correlation:** The visual color intensity perfectly matches the numerical values. The highest values (99.0% in Types 2 & 6) are the darkest maroon, while the lowest value (46.3% in Type 1) is a light orange, confirming the legend's accuracy.
### Interpretation
This heatmap provides a diagnostic view of the Qwen-2.5 7B model's generalization capability in a "Short-to-Long" scenario. The core insight is that **model performance is highly type-dependent and often degrades with increased sequence length.**
* **Robustness vs. Fragility:** Types 2 and 6 represent tasks or conditions where the model's performance is robust and does not suffer from increased length. This could indicate tasks with simpler patterns, better representation in the training data, or where the model's architecture is particularly well-suited.
* **Length Generalization Failure:** The declining trends in Types 1, 4, 5, and 7 demonstrate a failure to generalize to longer sequences. The sharp drops at specific lengths (e.g., Type 4 at Length 11) may point to a "breaking point" where the model's attention mechanism or context window becomes insufficient, or where the task complexity exceeds the model's capacity for longer inputs.
* **Task-Specific Evaluation:** The non-overlapping length ranges for different types strongly imply that "Type" corresponds to distinct evaluation benchmarks or task categories, each with its own characteristic input length distribution. The model's struggle with longer inputs in certain types highlights a potential limitation in its training or architecture for handling long-context dependencies across diverse tasks.
In summary, the data suggests that while the Qwen-2.5 7B model can achieve near-perfect accuracy on some tasks regardless of length, its performance on others is significantly compromised as input length increases, revealing a key area for potential improvement in long-context modeling.
</details>
Figure 15: Accuracy of MIND (Left) and Baseline (Right) Qwen-2.5 7B on short to long generalization decomposed by inference type and length.
<details>
<summary>extracted/6458430/figs/gpt-4o_heatmap_meta_overall_high.png Details</summary>
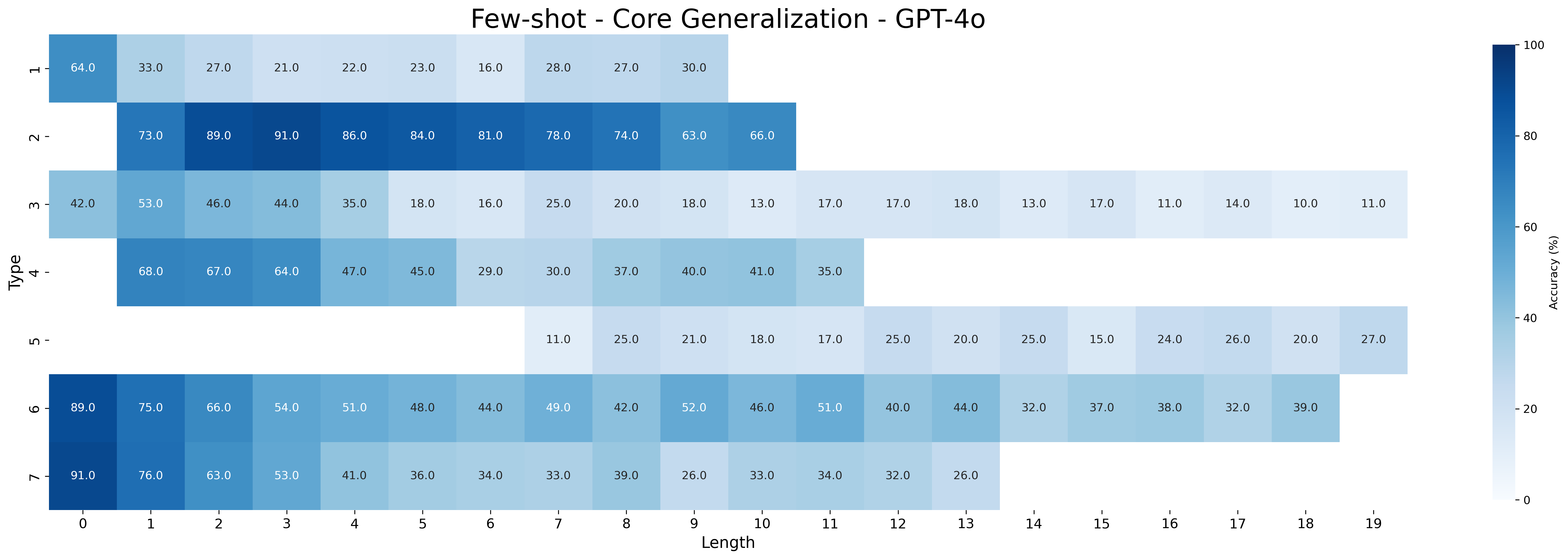
### Visual Description
## Heatmap: Few-shot - Core Generalization - GPT-4o
### Overview
This image is a heatmap visualizing the accuracy (in percentage) of the GPT-4o model on "Few-shot - Core Generalization" tasks. The performance is broken down by two categorical variables: "Type" (vertical axis, rows 1-7) and "Length" (horizontal axis, columns 0-19). The color intensity represents accuracy, with a scale from 0% (lightest blue/white) to 100% (darkest blue). The chart contains numerical data points within each cell, and some cells are empty, indicating no data for that specific Type-Length combination.
### Components/Axes
* **Title:** "Few-shot - Core Generalization - GPT-4o" (Top Center).
* **Vertical Axis (Y-axis):** Labeled "Type". Categories are numbered 1 through 7 from top to bottom.
* **Horizontal Axis (X-axis):** Labeled "Length". Categories are numbered 0 through 19 from left to right.
* **Color Bar/Legend:** Located on the right side. It is a vertical gradient bar labeled "Accuracy (%)". The scale runs from 0 at the bottom to 100 at the top, with tick marks at 0, 20, 40, 60, 80, and 100. Darker blue corresponds to higher accuracy.
* **Data Cells:** Each cell at the intersection of a Type and Length contains a numerical value representing the accuracy percentage. The background color of the cell corresponds to this value per the color bar.
### Detailed Analysis
The following table reconstructs the data from the heatmap. An empty cell indicates no data was recorded for that Type-Length pair.
| Type | Length 0 | Length 1 | Length 2 | Length 3 | Length 4 | Length 5 | Length 6 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 | Length 12 | Length 13 | Length 14 | Length 15 | Length 16 | Length 17 | Length 18 | Length 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 64.0 | 33.0 | 27.0 | 21.0 | 22.0 | 23.0 | 16.0 | 28.0 | 27.0 | 30.0 | | | | | | | | | | |
| **2** | | 73.0 | 89.0 | 91.0 | 86.0 | 84.0 | 81.0 | 78.0 | 74.0 | 63.0 | 66.0 | | | | | | | | | |
| **3** | 42.0 | 53.0 | 46.0 | 44.0 | 35.0 | 18.0 | 16.0 | 25.0 | 20.0 | 18.0 | 13.0 | 17.0 | 17.0 | 18.0 | 13.0 | 17.0 | 11.0 | 14.0 | 10.0 | 11.0 |
| **4** | | 68.0 | 67.0 | 64.0 | 47.0 | 45.0 | 29.0 | 30.0 | 37.0 | 40.0 | 41.0 | 35.0 | | | | | | | | |
| **5** | | | | | | | | 11.0 | 25.0 | 21.0 | 18.0 | 17.0 | 25.0 | 20.0 | 25.0 | 15.0 | 24.0 | 26.0 | 20.0 | 27.0 |
| **6** | 89.0 | 75.0 | 66.0 | 54.0 | 51.0 | 48.0 | 44.0 | 49.0 | 42.0 | 52.0 | 46.0 | 51.0 | 40.0 | 44.0 | 32.0 | 37.0 | 38.0 | 32.0 | 39.0 | |
| **7** | 91.0 | 76.0 | 63.0 | 53.0 | 41.0 | 36.0 | 34.0 | 33.0 | 39.0 | 26.0 | 33.0 | 34.0 | 32.0 | 26.0 | | | | | | |
**Trend Verification by Type:**
* **Type 1:** Starts at a moderate 64.0% (Length 0) and shows a general downward trend with fluctuations, ending at 30.0% (Length 9). The line slopes downward overall.
* **Type 2:** Begins at 73.0% (Length 1), peaks at 91.0% (Length 3), then follows a steady downward trend to 66.0% (Length 10). The line has an initial rise followed by a decline.
* **Type 3:** Starts at 42.0% (Length 0), has a brief rise to 53.0% (Length 1), then exhibits a consistent downward trend across all lengths, reaching a low of 10.0% (Length 18). The line slopes downward.
* **Type 4:** Starts at 68.0% (Length 1) and shows a general downward trend with a slight mid-range recovery, ending at 35.0% (Length 11). The line slopes downward.
* **Type 5:** Data begins at Length 7 (11.0%). The trend is relatively flat and low, fluctuating between 11.0% and 27.0% with no strong directional slope.
* **Type 6:** Starts very high at 89.0% (Length 0) and follows a clear downward trend with some volatility, ending at 39.0% (Length 18). The line slopes downward.
* **Type 7:** Starts at the highest observed value of 91.0% (Length 0) and shows a strong, consistent downward trend, ending at 26.0% (Length 13). The line slopes downward.
### Key Observations
1. **Performance Decay with Length:** For most Types (1, 2, 3, 4, 6, 7), there is a clear negative correlation between Length and Accuracy. As the Length increases, the model's accuracy generally decreases.
2. **High Initial Performance:** Types 2, 6, and 7 show very high accuracy (>89%) at the shortest measured lengths (Lengths 0-3).
3. **Low-Performance Cluster:** Type 5 and the latter half of Type 3 consistently show low accuracy, mostly below 30%.
4. **Data Sparsity:** The heatmap is not fully populated. Type 1 has no data beyond Length 9. Type 2 has no data at Length 0 or beyond Length 10. Type 4 has no data at Length 0 or beyond Length 11. Type 5 has no data before Length 7. Type 6 has no data at Length 19. Type 7 has no data beyond Length 13.
5. **Peak Accuracy:** The single highest accuracy value is 91.0%, achieved by both Type 2 (at Length 3) and Type 7 (at Length 0).
### Interpretation
This heatmap demonstrates that GPT-4o's ability to generalize in few-shot scenarios is highly dependent on both the specific "Type" of task and the "Length" parameter (which could represent sequence length, number of examples, or another complexity metric).
* **Core Finding:** The dominant trend is that performance degrades as Length increases. This suggests the model's core generalization capability is sensitive to scale or complexity; it performs best on shorter, presumably simpler, instances of a task type.
* **Task-Type Variability:** The significant difference in starting accuracy and decay rates between Types (e.g., Type 7 starting at 91% vs. Type 3 starting at 42%) indicates that some core generalization tasks are inherently easier for the model than others.
* **Practical Implication:** For applications relying on few-shot generalization, this data suggests that keeping the "Length" parameter low is crucial for maintaining high accuracy. The model may require different prompting strategies or fine-tuning for task types that show poor performance even at short lengths (like Type 3 and Type 5).
* **Anomaly:** Type 5's data starts only at Length 7 and shows a flat, low-accuracy trend. This could indicate a different experimental setup for this type or a category where the model fails to generalize until a certain length threshold is met, after which it performs poorly but consistently.
</details>
<details>
<summary>extracted/6458430/figs/gpt-4o_heatmap_base_overall_high.png Details</summary>
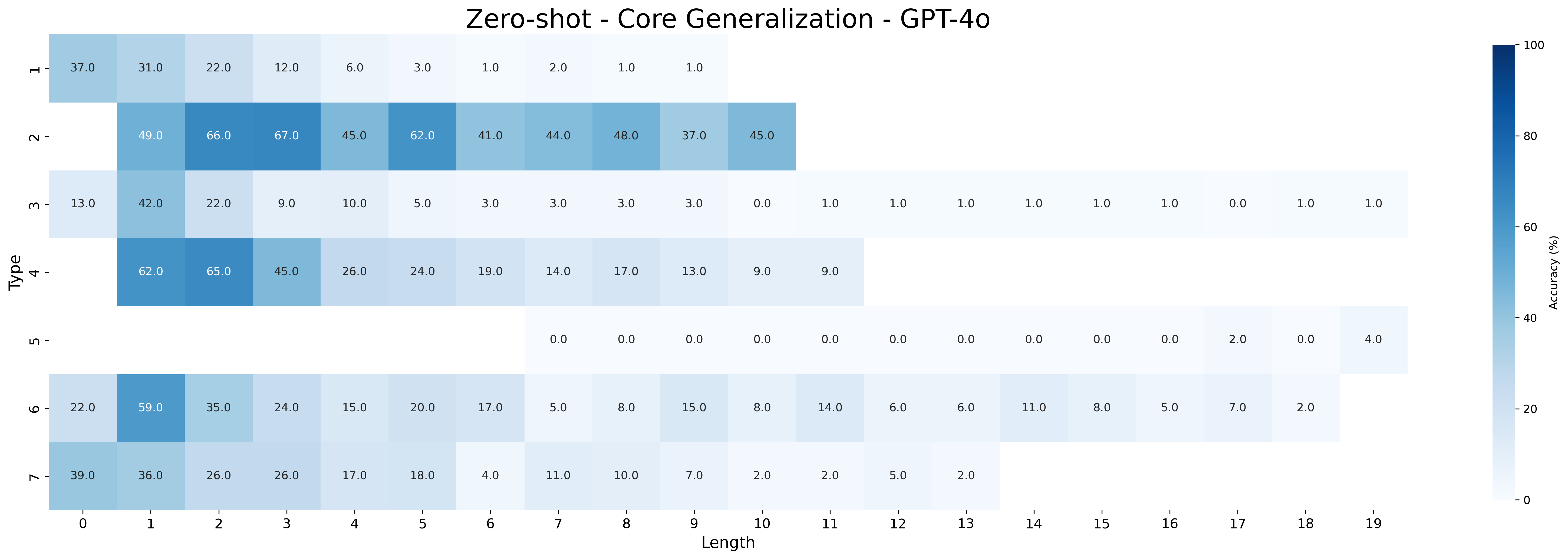
### Visual Description
## Heatmap: Zero-shot Core Generalization Performance of GPT-4o
### Overview
This image is a heatmap visualizing the zero-shot accuracy (in percentage) of a model identified as "GPT-4o" on a "Core Generalization" task. The performance is broken down across two dimensions: "Type" (vertical axis, categories 1-7) and "Length" (horizontal axis, values 0-19). The color intensity represents accuracy, with a scale from 0% (lightest) to 100% (darkest blue).
### Components/Axes
* **Title:** "Zero-shot - Core Generalization - GPT-4o"
* **Vertical Axis (Y-axis):** Labeled "Type". Contains 7 discrete categories, numbered 1 through 7 from top to bottom.
* **Horizontal Axis (X-axis):** Labeled "Length". Contains 20 discrete values, numbered 0 through 19 from left to right.
* **Color Bar/Legend:** Located on the far right. It is a vertical gradient bar labeled "Accuracy (%)". The scale runs from 0 at the bottom to 100 at the top, with tick marks at 0, 20, 40, 60, 80, and 100. The color transitions from very light blue/white (0%) to dark blue (100%).
* **Data Grid:** The main body of the chart is a grid of cells. Each cell corresponds to a specific (Type, Length) pair. The cell's background color and the numerical value printed within it indicate the accuracy percentage. Some cells are blank, indicating no data or a value of 0 that is not displayed numerically.
### Detailed Analysis
The following table reconstructs the accuracy data for each Type across the available Lengths. Values are transcribed directly from the image. Blank cells are noted as "N/A".
| Type | Length 0 | Length 1 | Length 2 | Length 3 | Length 4 | Length 5 | Length 6 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 | Length 12 | Length 13 | Length 14 | Length 15 | Length 16 | Length 17 | Length 18 | Length 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 37.0 | 31.0 | 22.0 | 12.0 | 6.0 | 3.0 | 1.0 | 2.0 | 1.0 | 1.0 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **2** | N/A | 49.0 | 66.0 | 67.0 | 45.0 | 62.0 | 41.0 | 44.0 | 48.0 | 37.0 | 45.0 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **3** | 13.0 | 42.0 | 22.0 | 9.0 | 10.0 | 5.0 | 3.0 | 3.0 | 3.0 | 3.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 | 1.0 |
| **4** | N/A | 62.0 | 65.0 | 45.0 | 26.0 | 24.0 | 19.0 | 14.0 | 17.0 | 13.0 | 9.0 | 9.0 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **5** | N/A | N/A | N/A | N/A | N/A | N/A | N/A | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 4.0 |
| **6** | 22.0 | 59.0 | 35.0 | 24.0 | 15.0 | 20.0 | 17.0 | 5.0 | 8.0 | 15.0 | 8.0 | 14.0 | 6.0 | 6.0 | 11.0 | 8.0 | 5.0 | 7.0 | 2.0 | N/A |
| **7** | 39.0 | 36.0 | 26.0 | 26.0 | 17.0 | 18.0 | 4.0 | 11.0 | 10.0 | 7.0 | 2.0 | 2.0 | 5.0 | 2.0 | N/A | N/A | N/A | N/A | N/A | N/A |
### Key Observations
1. **Performance Decay with Length:** For most Types (especially 1, 4, 6, 7), accuracy shows a clear downward trend as "Length" increases. The highest values are typically found at the shortest lengths (0-3).
2. **Type-Specific Performance:**
* **Type 2** demonstrates the strongest and most consistent performance, maintaining accuracies between 37% and 67% across its measured lengths (1-10).
* **Type 5** shows near-total failure, with accuracies of 0% for almost all lengths (7-19), except for minor blips of 2.0% and 4.0% at lengths 17 and 19.
* **Type 3** has a wide range of lengths (0-19) but generally low accuracy, peaking at 42.0% at Length 1 and frequently dropping to 0-1%.
3. **Data Coverage:** The heatmap is not a complete rectangle. Different Types have data for different ranges of Lengths. Type 3 has the broadest coverage (Lengths 0-19), while Type 2 and Type 4 have narrower ranges.
4. **Peak Values:** The highest accuracy recorded is **67.0%** for **Type 2 at Length 3**. The second highest is **66.0%** for **Type 2 at Length 2**.
### Interpretation
This heatmap provides a diagnostic view of GPT-4o's zero-shot generalization capabilities on a specific core task. The data suggests the following:
* **Task Difficulty Scales with Length:** The predominant trend of decreasing accuracy with increasing "Length" indicates that the core generalization task becomes significantly harder for the model as the sequence or problem length grows. This is a common challenge in language model evaluation.
* **Heterogeneous Task Types:** The "Type" axis likely represents different sub-tasks or problem formats within the core generalization benchmark. The stark performance differences between types (e.g., Type 2 vs. Type 5) reveal that the model's zero-shot capability is highly dependent on the specific structure or nature of the problem. Type 2 appears to be a format the model handles well, while Type 5 is almost completely intractable for it in a zero-shot setting.
* **Zero-Shot Limitations:** The overall low-to-moderate accuracy values (mostly below 50%) for longer lengths and certain types highlight the limitations of zero-shot prompting for complex generalization. The model struggles to infer the correct pattern or solution without examples, especially as problem complexity (length) increases.
* **Benchmark Design:** The structure of the heatmap, with its varying data ranges per type, suggests the benchmark itself may have different length distributions for different problem types, or that some types are only defined for certain lengths.
In summary, the image reveals that GPT-4o's zero-shot core generalization is highly uneven: it is moderately effective for short problems of certain types (notably Type 2) but degrades rapidly with length and fails almost completely on other problem types (notably Type 5). This points to specific areas where the model's reasoning or pattern-matching abilities are robust and where they are critically lacking.
</details>
Figure 16: Accuracy of Few-shot (Top) and Zero-shot (Bottom) GPT-4o on core generalization decomposed by inference type and length.
<details>
<summary>extracted/6458430/figs/o3-mini_heatmap_meta_overall_high.png Details</summary>
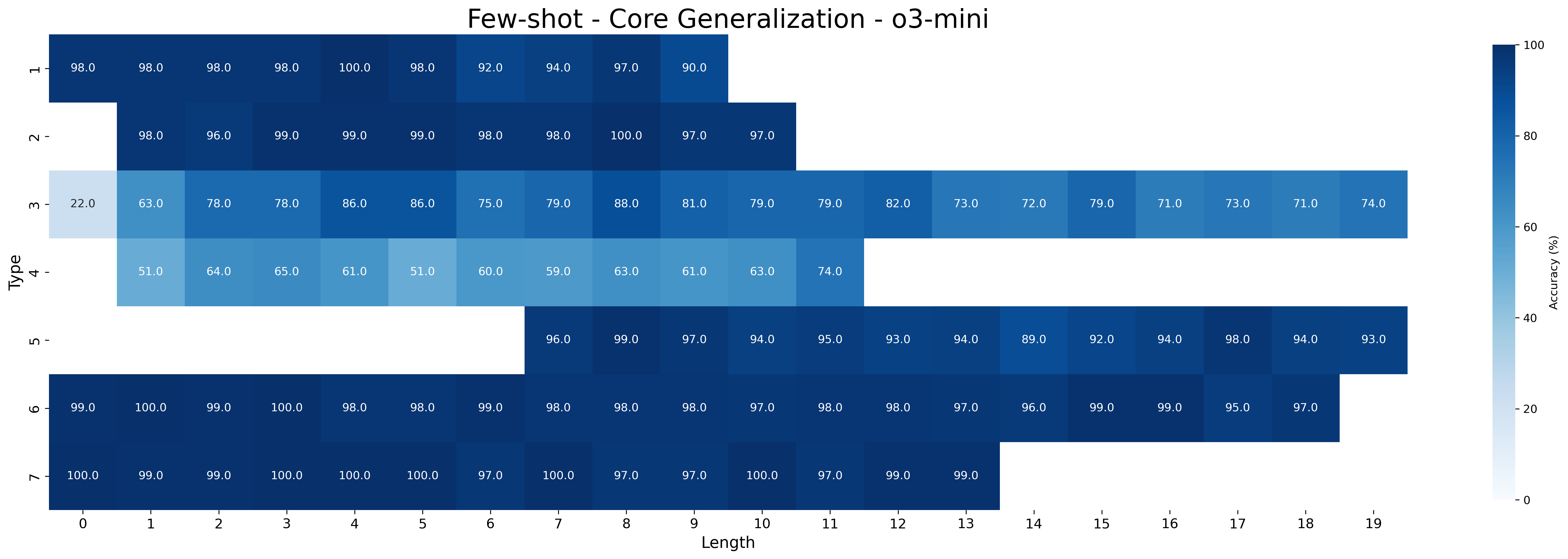
### Visual Description
## Heatmap: Few-shot - Core Generalization - o3-mini
### Overview
This image is a heatmap visualizing the accuracy (in percentage) of a model named "o3-mini" on a "Few-shot - Core Generalization" task. The performance is broken down by two categorical variables: "Type" (y-axis) and "Length" (x-axis). The chart uses a blue color gradient to represent accuracy, with darker blue indicating higher accuracy. The data is presented in a grid where each cell contains the exact accuracy value for a specific Type-Length combination.
### Components/Axes
* **Title:** "Few-shot - Core Generalization - o3-mini" (centered at the top).
* **Y-Axis (Vertical):** Labeled "Type". It lists 7 distinct categories, numbered 1 through 7 from top to bottom.
* **X-Axis (Horizontal):** Labeled "Length". It lists 20 discrete values, numbered 0 through 19 from left to right.
* **Legend/Color Bar:** Located on the far right. It is a vertical gradient bar labeled "Accuracy (%)". The scale runs from 0 (lightest blue/white) at the bottom to 100 (darkest blue) at the top, with tick marks at 0, 20, 40, 60, 80, and 100.
* **Data Grid:** The main body of the chart. Each cell corresponds to a unique (Type, Length) pair. The cell's background color corresponds to the accuracy value shown within it, mapped to the color bar. Some cells are empty (white), indicating no data for that combination.
### Detailed Analysis
The following table reconstructs the data from the heatmap. An empty cell is denoted by "N/A".
| Type | Length 0 | Length 1 | Length 2 | Length 3 | Length 4 | Length 5 | Length 6 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 | Length 12 | Length 13 | Length 14 | Length 15 | Length 16 | Length 17 | Length 18 | Length 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 98.0 | 98.0 | 98.0 | 98.0 | 100.0 | 98.0 | 92.0 | 94.0 | 97.0 | 90.0 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **2** | N/A | 98.0 | 96.0 | 99.0 | 99.0 | 99.0 | 98.0 | 98.0 | 100.0 | 97.0 | 97.0 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **3** | 22.0 | 63.0 | 78.0 | 78.0 | 86.0 | 86.0 | 75.0 | 79.0 | 88.0 | 81.0 | 79.0 | 79.0 | 82.0 | 73.0 | 72.0 | 79.0 | 71.0 | 73.0 | 71.0 | 74.0 |
| **4** | N/A | 51.0 | 64.0 | 65.0 | 61.0 | 51.0 | 60.0 | 59.0 | 63.0 | 61.0 | 63.0 | 74.0 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| **5** | N/A | N/A | N/A | N/A | N/A | N/A | N/A | 96.0 | 99.0 | 97.0 | 94.0 | 95.0 | 93.0 | 94.0 | 89.0 | 92.0 | 94.0 | 98.0 | 94.0 | 93.0 |
| **6** | 99.0 | 100.0 | 99.0 | 100.0 | 98.0 | 98.0 | 99.0 | 98.0 | 98.0 | 98.0 | 97.0 | 98.0 | 98.0 | 97.0 | 96.0 | 99.0 | 99.0 | 95.0 | 97.0 | N/A |
| **7** | 100.0 | 99.0 | 99.0 | 100.0 | 100.0 | 100.0 | 97.0 | 100.0 | 97.0 | 97.0 | 100.0 | 97.0 | 99.0 | 99.0 | N/A | N/A | N/A | N/A | N/A | N/A |
### Key Observations
1. **Performance Tiers:** The data shows distinct performance clusters.
* **High Performers (Types 1, 2, 6, 7):** These types consistently achieve accuracy above 90%, frequently reaching 98-100%. Their performance is stable across the lengths for which data is available.
* **Moderate Performer (Type 4):** Accuracy ranges from 51% to 74%, with no clear upward or downward trend across lengths.
* **Variable Performer (Type 3):** Shows the most dramatic change. It starts very poorly (22% at Length 0) but improves rapidly to the 70-80% range by Length 2 and remains there.
* **Late-Starting High Performer (Type 5):** Data only begins at Length 7, but from that point onward, it performs at a high level (89-99%), similar to the top tier.
2. **Data Sparsity:** The heatmap is not a complete rectangle. Data is missing for:
* Type 1: Lengths 10-19.
* Type 2: Length 0 and Lengths 11-19.
* Type 4: Length 0 and Lengths 12-19.
* Type 5: Lengths 0-6.
* Type 6: Length 19.
* Type 7: Lengths 14-19.
3. **Length Sensitivity:** For the high-performing types (1,2,6,7), accuracy does not appear to degrade significantly as Length increases within their available data range. Type 3 is the only one showing a strong positive correlation between Length and accuracy in the early stages (Lengths 0-2).
### Interpretation
This heatmap likely evaluates how well the "o3-mini" model generalizes to different problem "Types" when given a few examples ("Few-shot"), and how this generalization holds as the problem "Length" (possibly sequence length, number of steps, or complexity) varies.
* **Core Finding:** The model exhibits highly type-dependent performance. It has mastered certain problem types (1,2,6,7) to near-perfect accuracy regardless of length (within tested bounds). Other types (3,4) present a greater challenge.
* **The "Length" Variable:** For most types, increasing length does not harm performance, suggesting robustness. The exception is Type 3, where very short lengths (0,1) are particularly problematic, but the model quickly adapts as length increases. This could indicate that Type 3 problems require a minimum amount of context or steps to be solvable.
* **Missing Data Implications:** The pattern of missing data is not random. It suggests the evaluation was designed with specific length ranges in mind for each type. For example, Type 5 was only tested on longer sequences (Length ≥7), implying it might be a problem category that only manifests or is relevant at greater lengths.
* **Overall Model Capability:** The "o3-mini" model demonstrates strong few-shot core generalization capabilities for a majority of the tested types, maintaining high accuracy across varying lengths. The primary areas for potential improvement are in the specific categories represented by Types 3 and 4.
</details>
<details>
<summary>extracted/6458430/figs/o3-mini_heatmap_base_overall_high.png Details</summary>
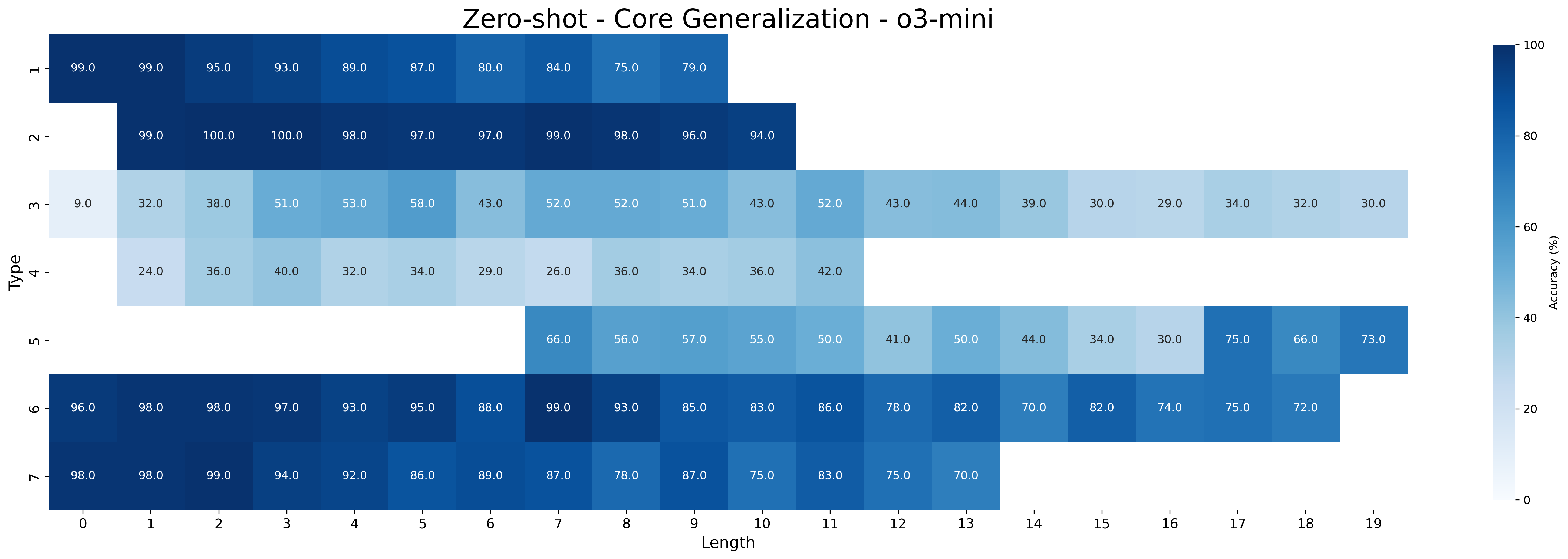
### Visual Description
## Heatmap: Zero-shot Core Generalization Performance of o3-mini Model
### Overview
This image is a heatmap titled "Zero-shot - Core Generalization - o3-mini". It visualizes the accuracy percentage of an AI model (o3-mini) across seven different task "Types" (y-axis) and varying input "Lengths" (x-axis). The chart uses a blue color gradient to represent accuracy, with darker blue indicating higher accuracy. The data appears to be from a technical evaluation of the model's zero-shot generalization capabilities.
### Components/Axes
* **Title:** "Zero-shot - Core Generalization - o3-mini" (Top center)
* **Y-Axis (Vertical):** Labeled "Type". Contains 7 discrete categories numbered 1 through 7.
* **X-Axis (Horizontal):** Labeled "Length". Contains 20 discrete categories numbered 0 through 19.
* **Color Bar/Legend:** Located on the right side. Labeled "Accuracy (%)". It is a vertical gradient bar ranging from 0 (lightest blue/white) to 100 (darkest blue). Key markers are at 0, 20, 40, 60, 80, and 100.
* **Data Cells:** Each cell in the grid contains a numerical value representing the accuracy percentage for a specific Type-Length combination. The cell's background color corresponds to this value per the color bar.
### Detailed Analysis
The following table reconstructs the accuracy data from the heatmap. Empty cells indicate no data was recorded for that Type-Length combination.
| Type | Length 0 | Length 1 | Length 2 | Length 3 | Length 4 | Length 5 | Length 6 | Length 7 | Length 8 | Length 9 | Length 10 | Length 11 | Length 12 | Length 13 | Length 14 | Length 15 | Length 16 | Length 17 | Length 18 | Length 19 |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **1** | 99.0 | 99.0 | 95.0 | 93.0 | 89.0 | 87.0 | 80.0 | 84.0 | 75.0 | 79.0 | | | | | | | | | | |
| **2** | | 99.0 | 100.0 | 100.0 | 98.0 | 97.0 | 97.0 | 99.0 | 98.0 | 96.0 | 94.0 | | | | | | | | | |
| **3** | 9.0 | 32.0 | 38.0 | 51.0 | 53.0 | 58.0 | 43.0 | 52.0 | 52.0 | 51.0 | 43.0 | 52.0 | 43.0 | 44.0 | 39.0 | 30.0 | 29.0 | 34.0 | 32.0 | 30.0 |
| **4** | | 24.0 | 36.0 | 40.0 | 32.0 | 34.0 | 29.0 | 26.0 | 36.0 | 34.0 | 36.0 | 42.0 | | | | | | | | |
| **5** | | | | | | | | 66.0 | 56.0 | 57.0 | 55.0 | 50.0 | 41.0 | 50.0 | 44.0 | 34.0 | 30.0 | 75.0 | 66.0 | 73.0 |
| **6** | 96.0 | 98.0 | 98.0 | 97.0 | 93.0 | 95.0 | 88.0 | 99.0 | 93.0 | 85.0 | 83.0 | 86.0 | 78.0 | 82.0 | 70.0 | 82.0 | 74.0 | 75.0 | 72.0 | |
| **7** | 98.0 | 98.0 | 99.0 | 94.0 | 92.0 | 86.0 | 89.0 | 87.0 | 78.0 | 87.0 | 75.0 | 83.0 | 75.0 | 70.0 | | | | | | |
**Trend Verification by Type:**
* **Type 1:** Shows a gradual downward trend in accuracy as length increases, starting at 99% (Length 0) and ending at 79% (Length 9).
* **Type 2:** Maintains exceptionally high accuracy (94-100%) across its measured lengths (1-10), with no significant downward trend.
* **Type 3:** Exhibits a complex trend. Accuracy starts very low (9% at Length 0), rises to a peak of 58% at Length 5, then generally declines with fluctuations, ending at 30% (Length 19).
* **Type 4:** Shows moderate, relatively stable accuracy in the 24-42% range across lengths 1-11, with no strong directional trend.
* **Type 5:** Displays a U-shaped or volatile trend. Accuracy is higher at the start (66% at Length 7) and end (73-75% at Lengths 17-19) of its range, with a dip in the middle lengths (as low as 30% at Length 16).
* **Type 6:** Maintains high accuracy (mostly 70-99%) across a wide range of lengths (0-18), with a slight overall decreasing trend.
* **Type 7:** Similar to Type 6, shows high accuracy (70-99%) for lengths 0-13, with a slight downward trend as length increases.
### Key Observations
1. **Performance Disparity:** There is a stark contrast in performance between task types. Types 1, 2, 6, and 7 consistently achieve high accuracy (often >80%), while Types 3 and 4 struggle, with accuracies frequently below 50%.
2. **Length Sensitivity:** The impact of increasing "Length" varies dramatically by type. Types 1, 6, and 7 show a mild negative correlation. Type 3 is highly sensitive, with performance peaking at mid-lengths. Types 2 and 4 are relatively insensitive to length within their measured ranges.
3. **Data Coverage:** The evaluation is not uniform. Some types (e.g., Type 3) are tested across all lengths (0-19), while others have limited ranges (e.g., Type 1 only up to Length 9). This suggests the tasks or their applicable lengths differ.
4. **Outliers:** The 9.0% accuracy for Type 3 at Length 0 is a significant low outlier. The 100.0% accuracy for Type 2 at Lengths 2 and 3 represents perfect performance.
### Interpretation
This heatmap provides a diagnostic view of the o3-mini model's zero-shot reasoning capabilities. The "Type" axis likely represents different categories of logical or cognitive tasks (e.g., arithmetic, spatial reasoning, syllogisms), while "Length" probably corresponds to problem complexity, such as the number of steps, variables, or tokens in the input.
The data suggests the model has robust, length-invariant performance on certain core task types (2, 6, 7), indicating strong foundational generalization for those domains. In contrast, its poor and variable performance on Type 3 reveals a specific weakness, possibly in a task requiring sequential or compositional reasoning where performance degrades with problem scale. The U-shape in Type 5 is intriguing, potentially indicating that the model uses different strategies for short vs. long problems within that category, or that the task distribution has distinct clusters.
For a developer or researcher, this chart is crucial for identifying which capabilities are reliable and which require further training or architectural improvement. It moves beyond a single accuracy score to show *where* and *how* the model's generalization breaks down.
</details>
Figure 17: Accuracy of Few-shot (Top) and Zero-shot (Bottom) o3-mini on core generalization decomposed by inference type and length.
KB with Query Hypothesis and Type 1 Inference:
<details>
<summary>extracted/6458430/figs/type_1_proof.png Details</summary>
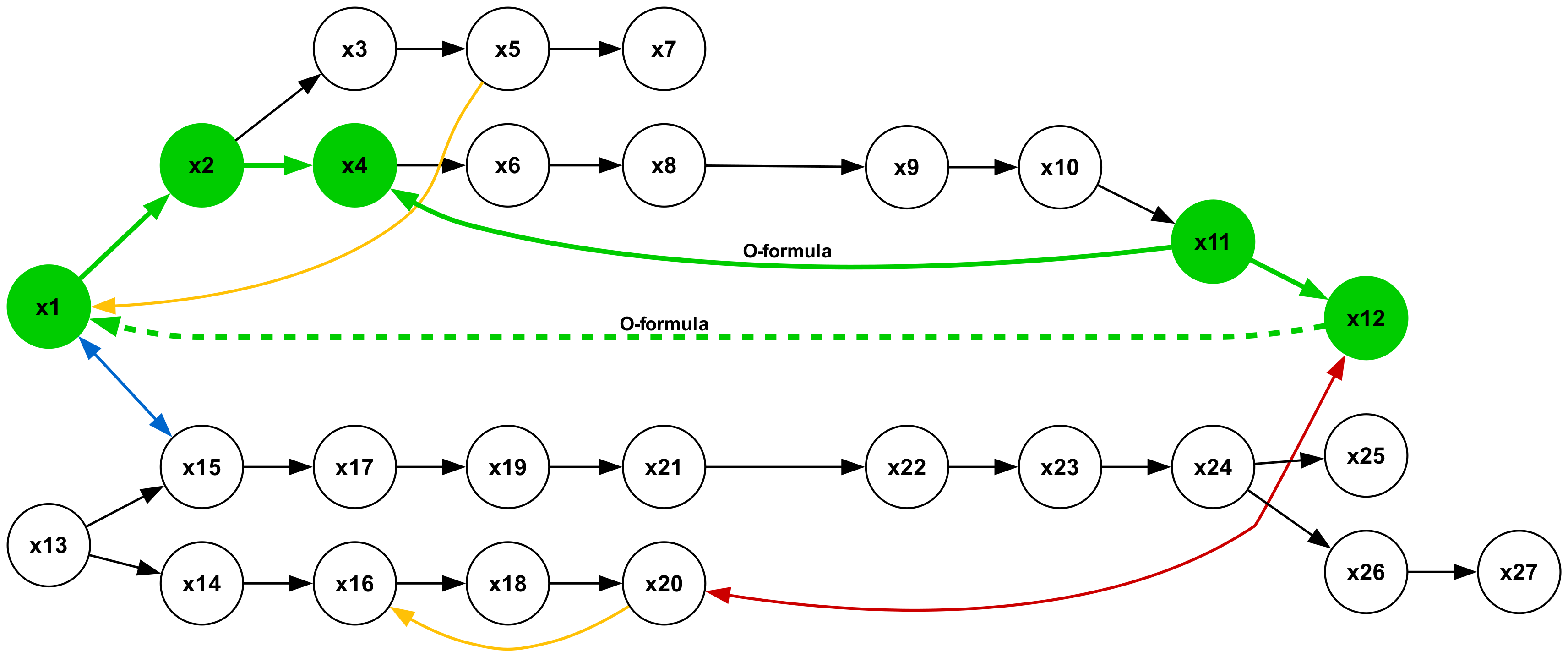
### Visual Description
## Directed Graph Diagram: Process Flow with Feedback Loops
### Overview
The image displays a directed graph (network diagram) consisting of 27 circular nodes labeled `x1` through `x27`. The nodes are interconnected by directed arrows of various colors, indicating different types of relationships or flows. Some nodes are highlighted in green, while others are white. Two specific connections are labeled with the text "O-formula". The diagram appears to model a complex process, system, or algorithm with multiple pathways, convergence points, and feedback loops.
### Components/Axes
* **Nodes:** 27 circular nodes, each containing a unique label from `x1` to `x27`.
* **Green Nodes:** `x1`, `x2`, `x4`, `x11`, `x12`. These appear to be key states, milestones, or active components.
* **White Nodes:** All other nodes (`x3`, `x5`, `x6`, `x7`, `x8`, `x9`, `x10`, `x13`, `x14`, `x15`, `x16`, `x17`, `x18`, `x19`, `x20`, `x21`, `x22`, `x23`, `x24`, `x25`, `x26`, `x27`).
* **Edges (Arrows):** Directed connections between nodes, differentiated by color and style.
* **Green Solid Arrows:** Indicate a primary or positive flow. Examples: `x1 -> x2`, `x2 -> x4`, `x4 -> x11` (labeled "O-formula"), `x11 -> x12`.
* **Black Solid Arrows:** The most common connection type, indicating standard sequential flow. Examples: `x3 -> x5`, `x6 -> x8`, `x15 -> x17`.
* **Yellow/Orange Solid Arrows:** Indicate an alternative or special flow. Examples: `x1 -> x4`, `x5 -> x4`, `x18 -> x16`.
* **Blue Solid Arrow:** A single instance connecting `x1 -> x15`.
* **Red Solid Arrows:** Indicate a reverse or feedback flow. Examples: `x24 -> x20`, `x24 -> x12`.
* **Green Dashed Arrow:** A special feedback connection from `x12 -> x1`, labeled "O-formula".
* **Text Labels:** The phrase "O-formula" appears twice, labeling two specific green arrows.
### Detailed Analysis
**Node Connectivity and Pathways:**
1. **Upper Primary Path (Green Initiation):**
* Starts at green node `x1`.
* `x1` branches to `x2` (green arrow) and `x15` (blue arrow).
* From `x2` (green), flow goes to `x3` (black) and `x4` (green).
* From `x4` (green), flow splits: one path goes to `x6` (black), and a labeled green "O-formula" arrow goes to `x11` (green).
* The path from `x6` continues linearly: `x6 -> x8 -> x9 -> x10 -> x11`.
* From `x11` (green), flow goes to `x12` (green).
* A dashed green "O-formula" arrow creates a feedback loop from `x12` back to `x1`.
2. **Lower Path (Initiated from `x13` and `x1`):**
* Starts at white node `x13`.
* `x13` branches to `x15` and `x14`.
* The `x15` branch (also receiving input from `x1` via blue arrow) continues: `x15 -> x17 -> x19 -> x21 -> x22 -> x23 -> x24`.
* The `x14` branch continues: `x14 -> x16 -> x18 -> x20`.
* A yellow arrow creates a local feedback from `x20` back to `x16`.
3. **Convergence and Final Outputs:**
* Node `x24` is a major convergence point. It receives flow from `x23`.
* From `x24`, flow splits into three directions:
* To `x25` (black arrow).
* To `x26` (black arrow), which then goes to `x27`.
* A red feedback arrow to `x20`.
* A red feedback arrow to green node `x12`.
**"O-formula" Connections:**
* **Solid Green Arrow:** From `x4` to `x11`. This represents a direct, possibly optimized or formulaic, pathway bypassing the intermediate nodes `x6`, `x8`, `x9`, and `x10`.
* **Dashed Green Arrow:** From `x12` back to `x1`. This represents a major system-level feedback loop, suggesting the process is cyclical or iterative, where the final state (`x12`) influences the initial state (`x1`).
### Key Observations
1. **Green Node Significance:** The green nodes (`x1`, `x2`, `x4`, `x11`, `x12`) form a critical backbone or control path through the upper section of the graph. They are involved in the "O-formula" shortcuts and the main feedback loop.
2. **Multiple Feedback Loops:** The system contains at least four feedback mechanisms:
* The major "O-formula" loop (`x12 -> x1`).
* The "O-formula" shortcut (`x4 -> x11`).
* A local loop in the lower path (`x20 -> x16`).
* Two red feedback paths from the convergence node `x24` back to `x20` and `x12`.
3. **Pathway Redundancy and Convergence:** There are multiple routes to reach key nodes. For example, `x11` can be reached via the long path (`x4->x6->...->x10`) or the direct "O-formula" path. Node `x24` acts as a funnel for the entire lower subsystem before distributing to final nodes (`x25`, `x26`, `x27`) and feeding back.
4. **Color-Coded Semantics:** The arrow colors likely denote different types of relationships (e.g., standard flow, optimization, feedback, initialization).
### Interpretation
This diagram models a complex, state-based system with both feedforward and feedback dynamics. The "O-formula" labels suggest the presence of mathematical or logical shortcuts that optimize part of the process. The structure implies a system that is not purely linear; it has parallel processing (the two main branches from `x1` and `x13`), convergence points (`x11`, `x24`), and cyclical behavior driven by feedback loops.
The green nodes likely represent stable, validated, or control states within the system. The feedback from `x12` to `x1` indicates an iterative process where the output of one cycle becomes the input for the next, common in algorithms, control systems, or learning models. The red feedback arrows from `x24` suggest that later-stage outcomes are used to regulate or adjust earlier states (`x20`, `x12`), which is characteristic of adaptive or self-correcting systems.
In essence, the graph depicts a sophisticated process where information or control flows through defined pathways, with mechanisms for optimization ("O-formula") and regulation (multiple feedback loops) to achieve a dynamic, possibly goal-oriented, operation.
</details>
Textual Translation:
knowledge base: All x1 are x2, All x2 are x3, All x2 are x4, All x3 are x5, All x4 are x6, All x5 are x7, All x6 are x8, All x8 are x9, All x9 are x10, All x10 are x11, All x11 are x12, All x13 are x14, All x13 are x15, All x14 are x16, All x15 are x17, All x16 are x18, All x17 are x19, All x18 are x20, All x19 are x21, All x21 are x22, All x22 are x23, All x23 are x24, All x24 are x25, All x24 are x26, All x26 are x27, No x20 are x12, Some x15 are x1, Some x11 are not x4, Some x5 are not x1, Some x20 are not x16 hypothesis: Some x12 are not x1 premises: All x1 are x2, All x2 are x4, All x11 are x12, Some x11 are not x4
Figure 18: Type 1 syllogistic inference on graphs. Visualization of a type 1 syllogistic inference using a graph representation of an example $KB$ , alongside the corresponding textual translation. In the graph (top), nodes represent predicates. Black edges indicate A-formulas (“All As are Bs”), blue edges indicate I-formulas (“Some As are Bs”), red edges indicate E-formulas (“No As are Bs”), and yellow edges indicate O-formulas (“Some As are not Bs”). The query hypothesis is represented by a dashed green edge, and the edges that prove the hypothesis are highlighted in green. The text translation illustrates how the abstract graph representation is converted into a text format suitable for LM processing by applying fixed templates that represent logical formulas.
KB with Query Hypothesis and Type 2 Inference:
<details>
<summary>extracted/6458430/figs/type_2_proof.png Details</summary>
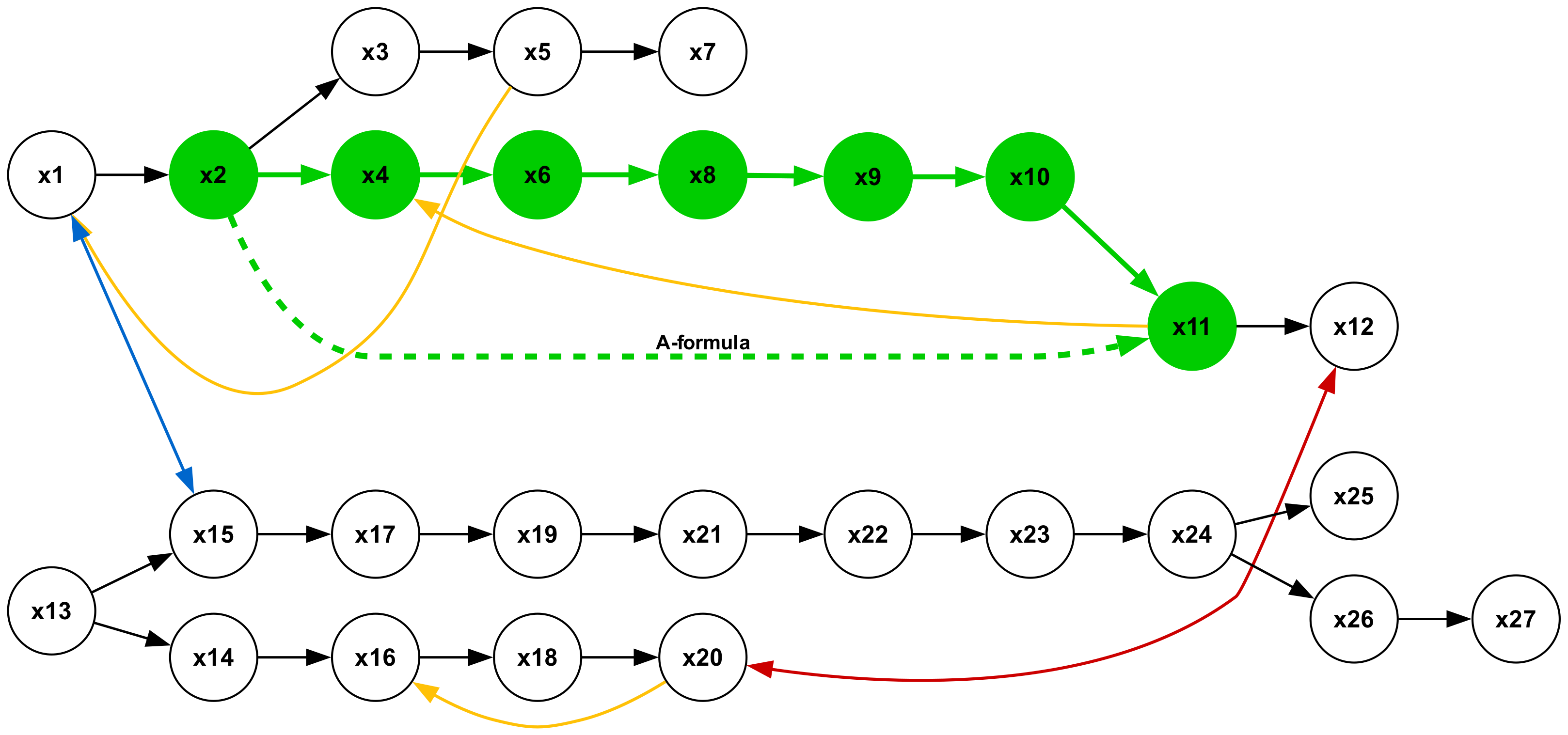
### Visual Description
## Directed Graph Diagram: System Flowchart with Conditional Paths
### Overview
The image displays a directed graph (flowchart) consisting of 27 nodes labeled `x1` through `x27`. The nodes are arranged in two primary horizontal sequences with multiple interconnecting paths. The diagram uses color-coding for nodes (green-filled vs. white-filled) and arrows (black, green, yellow, blue, red, dashed) to denote different types of relationships or flows within the system. A single text label, "A-formula," is present on a specific dashed arrow.
### Components/Axes
* **Nodes**: 27 circular nodes, each labeled with an identifier from `x1` to `x27`.
* **Green-filled nodes**: `x2`, `x4`, `x6`, `x8`, `x9`, `x10`, `x11`. These form a contiguous chain in the upper sequence.
* **White-filled nodes**: All other nodes (`x1`, `x3`, `x5`, `x7`, `x12` through `x27`).
* **Edges (Arrows)**: Directed arrows connecting nodes, differentiated by color and style:
* **Solid Black Arrows**: The most common connection type, indicating a standard flow or dependency.
* **Solid Green Arrows**: Connect the green nodes in sequence (`x2`→`x4`→`x6`→`x8`→`x9`→`x10`→`x11`).
* **Dashed Green Arrow**: Connects `x2` directly to `x11`. This arrow is labeled with the text **"A-formula"**.
* **Yellow Arrows**: Three instances: `x5`→`x4`, `x11`→`x4`, and `x20`→`x16`.
* **Blue Arrows**: Two instances: `x1`→`x15` and `x13`→`x15`.
* **Red Arrows**: Two instances: `x24`→`x12` and `x24`→`x20`.
* **Spatial Layout**:
* **Upper Sequence**: Runs horizontally from left (`x1`) to right (`x12`). The green nodes form the central spine of this sequence.
* **Lower Sequence**: Starts at `x13` (left) and splits into two parallel horizontal branches:
* **Upper Branch**: `x15` → `x17` → `x19` → `x21` → `x22` → `x23` → `x24`.
* **Lower Branch**: `x14` → `x16` → `x18` → `x20`.
* **Cross-Connections**: Several arrows bridge the upper and lower sequences (e.g., `x1`→`x15`, `x13`→`x15`, `x24`→`x12`, `x24`→`x20`).
### Detailed Analysis
**Node Connectivity and Flow Paths:**
1. **Primary Green Path (Upper Sequence)**:
* Flow: `x2` → `x4` → `x6` → `x8` → `x9` → `x10` → `x11`.
* This is a linear, forward-moving chain highlighted in green.
* **Special Connection**: A dashed green arrow labeled **"A-formula"** creates a direct link from `x2` to `x11`, bypassing the intermediate nodes `x4`, `x6`, `x8`, `x9`, `x10`.
2. **Upper Sequence Branches and Loops**:
* `x1` feeds into the green path at `x2`.
* `x3` → `x5` → `x7` is a separate, short branch off the main flow.
* **Feedback/Loop Arrows (Yellow)**:
* `x5` → `x4`: Connects the short branch back into the green path.
* `x11` → `x4`: Creates a loop from the end of the green path back to an earlier node (`x4`).
* The green path terminates at `x11`, which then connects to `x12`.
3. **Lower Sequence Structure**:
* `x13` is the root, splitting into two branches.
* **Upper Branch**: A linear chain from `x15` to `x24`.
* **Lower Branch**: A linear chain from `x14` to `x20`.
* **Internal Loop (Yellow)**: `x20` → `x16` creates a loop within the lower branch.
* **Termination**: `x24` splits, feeding into `x25` and `x26`→`x27`.
4. **Cross-Sequence Connections**:
* **Blue Arrows**: `x1` (upper) → `x15` (lower) and `x13` (lower) → `x15` (lower). This indicates `x15` receives input from both the start of the upper sequence and the start of the lower sequence.
* **Red Arrows**: `x24` (lower) → `x12` (upper) and `x24` (lower) → `x20` (lower). This shows the lower sequence's endpoint (`x24`) feeds back into the upper sequence's endpoint (`x12`) and also back into its own lower branch (`x20`).
### Key Observations
1. **Highlighted Process**: The green nodes and arrows (`x2` through `x11`) clearly denote a primary, emphasized process or critical path within the system.
2. **Formulaic Shortcut**: The "A-formula" dashed arrow represents an alternative, possibly optimized or rule-based, transition that skips several steps in the primary green path.
3. **Cyclic Dependencies**: The diagram contains multiple feedback loops (yellow arrows: `x11`→`x4`, `x5`→`x4`, `x20`→`x16`), suggesting iterative processes or state revisitation.
4. **Integration Points**: Nodes `x15` and `x24` act as major integration hubs. `x15` merges inputs from two different origins (`x1`, `x13`). `x24` distributes its output to three different destinations (`x12`, `x25`, `x26`), including a cross-sequence connection.
5. **Asymmetric Flow**: While the overall flow is left-to-right, the numerous backward-pointing arrows (yellow, red) create a complex web of dependencies rather than a simple linear progression.
### Interpretation
This diagram likely models a **complex system with parallel processes, conditional logic, and feedback mechanisms**. It could represent:
* A **computational workflow** where green nodes are core operations, "A-formula" is a mathematical shortcut, and colored arrows denote different data types or control signals.
* A **state machine** for a software system, where nodes are states and arrows are transitions. The green path might be the "happy path" or main execution thread.
* A **dependency graph** for a project or algorithm, showing task prerequisites. The loops indicate tasks that may need re-execution.
The **"A-formula"** is the most significant interpretive clue. It suggests that the relationship between `x2` and `x11` is governed by a specific rule or equation that allows for a direct transition, potentially bypassing intermediate calculations or steps represented by `x4` through `x10`. The presence of multiple feedback loops (yellow arrows) indicates the system is not purely feed-forward; it contains cycles where outputs can influence earlier stages, characteristic of control systems, iterative algorithms, or processes with revision steps.
The cross-connections via blue and red arrows show that the two main sequences are not independent; they interact at key points (`x15`, `x12`, `x20`), implying a higher-level coordination or data exchange between what might be two subsystems or modules.
</details>
Textual Translation:
knowledge base: All x1 are x2, All x2 are x3, All x2 are x4, All x3 are x5, All x4 are x6, All x5 are x7, All x6 are x8, All x8 are x9, All x9 are x10, All x10 are x11, All x11 are x12, All x13 are x14, All x13 are x15, All x14 are x16, All x15 are x17, All x16 are x18, All x17 are x19, All x18 are x20, All x19 are x21, All x21 are x22, All x22 are x23, All x23 are x24, All x24 are x25, All x24 are x26, All x26 are x27, No x20 are x12, Some x15 are x1, Some x11 are not x4, Some x5 are not x1, Some x20 are not x16 hypothesis: All x2 are x11 premises: All x2 are x4, All x4 are x6, All x6 are x8, All x8 are x9, All x9 are x10, All x10 are x11
Figure 19: Type 2 syllogistic inference on graphs. Visualization of a type 2 syllogistic inference using a graph representation of an example $KB$ , alongside the corresponding textual translation. In the graph (top), nodes represent predicates. Black edges indicate A-formulas (“All As are Bs”), blue edges indicate I-formulas (“Some As are Bs”), red edges indicate E-formulas (“No As are Bs”), and yellow edges indicate O-formulas (“Some As are not Bs”). The query hypothesis is represented by a dashed green edge, and the edges that prove the hypothesis are highlighted in green. The text translation illustrates how the abstract graph representation is converted into a text format suitable for LM processing by applying fixed templates that represent logical formulas.
KB with Query Hypothesis and Type 3 Inference:
<details>
<summary>extracted/6458430/figs/type_3_proof.png Details</summary>
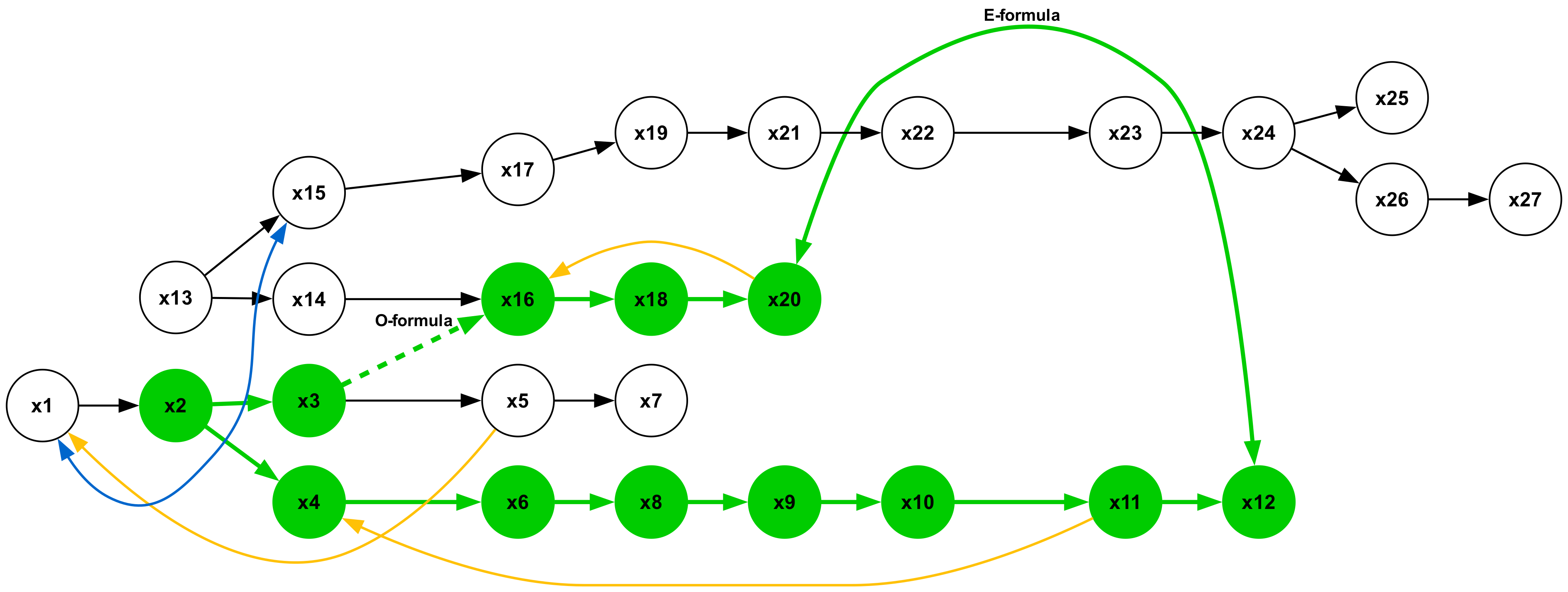
### Visual Description
## Directed Graph Diagram: Process Flow with Formulas
### Overview
The image displays a complex directed graph (flowchart) consisting of 27 circular nodes labeled `x1` through `x27`. The nodes are interconnected by arrows of different colors and styles, indicating various types of relationships or transitions. Two specific paths are annotated with the labels "E-formula" and "O-formula." The diagram appears to model a multi-stage process, system, or algorithm with branching paths, feedback loops, and conditional steps.
### Components/Axes
* **Nodes:** 27 circular nodes, each containing a unique identifier from `x1` to `x27`.
* **Node Types:** Nodes are visually distinguished by fill color:
* **Green-filled nodes:** `x2`, `x3`, `x4`, `x6`, `x8`, `x9`, `x10`, `x11`, `x12`, `x16`, `x18`, `x20`.
* **White-filled (outline only) nodes:** `x1`, `x5`, `x7`, `x13`, `x14`, `x15`, `x17`, `x19`, `x21`, `x22`, `x23`, `x24`, `x25`, `x26`, `x27`.
* **Edges (Arrows):** Directed arrows connecting nodes, differentiated by color and style:
* **Solid Black Arrows:** The most common connection type, indicating a standard forward flow.
* **Solid Green Arrows:** Primarily connect the green-filled nodes, suggesting a main or highlighted process path.
* **Solid Blue Arrows:** Form a feedback loop from `x2` back to `x1` and from `x13` to `x15`.
* **Solid Orange/Yellow Arrows:** Create longer feedback or cross-connections (e.g., from `x11` back to `x4`, from `x20` to `x16`).
* **Dashed Green Arrow:** A single dashed arrow connects `x3` to `x16`, labeled "O-formula."
* **Annotations:**
* **"E-formula":** Labels a long, curved green arrow that originates from node `x22` and points to node `x20`. A second curved green arrow, also under the "E-formula" label, originates from node `x24` and points to node `x12`.
* **"O-formula":** Labels the dashed green arrow from node `x3` to node `x16`.
### Detailed Analysis
**Spatial Layout & Node Connections:**
The graph flows generally from left (`x1`) to right (`x27`), but with significant branching and looping.
1. **Starting Point:** The process begins at node `x1` (white, far left).
2. **Primary Branching from `x1`:**
* `x1` → `x2` (green).
* `x2` splits into three paths:
* `x2` → `x3` (green).
* `x2` → `x4` (green).
* `x2` → `x15` (white, via a blue arrow).
3. **Path from `x3`:**
* `x3` → `x5` (white) → `x7` (white, terminal node).
* `x3` → `x16` (green) via a **dashed green arrow** labeled **"O-formula"**.
4. **Path from `x4`:**
* `x4` → `x6` (green) → `x8` (green) → `x9` (green) → `x10` (green) → `x11` (green) → `x12` (green, terminal node in this chain).
* An orange arrow creates a feedback loop from `x11` back to `x4`.
5. **Path from `x13`:**
* `x13` (white) → `x14` (white) → `x16` (green).
* `x13` → `x15` (white) via a blue arrow.
6. **Path from `x15`:**
* `x15` → `x17` (white) → `x19` (white) → `x21` (white) → `x22` (white).
7. **Path from `x16`:**
* `x16` → `x18` (green) → `x20` (green).
* An orange arrow creates a feedback loop from `x20` back to `x16`.
8. **Path from `x22`:**
* `x22` → `x23` (white) → `x24` (white).
* A **curved green arrow** labeled **"E-formula"** originates from `x22` and points to `x20`.
9. **Path from `x24`:**
* `x24` splits into two terminal paths:
* `x24` → `x25` (white, terminal).
* `x24` → `x26` (white) → `x27` (white, terminal).
* A second **curved green arrow** labeled **"E-formula"** originates from `x24` and points to `x12`.
**Summary of Node States:**
* **Green Nodes (12 total):** `x2`, `x3`, `x4`, `x6`, `x8`, `x9`, `x10`, `x11`, `x12`, `x16`, `x18`, `x20`.
* **White Nodes (15 total):** `x1`, `x5`, `x7`, `x13`, `x14`, `x15`, `x17`, `x19`, `x21`, `x22`, `x23`, `x24`, `x25`, `x26`, `x27`.
### Key Observations
1. **Two Formula-Driven Transitions:** The diagram explicitly highlights two special transitions governed by formulas:
* **O-formula:** A conditional or optional step (dashed line) from the green node `x3` to the green node `x16`.
* **E-formula:** Two long-range, curved transitions that bypass intermediate steps: one from `x22` to `x20`, and another from `x24` to `x12`.
2. **Feedback Loops:** There are at least three feedback mechanisms:
* Blue loop: `x2` → `x15` → `x13` → `x1` → `x2` (completing a cycle back to the start).
* Orange loop: `x11` → `x4`.
* Orange loop: `x20` → `x16`.
3. **Terminal Nodes:** Several nodes have no outgoing arrows, indicating endpoints: `x7`, `x12`, `x25`, `x27`.
4. **Color-Coded Pathways:** The green nodes and arrows appear to form a core or "happy path" through the system, which is then augmented by white-node branches and special formulaic jumps.
### Interpretation
This diagram likely represents a **state machine, workflow, or computational process** where `x1`-`x27` are states or steps. The color coding suggests a distinction between primary process states (green) and auxiliary, preparatory, or alternative states (white).
* **The "O-formula"** (dashed line) implies an **optional or observational** transition. It might represent a calculation or check that, if performed, allows the process to jump from state `x3` directly to state `x16`, potentially skipping steps `x5` and `x7`.
* **The "E-formula"** (curved green arrows) represents **exceptional or evaluative** transitions. These are long-range jumps that significantly alter the process flow:
* The jump from `x22` to `x20` could be an **early exit** or **correction** that sends the process back to an earlier green state (`x20`), bypassing `x23` and `x24`.
* The jump from `x24` to `x12` could be a **final evaluation** that sends the process directly to a terminal green state (`x12`), bypassing the final white-node branches (`x25`, `x26`, `x27`).
* **Feedback Loops** indicate **iterative processes, error correction, or recycling** of resources/states. The blue loop back to `x1` is particularly notable as it suggests the entire system can restart.
**Overall Purpose:** The graph models a complex system with a main linear progression (the green path), multiple side branches for alternative scenarios, and critical formula-based shortcuts that allow for dynamic rerouting based on conditions or evaluations. It emphasizes that the process is not strictly linear and contains mechanisms for optimization (E-formula), optionality (O-formula), and iteration (feedback loops).
</details>
Textual Translation:
knowledge base: All x1 are x2, All x2 are x3, All x2 are x4, All x3 are x5, All x4 are x6, All x5 are x7, All x6 are x8, All x8 are x9, All x9 are x10, All x10 are x11, All x11 are x12, All x13 are x14, All x13 are x15, All x14 are x16, All x15 are x17, All x16 are x18, All x17 are x19, All x18 are x20, All x19 are x21, All x21 are x22, All x22 are x23, All x23 are x24, All x24 are x25, All x24 are x26, All x26 are x27, No x20 are x12, Some x15 are x1, Some x11 are not x4, Some x5 are not x1, Some x20 are not x16 hypothesis: Some x3 are not x16 premises: All x2 are x3, All x2 are x4, All x4 are x6, All x6 are x8, All x8 are x9, All x9 are x10, All x10 are x11, All x11 are x12, All x16 are x18, All x18 are x20, No x20 are x12
Figure 20: Type 3 syllogistic inference on graphs. Visualization of a type 3 syllogistic inference using a graph representation of an example $KB$ , alongside the corresponding textual translation. In the graph (top), nodes represent predicates. Black edges indicate A-formulas (“All As are Bs”), blue edges indicate I-formulas (“Some As are Bs”), red edges indicate E-formulas (“No As are Bs”), and yellow edges indicate O-formulas (“Some As are not Bs”). The query hypothesis is represented by a dashed green edge, and the edges that prove the hypothesis are highlighted in green. The text translation illustrates how the abstract graph representation is converted into a text format suitable for LM processing by applying fixed templates that represent logical formulas.
KB with Query Hypothesis and Type 4 Inference:
<details>
<summary>extracted/6458430/figs/type_4_proof.png Details</summary>
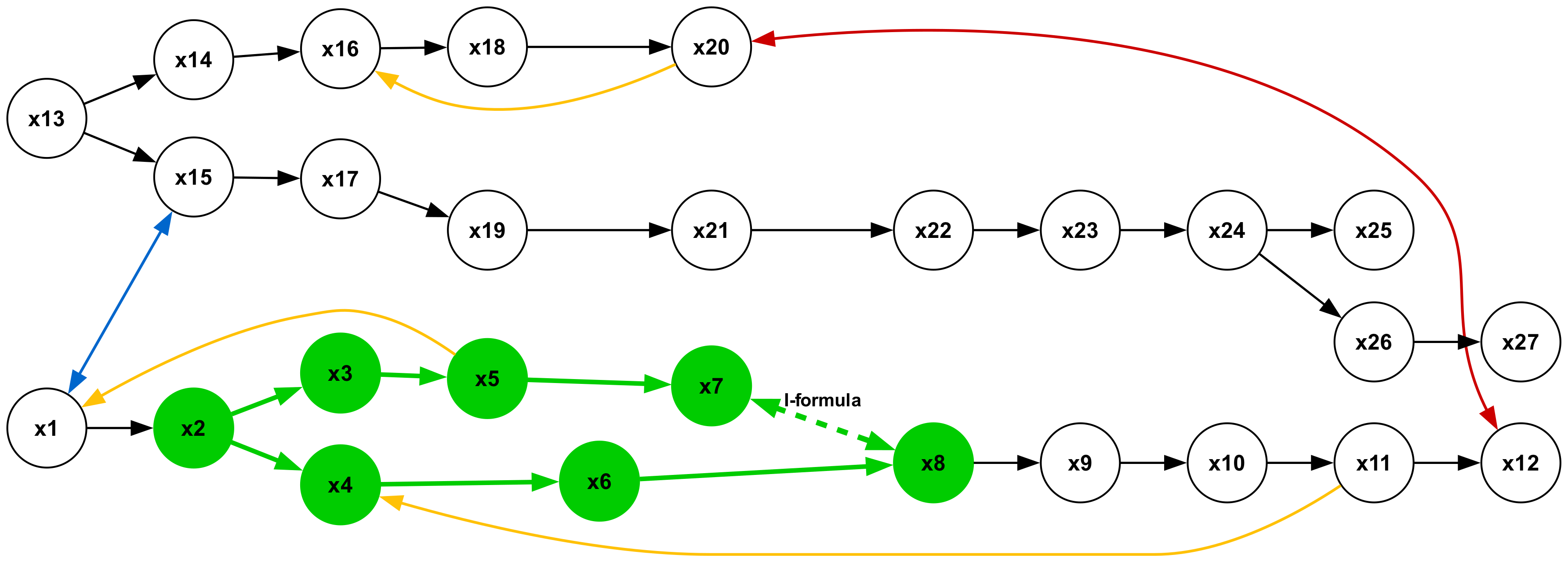
### Visual Description
## Directed Graph Diagram: Process Flow or Dependency Network
### Overview
The image displays a directed graph (network diagram) consisting of 27 circular nodes labeled `x1` through `x27`. The nodes are interconnected by directed arrows of various colors, indicating a flow or dependency relationship. The graph is organized into three approximate horizontal layers. A subset of nodes (`x2`, `x3`, `x4`, `x5`, `x6`, `x7`, `x8`) is highlighted in green, suggesting a distinct group or process phase. A specific relationship between nodes `x7` and `x8` is labeled with the text "I-formula".
### Components/Axes
* **Nodes:** 27 circular nodes, each containing a unique label from `x1` to `x27`.
* **Color Coding:** Nodes `x2`, `x3`, `x4`, `x5`, `x6`, `x7`, and `x8` are filled with a solid green color. All other nodes (`x1`, `x9`-`x27`) are white with a black outline.
* **Edges (Arrows):** Directed arrows connecting nodes, color-coded as follows:
* **Black:** The majority of arrows, indicating standard flow or dependency.
* **Blue:** One arrow from `x15` to `x1`.
* **Yellow/Orange:** Three arrows: `x20` to `x16`, `x11` to `x4`, and `x1` to `x5`.
* **Red:** Two long, curved arrows: `x20` to `x27` and `x27` to `x12`.
* **Green:** Arrows connecting the green nodes (`x2` through `x8`).
* **Dashed Green:** One arrow from `x7` to `x8`, labeled with the text "I-formula".
* **Text Label:** The string "I-formula" is placed above the dashed green arrow connecting `x7` to `x8`.
### Detailed Analysis
**Spatial Layout & Node Connections:**
The graph can be segmented into three primary horizontal regions:
1. **Top Layer (Nodes x13, x14, x16, x18, x20):**
* `x13` (leftmost) has two outgoing black arrows: to `x14` and `x15`.
* `x14` → `x16` (black).
* `x16` → `x18` (black).
* `x18` → `x20` (black).
* A yellow/orange arrow curves from `x20` back to `x16`.
* A red arrow originates from `x20` and curves down to `x27` in the middle layer.
2. **Middle Layer (Nodes x15, x17, x19, x21, x22, x23, x24, x25, x26, x27):**
* `x15` receives arrows from `x13` (black) and `x1` (blue). It has one outgoing black arrow to `x17`.
* `x17` → `x19` (black).
* `x19` → `x21` (black).
* `x21` → `x22` (black).
* `x22` → `x23` (black).
* `x23` → `x24` (black).
* `x24` splits: one black arrow to `x25`, another to `x26`.
* `x26` → `x27` (black).
* `x27` receives the red arrow from `x20` and has a red arrow pointing to `x12` in the bottom layer.
3. **Bottom Layer (Nodes x1, x2-x8 (green), x9, x10, x11, x12):**
* `x1` has a black arrow to `x2` and a yellow/orange arrow to `x5`. It receives a blue arrow from `x15`.
* **Green Node Subgraph:**
* `x2` → `x3` (green) and `x2` → `x4` (green).
* `x3` → `x5` (green).
* `x4` → `x6` (green).
* `x5` → `x7` (green).
* `x6` → `x8` (green).
* `x7` → `x8` (dashed green, labeled "I-formula").
* `x8` → `x9` (black).
* `x9` → `x10` (black).
* `x10` → `x11` (black).
* `x11` → `x12` (black). A yellow/orange arrow also curves from `x11` back to `x4`.
* `x12` receives arrows from `x11` (black) and `x27` (red).
### Key Observations
1. **Highlighted Path:** The green nodes (`x2` through `x8`) form a distinct, internally connected subgraph. The dashed arrow labeled "I-formula" between `x7` and `x8` is a unique, annotated relationship within this group.
2. **Feedback Loops:** The diagram contains several feedback or backward connections, indicated by the yellow/orange arrows: `x20`→`x16`, `x11`→`x4`, and `x1`→`x5`.
3. **Long-Range Connections:** The red arrows (`x20`→`x27` and `x27`→`x12`) create long-range dependencies from the top layer to the middle and then to the bottom layer, bypassing the intermediate sequential flow.
4. **Cross-Layer Connection:** The blue arrow from `x15` (middle layer) to `x1` (bottom layer) is the only connection of its color, linking the two main horizontal flows.
5. **Branching and Convergence:** The graph shows branching (e.g., `x13` to `x14`/`x15`, `x24` to `x25`/`x26`) and convergence (e.g., `x8` receives inputs from `x6` and `x7`; `x12` receives inputs from `x11` and `x27`).
### Interpretation
This diagram likely represents a **complex process flow, dependency network, or computational graph**. The structure suggests a system with multiple parallel and sequential stages.
* **The Green Subgraph (`x2`-`x8`):** This is the most salient feature. It could represent a **core algorithm, a critical processing module, or a specific mathematical transformation** (hinted at by the "I-formula" label). Its internal green arrows show a defined flow within this module.
* **Primary Flow:** The main sequential flow appears to run from `x13` through the top and middle layers (`x13`→...→`x27`) and from `x1` through the bottom layer (`x1`→...→`x12`). These two main streams are interconnected at key points (`x15`→`x1`, `x27`→`x12`).
* **Feedback Mechanisms:** The yellow/orange arrows indicate **feedback loops or iterative processes**, where the output of a later stage (`x20`, `x11`, `x1`) influences an earlier stage (`x16`, `x4`, `x5`). This is common in control systems, optimization algorithms, or recursive computations.
* **System Integration:** The red and blue arrows act as **integration or synchronization points**, linking disparate parts of the network. The red path (`x20`→`x27`→`x12`) might represent a shortcut, an override, or a final aggregation step that combines results from the top-level process with the bottom-level process.
**In summary, the graph depicts a sophisticated system where a core, formula-driven process (green nodes) is embedded within a larger workflow that includes sequential execution, parallel branching, feedback loops, and long-range integrative connections.** The "I-formula" is a key, explicitly noted operation within the core module.
</details>
Textual Translation:
knowledge base: All x1 are x2, All x2 are x3, All x2 are x4, All x3 are x5, All x4 are x6, All x5 are x7, All x6 are x8, All x8 are x9, All x9 are x10, All x10 are x11, All x11 are x12, All x13 are x14, All x13 are x15, All x14 are x16, All x15 are x17, All x16 are x18, All x17 are x19, All x18 are x20, All x19 are x21, All x21 are x22, All x22 are x23, All x23 are x24, All x24 are x25, All x24 are x26, All x26 are x27, No x20 are x12, Some x15 are x1, Some x11 are not x4, Some x5 are not x1, Some x20 are not x16 hypothesis: Some x7 are x8 premises: All x2 are x4, All x2 are x3, All x4 are x6, All x6 are x8, All x3 are x5, All x5 are x7
Figure 21: Type 4 syllogistic inference on graphs. Visualization of a type 4 syllogistic inference using a graph representation of an example $KB$ , alongside the corresponding textual translation. In the graph (top), nodes represent predicates. Black edges indicate A-formulas (“All As are Bs”), blue edges indicate I-formulas (“Some As are Bs”), red edges indicate E-formulas (“No As are Bs”), and yellow edges indicate O-formulas (“Some As are not Bs”). The query hypothesis is represented by a dashed green edge, and the edges that prove the hypothesis are highlighted in green. The text translation illustrates how the abstract graph representation is converted into a text format suitable for LM processing by applying fixed templates that represent logical formulas.
KB with Query Hypothesis and Type 5 Inference:
<details>
<summary>extracted/6458430/figs/type_5_proof.png Details</summary>
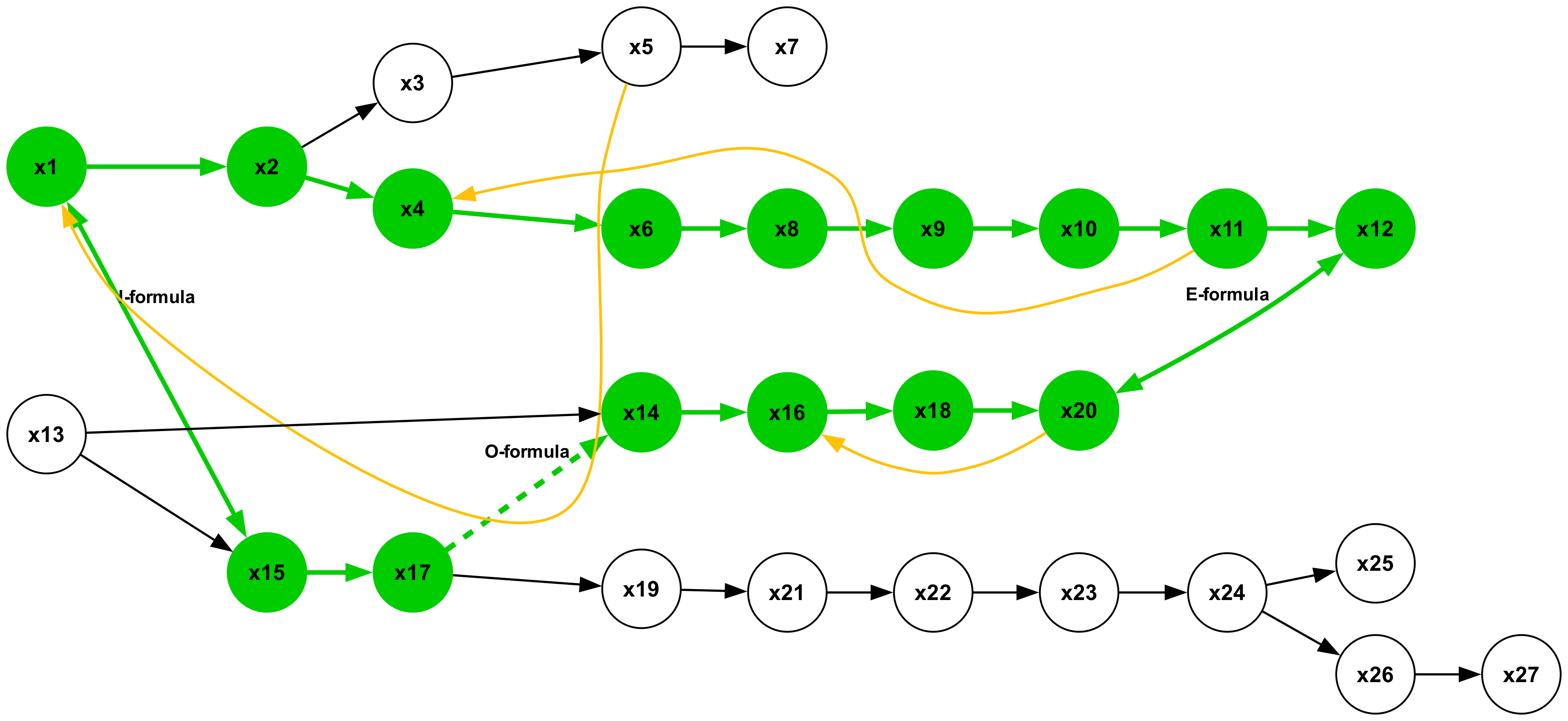
### Visual Description
## Directed Graph Diagram: State Transition Network with Feedback Loops
### Overview
The image displays a directed graph (network diagram) consisting of 27 nodes labeled `x1` through `x27`. Nodes are connected by directed edges (arrows) of three types: solid black, solid green, and curved orange. Some edges are annotated with formula labels. The graph illustrates a complex system of state transitions, with distinct pathways, branching points, and feedback loops. The visual encoding (node color, edge color/style) appears to signify different types of states or transition rules.
### Components/Axes
**Nodes:**
* **Total Nodes:** 27, labeled sequentially from `x1` to `x27`.
* **Node Types (by color):**
* **Green Nodes (15 total):** `x1`, `x2`, `x4`, `x6`, `x8`, `x9`, `x10`, `x11`, `x12`, `x14`, `x15`, `x16`, `x17`, `x18`, `x20`.
* **White Nodes (12 total):** `x3`, `x5`, `x7`, `x13`, `x19`, `x21`, `x22`, `x23`, `x24`, `x25`, `x26`, `x27`.
**Edges (Transitions):**
* **Solid Black Arrows:** Represent standard or primary transitions.
* **Solid Green Arrows:** Represent a specific class of transitions, some of which are labeled.
* **Curved Orange Arrows:** Represent feedback or secondary transitions, looping back to earlier nodes.
* **Dashed Green Arrow:** A single instance, labeled "O-formula".
**Labeled Formulas:**
1. **"I-formula":** Associated with the **green arrow** from node `x1` to node `x15`.
2. **"E-formula":** Associated with the **green arrow** from node `x20` to node `x12`.
3. **"O-formula":** Associated with the **dashed green arrow** from node `x17` to node `x14`.
### Detailed Analysis
**Spatial Layout & Pathways:**
The graph flows generally from left to right, with two primary entry points on the left (`x1` and `x13`).
**1. Upper Pathway (Starting from `x1`):**
* `x1` (green) → `x2` (green) [green arrow].
* From `x2`, the path splits:
* `x2` → `x3` (white) → `x5` (white) → `x7` (white) [black arrows].
* `x2` → `x4` (green) → `x6` (green) → `x8` (green) → `x9` (green) → `x10` (green) → `x11` (green) → `x12` (green) [green arrows].
* **Feedback Loops (Orange):**
* `x5` (white) → `x4` (green).
* `x9` (green) → `x8` (green).
**2. Lower Pathway (Starting from `x13`):**
* `x13` (white) splits into two green-arrow transitions:
* `x13` → `x14` (green).
* `x13` → `x15` (green).
* From `x15`:
* `x15` → `x17` (green) [green arrow].
* `x17` → `x19` (white) → `x21` (white) → `x22` (white) → `x23` (white) → `x24` (white) → `x25` (white) and `x26` (white) → `x27` (white) [black arrows].
* From `x14`:
* `x14` → `x16` (green) → `x18` (green) → `x20` (green) [green arrows].
* `x20` → `x12` (green) [green arrow, labeled "E-formula"].
* **Feedback Loop (Orange):** `x20` (green) → `x18` (green).
**3. Cross-Connections & Special Transitions:**
* **"I-formula":** A direct green-arrow transition from `x1` to `x15`, connecting the upper and lower pathways at their origins.
* **"O-formula":** A dashed green-arrow transition from `x17` to `x14`, creating a link from the lower pathway's branch (`x15`→`x17`) back to the start of the `x14`→`x16`→`x18`→`x20` chain.
* **Additional Orange Feedback:** An orange arrow also connects `x1` to `x15`, running parallel to the green "I-formula" arrow.
### Key Observations
1. **Node Color Segregation:** Green nodes form the core of the interconnected pathways, while white nodes are primarily at the periphery (start/end points like `x3`, `x5`, `x7`, `x13`, `x19`, `x21`-`x27`) or within a specific branch (`x3`, `x5`, `x7`).
2. **Convergence Point:** Node `x12` is a major convergence point, receiving inputs from the long upper chain (`x11`) and the lower pathway chain (`x20`).
3. **Feedback Mechanisms:** The system contains four distinct feedback loops (orange arrows), suggesting iterative processes or state corrections: `x5`→`x4`, `x9`→`x8`, `x20`→`x18`, and `x1`→`x15`.
4. **Formulaic Transitions:** Three transitions are explicitly governed by named formulas ("I", "E", "O"), indicating they follow specific, possibly mathematical or logical, rules distinct from the standard transitions.
5. **Dashed Line Significance:** The "O-formula" transition is uniquely represented by a dashed line, which may denote a conditional, optional, or probabilistic transition.
### Interpretation
This diagram models a **state machine or process flow** with complex interdependencies. The green nodes likely represent **active, processed, or "in-system" states**, while white nodes represent **initial, terminal, or external states**.
* **System Function:** The graph depicts a system where processes can follow multiple parallel paths (`x1`-branch and `x13`-branch), interact via cross-connections (`I-formula`, `O-formula`), and converge at a common endpoint (`x12`). The feedback loops imply that the system is **non-linear and self-correcting**; later stages can influence earlier ones, allowing for refinement or iteration.
* **Role of Formulas:** The labeled formulas ("I", "E", "O") mark **critical control points**. "I-formula" (`x1`→`x15`) may represent an **Initialization** or **Input** rule that seeds the lower pathway. "E-formula" (`x20`→`x12`) could be an **Exit** or **Evaluation** rule that finalizes a process. "O-formula" (`x17`→`x14`) might be an **Optional** or **Override** rule that redirects flow.
* **Anomaly/Notable Feature:** The dual connection from `x1` to `x15` (one green "I-formula", one orange feedback) is striking. This could indicate that the same state transition is triggered by two different mechanisms: a primary rule (green) and a feedback-driven correction (orange).
* **Overall Purpose:** The diagram is likely used in fields like **control theory, computer science (algorithm design), or systems engineering** to visualize the flow of data, control, or state changes in a complex, iterative system. It emphasizes connectivity, conditional pathways, and the importance of specific transformation rules.
</details>
Textual Translation:
knowledge base: All x1 are x2, All x2 are x3, All x2 are x4, All x4 are x6, All x3 are x5, All x6 are x8, All x5 are x7, All x8 are x9, All x9 are x10, All x10 are x11, All x11 are x12, All x13 are x14, All x13 are x15, All x14 are x16, All x15 are x17, All x16 are x18, All x17 are x19, All x18 are x20, All x19 are x21, All x21 are x22, All x22 are x23, All x23 are x24, All x24 are x25, All x24 are x26, All x26 are x27, No x20 are x12, Some x15 are x1, Some x11 are not x4, Some x5 are not x1, Some x20 are not x16 hypothesis: Some x17 are not x14 premises: All x1 are x2, All x2 are x4, All x4 are x6, All x6 are x8, All x8 are x9, All x9 are x10, All x10 are x11, All x11 are x12, All x14 are x16, All x15 are x17, All x16 are x18, All x18 are x20, No x20 are x12, Some x15 are x1,
Figure 22: Type 5 syllogistic inference on graphs. Visualization of a type 5 syllogistic inference using a graph representation of an example $KB$ , alongside the corresponding textual translation. In the graph (top), nodes represent predicates. Black edges indicate A-formulas (“All As are Bs”), blue edges indicate I-formulas (“Some As are Bs”), red edges indicate E-formulas (“No As are Bs”), and yellow edges indicate O-formulas (“Some As are not Bs”). The query hypothesis is represented by a dashed green edge, and the edges that prove the hypothesis are highlighted in green. The text translation illustrates how the abstract graph representation is converted into a text format suitable for LM processing by applying fixed templates that represent logical formulas.
KB with Query Hypothesis and Type 6 Inference:
<details>
<summary>extracted/6458430/figs/type_6_proof.png Details</summary>
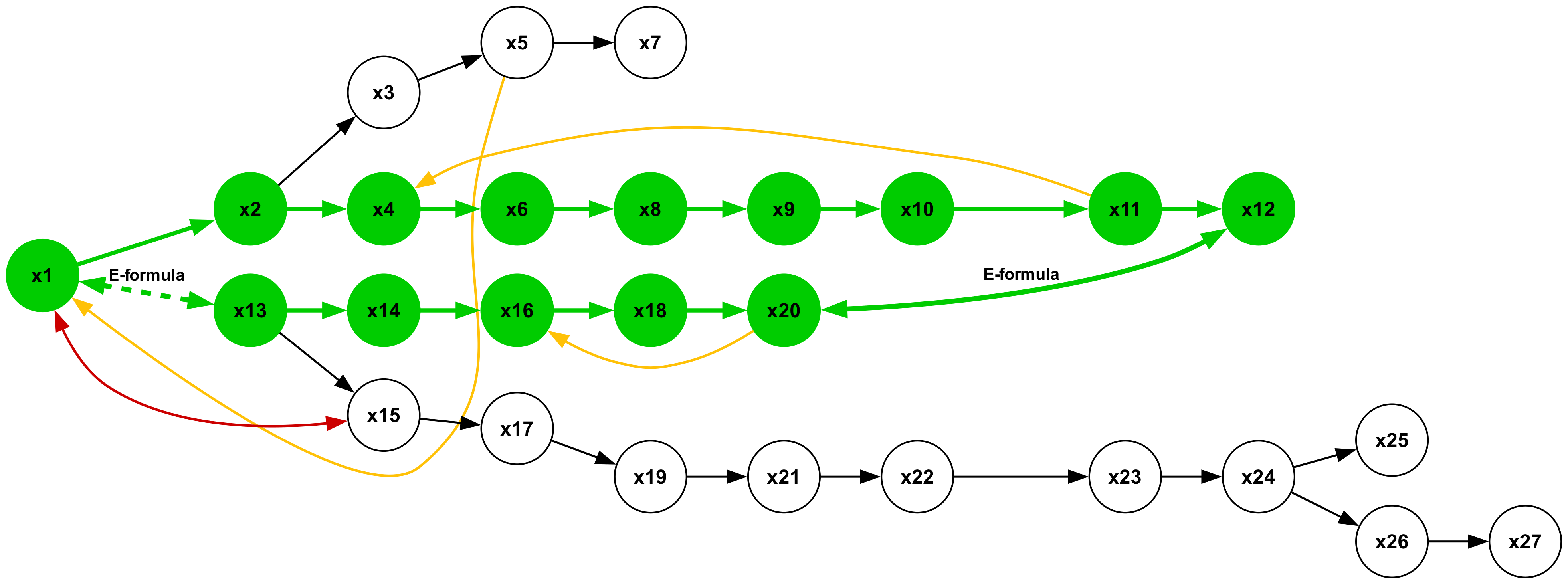
### Visual Description
## Directed Graph Diagram: Process Flow with Feedback Loops
### Overview
The image displays a directed graph (flowchart) consisting of 27 circular nodes labeled `x1` through `x27`. Nodes are connected by directed edges (arrows) of four distinct colors: green, black, yellow, and red. Some edges carry the label "E-formula". The graph illustrates a complex process flow with parallel paths, branching, and multiple feedback loops. The nodes are visually categorized by fill color: green-filled nodes and white-filled (unfilled) nodes.
### Components/Axes
**Nodes (27 total):**
* **Green-filled nodes (15):** `x1`, `x2`, `x4`, `x6`, `x8`, `x9`, `x10`, `x11`, `x12`, `x13`, `x14`, `x16`, `x18`, `x20`.
* **White-filled nodes (12):** `x3`, `x5`, `x7`, `x15`, `x17`, `x19`, `x21`, `x22`, `x23`, `x24`, `x25`, `x26`, `x27`.
**Edges (Connections):**
* **Green Arrows:** Represent primary forward flow paths.
* **Black Arrows:** Represent secondary or branching flow paths.
* **Yellow Curved Arrows:** Represent feedback or cross-connection loops.
* **Red Arrow:** Represents a specific return path.
* **Text Labels:** The phrase "E-formula" appears on two specific edges.
### Detailed Analysis
**Spatial Layout & Node Grouping:**
The graph is arranged horizontally. The central band contains two parallel chains of green nodes. Above this band is a small branch of white nodes (`x3`, `x5`, `x7`). Below the central band is a longer chain of white nodes (`x15`, `x17`, `x19`, `x21`, `x22`, `x23`, `x24`, `x25`, `x26`, `x27`).
**Complete Connection List (Source → Target, Color, Label):**
1. `x1` → `x2` (Green)
2. `x1` → `x13` (Green, Dashed, Label: **"E-formula"**)
3. `x2` → `x4` (Green)
4. `x2` → `x3` (Black)
5. `x3` → `x5` (Black)
6. `x4` → `x6` (Green)
7. `x5` → `x7` (Black)
8. `x5` → `x4` (Yellow, Curved)
9. `x6` → `x8` (Green)
10. `x8` → `x9` (Green)
11. `x9` → `x10` (Green)
12. `x10` → `x11` (Green)
13. `x11` → `x12` (Green)
14. `x11` → `x4` (Yellow, Curved)
15. `x13` → `x14` (Green)
16. `x13` → `x15` (Black)
17. `x14` → `x16` (Green)
18. `x15` → `x17` (Black)
19. `x15` → `x1` (Red)
20. `x15` → `x1` (Yellow, Curved)
21. `x16` → `x18` (Green)
22. `x17` → `x19` (Black)
23. `x18` → `x20` (Green)
24. `x19` → `x21` (Black)
25. `x20` → `x12` (Green, Label: **"E-formula"**)
26. `x20` → `x16` (Yellow, Curved)
27. `x21` → `x22` (Black)
28. `x22` → `x23` (Black)
29. `x23` → `x24` (Black)
30. `x24` → `x25` (Black)
31. `x24` → `x26` (Black)
32. `x26` → `x27` (Black)
**Primary Flow Paths:**
* **Upper Green Chain:** `x1` → `x2` → `x4` → `x6` → `x8` → `x9` → `x10` → `x11` → `x12`
* **Lower Green Chain:** `x1` → `x13` → `x14` → `x16` → `x18` → `x20` → `x12` (via "E-formula" edge)
**Feedback Loops (Yellow Arrows):**
1. From `x5` (top branch) back to `x4` (upper green chain).
2. From `x11` (end of upper green chain) back to `x4` (start of upper green chain).
3. From `x20` (end of lower green chain) back to `x16` (mid-point of lower green chain).
4. From `x15` (start of lower white chain) back to `x1` (graph origin).
**Special Return Path:**
* A **red arrow** provides a direct return from `x15` to `x1`.
### Key Observations
1. **Dual Origin:** The process originates at `x1` and splits immediately into two green paths (`x2` and `x13`).
2. **Convergence:** Both primary green chains converge at node `x12`.
3. **"E-formula" Significance:** The label "E-formula" marks two critical transitions: the initial split from `x1` to `x13`, and the final convergence from `x20` to `x12`. This suggests these are key transformation or calculation steps.
4. **Complex Feedback:** The system has four distinct feedback mechanisms (three yellow, one red), indicating a highly iterative or self-correcting process.
5. **Terminal Nodes:** The graph has multiple endpoints: `x7`, `x12`, `x25`, and `x27`. `x12` is the convergence point of the two main green processes, while the others are endpoints of branching paths.
6. **Color-Coded Semantics:** Green nodes/edges likely denote a primary or "active" process stream. White nodes/black edges denote secondary or "supporting" streams. Yellow denotes feedback, and red denotes a specific reset or return.
### Interpretation
This diagram models a complex, iterative system with parallel processing streams. The structure suggests a workflow where a core process (`x1` to `x12`) is supported by auxiliary branches and is heavily regulated by feedback loops.
* **Process Resilience:** The multiple feedback loops (especially from `x11` and `x20` back to earlier stages) imply the system is designed for refinement, error correction, or cyclical improvement. The process doesn't just flow linearly; it revisits and potentially optimizes previous steps.
* **"E-formula" as a Key Operator:** The placement of "E-formula" at the initiation of a major branch (`x1`→`x13`) and at the final integration step (`x20`→`x12`) suggests it is a fundamental operation or rule that governs both the creation and the synthesis of the parallel processes.
* **Hierarchical Structure:** The graph can be seen as having three tiers: a top branch (`x3`, `x5`, `x7`), a central processing core (the two green chains), and a bottom branch (`x15` onward). The bottom branch has its own long, linear sequence and feeds back into the origin, possibly representing a monitoring, logging, or resource-management subsystem.
* **Multiple Outcomes:** The existence of several terminal nodes (`x7`, `x12`, `x25`, `x27`) indicates the system can produce different final states or outputs depending on the path taken. `x12` appears to be the primary successful outcome of the core process.
In summary, this is not a simple linear flowchart but a model of a dynamic, interconnected system with built-in mechanisms for iteration, parallel execution, and multiple potential endpoints. It likely represents a computational algorithm, a business process with reviews, or a control system logic flow.
</details>
Textual Translation:
knowledge base: All x1 are x2, All x2 are x3, All x2 are x4, All x3 are x5, All x4 are x6, All x5 are x7, All x6 are x8, All x8 are x9, All x9 are x10, All x10 are x11, All x11 are x12, All x13 are x14, All x13 are x15, All x14 are x16, All x15 are x17, All x16 are x18, All x17 are x19, All x18 are x20, All x19 are x21, All x21 are x22, All x22 are x23, All x23 are x24, All x24 are x25, All x24 are x26, All x26 are x27, No x20 are x12, Some x15 are x1, Some x11 are not x4, Some x5 are not x1, Some x20 are not x16 hypothesis: No x1 are x13 premises: All x1 are x2, All x2 are x4, All x4 are x6, All x6 are x8, All x8 are x9, All x9 are x10, All x10 are x11, All x11 are x12, All x13 are x14, All x14 are x16, All x16 are x18, All x18 are x20, No x20 are x12,
Figure 23: Type 6 syllogistic inference on graphs. Visualization of a type 6 syllogistic inference using a graph representation of an example $KB$ , alongside the corresponding textual translation. In the graph (top), nodes represent predicates. Black edges indicate A-formulas (“All As are Bs”), blue edges indicate I-formulas (“Some As are Bs”), red edges indicate E-formulas (“No As are Bs”), and yellow edges indicate O-formulas (“Some As are not Bs”). The query hypothesis is represented by a dashed green edge, and the edges that prove the hypothesis are highlighted in green. The text translation illustrates how the abstract graph representation is converted into a text format suitable for LM processing by applying fixed templates that represent logical formulas.
KB with Query Hypothesis and Type 7 Inference:
<details>
<summary>extracted/6458430/figs/type_7_proof.png Details</summary>
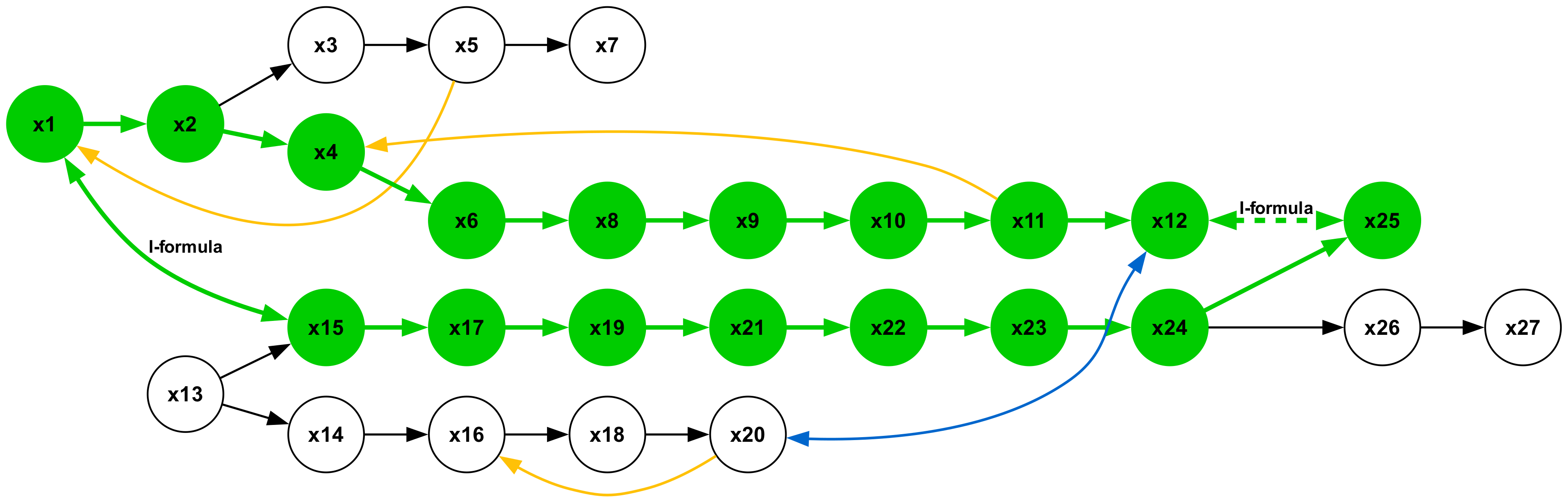
### Visual Description
## Directed Graph Diagram: System Flow with Feedback Loops
### Overview
The image displays a directed graph (flowchart) consisting of 27 circular nodes labeled `x1` through `x27`. The nodes are interconnected by directed edges (arrows) of four distinct colors: green, black, yellow, and blue. The diagram illustrates a complex process flow with multiple parallel paths, branching, convergence, and feedback loops. Two edges are explicitly labeled with the text "I-formula".
### Components/Axes
* **Nodes:** 27 circular nodes, each containing a unique label from `x1` to `x27`.
* **Green Nodes (16 total):** `x1`, `x2`, `x4`, `x6`, `x8`, `x9`, `x10`, `x11`, `x12`, `x15`, `x17`, `x19`, `x21`, `x22`, `x23`, `x24`, `x25`.
* **White Nodes (11 total):** `x3`, `x5`, `x7`, `x13`, `x14`, `x16`, `x18`, `x20`, `x26`, `x27`.
* **Edges (Arrows):** Directed connections between nodes, color-coded to indicate different types of relationships or flows.
* **Green Arrows:** Indicate the primary forward flow or main process path.
* **Black Arrows:** Indicate secondary or alternative forward flows.
* **Yellow Arrows:** Indicate feedback loops or backward connections.
* **Blue Arrow:** Indicates a specific, singular feedback connection.
* **Text Labels:** The text "I-formula" appears in two locations:
1. Above a **green dashed arrow** connecting node `x12` to node `x25`.
2. Above a **green arrow** forming a feedback loop from node `x15` back to node `x1`.
### Detailed Analysis
The graph can be segmented into several interconnected regions and paths.
**1. Primary Forward Flow (Green Path):**
This is the most prominent sequence, forming a central "spine" through the diagram.
* **Path:** `x1` → `x2` → `x4` → `x6` → `x8` → `x9` → `x10` → `x11` → `x12`.
* **Trend:** This path flows generally from the left side of the image to the right, with a slight upward then downward curve.
* **Branching from `x12`:**
* A **green dashed arrow** labeled "I-formula" connects `x12` to `x25` (located to its right).
* A **green arrow** connects `x12` to `x24` (located below it).
**2. Upper Branch (White Nodes):**
* **Path:** `x2` → `x3` → `x5` → `x7`.
* **Trend:** This branch splits upward from `x2` and flows horizontally to the right, ending at `x7`.
* **Feedback:** A **yellow arrow** creates a loop from `x5` back to `x4`.
**3. Lower Parallel Flow (Green Path):**
* **Path:** `x15` → `x17` → `x19` → `x21` → `x22` → `x23` → `x24`.
* **Trend:** This path runs parallel to and below the primary flow (`x6`-`x12`), flowing from left to right.
* **Convergence:** This path converges with the primary flow at node `x24`.
**4. Lower Branch (White Nodes):**
* **Path:** `x13` → `x14` → `x16` → `x18` → `x20`.
* **Trend:** This branch splits downward from `x13` and flows horizontally to the right, ending at `x20`.
* **Feedback:** A **yellow arrow** creates a loop from `x20` back to `x16`.
**5. Convergence and Final Paths:**
* **Node `x24`:** Receives input from both the lower green path (`x23`) and the primary green path (`x12`).
* **Paths from `x24`:**
* A **green arrow** goes to `x25`.
* A **black arrow** goes to `x26`, which then connects via another black arrow to `x27`.
* **Node `x25`:** Receives input from both `x12` (via "I-formula" dashed green arrow) and `x24` (via solid green arrow).
**6. Feedback Loops:**
* **Yellow Loop 1:** From `x5` (upper branch) back to `x4` (primary green path).
* **Yellow Loop 2:** From `x20` (lower white branch) back to `x16` (same branch).
* **Green "I-formula" Loop:** From `x15` (lower green path) back to `x1` (start of primary green path).
* **Blue Loop:** A single **blue arrow** from `x24` (convergence point) back to `x20` (end of lower white branch).
### Key Observations
1. **Color-Coded Semantics:** The node color (green vs. white) and edge color (green, black, yellow, blue) are used systematically to differentiate between primary processes, secondary paths, and feedback mechanisms.
2. **Multiple Feedback Mechanisms:** The system contains at least four distinct feedback loops, suggesting it models a process with significant iterative or corrective components.
3. **Convergence Points:** Nodes `x12`, `x24`, and `x25` act as key convergence points where multiple process streams merge.
4. **"I-formula" Significance:** The label "I-formula" is applied to two specific edges: one a forward connection (`x12`→`x25`) and one a major feedback loop (`x15`→`x1`). This suggests a specific rule, calculation, or transformation is applied at these transitions.
5. **Structural Symmetry:** There is a rough symmetry between the upper white branch (`x3`-`x7`) and the lower white branch (`x14`-`x20`), both originating from nodes in the primary green path (`x2` and `x13` respectively) and containing their own feedback loops.
### Interpretation
This diagram likely represents a **complex state machine, workflow, or computational model**. The green nodes and arrows form the core, successful execution path. The white nodes represent auxiliary, optional, or alternative sub-processes that can be triggered from the main path.
The presence of multiple feedback loops (yellow and blue arrows) indicates that the system is not purely linear; it includes mechanisms for iteration, error correction, or resource recycling. The "I-formula" label points to critical decision points or transformation steps governed by a specific formula or rule.
The convergence at `x24` and `x25` suggests these are integration or output stages where results from different process branches are combined. The final black-arrow path to `x27` may represent a terminal or output state.
In essence, the graph models a system where a primary process (`x1`→...→`x12`) can spawn parallel sub-processes, incorporate their results, and use feedback to adjust earlier stages, with specific formulaic operations applied at key junctures.
</details>
Textual Translation:
knowledge base: All x1 are x2, All x2 are x3, All x2 are x4, All x3 are x5, All x4 are x6, All x5 are x7, All x6 are x8, All x8 are x9, All x9 are x10, All x10 are x11, All x11 are x12, All x13 are x14, All x13 are x15, All x14 are x16, All x15 are x17, All x16 are x18, All x17 are x19, All x18 are x20, All x19 are x21, All x21 are x22, All x22 are x23, All x23 are x24, All x24 are x25, All x24 are x26, All x26 are x27, No x20 are x12, Some x15 are x1, Some x11 are not x4, Some x5 are not x1, Some x20 are not x16 hypothesis: Some x25 are x12 premises: All x1 are x2, All x2 are x4, All x4 are x6, All x6 are x8, All x8 are x9, All x9 are x10, All x10 are x11, All x11 are x12, All x15 are x17, All x17 are x19, All x19 are x21, All x21 are x22, All x22 are x23, All x23 are x24, All x24 are x25, Some x15 are x1
Figure 24: Type 7 syllogistic inference on graphs. Visualization of a type 7 syllogistic inference using a graph representation of an example $KB$ , alongside the corresponding textual translation. In the graph (top), nodes represent predicates. Black edges indicate A-formulas (“All As are Bs”), blue edges indicate I-formulas (“Some As are Bs”), red edges indicate E-formulas (“No As are Bs”), and yellow edges indicate O-formulas (“Some As are not Bs”). The query hypothesis is represented by a dashed green edge, and the edges that prove the hypothesis are highlighted in green. The text translation illustrates how the abstract graph representation is converted into a text format suitable for LM processing by applying fixed templates that represent logical formulas.